
Gabrielatos, C. (2013). Counting: Word frequency and beyond. Dubrovnik Fall School in Linguistic...
70
Corpus Linguistics 1 Counting: word frequency and beyond Costas Gabrielatos Edge Hill University [email protected] Dubrovnik Fall School in Linguistic Methods 20–26 October 2013
Transcript of Gabrielatos, C. (2013). Counting: Word frequency and beyond. Dubrovnik Fall School in Linguistic...

Corpus Linguistics 1 Counting: word frequency and beyond
Costas Gabrielatos
Edge Hill University
Dubrovnik Fall School in Linguistic Methods 20–26 October 2013

Preliminaries
Attitudes to statistics • http://www.youtube.com/watch?v=0n_Ty_72Qds
Stats in/for linguistics • http://www.youtube.com/watch?feature=player_detailpage&v=sau
xaWJynHo#t=26
Quantitative vs. Qualitative • http://www.dailymotion.com/video/xg28et_the-black-adder-
season-2-ep-02-part-1-2_shortfilms&start=38
Purpose of counting • http://www.youtube.com/watch?v=FmbmNp1RDCE

CL Methodology
Quite straightforward
• Get a corpus or random sample(s)
• Annotate (identify instances of linguistic feature)
• Count
• Proceed to analysis (statistical / linguistic)

CL Methodology
Quite straightforward
• Get a corpus or random sample(s)
• Annotate (identify instances of feature)
• Count
• Proceed to analysis (statistical/linguistic)

Counting: Questions
• What do we count?
• How do we count? Normalisation
• What do we count within?
• How do we delimit what we count within?
• How is frequency distributed?

Remember!
Whatever the quality/accuracy
of the data you’re inputting,
the statistical software will trust you!
GIGO

Aims and Scope
• Awareness of issues and possible angles.
• Issues of counting (what? how?) closely linked to …
… focus of analysis.
… theoretical orientation.
• Metrics and approaches that can be used …
… to supplement more sophisticated statistical analyses.
… instead of more sophisticated statistical analyses.

Word Frequency

Word Frequency: Quiz
• Focus: frequency of word X in two corpora
– Corpus 1: 5000 instances
– Corpus 2: 1000 instances
Question:
• In which corpus is X more frequent?
Correct response:
• We can’t tell; we don’t have all the information we need.

Normalised Word Frequency
• #1: What is the size of each corpus?
Raw frequency only is not enough.
Frequency counts of a linguistic item must be related to the size of the population in which they occur.
Normalised frequency.
Raw Corpus size Normalised
Corpus 1 5000 10,000,000 500/mil.
Corpus 2 1000 2,000,000 500/mil.

Normalised Word Frequency
#2: Which part of speech?
• play: 214.48/mil. (BNC, BNCweb)
Verb 147.68
Noun 66.80

Normalised Word Frequency
#3: Lemma or word-form?
• PLAY (v): (BNC, BNCweb)
play 133.24
plays 20.62
playing 95.26
played 95.17
Normalised Word Frequency
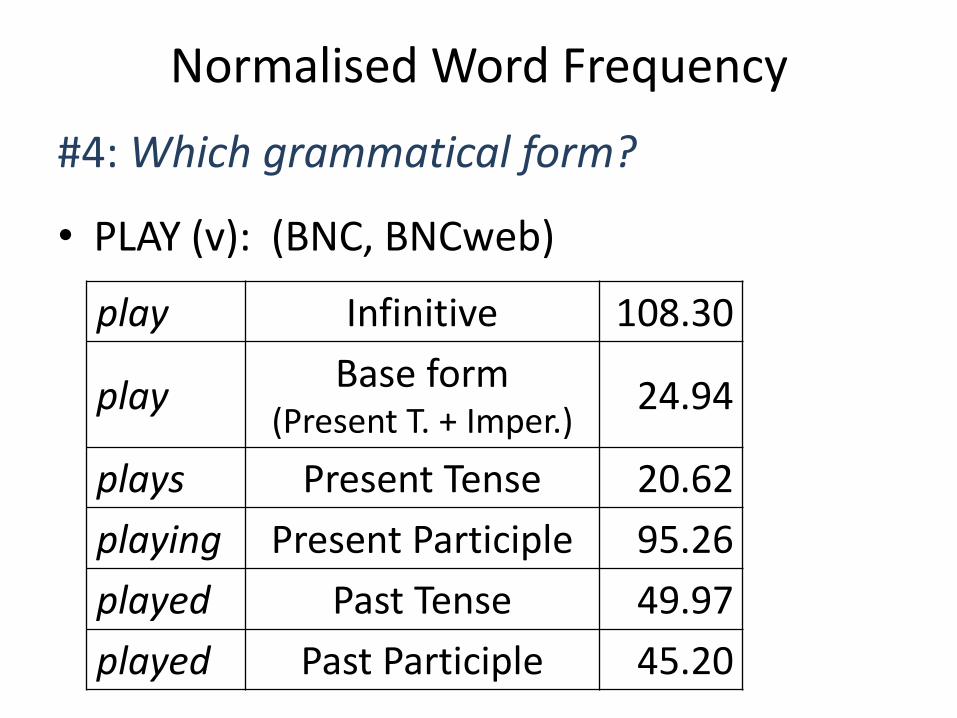
#4: Which grammatical form?
• PLAY (v): (BNC, BNCweb)
play Infinitive 108.30
play Base form
(Present T. + Imper.) 24.94
plays Present Tense 20.62
playing Present Participle 95.26
played Past Tense 49.97
played Past Participle 45.20

Normalised Word Frequency
#5: Which interface tokeniser / tagger?
• play (word-form) (BNC)
BNCweb Sketch Engine
Verb 147.68 129.50
Noun 66.80 58.70
Sometimes (often?) particular corpora are only available through particular corpus interfaces.

Normalised Word Frequency
#6: Which meaning/use?
• however – Critics from within the transport industry pointed
out, however, that while BR remained as the track and service authority, there was no guarantee that existing freight depots would remain open. [J2W]
– The tortoise is given an initial lead over Achilles, and the argument asserts that however fast Achilles runs he will never reach the tortoise [ASF].
Manual annotation.

Normalised Word Frequency
#7: Tokens or types?
• Tokens: all words frequency
• Types: unique words lexical richness
– e.g. work, work, work, play: 4 tokens, 2 types
Study example: • Topics in a specialised corpus
– Topic indicators: lexis indexing particular topics

The representation of Islam and Muslims in the UK press, 1998-2009
Source: Nexis UK (online database)
Query
• Alah OR Allah OR ayatolah OR burka! OR burqa! OR chador! OR fatwa! OR hejab! OR imam! OR Islam! OR Koran OR Mecca OR Medina OR Mohammedan! OR Moslem! OR Muslim! OR mosque OR mufti! OR mujaheddin! OR mujahedin! OR mullah! OR muslim! OR Prophet Mohammed OR Q'uran OR rupoush OR rupush OR sharia OR shari'a OR shia! OR shi-ite! OR Shi'ite! OR sunni! OR the Prophet OR wahabi OR yashmak! AND NOT Islamabad AND NOT shiatsu AND NOT sunnily
(Baker et al., 2013a,b; Gabrielatos et al., 2012)

Corpus
Business Daily Express + Sunday Express
Daily Mail + Mail on Sunday Daily Mirror + Sunday Mirror
Guardian + Observer Independent + Independent on Sunday
People Daily Star + Daily Star Sunday
Sun Telegraph + Sunday Telegraph
Times + Sunday Times
Articles: 200,000 Words: 143 million Spelling normalisation Sub-corpora: per newspaper per year (1998-2009) broadsheets/tabloids political orientation

Topic indicators: religion, culture, society, education
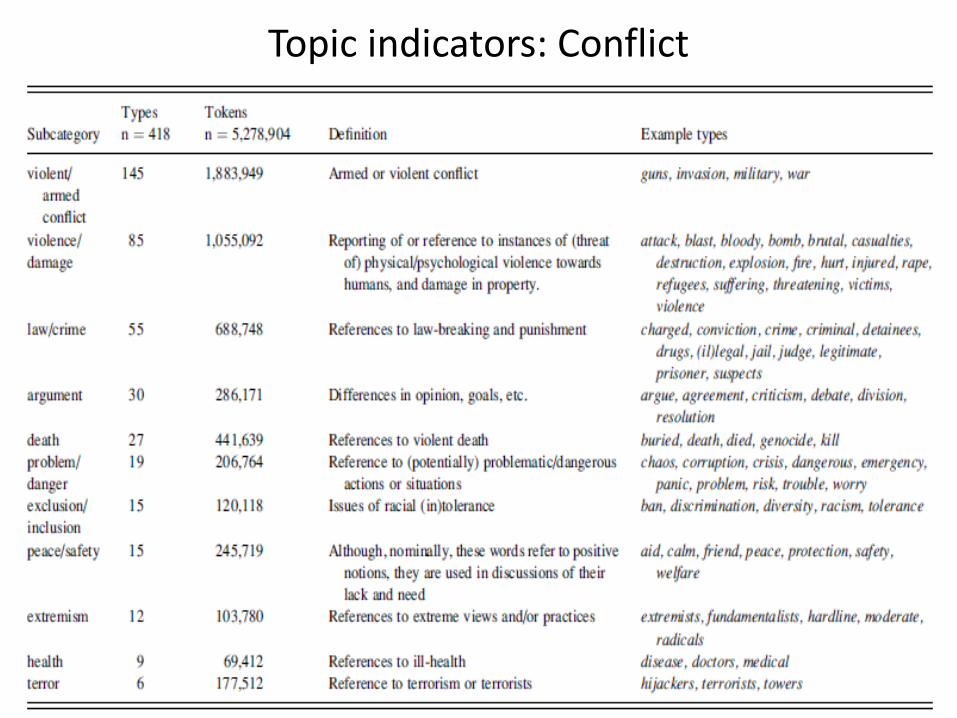
Topic indicators: Conflict

Topic indicators: Other

Topic indicators: Tokens and Types
Religion/Society/ Culture/Education
Conflict
Other
0
500000
1000000
1500000
2000000
2500000
3000000
3500000
4000000
4500000
5000000
5500000
0 50 100 150 200 250 300 350 400 450
Toke
ns
Types

Normalised Word Frequency
#8: Which parts of the corpus?
• If, even if, unless (BNC Sampler (w), WSmith)
if
even if
unless
It is not safe to assume that occurrences of a word will be distributed evenly in the corpus. • Overall high frequency may be due to particular
corpus sections. (See also Gries, 2008).

So far …
• Focus of counting: words
– lemma, word-form, form+POS, form+grammatical_function, form+meaning.
Common practice in CL.
• Normalisation basis: words
– Total words in corpus (sample).
Almost default practice in CL.

However …
• Focus on words as object of counting and/or normalisation basis is not a-theoretical.
Practice entails (implicit) acceptance of theoretical assumptions.

Lexical Grammar
Lexical Item / Extended Unit of Meaning
(Sinclair, 1996: 75, 90; Stubbs, 2009: 123-126)
The core (a word/phrase)
Its collocates Its semantic prosody
Its semantic preference Its colligations
Lexis independent of grammar
Grammar emerges from lexical patterning
Obligatory
Optional

However …
• Focus on words as object of counting and/or normalisation basis is not a-theoretical.
Practice entails (implicit) acceptance of theoretical assumptions.
• Focus may be on language features other than words (e.g. grammatical constructions).
• Whatever the focus, normalising frequency on the basis of the number of words in the corpus may be inappropriate.
Results may be skewed misleading.

Words vs. Opportunities: Examples
• Loaded terms in newspaper articles
• Collostructions – Focus: words + grammatical function
– Normalisation: per X constructions
• Modal Load of constructions (semantic focus) – Focus: modal markers (not necessarily single/contiguous words)
– Normalisation: per X clauses + per X constructions
• Use of indef. article a before vowel-initial words – Focus: a/an + vowel-initial word
– Normalisation: per X vowel-initial words preceded by an indefinite article.

Revealing contextual elements: Use of loaded/misleading terms
(Gabrielatos & Baker, 2008: 30-32; Gabrielatos, 2009)
Corpus Query
• refugee OR asylum OR deport* OR immigr* OR emigr* OR migrant* OR illegal alien* OR illegal entry OR leave to remain AND NOT deportivo AND NOT deportment
(see Gabrielatos, 2007)
Nonsensical (= loaded/misleading) terms
• illegal/legal refugee*/asylum seeker*
• bogus/genuine immigrant*/migrant*

Definitions
Longman Dictionary of Contemporary English (2003)
Refugee Council
refugee Someone who has been forced to leave their country, especially during a war, or for political or religious reasons.
Someone whose asylum application has been successful and who is allowed to stay in another country having proved they would face persecution back home.
asylum seeker
Someone who leaves their own country because they are in danger, especially for political reasons, and who asks the government of another country to allow them to live there.
Someone who has fled persecution in their homeland, has arrived in another country, made themselves known to the authorities and exercised the legal right to apply for asylum.
immigrant Someone who enters another country to live there permanently.
-----
migrant Someone who goes to live in another area or country, especially in order to find work.
[economic migrant] Someone who has moved to another country to work.
International Association for the Study of Forced Migration
Forced migration: refugees and asylum seekers
Voluntary migration: immigrants and (economic) migrants

Frequency of use of loaded terms in newspapers
• Per million words • However …
– Articles in broadsheets much longer than in tabloids (+80%).
– More chances for repetition in broadsheet articles … but up to a point
− Small number of high-repetition articles may not have as significant impact on readers as low-repetition, or single instances, in large number of articles.
Partial picture of frequency.
+ • Per thousand articles
(Gabrielatos & Baker, 2008: 30-32; Gabrielatos, 2009. See also Oakey, 2009)

Frequency of loaded/misleading terms
Business
Express
Guardian Independent
Mail Mirror
Observer
People
Star
Sun
Telegraph Times
0
2
4
6
8
10
12
14
16
18
20
22
24
26
28
0 1 2 3 4 5 6 7 8 9 10 11
Fre
q. p
er
mill
ion
wo
rds
Freq. per 1000 articles (Gabrielatos, 2009)

Collostructions (Stefanowitsch & Gries, 2003; Gries & Stefanowich, 2004)
Focus
• “[D]etermining the degree to which particular slots in a grammatical structure prefer, or are restricted to, a particular set of semantic class of lexical items” (2003: 211).
• “Collostructional analysis always starts with a particular construction and investigates which lexemes are strongly attracted or repelled by a particular slot in the construction” (2003: 214)
• E.g. NOUN waiting to happen


Collexemes and positions

Collostructional Analysis: Important points (Stefanowitsch & Gries, 2003)
• Identifying the lexemes in a given slot “requires item-by-item inspection and manual coding” (: 215)
• “Defining what counts as an instance of construction C may involve decisions … that have to be justified on theoretical grounds” (: 218)
• “Any actual utterance larger than a word is a simultaneous manifestation of several constructions” (: 213)

Modal Load (Gabrielatos, 2010, 2013)
Focus • Amount of modal marking in if-conditionals.
Research Questions
• Do if-conditionals have a heavier ML than … – average (i.e. written BE seen as a whole)? – conditionals with other subordinators (assuming, in case, on condition,
provided, supposing, unless). – concessive conditionals with even if and whether, – indirect interrogatives with if and whether, – comparative constructions with as if and as though – constructions with when and whenever (used as conjunctions) – non-conditional constructions taken collectively
• Do all conditionals have comparable ML? – assuming, if, in case, on condition, supposing, unless
• Do sub-types of if-conditionals have comparable ML?

Focus: Words/Constructions Normalisation Basis: Constructions
How do we account for …
… construction tokens of varying length and/or structural complexity? (Ball, 2004: 297-299; Halliday, 1994: 654)
… multiple slots within a construction?
… unequal number of slots between construction tokens
… grammatical (rather than lexical) slots
… constructional slots that may be non-contiguous? (Gabrielatos, 2010)

Delimiting a conditional construction
Dealing with ellipsis

Appended elements
If it can be easily reached, hook it out with your finger so it can't be swallowed again (be careful not to get bitten!). [G2T 1836] If it can be easily reached, hook it out with your finger so it can't be swallowed again (be careful not to get bitten!). [G2T 1836]
We must have a relief plan that the United Nations can implement throughout Somalia if there is to be peace and if the people are to be relieved. [HHV 23814]
We must have a relief plan that the United Nations can implement throughout Somalia if there is to be peace and if the people are to be relieved. [HHV 23814]
Co-ordination ellipsis (Quirk et al., 1985: 944, 953) Only the if selected by the ‘thin’ function is taken into account.

Embedded elements
If, on the other hand, the debt is incurred on a sole account, then it is the account holder alone who is responsible. [BPF 962]
If you suffer badly from these symptoms, go and see your doctor who should be able to help. [A0J 1467] If you suffer badly from these symptoms, go and see your doctor who should be able to help. [A0J 1467]
Non-restrictive relative clause (not part of the conditional)
Restrictive relative clause (part of the conditional)

Embedded Protases
[I]f a producer controls the production of a given commodity he is a monopolist -- if he is such -- not by virtue of any entrepreneurial role, but as a result of a resource monopoly. [HH2 743]
The embedded protasis (if he is such) modalises the clause he is a monopolist. It is part of the conditional construction.

Embedding + Ellipsis
They are people whom we rarely consider in this House, but when there is a suicide or accident on the railway, the driver, and his mate if appropriate, may be mentally scarred for life by the experience. [HHX 119]
They are people whom we rarely consider in this House, but when there is a suicide or accident on the railway, the driver may be mentally scarred for life by the experience, and if the driver has a mate who is present, then the mate may also be mentally scarred for life by the experience.
• The reconstruction of the conditional …
– … adds (unnecessary) words.
– … is tantamount to tampering with the data.
They are people whom we rarely consider in this House, but when there is a suicide or accident on the railway, the driver, and his mate if appropriate, may be mentally scarred for life by the experience. [HHX 119]

Ellipsis: Textually recoverable
One commentator […] asks whether we have the means by which deliberately to create a planned organizational ethos in a school. If we do, does this mean that the use of coercion, enthusiasm or the encouragement to be involved are equally acceptable? [HPX 125]
• Counter do have = no modal marking.
• Textually recoverable ellipsis (Quirk et al.,1985: 861; also Halliday & Hasan, 1976: 169).

Ellipsis: Non-recoverable
I quickly stuck my head between my knees, remembering ... remembering. Sometime, someone said, don't pull the body off or the head’ll stay in and go septic. Spray them with something. Alcohol? Was that it? What if it made them go deeper? [G02 1577]
• What could/would/might happen if …? [likelihood]
• What would he do if …? [volition]
• What should he do if …? [obligation]
• ????????????????????? [Why infer modal marking?]
There is no direct textual clue – only recourse to introspection (stereotypical/frequent types).
The speaker chose not to use an explicit marker (intended vagueness?)
No modal marking is counted.

Discontinuous conditionals: stem-list
Abdomen: When to seek advice
Urgently, Right now!
.........................................................
If the stool is bloody, black or tar-like. [B1R 681]
• The infinitive (to seek) has a modal (deontic) function (Huddleston & Pullum, 2002: 174).
If the stool is bloody, black or tar-like, seek advice urgently – right now!
Abdomen: When to seek advice
Urgently, Right now!
.........................................................
If the stool is bloody, black or tar-like. [B1R 681]

Discontinuous conditionals: Q-A
- "You intend to reside there ... wherever ... for some time?"
- "If I like it." [FPD 1593]
• If I like it is a “supplementary response”, which “presuppose[s] the entire question” (Halliday & Hasan, 1976: 213).
- "You intend to reside there ... wherever ... for some time?"
- “I intend to stay here for some time, if I like it."
- "You intend to reside there ... wherever ... for some time?"
- "If I like it." [FPD 1593]

What do we count within?

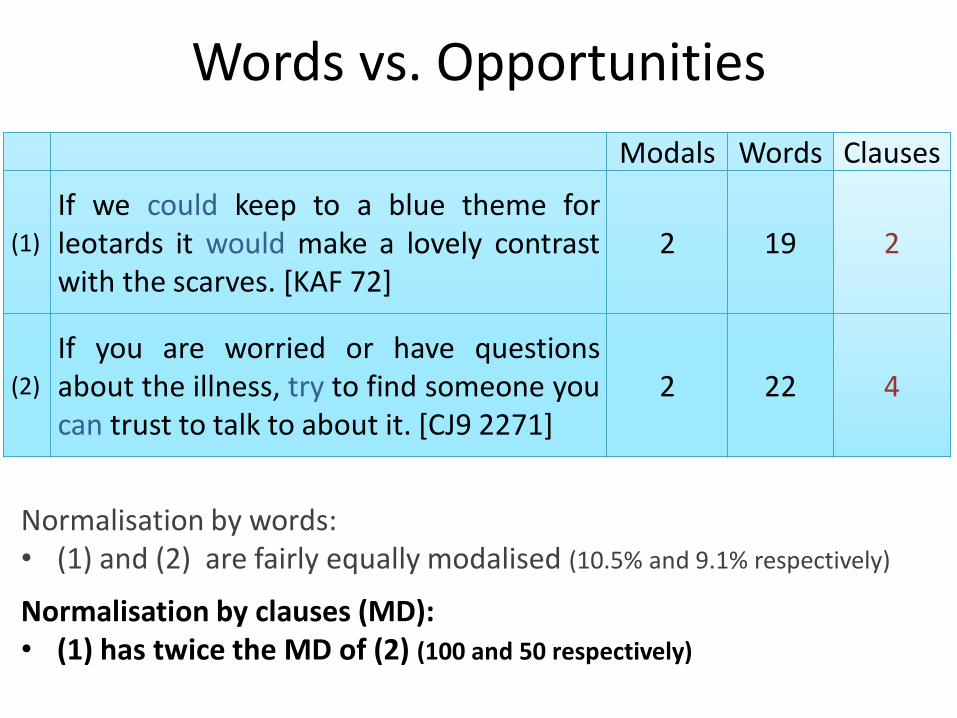
Words vs. Opportunities
Modals Words
(1)
If we could keep to a blue theme for leotards it would make a lovely contrast with the scarves. [KAF 72]
2 19
(2)
If you are worried or have questions about the illness, try to find someone you can trust to talk to about it. [CJ9 2271]
2 22
Normalisation by words:
• (1) and (2) are fairly equally modalised (10.5% and 9.1% respectively)
Clauses
2
4

Modal Density
Lexical Density:
• The average number of content words per clause (Halliday, 2004: 654-655).
• The percentage of the tokens in a text that are content words (Ure, 1971).
Definition Average number of modal markings per clause.
Expression Number of modal markings per 100 clauses (%).
Utility Helps comparisons between samples by normalising for the complexity of the constructions in each.
(Gabrielatos, 2010)
Words vs. Opportunities
Normalisation by words: • (1) and (2) are fairly equally modalised (10.5% and 9.1% respectively)
Normalisation by clauses (MD): • (1) has twice the MD of (2) (100 and 50 respectively)
Modals Words
(1)
If we could keep to a blue theme for leotards it would make a lovely contrast with the scarves. [KAF 72]
2 19
(2)
If you are worried or have questions about the illness, try to find someone you can trust to talk to about it. [CJ9 2271]
2 22
Clauses
2
4

Modalisation Spread
Definition Proportion of constructions that carry at least one modal marking.
Expression Proportion (%) of modalised constructions.
Utility Corrects for heavily modalised constructions in the sample.
(Gabrielatos, 2010)
Spread: The proportion of corpus speakers who use a particular language item (Gabrielatos & Torgersen, 2009; Gabrielatos et al., 2010).
Range: The number of corpus sections in which a lexical item has at least one occurrence (Leech et al., 2001).

Why not collostructional analysis?
• ML analysis not concerned with the frequency of co-occurrence of individual modal markers within a (fairly) simple construction, …
• … but with the collective frequency of modal senses, expressed by a variety of lexicogrammatical means within a complex construction.
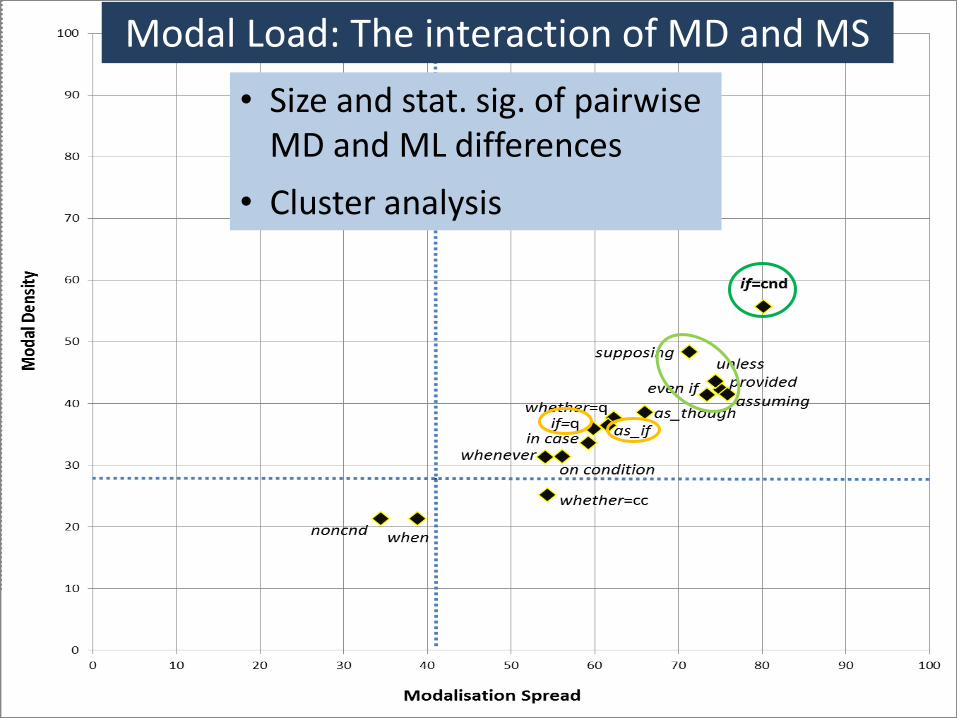
Modal Load: The interaction of MD and MS
• Size and stat. sig. of pairwise MD and ML differences
• Cluster analysis

Density and Spread supplementing more sophisticated statistical analysis
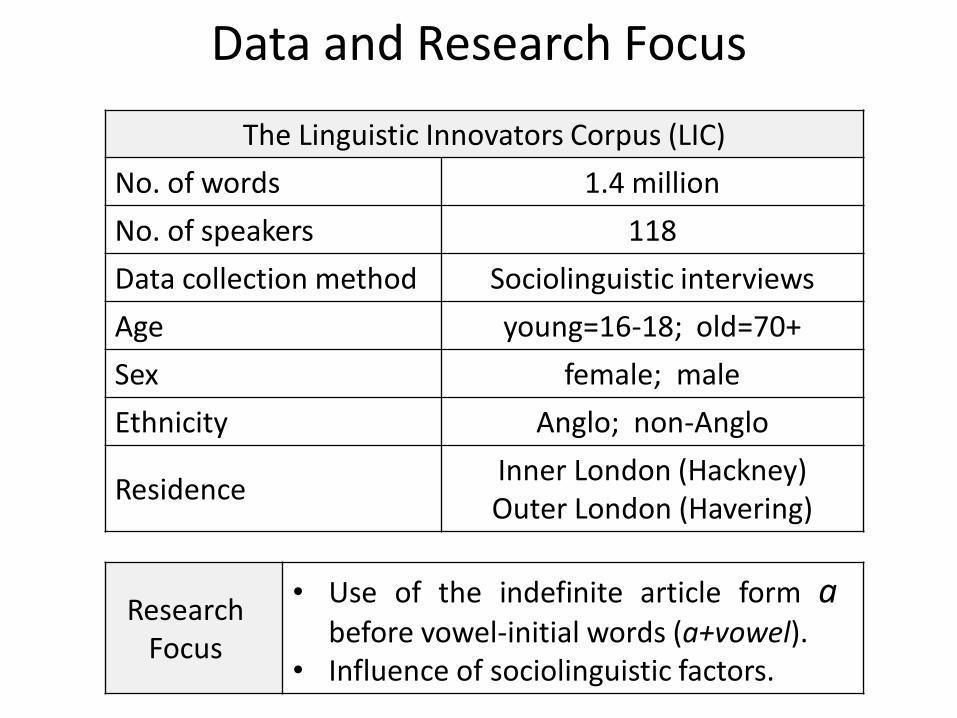
Data and Research Focus
The Linguistic Innovators Corpus (LIC)
No. of words 1.4 million
No. of speakers 118
Data collection method Sociolinguistic interviews
Age young=16-18; old=70+
Sex female; male
Ethnicity Anglo; non-Anglo
Residence Inner London (Hackney) Outer London (Havering)
Research Focus
• Use of the indefinite article form a before vowel-initial words (a+vowel).
• Influence of sociolinguistic factors.

Methodology
Logistic regression analysis • Sociolinguistic factors considered individually and in
pairwise cross-tabulations
Expression Utility
Density Frequency per 100 instances of a+vowel
Shows the relative frequency of a+vowel use as opposed to an+vowel
Spread Number of a+vowel users per 100 speakers
Shows the proportion of speakers using the feature.
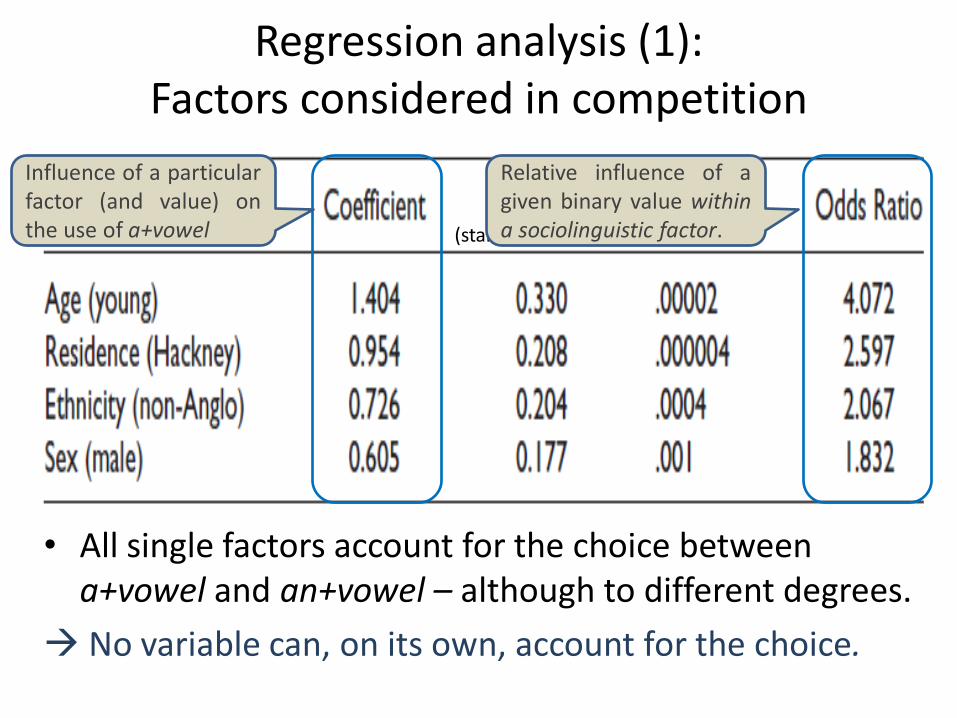
Regression analysis (1): Factors considered in competition
• All single factors account for the choice between a+vowel and an+vowel – although to different degrees.
No variable can, on its own, account for the choice.
(standardised error)
Influence of a particular factor (and value) on the use of a+vowel
Relative influence of a given binary value within a sociolinguistic factor.

Regression analysis (2): Cross-tabulations
• Only Ethnicity+Residence was shown to predict use of a+vowel (p < 0.01).
• The OR (3.31) indicates that non-Anglo Hackney speakers are about three times more likely to use a+vowel than Anglo Havering speakers.
• Ok, but could one of the two combined factors (ethnicity or residence) be more influential?
Examination of density and spread.

Ethnicity*Residence
AA+HK
AA+HV
NA+HK
NA+HV
0
10
20
30
40
50
60
70
80
90
100
0 10 20 30 40 50 60 70 80 90 100
De
ns
ity
Spread
AA=Anglo, NA=non-Anglo, HK=Hackney, HV=Havering

Ethnicity*Residence (1) Comparisons within each locality
AA+HK
AA+HV
NA+HK
NA+HV
0
10
20
30
40
50
60
70
80
90
100
0 10 20 30 40 50 60 70 80 90 100
De
ns
ity
Spread
AA=Anglo, NA=non-Anglo, HK=Hackney, HV=Havering
•Distance between AA and NA speakers is larger in HV than HK residents. • AA+HK speakers have higher D+S than AA+HV speakers.
This seems to indicate a stronger effect of Residence.
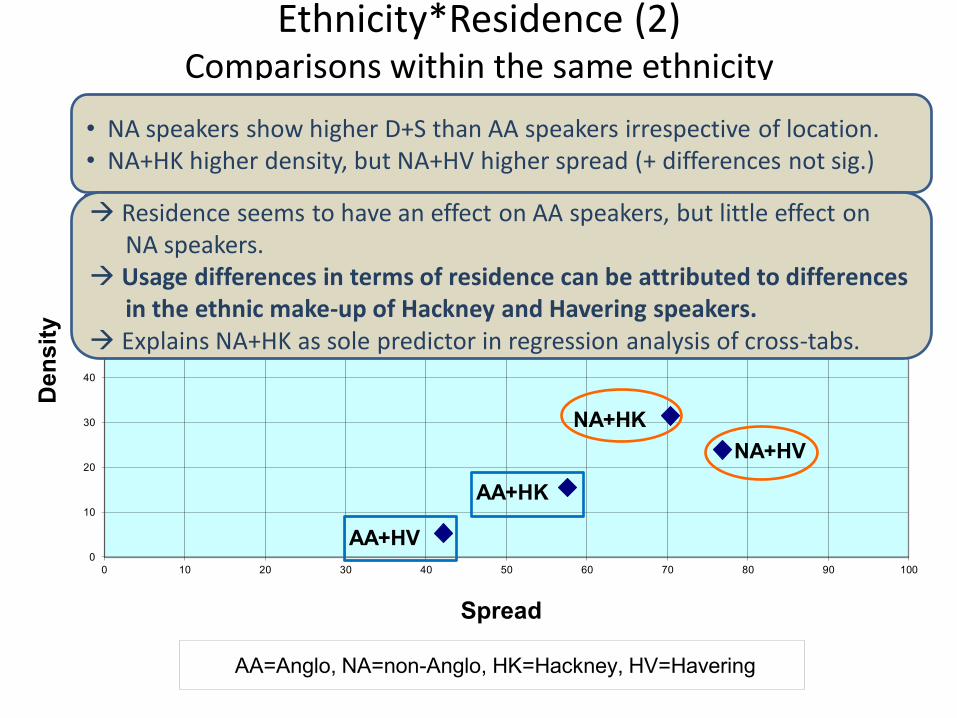
Ethnicity*Residence (2) Comparisons within the same ethnicity
AA+HK
AA+HV
NA+HK
NA+HV
0
10
20
30
40
50
60
70
80
90
100
0 10 20 30 40 50 60 70 80 90 100
De
ns
ity
Spread
AA=Anglo, NA=non-Anglo, HK=Hackney, HV=Havering
• NA speakers show higher D+S than AA speakers irrespective of location. • NA+HK higher density, but NA+HV higher spread (+ differences not sig.)
Residence seems to have an effect on AA speakers, but little effect on NA speakers. Usage differences in terms of residence can be attributed to differences in the ethnic make-up of Hackney and Havering speakers. Explains NA+HK as sole predictor in regression analysis of cross-tabs.

Combining types of analysis
• Logistic regression analysis informs conclusions regarding the predictive power the factors in focus.
– Considered individually, in competition, and in combinations.
• The detailed examination of density and spread can draw attention to patterns of use within factors that an automated statistical analysis cannot reveal.
– For example, young male speakers show higher density of use, but lower spread, than young female speakers.

Conclusions
• Counting …
… is not as straightforward as it might seem
… is theory-specific
• Object of counting and normalisation basis …
… need to be appropriate for language feature in focus.
… should be compatible with the theoretical framework adopted in the study
• Different features require different (combinations of) metrics and statistical analyses.
• Visual representation of counts can aid analysis.

Think and discuss
In your PhD projects …
a. What is the object of counting?
b. What would be a suitable normalisation basis?
c. Why have you chosen the particular (a) and (b)?
d. What are the theoretical frameworks informing your decisions re. (a), (b) and (c)?
e. Do you need to do manual annotation?
• If yes, how easy would it be to get random samples containing the feature in focus??
f. Do you see any limitations/problems regarding (a)-(e)?
• If so, can you think of solutions?

References and further reading (1) • Baker, P., Gabrielatos, C. & McEnery, T. (2013). Discourse Analysis and Media Attitudes:
The representation of Islam in the British press. Cambridge: Cambridge University Press.
• Baker, P., Gabrielatos, C. & McEnery, T. (2013). Sketching Muslims: A corpus-driven analysis of representation around the word “Muslim” in the British press, 1998-2009. Applied Linguistics, 34(3), 255–278.
• Baroni, M. & Evert, S. (2008). Statistical methods for corpus exploitation. In Lüdeling, A. & Kytö, M. (eds.) Corpus Linguistics. An International Handbook. Berlin: Mouton de Gruyter. [http://purl.org/stefan.evert/PUB/BaroniEvertHSK38_manuscript.pdf]
• Baroni, M. & Evert, S. (2005). Testing the extrapolation quality of word frequency models. In Danielsson, P. & Wagenmakers, M. (eds.) Proceedings of Corpus Linguistics 2005. [http://purl.org/stefan.evert/PUB/EvertBaroni2005.pdf]
• Evert, S. (2006). How random is a corpus? The library metaphor. Zeitschrift für Anglistik und Amerikanistik, 54(2), 177 - 190. [http://purl.org/stefan.evert/PUB/Evert2006.pdf]
• Evert, S. (2004). The statistical analysis of morphosyntactic distributions. In Proceedings of the 4th International Conference on Language Resources and Evaluation (LREC 2004) (1539-1542). Lisbon, Portugal. [http://purl.org/stefan.evert/PUB/Evert2004b.pdf]
• Evert, S. & Baroni, M. (2007). zipfR: Word frequency distributions in R. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Posters and Demonstrations Session. (29-32). Prague, Czech Republic.
[http://purl.org/stefan.evert/PUB/EvertBaroni2007.pdf]

References and further reading (2)
• Evert, S. & Krenn, B. (2005). Using small random samples for the manual evaluation of statistical association measures. Computer Speech & Language, 19(4), 450-466. [http://purl.org/stefan.evert/PUB/EvertKrenn2005.pdf]
• Gabrielatos, C. (2013). Using corpus analysis to compare the explanatory power of linguistic theories: A case study of the modal load in if-conditionals. Corpus Linguistics 2013, 23-26 July 20013, Lancaster University. [http://repository.edgehill.ac.uk/5322]
• Gabrielatos, C. (2010). A corpus-based examination of English if-conditionals through the lens of modality: Nature and types. PhD Thesis. Lancaster University. [bit.ly/CG-Thesis]
• Gabrielatos, C. (2009). Corpus-based methodology and critical discourse studies: Context, content, computation. Siena English Language and Linguistics Seminars (SELLS), University of Siena, 9 November 2009. [http://eprints.lancs.ac.uk/28460]
• Gabrielatos, C. (2007). Selecting query terms to build a specialised corpus from a restricted-access database. ICAME Journal, 31, 5-43.
• Gabrielatos, C. (2007). If-conditionals as modal colligations: A corpus-based investigation. In Davies, M., Rayson, P., Hunston, S. & Danielsson, P. (eds.) Proceedings of the Corpus Linguistics Conference: Corpus Linguistics 2007. Birmingham: University of Birmingham.
• Gabrielatos, C. & Baker, P. (2008). Fleeing, sneaking, flooding: A corpus analysis of discursive constructions of refugees and asylum seekers in the UK Press 1996-2005. Journal of English Linguistics, 36(1), 5-38.

References and further reading (3) • Gabrielatos, C. & McEnery, T. (2005). Epistemic modality in MA dissertations. In P.A.
Fuertes Olivera (ed.), Lengua y Sociedad: Investigaciones recientes en lingüística aplicada. Lingüística y Filología no. 61. (311-331). Valladolid: Universidad de Valladolid.
• Gabrielatos, C., McEnery, T., Diggle, P. & Baker, P. (2012). The peaks and troughs of corpus-based contextual analysis. International Journal of Corpus Linguistics, 37(2), 151-175.
• Gabrielatos, C., Torgersen, E., Hoffmann, S. & Fox, S. (2010). A corpus-based sociolinguistic study of indefinite article forms in London English. Journal of English Linguistics, 38(4), 297-334.
• Gabrielatos, C. & Torgersen, E. (2009). A corpus-based sociolinguistic analysis of indefinite article use in London English. ICAME 30, Lancaster, UK, 27-31 May 2009.
• Gries, S.Th. (forthcoming). Quantitative designs and statistical techniques. In Biber, D. & Reppen, R. (eds.) The Cambridge Handbook of Corpus Linguistics. Cambridge: Cambridge University Press.
[www.linguistics.ucsb.edu/faculty/stgries/research/InProgr_STG_QuantDesAndMethCorpLing_CUPHb.pdf]
• Gries, S.Th. (forthcoming). Frequency tables, effect sizes, and explorations. In Glynn, D. & Robinson, J. (eds.) Polysemy and Synonymy: Corpus methods and applications in Cognitive Linguistics. Amsterdam & Philadelphia: John Benjamins.
[http://www.linguistics.ucsb.edu/faculty/stgries/research/ToApp_STG_FreqTables_CorpMethCogLing.pdf]
• Gries, S.Th. (2012). Collostructions. In Robinson, P. (ed.), The Routledge Encyclopedia of second language acquisition. (92-95). London & New York: Routledge.

References and further reading (4)
• Gries, S.Th. (2012). Frequencies, probabilities, association measures in usage-/exemplar-based linguistics: some necessary clarifications. Studies in Language, 36(3), 477-510.
• Gries, S.Th. (2012). Corpus linguistics: quantitative methods. In Chapelle, C.A. (ed.), The Encyclopedia of Applied Linguistics. (1380-1385). Oxford: Wiley-Blackwell.
• Gries, S.Th. (2010). Useful statistics for corpus linguistics. In Sánchez, A. & Almela, M. (eds.) A Mosaic of Corpus Linguistics: Selected approaches. (269-291). Frankfurt am Main: Peter Lang.
• Gries, S.Th. (2008). Dispersions and adjusted frequencies in corpora. International Journal of Corpus Linguistics, 13(4), 403-437.
• Gries, S.Th. (2006). Exploring variability within and between corpora: Some methodological considerations. Corpora, 1(2), 109-151.
• Gries, S.Th. & Stefanowitsch, A. (2004). Extending collostructional analysis: a corpus-based perspective on 'alternations'. International Journal of Corpus Linguistics, 9(1), 97-129.
• Gries, S.Th. (2003). Multifactorial analysis in corpus linguistics: a study of Particle Placement. London & New York: Continuum Press.
• Gries, S.Th. (2010). Dispersions and adjusted frequencies in corpora: further explorations. In Gries, S.Th., Wulff, S. & Davies, M. (eds.) Corpus Linguistic Applications: Current studies, new directions. (197-212). Amsterdam: Rodopi.
• Gries, S.Th. (2008). Dispersions and adjusted frequencies in corpora. International Journal of Corpus Linguistics, 13(4), 403-437.

References and further reading (5) • Halliday, M.A.K. (2004). An Introduction to Functional Grammar (3rd ed.). London: Arnold.
• Hoffmann, S., Evert, S., Smith, N., Lee, D. & Berglund Prytz, Y. (2008). Corpus Linguistics with BNCweb: A practical guide. Frankfurt am Main: Peter Lang. [Chapter 5]
• Leech, G., Rayson, P. & Wilson, A. (2001). Word Frequencies in Written and Spoken English, based on the British National Corpus. London: Longman.
• Oakey, D. (2009). Fixed collocational patterns in isolexical and isotextual versions of a corpus. In Baker, P. (ed.) Contemporary Corpus Linguistics. (142-160). London: Continuum.
• Oakey, D.J. (2008). The form and function of fixed collocational patterns in research articles in different academic disciplines. PhD thesis. University of Leeds. [http://etheses.whiterose.ac.uk/708/1/uk_bl_ethos_487747.pdf]
• Sinclair J.McH. (1996). The search for units of meaning. Textus, 9(1), 75-106.
• Stubbs, M. (2009). The search for units of meaning: Sinclair on empirical Semantics. Applied Linguistics, 30(1), 115–137.
• Stefanowitsch, A. & Gries, S.Th. (2003). Collostructions: Investigating the interaction between words and constructions. International Journal of Corpus Linguistics, 8(2), 209-243.
• Torgersen, E., Gabrielatos, C., Hoffmann, S. & Fox, S. (2011). A corpus-based study of pragmatic markers in London English. Corpus Linguistics and Linguistic Theory, 7(1), 93-118.
• Ure, J. (1971). Lexical density and register differentiation. In Perren, G. & Trim, J.L.M. (eds.) Applications of Linguistics. Selected papers of the second International Congress of Applied Linguistics, Cambridge 1969. (443-452). London: Cambridge University Press.




















