Structural features of the human gene for muscle-specific enolase. Differential splicing in the...
8
Eur. J. Biochem. 214, 367-374 (1993) 0 FEBS 1993 Structural features of the human gene for muscle-specific enolase Differential splicing in the 5’-untranslated sequence generates two forms of mRNA Agata GIALLONGO, Silvana VENTURELLA, Daniele OLIVA, Giovanna BARBIERI, Patrizia RUBINO and Salvatore FEO Istituto di Biologia dello Sviluppo del Consiglio Nazionale delle Ricerche, Palermo, Italy (Received December 18, 1992) - EJB 92 1726/1 We report here the isolation and characterization of the human gene for the p or muscle-specific isoform of the glycolytic enzyme enolase. The nucleotide sequence analysis revealed structural features, such as organization as 11 coding exons, the first exon consisting of an untranslated sequence and hence resembling sequences of the other two members of the gene family, the a and y enolase genes. The p enolase locus spans about 6 kbp genomic DNA. Sequences matching the consensus sequence for muscle-specific regulatory factors are present in the 5’-flanking region and within the first intron. A combination of primer extension, S1 nuclease protection and RNA-sequ- encing experiments indicates that the gene has a unique transcriptional start site, 26 bp downstream of a TATA-like box; the differential usage of two donor sites within the untranslated exon I generates two alternatively spliced transcripts. The existence of the two mRNA, differing from one another in the presence or absence of a 42-nucleotide fragment in the leader sequence, was confirmed by cloning the corresponding cDNA using the rapid amplification of cDNA ends strategy. Secondary- structure predictions indicated that the leader sequences of the spliced forms could form hairpin structures with different free energies of formation, suggesting translational control. Enolases, the glycolytic enzymes responsible for the interconversion of 2-phosphoglycerate to phosphoenolpy- ruvate, exist as at least three structurally related but geneti- cally distinct isoforms in mammals and birds [l]. The three subunits, a, p and y, that form the active homodimeric en- zyme, are encoded by distinct genes, as established by cDNA cloning in different species and chromosomal mapping of the human loci 161. It is of particular interest that the expression of the enolase genes is regulated in a tissue-specific and de- velopmental-specific manner. The a isoform is expressed in all the embryonic tissues and in nearly every adult tissue; a developmental switch between a and y isoforms occurs in neurons and cells of neuronal origin, while a transition from a to p enolase takes place in developing skeletal muscle and heart [2-41. In order to elucidate the mechanisms respon- sible for the developmentally regulated and tissue-specific expression of the enolase genes, our group has been involved in the characterization of the human enolase gene family. We isolated and determined the primary structure of the genes encoding a and y enolase [5, 61, we mapped the p enolase gene to the short arm of chromosome 17 [7] and charac- terized a fourth enolase-related sequence, identified as a pro- cessed pseudogene derived from the a enolase functional gene, which is located on chromosome 1 [8]. Recently, we Correspondence ro A. Giallongo, Istituto di Biologia dello Svil- Fax: +39 91 6165665. Abbreviations. RACE, rapid amplification of cDNA ends; HLH, helix-loop-helix; AMV, avian myeloblastosis virus. Enzyme. Enolase, 2-phospho-~-glycerate hydrolase (EC 4.2.1.11). Note. The novel nucleotide sequence data published here have been submitted to the EMBL/GenBank/DDB J Nucleotide Sequence Databases and are available under accession number X56832. uppo C. N. R., Via Archirfi 20,I-90123 Palermo, Italy. and others [9, lo], studying the expression of a and p enolase during myogenesis in the mouse, found a striking increase in the amount of the muscle-specific transcript in the fetal stage of development, although earlier during embryogenesis the p enolase gene is transcriptionally active at a level that is ba- rely detectable by classical biochemical means [9], but clearly detected by in situ hybridization [lo]. In adult muscle, /3 enolase protein and transcripts are expressed at a higher level in fast-twitch fibers than in slow-twitch fibers [lo, 111. In myogenic cell lines, p enolase is expressed in proliferating myoblasts 112, 131 and it has been proposed that its ex- pression is independent of the activity of the helix-loop-helix (HLH) family of myogenic regulators [13]. Taken together, these data suggest the existence of a complex and multistep mechanism by which the expression of the enolase gene is controlled. As a first step towards the understanding this mechanism(s), we have determined the complete primary structure of the human p enolase gene. While this work was in progress, Peshvaria and Day [14] reported a partial se- quence of the human muscle-specific enolase gene and sug- gested the presence of micro-heterogeneity in the untrans- lated first exon. In this report, we demonstrate the existence, in human muscle, of two forms of p enolase transcript that differ in their 5’-untranslated sequence and are generated by alternative splicing. The potential role of the heterogeneous 5’-untranslated region in the regulation of gene expression is discussed. MATERIALS AND METHODS Isolation and nucleotide sequencing of the human /l enolase gene Six weakly hybridizing recombinant phages were isolated by screening a human genomic library with a 32P-labeled hu-
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Structural features of the human gene for muscle-specific enolase. Differential splicing in the...

Eur. J. Biochem. 214, 367-374 (1993) 0 FEBS 1993
Structural features of the human gene for muscle-specific enolase Differential splicing in the 5’-untranslated sequence generates two forms of mRNA
Agata GIALLONGO, Silvana VENTURELLA, Daniele OLIVA, Giovanna BARBIERI, Patrizia RUBINO and Salvatore FEO Istituto di Biologia dello Sviluppo del Consiglio Nazionale delle Ricerche, Palermo, Italy
(Received December 18, 1992) - EJB 92 1726/1
We report here the isolation and characterization of the human gene for the p or muscle-specific isoform of the glycolytic enzyme enolase. The nucleotide sequence analysis revealed structural features, such as organization as 11 coding exons, the first exon consisting of an untranslated sequence and hence resembling sequences of the other two members of the gene family, the a and y enolase genes. The p enolase locus spans about 6 kbp genomic DNA. Sequences matching the consensus sequence for muscle-specific regulatory factors are present in the 5’-flanking region and within the first intron. A combination of primer extension, S1 nuclease protection and RNA-sequ- encing experiments indicates that the gene has a unique transcriptional start site, 26 bp downstream of a TATA-like box; the differential usage of two donor sites within the untranslated exon I generates two alternatively spliced transcripts. The existence of the two mRNA, differing from one another in the presence or absence of a 42-nucleotide fragment in the leader sequence, was confirmed by cloning the corresponding cDNA using the rapid amplification of cDNA ends strategy. Secondary- structure predictions indicated that the leader sequences of the spliced forms could form hairpin structures with different free energies of formation, suggesting translational control.
Enolases, the glycolytic enzymes responsible for the interconversion of 2-phosphoglycerate to phosphoenolpy- ruvate, exist as at least three structurally related but geneti- cally distinct isoforms in mammals and birds [l]. The three subunits, a, p and y , that form the active homodimeric en- zyme, are encoded by distinct genes, as established by cDNA cloning in different species and chromosomal mapping of the human loci 161. It is of particular interest that the expression of the enolase genes is regulated in a tissue-specific and de- velopmental-specific manner. The a isoform is expressed in all the embryonic tissues and in nearly every adult tissue; a developmental switch between a and y isoforms occurs in neurons and cells of neuronal origin, while a transition from a to p enolase takes place in developing skeletal muscle and heart [2-41. In order to elucidate the mechanisms respon- sible for the developmentally regulated and tissue-specific expression of the enolase genes, our group has been involved in the characterization of the human enolase gene family. We isolated and determined the primary structure of the genes encoding a and y enolase [5, 61, we mapped the p enolase gene to the short arm of chromosome 17 [7] and charac- terized a fourth enolase-related sequence, identified as a pro- cessed pseudogene derived from the a enolase functional gene, which is located on chromosome 1 [8]. Recently, we
Correspondence ro A. Giallongo, Istituto di Biologia dello Svil-
Fax: +39 91 6165665. Abbreviations. RACE, rapid amplification of cDNA ends; HLH,
helix-loop-helix; AMV, avian myeloblastosis virus. Enzyme. Enolase, 2-phospho-~-glycerate hydrolase (EC
4.2.1.11). Note. The novel nucleotide sequence data published here have
been submitted to the EMBL/GenBank/DDB J Nucleotide Sequence Databases and are available under accession number X56832.
uppo C. N. R., Via Archirfi 20,I-90123 Palermo, Italy.
and others [9, lo], studying the expression of a and p enolase during myogenesis in the mouse, found a striking increase in the amount of the muscle-specific transcript in the fetal stage of development, although earlier during embryogenesis the p enolase gene is transcriptionally active at a level that is ba- rely detectable by classical biochemical means [9], but clearly detected by in situ hybridization [lo]. In adult muscle, /3 enolase protein and transcripts are expressed at a higher level in fast-twitch fibers than in slow-twitch fibers [lo, 111. In myogenic cell lines, p enolase is expressed in proliferating myoblasts 112, 131 and it has been proposed that its ex- pression is independent of the activity of the helix-loop-helix (HLH) family of myogenic regulators [13]. Taken together, these data suggest the existence of a complex and multistep mechanism by which the expression of the enolase gene is controlled. As a first step towards the understanding this mechanism(s), we have determined the complete primary structure of the human p enolase gene. While this work was in progress, Peshvaria and Day [14] reported a partial se- quence of the human muscle-specific enolase gene and sug- gested the presence of micro-heterogeneity in the untrans- lated first exon. In this report, we demonstrate the existence, in human muscle, of two forms of p enolase transcript that differ in their 5’-untranslated sequence and are generated by alternative splicing. The potential role of the heterogeneous 5’-untranslated region in the regulation of gene expression is discussed.
MATERIALS AND METHODS Isolation and nucleotide sequencing of the human /l enolase gene
Six weakly hybridizing recombinant phages were isolated by screening a human genomic library with a 32P-labeled hu-

368
man a-enolase cDNA, as previously reported [5]. The 3, clone, B.21, containing the longest insert of genomic DNA, was further characterized for restriction-cleavage sites and by Southern-blot analysis, according to standard procedures [15]. Different regions of the p enolase cDNA [16] were used as probes to locate 5’ and 3’ ends of the gene. DNA frag- ments spanning the entire p enolase gene were isolated from the B.21 3, phage and subcloned into the KS’ or KS- Bluescript vectors (Stratagene). The Bluescript clones were used directly or after progressive digestion with exonuclease I11 (Boehringer) for nucleotide sequencing according to Sanger et al. [17], as previously described [6]. The nucleotide sequence was determined on both strands (90%) or at least twice on the same strand routinely using T7 DNA poly- merase (Sequenase) and Tuq I polymerase (Promega) in case of the presence of G+C-rich regions of DNA. The final sequences was assembled and analyzed using the HIBIO DNAsis program of the Hitachi Software Engineering Co.
Primer extension and S1 nuclease mapping Total RNA was isolated following the method described
by Chomczynsh and Sacchi [18], and poly(A)-rich RNA was selected by passage over oligo(dT)-cellulose [15]. For primer extension experiments, oligomer a (5’-CCTTTACTACCTC- CACCCCCAGGGCTGGAAGATTCA-3’; complementary to the 5’ untranslated sequence indicated in Fig. 5 ) and olig- omer b (5’-CAAGATTTCCCGGGAAAGA’ITTTCTGCAT- GGCCAT-3’; complementary to the coding sequence indi- cated in Fig. 5) were 5’ end-labeled, and used as primers. The radiolabeled primers were annealed with 3 pg poly(A)- rich RNA from human skeletal muscle overnight at 30°C and the template reverse transcribed with avian myeloblastosis virus (AMV) reverse transcriptase (Boehringer), as pre- viously described [5]. The extended products were analyzed by electrophoresis on a 6% polyacrylamide/7 M urea se- quencing gel.
For S1 nuclease mapping, the 5’ end-labeled oligomer a was used to generate a 280-bp single-stranded probe by ex- tension with Klenow polymerase (Promega), using as tem- plate a Bluescript recombinant clone containing the 5’ end of the gene. After digestion with HincII, the radiolabeled frag- ment was isolated, then hybridized with 3 pg poly(A)-rich RNA, from human skeletal muscle, overnight at 37°C fol- lowed by digestion with S1 nuclease (Boehringer) under the conditions previously described [5]. The digestion products were analyzed by electrophoresis as in primer extension.
Northern-blot analysis and RNA sequencing Total RNA (15 pg) was electrophored on a 2.2 M formal-
dehyde/l % agarose gel and transferred to a nylon membrane (Hybond, Amersham) according to the manufacturer’s in- structions. Hybridization was carried out under the con- ditions previously described [19] with a 32P-labeled 754-bp XbuI fragment (X700) derived from the B.21 3, clone and containing the last three exons of the p enolase gene.
Direct dideoxynucleotide sequencing of RNA was per- formed as described by Geliebter et al. [20]. Briefly, poly(A)- rich RNA from human skeletal muscle (8 pg) was annealed with 5 ng 32P-labeled oligomer b (see Fig. 5) at 59OC for 1 h. The RNA-primer annealing solution was divided in four aliquots and each aliquot was reverse transcribed with 7 U AMV reverse transcriptase (Boehringer) and in the presence of one dideoxynucleotide triphosphate, incubating at 50 “C
for 1 h. The reaction was stopped by addition of loading buffer [20] and analyzed by electrophoresis through a se- quencing gel.
cDNA cloning by rapid ampWication of cDNA ends (RACE)
5’-end amplification of cDNA for human p enolase was carried out according to Frohman et al. [21]. 1 pg poly(A)- rich RNA from human skeletal muscle was annealed with 20 pmol 20-nucleotide oligomer, 5’-GTGGCATCC’M’CCC- ATACTT-3’, complementary to bases 622-641 of the pre- viously reported cDNA sequence [16] and reverse tran- scribed with 10 U AMV reverse transcriptase (Boehringer). After removing the excess oligomer by passage through a 2- ml Bio-Gel A-5m column (Bio-Rad), the single-strand cDNA was tailed with terminal deoxynucleotidyl transferase (BRL) in the presence of dATP. Polymerase-chain-reaction amplifi- cation was performed with 25 pmol adaptor, 5’-GACTCGA- GTCGACATCG-3’, containing the XhoI, SuZI, and CZuI rec- ognition sites, 10 pmol (dT),, adaptor, having the same se- quence as that of the previous adaptor plus 17 T residues at the 3’ end, and 25 pmol specific oligomer, 5’-CTTGAAGG- AGCTGGCTCCCA-3’, complementary to bases 545 -564 of the human /3 enolase cDNA [16], following the described procedure [21]. RACE products were digested with the re- striction enzymes SuZI and BclI, whose recognition sites are present in the adaptor and in the p enolase sequence, respect- ively. DNA fragments were separated by agarose gel elec- trophoresis and specific products were isolated by glass elu- tion [22], then cloned in a Bluescript vector (Stratagene). Plasmids containing /3 enolase cDNA inserts were identified by colony-lift hybridization using, as probe, one of the pre- viously isolated cDNA [16] corresponding to the 5’ coding region of the mRNA. Further screening of these isolated clones was performed with the 5’ end-labeled oligomer a (see Fig. 5), complementary to the nucleotides alternatively spliced in the 5’ untranslated region and the nucleotide se- quence of five hybridization-positive and three hybridization- negative clones was determinated as described above.
The RNA secondary structure was predicted using the FOLD pcogram [23] included in the Sequence Analysis Software package of the Genetic Computer Group, Univer- sity of Wisconsin.
RESULTS Isolation and nucleotide sequence analysis of the j? enolase gene
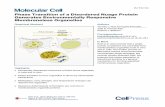
The screening of a human genomic library, using the full- length a enolase cDNA as a probe [24], resulted in the iso- lation of six weakly hybridizing clones in addition to clones containing sequences of the a enolase gene [5]. Restriction- mapping analysis revealed that this group of recombinant phages contained overlapping inserts of genomic DNA. When a hybridization-positive and repeat-free fragment of this DNA was used as probe in Northern-blot analysis, a 1.5- kb muscle-specific message was detected (Fig. l), suggesting that the isolated clones contained the gene coding for /? enol- ase which is expressed in muscle tissue. This was confirmed by cloning the corresponding cDNA from a human skeletal muscle library [16]. A partial restriction map of the 3, clone B.21, with a 21-kb insert of genomic DNA, is shown in Fig. 2. Several overlapping fragments of the B.21 DNA,
369
Fig. 1. Northern-blot analysis of RNA isolated from human tis- sues. Total RNA from human liver, skeletal muscle and fetal brain hybridized with the 32P-labeled genomic fragment X700, containing the last three exons of the human p enolase gene. The positions and sizes of RNA markers are indicated on the left.
-++ 4--f tt te-+ -+++++ + -
7 k b
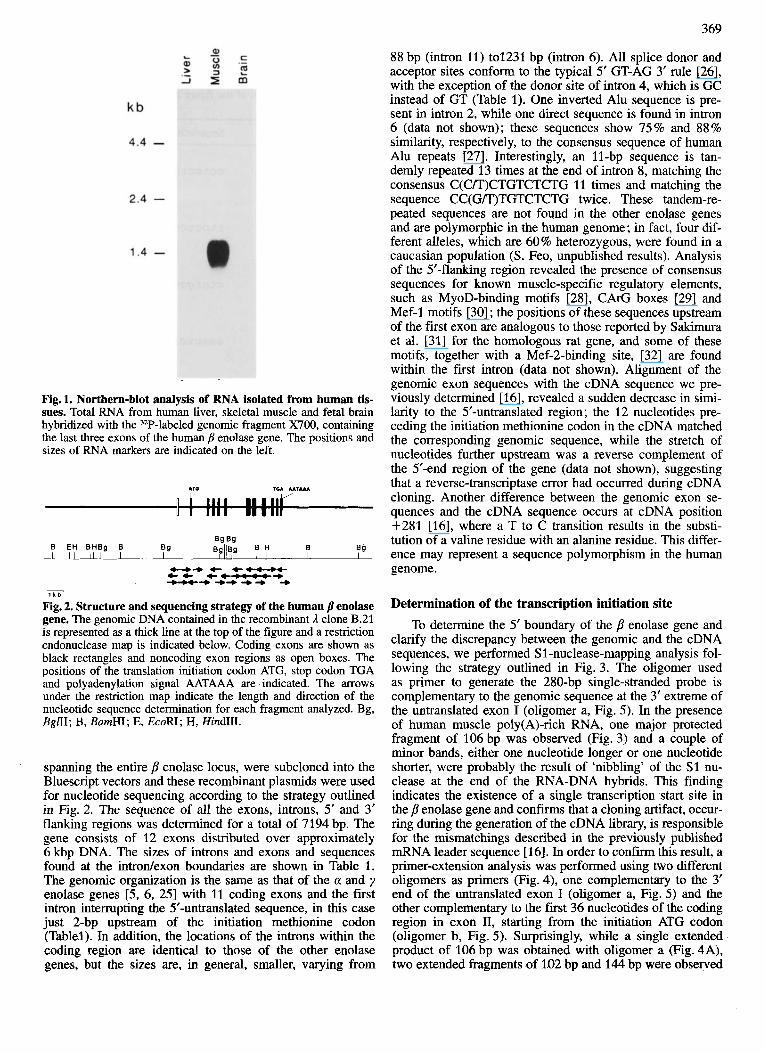
Fig. 2. Structure and sequencing strategy of the human /? enolase gene, The genomic DNA contained in the recombinant 3, clone B.21 is represented as a thick line at the top of the figure and a restriction endonuclease map is indicated below. Coding exons are shown as black rectangles and noncoding exon regions as open boxes. The positions of the translation initiation codon ATG, stop codon TGA and polyadenylation signal AATAAA are indicated. The arrows under the restriction map indicate the length and direction of the nucleotide sequence determination for each fragment analyzed. Bg, BglII; B, BamHI; E, EcoRI; H, HindLII.
spanning the entire p enolase locus, were subcloned into the Bluescript vectors and these recombinant plasmids were used for nucleotide sequencing according to the strategy outlined in Fig. 2. The sequence of all the exons, introns, 5‘ and 3’ flanking regions was determined for a total of 7194 bp. The gene consists of 12 exons distributed over approximately 6 kbp DNA. The sizes of introns and exons and sequences found at the introdexon boundaries are shown in Table 1. The genomic organization is the same as that of the a and y enolase genes [5, 6, 251 with 11 coding exons and the first intron interrupting the 5’-untranslated sequence, in this case just 2-bp upstream of the initiation methionine codon (Tablel). In addition, the locations of the introns within the coding region are identical to those of the other enolase genes, but the sizes are, in general, smaller, varying from
88 bp (intron 11) to1231 bp (intron 6). All splice donor and acceptor sites conform to the typical 5’ GT-AG 3’ rule [26], with the exception of the donor site of intron 4, which is GC instead of GT (Table 1). One inverted Alu sequence is pre- sent in intron 2, while one direct sequence is found in intron 6 (data not shown); these sequences show 75% and 88% similarity, respectively, to the consensus sequence of human Alu repeats [27]. Interestingly, an 11-bp sequence is tan- demly repeated 13 times at the end of intron 8, matching the consensus C(C/T)CTGTCTCTG 11 times and matching the sequence CC(G/T)TGTCTCTG twice. These tandem-re- peated sequences are not found in the other enolase genes and are polymorphic in the human genome; in fact, four dif- ferent alleles, which are 60% heterozygous, were found in a Caucasian population (S. Feo, unpublished results). Analysis of the 5’-flanking region revealed the presence of consensus sequences for known muscle-specific regulatory elements, such as MyoD-binding motifs [28], CArG boxes [29] and Mef-1 motifs [30] ; the positions of these sequences upstream of the first exon are analogous to those reported by Sakimura et al. [31] for the homologous rat gene, and some of these motifs, together with a Mef-2-binding site, [32] are found within the first intron (data not shown). Alignment of the genomic exon sequences with the cDNA sequence we pre- viously determined [16], revealed a sudden decrease in simi- larity to the 5’-untranslated region; the 12 nucleotides pre- ceding the initiation methionine codon in the cDNA matched the corresponding genomic sequence, while the stretch of nucleotides further upstream was a reverse complement of the 5’-end region of the gene (data not shown), suggesting that a reverse-transcriptase error had occurred during cDNA cloning. Another difference between the genomic exon se- quences and the cDNA sequence occurs at cDNA position $281 [16], where a T to C transition results in the substi- tution of a valine residue with an alanine residue. This differ- ence may represent a sequence polymorphism in the human genome.
Determination of the transcription initiation site To determine the 5‘ boundary of the p enolase gene and
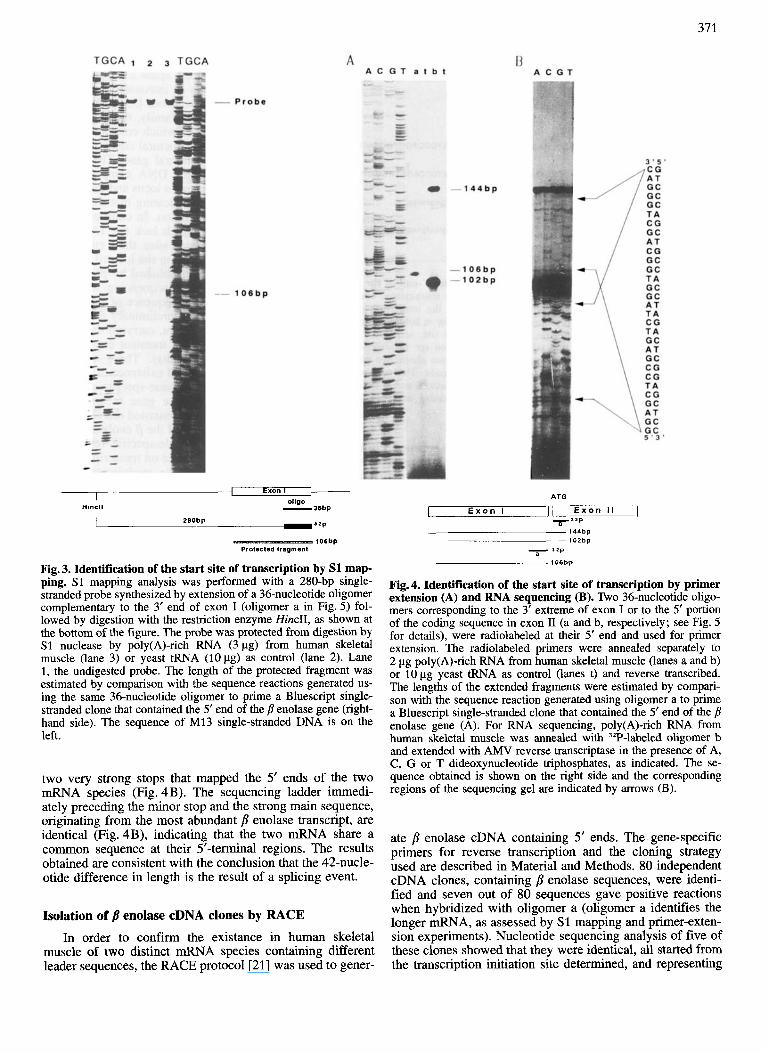
clarify the discrepancy between the genomic and the cDNA sequences, we performed S1 -nuclease-mapping analysis fol- lowing the strategy outlined in Fig. 3. The oligomer used as primer to generate the 280-bp single-stranded probe is complementary to the genomic sequence at the 3’ extreme of the untranslated exon I (oligomer a, Fig. 5). In the presence of human muscle poly(A)-rich RNA, one major protected fragment of 106 bp was observed (Fig. 3) and a couple of minor bands, either one nucleotide longer or one nucleotide shorter, were probably the result of ‘nibbling’ of the S1 nu- clease at the end of the RNA-DNA hybrids. This finding indicates the existence of a single transcription start site in the p enolase gene and confirms that a cloning artifact, occur- ring during the generation of the cDNA library, is responsible for the mismatchings described in the previously published mRNA leader sequence [ 161. In order to c o n f i i this result, a primer-extension analysis was performed using two different oligomers as primers (Fig. 4), one complementary to the 3‘ end of the untranslated exon I (oligomer a, Fig. 5) and the other complementary to the first 36 nucleotides of the coding region in exon 11, starting from the initiation ATG codon (oligomer b, Fig. 5) . Surprisingly, while a single extended product of 106 bp was obtained with oligomer a (Fig. 4A), two extended fragments of 102 bp and 144 bp were observed

370
Table 1. Intron-exon organization of the enolase gene. Exons sequences are in capital letters, intron sequences are in lower case. Coding nucleotides bordering the splice junctions are numbered above the DNA sequence with the first base of the ATG initiation codon designated as +1 (nucleotides within introns are not numbered). Amino acids are numbered from the alanine following the initiator methionine. Exon and intron sizes are indicated. The 3‘ end of exon XI1 is shown at the bottom of the figure and nucleotides not present in the cDNA are shown in lower case. Putative 3’-mRNA processing signals are underlined.
Exon Sequence Intron Sequence
-3 -2 I AGTAAAGGgtgagc 1 c c t c c t g t c c t g d a g C C A T G G C C
(603 bP) M e t A l a 1
(106 bP) (64 bp) CATCCCAGgtcggg (645 bp)
I1 (87 bPf
I11 (96 bp)
IV (59 bp)
V (70 bp)
VI (134 bP)
XI (59 bp)
85 GCCAAGGgtaaca A l a L y s G
27 181
GGGAAAGgtgagg G l y L y s G
59 240
C A A A A G g c a a g t G l n L y s
79
2 (876 bP)
86 t t c c t c c t g t c c c a g G C C G A
182 c t c t g g c c t g t c t a g G A G T C
lyVal 61
241 a a a c t c a c c t t c c a g A A A C T A
LysLeu 80
310 311 A A T A A G T g t g a g t 5 c t t g c c t c c t t c c a g C C A A G AsnL ys S (369 bP) e r L y s
102 104 444 445
G T G C C A g t g a g t 6 c t c t c c c c a t c t c a g G C C T T C Va lPro (1231 bp) AlaPhe
147 148 667 668
A A T G A G G g t c a g t 7 t t g g t c c t c c c c c a g C C C T G A s n G l u A (110 bP) l a L e u
221 223 865 866
T A T C C T G g t g a g g 8 t c c a a a c c c c a c c a g T G G T C T y r P r o V (337 bP) alVal
287 289 1067 1068
C A G G C g t g a g t 9 g t c c t c t c c a c t c a g G T G C G l n A l (428 bP) a C y s 354 356
1176 1177 G G A C A G g t a c t t 10 t t c t t c c c t c a t c a g A T C A A G G l y G l n (149 bP) I l e L y s
391 392 1235 1236
A T G A G g t a c a g 11 t t g c c t g c a t t c t a g G A T C M e t A r (88 bP) g I l e 410 412
CTGAAATAAACACTGGTGCCAACCaagacagc~~cttctttataa~a~ 1412
when oligomer b was used as primer (Fig.4A). The 106-bp and 144-bp extended products are consistent with the S1 nuclease analysis results and c o n f i i the existence of an untranslated exon I of 106 nucleotides, while the 102-bp ex- tended product indicates the presence of a transcript with a shorter 5’- untranslated region. This shorter leader sequence could be generated by alternative splicing of a primary tran- script, which suggests the presence of a splice-donor-like se-
quence within the 106-bp intron 1 (see Fig. 5), or the leader sequence could be the result of different promoter usage. To test these hypotheses and identify the cap site of the two RNA species corresponding to the extended products ob- tained with oligomer b, the same oligonucleotide was used in primer-extension dideoxy-chain-sequencing reactions with poly(A)-rich RNA from muscle tissue. All four reactions, carried out with different dideoxynucleotides, terminated in
371
1- Exon I t-
01tgLl Hlncll - 36bP
-32P 280bp
lO6bP Proleclsd fragment
Fig. 3. Identification of the start site of transcription by S1 map- ping. S1 mapping analysis was performed with a 280-bp single- stranded probe synthesized by extension of a 36-nucleotide oligomer complementary to the 3’ end of exon I (oligomer a in Fig. 5 ) fol- lowed by digestion with the restriction enzyme HincII, as shown at the bottom of the figure. The probe was protected from digestion by S1 nuclease by poly(A)-rich RNA (3 pg) from human skeletal muscle (lane 3) or yeast tRNA (1Opg) as control (lane 2). Lane 1, the undigested probe. The length of the protected fragment was estimated by comparison with the sequence reactions generated us- ing the same 36-nucleotide oligomer to prime a Bluescript single- stranded clone that contained the 5‘ end of the p enolase gene (right- hand side). The sequence of M13 single-stranded DNA i s on the left.
two very strong stops that mapped the 5’ ends of the two mRNA species (Fig. 4B). The sequencing ladder immedi- ately preceding the minor stop and the strong main sequence, originating from the most abundant /3 enolase transcript, are identical (Fig. 4B), indicating that the two mRNA share a common sequence at their 5’-terminal regions. The results obtained are consistent with the conclusion that the 42-nucle- otide difference in length is the result of a splicing event.
Isolation of /l enolase cDNA clones by RACE In order to confirm the existance in human skeletal
muscle of two distinct mRNA species containing different leader sequences, the RACE protocol [21] was used to gener-
ATG
E x o n I 11 E x o n I I I T ’ 2 P
7 3 1 p
106bp
Fig.4. Identification of the start site of transcription by primer extension (A) and RNA sequencing (B). Two 36-nucleotide oligo- mers corresponding to the 3’ extreme of exon I or to the 5’ portion of the coding sequence in exon I1 (a and b, respectively; see Fig. 5 for details), were radiolabeled at their 5’ end and used for primer extension. The radiolabeled primers were annealed separately to 2 pg poly(A)-rich RNA from human skeletal muscle (lanes a and b) or 10 pg yeast tRNA as control (lanes t) and reverse transcribed. The lengths of the extended fragments were estimated by compari- son with the sequence reaction generated using oligomer a to prime a Bluescript single-stranded clone that contained the 5’ end of the p enolase gene (A). For RNA sequencing, poly(A)-rich RNA from human skeletal muscle was annealed with 3ZP-labeled oligomer b and extended with AMV reverse transcriptase in the presence of A, C, G or T dideoxynucleotide triphosphates, as indicated. The se- quence obtained is shown on the right side and the corresponding regions of the sequencing gel are indicated by arrows (B).
ate p enolase cDNA containing 5’ ends. The gene-specific primers for reverse transcription and the cloning strategy used are described in Material and Methods. 80 independent cDNA clones, containing /3 enolase sequences, were identi- fied and seven out of 80 sequences gave positive reactions when hybridized with oligomer a (oligomer a identifies the longer mRNA, as assessed by S1 mapping and primer-exten- sion experiments). Nucleotide sequencing analysis of five of these clones showed that they were identical, all started from the transcription initiation site determined, and representing

372 ATQ
gpCtCag~pCpC.(CC~gagagggggtgagct~ACTQTCCCAQC~QCCACC
TAQACTCQQAGCTCCATCCAAACCTCCAQCQAAQACATCCCAQGTCQGGTG 1
-
1 MT~CCAGCCCTGQQGQ~GGAQGTAGT~GGgtgagcatg~g ...................
................... lntron l..O.B.kb .......................... cctcctgtcctgcagCCATQQCC
I Met Ala
Met Qln Lyo Ile Phe Ala Arg Qlu Ile Leu Asp Ser ATaCAQAAAATCmgCCCQQQAAATCTTOCICATCC ........................
b Fig.5. Genomic structure and sequence of the 5’-end of the hu- man fl enolase gene. The hatched box in the untranslated exon I represents the 42-nucleotide insert present in the long form of p enolase mRNA, whose sequence is shown below in boldface capital letters. Arrows indicate the transcription start site, sequences up- stream to the 5’ end and within the first intron are in lower-case letters. A TATA-like sequence is boxed. The two alternative splice donor sites are indicated by vertical arrowheads. The sequences underlined correspond to the synthetic oligomers, a and b used in primer extension, RNA-sequencing and screening of the RACE products.
a transcript with a 108-nucleotide leader sequence. Further- more, the sequences of three oligomer-a-negative cDNA clones were identical and represented a transcript different to the previously described mRNA for a 42-nucleotide deletion in the 5’-untranslated region. The relative abundance of the two classes of transcript, the shorter transcript being more abundant than the longer transcript (Fig. 4), is consistent with the recovery of each class from cDNA cloning. Alignment of the cDNA species and genomic sequences indicated that alternate splice-donor sites, at the 3’ end of exon I, and a common acceptor site, at the 5’ end of exon II, distinguish the two classes of transcript (Fig. 5).
Potential secondary structure of the B enolase mRNA leaders
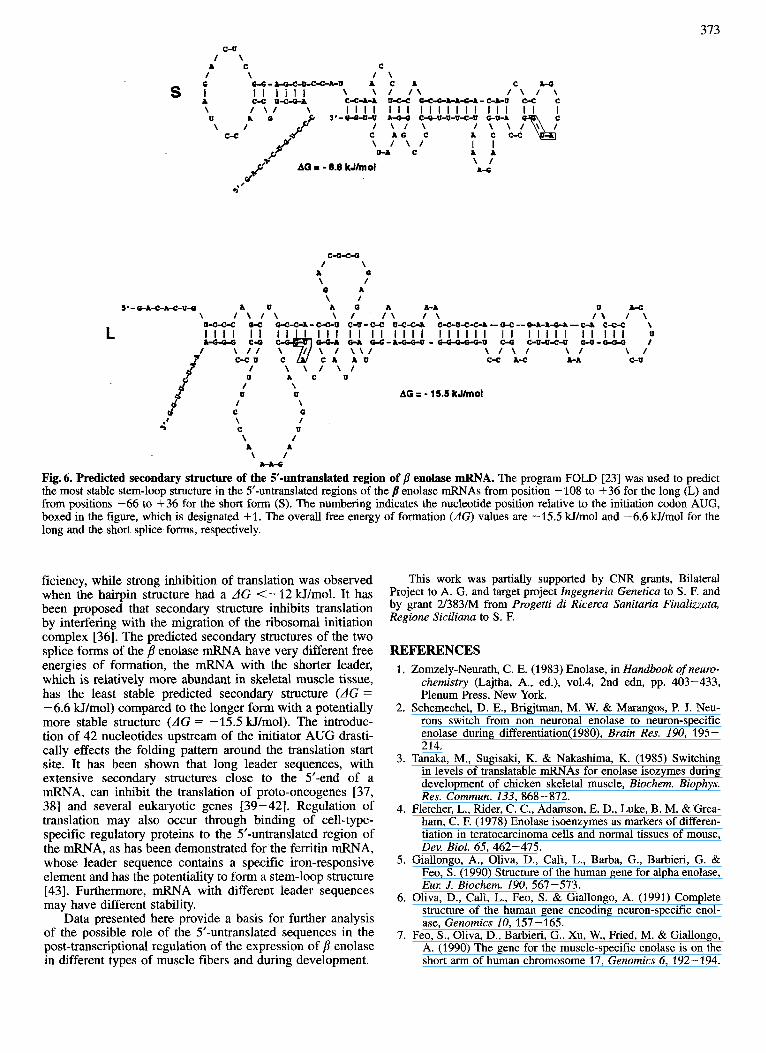
To determine whether the presence or the absence of the 42-nucleotide fragment in the 5’-untranslated region might have impact on the secondary structure of the mRNA, fold- ing of the two p enolase messages was analyzed using se- quences from the transcription start site to 36-nucleotides downstream from the AUG start codon. Computer-generated predictions of the most stable leader secondary structure of the two splice forms are illustrated in Fig. 6. Introduction of the 42-nucleotide fragment produced a markedly altered folding pattern, leading to the formation of a very stable stem-loop structure with AG = -15.5 kJ/mol. In contrast, the potential hairpin structure of the short transcript had a predicted AG = -6.6 Hfmol, representing a significantly less stable secondary structure. The presence of a potential stem-loop structure with predicted high stability within the 5’-untranslated region of the longer p enolase transcript, might explain the inversion of the genomic sequence found in the cDNA previously isolated [16].
DISCUSSION In the present study, we have isolated the human gene
encoding p or muscle-specific enolase and determined its
structural features. The j? locus, whose nucleotide sequence was completely determined, spans a region of genomic DNA of about 6 kb and shares an introdexon organization identi- cal to the a and y enolase genes [5, 6, 251. As for the other two members of the gene family, the /3 gene is distributed over 12 exons, the first of which contains only untranslated sequences. The extreme structural conservation suggests the existence of a single ancestral gene. The p locus covers a smaller region of genomic DNA compared to that of the other two genes (the human a locus and the y locus are 18 kb and 9 kb, respectively), indicating that the p gene probably diverged last during evolution. In contrast to that observed for the a and y genes which lack the TATA box and have multiple transcriptional start sites, the p enolase gene is tran- scribed from a single initiation site located 26 bp downstream of a TATA-like box, as established by primer extension, S1 nuclease mapping and RNA sequencing. Although this motif differs from the canonical sequence of RNA polymerase-11- dependent promoters [ 3 31, preliminary experiments indicate that a 202-bp DNA fragment, carrying this element, is able to promote transcription in transient expression assays (G. Barbieri, unpublished results). These characteristics, the presence of a TATA box and existence of a unique start site, are usually displayed by tissue-specific genes and, indeed, expression of the p enolase gene is restricted to striated muscle tissues. A computer-assisted search in the 5’-flanking region and the first intron of the /? enolase gene revealed the presence of potential muscle-specific regulatory elements, whose functional significance on transcriptional regulation is under investigation. However, modulation of the expression of p enolase during myogenesis and in adult fibers, differs from that established for other muscle-specific genes. The p enolase gene is transcribed during early myogenesis when MyoD is not expressed, and a striking increased expression conelates with the formation of the second generation of muscle fibers [9, 101. Furthermore, myogenic cell lines al- ready express low levels of p enolase when cultured as proli- ferating myoblasts [12, 131 and expression of p enolase is observed in mutant cell lines that do not fuse to form differ- entiated myotubes and do not express any of the helix-loop- helix muscle regulators [13]. These observations strongly suggest that other regulatory factors and/or other mechanisms might be involved in the control of gene expression.
We report here the existence, in human skeletal muscle, of two forms of p enolase mRNA that differ in length of the 5’-untranslated region and arise from alternative splicing within exon I via differential utilization of two donor sites and one acceptor splice site. We recently isolated two major classes of p enolase mRNA from murine muscle tissue that also differ in the 5‘-untranslated region (S. Venturella, unpub- lished results). Probably at least two classes of j3 enolase mRNA are present in rat muscle, as suggested by sequence comparison of human and rat cDNA leader sequences (this report and [34]). The evolutionary constraint to maintain at least two mRNA species, encoding the same protein but bearing different leader sequences from mouse to man, may reflect functional significance. Alternative splicing within the 5’-untranslated region is usually linked to alternative pro- moter usage; in this case multiple p enolase mRNA species arise from the same promoter, suggesting the possibility that regulated splicing [35] may control gene expression further. Alternatively, the various splice forms might be subjected to some kind of translational control. It was demonstrated by Kozak [36] that secondary structure at the 5‘-end of mRNA, with a AG >-7.2 kJ/mol, did not effect the translation ef-
373
L
C-U / \
A C C / \ / \
W-.-oc-O-C-C-LU A C A C A 4
c-c u-c-oa \ \ / / \ / \ I \ c-c -w u-c-c o-c-6A-A-a-&-c-A-u c-c c I I I l l 1
\ / \ / \ I I I I I l l I I I I I I I I l l I I U 3'-W-U-U A- C4U-U-U-C-0 +Q-A
/ \ / \ C A G C A C C - C \ / \ / 0 4 c
\ / C-C
\ / A-c AG I - 6.6 kJlmol
d 4'
c-o-c-6 / \
A 0 \ / 0 A \ I
5'-Q-A-C-A4-U4 A U A 0 A A-A \ / \ I \ \ I / \ / \
C - C U C ,!d C A A U C-C A 4 A-A c-u / \ \ I \ l U A C U
9 P \' a
/ \ U 0
/ \ C a \ / C u \ /
A A \ /
& - A 4
AG = - 15.5 k J h d
Fig. 6. Predicted secondary structure of the 5'-untranslated region of p enolase mRNA. The program FOLD [23] was used to predict the most stable stem-loop structure in the 5'-untranslated regions of the /I enolase mRNAs from position - 108 to +36 for the long (L) and from positions -66 to +36 for the short form (S). The numbering indicates the nucleotide position relative to the initiation codon AUG, boxed in the figure, which is designated +l. The overall free energy of formation (AG) values are -15.5 kJ/mol and -6.6 kJ/mol for the long and the short splice forms, respectively.
ficiency, while strong inhibition of translation was observed when the hairpin structure had a AG <-12 Wimol. It has been proposed that secondary structure inhibits translation by interfering with the migration of the ribosomal initiation complex [36]. The predicted secondary structures of the two splice forms of the p enolase mRNA have very different free energies of formation, the mRNA with the shorter leader, which is relatively more abundant in skeletal muscle tissue, has the least stable predicted secondary structure (dG = - 6.6 W/mol) compared to the longer form with a potentially more stable structure (AG = -15.5 W/mol). The introduc- tion of 42 nucleotides upstream of the initiator AUG drasti- cally effects the folding pattern around the translation start site. It has been shown that long leader sequences, with extensive secondary structures close to the 5'-end of a mRNA, can inhibit the translation of proto-oncogenes [37, 381 and several eukaryotic genes [39-421. Regulation of translation may also occur through binding of cell-type- specific regulatory proteins to the 5'-untranslated region of the mRNA, as has been demonstrated for the ferritin mRNA, whose leader sequence contains a specific iron-responsive element and has the potentiality to form a stem-loop structure [43]. Furthermore, mRNA with different leader sequences may have different stability.
Data presented here provide a basis for further analysis of the possible role of the 5'-untranslated sequences in the post-transcriptional regulation of the expression of /3 enolase in different types of muscle fibers and during development.
This work was partially supported by CNR grants, Bilateral Project to A. G. and target project Ingegneria Genetica to S . F. and by grant 2/383/M from Progetti di Ricerca Sanitaria Finaliuata, Regione Siciliana to S . F.
REFERENCES 1. Zomzely-Neurath, C. E. (1983) Enolase, in Handbook of neuro-
chemistry (Lajtha, A., ed.), vo1.4, 2nd edn, pp. 403-433, Plenum Press, New York.
2. Schemechel, D. E., Brigjtman, M. W. & Marangos, P. J. Neu- rons switch from non neuronal enolase to neuron-specific enolase during differentiation(l980), Brain Res. 190, 195 - 214.
3. Tanaka, M., Sugisaki, K. & Nakashima, K. (1985) Switching in levels of translatable mRNAs for enolase isozymes during development of chicken skeletal muscle, Biochem. Biophys. Res. Commun. 133, 868-872.
4. Fletcher, L., Rider, C . C., Adamson, E. D., Luke, B. M. & Grea- ham, C. F. (1978) Enolase isoenzymes as markers of differen- tiation in teratocarcinoma cells and normal tissues of mouse, Dev. Biol. 65, 462-475.
5. Giallongo, A., Oliva, D., Cali, L., Barba, G., Barbieri, G. & Feo, S. (1990) Structure of the human gene for alpha enolase, Eul: J. Biochem. 190, 567-573.
6. Oliva, D., Cali, L., Feo, S. & Giallongo, A. (1991) Complete structure of the human gene encoding neuron-specific enol- ase, Genomics 10, 157-165.
7. Feo, S., Oliva, D., Barbieri, G., Xu, W., Fried, M. & Giallongo, A. (1990) The gene for the muscle-specific enolase is on the short arm of human chromosome 17, Genomics 6, 192-194.

314
8. Feo, S., Oliva, D., Aricb, B., Barba, G., Cali, L. & Giallongo, A. (1990) The human genome contains a single processed pseudogene for alpha enolase located on chromosome 1, DNA Sequence I, 79-83.
9. Barbieri, G., De Angelis, L., Feo, S., Cossu, G. & Giallongo, A. (1990) Differential expression of muscle-specific enolase in embryonic and fetal myogenic cells during mouse develop- ment, Differentiation 45, 179-184.
10. Keller, A,, Ott, M. O., LamandB, N., Lucas, M., Gros, F., Buckingham, M.& Lazar, M. (1992) Activation of the gene encoding the glycolytic enzyme beta-enolase during early my- ogenesis precedes an increased expression during fetal muscle development, Mech. Dev. 38, 41 -54.
11. Ibi, T., Sahashi, K., Kato, K., Takahashi, A. & Sobue, I. (1983) Immunoistochemical demonstration of beta enolase in human skeletal muscle, Nerve & Muscle 6, 661 -663.
12. LamandB, N., Mazo, A. M., Lucas, M., Montarras, D., Pinset, C., Gros, F., Legault-Demare, L. & Lazar, M. (1989) Murine muscle-specific enolase : cDNA cloning, sequence, and devel- opmental expression, Proc. Natl Acad. Sci. USA 86, 4445- 4449.
13. Peterson, C. A., Cho, M., Rastinejad, F. & Blau, H. M. (1992) Beta-enolase is a marker of human myoblast heterogeneity prior to differentiation, Dev. Biol. 151, 626-629.
14. Peshavaria, M. & Day, I. N. M. (1991) Molecular structure of the human muscle-specific enolase gene (EN03), Biochem. J. 275,427-433.
15. Ausubel, F. M., Brent, R., Kingston, R. E., Moore, D. D, Seid- man, J, Smith, J. A., Struhl, K. (1988) Current protocols in molecular biology, Greene & Wiley-Interscience, New York.
16. Cali, L., Feo, S., Oliva, D. & Giallongo, A. (1990) Nucleotide sequence of a cDNA encoding the human muscle-specific enolase (MSE), Nucleic Acids Res. 18, 1893.
17. Sanger, F., Nicklen, S. & Coulson, A. R. (1978) DNA sequenc- ing with the chain-terminating inhibitors, Proc. Natl Acad. Sci. USA 74, 5463-5467.
18. Chomczynski, P. & Sacchi, N. (1987) Single step method of RNA isolation by acid guanidinium thiocyanate-phenol- chloroform extraction, Anal. Biochem. 162, 156- 159.
19. Oliva, D., Barba, G., Barbieri, G., Giallongo, A. & Feo, S. (1989) Cloning, expression and sequence homologies of cDNA for human gamma enolase, Gene (Amst.) 79, 355- 360.
20. Geliebter, J., Zeff, R. A., Melvold, R. W. & Nathenson, S. G. (1986) Mitotic recombination in germ cells generated two major histocompatibility complex mutant genes shown to be idential by RNA sequence analisis : KbM9 and Kbm6, Pmc. Natl Acad. Sci. USA 83, 3371 -3375.
21. Frohman, M. A., Dush, M. K. & Martin, R. G. (1988) Rapid production of full-length cDNAs from rare transcripts : ampli- fication using a single gene-specific oligonucleotide primer, Proc. Natl Acad. Sci. USA 85, 8998-9002.
22. Volgestein, B. & Gillespie, D. (1979) Preparative and analytical purification of DNA from agarose, Proc. Natl Acad. Sci. USA 76, 615-619.
23. Zuker, M. & Stiegler, P. (1981) Optimal computer folding of large RNA sequences using thermodynamics and auxiliary information, Nucleic Acids Res. 9, 133- 148.
24. Giallongo, A., Feo, S., Moore, R., Croce, C. M. & Showe, L. C. (1986) Molecular cloning and nucleotide sequence of a full-length cDNA for human alpha enolase, Proc. Natl Acad. Sci. USA 83, 6741-6745.
25. Sakimura, K., Kushiya, E., Takahashi, Y. & Suzuki, Y. (1987) The structure and expression of neuron-specific enolase gene, Gene (Amst.) 60, 103-113.
26. Mount, S. M. (1982) A catalogue of splice junction sequences, Nucleic Acids Res. 10, 459-472.
27. Kariya, Y., Kato, K., Hayashizaki, Y., Himeno, S., Tarui, S. & Matsubara, K. (1987) Revision of consensus sequence of human Alu repeats - a review, Gene (Amst.) 53, 1 - 10.
28. Lassar, A. B., Buskin, Y. N., Lockshond, D., Davis, R. L., Apone, S., Hauschka, S. D. & Weintraub, H. (1989) MyoD is a sequence specific DNA binding protein requiring a region of myc homology to bind muscle creatinine kinase enhancer, Cell 58, 823-831.
29. Gustafson, T. A. & Kedes, L. (1989) Identification of multiple proteins that interact with functional regions of the human cardiac alpha-actin promoter, Mol. Cell. Biol. 9, 3269-3283.
30. Buskin, J. N. & Hauschka, S. D. (1989) Identification of a my- ocite nuclear factor that binds to the muscle-specific enhancer of the mouse muscle creatine kinase gene, Mol. Cell. Bid. 9, 2627-2640.
31. Sakimura, K., Kushiya, E., Ohshima-Ichimura, Y., Mitsui, H. & Takahashi, Y. (1990) Structure and expression of rat muscle- specific enolase gene, FEBS Lett. 277, 78-82.
32. Gosset, L. A., Kelvin, D. J., Sternberg, E. A. & Olson, E. N. (1989) A new myocite-specific enhancer-binding factor that recognizes a conserved element associated with multiple muscle-specific genes, Mol. Cell. Biol. 9, 5022-5033.
33. Corden, J., Wasylyk, B., Buckwalder, A., Sassone-Corsi, P., Kedinger, C. & Chambon, P. (1980) Promoter sequence of eukaryotic protein-coding genes, Science 209, 1406- 1414.
34. Oshima, Y., Mitsui, H., Takayama, Y, Kushiya, E, Sakimura, K. & Takahashi, Y. (1989) cDNA cloning and nucleotide se- quence of rat muscle-specific enolase (beta-beta enolase),
35. Kozak, M. (1988) A profusion of controls, J. Cell Biol. 107,
36. Kozak, M. (1989) The scanning model for tanslation: an update, J. Cell Biol. 108, 229-241.
37. Propst, F., Rosenberg, M. P., Iyer, A., Kaul, K. & Vande Woode, G. F. (1987) c-mos proto-oncogene RNA transcripts in mouse tissues : structural features, developmental regulation, and localization in specific cell types, Mol. Cell. Biol. 7, 1629- 1637.
38. Rao, C. D., Pech, M., Robins, K. C. & Aaronson. S. A. (1988) The 5’ untranslated sequence of the c-sislplatelet-derived growth factor 2 transcript is a potent translational inhibitor, Mol. Cell. Biol. 8, 284-292.
39. Grens, A. & Scheffler, 1. E. (1990) The 5’- and 3’- untranslated regions of ornithine decarboxylase mRNA affect the trans- lational efficiency, J. Biol. Chem. 265, 11810-11 816.
40. Manzella, J. M. & Blackshear, P. J. (1990) Regulation of rat ornithine decarboxylase mRNA translation by its 5’-untrans- lated region, J. Biol. Chem. 265, 11 817-11 822.
41. Guan, K.-L. & Weiner, H. (1989) Influence of 5‘-end region of aldehyde dehydrogenase mRNA on translational efficiency, J. Biol. Chem. 264, 17764-17769.
42. Kim, S.-J., Park, K., Koeller, D., Kim, K. Y., Wakefield, L. M., Sporn, N. B. & Roberts, A. B. (1990) Post-transcriptional regulation regulation of the human transfonning growth fac- tor-beta1 gene, J. Biot. Chem. 267, 13702-13707.
43. Casey, J. L., Hentze, M. W., Koeller, D. M., Caughman, S. W., Rouault, T. A., Klausner, R. D. & Harford, J. B. (1988) Iron- responsive elements : regulatory RNA sequences that control mRNA levels and translation, Science 240, 924-928.
FEBS IRtt. 242,425-430.
1-7.