
An MCR-weighted protocol for multipoint-to-point communication over ABR service
16
An MCR-weighted protocol for multipoint-to-point communication over ABR service Shatha K. Habra a , Ahmed E. Kamal a,b, * ,1 a Department of Electrical and Computer Engineering, Kuwait University, P.O. Box 5969 Safat, Kuwait 13060 b Department of Electrical and Computer Engineering, Iowa State University, Ames, IA 50011–3060, USA Received 15 September 1999; received in revised form 24 March 2000; accepted 4 April 2000 Abstract In this paper, we propose an available bit rate (ABR) algorithm which can work with multipoint-to-point (mpt-to-pt) as well as with point-to-point (pt-to-pt) connections. The algorithm is an extension to the MCR-weighted max–min algorithm [Y. Hou, H. Tzeng, S. Panwar, IEEE GLOBCOM, 1997, pp. 492–497], which allocates rates to users in proportion to their MCR requirements. This paper shows how source-level information can be compensated for in order to achieve a performance comparable to that of the pt-to-pt algorithm. This is achieved by combining the current cell rate (CCR) and minimum cell rate (MCR) values of all merged connections hierarchically at each merging point and inserting the aggregate values in the outgoing FRM cells. However, we propose to combine the bottlenecked in- formation only in order to avoid mixing the rates of bottlenecked and non-bottlenecked sources. The same switch algorithm used for the pt-to-pt case can therefore still run on the VC level. A simulation study is conducted under dierent network configurations. Results show that the algorithm produces an oscillation-free allocation vector with almost the same convergence time of the pt-to-pt algorithm. The results also indicate that the additional buer requirements due to packet level service is minimal. Ó 2000 Elsevier Science B.V. All rights reserved. Keywords: ATM; ABR; Multipoint-to-point; Trac management 1. Introduction The available bit rate (ABR) service in ATM networks has been designed for applications which have vague bandwidth and delay requirements but at the same time require low cell loss rates in order to avoid throughput collapse [3]. Most of these applications are generated by data sources, which are highly bursty in nature. Since an explicit trac profile cannot be predicted at connection set up time, the open-loop preventive congestion control schemes of CBR and VBR trac become ine- cient for controlling such applications. If, on the other hand, pure reactive control schemes in which feedback is generated on the onset of congestion were used, the high bandwidth-delay product of ATM links would outdate the generated feedback. Therefore, congestion control of data trac poses more challenging problems than other services. In the course of trying to find satisfactory so- lutions to the above problem, several proposals Computer Networks 34 (2000) 363–378 www.elsevier.com/locate/comnet * Corresponding author. E-mail addresses: [email protected] (S.K. Habra), [email protected] (A.E. Kamal). 1 Tel.: +1-515-294-3580; fax: +1-515-294-8432. 1389-1286/00/$ - see front matter Ó 2000 Elsevier Science B.V. All rights reserved. PII: S 1 3 8 9 - 1 2 8 6 ( 0 0 ) 0 0 1 1 8 - 3
Transcript of An MCR-weighted protocol for multipoint-to-point communication over ABR service

An MCR-weighted protocol for multipoint-to-pointcommunication over ABR service
Shatha K. Habra a, Ahmed E. Kamal a,b,*,1
a Department of Electrical and Computer Engineering, Kuwait University, P.O. Box 5969 Safat, Kuwait 13060b Department of Electrical and Computer Engineering, Iowa State University, Ames, IA 50011±3060, USA
Received 15 September 1999; received in revised form 24 March 2000; accepted 4 April 2000
Abstract
In this paper, we propose an available bit rate (ABR) algorithm which can work with multipoint-to-point (mpt-to-pt)
as well as with point-to-point (pt-to-pt) connections. The algorithm is an extension to the MCR-weighted max±min
algorithm [Y. Hou, H. Tzeng, S. Panwar, IEEE GLOBCOM, 1997, pp. 492±497], which allocates rates to users in
proportion to their MCR requirements. This paper shows how source-level information can be compensated for in
order to achieve a performance comparable to that of the pt-to-pt algorithm. This is achieved by combining the current
cell rate (CCR) and minimum cell rate (MCR) values of all merged connections hierarchically at each merging point
and inserting the aggregate values in the outgoing FRM cells. However, we propose to combine the bottlenecked in-
formation only in order to avoid mixing the rates of bottlenecked and non-bottlenecked sources. The same switch
algorithm used for the pt-to-pt case can therefore still run on the VC level. A simulation study is conducted under
di�erent network con®gurations. Results show that the algorithm produces an oscillation-free allocation vector with
almost the same convergence time of the pt-to-pt algorithm. The results also indicate that the additional bu�er
requirements due to packet level service is minimal. Ó 2000 Elsevier Science B.V. All rights reserved.
Keywords: ATM; ABR; Multipoint-to-point; Tra�c management
1. Introduction
The available bit rate (ABR) service in ATMnetworks has been designed for applications whichhave vague bandwidth and delay requirements butat the same time require low cell loss rates in orderto avoid throughput collapse [3]. Most of theseapplications are generated by data sources, which
are highly bursty in nature. Since an explicit tra�cpro®le cannot be predicted at connection set uptime, the open-loop preventive congestion controlschemes of CBR and VBR tra�c become ine�-cient for controlling such applications. If, on theother hand, pure reactive control schemes in whichfeedback is generated on the onset of congestionwere used, the high bandwidth-delay product ofATM links would outdate the generated feedback.Therefore, congestion control of data tra�c posesmore challenging problems than other services.
In the course of trying to ®nd satisfactory so-lutions to the above problem, several proposals
Computer Networks 34 (2000) 363±378
www.elsevier.com/locate/comnet
* Corresponding author.
E-mail addresses: [email protected] (S.K. Habra),
[email protected] (A.E. Kamal).1 Tel.: +1-515-294-3580; fax: +1-515-294-8432.
1389-1286/00/$ - see front matter Ó 2000 Elsevier Science B.V. All rights reserved.
PII: S 1 3 8 9 - 1 2 8 6 ( 0 0 ) 0 0 1 1 8 - 3

have appeared in the literature. Among all pro-posed mechanisms, the rate-based closed-loopfeedback control that allows the network to con-trol the cell emission process at each source isconsidered to be the most e�ective solution. Thisservice de®nes a discipline in which the availablebandwidth left over by the CBR and VBR tra�c isdynamically (and fairly) shared among all activesources. During the admission phase, ABR usersare requested to specify upper and lower boundson the required bandwidth in terms of their mini-mum cell rate (MCR) and peak cell rate (PCR),respectively. The network would honor the MCRrequirements of each accepted connection andwould ensure low cell loss only to those connec-tions that respond properly in accordance with thenetwork feedback. The ATM forum has stan-dardized the source and destination behavior ofthe rate-based framework and has de®ned specialcontrol cells called resource management (RM)cells to convey control information to the con-nectionÕs end points. The speci®c algorithm in theswitches, which is used to perform the rate controlis not standardized and is left to the networkmanufactures. Consequently, numerous switch al-gorithms have been developed which di�er in theirbehavior in terms of fairness, e�ciency, complex-ity, responsiveness and robustness (see [8] for areview and comparison).
Fairness constitutes the most important aspectof any switch rate allocation algorithm. Althoughmany fairness policies are possible, the max±minfairness is the one commonly adopted [1]. Thispolicy simply distributes equal rates to connec-tions, which are able to e�ciently utilize their fairshare. However, it works only if ABR connectionsreceive zero guarantee for their MCR. The MCR-weighted algorithm in [10] has generalized themax±min fairness to support the MCR require-ments by allocating rates to connections in pro-portion to their MCR values in a max±minfashion. This algorithm makes use of the consis-tent marking technique proposed in [4].
Despite the enormous e�orts exerted for sup-porting the ABR tra�c, current solutions onlysupport point-to-point (pt-to-pt) and unidirec-tional point-to-multipoint (pt-to-mpt) connectionsbut do not provide scalable solutions for multi-
point-to-point (mpt-to-pt) connections. Thempt-to-pt communication achieves scalability interms of routing and reduces the overhead ofstoring the connection state inside the network.Moreover, when an adequate mpt-to-pt service issupported, it can be integrated with the dual pt-to-mpt service to provide a scalable multicast servicein which each member can equally be a sender orreceiver, i.e., a multipoint-to-multipoint service.Such a multicast service is essential for the supportof many applications including LAN emulationand IP multicasting over ATM [7,9]. The supportof mpt-to-pt ABR communication is conjugatedwith two major problems. If the cell streams frommultiple senders are mapped to one connection,cells will interleave at merging points. Since theATM adaptation layer 5 (AAL5) does not providea multiplexing identi®cation on the cell-basis, aparticular packet sender will not be identi®ed.Therefore new protocols at merging points areneeded to enforce an ordered packet delivery at thedestination side. The second problem is related tothe ABR switch algorithms. Since the sender willno longer be identi®ed by the VCI/VPI values inthe cell header, it will be impossible for the net-work to determine any sender-speci®c informationsuch as the sender rate or whether a source isbottlenecked at a particular link. This adds to thecomplexity of the ABR switch algorithms espe-cially to those algorithms, which attempt source-level accounting.
Several solutions to the cell interleaving prob-lem have been proposed in the literature. Thesesolutions tend to either avoid tra�c merging orprevent cell interleaving at merge points or provideenough information in the cell headers (e.g., se-quence numbers) to enforce a correct packet re-assembly at the receiver side [6]. The solutionadopted in this paper involves VC merging com-bined with packet level queuing and scheduling inwhich the cells of a packet are bu�ered in theswitch until the end of packet (EOP) marker isencountered. Only then, cells are sent out, back toback and without interleaving other cells on thesame virtual circuit [12].
The problem of supporting mpt-to-pt ABRtra�c is more involved and is only tackled byfew research papers, e.g., [5,6,11]. The main
364 S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378

consideration for current mpt-to-pt ABR algo-rithms is to avoid any attempt to estimate thenumber and rates of active sources or di�erentiatebetween under-loaded and over-loaded sources.However, the loss of such knowledge may increasethe transient response of many algorithms.
In this paper, we propose a new mpt-to-pt ABRalgorithm which can successfully use such infor-mation as in the pt-to-pt algorithm. The algorithmcan be applied to extend almost any pt-to-pt al-gorithm. In this paper, we apply to the MCR-weighted max±min allocation algorithm [10], andshow that it works well with both pt-to-pt andmpt-to-pt connections. Since the VC tra�c in ampt-to-pt connection originates from multiplesenders, the weight and rate of each VC in theextended algorithm is adjusted to hold the sum ofthe MCR and CCR values of all sources whosetra�c is being merged. The algorithm also pro-vides a mechanism to successfully detect bottle-necked information at the root of the multipointconnection.
The remainder of this paper is organized asfollows: In Section 2, we provide a brief back-ground of the ABR service model and the MCR-weighted max±min algorithm which constitutes thebasis of our mpt-to-pt protocol. We also reviewthe previous work on tra�c management of mpt-to-pt connections. Our mpt-to-pt algorithm will bepresented in Section 3. In Section 4, we study theperformance of the proposed algorithm by simu-lating it on a number of network con®gurations.Finally, Section 5 concludes the paper.
2. Background
2.1. The ABR service model
As mentioned in Section 1, the standard ABRcongestion control scheme is a rate-based, closed-loop mechanism which utilizes the feedback in-formation from the network to control the rate oftransmitting cells at the sources. Each ABR sourcegenerates RM cells in proportion to its currentdata cell rate. The source indicates its current rateto the network in a special ®eld in the RM cellcalled the CCR. It also indicates its requested rate
in the explicit rate ®eld (ER). RM cells travelingfrom the source to the destination are called for-ward RM (FRM) cells. When the destination re-ceives those cells it turns them around and sendsthem back to the source as backward RM (BRM)cells. A single bit in the RM cell payload, called thedirection bit, is used to distinguish between FRMand BRM cells. The RM cells are examined by theATM switches and possibly modi®ed in both di-rections to carry the feedback information of thestate of congestion and the fair rate allocation. TheRM cell provides such information in three ®elds:the congestion indication (CI) and no increase (NI)bits which are used to signal extreme and moderatecongestion, respectively, and the ER ®eld which isset by the network to the maximum availableservice rate in the reverse path. The detailed ac-tions of the source and destination behavior arespeci®ed by the ATM forum and can be found in[2].
2.2. The weighted max±min fair rate allocationalgorithm
The idea of the weighted max±min (WMM) fairrate allocation algorithm is to allocate bandwidthto sessions in proportion to their requested MCRvalues. In order to describe the algorithm formally,let N be a network with a set of links, L, and set ofsessions, S. Let the set of sessions on link l 2 L beSl and let the capacity on link l be Cl. Supposeeach session s 2 Sl is allocated rate rs. Then theaggregate allocated rate on link l is Fl �
Ps2Sl
rS .
De®nition 1. A rate vector r � f. . . ; rs; . . .g is saidto be WMM if the following three conditions aresatis®ed:1. MCRs6 rs6PCRs 8s 2 Sl.2. Fl6Cl 8l 2 L.3. 8s 2 S; and 8 vector r̂ satisfying 1 and 2 with
r̂s > rs, there exists some session t 2 S such thatrs=MCRs P rt=MCRt and rt > r̂t.
De®nition 2. Given an WMM vector r, a link l 2 Lis a WMM-bottlenecked link with respect to r for asession s traversing l if Fl � Cl and rs=MCRs Prt=MCRt for all other sessions, t 2 Sl.
S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378 365

It can be shown that a vector r is WMM if andonly if each session in this vector has either aWMM-bottlenecked link with respect to r, or has arate assignment equal to its PCR. A centralizedalgorithm for the computation of the WMM vec-tor is presented in [10].
The distributed implementation for the WMMpolicy is based on the consistent marking techniqueintroduced in [4], where a session is marked at alink if it is bottlenecked on this link. A session willbe bottlenecked at a link if it cannot use the linkÕsadvertised rate, either due to its PCR limitation, ordue to a limitation imposed upstream. The fol-lowing are the variables used in the algorithm: nl isnumber of sessions in Sl, Yl the set of sessionsmarked at link l, Ul the set of unmarked sessionsat link l, ri the CCR of session i, MCRi the MCRof session i, ll the MCR-normalized advertisedrate at link l, where l is calculated as follows:
ll �
Cl ÿP
s2SlrsP
s2SlMCRs
�maxs2S1
rs
MCRs; if nl � Ylj j;
Cl ÿP
s2YlrsP
s2UlMCRs
; otherwise:
8>>>>>><>>>>>>:Sources are assumed to transmit initially at theMCR, and the ER ®eld of the RM cell is used toindicate the PCR of the source. The destinationsimply turns around every RM cell back to thesource which adjusts its rate by setting AC-R � ER. Each switch maintains a table that keepstrack of the state information regarding the MCRand CCR values of each active VC (per-VC ac-counting). 2 For a particular link l, the switch al-gorithm computes the ll rate upon a sessioninitiation or termination, or upon rate change.Also, upon receiving a BRM, the explicit ratecomputation uses ll to allocate rates proportionalto MCR values. In order to conserve space, we donot repeat the switch algorithm here, but we referthe reader to [10].
2.3. Tra�c management for mpt-to-pt communica-tion
A mpt-to-pt connection can be implemented asa shared tree. A signaling mechanism calledSEAM is proposed in [9] which allows the use of asingle VC per link for the transmission of packetsfrom all sources of a multicast group. Based on thetree architecture of the mpt-to-pt connection, thefollowing four types of fairness can be de®nedwhich give rise to di�erent rate allocation vectors[6]:1. Source-based fairness: The bandwidth in this
case is fairly divided among active sources with-out any concern about group membership. Inthis case, a single mpt-to-pt connection withN sources is treated as N pt-to-pt connections,which is equivalent to the max±min fairness cri-terion. Observe, however, that this allocation ismax±min fair only at the source level, but not atthe VC level. In other words, a VC with N send-ers will be allocated a rate which is N timesgreater than a VC with a single sender. TheER value in BRM cells is set to the minimumrate supported by any switch in the path exactlyas in the pt-to-pt case.
2. VC/source fairness: In this case, the rate is ®rstfairly allocated at the VC level and then the VCbandwidth is allocated fairly among activesources in a max±min fashion.
3. Flow-based fairness: This policy gives fair allo-cation to each active ¯ow, where a ¯ow is de-®ned as a VC arriving on an input port. Inthis case, ¯ows which are merged several timeswill get less bandwidth than those which aremerged few times (i.e., those which are nearthe destination). The computation of the ERvalue in this case, as well as in case 4 describedbelow, requires that the aggregate ER valueswhich are computed at downstream switchesbe subdivided evenly among ¯ows at upstreamswitches.
4. VC/flow-based fairness: In this case, the band-width is ®rst divided among active VCs andthen the VC bandwidth is fairly divided among¯ows in the VC.
Notice that all these de®nitions give the same al-location for pt-to-pt connections. This is because
2 MCR values need not be stored in the table since they are
included in every RM cell. The switch just has to keep track of
their running sum.
366 S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378

in this case the notions of source, VC and a ¯oware all equivalent. Since the source-based fairnessis the one, which is equivalent to the de®nition ofthe classical max±min fairness, it is the one com-monly adopted for mpt-to-pt connections. How-ever since a VC in a mpt-to-pt connection is nolonger equivalent to a source, algorithms whichattempt VC accounting may have some problems.Although, it is possible for some of these algo-rithms to avoid using source-level information (asin the case with the ERICA+ algorithm), the lossof such knowledge may increase the transient re-sponse of such algorithms. On the other hand,algorithms such as the MIT scheme [4] will en-counter serious problems and will not actuallyoperate with mpt-to-pt connections without majorre®nement.
Another important issue which must be con-sidered by the switch algorithm in order to supportVC merged ABR connections is when, and towhich ¯ows the BRM cells at merging pointsshould be passed to. The switch algorithm musthave a provision for detecting the sender of an RMcell so that the number of transmitted FRM cells isbalanced with the number of received BRM cells.This is a necessary requirement from ¯ow controlpoint of view. If the feedback information is notdelivered in a timely manner the scheme will not beresponsive.
In [11], a mpt-to-pt algorithm was developed inwhich the rate allocation is computed exactly as inthe unicast case. The extended algorithm solves thecell interleaving problem by maintaining a sepa-rate queue for each connection traversing theswitch. The simple round robin scheduling policyis employed to determine the next queue of packetsto serve. Whenever an FRM cell is received at themerging point, it is forwarded to the root, andthe merging point will return a BRM cell to thesender. The ER value in the BRM cell is set to thevalue of a local register called MER, which ismaintained for each merging point. The value ofthe MER will then be reset to the PCR. When aBRM arrives at the merging point, its ER ®eld willbe used to reset the value of MER and the BRMcell will be then discarded, hence the ratio betweenthe transmitted FRM cells to the received BRMcells at sources is maintained at one exactly. The
algorithm is extremely simple, but requires thatswitches have the provision of generating BRMcell, which incurs more complexity and overhead.Moreover since the same FRM cells can be turnedaround at every merging point in the path to thedestination including the destination itself, toomany BRM cells may be generated which are thendiscarded. This makes the ratio of FRM cell toBRM cells less than one inside the network, whichis undesirable. Notice also that the algorithm waitsfor an FRM cell to arrive before a BRM cell fromthe merging point can be transmitted. This causesa feedback delay that is proportional to the num-ber of levels in the mpt-to-pt connection tree.Hence this algorithm is not easily scalable.
A better approach is employed in [5], where theERICA+ algorithm has been extended to workwith mpt-to-pt connections. This algorithm elimi-nates the need for merging point to turn aroundFRM cells and restricts this capability on thedestination. To keep track of which ¯ows in thempt-to-pt connection have sent FRM cells, a sin-gle bit is associated with each ¯ow. When a BRMcell arrives at the merging point it is duplicated(using the ATM switch multicast capability) andsent to each ¯ow for which the corresponding bit isset, see Fig. 1. All bits will then be cleared. In thisway, a BRM cell is returned to the sender for everyone or more FRM cells it sends. Thus the ratio ofBRM cells to the FRM cells is less than one.However, in steady state this ratio will approachone both at senders and inside the network. Anobvious advantage of this algorithm is de-corre-lating the feedback delay from the number oflevels in the mpt-to-pt connection, which supports
Fig. 1. Duplicating the BRM cell at merging points in the
ERICA+ algorithm.
S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378 367

the scalability of the scheme. (A similar approachwas proposed in [13].)
The extended ERICA+ algorithm introducessome changes to the basic algorithm to avoid usingsource-level information. Speci®cally, it avoidsestimating the number of active users and uses theCCR information in the FRM cells for rate allo-cation. Possible oscillation is ®ltered out by ex-ponential averaging of the various quantitiesmeasured by the scheme. The scheme, however, isnot integrated by a solution to preserve packetintegrity.
3. An MCR-weighted mpt-to-pt algorithm
Although, the use of CCR information fromFRM cells may be su�cient to achieve source-based fairness as the case with the ERICA+algorithm, it will not be su�cient with otheralgorithms which intrinsically use source-level in-formation such as [4,10]. The reason is that thesealgorithms store the CCR values in internal con-nection table and any incoming FRM cell shouldbe mapped with its appropriate entry in the table.But sources cannot be distinguished after themerging points. It appears that such algorithmsmay not work with mpt-to-pt connections. Ob-serve, however, that while source-level accountingis not possible in mpt-to-pt connections, ¯ow-levelaccounting is a feasible alternative. Our work, inthis paper, is motivated by the challenge to ®nd anextension to such algorithms, which intrinsicallyrequire source-based information without deteri-orating the performance of the scheme, in terms offairness and convergence time. We have selectedthe MCR-weighted max±min algorithm as thebase-line algorithm for our work. This choice isbased on the fact that this algorithm is one of thevery few that takes MCR values into account inorder to determine rate allocations.
To start with, notice that the number of in-coming FRM cells at any merging point is thesame as the number of outgoing FRM cells.Equivalently, the aggregate rate on a particular¯ow in a mpt-to-pt connection equals the sum ofrates of all sources whose tra�c is being mergedinto this ¯ow. Therefore, we can perform ¯ow-
level accounting and let the base-line switch algo-rithm operate at the ¯ow level. To do this, theCCR and MCR values in FRM cells are aggre-gated at merging points and the aggregate mea-surements are used to replace the CCR and MCR®elds of the outgoing FRM cells. The algorithmmakes use of the scalability advantage of VCmerging to reduce the computational complexityof the base-line switch algorithm in the down-stream switches. Thus, while the base-line algo-rithm has a complexity of O(N) on each switch inthe path, the complexity of the extended algorithmreduces gradually as we get closer to the destina-tion. We ®rst propose our baseline mpt-to-pt al-gorithm that takes the MCR and CCR values ofall ¯ows into account. However, this algorithmwill turn out to be de®cient in the sense that it doesnot result in the correct rate allocation. Therefore,we present a re®ned algorithm that overcomes thisde®ciency.
3.1. Algorithm description
Let VCL be a multipoint connection on a par-ticular link L. Let FVC be the set of ¯ows which aremerged into VCL. The switch maintains for eachoutput port a ¯ow table to keep track of the cur-rent CCR and MCR values of all active ¯ows.Each merging point is assumed to be equippedwith two registers, AMCR and ACCR which areused to store the aggregate CCR and MCR valuesof the merged ¯ows, respectively. Whenever aFRM cell arrives at the merging point, the ¯owtable is updated and the switch algorithm is calledto update the value of the advertised rate. TheAMCR and ACCR will then be updated asfollows:
AMCR :� AMCRÿMCR f i �MCR;
ACCR :� ACCR ÿ CCR f i � CCR;
where MCR f i and CCR f i are the MCR andCCR values of the ith ¯ow in the local ¯ow table,see Fig. 2. The new AMCR and ACCR will beused to replace the MCR and CCR ®elds in theoutgoing FRM cell making the aggregate mea-surements available to the next hop switch. Thiscombing procedure will hierarchically combine
368 S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378

¯ow rates until the root of the mpt-to-pt connec-tion is reached. At this point the AMCR andACCR will represent the total MCR and CCRvalues of all sources in the mpt-to-pt connection,respectively.
As we have seen in the ¯ow-based fairness, therate computed at downstream switches must beused for the computation of rates upstream. Sowhenever a BRM cell with ER value � ER\_BRMarrives at the merging point. The ER value of theith ¯ow is calculated as follows:
ERi �max�min �MCR f i� �lL�; MCR f i=AMCR� ��ER BRM�;MCR f i�;
where lL is the advertised rate on link L. Thismeans that the aggregate ER value from thedownstream node will be divided in an MCR-weighted max±min fashion among eligible ¯ows.Our procedure for the merging point is slightlydi�erent from the ERICA+ algorithm. Instead of asingle bit per ¯ow, we employ a counter (B_RM:balance of RM cells) which keeps track of thedi�erence between the transmitted FRM cells andthe received BRM cells (see Fig. 2). The BRM cellwill be duplicated to the branches whose countersare greater than zero. The counter will be incre-mented for each arriving FRM cell and will bedecremented for each received BRM cell. Thismethod achieves scalability as in the ERICA+ al-gorithm. It also has the advantage of keeping theratio between FRM cells and BRM cells exactlyone at all times, both at senders and inside thenetwork. Notice that because of duplication ofBRM cells at merging points to multiple ¯ows, thefeedback information in the BRM cells may reachthe source quite faster than in the pt-to-pt case
which in some network con®gurations mayeven reduce the convergence time of the switchalgorithm.
Although this algorithm provides a naturalmethod for extending the base-line algorithm, itactually fails to give the correct rate allocation.The reason is that it cannot di�erentiate betweenunder-loaded and over-loaded sources. A ¯owwith mixed bottlenecked and non-bottleneckedsources may or may not be considered bottlenec-ked. We illustrate this point by an example. Let 3and 6 be the current rates of two sources which aremerged at some link L. Suppose both sources haveMCR � 2. Let lL � 2 be the current advertisedrate on link L. This implies that the ®rst source isbottlenecked at link L while the second one is not.However, the whole ¯ow will have an MCR-weighted rate of �3� 6�=�2� 2� � 2:25 which isgreater than lL. Therefore the whole ¯ow will beconsidered non-bottlenecked. This shows that theadvertised rate computed at each link is onlymeaningful at the ¯ow level but not at the sourcelevel. Hence, although the marking procedure usedfor keeping track of bottlenecked sources is con-sistent at the ¯ow level, it is not at the source level.Therefore, it is possible for a ¯ow which combinesrates from bottlenecked and non-bottlenecked tobe unmarked. If this happens at the root of themultipoint connection, the bottlenecked informa-tion will be lost and will not be recovered any-more. Consequently, this algorithm only achievesmax±min allocation at the ¯ow level but does notguarantee max±min allocation at the source level.To illustrate the problem further, consider theparking lot network con®guration in Fig. 3, wherefor the mpt-to-pt case, it is assumed that allsources transmit to only one of the destinations,
Fig. 2. The ¯ow and VC tables used by the algorithm.
S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378 369

e.g., D1. The MCR and PCR values are as indi-cated in Table 1. After the ®rst iteration, the linkadvertised rates and the source rates would be as inthe unicast case, as shown in Tables 2 and 3.
After that, and when rates are combined atmerging points, the total rate 0.55 from switch sw1and rate 0.25 from source S3 will combine atswitch sw2 giving an aggregate output rate of 0.8.At link L3, both the ¯ows from switch sw2 andsource S4 will be bottlenecked with respect to thecurrent advertised rate (2.5). The advertised ratewill be re-computed as �1:0ÿ �0:8� 0:125��=0:4� 2:5 � 2:6875. In this way, the advertised ratewill be gradually increased by each arrival of aFRM cell from source S4 which is the closest to
the destination. The rate allocation will graduallyapproach the optimal WMM allocation (i.e., theadvertised rate on link L3 will approach 3) until atsome point the MCR-normalized rate of both¯ows will be greater than the advertised rate of thelink, and thus both of them would be unmarked.The bottlenecked information due to sources S1and S2 (0.55) will therefore be lost at the root andwill not be recovered at any level below. At thispoint, the rate allocation vector will return to thesame status after the ®rst iteration and this be-havior will repeat in a cyclic manner. A carefulobserver may notice that such anomaly would nothave happened if the e�ect of propagation delaywould have been neglected, i.e. the rate informa-tion from all sources reach the root synchronously.If this assumption was valid (which is unrealistic)then the bottlenecked information from sources S3and S4 would reach the root at the same time andthe advertised rate would be increased propor-tional to the sum of the MCR values of sources S3and S4 (� 0.15). The additional number of itera-tions it takes the advertised rate to reach the targetadvertised rate could be determined by solving thefollowing recurrence equation:
lnL � �1:0ÿ 0:55� 0:15� lnÿ1
L �=0:4� lnÿ1L ;
where l1L � 2:5; ltarget � 3:0 and ln
L is the adver-tised rate in the nth iteration.
3.2. The re®ned algorithm
To solve the problem in the previous example,we must be able to distinguish between bottlenec-ked and non-bottlenecked sources. We propose toimplement this distinction by combining only therate of bottlenecked sources at merging points. A¯ow with merged sources being all bottleneckedwould be bottlenecked as well. However, we willrun into the same problem of the previous algo-rithm since source S3 in Fig. 3 will be consideredbottlenecked at switch 2 and its rate will be com-bined with the bottlenecked information from theupstream switch.
In fact, we need here to slightly modify thede®nition of a bottlenecked source so that it canbe correctly identi®ed by root of the mpt-to-ptconnection.
Table 1
The MCR/PCR constraints for the sources in the network of
Fig. 4
Source MCR PCR
1 0.15 0.35
2 0.1 0.2
3 0.1 0.5
4 0.05 0.5
Table 2
The iterative WMM-advertised rates on the links
Iteration # L1 L2 L3
1 4.0 2.857 2.5
2 4.13 3.07 2.687
Table 3
The iterative WMM-advertised rate to sources
Iteration # s1 s2 s3 s4
1 0.35 0.2 0.25 0.125
2 0.35 0.2 0.268 0.134
Fig. 3. A network con®guration with a downstream bottleneck.
370 S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378

De®nition 3. A source in a multipoint connection isbottlenecked if its MCR-normalized rate is strictlyless than the advertised rate at the root of themultipoint connection.
Referring to the previous example, we observethat after the ®rst iteration sources can be groupedinto two categories with respect to the advertisedrate lr at the root r of the mpt-to-pt connection:1. Sources Sb which are either bottlenecked by
their PCR or are bottlenecked at some linkl 2 Lÿ frg, where L is the set of links compris-ing the shared tree of the multipoint connec-tion. This implies that if s 2 Sb and rs andMCRs are the CCR and MCR of s, respective-ly, then rs=MCRs < lr. Sources S1 and S2 inthe previous example belong to this category.
2. Sources Sb 0 which are only bottlenecked at r.This implies that a source s 2 Sb 0 if and only ifrs=MCRs P lr. In this case, if Sb 0 62 /, r willbe the bottlenecked link of all sources in Sb0 .Sources S3 and S4 in the previous example be-long to this category since they are bottleneckedat link L3.
The validity of this way of source grouping stemsfrom the interesting property of VC merged mpt-to-pt connections that once VCs have been mergedtogether at a particular link they never get splitthereafter.
Now, if the root r is able to distinguish betweenthese two types of sources, it can submit the raterequirement of sources in the ®rst category and usethe left over ABR capacity to allocate it in anMCR-weighted fashion among sources in thesecond category. However, if the rate of the twotypes of sources is already mixed at mergingpoints, the root will be unable to perform thisdistinction. The natural place to do this distinctionis at the leaves of the mpt-to-pt connection.Therefore, our approach is to allow only sourcesbelonging to the ®rst category to indicate theirrates in the FRM cells. Other sources will onlysend dummy FRM cells.
To see how this way of source grouping cansolve the whole problem, refer to the previousexample. After the ®rst iteration sources S1 and S2will be bottlenecked by their PCR. Hence they willbelong to the ®rst source category and will insert
their rate information in the FRM cells. Therefore,at switch sw1 the merging point will combine therate of sources S1 and S2 giving a total CCRof �0:35� 0:2 � 0:55� and a total MCR of�0:15� 0:1 � 0:25�. On the other hand, sources S3and S4 will belong to the second category becausetheir MCR-normalized rate � 2.5, which is thesame as the current advertised rate of the root.Therefore, the rate of source S3 will no longer becombined with the rate of the ¯ow from switch sw1and hence the total bottlenecked information outof switch sw2 will still be 0.55. The case withsource S4 is similar. The total bottlenecked ratereaching switch sw3 will be 0.55. The advertisedrate on link L3 will then be re-computed as�1ÿ 0:55�=0:15 � 3 which is the target advertisedrate. In this case, the rate allocation becomes max±min both at the source, ¯ow and VC levels. In-terestingly enough, with this implementation, thefour fairness de®nitions for multipoint connectionsshould actually yield the same rate allocation.
3.3. Implementation issues
The following issues must be taken into con-sideration when the above algorithm is to beimplemented:1. Packet interleaving at merging points is avoided
using packet reassembly until the EOP markerof the AAL5 is encountered.
2. Since the rates of bottlenecked sources are com-bined at merging points, the AMCR andACCR will refer to the aggregate bottleneckedinformation. The MCR of non-bottleneckedconnections can be easily inferred by subtract-ing the value of AMCR of all ¯ows from the to-tal MCR at the output port (a quantity which isreadily available by the call admission controlprocedure).
3. The leaves of a mpt-to-pt connection must beinstructed about the advertised rate at the root.We use the CCR ®eld in the BRM cell to recordthis information as this ®eld is only meaningfulin the forward direction in the case of mpt-to-ptconnections. Only when the ®rst BRM cell ar-rives from the root will the source insert its rateinformation in the FRM cell provided it be-longs to the ®rst source category.
S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378 371

4. The computed advertised rate is valid both atthe ¯ow and source levels. Therefore, to calcu-late the rate allocation upon arrival of a BRMcell we can either use the allocation method de-scribed earlier or we can reduce the computa-tion overhead by inserting the advertised rateitself in the ER ®eld. When the BRM cellarrives at the source, it would have carried theminimal advertised rate along the path andthe rate computation can be performed by thesource end system.
5. When all sources are bottlenecked at a particu-lar link, the computation of the advertised ratemay entail the value of the maximum MCR-normalized rate among all bottlenecked sourc-es. Since the advertised rate is now computedper source, this term may not be equivalent tothe maximum MCR-normalized rate at the ¯owlevel. We propose to use the ER ®eld in theFRM cell to register this information each timethe total number of ¯ows is found to be bottle-necked.
6. When all ¯ows at a particular merging point arefound to be non-bottlenecked, the downstreamswitches must be informed in order to avoidmisinterpretation of the CCR and MCR infor-mation. This can be achieved in one of twoways. The CCR and MCR values may be setto zero, which directly re¯ects a zero bottlenec-ked rate. The other approach may utilize a sin-gle bit from the unreserved bits in the RM cellto identify whether the FRM cell contains bot-tlenecked information or not. We use the ®rstapproach in our implementation.
The algorithm pseudo-code is given in Appen-dix A.
4. Simulation results
In this section, we conduct simulation experi-ments on a few benchmark network con®gurationssuggested by the ATM forum tra�c managementgroup. The network con®gurations that we use arethe peer-to-peer and the parking lot con®gura-tions. We shall compare the results of both thept-to-pt and mpt-to-pt algorithms. ATM switchesare assumed to employ FIFO queuing. Signaling
RM cells are assumed to have a prioritized serviceover data and ordinary RM cells. We assume thatpackets are reassembled until the EOP indicator ofthe AAL5 is encountered before they are for-warded to the output queue for transmission. Apacket size of ®ve cells is used unless otherwisestated. For simplicity, we assume that the ABRcapacity is normalized to one and for stability, weset the target utilization to be 0.95% of the linkspeed. The distance from each source to the accessswitch is assumed to be 100 m while the inter-switch distance is ®xed to 1000 km. A propagationdelay of 5 ls per 1 km is assumed. Thus, on majorlinks, the propagation delay is 5 ms. All sourcesare assumed to be persistent, that is they alwayshave cells to schedule. The performance measuresthat we compute are the allowed cell rate (ACR),link utilization and the queue size of the bottle-necked link vs simulation time. The time access isexpressed in units of milliseconds. We also studythe impact of packet size on the maximum bu�errequirement of the mpt-to-pt algorithm over thept-to-pt algorithm under di�erent packet sizedistributions.
4.1. The peer-to-peer network con®guration
Fig. 4 shows the peer-to-peer network con®gu-ration. In the pt-to-pt case, three pairs of con-nections are established between S1/d1, S2/d2 andS3/d3. In the mpt-to-pt case, the tra�c from thethree sources is merged at switch sw1 and all ofthem are assumed to be transmitting to the samedestination.
Obviously the bottlenecked link in both cases islink L1 which is assumed to have a unit ABRbandwidth. The PCR and MCR values of thesources are shown in Table 4.
Fig. 5 shows the allocated rate vs time for thept-to-pt and mpt-to-pt cases. The ®gure shows that
Fig. 4. Peer-to-peer network con®guration.
372 S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378
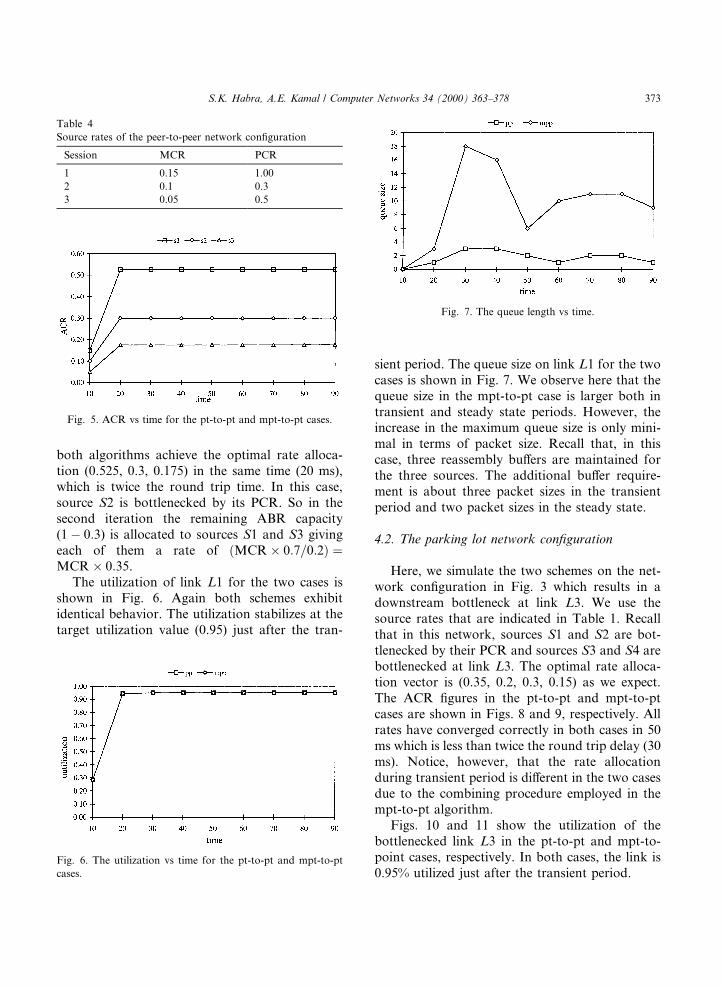
both algorithms achieve the optimal rate alloca-tion (0.525, 0.3, 0.175) in the same time (20 ms),which is twice the round trip time. In this case,source S2 is bottlenecked by its PCR. So in thesecond iteration the remaining ABR capacity(1ÿ 0:3) is allocated to sources S1 and S3 givingeach of them a rate of �MCR� 0:7=0:2� �MCR � 0:35.
The utilization of link L1 for the two cases isshown in Fig. 6. Again both schemes exhibitidentical behavior. The utilization stabilizes at thetarget utilization value (0.95) just after the tran-
sient period. The queue size on link L1 for the twocases is shown in Fig. 7. We observe here that thequeue size in the mpt-to-pt case is larger both intransient and steady state periods. However, theincrease in the maximum queue size is only mini-mal in terms of packet size. Recall that, in thiscase, three reassembly bu�ers are maintained forthe three sources. The additional bu�er require-ment is about three packet sizes in the transientperiod and two packet sizes in the steady state.
4.2. The parking lot network con®guration
Here, we simulate the two schemes on the net-work con®guration in Fig. 3 which results in adownstream bottleneck at link L3. We use thesource rates that are indicated in Table 1. Recallthat in this network, sources S1 and S2 are bot-tlenecked by their PCR and sources S3 and S4 arebottlenecked at link L3. The optimal rate alloca-tion vector is (0.35, 0.2, 0.3, 0.15) as we expect.The ACR ®gures in the pt-to-pt and mpt-to-ptcases are shown in Figs. 8 and 9, respectively. Allrates have converged correctly in both cases in 50ms which is less than twice the round trip delay (30ms). Notice, however, that the rate allocationduring transient period is di�erent in the two casesdue to the combining procedure employed in thempt-to-pt algorithm.
Figs. 10 and 11 show the utilization of thebottlenecked link L3 in the pt-to-pt and mpt-to-point cases, respectively. In both cases, the link is0.95% utilized just after the transient period.
Fig. 6. The utilization vs time for the pt-to-pt and mpt-to-pt
cases.
Fig. 7. The queue length vs time.
Fig. 5. ACR vs time for the pt-to-pt and mpt-to-pt cases.
Table 4
Source rates of the peer-to-peer network con®guration
Session MCR PCR
1 0.15 1.00
2 0.1 0.3
3 0.05 0.5
S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378 373
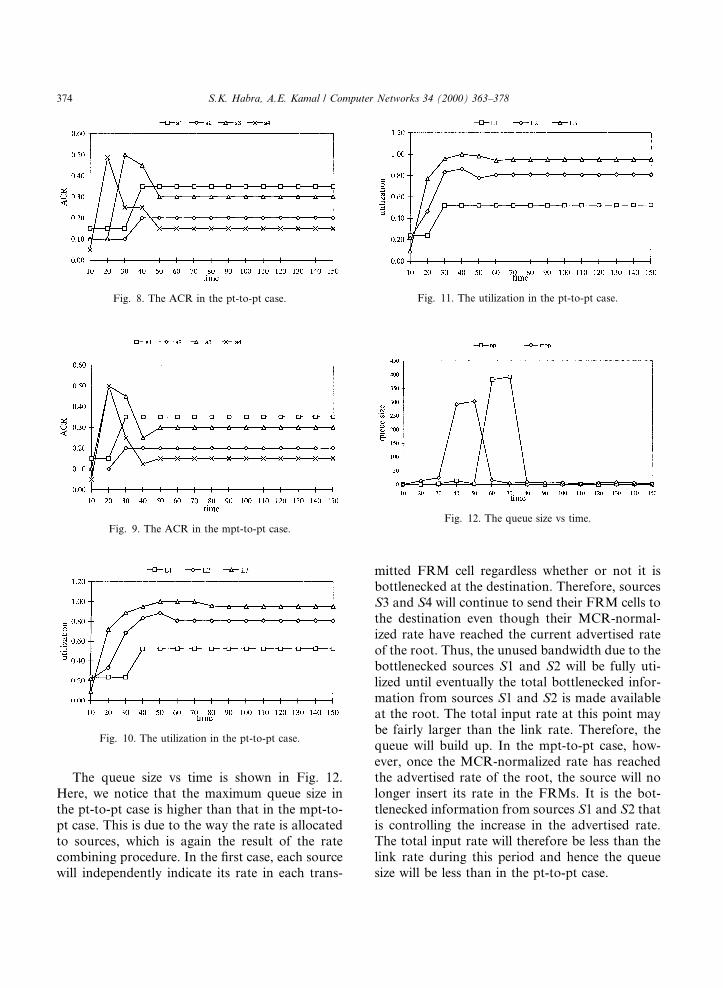
The queue size vs time is shown in Fig. 12.Here, we notice that the maximum queue size inthe pt-to-pt case is higher than that in the mpt-to-pt case. This is due to the way the rate is allocatedto sources, which is again the result of the ratecombining procedure. In the ®rst case, each sourcewill independently indicate its rate in each trans-
mitted FRM cell regardless whether or not it isbottlenecked at the destination. Therefore, sourcesS3 and S4 will continue to send their FRM cells tothe destination even though their MCR-normal-ized rate have reached the current advertised rateof the root. Thus, the unused bandwidth due to thebottlenecked sources S1 and S2 will be fully uti-lized until eventually the total bottlenecked infor-mation from sources S1 and S2 is made availableat the root. The total input rate at this point maybe fairly larger than the link rate. Therefore, thequeue will build up. In the mpt-to-pt case, how-ever, once the MCR-normalized rate has reachedthe advertised rate of the root, the source will nolonger insert its rate in the FRMs. It is the bot-tlenecked information from sources S1 and S2 thatis controlling the increase in the advertised rate.The total input rate will therefore be less than thelink rate during this period and hence the queuesize will be less than in the pt-to-pt case.
Fig. 9. The ACR in the mpt-to-pt case.
Fig. 8. The ACR in the pt-to-pt case. Fig. 11. The utilization in the pt-to-pt case.
Fig. 10. The utilization in the pt-to-pt case.
Fig. 12. The queue size vs time.
374 S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378
4.3. E�ect of the packet size
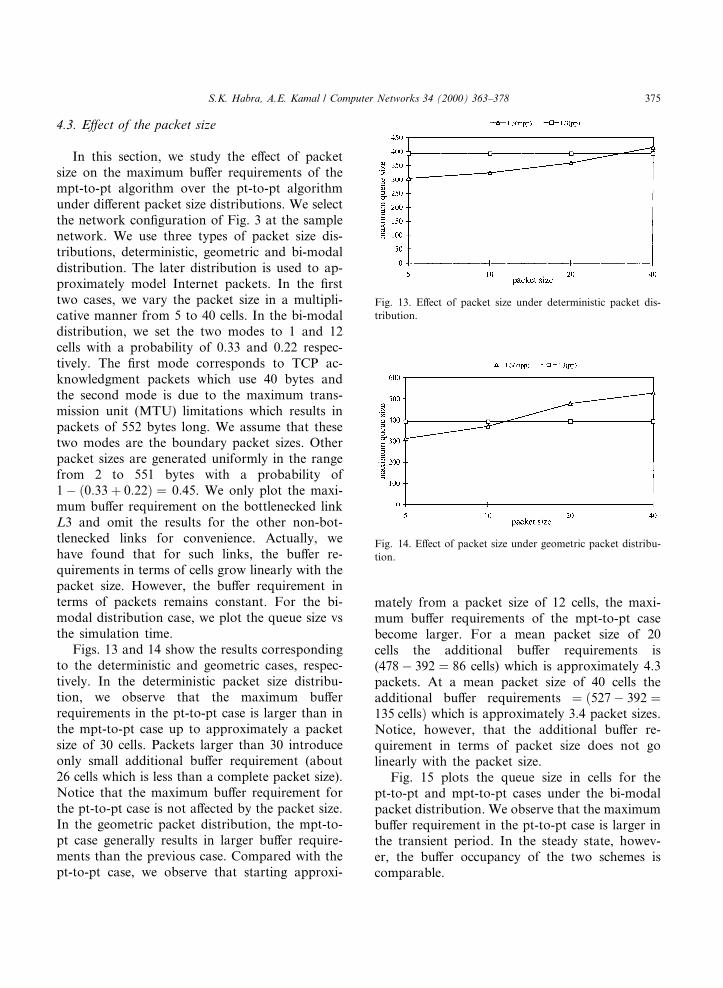
In this section, we study the e�ect of packetsize on the maximum bu�er requirements of thempt-to-pt algorithm over the pt-to-pt algorithmunder di�erent packet size distributions. We selectthe network con®guration of Fig. 3 at the samplenetwork. We use three types of packet size dis-tributions, deterministic, geometric and bi-modaldistribution. The later distribution is used to ap-proximately model Internet packets. In the ®rsttwo cases, we vary the packet size in a multipli-cative manner from 5 to 40 cells. In the bi-modaldistribution, we set the two modes to 1 and 12cells with a probability of 0.33 and 0.22 respec-tively. The ®rst mode corresponds to TCP ac-knowledgment packets which use 40 bytes andthe second mode is due to the maximum trans-mission unit (MTU) limitations which results inpackets of 552 bytes long. We assume that thesetwo modes are the boundary packet sizes. Otherpacket sizes are generated uniformly in the rangefrom 2 to 551 bytes with a probability of1ÿ �0:33� 0:22� � 0:45. We only plot the maxi-mum bu�er requirement on the bottlenecked linkL3 and omit the results for the other non-bot-tlenecked links for convenience. Actually, wehave found that for such links, the bu�er re-quirements in terms of cells grow linearly with thepacket size. However, the bu�er requirement interms of packets remains constant. For the bi-modal distribution case, we plot the queue size vsthe simulation time.
Figs. 13 and 14 show the results correspondingto the deterministic and geometric cases, respec-tively. In the deterministic packet size distribu-tion, we observe that the maximum bu�errequirements in the pt-to-pt case is larger than inthe mpt-to-pt case up to approximately a packetsize of 30 cells. Packets larger than 30 introduceonly small additional bu�er requirement (about26 cells which is less than a complete packet size).Notice that the maximum bu�er requirement forthe pt-to-pt case is not a�ected by the packet size.In the geometric packet distribution, the mpt-to-pt case generally results in larger bu�er require-ments than the previous case. Compared with thept-to-pt case, we observe that starting approxi-
mately from a packet size of 12 cells, the maxi-mum bu�er requirements of the mpt-to-pt casebecome larger. For a mean packet size of 20cells the additional bu�er requirements is(478ÿ 392 � 86 cells) which is approximately 4.3packets. At a mean packet size of 40 cells theadditional bu�er requirements � �527ÿ 392 �135 cells� which is approximately 3.4 packet sizes.Notice, however, that the additional bu�er re-quirement in terms of packet size does not golinearly with the packet size.
Fig. 15 plots the queue size in cells for thept-to-pt and mpt-to-pt cases under the bi-modalpacket distribution. We observe that the maximumbu�er requirement in the pt-to-pt case is larger inthe transient period. In the steady state, howev-er, the bu�er occupancy of the two schemes iscomparable.
Fig. 13. E�ect of packet size under deterministic packet dis-
tribution.
Fig. 14. E�ect of packet size under geometric packet distribu-
tion.
S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378 375

5. Conclusion
This paper has introduced a mpt-to-pt switchalgorithm which is an extension to the MCR-weighted algorithm, and which potentially requiressource-level information. The proposed algorithmworks fairly well with pt-to-pt and mpt-to-ptconnections. We have adapted the algorithm touse ¯ow-level information to achieve a perfor-mance comparable with that of the underlyingpt-to-pt algorithm. In our algorithm, we send andcombine the bottlenecked information at mergingpoints and pass them to the root. The root willthen be able to compute the advertised rate, whichis valid at the source, ¯ow and VC levels. Theextended algorithm makes use of the scalabilityadvantage of VC merging to reduce the complexityof the switch algorithm downstream. As such,the algorithm has an O(N) complexity at themerging points, which decreases as the root of thempt-to-pt tree is approached. Hence, the algorithmis easily scalable. A possible implementation of the
scheme is proposed and a simulation study isconducted to compare the performance of theproposed scheme with that of the pt-to-pt schemein terms of fairness and convergence time. In allconducted experiments, we were able to achievethe same convergence time of the underlying pt-to-pt algorithm. The results also show that bothschemes have achieved full link utilization justafter the transient period. We have also comparedthe queue size in both cases and found that themaximum bu�er occupancy in the mpt-to-pt caseis generally less than in the pt-to-pt case due to thecombining procedure. In the steady state, bothschemes result in small queue size. We have alsostudied the e�ect of packet size on the additionalbu�er requirements of the mpt-to-pt algorithmunder several packet size distributions. The generalobservation is that the additional bu�er require-ments due to packet reassembly is minimal interms of packet size.
Appendix A. Algorithm pseudo code
We shall use the following re®ned notations inour algorithm:
When an FRM cell is received from the ith ¯ow to the jth VC1. if RM cell signals flow termination then f2. F1 � F1=fig n1 � n1 ÿ 13. if the bottlenecked bit of ¯ow i is set4. clear bottlenecked bit of ¯ow i Yl � Yl=fig jYlj � jYlj ÿ 15. else U1 � U1=fig jU1j � jU1j ÿ 1g6. update table��7. AMCRj � AMCRj ÿMCR f i ACCRj � ACCRj ÿ CCR f ig8. else if RM cell signals initialization of new flow thenf
Fl the set of ¯ows on link lnl number of ¯ows in Fl
Yl set of ¯ows marked at link lUl set of unmarked ¯ows at link lAMCRj aggregate MCR of ¯ows merged in
the jth VC.ACCRj aggregate CCR of ¯ows merged in
the jth VC.
Fig. 15. E�ect of packet size under bi-modal packet distribu-
tion.
376 S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378

9. F1 � F1 [ fig n1 � n1 � 1 U1 � U1 [ fig jU1j � jU1j � 110. MCR fi �MCR CCR fi � CCR11. AMCRj � AMCRj �MCR f i ACCRj � ACCRj � CCR f i
12. update table��13. B RM � B RM� 1g14. else if RM belongs to an active flowf15. AMCRj :� AMCRj ÿMCR f i
16. ACCRj :� ACCRj ÿ CCR f i
17. if CCR > 0 f ``It is a rate from a bottlenecked ¯ow''18. if ri=MCRi6 l1f19. set bottlenecked bit of ¯ow i20. Yl � Yl [ fig jYlj � jY j � 121. MCR f i �MCR22. CCR f i � CCR23. update table��g24. else if the bottlenecked bit of flow i is set f25. clear bottlenecked bit of flow i26. Ul � Ul [ fig jUlj � jUlj � 1 Yl � Yl=fig jYlj � jYlj ÿ 127. MCR f i � 028. CCR f i � 029. update table�� gg30. else f31. if the bottlenecked bit of flow i is set f32. clear bottlenecked bit of flow i33. Ul � Ul [ fig jUlj � jUlj � 1 Yl � Yl=fig jYlj � jYlj ÿ 1 g34. MCR f i � 035. CCR f i � 036. update table�� g37. AMCRj :� AMCRj ÿMCR f i
38. ACCRj :� ACCRj ÿ CCR f i
39. B RM � B RM� 1 gWhen a BRM cell is received at the merging point40. if at destination switch f41. ER in BRM cell � ll
42. CCR in BRM cell � ll g43. else if at source44. ER � max�min; �PCR; ER �MCR�;MCR�45. else f46. ER in BRM cell � min(ER, ll)47. CCR in BRM cell � CCR48. for all flows in Fl f49. if B RM of ith flow > 0 f50. duplicate BRM cell on ith flow51. B RM � B RMÿ 1 ggg
S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378 377

References
[1] A. Arulambalam, X. Chen, Allocating fair rates for
available bit rate service in ATM networks, IEEE Comm.
Mag. (1996) 92±100.
[2] The ATM forum technical committee, Tra�c Management
Speci®cation Version 4.0, 1996.
[3] F. Bonomi, W. Fendick, The rate-based ¯ow control
framework for the available bit rate ATM service, IEEE
Network (1995) 25±39.
[4] A. Charny, D. Clark, R. Jain, Congestion control with
explicit rate indication, in: Proceedings of the IEEE
ICCÕ95, pp. 1954±1963.
[5] S. Fahmy, R. Jain, R. Goyal, B. Vandalore, A switch
algorithm for ABR multipoint-to-point connections, http://
www.cis.ohio-state.edu/�jain/atmf/a97-1085.htm.
[6] S. Fahmy, R. Jain, R. Goyal, B. Vandalore, Fairness for
ABR multipoint-to-point connections, http://www.cis.o-
hio-state.edu/�jain/atmf/a79-0832.htm.
[7] C. Fulton, S. Li, A. Lin, Impact analysis of packet-level
scheduling on an ATM shared-memory switch, IEEE
INFOCOM, 1998.
[8] N. Ghani, et al., ATM tra�c management considerations
for facilitating broadband access, IEEE Comm. 36 (11)
(1998) 98±105.
[9] M. Grossglauser, K.K. Ramakrishnan, SEAM: scalable
and e�cient ATM multicast, IEEE INFOCOM, 1997.
[10] Y. Hou, H. Tzeng, S. Panwar, A weighted max±min fair
rate allocation for available bit rate service, IEEE GLOB-
COM, 1997, pp. 492±497.
[11] W. Ren, K. Siu, Multipoint-to-point service in ATM
networks, IEEE ICC, 1997.
[12] I. Widjaja, A. Elwalid, Performance issues in VC-merge
capable switches for IP over ATM networks, IEEE
INFOCOM, 1998.
[13] W. Ren, et al., Multipoint-to-multipoint ABR service in
ATM, Computer Networks and ISDN Systems 30 (1998)
1793±1810.
Shatha K. Habra, a native of Syria,received a B.Sc. in Computer Scienceand a M.Sc. in Computer Engineering,both from Kuwait University in 1995and 1999, respectively. From 1995 to1998 she worked as a research assistantin the Department of Computer Sci-ence, Kuwait University dealing withLAN interconnection issues acrossATM backbone networks. She is cur-rently, working as a scienti®c pro-grammer in the Department ofComputer Science of Kuwait Univer-sity. Her research interests include hgh-
speed LANs and ATM networks, Performance evaluation, Webapplications technology and e-commerce. Her e-mail address [email protected].
Ahmed E. Kamal was born in Giza,Egypt. He received a B.Sc. (distinctionwith honours) and M.Sc. both fromCairo University, Giza, Egypt, andM.A.Sc. and a Ph.D. both from theUniversity of Toronto, Toronto,Canada, all in Electrical Engineering in1978, 1980, 1982 and 1986, respecti-vely. From 1978 to 1980, he was anInstructor in the Department of Elec-trical Engineering, Cairo University,and from 1980 to 1985, he was ateaching and a research assistant in theDepartment of Electrical Engineering,
University of Toronto. He was with the Department ofComputing Science at the University of Alberta, Edmonton,Canada, from January 1986 to June 1991 as an assistant professorand from July 1991 until August 1994 as an associate professor.He was also an adjunct professor at the TelecommunicationsResearch Labs, Edmonton, Alberta, from 1988 until 1994. InSeptember 1992, he joined the Department of Electrical andComputer Engineering at Kuwait University, Kuwait, as anassociate professor and became a professor in the same de-partment in 1997. He is currently a professor of Electrical andComputer Engineering at Iowa State University. His e-mailaddress is [email protected]. Kamal's teaching and researchinterests include high-speed networks, B-ISDN and ATM net-works, performance evaluation, optical networks, and internetsintegrated and di�erentiated services. He is a senior member ofthe IEEE, a member of the Association of ComputingMachinery, and a registered professional engineer in the provinceof Alberta, Canada. He was the co-recipient of the 1993 IEEHartree Premium for papers published in Computers andControl in IEE Proceedings for his paper entitled Study of theBehaviour of Hubnet.
378 S.K. Habra, A.E. Kamal / Computer Networks 34 (2000) 363±378




















