
A heat shock protein70 fusion protein with α1-antitrypsin in plasma of Type 1 diabetic subjects
Upload
independentCategory
view
3download
0
doi:10.1006/jmbi.2000.3642 available online at http://www.idealibrary.com on J. Mol. Biol. (2000) 297, 1183±1194
Structural Basis of Recognition of Monopartite andBipartite Nuclear Localization Sequences byMammalian Importin-aaa
Marcos R. M. Fontes, Trazel Teh and Bostjan Kobe*
Structural Biology LaboratorySt. Vincent's Institute ofMedical Research, 41 VictoriaParade, Fitzroy, Victoria 3065Australia
M.R.M.F. is on leave from DeptoInstituto de BiocieÃncias, UNESP, Ca18618-000, Botucatu/SP, Brazil.
Abbreviations used: Arm repeatsImpa(70-529), importin-a lacking thresidues; NLS, nuclear localizationnuclear pore complex; SV40, simianpeptide 126PKKKRKV132 correspondthe SV40 large T-antigen; nucleopla155KRPAATKKAGQAKKKK170 corrNLS of nucleoplasmin.
E-mail address of the [email protected]
0022-2836/00/051183±12 $35.00/0
Importin-a is the nuclear import receptor that recognizes cargo proteinswhich contain classical monopartite and bipartite nuclear localizationsequences (NLSs), and facilitates their transport into the nucleus. Todetermine the structural basis of the recognition of the two classes ofNLSs by mammalian importin-a, we co-crystallized an N-terminally trun-cated mouse receptor protein with peptides corresponding to the mono-partite NLS from the simian virus 40 (SV40) large T-antigen, and thebipartite NLS from nucleoplasmin. We show that the monopartite SV40large T-antigen NLS binds to two binding sites on the receptor, similar towhat was observed in yeast importin-a. The nucleoplasmin NLS-impor-tin-a complex shows, for the ®rst time, the mode of binding of bipartiteNLSs to the receptor. The two basic clusters in the NLS occupy the twobinding sites used by the monopartite NLS, while the sequence linkingthe two basic clusters is poorly ordered, consistent with its tolerance tomutations. The structures explain the structural basis for binding ofdiverse NLSs to the sole receptor protein.
# 2000 Academic Press
Keywords: importin-a/karyopherin-a; nuclear localization sequence (NLS)recognition; nucleoplasmin NLS; simian virus 40 (SV40) large T-antigenNLS; X-ray crystal structure
*Corresponding authorIntroduction
Nucleocytoplasmic transport occurs throughnuclear pore complexes (NPCs) that penetrate thedouble lipid layer of the nuclear envelope. NPCsare large structures, 125 MDa in mass, that contain50-100 distinct polypeptides in vertebrates. In prin-ciple, molecules of up to 9 nm in diameter(�60 kDa) can freely diffuse through the NPCs; inpractice, however, most macromolecules require anactive, signal-mediated transport process thatenables the passage of particles up to 25 nm in
. de FõÂsica e BiofõÂsicaixa Postal 510,
, armadillo repeats;e N-terminal 69sequence; NPC,
virus 40; SV40 NLS,ing to the NLS ofsmin NLS, peptideesponding to the
ing author:
diameter (�25 MDa). The ®rst and best character-ized nuclear targeting signals are the classicalnuclear localization sequences (NLSs) that containone or more clusters of basic amino acids(Dingwall & Laskey, 1991). The NLSs do not con-form to a speci®c consensus sequence, and fall intotwo distinct classes termed monopartite NLSs, con-taining a single cluster of basic amino acids, andbipartite NLSs, containing two basic clusters. Thetwo basic clusters in bipartite NLSs are interdepen-dent; a smaller upstream cluster, containing as fewas two lysine or arginine residues, is separated bya mutation-tolerant linker from a downstream clus-ter that resembles a monopartite NLS. Both clustersare usually required for nuclear targeting, and thepresence of the upstream cluster appears to relaxthe stringent requirements of monopartite signals(Robbins et al., 1991).
Despite the variability, the classical NLSs arerecognized by the same receptor protein termedimportin or karyopherin, a heterodimer of a and bsubunits (see recent reviews: Adam, 1999; Chooket al., 1999; Dingwall & Laskey, 1999; Gamblin &Smerdon, 1999; Hood & Silver, 1999; Kohler et al.,1999a; Macara, 1999; Mattaj & Conti, 1999;
# 2000 Academic Press

1184 NLS Recognition by Mammalian Importin-�
Moroianu, 1999; Sekimoto & Yoneda, 1999; Stewart& Rhodes, 1999; Talcott & Moore, 1999), for theprimary references on the characterization of thenuclear transport pathways and the nomenclatureof proteins involved). Importin-a contains the NLS-binding site and importin-b is responsible for thedocking of the importin-substrate complex to thecytoplasmic ®laments of the NPC and its transloca-tion through the pore. The transfer through thepore is facilitated by the proteins Ran (Ras-relatednuclear protein) and nuclear transport factor-2(NTF2). Once inside the nucleus, importin-b bindsto Ran-GTP, which causes the dissociation of theimport complex and importin-a becomes autoin-hibited; the importin subunits return to the nucleusseparately and without the cargo. The directional-ity of nuclear import is thought to be conferred byan asymmetric distribution of the GTP and GDP-bound forms of Ran between the cytoplasm andthe nucleus. This distribution is in turn controlledby various Ran regulatory proteins.
Importin-a consists of two structural and func-tional domains, a short basic N-terminal importin-b binding (IBB) domain (Gorlich et al., 1996; Weiset al., 1996; Moroianu et al., 1996), and a large NLS-binding domain built of armadillo (Arm) repeats(Peifer et al., 1996). The structural basis of NLS rec-ognition by importin-a was ®rst revealed by thecrystal structure of a truncated fragment of yeastimportin-a (residues 88-530; Kapa50) soaked witha peptide corresponding to the monopartite NLS ofthe simian virus 40 (SV40) large T-antigen (Contiet al., 1998). Further insights into the recognitionprocess have been obtained by the crystal structureof full-length mouse importin-a, which revealed anautoinhibitory pseudo-NLS within the N-terminaldomain (Kobe, 1999).
We now present a crystallographic analysis ofmonopartite and bipartite NLS binding to mamma-lian importin-a. To create the high af®nity receptor,we prepared a truncated mouse protein that lacksthe autoinhibitory sequence, and co-crystallized itwith peptides corresponding to the monopartiteNLS of the SV40 large T-antigen (SV40 NLS),126PKKKRKV132, and the bipartite NLS of nucleo-plasmin, 155KRPAATKKAGQAKKKK170. The struc-ture of the SV40 NLS-importin-a complex showstwo peptide binding sites, analogous to yeastKapa50 (Conti et al., 1998). The structure of impor-tin-a -nucleoplasmin NLS complex reveals, for the®rst time, the binding of a bipartite NLS to thereceptor. As predicted (Conti et al., 1998; Kobe,1999), the bipartite NLS spans the two bindingsites, each recognizing one of the basic clusters.The linker sequence between the two basic clustersmakes few contacts with the receptor, consistentwith its tolerance to mutations. For both peptides,there is evidence for the peptide binding simul-taneously in alternative modes. Our results explainthe structural determinants of diverse NLS bindingby the same receptor.
Results
Expression of truncated mouse importin-aaa,crystallization and structure determination
In the structure of full-length mouse importin-a(Kobe, 1999) the NLS binding site is occupied byan N-terminal autoinhibitory sequence (residues44-54; residues 1-43 and 55-69 are mobile).Although NLSs can bind to importin-a in theabsence of its activator importin-b (Hubner et al.,1997), the competition between the NLS and theautoinhibitory sequence could make the interpret-ation of the structural results dif®cult. We thereforeexpressed an N-terminally truncated importin-alacking residues 1-69 (Impa(70-529)).
Impa(70-529) crystallized in similar conditionsand isomorphously to the full-length importin-a(data not shown). Following soaking of these crys-tals with SV40 and nucleoplasmin NLS peptides,the electron density maps showed evidence forpeptide binding, but there was also loss of resol-ution. We consequently used co-crystallization toprepare the complex crystals. The co-crystals withboth peptides grow in similar conditions and iso-morphously to the native importin-a and Impa(70-529) (Table 1). Electron density maps based on theimportin-a model, following rigid body re®nement,clearly showed electron density corresponding tothe peptides. The structures were re®ned at 2.8and 2.9 AÊ resolution for SV40 and nucleoplasminNLS complexes, respectively (Table 1). Despite thelimited resolution, the conformation of the SV40NLS in two sites of the protein could unambigu-ously be interpreted in the electron density map(Figure 1 (a) and (b)). Similarly, the electron den-sity maps allowed the structure of the nucleoplas-min NLS to be unambiguously assigned for mostof the chain, except for the central region of thepeptide where few contacts are made with the pro-tein, the electron density is of poorer quality andthe model is consequently tentative (Figure 1 (c)).The electron density maps show some evidence ofpossible staggering of the peptides in the bindingsite, i.e. binding in alternative registers to the pro-tein. The major binding mode is discussed in detailin this section, but the implications of staggeringare addressed in Discussion.
Structure of importin-aaa in the complexes
Impa(70-529) forms a single elongated domainbuilt from ten Arm structural repeats (Figure 2),each containing three a-helices (H1, H2 and H3)connected by loops (Figure 2). The structure ofimportin-a is essentially identical in the crystals ofthe two complexes and of the full-length importin-a (r.m.s. deviations of Ca atoms of residues 72-496are 0.27 AÊ between SV40 and nucleoplasmin-Impa(70-529) complexes, and 0.24 and 0.27 AÊ
between full-length importin-a, and SV40 andnucleoplasmin-Impa(70-529) complexes, respect-ively).

Table 1. Structure determination
Diffraction data statistics SV40 NLS Nucleoplasmin NLS
Unit cell dimensions (AÊ )a 78.2 78.9b 89.9 89.8c 99.5 99.9
Resolution (AÊ ) 30-2.80 30-2.90Observations 126,036 121,070Unique reflections 17,900 (1669)a 16,370 (1598)a
Completeness (%) 93.1 (95.6)a 98.9 (100)a
Rmergeb (%) 15.9 (74.2)a 23.9 (96.2)a
Average I/s(I) 9.0 (1.6)a 7.2 (1.3)a
Refinement statisticsResolution (AÊ ) 40-2.8 40-2.9Number of reflections (F > 0) 16,610 (1667)a 16,102 (1590)a
Completeness (%) 93.1 (94.7)a 98.8 (100)a
Rcrystc (%) 21.5 (33.3)a 22.3 (34.5)a
Rfreed (%) 25.4 (41.2)a 26.8 (35.5)a
Number of non-hydrogen atoms:Protein 3245 3245Peptide 124 122
Mean B-factor (AÊ 2) 41.4 37.2r.m.s deviations from ideal values e:
Bond lengths (AÊ ) 0.007 0.008Bond angles (deg.) 1.2 1.4
Ramachandran plotf:Residues in most favored (disallowed) regions (%) 93.5 (0.3) 93.8 (0.3)
Coordinate error (AÊ ) e:Luzzati plot (cross-validated Luzzati plot) 0.34 (0.44) 0.36 (0.45)SIGMAA (cross-validated SIGMAA) 0.48 (0.58) 0.51 (0.55)
a Numbers in parentheses are for the highest resolution shell, 2.9-2.8 AÊ for SV40 NLS, 3.0-2.9 AÊ for nucleoplasmin NLS.b Rmerge � �hkl(�i(jIhkl,i ÿ hIhklij))/�hkl,ihIhkli, where Ihkl,i is the intensity of an individual measurement of the re¯ection with Miller
indices h, k and l, and hIhkli is the mean intensity of that re¯ection. Calculated for I > ÿ 3s(I).c Rcryst � �hkl(jjFobshklj ÿ jFcalchkljj)/jFobshklj, where jFobshklj and jFcalchklj are the observed and calculated structure factor ampli-
tudes.d Rfree is equivalent to Rcryst but calculated with re¯ections (10 %) omitted from the re®nement process.e Calculated with the program CNS (BruÈ nger et al., 1998).f Calculated with the program PROCHECK (Laskowski et al., 1993).
NLS Recognition by Mammalian Importin-� 1185
Binding of the monopartite SV40 NLSto importin-aaa
The peptide corresponding to the SV40 NLS,126PKKKRKV132, binds at two sites on the surfaceof the Impa(70-529) molecule (Figure 2(a)). In bothsites electron density is present for all seven pep-tide residues (Figure 1(a) and (b)). The peptideappears better ordered at the site in the N-terminalregion of importin-a, comprising residues betweenthe ®rst and fourth Arm motifs; this site will bereferred to as the major site. The second site(minor site) comprises residues between the fourthand eighth Arm motifs. The difference in peptideorder is re¯ected in the average B-factors for thepeptide, 35.3 and 78.9 AÊ 2 for the major and minorsites, respectively (the average B-factor forImpa(70-529) is 40.7 AÊ 2).
There is 1314 AÊ 2 of surface area buriedbetween the peptide and Impa(70-529) in themajor site (149 contacts <4 AÊ ), and 1194 AÊ 2 inthe minor site (110 contacts <4 AÊ ) (Supplemen-tary Figure 1). SV40 NLS residues 128-132 in themajor site have B-factors below the averagenumber for the entire structure, but the mobilitystarts increasing towards the termini, particularly
in the N-terminal direction. In the minor site,the B-factors are lowest for residues 127 and128, but still above the average for the entirestructure.
The general features of peptide bindingresemble those observed in yeast Kapa50 (Contiet al., 1998). Because of the repetitive structure ofthe Arm repeats, the binding at both sites exhi-bits similar features (Supplementary Figure 2).The peptides bind in an extended conformation,with the chain running antiparallel to the direc-tion of the Arm repeat superhelix. The base ofthe groove that contains the binding sites isformed mainly by the H3 helices of the Armrepeats, which carry some residues conservedamong the repeats, including the tryptophan andasparagine residues at the third and fourth turnsin H3 helices of the Arm repeats, respectively.All residues interacting with the peptides arepart of the H3 helices or sequences ¯ankingthese helices on the C-terminal end. The bindingsites exhibit four main features: (i) polar inter-actions through the conserved asparagine side-chains that bind the NLS backbone anddetermine its chain direction; (ii) hydrophobic
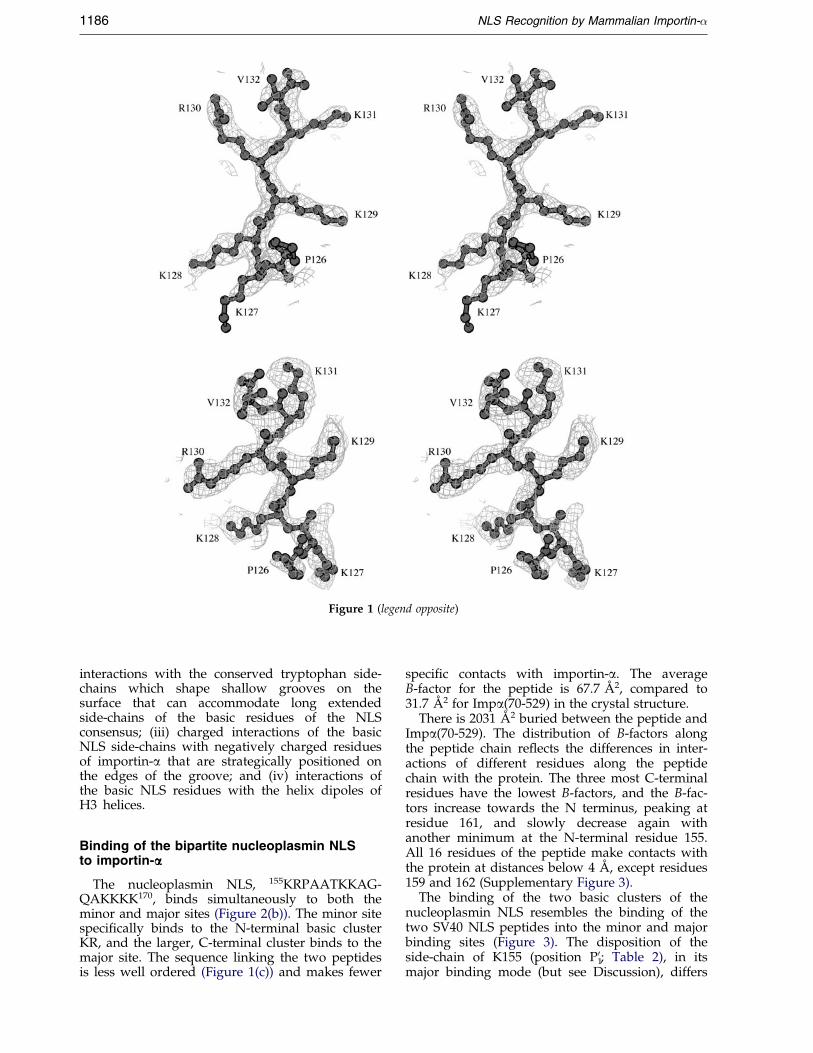
Figure 1 (legend opposite)
1186 NLS Recognition by Mammalian Importin-�
interactions with the conserved tryptophan side-chains which shape shallow grooves on thesurface that can accommodate long extendedside-chains of the basic residues of the NLSconsensus; (iii) charged interactions of the basicNLS side-chains with negatively charged residuesof importin-a that are strategically positioned onthe edges of the groove; and (iv) interactions ofthe basic NLS residues with the helix dipoles ofH3 helices.
Binding of the bipartite nucleoplasmin NLSto importin-aaa
The nucleoplasmin NLS, 155KRPAATKKAG-QAKKKK170, binds simultaneously to both theminor and major sites (Figure 2(b)). The minor sitespeci®cally binds to the N-terminal basic clusterKR, and the larger, C-terminal cluster binds to themajor site. The sequence linking the two peptidesis less well ordered (Figure 1(c)) and makes fewer
speci®c contacts with importin-a. The averageB-factor for the peptide is 67.7 AÊ 2, compared to31.7 AÊ 2 for Impa(70-529) in the crystal structure.
There is 2031 AÊ 2 buried between the peptide andImpa(70-529). The distribution of B-factors alongthe peptide chain re¯ects the differences in inter-actions of different residues along the peptidechain with the protein. The three most C-terminalresidues have the lowest B-factors, and the B-fac-tors increase towards the N terminus, peaking atresidue 161, and slowly decrease again withanother minimum at the N-terminal residue 155.All 16 residues of the peptide make contacts withthe protein at distances below 4 AÊ , except residues159 and 162 (Supplementary Figure 3).
The binding of the two basic clusters of thenucleoplasmin NLS resembles the binding of thetwo SV40 NLS peptides into the minor and majorbinding sites (Figure 3). The disposition of theside-chain of K155 (position P1
0; Table 2), in itsmajor binding mode (but see Discussion), differs

Figure 1. (a) Stereoview of the electron density (drawn with the program BOBSCRIPT; Esnouf, 1997) in the regionof the SV40 NLS peptide bound to the major binding site of Impa(70-529). All peptide residues were omitted fromthe model and simulated annealing run with the starting temperature of 1000 K. The electron density map was calcu-lated with coef®cients 3jFobsj ÿ 2jFcalcj and data between 40 and 2.8 AÊ resolution, and contoured at 1.5 standard devi-ations. Superimposed is the re®ned model of the peptide. (b) Stereoview of the electron density (contoured at 1.2standard deviations) in the region of the SV40 NLS peptide bound to the minor binding site of Impa(70-529), shownas in (a). (c) Stereoview of the electron density in the region of the nucleoplasmin NLS peptide bound to the minorbinding site of Impa(70-529), shown as in (a). The electron density was calculated using data between 40 and 2.9 AÊ
resolution, and contoured at 1.0 standard deviation.
NLS Recognition by Mammalian Importin-� 1187
from that of the side-chain of SV40 NLS (K128) inthe analogous position; it instead follows the pathof the main chain and side-chain of K127 of SV40NLS. In this mode, the amino group is unable tomake any speci®c short-range polar contacts. R156(position P2
0), on the other hand, superimposesclosely with SV40 NLS K129 (Figure 3). Furthertowards the C terminus, the peptide follows thesame path as SV40 NLS until residue A158 (SV40K131); at this point, the chain turns sharply inSV40 NLS, whereas nucleoplasmin continues in amore linear fashion. The main chain lifts up out ofthe pocket at residue K161, to avoid collision withthe side-chain of importin-a R315. The chain climbsback down closer to the surface of the groove withresidue A163, and joins the path of the main chainof SV40 NLS in the major binding site with residueQ165. Residues 166-169 superimpose closely withSV40 NLS residues 127-130. The side-chain of theC-terminal residue, K170, in its major bindingmode follows the path of the main chain of theSV40 residues 131-132 and points into solution.
The bipartite NLS ``linker'' or ``spacer'' sequencethat connects the two basic clusters makes fewfavorable interactions with importin-a, and is con-sequently poorly ordered and our model is rathertentative in the region 159-164. In our model,speci®c polar contacts made in this region includethe interactions of nucleoplasmin main chain withR315 side-chain (contacts nucleoplasmin A159),R238 side-chain (contacts nucleoplasmin G163 andQ164) and W231 side-chain (contacts nucleoplas-min Q164), and the interaction of nucleoplasminK161 side-chain with R315.
Discussion
Comparison of SV40 NLS binding to mouseand yeast importin-aaa
The mode of binding of a nonameric peptidecontaining the SV40 NLS, 125SPKKKRKVE133, tothe N-terminally truncated yeast importin-a homo-log, Kapa50, has previously been studied (Conti
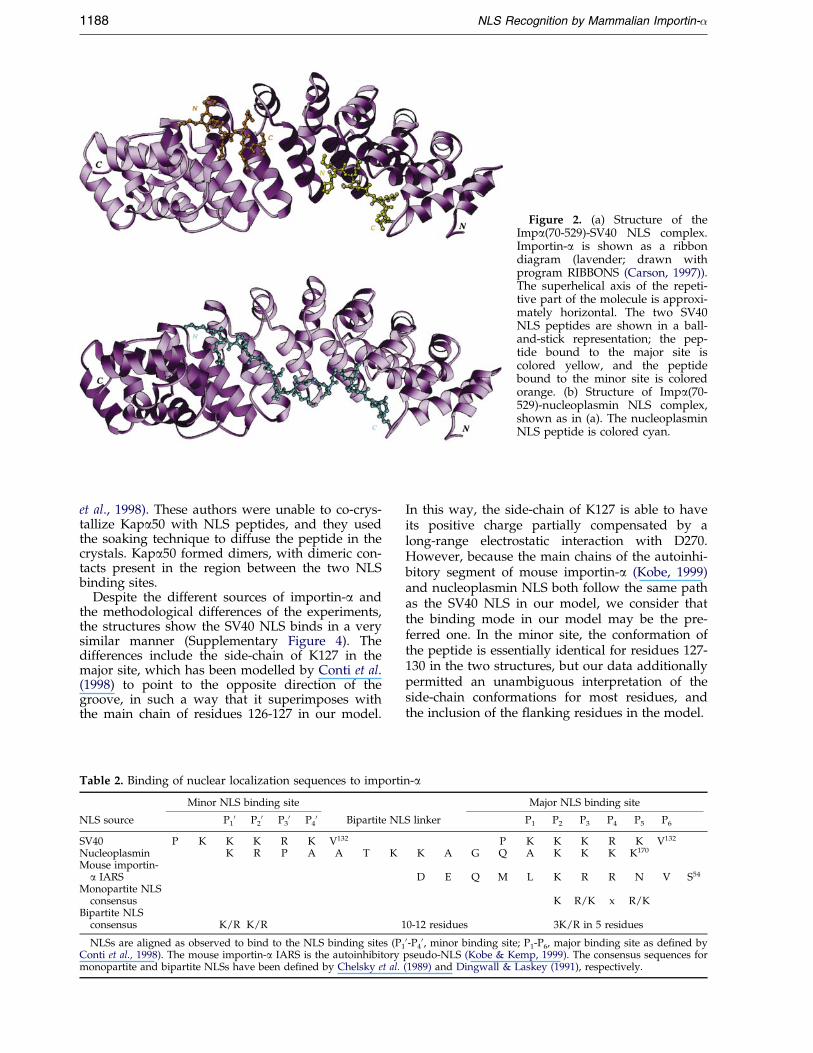
Figure 2. (a) Structure of theImpa(70-529)-SV40 NLS complex.Importin-a is shown as a ribbondiagram (lavender; drawn withprogram RIBBONS (Carson, 1997)).The superhelical axis of the repeti-tive part of the molecule is approxi-mately horizontal. The two SV40NLS peptides are shown in a ball-and-stick representation; the pep-tide bound to the major site iscolored yellow, and the peptidebound to the minor site is coloredorange. (b) Structure of Impa(70-529)-nucleoplasmin NLS complex,shown as in (a). The nucleoplasminNLS peptide is colored cyan.
1188 NLS Recognition by Mammalian Importin-�
et al., 1998). These authors were unable to co-crys-tallize Kapa50 with NLS peptides, and they usedthe soaking technique to diffuse the peptide in thecrystals. Kapa50 formed dimers, with dimeric con-tacts present in the region between the two NLSbinding sites.
Despite the different sources of importin-a andthe methodological differences of the experiments,the structures show the SV40 NLS binds in a verysimilar manner (Supplementary Figure 4). Thedifferences include the side-chain of K127 in themajor site, which has been modelled by Conti et al.(1998) to point to the opposite direction of thegroove, in such a way that it superimposes withthe main chain of residues 126-127 in our model.
Table 2. Binding of nuclear localization sequences to importi
Minor NLS binding site
NLS source P10 P2
0 P30 P4
0 Bipartite NL
SV40 P K K K R K V132
Nucleoplasmin K R P A A T KMouse importin-
a IARSMonopartite NLS
consensusBipartite NLS
consensus K/R K/R 1
NLSs are aligned as observed to bind to the NLS binding sites (P1
Conti et al., 1998). The mouse importin-a IARS is the autoinhibitorymonopartite and bipartite NLSs have been de®ned by Chelsky et al.
In this way, the side-chain of K127 is able to haveits positive charge partially compensated by along-range electrostatic interaction with D270.However, because the main chains of the autoinhi-bitory segment of mouse importin-a (Kobe, 1999)and nucleoplasmin NLS both follow the same pathas the SV40 NLS in our model, we consider thatthe binding mode in our model may be the pre-ferred one. In the minor site, the conformation ofthe peptide is essentially identical for residues 127-130 in the two structures, but our data additionallypermitted an unambiguous interpretation of theside-chain conformations for most residues, andthe inclusion of the ¯anking residues in the model.
n-a
Major NLS binding site
S linker P1 P2 P3 P4 P5 P6
P K K K R K V132
K A G Q A K K K K170
D E Q M L K R R N V S54
K R/K x R/K
0-12 residues 3K/R in 5 residues
0-P40, minor binding site; P1-P6, major binding site as de®ned by
pseudo-NLS (Kobe & Kemp, 1999). The consensus sequences for(1989) and Dingwall & Laskey (1991), respectively.

Figure 3. Superposition of the nucleoplasmin (cyan) and the two SV40 NLS peptides (major site, yellow; minorsite, orange). The Ca atoms of Impa(70-529) in the two complex structures were used in the superposition. Drawnwith the program RIBBONS (Carson, 1997).
NLS Recognition by Mammalian Importin-� 1189
All the available structural information onimportin-a-NLS recognition is of relatively limitedresolution, and the electron density is not of par-ticularly high quality in the regions where themodels differ; for these reasons, the electron den-sity corresponding to the peptide main chain couldin some cases be erroneously interpreted as side-chain density, especially near the terminal residuesof the peptides. Further structural information, pre-ferably at higher resolution, will be very useful tohelp understand the details of NLS binding toimportin-a.
Comparison of the binding of NLS peptidesand the autoinhibitory segment to importin-aaa
The autoinhibitory sequence comprising residues44-54 of importin-a binds to the major NLS bind-ing site, resembling NLS binding (Kobe, 1999). Thepath of the main chain of residues 47-53 is identicalwith the path of SV40 and nucleoplasmin NLS resi-dues in the major binding site. Only residues 44-46bind in a different mode than the analogousnucleoplasmin residues; however, in either case,few favorable interactions are formed in theseregions with the protein, and the chains are poorlyordered.
Alternative binding modes
The electron density maps for both complexesshow evidence for possible binding of the samepeptide in alternative binding modes, includingalternative rotamer conformations for some side-chains, and staggering of the peptide resulting indifferent alignments of the peptide residues withthe binding pockets. Examples include, for nucleo-plasmin NLS, the electron density in the vicinity ofthe P5, P1
0 (alternative rotamers), P6 (staggering ofKKKK cluster one position C-terminally) and P3
0-P40
(staggering of KR cluster two positions C-termin-ally) positions, and for SV40 NLS, the N-terminalportion in the minor binding site (staggering oneposition N-terminally).
Although the binding in alternative modesobserved in our structure could be limited to the
particular peptides chosen in the study, and the¯anking sequences present in intact protein car-goes may restrict the binding modes, it is import-ant for the possibility of staggering to be taken intoaccount when trying to understand the kineticsand thermodynamics of the interaction. If higherresolution diffraction data become available in thefuture, it may be possible to estimate the occu-pancies of the alternative modes.
A comparison of the previously proposed (Kobe,1999) theoretical model of nucleoplasmin NLS-importin-a complex with the crystal structurereveals a misalignment of the C-terminal basiccluster for one position. This observation, jointlywith the experimental evidence for simultaneousbinding in alternative binding modes, points to thefact that the prediction of the binding modes ofvarious NLSs may be dif®cult in the absence ofexperimental structural information.
Specificity determinants of NLS binding
The surface groove created by the Arm repeatstructure of importin-a represents an exceptionalsurface feature for binding of extended peptidessuch as the NLSs. The spacing of the Arm structur-al motifs appears to be commensurate with thespacing of amino acids in the peptide, and thepositioning of strategic amino acid side-chains inconserved consensus positions of the Arm repeatscreates a ladder of binding sites for individualamino acids in the peptide (Figure 4).
The two main importin-a-speci®c Arm repeatconsensus positions used to create the NLS bind-ing site are the tryptophan residues located atthe third turn of H3 helices, and asparagine resi-dues located at the fourth turn of the helix. Theasparagine side-chains bind the peptide mainchain through the carbonyl groups and de®nethe extended conformation and the direction ofbinding. The sequence speci®city is provided byother features of the binding site. The trypto-phan side-chains produce binding sites for longextended aliphatic side-chains on one side of thegroove; on the other side, the binding sites forside-chains are created by the Arm repeat struc-

Figure 4. Schematic diagram ofthe interactions of NLS peptideswith importin-a. The NLS back-bone is shown as a black line, withthe side-chains shown as perpen-dicular lines radiating from it. Indi-vidual Arm repeats of importin-aare separated by tilted lines. Someimportin-a side-chains interactingwith the NLS peptides are indi-cated: the invariant asparagine resi-dues in magenta, the invarianttryptophan residues in green, andsome nearby negatively chargedresidues are shown in red. Y277and R315 that interrupt the regularasparagine and tryptophan arrayare also shown.
1190 NLS Recognition by Mammalian Importin-�
ture itself, through the shallow grooves betweenthe ends of H3 helices, and the helix dipoles ofH3 helices create some negative potential at thisedge. Further speci®city is determined by impor-tin-a side-chains in other strategic locations atthe edges of the groove. Most of the latter resi-dues are not conserved at the same Arm repeatconsensus positions, thus creating some variationin the binding pockets for different NLS pos-itions. This may be important to reduce theoccurrence of staggering.
The rotamer conformations of all the invariantasparagine residues in the NLS binding site (resi-dues 146, 188, 235, 319, 361 and 403) are identical(the most common rotamer in the rotamer database(Jones et al., 1991)), resulting in a very regulararray for binding the NLS backbone, that is onlyinterrupted in Arm5 where tyrosine occupies theanalogous position. On the other hand, the invar-iant tryptophan residues have more diverse rota-mer conformations; W273 and W399 adopt themost common rotamer conformation in the rota-mer database, W231 and W357 adopt the secondmost common rotamer conformation, while W142and W184 have a rare conformation with the ringrotated 90 � relative to the conformation of W231and W357. The tryptophan array is further inter-rupted by R315 in the equivalent position in Arm6.This creates diversity in side-chain binding.
Speci®city determinants can be explained if weanalyze the binding pockets for the individualamino acid residues of the NLS. The positions thatare best de®ned and consistent among the struc-tures available are P2-P5 in the major binding siteand P1
0-P20 in the minor binding site. The conserved
tryptophan pairs from neighboring repeats createthe binding sites for the side-chains in P2
0, P3 and P5
positions, thus selecting for long aliphatic side-chains. Positive charges are compensated at a shortrange at positions P2
0, P40, and P2, and at a longer
range in positions P10, P3 and P5. Positive charges
will also be partially neutralized by helix H3dipoles at positions P1
0, P30, P1, P2 and P4. Positively
charged amino acids will therefore be particularlystrongly selected for in positions P2
0 and P2, butalso in positions P1
0, P3 and P5. This pattern entirelyreproduces the consensus determined by sequenceanalyses of many NLSs and mutational studies(Chelsky et al., 1989; Dingwall & Laskey, 1991;Table 2).
The structural interpretations correlate well withmutagenesis studies of SV40 NLS. Only the bind-ing to the major site may be physiologically rel-evant (Conti et al., 1998). A basic residue inposition P2 was found to be of crucial importance(Lanford & Butel, 1984; Kalderon et al., 1984a,b;Colledge et al., 1986). Even an arginine residue atthis position severely reduced nuclear accumu-lation (Colledge et al., 1986); in our structure, theside-chain nitrogen atom makes close polar con-tacts with D192, G150 and T155, suggesting anarginine side-chain may be too long to achieve thesame favorable bonding arrangement and wouldlikely destabilize main-chain interactions of theNLS by pushing it out of an optimal position. Thestructures suggest P3 could accommodate bothlysine and arginine, but would simultaneouslyappear to be less selective for basic residues, as thecompensating negative charges on the protein arelocated further away; mutant SV40 NLSs withmethionine and threonine at this position stilldirect some protein into the nucleus (Kalderonet al., 1984a). The P4 pocket does not compensatefor positive charge, but appears suited for bindinglong hydrophilic side-chains, including lysine orarginine residues found at this position in SV40and nucleoplasmin NLSs. Accordingly, shorterside-chains such as isoleucine or threonine do notfunction as well in the context of SV40 NLS(Kalderon et al., 1984a). At the P5 position, the com-pensating negative charge is located even fartheraway than at the P3 position, making this position

NLS Recognition by Mammalian Importin-� 1191
accessible to both arginine and lysine (Kalderonet al., 1984a), and even less selective for basic resi-dues; accordingly, methionine (Colledge et al.,1986), and to a lesser extent threonine (Kalderonet al., 1984a), side-chains in this position in thecontext of SV40 NLS retain substantial nuclearlocalization activity. The available structures alsosuggest that there may not be much requirementfor a basic residue at the P1 position, consistentwith mutagenesis studies (Kalderon et al., 1984a).
The results of mutagenesis studies of nucleoplas-min NLS similarly underscore the structural obser-vations. The lysine residue that binds into the P2
pocket is also the most important speci®city deter-minant in the nucleoplasmin NLS; the effects ofmutating other lysine residues in the larger basiccluster and combinations of these lysine residues(Robbins et al., 1991) are consistent with mutationsof SV40 NLS and the structural explanations pre-sented above. The P1
0 position favors lysine but canaccommodate arginine, consistent with the distanceto a negatively charged residue in this pocket inthe binding mode observed for SV40 NLS (Robbinset al., 1991); this is likely to be the preferred bind-ing mode for nucleoplasmin NLS in the context ofthe intact protein or peptides with N-terminal¯anking sequences present. The linker sequencebetween the two basic clusters is tolerant to var-ious mutations and insertions (Robbins et al., 1991;Makkerh et al., 1996), consistent with few favorableinteractions formed in this region. However, theinsertion of a more bulky and hydrophobic QPWLsequence reduced the targeting ef®ciency (Robbinset al., 1991). This suggests that sequences ¯ankingthe basic clusters do affect NLS binding to impor-tin-a, as also observed through mutagenesis of¯anking sequences in the context of SV40 and theoncoprotein c-Myc NLSs (Makkerh et al., 1996).Proline residues in the ¯anking regions oftenappear to have a positive effect on NLS activity,likely by reducing the energetic cost of binding byrestraining the NLS sequences in the extended con-formation. The more stringent sequence require-ments of the basic cluster of the monopartite NLSsare relaxed in the bipartite NLSs (Makkerh et al.,1996), by the second basic cluster compensating forthe reduction of favorable contacts in the majorsite.
Our structures ®nally suggest that residues at P30
and P40 positions may play a role, albeit minor, in
bipartite NLS binding. Indeed, many bipartiteNLSs contain more than two positively chargedresidues in the N-terminal basic cluster (Jans &Hubner, 1996) that could interact with importin-aat these positions.
Conclusions
The structures of importin-a-NLS peptide com-plexes presented here provide new insights intothe NLS binding determinants of the receptor pro-tein. Most importantly, they provide experimental
evidence to support the binding mode of bipartiteNLSs previously proposed based on monopartiteNLS binding (Conti et al., 1998; Kobe, 1999). Theyalso point to a possible complication in under-standing the NLS binding determinants by show-ing evidence of alternative binding modes for thesame peptide. It is clear that further structural, bio-physical and biochemical studies will be requiredfor deeper understanding of the recognition pro-cess. For example, the different importin-a iso-forms show different binding speci®cities fordifferent cargo proteins (Kohler et al., 1999b, andreferences therein), although most residues ident-i®ed from structural studies as important in NLSbinding are strictly conserved. High resolutionstructural studies of the binding to importin-a ofmore examples of NLS-containing peptides shouldbe one the ®rst steps in the quest for a detailedunderstanding of NLS recognition.
Materials and Methods
Expression and purification of N-terminallytruncated importin-aaa
N-terminally truncated mouse importin-a (a2 isoform;Kussel & Frasch, 1995) lacking 69 N-terminal residues(Impa(70-529)) was expressed recombinantly as a fusionprotein containing a hexa-histidine tag in Escherichia coli.A gene fragment encoding importin-a residues 70-529,¯anked by 50-BamHI and 30-SalI restriction sites was PCRampli®ed using the primer pair 50GGAAAACGGATCCAACCAGGGTACTG and 50GTTCGCCCTGGCGATGGCCGACGTCGACTTAGAAGTTAAAGGTCCC (restriction sites in bold), and pET30a DNA con-taining the full-length importin-a gene (Chi et al., 1996)as the template. The PCR product was digested withBamHI and SalI and ligated into the BamHI/SalI sites ofthe pET30a (Novagen) expression vector. The plasmidwas transformed into BL21 (DE3) E. coli cells. Forexpression, the cells were grown at 37 �C to an A(600 nm) of 1.0, induced with 1 mM isopropyl thio b-D-galactoside (IPTG) and grown for three hours at 30 �C.All subsequent puri®cation steps were performed at4 �C. Bacteria were lysed with 1 mg/ml lysozyme in buf-fer A (20 mM Hepes (pH 7.0), 500 mM NaCl, 1 mMMgCl2, 5 mM imidazole, 0.1 mM Tris(2-carboxyethyl)-phosphine hydrochloride (TCEP), 1 mg/ml leupeptin,1 mg/ml aprotinin, 1 mg/ml pepstatin, 1 mM phenyl-methyl-sulfonyl ¯uoride (PMSF)) and cell debris pelletedby centrifugation at 40,000 g for 30 minutes. Impa(70-529) was af®nity-puri®ed from the soluble fraction usingNi2�-agarose (Qiagen). After incubation with the resinfor one hour on the rotating wheel, the resin was washed®rst with buffer A, then buffer A containing 1 M NaCland 25 mM imidazole, and ®nally eluted with buffer Acontaining 150 mM imidazole. The protein was dialyzedagainst 20 mM Tris-HCl (pH 8.0), 100 mM NaCl, 2 mMdithiothreitol (DTT). The protein was >95 % pure asassessed by SDS-PAGE.
Peptide synthesis
The peptides PKKKRKV (SV40 NLS, corresponding tothe NLS of the SV40 large T-antigen, residues 126-132)and KRPAATKKAGQAKKKK (nucleoplasmin NLS, cor-responding to the NLS of nucleoplasmin, residues 155-

1192 NLS Recognition by Mammalian Importin-�
170) were synthesized using the Applied Biosystems433A peptide synthesizer, puri®ed by cation exchangechromatography followed by reverse phase chromatog-raphy, and analyzed by quantitative amino acid analysisusing a Beckman 6300 amino acid analyzer and electro-spray mass spectrometry (Sciex API 111, Perkin-Elmer)(Michell et al., 1996).
Crystallization
For crystallization, Impa(70-529) was concentratedto 18.8 mg/ml using a Centricon-30 (Amicon) andstored at ÿ20 �C. Crystallization conditions werescreened by systematically altering various parametersusing the crystallization conditions for the full-lengthprotein in the orthorhombic crystal form (Teh et al.,1999) as a starting point. The best crystals of nativeImpa(70-529) (rod shaped, 0.4 mm � 0.15 mm �0.1 mm) were obtained with 0.55 M sodium citrate asthe precipitant in 100 mM Hepes (pH 6.5) containing10 mM DTT; 1 ml of protein solution was combinedwith 1 ml of reservoir solution and suspended over0.5 ml of reservoir solution. These crystals weresoaked with varying concentrations of peptide withoutvisible deterioration of the crystals. However, the dif-fraction quality deteriorated after soaking. The bestcrystals of SV40 NLS-Impa(70-529) complex (rodshaped, 0.4 mm � 0.15 mm � 0.1 mm) were obtainedusing co-crystallization, by combining 1 ml of proteinsolution, 0.7 ml of peptide solution (1.7 mg/ml), and1 ml of reservoir solution and suspending over 0.5 mlof reservoir solution containing 0.55 M sodium citrate,80 mM Hepes (pH 6.0), 10 mM DTT. The best crystalsof nucleoplasmin NLS-Impa(70-529) complex (rodshaped, 0.3 mm � 0.1 mm � 0.05 mm) were obtainedby combining 1 ml of protein solution, 0.7 ml of pep-tide solution (3 mg/ml), and 1 ml of reservoir solutionand suspending over 0.5 ml of reservoir solution con-taining 0.50 M sodium citrate, 100 mM Hepes (pH 6.0),10 mM DTT.
Diffraction data collection
The crystals of native Impa(70-529) and the peptidecomplexes exhibit orthorhombic symmetry (space groupP212121; Table 1). Diffraction data were collected fromsingle crystals transiently soaked in a solution corre-sponding to the reservoir solution but supplementedwith 23 % (v/v) glycerol and ¯ash frozen at 100 K in anitrogen stream (Oxford Cryosystems), using a MAR-Research image plate detector and CuKa radiation froma Rigaku RU-200 rotating anode generator. Data wereauto-indexed and processed with the HKL suite(Otwinowski & Minor, 1997) (Table 1).
Structure determination and refinement
The crystals of peptide complexes were highly iso-morphous with the crystals of full-length mouseimportin-a (Teh et al., 1999), therefore the structure ofmouse importin a (Kobe, 1999; PDB entry 1IAL) withN-terminal residues omitted was used as a startingmodel for crystallographic re®nement. Electron densitymaps were inspected for the presence of the peptideafter rigid body re®nement using the programX-PLOR (BruÈ nger, 1996) (SV40 NLS-Impa(70-529)complex, Rcryst � 29.4 %, Rfree � 29.7 %, 10-3.5 AÊ
resolution; nucleoplasmin NLS-Impa(70-529) complex,
Rcryst � 29.6 %, Rfree � 30.1 %, 10-3 AÊ resolution; seeTable 1 for explanation of R-factors). Electron densitymaps calculated with coef®cients 3jFobsj ÿ 2jFcalcj andsimulated annealing omit maps (Figure 1) calculatedwith analogous coef®cients were generally used. Themodel was improved, as judged by the free R-factor(BruÈ nger, 1992), through rounds of crystallographicre®nement (positional and restrained isotropic individ-ual B-factor re®nement using programs X-PLOR andin the later stages CNS (BruÈ nger et al., 1998), with anoverall anisotropic temperature factor and bulk solventcorrection), and manual rebuilding (program O (Joneset al., 1990)). No solvent molecules were added due tolimited resolution. The data in the higher resolutionshells are weak, but were included in the re®nementjudged by the improvement of the electron densitymaps. N239 is an outlier in the Ramachandran plot asalso observed in the structure of full-length importin-a(Kobe, 1999). P242 is a cis-proline residue. The elec-tron density suggests more than one possible confor-mation for peptide binding and some of its side-chains (see Discussion); however, only the best popu-lated conformation has been included in the ®nalmodels. The ®nal models comprise residues 72-497 ofimportin-a, and all residues of the peptides (two pep-tides per Impa(70-529) for SV40 NLS, one peptide fornucleoplasmin NLS co-crystals). The structure determi-nation statistics are shown in Table 1.
Structure analysis
The quality of the models was checked with the pro-gram PROCHECK (Laskowski et al., 1993). The contactswere analyzed with the program CONTACT, and theburied surface areas were calculated using the programSURFACE (CCP4, 1994).
Atomic coordinates
The coordinates have been deposited in the RCSBProtein Data Bank (ID codes 1EJJL and 1EJY for theSV40 and nucleoplasmin complexes, respectively).
Acknowledgments
We thank Ian Jennings, Mark Lam, David Jans, andthe members of the Structural Biology Laboratory forhelp and discussions, Ian Jennings and Helen Blanchardfor reading the manuscript, and Frosa Katsis for peptidesynthesis. This work was supported by the WellcomeTrust and the National Health and Medical ResearchCouncil; M.R.M.F. is supported by the FundacËaÄo deAmparo aÁ Pesquisa do Estado de SaÄo Paulo, Brazil; B.K.is a Wellcome Senior Research Fellow in Medical Sciencein Australia.
References
Adam, S. A. (1999). Transport pathways of macromol-ecules between the nucleus and the cytoplasm.Curr. Opin. Cell Biol. 11, 402-406.
BruÈ nger, A. T. (1992). Free R value: a novel statisticalquantity for assessing the accuracy of crystal struc-tures. Nature, 355, 472-475.
BruÈ nger, A. T. (1996). X-PLOR Version 3.1, Yale Univer-sity, New Haven, CT.

NLS Recognition by Mammalian Importin-� 1193
BruÈ nger, A. T., Adams, P. D., Clore, G. M., DeLano,W. L., Gros, P., Grosse-Kunstleve, R. W., Jiang, J. S.,Kuszewski, J., Nilges, M., Pannu, N. S., Read, R. J.,Rice, L. M., Simonson, T. & Warren, G. L. (1998).Crystallography & NMR system: a new softwaresuite for macromolecular structure determination.Acta Crystallog. sect. D, 54, 905-921.
Carson, M. (1997). Ribbons. Methods Enzymol. 277, 493-505.
CCP4 (1994). The CCP4 suite: programs for protein crys-tallography. Acta Crystallog. sect. D, 50, 760-763.
Chelsky, D., Ralph, R. & Jonak, G. (1989). Sequencerequirements for synthetic peptide-mediated trans-location to the nucleus. Mol. Cell. Biol. 9, 2487-2492.
Chi, N. C., Adam, E. J., Visser, G. D. & Adam, S. A.(1996). RanBP1 stabilizes the interaction of Ranwith p97 nuclear protein import. J. Cell Biol. 135,559-569.
Chook, Y. M., Cingolani, G., Conti, E., Stewart, M.,Vetter, I. & Wittinghofer, A. (1999). Pictures in cellbiology. Structures of nuclear-transport com-ponents. Trends Cell Biol. 9, 310-311.
Colledge, W. H., Richardson, W. D., Edge, M. D. &Smith, A. E. (1986). Extensive mutagenesis of thenuclear location signal of simian virus 40 large-Tantigen. Mol. Cell. Biol. 6, 4136-4139.
Conti, E., Uy, M., Leighton, L., Blobel, G. & Kuriyan, J.(1998). Crystallographic analysis of the recognitionof a nuclear localization signal by the nuclearimport factor karyopherin alpha. Cell, 94, 193-204.
Dingwall, C. & Laskey, R. A. (1991). Nuclear targetingsequences-a consensus? Trends Biochem. Sci. 16, 478-481.
Dingwall, C. & Laskey, R. A. (1999). Nuclear import: atale of two sites. Curr. Biol. 8, R922-R924.
Esnouf, R. M. (1997). An extensively modi®ed version ofMolScript that includes greatly enhanced coloringcapabilities. J. Mol. Graph. 15, 133-138.
Gamblin, S. J. & Smerdon, S. J. (1999). Nuclear transport:what a kary-on. Structure, 7, R199-R204.
Gorlich, D., Henklein, P., Laskey, R. A. & Hartmann, E.(1996). A 41 amino acid motif in importin-alphaconfers binding to importin-beta and hence transitinto the nucleus. EMBO J. 15, 1810-1817.
Hood, J. K. & Silver, P. A. (1999). In or out? Regulatingnuclear transport. Curr. Opin. Cell Biol. 11, 241-247.
Hubner, S., Xiao, C. Y. & Jans, D. A. (1997). The proteinkinase CK2 site (Ser111/112) enhances recognitionof the simian virus 40 large T-antigen nuclear local-ization sequence by importin. J. Biol. Chem. 272,17191-17195.
Jans, D. A. & Hubner, S. (1996). Regulation of proteintransport to the nucleus: central role of phosphoryl-ation. Physiol. Rev. 76, 651-685.
Jones, T. A., Bergdoll, M. & Kjeldgaard, M. (1990). O: Amacromolecule modeling environment. In Crystallo-graphic and Modeling Methods in Molecular Design(Bugg, C. E. & Ealick, S. E., eds), pp. 189-195,Springer-Verlag, New York.
Jones, T. A., Zou, J.-Y., Cowan, S. W. & Kjeldgaard, M.(1991). Improved methods for building proteinmodels in electron density maps and the location oferrors in these models. Acta Crystallog. sect. A, 47,110-119.
Kalderon, D., Richardson, W. D., Markham, A. F. &Smith, A. E. (1984a). Sequence requirements fornuclear location of simian virus 40 large-T antigen.Nature, 311, 33-38.
Kalderon, D., Roberts, B. L., Richardson, W. D. & Smith,A. E. (1984b). A short amino acid sequence able tospecify nuclear location. Cell, 39, 499-509.
Kobe, B. (1999). Autoinhibition by an internal nuclearlocalization signal revealed by the crystal structureof mammalian importin alpha. Nature Struct. Biol. 6,388-397.
Kobe, B. & Kemp, B. E. (1999). Active site-directed pro-tein regulation. Nature, 402, 373-376.
Kohler, M., Haller, H. & Hartmann, E. (1999a). Nuclearprotein transport pathways. Exp. Nephrol. 7, 290-294.
Kohler, M., Speck, C., Christiansen, M., Bischoff, F. R.,Prehn, S., Haller, H., Gorlich, D. & Hartmann, E.(1999b). Evidence for distinct substrate speci®citiesof importin alpha members in nuclear proteinimport. Mol. Cell. Biol. 19, 7782-7791.
Kussel, P. & Frasch, M. (1995). Yeast Srp1, a nuclearprotein related to Drosophila and mouse pendulin, isrequired for normal migration, division, and integ-rity of nuclei during mitosis. Mol. Gen. Genet. 248,351-363.
Lanford, R. E. & Butel, J. S. (1984). Construction andcharacterization of an SV40 mutant defective innuclear transport of T antigen. Cell, 37, 801-813.
Laskowski, R. A., MacArthur, M. W., Moss, D. S. &Thornton, J. M. (1993). PROCHECK: a program tocheck the stereochemical quality of protein struc-tures. J. Appl. Crystallog. 26, 283-291.
Macara, I. G. (1999). Nuclear transport: randy couples.Curr. Biol. 9, R436-R439.
Makkerh, J. P. S., Dingwall, C. & Laskey, R. A. (1996).Comparative mutagenesis of nuclear localizationsignals reveals the importance of neutral and acidicamino acids. Curr. Biol. 6, 1025-1027.
Mattaj, I. W. & Conti, E. (1999). Snail mail to thenucleus. Nature, 399, 208-210.
Michell, B. J., Stapleton, D., Mitchelhill, K. I., House,C. M., Katsis, F., Witters, L. A. & Kemp, B. E.(1996). Isoform-speci®c puri®cation and substratespeci®city of the 50-AMP-activated protein kinase.J. Biol. Chem. 271, 28445-28450.
Moroianu, J. (1999). Nuclear import and export: trans-port factors, mechanisms and regulation. Crit. Rev.Eukaryot. Gene Expr. 9, 89-106.
Moroianu, J., Blobel, G. & Radu, A. (1996). The bindingsite of karyopherin alpha for karyopherin beta over-laps with a nuclear localization sequence. Proc. NatlAcad. Sci. USA, 93, 6572-6576.
Otwinowski, Z. & Minor, W. (1997). Processing of x-raydiffraction data collected in oscillation mode.Methods Enzymol. 276, 307-326.
Peifer, M., Berg, S. & Reynolds, A. B. (1996). A repeatingamino acid motif shared by proteins with diversecellular roles. Cell, 76, 789-791.
Robbins, J., Dilworth, S. M., Laskey, R. A. & Dingwall,C. (1991). Two interdependent basic domains innucleoplasmin nuclear targeting sequence: identi®-cation of a class of bipartite nuclear targetingsequence. Cell, 64, 615-623.
Sekimoto, T. & Yoneda, Y. (1999). Nuclear import andexport of proteins: the molecular basis for intra-cellular signalling. Cytok. Growth Factor Rev. 9, 205-211.
Stewart, M. & Rhodes, D. (1999). Switching af®nities innuclear traf®cking. Nature Struct. Biol. 6, 301-304.
Talcott, B. & Moore, M. S. (1999). Getting across thenuclear pore complex. Trends Cell Biol. 9, 312-318.

1194 NLS Recognition by Mammalian Importin-�
Teh, T., Tiganis, T. & Kobe, B. (1999). Crystallization ofimportin a, the nuclear import receptor. Acta Crys-tallog. sect. D, 55, 561-563.
Weis, K., Ryder, U. & Lamond, A. I. (1996). The con-served amino-terminal domain of hSRP1 alpha isessential for nuclear protein import. EMBO J. 15,1818-1825.
Edited by K. Nagai
(Received 4 January 2000; received in revised form 24February 2000; accepted 29 February 2000)
http://www.academicpress.com/jmb
Supplementary material comprising four Figures isavailable from JMB Online.
Copyright © 2022 FDOKUMEN




















