
Mining arabic text using soft-matching association rules
6
Mining Arabic Text Using Soft-Matching Association Rules Aya Al-Zoghby, Mansoura University, Ahmed Sharaf Eldin , Helwan University, Nabil A. Ismail, Menofyia University, and Taher Hamza, Mansoura University Abstract-Text mining concerns the discovery of knowledge from unstructured textual data. One important task is the discovery of rules that relate specific words and phrases. Textual entries in many database fields exhibit minor variations that may prevent mining algorithms from discovering important patterns. Varia- tions can arise from typographical errors, misspellings, abbrevia- tions, as well as other sources like ambiguity. Ambiguity may be due to the derivation feature, which is very common in the Arabic language. This paper introduces a new system developed to dis- cover soft-matching association rules using a similarity measure- ments based on the derivation feature of the Arabic language. In addition, it presents the features of using Frequent Closed Item- sets (FCI) concept in mining the association rules rather than Frequent Itemsets (FI). I. INTRODUCTION The explosive growth in data and databases has generated an urgent need for new techniques and tools that can intelligently and automatically transform the processed data into useful in- formation and knowledge. Data mining is among such tech- niques. Association rules mining is one of the important data mining techniques. Association rules are primarily useful in the description of the behavior that is captured in the database. They show relationships between items or Itemsets [1]. Some basic concepts of association rules such as frequent itemsets, support, and confidence are presented in [2]. Text mining is data mining applied to textual data. Com- pared with the kind of data stored in databases, text is unstruc- tured, amorphous, and difficult to deal with algorithmically. Nevertheless, in modern culture, text is the most common ve- hicle for the formal exchange of information. Therefore, the motivation for trying to extract information from it is compel- ling even if success is only partial [1]. Association rules can be used to mine texts for discovering useful and valuable rules. Regrettably, textual entries in many database fields exhibit minor variations that may prevent mining algorithms from dis- covering important patterns. Variations in database fields are particularly appear in data that is automatically extracted from unstructured or semi-structured documents or web pages. One approach to this problem is to standardize the name of each entity using either a manual “data cleaning” process or an au- tomated “de-duping” procedure. In that case, however, discov- ered associations are not able to capture all similarities between different items [2]. This paper explores the alternative of directly, “hard- matching”, mining textual data by discovering “soft-matching” association rules whose antecedents and consequents are eva- luated basing on sufficient similarity measurements to database entries. Similarity of text can be measured using standard “bag of words” metrics or edit-distance measures [2]. Also we can use the semantic as a similarity measurement [3] [4] [5]. The paper produced a new similarity function based on the deriva- tives of Arabic language, which means that the single word stem can produce a group of different, but have the same con- cept, words. The significance of this paper is due to the impor- tance of applying the similarity concept on the Arabic texts in order to generate meaningful rules. Without using the similar- ity, the support of the itemset - number of times the itemset appears in the database - that resulted from the exact matching of words will be always too little. That makes the generation of any associations seems a hopeless process especially if the cor- pus is a set of arbitrarily collected Arabic texts that are not pre- pared for any computational processes. For example, in Table І, each word in the Derivations column can be viewed as a dif- ferent occurrence of distinct word. However, using the defined similarity function, all derivations will be manipulated as mul- ti–occurrences of their stem. I.e., it will act as an accumulator to the counter of its stem, so the support of the itemsets will increase to the practical count of the stem occurrences instead of the real count of each of its derivatives. Furthermore, the paper presents the advantage of using the concept of ‘Closed Frequent Itemsets’ (FCI) in the elimination of the redundancy in the generated association rules. The presented technique will help in producing rules that are more accurate and extremely decrease the resulting rules to the meaningful ones. II. RELATED WORK A. Existing Serial Association Rule Mining Algorithms 1) Generating a Complete Set of Frequent Itemsets (FI): Referring to the history of Association Rule Mining (ARM), the category tasking on obtaining frequent itemsets (FI) has been first introduced. A number of serial ARM algorithms can be grouped into four approaches, [1], as viewed in Table II. TABLE І STEM WORDS AND DRIVATIVES Word Derivatives اﻹﺻﻼح وﻣﺼﻠﺤﺔ, ﻣﺼﺎﻝﺢ, اﻹﺻﻼﺡﻰ, ﺻﻼح أﺟﻬﺰة وأﺟﻬﺰﺗﻪ, اﻷﺟﻬﺰة, ﺟﻬﺎز, ﺑﺠﻬﺎز اﻝﻤﺼﺮي ﻣﺼﺮ, ﻣﺼﺮﻳﺔ, ﺑﻤﺼﺮ, ﻣﺼﺮﻳﻴﻦ أﺳﻠﺤﺔ ﺳﻼح, اﻷﺳﻠﺤﺔ, ﻣﺴﻠﺢ, ﺗﺴﻠﻴﺢ اﻧﺘﺸﺎر ﻳﻨﺘﺸﺮ, ﻣﻨﺘﺸﺮة, ﻧﺸﺮ421 1-4244-1366-4/07/$25.00 ©2007 IEEE
Transcript of Mining arabic text using soft-matching association rules

Mining Arabic Text Using Soft-Matching Association Rules
Aya Al-Zoghby, Mansoura University,
Ahmed Sharaf Eldin , Helwan University, Nabil A. Ismail, Menofyia University, and
Taher Hamza, Mansoura University
Abstract-Text mining concerns the discovery of knowledge from unstructured textual data. One important task is the discovery of rules that relate specific words and phrases. Textual entries in many database fields exhibit minor variations that may prevent mining algorithms from discovering important patterns. Varia-tions can arise from typographical errors, misspellings, abbrevia-tions, as well as other sources like ambiguity. Ambiguity may be due to the derivation feature, which is very common in the Arabic language. This paper introduces a new system developed to dis-cover soft-matching association rules using a similarity measure-ments based on the derivation feature of the Arabic language. In addition, it presents the features of using Frequent Closed Item-sets (FCI) concept in mining the association rules rather than Frequent Itemsets (FI).
I. INTRODUCTION The explosive growth in data and databases has generated an
urgent need for new techniques and tools that can intelligently and automatically transform the processed data into useful in-formation and knowledge. Data mining is among such tech-niques. Association rules mining is one of the important data mining techniques. Association rules are primarily useful in the description of the behavior that is captured in the database. They show relationships between items or Itemsets [1]. Some basic concepts of association rules such as frequent itemsets, support, and confidence are presented in [2].
Text mining is data mining applied to textual data. Com-pared with the kind of data stored in databases, text is unstruc-tured, amorphous, and difficult to deal with algorithmically. Nevertheless, in modern culture, text is the most common ve-hicle for the formal exchange of information. Therefore, the motivation for trying to extract information from it is compel-ling even if success is only partial [1]. Association rules can be used to mine texts for discovering useful and valuable rules. Regrettably, textual entries in many database fields exhibit minor variations that may prevent mining algorithms from dis-covering important patterns. Variations in database fields are particularly appear in data that is automatically extracted from unstructured or semi-structured documents or web pages. One approach to this problem is to standardize the name of each entity using either a manual “data cleaning” process or an au-tomated “de-duping” procedure. In that case, however, discov-ered associations are not able to capture all similarities between different items [2].
This paper explores the alternative of directly, “hard-matching”, mining textual data by discovering “soft-matching”
association rules whose antecedents and consequents are eva-luated basing on sufficient similarity measurements to database entries. Similarity of text can be measured using standard “bag of words” metrics or edit-distance measures [2]. Also we can use the semantic as a similarity measurement [3] [4] [5]. The paper produced a new similarity function based on the deriva-tives of Arabic language, which means that the single word stem can produce a group of different, but have the same con-cept, words. The significance of this paper is due to the impor-tance of applying the similarity concept on the Arabic texts in order to generate meaningful rules. Without using the similar-ity, the support of the itemset - number of times the itemset appears in the database - that resulted from the exact matching of words will be always too little. That makes the generation of any associations seems a hopeless process especially if the cor-pus is a set of arbitrarily collected Arabic texts that are not pre-pared for any computational processes. For example, in Table І, each word in the Derivations column can be viewed as a dif-ferent occurrence of distinct word. However, using the defined similarity function, all derivations will be manipulated as mul-ti–occurrences of their stem. I.e., it will act as an accumulator to the counter of its stem, so the support of the itemsets will increase to the practical count of the stem occurrences instead of the real count of each of its derivatives. Furthermore, the paper presents the advantage of using the concept of ‘Closed Frequent Itemsets’ (FCI) in the elimination of the redundancy in the generated association rules. The presented technique will help in producing rules that are more accurate and extremely decrease the resulting rules to the meaningful ones.
II. RELATED WORK
A. Existing Serial Association Rule Mining Algorithms 1) Generating a Complete Set of Frequent Itemsets (FI): Referring to the history of Association Rule Mining (ARM),
the category tasking on obtaining frequent itemsets (FI) has been first introduced. A number of serial ARM algorithms can be grouped into four approaches, [1], as viewed in Table II.
TABLE І
STEM WORDS AND DRIVATIVES Word Derivatives صالح, اإلصالحى , مصالح, ومصلحة اإلصالح بجهاز, جهاز, األجهزة, وأجهزته أجهزة مصريين, بمصر, مصرية , مصر المصري تسليح, مسلح, األسلحة, سالح أسلحة نشر, منتشرة,ينتشر انتشار
4211-4244-1366-4/07/$25.00 ©2007 IEEE

نووية.نوويا.نووي النووية يلإسرائ إلسرائيل,اسرائيليا.اسرائيلى
TABLE II
ASSOCIATION RULE MINING APPROCHES Approach ARM Algorithms
Semi-Apriori AIS SETM, OCD.
Pure-Apriori Apriori, AprioriTid, AprioriHyprid,
MONET, DHP, Partition, Sampling, DIC, CARMA, Msapriori,
Set-enumeration-tree-structure
Apriori-TFP-based algorithms, and FP-tree-based.
Vertical VIPER, SPAM, Vertical Partition, Diff-set, Medic.
2) Generating a Set of Maximal Frequent Itemsets (MFI): MFI significantly contributes on avoiding redundant works.
It focuses on seeking the maximal frequent itemsets (MFI) which are typically orders of magnitude fewer than all frequent patterns in dense domains; they lead to a loss of information. Moreover, it does not fit into the requirement of rule generation since subset frequency – needed for confidence computation- is not available. [2], [6], and [7].
3) Generating a Set of Frequent Closed Itemsets (FCI): The third category emphasizes on enumerating FCI, where
MFI ⊆ FCI ⊆ FI. FCI is suitable for both avoiding the redun-dant works and enabling the confidence computation. Closed sets are lossless in the sense that they can be used to uniquely determine the set of all frequent itemsets and their exact fre-quency, see Fig. 1. At the same time, closed sets can them-selves be orders of magnitude smaller than all frequent sets especially on dense databases, [2]. CHARM, which is applied in this research, is one of the algorithms included in this cate-gory [1].
4) Summary of Serial ARM Algorithms: Mining FCI has the same power as mining the complete set
of frequent itemsets, but it will substantially reduce redundant rules and increase both efficiency and effectiveness of mining. CHARM is unique in that it simultaneously explores both the itemset space and transaction space [8].
B. Text Mining (TM)
The goal of text mining is to discover new and previously unknown information - something that no one yet knows and so could not have yet written down -by automatically extract-ing information from different written resources. A key ele-ment is to linking the extracted information together to form new facts or new hypotheses to be explored further by more conventional means of experimentation [9].
Figure 1.Frequent, Closed and Maximal Itemsets
C. Association Rules in Text Mining
In text mining, the analysis collects frequent itemsets - that are the sets of terms that occur frequently together - and then finds the associations or correlation relationships among them. Hence, terms will refer to as keywords [10]. In a document database, each document can be viewed as a transaction, while a set of keywords in the document can be considered as a set of items in the transaction. That is, the database is in the format: {document_id, a_set_of_keywords}.So, the problem of key-word association mining in document databases is thereby mapped to the item association mining in transaction database [7].
Common framework of text mining: (1) Text pre-processing (TPP) and (2) Utilizing a typical data mining technique, herein it is the association rules.
Text Pre-Processing is used by most text mining applications for the document base (DOCB) to be “cleaned” or preproc-essed in some manner for further analyses by different data mining techniques. Hence, TPP - as an extremely important stage in text mining process - humanly and rationally generates a structured or semi-structured intermediate form from the original inputted textual data. Moreover, the unstructured tex-tual data is considered “rich”, which contains sufficient raw knowledge. It is quite easy to lose a large amount of raw knowledge by preprocessing texts with a critical method, i.e. a method that is unsuitable for the pre- determined text-mining target [11]. An attempted TPP algorithm, presented in the Im-plementation Details section, is used in this paper in order to generate a single-term-based intermediate form. It involves the using of an Arabic morphological analyzer and search engine in order to gather the similar words.
D. Present Researches and Applications
In the open literature, we found one paper dealing with Ara-bic mining using association rules at [12]. Even we were un-able to locate a single paper used “soft-matching association rules” for Arabic. That paper proposes a system for mining association rules be-tween words in Arabic textual datasets. Its proposed system consists of four steps. First, stopping words are removed from the document. Then, documents words are stemmed to their root. The third step is to detect pattern using association rules for a specified minimum support and confidence. Finally, the user starts mining the documents by specifying the interested word and minimum thresholds for support and confidence, this results in a list of documents that have the specified word and any associated words. [12]. However, this system uses the traditional “hard” matching technique. That’s because the frequencies of words, not of the shared roots, are used in the computing of the minimum sup-port and confidence.
In addition to these research efforts, there are some software products that deal with the Arabic texts mining such as:
1) [Basis Technology] introduces Rosette® Linguistics Platform which enabling search engines, text mining tools,
422

categorization engines for Arabic text [13], and its technical view is available at [14].
2) [SRA International Inc] introduces SRA text miner which defines an appropriate text mining architecture and how it will best fit with an IT infrastructure. it provide text mining tool recommendations and recommendations for other analytical tools that can take advantage of the text mining results, such as link analysis tools, OLAP tools, and data mining tools. SRA has extensive experience in developing text-mining solutions in a variety of foreign languages, including Arabic, Chinese, French, German, Japanese, Russian, Spanish, and Thai [15].
3) [Sakhr Software Co.] Produces text-mining tools such as Automatic Categorizer, and Automatic Summarizer [16].
Sakhr Keyword Extractor tool analyzes an Arabic document, and identifies its individual text phrases and key data items automatically [17].
However, for obvious reasons, the technical details of most of these products are not given. Also we didn't' find any thing signifies that they use the soft nor hard matching association rules in their researches for the Arabic language.
III. ARABIC LANGUAGE
A. Arabic Language in General
Arabic in all of its different dialects is the mother tongue of more than 250 million human beings. Classical Arabic is the language of the Qur'an, and is still the current written form of the language. Classical Arabic is used by approximately 1 bil-lion Muslims for prayer and scholarly religious discourse. Ara-bic belongs to the Semitic language family. The feature that is generally a minor shock to literate Anglophones is that Semitic languages are commonly written without the vowel marks which would indicate the short vowels. Semitic languages can get away with this because they all have a predictable root-pattern system [6].
B. Arabic vs. English
Most of text mining researches are made on the English text. Many examples, [3] [4] [5] [10] [18], are available in the open resources. On the other hand, there are very few researches on the Arabic language. This is due to the difficulties of the Ara-bic language over the English. One of these difficulties is that the Arabic is a highly inflectional and derivational language. Moreover, Arabic has many variations to the general rules of the language that is there is no one rule can be applied to all cases [19] which yields many irregular words. Also, Arabic has two kinds of plurals: sound and broken. The sound plurals are formed by adding suffixes to singular nouns. The formation of broken plurals is more complex and often irregular. Arabic, furthermore, provides the additional challenge of infixes while English handles only prefixes and suffixes [19].
C. Arabic and Association Rules Mining
In Arabic, the simplest form of a root is the third person, singular, masculine, and past tense of the first form. The root KTB ) آتب( holds within it the basic idea of writing. KaTaBa
ب( )آت means he wrote, KaaTiBun )ب )آات means writer, maKTuuBun )مكتوب( means something written, and maKTaBun
)مكتب ( means the place where writing occurs. The part of speech and the voweling, and hence the meaning, of a particu-lar word in a sentence can be readily recognized by someone familiar with the grammar and vocabulary of that language. Thus for a knowledgeable reader the vowel marks which indi-cate short vowels are superfluous in Arabic, but for the non-familiars, the problem of Polysemy appears. The polysemy problem means that the same keyword may mean different things depending on:
1) The context: e.g., the word: ذهب may mean “the gold ma-terial” in one context or “the past of the verb go” in another.
2) The vowel marks: e.g., the words: ر ر , ب ر , ب ب are three dif-ferent words and have three different meanings and the only change in their forms is the vowel marks.
Only the Qur'an and certain elementary textbooks are com-pletely vowelled. Since most verbs and nouns in Arabic are derived from trilateral (or, rarely, quadrilateral) roots, identify-ing the underlying root of each word theoretically retrieves most of the documents containing a given search term regard-less of form. The Arabic language feature, which can be ex-ploited in this research, is that the root can serve as the founda-tion for a wide variety of words with related meanings, as men-tioned above. Therefore, this feature will be used to compute the similarity of related words and then use them as the antece-dents and consequents of the soft association rules rather than using the traditional hard or exact matching association rules.
IV. IMPLEMENTATION DETAILS
This section introduces the problem of mining soft associa-
tion rules from databases and investigates how to utilize an existing association rule-mining algorithm to incorporate simi-larity in discovering associations.
As mentioned in the related work section, the common framework of text mining is to: (1) Text pre-processing (TPP) and [18] (2) Utilizing a typical data mining technique, herein it is the association rules. The attempted TPP algorithm works as follows:
Input: A Collection of Documents (COD) Output: A single-term-based intermediate form (DOCB) wordBase null for each document∈ the COD do docWordBase null class first line from file add document number to class table for each line ∈ document do
remove non-alphabetic characters remove non-Arabic characters for each word ∈ line do if (word ∈ stopWord.txt) remove word if (word ∈ similes .txt) then
substitute similar for word docWordBase docWordBase ∪ word
end loop wordBase wordBase ∪ docWordBase
end loop end loop assign each word ∈ wordBase back to each document return a horizontal (document-based) TDB as a DOCB
423

Thereafter, the association rules are generated using the re-sulted intermediate form (wordBase). As traditional association rules mining algorithms, soft association rules generates asso-ciation rules on the form X → Y, but X and Y are evaluated basing on sufficient similarity to database entries so, X and Y are sets of groups of similar keywords rather than sets of key-words[20]. For example, if we have the rules:
إسرائيل←انتشار , نووى, لحةأس/ نووى ←سرائيل / إصالح←أجهزةthen we can substitute the words : زة أجه ووى , أسلحة , إصالح , , ن with each of their derivations presented in Table , إسرائيل ,انتشار I , as a similar word, and the rule still true.
In this system, there are several similarity measurement functions - also called searching modes - used for grouping similar words as displayed in Table III.
In order to solve the problem of Polysemy that may occur when using the root-based search mode, the system provides the following choices for the ambiguous word that may mean different things or may belong to various roots:
-Selecting ALL probable solutions for the word, -Selecting MOST probable solution for the word, as the
morphological analyzer module was trained before, or -Select the solution MANUALLY. For example, the word ن is an ambiguous word since it تعل
may belongs to one of the roots displayed in Table IV espe-cially when it lacks vowel marks. The system, so, can somewhat overcome the ambiguity by choosing the most probable one - herein it is the first occurrence - or by grouping all words that derived from all possible roots as a similar words to the word ‘ ن These words may belong to those displayed .’تعلin Table V. Actually, the conclusive solution for this ambiguity is to choose the manual way to select the optimal choice, so the user can choose the root number 1, 2, 3 or 4. After detecting the desired search mode, the association rules will be generated in two steps as follows:
1- Finding frequent itemsets according to the selected search mode (similarity measurement functions). In this paper both FI and FCI will be generated by Apriori and CHARM algorithms respectively, so their efficiency can be compared. CHARM algorithm. It enumerates closed sets using a dual Itemset-Tidset search tree by an efficient hybrid search that skips many levels. It also uses a technique called Diffsets to reduce the memory footprint of intermediate computations. Finally, it uses a fast hash-based approach to remove any “nonclosed” sets found during computation [2].
TABLE III similarity
measurement functions
Word Similes (Derivatives)
فتقص, للقصف, بالقصف, قصفت, القصف قصف Word Root الفتاآة, تفتك, الفتاك, فتكا فتك واإلنتخابات,إنتخابات,اإلنتخابية إنتخاب Word Body فالبرنامج,برنامجها,لبرنامج,برنامجا,برنامج,البرنامج برنامج
Exact Word (Hard-
Matching) برنامج برنامج
TABLE IV
Root # Vowelled Word Root String علن تعلن 1 علو تعلن 2
عول تعلن 3 علل تعلن 4
TABLE V
Root Derivatives ..., أعلنت, يعلن, إعالن علن ..., عالء, عال, يعلو علو ..., عائلة, عائل, يعول عول ..., تعليل, يعلل علل
2-Generating high confidence rules: Using the predefined FI
and FCI, and the paper will show that using FCI eliminates the redundancy in the resulted Association rules.
The system is implemented on platform of Microsoft Win-dows XP Professional x64 Edition, Service Pack 1 operating system, Intel Pentium 4 CPU 3.04 GHz, and 1.00 GB of RAM.
V. SYSTEM ARCHETECTURE System that mines Arabic documents using soft-matching
association rules has been developed. The development phases were:
1) Indexing process: for accepting text-files from Arabic corpora to be indexed and generating a group of database files composing the corresponding index.
2) Natural language processing tools, or text preprocessing, for preparing the input text ,such as:
• Cleaning process: to draw the list of stop words- the set of words those are deemed “irrelevant"- such as ذي ذلك ,ال ...مع ,ل and to remove all non-Arabic elements.
• Morphological analyzing process: to group the similar words, according to the selected similarity measure, using the Arabic morphological analyzer of RDI Company. It employs search by morphemes and morpheme combinations in order to utilize the valuable nature of Arabic as a highly inflective lan-guage - whose huge vocabulary are mostly regular morpho-logical as well as semantic derivatives of a compact set of basic building entities (morphemes) - in achieving search results that are highly relevant to the user intentions implied by a search query.
3) Soft-matching associations generation process, through: • Finding FI and FCI, using Apriori and CHARM algo-
rithms. • Generating the associations. The system acts as described in Fig. 2.
VI. EXPERIMENTAL RESULTS
The system was tested with an Arabic textual database of 5524 record. These records are E-mail snippets about the ‘nu-clear’ subject. The database has 103253 distinct words - after discarding stop words [19] - and average record length of 18 words. The system presented the results displayed in Table VI using 15% as the minimum support and 70% as minimum con-fidence. In order to validate our system, it is tested on pre-solved example presented in the references [21], [2], and [22].
For emphasizing the efficiency of the soft-matching system, we apply the hard-matching also so we can compare the re-sults.
424
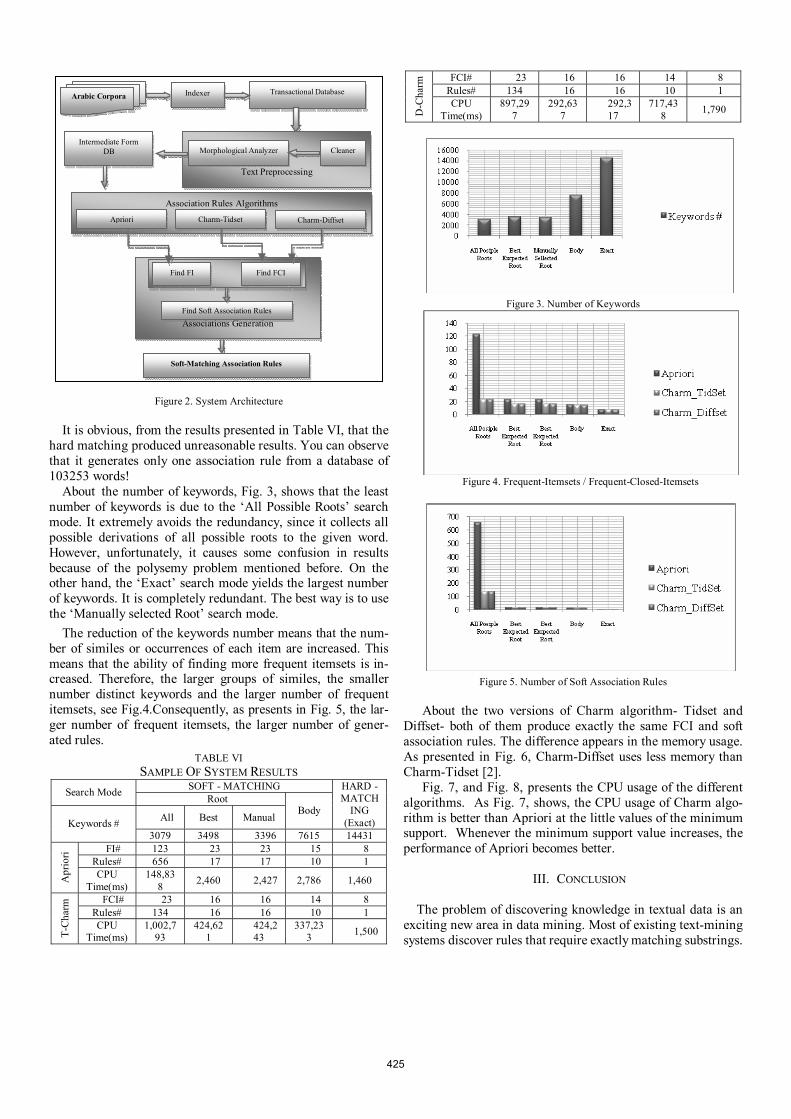
Figure 2. System Architecture
It is obvious, from the results presented in Table VI, that the hard matching produced unreasonable results. You can observe that it generates only one association rule from a database of 103253 words!
About the number of keywords, Fig. 3, shows that the least number of keywords is due to the ‘All Possible Roots’ search mode. It extremely avoids the redundancy, since it collects all possible derivations of all possible roots to the given word. However, unfortunately, it causes some confusion in results because of the polysemy problem mentioned before. On the other hand, the ‘Exact’ search mode yields the largest number of keywords. It is completely redundant. The best way is to use the ‘Manually selected Root’ search mode.
The reduction of the keywords number means that the num-ber of similes or occurrences of each item are increased. This means that the ability of finding more frequent itemsets is in-creased. Therefore, the larger groups of similes, the smaller number distinct keywords and the larger number of frequent itemsets, see Fig.4.Consequently, as presents in Fig. 5, the lar-ger number of frequent itemsets, the larger number of gener-ated rules.
TABLE VI SAMPLE OF SYSTEM RESULTS
SOFT - MATCHING Search Mode Root
All Best Manual Body
HARD - MATCH
ING (Exact) Keywords #
3079 3498 3396 7615 14431 FI# 123 23 23 15 8
Rules# 656 17 17 10 1
Apr
iori
CPU Time(ms)
148,838 2,460 2,427 2,786 1,460
FCI# 23 16 16 14 8 Rules# 134 16 16 10 1
T-C
harm
CPU Time(ms)
1,002,793
424,621
424,243
337,233 1,500
FCI# 23 16 16 14 8 Rules# 134 16 16 10 1
D-C
harm
CPU Time(ms)
897,297
292,637
292,317
717,438 1,790
Figure 3. Number of Keywords
Figure 4. Frequent-Itemsets / Frequent-Closed-Itemsets
Figure 5. Number of Soft Association Rules
About the two versions of Charm algorithm- Tidset and
Diffset- both of them produce exactly the same FCI and soft association rules. The difference appears in the memory usage. As presented in Fig. 6, Charm-Diffset uses less memory than Charm-Tidset [2].
Fig. 7, and Fig. 8, presents the CPU usage of the different algorithms. As Fig. 7, shows, the CPU usage of Charm algo-rithm is better than Apriori at the little values of the minimum support. Whenever the minimum support value increases, the performance of Apriori becomes better.
III. CONCLUSION
The problem of discovering knowledge in textual data is an
exciting new area in data mining. Most of existing text-mining systems discover rules that require exactly matching substrings.
Soft-Matching Association Rules
Arabic Corpora Transactional Database Indexer
Associations Generation Find Soft Association Rules
Find FI Find FCI
Association Rules Algorithms
Charm-DiffsetApriori Charm-Tidset
Text Preprocessing
Cleaner Morphological Analyzer Intermediate Form
DB
425

However, due to variability and diversity in natural-language data, some form of soft-matching based on textual similarity is needed. The paper has presented a system that uses new simi-larity measures and a modified association rule generation technique to discover soft-matching rules from Arabic textual databases automatically constructed from document corpora. This system induces accurate predictive rules despite the varia-tion of automatically extracted textual databases. The excel-lence of the soft- matching over the hard o exact matching is clear in the system results. About the mining algorithm used in the paper (CHARM), it is only pruning closed itemset lattice rather than all itemsets lattice. Since the numbers of itemsets of the closed itemset lattice of a database are much smaller than those of all itemsets lattice, CHARM can reduce both the num-ber of database passes and CPU overhead incurred by the fre-quent itemset search as well as the efficiency and effectiveness of the mined rules.
Figure 6. Charm Tidsets and Diffsets Memory Usage
Figure 7. Charm and Apriori CPU Time
Figure 8. CPU Time
REFERENCES [1] Mark Sharp, "Text Mining," Seminar in Information Studies, Prof. Tefko
Saracevic , December 2001. [2] Mohammed Zaki , "Efficient Algorithms for Mining Closed Itemsets and
Their Lattice Structure," IEEE Transactions On Knowledge And Data Engineering, vol. 17, no. 4, pp. 462-478 , April 2005.
[3] Catherine Blake and Wanda Pratt, "Better Rules, Fewer Features: A Semantic Approach to Selecting Features from Text," Proceedings of the IEEE International Conference on Data Mining, pp. 59-66, Novem-ber 2001.
[4] Michael Pan and Rob Raskin, "Automatic semantic acquisition through text mining techniques,",NASA Jet Propulsion Laboratory, California Institute of Technology, October 2002.
[5] Nitin Jindal and Bing Liu," Identifying Comparative Sentences in Text Documents," Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, pp. 244-251, 2006.
[6] Un Yong Nahm and Raymond Mooney , "Mining Soft-Matching Asso-ciation Rules," Proceedings of the Eleventh International Conference on Information and Knowledge Management (CIKM), pp. 681-683, No-vember 2002.
[7] Ricardo Baeza-Yates and Berthier Ribeiro-Neto, "Modern Information Retrieval," Addison-Wesley, 1999.
[8] Mohammed Zaki, "Mining Non-Redundant Association Rules," Data Mining and Knowledge Discovery: An International Journal, Vol. 9, Is-sue 3, pp. 223-248, November 2004.
[9] Marti Hearst ,"What Is Text Mining? ," SIMS,UC Berkeley, October 2003.
[10] Tao Jiang, Ah-Hwee Tan, and Ke Wang, "Mining Generalized Associa-tions of Semantic Relations from Textual Web Content," IEEE Transac-tions on Knowledge and Data Engineering, Vol. 19, No. 2, pp. 164-179, February 2007.
[11] Yanbo Wang.,"Various Approaches in Text Pre-processing". TM Work Paper No. 2004-2, Department of Computer Science, the University of Liverpool, Liverpool, UK, 2004.
[12] Ahmed Sharaf Eldin, Maha Attia Hana, Amira Fathy Elgohary, "Mining Arabic Textual Datasets Using Association Rules Technique," Fourth International Conference( INFOS2006) , 2006.
[13] http://www.basistech.com/base-linguistics/arabic/, 21August 2007. [14] http://www.basistech.com/products/#technicalView, 21 August 2007. [15] http://www.sra.com/services/index.asp?id=172, 21 August 2007. [16] http://www.sakhr.com/products/Mining/Default.aspx?sec=Product&item =Mining, 21 August 2007. [17] http://www.sakhr.com/Technology/Keyword/Default.aspx ?sec = Tech-
nology&item=Keyword, 21 August 2007. [18] Kjetil Norvag., Trond Oivind Eriksen, and Kjell-Inge Skogstad, "Mining
Association Rules in Temporal Document Collections," International Syposium on Methodologies for Intelligent Systems (ISMIS) Bari, Italy, vol. 4203, pp. 745-754, 2006.
[19] Amira Fathy, "Mining Arabic Textual Databases Using Association Rules," M. Sc. Thesis, January 2006.
[20] Un Yong Nahm and Raymond Mooney," Mining Soft-Matching Rules from Textual Data," Proceedings of the Seventeenth International Joint Conference on Artificial Intelligence (IJCAI-01), pp. 979 – 984, August 2001.
[21] Yanwei Chen and Csaba Egyhazy, "Comparative Study On Different Association Rule Mining Algorithms," Northern Virginia Center, Vir-ginia Tech, 2000.
[22] Mohamed Zaki and Ching-Jui Hsiao, "CHARM: An Efficient Algorithm for Closed Itemset Mining" 2nd SIAM International Conference on Da-ta Mining, Arlington, April 2002.
Mem
ory
Usa
ge (M
B)
Computation Progression
426




















