
Implementación de un Microprocesador MIPS multiciclo con excepciones en VHDL
10
1 Abstracto— En este documento se presenta la implementación de un Microprocesador MIPS multiciclo con soporte para excepciones. La implementación se realizó utilizando el lenguaje VHDL. Se presenta un análisis del desempeño del microprocesador a partir de un programa muestra. El trabajo concluye que el análisis del desempeño de un microprocesador se demuestra mejor con programas que ejerciten una amplia gama de instrucciones de manera homogénea. Índice de términos—Excepciones, Interrupciones, Microprocesador, Microprocesador MIPS. I. INTRODUCCIÓN L microprocesador MIPS ha sido utilizado durante bastante tiempo desde el punto de vista académico para mostrar a los estudiantes la manera en que los microprocesadores en general funcionan internamente. Existen muchas variaciones en cuanto a las implementaciones que pueden realizarse y van desde un procesador monociclo hasta un procesador multiciclo con pipelining y soporte para operaciones en punto flotante. Este trabajo pretende mostrar la forma en que puede implementarse un procesador MIPS multiciclo con soporte para excepciones. Tiene como base el trabajo presentado en [1] con pequeñas variaciones. La implementación de tal procesador se realizó en VHDL. Las secciones sucesivas presentan la motivación de un procesador multiciclos, las consideraciones especiales requeridas, el diagrama de estados del control del procesador así como su flujo de datos, la descripción de su rendimiento y finalmente las conclusiones. II. ¿POR QUÉ UN PROCESADOR MULTICICLOS? Anteriormente se presentó un trabajo en el que se mostraba la manera en que puede implementarse un procesador MIPS monociclo. En su momento se concluyó que dicho modelo si bien era sencillo desde el punto de vista de implementación, planteaba serios problemas en cuanto a tiempo de ejecución así como en cantidad de hardware interno requerido. En primer lugar uno podría pensar que un procesador monociclo es más rápido que uno multiciclo puesto que el primero solo requeriría, como su nombre lo indica, un solo ciclo para realizar cualquier instrucción, mientras que el segundo requeriría de más de uno. El problema es que en realidad el procesador monociclo requiere tanto tiempo para ejecutar cualquier instrucción como para ejecutar la instrucción más compleja. Por otro lado, dado que todas las operaciones posibles requieren implementarse en un solo ciclo, es necesario tener la habilidad de hacer cálculos en varios momentos y, por lo tanto, se requieren de varias ALUs, como se menciona en [ 1]. La implementación multiciclo se deshace de estos problemas y, al requerir menos hardware se implicaría también una reducción en el consumo de potencia. Implementación de un Microprocesador MIPS multiciclo con excepciones en VHDL Ricardo Zavaleta, Oracle MDC E
Transcript of Implementación de un Microprocesador MIPS multiciclo con excepciones en VHDL

1
Abstracto— En este documento se presenta la implementación de un Microprocesador MIPS multiciclo con soporte para
excepciones. La implementación se realizó utilizando el lenguaje VHDL. Se presenta un análisis del desempeño del microprocesador a
partir de un programa muestra. El trabajo concluye que el análisis del desempeño de un microprocesador se demuestra mejor con
programas que ejerciten una amplia gama de instrucciones de manera homogénea.
Índice de términos—Excepciones, Interrupciones, Microprocesador, Microprocesador MIPS.
I. INTRODUCCIÓN
L microprocesador MIPS ha sido utilizado durante bastante tiempo desde el punto de vista académico para mostrar a los
estudiantes la manera en que los microprocesadores en general funcionan internamente. Existen muchas variaciones en
cuanto a las implementaciones que pueden realizarse y van desde un procesador monociclo hasta un procesador multiciclo con
pipelining y soporte para operaciones en punto flotante.
Este trabajo pretende mostrar la forma en que puede implementarse un procesador MIPS multiciclo con soporte para
excepciones. Tiene como base el trabajo presentado en [1] con pequeñas variaciones. La implementación de tal procesador se
realizó en VHDL.
Las secciones sucesivas presentan la motivación de un procesador multiciclos, las consideraciones especiales requeridas, el
diagrama de estados del control del procesador así como su flujo de datos, la descripción de su rendimiento y finalmente las
conclusiones.
II. ¿POR QUÉ UN PROCESADOR MULTICICLOS?
Anteriormente se presentó un trabajo en el que se mostraba la manera en que puede implementarse un procesador MIPS
monociclo. En su momento se concluyó que dicho modelo si bien era sencillo desde el punto de vista de implementación,
planteaba serios problemas en cuanto a tiempo de ejecución así como en cantidad de hardware interno requerido.
En primer lugar uno podría pensar que un procesador monociclo es más rápido que uno multiciclo puesto que el primero solo
requeriría, como su nombre lo indica, un solo ciclo para realizar cualquier instrucción, mientras que el segundo requeriría de
más de uno. El problema es que en realidad el procesador monociclo requiere tanto tiempo para ejecutar cualquier instrucción
como para ejecutar la instrucción más compleja.
Por otro lado, dado que todas las operaciones posibles requieren implementarse en un solo ciclo, es necesario tener la habilidad
de hacer cálculos en varios momentos y, por lo tanto, se requieren de varias ALUs, como se menciona en [ 1].
La implementación multiciclo se deshace de estos problemas y, al requerir menos hardware se implicaría también una reducción
en el consumo de potencia.
Implementación de un Microprocesador MIPS
multiciclo con excepciones en VHDL Ricardo Zavaleta, Oracle MDC
E

2
III. COMPARACIÓN DE LOS CAMINOS DE DATOS ENTRE MONOCICLO Y MULTICICLO
Hennessy y Patterson presentaron dos diagramas a bloques que permiten apreciar de mejor manera las diferencias en cuanto a
hardware que existe entre las dos posibles implementaciones [1]. Dichos diagramas se presentan a continuación.
Fig 1. Camino de datos para una implementación monociclo
Fig 2. Camino de datos para una implementación multiciclos

3
Existen entonces varias características a considerar:
1) La primera impresión es que laversión multiciclos requiere más hardware. Esto es cierto desde el punto de vista
cuantitativo, pero nótese que en realidad el número de componentes aumenta debido a la presencia de varios
multiplexores, que son circuitos combinacionales simples. Además, nótese que la implementación monociclo requiere
de dos memorias y dos ALUs. Estos dos circuitos son más complicados que los multiplexores y necesitarán más
recursos a la hora de sintetizar el diseño en una FPGA.
2) A pesar de ser estrictamente una implementación Von Neumann, puede también considerarse como una arquitectura
Harvard. Nótese cómo existen dos registros que sirven de cierta manera como caché de la memoria.
3) La versión multiciclo requiere de registros (elementos de estado) entre varias etapas del camino de datos. Pueden
identificarse 4 etapas que empiezan respectivamente con (1) el PC, (2) el registro de memoria y el registro de datos, (3)
los registros a la salida del archivo de registros, y (4) el registro que almacena el resultado de la ALU. Son estos
registros los que permiten llevar la ejecución de las microinstrucciones de manera serial, síncrona y ordenada.
IV. OPERACIONES IMPLEMENTADAS
Es evidente que las instrucciones soportadas por un procesador determinan de manera fundamental la estructura del flujo de
datos y también la manera en que se desempeña la unidad de control. Para el caso de la implementación de MIPS presentada, se
consideran las siguientes operaciones:
Nombre Mnemónico Formato OPCODE/FUNC
Load Word LW I 0x23
Store Word SW I 0x2B
Add ADD R 0x00/0x20
Substract SUB R 0x00/0x22
Nor NOR R 0x00/0x27
Or OR R 0x00/0x25
And AND R 0x00/0x24
Set Less Than SLT R 0x00/0x2B
Branch on equal BEQ I 0x04
Jump J J 0x02
HALT HALT - 0x3F
La figura 3 muestra la manera en que se implementaría la unidad de control dado el camino de datos presentado y el soporte a
las instrucciones que se acaban de mencionar.
V. IMPLEMENTACIÓN DE EXCEPCIONES
En el contexto del procesador MIPS, se conoce como excepción a:
1) Aquellos eventos inesperados que ocurren dentro del procesador. Ejemplos pueden ser un overflow o una instrucción
inválida.
2) Aquellos eventos que llegan de fuera del procesador y que provocan un cambio en el flujo de ejecución de un programa.
Algunas otras arquitecturas consideran 1) como excepciones y a 2) como interrupciones. De acuerdo con [1], existen varias
maneras en las que pueden manejarse las excepciones. En la implementación presentada en este trabajo, el flujo es el siguiente:
1) Ocurre una excepción
2) El procesador guarda en un registro llamado EPC la dirección de la instrucción que provocó la excepción y la causa de la
excepción.
3) Se transfiere el control a la dirección de memoria 0x01001 y se ejecuta la rutina que ahí se encuentre.
4) Finaliza el programa.
Esta implementación soporta únicamente dos fuentes de interrupción: Overflows en la ALU e instrucciones inválidas.
1 En el MIPS original la dirección es la 0x80000180

4
Fig 3. Máquna de estados para un MIPS multiciclo
VI. PROGRAMA MUESTRA
El procesador obtenido fue ejercitado utilizando el siguiente código:
Código Ensamblador Código Máquina
LW S1, 0xA0(S0) 10001100
00000001
00000000
10100000
LW S2, 0xA4(S0) 10001100
00000010
00000000
10100100
ADD S1, S2, S3 00000000
00100010
00011000
00100000
SW S3, 0xB0(S0) 10101100
00000011
00000000

5
10110000
LW S4, 0xA8(S0) 10001100
00000100
00000000
10101000
LW S5, 0xAC(S0) 10001100
00000101
00000000
10101100
SUB S4, S5, S6 00000000
10000101
00110000
00100001
SW S6, 0xB4(S0) 10101100
00000110
00000000
10110100
OR S1, S2, S3 00000000
00100010
00011000
00100101
SW S3, 0xB0(S0) 10101100
00000011
00000000
10110000
AND S4, S5, S6 00000000
10000101
00110000
00100100
SW S6, 0xB4(S0) 10101100
00000110
00000000
10110100
BEQ S1, S2, 2 00010000
00100010
00000000
00000010
ADD S4, S5, S6 00000000
10000101
00110000
00100000
HALT 11111111
00000000
00000000
00000000
ADD S1, S2, S3 00000000
00100010
00011000
00100000
SW S3, 0xB0(S0) 10101100
00000011
00000000
10110000
HALT 11111111
00000000
00000000
00000000

6
VII. RESULTADOS
Para ejecutar el programa de muestra basta con simular el test bench llamado Test7.vhd. En esta sección comentaré las
generalidades del resultado, dejando de lado el análisis meticuloso de cada microinstrucción ejecutada. Solo explicaré a detalle
el primer conjunto de instrucciones que van de la carga de operandos hasta el almacenamiento del resultado en memoria.
A. LW S1, 0xA0(S0)
La primera operación que se ejecuta es una carga de memoria a registro. De la figura 3, puede notarse que las operaciones de
carga deberían ejecutarse en 5 ciclos de reloj. En la figura 4 se observa que la operación se está llevando en 6 ciclos de reloj y
que van de los 15[ns] hasta los 75[ns]. Esto es así debido a un detalle de implementación que no permitía leer la instrucción de
memoria señalada por el PC y al mismo tiempo escribir el valor en el registro de instrucción.
El primer ciclo de reloj toma el registro en PC y lee la instrucción de memoria como se observa en la fila “MemContent”. Al
siguiente ciclo de reloj la instrucción se escribe en el registro de instrucción (fila “Instrucción”). A los 35[ns] se realiza la
decodificación de la instrucción y al ciclo siguiente se calcula la dirección de memoria de donde se obtendrá el dato (fila
“result”). A los 55[ns] se obtiene el dato que en este caso es 0xFFFF0000 como se observa en la fila “MemContent”. Finalmente
se escribe ese valor en el registro S1 (fila “fr_datain”).
Fig 4. Carga de memoria
B. LW S2, 0xA4(S0)
Esta instrucción (Figura 5) es similar a la anterior. El resultado se puede observar a los 125[ns] en donde se observa que en S2 se
almacenará el valor 0x0000FFFF.
C. ADD S1, S2, S3
De las instrucciones anteriores puede inferirse que los primeros 3 ciclos de reloj corresponden a la etapa de búsqueda de la
instrucción, es decir, estos pasos estarán siempre presentes para cualquier instrucción.
Para el caso de la suma, se observa en la figura 6 que el cuarto ciclo de reloj corresponde a la ejecución. Obsérvese las filas
“operador_0”, “operador_1” y “result”. El resultado de sumar 0x0000FFFF y 0xFFFF0000 es efectivamente 0xFFFFFFFF.
El paso final es guardar el resultado en el registro especificado (fila “fr_datain”).

7
Fig 5. Carga del segundo operando
Fig 6. Instrucción de Suma
8
D. SW S3, 0xB0(S0)
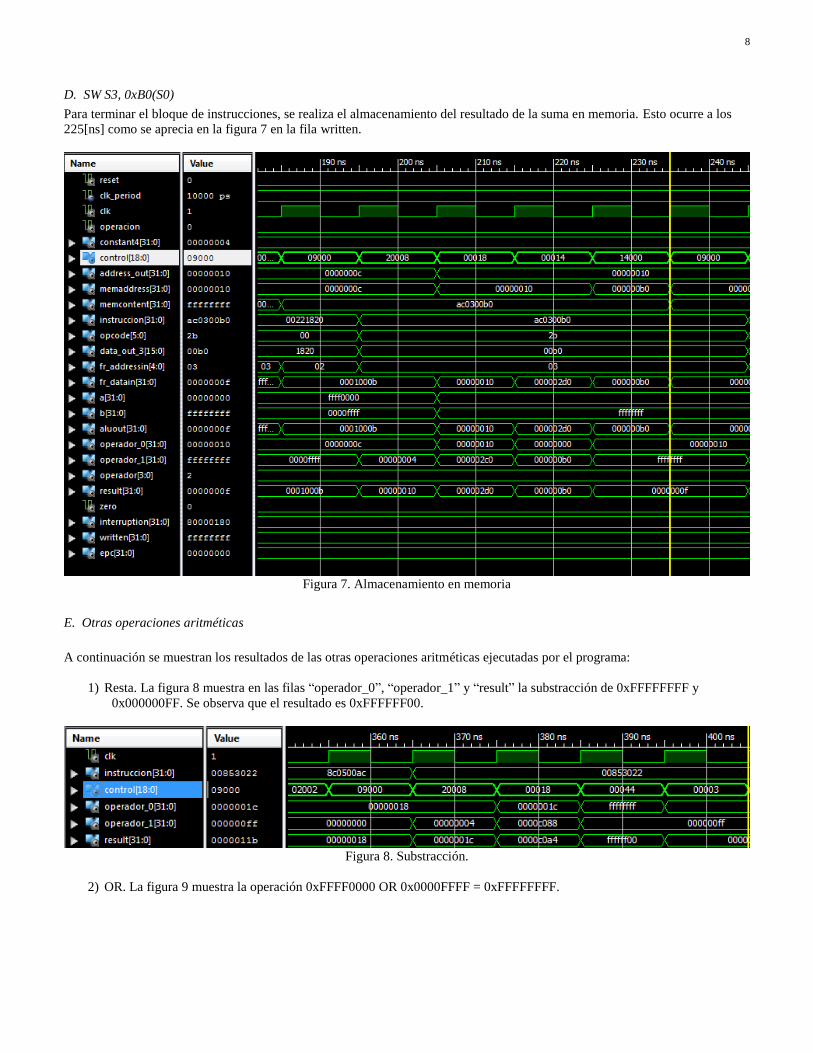
Para terminar el bloque de instrucciones, se realiza el almacenamiento del resultado de la suma en memoria. Esto ocurre a los
225[ns] como se aprecia en la figura 7 en la fila written.
Figura 7. Almacenamiento en memoria
E. Otras operaciones aritméticas
A continuación se muestran los resultados de las otras operaciones aritméticas ejecutadas por el programa:
1) Resta. La figura 8 muestra en las filas “operador_0”, “operador_1” y “result” la substracción de 0xFFFFFFFF y
0x000000FF. Se observa que el resultado es 0xFFFFFF00.
Figura 8. Substracción.
2) OR. La figura 9 muestra la operación 0xFFFF0000 OR 0x0000FFFF = 0xFFFFFFFF.

9
Figura 9. OR.
3) AND. La figura 10 muestra la operación 0xFFFFFFFF AND 0x000000FF = 0x000000FF
Figura 10. AND.
F. Excepciones
Finalmente, se muestra la manera en que funcionan las excepciones. Obsérvese que a los 725[ns] se realiza una operación de
suma que produce un Overflow. En consecuencia, se observa también que la siguiente instrucción a ejecutarse (a los 755[ns]) es
la que se encuentra en la dirección 0x100 (Fila “Address_out”).
Figura 11. Excepciones.
VIII. RENDIMIENTO
La siguiente tabla resume los tiempos de ejecución de las instrucciones que componen el programa (sin tomar en cuenta la
excepción):
Código Ensamblador CPI[ciclos] T[ns]
LW S1, 0xA0(S0) 6 60
LW S2, 0xA4(S0) 6 60
ADD S1, S2, S3 5 50
SW S3, 0xB0(S0) 5 50
LW S4, 0xA8(S0) 6 60
LW S5, 0xAC(S0) 6 60
SUB S4, S5, S6 5 50
SW S6, 0xB4(S0) 5 50
OR S1, S2, S3 5 50
SW S3, 0xB0(S0) 5 50
AND S4, S5, S6 5 50
SW S6, 0xB4(S0) 5 50
BEQ S1, S2, 2 4 40
ADD S4, S5, S6 5 50
HALT 3 30
TOTAL 76[ciclos] 760[ns]

10
IX. CONCLUSIONES
De la tabla presentada en la sección anterior puede verse que en promedio las operaciones tienen un costo de 5 ciclos de reloj
con una varianza muy baja. Esto parece indicar que de cierta manera no se tiene mucha ganancia con respecto a la
implementación monociclo. El problema parece estar en que en realidad gran parte de las operaciones ejercitadas corresponden a
operaciones aritméticas. Es decir, es posible que si se tuviera una distribución más homogénea en el tipo de instrucciones
utilizadas, la ganancia sería más notoria.
Por otro lado, es posible suponer que la utilización de una máquina de estados permitiría fácilmente integrar nuevas
instrucciones a este procesador. Sin embargo, es también evidente que un número de instrucciones muy grande no nos permitiría
manejar con esa sencillez la cantidad proporcional de estados en la máquina.
Para este último caso, [1] propone la utilización de microprogramación. Ese enfoque queda como trabajo futuro por lo que a mí
respecta.
X. REFERENCIAS
[1] Patterson, David y Hennessy, John, "Computer organization and design". Morgan Kaufmann, 2007.




















