
Aiding Test Case Generation in Temporally Constrained State Based Systems Using Genetic Algorithms
17
Aiding test case generation in temporally constrained state based systems using genetic algorithms ? Karnig Derderian 1 , Mercedes G. Merayo 2 , Robert M. Hierons 1 , Manuel N´ u˜ nez 2 1 Department of Information Systems and Computing, Brunel University Uxbridge, Middlesex, UB8 3PH United Kingdom, [email protected], [email protected] 2 Departamento de Sistemas Inform´ aticos y Computaci´ on Universidad Complutense de Madrid, Madrid, Spain, [email protected], [email protected] Abstract. Generating test data for formal state based specifications is computationally expensive. This paper improves a framework that addresses this issue by representing the test data generation problem as an optimisation problem and uses heuristics to help generate test cases. The paper considers the temporal constraints and behaviour of a certain class of finite state machines. A short case study of a communication protocol details how the test case generation problem can be presented as a search problem and automated. Genetic algorithms (GAs) and random search are used to generate test data and evaluate the approach. GAs show to outperform random search and seem to scale well as the problem size increases. A very simple fitness function is used that can be used with other evolutionary search techniques and automated test case generation suits. 1 Introduction As computer technology evolves the complexity of current systems increases. System implementations cannot be guaranteed, in most cases, that they fully comply to the specifications. Critical parts/aspects of some system are specified using formal specifications in order to better understand and model their be- haviour. Communication protocols and control systems, amongst others, have used formal specifications like finite state machines. Even though testing is an important part of the system development pro- cess that aims to increase the reliability of the implementation, it can be very expensive. This motivates research into methods that help the testing process. Finite state machines (FSMs) have been used to formally model systems in different areas like sequential circuits [1], software development [2] and commu- nication protocols [3]. ? Research partially supported by the Spanish MEC project WEST/FAST (TIN2006- 15578-C02-01).
Transcript of Aiding Test Case Generation in Temporally Constrained State Based Systems Using Genetic Algorithms

Aiding test case generation in temporallyconstrained state based systems using genetic
algorithms?
Karnig Derderian1, Mercedes G. Merayo2,Robert M. Hierons1, Manuel Nunez2
1 Department of Information Systems and Computing, Brunel UniversityUxbridge, Middlesex, UB8 3PH United Kingdom,
[email protected], [email protected] Departamento de Sistemas Informaticos y Computacion
Universidad Complutense de Madrid, Madrid, Spain,[email protected], [email protected]
Abstract. Generating test data for formal state based specificationsis computationally expensive. This paper improves a framework thataddresses this issue by representing the test data generation problem asan optimisation problem and uses heuristics to help generate test cases.The paper considers the temporal constraints and behaviour of a certainclass of finite state machines. A short case study of a communicationprotocol details how the test case generation problem can be presented asa search problem and automated. Genetic algorithms (GAs) and randomsearch are used to generate test data and evaluate the approach. GAsshow to outperform random search and seem to scale well as the problemsize increases. A very simple fitness function is used that can be used withother evolutionary search techniques and automated test case generationsuits.
1 Introduction
As computer technology evolves the complexity of current systems increases.System implementations cannot be guaranteed, in most cases, that they fullycomply to the specifications. Critical parts/aspects of some system are specifiedusing formal specifications in order to better understand and model their be-haviour. Communication protocols and control systems, amongst others, haveused formal specifications like finite state machines.
Even though testing is an important part of the system development pro-cess that aims to increase the reliability of the implementation, it can be veryexpensive. This motivates research into methods that help the testing process.
Finite state machines (FSMs) have been used to formally model systems indifferent areas like sequential circuits [1], software development [2] and commu-nication protocols [3].? Research partially supported by the Spanish MEC project WEST/FAST (TIN2006-
15578-C02-01).

Testing systems formally specified using FSMs and the automation of thetest data generation have been of interest [4–6]. In software testing one of theaims is to distinguish between the correct and incorrect behaviour of systemimplementations. While some systems only consider the correctness of the sys-tem results (outputs), other systems might have specific time requirements aswell. This can be especially relevant in environments where system resources areshared. In real-time systems the time it takes for a process to execute can be asimportant as the output.
Thus, formal testing techniques started to deal also with this kind of as-pects. In fact, there are already several proposals for formal testing of timedsystems(e.g. [7–10]). The problem of generating test sequences for such systemsis not trivial. There has been some work on using artificial intelligence techniqueslike genetic algorithms (GAs) to aid the test sequence generation of FSMs [11].
This problem is even more complicated in the case of timed systems. Oneof the main problems to overcome is that it is not enough to test that theimplementation system is doing what it is supposed to do, but it is necessaryalso to test that it is also taking the specified time to complete. In addition, thetests applied to system implementations have to consider when to test [12].
This paper addresses the issues related to generating test sequences for tem-porally constrained FSM based systems. It focuses on generating transition pathswith specific properties that can in turn be used to generate test input. The prob-lem of generating these paths is represented as a search problem and GAs areused to help automate the test data generation process.
2 Problem
FSMs are known to model appropriately sequential circuits and control portionsof communication protocols. However ordinary FSMs are not powerful enoughfor some applications where extended finite state machines (EFSMs) are usedinstead. Finite state systems are usually modelled using Mealy machines thatproduce an output for every transition triggered by an input. In EFSMs howeverthe transitions are associated with conditions. EFSMs have been widely used inthe telecommunications field, and are also now being applied to a diverse numberof other areas ranging over aircraft, train control, medical and packaging systems.Examples of languages based on EFSMs include SDL, Estelle and Statecharts.Here we consider EFSMs with the addition of time - timed EFSMs (TFSMs).
Usually the implementation of a system specified by an FSM or EFSM istested for conformance by applying a sequence of inputs and verifying that thecorresponding sequence of outputs is that which is expected. This commonlyinvolves executing a number of transition paths, until all transitions have beentested at least once. In EFSMs ,in order to execute a transition path it is neces-sary to satisfy all of the transition guards involved, in addition to using a specificinput sequence to trigger these transitions.

Definition 1. Given a EFSM M a transition path (TP) represents a sequence oftransitions in M where every transition starts from the state where the previoustransition finished.
When FSM based systems are tested for conformance with their specifica-tion, often a fault can be categorised as either an output fault (wrong output isproduced by a transition) or a state transfer fault (the state after a transitionis wrong). A test strategy would involve moving M to a state si, applying someinput x, verifying that the output is y as expected for that transition under test,and using a state verification technique to verify the transition’s end state. Toachieve this there are test sequences with different properties. State verificationsequences for example aim to check if the end state of a transition (or TP) isthe one expected and state identification sequences identify the unknown statethe system is in [4].
When TEFSMs are tested for conformance there are time related faults thatcould be present besides the output and transition faults. The time related faultsarise when a transition within the implementation takes longer to complete thanthe time specified by the TEFSM.
In EFSMs (and TEFSMs) test sequence generation is more complex than itis for FSMs. In FSMs all paths are feasible since there are no guards and actionsdo not affect the traversal [13]. With EFSMs (and TEFSMs), however, in orderto trigger the transition path it is necessary to satisfy the transition guards. Atransition guard may refer to the values of the internal variables and the inputparameters, which in turn can assume different values after each transition. Sometransition paths might have no conditions, some might have conditions that arerarely satisfied and some transition paths will be infeasible. The existence ofinfeasible transition paths creates difficulties for automating the test generationprocess for EFSMs (and TEFSMs).
With TEFSMs however there is the element of time that needs to be consid-ered as well, making the triggering of a path successfully harder than in EFSMs.One way of approaching the test sequence generation problem is to abstract awaythe data part of the TEFSM and consider it as an FSM on its own. However,a transition sequence for the underlying FSM of a TEFSM is not guaranteed tobe feasible for the actual TEFSM nor to satisfy the temporal constraints. Thisleads to the problem that an input sequence will only trigger a specific TP in aTEFSM if all the transition guards allow this and so an input sequence generatedon the basis of the FSM may not follow the required path in the TEFSM. An-other approach is to expand a TEFSM to an FSM and then use the techniquesused for FSMs. However this can lead to a combinatorial explosion.
The problem of TP feasibility in EFSMs was considered in [14]. This pa-per uses the TP feasibility approach proposed in that work and extends it toconsider TEFSMs and problems associated to testing the compliance of an imple-mentation to its temporal aspects of the specification. In addition to estimatingthe feasibility of a TP in this paper we examine how to consider the temporalproperties of a TP and help in related test case generation.

In order to generate a test case for a TEFSM M we can first consider theproperties of the TP that this test case is expected to trigger. The generalproblem of finding a (an arbitrary) feasible transition sequence for a TEFSMis uncomputable, as is generating the necessary input sequence to trigger sucha transition sequence. The task of finding a transition sequence with particulartemporal conditions complicates the problem even further. Test generation forEFSMs [3, 6] and TEFSMs [12] is still an open research problem.
While a random algorithm could be used it does not always produce accept-able results. Test case generation and optimisation for FSM based systems hasbeen of interest [13, 15, 5, 16]. Heuristic search techniques like genetic algorithms(GAs) have been used in problems like estimating feasibility of TPs in EFSMs[14], generating test sequences for FSMs [17, 11] and communicating FSMs [18].Heuristic search techniques can also be applied to the problem of generatingTPs with other characteristics if a robust fitness function can be defined. Hencea function that can estimate the likelihood that a TP in a TEFSM can be exe-cuted and also satisfies the temporal constraints imposed may help in areas liketest sequence generation. Heuristic search can be used to direct a search towardsTPs that are likely to satisfy the set requirements.
3 Timed extended finite state machine (TEFSM) model
EFSMs are those Mealy (finite state) machines with parameterised input andoutput, internal variables, operations and predicates defined over internal vari-ables and input parameters. Timed EFSMs (TEFSMs) are classical EFSMs withadded conditions on the time transitions need to take to complete.
To represent our timed EFSM assume that the number of different variablesis m. If we assume that each variable xi belongs to a domain Di thus the valuesof all variables at a given point if time can be represented by a tuple belongingto the cartesian product of D1 ×D2 × ...×Dm = ∆. Regarding the domain torepresent time we define that time values belong to a certain domain Time.
A TEFSM M can be defined as (S, s0, V, σ0, P, I, O, T, C) where S is thefinite set of logical states, s0 ∈ S is the initial state, V is the finite set of internalvariables, σ0 denotes the mapping from the variables in V to their initial values,P is the set of input and output parameters, I is the set of input declarations, Ois the set of output declarations, T is the finite set of transitions and C is suchthat C ∈ ∆.
A transition t ∈ T is defined by (ss, gI , gD, gC , op, sf ) where
– ss is the start state of t;– gI is the input guard expressed as (i, P i, gP i) wherei ∈ I∪{NIL}; P i ⊆ P ; and gP i is the input parameter guard that can eitherbe NIL or be a logical expression in terms of variables in V ′ and P ′ whereV ′ ⊆ V , ∅ 6= P ′ ⊆ P i;
– gD is the domain guard and can be either NIL or represented as a logicalexpression in terms of variables in V ′ where V ′ ⊆ V ;

– gC - gC : ∆→ Time is the time the transition needs to take to complete;– op is the sequential operation which is made of simple output and assignment
statements; and– sf is the final state of t.
The label of a transition in a TEFSM has two guards that decide the feasibil-ity of the transition: the input guard gI and the domain guard gD. In order for atransition to be executed gI , the guard for inputs from the environment must besatisfied. Some inputs may carry values or specific input parameters and M mayguard those values with the input parameter guard gP . Hence the values of theinput parameters may determine whether a transition is executed and affect theoutput of M . The input guard (NIL, ∅, NIL) represents no input being required(spontaneous transition). gD is the guard, or precondition, on the values of thesystem variables (e.g. v > 4, where v ∈ V ). Note that in order to satisfy thedomain guard gD of a transition t, it might be necessary to have taken somespecific path to the start state of t. op is a set of sequential statements such asv := v+1 and !o where v ∈ V , o ∈ O and !o means ‘output o to the environment’.Literal outputs (output directly observable by the user) are denoted with ! andoutput functions (an output function may produce different output dependingon the parameters it receives) without it (e.g. !o and u(v)). The operation of atransition in a TEFSM has only simple statements such as output statementsand assignment statements, no branching statements are allowed.
In a TEFSM the time a transition took to complete is also important. Thetime a transition needs to be completed by, represented by gC can be dependanton the current values of V ′ and P i, where V ′ ∈ V and P i ⊆ P .
Fig. 1. Class 2 transport protocol TEFSM M1. The transition table is on Figure 2.
We assume that none of the spontaneous transitions in a TEFSM are withoutany guards, gI = (NIL, ∅, NIL) and gD = NIL, because they will be uncontrol-lable. When a transition in a TEFSM is executed, all the actions of the operationspecified in its label are performed consecutively and only once and the transi-tion must not take more than gC Time to perform. The transition is considered

to have failed (in terms of compliance to the specification or be considered void)if it is not completed within the required time. Such transitions may be con-sidered void if they take longer than expected in some systems and in othersthey might still be executed even though they took longer than expected. OurTEFSM model and our work is applicable to both, however in our case studywe considered the former.
Definition 2. A TEFSM M is deterministic if any pair of transitions t and t′
initiating from the same state s that share the same input declaration x havemutually exclusive guards.
Upon an input, a TEFSM triggers a given transition depending not only onthe input, but on the values of the internal variables. Hence TEFSM may becalled dynamically deterministic. As stated before triggering a transition in aTEFSM involves satisfying all those guards and conditions. This makes trigger-ing a transition in TEFSMs more complex than in FSMs and EFSMs. As anexample consider the Class 2 transport protocol [19] represented as a TEFSM inFigure 1 and the transition table in Figure 2. There are two transitions initiatingfrom state S2 with the input declaration N?TrCC - t2 and t3. However they havemutually exclusive conditions - opt ind ≤ opt and opt ind > opt respectively.
Definition 3. A TEFSM is strongly connected if for every ordered pair of states(s, s′) there is some feasible path from s to s′.
We assume that any TEFSM considered is deterministic and strongly con-nected. Consider the TEFSM in Figure 1 again. There is a TP from the initialstate S1 to every other state. TEFSMs (inherently from EFSMs) have a notionknows as configuration that defines the subset of available transitions that canbe triggered at any point.
Definition 4. A configuration for a TEFSM M is a combination of state andvalues of the internal variables V of M .
A TEFSM starts in its initial configuration and there is a configuration forevery combination of state s and values of the set internal variables V .
3.1 TEFSM abstraction model
Now consider the problem of finding an input sequence that triggers a timedfeasible transition path (TFTP) from state si to state sj of a TEFSM M .
Definition 5. A timed feasible transition path (TFTP) for state si to state sj
of a TEFSM M is a sequence of transitions initiating from si that is feasiblefor at least one combination of values of the finite set of internal variables V(configuration) of M and ends in sj.

State identification and state verification sequences for a TEFSM must trig-ger a TFTP (where the end state is not important). Methods that can helpidentify TFTPs can potentially be used to help in the state identification andstate verification sequence generation problems.
In a transition path for FSMs each transition can be identified and thusrepresented by its start state and input (ss, i). However with TEFSMs (as wellas EFSMs) this information is not sufficient because there can be more thanone transitions sharing the same start state and input due to having mutuallyexclusive guards. Instead a transition t in a TEFSM M can be identified fromits start state, input declaration, input parameter, the input parameter guardand the domain guard (ss, i, P
i, gP i , gD). gP i and gD for a transition t in M canboth be logical expressions and their results may depend on input parameter P i
of t and the values of some of the internal variables of M . Transitions sharingthe same start state and input declaration can be classified according to theirinput guard predicate and domain guard predicate. These predicates consist oflogical expressions that can evaluate to either True or False depending on theinput parameters or internal variables of M . To identify these for every set oftransitions sharing the same start state s and input declaration i, the numberof unique input guards (input predicate branches) and unique domain guards(domain predicate branches) is counted and a predicate dependency tree forstate s and input declaration i can be constructed.
Consider the Sending state (S4) in the EFSM M1 on Figure 1 . There aretwo transitions initiating from this state that share the same input declara-tion N?TrAK and input parameters XpSsq and cr. These transitions have thesame input but differ only in their input parameter guards and domain guards.Hence a transition in a transition path of a TEFSM can be identified by a tuple(ss, i, gP i , gD) in which si is its start state, i is its input, gP i is its input guardand gD is its domain guard. The input parameter P i is not required in orderto be able to uniquely identify a transition in M . Note how in this case sometransitions with different domain guards share a common input predicate guard.
Not all transitions in TEFSMs have input parameter guards and domainguards and so transitions in a TEFSM M can be categorised in the followingway: simple transitions are those transitions that have no input parameterguard and no domain guard, gP i = NIL and gD = NIL; gP i transitions arethose transitions that have input parameter guard but not a domain guard,gP i 6= NIL and gD = NIL; gD transitions are those transitions that have adomain guard but not an input parameter guard, gD 6= NIL and gP i = NIL;gP i-gD transitions are those transitions that have both an input parameterguard and a domain guard, gP i 6= NIL and gD 6= NIL.
An assignment statement in the op part of a transition would not generateany observable output. However such assignment statements can still contributeto the value of the output generated in a later transition if the assignmentchanges the value of one of the output function’s parameters. It can also affectthe feasibility of the remaining transitions in the transition path and should also

be considered. In this paper we consider the importance that the op part of thetransition can have on the feasibility in TPs but leave this for future work.
Definition 6. An input sequence (IS) is a sequence of input declarations i ∈ Iwith associated input parameters P i ⊆ P of a TEFSM M .
Instead of using gP i and gD notations together in order to identify a transitionwe can simply use a label.
Definition 7. A predicate branch (PB) is a label that represents a pair of gP i
and gD for a given state s and input declaration i. A PB identifies a transitionwithin a set of transitions with the same start state and input declaration.
PBs can label conditional transitions and be used to help simulate the be-haviour of a potential input sequence for a TEFSM without the feasibility re-strictions.
Definition 8. An abstract input sequence (AIS) for M represents an input dec-laration sequence with associated PBs that triggers a TP in the abstracted M .
The advantages of using AIS and simulating the execution of a TEFSM isthat the configuration of the TEFSM is not considered. Hence transition traversalevaluations that can be used to estimate the characteristics of a TP can be donewithout complex computation.
4 Using genetic algorithms to aid test case generation
A Genetic algorithm (GA) [20, 21] is a heuristic optimisation technique whichderives its behaviour from a metaphor of the processes of evolution in nature.GAs have been widely used in search optimisation problems [20]. GAs and othermeta-heuristic algorithms have also been also used to automate software testing[22, 23, 11]. GAs are known to be particularly useful when searching large, mul-timodal and unknown search spaces. One of the benefits of GAs is their abilityto escape local minima in the search for the global minimum.
Generally a GA consists of a group of individuals (population of genomes),each representing a potential solution to the problem in hand. An initial popula-tion with such individuals is usually selected at random. Then a parent selectionprocess is used to pick a few of these individuals. New offspring individuals areproduced using crossover, which keeps some of their parent’s characterises andmutation, which introduces some new genetic material. An objective function,known as the fitness function, defines how close each individual is to being asolution and hence guides the search. The quality of each individual is hencemeasured by this fitness function, defined for the particular search problem.Crossover exchanges information between two or more individuals. The mutationprocess randomly modifies offspring individuals. The population is iteratively re-combined and mutated to evolve successive populations, known as generations.When the termination criterion specified is satisfied, the algorithm terminates.

When using GAs the first issue that needs to be addressed is how to rep-resent potential solutions in the GA population. A genotype is how a potentialsolution is encoded in a GA, while the phenotype is the real representation ofthat individual. There are different representation techniques, the most commonbeing binary and characters. Gray coding is a binary representation techniquethat uses slightly different encoding to standard binary. As it has been shown[24] that Gray codes are generally superior to standard binary by helping torepresent the solutions more evenly in the search space, we used it in this work.
The first step in a GA involves the initialisation of a population of usuallyrandomly generated individuals. The size of the population is specified at thestart. Every individual is evaluated using the fitness function. When ranking isused the population is sorted according to the fitness value of the individuals.Then each individual is ranked irrespective to the size of its and its predecessorsfitness. This is known as linear ranking. It has been shown that using linearranking helps reduce the chance of a few very fit individuals dominating thesearch leading to a premature convergence [25].
An important part of the algorithm is parent selection. A commonly usedtechnique is the roulette-wheel selection. Here the chance of an individual beingselected is directly proportional to its fitness or rank (if linear ranking is used).Hence the selection is biased towards fitter individuals.
The most common recombination technique used is crossover. During crossoverthe genes of the two parents are used to create one or more new offsprings. Thesimplest one is known as single point crossover [25]. In this work single pointcrossover was used with a randomly generated crossover point like in [25].
Mutation is applied to each individual after crossover. It randomly alters oneor more genes known as single point and multiple point mutation respectively[20]. A pre defined mutation rate (typically the reciprocal of the chromosomelength) determines which individuals are mutated. A single point mutation withrandomly selected point was used in this work as in [25].
There can be different termination criteria for a GA depending on the fit-ness function. If the fitness function is such that a solution would produce aspecific fitness value, which is known, then the GA can terminate when an indi-vidual with such fitness is generated. However in many cases this is not knowntherefore the GA must be given other termination criteria. Such a criterion canbe the specification of a maximum number of generations after which the GAwill terminate irrespective of whether a solution has been generated. We use acombination of termination criteria.
4.1 Fitness function
In order to achieve our objectives we require an easy to compute fitness functionthat estimates the feasibility of a TP but also helps us test our temporal con-straints. Computing the actual feasibility of a transition path is computationallyexpensive, so we need a method to estimate this.
Some transition paths consist of transitions with difficult to satisfy guards.It is always possible to execute a simple transition in a transition path since

there are no guards to be satisfied. The presence of gP i transitions could rendera transition path infeasible because of its input predicate guard. However theconditions of this guard are more likely to be satisfiable than domain guardsbecause the values of the input parameters P i ⊆ P can be chosen. When theseconditions depend also on some internal variables V ′ ⊆ V then such gP i tran-sitions might not be easier to trigger than gD transitions. In some cases theexecution of a gD transitions could require reaching its start state through aspecific transition path. The feasibility of gP i-gD transitions depends on bothissues outlined above for gP i transitions and gD transitions.
Since the presence of gD transitions and gP i-gD transitions seem to increasethe chance of a transition path being infeasible such transitions can be penalisedand simple transitions rewarded in a TP. In this paper we use the same feasibilityestimation framework as in [14].
Secondly we may consider the temporal constraints of the transitions in a TP.For example a test sequence may be needed to stress test the temporal aspectsof the system. Adequate test cases should be feasible (in order to be useful) andmay focus on transitions with complex temporal constraints. However since thetemporal constraints for every transition of M are dependant on the configu-ration of M (the current values if the internal variables) then it is difficult toknow the exact temporal constraints without executing the system and verifyingthe configuration of M . If the temporal constraints for M are listed in a tablethen we can analyse the constraints and categorise different transitions in a sim-ilar way as we classified them according to their guards above. However if thetemporal constraints are represented by one or more formulas the complexity ofanalysing all the possibilities the problem may become untrackable.
In their work [5] Petrenko et al. explored the idea of generating configura-tion confirming sequences. The potential problem of combinatorial complexityassociated with exploring all the configuration of an EFSM has been addressedby deriving a confirming test sequence for a designated reference configurationand a given black list of typical faulty configuration, supplied by the tester.
We may try to estimate the different temporal constraints associated witheach transition according to how the temporal constraint is defined. Note thatthe same transition may have different temporal constraints depending on thevalues of the internal variables of M . Some transitions may not have temporalconstraints at all, while others might have fixed temporal constraints that arenot dependant on the configuration of M . Other transitions may have temporalconstraints that are expressed using tables while some may have the temporalconstraints represented using formulas.
Based on these observations we may classify the transitions in a TEFSM Min the following way: no-time transitions are those transitions that have notemporal constraints; fixed-time transitions are those transitions that havetemporal constraints that are not effected by the values of the internal variablesV of M ; known-time transitions are those transitions that have temporalconstraints that are effected by the values of the internal variables V of M , butpresented in an easy to analyse way; variable-time transitions are transitions

that have temporal constraints that are effected by the values of the internalvariables V of M , but are presented by one or more formulas and the tempo-ral constraints are not easy to analyse without considering a subset of all theconfigurations of M .
A transition ranking process is completed before the fitness function can beused. This process first ranks each transition of the EFSM according to howmany penalty points are assigned to the transition guards. A simple transitiongets the highest rank (i.e. lowest amount of penalty points), an gP i transition isranked next etc. Transitions that have the same number of penalty points getthe same rank. This algorithm in essence sorts |T | elements and has complexityO(|T |.log|T |) where |T | is the number of transitions in M . Then the processranks each transition according to the its temporal constraint category. In ourcase if we are attempting to stress test the implementation then we can arguethat variable− time transitions can potentially have the most complex tempo-ral constrains hence be ranked highest (i.e. lowest amount of penalty points),known − time transitions can be ranked next as they still dependant on theinternal variables of M etc. The order can be reversed if the aim is to find a testsequence that will most likely work. Such test cases may be used in early stagesof software development.
Definition 9. The fitness is a function that given a TP of a TEFSM M , sumsthe penalty points (assigned through the transition ranking process for M andthe temporal constrain ranking for M) for each of the transition of the TP.
In this paper the two rankings are given equal weight before being combined,however different weights can be given to the rankings if required. We chose togive equal weight to the rankings following the conclusions of a similar experi-ment in [14] where different weights were used for a similar multi-optimisationproblem. However further work can be done to consider different ways to combinethe two matrices in the fitness function.
The fitness algorithm used in this work can be used to reward a potentialsolution to a TP generation problem according to the combined ranks of thetransitions in the sequence. The fitness function reflects the belief that the fewerconstraints a sequence contains, the more likely it is be feasible and the less wecan analyse the temporal constraints of a transition, the more likely it is thatthey are more complex. It is important to note that our particular temporalconstraints classification may not be fully applicable to all TEFSMs because itdepends on the particular specifications. However the main principles should stillhold even if different temporal constraints classification is used.
Estimating the feasibility of a TP is just the first part of the more difficultproblem of generating actual IS for a TFTP that do not always represent theshortest path between two states. Also there may be other computationally in-expensive analysis of a TP that can be added to the existing fitness functions tomake it more accurate. In this work we focus on evaluating our feasibility andcomplex temporal conditions estimation fitness function.
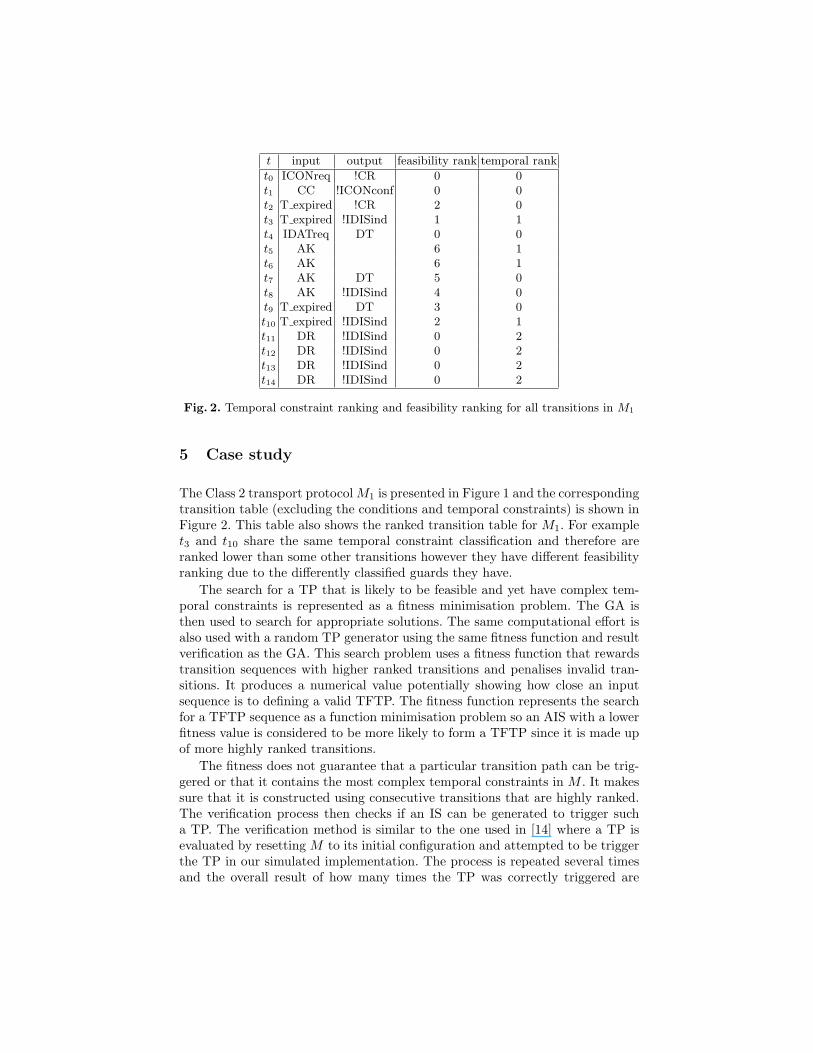
t input output feasibility rank temporal rank
t0 ICONreq !CR 0 0t1 CC !ICONconf 0 0t2 T expired !CR 2 0t3 T expired !IDISind 1 1t4 IDATreq DT 0 0t5 AK 6 1t6 AK 6 1t7 AK DT 5 0t8 AK !IDISind 4 0t9 T expired DT 3 0t10 T expired !IDISind 2 1t11 DR !IDISind 0 2t12 DR !IDISind 0 2t13 DR !IDISind 0 2t14 DR !IDISind 0 2
Fig. 2. Temporal constraint ranking and feasibility ranking for all transitions in M1
5 Case study
The Class 2 transport protocol M1 is presented in Figure 1 and the correspondingtransition table (excluding the conditions and temporal constraints) is shown inFigure 2. This table also shows the ranked transition table for M1. For examplet3 and t10 share the same temporal constraint classification and therefore areranked lower than some other transitions however they have different feasibilityranking due to the differently classified guards they have.
The search for a TP that is likely to be feasible and yet have complex tem-poral constraints is represented as a fitness minimisation problem. The GA isthen used to search for appropriate solutions. The same computational effort isalso used with a random TP generator using the same fitness function and resultverification as the GA. This search problem uses a fitness function that rewardstransition sequences with higher ranked transitions and penalises invalid tran-sitions. It produces a numerical value potentially showing how close an inputsequence is to defining a valid TFTP. The fitness function represents the searchfor a TFTP sequence as a function minimisation problem so an AIS with a lowerfitness value is considered to be more likely to form a TFTP since it is made upof more highly ranked transitions.
The fitness does not guarantee that a particular transition path can be trig-gered or that it contains the most complex temporal constraints in M . It makessure that it is constructed using consecutive transitions that are highly ranked.The verification process then checks if an IS can be generated to trigger sucha TP. The verification method is similar to the one used in [14] where a TP isevaluated by resetting M to its initial configuration and attempted to be triggerthe TP in our simulated implementation. The process is repeated several timesand the overall result of how many times the TP was correctly triggered are
counted and compared to the times it failed. Hence an estimation is derived tomeasure the feasibility of these TPs.
In our example we looked at a relatively simple temporal constraints range(hence the small range of rankings on Figure 2) and it was easy to manuallycheck the complexity of the temporal constraints for each transition. This wassufficient for our case study, but defining an automated estimation measure forthe temporal qualities of a TP remains future work.
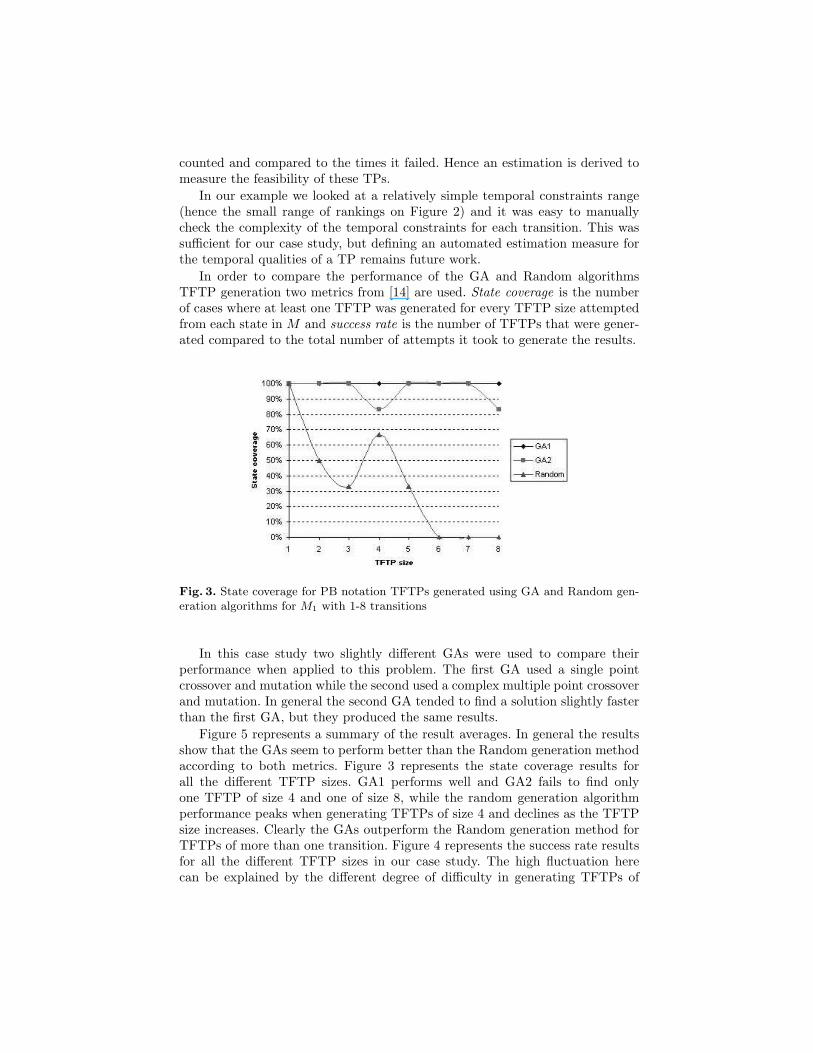
In order to compare the performance of the GA and Random algorithmsTFTP generation two metrics from [14] are used. State coverage is the numberof cases where at least one TFTP was generated for every TFTP size attemptedfrom each state in M and success rate is the number of TFTPs that were gener-ated compared to the total number of attempts it took to generate the results.
Fig. 3. State coverage for PB notation TFTPs generated using GA and Random gen-eration algorithms for M1 with 1-8 transitions
In this case study two slightly different GAs were used to compare theirperformance when applied to this problem. The first GA used a single pointcrossover and mutation while the second used a complex multiple point crossoverand mutation. In general the second GA tended to find a solution slightly fasterthan the first GA, but they produced the same results.
Figure 5 represents a summary of the result averages. In general the resultsshow that the GAs seem to perform better than the Random generation methodaccording to both metrics. Figure 3 represents the state coverage results forall the different TFTP sizes. GA1 performs well and GA2 fails to find onlyone TFTP of size 4 and one of size 8, while the random generation algorithmperformance peaks when generating TFTPs of size 4 and declines as the TFTPsize increases. Clearly the GAs outperform the Random generation method forTFTPs of more than one transition. Figure 4 represents the success rate resultsfor all the different TFTP sizes in our case study. The high fluctuation herecan be explained by the different degree of difficulty in generating TFTPs of

different sizes for some states. This relates to the guards of transition t14, whichis one of the core transitions. Although the guard conditions are complex inthe context of M1 they are very easy to satisfy. Hence the random algorithmcan easily select t14 in its TP search, while the GAs try to avoid it withoutrealising that it should not. GA2 shows the best performance with an averageperformance of 65%. GA1 performs mostly better than the random generationalgorithm, except for TFTPs of size 4 (average performance of 54%). For TFTPsof size 4 the random algorithm performs slightly better than GA1 and GA2. Therandom generation method did not find any TSTPs for sizes 4 to 6 while theGAs have different success rate for each size. This shows how different stateshave different properties. Hence future work may focus on more analysis of theguards and the temporal conditions to even out the search performance.
Fig. 4. Success rate for PB notation TFTPs generated using GA and Random gener-ation algorithms for M1 with 1-8 transitions
For both metrics the two GA search algorithms perform on average betterthan the random generation algorithm. This suggests that the fitness functionhere helps guide a heuristic search for TFTPs. In Figure 3 and Figure 4 we ob-serve that as longer TFTPs (and possibly when larger TEFSMs) are considered,the heuristics seems to perform increasingly better than the random generationalgorithm when given equal processing effort in terms of fitness evaluations andTFTP verifications. On all occasions the TFTPs generated by the GAs the hadequivalent or more complex temporal constraints compared to those generatedusing the random TP generation method. For a TEFSM of this size, as in ourcase study, it is expected to have similar performance for the small TFTPs be-cause the search space in those situations is not that big. However as the searchspace is increased (in or case study by increasing the size of the TFTPs) it be-comes clear that a random generation approach finds it hard to generate TPsthat feasible and satisfy the temporal constraints.

The state coverage metric is the easier one to satisfy. Not surprisingly theGAs found at least one TFTP for every state in M1. This measure howeverdiscards all the unsuccessful attempts to generate a given TFTP. Hence thesuccess rate metric considers those unsuccessful attempts as well. The successrates results are lower but the GAs seem to outperform the random algorithm.
State Coverage Success rate
GA1 100% 48%GA2 96% 47%
Random 35% 28%
Fig. 5. GA and Random search result averages for the Class 2 protocols for TFTPswith 1-8 transitions.
Overall both GAs performed well and generated very similar results. This in-dicates that the fitness function and the TP representation represent the problemof TFTP generation reasonably well. Hence future work can focus on refiningthe fitness function and evaluations of larger TEFSMs.
6 Conclusions and Future work
This paper defines a computationally inexpensive method to address an impor-tant problem in test data generation for TEFSMs. It extends some work onfeasibility of EFSMs [14] and considers temporal constraints.
We define the problem of finding a transition sequences that is likely to befeasible and to satisfy some temporal criteria as a search problem. We definea computationally efficient fitness function that is used to guide a GA. A casestudy of a communication protocol shows how the defined fitness function yieldssome positive results when GA search is applied to the problem. The GA almostfully satisfies the coverage criteria defined and increasingly outperforms randomgeneration as the TFTP size increases. The success rate fluctuated in this casestudy but the average success rate of the GA generated results was almost doublethat of the randomly generated results. Overall the limited results suggest thatthe approach scales well and could possibly be applied to larger TEFSMs.
Hence this computationally inexpensive fitness function may be used to aidthe generation of potentially computationally expensive test input generationsequences in a computationally inexpensive way.
Future work may focus on refining the fitness function to take into accountloops and other difficulties to estimate transitions. Further analysis of the condi-tions might also help. Further evaluation of the fitness function on other largerTEFSMs may also be beneficial to evaluate further how well the method scales.Different TEFSMs may present the need for alternative temporal constraintclassification, which will be very interesting to investigate.

Work on the combination of other related research like other test sequencegeneration [11] with feasibility estimation and temporal constraint satisfactioncan also be considered to aid the generation of test input sequences for TEFSMs.
References
1. Hennie, F.C.: Fault–detecting experiments for sequential circuits. In: Proceed-ings of Fifth Annual Symposium on Switching Circuit Theory and Logical Design,Princeton, New Jersey (1964) 95–110
2. Chow, T.S.: Testing software design modelled by finite state machines. IEEETransactions on Software Engineering 4 (1978) 178–187
3. Lee, D., Yannakakis, M.: Testing finite state machines: State identification andverification. IEEE Transactions on Computers 43 (1994) 306–320
4. Lee, D., Yannakakis, M.: Principles and methods of testing finite state machines -a survey. Proceedings of the IEEE 84 (1996) 1090–1123
5. Petrenko, A., Boroday, S., Gorz, R.: Confirming configurations in EFSMs. IEEETransactions on Software Engineering 30 (2004) 29–42
6. Duale, A.Y., Uyar, M.U.: A method enabling feasible conformance test sequencegeneration for EFSM models. IEEE Transactions Computers 53(5) (2004) 614–627
7. Mandrioli, D., Morasca, S., Morzenti, A.: Generating test cases for real time sys-tems from logic specifications. ACM Transactions on Computer Systems 13(4)(1995) 356–398
8. Larsen, K., Mikucionis, M., Nielsen, B.: Online testing of real-time systems usingUppaal. In: 4th Int. Workshop on Formal Approaches to Testing of Software,FATES’04, LNCS 3395, Springer (2004) 79–94
9. Brandan Briones, L., Brinksma, E.: Testing real-time multi input-output sys-tems. In: 7th Int. Conf. on Formal Engineering Methods, ICFEM’05, LNCS 3785,Springer (2005) 264–279
10. Nunez, M., Rodrıguez, I.: Conformance testing relations for timed systems. In:5th Int. Workshop on Formal Approaches to Software Testing, FATES’05, LNCS3997, Springer (2006) 103–117
11. Derderian, K., Hierons, R.M., Harman, M., Guo, Q.: Automated Unique InputOutput Sequence Generation for Conformance Testing of FSMs. The ComputerJournal 49(3) (2006) 331–344
12. Merayo, M., Nunez, M., Rodrıguez, I.: Generation of optimal finite test suites fortimed systems. In: 1st IEEE & IFIP Int. Symposium on Theoretical Aspects ofSoftware Engineering, TASE’07, IEEE Computer Society Pres (2007) 149–158
13. Duale, A.Y., Uyar, M.U.: Generation of feasible test sequences for EFSM Mod-els. In: TestCom ’00: Proceedings of the IFIP TC6/WG6.1 13th InternationalConference on Testing Communicating Systems, Deventer, The Netherlands, TheNetherlands, Kluwer, B.V. (2000) 91
14. Derderian, K.: Automated test sequence generation for Finite State Machines usingGenetic Algorithms. PhD thesis, Brunel University (2006)
15. Hierons, R.M., Ural, H.: Reduced length checking sequences. IEEE Transactionson Computers 51(9) (2002) 1111–1117
16. Hierons, R.M., Ural, H.: Optimizing the length of checking sequences. IEEETransactions on Computers 55(5) (2006) 618–629
17. Guo, Q., Hierons, R.M., Harman, M., Derderian, K.: Computing unique in-put/output sequences using genetic algorithms. In: Formal Approaches to Software

Testing: Third International Workshop, FATES 2003, LNCS vol. 2931, Springer,New York (2004) 169–184
18. Derderian, K., Hierons, R.M., Harman, M., Guo, Q.: Input sequence generationfor testing of communicating finite state machines CFSMs. In: LNCS vol. 3103,Springer (2004) 1429–1430
19. Ramalingom, T., Thulasiraman, K., Das, A.: Context independent unique stateidentification sequences for testing communication protocols modelled as extendedfinite state machines. Computer Communications 26(14) (2003) 1622–1633
20. Goldberg, D.E.: Genetic Algorithms in search, optimisation and machine learning.Addison-Wesley Publishing Company, Reading, Mass. USA (1989)
21. Srinivas, M., Patnaik, L.M.: Genetic algorithms: A survey. IEEE Computer 27(1994) 17–27
22. Jones, B.F., Eyres, D.E., Sthamer, H.H.: A strategy for using genetic algorithmsto automate branch and fault-based testing. The Computer Journal 41(2) (1998)98–107
23. Michael, C.C., McGraw, G., Schatz, M.A.: Generating software test data by evo-lution. IEEE Transactions on Software Engineering 27(12) (2001) 1085–1110
24. Whitley, D.: A free lunch proof for gray versus binary encodings. In: Proceedingsof the Genetic and Evolutionary Computation Conference. Volume 1., Orlando,Florida, USA, Morgan Kaufmann, CA, USA (July 1999) 726–733
25. Michalewicz, Z.: Genetic Algorithms + Data Structures = Evolution Programs.Springer-Verlag Berlinn Heidelberg New York (1996) Third, Revised and ExtendedEdition.




















