
Insight into the core and variant exoproteomes of Listeria monocytogenes species by comparative...
20
RESEARCH ARTICLE Insight into the core and variant exoproteomes of Listeria monocytogenes species by comparative subproteomic analysis Emilie Dumas 1 , Mickae ¨l Desvaux 1 , Christophe Chambon 2 and Michel He ´braud 1,2 1 INRA, UR454 Microbiologie, Saint-Gene ` s Champanelle, France 2 INRA, Plate-Forme d’Exploration du Me ´ tabolisme, Composante Prote ´ omique, Saint-Gene ` s Champanelle, France Received: September 26, 2008 Revised: February 17, 2009 Accepted: February 26, 2009 While Listeria monocytogenes is responsible for listeriosis, it is also a saprophytic species with exceptional survival aptitudes. Secreted proteins are one of the main tools used by bacteria to interact with their environment. In order to take into account the biodiversity of L. mono- cytogenes species, exoproteomic analysis was carried out on 12 representative strains. Following 2-DE and MALDI-TOF MS, a total of 151 spots were identified and corresponded to 60 non-orthologous proteins. To categorize and analyze these proteomic data, a rational bioinformatic approach predicting final subcellular localization was carried out. Fifty-two out of the 60 proteins identified (86.7%) were indeed predicted as localized in the extracellular milieu (gene ontology (GO): 0005576). Most of them (65.4%) were actually predicted as secreted via the Sec translocon. Comparative analysis allowed for proteins found in all or only in a subset of L. monocytogenes strains to be defined. While the core exoproteome included most proteins related to bacterial virulence, cell wall biogenesis, as well as proteins secreted by unknown pathways, a slight variation in the protein members of these categories were observed and constituted the variant exoproteome. This investigation resulted in the first definition of the core and variant exoproteomes of L. monocytogenes where corollaries on bacterial physiology are further discussed. Keywords: Biodiversity / Bioinformatic analysis / Extracellular proteome / Listeria monocytogenes / MALDI-TOF MS 1 Introduction Listeria monocytogenes is one of the major food-borne pathogenic bacteria and the etiologic agent of listeriosis, a rare but very serious infection particularly for high-risk groups, such as elderly, pregnant women, neonates or immunocompromised individuals, as it can have lethal consequences [1]. Despite the fact that equivocal data might result from phenotypic tests over molecular methods when identifying L. monocytogenes isolates [2], serotype is still largely used to discriminate different L. monocytogenes strains. Among the 13 L. monocytogenes serotypes described, 98% of human listeriosis are associated with strains 4b, 1/2b Abbreviations: ActA, actin assembly; FEA, flagellum export apparatus; FPE, fimbrilin-protein exporter; GO, gene ontology; HMM, hidden Markov model; holins, hole-forming; Iap, inva- sion-associated protein; IMP, integral membrane proteins; Inl, internalin; LLO, listeriolysin O; MnSOD, manganese-superoxide dismutase; MurA, muramidase A; Plc, phospholipase C; PSI- BLAST, position-specific iterated BLAST; SH3, Src homology-3; SVM, support vector machine; Tat, twin-arginine translocation; TBP, tributyl phosphine; TMD, transmembrane domain; Wss, WXG100 secretion system These authors contributed equally to this work and share first authorship. Correspondence: Dr. Michel He ´ braud, Institut National de la Recherche Agronomique (INRA), Centre de Recherche de Cler- mont-Ferrand, UR454 Microbiologie, Equipe Qualite ´ et Se ´ curite ´ des Aliments, Site de Theix, F-63122 Saint-Gene ` s Champanelle, France E-mail: [email protected] Fax: 133-4-73-62-45-81 & 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com 3136 Proteomics 2009, 9, 3136–3155 DOI 10.1002/pmic.200800765
Transcript of Insight into the core and variant exoproteomes of Listeria monocytogenes species by comparative...

RESEARCH ARTICLE
Insight into the core and variant exoproteomes of
Listeria monocytogenes species by comparative
subproteomic analysis
Emilie Dumas1�, Mickael Desvaux1�, Christophe Chambon2 and Michel Hebraud1,2
1 INRA, UR454 Microbiologie, Saint-Genes Champanelle, France2 INRA, Plate-Forme d’Exploration du Metabolisme, Composante Proteomique, Saint-Genes Champanelle, France
Received: September 26, 2008
Revised: February 17, 2009
Accepted: February 26, 2009
While Listeria monocytogenes is responsible for listeriosis, it is also a saprophytic species with
exceptional survival aptitudes. Secreted proteins are one of the main tools used by bacteria to
interact with their environment. In order to take into account the biodiversity of L. mono-cytogenes species, exoproteomic analysis was carried out on 12 representative strains.
Following 2-DE and MALDI-TOF MS, a total of 151 spots were identified and corresponded to
60 non-orthologous proteins. To categorize and analyze these proteomic data, a rational
bioinformatic approach predicting final subcellular localization was carried out. Fifty-two out
of the 60 proteins identified (86.7%) were indeed predicted as localized in the extracellular
milieu (gene ontology (GO): 0005576). Most of them (65.4%) were actually predicted as
secreted via the Sec translocon. Comparative analysis allowed for proteins found in all or only
in a subset of L. monocytogenes strains to be defined. While the core exoproteome included
most proteins related to bacterial virulence, cell wall biogenesis, as well as proteins secreted
by unknown pathways, a slight variation in the protein members of these categories were
observed and constituted the variant exoproteome. This investigation resulted in the first
definition of the core and variant exoproteomes of L. monocytogenes where corollaries on
bacterial physiology are further discussed.
Keywords:
Biodiversity / Bioinformatic analysis / Extracellular proteome / Listeria monocytogenes /
MALDI-TOF MS
1 Introduction
Listeria monocytogenes is one of the major food-borne
pathogenic bacteria and the etiologic agent of listeriosis, a
rare but very serious infection particularly for high-risk
groups, such as elderly, pregnant women, neonates or
immunocompromised individuals, as it can have lethal
consequences [1]. Despite the fact that equivocal data might
result from phenotypic tests over molecular methods when
identifying L. monocytogenes isolates [2], serotype is still
largely used to discriminate different L. monocytogenesstrains. Among the 13 L. monocytogenes serotypes described,
98% of human listeriosis are associated with strains 4b, 1/2b
Abbreviations: ActA, actin assembly; FEA, flagellum export
apparatus; FPE, fimbrilin-protein exporter; GO, gene ontology;
HMM, hidden Markov model; holins, hole-forming; Iap, inva-
sion-associated protein; IMP, integral membrane proteins; Inl,
internalin; LLO, listeriolysin O; MnSOD, manganese-superoxide
dismutase; MurA, muramidase A; Plc, phospholipase C; PSI-
BLAST, position-specific iterated BLAST; SH3, Src homology-3;
SVM, support vector machine; Tat, twin-arginine translocation;
TBP, tributyl phosphine; TMD, transmembrane domain; Wss,
WXG100 secretion system
�These authors contributed equally to this work and share
first authorship.
Correspondence: Dr. Michel Hebraud, Institut National de la
Recherche Agronomique (INRA), Centre de Recherche de Cler-
mont-Ferrand, UR454 Microbiologie, Equipe Qualite et Securite
des Aliments, Site de Theix, F-63122 Saint-Genes Champanelle,
France
E-mail: [email protected]
Fax: 133-4-73-62-45-81
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com
3136 Proteomics 2009, 9, 3136–3155DOI 10.1002/pmic.200800765

and 1/2a [3]. In other respects, the infectious cycle of
L. monocytogenes is now clearly established as well as the key
virulence factors involved in the major steps of intracellular
parasitism [4]. Briefly, cell-wall localized proteins internalin
A (InlA) and InlB are involved in adhesion to the surface of
the eukaryote cell and penetration into the host cell viaphagocytosis. Then, released listeriolysin O (LLO) and
phospholipases C (PlcA and PlcB) enable escape from the
phagocytic vacuole, whereas membrane-anchored actin
assembly (ActA) is responsible for actin-based motility
allowing for cell-to-cell spread. From this point and as
observed in other pathogenic bacteria [5], it is clearly
apparent that pathogenicity of L. monocytogenes depends
greatly on its ability to secrete virulence factors, which are
displayed on the bacterial cell surface, released into the
extracellular milieu or injected directly into a host cell [6].
As an ubiquitous species, L. monocytogenes is also able to
deal with stressful environmental conditions as it can grow
at high salt concentrations (up to 10%), in a wide range of
pH (from 4.3 to 9.6) and temperatures (from �0.4 to
45.01C), as well as low water availability (Aw down to 0.90)
[7, 8]. Its ability to form biofilms further increases its
adaptative and survival aptitudes in terms of resistance and
persistence [9, 10]. Thus, although at first glance L. mono-cytogenes is generally introduced as a pathogenic agent, it
should be primarily considered as a saprophytic bacterium
well adapted for survival in the environment [11, 12].
Indeed, the natural ecological niche of all L. monocytogenes is
soil and decaying vegetation, whereas the level of virulence
is highly variable from one L. monocytogenes strain to
another as a significant proportion of isolates is hypoviru-
lent and even apathogenic [13, 14]. This facet is sometimes
skipped by some authors but should not be overlooked as it
stresses that L. monocytogenes biodiversity must be taken into
consideration. Moreover, the molecular mechanisms
underlying the switch to a harmful bacterium are far from
being fully understood [12, 15, 16].
While secreted proteins, either displayed on the bacterial
cell surface or released into the extracellular milieu, play
pivotal roles in the colonization process in the environment
and subversion of the human host, the gating systems
involved in secretion of these effector molecules remain
elusive in L. monocytogenes. Following genomic analysis, six
protein secretion systems could be uncovered in L. mono-cytogenes, namely (i) Sec secretion system, (ii) Tat (twin-
arginine translocation) pathway, (iii) FEA (flagellum export
apparatus), (iv) FPE (fimbrilin-protein exporter), (v) holins
(hole-forming), and (vi) Wss (WXG100 secretion system)
also known as ESX-1 (ESAT-6 secretion-1) in Mycobacteriumspp. [6]. Focusing on one sequenced strain, L. monocytogenes1/2a EGD-e, proteomic analyses of extracellular and cell-wall
proteins were performed but unfortunately without taking
the protein secretion systems involved upstream into
account [17–20]. In order to take the biodiversity into
account and get a more objective overview of the exopro-
teome from L. monocytogenes species, i.e. the subset of
proteins present in the extracellular milieu, analysis of this
subproteome was carried out here on 12 representative
L. monocytogenes strains from different serotypes, origins
and virulence levels [21]. Besides, a rational bioinformatic
approach taking into account protein secretion systems,
subcellular targeting and localization motifs was applied to
proteins identified in order to categorize and analyze
proteomic data. This investigation results in the first
definition of the core and variant exoproteomes of
L. monocytogenes species.
2 Materials and methods
2.1 Bacterial strains and culture conditions
The 12 L. monocytogenes strains analyzed in this study were
obtained from the Pasteur Institute (Paris) and are listed in
Table 1. The strains were carefully chosen as previously
described [21] as they either belonged to serotype 1/2a, 1/2b
or 4b. They were isolated from different origins, i.e.epidemic cases, human asymptomatical carriage and envir-
onment. They were also categorized into two virulence levels
based on the mortality of infected chick embryos [22], where
level A corresponds to virulent strains (100% mortality
within 3 days) and level B corresponds to slightly attenuated
strains (80% mortality in more than 3 days).
Bacterial strains were cultured as previously described in
chemically defined medium MCDB202 (CryoBioSystem)
prior to proteomic analysis [21]. They were grown at 371C
with shaking until late exponential phase (OD600 nm 5 0.9)
before harvesting by centrifugation (15 min, 7500g, 41C).
2.2 2-DE of extracellular proteins
First, the supernatants were filtered on 0.2 mm membranes
and 0.2 mM PMSF was added to inhibit proteases activity.
An aliquot of 0.2 mg/mL Na deoxycholate was added to the
solution, which was incubated 30 min on ice. Na deoxy-
cholate supports protein precipitation that was carried out
by the addition of 10% trichloroacetic acid and incubation
overnight at 41C. After centrifugation (20 300� g, 30 min,
41C), the precipitate was washed with ice-cold acetone and
solubilized in IEF buffer (5 M urea, 2 M thiourea, 2%
CHAPS, 10 mM TrisHCl, in 50% trifluoroethanol and traces
of bromophenol blue).
For the IEF, non-linear pH 3–10 IPG strips were
passively rehydrated for 17.5 h in a reswelling tray with
400 mL of IEF buffer containing 0.3% v/v ampholytes 3–10,
2 mM tributyl phosphine (TBP) and 500 mg of proteins.
The proteins were first subjected to IEF for a total of
66450 Vh (7 h at 50 V, 2 h at 200 V, linear gradient until
1000 V in 2 h, 1 h at 1000 V, linear gradient until 8000 V in
5 h and 8000 V till the end). The strips were equilibrated
twice for 15 min in an equilibration solution (50 mM
Proteomics 2009, 9, 3136–3155 3137
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

TrisHCl, pH 8.8; 6 M urea; 2% w/v SDS; 30% v/v glycerol)
containing 2 mM TBP for the first step and 2.5% w/v
iodoacetamide and traces of bromophenol blue for the
second step. The second dimension (SDS-PAGE) was
carried out with 12.5% acrylamide gel in a Multicell Protean
II XL system (Bio-Rad). The gels were stained with
Coomassie blue, scanned by a GS-800 imaging densitometer
(Bio-Rad) and analyzed using Image Master 2D Platinum
software v5.0 (GE Healthcare).
2.3 Identification of proteins by MALDI-TOF MS
Protein spots separated by 2-DE stained with Coomassie
blue were excised. The gel pieces were destained and
submitted to tryptic digestion. First, the spots were washed
with the destaining solution (25 mM ammonium bicarbo-
nate/5% ACN) and twice with ammonium bicarbonate
(25 mM)/50% ACN). They were then dehydrated with 100%
ACN. The dried gels were reswelled in a solution containing
20 mg trypsin and the proteins in the gel were digested at
least 5 h at 371C. The resulting peptides were extracted
with 100% ACN. After 15 min at 371C, 1 mL of each sample
and a 1 mL saturated CHCA matrix were mixed onto the
MALDI-TOF target. Positive ion MALDI mass spectra were
recorded in the reflectron mode of a MALDI-TOF MS
(Voyager DE-Pro, Perseptive BioSystems) using voyager
software for data collection and analysis. The MS was cali-
brated with a standard peptide solution (Proteomix, LaserBio
Labs). Internal calibration of samples was achieved using
trypsin autolysis peptides. Monoisotopic peptide masses were
used for NCBI non-redundant database searches (http://
www.ncbi.nlm.nih.gov/BLAST/blast_databases.html) with the
MASCOT v.2.1 software, or Profound (http://www.unb.
br/cbsp/paginiciais/profound.htm) when MASCOT failed to
assign. The maximum fragment ion mass tolerance was set up
at 725 or 50 ppm and possible modification of cysteines by
carbamidomethylation as well as oxidation of methionine
could be considered.
2.4 Bioinformatic analyses
Bioinformatic analyses were performed from web-based
servers or under a Unix environment and Sun Grid Engine
from a Topaze server homed at MIG (Mathematiques
Informatique et Genomes) Research Unit (INRA).
N-terminal signal peptides were predicted combining
results [23] from (i) SPScan, an implementation of von
Heijne’s weight matrix approach with McGeoch criteria where
prompted parameters and optional parameter ADJustscores
were used [24, 25], (ii) SignalP v2.0 and v3.0 using both a
neural network and hidden Markov model (HMM) [26],
(iii) Phobius based on a HMM combining transmembrane
a-helices topology and signal peptide prediction [27], (iv)
SOSUIsignal based on tripartite signal peptide structureTab
le1.
Str
ain
so
fL.
mo
no
cyto
gen
es
use
din
this
stu
dy
Co
de
Str
ain
Sero
typ
eO
rig
inV
iru
len
ceR
efe
ren
ces
AC
LIP
80459
4b
Ep
idem
icA
[21,
104]
BC
LIP
90602
1/2
bE
pid
em
icA
[21]
CC
LIP
92347
1/2
aE
pid
em
icA
Past
eu
rIn
stit
ute
Co
llect
ion
DE
GD
-e1/2
aE
pid
em
icA
[78,
105]
EC
LIP
93667
4b
Carr
iag
eA
[106,
107]
FC
LIP
93679
4b
Carr
iag
eA
[106,
107]
GC
LIP
93672
1/2
bC
arr
iag
eB
[106,
107]
HC
LIP
93677
1/2
aC
arr
iag
eB
[106,
107]
IC
LIP
93665
4b
En
vir
on
men
tA
[21]
JC
LIP
93649
1/2
aE
nvir
on
men
tA
[21]
KC
LIP
93663
1/2
aE
nvir
on
men
tB
Past
eu
rIn
stit
ute
Co
llect
ion
LC
LIP
93657
1/2
aE
nvir
on
men
tB
Past
eu
rIn
stit
ute
Co
llect
ion
Th
e12
L.
mo
no
cyto
gen
es
stra
ins,
cod
ed
fro
mA
toL
for
the
pu
rpo
ses
of
this
invest
igati
on
,(i
)exh
ibit
ed
dif
fere
nt
sero
typ
es
(1/2
a,
1/2
bo
r4b
),(i
i)w
ere
iso
late
dfr
om
div
ers
eo
rig
ins
(ep
idem
icca
ses,
asy
mp
tom
ati
cal
carr
iag
es
an
den
vir
on
men
t),
(iii
)w
ere
cate
go
rize
din
totw
od
iffe
ren
tvir
ule
nce
levels
(Aan
dB
)b
ase
do
nth
em
ort
ali
tyo
fin
fect
ed
chic
kem
bry
os
(100
an
d80%
mo
rtali
tyw
ith
in3
days,
resp
ect
ively
).
3138 E. Dumas et al. Proteomics 2009, 9, 3136–3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

analysis [28], (v) PSORTb a support vector machine (SVM)
[29, 30] (vi) PrediSi [31] and (vii) Signal-3L [32]. These tools
were trained on prokaryotes or Gram-positive bacteria when-
ever possible with truncation disabled. Tat signal peptide
prediction was performed from TatP v1.0 [33] and TATFIND
v1.4 [34]. Pseudopilin-like signal peptides (class 3) were sear-
ched with ScanProsite syntax [35] for consensus motif
[AG]F[TS]LX[EF] located between the N- and H-domains as
recently described in Listeria [6]. Prediction of non-classical
secreted proteins, i.e. lacking a signal peptide, was performed
from SecretomeP v2.0 trained on bacteria [36].
For the identification of lipoproteins, sequences were
submitted to DOLOP [37], LipoP v1.0 [38], SPEPLip [39],
LipPred [40] and scanned by ScanProsite [35] with both
PS51257 profile and G1LPP pattern, i.e. [MV]-X(0,13)-[RK]-
DERKQ(6,20)-[LIVMFESTAG]-[LVIAM]-[IVMSTAFG]-[AG]-
C [41].
Modular architecture of proteins was analyzed from COG
v1.0 [42] using reverse position-specific BLAST [43] and
using a HMM [44] from InterPro v4.3 [45], Pfam v21.0 [46],
SMART v5.1 [47], TIGRfam v6.0 [48], SCOP v1.71 [49, 50],
PIRSF [51] and Prosite v20.7 [52] databases. WXL
domains were found scanning for the motif [LI][TE]W[TS]L
with ScanProsite where the C-terminal location of the
motif was also taken into account [53]. When needed,
e.g. for no significant or inconclusive matches, position-
specific iterated BLAST (PSI-BLAST) [43] searches
were executed against UniProt until convergence [54].
All searches were performed with E-value cutoff set
at 10�3.
Transmembrane a-helices were predicted combining (i)
HMMTOP v2.0 [55], (ii) TMHMM v2.0 [56], (iii) SOSUI v1.1
[57], (iv) THUMBUP v1.0 [58], (v) MEMSAT v3.4 [59] and
(vi) UMDHMMTMHP v1.0 [58].
These analyses were completed with results from SVMs
predicting the subcellular localization of proteins, i.e.SubLoc v1.0 [60] and LocTree [61] trained on prokaryotes,
CELLO v2.5 [62] and PSORTb v2.0.4 trained on Gram-
positive bacteria [30].
3 Results and discussion
The diversity of the extracellular proteomes of L. mono-cytogenes species was investigated analyzing a panel of 12
representative strains carefully chosen as previously descri-
bed (Table 1) [21]. In order to separate the proteins over a
wide pI range, a non-linear pH 3–10 IPG strip was used for
IEF separation in the first dimension. To facilitate
comparisons, a reference 2-DE gel was realized from a
mixture of an equivalent quantity of proteins from the 12
L. monocytogenes strains (Fig. 1). Two clusters of proteins
could be distinguished as the majority of the protein spots
were localized in a region between pH 4.0 and 6.0, whereas
some very abundant spots were present in the basic region.
Protein spots were sampled from gels corresponding to each
L. monocytogenes species and further identified from their
peptide mass fingerprinting obtained by MALDI-TOF MS
and MASCOT or Profound interrogation against the
Firmicutes database (NCBInr). The gels allowed for a
total of 151 spots to be resolved and identified. Several
proteins were resolved as two or more spots on the 2-DE,
which could be caused by post-translational modifications.
As listed in Table 2 and after manual inspections of the
output to remove protein fragments, redundant proteins (i.e.amino acid sequences 100% identical) as well as protein
orthologues, these 151 protein spots corresponded to 60
non-orthologous proteins (see also Supporting Information
Table S1).
3.1 Predicted subcellular localization of identified
proteins
In order to categorize the 60 proteins extracted from culture
supernatants of these 12 L. monocytogenes strains and iden-
tified by MALDI-TOF MS, bioinformatic analyses were
carried out. The rationale behind this approach is presented
in Fig. 2, and the summary of predictions is given as
Supporting Information Table S1.
3.1.1 Signal peptide and protein secretion system
prediction
Firstly, protein sequences were scanned for the presence of
N-terminal signal peptides using a large variety of bioin-
formatic tools, namely SPScan, SignalP, Phobius, SOSUI-
signal, PSORTb and PrediSi as described in Section 2,
which led to ten individual predictions. Fourty-six proteins
were predicted as possessing a signal peptide by at least one
tool, including ten proteins predicted as such by all predic-
tors. If at least half of the prediction tools gave a significant
positive result, a protein was predicted as possessing a
signal peptide, i.e. 37 proteins. When less than five out of
ten predictors identified a signal peptide, i.e. nine proteins,
proteins were further checked for subcellular localization
and function using appropriate prediction tools, namely
PSORTb, SubLoc, SecretomeP, CELLO and LocTree.
Finally, 42 proteins were predicted as possessing an N-
terminal signal peptide.
While a protein bearing an N-terminal signal peptide is
targeted to the membrane, it is not systematically translo-
cated via the Sec translocon. Further in silico analyses were
carried out in order to find and discriminate different types
of signal peptide. TatP and TATFIND searches failed to
identify Tat signal peptide and thus potential protein
translocated by this secretion system. Similarly, ScanProsite
searches for class 3 signal peptide motifs as recently
described in Listeria [6] could not identify Type 4 prepilins
potentially translocated by the FPE. The remaining proteins
lacking a signal peptide were checked as substrates for
Proteomics 2009, 9, 3136–3155 3139
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

alternative secretion systems. Using a database generated
from recent reviews on protein secretion in Listeria [6], PSI-
BLAST searches failed to identify protein substrates of FEA,
holins and Wss. However, following a SecretomeP search
and literature survey, 17 additional proteins were predicted
as secreted by unknown secretion systems. Finally, 42
proteins identified with an N-terminal signal peptide were
predicted as translocated via the Sec translocon and 17
proteins lacking a signal sequence were predicted as secre-
ted via unknown secretion systems.
3.1.2 Prediction of cell-envelope-binding motifs
The presence of N-terminal signal peptides (i.e. containing at
least N- and H-domains) unmistakably indicates proteins are
targeted to the cytoplasmic membrane but, contrary to what is
sometimes wrongly assumed in the literature, it is no guarantee
that these proteins are secreted into the extracellular milieu.
Indeed, such a protein can either (i) remain associated to the
cytoplasmic membrane, (ii) remain associated to the cell wall or
(iii) be released into the extracellular milieu.
3.00 4.50 4.95 5.95 6.50 7.00 7.80 8.35 9.65 10.00
64
32
16
8
pH
MM(kDa)
Figure 1. Reference 2-DE gel composed from a mixture of an equivalent quantity of extracellular proteins from each of the 12
L. monocytogenes strains investigated. The labels appear in white for the core proteome and in gray for the variant proteome. The
corresponding spot numbers indicated in Tables 2 and 3 are shown in Supporting Information Fig. 1S.
3140 E. Dumas et al. Proteomics 2009, 9, 3136–3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

3.1.2.1 Lipoproteins
Therefore, proteins predicted as Sec-dependent were further
scanned for the presence of class 2 signal peptides, i.e.presence of lipobox, which invariably includes a cysteine
residue located just after the signal peptide C-domain.
Following DOLOP, LipoP, SPEPLip, LipPred searches as
well as ScanProsite using both PS51257 profile and G1LPP
pattern [41], a protein was identified as lipoprotein if at least
three out of six individual predictions gave a significant
positive result, i.e. five proteins. Captivatingly, all the lipo-
proteins identified here in the extracellular milieu display a
glycine residue at position 12 of the predicted Type II signal
peptidase cleavage site. Indeed, this amino acid at this
particular position is considered as of major importance in
the lipoprotein release into the supernatant in Gram-posi-
tive bacteria [63–65]. Although lipoproteins are primarily
considered as anchored to the cytoplasmic membrane, some
of them can to some extent be released extracellularly.
3.1.2.2 LPXTG-like proteins
Motif searches were further carried out from InterPro,
Pfam, Smart, TIRGfam, SuperFamily, PIRsf and Prosite in
order to identify cell-wall retention motifs [23]. Two proteins
were predicted with a C-terminal LPXTG domain
(IPR001899, PF00746, TIGR01167; 2.4� 10�7rE-values
r9.7� 10�4) and thus would be covalently anchored to the
bacterial cell wall by sortases [66]. No YSIRK motif
(IPR005877, PF04650, TIGR01168) could be identified
within Sec-dependent signal peptides of these proteins;
when present, this motif is systematically associated
with an LPXTG motif and is required for efficient protein
secretion [67].
3.1.2.3 LysM proteins
Three proteins were predicted with LysM domains found in
two or four copies (IPR002482, PF01476, SM00257,
SSF54106; 3.7� 10�21rE-valuesr2.0� 10�12). LysM
28
Cell wall(GO:0005618)
12
FPE0
Yes
No
Tat0
Holin0
FEA0
Wss0
Unknown17
No
Non-orthologous proteins60
NoYes
Sec42
1
TMD?
IMP9
Cytoplasm(GO:0005737)
15
Extracellular(GO:0005576)
51
LPXTG2
LysM3
GW3
Signal peptide?
Secretion system? Yes
Cell envelope binding motif?
Lipobox5
seYoN
8124
Muramidase3
Cell wall degradation?
Cell wallamidase
2
5
Yes
NlpC/P602
Final localization? Membrane(GO:0005886)
13
3D1
3 141 420
2 12
1
11
Yes
Yes
25
oNoN No NoNo Yes oNoN Yes No Yes No
No No
No oNoN No
120 988 2 14414
8
3
ChW1
No
No
11
WXL1
No
1
No
1
5
5
28
Cell wall(GO:0005618)
12
FPE0
Yes
No
Tat0
Holin0
FEA0
Wss0
Unknown17
No
Non-orthologous proteins60
NoYes
Sec42
1
TMD?
IMP9
Cytoplasm(GO:0005737)
15
Extracellular(GO:0005576)
51
LPXTG2
LysM3
GW3
Signal peptide?
Secretion system? Yes
Cell envelope binding motif?
Lipobox5
seYoN
8124
Muramidase3
Cell wall degradation?
Cell wallamidase
2
5
Yes
NlpC/P602
Final localization? Membrane(GO:0005886)
13
3D1
3 141 420
2 12
1
11
Yes
Yes
25
oNoN No NoNo Yes oNoN Yes No Yes No
No No
No oNoN No
120 988 2 14414 3
ChW1
No
No
11
WXL1
No
1
No
1
5
5
8
Figure 2. Schematic representation of the bioinformatic analyses carried out to categorize the 60 non-othologous proteins identified in the
extracellular milieu of L. monocytogenes strains. In order to predict the final subcellular localization of the proteins identified following a
proteomic approach, the rationale of the in silico analysis carried out can be summarized as answering to six successive and fundamental
questions related to (i) the presence of N-terminal signal peptides, (ii) the secretion systems used, the presence of (iii) cell-envelope-
binding motifs, (iv) cell-wall degradation motifs or (v) transmembrane domains, and (vi) their assignment to subcellular compartments
recognized in Gram-positive bacteria. Detailed results are given as Supporting Information Table S1.
Proteomics 2009, 9, 3136–3155 3141
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

domains bind directly to peptidoglycan and binding is
hindered by secondary cell-wall polymers, supposedly lipo-
teichoic acids [68]. One of them, i.e. the invasion associated
protein P60 (P21171), also exhibits homology with an Src
homology-3 (SH3) domain (IPR003646, SSF50044, SM00287;
4.1� 10�15rE-valuesr1.3� 10�14), which belongs to the
SH3 clan (CL0010); it further appeared that these domains
were more specifically bacterial SH3 of Type 3 (IPR013247,
PF08239; 3.1� 10�20rE-valuesr2.1� 10�19).
3.1.2.4 Proteins
Three proteins were predicted with GW modules with
copies ranging between one and four (SSF82057;
3.0� 10�23rE-valuesr1.7� 10�12). This motif allows for
non-covalent interaction with lipoteichoic acids, where the
higher the number of GW modules, the stronger the
attachment [69]. However, proteins exhibiting only one GW
module are essentially present in the extracellular milieu
and not found attached to the bacterial cell surface [69, 70].
Therefore, two out of three proteins with GW modules were
primarily predicted as cell-wall-associated at this stage of the
analysis, as namely proteins of unknown function Q8Y572
and Q71WI7 bore two and four GW modules, respectively,
whereas autolysin Q4EHT4 exhibited only one GW module.
3.1.2.5 Other proteins with cell-wall-binding motifs
A serine protease (Q71YE5) bears three copies of a
ChW motif (IPR006637, SM00728, PF07538; 2.5� 10�16
rE-valuesr5.6� 10�11). As GW proteins, ChW proteins
contain a highly conserved Gly-Trp dipeptide motif origin-
ally described in Clostridium acetobutylicum where it was
suggested to enable protein cell surface anchoring [71] and
to be involved in a novel extracellular macromolecular
system. Similarly, protein CscB (Q8Y9E5) was suggested as
participating in cell-surface complexes for plant carbohy-
drate utilization [72]. Indeed, CscB exhibits a newly uncov-
ered domain WXL-mediating cell-wall attachment [73]. All
proteins bearing cell-wall-binding domain(s) were predicted
as secreted in a Sec-dependent manner.
3.1.3 Prediction of motifs involved in cell-wall
degradation
In addition to the autolysin exhibiting one GW module
(Q4EHT4), a protein originally annotated as hypothetical
(Q8Y707) first appeared clearly expressed and would also be
an N-acetylmuramoyl-L-alanine amidase (COG0860;
E-values 5 1.0� 10�48; IPR002508, PF01520; E-values 5 3.6
� 10�64), which further exhibits three SH3 domains of Type 3
(2.1� 10�24rE-valuesr1.8� 10�8). In addition, three
muramidases involved in the flagellar assembly were uncov-
ered (COG1705; 3.0� 10�52rE-valuesr9.0� 10�41) [74]; two
of them were GW proteins and one of them a LysM protein.
One protein (Q71WQ6) exhibited a 3-D domain (IPR010611,
PF06725; E-values 5 1.5� 10�35), which is a peptidase-like
active site containing three conserved aspartate residues and
involved in peptidoglycan turnover. This enzyme was also
predicted as a LysM protein. Including invasion associated
protein (Iap), also called P60 (protein of 60 kDa) or cell wall
hydrolase A, two proteins exhibited an NlpC/P60 domain
(IPR000064, PF00877; 3.5� 10�53rE-valuesr6.2� 10�51)
characteristic of cell-wall peptidases [75]; one of them (P21171)
has LysM domains. As active sites of all these cell-wall
degradation enzymes have affinity for cell-wall components,
they are most likely present within this subcellar compart-
ment. Contrary to what is sometimes assumed though, the
presence of such domains should not be considered as cell-
wall-binding motifs per se since the primary function of these
enzymes is to cleave cell-wall components according to
whether they find a new cleavage site or are released into the
extracellular milieu. Such proteins were then predicted as
localized in two final subcellular compartments, i.e. cell wall
and extracellular milieu. All cell-wall degradation enzymes
were primarily predicted as secreted via Sec.
3.1.4 Prediction of transmembrane a-helices
All proteins were further analyzed for the presence of trans-
membrane a-helices using HMMTOP, TMHMM, SOSUI,
THUMBUP, UMDHMMTMHP and MEMSAT. A protein
was predicted as possessing a transmembrane domain (TMD)
if at least three out of six tools gave a significant positive result.
In addition, the presence of motifs (e.g. LPXTG), signal
peptides and positions of TMD were carefully taken into
consideration for the prediction of integral membrane proteins
(IMP). In the first instance, 48 proteins were predicted as with
transmembrane a-helices but excluding signal peptide
H-domain and LPXTG region, IMPs were reestimated down
to nine. Only three of them did not display Sec-dependent
N-terminal signal peptides. Five proteins displayed only one
putative a-helical TMD and the remaining ones were predicted
as possessing at least two transmembrane a-helices, and up to
five in one of them, i.e. a sulphatase (Q8Y8H6). Excluding
their class 2 signal peptide H-domain, one out of the six
predicted lipoproteins exhibited two TMDs, i.e. AA3-600 quinol
oxidase subunit II (QoxA; Q8YAV0), and would thus be IMP
covalently attached to membrane long chain fatty acids.
However, shedding of QoxA into the culture supernatant was
previously reported in other Gram-positive bacteria as this
lipoprotein exhibits a Gly residue at position 12 [76].
3.1.5 Final prediction of subcellular localizations
All remaining proteins were further submitted to four SVMs
dedicated to bacterial subcellular localization. Four
localizations were considered, i.e. cytoplasmic, membrane,
cell wall and extracellular. Protein was predicted in a given
subcellular compartment if at least two out of four tools
predicted it. These results were combined to previous
3142 E. Dumas et al. Proteomics 2009, 9, 3136–3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

analyses for the final prediction of subcellular localization.
Following recommendations from the gene ontology (GO)
Consortium to unambiguously define protein localization in
a Gram-positive bacterium [77], GO numbers were given, i.e.cytoplasm (GO: 0005737), cytoplasmic membrane (GO:
0005886), cell wall (GO: 0005618) and extracellular milieu
(GO: 0005576). Finally, 15 proteins were predicted as cyto-
plasmic with 14 also predicted as extracellular. Thirteen
proteins were predicted as membrane associated and more
exactly as intrinsic to membrane (GO: 0031226) including
nine IMPs, i.e. integral to membrane (GO: 0005887), and
four lipoproteins without TMDs, i.e. anchored to membrane
(GO: 0046658). Twelve proteins were predicted as cell-wall
localized. Among the 51 proteins predicted as extracellular,
20 were predicted as secreted via the Sec pathway and finally
released into the extracellular milieu. Besides extracellular
localization, 31 out of these 51 proteins were predicted with
multiple final subcellular localization either as also (i)
present in the cell wall, i.e. nine proteins, (ii) localized at the
membrane, i.e. eight proteins or (iii) primarily cytoplasmic,
i.e. 14 proteins (Fig. 1 and Table 2). Altogether, 51 out of 60
non-orthologous proteins identified here (85%) could clearly
be predicted as extracellular.
3.2 Core and variant exoproteomes of
L. monocytogenes species
Comparison of exoproteomes of the 12 L. monocytogenesstrains investigated here revealed that 43 out of the 60 non-
orthologous proteins identified were commonly found in the
extracellular milieu of all strains (Tables 2 and 3, Fig. 2 and
Supporting Information Fig. 1S). As already mentioned,
several proteins were resolved as more than one single spot
that could result from post-translational modifications and/
or orthologues with different Mr and/or pI. Even though
some of these proteins were expressed in the 12 L. mono-cytogenes strains, some protein spots were specifically
present only in a subset of strains suggesting strain-specific
post-translational modifications (Table 2 and Fig. 2). Besides
this core exoproteome, 17 proteins appeared as expressed
only in some L. monocytogenes strains as these proteins
were at the most only present in or absent from one strain
(Table 3 and Fig. 2).
As expected from the high proportion of genes annotated
as hypothetical in L. monocytogenes genome in GenBank [78],
25 out of the 60 proteins identified here had unknown
functions (Supporting Information Table S1). In addition,
considering that automatic annotations may give false func-
tional identification [79], all the annotations were firstly
verified seeking for matches against various databases,
namely Pfam, Prosite, SMART, TIGRfam, SCOP and PIRSF.
For proteins resulting in inconclusive or no matches, PSI-
BLAST searches were performed against UniProt until
convergence was reached. Besides confirming and improving
original annotations, this approach allowed for the number of
proteins with unpredicted functions to be reduced to seven
(Tables 2 and 3 and Supporting Information Table S1).
3.2.1 Virulence factors
Several virulence factors were identified in the culture super-
natant of the different L. monocytogenes strains investigated. Key
extracellularly secreted virulence factors LLO (Spots 1038, 1041,
1418, 1461, 3743 and 3744) and phosphatidylcholine Plc (PlcB;
Spots 2082, 2085, 2088, 2174, 2177, 2178, 2208, 2267, 2280 and
2290) were identified in all the L. monocytogenes strains investi-
gated, though phosphatidylinositol Plc (PlcA; Spot 1957) was
absent from L. monocytogenes CLIP90602 (Tables 2 and 3 and
Supporting Information Fig. 1S). While LLO is required for
L. monocytogenes escape from vacuoles formed after inter-
nalization and cell-to-cell spreading, the combined action of
PlcA and PlcB allows for efficient hydrolysis of vacuolar
membranes [80]. ActA mediates the polarized actin tail forma-
tion within the host cell that propels the bacteria toward the
plasmic membrane, thus enabling cell-to-cell spreading [81].
ActA is a Type I integrated membrane protein but its limited
release from the bacterial cell surface was previously reported
[82]. Similarly, a membrane-anchored immunogenic protein
that elicits pathogen-specific CD41 T-cell responses was also
found in the culture supernatant (Table 2 and Supporting
Information Fig. 1S; Spots 1653, 1799 and 2295). Although its
role in pathogenesis remains unclear [83], the presumably Sec-
secreted InlC (Table 2 and Supporting Information Fig. 1S;
Spots 2076, 2079, 2102, 2155, 2184, 2181 and 2191), which
belongs to the third and last subfamily of Inl [84], was as
expected found extracellularly in the 12 L. monocytogenes strains
investigated. Antioxidant potential of manganese-superoxide
dismutase (MnSOD; Table 2 and Supporting Information
Fig. 1S; Spots 2441, 2472, 2488 and 2491) is critical in
L. monocytogenes pathogenesis [85]. Despite this protein lacking
an N-terminal signal peptide, MnSOD is secreted in a route
involving the alternative cytosolic ATPase SecA2, a paralogue of
SecA, that most certainly converges to the protein conducting-
channel constituted by the Sec translocon in L. monocytogenes[6, 85]. Surprisingly enough, MnSOD was neither predicted nor
identified as part of the exoproteome in previous L. mono-cytogenes proteomic analysis by Trost et al. [19]. Along with
MnSOD, Iap (Table 2 and Supporting Information Fig. 1S;
Spots 1085, 2708 3746 and 3747) is found in the supernatant of
the 12 L. monocytogenes strains and is secreted in a SecA2-
dependent manner [86].
3.2.2 Enzymes of cell-wall degradation/maturation
A number of proteins primarily involved in cell-wall degra-
dation and/or maturation were present extracellularly as
they are most certainly released from the cell wall as a result
of their catalytic activity and/or cell wall turnover, which
could further explain the presence of proteins primarily
Proteomics 2009, 9, 3136–3155 3143
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

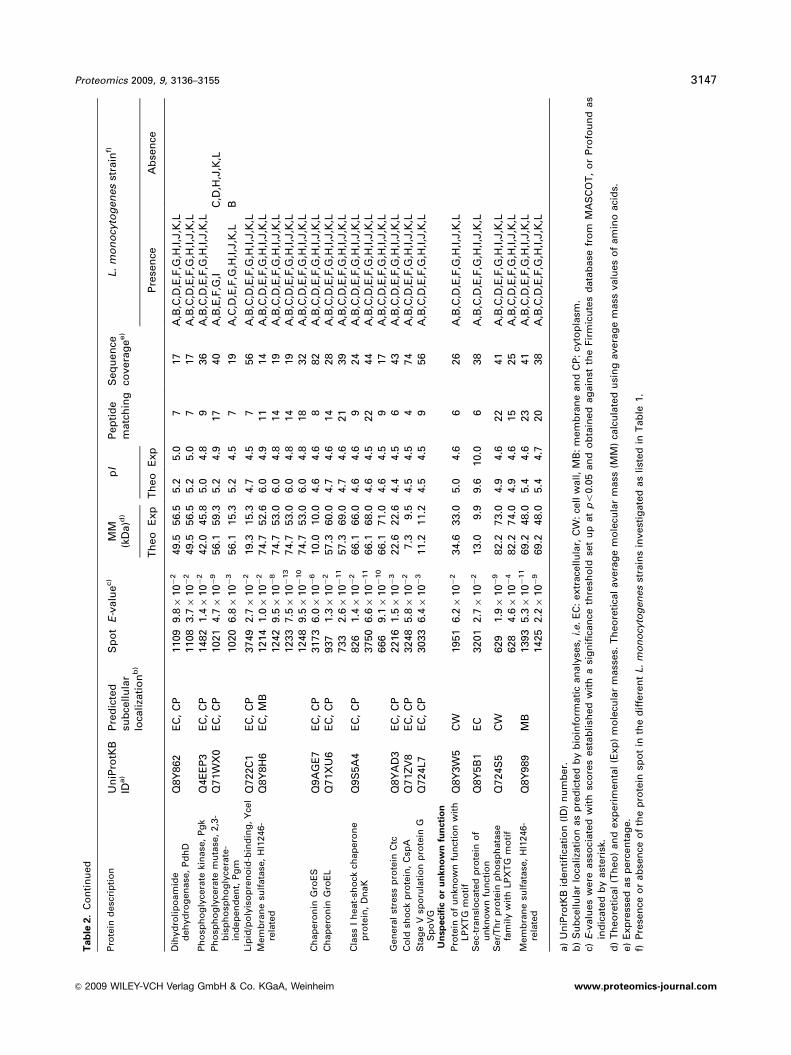
Tab
le2.
Co
reexo
pro
teo
me
of
L.
mo
no
cyto
gen
es
speci
es
foll
ow
ing
pro
tein
iden
tifi
cati
on
by
MA
LD
I-T
OF
MS
Pro
tein
desc
rip
tio
nU
niP
rotK
BID
a)
Pre
dic
ted
sub
cell
ula
rlo
cali
zati
on
b)
Sp
ot
E-v
alu
ec)
MM
(kD
a)d
)p
IP
ep
tid
em
atc
hin
gS
eq
uen
ceco
vera
ge
e)
L.
mo
no
cyto
gen
es
stra
inf)
Th
eo
Exp
Th
eo
Exp
Pre
sen
ceA
bse
nce
Vir
ule
nce
dete
rmin
an
ts
Lis
teri
oly
sin
O,
Hly
P13128
EC
1038
1.9�
10�
15
58.7
57.4
7.6
6.8
23
49
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1041
9.4�
10�
18
58.7
57.4
7.6
6.6
22
45
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1461
9.6�
10�
558.7
46.7
7.6
7.6
14
32
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1418
8.0�
10�
558.7
48.1
7.6
6.8
11
29
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
3743
1.9�
10�
10
58.7
60.7
7.6
6.9
18
40
A,C
,D,E
,F,H
,I,J
,K,L
B,G
3744
1.2�
10�
13
58.7
60.7
7.6
7.2
19
39
A,C
,D,E
,F,H
,I,J
,K,L
B,G
Ph
osp
hati
dylc
ho
lin
ep
ho
sph
oli
pase
C,
Plc
BP
33378
EC
2088
3.7�
10�
12
33.2
27.0
8.4
6.9
15
50
A,C
,D,E
,F,G
,H,I,J
,K,L
B2177
3.0�
10�
633.2
24.7
8.4
7.0
14
39
A,C
,D,E
,G,H
,I,J
,K,L
F,B
2178
5.4�
10�
533.2
24.6
8.4
7.0
10
39
A,C
,D,E
,G,H
,I,J
,K,L
F,B
2174
1.7�
10�
233.2
24.7
8.4
7.7
936
C,D
,E,F
,G,H
,I,J
,K,L
A,B
2280
5.3�
10�
433.2
22.6
8.4
7.4
13
41
B,C
,D,E
,F,H
,I,J
,K,L
A,G
2082
9.1�
10�
433.2
27.1
8.4
7.0
526
C,D
,E,F
,H,I
,J,K
,LA
,B,G
2085
3.7�
10�
833.2
27.0
8.4
7.0
13
32
C,D
,F,H
,J,K
,LA
,B,E
,G,I
2267
2.0�
10�
333.2
22.6
8.4
7.8
12
34
C,D
,F,H
,J,K
,LA
,B,E
,G,I
2290
1.9�
10�
333.2
22.6
8.4
7.0
13
43
A,B
,C,G
,H,L
D,E
,F,I
,J,K
2208
4.3�
10�
333.2
23.2
8.4
7.0
11
29
A,D
,E,F
,G,L
B,C
,H,I
,J,K
Act
in-a
ssem
bly
-in
du
cin
gp
rote
in,
Act
AP
33379
MB
1031
1.7�
10�
4�
70.3
59.3
5.0
4.6
14
30
A,B
,D,E
,H,L
C,F
,G,I
,J,K
673
6.1�
10�
12�
70.3
59.2
5.0
4.7
15
36
A,B
,D,E
,F,G
,H,I,J
,K,L
C609
2.2�
10�
2�
70.3
74.0
5.0
4.8
614
A,B
,D,E
,F,G
,H,I,J
,K,L
C757
5.8�
10�
5�
70.3
69.0
5.0
4.8
10
23
A,B
,D,E
,F,G
,H,I,J
,K,L
C1159
6.0�
10�
270.3
55.8
5.0
4.9
10
17
A,B
,E,F
,G,I
,J,L
C,D
,H,K
979
2.3�
10�
470.3
60.2
5.0
4.4
11
18
A,B
,D,E
,G,H
,I,J
,LC
,F,K
1099
6.3�
10�
470.3
57.5
5.0
4.6
10
18
A,B
,E,G
,H,I,J
,LC
,D,F
,K756
4.2�
10�
870.3
69.1
5.0
4.8
18
34
A,B
,D,E
,F,G
,H,I,J
,K,L
C942
1.6�
10�
270.3
62.0
5.0
4.6
10
18
A,B
,E,G
,H,I,J
,LC
,D,F
,K612
1.2�
10�
11
70.3
70.3
5.0
4.7
17
33
A,C
,D,E
,F,G
,H,I,J
,K,L
B1137
6.6�
10�
470.3
56.2
5.0
4.5
10
18
A,B
,E,G
,H,J
,LC
,D,F
,I,K
CD
41
T-c
ell
-sti
mu
lati
ng
an
tig
en
,T
csA
Q48754
MB
1653
3.1�
10�
638.4
35.8
5.0
4.6
12
35
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
2295
3.6�
10�
338.4
22.6
5.0
5.0
825
LA
,B,C
,D,E
,F,G
,H,I
,J,K
1799
1.2�
10�
438.4
34.3
5.0
4.6
933
LA
,B,C
,D,E
,F,G
,H,I
,J,K
Inte
rnali
nC
,In
lCQ
8Y
6A
8E
C2076
1.9�
10�
333.0
28.2
6.1
5.1
10
38
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
2155
5.6�
10�
333.0
25.1
6.1
4.9
832
A,B
,C,D
,E,F
,G,H
,I,J
,KL
2191
1.5�
10�
11
33.0
24.2
6.1
6.1
13
44
A,B
,C,D
,F,G
,H,J
,K,L
E,I
2184
1.1�
10�
233.0
24.4
6.1
5.6
618
A,C
,D,F
,G,H
,J,K
,LB
,E,I
2181
3.8�
10�
11
33.0
24.5
6.1
5.0
15
50
C,D
,F,G
,H,J
,KA
,B,E
,I,L
2102
1.9�
10�
233.0
28.0
6.1
5.0
830
C,D
,H,K
A,B
,E,F
,G,I,J
,L2079
8.9�
10�
633.0
24.5
6.1
5.6
13
46
AB
,C,D
,E,F
,G,H
,I,J
,K,L
3144 E. Dumas et al. Proteomics 2009, 9, 3136–3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

Tab
le2.
Co
nti
nu
ed
Pro
tein
desc
rip
tio
nU
niP
rotK
BID
a)
Pre
dic
ted
sub
cell
ula
rlo
cali
zati
on
b)
Sp
ot
E-v
alu
ec)
MM
(kD
a)d
)p
IP
ep
tid
em
atc
hin
gS
eq
uen
ceco
vera
ge
e)
L.
mo
no
cyto
gen
es
stra
inf)
Th
eo
Exp
Th
eo
Exp
Pre
sen
ceA
bse
nce
Man
gan
ese
-su
pero
xid
ed
ism
uta
se,
Mn
SO
DP
28764
EC
,C
P2472
2.5�
10�
11
22.6
22.6
5.2
5.0
13
70
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
2491
8.9�
10�
622.6
22.6
5.2
4.8
744
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
2488
1.4�
10�
422.6
22.6
5.2
5.0
947
E,F
,G,I
,JA
,B,C
,D,H
,K,L
2441
3.9�
10�
11
22.6
22.6
5.2
5.0
13
92
A,E
,F,G
,I,J
,K,L
B,C
,D,H
Invasi
on
-ass
oci
ate
dp
rote
in,
Iap
P21171
EC
,C
W3746
5.8�
10�
250.3
35.3
9.3
9.2
10
28
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
3747
8.2�
10�
450.3
34.8
9.3
9.1
11
27
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1085
4.7�
10�
950.3
53.0
9.3
9.3
14
38
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
2708
1.6�
10�
250.3
18.0
9.3
6.4
846
A,B
,E,F
,G,I
A,B
,E,F
,G,I
Cell
wall
deg
rad
ati
on
an
db
iog
en
esis
P45
pep
tid
og
lyca
nly
tic
pro
tein
,N
LP
/P60
fam
ily,
Sp
lQ
9R
E04
EC
,C
W1485
2.4�
10�
13
42.7
44.0
8.6
7.2
15
38
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1489
4.8�
10�
13
42.7
44.0
8.6
7.8
15
38
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1484
5.6�
10�
642.7
44.0
8.6
6.7
13
34
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1505
4.9�
10�
442.7
45.0
8.6
6.2
724
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
N-a
cety
lmu
ram
oyl-
L-a
lan
ine
am
idase
Q8Y
707
EC
,C
W1436
3.5�
10�
12
46.0
47.4
5.5
5.0
17
49
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1435
1.5�
10�
13
46.0
47.4
5.5
4.9
16
47
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1455
9.5�
10�
11
46.0
47.4
5.5
4.8
14
44
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
2103
2.4�
10�
14
46.0
27.4
5.5
5.4
17
49
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1444
1.1�
10�
14
46.0
47.4
5.5
5.2
19
53
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1428
6.9�
10�
546.0
47.6
5.5
5.4
721
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1438
8.4�
10�
546.0
47.6
5.5
5.4
11
26
C,E
,F,H
,I,K
,LA
,B,D
,G,J
Au
toly
sin
,M
urA
Q8Y
3Y
8E
C,
CW
1601
1.2�
10�
3�
63.5
38.0
9.7
6.1
68
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Mu
ram
idase
flag
ell
um
-sp
eci
fic
Q71W
I7E
C,
CW
1122
2.0�
10�
11
57.0
56.5
5.8
5.0
16
37
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1117
2.4�
10�
457.0
56.5
5.8
5.0
12
25
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1123
9.4�
10�
12
57.0
56.5
5.8
5.0
18
38
A,B
,G,I
C,D
,E,F
,H,J
,K,L
1110
3.7�
10�
10
57.0
56.9
5.8
5.3
14
27
C,D
,E,F
,G,H
,I,J
,K,L
A,B
1118
7.1�
10�
21
57.0
56.7
5.8
5.5
27
50
B,C
,D,E
,F,G
,H,J
,K,L
A,I
1126
6.0�
10�
29
57.0
57.0
5.8
5.8
28
55
C,D
,H,J
,K,L
A,B
,E,F
,G,I
1141
2.8�
10�
16
57.0
56.3
5.8
6.3
23
49
D,H
A,B
,C,E
,F,G
,I,J
,K,L
Mu
rein
tran
sgly
cosy
lase
Q71W
Q6
EC
,C
W2078
5.8�
10�
329.0
27.8
5.5
4.8
947
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
2073
4.9�
10�
729.0
27.6
5.5
4.9
14
61
A,B
,E,F
,G,I
C,D
,H,J
,K,L
2133
2.7�
10�
329.0
26.2
5.5
5.0
12
47
C,D
,H,J
,K,L
A,B
,E,F
,G,I
2086
4.4�
10�
229.0
26.5
5.5
5.0
938
C,D
,H,J
,K,L
A,B
,E,F
,G,I
2142
2.1�
10�
229.0
26.0
5.5
4.9
843
C,D
,H,J
,K,L
A,B
,E,F
,G,I
Pen
icil
lin
-bin
din
gp
rote
in,
tran
spep
tid
ase
/cell
div
isio
np
rote
inFts
I
Q8Y
763
EC
762
8.9�
10�
10
79.9
68.8
7.5
5.0
23
34
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
763
7.1�
10�
979.9
68.8
7.5
5.1
23
36
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Pen
icil
lin
-bin
din
gp
rote
in,
tran
spep
tid
ase
/cell
div
isio
np
rote
inFts
I
Q71X
X4
721
4.5�
10�
281.9
69.6
6.6
5.4
13
25
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
772
6.0�
10�
281.9
68.8
6.6
5.2
610
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Proteomics 2009, 9, 3136–3155 3145
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

Tab
le2.
Co
nti
nu
ed
Pro
tein
desc
rip
tio
nU
niP
rotK
BID
a)
Pre
dic
ted
sub
cell
ula
rlo
cali
zati
on
b)
Sp
ot
E-v
alu
ec)
MM
(kD
a)d
)p
IP
ep
tid
em
atc
hin
gS
eq
uen
ceco
vera
ge
e)
L.
mo
no
cyto
gen
es
stra
inf)
Th
eo
Exp
Th
eo
Exp
Pre
sen
ceA
bse
nce
Pen
icil
lin
-bin
din
gp
rote
in,
tran
spep
tid
ase
Q8Y
9I8
EC
1695
5.0�
10�
244.4
35.6
9.2
6.8
10
30
C,D
,H,J
,K,L
A,B
,E,F
,G,I
1669
4.4�
10�
244.4
35.6
9.2
7.2
820
A,C
,E,F
,H,K
,LB
,D,G
,I,J
1665
5.9�
10�
444.4
35.6
9.2
5.5
721
A,B
,G,I
C,D
,E,F
,H,,
K,L
1677
5.8�
10�
344.4
35.6
9.2
7.8
12
24
A,F
,HB
,C,D
,E,G
,I,J
,K,L
1676
6.3�
10�
444.4
35.6
9.2
6.9
11
34
IA
,B,C
,D,E
,F,G
,H,J
,K,L
Bif
un
ctio
nal
tran
sgly
cosy
lase
/tr
an
spep
tid
ase
pen
icil
lin
-b
ind
ing
pro
tein
,P
bp
A
Q71Y
C3
510
1.0�
10�
390.8
77.5
8.6
6.0
15
16
A,B
,E,F
,G,I
C,D
,H,J
,K,L
Cell
-en
velo
pe-r
ela
ted
tran
scri
pti
on
al
att
en
uato
rQ
8Y
9T
0E
C2257
2.0�
10�
534.1
22.6
9.1
5.1
13
32
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
2261
1.9�
10�
834.1
22.6
9.1
5.5
13
39
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Cell
-en
velo
pe-r
ela
ted
tran
scri
pti
on
al
att
en
uato
r,LytR
Q8Y
4D
2E
C1942
7.4�
10�
439.1
33.0
5.6
4.6
925
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1989
1.9�
10�
239.1
32.2
5.6
4.6
10
28
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1942
7.4�
10�
439.1
33.0
5.6
4.6
925
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Deg
rad
ati
ve
en
zym
es
Pep
tid
ase
M23B
fam
ily
Q8Y
AE
4E
C,
MB
1538
2.5�
10�
444.4
44.4
9.0
9.0
10
28
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
3748
4.7�
10�
244.4
22.6
9.0
6.2
921
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Pep
tid
ase
M23B
fam
ily
Q71W
S4
EC
1333
3.2�
10�
4�
47.0
51.0
6.3
5.5
815
C,D
,H,J
,K,L
A,B
,E,F
,G,I
1334
6.3�
10�
247.0
51.1
6.3
5.7
825
A,B
,E,F
,G,I
C,D
,H,J
,K,L
1326
6.3�
10�
347.0
51.0
6.3
6.0
933
A,E
,F,I
B,C
,D,G
,H,J
,K,L
Ch
itin
ase
,C
hiA
Q71Y
D3
EC
1679
6.3�
10�
337.9
35.4
6.3
4.9
723
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1739
7.0�
10�
637.9
35.0
6.3
5.2
11
43
LA
,B,C
,D,E
,F,G
,H,I
,J,K
Cell
-su
rface
com
ple
xp
rote
inB
,C
scB
Q8Y
9E
5C
W2168
1.7�
10�
2�
24.3
24.1
4.6
4.4
419
A,B
,D,E
,F,G
,H,I
,K,L
C,J
2094
9.4�
10�
324.3
27.6
4.6
4.3
637
C,J
A,B
,D,E
,F,G
,H,I,K
,LT
ran
sp
ort
an
dm
em
bra
ne
bio
en
erg
eti
cs
AB
C-t
yp
eo
lig
op
ep
tid
etr
an
spo
rtsy
stem
,so
lute
-bin
din
gp
rote
inco
mp
on
en
t,O
pp
A
Q9LA
T7
MB
890
1.7�
10�
262.5
63.5
5.3
4.8
11
28
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
AB
C-t
yp
ed
ipep
tid
etr
an
spo
rtsy
stem
,so
lute
-bin
din
gp
rote
inco
mp
on
en
t
Q8Y
AJ0
MB
1145
7.8�
10�
758.0
55.7
5.0
4.7
16
40
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
AA
3-6
00
qu
ino
lo
xid
ase
sub
un
itII
,Q
oxA
Q8Y
AV
0M
B1922
5.1�
10�
241.5
33.2
6.0
5.0
11
30
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1947
1.3�
10�
341.5
32.8
6.0
5.6
833
B,C
,G,H
,J,K
,LA
,D,E
,F,I
1931
1.9�
10�
241.5
33.2
6.0
5.1
514
C,E
,F,H
,I,K
A,B
,D,G
,J,L
1938
5.9�
10�
241.5
41.8
6.0
5.2
723
A,B
,D,G
,IC
,E,F
,H,J
,K,L
Co
facto
ran
dvit
am
inb
iosyn
thesis
Am
ino
deo
xych
ori
sm
ate
lyase
,Y
qzC
Q8Y
7E
9E
C3001
2.6�
10�
517.8
12.0
9.1
9.6
11
59
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
2917
7.9�
10�
417.8
13.6
9.1
7.8
947
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Secre
ted
by
un
kn
ow
nsecre
tio
nsyste
m
Gly
cera
ldeh
yd
e-3
-ph
osp
hate
deh
yd
rog
en
ase
,G
ap
Q8Y
4I1
EC
,C
P1581
2.4�
10�
936.3
36.5
5.2
4.9
13
42
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1585
1.3�
10�
336.3
36.9
5.2
5.0
12
30
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1582
4.8�
10�
236.3
36.2
5.2
5.0
12
32
A,B
,D,E
,F,G
,H,I
,J,K
,LC
En
ola
se,
En
oQ
71W
X1
EC
,C
P3745
6.0�
10�
17
46.5
47.1
4.7
4.5
21
54
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
3146 E. Dumas et al. Proteomics 2009, 9, 3136–3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com
Tab
le2.
Co
nti
nu
ed
Pro
tein
desc
rip
tio
nU
niP
rotK
BID
a)
Pre
dic
ted
sub
cell
ula
rlo
cali
zati
on
b)
Sp
ot
E-v
alu
ec)
MM
(kD
a)d
)p
IP
ep
tid
em
atc
hin
gS
eq
uen
ceco
vera
ge
e)
L.
mo
no
cyto
gen
es
stra
inf)
Th
eo
Exp
Th
eo
Exp
Pre
sen
ceA
bse
nce
Dih
yd
roli
po
am
ide
deh
yd
rog
en
ase
,P
dh
DQ
8Y
862
EC
,C
P1109
9.8�
10�
249.5
56.5
5.2
5.0
717
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1108
3.7�
10�
249.5
56.5
5.2
5.0
717
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Ph
osp
ho
gly
cera
teki
nase
,P
gk
Q4E
EP
3E
C,
CP
1482
1.4�
10�
242.0
45.8
5.0
4.8
936
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Ph
osp
ho
gly
cera
tem
uta
se,
2,3
-b
isp
ho
sph
og
lyce
rate
-in
dep
en
den
t,P
gm
Q71W
X0
EC
,C
P1021
4.7�
10�
956.1
59.3
5.2
4.9
17
40
A,B
,E,F
,G,I
C,D
,H,J
,K,L
1020
6.8�
10�
356.1
15.3
5.2
4.5
719
A,C
,D,E
,F,G
,H,I
,J,K
,LB
Lip
id/p
oly
iso
pre
no
id-b
ind
ing
,Y
ceI
Q722C
1E
C,
CP
3749
2.7�
10�
219.3
15.3
4.7
4.5
756
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Mem
bra
ne
sulf
ata
se,
HI1
246-
rela
ted
Q8Y
8H
6E
C,
MB
1214
1.0�
10�
274.7
52.6
6.0
4.9
11
14
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1242
9.5�
10�
874.7
53.0
6.0
4.8
14
19
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1233
7.5�
10�
13
74.7
53.0
6.0
4.8
14
19
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1248
9.5�
10�
10
74.7
53.0
6.0
4.8
18
32
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Ch
ap
ero
nin
Gro
ES
Q9A
GE
7E
C,
CP
3173
6.0�
10�
610.0
10.0
4.6
4.6
882
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Ch
ap
ero
nin
Gro
EL
Q71X
U6
EC
,C
P937
1.3�
10�
257.3
60.0
4.7
4.6
14
28
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
733
2.6�
10�
11
57.3
69.0
4.7
4.6
21
39
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Cla
ssI
heat-
sho
ckch
ap
ero
ne
pro
tein
,D
naK
Q9S
5A
4E
C,
CP
826
1.4�
10�
266.1
66.0
4.6
4.6
924
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
3750
6.6�
10�
11
66.1
68.0
4.6
4.5
22
44
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
666
9.1�
10�
10�
66.1
71.0
4.6
4.5
917
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Gen
era
lst
ress
pro
tein
Ctc
Q8Y
AD
3E
C,
CP
2216
1.5�
10�
322.6
22.6
4.4
4.5
643
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Co
ldsh
ock
pro
tein
,C
spA
Q71Z
V8
EC
,C
P3248
5.8�
10�
27.3
9.5
4.5
4.5
474
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Sta
ge
Vsp
oru
lati
on
pro
tein
GS
po
VG
Q724L7
EC
,C
P3033
6.4�
10�
311.2
11.2
4.5
4.5
956
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Un
sp
ecifi
co
ru
nkn
ow
nfu
ncti
on
Pro
tein
of
un
kno
wn
fun
ctio
nw
ith
LP
XT
Gm
oti
fQ
8Y
3W
5C
W1951
6.2�
10�
234.6
33.0
5.0
4.6
626
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Sec-
tran
slo
cate
dp
rote
ino
fu
nkn
ow
nfu
nct
ion
Q8Y
5B
1E
C3201
2.7�
10�
213.0
9.9
9.6
10.0
638
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Ser/
Th
rp
rote
inp
ho
sph
ata
sefa
mil
yw
ith
LP
XT
Gm
oti
fQ
724S
5C
W629
1.9�
10�
982.2
73.0
4.9
4.6
22
41
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
628
4.6�
10�
482.2
74.0
4.9
4.6
15
25
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
Mem
bra
ne
sulf
ata
se,
HI1
246-
rela
ted
Q8Y
989
MB
1393
5.3�
10�
11
69.2
48.0
5.4
4.6
23
41
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
1425
2.2�
10�
969.2
48.0
5.4
4.7
20
38
A,B
,C,D
,E,F
,G,H
,I,J
,K,L
a)
Un
iPro
tKB
iden
tifi
cati
on
(ID
)n
um
ber.
b)
Su
bce
llu
lar
loca
liza
tio
nas
pre
dic
ted
by
bio
info
rmati
can
aly
ses,
i.e.
EC
:extr
ace
llu
lar,
CW
:ce
llw
all
,M
B:
mem
bra
ne
an
dC
P:
cyto
pla
sm.
c)E
-valu
es
were
ass
oci
ate
dw
ith
sco
res
est
ab
lish
ed
wit
ha
sig
nifi
can
ceth
resh
old
set
up
at
po
0.0
5an
do
bta
ined
ag
ain
stth
eFir
mic
ute
sd
ata
base
fro
mM
AS
CO
T,
or
Pro
fou
nd
as
ind
icate
db
yast
eri
sk.
d)
Th
eo
reti
cal
(Th
eo
)an
dexp
eri
men
tal
(Exp
)m
ole
cula
rm
ass
es.
Th
eo
reti
cal
avera
ge
mo
lecu
lar
mass
(MM
)ca
lcu
late
du
sin
gavera
ge
mass
valu
es
of
am
ino
aci
ds.
e)
Exp
ress
ed
as
perc
en
tag
e.
f)P
rese
nce
or
ab
sen
ceo
fth
ep
rote
insp
ot
inth
ed
iffe
ren
tL.
mo
no
cyto
gen
es
stra
ins
invest
igate
das
list
ed
inT
ab
le1.
Proteomics 2009, 9, 3136–3155 3147
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

predicted as cell-wall attached in the extracellular milieu,
namely, proteins with LPXTG, GW, LysM or WXL motifs.
Among the six L. monocytogenes murein-hydrolase autolysins
characterized to date, namely, Iap, P45 (protein of 45 kDa),
amidase, muramidase A (MurA), autolysin and Lmo0327
[74, 87], P45 (Table 2 and Supporting Information Fig. 1S;
Spots 1484, 1485, 1489, and 1505) and MurA (Table 2 and
Supporting Information Fig. 1S; Spot 1601) along with Iap
could be identified here as core constituents of L. mono-cytogenes exoproteome. As Iap, MurA, which is also called
NamA (N-acetylmuramidase A), is secreted in a SecA2-
dependent manner [88, 89]. Similarly, cell-wall hydrolase
Q8Y707 (Table 2 and Supporting Information Fig. 1S; Spots
1428, 1435, 1436, 1438, 1444, 1455 and 2103) was newly
identified as expressed and as part of the core exoproteome
of L. monocytogenes, together with a muramidase Q71W17
(Table 2 and Supporting Information Fig. 1S; Spots 1110,
1117, 1118, 1122, 1123, 1126 and 1141) specifically involved
in the flagellum assembly (COG1705: E-values 5 1.00
� 10�51) and a murein transglycosylase Q71WQ6 (Table 2
and Supporting Information Fig. 1S; Spots 2073, 2078,
2086, 2133 and 2142) involved in the recycling of muro-
peptides during cell elongation and/or division (IPR010611,
PF06725: E-values 5 1.5� 10�35; COG2821: E-value 5 7.00
� 10�05). Conversely, autolysin Q4EHT4 (Table 3,
Supporting Information Fig. 1S; Spot 3253) and flagellum-
specific muramidase Q8Y572 (Table 3 and Supporting
Information Fig. 1S; Spots 1726 and 1727) were only
expressed in a subset of L. monocytogenes strains. Besides,
these murein hydrolases involved in several degradation
processes related to cell-wall turnover, peptidoglycan
maturation and cell division, four penicillin-binding
proteins (Q8Y763, Q71XX4, Q8Y9I8 and Q71YC3) as well as
two cell-envelope-related transcriptional attenuators
(Q8Y9T0 and Q8Y4D2) were part of the core exoproteome
(Table 2) and were related to peptidoglycan biosynthesis for
cell-wall formation in the course of cell division. Two of
them (Q8Y763 and Q71YC3) were neither predicted nor
identified as part of the exoproteome in previous secretomic
investigation of L. monocytogenes [19]. Altogether, this indi-
cates that the cell wall is the siege of high activity, which can
have consequences on numerous cellular processes includ-
ing cell growth, biofilm formation, genetic competence,
protein secretion and pathogenicity [74].
3.2.3 Other degradative enzymes
Besides cell-wall hydrolases, several secreted degradative
enzymes could be identified here in L. monocytogenes culture
supernatants. Two peptidases of the M23B family (Q8YAE4
and Q71WS4), i.e. metallopeptidases belonging to the
MEROPS peptidase family clan M subtype B [90], were
identified in all the strains investigated (Table 2). On the
contrary, a D-alanyl-D-alanine carboxypeptidase A Q9ZIC4
(Table 3 and Supporting Information Fig. 1S; Spot 1437), i.e.
a serine peptidase belonging to the MEROPS peptidase
family S11 clan SE, and a serine protease Q71YE5 (Table 3
and Supporting Information Fig. 1S; Spot 1339), most
probably belonging to the MEROPS peptidase family S1 and
the peptidase family S6 (SSF50494: E-values 5 1.7� 10�22;
PF00089: E-values 5 8.2� 10�05), were only identified in a
limited number of the 12 L. monocytogenes strains investi-
gated. Peptidases can be involved in a wide variety of
biological processes from protein degradation to cell-wall
biogenesis as well as bacterial virulence [91]. Besides these
peptidases, a chitinase Q71YD3 encoded by chiA gene was
also identified extracellularly (Table 2) [92]. In the natural
environment, chitin is the second most common carbohy-
drate after cellulose and a major source of carbon and
nitrogen [93, 94]. As a component of the core exoproteome,
the chitinolytic activity of L. monocytogenes is most certainly
involved in supporting a saprophytic lifestyle in soil and
sediments. However, a dual role cannot be excluded as
observed in Legionella pneumophila, where ChiA is involved
in bacterial pathogenesis as it promotes the persistence of
this pathogen in a mammalian host [95]. Similarly, CscB
Q8Y9E5 (Table 2 and Supporting Information Fig. 1S; Spots
2094 and 2168), which is described as putatively involved in
plant carbohydrate utilization as part of protein cell-surface
complexes [72], is also considered as a coaggregation-
promoting factor by mediating aggregation of other bacterial
species and might thus be of importance in the biofilm
formation process. Despite the prediction of CscB as an
extracellular protein, this protein was not identified in
previous investigation of L. monocytogenes exoproteome [19].
As already reported in Lactobacillus plantarum, CscB is non-
covalently bound to the bacterial cell surface as it can also be
found in the extracellular milieu.
3.2.4 Proteins secreted by unknown pathways
Several proteins lacking a putative N-terminal signal peptide
and with no legitimate protein secretion system explaining
for their final localization had, furthermore, no obvious
biological function in the extracellular milieu. These
proteins are primarily predicted as cytoplasmic, some of
them being first and foremost involved in the central
metabolism, such as glyceraldehyde-3-phosphate dehy-
drogenase or enolase (Table 2). However, the presence of
such proteins has been reported in the culture supernatant
of numerous bacterial species, including L. monocytogeneswhere they were in addition reported as also being localized
in the cell wall [19, 96]. Clearly, these proteins have multiple
final subcellular localizations. Among these proteins, cata-
lase and cysteine synthetase A appeared to be part of the
exoproteome only in a subset of L. monocytogenes strains
(Table 3). As further indicated by the presence of general
stress protein Ctc or cold shock protein CspA (Table 2), a
number of those proteins are primarily related to bacterial
stress resistance. Finally, this proteomic analysis also
3148 E. Dumas et al. Proteomics 2009, 9, 3136–3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

Tab
le3.
Vari
an
texo
pro
teo
me
of
L.
mo
no
cyto
gen
es
speci
es
foll
ow
ing
pro
tein
iden
tifi
cati
on
by
MA
LD
I-T
OF
MS
Pro
tein
desc
rip
tio
nU
niP
rotK
BID
a)
Pre
dic
ted
sub
cell
ula
rlo
cali
zati
on
b)
Sp
ot
E-v
alu
ec)
MM
(kD
a)d
)p
IP
ep
tid
em
atc
hin
gS
eq
uen
ceco
vera
ge
e)
L.
mo
no
cyto
gen
es
stra
inf)
Th
eo
Exp
Th
eo
Exp
Pre
sen
ceA
bse
nce
Vir
ule
nce
dete
rmin
an
ts
Ph
osp
hati
dyli
no
sito
l-sp
eci
fic
ph
osp
ho
lip
ase
C,
Plc
A
P34024
EC
1957
2.4�
10�
736.3
32.1
9.6
9.9
14
41
A,C
,D,E
,F,G
,H,I
,J,K
,LB
Cell
wall
deg
rad
ati
on
an
db
iog
en
esis
Au
toly
sin
Q4E
HT
4E
C,
CW
3253
4.7�
10�
2�
12.6
9.6
9.1
8.0
418
A,E
,FB
,C,D
,G,H
,I,J
,K,L
Mu
ram
idase
flag
ell
um
-sp
eci
fic
Q8Y
572
EC
,C
W1726
2.4�
10�
13
41.7
35.1
5.3
4.7
14
47
A,B
,C,D
,E,F
,G,I
,J,L
H,K
1727
4.7�
10�
241.7
35.0
5.3
4.8
721
C,L
A,B
,D,E
,F,G
,H,I,J
,KD
eg
rad
ati
ve
en
zym
es
Pep
tid
ase
S11
D-a
lan
yl-
D-a
lan
ine
carb
oxyp
ep
tid
ase
A
Q9Z
IC4
EC
1437
2.4�
10�
446.7
47.3
5.7
5.0
12
34
B,G
A,C
,D,E
,F,H
,I,J
,K,L
Seri
ne
pro
tease
,tr
yp
sin
-lik
ese
rin
ean
dcy
stein
ep
ep
tid
ase
Q71Y
E5
EC
,C
W1339
1.3�
10�
348.7
51.2
8.7
7.5
922
A,E
,F,I
B,C
,D,G
,H,J
,K,L
Tra
nsp
ort
an
dm
em
bra
ne
bio
en
erg
eti
cs
K1
-tra
nsp
ort
ing
AT
Pase
,C
sub
un
it,
Kd
pC
Q71W
91
EC
2795
6.2�
10�
220.9
16.0
6.8
5.3
647
A,B
,C,E
,F,G
,ID
,H,J
,K,L
NE
Ar
tran
spo
rter,
Svp
AQ
4E
LE
1M
B887
1.9�
10�
963.3
64.3
6.1
5.0
21
47
BA
,C,D
,E,F
,G,H
,I,J
,K,L
Act
ivato
ro
fo
smo
pro
tect
an
ttr
an
spo
rter,
Pro
P
Q8Y
9V
8M
B2131
5.1�
10�
3�
31.3
26.8
5.0
4.6
935
C,D
,H,K
A,B
,E,F
,G,I
,J,L
Tra
nsc
rip
tio
nal
reg
ula
tors
Sig
ma
54
mo
du
lati
on
pro
tein
/rib
oso
mal
pro
tein
S30E
A,
Yfi
A.
Q71W
R7
CP
2602
3.3�
10�
221.6
19.9
5.3
5.1
650
A,D
,E,F
,I,J
B,C
,G,H
,K,L
Secre
ted
by
un
kn
ow
nsecre
tio
nsyst
em
Cata
lase
,K
atA
Q4E
IV2
EC
,C
P1006
1.9�
10�
31
55.8
60.3
5.4
5.0
33
66
A,E
,F,I,B
,GC
,D,H
,J,K
,LC
yst
ein
esy
nth
ase
A,
CysK
Q8Y
AC
3E
C,
MB
2002
3.7�
10�
532.2
32.2
5.3
5.0
13
52
A,C
,D,E
,F,G
,H,I
,J,K
,LB
Un
sp
ecifi
co
ru
nkn
ow
nfu
ncti
on
Sec-
tran
slo
cate
dp
rote
ino
fu
nkn
ow
nfu
nct
ion
Q8Y
6D
5E
C2029
5.1�
10�
228.7
30.0
5.1
4.8
727
A,B
,C,D
,G,H
,I,J
,K,L
E,F
1999
1.5�
10�
828.7
32.0
5.1
4.7
10
32
C,D
,H,J
,KA
,B,E
,F,G
,I,L
2070
4.9�
10�
428.7
28.9
5.1
4.9
728
IA
,B,C
,D,E
,F,G
,H,J
,K,L
Sec-
tran
slo
cate
dp
rote
ino
fu
nkn
ow
nfu
nct
ion
Q721A
2E
C1935
4.4�
10�
430.6
33.0
8.5
6.4
637
A,E
,F,I
B,C
,D,G
,H,J
,K,L
Sec-
tran
slo
cate
dp
rote
ino
fu
nkn
ow
nfu
nct
ion
Q71X
Z2
EC
2816
4.1�
10�
415.5
15.4
4.5
4.4
658
A,E
,F,I,B
,GC
,D,H
,J,K
,L
Lip
op
rote
ino
fu
nkn
ow
nfu
nct
ion
Q8Y
850
MB
2058
8.9�
10�
430.8
30.1
5.9
5.6
939
A,B
,C,E
,F,G
,H,I
,J,K
,LD
2080
3.1�
10�
230.8
28.2
5.9
5.7
631
B,C
,G,H
,J,K
,LA
,D,E
,F,I
Proteomics 2009, 9, 3136–3155 3149
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

revealed the expression of several proteins whose genes
were originally annotated as hypothetical. However, their
functions remain unclear as no further insight could be
gained from additional in silico analyses as described above.
Four of them (Q8Y3W5, Q8Y5B1, Q724S5 and Q8Y989)
were part of the core exoproteome (Table 2), whereas the
remaining six (Q8Y6D5, Q721A2, Q71XZ2, Q8Y850,
Q721L6 and Q8Y9F2) were part of the variant exoproteome
(Table 3). Altogether, six of these proteins exhibited an
N-terminal signal peptide and were thus more likely trans-
located in a Sec-dependent manner, including one lipopro-
tein Q8Y850 (Table 2) and one LPXTG protein Q8Y3W5
(Table 3). One of them (Q721A2) was neither predicted nor
identified as part of the exoproteome from previous secre-
tomic analysis of L. monocytogenes [19].
4 Concluding remarks
From the present investigation, a large majority of the
proteins identified within the extracellular milieu were
indeed predicted as extracellular, i.e. 51 out of 60 proteins
(85%). Most of them were actually predicted as secreted viathe Sec pathway, i.e. 42 out of 60 proteins (70%) (Fig. 3). By
comparison, exoproteomes from other Gram positive
bacteria such as Bacillus licheniformis [97] and Bacillus subtilis[98] revealed that 62% (89/143) and 53% (48/90) of the
identified proteins could be predicted as secreted. As for
L. monocytogenes, most of them contained a Sec-type signal
peptide (75/89 and 34/48, respectively) and were probably
exported by the Sec pathway. In B. licheniformis and
B. subtilis, respectively, 4 and 14 of the predicted secreted
proteins exhibited a potential twin-arginine signal peptide
suggesting they were directed to the Tat machinery. Among
the ten remaining proteins known to be secreted in
B. licheniformis, seven were flagellum proteins most prob-
ably transported via the FEA and three phage-related
proteins were presumably secreted via holins [97].
While the first exoproteomic analysis by Trost et al. [19]
had the merit of giving an initial view of what makes
L. monocytogenes singular from a non-pathogenic counter-
part, i.e. Listeria innocua CIP11262, as it highlighted that
such differences manifest the most in the exoproteome, this
view was also biased by the fact that it focused on only one
L. monocytogenes strain. The present investigation on the
exoproteomes of 12 different L. monocytogenes strains
allowed taking the biodiversity into account and getting a
more objective overview of the exoproteome from L. mono-cytogenes species. Among the 60 proteins identified here in
the exoproteome of the 12 L. monocytogenes strains investi-
gated, 41 were common to the 105 proteins identified by
Trost et al. [19]. Among them, the major virulence factors
ActA, Hly, PlcB, InlC were identified in all the strains here
investigated. On the other hand, PlcA, a protein involved in
the escape from the phagocytic vacuole, was absent from
one strain. Some proteins primarily predicted as cyto-Tab
le3.
Co
nti
nu
ed
Pro
tein
desc
rip
tio
nU
niP
rotK
BID
a)
Pre
dic
ted
sub
cell
ula
rlo
cali
zati
on
b)
Sp
ot
E-v
alu
ec)
MM
(kD
a)d
)p
IP
ep
tid
em
atc
hin
gS
eq
uen
ceco
vera
ge
e)
L.
mo
no
cyto
gen
es
stra
inf)
Th
eo
Exp
Th
eo
Exp
Pre
sen
ceA
bse
nce
Hyd
rola
se,a/b
fold
fam
ily
Q721L6
EC
2060
8.5�
10�
432.5
29.5
5.8
5.2
931
A,E
,F,I,B
,GC
,D,H
,J,K
,L
Mem
bra
ne
pro
tein
of
un
kno
wn
fun
ctio
nD
UF1085
Q8Y
9F2
MB
1778
3.2�
10�
245.7
35.0
5.0
4.6
613
A,B
,C,D
,E,F
,G,H
,I,K
J,L
a)
Un
iPro
tKB
iden
tifi
cati
on
(ID
)n
um
ber.
b)
Su
bce
llu
lar
loca
liza
tio
nas
pre
dic
ted
by
bio
info
rmati
can
aly
ses,
i.e.
EC
:extr
ace
llu
lar,
CW
:ce
llw
all
,M
B:
mem
bra
ne
an
dC
P:
cyto
pla
sm.
c)E
-valu
es
were
ass
oci
ate
dw
ith
sco
res
est
ab
lish
ed
wit
ha
sig
nifi
can
ceth
resh
old
set
up
at
po
0.0
5an
do
bta
ined
ag
ain
stth
eFir
mic
ute
sd
ata
base
fro
mM
AS
CO
T,
or
Pro
fou
nd
as
ind
icate
db
yast
eri
sk.
d)
Th
eo
reti
cal
(Th
eo
)an
dexp
eri
men
tal
(Exp
)m
ole
cula
rm
ass
es.
Th
eo
reti
cal
avera
ge
mo
lecu
lar
mass
(MM
)ca
lcu
late
du
sin
gavera
ge
mass
valu
es
of
am
ino
aci
ds.
e)
Exp
ress
ed
as
perc
en
tag
e.
f)P
rese
nce
or
ab
sen
ceo
fth
ep
rote
insp
ot
inth
ed
iffe
ren
tL.
mo
no
cyto
gen
es
stra
ins
invest
igate
das
list
ed
inT
ab
le1.
3150 E. Dumas et al. Proteomics 2009, 9, 3136–3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

plasmic and with no protein secretion system explaining for
their final localization were found in the extracellular milieu
in our study as well as in the investigation of Trost et al. [19],
thus confirming their multiple subcellular localizations.
From this first investigation on the strain L. monocytogenesEGD-e, the maximum number of proteins present extra-
cellularly was predicted at 121. From our investigation, the
picture of L. monocytogenes proteins present extracellularly
has been broadened in relation to the protein secretion
systems involved [6]. Among the 60 exoproteins here iden-
tified 43 clearly appeared as part of the core exoproteome of
L. monocytogenes species and 17 were limited to a subset of
strains. Compared with Trost et al. [19], 19 proteins were
newly identified in our present investigation, including nine
proteins as part of the variant exoproteome.
While variations in the exoproteomes are linked to some
virulence factors, cell-wall hydrolases or degradative
enzymes, most of these proteins have unknown functions.
Considering the wide variety of biological processes in
which cell-wall hydrolases are involved, differences in their
expression from one L. monocytogenes strain to another
certainly result in the modification of their phenotypes for
example in terms of biofilm formation, genetic competence,
protein secretion or pathogenicity [74]. These potential
correlations between the presence of various cell-wall
hydrolases and a particular biological process should require
further investigation in order to gain insight into the
physiology of the L. monocytogenes species.
Among the 60 proteins identified extracellularly, 17 out
of 18 proteins primarily cytoplasmic were also predicted as
translocated by unknown secretion systems whereas the
remaining proteins were all predicted as secreted in a Sec-
dependent manner (Fig. 3 and Supporting Information
Table S1). As enolase, DnaK or EF-Tu, which were recently
demonstrated to bind human plasminogen [96], or glycer-
aldehyde-3-phosphate dehydrogenase, which was further
reported as interfering with Rab5a [99], some of these
listerial proteins with multiple subcellular localizations may
moonlight when present extracellularly and have a role in
bacterial virulence. In a previous investigation combining
two complementary techniques viz. 2-DE and HPLC-MS/
MS, 105 proteins could be identified as part of the exopro-
teome of L. monocytogenes EGD-e including 51 proteins
exhibiting no signal peptide and thus a specific mechanism
explaining their translocation was considered unknown [19].
However, it later appeared that some of these proteins were
most probably secreted via holins [6]. None of the proteins
identified in the present study and lacking a signal peptide
were predicted as substrates of the holins, FEA or Wss.
Some of these proteins might actually be secreted in a Sec-
dependent manner but in conjunction with SecA2, a para-
logue to the cytosolic ATPase SecA [6]. Indeed, SecA2 is
required for secretion of listerial FbpA and MnSod, both
lacking a putative N-terminal signal peptide [85, 100]. SecA2
was even confirmed as promoting the release of the heat
shock protein GroEL [89]. Alternatively, cell lysis could
explain the presence of these primarily cytoplasmic proteins
in the culture supernantant as suggested by the identifica-
tion of several cell-wall hydrolases. As reported in Strepto-coccus pneumoniae, however, rather than autolysis this could
result from allolysis, another kind of apoptotic mechanism
where competent cells triggered lysis of non-competent cells
in a tightly control process [101]. Such phenomenon could
explain the extracellular localization of primarily cyto-
plasmic proteins with no obvious mechanism of secretion,
though this possibility has not yet been questioned in
Figure 3. Schematic representation of protein secretion pathways predicted in Listeria spp [6]. Most of the proteins identified in the
exoproteome of the 12 L. monocytogenes strains investigated were predicted as secreted via the Sec pathway (70%), while all others were
predicted as translocated by unknown secretion systems (30%). Cyto: Cytoplasm; CM: Cytoplasmic Membrane; CW: Cell Wall; Ext:
Extracellular milieu; Sec: Secretion apparatus; Tat: Twin-arginine translocation; FPE: Fimbrilin-Protein Exporter; FEA: Flagella Export
Apparatus; Wss: WXG100 (proteins with WXG motif of �100 amino acyl residues) secretion system.
Proteomics 2009, 9, 3136–3155 3151
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

L. monocytogenes and undoubtedly requires further investi-
gations [6]. Eventually, it cannot be excluded that uncovered
secretion systems are present in L. monocytogenes.While this investigation gives the first picture of the core
and variant exoproteomes of L. monocytogenes species, this
comparative subproteomic analysis should be seen as an
initial statement giving a primal view of these exoproteomes
as the number of strains investigated was limited to 12.
Besides uncovering additional extracellular proteins, it can
be expected that the number of proteins presently described
as the core exoproteome decreases in favor of the variant
exoproteome as more extracellular proteomes from various
L. monocytogenes strains are deciphered. Ultimately, it could
establish to what extent the level of virulence of different
L. monocytogenes strains is correlated with the absence of
some extracellular virulence factors in the aim of uncovering
markers indicative of the biohazard of L. monocytogenesstrains isolated from food products [13, 102, 103].
This work received financial support from the ‘‘InstitutNational de la Recherche Agronomique’’ and the FrenchMinistere de l’agriculture et de la peche (DGAL N1 A03/02).Emilie Dumas is a PhD research fellow granted by the ‘‘Minis-tere de l’Education Nationale, de l’Education Superieure et de laRecherche’’. We are grateful to the INRA MIGALE bioinf-ormatics platform (http://migale.jouy.inra.fr) for providingcomputational resources.
The authors have declared no conflict of interest.
5 References
[1] Forsyth, T. J., Maney, L., Ramirez, A., Raviotta, G. et al.,
Nursing case management in the NICU: enhanced coor-
dination for discharge planning. Neonatal Netw. 1998, 17,
23–34.
[2] Liu, D., Identification, subtyping and virulence determina-
tion of Listeria monocytogenes, an important foodborne
pathogen. J. Med. Microbiol. 2006, 55, 645–659.
[3] Schuchat, A., Swaminathan, B., Broome, C. V., Epidemiology
of human listeriosis. Clin. Microbiol. Rev. 1991, 4, 169–183.
[4] Dussurget, O., Pizarro-Cerda, J., Cossart, P., Molecular
determinants of Listeria monocytogenes virulence. Annu.
Rev. Microbiol. 2004, 58, 587–610.
[5] Finlay, B. B., Falkow, S., Common themes in microbial
pathogenicity revisited. Microbiol. Mol. Biol. Rev. 1997, 61,
136–169.
[6] Desvaux, M., Hebraud, M., The protein secretion systems
in Listeria: inside out bacterial virulence. FEMS Microbiol.
Rev. 2006, 30, 774–805.
[7] Seeliger, H. P. R., Jones, D., Bergey’s Manual of Systematic
Bacteriology, Williams & Wilkins, Baltimore 1986. pp.
1235–1245.
[8] ICMSF (International Commission on Microbiological
Specifications for Foods of the International Union of
Biological Societies). Micro-organisms in Foods: Micro-
biological Specifications of Food Pathogens, Blackie
Academic & Professional, London 1996.
[9] Chavant, P., Martinie, B., Meylheuc, T., Bellon-Fontaine,
M. N. et al., Listeria monocytogenes LO28: surface physi-
cochemical properties and ability to form biofilms at
different temperatures and growth phases. Appl. Environ.
Microbiol. 2002, 68, 728–737.
[10] Borucki, M. K., Peppin, J. D., White, D., Loge, F. et al.,
Variation in biofilm formation among strains of Listeria
monocytogenes. Appl. Environ. Microbiol. 2003, 69,
7336–7342.
[11] Fenlon, D. R., Listeria, Listeriosis, and Food Safety, Marcel
Dekker, New York, NY 1999, pp. 21–38.
[12] Park, S. F., Kroll, R. G., Expression of listeriolysin and
phosphatidylinositol-specific phospholipase C is repres-
sed by the plant-derived molecule cellobiose in Listeria
monocytogenes. Mol. Microbiol. 1993, 8, 653–661.
[13] Roche, S. M., Gracieux, P., Albert, I., Gouali, M. et al.,
Experimental validation of low virulence in field strains of
Listeria monocytogenes. Infect. Immun. 2003, 71, 3429–3436.
[14] Roche, S. M., Velge, P., Bottreau, E., Durier, C. et al.,
Assessment of the virulence of Listeria monocytogenes:
agreement between a plaque-forming assay with HT-29
cells and infection of immunocompetent mice. Int. J. Food
Microbiol. 2001, 68, 33–44.
[15] Gray, M. J., Freitag, N. E., Boor, K. J., How the bacterial
pathogen Listeria monocytogenes mediates the switch
from environmental Dr. Jekyll to pathogenic Mr. Hyde.
Infect. Immun. 2006, 74, 2505–2512.
[16] Robinson, C., Bolhuis, A., Protein targeting by the twin-
arginine translocation pathway. Nat. Rev. Mol. Cell Biol.
2001, 2, 350–356.
[17] Calvo, E., Pucciarelli, M. G., Bierne, H., Cossart, P. et al.,
Analysis of the Listeria cell wall proteome by two-dimen-
sional nanoliquid chromatography coupled to mass spec-
trometry. Proteomics 2005, 5, 433–443.
[18] Mujahid, S., Pechan, T., Wang, C., Improved solubilization
of surface proteins from Listeria monocytogenes for 2-DE.
Electrophoresis 2007, 28, 3998–4007.
[19] Trost, M., Wehmhoner, D., Karst, U., Dieterich, G. et al.,
Comparative proteome analysis of secretory proteins from
pathogenic and nonpathogenic Listeria species. Proteo-
mics 2005, 5, 1544–1557.
[20] Ignatova, Z., Hornle, C., Nurk, A., Kasche, V., Unusual
signal peptide directs penicillin amidase from Escherichia
coli to the Tat translocation machinery. Biochem. Biophys.
Res. Commun. 2002, 291, 146–149.
[21] Severino, P., Dussurget, O., Vencio, R. Z., Dumas, E. et al.,
Comparative transcriptome analysis of Listeria mono-
cytogenes strains of the two major lineages reveals
differences in virulence, cell wall and stress response.
Appl. Environ. Microbiol. 2007, 73, 6078–6088.
[22] Olier, M., Pierre, F., Lemaitre, J. P., Divies, C. et al.,
Assessment of the pathogenic potential of two Listeria
monocytogenes human faecal carriage isolates. Micro-
biology 2002, 148, 1855–1862.
3152 E. Dumas et al. Proteomics 2009, 9, 3136–3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

[23] Desvaux, M., Hebraud, M., Analysis of cell envelope
proteins, in: Liu, D. (Ed.), Handbook of Listeria Mono-
cytogenes, CRC Press, Taylor and Francis Group, Boca
Raton, Florida, USA 2008, pp. 359–393.
[24] von Heijne, G., A new method for predicting signal sequence
cleavage sites. Nucleic Acids Res. 1986, 14, 4683–4690.
[25] McGeoch, D. J., On the predictive recognition of signal
peptide sequences. Virus Res. 1985, 3, 271–286.
[26] Bendtsen, J. D., Nielsen, H., von Heijne, G., Brunak, S.,
Improved prediction of signal peptides: SignalP 3.0.
J. Mol. Biol. 2004, 340, 783–795.
[27] K .all, L., Krogh, A., Sonnhammer, E. L., A combined
transmembrane topology and signal peptide prediction
method. J. Mol. Biol. 2004, 338, 1027–1036.
[28] Gomi, M., Sonoyama, M., Mitaku, S., High performance
system for signal peptide prediction: SOSUIsignal. Chem-
Bio Info. J. 2004, 4, 142–147.
[29] Cai, Y. D., Lin, S. L., Chou, K. C., Support vector machines
for prediction of protein signal sequences and their clea-
vage sites. Peptides 2003, 24, 159–161.
[30] Gardy, J. L., Laird, M. R., Chen, F., Rey, S. et al., PSORTb
v.2.0: expanded prediction of bacterial protein subcellular
localization and insights gained from comparative
proteome analysis. Bioinformatics 2005, 21, 617–623.
[31] Hiller, K., Grote, A., Scheer, M., Munch, R. et al., PrediSi:
prediction of signal peptides and their cleavage positions.
Nucleic Acids Res. 2004, 32, W375–W379.
[32] Shen, H. B., Chou, K. C., Signal-3L: a 3-layer approach for
predicting signal peptides. Biochem. Biophys. Res.
Commun. 2007, 363, 297–303.
[33] Bendtsen, J. D., Nielsen, H., Widdick, D., Palmer, T.,
Brunak, S., Prediction of twin-arginine signal peptides.
BMC Bioinformatics 2005, 6, 167.
[34] Rose, R. W., Bruser, T., Kissinger, J. C., Pohlschroder, M.,
Adaptation of protein secretion to extremely high-salt
conditions by extensive use of the twin-arginine translo-
cation pathway. Mol. Microbiol. 2002, 45, 943–950.
[35] de Castro, E., Sigrist, C. J., Gattiker, A., Bulliard, V. et al.,
ScanProsite: detection of PROSITE signature matches and
ProRule-associated functional and structural residues in
proteins. Nucleic Acids Res. 2006, 34, W362–365.
[36] Bendtsen, J. D., Kiemer, L., Fausboll, A., Brunak, S., Non-
classical protein secretion in bacteria. BMC Microbiol.
2005, 5, 58.
[37] Babu, M. M., Sankaran, K., DOLOP-database of bacterial
lipoproteins. Bioinformatics 2002, 18, 641–643.
[38] Juncker, A. S., Willenbrock, H., Von Heijne, G., Brunak, S.
et al., Prediction of lipoprotein signal peptides in Gram-
negative bacteria. Protein Sci. 2003, 12, 1652–1662.
[39] Fariselli, P., Finocchiaro, G., Casadio, R., SPEPlip: the
detection of signal peptide and lipoprotein cleavage sites.
Bioinformatics 2003, 19, 2498–2499.
[40] Taylor, P. D., Toseland, C. P., Attwood, T. K., Flower, D. R.,
LipPred: A web server for accurate prediction of lipopro-
tein signal sequences and cleavage sites. Bioinformation
2006, 1, 335–338.
[41] Sutcliffe, I., Harrington, D. J., Pattern searches for the
identification of putative lipoprotein genes in Gram-posi-
tive bacterial genomes. Microbiology 2002, 148,
2065–2077.
[42] Tatusov, R. L., Natale, D. A., Garkavtsev, I. V., Tatusova,
T. A. et al., The COG database: new developments in
phylogenetic classification of proteins from complete
genomes. Nucleic Acids Res. 2001, 29, 22–28.
[43] Altschul, S. F., Madden, T. L., Schaffer, A. A., Zhang, J.
et al., Gapped BLAST and PSI-BLAST: a new generation of
protein database search programs. Nucleic Acids Res.
1997, 25, 3389–3402.
[44] Eddy, S. R., Hidden Markov models. Curr. Opin. Struct.
Biol. 1996, 6, 361–365.
[45] Mulder, N. J., Apweiler, R., Attwood, T. K., Bairoch, A.
et al., New developments in the InterPro database. Nucleic
Acids Res. 2007, 35, D224–D228.
[46] Bateman, A., Coin, L., Durbin, R., Finn, R. D. et al., The
Pfam protein families database. Nucleic Acids Res. 2004,
32, D138–D141.
[47] Schultz, J., Milpetz, F., Bork, P., Ponting, C. P., SMART, a
simple modular architecture research tool: identification of
signaling domains. Proc. Natl. Acad. Sci. USA 1998, 95,
5857–5864.
[48] Selengut, J. D., Haft, D. H., Davidsen, T., Ganapathy, A. et al.,
TIGRFAMs and Genome Properties: tools for the assignment
of molecular function and biological process in prokaryotic
genomes. Nucleic Acids Res. 2007, 35, D260–D264.
[49] Murzin, A. G., Brenner, S. E., Hubbard, T., Chothia, C.,
SCOP: a structural classification of proteins database for
the investigation of sequences and structures. J. Mol. Biol.
1995, 247, 536–540.
[50] Wilson, D., Madera, M., Vogel, C., Chothia, C. et al., The
SUPERFAMILY database in 2007: families and functions.
Nucleic Acids Res. 2007, 35, D308–D313.
[51] Wu, C. H., Nikolskaya, A., Huang, H., Yeh, L. S. et al., PIRSF:
family classification system at the Protein Information
Resource. Nucleic Acids Res. 2004, 32, D112–D114.
[52] Hulo, N., Bairoch, A., Bulliard, V., Cerutti, L. et al., The
PROSITE database. Nucleic Acids Res. 2006, 34,
D227–D230.
[53] van Pijkeren, J. P., Canchaya, C., Ryan, K. A., Li, Y. et al.,
Comparative and functional analysis of sortase-dependent
proteins in the predicted secretome of Lactobacillus sali-
varius UCC118. Appl. Environ. Microbiol. 2006, 72,
4143–4153.
[54] Wu, C. H., Apweiler, R., Bairoch, A., Natale, D. A. et al., The
Universal Protein Resource (UniProt): an expanding
universe of protein information. Nucleic Acids Res. 2006,
34, D187–D191.
[55] Tusnady, G. E., Simon, I., The HMMTOP transmembrane
topology prediction server. Bioinformatics 2001, 17, 849–850.
[56] Sonnhammer, E. L., von Heijne, G., Krogh, A., A hidden
Markov model for predicting transmembrane helices in
protein sequences. Proc. Int. Conf. Intell. Syst. Mol. Biol.
1998, 6, 175–182.
Proteomics 2009, 9, 3136–3155 3153
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

[57] Hirokawa, T., Boon-Chieng, S., Mitaku, S., SOSUI: classi-
fication and secondary structure prediction system for
membrane proteins. Bioinformatics 1998, 14, 378–379.
[58] Zhou, H., Zhou, Y., Predicting the topology of transmem-
brane helical proteins using mean burial propensity and a
hidden-Markov-model-based method. Protein Sci. 2003,
12, 1547–1555.
[59] Jones, D. T., Improving the accuracy of transmembrane
protein topology prediction using evolutionary information.
Bioinformatics 2007, 23, 538–544.
[60] Hua, S., Sun, Z., Support vector machine approach for
protein subcellular localization prediction. Bioinformatics
2001, 17, 721–728.
[61] Nair, R., Rost, B., Mimicking cellular sorting improves
prediction of subcellular localization. J. Mol. Biol. 2005,
348, 85–100.
[62] Yu, C. S., Chen, Y. C., Lu, C. H., Hwang, J. K., Prediction
of protein subcellular localization. Proteins 2006, 64,
643–651.
[63] Antelmann, H., Tjalsma, H., Voigt, B., Ohlmeier, S. et al., A
proteomic view on genome-based signal peptide predic-
tions. Genome Res. 2001, 11, 1484–1502.
[64] Tjalsma, H., van Dijl, J. M., Proteomics-based consensus
prediction of protein retention in a bacterial membrane.
Proteomics 2005, 5, 4472–4482.
[65] Sibbald, M. J., Ziebandt, A. K., Engelmann, S., Hecker, M.
et al., Mapping the pathways to staphylococcal patho-
genesis by comparative secretomics. Microbiol. Mol. Biol.
Rev. 2006, 70, 755–788.
[66] Marraffini, L. A., Dedent, A. C., Schneewind, O., Sortases
and the art of anchoring proteins to the envelopes of
Gram-positive bacteria. Microbiol. Mol. Biol. Rev. 2006, 70,
192–221.
[67] Bae, T., Schneewind, O., The YSIRK-G/S motif of
staphylococcal protein A and its role in efficiency of
signal peptide processing. J. Bacteriol. 2003, 185, 2910–2919.
[68] Steen, A., Buist, G., Leenhouts, K. J., El Khattabi, M. et al.,
Cell wall attachment of a widely distributed peptidoglycan
binding domain is hindered by cell wall constituents.
J. Biol. Chem. 2003, 278, 23874–23881.
[69] Jonquieres, R., Bierne, H., Fiedler, F., Gounon, P. et al.,
Interaction between the protein InlB of Listeria mono-
cytogenes and lipoteichoic acid: a novel mechanism of
protein association at the surface of Gram-positive
bacteria. Mol. Microbiol. 1999, 34, 902–914.
[70] Braun, L., Dramsi, S., Dehoux, P., Bierne, H. et al., InlB:
an invasion protein of Listeria monocytogenes with a novel
type of surface association. Mol. Microbiol. 1997, 25,
285–294.
[71] Desvaux, M., Mapping of carbon flow distribution in the
central metabolic pathways of Clostridium cellulolyticum:
Direct comparison of bacterial metabolism with a soluble
versus an insoluble carbon source. J. Microbiol. Biotech-
nol. 2004, 14, 1200–1210.
[72] Siezen, R., Boekhorst, J., Muscariello, L., Molenaar, D.
et al., Lactobacillus plantarum gene clusters encoding
putative cell-surface protein complexes for carbohydrate
utilization are conserved in specific Gram-positive
bacteria. BMC Genomics 2006, 7, 126.
[73] Brinster, S., Furlan, S., Serror, P., C-terminal WXL domain
mediates cell wall binding in Enterococcus faecalis and
other Gram-positive bacteria. J. Bacteriol. 2007, 189,
1244–1253.
[74] Popowska, M., Analysis of the peptidoglycan hydrolases of
Listeria monocytogenes: multiple enzymes with multiple
functions. Pol. J. Microbiol. 2004, 53, 29–34.
[75] Anantharaman, V., Aravind, L., Evolutionary history,
structural features and biochemical diversity of the
NlpC/P60 superfamily of enzymes. Genome Biol. 2003, 4,
R11.
[76] Baumg .artner, M., K .arst, U., Gerstel, B., Loessner, M. et al.,
Inactivation of Lgt allows systematic characterization of
lipoproteins from Listeria monocytogenes. J. Bacteriol.
2007, 189, 313–324.
[77] Harris, M. A., Clark, J., Ireland, A., Lomax, J. et al., The
Gene Ontology (GO) database and informatics resource.
Nucleic Acids Res. 2004, 32, D258–D261.
[78] Glaser, P., Frangeul, L., Buchrieser, C., Rusniok, C. et al.,
Comparative genomics of Listeria species. Science 2001,
294, 849–852.
[79] Galperin, M. Y., Koonin, E. V., Sources of systematic error
in functional annotation of genomes: domain rearrange-
ment, non-orthologous gene displacement and operon
disruption. In Silico Biol. 1998, 1, 55–67.
[80] Portnoy, D. A., Auerbuch, V., Glomski, I. J., The cell biology
of Listeria monocytogenes infection: the intersection of
bacterial pathogenesis and cell-mediated immunity. J. Cell
Biol. 2002, 158, 409–414.
[81] Domann, E., Wehland, J., Rohde, M., Pistor, S. et al., A
novel bacterial virulence gene in Listeria monocytogenes
required for host cell microfilament interaction with
homology to the proline-rich region of vinculin. EMBO J.
1992, 11, 1981–1990.
[82] Moors, M. A., Levitt, B., Youngman, P., Portnoy, D. A.,
Expression of listeriolysin O and ActA by intracellular and
extracellular Listeria monocytogenes. Infect. Immun. 1999,
67, 131–139.
[83] Joseph, B., Przybilla, K., Stuhler, C., Schauer, K.
et al., Identification of Listeria monocytogenes genes
contributing to intracellular replication by expression
profiling and mutant screening . J. Bacteriol. 2006, 188,
556–568.
[84] Bierne, H., Sabet, C., Personnic, N., Cossart, P., Internalins:
complex family of leucine-rich repeat containing proteins
in Listeria monocytogenes. Microb. Infect. 2007, 9,
1156–1166.
[85] Archambaud, C., Nahori, M. A., Pizarro-Cerda, J., Cossart, P.
et al., Control of Listeria superoxide dismutase by phos-
phorylation. J. Biol. Chem. 2006, 281, 31812–31822.
[86] Lenz, L. L., Portnoy, D. A., Identification of a second
Listeria secA gene associated with protein secretion
and the rough phenotype. Mol. Microbiol. 2002, 45,
1043–1056.
3154 E. Dumas et al. Proteomics 2009, 9, 3136–3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com

[87] Popowska, M., Markiewicz, Z., Characterization of Listeria
monocytogenes protein Lmo0327 with murein hydrolase
activity. Arch. Microbiol. 2006, 186, 69–86.
[88] Machata, S., Hain, T., Rohde, M., Chakraborty, T., Simul-
taneous deficiency of both MurA and p60 proteins gener-
ates a rough phenotype in Listeria monocytogenes.
J. Bacteriol. 2005, 187, 8385–8394.
[89] Lenz, L. L., Mohammadi, S., Geissler, A., Portnoy, D. A.,
SecA2-dependent secretion of autolytic enzymes
promotes Listeria monocytogenes pathogenesis. Proc.
Natl. Acad. Sci. USA 2003, 100, 12432–12437.
[90] Rawlings, N. D., Morton, F. R., Kok, C. Y., Kong, J. et al.,
MEROPS: the peptidase database. Nucleic Acids Res. 2008,
36, D320–D325.
[91] Rawlings, N. D., Barrett, A. J., Evolutionary families of
peptidases. Biochem. J. 1993, 290, 205–218.
[92] Leisner, J. J., Larsen, M. H., Jorgensen, R. L., Brondsted, L.
et al., Chitin hydrolysis by Listeria spp. including L. mono-
cytogenes. Appl. Environ. Microbiol. 2008, 74, 3823–3830.
[93] Desvaux, M., Clostridium cellulolyticum: model organism
of mesophilic cellulolytic clostridia. FEMS Microbiol. Rev.
2005, 29, 741–764.
[94] Gooday, G. W., in: Marshall, K. C. (Ed.), Advances in
Microbial Ecology, Plenum Press, New York 1990, pp.
387–430.
[95] DebRoy, S., Dao, J., Soderberg, M., Rossier, O. et al.,
Legionella pneumophila Type II secretome reveals unique
exoproteins and a chitinase that promotes bacterial
persistence in the lung. Proc. Natl. Acad. Sci. USA 2006,
103, 19146–19151.
[96] Schaumburg, J., Diekmann, O., Hagendorff, P., Bergmann, S.
et al., The cell wall subproteome of Listeria monocytogenes.
Proteomics 2004, 4, 2991–3006.
[97] Voigt, B., Schweder, T., Sibbald, M. J., Albrecht, D. et al.,
The extracellular proteome of Bacillus licheniformis grown
in different media and under different nutrient starvation
conditions. Proteomics 2006, 6, 268–281.
[98] Tjalsma, H., Antelmann, H., Jongbloed, J. D., Braun, P. G.
et al., Proteomics of protein secretion by Bacillus subtilis:
separating the ‘‘secrets’’ of the secretome. Microbiol. Mol.
Biol. Rev. 2004, 68, 207–233.
[99] Alvarez-Dominguez, C., Madrazo-Toca, F., Fernandez-
Prieto, L., Vandekerckhove, J. et al., Characterization of a
Listeria monocytogenes protein interfering with Rab5a.
Traffic 2008, 9, 325–337.
[100] Dramsi, S., Bourdichon, F., Cabanes, D., Lecuit, M. et al.,
FbpA, a novel multifunctional Listeria monocytogenes
virulence factor. Mol. Microbiol. 2004, 53, 639–649.
[101] Guiral, S., Mitchell, T. J., Martin, B., Claverys, J. P.,
Competence-programmed predation of noncompetent
cells in the human pathogen Streptococcus pneumoniae:
Genetic requirements. Proc. Natl. Acad. Sci. USA 2005,
102, 8710–8715.
[102] Cappelier, J. M., Besnard, V., Roche, S. M., Velge, P. et al.,
Avirulent viable but non culturable cells of Listeria
monocytogenes need the presence of an embryo to be
recovered in egg yolk and regain virulence after recovery.
Vet. Res. 2007, 38, 573–583.
[103] Roche, S. M., Gracieux, P., Milohanic, E., Albert, I. et al.,
Investigation of specific substitutions in virulence genes
characterizing phenotypic groups of low-virulence field
strains of Listeria monocytogenes. Appl. Environ. Micro-
biol. 2005, 71, 6039–6048.
[104] de Valk, H., Vaillant, V., Jacquet, C., Rocourt, J. et al., Two
consecutive nationwide outbreaks of Listeriosis in France,
October 1999-February 2000. Am. J. Epidemiol. 2001, 154,
944–950.
[105] Mackaness, G. B., The immunological basis of acquired
cellular resistance. J. Exp. Med. 1964, 120, 105–120.
[106] Olier, M., Pierre, F., Rousseaux, S., Lemaitre, J. P. et al.,
Expression of truncated Internalin A is involved in
impaired internalization of some Listeria monocytogenes
isolates carried asymptomatically by humans. Infect.
Immun. 2003, 71, 1217–1224.
[107] Rousset, A., Lemaitre, J. P., Delcourt, A., Research of
Listeria monocytogenes from different sites (faecal, geni-
tal, and oropharyngeal secretions). Med. Mal. Infect. 1994,
1, 1174–1179.
Proteomics 2009, 9, 3136–3155 3155
& 2009 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.com




















