
Network measures for dyadic interactions: stability and reliability
10
American Journal of Primatology 73:1–10 (2011) RESEARCH ARTICLE Network Measures for Dyadic Interactions: Stability and Reliability BERNHARD VOELKL 1,2 , CLAUDIA KASPER 3 , AND CHRISTINE SCHWAB 4 1 Institute for Theoretical Biology, Humboldt University zu Berlin, Berlin, Germany 2 Center for Integrative Life Sciences (CILS), Berlin, Germany 3 Centre National pour la Recherche Scientifique, DEPE, Universite´Louis Pasteur, Strasbourg, France 4 KLI for Evolution and Cognition Research, Altenberg, Austria Social network analysis (SNA) is a general heading for a collection of statistical tools that aim to describe social interactions and social structure by representing individuals and their interactions as graph objects. It was originally developed for the social sciences, but more recently it was also adopted by behavioral ecologists. However, although SNA offers a full range of exciting possibilities for the study of animal societies, some authors have raised concerns about the correct application and interpretation of network measures. In this article, we investigate how reliable and how stable network measures are (i.e. how much variation they show under re-sampling and how much they are influenced by erroneous observations). For this purpose, we took a data set of 44 nonhuman primate grooming networks and studied the effects of re-sampling at lower re-sampling rates than the originally observed ones and the inclusion of two types of errors, ‘‘mis-identification’’ and ‘‘mis-classification,’’ on six different network metrics, i.e. density, degree variance, vertex strength variance, edge weight disparity, clustering coefficient, and closeness centrality. Although some measures were tolerant toward reduced sample sizes, others were sensitive and even slightly reduced samples could yield drastically different results. How strongly a metric is affected seems to depend on both the sample size and the structure of the specific network. The same general effects were found for the inclusion of sampling errors. We, therefore, emphasize the importance of calculating valid confidence intervals for network measures and, finally, we suggest a rough research plan for network studies. Am. J. Primatol. 73:1–10, 2011. r 2011 Wiley-Liss, Inc. Key words: social network; confidence interval; sampling error; primates; grooming INTRODUCTION In recent years, graph theory and social network analysis (SNA) have been increasingly applied in studies that investigate animal social behavior. SNA is rapidly establishing itself as a powerful tool for studying the structure and dynamics of social inter- actions among animals [Krause et al., 2007]. In primatology, SNA was already adopted quite early [Chepko-Sade et al., 1989; Dow & De Waal, 1989; Dunbar, 1984; Sade, 1972], but has gained increasing popularity only recently [Flack et al., 2006; Henzi et al., 2009; Kasper & Voelkl, 2009; Kudo & Dunbar, 2001; Lehmann & Boesch, 2009; Lehmann & Dunbar, 2009; Lehmann et al., 2010; Ramos- Ferna ´ndez et al., 2009; Sueur & Petit, 2008; Voelkl & Kasper, 2009; Wakefield, 2008]. However, although many behavioral ecologists welcome the new tools that SNA offers with enthusiasm, some authors have raised concerns about the sometimes ‘‘careless’’ application of SNA highlighting potential pitfalls and problems [James et al., 2009; Lusseau et al., 2008; Whitehead, 2008]. Decades ago, socio- logists had already asked questions, such as ‘‘How many samples of which size are needed to yield reliable results, e.g. for measuring (or describing) the network?’’ They developed [Granovetter, 1976] and reassessed [Erickson & Nosanchuk, 1983; Erickson et al., 1981] methods to estimate the amount of data needed to obtain satisfying results. Furthermore, they discussed how sampling procedure, sample size or network density would impact point centrality [Galaskiewicz, 1991], and to what extent reduced sample sizes would alter several network centrality measures [Costenbader & Valente, 2003]. Yet, obser- vational data of animal populations usually differ in several aspects from those of sociological studies. Unlike sociologists, whose concern is to recruit a representative sample of individuals, behavioral ecologists often deal with animal groups of limited size where it is feasible to include all members in the analysis. Consequently, they encounter slightly Published online in Wiley Online Library (wileyonlinelibrary.com). DOI 10.1002/ajp.20945 Received 10 August 2010; revised 28 January 2011; revision accepted 16 February 2011 Contract grant sponsor: KLI for Evolution and Cognition Research. Correspondence to: Christine Schwab, KLI for Evolution and Cognition Research, Adolf Lorenz Gasse 2, A-3422 Altenberg, Austria. E-mail: [email protected] r r 2011 Wiley-Liss, Inc.
-
Upload
independent -
Category
Documents
-
view
4 -
download
0
Transcript of Network measures for dyadic interactions: stability and reliability

American Journal of Primatology 73:1–10 (2011)
RESEARCH ARTICLE
Network Measures for Dyadic Interactions: Stability and Reliability
BERNHARD VOELKL1,2, CLAUDIA KASPER3, AND CHRISTINE SCHWAB4�1Institute for Theoretical Biology, Humboldt University zu Berlin, Berlin, Germany2Center for Integrative Life Sciences (CILS), Berlin, Germany3Centre National pour la Recherche Scientifique, DEPE, Universite Louis Pasteur, Strasbourg, France4KLI for Evolution and Cognition Research, Altenberg, Austria
Social network analysis (SNA) is a general heading for a collection of statistical tools that aim to describesocial interactions and social structure by representing individuals and their interactions as graphobjects. It was originally developed for the social sciences, but more recently it was also adopted bybehavioral ecologists. However, although SNA offers a full range of exciting possibilities for the study ofanimal societies, some authors have raised concerns about the correct application and interpretation ofnetwork measures. In this article, we investigate how reliable and how stable network measures are (i.e.how much variation they show under re-sampling and how much they are influenced by erroneousobservations). For this purpose, we took a data set of 44 nonhuman primate grooming networks andstudied the effects of re-sampling at lower re-sampling rates than the originally observed ones and theinclusion of two types of errors, ‘‘mis-identification’’ and ‘‘mis-classification,’’ on six different networkmetrics, i.e. density, degree variance, vertex strength variance, edge weight disparity, clusteringcoefficient, and closeness centrality. Although some measures were tolerant toward reduced sample sizes,others were sensitive and even slightly reduced samples could yield drastically different results. Howstrongly a metric is affected seems to depend on both the sample size and the structure of the specificnetwork. The same general effects were found for the inclusion of sampling errors. We, therefore,emphasize the importance of calculating valid confidence intervals for network measures and, finally, wesuggest a rough research plan for network studies. Am. J. Primatol. 73:1–10, 2011. r 2011 Wiley-Liss, Inc.
Key words: social network; confidence interval; sampling error; primates; grooming
INTRODUCTION
In recent years, graph theory and social networkanalysis (SNA) have been increasingly applied instudies that investigate animal social behavior. SNAis rapidly establishing itself as a powerful tool forstudying the structure and dynamics of social inter-actions among animals [Krause et al., 2007].In primatology, SNA was already adopted quite early[Chepko-Sade et al., 1989; Dow & De Waal, 1989;Dunbar, 1984; Sade, 1972], but has gained increasingpopularity only recently [Flack et al., 2006; Henziet al., 2009; Kasper & Voelkl, 2009; Kudo & Dunbar,2001; Lehmann & Boesch, 2009; Lehmann &Dunbar, 2009; Lehmann et al., 2010; Ramos-Fernandez et al., 2009; Sueur & Petit, 2008;Voelkl & Kasper, 2009; Wakefield, 2008]. However,although many behavioral ecologists welcome thenew tools that SNA offers with enthusiasm, someauthors have raised concerns about the sometimes‘‘careless’’ application of SNA highlighting potentialpitfalls and problems [James et al., 2009; Lusseauet al., 2008; Whitehead, 2008]. Decades ago, socio-logists had already asked questions, such as ‘‘Howmany samples of which size are needed to yieldreliable results, e.g. for measuring (or describing) the
network?’’ They developed [Granovetter, 1976] andreassessed [Erickson & Nosanchuk, 1983; Ericksonet al., 1981] methods to estimate the amount of dataneeded to obtain satisfying results. Furthermore,they discussed how sampling procedure, sample sizeor network density would impact point centrality[Galaskiewicz, 1991], and to what extent reducedsample sizes would alter several network centralitymeasures [Costenbader & Valente, 2003]. Yet, obser-vational data of animal populations usually differ inseveral aspects from those of sociological studies.
Unlike sociologists, whose concern is to recruita representative sample of individuals, behavioralecologists often deal with animal groups of limitedsize where it is feasible to include all members inthe analysis. Consequently, they encounter slightly
Published online in Wiley Online Library (wileyonlinelibrary.com).DOI 10.1002/ajp.20945
Received 10 August 2010; revised 28 January 2011; revisionaccepted 16 February 2011
Contract grant sponsor: KLI for Evolution and CognitionResearch.
�Correspondence to: Christine Schwab, KLI for Evolution andCognition Research, Adolf Lorenz Gasse 2, A-3422 Altenberg,Austria. E-mail: [email protected]
rr 2011 Wiley-Liss, Inc.

different methodological challenges, and as a resultthey started a discussion about the validity andreliability of SNA in parallel to the efforts in thesocial sciences [Franks et al., 2009; Kasper &Voelkl, 2009; Lusseau et al., 2008; Perreault, 2010;Sundaresan et al., 2009].
One promising perspective of applying SNA toobservational data of animal systems is the possibi-lity of comparing social structures between groups,species, or taxa [Croft et al., 2008; Kasper & Voelkl,2009; Krause et al., 2007; Kudo & Dunbar, 2001;Lehmann & Dunbar, 2009; Voelkl & Noe, 2008, 2010;Wey et al., 2008]. Such objectives could potentially beaffected by comparing unequal sample sizes. In thisstudy, we address these issues by investigating howstable and reliable several network statistics remainwhen the amount of observational data changes.
A second potential problem we are concernedwith is the inclusion of errors made by theresearcher. Independent of the precautions set upto prevent them, two main types of errors will stilloccur: the erroneous identification of an individualand the erroneous classification of a behavior.Although the former might happen anytime, thelatter might especially happen when studying specieswith a rich behavioral repertoire where it might bedifficult to precisely define distinct behavioral para-meters or types of interactions. They might alsooccur when data for one study are taken by morethan one observer. Still, most cases of ‘‘mis-identi-fication’’ (MI) and ‘‘mis-classification’’ (MC) mightnot arise because the researcher cannot tell apartthe alpha male ‘‘Bruce’’ from the juvenile female‘‘Sheila’’ or grooming from touching, but might beowing to writing, ticking, or typing errors duringdata acquisition or at any stage of the transcriptionprocess. Clearly, one must accept that such errorswill inevitably occur in any study. Therefore, weadditionally investigate potential effects that bothtypes of errors have on network statistics, bysimulating the occurrence of such errors at differentrates. Finally, we discuss how the frequently appliedcensoring of interaction data, i.e. ignoring inter-actions which occur at rates below a certain thresholdvalue, affects the variability of network measures.
METHODS
We used a data set consisting of groomingmatrices from 44 non-human primate groups. Four-teen groups were kept in captivity, 6 groups in parksor larger outdoor enclosures (semi-free ranging), and24 groups were observed in the wild. Data were partlytaken from the literature and partly from unpublishedmaterial, either collected by the authors (CK, BV) orprovided by colleagues. The data set comprises 26species of 15 genera and 4 families, including NewWorld and Old World primates. Group sizes rangefrom 4 to 35 individuals, with a median of 11 and an
interquartile range of 8–16 individuals. The totalnumber of observations per data set varies widelybetween 10 and 6,924 (median: 439). Seven data setshave less than 100 observations (later referred to as‘‘small samples’’) and eight data sets have more than2,000 observations (referred to as ‘‘large samples’’).Data acquisition adheres to the ASP ethical guidelinesfor the use of non-human primates in research.
A network is defined as a set of individuals thatare directly or indirectly connected to each other viagrooming interactions. Hence, single individuals orsmall subgroups of individuals that have not beenobserved engaging in grooming interactions withconspecifics were excluded from the sample. In twocases, this procedure led to the removal of a singleindividual, in two other cases two individuals wereremoved, and in one case data from an isolatedsubgroup of four individuals were not considered forfurther analysis. These exclusions were necessary fortechnical reasons as several network measures donot deliver meaningful results when applied todisconnected graphs.
All analyses were run using Mathematica 7.0(Wolfram Research Inc., Champaign, IL).
Re-sampling
Here, we compared values of network measuresfrom original data sets with those from reduced datasets, thereby asking the question of how stablemeasures are if the researcher would have collectedfewer data than she actually did. From the entiredata sets, we drew random samples without replace-ment ranging from 5 to 95% of the original data at5% increments. After re-sampling, we calculatednetwork statistics for the re-sampled data sets andtheir absolute differences to the observed statistics(i.e. statistics for the original and complete datasets). This procedure was repeated a thousand timesfor each observed primate group at each 5% incre-ment. To achieve a relative measure for the deviationof re-sampled statistics from observed statistics, themean difference is given as a percentage of theaccording observed network measure.
Mis-identification
This procedure mimics the effects of erroneousidentification of single individuals during dataacquisition and/or mistakes during the transcriptionprocess. To simulate these potential errors, werepresented observational data as a multigraph, inwhich vertices denote individuals and edges repre-sent interactions between them. In a multigraph,each observed interaction represents one edgebetween respective individuals. For example, ifindividuals A and B were observed interacting witheach other 22 times, then vertices A and B areconnected by 22 edges. To simulate MI, one edge ofthe graph was chosen at random, cut from one of the
Am. J. Primatol.
2 / Voelkl et al.

two vertices, and reconnected to a randomly chosenother vertex of the network (Fig. 1A). Otherwise,the procedure was similar as for re-sampling. First,we constructed erroneous network samples byreconnecting a specified percentage of edges fromthe original data sets ranging from 0.1 to 2% inincrements of 0.1%. Second, we calculated networkstatistics for the data sets with identification errorsand their absolute differences to observed statistics.Simulations were repeated 1,000 times per networkand incremental step. Deviations of the statistics forthe observed data and the error-added data weregiven in percent of the observed values.
Mis-classification
The MC of behavior is a second type of errorwhich observational protocols are prone to. We defineMC as the case where an observer records aninteraction between two individuals which did notoccur in reality. To simulate such errors, we randomlyintroduced new edges. However, if we had simplyadded edges, the network would have become increas-ingly denser and this, by itself, could have effects onseveral network measures. To avoid this, we kept thenumber of edges constant by simultaneously remov-ing a corresponding number of randomly chosenedges from the original data set. Technically, wesimulated the effects of such an error by using aparadigm equivalent to the MI procedure, with theexception that not only one but also both ends of arandomly chosen edge were reconnected to otherrandomly chosen vertices in the network (Fig. 1B).The result of this procedure is a graph of the samesize and magnitude as the original graph, but witha small number of original observations missing anda small number of erroneous observations added.In fact, this procedure simulates two types of errors:first, MC, the existence of an edge where in fact nonehad existed and second, the MI of both individuals of
an interaction. Assuming that MI of one individualoccurs at a low rate m, then MI of both individuals atthe same time should occur at an even much lowerrate of approximately m2. That is, if errors arereasonably rare, and if cases of MI and MC occur atsimilar rates (the same order of magnitude), thendouble MI will be a negligible quantity and theprocedure effectively measures the effect of MC.Constructing erroneous network samples, calculatingnetwork statistics for MC data sets, and assessingrelative deviation between observed and MC statisticsfollowed the same procedure as described above.
Data Censoring
Here, we investigated how the censoring of rawdata, by discarding all elements of the sociomatrixbelow a certain threshold value, could affect thevariation of binary network measures for re-sampledand error-added data. Sociomatrices were based ontwo censoring methods that differed in their assump-tions concerning the distribution of the data andconsequently in their threshold values. For the firstmethod, the complete matrix (CM) method, weassumed that observations could be distributedrandomly over all potential dyads (N(N�1) dyadsfor directed measures, where N is the group size) andwe evaluated the distribution of matrix entries forthe given number of observations. For the secondmethod, the partial matrix (PM) method, weassumed that observations would be distributedrandomly only within a certain subset of dyads.Here, we evaluated the distribution of the givennumber of observed interactions only for those dyadsthat were observed interacting with each other atleast once. For both methods, all entries of theinteraction matrix with a raw value within the lower5% tail for the expected distribution were set to zero,which constituted their censoring threshold values.The CM method is a more conservative method thatproduces slightly lower threshold values than PM,which might be the more appropriate method incases where interactions cannot be expected to occurbetween all combinations of two individuals (e.g.mating might only be possible between males andfemales). We then calculated density and degreevariance for a re-sampling rate of 50% and for MIand MC rates of 1%, following the proceduresmentioned above.
NETWORK MEASURES
Density indicates how well connected a graph isby giving the proportion of existing edges (connec-tions between vertices: grooming interactionsbetween individuals) relative to the total number ofpossible edges as d ¼ jEj=NðN � 1Þ=2; where E is theedge set of the graph and N the number of vertices[Wasserman & Faust, 1994].
Fig. 1. Sketch of MI (A) and MC (B) procedure. For MI, one edgeof the graph is chosen at random, cut from one of the twovertices, and reconnected to a randomly chosen other vertex ofthe network. For MC, both ends of a randomly chosen edge arecut and reconnected to randomly chosen other vertices in thenetwork.
Am. J. Primatol.
Stability of Social Network Measures / 3

Degree variance is a frequently used measurefor the heterogeneity of a graph given by Vard ¼
ð1=NÞPN
i¼1 ðki � jEj=NÞ2; where E is the edge set of
the graph, N is the number of vertices, and ki is thedegree of vertex i [Snijders, 1981].
For weighted graphs, vertex strength vari-ance can be calculated accordingly as Vars ¼
ð1=NÞPN
i¼1 ðsi � ð1=NÞPN
j¼1 sjÞ2; where the vertex
strength s is given by si ¼PN
j¼1 wij with wij beingthe weight of the edge connecting vertex i withvertex j [Voelkl, 2010].
Alternatively, edge weight disparity can be usedto quantify the variability of social interactionsand is given by Yi ¼
PNj¼1 ðwij=siÞ
2 [Barthelemyet al., 2005].
The clustering coefficient characterizes the localgroup cohesiveness by evaluating the extent to whichvertices adjacent to any vertex are also adjacent toeach other. It can be interpreted as a measure ofindividual sociality and is given by
ccwi ¼
1
siðki � 1Þ�X
j;l
ðwij1wilÞ
2aijailajl
with aij being the entry in the adjacency matrix ofthe graph indicating whether there is an edgebetween vertex i and vertex j [Barrat et al., 2004].
Closeness centrality measures how close anindividual is to others in the network in terms ofits ability to interact with others. It is assessed on thebasis of geodesic ( 5 shortest) distances and does notonly depend on direct, but also on indirect edges. It isgiven by CC
0
i ¼ ðN � 1Þ=PN
j¼1 dðvi; vjÞ; where d(vi,vj)is a distance function giving the number of edgesin the geodesic path linking individuals i and j[Wasserman & Faust, 1994].
RESULTS
Re-sampling
A general finding concerning all re-samplednetwork statistics apart from vertex strength vari-ance was that small network samples (i.e. originallyconsisting of less than 100 observations; open circlesin Fig. 2) were more sensitive to a decrease in samplesize than were large network samples (i.e. containingmore than 2,000 observations; open squares in Fig. 2).
Fig. 2. Relative deviation of re-sampled from observed network statistics concerning (A) density, (B) degree variance, (C) vertex strengthvariance, (D) edge weight disparity, (E) clustering coefficient, and (F) closeness centrality. The X-axis depicts the resample rate aspercent of the original sample size. The Y-axis indicates the relative deviation of re-sampled from observed network statistics in percentof the original value. Open circles: small samples of less than 100 observations; open squares: large samples of more than 2,000observations; filled circles: intermediate samples between 100 and 2,000 observations.
Am. J. Primatol.
4 / Voelkl et al.

Statistics from small samples showed higher relativedeviation from observed values than larger samples atall re-sampling levels.
Deviation from observed measures with regard todensity (Fig. 2A) and edge weight disparity (Fig. 2D)increased with decreasing sample size, although in thelatter re-sampled measures differed more drasticallyat lower sample sizes than in the former. However,when reducing the original sample size by 30% (i.e.70% re-sampling rate; Fig. 2A and D), re-sampledestimates for both measures showed only moderatedifferences to observed statistics of not more than20% relative deviation.
Concerning degree variance (Fig. 2B) and clus-tering coefficient (Fig. 2E), there was good evidencefor the sensitivity of small samples and the higherstability of large samples to the re-sampling proce-dure. Except for very small samples, we found againa reasonably linear increase in relative deviationof re-sampled measures to the observed statistics.Especially for the clustering coefficient, some smallsamples showed high deviations already at a 90%re-sampling rate (i.e. a decrease of 10% from originaldata). Overall variance of re-sampled statistics for
degree variance and clustering coefficient was higherthan for density and edge weight disparity.
For vertex strength variance, the variance ofre-sampled statistics was low (Fig. 2C). Here, differ-ences between re-sampled and observed values dras-tically increased with decreasing sample size, reaching20% of relative deviation already at the 95% incrementof the original sample size. In contrast to the formerfindings, small network samples were less sensitive todecreasing sample size than larger ones. Closenesscentrality (Fig. 2F) yielded the most heterogeneousresults. Values from large network samples wererather stable until the 10% level of original samplesize, and the majority of re-sampled statistics did notchange much until reaching the 45% re-sampling level.However, data of some groups suffered considerablyeven from small decreases of re-sampling size resultingin high variance of re-sampled statistics.
Mis-identification
Overall, network measures of MI data sets showeddiverse response patterns (Fig. 3). Edge weightdisparity (Fig. 3D) gave the most stable results with
Fig. 3. Relative deviation of MI from observed network statistics concerning (A) density, (B) degree variance, (C) vertex strengthvariance, (D) edge weight disparity, (E) clustering coefficient, and (F) closeness centrality. The X-axis depicts the percentage of‘‘misidentified’’ (MI) edges. The Y-axis indicates the relative deviation of MI from observed network statistics in percent of the originalvalue. Open circles: small samples of less than 100 observations; open squares: large samples of more than 2,000 observations; filledcircles: intermediate samples between 100 and 2,000 observations.
Am. J. Primatol.
Stability of Social Network Measures / 5
lowest variance, and less than 10% relative deviationbetween MI and observed values at all incrementalsteps. Neither density (Fig. 3A), nor vertex strengthvariance (Fig. 3C), nor clustering coefficient (Fig. 3E)exceeded 45% of relative deviation at any MI level.
In these three measures, the vast majority of MInetwork samples remained stable and well under 20%deviation. However, those that exceeded the 20%deviation limit are conspicuously different, dependingon the measure. With regard to density, we found onelarge sample to be more sensitive to errors than anyother network investigated (Fig. 3A), whereas con-cerning vertex strength variance one small samplegave the least stable results on all incremental steps(Fig. 3C). For the clustering coefficient, both smalland large samples led to comparable deviations fromthe observed values (Fig. 3E).
Degree variance (Fig. 3B) and closenesscentrality (Fig. 3F) showed the highest variancein the deviation of MI networks, but with differentpatterns. Concerning degree variance, statisticsof most network samples with added MI errorsremained under the 20% deviation limit for errorrates from 0 to 0.5%, but some samples showed very
high relative deviations nearly throughout theinvestigated range (Fig. 3B). Regarding closenesscentrality, the pattern was divided. MI values eitherdiffered less than 20% or more than 100% at all errorlevels (Fig. 3F). Interestingly, estimates for closenesscentrality seemed to be relatively vulnerable withregard to this type of error, even when they werebased on large samples.
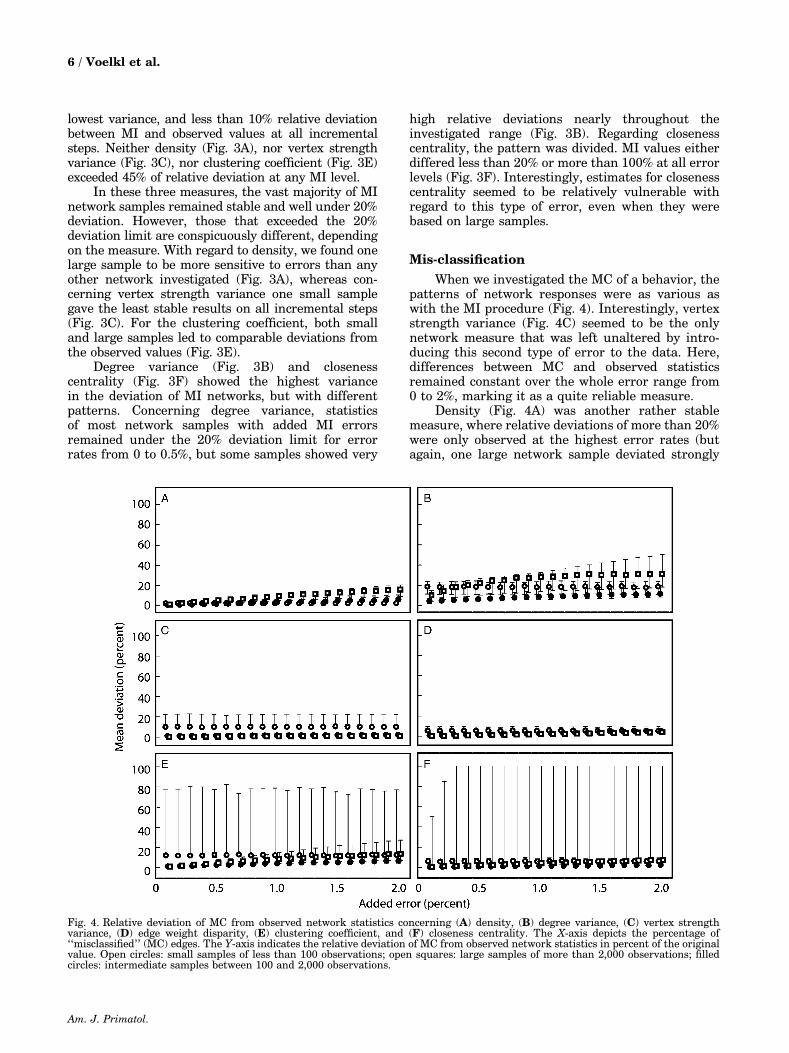
Mis-classification
When we investigated the MC of a behavior, thepatterns of network responses were as various aswith the MI procedure (Fig. 4). Interestingly, vertexstrength variance (Fig. 4C) seemed to be the onlynetwork measure that was left unaltered by intro-ducing this second type of error to the data. Here,differences between MC and observed statisticsremained constant over the whole error range from0 to 2%, marking it as a quite reliable measure.
Density (Fig. 4A) was another rather stablemeasure, where relative deviations of more than 20%were only observed at the highest error rates (butagain, one large network sample deviated strongly
Fig. 4. Relative deviation of MC from observed network statistics concerning (A) density, (B) degree variance, (C) vertex strengthvariance, (D) edge weight disparity, (E) clustering coefficient, and (F) closeness centrality. The X-axis depicts the percentage of‘‘misclassified’’ (MC) edges. The Y-axis indicates the relative deviation of MC from observed network statistics in percent of the originalvalue. Open circles: small samples of less than 100 observations; open squares: large samples of more than 2,000 observations; filledcircles: intermediate samples between 100 and 2,000 observations.
Am. J. Primatol.
6 / Voelkl et al.

from this pattern). Degree variance (Fig. 4B) wasvery sensitive to introducing MC errors to the data.At the 0.1% error level, many samples alreadyreached a 40% deviation and overall variance washigh. Closeness centrality (Fig. 4F) showed again itssplit character, with the majority of network samplesremaining under 20% of relative deviation and some,again including large samples, even exceeding 100%.But here, small samples were more sensitive to theMC procedure at higher error rates when comparedwith MI statistics. Finally, both edge weight dis-parity (Fig. 4D) and clustering coefficient (Fig. 4E)showed increased variance in deviation when com-pared with MI values. For the majority of networksamples, overall stability seemed acceptable with arelative deviation between MC and observed valuesof less than 20% until reaching the 1% error rate.However, some networks, mainly small samples,exceeded this limit drastically at all error levels.
Data Censoring
Finally, we asked how censoring of the raw datacould affect the variation in re-sampled and error-added data. We focused on two measures often usedfor binary graphs: density and degree variance. Inthe case of re-sampling at the 50% re-sampling rate,censoring had no positive effect, i.e. did not decreasethe average deviation of the re-sampled data for bothmeasures (Fig. 5A). In the case of both, MI and MC atthe 1% error rate, we found that censoring couldindeed reduce the relative deviation, though theeffect was quite small considering the total variation(Fig. 5B and C). For error-added data, both censoringtechniques, CM and PM, led to very similar results.
DISCUSSION
We studied the effects that different sampling sizesand the inclusion of errors have on descriptive networkstatistics of non-human primate interaction networks.By re-sampling at lower percentages and by censoringthe data, we basically pose the question, ‘‘What wouldhave happened if the researcher had observed thegroup for only six instead of seven months, startedobservations an hour later, did fewer and/or shorterfocal sessions per day, or selected stricter criteria forwhat counts as a social interaction?’’ By reconnectingedges, we mimic the effect of MIs of individuals and byexchanging edges we simulate the effect of MC ofbehaviors, examining how mistakes by the observer ortranscription errors influence the outcome of theanalysis. Our results show that the answers to thesequestions are not straightforward.
A rather obvious expectation would be thatnetwork statistics should be less affected by sam-pling variation the larger the sample of observedinteractions is. Thus, we should find two effectsin our simulation study. First, decreasing there-sampling ratio should lead to an increase in the
deviance of network estimates and second, largeroriginal samples should be affected less than thesmaller ones. Both expectations were confirmed bythe results. The re-sampling ratio explained most ofthe total variation in the data and original samplesize explained still between 1 and 35% of the residualvariance. Concerning the latter finding, we expectedan even better fit by considering the group size—or, more precisely, the number of dyads, which isapproximately a square function of group size.Interestingly, the ratio of sample size to the numberof dyads had only a slightly higher explanatory value.The reason why we did not find a stronger differencemight lie in the specifics of our data set which wasthat group sizes ranged between 4 and 35 individuals,
Fig. 5. Relative deviation of density and degree variance for(A) re-sampled data at a re-sampling rate of 50%, (B) data with1% ‘‘mis-identifications’’ added, and (C) data with 1% ‘‘mis-classifications’’ added. Bin: uncensored networks, CM: completematrix for which the censoring threshold is based on the numberof all dyads in the graph, PM: partial matrix for which thecensoring threshold is based on the number of dyads that havebeen observed interacting at least once.
Am. J. Primatol.
Stability of Social Network Measures / 7

with most of the groups having between 8 and 16members—thus, groups did not differ too much insize. Furthermore, although there was no overallcorrelation between group and sample size, all thelarger groups had at least reasonable sample sizes ofabout 1,000 or more observations, which mightexplain why they were not affected more stronglyby deletions or added errors.
For our analysis, we divided our data into threegroups: small, intermediate, and large. This dissectionwas rather arbitrary, but it served our purpose ofvisualizing the influence of sample size. As our resultsshow, the large samples generally produce morestable and, therefore, more reliable statistical valuesthan the small samples. Yet, there are exceptions, asthere are also some networks based on small sampleswhose values hardly differ from the original ones evenat a very low re-sampling level of 30%.
Our results also show that the effect of addingerrors depends on the specific type of error. Networkstatistics from samples with added MC show higherrelative deviation than do values for samples withadded MI. Hence, network measures are moresensitive to potential MC of behaviors than to MI ofsingle individuals. As with re-sampling, small samplesseem to respond more strongly to introduced errorsthan large samples; but again, there are exceptions tothis regularity in both ways. Some larger samplesshow similar unstable values as do most smallsamples as well as some small samples remain quitestable even at high error rates—especially concerningcloseness centrality or edge weight disparity.
Because it is difficult to offer a general judgmentabout the reliability of a single network sample, onemight introduce a sampling-specific benchmark foreach network statistic. Focusing on density estimates,Granovetter [1976] proposed to draw on thosere-sampling sizes that yield up to 20% relativedeviation for the majority of samples. In his study,Granovetter suggested a formula to determine howmany samples of which sizes are needed to calculate a,what he calls, ‘‘decent’’ density estimate that corres-ponds to permitting a 20% error which ‘‘will servemost purposes well enough’’ [Granovetter, 1976].
Behavioral ecologists have taken a differentapproach. This approach should not be understoodas an alternative but as a complement to anypreexperimental sample size estimate. Whitehead[2008] and Lusseau et al. [2008] have suggestedusing bootstrapping re-sampling plans in order toretrieve valid confidence intervals for networkmetrics. For this method, one has to resample withreplacement from the original data, whereby thesample size is not reduced but kept the same as forthe original data set. Because the idea of boot-strapping is to imitate the original sampling proce-dure, care has to be taken of how the re-sampling isdone. For association data, the observational unit isthe subgroup of animals that was observed together
at one sampling point. For dyadic interactions (suchas grooming interactions or nearest neighbor), theunit of observation is a single interaction betweentwo individuals. Apart from this detail, the procedureis identical in both cases. The bootstrapping routineis repeated several thousand times, each timecalculating the network statistic for the bootstrappedsample. These bootstrapped parameter estimatesare then used to build a confidence interval aroundthe observed value [Efron, 1979, 1982]. The idea ofbootstrapping nonparametric confidence intervalsfor network metrics was generally accepted bybehavioral ecologists [James et al., 2009], and isnow frequently applied.
A potential way to reduce the effects of randomerrors on the estimates for network parameters isthe use of a filter, which weeds out all entries in thesociomatrix that fall below a certain threshold value.This procedure is usually applied in combinationwith a binarization of the sociomatrix. The advan-tages are that: (1) one can also use a collection ofnetwork measures that was exclusively developedfor binary graphs, (2) the distribution of networkstatistics for binary graphs is better understood thanfor weighted graphs, where one usually has to rely onsimulation studies, and (3) one can hope to eliminatea good proportion of random noise owing to mea-surement errors by introducing a cut-off filter.The disadvantages of this procedure are: (1) anarbitrary selection of the threshold value, (2) theexclusion of interactions that occur at low frequen-cies but which are not necessarily artifacts norunimportant, and (3) the loss of valuable informationby reducing the observational data to a binarypresence/absence matrix. Especially the latter pointseems to be the reason why measures for weightedgraphs are becoming increasingly popular and whyseveral authors recommend the use of weightedmeasures whenever possible [e.g. Croft et al., 2004,2005; James et al., 2009; Kasper and Voelkl, 2009;Lusseau & Whitehead, 2008; Whitehead, 2008].In this study, we found that for two binary measurescensored data showed on average slightly lowerrelative deviations than uncensored data. However,the difference was relatively small in comparisonto the overall variance. That is, a little gain indecreased error variance has to be accounted againsta potential loss of information by marginalizinginteraction frequencies. Because the number ofnetwork metrics suitable for weighted graphs isincreasing steadily [Barrat et al., 2004; Newman,2004], we do not see any strong arguments in favorof binarizing and censoring interaction data fornetwork analysis at the moment. However, weacknowledge that specific cases might exist wheresuch a method could be advisable, and that this issuerequires further investigation.
One of the purposes of applying SNA to animalgroups is the opportunity to compare social structure
Am. J. Primatol.
8 / Voelkl et al.

across populations, species, or taxa. In this study, wecould show that unequal sample sizes can affect thecalculated network metrics, but that they are notnecessarily a hindrance for a comparative SNA.The key requirement is again that the parameterestimates are accompanied by valid confidenceintervals. Additionally, our approach can be used toassess the stability of network statistics when itcomes to the question of observer or interobserverreliability, which is mimicked by the two error-adding procedures.
Our main recommendation is to aim for ahigh number of observations—preferably severalthousand—especially when observing large groups.This is, of course, advisable for almost any statisticalanalyses of relational data. In this respect, theresults of this article might be considered as ‘‘badnews’’ for those who hoped that SNA is a kind ofmagic bullet that allows one to get somethinginteresting out of a thin data. Yet, we do not wantto throw out the baby with the bathwater. In thesame way that one cannot trust that a large samplesize guarantees reliable results, one should also nottake for granted that small samples will automati-cally yield unreliable results. Consequently, there isno simple answer to the question, ‘‘When is it safe toapply SNA?’’ It always depends on the specificnetwork and the measure in question. We, therefore,want to close by suggesting a seven-step researchstrategy for how to plan a SNA study: (1) decide onthe specific question you want to answer, (2) selectthe appropriate network metric for this question,(3) take the data of a group of comparable size andstructure and investigate how re-sampling anderrors affect the reliability of the selected measures,(4) based on these results, make a rough estimateof the required sample size, (5) collect the data,(6) calculate the network metrics together with validconfidence intervals (e.g. by using bootstrappingre-sampling plans), and (7) publish the networkmetrics together with their confidence intervals.
ACKNOWLEDGMENTS
C.S. is supported through a postdoctoralfellowship granted by the KLI for Evolution andCognition Research, Altenberg, Austria. We thankBernard Thierry, Odile Petit, Cecile Fruteau, andRuth Sonnweber for providing us with unpublishedgrooming data of their study groups and all thoseother colleagues who published their results insuch a way that allowed easy reusage of their datain the meta-analysis carried out in this study.We thank two anonymous reviewers for helpfulcomments and D. Nicholson for improving theEnglish. All data acquisition adhered to the ASPethical guidelines for the use of non-human primatesin research.
REFERENCES
Barrat A, Barthelemy M, Pastor-Satorras R, Vespignani A.2004. The architecture of complex weighted networks.Proceedings of the National Academy of Sciences 101:3747–3752.
Barthelemy M, Barrat A, Pastor-Satorras R, Vespignani A.2005. Characterization and modeling of weighted networks.Physica A 346:34–43.
Chepko-Sade DB, Reitz KP, Sade DS. 1989. Sociometrics ofmacaca mulatta IV: network analysis of social structure of apre-fission group. Social Networks 11:293–314.
Costenbader E, Valente TW. 2003. The stability of centralitymeasures when networks are sampled. Social Networks 25:283–307.
Croft DP, Krause J, James R. 2004. Social networks in theguppy (Poecilia reticulata). Biology Letters 271:S516–S519.
Croft DP, James R, Ward AJW, Botham MS, Mawdsley D,Krause J. 2005. Assortative interactions and social networksin fish. Oecologia 143:211–219.
Croft DP, James R, Krause J. 2008. Exploring animal socialnetworks. Princeton: Princeton University Press.
Dow MM, De Waal FBM. 1989. Assignment methods for theanalysis of network subgroup interactions. Social Networks11:237–255.
Dunbar RIM. 1984. Reproductive decisions: an economicanalysis of Gelada baboon social strategies. Princeton:Princeton University Press.
Efron B. 1979. Bootstrap methods: another look at thejackknife. The Annals of Statistics 7:1–26.
Efron B. 1982. The jackknife, the bootstrap and otherresampling plans. Philadelphia: SIAM.
Erickson BH, Nosanchuk TA. 1983. Applied network sampling.Social Networks 5:367–382.
Erickson BH, Nosanchuk TA, Lee E. 1981. Network samplingin practice: some second steps. Social Networks 3:127–136.
Flack JC, Girvan M, de Waal FBM, Krakauer DC. 2006.Policing stabilizes construction of social niches in primates.Nature 439:426–429.
Franks DW, James R, Noble J, Ruxton GD. 2009. A foundationfor developing a methodology for social network sampling.Behavioural Ecology and Sociobiology 63:1079–1088.
Galaskiewicz J. 1991. Estimating point centrality usingdifferent network sampling techniques. Social Networks13:347–386.
Granovetter M. 1976. Network sampling: some first steps.American Journal of Sociology 81:1287–1303.
Henzi PS, Lusseau D, Weingrill T, van Schaik CP, Barrett L.2009. Cyclicity in the structure of female baboon socialnetworks. Behavioral Ecology and Sociobiology 63:1015–1021.
James R, Croft DP, Krause J. 2009. Potential banana skins inanimal social network analysis. Behavioral Ecology andSociobiology 63:989–997.
Kasper C, Voelkl B. 2009. A social network analysis of primategroups. Primates 50:343–356.
Krause J, Croft DP, James R. 2007. Social network theory inthe behavioural sciences: potential applications. BehaviouralEcology and Sociobiology 62:15–27.
Kudo H, Dunbar RIM. 2001. Neocortex size and social networksize in primates. Animal Behaviour 62:711–722.
Lehmann J, Boesch C. 2009. Sociality of the dispersing sex: thenature of social bonds in West African female chimpanzees,Pan troglodytes. Animal Behaviour 77:377–387.
Lehmann J, Dunbar RIM. 2009. Network cohesion, groupsize and neocortex size in female-bonded Old Worldprimates. Proceedings of the Royal Society B 276:4417–4422.
Lehmann J, Andrews K, Dunbar RIM. 2010. Social networksand social complexity in female bonded primates. In:Dunbar RIM, Gamble C, Gowlett JA, editors. Social brain,distributed mind. Oxford: Oxford University Press.
Am. J. Primatol.
Stability of Social Network Measures / 9

Lusseau D, Whitehead H, Gero S. 2008. Incorporatinguncertainty into the study of animal social networks.Animal Behaviour 75:1809–1815.
Newman MEJ. 2004. Analysis of weighted networks. PhysicalReview E 70:056131.
Perreault C. 2010. A note on reconstructing animal socialnetworks from independent small-group observations.Animal Behaviour 80:551–562.
Ramos-Fernandez G, Boyer D, Aureli F, Vick LG. 2009.Association networks in spider monkeys (Ateles geoffroyi).Behavioural Ecology and Sociobiology 63:999–1013.
Sade DS. 1972. Sociometrics of Macaca mulatta. I. Linkages andcliques in grooming matrices. Folia Primatologica 18:196–223.
Snijders TAB. 1981. The degree variance: an index of graphheterogeneity. Social Networks 3:163–174.
Sueur C, Petit O. 2008. Organization of group members atdeparture is driven by social structure in Macaca. Interna-tional Journal of Primatology 29:1085–1098.
Sundaresan SR, Fischhoff IR, Dushoff J. 2009. Avoidingspurious findings of nonrandom social structure in associa-tion data. Animal Behaviour 77:1381–1385.
Voelkl B. 2010. The ‘‘hawk-dove’’ game and the speed of theevolutionary process in small heterogeneous populations.Games 1:103–116.
Voelkl B, Kasper C. 2009. Social structure of primateinteraction networks facilitates the emergence of coopera-tion. Biology Letters 5:462–464.
Voelkl B, Noe R. 2008. The influence of social structure on thepropagation of social information in artificial primategroups: a graph-based simulation approach. Journal ofTheoretical Biology 252:77–86.
Voelkl B, Noe R. 2010. Simulation of information propaga-tion in real-life primate networks: longevity, fecundity,fidelity. Behavioural Ecology and Sociobiology 64:1449–1459.
Wakefield ML. 2008. Grouping patterns and competitionamong female Pan troglodytes schweinfurthii at Ngogo,Kibale National Park, Uganda. International Journal ofPrimatology 29:907–929.
Wasserman S, Faust K. 1994. Social network analysis:methods and applications. New York: Cambridge UniversityPress.
Wey T, Blumstein DT, Shen W, Jordan F. 2008. Social networkanalysis of animal behaviour: a promising tool for the studyof sociality. Animal Behaviour 75:333–344.
Whitehead H. 2008. Analyzing animal societies: quantitativemethods for vertebrate social analysis. Chicago: Universityof Chicago Press.
Am. J. Primatol.
10 / Voelkl et al.




















