
Scene pathfinder: unsupervised clustering techniques for movie scenes extraction
22
Scene pathfinder: unsupervised clustering techniques for movie scenes extraction Mehdi Ellouze & Nozha Boujemaa & Adel M. Alimi Published online: 5 August 2009 # Springer Science + Business Media, LLC 2009 Abstract The need for watching movies is in perpetual increase due to the widespread of the internet and the increasing popularity of the video on demand service. The important mass of movies stored in the Internet or in VOD servers need to be structured to accelerate the browsing operation. In this paper, we propose a new system called "The Scene Pathfinder" that aims at segmenting the movies into scenes to give users the opportunity to have a non- sequential access and to watch particular scenes of the movie. This helps them to judge quickly the movie and decide if they have to buy or to download it and avoiding waste of time and money. The proposed approach is multimodal. We use both of visual and auditory information to accomplish the segmentation. We base on the assumption that every movie scene is either action or non- action scene. Non-action scenes are generally characterized by static backgrounds and occur in the same place. For this reason, we base on the content information and on the Kohonen map to extract these kinds of scenes (shots agglomerations). Action scenes are characterized by high tempo and motion. For this reason, we base on tempo features and on the Fuzzy CMeans to classify shots and to localize the action zones. The two processes are complementary. Indeed, the over segmentation that may occur in the extraction of action scenes by basing on the content information is repaired by the Fuzzy clustering. Our system is tested on a varied database and obtained results show the merit of our approach and that our assumptions are well- founded. Keywords Video . Scene detection . Video browsing . Movies- shots clustering . Video processing . Video segmentation Multimed Tools Appl (2010) 47:325–346 DOI 10.1007/s11042-009-0325-5 M. Ellouze (*) : A. M. Alimi REGIM: Research Group on Intelligent Machines, University of Sfax, ENIS, BP 1173, Sfax 3038, Tunisia e-mail: [email protected] A. M. Alimi e-mail: [email protected] N. Boujemaa INRIA: IMEDIA Team, BP 105, Rocquencourt, 78153 Le Chesnay Cedex, France e-mail: [email protected]
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Scene pathfinder: unsupervised clustering techniques for movie scenes extraction

Scene pathfinder: unsupervised clustering techniquesfor movie scenes extraction
Mehdi Ellouze & Nozha Boujemaa & Adel M. Alimi
Published online: 5 August 2009# Springer Science + Business Media, LLC 2009
Abstract The need for watching movies is in perpetual increase due to the widespread ofthe internet and the increasing popularity of the video on demand service. The importantmass of movies stored in the Internet or in VOD servers need to be structured to acceleratethe browsing operation. In this paper, we propose a new system called "The ScenePathfinder" that aims at segmenting the movies into scenes to give users the opportunity tohave a non- sequential access and to watch particular scenes of the movie. This helps themto judge quickly the movie and decide if they have to buy or to download it and avoidingwaste of time and money. The proposed approach is multimodal. We use both of visual andauditory information to accomplish the segmentation. We base on the assumption that everymovie scene is either action or non- action scene. Non-action scenes are generallycharacterized by static backgrounds and occur in the same place. For this reason, we baseon the content information and on the Kohonen map to extract these kinds of scenes (shotsagglomerations). Action scenes are characterized by high tempo and motion. For thisreason, we base on tempo features and on the Fuzzy CMeans to classify shots and tolocalize the action zones. The two processes are complementary. Indeed, the oversegmentation that may occur in the extraction of action scenes by basing on the contentinformation is repaired by the Fuzzy clustering. Our system is tested on a varied databaseand obtained results show the merit of our approach and that our assumptions are well-founded.
Keywords Video . Scene detection . Video browsing . Movies- shots clustering .
Video processing . Video segmentation
Multimed Tools Appl (2010) 47:325–346DOI 10.1007/s11042-009-0325-5
M. Ellouze (*) : A. M. AlimiREGIM: Research Group on Intelligent Machines, University of Sfax, ENIS, BP 1173, Sfax 3038, Tunisiae-mail: [email protected]
A. M. Alimie-mail: [email protected]
N. BoujemaaINRIA: IMEDIA Team, BP 105, Rocquencourt, 78153 Le Chesnay Cedex, Francee-mail: [email protected]

1 Introduction
Nowadays peoples are confronted to a great mass of information which is at the same timeimportant and difficult to exploit. The causes of this problem may be summarized into tworeasons. First, the acquisition machines become more and more sophisticated with popularprices. Now, we speak about cameras with mega pixels of resolution and with gigabytes ofstorage capacities. Second, the internet invaded all houses. The increasing bit rate and theevolution of compression techniques encouraged people to share big quantities ofinformation. Internet is not only the biggest network in the world but also the biggestdatabase.
In our previous works [11–13, 19, 20, 22] we have been interested to the news videoarchives and how to accelerate the browsing of news video archives. In this paper we willbe interested to movies and to movies archives
The movie industry is one of the greatest producers of video (movies). According toIMDB web portal [18], we have until now an important stock of movies representing a totalof thousands of hours. According to [36], the video-on-demand service becomes more andmore popular with millions video-on-demand homes in the United States. VOD is projectedto grow from its availability on approximately 53% of U.S. cable households to nearly 75%in the near future. Much of the attention is focused on the delivery of movies and networktelevision programming.
In front of this great mass of movies, the challenge for every user is to find what heneeds rapidly. The solution suggested by researchers is to segment every movie intosemantic entities and to give users the opportunity to have a non-sequential access and towatch particular scenes in the movie. This can help him to judge the importance of themovie to avoid waste of time. As it is difficult and time consuming to segment every movieinto scenes, the proposed systems are fully automatic. As a part of this research field, wepropose in this paper a robust and automatic method to do this segmentation. The videosegmentation and especially the video shot segmentation is not a new research field. It datessince the nineties.
Brunelli et al. [5] define the structuring of the video as decomposing the stream intoshots and scenes. A shot consists of a sequence of frames recorded by one cameracontiguously and representing a continuous action in time or space. A video scene consistsof a sequence of semantically correlated shots [25] (see Fig. 1).
Frame 1
Frame n
Shot
Scene
Video
Fig. 1 The video structure
326 Multimed Tools Appl (2010) 47:325–346

Now, the video shot detection systems have matured and become able to detect all typesof transitions with considerable recall and precision rates [10].
However, the video scene detection problem is more complicated and it is still asking formore work. Indeed, the major problem of scenes detection is the lack of an exact criterionto define a scene boundary. The only heuristic which may be used is that the shotsbelonging to one scene share the same actors and occur at the same moment and in thesame place. For this reason, as shown in the Fig. 2, all the proposed works proceed in threesteps to accomplish video scenes detection. First, the movie is segmented into shots.Second, a representative image is computed for every shot. Some works do not use onlyone representative frame but several frames. The Final step is the extraction of signaturesfrom these representative images and their grouping into scenes.
As a part of this effort, we propose in this paper a novel approach for video scenesdetection. It builds on the observations that video scenes may be discovered throughdiscovering shots agglomerations and that to avoid the over segmentation that occurs in thedetection of some scenes containing actions shots, a localization of action zones may beuseful. This new vision of scenes detection is proposed to remedy problems of classicapproaches which use one-to-one shot similarity to delimit the scenes.
The rest of the paper will be organized as follows; in section 2, we discuss works relatedto video scenes detection. In section 3, we will state the problem, present our approach anddetail our contribution. Results of our approach are shown in section 4. We conclude withdirections for future work.
2 Related works
We can classify all the proposed works into two categories: unimodal perspective andmultimodal perspective. The first perspective is based only on visual signatures to groupshots visually similar and temporally close. In this perspective we can evoke the importantand the pioneering work of Yeung et al. [42]. In this work, authors base on the assumptionthat every scene has a repetitive shot structure and use graphs to detect scenes boundaries.Each node of the graph represents a shot and the transitions between two nodes areweighted according to the visual similarity and to the temporal locality of the twocorresponding shots. This approach is effective with dialog scenes. However, it may failwith the other kinds as actions scenes (See Fig. 3). In their work, Riu et al. [33] have theadvantage of integrating the motion information to measure the similarity between twoshots. As Yeung et al. [42], they use the time locality and the visual similarity to groupshots in the same scene. The major drawback of their approach remains their clusteringalgorithm which depends heavily on many parameters and thresholds. Rasheed and Shah[32] follow the same trail of Riu et al. [33] by integrating the motion information in thecriteria of shots grouping. Their main contribution consists in basing on global similaritiesof shots and graph partitioning to cluster shots and to extract scenes. However, theirclustering technique is relatively complex. Besides, the integration of the motioninformation in the similarity measure is so straightforward. Hanjalic et al. [15] suggested
Shot Detection Computing representative
image(s) Shots Grouping
Detected scenes Original movie
Fig. 2 The general framework of scenes extraction
Multimed Tools Appl (2010) 47:325–346 327

a new way to compute shots keyframes through concatenating all shot images. Theirclustering algorithm is based on the block matching to measure the similarity of thekeyframes. They use 2 sliding windows to do the clustering and to detect scene boundaries.The two windows start from a given shot and perform a forward and a backward search tofind the nearest matching shot. The problem of this approach is also the important numberof parameters on which it depends. In fact, we have to fix the size of the matchingthreshold, the size of backward window and the size of the forward window. Tavanapongand Zhou [38] use the same clustering algorithm proposed by Hanjalic et al. [15]. However,they suggest a new way to compute the similarity between the shots. They compute colorfeatures only for the shots corners because they suppose that in the shots of a same sceneonly the corners remain unchanged. This is not always true and especially in action scenes.This assumption may be applicable for static dialog scenes. But its validity in action scenesis doubtful. Similarly to [15], authors in [43] and [40] proposed two approaches based alsoon sliding windows which try to gather successive similar shots. [40, 43] differ from [15]by their similarity measures and their clustering algorithms. However, as for [15] theproblem of this technique (the sliding window) remains the choice of the window size andof the sliding strategy. Yeo and Kender [21] proposed a memory based approach to segmentvideo into scenes. A buffer is used to store shots of a same scene. New shots will be addedto the buffer by measuring the visual distance between the incoming shots and the shots ofthe buffer. Ngo et al. [30] proposed an approach that performs a motion characterization ofshots and backgrounds mosaicking in order to reconstruct the scenes and to detect theirboundaries. Similarly, Chen et al. [9] proposed an approach for scenes detection basing onmosaic images. They do not represent every shot by one keyframe or a set of keyframes,but by a mosaic image in order to gather the maximum of information from the shot. Afterthat they extract from every mosaic image color and texture signatures and they base onsome cinematic rules to group shots into scenes. The idea of representing a shot by amosaic image is interesting. However, the creation of mosaic images is still a researchproblem. Besides, basing on cinematographic rules to detect some types of scenes is notalways efficient for two reasons. First, cinematographic rules are general rules, they change
Fig. 3 An example of an action scene
328 Multimed Tools Appl (2010) 47:325–346

continuously and filmmakers transgress always these rules. Second, quantifying cinemat-ographic rules effectively is still a difficult problem [14].
In the same way, authors in [6] have been based on cinematographic rules to detectscenes boundaries. They proposed to establish a finite state machine designed according tocinematographic rules and scenes patterns to extract dialog or action scenes. In [7] authorspresented a scene change detection system using an unsupervised segmentation algorithmand object tracking. Objects tracking will help to compute correlations between successiveframes and shots to detect scenes boundaries. In [26] Lin et al. presented an approach thatperforms in two steps to detect scenes boundaries. First a shot segmentation is performed.To describe well the significant changes that may occur into shots, some of them may besegmented into sub-shots. After that, scenes boundaries are extracted by analyzing thesplitting and merging force competitions at each shot boundary. The main drawback of [7,26] resides in the used features. Indeed they employed only the color information. This isnot always efficient, especially for action scenes.
The number of works done in the second perspective is not important relatively to thenumber of works proposed in the first one. In this perspective, we can evoke the well knownwork of Sundaram and Schang [37] in which authors define a scene as contiguous segment ofdata having consistent long term audio and video characteristics. They detect audio scenesbasing on ten auditory features and a sliding window that tries to detect significant changes.Nearly the same thing is done on the visual bound. The final step of the process is the mergeof the visual scenes and the auditory scenes to have the final scenes boundaries. In the sameperspective, we can evoke also the work of Huang et al. [17] in which authors follow thesame trail of Sundaram and Schang [37]. To detect scenes boundaries, they detect colorbreaks, audio breaks and motion breaks. They base on the assumption that a scene breakoccurs only when we have the 3 kinds of break at the same time.
3 Proposed framework
3.1 System framework
We think that to have an efficient system for scenes detection, we have to understand how thesescenes have been made. As it is said in [35], the video is the result of an authoring process.When producing a video, an author starts from a conceptual idea. The semantic intention isthen articulated in (sub) consciously selected conventions and techniques (rules) for thepurpose of emphasizing aspects of the content. In this section, we will have a quick look onsome important cinematic rules on which the majority of movies are built. According to [1,14, 41] there are 4 important rules used by filmmakers to make scenes and shots:
& Rule 1: The 180° Rule. This rule dictates that the camera should stay in one of the areason either side of the axis of action.
& Rule 2: Action Matching Rule. It indicates that motion direction should be the same onin two consecutive shots that record the continuous motion of actor
& Rule 3: Film Rhythm Rule. It indicates the perceived rate and regularity of sounds,series of shots, and motion within the shots. Rhythmic factors include beat, accent, andtempo. In same scene, the shots have the similar rhythm.
& Rule 4: Establishing Shot. It shows the spatial relations among the important figures,objects, and setting in a scene. Usually, the first and the last few shots in a dialog sceneare establishing shots.
Multimed Tools Appl (2010) 47:325–346 329

After reading these 4 rules we can deduce 2 important things. First, according to Rule 1,3 and 4, when trying to relax audience filmmakers use long shots with commonbackgrounds and surroundings, repetitive camera angles for subsequent shots, and usequiet auditory bounds constituted essentially of speech and silence segments [24]. Second,according to Rule 2 and 4, when trying to excite the viewer, filmmakers use sound effectswith a rough visual boundary to impose a tempo and a rhythm on the viewer. Basing onthese rules and these heuristics, we suggest a scene extraction approach composed of threesteps. The first step consists in using the visual content information to do a preliminaryscene detection. The second step consists in localizing action zones. Finally, in the thirdstep we merge the results of the two first ones.
In fact, the presence of action zones may cause an over segmentation because the visualcontent of shots of action scenes changes enormously. This over segmentation may berepaired by merging scenes that intersect with the same action zones.
Our approach is multimodal approach. Indeed, as filmmakers use visual and auditorymodalities to transmit their cinematographic messages, we think that proposing amultimodal approach will augment the chances of the success of the system. Relativelyto existing multimodal systems, our contribution consists in proposing a new way ofintegrating of the visual and the auditory information to determine scene boundaries.Existing systems use many rules to merge the results of the two kinds of boundaries. We donot agree with Sundaram and Schang who affirm in [37] that “audio data must be used tofind exact scenes boundaries and not only for identifying important regions or detectingevents as explosions in video sequences” because in a given scene the audio data andcontrary to visual data is changing a lot even in a dialog scene. In one scene, we may havesilences, male voices, female voices, car sounds, musical backgrounds... The ranges inwhich vary the auditory features will be wide. So it will be very difficult to delimit correctlythe scenes using the audio data. We agree in considering the auditory information importantto correctly detect scenes boundaries. However, their role must be corrective and especiallyin detecting action scenes. For this reason, the used features are not classified into visualand auditory features as the entire multimodal approaches have done, but into tempofeatures and content features to detect respectively action scenes and non-action sceneswhich are the principle categories of scenes (see Fig. 4).
The second contribution consists in proposing a new method for the detection of non-action scenes using content features and on the Kohonen map. In fact, in contrary to all theproposed works (unimodal and multimodal approaches), we extract scenes by localizing theagglomerations of shots and not by basing one-to-one shot similarity.
The third contribution consists in proposing for action scenes a new method totallydifferent from those used for the detection of the other kinds of scenes. In action movies,
Scenes
Action Scenes Non Action Scenes
Car chase War and gunfire Dialogue Monologue Landscape Fight Romance
Fig. 4 The general taxonomy of movie scenes
330 Multimed Tools Appl (2010) 47:325–346

where we have a lot of action scenes, we base on shots classification using Fuzzy CMeansand tempo features (motion, audio energy, shot frequency) to localize action scenes.
Indeed, there is sometimes over segmentation that may occur when extractingaction scenes through basing only on the content information. This over segmentationis repaired by localizing the action zones and merging scenes intersecting with thesame action zones (see Fig. 5)
3.2 Preliminary scene extraction
A scene is defined in [1] as a segment of a narrative film that usually takes place in asingle time and place, often with the same characters. As it is mentioned in the pioneeringwork of Yeung et al. [42], shots belonging to the same scene are characterized by twoimportant things. First, they share nearly the same surroundings and many commonobjects. Second, they are temporally close. For this reason, and as the majority ofproposed works [9, 15, 26, 30, 32, 33, 38, 42, 43] we will base on these criteria to clustershots.
Excepting [32, 42] which use the graph theory, all the others use one-to-one shotsimilarity and thresholds fixed by empiric studies to extract scenes. Basing on one-to-oneshot similarity may be particularly convenient because even the shots of a same scene aregenerally different and the direct comparison may be not useful. However, if we comparethem to shots of other scenes, they share some common properties as the background. Sogrouping shots into scenes must be done relatively to other shots and not through findingsimilarities between them.
To accomplish this, we will base on pattern recognition techniques and particularly theclustering techniques which are suitable to do such kind of processing. The clusteringoperation tries to gather elements that share common properties relatively to the otherelements basing on descriptors that quantify these properties.
To discover the shots agglomerations (scenes), we have to choose the rightdescriptors which can discriminate the shots suitably. Shots belonging to the samescene share two important things: the general luminance and the background (seeFig. 6).
Scene 1 Scene 2 Scene 3 Scene 4 …….. ……. ………. ………. ………... Scene n
Tempo Features (Mot, Audio Enrg, Shot Freq)
Content Features (HSV color hist, Four hist)
Fuzzy 2-Means
+
Results Fusion
Kohonen Map
Fig. 5 The scene pathfinder
Multimed Tools Appl (2010) 47:325–346 331

& The luminance information of a given image is the brightness distribution or theluminosity within this image. Generally two different scenes have two differentluminosities due to the difference in lighting conditions, in places and in time when thescenes take place (indoor, outdoor, day, night, cloudy weather, sunny weather…).
& The background information is also important because it describes the surroundings andthe place where the scene takes place. To extract the background information we baseessentially on two descriptors color and texture. Color is a general descriptor for allkind of backgrounds. Texture is also an important information for textured backgroundsas forests, buildings… (see Fig. 7)
To extract the luminance and the background information we used the standard HSV colorhistogram and the Fourier histogram. HSV histogram is a classical color signature in the HSVcolor space. This signature makes available information about color content of the image in itsnon-altered state. Its performances are good compared to other color signatures [4].
The Fourier histogram signature is computed on the gray level image and it containsinformation about the texture and scale. These two descriptors already existed in ourIKONA CBIR engine [4] and tested in many contexts in the field of image processing ascontent based image retrieval, relevance feedback, etc.
Dark luminosity Sunny luminosity
Fig. 6 The luminosity is one of the common features of shots belonging to the same scene
Fig. 7 The texture plays a key role to cluster shots
332 Multimed Tools Appl (2010) 47:325–346

3.3 Scenes agglomeration discovering through Kohonen maps
One of the drawbacks of proposed approaches is the fact that they based on one-to-one shotsimilarity instead of studying the agglomerations. Kohonen maps [23] proved theirperformance in doing that. We have already used them to do a macro-segmentation. In ourprevious work [13], we used the Kohonen map to segment news broadcast programs intostories by discovering the cluster (the agglomeration) of anchor shots. They are well suitedfor mapping high dimensional vectors (shots) into two dimensional space. In fact, theKohonen map is composed of two layers: the input layer which corresponds to the inputelements and an output layer which corresponds to a set of connected neurons. Every inputelement is represented by a n-dimensional vector X = (x1, x2, …, xn) and connected to mnodes of the map through weights Wij (see Fig. 8).
The mechanism of the Kohonen map may be summarized as follows:
& The connection weights are randomly initialised& For every input vector the weights of the connections linking this vector to the
neurons are updated. The key idea introduced by Kohonen maps is theneighbourhood relation. In fact, to keep the relation between all the neighbournodes, not only weights of the wining node are adjusted, but those of theneighbours are also updated. Thus, a node whose weight vector closely matchesthe input vector will have a small activation level, and a node whose weightvector is very different from the input vector will have a large activation level.The node in the network with the smallest activation level is deemed to be the"winner" for the current input vector. The further the neighbour is from thewinner, the smaller its weight changes.
& We compute the wining node using the following formula:
j� ¼ argmin j
Xni¼1
XiðtÞ �WijðtÞ� �2 ð1Þ
Fig. 8 The structure of the Kohonen map
Multimed Tools Appl (2010) 47:325–346 333

& The weight of the wining neuron is modified at every iteration as follows:
WijðtÞ ¼ Wij t � 1ð Þ þ aðtÞ XiðtÞ �Wij t � 1ð Þ� � ð2Þ& The weight of the neighbouring neurons is modified at every iteration as follows:
WijðtÞ ¼ Wij t � 1ð Þ þ aðtÞhj j�; tð Þ XiðtÞ �Wij t � 1ð Þ� � ð3ÞWhere “t” represents the time-step and a(t) is a small variable called the learning ratewhich decreases with time. h(t) represents the amount of influence of the trainingsample on the node. It is computed as follows:
hj j�; tð Þ ¼ exp� j� j�k k22r2ðtÞ ð4Þ
Where r(t) is the neighbourhood radius which typically decreases with time.
As we have already mentioned we compute for every shot two features the HSV colorhistogram and the Fourier histogram. The concatenation of these two features constitutes avector of 184 components. For every movie, we trained a Kohonen map with vectorsrepresenting the shots of this movie. As a result of the training process, every shot (trainingexample) will be attributed to a node (wining node).
After training the Kohonen map, we tried to discover the shots agglomerations thatrepresent the scenes of the movie (see Fig. 8). In fact, if we map the definition of a scene onthe Kohonen map we can say that it is the set of shots located in the same zone in the map.A zone in the map is identified by a set of nodes. After training the Kohonen map, everyshot is attached to a unique node called the wining node. So, shots attached to neighbouringnodes may eventually belong to a same scene.
In order to extract scenes from the Kohonen map, we base on the two followingassumptions. First, two shots which belong to the same scene either belong to one node orto two neighbouring nodes (see Fig. 8). Second, shots belonging to one scene must be alsotemporally close. As in [32], we fix the temporal threshold at 30 seconds. Two shots A andB belong to the same scene only if (MA-MB) is above 30 seconds, where MA and MB arerespectively the middle frames of the shots A and B. This threshold is discussed in theexperimentation section.
The pseudo code of our clustering algorithm is shown in the Fig. 9. First, we determinethe wining neuron of every shot. Then, if two shots, have the same wining neuron or theirwining neurons are neighbouring (direct neighbours, see Fig. 8) and they are temporallyclose (the temporal distance between their middle frames is above 30 seconds), therefore wewill put them into the same scene. At the end, if two scenes have one or more commonshots then they will be automatically merged into one scene. Besides, if two scenes aretemporally intersecting they will be also merged.
For instance if a given scene A contains the shot i, the shot i+2 and the shot i+3 and a scene Bcontains the shot i+1 and the shot i+4 then A and B will be merged into one scene. In fact, ascene may contain shots that are completely different and do not share any common object (seeFig. 10). The temporal continuity of the scene allows gathering all these shots.
3.4 Localizing action zones
The major drawback of all proposed works is the fact that they do not have a specific process tolocalize action zones. They use the same process to extract all kinds of scenes. They compute a
334 Multimed Tools Appl (2010) 47:325–346

list of features (generally visual features and features dealing only with the content) for all shotsand after that they cluster shots to detect the scenes boundaries. Some works as [32, 33] try tointroduce in this list of features some specific features as motion to take into account the caseof action scenes. After that they do an early fusion of all features before starting the clusteringprocess. However, this remains insufficient. In fact, in action scenes the visual content ischanging a lot and the tempo is nearly the same (high). So, the features describing the contentmay distort the clustering process and there is a chance to have an over segmentation. That’swhy in the majority of works the results are getting worst with action movies.
An action scene is characterized by 3 important phenomena [1, 41]. First, it contains alot of motion: motion of objects (motion of actors, motion of cars…) and camera motion(pan, tilt, zoom…).That’s why shots of the same scene do not share any commonbackground or surroundings. The second phenomenon is the special sound effects used toexcite and stimulate the viewer attention. Filmmakers amplify the actor voices. Theyintroduce explosions and gunfire sounds from times to times… The third importantphenomenon is the duration and the number of shots per minute. Action scenes are filmedby many cameras. For this reason, the filmmaker is switching permanently between allcameras to film the scene from many views.
INPUT: Video file (i.e., movie), Shot boundaries data
OUTPUT: Scene Boundaries
BEGIN
Scenes_Set={}
/* Extracting preliminary scenes from every clip */
Compute for every shot the feature vector (HSV and Fourier, see section 3.2)
Training the Kohonen map with the computed feature vectors
Compute for every shot the wining neuron
Compute for every neuron the immediate neighbours
Scenes_Set= {} /* set of intermediate scenes*/
For (every shoti of the movie not belonging to any scene) Do
WNi= wining neuron of shoti
Sci= new scene containing shoti
For (every shotj in the movie other than shoti ) Do
WNj= wining neuron of shotj
/* checking if the two shots have the same wining neuron or
their wining neurons are immediate neighbours */
If (((WNi= WNj) or (Neigh (WNi, WNj) ==true)) and ((shoti-shotj) <30s))
Add shotj to Sci
End If
Done
Add Sci to Scenes_Set
Done
/* Refining the extracted scenes*/
Merging all intersecting scenes (having one or more common shots)
Merging all temporally intersecting scenes /*(ex:{shoti,shoti+2,shoti+3}and{shoti+1,shoti+4})*/
/* Detecting action zones to remedy to over-segmentation*/
Compute for every shot the tempo feature vectors (see section 3.4)
Classify all the shots using the Fuzzy 2-Means
Extract the class of action shots and delimiting action zones
Merging all scenes intersecting with the same action zone
END
Fig. 9 Pseudo code of the scene pathfinder
Multimed Tools Appl (2010) 47:325–346 335

After a deep study of these phenomena, we suggest to quantify them by a need of threedescriptors that will be computed for every shot and on which we will base to cluster theseshots. These descriptors will be detailed in the next sections.
3.4.1 Motion activity analysis
The intensity of motion activity gives the viewer an information about the tempo of themovie. The motion intensity of a given segment tries to capture the intensity of the action ofthis segment [8, 34]. Action scenes have a high intensity of action due to high cameramotion and motion of objects. For non-action scenes as dialog scenes we have a lowintensity of action because we have generally fixed camera and static objects.
Many descriptors have been proposed to measure the motion activity. The Lukas Kanadeoptical flow [28] is often used to estimate the motion of one shot. It is used to estimate thedirection and the speed of objects motion from one frame to another in the same shot. Theestimation of optical flow is based on the assumption that the image intensity is constantbetween two times t and t+dt. This assumption may be mathematically formalized by thefollowing equation:
Ixuþ Ixvþ It ¼ 0 ð5ÞIn this equation Ix, Iy and It are the spatiotemporal image brightness derivatives, u is thehorizontal optical flow, and v is the vertical optical flow.
Let u(t,i), v(t,i) denote the flow computed between two frames of one shot andaveraged over the ith 16 x16 macroblock . The spatial activity matrix is defined asfollows:
Acti;j ¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiu t; ið Þ2 þ v t; ið Þ2
qð6Þ
The activity between two frames is computed by averaging the motion vectorsmagnitudes of macroblocks over the entire frame. It is computed as follows:
FrAct ¼ 1
NBlock
Xi
Xj
Acti;j ð7Þ
Fig. 10 An example of a scene that takes place in more than one place
336 Multimed Tools Appl (2010) 47:325–346

where NBlock is number of macroblocks in the frame. The activity of a shot is the averageof its frames activities. It is computed as follows:
ShotAct ¼ 1
NFrame
Xk
FrActk ð8Þ
Where NFrame is the number of frames per shot
3.4.2 Audio energy analysis
The audio bound has an important contribution to interpret the tempo of the movie.Action scenes are generally characterized by musical backgrounds with many soundeffects. As in [27], in order to discriminate between voiced and unvoiced sounds,researchers use generally the energy. Unvoiced sounds like music and sound effectshave a larger dynamic range than speech. They are generally characterized by animportant energy. We propose to compute the Short-Time Average Energy of theauditory bound of every shot. The Short-Time Average Energy of a discrete signal isdefined as follows:
E shotnð Þ ¼ 1
N
Xi
sðiÞ2 ð9Þ
Where s(i) is the discrete time audio signal, “i” is the time index and N is the number ofaudio samples of the Shotn. We have to mention that we compute the energy of everyshot of the movie. We aim at distinguishing energetic shots.
Indeed, the Fig. 11 displays to the variation of the Short-Time Average Energy of amovie. The picks correspond to action zones in the movie and the hollows are generallydialog scenes in which we find either silences or speech zones that are characterized by alow energy.
3.4.3 Shot frequency
Action scenes are characterized by an important number of short shots that stream rapidly.Our idea is to compute the shot frequency (i.e.) the number of shots per minute relatively toa given shot (the reference shot). We place every shot in the center of an interval of oneminute. After that we count the number of shots that belong to this interval (see Fig. 12).This number is the third feature of every shot.
Shots
Fig. 11 Audio short time energy of a movie
Multimed Tools Appl (2010) 47:325–346 337

3.4.4 Using Fuzzy CMeans to extract action shots
After computing for every shot the three features: Motion, audio energy and shotfrequency, the final step consists in using all these features to discriminate betweenaction and non-action shots. Two ways may be explored in this case. Either we baseon some heuristics and thresholds or we base on pattern recognition techniques.Pattern recognition techniques and in particular unsupervised clustering techniques aresuitable for doing such kind of task. They display a great efficiency in doing classesdiscrimination. Besides, our work is a typical problem of unsupervised clustering. Thenumber of classes is known: the class of action shots and the class of non-actionshots. One of the clustering techniques is the Fuzzy–CMeans introduced by Bezdeck[2]. The Fuzzy C-Means (FCM) algorithm is an iterative clustering method that producesan optimal C partitions, which minimizes the weighted within group sum of squared errorobjective function Jq(U,V)
Jq U ;Vð Þ ¼Xnk¼1
Xc
i¼1
uikð Þqd2 xk ; við Þ ð10Þ
Where X ¼ x1; x2; :::; xnf g � Rp is the set the of data items, n is the number of data items,c is the number of clusters with 2 � c � n, Uk is the degree of membership of xk in the ith
cluster, q is a weighting exponent, on each fuzzy membership, vi is the prototype of thecenter of cluster i, d²(xk,vi) is a distance measure between object xk and cluster center vi .A solution of the object function can be obtained via an iterative process. Themembership matrix (U)ij is randomly initialized. At each iteration we compute the newvalues of the coefficients of the matrix (U)ij and the new centers of each cluster. In ourcontext we have two classes. The data items are shots represented by vectors composed of3 components (motion, audio energy and shot frequency). At the end of the clustering,every shot is attributed to the cluster to which it has the highest membership degree. Afterthat, we extract the class of action scenes by finding the class with the higher values ofmotion. The action shots will be temporally ordered to localize exactly the action zones asit is shown in the Fig. 13.
However, action scenes do not start directly with action shots. They start by calm shotsand clam tempo and as time goes by, the tempo and the rhythm increase [1]. Besides, theygenerally finished by clam shots. This is not problematic for us because we do not aimthrough the detection of action zones to find the exact scenes boundaries. We aim atlocalizing action zones to remedy the over segmentation that may occur when extracting thescenes from the Kohonen map.
The results of the Fuzzy CMeans classifier will be the detection of the cores of actionscenes (action zones). Continual action zones will help us to merge over-segmented scenes.The preliminary scenes extracted from the Kohonen map that are intersecting with the sameaction zone will be merged.
An interval of 60 s
Fig. 12 The shot frequency relatively to the selected reference is 10
338 Multimed Tools Appl (2010) 47:325–346

4 Experiments
4.1 Scene change detection
To show the efficiency of our system we conduct experiments on five movies as shown inTable 1. This database has been already used by authors in [9] to test their approach.
We choose to test our system on this database for two reasons. First, this databaseincludes movies belonging to different cinematographic genres. And this will help us to testour system correctly (many kinds of scenes). Second, as we will compare our system to thatproposed in [9], it will be suitable to use the same database.
We use the recall and the precision rates as the measures of performance. They aredefined as follows:
recall ¼ Nc
Ngð11Þ
Precision ¼ Nc
Nc þ Nfð12Þ
Where Ng is the number of scenes of the ground truth, Nc is the number of scenes correctlydetected and Nf is the number of scenes wrongly detected.
The ground truth has been generated by two real users. We explained the definition of ascene to the two users before giving them the database. After that we asked every user towatch every movie of the database and to delimit the scenes. The results of the twosegmentation processes were merged to generate the final scenes boundaries.
Table 1 shows that our system presents in general encouraging results. However, theseresults vary according to the genre of the film. The best results are made with action movies(“Bugs” and “Dungeons and Dragons”). This shows the efficiency of our strategy ofextracting action scenes which is the weak spot of the majority of approaches. The majorproblem of action scenes remains always the significant change of lighting such asexplosions and flashing lights. As features related to tempo do not deal with content
Fig. 13 The temporal distribution of the classified video shots. Red squares represent action shots and greensquares represent non-action shots
Multimed Tools Appl (2010) 47:325–346 339

information the classification of shots into action/non-action shots using the Fuzzy CMeansclassifier was at the same time efficient and very useful to remedy the problem of oversegmentation.
Encouraging results are also shown in the movie “Little Voice”. This proves the merit ofthe Kohonen map in delimiting non-action scenes. Dramatic movies are essentiallycomposed of dialog scenes in which characters discuss into decors having many commonobjects and backgrounds. These encouraging results show that discovering shotsagglomerations is advantageous and this will be proved in the section (4.3), when wecompare our system to other systems in which authors base on one-to-one shot similarity tocluster shots into scenes.
However, there is more work to do in the context of comedic and musical movies. Thesekinds of movies do not respond to the common cinematographic rules. For instance, incomedic movies a given scene may evolve in different contexts and in different decors.That’s why the Kohonen map may miss a lot of scenes and make a lot of false detectionsbecause shots of one scene may be located in different zones of the map. For this reason,we have to think to add a third path to our system and use other kinds of assumptions tofind these kinds of scenes.
We have to mention also that there are some scenes which are ambiguous, and it is very hardto delimit them automatically. These kinds of scenes will be discussed in the following section.
4.2 Analysis of the ambiguity of some scenes
To establish the limitations of our technique and of scenes detection systems in general, it isimportant to discuss some types of scenes which are ambiguous and very difficult to delimitthem automatically.
Some consecutive scenes may occur in the same place or in the same conditions. Forinstance, in the movie “Dungeons and Dragons” many successive scenes take place in theforest (common background and common texture). The boundaries of these scenes areindistinguishable. Visual features and clustering techniques are incapable to delimit themproperly.
Lighting conditions may also perturb the detection process, especially when theconsecutive scenes take place at night or in indoor dark places. In these conditions, thebackground is very dark and the foreground objects as faces or decor elements areindistinguishable. We have encountered this kind of scenes in the movie "Bugs". Manyscenes of this movie take place in a train tunnel. This kind of scenes causes anundersegmenation for our system and for the majority of systems in general because thevisual information and even the auditory information are not able to distinguish betweenthese scenes.
Table 1 Experimental results with ground truth
Video title Genre Duration( min)
Scenes Correctdetection
Misseddetection
Falsedetection
Recall Precision
Bugs Action 82 76 63 13 15 82.89 80.76
Dungeons and Dragons Action 107 66 57 9 4 86.36 93.44
Little Voice Drama 96 141 117 24 29 82.97 80.13
Walk the Line Music 136 118 82 36 46 69.49 64.06
Hot Chick Comedy 104 104 77 27 16 74 82.79
340 Multimed Tools Appl (2010) 47:325–346

Multi-angular scenes are also ambiguous scenes. The visual coherence between the shotsof a multi-angular scene is reduced because they are filmed with many cameras and displaydifferent kinds of background and foreground objects. As example we may cite the dialogscenes which take place in streets (crowd scenes). In these scenes actors discuss, and fromtime to time we may see a passing car, a passing person, a building, a neon sign… In thiskind of scenes using the global visual features to cluster shots is not very efficient. Localvisual features may be the suitable solution.
Moreover, as shown in Fig. 14, the scenes that include shots having different camerasdistances are also ambiguous and may cause an over segmentation. As mentioned byBordwell and Thompson [3], we distinguish eight different types of shots: extreme longshot, long shot, medium long shot, medium close-up, medium shot, close-up, extremelong shot and extreme close-up. Indeed, due to cameras zooms we may have a mastershot followed by a close up shot followed by medium long shot… Clustering techniquesusing classical distances may not be very efficient in these conditions.
Our system and the systems proposed in the literature in general, are essentiallybased on the visual information. To delimit some ambiguous scenes we proved thatthe visual information is not very efficient. We think also that the solution may notcome from the auditory information for the reasons evoked in section 2. However, wethink that the solution can come from the textual information generated throughautomatic speech recognition. A deep semantic analysis of the textual informationthrough natural language processing techniques (NLP) may help in delimiting thesescenes. A study of the speeches of actors may be done to detect significant changesin linguistic concepts.
The solution may also come from users interacting to correct some defaults in delimitingthese ambiguous scenes. However, this solution may extend the achieving time of thescenes detection process.
3
4
+
3
4
4
4
3
3
4
0
1
0
Fig. 14 A scene including shots that have different cameras distances
Multimed Tools Appl (2010) 47:325–346 341

4.3 Determining the temporal tolerance factor τ
The temporal tolerance factor is the threshold used to decide if two similar shots belong tothe same scene. As in [32] we make a study to fix the suitable tolerance factor. We studiedhow the recall and the precision rates vary against the tolerance factor for the movies“Bugs” and “Walk the Line”. The movie “Bugs” is an action movie characterized by shortshots and short scenes. In this movie, the mean and standard deviation of scene duration arerespectively 106.27s and 106.48s. However, the movie “Walk the Line” is a musical moviecharacterized by long shots and scenes. In this movie, the mean and standard deviation ofscene duration are respectively160.59s and 60.37s.
The Fig. 15 shows that the threshold 30 seconds it is suitable for delimiting scenes of allkinds of movies. This threshold may be exceeded in the case of dramatic, musical andcomic movies because scenes of these movies are long enough and the risk of an oversegmentation is weak. However, in action movies this threshold is the optimum becausescenes in these movies are short and increasing the threshold may cause under-segmentations in case of presence of similar shots in neighbouring scenes.
4.4 Comparison results
We implemented the work [9] which presents good results relatively to the well known workof Yeung et al. [42]. However, as we failed to get the ground truth used in [9] we created ourown ground truth as follows: first, we segment the movies into shots [31] shots and then wemanually grouped shots into scenes according to strict scene definition. We implemented alsothe work of Tavanapong et al. [38]. This work is another shot-to-shot approach which isbased on the assumption that the shots of a same scene have common zones namely thecorners. Features used for the clustering process are computed on these corners.
The results of the comparison are shown in the Table 2. Generally, our system performsbetter than systems of Chen and Tavanapong. This confirms that basing on discoveringshots agglomeration may be an alternative to basing on shot-to-shot method. The lowresults obtained by Tavanapong’s system demonstrate the adequacy of this proposal.Indeed, Tavanapong’s system is a typical shot-to-shot approach which uses two slidingwindows (backward and forward) to cluster the shots into scenes.
Besides, regarding results obtained in action movies, we can affirm that to delimit actionscenes we have to base not only on content (case of the majority of approaches as those ofChen et al. and Tavanapong et al.) but also on tempo. Indeed, although Chen’s system andTavanapong’s system adopted two different strategies to describe the content information of
Fig. 15 Recall and precision against the tolerance factor
342 Multimed Tools Appl (2010) 47:325–346
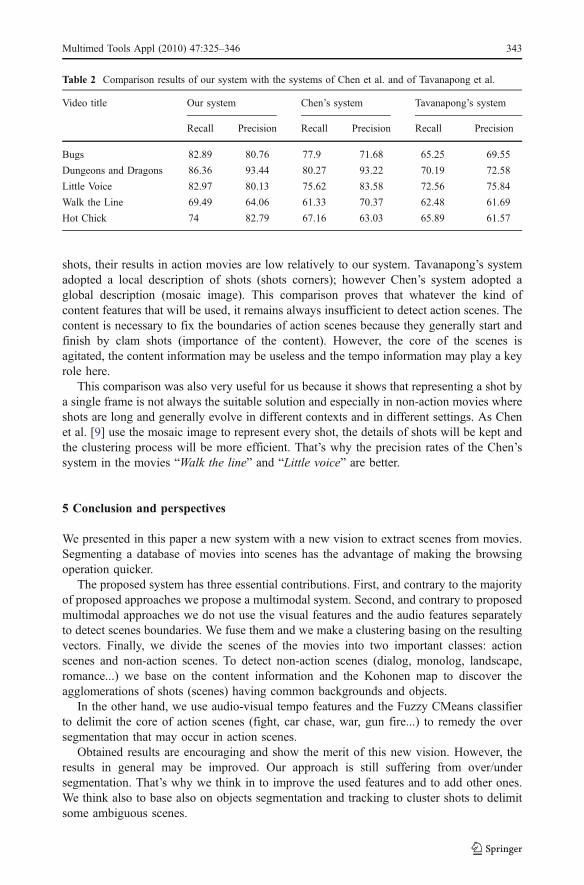
shots, their results in action movies are low relatively to our system. Tavanapong’s systemadopted a local description of shots (shots corners); however Chen’s system adopted aglobal description (mosaic image). This comparison proves that whatever the kind ofcontent features that will be used, it remains always insufficient to detect action scenes. Thecontent is necessary to fix the boundaries of action scenes because they generally start andfinish by clam shots (importance of the content). However, the core of the scenes isagitated, the content information may be useless and the tempo information may play a keyrole here.
This comparison was also very useful for us because it shows that representing a shot bya single frame is not always the suitable solution and especially in non-action movies whereshots are long and generally evolve in different contexts and in different settings. As Chenet al. [9] use the mosaic image to represent every shot, the details of shots will be kept andthe clustering process will be more efficient. That’s why the precision rates of the Chen’ssystem in the movies “Walk the line” and “Little voice” are better.
5 Conclusion and perspectives
We presented in this paper a new system with a new vision to extract scenes from movies.Segmenting a database of movies into scenes has the advantage of making the browsingoperation quicker.
The proposed system has three essential contributions. First, and contrary to the majorityof proposed approaches we propose a multimodal system. Second, and contrary to proposedmultimodal approaches we do not use the visual features and the audio features separatelyto detect scenes boundaries. We fuse them and we make a clustering basing on the resultingvectors. Finally, we divide the scenes of the movies into two important classes: actionscenes and non-action scenes. To detect non-action scenes (dialog, monolog, landscape,romance...) we base on the content information and the Kohonen map to discover theagglomerations of shots (scenes) having common backgrounds and objects.
In the other hand, we use audio-visual tempo features and the Fuzzy CMeans classifierto delimit the core of action scenes (fight, car chase, war, gun fire...) to remedy the oversegmentation that may occur in action scenes.
Obtained results are encouraging and show the merit of this new vision. However, theresults in general may be improved. Our approach is still suffering from over/undersegmentation. That’s why we think in to improve the used features and to add other ones.We think also to base also on objects segmentation and tracking to cluster shots to delimitsome ambiguous scenes.
Table 2 Comparison results of our system with the systems of Chen et al. and of Tavanapong et al.
Video title Our system Chen’s system Tavanapong’s system
Recall Precision Recall Precision Recall Precision
Bugs 82.89 80.76 77.9 71.68 65.25 69.55
Dungeons and Dragons 86.36 93.44 80.27 93.22 70.19 72.58
Little Voice 82.97 80.13 75.62 83.58 72.56 75.84
Walk the Line 69.49 64.06 61.33 70.37 62.48 61.69
Hot Chick 74 82.79 67.16 63.03 65.89 61.57
Multimed Tools Appl (2010) 47:325–346 343

Acknowledgments The authors would like to thank several individuals and groups for making theimplementation of this system possible. The authors would like to acknowledge the financial support of thiswork by grants from the General Direction of Scientific Research and Technological Renovation (DGRSRT),Tunisia, under the ARUB program 01/UR/11/02. We are also grateful, to EGIDE and INRIA, France, forsponsoring this work and the three-month research placement of Mehdi Ellouze from 1/11/2007 to 31/1/2008in INRIA IMEDIA Team in which parts of this work were done.
References
1. Arijon D (1991) Grammar of the Film Language. Silman James Press, Los Angeles2. Bezdek JC (1981) Pattern Recognition with Fuzzy Objective Function Algorithms. Plenum, New York3. Bordwell, D, Thompson K (1997) Film Art: An Introduction, 5th edn. McGraw-Hill4. Boujemaa N, Fauqueur J, Ferecatu M, Fleuret F, Gouet V, Saux BL, Sahbi H (2001) Ikona: Interactive
generic and specific image retrieval. In: Proceedings of the International workshop on Multimedia5. Brunelli R, Mich O, Modena CM (1999) A survey on the automatic indexing of video data. Journal of
Visual Communication Image Represent 10:78–1126. Chen L, Ozsu MT (2002) Rule-based scene extraction from video. In International Conference on Image
Processing, pp 737-7407. Chen SC, Shyu ML, Zhang CC, Kashyap RL (2001) Video Scene change detection method using
unsupervised segmentation and object tracking, In Proceedings of IEEE International Conference onMultimedia and Expo, pp 56-59
8. Chen HW, Kuo JH, Chu WT, Wu JL (2004) Action Movies Segmentation and Summarization Based onTempo Analysis, In Proceedings of the ACM SIGMM International Workshop on MultimediaInformation Retrieval, pp 251-258
9. Chen LH, Lai YC, Liao HYM (2008) Movie scene segmentation using background information. PatternRecognition 41:1056–1065
10. Cotsaces C, Nikolaidis N, Pitas I (2006) Video Shot Detection and Condensed Representation, A review.IEEE Signal Processing Magazine 23, pp 28–37
11. Ellouze M, Karray H, Alimi AM (2006) Genetic Algorithm For Summarizing News Stories. InProceedings of international conference on computer vision theory and applications, pp 303-308
12. Ellouze M, Karray H, Alimi AM (2008) REGIM, Research Group on Intelligent Machines, Tunisia, atTRECVID 2008, BBC Rushes Summarization, In Proceedings of international conference ACMMultimedia, TRECVID BBC Rushes Summarization Workshop
13. Ellouze M, Karray H, Soltana WB, Alimi AM (2007) Utilisation de la carte de Kohonen pour ladétection des plans présentateur d’un journal télévisé, In Proceedings of international conference TAIMA2007, cinquième édition des ateliers de travail sur le traitement et l'analyse de l’information, pp 271-276
14. Geng Y, Xu D, Wu A (2005) Effective Video Scene Detection Approach Based on Cinematic Rules. InProceedings 9th International Conference on Knowledge-Based Intelligent Information and EngineeringSystems, pp 1197-1203
15. Hanjalic A, Lagendijk RL, Biemond J (1999) Automated high-level movie segmentation for advancedvideo-retrieval systems. IEEE Transaction Circuits and Systems for Video Technology 9:580–588
16. Hanjalic A (2002) Shot-boundary detection: unraveled and resolved? IEEE Transactions on Circuits andSystems for Video Technology 12:90–105
17. Huang J, Liu Z, Wang Y (1998) Integration of Audio and Visual Information for Content-based VideoSegmentation. In Proceedings of IEEE International Conference on Image Processing, pp 526–529
18. IMDB (2008) http://www.imdb.com/, Last viewed July 200819. Karray H, Ellouze M, Alimi AM (2008) KKQ: K-frames and K-words extraction for quick news story
browsing. International Journal of Information and Communication Technology 1, pp. 69–7620. Karray H, Ellouze M, Alimi AM (2008) Indexing video summaries for quick video browsing.
Chapter in Computer Communications and Networks published by Springer Verlag, Germany. In Press21. Kender JR, Yeo BL (1998) Video Scene Segmentation Via Continuous Video Coherence, In Proceedings
of the conference of Computer Vision and Pattern Recognition, pp 367–37322. Kherallah M, Karray H, Ellouze M, Alimi AM (2008) Toward an Interactive Device for Quick News
Story Browsing. In Proceedings of international conference on pattern recognition. Accepted23. Kohonen T (1990) The Self-Organizing Map. In Proceedings of the IEEE, pp 1464-148024. Lehane B, O’Connor NE (2006) Movie Indexing via Event Detection. In Proceedings of the Workshop
on image analysis for multimedia interactive services, pp 1-4
344 Multimed Tools Appl (2010) 47:325–346

25. Lin T, Zhang HJ (2000) Automatic Video Scene Extraction by Shot Grouping. In proceedings of theInternational Conference of Pattern Recognition 6:39–42
26. Lin T, Zhang HJ, Shi QY (2001) Video scene extraction by force competition, In the proceedings ofIEEE International Conference on Multimedia and Expo, pp 753-756
27. Lu L, Zhang HJ, Jiang H (2002) Content Analysis for Audio Classification and Segmentation. IEEETransactions on Speech and Audio Processing 10:504–516
28. Lukas B, Kanade T (1981) An iterative image registration technique with an application to stereo vision.In Proceedings of the International Joint Conference on Artificial Intelligence, pp 674–679
29. Nagasaka A, Tanaka Y (1991) Automatic scene-change detection method for video works. In2ndWorking Conference on Visual Database Systems, pp 119–133
30. Ngo CW, Pong TC, Zhang HJ (2002) Motion-Based Video Representation for Scene Change Detection.International Journal of Computer Vision 2:127–142
31. Oh J, Hua KA, Liang N (2000) A content-based scene change detection and classification techniqueusing background tracking, In Proceedings of the conference on Multimedia Computing andNetworking, pp 254-265
32. Rasheed Z, Shah M (2005) Detection and Representation of Scenes in Videos. IEEE Transaction onMultimedia 7:1097–1105
33. Rui Y, Huang TS, Mehrotra S (1998) Constructing table of contents for videos. ACM J. MultimediaSystems, pp 359–368
34. Smeaton AF, Lehane B, O'Connor NE, Brady C, Craig G (2006) Automatically selecting shots for actionmovie trailers. In Proceedings of the ACM international workshop on Multimedia information , pp 231-238
35. Snoek CGM, Worring M, Geusebroek JM, Koelma DC, Seinstra FJ, Smeulders AWM (2006) TheSemantic Pathfinder: Using an Authoring Metaphor for Generic Multimedia Indexing. IEEE Trans-actions on Pattern Analysis and Machine Intelligence 28:1678–1689
36. Studio4networks (2008) http://www.studio4networks.com/, Last viewed July 200837. Sundaram H, Chang SF (2000) Video Scene Segmentation Using Video and Audio Features. In
Proceedings of the International Conference on Multimedia and Expo, pp1145-114838. Tavanapong W, Zhou J (2004) Shot clustering techniques for story browsing. IEEE Transactions on
Multimedia 6:517–52739. TRECVID (2008) http://www-nlpir.nist.gov/projects/trecvid/, Last viewed July 200840. Truong BT, Dorai C, Venkatesh S (2003) Automatic scene extraction in motion pictures. IEEE
Transactions in Circuits and Systems for Video Technology 1:5–1041. Yale film studies, 2008, http://classes.yale.edu/film-analysis/index.htm, Last viewed July 200842. Yeung M, Yeo BL, Liu B (1998) Segmentation of video by clustering and graph analysis, Computer
Vision and Image Understanding 71, pp 94-10943. Zhao L, Yang SQ, Feng B (2001) Video scene detection using slide windows method based on temporal
constrain shot similarity. In Proceedings of international conference on Multimedia and Expo, pp 1171–1174
Mehdi Ellouze received the Eng degree in computer science (2005) and the MSc degree in automatic control andindustrial computing (2006) both from the National School of Engineers in the University of Sfax where he iscurrently a PhD student. He was a visiting scientist at IMEDIA, INRIA Rocquencourt in 2007. His research interestfocus on video processing using pattern recognition techniques and especially video summarization. He is nowworking on designing a user oriented video summarization system in the TANIT project.
Multimed Tools Appl (2010) 47:325–346 345

Pr. Nozha Boujemaa is Director of Research at INRIA Paris - Rocquencourt. She obtained her PhD degree inMathematics and Computer Science in 1993 (Paris V) and her "Habilitation à Diriger des Recherches" in ComputerScience in 2000 (University of Versailles). She has been graduated previously with a Master degree with Honorsfrom University of Tunis. Her topics of interests include Multimedia Content Search, Image Analysis, PatternRecognition and Machine Learning. Her research activities are leading to next generation of multimedia searchengines and affect several applications domains such as audio-visual archives, Internet, security, biodiversity… Pr.Boujemaa has authored more than 100 international journal and conference papers. She has served on numerousscientific program committees in international conferences (WWW Multimedia Track, ACM Multimedia/MIR,ICPR, IEEE ICIP, IEEE Fuzzy systems, IEEE ICME, CIVR, CBMI, RIAO...) in the area of visual informationretrieval and pattern recognition.
Pr. Adel M. Alimi was born in Sfax, Tunisia, in 1966. He graduated in electrical engineering, in 1990. Heobtained a Ph.D. degree and then an HDR both in electrical engineering in 1995 and 2000, respectively. He is nowan Associate Professor in electrical and computer engineering at the University of Sfax. His research interestincludes applications of intelligent methods (neural networks, fuzzy logic, genetic algorithms) to patternrecognition, robotic systems, vision systems, and industrial processes. He focuses his research on intelligentpattern recognition, learning, analysis and intelligent control of large scale complex systems. He is an AssociateEditor of Pattern Recognition Letters, International Journal of Image andGraphics, International Journal of Roboticsand Automation. He was Guest Editor of several special issues of international journals, for example, Fuzzy Setsand Systems, Soft Computing, Journal of Decision Systems, Integrated Computer Aided Engineering, SystemsAnalysis Modelling and Simulations). He was the general chairman of the International Conference on MachineIntelligence ACIDCA-ICMI'2005 & 2000. He is an IEEE Senior Member and Member of IAPR, INNS, andPRS.
346 Multimed Tools Appl (2010) 47:325–346




















