
PDF optimized parametric vector quantization of speech line spectral frequencies
13
130 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 11, NO. 2, MARCH 2003 PDF Optimized Parametric Vector Quantization of Speech Line Spectral Frequencies Anand D. Subramaniam and Bhaskar D. Rao, Fellow, IEEE Abstract—A computationally efficient, high quality, vector quantization scheme based on a parametric probability density function (PDF) is proposed. In this scheme, the observations are modeled as i.i.d realizations of a multivariate Gaussian mixture density. The mixture model parameters are efficiently estimated using the Expectation Maximization (EM) algorithm. A low complexity quantization scheme using transform coding and bit allocation techniques which allows for easy mapping from observation to quantized value is developed for both fixed rate and variable rate systems. An attractive feature of this method is that source encoding using the resultant codebook involves very few searches and its computational complexity is minimal and independent of the rate of the system. Furthermore, the proposed scheme is bit scalable and can switch seamlessly between a memo- ryless quantizer and a quantizer with memory. The usefulness of the approach is demonstrated for speech coding where Gaussian mixture models are used to model speech line spectral frequencies. The performance of the memoryless quantizer is 1-3 bits better than conventional quantization schemes. Index Terms—Gaussian mixture models, source coding, speech coding, transform coding. I. INTRODUCTION R EALISTIC bandwidth and memory restrictions en- forced by digital communication channels compel one to perform quantization on a continuous valued source. For the purposes of transmission and storage, there is a need to build quantizers with reasonable search and computational complexity that provide good performance relative to a relevant distortion measure. Conventional nonadaptive quantization schemes design the quantizer using a large database of the source called the training data. The training data is so chosen that it encompasses all possible statistics of the source. Con- siderable progress has been made by conventional schemes in providing a good performance-complexity tradeoff. However, there is room for improvement and significant gains can be made by addressing the following aspects: 1) Computational Complexity: Full search quantization schemes have considerable search complexity and memory requirements. Vector quantizers, in particular, are known to have huge memory and computational costs [1]. This has lead to current schemes such as the Multistage Vector Quantizer Manuscript received February 13, 2001; revised November 14, 2002. This work was supported by Qualcomm, Inc., under the MICRO Grants 01-069 and 02-062. The associate editor coordinating the review of this manuscript and ap- proving it for publication was Dr. Sean A. Ramprashad. The authors are with the Department of Electrical and Computer En- gineering, University of California, San Diego, CA 92122 USA (e-mail: [email protected]; [email protected]). Digital Object Identifier 10.1109/TSA.2003.809192 (MSVQ) [3] and Split-VQ [4] which employ sub-optimal search and design techniques which then lead to sub-optimal quantizers. In spite of these suboptimalities, almost all current schemes still have exponential search and memory complexity. 2) Rate Dependence: The complexity of conventional schemes is dependent on the rate of the system. In particular, the complexity of vector quantizers varies exponentially with the rate of the system [1]. This implies that current schemes are infeasible in high bit-rate applications as is likely in Internet telephony. 3) Bit-rate Scalability: The current schemes are not easily bit-rate scalable. This means that quantizer design is usually done for a specific bit-rate and in case we need to operate at a dif- ferent bit-rate, the whole training process needs to be repeated. At best, with additional memory complexity, current schemes allow for quantization at a few distinct rates but do not allow for scalability in a continuum of rates. 4) Variable Rate Coding: The current quantizers do not allow for easy adaptation to variable-rate coding which holds promise in wireless CDMA communication environments. 5) Interoperability: Conventional quantization schemes are usually inflexible. They do not allow for easy switching between memoryless quantizers and quantizers with memory depending on channel conditions. 6) Learning: Conventional quantization schemes are typically unsuitable for operation in a learning environment. This is be- cause the structure of codebooks in the current schemes do not allow for efficient adaptation with the varying statistics of the source. This paper proposes a novel source coding scheme which ef- fectively addresses all the aforementioned drawbacks of present day quantizers and still delivers the performance quality of- fered by current schemes. The problem of quantizer design for a random source may be conveniently broken down into one of estimating the probability density function (pdf) of the random source and then efficiently quantizing the estimated pdf. This approach is implicit in many lossless source coding schemes such as arithmetic coding [5], [6]. In lossy source coding, this approach has several advantages over conventional VQ design and was first suggested in [7] for scalar quantization, the pdf being estimated using a nonparametric model. This paper ex- tends the design to the important vector case and presents a vector quantizer design scheme which is based on an estimate of the multidimensional pdf of a vector source using a parametric model. Fig. 1 depicts the overall source coding scheme. Irrespec- tive of the distortion measure used, the pdf of a random source 1063-6676/03$17.00 © 2003 IEEE
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of PDF optimized parametric vector quantization of speech line spectral frequencies

130 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 11, NO. 2, MARCH 2003
PDF Optimized Parametric Vector Quantization ofSpeech Line Spectral Frequencies
Anand D. Subramaniam and Bhaskar D. Rao, Fellow, IEEE
Abstract—A computationally efficient, high quality, vectorquantization scheme based on a parametric probability densityfunction (PDF) is proposed. In this scheme, the observations aremodeled as i.i.d realizations of a multivariate Gaussian mixturedensity. The mixture model parameters are efficiently estimatedusing the Expectation Maximization (EM) algorithm. A lowcomplexity quantization scheme using transform coding andbit allocation techniques which allows for easy mapping fromobservation to quantized value is developed for both fixed rateand variable rate systems. An attractive feature of this method isthat source encoding using the resultant codebook involves veryfew searches and its computational complexity is minimal andindependent of the rate of the system. Furthermore, the proposedscheme is bit scalable and can switch seamlessly between a memo-ryless quantizer and a quantizer with memory. The usefulness ofthe approach is demonstrated for speech coding where Gaussianmixture models are used to model speech line spectral frequencies.The performance of the memoryless quantizer is 1-3 bits betterthan conventional quantization schemes.
Index Terms—Gaussian mixture models, source coding, speechcoding, transform coding.
I. INTRODUCTION
REALISTIC bandwidth and memory restrictions en-forced by digital communication channels compel one
to perform quantization on a continuous valued source. Forthe purposes of transmission and storage, there is a need tobuild quantizers with reasonable search and computationalcomplexity that provide good performance relative to a relevantdistortion measure. Conventional nonadaptive quantizationschemes design the quantizer using a large database of thesource called thetraining data. The training data is so chosenthat it encompasses all possible statistics of the source. Con-siderable progress has been made by conventional schemes inproviding a good performance-complexity tradeoff. However,there is room for improvement and significant gains can bemade by addressing the following aspects:
1) Computational Complexity: Full search quantizationschemes have considerable search complexity and memoryrequirements. Vector quantizers, in particular, are known tohave huge memory and computational costs [1]. This has leadto current schemes such as the Multistage Vector Quantizer
Manuscript received February 13, 2001; revised November 14, 2002. Thiswork was supported by Qualcomm, Inc., under the MICRO Grants 01-069 and02-062. The associate editor coordinating the review of this manuscript and ap-proving it for publication was Dr. Sean A. Ramprashad.
The authors are with the Department of Electrical and Computer En-gineering, University of California, San Diego, CA 92122 USA (e-mail:[email protected]; [email protected]).
Digital Object Identifier 10.1109/TSA.2003.809192
(MSVQ) [3] and Split-VQ [4] which employ sub-optimalsearch and design techniques which then lead to sub-optimalquantizers. In spite of these suboptimalities, almost all currentschemes still have exponential search and memory complexity.
2) Rate Dependence: The complexity of conventionalschemes is dependent on the rate of the system. In particular,the complexity of vector quantizers varies exponentially withthe rate of the system [1]. This implies that current schemes areinfeasible in high bit-rate applications as is likely in Internettelephony.
3) Bit-rate Scalability: The current schemes are not easilybit-rate scalable. This means that quantizer design is usuallydone for a specific bit-rate and in case we need to operate at a dif-ferent bit-rate, the whole training process needs to be repeated.At best, with additional memory complexity, current schemesallow for quantization at a few distinct rates but do not allow forscalability in a continuum of rates.
4) Variable Rate Coding: The current quantizers do not allowfor easy adaptation to variable-rate coding which holds promisein wireless CDMA communication environments.
5) Interoperability: Conventional quantization schemes areusually inflexible. They do not allow for easy switching betweenmemoryless quantizers and quantizers with memory dependingon channel conditions.
6)Learning: Conventional quantization schemes are typicallyunsuitable for operation in a learning environment. This is be-cause the structure of codebooks in the current schemes do notallow for efficient adaptation with the varying statistics of thesource.
This paper proposes a novel source coding scheme which ef-fectively addresses all the aforementioned drawbacks of presentday quantizers and still delivers the performance quality of-fered by current schemes. The problem of quantizer design fora random source may be conveniently broken down into one ofestimating the probability density function (pdf) of the randomsource and then efficiently quantizing the estimated pdf. Thisapproach is implicit in many lossless source coding schemessuch as arithmetic coding [5], [6]. In lossy source coding, thisapproach has several advantages over conventional VQ designand was first suggested in [7] for scalar quantization, the pdfbeing estimated using a nonparametric model. This paper ex-tends the design to the important vector case and presents avector quantizer design scheme which is based on an estimate ofthe multidimensional pdf of a vector source using a parametricmodel.
Fig. 1 depicts the overall source coding scheme. Irrespec-tive of the distortion measure used, the pdf of a random source
1063-6676/03$17.00 © 2003 IEEE

SUBRAMANIAM AND RAO: PDF OPTIMIZED PARAMETRIC VECTOR QUANTIZATION 131
Fig. 1. Overall source coding scheme.
has all the necessary and sufficient information to build an op-timal finite rate quantizer for that source. Further, when the pdfof the source is estimated parametrically, the density estima-tion parameters form an alternate compact representation for thesource. In addition, if the quantizer design block can be realizedin closed form, the density estimation parameters become an al-ternate and compact representation of the quantizer codebook.This division of labor into density estimation followed by quan-tizer design has additional advantages. With varying bit rates,the density estimation block remains unaltered. All that is neces-sary is to use a different closed form expression for the quantizerdesign part. The same analogy also holds for interoperabilitybetween fixed rate and variable rate systems. When the statis-tics of the source varies with time, the closed form expressionused in the quantizer design block remains unaltered. Only thedensity estimation parameters needs to be re-estimated in orderto represent the current statistics of the source. The re-estima-tion may be done recursively using the old density estimationparameters and current data for easy implementation. Hence,parametric density estimation followed by closed form quan-tizer design gives us the advantages of bit scalability, variablerate coding, interoperability, and learning. Minimal and rate in-dependent computational complexity is achieved by a clever im-plementation of the quantizer design block.
The success of the quantization scheme presented in thispaper depends on an efficient methodology for density esti-mation using mixture models followed by a low complexitymapping from probability density to quantizer. For the purposesof source coding, the mixture models employed in this paperhave two specific advantages:
1) Simple and stable estimation algorithms such as the EMalgorithm [10] can be conveniently put to use to reliably esti-mate the mixture model parameters from the training data.
2) As shown in the paper, they lend themselves to efficientquantization schemes using transform coding and bit alloca-tion techniques that results in codebooks that involve very fewsearches in the decoder stage and have their computational com-plexity independent of the rate of the system.
A brief summary of related quantization schemes which bearsimilarity to the proposed scheme are presented. Gaussian mix-ture models have been employed for high rate vector quantizeranalysis and for design of vector quantizers in [13]. In [13], theemphasis has been on high rate quantization theory and den-sity estimation suitable for quantization purposes in contrast toour approach which emphasizes building efficient structures inorder to realize these vector quantizers in a practical way. Fur-ther, the analysis in [13] is restricted to diagonal covariance ma-
trices. The general scheme of density estimation using Gaussianmixtures followed by quantization has been used in image pro-cessing. Zhu and Xu, [32], used Gaussian mixtures and the EMalgorithm for the vector quantization of images. In this case,a stochastic scheme is used for image encoding. The clusterprobabilities are used to partition the interval [0,1] and a uni-form random number generator is used in order to decide aboutcoding the observation with the mean of the cluster. Su andMersereau, [31], performed image coding using Gaussian mix-tures and generalized Gaussian models. Here, the probabilitythat an observation belongs to a given cluster is computed andis used to compile an assignment map. The map is run-lengthcoded and then entropy coded. Grayet al. [33] considered theproblem of joint quantization and classification for the exampleof a simple Gaussian mixture. In this case, a Bayes vector quan-tizer was used for quantization.
The paper is organized as follows. Section II deals with theproblem of density estimation using mixture models and the EMalgorithm to efficiently estimate the mixture model parameters.Section III deals with quantization of the estimated pdf usingbit allocation and transform coding techniques along with a de-scription of the computational complexity and scalability of theproposed scheme. Section IV presents the performance of theproposed scheme in the speech coding application. Section Vcompares the performance of the proposed scheme with con-ventional schemes such as MSVQ [3], Split-VQ [4], and Clas-sified VQ [20]. In Section VI, a few refinements to the proposedscheme are suggested and in Section VII we conclude by sum-marizing the salient features of the proposed scheme.
II. DENSITY ESTIMATION
Traditionally, the problem of density estimation has beentackled using two distinct approaches: A parametric approachand a nonparametric approach. In the parametric approach, theunknown pdf of the source, , is assumed to belong to afamily of parametric densities, . The estimation proce-dure strives to find the particular value of the parameterthatbest explains the observations. This problem formulation fallsnaturally in the maximum likelihood framework of parameterestimation. The main advantage of this approach is that theparameter values can be learned from reasonably small numberof observations using computationally efficient techniques. Forexample, it is well known that the training data size scales lin-early with the number of parameters that needs to be estimated[8], [9]. However, the main drawback of this approach is thatana priori structure is enforced on the observed data and hence

132 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 11, NO. 2, MARCH 2003
this approach can lead to poor estimates of the unknown pdfsin those cases where this assumption is invalid.
Nonparametric density estimation techniques do not makeany assumptions regarding the form of the unknown pdf. Theyestimate the unknown pdf relying only on the observations athand. The salient feature of these techniques is that the esti-mates are consistent irrespective of the original form of theunknown pdf. These techniques, however require substantiallylarge number of observations to make their estimates. It is wellknown that the number of training samples scales exponentiallywith the dimension of the problem [8], [9]. Further, these es-timation techniques are almost always computationally inten-sive. However, the most important drawback of nonparametricdensity estimation techniques is that they do not allow for easybit scalability and learning. The quantizer design block can nolonger be easily implemented in closed form due to the exorbi-tant number of parameters used in the density estimation stage.
Density estimation using mixture models, [16], fall into aclass of quasiparametric density estimation techniques, whichtries to combine the advantages of both parametric and nonpara-metric approaches. In this approach, the unknown pdf is mod-eled as a mixture of parametric pdf’s, i.e.,
(1)
(2)
where are nonnegative constants and .is an individual parametric density parameterized by. Weshall refer to ascluster with denoting the numberof clusters. is the parameter set which defines the quasipara-metric model. The reason why mixture models are referred toas quasiparametric density estimation techniques is because thenumber of clusters, , to be used for density estimation is a de-sign parameter.
The mixture modeling approach to density estimationcombines the parametric advantage of efficient estimationwith small number of observations with the nonparametricadvantage of consistent estimates. For a given dimension,the number of mixture model parameters scales as .Since the training data size scales linearly with the numberof parameters, the training sample size scales quadraticallywith the dimension [9]. Furthermore, (1) may be interpretedas the functional decomposition of the unknown pdf in termsof known parametric pdfs, the parametric pdfs serving as basisfunctions for this decomposition [21].
An informative and convenient interpretation to the mixturemodeling scheme is that the observationmay be assumed tohave been generated by one of theclusters and the proba-bility that a given observation has been generated by clusteris . It must be clarified that this interpretation is just for thebenefit of understanding and does not constrain the working ofthe estimation scheme. Using this interpretation, the problem ofdensity estimation using mixture models falls under a generalclass of problems calledmissing data problems[17].
The mixture model parameter estimation problem is vastlysimplified if we knew which cluster is responsible for the gen-eration of a particular observation. For then, we may partition
the observations into sub-groups and then perform maximumlikelihood estimation for each of the individual parametric den-sities. In this case, the missing data is the information aboutwhich cluster a particular observation belongs to. The EM al-gorithm is basically a recursive algorithm which substitutes forthe missing data with their expected values given the observa-tion and the present estimate of the mixture model parameters(Expectation step). It then uses this conditional mean estimate toupdate the values of the mixture model parameters (Maximiza-tion step). The EM repeats these two steps till convergence.
Let be an observation of a-dimensional random sourceat time instant . Let the number of observations be.
Further, let the individual parametric densities be multivariateGaussians, i.e., . For the Gaussianmixture model, the EM steps can be computed in closed form[13]. Two observations about the Gaussian mixture models arein order:
1) Multivariate Gaussians have a well recorded history ofserving as good radial-basis functions for functional approxi-mation [21].
2) Functional approximation using Gaussian parametric pdfs,inherently solves the problem of over-fitting due to the smoothnature of the multivariate Gaussian pdf.
Elaborating on the last observation, over-fitting to the trainingdata is one of the common problems encountered in quantizerdesign. Due to over-fitting, the quantizer is tuned to the trainingdata and hence performs poorly on test data. Provided that thenumber of clusters is small, the smooth nature of the Gaussianpdf ensures that the estimation technique focuses on the formand not the details of the unknown pdf, thus circumventing theover-fitting problem.
Finally, a few words about the performance of the EMalgorithm. The EM algorithm is numerically stable with eachEM iteration increasing the likelihood (except when a localmaximum is reached in the algorithm) [10]. Further, it is easilyimplemented with minimal storage requirements since theupdates are available in closed form. The algorithm convergesto the local maxima which may be different from the globalmaxima. Further, it may converge slowly in certain situations.Fortunately, appropriate techniques have been developed toameliorate these deficiencies of the EM. Particularly, Aver-aging, Maximum penalized likelihood and Bayesian estimationtechniques have been used to improve Gaussian mixture prob-ability density estimates [25]. These techniques also tackle theproblem of over-fitting due to singularities in the log-likelihoodfunction. These refinements are discussed in a later section.
III. QUANTIZER DESIGN
Irrespective of the distortion measure used, the source pdfhas, in principle, the necessary and the sufficient information tobuild an optimal finite rate quantizer for the source. Assumingthe estimated pdf to be a good approximation to the originalpdf, the mixture model parameters, which define the estimatedpdf, have all the requisite information for building an optimalquantizer for the source. In practice, there is a clear need tobuild efficient quantizers. By efficient, we mean quantizationthat provides good distortion performance at low complexity.

SUBRAMANIAM AND RAO: PDF OPTIMIZED PARAMETRIC VECTOR QUANTIZATION 133
The complexity of a quantizer usually comprises of the searchcomplexity and memory requirements. Specifically, the com-plexity of conventional vector quantizers is known to increaseexponentially with the rate of the system [20]. Hence, there isa need to build quantizers which are matched to the pdf of thesource and still allow for easy adaptation and computationallyefficient mapping. The proposed quantization scheme tries toaccommodate these desired properties.
The codebook design scheme may be broadly explained asfollows. We consider the specific case of the Gaussian mix-ture model. Each of the clusters in the mixture model is quan-tized separately. The number of bits used to quantize a particularcluster depend on three factors
• whether the system is fixed rate or variable rate• the covariance matrix of the cluster• the cluster probability .
Within a cluster, transform coding and bit allocation techniquesare used to allocate bits amongst thecluster components (thesource is -dimensional and hence the covariance matrix of eachcluster has size . For each cluster component, a compander(compressor followed by uniform quantizer) is used to build thecodebook. A given observation is quantized using all clustersand we choose the codepoint that minimizes the relevant distor-tion measure. For the quantizer with memory, well known linearprediction techniques are used to remove the temporal correla-tion in the source prior to density estimation. In order to avoidquantizer error propagation, an error control scheme is used.
It must be noted that the proposed quantizer design is not op-timal for the given mixture model. However, the gains made insearch and memory complexity provide excellent justificationfor this loss in optimality. In a later section, the performance ofthe proposed scheme is compared to that of an optimal quan-tizer for the problem of quantization of speech Line spectralfrequencies (LSF) [15, pg. 34]. This comparison provides theexperimental justification for the fact that this scheme providesa very good performance-complexity trade-off.
A. Cluster Bit Allocation
Let be the total number of bits used to quantize the source.Let represent the number of bits used to quantize cluster,
. Let represent the mean square distortion ofan optimal bit transform coder of cluster. We use the highresolution expression for [14], [20]. In high resolution,it is well known that when the vector components are jointlyGaussian, the Karhunen-Leove transform is the best possibletransform for minimizing the overall distortion [14], [20]. Weshall first derive the bit allocation scheme among the clustersfor both fixed rate and variable rate systems for a memorylessquantizer.
1) Fixed Rate: In a fixed rate quantizer, the total numberof codepoints in the codebook is fixed. This implies
. Since is an estimate of the probability of occur-rence of cluster, the total average distortion of the quantizationscheme is upper-bounded by
(3)
This expression is exact when the clusters are well separated orwhen we choose to quantize an observation using the codebookof the cluster to which it belongs to. However, when the clustersare well mixed or when we quantize a given observation usingcodebooks of all clusters, the above expression for total averagedistortion is not necessarily a tight upper bound. The bit allo-cation scheme for the fixed rate case is decided by minimizingthe total average distortion subject to the constraint that the totalnumber of codepoints is fixed, i.e.,
subject to (4)
The high resolution expression for in the -dimensionalGaussian case is given as
(5)
(6)
(7)
(8)
where the last equation is the eigen value decomposition of the, the covariance matrix of cluster[20].Theorem 1 (Optimal Fixed-Rate Cluster Bit Allocation):The
optimal bit allocation scheme that minimizes the total averagemean square distortion , subject to thefixed rate constraint, , is given by
(9)
Proof: See the Appendix.2) Variable Rate: In a variable rate quantizer, the average
rate of the quantizer is fixed. Let be the number of bits usedto identify a particular cluster. Further, in the present scheme, ifa particular observation is quantized with cluster, then bitsare transmitted for that observation. The variable rate constraintis then given by . The expressionfor total average distortion is the same as the one used for thefixed rate case.
Theorem 2 (Optimal Variable-Rate Cluster Bit Alloca-tion): The optimal bit allocation scheme that minimizes thetotal average mean square distortion ,subject to the variable rate constraint, , is givenby
(10)Proof: See the Appendix.

134 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 11, NO. 2, MARCH 2003
Fig. 2. Cluster quantization.
B. Cluster Codebook
The codebook of a particular cluster is essentially built usinga transform coder [14], [35], [36], [37]. In the Gaussian case, it iswell known that the optimal transform is the Karhunen-Leouvetransform and the bit allocation amongst the cluster componentsis given as
(11)
where, is the number of bits allocated to theth componentof cluster [20]. The bit allocation obtained by (11) allocatesfractional bits to each dimension. For a practical implementa-tion, we round off the number of levels used in every dimension.Let be the optimal bit scalar quantizer of a univariateGaussian with variance . Let be the set of dimensionalvectors given by the Cartesian product .Then the codebook for cluster is given as
(12)
C. Quantization Scheme
The overall quantization scheme is explained by the fol-lowing steps.
1) A given observation,, is quantized using all the clusters.Fig. 2 depicts the details of how the observationis quantizedusing cluster . It consists of the following steps.
• We subtract the mean of the cluster,, from the observa-tion, , and then decorrelate it using the matrix .
• Each of the scalar components is then passed througha compressor and then a uniform quantizer whose numberof levels is given by the bit allocation among the clustercomponents.
• The quantized value in the transformed domain is thenpassed through an expander and a correlator,, and the clustermean, , is finally added to obtain , the quantized value of
from cluster .2) Among the probable quantized values, we choose the
one which minimizes the relevant distortion measure. In thespeech coding case, we choose that quantized value which min-imizes the Log spectral distortion [15], [18] [see (15)].
3) We transmit the index of the appropriate cluster codepointto the receiver. The receiver does a simple table look-up to ob-tain the quantized value. Fig. 3 depicts the above steps in a flow-chart form.
Remark 1: Compressor Function:The compressor functionused during cluster quantization can be represented in closedform. Bennett, [11] analyzed the mean squared error (MSE) ofscalar companding and showed that any scalar quantizer (e.g.,the optimal quantizer) can be implemented by companding.Panter and Dite, [12], found the compressor function thatminimizes MSE. If the individual probability density of ascalar component is given by , then the MSE minimizingcompressor function has the form
(13)
The compressor function is a monotonic nondecreasing func-tion and the expander is its inverse [26]. For a practical imple-mentation, the compressor and expander functions of a scalarGaussian random variable with unit variance is implemented asa table look-up which is fine tuned to the range of operation ofthe coder.
Remark 2: Closed Form Quantization:The uniform quan-tization of a scalar component can be accomplished in closedform. Let be the th scalar component which is quantized

SUBRAMANIAM AND RAO: PDF OPTIMIZED PARAMETRIC VECTOR QUANTIZATION 135
Fig. 3. Complete quantizer.
using a uniform scalar quantizer of cluster containinglevels. Then, the quantized value,is given as
round(14)
The above result means that the cluster quantization of an obser-vation can be accomplished with very few searches. This dras-tically reduces the complexity of the quantizer. A more detaileddiscussion of the complexity of the scheme is done in a latersection.
Remark 3: Log Spectral Distortion:The Log spectral distor-tion for a particular frame is given as [15]
(15)
where is the sampling frequency in Hz, and andare the original (unquantized) and quantized LPC power spectraof the frame.
Remark 4: Index Assignment:For easy and efficient indexassignment, we need a suitable method by which we can orderthe codepoints in our codebook. In the present scheme, weneed a rule to order the clusters and the codepoints within eachcluster. We suggest one way in which codepoint ordering can bedone for fixed rate and variable rate schemes. The clusters canbe ordered in the ascending order of cluster probabilities,.Since each cluster codebook is essentiallyscalar quantizersoperating in parallel, the codepoints within a cluster can alsobe easily ordered since the codepoints of a scalar quantizer arenaturally ordered. For ease of implementation, the decoder canstore the index values of the first codepoint of each cluster.
On receiving a particular index, the decoder can decide whichcluster the received codepoint belongs to and then find theposition of the codepoint within the cluster as the differencebetween the received index and the index of the first codepointof the cluster. In variable rate schemes, the firstbits identify the cluster to which a codepoint belongs to.
D. Quantizer With Memory
The present scheme can be easily modified to obtain a quan-tizer with memory. Instead of quantizing the actual observa-tions, we quantize the difference between successive observa-tions. Better outlier performance is possible if a prediction co-efficient less than one is employed to obtain these differencevalues. This scheme is very effective in the case of correlatedsources or sources which have been sampled at a very highsampling rate. In order to avoid quantizer error propagation, weadopt an error control scheme. Two specific choices emerge forquantizing the difference vectors.
1) Modified scheme: We may use the codebook obtained forthe memoryless case with a slight modification. In this case, wedo not subtract the mean of the cluster when we quantize a givendifference vector using the codebook of a particular cluster. Thisis appropriate since the decorrelated difference vectors are zeromean vectors and the cluster codebook without the mean can beused to quantize them. This scheme provides valuable flexibilityto a coding system by allowing one to easily switch betweena memoryless quantizer to a quantizer with memory withoutthe need for any additional training. Since the quantizer withmemory is sensitive to channel errors, the coding system maydecide to switch from memoryless quantizer to quantizer withmemory when the channel conditions are good and vice versa.
2) Trained scheme: If we decide to build a coding systemwhich specifically implements a quantizer with memory, we canthen train the Gaussian mixture model to the difference vectorsin the training set and build an appropriate quantizer for theestimated pdf as was done for the memoryless case.
In the error control scheme, we load the quantization errorduring the quantization of a particular difference vector on thenext difference vector and then quantize it. For example, let
and be successive observations. The differencevectors are given as and
. We first quantize to obtain . We then obtain byquantizing . Similarly, we obtain by quantizing
and by quantizing . At the re-ceiver, we obtain , and .This error control scheme is well-known in the literature as Dif-ferential Pulse Code Modulation (DPCM) for scalar quantiza-tion and predictive vector quantization for the VQ case [20].
E. Salient Features of the Proposed Quantizer
Rate-independent low computational complexity and scala-bility are two important salient features of the proposed scheme.
1) Computational Complexity and Memory Require-ments: One of the salient features of the proposed schemeis its rate-independent low computational complexity andmemory requirements. Let us consider the search complexityinvolved in quantizing a given observation of the source. Let
be the size of the codebook. The number of clusters

136 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 11, NO. 2, MARCH 2003
TABLE ICOMPLEXITY CALCULATIONS FORC
is . A full-search quantizer would quantize the observationafter comparing it with all the codepoints in the codebooks.Conventional quantizers employ sub-optimal search techniquesto quantize the observation by searching a fraction of thecodebook. In the proposed scheme, the given observation isquantized using all the clusters. In a practical implementation,the companding and expanding part of the cluster quantizeris implemented as a simple table look-up containingentries. The overall computational complexity of the schemecan be computed as flops perframe.1 The details of the complexity computation are providedin the Table I.
For a given -dimensional source, the number of clusters usedto model the probability density function of the source is a de-sign parameter. However, once the number of clusters requiredto model the source has been determined, it remains fixed andneed not be changed with the rate of the system. Furthermore,the size of the expander-compressor tables can be so chosen toaccomodate the range of operation of the coder. This impliesthat the computational complexity of the proposed scheme isonly , independent of the rate of the systemonce the valuesfor , the number of clusters and , the size of the look-uptables are chosen appropriately.
Let us now calculate the memory requirements of the pro-posed scheme. Conventional vector quantizers usually need tostore the entire codebook for quantization purposes. Further,since the codebook size varies exponentially with the rate of thesystem, the memory requirements for conventional quantizersvaries exponentially with the rate of the system. Let us calculatethe number of real numbers the encoder and the decoder needto store. For every cluster, we need the bit allocation,,real numbers), the mean, , real numbers), the diagonaleigen-value vector, , real numbers) and the decorrelatingmatrix, , real numbers). The number of parameters whichdefine the mixture model is given as ,where, is the number of clusters andis the dimension of
1In our analysis, each addition, multiplication or comparison is considered asone floating point operation (flop).
the source. Further, the compander and expander tables haveentries each. Therefore, the total memory required by the
proposed scheme is given byfloats.2 Hence the number of parameters that need to be storedat the source encoder in order to quantize a given observationis independent of the rate of the system. These values are suffi-cient for decoding at the receiver too, provided the receiver hasprior knowledge about the rate of the system. Summarizing, theproposed scheme has computational complexity and memoryrequirements which are constant and independent of the rate ofthe system.
2) Scalability: In order to respond to changing networkconditions, such as available bit rate or channel congestion,there is a clear need for layered or scalable compressionschemes [1]. The principle concept in scalability is that animprovement in source reproduction, namely, reduced distor-tion, can be achieved by sending only an incremental increasein rate over the current transmitted rate that is achieving acoarser reproduction of the source. Conventional vector quan-tization scheme are not scalable, since as the rate of the systemchanges, the whole codebook needs to be trained again for thenew bit rate. One possible solution is to have different code-books at different rates, but this has huge storage costs andcan provide codebooks only at specific rates and not in a con-tinuum of rates.
The proposed scheme is scalable. Once the mixture modelparameters which model the pdf of the source have been iden-tified, varying bit-rates corresponds directly to varying bit allo-cation among the clusters and cluster components. This meansthat as the bit-rate of the system changes, the new quantizercan be identified effortlessly without any need for re-training.In fact, the new bit allocation for the cluster components can beobtained from the old bit allocation using just floatingpoint operations. Hence the proposed scheme provides valuableflexibility in the following ways:
• easy adaptation to varying rates of the source;• easy switching between fixed rate and variable-rate
coding.
Central to all the aformentioned properties is the estimationof the mixture model parameters which model the pdf of thesource.
IV. PERFORMANCE
We demonstrate the efficacy of the proposed scheme by em-ploying it to an application of speech coding. In the speechcoding case, we model speech line spectral frequencies as i.i.drealizations of multivariate Gaussian mixture density. Letbea -dimensional observation of line spectral frequencies at timeinstant . As in Section II, we model as an i.i.d realizationof a parametric density, i.e.,
(16)
(17)
2In our analysis, float represents a single precision floating point unit.
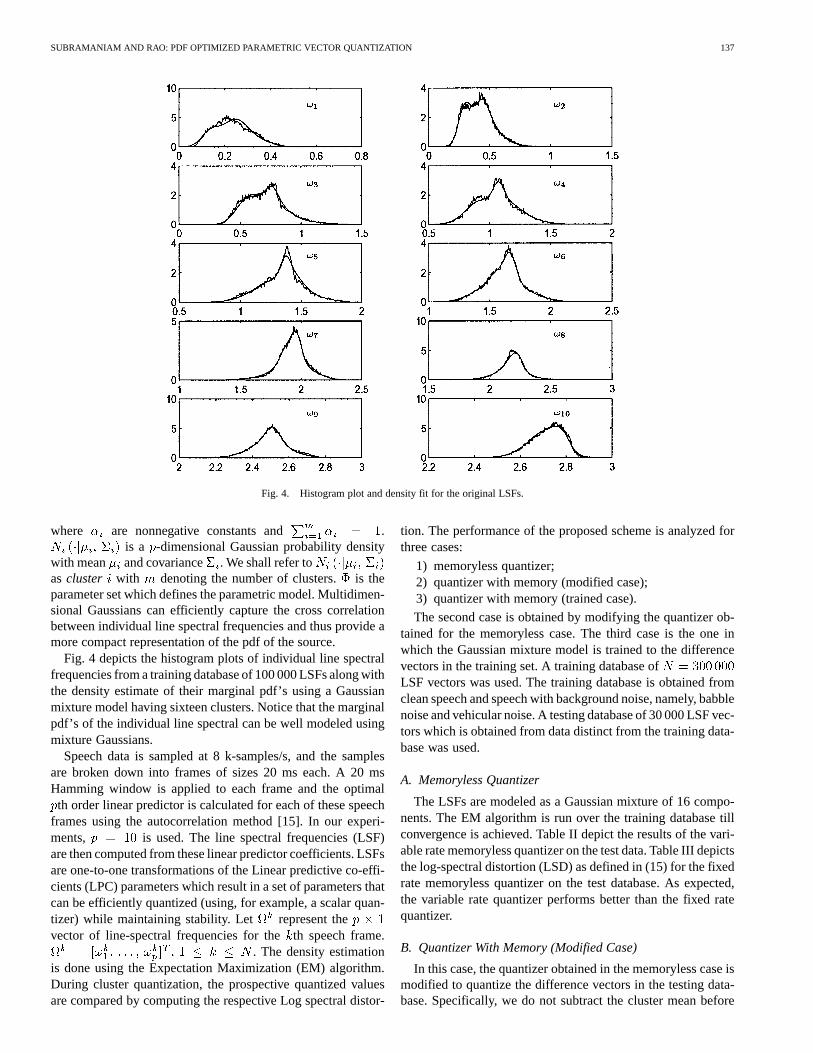
SUBRAMANIAM AND RAO: PDF OPTIMIZED PARAMETRIC VECTOR QUANTIZATION 137
Fig. 4. Histogram plot and density fit for the original LSFs.
where are nonnegative constants and .is a -dimensional Gaussian probability density
with mean and covariance . We shall refer toascluster with denoting the number of clusters. is theparameter set which defines the parametric model. Multidimen-sional Gaussians can efficiently capture the cross correlationbetween individual line spectral frequencies and thus provide amore compact representation of the pdf of the source.
Fig. 4 depicts the histogram plots of individual line spectralfrequencies from a training database of 100 000 LSFs along withthe density estimate of their marginal pdf’s using a Gaussianmixture model having sixteen clusters. Notice that the marginalpdf’s of the individual line spectral can be well modeled usingmixture Gaussians.
Speech data is sampled at 8 k-samples/s, and the samplesare broken down into frames of sizes 20 ms each. A 20 msHamming window is applied to each frame and the optimalth order linear predictor is calculated for each of these speech
frames using the autocorrelation method [15]. In our experi-ments, is used. The line spectral frequencies (LSF)are then computed from these linear predictor coefficients. LSFsare one-to-one transformations of the Linear predictive co-effi-cients (LPC) parameters which result in a set of parameters thatcan be efficiently quantized (using, for example, a scalar quan-tizer) while maintaining stability. Let represent thevector of line-spectral frequencies for theth speech frame.
. The density estimationis done using the Expectation Maximization (EM) algorithm.During cluster quantization, the prospective quantized valuesare compared by computing the respective Log spectral distor-
tion. The performance of the proposed scheme is analyzed forthree cases:
1) memoryless quantizer;2) quantizer with memory (modified case);3) quantizer with memory (trained case).
The second case is obtained by modifying the quantizer ob-tained for the memoryless case. The third case is the one inwhich the Gaussian mixture model is trained to the differencevectors in the training set. A training database ofLSF vectors was used. The training database is obtained fromclean speech and speech with background noise, namely, babblenoise and vehicular noise. A testing database of 30 000 LSF vec-tors which is obtained from data distinct from the training data-base was used.
A. Memoryless Quantizer
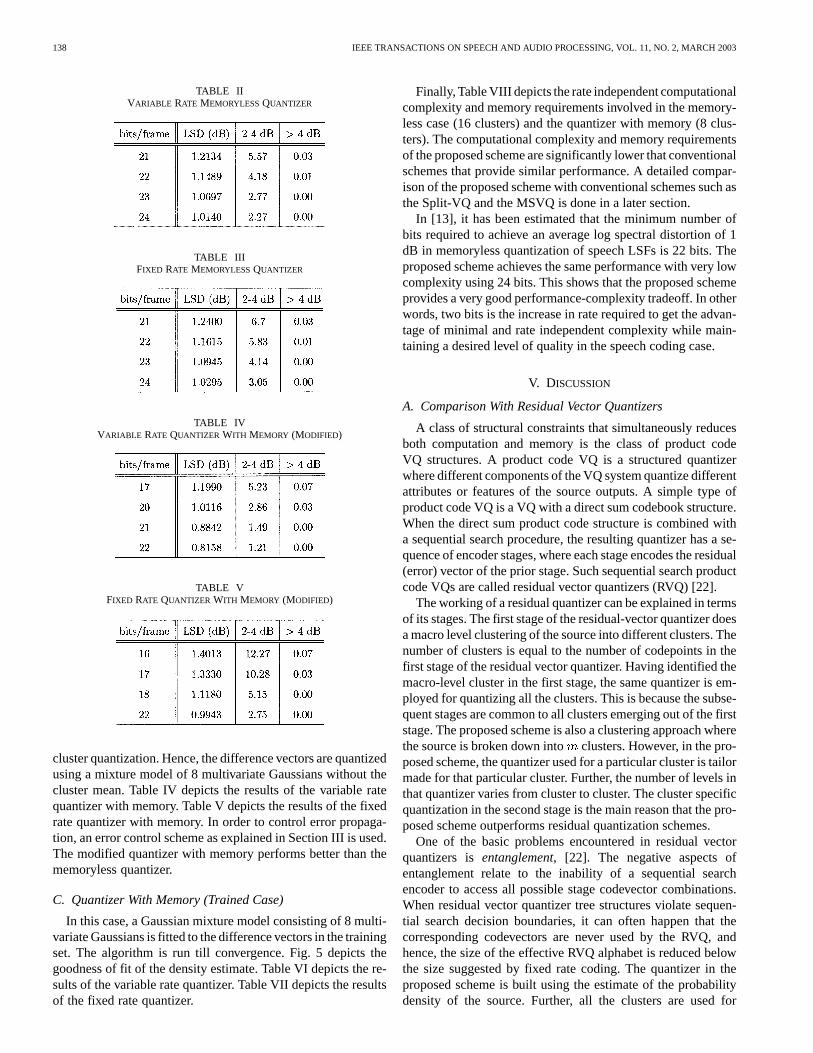
The LSFs are modeled as a Gaussian mixture of 16 compo-nents. The EM algorithm is run over the training database tillconvergence is achieved. Table II depict the results of the vari-able rate memoryless quantizer on the test data. Table III depictsthe log-spectral distortion (LSD) as defined in (15) for the fixedrate memoryless quantizer on the test database. As expected,the variable rate quantizer performs better than the fixed ratequantizer.
B. Quantizer With Memory (Modified Case)
In this case, the quantizer obtained in the memoryless case ismodified to quantize the difference vectors in the testing data-base. Specifically, we do not subtract the cluster mean before
138 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 11, NO. 2, MARCH 2003
TABLE IIVARIABLE RATE MEMORYLESSQUANTIZER
TABLE IIIFIXED RATE MEMORYLESSQUANTIZER
TABLE IVVARIABLE RATE QUANTIZER WITH MEMORY (MODIFIED)
TABLE VFIXED RATE QUANTIZER WITH MEMORY (MODIFIED)
cluster quantization. Hence, the difference vectors are quantizedusing a mixture model of 8 multivariate Gaussians without thecluster mean. Table IV depicts the results of the variable ratequantizer with memory. Table V depicts the results of the fixedrate quantizer with memory. In order to control error propaga-tion, an error control scheme as explained in Section III is used.The modified quantizer with memory performs better than thememoryless quantizer.
C. Quantizer With Memory (Trained Case)
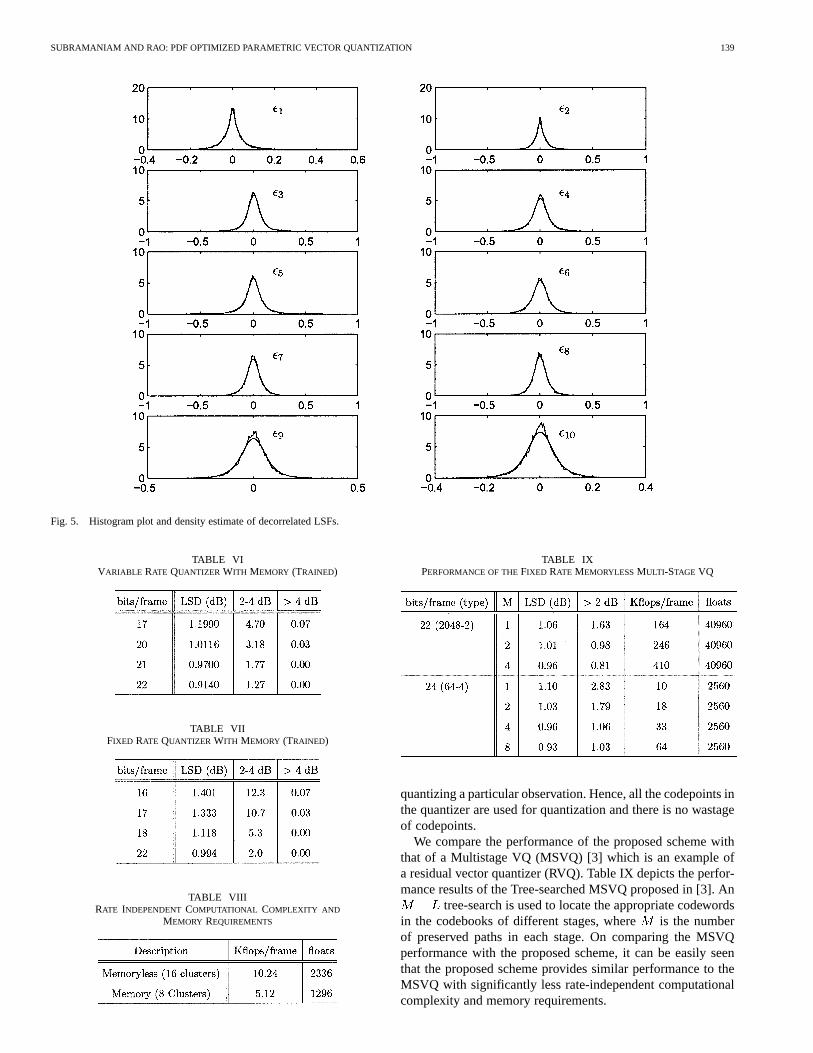
In this case, a Gaussian mixture model consisting of 8 multi-variate Gaussians is fitted to the difference vectors in the trainingset. The algorithm is run till convergence. Fig. 5 depicts thegoodness of fit of the density estimate. Table VI depicts the re-sults of the variable rate quantizer. Table VII depicts the resultsof the fixed rate quantizer.
Finally, Table VIII depicts the rate independent computationalcomplexity and memory requirements involved in the memory-less case (16 clusters) and the quantizer with memory (8 clus-ters). The computational complexity and memory requirementsof the proposed scheme are significantly lower that conventionalschemes that provide similar performance. A detailed compar-ison of the proposed scheme with conventional schemes such asthe Split-VQ and the MSVQ is done in a later section.
In [13], it has been estimated that the minimum number ofbits required to achieve an average log spectral distortion of 1dB in memoryless quantization of speech LSFs is 22 bits. Theproposed scheme achieves the same performance with very lowcomplexity using 24 bits. This shows that the proposed schemeprovides a very good performance-complexity tradeoff. In otherwords, two bits is the increase in rate required to get the advan-tage of minimal and rate independent complexity while main-taining a desired level of quality in the speech coding case.
V. DISCUSSION
A. Comparison With Residual Vector Quantizers
A class of structural constraints that simultaneously reducesboth computation and memory is the class of product codeVQ structures. A product code VQ is a structured quantizerwhere different components of the VQ system quantize differentattributes or features of the source outputs. A simple type ofproduct code VQ is a VQ with a direct sum codebook structure.When the direct sum product code structure is combined witha sequential search procedure, the resulting quantizer has a se-quence of encoder stages, where each stage encodes the residual(error) vector of the prior stage. Such sequential search productcode VQs are called residual vector quantizers (RVQ) [22].
The working of a residual quantizer can be explained in termsof its stages. The first stage of the residual-vector quantizer doesa macro level clustering of the source into different clusters. Thenumber of clusters is equal to the number of codepoints in thefirst stage of the residual vector quantizer. Having identified themacro-level cluster in the first stage, the same quantizer is em-ployed for quantizing all the clusters. This is because the subse-quent stages are common to all clusters emerging out of the firststage. The proposed scheme is also a clustering approach wherethe source is broken down into clusters. However, in the pro-posed scheme, the quantizer used for a particular cluster is tailormade for that particular cluster. Further, the number of levels inthat quantizer varies from cluster to cluster. The cluster specificquantization in the second stage is the main reason that the pro-posed scheme outperforms residual quantization schemes.
One of the basic problems encountered in residual vectorquantizers isentanglement, [22]. The negative aspects ofentanglement relate to the inability of a sequential searchencoder to access all possible stage codevector combinations.When residual vector quantizer tree structures violate sequen-tial search decision boundaries, it can often happen that thecorresponding codevectors are never used by the RVQ, andhence, the size of the effective RVQ alphabet is reduced belowthe size suggested by fixed rate coding. The quantizer in theproposed scheme is built using the estimate of the probabilitydensity of the source. Further, all the clusters are used for
SUBRAMANIAM AND RAO: PDF OPTIMIZED PARAMETRIC VECTOR QUANTIZATION 139
Fig. 5. Histogram plot and density estimate of decorrelated LSFs.
TABLE VIVARIABLE RATE QUANTIZER WITH MEMORY (TRAINED)
TABLE VIIFIXED RATE QUANTIZER WITH MEMORY (TRAINED)
TABLE VIIIRATE INDEPENDENT COMPUTATIONAL COMPLEXITY AND
MEMORY REQUIREMENTS
TABLE IXPERFORMANCE OF THEFIXED RATE MEMORYLESSMULTI-STAGE VQ
quantizing a particular observation. Hence, all the codepoints inthe quantizer are used for quantization and there is no wastageof codepoints.
We compare the performance of the proposed scheme withthat of a Multistage VQ (MSVQ) [3] which is an example ofa residual vector quantizer (RVQ). Table IX depicts the perfor-mance results of the Tree-searched MSVQ proposed in [3]. An
tree-search is used to locate the appropriate codewordsin the codebooks of different stages, whereis the numberof preserved paths in each stage. On comparing the MSVQperformance with the proposed scheme, it can be easily seenthat the proposed scheme provides similar performance to theMSVQ with significantly less rate-independent computationalcomplexity and memory requirements.

140 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 11, NO. 2, MARCH 2003
TABLE XPERFORMANCE OF THEFIXED RATE MEMORYLESSSPLIT VQ
B. Comparison With Split Vector Quantization
The proposed scheme was compared to the 2-part Split Vectorquantization scheme presented in [4]. In this scheme, each LSFvector is split into two parts of 4 and 6 dimensions. Next, eachpart is quantized by using a full search vector quantizer. The bitsare divided equally between the two parts, and for odd rates,the first part is given an extra bit. Table X depicts the perfor-mance of the fixed rate memoryless Split Vector Quantizer. Itcan be seen that the computational complexity and the memoryrequirements of the Split-VQ are much higher in comparison tothe proposed scheme.
C. Comparison With Classified VQ
The proposed scheme is related to the universal coding par-adigm that is prevalent in lossless source coding [19]. In theuniversal coding approach, a set of codes is designed and anobservation is compressed with all the codes. Finally, the codewhich has the best performance is chosen. In the classified VQapproach [20], the code is first selected and the observation isquantized with the selected code. It can be easily seen that theproposed scheme always outperforms such a classified VQ ap-proach. In the proposed scheme, a given observation is quan-tized using all the clusters and the codepoint which providesthe least perceptual distortion is then used for quantizing thegiven observation. In other words, the proposed scheme choosesthat cluster that minimizes the overall end-to-end perceptualdistortion.
VI. REFINEMENTS
The proposed scheme allows for various refinements that canenhance the performance without increasing the complexity.
• It is common practice to use weighted distortion measuressince they turn out to be perceptually important [27]. The pro-posed scheme allows for weighting matrices to be easily incor-porated. Specifically, the bit allocation amongst the cluster com-ponents can be varied depending on the particular weighting ma-trix. Let be the diagonal weighting matrix for cluster. Thebit allocation scheme among the cluster components for cluster
can be modified as
(18)
(19)
• Certain applications might warrant the use of individualparametric densities which are not as smooth as the Gaussiandensity. The scheme allows for a broad range of “natural” ex-ponential families [10] to be used for the individual parametricdensities. When the EM algorithm is applied in such situations,each successive maximum likelihood estimate is uniquely andexplicitly determined from its predecessor, almost always in acontinuous manner. Furthermore, a sequence of iterates pro-duced by the EM algorithm on such a problem is likely to haverelatively nice convergence properties.
• Density estimation using Gaussian mixtures can encountersevere problems due to singularities and local maxima in thelog-likelihood function. Particularly in high-dimensional spacesthese problems frequently cause the computed density estimatesto possess only relatively limited generalization capabilities interms of predicting the densities at new data points. Averagingusing “bagging” algorithms, Maximum Penalized Likelihoodand Bayesian estimation [25] can be put to use in order to im-prove our estimates of the mixture density parameters.
• Multidimensional companding techniques along with lat-tice structures [28] can be used to perform better quantizationof the clusters [26]. Instead of performing scalar quantization ofthe individual cluster components, we may choose to perform alattice vector quantization of the cluster as a whole. The gainsmade can be approximately quantified by the ratio of the nor-malized second moment of a cubic cell to that of the lattice cell.In other words, thespace fillingloss due to the implementationof a scalar product VQ is minimized by using a lattice quantizerin a higher dimension [1], [2].
• The scheme can be easily modified to operate in a learningenvironment. Specifically, we may choose to implement a re-cursive EM algorithm in order to adapt to changing statistics ofthe source.
VII. CONCLUSION
In this paper, we have proposed a pdf optimized vector quanti-zation scheme. The scheme has a low rate-independent compu-tational complexity with the search complexity and the memoryrequirements depending only on the number of clusters used inthe mixture model in order to estimate the pdf of the source.In this scheme, Multidimensional Gaussians are used to esti-mate the multivariate pdf of a multidimensional source. Thescheme allows for both fixed-rate and variable rate coding andeasy switching between them. The scheme also allows for quan-tization with and without memory allowing for easy switchingbetween these modes depending on channel conditions. Thescheme is scalable and allows for easy adaptation with changesin the bit-rate of the system.
Current research in this field is directed toward modifyingthe proposed scheme to work in a learning environment. Morespecifically, we update the value of the mixture model parame-ters using the previous estimate and current data. By doing so,the density estimate reflects the current statistics of the sourceand scheme becomes adaptive. Since the current quantizer de-pends solely on the current density estimate, the performance ofthis adaptive quantizer can be expected to be much better thanits performance in the nonadaptive case.

SUBRAMANIAM AND RAO: PDF OPTIMIZED PARAMETRIC VECTOR QUANTIZATION 141
APPENDIX
In the subsequent derivations, is the total number of bitsused for clusters with components per cluster. is thenumber of bits allocated per cluster and is the high reso-lution expression for the distortion caused by quantizing cluster
using bits. In the variable rate case, is the total numberof bits, , minus the number of bits required to identify a par-ticular cluster. is the total average mean-square distortion.
is a constant equal to .
A. Optimal Finite-Rate Bit Allocation
Minimize
B. Optimal Variable-Rate Bit Allocation
Minimize
ACKNOWLEDGMENT
The authors would like to thank the anonymous reviewer andthe Associate Editor, Dr. S. Ramprashad, for their detailed com-
ments that have helped in the development of the paper. The au-thors would also like to acknowledge the valuable suggestionsmade by Prof. K. Kreutz-Delgado in the field of density estima-tion and the useful discussions with Prof. K. Zeger in the subjectof quantizer design.
REFERENCES
[1] R. M. Gray and D. L. Neuhoff, “Quantization,”IEEE Trans. Inform.Theory, vol. 44, pp. 2325–2383, Oct. 1998.
[2] S. Na and D. L. Neuhoff, “Bennett’s integral for vector quantizers,”IEEE Trans. Inform. Theory, vol. 41, pp. 886–900, July 1995.
[3] W. P. LeBlanc, B. Bhattacharya, S. A. Mahmoud, and V. Cuperman,“Efficient search and design procedures for robust multi-stage VQ ofLPC Parameters for 4 kb/s speech coding,”IEEE Trans. Speech AudioProcessing, vol. 1, pp. 373–385, Oct. 1993.
[4] K. K. Paliwal and B. S. Atal, “Efficient vector quantization of LPC pa-rameters at 24 bits/frame,”IEEE Trans. Speech Audio Processing, vol.1, pp. 3–14, Jan. 1993.
[5] G. G. Langdon and J. Rissanen, “Compression of black–white imageswith arithmetic coding,”IEEE Trans. Commun., vol. COMM-29, pp.858–867, June 1981.
[6] I. H. Witten, R. M. Neal, and J. G. Cleary, “Arithmetic coding for datacompression,”Commun. ACM, vol. 30, pp. 520–540, June 1987.
[7] A. Ortega and M. Vetterli, “Adaptive scalar quantization without sideinformation,” IEEE Trans. Image Processing, vol. 6, pp. 665–676, May1997.
[8] D. W. Scott,Multivariate Density Estimation: Theory, Practice and Vi-sualization. New York: Wiley, 1992.
[9] R. O. Duda, P. E. Hart, and D. G. Stork,Pattern Classification. NewYork: Wiley, 2001, ch. 2.
[10] R. A. Redner and H. F. Walker, “Mixture densities, maximum likelihoodand the EM algorithm,”SIAM Rev., vol. 26, no. 2, pp. 195–239, Apr.1984.
[11] W. R. Benett, “Spectra of quantized signals,”Bell Syst. Tech. J., vol. 27,pp. 446–472, July 1948.
[12] P. F. Panter and W. Dite, “Quantization distortion in pulse count modu-lation with nonuniform spacing of levels,”Proc. IRE, vol. 39, pp. 44–48,Jan. 1951.
[13] P. Hedelin and J. Skoglund, “Vector quantization based on Gaussianmixture models,”IEEE Trans. Acoust., Speech, Signal Processing, vol.8, pp. 385–401, July 2000.
[14] J. J. Y. Huang and P. M. Schultheiss, “Block quantization of correlatedGaussian random variables,”IEEE Trans. Commun., Sept. 1963.
[15] W. B. Kleijn and K. K. Paliwal, Speech Coding and Syn-thesis. Amsterdam, The Netherlands: Elsevier, 1995.
[16] G. McLachlan and K. E. Basford,Mixture Models: Inference and Appli-cation to Clustering. New York: Marcel Dekker, 1988.
[17] R. J. A. Little and D. B. Rubin,Statistical Analysis With MissingData. New York: Wiley, 1987.
[18] R. Rabiner and B. H. Juang,Fundamentals of Speech Recogni-tion. Englewood Cliffs, NJ: Prentice-Hall, 1993.
[19] L. D. Davisson, “Universal noiseless coding,”IEEE Trans. Inform.Theory, vol. 19, pp. 783–795, Nov. 1973.
[20] A. Gersho and R. M. Gray,Vector Quantization and Signal Compres-sion. New York: Wiley, 1994.
[21] H. W. Sorenson and D. L. Aspach, “Recursive Bayesian estimation usingGaussian sums,”Automatica, vol. 7, pp. 465–479, 1971.
[22] C. F. Barnes, S. A. Rizvi, and N. M. Nasrabadi, “Advances in residualvector quantization,”IEEE Trans. Image Processing, vol. 5, pp.226–262, Feb. 1996.
[23] N. B. Karayiannis, “An axiomatic approach to soft vector quantizationand clustering,”IEEE Trans. Neural Networks, vol. 10, pp. 1153–1164,Sept. 1999.
[24] W.-Y. Chan, S. Gupta, and A. Gersho, “Enhanced multistage vectorquantization by joint codebook design,”IEEE Trans. Commun., vol.40, pp. 1693–1697, Nov. 1992.
[25] D. Ormoneit and V. Tresp, “Averaging, maximum penalized likelihoodand Bayesian estimation for improving Gaussian mixture probabilitydensity estimates,”IEEE Trans. Neural Networks, vol. 9, pp. 639–650,July 1998.
[26] P. W. Moo and D. L. Neuhoff, “Optimal compressor functions for mul-tidimensional companding,” inIEEE Int. Symp. Inform. Theory, NewYork, USA, June 1997, p. 515.

142 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 11, NO. 2, MARCH 2003
[27] W. R. Gardner and B. D. Rao, “Theoretical analysis of the high-ratevector quantization of LPC parameters,”IEEE Trans. Speech Audio Pro-cessing, vol. 3, pp. 367–381, Sept. 1995.
[28] D. G. Jeong and J. D. Gibson, “Uniform and piecewise uniform latticevector quantization for memoryless Gaussian and Laplacian sources,”IEEE Trans. Inform. Theory, vol. 39, pp. 786–804, May 1993.
[29] Y. Yoo, A. Ortega, and B. Yu, “Image subband coding using context-based classification and adaptive quantization,”IEEE Trans. Image Pro-cessing, vol. 8, pp. 1702–1715, Dec. 1999.
[30] Y. Zhang and C. J. S deSilva, “An isolated word recognizer using the EMalgorithm for vector quantization,” inProc. IREECON ’91. Edgecliff,NSW, Australia, Sept. 1991, pp. 289–292.
[31] J. K. Su and R. M. Mersereau, “Coding using Gaussian mixture andgeneralized Gaussian models,” inIEEE Int. Conf. Image Processing,Sept. 1996, pp. 217–220.
[32] C. Zhu and L. Xu, “Gaussian mixture and the EM algorithm for vectorquantization of images,” inProc. Int. Conf. Neural Information Pro-cessing—ICONIP ’95, Beijing, China, 1995, pp. 739–742.
[33] R. M. Gray, O. Perlmutter, and R. A. Olshen, “Quantization, classifica-tion, and density estimation for Kohonen’s Gaussian mixture,” inProc.Data Compression Conf., Apr. 1998, pp. 63–72.
[34] J. Pan and T. R. Fischer, “Vector quantization of speech line spectrumpair parameters and reflection coefficients,”IEEE Trans. Speech AudioProcessing, vol. 6, pp. 106–115, Mar. 1998.
[35] R. V. Cox and R. E. Crochiere, “Real-time simulation of adaptive trans-form coding,”IEEE Trans. Speech Audio Processing, vol. ASSP-29, pp.147–154, Apr. 1981.
[36] R. Zelinski and P. Noll, “Adaptive transform coding of speech signals,”IEEE Trans. Acoustics, Speech, Signal Processing, vol. ASSP-25, pp.299–309, Aug. 1977.
[37] P. Wintz, “Transform picture coding,”Proc. IEEE, vol. 60, pp. 809–820,July 1972.
[38] J. Pan and T. R. Fischer, “Two-stage vector quantization-lattice vectorquantization,”IEEE Trans. Inform. Theory, vol. 41, pp. 155–163, Jan.1995.
[39] Z. Gao, B. Belzer, and J. Villasenor, “A comparison of the Z,E , andLeech lattices for quantization of low-shape-parameter generalizedGaussian sources,”IEEE Trans. Inform. Theory, vol. 2, pp. 197–199,Oct. 1995.
[40] F. Chen, Z. Gao, and J. Villasenor, “Lattice vector quantization of gen-eralized Gaussian sources,”IEEE Trans. Inform. Theory, vol. 43, pp.92–103, Jan. 1997.
[41] C. Liu and D. X. Sun, “Acceleration of EM algorithm for mixture modelsusing ECME,”Bell Lab J., Aug. 1997.
[42] E. G. Schukat-Talamazzini, M. Bielecki, H. Niemann, T. Kuhn, and S.Rieck, “A nonmetrical space search algorithm for fast Gaussian vectorquantization,” inProc. ICASSP, May 1993, pp. 688–691.
[43] J.-Y. Tourneret, “Statistical properties of line spectrum pairs,” inProc.EURASIP, Mar. 1998, pp. 239–255.
Anand D. Subramaniam received the B. Tech de-gree from the Indian Institute of Technology, Madras,in 1999 and the M.S. degree from University of Cal-ifornia, San Diego, in 2001, both in electrical engi-neering. He is currently pursuing the Ph.D. degreein the Department of Electrical and Computer Engi-neering at University of California, San Diego.
He spent the summer of 2000 at Hughes NetworkSystems, German Town, MD, working on speechcoding for wireless communication applications. Healso interned at Qualcomm, Inc., San Diego, CA, in
the summer of 2002 where he worked on MIMO-OFDM for wireless LANs.His research areas include source coding, channel coding, information theory,and communication systems.
Bhaskar D. Rao (F’00) received the B. Tech.degree in electronics and electrical communicationengineering from the Indian Institute of Technology,Kharagpur, in 1979, and the M.S. and Ph.D. degreesfrom the University of Southern California in 1981and 1983, respectively.
Since 1983, he has been with the Universityof California, San Diego, where he is currentlya Professor in the Electrical and Computer Engi-neering Department. His interests are in the areasof digital signal processing, estimation theory, and
optimization theory, with applications to digital communications, speech signalprocessing, and human–computer interactions.
He has been a member of the IEEE Statistical Signal and Array ProcessingTechnical Committee. He is currently a member of the IEEE Signal ProcessingTheory and Methods Technical Committee.




















