
David Mangin, Philippe Panerai — Projet urbain / ISBN 2-86364-604-4

Projet Statistiques :Mortalité et Pollution aux U.S.A.
Sommaire
I. Etude descriptives des donnes II. Modèle de régression III. Analyse et conclusion
I. Etude descriptives des données I.1) Présentation des données :
Nous disposons d’une grande série de données dans 60 villes duterritoire américain :
Température moyenne en Janvier (degrés Fahrenheit) Température moyenne en Juillet (degrés Fahrenheit) Humidité relative Pluviométrie annuelle (inch) Taux de mortalité ajusté selon l’âge Education Densité de population Pourcentage de personnes noires Pourcentage de cadres Population Population par ménage Revenu moyen Potentiel de pollution aux hydrocarbones Potentiel de pollution aux oxydes nitreux Potentiel de pollution au dioxyde de sulfure Pollution aux oxydes nitreux
On compte donc 16 données quantitatives pour chacune des 60 villes, avec pour exception une ville dont il manque une donnée(a mettre) !

On peut analyser ce jeux de donnée selon différents déterminants : variables climatiques, socio culturelles, et en rapport avec la pollution, en plus de la pollution que l’on va chercher à expliquer par ses variables.
On peut schématiquer ainsi notre jeux de donnes :
Corrélation :
JanTemp JulyTemp RelHum Rain MortalityJanTemp 1.00000000 0.3462818637 0.067871580 0.04579248 -0.03030382JulyTemp 0.34628186 1.0000000000 -0.452809150 0.42659957 0.27718256RelHum 0.06787158 -0.4528091500 1.000000000 -0.10698464 -0.08817445Rain 0.04579248 0.4265995672 -0.106984639 1.00000000 0.43793713Mortality -0.03030382 0.2771825634 -0.088174447 0.43793713 1.00000000Education 0.11628379 -0.2385439433 0.176491464 -0.47584156 -0.51109395PopDensity -0.10005146 -0.0609940005 -0.124975764 0.09761286 0.26536255X.NonWhite 0.45377412 0.5753090461 -0.117957115 0.30214442 0.64369115
60 villes La mortalité Socio culturelles
- Education- Densité de
population- Pourcentage de
personnes noires- Pourcentage de
cadres
Climatiques :
- température moyenneen janvier
- température moyenneen juillet
- humidité relative- pluviométrie
annuelle
Pollution :
- Potentiel depollution auxhydrocarbones
- Potentiel depollution aux oxydesnitreux
- Potentiel de

X.WC 0.21168715 0.0004066572 0.009660717 -0.11725742 -0.29205185pop 0.21881624 -0.0141678762 -0.127547509 -0.22185813 0.07025316pop.house -0.32456998 0.2407740878 -0.140532862 0.19990761 0.36795085income 0.04198025 -0.3308851666 0.170502396 -0.20089104 -0.13112500HCPot 0.35080939 -0.3564941649 -0.020177818 -0.48768328 -0.17823724NOxPot 0.32150613 -0.3373728376 -0.045551780 -0.45196604 -0.07768549S02Pot -0.10780991 -0.0993481309 -0.102553922 -0.12051771 0.42562402 Education PopDensity X.NonWhite X.WC popJanTemp 0.1162838 -0.100051462 0.453774118 0.2116871470 0.21881624JulyTemp -0.2385439 -0.060994000 0.575309046 0.0004066572 -0.01416788RelHum 0.1764915 -0.124975764 -0.117957115 0.0096607173 -0.12754751Rain -0.4758416 0.097612857 0.302144421 -0.1172574156 -0.22185813Mortality -0.5110939 0.265362550 0.643691153 -0.2920518532 0.07025316Education 1.0000000 -0.243883480 -0.208773945 0.4874420140 0.18704892PopDensity -0.2438835 1.000000000 -0.005678491 0.2406719508 0.34815410X.NonWhite -0.2087739 -0.005678491 1.000000000 -0.0574158238 0.11556828X.WC 0.4874420 0.240671951 -0.057415824 1.0000000000 0.21073981pop 0.1870489 0.348154101 0.115568279 0.2107398104 1.00000000pop.house -0.3894332 -0.160391434 0.352770977 -0.3472787206 -0.30965531income 0.3177827 0.125478642 -0.068623686 0.2321346652 0.31103390HCPot 0.2868347 0.120282246 -0.025864740 0.1648713562 0.53137107

NOxPot 0.2241307 0.166736548 0.019417974 0.1263490440 0.54864948S02Pot -0.2343459 0.432086418 0.159293022 -0.0678345285 0.37444491 pop.house income HCPot NOxPot S02PotJanTemp -0.324569977 0.04198025 0.35080939 0.32150613 -0.107809912JulyTemp 0.240774088 -0.33088517 -0.35649416 -0.33737284 -0.099348131RelHum -0.140532862 0.17050240 -0.02017782 -0.04555178 -0.102553922Rain 0.199907605 -0.20089104 -0.48768328 -0.45196604 -0.120517712Mortality 0.367950854 -0.13112500 -0.17823724 -0.07768549 0.425624019Education -0.389433179 0.31778267 0.28683470 0.22413065 -0.234345940PopDensity -0.160391434 0.12547864 0.12028225 0.16673655 0.432086418X.NonWhite 0.352770977 -0.06862369 -0.02586474 0.01941797 0.159293022X.WC -0.347278721 0.23213467 0.16487136 0.12634904 -0.067834528pop -0.309655306 0.31103390 0.53137107 0.54864948 0.374444907pop.house 1.000000000 -0.19910102 -0.48742228 -0.44739694 -0.008127013income -0.199101015 1.00000000 0.27159571 0.26609589 0.124274252HCPot -0.487422284 0.27159571 1.00000000 0.98376311 0.282296257NOxPot -0.447396938 0.26609589 0.98376311 1.00000000 0.409782898S02Pot -0.008127013 0.12427425 0.28229626 0.40978290 1.000000000
Corrélation partielle
$estimate

JanTemp JulyTemp RelHum Rain MortalityJanTemp 1.000000000 0.287637470 0.301416026 0.04817798 -0.26932006JulyTemp 0.287637470 1.000000000 -0.586407632 0.07576193 -0.21853892RelHum 0.301416026 -0.586407632 1.000000000 -0.03581943 0.02135856Rain 0.048177981 0.075761933 -0.035819432 1.00000000 0.23737213Mortality -0.269320064 -0.218538921 0.021358555 0.23737213 1.00000000Education -0.209516458 -0.073929889 0.052319767 -0.34085218 -0.17553234PopDensity -0.109236620 -0.069759731 -0.076616705 0.01335572 0.15878050X.NonWhite 0.446753770 0.454381247 0.156373075 0.01799973 0.66416243X.WC 0.102791619 0.030194070 -0.039113047 0.13383013 -0.17461963pop 0.004472432 0.241883914 0.003495685 -0.02218470 0.12377553pop.house -0.392215564 -0.145470154 -0.141770882 -0.22291737 -0.13856458income 0.032952284 -0.286341245 -0.010878838 0.09074977 -0.12825990HCPot 0.018640008 -0.141974752 -0.013127602 -0.22519201 -0.22104753NOxPot 0.050247187 0.027544904 -0.071132479 0.17258930 0.19551414S02Pot -0.143711848 0.003802327 0.046345600 -0.30557240 0.09549823 Education PopDensity X.NonWhite X.WC popJanTemp -0.20951646 -0.10923662 0.44675377 0.10279162 0.004472432JulyTemp -0.07392989 -0.06975973 0.45438125 0.03019407 0.241883914RelHum 0.05231977 -0.07661670 0.15637308 -0.03911305 0.003495685Rain -0.34085218 0.01335572 0.01799973 0.13383013 -0.022184697

Mortality -0.17553234 0.15878050 0.66416243 -0.17461963 0.123775528Education 1.00000000 -0.36196999 0.21666817 0.45997867 0.188644204PopDensity -0.36196999 1.00000000 -0.05072915 0.43077403 0.242836317X.NonWhite 0.21666817 -0.05072915 1.00000000 0.07382658 -0.080021454X.WC 0.45997867 0.43077403 0.07382658 1.00000000 -0.046392421pop 0.18864420 0.24283632 -0.08002145 -0.04639242 1.000000000pop.house -0.30823058 -0.17863482 0.50935303 -0.03369978 -0.009797934income 0.15407064 0.06195743 0.14673047 0.04013821 0.222843410HCPot -0.12566248 0.04876446 0.14256242 0.07847244 0.148754587NOxPot 0.11523568 -0.06069018 -0.08713585 -0.09231844 -0.079568989S02Pot -0.21188907 0.16214499 0.05190832 0.08574697 0.155727077 pop.house income HCPot NOxPot S02PotJanTemp -0.392215564 0.03295228 0.01864001 0.05024719 -0.143711848JulyTemp -0.145470154 -0.28634125 -0.14197475 0.02754490 0.003802327RelHum -0.141770882 -0.01087884 -0.01312760 -0.07113248 0.046345600Rain -0.222917371 0.09074977 -0.22519201 0.17258930 -0.305572402Mortality -0.138564584 -0.12825990 -0.22104753 0.19551414 0.095498229Education -0.308230585 0.15407064 -0.12566248 0.11523568 -0.211889066PopDensity -0.178634823 0.06195743 0.04876446 -0.06069018 0.162144995X.NonWhite 0.509353027 0.14673047 0.14256242 -0.08713585 0.051908317X.WC -0.033699782 0.04013821 0.07847244 -0.09231844 0.085746967

pop -0.009797934 0.22284341 0.14875459 -0.07956899 0.155727077pop.house 1.000000000 0.01220198 -0.14305051 0.08022031 -0.098531789income 0.012201979 1.00000000 -0.02986129 0.01334716 0.055729372HCPot -0.143050514 -0.02986129 1.00000000 0.97946311 -0.639922755NOxPot 0.080220313 0.01334716 0.97946311 1.00000000 0.677760113S02Pot -0.098531789 0.05572937 -0.63992275 0.67776011 1.000000000
I.2)
Problème : - un jeu de données très importants, toutes quantitatives et
avec des gammes de valeurs très variables. - Une mortalité qui n’est pas spécifique aux morts liés à la
pollution
Problématisation : On cherche à étudier le lien entre pollution et mortalité aux Etats Unis. Cependant la donnée de mortalité delaquelle nous disposons, plusieurs facteurs de mortalité sont compris. Aussi pour réussir a étudier le lien entre pollution et mortalité auxEtats Unis, plusieurs pistes sont possible :
- Etudier le lien entre mortalité et chacun des différents déterminants : sociaux économiques, climatiques, pollution. Aussi nous pourrons comparer différents modèles.
- Trier les données, voir celles qui sont corrélés à la pollution au moyen d’une Analyse en Composante principale,puis effecteur de nouveau une régression avec les variables sélectionnés.
- Comparer avec une étude géographique des bassins industriels, riches etc. (Etudier la répartition géographique des villes selon les différentes données : une composante géographique, alors lié aux données

climatiques est elle présente ? lié au données socio démographique en classant plutôt les villes, ou a la pollution par rapport aux bassins indutriels et villes industrialisé ? )
- Comparer pour des villes dont les données socio démographiques, climatiques, sont proches, l’effet de la pollution sur la mortalité.
II. Modèle de régression
A. Regression linaire multiple entre mortalité et variable climatique Passer au log ? que la pluie significatif. 15% expliqué par ce modèle.

B. socio démographique
Vu residuals vs fitted : aussi passer au log ?

57% (ajustée R squarred) mieux, explique beaucoup plus la mortalité.
C. pollution
2. SÉLECTION DE DONNÉES ET EFFET DE LA POLLUTION PAR GROUPE SOCIO- DÉMOGRAPHIQUE.
Afin de tester l’effet de la pollution sur la mortalité, nous aimerions maintenant établir un modèle combinant maintenant lesdonnées socio démographique, climatique et de pollution.
Au vue des nombreuses données, nous allons effectuer une analyse en composante principale pour sélectionner les données les plus pertinentes, dans le but de construire un modèle le plus juste possible.
1.1
- entrée R : usa8<-usa7[,-c(16)]> acp.us=PCA(usa8,scale.unit=TRUE,ncp=15)> coscar1=acp.us$ind$cos2[,1]> coscar2=acp.us$ind$cos2[,2]> coscar12=coscar1+coscar2> cex=0.3+log(1+coscar12)

> coord12=acp.us$ind$coord[,1:2]> text(coord12[,1],coord12[,2],rownames(usa8),cex=0.3+log(1+coscar12))> abline(h=0,v=0)> contrib12=acp.us$ind$contrib[,1:2]> info.ind=round(data.frame(coord12,coscar12,contrib12),2)> colnames(info.ind)=c("coord1","coord2","coscar12","contrib1","contrib2")> > plot.PCA(acp.us, axes=c(1,2), choix="ind",cex=0.3+log(1+coscar12))
Sortie de R :

Au vue du graphe des valeur propre, on peut ne considérer que les deux première qui explique respectivement 27 et 18% des données.
D’après le cercle des variables on constate : - X non White est la variable la plus postiviement corrélé à
l’éducation, puis l’Education en étant positivement corrélé.
- NOxPot et HCPot forment un angle a 90° avec la Mortalité :ces données ne seraient donc pas du tout corrélé.
Ceci confirme :

- que les données socio démographique sont les plus explicatives et corrélés à la mortalité
- Au sein de ces nombreuses données, celles liés à la pollution ne paraissent pas du tout déterminante.
:
Afin de juger l’effet de la pollution sur la mortalité, il conviendrait donc de pouvoir négliger l’effet socio démographique déterminant. C’est à dire pouvoir observer si pour des villes dont les données socio démographique sont similaires, la variation de la pollution peut expliquer des variations de mortalité.
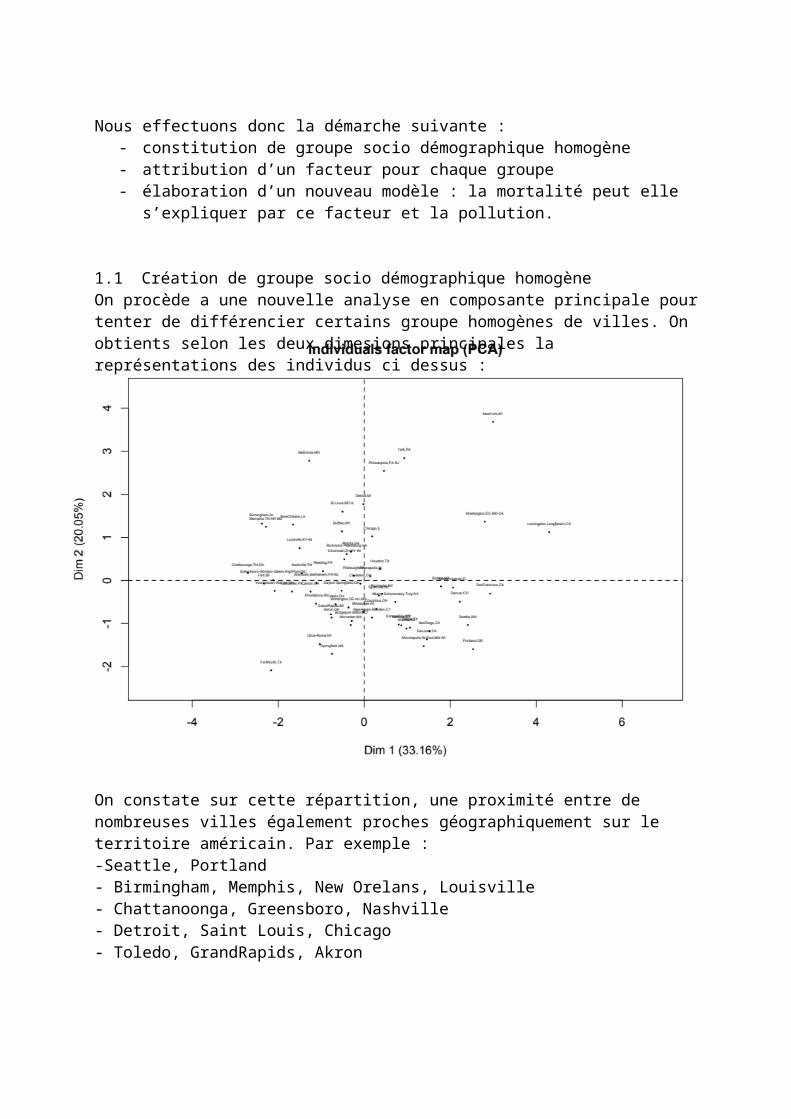
Nous effectuons donc la démarche suivante : - constitution de groupe socio démographique homogène- attribution d’un facteur pour chaque groupe - élaboration d’un nouveau modèle : la mortalité peut elle
s’expliquer par ce facteur et la pollution.
1.1 Création de groupe socio démographique homogèneOn procède a une nouvelle analyse en composante principale pourtenter de différencier certains groupe homogènes de villes. On obtients selon les deux dimesions principales la représentations des individus ci dessus :
On constate sur cette répartition, une proximité entre de nombreuses villes également proches géographiquement sur le territoire américain. Par exemple : -Seattle, Portland- Birmingham, Memphis, New Orelans, Louisville- Chattanoonga, Greensboro, Nashville- Detroit, Saint Louis, Chicago- Toledo, GrandRapids, Akron

Dans le cadre de notre étude ceci s’explique notamment par les corrélations entre données socio démographiques et certaines données climatiques :
- pluie et éducation négativement corrélé, - Température de juillet négativement corrélée à l’éducation
et positivement au pourcentage de population non blanche.
Le territoire Américain a en effet cette particularité de présenter des clivages entre différentes zones en termes économiques, sociologique, démographique, climatique, liés intrinsèquement à son histoire depuis sa découverte, colonisation, industrialisation. Par exmple : Le vieux Sud, dont la pourcentage de population noire est largement supérieur à la moyenne américaine, la moyenne des salaires bien plus basses etc.. la mégalopole du Nord Est. le bassins industriels autour des grands lacs
Ci dessous trois cartes représentant les données économiques, certaiens démographiqu et aussi climatique :
On remarque une superposition possible entre ces cartes.
De plus le Health Effects Institute aux Etats Unis, a produit une conséquente recherche titrée The National Morbidity, Mortality, and Air Pollution Study. Part II: Morbidity and Mortality from Air Pollution in the United States, étudiant l’effet de la pollution sur la mortalité et morbitié dans 20 puis 90 villes des Etats Unis, a eu recours a cette méthode de découpage du terrain américain justifié par les arguments que nous avons avancé précédemment. Aussi, nous nous permettons de reprendre leuur regroupement de villes qui suit la logique ci dessous :

1.2 Descriptions des nouvelles données : Nous affectons un coefficients compris entre 1 et 7 correspondant aux différentes zones : 1 : Northwest2 : Upper Midwest3 : Industrial Midwest4 : Northeast5 : Southern California6 : Southwest7 : Southeast
Nous ne conservons que les données liées à la pollution et cette nouvelle colonne titrée « Socio », qui est introduit en tant que facteur.
on obtient dans R :
> summary(test2) Mortality HCPot NOxPot S02Pot Socio Min. : 790.7 Min. : 1.00 Min. : 1.00 Min. : 1.00 1: 4 1st Qu.: 898.4 1st Qu.: 7.00 1st Qu.: 4.00 1st Qu.: 11.00 2: 4

Median : 943.7 Median : 14.50 Median : 9.00 Median : 30.00 3:17 Mean : 940.3 Mean : 37.85 Mean : 22.60 Mean : 53.77 4:21 3rd Qu.: 983.2 3rd Qu.: 30.25 3rd Qu.: 23.75 3rd Qu.: 69.00 5: 2 Max. :1113.2 Max. :648.00 Max. :319.00 Max. :278.00 6: 4 7: 8 1.3 Nouveaux modèles :
a) Séléction de données : - On cherche a expliquer la mortalité (donnée quantitative), par le facteur retenu nommé « socio » (lié à la sociologie et la climatologie), et la pollution. Afin de pouvoir bâtir un modèle simple, nous ne retiendrons comme donné de pollution quela donnée S02Pot, qui était apparu comme la plus corrélé à la mortalité (voir ACP ci dessus).
- Nous avons effectuer 7 groupes afin d’assurer la plus grande homogénéité possible entre les villes de même groupe. Cependant certains groupes sont très peu représentés (4 données seulement pour le groupe 1, 2 et 6 ; 2 pour le groupe 5). Aussi nous centrerons l’étude surles groupe 3,4 et 7.
b) on cherche à expliquer la mortalité par la classe « socio » de la ville et son taux de S02Pot. On construitdonc le modèle suivant :
Yi,j=(μ+αi)+(β+γi )∗xi,j+ei,j
où : i prend les valeurs 3,4 et 7j prend les valeurs de 1 a 21 Yi,j est la mortalité de la j-ième ville du groupe i xi,j est le taux S02Pot de la j-ième ville du groupe i les ei,j sont indépendantes, identiquement réparties et suivent une loi N¿)

αi représente l’effet du facteur i γi l’interaction entre le facteur i et le taux S02Potβl’effet du taux S02PotCe sont avec μ les paramètres à estimer.
Hypothèses du modèle :
Vérifier (mettre graph)
Sortie R :
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 931.4786 15.7033 59.317 <2e-16 ***S02Pot 0.2727 0.1288 2.117 0.0406 * Socio[T.4] -20.0374 21.0513 -0.952 0.3469 Socio[T.7] 56.9626 28.0762 2.029 0.0492 * S02Pot:Socio[T.4] 0.4642 0.2289 2.028 0.0493 * S02Pot:Socio[T.7] -0.1241 0.5759 -0.215 0.8305 ---Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 45.03 on 40 degrees of freedomMultiple R-squared: 0.3859, Adjusted R-squared: 0.3091 F-statistic: 5.026 on 5 and 40 DF, p-value: 0.00115
On effectue les test du modèle de type I et II à l’aide des fonctions anova et Anova
anova(test4.lm)Analysis of Variance Table
Response: Mortality Df Sum Sq Mean Sq F value Pr(>F) S02Pot 1 22068 22068.3 10.8854 0.002043 **Socio 2 20089 10044.7 4.9547 0.011956 * S02Pot:Socio 2 8794 4396.9 2.1688 0.127570 Residuals 40 81093 2027.3
Anova(test4.lm)Anova Table (Type II tests)

Response: Mortality Sum Sq Df F value Pr(>F) S02Pot 31181 1 15.3802 0.0003363 ***Socio 20089 2 4.9547 0.0119555 * S02Pot:Socio 8794 2 2.1688 0.1275698 Residuals 81093 40
Analyse : P valeur inférieur a 5%, bon modèle, mais d’aprèrs les deux tests d’anova, l’interaction n’apporte pas aux modèles.
2ème modèle :
Yi,j=(μ+αi)+(β )∗xi,j+ei,j
i prend les valeurs 3,4 et 7j prend les valeurs de 1 a 21 Yi,j est la mortalité de la j-ième ville du groupe i xi,j est le taux S02Pot de la j-ième ville du groupe i les ei,j sont indépendantes, identiquement réparties et suivent une loi N¿)
αi représente l’effet du facteur i βl’effet du taux S02PotCe sont avec μ les paramètres à estimer.
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 919.4240 14.6474 62.771 < 2e-16 ***S02Pot 0.4103 0.1075 3.817 0.000438 ***Socio[T.4] 9.2793 15.5481 0.597 0.553838 Socio[T.7] 61.1014 20.7703 2.942 0.005292 ** ---Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1

Residual standard error: 46.26 on 42 degrees of freedomMultiple R-squared: 0.3193, Adjusted R-squared: 0.2706 F-statistic: 6.566 on 3 and 42 DF, p-value: 0.0009671
Test du modèle :
> anova(test5.lm)Analysis of Variance Table
Response: Mortality Df Sum Sq Mean Sq F value Pr(>F) S02Pot 1 22068 22068.3 10.3115 0.002537 **Socio 2 20089 10044.7 4.6934 0.014466 * Residuals 42 89887 2140.2
Celui ci est pertinent et la donnée S02Pot est pertinente.
Copyright © 2022 FDOKUMEN




















