

1 Econometria Modelos de regressão linear
80
Transcript of 1 Econometria Modelos de regressão linear

RegressãoObjetivo: Estabelecer uma função matemática que des creva a relação entre uma variável contínua (variável exp licada ou dependente) e uma ou mais variáveis explicativas ou independentes.
y = f(x 1,x2,...,xK) + εεεε
� y denota a variável dependente.� x1,x2,...,xK denotam as variáveis independentes.� f(x1,x2,...,xK) descreve a variação sistemática � εεεε representa a variação não sistemática (erro aleatór io)
Modelos de regressão (função f) podem ser lineares ou não lineares.
A função f não é conhecida e deve ser inferida a par tir das observações das variáveis y, x 1,x2,...,xk.

Regressão Linear
Técnica estatística que pode ser usada para analisar a relação entre uma única variável dependente (explicada) e um conjunto de variáveis independentes (explicativas).
O objetivo da análise de regressão linear consiste em i dentificar uma equação linear que permita prever o valor da variável de pendente em função dos valores conhecidos das variáveis independe ntes.
Regressão linear simples: apenas uma variável independ ente.Exemplo: variável dependente = vendasvariável independente = despesas com propaganda
Regressão linear múltipla: duas ou mais variáveis inde pendentes.Exemplo: variável dependente = preço do imóvel variáveis independentes = área, nº de quartos, nº de ba nheiros, idade

Motivação (HANKE & WICHERN, 2006)Uma empresa transportadora deseja estimar o custo de agregar carga a um caminhão parcialmente cheio.A empresa acredita que o único incremento de custo, decorrente da agregação de carga, é o custo adicional de combustível, pois o rendimento (milhas por galão) seria menor.Admite-se que a frota da transportadora é formada por caminhões idênticos.No período 2009-2012 foram realizadas 5.428 viagens e uma amostra aleatória de 40 viagens foi tomada. Na tabela ao lado são apresentados os pesos e os rendimentos (milhas/galão) das 40 viagens selecionadas na amostra.
Um incremento no peso reduz o rendimento
A relação entre as variáveis não é
exata (estocástica)
Diagrama de dispersão
representação gráfica que permite visualizar a
relação/associação entre duas variáveis
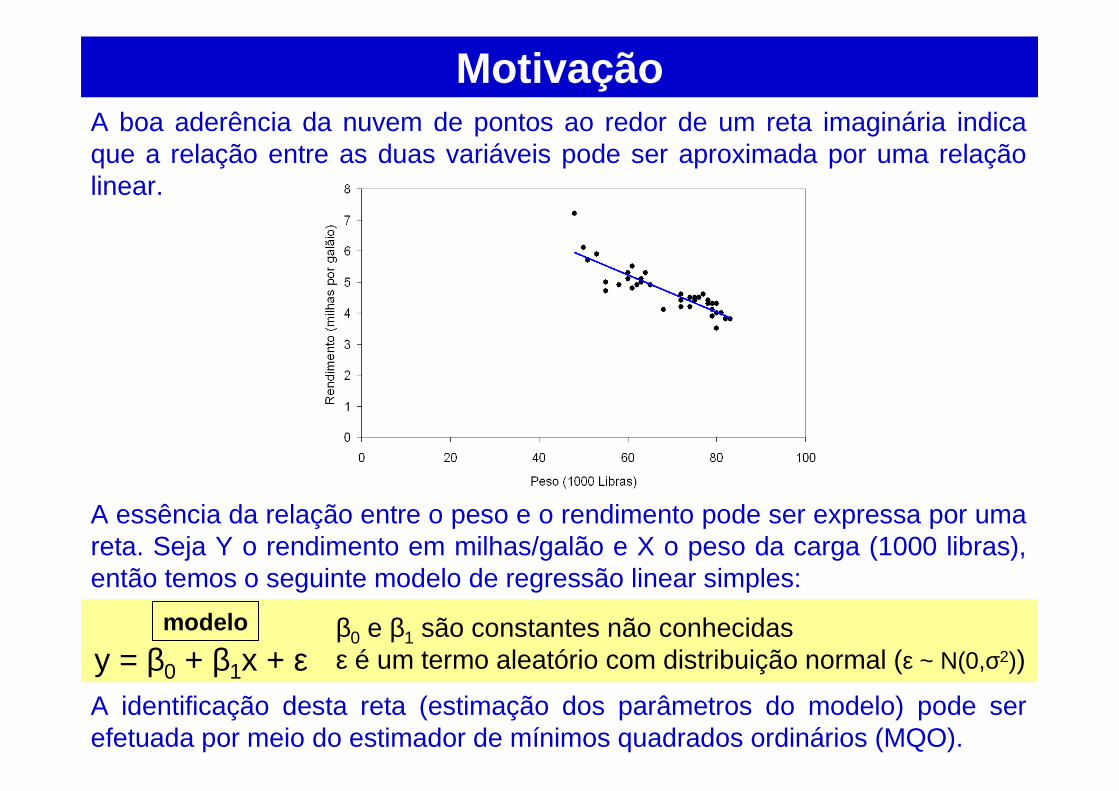
MotivaçãoA boa aderência da nuvem de pontos ao redor de um reta imaginária indica que a relação entre as duas variáveis pode ser aproximada por uma relação linear.
A essência da relação entre o peso e o rendimento pode ser expressa por uma reta. Seja Y o rendimento em milhas/galão e X o peso da carga (1000 libras), então temos o seguinte modelo de regressão linear simples:
A identificação desta reta (estimação dos parâmetros do modelo) pode ser efetuada por meio do estimador de mínimos quadrados ordinários (MQO).
y = β0 + β1x + εβ0 e β1 são constantes não conhecidas ε é um termo aleatório com distribuição normal (ε ~ N(0,σ2))
modelo

Motivação
Neste caso o rendimento (y) é explicado pelo peso da carga (x), então, y=f(x):
y = rendimento = variável dependentex = peso da carga = variável independente
A relação estocástica entre as duas variáveis pode ser modelada da seguinte forma:
y = β0 + β1x + ε
Onde:� β0 e β1 são coeficientes desconhecidos da reta que relaciona as variáveis x e y (estimados a partir dos dados da amostra).� ε é um termo aleatório (erro) que representa a imprecisão na relação entre x e y.

Motivação
Para uma carga de 70 mil libras (X= 70) espera-se u m rendimento de 4,62 milhas/galão ( Ê(Y|X) = 4,62 )
E(Y|X) = 8,8484 – 0,0604 x 70 ≅≅≅≅ 4,62
Equação da reta estimada por MQOÊ(Y|X) = 8,8484 – 0,0604 X
X
Y

MotivaçãoEstimação por mínimos quadrados ordinários (MQO)
Modelo ajustadoÊ(Y|X) = 8,8484 – 0,0604 X
xy 10ˆˆ β−=β
( )( )( )∑
∑
=
=
−
−−=β
n
ii
n
iii
xx
yyxx
1
2
11
ˆ
Estimador MQO
X é a variável independente ou explicativa, neste ca so o peso ( é a média amostral de X)
Y é a variável dependente ou explicada, neste caso é o rendimento (milhas por galão), é a média amostra l de Y
n é número de observações, neste caso 40
0β 1β
X
Y

Motivação
Interpretação da equação estimada
Ê(Y|X) = 8,8484 – 0,0604 X
Cada incremento de 1000 libras ( ∆∆∆∆X=1) na carga implica em uma redução, média, do rendimento (milhas/galão) da ordem de 0,0604 mil has/galão.
A transportadora paga $ 1,25 por galão de diesel, e ntão qual o incremento no custo para transportar 1000 libras adicionais por u m trajeto de 100 milhas, dado que o frete é o médio (68,6 1000 libras)?

Motivação
4,7 milhas/galão
100 milhas x 1,25 $/galão= $ 26,60
O custo da mesma viagem com 1000 libras adicionais é:
(4,7 – 0,0604) milhas/galão
100 milhas x 1,25 $/galão= $ 26,94
Ou seja, 1000 libras adicionais na carga aumenta o custo em 34 centavos
centróide
6,68=X
7,4=Y
A transportadora paga $ 1,25 por galão de diesel, então
qual o custo para transportar 1000 libras de carga em um
trajeto de 100 milhas ?
O rendimento médio é 4,7 milhas/galão, logo para um trajeto de 100 milhas com
trasporte do frete médio (68,6 1000 libras), em média, o
custo total é:

Modelos de regressão linear
Modelo de regressão linear simples: uma variável dependente explicada por uma variável independente.
y = β0 + β1x + ε
Modelo de regressão linear múltipla:Uma variável dependente explicada por pelo menos duas variáveis independentes.
y = β0 + β1x1 + ... + βKxK + ε (K≥2)
Objetivo : Identificar uma função linear que permita explicar uma variável dependente (y) em função das variáveis explicativas (x), ou seja, como y varia de acordo com mudanças em x.

Significado do erro εεεε
O erro ε representa:
� Todos os outros fatores que afetam a variável dependente Y, mas que não estão contempladas nas variáveis explicativas X.
� Erros de medição.
� Forma funcional inadequada, por exemplo,
y = β0 + β1x ou y = β0 + β1x + β1x2 ?
� Inerente variabilidade no comportamento dos agentes econômicos.

Modelo de Regressão Linear Simples
Equação de regressão populacional:
y = β0 + β1x + ε (apenas uma variável independente)
Os coeficientes ββββ0 e ββββ1 não são conhecidos e devem ser estimados a partir de uma amostra aleatória de tama nho n da população:
Amostra aleatória de tamanho n ⇒ (xi , yi), i=1,n
Em cada unidade amostrada tem-se que
yi = β0 + β1xi + εi i=1,n
Erro, variável aleatória não-observável
Componente determínistica

Hipóteses assumidas pelo modelo
H1) A relação entre as variáveis é linear yi = β0 + β1xi + εi i=1,n:
H2) Média nula: E(εi) = 0 para todo i=1,n
H3) Variância constante: V(εi) = σ2 para todo i=1,n
H4) Erros não correlacionados: Cov(εi,εk) = 0 para todo i≠k
H5) Distribuição Normal: εi ~ N(0,σ2) para todo i=1,n
εi são independentes e identicamente distribuídos N(0, σσσσ2)
H6) A variável explicativa X é fixa, i.e., não é estocástica
Modelo de Regressão Linear Simples

( ) 2σ=yV
ε+β+β= xy 10
Como o valor esperado do erro é zero E( εεεε)=0, o valor esperado de y condicionado ao valor de x é igual a:
( ) ( )ε+β+β= xExyE 10|
( ) ( )ε+β+β= ExxyE 10|
( ) xxyE 10| β+β=
Por hipótese a variável independente não é aleatória , assim tem-se:
( )210 ,~ σβ+β xNy
Como o erro tem distribuição Normal com média 0 e v ariância σσσσ2
Modelo de Regressão Linear Simples

( ) xxyE 10| ββ +=
Modelo de Regressão Linear Simples
Reta de regressão

Estimador de mínimos quadradosModelo de Regressão Linear Simples
yi = β0 + β1xi + εi ⇒ εi = yi - β0 - β1xi
( )[ ]∑∑==
β+β−=ε=n
iii
n
ii xyf
1
210
1
2
( )[ ]∑=ββ
β+β−=n
iii xyfMin
1
210
, 10
( )[ ] 001
100
=β+β−⇒=β∂∂
∑=
n
iii xy
f
( )[ ] 001
101
=β+β−⇒=β∂
∂∑
=
n
iiii xyx
f
∑∑==
=β+βn
ii
n
ii yxn
1110
∑∑∑===
=β+βn
iii
n
ii
n
ii yxxx
11
21
10
Soma dos quadrados dos erros
As estimativas de ββββ0 e ββββ1 devem minimizar a soma sos quadrados dos desvios
No ponto de mínimo as derivadas parciais são nulas
Sistema de equações normaisA solução deste sistema fornece os estimadores de ββββ0 e ββββ1

Estimador de mínimos quadrados
Modelo de Regressão Linear Simples
∑∑==
=β+βn
ii
n
ii yxn
1110
∑∑∑===
=β+βn
iii
n
ii
n
ii yxxx
11
21
10
Solução do sistema de equações normais
xy 10ˆˆ β−=β
( )( )( )∑
∑
=
=
−
−−=β
n
ii
n
iii
xx
yyxx
1
2
11
ˆ
Sistema de equações normais
Estimadores de mínimos quadrados

Estimador de mínimos quadrados
Modelo de Regressão Linear Simples
ii xy 10ˆˆˆ β+β=Valor estimado da variável dependente
y dado que x é igual a x i
Resíduo da i-ésima observação é igual a diferença entre o valor observado e o valor estimado da variável y i ( )iii
iii
xy
yy
10ˆˆˆ
ˆˆ
β+β−=ε
−=ε
Equação de regressão estimada ( ) xxyEy 10ˆˆ|ˆ β+β==

( )∑
∑
=
=
−= n
ii
n
ii
xxn
x
1
2
1
22
2ˆ0
ε
β
σσ
∑=
−= n
ii xx
1
22
22ˆ1
εβ
σσ
Se as hipóteses H1 até H6 forem satisfeitas, os estim adores de mínimos quadrados são estimadores lineares não tendenciosos d e variânciamínima (Teorema de Gauss Markov)
( ) 00ˆ β=βE
( ) 11ˆ β=βE
( )2ˆ00
0,~ˆ
βσββ N
( )2ˆ11
1,~ˆ
βσββ N
( )2
ˆˆ
2
ˆˆ 1
2
101
2
2
−
−−=
−=
∑∑==
n
xy
n
un
iii
n
ii ββ
σ ε
Modelo de regressão linear simples
Estimador da variância do
erro
O estimador MQO é não tendencioso
Os estimadores são normalmente
distribuídos

Modelo de regressão linear simplesDecomposição do erro
Y
X
Y
Y = b0 + b1X (reta de regressão )^
Yi (valor observado)
Yi -Y Yi (valor estimado pela reta )^
Yi - Y^
Yi -
Média davariáveldependente
Yi (resíduo )

Modelo de regressão linear simples
Decomposição do erro
SQT é a soma dos quadrados dos desvios de Y em relação a sua média, logo SQT é uma medida da variação total da variável dependente.
( )∑=
−=n
ii YYSQT
1
2Y
X
Y

Modelo de regressão linear simples
Decomposição do erro
SQR é a soma dos quadrados dos desvios entre a reta de regressão e a média da variável dependente Y.
SQR é uma medida da variação total da variável dependente explicada pela regressão.
( )∑=
−=n
ii YYSQR
1
2ˆY
X
Y
Y corresponde as estimativas definidaspela reta de regressão
^

Modelo de regressão linear simples
Decomposição do erro
SQE é a soma dos quadrados dos desvios de Y em relação a reta de regressão (resíduos).
SQE expressa a parcela da variação de Y não explicada pela reta de regressão.
Y
X
( )∑=
−=n
iii YYSQE
1
2ˆ
Y corresponde as estimativas definidaspela reta de regressão
^

Decomposição da soma de quadrados total
( ) ( ) ( )∑∑ ∑== =
−+−=−n
iii
n
i
n
iiii YYYYYY
1
2
1 1
22 ˆˆ
SQT = SQE + SQR
SQT = Soma de Quadrados Total (variação total da va riável dependente)
SQR = Soma de Quadrados da Regressão (parcela da va riação total explicada pelo modelo)
SQE = Soma de Quadrados dos Erros (Resíduos) (parce la da variação total não explicada pelo modelo)
n é o total de observações na amostra
Modelo de regressão linear simples

( )( ) SQT
SQE
YY
YY
SQT
SQRR
n
ii
n
iii
−=−
−==∑
∑
=
= 1
ˆ
1
2
1
2
2
Coeficiente de determinação
Modelo de regressão linear simples
10 2 ≤≤ R
� Se R2 estiver próximo de 1, a variável x explica a maior parte da variação total de y. Neste caso, a variável x é uma boa preditora da variável y.
� Se R2 estiver próximo de 0, a variável x explica muito pouco da variação total de y.Neste caso, a variável x não é uma boa preditora da variável y.

Análise da variância (ANOVA)
Modelo de regressão linear simples
2ˆεσ Estimador da variância do erro
SQT
SQRR =2
( )2−=
nSQE
SQRF
Fonte de variação Graus de liberdade
Soma dos quadrados Quadrados médios
Regressão 1 ( )∑=
−=n
ii XxSQR
1
221β 1/SQRQMR=
Resíduos n-2 ( )∑=
−=n
iii yySQE
1
2ˆ ( )2/ −= nSQEQME
Total n-1 2
1
2 YnySQTn
ii −=∑
=

No exemplo da transportadora tem-se que
Modelo de regressão linear simples
R2 = 0,76, ou seja, 76% da variação do rendimento éexplicada pela equação de regressão Y = 8,8484 – 0,0604X
SQR
SQE SQT
Resultados gerados pelo Excel
equação de regressão Y = 8,8484 – 0,0604X
Análise da variância (ANOVA)

2ˆ
1 ~ˆ
ˆ
1
−= Nttβσ
β
tcrítico é um valor tabelado para um nível de significância αααα, no Excel use INVT(alfa;N-2)
Modelo de regressão linear simples
Inferência Estatística
Teste t
Avalia a significância do coeficiente de regressão li near associado com uma determinada variável explicativa.
Sob H 0
t > tcrítico rejeita H0t < tcrítico aceita H0
Modelo de regressão linear simples: Y = ββββ0 + ββββ1X + εεεε
Estatística teste
H0 : ββββ1 = 0 ( ausência do efeito )H1 : ββββ1 ≠≠≠≠ 0 ( presença do efeito )

No exemplo da transportadora tem-se que
Modelo de regressão linear simples
Resultados gerados pelo Excel
Inferência Estatística (teste t)
1β1ˆˆ
βσ 9052,100055,0
0604,0ˆ
ˆ
1ˆ
1 −=−==βσ
βt
H0 : ββββ1 = 0H1 : ββββ1 ≠≠≠≠ 0
Ao nível de significância α de 5% o valor tabelado (tcrítico) de uma t com (40-2) = 38 graus de liberdade é 2,024 =INVT(0,05;38)
Valor absoluto do t calculado maior que tcrítico, logo H0 é rejeitada.
2ˆ
~ˆ
ˆ−= Ntt
βσβ
Estatística teste
t calculado

Exemplo modelo de regressão linear simples
Região de rejeição
Distribuição t
No exemplo da transportadora tem-se que
Inferência Estatística (teste t)
2,024- 2,024
tcalculado = -10,9052
tcrítico = INVT(0,05;38)
Região de rejeição bilateral
H0 : ββββ1 = 0H1 : ββββ1 ≠≠≠≠ 0
01
ˆ
1
ˆ
ˆ
βσβ=t

Exemplo modelo de regressão linear simples
O valor p (p-value) fornece uma forma direta de decidir e ntre a rejeição e a não rejeição da hipótese nula H0
P-valor é a probabilidade de encontrar um valor para a est atística teste mais extremo que o valor calculado para a estatística teste (t calculado ).
Se o valor p é menor que os níveis usuais de significâ ncia (1% ou 5%) devemos concluir pela rejeição da hipótese nula
Cálculo do valor p no exemplo da transportadora:
tcalculado = -10,9052valor p = P(t mais extremo que tcalculado) = P (t ≤ -10,9052 ou t ≥ 10,9052) = 2,91E-13
Inferência Estatística (teste t e valor p)
No Excel=DISTT(10,9052;38;2)
Probabilidade muito pequena e menor que o nível de significância adotado (5%), logo a hipótese nula (H0) deve ser rejeitada
H0 : ββββ1 = 0H1 : ββββ1 ≠≠≠≠ 0

Exemplo modelo de regressão linear simples
Inferência Estatística (teste t e p-valor)
Resultados gerados pelo Excel
Valor p menor que o nível de significância adotado (5%), logo a hipótese nula (H0) deve ser rejeitada

21
11
2111 1
ˆˆˆˆαβαβ σββσβ
−−⋅+≤≤⋅− tt
Modelo de regressão linear simples
Intervalo de confiança 100(1- αααα)%
Inferência Estatística (intervalo de confiança)
No exemplo da transportadora tem-se que
Resultados gerados pelo Excel
O intervalo -0,0716 ≤ β1 ≤ -0,0492 tem 95% de confiança de conter o valor do
coeficiente de regressão da variável peso
Valorestabelados

Previsor ( ) hhh XXYE 10ˆˆ|ˆ ββ +=
Erro de previsão ( ) ( ) ( ) ( ) hhhhhh XXYEXYE 1100ˆˆ|ˆ| ββββε −+−=−=
( ) ( )( )
−
−+=∑
=
n
ii
hh
XX
XX
nS
1
2
2
22 1ˆεσε
Intervalo de previsão
( ) ( ) ( ) ( )[ ]hchhhchh StXYEStXYE εε 22 |ˆ,|ˆ +−
Modelo de regressão linear simples
Previsão do valor esperado
2
Reˆ
−=
n
sSQεσ

Dado XT+h prever YT+h
Previsorhh XY 1
ˆˆˆ0
ββ +=
Erro de previsão ( ) ( ) hhhhh uXYY +−+−=−= 1100ˆˆˆ ββββε
( ) ( )( )
−
−++=∑
=
n
ii
hh
XX
XX
nS
1
2
2
22 11ˆεσε
Intervalo de previsão
( ) ( )[ ]hchhch StYStY εε 22 ˆ,ˆ +−
Modelo de regressão linear simplesPrevisão de uma observação
2
Reˆ
−=
n
sSQεσ

Modelo de regressão linear simples
Intervalo de previsão de uma observação
Intervalo de previsão do valor esperado

Exemplo
A Comissão de Serviços Públicos é responsável pela regulação dos serviços públicos, ou seja, atua no sentido de induzir as empresas a serem eficientes e prestarem serviços de qualidade ao preço justo para a população.
Em um determinado Estado atuam diferentes empresas de serviços públicos sob o regime de monopólio nas respectivas áreas de concessão. O trabalho do auditor consiste em visitar estas empresas e auditar seus registros financeiros para detectar se algum tipo de abuso está ocorrendo. A maior dificuldade do auditor é avaliar se os custos apresentados pelas empresas são razoáveis, pois as empresas têm diferentes tamanhos
O arquivo empresas.xls contêm registros do número de clientes e custos de manutenção de 12 empresas de serviço público.
• Estime o modelo de regressão.
• Qual o custo de manutenção esperado para uma empresa com 75.000 clientes ?
• Suponha que uma empresa com 75.000 clientes reporte uma despesa com manutenção de 1.500.000. Com base nos resultados da regressão linear, o auditor deve ver este número como razoável ou excessivo ?

Exemploclientes (1000) despesas com manutenção (1000 US$)
25.3 484.6
36.4 672.3
37.9 839.4
45.9 694.9
53.4 836.4
66.8 681.9
78.4 1037
82.6 1095.6
93.8 1563.1
97.5 1377.9
105.7 1711.7
124.3 2138.6
XY 02,1532,33ˆ +=Y = Despesa com manutençãoX = Nº de clientes

Qual o custo de manutenção esperado para uma empresa com 75.000 clientes ?
X = 75 →
Exemplo
82,11597502,1532,33ˆ =⋅+=YY = Despesa com manutençãoX = Nº de clientes
75
1159,82
→ US$ 1.159.820,00

Suponha que uma empresa com 75.000 clientes reporte uma despesa com manutenção de 1.500.000. Com base nos resultados da regressão linear, o auditor deve ver este número como razoável ou excessivo ?
Podemos responder esta pergunta por meio de um intervalo de previsão para uma observação.
Exemplo
( ) ( )[ ]hchhch StYStY εε 22 ˆ,ˆ +−
( ) ( )( )
−
−++=∑
=
n
ii
hh
XX
XX
nS
1
2
2
22 11ˆεσεonde
Obtido na AnovaQuadrado médio do resíduo 35236
Nº de observações = 12
t crítico com N-2 graus de liberdade ao nível de significância αααα. No Excel =INVT(0.05;10) = 2,2281
Valor estimado pelo modelo de regressão para variável dependente (Yh = 1159,2) quando Xh = 75.
Média da variável dependente70,67

O intervalo de confiança cobre o ponto (75, 1500), logo o valor do custo não éexcessivo.
Exemplo
X = 75 (1000 clientes)Y = 1500 (1000 US$)

Exemplo modelo de regressão linear simples no Excel1) Matriz de dados para regressão linear simples1 variável dependente1 variável independente
2) No menu Ferramentas escolha a opção Análise de dados
3) Na caixa de diálogo escolha a opção Regressão e clique em Ok
4) Informe os dados para regressão na caixa de diálogo

Exemplo modelo de regressão linear simples no Excel
Caixa de diálogo regressãoIntervalo com os valores da variável dependente
Intervalo com os valores da variável independente
Rótulos: nomes das variáveis Marque se tem rótulo
Grava resultados da regressão em uma nova planilha
Apresenta a série de resíduos
YY ˆ−
Gráfico com os valores observados e previstos
Gráfico dos resíduos contra a variável explicativa
Gráfico para avaliar se a hipótese de normalidade do erro é satisfeita

Exemplo modelo de regressão linear simples no ExcelPlanilha de Resultados
R2
2R
Valor PP(F>24,3492) = 0,0011
Valor P < 5% rejeito H0 no teste F
α β Valor PP( |t| >2,1495) = 0,0638
Valor PP( |t| >4,9345) = 0,0011
Intervalo de confiança
4,9345- 4,9345
Valor P < 5% rejeito H0 no teste F
Y YY ˆ−
Valores para a plotagem de probabilidade normal

Exemplo modelo de regressão linear simples no ExcelGráficos na planilha de Resultados
X Plotagem de resíduos
-20
0
20
0 10 20 30 40 50
X
Res
íduo
s
X Plotagem de ajuste de linha
0
10
20
30
40
50
60
0 10 20 30 40 50
X
Y
Y
Previsto(a) Y
Plotagem de probabilidade normal
0
10
20
30
40
50
60
0 20 40 60 80 100
Percentil da amostra
Y
Útil na verificação da hipótese de variância constante do erro
Útil na verificação da hipótese de normalidade do erro (valores ao
redor de uma reta imaginária indicam que a hipótese de
normalidade não foi violada)
Valores observados contra valores estimadosÚtil na avaliação da qualidade do ajuste

Regressões que se tornam lineares por anamorfose
iX
iiY εββ 10=(exponencial)
iii XY εβ β1
0=(potência)
ii
i XY εββ ++= 1
10(hipérbole)
iiii XXY εβββ +++= 2110
(polinomial)
As especificações a seguir são não-lineares, mas po dem se tornar lineares por anamorfose, ou seja, mediante alguma transformação das variáveis.
iii XY εββ lnlnlnln 10 +⋅+=
iii vXY +⋅+= *1
*0
* ββ
ii YY ln* =
0*0 ln ββ =
1*1 ln ββ =
iiv εln=
iii XY εββ lnlnlnln 10 ++=
iii vXY +⋅+= *1
*0
* ββii YY ln* =0
*0 ln ββ =
iiv εln=ii XX ln* =
iii XY εββ ++= *10
ii XX 1* =
iiii XXY εβββ +++= 21110
ii XX =12
2 ii XX =
Modelo linear
Modelo linear
Modelo linear
Modelo regressão linear múltiplaA substituição de variáveis é válida, pois a
relação entre X 1 e X2 é não linear

Modelo de regressão linear múltipla

A variável dependente é uma função linear de K variá veis independentes (K ≥≥≥≥2)
iKikiii XXXY εββββ +++++= K22110
Notação matricial
i=1,n
εβ += XY
=
nY
Y
Y
YM
2
1
=
knn
k
k
XX
XX
XX
X
1
212
111
1
1
1
M
L
β
ββ
β
=
0
1
M
k
=
nε
εε
εM
2
1
Modelo de regressão linear múltipla
ββββ1, ββββ2, ββββ3,...,ββββk, σσσσ2 são parâmetros do modelo que devem ser estimados
[ ] i
k
Kiii XXY ε
β
ββ
+
⋅=M
L1
0
,1,1 i=1,n
Na regressão linear simples (K=1), um caso particul ar da regressão linear múltipla

Hipóteses assumidas pelo modelo de regressão linear mú ltipla
H1) A relação entre as variáveis é linear yi = β0 + β1xi1 + β2x2i +...+ βkxki + εi i=1,n.
H2) A variável explicativa X é fixa, ou seja, não é aleatória.
H3) As colunas da matriz X são linearmente independentes, ou seja, não há uma relação linear perfeita entre duas ou mais as variáveis explicativas.
H4) Erros tem média nula: E(εi) = 0 para todo i=1,n.
H5) Variância do erro é constante (homocedasticidade):V(εi) = σ2 para todo i=1,n.
H6) Erros não correlacionados: Cov(εi,εk) = 0 para todo i≠k.
H7) Erros tem distribuição Normal: εi ~ N(0,σ2) para todo i=1,n.
H2,H3,H4 e H5 ⇒⇒⇒⇒ εεεεi são independentes e identicamente distribuídos N(0, σσσσ2)
Basicamente, são as mesmas hipóteses assumidas na r egressão linear simples

( ) YXXX TT 1ˆ −=β
=
∑∑∑∑
∑∑∑∑
∑∑∑∑
∑∑∑
====
====
====
===
n
iKi
n
iKii
n
iKii
n
iKi
n
ikii
n
ii
n
iii
n
ii
n
ikii
n
iii
n
ii
n
ii
n
iKi
n
ii
n
ii
T
XXXXXX
XXXXXX
XXXXXX
XXXn
XX
1
2
12
11
1
12
1
22
121
12
11
121
1
21
11
112
11
OM
L
Estimador de Mínimos Quadrados Ordinários (MQO)
Modelo de regressão linear múltipla
=
∑
∑
∑
∑
=
=
=
=
n
iiKi
n
iii
n
iii
n
ii
T
yx
yx
yx
y
YX
1
12
11
1
M
Equação de projeção [ ]
⋅=+++==
k
KKk XXXXXyEy
β
ββ
βββ
ˆ
ˆ
ˆ
1ˆˆˆ)|(ˆˆ 1
0
1110M
LK

( ) ( ) 12ˆ −=Σ XX Tσβ
kn
SQE
−=2σ
Estimador de mínimos quadradosPropriedades do estimador de mínimos quadrados
( ) ββ =ˆE
( )( )121 ,~ˆ −
+ XXN TK σββ
Se as hipóteses H1 até H6 forem satisfeitas, o estima dor de mínimos quadrados é o melhor estimador linear não tendencioso ( Teorema de Gauss Markov)
Estimador não tendencioso
Matriz de covariância dos estimadores
O vetor de estimadores tem distribuição normal multivariada
( )jjjj aN 2,~ˆ σββCada tem distribuição normal
ajj elemento da diagonal principal da inversa de X’X
jβ

Exemplo modelo de regressão linear múltipla (KUTNER et al, 2004)
X1 X2 Y68,5 16,7 174,445,2 16,8 164,491,3 18,2 244,247,8 16,3 154,646,9 17,3 181,666,1 18,2 207,549,5 15,9 152,8
52 17,2 163,248,9 16,6 145,438,4 16 137,287,9 18,3 241,972,8 17,1 191,188,4 17,4 23242,9 15,8 145,352,5 17,8 161,185,7 18,4 209,741,3 16,5 146,451,7 16,3 14489,6 18,1 232,682,7 19,1 224,152,3 16 166,5
Uma empresa de artigos infantis opera em 21 cidades de médio porte. A empresa está analisando a possibilidade de expansão em outra s cidades de médio porte e para isso deseja investigar se a vendas (Y) em uma localidade podem ser preditas com base no número de pessoas com até 16 anos de ida des (X1) e a renda per capita na localidade (X 2). Valores expressos em milhares.
Atualmente a empresa está presente em 21 localidades (N = 21), cujos dados são apresentados na tabela abaixo:
εβββ +++= 22110 XXY
Modelo de regressão linear múltipla a ser estimado
0
50
100
150
200
250
300
30 40 50 60 70 80 90 100
X1
Y
0
50
100
150
200
250
300
15 16 17 18 19 20
X2
Y

Exemplo modelo de regressão linear múltipla
( ) 2211021, XXXXYE i βββ ++=A equação de regressão
Os dados das 21 localidades podem ser dispostos em um gráfico, onde cada localidade é representada por um ponto.
define um plano
passando pelo meio da nuvem de pontos. Este plano r epresenta o valor esperado das vendas em função da renda e da população abaixo de 16 anos em uma localidade
populaçãorenda
vendas

Exemplo modelo de regressão linear múltiplaModelo de regressão linear
Estimação dos coeficientes de regressão por mínimos quadrados
iiii XXY εβββ +++= ,22,10
1 68,5 16,71 45,2 16,81 91,3 18,21 47,8 16,31 46,9 17,31 66,1 18,21 49,5 15,91 52 17,21 48,9 16,61 38,4 161 87,9 18,31 72,8 17,11 88,4 17,41 42,9 15,81 52,5 17,81 85,7 18,41 41,3 16,51 51,7 16,31 89,6 18,11 82,7 19,11 52,3 16
X =
174,4164,4244,2154,6181,6207,5152,8163,2145,4137,2241,9191,1
232145,3161,1209,7146,4
144232,6224,1166,5
Y =
21,00 1.302,40 360,001.302,40 87.707,94 22.609,19
360,00 22.609,19 6.190,26=XX T
3.820,00249.643,35
66.072,75=YX T
29,7289 0,0722 -1,99260,0722 0,0004 -0,0055
-1,9926 -0,0055 0,1363( ) =−1
XX T
( ) YXXX TT 1ˆ −=β
−=
3655,9
4546,1
8571,68
ˆ
ˆ
ˆ
2
1
0
βββ
Dados
ε+++−= 21 37,945,186,68 XXY
Equação estimada

Exemplo modelo de regressão linear múltiplaGráficos dos resíduos contra cada variável explicat iva e a variável explica exibe um padrão aleatório e a dispersão parece constante e, portanto, estão coerentes com as hipóteses (pressupostos) de covariâncias nul as entre os erros e variância do erro constante.

Exemplo modelo de regressão linear múltiplaO gráfico de probabilidade normal índica que a dist ribuição dos resíduos énormal, portanto, coerente com a hipótese (pressupo sto) de distribuição normal para o erro.

Análise da variância - ANOVA
( )( )∑
∑
=
=
−
−== n
ii
n
iii
YY
YY
SQT
SQRR
1
2
1
2
2
ˆ
( )kn
nRR
−−−−= 1
11 22
( )[ ]1+−==
knSQE
kSQR
QME
QMRF
Modelo de regressão linear múltiplaInferência Estatística no Modelo de Regressão Linear
Fonte de variação
Graus de liberdade
Soma dos quadrados Quadrados médios
Regressão K nyYXSQRn
ii
TT2
1
ˆ
−= ∑=
β KSQRQMR /=
Resíduos n - (K+1) YXYYSQE TTT β−= ( )[ ]1/ −−= KnSQEQME
Total n -1 nyYYSQTn
ii
T
2
1
−= ∑=

Exemplo modelo de regressão linear múltiplaConstrução da ANOVA para o exemplo da cadeia de loj as de roupas juvenis
iii XXY 21 3655,94546,18571,68ˆ ++−=SQE SQR SQT

Exemplo modelo de regressão linear múltiplaConstrução da ANOVA para o exemplo da cadeia de loj as de roupas juvenis
Fonte de variação
Soma dos quadrados
(A)
Graus de liberdade
(B)
Quadrado médio
(C=A/B)F
Regressão SQR 24015,28
2 12007,64 12007,64 / 121.1626 = 99,1035
Resíduo SQE2180,93
N-3=18 121,1626
Total SQT26196,21
N-1=20
ANOVA
2 variáveis explicativas 3 coeficientes
estimadosPor isso N – 3
O quadrado médio dos resíduos é uma estimativa da variância do erro
2ˆεσCoeficiente de determinação R2
917,021,26196
28.240152 ===SQT
SQRR

Teste t H0 : ββββ j = 0H1 : ββββ j ≠≠≠≠ 0
( )1~ˆ +−= kn
j tb
tjβσ
( )[ ]1+−=
knSQE
kSQRF
H0 : ββββ 1 = ββββ 2 = ββββ 3 =...= ββββ k =0H1 : pelo menos um ββββj ≠≠≠≠ 0
Teste F
t t rejeita Htabelado≥ ⇒ 0
F F rejeita Htabelado≥ ⇒ 0
Modelo de regressão linear múltipla
Inferência Estatística

Exemplo modelo de regressão linear múltiplaModelo de regressão linear
Estimativas dos erros padrão dos coeficientes de re gressão
( ) 12
2ˆˆˆˆˆ
ˆˆ2ˆˆˆ
ˆˆˆˆ2ˆ
ˆ
ˆˆˆ
ˆˆˆ
ˆˆˆ
22120
21110
20100−⋅=
= XXS Tε
βββββ
βββββ
βββββ
β σσσσ
σσσσσσ
0170,600347,3602ˆˆ 2ˆˆ00
=== ββ σσErros padrão dos estimadores dos coeficientes de regressão (valores informados pelo ajuste de regressão no Excel)
Resultado na ANOVA = 121,1626
29,7289 0,0722 -1,99260,0722 0,0004 -0,0055
-1,9926 -0,0055 0,1363
=βS3.602,0347 8,7459 -241,4230
8,7459 0,0449 -0,6724-241,4230 -0,6724 16,5158
2118,00449,0ˆˆ 2ˆˆ11
=== ββ σσ
0640,45158,16ˆˆ 2ˆˆ22
=== ββ σσ
Variâncias na diagonal principalCovariâncias fora da diagonal principal
iiii XbbXbY ε+++= ,22,10

Exemplo modelo de regressão linear múltiplaInferência do modelo
H0 : b 1 = b2 = 0 ( não há regressão de Y em X 1 e X2)H1 : b 1 ≠≠≠≠ 0 ou b 2 ≠≠≠≠ 0 ( presença do efeito )
( )1+−
=
Kn
SQEK
SQR
F
Fcalculado > Fcrítico logo rejeita H 0
1) Estatística teste
4) F crítico ao nível de significância de 5% = 3,5546=FINV(0,05;2;18) no Excel
Distribuição F
Teste F: Testa o efeito conjunto das variáveis expl icativas sobre a variável dependente.
( )1035,99
12211626,1212
64,007.12
=
+−
=F
2) Distribuição da estatística testes sob H 0
( )( )1,~
1
+−
+−
KnKF
Kn
SQEK
SQR
3) Valor da estatística teste na amostra observada (F calculado )
5) Conclusão

Exemplo modelo de regressão linear múltipla
tcalculado > tcrítico logo rejeita H 0
Distribuição t
Teste t: Testa a significância do coeficiente de re gressão linear associado com uma determinada variável explicativa.
H0 : b 1 = 0 ( ausência do efeito )H1 : b 1 ≠≠≠≠ 0 ( presença do efeito )
3ˆ
1 ~ˆ
ˆ
1
−Ntb
βσ
8682,62118,0
4546,1 ==t
4) t crítico ao nível de significância de 5% = 2,1=TINV(0,05;18) no Excel
1ˆ
1
ˆ
ˆ
βσb
t =
1) Estatística teste 2) Distribuição da estatística testes sob H 0
3) Valor da estatística teste na amostra observada (t calculado )
5) Conclusão
Inferência do modelo

Exemplo modelo de regressão linear múltipla
Distribuição t
Teste t: Testa a significância do coeficiente de re gressão linear associado com uma determinada variável explicativa.
H0 : b 2 = 0 ( ausência do efeito )H1 : b 2 ≠≠≠≠ 0 ( presença do efeito )
3045,20640,4
3655,9 ==t
3ˆ
2 ~ˆ
ˆ
2
−Ntb
βσ2ˆ
2
ˆ
ˆ
βσb
t =
1) Estatística teste 2) Distribuição da estatística testes sob H 0
3) Valor da estatística teste na amostra observada (t calculado )
4) t crítico ao nível de significância de 5% = 2,1=TINV(0,05;18) no Excel
5) Conclusão
tcalculado > tcrítico logo rejeita H 0
Inferência do modelo

Exemplo modelo de regressão linear múltiplaIntervalos 95% de confiança para os coeficientes da equação de regressão
( )( ) ( )( )%5,2ˆ
ˆ%5,2 11 +−+− ≤−≤− Kn
b
iiKn t
bbt
iσ
95%
2339,57948,1941,20170,60
8571,681,2 0
0 ≤≤−⇒≤−−≤− bb
8995,10096,11,22118,0
4546,11,2 1
1 ≤≤⇒≤−≤− bb
9036,178274,01,20640,4
3655,91,2 2
2 ≤≤⇒≤−≤− bb
Distribuição t
K = número de variáveis independentesn = tamanho da amostra

R2 ajustado
( )22 11
1 Rkn
nRajustado −
−−−=
Problema com a estatística R 2 : sempre aumenta a medida que novas variáveis são incluídas no modelo de regressão linear múltipl a, independentemente da variável adicionada.
No entanto cada variável adicionada ao modelo tem u m custo, pois mais um coeficiente deve ser estimado. Então é interessante ter uma medida que permita avaliar o benefício para melhoria do modelo com a a dição de uma nova variável explicativa em relação ao custo de estimar mais um coeficiente.
Esta medida é o R 2 ajustado
Onde n é o tamanho da amostraK é o número de parâmetros da equação de regressão.
O R2 ajustado é útil quando desejamos comparar dois model os diferentes ou comparar um mesmo modelo com tamanhos de amostras d iferentes

[ ]khhhTh XXXx L211=
Previsão
Dado
( ) khkhh XXXYE βββ ˆˆˆ|ˆ110 +++= K
hThprevisão xSxs β
2 =
khkhh XXY βββ ˆˆˆˆ110 +++= K
2ˆ
2 σβ += hThprevisão xSxs
Modelo de regressão linear múltipla
Previsão do valor esperado da variável dependente d ado Y
Previsão do valor da variável dependente dado YQuadrado médio dos resíduosValor obtido na ANOVA
Erro padrão das previsões

ExemploCalcule a previsão das vendas esperadas nas cidades A e B:
Cidade Anúmero de pessoas com até 16 anos de idades (X 1) : 65,4renda per capita na localidade (X 2) : 17,6
Cidade Bnúmero de pessoas com até 16 anos de idades (X 1) : 53,1renda per capita na localidade (X 2) : 17,7
10,1916,1737,94,6545,186,68 =⋅+⋅+−=
15,1747,1737,91,5345,186,68 =⋅+⋅+−=
[ ]6,174,651=Thx
[ ]7,171,531=Thx
Previsão da venda esperada na cidade A E(Y|X)
Previsão da venda esperada na cidade B E(Y|X)

ExemploIntervalos de confiança para as vendas esperadas na s cidades A e B:
Cidade Anúmero de pessoas com até 16 anos de idades (X 1) : 65,4renda per capita na localidade (X 2) : 17,6
Cidade Bnúmero de pessoas com até 16 anos de idades (X 1) : 53,1renda per capita na localidade (X 2) : 17,7
1626,121ˆ 2 =εσ
[ ]6,174,651=Thx
[ ]7,171,531=Thx
=βS3.602,0347 8,7459 -241,4230
8,7459 0,0449 -0,6724-241,4230 -0,6724 16,5158
Resultado da ANOVA slide 52Matriz de covariâncias dos
estimadores slide 54
Erro padrão das estimativas slide 60
hThprevisão xSxs β
2´ =
Cidade A = 11,35
Cidade B = 11,93

ExemploIntervalos de confiança para as vendas esperadas na s cidades A e B:
E(Y|X) é a média das vendas dado X
( ) 2)1(
2)1( 2
|2 previsãokNprevisãokN stprevisãoXYEstprevisão
+≤≤
− +−+−αα
Valor crítico da t com N-(k+1) graus de liberdade a o nível de confiança 1-alfa,podem ser obtidos no Excel, por exemplo, para 95% d e confiança =INVT(0,05;18),
cujo valor é aproximadamente 2,101
( ) 9,214|3,167 ≤≤ XYE
( ) 2,199|1,149 ≤≤ XYE
Cidade A
Cidade B
Note que os intervalos de confiança tem grande ampl itude apesar do elevado R 2
(0,92), portanto, valores elevados de R 2 não garantem necessariamente previsões precisas

Exemplo modelo de regressão linear múltipla no Excel1) Matriz de dados para regressão linear múltipla1 variável dependente2 variável independentes 2) No menu Ferramentas escolha a
opção Análise de dados
3) Na caixa de diálogo escolha a opção Regressão e clique em Ok
4) Informe os dados para regressão na caixa de diálogo

Exemplo modelo de regressão linear múltipla no Excel
Caixa de diálogo regressãoIntervalo com os valores da variável dependente
Intervalo com os valores da variável independente
Rótulos: nomes das variáveis Marque se tem rótulo
Grava resultados da regressão em uma nova planilha
Apresenta a série de resíduos
YY ˆ−
Gráfico com os valores observados e previstos
Gráfico dos resíduos contra a variável explicativa
Gráfico para avaliar se a hipótese de normalidade do erro é satisfeita

Exemplo modelo de regressão linear múltipla no Excel
0β1β
2β

Exemplo modelo de regressão linear múltipla no ExcelGráficos na planilha de Resultados
X1 Plotagem de resíduos
-30,00-20,00-10,00
0,0010,0020,0030,00
0 20 40 60 80 100
X1
Res
íduo
s
X2 Plotagem de resíduos
-40,00-20,00
0,0020,0040,00
0 5 10 15 20 25
X2
Res
íduo
s
X1 Plotagem de ajuste de linha
050
100150200250300
0 50 100
X1
Y
YPrevisto(a) Y
X2 Plotagem de ajuste de linha
0
100
200
300
0 10 20 30
X2
YYPrevisto(a) Y

Exemplo modelo de regressão linear múltipla no ExcelGráficos na planilha de Resultados
Plotagem de probabilidade normal
0
100
200
300
0 50 100 150
Percentil da amostra
Y

Problemas que podem acontecer em um modelo de regressão linear
Multicolinearidade: Quando há relações lineares exatas ou aproximadament e lineares entre as variáveis explicativas, a redundâ ncia entre as varáveis pode resultar em estimativas com valores elevados para o erro padrão ou impossibilitar a estimação dos coeficientes de regressão no caso d e relações lineares exatas.
Heterocedasticidade: A variância do erro não é uma constante, (violação d a hipótese de homocedasticidade). Não raro acontece q uando a amostra de observações é um corte transversal de unidades com “ tamanhos” heterogêneos. Na presença de heterocedasticidade o estimador MQO p ermanece não tendencioso, mas deixa de ser o melhor estimador. N estas situações deve-se utilizar o métodos mínimos quadrados ponderados (MQ P).
Autocorrelação: Os erros são autocorrelacionados, violação da hipót ese de covariância nula entre os erros. Problema frequente quando a amostra de dados éformada por séries temporais. Na presença de autoco rrelação serial dos erros o estimador MQO permanece não tendencioso, mas deixa de ser o melhor estimador. Nestas situações deve-se utilizar o méto dos mínimos quadrados generalizados (MQG).

Multicolinearidade
Ocorre quando qualquer variável independente é altamente correlacionada com um conjunto de outras variáveis inde pendentes.
No caso extremo, uma variável independente guarda uma relação linear com outra variável independente. Neste caso não é pos sível obter as estimativas de mínimos quadrados.
Consequências da multcolinearidade:• Estimativas mais imprecisas• Erros-padrão maiores• Dificuldade da separação dos efeitos de cada variável
Soluções para contornar a multicolineardade.• Coletar mais dados• Eliminar variáveis• Usar componentes principais para reduzir a dimensão dos dados

Avaliação da Multicolinearidade1) Coeficientes de correlação simples entre as variávei s independentes
2) Tolerância: quantia de variabilidade da variável dependente não explicada pelas outras variáveis independentes. Valo res altos significam um pequeno grau de multicolinearidade.
Tolerância= 1–R k2, se menor que 0,1 indica multicolinearidade
Onde R k2 é o coeficiente de determinação da variável independen te k nas
demais variáveis independentes.
3) Fator de inflação da variância (VIF): é o inverso da tolerância. Valores altos significam maiores níveis de multicolinearidad e.
VIF = 1 / Tolerância, se maior do que 10 já indica mul ticolinearidade

Referências Bibliográficas
Hanke, J.E.; Wichern, D.W. Pronósticos en los negocios, Naucalpan de Juárez: Pearson Education de México, 2006.
Kutner, M.H.; Nachtsheim, C.J.; Neter, J. Applied linear regression models, New York: McGraw-Hill Irwin, 2004.




















