
Identification of chemokines and a chemokine receptor in cichlid fish, shark, and lamprey
12
Immunogenetics (2003) 54:884–895 DOI 10.1007/s00251-002-0531-z ORIGINAL PAPER Noriyuki Kuroda · Tatiana S. Uinuk-ool · Akie Sato · Irene E. Samonte · Felipe Figueroa · Werner E. Mayer · Jan Klein Identification of chemokines and a chemokine receptor in cichlid fish, shark, and lamprey Received: 1 October 2002 / Revised: 25 November 2002 / Published online: 5 March 2003 # Springer-Verlag 2003 Abstract Chemokines are small, inducible, structurally related proteins that guide cells expressing the right chemokine receptors to sites of immune response. They have been identified and studied extensively in mammals, but little is known about their presence in other vertebrate groups. Here we describe seven new chemokines in bony fish and one in a cartilaginous fish, as well as one chemokine receptor in a jawless vertebrate. All eight chemokines belong to the SCYA (CC) subfamily charac- terized by four conserved cysteine residues of which the first two are adjacent. The chemokine receptor is of the CXCR4 type. Phylogenetic analysis does not reveal any clear evidence of orthology of fish and human chemo- kines. Although the divergence of the subfamilies began before the fish–tetrapod split, much of the divergence within the subfamilies took place separately in the two vertebrate groups. The existence of a chemokine receptor in the lamprey indicates that chemokines are apparently also present in the Agnatha. Keywords Chemokines and receptors · Cichlid fish · Shark · Lamprey · Small inducible cytokines Introduction Chemotactic cytokines (chemokines) are structurally related, low molecular mass (M r 8000–14,000) im- munoregulatory proteins secreted by cells of the immune system and characterized by the presence of three or four conserved cysteine residues (Schall and Bacon 1994; Hedrick and Zlotnik 1996; Rollins 1997; Vaddi et al. 1997; Baggiolini 1998; Mantovani 1999; Yoshie et al. 2001). When released from the cell, they form a concentration gradient that guides leukocytes to the site of inflammatory and immune response. More than 50 members of the chemokine superfamily have been identified in humans and divided into four families according to a sequence motif that includes the first two of the four conserved cysteine residues. The families are designated CXCL, CCL, CL, and CX3CL, where C stands for cysteine, X for other amino acid residues, and L for ligand (Zlotnik and Yoshie 2000). The CXCL family, in which the first two conserved cysteine residues are separated by one other amino acid residue, is further subdivided into two subfamilies according to the presence or absence of a glutamic acid–leucine–arginine (ELR) motif immediately preceding the first conserved cysteine residue. The ELR chemokines are angiogenic chemoat- tractants for neutrophils; the non-ELR chemokines are angiostatic chemoattractants for lymphocytes. The che- mokines of the CCL family, in which the first two cysteine residues are adjacent, are mostly directed at monocytes, but some of them are also specific for lymphocytes or eosinophils. In the remaining two minor families, either only one of the first two cysteine residues is conserved (the CL family) or the two cysteines are separated by three other amino acid residues (the CX3CL family). The proteins of the different families share a similar three-dimensional structure characterized by three distinct regions (Rollins 1997; Baggiolini 1998). The N-terminal region contains a short disordered segment that precedes the first conserved cysteine residue. The segment is believed to be involved in receptor triggering, possibly by fitting into the pocket of the receptor formed by the transmembrane domains. The central region of the cytokines contains three antiparallel b-strands stabilized by two disulfide bonds, one between the first and the third, and the other between the second and fourth cysteine residues. This part of the molecule is thought to confer specificity to the ligand–receptor interaction. The third, C-terminal region comprises an a-helix of ~20–30 amino acid residues believed to be involved in the binding The nucleotide sequences have been deposited in the GenBank database with accession numbers AY178962–AY178970 N. Kuroda · T. S. Uinuk-ool · A. Sato · I. E. Samonte · F. Figueroa · W. E. Mayer ( ) ) · J. Klein Abteilung Immungenetik, Max-Planck-Institut fɒr Biologie, Corrensstrasse 42, 72076 Tɒbingen, Germany e-mail: [email protected]
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Identification of chemokines and a chemokine receptor in cichlid fish, shark, and lamprey

Immunogenetics (2003) 54:884–895DOI 10.1007/s00251-002-0531-z
O R I G I N A L P A P E R
Noriyuki Kuroda · Tatiana S. Uinuk-ool · Akie Sato ·Irene E. Samonte · Felipe Figueroa · Werner E. Mayer ·Jan Klein
Identification of chemokines and a chemokine receptorin cichlid fish, shark, and lamprey
Received: 1 October 2002 / Revised: 25 November 2002 / Published online: 5 March 2003� Springer-Verlag 2003
Abstract Chemokines are small, inducible, structurallyrelated proteins that guide cells expressing the rightchemokine receptors to sites of immune response. Theyhave been identified and studied extensively in mammals,but little is known about their presence in other vertebrategroups. Here we describe seven new chemokines in bonyfish and one in a cartilaginous fish, as well as onechemokine receptor in a jawless vertebrate. All eightchemokines belong to the SCYA (CC) subfamily charac-terized by four conserved cysteine residues of which thefirst two are adjacent. The chemokine receptor is of theCXCR4 type. Phylogenetic analysis does not reveal anyclear evidence of orthology of fish and human chemo-kines. Although the divergence of the subfamilies beganbefore the fish–tetrapod split, much of the divergencewithin the subfamilies took place separately in the twovertebrate groups. The existence of a chemokine receptorin the lamprey indicates that chemokines are apparentlyalso present in the Agnatha.
Keywords Chemokines and receptors · Cichlid fish ·Shark · Lamprey · Small inducible cytokines
Introduction
Chemotactic cytokines (chemokines) are structurallyrelated, low molecular mass (Mr 8000–14,000) im-munoregulatory proteins secreted by cells of the immunesystem and characterized by the presence of three or fourconserved cysteine residues (Schall and Bacon 1994;Hedrick and Zlotnik 1996; Rollins 1997; Vaddi et al.1997; Baggiolini 1998; Mantovani 1999; Yoshie et al.
2001). When released from the cell, they form aconcentration gradient that guides leukocytes to the siteof inflammatory and immune response. More than 50members of the chemokine superfamily have beenidentified in humans and divided into four familiesaccording to a sequence motif that includes the first twoof the four conserved cysteine residues. The families aredesignated CXCL, CCL, CL, and CX3CL, where C standsfor cysteine, X for other amino acid residues, and L forligand (Zlotnik and Yoshie 2000). The CXCL family, inwhich the first two conserved cysteine residues areseparated by one other amino acid residue, is furthersubdivided into two subfamilies according to the presenceor absence of a glutamic acid–leucine–arginine (ELR)motif immediately preceding the first conserved cysteineresidue. The ELR chemokines are angiogenic chemoat-tractants for neutrophils; the non-ELR chemokines areangiostatic chemoattractants for lymphocytes. The che-mokines of the CCL family, in which the first twocysteine residues are adjacent, are mostly directed atmonocytes, but some of them are also specific forlymphocytes or eosinophils. In the remaining two minorfamilies, either only one of the first two cysteine residuesis conserved (the CL family) or the two cysteines areseparated by three other amino acid residues (the CX3CLfamily).
The proteins of the different families share a similarthree-dimensional structure characterized by three distinctregions (Rollins 1997; Baggiolini 1998). The N-terminalregion contains a short disordered segment that precedesthe first conserved cysteine residue. The segment isbelieved to be involved in receptor triggering, possibly byfitting into the pocket of the receptor formed by thetransmembrane domains. The central region of thecytokines contains three antiparallel b-strands stabilizedby two disulfide bonds, one between the first and thethird, and the other between the second and fourthcysteine residues. This part of the molecule is thought toconfer specificity to the ligand–receptor interaction. Thethird, C-terminal region comprises an a-helix of ~20–30amino acid residues believed to be involved in the binding
The nucleotide sequences have been deposited in the GenBankdatabase with accession numbers AY178962–AY178970
N. Kuroda · T. S. Uinuk-ool · A. Sato · I. E. Samonte · F. Figueroa ·W. E. Mayer ()) · J. KleinAbteilung Immungenetik,Max-Planck-Institut f�r Biologie,Corrensstrasse 42, 72076 T�bingen, Germanye-mail: [email protected]

of the cytokine to glucosaminoglycans of the extracellularmatrix. Its function might be to prevent rapid diffusion ofthe cytokine in tissues.
The genes encoding the different chemokines aredesignated by SCY (small inducible cytokine) followed bya letter, A, B, C, or D (corresponding to the CXCL, CCL,CL, and CX3CL protein designations, respectively), and anumber corresponding to the serial number of the protein[Online Mendelian Inheritance in Man (OMIM), http://www3.ncbi.nlm.nih.gov:80/Omim/]. There are, however,numerous aliases for both the genes and the proteins. Inhumans, most of the SCY genes are located in twoclusters, one on chromosome (Chr) 17 (region 17q11.2)and the other on Chr 4 (region 4q12–q13; Naruse et al.1996; Modi and Chen 1998). Other SCY genes have beenmapped to human Chr 1, 2, 9, 16, and 19.
Originally, chemokines were believed to participatemainly in inflammation by mediating both acute andchronic reactions (Yoshie et al. 2001). These “traditional”(“inflammatory”) chemokines attract neutrophils andmonocytes, they are relatively redundant and promiscuousin their interaction with receptors, and they are induced byinflammatory stimuli such as lipopolysaccharide, inter-leukin-1, tumor necrosis factor, and interferon g in a widerange of cells. Most of the human genes encoding thesecytokines map to Chr 4 and 17. More recently, a group of“immune” (“lymphoid”) chemokines has been discoveredcomprising proteins that are highly specific for lympho-cytes, less promiscuous in interactions with their recep-tors, and that map to chromosomes other than Chr 4 and17.
Chemokines stimulate target cells via receptors, agroup of structurally related seven-span transmembranemolecules coupled with G-proteins (Horuk 1994; Murphy1994; Murdoch and Finn 2000). Some 20 types of thesereceptors have been identified and designated CXCR,CCR, XCR, and CX3CR (followed by a serial number),corresponding to the four families of ligands they bind.The receptors are 340–370 amino acid residues long andthey contain a tyrosine sulfation motif in their highlyacidic N-terminal region, an Asp–Arg–Tyr (DRY) motifin their second intracellular domain (the sequence DRY-LAIVHA), two conserved cysteine residues, one in the N-terminal domain and the other in the third extracellularloop, and a serine-, threonine-rich cytoplasmic tail in theirC-terminal region. The conserved cysteines form adisulfide bond that stabilizes the binding pocket of thereceptor. Most of the human receptor genes are clusteredon Chr 2 and 3.
Most of the known chemokine and chemokine receptorgenes have been identified in mammals. Only a few areknown to be present in bony fish (teleosts), such as therainbow trout (Dixon et al. 1998; Secombes et al. 1998),carp (Fujiki et al. 1999), and sterlet (Alabyev et al. 2000).To our knowledge only one chemokine has thus far beenidentified in jawless fish such as the lamprey and hagfish(Najakshin et al. 1999). In the study described here, weidentified nine cDNA sequences, seven of which encode
chemokines in the cichlid fish, one a chemokine in theshark, and one a chemokine receptor in the lamprey.
Materials and methods
Fish
The cichlids Paralabidochromis chilotes and Melanochromisauratus (family Cichlidae, order Perciformes, class Actinopterygii)were collected by Dr. Herbert Tichy in Lake Victoria and LakeMalawi, East Africa, respectively. The cat shark Scyliorhinuscanicula (family Scyliorhinidae, order Carcharhiniformes, classChondrichthyes) was obtained from Wilhelma Zoological Gardenin Stuttgart, Germany. The sea lamprey Petromyzon marinus(family Petromyzontidae, order Petromyzontiformes, class Cepha-laspidomorphi, superclass Agnatha), collected in Lake Huron, wasprovided by Dr. James G. Seeley, Hammond Bay BiologicalStation, US Department of Interior.
Extraction of RNA, preparation of cDNA library,and polymerase chain reaction
Tissues (lower jaw or skin of adult cichlid fish, liver of adult catshark, and typhlosole of lamprey ammocoetes larvae) werehomogenized and total RNA was extracted from cell suspensionswith the help of the RNeasy Mini Kit (Qiagen, Hilden, Germany).The RNA was reverse-transcribed by the PowerScript reversetranscriptase (BD Biosciences Clontech, Heidelberg, Germany),subjected to cDNA amplification by long distance PCR, and used toprepare directed cDNA libraries with the SMART cDNA LibraryConstruction Kit (BD Biosciences Clontech). The cDNA was size-fractionated by chromatography on CHROMA SPIN-400 columnsand fractions containing cDNA fragments larger than 500 bp werepooled and ligated to the lTriplEx2 vector. Ligated DNA waspackaged into phage particles using the Gigapack Gold In VitroPackaging Kit (Stratagene, Amsterdam-Zuidoost, The Nether-lands), transfected into Escherichia coli strain XL1-Blue, andplated. A total of 2�106, 1.2�106, and 6�106 independent plaqueforming units were obtained from the lamprey, shark, and cichlidcDNAS, respectively. Single phage plaques were picked andtransferred to individual wells of 96 deep-well titer plates(Beckman Coulter, Unterschleißheim, Germany) or 96 microtestplates (Neolab, Heidelberg, Germany) containing 500 ml or 200 ml,respectively, of phage dilution buffer (0.1 m NaCl, 0.01 m MgSO4,0.035 m TRIS-HCl, pH 7.5, 0.01% gelatin).
Insert DNA was PCR-amplified with the primer pair Tri-plEx2LD5 (5'-CTCGGGAAGCGCGCCATTGTGTTGGT-3') andTriplEx2LD3 (5'-ATACGACTCACTATAGGGCGAATTGGCC-3') by either HotStar Taq polymerase (Qiagen) or by the ExpandLong Template PCR System (Roche Diagnostics, Mannheim,Germany) using the manufacturer’s buffer systems. Other PCRamplifications were carried out in 25 ml of reaction mixture usingthe PTC-100 or PTC-200 Programmable Thermal Controller (MJResearch, Biozym, Hess. Oldendorf, Germany). The mixturecontained 1� reaction buffer, 100 mm of each of the fourdeoxynucleoside triphosphates (Amersham Biosciences, Freiburg,Germany), 1 mm of each of the sense and antisense primers, 1 U ofTaq DNA polymerase (Amersham Biosciences), and 20–100 ng oftemplate DNA. The amplifications consisted of DNA denaturationfor 1 min at 94�C, followed by 35 cycles, each cycle consisting of15 s denaturation at 94�C, 15 s annealing at the requiredtemperature depending on the primer combination, and 2 minextension at 72�C. The reactions were terminated by a final primerextension for 10 min at 72�C. Rapid amplification of cDNA ends(RACE)-PCR (Frohman et al. 1988) and genome walker (GW)-PCR (Siebert et al. 1995) used to extend the sequences of the cloneswere carried out with the SMART RACE cDNA Amplification Kitand the Universal GenomeWalker Kit (BD Biosciences Clontech),
885

respectively, according to the protocols recommended by themanufacturer.
Production of expressed sequence tags
The PCR products obtained by the amplification from the cDNAlibraries were purified and sequenced by the custom sequencingservice of MediGenomix (Martinsried, Germany), Agowa (Berlin,Germany), or Qiagen using the primer pTripl5Seq2 (5'-GAAGCGCGCCATTGTGTT-3') annealing next to the 5' end ofthe insert cDNA. Insert sequences were used to perform BLASTXsearches (Altschul et al. 1997) against the nonredundant proteindatabase at the National Center for Biotechnology Information(NCBI). Candidate clones showing sequence similarity withcytokines were then subjected to further analysis.
DNA sequencing
The PCR products were purified from low-melting-point agarosegel slices (Invitrogen, Groningen, The Netherlands) with the aid ofthe QIAEX II Gel Extraction Kit (Qiagen), ligated to the pCR2.1vector (Invitrogen) under conditions recommended by the supplier,and used to transform Top10 competent E. coli bacteria (Invitro-gen). Double-stranded DNA, prepared with the aid of the QiagenPlasmid Mini Kit (Qiagen), was resuspended at a concentration of1 mg/ml and sequenced by the dideoxy chain-termination method(Sanger et al. 1977) using the Thermo Sequenase Fluorescent-labeled Primer Cycle Sequencing Kit (Amersham Biosciences).Sequencing reactions were processed by the LI-COR Long ReadIR4200 DNA Sequencer (MWG Biotech, Ebersberg, Germany).
Phylogenetic analyses
Homologous protein sequences identified by a BLASTX search ofthe NCBI database were aligned manually using the Seqpup 0.6fsoftware for Macintosh (Gilbert 1996) and Clustal W 1.82(Thompson et al. 1994). Phylogenetic trees were drawn by theneighbor-joining (NJ) method (Saitou and Nei 1987) using aminoacid sequence p-distances, or by the maximum parsimony methodwith the help of the PAUP*4.0b10 program (Swofford 2002) usingthe heuristic search algorithm. Positions with gaps were excludedfrom the analyses. The topological stability of the NJ trees wasassessed by 1000 bootstrap replications.
Results and discussion
As part of a different project, cDNA libraries wereprepared using RNA isolated from the lower jaws ofParalabidochromis chilotes (Pach), the skin of M.auratus (Meau), the liver of S. canicula (Scca), and thepurified lymphocyte-like cells of Petromyzon marinus(Pema). From these libraries 2734, 4024, 55, and 9312clones, respectively, were picked at random and theirinserts were sequenced. BLASTX searches of the trans-lated protein sequences revealed similarities of some ofthe sequences with a number of different immunologi-cally relevant molecules whose sequences are depositedin the databases. For the present study, nine sequenceshomologous to human chemokines or chemokine recep-tors were chosen for further analysis. The sequences wereconfirmed and completed to cover the entire coding partsby sequencing the rest of the clone or overlapping clones,or by RACE and anchor PCR. The full-length sequences
were then subjected to phylogenetic analysis to establishtheir identities and their relationships to related se-quences.
Eight of the nine sequences were identified asbelonging to the family of small inducible cytokines(SCYs); the ninth sequence could be assigned to the groupof chemokine receptors (CR). All of the eight SCYsequences could be shown by the presence of theconserved four-cysteine motif and by phylogenetic anal-ysis to be members of a single chemokine subfamilyhomologous to the human SYA subfamily. To indicatethis homology, we designate the fish sequences by theSCYA symbol used for the human small induciblecytokines in the OMIM database (http://www3.ncbi.nlm.-nih.gov:80/Omim/). Since, however, we cannot establishunambiguously the orthology of any of the eight fishsequences with any of the ~40 human SCYA genesdesignated SCYA1 through SCYA40 in the standardizednomenclature system (see below), we number the fishgenes and proteins separately, in order of discovery. Toprevent confusion between human and fish symbols, wenumber the fish proteins in a 100 series (i.e., SCYA101,SCYA102, etc.) and we prefix them with a four-letterabbreviation of the scientific genus and species names(i.e., Pach, Meau, and Scca; where necessary we refer tohuman, Homo sapiens, sequences as Hosa).
The properties of the eight fish chemokine sequences(and the one lamprey chemokine receptor sequence,which will be described later) are summarized in Table 1.The nucleotide sequences are given in Fig. 1 and theamino acid sequences translated from the nucleotidesequences in Fig. 2. The extended sequences range inlength from ~700 to >900 bp and their coding sequencestranslate into polypeptides 90 to 100 amino acid residueslong. The Pach-SCYA105 and Scca-SCYA107 sequencescontain one potential N-glycosylation site, but there areno potential O-glycosylation sites [as determined by usingthe NetOGlyc Prediction Server (http://www.cbs.dtu.dk/services/NetOGLYc/)] in any of the eight fish sequences.There are also no obvious adenylate–uridylate-richelements (AREs) such as TTATTTATT and only singleATTTA pentameric elements in Meau-SCYA101, Pach-SCYA101, Pach-SCYA104, and Scca-SCYA107. Theseinstability motifs have been reported to occur frequentlyin immunologically relevant genes (Xu et al. 1997;Bakheet et al. 2001) and have been found in some otherfish chemokines (e.g., Liu et al. 2002). The scarcity of theAREs in the sequences presented here could be due toincompletely sequenced 3'-untranslated regions or todifferentially regulated degradation of individual cytokinemRNA. Using the computer program of the World WideWeb Prediction Server Signal PV1.1 (http://www.cbs.dtu.dk/services/SignalP/), we predict the 20 to 25 posi-tions (depending on the sequence) of the translatedsequence to comprise the signal peptide so that the matureproteins are correspondingly shorter in length.
For comparative purposes, we prepared a proteinalignment that included the eight fish sequences reportedhere, all other fish sequences that we could retrieve from
886

the databases, and all of the 40 known human SCYs. Thealignment (not shown) and the phylogenetic tree based onit (to be discussed later) clearly placed the eight fishsequences in the SCYA subfamily. It also placed six othersequences (one from zebrafish, three from rainbow trout,one from common carp, and one from Japanese flounder,all teleost fishes) reported by other laboratories (Dixon
et al. 1998; Fujiki et al. 1999; Liu et al. 2002) andsequences listed in the GenBank under Accession num-bers NP571137 and CAC45063 into this subfamily. Allthese fish sequences contain the four conserved cysteineresidues of which the first two are adjacent, a character-istic feature of the SCYA subfamily (Zlotnik and Yoshie2000).
Fig. 1 Nucleotide sequences ofcDNAs encoding fish chemo-kines and the CXCR4 chemo-kine receptor. The codingregions are highlighted, theknown exon-intron borders areindicated by vertical lines,polyadenylation signals are un-derlined, ARE motifs are dou-ble-underlined, and potential N-glycosylation sites are boxed.Abbreviations of species namesare explained in Table 1
887
888

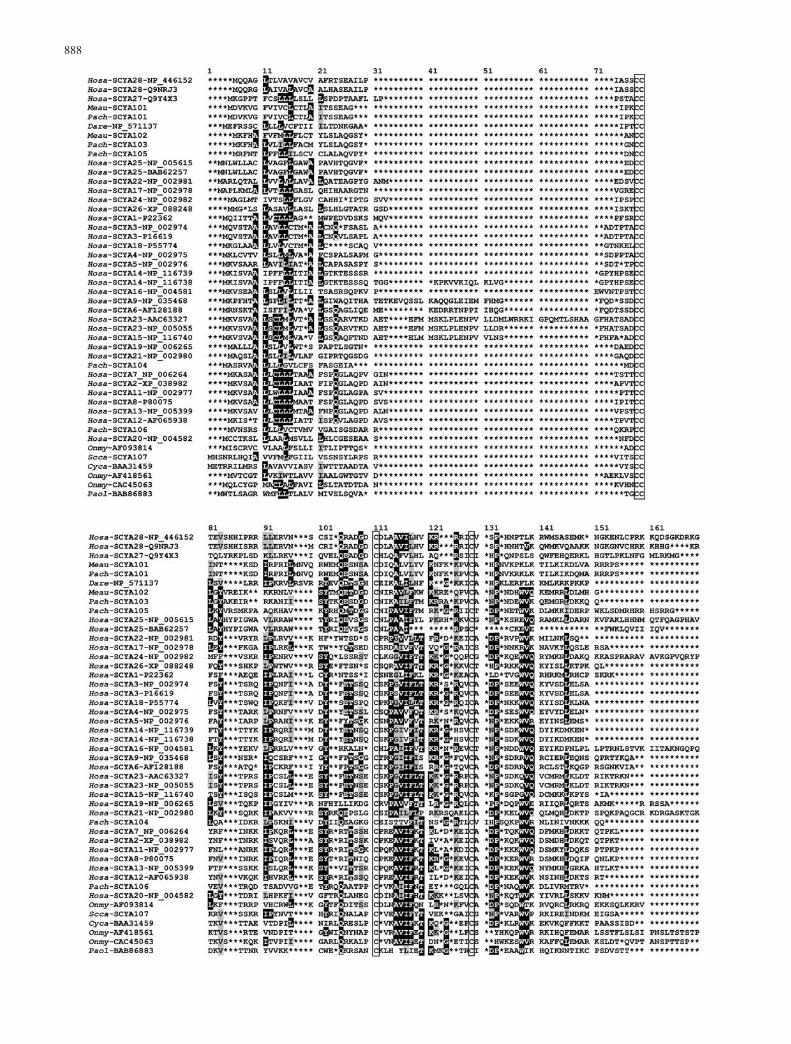
A new alignment was then prepared that included onlythe SCYA subfamily proteins of fishes (14) and humans(32; Fig. 2). In this alignment the four cysteine residuescharacterizing the subfamily are the only residues sharedby all of its members. This paucity of subfamily-specificresidues attests to the relatively relaxed constraints placedon the evolution of these proteins. Several residues withinthe subfamily, however, are partly conserved, beingshared by the majority of its members; these arehighlighted in Fig. 2. They include Tyr102 (in thenumbering used in Fig. 2), which in the human SCYA2(or MCP1) has been shown to play a key role in thespecificity of ligand–receptor interaction (Zhang et al.1994; Wells et al. 1996). Tyr102 is also present in six ofthe new fish sequences, while in Meau-SCYA101 andPach-SCYA101 (two very similar sequences of closelyrelated species) it is replaced by Trp, which is aconservative replacement. Another residue believed toparticipate in chemokine binding to a receptor is anaspartic acid near the N-terminus of the mature protein(Zhang et al. 1994).
In the human SCYA genes, there is an intron near theborder between the part encoding the signal peptide andthat specifying the mature protein (Vaddi et al. 1997;Baggiolini 1998); furthermore, some of these genes havean extra exon in this region (Berger et al. 1993;Nomiyama et al. 1999). These two facts are apparentlyresponsible for the variation in length of the N-termini inthe mature SCYA proteins. Because of this variation it isdifficult to align the sequences in this part of the proteinand hence to decide whether the Asp residues near theN-terminus do or do not occupy equivalent positions inthe different sequences. Whatever the case may be, thereis at least one Asp residue present near the N-termini ofthe Meau-SCYA106, Pach-SCY104, and Pach-SCYA105proteins, but not in the remaining five fish proteins. Whilepositions occupied by identical amino acid residues in allor nearly all SCYA proteins are rare, positions occupiedby chemically similar residues are relatively common andare distributed throughout the lengths of the proteins(Fig. 2). They are particularly conspicuous at positions 83(with Y or V and F or L or A), 115 (A or G), 116 (I, L, orV), 118 (F and L or I), and 139 (V and L or I). Comparedwith the most closely related human sequence, theidentity of the eight new fish proteins ranges from 23%to 39%, whereas sequence similarity is between 39% and54% (Table 1).
The only species in which nearly all the members ofthe small inducible cytokine family have been identified
Tab
le1
Pro
pert
ies
offi
shS
CY
Aan
dS
CY
rece
ptor
clon
es.
(AA
Ram
ino
acid
resi
dues
,bp
base
pair
s,SP
sign
alpe
ptid
e;M
eau,
Mel
anoc
hrom
isau
ratu
s;P
ach,
Par
alab
idoc
hrom
isch
ilot
es;
Pem
a,P
etro
myz
onm
arin
us;
Scca
,Sc
ylio
rhin
usca
nicu
la)
Cha
ract
eris
tic
Pac
h-S
CY
A10
1P
ach-
SC
YA
103
Pac
h-S
CY
A10
4P
ach-
SC
YA
105
Pac
h-S
CY
A10
6M
eau-
SC
YA
101
Mea
u-S
CY
A10
2Sc
ca-
SC
YA
107
Pem
a-C
XC
R4
Acc
essi
onco
deA
Y17
8964
AY
1789
65A
Y17
8966
AY
1789
67A
Y17
8968
AY
1789
62A
Y17
8963
AY
1789
70A
Y17
8969
Len
gth
ofcD
NA
clon
e(b
p)70
566
486
692
251
068
170
179
2>
1500
Len
gth
oftr
ansl
ated
sequ
ence
(AA
R)
9790
9210
591
9790
100
374
Per
cent
iden
tity
a23
.139
.139
.531
.428
.724
.235
.623
.137
.0P
erce
ntsi
mil
arit
ya41
.254
.450
.049
.549
.545
.446
.739
.054
.8P
redi
cted
leng
thof
SP
2220
2120
2222
2523
aW
ith
mos
tcl
osel
yre
late
dhu
man
prot
ein
sequ
ence
Fig. 2 Alignment of amino acid sequences of human and fishchemokines; widely shared identical and similar residues arehighlighted in black and gray, respectively. Conserved cysteineresidues are boxed. Asterisks indicate indels introduced to optimizethe alignment. Abbreviations of species names are as follows:Cyca, Cyprinus carpio; Dare, Danio rerio; Hosa, Homo sapiens;Meau, Melanochromis auratus; Onmy, Oncorhynchus mykiss;Pach, Paralabidochromis chilotes; Paol, Paralichthys olivaceus;Scca, Scyliorhinus canicula; Spau, Sparus aurata. Individualsequences are designated by their GenBank accession numbers
889

is the human (see entries under SCYA through SCYE inOMIM). For this reason, the phylogenetic analysis aimedat establishing the positions of the eight new fishsequences concentrated on the collection of the 40 humanSCY sequences. We also prepared an alignment of all theSCY sequences in the database with additional mam-malian sequences and a bird sequence (not shown), buttheir inclusion in the phylogenetic analysis did notinfluence the conclusions drawn from the human andfish dataset. In the analysis, two types of phylogenetic
trees were drawn, one based on the alignment of all thehuman and fish SCY family sequences known (Fig. 3) andthe other derived from the alignment shown in Fig. 2,which included only human and fish SCYA subfamilysequences (Fig. 4). The latter was produced in an effort toobtain a higher resolution within the SCYA subfamily byavoiding the use of more distantly related proteins. TheSCY family tree (Fig. 3) confirms the division of thehuman SCY proteins into two major groups, one encom-passing the SCYA, SCYC, and SCYD sequences, and the
Fig. 3 Neighbor-joining tree ofhuman and fish SCY familychemokines. The tree is basedon the alignment of proteinsequences. Numbers on nodesare bootstrap values. Abbrevia-tions of species names are as inFig. 2 legend
890

other comprising the SCYB proteins (see also Yoshie etal. 2001). While the B group may be monophyletic(depending on the placement of the root), the A group isclearly not, even if one considers the SCYC and SCYD asseparate subfamilies. Hence, either the classification ofchemokines on the basis of the conserved cysteine motifsis not natural (which would mean that the same arrange-ment of the Cys residues arose more than once indepen-dently) or unidentified convergences at other positions ledto the false placement of the SCYC and SCYD sequenceswithin the SCYA group. Several of the previouslyreported fish chemokines are placed outside of the twomajor groups and some of them appear to cluster with theonly known sequence of the human subclass SCYE. Thenew fish sequences (as well as some of the previouslyreported fish sequences) are found within the A group, inaccordance with their sharing of the CC motif. One of the
new sequences (Pach-SCYA106), however, clusters withthe C-subfamily sequences within the A group, althoughit differs from them by possessing the CC motif. Theclustering might be the result of a long branch attractioneffect (Hendy and Penny 1989).
The SCYA subfamily tree (Fig. 4) suggests certainrelationships within the group-A sequences. It providesstrong statistical support for the grouping of humanSCYA7, SCYA2, SCYA11, SCYA8, SCYA13, andSCYA12 into one clade; of human SCYA23 and SCYA15into another clade; and of human SCYA9 and SCYA6into a third clade. It also groups, albeit with weakersupport, human SCYA3 with SCYA18. As for the fishsequences, the tree strongly supports the grouping ofMeau-SCYA102 with Pach-SCYA103 and less stronglythe grouping of these two sequences with Pach-SCYA105, as well as the grouping of Cyca-BBAA32459,
Fig. 4 Neighbor-joining tree ofhuman and fish SCYA subfam-ily chemokines. Numbers onnodes are bootstrap values. Ab-breviations of species names areas in Fig. 2 legend
891

892

Onmy-AF418561 (CK-2), and Onmy-CAC45063. Theonly strongly supported grouping of fish with humansequences is that of Onmy-AF093814 (CK-1) with Hosa-SCYA20. The clustering of Meau-SCYA101, Pach-SCYA101, and Dare-NP571137 with Hosa-SCYA28 isweakly supported but emerges consistently in differenttrees. With the possible exception of Hosa-SCYA20 andOnmy-AF093814 (CK-1), there is thus no clear indicationof orthology between human and fish SCYA sequences; ifanything, the fish sequences seem to group together,separate from the human sequences. Whether this sepa-
rate grouping reflects the divergence of most humanSCYA sequences subsequent to the fish–tetrapod split orwhether it is a consequence of the relatively uncon-strained evolution of the SCYA proteins cannot bedecided at this point. The inclusion of the shark sequenceScca-SCYA107 in the SCYA subfamily (the A group)indicates, however, that the split between the A and Bgroups occurred before the divergence of cartilaginousfrom bony fishes.
The ninth EST analyzed in the present study was theclone 25B03 obtained from the cDNA library of the sealamprey. This clone was 457 bp long and translated into apeptide with significant similarity to the middle portion ofthe human chemokine receptor CXCR4. To extend theEST, RACE-PCR and GW-PCR were used. The RACE-PCR of the 5' end yielded a 604 bp product containing a51 bp overlap with the 5' part of the 25B03 clone.Similarly, the RACE-PCR of the 3' end resulted in an~2.3 kb fragment that contained an 84 bp overlap with the25B03 clone, the rest of the coding sequence (710 bp),and ~1.6 kb of 3' untranslated region. The GW-PCRproduced a 765 bp fragment that induced a 180 bp overlapwith the 3' end of the clone. The nonoverlapping part ofthe sequence was apparently derived from an intron, thebeginning of which is indicated by a splice site followingthe nucleotides coding for the amino acid residue K160 inFig. 5. The intron, which is >1.0 kb long, is not present inthe human CXCR4 gene. The combined sequence of thethree fragments (the 25B03 clone and the two RACE-PCR products) encompassed about 3 kb. The sequencecontained an open reading frame of 1122 bp capable ofspecifying 374 amino acid residues. An alignment of theamino acid sequence with homologous gnathostomesequences (Fig. 5), as well as phylogenetic analysis basedon this alignment (Fig. 6) confirmed the orthology of thelamprey sequence with the human CXCR4 protein. Thelamprey sequence is somewhat longer than the humanprotein (374 versus 352 amino acid residues), thedifference resulting mainly from two short internal indelsand additional residues at the ends of the lampreymolecule. The overall sequence identity (similarity)between the human and lamprey proteins is 37% (55%).The similarity extends over the entire length of the protein(except the first ~20 residues) and is particularly high inthe putative transmembrane regions (Fig. 5). Hydropho-bicity/hydrophilicity analysis of the lamprey sequence(not shown) predicts the presence of seven high-hy-drophobicity segments, presumably corresponding to theseven transmembrane regions (TM1 through TM7) of thehuman receptor (Fig. 5). Other conserved features of thelamprey sequence include the cysteine residues at posi-tions 42, 123, 215, 250, 285, 330, and 331 and a variant(ERY) of the DRY motif immediately adjacent to theTM3 region and characteristic of the G-protein-coupledreceptor family (Ansel and Cyster 2001). The lampreysequence contains 17 cysteine residues (compared withnine in the human receptor). It lacks, however, the secondcysteine residue of the CXC motif (two cysteine residuesseparated by another amino acid residue, here the Tyr
Fig. 6 Neighbor-joining tree of the lamprey and gnathostomeCXCR4 proteins. The tree is based on the alignment in Fig. 5 towhich the indicated human CXCR and CCR sequences have beenadded. Numbers on nodes are bootstrap values. Abbreviations ofspecies names are as in Fig. 5 legend
Fig. 5 Alignment of the lamprey and selected gnathostomeCXCR4 proteins. Residues that the lamprey shares with gnathos-tome proteins are highlighted in gray; conserved cysteine residuesare boxed. The seven putative transmembrane regions (TM1through TM7) are bracketed. Exon–intron borders in human andlamprey sequences are indicated by closed triangles with verticallines. Dots indicate absence of information; asterisks, indelsintroduced to optimize the alignment. The human IL-8 receptor asequence at the bottom represents the closest relative to the CXCR4proteins. Abbreviations of species names are as follows: Acru,Acipenser ruthenus; Bota, Bos taurus; Caja, Callithrix jacchus;Cyca, Cyprinus carpio; Dare, Danio rerio; Euma, Eulemurmacaco; Feca, Felis catus; Fugu, Takifugu rubripes; Gaga, Gallusgallus; Hosa, Homo sapiens; Male, Mandrillus leucophaeus;Mumu, Mus musculus; Nyco, Nycticebus coucang; Onmy, Onco-rhynchus mykiss; Pepo, Perodicticus potto; Xela, Xenopus laevis.Individual sequences are designated by their GenBank accessionnumbers
893

residue) in TM5 which is otherwise characteristic of theCXCR4 family. In the lamprey sequence, the secondcysteine residue is replaced by valine (in Mandrillusleucophaeus, it is replaced by tryptophan; GenBankaccession number AF172222).
The human CXCR4 is a receptor for the chemokineCXCL12 (also referred to as SCF1 or CD184; Murdoch2000). The ligand CXCL12 is secreted by the stromalcells of bone marrow and its binding to the CXCR4molecules on the surface of lymphopoietic progenitorcells guides these cells to the microenvironment in whichthey develop into lymphocytes (Ansel and Cyster 2001).In addition to the generation of chemotactic signals, theoccupancy of CXCR4 by its ligand also induces respira-tory bursts and transcription of cytokines. Furthermore,CXCR4 is also required for the normal development ofcertain organs during embryogenesis. The sea lampreydoes indeed possess lymphocyte-like cells (Mayer et al.2002), which are invested with at least some of thesignaling pathways characteristic of mammalian lympho-cytes (Uinuk-ool et al. 2002). On the other hand, allefforts to identify major histocompatibility complexmolecules, T-cell receptors, and B-cell receptors in thelamprey lymphocyte-like cells have failed (Mayer et al.2002). It seems therefore that agnathan lymphocyte-likecells are not fully functionally equivalent to gnathostomelymphocytes.
To our knowledge, the lamprey sequence is the firstagnathan chemokine receptor identified. Of the agnathanchemokines themselves, only an IL-8 homolog of theCXC type has been found thus far (Najakshin et al. 1999),but the remarkable sequence conservation between thegnathostome and lamprey CXCR4 proteins suggests thatit is merely a matter of time before more are identified.Even if the CXCR4 protein is involved in non-lymphoidfunctions and has not yet been recruited by the immunesystem, its expression and availability in the lampreylymphocyte-like cells supports the notion that these cellshave come close to becoming true lymphocytes charac-teristic of the adaptive immune system.
Acknowledgements We thank Ms. Jane Kraushaar for editorialand Ms. Heike Hausmann for technical assistance, as well as Drs.Herbert Tichy and James G. Seeley for providing the fish tissuesamples.
References
Alabyev BY, Najakshin AM, Mechetina LV, Taranin AV (2000)Cloning of a CXCR4 homolog in chondrostean fish andcharacterization of the CXCR4-specific structural features. DevComp Immunol 24:765–770
Altschul SF, Madden TL, Schaffer AA, Zhang J, Miller W, LipmanDJ (1997) Gapped BLAST and PSI-BLAST: a new generationof protein database search programs. Nucleic Acids Res25:3389–3402
Ansel KM, Cyster JG (2001) Chemokines in lymphopoiesis andlymphoid organ development. Curr Opin Immunol 13:172–179
Baggiolini M (1998) Chemokines and leukocyte traffic. Nature392:565–568
Bakheet T, Frevel M, Williams BRG, Greer W, Khabar KSA(2001) ARED: human AU-rich element-containing mRNAdatabase reveals an unexpectedly diverse functional repertoireof encoded proteins. Nucleic Acids Res 29:246–254
Berger MS, Kozak CA, Gabriel A, Prystowsky MB (1993) Thegene for c10, a member of the beta-chemokine family, islocated on mouse chromosome 11 and contains a novel secondexon not found in other chemokines. DNA Cell Biol 12:839–847
Dixon B, Shum B, Adams EJ, Magor KE, Hedrick RP, Muir DG,Parham P (1998) CK-1, a putative chemokine of rainbow trout(Oncorhynchus mykiss). Immunol Rev 166:341–348
Frohman MA, Dush MK, Martin GR (1988) Rapid production offull-length cDNAs from rare transcripts: amplification using asingle gene-specific oligonucleotide primer. Proc Natl Acad SciU S A 85:8998–9002
Fujiki K, Shin D-H, Nakao M, Yano T (1999) Molecular cloning ofcarp (Cyprinus carpio) CC chemokine, CXC chemokinereceptors, allograft inflammatory factor-1, and natural killercell enhancing factor by use of suppression subtractivehybridization. Immunogenetics 49:909–914
Gilbert DG (1996) SeqPup version 0.6f: a biosequence editor andanalysis application. http://iubio.bio.indiana.edu/soft/molbio
Hedrick JA, Zlotnik A (1996) Chemokines and lymphocytebiology. Curr Opin Immunol 8:343–347
Hendy MD, Penny D (1989) A framework for the quantitative studyof evolutionary trees. Syst Zool 38:297–309
Horuk R (1994) Molecular properties of the chemokine receptorfamily. Trends Pharmacol Sci 15:159–165
Liu L, Fujiki K, Dixon B, Sundick RS (2002) Cloning of a novelrainbow trout (Oncorhynhus mykiss) CC chemokine with afractalkine-like stalk and a TNF decoy receptor using cDNAfragments containing AU-rich elements. Cytokine 17:71–81
Mantovani A (1999) The chemokine system: redundancy for robustoutputs. Immunol Today 20:254–257
Mayer WE, Uinuk-ool T, Tichy H, Klein J, Cooper MD (2002)Isolation and characterization of lymphocyte-like cells from alamprey. Proc Natl Acad Sci U S A 99:14350–14355
Modi WS, Chen Z-Q (1998) Localization of the human CXCchemokine subfamily on the long arm of chromosome 4 usingradiation hybrids. Genomics 47:136–139
Murdoch C (2000) CXCR4: chemokine receptor extraordinaire.Immunol Rev 177:175–184
Murdoch C, Finn A (2000) Chemokine receptors and their role ininfectious diseases. Blood 95:3023–3043
Murphy PM (1994) The molecular biology of leukocyte chemoat-tractant receptors. Annu Rev Immunol 12:593–633
Najakshin AM, Mechetina LV, Alabyev BY, Taranin AV (1999)Identification of an IL-8 homolog in lamprey (Lampetrafluviatilis): early evolutionary divergence of chemokines. EurJ Immunol 29:375–382
Naruse K, Ueno M, Satoh T, Nomiyama H, Tei H, Takeda M,Ledbetter DH, Van Couillie E, Opdenakker G, Gunge N,Sakaki Y, Iio M, Miura R (1996) A YAC contig of the humanCC chemokine genes clustered on chromosome 17q11.2.Genomics 34:236–240
Nomiyama H, Fukuda S, Iio M, Tanase S, Miura R, Yoshie O(1999) Organization of the chemokine gene cluster on humanchromosome 17q11.2 containing the genes for CC chemokineMPIF-1, HCC-2, HCC-1, LEC, and RANTES. J InterferonCytokine Res 19:227–234
Rollins BJ (1997) Chemokines. Blood 90:909–928Saitou N, Nei M (1987) The neighbor-joining method: a new
method for reconstructing phylogenetic trees. Mol Biol Evol4:406–425
Sanger F, Nicklen S, Coulson AR (1977) DNA sequencing withchain-terminating inhibitors. Proc Natl Acad Sci USA 74:5463–5467
Schall TJ, Bacon KB (1994) Chemokines, leukocyte trafficking,and inflammation. Curr Opin Immunol 6:865–873
894

Secombes CJ, Zou J, Daniels G, Cunningham C, Koussounadis A,Kemp G (1998) Rainbow trout cytokine and cytokine receptorgenes. Immunol Rev 166:333–340
Siebert PD, Chenchik A, Kellogg DE, Lukyanov KA, Lukyanov SA(1995) An improved method for walking in uncloned genomicDNA. Nucleic Acids Res 23:1087–1088
Swofford DL (2002) PAUP: Phylogenetic Analysis Using Parsi-mony (and other methods). Version 4.0b10. Sinauer, Sunder-land, Mass
Thompson JD, Higgins DG, Gibson TJ (1994) CLUSTAL W:improving the sensitivity of progressive multiple sequencealignment through sequence weighting, positions-specific gappenalties and weight matrix choice. Nucleic Acids Res22:4673–4680
Uinuk-ool T, Sato A, Dongak R, Mayer WE, Cooper MD, Klein J(2002) Lamprey lymphocyte-like cells express homologs ofgenes involved in immunologically relevant activities ofmammalian lymphocytes. Proc Natl Acad Sci USA99:14356–14361
Vaddi K, Keller M, Newton RC (1997) The chemokine facts book.Academic Press, New York
Wells TN, Lusti-Narasimhan M, Chung CW, Cooke R, Power CA,Peitsch MC, Proudfoot AE (1996) The molecular basis ofselectivity between CC and CXC chemokines: the possibility ofchemokine antagonists as anti-inflammatory agents. Ann N YAcad Sci 796:245–256
Xu N, Chen CA, Shyu A (1997) Modulation of the fate ofcytoplasmic mRNA by AU-rich elements: key sequencefeatures controlling mRNA deadenylation and decay. Mol CellBiol 17:4611–4621
Yoshie O, Imai T, Nomiyama H (2001) Chemokines in immunity.Adv Immunol 78:57–110
Zhang YJ, Rutledge BJ, Rollings BJ (1994) Structure/activityanalysis of human monocyte chemoattractant protein-1 (MCP-1)by mutagenesis. Identification of a mutated protein that inhibitsMCP-1-mediated monocyte chemotaxis. J Biol Chem 269:15918–15924
Zlotnik A, Yoshie O (2000) Chemokines: a new classificationsystem and their role in immunity. Immunity 12:121–127
895




















