
On the hardware-software partitioning problem: System modeling and partitioning techniques
Upload
khangminh22Category
view
0download
0
AWAPart: Adaptive Workload-Aware Partitioning of
Knowledge GraphAmitabh Priyadarshi and Krzysztof J. Kochut
Presenter:Amitabh [email protected] of Computer ScienceUniversity of GeorgiaAthens, Georgia, USA
1

Resume
Highly motivated computer science PhD. Student, skilled in problem solving with a solid understanding of programming practices including full stack development, Machine Learning etc.• Research Interest: Partitioning the Knowledge Graph to improve performance of
various graph operations.
• Skills:• Java, Python• SQL, SPARQL, Graph database• Machine Learning• Java Script, jQuery, AJAX etc.
• Experience:• Enterprise Information Technology Services (UGA), GA, USA (2016-now)• Complex Carbohydrate Research Center (UGA), GA, UGA (2014-2015)• Oxient Technology , Pune, India(2009-2013)
• Education:• Pursuing PhD. In CS from University of Georgia, Athens, GA,USA• Master in Computer Application, Bharti Vidyapeeth University, Pune ,India• Bachelor in Computer Application, Indira Gandhi National University, Delhi,
India
Amitabh [email protected] of Computer ScienceUniversity of GeorgiaAthens, Georgia. USA
2

Overview
•Graph Partitioning Problem•Background•AWAPart• Implementation•Experiment•Future Work
3

Graph Partitioning Problem
• Graph partitioning is to splitting the graph G into smaller blocks, where connection between blocks are kept at minimum.• Given• Graph G = (V, E) and Number of Partition P
• Output• V = V0 ∪ V1 ∪ V2 ∪ … ∪ VP-1
• Where:• { Vi , Vj} are disjoint ⇒ Vi ∩ Vj = Ø• { Vi , Vj} are roughly balanced ⇒ |Vi| ~ |Vj|• Minimize |Ecut| where Ecut ≡ {(u, v) | u ∈ Vi , v ∈ Vj , i ≠ j }
4

Background
•Regular Graph vs. Knowledge Graph•Resource Description Framework•SPARQL Query Language•Federated SPARQL Query
5

Regular Graph vs. Knowledge graph
•Graphs includes undirected, directed, weighted, labelled, connected, multigraph etc.•Knowledge graph is based on a labelled directed
graph.
6
KGRegular Graph

Resource Description Framework (RDF)
• RDF enables embedding of machine-readable information• RDF statement (triple) has three parts (Subject, Predicate and Object)
• Subject: resource• Predicate : property• Object: value
• Popular formats in which RDF data can be serialized• Turtle, N-Triples / N-Quads, Notation 3, RDF/XML, RDF/JSON etc.
7
University of Georgia
rdf:type
https://www.uga.edu/onto/University
Statement: University of Georgia is a University

SPARQL Query Language
• SPARQL used for Querying the data in RDF graphs• SPARQL tries to match a triple pattern in a RDF graph.•Triple patterns are like a triple, except that any parts
of a triple(s, p, o) can be a variable.
8
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>PREFIX ub: <http://swat.cse.lehigh.edu/onto/univ-bench.owl#>SELECT ?X FROM <LUBM-Synthetic-Data> WHERE
{?X rdf:type ub:GraduateStudent.?X ub:takesCourse <http://www.Department0.University0.edu/GraduateCourse0>
}ORDER BY ?X DESC(?X)LIMIT 10
?xrdf:type
ub:GraduateStudent
GraduateCourse0
ub:takesCourse

Federated SPARQL Query
•Federated SAPARQL Query • It allow to combine solutions from different RDF datasets. • SERVICE keyword is used in the WHERE clause that directs
a portion of a query towards a particular SPARQL endpoint.• .
9
SPARQL Endpoint: http://172.19.48.181:8890/sparql where this query will execute.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>PREFIX ub: <http://swat.cse.lehigh.edu/onto/univ-bench.owl#>SELECT ?X FROM <LUBM-Synthetic-Data> WHERE{
SERVICE <http://172.19.48.183:8890/sparql>{?X rdf:type ub:GraduateStudent.}?X ub:takesCourse <http://www.Department0.University0.edu/GraduateCourse0>
}ORDER BY ?X DESC(?X)LIMIT 10
?x GraduateCourse0
ub:takesCourse
?xrdf:type
ub:GraduateStudent
Endpoint: http://172.19.48.183:8890/sparql
Endpoint: http://172.19.48.181:8890/sparql
SERVICE

Adaptive Workload-Aware Partitioning of Knowledge Graph
•Primary Goal:• Adaptive Graph partitioning system that partition based
on changing workloads.•Secondary Goal:• Handle Very Large Graphs• No Replication • Performance Gain• Adaptive Workload Aware System
10

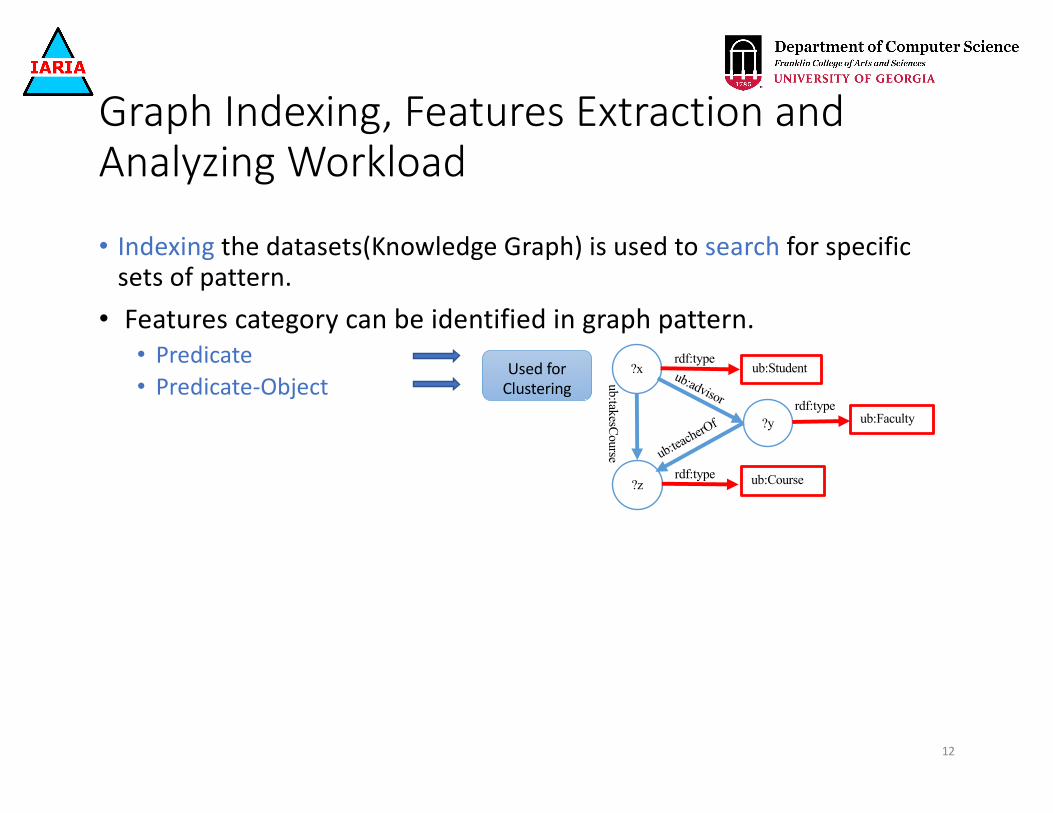
Graph Indexing, Features Extraction and Analyzing Workload
• Indexing the datasets(Knowledge Graph) is used to search for specific sets of pattern.• Features category can be identified in graph pattern.
• Predicate
11
rdf:type
?xrdf:typeub:advisor
ub:Student
?yrdf:type
ub:Faculty
?z ub:Course
ub:takesCourse ub:teacherOf
Graph Indexing, Features Extraction and Analyzing Workload
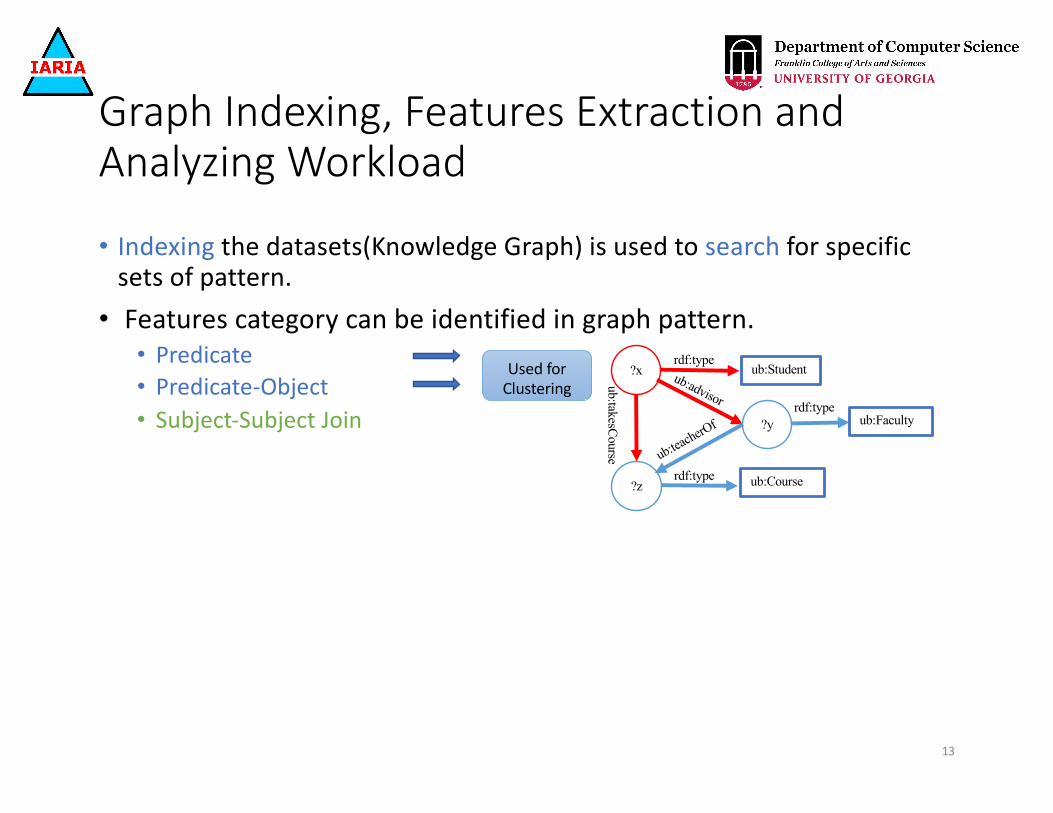
• Indexing the datasets(Knowledge Graph) is used to search for specific sets of pattern.• Features category can be identified in graph pattern.
• Predicate • Predicate-Object
12
Used for Clustering
rdf:type
?xrdf:typeub:advisor
ub:Student
?yrdf:type
ub:Faculty
?z ub:Course
ub:takesCourse ub:teacherOf
Graph Indexing, Features Extraction and Analyzing Workload
• Indexing the datasets(Knowledge Graph) is used to search for specific sets of pattern.• Features category can be identified in graph pattern.
• Predicate • Predicate-Object • Subject-Subject Join
13
Used for Clustering
rdf:type
?xrdf:typeub:advisor
ub:Student
?yrdf:type
ub:Faculty
?z ub:Course
ub:takesCourse ub:teacherOf

Graph Indexing, Features Extraction and Analyzing Workload
• Indexing the datasets(Knowledge Graph) is used to search for specific sets of pattern.• Features category can be identified in graph pattern.
• Predicate • Predicate-Object • Subject-Subject Join • Object-Subject Join
14
Used for Clustering
rdf:type
?xrdf:typeub:advisor
ub:Student
?yrdf:type
ub:Faculty
?z ub:Course
ub:takesCourse ub:teacherOf

Graph Indexing, Features Extraction and Analyzing Workload
• Indexing the datasets(Knowledge Graph) is used to search for specific sets of pattern.• Features category can be identified in graph pattern.
• Predicate • Predicate-Object • Subject-Subject Join • Object-Subject Join• Object-Object Join
15
Used for keeping
stats about features
Used for Clustering
rdf:type
?xrdf:typeub:advisor
ub:Student
?yrdf:type
ub:Faculty
?z ub:Course
ub:takesCourse ub:teacherOf

Graph Indexing, Features Extraction and Analyzing Workload
• Indexing the datasets(Knowledge Graph) is used to search for specific sets of pattern.• Features category can be identified in graph pattern.
• Predicate • Predicate-Object • Subject-Subject Join • Object-Subject Join• Object-Object Join
• Query analysis• Extraction of features from workload• Creation of Metadata of Features and Stats
16
Used for keeping
stats about features
Used for Clustering
rdf:type
?xrdf:typeub:advisor
ub:Student
?yrdf:type
ub:Faculty
?z ub:Course
ub:takesCourse ub:teacherOf

Distance Matrix and Hierarchical Clustering
• Jaccard Distance matrix: (1- Jsim) = 1- |A ∩ B| / |A ∪ B|
• Hierarchical Agglomerative Clustering• Cluster grouping : Based on shortest distance among all pairwise distances
between queries.• The first similarity measure is provided by the initial distance matrix.• Once the two most similar queries are grouped together, the distance matrix is
recalculated.• Recalculation of the distance matrix is based on the choice of the linkage (single,
complete, or average).• These steps are repeated until there is only one cluster left.
17
A
B
1-JSIM of sets A and B is 1 – ( 4/12 )= 1-0.33 = 0.67
Partial same
Complete Different
Same
0.66
1.00
0.00

18
Ø Query 2 has 6 features:3 PO features:
rdf:type® ub:GraduateStudentrdf:type® ub:Departmentrdf:type® ub:University
3 P features: ub:memberOfub:subOrganizationOfub:underGraduateDegreeFrom
Ø Query 8 has 5 features:3 PO features:
rdf:type® ub:Studentrdf:type® ub:Department
3 P features: ub:memberOfub:subOrganizationOfub:emailAddress
The distance between these queries is (1- Jsim) = 1- |Q2 ∩ Q8| / |Q2 ∪ Q8| = 1- 3/8= 0.625
�����������
�������������� ���"&���#��� ��#�"��"#���"�������� ���"&���#�����$� !�"&�������� ���"&���#����� "���"��������#������� ������������#��!#� ����'�"��� ������������#��#��� � ��#�"��� ��� ��������������������������������������������������
���������������������������� ���"&���#���"#���"�������� ���"&���#����� "���"��������#������� ������������#��!#� ����'�"��� ����""����%%%����$� !�"&����#���������#��������� �!!�����
�#������$���
�������� ��
������ ����� �����
�%������$���
������������
�$������$���
������!�����$�
�� �������� ������������
�
��� �
�����%���
�� ��
�#������$���
���� �����
�$� �����$��� ������������
�����
��� ��
��� � ��
���%�����
����������"""����!�����$���� ��
�%�
��������������
�
����������������������������
�� �� ������� � �� � ��� ������ ��� ���
�����
��
���
���
����
���
����
����
�

Adaptive Partitioning
• Input• Initial Knowledge Graph Partition*• HAC Dendrogram • Features Metadata
• Create Feature set of workload based on distance• Feature statistics to remove Replication and Balance the Partition
• PEER Features which moves together or Tightly connected features• SIZE of replicated features and theirs peer features• Dependency of Queries on these features.• Number of distributed JOINS it creates on each partition• Frequency of queries in Workload
• Search for features in graph and create partition based on feature sets.
19* A. Priyadarshi and K. J. Kochut, "WawPart: Workload-Aware Partitioning of Knowledge Graphs," Cham, 2021: Springer International Publishing, in Advances and Trends in Artificial Intelligence. Artificial Intelligence Practices, pp. 383-395.

Stats
20

Implementation
• Architecture
21
�#� &� �$ �"� (� ���!!� �
)� �*
�� "�"��������� �
)�*
�#� &�����&'� (���"# ���%" ��"� �)����*
���"# ���"���"��)�*
�� "�"���� �"���"��)��"�*
��#!"� ���� �)���*
� &�� ���+��%���������"���"�)�*�%��#"���� ����
� ������$�������
�#� &� �!#�"
���� �"����#� &
�
� ���!!�������,
� ������"� �
��� ���� ���!!�
�,
� ���!!�������� �
� ������"� �
��� ���� ���!!�
��
�"$� �
���� �"����#� &
���� �"����#� &
�#� &� �!#�"
�#� &� �!#�"
� ������%������
�!� !��"�!�"!
�#� & �!#�"
����%� (�!�� ��� �
)��*
�!"� ����

Experiment Setting
• For this experiment we have chosen • LUBM dataset of 10 universities with 1,563,927 triples.• 14 old LUBM Queries• 10 new mixed LUBM Queries
•WawPart as initial partition*.• A cluster of Intel i5-based systems running Linux Ubuntu
18.04.4 LTS 64-bit OS.• Openlink Virtuoso RDF triple store.
22* A. Priyadarshi and K. J. Kochut, "WawPart: Workload-Aware Partitioning of Knowledge Graphs," Cham, 2021: Springer International Publishing, in Advances and Trends in Artificial Intelligence. Artificial Intelligence Practices, pp. 383-395.
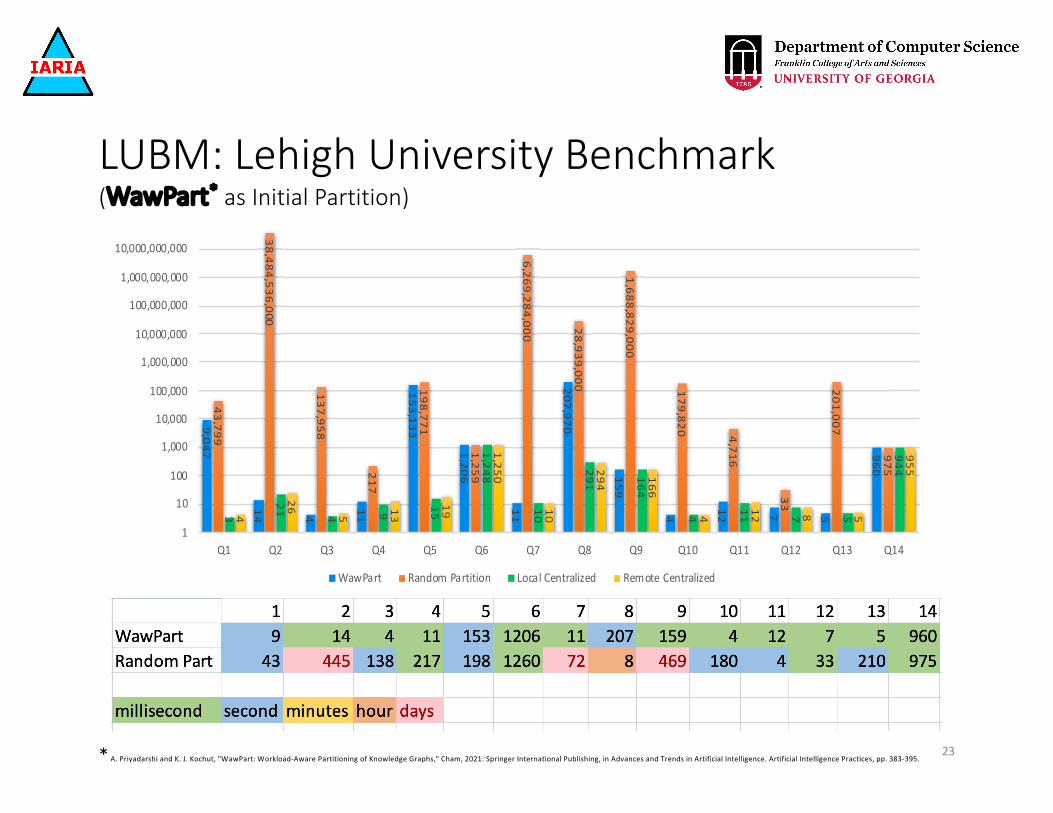
LUBM: Lehigh University Benchmark(WawPart* as Initial Partition)
23
!����
�� � ��
�������
�����
��
����!��
��!
� �� � �
!��
����!!
� �� ���������
����!�
���
�! ����
����!
����!�� ����� � �!�!����
��� � �!����
��!� �� �����
��
�������
!��
�
�� � ! ��
����
��
�!� ���
� �� � �
!��
�
��
� ��
�!
�����
��
�!� ���
� �� �
!��
�
��
���
�����
������
�������
���������
����������
�����������
�������������
��������������
�� �� �� �� �� �� �� � �! ��� ��� ��� ��� ���
������� ����������
������� ��������������� ��� ������� ��� ������������� ���
* A. Priyadarshi and K. J. Kochut, "WawPart: Workload-Aware Partitioning of Knowledge Graphs," Cham, 2021: Springer International Publishing, in Advances and Trends in Artificial Intelligence. Artificial Intelligence Practices, pp. 383-395.

LUBM: Initial Partitioning
24
����
������������
�� ���
������
������������������
������������������������������
�������������
������� ���� ���������� �������������� � �����������
��������������� ���������������������
Average query execution time
o WawPart (Initial Partition): 26 secondo Random Part : 38 dayso Centralized: 195 - 198 milliseconds
(Initial Partition)

Exp 1: Change in composition of the workload
25
��� �
�
��
������
�����
��
�������
���
�� �
��
��
������
�
����
��
��
���� �
���
����
��� ������
�
��
������
�����
��
�� ���
�����
�� �
���
��
�
��
���
��
�
��� ��
����
�����
���
�
��
���
�����
������
�������
�� �� � � �� �� � �� �� ��� ��� ��� �� �� ��� ��� �� �� ��� ��� �� ��� ��� ����
���������� ����������
�������� ����� ����������� �����
The modified workloads runtime on the initial partition and on our adaptive partitioning for the LUBM dataset were evaluated.o EQ1 to EQ10 ten new querieso Improved performance of new queries.
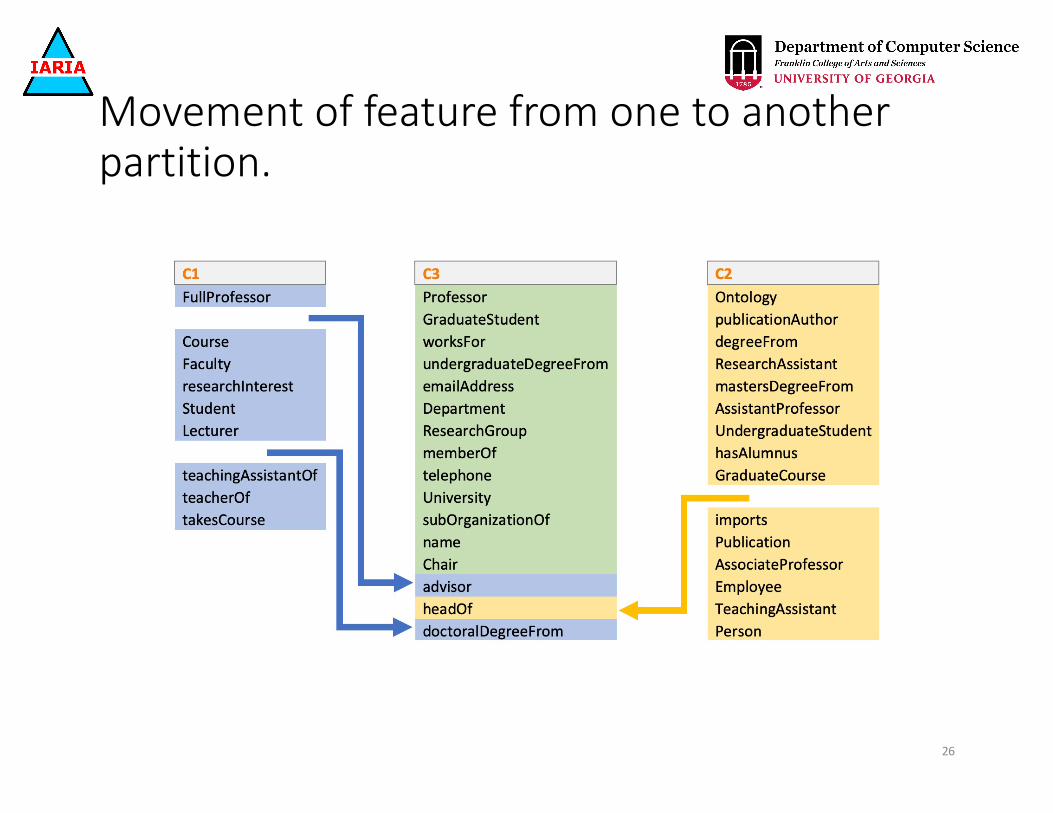
Movement of feature from one to another partition.
26
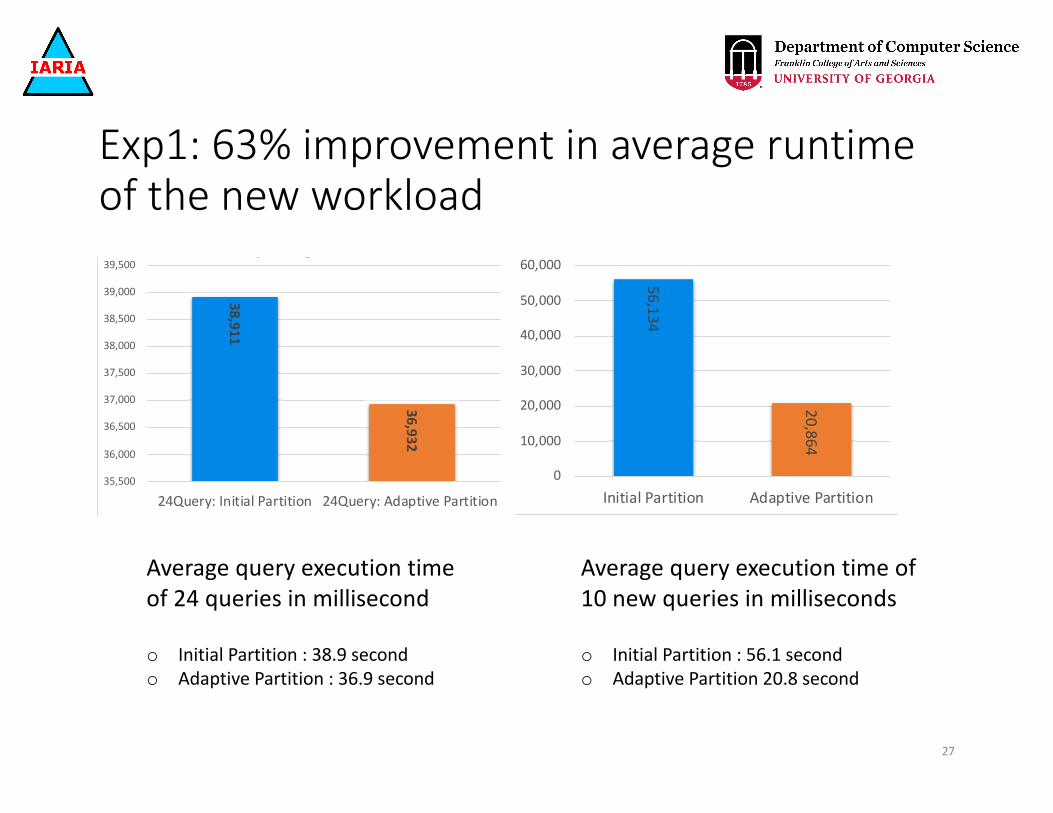
Exp1: 63% improvement in average runtime of the new workload
27
Average query execution time of 24 queries in millisecond
o Initial Partition : 38.9 secondo Adaptive Partition : 36.9 second
������
������
������
������
������
������
������
�����
�����
�����
�����
��������������������� ������������ �����������
����������������������� ������
������
������
�
������
������
������
������
������
�����
�������� ����� ����������� �����
� ����������� ����� �� ������� ������� �����
Average query execution time of 10 new queries in milliseconds
o Initial Partition : 56.1 secondo Adaptive Partition 20.8 second

Exp2: Change in the relative frequency of queries in the workload
28
����
��
�
��
�������
����
��
�����
���
�
�� �
��
�
����
�
��
�������
����
��
�����
���
�
�� �
��
�
��
���
�����
������
�������
�� �� �� �� � � �� �� � ��� ��� ��� ��� ���
������� ����������
�������� ����� ����������� �����The changes in the relative frequency of queries in the workload executed on theinitial partition as compared to the adaptive.o if Q1 in LUBM is executed more frequently than the other 13 queries. The workload
frequency share of query Q1 was increased to 50% of the whole workload. o For Example, If all queries executed a total of 1000 times. Then Q1 executed 425 times
and other 13 queries execute 45 times each approximately.

Movement of feature from one to another partition.
29
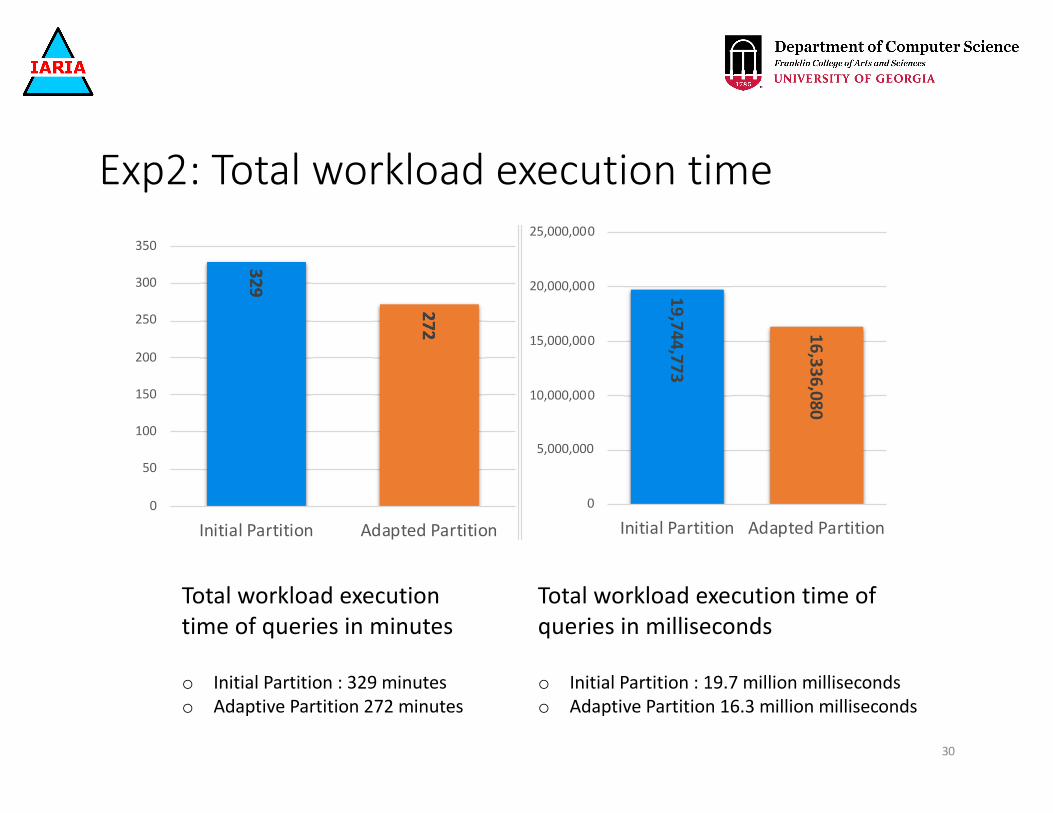
Exp2: Total workload execution time
30
���
��
�
��
���
���
���
���
���
���
�������� ����� ���������� �����
�������
��������
�
���������
����������
����������
����������
����������
�������� ����� ���������� �����
Total workload execution time of queries in minutes
o Initial Partition : 329 minuteso Adaptive Partition 272 minutes
Total workload execution time of queries in milliseconds
o Initial Partition : 19.7 million millisecondso Adaptive Partition 16.3 million milliseconds

Future Work
•To extend AWAPart into schema and Instance aware evolving knowledge graph adaptive re-partitioning system.• New entry of entity in knowledge graph• Old entry in knowledge graph is updated or deleted• Change in schema of Knowledge graph
31
Copyright © 2022 FDOKUMEN




















