
On-line Software Version Change Using State Transfer Between Processes
16
SOFTWARE-PRACTICE AND EXPERIENCE, VOL. 23(9), 949-964 (SEPTEMBER 1993) On-line Software Version Change Using State Transfer Between Processes DEEPAK GUF’TA AND PANKAJ JALOTE Department of Computer Science and Engineering, Indian Institute of Technology, Kanpur, 208016, India SUMMARY The usual way of installing a new version of a piece of software is to shut down the running program and then install the new version. This necessitates a sometimes unacceptable delay during which service is denied to the users of the software. An on-line software replacement system replaces parts of the software while it is in execution, thus eliminating the shutdown. In this paper, we describe a system for on-line software version change for software written in the C language. When the change is initiated by the user, the system instantiates a new process with the new version of the software, transfers state from the old process to the new one at an appropriate time, and transfers the control to the new process. The user sees a minimal delay in this switchover. KEY WORDS Software enhancement New version installation Process state On-line change Continuously operating software INTRODUCTION It is a well known fact in software engineering that programs undergo changes during their lifetime. These changes may be for bug correction, efficiency improvement or functional enhancement. The change is usually effected by stopping the currently running program and installing the new version. This necessarily implies a denial of service to the users of the software while the switchover is being made. In critical applications, this delay is not acceptable. For such systems it is desirable to have an on-line software modification system which eliminates the system shutdown for installing a new version of the software, thus allowing continuous service to the users of the software. This problem is different from the problems of configuration controll and version control,* which are essentially means to manage the changes made during the development of software. The goal of these techniques is to prevent uncontrolled changes and extreme proliferation of program versions. On the other hand, on-line replacement deals with the problem of installing a new software version after the development is complete. There are systems that allow flexible interconnection of software components to form the complete ~ystem.”~ Though such systems allow flexible interconnection of components, they frequently require interconnections to be specified before execution and do not usually permit changes to modules while the software is executing. Some systems allow the configuration of a distributed 0038-0644/93/090949-16$13 .OO 0 1993 by John Wiley & Sons, Ltd. Received 19 March 1992 Revised 15 February 1993
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of On-line Software Version Change Using State Transfer Between Processes

SOFTWARE-PRACTICE AND EXPERIENCE, VOL. 23(9), 949-964 (SEPTEMBER 1993)
On-line Software Version Change Using State Transfer Between Processes
DEEPAK GUF’TA AND PANKAJ JALOTE Department of Computer Science and Engineering, Indian Institute of Technology,
Kanpur, 208016, India
SUMMARY The usual way of installing a new version of a piece of software is to shut down the running program and then install the new version. This necessitates a sometimes unacceptable delay during which service is denied to the users of the software. An on-line software replacement system replaces parts of the software while it is in execution, thus eliminating the shutdown. In this paper, we describe a system for on-line software version change for software written in the C language. When the change is initiated by the user, the system instantiates a new process with the new version of the software, transfers state from the old process to the new one at an appropriate time, and transfers the control to the new process. The user sees a minimal delay in this switchover.
KEY WORDS Software enhancement New version installation Process state On-line change Continuously operating software
INTRODUCTION It is a well known fact in software engineering that programs undergo changes during their lifetime. These changes may be for bug correction, efficiency improvement or functional enhancement. The change is usually effected by stopping the currently running program and installing the new version. This necessarily implies a denial of service to the users of the software while the switchover is being made. In critical applications, this delay is not acceptable. For such systems it is desirable to have an on-line software modification system which eliminates the system shutdown for installing a new version of the software, thus allowing continuous service to the users of the software.
This problem is different from the problems of configuration controll and version control,* which are essentially means to manage the changes made during the development of software. The goal of these techniques is to prevent uncontrolled changes and extreme proliferation of program versions. On the other hand, on-line replacement deals with the problem of installing a new software version after the development is complete. There are systems that allow flexible interconnection of software components to form the complete ~ys tem.”~ Though such systems allow flexible interconnection of components, they frequently require interconnections to be specified before execution and do not usually permit changes to modules while the software is executing. Some systems allow the configuration of a distributed
0038-0644/93/090949-16$13 .OO 0 1993 by John Wiley & Sons, Ltd.
Received 19 March 1992 Revised 15 February 1993

950 D. GUPTA AND P. JALOTE
program to be changed dynamically by reassigning processes or modules to different nodes and by adding and deleting links, processes etc. dynamically.610
A few approaches have been described for on-line software version change.”-14 The system described in Reference 11 is restricted to dynamically changing the implementation of an abstract data type. The data repres’entation within these data types is changed by appropriate conversion routines to suit a new code version, on demand. The DAS operating system12 has the capability to modify procedures of a running program if the parameters and the return value of the procedures to be changed do not change across versions. DYMOSI3 is a dynamic modification system comprising a source code manager, an editor, a compiler and a run-time system to support on-line change. It requires a complicated locking protocol for every pro- cedure invocation regardless of whether an update is being performed or not. PODUS14.’5 is a dynamic updating system which has been shown to be scalable to the distributed case. l6
Most of these systems use indirect addressing tables to llink the different modules. These tables are dynamically changed if a module has to be replaced by a new version. The changing of the table is done in such a manner that it does not cause any inconsistencies. The major drawback of this approach is that the mechanisms used for dynamic updating are complicated and require new compilers and linkers to be written.
In this paper, we describe a new approach for on-line software replacement, and provide a theoretical framework for on-line modification of programs. We also describe a prototype implementation of our approach. Our basic approach to dynamic program version change is as follows. When a new version of the software is to be installed, a new process is created by the system with the new software. When none of the functions which have changed across versions is on the run-time stack, the system transfers the state of the old process (running the old software) to the new process (running the new software) and kills the old process. The user sees no discontinuity in the service of the software and only a marginal time overhead is imposed by the system. The system has currently been irnplemented on a Sun 3/60 and has been designed for C programs. However, it can easily be extended for other procedural languages and can be ported to other systems running Unix. The major advantage of our approach is that it lends itself to a very simple and efficient implementation and no special compiler or linker is required. The current imple- mentation is just about 1650 lines of C code.
VALID AND COMPLETE CHANGES
Clearly, arbitrary changes to the software cannot be allowed if we want to transfer state information from the old process to the new one. For example, on-line software replacement may not be feasible if the new version of the software is an entirely different program performing altogether different computations. In this section we study the requirements that must be satisfied if the change is to be installed on- line. Let the program II consist of a set of functions F,, ..., F,,. For explaining the underlying ideas and restrictions needed, we assume that during change no new functions are added and only existing functions are modified.

ON-LINE SOFTWARE VERSION CHANGE 95 1
Definition 1
to be changed and their new versions. Thus, A change A to II is defined as the set of ordered pairs of functions of II that are
def A = { (F i ,F i ) I Fi E II, Fi is the new version of Fi}
Definition 2 The new version II, of II under the change A is defined as
where,
A = {Fi I (Fi, FI) E A}
and
B = { F : (Fi, F : ) E A}
Let II and n, be specified as P{II}Q and Pr{IIA}Qf, respectively, where Q ( Q f ) is the desired post-condition of II(II,) and P(P') is its required pre-condition. An on- line change A made to II at time t( t > 0) is conceptually equivalent to the following sequence of steps. The execution of the program II is started with the pre-condition P true. At time t , the execution is stopped and the program code is replaced by the code of II, (the state of the process executing the program remains the same). Then the execution is resumed from the existing state (but with new code).
Suppose the execution of the program II is started from an initial state satisfying I , such that I P , and I * P ' . That is, from the initial state either II or II, could be successfully executed. An on-line replacement is considered valid if the final state produced by the system is either the state that would be produced by executing II completely, or the state that would be produced by executing II, completely. We now formally define a valid change.
Definition 3 An on-line change A made to II at some time t is said to be valid if either the
post-condition Qf of II, or the post-condition Q of II is true when the program terminates.
Whether a change is valid or not depends on the nature of the change (i.e. what has been changed), and the time when the change is installed. While the former restricts the changes allowed to a program, the latter restricts when the transfer of state from the old process to the new process can occur. Since a change in which Q holds on termination is a special case included in the definition for the sake of completeness (a change may be installed towards the very end of execution, and therefore may not have any effect on the final system state), from now on we will focus on the change due to which Q r holds on termination.

952 D. GUPTA AND P. JALOTE
Since a change in one function without a corresponding change in some related functions may take the system to a state not satisfying Q‘, the change of a function might require a corresponding change in another function. In other words, the set of functions to be changed must be ‘complete’. We now define the notion of completeness of change and then relate it to the validity of an on-line change. Let Qi(Qr) represent the post-condition of the function Fi ( F i ) , and Pi ( P i ) represent the weakest pre-condition” needed for the function to satisfy the post-condition after execution. Let 6,(Fi) denote the set of functions that may call the function Fi in the program II, i.e.
an(F,) = (Fj E II 16 may call Fi}
Definition 4 A change A to II is said to be complete if the following two conditions hold for
all (F, ,F:) E A and for every F, E 6,(Fi) such that 16 has not changed across versions, i.e. there is not a pair of the form (F,,Fj) in A:
1. Let S be the post-condition that the function F,. expects Fi to satisfy. Then
2. Let R be the pre-condition with which F, calls Fi. ‘Then R * PI. The first condition states that the functionality of the new version of a function
must be a superset of what a caller expects. If this is not true, then the change is not transparent to the caller which must consequently be modified. The second condition requires that the new version should be able to perform its function under the conditions in which a caller calls the old version. Bf this is not true, then the caller must know about this and will have to be modified to call it under the new conditions.
Let us now consider the second aspect of a valid chamge, namely the timing of the change. If A is complete, then if the change is in:stalled at a time when no function in A is executing, the execution will eventually terminate in Q’ (or Q ) , since the rest of the functions are unchanged. We now state a sufficient condition to ensure that an on-line change is valid. Let II,,(t) denote the set of procedures of II that are on the run-time stack of n at time t .
Q : = . S .
Proposition An on-line change A made to n at a time t is valid if 1. A is a complete change for n. 2. V(Fi,F;.) E A Fi II,,(t).
In this paper, we do not attempt a formal proof of the above proposition, but its truth can be argued as follows. The second condition ensures that the functions in progress at time t are unchanged across versions. Any changed function called now will be called under the conditions that its old version would expect. Since this condition implies the pre-condition of the new version, it will work correctly and the condition that will hold after it returns will be stronger than the one that would have held had the change not been made. This will ensure that the future executions of any changed (or unchanged) functions will also work correctly.

ON-LINE SOFTWARE VERSION CHANGE 953 Note that the above conditions imply that the main function of the program can
never be changed, since it will always be on the run-time stack during the execution of the program. However, in a well-structured program, most of the work is done by low-level functions, and it will usually not be required to change the main function.
So far, we have assumed that the set of functions remains the same for the two versions of the program, but the analysis can readily be extended to deletion and addition of functions. This can be done by adding dummy functions. In the case where new functions are added in the second version, dummy (empty) functions are added to the first version. In the case where functions are deleted, dummy functions are added to the second version. Note that these dummy functions are needed only to specify valid and complete changes in our framework. As we will see, they are not needed in the implementation.
If a function F has been added, then its first version (the dummy) can never be on the run-time stack at any time, and it also has no callers. Thus including or not including this function in the set of changes makes no difference to either the validity or the completeness of the change. If a function F has been deleted, all its callers have to be modified and hence included in the set of changed functions. Clearly, F cannot be on the run-time stack if none of its callers are. Again this implies that the completeness of the change is not affected by including or not including F in the set of changes.
SYSTEM DESIGN Our approach to on-line version change is different from the traditional one of dynamic linking. The basic idea is to transfer state at an appropriate time, from a process running the old version of the software to a process running its new version.
The user is responsible for developing, compiling, linking and debugging both the versions of the program. They must also be linked with a run-time library supplied with the system. Development of the new version is assumed to be done off-line. That is, it does not form a part of the on-line replacement system.
As discussed in the previous section, the set of functions being changed must be complete for the change to be valid. Since the system cannot interpret the semantics of programs, the checks for completeness cannot be performed by the system. We assume that the completeness and correctness of the change has been verified by the user. However, the system does make sure that the change is installed at the right time such that the on-line change is valid.
The major modules of the system are shown in Figure 1. The system presents a modijication shell to the user. This shell accepts some commands from the user and executes them. All commands related to on-line replacement go through this shell. The commands include those for running a program, replacing it with a new version etc. The list of the commands along with a summary of their functions is given in Table I.
The run module contains routines for running a user program, and the replace module contains routines to replace the currently running program with a new version. The executable file generated by the linker contains symbol table infor- mation for the program. The symbol table handling module contains routines to read this information from the file and store it in the form of an internal table. It
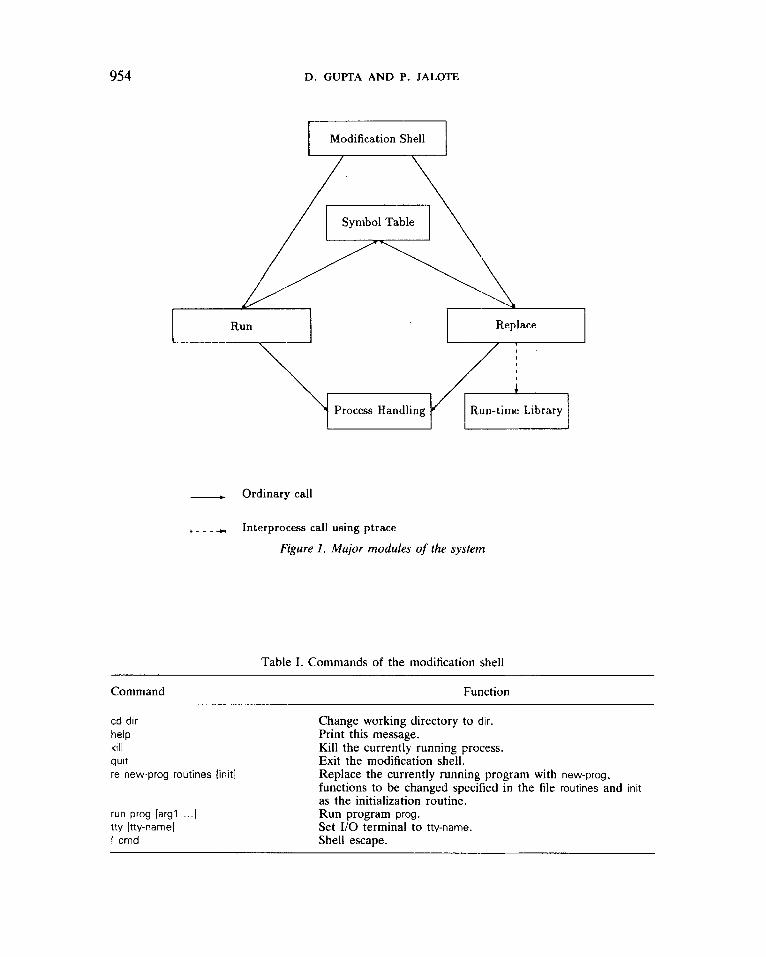
954 D. GUPTA AND P. JALOTE
Process Handling Run-time Library
- Ordinary call
, - - - + Interprocess call using ptrace
Figure I . Major modules of the system
Table I. Commands of the modification !jhell
Command Furiction
cd dir help kill quit re new-prog routines [init]
run prog [argl ... ] tty [tty-name] ! cmd
Change working directory to clir. Print this message. Kill the currently running process. Exit the modification shell. Replace the currently running program with new-prog, functions to be changed specified in the file routines and init as the initialization routine. Run program prog. Set I/O terminal to tty-name. Shell escape.

ON-LINE SOFTWARE VERSION CHANGE 955
also contains routines to search the symbol table, etc. The symbol table of the program is required to find the starting addresses of routines. These addresses are required to check if the stack contains any routine to be changed. These are also required later during actual state transfer so that the program counter and the return addresses on the stack can be mapped to their new values.
The run module as well as the replace module create new processes. These processes run as child processes of the modification shell, and are managed by the process handling module. The process handling module controls the two processes by means of the ptrace system call.'* The ptrace call allows a parent process to inspect or modify the address space and machine registers of its child. A running child process can be stopped by sending it a signal. The parent can resume the stopped child at any address. This mechanism is used to inspect the state of the process running the first version to determine if state transfer can be done consistently and for actually performing the state transfer. It is also used to make a child process call some run-time library routine.
To transfer state, the process running the first version is made to call a library routine* which stores the limits of data and stack addresses in variables whose names are known to the replacement system. This is necessary because the user program may dynamically alter these limits. The system reads these values and writes them onto the corresponding variables of the process running the new version. The new process is then made to call a library routine which expands the data and stack space to the limits specified by these values. The replace module then copies the data and stack of the first process onto the second. The machine registers are copied next. In the case of the program counter, a mapping needs to be made since the starting address of the currently executing routine might have changed. This is done by first finding which routine is currently executing and what is the offset of the currently executing instruction from the starting address of this routine. To do this, the value of the program counter is compared with the addresses of the various routines as given by the symbol table, which is kept sorted on the address. The new starting address of the routine is then found out from the symbol table for the new version of the program and this is added to the offset to get the new value for the program counter. A similar procedure is carried out for all the return addresses on the stack. After the state transfer is over, the old process is killed and the new one is continued.
IMPLEMENTATION
The system has been implemented on a Sun 3/60 workstation running SunOS. This section describes some of the implementation issues.
Maintaining consistency of pointers When data is copied from the old to the new version, it is necessary to preserve
the consistency of pointers. Our design ensures this is a very simple way. On MC68020 and other architectures using segment-based addressing, the first virtual data address of a process is always on a segment boundary after the text. We assume
* This routine is linked with the user program and its address is obtained from the symbol table.

956 D. GUPTA AND P. JALOTE
that the text in the two versions occupies the same number of segments.* The shell checks if this condition holds and gives an error message if it does not. We also assume that no extra global or static variables have been added in the new versi0n.t Under these two assumptions, except for addresses of local variables of changed functions, the address of any data object remains invariant across the two versions. Since the change is installed at a time when no changed functions are on the stack, all pointers into data point at the right places after the change. Addresses of the various routines may, however, change across versions, and our system does not guarantee the consistency of pointers into text.
Deciding when to transfer state The criteria for deciding when to transfer state are bawd on the proposition given
earlier. We assume that the change specified by the user is complete and, if not, the user is willing to accept partially consistent results. For valid on-line replacement, the system has to ensure that the state is transferred at a time when none of the routines are on the stack. To check if state can be transferred at some point in time, the shell unravels the run-time stack of the process running the older version of the user program to find all the return addresses on the stack. These addresses and the value of the program counter are compared with addresses of various routines stored in the symbol table to determine the set of routines which are on the run-time stack. Immediately after the new process has been created and its symbol table built, the system first checks if state transfer is possible. If state transfer is not possible at the time of the first check, then the shell finds the lowermost frame on the stack which corresponds to a routine to be changed. The return address from this frame is modified to the address of an illegal instruction which is a part of the library linked with the user program. The original return address is saved in a variable. The user process is then continued. When the last routine on the stack which is to be changed returns, the process incurs an illegal instruction trap and the shell which has been waiting for this event to occur is notified. At this point in time, the stack is guaranteed to contain no routines which are to be changed. State transfer takes place at this time. Note that if a program receives an illegal instruction trap due to some other reason, state transfer gets initiated at a wrong instant in time. However, for programs compiled by a correct compiler, this can never happen.
Handling open files When the state transfer takes place, the user program will typically have some
files open for input and output. The same files must be opened for the process running the second version at the same offsets for file I/O to work correctly. The shell process has no means of knowing which files a child process has opened. The run-time library of the system contains special versions of the open and close routines which do some bookkeeping also along with their normal functions. These versions have to be linked with the user program instead of the normal C library ones. The special version of the open routine adds an entry consisting of file name and mode of opening (read, write, append etc.) in an array whiclh is indexed by the file
* This is a reasonable assumption since the segment size is typically quite large (2MB in MC68020). t The system does provide a way to add new global data in an indirect manner. This is discussed later.

ON-LINE SOFTWARE VERSION CHANGE 957
descriptors. At the time of state transfer, before copying the data of the old to the new process, the shell makes the old process execute a library routine which stores the current file offsets of all open files in their respective entries in this array. When the data space is copied, this array also gets copied to the process running the new version. The shell then makes the new process call a library routine which opens files whose names are in this array with the specified opening modes and sets the current file offsets to their respective values. The order of opening the files is such that the file descriptors are preserved. This ensures correct file 110 after the modification has been done.
Handling changes in return value and parameter format
Frequently in programs, the parameter format and the type of the return value of a function also have to be changed. For example, consider a sort routine which sorts integers and which is required to be changed to a polymorphic sort routine so that other types of data can now be sorted. Assume further that a routine f called sort in the old version of the program. Now the polymorphic sort routine expects more parameters than f provides it. There are two possible ways to achieve modifi- cation without loss of consistency in such a scenario. One way is to simply write a new version of f which calls sort with the parameters that its new version expects and inform the shell that f has also changed across versions. The other way to do this is to write an interpr~cedurel~ called sort which is called with the old parameter format, maps them to the new format and then calls the polymorphic sort routine.*
Writing an interprocedure causes an extra overhead each time it is called. But the shell will have to wait for more time before state can be transferred, if f is modified. Further, if f represents the main loop of the program, then it will get off the run-time stack only near the completion of execution of the program, thereby making on-line modification meaningless. It is therefore left to the user to decide which scheme he wants to use in case either the parameter or the return value format of a procedure is to be changed.
Initialization routine
The programmer can provide an initialization routine in the new version of the program which will be called by the system at the time of the change. This routine can be used for data restructuring. For example, consider a program having functions which implement a stack using an array. If the new versions of these routines implement a stack using a linked list, then at the time of change, the stack must be ‘restructured’, i.e. a linked list containing the values currently in the stack must be built. This can be done by the initialization routine.
The initialization routine can also be used for other purposes. For example, many programs use an array containing pointers to functions and the array is unchanged during the execution of the program. In such a situation, the initialization routine can contain code to reinitialize these pointers since the system does not support automatic mapping of pointers to functions.
* This routine must not be named sort.

958 D. GUPTA AND P. JALOTE
Adding and deleting functions The capability to add new functions in a new version of a program is important
for functional enhancement of the program. Deleting unused functions may be necessary because of space considerations. In our system no restrictions are imposed on adding and deleting functions. Adding and deleting functions is treated as an integral part of program modification, and no special actions are needed for this purpose. Furthermore, no dummy versions of functions being added or deleted are required in either version of the program.
If a function is added or deleted, it need not appear iin the change specification file as explained in an earlier section. However, if a function is deleted, all its callers obviously have to be modified, and hence must be includedl in the change specification file. Similarly, if a new function is added, all the functioins which call it in the new version have to be modified and included in the change specification.
Adding and deleting global data As explained earlier, any change in global variables of the program may destroy
the consistency of pointers (local variables pose no such problems and can be added and deleted freely.) But new versions may require new data structures which may also need to be initialized with state information acquired so far. Our system provides the flexibility to add new global data, though in an indirect manner. To add new data, the original program must declare some extra pointer variables which are not used in the first version. The initialization routine must have code which allocates space using malloc or calloc, initializes this space and places a pointer to it in one of those pointer variables which are unused in the first version of the program. Since the initialization routine is called by the system after the data has been copied to the new process, it can use the values of other globall variables to initialize the space allocated. The area can then be accessed in the new version through the pointer. The main drawback of this scheme is that it requires the programmer to declare some extra pointer variables in the first version of the program so that new data can be added in future versions. Furthermore, wh,en variables are added in the new version, they cannot be given meaningful names. Though not very elegant, this scheme will suffice for changes that require new data sparingly.
Global data deletion is not allowed in our system, as it will destroy the consistency of pointers and other addresses. So, any data that becomes redundant in the new version must still be kept in the new version. Note that this requires careful handling of string constants, as the current C compilers typically treat string constants as global data for the purposes of memory allocation (i.e. they are assigned memory in the data segment of the process, rather than on the stack). If string constants within a function are treated as local variables (as, for example, is done in Pascal), this problem will cease to exist. For the existing C compilers, utility programs can easily be written to check if deletion of functions has inadvertently deleted any string constants or not.
Another approach to adding global data Another scheme for adding data, which is supported in our system and which
addresses some of the problems of the above approach,, is by declaring an array

ON-LINE SOFTWARE VERSION CHANGE 959
which is unused in the first version. All new variables in the second version are ‘assigned’ addresses overlapping with the address range of the unused array, provided that the total memory needed for the new variables is less than the size of the array. This scheme has the advantage that new variables can be accessed directly rather than through a pointer, as is done in the previous approach. Also, new variables can be given meaningful names. This scheme requires a translator to generate code for the new variables, to be linked with the second version, that ‘assigns’ memory to variables from this ‘reserved’ area. A translator for this purpose, though not yet implemented, can easily be written.
Other restrictions The system imposes some restrictions on user programs. The first restriction is
that the change being made must be complete. In addition, the system imposes restrictions on the use of system calls by the user program. This is because besides the data and stack, a process also has some other state information which is kept in the kernel. Since a user-level implementation such as ours cannot modify this information, the user program is prohibited from making system calls which modify such information. Most of these calls can be allowed if special versions for the system calls are written which store this information in some user variables before making the system call. The values of these variables will be copied to the new process at the time of state transfer. The new process can then be made to call a library routine which makes appropriate system calls to modify the kernel information in the same way as the old process. At present, this has been done only for read, write, open and close system calls, as explained in an earlier section. This approach will not work in certain cases. For example, if the user program creates a child process and is then replaced by a new version, the new process running the second version will bear no relationship to the child process.
However, these restrictions can easily be overcome in a kernel implementation of the system. Instead of copying state from one process to another, code of a process itself can be modified in such an implementation, and the replace operation can be implemented as a system call.
AN EXAMPLE Client-server type of interaction is commonly used in computer systems. In this interaction model, there is a server process which performs certain tasks on request from the clients. The server is typically a non-terminating process, whereas the clients run for short durations. In a client-server system, installing a new version of the server in the traditional manner will imply denial of service to all the clients for the duration of the installation. This can be avoided by on-line version change.
Let us consider a simple print server that, on getting a command from the client, formats a file for printing on a particular type of printer and then prints it on the printer. We will use this example to illustrate how a new version of the server can be installed on-line. For simplicity, in the example the client-server communication is done through a named pipe” (in an actual implementation, it is often done through Unix sockets).
In the first version of the program, the server accepts only one command from

960 D. GUPTA AND P. JALOTE
the client on the pipe which is of the form: fp filename. On receiving the command the server formats the file filename, keeping the formatted output in a temporary file, and then prints this temporary file. If the executable code of the server program is in the file server, then the server has to be started through the modification shell, by giving the command
run server [paramsl
The overall structure of parts of the server is given in Figure 2. Note that the variables extral, extra2, extra3 have been declared, though not used in the server. These are to support addition of global data, if needed.
In the second version, the client can give the server another command of the form: fpo infile outfile. On receiving this command the server formats and prints infile and also leaves a copy of the formatted file in outfile. Clearly, for this version of the server the routine read-command has to be modified. The formatting and printing routines will remain the same. The new version of the read-command function is given in Figure 3. In this new version, if the fpo command is given, the read-command function assigns the name of the file specified in the command to outfile, otherwise the temporary file in the /tmp area is assigned, as in the first version.
The user (the person who will install the new version) has to specify the change
char *extral, *extra2, *extra3 ; /* Some extra pointer variables being declared f o r future use */
main ( ) {
char char FILE
inf ile [MAXFILENAMELEM] ; outf ile[HAXFILENAMELENl ;
*fP ;
Create command pipe fp ; for ( ; ; I {
read_command(fp,infile,outfile) ; format(infile, outfile) ; print(outfi1e) ;
1
read-command(fp, inf ile ,*outf ile) FILE *fp ; char *infile ; char *outfile ;
char cmdC51 ; {
fscanf(fp."%s %s", cmd, infile) ; strcpy(outf ile,"/tmp/server") ;
1 Figure 2. Print server main loop

ON-LINE SOFlWARE VERSION CHANGE 96 1
read-command(fp,infile,outfile) FILE *fp ; char * i n f i l e ; char *outfile ;
char cmdC61 ; t
fscanf(fp,"%s %a", cmd, i n f i l e ) ;. if (!strcmp(extral,cmd))
fscani(fp.ertra2,outf i~e) ; else
sprintf (outf ile,"/tmp/server") ; 1 Figure 3. Version 2 of the read-command function
configuration file and the initialization routine for doing an on-line version change. Since only the read command function has been modified, the change configuration file just contains
-read-command
The initialization routine is necessary due to the use of extra variables. The initiali- zation routine init-change initializes the value of these variables, and is shown in Figure 4. The use of this routine by the system is explained earlier. To transfer control properly, the init-change routine calls a system-provided cause-trap function before exiting.
If the executable version of the new server program is kept in the file servermew and the change configuration file is named change-config, then the new version is installed by giving the command
re server.new change-config -init-change.
init-change()
extra1 = malloc(4*sizeof (char)) ; extra2 = malloc(3*s~izeof(char)) ; extrait01 = I f J ; extraiCi1 = 'p' ; extrait21 = ' 0 ' ; extralC31 = ' \ O r ; extra2COl = ; extra2ClI = ' a ' ; extrdC21 = I \ O 1 ; cause-trap0 ;
t
1 Figure 4. Change initialization routine for a print server

962 D. GUPTA AND P. JALOTE
SYSTEM PERFORMANCE We have conducted some experiments to determine the overhead incurred due to on-line replacement. The overhead can be divided into two parts-one is the over- head during normal execution when some extra activities are performed to help the replacement when required. The other is the overhead that is incurred during replacement.
In our experiments, we found that the overhead during normal execution is minimal. A program executed through our modification shell (but with no modifi- cation done) takes approximately the same time as it does if it were executed through the Unix Shell. This is to be expected since miniimal bookkeeping activities are being performed during normal execution.
The overhead during the actual replacement comes largely due to the transfer of state information, changing the addresses, and searching the stack. All of these depend on the program and the size of the stack. In our experiments we found the overhead due to these to be very small. For the example given in the previous section, where the function read-command was replaced with a new version, we found that on a moderately loaded Sun 3/60 system, the change takes about 200 ms (CPU time).
To test the effect of on-line version change on the performance of a running software, another experiment was conducted along the lines of the experiment described in Reference 14. The server code was modified to send a message to a performance monitoring program after processing each request received. The performance monitoring program records the number of messages received every second. The server was then run through the modification shell and heavily loaded by running a client which continuously sends it requests. The change to the second version of the server was then made at a random time and the performance of the system during the change was observed. The following was observed:
Rate of performing requests before the change 3-83 per second Duration of change 1-04 seconds Rate of performing requests during the 2 second interval containing the change 1-5 per second
The change duration of 1.04 s was spread over two one:-second intervals. During these two seconds, the number of requests processed was found to be one and two, respectively. This clearly shows that the installation of the change did not cause a significant deterioration in the performance of the server. The rate of performing requests after the change may, in general, increase or decrease and will depend on the difference between the old and the new versions. In this case, however, it remained the same, as there was only a minor difference between the two versions.
CONCLUSION It is now known that a piece of software undergoes many c:hanges during its lifetime. Changes take place to remove latent errors that are detected during operation, or to enhance the system. In either case, a program in operation has to be replaced by a new version. The most common approach to performing this version change is to shut down the system and then install the new version. This necessitates a

ON-LINE SOFTWARE VERSION CHANGE 963 sometimes unacceptable delay during which service is denied to the users of the software.
In this paper we have considered the problem of on-line version change, in which the version is changed while the software is executing, without shutting down the system. We have defined what it means for on-line replacement to be valid and have developed conditions that must be satisfied by the change for performing a valid on-line replacement.
We have also described a system that allows version change for C programs. The approach followed by our system is to create a new process with the new version. When the conditions for valid replacement are met, the state is transferred from the process running the old version to the process running the new version, and then the process for the old version is killed. The system can handle a wide variety of C programs, through it does impose some restrictions. The overhead of performing this replacement is very small.
Though currently implemented on a single node system, our system can easily be extended for on-line modification of a distributed program communicating via the remote procedure call (RPC)19,20 mechanism. RPC supports a client-server type of interaction (similar to our chosen example). In an RPC implementation, typically the client and the server are two independent processes executing on different machines. If only one of them needs to to changed, then the change is like the change in a single process system, and nothing extra needs to be done. If both the client and the server are to be changed, then the server must be modified before the client so that a new version of the client does not send any requests to the old version of the server, which may be unable to accept requests from new clients. To enforce this, the client update must wait till the server update is finished. This information can be given by the updating system running on the server site to the updating system running on the client site. To handle the case of an old version of the client calling a newer version of the server, interprocedures can be used, as was done for handling the change in return value and parameter format in the single process case. More work needs to be done to investigate the possibility of making on-line changes to distributed programs using more flexible methods of inter-process communication such as message passing.
REFERENCES 1. E. H. Bersoff, ‘Elements of software configuration management’, IEEE Trans. Software Eng.,
2. W. F. Tichy, ‘Design, implementation and evaluation of a revision control system’, Proc. 6th Int.
3 . J. Magee, J. Kramer and M. Sloman, ‘Constructing distributed systems in Conic’, IEEE Trans.
4. D . Perry, ‘The Inscape environment’, Proc. 11th Int. Conf. on Software Eng., 1989, pp. 2-12. 5. J. Purtillo, ‘The polylith software bus’, Tech. Report no. 2469, University of Maryland, 1990. Also
to appear in ACM Transactions on Programming Languages and Systems. 6. C. Hofmeister, E. White and J. Purtillo, ‘Surgeon: a package for dynamically reconfigurable
distributed applications’, Proc. IEEE International Conference on Configurable Distributed Systems, March 1992.
7. J . Purtillo and C. Hofmeister, ‘Dynamic reconfiguration of distributed programs’, IEEE Inter- national Conference on Distributed Computing Systems, May 1991, pp. 560-571.
8. J. Kramer and J. Magee, ‘Dynamic configuration for distributed systems’, IEEE Trans. Software Eng., SE-11, (4), 424-436 (1985).
10, (l), 79-87 (1984).
Conf. Software Eng., Tokyo, 1982, pp. 58-67.
Software Eng., 15, 663-675 (1989).

964 D . GUPTA A N D P. JALOTE
9. J . Kramer and J. Magee, ‘The evolving philosophers problem: dynamic change management’,
10. M. R. Barbacci, D. L. Doubleday and C. B. Weinstock, ‘Application-level programming’, IEEE
11. R. S . Fabry, ‘How to design systems in which modules can be changed on the fly’, Proc. 2nd Int.
12. H. Goullon, R. Isle and K. Lohr, ‘Dynamic restructuring in an iexperimental operating system’,
13. I. Lee, ‘DYMOS: a dynamic modification system’, Ph.D. Thesis, University of Wisconsin, 1983. 14. M. E. Segal and 0. Frieder, ‘Dynamic program updating: a software maintenance technique for
minimizing software downtime’, Software Maintenance: Research and Practice, 1, (l), 59-79 (1989). 15. 0. Frieder and M. E. Segal, ‘On dynamically updating a computer program: from concept to
prototype’, J. System Software, 14, (2), 111-128 (1991). 16. M. E. Segal and 0. Frieder, ‘Dynamically updating distributed software: supporting change in
uncertain and mistrustful environments’, Proc. IEEE Conference on Software Maintenance, October 1989.
17. E. W. Dijkstra, ‘Guarded commands, non-determinism and formal derivation of programs’, Com- munications of the ACM, 18, (8), 453-457 (1975).
18. Sun Microsystems Inc., Mountain View, CA. Sun 0 s Reference Manual, 1988. 19. A. Birell and B. Nelson, ‘Implementing remote procedure calls’, ACM Trans. Computer Systems,
20. A. D. Birell, ‘Secure communication using remote procedure calls’, ACM Trans. Computer Systems,
IEEE Trans. Software Eng., 16, ( l l ) , 1293-1306 (1990).
International Conference on Distributed Computing Systems, 1990, pp. 458-465.
Conf. Software Eng., 1976.
IEEE Trans. Software Eng., SE-4, (4), 298-307 (1978).
2, ( l) , 39-59 (1984).
3, (l), 1-14 (1985).




















