
UNA NUEVA PRUEBA PARA EL PROBLEMA DE IGUALDAD ...
45
Facultad de Estad´ ıstica Trabajo de Grado Enero 2017 UNA NUEVA PRUEBA PARA EL PROBLEMA DE IGUALDAD DE VARIANZAS A NEW TEST FOR THE PROBLEM OF EQUALITY VARIANCE Mario Felipe Garcia Calvo. a [email protected] Director: Andr´ es Felipe Ort´ ız Rico. b [email protected] Resumen En este documento se desarrolla la propuesta de una nueva prueba para el problema de igualdad de varianzas como un aporte a la literatura estad´ ıstica. Se repasan conceptos b´ asicos para tratar el tema como lo son: hip´ otesis estad´ ıstica, error de tipo I y II, potencia de una prueba, varianza, permutaciones; entre otros. Se establecen los objetivos del trabajo los cuales se desarrollan a lo largo de este documento as´ ı como tambi´ en se menciona la metodolog´ ıa que se usa para lograr dichos objetivos, se hace una explicaci´ on profunda de cada paso y herramienta que se utiliza para la construcci´ on de la prueba propuesta y para la realizaci´ on de los objetivos planteados. Tambi´ en se presentan los resultados obtenidos a trav´ es de gr´ aficas que facilitan entender lo encontrado al lector y se muestran las conclusiones de todo el trabajo realizado. Seguido se proponen algunos trabajos futuros y expectativas que quedaron luego de la realizaci´ on de este trabajo y finalmente se presentan los c´ odigos del software utilizado con los cuales se realiz´ o el trabajo y algunas tablas correspondientes a la investigaci´ on. Palabras clave : Varianza, prueba, error tipo I y II, potencia, igualdad, librer´ ıa. Abstract This paper develops the proposal of a new test for the problem of equality of variances as a contribution to the statistical literature. Basic concepts are discussed to treat the subject as they are: error of type I and II, power of a test, variance, permutations; among others. It establishes the objectives of the work which are developed throughout this document as well as the methodology used to achieve these objectives, a thorough explanation of each step and tool used for the construction of the test Proposal and for the achievement of the stated objectives. Also presented are the results obtained through graphs that facilitate to understand what was found to the reader and show the conclusions of all the work done. Some proposed future work and expectations after the completion of this work and finally the codes of the software used with which the work was done and some tables corresponding to the research are presented. Keywords : Variance, test, type I and type II errors, power, equal, library. a Estudiante de estad´ ısticaUniversidadSantoTom´asBogot´a b Docente de estad´ ıstica Universidad Santo Tom´as Bogot´ a 1
-
Upload
khangminh22 -
Category
Documents
-
view
5 -
download
0
Transcript of UNA NUEVA PRUEBA PARA EL PROBLEMA DE IGUALDAD ...

Facultad de EstadısticaTrabajo de Grado
Enero 2017
UNA NUEVA PRUEBA PARA EL PROBLEMA DEIGUALDAD DE VARIANZAS
A NEW TEST FOR THE PROBLEM OF EQUALITY VARIANCE
Mario Felipe Garcia Calvo.a
[email protected]: Andres Felipe Ortız Rico.b
Resumen
En este documento se desarrolla la propuesta de una nueva prueba para el problema de igualdad devarianzas como un aporte a la literatura estadıstica. Se repasan conceptos basicos para tratar el temacomo lo son: hipotesis estadıstica, error de tipo I y II, potencia de una prueba, varianza, permutaciones;entre otros. Se establecen los objetivos del trabajo los cuales se desarrollan a lo largo de este documento asıcomo tambien se menciona la metodologıa que se usa para lograr dichos objetivos, se hace una explicacionprofunda de cada paso y herramienta que se utiliza para la construccion de la prueba propuesta y para larealizacion de los objetivos planteados. Tambien se presentan los resultados obtenidos a traves de graficasque facilitan entender lo encontrado al lector y se muestran las conclusiones de todo el trabajo realizado.Seguido se proponen algunos trabajos futuros y expectativas que quedaron luego de la realizacion de estetrabajo y finalmente se presentan los codigos del software utilizado con los cuales se realizo el trabajo yalgunas tablas correspondientes a la investigacion.
Palabras clave: Varianza, prueba, error tipo I y II, potencia, igualdad, librerıa.
Abstract
This paper develops the proposal of a new test for the problem of equality of variances as a contributionto the statistical literature. Basic concepts are discussed to treat the subject as they are: error of typeI and II, power of a test, variance, permutations; among others. It establishes the objectives of thework which are developed throughout this document as well as the methodology used to achieve theseobjectives, a thorough explanation of each step and tool used for the construction of the test Proposaland for the achievement of the stated objectives. Also presented are the results obtained through graphsthat facilitate to understand what was found to the reader and show the conclusions of all the workdone. Some proposed future work and expectations after the completion of this work and finally thecodes of the software used with which the work was done and some tables corresponding to the researchare presented.
Keywords: Variance, test, type I and type II errors, power, equal, library.
aEstudiante de estadıstica Universidad Santo Tomas BogotabDocente de estadıstica Universidad Santo Tomas Bogota
1

2 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
Introduccion
Dentro del quehacer academico y laboral de la estadıstica, es muy frecuente enfrentarse al problema decomparar la varianza de varias poblaciones, es uno de los topicos tratados en cursos como inferenciaestadıstica, diseno de experimentos, series de tiempo y modelos lineales, ademas, ayuda a la solucion deproblemas que surgen en muchas ciencias. Para la solucion de este problema, existen muchas pruebasque han sido propuestas en la literatura, cada una de ellas con un desempeno especıfico. Cuando nuestroproblema se trata de 2 muestras y se cumple con el supuesto de normalidad, la prueba uniformementemas potente es la F de Fisher de acuerdo al teorema de Fisher-Neyman (Zhang & Gutierrez 2010), perocuando tenemos mas de dos muestras, tenemos varias pruebas para utilizar pero no se tiene definidoque haya una que tenga mejor desempeno que las demas. Se necesita inventariar las pruebas existentesy proponer una con bajo nivel de error tipo I y con alta potencia. Otro inconveniente que tenemos losestadısticos es que cuando necesitamos usar estas pruebas de varianza existentes, nos encontramos conque las pruebas estan dispersas en diferentes paquetes, razon por la cual, se ve la necesidad de construiruna librerıa que agrupe todas las pruebas.
Cuando nos referimos a los antecedentes de esta investigacion nos encontramos con que es un trabajoque se realiza frecuentemente en el mundo estadıstico dado que se conoce el problema y aun no seobtiene una solucion concreta y veraz. Maurice Stevenson Bartlett, estadıstico Ingles muy conocido porel mundo de la matematica y la estadıstica, fue uno de los pioneros en el tema. En el ano 1937 publicoen un articulo llamado “Properties of sufficiency and statistical tests” en donde propuso la conocidaprueba de Bartlett que se utiliza para la igualdad de varianzas en k muestras. George Edward PelhamBartlettBox, estadıstico britanico, 16 anos despues (1953), publica en un articulo (“Non-normality andtests on variances”) una nueva prueba para este problema y en 1960, tan solo 7 anos despues, H.Levenepropone una nueva prueba (conocida como prueba de Levene). Estos son solo algunos ejemplos paramostrar que este es un tema que se trabaja mucho en la literatura estadıstica y a lo largo del documentose observan otros ejemplos de pruebas propuestas a lo largo de la historia.
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 3
1. Marco Teorico
1.1. Hipotesis
Se les denomina ası a los supuestos (hipotesis) realizados con respecto a un parametro o estadıstico(varianza, media, proporcion, entre otros).
En este paso se definen dos tipos de hipotesis:
H0 Hipotesis nula.
H1 Hipotesis alterna (de la cual se sospecha pudiera ser cierta, es planteada por el investigador).
1.2. Error tipo I y II
Error Tipo I Si rechaza la hipotesis nula cuando esta es verdadera, usted comete un error de tipo I. Laprobabilidad de cometer un error de tipo I es α, que es el nivel de significancia que se establece parala prueba de hipotesis. Un α de 0.05 indica que usted esta dispuesto a aceptar una probabilidad de5 % de que esta equivocado cuando rechaza la hipotesis nula. Para reducir este riesgo, debe utilizarun valor mas bajo para α. Sin embargo, si utiliza un valor mas bajo para alfa, significa que tendramenos probabilidades de detectar una diferencia verdadera, si es que realmente existe.
Error Tipo II Cuando la hipotesis nula es falsa y usted no la rechaza, comete un error de tipo II. Laprobabilidad de cometer un error de tipo II es α, que depende de la potencia de la prueba. Puedereducir su riesgo de cometer un error de tipo II al asegurarse de que la prueba tenga suficientepotencia. Para ello, asegurese de que el tamano de la muestra sea lo suficientemente grande comopara detectar una diferencia practica cuando esta realmente exista.
Figura 1: Error tipo I y II
1.3. Potencia de una prueba
Es la probabilidad que tiene la prueba estadıstica para rechazar una hipotesis nula falsa. Tiene un rangode 0 a 1 y esta inversamente relacionada con el error de tipo II. En este estudio se requiere medirla potencia de las pruebas de varianza inventariadas junto con la prueba propuesta y trabajar paramaximizar la potencia de nuestra prueba.
La potencia de una prueba estadistica esta relacionada con el tamano de muestra, el valor de alfa (α) yel tamano del efecto.
Facultad de Estadıstica Trabajo de Grado Enero 2017

4 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
Potencia Error Tipo II
1.00.0 Si hay un efecto sera detec-tado
0.80.2 Si hay un efecto sera detec-tado el 80 % de las veces
0.50.5 Si hay un efecto sera detec-tado el 50 % de las veces
0.20.8 Si hay un efecto sera detec-tado el 20 % de las veces
0.01.0 Si hay un efecto, nunca seradetectado
Tabla 1: Potencia de una prueba estadıstica.
1.4. Descripcion pruebas estudiadas
1.4.1. F-Test
La distribucion F se forma por la division de dos variables chi-cuadrado independientes divididas porsus grados de libertad respectivos y es por esto que la distribucion F hereda varias de las propiedadesde la chi-cuadrado.
Este test se utiliza para probar si las varianzas de dos muestras (independientes) son iguales y esteinteres en terminos de la hipotesis que se quiere probar es:
H0 : σ2x = σ2
y (1)
H1 : σ2x 6= σ2
y. (2)
El valor de la F se calcula con la division de las varianzas muestrales como se muestra en la siguienteformula:
F =s21s22, (3)
F =
(m− 1)
n∑i=1
(Xi − X)2
(n− 1)
m∑i=1
(Yi − Y )2, (4)
donde s21 > s22 y esta tiene una distribucion F con m− 1 y n− 1 grados de libertad bajo H0. La pruebarechaza la hipotesis nula para:
F > Fα
2,N1−1,N2−1
. (5)
Algunos supuestos para esta prueba son:
El valor de la F siempre sera mayor que 1.
Dividir en 2 el alfa (α) para una prueba de dos colas (igualdad de varianzas) y luego encontrar elvalor crıtico a la derecha.
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 5
Las poblaciones de las que se obtuvieron las muestras deben ser normales.
Las muestras deben ser independientes.
Descripcion de la prueba:Librerıa: statsCodigo: var.test()Autores: George Waddel Snedecor y William Gemmell CochranArtıculo: Statistical Methods, Eighth Edition, Iowa State University Press.Ano: 1989Valida para: 2 muestras
1.4.2. Cochran’s C Test
Dado k grupos de datos, algunos analisis suponen que las varianzas son iguales para los k grupos. Porejemplo, la prueba F usada en el analisis de un factor de varianza puede ser sensible a las varianzasdesiguales en los k niveles del factor. Las pruebas de Levene y Bartlett son ampliamente utilizadaspara evaluar la homogeneidad de las varianzas en el caso de un factor (con k niveles). La prueba de lavarianza de Cochran creada por William G. Cochran es otra alternativa para evaluar la homogeneidadde las varianzas.
Aunque la prueba de Cochran tiene un proposito similar a las pruebas de Levene y Bartlett, tiendea utilizarse en un contexto algo diferente. La prueba de Levene y Bartlett se utiliza para evaluar lahomogeneidad general y se usan tıpicamente en el contexto de decidir si una prueba especıfica (porejemplo, una prueba F) es apropiada para un conjunto dado de datos. Estas pruebas no identifican quevarianzas son diferentes. Por otro lado, la prueba de la varianza de Cochran tiende a ser utilizada en elcontexto de las pruebas de aptitud.
La prueba de Cochran es esencialmente una prueba atıpica. La estadıstica de prueba original de Cochranse define como:
Cj =S2j
k∑i=1
S2i
, (6)
donde:Cj = Estadıstica C de Cochran para el conjunto de datos jSj = La desviacion estandar mayor del conjunto de datos jk = Numero de grupos de datos que permanecen en el conjunto de datosSi = Desviaciones estandar del conjunto de datos i (1 ≤i≤N)
Las hipotesis bajo las cuales trabaja la prueba son:
H0 : Todas las varianzas son igualesH1 : Al menos una varianza es significativamente mayor que las otras.
Valores crıticos
La varianza muestral de la serie de datos j se considera un valor atıpico al nivel de significancia α, si Cjexcede el valor crıtico del lımite superior CUL. CUL depende del nivel de significancia dado α, el numerode series de datos N consideradas y del numero de puntos de datos (n) por serie de datos.
Los valores para CUL se calculan a partir de:
CUL(α, n, k) =
[1 +
k − 1
Fc(α/k, (n− 1), (k − 1)(n− 1))
]−1, (7)
Facultad de Estadıstica Trabajo de Grado Enero 2017

6 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
donde:CUL = Valor crıtico del lımite superior para la prueba unilateral en un diseno equilibradoα = Nivel de significancian = Numero de datos por conjunto de datosFc = Valor crıtico de la distribucion F de Fisher el cual se puede obtener mediante las tablas de ladistribucion o un software especializado
Generalizacion
La prueba C se puede generalizar para incluir disenos desbalanceados, pruebas de lımite inferior unilate-ral y pruebas de dos colas en cualquier nivel de significancia α, para cualquier numero de series de datosk, y para cualquier numero de puntos de datos individuales nj en la serie de datos j.
Descripcion de la prueba:Librerıa: GADCodigo: C.test()Autores: William Gemmell CochranArtıculo: The distribution of the largest of a set of estimated variances as a fraction of their total.Ano: 1941Valida para: k muestras
1.4.3. Hartley’s Fmax Test
En estadıstica el test de Hartley, mas conocido como Fmax es usado para el analisis de varianza paraverificar si grupos diferentes tienen una varianza similar.
La prueba implica calcular la razon entre la varianza mas grande de los grupos y la varianza mas pequena(esta es la estadıstica de prueba). La razon resultante (Fmax), se compara con los valores crıticos de lastablas de la distribucion Fmax. Si el estadıstico de prueba calculado es menor que el valor crıtico, sesupone que los grupos tienen varianzas similares o iguales.
La prueba de Hartley supone que los datos para cada grupo se distribuyen normalmente, y que cadagrupo tiene un numero igual de elementos. Esta prueba, aunque conveniente, es bastante sensible a lasviolaciones de la suposicion de normalidad.
Estadıstico de prueba
Fmax =maxS2
i
minS2j
Descripcion de la prueba:Librerıa: SuppDistsCodigo: pmaxFratio() (no hay un codigo directo, el p-valor se saca en base a la distribucion)Autores: Herman Otto HartleyArtıculo: The use of Range in Analysis of variance.Ano: 1950Valida para: k muestras
1.4.4. Bartlett Test
La prueba de Bartlett se usa para probar si k muestras tienen varianzas iguales. La igualdad de varianzasentre muestras se denomina homogeneidad de varianzas. Algunas pruebas estadısticas, por ejemplo el
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 7
analisis de varianza, suponen que las varianzas son iguales entre grupos o muestras. La prueba de Bartlettse puede utilizar para verificar esa suposicion.
La prueba de Bartlett es sensible a las salidas de la normalidad. Es decir, si las muestras provienende distribuciones no normales, entonces la prueba de Bartlett puede ser simplemente la prueba de nonormalidad.
Las hipotesis bajo las cuales trabaja la prueba son:
H0 : σ21 = σ2
2 = σ23 ... = σ2
k
H1 : σ2i 6= σ2
j , para al menos un par (i, j)
Estadıstico de prueba
La estadıstica de la prueba de Bartlett esta disenada para probar la igualdad de varianzas entre gruposcon la alternativa de que las varianzas son desiguales para al menos dos grupos.
T =
(N − k) ln S2p −
k∑i=1
(Ni − 1) ln S2i
1 + (1/(3(k − 1)))((
k∑i=1
1/(Ni − 1))− 1/(N − k))
, (8)
donde:S2i = Varianza del i-esimo grupoN = Tamano total de la muestraNi = Tamano de la muestra del i-esimo grupok = Numero de gruposS2p = La varianza agrupada. La varianza agrupada es un promedio ponderado de las varianzas del grupo
y se define como:
S2p =
k∑i=1
(Ni − 1) S2i
(N − k)(9)
La prueba trabaja con un nivel de significancia α y las desviaciones se consideran diferentes si:
T > χ21−α,k−1 (10)
donde χ21−α,k−1 es el valor crıtico de una distribucion chi cuadrado con k − 1 grados de libertad y a un
nivel de significancia α.
Descripcion de la prueba:Librerıa: statsCodigo: bartlett.test()Autores: Snedecor y CochranArtıculo: Statistical Methods, Eighth Edition, Iowa State University PressAno: 1983Valida para: k muestras
1.4.5. Levene’s Test
La prueba de Levene se usa para probar si k muestras tienen varianzas iguales. La prueba de Levenees una alternativa a la prueba de Bartlett. La prueba de Levene es menos sensible que la prueba de
Facultad de Estadıstica Trabajo de Grado Enero 2017

8 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
Bartlett ante la violacion del supuesto de normalidad. Si se tiene una fuerte evidencia de que los datosen realidad provienen de una distribucion normal, o casi normal, entonces la prueba de Bartlett tiene unmejor rendimiento.
Las hipotesis bajo las cuales trabaja la prueba son:
H0 : σ21 = σ2
2 = σ23 ... = σ2
k
H1 : σ2i 6= σ2
j , para al menos un par (i, j)
Estadıstico de prueba
Dada una variable Y con una muestra de tamano N dividida en k subgrupos, donde Ni es el tamano demuestra del i-esimo subgrupo, el estadıstico de prueba de Levene se define como:
W =(N − k)
(k − 1)
k∑i=1
Ni (Zi. − Zi..)2
k∑i=1
Ni∑j=1
(Zij − Zi.)2(11)
donde Zij puede tomar 3 valores:
1. Zij = |Yij − Yi.|donde Yi. es la media de los i-esimos subgrupos
2. Zij = |Yij − Yi.|donde Yi. es la mediana de los i-esimos subgrupos
3. Zij = |Yij − Y ′i .|donde Y ′i . es la media recortada al 10 % de los i-esimos subgrupos
Zi. es el grupo de medias de Zij y Z.. es la media general de Zij
Las tres opciones para definir Zij determinan la potencia la prueba de Levene. Por potencia nos referimosa la capacidad de la prueba para detectar desigualdades cuando las varianzas son de hecho desiguales ola probabilidad de que la hipotesis nula sea rechazada cuando la hipotesis alternativa es verdadera (esdecir, la probabilidad de no cometer un error del tipo II).
La prueba trabaja con un nivel de significancia α y rechaza la hipotesis de que las varianzas son igualessi:
W > Fα,k−1,N−k (12)
donde Fα,k−1,N−k es el valor crıtico superior de una distribucion F con k− 1 y N − k grados de libertady a un nivel de significancia α.
El trabajo original de Levene solo propuso usar la media. Brown y Forsythe (1974) extendieron el testde Levene para usar la mediana o la media recortada ademas de la media. Realizaron estudios de MonteCarlo que indicaron que el uso de la media recortada se comporto mejor cuando los datos subyacentessiguieron una distribucion de Cauchy (es decir, de cola pesada) y la mediana se comporto mejor cuandolos datos subyacentes siguieron una distribucion χ2 (es decir, sesgada). El uso de la media proporciono lamejor potencia para las distribuciones simetricas de cola moderada. Aunque la eleccion optima dependede la distribucion subyacente, se recomienda la definicion basada en la mediana como la opcion queproporciona buena robustez frente a muchos tipos de datos no normales mientras se conserva una buena
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 9
potencia. Si tiene conocimiento de la distribucion subyacente de los datos, esto puede indicar el uso deuna de las otras opciones.
Descripcion de la prueba:Librerıa: carCodigo: leveneTest()Autores: Howard LeveneArtıculo: Contributions to Probability and Statistics: Essays in Honor of Harold Hotelling.Ano: 1960Valida para: k muestras
1.4.6. Breusch-Pagan Test
En estadıstica la prueba de Breusch-Pagan se utiliza para probar la heterocedasticidad en un modelode regresion lineal. Prueba si la varianza de los errores de una regresion depende de los valores de lasvariables independientes. En ese caso, la heteroscedasticidad esta presente.
Suponga que se estima el modelo de regresion:
y = β0 + β1x+ µ (13)
y obtenemos un conjunto de valores para u, los residuos. Con las restricciones de los Mınimos CuadradosOrdinarios la media es 0, de modo que dada la suposicion de que la varianza no depende de las variablesindependientes, la estimacion de la varianza se puede obtener a partir de la media de los valores al cua-drado. Si la suposicion no fuera correcta, podrıa ocurrir que la varianza estuviera relacionada linealmentecon las variables independientes. El supuesto de varianza constante se puede examinar haciendo una re-gresion de los residuos al cuadrado respecto de las variables independientes, empleando una ecuacion dela forma:
u2 = γ0 + γ1x+ ν (14)
Esta es la base de la prueba. Si el test-F confirma que las variables independientes son significativas,entonces se puede rechazar la hipotesis nula de homocedasticidad.
El test de Breusch-Pagan para heterocedasticidad es una prueba chi cuadrado donde el estadıstico deprueba es nχ2 con k grados de libertad. Prueba la hipotesis nula de homoscedasticidad. Si el valor de laChi cuadrado es significativo con un valor de p por debajo de un umbral apropiado, entonces la hipotesisnula de homoscedasticidad es rechazada y se asume la heteroscedasticidad. Si la prueba de Breusch-Pagandemuestra que hay heterocedasticidad condicional, la regresion original puede ser corregida usando elmetodo de Hansen, utilizando errores estandar robustos o re-ajustando la ecuacion de regresion cam-biando y/o transformando variables independientes.
Estadıstico de prueba
El siguiente multiplicador de Lagrange (LM) proporciona la estadıstica de prueba para la prueba deBreusch-Pagan:
LM =
(∂`
∂θ
)′(−E
[∂2`
∂θ ∂θ′
])−1(∂`
∂θ
). (15)
La prueba sigue los siguientes 3 pasos:
1. Paso 1: Aplicar MCO al modelo:
y = Xβ + ε. (16)
calcular los residuales.
Facultad de Estadıstica Trabajo de Grado Enero 2017

10 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
2. Armar la regresion auxiliar:
e2i = γ1 + γ2z2i + · · ·+ γpzpi + ηi. (17)
Siempre, z podrıa ser parcialmente reemplazado por variables independientes x.
3. La estadıstica de prueba es el resultado del coeficiente de determinacion de la regresion auxiliar enel paso 2 y el tamano de la muestra n con:
LM = nR2 . (18)
La estadıstica de prueba se distribuye asintoticamente como χ2p−1 bajo la hipotesis nula de homos-
cedasticidad.
Descripcion de la prueba:Librerıa: carCodigo: ncvTest()Autores: T.S Breuch y A.R PaganArtıculo: A simple test fot heterosttedasticity and random coefficient variation.Ano: 1979Valida para: k muestras
1.4.7. Fligner-Killeen Test
La prueba Fligner-Killeen hace un trabajo bastante similar a la de Levene, lo que significa que compruebala homogeneidad de la varianza, pero es una opcion mucho mejor cuando los datos no estan distribuidosnormalmente o cuando los problemas relacionados con los valores atıpicos en el conjunto de datos nopueden ser resueltos.
Estadıstico de prueba
El procedimiento Fligner-Killeen, modificado por Conover, para probar homogeneidad de varianzas con-siste en lo siguiente:
1. Ordene las variables∣∣∣Xij − Xi
∣∣∣ de menor a mayor, donde Xi es la mediana de las ni observaciones
de la poblacion i.
2. Defina:
aN,i = Φ−1(
1
2+
i
2 (N + 1)
)para i = 1, ..., N (19)
donde Φ(z) es la distribucion acumulada N(0, 1) de −∞ a z y ası Φ−1(p) es el percentil 100p de ladistribucion N(0, 1).
3. Sea
ai =
N∑j∈Gi
aN, j
ni(20)
donde Gi denota la muestra de la poblacion i, i, ..., k. Y
a =
N∑j=1
aN, j
N(21)
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 11
Entonces el estadıstico de prueba es:
x =
k∑i=1
ni (ai − a)2
N∑j=1
(aN, j − a)2
(n− 1)
(22)
Este estadıstico bajo H0 se distribuye aproximadamente χ2k−1. La prueba de Fligner es menos
sensible a violaciones del supuesto de normalidad (Mandasky 1988).
Descripcion de la prueba:Librerıa: statsCodigo: fligner.test()Autores: W.J Conover, M.E Johnson, M.M JohnsonArtıculo: A comparative study of the test for homogeneity of variances, with applications to the outercontinental shelf bidding data.Ano: 1981Valida para: k muestras
1.5. Permutaciones
Una permutacion es la variacion del orden o de la disposicion de los elementos de un conjunto ordenadoo un vector sin elementos repetidos, esta herramienta se enlaza con el concepto de Bootstrapping quees un metodo de remuestreo que se utiliza para aproximar la distribucion de un estadıstico. Se usafrecuentemente para aproximar el sesgo o la varianza de un analisis estadıstico, ası como para construirintervalos de confianza o realizar contrastes de hipotesis sobre parametros de interes. En la mayor partede los casos no pueden obtenerse expresiones cerradas para las aproximaciones bootstrap y por lo tantoes necesario obtener remuestras en un ordenador para poner a prueba el metodo. La enorme potenciade calculo de los ordenadores actuales facilita considerablemente la aplicabilidad de este metodo tancostoso computacionalmente. En este trabajo se considero este metodo para estimar el valor p a travesde generar permutaciones para el estadıstico de prueba.
Para claridad de esta herramienta presentaremos un ejemplo sencillo: Se tiene un vector de numerosaleatorios de tamano 5 (n = 5)
Y = (1.188, 1.282,−0.359, 0.939, 0.037, 3.030) (23)
El estadıstico de prueba para este vector de numeros es:
E1 = 0.9654594 (24)
Ahora, hacemos una permutacion sobre nuestro vector Y quedandonos ası:
Y = (0.037, 3.030, 1.188, 1.282,−0.359, 0.939) (25)
(Podemos ver que son los mismos numeros pero en diferente orden). Calculamos de nuevo el estadısticode prueba y obtenemos el siguiente:
E2 = 0.6046444 (26)
Con este ejemplo se puede observar que al hacer permutaciones a un vector Y dado obtenemos valoresdiferentes del estadıstico de prueba y esto sirve para estimar el valor p de la prueba propuesta.La estimacion del valor p a traves de esta herramienta vendrıa dado por:
V alorp =#Estadisticos > E1
#Permutaciones(27)
Facultad de Estadıstica Trabajo de Grado Enero 2017

12 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
2. Objetivos
2.1. Objetivo General
Proponer una nueva prueba para el problema de igualdad de varianzas en varias muestras.
2.2. Objetivo Especıficos
Construir un inventario de pruebas de varianza.
Cuantificar los errores de tipo I y II de las pruebas inventariadas.
Comparar el desempeno de la prueba propuesta contra las pruebas usuales usadas dentro del campoestadıstico en terminos del error de tipo I y II.
Construir una librerıa en R que agrupe las pruebas de varianza inventariadas.
3. Metodologıa
La metodologıa que se usara en este trabajo se basa en 5 puntos fundamentales:
Literatura Se buscaran los artıculos que hagan referencia al tema ya que es algo que se investiga muyfrecuente en la estadıstica, se leeran y analizaran para verificar lo que otras personas han hecho opropuesto. Tambien se leera la literatura sobre las pruebas clasicas mas conocidas.
Propuesta de la nueva prueba Se explicaran los principios que promueven la creacion de la nuevaprueba, ası como al estadıstico de prueba que se utilizara, su distribucion bajo la hipotesis nula ylos supuestos necesarios.
Ejercicios de simulacion para comparacion de las pruebas Se haran simulaciones en R para po-der verificar el desempeno de las pruebas inventariadas y ası mismo de la prueba propuesta. Conestas simulaciones lo que buscaremos es encontrar el nivel de error tipo I y II ademas de la potenciade cada prueba.
Programacion y construccion de la librerıa en R Se elaborara una librerıa en R la cual agrupetodas las pruebas inventariadas para brindar esa facilidad de encontrarlas todas en un mismopaquete al usuario.
Documentacion Elaborar un documento final en donde se relacione todo lo elaborado en el trabajo aligual que una presentacion para mostrar los resultados obtenidos.
3.1. Prueba propuesta
3.1.1. Motivacion
En estadıstica es comun validar los supuestos de un modelo de regresion para determinar si este esadecuado dado que si no lo es este representara incorrectamente los datos. Por ejemplo:
Los errores estandar de los coeficientes podrıan estar sesgados, conduciendo a valores t y p inco-rrectos.
Los coeficientes pueden tener el signo incorrecto.
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 13
El modelo puede verse afectado por uno o dos puntos.
Dado el modelo
Y = β0 + β1X + ε (28)
los supuestos a validar son:
Correcta especificacion del modelo E(ε) = 0
E(Yj) = β0 + β1X (29)
Homogeneidad de varianza en los errores V ar(εj) = σ2
V ar(Yj) = σ2; j = 1, 2, ..., n (30)
No correlacion de los errores
Cov(εi, εj) = 0 ∀ i 6= j (31)
Distribucion normal de los errores
ε ∼ Normal(0, σ2) (32)
El exito en el ajuste de un modelo de regresion, la validez de los hallazgos y las conclusiones obtenidas,dependen de los supuestos del modelo.
Vamos a enfocarnos en los errores del modelo, tenemos tres supuestos sobre estos:
Homogeneidad de varianza en los errores V ar(εj) = σ2
No correlacion de los errores
Distribucion normal de los errores
Cuando trabajamos un modelo de regresion y calculamos los residuales estimados los obtenemos de lasiguiente manera:
ε = Y − Y (33)
ε = (I −H)Y (34)
donde H = X(XtX)−1Xt.
Se espera que estos residuales sean independientes y tengan varianza constante, pero esto siempre es unproblema a la hora de validar el modelo, ya que estos dos supuestos muy rara vez se cumplen porqueteoricamente los residuales no son independientes ni tienen varianza constante, ası que, se torna algoilogico validar unos supuestos que por definicion estadıstica no tiene ese comportamiento.
Se espera que la varianza de los residuales se comporte de la siguiente manera:
V ar(ε) = (I −H)V ar(Y )(I −H) (35)
V ar(ε) = σ2(I −H) (36)
Pero como se viene diciendo, estos supuestos por definicion estadıstica (teorıa), no se cumplen. Luegode ver este inconveniente y despues de indagar en las herramientas estadısticas, nos encontramos con losresiduales estudentizados los cuales tienen caracterısticas y propiedades que nos permitirıan solucionarel inconveniente de los supuestos y ası mismo obtener mejores resultados.
Facultad de Estadıstica Trabajo de Grado Enero 2017

14 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
Residuales estudentizados Un residual estudentizado es el resultado de dividir un residual entre sudesviacion estandar estimada. Este se calcula con las n − 1 observaciones restantes. La principal razonpara estudentizar un residual es que, como lo habıamos mencionado antes, en el analisis de regresion, lasvarianzas de los residuales son en la mayorıa de veces, diferentes, incluso si las varianzas de los erroresen los diferentes valores de las variables de entrada. son iguales.
Consideremos el siguiente modelo:Y = β0 + β1X + ε. (37)
Dada una muestra aleatoria (Xi, Yi), i = 1, ..., n, cada par (Xi, Yi) satisface:
Yi = β0 + β1Xi + εi, (38)
donde los errores εi son independientes y todos tienen la misma varianza σ2. Los residuales no son loserrores verdaderos, e inobservables, sino mas bien son estimaciones, basadas en los datos observables, delos errores. Cuando el metodo de mınimos cuadrados se utiliza para estimar β0 y β1 entonces los residualesε, a diferencia de los errores, ε, no pueden ser independientes ya que satisfacen las dos restricciones
n∑i=1
εi = 0 (39)
y
n∑i=1
εiyi = 0. (40)
donde εi es el i-esimo error y εi es el i-esimo residual.
Ademas, y lo que es mas importante, los residuales, a diferencia de los errores, no tienen todos lamisma varianza: la varianza disminuye a medida que el valor Y correspondiente se aleja del valor Ypromedio. Esto tambien puede verse porque los residuales en los extremos dependen en gran medida dela pendiente de una lınea ajustada, mientras que los residuales en el centro son relativamente insensiblesa la pendiente. El hecho de que las varianzas de los residuales difieran, a pesar de que las varianzas delos errores verdaderos son todas iguales entre sı, es la razon principal de la necesidad de estudentizar.
Como estudentizar
Para un modelo sencillo, la matriz de diseno es:
X =
1 y1...
...1 yn
(41)
Y la matriz estimada H es la matriz de la proyeccion ortogonal sobre el espacio de la columna de lamatriz de diseno:
H = X(XTX)−1XT . (42)
La hii de apalancamiento es la i-esima entrada diagonal en la matriz estimada. La varianza del i-esimoresiduo es:
var(εi) = σ2(1− hii). (43)
En el caso de que la matriz de diseno Y tenga solo dos columnas (como en el ejemplo anterior), esto esigual a
var(εi) = σ2
(1− 1
n− (xi − x)2∑n
j=1(xj − x)2
). (44)
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 15
El correspondiente residual estudentizado es entonces
ti =εi√
σ2(1− hii)(45)
En base a esto lo mejor es verificar los supuestos sobre los residuales estudentizados y si no pasan lasvalidaciones entonces el modelo realmente esta fallando.
Hasta ahora todo lo que hemos visto es a manera general pero para la prueba propuesta pasaremosa algo mas especıfico y son los modelos a una vıa de clasificacion o mejor conocidos como los disenoscompletamente al azar.
Disenos Completamente al Azar Este diseno surge como la extension a las pruebas de diferenciade medias cuando se tiene mas de dos grupos. En el caso general se tiene a grupos o tratamientoscorrespondientes a los niveles de un factor y la hipotesis principal se centra en la igualdad de medias delos a grupos. Como en la mayorıa de disenos existen los balanceados y desbalanceados.
El modelo en un diseno completamente al azar es de la siguiente manera:
Yij = µ+ τi + εij (46)
Donde:
µ Representa un efecto promedio comun a todas las observaciones.
τi Representa el efecto del i-esimo tratamiento (puede ser un tratamiento, grupo o muestra).
ε Representa el termino de error del modelo.
yij Cada una de las observaciones de la tabla.
y.. Promedio de todas las observaciones.
yi. Promedio de cada tratamiento.
ni Cantidad de replicas para cada tratamiento.
Estos modelos a una vıa de clasificacion y bajo el enfoque de los disenos completamente al azar en dondese cuenta con una variable identificadora de grupos tienen un supuesto muy interesante:
V ar(Yij) = V ar(εij) (47)
En este punto juntamos las ideas de los residuales estudentizados y los disenos completamente al azarpara que estas sean la base de la prueba propuesta. Nos basamos en la prueba de Cochran para trabajarsobre esta ya que es una prueba robusta y es comun usarla en el diseno experimental.
Siendo ası la idea central del trabajo es construir la prueba de Cochran con residuales estudenti-zados.
De aquı en adelante llamaremos a la prueba propuesta, CFF.
3.1.2. Estadıstico de prueba
El estadıstico de prueba para CFF es basicamente el mismo que el que se usa en la prueba C de Cochran.Sabemos que para la prueba de Cochran el estadıstico de prueba es el resultado de dividir la varianza
mas grande del conjunto de datos j (S2j ) sobre la suma de las varianzas
N∑i=1
S2i .
Facultad de Estadıstica Trabajo de Grado Enero 2017

16 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
En nuestra prueba, el calculo de las varianzas, tanto la mayor de todos los grupos y la suma de todas, nose hace sobre los residuales sino sobre los residuales estudentizados. Siendo ası el estadıstico de pruebaes:
CFFj =S2j
N∑i=1
S2i
, (48)
donde:CFFj = Estadıstica CFF para el conjunto de datos jSj = La desviacion estandar mayor del conjunto de datos j calculada con los residuales estudentizadosN = Numero de grupos de datos que permanecen en el conjunto de datosSi = Desviaciones estandar del conjunto de datos i (1 ≤i≤N) calculadas con los residuales estudentizados.
La hipotesis bajo la cual trabaja la prueba es:
H0 : Todas las varianzas de los grupos son igualesH1 : Al menos una varianza de un grupo es significativamente mayor que las otras.
3.1.3. Percentiles
Los percetiles de la prueba CFF fueron calculados a partir de simulaciones las cuales se explicaran masadelante. En el anexo 1, se encontraran las tablas de los percentiles para la prueba dado un numerodeterminado de grupos (a) y un tamano de muestra especıfico (n). Las tablas estan para un nivel deconfiabilidad del 95 % y del 99 %.
3.1.4. Criterio de rechazo
Para rechazar la hipotesis nula que habla de que todas las varianzas de los grupos son iguales, se calculael estadıstico de prueba de CFF y se compara con el percentil que aparece en la tabla que se encuentra enel anexo 1, dado un a y un n especifico y bajo un nivel de confiabilidad (α), si este es mayor al percentilcorrespondiente entonces se rechaza H0.
3.2. Descripcion de las simulaciones
Se realizaron simulaciones para 4 procesos:
Simulacion con permutaciones para aproximar el valor p de la prueba CFF.
Estimacion de los percentiles de la prueba CFF.
Comparar el desempeno de la prueba CFF contra las pruebas inventariadas en terminos del errortipo I.
Cuantificar los errores tipo II (potencia) de la prueba CFF y de las inventariadas.
Simulacion con permutaciones para aproximar el valor p de la prueba CFF
Consideramos estimar el valor p a traves de simulaciones las cuales se construyeron de la siguientemanera:
Los datos simulados fueron sacados de una distribucion normal con media 0 y varianza diferente,es decir bajo la hipotesis alternativa (H1).
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 17
10.000 mil iteraciones de los Y.
Se simulo con 3 grupos (a=3).
Se realizaron 10.000 mil permutaciones.
Estimacion de los percentiles de la prueba CFF
Se construyo la tabla de percentiles para CFF y con esta se calcula la decision de rechazar o aceptar lahipotesis nula. Las simulaciones fueron construidas ası:
1. Se simulan N datos divididos en a grupos de tamano n provenientes de una distribucion normalcon media 0 y varianza constante igual a 1.
2. Se ajusta el modelo:
Y = r + trata+ ε
donde r es el vector de nuestros datos y trata es el vector donde se encuentra la variable identifi-cadora de grupos.
3. Se extraen los residuales estudentizados del modelo anterior.
4. Se calcula el estadıstico CFF segun la ecuacion CFFj =S2j
N∑i=1
S2i
y los residuales estudentizados del
paso anterior.
5. Este proceso se repite 5.000 veces y al final se calculan los percentiles 95 y 99 del estadıstico CFF.
6. El proceso se repite variando la cantidad de grupos a entre 3 y 10, ası como el tamano de los gruposentre 2 y 200.
Comparar el desempeno de la prueba CFF contra las pruebas inventariadas en terminosdel error tipo I
Caso Balanceado
Para ver como trabajan las pruebas inventariadas y la prueba propuesta bajo la hipotesis nula (H0) serealizaron simulaciones construidas de la siguiente manera:
1. Se simulan N datos divididos en a grupos de tamano n provenientes de una distribucion normalcon media 0 y varianza constante igual a 1.
2. Se ajusta el modelo:
Y = r + trata+ ε
donde r es el vector de nuestros datos y trata es el vector donde se encuentra la variable identifi-cadora de grupos.
3. Se extraen los residuales estudentizados del modelo anterior.
4. Se calcula el estadıstico CFF segun la ecuacion CFFj =S2j
N∑i=1
S2i
y los residuales estudentizados del
paso anterior.
Facultad de Estadıstica Trabajo de Grado Enero 2017

18 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
5. Se calcula el valor p para las demas pruebas.
6. Este proceso se repite 10.000 veces y se calcula el error de tipo I promedio para cada prueba.
7. El proceso se repite con una cantidad de grupos fijo (a = 3) y variando el tamano de los gruposentre 3 y 50.
Caso Desbalanceado
Se calcula una media armonica de los tamanos de los grupos y con el resultante se busca el percentilpara la prueba nueva.
n∗ =1
n∑i=1
1
ni
=1
1
n1+ · · ·+
1
nn
(49)
El proceso se repite 10.000 veces con un tamano de grupos fijo (a = 3) y los ni de la siguiente manera:
Para a = 3:
n1 n2 n3
5 6 710 11 1220 21 2230 31 3240 41 4250 51 52
Cuantificar los errores tipo II (potencia) de la prueba CFF y de las inventariadas
Para el calculo de la potencia se manejaron dos escenarios de la hipotesis alternativa.
1. Crecimiento progresivo
2. Crecimiento rapido
Durante el proceso de estudio de la potencia, los valores establecidos para cada escenario de la hipotesisalternativa se establecieron con el objetivo de que para las pruebas fuera mas difıcil detectar H1 yasimismo la potencia no llegara tan rapido a 1.
Por ejemplo, para el crecimiento progresivo de H1 con 3 grupos (a=3), el valor de las varianzas para lasimulacion de los datos fueron:
σ1 : 1
σ2 : 2
σ3 : 3
Mientras que bajo el mismo escenario de grupos pero con crecimiento rapido de la hipotesis alternativalos valores fueron:
σ1 : 1
σ2 : 1
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 19
σ3 : 2
Teniendo esto claro, las simulaciones para el calculo de la potencia se construyeron ası:
Caso Balanceado
1. Se simulan N datos divididos en a grupos de tamano n provenientes de una distribucion normalcon media 0 y varianza diferente (variando el escenario de H1).
2. Se ajusta el modelo:Y = r + trata+ ε
3. Se extraen los residuales estudentizados del modelo anterior.
4. Se calcula el estadıstico CFF segun la ecuacion CFFj =S2j
N∑i=1
S2i
y los residuales estudentizados del
paso anterior.
5. Se calcula el valor p para las demas pruebas.
6. Este proceso se repite 10.000 veces y se calcula el error de tipo II promedio para cada prueba.
7. El proceso se repite variando la cantidad de grupos a entre 3 y 10, ası como el tamano de los gruposentre 2 y 200.
Caso Desbalanceado
El proceso se repite 10.000 veces variando la cantidad de grupos entre 3,5 y7 y los ni de la siguientemanera:
Para a = 3:
n1 n2 n3
20 21 2220 20 3020 30 40
Para a = 5:
n1 n2 n3 n4 n5
20 20 21 21 2220 20 25 25 3520 20 30 30 40
Para a = 7:
n1 n2 n3 n4 n5 n6 n7
20 20 20 21 21 22 2220 20 20 25 25 35 3520 20 20 30 30 40 40
Facultad de Estadıstica Trabajo de Grado Enero 2017

20 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
3.3. Descripcion de la librerıa
La librerıa construida se llama varTest, en esta librerıa se encontraran las pruebas de varianza inventa-riadas y estudiadas en este documento agregando la prueba propuesta, CFF. El objetivo de esta librerıaes reunir las pruebas mas usadas en el quehacer estadıstico y brindar ası una facilidad al usuario ya queno tendra que extraer las pruebas de varias librerıas ya que las encontrara en una sola.
La librerıa se encuentra aun en construccion razon por la cual no esta en el momento enCRAN y por ende no se puede instalar desde R directamente, pero se deja un link enGithub en donde se podra descargar el proyecto del software R y ası se podra usar lalibrerıa.
Link Github: https://github.com/mfelipe15/varTest
3.3.1. Instalacion
Una vez la librarıa se encuentre en CRAN, la instalacion de esta es de la siguiente manera:
La instalacion de la librerıa es de la misma forma que cualquier otra en R. Hay tres maneras de instalarla librerıa desde RStudio:
1. Desde la consola
Abrimos RStudio
Escribimos en la consola el codigo install.packages(”varTest”)
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 21
Esperamos que instale y con el comando library(varTest) cargamos la librerıa y ası queda listapara su uso
Facultad de Estadıstica Trabajo de Grado Enero 2017

22 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
2. Desde el menu del panel Files, P lots, Packages,Help, V iewer
Abrimos RStudio
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 23
Vamos al panel de Files, P lots, Packages,Help, V iewer (su ubicacion puede variar depen-diendo la configuracion del usuario), hacemos click en la pestana Packages
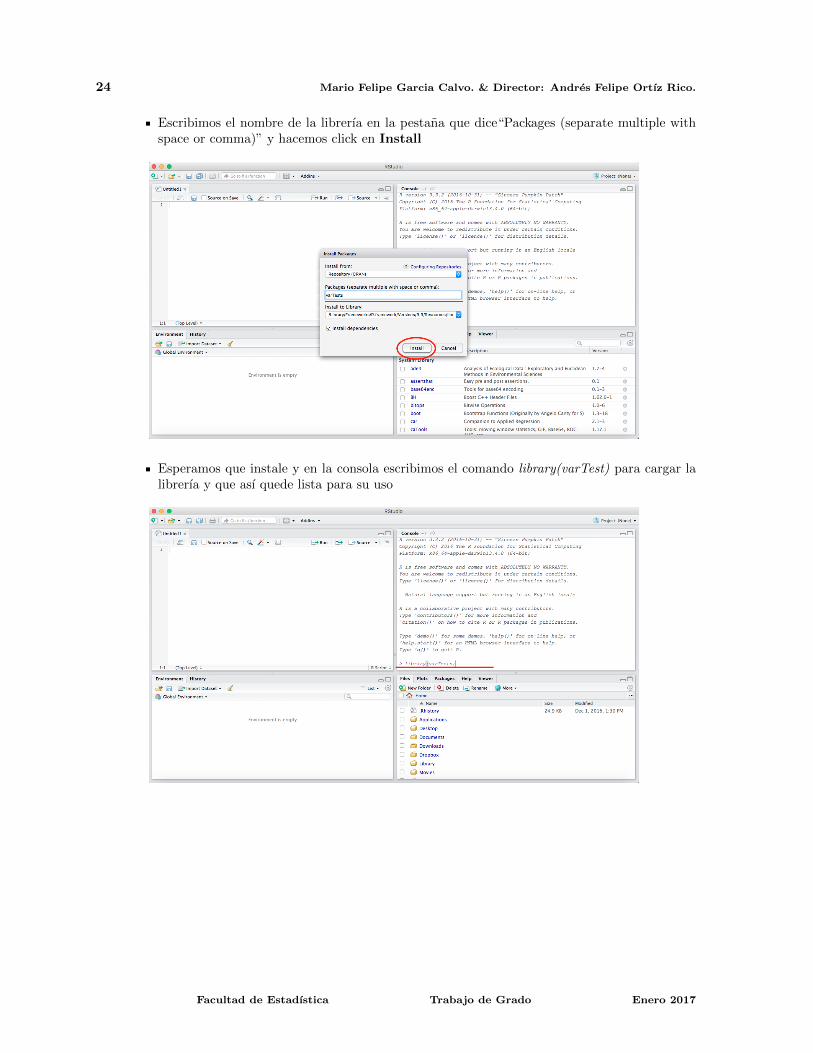
Luego hacemos click en Install
Facultad de Estadıstica Trabajo de Grado Enero 2017
24 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
Escribimos el nombre de la librerıa en la pestana que dice“Packages (separate multiple withspace or comma)” y hacemos click en Install
Esperamos que instale y en la consola escribimos el comando library(varTest) para cargar lalibrerıa y que ası quede lista para su uso
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 25
3. Desde la barra de herramientas.
Abrimos RStudio
Hacemos click en la pestana Tools
Luego click en la opcion Install Packages...
Facultad de Estadıstica Trabajo de Grado Enero 2017

26 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
Escribimos el nombre de la librerıa en la pestana que dice“Packages (separate multiple withspace or comma)” y hacemos click en Install
Esperamos que instale y en la consola escribimos el comando library(varTest) para cargar lalibrerıa y que ası quede lista para su uso
3.3.2. Manejo de funciones y ejemplos
Para la mayorıa de funciones el manejo es el mismo. Las funciones necesitan un vector r de valoresnumericos correspondientes a los datos y un vector trata correspondiente a la variable ID con la cualse identifica a que grupo pertenece cada dato. Estos dos son los insumos necesarios para correr lasfunciones de Bartlett, Levene media, Levene mediana, Fligner y CFF. Para la prueba de Cochran esnecesario establecer un modelo lineal y con este como insumo ya trabaja la funcion.Si no se tienen los datos y se requiere simular los pasos para usar la funcion son:
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 27
Se debe cargar la librerıa.
Se guarda la varianza de cada grupo en un vector por separado (en el ejemplo son las llamadassigma)
Se establece el tamano de muestra de cada grupo (n)
Se define la cantidad de grupos (a)
Se simulan los datos de cada grupo por separado con el tamano de muestra y la varianza anterior-mente establecidos.
En un vector se juntan todos los datos simulados y este sera nuestro vector (r).
Se crea un vector de ID con el cual se busca establecer a que grupo pertenece cada dato simulado(este sera nuestro vector trata).
Se ajusta un modelo con estos dos vectores (solo para la prueba de Cochran).
Ya con los vectores r y trata se pueden usar las funciones.
Las siguientes imagenes ilustran los pasos anteriormente descritos y muestran los ejemplos del uso yresultado de cada funcion:
Facultad de Estadıstica Trabajo de Grado Enero 2017
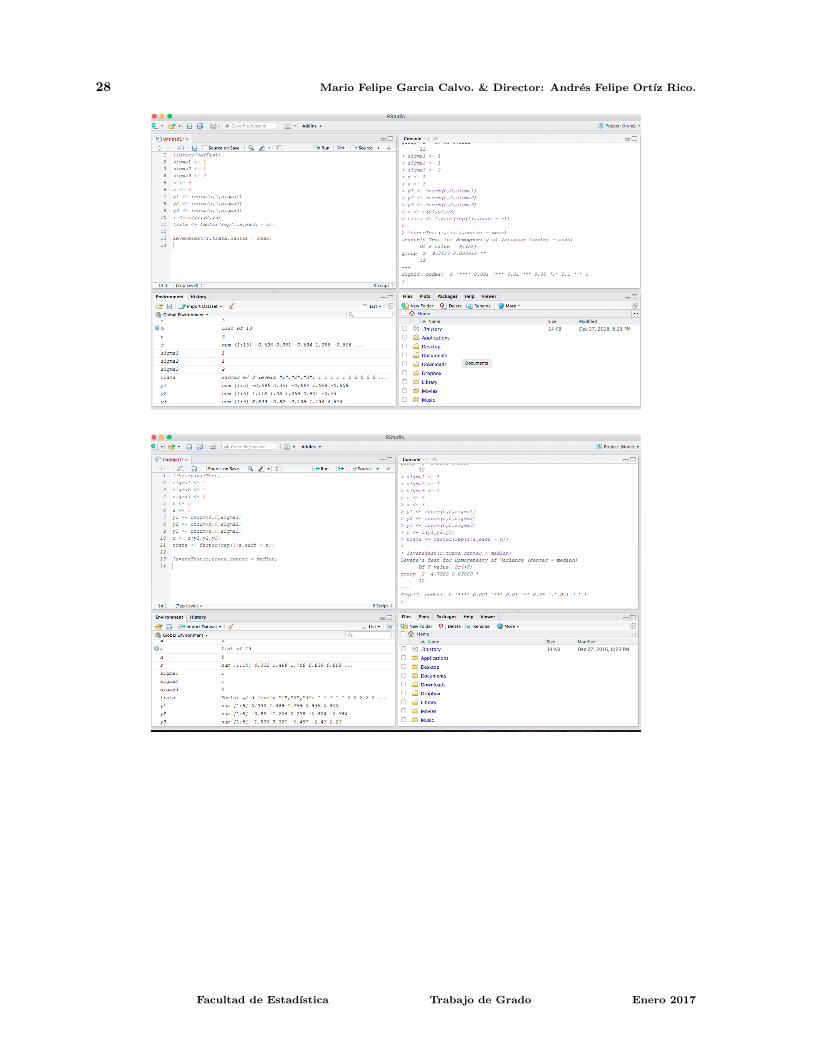
28 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 29
Facultad de Estadıstica Trabajo de Grado Enero 2017

30 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
4. Resultados
4.1. Simulaciones
En la simulacion con permutaciones para aproximar el valor p de la prueba CFF, pudimos observarque se disminuye notablemente la potencia, razon por la cual no se utilizo esta herramienta.
Luego de tener todos los resultados de las simulaciones se organizaron de una manera pertinente parapoder presentarlos.
Estimacion de los percentiles de la prueba CFF Tabular los valores encontrados para anexar lastablas al presente documento.
Comparar el desempeno de la prueba CFF contra las pruebas inventariadas en terminos del error tipo ISe tabulo la informacion y se realizo una grafica para evidenciar el desempeno de las pruebas.
Cuantificar los errores tipo II (potencia) de la prueba CFF y de las inventariadas Tabular losvalores encontrados y realizar las graficas en donde se pueda apreciar mejor la potencia de cadauna de las pruebas.
4.2. Error tipo I
Caso BalanceadoEn la siguiente grafica se puede ver el error tipo I de cada una de las prueba inventariadas cuandoel tamano de los grupos (n) es igual. El n se varıa entre 3 y 50.
- Se observa que el error de tipo I para la prueba CFF para cuando el n de cada grupo es diferente,esta controlado dado que este se mueve alrededor del 5 % como deberıa ser.- Las pruebas de Levene (media y mediana) y la de Fligner tienen un error de tipo I fuera del 5 %cuando los n son diferentes en cada grupo y los tamanos de estos son pequenos.
Facultad de Estadıstica Trabajo de Grado Enero 2017
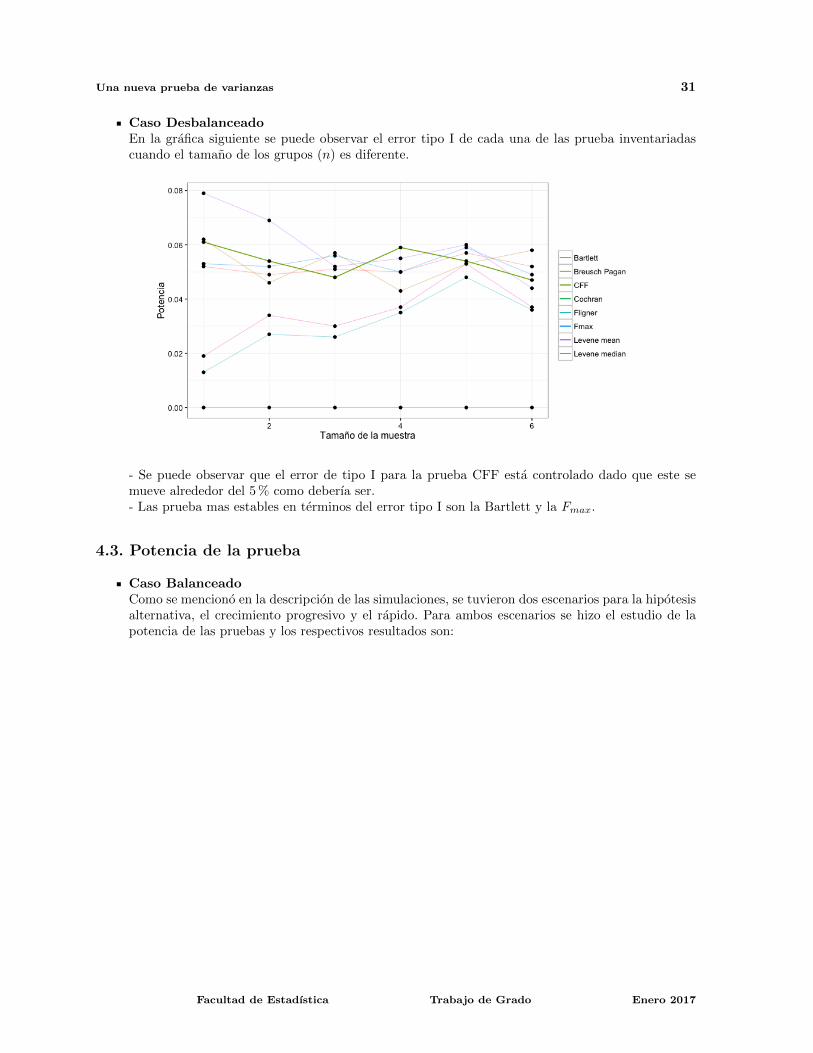
Una nueva prueba de varianzas 31
Caso DesbalanceadoEn la grafica siguiente se puede observar el error tipo I de cada una de las prueba inventariadascuando el tamano de los grupos (n) es diferente.
- Se puede observar que el error de tipo I para la prueba CFF esta controlado dado que este semueve alrededor del 5 % como deberıa ser.- Las prueba mas estables en terminos del error tipo I son la Bartlett y la Fmax.
4.3. Potencia de la prueba
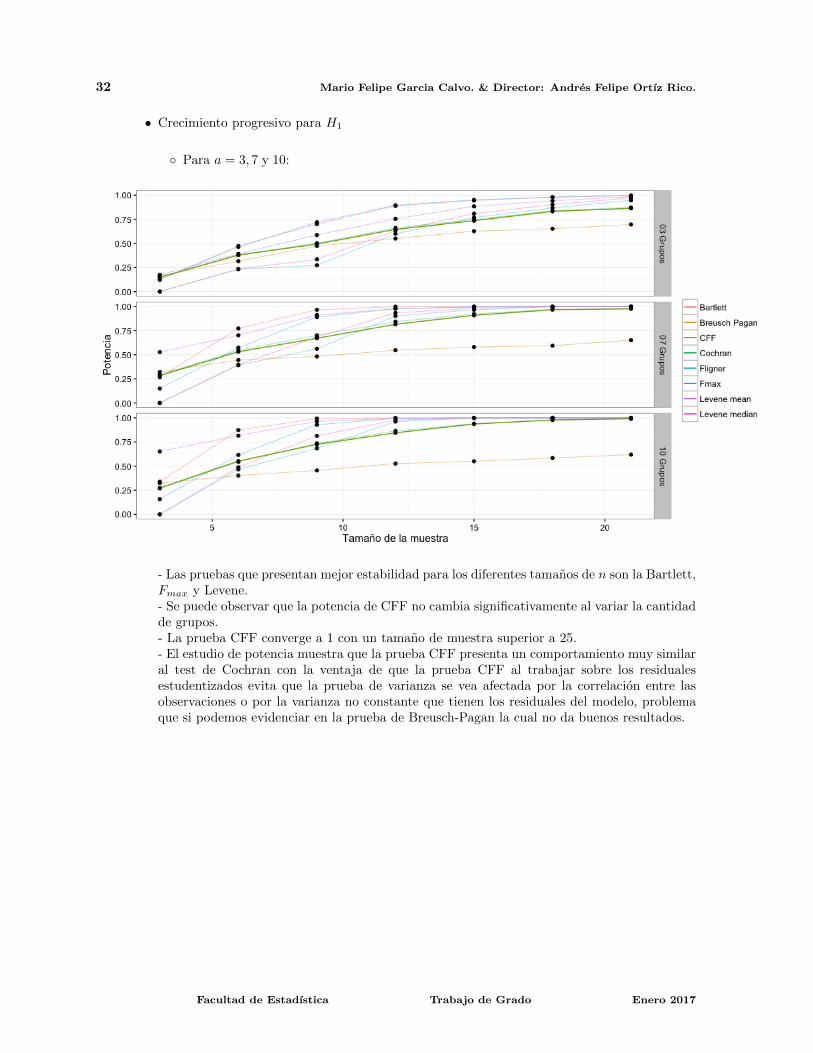
Caso BalanceadoComo se menciono en la descripcion de las simulaciones, se tuvieron dos escenarios para la hipotesisalternativa, el crecimiento progresivo y el rapido. Para ambos escenarios se hizo el estudio de lapotencia de las pruebas y los respectivos resultados son:
Facultad de Estadıstica Trabajo de Grado Enero 2017
32 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
• Crecimiento progresivo para H1
◦ Para a = 3, 7 y 10:
- Las pruebas que presentan mejor estabilidad para los diferentes tamanos de n son la Bartlett,Fmax y Levene.- Se puede observar que la potencia de CFF no cambia significativamente al variar la cantidadde grupos.- La prueba CFF converge a 1 con un tamano de muestra superior a 25.- El estudio de potencia muestra que la prueba CFF presenta un comportamiento muy similaral test de Cochran con la ventaja de que la prueba CFF al trabajar sobre los residualesestudentizados evita que la prueba de varianza se vea afectada por la correlacion entre lasobservaciones o por la varianza no constante que tienen los residuales del modelo, problemaque si podemos evidenciar en la prueba de Breusch-Pagan la cual no da buenos resultados.
Facultad de Estadıstica Trabajo de Grado Enero 2017
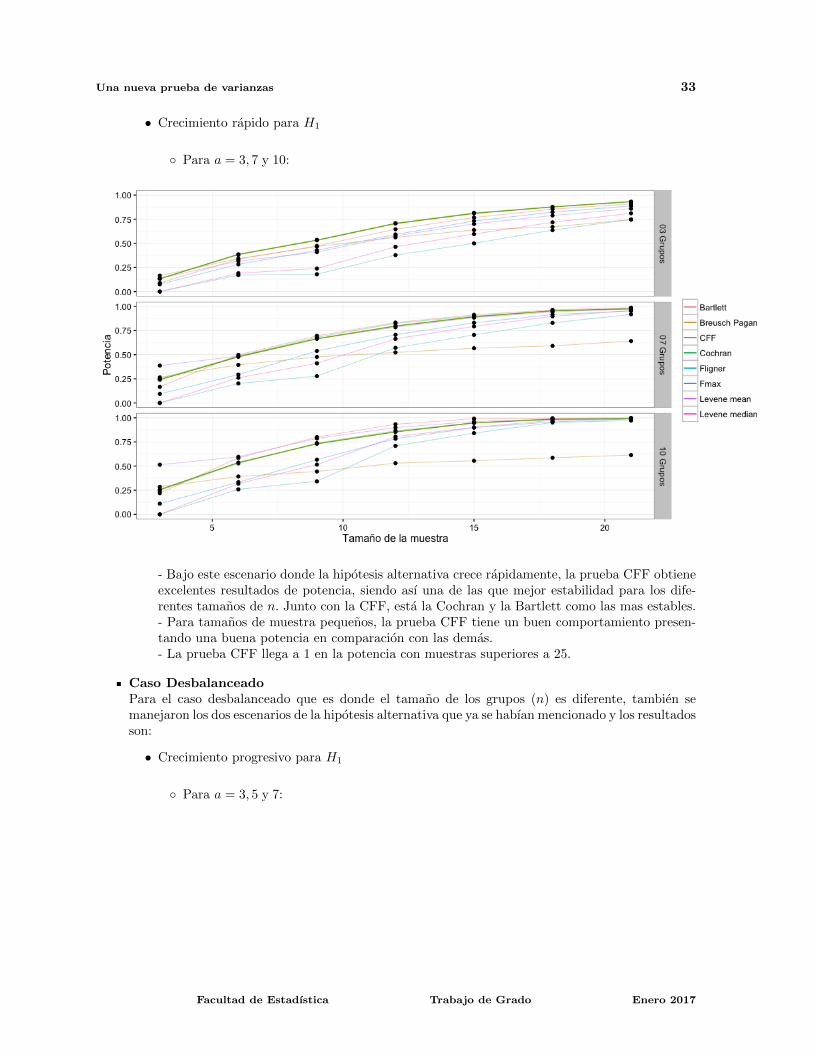
Una nueva prueba de varianzas 33
• Crecimiento rapido para H1
◦ Para a = 3, 7 y 10:
- Bajo este escenario donde la hipotesis alternativa crece rapidamente, la prueba CFF obtieneexcelentes resultados de potencia, siendo ası una de las que mejor estabilidad para los dife-rentes tamanos de n. Junto con la CFF, esta la Cochran y la Bartlett como las mas estables.- Para tamanos de muestra pequenos, la prueba CFF tiene un buen comportamiento presen-tando una buena potencia en comparacion con las demas.- La prueba CFF llega a 1 en la potencia con muestras superiores a 25.
Caso DesbalanceadoPara el caso desbalanceado que es donde el tamano de los grupos (n) es diferente, tambien semanejaron los dos escenarios de la hipotesis alternativa que ya se habıan mencionado y los resultadosson:
• Crecimiento progresivo para H1
◦ Para a = 3, 5 y 7:
Facultad de Estadıstica Trabajo de Grado Enero 2017
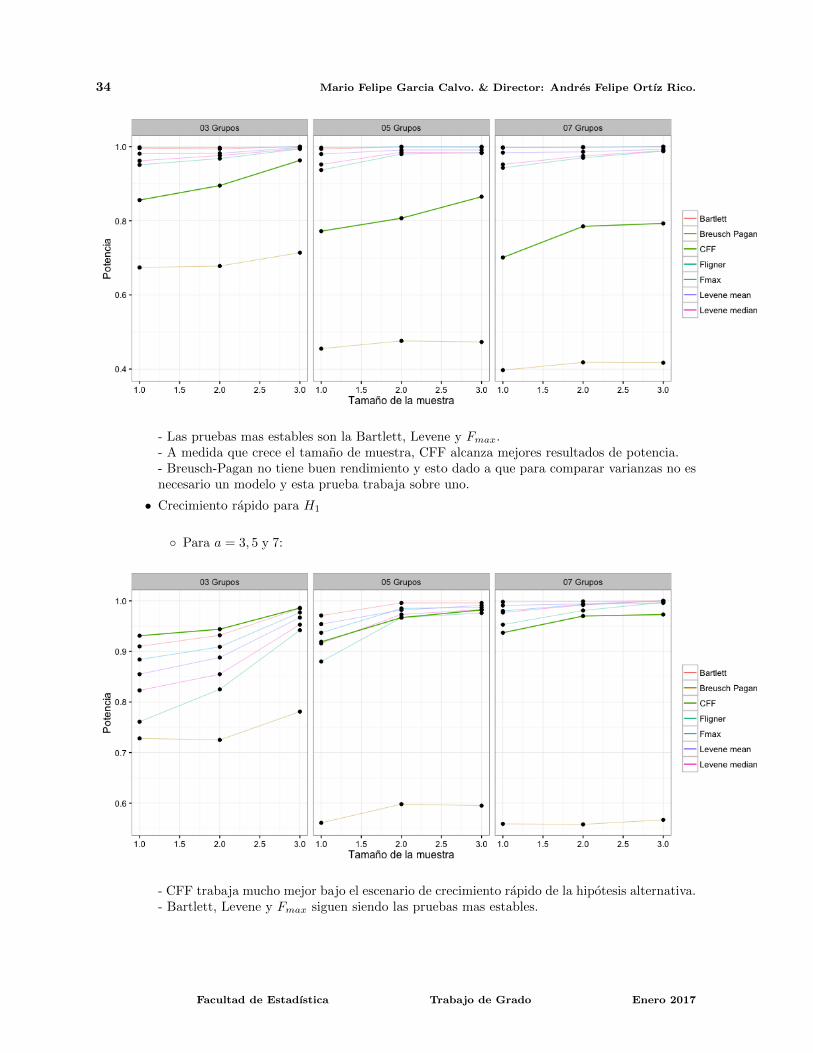
34 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
- Las pruebas mas estables son la Bartlett, Levene y Fmax.- A medida que crece el tamano de muestra, CFF alcanza mejores resultados de potencia.- Breusch-Pagan no tiene buen rendimiento y esto dado a que para comparar varianzas no esnecesario un modelo y esta prueba trabaja sobre uno.
• Crecimiento rapido para H1
◦ Para a = 3, 5 y 7:
- CFF trabaja mucho mejor bajo el escenario de crecimiento rapido de la hipotesis alternativa.- Bartlett, Levene y Fmax siguen siendo las pruebas mas estables.
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 35
5. Conclusiones
Con base en el trabajo realizado se puede concluir que:
1. Con respecto al comportamiento de la prueba propuesta:
Se pudo observar que la prueba CFF mantiene controlado el error de tipo I en los diferentestamanos de muestra.
La prueba CFF presenta un excelente rendimiento cuando la hipotesis alternativa crece rapi-damente y esto dado a que la base de CFF es la prueba de Cochran y sabemos que esta esmuy util para cuando se requiere verificar si una varianza es mucho mas grande que las demas.
Con tamanos de muestra pequenos la prueba CFF presenta mejores resultados que la mayorıade las otras pruebas.
CFF al trabajar sobre los residuales estudentizados evita que la prueba de varianza se veaafectada por la correlacion entre las observaciones o por la varianza no constante que tienenlos residuales del modelo.
2. Con respecto a las demas pruebas con las que se comparo CFF se puede concluir que:
Las pruebas mas potentes y estables son la de Bartlett, la Fmax y la de Levene (centrada enla media: mayor potencia y centrada en la mediana: mas robusta).
A tamanos de muestra pequenos la prueba de Levene centrada en media y la de Bartlett sonlas que mejor potencia tienen.
Para tamanos de muestra pequenos, las pruebas de Levene (centrada en media y mediana) yla de Fligner no conservan un error de tipo I alrededor del 5 %.
En su mayorıa, las pruebas llegan a una potencia de 1 cuando el tamano de muestra es mayora 15 (n ≥ 15).
De las pruebas inventariadas se observo que la prueba de Breusch-Pagan no dio muy buenosresultados y esto dado que esta prueba se basa en un modelo y como tal para compararvarianzas de a muestras, no se necesita un modelo.
3. La metodologıa de las permutaciones no resulto adecuada para estimar el valor p de la prueba CFFya que esta disminuyo notablemente la potencia de la prueba propuesta.
6. Trabajos futuros
1. Hallar la distribucion exacta del estadıstico de prueba de CFF.
2. Encontrar una manera de calcular el n en los casos desbalanceados para que la prueba CFF tengamejor rendimiento.
3. Agregar mas pruebas de varianza a la librerıa para facilitar al usuario la busqueda y uso de lasmismas.
Facultad de Estadıstica Trabajo de Grado Enero 2017

36 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
A. Anexos
A.1. Codigos de R
########################################################### Codigos usados ####################################################################################### Programacion prueba CFF ############################CFF<−function (y , t r a t a ) {
m <− lm( y˜ t r a t a )vare<−data . frame ( aggregate ( rstudent (m) , l i s t ( t r a t a ) ,var ) )c<−max( vare$x )/sum( vare$x )return (c )
}#################### Permutaciones ####################l ibrary (GAD)l ibrary ( car )l ibrary ( SuppDists )l ibrary ( lmtes t )
CFF<−function (y , t r a t a ) {m <− lm( y˜ t r a t a )vare<−data . frame ( aggregate ( rstudent (m) , l i s t ( t r a t a ) ,var ) )c<−max( vare$x )/sum( vare$x )a<−nrow( vare )n<−length ( y )/af <− (1/c − 1)/ ( a − 1)p <− 1−pf ( f , (n − 1)∗ ( a − 1) , (n − 1) )∗apval <− 1 − preturn (c (c , pval ) )
}
set . seed (1415)nr <− 10000nper <− 10001sigma1 <− 1sigma2 <− 3sigma3 <− 5a<−3n<−5r e s u l t s <− data . frame (matrix (NA,nrow=nr , ncol=7) )r e s u l t s sam <− rep (NA, nper )for ( i in 1 : nr ) {
y1 <− rnorm(n ,mean <− 0 , sd <− sigma1 )y2 <− rnorm(n ,mean <− 0 , sd <− sigma2 )y3 <− rnorm(n ,mean <− 0 , sd <− sigma3 )r <− c ( y1 , y2 , y3 )t r a t a <− factor ( rep ( 1 : a , each = n) )m <− lm( r˜ t r a t a )prueba=data . frame ( r , t r a t a )prueba2=data . frame ( aggregate ( prueba$r , l i s t ( prueba$ t r a t a ) ,var ) )fmax=max( prueba2$x )/min( prueba2$x )pvalfmax=pmaxFratio ( fmax , n−1, a , lower . t a i l=FALSE)r e s u l t s [ i , 1 ] <− b a r t l e t t . t e s t ( r , t r a t a )$p . va luer e s u l t s [ i , 2 ] <− f l i g n e r . t e s t ( r , t r a t a )$p . va luer e s u l t s [ i , 3 ] <− pvalfmaxr e s u l t s [ i , 4 ] <− ncvTest (m)$pr e s u l t s [ i , 5 ] <− l eveneTest ( r , t r a t a ) [ 1 , 3 ]r e s u l t s [ i , 6 ] <− C. t e s t (m)$p . va luer e s u l t s sam[1 ]=CFF( r , t r a t a ) [ 1 ]for ( j in 2 : ( nper ) ) {
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 37
r e s u l t s sam [ j ]=CFF(sample ( r ) , t r a t a ) [ 1 ]}r e s u l t s [ i , 7 ] <− sum( r e s u l t s sam [ 2 : nper ]> r e s u l t s sam [ 1 ] ) / ( nper−1)print ( i )
}colnames ( r e s u l t s )<−c ( ” B a r t l e t t pval ” , ” F l i gne r pval ” , ”Fmax pval ” ,
”B−P pval ” , ”Levene Median pval ” , ”Cochran pval ” ,”CFF pval e s t ” )
colMeans ( r e s u l t s <0.05)#################### P e r c e n t i l e s ####################CFF<−function (y , t r a t a ) {
m <− lm( y˜ t r a t a )var <− data . frame ( aggregate ( rstudent (m) , l i s t ( t r a t a ) ,var ) )c <− max(var$x )/sum(var$x )return (c )
}set . seed (1415)nr <− 5000sigma <− 3a <− 10n <− seq ( 2 , 50 , 1 )r e s u l t s <− matrix (NA,nrow<−nr , ncol<−length (n) )for ( j in 1 : length (n) ) {
for ( i in 1 : nr ) {y1 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )y2 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )y3 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )y4 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )y5 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )y6 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )y7 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )y8 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )y9 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )y10 <− rnorm(n [ j ] ,mean <− 0 , sd <− sigma )r <− c ( y1 , y2 , y3 , y4 , y5 , y6 , y7 , y8 , y9 , y10 )t r a t a <− factor ( rep ( 1 : a , each<−n [ j ] ) )print ( i )r e s u l t s [ i , j ]<− c (CFF( r , t r a t a ) )
}}colnames ( r e s u l t s )<−c ( ”CFF Stat n : 5 ” , ”CFF Stat n :10 ” , ”CFF Stat n :15 ” ,
”CFF Stat n :20 ” , ”CFF Stat n :25 ” , ”CFF Stat n :30 ” ,”CFF Stat n :35 ” , ”CFF Stat n :40 ” , ”CFF Stat n :45 ” ,”CFF Stat n :50 ” , ”CFF Stat n :75 ” , ”CFF Stat n :100 ” ,”CFF Stat n :125 ” , ”CFF Stat n :150 ” , ”CFF Stat n :175 ” ,”CFF Stat n :200 ” )
qua <− matrix (NA,nrow=length (n) , ncol<−2)for ( i in 1 : ncol ( r e s u l t s ) ) {
qua [ i , ] <− quantile ( r e s u l t s [ , i ] , c ( 0 . 9 5 , 0 . 9 9 ) )}colnames ( qua )<−c ( ”95 %” , ”99 %” )rownames( qua )<−c ( ”n : 5 ” , ”n :10 ” , ”n :15 ” , ”n :20 ” , ”n :25 ” , ”n :30 ” , ”n :35 ” ,
”n :40 ” , ”n :45 ” , ”n :50 ” , ”n :75 ” , ”n :100 ” , ”n :125 ” , ”n :150 ” ,”n :175 ” , ”n :200 ” )
write . table ( p e r c e n t i l e s , ” Percenti lesFINAL . csv ” , sep=” ; ” )
############################ Caso Balanceado ############################l ibrary (GAD)l ibrary ( car )l ibrary ( SuppDists )l ibrary ( lmtes t )
Facultad de Estadıstica Trabajo de Grado Enero 2017

38 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
CFF<−function (y , t r a t a ) {m <− lm( y˜ t r a t a )vare<−data . frame ( aggregate ( rstudent (m) , l i s t ( t r a t a ) ,var ) )c<−max( vare$x )/sum( vare$x )return (c )
}
set . seed (1415)nr <− 1000sigma1 <− 1sigma2 <− 2sigma3 <− 3a <− 3n <− 5r e s u l t s <− data . frame (matrix (NA,nrow=nr , ncol=8) )
for ( i in 1 : nr ) {y1 <− rnorm(n , 0 , sigma1 )y2 <− rnorm(n , 0 , sigma2 )y3 <− rnorm(n , 0 , sigma3 )r <− c ( y1 , y2 , y3 )t r a t a <− factor ( rep ( 1 : a , each = n) )m <− lm( r˜ t r a t a )prueba=data . frame ( r , t r a t a )prueba2=data . frame ( aggregate ( prueba$r , l i s t ( prueba$ t r a t a ) ,var ) )fmax=max( prueba2$x )/min( prueba2$x )pvalfmax=pmaxFratio ( fmax , n−1, a , lower . t a i l=FALSE)r e s u l t s [ i , 1 ] <− b a r t l e t t . t e s t ( r , t r a t a )$p . va luer e s u l t s [ i , 2 ] <− f l i g n e r . t e s t ( r , t r a t a )$p . va luer e s u l t s [ i , 3 ] <− pvalfmaxr e s u l t s [ i , 4 ] <− ncvTest (m)$pr e s u l t s [ i , 5 ] <− l eveneTest ( r , t r a t a ) [ 1 , 3 ]r e s u l t s [ i , 6 ] <− l eveneTest ( r , t rata , c en t e r=mean) [ 1 , 3 ]r e s u l t s [ i , 7 ] <− C. t e s t (m)$p . va luer e s u l t s [ i , 8 ] <− 1∗ (CFF( r , t r a t a ) >0.4578)print ( i )
}colnames ( r e s u l t s )<−c ( ” B a r t l e t t pval ” , ” F l i gne r pval ” , ”Fmax pval ” ,
”B−P pval ” , ”Levene Median pval ” , ”Levene Mean pval ” ,”Cochran pval ” , ”CFF pval e s t ” )
colMeans ( r e s u l t s [ , 1 : 7 ] <0 . 0 5 )mean( r e s u l t s [ , 8 ] )###### a=7 y a=10l ibrary (GAD)l ibrary ( car )l ibrary ( SuppDists )l ibrary ( lmtes t )
CFF<−function (y , t r a t a ) {m <− lm( y˜ t r a t a )vare<−data . frame ( aggregate ( rstudent (m) , l i s t ( t r a t a ) ,var ) )c<−max( vare$x )/sum( vare$x )return (c )
}
set . seed (1415)nr <− 1000sigma1 <− 1sigma2 <− 1sigma3 <− 2a <− 10n <− 21r e s u l t s <− data . frame (matrix (NA,nrow=nr , ncol=8) )
for ( i in 1 : nr ) {
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 39
y1 <− rnorm(n , 0 , sigma1 )y2 <− rnorm(n , 0 , sigma1 )y3 <− rnorm(n , 0 , sigma1 )y4 <− rnorm(n , 0 , sigma1 )y5 <− rnorm(n , 0 , sigma2 )y6 <− rnorm(n , 0 , sigma2 )y7 <− rnorm(n , 0 , sigma2 )y8 <− rnorm(n , 0 , sigma3 )y9 <− rnorm(n , 0 , sigma3 )y10 <− rnorm(n , 0 , sigma3 )r <− c ( y1 , y2 , y3 , y4 , y5 , y6 , y7 , y8 , y9 , y10 )t r a t a <− factor ( rep ( 1 : a , each = n) )m <− lm( r˜ t r a t a )prueba=data . frame ( r , t r a t a )prueba2=data . frame ( aggregate ( prueba$r , l i s t ( prueba$ t r a t a ) ,var ) )fmax=max( prueba2$x )/min( prueba2$x )pvalfmax=pmaxFratio ( fmax , n−1, a , lower . t a i l=FALSE)r e s u l t s [ i , 1 ] <− b a r t l e t t . t e s t ( r , t r a t a )$p . va luer e s u l t s [ i , 2 ] <− f l i g n e r . t e s t ( r , t r a t a )$p . va luer e s u l t s [ i , 3 ] <− pvalfmaxr e s u l t s [ i , 4 ] <− ncvTest (m)$pr e s u l t s [ i , 5 ] <− l eveneTest ( r , t r a t a ) [ 1 , 3 ]r e s u l t s [ i , 6 ] <− l eveneTest ( r , t rata , c en t e r=mean) [ 1 , 3 ]r e s u l t s [ i , 7 ] <− C. t e s t (m)$p . va luer e s u l t s [ i , 8 ] <− 1∗ (CFF( r , t r a t a ) >0.1935329)print ( i )
}colnames ( r e s u l t s )<−c ( ” B a r t l e t t pval ” , ” F l i gne r pval ” , ”Fmax pval ” ,
”B−P pval ” , ”Levene Median pval ” , ”Levene Mean pval ” ,”Cochran pval ” , ”CFF pval e s t ” )
colMeans ( r e s u l t s [ , 1 : 7 ] <0 . 0 5 )mean( r e s u l t s [ , 8 ] )
############################ Caso Desbalanceado ############################l ibrary (GAD)l ibrary ( car )l ibrary ( SuppDists )l ibrary ( lmtes t )
CFF<−function (y , t r a t a ) {m <− lm( y˜ t r a t a )vare<−data . frame ( aggregate ( rstudent (m) , l i s t ( t r a t a ) ,var ) )c<−max( vare$x )/sum( vare$x )return (c )
}
set . seed (1415)nr <− 1000sigma1 <− 1sigma2 <− 2sigma3 <− 3a <− 3n <− c (25 ,26 ,27)armonic <− 1/ (mean(1/n) )( armonic <− cei l ing ( armonic ) )
r e s u l t s <− data . frame (matrix (NA,nrow=nr , ncol=8) )for ( i in 1 : nr ) {
y1 <− rnorm(n [ 1 ] , 0 , sigma1 )y2 <− rnorm(n [ 2 ] , 0 , sigma2 )y3 <− rnorm(n [ 3 ] , 0 , sigma3 )#y4 <− rnorm (n [ 4 ] , 0 , sigma2 )#y5 <− rnorm (n [ 5 ] , 0 , sigma3 )#y6 <− rnorm (n [ 6 ] , 0 , sigma2 )
Facultad de Estadıstica Trabajo de Grado Enero 2017

40 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
#y7 <− rnorm (n [ 7 ] , 0 , sigma3 )r <− c ( y1 , y2 , y3 )#, y4 , y5 , y6 , y7 )t r a t a <− factor ( rep ( 1 : a , c (n [ 1 ] , n [ 2 ] , n [ 3 ] ) ) )m <− lm( r˜ t r a t a )prueba=data . frame ( r , t r a t a )prueba2=data . frame ( aggregate ( prueba$r , l i s t ( prueba$ t r a t a ) ,var ) )fmax=max( prueba2$x )/min( prueba2$x )pvalfmax=pmaxFratio ( fmax , cei l ing ( armonic )−1, a , lower . t a i l=FALSE)r e s u l t s [ i , 1 ] <− b a r t l e t t . t e s t ( r , t r a t a )$p . va luer e s u l t s [ i , 2 ] <− f l i g n e r . t e s t ( r , t r a t a )$p . va luer e s u l t s [ i , 3 ] <− pvalfmaxr e s u l t s [ i , 4 ] <− ncvTest (m)$pr e s u l t s [ i , 5 ] <− l eveneTest ( r , t r a t a ) [ 1 , 3 ]r e s u l t s [ i , 6 ] <− l eveneTest ( r , t rata , c en t e r=mean) [ 1 , 3 ]r e s u l t s [ i , 7 ] <− C. t e s t (m)$p . va luer e s u l t s [ i , 8 ] <− 1∗ (CFF( r , t r a t a )> 0 .5111)print ( i )
}colnames ( r e s u l t s )<−c ( ” B a r t l e t t pval ” , ” F l i gne r pval ” , ”Fmax pval ” ,
”B−P pval ” , ”Levene Median pval ” , ”Levene Mean pval ” ,”Cochran pval ” , ”CFF pval e s t ” )
colMeans ( r e s u l t s [ , 1 : 7 ] >0 . 0 5 )mean( r e s u l t s [ , 8 ] )
############################ Gra f icos ############################l ibrary ( ggp lot2 )ggp lot (data , aes (n) )+
geom l i n e ( aes ( y = Bart l e t t , c o l ou r = ” B a r t l e t t ” ) )+geom point ( aes (n , B a r t l e t t ) )+geom l i n e ( aes ( y = Fl igner , co l ou r = ” F l i gne r ” ) )+geom point ( aes (n , F l i gne r ) )+geom l i n e ( aes ( y = Fmax, co l our = ”Fmax” ) )+geom point ( aes (n , Fmax) )+geom l i n e ( aes ( y = Breusch . Pagan , co l our = ”Breusch Pagan” ) )+geom point ( aes (n , Breusch .
Pagan ) )+geom l i n e ( aes ( y = Levene . Median , co l ou r = ”Levene median” ) )+geom point ( aes (n , Levene .
Median ) )+geom l i n e ( aes ( y = Levene . Mean , co l ou r = ”Levene mean” ) )+geom point ( aes (n , Levene . Mean) )+geom l i n e ( aes ( y = CFF, co l ou r = ”CFF” ) , s i z e =0.3)+geom point ( aes (n ,CFF) )+labs ( x = ”Tamano de l a muestra” , y =” Potencia ” , co l ou r = ”” )+theme bw( )+f a c e t grid ( grupo˜ . )
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 41
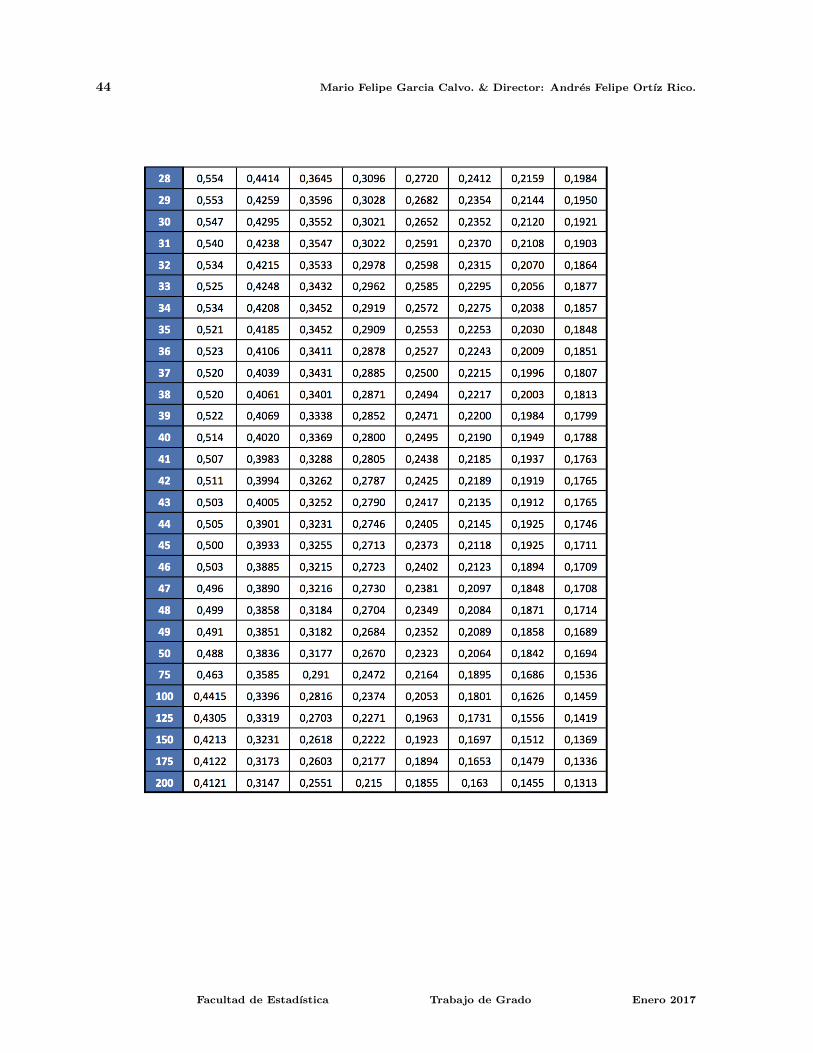
A.2. Tabla de percentiles prueba CFF
Facultad de Estadıstica Trabajo de Grado Enero 2017

42 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 43
Facultad de Estadıstica Trabajo de Grado Enero 2017
44 Mario Felipe Garcia Calvo. & Director: Andres Felipe Ortız Rico.
Facultad de Estadıstica Trabajo de Grado Enero 2017

Una nueva prueba de varianzas 45
Referencias
[1] William Gemmell Cochran. The distribution of the largest of a set of estimated variances as afraction of their total. 1941.
[2] Francisco Cribari and Gauss M. Cordeiro. On bartlett and bartlett-type corrections.
[3] Gene V. Glass. Testing homogeneity of variances. 2015.
[4] Herman Otto Hartley. The use of range in analysis of variance. 1950.
[5] Lucinia Rojas Juan Carlos Correa, Rene Iral. Estudio de potencia de pruebas de homogeneidad devarianza. 2006.
[6] Howard Levene. Contributions to probability and statistics: Essays in honor of harold hotelling.1960.
[7] R Development Core Team. R: A Language and Environment for Statistical Computing. R Foun-dation for Statistical Computing, Vienna, Austria, 2008. ISBN 3-900051-07-0.
[8] Snedecor and Cochran. Statistical methods. Iowa State University Press, 1983.
[9] George Waddel Snedecor and William Gemmell Cochran. Statistical methods, eighth edition. IowaState University Press, 1989.
[10] M.E Johnson W.J Conover and M.M Johnson. A comparative study of the test for homogeneity ofvariances, with applications to the outer continental shelf bidding data. 1981.
[11] Zhang and Gutierrez. Teorıa estadıstica aplicaciones y metodos. Universidad Santo Tomas, 2010.
[12] Shuqiang Zhang. Fourteen homogeneity of variance tests: When and how to use them. 1998.
Facultad de Estadıstica Trabajo de Grado Enero 2017




















