
Statistiktage Schweiz Journées suisses de la statistique ...
122
Statistikkultur und Statistikmarkt in der Schweiz Culture et marché de la statistique en Suisse Statistics culture and statistics market in Switzerland OFS BFS UST Neuchâtel, 2002 Statistiktage Schweiz Journées suisses de la statistique Giornate svizzere della statistica Swiss Days of Statistics
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of Statistiktage Schweiz Journées suisses de la statistique ...

Statistikkultur und Statistikmarkt in der Schweiz
Culture et marché de la statistique en Suisse
Statistics culture and statistics market in Switzerland
OFS BFS USTNeuchâtel, 2002
Stat
istik
tage
Sch
wei
zJo
urné
es s
uiss
es d
e la
sta
tistiq
ueG
iorn
ate
sviz
zere
del
la s
tatis
tica
Swis
s Da
ys o
f Sta
tistic
s

0 Statistische Grundlagen und Übersichten
1 Bevölkerung
2 Raum und Umwelt
3 Arbeit und Erwerb
4 Volkswirtschaft
5 Preise
6 Industrie und Dienstleistungen
7 Land- und Forstwirtschaft
8 Energie
9 Bau- und Wohnungswesen
10 Tourismus
11 Verkehr und Nachrichtenwesen
12 Geld, Banken, Versicherungen
13 Soziale Sicherheit
14 Gesundheit
15 Bildung und Wissenschaft
16 Kultur, Medien, Zeitverwendung
17 Politik
18 Öffentliche Verwaltung und Finanzen
19 Rechtspflege
20 Einkommen und Lebensqualität der Bevölkerung
21 Nachhaltige Entwicklung und regionale Disparitäten
Die vom Bundesamt für Statistik (BFS) herausgegebene Reihe «Statistik der Schweiz» gliedert sich in folgende Fachbereiche:
0 Bases statistiques et produits généraux
1 Population
2 Espace et environnement
3 Vie active et rémunération du travail
4 Economie nationale
5 Prix
6 Industrie et services
7 Agriculture et sylviculture
8 Energie
9 Construction et logement
10 Tourisme
11 Transports et communications
12 Monnaie, banques, assurances
13 Protection sociale
14 Santé
15 Education et science
16 Culture, médias, emploi du temps
17 Politique
18 Administration et finances publiques
19 Droit et justice
20 Revenus et qualité de vie de la population
21 Développement durable et disparités régionales
La série «Statistique de la Suisse» publiéepar l’Office fédéral de la statistique (OFS) couvreles domaines suivants:

Statistikkultur und Statistikmarkt in der Schweiz
Culture et marché de la statistique en Suisse
Statistics culture and statistics market in Switzerland
Office fédéral de la statistiqueBundesamt für StatistikUfficio federale di statisticaUffizi federal da statistica
OFS BFS USTNeuchâtel, 2002
Statistik der Schweiz Statistique de la Suisse Swiss Statistics
Herausgeber Bundesamt für StatistikEditeur Office fédéral de la statistiquePublisher Swiss Federal Statistical Office

2
Auskunft: Dr. Vera Herrmann, BFS; E-mail: [email protected] Angelo Fiala, BFS; E-mail: [email protected]
Vertrieb: Bundesamt für Statistik CH-2010 Neuchâtel Tel. 032 713 60 60 / Fax 032 713 60 61
Bestellnummer: 539-0000
Preis: Fr. 11.–
Reihe: Statistik der Schweiz
Fachbereich: 0 Statistische Grundlagen und Übersichten
Originaltext: Deutsch und englisch
Grafik/Layout: BFS
Copyright: BFS, Neuchâtel 2002 Abdruck – ausser für kommerzielle Nutzung – unter Angaben der Quelle gestattet
ISBN: 3-303-00245-2
Complément d’information: Dr. Vera Herrmann, OFS; E-mail: [email protected] Angelo Fiala, OFS; E-mail: [email protected]
Diffusion: Office fédéral de la statistique CH-2010 Neuchâtel Tél. 032 713 60 60 / Fax 032 713 60 61
No. de commande: 539-0000
Prix: 11 francs
Série: Statistique de la Suisse
Fachbereich: 0 Bases statistiques et vues d’ensemble
Langue du texte original: Allemand et anglais
Graphisme/Layout: OFS
Copyright: OFS, Neuchâtel 2002 La reproduction est autorisée, sauf à des fins commerciales, si la source est mentionnée
ISBN: 3-303-00245-2

3
InhaltsverzeichnisTable des matières
Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
Politik und RationalitätCarlo Malaguerra, Bundesamt für Statistik . . . . . . . . . . . . . . . . . . . . . . . 17
Statistik und ihre InterpretationHans Bühlmann und Werner Stahel, Eidg. Technische Hochschule Zürich . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
Neuere Entwicklungen in der theoretischen StatistikStephan Morgenthaler, Ecole polytechnique fédérale Lausanne . . . . . . 35
So überzeugt man mit StatistikWalter Krämer, Universität Dortmund . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
Diagnose von Fehlerquellen und methodische Qualität in der sozialwissenschaftlichen ForschungAndreas Diekmann, Universität Bern
Two-Way Plots Based on Mixed TracesThomas Gsponer, Swiss Federal Institute of Technology, Lausanne . . . 79
Raummetaphern und kartographische Methoden zur Analyse, Interpretation und Visualisierung von statistischer InformationMichael Hermann und Heiri Leuthold, Universität Zürich . . . . . . . . . . 93
IHA-GfM Online Research – Ein Griff aus unserem ErfahrungsschatzRena Snoy und Roland Huber, Online research IHA-GfM . . . . . . . . . . 109
Verzeichnis der Autoren / Liste des auteurs . . . . . . . . . . . . . . . . . . . . . . . 117

4
Die Statistiktage Schweiz 2000 wurden unterstützt durch
Les Journées suisses de la statistiques 2000 ont bénéficié du soutien de
The Swiss Days of Statistics 2000 were sponsored by
Sowie / et / and
APP Unternehmensberatung AG, Bern-Basel-ZürichLINK Institut für Markt- und Sozialforschung, Luzern-Lausanne-ZürichMummert & Partner Unternehmensberatung AG, ZürichSAS Institute AG, Brüttisellen
Institut für angewandte Mathematik, Statistik, InformatikInstitut für Marktanalysen AG, Hergiswil SPSS (Schweiz) AG, Zürich

5
Einleitung
Nachdem im Herbst 1999 erstmals in der Schweiz «Tage der amtlichen Sta-tistik» durchgeführt wurden1), folgten ein Jahr später in St. Gallen die «Statis-tiktage Schweiz». Dieser Anlass war die logische Fortsetzung der Bemühun-gen, die Schweizer Statistik institutionnell zu reorganisieren und, einem ge-meinsamen Leitbild folgend, ihre Präsenz auf Landesebene zu markieren.
Zur Durchführung dieser Tagung in Sankt Gallen hatten sich die in der Schweiz tätigen Organisationen der amtlichen und nichtamtlichen Statistik zusammengefunden und ein Thema ausgesucht, das möglichst viele Statisti-ker und Statistikerinnen ansprechen sollte. Mit dem Thema «Statistikkultur und Statistikmarkt in der Schweiz» gelang es, ein breites Spektrum von Inte-ressen zusammenzubringen.
Bei diesem ersten Anlass dieser Art ging es den Organisatoren darum, den Dialog zwischen den Akteuren aus den verschiedenen Sparten der sta-tistischen Tätigkeit zu fördern, sie im Statistikmarkt zu positionieren sowie Gemeinsamkeiten und Trennendes zu klären. So wurden in Plenarsitzungen aktuelle Probleme der Statistik von allgemeiner Tragweite aufgegriffen und in Parallelveranstaltungen spezifische Fragen und Resultate aus Fallstudi-en behandelt.
Als besonders attraktive Neuerung erwies sich der Statistikmarkt: An Marktständen präsentierten Institute, Ämter und private Unternehmen der Statistikbranche ihre Produkte und Dienstleistungen; es war auch ein Markt der Ideen und ein Ort der Begegnung.
Mit diesem Tagungsband, der leider aus technischen Gründen mit gros-ser Verspätung erscheint, wollen wir eine Auswahl von Referaten wiederge-ben, die im Rahmen des reichhaltigen Programms gehalten wurden. In der Reihenfolge sind zunächst die in Plenarsitzungen vorgetragenen Referate zu finden und anschliessend einige Referate spezifischen Inhalts aus einzel-nen Workshops.
In einem einleitenden Vortrag definierte Carlo Malaguerra (Bundesamt für Statistik) die Aufgaben der Statistik. Sie ergeben sich aus dem nicht im-mer spannungsfreien Verhältnis von Politik und Wissenschaft. Auch wenn sich in Demokratien die Politik bürokratischer Institutionen bediene, die
1) S. den Tagungsband «Register – die Zukunft der Statistik?», Hsg. SSS – Sektion amtliche Statistik, Neuchâtel 2000 (publiziert in der Reihe «Statistik der Schweiz» des Bundesamtes für Statistik).

6
zweckrationale Planungs- und Gestaltungsinstrumente entwickeln, folge, so Malaguerra, die Politik doch primär dem Steuerungsmedium Macht, wohin-gegen die Wissenschaft und mit ihr die Statistik der Wahrheit verpflichtet sei. Die heute gebotene Sachlichkeit politischen Handelns bedinge eine Nach-frage wissenschaftlicher Erkenntnisse, wobei dieser Erkenntnisgewinn un-terschiedlich, nicht immer eindeutig, motiviert sei. Die Wissenschaft könne in Anlehnung an Luhmann aufklärend, instrumentell oder strategisch einge-setzt werden oder auch nur zum Zwecke der Legitimation, d.h. der nachträg-lichen Rechtfertigung von Entscheidungen und Handlungen. Gleiches gel-te für die Statistik, die Malaguerra im gesellschaftlichen Wissensraum veror-tet. Die öffentliche Statistik stelle Schlüsselindikatoren als Orientierungshil-fe nicht nur der Politik sondern auch der sie kontrollierenden Öffentlichkeit zur Verfügung, erstelle Analysen basierend auf Daten aus Erhebungen oder Registern und führe diesen Datenpool nicht zuletzt zwecks weiterer Nut-zung durch externe Wissenschaftler/-innen. Damit sei die Statistik einerseits Teil des wissenschaftlich-rationalen Informationssystems und diene anderer-seits auch der Politikberatung. Daraus ergebe sich die besondere, nicht im-mer einfache Aufgabe, die Politiknähe bei der Entwicklung von Konzepten und bei der Diffusion von Ergebnissen zu suchen bei gleichzeitiger Wahrung der Unabhängigkeit.
Hans Bühlmann und Werner Stahel (ETH Zürich) brachten den Begriff der Rationalität in Verbindung mit der Frage nach der Objektivität der Zah-leninterpretation. Sie warfen zunächst den Blick in die weit zurückliegende Vergangenheit, um die Probleme der Datenerhebung und ihre Interpretati-on zu illustrieren. In der Folge zeigten die Autoren wie Dank den Fortschrit-ten der mathematischen Statistik im 20. Jahrhundert das Testen von Hypo-thesen, ausgehend von bestimmten Modellvorstellungen, den Weg für eine mögliche Problemlösung bietet. Trotzdem, so ihre Schlussfolgerung, liesse sich nicht immer eine eindeutige Antwort finden, so dass die Grundsatzfra-ge nach der objektiven Dateninterpretation erhalten bliebe bzw. neu formu-liert werden müsse: «Mit welchem Modell erleiden wir für eine bestimmte Tätigkeit den kleinsten Verlust?». Die Autoren gingen der Frage anhand ei-nes weiteren Beispiels nach und kamen dann zum Schluss, dass «neben dem wissenschaftlichen Ansatz auch immer die vom Problemverständnis gesteu-erte Intuition» eine Rolle spiele.
Das Referat von Stephan Morgenthaler (EPF Lausanne) behandelte neue Entwicklungen in der Statistik, wobei es hier um die theoretische Statistik ging. Mit Genugtuung stellte der Autor eine zunehmende Akzeptanz dieser Sparte der Statistik fest, gleichzeitig aber eine eher wachsende Diskrepanz zwischen Theorie und Praxis angesichts extremer Entwicklungen bei gewis-

7
sen statistischen Verfahren. Am Beispiel der Genetik, die in den letzten Jahr-zehnten durch die Molekularbiologie revolutioniert wurde, sah Morgentha-ler einen neuen und stimulierenden Anwendungsbereich, dahingehend, dass die Statistikerin bzw. der Statistiker dabei mit riesigen Datenmengen kon-frontiert seien, welche unter anderem bei der Behandlung von Krankheiten nutzbar gemacht werden könnten. So illustrierte der Autor in einem Über-blick, welche Rolle der Einsatz von statistischen Modellen im Fall von Krebs-krankheiten spielen könnten. Bezugnehmend auf andere Forschungen, wie etwa dem Berechnen von Integralen, plädierte Morgenthaler für eine ver-mehrte Orientierung der akademischen Statistik an praktischen, datenbezo-genen Problemen.
Walter Krämer (Universität Dortmund) sprach von der Notwendigkeit einer «basic literacy in statistics». In seinen lebhaft vorgetragenen Ausfüh-rungen, geschmückt mit vielen illustrierten Beispielen, zeigte er die Tücken auf, die bei der Interpretation statistischer Daten und Informationen entste-hen. Eine erste Konfusion entstände demzufolge bereits bei der Definition von Begriffen, weitere Fehlerquellen ergeben sich durch den Gebrauch ver-zerrter Stichproben (welche häufig nicht als solche erkannt werden), durch manipulative Fragestellungen und mangelnde Sorgfalt bei der Entwicklung von Skalen, Items oder der Zusammenstellung von Fragebögen. Probleme entständen ferner bei der Aufbereitung der Daten für die interessierte Öf-fentlichkeit, z.B. durch den Gebrauch ungeeigneter Mittelwerte oder feh-lender Gewichtung bzw. durch die Tatsache, dass derartige Kenntnisse nicht vermittelt würden, mit der Gefahr, dass Ergebnisse falsch interpretiert wür-den. Im Hinblick auf die Induktion stellt Krämer fest, dass vielfach die Be-dingung und das bedingte Ereignis verwechselt, Hintergrundvariablen über-sehen und «Nonsenskorrelation» produziert würden. Und schliesslich hät-ten die Daten auf dem Weg «zwischen der Wirklichkeit und dem Zielpubli-kum» weitere Hindernisse zu überwinden, die durch irreführende Grafiken und die Illusion der Präzision entständen. Krämer empfahl daher, den sta-tistischen Produkten (wie etwa den Medikamenten) einen Art «Beipackzet-tel» beizulegen.
Diesem Vorschlag folgte auch Andreas Diekmann (Universität Bern). Er legte einen Kriterienkatalog zwecks Prüfung der Umfragemethodik vor und forderte für jede Umfrage Aussagen zur Art der Stichprobenziehung, zur Auswahl von Haushalten und Zielpersonen (bei Zufallsstichproben und Face-to-Face-Interviews), zum Umfang der Stichprobe, zur Ausschöpfungs-quote, zur Erhebungsmethode, zur Zusammensetzung der Interviewer und Interviewerinnen, zur Feldkontrolle, zum Pretest, zur Reliabilität und Vali-dität der Fragen, zur Gewichtung und zur Datenanalyse. Auch er zeigte an-

8
hand von Beispielen, wie die Grösse eines Samples täuschen, eine Ausschöp-fungsquote schön gerechnet, Interviews gefälscht und eine blosse Nachschich-tung (redressment) als Nachgewichtung, die gemäss Stichprobenplan erfolgen sollte, «verkauft» werden können. Schliesslich berichtete er von einer unkon-ventionellen Methode zur Aufdeckung von Fälschungen. Sie basiere, so sei-ne Erläuterungen, die er mittels eigener Forschungsergebnisse untermauer-te, auf statistischen Regelmässigkeiten von Ziffernhäufigkeiten und der Tat-sache, dass «unter gewissen Bedingungen (...) die Ziffern von echten Daten Gesetzesmässigkeiten (gehorchen), die gefälschte Daten nicht gleichermas-sen erfüllen»; echte Zahlen folgten «Benfords Gesetz», gefälschte Daten wi-chen davon ab. Doch, derartige Prüfverfahren, so seine Warnung, befänden sich derzeit in einem ersten Versuchsstadium; ein «Lackmustest» für Fäl-schungen sei noch nicht entwickelt.
Zum Problemkreis der Visualisierung statistischer Informationen, dem Thema eines Workshops, befasste sich Thomas Gsponer (EPF Lausanne) in einem technisch abgefassten Beitrag mit Zwei-Weg-Diagrammen, die als ge-eignetes Verfahren für die Visualisierung einer Zwei-Weg-Tabelle bekannt ist. Diesem Verfahren zufolge liefert eine additive Tabelle Zwei-Weg-Diagramme, bestehend aus zwei parallelen Geradenscharen. Umgekehrt gilt, dass Zwei-Weg-Diagramme bestehend aus zwei parallelen Geradescharen ein additives Modell liefern. Das Ziel sei es nun, mögliche Interaktionen in der Zwei-Weg-Tabelle anhand von Zwei-Weg-Diagrammen zu modellieren. Hierzu benöti-ge man andere Spuren als parallele Geraden wie zum Beispiel Geradenbü-schel oder Hyperbeln. In seiner Arbeit diskutierte der Autor Zwei-Weg-Di-agramme auf der Grundlage von allgemeinen Spuren und konnte zeigen, dass die Resultate mit denjenigen übereinstimmen, die auf linearen Spuren basieren. Der Autor führte seine Untersuchung weiter und entwickelte da-bei neue Modelle unter Einsatz von gemischten Spuren, was bedeutet, dass man in der Konstruktion der Zwei-Weg-Diagramme zwei verschiedene Spu-ren einsetzt. Nicht zuletzt aber wegen Optimisationsschwierigkeiten, erach-tete er es als notwendig, die Forschungsarbeiten zu vertiefen.
Michael Hermann und Heiri Leuthold dokumentierten ebenfalls eine Methode der Visualisierung (und Interpretation) von grossen Datenmen-gen, die Spatialization, welche neuerdings in den Sozialwissenschaften im-mer häufiger zum Einsatz kommt. Dabei werden die sogenannten «anfallen-den Daten», die nicht eigens für wissenschaftliche oder kommerzielle Zwe-cke erhoben wurden, sondern quasi «als Abfallprodukte der elektronischen Unterstützung und Steuerung der verschiedenen Lebensbereiche anfallen» elektronisch aufbereitet. Im weiteren Verlauf einer solchen Sekundäranalyse suchten die Forscher mittels Ähnlichkeitsmassen nach inneren Zusammen-

9
hängen in den Daten, um diese anschliessend kartographisch darzustellen. Das Potenzial einer solchen Darstellungsform veranschaulichten Hermann/Leuthold eindrücklich mittels eines Fallbeispiels aus eigener Forschung: Sie stellten die Resultate der eidgenössischen Volksabstimmung in einen «Raum der Weltanschauungen».
Im Rahmen eines anderen Workshops zum Thema Statistikmarketing berichteten Rena Snoy und Roland Huber (IHA-GfM) über Verfahren und Ergebnisse ihres Instituts im Bereich der sogenannten «Online Research». Angesichts der grossen Verbreitung von Internet Anschlüssen (Internet-Pe-netration) in der Schweiz, stösst diese Art von Marktforschung auf wachsen-des Interesse. Die Autoren beschrieben die vielfältigen Möglichkeiten die-ses neuen Instruments, das ihrer Ansicht nach sowohl bei der Profilermitt-lung von Web-Site Besuchern, wie für Studien über Mitarbeiter- und Kun-denzufriedenheit oder auch für die Analyse von spezifischen Zielgruppen erfolgreich eingesetzt werden könne. Je nach Bedarf könnten quantitative oder qualitative Daten erhoben werden. Die Autoren sagten eine Weiterent-wicklung dieser Befragungsmethode voraus, betonten aber auch deren Gren-zen: So seien derzeit noch «keine bevölkerungsrepräsentativen Studien für die Schweiz» möglich.
* * *
Allen Referenten und Referentinnen, auch jenen, die ihre Beiträge nicht eigens für ihren Tagungsband aufbereiten konnten und allen Autoren der vor-liegenden Publikation sei an dieser Stelle für ihre Ausführungen gedankt.
Zum Erfolg dieser Statistiktage trug jedoch in nicht unerheblichem Aus-mass der Markt mit seinen Darbietungen und Begegnungen bei. Daher gilt unser Dank auch allen Ausstellern, namentlich:
AICOS Technologies, BAK Konjunkturforschung Basel, Buchhandlung Freihofer, Bundesamt für Statistik, COMSOL AG, Consult AG Bern, Euros-tat Data Shop Zürich, Konferenz der regionalen Statistischen Ämter KORS-TAT, Landert Farago Davatz & Partner, LINK Markt- und Sozialforschung, Luchsinger Services in Applied Mathematics, MIS Trend S.A., Oberzolldi-rektion, Seismo Verlag, Statistikinstitute der Universitäten Basel, Bern, Frei-burg, Genf, Zürich, ETH-Zürich, EPFL-Lausanne, Winterthur, Symplan Map AG, WISO Dr. Schoch & Partner.
Dank gebührt auch der Stadt und dem Kanton St. Gallen, die den Pfalz-keller und Räumlichkeiten im Regierungsgebäude zur Verfügung stellten und ihren statistischen Diensten, die sich für die Organisation vor Ort verant-

10
wortlich zeichneten: Theo Hutter (Fachstelle für Statistik, Kanton St. Gallen) und Eveline Vollmer (Statistisches Büro Stadt St. Gallen) hatten seinerzeit alle technischen und logistischen Probleme exzellent gemeistert. Die Heraus-gabe dieses Bandes (und das Verfassen dieser Zeilen) übernahmen Angelo Fiala und Vera Herrmann (beide Bundesamt für Statistik).
Besonderen Dank gilt unseren Hauptsponsoren, IHA-GfM Institut für Marktanalysen, MSI Dr. Wälti AG und SPSS AG, ohne deren finanzielle Be-teiligung diese Tage der Begegnungen mit der Statistik, ihren Produzenten und Interpreten nicht hätte stattfinden können.
Das Organisationskomitee der «Statistiktage St. Gallen 2000»
Angelo Fiala, Sekretär FEDESTAT und REGIOSTAT, Bundesamt für Statistik
Heinz Gilomen, Präsident der SSS-Sektion Amtliche Statistik, Bundesamt für Statistik
Vera Herrmann, Bundesamt für Statistik
Theo Hutter, Fachstelle für Statistik, Kanton St. Gallen
Gian Antonio Paravicini Bagliani, Präsident KORSTAT, Amt für Statistik des Kantons Luzern
Caterina Savi, Mitglied des Vorstands der Swiss Statistical Society, Wincare Versicherungen
Eveline Vollmer, Statistisches Büro Stadt St. Gallen

11
Introduction
Les «Journées suisses de la statistique» ont eu lieu à Saint-Gall un an après les pre mières «Journées de la statistique publique», qui se sont tenues en automne 19991. Ces journées étaient le prolongement logique des efforts visant à réorganiser la statistique suisse au plan institutionnel et à mettre en oeuvre des stratégies communes.
Pour ces journées saint-galloises, les organisations de statistique publique et privée de Suisse s’étaient accordées sur un thème susceptible de séduire un grand nombre de statisticiennes et de statisticiens. Le thème choisi, «Culture et marché de la statistique en Suisse», a en effet connu un succès remarquable dans les milieux intéressés.
Les organisateurs de la manifestation visaient plusieurs objectifs : promouvoir le dialogue entre les différents secteurs de la statistique, définir leur place sur le marché suisse de la sta tistique, mettre en évidence ce qui les rapproche et ce qui les distingue. Des questions de portée générale ont été abordées en séance plénière alors que différents ateliers ont été consacrés à des problèmes particuliers et à des études de cas.
Un espace a été spécialement aménagé pour permettre aux offices, aux instituts et aux entre prises qui s’occupent de statistique de présenter leurs produits et leurs prestations. Cet espace s’est révélé être un utile lieu de rencontre et d’échange d’idées.
La présente plaquette – dont la parution a été retardée pour des raisons techniques – contient une sélection d’exposés inscrits au programme de ces journées. On trouvera dans les pages qui suivent le texte de conférences données en séance plénière puis quelques contributions relatives à des sujets spécifiques traités en atelier.
Premier à prendre la parole, Carlo Malaguerra (Office fédéral de la statistique) s’est attaché à définir les tâches de la statistique. Situées à l’intersection du politique et du scientifique, ces tâches ne sont pas toujours exemptes de tensions. Même si, en démocratie, la politique s’exerce au moyen d’outils de planification rationnels, élaborés par des administrations spé cialisées, elle reste tributaire avant tout du jeu du pouvoir. En revanche, la science, et avec elle la statistique, n’ont de comptes à rendre qu’à la vérité.
1) 1 Cf. Les registres – l’avenir de la statistique?, publié par l’ASS – Section Statistique publique, Neuchâtel 2000 (dans la série «Statistique de la Suisse» de l’Office fédéral de la statistique).

12
L’action politique est aujourd’hui tenue de s’appuyer sur une connaissance objective du réel, mais la production de cette con naissance obéit à des motivations multiples, pas toujours transparentes. La science, selon Luhmann, peut être utilisée à des fins de connaissance, à des fins instrumentales, à des fins stratégiques, ou encore aux fins de légitimer ou de justifier a posteriori les décisions et les mesures qu’on a prises. Cela vaut également pour la statistique, qui fait partie des sciences qui étudient la société. La statistique publique produit des indicateurs desti nés non seulement à la politique mais à la collectivité qui la contrôle, elle élabore des analyses basées sur des données émanant d’enquêtes ou de registres administratifs, et elle met cet en semble de données à la disposition des scientifiques qui souhaitent les exploiter. La statistique est donc à la fois un système de production d’informations rationnelles et un auxiliaire de l’action politique. Dans les programmes qu’elle élabore, dans les résultats qu’elle diffuse, il lui incombe d’être proche du monde politique tout en préservant sont indépendance.
Hans Bühlmann et Werner Stahel (EPF Zurich) ont abordé le concept de rationa lité en relation avec la question de l’objectivité dans l’interprétation des chiffres. Les conférenciers ont d’abord tourné leurs regards vers le passé pour illustrer les problèmes que posent le relevé des données et leur interprétation. Ils ont ensuite montré comment, grâce aux progrès réalisés en statistique mathématique au cours du 20e siècle, les méthodes consistant à tester des hypothèses à l’aide de modèles pourraient ouvrir la voie à la résolution de ces problèmes. Les ora teurs on néanmoins reconnu qu’il n’est pas toujours possible de trouver une réponse univoque, de sorte que, en matière d’interprétation des données, la question fondamentale de l’objectivité de meure. Elle peut toutefois être reformulée ainsi: «Quel est, pour une activité donnée, le modèle qui engendre la moindre perte?». Les conférenciers ont examiné cette question à la lumière d’un exemple et ont conclu que «l’intuition, guidée par une juste compréhension du problème, jouera toujours, parallèlement à la démarche scientifique, un rôle non négligeable».
La communication de Stephan Morgenthaler (EPF Lausanne) portait sur certains développe ments récents de la statistique théorique. Tout en constatant avec satisfaction que ce secteur de la statistique suscite toujours plus d’intérêt, l’orateur observe qu’un fossé tend à se creuser entre la théorie et la pratique en raison du développement extrêmement pointu de certaines méthodes statistiques. Suivant l’exemple de la génétique, qui a été révolutionnée en quelques décennies par la biologie moléculaire, Morgenthaler observe qu’un champ d’application nou veau et prometteur s’ouvre à la statistique, en ce sens que les statisticiens sont confrontés à d’immenses quantités de données, dont l’exploitation pourrait s’avérer utile pour le traitement de certaines maladies.

13
Le conférencier a donné un aperçu du rôle que les modèles statistiques peuvent jouer dans le cas des maladies cancéreuses. Se référant à d’autres recher ches, notamment dans le domaine du calcul intégral, Morgenthaler a plaidé en faveur d’une plus grande orientation de la statistique universitaire vers des problèmes pratiques basés sur des données réelles.
Walter Krämer (Université de Dortmund) a souligné la nécessité d’une «basic literacy in statistics». Dans un exposé très vivant, illustré par de nombreux exemples, il a montré les pièges que comporte souvent l’interprétation des données et des informations statistiques. Une pre mière source de confusion réside déjà dans la définition des termes utilisés. D’autres erreurs proviennent de l’utilisation d’échantillons biaisés (qui souvent ne sont pas perçus comme tels), de la manière de formuler les problématiques et du manque de soin qu’on apporte par fois à l’élaboration des échelles, des items et des questionnaires. Des problèmes surgissent ensuite lors du traitement des données à l’intention du public intéressé (utilisation de moyen nes inappropriées, absence de pondérations, omission d’informations nécessaires à l’interpré tation correcte des données). Il arrive que les conditions d’un événement soient con fondues avec l’événement lui-même, que des variables contextuelles soient négligées et que des corrélations absurdes soient établies. Enfin, avant de parvenir à leurs destinataires, les données ont encore plusieurs obstacles à franchir, liés par exemple à des graphiques trom peurs ou à une précision illusoire. Walter Krämer recommande d’adjoindre à tout produit statistique une notice explicative (comme on le fait pour les médicaments).
Andreas Diekmann (Université de Berne) s’est rallié à cette recommandation. Il a présenté à l’assemblée une liste de critères pouvant être utilisés pour évaluer la méthodologie des en quêtes statistiques, puis a insisté sur la nécessité d’énoncer toujours clairement le mode de tirage de l’échantillon, le mode de sélection des ménages et des personnes cibles (dans les enquêtes par sondage et les interviews individuelles), la taille de l’échantillon, le taux de réponse, la mé thode d’enquête, la composition de l’équipe d’interview, les contrôles sur le terrain, les pré tests, la fiabilité et la validité des questions, les pondérations et l’analyse des données. Comme l’orateur précédent, Andreas Diekmann a montré à l’aide d’exemples comment la taille d’un échantillon peut être trompeuse, comment on peut «arranger» un taux de réponse ou falsifier des interviews, et comment on peut faire passer un simple redressement d’échantillon pour une véritable post-pondération. Pour terminer, le confé rencier à présenté une méthode non conventionnelle de détection des falsifications. Elle se fonde, selon ses explications, qui sont étayées par les résultats de ses propres recherches, sur la régu larité statistique de la fréquence de certains chiffres et sur le fait que, «sous certaines condi-

14
tions, […] les chiffres issus de données authentiques [obéissent] à des lois auxquelles les chif fres falsifiés n’obéissent pas de la même manière». Les chiffres authentiques obéissent à la «loi de Benford» tandis que les données falsifiées s’en écartent. Mais, a précisé le conféren cier, de telles méthodes de contrôle en sont au stade des tout premiers essais; aucune procé dure infaillible de détection des falsifications n’a encore été développée.
Thomas Gsponer (EPF Lausanne) s’est exprimé sur le thème de la visualisation des informa tions statistiques, qui faisait l’objet de l’un des ateliers de travail. Son exposé, très technique, a porté sur les diagrammes à deux voies, qui constituent un bon procédé de visualisation des tableaux à deux voies. Selon ce procédé, un tableau additif livre des diagrammes à deux voies composés de deux droites parallèles. Inversement, des diagrammes à deux voies composés de deux droites parallèles livrent un modèle additif. Le but consiste à utiliser les diagrammes à deux voies pour modéliser les interac-tions possibles dans le tableau à deux voies. On a besoin pour cela de traces autres que des droites parallèles, par exemple des faisceaux de droites ou des hyperbo les. Le conférencier à examiné des diagrammes à deux voies sur la base de traces générales et a montré que les résultats coïncident avec ceux basés sur des traces linéaires. Poussant plus loin son investigation, le conférencier a développé de nouveaux modèles basés sur des traces mixtes, c’est-à-dire utilisant deux traces différentes pour la construction des diagrammes à deux voies. En raison notamment de problèmes d’optimisation, Gsponer juge nécessaire d’approfondir encore les recherches.
Michael Hermann et Heiri Leuthold ont présenté une méthode de visualisation (et d’interpré tation) de grandes quantités de données qui est de plus en plus utilisée en sciences sociales: la spatialisation. Cette méthode consiste à traiter électronique ment les «données incidentes», c’est-à-dire les données qui ne sont pas relevées directement à des fins scientifiques ou commerciales, mais qui se présentent en quelque sorte «comme des sous-produits de la gestion et du traitement électronique des différents domaines de la vie». Les chercheurs ont tenté de mettre en évidence les relations inhérentes à ces données, pour ensuite les représenter cartographi quement. Herman et Leuthold ont montré le potentiel d’un tel mode de représentation au moyen d’un exemple tiré de leurs propres recherches, con sistant à présenter les résultats des votations fédérales dans un «espace d’opinions» («Raum der Welt anschauungen»).
Dans le cadre d’un atelier consacré au marketing de la statistique, Rena Snoy et Roland Huber (IHA-GfM) ont présenté les méthodes et les résultats de leur institut dans le domaine de la «recherche en ligne».Vu le développement

15
important des connexions internet en Suisse, ce mode d’exploration du marché suscite toujours plus d’intérêt. Les conférenciers ont montré les multiples possibilités de ce nouvel instrument, qui peut être utilisé pour déterminer le profil des visiteurs d’un site internet, pour étudier le degré de satisfaction des clients ou des employés d’une entreprise, ou encore pour analyser des groupes cibles spé cifiques. On peut, selon les besoins, obtenir ainsi des données quantitatives ou quali tatives. Les conférenciers estiment que cette méthode d’enquête est appelée à se dé velopper à l’avenir, mais ils en ont également souligné les limites. Cette méthode ne permet pas, pour l’instant, de procé der à des «études représen tatives sur la population suisse».
* * *
Nous remercions tous les conférenciers qui ont participé aux Journées suisses de la statistique, ainsi que les auteurs de la présente publication.
L’exposition de produits statistiques, organisée en marge des conférences, a contribué pour une part non négligeable au succès des journées saint-galloises. Nos remerciements vont donc également à tous les exposants, à savoir :
AICOS Technologies, BAK Konkunkturforschung Basel, Buchhandlung Freihofer, Bunde samt für Statistik, COMSOL AG, Consult AG Bern, Eurostat Data Shop Zürich, Konferenz der regionalen Statistischen Ämter KORSTAT, Landert Farago Davatz & Partner, LINK Markt- und Sozialforschung, Luchsinger Services in Applied Mathematics, MIS Trend S.A., Oberzolldirektion, Seismo Verlag, Statistikinstitute der Universitäten Basel, Bern, Freiburg, Genf, Zürich, ETH-Zürich, EPFL-Lausanne, Winterthur, Symplan Map AG, WISO Dr. Schoch & Partner.
Nous remercions la Ville et le Canton de Saint-Gall, qui ont mis à notre disposition le « Pfalzkeller » et des locaux dans le palais du gouvernement, ainsi que leurs services statistiques, qui ont assuré l’organisation sur place. Theo Hutter (Service statistique du Canton de Saint-Gall) et Eveline Vollmer (Bureau statistique de la Ville de Saint-Gall) ont maîtrisé à merveille tous les problèmes techniques et logistiques. La présente plaquette a été rédigée et publiée par les soins de Angelo Fiala et de Vera Herrmann (Office fédéral de la statistique).
Enfin, nous remercions tout particulièrement nos principaux sponsors, IHA-GfM Institut für Marktanalysen, MSI Dr. Wälti AG et SPSS AG, sans la participation financière desquels ces journées de rencontre avec les producteurs et interprètes des statistiques n’auraient pas été possibles.

16
Le comité d’organisation des «Journées Statistiques Saint-Gall 2000»
Angelo Fiala, secrétaire FEDESTAT et REGIOSTAT, Office fédéral de la statistique
Heinz Gilomen, président SSS-Section statistique publique, Office fédéral de la statistique
Vera Herrmann, Office fédéral de la statistique
Theo Hutter, Fachstelle für Statistik, Canton de Saint Gall
Gian Antonio Paravicini Bagliani, président CORSTAT, Amt für Statistik, Canton de Lucerne
Caterina Savi, membre du comité Swiss Statistical Society (SSS), Wincare Versicherungen
Eveline Vollmer, Statistisches Büro, ville de Saint Gall

17
Politik und Rationalität
Carlo MalaguerraBundesamt für Statistik, Neuchâtel
«Wie ist Erkenntnis der gesellschaftlichen Zusammenhänge im Hinblick auf politisches Handeln möglich? Wie und wie weit kann in einer politischen Lage wissenschaftlich geklärt werden, was zugleich praktisch notwendig und objektiv möglich ist?»1) Diese Frage von Jürgen Habermas in seinem frühen Werk zur Verbindung von Theorie und Praxis – bzw. zwischen Wissenschaft und Politik – symbolisiert den Ausgangspunkt meiner Ausführungen zur Be-ziehung zwischen Vernunft und Politik und damit zum Verhältnis zwischen Wissenschaft und Politik. Im Rahmen einer Veranstaltung, die sich mit Sta-tistikkultur und Statistikmarkt auseinandersetzt, geht die Diskussion dieses Themas von zwei Grundannahmen aus:
• Statistik ist ein Instrument der wissenschaftlichen Erkenntnis, und Fragen des Verhältnisses zwischen Wissenschaft und Politik sind auf die Be ziehung zwischen Statistik und Politik übertragbar.
• Statistische Arbeit wird klar im Kontext von Politikberatung im weitesten Sinne gesehen. Statistischer Erkenntnis im Interesse gesellschaftlicher Problemlösung wird Priorität eingeräumt vor anderen Funktionen, die Statistik ebenfalls erfüllen kann.
Das 20. Jahrhundert – Sieg der Zweckrationalität
Eine lange Geschichte wäre hier nachzuzeichnen, von Platon und Aris-toteles über Machiavelli, Descartes und Hegel bis zu Quetelet und Franscini, um das spannungsgeladene Verhältnis zwischen Vernunft und Politik und die Stellung von Wissenschaft und Statistik historisch aufzubereiten. Ich verzich-te darauf und beschränke mich auf das 20. Jahrhundert, in dem die Zweckra-tionalität ihren Siegeszug in Staat und Gesellschaft antritt
Max Weber befand, dass sich wissenschaftlich über Werte nicht urteilen lässt, dass aber dieser Verzicht der Wissenschaft Objektivität ermögliche. Er legte damit wichtige Grundlagen für die Ausgestaltung der empirischen So-zialwissenschaften und ihre Funktion in der Politikberatung. Denn auf der
1) Jürgen Habermas, (1971), Theorie und Praxis, Sozialphilosophische Studien. Suhrkamp, Frankfurt am Main. S. 51.

18
anderen Seite war auch der demokratische Verfassungsstaat nach der fran-zösischen Revolution Wirklichkeit geworden. Die Gewaltentrennung hatte sich durchgesetzt: Die Legislative hatte die Ziele und Zwecke festzulegen, die Exekutive die zu ihrer Erreichung geeigneten Mittel einsetzen.2)
Damit sieht Max Weber in der Bürokratie als zweckrational handelnder Institution die privilegierte Form staatlichen Handelns. Dabei kommt dem Fachwissen der Beamten entscheidende Bedeutung für die Überlegenheit bü-rokratischer gegenüber anderen Herrschaftsformen zu. Qualität und prakti-sche Relevanz dieses Fachwissens werden zu einer zentralen Voraussetzung staatlichen zweckrationalen Handelns. Dies um so mehr, je unübersehbarer sich Bürokratie vom blossen Herrschaftsmittel zu einem Planungs- und Ge-staltungsinstrument des modernen Sozialstaates entwickelt. Wissenschaftli-che Politikberatung wird nun zur Beratung der Amtsstellen im Hinblick auf den optimalen Mitteleinsatz, Verwissenschaftlichung der Politik bedeutet nun Verwissenschaftlichung der Verwaltung.
In der zweiten Hälfte des 20. Jahrhunderts wird die Staatstätigkeit zuneh-mend ausgebaut und auf neue Gebiete erweitert. Infrastrukturelle, sozialpoli-tische ökonomische und ökologische Aufgaben ergänzen das klassische Spek-trum. Gleichzeitig erhöht sich auch die Komplexität der Problemstellungen; dies unter anderem auch, weil der Staat nicht mehr nur rechtliche, gesetzge-berische Mittel sondern auch Geld – Subventionen – sowie kommunikative Massnahmen als regulatorische Instrumente einzusetzen beginnt.
Damit erhält auch die Nachfrage nach wissenschaftlicher Unter-stützung einen neuen Schub. Einerseits werden die Verwaltungsstellen selbstver wissenschaftlicht, wissenschaftliche Stäbe ausgebaut und wissen-schaftliche Argumentationsweisen verstärkt. Andererseits wird auch die Auf tragsforschung ausgebaut: orientierte Ressortforschung blüht auf, Exper-ten kommissionen werden eingesetzt und Gutachten als Steuerungs- und Ent-wicklungsinstrumente in Auftrag gegeben.
Im Rahmen dieser Versachlichung der Staatsaufgaben erhält auch die amtliche Statistik zunehmende Bedeutung. Vermehrt werden grundlegende Kennziffern zur Orientierung und zum Monitoring der Staatstätigkeit ver-langt. Zwar benötigen die visionären Ideen Stefano Francinis mehr als ein Jahrhundert bis das Konzept einer gesamtheitlichen, kohärenten Statistik auch in den gesetzlichen Bestimmungen verankert wird, doch erlebt die amt-liche Statistik vor allem in der zweiten Hälfte des 20. Jahrhunderts einen ge-
2) Ebd. S.7.

19
waltigen sektoriellen Ausbau: Die Volkszählung gewinnt zunehmend an Be-deutung als unverzichtbare Ausgangsbasis für die Bereitstellung weiterge-hender Information; in praktisch allen Verantwortungsbereichen des Staa-tes werden statistische Angaben erarbeitet, Indikatorensysteme entwickelt und Syntheseinformation entworfen; vor allem im wirtschaftlichen Bereich findet ein beeindruckender Ausbau statt, und mit der Volkswirtschaftlichen Gesamtrechnung (die in der Schweiz lange Zeit als Nationale Buchhaltung geführt wurde) entsteht eine Systematik, die zur synthetischen Verarbeitung unterschiedlicher Statistikdaten und damit als Leitlinie für die wirtschaftssta-tistische Tätigkeit dient. Amtliche Statistik wird damit zu einer unverzichtba-ren Orientierungshilfe in der öffentlichen Diskussion und in der politischen Entscheidfindung.
Komplexes Verhältnis zwischen Wissenschaft und Politik
Allerdings ist das Verhältnis zwischen Statistik bzw. Wissenschaft und Politik kein einfaches. Erfolgreiche Politikberatung durch das der Vernunft verpflichtete Wissenschaftssystem würde ja voraussetzen, dass das Politik-system durch die selben Prinzipien der Rationalität gesteuert wird. Dem ist jedoch nicht unbedingt so. So stellt etwa Luhmann fest3), dass das gesell-schaftliche Subsystem Politik primär dem Steuerungsmedium Macht ge-horcht, währenddem Wissenschaft durch Wahrheit charakterisiert ist. Eine reine eins-zu-eins-Beziehung zwischen den gesellschaftlichen Subsystemen ist deshalb kaum möglich.
Anders gesagt: Wissenschaft ist nur eine von mehreren Wissensarten, wel-che der Politik in ihrer Funktion der Regulierung von Macht zur Ver fügung stehen. Andererseits haben wissenschaftliche Erkenntnisse in der politischen Arbeit auch mehrfache Funktionen, die von etwa wie folgt beschrieben wer-den können:4)
• In der Aufklärungsfunktion analysiert die Wissenschaft als unabhängi-ge Instanz Fragen und Probleme, die sich der politischen Gemeinschaft stellen. Sie reflektiert, stellt Fragen neu, schafft Begriffssysteme, bringt die Dinge zur Sprache und macht komplexe Zusammenhänge verständ-lich. Sie übt damit unter anderem eine Monitorings- und Früherkennungs-funktion aus.
3) Niklas Luhmann (1974), Soziologische Aufklärung, Aufsätze zur Theorie sozialer Systeme. Bd.1. Westdeutscher Verlag, Opladen
4) Op. Cit. S. 17 ff. .

20
• Die instrumentelle Funktion kommt dann zum Tragen, wenn die grund-legenden Probleme erkannt und die Ziele klar gesetzt sind. Im wesentli-chen geht es um den optimalen Einsatz von Mitteln. Es handelt sich so-mit um technisches Wissen, das von der Wissenschaft produziert wird und etwa in Form von Problemanalysen, Prognosen, Evaluationen, etc. an die Politik weitergegeben wird.
• In der Funktion der Legitimationsbeschaffung werden wissenschaftliche Güter zur (vielfach nachträglichen) Rechtfertigung von Entscheiden und Handlungen benutzt. Hier geht es nicht mehr um den Einbezug von Fak-ten und Erkenntnissen in den Entscheidprozess, sondern um die Legiti-mierung bzw. um die Vermittlung bereits entschiedener Strategien und Massnahmen.
• Nahe verwandt damit ist die strategische Funktion der Wissenschaft. Die-se wird dabei in der politischen Auseinandersetzung als Koalitionspart-ner gesucht, mit dessen Hilfe die eigene Argumentation verstärkt und diejenige des Gegners als unglaubwürdig dargestellt wird.
Die Übergänge zwischen den verschiedenen Funktionen sind vielfach fliessend. Was als aufklärerische Funktion beginnt und instrumentell einge-setzt wird, kann rasch strategische Aufgaben übernehmen oder gar auch zu rein legitimatorischen Zwecken benutzt werden.
Der Informationsprozess von der Wissenschaft zur Politik
Vielfach gehen die Vorstellungen von den Beziehungen zwischen Wis-senschaft, bzw. Statistik und Politik von einem simplifizierenden Modell des Informations- und Entscheidprozesses aus. Dabei wird die Beratung über-mässig auf einen einzigen Entscheidträger, eine eindeutig lokalisierbare In-stanz ausgerichtet, die den Ausgang des Entscheidprozesses bestimmt. Dies beruht auf der Vorstellung eines einzelnen privilegierten «Policy Makers», der Information erhält und dann die Entscheide trifft.
Eine solche im Grunde genommen demokratiefeindliche Vorstellung ent-spricht nicht der Realität. Am Prozess der Entscheidfindung sind real vielfäl-tige Handlungsträger beteiligt, die untereinander in einem Beziehungsnetz stehen. Diese Akteure holen sich ihre Information nach Bedarf, wählen sie nach eigenem Bedarf aus und tauschen sie in der öffentlichen Debatte aus. Daraus kann dann Handeln resultieren. Besonders in der direktdemokrati-schen Auseinandersetzung ist schliesslich der Stimmbürger der letztendli-che Entscheidträger.

21
Aus dieser Konstellation ergibt sich ein komplexeres, der breiten Öffent-lichkeit verpflichtetes Informationskonzept der Wissenschaft. Im Bewusstsein, dass wissenschaftliche Erkenntnisse bei je einzelnen Akteuren nur selektiv aufgenommen, verarbeitet und verbreitet werden, vielfach auch in legitimato-rischer und strategischer Funktion Verwendung finden, ist vom Königs modell des privilegierten Entscheidträgers Abschied zu nehmen. Wissenschaftliche Information muss via verschiedene Kanäle und in oft interaktiven Prozes-sen einer Vielfalt von Akteuren, in Einzelfällen der gesamten Öffentlichkeit zugänglich gemacht werden.
Angesichts der Komplexität der Entscheidstrukturen und -prozesse in kollektiven Angelegenheiten ist die Verfügbarkeit von grundlegenden Re-ferenzwerten, an denen sich eine öffentliche Debatte orientieren kann, von besonderer Bedeutung. Solche Referenzwerte haben die Funktion, als An-haltspunkte bei umstrittenen Sachverhalten zu dienen, und als gemeinsam anerkannte Eckpunkte das Diskussionsfeld abzustecken. Das Indikatoren-konzept der amtlichen Statistik, das bereichsweise im Kontext eines Monito-ring-Ansatzes realisiert wird, geht in eine solche Richtung. Voraussetzung ist dabei natürlich die unbestrittene Glaubwürdigkeit der produzierenden Insti-tution sowie die Spitzenqualität der erarbeiteten Analysen.
Die Stellung der Amtlichen Statistik im gesellschaftlichen Wissensraum
Bisher habe ich grösstenteils von Wissenschaft oder von Wissenschaft und Statistik gesprochen und die beiden Gebiete gleichgesetzt. Im folgenden wer-de ich nun die Amtliche Statistik etwas präziser im gesellschaftlichen Wissens-raum verorten und versuchen, die Analogien und Differenzen zum Wissen-schaftsbereich genauer zu fassen. Wenn ich auch nicht in allen Teilen mit ihm übereinstimme, so lasse ich mich dabei doch von Helmut Spinner und seinen Arbeiten zur Informationsgesellschaft und zu der spezifischen Position der Amtlichen Statistik in diesem Gesellschaftsbereich inspirieren5).
Wir gehen zunächst davon aus, dass in einer Gesellschaft verschiedene Wissensarten und Wissensproduzenten existieren. Uns interessiert vor al-lem die Produktion jenes Wissens, das als Problemlösungswissen zu Handen der Bevölkerung erarbeitet wird. «Die Wissensgesellschaft muss eine immer besser informierte Gesellschaft» sein, fordert Spinner, und zu fragen ist nach dem Beitrag, den amtliche Statistik dabei leisten kann.
5) Helmut F. Spinner (2000), Datenwissen für alle? Der Beitrag der Amtlichen Statistik zur informierten Gesellschaft.

22
Grundsätzlich ist amtliche Statistik eine Wissenseinrichtung neben anderen, wie zum Beispiel die Wissenschaft, die Medien, Literatur, die Ver-waltung und die vielen Informationsdienste der modernen Gesellschaft. Das-selbe gilt bezüglich der damit verbundenen Wissensarten, also für wissen-schaftliches Wissen, das journalistische Wissen, die Verwaltungsinformation, etc. Um Wissenseinrichtungen und Wissensarten zu charakterisieren, kann eine Reihe von Kriterien angewandt werden, wie etwa
• Wissenschaftliche versus nichtwissenschaftliche Wissensbereiche
• Öffentliche versus private Einrichtungen der Wissensproduktion,
• Zweckfreie versus zweckgebundene Wissenstätigkeiten, wobei etwa in die letztere Kategorie die Propaganda – und Werbeaktivitäten fallen
• Hohe versus niedrige Qualität der Wissenssubstanz
• Hoher versus niedriger Grad der Technologiegebundenheit
• etc.
Unter diesen Aspekten ist dann Amtliche Statistik als Produktion von wissenschaftlicher / öffentlicher / zweckfreier / hoch technologiegebundener Information / von hoher Qualität zu charakterisieren.
Auf diesem Hintergrund kann jetzt in einem weiteren konkretisieren-den Schritt amtliche Statistik – wiederum gemäss Helmut Spinner – im ge-sellschaftlichen Wissensraum anhand von drei Perspektiven ordnungstheo-retisch, wissenstheoretisch und organisatorisch verankert werden:
Aus der ordnungstheoretischen Perspektive ist die Amtliche Statistik bei der Wissenschaft anzugliedern. Beide brauchen zur Erfüllung ihres Auftrages eine in vielem vergleichbare, in manchen Punkten sogar übereinstimmende Wissensordnung. Amtliche Statistik wie Wissenschaft orientieren sich an den Prinzipien der Unabhängigkeit, der parteipolitischen Neutralität, der Inter-essen- und Zweckfreiheit und stehen für den freien Zugang und die intersub-jektive Überprüfung der Resultate ein. Ordnungspolitische Unterschiede sind höchstens in bezug auf die Distanz zum Staat und zur staatlichen Verwaltung auszumachen: Wenn auch Amtliche Statistik wie Wissenschaft in der Regel dem öffentlich-rechtlichen Bereich zuzuordnen sind, ist doch die Statistik normalerweise staatsnäher als die (universitäre) Wissenschaft.
Aus der wissenstheoretischen Perspektive wird Statistik auch etwa als kognitiver Zwitter bezeichnet, da sie zwar mit hochwissenschaftlichen Me-

23
thoden arbeite, sich in ihrer Finalität jedoch eher beschreibend und wenig theoriegeleitet ausrichte; bei amtlicher Statistik handle es sich nicht um no-mologisches Theoriewissen – das Wissenschaft auszeichnet –, sondern um Datenwissen über empirische Einzelheiten, die als Gegebenheit des beste-henden Gesellschaftszustandes lediglich erhoben und aggregiert, nicht aber zu Theorien hochgeneralisiert werden.
Ohne hier eine wissenschaftstheoretische Diskussion vom Zaun reissen zu wollen, denke ich doch, dass diese Charakterisierung nicht richtig ist. Sie reduziert Wissenschaft allzu sehr auf Kausalanalyse und wissenschaftliche Erkenntnis auf kausale Erklärung. Zudem verkennt sie, dass auch Statistik in ihren jeweiligen Gegenstandsbereichen theoriegeleitet ist – auch wenn sie dies nicht immer transparent macht – und wenigstens implizit mit erklärenden Hypothesen arbeitet. Amtliche Statistik und Wissenschaft mögen sich zwar in diesen spezifischen Elementen vor allem in ihrem Auftritt unterscheiden, in der Art, wie sie diese Elemente vermitteln. Dies begründet jedoch keinen Unterschied prinzipieller Art, der in der wissenstheoretischen Beschaffen-heit von Statistik bzw. Wissenschaft liegen würde.
Auch in weiteren wissenstheoretischen Aspekten finden wir vor allem Über-einstimmung. Dies trifft in besonderem Masse auf Gütekriterien zu, die sowohl Wissenschaft als auch Statistik in für die erarbeiteten Ergebnisse Anspruch neh-men: Allen voran Richtigkeit, Objektivität, Neutralität, Unabhängigkeit und all-gemeine Übertragbarkeit. Ich vertrete deshalb ganz klar die Meinung, dass amtli-che Statistik wissenstheoretisch nicht eine ergänzende, vorlaufende, zutragende, aber doch von Wissenschaft unterscheidbare Hilfsfunktion innehat, sondern, dass sie vielmehr einen zwar speziellen Fall darstellt, aber doch als integrierter Teil der Wissenschaft – genauer der Gesellschaftswissenschaft – zu betrachten ist.
Damit steht auch aus organisationstheoretischer Sicht nicht eigentlich eine Arbeitsteilung zwischen Wissenschaft und Statistik zur Diskussion, sondern es geht vielmehr um unterschiedliche Akzentsetzungen und koor-dinierte Abstimmung innerhalb der Gesellschaftswissenschaften. Dabei hat Statistik in einer wissensbasierten Gesellschaft prioritär folgende Aufgaben zu übernehmen:
• Bereitstellung von Schlüsselindikatoren als Orientierungshilfen. Sie die-nen in der öffentlichen Debatte als das, was in der Wissenspsychologie als Anker bezeichnet wird6). Es sind Referenzgrössen, die weitgehend an-erkannt sind und in der Auseinandersetzung von den Kontrahenten in
6) Ebd. S.22

24
der Regel nicht bestritten werden. Bei der Erarbeitung dieser Schlüssel-grössen orientiert sich die Statistik sinnvollerweise an der Strategie der gezielten Dauerbeobachtung, die sich im systematischen Monitoring ge-sellschaftlicher Kernbereiche ausdrückt.
• Analytische Berichte auf der Makroebene. Die Makroebene – oder syste-mische Ebene – ist der privilegierte Objektbereich der amtlichen Statis-tik. Ihre spezifische Arbeitsweise mit repräsentativen Datensätzen, aus denen sie ihre Information produziert, ist besonders für Analysen geeig-net, die sich auf die Funktions- und Wirkungsweisen von Systemen bezie-hen. Indikatoren des Monitorings und analytische Berichte gehören zur Wissens-Grundversorgung einer an Vernunft orientierten Gesellschaft.
• Organisation und Koordination repräsentativer Erhebungen. Repräsen-tative Erhebungen bei der Bevölkerung, bei Betrieben oder öffentlichen Institutionen sind komplex, aufwendig und teuer. Ähnliches gilt für die Nutzbarmachung von Registern. Die amtliche Statistik hat die Aufgabe, die Datenbedürfnisse zu koordinieren und solche Erhebungen mit ho-her Professionalität durchzuführen, bzw. zu organisieren. Es ist selbstver-ständlich, dass die potentiellen Datenbezüger, insbesondere andere Be-reiche empirisch arbeitender Wissenschaften, bei der Ausgestaltung des Erhebungsprogrammes ein Mitbestimmungsrecht haben müssen.
• Führung des Datenpools. Es ist eine logische Folge der Erhebungsverant-wortung, dass die Amtliche Statistik vorhandene Datensätze in systema-tisch geordneter Weise einem weiteren Adressatenkreis zur Verfügung stellt. Der Datenpool Schweiz soll diese Aufgabe erfüllen, indem er In-dikatoren, Disaggregationen und einzelne Datensätze einem weiten Be-nutzerkreis auf elektronischem Wege zur Verfügung stellt. Wichtiges Ele-ment ist dabei die begleitende Dokumentation, die sogenannten Meta-daten, die erst eine sinnvolle Weiterbenutzung der Daten ermöglichen.
• Verwaltung von allgemein anerkannten Nomenklaturen und Kategorien-systemen. Vernetzte Informationsproduktion beruht auf der Grundbedin-gung harmonisierter Begriffs- und Nomenklatursysteme. Im Bereich der empirischer Indikatoren und Datensätze, die sich auf makrostrukturelle Gegebenheiten beziehen, ist es sinnvoll, der Amtlichen Statistik die Fe-derführung und Verwaltung solcher Systeme zu übertragen.

25
Schlussfolgerungen und Synthese
Lassen Sie mich abschliessend ein paar wenige zusammenfassende Schluss-folgerungen zur Rolle der Amtlichen Statistik im Kontext einer vernunftso-rientierten Gesellschaft und Politik entwickeln.
• Statistik ist Teil der Politikberatung. Auch wenn das Leitprinzip der Poli-tik die Verwaltung von Macht ist, stellen Vernunft und Rationalität wich-tige Komponenten der politischen Tätigkeit dar. Wissenschaftlich erarbei-tete empirische Information im Sinne von Problemlösungswissen nimmt deshalb einen bedeutenden Stellenwert in der politischen Auseinander-setzung ein. Die Statistik entwickelt ihre Indikatoren und Analysen pro-blemorientiert, zeichnet im Sinne eines Monitorings Entwicklungen in zentralen gesellschaftlichen Bereichen nach und macht auf Fehlentwick-lungen aufmerksam. Mit dieser Strategie stellt sie den Akteuren im poli-tischen Feld Referenzwerte und Argumentationsgrundlagen zur Verfü-gung. Statistik ist deshalb ein zentraler Teil der vernunfts- und wissens-basierten Politikberatung.
• Statistik ist ein Beitrag zur demokratischen Auseinandersetzung. In der Auseinandersetzung um kollektive Angelegenheiten spielen viele Ak-teure mit. Schliesslich ist es die allgemeine Öffentlichkeit, der Stimm-bürger, die ein gewichtiges Wort mitzureden hat. Durch das Öffentlich-keitsprinzip der Statistik werden wichtige Wissensgrundlagen der politi-schen Diskussion in der demokratischen Auseinandersetzung verfügbar gemacht. Politikberatung aus statistischer Sicht heisst deshalb nicht nur Beratung von Regierung und Verwaltung, sondern vor allem Bereitstel-lung von Information zuhanden einer breiten Öffentlichkeit.
• Statistik ist Teil des wissenschaftlich-rationalen Informationssystems. Sta-tistische Informationen werden nach wissenschaftlichen Grundsätzen er-arbeitet. Ihre Aussagensysteme gründen in den theoretischen Fundierun-gen der Themenbereiche und ihre Arbeitsweise folgt den Standards der empirischen Sozialforschung und der mathematischen Statistik. Im gesell-schaftlichen Wissensraum ist deshalb Statistik sowohl aus ordnungsthe-oretischer als auch aus wissenstheoretischer und organisatorischer Pers-pektive Teil des wissenschaftlich-rationalen Informationssystems.
• Statistik ist deshalb auch institutionell in das Wissenschaftssystem zu inte-grieren. Da die Arbeitsweise grundsätzlich eine empirisch wissenschaft-liche ist, und Statistik gleichzeitig auf ihre Unabhängigkeit von der Po-litik besteht, ist es sinnvoll, Statistik auch institutionell in den Wissen-schaftsbereich zu integrieren. Damit treffen wir uns mit den Empfeh-

26
lungen in der Peer Review, die Amtliche Statistik unabhängiger von der Politik zu formieren und sie im sogenannten dritten Kreis anzusiedeln. Das schließt auch mit ein, ein gesamtschweizerisches Leading-House mit einer beschränkten Anzahl regionaler Zentren zu verbinden und mit ih-nen das wissenschaftliche System Statistik Schweiz zu bilden.
• Statistik muss aus dieser wissenschaftlichen Position heraus die Politiknä-he in Konzeption und Diffusion suchen. Natürlich muss Statistik politik-verbunden bleiben, bzw. diese Verbundenheit noch verstärken. Aller-dings betrifft das vor allem die thematische Perspektive und nicht die in-stitutionelle Einbettung. Im Gegenteil: Die Statistik soll diese Politiknä-he aus der Position der distanzierten Unabhängigkeit suchen. Dabei hat sie ihre Fähigkeit zu politiknahen Aussagen zu verstärken durch:
• Förderung der Analysekapazität. Wir stellen heute ein Defizit der Ana-lysekapazität in der Amtlichen Statistik fest, das uns bedenklich stimmt. Der Auf- und Ausbau dieser Fähigkeiten stellt deshalb in den nächsten Jahren eine prioritäre Herausforderung dar.
• Weiterausbau des Indikatorenkonzeptes. Die Bereitstellung von Schlüsse-lindikatoren zum Monitoring von Kernbereichen unserer Gesellschaft er-achten wir als zentrale Grundaufgabe der Amtlichen Statistik. Die Richt-linienmotion der Spezialkommission «Legislaturplanung 1999-2003» des Nationalrates, welche die Erarbeitung eines Indikatorensystems als Füh-rungsinstrument der Legislatur-planung fordert, bestätigt uns in dieser Strategie.
• Realisieren von Observatorien in wichtigen Statistikbereichen. In Obser-vatorien sollen politiknahe Information durch Synergie von statistischer, wissenschaftlicher und dokumentarischer Information erarbeitet werden. Institutionell bedingen sie eine enge Kooperation zwischen Amtlicher Statistik und Wissenschaft, bzw. Dokumentation. Wir planen solche Ob-servatorien in den nächsten Jahren vor allem in den Bereichen Gesund-heit, Verkehr, Umwelt und Bildung.
• Statistik muss bei der Diffusionstechnologie an der Spitze mithalten. Wenn Statistik ihren Auftrag der Informationsvemittlung in einem demokrati-schen Prozess erfüllen will, muss sie grösste Sorgfalt in der Diffusion ihrer Resultate walten lassen. Inhaltlich natürlich – aber auch technologisch. Sie kann dies nur tun, wenn sie professionell auf dem Markt der Informatio-nen mithalten kann. Ich bin überzeugt, das wir dafür die elektronischen Mittel wesentlich ausbauen müssen. Investitionen in diesem Bereich stel-len deshalb in den nächsten Jahren eine vordringliche Aufgabe dar.

27
Schlussbemerkung
«A democratic State can only flourish if the level of intelligence of the community is high and its spiritual life dynamic»7).
Vernunft und Politik, das ist ein spannungsgeladenes Verhältnis. Es ist in der Realität aber nicht denkbar ohne empirische Wissenschaft, die der Wahrheit und der Unabhängigkeit verpflichtet ist, und es ist damit auch nicht denkbar, ohne qualitativ hochstehende statistische Information. Intelligenz in einer demokratischen Gemeinschaft, von der Benjamin Rowntree spricht, heisst in einer Wissensgesellschaft vor allem auch Verfügbarkeit von (vorläu-fig) gesichertem Wissen. Es ist die Aufgabe der Statistik, hier einen zentra-len Beitrag zu leisten.
7) Benjamin Seebohm Rowntree (1941), Poverty and Progress: A Second Survey of York. London.

28

29
Statistik und ihre Interpretation
Hans Bühlmann und Werner StahelEidg. Technische Hochschule, Zürich
In den 60-er Jahren sind in der Schweiz die ersten Lehrstühle für mathe-matische Statistik errichtet worden. Statistikprofessuren bestanden früher lediglich in den volkswirtschaftlichen Fakultäten. Was war der Grund da-für, dass die angewandte Mathematik die Statistik in ihren Fächerkanon auf-nahm? Weshalb hat heute die Statistik in praktisch allen mathematischen Fa-kultäten einen wichtigen Platz?
Die Antwort hat mit der Doppelfunktion der Statistik zu tun:
• dem Sammeln von Daten einerseits
• dem Interpretieren von Daten andrerseits
Das Sammeln von Daten, die für den Staat wichtig sind, geht in der west-lichen Kultur bis auf die Römer zurück. In der römischen Republik wurden die Mitglieder und der Besitz jeder Familie alle fünf Jahre vom Staat regis-triert. Kaiser Augustus führte bekanntlich Volkszählungen im ganzen römi-schen Reich durch, ein Unterfangen, das bis zum Ende des römischen Reichs periodisch wiederholt wurde. Nachher hat aber kein Nachfolgestaat die Usanz übernommen. Der Statista im italienischen Sprachgebrauch des Mittelalters war zwar jemand, der sich mit Fakten beschäftigte, die für das Staatswesen (stato) wichtig waren. Die Fakten konnten aber sehr allgemeiner Natur sein. Auch rein verbale Beschreibungen von Bevölkerung, Wirtschaft und Geo-graphie gehörten dazu. – Erst im 17. Jahrhundert begann man in den italieni-schen Stadt-Staaten Venedig und Florenz mit der systematischen Erhebung numerischer Daten ihrer Bevölkerung. Diese Tätigkeit zusammen mit dem italienischen Namen Statistica (Statistik) verbreitete sich rasch nach Frank-reich, Holland, Deutschland und Grossbritannien.
Interessanterweise hatte anfänglich die Tätigkeit der Interpretation der gesammelten Daten einen anderen Namen. Sie wurde, insbesondere von den Engländern, Political Arithmetic genannt. Gemäss Karl Pearson war John Sin-clair um das Jahr 1800 herum der erste, welcher das Fach Statistik umfassend verstand, d.h. bei ihm wurde die politische Arithmetik zum interpretierenden Teil der Statistik. Diese Gliederung hat sich heute durchgesetzt.
Die Statistik besitzt also wie Janus zwei Gesichter; mit dem einen schaut sie auf die gesammelten Daten. Wie schwierig und komplex es ist, in der Re-

30
alität Zahlen zu sammeln, das wissen Sie, meine Damen und Herren, besser als ich. Diese Zahlen, erhoben mit der nötigen Präzision und Sorgfalt sind die conditio sine qua non; ohne sie gibt es die Statistik nicht. Das andere Ge-sicht der Statistik hingegen schaut auf mögliche Erklärungen dieser Zahlen. Das ist die Sicht, welche dem Sammeln von Daten einen Sinn gibt.
Als der historisch belegte früheste Statistiker im Sinne dieser Doppel-funktion gilt der Engländer John Graunt, der Nachwelt überliefert durch sei-ne Publikation «Observations made on the Bills of Mortality» (1662). Bei den «Weekly Bills of Mortality» handelt es sich um Publikationen der Londoner Pfarrbezirke, welche sich grosser Beliebtheit erfreuten. Grund war die Angst vor der Pest, welche seit dem 14. Jahrhundert für beinahe 400 Jahre immer wieder die Stadt London befiel.
Schauen wir uns einmal eine der vielen Observations als Beispiel an. Die Tabelle zusammengefasst stammt aus einer Arbeit von Hald: «A His-tory of Probability and Statistics», 1990, auf der auch die folgenden Bemer-kungen beruhen.
Nun stellte er sich die folgenden Fragen
1. In welchem Jahr war die Peststerblichkeit am grössten?
2. In welchem Jahr war die Gesamtsterblichkeit am grössten?
3. Wie sind die Antworten auf 1) und 2) miteinander vereinbar?
Zu 1. Klarerweise das Jahr 1603
Zu 2. Unter der Annahme, dass die Gesamtpopulation der Stadt London proportional zur Zahl der Taufen sei, die Jahre 1603 und 1625
Zu 3. Graunt argumentiert, dass die Zahl der Nichtpesttoten im Jahre 1625 um die 7000 sein sollte. Er schliesst dies durch Interpolation der Er gebnisse des vorgängigen und nachherigen Jahres, die hier nicht
Tabelle 1
Teil des Jahres mit Pest ganzes JahrJahr Bestattungen Pesttote % Bestattungen Taufen %
1592 25’886 11’503 44 26’490 4’277 16
1593 17’844 10’662 60 17’844 4’021 23
1603 37’294 30’561 82 38’244 4’784 13
1625 51’758 35’417 68 54’265 6’983 13
1636 23’359 10’400 45 23’359 9’522 41

31
gezeigt werden. Effektiv ausgewiesen sind aber 54’265 - 35’417 = knapp 19‘000. Zieht man von diesen 7000 ab, so bleiben ca. 12’000 Tote, die nach seiner Interpretation falsch klassifiziert sind.
Graunt benützt das Argument aber nicht, um Aussage 1) zu korrigieren. Das erscheint wenig konsequent, aber verständlich, wenn er in einem ande-ren Zusammenhang formuliert:
«Die Durchführung der Analyse durch den Leser selbst, wird diesem mehr Spass und Befriedigung schenken, als die Analyse von jemand ande-rem zu übernehmen.»
Er versucht also wohl gar nicht, eine konsequente, «objektive» Interpre-tation zu geben.
Sie sehen, die Interpretation à la Graunt ist eine hohe Kunst. Sie ist der Ausdruck seiner persönlichen Einschätzung des Datenmaterials verbunden mit einem guten Verständnis der in den gestellten Fragen ausgesprochenen Problematik. Diese Art statistischer Interpretation ist auch heute noch ge-fragt und hat weiterhin ihre Bedeutung. Sie stösst aber an Grenzen, lässt z.B. in der politischen Diskussion oft soviel Spielraum, dass fast jede Interpreta-tion möglich ist (Denken Sie z.B. an die Zahlenkriege rund um die Sozial-versicherung). Sie ist für rein wissenschaftliche Erkenntnisse nicht genügend objektiv (Denken Sie z.B. an die Teilchenphysik: Beweisen die Informatio-nen aus dem Experiment, dass wirklich ein neues Teilchen gefunden worden ist oder haben wir nur Rauschen beobachtet?)
Die Frage liegt auf der Hand: Lässt sich der schliessende, der interpretie-rende Teil der Statistik objektivieren? Dieser Herausforderung haben sich die Pioniere der anfangs des 20. Jahrhundert entstandenen mathematischen Statis-tik gestellt. Viele von Ihnen kennen wohl die grossen Namen: Pearson, Fisher, Neyman um nur drei davon zu nennen. Diese Pioniere hatten dabei vor allem Fragestellungen aus dem Bereich der Naturwissenschaften vor Augen. Inter-essant ist in diesem Zusammenhang vor allem die Rolle der wissenschaftlich betriebenen Agronomie, die Sir Ronald Fisher in England zu grundlegenden Arbeiten über statistische Modelle und Methoden motiviert hat.
Lassen Sie mich auf ein Gebiet näher eingehen, welches aus dieser Her-ausforderung entstanden ist: Die Theorie des Testens von Hypothesen. Sie ist auch heute noch eines der bedeutungsvollsten Instrumente der Statistik.
Entscheidend für die Theorie ist ihr Bezug zu einem Modell, in diesem Fall der Modellvorstellung.

32
Da der wahre Wert nicht beobachtet werden kann, wird eine Theorie, welche den «wahren» Wert festlegt, so lange aufrechterhalten, als die ent-sprechende Störung nicht extrem unwahrscheinlich ist. Dieser Gedanken-gang ist mathematisch objektiv fassbar unter Angabe einer exakten Schran-ke für die zulässige Fehlerwahrscheinlichkeit.
Nehmen wir also an, ein bestimmter wahrer Wert, eine bestimmte Theo-rie also, sei in diesem Sinn mit den beobachteten Daten verträglich. Der glei-che Sachverhalt kann auch zutreffen für die Gegentheorie (Alternative). Der Wissenschafter wird dann deklarieren müssen, dass er auf Grund seiner Zah-len zu keinem Schluss kommen kann.
In der akademischen Welt ist diese Verhaltensweise absolut korrekt und es führt kein Weg um sie herum. Politisch und gesellschaftlich stossen wir Wis-senschafter aber gelegentlich auch auf Unverständnis, wenn wir auf Grund der Zahlen deklarieren müssen, wir könnten nicht sagen, ob eine Klimaverände-rung stattgefunden habe oder nicht, ob es das Waldsterben gebe oder nicht. Leider, weil eben die Öffentlichkeit meistens zu diesen Fragen eine Antwort will, gelangen gerade in solchen Situationen die mehr subjektiven Interpre-tationsweisen eher in die Schlagzeilen der Medien.
Interessanterweise ist in der mathematischen Statistik in den letzten Jah-ren ein anderer Denkansatz aufgetaucht, der in bestimmten Situationen als Alternative zum Testen von Hypothesen verwendet werden kann. Formali-siert haben den Gedankengang z.B. der Japaner Akaike und der Amerika-ner Mallows. Das Vorgehen ist unter dem Stichwort Modellwahl bekannt ge-worden und geht vom Postulat aus, dass man ein Modell wählen müsse. Die-se Situation entspricht oft eher der Realität in der Wirtschaft und Politik, wo in bestimmten Situationen die Option «wir treffen keine Entscheidungen» nicht zulässig ist. Die Fragestellung wird dann allerdings eine andere, nicht mehr: «Welches ist das wahre Modell?» sondern «Mit welchem Modell erlei-den wir für eine bestimmte Tätigkeit den kleinsten Verlust?» Dies lässt sich in der Tat ebenfalls mathematisch exakt formalisieren.
Tabelle 2 Daten = «wahrer» Wert + Störung = Signal + Noise { für diesen Teil gelten die Gesetze der Wahrscheinlichkeitstheorie

33
Dazu ein konkretes Beispiel: Es geht um eine nachträgliche Analyse ei-nes Abstimmungsergebnisses. Am 24. September 1995 wurde im Kanton Zü-rich über eine Initiative abgestimmt, die die Trennung von Kirche und Staat anstrebte. Für eine Stichprobe von 400 Personen wurden diese Merkmale erfragt:
Abgegebenes Votum (ja/nein); Geschlecht (Frau /Mann); Alter (3 Stufen); Politischer Standort (rechts/Mitte / links); Konfession (reformiert/katholisch/andere); Bildung (3 Stufen); Wohnort (Stadt/Agglomeration/Land).
Welche sozio-demografischen Variablen beeinflussen die Zustimmung zur Initiative? Die Antwort geben wir mit einem so genannten logistischen Regressionsmodell. Das erwähnte Kriterium für Modell-Selektion wählt ein Modell, in dem Alter und Bildung nicht vorkommen. Nun kann man mit der Idee der Hypothesen-Tests feststellen, dass ein Modell ohne das Merkmal Wohnort ebenfalls mit den Daten vereinbar ist. Wir haben also mindestens zwei vertretbare Modelle und sind in der Situation, dass mit Hilfe der statis-tischen Analyse auf die Ausgangsfrage keine eindeutige Antwort gegeben werden kann. Immerhin sagt die Analyse klar, dass Frauen der Initiative we-sentlich weniger abgewinnen konnten als Männer und dass Anghörige bei-der Landeskirchen natürlich viel weniger zustimmten als die Stimmenden mit «anderer» Konfession oder Religion. In beiden Kirchen war die Ablehnung etwa gleich heftig. So weit die Analyse dieses Beispiels.
Zurückkommend auf die beiden Gesichter der Statistik könnte man viel-leicht sagen, der mathematische Ansatz trage dazu bei, eine gewisse objekti-ve Kohärenz der beiden Blickfelder herzustellen. Komplette Parallelität wird es allerdings nie geben – und damit wird die Interpretation der Daten neben dem wissenschaftlichen Ansatz auch immer der vom Problemverständnis ge-steuerten Intuition Platz lassen. In meiner persönlichen Erfahrung hat ein amerikanischer Freund dies am treffendsten ausgedrückt.
Nehmen Sie an, es gehe darum für eine Transaktion einen Preis zwischen Käufer und Verkäufer auszuhandeln oder eine Streitsumme in einem Scha-denfall festzulegen. Wenn die beiden Seiten je durch einen Juristen vertreten sind so – dies sagte mein Freund – beträgt die Spanne der Preisvorstellung 1:7. Wenn die beiden Seiten je durch einen seriösen Statistiker vertreten sind so – auch dies sagte mein Freund – reduziert sich die Spanne auf 1:2.
Dies ist der Beitrag der Mathematik!

34

35
Neuere Entwicklungen in der theoretischen Statistik
Stephan MorgenthalerEcole polytechnique fédérale, Lausanne
Die Statistik ist eine junge Disziplin, welche erst im zwanzigsten Jahrhundert auf ein solides wissenschaftliches Fundament gestellt wurde und als selbstän-diges Gebiet Anerkennung fand. Auch heute noch ist es oft so, dass Neue-rungen ausserhalb der statistischen Gemeinde geschaffen werden, meistens von Leuten die direkt und intensiv mit Daten arbeiten. Neuronale Netzwer-ke oder das sogenannte boosting sind zwei Beispiele aus der jüngeren Ver-gangenheit. Allerdings ist die Statistik heute gereift und es ist sehr schwierig, etwas grundsätzlich neues oder sogar revolutionäres vorzuschlagen. Die neu-eren Entwicklungen haben ihre Triebfeder oft in der Technologie - Rechner, Programme oder automatisches Datensammeln kommen einem in den Sinn – und sind andererseits vom Fortschritt in der empirischen Forschung in an-deren Disziplinen abhängig – die finanzielle Statistik oder das Sequenzieren von DNA sind Beispiele von derartigen Entwicklungen. Um die neueren Ent-wicklungen besser zu veranschaulichen und zu bewerten möchte ich in mei-nem Vortrag einige konkrete Beispiele, die ich aus eigener Erfahrung kenne, in Hinblick auf ihre historische Entwicklung kommentieren.
Erstes Beispiel: Die Mathematische Statistik
R. A. Fisher und seine Schule verfügten schon Mitte der zwanziger Jah-re des letzten Jahrhunderts über ein detailliertes Wissen auf diesem Gebiet. Begriffe wie maximum likelihood, statistische Information, asymptotische Varianz, Signifikanz und Fiduzialwahrscheinlichkeiten waren bekannt und ihre Eigenschaften waren teilweise erforscht. Die allermeisten Anwender der Statistik haben hingegen auch heute noch bloss rudimentäre Kenntnisse in der theoretischen Statistik. Mittelwert und Standartabweichung sind in den Köpfen vorhanden, hingegen verstehen die wenigsten was die Standardab-weichung des Mittelwertes ist und bedeutet. Dieser Zustand ist für uns aka-demische Statistiker entmutigend, zeigt er doch, wie schwierig und langwie-rig der Dialog zwischen Theorie und Praxis ist. Eine der Folgen dieses Aus-bildungsdefizits ist eine allgemeine Unsicherheit im Umgang mit Daten und oft ein Verzicht auf eine seriöse und professionelle Datenauswertung.
Die mathematische Statistik ist das tägliche Brot der akademischen Sta-tistiker. In den letzten Jahrzehnten wurde ein sehr effizienter und allgemei-ner funktionalanalytischer Ansatz entwickelt, der es erlaubt, approximati-

36
ve Verteilungen für komplexe Schätzer herzuleiten. Das Studium der like-lihood Methode wurde bis an seine Grenzen vorangetrieben. Die Theorie wendet sich daher heute vermehrt dem Studium von verallgemeinerten Me-thoden wie zum Beispiel robusten oder funktionalen Modellen zu oder sie verschreibt sich spezielleren Problemen, wie zum Beispiel der Varianzschät-zung bei komplexen Stichprobenplänen oder dem Studium von Extremwer-ten. Die Diskrepanz zwischen der Theorie und der täglichen statistischen Pra-xis wird damit noch mehr anwachsen.
Eine der neueren Entwicklungen ist die breite Akzeptanz welche die Sta-tistik, auch in der Schweiz, erreicht hat. Die Benutzung von Statistiken und statistischen Methoden wird auch in der näheren Zukunft stark wachsen, zum Teil im Namen der Globalisierung. Es wird für die weitere Entwicklung wich-tig sein, dass bei statistischen Problemen auch ausgebildete Statistiker zumin-dest als Berater hinzugezogen werden. Sonst läuft die Statistik Gefahr, als wissenschaftliche Disziplin nicht Ernst genommen zu werden. Wir haben ge-genwärtig schon viel mehr Schwierigkeiten als andere Wissenschaften, neuere Forschungsergebnisse in der Praxis umzusetzen. Wir machen damit einen ge-spalten und unprofessionellen Eindruck. Nicht nur mangelnde Ausbildung ist schuld an diesem Zustand, auch die akademischen Statistiker selber müssten einen Beitrag zur Verbesserung leisten und zwar indem Sie ihre Forschungen weniger als ein Teil der Mathematik sehen und sich vermehrt von datenbe-zogenen praktischen Fragen leiten und inspirieren lassen.
Zweites Beispiel: Stochastische Modelle in der Genetik
In diesem Zusammenhang könnte man wieder R. A. Fisher, bekannt als Genetiker und Statistiker, als leuchtendes Beispiel zitieren. Am Anfang des 20ten Jahrhunderts war es vor allem die Evolutionstheorie von Darwin, wel-che Statistiker an der Genetik faszinierte. Seit den sechziger Jahren ist die Genetik durch die Molekularbiologie revolutioniert worden. Daraus eröff-nen sich Chancen für die Statistik, weil die anfallenden Datensätze riesig und komplex sind und weil die Molekulargenetiker eine Weile brauchen werden um statistisch aufzurüsten. Ich bin überzeugt, dass der Statistik eine Schlüs-selrolle zukommt in der Nutzbarmachung der genetischen Daten für medizi-nische Zwecke. Die Modelle für die Entstehung von Krebs (carcinogenesis) eignen sich gut dazu, die neueren Entwicklungen zu kommentieren.
In den fünfziger Jahren, im Zusammenhang mit der Erforschung der Ef-fekte radioaktiver Strahlung auf Tier und Mensch, wurde erstmals ein Modell vorgeschlagen, das die beobachteten Daten erklären sollte. Diese Daten wur-den mittels Tierexperimenten gewonnen und zeigten, dass durch Bestrahlung

37
n=2
n=3
Risiko
Alter
Zellkerne beschädigt werden können, dass diese Schäden vererbbar sind und dass sie zur Entstehung von Tumoren führen können. Bei N Zellen und einer jährlichen Beschädigungsrate von r hat man für die Anzahl der beschädigten Zellen pro Jahr eine Poissonverteilung mit Mittelwert Nr und die Anzahl der beschädigten Zellen im Alter t, X(t), verhält sich wie ein Poissonprozess mit In-tensitätsparameter Nr. Die Wahrscheinlichkeit bis zum Alter t keine beschädig-te Zelle zu haben, d.h. die Überlebenswahrscheinlichkeit S(t), ist damit gleich exp(-Nrt). Das altersspezifische Risiko (hazard) schliesslich ist h(t) = -d/dt [log{S(t)}] = Nr, und ist daher unabhängig vom Alter.
Diese Art von Modellen wurde seither weiterentwickelt und kann heu-te dank der molekularen Methode sogar experimentell getestet werden. Die wichtigsten Entwicklungsschritte waren:
1. Die Einsicht, dass die Beschädigung des Erbmaterials wird durch Muta-tionen verursacht werden (heute glaubt man allerdings, dass auch epige-netische Veränderungen nötig sind)
2. Wenn man statt einer einzigen Mutation n Mutationen benötigt um die Entstehung eines Tumors auszulösen, so erhält man als Risikokurve ein Polynom (n-1)sten Grades in t (=Alter).
Grafik 1

38
3. Diese n-Mutationen Modelle passen sich nicht sehr gut an menschliche Daten an. Einerseits beobachtet man ein kleines Risiko bei jungen Men-schen, so dass n gross gewählt werden sollte. Andererseits sind die Muta-tionsraten in der Natur so gering, dass das Risiko n Mutationen in einer einzigen Zelle zu beobachten viel zu klein wird, es sei denn, n sei klein.
4. Die Idee, ein Zwischenstadium der Zellentwicklung, sogenannte initiier-te Zellen, einzuführen, bei dem die Zellen höhere Mutationsraten und möglicherweise eine leicht erhöhte Wachstumsrate besitzen. Weitere Mu-tationen treten dann während der Promotion in diesen initiierten Zellen auf. Modelle dieser Art sind komplex, sowohl in der Formulierung als auch beim Anpassen an Daten.
Tabelle 1
Normale Zelle Initiierte Zelle Zelle in einemKrebsfrühstadium
→ →
Initiierung Promotion
Grafik 2

39
Die Grafik zeigt drei Beispiele von Risikokurven, wie man sie mit einem solchen Modell erhält. Die drei ansteigenden Kurven entstehen, wenn man annimmt, dass 2 Mutation zur Initiierung nötig sind und 1 weitere Mutation zur Promotion. Die initiierten Zellen haben dabei eine erhöhte Mutationsra-te und einen Wachstumsvorteil. Die durch die Punkte gezogene Kurve zeigt die Lungenkrebserkrankungen pro 100›000 unter den europäischstämmigen Amerikanern, die zwischen 1890 und 1900 geboren wurden. Die drei Modell-kurven unterscheiden sich durch die Wachstumsrate. Die am steilsten anstei-gende Kurve hat die grösste Wachstumsrate, die am wenigsten steil anstei-gende Kurve hat die kleinste. Die mittlere Kurve hat zwar die kleine Wachs-tumsrate, dafür aber eine grössere Mutationsrate.
5. Die Beobachtung, dass die Krebssterblichkeit im sehr hohen Alter wie-der abnimmt. Um dies zu berücksichtigen kann man davon ausgehen, dass es Individuen gibt, die genetisch oder durch Verhaltensweisen vor Krebs geschützt sind.
Risiko
Alter
Grafik 3

40
Eine Erklärung für dieses Phänomen kann daran aufgebaut werden, dass nur eine bestimmte Proportion F der Bevölkerung überhaupt am Krebs den man modellieren will erkranken kann. Die restlichen Personen, 1-F, sind ent-weder genetisch oder durch ihr Verhalten geschützt. In so einem Fall wür-de das altersabhängige Risiko sinken, weil die geschützten Personen schlus-sendlich überwiegen. Um die Proportion der geschützten unter allen Über-lebenden zu berechnen, muss man noch mindestens eine zweite neue Grösse ins Spiel bringen, nämlich die Sterblichkeit durch den Krebs relativ zu ande-ren Todesursachen. Unter der Annahme von proportionalen Risikokurven kann man dann das Gesamtrisiko ausrechnen. Die Grafik zeigt, wie sich die-se Idee im Lungenkrebsfall auswirkt. Die beiden Modellkurven verwenden 2 oder 3 Initiierungsmutationen und eine Promotionsmutation. Bei 3 Initi-ierungsmutationen wird das Knie der Datenkurve besser erklärt. In beiden Fällen ist F = 33%.
Grafik 4

41
Um diese Ideen zu testen und besser abzustützen sind biologische Studien von Mutationsraten in menschliche Organen nötig, sowie ganz allgemein Fort-schritte im Verständnis von zellulären Prozessen. Mathematische und statistische Modell können dazu benutzt werden, um Hypothesen zu generieren und zu tes-ten. Untersuchungen bei Rauchern zum Beispiel scheinen den bisherigen Muta-tionsmodellen zu widersprechen.
Die existierenden Modelle legen die Idee nahe, genetische Unterschiede bei Genen, die für die Zellfunktion wichtig sind, von sehr jungen und sehr alten Menschen zu erfassen, um die krankheitsfördernden und vor Krankheit schüt-zenden Differenzen zu bestimmen. Man sollte sich ganz allgemein um geneti-sche Unterschiede kümmern. Schlussendlich führt dieser Gedanken auf die Fra-ge, auf welche Art und Weise man die molekularen Datensätze einsetzen kann, um krankheitserregende und -verhindernde Variationen, sogenannte Polymor-phismen oder SNPs zu finden.
Der Einsatz der Statistik in der Genetik ist für mich eine erfreuliche Entwick-lung. Die Statistik hat ein Arsenal von Methoden und Ideen entwickelt, die es nun heisst anzupassen und einzusetzen. Wir Statistiker werden dabei gezwungen, uns mit sehr grossen Datensätzen auseinanderzusetzen, eine Entwicklung, die sich auch andernorts abzeichnet. Auch die Fragen, die man an die Daten stellt werden feiner. Man sucht nämlich nach Antworten, die auf ein Individuum passen und nicht mehr bloss solche, die auf eine ganze Bevölkerung zutreffen. Dies zwingt uns Statistiker dazu, neue Methoden und Ansätze zu entwickeln. In den Model-len, die wir besprochen haben, ist der Wachstumsvorteil und die Erhöhung der Mutationsrate in initiierten Zellen möglicherweise individuell verschieden. Mo-delle mit latenten Variablen können uns helfen solche Effekte zu analysieren.
Drittes Beispiel: Die Integration
Es bleibt mir nicht mehr genügend Zeit, um dieses Thema im Detail zu erör-tern. Es ist klar, dass das Berechnen von Integralen und Mittelwerten ein funda-mentales Problem der Statistik ist. Früher konnten wir nur jene Probleme ange-hen, die auf Integranden führten, welche analytisch gerechnet werden konnten. Dies hat zur Beschränkung auf die Normalverteilung als der Modellverteilung schlechthin beigetragen. Heute werden in vermehrtem Masse rechnerintensive Simulationen eingesetzt, was zu einem Innovationsschub in mehreren Gebie-ten der Statistik geführt hat. Wir werden allerdings noch sehr grosse Fortschrit-te im Berechnen von höherdimensionalen Integralen benötigen. In diesem Ge-biet setzt sich langsam die Erkenntnis durch, dass eine Mischung von systema-tischen Methoden (quasi-Monte Carlo, Blockstichproben) und zufälligen Algo-rithmen am geeignetsten ist.

42
Die Statistik als wissenschaftliche akademische Disziplin wird sich paral-lel mit der vermehrten Anwendung von statistischen Methoden weiter entwi-ckeln. Ich hoffe, es wird uns in der Zukunft vermehrt gelingen zu einer bes-seren Zusammenarbeit aller Akteure zu finden und neuere Entwicklungen rascher und nachhaltiger in der Praxis umzusetzen.

43
So überzeugt man mit Statistik
Walter KrämerUniversität Dortmund
Vielen Dank für die Einladung zu diesem Vortrag hierher in das schö-ne St. Gallen, und für Ihr Interesse an dem, was der Herr Krämer aus Dort-mund zur Rolle der Statistik in Wirtschaft und Gesellschaft zu sagen hat, und dazu, wie die Statistik diese Rolle am besten ausfüllen könnte. Ich glaube, das hat noch niemand so schön formuliert wie die berühmte Krankenschwes-ter Florence Nightingale, die auch, was nur wenige wissen, als Sozialstatis-tikerin bedeutendes geleistet hat: «The true foundation of theology is to as-certain the character of God», hat sie einmal geschrieben. «It is by the aid of statistics that law in the social sphere can be ascertained and codified, and certain aspects of the character of God thereby revealed. The study of stati-stics is thus a religious service.»
Zwar scheint mir die Sache mit dem «religious service» etwas übertrie-ben. Aber ganz so falsch ist die Analogie auch nicht. In gewisser Weise beklei-den wir Statistiker nämlich durchaus ein öffentliches Amt, vergleichbar etwa den Lehrern oder den Geisteswissenschaftern allgemein. Diese bekämpfen das Analphabetentum, sie befähigen die Menschen, mit Kultur und Sprache sinnvoll umzugehen. Die Statistik nun bekämpft das «In-numeratentum», sie lehrt, mit quantitativen Informationen rational und sinnvoll umzugehen. Das eine so wichtig wie das andere, und das wird, vor allem im angelsächsischen Ausland, auch schon seit langem so gesehen. «A basic literacy in statistics», so schreibt der englische Romancier H. G. Wells, «will one day be as neces-sary for efficient citisenship as the ability to read and write».
Von dieser «basic literacy» sind wir immer noch recht weit entfernt. Unse-re Medien sind voll von Beispielen geradezu grotesker Fehler, die man heute beim Umgang mit den Daten macht. «Jeder 2. Frankfurter lebt allein» schreibt eine große Zeitung dieser Stadt. Beweis (in einer großen Grafik nochmals bildlich dargestellt): Die Hälfte aller Frankfurter Haushalte sind Ein-Perso-nen-Haushalte. Eine deutsche Frauenzeitschrift behauptet, Mädchen seien intelligenter als Jungen. Statistischer «Beweis»: An den Gymnasien Baden-Württembergs hätten das Jahr zuvor 5100 Jungen, aber nur 3800 Mädchen das Klassenziel verfehlt. Fazit: «Was meßbare Intelligenz angeht, kommen Frau-en besser weg». Daß hier auch die Gesamtzahl der männlichen und weibli-chen Schüler eine Rolle spiele könnte, blieb der Redaktion verborgen. «Geld von Pfandhaus billiger als von der Bank», verkündet eine große Fernseh-Pro-

44
grammzeitschrift. Denn bei der Bank zahlt man für einen Kredit 12 Prozent Zinsen, beim Pfandhaus 10 Prozent. So wurde auch im Text die Schlagzeile erklärt. Daß diese Zinsen bei der Bank alle Jahre, beim Pfandhaus alle Quar-tale fällig werden, erschien der Redaktion keiner Beachtung wert.
«Im Sommersemester X legten die ersten Absolventen des Studiengangs Betriebswirtschaftslehre an der Universität Y in Z ihre Diplomprüfung ab», läßt eine große deutsche Universität verlauten. «Die Absolventen benötigten für ihr Studium maximal neun Semester und erzielten, so berichtet der Fach-bereich, überdurchschnittlich gute Noten. Sie zeigten damit, daß die Bemü-hungen des Fachbereichs so-und-so um eine Verkürzung der Studiendauer durch sinnvolle Gestaltung der Studienordnung erfolgreich sind...»
Vielleicht waren die «Bemühungen um eine Verkürzung der Studien-dauer» wirklich erfolgreich, vielleicht aber auch nicht. Die zitierte Statis-tik jedenfalls ist dazu ohne Wert. Denn wie viele Semester konnten die ers-ten Absolventen neun Semester nach Eröffnung eines Studiengangs maxi-mal studieren...
Auch die gemeldeten «überdurchschnittlich guten Noten» überraschen keinesfalls. Die kleine Minderheit der Studierenden, die innerhalb der Re-gelzeit ihr Studium beenden, sind natürlich auch begabter als die Bumme-lanten; daraus auf die Studierenden insgesamt zu schließen, ist reichlich naiv. Hätte die für diese Meldung verantwortliche Pressestelle gewartet, bis auch der letzte Anfänger des ersten Studienjahres in den Hafen des Examens ein-gelaufen wäre, hätte sich ein ganz anderes Bild ergeben. Schließlich würden wir auch niemals auf den Einfall kommen, die Zeiten der zehn Schnellsten eines Marathonlaufes auf alle Starter insgesamt zu übertragen ...
Sie sehen, da gibt es einiges zu tun, um die Endverbraucher aufzuklären, um zu erreichen, daß die Leute Statistik auch verstehen.
Wie erreichen wir also ein besseres Verständnis von Statistik und Statis-tiken, bzw. welche Hindernisse stehen diesem besseren Verständnis haupt-sächlich entgegen?
Ich sehe vor allem drei Hindernisse. Erstens: Ein intellektuelles Unver-mögen der Daten-Rezipienten, wie es sich etwa in den obigen Beispielen aus-drückt; da sind wir Statistiker machtlos. Zweitens: Ein fehlendes Einfühlungs-vermögen der Daten-Produzenten. Das äußert sich in unnötigem Fachjargon, in überladenen Grafiken und unübersichtliche Tabellen. Die handwerklichen Tricks, um dieses Hindernis zu umschiffen, sind seit langem wohl bekannt und werden etwa im Statistischen Jahrbuch der Schweiz, das ein Muster an Be-
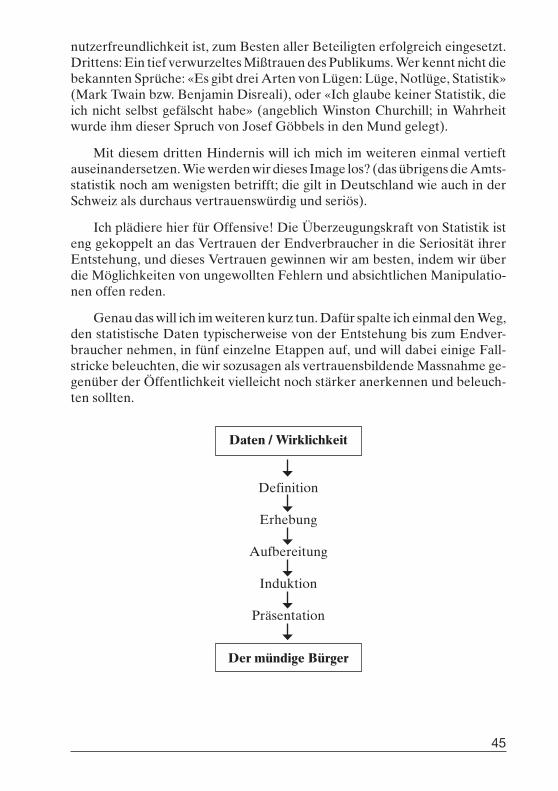
45
nutzerfreundlichkeit ist, zum Besten aller Beteiligten erfolgreich eingesetzt. Drittens: Ein tief verwurzeltes Mißtrauen des Publikums. Wer kennt nicht die bekannten Sprüche: «Es gibt drei Arten von Lügen: Lüge, Notlüge, Statistik» (Mark Twain bzw. Benjamin Disreali), oder «Ich glaube keiner Statistik, die ich nicht selbst gefälscht habe» (angeblich Winston Churchill; in Wahrheit wurde ihm dieser Spruch von Josef Göbbels in den Mund gelegt).
Mit diesem dritten Hindernis will ich mich im weiteren einmal vertieft auseinandersetzen. Wie werden wir dieses Image los? (das übrigens die Amts-statistik noch am wenigsten betrifft; die gilt in Deutschland wie auch in der Schweiz als durchaus vertrauenswürdig und seriös).
Ich plädiere hier für Offensive! Die Überzeugungskraft von Statistik ist eng gekoppelt an das Vertrauen der Endverbraucher in die Seriosität ihrer Entstehung, und dieses Vertrauen gewinnen wir am besten, indem wir über die Möglichkeiten von ungewollten Fehlern und absichtlichen Manipulatio-nen offen reden.
Genau das will ich im weiteren kurz tun. Dafür spalte ich einmal den Weg, den statistische Daten typischerweise von der Entstehung bis zum Endver-braucher nehmen, in fünf einzelne Etappen auf, und will dabei einige Fall-stricke beleuchten, die wir sozusagen als vertrauensbildende Massnahme ge-genüber der Öffentlichkeit vielleicht noch stärker anerkennen und beleuch-ten sollten.
Daten / Wirklichkeit
Definition
Erhebung
Aufbereitung
Induktion
Präsentation
Der mündige Bürger

46
Der Definitionsschritt
Eine erste Quelle von Konfusion und Missverständnissen, vielleicht so-gar die größte, die immer wieder für falsche Interpretationen sorgt, ist eine Verwirrung der Begriffe: Man benutzt die gleichen Wörter für verschiede-ne Dinge (der erste Fehler), oder man benutzt verschiedene Wörter für die gleichen Dinge (der zweite Fehler). Der erste Fehler ist folgenschwerer und kommt auch öfter vor, ich gehe gleich darauf noch tiefer ein. Zunächst eini-ge Beispiele für Fehler Nr. 2, der in aller Regel mit Absicht begangen wird, nämlich mit der Absicht, die Leute über gewisse Aspekte eines Sachverhal-tes hinters Licht zu führen.
Mein Lieblingsbeispiel für eine derartige Manipulation ist die alte DDR-Definition einer Melone. Sind Melonen Obst oder Gemüse?
Je nachdem, so die Praxis in der DDR. Je nach Knappheitslage wurde die Melonen, da schwer von Gewicht, um die Planerfüllung nach Tonnen sicher-zustellen, einmal dem Obst und einmal dem Gemüse zugeschlagen.
Falls Sie jetzt denken: so was gibt es nur im Kommunismus, das können Kapitalisten mindestens genau so gut. Wußten Sie z. B, daß es in der deut-schen Kfz-Haftpflicht (und in der Schweizerischen vermutlich auch), einen Straftarif für Männer gibt. Er heißt nur anders, man nennt ihn auch «Rabatt für Frauen». Oder daß es in fast allen Steuer-Systemen eine Strafsteuer für Kinderlose gibt. Man nennt sie «Kinderfreibetrag». Es ist unglaublich, wie leicht die Menschen auf solche Tricks hereinfallen. Die Deutsche Bahn AG hatte kürzlich heftige Proteste wegen eines Planes auszuhalten, im Zug ge-löste Fahrscheine noch kräftiger als bisher zu verteuern. Statt dessen sagt man jetzt: Die am Schalter gelösten Fahrscheine sind billiger, und der Pro-test hat aufgehört.
Oder nehmen sie die folgende Reklame der Autofirma Mazda, die vor ei-nem Jahr ganz groß im Focus und im Spiegel zu sehen war. «Bei Ihrem neuen Mazda kostet der Airbag keinen Pfennig», verspricht der Text. «Aber wenn Sie keinen wollen, kriegen Sie von uns 2000 Mark.» Im Klartext: ein Mazda mit Airbag ist 2000 Mark teurer als ein Mazda ohne Airbag, also kostet ein Airbag 2000 Mark.
Das zum Thema: verschiedene Wörter für die gleiche Sache. Jetzt zum Punkt 2: gleiche Wörter für verschiedene Sachen, irreführende oder mani-pulative Benutzung eine und desselben Wortes für unterschiedliche Sachver-halte oder Zusammenhänge.

47
Angenommen z.B. ich fahre auf dem Heimweg gegen einen Baum. Und versterbe nächste Woche im Krankenhaus. Bin ich ein Verkehrstoter? In der alten DDR wäre ich keiner, im Westen Deutschlands schon. Denn in der DDR zählte nur der als Verkehrstoter, der binnen dreier Tage nach dem Un-fall starb. Im Westen dagegen hatte man vier Wochen Zeit.
Oder nehmen wir die Säuglingssterblichkeit. Wann ist ein Säugling gestor-ben? Eine erste Bedingung ist: er muß lebend geboren sein. Also: Wann ist ein Säugling lebend geboren? In Deutschland-West: Wenn die Atmung funk-tioniert oder das Herz schlägt. Deutschland-Ost: Wenn die Atmung funkti-oniert und das Herz schlägt.
Das Paradebeispiel für das verbreitete Vorurteil, daß mit Statistik al-les zu beweisen sei, ist natürlich die Messung der Arbeitslosigkeit. Die bun-desdeutsche Arbeitslosenstatistik etwa zählt als arbeitslos, wer (i) für mehr als 18 Stunden in der Woche und nicht nur vorübergehend Arbeit sucht, (ii) dem Arbeitsmarkt unmittelbar zur Verfügung steht, und (iii) als arbeitslos gemeldet ist. Außerdem muß die betreffende Person älter als 15 und jünger als 65 Jahre sein.
Das große Problem ist die Bedingung (iii). Denn viele als arbeitslos ge-meldete suchen in Wahrheit gar keine Arbeit. Das wird jeder Arbeitgeber gerne bestätigen. Sie wollen die Zeit zwischen zwei Beschäftigungsverhältnis-sen überbrücken oder einfach nur das Arbeitslosengeld kassieren. Und viele Menschen, die tatsächlich Arbeit suchen, sind nicht als arbeitslos gemeldet. Diese «stille Reserve» nimmt oft in einem Wirtschaftsabschwung zu (weil vie-le Arbeitssuchende die Hoffnung aufgeben und sich bei den Arbeitsämtern abmelden), in einem Wirtschaftsaufschwung aber ab: Jetzt fassen die Men-schen wieder Mut und fragen beim Arbeitsamt nach einer Arbeit nach, mit dem Ergebnis, daß trotz Aufschwung die Arbeitslosenzahl nicht fällt, viel-leicht sogar noch steigt.
Ein weiteres Problem ist die Bedingung (ii) – dem Arbeitsmarkt unmit-telbar zur Verfügung stehen. Danach sind Teilnehmer von Schul- und Um-schulungsmaßnahmen, da nicht unmittelbar dem Arbeitsmark zur Verfü-gung stehend, offiziell nicht arbeitslos. Auch Frührentner oder Teilnehmer von Rehabilitationsprogrammen sind aus dem Kreis der Arbeitslosen aus-geschlossen. Unter anderem auch deshalb sind die jeweils regierenden, aus nachvollziehbaren Gründen an niedrigen Arbeitslosenzahlen interessierten Kreise so große Freunde von Langzeitstudenten und Umschulungsprogram-men aller Art.

48
Anderswo ist es weitaus einfacher, statistisch arbeitslos zu werden. In den USA z.B. gibt es kaum Altersbeschränkungen; auch spielt die Meldung bei irgendeiner Behörde keine Rolle. Aber auch engere Definitionen kommen vor. In Japan etwa muß man, um arbeitslos zu werden, vorher Arbeit haben. Mit anderen Worten, Schüler und Studenten, die nach der Ausbildung keine Arbeit finden, sind dort offiziell nie arbeitslos. Diese Besonderheiten sollte man bei internationalen Vergleichen stets im Auge haben.
Das größte Ärgernis für mich selber sind aber die ewigen Debatten um die Armut, die wir in Deutschland, und Sie in der Schweiz vermutlich eben-falls, jedes Jahr von neuen zu erdulden haben. «Immer mehr Armut in der reichen Republik» lautete etwa eine kürzliche Schlagzeile in der deutschen Tagespresse.
Dieser seit Jahrzehnten gleiche Jammerchor kommt nur durch einen sta-tistischen Trick zustande. Nach den Maßstäben der Vereinten Nationen gilt als arm, wer weniger als einen Dollar täglich zum Überleben zur Verfügung hat. Damit ist in Deutschland niemand, weltweit aber jeder fünfte arm, zu-sammen über eine Milliarde Menschen, die unter erbärmlichen hygienischen Verhältnissen in den Elendsquartieren dieser Erde am Rande des Verhun-gerns mehr vegetieren als menschenwürdig leben. Diese Menschen kennen das Wort «medizinische Versorgung» nur vom Hörensagen, haben weder sau-beres Trinkwasser noch ein festes Dach über dem Kopf, und würden sich ver-mutlich sehr verwundern, wenn sie Frau Engelen-Kefer von Deutschen Ge-werkschaftsbund zuhören dürften, die einen deutschen Halbstarken als arm betrachtet, wenn er sich keine Diesel-Lederjacke leisten kann.
Denn für die Bundesregierung und den Deutschen Gewerkschaftsbund ist jeder elfte Bundesbürger – und jedes fünfte Kind in Deutschland – arm. Aber nicht, weil sie nichts zu essen oder anzuziehen hätten, sondern weil der DGB es so bestimmt.
Der DGB, dem auch der Armutsbericht der Bundesregierung folgt, defi-niert als arm, wer weniger als die Hälfte des durchschnittlichen Einkommens zur Verfügung hat. Damit ist aber Armut praktisch niemals auszurotten. Auch wenn die Opec oder der Sultan von Brunei das Einkommen aller Bundes-bürger real verdoppeln würde: der Anteil derjenigen, die weniger haben als die Hälfte des Durchschnitts, bliebe der gleiche wie zuvor. So wie der Teil ei-nes Schiffes in einer Schleuse, der unter der Wasseroberfläche liegt, dersel-be bleibt, ganz gleich wie hoch das Wasser in der Schleuse steigt, bleibt auch der Anteil der Armen in Deutschland immer derselbe, ganz gleich wie hoch der allgemeine Reichtum steigt.

49
Der Erhebungsschritt
Ein Psychiater schrieb einmal, die ganze Menschheit sei verrückt. Gefragt, wie er zu dieser Meinung käme, sagte er: «Sehen sie sich doch die Leute an, die in meiner Praxis sind ...»
Dieser Mann schließt aufgrund einer extrem verzerrten Stichprobe. Das kommt häufiger vor als man denkt. Während einer Gastprofessur in Kanada hatte ich einmal zu meiner großen Verblüffung festgestellt, daß ausländische Studenten, vor allem aus China und Hongkong, oft besser waren als die kana-dischen; in meinen Kursen fiel kein einziger von ihnen durch, verglichen mit einem Drittel der Einheimischen. Eine Weile spielte ich daher mit der Theo-rie, daß Asiaten vielleicht begabter für Statistik sind, dann fiel mir auf, daß hier der gleiche Mechanismus wirkt: Eine Familie in Hongkong schickt ihren Sohn oder ihre Tochter doch nur bei einem sicheren Erfolg zum Studium nach Kana-da (d.h., nur die wirklich Cleveren werden nach Übersee geschickt), verglichen mit weit bescheideneren Standards in Kanada. Vermutlich gibt es dort genauso viele Dummköpfe und Genies wie überall, nur war die Auswahl, die mir auf der Universität begegnete, eine andere als bei den Studenten aus Hongkong.
Wenn ich in der Presse lese, Entbindungen zu Hause seien sicherer als im Krankenhaus, oder daß sogenannte «Retortenbabys» dreimal häufiger als an-dere Babys bei der Geburt sterben, so sind auch hier zumindest teilweise ver-zerrte Stichproben im Spiel. Einmal bleibt eine schwangere Frau bei drohen-den Komplikationen nicht gern daheim, so daß fast alle «kritischen» Fälle im Krankenhaus versammelt sind, und zum anderen sind Mütter künstlich gezeug-ter Babys bei deren Geburt im Durchschnitt fünf Jahre älter als andere. Kein Wunder, daß diese Geburten dann weniger glatt verlaufen als der Durchschnitt der übrigen Entbindungen.
Oder nehmen wir die folgende Hiobsbotschaft aus der Londoner Times: «60 Prozent aller Piloten in der zivilen Luftfahrt sterben vor dem 65. Lebens-jahr!» (30. März 1990, Seite 2). Die Vorsitzenden der Pilotengewerkschaft sei-en aufs höchste alarmiert, eine sicher nicht billige Studie der «International Federation of Airline Pilots Associations» mit Befragung von 70000 Piloten zu Trink- und Rauchgewohnheiten, Streß und sexuellen Spannungen sei geplant, um dieses mysteriöse Pilotensterben aufzuklären ...
Der folgende Rat ist dagegen ganz umsonst: Nachsehen, wie die Stichpro-be zustandekam. Die Times schreibt von Pensionskassen und Lebensversiche-rungen in Großbritannien, Südamerika und Kanada. Auch wenn wir einmal unterstellen, deren Kunden wären für die Piloten weltweit repräsentativ, bleibt die Frage, worauf sich diese 60 Prozent Todesfälle beziehen.

50
Gemeint ist offenbar, wie es in der Meldung ja auch wörtlich heißt: zwei Drittel aller Piloten, die es derzeit gibt, sterben vermutlich vor ihrem 65. Le-bensjahr. So genau kann die Times das aber gar nicht wissen, es sei denn, sie steht mit dem lieben Gott in Telefonkontakt. Schließlich leben diese Piloten ja noch. Vermutlich sind also die 60 Prozent so zu verstehen: Von den akti-ven und ehemaligen Piloten, die im letzten Jahr verstorben sind, waren 60 Prozent weniger als 65 Jahre alt.
Diese Stichprobe der im Jahr zuvor verstorbenen Piloten ist aber ver-zerrt. Das ist leicht zu sehen, wenn wir das Problem einmal auf Fußballspie-ler übertragen. «Alarm!», so könnte eine Schlagzeile der Bild-Zeitung ver-künden, «Bundesliga-Fußballspieler werden keine 65 Jahre alt!»
Die Fußball-Bundesliga existiert seit 1963. Die ältesten Spieler waren damals Mitte 30 und damit 1990, zur Zeit des Times-Artikels, keine 65. Mit anderen Worten, alle bis dato aus welchen Gründen auch immer verstorbe-nen Spieler – Alkohol, Herzinfarkt, Verkehrsunfall, eben alles, was uns auch schon jung bedroht – können bei ihrem Tod noch keine 65 Jahre alt gewe-sen sein; sie starben aber nicht an den Spätfolgen des Fußballspiels, sondern weil es in dieser Risikogruppe keine älteren Personen gab. Und wenn es in welcher Gruppe von Menschen auch immer keine über 65jährigen gibt, kann auch keiner im Alter von über 65 sterben (oder wie es so schön in der Hes-sischen Allgemeinen einmal hieß: «Statistisch erwiesen: Aus parkenden Au-tos, in denen keine Fotoapparate rumliegen, werden auch keine Fotoappa-rate geklaut»).
So gesehen ist das mysteriöse Pilotensterben also gar nicht mehr so mys-teriös: Die zivile Luftfahrt hat zwischen 1960 und 1990 gewaltig expandiert, so daß die meisten aktiven und ehemaligen Piloten zur Zeit des Times-Ar-tikels weniger als 65 Jahre zählten. Zwanzig Jahre später sieht das ganze schon ganz anders aus; damals waren die Veteranen eine kleine Minderheit – nicht notwendig, weil sie wie die Fliegen vor dem Rentenalter starben, sondern vielleicht auch deshalb, weil es nicht viele ältere Piloten gab. (Übri-gens: noch gefährlicher als Piloten leben die Studenten; diese sterben schon mit unter 30...)
Eine weitere Fehlerquelle bei der Datenerhebung sind manipulierte Um-fragen. Davon gibt es leider eine ganze Menge. Oft z.B. sind in solche Um-fragen die Antworten gleich mit eingebaut. Nach einer Umfrage der IG Me-tall lehnen 95 Prozent aller bundesdeutschen Arbeitnehmer das Arbeiten am Samstag ab. «Votum für das freie Wochenende», steht auf dem Fragebo-gen obenan. «Die Gewerkschaften haben die 5-Tage-Woche von montags bis

51
freitags in den fünfziger/sechziger Jahren durchgesetzt (...). Dadurch sind für alle zusätzliche Möglichkeiten gemeinsamer Freizeitgestaltung entstanden, an die wir uns gewöhnt haben. Was entspricht Deiner/Ihrer Meinung?» Und dann folgen diese Auswahlmöglichkeiten:
• Nach meiner Ansicht wäre die Abschaffung des freien Wochenendes ein schwerer Schlag für Familie, Freundschaften, Partnerschaften, für Gesel-ligkeit, Vereine, den Sport und das Kulturleben (1)
• Ich halte den gemeinsamen Freizeitraum des Wochenendes für nicht so wichtig. Seine Abschaffung würde zur besseren Auslastung der Freizeit- und Verkehrseinrichtungen führen (2)
• Weiß nicht/keine Angabe (3)
Genauso ist auch zum Stichwort «Der Samstag» die Antwort gleich mit eingebaut: «Die Arbeitgeber und manche Politiker wollen vor allem den Sams-tag wieder zum normalen Arbeitstag machen», heißt es hier. «Wie wäre das, wenn Du/Sie regelmäßig am Samstag arbeiten müßtest/müßten? Würde mir nichts ausmachen (1) Wäre Verlust an Lebensqualität (2)». Die 95 Prozent aller Stimmen für Alternative 2 überraschen hier niemanden. Viel eher soll-te schon bedenklich stimmen, daß trotz dieses ideologischen Trommelfeuers immerhin noch 5 Prozent aller Befragten ihr Kreuz dort markierten, wo es für einen Gewerkschafter eigentlich nicht hingehört.
Bei Ja-Nein-Entscheidungen ist es ferner wichtig, welche Alternative in der Ja-Form steht. Denn die meisten Menschen sagen lieber ja. Als ameri-kanische Meinungsforscher fragten, «Stimmen Sie der Behauptung zu: Für die zunehmende Kriminalität in unserem Land sind in erster Linie die Men-schen mit ihrem individuellen Fehlverhalten und nicht die gesellschaftlichen Verhältnisse verantwortlich?» erhielten sie 60 Prozent Zustimmung. Als sie fragten: «Stimmen Sie der Behauptung zu: Für die zunehmende Kriminalität in unserem Land sind in erster Linie die gesellschaftlichen Verhältnisse und nicht die Menschen mit ihrem individuellen Fehlverhalten verantwortlich?» stimmten wieder 60 Prozent der Befragten zu.
Auch die Reihenfolge der Fragen ist nicht egal. Die Frage «Befürworten Sie Meinungsfreiheit auch für Neonazis» wird von mehr Menschen mit «ja» beantwortet, wenn zuvor gefragt wurde, ob man generell ein Freund der Mei-nungsfreiheit sein. Ganz allgemein bestimmt der Zusammenhang, in dem ein Frage auftaucht, die Antworten entscheidend mit. Die Einstellung der Deut-schen zu Studiengebühren etwa ist eine andere, je nachdem ob die vorausge-gangenen Fragen die Geldnöte der deutschen Studenten oder die Geldnöte

52
der deutschen Universitäten zum Inhalt hatten, und genauso hängen auch die Antworten zur Asylproblematik, zu Auslandseinsätzen der Bundeswehr, zur Genforschung und Gott weiß was alles unter anderem auch davon ab, was sonst noch indem Fragebogen steht.
Ein weiterer Störfaktor ist der Interviewer. Wenn weiße Frauen weiße Frau-en fragen: «Sind Sie für die Todesstrafe?» kommt etwas anderes heraus, als wenn schwarze Männer weiße Frauen fragen. Bei einer Umfrage zur Rassendiskri-minierung unter schwarzen amerikanischen Soldaten fühlten sich 11 Prozent der Befragten diskriminiert, wenn der Fragesteller Weißer war. War der Fra-gesteller ebenfalls ein Schwarzer, stieg der Prozentsatz auf 35 Prozent.
Oder die Befragten reden den Befragern nach dem Mund. So achten die Deutschen beim Autokauf in erster Linie auf Sicherheit und Benzinverbrauch (57 bzw. 53% der Befragten), kaum dagegen auf PS (22%) oder Geschwin-digkeit (16%) – es gehört sich eben so. 73 Prozent der Deutschen wollen ihre Organe spenden, 76 Prozent sehen im Fernsehen am liebsten die Nachrich-ten, 91 Prozent lehnen Gewalt gegen Asylbewerber ab – alles politisch sehr korrekt, aber ob diese Antworten wirklich des Volkes wahre Meinung wie-dergeben, weiß der liebe Gott allein.
Der Aufbereitungsschritt
Das ist die Domäne der Leute, die wissen, was Mittelwerte und Stan-dardabweichungen sind. Vorausgesetzt, man weiß, welchen Mittelwert man nehmen muß. Wenn ich ein Wertpapierdepot mit 1000 Euro eröffne, und das Depot steigt im ersten Jahr im Wert auf 1600 Euro, ist das eine Rendite von 60 Prozent. Fällt das Depot im Jahr darauf auf 800 Euro, ist das eine Ren-dite von -50 Prozent (alias ein Verlust). «Ich weiß gar nicht, was Du hast,» sagt dann mein Wertpapierberater: «Du hast pro Jahr eine Rendite vom im Durchschnitt 5 Prozent!»
Das ist einerseits richtig: das arithmetische Mittel von +60 und -50 ist (60 - 50)/2 = +5. Andererseits ist es natürlich Unfug – bei Renditen oder Wachs-tumsraten ist das arithmetische Mittel als Durchschnitt nicht geeignet.
Trotzdem wird es in der deutschen Wirtschaftspresse zur Berechnung von durchschnittlichen Wachstumsraten standardmäßig eingesetzt. Auf mei-ne Beschwerde beim Handelsblatt erhielt ich die Antwort: «Die Leute ver-stehen es sonst nicht.»
Ein weiteres Problem sind gewichtete arithmetische Mittel. Wie etwa be-rechnet man korrekt den durchschnittlichen Zollsatz, den ein Land an seinen

53
Grenzen erhebt? Angenommen etwa, man importiere nur Autos und Lebens-mittel, etwa Dosen-wurst. Der Zoll auf Automobile betrage 50 und der auf Lebensmittel 10 Prozent. Wie hoch ist der durchschnittliche Zoll?
Klar: die einzelnen Zollsätze müssen unterschiedlich gewichtet werden. Die Frage ist nur, wie?
Ein auf den ersten Blick vernünftiges Gewicht ist offenbar der wertmäßi-ge Anteil des Produkts an der Gesamteinfuhr. Angenommen, in unserem Bei-spiel tragen Automobile 80 und Lebensmittel 20 Prozent zum Importwert bei. Nach diesem Gewichtungsschema beträgt der durchschnittliche Zoll damit
0,8 × 50% + 0,2 × 10% = 42%.
Dieses System hat aber einen Pferdefuß. Angenommen, der Zoll auf Au-tomobile steigt auf 200 Prozent. Als Konsequenz geht wie gewünscht der Im-portanteil ausländischer PKWs zurück, etwa auf 10 Prozent, und der durch-schnittliche Zoll beträgt jetzt nur noch
0,1 × 200% + 0,9 × 10% = 29%!
Eine weitere Konfusion betrifft die Zahl, durch die man beim arithme-tischen Mittel die Merkmalsumme teilt. Beispiel Verkehrssicherheit: Womit ist man sicherer unterwegs, mit dem Flugzeug oder mit der Bahn? (Das Auto als Killer Nr. 1 lassen wir von vornherein außen vor.)
Hier gibt es zwei Antworten, eine aus dem Kopf und eine aus dem Bauch. Der Kopf sagt uns, Fliegen ist sicherer. Haben wir nicht tausendmal gelesen, in den gleichen Zeitungen und Illustrierten, die keine Katastrophe auslassen, um mit Flugzeugwracks und Leichenteilen ihre Auflage zu steigern, daß Flie-gen trotzdem sicherer ist? Im Durchschnitt, so das Standardargument, kom-men dadurch weniger Menschen um als durch die Eisenbahn.
Die Frage ist jedoch, wie rechnen wir den Durchschnitt aus? Der Stan-dard-Nenner sind die insgesamt zurückgelegten Passagier-Kilometer. Damit erhalten wir:
Bahn: 9 Verkehrstote pro 10 Milliarden Passagierkilometer
Flugzeug: 3 Verkehrstote pro 10 Milliarden Passagierkilometer
Diese oder eine ähnliche Statistik kennen wir; sie bestätigt die bekannte Beruhigungsformel, denn so gesehen ist Bahnreisen in der Tat gefährlicher. Wenn diese Statistik stimmt, kommen in der Eisenbahn dreimal so viele Men-schen ums Leben wie im Luftverkehr.

54
Wieso bricht uns dann beim Besteigen eines Flugzeugs der Angstschweiß aus, beim Besteigen eines Zuges aber nicht? Wie die nächste Statistik zeigt, ist das gar nicht so irrational, wie viele denken. Mit dem gleichen Recht, mit dem wir die Zahl der Verkehrstoten auf die zurückgelegten Kilometer bezie-hen, können wir sie nämlich auch auf die Stunden beziehen, die wir in Gefahr verbringen. Für mich selbst jedenfalls ist diese Zahl weit wichtiger – schließ-lich habe ich auch beim Besteigen eines Bettes keine Angst, obwohl die Wahr-scheinlichkeit, darin zu sterben, fast 99 Prozent beträgt.
Um daher zu entscheiden, ob ich rationalerweise Angst haben darf oder nicht, ist die Wahrscheinlichkeit, auf den nächsten tausend Kilometern um-zukommen, vielleicht gar nicht so wichtig. Viel mehr interessiert mich die Wahrscheinlichkeit, in den nächsten 10 Minuten (oder in der nächsten Stunde) umzukommen. Mit anderen Worten, nicht die Passagier-Kilometer, sondern die Passagier-Stunden gehören in den Nenner unseres Bruchs. Die Durch-schnitte betragen jetzt:
Bahn: 7 Verkehrstote pro 100 Millionen Passagier-Stunden
Flugzeug: 24 Verkehrstote pro 100 Millionen Passagier-Stunden
Der Vorteil des Fliegens hat sich also umgekehrt – pro Stunde produ-ziert der Flugverkehr mehr als dreimal so viel tödliche Unfälle wie die Ei-senbahn.
Der Induktionsschritt
Die häufigsten Fehler im Induktionsschritt sind ein falscher Umgang mit bedingten Wahrscheinlichkeiten und ein ungerechtfertigter Schluß von Kor-relation auf Kausalität.
In der ADAC-Motorwelt war einmal die folgende Schlagzeile zu lesen: «Der Tod fährt mit! Vier von zehn tödlich verunglückten Autofahrern tru-gen keinen Sicherheitsgurt!»
Was will uns diese Nachricht sagen?
Gemeint war offensichtlich folgendes: «Leute, schnallt Euch an! Sonst ist Eure Überlebenschance bei einen Unfall weitaus geringer!»
Aber: um dieses Argument zu stützen, sind diese Zahlen völlig ungeeig-net; genauso könnte man daraus auch schließen, daß Gurte höchst gefähr-lich sind. Denn hatten sich nicht sechs von zehn tödlich verunglückten Au-tofahrern vorher angeschnallt ...

55
Zehn Autofahrer sterben, sechs mit Gurt und vier ohne. Wenn wir wei-ter nichts von dem Verkehrsgeschehen wissen, bleibt nur diese Überlegung übrig: Zehn Autofahrer sterben, die meisten davon angeschnallt, also Hän-de weg von diesen Teufelsdingen ...
Dieser Schluß ist falsch, wie wir alle wissen, denn worauf es hier ganz of-fensichtlich ankommt, ist: Wieviele Unfallbeteiligte tragen einen Sicherheits-gurt, und wieviele tragen keinen? Für beide Gruppen würde man dann gern den Anteil derer wissen, die den Unfall überleben, wobei vermutlich heraus-kommt, daß dieser Anteil für die Angeschnallten weitaus größer ist. Aber dazu sagt die ADAC-Statistik überhaupt nichts aus ...
Wir sind hier Zeugen einer globalen Konfusion, nämlich der Neigung vie-ler Menschen inklusive vieler Journalisten, bei bedingten Wahrscheinlichkei-ten die Bedingung und das bedingte Ereignis zu verwechseln. Beim Pro und Contra Sicherheitsgurte etwa ist die in der ADAC-Motorwelt genannte be-dingte Wahrscheinlichkeit von vierzig Prozent, einen Gurt zu tragen, gegeben ein tödlicher Unfall ist geschehen, völlig irrelevant. Interessant ist doch nur die bedingte Wahrscheinlichkeit, zu sterben, gegeben wir sind angeschnallt, also das Ganze quasi umgedreht. Und die würden wir dann gern vergleichen mit der bedingten Wahrscheinlichkeit zu sterben, gegeben wir sind nicht ange-schnallt (mit dem voraussichtlichen Ergebnis, daß letztere beträchtlich größer ist). Aber zu diesen Wahrscheinlichkeiten sagt die eingangs zitierte Schlag-zeile überhaupt nichts aus.
Viele Menschen scheinen hier zu glauben: «Eine große bedingte Wahr-scheinlichkeit von A, gegeben B, ist gleichbedeutend mit einer großen be-dingten Wahrscheinlichkeit von B, gegeben A,» und das ist falsch. So habe ich einmal gelesen, daß Autofahrer in der Nähe ihrer Wohnung besonders un-vorsichtig fahren würden, denn mehr als die Hälfte aller Verkehrsunfälle ge-schähen in einem Radius von dreißig Kilometern um den Wohnort eines der Beteiligten. Mit anderen Worten, die bedingte Wahrscheinlichkeit von «Hei-matnähe», gegeben «Unfall», ist sehr groß, und daraus wird dann geschlossen, daß auch die bedingte Wahrscheinlichkeit von «Unfall», gegeben «Heimatnä-he», groß sein muß. Das kann zwar zutreffen, muß aber nicht, denn mit der gleichen Logik könnten wir auch «beweisen», daß Autofahren tagsüber ge-fährlicher ist als nachts (die meisten Unfälle geschehen tags), daß man umso sicherer fährt, je schneller man rast (je höher die Geschwindigkeit, desto we-niger Unfälle; meines Wissens wurde auf deutschen Straßen noch nie ein Un-fall bei Tempo 400 registriert), daß man durch den Genuß von Milch zum Kri-minellen wird (alle Verbrecher haben irgendwann in ihrem Leben Milch ge-trunken), daß Krankenhäuser der Gesundheit schaden (mehr als die Hälf-

56
te aller Bundesbürger sterben dort), oder daß man in New York besser im Central Park als in der Wohnung schläft (die meisten ermordeten New Yor-ker werden in ihren eigenen vier Wänden umgebracht).
Hier drei weitere Beispiele aus der deutschen und internationalen Presse:
«Fußballer sind ... die reinsten Bruchpiloten» (aus dem Stern). Denn «sie ver-ursachen fast die Hälfte der jährlich rund eine Million Sportunfälle.»
«Frauen, hütet Euch vor Euren Ehemännern!» Denn «die Hälfte aller er-mordeten Frauen werden von Ihrem eigenen Mann oder Liebhaber umge-bracht» (aus der Londoner Times).
«Schäferhunde sind gefährlich!» (aus meiner lokalen Tageszeitung). «Jeder dritte Biß geht auf das Konto dieser Rasse.»
Usw.
Seltener, weil leichter zu erkennen, ist der Fehler, bedingte und unbeding-te Wahrscheinlichkeiten zu verwechseln. So findet man z.B. immer wieder in den Medien die Behauptung, junge Menschen seien besonders selbstmordge-fährdet. Und auf den ersten Blick scheint das auch zuzutreffen: nicht erst seit Goethes Werther treibt eine enttäuschte erste Liebe viele junge Menschen in den Tod, und daraus wird dann oft geschlossen, daß junge Menschen mehr als ältere zum Selbstmord neigen.
Typisch für diese Logik ist eine Zeitungsmeldung, die unter dem Titel «Im Alter wirst Du glücklicher» folgendermaßen argumentiert: Der Anteil der Selbstmorde an allen Todesfällen ist bei Jugendlichen am größten, rund fünfundzwanzig Prozent bei unter 20-jährigen, verglichen mit zehn Prozent bei 30- bis 40-jährigen und weniger als zwei Prozent bei über 70-jährigen. «Es verringert sich also der Entschluß zum Selbstmord immer mehr, je wei-ter das Alter fortschreitet», schreibt die Zeitung, wir werden mit wachsen-dem Alter immer glücklicher.
In Wahrheit ist jedoch genau das Gegenteil der Fall. Die Selbstmorde pro Jahr und Altersklasse steigen strikt mit unserem Alter an, von weniger als fünf pro hunderttausend in der Gruppe der unter 20-jährigen bis auf fast fünf-zig pro hunderttausend bei den über 70-jährigen. Je älter wir werden, desto eher scheiden wir aus freien Stücken aus dem Leben, und zwar zu allen Zei-ten und in allen Ländern. Daß dennoch die Selbstmorde gerade bei Jugend-lichen eine solch prominente Rolle spielen, liegt allein daran, daß Jugendli-che eben generell nur selten sterben. Sie haben selten Krebs und Kreislauflei-den, sie haben keine Altersschwäche und kein Alzheimer, und auch Schlag-

57
anfälle oder Leberschäden kommen unter Jugendlichen nicht sehr häufig vor. Mit anderen Worten, in diesem Alter sind Unfall, Mord und Selbstmord fast die einzigen Todesursachen, die noch übrig bleiben, so daß der hohe Anteil an Selbstmördern unter den Verstorbenen bei näherem Hinsehen überhaupt nicht überrascht. Ganz offensichtlich wurde hier die für Jugendliche in der Tat sehr große bedingte Wahrscheinlichkeit, durch Selbstmord umzukom-men, gegeben man stirbt überhaupt, mit der «normalen» Wahrscheinlichkeit für Selbstmord verwechselt, die aber weitaus kleiner ist.
Die zweite Fehlerquelle bei der Induktion ist der falsche Schluß von Kor-relation auf Kausalität. Unter dem Stichwort «Methusalems machen Kasse» lese ich im Handelsblatt: «Ein langes Studium zahlt sich in barer Münze aus. Zu diesem überraschenden Ergebnis kommt eine Studie über die Einstiegs-gehälter von Berufsanfängern, für die die Deutsche Gesellschaft für Perso-nalführung 44 Firmen befragt hat.»
Das überrascht mich in der Tat. Seit Jahren bete ich meinen Studenten vor: Laßt euch nicht so hängen, zieht zügig euer Studium durch, jedes Semes-ter über der Regelstudienzeit drückt aufs Gehalt. Und nun das!
In Wahrheit ist es natürlich eine Illusion, daß langes Studieren ein hohes Starteinkommen fördert. In den akademischen Fächern, in denen ich selbst aktiv oder passiv an der Ausbildung beteiligt war oder bin, haben «Bummel-studenten» eher bescheidene Aussichten auf eine gute Anstellung; in aller Regel geht das Startgehalt mit steigender Semesterzahl zurück.
Daran ändern auch das Handelsblatt und seine Studien-Statistik nichts. Die dort gemeldete positive Korrelation von Studiendauer und Gehalt liegt einfach daran, daß alle Fächer in einen Topf geworfen sind. Und in diesem großen Topf haben bzw. hatten diejenigen Hochschulabsolventen und -ab-solventinnen mit den langwierigsten Fächern, wie Chemie und Medizin, die höchsten Startgehälter. Aber diese hohen Startgehälter hatten sie nicht we-gen der Länge, sondern wegen der Schwere ihres Studiums; die Länge als solche trägt dazu überhaupt nichts bei. Im Gegenteil, auch in der Chemie ist ein schneller Abschluß einen Bonus wert, nur ist dieser schnelle Abschluß hier viel schwieriger.
Ganz anders die Betriebswirtschaft. Die hier geforderten Fähigkeiten sind eher praktischer als akademischer Natur und in kürzerer Zeit vermittel-bar (falls überhaupt: das Zeug zum Vorstandssprecher der Deutschen Bank hat man oder hat man nicht, und wenn nicht, nützt auch das beste Studium nichts). Daher schließen auch Diplom-Betriebswirte (FH) mit ihren sechs Se-mestern Studium die Liste der Startgehälter nach unten ab, aber nicht, weil

58
sie zu schnell studieren, sondern weil hier ein Überangebot besteht. Auch hier wird, wie in der Chemie, ein schnelles Studium belohnt, wenn auch von einer kleineren Basis aus.
Hält man aber die dritte Variable, nämlich das Studienfach, konstant, ist der Zusammenhang zwischen Studiendauer und Gehalt in allen Fächern negativ.
In abgeschwächter Form tritt dieses Phänomen auch bei der bekannten Korrelation zwischen Rauchen und frühem Sterben auf. Hier wird in der Re-gel das Rauchen als Ursache für frühes Sterben unterstellt. Wenn man der Bundeszentrale für gesundheitliche Aufklärung glauben darf, stirbt z.B. ein 30jähriger Raucher mit einem Konsum von ein bis zwei Päckchen Zigaret-ten am Tag sechs Jahre früher als ein Nichtraucher, laut Wissenschaftlichem Institut der Ortskrankenkassen sogar 12 Jahre früher.
Daraus folgt jedoch noch nicht, daß alle diese Jahre dem Tabak anzulas-ten sind. Denn Raucher werden auch öfter als Nichtraucher ermordet oder von Bussen überfahren, und das kann mit dem Rauchen als solchem wohl kaum direkt zusammenhängen. Vielmehr ist hier eine Hintergrund-Variable «Charakter» bzw. «Raucherpersönlichkeit» im Spiel, die viele gefährliche Ge-wohnheiten gleichermaßen fördert, so daß unsere modernen Raucher auch dann früher, wenn auch mit einem kleineren Vorsprung, sterben würden, hät-te Kolumbus Amerika und den Tabak nie entdeckt.
Genauso stützt auch die hohe Korrelation von Schulbildung und Ein-kommen für sich allein noch keineswegs die These, daß Bildung bare Mün-ze bringt. Hier wird eine dritte Variable «Ehrgeiz» und «Talent» vernachläs-sigt, die Schul- und Berufserfolg in gleicher Weise positiv berührt. Mit ande-ren Worten, viele erfolgreiche Menschen hätten auch ohne Abitur Erfolg ge-habt (genauso wie viele Raucher auch ohne Tabak früher sterben würden). Berufserfolg und Bildung gehen zum Teil auch deshalb Hand in Hand, weil beide sich bei Menschen mit bestimmten Eigenschaften häufen.
Durch das geschickte Auslassen solcher Hintergrundvariablen verdreht man jede Wahrheit leicht ins Gegenteil. Mitte der 70er Jahre etwa fand sich eine große amerikanische Universität der Diskriminierung gegen Frauen an-geklagt. Sie lasse prozentual mehr männliche als weibliche Bewerber zu und habe gefälligst etwas für die Emanzipation zu tun.
«Falsch!» konterte die beschuldigte Universität. «Wir lassen allem Män-nerüberschuß zum Trotz in allen Fällen mehr Frauen zu als Männer!»

59
Und so war es auch. Der Frauenanteil insgesamt war klein nicht wegen der Diskriminierung des weiblichen Geschlechts, sondern weil sich Frauen auf Fächer kaprizierten, in denen ein großer Bewerberüberhang bestand. Allein deshalb blieben relativ mehr Frauen als Männer vor der Tür. In jedem einzel-nen Fach waren sie bei der Zulassung aber erfolgreicher als Männer.
Wie schon bei den Bummelstudenten entsteht auch hier ein falscher Ein-druck durch Übersehen der Hintergrundvariablen «Studienfach». Hätten sich Frauen ebenso zahlreich wie Männer für Fächer beworben, in denen der Zu-gang leichter war, wären sie auch stärker an der Universität vertreten.
Aus dem gleichen Grund können auch die Klagen unserer Ärzte über sin-kende Einkommen nicht ganz überzeugen. Wenn man etwa der Kassenärzt-lichen Bundesvereinigung glauben darf, ging das durchschnittliche Einkom-men der niedergelassenen Ärzte in der Bundesrepublik in den letzten Jah-ren um mehrere Prozent zurück. In Wahrheit nahm jedoch das Einkommen der Ärzte, von Ausnahmen abgesehen, weiter zu. Daß trotzdem das Durch-schnittseinkommen sank, liegt einfach an der wachsenden Zahl junger Ärz-te mit noch kleiner Praxis, die erst am Anfang ihrer Großverdiener-Karriere stehen. Mit anderen Worten, auch wenn in jeder Altersklasse das Einkommen steigt, kann das Durchschnittseinkommen trotzdem sinken, nämlich wenn die Belegung der relativ einkommensschwachen Jahrgänge steigt.
Oder nehmen wir die Krebsgefahr. Hier müssen wir fast täglich in den Medien hören oder lesen, wie uns diese Menschheitsgeißel von Jahr zu Jahr vermehrt bedroht. In Wahrheit ist jedoch das Gegenteil der Fall: Die Wahr-scheinlichkeit, an Krebs zu sterben, hat quer durch alle Altersklassen und für Männer wie für Frauen gleichermaßen in den letzten dreißig Jahren ab-genommen. Daß dennoch immer mehr von uns an dieser Krankheit sterben (aktuell rund 23% verglichen mit weniger als 10% zu Anfang des Jahrhun-derts), liegt allein daran, daß wir im Durchschnitt immer älter werden. Auch hier wird eine Hintergrundvariable, nämlich Lebensalter, übersehen. Daß die Zeitgenossen Kaiser Wilhelms so selten Krebs bekamen, lag nicht an ihrem gesunden Lebenswandel, sondern daran, daß sie im Durchschnitt schon mit 45 Jahren an anderen Krankheiten gestorben sind.
Solche übersehenen Hintergrundvariablen produzieren Nonsenskorrela-tionen zuhauf. Angefangen bei den Klapperstörchen, deren Zahl hoch positiv mit den bundesdeutschen Geburten korreliert, über die Zahl der unverhei-rateten Tanten eines Menschen und den Kalziumgehalt seines Skeletts (ne-gative Korrelation), Heuschnupfen und Weizenpreis (negative Korrelation), Schuhgröße und Lesbarkeit der Handschrift (positive Korrelation), Schulbil-

60
dung und Einkommen (positive Korrelation) bis zu Ausländeranteil und Kri-minalität (positive Korrelation) spannt sich ein weiter Bogen eines falsch ver-standenen bzw. absichtlich mißbrauchten Korrelationsbegriffs.
Bei den Geburten und Klapperstörchen macht das weiter nichts. Zwar sind diese tatsächlich in manchen Gegenden eng korreliert, aber trotzdem glaubt deswegen niemand, daß der Storch die Kinder bringt. Die positive Korrela-tion von Ausländeranteil und Kriminalität in den Gemeinden der Bundesre-publik ist schon gefährlicher; hier unterstützt die Statistik unter Umständen nur ein ebenso populäres wie falsches Vorurteil, denn große Gemeinden zie-hen sowohl Ausländer wie Kriminelle an.
Die negative Korrelation von Weizenpollenallergien und Weizenpreis, über die aus den Staaten des mittleren Westens der USA berichtet wird, ent-steht dagegen durch das Wetter: Wenn der Weizen wegen guten Wetters gut gedeiht und heftig blüht, sinkt, wie jeder Ökonomiestudent im ersten Semes-ter lernt, aufgrund des hohen Angebots der Preis. Bei unverheirateten Tan-ten und Kalziumgehalt wie auch bei Schuhgröße und Handschrift ist dage-gen das Alter der jeweiligen Person der Bösewicht: Junge Menschen haben mehr unverheiratete Tanten als ältere, dafür in den Knochen weniger Kalzi-um. Ältere Schüler haben größere Füße und eine schönere Handschrift (und ältere Männer weniger Haare, aber mehr Geld ...).
Die Spitze aller vernachlässigten Hintergrund-Variablen hält jedoch die Zeit. Zeitreihendaten wie Volkseinkommen, Staatsverschuldung, Aktien- oder Preisindex, Studentenzahlen, Auslandsurlauber, Konsum von Südfrüchten oder Mitgliedschaft im Deutschen Fußballbund zeigen aus verschiedenen Gründen oft einen monotonen Trend. Weist dieser Trend bei beiden Variab-len in die gleiche Richtung (ob nach oben oder unten, ist dabei egal), so kor-relieren die Variablen positiv, und weisen die Trends in verschiedene Rich-tungen, so korrelieren die Variablen negativ, unabhängig davon, ob ein kau-saler Zusammenhang besteht oder nicht. Dieser gemeinsame Trend ist etwa für die Korrelation von Klapperstörchen und Geburten in der Bundesre-publik verantwortlich, denn beide Variablen nahmen lange Zeit im Gleich-schritt ab. Hier sprießen die Korrelationen nur so aus den statistischen Jahr-büchern hervor. Wer zum Beispiel glaubt, an allem Übel dieser Welt sei nur der Reichtum schuld (eher geht ein Kamel durchs Nadelöhr ...), findet hier reichlich Bestätigung. Da in allen westlichen Industrienationen seit mehre-ren Jahrzehnten das Volkseinkommen steigt, ist dieses automatisch mit al-len Variablen, die in dieser Zeit ebenfalls gestiegen sind, wie Mord und Tot-schlag, Krebs, Verkehrsunfällen, Alkoholkonsum und Ehescheidung, bes-tens korreliert.

61
Der Präsentationsschritt
Die zwei wichtigsten Fehlerquellen in diesem letzten Schritt, den die Da-ten zwischen der Wirklichkeit und dem Zielpublikum zurückzulegen haben, sind irreführende Grafiken und die Illusion der Präzision. Hier nur einige An-merkungen zu der letzten Fehlerquelle, der künstlichen Erzeugung von Auto-rität durch eine scheinbare Präzision von Zahlenangaben: «Himmel und Erde und alles was dazugehört,» schreibt der englische Theologe John Lightfoot. «wurden vom dreifaltigen Gott zusammen und zur gleichen Zeit erschaffen am Sonntag, dem 21. Oktober 4004 vor Christus, 9 Uhr morgens.» Damit ist jeder Zweifel ausgeräumt.
Wenn wir also in der Zeitschrift Nature lesen, daß es in England 30‘946 Prostituierte mit zusammen 4’641’900 Sexualkontakten jährlich gibt, so soll-ten wir das nicht zu wörtlich nehmen. Laut Kicker Sportmagazin haben die Olympischen Spiele in Barcelona 1992 alles in allem 2’409’196’600 Mark ge-kostet, aber jede andere Zahl zwischen zwei und vier Milliarden wäre genau-so richtig. Und das gilt für die ganze Latte anderer moderner Präzisionszif-fern genauso. Ein Keksfabrikant wirbt mit der Meldung, pro Monat würden in den USA 59’080’165 Portionen seiner Backwaren gegessen. Nach dem World-Factbook des amerikanischen CIA lebten am 21. März 1995 in der Volksrepu-blik China 1’127’519’327 Menschen. Laut Bild-Zeitung arbeitet eine typische Ehefrau pro Tag insgesamt eine Stunde, 50 Minuten und 13 Sekunden nur für ihren Mann (darunter 4 Minuten Hemden bügeln, 2 Minuten 30 Sekunden Bett machen, 1 Minute Barthaare aus dem Ausguß fischen und 15 Sekunden Klobrille schließen). Im September 1992 wurden nach Zählung des Statisti-schen Bundesamtes 3384 Gartenschirme aus Polen nach Deutschland einge-führt, dafür 934 gebrauchte Klaviere von Deutschland nach England expor-tiert. Der Gesamtumsatz an Aktien und Renten an der Frankfurter Börse be-lief sich am 27. Oktober 1994 auf 17’903’906’077 Mark (und 89 Pfennig). Laut der Zeitschrift Wachtturm der Zeugen Jehovas vom 1. Januar 1996 haben im Jahr 1995 zusammen 244’591 Argentinier an Gedächtnismählern dieser Reli-gionsgemeinschaft teilgenommen (verglichen mit 287’321 Deutschen, 21 Li-byern, 2262 Makedoniern und 3109 Zyprioten). Die Gesamtkosten des Ers-ten Weltkriegs beliefen sich für alle kriegführenden Parteien zusammen auf 186’333’637’097 Dollar. Im Jahr 1992 wurden in Deutschland 523’253 Fahrrä-der gestohlen (so der ADAC), und so weiter – alle diese Zahlen sind eigent-lich nur grobe, mit Phantasieziffern garnierte Schätzungen.

62
Fazit
Damit zurück zur Ausgangsfrage: Wie überzeugt man mit Statistik?
Antwort: Indem wir über Fehler offen reden und damit den Leuten Angst vor der Statistik nehmen. Wir sollten wie die Ärzte über Nebenwirkungen of-fen reden und unseren Produkten quasi einen Beipackzettel mitgeben. Dann könnten wir nämlich diese ganze Missbrauchsdiskussion ins Positive kehren. Ich behaupte nämlich, die Welt wäre ein besserer Platz, wenn auch in ande-ren Lebensbereichen und Wissenschaften die Fehler so leicht zu erkennen wären wie in der Statistik.

63
Diagnose von Fehlerquellen und methodische Qualität in der sozialwissenschaftlichen Forschung1
Andreas DiekmannInstitut für Soziologie der Universität Bern
Zusammenfassung
Umfragen liefern heute das Zahlenmaterial für wirtschaftliche und ad-ministrative Entscheidungen sowie sozialwissenschaftliche Untersuchungen. Fehler können dabei teuer zu stehen kommen. Der per Befragung erhobe-ne IFO-Geschäftsklima-Index zum Beispiel hat nach Bekanntgabe unmit-telbaren Einfluss auf den Kurs des Euro. Media-Analysen entscheiden über die Verteilung umfangreicher Werbebudgets. Und Irrtümer bei der Ermitt-lung des Preisindex wirken sich auf zahlreiche Verträge aus, die direkt oder indirekt mit dem Index verkoppelt sind. Die Sicherung methodischer Quali-tät und Transparenz bezüglich der Gütekriterien von Erhebungen ist daher eine nachdrückliche Forderung.
In dem Vortrag werden Fehlerquellen bei der Befragung, der Stichproben-ziehung und der Datenanalyse aufgezeigt sowie Möglichkeiten zur Behebung zumindest einiger typischer Fehlerquellen vorgeschlagen. Dabei wird auch das Thema betrügerischer Datenmanipulationen angesprochen. Zur Diagno-se von Datenfälschungen wurden in jüngster Zeit Testverfahren entwickelt, die sich allerdings noch in der Erprobungsphase befinden. Diese Verfahren und ihre Anwendungsmöglichkeiten werden abschliessend vorgestellt.
1 Einleitung
Umfragen liefern heute das Zahlenmaterial für wirtschaftliche Entschei-dungen, administrative Planung und für sozialwissenschaftliche Untersuchun-gen. Die Resultate haben oftmals weitreichende soziale und wirtschaftliche Konsequenzen. Media-Analysen zur Reichweite von Zeitungen und Zeitschrif-ten z.B. entscheiden über die Verteilung umfangreicher Werbebudgets.
1) Für Auswertungen mit der Schweizerischen Arbeitskräfteerhebung 1991 und mit den Mikrozensus Familie 1994/95 bedanke ich mich bei Ben Jann und Kurt Schmidheiny.

64
Der Geschäftsklima-Index des Münchner ifo-Instituts für Wirtschaftsfor-schung basiert auf einer schriftlichen Befragung mit dreizehn Fragen, die ei-ner Stichprobe von 7000 Unternehmen im monatlichen Rhythmus vorgelegt werden. Am 20. September 2000 berichtete die deutsche Presseagentur dpa, dass der deutsche Aktienindex u.a. infolge der neuesten ifo-Zahlen deutliche Einbussen erlitten hatte. Der ifo-Index war im Vergleich zum Vormonat von 99,1 auf 99 Punkte gefallen. Der erneute Rückgang des Index hatte milliar-denschwere Auswirkungen auf die Devisen- und Aktienmärkte.
Wenn Umfrageergebnisse teure Folgen haben, können Umfragefehler teuer zu stehen kommen. Deshalb ist es eine wichtige Aufgabe, die methodi-sche Qualität von Umfragen zu sichern und Transparenz darüber herzustel-len, inwieweit Umfragen die methodischen Gütekriterien erfüllen.
Zunächst werde ich auf einige Qualitätsmerkmale sozialwissenschaftli-cher Erhebungen eingehen. Sodann werde ich mich mit einem Thema be-fassen, das gerne vernachlässigt und verdrängt wird: dem Problem der Fäl-schung von Daten.
2. Gütekriterien von Umfragen
Als Verbraucher wird man heute über alle möglichen Produkteigenschaf-ten aufgeklärt. Jeder Beipackzettel einer Kopfschmerztablette enthält eine lange Liste von Risiken und Nebenwirkungen. Auf der Verpackung eines Jo-ghurtbechers werden die Inhaltsstoffe in der Terminologie der Lebensmittel-chemie minutiös aufgelistet. Bei Umfrageergebnissen erhält man dagegen, oftmals selbst als Auftraggeber, nur spärliche Informationen über die Qua-lität des Produkts. In Veröffentlichungen heißt es häufig lapidar: Repräsen-tativumfrage mit z.B. 1200 Befragten. Dann werden in der Regel noch der Fragetext und die Ergebnisse mitgeteilt.
Was ist eine Repräsentativumfrage? In der Statistik gibt es streng ge-nommen überhaupt keine Repräsentativumfragen. Eine Stichprobe kann niemals in allen Merkmalen ein repräsentatives Abbild der Population sein. Man könnte sich allenfalls darauf einigen, dass «repräsentativ» ein bildhaf-tes Kürzel für bestimmte Verfahren der Stichprobenziehung darstellt. Bis-lang gibt es aber keine in der Profession allgemein akzeptierte Definition von Repräsentativumfragen.
Wichtiger als das schwammige Etikett «Repräsentativumfrage» ist die Angabe der zentralen Merkmale der Erhebungsprozedur. Nur anhand sol-cher Kriterien kann die Qualität von Umfragedaten beurteilt werden. Wie

65
wir noch anhand von Beispielen sehen werden, steckt dabei das Problem oft-mals im Detail.
Ohne Anspruch auf Vollständigkeit sei hier eine Liste wichtiger Ge-sichtspunkte bzw. Fragen zur Beurteilung der Qualität der Umfragemetho-dik aufgeführt:
1. Art der Stichprobenziehung. Zufallsstichprobe oder anderes Verfahren? Wie genau sieht der Stichprobenplan aus?
2. Bei Zufallsstichproben und Face-to-Face-Interviews: Auswahl der Haus-halte per Random Route (der Interviewer ermittelt den Haushalt selbst nach vorgegebenen Begehungsregeln) oder mittels Adressrandom (der Interviewer erhält vorgegebene Haushaltsadressen, die zuvor per Zufall-sauswahl ermittelt wurden). Wie erfolgt die Auswahl der Zielperson im Haushalt? Wird die zu befragende Person im Haushalt zufällig ausgewählt, z.B. nach der «Geburtstagsmethode» oder per «Schwedenschlüssel»?
3. Umfang der Stichprobe.
4. Ausschöpfungsquote. Wie hoch ist die Ausschöpfungsquote und nach wel-chem Schema wurde sie berechnet?
5. Erhebungsmethode. Face-to-face, telefonisch, schriftlich. Mit oder ohne Computerunterstützung (CAPI, CATI)?
6. Interviewer. Wie setzt sich der Interviewerstab zusammen und wie wur-den die Interviewer und Interviewerinnen geschult? Wie werden die In-terviewer bezahlt?
7. Feldkontrolle. Wie erfolgt die Kontrolle der Interviewer und wie hoch ist der Anteil kontrollierter Interviews?
8. Pretest. Gab es mindestens einen oder mehrere Pretests?
9. Omnibuserhebung. Handelt es sich um eine eigenständige Umfrage oder stammt das Ergebnis aus einer «Omnibus-Erhebung»? Wenn ja, wo wur-den die Fragen platziert?
10. Reliabilität und Validität der Fragen bzw. Indizes.
11. Gewichtung. Basieren die Ergebnisse auf gewichteten Daten? Wenn ja, erfolgte die Gewichtung mit Designgewichten gemäss Stichprobenplan und Stichprobentheorie der Statistik? Oder wurden einfach demographi-sche Merkmale an bekannte Randverteilungen angepasst (Nachgewich-

66
tung oder so genanntes Redressment)? Redressment ist höchst umstrit-ten, basiert nicht auf statistischer Theorie, wird aber dennoch fast über-all praktiziert.
12. Datenanalyse. Wurden die dem Forschungsproblem und der Datenqua-lität angemessenen statistischen Verfahren angewandt? Wie wurde mit fehlenden Werten («missing values») umgegangen? Wurden die Schät-zungen korrekt interpretiert?
Welche Probleme bei der Beurteilung der Datenqualität auftreten kön-nen und welche oftmals vernachlässigten Detailfragen dabei eine Rolle spie-len, möchte ich jetzt an einigen Beispielen illustrieren.
Beispiel 1: Größe kann täuschen!
Nach der schweizerischen Volkszählung von 1990 beträgt der Anteil teil-zeitarbeitender Erwerbstätiger an allen Erwerbstätigen 19 Prozent. Mit der Stichprobe der schweizerischen Arbeitskräfteerhebung (SAKE, Zufalls-stich-probe von ca. 16›000 telefonisch befragten Personen) ergab sich 1991 bei gleicher Definition eine Teilzeitquote von 26 Prozent. Sieben Prozentpunk-te Differenz bei einer zentralen Arbeitsmarktstatistik ist schon eine bedenk-liche Unschärfe. Geht man nach dem Umfang der Erhebung - hier Vollerhe-bung versus Stichprobe - würde man dem Ergebnis der Volkszählung Glau-ben schenken. Buhmann et al. (1994) vom Bundesamt für Statistik haben nun mit Hilfe weiterer Datenquellen die Unterschiede zwischen den verschiede-nen Erhebungen genauer unter die Lupe genommen. Ihr Befund lautet, dass die Anzahl von Personen mit geringer Erwerbstätigkeit in der Volkszählung unterschätzt wurde. Die Fehlerquelle sei die Selbst-deklaration im Volkszäh-lungsfragebogen. Gering-fügig erwerbstätige Personen stufen sich selbst oft-mals als nicht erwerbstätig ein. Ob dies der Grund für die Verzerrung ist, sei hier dahingestellt. (Im Schweizerischen Arbeits-marktsurvey hatten wir eine ähnliche Frage wie in der Volkszählung gestellt, ohne dass sich eine gravie-rende Abweichung zum SAKE-Resultat ergab.) Gehen wir aber einmal da-von aus, dass die Erklärung von Buhmann et al. zutrifft und dass die SAKE die tatsächliche Teilzeitquote besser trifft als die Volkserzählung. Es zeigt sich dann wieder einmal, dass Größe täuschen kann (wie in Abbildung 1).
Wichtiger als die Aufstockung von Stichproben ist die Vermeidung von gravierenden Verzerrungen. Häufig sind selektive Stichproben die Ursache für eine verzerrte Schätzung. Aber auch die Frageformulierung kann der Grund für einen «Bias» sein. Man spart jedenfalls am falschen Ende, wenn man auf sehr genaue Tests der Fragen in eventuell mehreren Pretests verzichtet.

67
Abbildung 1: Grösse kann täuschen

68
Wenn ein systematischer Fehler vorliegt, kann auch eine noch so große Stichprobe nicht für die Verzerrung kompensieren. Vergrößert man den Stich-probenumfang, trifft man den falschen Wert sozusagen mit größerer Genau-igkeit. Eine Erhöhung des Stichprobenumfangs bewirkt bei einem starken Bias nur, dass sich die Masse der Stichprobenverteilung enger um den fal-schen Wert konzentriert. Bei einem knappen Budget ist man also gut bera-ten, einen Teil der Mittel zur Abhilfe von Verzerrungen zu investieren (z.B. durch eine Steigerung der Ausschöpfungsquote; dazu weiter unten), statt die Fallzahl zu maximieren.
Beispiel 2: Ausschöpfungsquote schön gerechnet!
Lehrbuchgerechte Zufallsstichproben hat man in der Praxis bekanntlich selten oder nie. Für landesweite Befragungen liegen die Ausschöpfungsquo-ten etwa im Bereich von 50 bis 70 Prozent. Je niedriger die Ausschöpfungs-quote, desto größer ist – abhängig vom untersuchten Merkmal – die Gefahr eines Stichprobenselektionsfehlers und damit die Gefahr mehr oder minder verzerrter Schätzungen. Deshalb möchte man bei Umfragen natürlich eine möglichst hohe Ausschöpfungsquote erreichen.
Die Ausschöpfungsquote entspricht der Anzahl auswertbarer Interviews dividiert durch den Umfang der Nettostichprobe. Letzterer errechnet sich aus dem Umfang der Bruttostichprobe abzüglich der stichprobenneutralen Aus-fälle. Wann aber sind Ausfälle neutral und wann systematisch? Je mehr Aus-fälle als neutral deklariert werden, desto höhere Werte lassen sich für die Aus-schöpfungsquote errechnen. Da verbindliche Normen nicht existieren, gibt es hier einigen Gestaltungsspielraum. Man betrachte dazu das in der Tabel-le aufgeführte Beispiel. Das beauftragte Institut hatte eine Ausschöpfungs-quote von rund 63 Prozent angegeben. Wir haben die stichprobenneutralen Ausfälle geprüft und nachgerechnet. Bei Anlegung der üblichen Maßstäbe ergibt sich eine Ausschöpfungsquote von gerade 53 Prozent.
Die Ausschöpfungsquote ist ein Gütekriterium wie bei einem Auto z.B. die Angabe eines sparsamen Benzinverbrauchs. Nur wird der Verbrauch bei einem Auto nach einer einheitlichen europäischen Vorschrift ermittelt. Sol-che Normierungen existieren in der Umfragepraxis leider noch nicht. Das Bei-spiel der Ausschöpfungsquote zeigt, das die Beurteilung der methodischen Qualität von Erhebungen unnötig erschwert wird, weil man es versäumt hat, gewisse Standards festzulegen.

69
Das Beispiel zeigt die Berechnung des Meinungsforschungsinstituts zur Aus-schöpfung bei einer telefonischen Befragung. Nach der Institutsrechnung be-trägt die Ausschöpfungsquote 62,6%. Die vier Kategorien Telephonbeant-worter, Krankheit, abwesend, nicht erreichbar wird man aber kaum zu den stichprobenneutralen Ausfallgründen rechnen können. Zählt man diese Kate-gorien zu den systematischen Ausfällen, dann vermindert sich die Ausschöp-fungsquote auf 52,6%! Rechnet man auch noch «Sprachprobleme» hinzu, er-halten wir eine Ausschöpfungsquote von 50%.
Tabelle 1: Die Berechnung der Ausschöpfungsquote in der Praxis
Bruttostichprobe 8218 100%
Kein Anschluß unter der Nummer 361
Modem/Fax/Natel im Tunnel 28
Telephonbeantworter 218
Andere technische Probleme 89
Kein Privathaushalt 294
Gehört nicht zur Grundgesamtheit 1410
Sprachproblem 291
Nicht verfügbar: Krankheit 265
Nicht verfügbar: abwesend 358
Zielperson nicht erreichbar 82
Stichprobenneutrale Ausfälle insgesamt 3396 41,32%
Bereinigter Stichprobenansatz 4822 100%
kein Interesse 718
keine Auskunft zum Thema 166
keine Zeit 383
keine Auskunft am Telephon 233
Hörer aufgelegt 145
Andere Verweigerung 146
Kein Kontakt nach 99 Versuchen 12
Systematische Ausfälle insgesamt 1803 37,39%
Durchgeführte Interviews und Ausschöpfungsquote 3019 62,60%

70
Beispiel 3: Nachgewichtung ist kein Heilmittel!
In der Regel weichen die Randverteilungen einiger Merkmale in neu er-hobenen Stichproben wie Alter, Zivilstand, Geschlecht, Erwerbsstatus, Bil-dung usw. von den Randverteilungen der amtlichen Statistik ab. Unter der durchaus diskussionswürdigen Annahme, dass die amtliche Statistik näher an der Wahrheit liegt, wird in der Praxis meist nachgewichtet. Man spricht auch von Redressment oder «Nachschichtung». Dies ist etwas ganz anderes als eine Designgewichtung gemäss Stichprobenplan. Eine Designgewichtung erfolgt auf der Grundlage der Stichprobentheorie und korrigiert für unter-schiedliche Auswahlwahrscheinlichkeiten. Wenn z.B. Tessiner Befragte mit einer x-mal höheren Wahrscheinlichkeit in die Stichprobe aufgenommen wer-den, kann hierfür mit einem Gewicht korrigiert werden, das dem Kehrwert der Auswahlwahrscheinlichkeit entspricht. Nachgewichtung dagegen ist durch keine Theorie gedeckt.
Wenn man viele Merkmale erhebt, ist auch bei perfekten Zufallsstichpro-ben zu erwarten, dass «rein zufällig» bei der einen oder anderen Randvertei-lung signifikante Abweichungen von der Verteilung in der Population auftre-ten. Aber selbst bei systematischen Fehlern gibt es keine Garantie, dass eine Nachgewichtung die Schätzungen verbessert. Natürlich wird es als «unschön» empfunden, wenn z.B. Frauen, bestimmte Altersklassen oder Bildungskatego-rien krass über- oder unterrepräsentiert sind. Anpassung an bekannte Rand-verteilungen stellt rein optisch die Proportionen wieder her. Die entscheiden-de Frage ist aber, ob durch die Nachgewichtung auch die Schätzungen ande-rer Verteilungen, d.h. Verteilungen von Merkmalen, die nicht in die Gewich-tungsformel eingehen, im allgemeinen verbessert und nicht verschlechtert werden. Hierfür kenne ich aber keinen überzeugenden Nachweis.
Mit einem Kollegen analysiere ich derzeit die Daten des «Family and Fer-tility Surveys» (FFS) bezüglich einer Hypothese, die einen Zusammenhang zwischen dem Geschlecht von Kindern und dem Scheidungsrisiko der Eltern behauptet. Demnach sollen Ehen mit Töchtern – ceteris paribus – instabiler sein als Ehen mit Söhnen. Nebenbei bemerkt, hat sich die in der Demogra-phie vielzitierte Hypothese bei einer Prüfung anhand der FFS-Stichproben aus rund zwanzig Ländern eindeutig als falsch herausgestellt. Beim Schwei-zer Datensatz (ca. 6000 Face-to-Face-Interviews 1994/95, Stichprobenziehung aus dem Telefonregister) fiel uns eine Besonderheit auf. Im Gegensatz zu an-deren Datenquellen nimmt das Scheidungsrisiko in der jüngsten Eheschlie-ßungskohorte (1985-89) im Vergleich zu den Vorgängerkohorten nicht zu, sondern der Tendenz nach sogar ab. Diese Entwicklung steht so sehr im Wi-derspruch zu anderen Statistiken, dass man wohl eher von Stichprobenfeh-

71
lern oder anderen Erhebungsfehlern ausgehen kann. Wie üblich wurde auch eine Nachgewichtung mit den Variablen Alter, Nationalität (Schweizer bzw. Ausländer) und Zivilstand vorgenommen. Betrachten wir jetzt das Schei-dungsrisiko nach Kohorten vor und nach der Gewichtung (Abbildung 2). Es zeigt sich, dass die Nachgewichtung die Abweichung noch vergrößert. Wenn man es nicht besser wüsste, würde man jetzt prognostizieren, dass die Ent-wicklung der Ehescheidungen rückläufig ist.
a) Ohne Gewichtung
b) Mit Nachgewichtung
Schweizer Mikrozensus Familie Teilstichprobe Frauen; N = 2143.Nachgewichtung mit den Variablen Alter, Zivilstand und Nationalität.
5.5 5.7
8.3 8
1970-74 1975-79 1980-84 1985-89
Heiratskohorten
5.25.8
8.2
6.9
1970-74 1975-79 1980-85 1986-89
Heiratskohorten
Abbildung 2: Prozentualer Anteil geschiedener Erstehen nach fünf Jahren Ehedauer

72
Stattdessen ist der Grund vielleicht, dass die jüngeren Geschiedenen ein-fach schlechter erreichbar waren. Die Nachgewichtung hat dabei den Feh-ler noch vergrößert.
Die Beispiele demonstrieren, dass eine Bewertung der Qualität von Um-fragen sich nicht schematisch auf wenige oberflächliche Hinweise wie die an-gebliche «Repräsentativität» und den Stichprobenumfang stützen kann. Zu viele Details spielen eine Rolle. Eine wichtige Forderung ist aber, dass ers-tens über die einzelnen Merkmale der Erhebungsmethodik informiert wird. Die obige, eventuell ergänzungsbedürftige Liste könnte dabei als Richtschnur oder «Checkliste» dienen. Zweitens erscheint es wünschenswert, die Details von Berechnungen zu standardisieren. Die Ausschöpfungsquote z.B. sollte von jedem Institut nach einem Standardschema zur Kategorisierung stich-probenneutraler und systematischer Ausfälle berechnet werden. Abwei-chungen von den Standards stehen jedem frei, müssen aber begründet wer-den. Transparenz und Standardisierung vereinfachen die Evaluation der Er-hebungsmethodik.
3 Datenfälschung: Umfang, Konsequenzen und Diagnose
Zur Datenqualität zählt sicher auch, dass die Daten nicht gefälscht sind. Datenfälschung ist vor allem bei Face-to-Face-Interviews ein ernstzunehmen-des Problem. Dabei handelt es sich meist um Teilfälschungen, die bei den üb-lichen Feldkontrollen nicht entdeckt werden. Bei Teilfälschungen stellt der Interviewer einige Fragen und ergänzt später die Kurzinterviews. Interview-er, die von ihrem Beruf leben müssen und im Akkord arbeiten, ist dies nicht einmal zu verdenken. Und die Institute beschwichtigen und verdrängen das Problem (Dorroch 1994).
Eine extreme These besagt, dass Interviewfälschungen die Datenqua-lität nicht beeinträchtigen. Sind hundert Prozent der Interviews gefälscht, dann hat man eben eine Befragung von Interviewern und die wissen meist besser Bescheid als die Befragten selbst. Gefälschte Interviews sind gewis-sermaßen Experteninterviews. Natürlich ist diese These unhaltbar, denn ers-tens sind Interviewer ein selektives Sample und zweitens können sie kaum stellvertretend für die Zielpersonen sprechen, wenn es um neue Themen und Stimmungen oder ihnen unbekannte Sachverhalte geht. Weniger radikal ist die Auffassung, dass bis zu fünf Prozent gefälschte Interviews die Ergebnis-se nur wenig beeinflussen. Die Toleranzgrenze von fünf Prozent wurde mit Simulationsrechnungen ermittelt (Schnell 1991; siehe auch Reuband 1990). Ob solche Befunde, die dann häufig als legitimierende Daumenregeln her-angezogen werden, wirklich verallgemeinerbar sind, sei dahingestellt. Eini-

73
ge Indizien deuten aber darauf hin, dass der Umfang gefälschter Interviews fünf Prozent erheblich übertreffen kann. Hier einige Indizien, die diese Ver-mutung unterstützen:
• Kommen wir zurück auf die Alternative Adressrandom oder random rou-te. In der Theorie ist random route gut, sofern sich Interviewer daran hal-ten. Die Einhaltung ist aber kaum kontrollierbar. Und die Interviewer ha-ben einen Anreiz, von den Regeln abzuweichen, wenn der Zielhaushalt schlecht erreichbar oder im Haushalt keine Person anwesend ist. Dann wird eben beim Nachbarn geläutet. Beim «Deutschen Familiensurvey» (ca. 10›000 Face-to-Face-Interviews, 1988) wurde eine Teilstichprobe aus Gemeinderegistern gezogen (Adressrandom), die Befragten der zweiten Teilstichprobe wurden per random route ermittelt. Dieser einmalige Me-thoden-Split erlaubt u.a. einen Vergleich der beim ersten Kontakt reali-sierten Interviews. Es sollte bei Einhaltung der Regeln zur Auswahl der Befragten eigentlich keinen Unterschied geben. Tatsächlich findet man eine sehr starke Differenz. Random-Route-Interviewer realisieren beim ersten Kontakt weitaus mehr Interviews als ihre Kollegen mit den vorge-gebenen Adressen der Zielpersonen aus der Gemeindestichprobe (Ab-bildung 3).
RandomRoute
Einwohnermeldeamt(Adressrandom)
Familiensurvey des Deutschen Jugendinstituts.Einwohnermeldeamt: N = 3011Random Route: N = 6931
Angaben nach Alt (1991).
25%
44%
Abbildung 3: Interviewhäufigkeit beim
ersten Kontaktversuch

74
• In einer Rostocker Verkehrsstudie im Auftrag der Bundesanstalt für Stra-ßenverkehr, an der ich mitbeteiligt war, wurden von dem beauftragten Meinungs-forschungsinstitut ca. 600 Face-to-Face-Interviews durchge-führt. Eine Teilgruppe von 80 Autofahrern wurde wenig später zur Vor-bereitung einer Interventionsstudie erneut befragt. Dabei stellte sich her-aus, dass manche «Autofahrer» über kein Auto verfügten oder sogar kei-nen Führerschein hatten. Eine intensive Kontrolle aller 80 Interviews er-gab 16 vollständige oder Teilfälschungen. Hochgerechnet also 20 Prozent Fälschungsquote. Das Institut hatte eine Feldkontrolle durchgeführt und dabei keines der gefälschten Interviews entdeckt. (Unsere Reaktion: Wir haben die Daten aller 600 Interviews weggeworfen und eine vollständig neue Erhebung mit ausgeklügelten Kontrollen durchgeführt.)
• Teilnehmer an einer medizinischen Studie sollten nach vorgegebenen Re-geln täglich ein Inhalationsgerät benutzen. Die Teilnehmer wussten, dass die verbrauchte Menge gemessen wurde. Wem die Einnahme lästig war, der hatte allerdings die Möglichkeit – so konnte man denken – kurz vor dem Kontrollbesuch unbemerkt die gesamte Ladung zu versprühen. Tat-sächlich wurde aber die Regelverletzung mit einer den Versuchspersonen unbekannten elektronischen Vorrichtung registriert. Innerhalb von zwölf Monaten hatten 30 Prozent der Versuchspersonen (30 von 101) mindes-tens einmal vorgetäuscht, dass sie das Medikament eingenommen hät-ten, obwohl dies nicht der Fall war (Simmons et al. 2000).
Fälschungen kommen häufiger vor, als man denkt. Nicht nur bei Inter-viewern, auch bei Wissenschaftlern.
Gibt es Diagnosemöglichkeiten? Man kann eine wesentlich genauere Feldkontrolle praktizieren (mit der Abfrage einer Kombination objektivier-barer Merkmale), um auch Teilfälschungen auf die Schliche zu kommen. Die-se Methode prüfen wir derzeit bei der neuen Erhebung des Deutschen Fa-miliensurveys. Ich möchte abschließend aber noch über eine unkonventio-nelle Methode sprechen, die ich derzeit ausprobiere. Diese Methode basiert auf statistischen Regelmäßigkeiten von Ziffernhäufigkeiten.
Statistische Daten sind meistens Zahlen und Ziffern. Unter gewissen Be-dingungen folgen die Ziffern von echten Daten Gesetzmäßigkeiten, die ge-fälschte Daten nicht gleichermaßen erfüllen.
Ein einfaches Beispiel von Hill (1998) zur Erläuterung des Prinzips. Stel-len Sie sich vor, Ihnen wird die folgende Aufgabe gestellt. Sie sollen die Da-ten von 200 Münzwürfen als Abfolge von «Kopf» und «Wappen» notieren. Sie können eine Münze werfen und echte Daten berichten; Sie können sich

75
aber auch die Daten ausdenken. Ich behaupte nun, dass ich über magische Kräfte verfüge und die echten von den gefälschten Versuchsreihen unter-scheiden kann. Das ist ganz einfach. Mit sehr hoher Wahrscheinlichkeit fin-det man bei einem echten Zufallsexperiment von 200 Münzwürfen eine Ab-folge von mindestens sechsmal Kopf oder Wappen in ununterbrochener Fol-ge. Wer dagegen solche Daten fälscht, schreibt höchst selten sechsmal hinter-einander das gleiche Symbol.
Ähnlich verhält es sich mit Ziffern, die aus natürlichen oder sozialen Pro-zessen resultieren. Auch hier ein Beispiel. Ich biete einer Person folgende Wette an: Ich setze darauf, dass die erste Ziffer in dem Artikel rechts unten auf der Wirtschaftsseite der Ausgabe der Neuen Zürcher Zeitung, die am nächsten Tag erscheinen wird, im Bereich eins bis vier liegt. Ich verliere die Wette, wenn sich die Ziffer im Bereich fünf bis neun befindet. Bei Gewinn erhalte ich zehn Franken, bei Verlust zahle ich die gleiche Summe an meinen Wettpartner. Ist das ein gutes Angebot?
Ist es nicht. Denn die ersten Ziffern von Zahlen verschiedenster Din-ge wie Hausnummern, Börsenkurse, die Fläche von Gewässern, die Flügel-spannweite von Vögeln u.s.w. sind nicht gleichverteilt. Die «1» z.B. kommt wesentlich häufiger vor als die «9». Unter bestimmten Voraussetzungen folgt die erste Ziffer vieler Daten einer logarithmischen Verteilung, der so genann-ten Benford-Verteilung.
«Benfords Gesetz» hat man sich z.B. zunutze gemacht, um Steuerbetrug und Bilanzfälschungen aufzudecken. Die Logik ist ganz einfach. Echte Zahlen folgen der Benford-Verteilung, gefälschte Daten weichen davon ab. Weitere Tests kann man entwickeln, indem man die zweite und dritte Ziffer heranzieht und darüber hinaus die bedingten Verteilungen (z.B. die Verteilung der zwei-ten Ziffer unter der Voraussetzung, dass die erste Ziffer n ist) inspiziert.
Die Untersuchung betrügerischer Manipulationen in der Buchhaltung von Unternehmen, von Steuererklärungen usw. durch Nigrini (1997,1999) zeigt, dass der Benford-Test zumindest in diesem Bereich Anhaltspunkte liefert, um gefälschte Daten herauszufiltern. Bei den gefälschten Daten kommen bestimm-te Ziffern viel häufiger vor als bei den echten Angaben (Abbildung 4).
Die ersten Ziffern der Angaben aus 169662 Steuererklärungen, die von M. Nigrini ausgewertet wurden, stimmen sehr gut mit Benfords Gesetz über-ein. Dies war bei betrügerischen Geschäftsdaten nicht der Fall. Ebenso stim-men die ersten Ziffern der Angaben von 743 Studenten, die gebeten wur-den, sechsstellige Zufallszahlen aufzuschreiben, nicht mit der Benford-Ver-teilung überein (nach Hill 1998).

76
Nach diesem ermutigenden Schritt hat man mit Benfords Gesetz auch die Steuererklärung von U.S. Präsident Bill Clinton inspiziert. Der Test war ne-gativ. Kein Fall für Kenneth Starr. Es gab keine Hinweise auf auffällige Zif-fernhäufigkeiten.
Nun wird man natürlich einwenden, dass Fälscher sich schnell auf den Benford-Test einstellen werden. Das ist aber kaum möglich. Es ist ungeheu-er schwierig, Daten konsistent zu fälschen und dann noch Benford-konform zu frisieren, insbesondere, wenn auch noch die zweite und dritte Ziffer be-rücksichtigt werden muss.
Was bei der Entdeckung gefälschter Steuererklärungen und Bilanzfäl-schungen hilfreich ist, könnte sich auch bei gefälschten Interviews und generell zur Diagnose gefälschter wissenschaftlicher Daten als nützlich erweisen.
In vielen empirischen Studien werden z.B. tabellenweise Regressions-koeffizienten berichtet. Um eine Art Referenzstichprobe zu gewinnen, habe ich eine Auszählung der ersten Ziffer von tausend geschätzten Regressions-koeffizienten aus Artikeln des American Journal of Sociology veranlasst. Es ist auch statistisch ganz interessant, dass die Häufigkeitsverteilung recht gut mit der Benford-Verteilung übereinstimmt (Abbildung 5). Gerät eine Ver-öffentlichung unter Fälschungsverdacht, könnte man den Benford-Test auf die Ziffern geeigneter Statistiken anwenden. Bevor das gemacht wird, sind aber weitere Tests erforderlich.
Aus: Hill (1998)
Erste Ziffer
0
10
20
30
40
1 2 3 4 5 6 7 8 9
Benford’s Law
True tax data
Fraudulent data
Random guess data
Abbildung 4: Aufdeckung von Fälschungen mit Benfords Gesetz

77
Drei Experimente wurden dazu am Institut für Soziologie in Bern mit Stu-dierenden durchgeführt. In einem ersten Experiment sollten die Versuchsper-sonen Zufallszahlen generieren. In zwei weiteren Experimenten wurden die Teilnehmer und Teilnehmerinnen an einem Statistik-Seminar in Soziologie so-wie Studierende der Ökonometrie gebeten, zu tun, was sie sonst nie tun dürfen, nämlich Tabellen mit Regressionskoeffizienten «passend» zu einer vorgegebe-nen Hypothese zu erfinden. In allen drei Experimenten waren bei der ersten Ziffer keine auffälligen Abweichungen zu erkennen. In den zwei Experimen-ten mit gefälschten Tabellen entsprachen auch die gefälschten ersten Ziffern der Benford-Verteilung, obwohl die Versuchspersonen mit dieser nicht vertraut gemacht wurden. Interessanterweise zeigten sich aber in den drei Experimen-ten übereinstimmend signifikante Abweichungen gegenüber der statistischen Erwartung (Zufallszahlen) bzw. Benford-Verteilung (Regressionskoeffizien-ten) bei der zweiten Ziffer, wobei allerdings nicht immer dieselben Ziffern als Ausreisser in Erscheinung traten. Ein ähnliches Resultat bezüglich der Fabri-kation von Zufallszahlen berichten Mosimann et al. (1995). Wenn diese Ergeb-nisse robust sein sollten, müsste demnach bei Fälschungsverdacht insbesonde-re die Verteilung zweiter Ziffern unter die Lupe genommen werden.
Um keine ins Kraut schiessenden Erwartungen bezüglich eines einfachen «Lackmustests» für Fälschungen zu wecken, sei deutlich betont: Die Prüfung des Verfahrens befindet sich in einem ersten Versuchsstadium. Ob etwas he-rauskommt, wird sich zeigen. Ich denke aber, es lohnt sich, unkonventionel-le Methoden zu testen, um Fälschungen auf die Spur zu kommen.
Stichprobe aus Tabellen von Artikeln, die im Zeitraum von Januar 1996 (Vol 101) bis Mai1997 (Vol 102) im American Journal of Sociology publiziert wurden (N = 1000).
��������������������� ������������������
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
30.0%
35.0%
���
���
����
�� ���
����
AJS 30.65% 18.00% 12.99% 8.15% 7.56% 7.13% 6.71% 5.01% 3.82%
Benford 30.10% 17.60% 12.50% 9.70% 7.90% 6.70% 5.80% 5.10% 4.60%
1 2 3 4 5 6 7 8 9
Abbildung 5: Verteilung der ersten Ziffer von unstandardisierten Regressionskoeffizienten

78
Literatur
Alt, C. (1991): Stichprobe und Repräsentativität, in: H. Bertram (Hg.); Die Familie in Westdeutschland. Stabilität und Wandel familialer Lebensformen, DJI: Familien-Survey 1, Opladen: Leske & Budrich, S. 497-531.
Buhmann, B.; Achermann, Y. und Martinovits, A. (1994): Comparability of La-bour Force Data from Different Sources. SAKE-News 3/94, Neuenburg: Bun-desamt für Statistik.
Diekmann, A. (2001): Empirische Sozialforschung, 7. Aufl. Reinbek: Rowohlt.
Diekmann, A.; Engelhardt, H.; Jann, B.; Armingeon, K.; und Geissbühler, S. (1999): Der Schweizer Arbeitsmarktsurvey 1998. Codebuch. Universität Bern: Mimeo.
Hill, T. P. (1998): The First Digit Phenomenon, in: American Scientist, 86: 358-363.
Mosimann, J.E.; Wiseman, C.V. und Edelman, R.E. (1995): Data Fabrication: Can People Generate Random Digits? In: Accountability in Reasearch, 4: 31-55.
Nigrini, M. (1999): I’ve Got Your Number. How a Mathematical Phenomenon Can Help CPAs Uncover Fraud and Other Irregularities, in: Journal of Accoun-tancy: 79-83.
Nigrini, M. (2000): Digital Analysis Using Benford’s Law, Vancouver: Global Audit Publications.
Reuband, K.-H. (1990): Interviews, die keine sind. «Erfolge» und «Misserfolge» beim Fälschen von Interviews, in: Kölner Zeitschrift für Soziologie und Sozial-psychologie, 42: 706-733.
Schnell, R. (1991): Der Einfluss gefälschter Interviews auf Survey-Ergebnisse, in: Zeitschrift für Soziologie, 20: 25-35.
Simmons, M. S., Nides, M. A., Rand, C. S., Wise, R. A. und Tashkin, D. P. (2000): Unpredictability of Deception in Compliance With Physician-Prescribed Bron-chodilator Inhaler Use in a Clinical Trial, in: Chest, 118: 290-295.

79
Two-Way Plots Based on Mixed Traces
Thomas GsponerDepartment of Mathematics, Swiss Federal Institute of Technology, Lausanne
Abstract
The two-way plot is a well-known tool to visualize the fit of a two-way ta-ble. An additive fit can be represented by two sets of parallel traces, whose in-tersection ordinates equal the fitted values. Based on linear traces, a variety of other two-way plots were investigated recently. In this work we present two-way plots based on general traces. We show that the resulting fits equal the ones using linear traces. Hence, we also study mixed traces: hyperbolic ones to rep-resent the columns and linear ones to represent the rows of a two-way table.
1 Introduction
The analysis of variance is a statistical tool to study measurements of a variable under varying conditions as described by a row factor and a co-lumn factor. The data of such measurements are summarized in two-way ta-bles of dimension RXC, where is the number of row levels and is the number of column levels of the variable d. The traditional analysis consists of adjusting to the two-way table an additive model of the form
���������� ε+++= ,
where r is the row index ( )�� ≤≤1 , � is the column index ( )�� ≤≤1 , �
� is the row factor effect,�� is the column factor effect and
��ε is a random
error. Unfortunately, the residuals of this model are often structured becau-se of the presence of interactive effects. The classical solution to this problem is to include an additional term,
��γ , describing the interaction in the additi-
ve model. Hence
������������ εγ ++++= .
In practice, however, this solution is not the best. The adjusted interac-tion is difficult to interpret and even more difficult to explain to practitioners. Therefore there is a need to develop tools in order to describe the influence of non-additive effects in a simple and efficient way, which is the aim of this article. The work is based on the ideas of Tukey (1949), Mandel (1995) and Morgenthaler and Tukey (2000).
(1)

80
This article is organized as follows: in Section 2 we resume the two-way plots based on linear traces and show that two-way plots based on general traces do not change the results; in Section 3 we discuss two-way plots based on mixed traces and some concluding remarks are given in Section 4. As data we consider throughout this article selected personal consumption expenditu-res for the U.S. (Tukey, 1977, page 345).
2 Two-way plots based on linear traces
The following data describes the expenditures for five kinds of personal consumption at five-year intervals from 1940 to 1960 (in billions of dollars).
Tabelle 1
A classical data analysis consists of fitting an additive model to the data. The additive model can be described as given in (1) wit R=5 and C=5. This additive decomposition of the two-way table can be visualized by means of a two-way plot. Such a picture consists of two families of parallel line segments, one for the rows with slope and one for the columns with slope . Fi-gure 1 shows the two-way plot of these data.
The idea behind this graphical representation is to plot the points in the ( )
����� ,+ Euclidean plane. This gives a rectangular grid whose horizon-
tal vertices represent the row effects and the vertical vertices represent the column effects. Rotating this figure by 45° results in the two-way plot. Mor-genthaler and Tukey (2000) inverse this construction procedure by starting to propose two families of line segments. Then they compute the intersection ordinates and derive the corresponding fits. For example, to get the additive fit, consider the two families of line segments with intercepts ( )��
�,, =α
and abscissae
1940 1945 1950 1955 1960
Food and Tabacco 22.2 44.5 59.6 73.2 86.8
Household Operation 10.5 15.5 29.0 36.5 46.2
Medical Care and Health 3.53 5.76 9.71 14.0 21.1
Personal Care 1.04 1.98 2.45 3.40 5.40
Private Education and Research .641 .974 1.80 2.60 3.64

81
.,,1,
;,,1,
���
���
��
��
�
�
=−==+=
αα
(2)
The intersections of a row trace with a column trace occur at
.,1;,,1,2
;,1;,,1,2
�����
����
��
��
��
��
��
��
==+
=
==−
=
αα
αα
The ordinate of such a plot represents the additive fit of the two-way table. In-deed, and illustrate this fact. Note that the num-ber of degrees of freedom for the additive fit is , but the construc-tion of the two-way plot seems to need R+C constants. This discrepancy can be explained by the invariance of the fit with respect to translations, i.e. if we replace in (2) by x–A, where is a constant, the fit does not change. Now, one can impose a constraint on the constants and thus the two-way plot has also degrees of freedom.
The user of such two-way plots can spot a variety of phenomena. In fol-lowing the trace representing ‘Food and Tabacco’ in Figure 1, one notes that the fitted expenditures increase from 1940 to 1960. In following the trace re-presenting the year 1960, one notes that the most important expenditures correspond to ‘Food and Tabacco’ and the less important expenditures cor-
Figure 1 -- The two-way plot for the consumption data. The lines with slope represent the five kinds of personal consumption. ‘Food and Tabacco’
corresponds to the top line and ‘Private Education and Research’ corresponds to the bottom line. The lines with slope represent the years 1940 to 1960 (from bottom to top).

82
respond to ‘Private Education and Research’. One also notes that ‘Personal Care’ and ‘Private Education and Research’ are quite close together, indica-ting a similar behaviour.
Nevertheless, a look at the data suggests that the additive model is not a good approach. Either there is some interaction to model or the data should be transformed. In this article only the former idea will be pursued.
Instead of choosing two families of parallel line segments, resulting inan orthogonal grid, one can assume nothing else than linearity, construct the two-way plot and finally derive the corresponding fits. In this case, con-sider the two families of line segments with intercepts ( )��
�,, =α , slopes
( )���
,, =β and abscissae x
.,,1,
;,,1,
���
���
���
���
�
�
=−==+=
βαβα
The intersections of a row trace with a column trace occur at
.,1;,,1,
;,1;,,1,
�����
����
��
����
��
��
��
��
��
��
==++
=
==+−
=
ββαβαβ
ββαα
Again the ordinate shows the fit corresponding to a general ‘net’ to be non-additive unless constraints are put onto the traces’ coefficients. For the realization of such a ‘net’ we need constants. The number of degrees of freedom for the corresponding fit is , because the-re is a three-dimensional family of invariant transformations. The first trans-formation corresponds to a shift of the horizontal axis variable, the second to a rescaling of the horizontal axis and the third is a nonlinear transforma-tion, mainly used to improve the visual aspects of the two-way plot. This ge-neral fit describes the non-additivity in the form of a ‘Rational-Product-In-teraction’ (RPI).
Morgenthaler and Tukey (2000) discussed different fits according to the constraints they put on the two families of line segments, each describing in one or another way the non-additivity of a two-way table. For example, they considered parallel line segments for the row part and a fan of straight li-nes for the column part resulting in a ‘Row-Column-Product-Interaction’,

83
or non-constraint line segments for the row part and parallel line segments for the column part resulting in Column-Product-Interaction and so on. The models for interaction derived from two-way plots are shown to have a hie-rarchical structure and it is shown how to construct SS/df/MS tables. Figure 2 shows the most general fit, called RPI in Morgenthaler and Tukey (2000), for the consumption data.
This two-way plot allows recognizing much more characteristics of the data than the one in Figure 1. For example, it shows that the expenditures from 1940 to 1960 do not increase in the same way for all five kinds of con-sumptions.
But are linear traces really the best way to represent this two-way table? To answer this question, Figure 3 illustrates the columns of the consumpti-on data.
FIGURE 2 -- � �� �������� ����� ���� � �� ����������� ����� � ��� �������� �� � �"��������&�����������������%� ���� � �� ���� ��.������ �� � ������� ��������������� � ��������'(+*����'()*���������� ���$�������� �� ������.�������� ��.����� ������ ���������� � �� ���� !���� ��� ��������� ������������ � "#���������$����%� ������������ ��� � �� ���� ���� ���� "&��������������� ����������� %���������������� ��$����������

84
Figure 3 shows that the columns of the consumption data do not exhi-bit any linearity. This suggests us to choose general traces of the form
,,,1),(
;,,1),(
���
���
���
���
�
�
=−==+=
ϕβαϕβα
to construct the two-way plot, for some bijection . The intersection of a row trace with a column trace in this case occur at
.,1;,,1,
;,1;,,1,1
�����
����
�
����
��
��
��
��
��
��
==++
=
==
+−
= −
ββαβαβββααϕ
The choice of the traces does not affect the resulting fit and we even get the same two-way plots, except that one or another trace represents the data bet-ter. The only difference are the estimated parameters. Figure 4 shows examp-les of four different traces: lines segments, hyperbola, exponentials and para-bola. In the next section we discuss the case where mixed traces are chosen to construct the two-way plot.
FIGURE 3 -- � �������������� �������������������������� $��������������� ���������������������������� �������'(+*������ ��$������������������������� '()*�� #�� ������ ���� "#���� ���� ��$����%/� 01� ���� "0���� ���� 1�������%/2�0�����"2���������������0���� %/�&������"&������������%������������&������"&�������������������������� %�

85
FIGURE 4 -- #���� ��������������$�������� �������������� ������������ ����3� �����.�����4� ���� �. �3� ����$���4� $������ ����3� ����������4� $������ �. �3����$����

86
3 Two-way plots based on mixed traces
The plot of the rows and the columns of the consumption data is given Figure 5.
Figure 5 suggests the use of one family of traces for the columns and ano-ther for the rows. Therefore consider the two families of traces defined by
,,,1,
;,,1,
���
���
���
���
�
�
=+==+=
βαβα
for the construction of the two-way plot. The intersection of a row trace with a column trace in this case occur at
{ } ,2)(4)( 2���������
−++−= βααββαα
{ } ,2)(4 2���������
−+++= ααββαα
FIGURE 5 -- ���� �������������� ��������� of � ����������������������� ����� ���������������������������� �������'(+*������ ��$�������������������������� '()*�� #�� ������ ���� "#���� ���� ��$����%/� 01� ���� "0���� ���� ��������%/2�0�����"2���������������0���� %/�&������"&������������%������������&������"&�������������������������� %������ ���. ��������� ����������� ����$���������������� �����������������������#������� ��$������������&���
.,,1;,,1 ���� �� ==
.,,1;,,1 ���� �� ==

87
In this case the ordinate gives a new fit composed of the additive part and a square root part describing the interaction. This non-additive compo-nent can be called ‘Radical-Row-Column-Product-Interaction’ (RRCPI). The parameters and are chosen in a way that the expressions are neither undefined nor complexe. For the realization of a two-way plot based on these mixed traces one needs degrees of freedom. Again the resulting fit is invariant with respect to at least two transformations that are resumed in the table below, where A and B= 0 are constants.
������������ � ������������ �
���
+→ αα��
αα →
���ββ →
���
−→ αα��
αα →
���
/ββ →
)( ������
+−→ ααββ
The number of degrees of freedom for the fit is at most . Ac-cording to the constraints put onto the parameters, eight different models de-scribing the non-additivity were found showing the same hierarchical struc-ture as the models derived from two-way plots based on linear traces; details of these eight models can be found in Gsponer (2000, Section 2.3). Figure 6 illustrates this structure in a diagram showing all possible fits in increasing order of complexity.
88
)1)(1( −−= �����
parallel-parallel fit:‘Additive’
[2]
2)1)(1( −−−= �����
fan-parallel fit [C-2] [R-2]
1)1)(2( −−−= �����
1)2)(1( −−−= �����
[1] parallel-unconstrained fit unconstrained-parallel fit
3)1)(1( −−−= �����
[1] [1]fan-fan fit
[C-2] [R-2]
2)1)(2( −−−= �����
2)2)(1( −−−= �����
fan-unconstrained fit unconstrained-fan fit
[R-2] [C-2]2)2)(2( −−−= ����
�
unconstrained-unconstrained fit:‘Radical-Row-Column-Product-Interaction’
FIGURE 6 -- � �� ��.���� � ���� � �� ����$��� ���� �� �������.� ������ ������������5������������ ����������.��� ���������������������������� ����� ��� . ��� ��������� � � � �������� � �� ����� ��� ��� �� ������� ������ � ����$������$���!�������������� ��������������� �����$���������������������.����� ��� �������� ������� $�� � �� ����� ������� ���� ���� ��� ��� � ��/� � ����$��������.��������������������� ������������������

89
In the context of mixed traces two traces are said to be parallel if, for ex-ample, for all . According to the constraints put on the para-meters and one can increase or decrease the complexity of the models. The constraints are reflected in the number of degrees of freedom. Consider the additive fit. Forcing the straight line segments to pass through one com-mon point increases the model’s number of degrees of freedom by two and, hence, the error’s number of degrees of freedom decreases by two. Figure 7 shows the two-way plots resulting in the simplest and the most general fit.
By comparing the two-way plot in the left panel of Figure 7 with the one in Figure 1, one notes that no difference can be detected. Thus, the fits must be the same. Indeed, if we change the scale of in the fit resulting from the two-way plot based on mixed traces with for all and all , we get
22 )(42������
�� αααα −+++= . . Choosing a large with respect towe can forget about this difference and we find ��
����++≈ αα2 ,
which represents the additive fit.
The two-way plot in the right panel of Figure 7 is also similar to the two-way plots shown in Figure 4 but the fits are not the same. The table below gi-ves the residual sum of squares and the corresponding degrees of freedom (df) for the additive fit derived from two-way plots based on straight line segments and based on mixed traces. It also compares the residual sum of squares of the ‘Rational-Product-Interaction’ (RPI) fit and the ‘Radical-Row-Column-Product-Interaction’ (RRCPI) fit.
Figure 7 -- Two-way plots based on line segments to represent the five kinds of consumption and hyperbola to represent the years from 1940 to 1960. The left panel shows the case where 1==
��ββ for all and all . The right panel
shows the most general case.

90
Because of computational problems these umbers need to be conside-red with care, except for the additive fit. But they show that the models RPI and RRCPI perform well. Furthermore, even if the models derived from two-way plots based on mixed traces show a hierarchical structure, the construc-tion of the SS/df/MS table in the usual sense is not exact any more, becau-se we do not project in linear subspaces. But anyway, it allows getting an im-pression of the model’s quality.
Note that the choice of the traces is individual. It is possible to find bet-ter models by choosing more appropriate traces. The example treated in this article is a small data set mainly chosen to illustrate the ideas behind the two-way plots. Clearly the method is also applicable to larger data sets but at the moment this can not be done in an efficient way.
4 Conclusion
In this article the method of describing non-additivity in two-way tables introduced by Morgenthaler and Tukey (2000) was generalized at two sta-ges. First, instead of choosing linear traces to construct the two-way plots, it was proposed to use general traces and it was shown that the fits derived from the new two-way plots correspond to the fits derived from the two-way plots based on linear traces. Second, choosing mixed traces, eight new mo-dels were derived showing the same hierarchical structure as the models by Morgenthaler and Tukey (2000). Although the analysis of variance decom-position in the context of mixed traces is not exact, because of the projection in non-linear subspaces, the SS/df/MS tables can be used to choose the ap-propriate model.
The computational problems coming across while fitting the new models to the data will be the subject of further investigations. Moreover we did not find a convincing implementation to deal with non-linear least squares pro-blems under non-linear constraints. These problems resolved, two-way plots would be the right tool to analyze non-additive two-way tables.
Tabelle 2
Linear Df df Mixed
Additive 1661.19 16 Additive 16 1661.94
RPI 4.78645 8 RRCPI 7 4.15035

91
Acknowledgements
The author thanks Prof. S. Morgenthaler for the supervision of his un-dergraduate thesis treating two-way plots. Thanks also to R. Furrer and Dr D. Kuonen for proofreading this article.
References
Gsponer, T. (2000). Diagrammes à deux voies utilisant des traces hyper-boliques. Undergraduate thesis, Department of Mathematics, Swiss Federal Institute of Technology, CH-1015 Lausanne.
Mandel, J. (1995). Analysis of Two-Way Layouts. Chapman and Hall, London.
Morgenthaler, S. and Tukey J. W. (2000). Two-Way Plots: I. The Case of Straight Line Segments. Journal of Statistical Computation and Simulation, to appear.
Tukey, J. W. (1949). One Degree of Freedom for Non-Additivity. Bio-metrics, 5, 232-242.
Tukey, J. W. (1977). Exploratory Data Analysis. Addison-Wesley, Rea-ding, Massachussetts.

92

93
Raummetaphern und kartographische Methoden zur Analyse, Interpretation und Visualisierung von statistischer Information
Michael Hermann und Heiri LeutholdGruppe sotomo, Geographisches Institut der Universität Zürich
Abstract
Die Verfügbarkeit grosser Datenmengen in digitaler Form verlangt nach neuen Methoden der explorativen Datenanalyse, die helfen, sich in der Fülle von Information zu orientieren und in den Daten eingelagerte Strukturen zu erkennen und zu verstehen. Neue Methoden der Visualisierung sind zur Ver-mittlung und Kommunikation notwendig. «Spatialization» ist eine Methode für die visuelle Kommunikation dient aber auch der Interpretation von Da-ten. Es verbindet Informationsverdichtung und Strukturierung in metapho-rischen Räumen mit Visualisierung (Info-Maps). Grosser Nutzen bietet da-bei die über Jahrhunderte gewachsene kartographische Sprache. Raumme-taphern und Info-Maps werden intuitiv verstanden, weil räumliches Denken und Kartenlesen für die meisten Menschen alltägliche Routinen sind. Mit den Werkzeugen von Geographischen Informationssystemen (GIS) und Compu-terkartographie können «Karten» oder «Landschaften» als Interface für Da-tenarchive oder Datenbanken modelliert werden. Karten von abstrakten Ei-genschaftsräumen sind aber auch als Analysesysteme für komplexe soziale Zusammenhänge hilfreich.
Der im vorliegenden Beitrag vorgestellte «Raum der Weltanschauungen» ist ein Beispiel für eine sozialwissenschaftliche Anwendung von «Spatializa-tion». Im Sinne einer «Hermeneutik mit quantitativen Methoden» wurde er aus den Gemeinderesultaten aller eidgenössischen Volksabstimmungen zwi-schen 1981 und 2000 erzeugt. Die Modellierung und Darstellung des Rau-mes der Weltanschauung mit GIS erlaubt eine differenzierte Analyse von politischen Auseinandersetzungen und regionalen Mentalitätsunterschie-den in der Schweiz.
Renaissance der Exploration
Die digitale Revolution der neunziger Jahre hat dazu geführt, dass grosse Mengen von Daten und Texten in digitaler Form abgespeichert werden. Da-

94
durch hat sich auch die Verfügbarkeit von wissenschaftlich verwertbarer In-formation gegenüber den achtziger Jahren um ein Vielfaches erhöht. Einmal erhobene Datensätze werden für die weitere Verwendung zur Verfügung ge-stellt und können aus digitalen Archiven, allgemein zugänglichen Datenban-ken und Datawarehouses bezogen werden. Die Flut an einfach zugänglicher, wissenschaftlich verwertbarer Information hat Konsequenzen für die empi-rischen Wissenschaften insgesamt und für die Sozialwissenschaften ganz be-sonders, denn oftmals ist heute nicht die Erhebung von adäquaten Daten in genügend grosser Anzahl das zentrale Problem, sondern deren Auffindung und Interpretation.
Erhobene und angefallene Daten
Mit der Verbreitung der Digitalisierung ist nicht nur die Menge an verfüg-baren Daten angestiegen, sondern es ist auch ein neuer Datentypus entstan-den. Die sogenannt «angefallenen Daten» unterscheiden sich in wesentlichen Punkten von herkömmlichen, im klassischen Sinne erhobenen Daten.
Bei den Beständen in allgemein zugänglichen Datenbanken handelt es sich in der Regel um Daten, die zu wissenschaftlichen oder kommerziellen Zwecken erhoben wurden. Sie werden gesammelt zur statistischen Verarbei-tung und sind meist gut strukturiert und ausführlich dokumentiert. Daten aus Erhebungen, die eigens für die Wissenschaft hergestellt werden, sind wissen-schaftliche «Artefakte». Das heisst, sie bilden eine künstlich geschaffene Si-tuation der Beantwortung von Fragen oder der Messung eines bestimmten Phänomens ab. Darin unterscheiden sich «erhobene Daten» von den «ange-fallenen Daten». Unter angefallenen Daten verstehen wir elektronische Auf-zeichnungen von alltäglichen Verrichtungen, die gewissermassen als Abfall-produkte der elektronischen Unterstützung und Steuerung der verschiedens-ten Lebensbereiche anfallen. Solche Spuren des alltäglichen Handelns sind keine wissenschaftlichen Konstrukte wie Befragungsdaten, Zählungen oder Messungen, sondern mehr oder weniger direkte Beobachtungen von realen Gegebenheiten.
Die Bedeutung, welche angefallene Daten heute haben, wird deutlich, wenn man sich die grosse Anzahl von elektronischen Protokollen vergegen-wärtigt, die bei Einkäufen (z.B. Scannerkassen, Geldautomaten), Reisen (z.B. SBB-Ticketautomaten) oder Kinobesuchen (z.B. Cinecard) erstellt und ge-speichert werden. Die hier aufgezählten Beispiele allein geben bereits statt-liche Datensätze mit einem grossen Potenzial für die sozialwissenschaftliche Empirie her, bilden aber dennoch nur einen kleinen Teil der elektronisch auf-gezeichneten Alltagshandlungen.

95
Eine weitere, beinahe unerschöpfliche neue Datenquelle sind im WWW publizierte Texte wie z.B. amtliche Dokumente, Protokolle, Zeitungen, Ver-anstaltungskalender usw. Auch diese Daten fallen unter den Begriff der ange-fallenen Daten, da sie nicht zum Zweck der empirischen Analyse erstellt wur-den. Die Sammlung von digitalen Texten kann mit Unterstützung von Soft-ware-Agenten, Such- und Filterprogrammen automatisiert werden, ebenso wie ihre Aufarbeitung und Integration in eine Datenbank. Auch die Struk-turierung und die inhaltliche Sortierung von Textdokumenten kann mit Hil-fe von Programmen zur Wort- und Syntaxerkennung weitgehend automati-siert werden.
Typisch für angefallene Daten ist, dass die Bedingungen, unter denen sie produziert wurden gar nicht oder nur sehr schlecht bekannt sind und dass die Daten häufig in sehr heterogener und unstrukturierter Form vorliegen. Als Spuren und Produkte des Alltags sind angefallene Daten jedoch eine wich-tige neue Quelle für die sozialwissenschaftliche Empirie.
Die Sozialwissenschaften stehen damit vor einem eigentlichen Paradig-menwechsel, was den Umgang mit Daten betrifft. Lange Zeit wurde eine Da-tenerhebung immer auf eine spezifische Hypothese ausgerichtet, die über-prüft werden sollte. Dieses deduktiv-konfirmatorische Vorgehen drängte sich deshalb auf, weil soziale Daten nur in kleinen Mengen vorhanden, Da-tenerhebungen mit grossem Aufwand verbunden und die Stichproben dem-entsprechend klein waren. Diese Voraussetzungen haben sich grundlegend gewandelt, denn grosse Mengen von elektronisch aufgezeichneten und ver-wertbaren Beobachtungen des Alltags liegen sozusagen auf der Strasse und man braucht sie nur noch aufzuheben. Neben konfirmativen Forschungsde-signs sind deshalb auch vermehrt explorative Arbeiten gefordert, um neue Erkenntnisse zu gewinnen.
Quantitative Hermeneutik
Exploratives Erkunden allein reicht jedoch nicht aus, um im Alltag an-gefallene Daten für die Wissenschaft verwendbar zu machen. Weil man den Kontext der Datenproduktion bzw. die Alltagssituation, deren Spuren aufge-zeichnet wurden, nicht kennt, ist es auch notwendig, dass man ein Verständnis davon erwirbt, was die Daten eigentlich abbilden und unter welchen Bedin-gungen sie entstanden sind. Wir sprechen in diesem Zusammenhang von ei-ner «Hermeneutik quantitativer Daten». Hermeneutik ist eine Methode aus den Geisteswissenschaften, die zum Verständnis und zur Auslegung von his-torischen Texten angewendet wird. Es besteht aus einer zirkulären Heran-gehensweise von wechselseitigem Textverstehen und Erweiterung des Vor-

96
verständnis über den Sachverhalt und seinen Kontext. Ein hermeneutisches Vorgehen eignet sich zur Deutung und Interpretation von angefallenen Da-ten, da man letztere als eine Art von «Text» betrachten kann; Text, im Sinne eines Produktes, das von «Autoren» mit einem bestimmten Sinn und Zweck hergestellt wurde (vgl. auch Hitzler/Hohner, 1997).
Zur interpretativen Verarbeitung von angefallenen Daten müssen diese in eine Ordnung gebracht werden können. Dies kann deduktiv von aussen geschehen, indem für die Codierung der einzelnen Fälle ein theoretisch ab-geleitetes Kategorienschema verwendet wird, oder aber hermeneutisch-in-duktiv. In diesem Falle wird auf die vorgängige Festlegung von ordnenden Kategorien verzichtet. Aufgrund von Ähnlichkeitsmassen wird versucht in-nere Zusammenhänge in den Daten aufzuspüren, und diese dann inhaltlich zu interpretieren. Statistische Methoden zur Reduktion der Information wie Faktorenanalyse oder Multidimensionale Skalierung (MDS) dienen dem Er-kennen von in den Daten eingelagerten Strukturen und der Schaffung von Ordnung aufgrund von Ähnlichkeiten. Zur inhaltlichen Interpretation dieser Ordnung wird mit Methoden der qualitativen Forschung (Text- bzw. Inhalts-analyse) die Bedeutung der Daten und ihr Herstellungskontext erschlossen. Durch die Kombination von quantitativ-ordnenden statistischen und qualita-tiv-inhaltlichen Verfahren, erreicht man eine Systematisierung der Interpre-tation eines Sachverhaltes, der durch die Daten abgebildet wird.
Raum als formaler Ordnungsraster
Der Zweck der obengenannten quantitativen Analyseverfahren ist die Reduktion der Komplexität auf einige wenige latente Variabeln, welche ei-nen grossen Teil der Varianz bzw. der Heterogenität der Daten erklären. Zur Veranschaulichung der relativen Unterschiede zwischen den einzelnen Fäl-len oder den Ausprägungen einer Variable werden diese häufig als Punkte in einem Raum dargestellt, dessen Dimensionen die latenten Variabeln bil-den. Die Verwendung einer solchen räumlichen Metapher zur Modellierung von mehrdimensionalen Zusammenhängen hat drei wesentliche Vorzüge: die Relationalität von Raum, seinen klassifikatorischen Charakter und das Po-tenzial für eine graphische Darstellung (vgl. Werlen, 1995).
Mit Relationalität eines Raumes ist gemeint, dass die wechselseitigen Bezie-hungen von Objekten zueinander in Form von Positionen, Abständen, und Aus-richtungen ausgedrückt werden können. Einen klassifikatorischen Charakter hat Raum, weil mit räumlichen Kategorien Ordnung geschaffen wird. In diesem Sinn ist Raum als ein formaler Ordnungsraster zu begreifen, mit Hilfe dessen belie-bige Dinge (materieller und immaterieller Natur) miteinander in Beziehung ge-

97
setzt werden können. Der dritte Aspekt – die Visualisierung – hängt eng mit der Relationalität zusammen, denn wir sind es uns gewohnt relative Distanzen, Nähe und Ferne aus einer planimetrischen Abbildung heraus zu lesen und kompetent zu interpretieren. Zudem lassen sich mehrdimensionale Phänomene visuell be-deutend einfacher und besser kommunizieren als in schriftlicher Form.
Karten metaphorischer Räume
Die kartographische Darstellung ist ein geeignetes Instrument zur Visua-lisierung von räumlichen Phänomenen. Obwohl Karten ursprünglich als Ab-bilder der Erdoberfläche konzipiert wurden und vor allem zur Orientierung und Navigation in der physisch-materiellen Welt dienten, können die Prin-zipien der Kartographie auch unabhängig vom geographischen Raum ange-wendet werden. Grundsätzlich können beliebige Sachverhalte, die räumlich repräsentierbar sind, mit Geographischen Informationssystemen modelliert und mittels Computerkartographie visualisiert werden.
Damit eine Übertragung von Methoden und Denkweisen von einer Wis-senschaft auf eine andere möglich wird, muss von ihren konkreten Anwen-dungsbereichen abstrahiert werden, so dass ihre formale Struktur freigelegt wird (vgl. Bischof 1995, S. 15ff). Sollen in diesem Sinne die Methoden von GIS und die Sprache der Kartographie fruchtbar in andere Gebiete (z.B. So-zialwissenschaften) übertragen werden, dann müssen sie von ihrer starken inhaltlichen Bindung an die Erdoberfläche losgelöst werden. Dazu bedarf es einer Erweiterung des Begriffes «Karte».
Das Konzept Karte
Die «kartographische Semiologie» (Bertin 1974) ist eine ausgereifte gra-phische Sprache, um komplexe und vielschichtige Zusammenhänge in einem mehrdimensionalen Bezugsystem darzustellen und zu kommunizieren. Ein wichtiger Grund für die Eignung von kartographischen Abbildungen für mehr-dimensionale, abstrakte Phänomene ist das weitverbreitete Verständnis von Karten und der kartographischen Sprache. Sie bietet sich geradezu an zur Vi-sualisierung von Informationen irgendwelcher Art, seien es nun Börsendaten, Bibliotheksbestände, politische Meinungsäusserungen oder Medienerzeugnis-se. Die Vorteile der kartographischen Sprache gilt es für die Exploration von angefallenen digitalen Daten zu nutzen und damit für die sozialwissenschaft-liche Forschung zu erschliessen. Im Sinne einer solchen Übertragung halten wir im Folgenden zuerst die Eigenheiten einer kartographischen Darstellung, um danach dann vom engen erdräumlichen Bezug zu abstrahieren.

98
Ältere Definitionen betonen, dass Karten einen vereinfachten und ver-kleinerten Ausschnitt der Erdoberfläche als Grundrissbild in einer Ebene ab-bilden. Neuere Definitionen zählen zusätzlich Dimensionalität und Ausrich-tung an einem geodätischen Koordinatensystem, die Darstellung von räum-lichen Beziehungen zwischen Objekten sowie die Symbolisierung von In-formation mittels graphischer Zeichen zu den Charakteristiken von Karten (vgl. Witt 1979, Dorling/Fairbairn 1997). Entkleidet man nun den gewonne-nen Kartenbegriff von seiner Fixierung auf den Erdraum, so kann das We-sen einer Karte wie folgt umschrieben werden:
Eine Karte ist eine planimetrische Darstellung und dient der Kommuni-kation von räumlichen Informationen und Zusammenhängen. Karten sind ge-neralisiert. Die Kartenobjekte werden durch konventionelle graphische Zei-chen wiedergegeben. Ihre Verortung wird möglich durch Einordnung in ein Netz von Koordinaten, die durch Raumdimensionen gegeben sind. Eine gros-se Stärke des Konzeptes Karte ist das Ebenen-Prinzip, d.h. dass verschiede-ne thematische Ebenen übereinandergelegt werden können, indem Sie auf-grund ihrer Symbolisation unterschieden werden.
Spatialization
In der Kartographie erfolgte bereits in den Sechzigerjahren eine Aufwei-chung des herkömmlichen Kartenbegriffs, als mit Mental-Maps, Kartogram-men und Zeitkarten experimentiert wurde (vgl. Dorling/Fairbairn, 1997). Die Neuerung zielte jedoch einzig auf eine flexibilisierte Geometrie ab, behielt aber die Orientierung am erdräumlichen Koordinatensystem bei. Erst in jüngster Zeit sind Anstrengungen unternommen worden, die Visualisierung von me-taphorischen Räumen weiterzuentwickeln. Unter dem Namen «Spatializati-on» hat sich eine neue Methode der Kartographie ausgebildet, die sich die ko-gnitiven Fähigkeiten des Menschen des räumlichen Denkens und Ordnens zu Nutze macht und eine konsequente Übertragung der Kartographie physischer Räume auf konzeptionelle (metaphorische) Räume umsetzt (Lakoff 1987).
Spatialization wird gegenwärtig vor allem eingesetzt, um Inhalte von Da-tenbanken mit räumlichen Kategorien wie Nähe und Entfernung zu ordnen und als Karte darzustellen (z.B. Fabrikant 1999). Das Prinzip ist einfach: Was sich inhaltlich ähnlich ist, rückt nahe zusammen und was sich unähnlich ist, rückt auseinander. Neben der Relationalität ist die Möglichkeit, dass interak-tiv in grössere Massstäbe «hineingezoomt» und somit in detailliertere Zonen der Datenbank vorgestossen werden kann, ein wesentlicher Vorteil der Kar-te als Datenbankinterface (für implementierte Beispiele vgl. URL1, URL2, für eine Übersicht vgl. URL3).

99
Fallbeispiel: Raum der Weltanschauungen
Die Resultate der eidgenössischen Volksabstimmungen sind typische Bei-spiele für angefallene Daten. Sie wurden nicht zum Zweck der Erforschung von Meinungen erhoben, sondern sind ein Abfallprodukt aus dem in der Schweiz üblichen Prozess der politischen Entscheidungsfindung. Im Rahmen des Nationalfondsprojektes «Sozialtopologie und Modernisierung» benutzen die beiden Autoren Volksabstimmungsresultate, um daraus die grundlegen-den Wertkonflikte in den politischen Auseinandersetzungen in der Schweiz zu erschliessen (vgl. Hermann/Leuthold, 2001). Die folgenden exemplarischen Erläuterungen zur Konstruktion, Interpretation und Visualisierung von an-gefallenen Daten mit Hilfe eines metaphorischen Raumes basieren auf die-sen Forschungsresultaten.
Raumkonstruktion und Interpretation
Die Ausgangsdaten der Analyse sind die Resultate aller 172 eidgenössischen Volksabstimmungen der Periode von 1981 bis 2000. Bei den Volksabstimmun-gen handelt es sich um Plebiszite zu Sachfragen aus sämtlichen Politikbereichen. Weil die Abstimmungen auf kommunaler Ebene durchgeführt und ausgezählt werden, ergibt sich ein Datensatz mit über 3000 (Anzahl Gemeinden) «Mei-nungsäusserungen» zu 172 Sachfragen. Die Ja-Stimmen-Anteile der Gemein-den zu allen Vorlagen flossen in eine explorative Faktorenanalyse ein. Daraus resultierten drei Faktoren, die nach einer VARIMAX-Rotation alle ungefähr gleich stark waren. Die drei Faktoren bilden das Bezugs- und Koordinatensys-tem für die kartographische Darstellung.
Damit die relativen Lagen der dargestellten Objekte und ihre wechselsei-tigen räumlichen Beziehungen wie Nähe oder Abstand auch interpretiert wer-den können, bedarf es einer inhaltlichen Bestimmung der Raumdimensionen. Die Benennung kann jedoch nicht allein aus den Daten heraus erfolgen, son-dern erfordert gute Kenntnisse des Sachverhaltes und der Umstände der Da-tenproduktion. Im hier vorliegenden Fall waren es die politischen Auseinan-dersetzungen zu verschiedenen Abstimmungsvorlagen, die als Entstehungskon-text für die Daten von Interesse waren.
Im Sinne eines induktiv-hermeneutischen Zugangs, wie er oben beschrie-ben ist, wurde eine qualitative Inhaltsanalyse der Abstimmungskämpfe zu den verschiedenen Vorlagen durchgeführt, um so ein Verständnis über die den Ab-stimmungsentscheiden zugrunde liegenden gegensätzlichen Werthaltungen zu erlangen. Dabei wurden jeder Sachfrage jene politischen Ziele zugeordnet, die Grundlage einer Vorlage waren bzw. zu deren Bekämpfung angeführt worden

100
waren. Aufgrund der Faktorenladungen der Abstimmungen und der politischen Ziele wurden die drei Faktoren als weltanschauliche Grundkonflikte identifiziert. Die drei Komponenten wurden entsprechend der jeweils spezifischen Kombi-nation der darauf ladenden politischen Ziele mit Links gegen Rechts, Liberal gegen Konservativ und Ökologisch gegen Technokratisch bezeichnet.
Die Punktwolke der Variablen im Faktorraum ist die Grundlage für die uns hier interessierenden Modellierungen. Der Informationsgehalt eines ein-fachen Scatterplots wird durch den Einsatz von einfachen Konzepten der The-makartographie gesteigert. Abbildung 1 zeigt eine zweidimensionale Ansicht des Raums der Weltanschauungen mit den beiden Achsen Rechts vs. Links und Liberal vs. Konservativ. Die im Raum der Weltanschauungen verorteten poli-
Abb. 1: Lage und Häufigkeit der politischen Ziele im Raum der Weltan-schauungen (aus: Hermann/Leuthold 2001)
-0.4-0.8 0.80.4
-0.4
-0.8
0.8
0.4
Wertorientierte Ziele
Institutionelle Ziele
Sachziele
(Grösse entspricht Häufigkeit)
Nationale Unabhängigkeit
Ausgabenreduzieren
Atomenergie
DirekteDemokratie
Parlamen-tarismusKultur-
förderung
EuropäischeIntegration
Gleichstellungder Frau
Öffnungnach Aussen
MilitärischeVerteidigung
Pazifismus
TraditionellerLebensstil
SelbstbestimmterLebensstil
Arbeitnehmer-schutz
SozialeWohlfahrt
WirtschaftlicheEigenverantwortung
Recht undOrdnung
Autoritätskritik
Abgrenzunggegen Fremde
Integrationvon Fremden
Föderalismus
Zentralismus
Institutionelle Reformen
Zivildienst
Handels- undUnternehmensfreiheit
(Liberal)
(Konservativ)
(Lin
ks)
(Rechts)
3. F
akto
r
2. Faktor
Lagen, Häufigkeiten, Wege

101
tischen Ziele sind als Kreisscheibendiagramme dargestellt, wobei die Kreisflä-che proportional zur Häufigkeit des Vorkommens des entsprechenden politi-schen Ziels in allen Abstimmungskämpfen ist. Weitere Merkmalsebenen kön-nen durch die Verwendung unterschiedlicher Farben und Symbole dargestellt werden. So zeigen die unterschiedlichen Grauwerte die Zugehörigkeit der Zie-le zu einer inhaltsanalytischen Kategorie an.
Zum Wesen und zur Stärke von Karten gehört, dass darin nicht nur die abso-lute Lage von Informationseinheiten erkennbar ist, sondern auch relative Bezü-ge und Verbindungen ersichtlich werden. Dieses Charkteristikum kann genutzt werden, indem nicht nur lokale Signaturen, sondern auch inhaltliche Verbin-dungen zwischen den dargestellten Objekten mit Hilfe von einfachen Kanten eingetragen werden. Verschiedene Variablen erscheinen dabei als themati-sche Ebenen (Layers).
Hochschule
HöhereFachschule
Maturität
HöhereBerufsschule
Berufsschule
Grundschule
Landwirtschaft
Dienstleistungen
Produktion
< Fr. 30'000
. Fr. 30-40'000
Fr. 50-75'000
Fr. 40-50'000
> Fr. 75'000
Reineinkommen
Wirtschaftssektoren
Schulabschluss
Rechts
Liberal
Links
Konservativ
Abb. 2: Sozialstruktur und Weltanschauung in der deutschen Schweiz

102
Grundlage der Darstellung in Abbildung 2 sind die Faktorwerte der Ge-meinden. Eingetragen sind die Lagen einiger wichtiger sozialstruktureller Indikatoren der deutschen Schweiz. Mit Linien verbunden spannen die drei Wirtschaftssektoren ein Dreieck auf. Es wird ersichtlich, dass die linke Welt-anschauung des zweiten Sektors mit einer konservativen und die des dritten Sektors mit einer liberalen Weltanschauung gekoppelt ist.
Besonders geeignet sind lineare Verbindungen zwischen räumlichen La-gen zur Darstellung von ordinal skalierten Merkmalen. Die Verbindungslinie der Einkommensklassen in Abbildung 2 verläuft von unten nach oben paral-lel zur Achse Konservativ-Liberal. Daraus wird deutlich, dass in der Deutsch-schweiz der Konflikt zwischen einer konservativen und einer liberalen Ein-stellung mit den verfügbaren Ressourcen zusammenhängt. Schliesslich kön-nen auch zeitliche Veränderungen als Spuren durch einen metaphorischen Raum gelegt werden, indem die Position einer Gemeinde zu verschiedenen Zeitpunkten dargestellt und verbunden werden.
Regionalisierung
Eine weitergehendene Analyse als die blosse Positionierung eines Mittel-wertes ist die Modellierung von Regionen in metaphorischen Räumen. Eine Menge von Punkten, die sich aufgrund eines Merkmales ähnlich sind (z.B. Gemeinden mit ähnlicher Wirtschaftsstruktur oder derselben Amtssprache) und auch eine ähnliche Lage im Raum der Weltanschauung haben, wird als Zone abgebildet.
Mit der Bildung von Regionen wird nicht nur der Streuung Rechnung getragen, sondern aus der Gestalt von Regionen kann auch zusätzliche In-formation über das von der Region repräsentierte Merkmal herausgelesen werden. Die Bedeutung von Gestalt kommt in Abbildung 3 zum Ausdruck. Sie zeigt die Regionalisierung des Raumes der Weltanschauungen aufgrund der sprachregionalen Dreiteilung der Schweiz. Die längliche Form aller drei Sprachregionen lässt den strengen positiven Zusammenhang zwischen linker und ökologischer Weltanschauung innerhalb einer Kulturregion erkennen.
Die einfachste Methode zur Regionenbildung ist die Berechnung einer Umhüllenden (Konvexhülle) um alle Objekte, die sich durch ein gemeinsa-mes Merkmal auszeichnen. Die Problematik dieser geometrischen Art der Re-gionalisierung ist, dass sie durch Ausreisser bestimmt wird. Statistische Ver-fahren zur Klassierung wie z.B. Cluster- oder Diskriminanzanalysen liefern ebenfalls nicht in jeder Hinsicht befriedigende Resultate, da sie eine eindeu-tige und ausschliessliche Zuordnung der Merkmalsträger zu einer bestimm-

103
ten Region vornehmen. Sich gegenseitig durchdringende Punktwolken, die jedoch signifikant verschiedene Mittelzentren haben, sind damit schwierig zu behandeln.
Ein anderer Zugang zur Regionalisierung kann mit dem Einsatz von GIS-Methoden erreicht werden. Mit sogenannten fokalen Funktionen wird für je-den Punkt eines Raums auf der Basis von benachbarten Merkmalsträgern ein Wert berechnet. Fokale Funktionen können zur Berechnung von Regiona-lisierungen beigezogen werden, indem für jeden Punkt des Raums ein Kon-zentrations- bzw. Dichtewert aus den Werten der umgebenden Merkmals-träger berechnet wird. Die Verdichtungszonen in Abbildung 3 wurden mit einem Gausschen Kernel-Dichtealgorithmus berechnet. Somit gehören zur Verdichtungszone der deutschen Schweiz alle Punkte im Raum der Weltan-schauungen, in deren Nachbarschaft relativ viele und/oder grosse deutsch-sprachige Gemeinden liegen. Ausschlaggebend für die Gestalt der Verdich-tungszonen ist schliesslich die Festlegung des minimalen Dichtewertes als Grenzwert der Region (z.B. 2% des Maximalwertes). Ein solcher sollte em-pirisch ermittelt werden.
Ökologisch
Links Rechts
Technokratisch
ProtestantischKatholisch
ProtestantischKatholisch
Katholisch
Deutsche Schweiz
Französische Schweiz
Italienische Schweiz
Verdichtungszonen
Abb. 3: Sprachkulturelle und konfessionelle Regionalisierung im Raum der Weltanschauungen

104
Die Regionalisierungen in Abbildung 3 sind als einfache Zonen darge-stellt. Dadurch wird ein wesentlicher Teil der bekannten Information über die Verdichtungszonen nicht gezeigt. Das Produkt einer Dichteberechnung ist eine stetige Oberfläche, die den Konzentrationswert an jedem Ort angibt. Anstatt nur ein Schnitt oder eine Konturlinie dieser Oberfläche zu zeichnen, kann die Oberfläche selber dargestellt werden.
Metaphorische Landschaften
Durch die Verbreitung von standardisierten kartographischen Darstellung der Geländemorphologie besteht heute ein verbreitetes Verständnis für zwei-dimensionale Darstellungen von Oberflächen, Bergen und Tälern. Schräg-lichtschattierung und farblich gebänderte Höhenstufen sind Sprachelemen-te, die alle mehr oder weniger geübten Leser von topographischen Karten verstehen. Auf diese Darstellungsform kann immer zurückgegriffen werden, wenn stetige Oberfläche dargestellt werden sollen.
Abb.4: Politische Landschaft der Schweiz
Ökologisch
Links Rechts
Technokratisch
Franzšsische Schweiz
Deutsche Schweiz
Italienische Schweiz

105
In Abbildung 4 sind die Verdichtungszonen der drei grossen Sprachregio-nen als Oberflächen umgesetzt. Durch den Einsatz von Algorithmen zur Be-rechnung der Schräglichtschattierung, werden nicht nur die Umrisse, sondern auch die Dichteunterschiede innerhalb der gegebenen Umrisse sichtbar. Der metaphorische Raum wird dadurch zu einer Art Landschaft, aus der die ver-schiedensten Zusammenhänge gelesen werden können. Die beiden mächti-gen Gebirgsketten der französischen und der deutschen Schweiz haben beide ihre höchsten Erhebung an den linksgrünen Enden. Dies, weil in den grossen Städten der deutschen wie auch der französischen Schweiz eine linkere und ökologischere Weltanschauung dominiert als in den Kleinstädten und Land-gemeinden des jeweiligen Landesteils.
Ein weiterer Vorzug der Umsetzung metaphorischer Räume als Land-schaften ist, dass mehrere Informationsebenen integriert werden können. Wie bei einer topographischen Karte kann der metaphorischen Karte ein Merk-mal (z.B. Einwohnerzahl, Anzahl Stimmberechtigte) als Höhenwert ange-geben werden und ein weiteres Thema für Einfärbung der Oberfläche (z.B. Amtssprache) verwendet werden. Über dieses Grundthema können weitere Ebenen mit linearen und punktförmigen Elementen gelegt werden, wie sie weiter vorne vorgestellt wurden.
Schlussbemerkung
Mit den Ausführungen zur Konstruktion und zur Visualisierung des Raums der Weltanschauungen sollte ein Eindruck vermittelt werden, wel-che Möglichkeiten Spatialization und vor allem die Visualisierung mit kar-tographischen Methoden für die Exploration von angefallenen Daten bietet. In Anbetracht der bereits bestehenden Fülle von digital verfügbarer Infor-mation und der zu erwartenden Zunahme von statistisch auswertbaren Da-ten als Abfallprodukte des alltäglichen Handelns, sehen wir einen steigen-den Bedarf für Werkzeuge zur Strukturierung und Erkundung von Daten in den empirischen Sozialwissenschaften.
Ein grosses Potenzial für die Anwendung von Spatialization liegt im Be-reich des WWW. Das weitverbreitete Verständnis für Karten in der Bevölke-rung ist eine gute Grundlage um komplexe Informationen auf anschauliche Art zu vermitteln. Besonders interessant ist eine solche Karte, wenn sie lau-fend (on-the-fly) neu generiert bzw. aktualisiert wird, indem frisch angefal-lene Daten direkt verarbeitet und integriert werden. Über das WWW kann ein Benutzer nicht nur die Karte betrachten, sondern kann, so wie es bei di-gitalen Stadtplänen bereits heute üblich ist, geometrische, auf räumlicher

106
Nähe basierende Auswahlen treffen, thematische Selektionen vornehmen oder einzelne thematische Ebenen zuschalten. Darüber hinaus ist es denk-bar, dass sich ein Benutzer aufgrund eigener Angaben in einem Online-For-mular selber in der Karte positioniert. In diesem Sinne wird die hermeneuti-sche Exploration von Alltagsspuren zumindest teilweise individualisiert und dem Endbenutzer überlassen bzw. an den Endbenutzer delegiert.
Die Realisierbarkeit einer Informationsplattform im WWW, so wie sie hier kurz skizziert wurde, liegt durchaus im Bereich des Möglichen, denn die verschiedenen dazu notwendigen Technologien sind vorhanden und werden auch angewandt. Dennoch besteht unseres Wissens noch keine solche inte-grierte Plattform mit der Verwendung von Spatialization. Unseres Erachtens sind Raummetaphern und die universelle kartographische Sprache geeigne-te Instrumentarien dafür und könnten zu einer Art Standard in der interak-tiven Kommunikation von heterogener, teilweise vorstrukturierter Informa-tion im WWW werden.

107
Literatur
Bertin, J. (1974): Graphische Semiologie, New York.
Bischof, N. (1995): Struktur und Bedeutung. Eine Einführung in die System-theorie, Bern.
Dorling, D./Fairbairn, D. (1997): Mapping: Ways of Representing the World, Essex.
Fabrikant, S. I. (1999): Spatial Metaphors for Browsing Large Data Archi-ves, Dissertation am Department of Geography an der University of Boul-der, Colorado.
Lakoff, G. (1987): Women, Fire, And Dangerous Things: What Categories Reveal About The Mind, Chicago.
Hermann, M./Leuthold, H. (2001): Weltanschauung und ihre soziale Basis im Spiegel eidgenössischer Volksabstimmungen. In: Schweizerische Zeitschrift für Politikwissenschaft, 7 (4).
Hitzler, R./Hohner A. (1997): Hermeneutik in der deutschsprachigen Sozio-logie heute. In: Hitzler, R. und A. Hohner: Sozialwissenschaftliche Herme-neutik. Eine Einführung, Opladen.
Werlen, B. (1995): Sozialgeographie alltäglicher Regionalisierungen. Band 1Zur Ontologie von Gesellschaft und Raum, Stuttgart.
Witt, W. (1979): Lexikon der Kartographie, Wien.
URL1: http://www.smartmoney.com/marketmap/
URL2: http://www.webmap.com/
URL3: http://www.cybergeography.org/atlas/info_maps.html

108

109
IHA·GfM Online Research - Ein Griff aus unserem Erfahrungsschatz
Rena Snoy / Roland HuberOnline Research IHA·GfM
Die ersten hohen Wellen für das Medium Internet und den daraus resul-tierenden Möglichkeiten haben sich geglättet. Dennoch blickt das Online Re-search der IHA·GfM auf zwei bewegte und intensive Jahre zurück.
Welche Online Studien haben sich etabliert?
Welche Ansätze haben weiteres Entwicklungspotential?
Wie geht es weiter?
Internet-Penetration in der Schweiz
Die gesamtschweizerische Internet-Penetration beträgt gemäss Stand No-vember 2001 49,1 Prozent. Die Anzahl Internet-User ist somit in der Schweiz seit Juni 2001 von 47 Prozent nur noch leicht gestiegen. Das Geschlechterver-
©
���������������������� ������
N=10070
9.9
20.9
27.6
21.4
14.2
6.0
0.0 10.0 20.0 30.0 40.0 50.0
15-19 Jahre
20-29 Jahre
30-39 Jahre
40-49 Jahre
50-59 Jahre
60-74 Jahre %
%
%
%
%
%
Angaben in %

110
hältnis nähert sich an: 43 Prozent Frauen-Anteil, 57 Prozent Männer, die das Internet täglich bis weniger häufig nutzen. Hinsichtlich Altersklassen zeigt sich folgende Häufigkeitsverteilung:
Quantitative Website Evaluierungen
Usability Tests oder Checks sind die grossen Schlagwörter zur Evaluie-rung von Websites.
Einige Unternehmen haben sich auf rein technische Varianten speziali-siert, andere gehen die Untersuchungen von Websites qualitativ an. IHA·GfM hat gute Erfahrungen sowohl mit dem qualitativen und quantitativen An-satz gemacht.
WebProfiler
Eine quantitative standardisierte Kurzform mit Focus auf die Website-besucher stellt der WebProfiler dar. Der WebProfiler wird als selbstrekrutie-rendes Erhebungs-Tool auf der zu untersuchenden Website als PopUp-Fens-ter installiert. Je nach Besucheranzahl der Website pro Tag oder Woche wird die entsprechende Kadenz eingestellt, um nach ca. 1 Woche eine Stichpro-bengrösse von n=500 zu erhalten. Kernfragen des Instruments richten sich auf das Profil der Website-Besucher:
Wie oft nutzen die Besucher die Website?, Wie wurden die Besucher auf die Website aufmerksam?, Aus welchen Gründen wurde die Website besucht?, Was erwartet der Besucher von der Website?, Sind die Erwartungen erfüllt? Diese Daten werden mit dem demographischen Profil der Besucher komplettiert.
Response-Rates von den bisher durchgeführten Studien aus den ver-schiedensten Branchen bestätigen diese effiziente Erhebungsmethode zum User-Profil einer Website. Die bisherigen Erfahrungen zeigen, dass zwischen 13 Prozent und 20 Prozent aller Besucher, die den Fragebogen online offe-riert erhalten, den Fragebogen auch tatsächlich komplett ausfüllen.
Online Mitarbeiter- und Kundenzufriedenheitsstudien
Stichwort Response-Rates: Online Mitarbeiter- und Kundenzufrieden-heitsstudien bieten die höchsten zu erwartenden Response-Rates.
Seit 1996 misst IHA·GfM zweimal jährlich das Führungsverhalten der Vorgesetzten, die Motivation und die Gesamtzufriedenheit ihrer Mitarbei-

111
ter. Der 12. Ted-Monitor (telefonische Befragung) wurde im Juni 2001 erst-mals online durchgeführt. Die neue Art der Umfrage stiess - übrigens, wie auch andere Studien zeigen, nicht nur bei den eigenen Mitarbeitern - auf sehr grosse Akzeptanz. 68 Prozent der Teilnehmer fanden die Art der Umfrage sehr gut, 28,1 Prozent gut. Personen, die normalerweise nicht den Umgang mit dem PC oder dem Internet gewohnt waren, erhielten auf Wunsch eine persönliche Unterstützung durch die Online Research-Hotline und zeigten grosse Begeisterung, sogar einen gewissen Stolz über ihre schnell erworbe-nen Fähigkeiten im Umgang mit dem Online Fragebogen.
Bereits am ersten Tag nach Umfragestart zeichnete sich eine Beteiligung von 41 Prozent ab. Die Beteiligung am 5. Tag und somit am Ende der Studie hat mit 85,4 Prozent einen neuen Rekordwert erreicht.
Mitarbeiter- und Kundenzufriedenheitsstudien sind ebenfalls ein gutes Beispiel für die Effizienz der Online Methode. So ist es kein Wunder, dass Sie als «Spitzenreiter» in der Online Research-Hitparade fungieren. Viele Unter-nehmen haben die Möglichkeiten dieses Tools entdeckt. Eine anfangs 2001 online durchgeführte Mitarbeiterbefragung für einen Anbieter von Laborau-tomationssystemen brachte ebenfalls eine Responserate von 71 Prozent.
Einzige Voraussetzung für die online Befragung ist, einen Internetzugang für alle zu befragenden Mitarbeiter zu gewährleisten.
Überzeugt von diesem innovativen Instrument hat sich die Hirslanden Holding entschlossen anfangs 2002 – in Anlehnung an die Volkszählung, ihre Mitarbeiterinnen und Mitarbeiter online zu befragen. Mitarbeiter, die den Fragebogen nicht online ausfüllen wollen, können auf die konventionnelle Papierversion zurückgreifen. Wir dürfen schon auf die Verteilung online ver-sus schriftlich gespannt sein.
Folgende Argumente sprechen für Online Befragungen:
• Hohe Teilnehmermotivation
• Höchste Flexibilität für die Befragten
• Anonymität erhöht die Mitteilungsbereitschaft und die Offenheit der Mitteilung
• Hohe Response-Rates – besonders bei kurzen Mitarbeiterbefragungen
• Hohe Transparenz und hoher Aktualisierungsgrad durch Online Reporting

112
• Qualitativ hochstehende Datensätze durch computergestützte Datener-fassung bei offenen Fragen
• Schnell verfügbare Ergebnisse
• Attraktives Kosten-/Leistungsverhältnis
• Weltweite Durchführbarkeit
Webbasierte Interviews bei spezifischen Zielgruppen
Neben den online Kundenzufriedenheits-Studien haben sich auch WebI-nterviews zu internetspezifischen und internetunabhängigen Themen etab-liert. Hier richten sich unsere Studien meist an eine spezielle Zielgruppe, die auch im Internet repräsentiert ist.
Neben der Zielgruppe der Jugendlichen haben wir auch eine sehr inte-ressante Studie mit und über die Menschen im Alter ab 50 Jahren durch-geführt. Es handelte sich dabei um eine PopUp-Befragung auf den Sites www.bluewin.ch und auf www.seniorweb.ch.
Interessanterweise zählt laut dieser Studie das Internet unter 21 abge-fragten Wirtschaftsbranchen zu den Gewinnern. Während heute ungefähr 15 Prozent der Menschen ab 50 Jahren im Internet aktiv sind, erwarten die Be-fragten bis in fünf Jahren eine Steigerung auf 30 Prozent, bis in zehn Jahren eine Steigerung auf 45 Prozent. In fünf Jahren wäre demnach der Anteil der Internet-Nutzer ab 50 doppelt so hoch, in zehn Jahren dreimal so hoch wie heute. Am meisten nutzt die befragte Zielgruppe das Internet zum E-Mailen, Informationen beschaffen und Bankgeschäfte elektronisch abwickeln.
Neben den PopUp-Befragen erfreuen sich E-Mail-Befragungen mit in-tegriertem Link ebenfalls grosser Beliebtheit. Erleichternd für die Realisie-rung einer solchen Umfrage wirkt die Tatsache, dass IHA·GfM auf einen In-ternet Access-Pool von annähernd 3000 Internet-Usern aus der Deutsch- und Westschweiz zugreifen kann, die sich bereit erklärt haben, höchstens einmal im halben Jahr an Internet-Studien teilzunehmen.
Mehrstufige Konzepte – qualitativ und quantitativ
Um den Faden zum Beginn des Artikels wieder aufzunehmen, wird auf die Kombination von einem qualitativen und quantitativen Ansatz einge-gangen.

113
Sehr interessant haben sich die Studien entwickelt, die nach diesem- auch sonst in der Marktforschung oft üblichen Model der Mehrstufigkeit aufge-baut sind. Die Rede ist von einem qualitativen Ansatz in Form von Online Focus Groups (Abb.1) gepaart mit einer quantitativen Evaluierung, die die Hypothesen aus der Vorphase überprüft.
Im November 2001 führte die IHA·GfM Online Reseach in Zusammen-arbeit mit dem Institut für Medien- und Kommunikationsmanagement in St. Gallen eine empirische Studie zur Qualität im Internet durch.
Um den Fragebogen zur Qualität von Internetangeboten zu erstellen und um das Thema besser auf die Bedürfnisse der Internet-User ausrichten zu können, haben wir im Sommer 2001 eine Reihe von Online Focus Groups durchgeführt, bei denen jeweils sechs bis sieben Teilnehmer in neunzigminü-tigen, moderierten online chats mit eingeblendeten Websites über die Quali-tät von Websites diskutieren konnten. Bei den Teilnehmern dieser Gruppen handelte es sich um sieben Personen im Ruhestand, sieben Studierende, so-wie sechs aktive Managerinnen und Unternehmer.
Abbildung 1
©
• �������������� �� �� ����������������
• �������������� �� �� ����������������• ����� �������������� ��������������������� �• � ��� ����������������������� �!��������� ����� ���� �• �����"�#�$#� �����• ������� �������� �����%����� ������������&�� �����������
'��(�������� ��)���* ��������
•+����������� � ����,������������
•'��� � ��������
•-�� �����������
•.������ ������� ������� �����* ����������
•������� �)� �� �� �������� �
•����*� �������
•/����������0���� ��� ������)����
���������������
� ��������������������������������������
����������� ��

114
Abbildung 2
Abbildung 3

115
Basierend auf den Vorschlägen, Meinungen und artikulierten Proble-men dieser Teilnehmer in Bezug auf die Qualität von Internetinhalten wur-de ein Fragebogen (die Befragten erhielten eine E-Mail mit einem Link, der zu dem Fragebogen führte) erstellt, den 919 Internet-Nutzer aus der Schweiz ausgefüllt haben. Von den retournierten Fragebögen wählten wir diejenige aus, welche bis zum Schluss ausgefüllt wurden. Dies ergab eine Datenbasis von 673 Fragebögen. Die Studie zeigte, dass die Qualität der Infrastruktur (d.h. die Zugänglichkeit, Sicherheit, Wartung und Schnelligkeit der Websi-te) und die Qualität der Website Inhalte (Kompaktheit, Korrektheit, Kon-sistenz, Aktualität) einen direkten Einfluss auf die Loyalität (ob die Website wieder besucht wird oder nicht) hat. Qualitativ hochwertige, auf spezifische Zielgruppen ausgerichtete und gut erschliessbare Inhalte führen tendenziell zu treuen Usern. Als Ärgerpunkte oder Qualitätsmängel stellten sich lange Ladezeiten, tote oder falsch gesetzte Links, Registrierungen, viele Klicks bis zur gewünschten Information, automatisch aufgeschaltete Fenster, Banner Werbung, Flash Intros und lange Scroll-Texte heraus.
WebCheck InDepth – qualitativer Ansatz zur Website Evaluierung
Ein weiterer qualitativer Ansatz im Bereich Online Research sind Websi-te Evaluierungen durch Tiefeninterviews. Bei diesem Ansatz wenden wir die Methode des «Lauten Denkens» an; d.h. der Proband wird von einem psy-chologisch geschulten Interviewer gebeten auf der zu untersuchenden Websi-te zu surfen, während des Surfens laut zu denken und alles mündlich zu kom-mentieren, was er/sie macht und warum er/sie es macht.
Die Website Evaluierung (WebCheck InDepth) ist in verschiedene Pha-sen eingeteilt: Zunächst soll der Proband frei surfen und dabei laut denken. Dann erhält er eine Aufgabenstellung wie zum Beispiel «Suchen Sie auf die-ser Website....» Während die Aufgabe gelöst wird, achtet der Interviewer dar-auf, wie viel Zeit der Proband benötigt, um seine Aufgabe zu lösen. Eben-falls werden die Mausbewegungen und das «Laute Denken» aufgenommen, so dass bei der späteren Analyse auf diese Aufzeichnungen zurückgegriffen werden kann.
In einer aktuellen Website Evaluierung nach dieser Methode haben wir reifere Frauen in unser Testlabor eingeladen, um eine Informations-Website im Gesundheitsbereich beurteilen zu lassen. Hier zeigte sich, dass sowohl die Probandinnen als auch unser Auftraggeber von dieser Methode überzeugt waren. Durch die 1:1 Surfsituation konnte das Surfverhalten der Testperso-nen sehr gut nachempfunden werden.

116
Wie geht es weiter?
Welche Studien werden sich im Online Bereich durchsetzen? Aufgrund des bekundeten Interesses unser Kunden gehen wir davon aus, dass online Mitarbeiterbefragungen und online Befragungen von strategisch wichtigen Kunden in Zukunft noch mehr an Relevanz gewinnen werden.
Erwähnenswert ist allerdings auch, dass die Online Erhebung nicht als das «non plus ultra» angesehen werden soll. Diese Methode unterliegt ge-wissen Beschränkungen: Es können noch immer keine bevölkerungsreprä-sentativen Studien für die Schweiz durchgeführt werden. Trotzdem hat sich die Methode bewährt. Immer mehr Kunden haben die Möglichkeiten dieser innovativen, schnellen und effektiven Methode entdeckt.
Auf jeden Fall wurde die Marktforschung durch das Internet um eine weitere Methode bereichert. IHA·GfM ist bereit für den nächsten Griff aus ihrer Schatztruhe: Was dürfen wir Ihnen anbieten?

117
Verzeichnis der AutorenListe des auteurs
Bühlmann, Hans, Prof. Dr. (Emeritus)Nidelbadstrasse 22, CH - 8803 Rüschlikon
Diekmann, Andreas, Prof. Dr.Universität Bern, Institut für Soziologie, Unitobler, Lerchenweg 36, CH - 3000 Bern 9 Tel. 031 631 48 17, E-Mail: [email protected]
Gsponer, ThomasEPF Lausanne, Departement Mathématiques Appliquées, CH - 1015 LausanneTel. 021 693 27 84, E-Mail: [email protected]
Herman, MichaelUniversität Zürich, Geographisches Institut, Winterthurerstrasse 190, CH - 8057 ZürichTel. 01 635 51 87, E-Mail: [email protected]
Huber, Roland IHA-GfM, Obermattweg 9, CH - 6052 HergiswilTel. 041 632 94 73, E-Mail: [email protected]
Krämer, Walter, Prof. Dr.Universität Dortmund, FB 05, D - 44221 DortmundTel. 0049 231 755 31 25, E-Mail: [email protected]
Leuthold, HeiniUniversität Zürich, Geographisches Institut, Winterthurerstrasse 190, CH - 8057 ZürichTel. 01 635 51 54, E-Mail: [email protected]
Malaguerra, Carlo, Dr.Ancien Directeur Office fédéral de la statistique / Hausmattweg 43, CH – 3074 Muri b. Bern

118
Morgenthaler, Stephan, Prof. Dr.EPF Lausanne, Département Mathématiques Appliquées, CH - 1015 LausanneTel. 021 693 25 65, E-Mail: [email protected]
Snoy, Rena IHA-GfM, Obermattweg 9, CH - 6052 HergiswilTel. 041 632 94 18, E-Mail: [email protected]
Stahel, Werner, Dr.ETH Zentrum Zürich, Seminar für Statistik, CH - 8092 ZürichTel. 01 632 34 30, E-Mail: [email protected]
Das Bundesamt für Statistik (BFS) hat – als zentrale Stati-stikstelle des Bundes – die Aufgabe, statistische Informatio-nen breiten Benutzer kreisen zur Verfügung zu stellen.
Die Verbreitung der statistischen Information geschieht ge gliedert nach Fachbereichen (vgl. Umschlagseite 2) und mit ver schiedenen Mitteln:
En sa qualité de service central de statistique de la Con-fédération, l’Offi ce fédéral de la statistique (OFS) a pour tâche de rendre les informations statistiques accessibles à un large public.
L’information statistique est diffusée par domaine (cf. verso de la première page de couverture); elle emprunte diverses voies:
Publikationsprogramm BFS Programme des publications de l’OFS
Nähere Angaben zu den verschiedenen Diffusions mitteln liefert das laufend nachgeführte Publikations ver zeich nis im Internet unter der Adresse www.statistik.admin.ch >>News>>Neuerscheinungen.
La Liste des publications mise à jour régulièrement, donne davantage de détails sur les divers moyens de diffusion. Elle se trouve sur Internet à l’adresse www.statistique.admin.ch>>Actualités>>Nouvelles publi-cations.
Statistisches Jahrbuch der Schweiz 2002, inkl. CD-ROM, Neuchâtel 2002 (via Buchhandel oder NZZ-Verlag erhältlich)
Kantone und Städte der Schweiz – Statistische Übersichten 2002 / Bestell-Nr. 043-0200
Szenarien zur Bevölkerungsentwicklung der Schweiz 2000-2060, Neuchâtel 2002; Bestell-Nr. 201-0200
Demographisches Porträt der Schweiz 2001, Neuchâtel 2001; Bestell-Nr. 479-0100
Für das Leben gerüstet? Die Grundkompetenzen der Jugendli-chen – Nationaler Bericht der Erhebung PISA 2000, Neuchâtel 2002; Bestell-Nr. 470-0000
Kosten des Gesundheitswesens – Methoden, detaillierte Ergebnisse und Entwicklung 1995-1999; Bestell-Nr. 026-9900 (Ergebnisse für das Jahr 2000 als Pressemitteilung erhält-lich)
Arbeitsmarktindikatoren 2001, Neuchâtel 2001; Bestell-Nr. 206-0100
Mode Effects in Panel Surveys: A Comparison of CAPI and CATI, Neuchâtel 2001; Bestell-Nr. 448-0100 (BFS aktuell)
Annuuaire statistique de la Suisse 2002, y compris CD-ROM, Neuchâtel 2002 (disponible en librairie ou chez l’éditeur NZZ)
Cantons et villes suisses – Données statistiques 2002, Neuchâtel 2002; numéro de commande 043-0200
Les scénarios de l’évolution démographique de la Suisse 2000-2060, Neuchâtel 2002; numéro de commande 202-9200
Portrait démographique de la Suisse 2001, Neuchâtel 2001; numéro de commande 480-0100
Préparés pour la vie? Les compétences de base des jeunes – Rapport national de l’enquête PISA 2000; numéro de com-mande 471-0000
Coûts du système de santé – Méthodologie, résultats détaillés et évolution 1995-1999, Neuchâtel 2002; numéro de com-mande 026-9900 (Résultats pour l’année 2000 disponibles sous forme de communiqué de presse)
Indicateurs du marché du travail 2001, Neuchâtel 2001; numéro de commande 206-0100
Mode Effects in Panel Surveys: A Comparison of CAPI and CATI, Neuchâtel 2001; numéro de commande 448-0100 (Actualités OFS)
Diffusionsmittel Kontakt Moyen de diffusion No à composer
Individuelle Auskünfte 032 713 60 11 Service de renseignements individuels [email protected]
Das BFS im Internet www.statistik.admin.ch L’OFS sur Internet
Medienmitteilungen zur raschen Information www.news-stat.admin.ch Communiqués de presse: information rapideder Öffentlichkeit über die neusten Ergebnisse concernant les résultats les plus récents
Publikationen zur vertieften Information 032 713 60 60 Publications: information approfondie(zum Teil auch als Diskette/CD-Rom) [email protected] (certaines sont disponibles sur disquette/CD-Rom)
Online-Datenbank 032 713 60 86 Banque de donées (accessible en ligne) www.statweb.admin.ch
Hinweise auf Publikationen Choix de titres

Ende 2000 organisierten erstmals die Organe und Vereinigungen der amtlichen, der universitären und der privatwirtschaftlich tätigen Statistik die «Statistiktage Schweiz». Idee der Veranstaltung war es, den Dialog zwischen den Akteuren aus den einzelnen Segmenten der statistischen Tätigkeit zu fördern, sie im Statistikmarkt Schweiz zu positionieren und Gemeinsamkeiten und Trennendes zu klären. Dies bedingt unter anderem, sich der gesellschaftlich-kulturellen Rah-menbedingungen bewusst zu werden und wichtige Entwicklungslinien zu erkennen. Der vorliegende Band enthält einige Referate, die den Stellenwert der Statistik im politischen und wissenschaftlichen Umfeld behandeln, sowie aktuelle Aspekte aufgreifen, so zum Beispiel zum Umgang mit riesigen Datenmengen, zur Visuali-sierung von Ergebnissen und zum richtigen Gebrauch statistischer Informationen.
Les «Journées suisses de la statistique» réunissaient pour la première fois, fi n 2000, des spécialistes issus des milieux universitaires, de l’économie privée et des institutions de la statistique publique. L’idée d’une telle manifestation était de promouvoir le dialogue entre ces différents secteurs, de les situer sur le marché de la statistique suisse et de mettre en évidence ce qui les rapproche et ce qui les dis-tingue. Il importe, à cet effet, de bien comprendre les réalités sociales et culturelles qui constituent le cadre des activités statistiques et d’en appréhender les grandes orientations. La présente plaquette contient un choix d’exposés qui portent sur le rôle de la statistique en relation avec le contexte politique et scientifi que, ainsi que sur certains problèmes d’actualité, tels que le traitement de masses de données, la visualisation des résultats et l’utilisation correcte des informations statistiques.
Bestellnummer: Bestellungen: Preis:No. de commande: Commandes: Prix:Order Number: Orders: Price: 539-0000 032 713 60 60 Fax: 032 713 60 61 11.– ISBN 3-303-00245-2
Institut für angewandte Mathematik, Statistik, InformatikInstitut für Marktanalysen AG, Hergiswil SPSS (Schweiz) AG, Zürich




















