
Learning Classifier System with Self-adaptive Discovery Mechanism
11
Learning Classifier System with Self-adaptive Discovery Mechanism Maciej Troc and Olgierd Unold Abstract Learning Classifier System which replaces the genetic algorithm with the evolving cooperative population of discoverers is a focus of current research. This paper presents a modified version of XCS classifier system with self-adaptive discovery module. The new model was confirmed experimentally in a multiplexer environment. The results prove that XCS with the self-adaptive method for deter- mining mutation rate had a better performance than the classic architecture with fixed mutation. 1 Introduction Learning classifier systems (LCSs) introduced by John Holland in the 70s [7], have gained growing interest in the evolutionary literature. LCSs are rule based classifiers, often called Genetics Based Machine Learning tools, consisting of a set of rules and procedures for performing classifications and discovering rules using genetic and nongenetic operators. LCSs have been studied in a wide range of ar- eas [8]. We are currently undertaking the research in the area of self-adapting LCS. XCS [13] has become our baseline, because it is considered as one of the most ad- vanced LCS. XCS evolves a complete map of all possible pairs condition-action for each possible level of reward. In other words, the system maintains both correct and incorrect classifiers as long as they can predict correctly the payoff from the environment. This paper introduces a new kind of self-adaptation in discovery mechanism of XCS. The genetic algorithm (GA) with static parameters is replaced with the evolving cooperative population of discoverers, which are able to adapt both classi- fiers and GA parameters. M. Troc and O. Unold Institute of Computer Engineering, Control and Robotics, Wroclaw University of Technology, Wyb. Wyspianskiego 27, 50-370 Wroclaw, Poland {maciej.troc, olgierd.unold}@pwr.wroc.pl M. Troc and O. Unold: Learning Classifier System with Self-adaptive Discovery Mechanism, Studies in Computational Intelligence (SCI) 129, 273–283 (2008) www.springerlink.com c Springer-Verlag Berlin Heidelberg 2008
Transcript of Learning Classifier System with Self-adaptive Discovery Mechanism

Learning Classifier System with Self-adaptiveDiscovery Mechanism
Maciej Troc and Olgierd Unold
Abstract Learning Classifier System which replaces the genetic algorithm withthe evolving cooperative population of discoverers is a focus of current research.This paper presents a modified version of XCS classifier system with self-adaptivediscovery module. The new model was confirmed experimentally in a multiplexerenvironment. The results prove that XCS with the self-adaptive method for deter-mining mutation rate had a better performance than the classic architecture withfixed mutation.
1 Introduction
Learning classifier systems (LCSs) introduced by John Holland in the 70s [7],have gained growing interest in the evolutionary literature. LCSs are rule basedclassifiers, often called Genetics Based Machine Learning tools, consisting of a setof rules and procedures for performing classifications and discovering rules usinggenetic and nongenetic operators. LCSs have been studied in a wide range of ar-eas [8]. We are currently undertaking the research in the area of self-adapting LCS.XCS [13] has become our baseline, because it is considered as one of the most ad-vanced LCS. XCS evolves a complete map of all possible pairs condition-actionfor each possible level of reward. In other words, the system maintains both correctand incorrect classifiers as long as they can predict correctly the payoff from theenvironment.
This paper introduces a new kind of self-adaptation in discovery mechanismof XCS. The genetic algorithm (GA) with static parameters is replaced with theevolving cooperative population of discoverers, which are able to adapt both classi-fiers and GA parameters.
M. Troc and O. UnoldInstitute of Computer Engineering, Control and Robotics, Wroclaw University of Technology,Wyb. Wyspianskiego 27, 50-370 Wroclaw, Poland{maciej.troc, olgierd.unold}@pwr.wroc.pl
M. Troc and O. Unold: Learning Classifier System with Self-adaptive Discovery Mechanism, Studies in ComputationalIntelligence (SCI) 129, 273–283 (2008)www.springerlink.com c© Springer-Verlag Berlin Heidelberg 2008

274 M. Troc, O. Unold
The paper is structured as follows. Section 2 provides a short overview of XCSwith all details that are important for the remainder of paper. The extended XCS withself-adaptation of discovery mechanism is introduced in Section 3. The new modelis confirmed experimentally in Section 4. In Section 5 related works are given, andfinally, in Section 6 the conclusions are drawn and future plans are briefly discussed.
2 The XCS Model
XCS, introduced by Wilson [13], evolves a set of rules [P], the so-called populationof classifiers. Rules are evolved by the means of a GA. Each classifier consists offive elements: the condition C ∈ 0,1,#L specifies the subspace of the input space ofdimensionality L in which the classifier is applicable, or matches; the “don’t care”symbol # matches both 0 and 1; the action part A specifies the advocated action; thepayoff prediction p estimates the average payoff encountered after executing actionA in the situations in which condition C matches. The prediction error ε estimatesthe average deviation, or error, of the payoff prediction p. The fitness f reflects thescaled average relative accuracy of the classifier with respect to other overlappingclassifiers. XCS is designed to evolve a representation of the expected payoff in eachpossible situation-action combination.
Given current input s, the set of all classifiers in [P] whose conditions matchs is called the match set [M]. If some action is not represented in [M], a cover-ing mechanism is applied. Covering creates classifiers that match s and specify theactions not covered. Given a match set, XCS can estimate the payoff for each pos-sible action forming a prediction array. Essentially, the prediction array reflects thefitness-weighted average of all reward prediction estimates of the classifiers in [M]that advocate classification a. The payoff predictions determine the appropriate clas-sification.
After the action is selected by the means of the prediction array and applied tothe problem, the scalar feedback ρ is received. In a classification problem, classifierparameters are updated with respect to the immediate feedback in the current actionset [A]t (in the single-step mode denoted as [A]), which comprises all classifiersin [M] that advocate the chosen classification a. In a multistep problem, classifiersare updated in the previous action set [A]t−1 with respect to the previous rewardρ − 1 and the maximum value in the prediction array. After rule evaluation andpossible GA invocation, the next iteration starts. Parameter updates are usually donein the order: prediction error, prediction, fitness. Prediction error is updated by ε ←ε+β (|R− p|− ε) where β (β ∈ [0,1]) denotes the learning rate and R denotes theimmediate feedback ρ in a classification problem and the combination of previousimmediate feedback and maximum predicted reward. Next, prediction is updated in[A] by p← p+β (R− p). The fitness value of each classifier in [A] is updated withrespect to its current scaled relative accuracy κ ′:

Learning Classifier System with Self-adaptive Discovery Mechanism 275
κ ={
1 if ε < ε0α(ε/ε0)−v otherwise (1)
f ← f +β (κ ′ − f ) (2)
The parameter ε0(ε0 > 0) controls the tolerance for prediction error ε; param-eters α(α ∈ (0,1)) and v(v > 0) are constants controlling the rate of decline inaccuracy κ when ε0 is exceeded. The accuracy values κ in the action set [A] arethen converted to set-relative accuracies κ ′. Finally, classifier fitness f is updatedtowards the classifier’s current set relative accuracy. All parameters except fitnessf are updated using the technique MAM (Moyenne Adaptive Modife). This tech-nique sets parameter values directly to the average of the encountered cases so faras long as the experience of a classifier is less than 1/β . Each time the parametersof a classifier are updated, the experience counter exp of the classifier is increasedby one.
Besides the covering mechanism XCS applies a GA for rule evolution. A GA isinvoked if the average time since the last GA application ts upon the classifiers in[A] exceeds thresholdΘGA. The GA selects two parental classifiers using selection.Two offspring are generated reproducing the parents and applying crossover andmutation. In the insertion process, subsumption deletion may be applied to stressgeneralization. GA subsumption checks offspring classifiers to see whether theirconditions are logically subsumed by the condition of another accurate and suffi-ciently experienced classifier in [A]. If an offspring is subsumed, it is not inserted inthe population but the subsumer’s numerosity is increased. The population of clas-sifiers [P] is of fixed size N. Excess classifiers are deleted from [P] with probabilityproportional to an estimate of the size of the action sets that the classifiers occur in(stored in the additional parameter as and updated similar to prediction p). If theclassifier is sufficiently experienced and its fitness f is significantly lower than theaverage fitness of classifiers in [P], its deletion probability is further increased.
For a more detailed introduction to XCS the interested reader is referred tothe [13]. Although the basic XCS system was dedicated only to binary problems,there has been an extensive effort over the last years to develop more general ap-proach. Lanzi [11] has previously introduced messy coding and S-expressions, Bulland O’Hara [1] extended the basic XCS classifier to multi-layer perceptron clas-sifiers, and Wilson [14] enhanced the XCS system to the integer- and real-valuedproblem domains.
3 The XCS with an Adaptation of Discovery Mechanism
As it has been mentioned above, two discovery mechanisms are used in XCS:covering and genetic algorithm. The first is rather simple and is mostly used at thebeginning of the learning process [3], however the second is described by large setof parameters (like the mutation rate) and is used frequently during whole process.Based on these reasons, we decided to adapt the genetic algorithm.

276 M. Troc, O. Unold
The adaptation is done in a co-evolutionary way, but in contrast to relatedworks [9], the values of parameters of discovery mechanisms haven’t be the partof classifiers. The basic XCS model has been extended by the population of discov-ering components [D] (called discoverers) and procedures to operate on them. Thesize of population [D] is denoted as ND.
Every individual in [D] includes the structure of parameters for the genetic algo-rithm. It plays the role of a genome. When the invocation of GA takes place, therandom constant-size (nD) fraction of discoverers creates new classifiers accordingto their own genomes. The fitness of every discoverer is calculated later basing onthe fitness of classifiers it has created.
Please note, that in the classic XCS architecture, only two classifiers are createdduring GA. In our model the larger number of classifiers created the more pre-cise the evaluation of discoverers’ fitness becomes. On the other hand, if all newunchecked rules were placed in the main classifiers population [P] (causing deletionprocedure), the performance of the system would be significantly decreased. Thatis why every discoverer i is equipped with its own helping population [P′i ] (withcapacity N′i ) where new classifiers are placed and tested. They don’t take part inaction selection at this time. Observe, that some additional mechanisms are neededfor learning classifiers in [P′i] and for migrating them to [P]. They will be describedlater. Now we will shortly describe basic components of our architecture (Fig. 1)which is limited to resolving single-step problems.
ENVIRONMENT
ReceptorCovering
Efector
a(t)
a(t)
s(t) r(t+1)
r(t+1), as, accSum
Prediction array
Discoverer 1
Genome Genetic Algorithm
Discoverer nDiscoverer i
Discoverers EvolutionSYSTEM
[D]
[A][P]
[P'1] [M'1] [A'1]
[M]
Receptor
[T]
Fig. 1 Schematic of XCS with the adaptation of the discovery mechanism. The architecture of anexample discoverer i has been emphasized

Learning Classifier System with Self-adaptive Discovery Mechanism 277
3.1 Performance and Reinforcement Components
An action of the system is chosen in the same way as in classic XCS, that is either de-terministically (during the exploitation phase) or randomly (during the explorationphase). As it has been mentioned, the selection is influenced only by the classifiersstored in the main population [P].
After performance, parameters of classifiers in [A] are updated as it has beenshown in Section 2. Then the environmental state st , the action at , and the rewardrt+1 are sent to all discoverers. In the discoverer i, the local match set [M′i ] is createdbased on the helping classifiers list [P′i ] and the value of st. To form [A′i] the valueof at is used (remember that discoverers don’t take part in the action selection). Theprediction p and the prediction error ε of classifiers in [A′i] are updated with the helpof rt+1. To update a niche size as and a fitness f , values are used both from [A] and[A′i]. For example to update fitness fx of classifier x in [A′i], we must compute therelative prediction accuracy κ ′x as follows:
κ ′x =κx
∑ j∈[A]κ j +∑g∈[A′i]κg(3)
where κx-prediction accuracy of classifier x.Thanks to using the accuracy sum of classifiers in [A], rules in [A′i] are evaluated
also in respect of the common knowledge stored in [P] and the evaluation and com-parison of the discoverers becomes possible.
The fitness f of classifiers placed in the helping populations [P′x] is used duringthree processes, that is: the discovering, the migration, and the discoverers evolution.
Discovery mechanisms
Covering is applied only in the main population [P], but the genetic algorithm isapplied only by the discoverers. When an average time from last GA invocationin [A] is greater then ΘGA, the random, constant size (nD) fraction of discovererscreates new classifiers. The discoverer i takes the sum of sets: [A] and [A′i] as aninput for the discovery process, then it uses its inner parameters (genome) to select,reproduce, recombine and mutate classifiers. Finally, every new rule is placed inthe local population [P′i ] with an additional parameter, which represents the timeof creation. The time of GA application is then updated for the classifiers in [A]and [A′i].
Observe, that every discoverer creates classifiers based on its “private”knowledge (from [A′i]) and the “public” knowledge common for all individuals(from [A]). Because the discoverer doesn’t use the “private” knowledge of otherdiscoverers, it doesn’t leech on them.
Classifiers migration
In every iteration of system’s work the migration of classifiers from helping pop-ulations ([P′1], [P′2], . . . , [P′n]) to main population [P] may occur. Classifiers which

278 M. Troc, O. Unold
age (number of iterations passed from the time of creation) exceeds some thresholdΘtest , are transferred to the separated transfer set [T ]. Then the selection based onfitness f happens (for example roulette-wheel selection) and a part of [T ] members(with quantity n′imp) is placed in [P]. The value Θtest represents the time needed forpreliminary evaluation of the usability of classifiers.
Discoverers evolution
At some number of iterations (ItD), the step of discoverers evolution takes place.The fitness of the discoverer i is calculated as an average fitness of classifiers, whichit placed in [T ] during last (ItD) iterations. After the evaluation, 40% of the worstdiscoverers are replaced by successors of the remainders (according to the randomor roulette wheel selection) and evolutionary operators like mutation are appliedfor the Parameters (genomes) they include. Every new discoverer j has an emptyhelping population [P′j] at the beginning, not to use the knowledge of its ancestor orancestors.
4 The 11-MP Experiment and Analysis
We tested proposed architecture in the 11-MP environment, which is a version ofthe benchmark problem: n-bit multiplexer. The system is receiving binary strings(problems), where the first three bits represent the address (index) of the binary po-sition in the next eight data bits. In every step the goal of the system is to determinethe value at the position pointed by the address. The reward from environment is1000 for good answers and 0 for bad ones.
In these early experiments with the model we carried out the adaptation of oneparameter: mutation rate µ . The genome of every discoverer included only one real-valued gene. During discoverers evolution, asexual replication was used and µ ofchild discoverers was modified by adding random value (−0.1,0.1) to it.
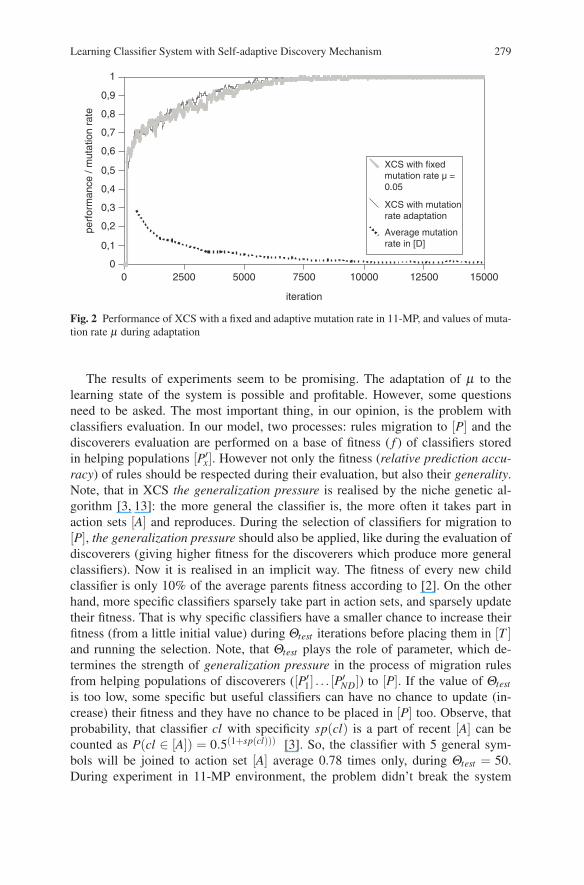
Figure 2 presents the performance of two architectures: classic XCS (with N =1200 and µ = 0.05) and our model (with N = 800 , N′i = 50 and adapted µ). Theperformance in iteration i is computed as the fraction of correct answers for 50 lastexploit trials before x, which is like a moving average. Moreover, all curves are theaverages of 10 independent runs.
We used the following values of parameters [2,4]: β=0.2,α=0.1,v=5,ε0 =10,pI =10,εI = 0,FI = 10,ΘGA = 25,χ = 0.71,P# = 0.33,Pexplr = 0.5,Θdel = 20,δ =0.1,subsumption = f alse,GAsubsumption = f alse,N = 800,ND = 10,nD =10,N′x = 40,n′imp = 2,Θtest = 50, ItD = 500.
XCS with adaptive mutation rate had a better performance than the classic archi-tecture with a fixed one. Moreover in adaptive system, the average mutation rate ofdiscoverers was decreasing during the whole learning process, what is common withother works related to adaptation or self-adaptation of µ also in learning classifiersystems [4, 9].
Learning Classifier System with Self-adaptive Discovery Mechanism 279
0 2500 5000 7500 10000 12500 150000
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
XCS with fixedmutation rate µ =0.05
XCS with mutationrate adaptation
Average mutationrate in [D]
iteration
perf
orm
ance
/ m
utat
ion
rate
Fig. 2 Performance of XCS with a fixed and adaptive mutation rate in 11-MP, and values of muta-tion rate µ during adaptation
The results of experiments seem to be promising. The adaptation of µ to thelearning state of the system is possible and profitable. However, some questionsneed to be asked. The most important thing, in our opinion, is the problem withclassifiers evaluation. In our model, two processes: rules migration to [P] and thediscoverers evaluation are performed on a base of fitness ( f ) of classifiers storedin helping populations [P′x]. However not only the fitness (relative prediction accu-racy) of rules should be respected during their evaluation, but also their generality.Note, that in XCS the generalization pressure is realised by the niche genetic al-gorithm [3, 13]: the more general the classifier is, the more often it takes part inaction sets [A] and reproduces. During the selection of classifiers for migration to[P], the generalization pressure should also be applied, like during the evaluation ofdiscoverers (giving higher fitness for the discoverers which produce more generalclassifiers). Now it is realised in an implicit way. The fitness of every new childclassifier is only 10% of the average parents fitness according to [2]. On the otherhand, more specific classifiers sparsely take part in action sets, and sparsely updatetheir fitness. That is why specific classifiers have a smaller chance to increase theirfitness (from a little initial value) during Θtest iterations before placing them in [T ]and running the selection. Note, that Θtest plays the role of parameter, which de-termines the strength of generalization pressure in the process of migration rulesfrom helping populations of discoverers ([P′1] . . . [P
′ND]) to [P]. If the value of Θtest
is too low, some specific but useful classifiers can have no chance to update (in-crease) their fitness and they have no chance to be placed in [P] too. Observe, thatprobability, that classifier cl with specificity sp(cl) is a part of recent [A] can becounted as P(cl ∈ [A]) = 0.5(1+sp(cl))) [3]. So, the classifier with 5 general sym-bols will be joined to action set [A] average 0.78 times only, during Θtest = 50.During experiment in 11-MP environment, the problem didn’t break the system
280 M. Troc, O. Unold
performance, probably the reason being, that niches had an equally large size andoptimal classifiers characterised high generality (4 specific symbols and 7 generalsymbols). Nevertheless Θtest needs to be tuned in respect of the problem. To omitthis disadvantage another migration schema shall be applied in future research.
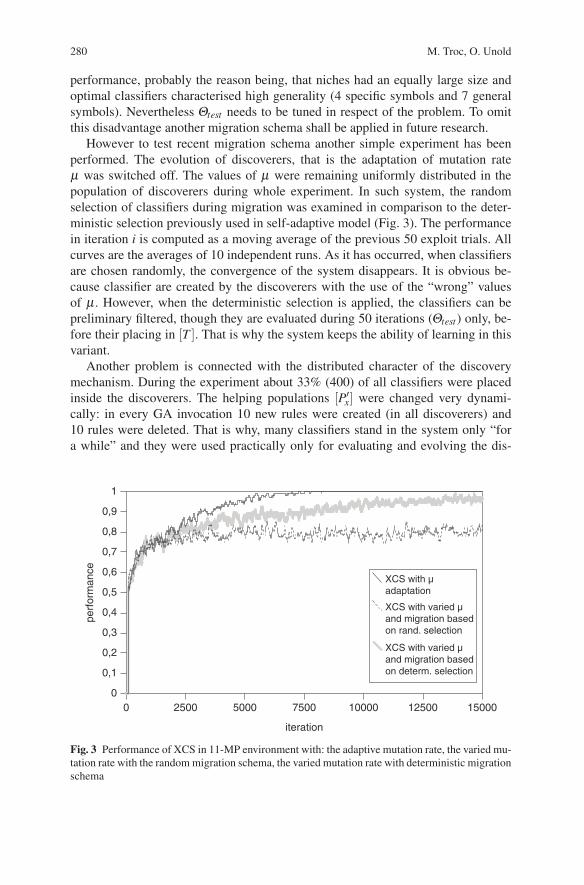
However to test recent migration schema another simple experiment has beenperformed. The evolution of discoverers, that is the adaptation of mutation rateµ was switched off. The values of µ were remaining uniformly distributed in thepopulation of discoverers during whole experiment. In such system, the randomselection of classifiers during migration was examined in comparison to the deter-ministic selection previously used in self-adaptive model (Fig. 3). The performancein iteration i is computed as a moving average of the previous 50 exploit trials. Allcurves are the averages of 10 independent runs. As it has occurred, when classifiersare chosen randomly, the convergence of the system disappears. It is obvious be-cause classifier are created by the discoverers with the use of the “wrong” valuesof µ . However, when the deterministic selection is applied, the classifiers can bepreliminary filtered, though they are evaluated during 50 iterations (Θtest) only, be-fore their placing in [T ]. That is why the system keeps the ability of learning in thisvariant.
Another problem is connected with the distributed character of the discoverymechanism. During the experiment about 33% (400) of all classifiers were placedinside the discoverers. The helping populations [P′x] were changed very dynami-cally: in every GA invocation 10 new rules were created (in all discoverers) and10 rules were deleted. That is why, many classifiers stand in the system only “fora while” and they were used practically only for evaluating and evolving the dis-
0 2500 5000 7500 10000 12500 150000
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
XCS with µadaptation
XCS with varied µand migration basedon rand. selection
XCS with varied µand migration basedon determ. selection
iteration
perf
orm
ance
Fig. 3 Performance of XCS in 11-MP environment with: the adaptive mutation rate, the varied mu-tation rate with the random migration schema, the varied mutation rate with deterministic migrationschema

Learning Classifier System with Self-adaptive Discovery Mechanism 281
coverers population. Moreover when GA was run in particular discoverer i, onlythe part of classifiers available in the system (placed in “public” action set [A] and“private” action set [A′i]) was used for creating new rules. It makes a big differencebetween classic XCS system and our architecture, and it may cause doubts, that alarge amount of space for knowledge (for the rules) is lost to make an adaptation ofthe discovery mechanism. However, described problems didn’t show the decrease ofperformance during the experiments. It shall also be investigated in future research.
5 Related Works
Adaptation and self-adaptation of genetic algorithms have been investigated innumerous projects also with the connection to learning classifier systems [4, 9].
In [9], meta-GP model has been used to adapt µ , β and other parameters insystems (XCS and ZCS) resolving multistep problems. The values of parameterswere stored in every rule as real-valued genes, they were used on which to operate(during mutation or learning) and passed to its children. After passing, parameterswere modified by evolutionary operators. The model presents classic self-adaptingattitude, individual-level in Angeline’s classification (described e.g. in [12]). Theresults of experiments show the higher performance in comparison to the clas-sic architecture for some sets of parameters both in stationary and non-stationaryenvironments.
In [4] the co-adaptation between two learning classifier systems: the Main-LCS(which aimed at resolving the problem) and the Meta-XCS (which aimed at controlparameters in the Main-LCS) was used. The Meta-XCS was based on two architec-tures: XCS and Dyna. It learned rules which anticipated the future metrics of themain system (like performance or population size) based on the recent metrics andthe action of changing the parameters in Main-LCS. The latent learning was applied.Thanks to this solution, completely model of the Main-LCS behaviour in respect ofthe values of parameters was built. Based on Angeline’s classification [12] we couldalso say, that it is the population-level type of adaptation. The model was tested onthe adaptation of mutation ratio in 6-bit multiplexer environment and showed highperformance.
In respect to the co-evolution between discoverers and classifiers, our model issimilar to some other projects connected with self-adaptation, for example with [5]and [10], where the adaptation of the recombination operator for genetic program-ming was done as the co-evolution between operators and individuals. Additionallyin respect to using “private” and “public” knowledge of discoverers, the model issimilar to some projects for modelling the scientific societies [6].

282 M. Troc, O. Unold
6 Summary and Future Work
In this paper, we presented a modified version of XCS using the evolving populationof discoverers instead of static GA. The results show that XCS with the self-adaptivemethod to change the mutation rate had a better performance than the classic archi-tecture with fixed mutation.
In our model, the genetic algorithm is seen as a separated, complete component(discoverer), which can autonomously produce classifiers and compete with otherindividuals. We hope, that this attitude shall let us regulate the range of self-adaptation in an easy and flexible way by determining the structure and the semanticof the discoverer’s genome. The genome could be for example a set of rules (or asingle rule), which determine the value of mutation rate in respect to the currentmetrics of the action set [A] or it could be the vector of parameters for other meta-heuristics than GA (if implemented).
Moreover, we have noticed, that the distribution of our system among severalconnected computing machines is also possible. Applying this solution, we couldcarry out some computations in a parallel way.
The most often adapted parameter in LCS systems is mutation ratio µ . Neverthe-less, some other parameters of the discovery mechanism should be considered, forexample the bit which determines the type of crossover operator (one-point or uni-form). Another possible parameter is tournament size, for the tournament selectionmethod.
References
1. Bull L, O’Hara T (2002) Accuracy-based neuro and neuro-fuzzy classifier systems. In:Proceedings of the Fourth Genetic and Evolutionary Computation Conference (GECCO-2002) 905–911
2. Butz M, Wilson SW (2002) An algorithmic description of XCS. Soft Comput 6(3-4): 144–1533. Butz M, Kovacs T, Lanzi PL, Wilson SW (2004) Toward a Theory of Generalization and
Learning in XCS. IEEE Transactions on Evolutionary Computation 8(1): 28–464. Chung-Yuan H, Chuen-Tsai S (2004) Parameter Adaptation within Co-adaptive Learning
Classifier Systems. In: GECCO (2) 774–7845. Edmonds B (2001) Meta-Genetic Programming: Co-evolving the Operators of Variation.
Turkish Journal Electrical Engineering and Computer Sciences, Elektrik, 9(1): 13–296. Edmonds B (2004) Artificial Science - a simulation test-bed for studying the social pro-
cesses of science. In: Edmonds B (eds) Proceedings European Social Simulation Conference,Valadollid Spain
7. Goldberg DE (1989) Genetic Algorithms in Search, Optimization and Machine Learning.Addison-Wesley Pub. Co
8. Holmes JH, Lanzi PL, Stolzmann W, Wilson SW (2002) Learning classifier systems: Newmodels, successful applications. Inf. Process. Lett. 82(1): 23–30
9. Hurst J, Bull L (2003) Self-Adaptation in Classifier System Controllers. Artificial Life andRobotics 5(2): 109–119
10. Kantschik W, Dittrich P, Brameier M, Banzhaf W (1999) Meta-Evolution in Graph-GP. In:Proceedings of the Second European Conference on Genetic Programming (EuroGP ’99),Springer, Berlin 15–28

Learning Classifier System with Self-adaptive Discovery Mechanism 283
11. Lanzi PL (1999) Extending the Representation of Classifier Conditions Part II: From MessyCoding to S-Expressions. In: Proceedings of the Genetic and Evolutionary ComputationConference(GECCO-99) 345–352
12. Meyer-Nieberg S, Beyer HG, Self-Adaptation in Evolutionary Algorithms. http://www2.staff.fh-vorarlberg.ac.at/ hgb/New-Papers/self-adaptation.pdf
13. Wilson SW (1995) Classifier fitness based on accuracy. Evolutionary Computation 3(2):149–175
14. Wilson SW (2000) Get real! XCS with continuous-valued inputs. In: Lanzi PL, Stolzmann W,Wilson SW (eds) Learning classifier systems: From foundations to applications (LNAI 1813)Springer-Verlag, Berlin Heidelberg 209–219




















