
On the Modeling of Entities for Ad-Hoc Entity Search in the Web of Data
13
On the Modeling of Entities for Ad-Hoc Entity Search in the Web of Data Robert Neumayer, Krisztian Balog, and Kjetil Nørvåg Norwegian University of Science and Technology, Trondheim, Norway {robert.neumayer,krisztian.balog,kjetil.norvag}@idi.ntnu.no Abstract. The Web of Data describes objects, entities, or “things" in terms of their attributes and their relationships, using RDF statements. There is a need to make this wealth of knowledge easily accessible by means of keyword search. Despite recent research efforts in this direction, there is a lack of understanding of how structured semantic data is best represented for text-based entity retrieval. The task we are addressing in this paper is ad-hoc entity search: the retrieval of RDF resources that represent an entity described in the keyword query. We build upon and formalise existing entity modeling approaches within a genera- tive language modeling framework, and compare them experimentally using a standard test collection, provided by the Semantic Search Challenge evaluation series. We show that these models outperform the current state-of-the-art in terms of retrieval effectiveness, however, this is done at the cost of abandoning a large part of the semantics behind the data. We propose a novel entity model capable of preserving the semantics associated with entities, without sacrificing retrieval effectiveness. 1 Introduction In recent years the Web of Data (WoD) has emergedas a way of exposing structured data on the Web. The past three years in particular have seen a significant increase both in the number of knowledge bases published as Linked Data (such as DBpe- dia, Freebase, and others) and in the availability of metadata embedded inside web pages (RDF, RDFa, Microformats, and others) [24]. These knowledge repositories typ- ically contain entities (such as people, locations, organisations, etc.) and the relation- ships between them (such as birthPlace, academicAdvisor, parentCompany, etc.). Each entity is uniquely identified by its URI (Uniform Resource Identifier). WoD datasets can be queried using formal, structured query languages such as SPARQL. Issuing such queries, however, is beyond the capabilities of ordinary Web users as it requires the knowledge of the underlying schema as well as that of the query language. Also, SPARQL-like languages are often too restrictive, and Boolean-type matches cannot pro- vide a ranked list of results that users would prefer seeing [14]. Keyword search, which has become the main paradigm to perform search tasks on the Web, has recently emerged as a viable alternative. Indeed, there is a growing body of work on adapting IR ranking models for searching in RDF data, e.g., [5, 14, 23]. The introduction of the Semantic Search (SemSearch) evaluation series [4, 15] has fur- ther propelled research in this direction, by providing a common evaluation platform to R. Baeza-Yates et al. (Eds.): ECIR 2012, LNCS 7224, pp. 133–145, 2012. c Springer-Verlag Berlin Heidelberg 2012
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of On the Modeling of Entities for Ad-Hoc Entity Search in the Web of Data

On the Modeling of Entities for Ad-Hoc Entity Searchin the Web of Data
Robert Neumayer Krisztian Balog and Kjetil Noslashrvaringg
Norwegian University of Science and Technology Trondheim Norwayrobertneumayerkrisztianbalogkjetilnorvagidintnuno
Abstract The Web of Data describes objects entities or ldquothings in terms oftheir attributes and their relationships using RDF statements There is a need tomake this wealth of knowledge easily accessible by means of keyword searchDespite recent research efforts in this direction there is a lack of understandingof how structured semantic data is best represented for text-based entity retrievalThe task we are addressing in this paper is ad-hoc entity search the retrievalof RDF resources that represent an entity described in the keyword query Webuild upon and formalise existing entity modeling approaches within a genera-tive language modeling framework and compare them experimentally using astandard test collection provided by the Semantic Search Challenge evaluationseries We show that these models outperform the current state-of-the-art in termsof retrieval effectiveness however this is done at the cost of abandoning a largepart of the semantics behind the data We propose a novel entity model capableof preserving the semantics associated with entities without sacrificing retrievaleffectiveness
1 Introduction
In recent years the Web of Data (WoD) has emerged as a way of exposing structureddata on the Web The past three years in particular have seen a significant increaseboth in the number of knowledge bases published as Linked Data (such as DBpe-dia Freebase and others) and in the availability of metadata embedded inside webpages (RDF RDFa Microformats and others) [24] These knowledge repositories typ-ically contain entities (such as people locations organisations etc) and the relation-ships between them (such as birthPlace academicAdvisor parentCompany etc) Eachentity is uniquely identified by its URI (Uniform Resource Identifier) WoD datasetscan be queried using formal structured query languages such as SPARQL Issuingsuch queries however is beyond the capabilities of ordinary Web users as it requiresthe knowledge of the underlying schema as well as that of the query language AlsoSPARQL-like languages are often too restrictive and Boolean-type matches cannot pro-vide a ranked list of results that users would prefer seeing [14]
Keyword search which has become the main paradigm to perform search tasks onthe Web has recently emerged as a viable alternative Indeed there is a growing bodyof work on adapting IR ranking models for searching in RDF data eg [5 14 23]The introduction of the Semantic Search (SemSearch) evaluation series [4 15] has fur-ther propelled research in this direction by providing a common evaluation platform to
R Baeza-Yates et al (Eds) ECIR 2012 LNCS 7224 pp 133ndash145 2012ccopy Springer-Verlag Berlin Heidelberg 2012
134 R Neumayer K Balog and K Noslashrvaringg
dbpediaAudi_A4
dbpediaVolkswagen_Group
parentCompany
1996 2002 2005 2007
modelYears
abstract
dbpediaCategoryCompact_executive_cars
dbpediaCategoryAll_wheel_drive_vehicles
dbpediaCategoryFront_wheel_drive_vehiclessubject
httpschemaorgProduct
type
dbpediaAudi_80
dbpediaAudi_A5
successor
predecessor
The Audi A4 is a compact executive car produced since late 1994 by the
German car manufacturer Audi
httprdffreebasecomnsm030qmx
httpwww4wiwissfu-berlindeAudi_A4
sameAs
Fig 1 Excerpt from an RDF graph Rounded rectangles represent entities (ie URIs) rectanglesdenote attributes (ie literal values) URIs are shortened and predicate prefixes are ignored
empirically assess methods and algorithms devised for the task that has been termed ad-hoc entity retrieval ldquoanswering arbitrary information needs related to particular aspectsof objects [entities] expressed in unconstrained natural language and resolved using acollection of structured data [24] Since WoD is inherently organised around objectsor entities having entities as the unit of retrieval follows naturally
Commonly the ad-hoc entity retrieval task is approached by adapting standard doc-ument retrieval methods A textual representation (ldquopseudo document) is built for eachentity and these representations can then be ranked using conventional IR models Themain challenge of course is how to obtain these textual representations from structureddata WoD conceptually forms a large directed labelled graph with nodes correspond-ing to entities and edges denoting relationships and is described in the form of subject-predicate-object (SPO) triples of the RDF data model Figure 1 shows a small excerptfrom an RDF graph centred around a given entity
A natural solution would be to represent each entity using a fielded structure wherefields correspond to predicates (ie arrows on Figure 1) and associated nodes (or ratherthe text extracted from them) are used as field values These representations can then beranked using any fielded document retrieval model such as BM25F [25] or the mixtureof language models (MLM) [20] However with this approach the number of documentfields soon becomes computationally prohibitive making the estimation of field weightsintractable A commonly used workaround is to group predicates together into a smallset of predefined categories and as such create documents comprising of only a handfulof fields This grouping (or ldquopredicate folding) can be based on for example the typeof predicates (attributes inout-relations etc) [23] or on their (manually determined)importance [5] This leads to a data model where the optimisation of field weightsis easily tractable even using exhaustive search over the parameter space While thisapproach seems to work well in practice it seriously limits the semantic expressivity ofentity models as it is no longer possible to access the content of individual predicatesor might be too dependent on the data collection
The overall research question we address in this paper is how to represent entitiesin the Web of Data for the purpose of text-based retrieval As our first step on the pathto investigating this issue in Section 2 we formalise the aforementioned two entitymodeling strategies within a generative language modeling framework One approach(Unstructured Entity Model) collapses all text associated with the entity into a single
On the Modeling of Entities for Ad-Hoc Entity Search 135
flat-text representation The other approach (Structured Entity Model) groups predicatestogether into a small number of categories and considers their weighted combinationWe perform an experimental evaluation of the two models using the 2010 and 2011 testsets of the Semantic Search Challenge evaluation campaign in Section 3 We find thatthese models outperform the current state-of-the-art in terms of retrieval effectivenesson these collections However this is done at the cost of abandoning a large part ofthe semantics behind the data Subsequently in Section 4 we propose a novel entitymodel (Hierarchical Entity Model) capable of preserving the semantics associated withentities It uses the idea of having a two-level hierarchy for entity representation onebased on the predicate types another based on the individual predicates We report onexperiments using our hierarchical model in Section 5 and show that modeling individ-ual predicates of a given type is more effective than folding their contents into a flatrepresentation We put our work in a broader context in Section 6 Finally we concludewith a discussion of our findings and outline our plans for future research in Section 7
2 Baseline Entity Models
In this section we formalise and draw upon two existing entity modeling approacheswithin a generative language modeling framework
21 Retrieval Framework
Language models (LMs) are attractive because of their solid theoretical foundations thatcouples with good empirical performance [26] LMs have been successfully applied toa wide range of entity-related search tasks see eg [1 8 14 18]
We rank candidate entities (e) according to their probability of being relevant givenquery q P (e|q) Instead of estimating this probability directly we apply Bayesrsquo rule anddrop the denominator as it does not influence the ranking (for a given query) P (e|q) =P (q|e)P (e)
P (q)
rank= P (q|e)P (e) Here P (e) is the prior probability of choosing a particular
entity e that we subsequently attempt to draw the query q from with probabilityP (q|e)Here we assume that P (e) is uniform thus does not affect the ranking Priors couldotherwise be used to incorporate query-independent features [6 10]
Each entity e is represented by a multinomial probability distribution over the vo-cabulary of terms The entity model θe is used to predict how likely the entity wouldproduce a given term t that is P (t|θe) Assuming that query terms are sampled iden-tically and independently the query likelihood is obtained by taking the product acrossall the terms in the query such that P (q|θe) =
prodtisinq P (t|θe)tf(tq) where tf(t q) is
the (raw) frequency of term t in the query Note that P (t|θe) gt 0 must be ensured forall vocabulary terms otherwise the product might end up being zero
The main question we will be concerned with for the remainder of this paper is theestimation of the entity model ie the probability distribution P (t|θe)
22 Unstructured Entity Model
The simplest approach to constructing entity models is to fold all text associated withthe entity into one ldquobag-of-words see Figure 2(a) for an illustration Following the
136 R Neumayer K Balog and K Noslashrvaringg
Text
Audi A41996 2002 2005 2007The Audi A4 is a compact executive carVolkswagen GroupCompact executive carsAll wheel drive vehiclesFront wheel drive vehiclesProductAudi A4Audi 80Audi A5Audi A4
(a) Unstructured Entity Model
Pred type Value
Name Audi A4Attributes 1996 2002 2005 2007
The Audi A4 is a compact executive carOutRelations Volkswagen Group
Compact executive carsAll wheel drive vehiclesFront wheel drive vehiclesProductAudi A4
InRelations Audi 80Audi A5Audi A4
(b) Structured Entity Model
Fig 2 Examples of baseline entity models corresponding to Figure 1 URIs are resolved (iereplaced with the name of the corresponding entity)
standard language modeling approach to document retrieval we implement the entitymodel as a Dirichlet-smoothed multinomial distribution
P (t|θe) = tf(t e) + μP (t|θc)|e|+ μ
(1)
where tf(t e) is the raw frequency of term t in the representation of e and |e| is the sizeof this representation ie
sumt tf(t e) The smoothing parameter μ is set to the average
entity representation size in the collection The term generation process is shown inFigure 3 (Left)
Several SemSearch participants employed variations of this approach consideringonly triples where the entity stands as a subjects (thereby ignoring incoming rela-tions) [3 8 19] or extracting text only from the subject itself [13]
23 Structured Entity Model Using Predicate-Folding
Instead of folding all predicates together they might be grouped into multiple categoriesin order to preserve some of the original structure Prior work presents examples of suchgrouping based on the type of the predicates [3 8 16 23] or based on their manuallydetermined importance [5] We group RDF triples into four main predicate types pt fora given entity e as follows
ndash Name the subject is e the object is a literal and the predicate comes from a prede-fined list (eg foafname or rdfslabel) or ends with ldquoname ldquolabel or ldquotitle
ndash Attributes the subject is e the object is a literal and the predicate is not of typename
ndash OutRelations the subject is e and the object is a URI We resolve the URI byreplacing it with the name of the corresponding entity see Section 31 for details
ndash InRelations e stands as the object the subject entity URI is resolved
Figure 2(b) presents an example A separate language model θpte is estimated for each
predicate type from all predicates of that type (associated with the given entity)
P (t|θpte ) =
tf(t pt e) + μptP (t|θptc )
|pt e|+ μpt
(2)
On the Modeling of Entities for Ad-Hoc Entity Search 137
where tf(t pt e) is the sum of the term frequencies for t for all predicates of type pt as-sociated with e and |pt e| =
sumt tf(t pt e) Essentially we concatenate all text from
the predicates of type pt and then apply Dirichlet smoothing using a collection-widebackground model P (t|θpt
c ) (that is a maximum-likelihood estimate from all predi-cates of that type in the collection) The smoothing parameter μpt is set to the averagepredicate type representation length in the collection
The entity model is a linear mixture of the predicate type language models (P (t|θpte ))
weighted with the importance of that predicate type (P (pt))
P (t|θe) =sum
pt
P (t|θpte )P (pt) (3)
Figure 3 (Middle) illustrates the term generation process Viewing entities as documentsand predicate types as document fields this model is equivalent with the Mixture ofLanguage Models approach by Ogilvie and Callan [20]
3 Evaluation of Baseline Entity Models
In this section we first introduce our experimental setup then perform an evaluation ofour baseline entity models
31 Experimental Setup
We use the test suites of the 2010 and 2011 editions of the Semantic Search (SemSearch)Challenge [4 15] The task we address is ad-hoc entity search given a keyword querytargeting a particular entity provide a ranked list of relevant entities identified by theirURIs The data set queries and relevance assessments are publicly available1
Data set The data collection used is the Billion Triple Challenge 2009 dataset It wasmainly crawled during FebruaryMarch 2009 and comprises about 114 billion RDFstatements and describes entities from domains like dbpediaorg livejournalcom orgeonamesorg2 In our evaluations we considered the 500 most frequent predicates
Topics and relevance assessments There are two topic sets consisting of 92 and50 keyword queries for years 2010 and 2011 respectively The queries were sampledfrom web search engine logs Relevance judgments were obtained using Amazonrsquos Me-chanical Turk Human assessors were presented with a simplified HTML summary ofentities and had to judge relevance on a 3-point scale (excellent fair and irrelevant)
Evaluation metrics We use standard IR evaluation metrics Mean Average Pre-cision (MAP) Precision at rank 10 (P10) and Normalized Discounted CumulativeGain (NDCG)3 To check for significant differences between runs we use a two-tailedpaired t-test and write daggerDagger to denote significance at the 005001 levels respectively
Resource resolution If a relation (predicate targeted at a URI rather than a literalvalue) points to an entity within the collection we replace the URI with that entityrsquosname Otherwise we extract terms from the relative part of the URI
1 httpkmaifbkiteduwssemsearch10|112 httpvmlion25deriie3 Note that the two editions used different gain values for computing NDCG scores 3 and 2
(2010) vs 2 and 1 (2011) for excellent and fair respectively We use these values unchanged
138 R Neumayer K Balog and K Noslashrvaringg
Table 1 Retrieval results using the Unstructured Entity Model Significance is tested against theALL setting (first line) Best scores for each topic set are typeset boldface
2010 2011Predicate types MAP P10 NDCG MAP P10 NDCG
ALL 02069 03141 03827 02072 01880 02947Name-only 02054dagger 03043 03969 02004 01900 03097Attributes-only 02058Dagger 03391dagger 03915 02200dagger 01900 03330dagger
OutRelations-only 00866Dagger 01761Dagger 02185Dagger 00935Dagger 01020Dagger 01667Dagger
InRelations-only 00955Dagger 01967Dagger 02257Dagger 00689Dagger 00980Dagger 01540Dagger
ALL-but-Name 01568Dagger 02620Dagger 03210Dagger 01563Dagger 01440Dagger 02467Dagger
ALL-but-Attributes 01820Dagger 02859Dagger 03416Dagger 01637Dagger 01600Dagger 02419Dagger
ALL-but-OutRelations 02029Dagger 03109 03685Dagger 02002Dagger 01800 02826ALL-but-InRelations 02125 03196 03848 02037Dagger 01900 02826
32 Unstructured Entity Model
Recall that this model creates an unstructured entity representation by collapsing textassociated with the entity into one bag-of-words We perform three sets of experimentsand report the results in Table 1 First identified by the lsquoALLrsquo row we consider allfour predicate types Next shown in the lsquofield type-onlyrsquo rows we use only a singlepredicate type at a time Finally in the rows named lsquoALL-but-field typersquo we presentresults by omitting one of the types in turn
Our findings are as follows The absolute performance of the ALL model (that simplyuses all text associated with the entity) is remarkable on the 2010 topic set it outper-forms the best SemSearch 2010 submission (MAP=01919) [15] while on the 2011 setit would have ranked third (best was MAP=02346) [4] As for the individual predi-cate types Name and Attributes perform best with only minor differences between thetwo in fact either of these predicates types alone is on a par with the ALL model Thescores for incoming and outgoing relations are much lower Looking at the combina-tions of all but one predicate types Name contributes the most and Attributes comessecond without either the scores drop substantially Removing either incoming or out-going relations has hardly any overall impact in the lsquoALL-but-InRelationsrsquo 2010 casethe scores marginally improve but the difference is not statistically significant
33 Structured Entity Model
Our second baseline model employs a weighted combination of four language modelscorresponding to predicate types We consider three different configurations in Table 2(1) equal weights on all types (2) all weights allocated to Name and Attributes in equalproportion and (3) most of the weights assigned to Name and Attributes again butthis time taking relations too into account In the lack of training data or any back-ground knowledge about the collection or queries (1) is a natural choice (2) and (3)are motivated by the results from the previous subsection however knowing from thetask definition that each query targets a particular entity one could intuitively argue forsuch weight distributions Note that when a single predicate type is used the StructuredEntity Model is equivalent to the unstructured case (Table 1 middle block)
On the Modeling of Entities for Ad-Hoc Entity Search 139
Table 2 Retrieval results using Structured Entity Models Significance is tested against the ALLsetting of the Unstructured Entity Model (Table 1 first line) Best scores are typeset boldface
Pred type weights 2010 2011Name Attr OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02816Dagger 03989Dagger 04943Dagger 02605Dagger 02420Dagger 03966Dagger
5 5 02490Dagger 03663Dagger 04608Dagger 02506Dagger 02300Dagger 03845Dagger
35 35 15 15 02804Dagger 04043Dagger 04934Dagger 02614Dagger 02300Dagger 03968Dagger
All settings improve significantly and substantially over the unstructured baselineWe find somewhat surprisingly that the uniform weighting performs best of all thesenumbers are the highest that were ever reported for either topic sets (which are MAP=02705 for 2010 [5] and MAP=02346 for 2011 [4]) Even though Name and Attributeswere shown to be the two most lsquousefulrsquo predicate types using them without relationalinformation is clearly suboptimal (row 2 vs rows 1 and 3) The third setting (row 3)suggests that as long as all predicate types are considered the model is robust with re-spect to the actual weight distribution used We experimented with other configurationstoo but none of them improved significantly over the uniform weighting
4 Hierarchical Entity Model
In this section we introduce a novel entity modeling approach Before presenting ourproposal we briefly review the considerations leading to the choice of this particularmodel (1) In a heterogeneous environment the number of distinct predicates is hugeIt is not feasible to optimise their weights directly (because of the computational com-plexity and because of the enormous amounts of training material it would require)(2) Entities are sparse with respect to the different predicates ie most entities haveonly a handful of distinct predicates associated with them (3) As we have shown withthe Structured Entity Model folding predicates based on their type is a viable alterna-tive that works well in practice Nevertheless we need a different solution if we wishto preserve the semantics in the entity model ie keep individual predicates and theircontents accessible (and possibly exploit this information in the retrieval model) Userscan only be offered to make use of single predicates if they are preserved individu-ally such kind of faceted search may not improve effectiveness in the context of theSemantic Search Challenge but might be a requirement given from the user side
The main idea behind our model is to organise information belonging to a given en-tity into a hierarchy of two levels with predicate types (ie name attributes incomingand outgoing relations) on the first level and individual predicates of that type on thesecond level This preserves the original structure associated with the given entity andallows for setting the importance individual predicates conditioned on their type and onthe entity Formally this is expressed as follows
P (t|θe) =sum
pt
P (t|pt e)P (pt|e) (4)
=sum
pt
( sum
pisinpt
P (t|p pt)P (p|pt e))P (pt|e) (5)
140 R Neumayer K Balog and K Noslashrvaringg
e
ppt
t
ppt t
e
tpt
tpt
e
t
t
Fig 3 Graphical representations of entity models (Left) Unstructured Entity Model (Middle)Structured Entity Model using Predicate-folding (Right) Hierarchical Entity Model
The term generation process under this model is shown in Figure 3 (Right) Next wediscuss the three components from Eq 5 term generation (P (t|p pt)) predicate gen-eration (P (p|pt e)) and predicate type generation (P (pt|e))
Term Generation The importance of a term is jointly determined by the predicate inwhich it occurs as well as all other predicates of that type associated with the entity
P (t|p pt) = (1minus λ)P (t|p) + λP (t|θpte ) (6)
where P (t|p) is a maximum-likelihood estimate (ie the relative frequency of term t inpredicate p) and P (t|θpt
e ) is the Dirichlet-smoothed LM for predicate type pt estimatedusing Eq 2 The parameter λ isin [01] controls the influence of the predicate type modelFor the sake of simplicity we set λ to 05 in our experiments
Predicate Generation The importance of a given predicate p is conditioned on thetype of the predicate pt and the entity e P (p|pt e) We consider four natural options4
ndash Uniform All the predicates of the same type are treated equally importantP (p|pt e) = 1n(e pt) where n(e pt) is the number of predicates of type ptassigned to e5
ndash Length The probability mass is allocated to predicates proportional to their lengthP (p|pt e) = |p e||pt e| where |p e| and |pt e| are the lengths of p and pt re-spectively measured in the number of terms they contain
ndash Average length We use the average length of the predicate p in the collection rela-tive to the average length of all predicates of type pt
ndash Popularity We regard popular predicates more important where popularity is mea-sured in terms of the number of triples that have the given predicate P (p|pt e) =n(p)n(pt) where n(p) and n(pt) are the total number of triples in the collectionwith predicate p and predicate type pt respectively
4 It is by design that predicate importance is independent of the query this way other possiblycomputationally heavy alternatives for setting this probability could be estimated offline
5 Since predicates encoding the entity name are all equally important we do not vary theirimportance hence we always use the uniform distribution for pt = ldquonamerdquo
On the Modeling of Entities for Ad-Hoc Entity Search 141
Table 3 Retrieval results using Hierarchical Entity Models using a single predicate type
Predicate Predicate 2010 2011type weighting MAP P10 NDCG MAP P10 NDCG
Attributes Uniform 02350Dagger 03261 04403Dagger 02423Dagger 02140 03738Length 02116Dagger 02870Dagger 04149 02292Dagger 02060 03477AvgLength 02129Dagger 02859Dagger 04144 02287Dagger 02060 03511Popularity 02318Dagger 03109dagger 04385Dagger 02514Dagger 02140 03791
OutRelations Uniform 01185Dagger 01783 02607 01221Dagger 01220dagger 02046Dagger
Length 00915Dagger 01663 02122 00980Dagger 00920 01647AvgLength 00908Dagger 01533dagger 02131 00958Dagger 00940 01677Popularity 01067Dagger 01674 02439 01233Dagger 01260dagger 02070Dagger
InRelations Uniform 01073Dagger 02054dagger 02387 00800Dagger 01160dagger 01749Dagger
Length 00941Dagger 01793dagger 02188 00703 00940 01593AvgLength 00921Dagger 01696Dagger 02212 00776Dagger 00980 01751Dagger
Popularity 01117Dagger 02022 02452dagger 00891Dagger 01240dagger 01903Dagger
Table 4 Retrieval results using Hierarchical Entity Models and uniform term weighting Signif-icance is tested against the Structured Entity Model (corresponding row in Table 2) Best scoresfor each year are typeset boldface
Pred type 2010 2011Name Att OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02349Dagger 03261Dagger 04394Dagger 02423Dagger 02140Dagger 03738dagger
5 5 02242Dagger 03359Dagger 04125Dagger 02038Dagger 02000Dagger 03195Dagger
35 35 15 15 02561Dagger 03641Dagger 04614Dagger 02436Dagger 02240 03717dagger
Predicate Type Generation The model in Eq 5 allows us to set predicate type impor-tance on a per-entity basis To simplify matters however we make the conditional in-dependence assumption between predicate types and entities hence P (pt|e) = P (pt)This allows us to use estimation methods (or the actual values) from the StructuredEntity Model as this component is identical in the two models (cf Eq 3)
5 Evaluation of the Hierarchical Entity Model
In order to evaluate the hierarchical entity model we first show the results obtained foreach of the predicate types in turn analogous to the second block in Table 1 This is alsothe baseline we test against Table 3 presents the results for each of the predicate typesand different weighting models for individual predicates As indicated improvementsare significant in the majority of cases We show improvements over the results reportedfor the unstructured model in every category illustrating that the additional level ofnormalisation can cover the structure of the entities The lsquouniformrsquo weighting strategyperforms best for all types with lsquopopularityrsquo coming second Therefore we omit theresults for the remaining predicate weighting strategies in Table 4 where we show the
142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

134 R Neumayer K Balog and K Noslashrvaringg
dbpediaAudi_A4
dbpediaVolkswagen_Group
parentCompany
1996 2002 2005 2007
modelYears
abstract
dbpediaCategoryCompact_executive_cars
dbpediaCategoryAll_wheel_drive_vehicles
dbpediaCategoryFront_wheel_drive_vehiclessubject
httpschemaorgProduct
type
dbpediaAudi_80
dbpediaAudi_A5
successor
predecessor
The Audi A4 is a compact executive car produced since late 1994 by the
German car manufacturer Audi
httprdffreebasecomnsm030qmx
httpwww4wiwissfu-berlindeAudi_A4
sameAs
Fig 1 Excerpt from an RDF graph Rounded rectangles represent entities (ie URIs) rectanglesdenote attributes (ie literal values) URIs are shortened and predicate prefixes are ignored
empirically assess methods and algorithms devised for the task that has been termed ad-hoc entity retrieval ldquoanswering arbitrary information needs related to particular aspectsof objects [entities] expressed in unconstrained natural language and resolved using acollection of structured data [24] Since WoD is inherently organised around objectsor entities having entities as the unit of retrieval follows naturally
Commonly the ad-hoc entity retrieval task is approached by adapting standard doc-ument retrieval methods A textual representation (ldquopseudo document) is built for eachentity and these representations can then be ranked using conventional IR models Themain challenge of course is how to obtain these textual representations from structureddata WoD conceptually forms a large directed labelled graph with nodes correspond-ing to entities and edges denoting relationships and is described in the form of subject-predicate-object (SPO) triples of the RDF data model Figure 1 shows a small excerptfrom an RDF graph centred around a given entity
A natural solution would be to represent each entity using a fielded structure wherefields correspond to predicates (ie arrows on Figure 1) and associated nodes (or ratherthe text extracted from them) are used as field values These representations can then beranked using any fielded document retrieval model such as BM25F [25] or the mixtureof language models (MLM) [20] However with this approach the number of documentfields soon becomes computationally prohibitive making the estimation of field weightsintractable A commonly used workaround is to group predicates together into a smallset of predefined categories and as such create documents comprising of only a handfulof fields This grouping (or ldquopredicate folding) can be based on for example the typeof predicates (attributes inout-relations etc) [23] or on their (manually determined)importance [5] This leads to a data model where the optimisation of field weightsis easily tractable even using exhaustive search over the parameter space While thisapproach seems to work well in practice it seriously limits the semantic expressivity ofentity models as it is no longer possible to access the content of individual predicatesor might be too dependent on the data collection
The overall research question we address in this paper is how to represent entitiesin the Web of Data for the purpose of text-based retrieval As our first step on the pathto investigating this issue in Section 2 we formalise the aforementioned two entitymodeling strategies within a generative language modeling framework One approach(Unstructured Entity Model) collapses all text associated with the entity into a single
On the Modeling of Entities for Ad-Hoc Entity Search 135
flat-text representation The other approach (Structured Entity Model) groups predicatestogether into a small number of categories and considers their weighted combinationWe perform an experimental evaluation of the two models using the 2010 and 2011 testsets of the Semantic Search Challenge evaluation campaign in Section 3 We find thatthese models outperform the current state-of-the-art in terms of retrieval effectivenesson these collections However this is done at the cost of abandoning a large part ofthe semantics behind the data Subsequently in Section 4 we propose a novel entitymodel (Hierarchical Entity Model) capable of preserving the semantics associated withentities It uses the idea of having a two-level hierarchy for entity representation onebased on the predicate types another based on the individual predicates We report onexperiments using our hierarchical model in Section 5 and show that modeling individ-ual predicates of a given type is more effective than folding their contents into a flatrepresentation We put our work in a broader context in Section 6 Finally we concludewith a discussion of our findings and outline our plans for future research in Section 7
2 Baseline Entity Models
In this section we formalise and draw upon two existing entity modeling approacheswithin a generative language modeling framework
21 Retrieval Framework
Language models (LMs) are attractive because of their solid theoretical foundations thatcouples with good empirical performance [26] LMs have been successfully applied toa wide range of entity-related search tasks see eg [1 8 14 18]
We rank candidate entities (e) according to their probability of being relevant givenquery q P (e|q) Instead of estimating this probability directly we apply Bayesrsquo rule anddrop the denominator as it does not influence the ranking (for a given query) P (e|q) =P (q|e)P (e)
P (q)
rank= P (q|e)P (e) Here P (e) is the prior probability of choosing a particular
entity e that we subsequently attempt to draw the query q from with probabilityP (q|e)Here we assume that P (e) is uniform thus does not affect the ranking Priors couldotherwise be used to incorporate query-independent features [6 10]
Each entity e is represented by a multinomial probability distribution over the vo-cabulary of terms The entity model θe is used to predict how likely the entity wouldproduce a given term t that is P (t|θe) Assuming that query terms are sampled iden-tically and independently the query likelihood is obtained by taking the product acrossall the terms in the query such that P (q|θe) =
prodtisinq P (t|θe)tf(tq) where tf(t q) is
the (raw) frequency of term t in the query Note that P (t|θe) gt 0 must be ensured forall vocabulary terms otherwise the product might end up being zero
The main question we will be concerned with for the remainder of this paper is theestimation of the entity model ie the probability distribution P (t|θe)
22 Unstructured Entity Model
The simplest approach to constructing entity models is to fold all text associated withthe entity into one ldquobag-of-words see Figure 2(a) for an illustration Following the
136 R Neumayer K Balog and K Noslashrvaringg
Text
Audi A41996 2002 2005 2007The Audi A4 is a compact executive carVolkswagen GroupCompact executive carsAll wheel drive vehiclesFront wheel drive vehiclesProductAudi A4Audi 80Audi A5Audi A4
(a) Unstructured Entity Model
Pred type Value
Name Audi A4Attributes 1996 2002 2005 2007
The Audi A4 is a compact executive carOutRelations Volkswagen Group
Compact executive carsAll wheel drive vehiclesFront wheel drive vehiclesProductAudi A4
InRelations Audi 80Audi A5Audi A4
(b) Structured Entity Model
Fig 2 Examples of baseline entity models corresponding to Figure 1 URIs are resolved (iereplaced with the name of the corresponding entity)
standard language modeling approach to document retrieval we implement the entitymodel as a Dirichlet-smoothed multinomial distribution
P (t|θe) = tf(t e) + μP (t|θc)|e|+ μ
(1)
where tf(t e) is the raw frequency of term t in the representation of e and |e| is the sizeof this representation ie
sumt tf(t e) The smoothing parameter μ is set to the average
entity representation size in the collection The term generation process is shown inFigure 3 (Left)
Several SemSearch participants employed variations of this approach consideringonly triples where the entity stands as a subjects (thereby ignoring incoming rela-tions) [3 8 19] or extracting text only from the subject itself [13]
23 Structured Entity Model Using Predicate-Folding
Instead of folding all predicates together they might be grouped into multiple categoriesin order to preserve some of the original structure Prior work presents examples of suchgrouping based on the type of the predicates [3 8 16 23] or based on their manuallydetermined importance [5] We group RDF triples into four main predicate types pt fora given entity e as follows
ndash Name the subject is e the object is a literal and the predicate comes from a prede-fined list (eg foafname or rdfslabel) or ends with ldquoname ldquolabel or ldquotitle
ndash Attributes the subject is e the object is a literal and the predicate is not of typename
ndash OutRelations the subject is e and the object is a URI We resolve the URI byreplacing it with the name of the corresponding entity see Section 31 for details
ndash InRelations e stands as the object the subject entity URI is resolved
Figure 2(b) presents an example A separate language model θpte is estimated for each
predicate type from all predicates of that type (associated with the given entity)
P (t|θpte ) =
tf(t pt e) + μptP (t|θptc )
|pt e|+ μpt
(2)
On the Modeling of Entities for Ad-Hoc Entity Search 137
where tf(t pt e) is the sum of the term frequencies for t for all predicates of type pt as-sociated with e and |pt e| =
sumt tf(t pt e) Essentially we concatenate all text from
the predicates of type pt and then apply Dirichlet smoothing using a collection-widebackground model P (t|θpt
c ) (that is a maximum-likelihood estimate from all predi-cates of that type in the collection) The smoothing parameter μpt is set to the averagepredicate type representation length in the collection
The entity model is a linear mixture of the predicate type language models (P (t|θpte ))
weighted with the importance of that predicate type (P (pt))
P (t|θe) =sum
pt
P (t|θpte )P (pt) (3)
Figure 3 (Middle) illustrates the term generation process Viewing entities as documentsand predicate types as document fields this model is equivalent with the Mixture ofLanguage Models approach by Ogilvie and Callan [20]
3 Evaluation of Baseline Entity Models
In this section we first introduce our experimental setup then perform an evaluation ofour baseline entity models
31 Experimental Setup
We use the test suites of the 2010 and 2011 editions of the Semantic Search (SemSearch)Challenge [4 15] The task we address is ad-hoc entity search given a keyword querytargeting a particular entity provide a ranked list of relevant entities identified by theirURIs The data set queries and relevance assessments are publicly available1
Data set The data collection used is the Billion Triple Challenge 2009 dataset It wasmainly crawled during FebruaryMarch 2009 and comprises about 114 billion RDFstatements and describes entities from domains like dbpediaorg livejournalcom orgeonamesorg2 In our evaluations we considered the 500 most frequent predicates
Topics and relevance assessments There are two topic sets consisting of 92 and50 keyword queries for years 2010 and 2011 respectively The queries were sampledfrom web search engine logs Relevance judgments were obtained using Amazonrsquos Me-chanical Turk Human assessors were presented with a simplified HTML summary ofentities and had to judge relevance on a 3-point scale (excellent fair and irrelevant)
Evaluation metrics We use standard IR evaluation metrics Mean Average Pre-cision (MAP) Precision at rank 10 (P10) and Normalized Discounted CumulativeGain (NDCG)3 To check for significant differences between runs we use a two-tailedpaired t-test and write daggerDagger to denote significance at the 005001 levels respectively
Resource resolution If a relation (predicate targeted at a URI rather than a literalvalue) points to an entity within the collection we replace the URI with that entityrsquosname Otherwise we extract terms from the relative part of the URI
1 httpkmaifbkiteduwssemsearch10|112 httpvmlion25deriie3 Note that the two editions used different gain values for computing NDCG scores 3 and 2
(2010) vs 2 and 1 (2011) for excellent and fair respectively We use these values unchanged
138 R Neumayer K Balog and K Noslashrvaringg
Table 1 Retrieval results using the Unstructured Entity Model Significance is tested against theALL setting (first line) Best scores for each topic set are typeset boldface
2010 2011Predicate types MAP P10 NDCG MAP P10 NDCG
ALL 02069 03141 03827 02072 01880 02947Name-only 02054dagger 03043 03969 02004 01900 03097Attributes-only 02058Dagger 03391dagger 03915 02200dagger 01900 03330dagger
OutRelations-only 00866Dagger 01761Dagger 02185Dagger 00935Dagger 01020Dagger 01667Dagger
InRelations-only 00955Dagger 01967Dagger 02257Dagger 00689Dagger 00980Dagger 01540Dagger
ALL-but-Name 01568Dagger 02620Dagger 03210Dagger 01563Dagger 01440Dagger 02467Dagger
ALL-but-Attributes 01820Dagger 02859Dagger 03416Dagger 01637Dagger 01600Dagger 02419Dagger
ALL-but-OutRelations 02029Dagger 03109 03685Dagger 02002Dagger 01800 02826ALL-but-InRelations 02125 03196 03848 02037Dagger 01900 02826
32 Unstructured Entity Model
Recall that this model creates an unstructured entity representation by collapsing textassociated with the entity into one bag-of-words We perform three sets of experimentsand report the results in Table 1 First identified by the lsquoALLrsquo row we consider allfour predicate types Next shown in the lsquofield type-onlyrsquo rows we use only a singlepredicate type at a time Finally in the rows named lsquoALL-but-field typersquo we presentresults by omitting one of the types in turn
Our findings are as follows The absolute performance of the ALL model (that simplyuses all text associated with the entity) is remarkable on the 2010 topic set it outper-forms the best SemSearch 2010 submission (MAP=01919) [15] while on the 2011 setit would have ranked third (best was MAP=02346) [4] As for the individual predi-cate types Name and Attributes perform best with only minor differences between thetwo in fact either of these predicates types alone is on a par with the ALL model Thescores for incoming and outgoing relations are much lower Looking at the combina-tions of all but one predicate types Name contributes the most and Attributes comessecond without either the scores drop substantially Removing either incoming or out-going relations has hardly any overall impact in the lsquoALL-but-InRelationsrsquo 2010 casethe scores marginally improve but the difference is not statistically significant
33 Structured Entity Model
Our second baseline model employs a weighted combination of four language modelscorresponding to predicate types We consider three different configurations in Table 2(1) equal weights on all types (2) all weights allocated to Name and Attributes in equalproportion and (3) most of the weights assigned to Name and Attributes again butthis time taking relations too into account In the lack of training data or any back-ground knowledge about the collection or queries (1) is a natural choice (2) and (3)are motivated by the results from the previous subsection however knowing from thetask definition that each query targets a particular entity one could intuitively argue forsuch weight distributions Note that when a single predicate type is used the StructuredEntity Model is equivalent to the unstructured case (Table 1 middle block)
On the Modeling of Entities for Ad-Hoc Entity Search 139
Table 2 Retrieval results using Structured Entity Models Significance is tested against the ALLsetting of the Unstructured Entity Model (Table 1 first line) Best scores are typeset boldface
Pred type weights 2010 2011Name Attr OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02816Dagger 03989Dagger 04943Dagger 02605Dagger 02420Dagger 03966Dagger
5 5 02490Dagger 03663Dagger 04608Dagger 02506Dagger 02300Dagger 03845Dagger
35 35 15 15 02804Dagger 04043Dagger 04934Dagger 02614Dagger 02300Dagger 03968Dagger
All settings improve significantly and substantially over the unstructured baselineWe find somewhat surprisingly that the uniform weighting performs best of all thesenumbers are the highest that were ever reported for either topic sets (which are MAP=02705 for 2010 [5] and MAP=02346 for 2011 [4]) Even though Name and Attributeswere shown to be the two most lsquousefulrsquo predicate types using them without relationalinformation is clearly suboptimal (row 2 vs rows 1 and 3) The third setting (row 3)suggests that as long as all predicate types are considered the model is robust with re-spect to the actual weight distribution used We experimented with other configurationstoo but none of them improved significantly over the uniform weighting
4 Hierarchical Entity Model
In this section we introduce a novel entity modeling approach Before presenting ourproposal we briefly review the considerations leading to the choice of this particularmodel (1) In a heterogeneous environment the number of distinct predicates is hugeIt is not feasible to optimise their weights directly (because of the computational com-plexity and because of the enormous amounts of training material it would require)(2) Entities are sparse with respect to the different predicates ie most entities haveonly a handful of distinct predicates associated with them (3) As we have shown withthe Structured Entity Model folding predicates based on their type is a viable alterna-tive that works well in practice Nevertheless we need a different solution if we wishto preserve the semantics in the entity model ie keep individual predicates and theircontents accessible (and possibly exploit this information in the retrieval model) Userscan only be offered to make use of single predicates if they are preserved individu-ally such kind of faceted search may not improve effectiveness in the context of theSemantic Search Challenge but might be a requirement given from the user side
The main idea behind our model is to organise information belonging to a given en-tity into a hierarchy of two levels with predicate types (ie name attributes incomingand outgoing relations) on the first level and individual predicates of that type on thesecond level This preserves the original structure associated with the given entity andallows for setting the importance individual predicates conditioned on their type and onthe entity Formally this is expressed as follows
P (t|θe) =sum
pt
P (t|pt e)P (pt|e) (4)
=sum
pt
( sum
pisinpt
P (t|p pt)P (p|pt e))P (pt|e) (5)
140 R Neumayer K Balog and K Noslashrvaringg
e
ppt
t
ppt t
e
tpt
tpt
e
t
t
Fig 3 Graphical representations of entity models (Left) Unstructured Entity Model (Middle)Structured Entity Model using Predicate-folding (Right) Hierarchical Entity Model
The term generation process under this model is shown in Figure 3 (Right) Next wediscuss the three components from Eq 5 term generation (P (t|p pt)) predicate gen-eration (P (p|pt e)) and predicate type generation (P (pt|e))
Term Generation The importance of a term is jointly determined by the predicate inwhich it occurs as well as all other predicates of that type associated with the entity
P (t|p pt) = (1minus λ)P (t|p) + λP (t|θpte ) (6)
where P (t|p) is a maximum-likelihood estimate (ie the relative frequency of term t inpredicate p) and P (t|θpt
e ) is the Dirichlet-smoothed LM for predicate type pt estimatedusing Eq 2 The parameter λ isin [01] controls the influence of the predicate type modelFor the sake of simplicity we set λ to 05 in our experiments
Predicate Generation The importance of a given predicate p is conditioned on thetype of the predicate pt and the entity e P (p|pt e) We consider four natural options4
ndash Uniform All the predicates of the same type are treated equally importantP (p|pt e) = 1n(e pt) where n(e pt) is the number of predicates of type ptassigned to e5
ndash Length The probability mass is allocated to predicates proportional to their lengthP (p|pt e) = |p e||pt e| where |p e| and |pt e| are the lengths of p and pt re-spectively measured in the number of terms they contain
ndash Average length We use the average length of the predicate p in the collection rela-tive to the average length of all predicates of type pt
ndash Popularity We regard popular predicates more important where popularity is mea-sured in terms of the number of triples that have the given predicate P (p|pt e) =n(p)n(pt) where n(p) and n(pt) are the total number of triples in the collectionwith predicate p and predicate type pt respectively
4 It is by design that predicate importance is independent of the query this way other possiblycomputationally heavy alternatives for setting this probability could be estimated offline
5 Since predicates encoding the entity name are all equally important we do not vary theirimportance hence we always use the uniform distribution for pt = ldquonamerdquo
On the Modeling of Entities for Ad-Hoc Entity Search 141
Table 3 Retrieval results using Hierarchical Entity Models using a single predicate type
Predicate Predicate 2010 2011type weighting MAP P10 NDCG MAP P10 NDCG
Attributes Uniform 02350Dagger 03261 04403Dagger 02423Dagger 02140 03738Length 02116Dagger 02870Dagger 04149 02292Dagger 02060 03477AvgLength 02129Dagger 02859Dagger 04144 02287Dagger 02060 03511Popularity 02318Dagger 03109dagger 04385Dagger 02514Dagger 02140 03791
OutRelations Uniform 01185Dagger 01783 02607 01221Dagger 01220dagger 02046Dagger
Length 00915Dagger 01663 02122 00980Dagger 00920 01647AvgLength 00908Dagger 01533dagger 02131 00958Dagger 00940 01677Popularity 01067Dagger 01674 02439 01233Dagger 01260dagger 02070Dagger
InRelations Uniform 01073Dagger 02054dagger 02387 00800Dagger 01160dagger 01749Dagger
Length 00941Dagger 01793dagger 02188 00703 00940 01593AvgLength 00921Dagger 01696Dagger 02212 00776Dagger 00980 01751Dagger
Popularity 01117Dagger 02022 02452dagger 00891Dagger 01240dagger 01903Dagger
Table 4 Retrieval results using Hierarchical Entity Models and uniform term weighting Signif-icance is tested against the Structured Entity Model (corresponding row in Table 2) Best scoresfor each year are typeset boldface
Pred type 2010 2011Name Att OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02349Dagger 03261Dagger 04394Dagger 02423Dagger 02140Dagger 03738dagger
5 5 02242Dagger 03359Dagger 04125Dagger 02038Dagger 02000Dagger 03195Dagger
35 35 15 15 02561Dagger 03641Dagger 04614Dagger 02436Dagger 02240 03717dagger
Predicate Type Generation The model in Eq 5 allows us to set predicate type impor-tance on a per-entity basis To simplify matters however we make the conditional in-dependence assumption between predicate types and entities hence P (pt|e) = P (pt)This allows us to use estimation methods (or the actual values) from the StructuredEntity Model as this component is identical in the two models (cf Eq 3)
5 Evaluation of the Hierarchical Entity Model
In order to evaluate the hierarchical entity model we first show the results obtained foreach of the predicate types in turn analogous to the second block in Table 1 This is alsothe baseline we test against Table 3 presents the results for each of the predicate typesand different weighting models for individual predicates As indicated improvementsare significant in the majority of cases We show improvements over the results reportedfor the unstructured model in every category illustrating that the additional level ofnormalisation can cover the structure of the entities The lsquouniformrsquo weighting strategyperforms best for all types with lsquopopularityrsquo coming second Therefore we omit theresults for the remaining predicate weighting strategies in Table 4 where we show the
142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

On the Modeling of Entities for Ad-Hoc Entity Search 135
flat-text representation The other approach (Structured Entity Model) groups predicatestogether into a small number of categories and considers their weighted combinationWe perform an experimental evaluation of the two models using the 2010 and 2011 testsets of the Semantic Search Challenge evaluation campaign in Section 3 We find thatthese models outperform the current state-of-the-art in terms of retrieval effectivenesson these collections However this is done at the cost of abandoning a large part ofthe semantics behind the data Subsequently in Section 4 we propose a novel entitymodel (Hierarchical Entity Model) capable of preserving the semantics associated withentities It uses the idea of having a two-level hierarchy for entity representation onebased on the predicate types another based on the individual predicates We report onexperiments using our hierarchical model in Section 5 and show that modeling individ-ual predicates of a given type is more effective than folding their contents into a flatrepresentation We put our work in a broader context in Section 6 Finally we concludewith a discussion of our findings and outline our plans for future research in Section 7
2 Baseline Entity Models
In this section we formalise and draw upon two existing entity modeling approacheswithin a generative language modeling framework
21 Retrieval Framework
Language models (LMs) are attractive because of their solid theoretical foundations thatcouples with good empirical performance [26] LMs have been successfully applied toa wide range of entity-related search tasks see eg [1 8 14 18]
We rank candidate entities (e) according to their probability of being relevant givenquery q P (e|q) Instead of estimating this probability directly we apply Bayesrsquo rule anddrop the denominator as it does not influence the ranking (for a given query) P (e|q) =P (q|e)P (e)
P (q)
rank= P (q|e)P (e) Here P (e) is the prior probability of choosing a particular
entity e that we subsequently attempt to draw the query q from with probabilityP (q|e)Here we assume that P (e) is uniform thus does not affect the ranking Priors couldotherwise be used to incorporate query-independent features [6 10]
Each entity e is represented by a multinomial probability distribution over the vo-cabulary of terms The entity model θe is used to predict how likely the entity wouldproduce a given term t that is P (t|θe) Assuming that query terms are sampled iden-tically and independently the query likelihood is obtained by taking the product acrossall the terms in the query such that P (q|θe) =
prodtisinq P (t|θe)tf(tq) where tf(t q) is
the (raw) frequency of term t in the query Note that P (t|θe) gt 0 must be ensured forall vocabulary terms otherwise the product might end up being zero
The main question we will be concerned with for the remainder of this paper is theestimation of the entity model ie the probability distribution P (t|θe)
22 Unstructured Entity Model
The simplest approach to constructing entity models is to fold all text associated withthe entity into one ldquobag-of-words see Figure 2(a) for an illustration Following the
136 R Neumayer K Balog and K Noslashrvaringg
Text
Audi A41996 2002 2005 2007The Audi A4 is a compact executive carVolkswagen GroupCompact executive carsAll wheel drive vehiclesFront wheel drive vehiclesProductAudi A4Audi 80Audi A5Audi A4
(a) Unstructured Entity Model
Pred type Value
Name Audi A4Attributes 1996 2002 2005 2007
The Audi A4 is a compact executive carOutRelations Volkswagen Group
Compact executive carsAll wheel drive vehiclesFront wheel drive vehiclesProductAudi A4
InRelations Audi 80Audi A5Audi A4
(b) Structured Entity Model
Fig 2 Examples of baseline entity models corresponding to Figure 1 URIs are resolved (iereplaced with the name of the corresponding entity)
standard language modeling approach to document retrieval we implement the entitymodel as a Dirichlet-smoothed multinomial distribution
P (t|θe) = tf(t e) + μP (t|θc)|e|+ μ
(1)
where tf(t e) is the raw frequency of term t in the representation of e and |e| is the sizeof this representation ie
sumt tf(t e) The smoothing parameter μ is set to the average
entity representation size in the collection The term generation process is shown inFigure 3 (Left)
Several SemSearch participants employed variations of this approach consideringonly triples where the entity stands as a subjects (thereby ignoring incoming rela-tions) [3 8 19] or extracting text only from the subject itself [13]
23 Structured Entity Model Using Predicate-Folding
Instead of folding all predicates together they might be grouped into multiple categoriesin order to preserve some of the original structure Prior work presents examples of suchgrouping based on the type of the predicates [3 8 16 23] or based on their manuallydetermined importance [5] We group RDF triples into four main predicate types pt fora given entity e as follows
ndash Name the subject is e the object is a literal and the predicate comes from a prede-fined list (eg foafname or rdfslabel) or ends with ldquoname ldquolabel or ldquotitle
ndash Attributes the subject is e the object is a literal and the predicate is not of typename
ndash OutRelations the subject is e and the object is a URI We resolve the URI byreplacing it with the name of the corresponding entity see Section 31 for details
ndash InRelations e stands as the object the subject entity URI is resolved
Figure 2(b) presents an example A separate language model θpte is estimated for each
predicate type from all predicates of that type (associated with the given entity)
P (t|θpte ) =
tf(t pt e) + μptP (t|θptc )
|pt e|+ μpt
(2)
On the Modeling of Entities for Ad-Hoc Entity Search 137
where tf(t pt e) is the sum of the term frequencies for t for all predicates of type pt as-sociated with e and |pt e| =
sumt tf(t pt e) Essentially we concatenate all text from
the predicates of type pt and then apply Dirichlet smoothing using a collection-widebackground model P (t|θpt
c ) (that is a maximum-likelihood estimate from all predi-cates of that type in the collection) The smoothing parameter μpt is set to the averagepredicate type representation length in the collection
The entity model is a linear mixture of the predicate type language models (P (t|θpte ))
weighted with the importance of that predicate type (P (pt))
P (t|θe) =sum
pt
P (t|θpte )P (pt) (3)
Figure 3 (Middle) illustrates the term generation process Viewing entities as documentsand predicate types as document fields this model is equivalent with the Mixture ofLanguage Models approach by Ogilvie and Callan [20]
3 Evaluation of Baseline Entity Models
In this section we first introduce our experimental setup then perform an evaluation ofour baseline entity models
31 Experimental Setup
We use the test suites of the 2010 and 2011 editions of the Semantic Search (SemSearch)Challenge [4 15] The task we address is ad-hoc entity search given a keyword querytargeting a particular entity provide a ranked list of relevant entities identified by theirURIs The data set queries and relevance assessments are publicly available1
Data set The data collection used is the Billion Triple Challenge 2009 dataset It wasmainly crawled during FebruaryMarch 2009 and comprises about 114 billion RDFstatements and describes entities from domains like dbpediaorg livejournalcom orgeonamesorg2 In our evaluations we considered the 500 most frequent predicates
Topics and relevance assessments There are two topic sets consisting of 92 and50 keyword queries for years 2010 and 2011 respectively The queries were sampledfrom web search engine logs Relevance judgments were obtained using Amazonrsquos Me-chanical Turk Human assessors were presented with a simplified HTML summary ofentities and had to judge relevance on a 3-point scale (excellent fair and irrelevant)
Evaluation metrics We use standard IR evaluation metrics Mean Average Pre-cision (MAP) Precision at rank 10 (P10) and Normalized Discounted CumulativeGain (NDCG)3 To check for significant differences between runs we use a two-tailedpaired t-test and write daggerDagger to denote significance at the 005001 levels respectively
Resource resolution If a relation (predicate targeted at a URI rather than a literalvalue) points to an entity within the collection we replace the URI with that entityrsquosname Otherwise we extract terms from the relative part of the URI
1 httpkmaifbkiteduwssemsearch10|112 httpvmlion25deriie3 Note that the two editions used different gain values for computing NDCG scores 3 and 2
(2010) vs 2 and 1 (2011) for excellent and fair respectively We use these values unchanged
138 R Neumayer K Balog and K Noslashrvaringg
Table 1 Retrieval results using the Unstructured Entity Model Significance is tested against theALL setting (first line) Best scores for each topic set are typeset boldface
2010 2011Predicate types MAP P10 NDCG MAP P10 NDCG
ALL 02069 03141 03827 02072 01880 02947Name-only 02054dagger 03043 03969 02004 01900 03097Attributes-only 02058Dagger 03391dagger 03915 02200dagger 01900 03330dagger
OutRelations-only 00866Dagger 01761Dagger 02185Dagger 00935Dagger 01020Dagger 01667Dagger
InRelations-only 00955Dagger 01967Dagger 02257Dagger 00689Dagger 00980Dagger 01540Dagger
ALL-but-Name 01568Dagger 02620Dagger 03210Dagger 01563Dagger 01440Dagger 02467Dagger
ALL-but-Attributes 01820Dagger 02859Dagger 03416Dagger 01637Dagger 01600Dagger 02419Dagger
ALL-but-OutRelations 02029Dagger 03109 03685Dagger 02002Dagger 01800 02826ALL-but-InRelations 02125 03196 03848 02037Dagger 01900 02826
32 Unstructured Entity Model
Recall that this model creates an unstructured entity representation by collapsing textassociated with the entity into one bag-of-words We perform three sets of experimentsand report the results in Table 1 First identified by the lsquoALLrsquo row we consider allfour predicate types Next shown in the lsquofield type-onlyrsquo rows we use only a singlepredicate type at a time Finally in the rows named lsquoALL-but-field typersquo we presentresults by omitting one of the types in turn
Our findings are as follows The absolute performance of the ALL model (that simplyuses all text associated with the entity) is remarkable on the 2010 topic set it outper-forms the best SemSearch 2010 submission (MAP=01919) [15] while on the 2011 setit would have ranked third (best was MAP=02346) [4] As for the individual predi-cate types Name and Attributes perform best with only minor differences between thetwo in fact either of these predicates types alone is on a par with the ALL model Thescores for incoming and outgoing relations are much lower Looking at the combina-tions of all but one predicate types Name contributes the most and Attributes comessecond without either the scores drop substantially Removing either incoming or out-going relations has hardly any overall impact in the lsquoALL-but-InRelationsrsquo 2010 casethe scores marginally improve but the difference is not statistically significant
33 Structured Entity Model
Our second baseline model employs a weighted combination of four language modelscorresponding to predicate types We consider three different configurations in Table 2(1) equal weights on all types (2) all weights allocated to Name and Attributes in equalproportion and (3) most of the weights assigned to Name and Attributes again butthis time taking relations too into account In the lack of training data or any back-ground knowledge about the collection or queries (1) is a natural choice (2) and (3)are motivated by the results from the previous subsection however knowing from thetask definition that each query targets a particular entity one could intuitively argue forsuch weight distributions Note that when a single predicate type is used the StructuredEntity Model is equivalent to the unstructured case (Table 1 middle block)
On the Modeling of Entities for Ad-Hoc Entity Search 139
Table 2 Retrieval results using Structured Entity Models Significance is tested against the ALLsetting of the Unstructured Entity Model (Table 1 first line) Best scores are typeset boldface
Pred type weights 2010 2011Name Attr OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02816Dagger 03989Dagger 04943Dagger 02605Dagger 02420Dagger 03966Dagger
5 5 02490Dagger 03663Dagger 04608Dagger 02506Dagger 02300Dagger 03845Dagger
35 35 15 15 02804Dagger 04043Dagger 04934Dagger 02614Dagger 02300Dagger 03968Dagger
All settings improve significantly and substantially over the unstructured baselineWe find somewhat surprisingly that the uniform weighting performs best of all thesenumbers are the highest that were ever reported for either topic sets (which are MAP=02705 for 2010 [5] and MAP=02346 for 2011 [4]) Even though Name and Attributeswere shown to be the two most lsquousefulrsquo predicate types using them without relationalinformation is clearly suboptimal (row 2 vs rows 1 and 3) The third setting (row 3)suggests that as long as all predicate types are considered the model is robust with re-spect to the actual weight distribution used We experimented with other configurationstoo but none of them improved significantly over the uniform weighting
4 Hierarchical Entity Model
In this section we introduce a novel entity modeling approach Before presenting ourproposal we briefly review the considerations leading to the choice of this particularmodel (1) In a heterogeneous environment the number of distinct predicates is hugeIt is not feasible to optimise their weights directly (because of the computational com-plexity and because of the enormous amounts of training material it would require)(2) Entities are sparse with respect to the different predicates ie most entities haveonly a handful of distinct predicates associated with them (3) As we have shown withthe Structured Entity Model folding predicates based on their type is a viable alterna-tive that works well in practice Nevertheless we need a different solution if we wishto preserve the semantics in the entity model ie keep individual predicates and theircontents accessible (and possibly exploit this information in the retrieval model) Userscan only be offered to make use of single predicates if they are preserved individu-ally such kind of faceted search may not improve effectiveness in the context of theSemantic Search Challenge but might be a requirement given from the user side
The main idea behind our model is to organise information belonging to a given en-tity into a hierarchy of two levels with predicate types (ie name attributes incomingand outgoing relations) on the first level and individual predicates of that type on thesecond level This preserves the original structure associated with the given entity andallows for setting the importance individual predicates conditioned on their type and onthe entity Formally this is expressed as follows
P (t|θe) =sum
pt
P (t|pt e)P (pt|e) (4)
=sum
pt
( sum
pisinpt
P (t|p pt)P (p|pt e))P (pt|e) (5)
140 R Neumayer K Balog and K Noslashrvaringg
e
ppt
t
ppt t
e
tpt
tpt
e
t
t
Fig 3 Graphical representations of entity models (Left) Unstructured Entity Model (Middle)Structured Entity Model using Predicate-folding (Right) Hierarchical Entity Model
The term generation process under this model is shown in Figure 3 (Right) Next wediscuss the three components from Eq 5 term generation (P (t|p pt)) predicate gen-eration (P (p|pt e)) and predicate type generation (P (pt|e))
Term Generation The importance of a term is jointly determined by the predicate inwhich it occurs as well as all other predicates of that type associated with the entity
P (t|p pt) = (1minus λ)P (t|p) + λP (t|θpte ) (6)
where P (t|p) is a maximum-likelihood estimate (ie the relative frequency of term t inpredicate p) and P (t|θpt
e ) is the Dirichlet-smoothed LM for predicate type pt estimatedusing Eq 2 The parameter λ isin [01] controls the influence of the predicate type modelFor the sake of simplicity we set λ to 05 in our experiments
Predicate Generation The importance of a given predicate p is conditioned on thetype of the predicate pt and the entity e P (p|pt e) We consider four natural options4
ndash Uniform All the predicates of the same type are treated equally importantP (p|pt e) = 1n(e pt) where n(e pt) is the number of predicates of type ptassigned to e5
ndash Length The probability mass is allocated to predicates proportional to their lengthP (p|pt e) = |p e||pt e| where |p e| and |pt e| are the lengths of p and pt re-spectively measured in the number of terms they contain
ndash Average length We use the average length of the predicate p in the collection rela-tive to the average length of all predicates of type pt
ndash Popularity We regard popular predicates more important where popularity is mea-sured in terms of the number of triples that have the given predicate P (p|pt e) =n(p)n(pt) where n(p) and n(pt) are the total number of triples in the collectionwith predicate p and predicate type pt respectively
4 It is by design that predicate importance is independent of the query this way other possiblycomputationally heavy alternatives for setting this probability could be estimated offline
5 Since predicates encoding the entity name are all equally important we do not vary theirimportance hence we always use the uniform distribution for pt = ldquonamerdquo
On the Modeling of Entities for Ad-Hoc Entity Search 141
Table 3 Retrieval results using Hierarchical Entity Models using a single predicate type
Predicate Predicate 2010 2011type weighting MAP P10 NDCG MAP P10 NDCG
Attributes Uniform 02350Dagger 03261 04403Dagger 02423Dagger 02140 03738Length 02116Dagger 02870Dagger 04149 02292Dagger 02060 03477AvgLength 02129Dagger 02859Dagger 04144 02287Dagger 02060 03511Popularity 02318Dagger 03109dagger 04385Dagger 02514Dagger 02140 03791
OutRelations Uniform 01185Dagger 01783 02607 01221Dagger 01220dagger 02046Dagger
Length 00915Dagger 01663 02122 00980Dagger 00920 01647AvgLength 00908Dagger 01533dagger 02131 00958Dagger 00940 01677Popularity 01067Dagger 01674 02439 01233Dagger 01260dagger 02070Dagger
InRelations Uniform 01073Dagger 02054dagger 02387 00800Dagger 01160dagger 01749Dagger
Length 00941Dagger 01793dagger 02188 00703 00940 01593AvgLength 00921Dagger 01696Dagger 02212 00776Dagger 00980 01751Dagger
Popularity 01117Dagger 02022 02452dagger 00891Dagger 01240dagger 01903Dagger
Table 4 Retrieval results using Hierarchical Entity Models and uniform term weighting Signif-icance is tested against the Structured Entity Model (corresponding row in Table 2) Best scoresfor each year are typeset boldface
Pred type 2010 2011Name Att OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02349Dagger 03261Dagger 04394Dagger 02423Dagger 02140Dagger 03738dagger
5 5 02242Dagger 03359Dagger 04125Dagger 02038Dagger 02000Dagger 03195Dagger
35 35 15 15 02561Dagger 03641Dagger 04614Dagger 02436Dagger 02240 03717dagger
Predicate Type Generation The model in Eq 5 allows us to set predicate type impor-tance on a per-entity basis To simplify matters however we make the conditional in-dependence assumption between predicate types and entities hence P (pt|e) = P (pt)This allows us to use estimation methods (or the actual values) from the StructuredEntity Model as this component is identical in the two models (cf Eq 3)
5 Evaluation of the Hierarchical Entity Model
In order to evaluate the hierarchical entity model we first show the results obtained foreach of the predicate types in turn analogous to the second block in Table 1 This is alsothe baseline we test against Table 3 presents the results for each of the predicate typesand different weighting models for individual predicates As indicated improvementsare significant in the majority of cases We show improvements over the results reportedfor the unstructured model in every category illustrating that the additional level ofnormalisation can cover the structure of the entities The lsquouniformrsquo weighting strategyperforms best for all types with lsquopopularityrsquo coming second Therefore we omit theresults for the remaining predicate weighting strategies in Table 4 where we show the
142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

136 R Neumayer K Balog and K Noslashrvaringg
Text
Audi A41996 2002 2005 2007The Audi A4 is a compact executive carVolkswagen GroupCompact executive carsAll wheel drive vehiclesFront wheel drive vehiclesProductAudi A4Audi 80Audi A5Audi A4
(a) Unstructured Entity Model
Pred type Value
Name Audi A4Attributes 1996 2002 2005 2007
The Audi A4 is a compact executive carOutRelations Volkswagen Group
Compact executive carsAll wheel drive vehiclesFront wheel drive vehiclesProductAudi A4
InRelations Audi 80Audi A5Audi A4
(b) Structured Entity Model
Fig 2 Examples of baseline entity models corresponding to Figure 1 URIs are resolved (iereplaced with the name of the corresponding entity)
standard language modeling approach to document retrieval we implement the entitymodel as a Dirichlet-smoothed multinomial distribution
P (t|θe) = tf(t e) + μP (t|θc)|e|+ μ
(1)
where tf(t e) is the raw frequency of term t in the representation of e and |e| is the sizeof this representation ie
sumt tf(t e) The smoothing parameter μ is set to the average
entity representation size in the collection The term generation process is shown inFigure 3 (Left)
Several SemSearch participants employed variations of this approach consideringonly triples where the entity stands as a subjects (thereby ignoring incoming rela-tions) [3 8 19] or extracting text only from the subject itself [13]
23 Structured Entity Model Using Predicate-Folding
Instead of folding all predicates together they might be grouped into multiple categoriesin order to preserve some of the original structure Prior work presents examples of suchgrouping based on the type of the predicates [3 8 16 23] or based on their manuallydetermined importance [5] We group RDF triples into four main predicate types pt fora given entity e as follows
ndash Name the subject is e the object is a literal and the predicate comes from a prede-fined list (eg foafname or rdfslabel) or ends with ldquoname ldquolabel or ldquotitle
ndash Attributes the subject is e the object is a literal and the predicate is not of typename
ndash OutRelations the subject is e and the object is a URI We resolve the URI byreplacing it with the name of the corresponding entity see Section 31 for details
ndash InRelations e stands as the object the subject entity URI is resolved
Figure 2(b) presents an example A separate language model θpte is estimated for each
predicate type from all predicates of that type (associated with the given entity)
P (t|θpte ) =
tf(t pt e) + μptP (t|θptc )
|pt e|+ μpt
(2)
On the Modeling of Entities for Ad-Hoc Entity Search 137
where tf(t pt e) is the sum of the term frequencies for t for all predicates of type pt as-sociated with e and |pt e| =
sumt tf(t pt e) Essentially we concatenate all text from
the predicates of type pt and then apply Dirichlet smoothing using a collection-widebackground model P (t|θpt
c ) (that is a maximum-likelihood estimate from all predi-cates of that type in the collection) The smoothing parameter μpt is set to the averagepredicate type representation length in the collection
The entity model is a linear mixture of the predicate type language models (P (t|θpte ))
weighted with the importance of that predicate type (P (pt))
P (t|θe) =sum
pt
P (t|θpte )P (pt) (3)
Figure 3 (Middle) illustrates the term generation process Viewing entities as documentsand predicate types as document fields this model is equivalent with the Mixture ofLanguage Models approach by Ogilvie and Callan [20]
3 Evaluation of Baseline Entity Models
In this section we first introduce our experimental setup then perform an evaluation ofour baseline entity models
31 Experimental Setup
We use the test suites of the 2010 and 2011 editions of the Semantic Search (SemSearch)Challenge [4 15] The task we address is ad-hoc entity search given a keyword querytargeting a particular entity provide a ranked list of relevant entities identified by theirURIs The data set queries and relevance assessments are publicly available1
Data set The data collection used is the Billion Triple Challenge 2009 dataset It wasmainly crawled during FebruaryMarch 2009 and comprises about 114 billion RDFstatements and describes entities from domains like dbpediaorg livejournalcom orgeonamesorg2 In our evaluations we considered the 500 most frequent predicates
Topics and relevance assessments There are two topic sets consisting of 92 and50 keyword queries for years 2010 and 2011 respectively The queries were sampledfrom web search engine logs Relevance judgments were obtained using Amazonrsquos Me-chanical Turk Human assessors were presented with a simplified HTML summary ofentities and had to judge relevance on a 3-point scale (excellent fair and irrelevant)
Evaluation metrics We use standard IR evaluation metrics Mean Average Pre-cision (MAP) Precision at rank 10 (P10) and Normalized Discounted CumulativeGain (NDCG)3 To check for significant differences between runs we use a two-tailedpaired t-test and write daggerDagger to denote significance at the 005001 levels respectively
Resource resolution If a relation (predicate targeted at a URI rather than a literalvalue) points to an entity within the collection we replace the URI with that entityrsquosname Otherwise we extract terms from the relative part of the URI
1 httpkmaifbkiteduwssemsearch10|112 httpvmlion25deriie3 Note that the two editions used different gain values for computing NDCG scores 3 and 2
(2010) vs 2 and 1 (2011) for excellent and fair respectively We use these values unchanged
138 R Neumayer K Balog and K Noslashrvaringg
Table 1 Retrieval results using the Unstructured Entity Model Significance is tested against theALL setting (first line) Best scores for each topic set are typeset boldface
2010 2011Predicate types MAP P10 NDCG MAP P10 NDCG
ALL 02069 03141 03827 02072 01880 02947Name-only 02054dagger 03043 03969 02004 01900 03097Attributes-only 02058Dagger 03391dagger 03915 02200dagger 01900 03330dagger
OutRelations-only 00866Dagger 01761Dagger 02185Dagger 00935Dagger 01020Dagger 01667Dagger
InRelations-only 00955Dagger 01967Dagger 02257Dagger 00689Dagger 00980Dagger 01540Dagger
ALL-but-Name 01568Dagger 02620Dagger 03210Dagger 01563Dagger 01440Dagger 02467Dagger
ALL-but-Attributes 01820Dagger 02859Dagger 03416Dagger 01637Dagger 01600Dagger 02419Dagger
ALL-but-OutRelations 02029Dagger 03109 03685Dagger 02002Dagger 01800 02826ALL-but-InRelations 02125 03196 03848 02037Dagger 01900 02826
32 Unstructured Entity Model
Recall that this model creates an unstructured entity representation by collapsing textassociated with the entity into one bag-of-words We perform three sets of experimentsand report the results in Table 1 First identified by the lsquoALLrsquo row we consider allfour predicate types Next shown in the lsquofield type-onlyrsquo rows we use only a singlepredicate type at a time Finally in the rows named lsquoALL-but-field typersquo we presentresults by omitting one of the types in turn
Our findings are as follows The absolute performance of the ALL model (that simplyuses all text associated with the entity) is remarkable on the 2010 topic set it outper-forms the best SemSearch 2010 submission (MAP=01919) [15] while on the 2011 setit would have ranked third (best was MAP=02346) [4] As for the individual predi-cate types Name and Attributes perform best with only minor differences between thetwo in fact either of these predicates types alone is on a par with the ALL model Thescores for incoming and outgoing relations are much lower Looking at the combina-tions of all but one predicate types Name contributes the most and Attributes comessecond without either the scores drop substantially Removing either incoming or out-going relations has hardly any overall impact in the lsquoALL-but-InRelationsrsquo 2010 casethe scores marginally improve but the difference is not statistically significant
33 Structured Entity Model
Our second baseline model employs a weighted combination of four language modelscorresponding to predicate types We consider three different configurations in Table 2(1) equal weights on all types (2) all weights allocated to Name and Attributes in equalproportion and (3) most of the weights assigned to Name and Attributes again butthis time taking relations too into account In the lack of training data or any back-ground knowledge about the collection or queries (1) is a natural choice (2) and (3)are motivated by the results from the previous subsection however knowing from thetask definition that each query targets a particular entity one could intuitively argue forsuch weight distributions Note that when a single predicate type is used the StructuredEntity Model is equivalent to the unstructured case (Table 1 middle block)
On the Modeling of Entities for Ad-Hoc Entity Search 139
Table 2 Retrieval results using Structured Entity Models Significance is tested against the ALLsetting of the Unstructured Entity Model (Table 1 first line) Best scores are typeset boldface
Pred type weights 2010 2011Name Attr OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02816Dagger 03989Dagger 04943Dagger 02605Dagger 02420Dagger 03966Dagger
5 5 02490Dagger 03663Dagger 04608Dagger 02506Dagger 02300Dagger 03845Dagger
35 35 15 15 02804Dagger 04043Dagger 04934Dagger 02614Dagger 02300Dagger 03968Dagger
All settings improve significantly and substantially over the unstructured baselineWe find somewhat surprisingly that the uniform weighting performs best of all thesenumbers are the highest that were ever reported for either topic sets (which are MAP=02705 for 2010 [5] and MAP=02346 for 2011 [4]) Even though Name and Attributeswere shown to be the two most lsquousefulrsquo predicate types using them without relationalinformation is clearly suboptimal (row 2 vs rows 1 and 3) The third setting (row 3)suggests that as long as all predicate types are considered the model is robust with re-spect to the actual weight distribution used We experimented with other configurationstoo but none of them improved significantly over the uniform weighting
4 Hierarchical Entity Model
In this section we introduce a novel entity modeling approach Before presenting ourproposal we briefly review the considerations leading to the choice of this particularmodel (1) In a heterogeneous environment the number of distinct predicates is hugeIt is not feasible to optimise their weights directly (because of the computational com-plexity and because of the enormous amounts of training material it would require)(2) Entities are sparse with respect to the different predicates ie most entities haveonly a handful of distinct predicates associated with them (3) As we have shown withthe Structured Entity Model folding predicates based on their type is a viable alterna-tive that works well in practice Nevertheless we need a different solution if we wishto preserve the semantics in the entity model ie keep individual predicates and theircontents accessible (and possibly exploit this information in the retrieval model) Userscan only be offered to make use of single predicates if they are preserved individu-ally such kind of faceted search may not improve effectiveness in the context of theSemantic Search Challenge but might be a requirement given from the user side
The main idea behind our model is to organise information belonging to a given en-tity into a hierarchy of two levels with predicate types (ie name attributes incomingand outgoing relations) on the first level and individual predicates of that type on thesecond level This preserves the original structure associated with the given entity andallows for setting the importance individual predicates conditioned on their type and onthe entity Formally this is expressed as follows
P (t|θe) =sum
pt
P (t|pt e)P (pt|e) (4)
=sum
pt
( sum
pisinpt
P (t|p pt)P (p|pt e))P (pt|e) (5)
140 R Neumayer K Balog and K Noslashrvaringg
e
ppt
t
ppt t
e
tpt
tpt
e
t
t
Fig 3 Graphical representations of entity models (Left) Unstructured Entity Model (Middle)Structured Entity Model using Predicate-folding (Right) Hierarchical Entity Model
The term generation process under this model is shown in Figure 3 (Right) Next wediscuss the three components from Eq 5 term generation (P (t|p pt)) predicate gen-eration (P (p|pt e)) and predicate type generation (P (pt|e))
Term Generation The importance of a term is jointly determined by the predicate inwhich it occurs as well as all other predicates of that type associated with the entity
P (t|p pt) = (1minus λ)P (t|p) + λP (t|θpte ) (6)
where P (t|p) is a maximum-likelihood estimate (ie the relative frequency of term t inpredicate p) and P (t|θpt
e ) is the Dirichlet-smoothed LM for predicate type pt estimatedusing Eq 2 The parameter λ isin [01] controls the influence of the predicate type modelFor the sake of simplicity we set λ to 05 in our experiments
Predicate Generation The importance of a given predicate p is conditioned on thetype of the predicate pt and the entity e P (p|pt e) We consider four natural options4
ndash Uniform All the predicates of the same type are treated equally importantP (p|pt e) = 1n(e pt) where n(e pt) is the number of predicates of type ptassigned to e5
ndash Length The probability mass is allocated to predicates proportional to their lengthP (p|pt e) = |p e||pt e| where |p e| and |pt e| are the lengths of p and pt re-spectively measured in the number of terms they contain
ndash Average length We use the average length of the predicate p in the collection rela-tive to the average length of all predicates of type pt
ndash Popularity We regard popular predicates more important where popularity is mea-sured in terms of the number of triples that have the given predicate P (p|pt e) =n(p)n(pt) where n(p) and n(pt) are the total number of triples in the collectionwith predicate p and predicate type pt respectively
4 It is by design that predicate importance is independent of the query this way other possiblycomputationally heavy alternatives for setting this probability could be estimated offline
5 Since predicates encoding the entity name are all equally important we do not vary theirimportance hence we always use the uniform distribution for pt = ldquonamerdquo
On the Modeling of Entities for Ad-Hoc Entity Search 141
Table 3 Retrieval results using Hierarchical Entity Models using a single predicate type
Predicate Predicate 2010 2011type weighting MAP P10 NDCG MAP P10 NDCG
Attributes Uniform 02350Dagger 03261 04403Dagger 02423Dagger 02140 03738Length 02116Dagger 02870Dagger 04149 02292Dagger 02060 03477AvgLength 02129Dagger 02859Dagger 04144 02287Dagger 02060 03511Popularity 02318Dagger 03109dagger 04385Dagger 02514Dagger 02140 03791
OutRelations Uniform 01185Dagger 01783 02607 01221Dagger 01220dagger 02046Dagger
Length 00915Dagger 01663 02122 00980Dagger 00920 01647AvgLength 00908Dagger 01533dagger 02131 00958Dagger 00940 01677Popularity 01067Dagger 01674 02439 01233Dagger 01260dagger 02070Dagger
InRelations Uniform 01073Dagger 02054dagger 02387 00800Dagger 01160dagger 01749Dagger
Length 00941Dagger 01793dagger 02188 00703 00940 01593AvgLength 00921Dagger 01696Dagger 02212 00776Dagger 00980 01751Dagger
Popularity 01117Dagger 02022 02452dagger 00891Dagger 01240dagger 01903Dagger
Table 4 Retrieval results using Hierarchical Entity Models and uniform term weighting Signif-icance is tested against the Structured Entity Model (corresponding row in Table 2) Best scoresfor each year are typeset boldface
Pred type 2010 2011Name Att OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02349Dagger 03261Dagger 04394Dagger 02423Dagger 02140Dagger 03738dagger
5 5 02242Dagger 03359Dagger 04125Dagger 02038Dagger 02000Dagger 03195Dagger
35 35 15 15 02561Dagger 03641Dagger 04614Dagger 02436Dagger 02240 03717dagger
Predicate Type Generation The model in Eq 5 allows us to set predicate type impor-tance on a per-entity basis To simplify matters however we make the conditional in-dependence assumption between predicate types and entities hence P (pt|e) = P (pt)This allows us to use estimation methods (or the actual values) from the StructuredEntity Model as this component is identical in the two models (cf Eq 3)
5 Evaluation of the Hierarchical Entity Model
In order to evaluate the hierarchical entity model we first show the results obtained foreach of the predicate types in turn analogous to the second block in Table 1 This is alsothe baseline we test against Table 3 presents the results for each of the predicate typesand different weighting models for individual predicates As indicated improvementsare significant in the majority of cases We show improvements over the results reportedfor the unstructured model in every category illustrating that the additional level ofnormalisation can cover the structure of the entities The lsquouniformrsquo weighting strategyperforms best for all types with lsquopopularityrsquo coming second Therefore we omit theresults for the remaining predicate weighting strategies in Table 4 where we show the
142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

On the Modeling of Entities for Ad-Hoc Entity Search 137
where tf(t pt e) is the sum of the term frequencies for t for all predicates of type pt as-sociated with e and |pt e| =
sumt tf(t pt e) Essentially we concatenate all text from
the predicates of type pt and then apply Dirichlet smoothing using a collection-widebackground model P (t|θpt
c ) (that is a maximum-likelihood estimate from all predi-cates of that type in the collection) The smoothing parameter μpt is set to the averagepredicate type representation length in the collection
The entity model is a linear mixture of the predicate type language models (P (t|θpte ))
weighted with the importance of that predicate type (P (pt))
P (t|θe) =sum
pt
P (t|θpte )P (pt) (3)
Figure 3 (Middle) illustrates the term generation process Viewing entities as documentsand predicate types as document fields this model is equivalent with the Mixture ofLanguage Models approach by Ogilvie and Callan [20]
3 Evaluation of Baseline Entity Models
In this section we first introduce our experimental setup then perform an evaluation ofour baseline entity models
31 Experimental Setup
We use the test suites of the 2010 and 2011 editions of the Semantic Search (SemSearch)Challenge [4 15] The task we address is ad-hoc entity search given a keyword querytargeting a particular entity provide a ranked list of relevant entities identified by theirURIs The data set queries and relevance assessments are publicly available1
Data set The data collection used is the Billion Triple Challenge 2009 dataset It wasmainly crawled during FebruaryMarch 2009 and comprises about 114 billion RDFstatements and describes entities from domains like dbpediaorg livejournalcom orgeonamesorg2 In our evaluations we considered the 500 most frequent predicates
Topics and relevance assessments There are two topic sets consisting of 92 and50 keyword queries for years 2010 and 2011 respectively The queries were sampledfrom web search engine logs Relevance judgments were obtained using Amazonrsquos Me-chanical Turk Human assessors were presented with a simplified HTML summary ofentities and had to judge relevance on a 3-point scale (excellent fair and irrelevant)
Evaluation metrics We use standard IR evaluation metrics Mean Average Pre-cision (MAP) Precision at rank 10 (P10) and Normalized Discounted CumulativeGain (NDCG)3 To check for significant differences between runs we use a two-tailedpaired t-test and write daggerDagger to denote significance at the 005001 levels respectively
Resource resolution If a relation (predicate targeted at a URI rather than a literalvalue) points to an entity within the collection we replace the URI with that entityrsquosname Otherwise we extract terms from the relative part of the URI
1 httpkmaifbkiteduwssemsearch10|112 httpvmlion25deriie3 Note that the two editions used different gain values for computing NDCG scores 3 and 2
(2010) vs 2 and 1 (2011) for excellent and fair respectively We use these values unchanged
138 R Neumayer K Balog and K Noslashrvaringg
Table 1 Retrieval results using the Unstructured Entity Model Significance is tested against theALL setting (first line) Best scores for each topic set are typeset boldface
2010 2011Predicate types MAP P10 NDCG MAP P10 NDCG
ALL 02069 03141 03827 02072 01880 02947Name-only 02054dagger 03043 03969 02004 01900 03097Attributes-only 02058Dagger 03391dagger 03915 02200dagger 01900 03330dagger
OutRelations-only 00866Dagger 01761Dagger 02185Dagger 00935Dagger 01020Dagger 01667Dagger
InRelations-only 00955Dagger 01967Dagger 02257Dagger 00689Dagger 00980Dagger 01540Dagger
ALL-but-Name 01568Dagger 02620Dagger 03210Dagger 01563Dagger 01440Dagger 02467Dagger
ALL-but-Attributes 01820Dagger 02859Dagger 03416Dagger 01637Dagger 01600Dagger 02419Dagger
ALL-but-OutRelations 02029Dagger 03109 03685Dagger 02002Dagger 01800 02826ALL-but-InRelations 02125 03196 03848 02037Dagger 01900 02826
32 Unstructured Entity Model
Recall that this model creates an unstructured entity representation by collapsing textassociated with the entity into one bag-of-words We perform three sets of experimentsand report the results in Table 1 First identified by the lsquoALLrsquo row we consider allfour predicate types Next shown in the lsquofield type-onlyrsquo rows we use only a singlepredicate type at a time Finally in the rows named lsquoALL-but-field typersquo we presentresults by omitting one of the types in turn
Our findings are as follows The absolute performance of the ALL model (that simplyuses all text associated with the entity) is remarkable on the 2010 topic set it outper-forms the best SemSearch 2010 submission (MAP=01919) [15] while on the 2011 setit would have ranked third (best was MAP=02346) [4] As for the individual predi-cate types Name and Attributes perform best with only minor differences between thetwo in fact either of these predicates types alone is on a par with the ALL model Thescores for incoming and outgoing relations are much lower Looking at the combina-tions of all but one predicate types Name contributes the most and Attributes comessecond without either the scores drop substantially Removing either incoming or out-going relations has hardly any overall impact in the lsquoALL-but-InRelationsrsquo 2010 casethe scores marginally improve but the difference is not statistically significant
33 Structured Entity Model
Our second baseline model employs a weighted combination of four language modelscorresponding to predicate types We consider three different configurations in Table 2(1) equal weights on all types (2) all weights allocated to Name and Attributes in equalproportion and (3) most of the weights assigned to Name and Attributes again butthis time taking relations too into account In the lack of training data or any back-ground knowledge about the collection or queries (1) is a natural choice (2) and (3)are motivated by the results from the previous subsection however knowing from thetask definition that each query targets a particular entity one could intuitively argue forsuch weight distributions Note that when a single predicate type is used the StructuredEntity Model is equivalent to the unstructured case (Table 1 middle block)
On the Modeling of Entities for Ad-Hoc Entity Search 139
Table 2 Retrieval results using Structured Entity Models Significance is tested against the ALLsetting of the Unstructured Entity Model (Table 1 first line) Best scores are typeset boldface
Pred type weights 2010 2011Name Attr OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02816Dagger 03989Dagger 04943Dagger 02605Dagger 02420Dagger 03966Dagger
5 5 02490Dagger 03663Dagger 04608Dagger 02506Dagger 02300Dagger 03845Dagger
35 35 15 15 02804Dagger 04043Dagger 04934Dagger 02614Dagger 02300Dagger 03968Dagger
All settings improve significantly and substantially over the unstructured baselineWe find somewhat surprisingly that the uniform weighting performs best of all thesenumbers are the highest that were ever reported for either topic sets (which are MAP=02705 for 2010 [5] and MAP=02346 for 2011 [4]) Even though Name and Attributeswere shown to be the two most lsquousefulrsquo predicate types using them without relationalinformation is clearly suboptimal (row 2 vs rows 1 and 3) The third setting (row 3)suggests that as long as all predicate types are considered the model is robust with re-spect to the actual weight distribution used We experimented with other configurationstoo but none of them improved significantly over the uniform weighting
4 Hierarchical Entity Model
In this section we introduce a novel entity modeling approach Before presenting ourproposal we briefly review the considerations leading to the choice of this particularmodel (1) In a heterogeneous environment the number of distinct predicates is hugeIt is not feasible to optimise their weights directly (because of the computational com-plexity and because of the enormous amounts of training material it would require)(2) Entities are sparse with respect to the different predicates ie most entities haveonly a handful of distinct predicates associated with them (3) As we have shown withthe Structured Entity Model folding predicates based on their type is a viable alterna-tive that works well in practice Nevertheless we need a different solution if we wishto preserve the semantics in the entity model ie keep individual predicates and theircontents accessible (and possibly exploit this information in the retrieval model) Userscan only be offered to make use of single predicates if they are preserved individu-ally such kind of faceted search may not improve effectiveness in the context of theSemantic Search Challenge but might be a requirement given from the user side
The main idea behind our model is to organise information belonging to a given en-tity into a hierarchy of two levels with predicate types (ie name attributes incomingand outgoing relations) on the first level and individual predicates of that type on thesecond level This preserves the original structure associated with the given entity andallows for setting the importance individual predicates conditioned on their type and onthe entity Formally this is expressed as follows
P (t|θe) =sum
pt
P (t|pt e)P (pt|e) (4)
=sum
pt
( sum
pisinpt
P (t|p pt)P (p|pt e))P (pt|e) (5)
140 R Neumayer K Balog and K Noslashrvaringg
e
ppt
t
ppt t
e
tpt
tpt
e
t
t
Fig 3 Graphical representations of entity models (Left) Unstructured Entity Model (Middle)Structured Entity Model using Predicate-folding (Right) Hierarchical Entity Model
The term generation process under this model is shown in Figure 3 (Right) Next wediscuss the three components from Eq 5 term generation (P (t|p pt)) predicate gen-eration (P (p|pt e)) and predicate type generation (P (pt|e))
Term Generation The importance of a term is jointly determined by the predicate inwhich it occurs as well as all other predicates of that type associated with the entity
P (t|p pt) = (1minus λ)P (t|p) + λP (t|θpte ) (6)
where P (t|p) is a maximum-likelihood estimate (ie the relative frequency of term t inpredicate p) and P (t|θpt
e ) is the Dirichlet-smoothed LM for predicate type pt estimatedusing Eq 2 The parameter λ isin [01] controls the influence of the predicate type modelFor the sake of simplicity we set λ to 05 in our experiments
Predicate Generation The importance of a given predicate p is conditioned on thetype of the predicate pt and the entity e P (p|pt e) We consider four natural options4
ndash Uniform All the predicates of the same type are treated equally importantP (p|pt e) = 1n(e pt) where n(e pt) is the number of predicates of type ptassigned to e5
ndash Length The probability mass is allocated to predicates proportional to their lengthP (p|pt e) = |p e||pt e| where |p e| and |pt e| are the lengths of p and pt re-spectively measured in the number of terms they contain
ndash Average length We use the average length of the predicate p in the collection rela-tive to the average length of all predicates of type pt
ndash Popularity We regard popular predicates more important where popularity is mea-sured in terms of the number of triples that have the given predicate P (p|pt e) =n(p)n(pt) where n(p) and n(pt) are the total number of triples in the collectionwith predicate p and predicate type pt respectively
4 It is by design that predicate importance is independent of the query this way other possiblycomputationally heavy alternatives for setting this probability could be estimated offline
5 Since predicates encoding the entity name are all equally important we do not vary theirimportance hence we always use the uniform distribution for pt = ldquonamerdquo
On the Modeling of Entities for Ad-Hoc Entity Search 141
Table 3 Retrieval results using Hierarchical Entity Models using a single predicate type
Predicate Predicate 2010 2011type weighting MAP P10 NDCG MAP P10 NDCG
Attributes Uniform 02350Dagger 03261 04403Dagger 02423Dagger 02140 03738Length 02116Dagger 02870Dagger 04149 02292Dagger 02060 03477AvgLength 02129Dagger 02859Dagger 04144 02287Dagger 02060 03511Popularity 02318Dagger 03109dagger 04385Dagger 02514Dagger 02140 03791
OutRelations Uniform 01185Dagger 01783 02607 01221Dagger 01220dagger 02046Dagger
Length 00915Dagger 01663 02122 00980Dagger 00920 01647AvgLength 00908Dagger 01533dagger 02131 00958Dagger 00940 01677Popularity 01067Dagger 01674 02439 01233Dagger 01260dagger 02070Dagger
InRelations Uniform 01073Dagger 02054dagger 02387 00800Dagger 01160dagger 01749Dagger
Length 00941Dagger 01793dagger 02188 00703 00940 01593AvgLength 00921Dagger 01696Dagger 02212 00776Dagger 00980 01751Dagger
Popularity 01117Dagger 02022 02452dagger 00891Dagger 01240dagger 01903Dagger
Table 4 Retrieval results using Hierarchical Entity Models and uniform term weighting Signif-icance is tested against the Structured Entity Model (corresponding row in Table 2) Best scoresfor each year are typeset boldface
Pred type 2010 2011Name Att OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02349Dagger 03261Dagger 04394Dagger 02423Dagger 02140Dagger 03738dagger
5 5 02242Dagger 03359Dagger 04125Dagger 02038Dagger 02000Dagger 03195Dagger
35 35 15 15 02561Dagger 03641Dagger 04614Dagger 02436Dagger 02240 03717dagger
Predicate Type Generation The model in Eq 5 allows us to set predicate type impor-tance on a per-entity basis To simplify matters however we make the conditional in-dependence assumption between predicate types and entities hence P (pt|e) = P (pt)This allows us to use estimation methods (or the actual values) from the StructuredEntity Model as this component is identical in the two models (cf Eq 3)
5 Evaluation of the Hierarchical Entity Model
In order to evaluate the hierarchical entity model we first show the results obtained foreach of the predicate types in turn analogous to the second block in Table 1 This is alsothe baseline we test against Table 3 presents the results for each of the predicate typesand different weighting models for individual predicates As indicated improvementsare significant in the majority of cases We show improvements over the results reportedfor the unstructured model in every category illustrating that the additional level ofnormalisation can cover the structure of the entities The lsquouniformrsquo weighting strategyperforms best for all types with lsquopopularityrsquo coming second Therefore we omit theresults for the remaining predicate weighting strategies in Table 4 where we show the
142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)
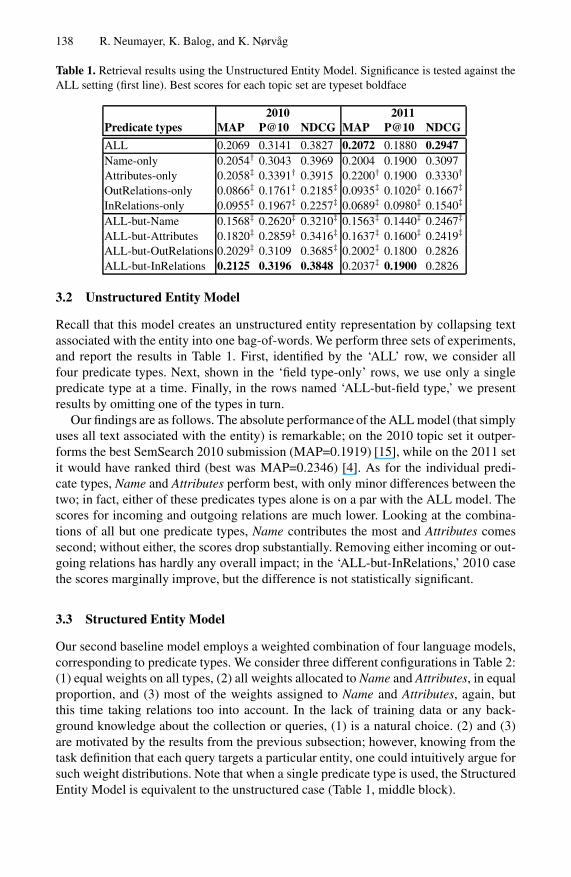
138 R Neumayer K Balog and K Noslashrvaringg
Table 1 Retrieval results using the Unstructured Entity Model Significance is tested against theALL setting (first line) Best scores for each topic set are typeset boldface
2010 2011Predicate types MAP P10 NDCG MAP P10 NDCG
ALL 02069 03141 03827 02072 01880 02947Name-only 02054dagger 03043 03969 02004 01900 03097Attributes-only 02058Dagger 03391dagger 03915 02200dagger 01900 03330dagger
OutRelations-only 00866Dagger 01761Dagger 02185Dagger 00935Dagger 01020Dagger 01667Dagger
InRelations-only 00955Dagger 01967Dagger 02257Dagger 00689Dagger 00980Dagger 01540Dagger
ALL-but-Name 01568Dagger 02620Dagger 03210Dagger 01563Dagger 01440Dagger 02467Dagger
ALL-but-Attributes 01820Dagger 02859Dagger 03416Dagger 01637Dagger 01600Dagger 02419Dagger
ALL-but-OutRelations 02029Dagger 03109 03685Dagger 02002Dagger 01800 02826ALL-but-InRelations 02125 03196 03848 02037Dagger 01900 02826
32 Unstructured Entity Model
Recall that this model creates an unstructured entity representation by collapsing textassociated with the entity into one bag-of-words We perform three sets of experimentsand report the results in Table 1 First identified by the lsquoALLrsquo row we consider allfour predicate types Next shown in the lsquofield type-onlyrsquo rows we use only a singlepredicate type at a time Finally in the rows named lsquoALL-but-field typersquo we presentresults by omitting one of the types in turn
Our findings are as follows The absolute performance of the ALL model (that simplyuses all text associated with the entity) is remarkable on the 2010 topic set it outper-forms the best SemSearch 2010 submission (MAP=01919) [15] while on the 2011 setit would have ranked third (best was MAP=02346) [4] As for the individual predi-cate types Name and Attributes perform best with only minor differences between thetwo in fact either of these predicates types alone is on a par with the ALL model Thescores for incoming and outgoing relations are much lower Looking at the combina-tions of all but one predicate types Name contributes the most and Attributes comessecond without either the scores drop substantially Removing either incoming or out-going relations has hardly any overall impact in the lsquoALL-but-InRelationsrsquo 2010 casethe scores marginally improve but the difference is not statistically significant
33 Structured Entity Model
Our second baseline model employs a weighted combination of four language modelscorresponding to predicate types We consider three different configurations in Table 2(1) equal weights on all types (2) all weights allocated to Name and Attributes in equalproportion and (3) most of the weights assigned to Name and Attributes again butthis time taking relations too into account In the lack of training data or any back-ground knowledge about the collection or queries (1) is a natural choice (2) and (3)are motivated by the results from the previous subsection however knowing from thetask definition that each query targets a particular entity one could intuitively argue forsuch weight distributions Note that when a single predicate type is used the StructuredEntity Model is equivalent to the unstructured case (Table 1 middle block)
On the Modeling of Entities for Ad-Hoc Entity Search 139
Table 2 Retrieval results using Structured Entity Models Significance is tested against the ALLsetting of the Unstructured Entity Model (Table 1 first line) Best scores are typeset boldface
Pred type weights 2010 2011Name Attr OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02816Dagger 03989Dagger 04943Dagger 02605Dagger 02420Dagger 03966Dagger
5 5 02490Dagger 03663Dagger 04608Dagger 02506Dagger 02300Dagger 03845Dagger
35 35 15 15 02804Dagger 04043Dagger 04934Dagger 02614Dagger 02300Dagger 03968Dagger
All settings improve significantly and substantially over the unstructured baselineWe find somewhat surprisingly that the uniform weighting performs best of all thesenumbers are the highest that were ever reported for either topic sets (which are MAP=02705 for 2010 [5] and MAP=02346 for 2011 [4]) Even though Name and Attributeswere shown to be the two most lsquousefulrsquo predicate types using them without relationalinformation is clearly suboptimal (row 2 vs rows 1 and 3) The third setting (row 3)suggests that as long as all predicate types are considered the model is robust with re-spect to the actual weight distribution used We experimented with other configurationstoo but none of them improved significantly over the uniform weighting
4 Hierarchical Entity Model
In this section we introduce a novel entity modeling approach Before presenting ourproposal we briefly review the considerations leading to the choice of this particularmodel (1) In a heterogeneous environment the number of distinct predicates is hugeIt is not feasible to optimise their weights directly (because of the computational com-plexity and because of the enormous amounts of training material it would require)(2) Entities are sparse with respect to the different predicates ie most entities haveonly a handful of distinct predicates associated with them (3) As we have shown withthe Structured Entity Model folding predicates based on their type is a viable alterna-tive that works well in practice Nevertheless we need a different solution if we wishto preserve the semantics in the entity model ie keep individual predicates and theircontents accessible (and possibly exploit this information in the retrieval model) Userscan only be offered to make use of single predicates if they are preserved individu-ally such kind of faceted search may not improve effectiveness in the context of theSemantic Search Challenge but might be a requirement given from the user side
The main idea behind our model is to organise information belonging to a given en-tity into a hierarchy of two levels with predicate types (ie name attributes incomingand outgoing relations) on the first level and individual predicates of that type on thesecond level This preserves the original structure associated with the given entity andallows for setting the importance individual predicates conditioned on their type and onthe entity Formally this is expressed as follows
P (t|θe) =sum
pt
P (t|pt e)P (pt|e) (4)
=sum
pt
( sum
pisinpt
P (t|p pt)P (p|pt e))P (pt|e) (5)
140 R Neumayer K Balog and K Noslashrvaringg
e
ppt
t
ppt t
e
tpt
tpt
e
t
t
Fig 3 Graphical representations of entity models (Left) Unstructured Entity Model (Middle)Structured Entity Model using Predicate-folding (Right) Hierarchical Entity Model
The term generation process under this model is shown in Figure 3 (Right) Next wediscuss the three components from Eq 5 term generation (P (t|p pt)) predicate gen-eration (P (p|pt e)) and predicate type generation (P (pt|e))
Term Generation The importance of a term is jointly determined by the predicate inwhich it occurs as well as all other predicates of that type associated with the entity
P (t|p pt) = (1minus λ)P (t|p) + λP (t|θpte ) (6)
where P (t|p) is a maximum-likelihood estimate (ie the relative frequency of term t inpredicate p) and P (t|θpt
e ) is the Dirichlet-smoothed LM for predicate type pt estimatedusing Eq 2 The parameter λ isin [01] controls the influence of the predicate type modelFor the sake of simplicity we set λ to 05 in our experiments
Predicate Generation The importance of a given predicate p is conditioned on thetype of the predicate pt and the entity e P (p|pt e) We consider four natural options4
ndash Uniform All the predicates of the same type are treated equally importantP (p|pt e) = 1n(e pt) where n(e pt) is the number of predicates of type ptassigned to e5
ndash Length The probability mass is allocated to predicates proportional to their lengthP (p|pt e) = |p e||pt e| where |p e| and |pt e| are the lengths of p and pt re-spectively measured in the number of terms they contain
ndash Average length We use the average length of the predicate p in the collection rela-tive to the average length of all predicates of type pt
ndash Popularity We regard popular predicates more important where popularity is mea-sured in terms of the number of triples that have the given predicate P (p|pt e) =n(p)n(pt) where n(p) and n(pt) are the total number of triples in the collectionwith predicate p and predicate type pt respectively
4 It is by design that predicate importance is independent of the query this way other possiblycomputationally heavy alternatives for setting this probability could be estimated offline
5 Since predicates encoding the entity name are all equally important we do not vary theirimportance hence we always use the uniform distribution for pt = ldquonamerdquo
On the Modeling of Entities for Ad-Hoc Entity Search 141
Table 3 Retrieval results using Hierarchical Entity Models using a single predicate type
Predicate Predicate 2010 2011type weighting MAP P10 NDCG MAP P10 NDCG
Attributes Uniform 02350Dagger 03261 04403Dagger 02423Dagger 02140 03738Length 02116Dagger 02870Dagger 04149 02292Dagger 02060 03477AvgLength 02129Dagger 02859Dagger 04144 02287Dagger 02060 03511Popularity 02318Dagger 03109dagger 04385Dagger 02514Dagger 02140 03791
OutRelations Uniform 01185Dagger 01783 02607 01221Dagger 01220dagger 02046Dagger
Length 00915Dagger 01663 02122 00980Dagger 00920 01647AvgLength 00908Dagger 01533dagger 02131 00958Dagger 00940 01677Popularity 01067Dagger 01674 02439 01233Dagger 01260dagger 02070Dagger
InRelations Uniform 01073Dagger 02054dagger 02387 00800Dagger 01160dagger 01749Dagger
Length 00941Dagger 01793dagger 02188 00703 00940 01593AvgLength 00921Dagger 01696Dagger 02212 00776Dagger 00980 01751Dagger
Popularity 01117Dagger 02022 02452dagger 00891Dagger 01240dagger 01903Dagger
Table 4 Retrieval results using Hierarchical Entity Models and uniform term weighting Signif-icance is tested against the Structured Entity Model (corresponding row in Table 2) Best scoresfor each year are typeset boldface
Pred type 2010 2011Name Att OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02349Dagger 03261Dagger 04394Dagger 02423Dagger 02140Dagger 03738dagger
5 5 02242Dagger 03359Dagger 04125Dagger 02038Dagger 02000Dagger 03195Dagger
35 35 15 15 02561Dagger 03641Dagger 04614Dagger 02436Dagger 02240 03717dagger
Predicate Type Generation The model in Eq 5 allows us to set predicate type impor-tance on a per-entity basis To simplify matters however we make the conditional in-dependence assumption between predicate types and entities hence P (pt|e) = P (pt)This allows us to use estimation methods (or the actual values) from the StructuredEntity Model as this component is identical in the two models (cf Eq 3)
5 Evaluation of the Hierarchical Entity Model
In order to evaluate the hierarchical entity model we first show the results obtained foreach of the predicate types in turn analogous to the second block in Table 1 This is alsothe baseline we test against Table 3 presents the results for each of the predicate typesand different weighting models for individual predicates As indicated improvementsare significant in the majority of cases We show improvements over the results reportedfor the unstructured model in every category illustrating that the additional level ofnormalisation can cover the structure of the entities The lsquouniformrsquo weighting strategyperforms best for all types with lsquopopularityrsquo coming second Therefore we omit theresults for the remaining predicate weighting strategies in Table 4 where we show the
142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

On the Modeling of Entities for Ad-Hoc Entity Search 139
Table 2 Retrieval results using Structured Entity Models Significance is tested against the ALLsetting of the Unstructured Entity Model (Table 1 first line) Best scores are typeset boldface
Pred type weights 2010 2011Name Attr OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02816Dagger 03989Dagger 04943Dagger 02605Dagger 02420Dagger 03966Dagger
5 5 02490Dagger 03663Dagger 04608Dagger 02506Dagger 02300Dagger 03845Dagger
35 35 15 15 02804Dagger 04043Dagger 04934Dagger 02614Dagger 02300Dagger 03968Dagger
All settings improve significantly and substantially over the unstructured baselineWe find somewhat surprisingly that the uniform weighting performs best of all thesenumbers are the highest that were ever reported for either topic sets (which are MAP=02705 for 2010 [5] and MAP=02346 for 2011 [4]) Even though Name and Attributeswere shown to be the two most lsquousefulrsquo predicate types using them without relationalinformation is clearly suboptimal (row 2 vs rows 1 and 3) The third setting (row 3)suggests that as long as all predicate types are considered the model is robust with re-spect to the actual weight distribution used We experimented with other configurationstoo but none of them improved significantly over the uniform weighting
4 Hierarchical Entity Model
In this section we introduce a novel entity modeling approach Before presenting ourproposal we briefly review the considerations leading to the choice of this particularmodel (1) In a heterogeneous environment the number of distinct predicates is hugeIt is not feasible to optimise their weights directly (because of the computational com-plexity and because of the enormous amounts of training material it would require)(2) Entities are sparse with respect to the different predicates ie most entities haveonly a handful of distinct predicates associated with them (3) As we have shown withthe Structured Entity Model folding predicates based on their type is a viable alterna-tive that works well in practice Nevertheless we need a different solution if we wishto preserve the semantics in the entity model ie keep individual predicates and theircontents accessible (and possibly exploit this information in the retrieval model) Userscan only be offered to make use of single predicates if they are preserved individu-ally such kind of faceted search may not improve effectiveness in the context of theSemantic Search Challenge but might be a requirement given from the user side
The main idea behind our model is to organise information belonging to a given en-tity into a hierarchy of two levels with predicate types (ie name attributes incomingand outgoing relations) on the first level and individual predicates of that type on thesecond level This preserves the original structure associated with the given entity andallows for setting the importance individual predicates conditioned on their type and onthe entity Formally this is expressed as follows
P (t|θe) =sum
pt
P (t|pt e)P (pt|e) (4)
=sum
pt
( sum
pisinpt
P (t|p pt)P (p|pt e))P (pt|e) (5)
140 R Neumayer K Balog and K Noslashrvaringg
e
ppt
t
ppt t
e
tpt
tpt
e
t
t
Fig 3 Graphical representations of entity models (Left) Unstructured Entity Model (Middle)Structured Entity Model using Predicate-folding (Right) Hierarchical Entity Model
The term generation process under this model is shown in Figure 3 (Right) Next wediscuss the three components from Eq 5 term generation (P (t|p pt)) predicate gen-eration (P (p|pt e)) and predicate type generation (P (pt|e))
Term Generation The importance of a term is jointly determined by the predicate inwhich it occurs as well as all other predicates of that type associated with the entity
P (t|p pt) = (1minus λ)P (t|p) + λP (t|θpte ) (6)
where P (t|p) is a maximum-likelihood estimate (ie the relative frequency of term t inpredicate p) and P (t|θpt
e ) is the Dirichlet-smoothed LM for predicate type pt estimatedusing Eq 2 The parameter λ isin [01] controls the influence of the predicate type modelFor the sake of simplicity we set λ to 05 in our experiments
Predicate Generation The importance of a given predicate p is conditioned on thetype of the predicate pt and the entity e P (p|pt e) We consider four natural options4
ndash Uniform All the predicates of the same type are treated equally importantP (p|pt e) = 1n(e pt) where n(e pt) is the number of predicates of type ptassigned to e5
ndash Length The probability mass is allocated to predicates proportional to their lengthP (p|pt e) = |p e||pt e| where |p e| and |pt e| are the lengths of p and pt re-spectively measured in the number of terms they contain
ndash Average length We use the average length of the predicate p in the collection rela-tive to the average length of all predicates of type pt
ndash Popularity We regard popular predicates more important where popularity is mea-sured in terms of the number of triples that have the given predicate P (p|pt e) =n(p)n(pt) where n(p) and n(pt) are the total number of triples in the collectionwith predicate p and predicate type pt respectively
4 It is by design that predicate importance is independent of the query this way other possiblycomputationally heavy alternatives for setting this probability could be estimated offline
5 Since predicates encoding the entity name are all equally important we do not vary theirimportance hence we always use the uniform distribution for pt = ldquonamerdquo
On the Modeling of Entities for Ad-Hoc Entity Search 141
Table 3 Retrieval results using Hierarchical Entity Models using a single predicate type
Predicate Predicate 2010 2011type weighting MAP P10 NDCG MAP P10 NDCG
Attributes Uniform 02350Dagger 03261 04403Dagger 02423Dagger 02140 03738Length 02116Dagger 02870Dagger 04149 02292Dagger 02060 03477AvgLength 02129Dagger 02859Dagger 04144 02287Dagger 02060 03511Popularity 02318Dagger 03109dagger 04385Dagger 02514Dagger 02140 03791
OutRelations Uniform 01185Dagger 01783 02607 01221Dagger 01220dagger 02046Dagger
Length 00915Dagger 01663 02122 00980Dagger 00920 01647AvgLength 00908Dagger 01533dagger 02131 00958Dagger 00940 01677Popularity 01067Dagger 01674 02439 01233Dagger 01260dagger 02070Dagger
InRelations Uniform 01073Dagger 02054dagger 02387 00800Dagger 01160dagger 01749Dagger
Length 00941Dagger 01793dagger 02188 00703 00940 01593AvgLength 00921Dagger 01696Dagger 02212 00776Dagger 00980 01751Dagger
Popularity 01117Dagger 02022 02452dagger 00891Dagger 01240dagger 01903Dagger
Table 4 Retrieval results using Hierarchical Entity Models and uniform term weighting Signif-icance is tested against the Structured Entity Model (corresponding row in Table 2) Best scoresfor each year are typeset boldface
Pred type 2010 2011Name Att OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02349Dagger 03261Dagger 04394Dagger 02423Dagger 02140Dagger 03738dagger
5 5 02242Dagger 03359Dagger 04125Dagger 02038Dagger 02000Dagger 03195Dagger
35 35 15 15 02561Dagger 03641Dagger 04614Dagger 02436Dagger 02240 03717dagger
Predicate Type Generation The model in Eq 5 allows us to set predicate type impor-tance on a per-entity basis To simplify matters however we make the conditional in-dependence assumption between predicate types and entities hence P (pt|e) = P (pt)This allows us to use estimation methods (or the actual values) from the StructuredEntity Model as this component is identical in the two models (cf Eq 3)
5 Evaluation of the Hierarchical Entity Model
In order to evaluate the hierarchical entity model we first show the results obtained foreach of the predicate types in turn analogous to the second block in Table 1 This is alsothe baseline we test against Table 3 presents the results for each of the predicate typesand different weighting models for individual predicates As indicated improvementsare significant in the majority of cases We show improvements over the results reportedfor the unstructured model in every category illustrating that the additional level ofnormalisation can cover the structure of the entities The lsquouniformrsquo weighting strategyperforms best for all types with lsquopopularityrsquo coming second Therefore we omit theresults for the remaining predicate weighting strategies in Table 4 where we show the
142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

140 R Neumayer K Balog and K Noslashrvaringg
e
ppt
t
ppt t
e
tpt
tpt
e
t
t
Fig 3 Graphical representations of entity models (Left) Unstructured Entity Model (Middle)Structured Entity Model using Predicate-folding (Right) Hierarchical Entity Model
The term generation process under this model is shown in Figure 3 (Right) Next wediscuss the three components from Eq 5 term generation (P (t|p pt)) predicate gen-eration (P (p|pt e)) and predicate type generation (P (pt|e))
Term Generation The importance of a term is jointly determined by the predicate inwhich it occurs as well as all other predicates of that type associated with the entity
P (t|p pt) = (1minus λ)P (t|p) + λP (t|θpte ) (6)
where P (t|p) is a maximum-likelihood estimate (ie the relative frequency of term t inpredicate p) and P (t|θpt
e ) is the Dirichlet-smoothed LM for predicate type pt estimatedusing Eq 2 The parameter λ isin [01] controls the influence of the predicate type modelFor the sake of simplicity we set λ to 05 in our experiments
Predicate Generation The importance of a given predicate p is conditioned on thetype of the predicate pt and the entity e P (p|pt e) We consider four natural options4
ndash Uniform All the predicates of the same type are treated equally importantP (p|pt e) = 1n(e pt) where n(e pt) is the number of predicates of type ptassigned to e5
ndash Length The probability mass is allocated to predicates proportional to their lengthP (p|pt e) = |p e||pt e| where |p e| and |pt e| are the lengths of p and pt re-spectively measured in the number of terms they contain
ndash Average length We use the average length of the predicate p in the collection rela-tive to the average length of all predicates of type pt
ndash Popularity We regard popular predicates more important where popularity is mea-sured in terms of the number of triples that have the given predicate P (p|pt e) =n(p)n(pt) where n(p) and n(pt) are the total number of triples in the collectionwith predicate p and predicate type pt respectively
4 It is by design that predicate importance is independent of the query this way other possiblycomputationally heavy alternatives for setting this probability could be estimated offline
5 Since predicates encoding the entity name are all equally important we do not vary theirimportance hence we always use the uniform distribution for pt = ldquonamerdquo
On the Modeling of Entities for Ad-Hoc Entity Search 141
Table 3 Retrieval results using Hierarchical Entity Models using a single predicate type
Predicate Predicate 2010 2011type weighting MAP P10 NDCG MAP P10 NDCG
Attributes Uniform 02350Dagger 03261 04403Dagger 02423Dagger 02140 03738Length 02116Dagger 02870Dagger 04149 02292Dagger 02060 03477AvgLength 02129Dagger 02859Dagger 04144 02287Dagger 02060 03511Popularity 02318Dagger 03109dagger 04385Dagger 02514Dagger 02140 03791
OutRelations Uniform 01185Dagger 01783 02607 01221Dagger 01220dagger 02046Dagger
Length 00915Dagger 01663 02122 00980Dagger 00920 01647AvgLength 00908Dagger 01533dagger 02131 00958Dagger 00940 01677Popularity 01067Dagger 01674 02439 01233Dagger 01260dagger 02070Dagger
InRelations Uniform 01073Dagger 02054dagger 02387 00800Dagger 01160dagger 01749Dagger
Length 00941Dagger 01793dagger 02188 00703 00940 01593AvgLength 00921Dagger 01696Dagger 02212 00776Dagger 00980 01751Dagger
Popularity 01117Dagger 02022 02452dagger 00891Dagger 01240dagger 01903Dagger
Table 4 Retrieval results using Hierarchical Entity Models and uniform term weighting Signif-icance is tested against the Structured Entity Model (corresponding row in Table 2) Best scoresfor each year are typeset boldface
Pred type 2010 2011Name Att OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02349Dagger 03261Dagger 04394Dagger 02423Dagger 02140Dagger 03738dagger
5 5 02242Dagger 03359Dagger 04125Dagger 02038Dagger 02000Dagger 03195Dagger
35 35 15 15 02561Dagger 03641Dagger 04614Dagger 02436Dagger 02240 03717dagger
Predicate Type Generation The model in Eq 5 allows us to set predicate type impor-tance on a per-entity basis To simplify matters however we make the conditional in-dependence assumption between predicate types and entities hence P (pt|e) = P (pt)This allows us to use estimation methods (or the actual values) from the StructuredEntity Model as this component is identical in the two models (cf Eq 3)
5 Evaluation of the Hierarchical Entity Model
In order to evaluate the hierarchical entity model we first show the results obtained foreach of the predicate types in turn analogous to the second block in Table 1 This is alsothe baseline we test against Table 3 presents the results for each of the predicate typesand different weighting models for individual predicates As indicated improvementsare significant in the majority of cases We show improvements over the results reportedfor the unstructured model in every category illustrating that the additional level ofnormalisation can cover the structure of the entities The lsquouniformrsquo weighting strategyperforms best for all types with lsquopopularityrsquo coming second Therefore we omit theresults for the remaining predicate weighting strategies in Table 4 where we show the
142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)
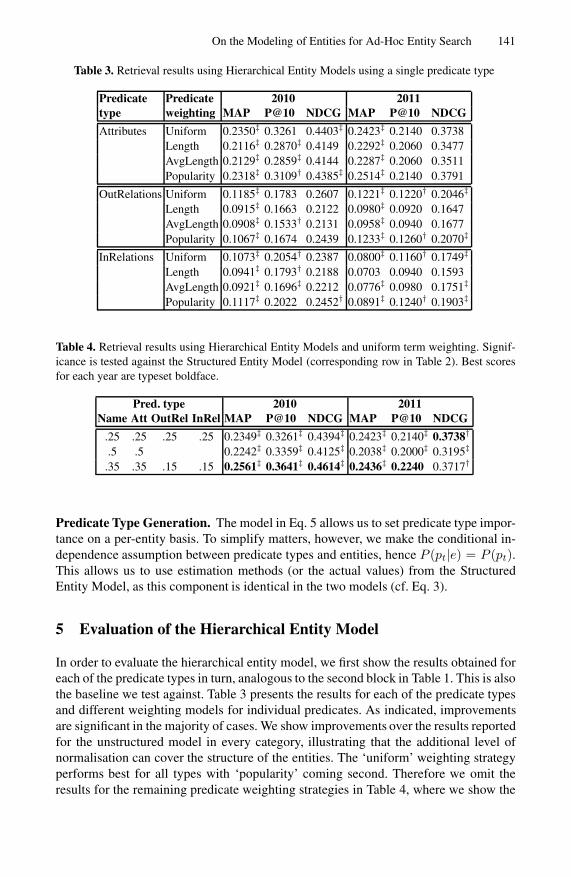
On the Modeling of Entities for Ad-Hoc Entity Search 141
Table 3 Retrieval results using Hierarchical Entity Models using a single predicate type
Predicate Predicate 2010 2011type weighting MAP P10 NDCG MAP P10 NDCG
Attributes Uniform 02350Dagger 03261 04403Dagger 02423Dagger 02140 03738Length 02116Dagger 02870Dagger 04149 02292Dagger 02060 03477AvgLength 02129Dagger 02859Dagger 04144 02287Dagger 02060 03511Popularity 02318Dagger 03109dagger 04385Dagger 02514Dagger 02140 03791
OutRelations Uniform 01185Dagger 01783 02607 01221Dagger 01220dagger 02046Dagger
Length 00915Dagger 01663 02122 00980Dagger 00920 01647AvgLength 00908Dagger 01533dagger 02131 00958Dagger 00940 01677Popularity 01067Dagger 01674 02439 01233Dagger 01260dagger 02070Dagger
InRelations Uniform 01073Dagger 02054dagger 02387 00800Dagger 01160dagger 01749Dagger
Length 00941Dagger 01793dagger 02188 00703 00940 01593AvgLength 00921Dagger 01696Dagger 02212 00776Dagger 00980 01751Dagger
Popularity 01117Dagger 02022 02452dagger 00891Dagger 01240dagger 01903Dagger
Table 4 Retrieval results using Hierarchical Entity Models and uniform term weighting Signif-icance is tested against the Structured Entity Model (corresponding row in Table 2) Best scoresfor each year are typeset boldface
Pred type 2010 2011Name Att OutRel InRel MAP P10 NDCG MAP P10 NDCG
25 25 25 25 02349Dagger 03261Dagger 04394Dagger 02423Dagger 02140Dagger 03738dagger
5 5 02242Dagger 03359Dagger 04125Dagger 02038Dagger 02000Dagger 03195Dagger
35 35 15 15 02561Dagger 03641Dagger 04614Dagger 02436Dagger 02240 03717dagger
Predicate Type Generation The model in Eq 5 allows us to set predicate type impor-tance on a per-entity basis To simplify matters however we make the conditional in-dependence assumption between predicate types and entities hence P (pt|e) = P (pt)This allows us to use estimation methods (or the actual values) from the StructuredEntity Model as this component is identical in the two models (cf Eq 3)
5 Evaluation of the Hierarchical Entity Model
In order to evaluate the hierarchical entity model we first show the results obtained foreach of the predicate types in turn analogous to the second block in Table 1 This is alsothe baseline we test against Table 3 presents the results for each of the predicate typesand different weighting models for individual predicates As indicated improvementsare significant in the majority of cases We show improvements over the results reportedfor the unstructured model in every category illustrating that the additional level ofnormalisation can cover the structure of the entities The lsquouniformrsquo weighting strategyperforms best for all types with lsquopopularityrsquo coming second Therefore we omit theresults for the remaining predicate weighting strategies in Table 4 where we show the
142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

142 R Neumayer K Balog and K Noslashrvaringg
effect of using multiple field types and combine them We can not improve results herewhich we attribute to a certain inability of the model to exploit the semantic informationThis is somewhat surprising since we showed we can cover for individual predicatetypes and as such can contribute to better predicate modeling (as shown in Table 3)
6 Related Work
It has been shown that that over 40 of Web search queries target entities [24] Fol-lowing up on this trend a range of commercial providers now support entity-orientedsearch dealing with a broad range of entity types such as people companies servicesor locations This shows that the problem studied in this paper searching entities instructured semantic data ldquohas direct relevance to the operation of Web search engineswhich increasingly incorporate structured data in their search results pages [5]
Research on entity retrieval in IR got a major boost with the introduction of theexpert finding task at the TREC Enterprise track in 2005 [7] The task requests a rankedlist of experts returned for a given query topic A separate Entity search track started atTREC in 2009 and defined the related entity finding task return a ranked list of entities(of a specified type) that engage in a given relationship with a given source entity [2]Common to both tasks is that entities are not directly represented as retrievable unitsone of the challenges is to recognise entities in the document collection then aggregatethe textual information associated with them for the purpose of retrieval [1] INEX hasalso featured an Entity Ranking track between 2007 and 2009 [9 11] There entitiesare represented by their corresponding Wikipedia article The availability of categoryinformation and the rich link structure of Wikipedia clearly distinguishes this task fromplain document retrieval [12]
The ad-hoc entity retrieval task over RDF data we studied in this paper was pro-posed and formalised in [24] This task bears some resemblance to keyword search inrelational databases [22] and to XML retrieval [17] The former has no direct relevanceas methods developed for structured databases are not directly applicable to RDF dataAs for the latter Kim et al [18] presented a probabilistic retrieval model for semi-structured data (PRM-S) that allows for a weighted mapping of query terms to (entity)attributes Dalton and Huston [8] tested this model on the SemSearch 2010 data setand found that a key limitation of the PRM-S approach is that ldquoit assumes a collectionwith a single or very few clearly defined entity types Unlike the IMDB and Monstercollections used in [18] the BTC-2009 corpus is very heterogeneous Additionally twospecific problems were identified (1) computing the query term to attribute mappingprobabilities suffers from attribute sparsity and (2) mapping probabilities are estimatedfor each query term independently Finally Ogilvie and Callan [21] considered model-ing documents with a hierarchical structure for XML retrieval Our Hierarchical EntityModel has been developed in a similar spirit but hierarchy in [21] is defined by doc-ument structure (markup) while in our case it is organised around semantic relation-ships Both works estimate language models on the component levels and incorporateevidence from multiple levels within the hierarchy but the task addressed in [21] (XMLcomponent retrieval) and hence the actual models are very different from ours
On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

On the Modeling of Entities for Ad-Hoc Entity Search 143
7 Discussion and Conclusions
We have addressed the task of ad-hoc entity retrieval in the Web of Data returning aranked list of RDF resources that represent an entity described in the keyword queryThe main research question we have been concerned with is the modeling of entitiesdescribed in the form of subject-predicate-object triples for text-based retrieval Priorwork suggested two main directions (1) collapsing all text associated with the entityinto a single flat-text representation and then using standard IR models for documentretrieval and (2) grouping predicates together into a small number of categories repre-senting them as document fields and applying fielded extensions of document retrievalmethods We formalised both strategies using generative language models and termedthem Unstructured Entity Model (UEM) and Structured Entity Model (SEM) Exper-imental evaluation was performed using the 2010 and 2011 test sets of the SemanticSearch Challenge evaluation campaign The structured approach was shown to outper-form a very strong baseline provided by the unstructured model
Specifically we grouped predicates based on their types into four categories nameattributes outgoing and incoming relations Out of these name and attributes provedto be the most useful ones for our task The combination of multiple predicate typesfailed in the unstructured case incorporating relations did not bring in any improve-ments over using names or attributes alone The reason for this behavior is that thereis more textual content for relation type predicates (355 and 133 terms on average forin- and out-relations respectively) than for name (395) or attributes (266) and thisway the entity language model may lose the focus from the entity itself The structuredmodel represents predicate types as language models and considers their weighted lin-ear combination Taking all types with equal weights delivers very strong results andoutperforms the existing state-of-the-art Importantly we showed that relations can con-tribute to overall performance under this approach
While the above two models perform well empirically they suffer from a severelimitation they abandon a large part of the semantics behind the data We propose anovel approach referred to as Hierarchical Entity Model (HEM) that is capable of pre-serving the semantics associated with entities It organises predicates into a two-levelstructure with predicate types on the top level and individual predicates on the bottomlevel The weight of predicate types can be set similarly to the SEM model while theimportance of individual predicates can be estimated in an unsupervised way Our ex-periments showed that modeling individual predicates of a given type is more effectivethan folding their contents into a flat representation When multiple predicate types arecombined for the entity the HEM model delivers substantially higher results than theUEM baseline but fails to outperform SEM One issue for future investigation is tofind out why the combination does not benefit from the improved component models Itmay be the case that the entity model is now more semantically informed but the queryrepresentation and retrieval model are yet unable to exploit this fact Future work willmainly be concerned with extending the current approach by segmenting the query andmapping its components to individual predicates within the hierarchical entity model
144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

144 R Neumayer K Balog and K Noslashrvaringg
References
[1] Balog K Azzopardi L de Rijke M A language modeling framework for expert findingInf Process Manage 45 1ndash19 (2009)
[2] Balog K de Vries AP Serdyukov P Thomas P Westerveld T Overview of the TREC2009 entity track In Proc of the 18th Text Retrieval Conference TREC 2009 (2010)
[3] Balog K Ciglan M Neumayer R Wei W Noslashrvaringg K NTNU at SemSearch 2011 InProc of the 4th Intl Semantic Search Workshop (2011)
[4] Blanco R Halpin H Herzig DM Mika P Pound J Thompson HS Duc TT Entitysearch evaluation over structured web data In Proc of the 1st International Workshop onEntity-Oriented Search (EOS 2011) pp 65ndash71 (2011)
[5] Blanco R Mika P Vigna S Effective and efficient entity search In Proc of the 9th IntlSemantic Web Conf pp 83ndash97 (2011)
[6] Campinas S Delbru R Rakhmawati NA Ceccarelli D Tummarello G SindiceBM25F at SemSearch 2011 In Proc of the 4th Intl Semantic Search Workshop (2011)
[7] Craswell N De Vries AP Soboroff I The TREC 2005 enterprise track In Proc of the14th Text Retrieval Conference (TREC 2005) (2005)
[8] Dalton J Huston S Semantic entity retrieval using web queries over structured RDF dataIn Proc of the 3rd Intl Semantic Search Workshop (2010)
[9] de Vries AP Vercoustre A-M Thom JA Craswell N Lalmas M Overview of theINEX 2007 Entity Ranking Track In Fuhr N Kamps J Lalmas M Trotman A (eds)INEX 2007 LNCS vol 4862 pp 245ndash251 Springer Heidelberg (2008)
[10] Delbru R Toupikov N Catasta M Tummarello G A Node Indexing Scheme for WebEntity Retrieval In Aroyo L Antoniou G Hyvoumlnen E ten Teije A StuckenschmidtH Cabral L Tudorache T (eds) ESWC 2010 LNCS vol 6089 pp 240ndash256 SpringerHeidelberg (2010)
[11] Demartini G de Vries AP Iofciu T Zhu J Overview of the INEX 2008 Entity RankingTrack In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631 pp 243ndash252 Springer Heidelberg (2009)
[12] Demartini G Firan CS Iofciu T Krestel R Nejdl W Why finding entities inWikipedia is difficult sometimes Information Retrieval 13(5) 534ndash567 (2010)
[13] Demartini G Kaumlrger P Papadakis G Fankhauser P L3S Research Center at the Sem-Search 2010 Evaluation for Entity Search Track In Proc of the 3rd Intl Semantic SearchWorkshop (2010b)
[14] Elbassuoni S Ramanath M Schenkel R Sydow M Weikum G Language-model-based ranking for queries on RDF-graphs In Proc of the 18th Intl Conf on Informationand Knowledge Management pp 977ndash986 (2009)
[15] Halpin H Herzig DM Mika P Blanco R Pound J Thompson HS Tran DTEvaluating ad-hoc object retrieval In Proc of the Intl Workshop on Evaluation of SemanticTechnologies (2010)
[16] Herzig DM Tran TD Scoring model for entity search on RDF graphs In Proc of the3rd Intl Semantic Search Workshop (2010)
[17] Kamps J Geva S Trotman A Woodley A Koolen M Overview of the INEX 2008Ad Hoc Track In Geva S Kamps J Trotman A (eds) INEX 2008 LNCS vol 5631pp 1ndash28 Springer Heidelberg (2009)
[18] Kim J Xue X Croft WB A Probabilistic Retrieval Model for Semistructured DataIn Boughanem M Berrut C Mothe J Soule-Dupuy C (eds) ECIR 2009 LNCSvol 5478 pp 228ndash239 Springer Heidelberg (2009)
[19] Liu X Fang H A study of entity search in semantic search workshop In Proc of the 3rdIntl Semantic Search Workshop (2010)
On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)

On the Modeling of Entities for Ad-Hoc Entity Search 145
[20] Ogilvie P Callan J Combining document representations for known-item search InProc of the 26th Annual Intl ACM SIGIR Conf on Research and Development in Infor-mation Retrieval pp 143ndash150 (2003)
[21] Ogilvie P Callan J Hierarchical Language Models for XML Component Retrieval InFuhr N Lalmas M Malik S Szlaacutevik Z (eds) INEX 2004 LNCS vol 3493 pp 224ndash237 Springer Heidelberg (2005)
[22] Park J Lee S-G Keyword search in relational databases Knowl Inf Syst 26 175ndash193(2011) ISSN 0219-1377
[23] Peacuterez-Aguumlera JR Arroyo J Greenberg J Iglesias JP Fresno V Using BM25F forsemantic search In Proc of the 3rd Intl Semantic Search Workshop pp 1ndash8 (2010)
[24] Pound J Mika P Zaragoza H Ad-hoc object retrieval in the web of data In Proc ofthe 19th Intl Conf on World Wide Web pp 771ndash780 (2010)
[25] Robertson S Zaragoza H Taylor M Simple BM25 extension to multiple weightedfields In Proc of the 13th Intl Conf on Information and Knowledge Management pp42ndash49 (2004)
[26] Zhai C Statistical language models for information retrieval a critical review Foundationsand Trends in Information Retrieval 2 137ndash213 (2008)




















