
LAPORAN PRAKTIKUM METSTAT II
24
LAPORAN PRAKTIKUM METODE STATISTIKA II Yogyakarta, 12 Juni 2015 Nama : Yulia Kurniasih NIM : 14/364976/PA/16067 Prodi : Matematika Dosen Pengampu : Vemmie Nastiti Lestari, S.Si., M.Sc. Asisten Praktikum : Bagus Setyawan (15420) Muhammad Ifdhal Zaky Elyasa (15692) LABORATORIUM KOMPUTASI MATEMATIKA DAN STATISTIKA JURUSAN MATEMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS GADJAH MADA YOGYAKARTA 2015
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of LAPORAN PRAKTIKUM METSTAT II

LAPORAN PRAKTIKUM
METODE STATISTIKA II
Yogyakarta, 12 Juni 2015
Nama : Yulia Kurniasih
NIM : 14/364976/PA/16067
Prodi : Matematika
Dosen Pengampu : Vemmie Nastiti Lestari, S.Si., M.Sc.
Asisten Praktikum : Bagus Setyawan (15420)
Muhammad Ifdhal Zaky Elyasa (15692)
LABORATORIUM KOMPUTASI MATEMATIKA DAN STATISTIKA
JURUSAN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS GADJAH MADA
YOGYAKARTA
2015

BAB I
PERMASALAHAN
1. Tiga varietas kentang hendak dibandingkan hasilnya. Percobaannya hendak dilaksanakan
dengan menggunakan 9 petak yang seragam di masing-masing 4 lokasi yang berbeda. Di
setiap lokasi setiap varietas dicobakan pada 3 petak yang ditentukan secara acak.
Hasilnya, dalam kwintal per petak, adalah sebagai berikut:
Lokasi Varietas Kentang
A B C
1 16 20 22
19 24 17
12 18 14
2 17 24 26
10 18 19
13 22 21
3 9 12 10
12 15 5
5 11 8
4 14 21 19
8 16 15
11 14 12
a) Analisis apa yang digunakan untuk kasus di atas? Mengapa?
b) Apakah terdapat perbedaan produksi kentang? Lakukan analisis lengkap namun
singkat padat jelas !
c) Sebagai seorang statistis, apa saran yang bisa kalian berikan kepada petani kentang?
2. Suatu survey dilaksanakan pada tujuh rumah sakit yang relatif sama di suatu kota untuk
mengetahui jumlah bayi yang lahir selama periode 1 tahun (12 bulan). Periode ini dibagi
menjadi 4 musim untuk mengetahui apakah tingkat kelahiran pada setiap musim sama
atau tidak. Hasilnya adalah sebagai berikut.
Rumah Sakit Jumlah kelahiran
Musim Dingin Musim Semi Musim Panas Musim Gugur
A 92 112 94 77
B 9 11 10 12
C 98 109 92 81
D 19 26 19 18
E 21 22 23 24
F 26 25 24 27

G 42 49 44 41
a) Analisis apa yang digunakan untuk kasus di atas? Mengapa?
b) Apakah terdapat perbedaan jumlah kelahiran bayi pada tiap musim? Lakukan analisis
lengkap namun singkat padat dan jelas!
3. Pada suatu hari Rani ingin meneliti apakah orang yang mengonsumsi sambal akan
menyebabkan sakit perut. Pada saat makan siang, Rani menanyakan mahasiswa yang
sedang makan siang di Kantin Kluster Sains. Dari 263 mahasiswa yang ditanya Rani, 225
diantaranya makan memakai sambal. Ada 150 mahasiswa yang mengaku tidak sakit
perut dan diantaranya 116 mahasiswa makan memakai sambal. Hanya 4 orang yang tidak
makan memakai sambal namun sakit perut.
a) Buatlah tabel kontingensi dari keterangan di atas!
b) Apakah penggunaan sambal independen terhadap sakit perut?
c) Berapa resiko orang yang makan memakai sambal untuk terserang sakit perut!
Interpretasikan!
4. Ingin diketahui apakah Penguasaan Kosa Kata, Pemahaman Tema, Pengetahuan Tata
Bahasa memengaruhi Kemampuan Menulis Siswa SMA?
a) Apakah uji asumsi terpenuhi?
b) Variabel apa saja yang mempengaruhi Kemampuan Menulis Siswa SMA?
c) Interpretasikan model terbaik!
No Penggunaan
Kosa Kata
Pemahaman
Tema
Pengetahuan
Tata Bahasa
Kemampuan
Menulis
1 8 10 20 6
2 8 12 21 7
3 7 12 21 6
4 9 14 23 7
5 8 15 24 7
6 8 8 20 6
7 9 15 22 7
8 6 8 18 5
9 7 20 26 8
10 9 18 28 8
11 6 10 16 5
12 5 7 15 4
13 10 22 30 9
14 9 12 19 6
15 10 15 20 7

5. Buatlah :
a) Kritik dan saran untuk asisten praktikum selama praktikum metode statistika II
kelas C
b) Pada praktikum metode statistika II, materi bagian manakah yang menurut Anda
cukup sulit, jelaskan alasan Anda!
BAB II
PEMBAHASAN
1. a. Permasalahan ini diselesaikan dengan Analisis Variansi 2 Arah (Anova 2 Arah).
Karena akan membandingkan hasil kentang dari tiga varietas kentang yang berbeda dari
4 lokasi berbeda.
b. Sebelum melakukan Uji Anova 2 Arah dilakukan terlebih dahulu uji asumsi, yaitu
a) -- Uji Normalitas Data Lokasi Setiap Varietas Kentang
- Uji Hipotesis
H0 : Data lokasi setiap varietas kentang berdistribusi normal
H1 : Data lokasi setiap varietas kentang tidak berdistribusi normal
- Tingkat Signifikansi
α = 5 %
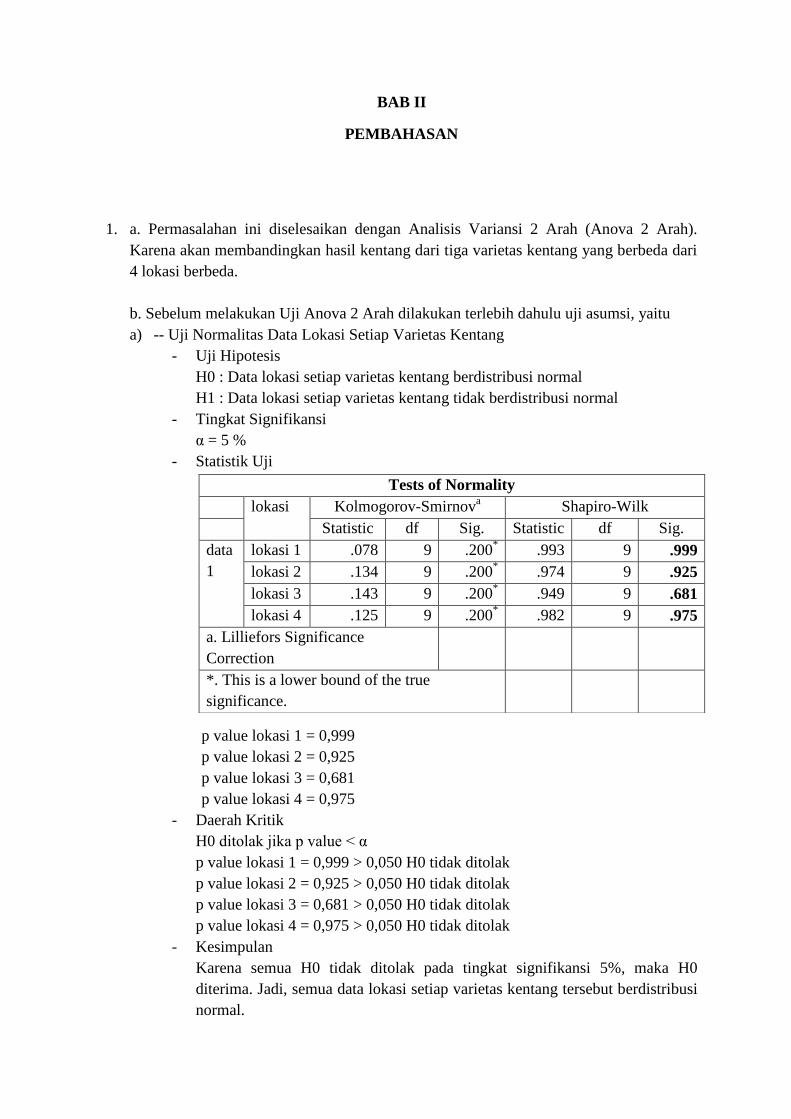
- Statistik Uji
p value lokasi 1 = 0,999
p value lokasi 2 = 0,925
p value lokasi 3 = 0,681
p value lokasi 4 = 0,975
- Daerah Kritik
H0 ditolak jika p value < α
p value lokasi 1 = 0,999 > 0,050 H0 tidak ditolak
p value lokasi 2 = 0,925 > 0,050 H0 tidak ditolak
p value lokasi 3 = 0,681 > 0,050 H0 tidak ditolak
p value lokasi 4 = 0,975 > 0,050 H0 tidak ditolak
- Kesimpulan
Karena semua H0 tidak ditolak pada tingkat signifikansi 5%, maka H0
diterima. Jadi, semua data lokasi setiap varietas kentang tersebut berdistribusi
normal.
Tests of Normality
lokasi Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic df Sig.
data
1
lokasi 1 .078 9 .200* .993 9 .999
lokasi 2 .134 9 .200* .974 9 .925
lokasi 3 .143 9 .200* .949 9 .681
lokasi 4 .125 9 .200* .982 9 .975
a. Lilliefors Significance
Correction
*. This is a lower bound of the true
significance.
-- Uji Normalitas Data Varietas Kentang
- Uji Hipotesis
H0 : Data varietas kentang berdistribusi normal
H1 : Data varietas kentang tidak berdistribusi normal
- Tingkat Signifikansi
α = 5 %
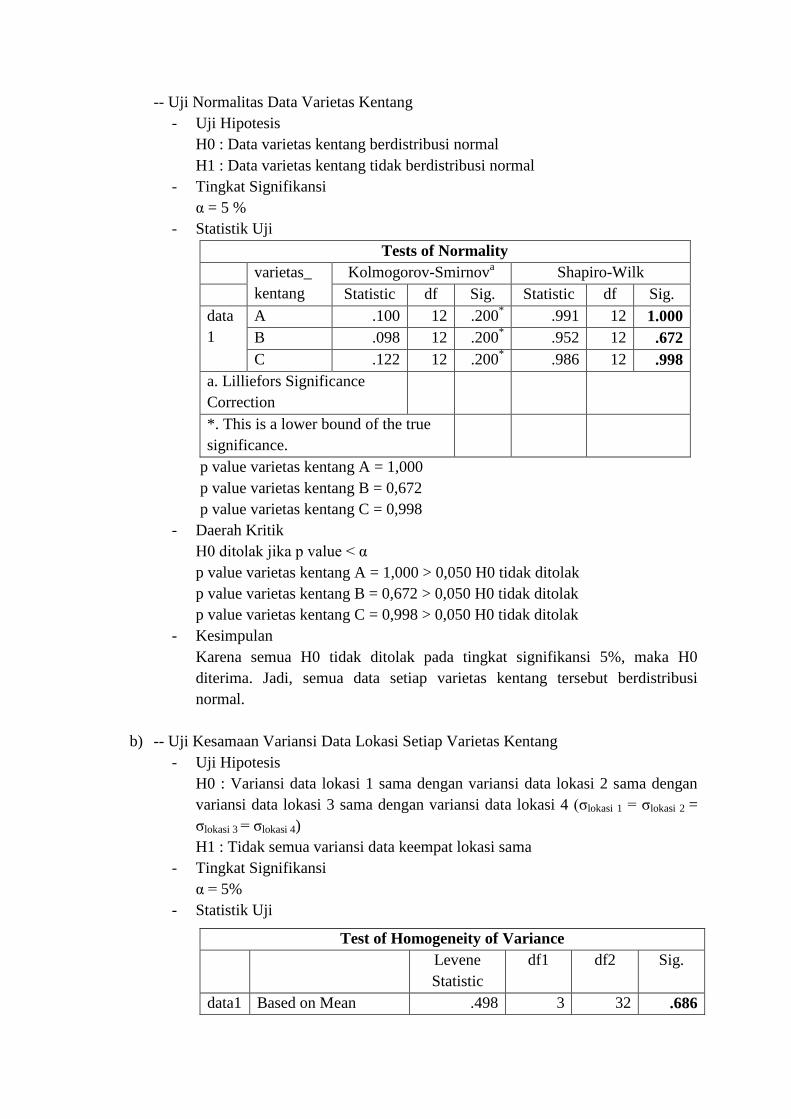
- Statistik Uji
Tests of Normality
varietas_
kentang
Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic df Sig.
data
1
A .100 12 .200* .991 12 1.000
B .098 12 .200* .952 12 .672
C .122 12 .200* .986 12 .998
a. Lilliefors Significance
Correction
*. This is a lower bound of the true
significance.
p value varietas kentang A = 1,000
p value varietas kentang B = 0,672
p value varietas kentang C = 0,998
- Daerah Kritik
H0 ditolak jika p value < α
p value varietas kentang A = 1,000 > 0,050 H0 tidak ditolak
p value varietas kentang B = 0,672 > 0,050 H0 tidak ditolak
p value varietas kentang C = 0,998 > 0,050 H0 tidak ditolak
- Kesimpulan
Karena semua H0 tidak ditolak pada tingkat signifikansi 5%, maka H0
diterima. Jadi, semua data setiap varietas kentang tersebut berdistribusi
normal.
b) -- Uji Kesamaan Variansi Data Lokasi Setiap Varietas Kentang
- Uji Hipotesis
H0 : Variansi data lokasi 1 sama dengan variansi data lokasi 2 sama dengan
variansi data lokasi 3 sama dengan variansi data lokasi 4 (σlokasi 1 = σlokasi 2 =
σlokasi 3 = σlokasi 4)
H1 : Tidak semua variansi data keempat lokasi sama
- Tingkat Signifikansi
α = 5%
- Statistik Uji
Test of Homogeneity of Variance
Levene
Statistic
df1 df2 Sig.
data1 Based on Mean .498 3 32 .686

p value = 0,686
- Daerah Kritik
H0 ditolak jika p value < α
0,686 > 0,050
H0 tidak ditolak
- Kesimpulan
Karena H0 tidak ditolak pada tingkat signifikansi 5%, maka H0 diterima.
Sehingga, variansi data lokasi 1 sama dengan variansi data lokasi 2 sama
dengan variansi data lokasi 3 sama dengan variansi data lokasi 4 (σlokasi 1 =
σlokasi 2 = σlokasi 3 = σlokasi 4) artinya semua data lokasi memiliki variansi yang
sama.
-- Uji Kesamaan Variansi Data Varietas Kentang
- Uji Hipotesis
H0 : Variansi data varietas kentang A sama dengan variansi data varietas
kentang B sama dengan variansi data varietas kentang C (σkentang A = σkentang B
= σkentang C)
H1 : Tidak semua variansi ketiga varietas kentang sama
- Tingkat Signifikansi
α = 5%
- Statistik Uji
p value = 0,203
- Daerah Kritik
H0 ditolak jika p value < α
0,203 > 0,050
H0 tidak ditolak
- Kesimpulan
Karena H0 tidak ditolak pada tingkat signifikansi 5%, maka H0 diterima.
Sehingga, variansi data varietas kentang A sama dengan variansi data varietas
Based on Median .493 3 32 .690
Based on Median and
with adjusted df
.493 3 28.840 .690
Based on trimmed
mean
.485 3 32 .695
Test of Homogeneity of Variance
Levene
Statistic
df1 df2 Sig.
data1 Based on Mean 1.672 2 33 .203
Based on Median 1.683 2 33 .201
Based on Median and
with adjusted df
1.683 2 29.696 .203
Based on trimmed
mean
1.668 2 33 .204
kentang B sama dengan variansi data varietas kentang C (σkentang A = σkentang B
= σkentang C).
Setelah semua asumsi terpenuhi maka akan dilakukan uji interaksi.
c) Uji Interaksi
- Uji Hipotesis
H0 : Tidak ada interaksi antara keempat lokasi (lokasi 1, lokasi 2, lokasi 3,
dan lokasi 4) dengan ketiga varietas kentang (kentang A, kentang B, dan
kentang C)
H1 : Ada interaksi antara keempat lokasi (lokasi 1, lokais 2, lokasi 3, dan
lokasi 4) dengan ketiga varietas kentang (kentang A, kentang B, dan kentang
C)
- Tingkat Signifikansi
α = 5%
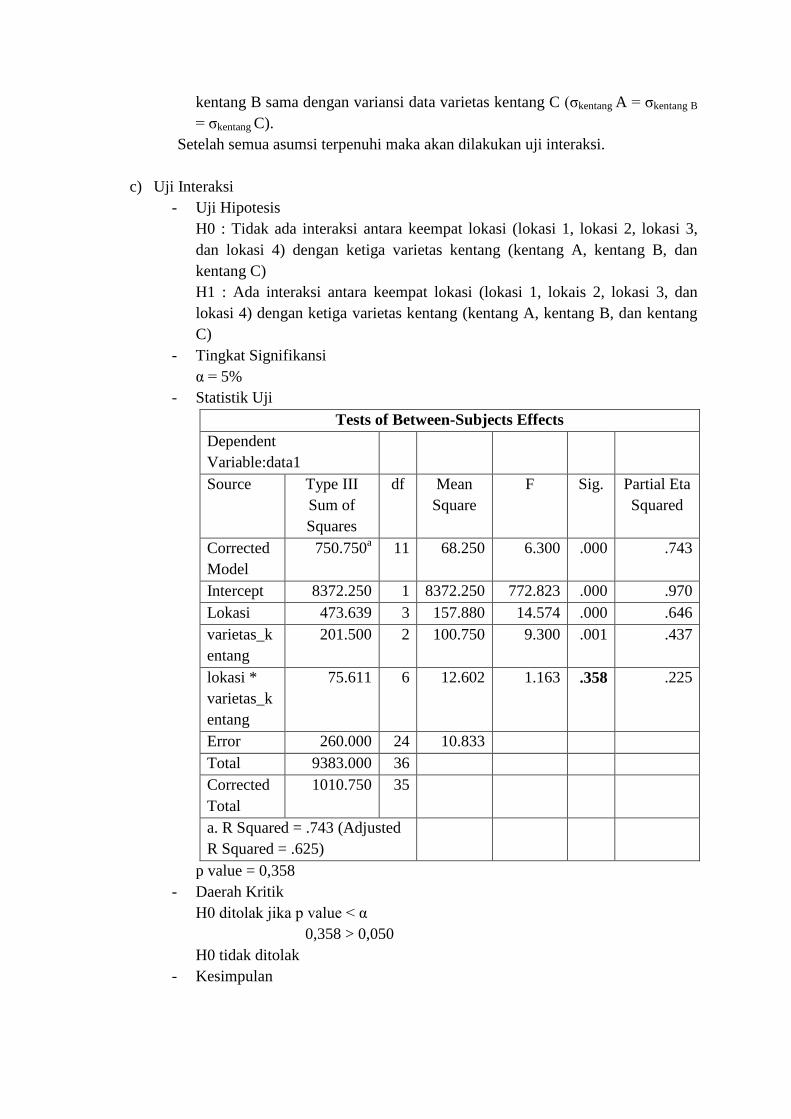
- Statistik Uji
Tests of Between-Subjects Effects
Dependent
Variable:data1
Source Type III
Sum of
Squares
df Mean
Square
F Sig. Partial Eta
Squared
Corrected
Model
750.750a 11 68.250 6.300 .000 .743
Intercept 8372.250 1 8372.250 772.823 .000 .970
Lokasi 473.639 3 157.880 14.574 .000 .646
varietas_k
entang
201.500 2 100.750 9.300 .001 .437
lokasi *
varietas_k
entang
75.611 6 12.602 1.163 .358 .225
Error 260.000 24 10.833
Total 9383.000 36
Corrected
Total
1010.750 35
a. R Squared = .743 (Adjusted
R Squared = .625)
p value = 0,358
- Daerah Kritik
H0 ditolak jika p value < α
0,358 > 0,050
H0 tidak ditolak
- Kesimpulan
Karena H0 tidak ditolak pada tingkat signifikansi 5%, maka H0 diterima.
Sehingga, tidak ada interaksi antara keempat lokasi (lokasi 1, lokasi 2, lokasi
3, dan lokasi 4) dengan ketiga varietas kentang (kentang A, kentang B, dan
kentang C).
Karena H0 tidak ditolak maka selanjutnya akan dilakukan uji efek faktor
lokasi dan uji efek faktor varietas kentang.
d) -- Uji Efek Faktor Lokasi
- Uji Hipotesis
H0 : Tidak ada efek faktor lokasi terhadap hasil produksi kentang
H1 : Ada efek faktor lokasi terhadap hasil produksi kentang
- Tingkat Signifikansi
α = 5%
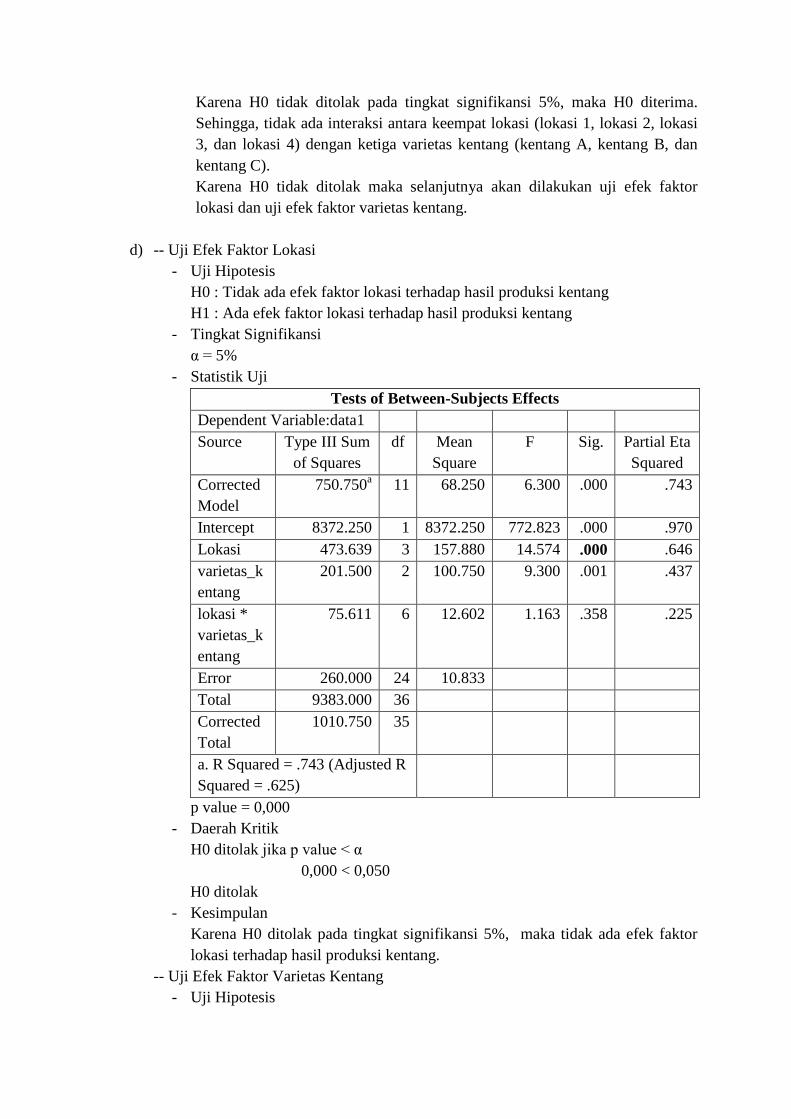
- Statistik Uji
Tests of Between-Subjects Effects
Dependent Variable:data1
Source Type III Sum
of Squares
df Mean
Square
F Sig. Partial Eta
Squared
Corrected
Model
750.750a 11 68.250 6.300 .000 .743
Intercept 8372.250 1 8372.250 772.823 .000 .970
Lokasi 473.639 3 157.880 14.574 .000 .646
varietas_k
entang
201.500 2 100.750 9.300 .001 .437
lokasi *
varietas_k
entang
75.611 6 12.602 1.163 .358 .225
Error 260.000 24 10.833
Total 9383.000 36
Corrected
Total
1010.750 35
a. R Squared = .743 (Adjusted R
Squared = .625)
p value = 0,000
- Daerah Kritik
H0 ditolak jika p value < α
0,000 < 0,050
H0 ditolak
- Kesimpulan
Karena H0 ditolak pada tingkat signifikansi 5%, maka tidak ada efek faktor
lokasi terhadap hasil produksi kentang.
-- Uji Efek Faktor Varietas Kentang
- Uji Hipotesis
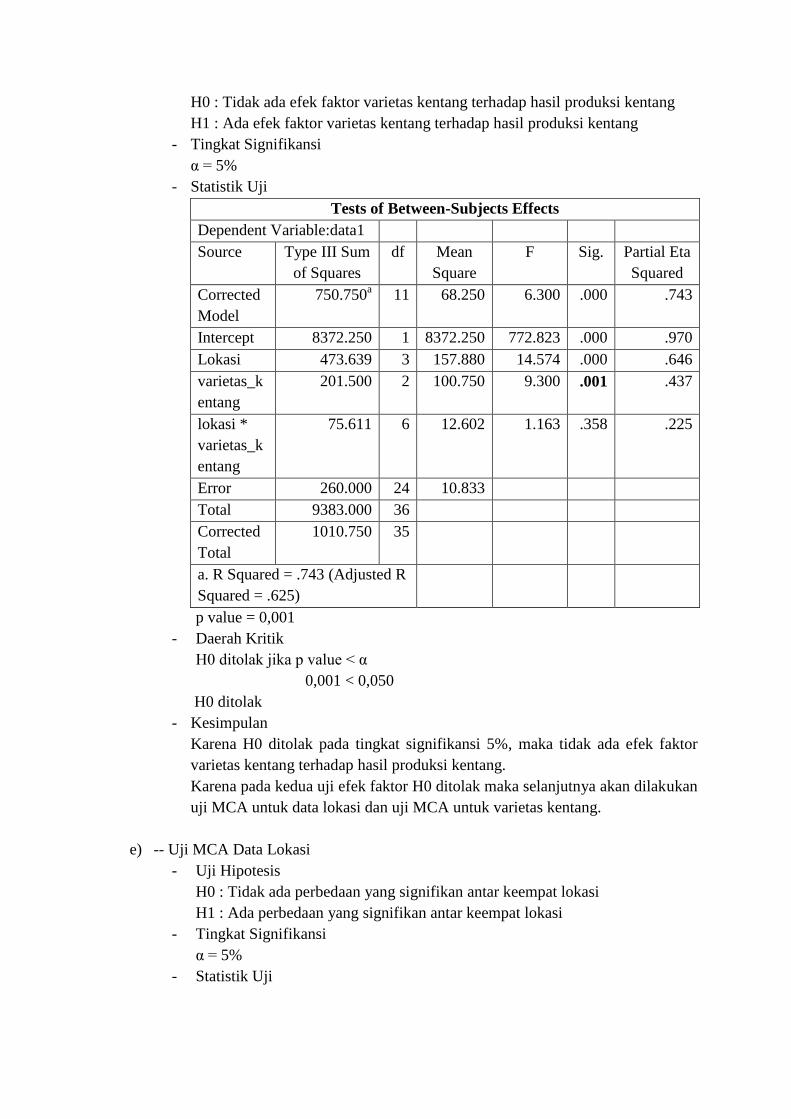
H0 : Tidak ada efek faktor varietas kentang terhadap hasil produksi kentang
H1 : Ada efek faktor varietas kentang terhadap hasil produksi kentang
- Tingkat Signifikansi
α = 5%
- Statistik Uji
Tests of Between-Subjects Effects
Dependent Variable:data1
Source Type III Sum
of Squares
df Mean
Square
F Sig. Partial Eta
Squared
Corrected
Model
750.750a 11 68.250 6.300 .000 .743
Intercept 8372.250 1 8372.250 772.823 .000 .970
Lokasi 473.639 3 157.880 14.574 .000 .646
varietas_k
entang
201.500 2 100.750 9.300 .001 .437
lokasi *
varietas_k
entang
75.611 6 12.602 1.163 .358 .225
Error 260.000 24 10.833
Total 9383.000 36
Corrected
Total
1010.750 35
a. R Squared = .743 (Adjusted R
Squared = .625)
p value = 0,001
- Daerah Kritik
H0 ditolak jika p value < α
0,001 < 0,050
H0 ditolak
- Kesimpulan
Karena H0 ditolak pada tingkat signifikansi 5%, maka tidak ada efek faktor
varietas kentang terhadap hasil produksi kentang.
Karena pada kedua uji efek faktor H0 ditolak maka selanjutnya akan dilakukan
uji MCA untuk data lokasi dan uji MCA untuk varietas kentang.
e) -- Uji MCA Data Lokasi
- Uji Hipotesis
H0 : Tidak ada perbedaan yang signifikan antar keempat lokasi
H1 : Ada perbedaan yang signifikan antar keempat lokasi
- Tingkat Signifikansi
α = 5%
- Statistik Uji
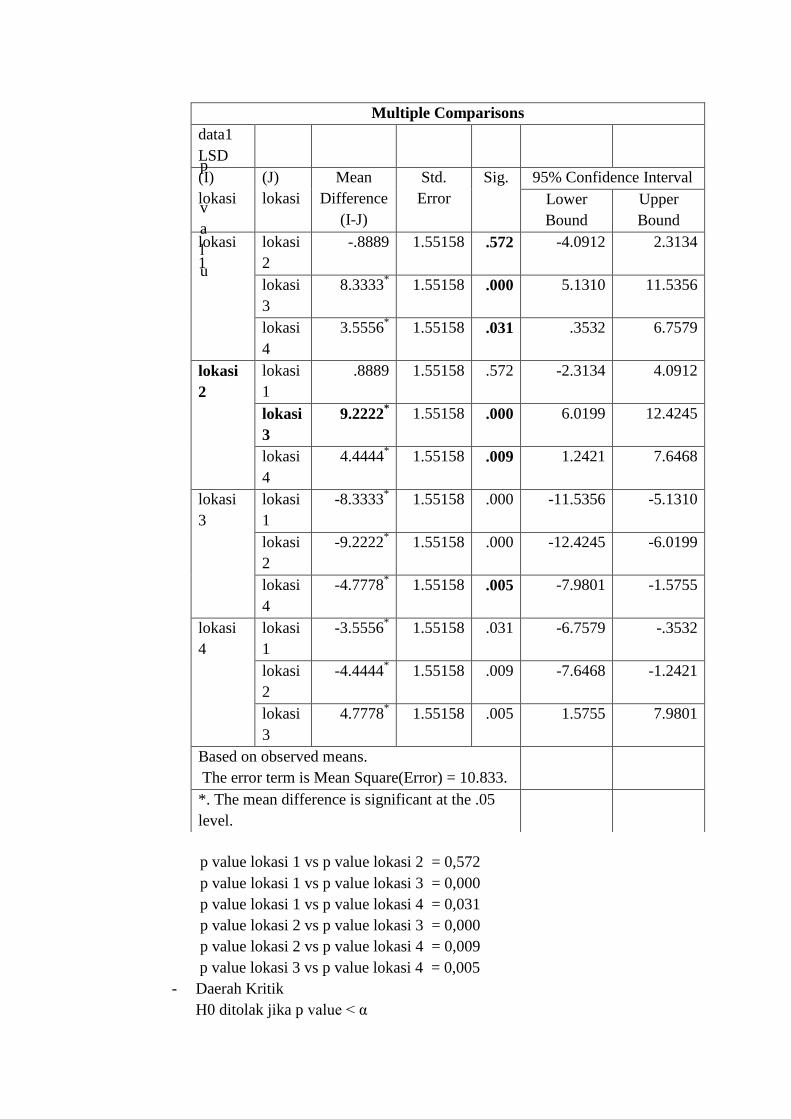
p
v
a
l
u
p value lokasi 1 vs p value lokasi 2 = 0,572
p value lokasi 1 vs p value lokasi 3 = 0,000
p value lokasi 1 vs p value lokasi 4 = 0,031
p value lokasi 2 vs p value lokasi 3 = 0,000
p value lokasi 2 vs p value lokasi 4 = 0,009
p value lokasi 3 vs p value lokasi 4 = 0,005
- Daerah Kritik
H0 ditolak jika p value < α
Multiple Comparisons
data1
LSD
(I)
lokasi
(J)
lokasi
Mean
Difference
(I-J)
Std.
Error
Sig. 95% Confidence Interval
Lower
Bound
Upper
Bound
lokasi
1
lokasi
2
-.8889 1.55158 .572 -4.0912 2.3134
lokasi
3
8.3333* 1.55158 .000 5.1310 11.5356
lokasi
4
3.5556* 1.55158 .031 .3532 6.7579
lokasi
2
lokasi
1
.8889 1.55158 .572 -2.3134 4.0912
lokasi
3
9.2222* 1.55158 .000 6.0199 12.4245
lokasi
4
4.4444* 1.55158 .009 1.2421 7.6468
lokasi
3
lokasi
1
-8.3333* 1.55158 .000 -11.5356 -5.1310
lokasi
2
-9.2222* 1.55158 .000 -12.4245 -6.0199
lokasi
4
-4.7778* 1.55158 .005 -7.9801 -1.5755
lokasi
4
lokasi
1
-3.5556* 1.55158 .031 -6.7579 -.3532
lokasi
2
-4.4444* 1.55158 .009 -7.6468 -1.2421
lokasi
3
4.7778* 1.55158 .005 1.5755 7.9801
Based on observed means.
The error term is Mean Square(Error) = 10.833.
*. The mean difference is significant at the .05
level.

p value lokasi 1 vs p value lokasi 2 = 0,572 > 0,050 H0 tidak ditolak
p value lokasi 1 vs p value lokasi 3 = 0,000 < 0,050 H0 ditolak
p value lokasi 1 vs p value lokasi 4 = 0,031 < 0,050 H0 ditolak
p value lokasi 2 vs p value lokasi 3 = 0,000 < 0,050 H0 ditolak
p value lokasi 2 vs p value lokasi 4 = 0,009 < 0,050 H0 ditolak
p value lokasi 3 vs p value lokasi 4 = 0,005 < 0,050 H0 ditolak
- Kesimpulan
Untuk lokasi 1 dan lokasi 2, H0 tidak ditolak pada tingkat signifikansi 5%,
sehingga dapat disimpulkan bahwa tidak ada perbedaan yang signifikan antara
lokasi 1 dengan lokasi 2
Untuk lokasi 1 dan lokasi 3, H0 ditolak pada tingkat signifikansi 5%, sehingga
dapat disimpulkan bahwa ada perbedaan yang signifikan antara lokasi 1
dengan lokasi 3
Untuk lokasi 1 dan lokasi 4, H0 ditolak pada tingkat signifikansi 5%, sehingga
dapat disimpulkan bahwa ada perbedaan yang signifikan antara lokasi 1
dengan lokasi 4
Untuk lokasi 2 dan lokasi 3, H0 ditolak pada tingkat signifikansi 5%, sehingga
dapat disimpulkan bahwa ada perbedaan yang signifikan antara lokasi 2
dengan lokasi 3
Untuk lokasi 2 dan lokasi 4, H0 ditolak pada tingkat signifikansi 5%, sehingga
dapat disimpulkan bahwa ada perbedaan yang signifikan antara lokasi 2
dengan lokasi 4
Untuk lokasi 3 dan lokasi 4, H0 tidak ditolak pada tingkat signifikansi 5%,
sehingga dapat disimpulkan bahwa tidak ada perbedaan yang signifikan antara
lokasi 3 dengan lokasi 4
Kemudian, jika dilihat dari nilai pada kolom Mean Difference, nilai Mean
Difference pada lokasi 2 – lokasi 3, maka dapat disimpulkan bahwa lokasi 2
lebih baik dibandingkan lokasi 3, lokasi 1, dan lokasi 4.
-- Uji MCA Data Varietas Kentang
- Uji Hipotesis
H0 : Tidak ada perbedaan yang signifikan antar ketiga varietas kentang
H1 : Ada perbedaan yang signifikan antar ketiga varietas kentang
- Tingkat Signifikansi
α = 5%
- Statistik Uji
Multiple Comparisons
data1
LSD
(I)
varie
tas_
kent
ang
(J)
varie
tas_
kent
ang
Mean
Difference
(I-J)
Std.
Error
Sig. 95% Confidence Interval
Lower
Bound
Upper
Bound
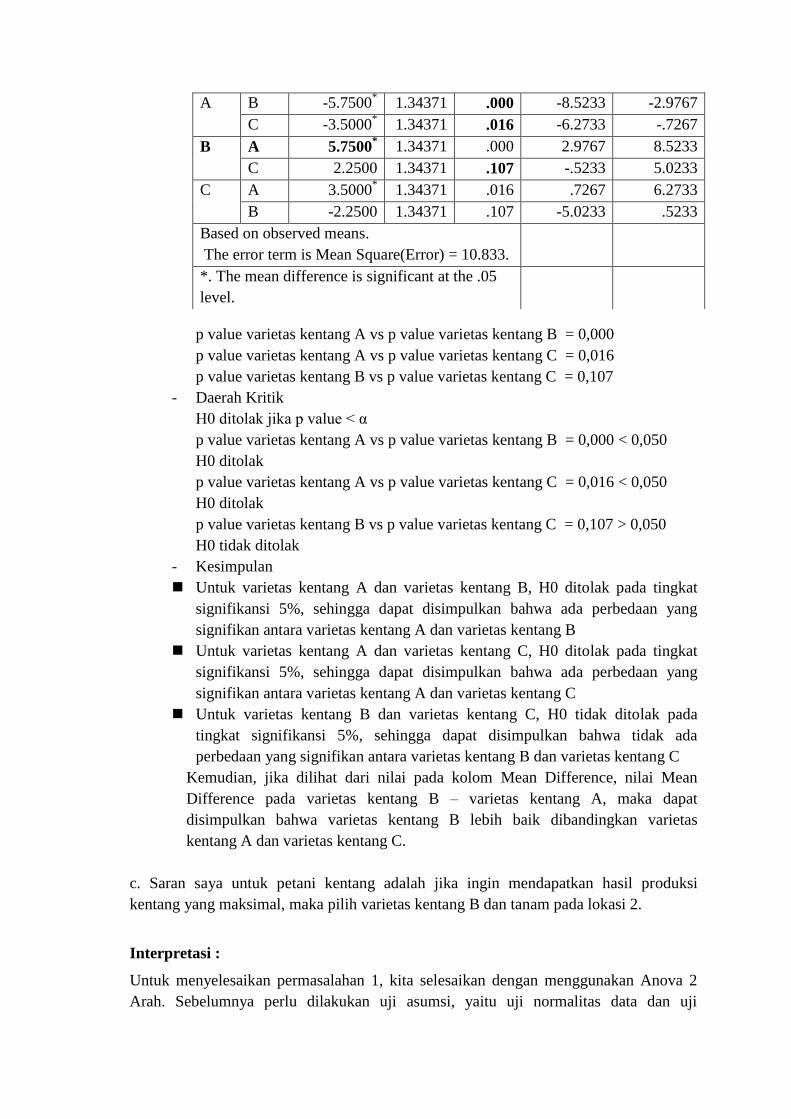
p value varietas kentang A vs p value varietas kentang B = 0,000
p value varietas kentang A vs p value varietas kentang C = 0,016
p value varietas kentang B vs p value varietas kentang C = 0,107
- Daerah Kritik
H0 ditolak jika p value < α
p value varietas kentang A vs p value varietas kentang B = 0,000 < 0,050
H0 ditolak
p value varietas kentang A vs p value varietas kentang C = 0,016 < 0,050
H0 ditolak
p value varietas kentang B vs p value varietas kentang C = 0,107 > 0,050
H0 tidak ditolak
- Kesimpulan
Untuk varietas kentang A dan varietas kentang B, H0 ditolak pada tingkat
signifikansi 5%, sehingga dapat disimpulkan bahwa ada perbedaan yang
signifikan antara varietas kentang A dan varietas kentang B
Untuk varietas kentang A dan varietas kentang C, H0 ditolak pada tingkat
signifikansi 5%, sehingga dapat disimpulkan bahwa ada perbedaan yang
signifikan antara varietas kentang A dan varietas kentang C
Untuk varietas kentang B dan varietas kentang C, H0 tidak ditolak pada
tingkat signifikansi 5%, sehingga dapat disimpulkan bahwa tidak ada
perbedaan yang signifikan antara varietas kentang B dan varietas kentang C
Kemudian, jika dilihat dari nilai pada kolom Mean Difference, nilai Mean
Difference pada varietas kentang B – varietas kentang A, maka dapat
disimpulkan bahwa varietas kentang B lebih baik dibandingkan varietas
kentang A dan varietas kentang C.
c. Saran saya untuk petani kentang adalah jika ingin mendapatkan hasil produksi
kentang yang maksimal, maka pilih varietas kentang B dan tanam pada lokasi 2.
Interpretasi :
Untuk menyelesaikan permasalahan 1, kita selesaikan dengan menggunakan Anova 2
Arah. Sebelumnya perlu dilakukan uji asumsi, yaitu uji normalitas data dan uji
A B -5.7500* 1.34371 .000 -8.5233 -2.9767
C -3.5000* 1.34371 .016 -6.2733 -.7267
B A 5.7500* 1.34371 .000 2.9767 8.5233
C 2.2500 1.34371 .107 -.5233 5.0233
C A 3.5000* 1.34371 .016 .7267 6.2733
B -2.2500 1.34371 .107 -5.0233 .5233
Based on observed means.
The error term is Mean Square(Error) = 10.833.
*. The mean difference is significant at the .05
level.
kesamaan variansi. Dari uji normalitas didapatkan bahwa semua data setiap varietas
kentang berdistribusi normal begitu juga dengan semua data lokasi setiap berdistribusi
normal. Pada uji kesamaan variansi didapatkan bahwa semua data lokasi memiliki
variansi yang sama begitu pula dengan semua data varietas kentang memiliki variansi
yang sama. Selanjutnya, dilakukan uji interaksi, didapatkan bahwa H0 ditolak.
Sehingga, tidak ada interaksi antara keempat lokasi dengan ketiga varietas kentang.
Karena H0 tidak ditolak maka selanjutnya akan dilakukan uji efek faktor. Didapatkan
bahwa H0 ditolak, maka tidak ada efek faktor lokasi dan tidak ada efek faktor varietas
kentang terhadap hasil produksi kentang. Langkah selanjutnya adalah uji MCA faktor
lokasi dan faktor varietas kentang. Didapatkan hasil bahwa lokasi 2 lebih baik
dibandingkan lokasi lainnya dan varietas kentang B lebih baik dibandingkan varietas
kentang lainnya. Jadi, untuk mendapatkan hasil produksi kentang yang maksimal, maka
pilih varietas kentang B dan tanam pada lokasi 2.
2. a. Permasalahan ini diselesaikan dengan Statistika Non Parametrik dengan
menggunakan Uji Kruskal Wallis. Karena akan diuji signifikansi perbedaan antara tujuh
kelompok atau sampel independen (rumah sakit).
b. Uji Asumsi
a) Uji Normalitas
- Uji Hipotesis
H0 : Data jumlah bayi yang lahir di tiap musim berdistribusi normal
H1 : Data jumlah bayi yang lahir ditiap musim tidak berdistribusi normal
- Tingkat Signifikansi
α = 5 %
- Statistik Uji
Tests of Normality
musim Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic df Sig.
data dingin .260 7 .167 .818 7 .062
semi .290 7 .077 .793 7 .035
panas .284 7 .093 .807 7 .048
gugur .250 7 .200* .844 7 .108
a. Lilliefors Significance
Correction
*. This is a lower bound of the true
significance.
p value musim dingin = 0,062
p value musim semi = 0,035
p value musim panas = 0,048
p value musim gugur = 0,108
- Daerah Kritik
H0 ditolak jika p value < α
p value musim dingin = 0,062 > 0,050 H0 tidak ditolak
p value musim semi = 0,035 < 0,050 H0 ditolak
p value musim panas = 0,048 < 0,050 H0 ditolak
p value musim gugur = 0,108 > 0,050 H0 tidak ditolak
- Kesimpulan
Untuk data musim dingin, H0 tidak ditolak pada tingkat signifikansi 5%,
sehingga dapat disimpulkan bahwa data jumlah bayi yang lahir di musim
dingin berdistribusi normal.
Untuk data musim semi, H0 ditolak pada tingkat signifikansi 5%, sehingga
dapat disimpulkan bahwa data jumlah bayi yang lahir di musim semi tidak
berdistribusi normal.
Untuk data musim panas, H0 ditolak pada tingkat signifikansi 5%, sehingga
dapat disimpulkan bahwa data jumlah bayi yang lahir di musim panas tidak
berdistribusi normal.
Untuk data musim gugur, H0 tidak ditolak pada tingkat signifikansi 5%,
sehingga dapat disimpulkan bahwa data jumlah bayi yang lahir di musim
gugur berdistribusi normal.
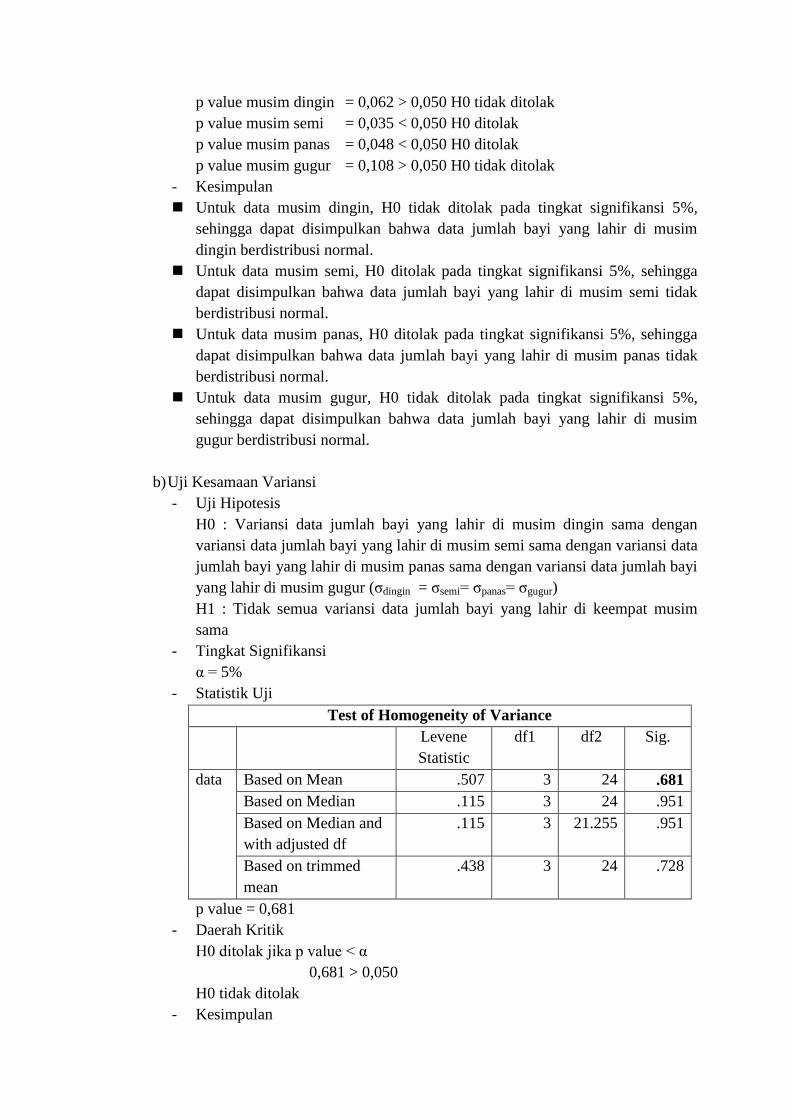
b) Uji Kesamaan Variansi
- Uji Hipotesis
H0 : Variansi data jumlah bayi yang lahir di musim dingin sama dengan
variansi data jumlah bayi yang lahir di musim semi sama dengan variansi data
jumlah bayi yang lahir di musim panas sama dengan variansi data jumlah bayi
yang lahir di musim gugur (σdingin = σsemi= σpanas= σgugur)
H1 : Tidak semua variansi data jumlah bayi yang lahir di keempat musim
sama
- Tingkat Signifikansi
α = 5%
- Statistik Uji
Test of Homogeneity of Variance
Levene
Statistic
df1 df2 Sig.
data Based on Mean .507 3 24 .681
Based on Median .115 3 24 .951
Based on Median and
with adjusted df
.115 3 21.255 .951
Based on trimmed
mean
.438 3 24 .728
p value = 0,681
- Daerah Kritik
H0 ditolak jika p value < α
0,681 > 0,050
H0 tidak ditolak
- Kesimpulan

Karena H0 tidak ditolak pada tingkat signifikansi 5%, maka H0 diterima.
Sehingga, variansi data jumlah bayi yang lahir di musim dingin sama dengan
variansi data jumlah bayi yang lahir di musim semi sama dengan variansi data
jumlah bayi yang lahir di musim panas sama dengan variansi data jumlah bayi
yang lahir di musim gugur (σdingin = σsemi= σpanas= σgugur).
c) Uji Kruskal Wallis
- Uji Hipotesis
H0 : Rata-rata jumlah bayi yang lahir di musim dingin sama dengan rata-rata
jumlah bayi yang lahir di musim semi sama dengan rata-rata jumlah bayi yang
lahir di musim gugur sama dengan rata-rata jumlah bayi yang lahir di musim
panas (µbayi lahir di musim dingin = µbayi lahir di musim semi = µbayi lahir di musim gugur = µbayi lahir
di musim panas)
H1 : Ada rata-rata jumlah bayi yang lahir di suatu musim tertentu tidak sama
dengan rata-rata jumlah bayi yang lahir di musim lainnya (µbayi lahir di musim i ≠)
- Tingkat Signifikansi
α = 5%
- Statistik Uji
Ranks
musim N Mean Rank
data dingin 7 13.93
semi 7 16.36
panas 7 13.93
gugur 7 13.79
Total 28
Test Statisticsa,b
data
Chi-Square .478
Df 3
Asymp. Sig. .924
a. Kruskal Wallis Test
b. Grouping Variable: musim
p value = 0,924
- Daerah Kritik
H0 ditolak jika p value < α
0,924 > 0,050
H0 tidak ditolak
- Kesimpulan
Karena H0 tidak ditolak pada tingkat signifikansi 5%, maka didapatkan
bahwa rata-rata jumlah bayi yang lahir di musim dingin sama dengan rata-rata
jumlah bayi yang lahir di musim semi sama dengan rata-rata jumlah bayi yang
lahir di musim gugur sama dengan rata-rata jumlah bayi yang lahir di musim

panas (µbayi lahir di musim dingin = µbayi lahir di musim semi = µbayi lahir di musim gugur = µbayi lahir
di musim panas) artinya semua rata-rata jumlah bayi yang lahir disetiap musim
adalah sama.
Interpretasi :
Untuk menyelesaikan permasalahan 2, kita selesaikan dengan menggunakan Uji
Kruskal Wallis. Setelah dilakukan uji kruskal wallis didapatkan bahwa H0 tidak
ditolak pada tingkat signifikansi 5%, maka rata-rata jumlah bayi yang lahir di
musim dingin sama dengan rata-rata jumlah bayi yang lahir di musim semi sama
dengan rata-rata jumlah bayi yang lahir di musim gugur sama dengan rata-rata
jumlah bayi yang lahir di musim panas (µbayi lahir di musim dingin = µbayi lahir di musim semi =
µbayi lahir di musim gugur = µbayi lahir di musim panas) artinya semua rata-rata jumlah bayi yang
lahir disetiap musim adalah sama.
3. Permasalahan ini diselesaikan dengan Analisis Data Kategorik dengan menggunakan Uji
Independensi
a. Tabel kontigensi
Sakit Perut Tidak Sakit Perut Total
Makan Sambel 109 116 225
Tidak Makan Sambel 4 34 38
Total 113 150 263
b. Uji Independensi
a) Uji Hipotesis
H0 : Variabel makan memakai sambel atau tidak independen terhadap variabel
terserang sakit perut atau tidak (P(AB)=P(A)P(B))
H1 : Variabel makan memakai sambel atau tidak dependen terhadap variabel
terserang sakit perut atau tidak (P(AB) ≠ P(A)P(B))
b) Tingkat Signifikansi
α = 5%
c) Statistik Uji
sambel * sakit Crosstabulation
sakit Total
sakit perut tidak sakit
perut
sambel makan
sambel
Count 109 116 225
Expected 96.7 128.3 225.0

Count
tidak
makan
sambel
Count 4 34 38
Expected
Count
16.3 21.7 38.0
Total Count 113 150 263
Expected
Count
113.0 150.0 263.0
Chi-Square Tests
Value df Asymp. Sig.
(2-sided)
Exact Sig.
(2-sided)
Exact Sig.
(1-sided)
Pearson Chi-
Square
19.074a 1 .000
Continuity
Correctionb
17.558 1 .000
Likelihood Ratio 22.101 1 .000
Fisher's Exact
Test
.000 .000
Linear-by-Linear
Association
19.002 1 .000
N of Valid Casesb 263
a. 0 cells (.0%) have expected count less than 5. The minimum expected count
is 16.33.
b. Computed only for
a 2x2 table
p value = 0,000
d) Daerah Kritik
H0 ditolak jika p value < α
0,000 < 0,050
H0 ditolak
e) Kesimpulan
Karena H0 ditolak pada tingkat signifikansi 5%, maka didapatkan bahwa variabel
makan memakai sambel atau tidak dependen terhadap variabel terserang sakit
perut atau tidak.
c. Perhatikan tabel dibawah ini
Risk Estimate
Value 95% Confidence Interval
Lower Upper
Odds Ratio for sambel (makan sambel
/ tidak makan sambel)
7.987 2.744 23.251
For cohort sakit = sakit perut 4.602 1.804 11.743

For cohort sakit = tidak sakit perut .576 .488 .681
N of Valid Cases 263
Interpretasi :
Orang yang makan sambel 7,987 kali lebih besar beresiko sakit perut dibandingkan
orang yang tidak makan sambel.
Interpretasi :
Untuk menyelesaikan permasalahan 3, kita selesaikan dengan menggunakan Uji
Independensi. Setelah dilakukan uji independensi, didapatkan bahwa H0 ditolak pada
tingkat signifikansi 5%, maka didapatkan bahwa variabel makan memakai sambel
atau tidak dependen terhadap variabel terserang sakit perut atau tidak. Diketahu
bahwa orang yang makan sambel 7,987 kali lebih besar beresiko sakit perut
dibandingkan orang yang tidak makan sambel.
4. Permasalahan ini diselesaikan dengan Analisis Regresi Linear Ganda
a. Sebelum melakukan Uji Analisis Regresi Linear Ganda dilakukan terlebih dahulu uji
asumsi, yaitu
a) Uji Normalitas Variabel Dependen (Kemampuan Menulis Siswa SMA)
- Uji Hipotesis
H0 : Data hasil ternak berdistribusi normal
H1 : Data hasil ternak tidak berdistribusi normal
- Tingkat Signifikansi
α = 5 %
- Statistik Uji
p value = 0,666
- Daerah Kritik
H0 ditolak jika p value < α
0,666 > 0,050
H0 tidak ditolak
- Kesimpulan
Karena H0 tidak ditolak pada tingkat signifikansi 5%, maka H0 diterima.
Sehinga, didapatkan bahwa data kemampuan menulis siswa SMA
berdistribusi normal.
Tests of Normality
Kolmogorov-Smirnova Shapiro-Wilk
Statistic Df Sig. Statistic df Sig.
kemampuan_menulis .173 15 .200* .958 15 .666
a. Lilliefors Significance Correction
*. This is a lower bound of the true significance.

b) Uji Linearitas
Didapatkan output seperti gambar dibawah ini
Interpretasi :
Variabel Kemampuan Menulis dengan variabel Penggunaan Kosakata
memiliki hubungan linear yang positif. (Karena garis menuju arah yang
menaik)
Variabel Kemampuan Menulis dengan variabel Pemahaman Tema memiliki
hubungan linear yang positif. (Karena garis menuju arah yang menaik)
Variabel Kemampuan Menulis dengan variabel Pengetahuan Tatabahasa
memiliki hubungan linear yang positif. (Karena garis menuju arah yang
menaik)
Setelah dilakukan uji asumsi, maka langkah selanjutnya adalah melakukan uji regresi
a) Uji Overall
- Uji Hipotesis

H0: Model regresi tidak layak digunakan
H1: Model regresi layak digunakan
- Tingkat Signifikansi
α = 5 %
- Statistik Uji
ANOVAc,d
Model Sum of
Squares
df Mean
Square
F Sig.
1 Regression 9959.994 3 3319.998 4.304E5 .000a
Residual 2.006 260 .008
Total 9962.000b 263
a. Predictors: pengetahuan_tatabahasa, penggunaan_kosakata,
pemahaman_tema
b. This total sum of squares is not corrected for the constant because the
constant is zero for regression through the origin.
c. Dependent Variable: kemampuan_menulis
d. Linear Regression through the Origin
p value = 0,000
- Daerah Kritik
H0 ditolak jika p value < α
0,000 < 0,050
H0 ditolak
- Kesimpulan
Karena H0 ditolak pada tingkat signifikansi 5%, maka H1 diterima. Sehinga,
didapatkan bahwa model regresi layak digunakan.
b) Uji Parsial
- Uji Hipotesis
H0 : Konstan tidak signifikan
H1 : Konstan signifikan
- Tingkat Signifikansi
α = 5 %
- Statistik Uji
Perhatikan tabel koefisien berikut ini :
Coefficientsa,b
Model Unstandardized
Coefficients
Standardized
Coefficients
t Sig.
B Std.
Error
Beta
1 penggunaan_
kosakata
.297 .010 .374 30.079 .000

pemahaman_
tema
.076 .007 .142 10.184 .000
pengetahuan_
tatabahasa
.144 .007 .486 20.988 .000
a. Dependent Variable:
kemampuan_menulis
b. Linear Regression through the
Origin
- Kesimpulan
Sehingga akan didapatkan model regresi terbaik yaitu
Kemampuan menulis = 0,297 penggunaan kosakata + 0,076 pemahaman tema +
0,144 pengetahuan tatabahasa
c) Model Summary
Model Summary
Model R R Squareb Adjusted R Square Std. Error of the Estimate
1 1.000a 1.000 1.000 .08783
a. Predictors: pengetahuan_tatabahasa, penggunaan_kosakata,
pemahaman_tema
b. For regression through the origin (the no-intercept model), R Square
measures the proportion of the variability in the dependent variable about the
origin explained by regression. This CANNOT be compared to R Square for
models which include an intercept.
R = 1,00
Artinya, variabel independen (penggunaan kosakata, pemahaman tema, dan
pengetahuan tatabahasa) erat hubungannya dengan variabel dependen
(kemampuan menulis siswa SMA) sebesar 100%. Hubungan yang ada
menunjukkan hubungan erat yang positif karena nilai R > 0,5.
R square = 1,00
Artinya, sebesar 100 % variabel dependen (kemampuan menulis siswa SMA)
dapat dijelaskan dengan variabel independen (penggunaan kosakata,
pemahaman tema, dan pengetahuan tatabahasa).
Adjusted R Square = 1,00
Artinya, nilai korelasi R square yang di dapat sebesar 100 %.
d) Model terbaik
Jadi, model terbaik untuk mengestimasi variabel dependen jika variabel
independen diketahui adalah
Kemampuan menulis = 0,297 penggunaan kosakata + 0,076 pemahaman tema +
0,144 pengetahuan tatabahasa

b. Variabel yang mempengaruhi kemampuan menulis siswa SMA adalah variabel
penggunaan kosakata, variabel pemahaman tema, dan variabel pengetahuan
tatabahasa.
c. Model terbaik
Kemampuan menulis = 0,297 penggunaan kosakata + 0,076 pemahaman tema +
0,144 pengetahuan tatabahasa
Artinya, setiap kenaikan 1 satuan penggunaan kosakata, maka nilai kemampuan
menulis akan ditambahkan sebesar 0,297 satuan, dengan mengabaikan variabel
lain.
Artinya, setiap kenaikan 1 satuan pemahaman tema, maka nilai kemampuan
menulis akan ditambahkan sebesar 0,076 satuan, dengan mengabaikan variabel
lain.
Artinya, setiap kenaikan 1 satuan pengetahuan tatabahasa, maka nilai
kemampuan menulis akan ditambahkan sebesar 0,144 satuan, dengan
mengabaikan variabel lain.
Interpretasi :
Untuk menyelesaikan permasalahan 4, kita selesaikan dengan menggunakan
Analisis Regresi Linear Sederhana. Sebelumnya akan dilakukan uji asumsi, yaitu uji
normalitas data dependen dan uji linearitas. Pada uji normalitas didapatkan bahwa
H0 ditolak pada tingkat signifikansi 5%, maka didapatkan hasil bahwa data
kemampuan menulis siswa SMA berdistribusi normal. Pada uji linearitas didapatkan
hasil bahwa semua variabel independen (penggunaan kosakata, pemahaman tema,
dan pengetahuan tatabahasa) memiliki hubungan linear yang positif terhadap
variabel dependen (kemampuan menulis siswa SMA). Selanjutnya dilakukan uji
overall, pada uji ini didapatkan bahwa H0 ditolak pada tingkat signifikansi 5%,
maka H1 diterima. Sehinga, model regresi layak digunakan. Pada uji parsial
didapatkan bahwa model terbaik Kemampuan menulis = 0,297 penggunaan kosakata
+ 0,076 pemahaman tema + 0,144 pengetahuan tatabahasa.
5. a. Kritik dan saran untuk asisten praktikum selama praktikum metode statistika II kelas
C : sejauh ini sudah baik dan sudah bagus menjadi asisten praktikumnya, penjelasannya
juga tidak membuat binggung, masalahnya pada sarana dan prasarana yang ada, tulisan
di papan agak lebih besar aja dan harus keliatan tulisannya.
b. Pada praktikum metode statistika II, materi mengenai Statistika Non Parametrik,
karena belum begitu banyak latihan soalnya dan masih merasa agak sulit untuk
membedakan mana yang dependen dan mana yang independen.

BAB III
KESIMPULAN
1. a. Analisis yang digunakan adalah Analisis Variansi 2 Arah (Anova 2 Arah). Karena
akan membandingkan hasil kentang dari tiga varietas kentang yang berbeda dari 4 lokasi
berbeda.
b. Terdapat perbedaan produksi kentang. Dapat disimpulkan bahwa varietas kentang B
lebih baik dibandingkan varietas kentang A dan varietas kentang C. Dan penanaman
pada lokasi 2 lebih baik daripada penanaman pada lokasi 1, lokasi 3, dan lokasi 4.
c. Saran saya untuk petani kentang adalah jika ingin mendapatkan hasil produksi
kentang yang maksimal, maka pilih varietas kentang B dan tanam pada lokasi 2.
2. a. Analisis yang digunakan adalah Statistika Non Parametrik dengan menggunakan Uji
Kruskal Wallis. Karena akan diuji signifikansi perbedaan antara tujuh kelompok atau
sampel independen (rumah sakit).
b. Tidak terdapat perbedaan jumlah kelahiran bayi pada tiap musim, rata-rata jumlah
bayi yang lahir di musim dingin sama dengan rata-rata jumlah bayi yang lahir di musim
semi sama dengan rata-rata jumlah bayi yang lahir di musim gugur sama dengan rata-
rata jumlah bayi yang lahir di musim panas artinya semua rata-rata jumlah bayi yang
lahir disetiap musim adalah sama.
3. a. Tabel kontingensi :
Sakit Perut Tidak Sakit Perut Total
Makan Sambel 109 116 225
Tidak Makan Sambel 4 34 38
Total 113 150 263
b. Penggunaan sambal dependen terhadap sakit perut.
c. Orang yang makan sambel 7,987 kali lebih besar beresiko sakit perut dibandingkan
orang yang tidak makan sambel.
4. a. Asumsi terpenuhi, data kemampuan menulis siswa SMA berdistribusi normal.
b. Variabel yang mempengaruhi Kemampuan Menulis Siswa SMA adalah penggunaan
kosakata, pemahaman tema, dan pengetahuan tatabahasa.
c. Model terbaik : Kemampuan menulis = 0,297 penggunaan kosakata + 0,076
pemahaman tema + 0,144 pengetahuan tatabahasa
5. a. Kritik dan saran untuk asisten praktikum selama praktikum metode statistika II kelas
C : sejauh ini sudah baik dan sudah bagus menjadi asisten praktikumnya, penjelasannya
juga tidak membuat binggung, masalahnya pada sarana dan prasarana yang ada, tulisan
di papan agak lebih besar aja dan harus keliatan tulisannya.
b. Pada praktikum metode statistika II, materi mengenai Statistika Non Parametrik,
karena belum begitu banyak latihan soalnya dan masih merasa agak sulit untuk
membedakan mana yang dependen dan mana yang independen.




















