
I materiali compositi FRP a matrice organica e i criteri ...

Studio di fattibilita inerente alla stima della corrosionesu materiali mediante dati provenienti
da termografie all’infrarosso
Giulia DeolmiDipartimento di Matematica Pura ed ApplicataUniversita degli Studi di Padova
Fabio MarcuzziDipartimento di Matematica Pura ed ApplicataUniversita degli Studi di Padova
Sergio MarinettiIstituto per le Tecnologie della CostruzioneCNR Padova
Silvia PolesESTECO srl
NUMLAB-Technical Report No. 2008-1 Settembre 2008
Via Trieste, 63 -35121 Padova - Italia
http://numlab.math.unipd.it/


Abstract
Questo report ha lo scopo di analizzare le variazioni di spessore dovute allacorrosione in una lamina di metallo, di dimensioni e materiale noti, adottandouna tecnica non distruttiva.
Supponiamo di conoscere solamente la morfologia di una faccia della lami-na e supponiamo che le altre facce siano isolate termicamente. Per individua-re un’eventuale zona corrosa, la faccia nota viene sollecitata termicamenteed osservata tramite una matrice di sensori della radiazione infrarossa. L’o-biettivo e la ricerca del dominio ottimale D in cui la risoluzione numericadell’equazione del calore fornisca una buona approssimazione dei dati spe-rimentali. Per semplicita supponiamo che la lamina e la corrosione sianocostanti lungo l’asse verticale, riducendoci cosı a un problema 2-D. Supponi-amo inoltre che sul segmento noto, S, gli N sensori siano equispaziati. Perdescrivere il dominio D usiamo una griglia G con passo dy pari al 10% dellaprofondita del dominio, e passo orizzontale uniforme dx, pari alla risoluzionespaziale sperimentale. Descriviamo il profilo di corrosione mediante una fun-zione a scalino tale che l’altezza di ogni scalino sia pari alla corrosione inquell’intervallo. Trovare il dominio ottimale, equivale a risolvere contempo-raneamente due problemi: determinare il sottoinsieme ottimale di G e, fissatoquesto, trovare il valore ottimale della profondita degli scalini. Per risolverequest’ultimo problema utilizziamo il Prediction Error Method (PEM). Percostruire la griglia ottimale, invece, utilizziamo due strategie diverse: il raf-finamento locale e gli algoritmi genetici. Il primo consiste nell’applicare ilPEM a una fissata suddivisione, determinando cosı le profondita degli scali-ni. Ad ogni iterazione, ciascun segmento della suddivisione con uno scalinomaggiore della precedente, viene raffinato aggiungendo il punto medio. Es-sendo fortemente connesso al problema in questione, questo metodo si rivelaadatto alla risoluzione di problemi di piccola dimensione, ma essendo basatosu un approccio puramente deterministico, diviene ben presto inefficientequando la dimensione del problema aumenta. Gli algoritmi genetici, invece,ci permettono di adottare un metodo di indagine stocastico, attraverso laminimizzazione di due obiettivi: la norma dei residui e il numero di nodi
i

ii
della griglia. Questo metodo e piu robusto e permette di risolvere il proble-ma della stima, anche se il dominio in questione e grande. Purtroppo, pero,questo approccio risulta essere molto lento e quindi poco efficiente. Dopoaver confrontato le performance dei due metodi su un problema di piccoladimensione, formuleremo, l’algoritmo NSGA II modificato che racchiude inse sia l’approccio stocastico degli algoritmi genetici, sia la tecnica del raffi-namento locale: esso rappresenta quindi un compromesso tra i due metodi eci permettera di analizzare un problema di grande dimensione.

iii
[...]La filosofia e scritta in questo grandissimo libroche continuamente ci sta aperto innanzi a gli occhi (iodico l’universo), ma non si puo intendere se prima nons’impara a intender la lingua, e conoscer i caratteri,ne’ quali e scritto. Egli e scritto in lingua matema-tica, e i caratteri son triangoli, cerchi, ed altre figuregeometriche, senza i quali mezi e impossibile a inten-derne umanamente parola; senza questi e un aggirarsivanamente per un oscuro laberinto.
Galileo Galilei, ”Il Saggiatore”, 1623.

Prefazione
Questo report e un resoconto dei risultati a cui siamo pervenuti nel periodoAprile 2007 - Gennaio 2008 grazie alla borsa di studio ”Studio di fattibilitainerente alla stima della corrosione su materiali mediante dati provenienti datermografie all’infrarosso”, erogata dalla ditta ESTECO srl in collaborazionecon l’Universita di Padova, fruita da Giulia Deolmi, sotto la direzione sci-entifica del Dott. Fabio Marcuzzi. Al progetto hanno collaborato in modosignificativo anche la Dott.ssa Silvia Poles e il Dott. Sergio Marinetti.
I contenuti teorici di queste note non hanno quindi la pretesa di essereesaustivi in merito agli argomenti trattati: abbiamo pensato di includere soloi concetti che sono stati utili alla nostra indagine del problema e rimandiamoquindi a testi specifici per eventuali approfondimenti. Abbiamo inserito nellasezione bibliografica alcuni possibili riferimenti.
Gli autori.
iv

Indice
1 Presentazione del problema 21.1 Presentazione del probema . . . . . . . . . . . . . . . . . . . . 21.2 Costruzione del modello matematico . . . . . . . . . . . . . . 4
2 Idee chiave 72.1 Ipotesi nella costruzione del modello numerico . . . . . . . . . 72.2 Modello numerico . . . . . . . . . . . . . . . . . . . . . . . . . 8
3 Prediction Error Method (PEM) 113.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.2 Premessa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.3 Il metodo di Newton . . . . . . . . . . . . . . . . . . . . . . . 133.4 Prediction Error Method . . . . . . . . . . . . . . . . . . . . . 14
4 Il raffinamento locale 16
5 Gli algoritmi genetici 185.1 Ottimizzazione multiobiettivo . . . . . . . . . . . . . . . . . . 185.2 Gli algoritmi genetici . . . . . . . . . . . . . . . . . . . . . . . 18
5.2.1 Rappresentazione delle variabili . . . . . . . . . . . . . 195.2.2 Rappresentazione della funzione obiettivo e delle re-
strizioni . . . . . . . . . . . . . . . . . . . . . . . . . . 205.2.3 Operatori genetici . . . . . . . . . . . . . . . . . . . . . 215.2.4 Elitismo e convergenza . . . . . . . . . . . . . . . . . . 22
6 Verso l’algoritmo risolutivo 246.1 Il modello numerico FEM . . . . . . . . . . . . . . . . . . . . 246.2 Il PEM applicato al nostro problema . . . . . . . . . . . . . . 24
6.2.1 Implementazione del PEM . . . . . . . . . . . . . . . . 256.2.2 SVD applicata al PEM . . . . . . . . . . . . . . . . . . 26
6.3 Gli AG applicati al nostro problema . . . . . . . . . . . . . . . 27
v

6.4 Tappe fondamentali . . . . . . . . . . . . . . . . . . . . . . . . 28
7 Problemi di piccola dimensione 307.1 Aspetti fondamentali . . . . . . . . . . . . . . . . . . . . . . . 307.2 Strutture dati che definiscono la parametrizzazione . . . . . . 307.3 Un esempio simulato . . . . . . . . . . . . . . . . . . . . . . . 31
8 Problemi di grande dimensione 338.1 Aspetti fondamentali . . . . . . . . . . . . . . . . . . . . . . . 338.2 Strutture dati che definiscono la parametrizzazione . . . . . . 338.3 NSGA II modificato . . . . . . . . . . . . . . . . . . . . . . . 348.4 Un esempio simulato . . . . . . . . . . . . . . . . . . . . . . . 34
9 Riassunto dei contenuti 38
A I dati sperimentali 41A.1 Il modello di riferimento . . . . . . . . . . . . . . . . . . . . . 41A.2 La raccolta dei dati sperimentali . . . . . . . . . . . . . . . . . 42A.3 Stima delle costanti fisiche del modello . . . . . . . . . . . . . 45
Bibliografia 49

Introduzione
Questo report si apre con la presentazione del problema fisico che intendi-amo analizzare: data una lamina metallica, supponiamo di poter interagiresolamente con una faccia della stessa. Ci chiediamo allora se sia possibileadottare un metodo di indagine non distruttivo che ci permetta di compren-dere se la parte incognita del materiale sia o meno corrosa. La tecnica dianalisi che adotteremo sara basata sulla termografia.
Nei capitoli successivi ci chiederemo come possiamo condurre questa in-dagine. In particolare distingueremo due diverse situazioni: dapprima sup-porremo di trattare un problema in cui il dominio sia relativamente piccolo evedremo che sara preferibile adottare un metodo di indagine deterministico,che si basa su un metodo di Newton (Prediction Error Method) e sulla tecni-ca del raffinamento locale, che introdurremo in seguito. Una volta sviluppatoquesto problema volgeremo la nostra attenzione ai problemi di grande dimen-sione, per affrontare i quali un algoritmo deterministico si rivela inefficiente:introdurremo quindi un approccio stocastico, basato sull’utilizzo di algoritmigenetici. Cercheremo infine di fondere in un solo algoritmo, NSGA II modifi-cato, le due tecniche presentate, definendo cosı una strategia di ricerca dellacorrosione per problemi di grande dimensione.
1

Capitolo 1
Presentazione del problema
1.1 Presentazione del probema
Come raffigurato nell’immagine 1.1 (a), consideriamo una lamina di metallodi materiale noto, avente dimensioni l,d, 2z0 note. Vorremmo capire se al suointerno, il materiale di cui essa e composta, presenti o meno una zona di cor-rosione. Per fare questo adottiamo una tecnica non distruttiva: supponiamoquindi di conoscere la morfologia della faccia S della sbarra indicata dalle frec-ce in blu e cerchiamo di ricostruire la faccia opposta, che assumiamo essereincognita, attraverso lo studio dell’evoluzione della temperatura all’internodella lamina. Per fare questo utilizziamo la seguente tecnica: nell’istante t0colpiamo con un impulso di calore S, sulla quale sono posti dei sensori ter-mici. Aspettiamo un intervallo di tempo ∆t e misuriamo sperimentalmentesulla stessa la temperatura. Attraverso i dati sperimentali raccolti in questomodo, vorremmo riuscire a ricostruire la struttura della faccia incognita: perfare questo supponiamo che la superficie della lamina, ad escusione di S, siaisolata, ossia supponiamo di essere in condizioni adiabatiche (questa assun-zione sara discussa con maggior dettaglio nell’appendice A). Analizziamoquindi l’evoluzione della temperatura nella lamina attraverso l’equazione delcalore, ponendo come condizioni iniziali la temperatura in t0 della stessa ela quantita di calore assorbita q. Osserviamo che applicare l’equazione delcalore equivale a ricostruire l’evoluzione della temperatura su un dominio, no-to quest’ultimo. Il nostro problema quindi e opposto: date le temperature suS vogliamo capire qual e il dominio ottimale sul quale deve agire l’equazionedel calore per produrre delle temperature stimate che approssimino bene idati raccolti. L’idea quindi e formulare un problema inverso della forma
t = f(x) + e, (1.1)
2

1.1. PRESENTAZIONE DEL PROBEMA 3
Figura 1.1: (a) In figura la lamina di metallo in grigio e la stessa corrosa in rosso,assorbono il calore q; (b) Riduzione del problema in dimensione due, considerandola sezione della lamina sul piano z = 0.
dove x e il vettore incognito che rappresenta il profilo di corrosione e definiscequindi il dominio, t sono le temperature sperimentali e f(x) sono quellericostruite dal modello FEM, se il dominio e individuato da x. Osserviamoche t−f(x) rappresenta il residuo del modello, cioe la parte che non riusciamoa modellare, e pertanto viene inserito un errore additivo e.
Il problema che risolveremo dunque sara trovare x∗ tale che
x∗ = arg minx‖t− f(x)‖2
2 , (1.2)
che equivale a determinare un profilo di corrosione in modo che il modelloFEM approssimi al meglio le temperature sperimentali.

4 CAPITOLO 1. PRESENTAZIONE DEL PROBLEMA
Possiamo semplificare ulteriormente il problema: supponiamo che l’al-tezza della lamina z0 sia sufficientemente piccola in modo che la corrosione,illustrata in rosso in figura, possa essere considerata costante lungo z. Conquesta ipotesi possiamo limitarci ad analizzare il problema bidimensionale,come illustrato in figura 1.1 (b). Studiamo quindi l’equazione del calore condominio incognito Dc.
Il problema che dovremo risolvere quindi si riduce a questo: capire comemeglio scegliere il profilo f(x), affinche la temperatura in t0 + ∆t su S,ricostruita attraverso l’equazione del calore e con dominio Dc, approssimi almeglio i dati sperimentali che possediamo.
1.2 Costruzione del modello matematico
Come anticipato nel precedente paragrafo, faremo riferimento alla situazioneillustrata in figura 1.1 (b).
Definiamo l’insieme = = {f t.c. f : [0, d] −→ [0, l], f costante a tratti }.Sia f ∈ =, e siamo {x1, ..., xN} i punti di salto di f . Definiamo Dc =[0, d] × [0, l]/
∑N−1i=1 f(xi)(xi+1 − xi), area rappresentata in rosso in figura
1.1(b).
Il problema dunque e ricercare all’interno di =, che rappresenta l’insiemedei possibili profili di corrosione, la funzione f tale che la temperatura sulsegmento noto S, in t0 + ∆t, costruita attraverso l’equazione del calore suldominio Dc, sia approssimativamente uguale ai dati sperimentali.
Il modello matematico che regola l’evoluzione della temperatura T =T (t, x, y) e il seguente:
ρC∂
∂tT + ρC ∇T · e = r + k ∆T
dove ρC rappresenta la capacita termica del materiale di cui e composta lalamina (C e il calore specifico), ∇T = ( ∂
∂xT, ∂
∂yT ), e e la velocita della lamina,
r rappresenta il calore assorbito dalle sorgenti di calore interne al dominio e ke il coefficiente di conducibilita termica del materiale che costituisce la lamina(supponiamo che il materiale sia isotropo e quindi il tensore di conducibilitatermica K = k · I2).
Nel nostro caso, quindi, supponiamo di conoscere ρC e k: cio e possibileanche attraverso considerazioni sperimentali, come sara spiegato nell’appen-dice A. Inoltre, assumiamo noto q = q(t) e poniamo r = 0, e = 0. Pertanto,indicando con nS la normale esterna ad S e con n la normale esterna a δDc/S,l’equazione diventa:

1.2. COSTRUZIONE DEL MODELLO MATEMATICO 5
ρC∂
∂tT = k ∆T (1.3)
k ∇T · nS = q(t) (1.4)
k ∇T · n = 0, su δDc/S (1.5)
T (t0, x, y) = T0(x, y) (1.6)
Osserviamo che le condizioni al contorno variano nel tempo: questo percheq(t) = q−q
′, dove q rappresenta la quantita di calore ceduta al campione da
un impulso termico (il flash di una termocamera) e q′e la quantita di calore
che il sistema scambia per convezione con l’ambiente esterno attraverso S,quindi
∣∣q′∣∣ = h(Taria − TS), con h coefficiente di scambio convettivo. Noiesaminiamo il sistema in un intervallo ∆T tale che il sistema sia approssima-tivamente adiabatico lungo δDc/S e tale che lo scambio con l’esterno q
′sia
trascurabile. Sotto queste ipotesi q(t) avra approssimativamente la forma diun impulso di Dirac concentrato in t0.
Nella trattazione che segue f = fϑ, dove ϑ e un’opportuno vettore diparametri che individuano la funzione. Identifichiamo ogni parametro con laprofondita della corrosione in quell’intervallo, ossia se in [xi, xi+1] f(x) haun salto, ϑi sara uguale a f(xi), con i = 1, . . . , N − 1.
Questa approssimazione del profilo di corrosione reale mediante una fun-zione a scalino, ci porta a formulare ulteriori ipotesi per la definizione delmodello. Infatti e necessario richiedere che ad ogni parametro corrispondauna precisa zona spaziale del profilo di corrosione, l’ampiezza della qualenon deve essere troppo grande. Questo ci assicura la convergenza ad unastima sufficientemente accurata del profilo di corrosione. Se non formulassi-mo quest’ipotesi rischieremmo di trovarci in una condizione in cui all’internodella zona spaziale descritta da un solo parametro vengano mediati tutti ifronti di corrosione interni, ma questi possono essere anche molto diversi traloro. Supponiamo inoltre di considerare parametri non sovrapposti, ossiaipotizziamo che parametri diversi siano riferiti a zone spaziali disgiunte di S.
Poiche noi non sappiamo a priori se e presente una corrosione della lami-na, e in ogni caso non ne conosciamo la struttura, poiche non abbiamo nes-suna informazione su f(x), dovremo procedere nel modo seguente: partiremoda una suddivisione iniziale del segmento S, che, per fissare le idee, possi-amo supporre uniforme. Poiche vogliamo dei parametri che siano adattativi,andremo a infittire localmente tale suddivisione, costruendo delle sottosuddi-visioni e, su ognuna di queste, applicheremo un algoritmo di ottimizzazionedi Newton (il Prediction error method (PEM)), per determinare il valore

6 CAPITOLO 1. PRESENTAZIONE DEL PROBLEMA
migliore dei parametri. Poiche utilizzeremo un algoritmo iterativo, dovremopartire da un vettore iniziale che rappresenti le profondita in ogni segmentodella suddivisione. Possiamo supporre che tale vettore sia nullo: quest’ultimaassunzione equivale proprio a testare la presenza di corrosione.
Approfondiremo questi aspetti nei prossimi capitoli.

Capitolo 2
Idee chiave nella formulazionedell’algoritmo risolutivo
2.1 Ipotesi nella costruzione del modello nu-
merico
Vediamo piu in dettaglio quali saranno i passi che ci porteranno alla definzionedi un modello.
Le ipotesi fondamentali, alla base della nostra analisi sono le seguenti:
1. supponiamo che il campione sano sia ben descrivibile con un modellodel tipo
x(k + 1) = A · x(k) +B · u(k) + v(k) (2.1)
y(k) = C · x(k) +D · u(k) + w(k)
dove x e il vettore di stato da stimare, y e il vettore delle uscite misu-rate, u e il vettore degli ingressi, che supponiamo noti, v e il vettorerumore di modello e w e il vettore rumore di misura. Supponiamo chei vettori stocastici v e w siano caratterizzati da due matrici di covar-ianza rispettivamente Q e R. E’ bene sottolineare che le equazioni distato
x(k + 1) = A · x(k) +B · u(k)y(k) = C · x(k) +D · u(k)
sono ottenibili dapprima costruendo un modello agli elementi finiti chediscretizzi l’equazione del calore nello spazio, e applicando in seguito
7

8 CAPITOLO 2. IDEE CHIAVE
un metodo di eulero per approssimare l’equazione ordinaria ottenuta.Possiamo pensare ad u = q, y = T |S e x = T .
2. ipotizziamo che anche il campione corroso sia ben descrivibile attraver-so il sistema 2.1: in questa seconda fase, quindi, utilizzeremo il mo-dello costruito nel caso non corroso, e attraverso opportune tecnichecercheremo di individuare il dominio che descrive con un grado di ap-prossimazione pari a quella del modello non corroso, il nostro proble-ma. Questo equivale a ipotizzare che la corrosione non modifichi laparte deterministica e stocastica del modello, come avviene, per esem-pio, nella fresatura, dove si ha asportazione di materiale in condizioniadiabatiche.
2.2 Definizione del modello numerico nella
risoluzione del problema inverso
Per analizzare il problema dal punto di vista numerico e necessario discretiz-zare opportunamente il problema fisico continuo che abbiamo introdotto nelcapitolo 1.
Come abbiamo gia accennato, sul segmento S e presente una matricedi N sensori termici equispaziati, attraverso i quali, dopo aver colpito lafaccia con un flash termico, costruiamo la matrice dei dati sperimentali taleche la colonna i-esima rappresenti l’evoluzione nel tempo della temperaturamisurata dal sensore i-esimo.
Ad S possiamo associare la suddivisione piu fine Sh, determinata esat-tamente dai punti di S nei quali e presente un sensore termico. A partireda questa e possibile costruire una griglia sul dominio corroso con passocostante anche lungo y, come illustrato in figura 2.1 a sinistra. L’idea e quel-la di costruire un modello, basato sul metodo degli elementi finiti (FEM),che risolva l’equazione del calore sui nodi di questa griglia.
Tuttavia, se il numero di sensori diventa molto grande, e impensabileutilizzare quest’approccio: cercheremo, quindi, di determinare la suddivisioneottimale, ossia la suddivisione tale che i suoi punti interni siano esattamente ipunti di discontinuita di f , come illustrato in figura 2.1 a destra, a partire daSh. Su questa suddivisione ottimale costruiremo una griglia uniforme, doverisolveremo il problema di stima dei parametri attraverso il PEM, utilizzandoil modello FEM per determinare il residuo.
Ricostruire il profilo di corrosione reale equivale, quindi, a determinare

2.2. MODELLO NUMERICO 9
Figura 2.1: Suddivisione piu fine a sinistra e suddivisione ottimale a destra.
la funzione a scalino f tale che i residui stimati siano minimi. Tuttaviadeterminare f significa risolvere due problemi:
1. trovare la suddivisione di S che individua f , ossia i punti di disconti-nuita della funzione a scalino;
2. fissata la suddivisione di S, determinare la profondita di ogni scalino.
I due problemi sono fortemente correlati tra loro, ma richiedono tecnichediverse per la loro risoluzione. Abbiamo gia anticipato che, per risolvere2, adotteremo un algoritmo di ottimizzazione di Newton, il Prediction Er-ror Method(PEM): nel seguito cercheremo di approfondire questo concettoe di capire come determinare la suddivisione ottimale di f . Nei prossimicapitoli, quindi, dapprima introdurremo i concetti matematici che ci servi-ranno per definire una strategia risolutiva e poi presenteremo quest’ultima.Sottolineiamo fin d’ora che sara necessario distinguere tra due classi di prob-lemi, rispettivamente di piccola e di grande dimensione, per risolvere i qualiadotteremo tecniche diverse.
Osservazione. In questo report abbiamo deciso di focalizzare la nostraattenzione sul problema della stima del dominio, approfondendo solo gli as-petti teorici essenziali per comprenderlo. Per questo motivo non abbiamointrodotto la teoria degli elementi finiti, anche se questa e fondamentale nella

10 CAPITOLO 2. IDEE CHIAVE
descrizione dei problemi fisici in generale. Qualora il lettore fosse interessatoad approfondire questi concetti, puo consultare, per esempio, [7] e [2].

Capitolo 3
Prediction Error Method(PEM)
3.1 Introduzione
In questo capitolo ci occuperemo di presentare l’algoritmo Prediction Er-ror Method (PEM) che useremo nel seguito per la stima dei paramentri delmodello.
Dapprima cercheremo brevemente di collocare il PEM all’interno delpanorama della programmazione matematica, facendo riferimento al con-tenuto del testo [3]. Nella seconda parte del capitolo lo analizzeremo indettaglio, riferendoci alla trattazione presente in [5].
3.2 Premessa: programmazione matematica
non lineare senza vincoli
La programmazione matematica e uno strumento utile nella risoluzione diun problema di ricerca operativa. Il procedimento risolutivo in genere si ar-ticola in due fasi: dapprima avviene la formulazione del modello matematicodel problema e in un secondo tempo si sceglie l’algoritmo di soluzione e siimplementa quest’ultimo sul calcolatore.
Nella creazione del modello il problema di partenza viene espresso at-traverso una funzione obiettivo f , che esprime quanto si vuole ottimizzare.A seconda della struttura di f e di eventuali funzioni di vincolo cui essa esottoposta, viene determinata la natura del problema, che puo essere lineareo non lineare. Nel seguito ci oppuremo di introdurre questa seconda classedi problemi.
11

12 CAPITOLO 3. PREDICTION ERROR METHOD (PEM)
La formulazione generale di un problema senza vincoli e la seguente:
minx∈Xf(x),
X ⊆ Rn.
Il problema di massimizzare f puo essere espresso anch’esso nei terminidella formula precedente, ponendo:
maxx∈Xf(x) = −minx∈X − f(x) (3.1)
Il problema di ottimizzazione coincide col determinare una configurazione”migliore possibile” tra un insieme di parametri, in modo da massimizzareo minimizzare f . Non sempre e possibile determinare un punto di ottimoglobale, cioe x tale che f(x) ≤ f(y), ∀y ∈ X. In tal caso si cerca unottimo locale, ossia x tale che f(x) ≤ f(y), ∀y ∈ N(x), dove N(x) ={y ∈ X t.c. ‖x− y‖ ≤ ε}, ε e una costante arbitrariamente piccola e ‖.‖ euna norma in Rn, per esempio la norma euclidea.
Nel seguito considereremo X = Rn e il problema non lineare.Supponiamo che f sia una funzione sufficientemente regolare, almeno di
classe C2(Rn,R). Inoltre indichiamo con g(x) = ∇f(x), gradiente di f , conG(x) = ∇2f(x), l’Hessiano di f e con x∗ un punto di ottimo locale.
Consideriamo la retta x∗ + α s, con s ∈ S2 opportuna direzione. Calco-liamo ora le seguenti derivate lungo la retta:
∂
∂αf(x∗ + α s) =
∂
∂xf s = g · s
∂2
∂α2f(x∗ + α s) = sTGs
Imponendo la condizione che x∗ sia un minimo locale dalle equazioniprecedenti, si ottengono:
∂
∂αf |α=0 = g∗ · s = 0, ∀s
∂2
∂α2f |α=0 = sTG∗s ≥ 0
che equivalgono a:
g∗ = 0 (3.2)
sTG∗s ≥ 0, ∀s. (3.3)

3.3. IL METODO DI NEWTON 13
Queste ultime relazioni sono dette rispettivamente condizioni necessariedel primo e del secondo ordine.
Gli algoritmi risolutivi per problemi non lineari non vincolati sono itera-tivi e si articolano nei passi dell’algoritmo 1.
Algoritmo 1 Algoritmo risolutivo per problemi lineari non vincolati:1: determinazione della direzione sk = s(xk), con xk k-esima iterazione;2: ricerca di αk, opportuno scalare che minimizza f(xk + αsk) rispetto ad α;3: calcolo la nuova iterata: xk+1 = xk + αksk.
3.3 Il metodo di Newton
I punti chiave dell’algoritmo risolutivo presentato alla fine del paragrafoprecedente sono la determinazione della direzione sk e la scelta di αk.
Per fare questo e dapprima necessario approssimare f . Una possibilescelta e usare il modello quadratico, che utilizza lo sviluppo in serie di Taylortroncato al secondo ordine.
Il metodo di Newton usa un’approssimazione di questo tipo: si pone
f(xk+1) = f(xk +δk) ≈ qk(δk) = fk +δk ·gk + 12δkT
Gk δk, con δk = xk+1−xk.
Sia quindi f(xk+1) = fk + δk · gk + 12δkT
Gk δk: deriviamo ambo i membririspetto a δk e, poiche cerchiamo un punto stazionario, imponiamo che talederivata sia pari a zero. Otteniamo quindi gk +Gk δk = 0. Osserviamo che,se Gk e definita positiva, l’unico punto di minimo si ottiene quindi risolvendoil seguente sistema:
Gkδk = −gk.
Le fasi in cui si articola l’algoritmo di Newton sono riassunte nell’algorit-mo 2.
Algoritmo 2 Algoritmo di Newton:1: trovare sk = δk = −(Gk)−1gk, risolvendo cioe il sistema Gksk = −gk;2: calcolare la nuova iterazione: xk+1 = xk + sk
Sono necessarie O(n3) operazioni per iterazione, ma quando x0 e suffi-cientemente vicino a x∗, la convergenza e quadratica, cioe nell’intorno di x∗,
posto hk = xk − x∗, si ha‖hk+1‖‖hk‖2 → a, con a ∈ R.
Quando Gk non e definita positiva si puo modificare la direzione di ricercaalla riga 1 orientandola di piu verso la direzione del gradiente, ottenendol’algoritmo 3.

14 CAPITOLO 3. PREDICTION ERROR METHOD (PEM)
Algoritmo 3 Algoritmo di Newton:1: risolvere (Gk + νId)sk = −gk, con νId multiplo della matrice identita.2: calcolare la nuova iterazione: xk+1 = xk + sk
Un inconveniente del metodo di Newton e che richiede la valutazione dellederivate seconde di f , per costruireG. A questo si puo ovviare approssimandoGk con le differenze finite, cioe ponendo Gk = 1
2(G+ GT ), dove la colonna i-
esima della matrice matrice G, G(:, i) = 1hi
[g(xk+hiei)−gk], con hi i = 1, ..., nopportuni incrementi di ogni variabile, e ei base canonica di Rn.
3.4 Dal metodo di Newton al Prediction Er-
ror Method
Consideriamo ora un caso particolare del metodo di Newton: il PredictionError Method.
Il modello numerico sara caratterizzato da un vettore di n parametri,che nel seguito indicheremo con ϑ ∈ Rn, dove n e il numero di scalini dellafunzione che rappresenta il profilo di corrosione (quindi 0 ≤ n ≤ N − 1).Fissata {x1, . . . , xn+1} suddivisione di S, sottoinsieme di quella piu fine Sh
determinata dagli N sensori termici, il parametro ϑi quantifica quindi laprofondita della corrosione nel segmento [xi, xi+1], dove i = 1, . . . , n.
Sia data una matrice reale TS ∈ Mat(τ,N), che rappresenta le misuresperimentali: N indica il numero di punti in cui sono state registrate letemperature su S e τ il numero di istanti temporali in cui sono state fatte lemisurazioni. Indichiamo con y ∈Mat(τ, n+1) la sottomatrice di TS ottenutaselezionando le n+ 1 colonne che corrispondono ai nodi {x1, . . . , xn+1}. Conil modello numerico vogliamo costruire una matrice y(ϑ) ∈ Mat(τ, n + 1),tale da approssimare i dati sperimentali, determinando opportuni valori diϑ. Definiamo quindi errore di predizione la matrice e(ϑ) ∈Mat(τ, n+ 1)
e(ϑ) ≡ y− y(ϑ)
e, mediante questa, una possibile definizione della funzione di costo V e laseguente:
V (ϑ) =1
n+ 1
n+1∑i=1
Vi(ϑ), (3.4)
Vi(ϑ) =1
τ‖ei(ϑ)‖2
2 =1
τ
τ∑j=1
|eji|2 ,

3.4. PREDICTION ERROR METHOD 15
dove ei(ϑ) rappresenta l’i-esima colonna della matrice e(ϑ) = (eji)j=1...τ,i=1...n+1,cioe l’errore di predizione calcolato in xi.
Quello che faremo nel seguito sara applicare il metodo di Newton vistonel paragrafo precedente, ponendo f(x) ≡ V (ϑ), per risolvere il seguenteproblema di ottimizzazione:
ϑ∗ = arg minϑ∈Rn
V (ϑ).
Aggiorniamo quindi i passi del metodo di Newton, usando le notazioniappena introdotte e otteniamo l’algoritmo 4.
Algoritmo 4 Prediction Error Method:1: ϑ0 = 0;2: finche soddisfi un criterio di arresto fai // ( V < soglia )
3: trovare sk = −[V
′′(ϑk)
]−1
V′(ϑk), risolvendo cioe il sistema: V
′′(ϑk)sk = −V
′(ϑk),
con sk ∈ Rn 3 V′e V
′′ ∈ Mat(n, n);4: calcolare la nuova iterazione: ϑk+1 = ϑk + sk.5: calcola y(ϑk+1)6: calcola e(ϑk+1)7: calcola V (ϑk+1)8: fine finche
Osserviamo che puo essere adottato un accorgimento che permette direndere piu’ veloce l’algoritmo PEM. A questo scopo definiamo µk il passovariabile, e con questo sostituiamo la riga 4 ottenendo l’algoritmo 5.
Algoritmo 5 Prediction Error Method:1: ...2: calcolare la nuova iterazione: ϑk+1 = ϑk + µk sk.3: ...
A partire da µ1 = 1, ad ogni iterazione aggiorniamo la valutazione di µnel modo seguente:
1. µk+1 = µk, se V (ϑk+1) < V (ϑk);
2. µk+1 = µk
2, se V (ϑk+1) ≥ V (ϑk).
In questo modo procediamo a calcolare un nuovo ϑk attraverso l’algoritmoPEM sopra esposto solo quando e soddisfatta la condizione (1), mentre, nel
caso in cui valga la (2), ci limitiamo a porre ϑk+1 = ϑk−1+ µk
2sk. In alternativa
e possibile compiere sempre la diminuzione del passo µ, indipendentementedal valore di V , cosı da avere una convergenza piu veloce.
Per approfondimenti relativi al PEM si puo consultare [4].

Capitolo 4
Il raffinamento locale
Il raffinamento locale e un semplice algoritmo formulato appositamenteper risolvere il problema di stima della corrosione che stiamo affrontando.Vediamone quindi gli aspetti essenziali, supponendo che il segmento notoS = [0, 1] ⊂ R.
Supponiamo di partire dalla suddivisione iniziale Λ0 = {x1, ..., xn+1},e da ϑ=0=(ϑ1, ..., ϑn), cioe da un profilo non corroso. A questa suddivi-sione applichiamo il PEM e determiniamo quindi i parametri ottimali suogni segmento di S.
Procediamo poi nel modo seguente: se nel segmento di estremi {xi;xi+1}ϑi 6= 0, cioe se troviamo corrosione maggiore rispetto all’iterazione prece-dente, allora raffiniamo localmente la suddivisione aggiungendo il punto medio,ossia ponendo Λ1 =
{x1, ..., xi,
xi+xi+1
2, xi+1, ..., xn+1
}. Questo raffinamento
si fa per ogni i = 1, ..., n+1 che verifica la condizione precedente. Si procedequindi applicando il PEM a questa nuova suddivisione e cercando i parametriottimali e successivamente infittendo la suddivisione dove questi ultimi sonomaggiori di quelli determinati all’iterazione precedente.
Quando ci si ferma? Quando il segmento non e piu divisibile, cioe quandosi e raggiunta la distanza minima possibile tra due punti dx, data dalladistanza tra due sensori termici, ossia dal passo della mesh piu fine Sh.
Schematizziamo il ragionamento mediante l’algoritmo 6. In esso indichi-amo con Λi = {0, xi,1, ..., xi,n+1, 1} la i-esima suddivisione di S.
16

17
Algoritmo 6 Raffinamento locale:1: Suddivisione di partenza: Λ0 ⊂ Sh, ϑ=0;2: i=0; continua=1;3: finche Λi ⊂ Sh e continua=1; fai4: applico il PEM a Λi;5: j=i+1;6: per ogni k tale che la corrosione stimata in [xi,k, xi,k+1] sia maggiore della
corrosione dell’iterazione i− 1 e t.c. |xi,k − xi,k+1| > dx fai7: Λj = Λi ∪ xi−1,k+xi−1,k+1
28: fine per9: se Λj = Λi allora
10: continua=0;11: fine se12: i=j;13: fine finche
In figura 4.1 e rappresentato un esempio del procedimento che abbiamodescritto in questo capitolo.
Figura 4.1: Funzionamento del raffinamento locale. Da sinistra verso destra:parto con un profilo di corrosione nulla; applico il PEM e stimo la corrosionesu ogni segmento; raffino localmente la suddivisione dove c’e corrosione maggiorerispetto all’iterazione precedente. La suddivisione piu fine di S e evidenziata ilverde, quella iniziale in viola e il raffinamento di quest’ultima in blu.
Osservazione. Dunque raffinare localmente equivale a considerare unaquantita maggiore di informazione attorno ad un punto nel quale si e stimatacorrosione.

Capitolo 5
Gli algoritmi genetici
In questa sezione si e seguito il testo [8].
5.1 Ottimizzazione multiobiettivo
Un problema di ottimizzazione multiobiettivo puo essere riassunto nel modoseguente: trovare x=(x1, ..., xn) tale che minimizza le k funzioni obiettivoreali f1 (x) , ..., fk (x), soggetto alle m restrizioni reali gj (x) ≤ 0 j = 1, ...,m.
In genere non esiste un tale vettore x che minizzi contemporaneamente lek funzioni obiettivo. Viene usato allora un nuovo concetto: soluzione ottimadi Pareto. Una soluzione ammissibile x, cioe tale che soddisfi le m restrizioni,e detto ottimo di Pareto, se non esiste alcuna soluzione ammissibile y taleche ∀ i = 1, ..., k si abbia fi (y) ≤ fi (x) e ∃ j tale che fj (y) < fj (x). In altreparole x ammissibile, e detto ottimo di Pareto se ogni altra soluzione ammissi-bile y che diminuisce il valore di una funzione obiettivo, contemporaneamentecausa l’aumento di almeno una delle altre.
5.2 Gli algoritmi genetici
Molti problemi pratici in cui e necessario trovare l’ottimo di una o piu fun-zioni obiettivo, tendono a mescolare variabili continue e discrete. Se perun problema di questo tipo usiamo la programmazione classica non lineare,essa si rivelera inefficiente, computazionalmente onerosa e spesso tendera atrovare l’ottimo locale piu vicino al punto di partenza. Ci vengono in aiutogli algoritmi genetici (AG)1, che con una probabilita elevata trovano l’otti-
1In letteratura gli algoritmi genetici sono indicati con la sigla GA, che significa GeneticAlgorithms.
18

5.2. GLI ALGORITMI GENETICI 19
mo globale. Questi ultimi si basano sui principi della genetica e della se-lezione naturale. Gli elementi fondamentali della genetica, cioe riproduzione,crossover e mutazione, sono usati nella ricerca dell’ottimo.
Le caratteristiche che distinguono gli AG dalle tecniche classiche sono leseguenti:
1. gli AG partono da una popolazione di punti x = (x1, ..., xn), anzicheda un singolo punto. Inoltre se il numero di variabili e n (cioe se ladimensione dello spazio in cui vive il vettore x e n), di solito si parte dauna popolazione tra i 2n e i 4n elementi. L’insieme di questi punti, seben distribuiti nel dominio, permette all’algoritmo di evitare gli ottimilocali. Osserviamo che ogni elemento della popolazione x, puo a suavolta essere un vettore: xi = (xi)j=1,...,s , ∀ i = 1, ..., n. Tuttavia nelseguito sara considerato il caso xi scalare.
2. Gli AG usano solo il valore della funzione obiettivo, e non le suederivate.
3. Negli AG le variabili sono rappresentate da stringhe binarie che, ingenetica, corrispondono ai cromosomi. Per questo motivo il metodo diricerca dell’ottimo si adatta bene a risolvere sia problemi discreti siacontinui. In quest’ultimo caso, la lunghezza della stringa puo variare aseconda della precisione che si desidera raggiungere.
4. Il valore della funzione obiettivo, che corrisponde ad un certo vettorexi, rappresenta il fitness in genetica.
5. Per ogni nuova generazione creata, sono prodotte delle stringhe nuovescegliendo in modo random i genitori e applicando gli operatori genetici.E’ bene osservare che sebbene usino scelte random, gli AG non sonobanalmente tecniche di ricerca random: essi al contrario esplorano ildominio anche attraverso le nuove combinazioni di vecchie stringhe conlo scopo di trovare una nuova generazione con un fitness piu alto.
5.2.1 Rappresentazione delle variabili
Negli AG ogni variabile xi, i = 1, ..., n e rappresentata da una stringa di 0 e1; se ognuna di queste stringhe e lunga q, allora il vettore della popolazione xavra una lunghezza complessiva di nq. In generale, se b = (bq bq−1 ... b1 b0) eun numero binario, bi ∈ {0, 1}, allora l’intero corrispondente e y =
∑qk=0 2kbk.
Usando solo questa formula, se la variabile x e continua, essa potrebbe essere

20 CAPITOLO 5. GLI ALGORITMI GENETICI
rappresentata solamente da un insieme discreto di valori binari. Per consid-erare anche la parte decimale e necessario introdurre una nuova formula.Poniamo xl, xu i limiti inferiore e superiore del vettore x, rappresentati aloro volta da stringhe binarie di lunghezza q. Allora x = xl+ xu+xl
2q−1
∑qk=0 2kbk.
Quindi se la variabile e discreta, gli AG si prestano bene a risolvere il prob-lema di ottimizzazione discreta. Se si vuole invece un’elevata accuratezzanella determinazione di x continua, e necessario aumentare q: infatti il nu-mero di cifre binarie q necessarie a rappresentare una variabile continua conprecisione ∆x e stimabile con 2q ≥ xu+xl
∆x+ 1.
E’ bene sottolineare che la codifica e strettamente legata al problemache si vuole risolvere. Quindi, in generale, e possibile considerare diverseformulazioni; tuttavia, la codifica binaria e una delle piu semplici e intuitive.Per approfondimenti e possibile consultare [9].
5.2.2 Rappresentazione della funzione obiettivo e dellerestrizioni
Gli AG cercano il massimo di un problema non vincolato. Per risovere unproblema di minimizzazione vincolata
minf(y),
gj(y) ≤ 0, j = 1, ...,m,
y ∈ R,
dobbiamo trasformare il problema di partenza. Dapprima consideriamo unproblema equivalente privo di vincoli, introducendo una funzione di penalitaΦ tale che
Φ(Z) =
{Z2, se Z > 0;0 se Z ≤ 0.
Otteniamo cosı
min f(y) +Rm∑
j=1
Φ(gj(y)),
soggetto a yl ≤ y ≤ yu;
dove R e una costante detta parametro di penalita.Ora e necessario applicare una seconda trasformazione per riscrivere il
problema di minimizzare di f(y), nella massimizzazione della funzione difitness F (y), definita nel modo seguente:

5.2. GLI ALGORITMI GENETICI 21
F (y) = Fmax −
(f(y) +R
m∑j=1
Φ(gj(y))
)= Fmax − f(y);
dove Fmax e scelto in modo che sia maggiore del supf(y) per ogni y neldominio di f .
5.2.3 Operatori genetici
Nell’ottimizzazione numerica sono implementate la selezione, il crossover ela mutazione.
• La selezione e un processo durante il quale gli individui vengono sceltiin base al valore della loro funzione di fitness, rispetto al resto dellapopolazione. Ad ogni stringa (che corrisponde ad ogni componente xi
della popolazione x) e assegnata una probabilita pi di riprodursi, dovepi = fi∑k
j=1 fj, fi e il valore della funzione obiettivo, o della funzione di
fitness, dell’i-esimo individuo xi della popolazione x, e k e la dimensionedi x. Quindi gli individui con un valore di fitness maggiore hanno unamaggiore probabilita di essere scelti per la riproduzione e di tramandarei loro geni: questi ultimi tenderanno a vivere e riprodursi, mentre gliindividui con fitness minore moriranno.
• Dopo la selezione avviene il crossover, che e implementato in due fasi:dapprima due individui (stringhe) sono selezionati in modo random trai genitori selezionati. Successivamente, in modo random, viene sceltauna posizione lungo le stringhe, e si scambiano nelle due stringhe lecifre binarie (gli alleli) che seguono questa posizione. Si generano cosıdue discendenti degli individui di partenza, che vengono inserite nellanuova popolazione.
• Per finire, la mutazione e applicata alle nuove stringhe, secondo unacerta probabilita di mutazione. Essa consiste nell’alterazione randomdi una cifra binaria (cioe del valore di un allele): in altre parole 1viene scambiato con 0 o viceversa (se facciamo riferimento alla codificabinaria). Combinando la mutazione con la selezione e il crossover, epossibile prevenire la perdita di importante materiale genetico.

22 CAPITOLO 5. GLI ALGORITMI GENETICI
5.2.4 Elitismo e convergenza
Secondo quanto introdotto nel paragrafo precedente, la selezione, il crossovere la mutazione vengono applicate ad una popolazione di N cromosomi fincheviene generato un nuovo insieme di N individui, che diviene la nuova popo-lazione. Tuttavia questa strategia puo sembrare poco convenienete dal pun-to di vista dell’ottimizzazione, in quanto dopo aver costruito una buonasoluzione si corre il rischio di perderla, qualora questa non rientri nel mecca-nismo riproduttivo.
Per superare questo ostacolo, nel 1975, K.A.De Jong, nell’opera An ana-lysis of the behaviour of a class of genetic adaptive systems, introduce ilconcetto di elitismo. Una strategia basata su quest’ultimo assicura la so-pravvivenza del miglior individuo nella popolazione successiva, attraverso ilsuo inserimento nella generazione seguente, nella quale vengono sostituitisolamente i restanti N − 1 cromosomi.
In effetti si puo dimostrare che, per costruire un AG convergente allasoluzione ottima, e sufficiente memorizzare ad ogni passo dell’algoritmo l’in-dividuo migliore trovato fino a quel momento: infatti in questo modo sigenera una successione di valori della funzione di fitness che non descrescee, se questa e superiormente limitata, cioe se il problema ammette valoreottimo finito, allora essa e anche convergente. Questa e l’idea su cui si fondal’elitismo.
In modo piu formale, diremo che un AG e dotato di elitismo se per ognitempo t, definito k il miglior individuo in t, al tempo t+ 1
1. k e nella popolazione, o
2. almeno un individuo migliore di k e nella popolazione.
Ogni AG puo essere dotato di elitismo mediante l’algoritmo 7.
Algoritmo 7 Elitismo in un AG:1: . . .2: memorizza k, il miglior individuo nella popolazione corrente3: genera la popolazione seguente4: se (nessun elemento della nuova popolazione e migliore di k) allora5: sostituisci K ad un altro individuo della popolazione6: fine se7: . . .
Il valore obiettivo dell’individuo migliore genera quindi una successionenon descrescente e limitata superiormente e quindi convergente.

5.2. GLI ALGORITMI GENETICI 23
Osservazione. E’ possibile dimostrare che un algoritmo genetico e un pro-cesso di Markov, in quanto ogni popolazione dipende esclusivamente dallaprecedente. Inoltre, se esso e dotato di elitismo e di probabilita di mutazionecostante, il processo stocastico X0, X1, . . . tale che Xi sia miglior individuodell’i-esima popolazione converge q.c. alla soluzione ottima.
In questo report non approfondiamo questi concetti, rimandando a [9] pereventuali approfondimenti.
Osservazione. Un importante aspetto da considerare quando si valuta unalgoritmo e analizzarne la complessita e quindi la velocita di convergenza. Acausa della complessa natura degli AG, e molto difficile provare un risultatogenerale di questo tipo: lo sviluppo di tecniche per stimare il tempo di cal-colo degli AG e attualmente tema di ricerca. Pur non essendoci una teoriagenerale, esistono dei metodi di stima numerici per valutare la performancedi uno specifico AG.

Capitolo 6
Verso l’algoritmo risolutivo
Nei capitoli precedenti abbiamo introdotto gli argomenti teorici essenzialiche guidano la nostra ricerca della corrosione. Ora cerchiamo di capire comequesti possano essere adattati allo studio del problema in questione.
6.1 Il modello numerico FEM
Come abbiamo introdotto nel capitolo 2, abbiamo formulato un modello nu-merico FEM che consiste nella discretizzazione dell’equazione del calore. Essoe fondamentale per calcolare una stima numerica delle temperature sul seg-mento noto, una volta che e stato fissato il dominio. Nei prossimi paragraficapiremo come i concetti teorici che abbiamo introdotto possano essere uti-lizzati per risolvere il problema della stima del dominio dell’equazione delcalore.
6.2 Il PEM applicato al nostro problema
Supposta nota la suddivisione del segmento S, per costruire un modello nu-merico che approssimi bene la matrice dei dati sperimentali, vorremmo de-terminare i parametri che definiscono il dominio del problema, ossia l’altezzadi ogni scalino della funzione costante a tratti che descrive il profilo di cor-rosione. Il PEM, sintetizzato nell’algoritmo 4, risolve iterativamente questoproblema di stima. E’ bene sottolineare che il modello FEM e essenzialein questa ricerca: ad ogni iterazione dell’algoritmo di ottimizzazione, la dis-cretizzazione dell’equazione del calore ci permette di calcolare il residuo delmodello, e quest’ultimo guida la ricerca dei parametri all’interno del PEM.
24

6.2. IL PEM APPLICATO AL NOSTRO PROBLEMA 25
6.2.1 Implementazione del PEM
Consideriamo quindi l’algoritmo 4 e concentriamoci sulle righe di propriedell’algoritmo di Newton, riassunte nell’algoritmo 8.
Algoritmo 8 Prediction Error Method:1: ...2: risolvere il sistema: V
′′(ϑk)sk = −V
′(ϑk);
3: calcolare la nuova iterazione: ϑk+1 = ϑk + sk.4: ...
Cerchiamo ora di esplicitare alcuni conti, cosı da rendere piu agevole ilcalcolo delle derivate di V (ϑ), che compaiono nell’algoritmo; ricordiamo cheϑ = (ϑ1, ..., ϑn).
V′(ϑ) =
(∂
∂ϑlV (ϑ)
)l=1,...,n
, dove ∂∂ϑlV (ϑ) = 1
n+1
∑n+1i=1
∂∂ϑlVi(ϑ).
∂∂ϑlVi(ϑ) = 2
τei ·ψi(:, l), avendo posto ψi(:, l) = ∂
∂ϑlei(ϑ) = − ∂
∂ϑlyi(ϑ), yi ∈ Rτ
colonna i-esima della matrice dei dati sperimentali (relativa al nodo i-esimo),ψi = −∇yi(ϑ) = (ψi(:, l)l=1,...,n) ∈Mat(τ, n).Quindi ∂
∂ϑlV (ϑ) = 2
τ(n+1)
∑n+1i=1 ei · ψi(:, l).
Calcoliamo ora la derivata seconda di V : V′′(ϑ) =
(∂2
∂ϑl∂ϑkV (ϑ)
)l=1...n,k=1...n
,
dove ∂2
∂ϑl∂ϑkV (ϑ) = ∂
∂ϑk
(∂
∂ϑlV (ϑ)
)=
= ∂∂ϑk
[2
τ(n+1)
∑n+1i=1 ei · ψi(:, l)
]= 2
τ(n+1)
∑n+1i=1
[ψi(:, k) · ψi(:, l) + ei · ∂
∂ϑkψi(:, l)
].
In un intorno sufficientemente piccolo del minimo, se il modello e costruitobene, si ha ei(ϑ) ≈ 0 e quindi
∂2
∂ϑl∂ϑkV (ϑ) ≈ 2
τ(n+1)
∑n+1i=1 ψi(:, k) · ψi(:, l) = 2
τ(n+1)
∑n+1i=1 Hi(k, l), avendo
posto Hi = ψTi ψi, Hi ∈Mat(n, n), i = 1, . . . , n+ 1.
Ci siamo quindi ricondotti a calcolare esclusivamente ψi(ϑ), i = 1, . . . , n+1.Un’aspetto interessante da analizzare, visto che poi l’algoritmo andra
implementato sul calcolatore, e come calcolare ψi(ϑ). Una possibile soluzionee approssimare il vettore ψi(:, l), colonna l-esima della matrice ψi, con unadifferenza finita centrata:ψi(:, l) = − ∂
∂ϑlyi(ϑ) = 1
δϑ[yi(ϑl + δϑ
2)− yi(ϑl − δϑ
2)].
Osserviamo quindi che per costruire la matrice ψi sara necessario calcolare inmodo indipendente ogni colonna l perturbando il corrispondente parametroϑl. Questo passaggio puo dunque essere eseguito in parallelo.
Singular Value Decomposition (SVD)
Data una matrice reale H ∈ Mat(N, n), calcolarne la singular value de-composition (SVD) consiste nello scomporre H nel prodotto di tre matrici

26 CAPITOLO 6. VERSO L’ALGORITMO RISOLUTIVO
H = UΣV , tali che U e V siano due matrici ortogonali quadrate rispettiva-mente di dimensioni N × N e n × n, e Σ sia una matrice pseudodiagonale
N × n della forma Σ =
(Σ+
0
), dove Σ+ e una matrice diagonale n × n, i
cui elementi diagonali sono detti valori singolari di H e sono posizionati inordine descrescente.
La SVD e di fondamentale importanza, poiche puo essere utilizzata nellarisoluzione di problemi di minimi quadrati lineari, soprattutto quando sonomalcondizionati e per le approssimazioni di rango minimo di una matrice(mediante SVD troncata). Per maggiori informazioni sulla SVD e sui suoipossibili utilizzi si vedano, per esempio, [10], [?] e [5].
6.2.2 SVD applicata al PEM
Per ridurre il malcondizionamento del problema, si puo procedere nel modoseguente all’interno dell’algoritmo PEM : si calcola la matrice V
′′e di questa
si considera la SVD troncata, ponendo a zero i valori singolari al di sotto diuna certa soglia di precisione determinata dalle misure: quindi V
′′= UΣV T
e si pone sj = 0, per ogni j = 1, · · · , n tale che σj < soglia, dove sj indica il
j-esimo valore singolare della matrice V′′: si ottiene in questo modo Σ.
Calcolata la SVD troncata di V′′, si risolve il sistema V
′′(ϑ
k)sk = −V ′
(ϑk)
ponendo sk = −(V Σ−1UT )V′, dove (V
′′)+ = (V Σ−1UT ) e la pseudo-inversa
di Moore Penrose di V′′. In questo modo si determina la nuova iterazione
del PEM.
Per concludere osserviamo che e possibile adottare una strategia che cipermette di semplificare ulteriormente il problema. Consideriamo la matricee(ϑ) ∈Mat(τ, n+1), come un vettore in Rτ(n+1), per esempio giustapponendole colonne della matrice. E’ quindi possibile ridefinire la funzione di costo 3.4nel modo seguente:
V (ϑ) =1
τ(n+ 1)‖e(ϑ)‖2
2 =1
τ(n+ 1)
τ(n+1)∑j=1
|e(j)|2 . (6.1)
In modo analogo a quanto abbiamo fatto e possibile ripetere i conti cheabbiamo effettuato ottenendo
V′(ϑ) =
(∂
∂ϑlV (ϑ)
)l=1,...,n
, dove ∂∂ϑlV (ϑ) = 2
τ(n+1)e · ψ(:, l), avendo posto
ψ = −∇y(ϑ) ∈Mat(τ(n+ 1), n).
Quindi V′(ϑ) = 2
τ(n+1)ψTe.

6.3. GLI AG APPLICATI AL NOSTRO PROBLEMA 27
V′′(ϑ) =
(∂2
∂ϑl∂ϑkV (ϑ)
)l=1...n,k=1...n
, dove ∂2
∂ϑl∂ϑkV (ϑ) = 2
τ(n+1)ψ(:, k) · ψ(:, l) +
e · ∂∂ϑk
ψ(:, l) ≈ 2τ(n+1)
(ψTψ
)kl.
Quindi V′′(ϑ) = 2
τ(n+1)ψTψ.
Osserviamo infine che le due definizioni di V , (3.4) e (6.1) sono equivalenti:V (ϑ) = 1
n+1
∑n+1i=1 Vi(ϑ) = 1
τ(n+1)
∑n+1i=1 ‖ei(ϑ)‖2
2 = 1τ(n+1)
∑n+1i=1
∑τk=1 |eki|2 =(∗)
= 1τ(n+1)
∑τ(n+1)j=1 |e(j)|2 = 1
τ(n+1)‖e(ϑ)‖2
2,
dove nell’uguaglianza (∗) si e interpretata la matrice e come un vettore,giustapponendone le colonne. La scelta della formula e puramente formale:mentre la definizione (3.4) e piu vicina al problema fisico, mantenendo lastruttura matriciale dei dati, la seconda (6.1) e piu comoda dal punto di vistaimplementativo, in quanto permette di semplificare il problema, pur aumen-tando la dimensione dei vettori considerati. Infatti utilizzando la definizione(6.1) di V otteniamo:V
′′(ϑk)sk = −V ′
(ϑk) ⇐⇒ 2τ(n+1)
ψT ψ s = − 2τ(n+1)
ψT e ⇐⇒ ψ s = −e, ossia
non e necessario calcolare esplicitamente V′′, per avere la nuova iterazione
del PEM. Ci si puo dunque limitare a risolvere ψs = −e, mediante SVD tron-cata di ψ, definendo ψ matrice di sensitivita. Questo procedimento si rivelaparticolarmente utile quando le colonne di ψ non sono sufficientemente in-dipendenti rispetto all’errore relativo presente nei dati sperimentali: in questocaso infatti il malcondizionamento della matrice (misurato dal rapporto tra ilmassimo valore singolare e il minimo) comprometterebbe l’algoritmo stesso.In questa situazione poniamo allora soglia = σ ‖ψ‖∞, dove σ e la deviazionestandard dell’errore di misura.
Dobbiamo quindi affrontare il problema della scelta della suddivisione delsegmento noto S, cui verra poi applicato il PEM. Le tecniche che abbiamoutilizzato sono due: il raffinamento locale, che abbiamo gia analizzato nelcapitolo 4 e gli algoritmi genetici. Vediamo ora come questi ultimi possanoessere applicati nel nostro contesto.
6.3 Gli AG applicati al nostro problema
Per individuare attraverso gli algoritmi genetici i sottoinsiemi della suddi-visione piu fine Sh di S, identifichiamo questi ultimi con le sequenza bina-rie lunghe tanto quanti sono i punti di Sh, attraverso una corrispondenzabionivoca .
Gli obiettivi che andremo a minimizzare saranno due:

28 CAPITOLO 6. VERSO L’ALGORITMO RISOLUTIVO
1. trovare il vettore binario tale che la suddivisione corrispondente di Sabbia il numero minimo di nodi;
2. trovare il vettore binario tale che sia minima la funzione di costo cal-colata col PEM a partire dalla suddivisione di S corrispondente.
Essendo un problema multiobiettivo ci aspettiamo come soluzione uninsieme di punti, che andranno a determinare il fronte di Pareto.
6.4 Le tappe fondamentali nella stima della
corrosione
Dopo aver introdotto gli ingredienti fondamentali vediamo quali sono le tappein cui si articola la nostra ricerca.
• Costruzione del modello relativo al dominio non corroso: note Q, R, ildominio e le condizioni iniziali della temperatura su queste, si costruisceun modello analogo al sistema 2.1, confrontando l’uscita del modelloy con le temperature sperimentali relative al campione sano ysano, chesi suppongono note, in modo da avere un piccolo errore di modellow. In questa prima fase ϑ e un vettore di zeri. Alla fine di questafase si calcola il valore della funzione costo, che costituisce un valoredi riferimento e rappresenta il valore ideale che vogliamo raggiungerequando stimiamo un campione corroso.
• Nel caso in cui non si usino dati sperimentali reali, e necessario costru-ire dei dati simulati : si sceglie dapprima un profilo di corrosione, cioeuna funzione a scalino f , individuata da un vettore ϑ. Poiche nel capi-tolo 2 abbiamo ipotizzato che la corrosione non modifichi il modellonello spazio degli stati, se ne costruisce l’uscita, variandone solamenteil dominio, rispetto al caso non corroso. In questo modo si determinail vettore delle temperature sperimentali ysperimentali su S in t0 + ∆t.
• Lo scopo di questa parte e ricostruire f , cioe determinare ϑ∗ ottimale,tale che ϑ∗ = arg minϑ∈Rn V (ϑ). Per fare questo per prima cosa siverifica se il materiale e corroso, poiche questa non e un’informazioneche si ha a priori. Si comincia quindi la ricerca di ϑ ponendo ϑ=0. SeV (0) e inferiore ad una soglia di tolleranza fissata, allora si concludeche il campione e sano.

6.4. TAPPE FONDAMENTALI 29
In caso contrario e necessario distinguere tra problemi di dimensionepiccola o grande, che verranno trattati separatamente nei prossimi capi-toli. Sottolineiamo fin d’ora che ai problemi di scelta della suddivisionedi S e di determinazione della corrosione per ogni suddivisione fissata,che abbiamo introdotto nel capitolo 2, abbiamo associato due tappedistinte negli algoritmi risolutivi. Mentre il primo e affidato ad unOUTER LOOP e coinvolge il raffinamento locale e gli algoritmi geneti-ci, la determinazione della profondita della corrosione mediante il PEMe gestita attraverso un INNER LOOP.

Capitolo 7
Problemi di piccola dimensione
In questo capitolo vedremo che, per risolvere problemi nei quali il dominio epiccolo (ossia nei quali il numero di sensori termici su S e piccolo), il raffina-mento locale si rivelera la scelta migliore per descrivere in modo accurato ilprofilo di corrosione. Per approfondire questa sezione e possibile consultare[6].
7.1 Aspetti fondamentali
Per questo tipo di problemi, la parametrizzazione che adotteremo coprira tut-to il dominio, e quindi la scelta dei parametri che caratterizzano il segmentoS avverra in modo deterministico.
Di conseguenza, l’OUTER LOOP, il cui compito e determinare il sottoin-sieme di Sh su cui l’INNER LOOP operera con il PEM, dovra solamenteregolare l’adattamento della parametrizzazione, ossia scegliere quali nodi diSh considerare.
7.2 Strutture dati che definiscono la parame-
trizzazione
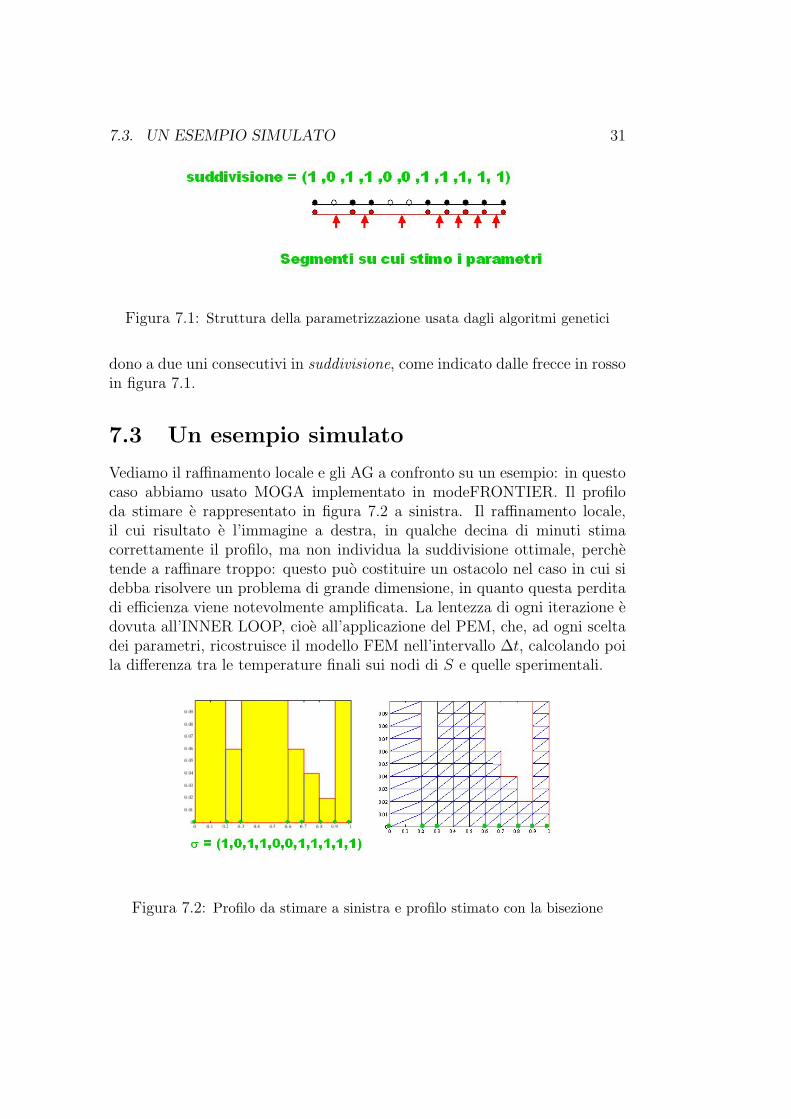
Per utilizzare gli algoritmi genetici e necessario definire la corrispondenzabiunivoca tra sottoinsiemi di Sh e vettori binari. La strada seguita e illustratain figura 7.1. Ad ogni sottoinsieme Λ di Sh corrisponde il vettore binariosuddivisione tale che suddivisione(i) = 1 se l’i-esimo nodo di Sh appartienea Λ, suddivisione(i) = 0 altrimenti.
Inoltre si stima la corrosione sui tutti i segmenti della mesh che corrispon-
30
7.3. UN ESEMPIO SIMULATO 31
Figura 7.1: Struttura della parametrizzazione usata dagli algoritmi genetici
dono a due uni consecutivi in suddivisione, come indicato dalle frecce in rossoin figura 7.1.
7.3 Un esempio simulato
Vediamo il raffinamento locale e gli AG a confronto su un esempio: in questocaso abbiamo usato MOGA implementato in modeFRONTIER. Il profiloda stimare e rappresentato in figura 7.2 a sinistra. Il raffinamento locale,il cui risultato e l’immagine a destra, in qualche decina di minuti stimacorrettamente il profilo, ma non individua la suddivisione ottimale, perchetende a raffinare troppo: questo puo costituire un ostacolo nel caso in cui sidebba risolvere un problema di grande dimensione, in quanto questa perditadi efficienza viene notevolmente amplificata. La lentezza di ogni iterazione edovuta all’INNER LOOP, cioe all’applicazione del PEM, che, ad ogni sceltadei parametri, ricostruisce il modello FEM nell’intervallo ∆t, calcolando poila differenza tra le temperature finali sui nodi di S e quelle sperimentali.
Figura 7.2: Profilo da stimare a sinistra e profilo stimato con la bisezione

32 CAPITOLO 7. PROBLEMI DI PICCOLA DIMENSIONE
In figura 7.3 riportiamo il risultato ottenuto applicando gli AG.
Figura 7.3: Fronte di Pareto calcolato con MOGA
La suddivisione ottimale sta sul fronte di Pareto, come indica la freccia,ma converge dopo diverse ore. Inoltre non si riesce a ridurre sensibilmentela velocita di convergenza nemmeno riducendo a uno il numero di obiettivi,trasfromando la minimizzazione della funzione di costo in due vincoli. Questometodo dunque e troppo costoso.
Per problemi di piccola dimensione, quindi, il raffinamento locale e una buonasoluzione per una stima accurata del profilo.
Si pone pero il seguente problema: e possibile formulare un algoritmogenetico che abbia una velocita di convergenza al fronte di Pareto maggiore?Questa questione diventa fondamentale nei problemi di grande dimensione,per i quali e impensabile utilizzare il raffinamento locale.
Cercheremo di rispondere a questa domanda nel prossimo capitolo.

Capitolo 8
Problemi di grande dimensione
8.1 Aspetti fondamentali
Per questo tipo di problemi, e fondamentale limitare il carico computazionalee quindi e necessario che il numero di parametri resti contenuto. Poicheabbiamo ipotizzato che la zona spaziale di ogni parametro non sia troppogrande, in modo che sia possibile stimare accuratamente il profilo di cor-rosione, dovremo supporre che, su domini grandi, la copertura avvenga inmodo probabilistico.
L’OUTER LOOP quindi dovra trovare un modo efficiente per analizzare ildominio, con basso margine di rischio, mediante parametrizzazioni sparse.
Vedremo che in questo tipo di problemi gli AG e il raffinamento localedaranno un contributo fondamentale per trovare in modo efficiente zonecorrose su un dominio esteso.
8.2 Strutture dati che definiscono la parame-
trizzazione
Per problemi di grande dimensione siamo in presenza di vettori di parametrisparsi quindi un approccio come quello introdotto nel capitolo 7 non e cor-retto: infatti tenderebbe a mediare la corrosione presente in un intervalloampio del dominio, poiche applicherebbe il PEM in tutti i segmenti indivi-duati da due uni consecutivi, non rispettando l’ipotesi che ad ogni parametrocorrisponda una piccola zona.
Dobbiamo quindi ridefinire la parametrizzazione, come illustrato in figura8.1.
A partire da un vettore binario sparso suddivisione, che e un individuo
33

34 CAPITOLO 8. PROBLEMI DI GRANDE DIMENSIONE
Figura 8.1: Struttura della parametrizzazione usata per problemi di grandedimensione
nell’AG, costruiamo il vettore binario pixel aggiungendo un uno agli estremie a sinistra di ogni uno in suddivisione. Gli uni in pixel rappresentano i nodidi Sh che andiamo a considerare. Inoltre andiamo a stimare la corrosionesolo tra due uni consecutivi in pixel, cioe in ogni segmento della mesh piufine, che si trova subito a sinistra di un uno in suddivisione, come indicatodalle frecce rosse in figura 8.1.
8.3 NSGA II modificato
Cerchiamo quindi di formulare un algoritmo che sintetizzi sia le proprietadel raffinamento locale, sia quelle degli algoritmi genetici. A questo scopoutilizziamo l’algoritmo NSGA II ([11]) e lo modifichiamo, adattandolo alproblema specifico.
Otteniamo cosı l’algoritmo 9.
In esso il raffinamento locale e implementato nel seguente modo: si con-sidera l’individuo della popolazione corrente, che e un vettore sparso. Dovec’e un uno, si arricchiscono localmente i parametri, cioe si aggiungono uni adestra e a sinistra finche si trova corrosione nulla o finche si raggiunge un lim-ite massimo di iterazioni (fissato a priori). Importante e il confronto costantecon il vettore costanti, che dice dove e gia stato utilizzato il raffinamento: sec’e uno zero in costanti allora lı non c’e corrosione, mentre se c’e un uno lıc’e corrosione. Le zone non visitate sono i −1 in costanti.
8.4 Un esempio simulato
Abbiamo testato questo algoritmo su un esempio in cui il numero di nodi epari a 51: esso converge alla soluzione ottimale, come illustrato in figura 8.2.Inoltre la soluzione viene determinata gia nelle prime generazioni e appartieneal fronte di Pareto, come illustrato dalla freccia in figura 8.2.

8.4. UN ESEMPIO SIMULATO 35
Algoritmo 9 NSGA II modificato:1: Fissa la cardinalita della popolazione Npop e la probabilita di mutazione p.2: Crea una popolazione iniziale random e sparsa, formata da Npop individui.3: OUTER LOOP:4: finche soddisfi un criterio di arresto, per esempio sul numero delle generazioni fai5: per ogni individuo della popolazione corrente fai6: INNER LOOP:7: stima i valori dei parametri col PEM;8: per ogni parametro maggiore di TOLL ( = corrosione significativa): fai9: finche soddisfi un criterio di arresto fai // puo essere compiuto in parallelo
10: arricchisci localmente di parametri;11: stima i valori dei parametri (arricchiti);12: fine finche13: fine per14: fine per15: raccogli le informazioni dell’inner loop in un vettore costanti che inizializzi a −1 e
ne modifichi le componenti rispettivamente in 1 e 0 a seconda che nell’intervallo asinistra ci sia o meno corrosione.
16: A partire dalla popolazione trasformata, seleziona i genitori.17: Applica ai genitori la mutazione, con probabilita p, e il crossover con probabilita
1− p, Npop volte, generando cosı i discendenti.18: Considera l’insieme genitori e discendenti e seleziona i migliori Npop individui, che
costituiscono la nuova popolazione. La selezione garantisce l’elitismo.19: fine finche
Concludiamo questa analisi con le immagini 8.3, 8.4 e 8.5, che mostranoil funzionamento del raffinamento locale.Osservazione. L’elitismo e la probabilita di mutazione costante, garantis-cono la convergenza dell’algoritmo alla soluzione ottimale.

36 CAPITOLO 8. PROBLEMI DI GRANDE DIMENSIONE
Figura 8.2: Il profilo ottimale sta sul fronte di Pareto
Figura 8.3:

8.4. UN ESEMPIO SIMULATO 37
Figura 8.4:
Figura 8.5: Successione dei profili stimati dal raffinamento locale nell’esempio chestiamo analizzando.

Capitolo 9
Riassunto dei contenuti
Prima di concludere questo report, forniamo un riassunto delle tematicheaffrontate, con lo scopo di renderle il piu chiare possibile.
1. Presentazione del problema
• Ipotesi:
(a) lamina metallica di materiale e dimensioni noti;
(b) e possibile interagire solo con una faccia della lamina S, laquale e dotata di N sensori termici;
(c) investiamo tale faccia con un flash termico e raccogliamo idati sperimentali;
(d) supponiamo che la corrosione sia uniforme lungo z, pertantoci limitiamo a studiare il caso bidimensionale;
(e) ipotizziamo che ad eccezione della faccia nota, la superficiedella lamina sia adiabatica.
(f) il profilo di corrosione e descritto da una funzione a scalino f ,individuata da un vettore di parametri che rappresentano laprofondita di ogni scalino;
(g) ad ogni parametro corrisponde una precisa zona spaziale delprofilo di corrosione, l’ampiezza della quale non deve esseretroppo grande se si vuole una stima accurata;
(h) supponiamo che i parametri siano non sovrapposti.
• Scopo: ricostruire il profilo di corrosione incognito a partire daidati sperimentali registrati: definizione del problema inverso.
38

39
2. Formulazione di un modello numerico FEM che descriva l’evoluzionedel calore all’interno della lamina, che discretizzi quindi il problemadiretto corrispondente;
• Ipotesi: supponiamo che la corrosione non modifichi il modelloFEM, ma solamente il dominio.
3. Algoritmi per la risoluzione problema inverso, utilizzando il modellonumerico:
(a) definizione della griglia che discretizza il dominio: OUTER LOOP ;
(b) per ogni elemento della suddivisione del segmento noto S deter-minazione di una stima ottimale del profilo di corrosione localemediante la minimizzazione della funzione di costo: PredictionError Method - INNER LOOP.
4. OUTER LOOP: confronto tra due algoritmi
• raffinamento locale: approccio deterministico che si rivela la stra-da migliore da seguire nei problemi di piccola dimensione, nei qualila parametrizzazione copre tutto il dominio
• algoritmi genetici : affrontano il problema della stima dal punto divista stocastico e, a causa del loro costo computazionale, sono dautilizzare solo per problemi di grande dimensione. In questi ultimila copertura del dominio avviene in modo probabilistico, poichee necessario limitare il numero dei parametri per ridurre il costocomputazionale dell’algoritmo.
5. Problemi di grande dimensione: formulazione dell’algoritmo NSGA IImodificato che rappresenta un compromesso tra algoritmi genetici eraffinamento locale.

Conclusioni
I risultati cui siamo pervenuti, e che abbiamo descritto in questo report, sonostati riassunti in un intervento tenuto dagli autori all’EnginSoft User’s Meet-ing 2007, dal titolo ”Applicazione degli algoritmi genetici alla stima dellacorrosione mediante termografie”. Lo studio di queste tematiche in seguito eproseguito, anche grazie al rinnovo della borsa di studio da parte di ESTECOsrl e dell’Universita di Padova. Ci siamo concentrati sul caso tridimension-ale, abbandonando quindi l’ipotesi di corrosione uniforme lungo l’asse z, esu problemi di grande dimensione. I risultati che abbiamo ottenuto sonoraccolti nella tesi di laurea ”Studio di algoritmi genetici per l’analisi dellacorrosione su strutture di grandi dimensioni” di Giulia Deolmi, a cui hannocollaborato il Dott. Fabio Marcuzzi e la Dott.ssa Silvia Poles rivestendo iruoli rispettivamente di relatore e correlatore.
40

Appendice A
I dati sperimentali
In questa appendice cerchiamo di capire come vengono raccolti i dati spe-rimentali, che costituiscono il nostro punto di partenza nella risoluzione delproblema inverso di stima della corrosione in una lamina.
A.1 Il modello di riferimento
Come abbiamo accennato nel report, e essenziale che il modello per il cam-pione non corroso sia il piu accurato possibile, in quanto questo e il punto dipartenza per la stima del campione corroso, poiche abbiamo ipotizzato chela corrosione non modifichi le caratteristiche del sistema 2.1. Come costruirequesto modello se analizziamo un problema reale?
Sia y = TS ∈ Mat(τ,N) la matrice reale dalle misure sperimentali delletemperature sugli N nodi di S, dove τ indica il numero di istanti tempo-rali considerati. Se il materiale fisico e ignoto, attraverso TS cercheremo dicapire come si possano determinare le costanti fisiche che lo caratterizzano;se invece esso e noto supporremo di conoscere questi parametri. La quantifi-cazione di queste costanti e importante, poiche esse compaiono nella PDEdel calore e nelle sue condizioni iniziali, e quindi condizionano le tempera-ture che ricostruiamo numericamente e indichiamo con y. Come abbiamovisto piu volte, vorremmo che y approssimi TS. Facendo riferimento allaformulazione stocastica del problema 2.1, quello che vogliamo fare, quindi, edeterminare i coefficienti del modello 2.1, in modo che l’errore di predizione,sia approssimativamente rumore bianco e gaussiano.
41

42 APPENDICE A. I DATI SPERIMENTALI
A.2 La raccolta dei dati sperimentali
In questo paragrafo vediamo brevemente come vengono raccolti i dati speri-mentali.
Consideriamo, quindi, una lamina metallica e supponiamo che questaabbia dimensioni rispettivamente d,l e 2z0 lungo x, y e z. Supponiamo chein alcuni punti questa lamina presenti dei solchi a forma di parallelepipedo:nella figura A.1, a sinistra, si vede una sezione a y costante della lamina.Notiamo che questi solchi sono scavati all’interno, cioe la figura rappresentauna sezione interna del materiale. Attraverso una lamina di questo tipo epossibile generare le matrici dei dati sperimentali nel modo seguente. Lasuperficie parallela al piano (x, z) su cui non ci sono i solchi rappresentala superficie nota S, che coincide con la sezione della lamina in y = l, infigura 1.1 (a); investiamola, quindi, con il flash. In questo modo creiamo unaserie di matrici tali che ognuna corrisponde ad un multiplo del periodo dicampionamento e rappresenta l’evoluzione della temperatura su ogni nodo(x, y) della lamina. Per generare il modello del campione sano, di ognunadi queste matrici prendiamo la riga relativa al segmento disegnato in rossoin figura, che corrisponde a selezionare i nodi della lamina che si trovanoad un certo z costante. Se consideriamo l’insieme di queste righe, al variaredei multipli del periodo di campionamento, generiamo la matrice dei datisperimentali.
Per generare il modello corroso facciamo la stessa cosa, ma consideriamoil segmento verde, o una parte di esso. La figura A.1 a destra rappresenta idomini del nostro problema ricavati in questo modo.
I dati sperimentali prodotti in questo modo vengono quindi immagazzi-nati in una matrice (TS(x, t)) le cui entrate rappresentano la temperatura TS
misurata in un determinato nodo x di S e in un determinato istante t. Inparticolare ogni riga della matrice rappresenta la distibuzione della temper-atura lungo S, in un determinato istante temporale; ogni colonna, invece,rappresenta l’evoluzione temporale della temperatura in un fissato nodo x diS.
Per il modello non corroso l’evoluzione della temperatura lontano daibordi avviene uniformemente lungo y e quindi nel tempo, come viene spie-gato con maggior dettaglio nel prossimo paragrafo. Pertanto le righe dellasottomatrice interna a (TS(x, t)), relativa ai punti lontano dai bordi, sarannocostanti. Osserviamo che se il campionamento dei dati su S tiene conto anchedel periodo in cui si ha il flash, i primi dati non dovrano essere considerati,in quanto la termocamera che usiamo per misurare l’evoluzione della tem-peratura su S, registra anche il calore riflesso dalla lamina, come risposta al

A.2. LA RACCOLTA DEI DATI SPERIMENTALI 43
Figura A.1:
flash: pur essendo la lamina dipinta di nero, una piccola percentuale di caloreviene riflessa; inoltre, essendo il flash molto potente, questa percentuale none trascurabile.
Una volta costruito un accurato modello non corroso, in modo analogo siraccolgono anche i dati sperimentali relativi al campione corroso.
Come si presentera la matrice dei dati sperimentali in questo caso? Lerighe della sottomatrice non saranno piu costanti, in quanto e la temperaturastessa a rivelare la presenza della corrosione. Un esempio e riportato infigura A.2: in questa si analizza l’evoluzione della temperatura all’interno diun campione corroso di dimensioni ∆S e l, lontano dai bordi della lamina:questo equivale a considerare i dati sperimentali per una sezione interna delsegmento disegnato in verde in figura A.1.
Inizialmente il calore si propaga uniformemente all’interno della lamina.Quando pero raggiunge la corrosione, comincia ad essere deviato dal difet-to e non si propaga piu linearmente lungo y. E’ interessante notare che inquesto breve frangente, la temperatura di ∆S comincia a variare e in par-ticolare evidenzia con maggiore precisione qual’e l’intervallo di ∆S su cui epresente la corrosione, pur essendo piccola l’intensita della variazione di T∆S.Andando avanti cresce l’intensita della variazione, e quindi diventa evidentela presenza di un difetto, ma diventa piu difficile localizzarlo, in quanto la

44 APPENDICE A. I DATI SPERIMENTALI
Figura A.2:

A.3. STIMA DELLE COSTANTI FISICHE DEL MODELLO 45
temperatura iniziale di T∆S viene alterata su tutta la lunghezza S e non siriesce piu a capire quanto sia esteso il difetto. Tuttavia si puo capire quantoesso sia profondo, a seconda di quanto viene amplificata T∆S.
Come procediamo nella costruzione del modello nel caso in cui il materialedi cui e composta la lamina sia ignoto? Discutiamo questo aspetto nellaprossima sezione. Osserviamo che, se conosciamo la natura del materiale,possiamo evitare queste stime sperimentali e trovare le costanti che ci servonoin opportune tabelle.
A.3 Stima delle costanti fisiche del modello
Dopo aver raccolto i dati sperimentali relativi al campione non corroso cos-tituito da materiale incognito, con il metodo illustrato nel paragrafo prece-dente, ci chiediamo come possiamo ricostruire le costanti fisiche che lo carat-terizzano.
Per rispondere a questa domanda, cominciamo analizzando piu in det-taglio cosa avviene quando colpiamo la lamina non corrosa con un flash.
Osserviamo che il flash ha una particolare forma analitica: infatti, noisupponiamo di avere a che fare con materiali metallici, cioe dotati di un’ele-vata conduttivita termica (a parita di intervallo temporale ∆T , maggiore e laconduttivita maggiore e lo strato di materiale interessato dal riscaldamento).Noi supponiamo che il flash duri un intervallo di tempo infinitesimo δT e chein questo frangente si abbia trasferimento di calore solo su S; solo nell’inter-vallo di tempo successivo ∆T , il calore si propaghera anche all’interno dellalamina.
La situazione fisica e quella rappresentata in figura A.3. Supponiamo chel’unica parte della lamina che interagisce con l’esterno scambiando calore, siaS, ossia il segmento noto. Attraverso il flash, alla lamina, che supponiamosi trovi inizialmente ad una temperatura uniforme T0, viene trasferita unaconsistente quantita di calore q (indicata in rosso in figura).
Supponiamo di analizzare una porzione della lamina lontano dai bordi,ossia consideriamo un rettangolo di altezza l e base ∆S, come illustrato infigura A.3. In questo dominio possiamo supporre che ci sia un flusso di caloreunidimensionale, nella direzione dell’asse y ed equiverso a questa. Supponi-amo che il flash duri un istante di tempo molto piccolo δT . Essendo ∆Sinteragente con l’esterno, oltre ad assorbire calore, tendera anche a cederneall’ambiente esterno per convezione q
′(indicata in verde in figura). Tuttavia
subito dopo aver spento il flash la temperatura dell’aria a contatto con ∆S

46 APPENDICE A. I DATI SPERIMENTALI
Figura A.3:
differira di poco da quella di ∆S, e il calore scambiato per convezione e pro-porzionale alla differenza di temperatura, quindi in un opportuno intervallodi tempo ∆T , possiamo considerare trascurabile lo scambio con l’esterno q
′
e considerare adiabatico il sistema costituito dalla sezione della lamina. Inquesto frangente il sistema sara dunque isolato dall’esterno e al suo internola temperatura evolvera uniformemente lungo l’asse y.
Un andamento tipico della temperatura e rappresentato in figura A.4,dove il picco rappresenta l’istante in cui e stato spento il flash e il raf-freddamento di ∆S e dovuto alla conduzione del calore all’interno dellalamina.
La forma della temperatura T∆S rappresentata in figura A.4, e funzionedell’impulso iniziale e della diffusivita α [m2
s], che dipende esclusivamente
dalla natura del materiale. Supponendo di aver fissato la forma dell’impulsoiniziale, consideriamo la famiglia parametrica y(α), cioe la famiglia di curvedi temperatura di S, al variare della diffusivita. Quello che vogliamo e deter-minare α, tale che
∥∥(T∆S(x, t))− (yα(x, t))∥∥
2< ε, dove ε e una predefinita
soglia d’errore.
Per fare questo costruiamo un modello 1-dimensionale FEM, che, notil’impulso iniziale e la diffusivita α, ricostruisca l’evoluzione della temperatu-ra lungo l’asse y nell’intervallo ∆T e quindi costruisca la matrice (y(α)(x, t)),che rappresenta l’evoluzione della temperatura al variare di x in S e di t in

A.3. STIMA DELLE COSTANTI FISICHE DEL MODELLO 47
Figura A.4:
∆T . Quindi per ricostruire le costanti sperimentali ci mettiamo nelle con-dizioni in cui non abbiamo effetti di bordo e siamo in condizioni adiabatiche, ein questo modo semplifichiamo il problema costruendo per l’evoluzione dellatemperatura sulla sezione della lamina un modello undimensionale (poiche latemperatura varia uniformemente in y, analizziamo solo la sua evoluzionelungo un segmento parallelo a y e lungo l). Questo modello particolar-mente semplice lo useremo solo in questo frangente. Una volta determinate lecostanti fisiche costruiamo il modello FEM 2-D per il campione non corroso,che abbiamo descritto nel report nel capitolo 2, e che descrive l’evoluzionedella temperatura su tutta la lamina.
Osserviamo che la diffusivita termica α = kρC
, dove k e il coefficiente di
conducibilita termica [ WmK
], ρ e la densita del materiale [Kgm3 ] e C e il calore
specifico [ JKgK
], e sono le costanti che compaiono nell’equazione del calore
(1.3). In pratica dunque decidere α equivale a fissare le tre costanti fisichek, ρ e C. Osserviamo che mentre la forma dell’onda y(α)(x, ·), al variare di tin ∆T (figura A.4), dipende dal parametro α, la sua ampiezza dipende o dak o da ρC. Per determinare α e quindi necessario fissare arbitrarimente ρ eC, e poi ottimizzare k, determinando cosı k. Con questi parametri fisici ρ,Ce k si puo costruire un modello accurato per il campione non corroso.
Osservazione. E’ importante determinare accuratamente i coefficienti delmodello in modo che valgono tutte le ipotesi che abbiamo posto nella trat-tazione. Per esempio abbiamo supposto che in un opportuno intervallo di

48 APPENDICE A. I DATI SPERIMENTALI
tempo che abbiamo indicato con ∆T , lontano dai bordi, la lamina sia un sis-tema con buona approssimazione adiabatico (figura A.3). Il numero di BiotBi = h l
k, dove h e il coefficiente di scambio di calore per convezione, misura
quanto un materiale e adiabatico. Affinche valgano le ipotesi di adiabaticita,cioe affinche il flusso di calore da ∆S verso l’esteno sia trascurabile rispettoal flusso di calore all’interno della lamina, e necessario che Bi sia sufficiente-mente piccolo: dunque, h e k dovranno essere fissati in modo che soddisfinoquesta condizione, ma, poiche k non e arbitrario, bisogna scegliere h, ρ e Cin modo che Bi sia piccolo.

Elenco delle figure
1.1 (a) In figura la lamina di metallo in grigio e la stessa corrosain rosso, assorbono il calore q; (b) Riduzione del problema indimensione due, considerando la sezione della lamina sul pianoz = 0. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1 Suddivisione piu fine a sinistra e suddivisione ottimale a destra. . . 9
4.1 Funzionamento del raffinamento locale. Da sinistra verso destra:parto con un profilo di corrosione nulla; applico il PEM e stimola corrosione su ogni segmento; raffino localmente la suddivisionedove c’e corrosione maggiore rispetto all’iterazione precedente. Lasuddivisione piu fine di S e evidenziata il verde, quella iniziale inviola e il raffinamento di quest’ultima in blu. . . . . . . . . . . . 17
7.1 Struttura della parametrizzazione usata dagli algoritmi genetici . . 317.2 Profilo da stimare a sinistra e profilo stimato con la bisezione . . . 317.3 Fronte di Pareto calcolato con MOGA . . . . . . . . . . . . . . . 32
8.1 Struttura della parametrizzazione usata per problemi di grandedimensione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
8.2 Il profilo ottimale sta sul fronte di Pareto . . . . . . . . . . . . . 368.3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 368.4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 378.5 Successione dei profili stimati dal raffinamento locale nell’esempio
che stiamo analizzando. . . . . . . . . . . . . . . . . . . . . . . 37
A.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43A.2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44A.3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46A.4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
49

Bibliografia
[1] G.Deolmi, F.Marcuzzi, S.Poles, S.Marinetti, Applicazione degli algorit-mi genetici alla stima della corrosione mediante termografie, EnginSoftUsers Meeting, Bergamo, 2007
[2] L.Formaggia, F.Saleri, A.Veneziani, Applicazioni ed esercizi dimodellistica numerica per problemi differenziali, 2005
[3] F. Maffioli, Elementi di programmazione matematica, 2000
[4] T. McKelvey, Identification of state-space models from time andfrequency data, 1995
[5] F. Marcuzzi, Analisi dei Dati mediante Modelli Matematici - Dispensaper il corso di Metodi Numerici per l’analisi dei dati, 2008
[6] F.Marcuzzi, S.Marinetti, Efficient reconstruction of corrosion profiles byinfrared thermography, Applied Inverse Problems - AIP 07, Vancouver,Canada, 2007
[7] A.Quarteroni, Modellistica numerica per problemi differenziali, 2003
[8] S. S. RAO, Engineering Optimization, 1996
50

BIBLIOGRAFIA 51
[9] C.R.Reeves, J.E.Rowe Genetic Alghorithms - Principles and persped-tives, 2003
[10] L.Salce, Lezioni sulle matrici, 1993
[11] N. Srinivas, Kalyanmoy Deb, Multiobjective Optimization Using Non-dominated Sorting in Genetic Algorithms - Evolutionary Computation,1994

Ringraziamenti
Ringraziamo la ditta ESTECO srl e l’Universita di Padova che, finanzian-do questa borsa di studio, ci hanno permesso di condurre questa ricercasulla corrosione. Un grazie va inoltre all’ Istituto per le Tecnologie dellaCostruzione del CNR (Padova) per averci fornito i dati sperimentali chehanno motivato la nostra indagine.
52
Copyright © 2022 FDOKUMEN




















