
Atps - Estatistica
34
FACULDADE ANHANGUERA EDUCACIONAL DE TABOÃO DA SERRA ADMINISTRAÇÃO ESTATÍSTICA ATIVIDADES PRÁTICAS SUPERVISIONADAS DAIANE GONZA DE JESUS – RA: 5670152587 MARCONI JOAQUIM DA SILVA – RA: 4259835644 RAQUEL SANTOS DE ALMEIDA – RA: 4200057011 ROSIVALDO PIRES DE JESUS – RA: 3721656688 STEPHANIE DE OLIVEIRA SOUZA – RA: 3730726568 TAMARA DA SILVA NEVES - RA: 4267925737
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of Atps - Estatistica

FACULDADE ANHANGUERA EDUCACIONAL
DE TABOÃO DA SERRA
ADMINISTRAÇÃO
ESTATÍSTICA
ATIVIDADES PRÁTICAS SUPERVISIONADAS
DAIANE GONZA DE JESUS – RA: 5670152587
MARCONI JOAQUIM DA SILVA – RA: 4259835644
RAQUEL SANTOS DE ALMEIDA – RA: 4200057011
ROSIVALDO PIRES DE JESUS – RA: 3721656688
STEPHANIE DE OLIVEIRA SOUZA – RA: 3730726568
TAMARA DA SILVA NEVES - RA: 4267925737

TABOÃO DA SERRA
Novembro/2013
INTRODUÇÃO À ESTATÍSTICA DESCRITIVA
Estatística descritiva se consiste em dados de informações que
vem observações, contagens, medições ou respostas. O uso da
estatísticas remota aos censos feitos na antiga Babilônia,
onde os dados eram coletados sobre assuntos relacionados ao
estado, tais como nascimentos e óbitos. A palavra estatística
é derivada do latino status, que significa “estado”.
Estatística é a ciência que coleta, organiza, analisa e
interpreta dados à tomada de decisões.
Conjunto de dados
Há dois tipos de conjuntos de dados usados em estatística.
Esses conjuntos são chamados de população e amostra.
População é uma coleção de todos os resultados, respostas,
medições ou contagens que são de interesse.
Amostra é u, subgrupo de uma população.
Estatística descritiva é o ramo da estatística que envolve
organização, o resumo é representação dos dados.
Distribuição de frequência

Distribuição de frequência é uma tabela que mostra classes ou
intervalos das entradas de dados com uma contagem do número de
entradas em cada classe. A frequência F de uma classe é o
número de entrada de dados em uma classe.
Gráficos de distribuição de frequência
Histograma de frequência
Histograma de frequência é um diagrama de barras que
representa a distribuição de um conjunto de dados. Um
histograma tem as seguintes propriedades:
A escala horizontal é quantitativa e mede os valores dos
dados;
A escala vertical mede as frequências de cada classes;
As barras consecutivas devem estar encostadas umas nas outras.
Em virtude das barras consecutivas no histograma estarem
encostadas elas devem começar e terminar na fronteiras de
classe ao invés em seus limites. As fronteiras de classe são
números que separam as classes sem formar lacunas entre elas.
Pode marcar a escala horizontal tanto nos pontos médios quanto
nas fronteiras das classes.
Polígono de Frequência
Polígono de frequência para distribuição de frequência.
Para se construir um polígono de frequência use as mesmas
escalas horizontais e verticais que foram usadas no histograma
nomeado com os pontos médios.

Represente os pontos médios e a frequência de cada classe e
conecte o pontos em ordem da esquerda para a direita. Já que o
gráfico deve começar e terminar o eixo horizontal, prolongue o
lado esquerdo a uma largura de classe antes do ponto médio da
primeira classe e prolongue o lado direito a uma largura de
classe depois do ponto médio da última classe.
Ogiva
Um gráfico de frequência acumulada ou ogiva (pronuncia-se O
´jiva) um gráfico de linhas que mostra as frequências
acumuladas da cada classe em sua fronteira de classe superior.
As fronteiras superiores são marcadas no eixo horizontal e as
frequências acumuladas são marcadas no eixo vertical.
Diagrama de ramo-e-folhas
Uma nova maneira de representar dados quantitativos, chamada
diagrama ramo-e-folha. Os gráficos ramo-e-folhas, são exemplos
da analise exploratória de dados (EAD em inglês EXPLORATORY
DATA ANALYSIS), que foi desenvolvida por Jonh Turkey em 1977.
Em um diagrama de ramo-e-folhas cada número é separado em um
ramo.
Devem-se ter tantas folhas quanto entradas no conjunto de
dados original. Um diagrama de ramo-e-folhas é similar a um
histograma, mas tem vantagem que o gráfico ainda contém os
valores originais dos dados outra vantagem de um diagrama

ramo-e-folhas é que ele fornece uma maneira rápida de se
classificar dados.
1. DESAFIO A – Diagrama de caule e folha para cada um das
amostras.
Marca A:
Chave = 6/84 = 684 109/3 = 109368 469 770 71 72 073 74 75 76 77 378 79 80 81 82 183 1584 885 22986 887 688 89 3990 5991 192 246693 8994 3695 496 97 12798 499

100 5101 46102 103 104 1105 2106 107 108 0109 3
Marca B:
Chave = 81/9 = 819 123/0 =123031 281 982 83 384 85 86 87 88 889 790 37 91 892 93 94 2395 2996 297 98 699 24100 457101 568102 2103 48104 105 106

107 277108 2109 6110 0111 336112 113 114 115 34116 117 4118 8119 120 121 122 123 0
2. DESAFIO B – Distribuição de frequências com intervalos de
classe para:
Lâmpada marca A
CLASSE NI FI FCC D PM680-749 3 0,075 0,075 0,001 714,5750-819 1 0,025 0,1 3,571 784,5820-889 11 0,275 0,375 0,003 854,5890-959 14 0,35 0,725 0,005 924,5960-1029 7 0,175 0,9 0,003 994,51030-1099 4 0,1 1 0,001
1064,5
N= 40
Fi = fi= = fi = 0,075

D = D= = D= 0,001
Ponto médio =
Lâmpada marca B
CLASSE NI FI FCC D PM815-884 2 0,05 0,05 7,142 849,5885-954 9 0,225 0,275 0,003 919,5955-1024 13 0,325 0,6 0,004 989,51025-1094 6 0,15 0,75 0,002
1059,5
1095-1164 7 0,175 0,925 0,003
1129,5
1165-1234 3 0,075 1 0,001
1199,5
N= 40
Fi = fi= = fi = 0,05
D = D= = D= 7,142
Ponto médio =
3. DESAFIO C

MARCA A MARCA BTempo de vidaútil em horas Lâmpadas
Tempo de vidaútil em horas Lâmpadas
715 3 850 2785 1 920 9855 11 990 13925 14 1060 6995 7 1130 71065 4 1200 3
HISTOGRAMA

O POLÍGONO DE FREQUÊNCIA

A OGIVA

Medidas de posição e dispersão
Fractis são números que separam ou dividem de dados ordenado
em partes iguais. Por exemplo, a mediana é um fractil por que
divide um conjunto de dados ordenados em duas partes iguais.
Os três quartis Q1, Q2 e Q, dividem aproximadamente um
conjunto de dados ordenado em quatro partes iguais.
Aproximadamente 1/4 dos dados está acima ou abaixo do primeiro
quartil Q. Aproximadamente metade dos dados está acima do
segundo quartil Q2 (o segundo quartil é o mesmo que a mediana
do conjunto de dados). Aproximadamente 3/4dos dados estão
acima ou abaixo do terceiro quartil Q3.

CALCULO DOS QUARTIS :Marca A
Classe Fi %680-749 7,50%750-819 2,50%820-889 27,50%890-959 35%960-1029 17,50%1030-1099 10%
Q1 – =
0,275. (Q1-820) = 70. 0,15

0,275 Q1 - 225,35 = 10,5
0,275 Q1 = 10,5 +225,5
0,275 Q1 = 236
Q1 = = 858,18
Q2 – =
0,35. (Q2-890) = 70. 0,1250,35 Q2 - 311,5 = 8,75
0,35 Q2 = 8,75 +311,5
0,35 Q2 = 320,25
Q2 = = 915

Q3 – =
0,175. (Q3-960) = 70. 0,025
0,175 Q3 – 168 = 1,75
0,175 Q3 = 1,75 + 168
0,175 Q3 = 169,75
Q3 = = 970
MARCA B
Classe Fi%815-884 5%885-954 22,50%955-1024 32,50%1025-1094 15%
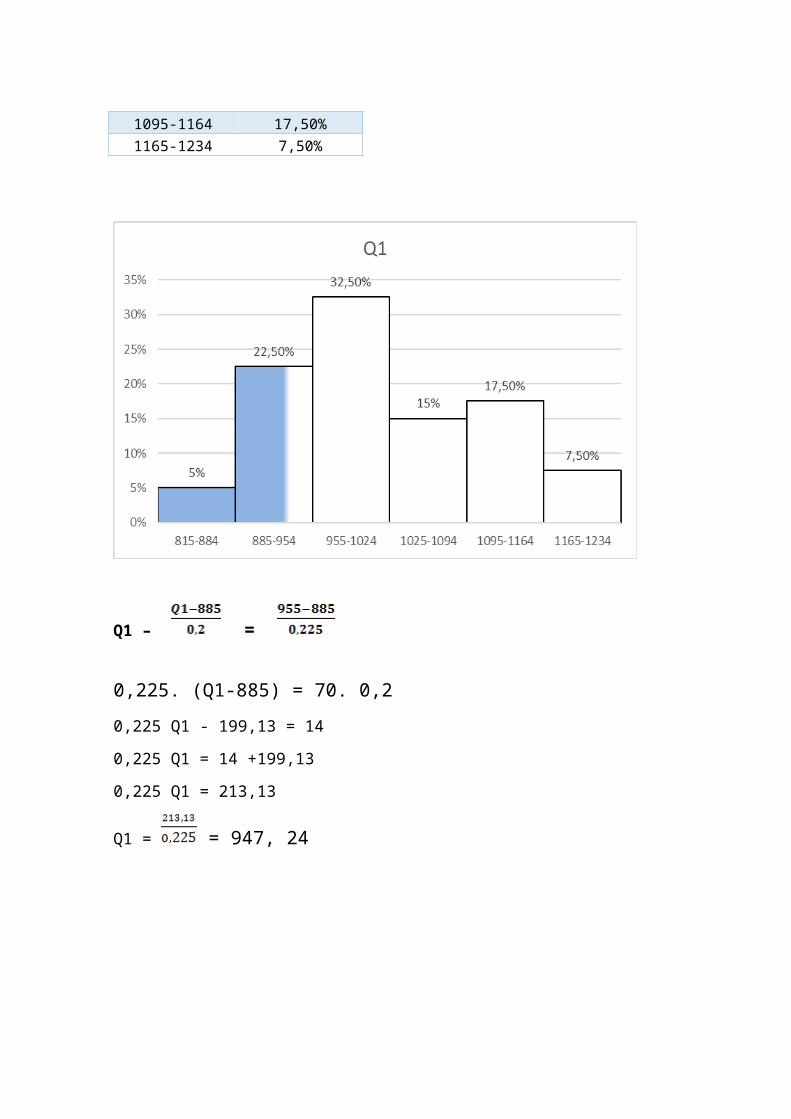
1095-1164 17,50%1165-1234 7,50%
Q1 – =
0,225. (Q1-885) = 70. 0,20,225 Q1 - 199,13 = 14
0,225 Q1 = 14 +199,13
0,225 Q1 = 213,13
Q1 = = 947, 24

Q2 – =
0,325. (Q2-955) = 70. 0,225
0,325 Q2 – 310,38 = 15,75
0,325 Q2 = 15,75 + 310,38
0,325 Q2 = 326,13
Q2 = = 103,47

Q3 – =
0,15. (Q3- 1025) = 70. 0,15
0,15 Q3 – 153,75 = 10,5
0,15Q3 = 10,5 + 153,75
0,15 Q3 = 164,25
Q3 = = 1095

Gráfico BOX-PLOT
Marca AMarca B
1° quartil 858,18 947,24Mínimo 680 815Mediana 889,5 1024,5Máximo 1099 12343°quartil 970 1095

RESULTADO DO DESAFIO:
I – o tempo médio de vida útil das lâmpadas A e B são
respectivamente: 894,65 horas e
1003,35 horas. = 1
II – comumente, as lâmpadas da marca A duram 852 horas e da as
marca B 1.077 horas; = 1
III – o tempo mediano de vida útil para a lâmpada da marca A é
910 horas e para a lâmpada
B é 1.015,5 horas; = 0
IV – de todas as medidas de tendência central obtidas no
estudo de caso em questão, a média
é a que melhor representa o tempo de vida útil da lâmpada da
marca B; = 0
V – a moda é a melhor medida representativa para a sequência
de dados referentes à
lâmpada da marca B; = 0
VI – a sequência de dados referentes à lâmpada da marca A
apresenta uma forte
concentração de dados em sua área central; = 1

VII – a lâmpada da marca B possui uma distribuição assimétrica
positiva; = 1
VIII – 75% dos valores apresentados na tabela 1, para a
lâmpada da marca A, possuem um
tempo de vida útil menor do que 971 horas; = 1
IX – 25% dos valores apresentados na tabela 1, para a lâmpada
da marca B, possuem um
tempo de vida útil maior do que 1.000 horas; = 0
X – os gráficos Box-Plot para os dados amostrais da lâmpada da
marca A e marca B são: = 1
Relatório 3 – Probabilidade
RESOLUÇÃO DO DESAFIO PROPOSTO
I – a probabilidade de a 1ª carta ser um às, a 2ª carta ser
uma figura e a 3ª carta ser um

Número é de 1,30317%;
Considerando que o baralho tem 52 duas cartas e no mesmo
baralho existem 4 às, 12 figuras e 36 números, resolveremos o
desafio.
Probabilidade de a 1º carta ser um às: 4/52
A segunda ser uma figura: 12/51
A terceira ser um número: 36/50
Multiplicando as três probabilidades temos: 1,30317%
Para realizarmos esses cálculos no Excel, primeiramente
organizaremos, em uma tabela todos os dados necessários para o
desenvolvimento dessa atividade, tais como a quantidade de às
números e figuras cada carta esta registrada em uma célula na
tabela, agora vamos encontrar o total de dados registrado,
para isso utilizaremos a formula “=CONT.VALORES(:), e
selecionaremos todas as células onde estão os dados assim o
Excel retornara o total de dados em nossa tabela. Agora
acharemos as frequências de ocorrências dos dados, e para isso
utilizaremos a formula “=CONT.SE(), e depois selecionaremos as
células da tabela que contém os dados e depois selecionaremos
uma outra célula onde teremos a condição para que o excel
busque na tabela o contagem de células correspondentes, que
nesse caso é Ás, números e figuras. Obtendo as frequências
podemos encontrar a probabilidade dos eventos ocorrerem, para
isso utilizaremos a formula “=(selecionado a célula referente
a frequência de um evento) / (que no excel representa divisão)
e (selecionamos o total de eventos)” assim o Excel nos
retornara a probabilidade do evento ocorrer.
Cartas Qnt. Probabilidade dos

eventos ocorreremÁs 4 1.333333333
Números 12 4Figuras 36 12
Total de
dados 3 As
frequênciasde
ocorrênciasdos dados 0
Afirmação correta
II – a probabilidade de todas as cartas serem um valete é de
4%;
Sabendo que temos quatro valetes no baralho, Temos:
4/52+3/51+2/50 = 0.1757466 transformando em porcentagem temos
17.57%
No Excel utilizaremos a formula ““=CONT.SE()” para termos a
quantidade de valetes no baralho, e por fim dividiremos pelo
total de dados para obtermos a probabilidade, que nesse caso
foi de 17,57%, ou seja:
Afirmação incorreta
III – a probabilidade de que pelo menos uma delas seja uma
carta de copas é de 58,647%
Sabendo que temos 12 copas em nosso baralho:
Probabilidade de sair copas na 1º = 12/52
Probabilidade de sair copas na 2º = 12/51
Probabilidade de sair copas na 3º = 12/50

Multiplicando as probabilidades temos 0,7060633484, que em
porcentagem representa 70,60%
Afirmativa incorreta
IV – a probabilidade de a 3ª carta ser de 7 de paus, sabendo
que a 1ª carta é um 8 de espadas e a 2ª carta um rei de ouros
é de 5,60412%
Sabendo que só temos um 7 de paus no baralho, e que já foram
retiradas duas carta do baralho podemos concluir que a
probabilidade de sair um 7 de paus na terceira carta é de
1/50, ou 0,02 que em porcentagem representa 2%, ou seja:
SEQUÊNCIA NÚMERICA:
(0,0,0,1).
1. Qual a probabilidade de sair o ás de ouros quando retiramos
uma carta de um baralho de 52 cartas?
Solução:
Num baralho comum há 52 cartas, sendo 13 de cada naipe.
As cartas são: A (ás), 2, 3, 4, 5, 6, 7, 8, 9, 10, J (valete),
Q (dama) e K(rei).
Os naipes são:
Os naipes são:
13 copas: 2 3 4 5 6 7 8 9 10 J Q K A
13 ouros: 2 3 4 5 6 7 8 9 10 J Q K A
13 naipe de paus: 2 3 4 5 6 7 8 9 10 J Q K A
13 espadas: 2 3 4 5 6 7 8 9 10 J Q K A

Como só há um ás de ouros, o número de elementos do evento é
1; logo: P = 1/52
2. Qual a probabilidade de sair um rei quando retiramos uma
carta de um baralho de 52 cartas?
Solução:
Como há 4 reis, o número de elementos do evento é 4; logo:
P = 4/52 = 1/13
7. De um baralho de 52 cartas retiram‐se, ao acaso, duas
cartas sem reposição. Qual a probabilidade da carta da
primeira carta ser o ás de paus e a segunda ser o rei de paus?
Solução:
A probabilidade de sair o ás de paus na primeira carta é: P1 =
1/52
Após a retirada da primeira carta, restam 51 cartas no
baralho, já que a carta
retirada não foi reposta. Assim, a probabilidade da segunda
ser o rei de paus é:
P2 = 1/51
Como esses dois acontecimentos são independentes, temos: P =
1/52 X 1/51 = 2.652
8. Qual a probabilidade de sair uma figura quando retiramos
uma carta de um baralho de 52 cartas?
Solução:
Temos: Pr = 4/52=1/13, Pd = 1/13, Pv =1/13

Como os eventos são mutuamente exclusivos, vem: P =
1/13+1/13+1/13=3/13
NOTA: Este problema pode ser resolvido, ainda, com o seguinte
raciocínio: Como em um
baralho temos 12 figuras (4 damas, 4 valetes, 4 reis), vem: P
=12/52=3/13
9. Qual a probabilidade de sair uma carta de copas ou de ouros
quando retiramos uma carta de um baralho de 52 cartas?
Solução:
Temos: Pc = 13/52 =1/4, Po =13/52 =1/4
Como os eventos são mutuamente exclusivos, vem: P =1/4 +1/4
=2/4 =1/2
11. São dados dois baralhos de 52 cartas. Tiramos, ao mesmo
tempo, uma carta do primeiro baralho e uma carta do
segundo. Qual é a probabilidade de tirarmos uma dama e um rei,
não necessariamente nessa ordem?
Solução:
A probabilidade de tirarmos uma dama do primeiro baralho
(4/52) e um rei do
segundo (4/52) é, de acordo com o problema 7: P1 =4/52 x4/52
=1/13 x1/13 =1/169
A probabilidade de tirarmos um rei do primeiro baralho e uma
dama do segundo é:
P2 =4/52 x4/52 =1/169

Como esses dois eventos são mutuamente exclusivos, temos: P
=1/169+1/169 =2/169
CORRELAÇÃO E REGRESSSÃO
CORRELAÇÃO
Ao se estudar uma variável o interesse eram as medidas de
tendência central, dispersão, Assimetria, etc. Com duas ou
mais variáveis além destas medidas individuais também é de
interesse.
Conhecer se elas tem algum relacionamento entre si, isto é, se
valores altos (baixos) de uma das variáveis implicam em
valores altos (ou baixos) da outra variável. Por exemplo,
pode-se verificar se existe associação entre a taxa de
desemprego e a taxa de criminalidade em uma grande cidade,
entre verba investida em propaganda e retorno nas vendas, etc.
A associação entre duas variáveis poder ser de dois tipos:
correlacional e experimental. Numa
relação experimental os valores de uma das variáveis são
controlados pela atribuição ao acaso do objeto sendo estudado
e observando o que acontece com os valores da outra variável.
Por exemplo, pode-se atribuir dosagens casuais de uma certa
droga e observar a resposta do organismo; pode-se atribuir
níveis de fertilizante ao acaso e observar as diferenças na
produção de uma determinada cultura.
No relacionamento correlacional, por outro lado, não se tem
nenhum controle sobre as variáveis sendo estudadas. Elas são
observadas como ocorrem no ambiente natural, sem nenhuma

interferência, isto é, as duas variáveis são aleatórias. Assim
a diferença entre as duas situações é que na experimental nós
atribuímos valores ao acaso de uma forma não tendenciosa e na
outra a atribuição é feita pela natureza.
Vários tipos de relacionamento entre as variáveis X e Y
Frequentemente é necessário estudar o relacionamento entre
duas ou mais variáveis. Ao estudo do relacionamento entre duas
ou mais variáveis denominamos de correlação e regressão. Se o
estudo tratar apenas de duas variáveis tem-se a correlação e a
regressão simples, se envolver mais do que duas variáveis,
tem-se a correlação e a regressão múltiplas. A regressão e a
correlação tratam apenas do relacionamento do tipo linear
entre duas variáveis.
A análise de correlação fornece um número que resume o grau de
relacionamento linear entre
as duas variáveis. Já a análise de regressão fornece uma
equação que descreve o comportamento de uma das variáveis em
função do comportamento da outra variável.
REGRESSÃO
Uma vez constatado que existe correlação linear entre duas
variáveis, pode-se tentar prever o
Comportamento de uma delas em função da variação da outra.
Para tanto será suposto que existem apenas duas variáveis. A
variável X (denominada variável
Controlada, explicativa ou independente) com valores
observados X1, X2, ..., Xn e a variável Y (denominada variável

dependente ou explicada) com valores Y1, Y2, ..., Yn. Os
valores de Y são aleatórios, pois eles dependem não apenas de
X, mas também de outras variáveis que não estão sendo
representadas no modelo. Estas variáveis são consideradas no
modelo através de um termo aleatório denominado “erro”. A
variável X pode ser aleatória ou então controlada.
Desta forma pode-se considerar que o modelo para o
relacionamento linear entre as variáveis X e Y seja
representado por uma equação do tipo: Y = α + βX + U, onde “U”
é o termo erro, isto é, “U” representa as outras influências
na variável Y além da exercida pela variável “X”.
Esta equação permite que Y seja maior ou menor do que α + βX,
dependendo de “U” ser positivo ou negativo. De forma ideal o
termo “U” deve ser pequeno e independente de X, de modo que se
possa modificar X, sem modificar “U”, e determinar o que
ocorrerá, em média, a Y, isto é:
E(Y/X) = α + βX
Os dados {(Xi, Yi), i = 1, 2, ..., n} podem ser representados
graficamente marcando-se cada par (Xi, Yi) como um ponto de um
plano. Os termos Ui são igual à distância vertical entre os
pontos observados (Xi, Yi), e os pontos calculados (Xi, α +
βXi).
Um modelo de regressão consiste em um conjunto de hipóteses
sobre a distribuição dos termos “erro” e as relações entre as
variáveis X e Y.
Algumas destas hipóteses são:
(i) E(Ui) = 0;
(ii) Var(Ui) = σ2

Na hipótese (i) o que se está supondo é que os Ui são
variáveis aleatórias independentes com valor esperado igual a
zero e na (ii) que a variância de cada Ui é a mesma e igual a
σ2 , para todos os valores de X.
Supõem-se ainda que a variável independente X, permaneça fixa,
em observações sucessivas e que a variável dependente Y seja
função linear de X. Os valores de Y devem ser independentes um
do outro. Isto ocorre em geral, mas em alguns casos, como, por
exemplo, observações diferentes são feitas no mesmo indivíduo
em diferentes pontos no tempo está suposição poderá não
ocorrer.
Como o valor esperado de Ui é zero, o valor esperado da
variável dependente Y, para um determinado valor de X, é dado
pela função de regressão α + βX ou seja:
E(Y/X) = E(α + βX + U) = α + βX + E(U) = α + βX [1]
já que α + βX é constante para cada valor de X dado.
O símbolo E(Y/X) é lido valor esperado de Y, dado X. A
variância de Y, para determinado valor de X, é igual a:
V(Y/X) = V(α + βX + U) = V(U) = σ2
A hipótese de que V(Y/X) é a mesma para todos os valores de X,
denominada de
homocedasticidade, é útil pois permite que se utilize cada uma
das observações sobre X e Y para estimar σ2 . O termo “homo”
significa “o mesmo” e “cedasticidade” significa “disperso”. De
[1] e [2] decorre que, para um dado valor de X, a variável

dependente Y tem função densidade de probabilidade
(condicional) com média α + βX e variância σ2
Na parte superior da figura é ilustrado o caso heterocedástico
e na parte inferior o
Caso homocedástico.
A posição da função densidade f(Y/X) varia em função da
variação do valor de X. Note-se que a média da função
densidade se desloca ao longo da função de regressão α + βX.
Em resumo, o modelo de regressão proposto consiste nas
seguintes hipóteses:
1. Y = α + βX + U;
2. E(Y/X) = α + βX;
3. V(Y/X) = σ2
;
4.
Cov(Ui, Uj) = 0, para i ≠ j;
5. A variável X permanece fixa em observações sucessivas;
6. Os erros U são normalmente distribuídos.
Probabilidade
Probabilidade tem como seu principal objetivo usar dados
coletados e descritos parar escrever resumos, tomar decisões e
formar conclusões.
A palavra probabilidade deriva do latin Probare (provar ou
testas). A palavra provável é utilizada para eventos incertos
ou conhecidos, tendo substituição por algumas palavras como

“sorte”, “risco”, “incerteza”, “duvidoso”, assim dependendo do
contexto.
Existe um conjunto de regras matemáticas para se manipular a
probabilidade e existem
regras para quantificar a incerteza as leis da probabilidade
tal como são entendidas.
Exemplo:
A probabilidade dede a primeira mala escolhida pelo
participante contenha $ 1.000.000,00 é de 1/26, pois há 26
malas no inicio do jogo e somente 1 mala contém $
1.000.000,00. A tabela mostra que a probabilidade de que o
participante contenha $ 1.000.000,00 se a mala com essa
quantia ainda não foi aberta.
Distribuições discretas de probabilidade
Em estatística, uma distribuição de probabilidade descreve a chance que uma variável pode assumir ao longo de um espaço de valores. Ela é uma função cujo domínio são os valores da variável e cuja imagem são as probabilidades de a variável assumir cada valor do domínio. O conjunto imagem deste tipo de função está sempre restrito ao intervalo entre 0 e 1.
Distribuição normal de probabilidade
A distribuição normal é uma das mais importantes distribuições da estatística, conhecida também como Distribuição de Gauss ou Gaussiana.Foi primeiramente introduzida pelo matemático
Além de descrever uma série de fenômenos físicos e financeiros, possui grande uso na estatística inferência. E inteiramente descrita por seus parâmetros de media e desvio padrão, ou seja, conhecendo-se estes consegue-se determinar qualquer probabilidade em uma distribuição Normal.

Um interessante uso da Distribuição Normal é que ela serve de aproximação para o cálculo de outras distribuições quando o número de observações fica grande. Essa importante propriedade provém do Teorema do limite central que diz que "toda soma de variáveis aleatóriasindependentes de média finita e variância limitada é aproximadamente Normal, desde que o número de termos da soma seja suficientemente grande" (ver o teorema para um enunciado mais preciso).
Em teoria da probabilidade e estatística, correlação, também chamada de coeficiente de correlação, indica a força e a direção do relacionamento linear entre duas vaiáveis aleatórias. No uso estatístico geral, correlação ou co-relação se refere a medida da relação entre duas variáveis, embora correlação não implique causalidade. Neste sentido geral,existem vários coeficientes medindo o grau de correlação, adaptados à natureza dos dados.
Vários coeficientes são utilizados para situações diferentes. O mais conhecido é coeficiente de correção de Pearson , o qual é obtido dividindo a covariância de duas variáveis pelo produto de seus desvios padrão. Apesar do nome, ela foi apresentada inicialmente por Francis Galton.
A correlação falha em capturar dependência em algumas instancias.
Em geral é possível mostrar que há pares de variáveis aleatórias com forte dependência estatística e que no entanto apresentam correlação nula. Para esse caso devem-se usar outras medidas de dependência.
REFERÊNCIAS BIBLIOGRÁFICAS
http://www.portalaction.com.br/content/31-boxplot
http://usuariosdoexcel.wordpress.com/2011/07/04/graficos-box-
whisker/

https://docs.google.com/file/d/0B30OueqS8kbtSGMybTBHQ2dVZnc/
edit?usp=sharing
https://docs.google.com/file/d/0B30OueqS8kbtQnlUbm1EazRXdGc/
edit?usp=sharing
LARSON, Ron; FARBER, Betsy. Estatística aplicada. 2ª ed. São
Paulo: Pearson, 2008.




















