
Robust and efficient automated detection of tooling defects in polished stone
15
Robust and efficient automated detection of tooling defects in polished stone J.R.J. Lee, M.L. Smith * , L.N. Smith, P.S. Midha Machine Vision Laboratory, Faculty of Computing, Engineering and Mathematical Sciences, University of the West of England, Frenchay Campus, Bristol BS16 1QY, UK Received 1 December 2004; received in revised form 31 March 2005; accepted 31 May 2005 Available online 7 October 2005 Abstract The automated detection of process-induced defects such as tooling marks is a common and important problem in machine vision. Such defects are often distinguishable from natural flaws and other features by their geometric form, for example their circularity or linearity. This paper discusses the automated inspection of polished stone, where process-induced defects present as circular arcs. This is a particularly demanding circle detection problem due to the large radii and disrupted form of the arcs, the complex nature of the stone surface, the presence of other natural flaws and the fact that each circle is represented by a relatively small proportion of its total boundary. Once detected and characterized, data relating to the defects may be used to adaptively control the polishing process. We discuss the hardware requirements of imaging such a surface and present a novel implementation of a randomised circle detection algorithm that is able to reliably detect these defects. The algorithm minimizes the number of iterations required, based on a failure probability specified by the user, thus providing optimum efficiency for a specified confidence whilst requiring no prior knowledge of the image. The probabilities of spurious results are also analyzed, and an optimization routine introduced to address the inaccuracies often associated with randomized techniques. Experimental results demonstrate the validity of this approach. # 2005 Published by Elsevier B.V. Keywords: Circle detection; Circle Hough transform; Randomised algorithm; Surface inspection; Polished stone 1. Introduction The automated visual detection and classification of surface defects, such as scratches and tooling marks, is a common and important problem in the manufacturing industry. A rudimentary literature search will reveal examples too numerous to mention. Many industrial inspection applications demand the accurate and timely location of circular or linear objects or defects in the presence of noise, discontinuities and varying levels of occlusion. The research described in this paper attempts to respond to a particularly demanding problem relating to the automated inspec- tion of polished stone. The ornamental stone industry www.elsevier.com/locate/compind Computers in Industry 56 (2005) 787–801 * Corresponding author. 0166-3615/$ – see front matter # 2005 Published by Elsevier B.V. doi:10.1016/j.compind.2005.05.006
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Robust and efficient automated detection of tooling defects in polished stone

Robust and efficient automated detection of tooling defects
in polished stone
J.R.J. Lee, M.L. Smith *, L.N. Smith, P.S. Midha
Machine Vision Laboratory, Faculty of Computing, Engineering and Mathematical Sciences, University of the West of England,
Frenchay Campus, Bristol BS16 1QY, UK
Received 1 December 2004; received in revised form 31 March 2005; accepted 31 May 2005
Available online 7 October 2005
Abstract
The automated detection of process-induced defects such as tooling marks is a common and important problem in machine
vision. Such defects are often distinguishable from natural flaws and other features by their geometric form, for example their
circularity or linearity. This paper discusses the automated inspection of polished stone, where process-induced defects present
as circular arcs. This is a particularly demanding circle detection problem due to the large radii and disrupted form of the arcs, the
complex nature of the stone surface, the presence of other natural flaws and the fact that each circle is represented by a relatively
small proportion of its total boundary. Once detected and characterized, data relating to the defects may be used to adaptively
control the polishing process. We discuss the hardware requirements of imaging such a surface and present a novel
implementation of a randomised circle detection algorithm that is able to reliably detect these defects. The algorithm minimizes
the number of iterations required, based on a failure probability specified by the user, thus providing optimum efficiency for a
specified confidence whilst requiring no prior knowledge of the image. The probabilities of spurious results are also analyzed,
and an optimization routine introduced to address the inaccuracies often associated with randomized techniques. Experimental
results demonstrate the validity of this approach.
# 2005 Published by Elsevier B.V.
Keywords: Circle detection; Circle Hough transform; Randomised algorithm; Surface inspection; Polished stone
www.elsevier.com/locate/compind
Computers in Industry 56 (2005) 787–801
1. Introduction
The automated visual detection and classification
of surface defects, such as scratches and tooling
marks, is a common and important problem in the
manufacturing industry. A rudimentary literature
* Corresponding author.
0166-3615/$ – see front matter # 2005 Published by Elsevier B.V.
doi:10.1016/j.compind.2005.05.006
search will reveal examples too numerous to mention.
Many industrial inspection applications demand the
accurate and timely location of circular or linear objects
or defects in the presence of noise, discontinuities and
varying levels of occlusion. The research described
in this paper attempts to respond to a particularly
demanding problem relating to the automated inspec-
tion of polished stone. The ornamental stone industry

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801788
Fig. 1. Arrangement of camera and light source.
is an important and rapidly developing sector. Recent
analyses report a world trade growth rate of around 7%
per annum, with trade in ornamental stone accounting
for more than 2% of gross national product in China,
Italy, Spain, India and South Korea in 2001 [1]. When
processing the raw material, dislodged grit from
rotating tool heads often leads to large, disjointed
circular arcs being imprinted on the surface of the slab,
particularly in softer stones such as marble. A typical
polishing line will incorporate up to 18 stages, with
each stage bearing a rotating grinding/polishing
head with progressively finer grit. As such, the severity
of these circular arcs varies considerably. Finer
scratches will only normally be visible at close range
and when they disrupt a specular reflection highlight
from a light source. However, the fact that the human
eye is naturally drawn to such geometrically definable
features makes their detection imperative. As such,
the operator or in many cases the proprietor of the
processing plant will spend several minutes tilting
the slab under a skylight or a striplight in order to
manually identify any defects. This is an important
process, as the aesthetic quality of the stone will have
a substantial impact on its value and hence its
application.
Automating the detection of such defects using
machine vision is challenging for a number of reasons.
The first task is to distinguish between variations in
albedo, such as the veins and colorations associated
with natural stone products, and variations in surface
topography. This has previously been accomplished
using photometric stereo [2,3]. However, in this case
the highly specular, crystalline nature of the surface
tends to prohibit the immediate application of a
photometric technique. Instead, we replicate the
manual technique used in the industry, by looking
for disruptions to the specular reflection from an
extended light source. A linescan camera is positioned
such that it captures an image of the light source
reflected from the polished stone slab, as shown in
Fig. 1.
The acquired image, generated from concatenated
lines with the aid of an encoder signal as the slab
moves along a conveyor, is then a function of the
glossiness or reflectance value of the slab at a given
incident angle of illumination. This effectively
removes the effects of colour variations on the
intensity of the image whilst enhancing the visibility
of natural fissures, process-induced defects and
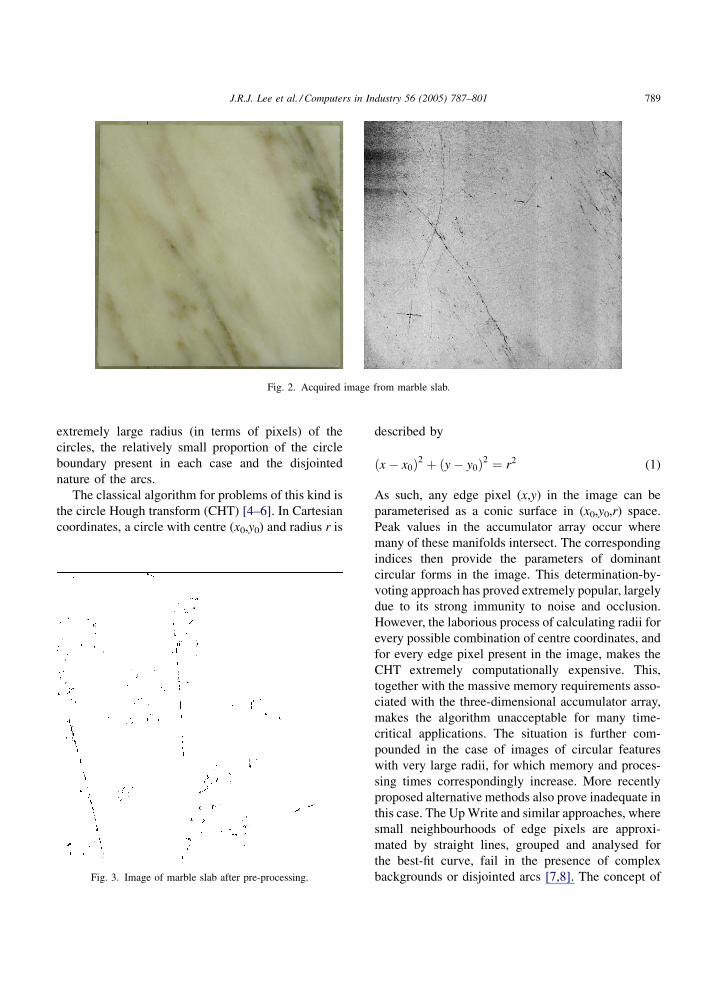
variations in finish quality. Fig. 2 shows an image
acquired from a 300 cm2 marble slab, to the right of a
conventional image of the same slab acquired under
diffuse illumination for comparison. It should be noted
that the image contains approximately 3000 � 3000
pixels at full resolution.
It can be seen that the image on the right contains a
great deal of information on the condition of the
surface of the slab. Process-induced defects, i.e.
circular arcs with large radii, are apparent at varying
levels of severity. A poorly finished region, typically
caused when a misaligned grinding tool at an early
stage of processing removes too much material, can be
seen in the top left corner. Various natural fissures,
often associated with the presence of a vein in the
stone, are also apparent. Finally, natural variations in
reflectance due to the metamorphic nature of the stone
are represented by the intensity variation seen
throughout the image.
The focus of this paper is the detection and
quantification of process-induced scratches. As such,
the influence of the latter three artefacts can be
reduced to varying extents using standard edge
detection and filtering techniques, resulting in images
of a similar nature to that shown in Fig. 3. Note that
this relates to a small section of the total slab shown at
full resolution.
It can be seen that the process-induced scratches are
now among the dominant features of the image, and as
such the problem becomes one of circle detection.
This is particularly challenging in this case due to the
J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801 789
Fig. 2. Acquired image from marble slab.
extremely large radius (in terms of pixels) of the
circles, the relatively small proportion of the circle
boundary present in each case and the disjointed
nature of the arcs.
The classical algorithm for problems of this kind is
the circle Hough transform (CHT) [4–6]. In Cartesian
coordinates, a circle with centre (x0,y0) and radius r is
Fig. 3. Image of marble slab after pre-processing.
described by
ðx� x0Þ2 þ ðy� y0Þ2 ¼ r2 (1)
As such, any edge pixel (x,y) in the image can be
parameterised as a conic surface in (x0,y0,r) space.
Peak values in the accumulator array occur where
many of these manifolds intersect. The corresponding
indices then provide the parameters of dominant
circular forms in the image. This determination-by-
voting approach has proved extremely popular, largely
due to its strong immunity to noise and occlusion.
However, the laborious process of calculating radii for
every possible combination of centre coordinates, and
for every edge pixel present in the image, makes the
CHT extremely computationally expensive. This,
together with the massive memory requirements asso-
ciated with the three-dimensional accumulator array,
makes the algorithm unacceptable for many time-
critical applications. The situation is further com-
pounded in the case of images of circular features
with very large radii, for which memory and proces-
sing times correspondingly increase. More recently
proposed alternative methods also prove inadequate in
this case. The UpWrite and similar approaches, where
small neighbourhoods of edge pixels are approxi-
mated by straight lines, grouped and analysed for
the best-fit curve, fail in the presence of complex
backgrounds or disjointed arcs [7,8]. The concept of

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801790
polling an image for circles by examining their inter-
section with random lines, proposed by Cheng and Liu
[9], is also unsuitable in applications such as those
described in this paper. In this case there is simply not
a large enough proportion of the total circle present to
ensure a reliable detection.
In this paper we show how a randomised
‘hypothesise and test’ circle detection technique can
be adapted to provide robust and efficient classifica-
tion under difficult conditions. The algorithm adap-
tively minimises the number of iterations required,
based on a failure probability specified by the user,
thus providing optimum efficiency for a specified
confidence whilst requiring no a priori knowledge of
the image. A simple optimisation routine is introduced
to address the inaccuracies often associated with
randomised techniques, and the probability of
spurious results is analysed. Whilst it would not be
possible to cover, within the bounds of this article, the
hundreds of papers published on circle detection and
modifications to the CHT, the major developments are
briefly reported in the following section. The
interested reader is also directed to Leavers [4] and
Kalviainen et al. [10], who provide excellent reviews
of significant developments in the field. The remainder
of this paper will detail our own algorithm and present
a range of experimental results.
2. Background
Many proposed improvements to the CHT have
attempted to utilise geometrical properties of the circle
in order to reduce the computational complexity and
memory requirements of the algorithm whilst retain-
ing the principal desirable property of strong noise
immunity. Perhaps the most intuitive such property
concerns the observation that a normal to the
circumference at any point will intercept the centre
of the circle. Thus, several researchers have attempted
to use the gradient orientation generated by edge
detection algorithms, such as the Sobel operator, to
reduce the space transform to a two-dimensional
(x0,y0) parameterisation [4,6]. Whilst this implemen-
tation works well under ideal conditions, its sensitivity
to noise and discretisation errors makes it unworkable
in practice [11]. More recently, Ioannou et al. [12]
used the fact that a line perpendicularly bisecting any
chord of a circle will pass through its centre, whilst
Kim and Kim [11] calculate centre positions from
pairs of intersecting chords. Both approaches use an
initial (x0,y0) parameterisation followed by filtered
histogramming to validate the circles and to locate the
corresponding radii, thus reducing the memory
requirements and computational complexity from
O(n3) to O(n2 + n), where n is the number of edge
pixels in the image. Foresti et al. [13] use an
alternative parameterisation to improve the efficiency
of the HT, based on two dependent equations of the
first order rather than the classical second order
equation. Dynamic memory allocation is used to
alleviate the problems associated with the use of a
three-dimensional accumulator array. The approach
requires edge gradient direction information, however
the authors assert that an improved peak validation
algorithm overcomes the inherent uncertainty in edge
orientation. Guil and Zapata [14] combine the use of
the gradient vectors associated with points on the
circumference of the circle with a coarse-to-fine
focussing algorithm to reduce computation time.
Huddleston and Jezekiel [15] also use edge orienta-
tion, together with analysis of proximity and circular
symmetry, in their distributed Hough transform
(DHT). The six-stage algorithm is centered around
the property that a signed curvature alone is enough to
uniquely assign an edge pixel to a particular feature,
thus reducing the parameter space from three to one
dimension. Probabilistic analysis is used to progres-
sively refine the curvature calculations as the edge
pixels are grouped into entities. However, as with all
such techniques the algorithm degrades in the
presence of edge orientation noise. Documented
variants of these approaches are too numerous for
comprehensive review in this paper, the interested
reader is again referred to Leavers [4].
The drive for increased efficiency has steered many
researchers away from the one-to-many mapping,
used in the traditional Hough transform techniques,
towards a convergent, or many-to-one, mapping.
Individual edge pixels transform into n-dimensional
manifolds in parameter space. The mapping of
multiple pixels simultaneously can be used to either
reduce uncertainty in the parameter space or to reduce
the dimensionality of the parameter space. Many
diverse implementations of this hypothesis have been
seen over the previous decade. Chutatape and Linfeng

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801 791
[16] combine this approach with the dynamic
allocation of memory and the elimination of feature
points already attributed to a line in order to reduce the
computational burden and storage requirements of the
HT. Olson [17,18] also uses a many-to-one mapping
and proposes an algorithm whereby only those pixel
groupings that share some distinguished set of j edge
pixels are mapped into the parameter space. However,
the major trend in circle detection over recent years
has been towards randomised or probabilistic algo-
rithms. Xu et al. [19] introduced the randomised
Hough transform (RHT) in 1990. This was one of the
first approaches to suggest that mapping n edge pixels,
for an n parameter curve, to a single point in the
parameter space could alleviate many of the problems
associated with traditional Hough transform techni-
ques, such as low speed and the generation of false
positives. Xu’s approach combines this many-to-one
mapping with a sampling algorithm, whereby sets of n
pixels are randomly selected to generate a system of n
equations in n unknowns. Much statistical analysis has
been done towards deriving robust stopping criteria for
the RHT, see for example Xu and Oja [20], Kalviainen
et al. [10] and Shaked et al. [21]. Kiryati et al. [22] also
proposed randomly polling a small subset of the edge
data in their probabilistic Hough transform (PHT),
choosing however to use the conventional one-to-
many mapping into parameter space. Their work
demonstrated that the random polling approach can
dramatically reduce computation time with only a
slight degradation in performance. Kiryati et al. [23]
compared the performance of the RHT and the PHT,
concluding that in their basic forms the RHT is more
efficient for analysis of high quality, low noise edge
images whilst the PHT becomes preferable in the
presence of increasing noise degradation.
Matas et al. [24] present the progressive probabil-
istic Hough transform (PPHT). The algorithm retains
the traditional one-to-many voting process but
implemented in a much more efficient algorithm.
An edge pixel is selected at random from the image,
the accumulator array is updated and the pixel is
removed from the image. If the highest cell value
modified by the pixel exceeds a noise threshold
derived from statistical analysis of random voting, the
feature is registered, all the pixels in the corresponding
feature are removed and all their votes cast are
retracted from the accumulator array. The randomised
circle detector (RCD) algorithm proposed by Chen
and Chung [25] works on a similarly progressive basis
but uses a many-to-one mapping that allows the
requirement for an accumulator array to be removed
altogether. The algorithm first picks four points at
random from the set of edge pixels V in the image and,
subject to a minimum separating distance criterion,
tests whether they are concyclic within an error margin
designed to account for discretisation. Having located
a possible circle, the algorithm determines how many
of the remaining edge pixels lie on the same circle.
This is conceptually similar to ‘hypothesise and test’
algorithms such as RANSAC [26,27]. If the number of
edge pixels found to satisfy the equation of the circle
exceeds a predetermined threshold Tr, scaled to reflect
the circumference of the possible circle, the circle is
accepted and the contributory edge pixels are deleted
from V. The algorithm repeats this procedure until the
number of edge pixels remaining (jVj) falls below a
predetermined threshold Tmin.
The simplicity, computational efficiency and
minimal storage requirements of this approach make
it more attractive than those previously discussed,
particularly as the identification of circular features
with extremely large radii prohibits the use of any
accumulator-based technique. Practical experimenta-
tion, however, identifies a number of issues that
degrade the performance of the algorithm. In a real
image, it is highly unlikely that the level of noise or
non-circular features contributing to Vwill be known a
priori. Thus, given that W edge pixels (where W � V)
do not contribute to any circular features, a manually
and arbitrarily selected Tmin could result in false
negatives (a genuine circular object remaining unde-
tected) if Tmin >W or an infinite loop if Tmin < W.
For example, suppose that we set Tmin to 500 pixels.
The algorithm stops before it detects the light,
diagonal scratch in Fig. 6a. However, when applied
to the noisier edge image shown in Fig. 8a the
algorithm detects the circular feature present but
continues searching indefinitely, or until it is drawn to
a close by an arbitrary failure count threshold. The
desirable case of Tmin = W is extremely unlikely
without prior knowledge of the image.
The use of arbitrary stopping criteria such as these
results in our having little idea of the probability of
circular features being missed, the probability of
spurious circles being detected or the propriety of the

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801792
number of iterations effected. The algorithm also
suffers from poor accuracy under certain conditions,
as the equation determined by four points selected at
random from a particular circular feature may not
represent the best fit through the feature as a whole.
This can lead to both underestimation and over-
estimation of the radii, with corresponding errors in
the location of the centre of the circle.
In this paper we address the limitations of the RCD
to provide an adaptive algorithm that allows the user to
specify the probability of a circular feature being
missed. The number of iterations required to reduce
the probability of failure to the specified level is
continually reevaluated as the set of edge pixels is
reduced. This thereby provides an adaptive, robust
stopping criterion for the algorithm and removes the
need for a maximum remaining pixel threshold Tmin.
When a genuine circle is detected, a refinement
subroutine is used to eliminate the inaccuracies often
present in randomised detection routines. The prob-
ability of spurious results being returned by the
algorithm is also analysed.
3. Algorithm and mathematical background
3.1. Mathematical preliminaries
The equation of the circle passing through the three
points (x1,y1), (x2,y2) and (x3,y3) can be expressed in
matrix form as
x2 þ y2 x y 1
x21 þ y22 x1 y1 1
x22 þ y22 x2 y2 1
x23 þ y23 x3 y3 1
���������
���������¼ 0 (2)
To find the centre coordinates and the radius of the
circle we assign coefficients of a general quadratic:
ax2 þ by2 þ cxyþ dxþ eyþ f ¼ 0 (3)
In the case of a circle, a = b and c = 0. Thus, complet-
ing the square gives:
a
�xþ d
2a
�2
þ a
�yþ e
2a
�2
þ f � d2 þ e2
4a¼ 0
(4)
where
a ¼x1 y1 1
x2 y2 1
x3 y3 1
������������ (5)
d ¼ �x21 þ y21 y1 1
x22 þ y22 y2 1
x23 þ y23 y3 1
�������
�������(6)
e ¼x21 þ y21 x1 1
x22 þ y22 x2 1
x23 þ y23 x3 1
�������
�������(7)
f ¼ �x21 þ y21 x1 y1
x22 þ y22 x2 y2
x23 þ y23 x3 y3
�������
�������(8)
The centre and radius can then be determined as
x0 ¼ � d
2a(9)
y0 ¼ � e
2a(10)
r ¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffid2 þ e2
4a2� f
a
r(11)
Thus, given three points selected at random we can
determine the parameters of the corresponding circle.
Chen and Chung’s algorithm works on the basis that,
whilst three non-collinear points are trivially concyc-
lic, four concyclic points provide a strong indication of
the presence of a genuine circle. Having calculated the
parameters of the circle corresponding to the first three
points, the distance between the fourth point and the
boundary of the circle can be easily determined as
follows:
d4! 123 ¼ jffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiðx4 � x0Þ2 þ ðy4 � y0Þ2
q� rj (12)
3.2. Accuracy issues
There are various cases where the robustness of the
RCD algorithm suffers. Firstly, four contiguous edge
pixels, attributable to either noise or a genuine circular
feature, could be construed as forming a small circle.

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801 793
This case can be easily avoided by removing the scaling
factor associated with the minimum weighting thresh-
old Tr. We contend that it is not necessary to scale the
weighting threshold according to the radius of the
possible circle, particularly as this will discriminate
against extremely large circles where only a small
proportion of the circumference intersects the image.Trshould be set to reflect the smallest absolute circle
weighting we would expect to encounter; the presence
of more heavily weighted circles will not affect the
performance of the algorithm. Chen and Chung [25]
identify the case where two of the three selected edge
pixels are unacceptably close, leading to a spurious
circle intersecting the genuine feature. This is avoided
by imposing a minimum separation criterion, whereby
the randomly selected edge pixels are only accepted if
any two of the three pixels are separated by more than
this minimum distance. In practice, however, this is
simply not an issue. The spurious circle identified is
extremely unlikely to contain enough edge pixels to be
counted as a genuine feature. Furthermore, the
minimum separation criterion increases the computa-
tion required on every random selection of edge pixels
and makes reliable probability estimation impossible.
A far more common and more serious weakness of
randomised techniques occurs when a slight under-
estimation or overestimation of the circle radius leads
to multiple partial circles being detected from a single
genuine feature, as illustrated in Fig. 4.
Thus, we propose an alternative to the minimum
point separation criterion that ensures that any circles
detected are the best possible fit through the edge pixels
that form the corresponding feature. Supposewe detect
Fig. 4. (a) Underestimation of circle and
a circle that satisfies the minimum weighting criterion.
We find that U edge pixels lie within the annulus
defined by the circle parameters and the maximum
discretisation error. From the original set of three pixels
used to derive the circle parameters, we replace the first
pixel with alternatives taken exclusively from the
subset U, reevaluating the vote after each replacement
until the optimal value is located. We then repeat the
procedure for the second and third seed pixels. The
circle parameters associated with the maximum vote
returned by this subroutine will thus correspond to the
’best fit’ through the detected feature. This is a far more
constrained and efficient optimisation than would be
achieved by randomly selecting a series of three-pixel
sets from the subsetU. Note this is only effective due to
the finite width of the scratch segments detected. If the
width of the annulus were to exceed 2–3 pixels this
point-by-point optimisation could fail to resolve the
optimal circle fit. In this case a better alternative would
be to continually select one of the three seed pixels at
random, testing alternatives on a keep or replace basis,
until the algorithm settles on the optimal fit. However
we anticipate that in most applications, as in our own,
the point-by-point optimisation approach will provide
consistently good results at a low computational cost.
Although this results in a slight increase in
computation time there is no significant impact on
performance as the refinement subroutine need only
be executed when a genuine circle, with weighting
exceeding the threshold Tr, is detected. Experimental
results demonstrate that this approach effectively
eliminates the inaccuracies often associated with
randomised algorithms such as the RCD.
(b) overestimation of circle radius.

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801794
3.3. Probability of false negatives
In the following derivation we will generalise the
algorithm such that instead of picking four points at
random, we pick m points at random. Each iteration of
the circle detection algorithm can be regarded as a
Bernoulli trial, with an independent probability of
detecting a circular feature of given prominence.
Suppose that there are jVjedge pixels remaining in the
image and we are searching for circular features of
prominence U, where U � V. It is important here to
distinguish between the probability of any circular
feature being detected and the probability of a
particular circular feature being detected. In this case
we are interested in the latter. The probability that a
particular circular feature will be detected is the
probability that m points, randomly selected from V,
will lie on the feature:
p ¼ U
V� U � 1
V � 1� U � 2
V � 2� � � � � U � m
V � m
¼ U!ðV � mÞ!V !ðU � mÞ! (13)
As such, we can determine the probability of a circular
feature remaining undetected after n iterations of the
algorithm:
pfailure ¼�1�
�U!ðV � mÞ!V !ðU � mÞ!
��n
(14)
As U � Tr, we can continually tailor the number of
iterations required to achieve the desired failure prob-
ability on a ’worst case scenario’ basis (the prob-
ability of a feature being detected reduces to a mini-
mum as U! Tr). Thus we define a failure probability,
pfn, as
pfn ��1�
�Tr!ðV � mÞ!V!ðTr � mÞ!
��n
(15)
In practice the factorial terms make this incalculable
for large values of Tr and V. Thus given that Tr and V
are much larger than m and that for large values there
is little difference between sampling with or without
replacement, the probability of false negatives can be
reliably approximated as follows:
pfn ��1�
�TrV
�m�n
(16)
3.4. Probability of false positives
We can also analyse the probability of false
positives, a major concern in standard CHT techniques
due to random accumulation of votes as a result of the
one-to-many mapping. We cannot determine the
general probability of a false positive being returned,
as the form of the probability distribution will depend
on the circumferences of the individual possible
circles. We can however determine the likelihood that
a circle detected by the algorithm is a false positive. In
this case, the probability of a non-existent circular
feature being detected is a combination of:
(a) T
he probability that Tr or more randomlydistributed edge pixels are mutually concylic.
(b) T
he probability that m pixels from the pseudo-feature will be simultaneously selected by the
algorithm within n iterations.
The analysis described in Section 3.2 is used by the
algorithm to ensure that the probability of (b) occurring
will be close to one. As such, we need only concern
ourselves with the probability of (a) occurring, and the
derivation proceeds as follows. Let I denote the com-
plete set of image pixels, V the subset of edge pixels
where V � I and Tr the minimum vote threshold as
before. Any three pixels picked at random are said to be
trivially concyclic (except when they are collinear) and
define a circle c123. The probability that a fourth edge
pixel v4 picked at random will lie on the same circle is
Pðv4 2 c123Þ ¼V � 3
I � 3(17)
However, as the number of possible pixels on the
circle boundary increases, the number of possible
outcomes becomes combinatorially explosive as the
probabilities of subsequent pixels contributing to the
circle are dependent on all previous results. As we are
in effect sampling from a finite population, this can be
formulated as a hypergeo metric distribution
H(I,V,2pr). In a population of I pixels, V are edge
pixels and I–Vare background pixels. If a group of 2pr
pixels (where 2pr is the maximum number of pixels
that could lie on the circular feature identified by the
first four points) is selected at random, we wish to
determine the probability that the chosen group will
contain Tr or more edge pixels. In order to do this we

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801 795
initially define a probability pk that the chosen group
will contain exactly k edge pixels and 2pr–k back-
ground pixels. A feature pixel can be chosen in
Vk
� �
different ways, whilst a background pixel can be
chosen in
I�V2pr�k
� �
differentways.Given that any choice of k feature pixels
can be combinedwith any choice of background pixels:
Pk ¼
Vk
� �I�V2pr�k
� �
I2pr
� � (18)
However, the factorial terms in thebinomial coefficients
againmake this incalculable in practice. As the popula-
tion I is very large and the sample size 2pr is large, we
can use a Poisson approximation to the hypergeometric
distribution with minimal error, such that
pk �e�llk
k!(19)
where l = 2Vpr/I. Thus, the probability pfp that a
circular feature has been inferred from randomly
distributed pixels is the sum of all probabilities pk,
where Tr < k � 2pr:
pfp ¼X2prk¼Tr
pk (20)
This information can then be used to provide a con-
fidence rating that a circle detected is a genuine
circular feature. Whilst this is unlikely to be necessary
in normal industrial operation it can be useful when
setting up the system, for example in choosing thresh-
old values and setting the minimum circle vote Tr.
One might question the validity of the assumption
that edge pixels pertaining to non-circular features are
randomly distributed in the image. In our case these fall
into two categories: those relating to ’surface noise’, i.e.
local variations in the reflectivity of the stone slab, and
those relating to natural defects such as pits andfissures.
The former are evidently randomly distributed. The
latter are not: they are often grouped into similarly
orientated clusters, which may contribute to false
detections. In this case, analysis of the typicalwidth of a
process-induced circular scratch is usually sufficient to
exclude such clusters from the voting process.
3.5. The algorithm
In this section, we present an outline of our
algorithm. First, we define a value for the minimum
circle vote Tr. In practice this should be fixed as the
smallest weighting wewould expect to encounter in an
image. Whilst Eqs. (19) and (20) could be used to
determine a value of Tr that will admit all but spurious
features, the substitution of typical values into these
equations indicate that there is likely to be a
considerable gap between the weightings indicative
of a genuine circle and the weightings likely to
correspond to a false positive. For the sake of
efficiency Tr needs to be fixed as high as possible,
as the number of iterations required will increase
exponentially as the ratio Tr/V decreases. We also need
to define a step size s, a minimum point separation dsand an acceptable probability of failure, pf. The
algorithm then proceeds as follows:
(1) D
efine a set V of all the edge pixels in the image(following edge detection and thresholding
processes).
(2) E
valuate the probability of false negatives(Eq. (16)). If pfn < pf then stop.
(3) S
elect four pixels vi (where i = 1, . . ., 4) at randomfrom V. Check that all pixel pairs satisfy theminimum distance criteria ds. Otherwise, discard
the points and go to step (2).
(4) D
efine a circle c123 from v1, v2 and v2 (Eqs. (2)–(11)). Evaluate the distance d4!123 (Eq. (12)). Ifd4!123 is greater than an acceptable discretisation
error then go to step (2).
(5) E
valuate the number of pixels U (where U � V)that lie within an acceptable discretisation error of
the circle boundary (Eq. (12)). If U > Tr then
V = V � U. Otherwise, go to step (2).
(6) O
ptimise the detected circle using the refinementsubroutine described in Section 3.2. Store the
circle parameters x0, y0 and r and the weightingU.
Calculate the probability pfp that the circle is
spurious (Eq. (20), if required. Return to step (2).

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801796
Fig. 5. (a) Bright field image, (b) extracted edge data, and (c) detected circles.
Fig. 6. (a) Bright field image, (b) extracted edge data, and (c) detected circles.
Fig. 7. (a) Bright field image, (b) extracted edge data, and (c) detected circles.

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801 797
Fig. 8. (a) Bright field image, (b) extracted edge data, and (c) detected circles.
4. Experimental results
The algorithm was tested using a range of images
showing defects encountered in the inspection of
polished stone surfaces. Fig. 5 shows a light scratch in
the presence of noisy surface data. Note that all these
scratches will have radii of at least 6000 pixels.
Fig. 6 shows light and heavy scratches in the
presence of noisy surface data and natural flaws in the
surface of the stone.
Fig. 7 shows multiple light and heavy scratches in
the presence of noisy surface data and natural defects.
Note that the edge extraction routine is tailored to
exclude very light scratches, which are not visible to
the naked eye.
Fig. 8 shows a light scratch in the presence of
substantial natural defects, of the kind often found to
coincide with the location of veins in polished marble.
Fig. 9. (a) Large disrupted circular feature, (b) RCD circle detec-
tion, and (c) current algorithm circle detection.
5. Discussion
5.1. Technical issues
The algorithmwe have developed is an extension of
the four-point method proposed by Chen and Chung
[25]. Kim et al. [8] identify three main problems with
randomised approaches such as the four-point algo-
rithm; namely probability estimation, accuracy and
the relationship between speed and the proportion of
edge pixels belonging to circular features to the total
number present. We have comprehensively addressed
the first point with a robust stopping criterion based on
probabilistic analysis. Furthermore, we would assert
that the optimisation routine introduced in Section 3.2
overcomes the inaccuracies associated with techni-
ques of this kind. The improvements attained using

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801798
Fig. 10. (a) Detection errors in original RCD where U Tr and (b) current algorithm circle detection.
Fig. 11. Relationship between n and Tr/V.
this approach can be illustrated as follows. Fig. 9a
shows a synthesised image of a large, disrupted
circular feature. The original RCD algorithm repeat-
edly excludes smaller sections of the boundary from
the fitted circle, as illustrated in Fig. 9b (close up of the
circle fitting through the lower right segment of the
circle). The current algorithm, on the other hand,
consistently finds the best fit through all the boundary
points, thus providing a more accurate determination
as shown in Fig. 9c.
If the circle is large with respect to the minimum
weighting Tr, the errors can become considerably
more pronounced, as illustrated in Fig. 10a.
The current algorithm again returns consistently
accurate results as shown in Fig. 10b, revealing
another advantage to this approach. Not only does the
optimisation routine lead to more accurate circle
detection, but the algorithm becomes less sensitive to
the selected threshold value Tr.
However, the dependence of the speed of the
algorithm on the signal-to-noise ratio of the image
remains a concern. Fig. 11 shows the relationship
between the number of iterations required to achieve a
given probability of failure and the ratio Tr/V.
This emphasises the need for careful selection of
the minimum vote threshold Tr. However, in real
images the shape characteristics of pixel groups

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801 799
Fig. 12. Relationship between pfn and n.
relating to machining defects (i.e. circles) are often
very different from those relating to natural defects or
other noise in the image. Thus, a level of preliminary
filtering can often significantly reduce the number of
pixels not contributing to any circular feature.
The advantages of statistically determining a stopp-
ing point for the algorithm can be reiterated by consi-
dering the inverse exponential relationship between the
probability of failure, pfn, and the number of iterations
performed. This is shown graphically in Fig. 12.
It can be seen that for any value of Tr/V there will be
an optimum point at which to stop the algorithm (in
Fig. 12 this is more apparent for the higher ratios). If
the number of iterations is cut short, the probability
of failure rises rapidly. If, on the other hand, the
algorithm is allowed to continue unnecessarily,
execution speed will suffer with little effect on the
probability of failure. Our algorithm ensures that only
the minimum number of iterations necessary to ensure
a reliable detection are performed.
5.2. Implementation issues
In its current form this system would be used as a
labour saving tool by providing a fast, objective
alternative to manual inspection of the finished stone
product. In practice, the perceived severity of process-
induced scratches is related to the distance at which
they become visible to a human observer. This is not
necessarily a function of thewidth, depth or length of a
particular scratch, instead it depends directly on the
extent towhich the scratch disrupts the image of a light
source reflected from the surface, a phenomenon that
will depend on the intrinsic properties of the material
and the glossiness of the overall finish. Classification
along these lines is commensurate with the require-
ments of the end user: for example, scratches only
visible from within 1 m will not preclude the stone
from use as external cladding on the upper storeys of a
building. This method of grading the severity of
process-induced defects can be replicated by the
machine vision system, by considering the resolution
at which the defect becomes apparent. For example,
the circle detection algorithm and the precursory
processing steps can be applied to representations of
the acquired image at 10�, 5�, 2� and l� reduced
resolutions. The resolution at which the defect became
apparent, and as such the severity of the defect, can be
indicated to the operator by colour-coding the defect
on the monitor. This approach has little impact on
processing time, as a featureless image will be passed
very quickly by the adaptive algorithm. On the other
hand, if a process-induced defect is detected at l0�reduced resolution there is little to be gained from
closer inspection of the surface.
It is also hoped that the classification of defect
severity will allow the extension of the technology to
provide some level of process control on the polishing
line. It should be possible to relate the nature of the
defect to the processing stage at which the damage
occurred. Early indication of a problem at a particular
stage would allow remedial action to be taken before
further damage occurs, thus reducing wastage and
improving overall output quality. The development of
imaging technology capable of quantifying defects in
polished stone also paves the way for the introduction
of new standards, which should improve quality
assurance and aid specifiers when selecting stone for a
particular application.
6. Conclusions
In this paper we have discussed the automated
inspection of polished stone and described how a
randomized circle detection algorithm can be adapted
to provide robust defect detection in challenging
industrial environments. An overall view of the
acquisition process was given and the requirements
of the stone polishing industry were discussed. A
circle detection algorithm was developed which
allows the user to control the trade-off between speed

J.R.J. Lee et al. / Computers in Industry 56 (2005) 787–801800
and reliability by means of a failure probability. This is
an extension of the randomised four-point selection
approach proposed by Chen and Chung [25].
Statistical modeling was used to relate the size of
the circles of interest, and the total number of edge
pixels in the image, to the number of iterations
required and the likelihood of spurious results being
returned. The algorithm thus provides optimum
efficiency for a given level of confidence. A
refinement procedure was also introduced to counter-
act the inaccuracies often associated with randomised
techniques. Extensive validation was undertaken using
images of real defects encountered in the inspection of
polished stone. We conclude that this approach offers
a robust, efficient solution to the circle detection
problem in conditions where conventional techniques
fail. The development of technologies such as these
has the potential to make a substantial impact on the
ornamental and dimensional stone sectors, paving the
way for improved quality assurance and adaptive
process control.
Acknowledgement
The authors wish to express their gratitude to Paul
White at UWE for his contribution to the statistical
modeling and analysis.
References
[1] R. Bruno, I. Paspaliaris (Eds.), Ornamental and Dimensional
Stone Market Analysis, vol. 13, OSNET Editions, Laboratory
of Metallurgy, National Technical University of Athens, 2004.
[2] A.R. Farooq, M.L. Smith, L.N. Smith, P.S. Midha, Towards
fully automated inspection of stone surfaces containing both
two- and three-dimensional texture features, in: Proceedings of
the 17th National Conference on Manufacturing Research,
2001.
[3] M. Smith, L. Smith, Ch. Machine Vision Inspection, in: X. Xu
(Ed.), Machining of Natural Stone Materials, Trans Tech
Publications Ltd., 2003, ISBN: 0-87849-927-X.
[4] V.F. Leavers, Which Hough transform? CVGIP: Image Under-
standing 58 (2) (1993) 250–264.
[5] Soo-Chang Pei, Ji-Hwei Horng, Circular arc detection based
on Hough transform, Pattern Recognition Letters 16 (1995)
615–625.
[6] T.J. Atherton, D.J. Kerbyson, Size invariant circle detection,
Image and Vision Computing 17 (1999) 795–803.
[7] Robert A. McLaughlin, Michael D. Alder, The Hough trans-
form versus the up write, IEEE Transactions on Pattern
Analysis and Machine Intelligence 20 (4) (1998).
[8] Euijin Kim, Miki Haseyama, Hideo Kitajima, Extraction of
circles from arcs segmented into short straight lines, in:
Proceedings of the ICITA, Bathurst, 2002.
[9] Y.C. Cheng, Y.-S. Liu, Polling an Image for Circles by Random
Lines, IEEE Transactions on Pattern Analysis and Machine
Intelligence 25 (1) (2003).
[10] Heikki Kalviainen, Petri Hirvonen, Lei Xu, Erkki Oja, Prob-
abilistic and non-probabilistic Hough transforms: overview
and comparisons, Image and Vision Computing 13 (1995)
239–252.
[11] Heung-Soo Kim, Jong-Hwan Kim, A two-step circle detection
algorithm from the intersecting chords, Pattern Recognition
Letters 22 (2001) 787–798.
[12] Dimitrios Ioannou, Walter Huda, Andrew F. Laine, Circle
recognition through a 2D Hough transform and radius histo-
gramming, Image and Vision Computing 17 (1999) 15–26.
[13] Gian Luca Foresti, Carlo S. Regazzoni, Gianni Vernazza,
Circular arc extraction by direct clustering in a 3D Hough
parameter space, Signal Processing 41 (1995) 203–224.
[14] N. Guil, E.L. Zapata, Lower order circle and ellipse Hough
transform, Pattern Recognition 30 (10) (1997) 1729–1744.
[15] James N. Huddleston, Ben-Arie Jezekiel, Edgels into structural
entities using circular symmetry, the distributed Hough trans-
form, and probabilistic non-accidentalness CVGIP, Image
Understanding 57 (2) (1993) 227–242.
[16] Opas Chutatape, Guo Linfeng, A modified Hough transform
for line detection and its performance, Pattern Recognition 32
(1999) 181–192.
[17] Clark F. Olson, Decomposition of the Hough transform: curve
detection with efficient error propagation, in: Proceedings of
the European Conference on Computer Vision, 1996, pp. 263–
272.
[18] Clark F. Olson, Constrained Hough transforms for curve
detection, Computer Vision and Image Understanding 73
(3) (1999) 329–345.
[19] Lei Xu, Erkki Oja, Pekka Kultanen, A new curve detection
method: randomised Hough transform (RHT), Pattern Recog-
nition Letters 11 (1990) 331–338.
[20] Lei Xu, Erkki Oja, Randomised Hough transform (RHT): basic
mechanisms, algorithms, and computational complexities,
CVGIP: Image Understanding 57 (2) (1993) 131–154.
[21] D. Shaked, O. Yaron, N. Kiryati, Deriving stopping rules for
the probabilistic Hough transform by sequential analysis,
Computer Vision and Image Understanding 63 (3) (1996)
512–526.
[22] N. Kiryati, Y. Eldar, A.M. Bruckstein, A probabilistic Hough
transform, Pattern Recognition 24 (4) (1991) 303–316.
[23] Nahum Kiryati, Heikki Kalviainen, Satu Alaoutinen, Rando-
mised or probabilistic Hough transform: unified performance
evaluation, Pattern Recognition Letters 21 (2000) 1157–
1164.
[24] J. Matas, C. Galambos, J. Kittler, Robust detection of lines
using the progressive probabilistic Hough transform, Compu-
ter Vision and Image Understanding 78 (2000) 119–137.

J.R.J. Lee et al. / Computers in In
[25] Teh-Chuan Chen, Kuo-Liang Chung, An efficient randomised
algorithm for detecting circles, Computer Vision and Image
Understanding 83 (2001) 172–191.
[26] R.C. Bolles, M.S. Fischler, A RANSAC-based approach to
model fitting, in: International Joint Conference on Artificial
Intelligence, 1981, 637–642.
[27] G. Roth, M.D. Levine, Extracting geometric primitives,
CVGIP: Image Understanding 58 (1) (1993) 1–22.
Jason Lee is a research student in the
Faculty of Computing, Engineering and
Mathematical Sciences at the University
of the West of England. He studied Elec-
tronic Engineering at the University of
Bristol, and after a period in industry
returned to academia to continue his edu-
cation. His research interests centre
around the automated inspection of nat-
ural materials.
Melvyn Smith is Reader in Machine
Vision within the Faculty of Computing,
Engineering and Mathematical Sciences
at the University of the West of England
(UWE), Bristol, UK. He received his
BEng (Hons) degree in Mechanical Engi-
neering from the University of Bath in
1987, MSc in Robotics and Advanced
Manufacturing Systems from the Cran-
field Institute of Technology in 1988 and
his PhD from the University of the West of England in 1998. He is
Co-director of the Centre for IntelligentManufacturing andMachine
Vision Systems (CIMMS) at UWE. His research interests include
machine vision, industrial manufacturing and quality control sys-
tems. He has published a book as well as numerous journal and
conference papers in connection with his work.
Lyndon Smith is an active researcher andlecturer at the University of the West of
England, Bristol, UK. His research has
been reported in refereed journal papers
and technical presentations at various
dustry 56 (2005) 787–801 801
international locations, with a current
career total of over 60 publications. He
has experience in various areas of man-
ufacturing, including advanced machine
vision techniques for inspection and
metrology. He recently completed a 1-year secondment at The
Pennsylvania State University, and he acted as the EU Organising
Chairman for the 2002 International Conference on Process Model-
ling in PowderMetallurgy and Particulate Materials, held in Newport
Beach, CA, USA. He is also on the Editorial Board of the leading
international journal ’Powder Metallurgy’ (published by the Institute
ofMaterials,Minerals andMining in theUK).Since obtaininghisPhD
in 1997 he has continued to develop his research interests, through
successful application for research funding from various sources.
Sagar Midha is Reader and Research
Leader in the Mechanical, Manufacturing
and Aerospace Engineering School
within the Faculty of Computing, Engi-
neering and Mathematical Sciences at the
University of the West of England
(UWE), Bristol, UK. He received his
BSc Eng (Mech) from Punjab University
in India and his PhD from the Loughbor-
ough University in 1975. He is the Direc-
tor of the Centre for Intelligent Manufacturing and Machine Vision
Systems (CIMMS) at UWE. His research interests include machine
vision, Modelling and Knowledge Based Systems in Manufacturing
processes including stone polishing and Concurrent Engineering. He
has edited three books and has published numerous journal and
conference papers in connection with his work.




















