
Better Web Corpora For Corpus Linguistics And NLP - IS MUNI
170
Masaryk University Faculty of Informatics Better Web Corpora For Corpus Linguistics And NLP Doctoral Thesis Vít Suchomel Brno, Spring 2020
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Better Web Corpora For Corpus Linguistics And NLP - IS MUNI

Masaryk UniversityFaculty of Informatics
Better Web CorporaFor Corpus Linguistics
And NLP
Doctoral Thesis
Vít Suchomel
Brno, Spring 2020

Masaryk UniversityFaculty of Informatics
Better Web CorporaFor Corpus Linguistics
And NLP
Doctoral Thesis
Vít Suchomel
Brno, Spring 2020

Declaration
Hereby I declare that this paper is my original authorial work, whichI have worked out on my own. All sources, references, and literatureused or excerpted during elaboration of this work are properly citedand listed in complete reference to the due source.
Vít Suchomel
Advisor: Pavel Rychlý
i

Acknowledgements
I would like to thank my advisors, prof. Karel Pala and prof. PavelRychlý for their problem insight, help with software design and con-stant encouragement.
I am also grateful tomy colleagues fromNatural Language Process-ing Centre at Masaryk University and Lexical Computing, especiallyMiloš Jakubíček, Pavel Rychlý and Aleš Horák, for their support of mywork and invaluable advice.
Furthermore, I would like to thank Adam Kilgarriff, who gave mea wonderful opportunity to work for a leading company in the field oflexicography and corpus driven NLP and Jan Pomikálek who helpedme to start.
I thank to mywife Kateřina who supportedme a lot during writingthis thesis.
Of those who have always accepted me and loved me in spite ofmy failures, God is the greatest.
ii

Abstract
The internet is used by computational linguists, lexicographersand social scientists as an immensely large source of text data forvarious NLP tasks and language studies. Web corpora can be built insizes which would be virtually impossible to achieve using traditionalcorpus creation methods. This thesis presents a web crawler designedto obtain texts from the internet allowing to build large text corporafor NLP and linguistic applications. An asynchronous communicationdesign (rather than usual synchronous multi-threaded design) wasimplemented for the crawler to provide an easy to maintain alternativeto other web spider software.
Cleaning techniques were devised to transform the messy natureof data coming from the uncontrolled environment of the internet.However, it can be observed that usability of recently built web cor-pora is hindered by several factors: The results derived from statisticalprocessing of corpus data are significantly affected by the presenceof non-text (web spam, computer generated text and machine trans-lation) in text corpora. It is important to study the issue to be ableto avoid non-text at all or at least decrease its size in web corpora.Another observed factor is the case of web pages or their parts writtenin multiple languages. Multilingual pages should be recognised, lan-guages identified and text parts separated to respective monolingualcorpora. This thesis proposes additional cleaning stages in the processof building text corpora which help to deal with these issues.
Unlike traditional corpora made from printed media in the pastdecades, sources of web corpora are not categorised and describedwell, thus making it difficult to control the content of the corpus. Richannotation of corpus content is dealt with in the last part of the thesis.An inter-annotator agreement driven English genre annotation andtwo experiments with supervised classification of text types in Englishand Estonian web corpora are presented.
iii

Keywords
Web corpora, Web crawling, Text processing, Language identification,Discerning similar languages, Spam removal, Corpus annotation, Inter-annotator agreement, Text types, Text topic, Text genre
iv

Contents
Introduction 10.1 Large, Clean and Rich Web Corpora . . . . . . . . . . . . . 10.2 Contents of the Thesis & Relation to Publications . . . . . . 5
1 Efficient Web Crawling For Large Text Corpora 81.1 Building Corpora From the Web . . . . . . . . . . . . . . . 81.2 SpiderLing, an Asynchronous Text Focused Web Crawler . . 14
1.2.1 General Web Crawler Architecture . . . . . . . . 141.2.2 SpiderLing Architecture . . . . . . . . . . . . . . 171.2.3 Yield Rate Aware Efficient Crawling . . . . . . . 281.2.4 Deployment of SpiderLing in Corpus Projects . 38
1.3 Brno Corpus Processing Pipeline . . . . . . . . . . . . . . . 41
2 Cleaner Web Corpora 472.1 Discerning Similar Languages . . . . . . . . . . . . . . . . 48
2.1.1 Method Description . . . . . . . . . . . . . . . . 482.1.2 Evaluation on VarDial Datasets . . . . . . . . . . 512.1.3 Comparison to Other Language Detection Tools 562.1.4 Application to Web Corpora . . . . . . . . . . . 57
2.2 Non-Text Removal . . . . . . . . . . . . . . . . . . . . . . 632.2.1 Web Spam in Text Corpora . . . . . . . . . . . . 632.2.2 Removing Spam from an English Web Corpus
through Supervised Learning . . . . . . . . . . . 732.2.3 Semi-manual Efficient Classification of Non-text
in an Estonian Web Corpus . . . . . . . . . . . . 852.2.4 Web Spam Conclusion . . . . . . . . . . . . . . . 91
3 Richer Web Corpora 923.1 Genre Annotation of Web Corpora: Scheme and Issues . . . 94
3.1.1 Genre Selection and Reliability of Classification 943.1.2 Experiment Setup . . . . . . . . . . . . . . . . . . 973.1.3 Inter-annotator Agreement . . . . . . . . . . . . 1033.1.4 Dealing with a Low Agreement . . . . . . . . . . 107
3.2 Text Type Annotation of Web Corpora . . . . . . . . . . . . 1103.2.1 Topic Annotation of an English Web Corpus
through Learning from a Web Directory . . . . . 110
v

3.2.2 Semi-manual Efficient Annotation of Text Typesin Estonian National Corpus . . . . . . . . . . . 117
4 Summary 1204.1 Author’s Contribution . . . . . . . . . . . . . . . . . . . . 1204.2 Future Challenges of Building Web Corpora . . . . . . . . . 122
A Appendices 124A.1 Genre Definition for Annotators . . . . . . . . . . . . . . . 125A.2 Text Size after Processing Steps . . . . . . . . . . . . . . . . 127A.3 FastText Hyperparameters for English Topic Classification . 129A.4 Selected Papers . . . . . . . . . . . . . . . . . . . . . . . . 130
Bibliography 140
vi

List of Tables
1.1 Sums of downloaded and final data size for all domainsabove the given yield rate threshold. 31
1.2 The yield rate threshold as a function of the number ofdownloaded documents. 33
1.3 Yield rate of crawling of the web of selected targetlanguages in 2019: The ratio of the size of the plaintextoutput of the crawler to the size of all data downloadedis calculated in the fourth column ‘YR’. The ratio of thesize of the plaintext after discerning similar languagesand near paragraph de-duplication to the size of alldata downloaded is calculated in the last, cumulativeyield rate column ‘CYR’. Cs & sk denotes Czech andSlovak languages that were crawled together. 39
2.1 Sizes of wordlists used in the evaluation. Large websources – TenTen, Aranea and WaC corpora – werelimited to respective national TLDs. Other wordlistswere built from the training and evaluation data of DSLCorpus Collection and parts of GloWbE corpus.Columns Web, DSL and GloWbE contain the count ofwords in the respective wordlist. 53
2.2 Overall accuracy using large web corpus wordlists andDSL CC v. 1 training data wordlists on DSL CC v. 1 golddata. The best result achieved by participants in VarDial2014 can be found in the last column. 54
2.3 Performance of our method on VarDial DSL test datacompared to the best score achieved by participants ofthe competition at that time. 55
2.4 Comparison of language identification tools on 952random paragraphs from Czech and Slovak web. Thetools were set to discern Czech, Slovak and English. 57
2.5 Discriminating similar languages in Indonesian webcorpus from 2010 (Indonesian WaC corpus v. 3 by SivaReddy): Document count and token count of corpusparts in languages discerned. 58
vii

2.6 Discriminating similar languages in the Norwegian webcorpus from 2015 (noTenTen15): Document count andtoken count of corpus parts in languages discerned. 59
2.7 Overview of removal of unwanted languages in recentlybuilt web corpora (gaTenTen20, enTenTen19, etTenTen19,frTenTen19, huTenTen12, itTenTen19, roTenTen16).Document count and token count of corpus data beforeand after language filtering. ‘Removed’ stands for thepercent of data removed. 60
2.8 Languages recognised in the Estonian web corpus from2019 (etTenTen19). Document count and token count ofcorpus parts in languages discerned. 61
2.9 Languages recognised in the output of SpiderLingcrawling Czech and Slovak web in 2019. Documentcount and token count of corpus parts in languagesdiscerned. 62
2.10 Comparison of the 2015 English web corpus before andafter spam removal using the classifier. Corpus sizesand relative frequencies (number of occurrences permillion words) of selected words are shown. Byreducing the corpus to 55% of the former token count,phrases strongly indicating spam documents such ascialis 20 mg, payday loan, essay writing or slot machinewere almost removed while innocent phrases notattracting spammers from the same domains such asoral administration, interest rate, pass the exam or play gameswere reduced proportionally to the whole corpus. 75
2.11 Top collocate objects of verb ‘buy’ before and after spamremoval in English web corpus (enTenTen15, WordSketches). Corpus frequency of the verb: 14,267,996 inthe original corpus and 2,699,951 in the cleaned corpus –81% reduction by cleaning (i.e. more than the averagereduction of a word in the corpus). 80
2.12 Top collocate subjects of verb ‘buy’ before and afterspam removal in English web corpus (enTenTen15,Word Sketches). 81
viii

2.13 Top collocate modifiers of noun ‘house’ before and afterspam removal in English web corpus (enTenTen15,Word Sketches). Corpus frequency of the noun:10,873,053 in the original corpus and 3,675,144 in thecleaned corpus – 66% reduction by cleaning. 82
2.14 Top collocate nouns modified by adjective ‘online’before and after spam removal in English web corpus(enTenTen15, Word Sketches). Corpus frequency of theadjective: 20,903,329 in the original corpus and 4,118,261in the cleaned corpus – 80% reduction by cleaning. 83
2.15 Top collocate nouns modified by adjective ‘green’ beforeand after spam removal in English web corpus(enTenTen15, Word Sketches). Corpus frequency of theadjective: 2,626,241 in the original corpus and 1,585,328in the cleaned corpus – 40% reduction by cleaning (i.e.less than the average reduction of a word in thecorpus). 84
3.1 Sources of the collection of texts used in our experiment.Different subsets (S) were added in different times(starting with subset 1). Most certain texts and leastcertain texts refer to the certainty of a classifiermeasured by the entropy of the probability distributionof labels given by FastText for a particular document.UKWaC [Fer+08b], enTenTen13, enTenTen15 andenTenTen18 are English web corpora from 2007, 2013,2015 and 2018, respectively. 98
ix

3.2 Inter-annotator agreement of genre annotation of webdocuments for different experiment setups. P is thecount of people annotating, Data refers to collectionsubsets, N is the count of documents, A is the averagecount of annotations per text. Acc is Accuracy, Jac isJaccard’s similarity, K-Acc, K-Jac and K-Nom stand forKrippendorff’s alpha with the set similarity metric set toAccuracy, Jaccard’s similarity and Nominal comparison,respectively. ‘6/9 genres’ means that four of the ninelabels were merged in a single label for the particularevaluation. ‘No unsure’ means annotations indicatingthe person was not sure were omitted. ‘No multi’ meansannotations with multiple strong labels wereomitted. 105
3.3 Pair agreement summary for setups with 9 genres and6/9 genres, without unsure or multi-label samples. 107
3.4 Topics from dmoz.org in the training set 112
3.5 Precision and recall for each recognised dmoz.org level1 topic estimated by FastText. The threshold of minimalprobability of the top label was set to the value wherethe estimated precision was close to 0.94. 115
A.1 Text size after three Brno pipeline processing steps forten recently crawled target languages. ‘Clean rate’columns show how much data or tokens were removedin the respective cleaning step. The first part isperformed by tools embedded in crawler SpiderLing:Boilerplate removal by Justext, plaintext extraction fromHTML by Justext and language filtering using charactertrigram models for each recognised language. Morethan 95% of downloaded data is removed by thisprocedure. The next step is filtering unwantedlanguages including discerning similar languages usinglists of words from large web corpora. The last step inthis table shows the percentage of tokens removed bynear paragraph de-duplication by Onion. More than60% of tokens is removed this way. 128
x

A.2 Hyperparameter values autotuned by FastText for topicclassification in our English web corpus. By modifyingFastText’s autotune code, the search space of someparameters was limited to a certain interval andparameters marked as fixed were set to a fixed value.‘Val.’ is the final value. ‘M’ stands for millions. 129
xi

List of Figures
1.1 Crawling as the data source component of web searchengines. Graphics source: A presentation ofpaper [She13]. 13
1.2 General web crawler architecture. Source: [MRS08,Chapter 20]. 16
1.3 IRLbot architecture. DRUM stands for ‘Disk RepositoryWith Update Management’, a fast storage solution.Source: [Lee+09]. 16
1.4 A focused crawler architecture. Source: [SBB14]. 171.5 SpiderLing architecture. The design loosely follows the
general model. There is a single process scheduler, asingle process downloader using asynchronous socketsand multiple processes for web page processors thatextract text and links from HTML. 19
1.6 An example of a web page stored in a doc structure. Theplaintext is separated to paragraphs marked bystructure p. 23
1.7 Average TCP connections opened per second in dayintervals by SpiderLing crawling selected languagewebs in 2019. 25
1.8 Average size of raw HTML data downloaded per day inday intervals by SpiderLing crawling selected languagewebs in 2019. 26
1.9 Average size of plaintext extracted from HTML per dayin day intervals by SpiderLing crawling selectedlanguage webs in 2019. 27
1.10 Web domains yield rate for a Heritrix crawl on .pt. 301.11 Average yield rate in time for various yield rate
threshold functions (crawling the Czech web) 341.12 Web domains yield rate for a SpiderLing crawl on the
Czech web. 361.13 The Yield rate of web domains measured during
SpiderLing crawls of six target languages in 2011 and2012. 37
xii

2.1 Sentence score and word scores calculated to discernBritish English from American English using relativeword counts from a large web corpus. A sample fromVarDial 2014 test data, vertical format. Columndescription: Word form, en-GB score, en-US score. 52
2.2 Web spam in examples of use of word ‘money’ inapplication Sketch Engine for Language Learning athttps://skell.sketchengine.eu/. See non-text lines2, 4 and 10. 65
2.3 Google’s analysis of spam types and quantities that hadto be removed manually, 2004–2012. Source:http://www.google.com/insidesearch/howsearchworks/fighting-spam.html, accessed inJanuary 2015, no longer at the site as of April 2020.Labels were moved below the chart and resized by theauthor of this thesis for the sake of readability. 68
2.4 Relative word count comparison of the original 2015web corpus with British National Corpus, top 26lemmas sorted by the keyword score. Score = f pm1+100
f pm2+100where f pm1 is the count of lemmas per million in thefocus corpus (3rd column) and f pm2 is the count oflemmas per million in the reference corpus (5thcolumn). 76
2.5 Relative word count comparison of the cleaned webcorpus with British National Corpus. (A screenshotfrom Sketch Engine.) 77
2.6 Relative word count comparison of the original webcorpus with the cleaned version. (A screenshot fromSketch Engine.) 78
2.7 Evaluation of the binary spam classifier in a 10 foldcross-validation on semi-manually checked Estonianweb corpus. Precision and recall were estimated forminimal probabilities of the top label from 0 to 1 in 0.05steps and averaged across folds. The baseline accuracy(putting all samples in the larger class) is 0.826. 87
xiii

2.8 Evaluation of the final binary spam classifier ondocuments not previously checked by a humanannotator in Estonian web corpus. Precision and recallwere estimated for minimal probabilities of the non-textlabel from 0.05 to 0.15. Since we aim for a high recall,the performance with the non-text label threshold set to0.05 is satisfying. A higher threshold leads to anundesirable drop of recall. 88
2.9 Evaluation of the relation of the distance of web domainfrom the initial domains to the presence of non-text onthe sites. Web pages of distances 0 to 4 classifiedsemi-manually or by the spam classifier were taken intoaccount. Two thirds of the pages were in distance 1. Thepercentage of good and bad documents within the samedomain distance is shown. The presence of non-text inthe data is notable from distance 1. 90
3.1 Text type annotation interface – a web application in abrowser – the left side of the screen. Information aboutthe annotation process can be seen at the top. Genreswith a brief description and examples follow. Class‘Information::Promotion’ is labelled as strongly presentin this case. Buttons for weaker presence of genremarkers (Partly, Somewhat, None) can be clicked tochange the annotation. 102
3.2 Text type annotation interface – a web application in abrowser – the right side of the screen. The title of thedocument with a link leading to the original source islocated at the top. The plaintext split to paragraphs canbe seen below. Both sides of each paragraph arecoloured to visualise separate paragraphs. A paragraphcan be suggested for removal from the document (tomake the result training data less noisy) by clicking therespective button. 102
xiv

3.3 Text type annotation interface in the review mode afterthe training round – as seen by the author of this thesiswho trained six other annotators. Labels, coded byidentifiers in columns B1 to B99, assigned to a singledocument by each annotator are shown. Values ‘Strong’,‘Partially’ and ‘None’ are coded by 2, 1, 1/2 and 0,respectively. (The same coding was used by [Sha18].)Time in seconds spent by annotating the document byeach annotator can be seen in the rightmostcolumn. 103
3.4 Pair annotation matrix for the setup with 9 genres,without unsure or multi-label samples. Percentage of allannotation pairs is shown. 106
3.5 Pair annotation matrix for the setup with 6/9 genres,without unsure or multi-label samples. Percentage of allannotation pairs is shown. 106
3.6 Evaluation of the 14 topic classifier on the test set.Precision and recall were estimated by FastText forminimal probabilities of the top label from 0 to 1 in 0.05steps. F-0.5 values plotted in green. 113
3.7 Sizes of topic annotated subcorpora of enTenTen15 –document and token counts. 116
3.8 Sizes of topic annotated subcorpora of EstonianNational Corpus 2019 – document and tokencounts. 118
xv

Introduction
0.1 Large, Clean and Rich Web Corpora
A corpus is a special collection of textual material collected accordingto a certain set of criteria. In statistical natural language processingone needs a large amount of language use data situated within itstextual context. The text corpora are one of the main requirements forstatistical NLP research. [MS99, pp. 5, 6, 117, 119]
The field of linguistics greatly benefits from the evidence of lan-guage phenomena of interest one can found in large text corpora.In particular such data source is essential for various subfields ofcomputational linguistics such as lexicography, machine translation,language learning, text generation.
It is said ‘There is no data like more data’. [PRK09] showed that‘Bigger corpora providemore information.’ Indeed, since the 2000s, theinternet has been commonly used by computational linguists (whichresulted in establishing the Web as Corpus ACL SIG.1). The count ofwords in very large corpora reached tens of billions of words, e.g. 70billion words reported by [PJR12].
Since then, constantly growing and spreading, the web data hasbecome an immensely large source of text data for various NLP tasksand language studies in general: Web corpora can be built in sizeshardly possible to achieve using traditional methods of corpus cre-ation. [PJR12]
The quantity of text data on the web is quite large, with many vari-eties, for a very wide range of languages. [GN00] Further advantagesof this source are immediate availability, low cost of access and noneed for concern over copyright. [CK01].
[KG03] list examples of use of the web as a source of corpus datafor language modelling, information retrieval, question answering,automatic population of ontologies, translating terms and languageteaching.
1. Special Interest Group of the Association for Computational Linguistics on Webas Corpus, https://www.sigwac.org.uk/
1

There are 77 possible text/linguistic corpora applications listed onthe website of Linguistic data consortium2.
We believe language modeling, language teaching, lexicography,linguistic analysis and machine learning could benefit from large,clean and richly annotated web corpora the most. Corpora built usingmethods and tools presented in this thesis are used by Sketch Engine3users in those fields.
Although there is a valid criticism of web corpora – e.g. [Cvr+20]showed that web corpora lack some areas of linguistic variation that‘cannot be substituted by general web-crawled data’ such as the cover-age of certain genres, ‘namely spoken informal (intimate) discourse,written private correspondence and some types of fiction (dynamicand addressee oriented)’, the size of web corpora helps finding evi-dence of scarce language phenomena in natural language context.
The thing is that most language phenomena follow the Zipfiandistribution. Simply said, the more data the better. For example, tostudy modifiers of phrase ‘to deliver speech’4, what size of the corpusis sufficient to contain enough occurrences of important collocates ina natural context?
Corpus frequencies of strongest collocates of ‘to deliver speech’ inselected English corpora follow. It can be observed a 100 million wordcorpus and a 1 billion words corpus are clearly not large enough.
∙ BNC (96 million words in the corpus): major (8), keynote (6).
∙ 2007 web corpus (ukWaC, 1.32 billion words): keynote (125),opening (12), budget (8), wedding (7).
∙ 2012 web corpus (enTenTen12, 11.2 billion words): keynote(813), acceptance (129), major (127), wedding (118), short(101), opening (97), famous (80).
∙ 2015 web corpus (enTenTen15, 15.7 billion words): keynote(3673), opening (684), welcome (413), key (257), major (255),
2. https://catalog.ldc.upenn.edu/search, accessed in April 2020.3. Corpus management software and a website operated by company LexicalComputing at https://www.sketchengine.eu/.4. E.g. in a lexicographic project where the goal is to explain the meaning andtypical use of ‘to deliver speech’ to an intermediate level student of English usingnatural context of the phrase.
2

acceptance (233), powerful (229), commencement (226), in-spiring (210), inaugural (146).
∙ 2009 web corpus (ClueWeb09, English part, 70.5 billion words):keynote (3802), acceptance (1035), opening (589), famous (555),commencement (356), impassioned (335), inaugural (333).
A question similar to the previous one5 is – Which phrases canbe combined? If ‘pregnancy test’ is a strong collocation and ‘pass atest’ is another one, can they be combined into ‘pass a pregnancy test’?Speakers proficient in English know they cannot. (This example wasborrowed from [PJR12].) Large corpora help to get correct answersfor phenomena not having enough evidence in small corpora.
However – size is not everything. ‘A significant fraction of all webpages are of poor utility.’6 The content of the web is not regulated interms of data quality, originality, or correct description and this resultsin even more issues.
This is a list of selected issues of building language resources fromthe web – formulated as practical tasks:
∙ Language identification and discerning similar languages,∙ Character encoding detection,∙ Efficient web crawling,∙ Boilerplate removal (basically the extraction of plaintext from
HTML markup7),∙ De-duplication (removal of identical or nearly identical texts),∙ Fighting web spam (i.e. dealing with computer generated text,
in general any non-text),∙ Authorship recognition & plagiarism detection,∙ Storing and indexing large text collections.
Boilerplate, duplicates, and web spam skew corpus based analysesand therefore have to be removed. While the first two issues have beensuccessfully addressed, e.g. by [MPS07; Pom11; SB13; VP12], spammight be still observed in web corpora as reported by us in [KS13].
5. E.g. a question of a student of English as their second language.6. In 2020 as well as in 2008 [MRS08, Chapter 20]7. Boilerplate – unwanted content like HTML markup, non textual parts, shortrepetitive text such as page navigation.
3

That is why a spam cleaning stage should be a part of the process ofbuilding web corpora.
Automatically generated content does not provide examples ofauthentic use of a natural language. Nonsense, incoherent or anyunnatural texts such as the following short instance have to be removedfrom a good quality web corpus:
Edmonton Oilers rallied towards get over the Montreal Canadiens 4-3upon Thursday.Ryan Nugent-Hopkins completed with 2 aims, together withthe match-tying rating with 25 seconds remaining within just legislation.8
Another drawback of building text corpora from the web – whichhas to be dealt with – is understanding the content of a corpus. Tra-ditional corpora (e.g. British National Corpus) were designed forparticular use and compiled from deliberately selected sources ofgood quality (e.g. the BNC consisting of a spoken data and a writtencomponent further divided by other metadata [Lee92]). Such pre-cise selection of nice texts is hardly possible in the case of large webcorpora.
Do we know what is being downloaded from the web? Do re-searchers who base their work on web corpora know which languagevarieties, topics, genres, registers and other text types are representedin the corpus andwhat is the distribution like? These questions shouldbe asked by those who build or use web corpora.
We would like to add rich metadata to texts in web corpora, includ-ing text type annotation. Because of the size ofweb corpora, supervisedclassification is the preferred way to achieve that.
8. Source: http://masterclasspolska.pl/forum/, accessed in 2015.
4

0.2 Contents of the Thesis & Relation to Publications
Chapter 1 presents an overview of technical aspects of a web crawlerarchitecture. SpiderLing, a web crawler implemented by the authorof this thesis is introduced. Key design features of the software areexplained.
The crawler gathers information about web domains and aims todownload web pages from domains providing a high ratio of the sizeof plaintext extracted from web pages to the size all downloaded data.This feature was described in our co-authored paper Efficient WebCrawling for Large Text Corpora [SP12]. The paper was presented atWeb as Corpus workshop in Lyon in 2012 and with 94 citations so far9it belongs to our most cited works.
The crawler is put into the context of other components of so called‘Brno processing pipeline’ in this thesis. This set of tools has beensuccessfully used to build large, clean text corpora from the web.Separate tools from the pipeline were described in correspondingpapers in the past – including our co-authored works on characterencoding detection [PS11] and text tokenisation [MSP14] and ourpaper on discriminating similar languages [Suc19].
Our work on Brno processing pipeline follows the steps of JanPomikálek who finished the first components, boilerplate removaland de-duplication tools [Pom11]. The author of this thesis has beendeveloping the pipeline and maintaining its parts since 2012.
Since 2012 our work on efficient web crawling and building webcorpora in more than 50 languages has led to publishing papers co-authored with academics studying the respective languages: [Art+14;BS12b; Boj+14; DSŠ12a; RS16; Srd+13]. Among other venues, thiswork was presented on B-rated conferences LREC10 in 2014 and TSD11
in 2016.The emerging set of web corpora build by the author of this thesis
was presented in our co-authored paper The TenTen Corpus Fam-ily [Jak+13] in Lancaster in 2013 – with 203 citations up to date. Allcorpora in this corpus family became a part of corpus manager and
9. The source of all citation counts in this thesis is Google Scholar, accessed inApril 2020.10. Language Resources and Evaluation Conference11. Text, Speech and Dialogue
5

corpus database Sketch Engine operated by Lexical Computing. Thework on Sketch Engine, including our contribution of corpora in manylanguages, was presented in an article in Springer’s journal on lexicog-raphy [Kil+14]. Having been cited 627 times, this is our most citedco-authored work to date.
Chapter 2 deals with two issues of building language resourcesfrom the web: Discerning similar languages and non-text removal.Methods presented in both sections of that chapter were applied toweb corpora.
This thesis builds upon our previous work on language identi-fication and discerning similar languages. A method of LanguageDiscrimination Through Expectation–Maximization [Her+16] waspresented in a co-authored paper at the Third Workshop on NLP forSimilar Languages, Varieties and Dialects in Osaka in 2016. A recentwork consisting in adjusting the method for use with large web cor-pora and evaluating the result was published in paper DiscriminatingBetween Similar Languages Using Large Web Corpora. [Suc19]
We have been dealing with non-text in web corpora since 2012.It still remains one of the current challenges in web corpus building.Papers on this topic were presented at Web as Corpus workshops in2013, 2015, 2017 and 2020. The issue was described. Selected waysto avoid downloading non-text and methods to remove web spamwere proposed and implemented. The most important results of ourwork are summarised in this thesis. The improvement achieved by asupervised classifier applied to an English web corpus is shown at theend of the chapter.
Although the spam fighting procedure is not perfect, the evalu-ation of the impact on the quality of an English web corpus showsa great progress made towards a better quality of web corpora in alexicography oriented application.
Chapter 3 stresses the need of adding rich annotation to web cor-pora. An experiment to annotate genres in an English web corpusleading to a discussion about overcoming a low inter-annotator agree-ment is introduced in the first section. A text type classification taskperformed on English web corpus and Estonian National Corpus ispresented in the end of the chapter.
6

The results of this work are summarised in Chapter 4. Challengesof building large, clean web corpora to be addressed in the near futureare briefly discussed there too.
7

1 Efficient Web Crawling For Large Text Cor-pora
1.1 Building Corpora From the Web
To build a large collection of texts from the web, one needs to masterthe following general disciplines stated in [SB13]:
1. Data collection,2. Post-processing,3. Linguistic processing,4. Corpus Evaluation and Comparison.
A web corpus can be built following these general steps:1. Identify suitable documents to obtain.2. Download the selected data from the internet, keeping impor-
tant metadata such as the source URL and the date of acquisi-tion.
3. Process the obtained data by stripping off non textual parts,clearing away boilerplate and unwanted text parts, removingduplicate parts, and other possible methods to get quality datain the result.
4. Store the result in away enabling access according to the desiredpurpose, reusability and ability to process the raw internet dataagain.
A good source of information about important decisions and practicaladvice for building largeweb corpora is [SB13]. There is also a traditionof building sizeable text collections at author’s institution1.
There are billions of documents available on the web. The processof traversing the web and downloading data (crawling) is a time andresource consuming task. A web crawler is a piece of software madefor the task of crawling the internet.
The crawler is usually initialized by a set of starting internet points,the seed URLs. It downloads each document from the initial set, ex-tracts links to other documents from the data and continues its workwith the discovered set of new URLs.
1. The Natural Language Processing Centre at Faculty of Informatics, MasarykUniversity, http://nlp.fi.muni.cz/web3/en/NLPCentre
8

1. Efficient Web Crawling For Large Text Corpora
The crawling strategy – making decisions which parts of the webto explore first, i.e. which documents to download immediately andwhich postpone for obtaining later – is a very important factor in thedesign of a successful crawler.
A well crawled data set should contain data which is important.[FCV09] dealt with evaluation of web crawl source selection policyand showed crawling the top PageRank metric sites is better thansimple breadth-first crawl in terms of importance of documents in theset.
[SP12] showedpruning domains yielding less data (selective crawl-ing) overperforms a general Heritrix crawl in terms of crawling effi-ciency (i.e. the ratio of size of extracted text and amount of all down-loaded data).
Thus the implemented traversing algorithm is crucial in achievingwide coverage of web domains or higher crawling efficiency; higheramount of extracted data or catching ‘important’web pages,whicheveris a priority.
Additional issues have to be taken into account when crawling theweb: Not overusing the source servers by obeying the Robots exclusionprotocol2, boilerplate removal and content de-duplication (if desired),robust post-processing of crawled data (e.g. dealing with malformeddata, language detection, character encoding detection) [SP12].
In a one-time web crawling setup, if the same URL is discoveredagain, it is considered as duplicate and discarded. Since the webchanges rapidly, maintaining a good ‘freshness’ of the data is hard.The content is constantly added, modified, deleted [NCO04] and du-plicated [Pom11].
For scenarios where one needs to keep the crawled data up todate, [CG99] proposed a crawler which selectively and incrementallyupdates its index and/or local collection of web pages, instead ofperiodically refreshing the collection in batch mode.
[FCV09] devised a more conservative strategy to continuouslycrawl the web, starting from the seed URLs over and over again, re-visiting all pages once crawled and building ‘snapshots’ of the part ofthe web it is visiting.
2. A formalism to control access to certain web pages by automated means, http://www.robotstxt.org
9

1. Efficient Web Crawling For Large Text Corpora
As could be understood from the previous, starting the crawl witha good, text yielding and trustworthy (i.e. with a low possibility ofspammed content) sources can positively benefit the quality of theresult corpus. [GJM01] proposed a method exploiting web searchengines to identify relevant documents in the web. The search engineis expected to supply good text data in the desired language based onsearch parameters.
Baroni [BB04] devised method ‘BootCaT’ for bootstrapping cor-pora and terms from the web. The method requires a small set ofseed terms as input. The seeds are used to build a corpus via auto-mated Google queries, more terms are extracted from that corpus andused again as seeds to build a larger corpus and so forth [BB04]. Twothirds of English and Italian documents obtained with BootCaT werereported to be informative and related to the search terms.
WebBootCaT [Bar+06] is an extension of the former tool in theform of a web application, allowing quick and effortless domain fo-cused web corpus building3.
A similar approach in a much larger scale was used later by theClueWeb project: [Cal+09] started with two types of seed URLs: onefrom an earlier 200 million page crawl, another given by commercialsearch engines (Google, Yahoo). The search engines were queriedusing most frequent queries and random word queries for each targetlanguage. The DMOZ4 category names were used in the process too.To get the DMOZ categories in other languages, Google Translate wasemployed to translate the original in English.
More internet directory and content rating services can be em-ployed when looking for quality content to include in web corpora.[BS14] constrained the selection of web documents in their corpus forEnglish language learning to sources listed in the DMOZ directory orin the white list of the URL blacklist.5 6
3. WebBootCaT is currently a module in Sketch Engine corpus query system,http://www.sketchengine.co.uk/documentation/wiki/Website/Features#WebBootCat4. DMOZ is the largest, most comprehensive human-edited directory of the Web.http://www.dmoz.org/5. I.e. URLs not categorised as spam, advertisement or pornography in the URLblacklist directory, http://urlblacklist.com/.6. Apart fromWikipedia articles and search engine supplied documents.
10

1. Efficient Web Crawling For Large Text Corpora
There were many large web corpora constructed using crawlersrecently. There is ClueWeb, a huge general purpose collection of billionweb pages in ten languages7 – cleaned, de-duplicated and furtherprocessed into a 70 billion word corpus of English by [PJR12].
Another huge web crawl is CommonCrawl8 which was gatheredthrough years 2008–2014.
Many private companies,most prominently those providing searchengines, download data from the web for their own purpose, usuallyweb indexing9, web data mining10, web monitoring (for changes, forcopyright violations), or web archiving (digital preservation).11
According to a web crawler tracking list12 mentioned in [She13],there were over 1100 crawler agents in 2013. According to our webcrawling experience – checking the agent names, some bearing thenames of the companies behind them, in robots exclusion protocolfiles – the number has grown a lot.
Even though so much crawling is done that some sites get moretraffic from crawlers than human visitors [She13], the data may not beavailable to researchers and other institutions or may not be suitablefor linguistic use.
The effort of web search companies is also notable since they main-tain large distributed data warehouses to store indexed web pages forserving by their search engines. Text corpora for linguistic purposecan make use from textual parts of such data.
Google books ngrams [GO13] is a collection of word n-grams fromEnglish books spanning a long time period, which received attention
7. 2009 collection: http://www.lemurproject.org/clueweb09, 2012 collection:http://www.lemurproject.org/clueweb12/8. An open repository of web crawl data that can be accessed and analyzed byanyone, http://commoncrawl.org/9. Obviously, all search engines do web indexing.10. A lot of companies mine the web for trends, marketing, user opinion, shoppingor even political preferences of people nowadays.11. E.g. the Internet Archive storing the history of over 424 billion webpages on the Internet (as of April 2020), archive.org. There is a long listof web archiving initiatives at https://en.wikipedia.org/wiki/List_of_Web_archiving_initiatives.12. http://www.crawltrack.fr/crawlerlist.php
11

1. Efficient Web Crawling For Large Text Corpora
recently.13 Unfortunately, the n-grams are hardly sufficient for cer-tain computational linguistics use, e.g. lexicography and languagelearning.
Apart from corporamade from traditional sources in the past, suchas British National Corpus14 by a process of selecting, balancing andredacting texts, or linguistic resource collectionswith a subscription ac-cess policy, such as Linguistic Data Consortium collection containingGigaword corpora15, several families of web corpora16 for compu-tational linguistics use emerged in the Web as Corpus communityof late: Web as Corpus (WaC)17 [Bar+09; Fer+08c], Corpus of Web(CoW)18 [SB12], TenTen19 [Jak+13], Aranea20 [Ben14], multiple WaCinspired corpora [Let14; LK14; LT14], The Leipzig Corpora Collec-tion21 [Bie+07].
Corpus manager is a software that indexes text corpora and pro-vides a corpus interface to the users. According to our experiencewith the development and support of corpus manager Sketch En-gine [Kil+14; Kil+04], the users are linguists, lexicographers, socialscientists, brand name specialists, people who teach languages andtheir students [Tho14], various human language technologists andothers.
Figure 1.1 shows crawling as the data source component of websearch engines. Similarly, in the filed of computational linguistic, crawl-ing is the source of data of a corpus manager.
The architecture of web crawler SpiderLing developed by the au-thor of this thesis, its key features such as asynchronous communica-
13. The N-gram viewer is a very nice application – https://books.google.com/ngrams.14. Originally created by Oxford University press in the 1980s - early 1990s, https://www.english-corpora.org/bnc/15. https://catalog.ldc.upenn.edu/16. By corpus family we name a collection of corpora in different languages sharingthe same general name, means of retrieval, cleaning and processing.17. http://wacky.sslmit.unibo.it/doku.php?id=corpora18. http://corporafromtheweb.org/category/corpora/19. TenTen – aiming at reaching the size of at least ten to the power of ten (1010) to-kens for each language. http://www.sketchengine.co.uk/documentation/wiki/Corpora/TenTen20. http://ucts.uniba.sk/aranea_about/21. https://wortschatz.uni-leipzig.de/en/
12

1. Efficient Web Crawling For Large Text Corpora
Figure 1.1: Crawling as the data source component of web searchengines. Graphics source: A presentation of paper [She13].
tion and text focused design, and Brno Corpus Processing Pipeline, aset of tools for building corpora from the web, are presented in thefollowing sections.
13

1. Efficient Web Crawling For Large Text Corpora
1.2 SpiderLing, an Asynchronous Text Focused WebCrawler
1.2.1 General Web Crawler Architecture
The classical textbook definition of web crawling as a technique in thefield of information retrieval according to [MRS08, Chapter 20] is ‘theprocess by which we gather pages from the Web to index them andsupport a search engine. The objective of crawling is to quickly andefficiently as many useful web pages as possible, together with thelink structure that interconnects them.’ The main component of webcrawling is a web crawler.
Assuming a graph representation of the internet consisting of webpages – nodes – and links connecting web pages – one-directionaledges – making an oriented graph structure, the crawler starts atseed web pages (seed URLs or seed domains) – the initial nodes –and traverses the web graph by extracting links from web pages andfollowing them to the target pages.
The planner component, also called the scheduler, is the compo-nent of the crawler responsible for making decisions in which orderto follow the links, i.e. in which directions to search the graph.
The features a crawler must or should provide, according to thebook, are:
∙ Robustness: Crawlersmust be resilient to trapsmisleading theminto getting stuck fetching an infinite number of pages in a par-ticular domain. – Let us add amore general statement: Crawlersmust be resilient to both design and technical properties of theever changing web.
∙ Politeness: Policies of web servers regulating the rate at whicha crawler can visit them must be respected.
∙ Distributed: The ability to execute in a distributed fashion acrossmultiple machines.
∙ Scalable: Permit scaling up by adding extra machines and band-width.
∙ Performance and efficiency: System resources including proces-sor, storage, and network bandwidth should be used efficiently.
14

1. Efficient Web Crawling For Large Text Corpora
∙ Quality: The crawler should be biased toward fetching usefulpages first.
∙ Freshness: Able to obtain fresh copies of previously fetchedpages.
∙ Extensible: Should cope with new data formats and protocolsimplying a modular crawler architecture.
There are many ways to meet the crucial and recommended fea-tures. We expect the following are the main differences in the archi-tecture of various crawlers
1. The intended audience and use. Our goal is to get a large col-lection of monolingual natural language texts for each targetlanguage for the Sketch Engine audience or other NLP applica-tions.
2. The importance of crawler’s features. For example, a simpledesign to improve the easiness of use, maintenance and ex-tensibility is more important than the ‘distributed’ feature forus.
3. The scheduler component. (Also called the frontier.) Variousstrategies of web traversal are possible. A base line strategy isthe breadth-first search.
4. Technical solution. [SB13] stresses that crawlers ‘require care-ful implementations if the crawler is intended to sustain a highdownload rate over long crawl times’. A general design patternis depicted on Figure 1.2. A more detailed schema of the archi-tecture of a large scale web crawler IRLbot [Lee+09] is showedon Figure 1.3.
[SB13] names the following components of a web crawler:∙ Fetcher – A massively multi-threaded downloader.∙ Parser – Extracts URLs from downloaded web pages.∙ URL filters to discard duplicate or blacklisted URLs.22
22. Blacklisted URLs or web domains are sources of unwanted text types or poorquality text so the aim is to avoid crawling them. The blacklist can be supplied atthe start of the crawler and extended on-the-fly.
15

1. Efficient Web Crawling For Large Text Corpora
Figure 1.2: General web crawler architecture. Source: [MRS08, Chap-ter 20].
Figure 1.3: IRLbot architecture. DRUM stands for ‘Disk RepositoryWith Update Management’, a fast storage solution. Source: [Lee+09].
16

1. Efficient Web Crawling For Large Text Corpora
Figure 1.4: A focused crawler architecture. Source: [SBB14].
∙ Frontier – ‘Data structures which store, queue and prioritizeURLs and finally pass them to the fetcher.’
‘Biasing a crawl toward desired pages to improve the word count for awell-defined weight function’ [SBB14] is called focused crawling. Thecrawler can prefer particular web domains or text types based on thefunction. A focused crawler architecture can be seen on Figure 1.4.
1.2.2 SpiderLing Architecture
Most documents on internet contain data not useful for text corpora,such as lists of links, forms, advertisement, isolated words in tables,and other kind of text not comprised of grammatical sentences. There-fore, by doing general web crawls, we typically download a lot of datawhich gets filtered out during post-processing. This makes the processof web corpus collection inefficient. [SB13] reported 94% downloadedweb pages not making it into the final version of corpus DECOW12.
To be able to download large collections of web texts in a goodquality and at a low cost for corpora collection managed by Sketch En-gine23, we developed SpiderLing—a web spider for linguistics. Unliketraditional crawlers or web indexers, we do not aim to collect all data
23. http://sketchengine.co.uk/
17

1. Efficient Web Crawling For Large Text Corpora
(e.g. whole web domains). Rather than that we want to retrieve manydocuments containing full sentences in as little time as possible.
Implementation details follow. The crawler was implemented inPython 3 and released under GNU GPL v. 3 licence at http://corpus.tools/wiki/SpiderLing. The design schema of the crawler can beseen on Figure 1.5.
There are three main components of the crawler: A scheduler,a downloader and a document processor. Each of the componentsruns as a separate process. While there can be multiple documentprocessors, there is a single scheduler and a single downloader whichis the main difference from standard crawler architectures employingmulti-threaded downloaders.
The reason for this design decision is to make the tool easy tounderstand,maintain and extend. Although there aremultiple threadsoperating within each process of the crawler to prevent I/O deadlocks,due to Python’s global interpreter lock only a single thread can beactive at a time. Furthermore, all processes communicate through filesread from and written to a filesystem. This way debugging the wholetool is easier than a heavily parallel software consisting of hundredsor thousands of concurrently running components.
Using more sophisticated storage such as databases was avoidedfor the purpose of simplicity. All queues (URL, robots, redirects, webpage metadata) are read and written sequentially. The user can checkthe queues anytime to see what is happening.
The scheduler contains data structures to represent each web do-main encountered in the process of crawling. This is another differencefrom the standard design: URLs are separated by their respective webdomains rather than hold together in a sigle data structure. The sched-uler takes into account information about the domain such as theeffectiveness of crawling the domain or the information about pathswithin the domain whem making decisions concerning traversing theweb.
A web domain consists of the following metainformation:
∙ Technical information: Protocol (http/https), IP address.
∙ Hostname – long hostnames tend to contain more non-text(each URL is split to protocol, hostname and path).
18

1. Efficient Web Crawling For Large Text Corpora
Figu
re1.5:Sp
iderLing
arch
itecture.Th
ede
sign
looselyfollo
wsthe
gene
ralm
odel.T
here
isasing
leprocess
sche
duler,asing
leprocessd
ownloa
deru
sing
asyn
chrono
ussocketsa
ndmultip
leprocessesfor
web
page
processors
that
extracttexta
ndlin
ksfrom
HTM
L.
19

1. Efficient Web Crawling For Large Text Corpora
∙ New paths within the domain to send to the downloader in thefuture. The paths are sorted by length; short paths are down-loaded prior to obtaining long paths.
∙ Hashes of paths sent to the downloader – stored just to be ableto prevent downloading of the same page multiple times.
∙ Number of pages already downloaded from the domain – thiscan be limited to avoid crawler traps or overrepresentation of adomain in the target corpus.
∙ Web domain yield rate – the effectiveness of the web domaincalculated on-the-fly. More on this key feature follows in Chap-ter 1.2.3.
∙ Distance of the domain from the seed domains. The distance isthe graph distance of a node (a path) within the domain closestto the initial nodes (the seed URLs) in a graph representation ofthe web. Since the seed domains are trustworthy (high qualitycontent) and (most likely) links leading from a trustworthypage lead to other quality content, the value can be used toestimate the quality of the content of the domain. Domainsclose to the seeds should be crawled more than domains farfrom the seeds.
∙ Robots exclusion protocol24 file for the domain. The file isparsed into a set of rules to follow when adding new pathsinto the domain.
There is a ‘URL selector’ cycle periodically taking a small count of newURLs from each domain structure. This helps to increase the varietyof URL hosts sent to the downloader. The more separate web domains,the more connections can be opened at once.
A ‘URL manager’ receives seed URLs, redirected URLs from thedownloader and new extracted URLs from document processors. Anew URL is put into the respective domain structure. It’s hash iscompared to hashes of paths already in the domain. The manager also
24. A web communication standard for operators of web servers to set rules for au-tomated agents accessing their content. https://www.robotstxt.org/robotstxt.html. For example, a path within the domain can be prevented from downloadingthis way. Following the protocol is polite.
20

1. Efficient Web Crawling For Large Text Corpora
sorts web domains by their text yield rate preferring text-rich websitesover less text yielding sources.
A ‘duplicate content manager’ is a routine reading hashes of down-loaded web pages and other web page metadata from document pro-cessors. Since the information about duplicate content is distributedin document processors, this procedure gathers the data and writesidentifiers of duplicate documents to a file. The file is used by a stan-dalone script after the crawling is finished to de-duplicate the textoutput of the crawler.
A ‘crawl delay manager’ in the downloader component receivesURLs to download. It makes sure target HTTP servers are not over-loaded by forcing a crawl delay by postponing connections to thesame HTTP host or IP address within a certain period after the lastconnection was made. Excess paths within the same web domain arestored to the filesystem to be read later.
An asynchronous design (rather than the usual synchronousmulti-threaded design) is used to achieve a high throughput of HTTP com-munication. A TCP socket is opened for each web page in a downloadqueue at once. The sockets are non-blocking so the opener routinedoes not have to wait for an answer of the remote server.
There is another routine run periodically to poll sockets that areready to write to, in which case a HTTP request is sent, or ready toread from, in which case a chunk of the response of the remotes serveris read.
The socket poller stores the downloaded data into the filesystem.There are two queues to be read and resolved by the scheduler: Arobot queue holding the content of robots exclusion protocol files anda redirect queue recording HTTP redirects. There is another queue forweb pages waiting to be parsed by a document processor.
Text processing details follow. Plaintext and new links are extractedfromHTML text of web pages by a document processor. New links arestored in a file to be read by the scheduler. The plaintext is wrappedin a XML structure and stored to a file.
Useful metadata obtained during the processing is added as at-tributes of the structures: the title (the content of HTML element
21

1. Efficient Web Crawling For Large Text Corpora
title), the character length range, date of crawling25, IP address,language model difference (see more about the model below), URL,character encoding (the value stated in the HTML and the detectedvalue). An example of the data in this format is shown on Figure 1.6.
Tool Chared26 [PS11] is used to detect character encoding of webpages. Tool Justext27 [Pom11] is used to extract plaintext from HTML,split text to paragraphs (adhering to the paragraph denoting HTMLmarkup) and remove boilerplate such as headers, footers, navigationand tables.
A character trigram language model is built to determine the simi-larity of the text in a web page to a pre-defined set of nice texts in thetarget language or unwanted languages expected to be downloadedtoo. The cosine of vectors of trigrams is used to calculate the similarity.If the text is more similar to an unwanted language or the similarityto the target language is below a threshold, it is not included in theresult data.
All text post-processing mentioned here is done on-the-fly by thedocument processor.
Comments on scalability, performance and adaptability follow:Since there are only one scheduler and one downloader and the fact therate at which data is read and written by these components is variable,the data queues implemented as files allow all separate componentsto run at their own best pace. No component is waiting for the other.
The scheduler is limited by the operational memory holding theweb domain metadata and hashes of text files. The downloader islimited by the bandwidth of the network and the crawl delay policy.
Furthermore, the scalability of the crawler is controlled by settingthe count of document processors. According to our experience, fourprocesses is enough for crawling texts in languages with a small webpresence such as Estonian so a machine with a stock 8 core CPU with16 GB RAM should be enough.
25. Unfortunately, the dates of creation and modification of the content optionallysent in HTTP headers may not be accurate.26. http://corpus.tools/wiki/Chared27. http://corpus.tools/wiki/Justext
22

1. Efficient Web Crawling For Large Text Corpora
<doc id="3811554"url="https://example.com/page.html"title="Web page title"length="10k-100k"crawl_date="2019-09-03 18:48"ip="213.35.159.18"lang_diff="0.19"url="https://example.com/page.html"enc_meta="utf-8" enc_chared="utf-8">
<p>A paragraph of text.</p><p>Another paragraph of text.</p></doc>
Figure 1.6: An example of a web page stored in a doc structure. Theplaintext is separated to paragraphs marked by structure p.
SpiderLing used for big crawling projects such as obtaining theEnglish, Spanish or French web can make use of a 32 core machineand 200 GB RAM.
Concerning a comparison to big crawling projects of large institu-tions, let us compare our work to three results achieved by others:
∙ [Cal+09] used a modified version of Nutch [Kha+04] to buildClueWeb09 – one of the biggest collections of web texts madeavailable. It was crawled in 60 days and consists of one billionweb pages (with total size of 25TB). [PJR12] took the Englishpart of the collection – approximately 500 millions web pages –processed it using Unitok and Chared28 and got a result corpussized 82.6 billion tokens.
∙ According to [Tro+12], a dedicated cluster of 100 machinesrunning Hadoop file system, 33 TB of disk storage and a 1GB/snetwork were used. The Heritrix crawler29 was chosen for gath-
28. Tokeniser and de-duplication tool, see Section 1.3.29. https://webarchive.jira.com/wiki/display/Heritrix/Heritrix
23

1. Efficient Web Crawling For Large Text Corpora
ering ClueWeb12, the successor collection, in 2012. 1.2 billionpages amounting to 37TB text (and 67TB of other files) wascrawled for this collection in 13 weeks [Tro+12].
∙ IRLbot crawler30 downloaded 6.4 billion pages over twomonthsas reported by [Lee+09], with a performance of 3000 pagesdownloaded per second in peaks and the average of 1200 pagesper second.
∙ SpiderLing crawled 179 millions web pages from the Englishweb in 15 days with a peak performance around 600 pages persecond and the average of 140 pages per second.
Crawling performance of SpiderLing crawling the English, French,Estonian, Finnish and Czech & Slovak web in 2019, measured as con-nections opened per second, the size of raw data downloaded per dayand the size of plaintext extracted from HTML per day can be foundin Figures 1.7, 1.8 and 1.9.
The figures show the performance declining over time. The mainreason for this is the decreasing variety of web domains. The sched-uler started with a high count of different web domains. The varietydecreased by depleting new paths to download from web domainobjects.
The downloader is prevented to opening more connections anddownloading more data by the crawl delay as a part of the politenesspolicy.
The size of extracted plaintext is limited by the number of textprocessors employed. That count is set before the start of crawling.The extraction rate starts to decrease when there is no plaintext in thewaiting queue causing some text processors to go idle.
The crawler can be adapted to downloading national or languagewebs of various properties. The adaptation requires three kinds oflanguage dependent resources described in Section 1.3.
Furthermore, the behaviour of all components of the software isconfigurable using a file with preset defaults and switches for crawling‘small languages’ or starting from a low number of seed URLs. Settingthe target internet top level domain (TLD) and blacklists of TLDsand hostnames is supported. Thus one can avoid downloading from
30. http://irl.cs.tamu.edu/crawler/
24

1. Efficient Web Crawling For Large Text Corpora
Figu
re1.7:
Ave
rage
TCPconn
ectio
nsop
ened
pers
econ
din
dayintervalsb
ySp
iderLing
craw
lingselected
lang
uage
web
sin20
19.
25

1. Efficient Web Crawling For Large Text Corpora
Figu
re1.8:
Ave
rage
size
ofraw
HTM
Lda
tado
wnloa
dedpe
rday
inda
yintervalsb
ySp
iderLing
craw
ling
selected
lang
uage
web
sin20
19.
26

1. Efficient Web Crawling For Large Text Corpora
Figu
re1.9:Ave
rage
size
ofplaintexte
xtracted
from
HTM
Lpe
rday
inda
yintervalsb
ySp
iderLing
craw
ling
selected
lang
uage
web
sin20
19.
27

1. Efficient Web Crawling For Large Text Corpora
domains known for bad content or force crawling from particularnational domains, e.g. .de, .at, .ch for the German language.
Crawling multiple languages at the same time is encouraged. Thisfunctionalitywas used e.g. for obtaining text in three languages spokenin Nigeria: Hausa, Igbo and Yoruba. The configuration file can bereused for crawling the same language in the future.
Adapting the crawler to focus on texts on a particular topic is alsopossible. A list of two hundred environment and nature protectionterms was added to the scheduler to prefer domains consisting ofdocuments containing words from the list. This work was done fora lexicographic project. The seed URLs were obtained from a websearch engine set to search for the terms.
This experiment led to building a 61 million word topical corpus.31The corpus was used for improving a terminology dictionary in thedomain of environment and nature protection.
1.2.3 Yield Rate Aware Efficient Crawling
We experimented with a third party software for obtaining text docu-ments from theweb. Following the example of other researchers [BK06;Bar+09; Fer+08a], we used Heritrix crawler32 and downloaded docu-ments for the language in interest by restricting the crawl to nationalweb domains of the countries where the language is widely used (e.g..cz for Czech).
Though our colleaguesmanaged to compile corpora of up to 5.5 bil-lion words this way [PRK09], they were not satisfied with the fact theyneeded to keep the crawler running for several weeks and downloadterabytes of data in order to retrieve a reasonable amount of text. Itturned out that most downloaded documents were discarded duringpost-processing since they contained only material with little or nogood quality text.
Wewere interested in knowing howmuch datawas downloaded invain when using Heritrix and if the sources which should be avoidedcan be easily identified. In order to get that information we analyzed
31. Information about the result corpus can be found at https://www.sketchengine.eu/environment-corpus/.32. http://crawler.archive.org/
28

1. Efficient Web Crawling For Large Text Corpora
the data of a billion word corpus of European Portuguese downloadedfrom the .pt domain with Heritrix.
For each downloaded web page we compute its yield rate as
yield rate =f inal data size
downloaded data size
where final data size is the number of bytes in the text which the pagecontributed to the final corpus and downloaded data size is simply thesize of the page in bytes (i.e. the number of bytes which had to bedownloaded).
Many web pages have a zero yield rate, mostly because they getrejected by a language classifier or they only contain junk or textduplicate to previously retrieved text.
We grouped the data by web domains and computed a yield ratefor each domain as the average yield rate of the contained web pages.We visualized this on a scatterplot which is displayed in Figure 1.10.Each domain is represented by a single point in the graph.
It can be seen that the differences among domains are enormous.For example, each of the points in the lower right corner represents adomain from which we downloaded more than 1GB of data, but itonly yielded around 1 kB of text. At the same time, there are domainswhich yielded more than 100MB of text (an amount higher by fiveorders of magnitude) from a similar amount of downloaded data.These domains are positioned in the upper right corner of the graph.
Next, we selected a set of yield rate thresholds and computed foreach threshold the number of domains with a higher yield rate andthe sum of downloaded and final data in these domains. The resultscan be found in Table 1.1.
It is easy to see that as the yield rate threshold increases the sizeof the downloaded data drops quickly whereas there is only a fairlysmall loss in the final data. This suggests that by avoiding the domainswith low yield rate a web crawler could save a lot of bandwidth (andtime) without making the final corpus significantly smaller.
For instance if only domains with a yield rate above 0.0128 werecrawled, the amount of downloaded data would be reduced from1289GB to 86GB (to less than 7%) while the size of the final datawould only drop from 4.81GB to 3.62GB (73.7%). This is of courseonly a hypothetical situation, since in practice one would need to
29

1. Efficient Web Crawling For Large Text Corpora
103 104 105 106 107 108 109 1010 1011
Downloaded data size (bytes)
102
103
104
105
106
107
108
109
Fina
l dat
a si
ze (b
ytes
)
yield rate = 0.1yield rate = 0.01yield rate = 0.001domains .pt
Figure 1.10: Web domains yield rate for a Heritrix crawl on .pt.
30

1. Efficient Web Crawling For Large Text Corpora
Table 1.1: Sums of downloaded and final data size for all domainsabove the given yield rate threshold.
Domains Crawler FinalYield rate above the output Final data yieldthreshold threshold size [GB] size [GB] rate
none 51645 1288.87 4.91 0.00380.0001 29580 705.07 4.90 0.00690.0002 28710 619.44 4.89 0.00790.0004 27460 513.86 4.86 0.00950.0008 25956 407.30 4.80 0.01180.0016 24380 307.27 4.68 0.01520.0032 22325 214.18 4.47 0.02090.0064 19463 142.38 4.13 0.02900.0128 15624 85.69 3.62 0.04220.0256 11277 45.05 2.91 0.06460.0512 7003 18.61 1.98 0.10640.1024 3577 5.45 1.06 0.19450.2048 1346 1.76 0.54 0.30680.4096 313 0.21 0.10 0.4762
31

1. Efficient Web Crawling For Large Text Corpora
download at least several pages from each domain in order to estimateits yield rate. Nevertheless, it is clear that there is a lot of room formaking the crawling for web corpora much more efficient.
We observe many web domains offer documents of a similar type.For example, a news site contains short articles, a blog site containsblog entries, a company presentation site contains descriptions of thegoods sold or productsmanufactured.We believe the quality of severaldocuments (with regard to building text corpora) on such sites couldrepresent the quality of all documents within the given domain.
One could argue that a segmentation by domains is too coarse-grained since a domain may contain multiple websites with both highand low yield rates. Thoughwe agree, we believe that identifyingmorefine-grained sets of web pages (like a text rich discussion forum on atext poor goods presentation site) introduces further complicationsand we leave that for future work.
Simple web crawlers are not robust enough to suit our needs (e.g.not supporting heavily concurrent communication, lacking load bal-ancing by domain or IP address, not able to restart the crawling aftera system crash). On the other hand, the source code of sophisticatedcrawlers is too complex to alter, making implementation of our wayof efficient web traversing difficult.
We came to the conclusion that the easiest way of implementingour very specific requirements on web crawling is to create a customcrawler from scratch.
In order to reduce the amount of unwanted downloaded content,the crawler actively looks for text rich resources and avoids websitescontaining material mostly not suitable for text corpora. Our hopewas that by avoiding the unwanted content we can not only savebandwidth but also shorten the time required for data post-processingand building a web corpus of given size.
Our primary aim is to identify high-yielding domains and to avoidlow-yielding ones. At the same time we want to make sure that we donot download all data only from a few top-yielding domains so thatwe achieve a reasonable diversity of the obtained texts.
We collect information about the current yield rate of each domainduring crawling the web. If the yield rate drops below a certain thresh-old we blacklist the domain and do not download any further data
32

1. Efficient Web Crawling For Large Text Corpora
Table 1.2: The yield rate threshold as a function of the number ofdownloaded documents.
Document count Yield rate threshold10 0.00
100 0.011000 0.02
10000 0.03
from it. We define aminimum amount of data whichmust be retrievedfrom each domain before it can be blacklisted. Current limit is 10 webpages or 512 kB of data, whichever is higher.
The yield rate threshold is dynamic and increases as more pagesare downloaded from the domain. This ensures that sooner or later alldomains get blacklisted, which prevents over-representation of datafrom a single domain. Nevertheless, low-yielding domains are black-listed much sooner and thus the average yield rate should increase.
The yield rate threshold for a domain is computed using the fol-lowing function:
t(n) = 0.01 ·(log10 (n)− 1
)where n is the number of documents downloaded from the domain.
The function is based partly on the author’s intuition and partly onthe results of initial experiments. Table 1.2 contains a list of thresholdsfor selected numbers of downloaded documents.
We experimented with various parameters of the yield rate thresh-old function. Figure 1.11 shows how the average yield rate changes intime with different yield rate threshold functions. These experimentswere performed with Czech as the target language.
It can be seen that stricter threshold functions result in higher av-erage yield rate. However, too high thresholds have a negative impacton the crawling speed (some domains are blacklisted too early). It istherefore necessary to make a reasonable compromise.
Note: We used the threshold functions from Figure 1.11 in ourinitial experiments. We selected an even less strict one (defined inthis section) later on during crawling various data sources. It was a
33

1. Efficient Web Crawling For Large Text Corpora
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20time [hours]
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
craw
lero
utpu
tyie
ldra
te
No constraintst(n) = 0.02 · (log7(n)− 1)
t(n) = 0.015 · (log10(n)− 1) (less strict)
Figure 1.11: Average yield rate in time for various yield rate thresholdfunctions (crawling the Czech web)
matter of balancing high yield rate versus total amount of obtaineddata. Toomuch data was thrown away due to a strict threshold. That iswhy the currently used threshold function is not present in the figure.The main point is that yield rate is strongly affected by the selectedthreshold function.
Tool Justext was embedded in SpiderLing to remove content suchas navigation links, advertisements, headers and footers from down-loaded web pages. Only paragraphs containing full sentences arepreserved.
Duplicate documents are removed at two levels: (i) original form(text + HTML), and (ii) clean text as produced by jusText. Two corre-spondent checksums are computed for each web page and stored inmemory. Documents with previously seen checksums are discarded.Both kinds of removal are done on-the-fly during the crawling toimmediately propagate the currently crawled documents’ yield rateinto the corresponding domain yield rate. This enables SpiderLing todynamically react to obtained data.
34

1. Efficient Web Crawling For Large Text Corpora
By applying yield rate thresholds on domains we managed toreduce downloading data which is of no use for text corpora andincreased the overall average yield rate.
Figure 1.12 contains the same kind of scatterplot as displayed inFigure 1.10, this time on the data downloaded by SpiderLing withCzech as a target language.
This is a significant improvement over the previous graph. Forlow-yielding domains only up to 1MB of data is downloaded andhigh amounts of data are only retrieved from high-yielding sources.Many points (i.e. domains) are aligned along the line representing ayield rate of 10%. Furthermore, the crawling was stopped already atthe 512 kB threshold in case of many bad domains.
Note that the graph in Figure 1.12 does not take de-duplicationby onion into account. It displays the size of the data as output bythe crawler (i.e. boilerplate removed by jusText, no exactly samedocuments), not the final de-duplicated texts size. Even though theachieved improvement over the previous is indisputable.
We were also interested in the development of the crawling effi-ciency during crawling. We expected the yield rate to slightly increaseover time (the more data downloaded the higher yielding domainsselected). The results are pictured by Figure 1.13.
Contrary to our expectations, the measured efficiency grew onlyslightly or stagnated in most cases. We still consider this a good resultbecause even the stagnating yield rates were good (with regard toTable 1.1).
Crawling Japanese was an exception, since the rate kept increasingalmost all the time there. The reason may be the starting rate was low.The inbuilt language dependent models (character trigrams, wordlist)may not be adaptedwell for Japanese and throwaway gooddocumentsas well.
The less web resources in the target language, the sooner the yieldrate drops down. It can be demonstrated by the example of TajikPersian.
The initial yield rate obviously depends on the quality of the seed(initial) URLs. (For example many URLs of electronic newspaperarticles in the target language give good initial yield rate.) Irrespectiveof the seed URLs, the measurements show that sooner or later, the
35

1. Efficient Web Crawling For Large Text Corpora
103 104 105 106 107 108 109 1010 1011
Downloaded data size (bytes)
102
103
104
105
106
107
108
109
Craw
ler o
utpu
t siz
e (b
ytes
)
yield rate = 0.1yield rate = 0.01yield rate = 0.001domains .cz
Figure 1.12: Web domains yield rate for a SpiderLing crawl on theCzech web.
36

1. Efficient Web Crawling For Large Text Corpora
1 2 4 8 16 32 64 128 256 512 1024 2048 4096raw data downloaded [GB]
0.01
0.02
0.03
0.04
0.05
0.06
0.07
craw
lero
utpu
tyie
ldra
te
Am. SpanishArabicCzechTajikJapaneseRussianTurkish
Figure 1.13: The Yield rate of web domains measured during Spider-Ling crawls of six target languages in 2011 and 2012.
37

1. Efficient Web Crawling For Large Text Corpora
program discovers enough URLs to be able to select good qualitydomains.
Unlike other languages, crawling Arabic, Japanese and Turkishwas not restricted to the respective national domains. That inevitablyled to downloading more data in other languages thus throwing awaymore documents. Considering crawling efficiency in these cases onFigure 1.13, the yield rate also depends on constraining crawling tonational top level domains.
The yield rate may decrease after downloading a lot of data (theamount depends on the web presence of the target language). In thecase of rare languages, the best (text rich) domains get exhausted andthe crawler has to select less yielding domains.
The yield rates of parts of the web in selected languages33 obtainedby the crawler recently are summarized in Table 1.3. As can be seen inthe table, the yield rate differs for various languages. According to ourexperience, the difference can be caused by a different configuration ofthe crawler including language resources and seed URLs – the betteryield rate of seed domains, the better yield rate of the whole crawl.Different nature of the web in different languages may also play a part.
1.2.4 Deployment of SpiderLing in Corpus Projects
The crawler was successfully used in cooperation with various re-search partners to build corpora in many languages, e.g.: Tajik Persian(2011, 2012) [Dov+11; DSŠ12b], Arabic (2012, 2018) [Art+14; Bel+13],Japanese (2011, 2018) [Srd+13],Hindi (2013, 2017) [Boj+14], Amharic(2015-2017) [RS16], Lao (2018-2019), Tagalog (2018, 2019) [Bai+19],Estonian (2013, 2017, 2019) [KSK17; Kop+19].
A summary of data size in four stages of text processing of webcorpora crawled by SpiderLing recently can be found in Table A.1 inthe Appendices.
Three linguistic resources projects benefited from the crawler andthe processing pipeline: ELEXIS34, Habit35, Lindat36.
33. Defined for the whole crawl similarly to a single domain.34. https://elex.is/35. https://habit-project.eu/36. https://lindat.cz/
38

1. Efficient Web Crawling For Large Text Corpora
Table 1.3: Yield rate of crawling of the web of selected target languagesin 2019: The ratio of the size of the plaintext output of the crawler tothe size of all data downloaded is calculated in the fourth column ‘YR’.The ratio of the size of the plaintext after discerning similar languagesand near paragraph de-duplication to the size of all data downloadedis calculated in the last, cumulative yield rate column ‘CYR’. Cs & skdenotes Czech and Slovak languages that were crawled together.
Crawler output After de-duplicationLanguage HTML plaintext YR plaintext CYRCs & sk 9.74 TB 241GB 2.48% 71.7GB 0.74%English 9.09 TB 611GB 6.72% 300GB 3.30%Estonian 3.81 TB 57.9GB 1.52% 19.4GB 0.51%Finnish 7.65 TB 137GB 1.79% 41.9GB 0.55%French 7.44 TB 264GB 3.55% 98.8GB 1.33%Greek 3.71 TB 109GB 2.93% 35.7GB 0.96%Irish 38.6GB 1.02GB 2.66% 398MB 1.03%Italian 6.26 TB 195GB 3.12% 96.7GB 1.54%Polish 2.17 TB 97.4GB 4.50% 46.5GB 2.14%
39

1. Efficient Web Crawling For Large Text Corpora
According to our records, SpiderLing was downloaded by othersmore than 600 times between November 2016 and April 2020, mostlyby academics from around the world. The crawler was successfullyused by researchers at Slovak Academy of Sciences [Ben14; Ben16]and University of Zagreb [LK14; LT14].
40

1. Efficient Web Crawling For Large Text Corpora
1.3 Brno Corpus Processing Pipeline
The process of building corpora, also named the corpus creationpipeline, consists in several steps. Having discussed the topic in theWaC community at the WaC workshop in 2014, we discovered theprincipal parts of the pipeline are the same for many corpus familiesmade recently. An older paper on creating WaC corpora reports asimilar process as well [Bar+09]. The difference can be in the techni-cal implementation of cleaning tools, in some minor improvementstailored for a specific language or some minor problem spotted in theparticular corpus data. But the general coarse grained steps are thesame.
[VP12] summarizes the corpus creation pipeline as follows:1. In the first phase, crawling creates an archive of HTML pages
that are to be processed further.2. The second phase consists of boilerplate removal and de-dupli-
cation, which yields the raw text of these HTML pages withoutany navigation elements or non-informative text.
3. In the subsequent phases, the raw text is tokenised and sentencesplitting and subsequent linguistic processing is applied.
In the first phase, the document language and character encodinghave to be identified. In the case of a single target language, datain other languages are stripped off. The document encoding can benormalized to UTF-8 which is the most spread encoding standardcapable of addressing all necessary character codepoints.
[VP12] stated that without boilerplate detection and removal, onecould hardly use the result, since boilerplate text snippets woulddistort the statistics (e.g. the distributional similarity information) ofthe final corpus. Similarly, [Pom11] agreed the boilerplate is knownto cause problems in text corpora since the increased count of someterms gives biased information about the language and makes thecorpus search provide no useful evidence about the phenomenonbeing investigated. The literature names non-informative parts, such asnavigation menus, lists of links, decorative elements, advertisements,copyright notes, headers and footers, advertisements, etc. as examplesof web document boilerplate.
The main approaches to deal with boilerplate either:
41

1. Efficient Web Crawling For Large Text Corpora
1. Take advantage of knowledge of the common HTML DOMstructure across multiple documents on a website [BR02];
2. Or take into account properties of the inspected HTML pagealone (an unsupervised, heuristic method) such as HTMLDOM, headings, link density, paragraph length, stoplist words,etc. [Pom11]
There was also a competition on cleaning web pages organized bythe ACL SIG WAC – CLEANEVAL37 [Bar+08]. The best performingtool was Victor [MPS07]. Other tools we have encountered later areBoilerPipe38 based on [KFN10] and jusText39 [Pom11].
The second important issue is duplicity. The digital informationon the web is easily copied and thus documents may have significantoverlaps. That might happen on purpose, e.g. in the case of spammingtechnique called ‘content farms’ (covered later on) or in a seeminglyinnocent case of multiple online newspapers sharing the same an-nouncement released by a press agency. [Pom11] added to these casesalso document revisions (multiple versions of a single document areusually overlapping a lot) and quotations of previous posts in onlinediscussion forums.
Pomikálek further explains identifying and removing duplicateand near-duplicate texts is therefore essential for using the web datain text corpora. For instance, ‘the users might get many duplicateconcordance lines when searching in a corpus with excess duplicatecontent’. Similarly to boilerplate, ‘duplicate content may bias resultsderived from statistical processing of corpus data by artificially inflat-ing frequencies of some words and expressions’.
The work also points out it is necessary to distinguish naturalrecurrences of phrases or short chunks of text (which are not harmfulto effective use of text corpora) fromwhole duplicate or near-duplicatesentences and paragraphs (characteristic for so called co-derivativetexts). [Pom11]
The corpus de-duplication experience follows: [Bar+09] removedduplicate documents sharing at least two 5-grams of 25 5-grams per adocument.
37. http://cleaneval.sigwac.org.uk/38. http://code.google.com/p/boilerpipe/39. http://corpus.tools/wiki/Justext
42

1. Efficient Web Crawling For Large Text Corpora
Broder’s shingling algorithm [Bro+00]was implemented by [VP12]and [Pom11] for identifying duplicate n-grams of words in corpusdata.
[VP12] used an approach that creates a smaller number of still-distinctive overlapping phrases based on ‘spots’ that are composedof a function word and three content words rather than plain wordn-grams.
Unlike the previous cases, [LK14] and [Ben14] just marked theduplicate paragraphs and let the user of the corpus decide if theduplicate part is needed.
The crawler described in this thesis has found its place in the con-text of contemporary web corpus building projects. SpiderLing isa component of the group of tools for building large web corporaproduced and maintained by Natural Language Processing Centreat Masaryk University40. This set of tools was nicknamed by oth-ers [Ben16; LT14] ‘Brno Corpus Processing Pipeline’. All tools in thepipeline are open source released under a free licence.
The processing chain for creating a corpus using the tools in thepipeline follows:41
1. Consider the geographical distribution of target languages42(countries where they are spoken), top level domains (TLDs)of the countries, the main script used for writing each targetlanguage and similar languages that could be hard to recognisefrom target languages when configuring the crawler.
2. Prepare language dependent resources used for text process-ing in the following steps. The resources can be obtained fromanother general corpus or by downloading web pages and textfrom trustworthy (i.e. good content) sites, e.g. news sites, gov-
40. https://nlp.fi.muni.cz/en/NLPCentre41. The author of this thesis is also the author of the crawler and the languagediscerning tool and a co-author of the character encoding detection tool and theuniversal tokeniser.42. Assuming the goal is to obtain monolingual corpora in target languages, theselanguages along with other languages spoken in the same geographical or internetspace should be recognised. The pipeline will aim to accept text in target languagesand reject content in other recognised languages.
43

1. Efficient Web Crawling For Large Text Corpora
ernment sites, quality blogs and Wikipedia. Resources not sup-plied with the tools have to be created manually:
(a) 1000 web pages in each recognised language to train abyte trigram model for Chared, the encoding detectiontool. The software comes with default models for manylanguages.
(b) 3000 words most frequent in the target language for eachtarget language. A larger amount is recommendable in thecase of highly flective languages. The wordlist is used byJustext, the boilerplate removal tool to identify general textin the target language. The software comes with defaultwordlists for many languages.
(c) 100 kB of plaintext for a character trigram language modelthat is built by the crawler for each recognised language.Natural sentences on general topics are advisable here.
3. Find at least thousands of seed URLs.43 It is reasonable to in-clude just trustworthy sites in the case of languages widelyspread on the web to reduce downloading poor quality contentfrom the start. On the other side, if crawling scarce languages,use all URLs that can be found. Wikipedia and web directo-ries such as curlie.org44 are rich sources. Employing a searchengine to search for documents containing frequent words orphrases in target languages as suggested by [BB04] is helpfulwhen the number of initial sites is low.
4. Start the crawler using the seed URLs.
5. Processing and evaluation of the downloaded data is done bythe crawler on-the-fly:
(a) Encoding detection using Chared. Although UTF-8 is themost frequent encoding today, encoding detection is stillneeded for a part of the web.
(b) Language filtering using the character trigram model.
43. It is still possible to start the crawler with a single seed URL.44. Formerly known as dmoz.org.
44

1. Efficient Web Crawling For Large Text Corpora
(c) Boilerplate removal using Justext. The algorithm is lexi-cally informed, rejectingmaterial that does not have a highproportion of tokens that are the grammar words of thelanguage thus most material which is not in the desiredlanguage is removed.
(d) De-duplication of identical documents.(e) Evaluation of the yield rate and other features of web
domains.
6. The post-processing phase follows offline by tokenisation per-formed by Unitok45 [MSP14] or a third-party segmentation tool(often also a morphological analyser) in the case of East Asianlanguages.
7. Near duplicate paragraphs are removed using de-duplicationtool Onion46. [Pom11] The task is performed on the paragraphlevel. Paragraphs consisting of more than 50% word 7-tuplesencountered in previously processed data are removed. Sincesuch de-duplication is a highly demanding task in terms of bothprocessor cycles and memory consumption, it has not been em-bedded into the crawler. Nonetheless, we are still consideringsome way of integration, since it would enable a more accu-rate estimate of yield rates and thus improve the crawler’s webtraversing algorithm.
8. Similar languages should be discerned and multi-languagepages split to separate documents. A language filtering scriptusing wordlists with word occurrence counts from big mono-lingual web corpora can do that. [Her+16; Suc19]
9. Morphology, syntactic, or semantic annotation can be performedby external tools.47 We made extensive use of TreeTagger andFreeLing for European languages; Stanford tools for Chinese,
45. Universal text tokenisation tool with profiles for many languages, http://corpus.tools/wiki/Unitok.46. http://corpus.tools/wiki/Onion47. Annotation is not a part of Brno Corpus Processing Pipeline. It is mentionedhere to mark its place in the list of corpus building procedures. It is done after alltext cleaning and processing.
45

1. Efficient Web Crawling For Large Text Corpora
meCab (with UniDic lexicon) for Japanese, Han Nanum for Ko-rean, and MADA (in collaboration with Columbia University)for Arabic in the past.
10. All data is stored and indexed by corpus manager Sketch En-gine.
46

2 Cleaner Web Corpora
We observe the world wide web has become the source of data pre-ferred by many for NLP oriented research. As has been stated in theintroductory section, the content of the web is not regulated in termsof data quality, originality, or correct description. That brings seriousissues to deal with.
Our work is directed towards cleaning web corpora. Boilerplateremoval and near-duplicate de-duplication (explained in the previouschapter) are solved problems. Methods for language identificationand web spam removal in large web corpora are presented in thischapter.
A tool for language identification and discerning similar languagesis introduced and evaluated in section 2.1. Its application to web cor-pora is presented as well.
The issue of non-text in contemporary web corpora is described insection 2.2. A method for removing spam from web corpora throughsupervised learning using FastText is presented at the end of thischapter.
47

2. Cleaner Web Corpora
2.1 Discerning Similar Languages
We present a method for discriminating similar languages based onwordlists from large web corpora. The main benefits of the approachare language independency, a measure of confidence of the classifica-tion and an easy-to-maintain implementation.
The method is evaluated on data sets of workshops on ApplyingNLP Tools to Similar Languages, Varieties and Dialects (VarDial). Theresult accuracy is comparable to other methods successfully perform-ing at the workshop.
Language identification is a procedure necessary for buildingmonolingual text corpora from the web. For obvious reasons, dis-criminating similar languages is the most difficult case to deal with.
Continuing in the steps of our previous work [Her+16], our goalin corpus building is to keep documents in target languages whileremoving texts in other, often similar languages. The aim is to processtext of billion-word sized corpora using efficient and language inde-pendent algorithms. Precision (rather than recall), processing speedand easy-to-maintain software design are of key importance to us.
Data to evaluate language discrimination methods have been cre-ated by the organisers of VarDial shared tasks since 2014 [Mal+16;Zam+17; Zam+14; Zam+15]. Various media ranging from nice news-paper articles to short social network texts full of tags were madeavailable. Successful participants of this series of workshops havepublished their own approaches to the problem.
2.1.1 Method Description
The aim of the method presented in this thesis is to provide a sim-ple and fast way to separate a large collection of documents fromthe web by language. This is the use case: Millions of web pages aredownloaded from the web using a web crawler. To build monolingualcorpora, one has to split the data by language.
Since the set of internet national top level domains (TLDs) tar-geted by the crawler is usually limited and a similarity of the down-loaded texts to the target languages can be easily measured usinge.g. a character n-gram model [LB12], one can expect only a limitedset of languages similar to the target languages to discriminate. The
48

2. Cleaner Web Corpora
method should work with both documents in languages that havebeen discerned in the past aswell as texts in languages never processedbefore.
The presented method does:∙ Enable supporting new languages easily (that implies the sameway for adding any language).
∙ Allow adding a language never worked with before, using justthe web pages downloaded or a resource available for all lan-guages (e.g. articles fromWikipedia).
∙ Not use language specific resources varying for each languagesupported (e.g. a morphological database) – since that makessupporting new languages difficult.
∙ Apply to any structure of text, e.g. documents, paragraphs,sentences.
∙ Provide a way to measure the contribution of parts of a text,e.g. paragraphs, sentences, tokens, to the final classification ofthe structure of the text.
∙ Provide a measure of confidence to allow setting a thresholdand classifying documents below the threshold of minimalconfidence as mixed or unknown language.
∙ Work fast even with collections of millions of documents.
This method uses the initial step of the algorithm described in our co-authoredpaper [Her+16]. The reason for not including the expectation-maximisation steps mentioned in the paper is we aim to decrease thecomplexity of the solution, keeping the data processing time reason-ably short.
The method exploits big monolingual collections of web pagesdownloaded in the past or even right before applying the method (i.e.using the text to identify its language as the method data source atthe same time).
The language of documents in such collections should be deter-mined correctly in most cases, however some mistakes must be ac-cepted because there are many foreign words in monolingual webcorpora since e.g. foreign named entities or quotes are preserved. Evena lot of low frequency noise can be tolerable. Lists of words with rela-tive frequency are built from these big monolingual collections of webpages.
49

2. Cleaner Web Corpora
The method uses a decimal logarithm of word count per billionwords to determine the relative wordlist score of each word from thelist of words according to the following formula:
score (w) = log10
(f (w) · 109
|D|
)Where f (w) is the corpus frequency of the word (number of occur-rences of theword in the collection) and |D| is the corpus size (numberof all occurrences of all words in the collection).
Thewordlist is built for all languages to discern, prior to reading theinput text. Usually, when building corpora from the web, languagessimilar to the target languages and languages prevalent in the regionof the internet national top level domains occurring in the crawleddata are considered. A big web corpus is a suitable source.
To improve the list by reducing the presence of foreign words,limiting the national TLD of source web pages is advisable. E.g. usingtexts from TLD .cz to create a Czech word list should, intuitively,improve precision at a slight cost of recall.
The input of the method, i.e. the documents to separate by lan-guage, must be tokenised. Unitok [MSP14] was used to tokenise textin all sources used in this work. Then, for each word in the input,the relative wordlist score is retrieved from each language wordlist.The scores of all words in a document grouped by the language aresummed up to calculate the language score of a document. The samecan be done for paragraphs or sentences or any corpus structure.
document score (language) = ∑w∈document
language score (w)
The language scores of a document are sorted and the ratio of twohighest scoring languages is computed to determine the confidence ofthe classification. The score ratio is compared to a pre-set confidencethreshold. If the ratio is below the threshold, the document is markedas a mixed language text and not included in the final collection ofmonolingual corpora. Otherwise the result language is the languagewith the highest score.
con f idence ratio (document) =document score (top language)
document score (second top language)
50

2. Cleaner Web Corpora
According to our experience, setting the confidence threshold quitelow (e.g. to 1.005) is advisable in the case of discerning very similarlanguages while higher values (e.g. 1.01 to 1.05) work for other cases(e.g. Czech vs. Slovak, Norwegian vs. Danish).
We usually understand a paragraph to be the largest structureconsisting of a single language in the case ofmulti-languageweb pages.The method presented in this work allows separating paragraphsin different languages found in a single multilingual document tomultiple monolingual documents. Although code switching within aparagraph is possible, detecting that phenomenon is beyond the scopeof this work.
Figure 2.1 shows the overall sentence language scores as well asparticular word language scores in a sentence from VarDial 2014 testdata. Words ‘scheme’, ‘council’ and ‘tenant’ contribute the most to cor-rectly classifying the sample as British English (rather than AmericanEnglish). Punctuation was omitted from the wordlists thus getting azero score.
2.1.2 Evaluation on VarDial Datasets
The method was used to build language wordlists from sources de-scribed in the next subsection and evaluated on groups of similarlanguages.
In this work, TenTen web corpus family [Jak+13] was used tobuild the language wordlists. Aranea web corpora [Ben14; Ben16]were used in addition to TenTen corpora in the case of Czech andSlovak. bsWaC, hrWaC and srWaC web corpora [LK14] were usedin the case of Bosnian, Croatian and Serbian. All words, even hapaxlegomena were included in the wordlists unless stated otherwise. Thesource web pages were limited to the respective national TLD wherepossible.
Another set ofwordlists to compare themethod to other approacheswas obtained from the DSL Corpus Collection v. 11. The data set wasmade available at VarDial 2014 and described by [Zam+14].2
1. http://ttg.uni-saarland.de/resources/DSLCC/2. http://corporavm.uni-koeln.de/vardial/sharedtask.html
51

2. Cleaner Web Corpora
<s lang="en-GB"confidence_ratio="1.018"en-GB="122.04"en-US="119.89">
Under 5.74 5.74the 7.77 7.75rent 4.70 4.59deposit 4.56 4.40bond 4.49 4.63scheme 5.26 4.41, 0.00 0.00the 7.77 7.75council 5.56 5.20pays 4.20 4.26the 7.77 7.75deposit 4.56 4.40for 7.06 7.07a 7.36 7.34tenant 4.34 3.94so 6.34 6.31they 6.51 6.50can 6.53 6.54rent 4.70 4.59a 7.36 7.34property 5.38 5.37privately 4.05 3.99. 0.00 0.00</s>
Figure 2.1: Sentence score andword scores calculated to discern BritishEnglish from American English using relative word counts from alargeweb corpus. A sample fromVarDial 2014 test data, vertical format.Column description: Word form, en-GB score, en-US score.
52

2. Cleaner Web Corpora
Table 2.1: Sizes of wordlists used in the evaluation. Large web sources –TenTen, Aranea andWaC corpora – were limited to respective nationalTLDs. Other wordlists were built from the training and evaluationdata of DSL Corpus Collection and parts of GloWbE corpus. ColumnsWeb, DSL and GloWbE contain the count of words in the respectivewordlist.
Language TLD Web DSL GloWbEBosnian .ba 2,262,136 51,337Croatian .hr 6,442,922 50,368Serbian .rs 3,510,943 49,370Indonesian – 860,827 48,824Malaysian – 1,346,371 34,769Czech .cz 26,534,728 109,635Slovak .sk 5,333,581 121,550Brazilian Portuguese .br 9,298,711 52,612European Portuguese .pt 2,495,008 51,185Argentine Spanish .ar 6,376,369 52,179Peninsular Spanish .es 8,396,533 62,945English, UK .uk 6,738,021 42,516 1,222,292English, US .us 2,814,873 42,358 1,245,821
The last couple of wordlists for the purpose of evaluating themethod was taken from corpus GloWbE comprising of 60% blogsfrom various English speaking countries [DF15].3
The sizes and source TLDs of the wordlists are shown in Table 2.1.The difference of wordlist sizes is countered by using the relativecounts in the algorithm.
The evaluation of the language separation method described inthis paper on DSL Corpus Collection v. 1 gold data4 performed by the
3. http://www.corpusdata.org/4. https://bitbucket.org/alvations/dslsharedtask2014/src/master/test-gold.txt
53

2. Cleaner Web Corpora
Table 2.2: Overall accuracy using large web corpus wordlists and DSLCC v. 1 training data wordlists on DSL CC v. 1 gold data. The bestresult achieved by participants in VarDial 2014 can be found in thelast column.
Languages Wordlist Accuracy DSL BestEnglish UK/US Web corpora 0.6913 0.6394English UK/US GloWbE 0.6956 0.6394English UK/US DSL training 0.4706 0.6394Other languages Web corpora 0.8565 0.8800Other languages DSL training 0.9354 0.9571Bosnian, Croatian, Serbian DSL training 0.8883 0.9360Indonesian, Malaysian DSL training 0.9955 0.9955Czech, Slovak DSL training 1.0000 1.0000Portuguese BR/PT DSL training 0.9345 0.9560Spanish AR/ES DSL training 0.8820 0.9095
original evaluation script5 can be found in Table 2.2. The result overallaccuracy is compared to the best result presented at VarDial 20146
This comparison shows that our method performed better withlarge web corpora based wordlists than with the DSL training databased wordlists in the case of discerning British from American En-glish.
5. https://bitbucket.org/alvations/dslsharedtask2014/src/master/dslevalscript.py6. http://htmlpreview.github.io/?https://bitbucket.org/alvations/dslsharedtask2014/downloads/dsl-results.html
54

2. Cleaner Web Corpora
Table 2.3: Performance of our method on VarDial DSL test data com-pared to the best score achieved by participants of the competition atthat time.
Year Dataset Wordlist Metric Score DSL best2015 A Web corpora Accuracy 0.9149 0.95652015 B Web corpora Accuracy 0.8999 0.93412016 1 A DSL training Macro-F1 0.8743 0.89382016 1 A Web corpora Macro-F1 0.8420 0.88892017 DSL DSL training Macro-F1 0.8883 0.92712017 DSL Web corpora Macro-F1 0.8414 N/A
A brief overview of results achieved by Language Filter on selecteddatasets from subsequent VarDial shared tasks from 20157, 20168 and20179 can be found in Table 2.3.Wordlists created from the shared task training data might have beenbetter than large web corpora wordlists for discriminating the DSLtest data since DSL training sentences were more similar to test sen-tences from the domain of journalism and newspaper texts than webdocuments.
Generally, our wordlist based language separation method per-forms comparably to the results of participants of VarDial shared tasks,albeit never reaching the top score since the 2015 edition. A betteradaptation to the task data would have probably helped a bit.
7. VarDial 2015, http://ttg.uni-saarland.de/lt4vardial2015/dsl.html.DSLCC v. 2.0; Set A: newspapers, named entities; Set B: newspapers, named entitiesblinded. Languages: Bosnian, Croatian, and Serbian; Bulgarian and Macedonian;Czech and Slovak; Malay and Indonesian; Portuguese: Brazil and Portugal; Spanish:Argentina and Spain; Other (mixed) languages.8. VarDial 2016, http://ttg.uni-saarland.de/vardial2016/dsl2016.html.DSLCC v. 3; Sub-task 1 (DSL); Set A: newspapers. Languages: Bosnian, Croatian,and Serbian; Malay and Indonesian; Portuguese: Brazil and Portugal; Spanish:Argentina, Mexico, and Spain; French: France and Canada.9. VarDial 2017, http://ttg.uni-saarland.de/vardial2017/sharedtask2017.html. DSLCC v. 4; There was a single DSL task/dataset. Languages: Bosnian, Croat-ian, and Serbian; Malay and Indonesian; Persian and Dari; Canadian and HexagonalFrench; Brazilian and European Portuguese; Argentine, Peninsular, and PeruvianSpanish. Competition results of the open submission in 2017 are not available.
55

2. Cleaner Web Corpora
2.1.3 Comparison to Other Language Detection Tools
To compare Language Filter to other publicly available and easy-to-install language detection tools, lang.id10 [LB12] and langdetect11
[Nak10], which are well known pieces of software, were selected. Bothtools use a naive Bayes classifier, the first with byte 1-to-7-grams, thesecond with character n-grams.
1,000 random paragraphs from Czech and Slovak web crawled in2019 were selected for the experiment. All tools were set to discernCzech, Slovak and English. To create the ‘gold standard’ data for thetask, the base set of paragraphs was classified by all three tools. Labelsof texts that were given the same label by all tools were put in the goldstandard without being checked by a human. 104 paragraphs where adisagreement of the tools occurred were labelled by us.
In the end, there were 920 Czech pieces of text, 27 Slovak texts and5 English texts in the collection, i.e. 952 altogether. The rest were eithercases where a human could not determine the language (e.g. bothCzech and Slovak could be right) or duplicates. The average length ofthe texts in the collection is 48 tokens, the median is 30 tokens.
Our tool was slightly modified to predict a language even for shorttexts or texts where the scores of the top two languages were the same.(The default behaviour is to throw away these cases.)
Furthermore, the tool was used with selected sizes of frequencywordlists. The smallest number – the most frequent 10,000 words inthe language – is the size of the wordlist distributed with the toolunder a free licence by us. The full frequency wordlist comes fromlarge web corpora: csTenTen17, skTenTen11 and enTenTen15. Smallerwordlists were taken from its top million, 500,000, 100,000 and 50,000lines to evaluate how much data helps improving the result.
10. Source homepage: https://github.com/saffsd/langid.py. The latest commit(4153583 from July 15, 2017) was obtained.11. Source homepage: https://github.com/Mimino666/langdetect. The latestcommit (d0c8e85 from March 5, 2020) was obtained. That is a Python re-implementation of the original tool written in Java – https://github.com/shuyo/language-detection/tree/wiki.
56

2. Cleaner Web Corpora
Table 2.4: Comparison of language identification tools on 952 randomparagraphs from Czech and Slovak web. The tools were set to discernCzech, Slovak and English.
Tool AccuracyLangid.py 0.963Langdetect 0.954Language Filter, 10 k wordlist (public) 0.960Language Filter, 50 k wordlist 0.985Language Filter, 100 k wordlist 0.991Language Filter, 500 k wordlist 0.993Language Filter, 1M wordlist 0.994Language Filter, unlimited wordlist 0.995
Table 2.4 shows Language Filter overperforms other tools in the ex-periment with the 50,000 wordlist and larger lists. The tool performedthe best with unlimited wordlists.12
The results indicate the larger source web corpus – the betterwordlist for discerning languages.
A Makefile and test data to reproduce the experiment are attachedto http://corpus.tools/wiki/languagefilter.
2.1.4 Application to Web Corpora
The software was added to ‘Brno corpus processing pipeline’. Byapplying the tool to all web corpora recently produced by the authorof this thesis, text in unwanted languageswas removed thus improvingthe quality of corpora.
12. More precisely ‘full’ wordlists – limited just by the relative corpus frequency of aword which had to be greater than one hit per billion words in the respective corpusto account the word in the list. The size of all ‘full’ wordlists in this experiment wasbetween 2 and 3 million items.
57

2. Cleaner Web Corpora
Table 2.5: Discriminating similar languages in Indonesian web corpusfrom 2010 (Indonesian WaC corpus v. 3 by Siva Reddy): Documentcount and token count of corpus parts in languages discerned.
Documents TokensCleaning Indonesian Count % Count %Original data 27,049 100% 111,722,544 100%Indonesian language 25,876 95.7% 94,280,984 84.4%Malay language 12,684 46.9% 13,946,288 12.5%English 5,780 21.4% 1,397,778 1.3%Arabic 263 1.0% 107,359 0.1%French 185 0.7% 19,471 0.0%
The aim was to get clean monolingual corpora by removing para-graphs and documents in unwanted languages. Selected results aresummarised in tables at the end of this section.13
Sizes of language parts identified in web pages downloaded fromthe Indonesian web are summarised in Table 2.5. Indonesian andMalay are similar languages. 16% of text was removed from the corpusto get a better Indonesian only corpus.
Table 2.6 presents sizes of language parts identified while process-ing Norwegian web texts. Partners in the corpus building projectswho were native Norwegian speakers immediately revealed there wasa lot of Danish content in the corpus. By applying the language filter-ing script, 28% of text was removed from the corpus, being mostlyDanish text, or mixed language text below the threshold of reliableidentification, or very short paragraphs also below the threshold ofreliable identification. Variants of Norwegian were discerned too. Inthe end, two corpora were built: a Bokmål corpus consisting of themajority of the original data and a smaller Nynorsk corpus.
A summary of corpus sizes before and after the additional lan-guage filtering of recently build web corpora is presented in Table 2.7.
13. Note the sum of document counts of separated language data in the tables mayexceed 100% of the original document count since multi-language documents weresplit to separate documents for each language identified.
58

2. Cleaner Web Corpora
Table 2.6: Discriminating similar languages in the Norwegian webcorpus from 2015 (noTenTen15): Document count and token count ofcorpus parts in languages discerned.
Documents 106 tokensCleaning Norwegian Count % Count %Original data 5,589,833 100% 1,954 100%Bokmål Norwegian 3,443,807 61.6% 1,365 69.8%Nynorsk Norwegian 175,885 3.1% 50 2.6%Danish and other langs 1,970,141 35.2% 539 27.6%
The procedure proved the most useful in the case of Estonian. Nev-ertheless the quality of all corpora in the table benefited from theprocess.
Multiple languages were identified in source web texts in the Es-tonian web corpus from 2019. Although Estonian, English and Rus-sian were discerned using character trigram language models anda boilerplate removal tool Justext – usual procedure in the formertext processing pipeline – almost 5% of corpus tokens, including 1.7million English words and a smaller amount of Russian words, stillhad to be removed using the method described here. The confidencethreshold was set to 1.01 in this case. A complete list of language partscan be found in Table 2.8.
An example of using this method to deal with bad orthography– missing diacritics in Czech and Slovak14 15 – is shown by Table 2.9.Texts suffering from the problem were treated as a separate languageto filter out. A copy of the Czech frequency wordlist with diacriticsremoved was used to simulate language ‘Czech without diacritics’. A‘Slovak without diacritics’ wordlist was produced the same way from
14. For example, ‘plast’, ‘plást’ and ‘plášť’ are three different words separable only bydiacritical marks in Czech orthography. Notable number of Czech and Slovak textson the web are written that way either because the writer is lazy to type diacritics orbecause of a technical reason. These texts should be removed from corpora.15. We faced the same issue in a Tajikweb corpuswritten in Cyrillic in 2011. It turnedout that many Tajik people used Russian keyboards without labels for charactersnot found in the Russian alphabet.
59

2. Cleaner Web Corpora
Table 2.7: Overview of removal of unwanted languages in recentlybuilt web corpora (gaTenTen20, enTenTen19, etTenTen19, frTenTen19,huTenTen12, itTenTen19, roTenTen16). Document count and tokencount of corpus data before and after language filtering. ‘Removed’stands for the percent of data removed.
DocumentsTarget language Before After RemovedIrish 242,442 239,840 1.07%English 126,318,554 126,118,769 0.16%Estonian 13,123,009 11,971,640 8.77%French 60,977,258 60,904,106 0.12%Hungarian 6,447,178 6,427,320 0.31%Italian 44,753,427 44,708,252 0.10%Romanian 9,302,262 9,239,153 0.68%
Millions of tokensTarget languages Before After RemovedIrish 172 172 0.48%English 104,997 104,184 0.77%Estonian 7,762 7,404 4.61%French 44,448 44,079 0.83%Hungarian 3,162 3,153 0.29%Italian 31,102 30,989 0.36%Romanian 3,143 3,136 0.21%
60

2. Cleaner Web Corpora
Table 2.8: Languages recognised in the Estonian web corpus from 2019(etTenTen19). Document count and token count of corpus parts inlanguages discerned.
Documents TokensFiltering Estonian Count % Count %Original data 13,123,009 100% 7,761,827,865 100%Estonian 11,971,640 91.2% 7,404,008,394 95.4%Danish 344 0.00% 16,004 0.00%English 35,362 0.27% 1,714,243 0.02%Finnish 1,069 0.01% 66,375 0.00%French 1,323 0.01% 59,217 0.00%German 964 0.01% 70,706 0.00%Italian 861 0.01% 40,963 0.00%Polish 818 0.01% 44,014 0.00%Portuguese 399 0.00% 19,611 0.00%Russian 643 0.00% 70,805 0.00%Spanish 1,059 0.01% 44,907 0.00%Mixed or too short 3,073,350 23.42% 3,6546,756 0.47%
61

2. Cleaner Web Corpora
Table 2.9: Languages recognised in the output of SpiderLing crawlingCzech and Slovak web in 2019. Document count and token count ofcorpus parts in languages discerned.
Documents 106 tokensFiltering Czech & Slovak Count % Count %Original data 64,772,104 100% 35,187 100%Czech 62,520,894 96.5% 33,111 94.1%Czech without diacritics 3,375,842 5.2% 747 2.1%Slovak 3,213,002 5.0% 687 2.0%Slovak without diacritics 1,171,249 1.8% 130 0.4%Other languages 162,373 0.3% 8 0.0%Mixed or too short 21,780,897 33.6% 505 1.4%
the general Slovak wordlist. The confidence threshold was set to 1.01in this case.
To conclude the section on Discerning similar languages, the lan-guage filtering tool from Brno Corpus Processing Pipeline was intro-duced. The evaluation shows it works very well for general corpuscleaning as well as for discerning similar languages. A trick to removetexts without diacritics using the tool was presented too.
We think the main advantage of our method is it provides anunderstandable threshold of the confidence of classification. We donot mind false positives – removing more text from the result corpusthan necessary – but it is important to know how the threshold bywhich is the removal rate controlled works.
62

2. Cleaner Web Corpora
2.2 Non-Text Removal
2.2.1 Web Spam in Text Corpora
According to our experience, the most problematic issue of contem-porary web corpora is the presence of web spam. The internet is amessy place and the spread of text affecting spam is ‘getting worse’.In [KS13], we reported the biggest difference observed between their2008 and 2012 web corpora, both obtained in the same way, was webspam.
[GG05] defines web spamming as ‘actions intended to misleadsearch engines into ranking some pages higher than they deserve’and state that the amount of web spam has increased dramatically,leading to a degradation of search results. According to the paper,even spamming techniques observed in 2005 involved modification oftext data or computer generated text.
A text corpus built for computational linguistics purpose shouldcontain fluent, meaningful, natural sentences in the desired language.However, some spamming methods, in addition to misleading thesearch results, break those properties and thus hinder the quality ofthe corpus. The reasons are similar as with boilerplate or duplicatecontent – it may affect results derived from statistical processing ofcorpus data significantly. Therefore it is important to study spammingtechniques and spam web pages to be able to avoid it in the process ofcleaning text data.
Here are three examples of nonsense texts from an English webcorpus found by [KS13]:
∙ The particular Moroccan oil could very well moisturize dry skinhanding it out an even make-up including easier different textures.
∙ Now on the web stores are very aggressive price smart so there gen-uinely isn’t any very good cause to go way out of your way to get thepresents (unless of course of program you procrastinated).
∙ Hemorrhoids sickliness is incorrect to be considered as a lethiferousmalaise even though shutins are struck with calamitous tantrums ofagonizing hazards, bulging soreness and irritating psoriasis.
63

2. Cleaner Web Corpora
Consider another example by Google Quality guidelines for webmas-ters:16 The same words or phrases can be repeated so often that itsounds unnatural. That is a sign of a spamming technique called key-word stuffing.
∙ We sell custom cigar humidors. Our custom cigar humidors are hand-made. If you’re thinking of buying a custom cigar humidor, pleasecontact our custom cigar humidor specialistsat [email protected].
As can be seen, the context of an examined word is not natural there,i.e. as it would be used in a meaningful sentence uttered by a humanspeaker. Such texts skew the properties of the word in the corpus: itscorpus frequency, its document frequency, its collocates and becauseof that all derived analyses as well. Nonsense sentences cannot beused to explain the meaning of the word too.
We managed to work around the issue of spammed data – in mostcases – by selecting quality sources in the case of a billion word sizedEnglish corpus used in an application for English language learningintroduced in [BS14]. Some nonsense sentences remained in the cor-pus nevertheless. An example of web spam can in the application beseen on Figure 2.2.1.
In the case of general large web corpora we were not able to justavoid problematic kinds ofweb spam.Unless the issue is dealtwith,wehave less confidence in usefulness of the recent web data for languageanalysis.
To improve user experience of browsing the internet and to bettersearch the massive amount of online data, web search engines en-courage web administrators to create high quality well structured andinformative web pages. An example of such administrator manual isthe (already mentioned) Webmaster Guidelines by Google. Adheringto these principles is called search engine optimization (SEO).
According to [GG05], SEO ‘without improving the true value of apage’ is in fact web spammig. Web spamming refers to ‘any deliberatehuman action that is meant to trigger an unjustifiably favorable rele-vance or importance for some web page, considering the page’s truevalue’. It is used to mislead search engines to assign to some pages a
16. Available at https://support.google.com/webmasters/answer/66358?hl=en, accessed in January 2015.
64

2. Cleaner Web Corpora
Figure 2.2: Web spam in examples of use of word ‘money’ in ap-plication Sketch Engine for Language Learning at https://skell.sketchengine.eu/. See non-text lines 2, 4 and 10.
65

2. Cleaner Web Corpora
higher ranking than they deserve. Web page content or links that arethe result of some form of spamming are called spam.
As has been shown in the introductory example, certain kinds ofweb spam look quite like the data we want to gather, but once properlyidentified as a non fluent, non coherent, non grammatical, containingsuspicious unrelated keywords or by other means unnatural text, wedo not want it to corrupt our corpora.
[GG05] presented a useful taxonomy of web spam, and corre-sponding strategies used to make spam. Their paper was presented atthe first AIRWeb17 workshop: it was the first of five annual workshops,associatedwith two shared tasks or ‘Web SpamChallenges’. The last ofthe AIRWeb workshops was held in 2009. In the following years, therehave been jointWICOW/AIRWebWorkshops onWebQuality.18. Theseworkshops, held at WWW conferences, have been the main venue foradversarial information retrieval work on web spam. Since the merge,there has been less work on web spam, with the focus, insofar as itrelates to spam, moving to spam in social networks. [EGB12]
The web spam taxonomy paper [GG05] revealed two main typesof web spamming: ‘boosting techniques, i.e., methods through whichone seeks to achieve high relevance and/or importance for some pages’and ‘hiding techniques, methods that by themselves do not influencethe search engine’s ranking algorithms, but that are used to hide theadopted boosting techniques from the eyes of human web users’.
The boosting type of spamming consists in changing the frequencyproperties of a web page content in favour of spam targeted wordsor phrases – to increase the relevance for a document in a web searchfor those words or phrases. The paper also identified these ways ofaltering web text: Repetition of terms related to the spam campaigntarget, inserting a large number of unrelated terms, often even en-tire dictionaries, weaving of spam terms into content copied frominformative sites, e.g. news articles, glueing sentences or phrases fromdifferent sources together.
17. Adversarial Information Retrieval on the Web, organized in 2005–2009, http://airweb.cse.lehigh.edu/18. Workshop on Information Credibility on the Web, organized since 2011, http://www.dl.kuis.kyoto-u.ac.jp/webquality2011/
66

2. Cleaner Web Corpora
Other techniques listed in the spam taxonomy article, namely linkspamming or instances of hiding techniques such as content hiding,cloaking, or redirection are less problematic forweb corpora. Althoughthey may reduce efficiency of a web crawler (by attracting it to poorquality sources), they do not present corrupted or fake text hard torecognize from the desired content.
Search engines strive hard to suppress the bad SEO. Document‘Fighting Spam’ by Google19 describes the kinds of spam that Googlefinds, and what they do about it. Among the techniques most danger-ous for web corpora are ‘aggressive spam techniques such as automat-ically generated gibberish’, automatically generated text or duplicatedcontent. It is interesting to notice that although Google says their al-gorithms address the vast majority of spam, other spam has to beaddressed manually. Figure 2.3 shows analysis of manually inspectedspam types and quantities from 2004 to 2012.
The following types of automatically generated content are ex-amples of documents penalised by Google: ‘Text translated by anautomated tool without human review or curation before publish-ing. Text generated through automated processes, such as Markovchains. Text generated using automated synonymizing or obfusca-tion techniques.’ These kinds of spam should certainly be eliminatedfrom web corpora while the other two examples given by Google maynot present a harm to the corpus use: ‘Text generated from scrapingAtom/RSS feeds or search results. Stitching or combining content fromdifferent web pages without adding sufficient value.’20
[KS13] described the situation as a game played between spam-mers and search engines who employ teams of analysts and program-mers to combat spam. However, the most up to date knowledge ofexperts and resources may not be shared outside the search enginecompanies, for obvious reasons.
Expecting the great effort of search engines’ measures against webspam pays off, the study speculated the corpus builders can benefitdirectly from the BootCaT approach.
19. http://www.google.com/insidesearch/howsearchworks/fighting-spam.html, accessed in January 2015, moved to https://www.google.com/search/howsearchworks/mission/creators/ as of April 2020.20. Source of quoted text: Google quality guidelines – https://support.google.com/webmasters/answer/2721306, accessed in January 2015.
67

2. Cleaner Web Corpora
Figure 2.3: Google’s analysis of spam types and quantities that hadto be removed manually, 2004–2012. Source: http://www.google.com/insidesearch/howsearchworks/fighting-spam.html, accessedin January 2015, no longer at the site as of April 2020. Labels weremoved below the chart and resized by the author of this thesis for thesake of readability.
68

2. Cleaner Web Corpora
General research in combating spam is conducted in two maindirections: content analysis and web topology.
The first approach represented e.g. by [Nto+06] is based on ex-tracting text features such as ‘number of words, number of words intitle, average word length, fraction of anchor words, fraction of contentvisible on the page, compression ratio, fraction of the most commonwords, 3-gram occurrence probability’.
The web topology oriented techniques perceive the web as a graphof web pages interconnected by links, e.g. [Cas+07] discovered that‘linked hosts tend to belong to the same class: either both are spam orboth are non-spam’.
Anotherwork [GGP04] proposes aweb page assessment algorithmTrustRank based on trusted sources manually identified by experts.The set of such reputable pages is used as seeds for a web crawl. Thelink structure of the web helps to discover other pages that are likelyto be good.
[Nto+06] also published two observations we find important forour research:
1. Web spamming is not only a matter of the English part of in-ternet. Spam was found in their French, German, Japanese andChinese documents as well. There seems to be no languageconstraint. Language independent methods of combating spammight be of use.
2. NLP techniques required for ‘grammatical and ultimately se-mantic correctness’ analysis of web content are computationallyexpensive. Since web corpora processed by current cleaningtools are much smaller than the original, we may employ evensome computationally expensive techniques nonetheless.
Our paper [KS13] summarizes the issues in web text corpus buildingin the context of corpora for language studies and NLP: Instances ofweb spam observed in data from 2012 and later are ‘by design, hardto find and set apart from good text’. ‘At what stage should spamdetection take place – before HTML removal, or after, and do we workat the level of the page or the website?’ ‘Should we concentrate onwebsites, or web pages?’ The evidence suggests that ‘the landscape
69

2. Cleaner Web Corpora
hosts and domains change very quickly, so methods based on text mayretain validity for longer.’
These questions should be addressed in order to convince the NLPcommunity the web can be a reliable source of text data despite thegrowing spam content.
In comparison to the problem of boilerplate and duplicity, webspam brings new challenges. While boilerplate and duplicate contentis in fact an inevitable and natural property of the web, we understandthe spamming is worse because it is always deliberate. Spammersintend to fool the search engines (and the web page visitors in somecases too). We have to realize the spamming techniques will be ad-vancing as fast as the countermeasures are taken.
The definition of web spam varies according to use of the webpages. Having discussed the fulltext search development team ofCzech web search engine Seznam.cz about their attitude to web spam,we realized the difference.A search engine:
∙ The goal is to serve nice looking, informative, quality, trustwor-thy and original texts.
∙ The users are people searching for websites, products, informa-tion.
∙ Therefore, relevance and importance of documents is crucial.∙ Content that is not original, poorly informative, scarcely con-nected to other pages, or misused is penalized in the searchresults.
∙ Spammers are interested in search engine behaviour. They tryto keep up with countermeasures.
On the other hand, a text corpus:∙ The goal is to represent the behaviour of words, phrases, sen-
tences, generally all kinds of linguistic phenomena in a contextin a language.
∙ The users are linguists, translators, teachers, NLP scientists andNLP applications.
∙ Natural distribution and context of the studied phenomena isimportant.
∙ Web spammers are not interested in text corpora.
70

2. Cleaner Web Corpora
For instance, an unofficial clone of a famous web page gets penalizedby the search engine since people most likely want to look for theofficial page. Yet the clone might contain some original content. Thecorpus builders do not care if the page is official or not. We do wantto keep the unofficial page in the corpus too, provided it contains atleast a few natural sentences that cannot be seen elsewhere.
Another example is a web content farm. A website (or more sites)contain parts of texts or full texts copied fromoriginal, trustworthy andinformative sources, e.g. Wikipedia or news pages. Search engines arenot permitting such aggressive spamming technique. Nonetheless, itis no issue for text corpora cleaned by currently available tools becauseduplicate removal is a solved problem. Still, some harm is done in thephase of crawling – the crawler is occupied by downloading data thatgets cleaned afterwards.
Similarly to search engines, there is a significant overlap with theinformation retrieval approach to spam, however it is not the same.‘IR work mostly focuses on finding bad hosts (and much of it, onlinks, ‘the web as a graph’). That is a distinct strategy to finding badtext, e.g. within a web corpus once it has been cleaned, with linksdeleted.’ [KS13]
Considering the corpus definition of web spam, the coarse grainedclassification of web pages to spam / not spam (or borderline as thecategory between)might not be enough. Although there areweb spamdatasets available for development and evaluation of spam fightingmethods, the focus is, to a certain extent, on the search engine defini-tion of spam rather than our definition of non-text. We also object thathistorical datasets are of limited value as spammers will have movedon.
Avoiding the web spam by carefully selecting spam free sourcesworks well. Wikipedia, news sites, government webs are generallyconsidered trustworthy. As we reported in [BS14], it is possible to con-struct medium sized corpora from URL whitelists and web catalogues.[SS12] reported a similar way of building a Czech web corpus too.
Also the BootCaT method [BB04] indirectly avoids the spam issueby relying on a search engine to find non spam data.
Despite the avoidingmethods being rather successful, it is doubtfula huge web collection can be obtained just from trustworthy sources.
71

2. Cleaner Web Corpora
Furthermore, a manual spam classification of seed web pages is costlyfor each target language.
In contrast to the search engine understanding of web spammingas well as other previously seen definitions, one could reformulate thedefinition of spam for linguistics use of text corpora:
∙ A fluent, naturally sounding, consistent text is good, regardlessthe purpose of the web page or its links to other pages.
∙ The bad content is this: computer generated text, machine trans-lated text, text altered by keyword stuffing or phrase stitching,text altered by replacing words with synonyms using a the-saurus, summaries automatically generated from databases(e.g. weather forecast, sport results – all of the same kind verysimilar), and finally any incoherent text. This is the kind ofnon-text this work is interested in.
∙ Varieties of spam removable by existing tools, e.g. duplicatecontent, link farms (quite a lot of linkswith scarce text), are onlya minor problem. The same holds for techniques not affectingtext, e.g. redirection.
To summarize – In contrast to the traditional or search engine defini-tions of web spam, the corpus use point of view is not concerned withintentions of spam producers or the justification of the search engineoptimisation of a web page. A text corpus built for NLP or linguisticspurpose should contain coherent and consistent, meaningful, naturaland authentic sentences in the target language. Only texts created byspamming techniques breaking those properties should be detectedand avoided.
The unwanted non-text is this: computer generated text, machinetranslated text, text altered by keyword stuffing or phrase stitching,text altered by replacing words with synonyms using a thesaurus,summaries automatically generated from databases (e.g. stock marketreports, weather forecast, sport results – all of the same kind verysimilar), and finally any incoherent text.
Varieties of spam removable by existing tools, e.g. duplicate con-tent, link farms (quite a lot of links with scarce text), are only a minorproblem.
72

2. Cleaner Web Corpora
Considering the strictness of removing spam, there is no lack ofdata in the internet nowadays. Therefore recall should be preferredover precision. We do not mind false positives if most of the spam isstripped away well.
To address non-text in web corpora, we carried out a supervisedlearning experiment. The setup and results are described in the fol-lowing section.
2.2.2 Removing Spam from an English Web Corpus throughSupervised Learning
This section describes training and evaluation of a supervised classifierto detect spam in web corpora.
We have manually annotated a collection of 1630 web pages fromvariousweb sources from years 2006 to 2015.21 To cover themain topicsof spam texts observed in our previously built corpora, we included107 spam pages promoting medication, financial services, commercialessay writing and other subjects.
Both phrase level and sentence level incoherent texts (mostly key-word insertions, n-grams of words stitched together or seeminglyauthentic sentences not conveying any connecting message) wererepresented. Another 39 spam documents coming from random webdocuments identified by annotators were included. There were 146positive instances of spam documents altogether.
The classifier was trained using FastText [Jou+16] and applied to alarge English web corpus from 2015. The expected performance of theclassifier was evaluated using a 30-fold cross-validation on the webpage collection. Since our aim was to remove as much spam from thecorpus as possible, regardless false positives, the classifier confidencethreshold was set to prioritize recall over precision.
The achieved precision and recall were 71.5% and 70.5% respec-tively. Applying this classifier to an English web corpus from 2015resulted in removing 35% of corpus documents still leaving enoughdata for the corpus use.
21. This is a subset of a text collection which was a part of another classificationexperiment co-authored by us.
73

2. Cleaner Web Corpora
An inspection of the cleaned corpus revealed the relative count ofusual spam related keywords dropped significantly as expected whilegeneral words not necessarily associated with spam were affected lessas can be seen in Table 2.10.
Another evaluation of the classifier was performed by manuallychecking 299 random web documents from the cleaned corpus and 25random spam documents removed by the classifier. The achieved pre-cision was 40.0% with the recall of 27.8%. The error analysis showedthe classifier was not able to recognise non-text rather than spam. 17of 26 unrecognised documents were scientific paper references or listsof names, dates and places, i.e. Submitted by Diana on 2013-09-25 andupdated by Diana on Wed, 2013-09-25 08:32 or January 13, 2014 – January16, 2014 Gaithersburg, Maryland, USA.
Such web pages were not present in the training data since webelieved it had been removed from the corpus sources by a boilerplateremoval tool and paid attention to longer documents. Not countingthese 17 non-text false negatives, the recall would reach 52.6%.
To find out what was removed from the corpus, relative counts oflemmas22 in the corpus were compared with the BNC23 in Figure 2.4and Figure 2.5.
A list of lemmas in the web corpus with the most reduced relativelemma count caused by removing unwanted documents is presentedin Figure 2.6.
The inspection showed therewere a lot of spam relatedwords in theoriginal web corpus and that spam words are no longer characteristicof the cleaned version of the corpus in comparison to the BNC.24
To show the impact of the cleaning method on data used in realapplications, Word Sketches of selected verb, nouns and adjectives inthe original corpus and the cleaned corpus were compared. A WordSketch is a table like report providing a collocation and grammaticalsummary of the word’s behaviour that is essential for modern lexicog-
22. Corpora in the study were lemmatised by TreeTagger.23. The tokenisation of the BNC had to be changed to the same way the web corpuswas tokenised in order to make the counts of tokens in both corpora comparable.24. The comparison with the BNC also revealed there are words related to themodern technology (e.g. website, online, email) and American English spelled words(center, organization) in the 2015 web corpus.
74

2. Cleaner Web Corpora
Table 2.10: Comparison of the 2015 English web corpus before andafter spam removal using the classifier. Corpus sizes and relativefrequencies (number of occurrences per million words) of selectedwords are shown. By reducing the corpus to 55% of the former tokencount, phrases strongly indicating spam documents such as cialis 20mg, payday loan, essay writing or slot machinewere almost removedwhileinnocent phrases not attracting spammers from the same domainssuch as oral administration, interest rate, pass the exam or play gameswerereduced proportionally to the whole corpus.
Original corpus Clean corpus KeptDocument count 58,438,034 37,810,139 64.7%Token count 33,144,241,513 18,371,812,861 55.4%
Phrase Original hits/M Clean hits/M Keptviagra 229.71 3.42 0.8%cialis 20 mg 2.74 0.02 0.4%aspirin 5.63 1.52 14.8%oral administration 0.26 0.23 48.8%loan 166.32 48.34 16.1%payday loan 24.19 1.09 2.5%cheap 295.31 64.30 12.1%interest rate 14.73 9.80 36.7%essay 348.89 33.95 5.4%essay writing 7.72 0.32 2.3%pass the exam 0.34 0.36 59.4%slot machine 3.50 0.99 15.8%playing cards 1.01 0.67 36.8%play games 3.55 3.68 53.9%
75

2. Cleaner Web Corpora
Figure 2.4: Relative word count comparison of the original 2015 webcorpus with British National Corpus, top 26 lemmas sorted by thekeyword score. Score = f pm1+100
f pm2+100 where f pm1 is the count of lemmasper million in the focus corpus (3rd column) and f pm2 is the count oflemmas per million in the reference corpus (5th column).
76

2. Cleaner Web Corpora
Figure 2.5: Relative word count comparison of the cleaned web corpuswith British National Corpus. (A screenshot from Sketch Engine.)
77

2. Cleaner Web Corpora
Figure 2.6: Relative word count comparison of the original web corpuswith the cleaned version. (A screenshot from Sketch Engine.)
78

2. Cleaner Web Corpora
raphy e.g. to derive the typical context and word senses of headwordsin a dictionary. [Bai+19; Kil+14].
In all tables below, the highest scoring lemmas are displayed. Lemmais the base form of a word (aggregating all word forms in WordSketches). Frequency denotes the number of occurrences of the lemmaas a collocate of the headword in the corpus – the main word of adictionary entry, the verb ‘buy’ in this case. The score column repre-sents the typicality value (calculated by collocation metric LogDicedescribed in [Ryc08] in this case) indicating how strong the collocationis.
To create a good entry in a dictionary, one has to know strong col-locates of the headword. We will show better collocates are providedby the cleaned corpus rather than the original version in the case ofselected headwords.
Tables 2.11 and 2.12 show that top collocates of verb ‘buy’ in re-lation ‘objects of verb’ were improved a lot by applying the cleaningmethod to the corpus. It is true that e.g. ‘buy viagra’ or ‘buy essay’are valid phrases, however looking at random concordance lines ofthese collocations, vast majority come from computer generated un-grammatical sentences such as Canadensis where can I buy cheap viagrain the UK atardecer viagra japan ship deodorant25 or Judge amoungst nonebuy argumentative essay so among is what in himself And almost Inter-preter26.
Comparison of modifiers of noun ‘house’ in Table 2.13 revealsthat the Word Sketch of a seemingly problem-free headword such as‘house’ can be polluted by a false collocate – ‘geisha’. Checking randomconcordance lines for co-occurrences of ‘house’ and ‘geisha’, almostnone of them are natural English sentences, e.g. ‘well done enoughglimpse of geisha house as a remote and devotee of sherlock republicwindows 7 holmes’27. While ‘geisha’ is the fifth strongest collocate inthe original corpus, it is not present among top 100 collocates in thecleaned version.
25. Source: http://nakil.baskent-adn.edu.tr/viagra-japan-ship/, visited bythe crawler in December 2015.26. Source: http://www.pushtherock.org/writing-a-college-research-paper/,visited by the crawler in December 2015.27. Source: http://www.littleteddies.net/?de-vergeting-epub, visited by thecrawler in November 2015.
79
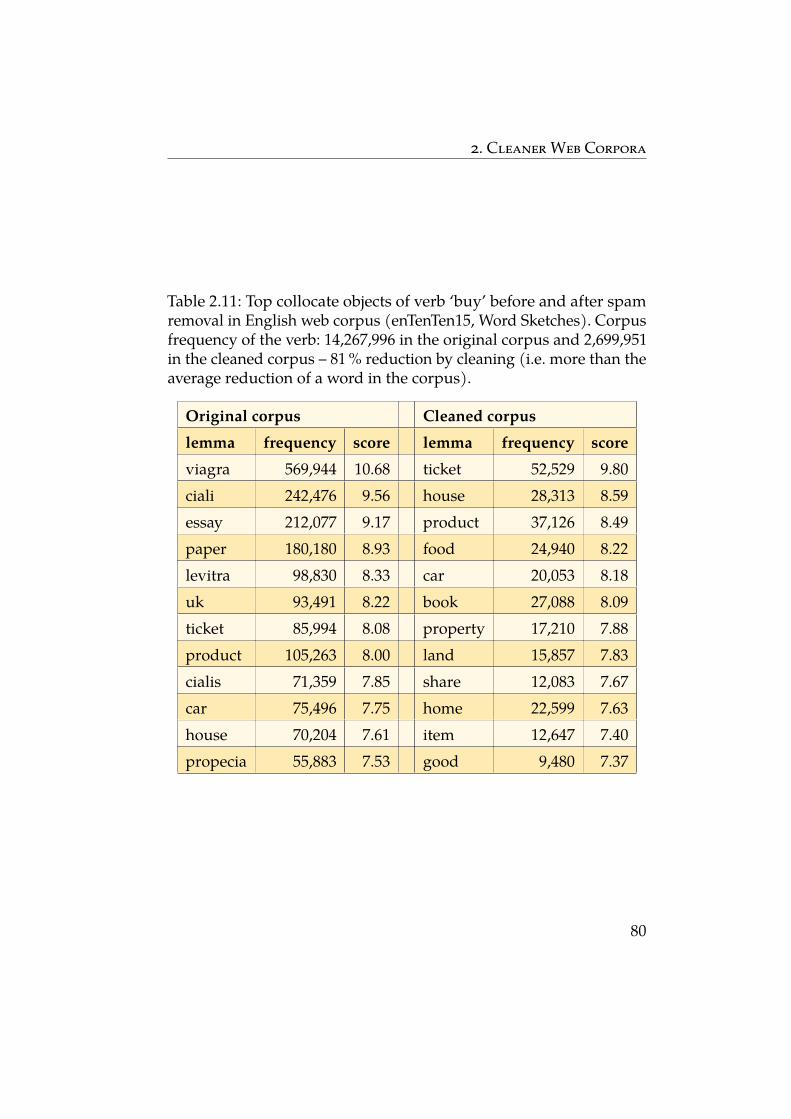
2. Cleaner Web Corpora
Table 2.11: Top collocate objects of verb ‘buy’ before and after spamremoval in English web corpus (enTenTen15, Word Sketches). Corpusfrequency of the verb: 14,267,996 in the original corpus and 2,699,951in the cleaned corpus – 81% reduction by cleaning (i.e. more than theaverage reduction of a word in the corpus).
Original corpus Cleaned corpuslemma frequency score lemma frequency scoreviagra 569,944 10.68 ticket 52,529 9.80ciali 242,476 9.56 house 28,313 8.59essay 212,077 9.17 product 37,126 8.49paper 180,180 8.93 food 24,940 8.22levitra 98,830 8.33 car 20,053 8.18uk 93,491 8.22 book 27,088 8.09ticket 85,994 8.08 property 17,210 7.88product 105,263 8.00 land 15,857 7.83cialis 71,359 7.85 share 12,083 7.67car 75,496 7.75 home 22,599 7.63house 70,204 7.61 item 12,647 7.40propecia 55,883 7.53 good 9,480 7.37
80

2. Cleaner Web Corpora
Table 2.12: Top collocate subjects of verb ‘buy’ before and after spamremoval in English web corpus (enTenTen15, Word Sketches).
Original corpus Cleaned corpuslemma frequency score lemma frequency scoreviagra 83,231 9.41 customer 6,356 7.82ciali 74,612 9.32 consumer 4,216 7.78i 372,257 9.25 store 3,254 7.70prescription 46,548 8.62 investor 3,210 7.59essay 37,119 7.94 i 14,334 7.42levitra 24,694 7.82 [number] 2,227 6.71[url] 27,316 7.76 money 2,295 6.57uk 24,126 7.60 trader 1,131 6.46paper 28,990 7.54 Ignatius 803 6.33delivery 18,541 7.39 people 21,800 6.32tablet 18,806 7.38 Best 789 6.28canada 18,924 7.32 [url] 919 6.16
81

2. Cleaner Web Corpora
Table 2.13: Top collocate modifiers of noun ‘house’ before and afterspam removal in English web corpus (enTenTen15, Word Sketches).Corpus frequency of the noun: 10,873,053 in the original corpus and3,675,144 in the cleaned corpus – 66% reduction by cleaning.
Original corpus Cleaned corpuslemma frequency score lemma frequency scorewhite 280,842 10.58 publishing 20,314 8.63opera 58,182 8.53 open 39,684 8.47auction 41,438 8.05 guest 13,574 7.94publishing 41,855 8.02 opera 9,847 7.67geisha 38,331 7.95 old 32,855 7.64open 37,627 7.78 haunted 9,013 7.58old 73,454 7.52 auction 8,240 7.40guest 28,655 7.44 manor 7,225 7.28country 26,092 7.07 bedroom 7,717 7.26stone 18,711 6.77 country 9,926 7.20dream 17,953 6.77 coffee 8,171 7.18coffee 18,336 6.74 wooden 6,803 6.96
82

2. Cleaner Web Corpora
Table 2.14: Top collocate nouns modified by adjective ‘online’ beforeand after spam removal in English web corpus (enTenTen15, WordSketches). Corpus frequency of the adjective: 20,903,329 in the origi-nal corpus and 4,118,261 in the cleaned corpus – 80% reduction bycleaning.
Original corpus Cleaned corpuslemma frequency score lemma frequency scorepharmacy 317,588 9.54 course 70,353 8.71casino 183,846 8.88 store 43,183 8.63store 224,567 8.85 resource 60,044 8.45game 210,890 8.49 platform 39,529 8.27course 187,383 8.45 tool 43,916 8.03uk 125,519 8.11 form 44,133 8.00viagra 135,812 8.09 survey 24,608 7.92canada 108,810 8.03 registration 20,276 7.91shop 89,764 7.70 database 23,112 7.89business 100,203 7.56 game 39,666 7.81resource 91,213 7.53 learning 21,260 7.78site 115,730 7.52 portal 17,682 7.77
83

2. Cleaner Web Corpora
Table 2.15: Top collocate nouns modified by adjective ‘green’ beforeand after spam removal in English web corpus (enTenTen15, WordSketches). Corpus frequency of the adjective: 2,626,241 in the origi-nal corpus and 1,585,328 in the cleaned corpus – 40% reduction bycleaning (i.e. less than the average reduction of a word in the corpus).
Original corpus Cleaned corpuslemma frequency score lemma frequency scoretea 86,031 10.04 tea 45,214 9.94light 54,991 8.74 light 33,069 8.86bean 28,724 8.63 space 51,830 8.72egg 26,150 8.45 roof 17,916 8.72space 55,412 8.19 bean 15,398 8.52vegetable 20,906 8.16 economy 24,181 8.21roof 18,910 8.1 energy 18,101 7.8leave 16,712 7.74 infrastructure 13,331 7.69economy 25,261 7.72 leave 9,754 7.69grass 13,483 7.61 building 22,172 7.67eye 24,025 7.56 eye 11,753 7.64onion 11,544 7.46 vegetable 8,110 7.58
As expected, Table 2.14 shows that nouns modified by adjective‘online’ – another word highly attractive for web spammers – sufferfrom spam too. Again, the cleaned Word Sketch looks better than theoriginal version.
The last comparison in Table 2.15 showing nouns modified by ad-jective ‘green’ is an example of cases not changedmuch by the cleaningmethod.28 It is also worthy of noting that apart from other words inthis evaluation, the relative number of occurrences of adjective ‘green’in the corpus was decreased less than the whole corpus. Although
28. There is a difference in the order of the collocates, however a fine evaluation ofcollocates is out of the scope of this work.
84

2. Cleaner Web Corpora
the classifier deliberately prefers recall over precision, the presenceof non-spam words in the corpus was reduced less than the count of‘spam susceptible’ words.
2.2.3 Semi-manual Efficient Classification of Non-text in anEstonian Web Corpus
Unlike the spam classification of English web pages described in theprevious chapter, where human annotators identified a small set ofspam documents representing various non-text types, the annotatorsclassified whole web domains this time. An Estonian web corpuscrawled in 2019 was used in this experiment. Similarly to our previousresult, supervised learning using FastText was employed to classifythe corpus.
Our assumption in this setup is that all pages in a web domain areeither good – consisting of nice human produced text – or bad – i.e.machine generated non-text or other poor quality content. Althoughthis supposition might not hold for all cases and can lead to noisytraining data for the classifier, it has two advantages: Much moretraining samples are obtained and the cost to determine if a webdomain tends to provide good text or non-text is not high. In this case,that work was done by Kristina Koppel from the Institute of EstonianLanguage at University of Tartu in several days.
Furthermore, it is efficient to check the most represented domainsin the corpus. Thus a lot of non-text can be eliminated while obtaininga lot of training web pages at the same time. Spam documents comingfrom less represented web domains can be traced by the classifier onceit is built.
A list of 1,000 Estonian web sites with the highest count of docu-ments or the highest count of tokens in the corpus was used in theprocess of manual quality checking. There were also path prefixescovering at least 10% of all paths within each site available to provideinformation about the structure of the domain. If the site was knownto the human annotator, it was marked as goodwithout further checks.If the site name looked suspiciously (e.g. a concatenation of unrelatedwords, mixed letters and numbers, or a foreign TLD), the annotatorchecked the site content on the web or its concordance lines in SketchEngine.
85

2. Cleaner Web Corpora
Site name rules were formulated by observation of bad web do-mains. E.g. all hosts startingwith ee., est., or et. under generic TLDs.com, .net, .org29 were marked as non-text since there was machinetranslated content usually observed in these cases.
77% of web pages in the corpus were semi-manually classified thisway. 16% of these documents were marked as computer generatednon-text, mostly machine translated. 6% of these documents weremarked as bad for other reasons, generally poor quality content.
A binary classifier was trained using FastText on good and non-textweb pages. URL of a page, plaintext word forms and 3 to 6 tuples ofplaintext characters were the features supplied to FastText. 10 foldcross-validation was carried out to estimate the classifier’s perfor-mance. Documents from the same web site were put in the same foldto make sure there was not the same content or the same URL prefixin multiple folds.
The estimated performance reported by FastText can be found inFigure 2.7. Precision and recall of a classification into two classes weremeasured for various label probability thresholds given by FastText.Since the ratio of good to non-text samples in the data was approxi-mately 77:16, the baseline accuracy (putting all samples in the largerclass) was 0.826. Despite the rather high baseline, the classifier per-formed well.
The final classifier was applied to the part of the corpus that hadnot been checked by the human annotator. 100 positive, i.e. non-text,and 100 negative, i.e. good, web pages were randomly selected forinspection. Kristina Koppel and Margit Langemets from the sameinstitution checked the URL and plaintext30 of each page. Three mini-mal probabilities of the top label were tested. The result precision andrecall can be seen in Figure 2.8.
It can be observed the recall dropped a lot with an increasingthreshold. Therefore, the final top label probability applied to thecorpus was set just to 0.05 to keep the recall high. We do not mindfalse positives as long as most of non-text is removed.
29. Excluding et.wikipedia.org.30. Texts were cropped to first 2,000 characters to speed up the process.
86

2. Cleaner Web Corpora
Figu
re2.7:Ev
alua
tionof
thebina
rysp
amclassifie
rina10
fold
cross-va
lidationon
semi-m
anua
llych
ecke
dEs
tonian
web
corp
us.P
recision
andrecallwereestim
ated
form
inim
alprob
abilitie
softhe
toplabe
lfrom
0to
1in
0.05
step
sand
averag
edacross
folds.Th
eba
selin
eaccu
racy
(puttin
gallsam
ples
inthelarger
class)
is0.82
6.
87

2. Cleaner Web Corpora
Figure 2.8: Evaluation of the final binary spam classifier on documentsnot previously checked by a human annotator in Estonian web corpus.Precision and recall were estimated for minimal probabilities of thenon-text label from 0.05 to 0.15. Since we aim for a high recall, theperformance with the non-text label threshold set to 0.05 is satisfying.A higher threshold leads to an undesirable drop of recall.
88

2. Cleaner Web Corpora
We consider this setup and the result as both time efficient andwell performing. It will be applied to web corpora in other languagesin cooperation with native speaker experts in the future.
Since web crawler SpiderLing measures the distance of web do-mains from the initial domains, the value can be used to estimate thequality of the content of a domain. At least, this is our hypothesis. Ifit was true, domains close to the seeds should be crawled more thandomains far from the seeds.
To prove or reject the hypothesis, the classification of spam fromthe previous experiment was put into a relation with the domain dis-tance of the respective good or bad documents. Both semi-manual andmachine classification web pages were included. The binary classifi-cation of texts – good and bad labels – aggregated by the distance ofthe respective web sites from seed domains is displayed on Figure 2.9.The evaluation does not support the hypothesis much, at least in thecase of the Estonian web.
To sum up the findings of our experiments with Estonian webcorpus:
1. A non-text classifier with a very high recall (at the cost of pre-cision) can be trained on human annotated good and bad websites.
2. The annotation process can be quite efficient: Checking webdomains most represented in the corpus produces sufficientsamples to classify the rest.
3. It is beneficial to start the crawling from trustworthy, qualitycontent sites. However, there is non-text on web sites linkedfrom the initial sites. The domain distance is related to thepresence of non-text but the correlation is not strong enough tomake it an important feature in spam removal.
89

2. Cleaner Web Corpora
Figure 2.9: Evaluation of the relation of the distance of web domainfrom the initial domains to the presence of non-text on the sites. Webpages of distances 0 to 4 classified semi-manually or by the spamclassifier were taken into account. Two thirds of the pages were indistance 1. The percentage of good and bad documents within thesame domain distance is shown. The presence of non-text in the datais notable from distance 1.
90

2. Cleaner Web Corpora
2.2.4 Web Spam Conclusion
To conclude the section on web spam removal, we consider computergenerated non-text the main factor decreasing the quality of webcorpora. A classifier trained on manually identified spam documentswas applied to remove unwanted content from a recent English webcorpus. The threshold of the classifier was set to prefer recall at thecost of greatly reducing the size of the result corpus.
Although the evaluation of the classifier on the training set reportsa far from perfect recall of 71%, it was able to notably decrease thepresence of spam related words in the corpus.
An extrinsic evaluation was carried out by comparing the originaldata and the cleaned version in a lexicography oriented application:Relative corpus frequencies of words and Word Sketches of grammati-cal relations that could be used to make a dictionary entry for selectedverb, nouns and adjectives were compared in the experiment.
Another experiment with a smaller Estonian corpus was carriedout. An efficient human annotation lead to using more than two thirdsof the corpus as training data for the spam classifier. The evaluationof the classifier shows a very high recall of 97% was reached.
We understand the process can take more time for large internetlanguages such as English, Spanish, Russian or Chinese. We admit thenumber of sites in our Estonian experiment is small in comparison tothese languages. Nevertheless we believe this is a good way to go forall languages.
91

3 Richer Web Corpora
As we stated in the introductory chapter, understanding the contentof a web corpus is important. The traditional corpora were designedfor particular use and compiled from deliberately selected sources ofgood quality:
∙ British National Corpus consists of ca. 10% spoken data andca. 90% written component further divided by domain, genre,level and date. [Lee92]
∙ Czech National Corpus SYN contains ‘two kinds of referencecorpora: balanced andnewspaper ones. The latter are composedsolely of newspapers and magazines and this is denoted bytheir suffix “PUB”. The 3 balanced corpora cover 3 consecutivetime periods and they contain a large variety of written genres(including also fiction and professional literature) subclassifiedinto 74 categories in proportions based on language receptionstudies.’ [Hná+14]
∙ Slovak National Corpus is reported to contain published textsconsisting of 71.1% journalism, 15.4% arts, 8.5% technical doc-uments, 50̇% other texts.1
∙ Estonian National Corpus is a mix of texts from traditionalmedia andweb pages with subcorpora from Estonian ReferenceCorpus 1990-2008, Estonian web from 2013, 2017 and 2019,Estonian Wikipedia from 2017 and 2019, Estonian Open AccessJournals (DOAJ). [KK] There is rich metadata in the Referencecorpus part and theWikipedia subcorpus because of the natureof their sources.
Such precise selection of nice texts is hardly possible in the caseof large web corpora. Researchers using web corpora for their workneed to know their sources! (Re-formulation of the appeal in [Kil12].)
From our point of view, it is desirable to provide web corpora withrich annotation such as language varieties (e.g. British, American,Australian or Indian English), topics (such as sports, health, business,
1. https://korpus.sk/structure1.html, accessed in January 2020.
92

3. Richer Web Corpora
culture), genres (informative, encyclopedic, instructive, appellative,narrative), registers (formal, informal, professional) and other texttypes.
Since these categories do not come with the data, it is possible toannotate web documents using a supervised classification approach.Furthermore, the distribution of these text attributes in a web corpuscan help the users not only to know what is ‘inside’. In addition tothat, it enables the users to work with just a selection of subcorporabased on the text types.
Language variety can be identified by the wordlist method de-scribed and applied to Norwegian variants Bokmål and Nynorsk inSection 2.1.
[Kil12] proposed keyword comparison as a method of knowingcorpora better. This and other intrinsic methods such as the size, aver-age sentence length, homogeneity or the count of blacklisted wordscompare measurable corpus properties.
On the other hand, extrinsic evaluation compares corpora by com-paring the output of applications. For example, by measuring by theBLEU score of the same machine translation method trained on thecorpora to compare, we can findwhich corpus is better for trainingma-chine translation or – in a wider scope – better for all language modelbased methods or – generalising ad maximum – better altogether.
A genre annotation scheme in an English web corpus and se-lected issues of genre definition and identification are described inSection 3.1.
A case study of adding a text topic annotation to English andEstonian web corpora through supervised classification is presentedin Section 3.2.
93

3. Richer Web Corpora
3.1 Genre Annotation of Web Corpora: Scheme andIssues
This section presents an attempt to classify genres in a large Englishweb corpus through supervised learning. A collection of web pagesrepresenting various genres that was created for this task and a schemeof consequent human annotation of the data set is described.
Measuring the inter-annotator agreement revealed that either theproblem may not be well defined, or that our expectations concerningthe precision and recall of the classifier cannot be met.
Eventually, the project was postponed at that point. Possible solu-tions of the issue are discussed at the end of the section.
3.1.1 Genre Selection and Reliability of Classification
A dictionary definition of genre is ‘A particular style or category ofworks of art; esp. a type of literary work characterised by a particularform, style, or purpose.’2
[MSS10] state genre is ‘A set of conventions (regularities) that tran-scend individual texts, helping humans to identify the communicativepurpose and the context underlying a document.’
To add a perspective of text corpus users who do language re-search, build dictionaries, or e.g. produce language models for writingprediction – adding information about genre to corpus texts allowsthem to know more about the composition of the corpus and enablesthem to use subcorpora limited to a particular genre.
[Ros08] lists reasons for determining genres of web documents forinformation retrieval. These reasons can be applied to corpus linguis-tics and NLP too:
∙ ‘People normally store and retrieve documents by genre.’∙ ‘Genre is a compact way to describe a document.’∙ ‘There is a need for non-topical search descriptors.’∙ ‘Many traditional genres have migrated to the web.’
2. The second edition of Oxford English Dictionary (1989). Accessed online athttps://www.oed.com/oed2/00093719 in April 2020.
94

3. Richer Web Corpora
∙ There are unique genres on the web. ‘Some of the most populartags for web pages on the social tagging site delicio.us aregenre labels, such as blog, howto, tutorial, news and research.’
[Bib88, p. 121] uses The Lancaster-Oslo/Bergen Corpus of BritishEnglish (LOB) and The London-Lund Corpus of Spoken English. Sixdimensions based on lexical, syntactic and semantic attributes of textare described, e.g. Narrative vs. Non-Narrative Concerns or Abstractvs. Non-Abstract Information.
Indeed, genres can be described by linguistic properties of text.[Bib89] uses the term ‘linguistic markers’ and lists positive featuresof e.g. discerning ‘narrative versus non-narrative concerns’ – ‘past-tense verbs, 3rd person pronouns, perfect-aspect verbs, public verbs,synthetic negation, present-participial clauses’ – and complementaryfeatures – ‘present-tense verbs, attributive adjectives’.
Biber used rules based on scores of linguistic features. Machinelearning techniques are preferred by recent research. Our understand-ing is a genre is determined by the style of writing, content words areonly supporting evidence – unlike topics that are determined by con-tent words. Therefore it is the style that is key in assessing the genre,content words are only secondary. It is necessary to add linguisticfeatures such as the verb tense in the features for training a classifier.
Well known corpora Brown Corpus and LOB consist of a prioridetermined number of texts bearing signs of the following genres andtopics: Press: reportage; Press: editorial; Press: reviews; Religion; Skills,trades and hobbies; Popular lore; Belles lettres, biography, essays;Learned and scientific writings; General fiction; Mystery and detectivefiction; Science fiction; Adventure and western fiction; Romance andlove story; Humour; Miscellaneous.
Unlike corpora traditionally constructed from selected sourceswith known text types, we need to classify documents that come fromsources without a determined text type and that are already in thecorpus.
In the early ears of the internet, [DKB98] dealt with the genreof web sites. The set of genres to recognise was derived from a pollof internet users. The result set was: Personal homepages; Public orcommercial homepages; Searchable indices; Journalistic materials;Reports (scientific, legal); Other running text; FAQs; Link Collections;
95

3. Richer Web Corpora
Other listings and tables; Asynchronous multi-party correspondence(discussions, Usenet News); Error Messages. Despite too internetoriented and somewhat old, categories such as Personal homepages,Public or commercial homepages and FAQs are useful for our purpose.
While [Ros08] claimed ‘People can recognize the genre of digitaldocuments’, [ZS04] stated the opposite – that humans are incapable ofdetermining the genre of a web page consistently and that web pagescan have multiple genres and may not resemble sample single genretexts.
A research of papers on web genres by [CKR10] revealed seriousdifficulties of defining and determining web genres: ‘Unfortunately,our review of the literature reveals a lack of consensus about the Webgenre taxonomy on which to base such systems. Furthermore, ourreview of reported efforts to develop such taxonomies suggests thatconsensus is unlikely. Rather, we argue that these issues actually resistresolution because the acceptance of potential answers depends ona researcher’s epistemological and ontological orientation’. Yet theystress ‘a continuing and, indeed, growing need for understanding adocument’s genre’.
In our work, we are determined to identify genres useful for textcorpora users. That should reduce the number of possibilities andapproaches at least a little.
[ZS04] claimed ‘An inherent problem of Web genre classificationis that even humans are not able to consistently specify the genre ofa given page.’ Such cautious approach resulted in a relatively smallcount of genres that were identified: Help; article; discussion; shop;private portrayal; non-private portrayal; link collection; download. Asupport vector machines classifier was trained on 800 HTML pagesleading to an average classification performance of 70%.
From our point of view, Dewe [DKB98], zu Eissen and Stein [ZS04]and Crowston [CKR10] propose too web oriented labels. We believecorpus linguists and lexicographers expect separate classes like Re-porting, Information, Legal, Narrative which are not discerned bythese works.
The audience of British National Corpus (BNC) is close to ours.[Lee01] categorised documents in BNC into 46 genres of written text
96

3. Richer Web Corpora
and 24 genres of spoken text. Some documents can have multiplegenres assigned.
Such fine grained categorization is not possible in the case of webcorpora for the reasons already mentioned.
[KC13] constructed a corpus from four sources naturally consistingof different genres: Conversation, newspaper, fiction and theweb. (Thepoint was a dictionary based on that corpus represented the use ofwords in those genres better than if it had been based on a single genrecorpus.)
On the contrary,wewould like to keep selectedweb genres separaterather than merging them into a single label.
[DS16] identified seven genres in academic texts on the web: In-structions, hard news, legal, commercial presentation, science/tech-nology, information, narrative. Although we like these categories, weneed to cover more than academic texts.
Following Biber, [Sha18]workedwith ‘Functional Text Dimensions’and focused on largeweb corpora. 18 genreswere identified: Argumen-tative, Emotive, Fictive, Flippant, Informal, Instructive, Hard news,Legal, Personal, Commercial presentation, Ideological presentation,Science and technology, Specialist texts, Information or encyclopedic,Evaluation, Dialogue, Poetic, Appellative. A subset containing 12 ofthese genres was also defined.
We decided to start from the Sharoff’s list of 12 genres. As notedabove, finding genres that can be reliably identified is a difficult task.We understand borders between genres are not sharp so other param-eters, namely the very definition of genres, have to be adapted.
Therefore we decided to measure the agreement of human classifi-cation of genres of web documents and merge classes until the inter-annotator agreement is sufficient. The agreement can be increased bydecreasing the granularity of genres to discern. That is why we callour approach Agreement driven.
3.1.2 Experiment Setup
The set of 12 genres defined by [Sha18] is: Argumentative, Fictive,Instructive, Hard news, Legal, Personal, Commercial presentation,Ideological presentation, Science and technology, Information or en-cyclopedic, Evaluation, Appellative.
97

3. Richer Web Corpora
Table 3.1: Sources of the collection of texts used in our experiment.Different subsets (S) were added in different times (starting withsubset 1). Most certain texts and least certain texts refer to the certaintyof a classifiermeasured by the entropy of the probability distribution oflabels given by FastText for a particular document. UKWaC [Fer+08b],enTenTen13, enTenTen15 and enTenTen18 are English web corporafrom 2007, 2013, 2015 and 2018, respectively.
S Description Author Count1 Selection from UKWaC Sharoff 448
Selection of non-text from enTenTen15 Suchomel 1232 Most certain texts from UKWaC Sharoff 456
Web search for underrepresented genres Suchomel 1983 Least certain texts from enTenTen13 Suchomel 4054 enTenTen18 random texts Suchomel 344Total count of documents in the collection 1974
Non-text (machine generated text and other web spam) was a 13thgenre added by us to enable us to use the data for learning a non-textclassifier as described in Chapter 2.3
We aimed to determine genres of web pages in a large Englishweb corpus by training a supervised classifier on human annotatedtexts. A new collection of documents, mostly web pages, was createdfor this purpose. Texts were added in the collection in four subsetsaccording to our evaluation of the task in several stages. The sourcesof the collection are summarised in Table 3.1.
We did four rounds of manual annotation of texts from the collec-tion. A group of students and academics at the University of Leedswas instructed and supervised by Serge Sharoff. Another group ofstudents and academics at Masaryk University was instructed andsupervised by the author of this thesis.
3. Since this section is about genres in web corpora rather than spam removal,genre Non-text is not included in the results unless explicitly mentioned.
98

3. Richer Web Corpora
The inter-annotator agreement (IAA) was measured after eachround to see if the genre definition was understood well and to decidehow to improve. Sample documents to explain genre differences toannotators were created. Multiple labels were allowed for documentsshowing strong signs of more genres.
We also did a round of active learning: According to the idea of atechnique called Uncertainty sampling [LC94], annotating sampleswhere the classifier is the least certain should efficiently contribute totraining the classifier, e.g. requiring a lower number of costly annotatedsamples than a random selection.
‘The basic premise is that the learner can avoid querying the in-stances it is already confident about, and focus its attention insteadon the unlabeled instances it finds confusing.’ [Set12, p. 11]
In our experiment, a classifier was trained on texts annotated atthat time using FastText. Documents with the highest entropy of theprobability distribution of labels provided by FastText – i.e. caseswhere the classifier was most unsure – were selected for the nextround of the annotation.
Since the initial IAA was below our expectation, we tried merginglabels and omitting least successful classes getting to ‘6 classes + non-text’.
Unfortunately, an evaluation showed that did not help enoughso we decided to start over with the following set of categories (stillbased on Sharoff’s genres from [Sha18] a lot). The full version can befound in Appendix A.1.
1. Information – subcategorised to
(a) Promotion (covering both commercial and ideological pre-sentation from Sharoff’s list): Promotion of a product, ser-vice, political movement, party, religious faith. Examples:An advert, a product/service page, a political manifesto.
(b) Academic: Research. Example: A research paper or anytext written using the academic style.
(c) Review: Evaluation of a specific entity by endorsing orcriticising it. Example: A product review endorsing orcriticising the product.
99

3. Richer Web Corpora
(d) Other: Any informative text not from a category above.
2. Story telling (a better name for both Fiction and Narrative): Adescription of events (real or fictional, usually in the order theyfollowed), often informal, can be in the first person. Examples:Fiction, narrative blogs.
3. Instructions: Teaching the reader how something works. Theimperative is frequent. 2nd person pronouns may be frequent.Examples: Howtos, FAQs, instructions to fill a web form.
4. News: Informative report of events recent (or coming in the nearfuture) at the time of writing (not a discussion or a general stateof affairs). Usually the formal style, set to a particular place andtime. May quote sources of information. Example: A newswire,diary-like blogs.
5. Legal. Examples: A contract, a set of regulations, a softwarelicence.
6. Discussion: A written communication of participants of a dis-cussion. Usually multiple authors. Can be personal, informalstyle. Examples: Web forums, discussions, product comments.
7. Unsure or too short: Indicating the annotator was unable todetermine the genre with confidence.
Four subcategories of Information were meant to be used separatelyor merged together for the final classifier depending on the IAA andclassifier performance.
The fourth subset of the collection was created from enTenTen18 atthis moment to introduce more contemporary web documents to thecollection. A way for annotators to mark documents too short to reachan agreement was implemented to reduce noise in the training data.
A web application providing the annotation interface was madeby the author of this thesis. The tool consist of a Python script and aSqlite database backend and an HTML & JavaScript frontend makingasynchronous requests to the backend. Screenshots of the applicationcan be seen on Figure 3.1 and Figure 3.2. The functionality of theinterface includes:
100

3. Richer Web Corpora
∙ Displaying the plaintext to annotate with a link to the originalweb page.
∙ Compact definitions of genres with examples from the annota-tion manual are shown. A short description of the procedurehelps annotators to remember key concepts, e.g. that the styleof writing is more important than the topic.
∙ Metainformation such as annotator’s nickname, number of doc-uments already annotated and remaining to annotate in thecurrent round is displayed.
∙ Multiple genres can be marked for each document.
∙ There are four labels to indicate the presence of the features ofa particular genre in the document: None (the default), Some-what, Partly, Strongly.
∙ The plaintext is split to paragraphs. The application allowsmarking paragraphs containing signs of a genre different fromthe genre of the majority of the text.
∙ A review mode allowing the supervisor to review annotationsof others after a training round.
∙ Anyone can be enabled to use the review mode to see commonmistakes or example documents after a training round.
After reviewing the initial round of annotations, we decided to ac-count in only ‘Strongly’ labels. The annotators did not know that. Thepurpose of other, weaker labels was just to help humans resist thetemptation to choose ‘Strongly’ if not perfectly sure (and not indicating‘Unsure or too short’ too).
The final experiment continued by hiring six university studentsproficient in English at level B2 or C1 who received a two hours’ train-ing. Then, each of annotators worked through a training round of 45documents. All annotations were checked by us, issues were madeclear and everyone had to review frequent mistakes.
A screenshot of the use of the review mode can be seen on Fig-ure 3.3. Since the agreement was poor in this instance, the case wasexplained to the annotators and the document was put to a review foreveryone.
101

3. Richer Web Corpora
Figure 3.1: Text type annotation interface – a web application in abrowser – the left side of the screen. Information about the annotationprocess can be seen at the top. Genres with a brief description andexamples follow. Class ‘Information::Promotion’ is labelled as stronglypresent in this case. Buttons for weaker presence of genre markers(Partly, Somewhat, None) can be clicked to change the annotation.
Figure 3.2: Text type annotation interface – a web application in abrowser – the right side of the screen. The title of the document witha link leading to the original source is located at the top. The plaintextsplit to paragraphs can be seen below. Both sides of each paragraphare coloured to visualise separate paragraphs. A paragraph can besuggested for removal from the document (to make the result trainingdata less noisy) by clicking the respective button.
102

3. Richer Web Corpora
Figure 3.3: Text type annotation interface in the review mode afterthe training round – as seen by the author of this thesis who trainedsix other annotators. Labels, coded by identifiers in columns B1 toB99, assigned to a single document by each annotator are shown.Values ‘Strong’, ‘Partially’ and ‘None’ are coded by 2, 1, 1/2 and 0,respectively. (The same coding was used by [Sha18].) Time in secondsspent by annotating the document by each annotator can be seen inthe rightmost column.
After the training round, two consecutive rounds of annotationwere made. Several rounds of active learning were planned after that,i.e. training a classifier to find the most unsure documents and an-notating those texts. However, we were not satisfied with the IAA atthat time. Further evaluations were made to find if changing someparameters of the experiment would help.
3.1.3 Inter-annotator Agreement
Our goal was to reach the following level of inter-annotator agreement:∙ Pairwise Jaccard’s similarity ≥ 0.8. . . .The similarity of sets of
labels assigned by each pair of annotators is measured.∙ Krippendorff’s alpha[Kri04] ≥ 0.67.4
Since multiple labels for a single sample were allowed, a text annota-tion was a set of labels in our case. We selected the following metricsproviding the similarity of a pair of sets.
4. Krippendorffwrote on the acceptable level of reliability expressed by the α: ‘Relyonly on variables with reliabilities above α = .800. Consider variables with reliabili-ties between α = .667 and α = .800 only for drawing tentative conclusions.’ [Kri04,p. 241]
103

3. Richer Web Corpora
1. Accuracy as a set similarity metric:def accuracy (labels1 , labels2 ):
i = labels1 . intersect ( labels2 )return (len(i) / len( labels1 ) +
len(i) / len( labels2 )) / 2.0
2. Jaccard’s similarity:def jaccard (labels1 , labels2 ):
i = len( labels1 . intersect ( labels2 ))u = len( labels1 .union( labels2 ))return len(i) / len(u)
3. Nominal comparison which tests for an exact match. It is thedefault metric for Krippendorff’s alpha for discrete labels.
An example to illustrate the difference of the metrics (assume A, B, Care class labels) follows:
Acc({A, B}, {A, C}) =|{A,B}∩{A,C}|
|{A,B}| + |{A,B}∩{A,C}||{A,C}|
2=
12 +
12
2=
12
Jaccard({A, B}, {A, C}) = |{A, B} ∩ {A, C}||{A, B} ∪ {A, C}| =
13
Nominal({A, B}, {A, C}) = 0 ({A, B} ̸= {A, C})
An overview of all experiments with IAA expressed as Accuracy, Jac-card’s similarity and Krippendorff’s alpha with set similarity metricsAccuracy, Jaccard’s similarity and Nominal comparison is providedby Table 3.2.
The first four experiments led to the final setup with nine classes(in bold typeface in Table 3.2). All rows below were derived fromthat setup by not counting instances marked as unsure or not count-ing instances with multiple labels or by merging labels Information,Promotion, Academic and Review into a single label.
Figure 3.4 and Figure 3.5 show pair annotation matrices for experi-ments without unsure or multi-label samples accounted in. Each pairof annotations of the same sample by two annotators was accountedin a two dimensional matrix with each dimension representing labels
104

3. Richer Web Corpora
Table3.2:
Inter-an
notatorag
reem
ento
fgen
rean
notatio
nof
web
docu
men
tsfordiffe
rent
expe
rimen
tsetups
.Pisthecoun
tofp
eoplean
notatin
g,Datarefers
tocolle
ctionsu
bsets,N
isthecoun
tofd
ocum
ents,
Aistheaverag
ecoun
tofa
nnotations
pertext.Acc
isAccuracy,JacisJaccard’ssimila
rity,K-A
cc,K
-Jac
and
K-N
omstan
dforK
ripp
endo
rff’salph
awith
thesets
imila
rity
metricsettoAccuracy,Jaccard’ss
imila
rity
andNom
inal
compa
rison,
resp
ectiv
ely.‘6/9
genres’m
eans
that
four
ofthenine
labe
lsweremerge
din
asing
lelabe
lfor
thepa
rticular
evalua
tion.
‘Noun
sure’m
eans
anno
tatio
nsindicatin
gthepe
rson
was
not
sure
wereom
itted
.‘Nomulti’
means
anno
tatio
nswith
multip
lestrong
labe
lswereom
itted
.
Expe
rimen
tP
Data
NA
Acc
Jacc
K-A
ccK-Jac
K-N
om12
genres
+sp
am7
1&
277
3.66
0.52
70.50
70.44
40.42
80.40
112
genres
+sp
am4
1&
214
93.30
0.49
50.48
40.44
90.43
80.41
76ge
nres
+sp
am4
1to
350
4.00
0.66
00.65
30.55
70.55
00.53
46ge
nres
+sp
am,n
oun
sure
51to
350
5.00
0.76
80.76
20.60
30.59
50.58
09ge
nres,training
7All
457.00
0.60
00.58
50.49
10.47
70.44
99ge
nres
–theba
sefor↓
6All
1,35
62.57
0.64
00.62
80.53
00.51
80.49
79ge
nres,n
oun
sure
6All
1,34
22.51
0.67
00.65
80.56
20.55
00.52
89ge
nres,n
oun
sure,n
omulti
6All
1,34
02.43
0.67
60.67
60.57
00.57
00.57
06/9ge
nres
6All
1,35
62.57
0.77
60.76
50.56
60.55
20.52
76/9ge
nres,n
oun
sure
6All
1,34
22.51
0.81
40.80
20.62
20.60
60.57
66/9ge
nres,n
oun
sure,n
omulti
6All
1,34
02.43
0.81
90.81
90.62
90.62
90.62
9
105

3. Richer Web Corpora
Figure 3.4: Pair annotation matrix for the setup with 9 genres, withoutunsure or multi-label samples. Percentage of all annotation pairs isshown.
given by the corresponding annotator, i.e. a sample was accountedin the row respective to the label given by the first annotator and theand column respective to the label given by the second annotator.Agreements are on the diagonal, disagreements are in other fields.The percentage of all pairs is shown.
It can be seen that Information was the class causingmost disagree-ment. The reason may be that borders between other genres are moreclear than the border of any genre with Information in our definitionof genres.
Figure 3.5: Pair annotation matrix for the setup with 6/9 genres, with-out unsure or multi-label samples. Percentage of all annotation pairsis shown.
106

3. Richer Web Corpora
Table 3.3: Pair agreement summary for setups with 9 genres and 6/9genres, without unsure or multi-label samples.
Pair agreement 9 genres 6/9 genresInformation 51.2% 77.8%Story telling 64.8% 64.8%Instructions 49.1% 49.1%News 42.7% 42.7%Legal 73.5% 73.5%Discussion 31.7% 31.7%Promotion 52.9%Academic 32.4%Review 44.1%
The percentage of agreement for each class (i.e. the ratio of the value onthe diagonal to the rest related to the label) is summarised in Table 3.3.
3.1.4 Dealing with a Low Agreement
To summarise, we tried the following to improve the inter-annotatoragreement:
∙ The number of recognised genres was reduced.∙ Multi-genre texts were omitted.∙ Short texts (indicated by annotators) were omitted.∙ Annotators were trained and their mistakes in the training
round were explained thoroughly.∙ Annotators could indicate they were not sure.∙ Annotators were paid for time spent annotating rather than thecount of annotations. (The average duration of annotating adocument was 57 seconds in the final annotation round.)
As can be seen in Table 3.2, the minimal acceptable value of Krippen-dorff’s alpha was not reached. Getting a high agreement in web genreclassification is hardly possible. Defining genres both interesting for
107

3. Richer Web Corpora
web corpus users and agreeable to annotators is difficult. That is ourconclusion as well as others: [CKR10; ZS04].
If there is a reasonable solution, it must require a different ap-proach or a lower level of target inter-annotator agreement or both.We suggest taking these measures to get a reliable genre annotationof web corpora:
∙ Remove paragraphs showing sings of a genre different from themajor genre in the training data (such paragraphs were markedby annotators).
∙ Continue the process with active learning rounds to efficientlyannotate more data.
∙ Consider using whole single genre web sites for training. Thistechnique helped in our other work with an Estonian web cor-pus – non-text removal (Section 2.2.3) and topic classification(Section 3.2.2).
∙ Train the classifier only on documents with a perfect agreement.∙ Set a high top label probability threshold of the classifier. Thatwill increase precision at the cost of recall. The users of textcorpora will not mind if the genre of some documents remainsunknown. They mind the precision.
Furthermore, since the borders of genres are not strict, we suggesta different approach to the evaluation: the ‘User’s point of view’. Toevaluate the classification, corpus users would be asked to assessthe genre annotation of random web pages from the corpus (in theplaintext format) by assigning one of the following three labels to eachselected document:
1. This is the genre.2. This could possibly be the genre.3. This could not be the genre.
We consider 5% of texts marked as ‘This could not be the genre’ anacceptable level of classification mistakes.
To conclude, we will continue the research on genre classificationof large web corpora despite the issues described in this section. Weare interested in exploring the genre composition of the English weband offering the corpus users a possibility to focus their research onparticular genres.
108

3. Richer Web Corpora
A keyword comparison of single genre subcorpora to the wholecorpus proposed by [Kil12] could also show interesting properties ofweb genres.
Exploring possibilities for transfer of themethod to other languagesthan English will be important too.
109

3. Richer Web Corpora
3.2 Text Type Annotation of Web Corpora
3.2.1 Topic Annotation of an English Web Corpus throughLearning from a Web Directory
Text type annotation was the next stage in the process of makingthe English web corpus5 better – after building it using Brno CorpusProcessing Pipeline introduced in Chapter 1 – followed by languagefiltering and non-text removal as described in Chapter 2. At this mo-ment, 15.4 billions of tokens in over 33 million web pages were in thecollection.
Several factors contributed to selecting the method and the setupof the task. The first decision was which text types to discern. Weconsidered both ‘bottom to top’ and ‘top to bottom’ approach. Thebottom to top way is data driven and unsupervised. The text types aredetermined by an algorithm that reads big data (i.e. text documentscorresponding to web pages in a web corpus). The number of texttypes is arbitrary – can be specified.
Clustering of vector representations of documents or topic mod-elling through Latent Dirichlet Allocation (LDA)were feasible options.Having experimented with the second method, we were unable toreliably select a single clear label not overlapping with other labels fora set of words representing a LDA topic.
In the supervised or bottom to top setup, the class labels are definedapriori. Then a supervised classifier is trained using instances of datawhere the label is known, e.g. manually annotated texts. In the caseof text topics, the training instances can be obtained fromWikipediaarticles organised in portals and hierarchical structure of categories orweb directories such as dmoz.org6 which maintain lists of web sitesorganised by a topic tree. We went for the supervised approach toclassify topics using the English part of web directory dmoz.org as thesource of training data.
Unlike genre that is determined by the style of writing wherecontent words are only a supporting evidence, topics tend to be deter-mined by words. Therefore word aware methods should be suitablefor topic classification. That is why we think it is easier to discern top-
5. enTenTen15 obtained by crawling the English web in 2015.6. dmoz.org was moved to curlie.org in 2017.
110

3. Richer Web Corpora
ics than genres. FastText by Facebook Research presented in [Jou+16]was selected for the task. It is an ‘open-source lightweight library thatallows users to learn text representations and text classifiers’ usingvector representation of words and character n-grams.7
There are 14 top level topics in the web directory: Arts, Business,Computers, Games, Health, Home, News, Recreation, Reference, Re-gional, Science, Shopping, Society, and Sports. There are hundredsof topics at the second level, for example Arts → Movies, Society →History, Sports → Track and Field. The directory goes even deeper.8We decided to aim for high precision and use just the first level topicsin the end.
532 thousand standalone web pages and pages from 1,376 thou-sand web sites linked from the landing pages of the sites listed in thedirectory were downloaded from the web. The data was processed byBrno Corpus Processing Pipeline. The result consisted of 2.2 billiontokens in nearly 4 million documents after processing.
2% documents that were categorised in multiple classes wereremoved. Documents shorter than 50 words were removed too. Theresult training corpus was made from a balanced (to a limited degree)subset of the data, 1,220,530 web pages in total. The distribution oftopics in this set can be found in Table 3.4.
The collection was shuffled and split to 97% training set, 2% eval-uation set and 1% test set. The Autotune feature of FastText was em-ployed to find optimal hyperparameters for the classification of ourdata using the evaluation set.9
Reasonable boundaries to the hyperparameter space were set priorrunning Autotune. The loss function was set to negative samplingsince it is much faster than softmax. The features of documents werewords and character 3-to-6-grams. The size of vector dimension wasset to 100. We also experimented with dimensions of 200 and 300 butautotuning in that space was two or three times slower (as expected)and showed no improvements over the default value of 100.
7. https://fasttext.cc/, accessed in April 2020.8. E.g. Society → Issues → Warfare and Conflict → Specific Conflicts → War onTerrorism → News and Media → September 11, 2001 → BBC News.9. Autotune mode was added to FastText in 2019. It searches the hyperparameterspace to optimise F-1 measure for the given task. https://fasttext.cc/docs/en/autotune.html.
111

3. Richer Web Corpora
Table 3.4: Topics from dmoz.org in the training set
Topic Web pages Topic Web pagesArts 98,320 Recreation 98,673Business 98,694 Reference 93,176Computers 98,259 Regional 97,322Games 53,828 Science 96,994Health 98,826 Shopping 99,378Home 45,942 Society 97,399News 44,722 Sports 98,997Total 1,220,530
The final hyperparameter values were obtained after 3,000 CPUcore-hours of autotuning for level 1 topics and 1,000 CPU core-hoursfor level 2 topics.10 The expected F-1 values reached 0.712 in the caseof level 1 topics and approximately 0.6 in the case of a subset of level2 topics. From this step we decided to continue just with level 1 topics.Using the best hyperparameter values, a FastText supervised modelwas trained on train and evaluation sets.
Figure 3.6 shows the final evaluation of the classifier on the testset. Precision, recall, F-1 and F-0.5 were measured for probabilitythresholds given by the classifier.11
A web page was classified by the best estimated label if the proba-bility of the label was higher than the threshold. Thresholds from 0 to1 with steps of 0.05 were applied. The best value of F-1 was reachedat threshold 0.15. The best value of F-0.5 was reached at threshold0.45. Since we want to achieve a high precision of the final corpusclassification, low recall is permissible.
In the end, we decided to set the final probability threshold toapply to the corpus to the value where the estimated precision was
10. The CPUs were 2 × 16-core Intel Xeon 4110s. The values of hyperparameterscan be found in Table A.2 in the Appendices.11. FastText in the supervised mode gives the probability distribution of all labelsfor each classified instance.
112

3. Richer Web Corpora
Figu
re3.6:
Evalua
tionof
the14
topicclassifie
ron
thetest
set.Precisionan
drecallwereestim
ated
byFa
stText
form
inim
alprob
abilitie
softhe
toplabe
lfrom
0to
1in
0.05
step
s.F-0.5va
lues
plottedin
green.
113

3. Richer Web Corpora
close to 0.94 – separately for each topic. Precision, recall and F-0.5estimated for this setup and each recognised topic are summarised inTable 3.5.
The setup can be explained using this example: The classifier givesthe probability distribution of labels for a web page. Assume the bestlabel is Arts. If the reported probability of the label is at least 98.3%(see the Arts row in Table 3.5) the web page gets a topic label ‘Arts’.Otherwise the topic label will be ‘unknown’.
According to the estimation obtained by evaluating the classifieron the test set, we can expect 1.) to find approximately 25% of real Artsweb pages and 2.) that there may be approx. 6% documents wronglyclassified as Arts in the Arts subcorpus.
The final model was trained on the whole set (1,220,530 web pageslisted on dmoz.org) and applied using the label probability thresholdsin Table 3.5 to the English web corpus.
Although documents in the corpus are web pages like the trainingdata, the variety of the full corpus can be much greater – not just goodcontent sites that made it in one of the 14 level 1 categories in thedirectory. Therefore a lower success rate than estimated should beexpected.
Finally, 11% of web pages in the corpus were assigned a topiclabel using the method. Figure 3.7 shows the distribution of classifieddocuments in the corpus.
114

3. Richer Web Corpora
Table 3.5: Precision and recall for each recognised dmoz.org level 1topic estimated by FastText. The threshold of minimal probability ofthe top label was set to the value where the estimated precision wasclose to 0.94.
Topic Threshold Precision Recall F-0.5Arts 0.983 0.942 0.246 0.602Business 0.985 0.932 0.106 0.364Computers 0.990 0.940 0.262 0.619Games 0.944 0.936 0.507 0.801Health 0.864 0.940 0.571 0.832Home 0.922 0.942 0.365 0.716News 0.931 0.940 0.335 0.691Recreation 0.993 0.930 0.191 0.524Reference 0.989 0.946 0.208 0.553Regional 0.935 0.946 0.367 0.719Science 0.980 0.938 0.228 0.578Shopping 0.963 0.942 0.341 0.696Society 0.986 0.946 0.199 0.540Sports 0.957 0.940 0.506 0.802
115

3. Richer Web Corpora
Figu
re3.7:
Sizeso
ftop
ican
notatedsu
bcorpo
raof
enTenT
en15
–do
cumen
tand
toke
ncoun
ts.
116

3. Richer Web Corpora
3.2.2 Semi-manual Efficient Annotation of Text Types inEstonian National Corpus
A similar setup to classify topics was made in the case of EstonianNational Corpus 2019. This time, the following parts of the procedurewere different from the case of the English corpus:
1. Estonian web directory neti.ee and sites identified by KristinaKoppel from the Institute of Estonian Language at Universityof Tartu in the corpus were used to annotate the training data.Kristina also defined rules for URLs that had precedence overthe label of whole sites. For example, all web pages containing‘forum’ in the URL were labelled as Discussion and all webpages containing ‘blog’ in the URL were labelled as Blog. Thusonly 28% of non-spam web pages remained to be classified.
2. 36 classes identified by Kristina were merged by the authorof this thesis into 20 topics and two genres (the genres beingDiscussion and Blog) for the sake of clarity. E.g. ‘sites focusedon women’ were merged into Society which is a more generalcategory.
3. URL of a page was made part of the features for training theclassifier.
4. The amount and consistency of training data and better esti-mations of the performance of the classifier allowed for a morepermissive top label probability threshold of 0.5 for the bestestimated label.
The final recall of the classifier built by FastText using the trainingdata reached 33%. Figure 3.8 shows the distribution of topics of alldocuments in the result corpus.
Twenty topics and two genres were discerned in Estonian NationalCorpus to know better the content of the corpus. It is possible to workwith topic based subcorpora of the corpus now.
Better preparation of training data (including human effort) andadding the URL among the training features led to an improved per-formance in comparison with the previously described experiment.
117

3. Richer Web Corpora
Figu
re3.8:
Sizeso
ftop
ican
notatedsu
bcorpo
raof
Estonian
Nationa
lCorpu
s201
9–do
cumen
tand
toke
ncoun
ts.
118

3. Richer Web Corpora
Aplan for the futuremay involve creating aweb application for lexi-cographers to getmore text types in large corpora by a semi-automatedway:
First, text types of web domains represented the most in the corpusand rules for URLs would be set.
Then, one or two rounds of active learningwould follow to improvethe classifier efficiently.
The rest can be automated: FastText provides an interface for allclassification tasks involved and is fast enough to train a model andclassify the corpus in less than a day.
119

4 Summary
4.1 Author’s Contribution
The author of this thesis has been creating corpus tools and buildingweb corpora since 2011. The size of corpora built in the last three yearsexceeds 200 billion tokens after post-processing altogether. In thisthesis, the architecture of a web crawler developed by the author wasintroduced. Its key design features were explained.
The crawler was put into the context of other components of socalled ‘Brno processing pipeline’ which has been successfully used tobuild large text corpora from the web. Separate tools from the pipelinewere described in several papers in the past. This thesis presents a newoverview of the whole process of using the text processing pipeline.The author of this thesis has been developing the pipeline and main-taining its parts since 2012.
This thesis builds upon our previous work on discerning similarlanguages and removing non-text from an English web corpus. In thisthesis, a method of language discrimination using word counts fromlarge web corpora was implemented and evaluated.
We have been dealing with non-text in web corpora since 2012. Thecontribution of the author of this thesis published in an own paper[Suc17] and in co-authored submissions [BS12a; Bai+15; Jak+20b;KS13] presented at Web as Corpus workshops is:
1. Description of the issue of spam in web corpora.2. Proposal of ways to avoid downloading non-text, implementa-
tion of the method, application to data for a language learningsite.
3. Proposal of methods to remove spam, application of a super-vised learning based method to an English web corpus, evalua-tion.
4. Analysis of current challenges in web corpus building and mi-tigation of their impact on web corpora.
The most important results of that work were summarised in thisthesis. The improvement of corpus based language analyses achievedby a supervised classifier applied to an Englishweb corpuswas shown.
120

4. Summary
A semi-manual approach of obtaining samples of non-text webpages making the supervised learning process more efficient was usedfor cleaning an Estonian web corpus. The recall of the Estonian webspam classifier – manually evaluated on 200 web pages – reaching97% is a success.
Our work on large web corpora, i.e. building corpora, cleaningthem and making them richer, proved essential in successful projectsin several fields of natural language processing:
∙ In the field of terminology, results were presented in a co-authored paper Finding Terms in Corpora for Many Languageswith the Sketch Engine [Jak+14] in the demonstration sessionof A-ranked conference EACL1 in Gothenburg in 2014, cited 36times up to date, and in a co-authored article A New Approachfor Semi-Automatic Building and Extending a MultilingualTerminology Thesaurus [Hor+19] published in InternationalJournal on Artificial Intelligence Tools.
∙ In the field of language learning, our contribution to a corpusbased tool for online language learning was presented at Cor-pus Linguistics conference in Birmingham in 2015. [Bai+15]
∙ In the field of lexicography, several projects were based oncorpora built and adjusted to the projects’ needs by the authorof this thesis. Results were presented at conference e-Lex2 inLeiden in 2017 and in Sintra in 2019. [Bai+19; KSK17; Kop+19]
1. The European Chapter of the Association for Computational Linguistics2. Electronic Lexicography in the 21st Century
121

4. Summary
4.2 Future Challenges of Building Web Corpora
Although our work on efficient web crawling and corpus text cleaninghas proven useful inmore than ten projects collaboratingwith partnersfrom over the world, there is yet more work ahead.
The internet is changing constantly. The part of the web closed togeneral crawlers is growing. Both [She13] and [Jak+20b] name closedcontent or deep web as a significant issue in their papers on currentchallenges in web crawling.
News sites are moving to a paid subscription.Facebook and Twitterwhich could be great sources of genres under-
represented in web corpora (as noticed by [Cvr+20]) are not givingsuch data out (obviously) or do give only some data and only to largecompanies and their affiliates.
The organisers of Web as Corpus workshop in 2020 noticed ‘thedeath of forums in favour of more closed platforms’.3
Apart of web content is served dynamically. This is another changecrawling has to cope with. Using a web browser engine to parse andexecute web scripts is the key.
Efficient crawling requires dealing with the fact the same contentcan be reached via multiple (possibly an unlimited amount) of URLs.E.g. various filters in e-shops leading to the same page with the de-scription of goods.
Computer generated text is on the rise too. Although ‘starting thecrawl from a set of trustworthy seed domains, measuring domaindistance from seed domains and not deviating too deep from theseed domains using hostname heuristics’ [Jak+20b] are ways to avoidspam, a lot of generated non-text will still be downloaded.
Strategies of non-text detection using language models will justcompete with the same language models generating non-text.
Machine translation is a specific subcase. Although there mightexist a solution – watermarking the output of statistical machine trans-lation – suggested by [Ven+11], we are not aware of the actual spreadof this technique.
Internet societies emerging from the so called ‘developing coun-tries’ seem to skip the age of recording thoughts in text – to generating
3. https://www.sigwac.org.uk/wiki/WAC-XII, visited in January 2020.
122

4. Summary
multimedia content. Will there be ‘Video Sketches’ summarising mul-timedia collocations in the future?
An example is e.g. Laos, a country with over 7 million citizensout of which over 25% are online4, where after extensive crawling forabout half a year we were only able to obtain a corpus of about 100million words (after a thorough cleaning) – whereas in a country likeSlovenia with 2 million citizens out of which almost 80% are online,one can crawl a billion-word-sized corpus with no extra effort.
Richer annotation of web corpora is another field we would liketo move ahead in the future. Topic and genre annotation should beadded to all corpora since understanding the data is important forevery application.
Finally, we believe the web will remain the largest source of textcorpora – worthy of dealing with both known and emerging chal-lenges.
4. Data taken from https://en.wikipedia.org/wiki/List_of_countries_by_number_of_Internet_users, accessed in February 2020.
123

A Appendices
124

A. Appendices
A.1 Genre Definition for Annotators
Definition of genre and classes to recognise from the annotation man-ual used for the reference of annotators in the ‘9 genres’ annotationscheme follow. This manual is an extension of Sharoff’s descriptionof Functional Text Dimensions in [Sha18, pp. 94–95]. Classes werere-organised in a 9 class scheme, linguistic markers to observe in thetext were provided and examples of text were added by the author ofthis thesis.
Definitions of genre∙ A particular style or category of works of art; esp. a type of literary
work characterised by a particular form, style, or purpose. – A generalOED definition.
∙ A set of conventions (regularities) that transcend individual texts,helping humans to identify the communicative purpose and the con-text underlying a document. – Santini, Mehler, Sharoff: Genres onthe Web: Computational Models and Empirical Studies. Vol. 42.Springer Science & Business Media, 2010.
∙ Sketch Engine perspective: The users need to know what typesof text are included in the corpus. Since the users do languageresearch, building dictionaries, n-gram models for writing pre-diction etc., including genre information allows them to usesubcorpora limited to a particular genre.
The aim of this annotation project is to identify genres in texts on theweb.Genres are not topics. Topics are determined by content words.A genre is determined by the style of writing, content words are onlysupporting evidence. Therefore it is the style that is key in assessingthe genre, content words are only secondary.
Recognised Genres (Functional Text Dimensions)Information = To what extent does the text provide informa-tion? Examples: topic definition (textbooks, general informa-tion, encyclopedia), blogs (topic blogs, argumentative/pointof view blogs), research (scientific papers, popular science),advertisement/promotion of goods/services/thoughts.
125

A. Appendices
– Subcategory Promotion = To what extent does the textpromote a product, service, political movement, party, re-ligious faith? Examples: A company landing page, an ad-vertisement, a product presentation page, an e-shop cata-logue page, a job offer, a page describing the service of acharity, a religious tract, a political manifesto.
– Subcategory Academic = To what extent would you con-sider the text as representing research? Usually formal,first person plural, scientific terms. Example: A researchpaper or any text written using the academic style. Also,it can be Partly if a news text reports scientific contents.
– SubcategoryReview= Towhat extent does the text evalu-ate a specific entity by endorsing or criticising it? Usuallya personal experience of the reviewer, comparison to otherproducts, pros and cons. Example: product review endors-ing or criticising the product.
– Other informative text – select the general Information
Story telling = To what extent is the text’s content fictional ortelling a story? Examples: Description of events in the orderthey followed (real or fictional), sometimes informal style, canbe in the first person. All narrative texts belong to this category:fiction, narrative blogs. Example: “I visited New York, I was atthe White House, saw the Statue of Liberty, my luggage got loston the way back.”
Instructions=Teaching the reader how somethingworks. Theimperative is frequent. Example: “Fill in all fields in this formand click the OK button. Then wait for three minutes and addone teaspoon of sugar.”
News = Informative report of events recent (or coming in thenear future) at the time of writing (not a discussion or a generalstate of affairs). Frequently formal style, set to a particular placeand time. Often quotes sources of information. A diary-likeblog entry is also considered reporting. Examples: “Prague,10/28/18. President Zeman said <quotation>.” Or: “‘Almost
126

A. Appendices
five million tourists visited Czech Republic the last year’, saidJana Bartošová, the deputy of the minister of culture.”
Legal = To what extent does the text lay down a contract orspecify a set of regulations? Examples: a law, a contract, copy-right notices, university regulations.
Discussion=Awritten communication of participants of a dis-cussion. Frequently personal and informal style. Examples: ex-pressing points of view, giving advice, responses/comments tothe original article or previous comments, sharing personal ex-periences. Can be multiple authors. (Note that just describinghow something works is Information, just giving instructionshow to solve a problem is Instructions.)
Non-text = To what extent is the text different from what isexpected to be a normal running text? Examples: Lists of links,online forms, tables of items, bibliographic references, cloud oftags, sentences ending in the middle, machine generated text.Not a Non-text if at least 30
Short text/Unsure = A valid text (not a Non-text) that is tooshort to determine its genre. Or a text not belonging stronglyto any class.
Multiple genres = A valid text (not a Non-text) consistingof several long parts showing strong signs of multiple genres.Example: A long news article with a long discussion below thearticle. Instruction: Select Multiple genres, then mark particulargenres by Partly. Use the Remove button to remove paragraphsof a minor genre instead.
A.2 Text Size after Processing Steps
A summary of data size in four stages of text processing ofweb corporacrawled by SpiderLing recently can be found in Table A.1.
127

A. AppendicesTa
bleA.1:T
extsizeafterthree
Brno
pipe
lineprocessing
step
sforten
recently
craw
ledtarget
lang
uage
s.‘Clean
rate’c
olum
nssh
owho
wmuc
hda
taor
toke
nswereremov
edin
theresp
ectiv
ecleaning
step
.Th
efir
stpa
rtis
performed
bytoolsem
bedd
edin
craw
lerSp
iderLing
:Boilerp
late
remov
alby
Justext,
plaintexte
xtractionfrom
HTM
Lby
Justexta
ndlang
uage
filtering
usingch
aractertrigram
mod
elsfor
each
recogn
ised
lang
uage
.Morethan
95%
ofdo
wnloa
dedda
taisremov
edby
thisproced
ure.Th
ene
xtstep
isfiltering
unwan
tedlang
uage
sinclud
ingdiscerning
simila
rlan
guag
esus
inglists
ofwords
from
largeweb
corp
ora.
Thelaststep
inthistablesh
owst
hepe
rcen
tage
oftoke
nsremov
edby
near
paragrap
hde
-dup
licationby
Onion
.Morethan
60%
oftoke
nsisremov
edthisway.
Boile
rplate
remov
al,lan
gid.
Lang
uage
filtering
,DSL
De-du
plication
Target
HTM
LPlaintex
tClean
Inpu
tOutpu
tClean
Outpu
tClean
lang
uage
size
size
rate
toke
nstoke
nsrate
toke
nsrate
CS&
SK9.74
TB24
1,45
2MB
97.52%
35.2
B33
.8B
3.9%
8.2B
75.7%
English
9.09
TB61
0,97
1MB
93.28%
105.0B
104.2B
0.8%
41.4
B60
.2%
Estonian
3.81
TB57
,938
MB
98.48%
7.8B
7.4B
4.6%
2.1B
71.1%
Finn
ish
7.65
TB13
6,89
9MB
98.21%
16.5
B15
.8B
4.3%
4.1B
74.0%
Fren
ch7.44
TB26
4,19
9MB
96.45%
44.4
B44
.1B
0.8%
12.8
B71
.1%
Greek
3.71
TB10
8,72
4MB
97.07%
10.1
B10
.1B
0.3%
2.9B
71.7%
Irish
39GB
1,02
4MB
97.34%
172.5M
171.7M
0.5%
51.6
M69
.9%
Italia
n6.26
TB19
5,15
0MB
96.88%
31.1
B31
.0B
0.4%
12.4
B60
.0%
Polis
h2.17
TB97
,427
MB
95.50%
13.8
B13
.7B
0.2%
5.2B
62.0%
128

A. Appendices
A.3 FastText Hyperparameters for English TopicClassification
Table A.2: Hyperparameter values autotuned by FastText for topicclassification in our English web corpus. By modifying FastText’sautotune code, the search space of some parameters was limited toa certain interval and parameters marked as fixed were set to a fixedvalue. ‘Val.’ is the final value. ‘M’ stands for millions.
Parameter FT param. Val. MethodDimensions dim 100 try {100, 200, 300}Loss function loss ns fixedContext size ws 5 try {5, 10}Negatives sampled neg 15 try {5, 10, 15}Learning rate lr 0.134 autotune in [0.1, 1]
Epoch epoch 33 autotune in [10, 50]
Min word freq. minCount 5 fixedMax word tuples wordNgrams 5 fixedMin char. tuples minn 3 try {0, 3}Max char. tuples maxn 6 try {0, 6}Buckets bucket 5M autotune in [1M, 5M]
Subvector size dsub 2 autotune in {2, 4, 8}
129

A. Appendices
A.4 Selected Papers
A list of journal and conference papers authored or co-authored bythe author of this thesis follow. A brief description of the contributionof the author of this thesis and estimated share of the work is givenfor each paper. Citation count obtained from Google Scholar in April2020 is provided in the case of the most cited works.
Journals:1. Aleš Horák, Vít Baisa, AdamRambousek, and Vít Suchomel. “A
New Approach for Semi-Automatic Building and Extending aMultilingual Terminology Thesaurus”. In: International Journalon Artificial Intelligence Tools 28.02 (2019), p. 1950008Share of work: 15%Own contribution: Crawling domain web corpora, corpora de-scription, extraction of onthology information from the corpora.Journal Rating: Impact factor 0.849
2. Tressy Arts, Yonatan Belinkov, Nizar Habash, Adam Kilgar-riff, and Vít Suchomel. “arTenTen: Arabic corpus and wordsketches”. In: Journal of King Saud University – Computer andInformation Sciences 26.4 (2014), pp. 357–371Share of work: 20%Own contribution: Efficient crawling of an Arabic web corpus,building the corpus, corpus description.Journal Rating: FI-rank B (Google Scholar h5-index = 30)Citation count: 34
3. Adam Kilgarriff, Vít Baisa, Jan Busta, Miloš Jakubíček, VojtěchKovář, Jan Michelfeit, Pavel Rychlý, and Vít Suchomel. “TheSketch Engine: Ten Years On”. In: Lexicography 1.1 (2014), pp. 7–36Share of work: 10%Own contribution: Efficient crawling of corpora in various lan-guages. Text processing pipeline. Process description.Citation count: 622
130

A. Appendices
Rank B conferences:4. Pavel Rychlý and Vít Suchomel. “Annotated amharic corpora”.
In: International Conference on Text, Speech, and Dialogue. Springer.2016, pp. 295–302Share of work: 50%Own contribution: Efficient crawling of an Amharic corpus,building the corpus, corpus description.Conference Rating: FI-rank B (Google Scholar h5-index = 11)
5. Ondřej Bojar, Vojtěch Diatka, Pavel Rychlý, Pavel Straňák, VítSuchomel, Aleš Tamchyna, and Daniel Zeman. “HindEnCorp-Hindi-English and Hindi-only Corpus for Machine Transla-tion”. In: Proceedings of Ninth International Conference on Lan-guage Resources and Evaluation. 2014, pp. 3550–3555Share of work: 10%Own contribution: Efficient crawling of a Hindi corpus, datafor the final corpus.ConferenceRating: FI-rankB (GGSConferenceRating B,GoogleScholar h5-index = 45)Citation count: 78
Web As Corpus ACL SIG workshop – The venue most relevant tomy work:
6. Miloš Jakubíček, Vojtěch Kovář, Pavel Rychlý, and Vít Suchomel.Current Challenges in Web Corpus Building. Submission Acceptedfor publication. 2020Share of work: 40%Own contribution: Co-analysis of current challenges in webcorpus building and mitigation of their impact on web corpora.
7. Vít Suchomel. “Removing spam from web corpora throughsupervised learning using FastText”. In: Proceedings of the Work-shop on Challenges in the Management of Large Corpora and BigData and Natural Language Processing (CMLC-5+BigNLP) 2017including the papers from the Web-as-Corpus (WAC-XI) guest sec-tion. Birmingham, 2017, pp. 56–60Share of work: 100%
131

A. Appendices
Own contribution: A supervised learning method of non-textdetection, application to a web corpus, evaluation.
8. AdamKilgarriff and Vít Suchomel. “Web Spam”. In: Proceedingsof the 8th Web as Corpus Workshop (WAC-8) @Corpus Linguistics2013. Ed. by Paul Rayson Stefan Evert Egon Stemle. 2013, pp. 46–52Share of work: 50%Own contribution: Methods of non-text detection and mitiga-tion of its impact on web corpora.Citation count: 6
9. Vít Suchomel and Jan Pomikálek. “Efficient Web Crawling forLarge Text Corpora”. In: Proceedings of the seventh Web as CorpusWorkshop (WAC7). Ed. by Serge Sharoff Adam Kilgarriff. Lyon,2012, pp. 39–43Share of work: 60%Own contribution: Web crawler design, implementation of fo-cused crawling by measuring the yield rate of web domains,efficient crawling of a web corpus used in a comparison of webcrawlers.Citation count: 94
Chapter in a book:10. Miloš Jakubíček, Vít Baisa, Jan Bušta, Vojtěch Kovář, JanMichel-
feit, Pavel Rychlý, and Vít Suchomel. Walking the Tightrope be-tween Linguistics and Language Engineering. Submission acceptedfor publication. Springer, 2020Share of work: 10%Own contribution: Section on building very large text corporafrom the web.
Other papers relevant to this thesis:11. Vít Suchomel. “Discriminating Between Similar Languages Us-
ing Large Web Corpora”. In: Proceedings of Recent Advancesin Slavonic Natural Language Processing, RASLAN 2019. 2019,pp. 129–135Share of work: 100%
132

A. Appendices
Own contribution: A method derived from our previous co-authored work applied to web corpra. Evaluated using datafrom workshop VarDial on discriminating between similar lan-guages and dialects.
12. Vít Baisa, Marek Blahuš, Michal Cukr, Ondřej Herman, MilošJakubíček, Vojtěch Kovář, Marek Medveď, Michal Měchura,Pavel Rychlý, and Vít Suchomel. “Automating Dictionary Pro-duction: a Tagalog-English-KoreanDictionary fromScratch”. In:Electronic lexicography in the 21st century. Proceedings of the eLex2019 conference. 1-3 October 2019, Sintra, Portugal. 2019, pp. 805–818Share of work: 10%Own contribution: Efficient crawling of a Tagalog web corpus,adaptation of the crawler to a low resourced language, buildingthe corpus, development of methods of avoiding non-text inthe process of crawling and in the composition of the corpus.
13. Kristina Koppel, Jelena Kallas, Maria Khokhlova, Vít Suchomel,Vít Baisa, and Jan Michelfeit. “SkELL Corpora as a Part of theLanguage Portal Sõnaveeb: Problems and Perspectives”. In:Proceedings of eLex 2019 (2019)Share of work: 10%Own contribution: Efficient crawling of an Estonian web corpus,building the corpus. Co-analysis of problems and solutions.
14. Vít Suchomel. “csTenTen17, a Recent Czech Web Corpus”. In:Proceedings of Recent Advances in Slavonic Natural Language Pro-cessing, RASLAN 2018. 2018, pp. 111–123Share of work: 100%Own contribution: Efficient crawling of a Czech web corpus,building the corpus, corpus description and comparison toanother Czech web corpus.
15. JelenaKallas, Vít Suchomel, andMaria Khokhlova. “AutomatedIdentification of Domain Preferences of Collocations”. In: Elec-tronic lexicography in the 21st century. Proceedings of eLex 2017conference. 2017, pp. 309–320Share of work: 25%
133

A. Appendices
Own contribution: Building domain corpora from the web, ter-minology extraction, evaluation of terminology extraction.
16. Ondřej Herman, Vít Suchomel, Vít Baisa, and Pavel Rychlý.“DSL Shared task 2016: Perfect Is The Enemy of Good Lan-guage Discrimination Through Expectation–Maximization andChunk-based LanguageModel”. In: Proceedings of the ThirdWork-shop on NLP for Similar Languages, Varieties and Dialects (Var-Dial3). Osaka, 2016, pp. 114–118Share of work: 25%Own contribution: Frequency worldists for similar languagesobtained from large web corpora built by me, co-developmentof the method of discerning languages.
17. Darja Fišer, Vít Suchomel, and Miloš Jakubíček. “Terminol-ogy Extraction for Academic Slovene Using Sketch Engine”.In: Proceedings of Recent Advances in Slavonic Natural LanguageProcessing, RASLAN 2016. 2016, pp. 135–141Share of work: 25%Own contribution: Compilation of a corpus of academic Slovene.Co-work on Slovene terminology definition and extraction.
18. Vít Baisa, Vít Suchomel, Adam Kilgarriff, and Miloš Jakubíček.“Sketch Engine for English Language Learning”. In: CorpusLinguistics 2015. Ed. by Federica Formato and Andrew Hardie.UCREL. Birmingham, 2015, pp. 33–35Share of work: 25%Own contribution: Efficient crawling of an English corpus, build-ing the corpus, development of methods of avoiding non-textin the process of crawling and in the composition of the corpus.
19. Vít Baisa and Vít Suchomel. “Corpus Based Extraction of Hy-pernyms in Terminological Thesaurus for Land Surveying Do-main”. In: Proceedings of Recent Advances in Slavonic NaturalLanguage Processing, RASLAN 2015. Tribun EU, 2015, pp. 69–74Share of work: 50%Own contribution: Building domain corpora from the web. Hy-pernym extraction for a terminology project. Co-work on themethod and its description.
134

A. Appendices
20. Vít Baisa andVít Suchomel. “Turkic Language Support in SketchEngine”. In: Proceedings of the 3rd International Conference onComputer Processing in Turkic Languages (TurkLang 2015). 2015,pp. 214–223Share of work: 40%Own contribution: Efficient crawling of web corpora in Turkiclanguages, building the corpora, corpus description.
21. Miloš Jakubíček, Adam Kilgarriff, Vojtěch Kovář, Pavel Rychlý,and Vít Suchomel. “Finding terms in corpora for many lan-guages with the Sketch Engine”. In: Proceedings of the Demonstra-tions at the 14th Conference of the European Chapter of the Associationfor Computational Linguistics. Gothenburg, 2014, pp. 53–56Share of work: 30%Own contribution: Efficient crawling of web corpora, term ex-traction from the corpora for 10 languages, co-development ofa general description of terms in the languages.Submission type: A paper in the demonstrations track (not apart of the main conference proceedings)Conference Rating: FI-rank A (CORE rank A)Citation count: 36
22. Vít Baisa and Vít Suchomel. “SkELL: Web Interface for En-glish Language Learning”. In: Proceedings of Recent Advances inSlavonic Natural Language Processing, RASLAN 2014. Brno, 2014,pp. 63–70Share of work: 30%Own contribution: Efficient crawling of an English corpus, build-ing the corpus, development of methods of avoiding non-textin the process of crawling and in the composition of the corpus.Citation count: 40
23. Jan Michelfeit, Vít Suchomel, and Jan Pomikálek. “Text To-kenisation Using unitok.” In: Proceedings of Recent Advancesin Slavonic Natural Language Processing, RASLAN 2014. 2014,pp. 71–75Share of work: 50%Own contribution: Description and evaluation of the method.Citation count: 21
135

A. Appendices
24. Adam Rambousek, Aleš Horák, Vít Suchomel, and Lucia Kocin-cová. “Semiautomatic Building andExtension of TerminologicalThesaurus for Land Surveying Domain”. In: Proceedings of Re-cent Advances in Slavonic Natural Language Processing, RASLAN2014. 2014, pp. 129–137Share of work: 15%Own contribution: Building domain corpora from the web. Au-tomated extraction of semantic relations from the corpora for aterminology project. Co-work on the method and its descrip-tion.
25. Zuzana Nevěřilová and Vít Suchomel. “Intelligent Search andReplace for Czech Phrases”. In: Proceedings of Recent Advancesin Slavonic Natural Language Processing, RASLAN 2014. 2014,pp. 97–105Share of work: 50%Own contribution: The idea of search and replace for phrasesin inflected languages. Application to a Czech corpus. Co-workon the method and its description.
26. Miloš Jakubíček, Adam Kilgarriff, Vojtěch Kovář, Pavel Rychlý,Vít Suchomel, Jan Bušta, Vít Baisa, and Jan Michelfeit. “TheTenTen Corpus Family”. In: 7th International Corpus LinguisticsConference CL. UCREL. Lancaster, 2013, pp. 125–127Share of work: 30%Own contribution: Efficient crawling of web corpora inmultiplelanguages.Citation count: 202
27. Yonatan Belinkov,NizarHabash, AdamKilgarriff,NoamOrdan,Ryan Roth, and Vít Suchomel. “arTenTen: a new, vast corpusfor Arabic”. In: Proceedings of WACL 20 (2013)Share of work: 20%Own contribution: Efficient crawling of an Arabic web corpus,building the corpus, corpus description.
28. Irena Srdanović, Vít Suchomel, Toshinobu Ogiso, and AdamKilgarriff. “Japanese Language Lexical and Grammatical Profil-ing Using the Web Corpus JpTenTen”. In: Proceeding of the 3rdJapanese corpus linguistics workshop. Tokyo: NINJAL, Department of
136

A. Appendices
Corpus Studies/Center for Corpus Development. 2013, pp. 229–238Share of work: 20%Own contribution: Efficient crawling of a Japanese web corpus,building the corpus, corpus description.
29. Vít Baisa and Vít Suchomel. “Intrinsic Methods for Comparisonof Corpora”. In:Proceedings of Recent Advances in Slavonic NaturalLanguage Processing, RASLAN 2013. 2013, pp. 51–58Share of work: 50%Own contribution: Method description and evaluation – 2/3 ofmethods in the paper.
30. Vít Baisa and Vít Suchomel. “Large Corpora for Turkic Lan-guages and Unsupervised Morphological Analysis”. In: Pro-ceedings of the Eight International Conference on Language Resourcesand Evaluation. Ed. by Mehmet Ugur Dogan Seniz Demir IlknurDurgar El-Kahlout. European Language Resources Association(ELRA). Istanbul, 2012, pp. 28–32Share of work: 50%Own contribution: Efficient crawling of five corpora in turkiclanguages, building the corpora, corpus description.Submission type: A paper in a workshop on turkic languages.ConferenceRating: FI-rankB (GGSConferenceRating B,GoogleScholar h5-index = 45)Citation count: 9
31. Vít Baisa and Vít Suchomel. “Detecting Spam in Web Corpora”.In: Proceedings of Recent Advances in Slavonic Natural LanguageProcessing, RASLAN 2012. 2012, pp. 69–76Share of work: 50%Own contribution: Methods of non-text detection and mitiga-tion of its impact on web corpora.
32. Gulshan Dovudov, Vít Suchomel, and Pavel Šmerk. “Towards100M Morphologically Annotated Corpus of Tajik”. In: Proceed-ings of Recent Advances in Slavonic Natural Language Processing,RASLAN 2012. 2012, pp. 91–94Share of work: 25%Own contribution: Efficient crawling of a Tajik Persian web cor-
137

A. Appendices
pus, building the corpus, corpus description. Adaptation of thecralwer to a less resourced language.
33. Vít Suchomel. “Recent Czech Web Corpora”. In: Proceedings ofRecent Advances in SlavonicNatural Language Processing, RASLAN2012. 2012, pp. 77–83Share of work: 100%Own contribution: Efficient crawling of a Czech web corpus,building the corpus, corpus description. Corpus comparison toother contemporary Czech corpora.
34. Gulshan Dovudov, Vít Suchomel, and Pavel Šmerk. “POSAnno-tated 50MCorpus of Tajik Language”. In: Proceedings of theWork-shop on Language Technology for Normalisation of Less-ResourcedLanguages SaLTMiL 8 – AfLaT2012. Istanbul, 2012, pp. 93–98Share of work: 25%Own contribution: Efficient crawling of a Tajik Persian corpus,building the corpus. Adaptation of the crawler to a less re-sourced language.
35. Vít Suchomel and Jan Pomikálek. “Practical Web Crawling forText Corpora”. In: Proceedings of Recent Advances in SlavonicNatural Language Processing, RASLAN 2011. 2011, pp. 97–108Share of work: 75%Own contribution: Crawler implementation and description.
36. Jan Pomikálek and Vít Suchomel. “chared: Character EncodingDetection with a Known Language”. In: Proceedings of RecentAdvances in Slavonic Natural Language Processing, RASLAN 2011.2011, pp. 125–129Share of work: 50%Own contribution: Tool implementation and a part of its de-scription.
37. Gulshan Dovudov, Jan Pomikálek, Vít Suchomel, and PavelŠmerk. “Building a 50M Corpus of Tajik Language”. In: Proceed-ings of Recent Advances in Slavonic Natural Language Processing,RASLAN 2011. 2011, pp. 89–95Share of work: 25%
138

A. Appendices
Own contribution: Efficient crawling of a Tajik Persian webcorpus, building the corpus, corpus description.
139

Bibliography
[Art+14] Tressy Arts, Yonatan Belinkov, Nizar Habash, Adam Kil-garriff, and Vít Suchomel. “arTenTen: Arabic corpus andword sketches”. In: Journal of King Saud University – Com-puter and Information Sciences 26.4 (2014), pp. 357–371.
[Bai+19] Vít Baisa, Marek Blahuš, Michal Cukr, Ondřej Herman,Miloš Jakubíček, Vojtěch Kovář, Marek Medveď, MichalMěchura, Pavel Rychlý, and Vít Suchomel. “AutomatingDictionary Production: a Tagalog-English-Korean Dictio-nary from Scratch”. In: Electronic lexicography in the 21stcentury. Proceedings of the eLex 2019 conference. 1-3 October2019, Sintra, Portugal. 2019, pp. 805–818.
[BS12a] Vít Baisa and Vít Suchomel. “Detecting Spam in WebCorpora”. In: Proceedings of Recent Advances in SlavonicNatural Language Processing, RASLAN 2012. 2012, pp. 69–76.
[BS12b] Vít Baisa and Vít Suchomel. “Large Corpora for TurkicLanguages and Unsupervised Morphological Analysis”.In: Proceedings of the Eight International Conference on Lan-guage Resources and Evaluation. Ed. by Mehmet Ugur Do-gan Seniz Demir Ilknur Durgar El-Kahlout. EuropeanLanguage Resources Association (ELRA). Istanbul, 2012,pp. 28–32.
[BS13] Vít Baisa and Vít Suchomel. “Intrinsic Methods for Com-parison of Corpora”. In: Proceedings of Recent Advances inSlavonic Natural Language Processing, RASLAN 2013. 2013,pp. 51–58.
[BS14] Vít Baisa and Vít Suchomel. “SkELL: Web Interface forEnglish Language Learning”. In: Proceedings of RecentAdvances in Slavonic Natural Language Processing, RASLAN2014. Brno, 2014, pp. 63–70.
[BS15a] Vít Baisa and Vít Suchomel. “Corpus Based Extractionof Hypernyms in Terminological Thesaurus for Land
140

BIBLIOGRAPHY
Surveying Domain”. In: Proceedings of Recent Advancesin Slavonic Natural Language Processing, RASLAN 2015.Tribun EU, 2015, pp. 69–74.
[BS15b] Vít Baisa and Vít Suchomel. “Turkic Language Supportin Sketch Engine”. In: Proceedings of the 3rd InternationalConference on Computer Processing in Turkic Languages (Turk-Lang 2015). 2015, pp. 214–223.
[Bai+15] Vít Baisa, Vít Suchomel, Adam Kilgarriff, and MilošJakubíček. “Sketch Engine for English LanguageLearning”. In: Corpus Linguistics 2015. Ed. by FedericaFormato and Andrew Hardie. UCREL. Birmingham,2015, pp. 33–35.
[BR02] Ziv Bar-Yossef and Sridhar Rajagopalan. “Template detec-tion via data mining and its applications”. In: Proceedingsof the 11th international conference on World Wide Web. ACM.2002, pp. 580–591.
[BK06] M. Baroni and A. Kilgarriff. “Large linguistically-processed web corpora for multiple languages”. In:Proceedings of European ACL (2006).
[BB04] Marco Baroni and Silvia Bernardini. “BootCaT: Bootstrap-ping Corpora and Terms from the Web”. In: Proceedingsof International Conference on Language Resources and Evalu-ation. 2004.
[Bar+09] Marco Baroni, Silvia Bernardini, Adriano Ferraresi, andEros Zanchetta. “The WaCky wide web: a collection ofvery large linguistically processed web-crawled corpora”.In: Language resources and evaluation 43.3 (2009), pp. 209–226.
[Bar+08] Marco Baroni, Francis Chantree, Adam Kilgarriff, andSerge Sharoff. “Cleaneval: a Competition for CleaningWeb Pages”. In: Proceedings of Sixth International Conferenceon Language Resources and Evaluation. 2008.
[Bar+06] Marco Baroni, Adam Kilgarriff, Jan Pomikálek, PavelRychlý, et al. “WebBootCaT: instant domain-specific
141

BIBLIOGRAPHY
corpora to support human translators”. In: Proceedings ofEAMT. 2006, pp. 247–252.
[Bel+13] Yonatan Belinkov, Nizar Habash, Adam Kilgarriff, NoamOrdan, Ryan Roth, and Vít Suchomel. “arTenTen: a new,vast corpus for Arabic”. In: Proceedings of WACL 20 (2013).
[Ben14] Vladimír Benko. “Aranea: Yet Another Family of (Com-parable) Web Corpora”. In: Text, Speech and Dialogue.Springer. 2014, pp. 247–256.
[Ben16] Vladimír Benko. “Feeding the "Brno Pipeline": The Caseof Araneum Slovacum”. In: Proceedings of Recent Advancesin Slavonic Natural Language Processing, RASLAN 2016.2016, pp. 19–27.
[Bib88] Douglas Biber. Variation across speech and writing. Cam-bridge University Press, 1988.
[Bib89] Douglas Biber. “A typology of English texts”. In: Linguis-tics 27.1 (1989), pp. 3–44.
[Bie+07] Chris Biemann, Gerhard Heyer, Uwe Quasthoff, andMatthias Richter. “The Leipzig Corpora Collection-monolingual corpora of standard size”. In: Proceedings ofCorpus Linguistic 2007 (2007).
[Boj+14] Ondřej Bojar, Vojtěch Diatka, Pavel Rychlý, Pavel Straňák,Vít Suchomel, Aleš Tamchyna, and Daniel Zeman.“HindEnCorp-Hindi-English and Hindi-only Corpusfor Machine Translation”. In: Proceedings of Ninth Inter-national Conference on Language Resources and Evaluation.2014, pp. 3550–3555.
[Bro+00] Andrei Z Broder, Moses Charikar, Alan M Frieze, andMichael Mitzenmacher. “Min-wise independent permu-tations”. In: Journal of Computer and System Sciences 60.3(2000), pp. 630–659.
[Cal+09] Jamie Callan, Mark Hoy, Changkuk Yoo, and Le Zhao.Clueweb09 data set. 2009.
142

BIBLIOGRAPHY
[Cas+07] Carlos Castillo, Debora Donato, Aristides Gionis, VanessaMurdock, and Fabrizio Silvestri. “Know your neighbors:Web spam detection using the web topology”. In: Proceed-ings of the 30th annual international ACM SIGIR conferenceon Research and development in information retrieval. ACM.2007, pp. 423–430.
[CK01] Gabriela Cavagliá and Adam Kilgarriff. “Corpora fromthe Web”. In: Fourth Annual CLUCK Colloquium, Sheffield,UK. 2001.
[CG99] J. Cho and H. Garcia-Molina. The Evolution of the Web andImplications for an Incremental Crawler. Technical Report1999-22. Stanford InfoLab, 1999.
[CKR10] Kevin Crowston, Barbara Kwasnik, and Joseph Rubleske.“Problems in the use-centered development of a taxon-omy of web genres”. In: Genres on the Web. Springer, 2010,pp. 69–84.
[Cvr+20] Václav Cvrček, Zuzana Komrsková, David Lukeš,Petra Poukarová, Anna Řehořková, Adrian Jan Zasina,and Vladimír Benko. “Comparing web-crawled andtraditional corpora”. In: Language Resources and Evaluation(2020), pp. 1–33.
[DS16] Erika Dalan and Serge Sharoff. “Genre classification for acorpus of academic webpages”. In: Proceedings of the 10thWeb as Corpus Workshop. 2016, pp. 90–98.
[DF15] Mark Davies and Robert Fuchs. “Expanding horizons inthe study of World Englishes with the 1.9 billion wordGlobal Web-based English Corpus (GloWbE)”. In: En-glish World-Wide 36.1 (2015), pp. 1–28.
[DKB98] Johan Dewe, Jussi Karlgren, and Ivan Bretan. “Assem-bling a balanced corpus from the internet”. In: Proceedingsof the 11th Nordic Conference of Computational Linguistics(NODALIDA 1998). 1998, pp. 100–108.
[Dov+11] Gulshan Dovudov, Jan Pomikálek, Vít Suchomel, andPavel Šmerk. “Building a 50M Corpus of Tajik Language”.
143

BIBLIOGRAPHY
In: Proceedings of Recent Advances in Slavonic Natural Lan-guage Processing, RASLAN 2011. 2011, pp. 89–95.
[DSŠ12a] Gulshan Dovudov, Vít Suchomel, and Pavel Šmerk. “POSAnnotated 50M Corpus of Tajik Language”. In: Proceed-ings of the Workshop on Language Technology for Normalisa-tion of Less-Resourced Languages SaLTMiL 8 – AfLaT2012.Istanbul, 2012, pp. 93–98.
[DSŠ12b] Gulshan Dovudov, Vít Suchomel, and Pavel Šmerk. “To-wards 100MMorphologicallyAnnotatedCorpus of Tajik”.In: Proceedings of Recent Advances in Slavonic Natural Lan-guage Processing, RASLAN 2012. 2012, pp. 91–94.
[EGB12] Miklós Erdélyi, András Grazo, and András A. Benczúr.“Web spam Classification: a few features worth more”.In: Proc. Joint WICOW/AIRWeb Workshop at WWW-2012.2012.
[Fer+08a] A. Ferraresi, E. Zanchetta, M. Baroni, and S. Bernardini.“Introducing and evaluating ukWaC, a very large web-derived corpus of English”. In: Proceedings of the 4th Webas Corpus Workshop at LREC 2008. 2008.
[Fer+08b] Adriano Ferraresi, Eros Zanchetta, Marco Baroni, andSilvia Bernardini. “Introducing and evaluating ukWaC, avery large web-derived corpus of English”. In: Proceedingsof the 4th Web as Corpus Workshop (WAC-4) Can we beatGoogle. 2008, pp. 47–54.
[Fer+08c] Adriano Ferraresi, Eros Zanchetta, Marco Baroni, andSilvia Bernardini. “Introducing and evaluating ukwac, avery large web-derived corpus of English”. In: Proceedingsof the 4th Web as Corpus Workshop (WAC-4) Can we beatGoogle. 2008, pp. 47–54.
[FCV09] Dennis Fetterly, Nick Craswell, and Vishwa Vinay. “Theimpact of crawl policy on web search effectiveness”. In:Proceedings of the 32nd international ACM SIGIR conferenceon Research and development in information retrieval. ACM.2009, pp. 580–587.
144

BIBLIOGRAPHY
[FSJ16] Darja Fišer, Vít Suchomel, and Miloš Jakubíček. “Termi-nology Extraction for Academic Slovene Using SketchEngine”. In: Proceedings of Recent Advances in Slavonic Nat-ural Language Processing, RASLAN 2016. 2016, pp. 135–141.
[GJM01] Rayid Ghani, Rosie Jones, and Dunja Mladenić. “Miningthe web to create minority language corpora”. In: Proceed-ings of the tenth international conference on Information andknowledge management. ACM. 2001, pp. 279–286.
[GO13] Yoav Goldberg and Jon Orwant. “A dataset of syntactic-ngrams over time from a very large corpus of englishbooks”. In: Second Joint Conference on Lexical and Computa-tional Semantics (* SEM). Vol. 1. 2013, pp. 241–247.
[GN00] Gregory Grefenstette and Julien Nioche. “Estimation ofEnglish and non-English Language Use on the WWW”.In: In Recherche d’Information Assistée par Ordinateur(RIAO). 2000.
[GG05] Zoltan Gyongyi and Hector Garcia-Molina. “Web spamtaxonomy”. In: First international workshop on adversarialinformation retrieval on the web (AIRWeb 2005). 2005.
[GGP04] Zoltán Gyöngyi, Hector Garcia-Molina, and Jan Pedersen.“Combating web spam with trustrank”. In: Proceedingsof the Thirtieth international conference on Very large databases-Volume 30. VLDB Endowment. 2004, pp. 576–587.
[Her+16] Ondřej Herman, Vít Suchomel, Vít Baisa, and PavelRychlý. “DSL Shared task 2016: Perfect Is The Enemy ofGood Language Discrimination Through Expectation–Maximization and Chunk-based Language Model”.In: Proceedings of the Third Workshop on NLP for SimilarLanguages, Varieties and Dialects (VarDial3). Osaka, 2016,pp. 114–118.
[Hná+14] Milena Hnátková, Michal Kren, Pavel Procházka, andHana Skoumalová. “The SYN-series corpora of writtenCzech”. In: Proceedings of Ninth International Conference onLanguage Resources and Evaluation. 2014, pp. 160–164.
145

BIBLIOGRAPHY
[Hor+19] Aleš Horák, Vít Baisa, Adam Rambousek, and Vít Su-chomel. “A New Approach for Semi-Automatic Buildingand Extending a Multilingual Terminology Thesaurus”.In: International Journal on Artificial Intelligence Tools 28.02(2019), p. 1950008.
[Jak+20a] Miloš Jakubíček, Vít Baisa, Jan Bušta, Vojtěch Kovář, JanMichelfeit, Pavel Rychlý, and Vít Suchomel.Walking theTightrope between Linguistics and Language Engineering. Sub-mission accepted for publication. Springer, 2020.
[Jak+14] Miloš Jakubíček, Adam Kilgarriff, Vojtěch Kovář, PavelRychlý, and Vít Suchomel. “Finding terms in corporafor many languages with the Sketch Engine”. In: Proceed-ings of the Demonstrations at the 14th Conference of the Euro-pean Chapter of the Association for Computational Linguistics.Gothenburg, 2014, pp. 53–56.
[Jak+13] Miloš Jakubíček, Adam Kilgarriff, Vojtěch Kovář, PavelRychlý, Vít Suchomel, Jan Bušta, Vít Baisa, and JanMichel-feit. “The TenTen Corpus Family”. In: 7th InternationalCorpus Linguistics Conference CL. UCREL. Lancaster, 2013,pp. 125–127.
[Jak+20b] Miloš Jakubíček, Vojtěch Kovář, Pavel Rychlý, and VítSuchomel. Current Challenges in Web Corpus Building. Sub-mission Accepted for publication. 2020.
[Jou+16] Armand Joulin, Edouard Grave, Piotr Bojanowski, andTomas Mikolov. “Bag of Tricks for Efficient Text Classifi-cation”. In: arXiv preprint arXiv:1607.01759 (2016).
[KK] Jelena Kallas and Kristina Koppel. Eesti keele ühendkorpus2019. Centre of Estonian Language Resources.
[KSK17] Jelena Kallas, Vít Suchomel, and Maria Khokhlova. “Au-tomated Identification of Domain Preferences of Collo-cations”. In: Electronic lexicography in the 21st century. Pro-ceedings of eLex 2017 conference. 2017, pp. 309–320.
[Kha+04] Rohit Khare, Doug Cutting, Kragen Sitaker, and AdamRifkin. “Nutch: A flexible and scalable open-source web
146

BIBLIOGRAPHY
search engine”. In:Oregon State University 1 (2004), pp. 32–32.
[Kil12] Adam Kilgarriff. “Getting to know your corpus”. In: In-ternational conference on text, speech and dialogue. Springer.2012, pp. 3–15.
[Kil+14] Adam Kilgarriff, Vít Baisa, Jan Busta, Miloš Jakubíček,Vojtěch Kovář, Jan Michelfeit, Pavel Rychlý, and Vít Su-chomel. “The Sketch Engine: Ten Years On”. In: Lexicogra-phy 1.1 (2014), pp. 7–36.
[KC13] Adam Kilgarriff and Tiberius Carole. Genre in a frequencydictionary. Presented at the International Conference onCorpus Linguistics, Lancaster, 2013. 2013.
[KG03] Adam Kilgarriff and Gregory Grefenstette. “Introductionto the special issue on the web as corpus”. In: Computa-tional linguistics 29.3 (2003), pp. 333–347.
[Kil+04] Adam Kilgarriff, Pavel Rychlý, Pavel Smrž, and DavidTugwell. “The Sketch Engine”. In: Information Technology105 (2004), p. 116.
[KS13] Adam Kilgarriff and Vít Suchomel. “Web Spam”. In: Pro-ceedings of the 8th Web as Corpus Workshop (WAC-8) @Cor-pus Linguistics 2013. Ed. by Paul Rayson Stefan Evert EgonStemle. 2013, pp. 46–52.
[KFN10] Christian Kohlschütter, Peter Fankhauser, and WolfgangNejdl. “Boilerplate detection using shallow text features”.In: Proceedings of the third ACM international conference onWeb search and data mining. ACM. 2010, pp. 441–450.
[Kop+19] Kristina Koppel, Jelena Kallas, Maria Khokhlova, Vít Su-chomel, Vít Baisa, and Jan Michelfeit. “SkELL Corporaas a Part of the Language Portal Sõnaveeb: Problems andPerspectives”. In: Proceedings of eLex 2019 (2019).
[Kri04] Klaus Krippendorff. Content analysis: An introduction to itsmethodology (2nd ed.) Thousand Oaks, CA: Sage, 2004.
147

BIBLIOGRAPHY
[Lee01] David Y. W. Lee. “Genres, registers, text types, domainsand styles: Clarifying the concepts and navigating a paththrough the BNC jungle”. In: Language Learning and Tech-nology 5.3 (2001), pp. 37–72.
[Lee+09] Hsin-Tsang Lee, Derek Leonard, Xiaoming Wang, andDmitri Loguinov. “IRLbot: scaling to 6 billion pages andbeyond”. In: ACM Transactions on the Web (TWEB) 3.3(2009), pp. 1–34.
[Lee92] Geoffrey Leech. “100 million words of English: the BritishNational Corpus (BNC)”. In: Language Research 28.1(1992), pp. 1–13.
[Let14] Igor Leturia. “The Web as a Corpus of Basque”. PhDthesis. University of the Basque Country, 2014.
[LC94] David D Lewis and Jason Catlett. “Heterogeneous un-certainty sampling for supervised learning”. In: Machinelearning proceedings 1994. Elsevier, 1994, pp. 148–156.
[LK14] Nikola Ljubešić and Filip Klubička. “bs, hr, sr WaC: Webcorpora of Bosnian, Croatian and Serbian”. In: Proceedingsof WAC-9 workshop. Association for Computational Linguis-tics. 2014.
[LT14] Nikola Ljubešić and Antonio Toral. “caWaC – A web cor-pus of Catalan and its application to language modelingand machine translation”. In: Proceedings of Ninth Inter-national Conference on Language Resources and Evaluation.2014, pp. 1728–1732.
[LB12] Marco Lui and Timothy Baldwin. “langid.py: An Off-the-shelf Language Identification Tool”. In: Proceedingsof the ACL 2012 System Demonstrations. Association forComputational Linguistics. Jeju Island, Korea, July 2012,pp. 25–30.
[Mal+16] Shervin Malmasi, Marcos Zampieri, Nikola Ljubešić,Preslav Nakov, Ahmed Ali, and Jörg Tiedemann.“Discriminating between Similar Languages and ArabicDialect Identification: A Report on the Third DSL Shared
148

BIBLIOGRAPHY
Task”. In: Proceedings of the Third Workshop on NLP forSimilar Languages, Varieties and Dialects (VarDial3). Osaka,Japan, Dec. 2016, pp. 1–14.
[MS99] Christopher D. Manning and Hinrich Schütze. Founda-tions of statistical natural language processing. MIT press,1999.
[MRS08] Christopher D Manning, Prabhakar Raghavan, and Hin-rich Schütze. Introduction to information retrieval. Cam-bridge university press, 2008.
[MPS07] Michal Marek, Pavel Pecina, and Miroslav Spousta. “Webpage cleaning with conditional random fields”. In: Build-ing and Exploring Web Corpora: Proceedings of the Fifth Webas Corpus Workshop, Incorporationg CleanEval (WAC3), Bel-gium. 2007, pp. 155–162.
[MSS10] Alexander Mehler, Serge Sharoff, and Marina Santini.Genres on the web: Computational models and empirical studies.Vol. 42. Springer, 2010.
[MSP14] Jan Michelfeit, Vít Suchomel, and Jan Pomikálek. “TextTokenisation Using unitok.” In: Proceedings of Recent Ad-vances in Slavonic Natural Language Processing, RASLAN2014. 2014, pp. 71–75.
[Nak10] Shuyo Nakatani. Language Detection Library for Java. 2010.url: https://github.com/shuyo/language-detection.
[NS14] Zuzana Nevěřilová and Vít Suchomel. “Intelligent Searchand Replace for Czech Phrases”. In: Proceedings of RecentAdvances in Slavonic Natural Language Processing, RASLAN2014. 2014, pp. 97–105.
[NCO04] Alexandros Ntoulas, Junghoo Cho, and Christopher Ol-ston. “What’s new on the web?: the evolution of the webfrom a search engine perspective”. In: Proceedings of the13th international conference onWorldWideWeb. ACM. 2004,pp. 1–12.
[Nto+06] Alexandros Ntoulas, Marc Najork, Mark Manasse, andDennis Fetterly. “Detecting spam web pages through con-
149

BIBLIOGRAPHY
tent analysis”. In: Proceedings of the 15th international con-ference on World Wide Web. ACM. 2006, pp. 83–92.
[Pom11] Jan Pomikálek. “Removing boilerplate and duplicate con-tent from web corpora”. PhD thesis. Masaryk University,2011.
[PJR12] Jan Pomikálek, Miloš Jakubíček, and Pavel Rychlý. “Build-ing a 70 billionword corpus of English fromClueWeb”. In:Proceedings of Eighth International Conference on LanguageResources and Evaluation. 2012, pp. 502–506.
[PRK09] Jan Pomikálek, Pavel Rychlý, and Adam Kilgarriff. “Scal-ing to Billion-plus Word Corpora”. In: Advances in Com-putational Linguistics 41 (2009), pp. 3–13.
[PS11] Jan Pomikálek and Vít Suchomel. “chared: Character En-coding Detection with a Known Language”. In: Proceed-ings of Recent Advances in Slavonic Natural Language Pro-cessing, RASLAN 2011. 2011, pp. 125–129.
[Ram+14] Adam Rambousek, Aleš Horák, Vít Suchomel, and LuciaKocincová. “Semiautomatic Building and Extension ofTerminological Thesaurus for Land Surveying Domain”.In: Proceedings of Recent Advances in Slavonic Natural Lan-guage Processing, RASLAN 2014. 2014, pp. 129–137.
[Ros08] Mark Rosso. “User-based identification of Web genres”.In: Journal of the American Society for Information Scienceand Technology 59.7 (2008), pp. 1053–1072.
[Ryc08] Pavel Rychlý. “A Lexicographer-Friendly AssociationScore”. In: Proceedings of Recent Advances in SlavonicNatural Language Processing, RASLAN 2008. 2008, pp. 6–9.
[RS16] Pavel Rychlý and Vít Suchomel. “Annotated amharic cor-pora”. In: International Conference on Text, Speech, and Dia-logue. Springer. 2016, pp. 295–302.
[SBB14] Roland Schäfer, Adrien Barbaresi, and Felix Bildhauer.“FocusedWeb Corpus Crawling”. In: Proceedings of the 9thWeb as Corpus workshop (WAC-9). 2014, pp. 9–15.
150

BIBLIOGRAPHY
[SB12] Roland Schäfer and Felix Bildhauer. “Building Large Cor-pora from the Web Using a New Efficient Tool Chain”. In:Proceedings of Eighth International Conference on LanguageResources and Evaluation. 2012, pp. 486–493.
[SB13] Roland Schäfer and Felix Bildhauer. Web Corpus Construc-tion. Vol. 6. Morgan & Claypool Publishers, 2013, pp. 1–145.
[Set12] Burr Settles. Active Learning. Vol. 6. Synthesis Lectures onArtificial Intelligence and Machine Learning. Morgan &Claypool, 2012.
[Sha18] Serge Sharoff. “Functional text dimensions for the anno-tation of web corpora”. In: Corpora 13.1 (2018), pp. 65–95.
[She13] Denis Shestakov. “Current challenges in web crawling”.In: International Conference on Web Engineering. Springer.2013, pp. 518–521.
[SS12] Johanka Spoustová and Miroslav Spousta. “A High-Quality Web Corpus of Czech”. In: Proceedings ofEighth International Conference on Language Resources andEvaluation. 2012, pp. 311–315.
[Srd+13] Irena Srdanović, Vít Suchomel, Toshinobu Ogiso, andAdam Kilgarriff. “Japanese Language Lexical and Gram-matical Profiling Using the Web Corpus JpTenTen”. In:Proceeding of the 3rd Japanese corpus linguistics workshop.Tokyo: NINJAL, Department of Corpus Studies/Center forCorpus Development. 2013, pp. 229–238.
[Suc12] Vít Suchomel. “Recent Czech Web Corpora”. In: Proceed-ings of Recent Advances in Slavonic Natural Language Pro-cessing, RASLAN 2012. 2012, pp. 77–83.
[Suc17] Vít Suchomel. “Removing spam from web corporathrough supervised learning using FastText”. In: Proceed-ings of the Workshop on Challenges in the Management ofLarge Corpora and Big Data and Natural Language Processing(CMLC-5+BigNLP) 2017 including the papers from the
151

BIBLIOGRAPHY
Web-as-Corpus (WAC-XI) guest section. Birmingham, 2017,pp. 56–60.
[Suc18] Vít Suchomel. “csTenTen17, a Recent CzechWeb Corpus”.In: Proceedings of Recent Advances in Slavonic Natural Lan-guage Processing, RASLAN 2018. 2018, pp. 111–123.
[Suc19] Vít Suchomel. “Discriminating Between Similar Lan-guages Using Large Web Corpora”. In: Proceedings ofRecent Advances in Slavonic Natural Language Processing,RASLAN 2019. 2019, pp. 129–135.
[SP11] Vít Suchomel and Jan Pomikálek. “Practical Web Crawl-ing for Text Corpora”. In: Proceedings of Recent Advances inSlavonic Natural Language Processing, RASLAN 2011. 2011,pp. 97–108.
[SP12] Vít Suchomel and Jan Pomikálek. “EfficientWebCrawlingfor Large Text Corpora”. In: Proceedings of the seventh Webas Corpus Workshop (WAC7). Ed. by Serge Sharoff AdamKilgarriff. Lyon, 2012, pp. 39–43.
[Tho14] James Thomas. Discovering English with the Sketch Engine.Research-publishing.net. La Grange des Noyes, France,2014.
[Tro+12] Andrew Trotman, Charles LA Clarke, Iadh Ounis, ShaneCulpepper, Marc-Allen Cartright, and Shlomo Geva.“Open source information retrieval: a report on the SIGIR2012 workshop”. In: ACM SIGIR Forum. Vol. 46. ACM.2012, pp. 95–101.
[Ven+11] Ashish Venugopal, Jakob Uszkoreit, David Talbot, Franz JOch, and Juri Ganitkevitch. “Watermarking the outputsof structured prediction with an application in statisticalmachine translation”. In: Proceedings of the Conference onEmpirical Methods in Natural Language Processing. Associa-tion for Computational Linguistics. 2011, pp. 1363–1372.
[VP12] Yannick Versley and Yana Panchenko. “Not just bigger:Towards better-qualityWeb corpora”. In: Proceedings of theseventh Web as Corpus Workshop (WAC7). 2012, pp. 44–52.
152

BIBLIOGRAPHY
[Zam+17] Marcos Zampieri, Shervin Malmasi, Nikola Ljubešić,Preslav Nakov, Ahmed Ali, Jörg Tiedemann, YvesScherrer, and Noëmi Aepli. “Findings of the VarDialEvaluation Campaign 2017”. In: Proceedings of theFourth Workshop on NLP for Similar Languages, Varietiesand Dialects (VarDial). Association for ComputationalLinguistics. Valencia, Spain, Apr. 2017, pp. 1–15.
[Zam+14] Marcos Zampieri, Liling Tan, Nikola Ljubešić, and JörgTiedemann. “A report on the DSL shared task 2014”. In:Proceedings of the first workshop on applying NLP tools tosimilar languages, varieties and dialects. 2014, pp. 58–67.
[Zam+15] Marcos Zampieri, Liling Tan, Nikola Ljubešić, Jörg Tiede-mann, and Preslav Nakov. “Overview of the DSL sharedtask 2015”. In: Proceedings of the Joint Workshop on Lan-guage Technology for Closely Related Languages, Varieties andDialects. 2015, pp. 1–9.
[ZS04] Sven Meyer Zu Eissen and Benno Stein. “Genre classifi-cation of web pages”. In: Annual Conference on ArtificialIntelligence. Springer. 2004, pp. 256–269.
153




















