
37th International Symposium on Intensive ... - Critical Care
Upload
kalasalingamCategory
view
4download
0
Attacks on Collaborative Filtering Recommender System: A Review
Mrs.L.Anitha
1, P.Anjali devi
2
Assistant Professor
1, PG Scholar
2
Department of Computer Science and Engineering
VPMM College of Engineering for Women, Krishnan koil.
ABSTRACT— In recent years Recommender System overcomes the problem of “Information Overload” and
gives “Personalized” recommendations to the users. The internet growing in a huge speed, the users are unable to retrieve what they exactly need. Moreover they have to depend on either friends or experts to get suggestions for what they must read or listen next. Because the user’s trust those relations. A System can also provide trusted information to the users is done by the recommender System. A malevolent user might, for instance, try to influence the behaviour of the recommender system in such a way that it includes certain item very often (or very seldom) in its recommendation list. This operation defined as an Attack on the recommender system. When a person expresses his or her genuine negative opinion which can be based on any reasons this is not seen as
an attack. An attack occurs when an agent tries to influence the functioning of the system intentionally. In general the goals of attackers might be to promote the particular product or item, or to bias the system as whole in order the recommender system can no longer produce efficient recommendations to the users. In this paper, we discussed the various different attacks and how the attackers intrude the system .
Keywords— Recommender System, Collaborative filtering, Fake Profiles. 1.INTRODUCTION
The software system that determines which books should be shown to a particular visitor is called Recommender system. These are systems that help a user or users to choose items from a large item or information space (McNee, Riedl, & Konstan, 2006a) by proactively suggesting relevant items. Recommender systems were introduced in the early 90s with systems like Tapestry for filtering e-
mails (Goldberg, Nichols, Oki, & Terry, 1992), GroupLens for netnews recommendations (Resnick, Iacovou, Suchak, Bergstrom, & Riedl, 1994), or Ringo for music recommendation (Shardanand & Maes, 1995), and several factors have helped to increase their popularity over time. Recommender
System: definition given by (McNee et al., 2006a) for its simplicity and clarity: “a recommender or recommendation system aims to help a user or a group of users in a system to select items from a crowded item or information space”. Recommendation environment can be defined as[1], Let A be the set of all users and let I be the set of all possible Items that can be recommended such as movies, news, restaurants, books etc. The space V of possible items can be very large. Let f be a utility function that measures usefulness of items i to user a, i.e. f: A×V→R where R is set of non negative ordered values
within a specific range and utility function of an item noted by ratings. Then for each user , we want to choose such item i I that maximizes the user‟s utility. The representation,
(1)
There are various recommendation approaches such as Content-based filtering, collaborative filtering and hybrid approach. Recommendation Process are entirely based on the input (rating, user profile) provided by the visitors or users (Fig1.1). Due to this reason the system is highly vulnerable to the attacks. The competitors in the selling market who are interested in promoting

their own product to yield high revenue or else interested in de promoting the opponent sellers product, they do bias the recommender system which have influence on the customers. The attacker creates fake profile and inject into recommender database as like a genuine users.
In this paper we consider the task of attack profile Detection. For this first we discuss various attack models on collaborative recommendation systems. In attack profile detection we are interested in classifying the attack profiles and genuine user‟s profile using different techniques. Second the various Recommendation approaches are studied. Third the Metrics for evaluating the systems are discussed.
Fig1.1 Recommendation Process
1.1 COLLABORATIVE FILTERING RECOMMENDATION
Collaborative recommender systems are vulnerable to malicious users who seek to bias their output, causing them to recommend (or not recommend) particular items. Collaborative recommender systems are dependent on the goodwill of their users. There is an implicit assumption – note the word “collaborative” – that users are in some sense “on the same side”, and at the very least, that they will interact with the system with the aim of getting good recommendations for themselves while providing useful data for their neighbors. Herlocker et al. [1999] use the analogy of the “water-cooler chat”, whereby co-workers exchange tips and opinions. However, as contemporary experience has shown, the Internet is not solely inhabited by good-natured collaborative types. Users will have a range of purposes in interacting with recommender systems, and in some cases, those purposes may be counter to those of the system owner or those of the majority of its user population. In Collaborative recommender system SPC(Statistical Process Control) method is used to identify the items under attack. SPC is quite often used for long term monitoring of some parameter values related to a particular process. Once a parameter has been chosen for monitoring, an estimate of its distribution can be made and its future observations can be automatically monitored. Figure1.2 shows an example of a control chart that applies to the area of collaborative filtering.

Fig1.2 Example of Control Chart
Here, data points are average rating of an item, measured in real time, assuming that they are not under attack and are hence unbiased. Two other horizontal lines are called upper limit and lower limit. They are so chosen in such a way that all of the data points fall within these limits as long as there is no danger to the system. This figure shows that an item‟s average rating is outside the range of the limits. This indicates an anomaly that could be due to an attack on the System.
2.ATTACKS
As mentioned earlier Recommendation Process are entirely based on the input (rating, user profile) provided by the visitors or users (Fig1.1). Due to this reason the system is highly vulnerable to the attacks. The competitors in the selling market who are interested in promoting their own product to yield high revenue or else interested in de promoting the opponent sellers product, they do bias the recommender system which have influence on the customers. The attackers can use automated tools to throw in a big number of biased profiles into such a system. These type of attacks has been termed as “Shilling” attacks [Burke et al. 2005; Lam and Riedl 2004; O‟Mahony et al. 2004] or Profile injection attacks [Burke; Lam and Riedl; O‟Mahony et al. 2007]. This may result in the system producing false recommendations. Biased profiles can either favor or disfavor certain items.
The general form of an attack profile, consisting of the target item, a (possibly empty) set of selected items that are used in some attack models, a set of so-called filler items, and a set of unrated items is shown in fig1.3.
Attacks can be categorized by []:
Attack Model: The rating characteristics of the attack profile are defined by the attack model. The model associated with an attack, describes the details of the rating pattern, the items that should be given ratings in the attack profiles and the strategy that should be used in giving ratings to the selected items.
Attack Intent: Different attacks might have very different intents for attacking the system.
Although the main intent of an attack is usually to change or bias the recommendations that are provided to the customer, but the ultimate motive can be of an attacker can be one of several options.
The two main clears intents are to popularize one or more items in the recommender system in order to have them recommended to more often to the users, or else try to nuke some items and cause them to
be recommended to less often and to fewer users. Another possible intent may be to cause the system to fail. This may result in reduced recommendation quality across the entire system and this may
further result in loss of trust of the users. If the users feel that they are not being provided good

recommendations matching their taste quite often they may eventually stop using these predictions. Such attacks might be of interest for competitive recommender systems.
Attack Profile Size: The attack profile size is the number of item ratings given in a given attack profile. It is considered that creating a new attack profile is much costlier than assigning a large number of ratings in a given attack profile. While creating attack profiles, rating a large number of items involves risk of being identified. Genuine users can mostly rate only a small fraction of the entire set of items in a large recommendation system. It is not possible for any user to try out every product on the product list, read every book published and that is there in the system, sample very drink, or view every movie in the recommendation system. Hence, the attack profiles with a huge number of ratings are easy to detect and differentiate from the genuine user profiles. In other words, the huge number of rated items is an indicator of an attack.
Attack Size: The number of fake or spam profiles inserted into the system related to an attack is known as the attack size. It is believed that most of the sophisticated attacks normally use automated tools to generate and inject attack profiles in the system. Hence, by detecting the anomaly of huge number of rated items, such attack profiles can be eliminated from the system. System owners can also require some initial registration processes by every user before participating in the process of rating items. This human involvement might increase the cost of spam profile generation and hence discourage the attackers.
Required Knowledge: Attackers may require some level of knowledge about the items, ratings and algorithms in the recommender system that they aim to attack. A well-informed attack has better chances of having a larger impact on the system than an uninformed attack. Additional knowledge about the recommender system such as knowledge about ratings distribution and algorithm parameters may assist to choose the appropriate attack strategies. Also tracking and tuning attack parameters may help to maximize effectiveness and minimize the chances of the fake profiles being detected. 3. ATTACK MODELS
THE RANDOM ATTACK: In the random attack, as introduced by Lam and Riedl (2004), all item ratings of the injected profile (except the target item rating, of course) are filled with random values drawn from a normal distribution that is determined by the mean rating value and the standard deviation of all ratings in the database. The intuitive idea of this approach is that the generated profiles should contain “typical” ratings so they are considered as neighbors to many other real profiles. The actual parameters of the normal distribution in the database might not be known: still, these values can be determined empirically relatively easily. In the well-known MovieLens data set, for example, the mean value is 3.6 on a five-point scale (Lam and Riedl 2004). Thus, users tend to rate items rather positively. The standard deviation is 1.1. As these numbers are publicly available, an attacker could base an attack on similar numbers, assuming that the rating behavior of users may be comparable across different domains. Although such an attack is therefore relatively simple and can be launched with limited knowledge about the ratings database, evaluations show that the method is less effective than other, more knowledge-intensive, attack models (Lam and Riedl 2004). The random attack model is an attack model defined as,
Ϻrand = (Χrand, δrand, σrand, γrand) (2) THE AVERAGE ATTACK: A bit more sophisticated than the random attack is the average attack. In this method, the average rating per item is used to determine the rating values for the profile to be injected. Intuitively, the profiles that are generated based on this strategy should have more neighbors, as more details about the existing rating datasets are taken into account. In fact, experimental evaluations and a comparison with the random attack show that this attack type is more effective when applied to memory-based user-to-user collaborative filtering systems. The price for this is the additional knowledge that is required to determine the values – that is, one needs to estimate the average rating value for every item. In some recommender systems, these average rating values per
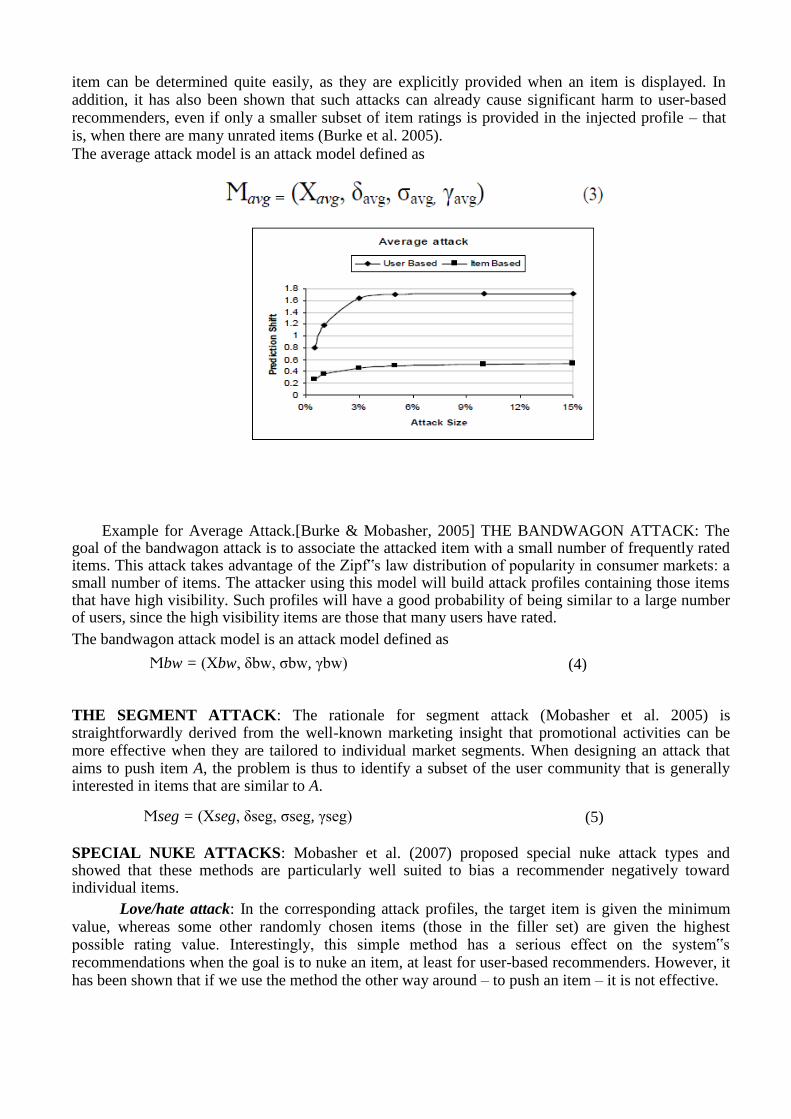
item can be determined quite easily, as they are explicitly provided when an item is displayed. In addition, it has also been shown that such attacks can already cause significant harm to user-based recommenders, even if only a smaller subset of item ratings is provided in the injected profile – that is, when there are many unrated items (Burke et al. 2005). The average attack model is an attack model defined as
Example for Average Attack.[Burke & Mobasher, 2005] THE BANDWAGON ATTACK: The goal of the bandwagon attack is to associate the attacked item with a small number of frequently rated items. This attack takes advantage of the Zipf‟s law distribution of popularity in consumer markets: a small number of items. The attacker using this model will build attack profiles containing those items that have high visibility. Such profiles will have a good probability of being similar to a large number of users, since the high visibility items are those that many users have rated. The bandwagon attack model is an attack model defined as THE SEGMENT ATTACK: The rationale for segment attack (Mobasher et al. 2005) is straightforwardly derived from the well-known marketing insight that promotional activities can be more effective when they are tailored to individual market segments. When designing an attack that aims to push item A, the problem is thus to identify a subset of the user community that is generally interested in items that are similar to A.
Ϻseg = (Χseg, δseg, σseg, γseg) (5) SPECIAL NUKE ATTACKS: Mobasher et al. (2007) proposed special nuke attack types and showed that these methods are particularly well suited to bias a recommender negatively toward individual items.
Love/hate attack: In the corresponding attack profiles, the target item is given the minimum value, whereas some other randomly chosen items (those in the filler set) are given the highest possible rating value. Interestingly, this simple method has a serious effect on the system‟s recommendations when the goal is to nuke an item, at least for user-based recommenders. However, it has been shown that if we use the method the other way around – to push an item – it is not effective.
Ϻbw = (Χbw, δbw, σbw, γbw) (4)

The Love/Hate attack is an attack model defined as
Ϻlh = (Χlh, δlh, σlh, γlh) (6)
Reverse bandwagon: The idea of this nuke attack is to associate the target item with other items that are disliked by many people. Therefore, the selected item set in the attack profile is filled with minimum ratings for items that already have very low ratings. Again, the amount of knowledge needed is limited because the required small set of commonly low-rated items (such as recent movie flops) can be identified quite easily.
Ϻrbw = (Χrbw, δrbw, σrbw, γrbw) (7)
IV.ATTACK DETECTION PROCESS
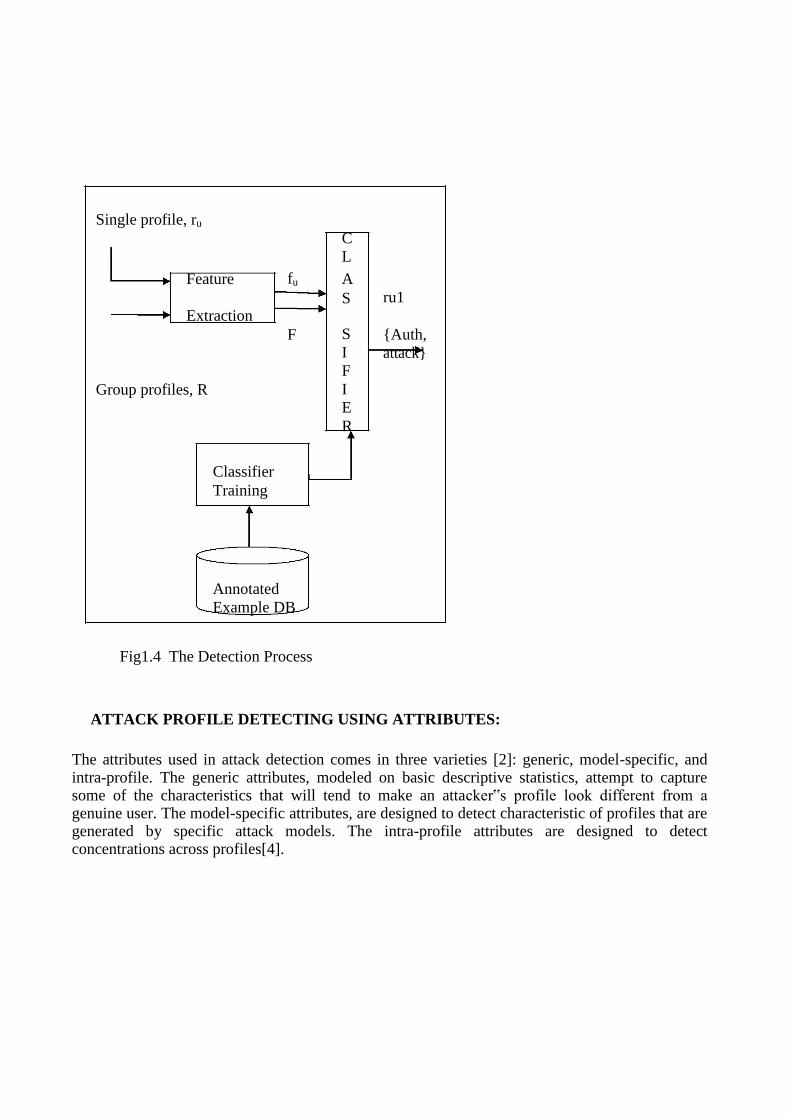
This is a binary classification problem, with two possible outcomes for each profile, namely, Authentic, meaning that the classifier has determined that the profile is that of a genuine system user or Attack, meaning that the classifier has determined that this is an instance of an attack profile. One approach to the detection problem, followed by work such as [2,3], has been to view it as a problem of determining independently for each profile in the dataset, whether or not it is an attack profile. This is the „single profile‟ input shown in Figure1.4. The input is a single rating vector ru, for some user u from the dataset. Before processing by the classifier, a feature extraction step may extract a set of features, fu = ( f1,. . . , fk) from the raw rating vector ru. The classifier takes fu as input and outputs, “Attack” or “Authentic”. If the classifier is a supervised classifier, then a training phase makes use of annotated dataset of profiles, i.e. a set of profiles labeled as Authentic or Attack, in order to learn the classifier parameters. Because most attack scenarios consist of groups of profiles working in concert to push or nuke a particular item, work such as [4,5] has suggested that there is benefit to considering groups of profiles together when making the classification. This is represented by the „Group of Profiles‟ input, in which the classifier considers an entire group of profiles, possibly after some feature extraction, and outputs a label for each profile in the group. Note that not all steps may take place in any particular scenario. For instance, there may be no feature extraction, in which case, f = r and if unsupervised classifiers are used, then there is no need for a training phase.
Single profile, ru
C
L
Feature fu A
ru1
Extraction
S
F S {Auth,
I attack}
F
Group profiles, R I
E
R
Classifier
Training
Annotated
Example DB
Fig1.4 The Detection Process
ATTACK PROFILE DETECTING USING ATTRIBUTES:
The attributes used in attack detection comes in three varieties [2]: generic, model-specific, and intra-profile. The generic attributes, modeled on basic descriptive statistics, attempt to capture some of the characteristics that will tend to make an attacker‟s profile look different from a genuine user. The model-specific attributes, are designed to detect characteristic of profiles that are generated by specific attack models. The intra-profile attributes are designed to detect concentrations across profiles[4].

a) Generic Attributes for Detection: Generic attributes are based on hypothetical method which detects the attack profile from authentic profiles. The attributes are : i) Rating Deviation From Mean Agreement :RDMA is intended to identify attackers through examining the profile‟s average deviation per item, weighted by the inverse of the number of ratings for that item.
ii) Weighted Deviation From Mean Agreement: WDMA designed to help identify anomalies, places a high weight on rating deviations for sparse items.
iii) Degree of Similarity with Top Neighbors: DegSim captures the average similarity of a profile‟s k nearest neighbors. iv) Length Variance (LengthVar) is introduced to capture how much the length of a given profile varies from the average length in the database.
b) Model-Specific Attributes: The model-specific attributes, are designed to detect characteristic of profiles that are generated by specific attack models. i) Filler Mean Difference, which is the average of the absolute value of the difference between the user‟s rating and the mean rating (rather than the squared value as in the variance.) ii) Profile Variance, capturing within-profile variance as this tends to be low compared to authentic users.
DETECTING ATTACK PROFILES USING CLUSTERING: Attacks consist of multiple profiles which are highly correlated with each other, as well as having high similarity with a large number of authentic profiles. This insight motivates the development of a clustering approach to attack detection, using Probabilistic Latent Semantic Analysis (PLSA) and Principal Component Analysis (PCA). V.EVALUVATION METRICS The most common property to evaluate in recommender systems is accuracy, which measures how close a predicted rating for an item is to a user‟s actual rating. Taking a „positive‟ classification to mean the labeling of a profile as Attack, a confusion matrix of the classified data contains four sets, two of which – the true positives and true negatives – consist of profiles that were correctly classified as Attack or Authentic, respectively; and two of which – the false positives and false negatives – consist of profiles that were incorrectly classified as Attack or Authentic, respectively. Various measures are used in the literature to compute performance based on the relative sizes of these sets. There exists several different metrics which can be used to measure accuracy; mean absolute error (MAE), Precision/Recall and ROC Curves to name a few (Herlocker et al. 2004, p. 19-25). Recall which is also called sensitivity presents this count as a fraction of the total number of actual attacks in the system. Precision, which is also called the positive predictive value (PPV), presents this count as a fraction of the total number of profiles labeled as Attack:
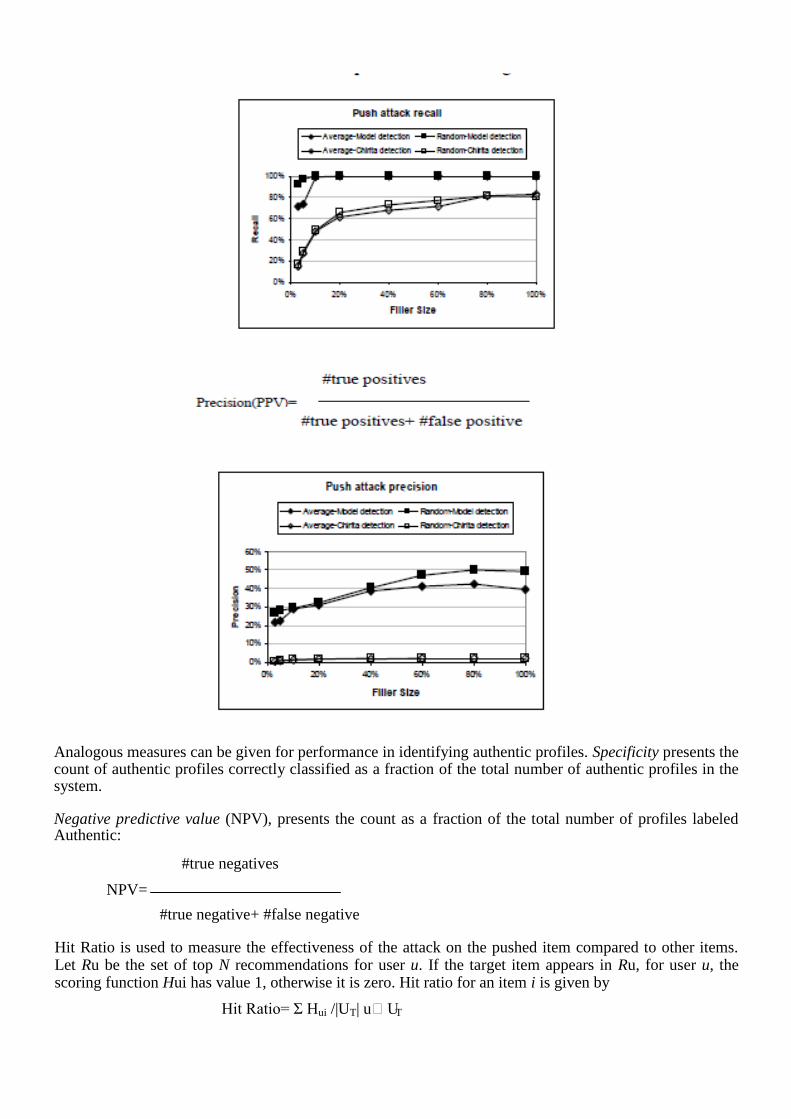
Analogous measures can be given for performance in identifying authentic profiles. Specificity presents the count of authentic profiles correctly classified as a fraction of the total number of authentic profiles in the system. Negative predictive value (NPV), presents the count as a fraction of the total number of profiles labeled Authentic: #true negatives
NPV=
#true negative+ #false negative Hit Ratio is used to measure the effectiveness of the attack on the pushed item compared to other items. Let Ru be the set of top N recommendations for user u. If the target item appears in Ru, for user u, the scoring function Hui has value 1, otherwise it is zero. Hit ratio for an item i is given by
Hit Ratio= Ʃ Hui /|UT| uUT

VI.CONCLUSION Thus the problem of “information overload” has been solved by the Recommender system. This efficiently
provides a personalized list of recommendations based on the user‟s behaviour and interests, so the users
need not depend on someone to recommend what he has to do next. Most of the recommender system fully
based on users interests (ratings made) and to recommend an item to particular user we go for finding
similar users. Likewise there are item based recommendation can also be made. As discussed, in order to
prevent our system from attackers who uses various attack models to generate fake profiles, those attack
models are studied. We also discussed various methods to identify fake profiles. Once the attack profiles
are identified and eliminated, Recommender system performs well and provide personalized
recommendation to users.
VII.REFERENCES [1] ADOMAVICIUS, G. & TUZHILIN, A. 2005. Toward the Next Generation of Recommender Systems:
A Survey of the State-of-the-Art and Possible Extensions. IEEE Transactions on Knowledge and Data
Engineering, 17 (6), pp. 734–749.
[2] MOBASHER B, BURKE R, BHAUMIK R, WILLIAMS C. Toward trust- worthy recommender
systems: An analysis of attack models and algorithm robustness. ACM Trans. Internet Technol.,Oct. 2007,
7(4): Article No.23.
[3] A.WILLIAMS, C., MOBASHER, B., BURKE, R.: Defending recommender systems: detection of
profile injection attacks. Service Oriented Computing and Applications pp. 157–170 (2007)
[4] CHIRITA, P.A., NEJDL, W., ZAMFIR, C.: Preventing shilling attacks in online recommender
systems. In Proceedings of the ACM Workshop on Web Information and Data Management
(WIDM‟2005) pp. 67–74 (2005)
[5] MEHTA, B., HOFMANN, T., FANKHAUSER, P.: LIES AND PROPAGANDA: Detecting spam
users in collaborative filtering. In: Proceedings of the 12th international conference on Intelligent user
interfaces, pp. 14–21 (2007)
[6] O‟Mahony, M.P., Hurley, N.J., Silvestre, C.C.M.: An evaluation of neighborhood formation on the
performance of collaborative filtering. Artificial Intelligence Review 21(1), 215–228 (2004).
[7] MEHTA, B., NEJDL, W.: Unsupervised strategies for shilling detection and robust
collaborativefiltering. User Modeling and User-Adapted Interaction 19(1-2), 65–97 (2009). DOI http:
//dx.doi.org/10.1007/s11257-008-9050-4.
Copyright © 2022 FDOKUMEN



















