
Rapport projet : Segmentation de mouvement
16
Matthieu Boussard Stanislas Dion Projet de fin d’étude – Option SARP Janvier 2000 Responsable : F. Meunier Parallélisation d'une méthode de segmentation de mouvement Table des matières 1 OBJECTIF DU PROJET 2 MÉTHODE 2.1 Présentation 2.2 La segmentation 2.3 L'estimation de mouvement 2.4 Fusion de regions de mouvements semblables 3 RÉALISATION 3.1 Principe de la parallelisation 3.2 Ossature PVM - Récupération des données - Initialisation - Calcul des critères de ressemblance et fusion 3.3 Iincorporation de certains calculs sequentiels 3.4 Presentation du programme 4 PERSPECTIVES 4.1 Ameliorations de l'existant
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Rapport projet : Segmentation de mouvement
Matthieu Boussard Stanislas Dion Projet de fin d’étude – Option SARP Janvier 2000 Responsable : F. Meunier
Parallélisation d'une méthode de segmentation de mouvement
Table des matières
1 OBJECTIF DU PROJET
2 MÉTHODE
2.1 Présentation
2.2 La segmentation
2.3 L'estimation de mouvement 2.4 Fusion de regions de mouvements semblables
3 RÉALISATION
3.1 Principe de la parallelisation
3.2 Ossature PVM
- Récupération des données
- Initialisation
- Calcul des critères de ressemblance et fusion
3.3 Iincorporation de certains calculs sequentiels
3.4 Presentation du programme
4 PERSPECTIVES
4.1 Ameliorations de l'existant

4.1.1 Méthode réaliste
4.1.2 Codage
4.1.3 Parallèlisation
4.2 Directions de travaux ulterieurs
1 Objectif du projet
La segmentation du mouvement des objets d’une scène a pour but de détecter les régions d'une image ayant un mouvement homogène et indépendant. Ses applications sont multiples, avec en premier plan la reconnaissance d'objets en mouvement. La méthode utilisée est celle proposée par L. Bergen et F. Meyer du Centre de Morphologie Mathématique de l'Ecole Mathématique de Paris dans " Segmentation du mouvement des objets dans une scène ". Pour atteindre un temps de traitement acceptable, le but du projet est de mettre en oeuvre une version parallèle de cette méthode. Plus précisément, pour travailler sur un réseau de stations sous PVM, il faudra appliquer une parallélisation à gros grains. Pour commencer, il faudra définir les principes de cette dernière, réaliser une ossature PVM opérationnelle, pour finalement incorporer progressivement des programmes testés en séquentiel.
2 Méthode
2.1 Présentation
La méthode proposée permet de s'affranchir des problèmes de précision rencontrées dans des méthodes précédentes en s'appuyant sur la segmentation spatiale d'une part, et l'estimation du mouvement normal par pixel de l'image d'autre part.La segmentation spatiale permet d'obtenir des régions cohérentes par rapport à certains critères (tels que l'homogénéité de niveaux de gris, de couleurs, ou lignes de partage des eaux sur l'image des gradients. Quant à l'estimation de mouvement de chaque pixel, on sait que seule la composant normale à la ligne d'iso-intensite peut etre obtenue, a cause du " problème de l’ouverture " (aperture problem) Ainsi munis, pour chaque pixel de l'image, des informations relatives à son appartenance à une région et à son mouvement, il est possible par interpolation, d'estimer les paramètres de mouvement pour chaque région issue de la segmentation. Ces régions sont généralement trop nombreuses par "sursegmentation" , et il faut fusionner des regions, selon les critères choisis. Dans notre cas il s'agit de fusionner des régions de mouvement semblable.
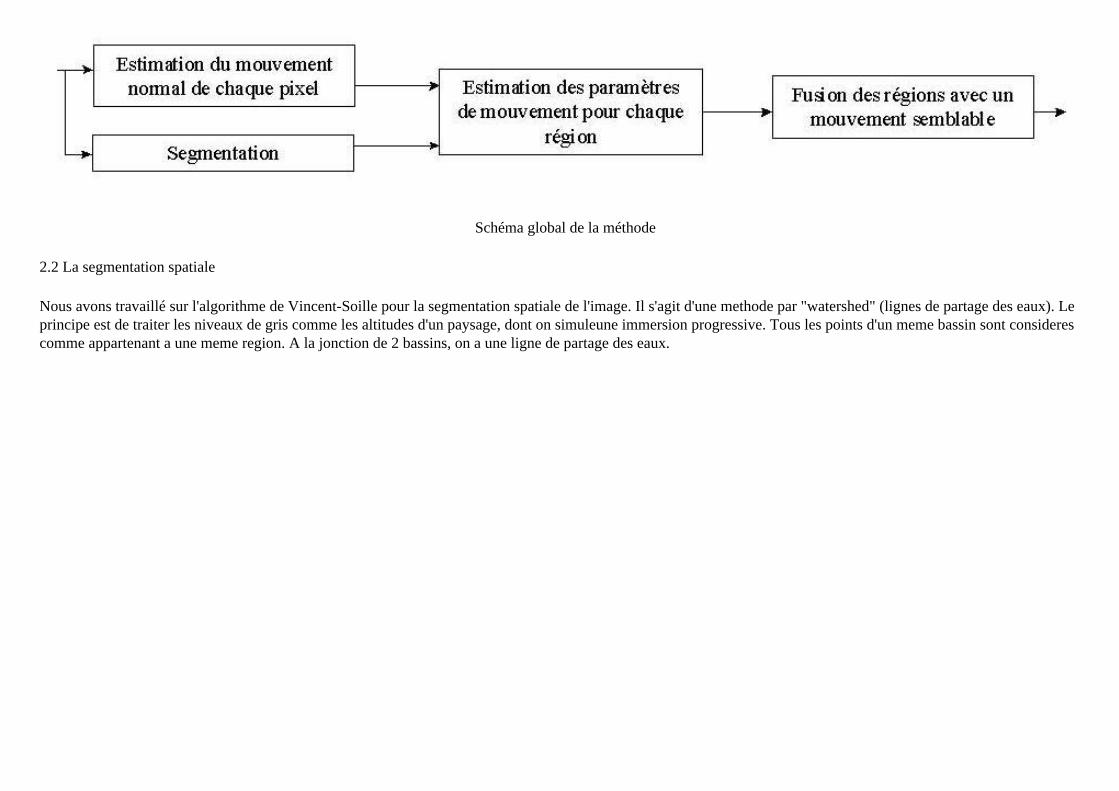
Schéma global de la méthode
2.2 La segmentation spatiale
Nous avons travaillé sur l'algorithme de Vincent-Soille pour la segmentation spatiale de l'image. Il s'agit d'une methode par "watershed" (lignes de partage des eaux). Le principe est de traiter les niveaux de gris comme les altitudes d'un paysage, dont on simuleune immersion progressive. Tous les points d'un meme bassin sont consideres comme appartenant a une meme region. A la jonction de 2 bassins, on a une ligne de partage des eaux.

Pour etre pertinente, une methode de "watershed" doit etre appliquee a une "image" auxiliaire, cad. le tableau 2D des normes du gradient d'intensite.

Exemples :
- a gauche: vue extraite de la sequence "taxi de Hambourg"
- a droite: image des normes des gradients d'intensite
On demande en general a la phase de segmentation de produire une certaine sursegmentation, cad. un nombre de regions plus eleve que le nombre d'objets visibles. Ceci est preferable a l'agregation a tort, dans une meme region, de parties correspondant en fait a des objets differents. Apres segmentation, un principe general est donc de chercher a fusionner les differentes regions qui correspondent a un meme objet de la scene. Dans notre cas, ce sera en fonction d'un critere d'homogeneite de mouvements.
La methode de Vincent-Soille est tres rapide, mais fournit une sursegmentation tres importante, plus qu'il n'est necessaire pour un processus normal de fusion de regions a fins d'identification d'objets. Pour reduire cette sursegmentation exageree, les auteurs proposent de reiterer le meme principe, en l'appliquant au graphe d'adjacence des regions de la segmentation initiale. D'autres auteurs proposent d'autres procedes de reduction de sursegmentation. Dans notre travail nous n'avons pas cherche a reduire la sursegmentation.
2.3 L'estimation des mouvements
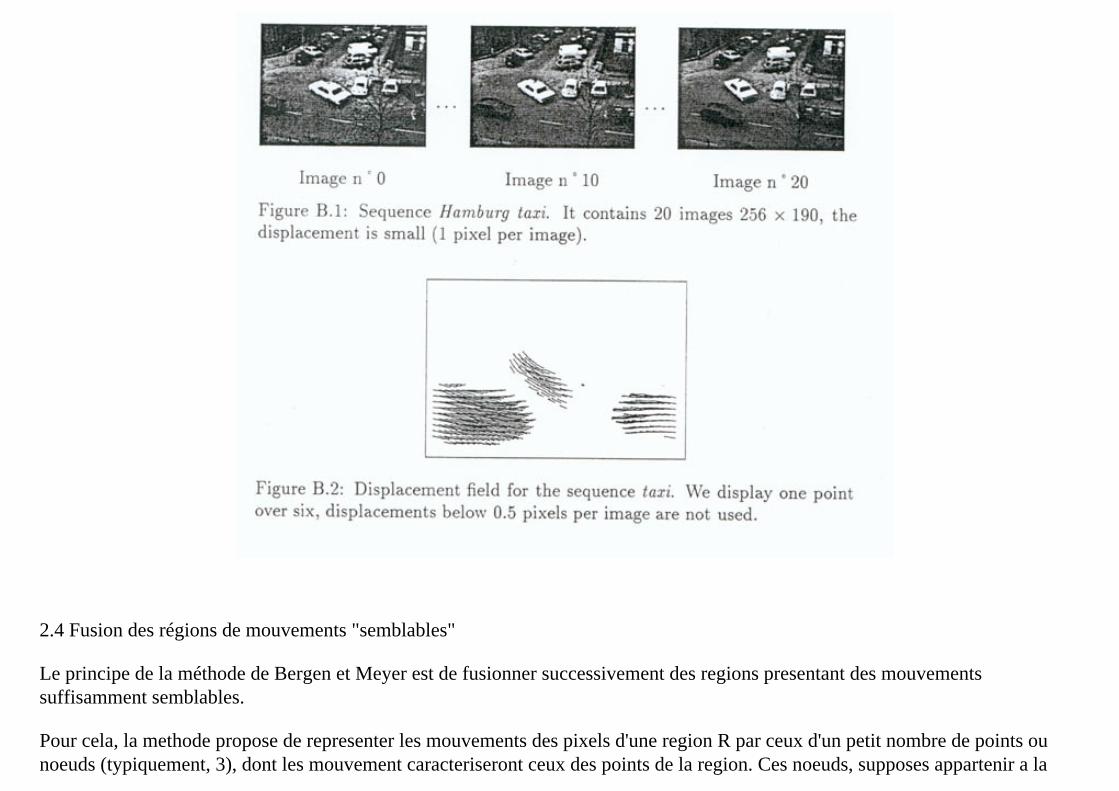
Elle est basee sur une mise en correspondance des pixels de l'image t avec ceux de l'image t+1. Deux pixels sont mis en correspondance s'ils correspondent a un meme point physique de la scene observee. L'ensemble des vecteurs deplacements obtenu constitue le champ de mouvements de l'image t. Pour une image de dimensions M x N, il s'agit donc d'un tableau de M x N vecteurs.

Il existe de tres nombreuses methodes pour calculer les champs de mouvements. Noter que la mise en correspondance ne peut pas, en genereal, etre parfaite : certains points de l'image t n'ont plus de correspondants dans l'image t+1 (occlusions); inversement des points nouveaux peuvent apparaitre dans celle-ci.
Dans notre cas, les champs de mouvements nous sont fournis par une methode differentielle multiresolution, la methode de Weng (ayant fait l'objet recemment a l'INT de diverses parallelisations par Laurent Gatineau). Afin de mieux nous concentrer sur notre probleme propre, nous avons choisi de faire relire des "images" de champs de mouvements, precalculees. Ulterieurement, on pourra remplacer ce processus de lecture par un processus de calcul ds champs de mouvements (ou encore mieux par un ensemble de processus paralleles a cet effet).
Par ailleurs, pour les calculs impliques par la methode de Bergen et Meyer, nous avions besoin en chaque pixel de la composante de sa vitesse dans la direction du gradient d'intensite. Nous avons utilise pour cela un programme de filtre de Deriche.
Exemple de champs de mouvement
2.4 Fusion des régions de mouvements "semblables"
Le principe de la méthode de Bergen et Meyer est de fusionner successivement des regions presentant des mouvements suffisamment semblables.
Pour cela, la methode propose de representer les mouvements des pixels d'une region R par ceux d'un petit nombre de points ou noeuds (typiquement, 3), dont les mouvement caracteriseront ceux des points de la region. Ces noeuds, supposes appartenir a la

region, n'ont en fait pas besoin d'y etre reellement. Dans n'importe quelle image, et pour traiter n'iporte quelle region, on peut les choisir toujours aux memes endroits. Pour une region R, on determinera les vecteurs mouvements V1, V2, V3 des noeuds caracteristiques pour qu'ils representent au mieux les mouvements de tous les points de R. Inversement, si on connait les mouvements des noeuds caracteristiques, ceux des points de R s'en deduisent par combinaisons lineaires (selon une technique de "krigeage").
Les vecteurs V1, V2, V3 representant au mieux les vecteurs mouvements des points de la region R sont ceux qui minimisent l'erreur dans un systeme surdetermine, de facon un peu analogue aux problemes de moindre carres. Pour les calculer, on utilise la methode de decomposition en valeurs singulieres (SVD), pour laquelle un code sequentiel existe (issu de Numerical recipes in C).
En vue d'eventuellement fusionner deux regions R1 et R2, on evalue si la region R qui en resulterait serait pertinente, en termes d'homogeneite des mouvements. Cette qualite est evaluee en trois temps. D'abord on calcule les vecteurs V1,V2,V3 qui correspondraient a R. Puis les vecteurs mouvements que V1, V2, V3 induiraient en tous points de R (par interpolation). Enfin on calcule le total des ecarts entre mouvements ainsi calcules et mouvements reels des points de R.
Ce critere est calcule pour chaque paire de regions potentiellement fusionables. En principe, on devrait considerer a priori qu'une region R1 donnee peut fusionner avec n'importe quelle autre region R2. En effet si R1 et R2 correspondent a un meme objet de la scene, celui-ci peut tres bien etre en partie occulte par une objet situe entre elles. En pratique, le cas le plus frequent est celui de la fusion de regions voisines; c'est cette hypothese simplificatrice que nous avons faite dans ce travail.
On choisit de fusionner le couple de regions présentant le meilleur critère de ressemblance. Il faut alors recalculer le critère de

ressemblance des couples composés de la nouvelle région et de ses voisins, avant d'entreprendre au besoin une nouvelle fusion.
Exemple de réalisation de la méthode : la séquence Foreman
... et les fusions effectuées (10 fusions entre chaque image)

3 Réalisation
3.1 Principe de la parallélisation
Nous avons retenu une architecture à grosse granularité suivant un schéma de ferme. L'ensemble est articulé autour d’une tâche maître qui répartit les calculs, et synchronise l’ensemble.
Toutes les communications sont synchrones. Les données sont dupliquées pendant la deuxième phase (voir plus bas) et sont mis à jour localement ensuite afin de limiter au maximum les flux.
3.2 Ossature PVM
Le travail principal accompli a été la réalisation d'une ossature PVM pour la méthode. Nous avons choisi de coder de façon assez statique, pour limiter les problèmes à la parallélisation (voir améliorations dans la partie 4). Ainsi, tout est stocké dans des matrices de taille prédéfinie.
Le programme se décompose suivant les trois étapes suivantes :
- Récupération des données La tâche maître, appelée fusion, crée trois tâches esclaves spécialisées chargées de générer la table des régions, la table des gradients

normés et celle des mouvements. La version actuelle ne fait que relire les résultats (fichiers) des trois programmes chargés d'effectuer ces calculs, et exécutés au préalable. Les tâches esclaves sont détruites après exécution.

- Initialisation
Fusion crée un nombre donné d'esclaves (workers), à qui elle transmet les trois tables obtenues précédemment. Ces trois tables seront conservées pendant toute l'exécution par toutes les tâches, et modifiées par ces dernières si nécessaire. Les workers s'attellent au calcul des estimations de mouvement. Pendant ce temps, fusion calcule la matrice d'adjacence des régions. Chaque worker est notifié de son rang, ce qui lui permet de décider par une politique simple des régions qu'il devra traiter. Dans notre mise en oeuvre, chaque worker s'occupe des régions de numéro son rang modulo le nombre de workers prédéfini. Les résultats sont ensuite transmis à fusion, qui les regroupe.

- Calcul des critères de ressemblance et fusion
Chaque worker reçoit la matrice d'adjacence de fusion et calcule les critères de ressemblance des régions dont il a la charge avec ses voisines de label supérieur. Les résultats sont envoyés à fusion, qui peut ainsi décider du meilleur couple à fusionner. Commence alors la boucle de fusion :
1. Notification du couple à fusionner aux workers 2. Mise à jour par chaque tâche de ses tables de labels, d'adjacence et de vecteur de référence, en tenant compte d'un tableau de validité des régions 3. Calcul par les workers des critères de ressemblances affectés par la fusion (voisins de la nouvelle région) 4. Envoi des résultats à fusion et décision du nouveau couple à fusionner
Le critère d’arrêt de la boucle est pour l'instant l'arrivée à un nombre de régions réduit de moitié.

3.3 Incorporation de certains calculs séquentiels
Pour ce qui est des calculs des tables de labels, des gradients normés de luminance et des mouvements, nous avons choisi dans un premier temps de réaliser des programmes séquentiels et indépendants stockant les résultats dans un fichier. Ces programmes sont des adaptations de programmes existants ou codages d’algorithmes dus à a Laurent Gatineau et François Meunier.

Ceux-ci ont donc été exécuté au préalable, et il suffit aux tâches du programme principal d’aller relire les fichiers résultats. Ensuite, pour tester les différents éléments, nous avons créés quelques images artificielles pour nous rendre compte à travers une démonstration allégée de l'efficacité de l’ossature PVM complète.
3.4 Présentation du programme
Les sources se répartissent comme suit :
- common.h- fusion.c, qui décrit le programme principal (annexe ***)> - worker.c - la bibliothèque de calcul pour svd - segmentation.c - mvt.c - deriche.c
4 Perspectives
4.1 Amélioration de l'existant
4.1.1 Méthode réaliste
Il faudra incorporer de vrais calculs sur le critère de ressemblance, et en particulier la SVD, qui est à la base de ceux-ci. Sans ce critère, il est impossible de mettre en oeuvre la méthode de segmentation de mouvement.
Ensuite, il faudra travailler sur le critère d'arrêt. En effet, l'algorithme permet de poursuivre jusqu'à l'obtention d'une région unique contenant toute l'image. Les questions qu'il faut alors se poser portent sur le nombre de régions à conserver. Ce nombre peut être fonction du nombre de régions au départ, ou absolu (dans ce dernier cas, il nécessitera une intervention humaine liée à l'environnement de l'image analysée).

4.1.2 Codage
Au niveau du codage, toutes les allocations ont été réalisées de manière statique. Il faudrait donc allouer les ressources de manière dynamique afin de réduire l'occupation mémoire et le temps d'accès.
4.1.3 Parallèlisation
Il doit être possible d'améliorer la politique de répartition du travail entre les workers et éventuellement d'avoir un pool dynamique de workers.
4.2 Direction des travaux ultérieurs
Les travaux ultérieurs pourront s'orienter vers l'incorporation d'améliorations qualitatives qui pourront être apportées par des spécialistes de l'image. En effet les calculs directement liés à l'image sont très coûteux.Ensuite on pourra se pencher sur de nouveaux principes de parallèlisation, et en particulier penser à une parallèlisation à grain fin pour certaines fonctions.




















