
Nagib Yassin ESTATÍSTICA EXPERIMENTAL ESTATÍSTICA EXPERIMENTAL
210
Nagib Yassin ESTATÍSTICA EXPERIMENTAL 1 ESTATÍSTICA EXPERIMENTAL Professor Nagib Yassin Rio Verde 2012
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Nagib Yassin ESTATÍSTICA EXPERIMENTAL ESTATÍSTICA EXPERIMENTAL

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
1
ESTATÍSTICA EXPERIMENTAL
Professor Nagib Yassin
Rio Verde 2012

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
2
Ementa Introdução. Princípios básicos da experimentação. Comparações múltiplas. Experimentos inteiramente casualizados. Experimentos em blocos casualizados. Experimentos em quadrados latinos. Experimentos Fatoriais. Experimentos em parcelas subdivididas. Experimentos em faixas. Reticulados Quadrados. Regressão na análise da variância. Teste de qui-quadrado. Análise de Covariância. Análise de variância multidimensional. Superfícies de resposta. Testes não-paramétricos.
Objetivos
Reconhecer o significado dos métodos estatísticos, aplicando-os em problemas
específicos da área
Conteúdo
Cap. 1 Testes de Hipóteses
Cap. 2 Contrastes
Cap. 3 Introdução à Experimentação
Cap. 4 Delineamento Inteiramente Casualizado
Cap. 5 Procedimentos para Comparações Múltiplas
Cap. 6 Delineamento em Blocos Casualizados
Cap. 7 Delineamento em Quadrado Latino
Cap. 8 Experimentos Fatoriais
Cap. 9 Experimentos em Parcelas Subdivididas
Cap.10 – Regressão

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
3
ESTRATÉGIAS DE AVALIAÇÃO
O sistema de avaliação constará de três provas, com pesos iguais. As datas das provas estão apresentadas no planejamento da disciplina em anexo.
O assunto pertinente as 1a, 2
a e 3
a provas, será divulgado em sala de aula na semana
que a prova ocorrerá.
O estudante que perdeu a 1a ou a 2
a ou a 3
a prova, por qualquer motivo que seja
(viagem de caráter particular, atestado médico, participação em congressos, etc.), poderá fazer a Prova Substitutiva, sendo esta única cujo valor será 100%. Esta prova substitutiva abordará todo o assunto do semestre. Não é necessário apresentar justificativa para fazer a prova substitutiva. A data da prova substitutiva também se encontra no planejamento em anexo. O estudante deve também levar o seu conjunto de tabelas, pois as mesmas são de uso individual. Estas tabelas não devem conter nenhuma informação adicional. A existência de tais informações adicionais implica o uso de cola, estando o estudante sujeito A penalidades. Os alunos que não obtiverem média final para aprovação, poderão realizar a prova final, cujo assunto é toda a matéria lecionada durante o período letivo. Divulgação das Notas de Provas As notas da 1ª e 2ª provas serão divulgadas no máximo, até 3 semanas após a
realização de cada uma delas. Já as provas 3a e substitutiva terão as notas divulgadas
até 3 dias após a realização da prova substitutiva. Revisão de Prova O Professor marcará um período ÚNICO de revisão para cada uma das provas. O estudante deve respeitar este período de revisão, pois não serão abertas exceções para que o estudante faça a revisão de suas provas fora do período de revisão estabelecido.
A média de aproveitamento (MA) será obtida, calculando:
( ) ( )+ += 8 3 NP 3 NT 2(MEP)
MA
Sendo:
(NP) Nota de uma única prova
(NT) Nota referente a um trabalho mensal
(MEP) Nota referente a 2 listas menais de exercícios.
Trabalhos
Obs:
As notas de NT e de MEP não darão direito ao aluno requerer 2a chamada

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
4
A freqüência comporá o sistema de avaliação – (5% a menos para cada falta e/ou
capítulo)
METODOLOGIA
O conteúdo programático será desenvolvido através de aulas expositivas dialogadas,
além da participação efetiva do aluno na construção e resolução de exercícios. Trabalhos
em grupo na classe e extra classe, solucionando problemas práticos ou envolvendo parte
teórica de tópicos do conteúdo programático.
Bibliografia AQUINO, L. H. Técnica experimental com animais. Escola Superior de Agricultura de Lavras, Lavras, MG, 1992. 385p BANZATTO, D.A. e KRONKA, S.N. Experimentação Agrícola. FUNEP, Jaboticabal, 1989. CAMPOS, H.. Estatística Aplicada à Experimentação com Cana-de-açúcar. FEALQ, Piracicaba, l984. FERREIRA, P. V. Estatística Experimental Aplicada à Agronomia. Maceió: EDUFAL, 1991 GOMES, F.P. Curso de Estatística Experimental. 11a ed., Livraria Nobel, São Paulo, 1985. RODRIGUES, M. I., IEMMA, A. F. Planejamento de Experimentos e Otimização de Processos, 1ºed. –Campinas –SP, Casa do Pão Editora, 2005

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
5
ÍNDICE C A P Í T U L O 1 9
TESTES DE HIPÓTESES 9
1.1.Testes de hipóteses para média populacional 13
1.2 Testes de hipótese para a razão de duas variâncias 15
13 Testes de hipóteses para a diferença entre médias populacionais 16
1.4. Testes de hipóteses para diferença entre proporções 23
1.5 Teste do qui-quadrado de independência 24
Exercícios 27
34 C A P Í T U L O 2
ESTATÍSTICA EXPERIMENTAL 34
2.1 Introdução 34
2.1.1 Objetivo 34
2.1.2 A necessidade da estatística 34
2.2. Conceitos importantes em experimentação 36
2.2.1 Etapas da pesquisa científica 37
2.3 Escolha dos fatores e seus respectivos níveis 38
2.3.1 Escolha da Unidade Experimental 38
2.3.2 Escolha das Variáveis a Serem Medidas 38
2.3.3 Regras Segundo as quais os Tratamentos são Atribuídos as Unidades Experimentais 39
2.4 Princípios básicos da experimentação 50
2.4.1 Princípio da repetição 40
2.4.2 Princípio da casualização 41
2.4.3 Princípio do controle local 43
2.5 Número de repetições 44
2.6 Bordaduras 44
Exercícios 46
52 C A P Í T U L O 3
TESTES DE SIGNIFICÂNCIA 52
3.1. Introdução 52
3.2. Contrastes 53
3.2.1. Introdução 53
3.2.2. Definições 53
3.2.3. Medidas de dispersão associadas a contrastes 54
3.2.4. Contrastes Ortogonais 55
3.3. Métodos para obtenção de grupos de contrastes mutuamente ortogonais Obtenção por Meio de Sistema de Equações Lineares 57
Exercícios 59

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
6
3.4 Teste F para a análise de variância 64
3.4.1. Regra de decisão 66
3.5 Análise de variância (ANAVA) 68
3.5.1 Quadro da análise de variância do DIC 69
3.6. Teste t de Student 69
3.6.1. Regra de decisão 71
74 C A P Í T U L O 4
DELINEAMENTO INTEIRAMENTE CASUALIZADO (DIC) 74
4.1 Introdução 74
4.2 Análise de variância (ANAVA) 75
4.3 Modelo matemático do DIC com efeitos de tratamentos fixos 75
4.4 Suposição associada ao modelo 76
4.5 Hipóteses estatísticas 76
4.6 Partição da soma de quadrados 76
4.7 Quadrados médios 78
4.8 Estatística e região crítica do teste 78
4.9 Quadro da análise de variância (ANAVA) 79
4.10 Detalhe computacional 80
4.11 Estimadoresde mínimos quadrados 84
4.12 Coeficiente de determinação (R2) e de variação (CV). 86
4.13 Checando as violaçãoes das suposições da ANAVA. 87
4.14. Experimentos Inteiramente Casualizados com parcela perdida 88
4.15 Vantagens e desvantagens do DIC. 89
4.16 Resumo 90
Exercícios 91
95 C A P Í T U L O 5
TESTES DE COMPARAÇÕES MÚLTIPLAS 95
5.1 Introdução 95
5.2. Alguns Procedimentos Para Comparações Múltiplas 97
5.5.2.1.Teste de Tukey 97
5.2.2. Teste de Duncan 98
5.2.3. Teste t de Student 100
5.2.4. Teste de Scheffé 101
5.3. Vantagens e Desvantagens dos Procedimentos Para Comparações Múltiplas 102
Exercícios 103
106 C A P Í T U L O 6
DELINEAMENTO EM BLOCOS CASUALIZADOS (DBC) 106
6.1 Introdução 106
6.2 Vantagens e devantagens de um DBC 107

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
7
6.3 Organização do dados no DBC 108
6.4 Modelo matemático do DBC 108
6.5. Suposições do modelo 109
6.6. Hipótese estatística 109
6.7 Partição da soma de quadrados 109
6.8 Quadrados médios 111
6.9 Estatística e região crítica do teste 112
6.10 Quadro da análise de variância (ANAVA) 112
6.11 Detalhes computacionais 113
6.12. O problema da perda de parcela 115
6.13 Análise de variância de medidas repetidas 118
Exercícios 120
126 C A P Í T U L O 7
DELINEAMENTO EM QUADRADO LATINO (DQL) 126
7.1 Introduão 126
7.2 Modelo Matemático. Hipóteses 126
7.3 Objetivo do Controle em 2 Direções 127
7.4 Caracterização do Quadrado Latino 127
7.5 Partição da soma de quadrados 128
7.6. Quadrados médios 129
7.7 Eestatística e região crítica do teste 129
7.8 Quadro da análise de variância (ANAVA) 130
7.9 Detalhes computacionais 130
7.10 Como contornar o problema de pequeno número de graus de liberdade para o resíduo ? 134
7.11 Casualização dos tratamentos 137
7.12. Exemplos em que as unidades experimentais são animais ou pessoas 138
Exercícios 141
144 C A P Í T U L O 8
EXPERIMENTOS FATORAIS 144
8.1 Introdução 144
8.2. Tipos de efeitos avaliados em um experimento fatorial 144
8.2.1. Efeito simples de um fator 144
8.2.2. Efeito principal de um fator 145
8.5 Efeito de interação entre os dosi fatores 145
8.3. Quadro de tabulação de dados 147
8.4 Modelo matemático de um experimento fatorial 148
8.5. Análise de Variância 149
8.5.1 Interação não-significativa 150
8.5.2 Interação significativa 157
8.6. Vantagens e desvantagens de um experimento fatorial 166

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
8
Exercícios 167
C A P Í T U L O 9 172
EXPERIMENTOS EM PARCELAS SUBDIVIDIDAS 172
9.1 Introdução 172
9.2 Vantagem e desvantagem de um experimento em parcelas subdividas 174
9.3. Análise de variância (ANAVA) 174
9.4 Modelo matemático e suposições 174
9.5 Hpótese estatística 175
9.6 Somas de quadrados 176
9.7 Comparações múltiplas entre mádias de tratamentos 177
Exercícios 187
191 C A P Í T U L O 10
Regressão na análise de variância 191
10.1 Introdução 191
10.2. Escolha do modelo para equacionar o fenômeno em estudo 191
10.3. Método para obter a equação estimada 192
10.3.1. Modelo linear de 1º grau 192
10.3.2. Modelo linear de 2º grau 194
10.4. Análise de variância da regressão 194
10.4.1. Apenas um único valor observado para cada nível da variável independente 195
10.4.2. Mais de um valor observado para cada nível da variável independente 196
10.5. Coeficiente de determinação (R2) 198
Exercícios 199
Tabelas 205

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
9
C A P Í T U L O 1 TESTES DE HIPÓTESES
Na teoria de decisão estatística, os testes de hipóteses assumem uma importância
fundamental, já que estes permitem nos dizer, por exemplo, se duas populações são de
fato iguais ou diferentes, utilizando para isso amostras destas populações. Desta forma, a
tomada de decisão de um gestor, deve estar baseada na análise de dados a partir de um
teste de hipótese.
Então, você pode definir as hipóteses a serem testadas, retirar as amostras das populações a serem estudadas, calcular as estatísticas delas e, por fim, determinar o grau de aceitação de hipóteses baseadas na teoria de decisão, ou seja, se uma
determinada hipótese será validada ou não.
Para você decidir se uma hipótese é verdadeira ou falsa, ou seja, se ela deve ser aceita
ou rejeitada, considerando uma determinada amostra, precisamos seguir uma série de
passos. Os passos são mostrados a seguir.
1) Definir a hipótese de igualdade (H0) e a hipótese alternativa (H1) para tentar rejeitar
H0 (possíveis erros associados à tomada de decisão).
2) Definir o nível de significância (α).
3) Definir a distribuição amostral a ser utilizada.
4) Definir os limites da região de rejeição e aceitação.
5) Calcular a estatística da distribuição escolhida a partir dos valores amostrais obtidos e
tomar a decisão.
Você deve tomar a decisão baseada na seguinte regra: se o valor da estatística da
distribuição calculado estiver na região de rejeição, rejeitar, então, a hipótese nula, senão
a decisão será que a hipótese nula não poderá ser rejeitada ao nível de ignificância
determinada.
Diversos conceitos serão apresentados ao longo do detalhamento dos passos a serem
seguidos na formulação de um teste de hipótese.
Detalhamento dos passos na formulação de um teste de hipótese: 1) Formular as
hipóteses (H0 e H1).
Primeiramente, vamos estabelecer as hipóteses nula e alternativa.
Para exemplificar, se deve considerar um teste de hipótese para uma média. Então, a
hipótese de igualdade é chamada de hipótese de nulidade ou Ho. Suponha que você

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
10
queira testar a hipótese de que o tempo médio de ligações é igual a 50 segundos. Então,
esta hipótese será simbolizada da maneira apresentada a seguir:
Ho: µ = 50 (hipótese de nulidade)
Esta hipótese, na maioria dos casos, será de igualdade.
Se você rejeitar esta hipótese, vai aceitar, neste caso, outra hipótese, que chamamos de
hipótese alternativa. Este tipo de hipótese é simbolizada por H1 ou Ha. As hipóteses
alternativas mais comuns são as apresentadas a seguir a partir do nosso exemplo:
H1: µ > 50 (teste unilateral ou unicaudal à direita)
O tempo médio de ligação é superior a 50 segundos
H1: µ < 50 (teste unilateral ou unicaudal à esquerda)
O tempo médio de ligação é inferior a 50 segundos
H1: µ ≠ 50 (teste bilateral ou bicaudal)
O tempo médio de ligação pode ser superior ou inferior a 50 segundos.
Surge uma dúvida. Qual hipótese alternativa será utilizada? A resposta é bem simples. A hipótese alternativa será definida por você, em função do tipo de decisão que deseje
tomar.
Veja o seguinte exemplo: você inspeciona uma amostra de uma grande remessa,
encontrando-se 8% defeituosa. O fornecedor garante que não haverá mais de 6% de
peças defeituosas em cada remessa. O que devemos responder, com auxílio dos testes
de significância, é se a afirmação do fornecedor é verdadeira.
As hipóteses que serão formuladas são:
H0: p = 0,06;
H1: p > 0,06.
É importante ressaltar que o sinal de igual para a hipótese Ho corresponde a um sinal de
menor ou igual (neste exemplo), pois o teste é unilateral à direita (p1 > 0,06). Portanto,
sempre que o teste for unilateral, deve ser feita esta consideração.
2) Definir o nível de significância.
O nível de significância de um teste é dado pela probabilidade de se cometer erro do tipo
I (ocorre quando você rejeita a hipótese H0 e esta hipótese é verdadeira). Com o

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
11
valor desta probabilidade fixada, você pode determinar o chamado valor crítico, que
separa a chamada região de rejeição da hipótese Ho da região de aceitação da hipótese
H0.
Na Figura abaixo, as áreas escuras correspondem à significância do teste, ou seja, à
probabilidade de se cometer o chamado erro tipo I (rejeitar H0 quando ela é verdadeira).
Esta probabilidade é chamada de α, e geralmente os valores mais utilizados são 0,01 e
0,05. O complementar do nível de significância é chamado de nível de confiança e é dado
por 1 - α.
α
Unilateral à direita H0: µ = 50 H0: µ > 50
Unilateral à esquerda H0: µ = 50 H0: µ < 50
Bilateral H0: µ = 50 H0: µ # 50
αααα/2 αααα/2
α
α

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
12
3) Definir a distribuição amostral a ser utilizada.
A estatística a ser utilizada no teste, você definira em função da distribuição amostral a
qual os dados seguem. Se você fizer um teste de hipótese para uma média ou diferença
entre médias, utilize a distribuição de Z ou t de Student. Outro exemplo é se você quiser
comparar a variância de duas populações, então deverá trabalhar com a distribuição F,
ou seja, da razão de duas variâncias. Note que o conhecimento das distribuições
amostrais vistas na Unidade 3 é muito importante.
4) Definir os limites da região de rejeição.
Os limites entre as regiões de rejeição e aceitação da hipótese Ho, você definirá em
função do tipo de hipótese H1, do valor de (nível de significância) e da distribuição
amostral utilizada. Considerando um teste bilateral, você terá a região de aceitação (não-
rejeição)
com uma probabilidade de 1- α e uma região de rejeição com probabilidade α ( α/2 + α/2).
5) Tomar a decisão.
Para tomar a decisão, você deve calcular a estimativa do teste estatístico que será
utilizado para rejeitar ou não a hipótese Ho. A estrutura deste cálculo para a média de
forma generalista é dada por:
Valor obtido da
distribuição
amostral
(tabela)
Valor obtido da
distribuição
amostral
(tabela)

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
13
Estatística da distribuição = ( )Estimativa patâmetro
Erro padrão da estimativa
−
Podemos exemplificar pela distribuição de Z, que será:
( )Calc
X µZ
σ
n
−=
Se o valor da estatística estiver na região crítica (de rejeição), rejeitar Ho; caso contrário,
aceitar H0. O esquema abaixo mostra bem a situação de decisão.
1.1.Teste de hipótese para média populacional
Quando você retira uma amostra de uma população e calcula a média desta amostra, é possível
verificar se a afirmação sobre a média populacional é verdadeira. Para tanto, basta verificar se a
estatística do teste estará na região de aceitação ou de rejeição da hipótese Ho. Aqui você tem três
situações distintas:
1ª) se o desvio-padrão da população é conhecido ou a amostra é considerada grande (n >30), a
distribuição amostral a ser utilizada será da Normal ou Z e a estatística-teste que será utilizado:
Estatística do teste Variavilidade das médias
H0 é aceita
H0 é rejeitada H0 é rejeitada
Região crítica Região crítica
Região de rejeição Região de rejeição Região de aceitação

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
14
x µz
σ
n
−=
Onde x: média amostral; µ: média populacional; σ: desviopadrão populacional e n:
tamanho da amostra.
2ª) agora, se você não conhecer o desvio-padrão populacional e a amostra for pequena (
), então, a distribuição amostral a ser utilizada será a t de Student, e a estatísticateste
será:
x µt
s
n
−=
Uma observação importante: quando trabalhamos com amostras grandes, ou seja, n > 30, a distribuição de Z e t de Student apresentam comportamentos próximos e valores da estatística próximos também.
Veja uma situação utilizando o teste de hipótese para uma média usando Z. Registros dos últimos
anos de funcionários de uma determinada empresa atestam que sua média num teste de QI foi 115,
com um desvio-padrão de 20. Para saber se uma nova equipe de funcionários é
típica desta empresa, retirou-se uma amostra aleatória de 50 funcionários rios desta nova equipe,
encontrando-se média de 118. Com uma significância de 5%, teste a hipótese de que esta nova
equipe apresente a mesma característica dos funcionários da empresa, com relação ao QI.
Resolução
H0: µ = 115
H1: µ # 115
Estatística a ser utilizada →→→→ Z X µ
Z ,σ
n
− −= = =
01 1 8 1 1 5 1 0 62 0
5 0
Conclusão: como o valor da estatística calculado está na região de aceitação, então
deve-se aceitar H0 como verdadeiro
Exercício 1: um fabricante afirma que seus pneus radiais suportam em média uma
quilometragem com mais de 40.000 km. Para testar essa afirmação, um comprador
selecionou uma amostra de 49 pneus.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
15
Os testes nessa amostra forneceram uma média de 43.000 km. Sabe-se que a
quilometragem de todos os pneus tem desvio-padrão de 6.500 km. Se o comprador testar
essa afirmação ao nível de significância de 5%, qual será sua conclusão?
Veja agora uma situação aplicando o teste t de Student.
O tempo médio gasto para profissionais da área de Ciências Contábeis realizarem um determinado
procedimento tem sido de 50 minutos. Um novo procedimento está sendo implementado. Neste
novo procedimento, retirou-se uma amostra de 12 pessoas, com um tempo
médio de 42 minutos e um desvio-padrão de 11,9 minutos. Teste a hipótese de que a média
populacional no novo procedimento é menor do que 50.
H0: µ = 115
H1: µ < 115
Estatística a ser utilizada →→→→ t
X µt ,
σ ,
n
− −= = = −
04 2 5 0 2 5 31 1 9
1 2
Conclusão: como o valor da estatística calculado está na região de rejeição, então deve-
se rejeitar H0 como verdadeiro
1.2 Testes de hipóteses para a razão de duas variâncias.
Este teste de hipótese é utilizado para saber se duas variâncias populacionais são
estatisticamente iguais ou se uma é maior do que a outra. Então, utilizando a distribuição
F, poderemos formular o teste de hipótese da razão entre duas variâncias e chegar à
conclusão baseados apenas nas estimativas calculadas a partir das amostras. As
hipóteses H0 e H1 serão:
1
H : σ =σ
H : σ σ>
2 20 1 2
2 21 2
Como está se utilizando um teste unilateral à direita (questões didáticas), então, no cálculo da estatística de F, teremos a maior variância dividida pela menor variância.
A maior variância amostral encontrada será chamada de S
21 (proveniente de uma
amostra de tamanho n1), e a menor variância amostral será chamada S22 (proveniente de
amostra de tamanho n2).

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
16
Vamos supor que tivéssemos duas amostras provenientes de duas populações.
Desejamos saber se as variâncias das populações são estatisticamente iguais ou uma é
maior do que a outra. Considere uma significância de 2,5%. Os resultados amostrais são
apresentados a seguir:
S21= 0,5184 com n1 = 14
S22= 0,2025 com n2 = 21
A estatística será dada por:
Então, a variável de teste do teste F será:
s
σF
s
σ
=
21212222
Como em H0, estou considerando que as variâncias populacionais são iguais, então, na
expressão acima as duas variâncias populacionais vão se cancelar. No nosso exemplo,
teremos:
s ,F ,
,s= = =
2122
0 5 1 8 4 2 5 60 2 0 2 5
O valor tabelado (crítico) da distribuição de F será obtido na tabela da distribuição com
uma significância de 2,5%. Considerando como graus de liberdade iguais a 13 (n1 – 1)
para o numerador (v1) e 20 (n2 – 1) para o denominador (v2), chegaremos ao seguinte
resultado: valor tabelado igual a 2,637.
O valor calculado da estatística foi menor do que o tabelado, então, ele caiu na região de
aceitação de H0. Assim, aceitamos H0 e consideramos que a variância da população 1 é
estatisticamente igual à variância da população 2, ou seja, não ocorre uma diferença
entre elas.
Este teste servirá de base na escolha do próximo teste (diferença entre médias para
amostras independentes), ou seja, escolher o tipo de teste a ser utilizado.
1.3. Testes de hipóteses para a diferença entre médias populacionais
Quando queremos comparar a média de duas populações, retiramos amostras das duas,
e estas amostras podem apresentar tamanhos diferentes. Vamos considerar as situações
de amostras independentes (as populações não apresentam nenhuma relação entre si) e
amostras dependentes (uma população sofre uma intervenção e avalia-se antes e depois
da intervenção para saber se esta resultou em algum efeito).

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
17
1ª situação: amostras independentes e grandes (n>30).
2ª situação: amostras independentes e pequenas, mas que apresentam variâncias
populacionais estatisticamente iguais.
3ª situação: amostras independentes e pequenas, mas que apresentam variâncias
populacionais estatisticamente desiguais.
4ª situação: amostras dependentes.
Agora você vai estudar cada uma destas situações. Lembre-se que as considerações
anteriores em relação aos passos para formulação dos testes de hipóteses permanecem
as mesmas.
A grande diferença que você vai ver ocorre só na determinação das hipóteses a serem
testadas. A hipótese H0será:
H0: µ1 – µ1 = d0
Onde: µ1: média da população 1 e µ2: média da população 2.
Já do corresponde a uma diferença qualquer que você deseje testar.
Geralmente, quando queremos saber se as médias das duas populações são
estatisticamente iguais, utilizamos o valor de do igual a zero.
As hipóteses alternativas seguem a mesma linha de raciocínio.
Abaixo temos um quadro que nos auxiliará a visualizar estas considerações.
H0 H1
µ1 – µ2 = d0 µ1 – µ2 < d0
µ1 – µ2 > d0
µ1 – µ2 ≠ d0
É importante ressaltar que, se as hipóteses alternativas forem unilaterais, o sinal da
hipótese Ho será menor ou igual, maior ou igual, dependendo da hipótese alternativa,
apesar de utilizarmos a notação de igual (conforme comentado anteriormente).
Todas as outras considerações em relação aos testes de hipótese permanecem as
mesmas. Vamos, então, procurar entender cada situação para os testes de hipóteses
para diferença entre médias.
1ª situação: amostras independentes e grandes (n>30).
Como estamos trabalhando aqui com amostras grandes, ou quando se conhecem os
desvios-padrão populacionais, devemos trabalhar com a distribuição amostral de Z

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
18
(raciocínio semelhante ao utilizado no teste de hipótese para uma média). Portanto, a
estatística do teste será dada por:
( ) ( )X X µ µZ
σ σ
n n
− − −=
+
1 2 1 2
2 21 2
1 2
Sendo
X 1: média da amostral 1;
X 2: média da amostral 2;
µ1: média da população 1; µ2: média da população 2;
σ21 : variância da população 1;
σ22 : variância da população 2;
n1: tamanho da amostra 1; n2 tamanho da amostra 2.
OBS: se trabalharmos com amostras grandes poderemos substituir as variâncias populacionais pelas variâncias amostrais. Vamos, então, ver como podemos aplicar o teste de hipótese para a diferença entre
médias nesta situação.
Foram retiradas amostras de aparelhos usados de duas marcas, e os resultados são
apresentados na tabela a seguir. Verifique se as duas marcas têm uma mesma
durabilidade ou se são diferentes, com uma significância de 0,05.
Marcas A B
Média 1.160 1.140
Desvio-padrão 90 80
tamanho amostra 100 100
Reolução
A B
A B
H :µ µ
H :µ µ
− =
− ≠
0
0
00
α = 0,05
Estatística a ser utilizada →→→→ Z

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
19
( ) ( ) ( ) ( ) ( )X X µ µ . .Z ,
σ σ
n n
− − − − −= = =
++
1 2 1 2
2 2 2 21 2
1 2
1 1 6 0 1 1 4 0 01 9 6
9 0 8 01 0 0 1 0 0
Conclusão: como o valor da estatística calculado está na região de aceitação, então
deve-se aceitar H0 como verdadeiro
2ª situação: amostras independentes e pequenas, mas que apresentam variâncias
populacionais estatisticamente iguais.
Como as amostras com que estamos trabalhando são pequenas, e as variâncias
populacionais, desconhecidas, então, você deve trabalhar com a distribuição t de
Student.
Aqui consideraremos que as variâncias populacionais são estatisticamente iguais, pois
esta situação influenciará nos cálculos e, conseqüentemente, no processo decisório. Para
saber se as variâncias podem ser consideradas iguais, deve-se fazer um teste da razão
de duas variâncias (teste F) mostrado anteriormente.
A estatística do teste será dada por:
( ) ( )
p
X X µ µt
Sn n
− − −=
+
1 2 1 2
1 2
1 1
Aqui aparece um termo novo (Sp). Ele corresponde ao desvio padrão ponderado pelos
graus de liberdade, ou seja, calculamos um novo desvio-padrão, no qual o fator de
ponderação corresponde ao grau de liberdade de cada amostra. Veja a seguir:
( ) ( )p
n s n sS
n n
− + −=
+ −
2 21 1 2 2
1 2
1 12
Para você encontrar o valor tabelado que limita as regiões de aceitação e rejeição na
tabela t de Student (revise na Unidade 3), o número de graus de liberdade (v) será dado
por:
v n n= + −1 22
Vamos agora resolver um exemplo.
Um treinamento na área contábil de um grupo empresarial é ministrado a 12 profissionais
pelo método convencional. Um segundo grupo de dez profissionais recebeu o mesmo
treinamento por um método programado. Os resultados de notas dos dois métodos são

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
20
apresentados na tabela a seguir. Determine se há diferença entre os dois métodos
considerando uma significância de 0,01.
Método Convencional Programado
Média 85 81
Desvio-padrão 4 5
OBS: no teste F, não foram encontradas diferenças entre as variâncias populacionais. Resolução
c p
c p
H :µ µ
H :µ µ
− =
− ≠
0
0
00
Estatística a ser utilizada →→→→ t
( ) ( ) ( ) ( )A B A B
p
A B
X X µ µt ,
S ,n n
− − − − −= = =
+ +
8 5 8 1 02 0 7
1 1 1 14 4 7 81 2 1 0
V = 22 – 2 = 20 gl
α ,t t ,= =2 0 0 0 52 8 4 5
Conclusão: como o valor da estatística calculado está na região de aceitação, então
deve-se aceitar H0 como verdadeiro
Exercício 2: duas técnicas de venda são aplicadas em dois grupos de vendedores. A
técnica A foi aplicada em um grupo de 12 vendedores, resultando em um número de
vendas efetivadas em média de 76 e uma variância de 50. Já a técnica B foi aplicada em
um grupo de 15 vendedores, resultando em um número de vendas efetivadas em
média de 68 e uma variância de 75. Considerando as variâncias estatisticamente iguais,
e com uma significância de 0,05, verifique se as médias são estatisticamente iguais.
3ª situação: amostras independentes e pequenas, mas que apresentam variâncias
populacionais estatisticamente desiguais. A diferença desta situação para a anterior é
que você considera que as populações apresentam variâncias estatisticamente
desiguais. Também utilizare mos a estatística do teste a partir da distribuição t de
Student. A estatística do teste será dada por:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
21
( ) ( )A B A BX X µ µt
s s
n n
− − −=
+
2 21 2
1 2
Outra diferença esta no cálculo do número de graus de liberdade, pois nesta situação
utilizaremos uma aproximação que é dada pela expressão a seguir:
s s
n nv gl
s s
n n
n n
+
= = +
− −
22 21 2
1 22 22 2
1 2
1 2
1 21 1
Se este valor calculado apresentar valores decimais, deve ser feito o arredondamento
para um número inteiro. Vamos a um exemplo.
Para estudar o efeito da certificação ambiental no valor de empresas, consideraram-se
amostras de empresas da mesma área, com e sem certificação ambiental. Obtiveram-se
os seguintes resultados. Após ter sido testado, verificou-se que as populações
apresentam variâncias desiguais. Teste a hipótese de que os dois padrões de empresas
apresentam médias de valor diferentes.
Método Com certificação ambiental Sem certificação ambiental
Média 24 13,3
Desvio-padrão 1,7 2,7
N 8 21
Resolução
c p
c p
H :µ µ
H :µ µ
− =
− ≠
0
0
00
Estatística a ser utilizada →→→→ t
( ) ( ) ( ) ( )A B A B
p
A B
X X µ µ ,t ,
S ,n n
− − − − −= = =
+ +
2 4 1 3 3 02 0 7
1 1 1 14 4 7 81 2 1 0
V = 22 – 2 = 20 gl
α ,t t ,= =2 0 0 0 52 8 4 5

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
22
4ª situação: amostras dependentes.
Relembrando, amostras dependentes ocorrem quando se faz uma intervenção e se
deseja saber se os resultados antes da intervenção são iguais aos resultados depois da
intervenção.
Um ponto importante nesta situação é que são calculadas primeiramente as diferenças
de antes e depois. Esta diferença é chamada de di. Então, você pode ver que:
di = valor antes - valor depois
Com base nestas diferenças (di) você vai calcular a média (D) e o desvio- padrão destas
diferenças (SD)
n
i
i
d
Dn
==∑1
n
ini
iD
d
dn
Sn
=
=
−
=−
∑∑
2
121
11
Veja que estas fórmulas são iguais às de cálculo da média e desvio-padrão apresentados
na Unidade 1. Neste caso, no lugar da variável x, são utilizados os valores de di
(diferenças).
Com estes valores, a estatística teste será dada por:
D
D dt
S
n
−=
0
O valor de n corresponde ao número de diferenças calculadas, e o grau de liberdade para
ser olhado na tabela t de Student será dado por n - 1.
Em um estudo, procurou-se investigar a não-eficácia de uma propaganda na percepção
de clientes. O Quadro a seguir dá os resultados de pessoas selecionadas anteriormente.
No nível de 5% de significância, teste a afirmação de que as percepções sensoriais são
inferiores após a propaganda, ou seja, a propaganda não é eficaz. (Os valores se referem
a antes e depois da propaganda; medidas em uma escala de zero a doze.)
Pessoa A B C D f G H I
Antes 6,6 6,5 9,0 10,3 11,3 8,1 6,3 11,6
Depois 6,8 2,4 7,4 8,5 8,1 6,1 3,4 2,0

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
23
Resolução
D
D
H :µ
H :µ
=
<
0
0
00
αααα = 0,05 Estatística a ser utilizada →→→→ t
d
D
α ,
D µ ,t ,
S ,
n
t t ,
− −= = =
= =0 0 5
2 9 1 1 4 0 2 7 13 0 3 68
1 8 9 5
Conclusão: como o valor da estatística calculado está na região de rejeição, então deve-
se rejeitar H0 como verdadeiro
1.4. Testes de hipóteses para diferença entre proporções
Em diversas situações, o que nos interessa é saber se a proporção de sucessos (evento
de interesse) em duas populações apresenta a mesma proporção ou não. Neste caso, os
dados seguem uma distribuição de Bernoulli (vista na Unidade 2) com média p e
variância pq. Portanto, a expressão da estatística-teste (no caso utilizaremos a
distribuição de Z) será dada por:
( ) ( )( ) ( )( )
ˆ ˆp p p pz
ˆ ˆˆ ˆ p qp q
n n
− − −=
1 2 1 2
2 21 1
1 2
Nesta expressão, você tem:
p 1 e p 2correspondem à proporção de sucesso nas amostras 1 e 2, respectivamente.
p1 e p2 correspondem à proporção de sucesso nas populações 1 e 2, respectivamente.
Você deve se lembrar que a proporção de fracasso (q) é dada por um, menos a
proporção de sucesso.
Vejamos, então, como aplicar o teste da diferença de proporções.
Uma questão de teste é considerada boa, se permitir discriminar entre estudantes
preparados e estudantes não preparados. A primeira questão de um teste foi respondida
corretamente por 62, dentre 80 alunos preparados, e por 23, dentre 50 alunos não
preparados. Com um nível de 5% de significância, teste a afirmação de que esta questão
foi respondida corretamente por uma proporção maior de estudantes
preparados.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
24
H :p p
H :p p
− =
> =
0 1 2
1 1 2
00
Estatística a ser utilizada →→→→ Z
( ) ( )( ) ( )( )
( ) ( )( )( ) ( )( )
ˆ ˆp p p p , ,z ,
, , , ,ˆ ˆˆ ˆ p qp q
n n
− − − − −= = =
++
1 2 1 2
2 21 1
1 2
0 7 7 5 0 4 6 03 7 3
0 7 7 5 0 2 2 5 0 4 6 0 5 48 0 5 0
α ,Z Z ,= =0 0 51 6 5
Conclusão: como o valor da estatística calculado está na região de rejeição, então deve-
se rejeitar H0 como verdadeiro
1.5. Teste do qui-quadrado de independência
O teste do qui-quadrado de independência está associado a duas variáveis qualitativas,
ou seja, uma análise bidimensional (visto na Unidade 2). Você se lembra que as tabelas
de contingência permitem verificar a relação de dependência entre as duas variáveis
analisadas.
Neste caso, procura-se calcular a freqüência de ocorrência das características dos
eventos a serem estudados. Por exemplo, podemos estudar a relação entre o sexo de
pessoas (masculino e feminino) e o grau de aceitação do governo (ruim, médio e bom).
Então, você vaiobter, por exemplo, o número de pessoas (freqüência) que são do sexo
feminino e que acham o governo bom. Todos os cruzamentos das duas variáveis são
calculados.
Vamos apresentar a você, como exemplo, os possíveis resultados da situação
apresentada anteriormente (dados simulados).
Sexo Função
Ruim Médio Bom Total
Masculono 157 27 74 258
Feminino 206 0 10 276
Total 363 27 84 474
Podemos, então, querer determinar o grau de associação entre essas duas variáveis, ou
seja, se o grau de aceitação do governo depende do sexo ou existe uma relação de
dependência.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
25
As hipóteses a serem testadas são:
H0: variável linha independe da variável coluna
H1: variável linha está associada com a variável coluna
A estatística de qui-quadrado será dada por meio da seguinte expressão:
( )i i
i
ko e
c
i e
f fχ
f=
−=∑
2
2
1
Onde o valor k corresponde ao número de classes (freqüências encontradas). Você pode
verificar que f0 corresponde à freqüência observada, ou seja, o valor encontrado na
tabela de contingência.
Já fe corresponde à freqüência esperada caso as variáveis não tenham nenhuma relação
de dependência, ou seja, as duas variáveis sejam independentes. Em função desta
definição, a freqüência esperada (fe) será obtida por:
( )( )e
total linha total colunaf
total geral=
Neste caso, os graus de liberdade (v), para que possamos olhar a tabela de qui-
quadrado, são dados por:
v = (h-1) (k-1) nas tabelas com h linhas e k colunas Então, para cada célula da tabela de
contingências, você vai calcular a diferença entre fe e. fo. Esta diferença é elevada ao
quadrado para evitar que as diferenças positivas e negativas se anulem. A divisão
pela freqüência esperada é feita para obter diferenças em termos relativos.
Para entendermos melhor o teste de qui-quadrado do tipo independência, vamos
trabalhar com a seguinte situação: para testar se determinada droga era capaz de inibir a
absorção de álcool pelo organismo humano, realizou-se um experimento com a
participação de 60 voluntários (homens saudáveis, idade entre 25 e 28 anos). Metade
dos voluntários tomou a droga, e a outra metade não tomou. Todos os voluntários
tomaram duas doses de uísque. Uma hora mais tarde, selecionou-se uma amostra do
sangue de cada sujeito, observando-se os resultados a seguir. Usando 5% de
significância, pode-se concluir que o resultado do teste está associado à ingestão da
droga?

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
26
Teste droga Presença de álcool Ausência de álcool
Tomaram 8 32
Não tomaram 16 40
H0: Presença ou ausência de álcool independe de tomar droga
H1: Presença ou ausência de álcool está associada a tomar droga
Teste droga Presença de álcool Ausência de álcool
Tomaram 8 (10) 32 (30) 40
Não tomaram 16 (14) 40 (42) 56
96
.=
5 0 2 4 1 49 6
Valores entre parênteses (fe)
( ) ( ) ( ) ( ) ( )i i
i
ko e
c
i e
f fχ ,
f=
− − − − −= = + + + =∑
2 2 2 2 22
1
8 1 0 3 2 3 0 1 6 1 4 4 0 4 20 9 1 4
1 0 3 0 1 4 4 2
v = (2-1) . (2-1) = 1 gl
α = 0,05 → Qui-quadrado tabelado = 3,8415
Como o valor calculado (0,914) foi menor do que o tabelado, então o calculado caiu
na região de aceitação de H0.
Portanto, não temos indícios para rejeitar a hipótese H0, ou seja, o uso da droga não levou a uma inibição da absorção de álcool.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
27
Exercícios 1. Pretende-se lançar uma moeda 5 vezes e rejeitar a hipótese de que a moeda é não-
tendenciosa, isto é, pretende-se rejeitar Ho: π = 0,50, se em 5 (cinco) jogadas ocorrerem
5 coroas ou 5 caras. Qual é a probabilidade de se cometer erro do tipo I?
2. Você suspeita que um dado é viciado, isto é, você suspeita que a probabilidade de
obter face 6 é maior do que 1/6. Você decide testar a hipótese de que o dado é não-
viciado, jogando-o cinco vezes e rejeitando essa hipótese se ocorrer a face 6 (seis), 4 ou
5 vezes. Qual o nível de significância do teste?
3. Uma urna contém 6 fichas, das quais θ são brancas e 6 - θ são pretas. Para testar a
hipótese de nulidade de que θ = 3, contra a alternativa de que θ ≠ 3, são retiradas 2
(duas) fichas da urna ao acaso e sem reposição. Rejeita-se a hipótese nula se as duas
fichas forem da mesma cor.
(a) Determine P(Erro do Tipo I).
(b) Determine o poder do teste para os diferentes valores de θ.
(c) Considere, agora, que a segunda ficha é retirada após a reposição da primeira.
Calcule, novamente, o nível de significância e os valores do poder do teste.
(d). Compare os dois procedimentos (com e sem reposição da segunda ficha retirada).
Qual a conclusão?
4. Para decidirmos se os habitantes de uma ilha são descendentes da civilização A ou B,
iremos proceder da seguinte forma:
(i) Selecionamos uma amostra aleatória de 100 moradores adultos da ilha e
determinamos a altura média;
(ii) Se a altura média for superior a 176 cm, diremos que os habitantes são descendentes
de B, caso contrário, admitiremos que são descendentes de A.
Os parâmetros das duas civilizações são: A: µA = 175 cm e σA = 10 cm e B: µB = 177 cm
e σB = 10 cm.
Define-se ainda: erro do tipo I como sendo “dizer que os habitantes são descendentes de
B quando, na realidade, são de A” e erro do tipo II “dizer que os habitantes são de A
quando, na realidade, são descendentes de B”.
(a) Qual a probabilidade de erro do tipo I e do tipo II?

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
28
(b) Se σA = σB = 5, como ficariam os valores dos erros do tipo I e II?
(c) Qual deve ser a regra de decisão se quisermos fixar a a probabilidade de Erro I em
5%. Qual a probabilidade de erro II neste caso?
(d) Quais as probabilidades de Erro II, se as médias forem: µA = 178 e se µB = 180?
5. Fazendo o teste H0: µ = 1150 (σ = 150) contra H1: µ = 1200 (σ = 200) e com n = 100,
estabeleceuse a seguinte região crítica: RC = [1170, +∞).
(a) Qual a probabilidade α de rejeitar H0 quando verdadeira?
(b) Qual a probabilidade β de Aceitar H0 quando H1 é verdadeira?
6. Numa linha de produção é importante que o tempo gasto numa determinada operação
não varie muito de empregado para empregado. Em operários bem treinados a
variabilidade fica em 100 u2. A empresa colocou 11 novos funcionários para trabalhar na
linha de produção, supostamente bem treinados, e observou os seguintes valores, em
segundos:
125 135 115 120 150 130 125 145 125 140 130
Testar se a tempo despendido por estes funcionários pode ser considerado mais variável
do que os demais funcionários. Utilize 5% de significância.
7. Diversas políticas, em relação às filiais de uma rede de supermercados, estão
associadas ao gasto médio dos clientes em cada compra. Deseja-se comparar estes
parâmetros de duas novas filiais, através de duas amostras de 50 clientes,selecionados
ao acaso, de cada uma das novas filiais. As médias obtidas foram 62 e 71 unidades
monetárias. Supondo que os desvios padrões sejam idênticos e iguais a 20 um, teste a
hipótese de que o gasto médio dos clientes não é o mesmo nas duas filiais. Utilize uma
significância de 2,5%?
8. Em dois anos consecutivos foi feito um levantamento de mercado sobre a preferência
dos consumidores pelo por um determinado produto. No primeiro ano o produto era
anunciado com freqüência semanal nos veículos de comunicação e no segundo ano com
freqüência mensal. No levantamento foram utilizados duas amostras independentes de
400 consumidores cada. No primeiro ano o percentual de compradores ficou em 33% e
no segundo ano em 29%. Considerando o nível de significância de 5%, teste a hipótese
de que a freqüência do anúncio tem influência na manutenção da fatia de mercado.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
29
9. Para verificar se uma moeda é honesta, com base em 20 lançamentos independentes,
adotamos o seguinte critério: consideramos a moeda não honesta se o resultado for
menor do que 7 ou maior do que 13.
(a) Formule esse problema como um problema de teste de hipóteses.
(b) Quais são os significados dos erros tipo I e II?
(c) Qual é o nível de significância do teste?
10. No ano de 2003 foi feita uma pesquisa em uma estância turística e constatou-se que
apenas 60% dos visitantes estavam satisfeitos com a infraestrutura oferecida. Com o
intuito de aumentar essa proporção a prefeitura fez algumas melhorias na cidade e
depois de um ano, resolveu verificar se as mesmas produziram o efeito desejado. Para
isso entrevistou 50 turistas.
(a) Formule esse problema como um problema de teste de hipóteses.
(b) Quais são os significados dos erros tipo I e tipo II?
(c) Qual é a região crítica associada a um nível de significância de 10%.
(d) Se 37 dos 50 turistas entrevistados estavam satisfeitos com a infraestrutura oferecida,
qual é asua conclusão?
11. A marca Z de um produto é responsável por 50% das vendas desse produto em um
supermercado. Uma campanha promocional foi contratada e os promotores garantem
que a marca Z passará a ser responsável por uma porcentagem maior das vendas. O
dono do supermercado propõe entrevistar alguns clientes após o encerramento da
campanha promocional e perguntar a cada um deles se ele usualmente compra a marca
Z do produto.Sendo p a porcentagem de vendas do produto Z após a campanha (a)
Estabeleça as hipóteses apropriadas.
(b) Quais são os significados dos erros tipo I e tipo II para o problema?
(c) Se entre 18 clientes entrevistados, 12 responderam sim, qual é a sua conclusão com
base no nível descritivo?
(d) Se entre 324 clientes entrevistados, 178 responderam sim, qual é a sua conclusão
com base no nível descritivo?
12. Com o objetivo de testar uma hipótese H0 contra a hipótese alternativa Ha, um
pesquisador fixou as probabilidades de erros de 1ª e 2ª espécies, respectivamente, em
5% e 10%.
Realizado o teste, imaginem-se 2 situações diferentes:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
30
Em A: O pesquisador rejeitou a hipótese de nulidade
Em B: O pesquisador não rejeitou a hipótese de nulidade.
Para cada situação (A e B) assinale a alternativa correta e justifique.
a) O pesquisador certamente estará cometendo um erro cuja probabilidade de ocorrência
é igual a 5%;
b) O pesquisador certamente estará cometendo um erro cuja probabilidade de ocorrência
é igual a 10%;
c) Se o pesquisador estiver cometendo um erro, a probabilidade de ocorrência associada
a este erro é de 15%;
d) Se o pesquisador estiver cometendo um erro, a probabilidade de ocorrência associada
a este erro é de 10%;
e) Se o pesquisador estiver cometendo um erro, a probabilidade de ocorrência associada
a este erro é de 5%.
12. A resistência ao resfriado comum em uma dada indústria, durante o inverno, é de
p=0,60. Foi proposto um tratamento preventivo com a finalidade de aumentar a
resistência ao resfriado para p=0,70. Então:
a) formule as hipóteses.
b) fixando a= 0,05 (ou valor mais próximo) e admitindo ter sido sorteada uma amostra de
tamanho n=20, observou-se que 4 operários ficaram resfriados. Nestas condições, qual é
a conclusão quanto à eficiência do medicamento?
13. Para se estimar a letalidade da doença B, acompanhou-se uma amostra de 30
doentes durante um ano. Após esse período, cinco deles haviam morrido. Testar a
hipótese de que essa letalidade é igual a 20%. Fixe o erro de 1º espécie em um a=10%.
14. Certa comunidade apresentou em um período de vários anos coeficiente de
incidência da doença X de 12 por 10.000 hab.. Em 1999, a incidência foi de 70 casos e a
população estimada foi igual a 50.000 habitantes. Nestas condições, ao nível de
significância de 1% (ou mais próximo) diga se concorda com as autoridades sanitárias
que consideraram a situação dentro do esperado.
15. Desejando-se conhecer o coeficiente de prevalência de determinada doença na
cidade A, selecionou-se uma amostra aleatória de 500 pessoas. Nesta amostra

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
31
detectaram-se 20 doentes. Teste a hipótese de que a prevalência é semelhante à
descrita na literatura de 10%. (Fixando a=5%)
16. Uma nova espécie de trigo desenvolvida em laboratórios será testada quanto a sua
produtividade, em comparação com a espécie tradicional. Dados do governo revelam
que a produtividade média de lavouras que se utilizam da espécie tradicional é de 25
ton/ha. A produtividade de uma fazenda é uma variável aleatória normalmente
distribuída. Dezesseis fazendas foram preparadas para a avaliação da nova espécie.
Qual seria o seu parecer sobre a nova espécie se, em seu experimento você
observasse na amostra média de 28 ton/ha e variância de 12( ton / ha)2 .
17. Um novo método de emagrecimento é anunciado como o fim das gordurinhas a mais
que perseguem a parcela mais abonada da sociedade. Preocupado com a seriedade
profissional dos responsáveis pelo uso do método, o conselho de medicina decide
promover um experimento para avaliar a eficácia do tratamento. Trinta e dois voluntários
são divididos em 2 grupos de igual tamanho, recebendo cada grupo um tratamento
diferente. Um deles recebe o novo método e o outro o método tradicional. Anotou-se a
variação de peso de cada indivíduo após o final do tratamento. Os resultados foram:
ind. 1 2 3 4 5 6 7 8 9 10 11 1
2
13 14 15 16
Novo 5.3 -
3.4
-
8.1
-
9.0
1.3 -
3.4
-
8.0
2.3 -
3.1
-
13.4
-
8.9
3.
1
-
4.3
-
3.0
-
3.2
2.0
trad. 4.2 -
2.0
-
5.0
-
3.0
2.8 -
0.3
-
6.0
-
3.1
0.3 -
12.0
-
6.0
2.
0
-
2.1
-
1.0
-
2.0
-
1.0
Suponha que tanto a variação do peso com o tratamento novo, quanto a
variação com o tratamento tradicional sejam variáveis aleatórias com
distribuições normais.
(a) Teste a hipótese de que não há diferença entre os dois métodos, a um nível
de 0,01. Suponha que os dois grupos de voluntários sejam independentes (b)
suponha agora que os indivíduos do primeiro grupo são irmãos gêmeos dos
indivíduos do outro grupo(pares de gêmeos, é claro). Para cada par aplicou-se a
um dos gêmeos o tratamento novo e ao outro o tradicional. Teste com base
nessa informação adicional a mesma hipótese do item anterior, ao mesmo nível
de significância.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
32
18. Um novo método de aprendizagem foi testado através do seguinte experimento.
Em uma turma de 30 alunos utilizou-se o método novo e em outra turma de 30 alunas de
outra escola manteve-se o método tradicional. Ao final do curso aplicou-se um mesmo
exame às duas turmas. Os resultados foram:
Turma1-método novo: média=69 desvio padrão=10
Turma2-método antigo: média=60 desvio padrão=9.
Com base nestas informações, teste se há diferença significativa entre os dois
métodos, a um nível de 0,05. Suponha as notas individuais de cada aluno como v.a.
normais de mesma variância e médias possivelmente diferentes.
19. Um novo tratamento anti-corrosivo para chapas de aço foi testado. O experimento
realizado foi o seguinte: 9 chapas diferentes foram selecionadas sendo cada uma
dividida em duas. A uma das metades aplicou-se o tratamento novo e a outra metade
o tratamento antigo. Anotou-se, então, o tempo até o início da corrosão em cada
metade.Os resultados obtidos foram:
chapa 1 2 3 4 5 6 7 8 9
metade/novo 36.2 48.3 35.4 39.3 40.2 37.4 39.3 42.3 36.0
metade/antigo 31.4 39.2 35.0 33.4 41.3 36.8 38.1 43.0 35.0
Suponha que o tempo até a corrosão em cada metade é uma variável com
distribuição normal, e que o tratamento não influencia na variância desta variável, mas
apenas na sua média. Qual dos tratamentos voce recomendaria que fosse utilizado?
20. Um estudo é desenvolvido para investigar o efeito de um certo tratamento para
controlar a temperatura do corpo de porcos criados em laboratório e que possuem
uma deficiência genética que provoca redução na temperatura corpórea dos
porcos. As temperaturas de interesse foram medidas um dia antes e um dia
depois de submeterem os porcos ao tratamento. Os dados obtidos estão
apresentados na tabela abaixo.
animal 1 2 3 4 5 6 7 8 9 10
antes 38.1 38.4 38.3 38.2 38.2 37.9 38.7 38.6 38 38.2
depois 38.9 38.6 38.2 38.2 39.4 38.5 38.3 38.4 38.8 38.7
a) Há evidências de que o tratamento permite o controle da temperatura ?
b) Calcule um intervalo de confiança para a temperatura após a aplicação do
tratamento.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
33
21. Um entomologista está investigando se um inseto é predador de uma variedade
de uma espécie de plantas com folhas rugosas e uma outra com folhas lisas. Ele
acompanha o crescimento de cinco plantas de cada variedade e conta o número
de ovos do inseto em cada uma delas. Infelizmente ele perde uma observação
referente a planta de folha lisa. Para as 9 plantas que sobraram , ele obtem uma
quantidade média de 48,5 para lisa e 37,2 para rugosa. Fazendo os cálculos ele
encontra um valor t=2,65 com 7 graus de liberdade.
Após verificar melhor seus registros ele encontra a observação perdida, cujo valor é 110.
a) qual é agora o número médio de ovos do inseto para a planta lisa? b) como você acha
que ele determinou o valor de t? c) quando ele repete os cálculos fica surpreso de não
encontrar diferença sigificativa entre o número médio de ovos para os dois tipos de
folhas. O que pode ter acontecido?

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
34
C A P Í T U L O 2
ESTATÍSTICA EXPERIMENTAL
2.1 Introdução
Numa pesquisa científica o procedimento geral é formular hipóteses e verificá-las
diretamente ou por suas conseqüências.
Para isto é necessário um conjunto de observações e o planejamento de experimentos é
então essencial para indicar o esquema sob o qual as hipóteses possam ser verificadas
com a utilização de métodos de análise estatística que dependem da maneira sob a qual
as observações foram obtidas. Portanto, planejamento de experimentos e análise dos
resultados estão intimamente ligados e devem ser utilizados em uma seqüência nas
pesquisas científicas das diversas áreas do conhecimento. Isto pode ser visto por meio
da seguinte representação gráfica da circularidade do método científico.
2.1.1 Objetivo
Estudo dos experimentos, isto é, seu planejamento, execução, análise dos dados obtidos
e interpretação dos resultados.
2.1.2 A necessidade da estatística
Numa pesquisa científica, o procedimento geral é formular hipóteses e verificá-las
diretamente ou através de suas circunstâncias. Para tanto, é necessário um conjunto de
observações ou dados e o planejamento de experimentos é, então, essencial para indicar
o esquema sob o qual as hipóteses podem ser testadas.
O que nos obriga a utilizar a análise estatística, para testar as hipóteses formuladas é a
presença em todas as observações de efeito de fatores não controlados, que causam as
variações, tais como:
Diferenças genéticas dos animais, diferenças de fertilidade, etc.
Esses efeitos que sempre ocorrem, não podem ser medidos individualmente e tendem a
mascarar o efeito do tratamento em estudo.
O conjunto de efeitos de fatores não controlados é denominado de variação ao acaso ou
variação aleatória.
Visando tornar mínima a variação do acaso, o experimentador deve fazer o planejamento
de tal forma que consiga isolar os efeitos de todos os fatores que podem ser controlados.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
35
(2)
Observações
(1) (3)
Formulação de hipóteses Verificação das hipóteses formuladas
(4)
Desenvolvimento da teoria
Fica bastante claro neste esquema que técnicas de planejamento devem ser utilizadas
entre as etapas (1) e (2) e os métodos de análise estatística devem ser utilizados na
etapa (3).
Desenvolvendo um pouco mais está idéia podemos dizer que uma pesquisa científica
estatisticamente planejada consiste nas seguintes etapas
1. Enunciado do problema com formulação de hipóteses.
2. Escolha dos fatores (variáveis independentes) que devem ser incluídos no estudo.
3. Escolha da unidade experimental e da unidade de observação.
4. Escolha das variáveis que serão medidas nas unidades de observação.
5. Determinação das regras e procedimentos pelos quais os diferentes tratamentos são
atribuídos às unidades experimentais (ou vice versa).
6. Análise estatística dos resultados.
7. Relatório final contendo conclusões com medidas de precisão das estimativas,
interpretação dos resultados com possível referência a outras pesquisas similares e uma
avaliação dos itens de 1 a 6 (desta pesquisa) com sugestões para possíveis alterações
em pesquisas futuras.
EXEMPLO - Um pesquisador está interessado em estudar o efeito de vários tipos de
ração que diferem pela quantidade de potássio no aumento do peso de determinado tipo
de animal.
Este objetivo pode ser atingido se planejarmos a pesquisa com a finalidade de: comparar
as médias dos aumentos de peso obtidas com cada uma das rações. Neste exemplo, a
variável independente “ração” é um fator e os tipos de rações são os níveis deste fator,
ou tratamentos.
As medidas realizadas nas unidades experimentais após terem sido submetidas aos
tratamentos constituem os valores da variável dependente (ganho de peso).
Um delineamento experimental apropriado e bem conduzido deve ser o mais simples
possível, ter uma alta probabilidade de atingir seu objetivo e evitar erros sistemáticos.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
36
Suas conclusões devem ser as mais amplas possíveis e as respostas obtidas (dados)
devem ser analisados por
procedimentos estatísticos válidos.
Estudos dos experimentos, isto é, seu planejamento, execução, análise dos dados
obtidos e interpretação dos resultados.
Na etapa 5 de uma pesquisa cientifica descrita acima existem três princípios inerentes
em todos os delineamentos experimentais que são essenciais aos objetivos da ciência
estatística:
2.2. Conceitos importantes em experimentação
a. Experimento ou ensaio
É um trabalho previamente planejado, que segue determinados princípios básicos e no
qual se faz a comparação dos efeitos dos tratamentos.
b. Tratamento ou fator
é o método, elemento ou material cujo efeito desejamos medir ou comparar em um
experimento. Exemplos: a) variedades de milho; b) níveis de proteína na ração e c)
diferentes temperaturas de pasteurização do leite.
c. Unidade experimental ou parcela:
É a unidade que vai receber o tratamento e fornecer os dados que deverão refletir seu
efeito. Em qualquer pesquisa é necessário que o pesquisador discuta com o estatístico a
definição adequada do que constituirá a unidade experimental ou parcela. De um modo
geral, a escolha da parcela deve ser orientada de forma a minimizar o erro experimental,
ou seja, as parcelas devem ser o mais uniforme possível, para que, ao serem submetidas
a tratamentos diferentes, seus efeitos sejam detectados. Exemplos: a) uma fileira de
plantas com 3 metros de comprimento no campo; b) um leitão e c) um litro de leite.
d. Variações de Acaso
São variações que ocorrem nos experimentos atribuídos a efeito de fatores não
controlados, conhecidos ou não, que afetam os resultados experimentais.
Ex.:-diferenças genéticas entre os seres vivos;
-pequenas diferenças de fertilidade de solo;

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
37
-pequenas variações nas condições ambientais;
-pequenas variações nas doses de adubos, inseticidas, fungicidas, herbicidas, etc
-pequenos erros de pesagem ou de medida de nutrientes, de pesticidas ou do
produto agrícola, etc.;
-ligeiras variações na distribuição de rações
e. Delineamento experimental
É o plano utilizado na experimentação, e implica na forma como os tratamentos são
designados às unidades experimentais e em um amplo entendimento das análises a
serem feitas quando todos os dados estiverem disponíveis.
Como por exemplo temos:
Delineamento inteiramente casualizado ( DIC )
Delineamento em blocos casualizados (DBC)
Delineamento em quadrado latino (DQL)
f. Variável resposta
É a variável mensurada usada para avaliar o efeito de tratamentos.
g. Erro experimental: é o efeito de fatores que atuam de forma aleatória e que não são
passíveis de controle pelo experimentador.
2.2.1 Etapas da Pesquisa Cientıfica:
1. Enunciado do problema com formulação de hipóteses.
2. Escolha dos fatores (variáveis independentes) que devem ser incluídos no estudo.
3. Escolha da unidade experimental e da unidade de observação.
4. Escolha das variáveis que serão medidas nas unidades de observação.
5.Determinação das regras e procedimentos pelos quais os diferentes tratamentos
(combinação de níveis de fatores) são atribuídos às unidades experimentais (ou vice-
versa).
6. Análise estatística dos resultados.
7. Relatório final contendo conclusões com medidas de precisão das estimativas,
interpretação dos resultados com possível referência a outras pesquisas similares e uma

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
38
avaliação dos itens de 1 a 6 (desta pesquisa) com sugestões para possíveis alterações
em pesquisas futuras.
Exemplo: Estudar o efeito de 4 Rações e 3 Vitaminas no ganho de pesos de bovinos.
Denominações:
Fatores: são as variáveis independentes. Podem ser Fixos ou Aleatórios. No exemplo,
temos 2 fatores: A (Rações) e B ( Vitaminas)
Níveis:
No exemplo, temos 4 níveis de Rações (A1, A2, A3 e A4) e 3 níveis de variedade de
vitaminas(B1, B2, B3)
Tratamentos: Combinações dos níveis dos fatores
No exemplo, temos 4 x 3 tratamentos: A1B1;A1B2; ... ;A4B3
Tipos de fatores: Fixos ou hierárquicos
Classificação dos fatores: Cruzada ou Hierárquica
2.3 Escolha dos fatores e seus respectivos níveis 2.3.1 Escolha da Unidade Experimental
Em um grande número de situações práticas a unidade experimental é determinada pela
própria natureza do material experimental. Por exemplo, em experimentos com animais,
em geral, a unidade experimental é um animal.
Em outras situações, a escolha da unidade não é assim tão evidente, exigindo do
pesquisador juntamente com o estatístico algum estudo no sentido escolher a unidade
experimental mais adequada. Por exemplo, em experimentos com plantas, a unidade
experimental pode ser as vezes uma planta, um conjunto de plantas ou uma área. A
escolha da unidade experimental, de um modo geral, deve ser orientada no sentido de
minimizar o erro experimental, isto é, as unidades experimentais devem ser o mais
homogêneas possível, para que quando submetidas a dois tratamentos diferentes, seus
efeitos sejam facilmente detectados.
2.3.2 Escolha das Variáveis a Serem Medidas
As medidas realizadas nas unidades experimentais após terem submetidas aos
tratamentos constituem os valores da variável dependente. A variável dependente, em
geral, é pré-determinada pelo pesquisador, isto é, ele sabe qual a variável que ele quer

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
39
medir. O que constitui problema, às vezes, ´e a maneira como a variável é medida, pois
disto dependem a precisão das observações, e a distribuição de probabilidade da variável
a qual ´e essencial para a escolha do método de análise estatística. Assim, por exemplo,
se os valores de uma variável são obtidos diretamente por meio de um instrumento de
medida, (réguas, paquímetro, termômetro, etc.) a precisão de nossas observações vai
aumentar se, quando possível, utilizarmos como observação a média de três medidas da
mesma unidade experimental. Com relação à distribuição de probabilidade, em muitas
situações, as observações não são obtidas diretamente, e sim por meio de expressões
matemáticas que as ligam a outros valores obtidos diretamente. Neste caso, a
distribuição de probabilidade das observações vai depender da distribuição de
probabilidade da variável obtida diretamente e da expressão matemática que as
relaciona.
Portanto, as variáveis necessariamente presentes em um experimento são a variável
dependente, medida nas unidades experimentais, e o conjunto de fatores (variáveis
independentes), que determinam as condições sob as quais os valores da variável
dependente são obtidos. Qualquer outra variável que possa influir nos valores da variável
dependente deve ser mantida constante. Suponhamos, por exemplo, que o tempo
necessário para executar um experimento seja de 20 dias e que a temperatura ambiente
tenha influência sobre a variável dependente.
Neste caso, a temperatura ambiente deve ser mantida constante durante a execução do
experimento. Se, por problemas experimentais, for impossível mantermos a temperatura
ambiente constante, então devemos, além da variável dependente, medir a temperatura
correspondente a cada unidade experimental. Variáveis deste tipo são consideradas no
estudo como covariadas e sua informação é utilizada para reduzir o erro experimental.
2.3.3 Regras Segundo as quais os Tratamentos são Atribuídos as Unidades
Experimentais
Nas discussões apresentadas sobre cada um dos itens anteriores, a colaboração da
estatística é bem limitada exigindo-se a essencial colaboração do pesquisador. Porém, o
assunto discutido neste ıtem é o que poderíamos denominar planejamento estatístico de
experimentos. Trata-se de regras que associam as unidades experimentais aos
tratamentos e que praticamente determinam os diferentes planos experimentais.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
40
Lembramos neste ponto que os tratamentos são cada uma das combinações entre os
níveis de todos os fatores envolvidos no experimento.
Para que a metodologia estatística possa ser aplicada aos resultados de um experimento
é necessário, que em alguma fase do experimento o princípio a ser obedecido ´e a
repetição, segundo o qual devemos ter repetições do experimento para que possamos
produzir uma medida de variabilidade necessária aos testes de presença de efeitos de
tratamentos ou `a estimação desses efeitos.
Discutiremos a seguir estes dois princípios.
2.4 Princípios básicos da experimentação
Um delineamento experimental apropriado e bem conduzido deve ser o mais simples
possível, ter uma alta probabilidade de atingir seu objetivo e evitar erros sistemáticos.
Suas conclusões devem ser as mais amplas possíveis e as respostas obtidas (dados)
devem ser analisados por procedimentos estatísticos válidos.
Estudos dos experimentos, isto é, seu planejamento, execução, análise dos dados
obtidos e interpretação dos resultados.
2.4.1 Princípio da repetição
Repetição significa que um tratamento é repetido duas ou mais vezes. Sua função é
fornecer uma estimativa do erro experimental e dar uma medida mais precisa dos efeitos
dos tratamentos. O número de repetições que serão requeridas em um particular
experimento depende da magnitude das diferenças que o pesquisador deseja detectar e
da variabilidade dos dados com que se esta trabalhando. Levando-se em conta estas
duas coisas no começo do experimento, muitos problemas e frustrações serão evitadas.
Em condições de campo temos:
- Sem repetição
Baia 1 Baia 2
A B
- Com repetição
Baia 1 Baia 2 Baia 3 Baia 4 Baia 5
A A A A A
Baia 6 Baia 7 Baia 8 Baia 9 Baia 10
B B B B B

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
41
As principais funções da repetição são:
(i) o erro experimental é uma medida da variação que existe entre as observações de
parcelas tratadas semelhantemente. Esta variação, que é conhecida como variação
casual ou variação de acaso, é oriunda de 2 fontes principais: a variabilidade inerente
do material e aquela resultante da falta de uniformidade na condução física do
experimento.
(ii) O erro experimental é indispensável na determinação do erro de estimativa (por
ponto e por intervalo), no dimensionamento de amostra e na construção de testes de
hipóteses.
(iii) Através da repetição é que nos é possível estimar o erro experimental. Num experimento sem
repetição não nos é possível dizer se uma diferença constatada entre tratamentos pode ser
explicada como uma diferença entre tratamentos ou entre parcelas experimentais.
2.4.2 Princípio da casualização
Casualização é a designação dos tratamentos às unidades experimentais, tal que estas
têm a mesma chance (mesma probabilidade) de receber um tratamento. Sua função é
assegurar estimativas não-viesadas das médias dos tratamentos e do erro experimental.
Nesta fase do planejamento de um experimento já sabemos quais fatores serão
estudados e o número de níveis de cada fator que estarão presentes no experimento.
Sabemos ainda qual é a unidade experimental escolhida e a variável dependente.
Podemos imaginar que de um lado temos um conjunto U de unidades experimentais, e
de outro um conjunto T de tratamentos, que podem ser as combinações dos níveis de
todos os fatores envolvidos. Precisamos estabelecer esquemas que associam
subconjuntos de elementos de U a cada elemento de T. Vamos apresentar o esquema
mais simples. Para efeitos de notação vamos supor que o conjunto U tem n elementos, o
conjunto T tem k elementos, e o número de elementos de U submetidos ao tratamento Ti
é ri, com i=1, 2, ..., k, de tal modo que k
r nii 1
=∑=
O plano completamente aleatorizado é um esquema em que as unidades
experimentais que vão ser submetidas a cada tratamento são escolhidas completamente
ao acaso. Isto significa que cada unidade experimental tem igual probabilidade de
receber qualquer um dos tratamentos. Por exemplo, um pesquisador quer realizar um
experimento para estudar o efeito de um resíduo industrial que é adicionado em rações
de animais. Ele suspeita que este resíduo contém uma substância tóxica, cuja presença

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
42
no organismo produz um aumento relativo de alguns órgãos, como o fígado por exemplo.
Após uma entrevista com o pesquisador conseguimos as seguintes informações • O
experimento irá envolver um único fator, ração, com três níveis: t1 - ração normal, sem
resíduo industrial (grupo controle; t2 - ração normal com o resíduo tratado, e t3 - ração
normal com resíduo não tratado.
• Um conjunto de 18 camundongos foi selecionado. Todos, recém nascidos, com o
mesmo peso inicial e homogêneos com relação às características genéticas gerais. Por
isto foi decidido distribuir completamente ao acaso 6 animais para cada tratamento.
• A variável dependente (resposta) é o peso relativo do fígado após 90 dias do início do
experimento.
Uma maneira de se proceder ao sorteio é a seguinte:
• enumera-se as unidades experimentais de 1 a 18.
• coloca-se os tratamentos em seqüência , por exemplo:
T1 T1 T1 T1 T1 T1 , T2 T2 T2 T2 T2 T2 , T3 T3 T3 T3 T3 T3
• sorteia-se uma sequência de 18 números aleatórios. Pode-se obter, por exemplo, a
sequência :3, 1, 11, 15, 18, 16, 4, 5, 9, 12, 8, 7, 17, 14, 2, 6, 13, 10
• Distribuição das unidades experimentais segundo os tratamentos
Tratamentos Repetiçõe
T1 A3 A1 A11 A15 A18 A16
T2 A4 A5 A9 A12 A8 A7
T3 A17 A14 A2 A6 A13 A10
. Em condições de campo, temos:
- Sem casualização (com repetição)
Baia 1 Baia 2 Baia 3 Baia 4 Baia 5
A A A A A
Baia 6 Baia 7 Baia 8 Baia 9 Baia 10
B B B B B
- Com casualização (com repetição)

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
43
Baia 1 Baia 2 Baia 3 Baia 4 Baia 5
A B A B B
Baia 6 Baia 7 Baia 8 Baia 9 Baia 10
B A A B A
Se, após a repetição e a casualização, a ração A apresentar maior desempenho,
é de se esperar que esta conclusão seja realmente válida.
2.4.3 Princípio do controle local:
Este princípio de delineamento experimental permite certas restrições na aleatorização
para reduzir o erro experimental. Isto é comum quando o conjunto U de unidades
experimentais for muito heterogêneo (em termos da variável independente), o plano
experimental completamente casualizado torna-se pouco preciso porque o erro
experimental é muito grande. Em algumas situações dispomos de informações segundo
as quais, antes da realização do experimento, é possível agruparmos as unidades
experimentais em subconjunto de k unidades experimentais mais ou menos
homogêneas, sendo k o número de tratamentos envolvidos no experimento. Estes
subconjuntos são denominados blocos. Assim, a maior parte da heterogeneidade interna
do conjunto U é expressa pela heterogeneidade entre os blocos. A distribuição das
unidades experimentais entre os tratamentos obedece a uma restrição imposta pelos
blocos, isto é, as k unidades de cada bloco são distribuídas aleatoriamente entre os
tratamentos. Na análise de um experimento em blocos, além dos fatores de interesse,
deve-se levar em conta o fator controle experimental, blocos, diminuindo desta maneira
o erro experimental. Quanto maior for a heterogeneidade entre blocos, maior é a
eficiência deste plano experimental em relação ao completamente casualizado.
Em condições de campo, temos:
- Sem repetição, sem casualização, sem controle local
Baia 1 Baia 2
A B
- Com repetição, com casualização, com controle local
Bloco 1 Bloco 2 Bloco 3

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
44
A B B A B A
Bloco 4 Bloco 5 Bloco 6
A B A B B A
O controle local constitui restrições impostas na casualização para corrigir os efeitos da
variação conhecida ou suspeitada do material experimental. Considerando o controle
local, temos os seguintes tipos de delineamentos:
-Delineamento Inteiramente Casualizado (DIC) - sem controle local;
-Delineamento em Blocos Casualizados (DBC) - controle feito através de blocos
horizontais;
-Delineamento em Quadrado Latino (DQL) - controle feito através de blocos horizontais e
verticais.
A finalidade do controle local é dividir um ambiente heterogêneo em sub-ambientes
homogêneos. Este procedimento torna o experimento mais eficiente porque reduz o erro
experimental.
2.5 Número de repetições
O número de repetições de um experimento depende de uma série de fatores dos quais o
mais importante é o grau de precisão desejado.
Quanto menor a diferença real entre tratamentos que se quer detectar, maior é o número
de repetições necessárias. Há pouco valor em usar 10 repetições para detectar uma
diferença que 4 repetições detectaria; da mesma forma, há pouco valor em se executar
um experimento onde o número de repetições não é suficiente para detectar diferenças
que são importantes.
A heterogeneidade do material experimental é um fator que afeta o número de
repetições. Quanto maior o grau de heterogeneidade do material, maior deve ser o
número de repetições.
Como uma regra geral, aconselha-se usar um número de repetições que proporcione no
mínimo 10 graus de liberrdade para se estimar a variância residual (s2).
2.6 Bordaduras
São áreas que separamos na parcela para evitar a influência dos tratamentos aplicados
nas parcelas vizinhas. Assim, temos a área total e a área útil da parcela. Os dados a

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
45
serem usados na análise estatística serão aqueles coletados apenas na área útil da
parcela.
Como exemplo, temos : 10 m Área Total
Área Útil 4 m

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
46
Exercícios
1. Um experimento deve conter no mínimo o(s) seguinte(s) princípio(s) básico(s) da
experimentação:
a) repetição
b) casualização
c) controle local
d) repetição e controle local
e) repetição e casualização
f) casualização e controle local
g) nenhuma das respostas anteriores
2. A repetição tem a função de:
a) fornecer uma estimativa do erro experimental
b) validar a estimativa do erro experimental
c) controlar a heterogeneidade das unidades experimentais
d) nenhuma das anteriores
3. A casualização tem a função de:
a) fornecer uma estimativa do erro experimental
b) validar a estimativa do erro experimental
c) controlar a heterogeneidade das unidades experimentais
d) nenhuma das anteriores
4. Um extensionista, desejando comparar 10 rações para ganho de peso em animais,
procedeu da seguinte forma:
- tomou 10 animais de uma propriedade rural. Estes 10 animais visivelmente não eram
homogêneos entre si, porque foram oriundos de diferentes cruzamentos raciais e
apresentavam idades diferentes.
- as rações que o extensionista julgou ser as melhores foram designadas aos melhores
animais, e as rações que o extensionista julgou ser as piores foram designadas aos
piores animais, de tal forma que cada animal recebeu uma única ração.
- ao final de sua pesquisa, o extensionista recomendou a ração que proporcionou maior
ganho de peso nos animais.
Baseado nestas informações, pergunta-se:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
47
a) Quantos e quais foram os tratamentos em teste nesta pesquisa? Justifique sua
resposta.
b) Qual foi a constituição de cada unidade experimental nesta pesquisa? Justifique sua
resposta.
c) Qual(is) foi(ram) o(s) princípio(s) básico(s) da experimentação utilizados nesta
pesquisa? Justifique a sua resposta.
d) É possível estimar o erro experimental nesta pesquisa? Justifique sua resposta.
e) A conclusão dada pelo extensionista ao final da pesquisa, é estatisticamente
aceitável? Justifique a sua resposta.
5. Um bioquímico desejando verificar qual entre 5 enzimas (identificadas como E1, E2,
E3, E4 e E5) produz maiores fragmentos de DNA de células epiteliais de cobaias,
realizou o seguinte ensaio:
- selecionou um conjunto de 15 cobaias (sistematicamente identificadas como 1, 2, 3, 4,
5, 6, 7, 8, 9, 10, 11, 12, 13, 14 e 15) que eram supostamente homogêneas para as
características essenciais;
- de cada uma das 15 cobaias, tomou uma amostra de tecido epitelial de cada um dos
seguintes membros: superior, mediano e inferior. Procedeu posteriormente a uma mistura
das amostras coletadas dos três membros, denominada de amostra composta;
- cada amostra composta foi convenientemente tratada para a extração do DNA. A
amostra obtida contendo apenas o DNA foi denominada amostra genômica. As amostras
genômicas foram identificadas de acordo com o número da cobaia que a originou, ou
seja, a amostra genômica identificada como C1, conteve DNA extraído da cobaia 1; a
amostra genômica identificada como C2, conteve DNA extraído da cobaia 2; e assim por
diante. Ao final obteve-se as amostras genômicas C1, C2, C3, C4, C5, C6, C7, C8, C9,
C10, C11, C12, C13, C14 e C15;
- cada uma das amostras genômicas foi tratada com um tipo de enzima. A distribuição
das enzimas às amostras foi feita da seguinte forma sistemática: E1 foi destinada às
amostras genômicas C1, C2 e C3; E2 foi destinada às amostras genômicas C4, C5 e C6;
E3 foi destinada às amostras genômicas C7, C8 e C9; E4 foi destinada às amostras
genômicas C10, C11 e C12; e E5 foi destinada às amostras genômicas C13, C14 e C15;
- uma amostra de 1 ml de cada substrato químico dos fragmentos de DNA foi colocado
para correr em um gel. O tempo, em minutos, gasto por cada uma das 15 amostras para

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
48
percorrer a distância de 25 cm foi registrado para comparar o efeito das enzimas E1, E2,
E3, E4 e E5.
Com base nas informações fornecidas deste ensaio e das explicações fornecidas em sala
de aula, pergunta-se:
a) Quais foram os tratamentos em teste neste experimento? Justifique a sua resposta.
b) Neste experimento os tratamentos surgiram de uma forma aleatória, premeditada ou
sistemática? Justifique a sua resposta.
c) Qual foi a unidade experimental nesta pesquisa? Justifique a sua resposta.
d) O princípio da repetição foi utilizado nesta pesquisa? Justifique a sua resposta. Em
caso afirmativo, explique porque diferentes observações obtidas para um mesmo
tratamento não são iguais. Em caso negativo, faça uma análise crítica quanto à
necessidade do uso de repetições num experimento.
e) O princípio da casualização foi utilizado nesta pesquisa? Justifique a sua resposta.
f) O princípio do controle local foi utilizado nesta pesquisa? Justifique a sua resposta.
Em termos gerais, quando que o princípio do controle local deve ser utilizado em um
experimento?
g) É possível estimar o erro experimental nesta pesquisa? Justifique a sua resposta.
Em caso afirmativo, a estimativa do erro experimental é válida? Justifique a sua resposta.
Em caso negativo, indique o que deveria ser feito de diferente neste ensaio para ser
possível estimar o erro experimental. Justifique a sua resposta.
h) Neste ensaio, qual foi a variável resposta utilizada para comparar os efeitos de
tratamentos? Justifique a sua resposta.
6. Um pesquisador desejava comparar os efeitos que 8 tipos de óleo têm sobre o teor de
gordura total em preparos de maionese. Com esta finalidade, esse pesquisador procedeu
da seguinte forma:
- para a avaliação do teor de gordura total, o pesquisador tinha à sua disposição 8
bioquímicos. Devido à falta de experiência dos bioquímicos, o pesquisador temia que a
medição dos mesmos pudesse interferir na comparação dos tipos de óleo.
Visando controlar esta fonte de variação, o pesquisador decidiu que cada um dos 8
bioquímicos deveria fazer a medição do teor de gordura dos preparos de maionese
produzidos utilizando os 8 tipos de óleo;
- baseado em experimentos anteriores, o pesquisador sabia que, apesar do controle de
qualidade, havia variação entre os lotes de substrato de preparos de maionese.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
49
O substrato de preparo da maionese é o composto que tem todos os ingredientes do
preparo da maionese, exceto o óleo. Como um lote de substrato não seria suficiente para
testar os 8 tipos de óleo em todas as repetições desejadas, o pesquisador decidiu que
prepararia 8 lotes de substrato e dividiria cada lote em 8 partes iguais. Cada uma das 64
partes, assim obtidas, seria denominada de amostra básica;
- foi então realizada uma distribuição ao acaso dos 8 tipos de óleo às amostras básicas,
tendo as seguintes restrições na casualização:
1a) cada tipo de óleo deveria ser aplicado em uma única amostra básica de cada um dos
8 lotes de substrato.
2a) os 8 tipos de preparo de maionese obtidos misturando cada uma das amostras
básicas com cada um dos 8 tipos de óleo, deveriam ser avaliadas por cada um dos 8
bioquímicos;
No local que foi conduzido o experimento, o pesquisador constatou que, após certo
tempo do experimento ter sido instalado, houve uma pequena contaminação por fungo
em algumas unidades experimentais. O pesquisador, usando do seu conhecimento
técnico na área, julgou que a contaminação não comprometeria os resultados obtidos no
experimento.
Baseando-se nestas informações, responda com objetividade e clareza, as seguintes
perguntas:
a Quais foram os tratamentos em teste? Justifique a sua resposta.
b Como você classificaria a fonte de variação contaminação por fungo, observada
nesse experimento? Justifique a sua resposta.
c Qual foi a unidade experimental utilizada nesta pesquisa? Justifique a sua resposta.
d O princípio da repetição foi utilizado nesta pesquisa? Se sua resposta for afirmativa,
responda qual foi o número de repetições utilizado. Se a sua resposta for negativa,
responda se o procedimento do pesquisador está correto.
e O princípio da casualização foi utilizado nesta pesquisa? Justifique a sua resposta.
f O princípio do controle local foi utilizado nesta pesquisa? Se a sua resposta for
afirmativa, explique como este princípio foi utilizado. Se a sua resposta for negativa,
explique por que não houve a necessidade da utilização deste princípio.
g Qual foi a característica utilizada pelo pesquisador para avaliar o efeito de
tratamentos neste experimento. Justifique a sua resposta.
7. Um fabricante de móveis realizou um experimento para verificar qual dentre cinco

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
50
marcas de verniz proporciona maior brilho. Com esta finalidade, procedeu da seguinte
forma:
- Em sua fábrica identificou amostras de madeira que estariam disponíveis para a
realização deste experimento. Verificou que possuía cinco tábuas de Jatobá, cinco
tábuas de Cerejeira, cinco tábuas de Mogno, cinco tábuas de Goiabão e cinco tábuas de
Castanheira. Constatou também que as cinco tábuas de cada tipo de madeira eram
homogêneas para as características essenciais e que havia uma grande variedade de
cores entre os cinco tipos de madeira (Jatobá, Cerejeira, Mogno, Goiabão e Castanheira).
Sabe-se que a cor da madeira pode influenciar muito o brilho da mesma quando
envernizada;
- Resolveu então distribuir ao acaso as cinco marcas de verniz às tábuas de
madeira, de tal forma que cada tipo de madeira fosse testada com todas as marcas de
verniz;
- O brilho foi medido por meio de um aparelho que mede a refletância da luz branca
projetado sobre a tábua de madeira envernizada;
Baseado nas informações deste experimento, pergunta-se:
a. Qual foi a unidade experimental utilizada neste experimento? Justifique a sua resposta.
b. Quais foram os tratamentos comparados neste experimento? Justifique a sua resposta.
c. Quais foram os princípios básicos da experimentação utilizados neste experimento?
Justifique a sua resposta.
d. É possível estimar o erro experimental neste experimento? Justifique a sua resposta.
Se a resposta for afirmativa, a estimativa do erro é válida? Justifique. Se a resposta foi
negativa, explique o que deveria ser feito para obter uma estimativa válida para o erro
experimental.
e. O que faz surgir o erro num experimento? É possível eliminar totalmente o efeito do
erro experimental em um experimento? Justifique a sua resposta.
f. O procedimento adotado pelo pesquisador de distribuir as marcas de verniz ao acaso
dentro de cada tipo de madeira foi realmente necessário? Justifique a sua resposta.
8. Um pesquisador de uma indústria de alimentos desejava verificar se seis sabores de
sorvete apresentavam o mesmo o teor de glicose. O pesquisador, baseado em
experimentos anteriores, sabia que duas outras fontes de variação indesejáveis poderiam
influenciar o valor mensurado do teor de glicose: o tipo de recipiente utilizado para
armazenagem do sorvete e o equipamento utilizado para mensuração do teor de glicose.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
51
Para controlar estas duas fontes de variação o pesquisador decidiu que cada sabor
deveria ser avaliado em cada um dos seis equipamentos disponíveis; e armazenado em
cada um dos seis tipos de recipientes disponíveis. Com esta finalidade, o pesquisador
planejou o experimento da seguinte maneira:
- preparar 6 lotes de 100 ml de cada sabor. O total de lotes a serem preparados seria de
36 lotes;
- os lotes de sorvetes deveriam ser distribuídos ao acaso aos recipientes, com a restrição
de que cada tipo de recipiente recebesse todos os 6 sabores uma única vez;
os lotes de sorvetes seriam designados ao acaso aos equipamentos para a análise do
teor de glicose, com a restrição de que cada equipamento avaliasse cada um dos seis
sabores uma única vez.
Baseando-se nestas informações, pergunta-se:
a. Quais foram os tratamentos em teste neste experimento? Justifique a sua resposta.
b. O princípio da repetição foi utilizado neste experimento? Justifique a sua resposta.
c. O princípio do controle local foi utilizado neste experimento? Justifique a sua resposta.
Se a resposta for afirmativa, quantas vezes o mesmo foi utilizado? Se a resposta for
negativa, discuta sobre a necessidade do mesmo ser utilizado neste experimento.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
52
C A P Í T U L O 3
TESTES DE SIGNIFICÂNCIA
3.1. Introdução
Um dos principais objetivos da estatística é a tomada de decisões à respeito da
população com base nas observações de amostras.
AMOSTRAGEM
Inferência
estatística
População Amostra
Ao tomarmos decisões, é conveniente a formulação de Hipóteses relativas às
populações, as quais podem ser ou não verdadeiras.
Exemplo: Um veterinário está interessado em estudar o efeito de 4 tipos de rações que
diferem pela quantidade de potássio no aumento de peso de coelhos.
H0: Não existe diferença entre as rações, ou seja, quaisquer diferenças observadas são
devidas a fatores não controlados
H1: As rações propiciam aumentos de pesos distintos,
H0 é denominada de hipótese de nulidade, a qual assume que não existe efeito dos
tratamentos e H1 é a contra hipótese.
µ
Média populacional
X Média amostral

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
53
3.2. Contrastes 3.2.1. Introdução
O estudo de contrastes é muito importante na Estatística Experimental, principalmente
quando o experimento em análise é composto por mais do que dois tratamentos. Com o
uso de contrastes é possível ao pesquisador estabelecer comparações, entre tratamentos
ou grupos de tratamentos, que sejam de interesse.
Este capítulo visa dar fundamentos para estabelecer grupos de contrastes, obter a
estimativa para cada contraste estabelecido, bem com estimar a variabilidade associada
a cada um destes contrastes. Todos os conhecimentos adquiridos neste capítulo serão
utilizados no Capítulo 5 para se realizar testes de hipóteses para o grupo de contrastes
estabelecidos.
3.2.2. Definições
a. Contraste
Considere a seguinte função linear de médias populacionais de tratamentos
C = a1 m1 + a2 m2 + ... + aI mI
C será um contraste entre médias se satisfizer a seguinte condição: i
i
I
a=
=∑1
0
b. Estimador do Contraste
Na prática, geralmente não se conhece os valores das médias populacionais mi ,mas
suas estimativas. Daí, em Estatística Experimental, não se trabalhar com o contraste C
mas com o seu estimador Cˆ , que também é uma função linear de médias obtidas por
meio de experimentos ou amostras. Assim tem-se que o estimador para o contraste de
médias é dado por:
1 1 2 2 I IC a m a m ... a m= + + +

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
54
Exercício
3.1 Num experimento de consórcio na cultura do abacaxi, com 5 repetições, as médias
de produção de frutos de abacaxi (em t/ha), foram as seguintes:
Tratamentos m
1 - Abacaxi (0,90 x 0,30m) monocultivo 53,5 2 - Abacaxi (0,80 x 0,30 m) monocultivo 56,5 3 - Abacaxi (0,80 x 0,30 m) + amendoim 62,0 4 - Abacaxi (0,80 x 0,30 m) + feijão 60,4
Pede-se obter as estimativas dos seguintes contrastes:
C1 = m1 + m2 – m3 – m4
C2 = m1 – m2
C3 = m3 – m4
3.2.3. Medidas de dispersão associadas a contrastes
Considere o estimador do contraste C, dado por:
1 1 2 2 I IC a m a m ... a m= + + +
A variância do estimador do contraste é dada por:
1 1 2 2 I Iˆ V(C) V(a m a m ... a m )= + + +
Admitindo independência entre as médias
1 1 2 2 I IˆV(C) V(a m ) V(a m ) ... V(a m )= + + +
1 2 i Iˆ V(C) a V(m ) a V(m ) ... a V(m )= + + +
2 2 21 2
Sabe-se que: iI
i
σV(m )
r=
2
assim,
ii
i
σ σ σˆV(C) a a ... ar r r
= + + +
2 2 22 2 21 21 2
1 2
Admitindo-se homogeneidade de variâncias, ou seja n
σ σ ...σ σ= = =2 2 2 21 2 então,
Ii i
ii i
a a a aˆ V(C) ... σ σr r r r=
= + + + =
∑2 2 2 2
2 21 21
11 2

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
55
Na prática, geralmente, não se conhece a variância σ2 , mas sua estimativa a qual obtida
por meio de dados experimentais. Esta estimativa é denominada como estimador comum
(c
S2
)
Então o que normalmente se obtém é o valor do estimador da variância do estimador do
contraste, a qual é obtida por
( )I
ic
i i
aˆV C Sr=
= ∑2
2
1
Exercício
2.2 Por meio dos dados e dos contrastes fornecidos abaixo, obter as estimativas dos
contrastes e as estimativas das variâncias das estimativas dos contrastes.
m 1=11,2 m 2= 10,5 m 3= 10,0 m 4= 21,0
r r= =1 2 6 r =3 4 r =4 5 c
S2
=0,45
C1 = m1 + m2 – m3 – m4
C2 = m1 – m2
C3 = m3 – m4
3.2.4. Contrastes Ortogonais
Em algumas situações desejamos testar um grupo de contrastes relacionados com o
experimento em estudo. Alguns tipos de testes indicados para este objetivo, necessitam
que os contrastes, que compõem o grupo a ser testado, sejam ortogonais entre si. A
ortogonalidade entre os contrastes indica independência linear na comparação
estabelecida por um contraste com a comparação estabelecida pelos outros contrastes.
Sejam os estimadores dos contrastes de C1 e C2 dados, respectivamente, por:
1 1 2 2 I IC a m a m ... a m= + + +1
1 1 2 2 I IC b m b m ... b m= + + +2
A covariância entre ˆ ˆC e C1 2 supondo independência entre tratamentos, é obtida
por
i i Iˆ ˆCOV(C , C ) a b V(m ) a b V(m )... a b V(m )= + +1 2 1 1 1 2 2 2
A variância da média amostral é dada por: iI
i
σV(m )
r=
2
, para i = 1, 2, ..., I. Logo,

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
56
ii i
i
σ σ σˆ ˆCOV(C , C ) a b a b V ... a br r r
= + + +
2 2 21 2
1 2 1 1 2 21 2
Admitindo que exista homogeneidade de variâncias entre os tratamentos, ou seja
nσ σ ...σ σ= = =
2 2 2 21 2 então:
Ii i i i
ii i
a b a b a b a bˆ ˆCOV(C , C ) ... σ σr r r r=
= + + + =
∑2 21 1 2 2
1 211 2
Sabe-se que, se duas variáveis aleatórias são independentes, a covariância entre
elas é igual a zero. Assim, se 1 Cˆ e 2 Cˆ são independentes, a covariância entre eles é
igual
a zero, isto é:
ˆ ˆCOV(C , C ) =1 20
Para que a covariância seja nula, é necessário, portanto que: I
i i
i i
a b
r=
=∑1
0
Esta é a condição de ortogonalidade entre dois contrastes para um experimento com
número diferente de repetições para os tratamentos. Para um experimento com o mesmo
número de repetições, satisfazendo as mesmas pressuposições (médias independentes
e homogeneidade de variâncias), a condição de ortogonalidade se resume
a: I
i i
i
a b=
=∑1
0
Para um experimento com I tratamentos, podem ser formados vários grupos de
contrastes ortogonais, no entanto cada grupo deverá conter no máximo (I-1) contrastes
ortogonais, o que corresponde ao número de graus de liberdade para tratamentos.
Dentro de um grupo de contrastes ortogonais, todos os contrastes tomados dois a dois,
serão também ortogonais.
Exercícios
1. Verificar se os contrastes do Exercício 2.1 formam um grupo de contrastes ortogonais.
2. Verificar se os contrastes do Exercício 2.2 formam um grupo de contrastes ortogonais.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
57
33. Métodos para obtenção de grupos de contrastes mutuamente ortogonais
Obtenção por Meio de Sistema de Equações Lineares
Neste método, deve-se estabelecer, a princípio, um contraste que seja de interesse e, a
partir deste é que os demais são obtidos. Por meio da imposição da condição de
ortogonalidade e da condição para ser um contraste, obtém-se equações lineares, cujas
incógnitas são os coeficientes das médias que compõem o contraste. Como o número de
incógnitas é superior ao número de equações existentes, será sempre necessário atribuir
valores a algumas incógnitas. É desejável que os valores a serem atribuídos, permitam
que os coeficientes sejam números inteiros.
Exercício
1. Foi instalado para avaliar a produção de 4 híbridos cujas características são
apresentadas na tabela a seguir.
Hibrido 1 2 3 4
Porte Alto Alto Alto Baixo Inicio do Florescimento
Precoce
Tardio
Tardio
Precoce
Índice de acamamento
Médio
Alto
Baixo
Médio
ri 3 3 3 3
Suponha que ao estabelecer as comparações dos híbridos com relação a produção, seja
levado em consideração
• o porte;
• o início do florescimento;
• o índice de acamamento.
Obtenha um grupo de contrastes ortogonais que permita testar as comparações segundo
os critérios citados.
Obtenção por Meio de Regras Práticas
Por meio desta metodologia, é possível estabelecer facilmente um grupo de contrastes
ortogonais. A metodologia pode ser resumida nos seguintes passos (BANZATTO e
KRONKA, 1989):

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
58
Divide-se o conjunto das médias de todos os tratamentos do experimento em dois
grupos. O primeiro contraste é obtido pela comparação das médias de um grupo contra
as médias do outro grupo. Para isso atribui-se sinais positivos para membros de um
grupo e negativos para membros do outro grupo.
Dentro de cada grupo formado no passo anterior, que possui mais que uma média,
aplica-se o passo 1, subdividindo-os em subgrupos. Repete-se este passo até que se
forme subgrupos com apenas uma média. Ao final, deveremos ter formado (I-1)
comparações.
Para se obter os coeficientes que multiplicam cada média que compõem os contrastes
estabelecidos, deve-se, para cada contraste:
Verificar o número de parcelas experimentais envolvidas no 1º grupo, digamos g1, e o
número de parcelas experimentais envolvidas no 2º grupo, digamos g2. Calcula-se o
mínimo múltiplo comum (m.m.c.) entre g1 e g2.
Dividir o m.m.c. por g1. O resultado será o coeficiente de cada média do 1º grupo
Dividir o m.m.c. por g2. O resultado será o coeficiente de cada média do 2º grupo.
Multiplicar os coeficientes obtidos pelo número de repetições da respectiva média.
Se possível, simplificar os coeficientes obtidos por uma constante. No caso em que o
número de repetições é igual para todos os tratamentos, este passo pode ser eliminado.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
59
Exercícios
1. Num experimento inteiramente casualizado, com 4 repetições, foram comparados os
efeitos de 5 tratamentos em relação ao crescimento de mudas de Pinus oocarpa, 60 dias
após a semeadura. Os tratamentos utilizados e os resultados obtidos foram (BANZATTO
e KRONKA, 1989):
Tratamentos Totais
1 – Solo de cerrado (SC) 21,0
2 – Solo de cerrado + esterco (SC+E) 27,1
3 – Solo de cerrado + esterco + NPK (SC+E+NPK) 26,6
4 – Solo de cerrado + vermiculita (SC+V) 22,1
5 – Solo de cerrado + vermiculita + NPK (SC+V+NPK)
25,6
Obtenha um grupo de contrastes ortogonais entre as médias.
2. Suponha agora para o exemplo 1 que os tratamentos 1 e 4 tenham 3 repetições e os
tratamentos 2, 3 e 5 tenham 4 repetições. Obtenha um grupo de contrastes ortogonais
entre médias.
3. Dados
Tratamentos Média Repetições
1 25,0 5
2 18,7 5
3 30,4 5
4 27,5 6
e os contrastes
C1 =m1 – m2
C2 =m1 + m2 - 2 m3
C3 = m1 + m2 + m3 – 3 m4
Admitindo-se que os estimadores das médias sejam independentes e que c
S2
=0,45,
pede-se
ˆ ˆC , C1 2 e C 3
ˆ ˆV(C ),V(C )1 2 e ˆV(C )3

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
60
c) as estimativas das covariâncias entre os estimadores dos contrastes, e por meio das
mesmas, dizer quais são os contrastes ortogonais entre si.
4. Supondo independência entre médias, homogeneidade de variâncias entre
tratamentos e admitindo que 1 2 3 m ,m e m têm, respectivamente, 5, 3 e 6 repetições,
verificar se os contrastes dados abaixo são ortogonais.
C1 = m1 – m2
C2 =m1 + m2 -2 m3
.
5. Considere um experimento com 4 tratamentos e as seguintes informações:
cS
2
=4,10
r r r= =1 2 3=4; r =4 3
C1 =m1 + m2 + m3 - 3 m4
C2 = m1 – 2 m2 + m3
Pede-se:
a) Forme um grupo de contrastes ortogonais, a partir dos contrastes C1 e C2, por meio
do método do sistema de equações lineares.
b. Obtenha ( )ˆV C 1
c. Obtenha ( )V C 1
6. Num experimento com 4 tratamentos e 5 repetições, são dados os seguintes
contrastes ortogonais:
C1 = m2 – m4
C2 = − 2m1 + m2 + m4
Determinar um contraste C3 que seja ortogonal a C1 e C2.
7. Com os dados abaixo, obter o contraste C3 ortogonal aos contrastes C1 e C2 .
C1 m1 - m2 r1 = r3 - 4
C2 4m1 + 5m2 - 9m4 r2 =r4 = 5

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
61
8. Dado o contraste C1 = 2m1 – m2 – m3, referente a um experimento com 3 tratamentos
(r1 = r2 = r3 = 5), obter um contraste ortogonal C2 em relação a C1.
9. Dado o contraste C1 = 2m1 – m2 – m3, referente a um experimento com 3
tratamentos (r1 = r2 = 4 e r3 = 5), obter um contraste ortogonal C2 em relação a C1
10. Dado o contraste C1 = 9m1 – 4m2 – 5m3, referente a um experimento com 3
tratamentos (r1 = r2 = 4 e r3 = 5), obter um contraste ortogonal C2 em relação a C1.
11. Dados os contrastes C1 = m2 – m4 e Y2 = – 2m1 + m2 + m4, referente a um
experimento com 4 tratamentos (r1 = r2 = r3 = r4 = 5), obter um contraste ortogonal C3 em
relação a C1 e C2.
12. Dados os contrastes C1 = m1 + m2 + m3 – 3m4 e C2 = m1 – 2m2 + m3, referente a um
experimento com 4 tratamentos (r1 = r2 = r3 = 4 e r4 = 3), obter um contraste ortogonal C3
em relação a C1 e C2.
13. Dados os contrastes C1 = m1 – 4m2 + m3 + 2m4 e C2 = m1 – m3, referente a um
experimento com 4 tratamentos (r1 = r3 = 6, r2 = 4 e r4 = 5), obter um contraste ortogonal
C3 em relação a C1 e C2.
.
14. Para verificar o efeito de três tipos de adoçantes no teor de glicose no sangue, foi
realizada uma pesquisa em que se ministrou cada um destes tipos de adoçantes a um
determinado grupo de cobaias, por certo período de tempo. Ao final deste período, o teor
médio de glicose (i
m ) no sangue foi avaliado para cada grupo, obtendo-se os seguintes
resultados:
Adoçante No de Cobaias i
m S2
1-Químico 8 115 30
2-Químico 10 90 30
3- Natural 5 75 30

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
62
A partir dos dados fornecidos acima, pede-se:
a).Desejando-se testar o teor médio de glicose do conjunto de cobaias que recebeu
adoçante químico contra o grupo que recebeu adoçante natural, qual seria o contraste
apropriado? Qual o valor da estimativa deste contraste?
b) Suponha que seja de interesse testar a seguinte comparação: C1 = m2 – m3, no
entanto, desejamos testar outros contrastes que sejam ortogonais a C1. Obtenha o (s)
outro (s) contraste (s) ortogonal (is) necessário (s) para completar o grupo de contrastes
ortogonais a C1.
15. Num experimento, 4 novos tipos de herbicida foram comparados para verificar se
são eficazes para combater ervas daninhas e assim manter a produção de milho em
níveis elevados. Um resumo do experimento é dado a seguir
Herbicida Média de produção (kg/ha)
Repetições
1 – Biológico 46 4
2 – Químico à base de nitrogênio e enxofre 31 4
3 – Químico à base de nitrogênio e fósforo 32 4
4 – Químico à base de inativadores enzimáticos 25 4
Suponha que seja de interesse testar o seguinte contraste entre as médias de
tratamentos C1 = 3m1 – m2 – m3 – m4 . Suponha ainda que todos os tratamentos
possuam uma mesma variância e que sua estimativa é igual a 35 (kg/ha)2 . Pergunta-se:
a) Qual a comparação que está sendo feita pelo contraste C1? Qual a estimativa para
este contraste?
b) Por meio da estimativa obtida para o contraste C1 pode-se AFIRMAR que exista um
grupo melhor de herbicidas do que outro? Justifique a sua resposta.
c) Qual a estimativa da variância para a estimativa do contraste C1?
d) Forme um grupo de contrastes ortogonais a partir do contraste C1. Descreva qual
comparação que está sendo feita por cada contraste que você obteve. Baseando-se nos
dados amostrais fornecidos, obtenha também a estimativa para cada um dos contrastes.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
63
16. Considere um experimento, onde foi avaliada a variável produção (kg/parcela) de
quatro tratamentos (adubações), denominados como: T1 = Sulfato de Amônio, T2 =
Sulfato de Amônio + Enxofre, T3 = Nitrocálcio e T4 = Nitrocálcio + Enxofre. Os resultados
obtidos foram:
Tratamentos Média Repetições
1 – Sulfato de Amônio 24,0 4
2 – Sulfato de Amônio + Enxofre 28,0 5
3 – Nitrocálcio 27,0 4
4 – Nitrocálcio + Enxofre 25,0 5
cS =
2
0,75 a) Estabelecer as seguintes comparações de interesse (as comparações solicitadas, não
são necessariamente ortogonais):
i) Sulfato de Amônio versus Nitrocálcio na ausência de Enxofre
ii) Sulfato de Amônio versus Sulfato de Amônio + Enxofre
iii) Nitrocálcio versus Nitrocálcio + Enxofre
b) Sendo dados, com base em outros critérios, os seguintes contrastes:
C1 = m1 – m2
C2 = 4m1 + 5m2 + 4m3 – 13m4
Pede-se:
i) Obter a estimativa do contraste C2.
ii) Obter a estimativa da variância da estimativa do contraste C2.
iii) Obter a variância do contraste C.
iv) Os contrastes C1 e C2 são ortogonais? Justifique a sua resposta.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
64
3.4 Teste F para a análise de variância
O teste F é a razão entre duas variâncias e é usado para determinar se duas estimativas
independentes da variância pode ser assumida como estimativas da mesma variância.
Na análise de variância, o teste F é usado para testar a igualdade de médias, isto é, para
responder a seguinte questão, é razoável supor que as médias dos tratamentos são
amostras provenientes de populações com médias iguais? Considere o seguinte exemplo
de cálculo da estatística F; vamos supor que de uma população normal N (µ, σ2) foram
retiradas, aleatoriamente, 5 (n=5) amostras de tamanho 9 (r=9).
Calcule as médias das 5 amostras e (((( ))))(((( ))))
−−−−====
−−−−
2222y yy yy yy y11112222SSSS iiii 9 19 19 19 1
Estime σ2 por meio da fórmula: 5
25
S22
S21
S2S
+++
=...
, a qual é uma média das
variâncias das amostras e será denominada de variabilidade dentro das amostras
2
DS .
Estime a variância populacional das médias 2y
σ , por meio das médias das 5 amostras:
15
5
1i
2y2
iy
2y
S−
∑=
++−+=
De 2y
S estime novamente , usando a relação 2y
S ou S2 = 2y
rs , denominada de
variabilidade entre as amostras
2
ES .
Calcule 2D
S
2E
S
cF =
A estimativa de 2E
S do numerador foi feita com base em n - 1 = 4 graus de liberdade ( n é
o número de amostras) e a estimativa de 2D
S do denominador foi feita com base em n(r –
1) = 5(9 -1) = 40. A repetição deste procedimento amostral muitas vezes gera uma
população de valores de F, os quais quando colocados em um gráfico de distribuição de
freqüência tem o seguinte formato

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
65
O valor de F = 2,61 é o valor acima do qual, 5% dos valores de F calculados têm valor
acima dele. Este é o valor para um nível de 5% encontrado na Tabela F para 4 e 40
graus de liberdade (veja Tabela F).
Dado que as estimativas da variância utilizadas estatística F são estimativas da mesma
variância σ2, espera-se que o valor de F seja bem próximo de 1,a menos que um conjunto
de amostras não usual foi retirado.
Para qualquer conjunto de amostras retiradas de n = 5 e r = 9 a probabilidade (ou a
chance) de um valor de F calculado ser maior ou igual a 2,61 é 0,05 (5%) (P[F >2,61]
= 0,05 ).
As hipóteses estatísticas que testamos quando aplicamos o teste F são
22
211H
22
210H
σσ:
σσ:
>
=
A Hipótese H0 estabelece que as duas variâncias populacionais são iguais, o que
equivale a admitir que as amostras foram retiradas da mesma população. A hipótese H1
(contra hipótese, ou hipótese alternativa) estabelece que as variâncias são provenientes
de populações diferentes e, mais ainda, a variância da primeira é maior que a variância
da segunda. Os valores de F são tabelados em função dos graus de liberdade das
estimativas de s2 do numerador (n1) e do denominador (n2) no cálculo da estatística F e
para diferentes valores de níveis de significância (5%, 1%,etc.).

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
66
3.4.1. Regra de decisão
Todos os possíveis valores que o teste estatístico pode assumir são pontos no eixo
horizontal do gráfico da distribuição do teste estatístico e é dividido em duas regiões; uma
região constitui o que denominamos de região de rejeição e a outra região constitui o que
denominamos de região de aceitação. Os valores do teste estatístico que formam a
região de rejeição são aqueles valores menos prováveis de ocorrer se a hipótese nula é
verdadeira, enquanto que os valores da região de aceitação são os mais prováveis de
ocorrer se a hipótese nula é verdadeira. A regra de decisão nos diz para rejeitar H0 se o
valor do teste estatístico calculado da amostra é um dos valores que está na região de
rejeição e para não rejeitar H0 se o valor calculado do teste estatístico é um dos valores
que está na região de aceitação. O procedimento usual de teste de hipóteses é baseado
na adoção de um critério ou regra de decisão, de tal modo que α = P(Erro tipo I) não
exceda um valor pré-fixado. Porem, na maioria das vezes, a escolha de α é arbitrária. Um
procedimento alternativo consiste em calcular o “menor nível de significância para o qual
a hipótese H0 é rejeitada, baseado nos resultados amostrais”. Este valor, denominado de
nível descritivo do teste ou nível mínimo de significância do teste, será denotado por valor
de p (ou “p-value”). Todos os programas computacionais modernos calculam este valor.
A representação gráfica a seguir mostra uma ilustração da regra de decisão do teste F,
visto anteriormente.
Região de aceitação Região de rejeição
EXEMPLO: Amostras aleatórias simples e independentes, após dois tipos de esforços, do
nível de glicose no plasma de ratos após uma experiência traumática forneceram os
seguintes resultados:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
67
Esforço 1: 54 99 105 46 70 87 55 58 139 91
Esforço 2: 93 91 93 150 80 104 128 83 88 95 94 97
Estes dados fornecem suficiente evidência para indicar que a variância é maior na
população de ratos submetidos ao esforço 1 do que nos ratos submetidos ao esforço 2.
Quais as suposições necessárias para se aplicar o teste?
Solução:
●As variâncias amostrais são =21
S 852,9333 e =22
S 398, 2424 respectivamente.
●Suposições: Os dados constituem amostras aleatórias independentes retiradas, cada
uma, de uma população com distribuição normal. (Esta é a suposição geral que deve ser
encontrada para que o teste seja válido).
●Hipóteses estatísticas
22
211H
22
210H
σσ:
σσ:
>
=
●Cálculo do Teste Estatístico
1417222
S
21
S
cF , 2424 398,
852,9333===
●Distribuição do Teste Estatístico: quando H0 é verdadeira a estatística F tem distribuição
F com n1 – 1 e n2 – 1 graus de liberdade.
●Regra de Decisão: fazendo α = 5%, o valor crítico de F(9,11,0,05) = 2,896, então, rejeita-se
H0 se FC ≥ 2,896, . A ilustração gráfica desta regra de decisão é mostrada a seguir,

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
68
Região de aceitação Região de rejeição
2,896
●Decisão estatística: não podemos rejeitar H0, dado que 2,1417<2,896; isto é, o FC
calculado caiu na região de aceitação.
● Conclusão: não podemos concluir que as variâncias dos esforços 1 e 2 são diferentes,
o nível mínimo de significância do teste é p=0,116 .
3.5 Análise de variância (ANAVA)
Embora o teste F possa ser aplicado independentemente, a sua maior aplicação é na
análise de variância dos Delineamentos Experimentais.
Vamos considerar os seguintes dados de Delineamento Inteiramente Casualizado, (DIC).
TRATAMENTOS REPETIÇÕES
1 2 3 4
A B C D
12,4 15,2 14,3 12,6 13,2 16,2 14,8 12,9 12,1 11,3 10,8 11,4 10,9 9,8 9,4 8,3
ES
Dentro de um mesmo tratamento o valor observado nas diferentes repetições não é o
mesmo, pois estes valores estão sujeitos à variação ao acaso
2
eσ . Quando passamos
de um tratamento para outro, os dados também não são iguais, pois estes estão sujeitos
a uma variação do acaso acrescida de uma variação devida ao efeito do tratamento, i.é,
2t
2e σσ +
2,1417

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
69
3.5.1 Quadro da análise de variância do DIC
Considere os dados do exemplo anterior, onde tínhamos 4 tratamentos (k=4) e 4
repetições. A Tabela da Análise de variância fica sendo
Fonte de variação G.L. Soma de Quad. Quadrado Médio teste F
Tratamentos k – 1 ( )2 2t y y1
r k ri 1 .+++ −∑
=
1r
SQTrat
−
sidQM
QMTrat
Re
Resíduo k.r – k ∑=
∑=
∑=
+−t
1i
r
1j
t
1i r
2iy2
ijy
)( SQ s
k r 1
Re
. −
Total k.r – 1 ∑=
∑=
∑=
++−t
1i
r
1j
t
1i kr
2y2ij
y)(
Deste quadro notamos que o Quadrado médio do resíduo estima a variação casual (do
resíduo) 2eσ . Enquanto que o quadrado médio dos tratamentos estima a variação casual
(resíduo) acrescida de uma possível variância devido ao efeito dos tratamentos
+ 2
T2e σσ então
2e
2T
2e
F
σ
σσ +=
Se não houver efeito dos tratamentos os dois quadrados médios (Quadrado médio dos
tratamentos e quadrado médio do resíduo) estimam a mesma variância, o que implica o
valor de F 1,0, e qualquer diferença que ocorra entre os valores médios dos tratamentos
é meramente casual.
3.6. Teste t de Student. Considere uma outra retirada de amostras repetidas de um
determinado tamanho, por exemplo, r=5 de uma população normal.
Para cada amostra calcule a média y o desvio padrão, s , o erro padrão da média y s e
uma outra estatística
yS
yct
µ−=
Graficamente temos

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
70
amostra1 ( )
1ys
1y1t
5
21s
1ys
15
2y1y21
Sµ
;;−
==−
−=
amostra 2 ............................................................
amostra M ( )
1ys
1yMt
5
21s
Mys
15
2y1y2M
Sµ
;;−
==−
−=
Organizando estes milhares de valores da estatística t em distribuição de freqüência.
Esta distribuição de freqüência terá a seguinte forma
Existe uma única distribuição t para cada tamanho de amostra. Neste exemplo em que
r=5 (tamanho 5), 2,5 % dos valores de t serão maiores ou iguais do que 2,776 e 2,5%
serão menores do que -2,776. Os valores da estatística t – student são apresentados em
tabelas (ver Tabela da distribuição t ). Por exemplo, para 10 graus de liberdade, o valor

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
71
tabelado esperado para t com probabilidade de 0,01 (1%) é 3,169. A distribuição t –
student converge rapidamente para a distribuição normal. Quanto maior
for a amostra maior é aproximação da distribuição t – student com a distribuição normal.
Quando os valores de t são calculados em amostras de tamanho r=60, estes são bem
próximos dos valores da distribuição normal.
3.6.1. Regra de decisão
Todos os possíveis valores que o teste estatístico pode assumir são pontos no eixo
horizontal do gráfico da distribuição do teste estatístico e é dividido em duas regiões; uma
região constitui o que denominamos de região de rejeição e a outra região constitui o que
denominamos de região de aceitação. Os valores do teste estatístico que formam a
região de rejeição são aqueles valores menos prováveis de ocorrer se a hipótese nula é
verdadeira, enquanto que os valores da região de aceitação são os mais prováveis de
ocorrer se a hipótese nula é verdadeira. A regra de decisão nos diz para rejeitar H0 se o
valor do teste estatístico calculado da amostra é um dos valores que está na região de
rejeição e para não rejeitar H0 se o valor calculado do teste estatístico é um dos valores
que está na região de Testes de Significância
aceitação. Em particular, no caso do teste t – student a regra de decisão fica sendo:
rejeita-se H0 se t tcn 1
2
α,
≥ −

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
72
Exemplo: Em um hospital veterinário amostras de soro de amilase de 15 animais sadios e
22 animais hospitalizados foram colhidos. Os resultados da média e dos desvios-padrões
foram as seguintes:
y1 =120 unidades/ml, s1= 40 unidades/ml
y2 =96 unidades/ml, s1= 35 unidades/ml
Neste exemplo, o erro padrão amostral y s da fórmula da estatística t, será substituído
pelo erro padrão da média “pooled”, ou seja,
( ) ( )
2 2r 1 S r 1 S1 22 1 2Sp
r 1 r 11 2
( ) ( )− + −=
− −
Cálculos:
Suposições: os dados constituem duas amostras independentes, cada uma, retirada de
uma população normal. As variâncias populacionais são desconhecidas e assumidas
iguais;
Hipóteses: H0: µ1 = µ2
H1: µ1 ≠ µ2
Teste estatístico: tc = ( ) ( )y y1 2 1 2
2 2S Sp p
r r1 2
µ µ− − −
+
Distribuição do teste estatístico: quando H0 for verdadeira, o teste segue uma distribuição
t – Student com r1 + r2 – 2 graus de liberdade;
Regra de decisão: Rejeita-se H0 se t tcr r 21 2
2
α,
≥ + −
,, neste exemplo, t 2 03c ,≥ ;
Cálculo do teste estatístico: primeiro o cálculo da variância amostral
2 214 40 21 352S 1450p
14 21
120 96 0 24t 1 88c
12 751450 1450
15 22
( ) ( ),
( ),
,
+= =
+− −
= = =
+
Decisão estatística: não se rejeita H0, visto que 2,030 1,88 2,030 ; ou seja, 1,88 caiu
na região de aceitação;

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
73
Conclusão: com base nestes dados não podemos concluir que as médias das duas
populações são diferentes. Neste teste o nível mínimo de significância do teste está entre
0,05 e 0,10(0,05<p<0,10).

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
74
C A P Í T U L O 4
DELINEAMENTO INTEIRAMENTE CASUALIZADO (DIC)
4.1 Introdução
O DIC é mais simples dos delineamentos. No Delineamento Inteiramente Casualizado
(DIC) a distribuição dos tratamentos às unidades experimentais é feita inteiramente ao
acaso. Os outros delineamentos experimentais, por exemplo: blocos casualizados e
quadrado latino, se originam do DIC pelo uso de restrição na casualização. O DIC utiliza
apenas os princípios básicos da repetição e da casualização.
Como não faz restrições na casualização, o uso do DIC pressupõe que as unidades
experimentais estão sob condições homogêneas. Estas condições homogêneas
geralmente são obtidas em locais com ambientes controlados tais como laboratórios,
estufas e casas de vegetação..
Vamos começar com um exemplo:
• Em um estudo do efeito da glicose na liberação de insulina, 12 espécies de tecido
pancreático idênticas foram subdivididas em três grupos de 4 espécies cada uma. Três
níveis (baixo - tratamento 1, médio tratamento - 2 e alto tratamento - 3) de concentração
de glicose foram aleatoriamente designados aos três grupos, e cada espécie dentro de cada
grupo foi tratado com o nível de concentração de glicose sorteado a eles. A quantidade de insulina
liberada pelos tecidos pancreáticos amostrados são as seguintes:
Tratamento Repetições 1 2 3 4
Nº de repetições
Total
Média
Variância
Nível baixo (T1) Nível médio (T2) Nível alto (T3)
1,59 1,73 3,64 1,97 3,36 4,01 3,49 2,89 3,92 4,82 3,87 5,39
4 4 4
8,93 13,75 18,00
2,23 3,44 4,50
0,91 0,21 0,54
Total 12 40,68
Este é um estudo experimental com 12 unidades experimentais (amostras de tecido
pancreático) e k=3 tratamentos. Cada tratamento é um nível de fator simples:
concentração de glicose. Existem 4 repetições para cada tratamento. Os dados,
quantidade de insulina liberada pelo tecido pancreático podem ser considerados como
três amostras aleatórias, cada uma com r=4 repetições, ou de tamanho r=4 sorteadas de
três populações.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
75
Dado que os tratamentos são designados às unidades experimentais completamente ao
acaso, este delineamento é denominado de DELINEAMENTO INTEIRAMENTE AO
ACASO (DIC). Em geral em um
DIC, um número fixo de k tratamentos são sorteados às N unidades experimentais de tal
forma que o i-ésimo tratamento é sorteado a exatamente ri unidades experimentais.
Assim, ri é o número de repetições
do i-ésimo tratamento e r1+r2+r3+...+rk. No caso em que ri são iguais, i.é., r1=r2=r3=...=rk,
então N = rk e o delineamento é balanceado.
Notação:
Repetições Tratamento
1 2 3 ... j ... r Total Média
1 2 3 . . . . I . . . k
y11 y21 y31
y12 y22 y32
y13 y23 y33
...
...
... . . . . . . .
...
...
... . . . yij. . .
.
y1r y2r y3r .
.
.
.
.
.
ykr
y1+ y2+ y3+ .
.
.
.
.
.
.
y1+
y2+
y3+
.
.
.
.
. yk+
N=rk Y++ y++
Convenções: yi+ e yi+ representam, respectivamente, o total e a média do iésimo tratamento,
respectivamente, Y++ e y++ representam, respectivamente, o total geral (soma de todas as observações) e
a média geral de todas as observações.
4.2 Análise de variância (ANAVA)
O método da análise de variância pode ser visto como uma extensão do teste t de
student para amostras independentes. Como no teste t de amostras independentes, o
método da ANAVA compara uma medida da magnitude variabilidade observada dentro
das k amostras com uma medida da variabilidade entre as médias das k amostras.
4.3 Modelo matemático do DIC com efeitos de tratamentos fixos
O modelo associado ao DIC com efeitos fixos é

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
76
i
jiiji
rj
tiEty
,...,2,1
,...,2,1,)(
=
=++=µ
onde:
yij = valor da parcela que recebeu o tratamento i na repetição j;
µµµµ = média geral;
ti = efeito do tratamento i;
E(i)j = erro da parcela que recebeu o tratamento i na repetição j.
Pela definição de µ e ti acima, temos que este modelo possui a restrição
1
0i
k
i ii
n t
=
=∑ ,pois, ( )1 1 1
0i
k k k
i i i i i ii i i
r t r r rµ µ µ µ
= = =
= = − = − =∑ ∑ ∑
4.4 Suposição associada ao modelo
As suposições usualmente associadas aos componentes do modelo do DIC são que os
eij são variáveis aleatórias independentes e identicamente distribuídas com distribuição N
(0 ,σσσσ2 ) . Como os yij são funções lineares dos eij , das suposições sobre os erros
decorre que:
i E( yij )= µtiµ;
Var (yij) = σσσσ2;
yij são normalmente distribuídos e independentes, ou, resumidamente que yij ~ N (µi ,σσσσ2 )
Portanto, estamos supondo que as observações do experimento a ser analisado
correspondem a amostras aleatórias de k populações normais com a mesma variância e
que podem ou não ter médias diferentes.
4.5 Hipóteses estatísticas
A Hipótese geral é:
H0=t1 = t2 = ...= tk ,
ou seja, vamos testar a não existência de efeito do fator (tratamento).
4.6 Partição da soma de quadrados
Voltemos ao quadro de representação das observações no DIC

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
77
Repetições Tratamento
1 2 3 ... j ... r Total Média
1 2 3 . . . . I . . . k
y11 y21 y31
y12 y22 y32
y13 y23 y33
...
...
... . . . . . . .
...
...
... . . . yij. . .
.
y1r y2r y3r .
.
.
.
.
.
ykr
y1+ y2+ y3+ .
.
.
.
.
.
.
y1+
y2+
y3+
.
.
.
.
. yk+
N=rk Y++ y++
Podemos identificar os seguintes desvios:
• yij − y++ , como o desvio de uma observação em relação a média amostral geral;
• yij − yi+ ,como o desvio da observação em relação à média de seu grupo ou do i-ésimo
tratamento;
• y yi −+ ++ , como o desvio da média do i-ésimo tratamento em relação á média geral.
Consideremos a identidade
(yij − y++ ) = (yij − yi+ ) = ( y yi −+ ++ )
a qual diz que a “ a variação de uma observações em relação à média geral amostral é
igual à soma variação desta observação em relação à média de seu grupo com a
variação da média do i-ésimo tratamento em que se encontra esta observação em
relação à média geral amostral “.
Elevando-se ao quadrado os dois membros da identidade acima e somando em relação
aos índices i e j, obtemos:
( ) ( ) ( )1 1
22
1 1 1 1 1
r rk k k
i j i j i i ii j i j i
y y y y r y y++ + + ++
= = = = =
− = + +∑∑ ∑∑ ∑
os duplos produtos são nulos.
O termo
( )1
1 1
0rk
i ji j
y y++
= =
− =∑∑

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
78
é denominado de Soma de Quadrados Total e vamos denotá-lo por SQT.O número de
graus de liberdade associado à SQT é kr - 1, ou N – 1, pois temos N observações e a
restrição
( )+=
−∑2
1
ir
i j ij
y y,
Possui ri – 1 graus de liberdade. Assim, o número de graus de liberdade associado à
SQR é:
( )1
1j k
ii
r k r k N k
=
− = − = −∑
A componente ( )21
k
i i
i
r y y+ ++=
−∑ , mede a variabilidade entre as médias dos tratamentos
e por isso é denominada de Soma de Quadrados Entre Tratamentos, representada por
SQTr. Quanto mais diferentes entre si forem as médias dos tratamentos, maior será a
SQTr. Desde que temos k tratamentos e a restrição de que
( )1
0k
i ii
r y y+ ++
=
− =∑
A SQTr possui k - 1 graus de liberdade. Com esta notação, podemos escrever que:
SQT = SQR + SQTr.
4.7 Quadrados médios
Dividindo a SQR e SQTr pelos correspondentes graus de liberdade, obtemos,
respectivamente o Quadrado Médio Residual (QMR) e o Quadrado Médio Entre
Tratamentos (QMTr), isto é, S Q RQ M RN k=−
e 1S Q T rQ M T rk=−
4.8 Estatística e região crítica do teste
A estatística para o teste é
=C
Q M T rFQ M R
a qual, deve ser próximo de 1 se H0 for verdadeira, enquanto que valores grandes dessa
estatística são uma indicação de que H0 é falsa. A teoria nos assegura que Fc tem sob

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
79
H0 distribuição F – Snedecor com (k -1) e (N – k) graus de liberdade. Resumidamente,
indicamos:
FC~F(K-1,N-K), sob H0
Rejeitamos H0 para o nível de significância α se
FC>F(K-1,N-K,α),
sendo, F(K-1,N-K)o quantil de ordem (1 −α ) da distribuição F-Snedecor com (k -1) e (N – k)
graus de liberdade. Graficamente temos:
4.9 Quadro da análise de variância (ANAVA)
Dispomos as expressões necessárias ao teste na Tabela abaixo denominada de Quadro
de Análise de Variância (ANAVA).
Fonte de Variação g. l. S. Q. Q. M. Fc Entre Tratamentos
(I - 1)
( )+++
=
−∑iiiirrrr
iiii
iiii iiii
YYYYYYYYJ NJ NJ NJ N
22
1 =−
S Q T rS Q T rS Q T rS Q T rQ M T rQ M T rQ M T rQ M T rIIII 1
Q M T rQ M T rQ M T rQ M T rQ M RQ M RQ M RQ M R
Resíduo (dentro dos tratamentos)
I(J-1) (((( ))))++++
= = == = == = == = =
−−−−∑∑ ∑∑∑ ∑∑∑ ∑∑∑ ∑k r kk r kk r kk r k
iiiii ji ji ji j
i j ii j ii j ii j i
YYYYYYYY
JJJJ
2
2
1 1 1 =−
S Q RS Q RS Q RS Q RQ M RQ M RQ M RQ M R
(
I J
)(
I J
)(
I J
)(
I J
)
1
Total
(J – 1)
( )++
= = =
−∑∑ ∑k r kk r kk r kk r k
i ji ji ji ji j ii j ii j ii j i
YYYYYYYY
nnnn
2
2
1 1 1
Pode-se provar que:
• E(QMR) =σ2 , ou seja, QMR é um estimador não viesado da variância σ2 ;

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
80
• E( QMTr) = =
=− ∑
2
1(
1
)
k
ii
r tkσ , ou seja, QMTr é um estimador não viesado da
variância 2 s se a hipótese H0 t1 =t2 =... =tk= é verdadeira.
4.10 Detalhe computacional
Apresentaremos alguns passos que facilitam os cálculos das somas de quadrados da
ANAVA.
• Calcule a correção para a média ( )++=
2YC M
N
• Calcule a Soma de Quadrados dos Totais (SQT)
= =
= −∑∑2
1 1
irk
i ji j
S Q T Y C M
• Calcule a Soma de Quadrados Entre os Tratamentos (SQTr)
+= −
2i
i
YS Q T r C Mr
• Calcule a Soma de Quadrados Residual (SQR) pela diferença, isto é,SQR = SQT −
SQTr ;
• Calcule os Quadrados Médios Entre os Tratamentos (QMTr) e o Quadrado Médio
Residual (QMR)
=−
1S Q T rQ M T rk e =
−
S Q RQ M RN k
• Calcule Fc para tratamentos =C
Q M T rFQ M R
Notem que estas fórmulas computacionais assumem que existe ri repetições para o i-
ésimo tratamento; consequentemente, para umexperimento balanceado com r repetições
para cada tratamento, ri deve ser
substituído por r. Estas várias soma de quadrados obtidas nestes cinco passos podem
ser resumidas no quadro da ANOVA apresentado no item 8.
Exemplo 1
Vamos considerar os dados apresentados no item 1. Desejamos testar a hipótese nula
H0: µ1 = µ2 = µ3
H1: µi ≠ µj para pelo menos um par i ≠ j

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
81
Os cálculos para montar-mos o quadro da ANOVA são: temos k = 3, r = 4, e N = 3x4 =12.
Então
• Graus de liberdade:
Total = N – 1 = 12 – 1 = 11; Trat. = k – 1 =3 -1 = 2; Res. = N – k = 12 – 3 = 9
•( )
24 0 , 6 81 3 7 , 9 1
1 2C M
= =
• ( ) ( ) ( )2 2 21 , 5 9 1 , 7 3 . . . 5 , 3 9 1 5 3 , 1 8 1 3 7 , 1 8 1 5 , 2 8S Q T C M
= + + + − = − =
•( ) ( ) ( )
= + + − = − =
2 2 28 , 9 3 1 3 , 7 5 1 8 , 0 01 4 8 , 2 0 1 3 7 , 9 1 1 0 , 3 0
4 4 4S Q T r C M
•SQR = SQT − SQTr = 15,28 − 10,30 = 4,98
• = =
1 0 , 3 0 5 , 1 52
Q M T r
• = =
4 , 9 8 0 , 5 59
Q M R
• = =
5 , 1 5 9 , 3 60 , 5 5C
F
O quadro da ANAVA para a variável insulina liberada é o seguinte:
Fonte de Variação g. l. S. Q. Q. M. Fc Entre Tratamentos
2
10.30 5,15 9,36
Resíduo (dentro dos tratamentos)
9
4,98 0,55
Total
11
15,28
Das tabelas das distribuições F, temos queF(2,9;0.05)= 4,257 e F(2,9;0,01)= 8,022. O valor Fc=9,31 é
maior do que estes valores tabelados, então rejeitamos a hipótese nula H0 a um nível a = 0,01, ou
1% de probabilidade (se é significativo a 1%, logo também é significativo a 5%).

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
82
Podemos concluir que, para um nível de α= 0,01, ou 1%, que a quantidade de insulina
liberada é diferente para pelo menos dois níveis de glicose.
: Em um experimento em que se mediu o peso corporal (kg), 19 porcos foram distribuídos
aleatoriamente a 4 grupos. Cada grupo foi alimentado com dietas diferentes. Deseja-se
testar se oos pesos dos porcos são os mesmos para as 4 dietas.
Desejamos testar a hipótese nula
H0: µ1 = µ2 = µ3
H1: µi ≠ µj para pelo menos um par i ≠ j
As observações obtidas são
Tratamento Repetições
1 2 3 4 5
Nº de repetições
Total
Dieta 1 60,8 57,7 65,0 58,6 61,7 5 303,1
Dieta 2 68,7 67,7 74,0 66,3 69,8 5 346,5
Dieta 3 102,6 102,1 100,2 96,5 * 4 401,4
Dieta 4 87,9 84,2 83,1 85,7 90,3 5 431,2
Total 1482,2
Temos um experimento desbalanceado com número de repetições desigual para os
tratamentos. Então, os cálculos para montar-mos o quadro da ANAVA são:
• Graus de liberdade:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
83
Total = N – 1 = 19 – 1 = 18; Trat. = k – 1 =4 -1 = 3; Res. = N – k = 19 – 4 = 15
•( )
= =
21 4 8 2 , 21 1 5 . 6 2 7 , 2 0 2
1 9C M
• ( ) ( ) ( )= + + + −
= − =
2 2 26 0 , 8 5 7 , 7 . . . 9 0 , 31 1 9 . 9 8 1 , 9 0 0 1 1 5 . 6 2 7 , 2 0 2 4 . 3 5 4 , 6 9 8
S Q T C MS Q T
•( ) ( ) ( ) ( )
= + + + −
=
2 2 2 23 0 3 , 1 0 3 4 6 , 5 0 4 0 1 , 4 0 4 3 1 , 25 5 4 5
1 1 9 . 8 5 3 , 9 0 0 - 1 1 5 . 6 2 7 , 2 0 2 = 4 . 2 2 6 , 3 4 8
S Q T r C M
S Q T r
•SQR = SQT − SQTr = 4354,698 - 4226,202 =128,350
• = =
4 . 2 2 6 , 3 4 8 1 . 4 0 8 , 7 8 33
Q M T r
• = =
1 2 8 , 3 5 0 8 , 5 5 71 5
Q M R
• = =
1 . 4 0 8 , 7 8 3 1 6 58 , 5 5 7C
F
O quadro da ANAVA para a variável insulina liberada é o seguinte:
Fonte de Variação g. l. S. Q. Q. M. Fc Entre Tratamentos
3
4.226,348 1.408,783 165
Resíduo (dentro dos tratamentos)
15
8,557 8,557
Total
18
4.354,698
Das tabelas das distribuições F, temos queF(3,15;0.05)= 3,287 e F(3,15;0,01)= 5,417 é maior que estes
valores, então, rejeitamos a hipótese nula H0 a um nível α = 0,01, ou 1% de probabilidade (se é
significativo a 1%, logo também é significativo a 5%).
Graficamente a regra de decisão fica

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
84
Podemos concluir que, para um nível de α = 0,01, ou 1%, que os pesos dos porcos são
diferentes para pelo menos duas dietas.
4.11 Estimadoresde mínimos quadrados
Nesta seção mostraremos os estimadores do modelo do DIC jiiji Ety )(++=µ . Estes
estimadores são obtidos minimizando-se a expressão do erro deste modelo
( )= =
−∑∑⌢
2
1 1
irk
i j i ji j
y y
Em relação a µ e ti , i=1, 2, ...k, sujeito a restrição =
=∑1
0k
i ii
r t. Assim procedendo,
obtemos os estimador de ++=
=∑ ⌢
1
k
i
yµ e + ++= −
⌢
i it y y
e oestimador de
+= − = =⌢
⌢ ⌢1 , 2 , . . . ,
i i it y i k
µ µ . Para construir um intervalo de confiança para a média
de cada tratamento, devemos notar que:
( )+
−
−,
~i in k
i
y tQ M R
r
µ
i.é. tem distribuição t – Student com (n – k) graus de liberdade. Um intervalo de confiança
para i

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
85
µ com um coeficiente de confiança (1 −a ) é dado por
( ) + −
− = ± ;2
; 1 ,i i N k
Q M RI C y tr
αµ α
sendo,
−
;2
N k
tα
o quantil de ordem
−
12α da distribuição t – Student com (n – k) graus
de liberdade, os mesmos graus de liberdade do resíduo da ANAVA.
Como primeiro exemplo, vamos considerar os dados do experimento apresentado no
item 11. As médias destes dados são:
•
+ +
+ +
++
= = = =
= = = =
1 2
3 4
3 0 3 , 1 0 3 4 6 , 5 06 0 , 6 2 ; 6 9 , 3 0 ;5 5
4 0 1 , 4 0 4 3 1 , 2 01 0 0 , 3 5 ; 8 6 , 2 44 5
e a m d i a g e r a l 7 9 , 1 3
y y
y y
é é y
• do quadro da ANOVA temos o valor de QMR para calcular desvio padrão médio para os
tratamentos 1, 2 e 4 é
= =
= =
8 , 5 5 7 1 , 3 1 ; P a r a o t e r c e i r o t r a t a m e n t o o e r r o p a d r ã o5
8 , 5 5 7m é d i o é 1 , 4 64
i
i
Q M Rr
Q M Rr
• o valor de t(0,025;15) =2,1314 •
Assim, os intervalos são:
( ) + += ± = ±
8 , 5 5 7; 9 5 % 2 , 1 3 1 4 1 , 3 15i i i
I C y yµ para i = 1,2,3 e 4
( ) + += ± = ±
8 , 5 5 7; 9 5 % 2 , 1 3 1 4 1 , 4 64i i i
I C y yµ para i =3
Dieta 1 Dieta 2 Dieta 3 Dieta 4
µi 60,62 69,30 100,35 86,24
IC (µi ,95%) (59,31; 61,93) (67,99; 70,61) (98,89 101,81) (84,93; 87,55)
Problema: identificar quais as Dietas (tratamentos) que tiveram efeitos não nulos sobre o peso dos
suínos.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
86
Como segundo exemplo, vamos considerar os dados do experimento apresentado no
item 1, cujos cálculos foram mostrados no item 10. As médias destes dados são:
• + + +
++
= = = = = =1 2 3
8 , 9 3 1 3 , 7 5 1 8 , 0 02 , 2 3 ; 3 , 4 4 ; 4 , 54 4 4
e 3 , 3 9
y y y
y
• do quadro da ANOVA temos o valor de QMR para calcular
= =
0 , 5 5 3 0 , 3 7 2 ;4
Q M Rr
•o valor de t(0,025;9)= 2,262 .
Assim, os intervalos são:
( ) + += ± = ±
0 , 5 5 3; 9 5 % 2 , 2 6 2 0 , 8 4 14i i i
I C y yµ
Nível baixo de glicose Nível baixo de glicose Nível baixo de glicose
µi 2,23 3,44 4,50
IC (µi ,95%) (1,389; 3,071) (2,599; 4,281) (3,659; 5,341)
Problema: identificar quais os níveis de glicose (tratamentos) que tiveram efeitos não
nulos sobre a liberação de insulina dos tecidos.
4.12 Coeficiente de determinação (R2) e de variação (CV).
A parte da Soma de Quadrados Total (SQT), a variação total nas observações , que pode
ser explicada pelo modelo matemático do DIC, é denominada de coeficiente de
determinação. Assim, o coeficiente de
determinação para modelo do DIC, yij = µ +ti + eij , é definido como
=2
S Q T rRS Q T
Pode ser verificado que 0 ≤ R2 ≤ 1 e que R2 = 1 quando toda variabilidade nas
observações esta sendo explicada pelo modelo matemático do DIC.
A variabilidade entre as unidades experimentais de experimentos envolvendo diferentes
unidades de medidas e/ou tamanhos de parcelas pode ser comparada pelos coeficientes

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
87
de variação, os quais expressam o desvio padrão por unidade experimental como uma
porcentagem da média geral do experimento, ou seja,
++
=* 1 0 0SC V
Y
mas, da ANOVA sabemos que S = Q M R
, daí resulta que
++
=* 1 0 0Q M RC V
Y
Como exemplo vamos considerar os dados do experimento apresentado no item 1, cujos
cálculos foram mostrados no item 10. Neste exemplo temos:
• SQT = 15,28 e SQTr = 10,30 então = = =2
1 0 , 3 0 0 , 6 7 41 5 , 2 8
S Q T rRS Q T
• ++
= = =
0 , 5 5* 1 0 0 * 1 0 0 2 1 , 8 83 , 3 9
Q M RC VY
Concluímos que 67,4% da variabilidade que existe nas observações deste experimento
são explicadas pelo modelo matemático do DIC e que este experimento apresenta um
coeficiente de variação de aproximadamente 22%.
4.13 Checando as violaçãoes das suposições da ANAVA.
Falando de um modo geral, o teste F da ANAVA não é muito sensível às violações da
suposição de distribuição normal. Ele também é moderadamente insensível às violações
de variâncias iguais, se os tamanhos das amostras são iguais e não muito pequenas em
cada tratamento. Entretanto, variâncias desiguais podem ter um efeito marcante no nível
do teste, especialmente se amostras pequenas estão associadas com tratamentos que
têm as maiores variâncias. Existe uma série de procedimentos para se testar se as
suposições da ANOVA são violados.
Entre estes temos o teste de Anderson-Darling, teste de Shapiro-Wilks e teste de
Kolmogorov-Smirnov, que testam a normalidade da população. A igualdade das
variâncias (homocedasticidade) pode ser testada pelos testes de Bartlett e de Levene.
Com o advento dos modernos computadores, métodos gráficos são ferramentas muito
populares para checar as violações das hipóteses da ANAVA. Alguns destes métodos

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
88
gráficos mais comumente usados para checar as suposições da ANAVA são baseados
em gráficos denominados gráficos dos resíduos.
Resíduos. O resíduo correspondente a uma observação yij é definido como:
+= − = − − = −⌢ ⌢i j i j i j i j i i j i
e y y y t y yµ
ou seja, o resíduo corresponde á parte da observação que não foi explicada pelo modelo.
Calculando os resíduos correspondentes a todas as observações de um experimento e
analisando-os descritivamente de forma apropriada, podemos saber se as suposições da
ANOVA estão sendo satisfeitas.
4.14. Experimentos Inteiramente Casualizados com parcela perdida
É comum nos ensaios de campo, laboratório, casa de vegetação, viveiros, galpões ou
outros locais experimentais, quer na área vegetal ou animal, ocorrer a perda de parcela
ocasionada pela morte de planta ou de animais, ou ainda, por causas acidentais. No
experimento em DIC, estas perdas não causam nenhum problema mais sério e a análise
de variância pode ser desenvolvida sem grandes complicações.
A partição da variação é feita seguindo o mesmo processo visto nas estruturas
balanceadas.
Temos:
( ) ( ) ( ). . . . . .y y y y y y
Variação Total Variação Entre Variação Dentro
i jj
r
i
t
ij
r
i
t
i j ij
r
i
ti i i
−−−− ==== −−−− ++++ −−−−======== ======== ========∑∑∑∑∑∑∑∑ ∑∑∑∑∑∑∑∑ ∑∑∑∑∑∑∑∑2
11
2
11
2
11
Variação Total = SQTO = ( ). .
. .y y y
y
ni j
j
r
i
t
i jj
r
i
ti i
−−−− ==== −−−−======== ========∑∑∑∑∑∑∑∑ ∑∑∑∑∑∑∑∑2
11
2
2
11
= y Ci jj
r
i
t i2
11
−−−−========∑∑∑∑∑∑∑∑ , onde C
y
nn ri
i
t
==== ========∑∑∑∑
. .,
2
1
SQTotal = y Ci jj
r
i
t i2
11
−−−−========∑∑∑∑∑∑∑∑
Variação Entre = SQTrat = ( ). . .y yij
r
i
t i
−−−− ============∑∑∑∑∑∑∑∑ 2
11
==== −−−− ==== −−−− ==== −−−−==== ====∑∑∑∑ ∑∑∑∑ ∑∑∑∑
y
r
y
n
y
rC
T
rC
i
ii
ti
ii
ti
ii
. . . .
2 2
1
2
1
2
SQTrat = T
rCi
ii
2
−−−−∑∑∑∑

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
89
Variação Dentro = SQE = SQR = ( ).y yi j ij
r
i
t i
−−−− ============∑∑∑∑∑∑∑∑ 2
11
==== −−−− ==== −−−− −−−− −−−−
==== −−−− −−−− −−−− ==== −−−−
∑∑∑∑∑∑∑∑∑∑∑∑ ∑∑∑∑∑∑∑∑ ∑∑∑∑
∑∑∑∑∑∑∑∑ ∑∑∑∑
======== ========
========
yT
ry
y
n
T
r
y
n
y CT
rC SQTO SQTrat
i j
i
iij
r
i
t
i jj
r
i
ti
ii
i jj
r
i
ti
ii
i i
i
22
11
2
2
11
2 2
2
11
2
( ) ( )
( ) ( )
. . . .
= SQErro = SQTO - SQTrat
Os quadrados médios e o teste F são calculados do mesmo modo que no modelo
balanceado. A análise de variância está apresentada na Tabela 2.3.
TABELA 2.3. Análise de variância de um experimento inteiramente ao acaso
não balanceado com t tratamentos e ri repetições. Causas de Variação
G. L. S. Q. Q. M. F
Tratamentos t - 1 SQT QMT QMT / QME Erro n - t SQE QME Total n - 1 SQTO
n rii
t
========∑∑∑∑
1
4.15 Vantagens e desvantagens do DIC.
As principais vantagens do DIC
• é fácil de ser planejado e é flexível quanto ao número de tratamento e de repetições
tendo como única limitação o número de unidades experimentais disponíveis para o
experimento;
• o número de repetições pode variar de tratamento para tratamento, embora o desejável
é ter o mesmo número de unidades experimentais em todos os tratamentos;
• o DIC proporciona o número máximo de graus de liberdade para o resíduo;
• a análise estatística é simples mesmo que se perca algumas unidades experimentais.
Algumas desvantagens
• é mais apropriado para um pequeno número de tratamentos e para um material
experimental homogêneo;

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
90
• todas as fontes de variação não associadas aos tratamentos farão parte do resíduo,
podendo comprometer a precisão das análises;
• super-estima a variância residual.
4.16 Resumo
. O DIC é mais útil onde não existe nenhuma fonte de variação identificável entre as
unidades experimentais, exceto às dos efeitos dos tratamentos. É o mais flexível com
respeito ao arranjo físico das unidades experimentais. Ele maximiza os graus de
liberdade para a estimação da variância por unidade experimental (erro experimental ou
erro residual) e minimiza o valor da estatísca F requerido para a significância estatística.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
91
Exercícios
1. Para comparar a produtividade de quatro variedades de milho, um agrônomo tomou
vinte parcelas similares e distribuiu, inteiramente ao acaso, cada uma das 4 variedades
em 5 parcelas experimentais. A partir dos dados experimentais fornecidos abaixo, é
possível concluir que existe diferença significativa entre as variedades com relação a
produtividade, utilizando o nível de significância de 5%?
Variedades
A B C D
25 31 22 33
26 25 26 29
20 28 28 31
23 27 25 34
21 24 29 38
Totais 115 135 130 165
Médias 23 27 26 33
2. Um treinador de corrida rústica, objetivando melhorar o desempenho de seus atletas,
testou três novas técnicas de preparação. Para tanto trabalhou com um grupo de 15
atletas completamente homogêneos para as aracterísticas essenciais. A designação das
técnicas de preparação aos atletas foi feita totalmente ao acaso e de tal forma que o
número de atletas avaliados em cada uma das técnicas fosse o mesmo. Os resultados
obtidos, após um determinado período de tempo de aprendizado da técnica pelos atletas,
foram os seguintes (minutos / 25 Km):
Técnicas de Preparação
Repetições 1 2 3
1 130 125 135
2 129 131 129
3 128 130 131
4 126 129 128
5 130 127 130
Totais 643 642 653
De acordo com os resultados obtidos, pede-se.
a) Quais foram os Princípios Básicos da Experimentação utilizados pelo pesquisador
neste experimento?

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
92
b) Qual foi a unidade experimental nesta pesquisa?
c) É possível concluir que existe diferença entre as técnicas de preparação com relação
ao tempo médio gasto para percorrer a distância de 25 km? (α = 1%)
d) Qual seria a técnica a ser recomendada?
3. Com o objetivo de diminuir o consumo dos motores à gasolina, uma determinada
indústria petroquímica testou 4 novas formulações de gasolina, as quais se diferenciavam
pelo tipo de aditivo que era acrescentado à mesma durante o seu processo de
fabricação.
Para efetuar o teste, a indústria petroquímica utilizou carros completamente homogêneos
para todas as características. A designação das formulações aos carros foi feita
inteiramente ao acaso. Após os testes de rodagem, os resultados obtidos foram (km/l):
Aditivo a base de Ácido Forte Ácido Fraco Base Forte Base Fraca Médias 14,81 6,56 10,06 10,09 Nº de carros 10 10 10 10
SQResíduo=6,0264 Com base nos resultados acima, pede-se:
a) Existe diferença entre os 4 tipos de formulações? (α = 5%)
b) Estabeleça um contraste entre o grupo à base de formulação ácida contra o grupo à
base de formulação básica. Obtenha a estimativa para este contraste.
c) Estabeleça um contraste para comparar aditivos de formulação ácida. Obtenha a
estimativa para este contraste.
d) Estabeleça um contraste para comparar aditivos de formulação básica. Obtenha a
estimativa para este contraste.
4. Com o objetivo de verificar se a parótida tem influência na taxa de glicose no sangue,
em ratos, um experimento no DIC foi realizado. Vinte e quatro ratos machos da raça W
foram escolhidos aleatoriamente e separados em três grupos. Os dados referentes as
taxas de glicose, em miligramas por 100 ml de sangue, segundo o grupo, em ratos
machos com 60 dias de idade são dados abaixo:
Parotidectomizado 96,0 95,0 100,0 108,0 120,0 110,5 97,0 92,5
Pseudoparotidectomizado 90,0 93,0 89,0 88,0 87,0 92,5 87,5 85,0
Normal 86,0 85,0 105,0 105,0 90,0 100,0 95,0 95,0
Usando α = 5%, testar a hipótese de que as médias relativas aos três grupos são iguais,
e concluir.
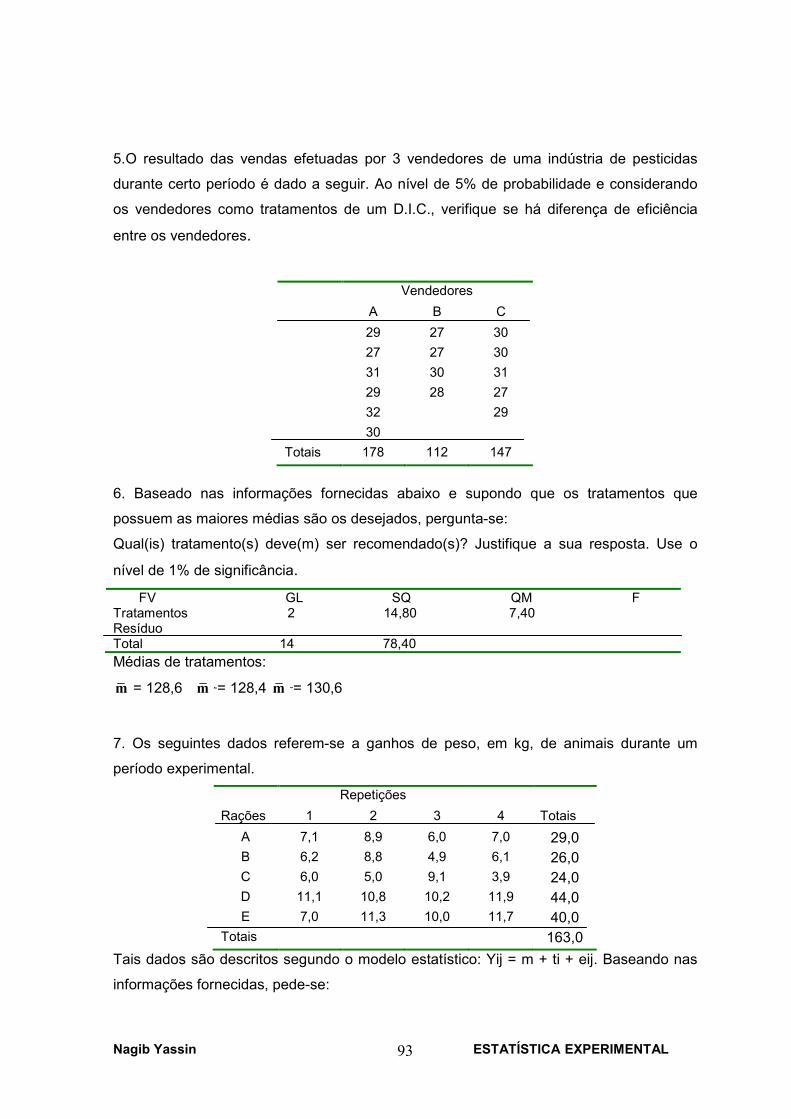
Nagib Yassin ESTATÍSTICA EXPERIMENTAL
93
5.O resultado das vendas efetuadas por 3 vendedores de uma indústria de pesticidas
durante certo período é dado a seguir. Ao nível de 5% de probabilidade e considerando
os vendedores como tratamentos de um D.I.C., verifique se há diferença de eficiência
entre os vendedores.
Vendedores
A B C
29 27 30
27 27 30
31 30 31
29 28 27
32 29
30
Totais 178 112 147
6. Baseado nas informações fornecidas abaixo e supondo que os tratamentos que
possuem as maiores médias são os desejados, pergunta-se:
Qual(is) tratamento(s) deve(m) ser recomendado(s)? Justifique a sua resposta. Use o
nível de 1% de significância.
FV GL SQ QM F Tratamentos 2 14,80 7,40 Resíduo Total 14 78,40
Médias de tratamentos:
m 1= 128,6 m 2= 128,4 m 3= 130,6
7. Os seguintes dados referem-se a ganhos de peso, em kg, de animais durante um
período experimental.
Repetições Rações 1 2 3 4 Totais
A 7,1 8,9 6,0 7,0 29,0 B 6,2 8,8 4,9 6,1 26,0 C 6,0 5,0 9,1 3,9 24,0 D 11,1 10,8 10,2 11,9 44,0 E 7,0 11,3 10,0 11,7 40,0
Totais 163,0
Tais dados são descritos segundo o modelo estatístico: Yij = m + ti + eij. Baseando nas
informações fornecidas, pede-se:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
94
a. Proceda a análise de variância dos dados (use α = 5%)
b. De acordo com o resultado do teste F, pode-se concluir que existe efeito
significativo de rações com relação ao ganho de peso médio proporcionado pelas
mesmas?
c. Proponha um contraste que compare as rações B e C juntas contra as rações D e E.
Obtenha a estimativa para este contraste.
d. Calcule o coeficiente de variação e interprete-o.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
95
C A P Í T U L O 5
TESTES DE COMPARAÇÕES MÚLTIPLAS
5.1 Introdução
O fator ou fatores em avaliação em um experimento podem ser classificados como
qualitativo ou quantitativo. Um fator quantitativo é aquele onde cada nível é descrito por
uma quantidade numérica em uma escala. Como exemplos tem-se temperatura,
umidade, concentração de um princípio ativo, níveis de insumo, pH, etc ... Para estudar o
efeito deste tipo de fator recomenda-se realizar uma análise de regressão, assunto que
será abordado no Capítulo 10.
Por outro lado, um fator qualitativo é aquele onde os níveis diferem por algum atributo
qualitativo. Como exemplos têm-se variedades, tipos de defensivos, métodos de conduzir
uma determinada tarefa, etc. Para estudar o efeito deste tipo de fator, deve-se proceder à
análise de variância dos dados e, se for conveniente, proceder às comparações entre as
médias dos níveis do fator usando algum dos procedimentos para comparações múltiplas
descritos neste capítulo.
A análise de variância, conforme visto no capítulo anterior, serve para verificar se existe
alguma diferença significativa entre as médias dos níveis de um fator a um determinado
nível de significância. Se o teste F para a fonte de variação que representa o fator em
estudo for não-significativa, ou seja, a hipótese de nulidade (Ho: m1 = m2 = ... = mI) não
for rejeitada, todos os possíveis contrastes entre médias de tratamentos são
estatísticamente nulos. Neste caso, não é necessário a aplicação de nenhum
procedimento de comparações múltiplas.
Por outro lado se o teste F for significativo, ou seja a hipótese de nulidade for rejeitada,
implica que existe pelo menos um contraste entre médias estatisticamente diferente de
zero. Os procedimentos de comparações múltiplas a serem vistos neste capítulo, visam
identificar qual(is) é(são) esse(s) contraste(s), para podermos por conseqüência
identificarmos qual(is) é(são) o(s) nível(is) do fator em estudo que apresentou(ram)
maior(es) média(s).
Dentre os diversos testes existentes na literatura, serão vistos os quatro testes mais
comumente utilizados. Estes testes podem ser divididos em duas categorias principais de
acordo com os tipos de contrastes que podem ser testados:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
96
1a) Procedimentos para testar todos os possíveis contrastes entre duas médias dos
níveis do fator em estudo
a) Teste de Tukey
b) Teste de Duncan
2a) Prodedimentos para testar todos os possíveis contrastes entre médias dos níveis
do fator em estudo
a) Teste t de Student
b) Teste de Scheffé
Todos os procedimentos se baseiam no cálculo de uma diferença mínima significativa
(dms). A dms representa o menor valor que a estimativa de um contraste deve apresentar
para que se possa considerá-lo como significativo. Por exemplo, para um contraste entre
duas médias, a dms representa qual é o menor valor que tem que ser detectado entre as
suas estimativas para que se possa concluir que os dois tratamentos produzam efeitos
significativamente diferentes.
A princípio um determinado contraste, por exemplo, entre duas médias poderia ser
testado por cada um dos procedimentos aqui apresentados. A conclusão a respeito da
significância do contraste pode variar de um procedimento para outro, pois o valor da
dms varia de um teste para outro, pois cada um se baseia numa distribuição de
probabilidades específica. Devido a esta possibilidade na diferença de conclusões a
respeito da significância do contraste, nós podemos dizer que um teste é mais
conservador (ou rigoroso) que o outros. Na estatística dizemos que um teste é mais
conservador que o outro quando a dms dele é maior, pois ele tende a “conservar” a
hipótese de igualdade entre médias como verdadeira. Isto porque quanto maior a dms
mais difícil se torna rejeitar a hipótese de nulidade.
Este maior ou menor conservadorismo de um teste pode ajudar o pesquisador a escolher
um procedimento de comparação múltipla. Se por exemplo, por experiência própria o
pesquisador sabe que as diferenças entre os efeitos dos níveis do fator em teste são
pequenas e ele deseja detectar estas pequenas diferenças, então ele deve usar um
procedimento menos conservador, ou seja, que apresenta uma menor dms. Se por outro
lado, ele quer concluir que os níveis do fator têm efeitos diferentes somente quando a
diferença nos seus efeitos for realmente grande, então ele deve usar um teste mais
conservador, ou seja, com maior dms.
Vamos ver a partir de agora cada procedimento com mais detalhe. Considere para tanto,
que estamos interessados em comparar as médias dos I níveis de um fator qualitativo, as

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
97
quais foram obtidas a partir da realização de um experimento no delineamento
inteiramente casualizado com J repetições, para o qual o teste F para fator foi
significativo; e que o número de graus de liberdade para o fator em estudo foi igual a n1 e
para o resíduo foi igual a n2, ou seja,
FV GL SQ QM F
Fator I-1 SQFator QMTrat significativo
Resíduo I(J-1) SQRes QMRes
Total IJ - 1 SQTotal
5.2. Alguns Procedimentos Para Comparações Múltiplas
Dentre vários procedimentos existentes para comparações múltiplas, serão apresentados
quatro: teste de Tukey, teste de Duncan, teste t de Student e teste de Scheffé.
5.2.1.Teste de Tukey
O teste de Tukey, pode ser utilizado para comparar a totalidade dos contrastes entre
duas médias, ou seja, para os I(I−1)/2 contrastes do tipo C=mi – mu; para 1 ≤ i < u ≤ I, em
que I é o número de níveis do fator em estudo. Este teste baseia-se na diferença mínima
significativa (d.m.s.) representada por ∆ e dada por:
( )ˆˆq V C∆∆∆∆ =
12
em que,
q = qα (I,n2 ) = é o valor tabelado da amplitude total estudentizada, que é obtido em
função do nível α de significância do teste, número de níveis do fator em estudo (I) e
número de graus de liberdade do resíduo (n2) da análise de variância.
( )i u
ˆV C QMResr r
= +
1 1
No caso em que todos os tratamentos apresentaram o mesmo número de
repetições, ou seja, ri = ru = K, o valor de ∆ é simplificado com a seguinte
expressão

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
98
QMResq
k∆∆∆∆ =
Para a realização do teste Tukey,a um nível de significância α, é necessário:
1. Enunciar as hipóteses: H0: C = 0 vs Ha: C≠ 0, em que C = mi – mu, para i ≠ u;
2. Obtenção das estimativas dos contrastes, i u
C m m= − , com base nos valores
amostrais;
3. Cálculo do ∆ ;
4. Concluir a respeito da significância dos I(I−1)/2 contrastes em teste, usando a seguinte
relação: se C ≥ ∆ , rejeita-se H0 ; caso contrário, não se rejeita H0 . Neste caso, indicar
as médias iguais, seguidas por uma mesma letra.
Considerações:
1. O teste de Tukey é válido para a totalidade dos contrastes de duas médias.
2. O teste de Tukey exige, em princípio, balanceamento. Mas, no caso dos tratamentos
apresentarem números de repetições diferentes, o resultado obtido por este teste é
apenas uma aproximação.
3. O teste de Tukey é exato para testar a maior diferença, nos demais casos é
conservador.
5.2.2. Teste de Duncan
Tal como o teste de Tukey, o teste de Duncan é um procedimento seqüencial, válido para
a totalidade dos contrastes de duas médias do tipo C = mi – mu. O teste de Duncan
necessita a prévia ordenação das médias, dos níveis do fator em estudo. Este teste
baseia-se na amplitude total mínima significativa (Di) dada por:
( )i iˆˆD Z V C=
12
em que,
Zi = Zα(n, n2)= é o valor tabelado da amplitude total estudentizada, que é obtido em
função do nível α de probabilidade, número de médias ordenadas abrangidas pelo
contraste entre os níveis do fator em estudo (i) e número de g.l. do resíduo da ANOVA

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
99
(n2). Como se trata de um processo seqüencial, n1 varia seu valor durante a aplicação do
teste;
( )i u
ˆV C QMResr r
= +
1 1
i i
QMResD Z
k=
Para a realização do teste Duncan a um nível de significância α é necessário:
1. Enunciar as hipóteses: H0: C = 0 vs Ha: C≠ 0, em que C = mi – mu, para i ≠ u;
2. Ordenar as médias do fator em estudo em ordem crescente ou decrescente;
3. Obter o valor da estimativa do contraste entre a maior e a menor média, com base nos
valores amostrais;
4. Calcular o valor de i D , com base no número de médias ordenadas abrangidas pelo
contraste. Neste primeiro passo i= I;
5. Concluir a respeito da significância do contraste em teste, usando o seguinte critério:
a) Se o valor de i D for maior do que o módulo da estimativa do contraste, não rejeita-se 0
H e as médias são ligadas por um traço, indicando que não há diferença entre elas;
b) Caso contrário, reduzir de uma unidade o valor de n1. Calcula-se o novo valor de i D e,
para todos os pares de médias que não estejam ligadas por um mesmo traço e que
envolvem n1 médias, repetir o procedimento que consta no item 3 e nos seguintes;
6. Proceder ao item 3 e seguintes até que i = 2.
Este teste tem como inconveniente, além de ser um teste trabalhoso, o fato das médias
ordenadas não serem independentes e o valor de zi em conseqüência, não ser exato.
Considerações:
1. O teste Duncan é um procedimento seqüencial válido para a totalidade dos contrastes
de duas médias.
2. Tal como o teste de Tukey, o teste de Duncan exige, em princípio, balanceamento.
Mas, no caso de serem diferentes os números de repetições este teste pode ainda ser
usado, mas então é apenas aproximado.
3. Quando a maior média não diferir significativamente da menor, não se admitirá
diferença significativa, entre as médias intermediárias.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
100
5.2.3. Teste t de Student
O teste t pode ser utilizado para testar contrastes envolvendo duas ou mais médias.
Porém este teste exige que:
1. as comparações a serem realizadas sejam escolhidas a priori, ou seja, antes de serem
examinados os dados;
2. podem-se testar no máximo, tantos contrastes quantos são os graus de liberdade para
tratamentos, e estes contrastes devem ser ortogonais.
A ortogonalidade entre os contrastes indica independência linear na comparação
estabelecida por um contraste com a comparação estabelecida pelos outros contrastes.
Entre I médias de um fator, podem ser obtidos I – 1 contrastes ortogonais.
Consideremos um contraste de médias, entre os níveis de um fator, em sua forma geral:
C = a1 m1 + a2 m2 + ... + ai mi
do qual obtemos a estimativa por meio do estimador
1 1 2 2 I IC a m a m ... a m= + + +
que pode ser testada pelo teste t, calculando-se a estatística t, dada por.
( ) Ii
i i
ˆ ˆC C C Ct
ˆˆ aV C QMResr=
− −= =
∑2
1
que tem distribuição t de Student com n2 graus de liberdade, sendo n2 o número de
graus de liberdade do resíduo e QMResíduo o quadrado médio residual da análise de
variância.
Caso o número de repetições seja o mesmo para todos os tratamentos, ou seja
r1 = r2 =...= rI = K, então a fórmula para a aplicação do teste t é
Ii
i i
C Ct
aQMRes
r=
−=
∑2
1
Quando aplicamos o teste t a um contraste, C, geralmente o interesse é testar as
hipóteses: H0: C = 0 vs Ha: C ≠ 0.
O valor tabelado de t é obtido por ttab=t α (n2).
A regra de decisão, neste caso, é a seguinte:
Se |t| ≥ ttab ⇒ rejeita-se H0 .
Caso contrário não se rejeita H0 .

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
101
Considerações:
1. O nível de significância α é válido para um único contraste, e não para uma série deles;
2. O nível de significância α é válido somente se o contraste for estabelecido a priori e
não sugerido pelos dados, pois, pode ficar caracterizado uma estatística de ordem ao
querer comparar a maior com a menor média, o que acarretaria certa dependência entre
as médias.
5.2.4. Teste de Scheffé
Este teste pode ser aplicado para testar todo e qualquer contraste entre médias, mesmo
quando sugerido pelos dados. É freqüentemente utilizado para testar contrastes que
envolvam grupos de médias. É um teste mais conservador que o teste t, porém não exige
que os contrastes a serem testados sejam ortogonais e nem que estes contrastes sejam
estabelecidos antes de se examinar os dados.
Se o valor de F obtido não for significativo, nenhum contraste poderá ser significativo pelo
teste de Scheffé, e sua utilização não se justifica.
A estatística do teste, denotada por S, é calculada por:
( ) ( )TABˆˆS I F V C= −
1
em que,
I = é o número de níveis do fator em estudo;
Ftab = Fα(I-1; n2) é o valor tabelado de F, obtido em função do nível α de probabilidade,
número de graus de liberdade do fator em estudo, ou seja I-1, e número de graus de
liberdade do resíduo, ou seja n2;
( )I
i
i i
aˆV C QMResr=
= ∑2
1
Caso o número de repetições seja o mesmo para todos os tratamentos, ou seja,
r1=r2=...= rI = K, então a fórmula para a aplicação do teste Schheffé é
( )I
iTAB
i i
aS I F QMRes
r=
= − ∑2
1
1
Deve-se então, calcular a estimativa do contraste C, ou seja

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
102
1 1 2 2 I IC a m a m ... a m= + + +
Se verificarmos que C ≥ S, dizemos que o contraste é significativamente diferente de
zero ao nível α de probabilidade, indicando que os grupos de médias confrontados no
contraste diferem entre si a esse nível de probabilidade.
Considerações:
1. O teste de Scheffé é válido para a totalidade dos contrastes.
2. Para testar um único contraste, ou para testar um número pequeno deles, o teste de
Scheffé é bastante rigoroso.
5.3. Vantagens e Desvantagens dos Procedimentos Para Comparações
Múltiplas
O teste t não é recomendado para testar todas as possíveis comparações entre médias
de um experimento, pois este teste aponta pequenas diferenças como significativas. O
procedimento de Duncan também é sensitivo, no sentido de declarar pequenas
diferenças como significativas. Para estes dois testes, Duncan e t, o nível de significância
conjunto para um grande número de comparações é elevado. Quando são utilizados para
esta finalidade, estes testes podem apontar como significativos contrastes, quando na
verdade estes contrastes são não-significativos. Neste acaso o erro tipo I tende a ocorrer
mais frequentemente do que o estabelecido pelo nível de significância do teste.
O teste de Tukey é bastante rigoroso no sentido de apontar diferenças significativas.
Este teste é útil quando se deseja informações preliminares a respeito das diferenças
entre os efeitos dos níveis de um fator. O procedimento de Scheffé é ainda mais rigoroso
que o Tukey para comparar pares de médias.
Para a comparação de um número grande de médias, não há um procedimento
ideal. Testes como Tukey ou Scheffé, tornam-se extremamente rigorosos, pois o nível de
significância conjunto para a maioria dos contrastes é muito menor do que o
estabelecido.
O inverso ocorre com o teste t e Duncan.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
103
Exercícios
1. Aplique os testes Tukey e Duncan, aos exemplos dados ao final da apostila do
Capítulo de Delineamento Inteiramente Casualizado.
2. Para os dados fornecidos a seguir, conclua pelo teste Duncan e Tukey (α = 5%) .
m =1 370 m =2 338 m =3 380 m =4 320 m =5 325 m =6 367
D6 = 31 D5 = 30,2 D4 = 28,7 D3 = 26 D2 = 24,6 ∆ = 33
3. Aplicar o teste de Duncan às comparações múltiplas obtidas com as médias dos
tratamentos instalados em um experimento segundo o Delineamento Inteiramente
Casualizado (DIC).Concluir para α = 5% de probabilidade.
T1 = 452,16 T2 = 481,80 T3 = 442,56 T4 = 469,52 T5 = 439,48 T6 = 461,6
SQTratamento 331,8677 SQTotal 783,4964 r 4
4. Um experimento para avaliar a influência de 4 tipos de aleitamento no ganho de peso
de leitões foi conduzido utilizando-se o delineamento inteiramente casualizado com 4
repetições. Foram obtidos os seguintes resultados parciais:
Tratamentos 1 2 3 4
Totais 37,2 44,8 31,6 32,8
FV GL SQ QM F
Tratamento 26,76
Resíduo
Total 33,82
Complete o quadro da ANOVA e, considerando-se α = 1%, responda qual(is) o(s)
melhor(es) tipo(s) de aleitamento. (Use o teste de Tukey, se necessário)

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
104
5. Com o objetivo de verificar se existe diferença, no tempo médio gasto para ir de 0-100
km/h, entre 5 marcas de carro de mesma categoria, 4 carros de cada marca foram
escolhidos inteiramente ao acaso da linha de produção de cada marca e avaliados em
uma pista de provas apropriada. Os resultados obtidos, em segundos, foram:
Marcas
1 2 3 4 5
12 12 8 12 13
11 10 7 12 14
11 10 8 10 15
13 11 6 11 13
Usando o nível de 5% de probabilidade
a. Existe de diferença significativa entre as marcas de carro quanto ao tempo médio
gasto para ir de 0-100 km/h?
b. Qual(is) é(são) a(s) marca(s) mais lenta(s) para ir de 0-100 km/h, pelo teste de
Duncan?
c. Qual(is) é(são) a(s) marca(s) mais rápida(s) para ir de 0-100 km/h, pelo teste de
Tukey?
d. Suponha que em termos de custo final ao consumidor pode-se classificar os carros
produzidos pela marca 1 como de custo alto, os produzidos pelas marcas 2 e 3 de custo
médio e aqueles produzidos pelas marcas 4 e 5 como de custo alto. Suponha também
que este experimento tinha como objetivos verificar se existe diferença no tempo médio
para ir de 0-100 km/h entre: 1) os carros de custo alto e os demais carros; 2) entre os
carros de custo médio e os de custo alto; 3) os carros de custo médio; e 4) os carros de
custo baixo. Utilize os testes de Scheffé e de t para verificar se estas comparações são
significativas.
6. Quatro padarias da cidade de São Paulo, oram fiscalizadas para verificar a quantidade
de bromato de potássio existente nos pães franceses que elas produzem.
Com esta finalidade foi tomada uma amostra de pães, inteiramente ao acaso, de cada
padaria e para cada um deles foi avaliado o teor de bromato de potássio (mg de bromato
de potássio/1kg de pão). O resumo da avaliação é fornecido a seguir:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
105
Padaria 1 2 3 4
Teor médio 10 11 8 9
Núm. de pães avaliados 7 8 7 8
SQResíduo = 52
Usando o nível de 5% de probabilidade a. Pode-se concluir que existe diferença
significativa no teor médio de bromato de potássio no pão entre as padarias avaliadas?
b. Suponha que as padarias 1 e 2 suprem a classe social A, a padaria 3 a classe B e a 4
a classe C. Verifique, por meio de um contraste, pelo teste de Scheffé e pelo teste t, se
existe diferença no teor médio de bromato de potássio entre as padarias que suprem as
classes A e C.
7. Com os dados fornecidos a seguir oriundos de um experimento instalado no DIC com 4
repetições, para o qual o teste F da ANOVA para tratamentos foi significativo, aplicar o
teste de Duncan e o teste de Tukey para se concluir qual(is) tratamento(s)
apresentou(aram) maior(es) média(s) ao nível de 5% de probabilidade.
SQResíduo = 905,6790
T1 = 813,44 T2 = 729,52 T3 = 786,32 T4 = 661,52 T5 = 755,44 T6 = 612,50

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
106
C A P Í T U L O 6
DELINEAMENTO EM BLOCOS CASUALIZADOS (DBC)
6.1 Introdução
Suponha que um experimentador esteja interessado em estudar os efeitos de 3
diferentes dietas. A primeira providência do pesquisador foi a de se inteirar a respeito da
natureza do material experimental disponível. Feito isto, constatou que ele disporia de 12
animais com aproximadamente o mesmo peso. Entretanto, estes 12 animais eram
provenientes de 4 ninhadas, cada uma contendo três animais. Dentro de uma ninhada, os
três animais foram sorteados às três dietas. Os animais foram colocados em 12 baias
idênticas e alimentados com as dietas sorteadas, em idênticas condições.
Mediu-se, então, o ganho de peso desses animais depois de 12 semanas. Os dados
obtidos são apresentados no quadro abaixo:
Dieta
Ninhada
1 2 3 4
Total
1 28,7 29,3 28,2 28,6 114,8
2 30,7 34,9 32,6 34,4 132,6
3 31,9 34,2 34,9 35,3 136,3
Total 91,3 98,4 95,7 98,3 383,7
O delineamento experimental para este ensaio de dietas é um exemplo de um
Delineamento em Blocos Casualizados com três tratamentos e quatro blocos. Os
tratamentos são níveis de um fator experimental, as três dietas; os blocos são os níveis
do fator confundido, as ninhadas. Dado que os animais em diferentes ninhadas
respondem diferentemente a uma dada dieta, a ninhada é considerada, um fator de
confundimento. As 12 unidades experimentais (animais) são agrupados em 4 blocos de
tal forma que, dentro de cada grupo, três unidades são afetadas pelo mesmo nível do
fator de confundimento. Por causa da porção das características inerentes aos animais
dentro de uma mesma ninhada (bloco), suas respostas serão muito similares, enquanto
que as respostas dos animais pertencentes a diferentes ninhadas irão variar muito; isto é,
as unidades experimentais são mais homogêneas dentro dos blocos do que entre os
blocos. Assim, resumidamente, podemos definir que um DBC é um delineamento no qual

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
107
as unidades (unidades experimentais) às quais os tratamentos são aplicados são
subdivididos em grupos homogêneos, denominados de blocos, tal que o número de
unidades experimentais em um bloco é igual ao número (ou algum múltiplo do número)
de tratamentos estudados. Os tratamentos são então sorteados às unidades
experimentais dentro de cada bloco. Deve-se ressaltar que cada tratamento aparece em
cada bloco, e todo bloco recebe todos os tratamentos. Quando se usa o DBC, o objetivo
é isolar e remover do termo de erro (resíduo) a variação atribuída ao bloco, garantindo
assim, que as médias dos tratamentos estão livres do efeito dos blocos. A efetividade
deste delineamento depende da habilidade em se obter blocos homogêneos de unidades
experimentais. A habilidade para formar blocos homogêneos depende do conhecimento
que o pesquisador tem do material experimental. Quando os blocos são usados
adequadamente, o QMR (quadrado médio do resíduo) no quadro da ANOVA será
reduzido, a estatística F aumentará, e a chance de se rejeitar H0 (hipótese de nulidade)
será maior.
Em experimentos com animais, quando acredita-se que diferentes raças de animais
responderá diferentemente ao mesmo tratamento, a raça do animal pode ser usada como
um fator a ser considerado na formação dos blocos. O DBC pode, também, ser
empregado efetivamente quando um experimento deve ser conduzido em mais de um
laboratório (bloco) ou quando vários dias (blocos) são requeridos para a realização do
experimento. No DBC temos os três princípios básicos da experimentação: repetição,
casualização e controle local.
6.2 Vantagens e devantagens de um DBC
Vantagens
Com o agrupamento das parcelas, geralmente se obtém resultados mais precisos que
aqueles obtidos num DIC.
a) Desde exista material experimental suficiente, o delineamento será sempre
balanceado, podendo-se incluir qualquer número de tratamentos.
b) A análise estatística é bastante simples.
c) Se a variância do erro experimental é maior para alguns tratamentos que para outros,
pode-se obter um erro não viesado para testar qualquer combinação específica das
médias dos tratamentos.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
108
Desvantagem
Aparece quando da perda de parcela(s) em algum tratamento. Apesar de existir um
método apropriado de estimação desses valores, há a perda de eficiência na comparação
de médias envolvendo esses tratamentos.
6.3 Organização do dados no DBC
Vamos considerar k -tratamentos; r – blocos e ij y é o valor observado na parcela que
recebeu o tratamento i e se encontra no bloco j. Assim, um quadro para representar os
valores amostrais de um DBC pode ser da forma abaixo:
Tratamentos Blocos 1 2 3 4 5 Totais de blocos
1 y11 y21 y31 y41 y51 1 Y+
2 y12 y22 y32 y42 y52 2 Y+
3 y13 y23 y33 y43 y53 3 Y+
4 y14 y24 y34 y44 y54 4 Y+
Totais de tratamentos 1 Y + 2 Y + 3 Y + 4 Y + 5 Y + Y++
Média dos tratamentos 1 Y + 2 Y + 3 Y + 4 Y + 5 Y +
6.4 Modelo matemático do DBC
O modelo matemático deste experimento é:
y t b E i
j
i j i j i j==== ++++ ++++ ++++ ====
====
µµµµ ( ) , , , , ,
, , ,
1 2 3 4 5
1 2 3 4
onde,
yij = produção porcentual de ovos das aves que receberam o tipo de calcário i no
estágio de produção j;
µµµµ = média geral do experimento;
ti = efeito do calcário i;
bj = efeito do estágio de produção j;
E(ij) = erro associado à produção porcentual de ovos das aves que receberam o
tipo de calcário i no estágio de produção j.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
109
6.5. Suposições do modelo
Neste modelo,
• cada ij y observado constitui uma amostra aleatória independente de tamanho 1 de
cada uma das kr populações
• os e ij são independentes e normalmente distribuídos com média 0 e variância σ2, ou
seja, εij~ N (0 , σ2 ) . Isto implica em que as kr populações são normalmente distribuídas
com média µij e a mesma variância σ2 , ou seja, yij ~N (µi , σ2 ) ;
• os efeitos de blocos e tratamentos são aditivos. Esta suposição pode ser interpretada
como não existe interação entre tratamentos e blocos. Em outras palavras, uma particular
combinação bloco-tratamento não produz um efeito que é maior que ou menor que a
soma dos efeitos individuais.
6.6. Hipótese estatística
Podemos testar
H0: ζi = 0, com i = ,1 2,..., k
H1: nem todos os ζi= 0
Geralmente o teste de hipótese com relação aos efeitos de blocos não é feito por dois
motivos: primeiro o interesse principal é testar os efeitos de tratamento, o propósito usual
dos blocos é eliminar fontes estranhas de variação. Segundo, embora as unidades
experimentais sejam distribuídas aleatoriamente aos tratamentos, os blocos são obtidos
de uma maneira não aleatória.
6.7 Partição da soma de quadrados
Voltemos ao quadro de representação das observações no DBC
Tratamentos Blocos 1 2 3 4 5 Totais de blocos
1 y11 y21 y31 y41 y51 1 Y+
2 y12 y22 y32 y42 y52 2 Y+
3 y13 y23 y33 y43 y53 3 Y+
4 y14 y24 y34 y44 y54 4 Y+
Totais de tratamentos 1 Y + 2 Y + 3 Y + 4 Y + 5 Y + Y++
Média dos tratamentos 1 Y + 2 Y + 3 Y + 4 Y + 5 Y +
Podemos identificar os seguintes desvios:
• Yij Y − ++ , como o desvio de uma observação em relação a média amostral geral;

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
110
• Yij i Y − + , como o desvio da observação em relação à média de seu grupo ou do i-
ésimo tratamento;
• Yi Y −+ ++ , como o desvio da média do i-ésimo tratamento em relação á média geral.
• Yj Y −+ ++ ,como o desvio da média do j-ésimo bloco em relação á média geral.
Consideremos a identidade
( ) ( )y yi j
y y y y y y y y y yij i j ij i jTotal
( ) ( )− ++
= − = − + − + − ++ ++ + ++ +− + ++++
a qual representa a “ a variação de uma observações em relação à média geral amostral
como uma soma da variação desta observação em relação à média de seu grupo, com a
variação desta observaçãoem relação à média do j-ésimo bloco em que se encontra esta
observação, com a variação do erro experimental “. Elevando-se ao quadrado os dois
membros da identidade acima e somando em relação aos índices i e j, obtemos:
( ) ( ) ( ) ( )k r k r k r k r2 2 2 2
y y y y y y y y y yij ij i j ij i ji 1 j 1 i 1 j 1 i 1 j 1 i 1 j 1
− = − + − + − − +∑ ∑ ∑ ∑ ∑ ∑ ∑ ∑++ + + ++ + + ++= = = = = = = =
O termo
( )k r 2
y yiji 1 j 1
−∑ ∑ ++= =
é denominado de Soma de Quadrados Total e vamos denotá-lo por SQT.O número de
graus de liberdade associado à SQT é kr - 1, ou N – 1, pois temos N observações e a
restrição
( )k r 2
y y 0iji 1 j 1
− =∑ ∑ ++= =
O termo:
( )k r 2
y yii 1 j 1
−∑ ∑ + ++= =
é denominado de Soma de quadrados de tratamentos, representada por SQTr, e é
uma medida da variabilidade entre os tratamentos. Quanto mais diferentes entre si forem
as médias dos tratamentos, maior será a SQTr. Desde que temos k tratamentos e a
restrição de que

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
111
( )k r 2
y y 0ii 1 j 1
− =∑ ∑ + ++= =
a SQTr está associada a k-1 graus de liberdade.
O termo
( )k r 2
y yji 1 j 1
−∑ ∑ + ++= =
É denominado de Soma de quadrados de blocos, representada por SQB, e é uma
medida da variabilidade entre os blocos. Quanto mais diferentes entre si forem as médias
dos blocos, maior será a SQB, justificando assim, a utilização do delineamento em
blocos. Desde que temos r blocos e a restrição de que
( )k r 2
y y 0ji 1 j 1
− =∑ ∑ + ++= =
a SQB está associada a r-1 graus de liberdade.
Finalmente, o termo
( )k r 2
y y y yij i ji 1 j 1
− − +∑ ∑ + + ++= =
Notem que a magnitude da SQR não depende da diferença entre as médias dos
tratamentos. Os graus de liberdade associada à SQR é (k-1)(r-1), isto é, o produto dos
graus de liberdade dos tratamentos e blocos SQT = SQB + SQTr + SQR ,
e os graus de liberdade associados a cada membro da equação acima fica
total = blocos + tratamentos + resíduo kr-1 = (r-1) + (k-1) + (k-1)(r-1)
6.8 Quadrados médios
Dividindo a SQB, SQTr e SQR pelos correspondentes graus de liberdade, obtemos,
respectivamente o Quadrado Médio Blocos (QMB), o Quadrado Médio Entre
Tratamentos (QMTr) e o Quadrado Médio Resíduo, isto é,

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
112
( ) ( )
SQBQMB
r 1
SQTrQMTr
k 1
SQRQMR
k 1 r 1
=−
=−
=− −
6.9 Estatística e região crítica do teste
A estatística para o teste é
QMTrFc
QMR=
a qual, deve ser próximo de 1 se H0 for verdadeira, enquanto que valores grandes dessa
estatística são uma indicação de que H0 é falsa. A teoria nos assegura que Fc tem, sob
H0 distribuição F – Snedecor com (k -1) e (k-1)(r-1) graus de liberdade no numerador e
no denominador, respectivamente. Resumidamente, indicamos:
FC ~ F((k-1),(k-1),(r-1),α) , sob H0
Rejeitamos H0 para o nível de significância α se
FC > F((k-1),(k-1),(r-1),α),
sendo, F((k-1),(k-1),(r-1),α), o quantil de ordem (1 −a ) da distribuição F-Snedecor com (k -1) e
(k-1)(r-1) graus de liberdade no numerador e no denominador.
6.10 Quadro da análise de variância (ANAVA)
Dispomos as expressões necessárias ao teste na Tabela abaixo, denominada de Quadro
de Análise de Variância (ANAVA).
Fonte de Variação g. l. S. Q. Q. M. Fc Tratamentos
k - 1
( )+ ++
=
−∑
22
1
ir
i
i
YYr k r =
−1
S Q T rQ M T rk
Q M T rQ M R
Blocos r - 1
( )+ ++
=
−∑
22
1
rj
j
YYk k r =
−1
S Q BQ M Br
Q M BQ M R
Resíduo
(k – 1)(r – 1)
≠ ( ) ( )
=− −
1 1S Q RQ M R
k r
Total
N - 1
( )+ +
= = =
−∑∑ ∑
2
2
1 1 1
k r k
i ji j i
YY
k r

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
113
Pode-se provar que:
• E(QMR) = σ2 , ou seja, QMR é um estimador não viesado da variância σ2 ;
• E( QM)r) σ2 +( )
krti
k 1 i 1∑
− =, ou seja, QMTr é um estimador não viesado da variância σ2
se a hipótese H0 : t1 =t2 =... =tk = é verdadeira.
• E( QMB) σ2 +( )
rkj
r 1 j 1
β∑− =
6.11 Detalhes computacionais
Apresentaremos alguns passos que facilitam os cálculos das somas de quadrados da
ANAVA.
• Calcule a correção para a média ( )++=
2YC M
N
• Calcule a Soma de Quadrados dos Totais (SQT)
= =
= −∑∑2
1 1
irk
i ji j
S Q T Y C M
• Calcule a Soma de Quadrados Entre os Tratamentos (SQTr)
+= −
2i
i
YS Q T r C Mr
• Calcule a Soma de Quadrados de blocos (SQB) ( )+ ++
=
= −∑
22
1
rj
j
Y YS Q B
k k r
• Calcule a Soma de Quadrados Residual (SQR) pela diferença, isto é,SQR = SQT –
SQTr - SQB ;
• Calcule os Quadrados Médios Entre os Tratamentos (QMTr), o Quadrado Médio
Residual (QMR) e o Quadrado Médio de Blocos
=−
1S Q T rQ M T rk , =
−
S Q RQ M RN k e =
−1
S Q BQ M Br
• Calcule Fc para tratamentos e FC para blocos =C T r
Q M T rFQ M R =C B l
Q M BFQ M R
EXEMPLO 1: Vamos considerar os dados apresentados no item 1.
Os cálculos para montar-mos o quadro da ANOVA são: k = 3, r = 4, e kr = N =(3)(4) =12.
Então

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
114
• Graus de liberdade:
Total = Kr – 1 = N – 1 = (3)(4) – 1 = 11; Trat = k – 1 = 3 – 1 = 2
Blocos = r – 1 = 4 – 1 = 3 e Res. = (3-1) (4-1) = 6
•( )2383 80
CM 12 275 2012
,. ,= =
•
( ) ( ) ( )2 2 2SQT 28 70 29 30 35 30 CM
SQT 12.353,35 -12.268,81 =84,54
, , ... ,= + + + −
=
•
( ) ( ) ( )2 2 2114 80 132 60 136 30
SQTr CM4 4 4
SQTr 12.334,7 - 12.268,81 = 66,06
, , ,= + + −
=
•
( ) ( ) ( ) ( )2 2 2 291 30 98 40 95 70 98 30
SQB CM3 3 3 3
SQB 12.279,88 -12.268,81 =11,07
, , , ,= + + + −
=
•
66 02QMTR 33 03
2
11 07QMB 3 69
3
7 41QMR 1 24
6
,,
,,
,,
= =
= =
= =
•
QMTr 33 03F 26 64cTr
QMR 1 24
QMB 3 69F 2 99CBl
QMR 1 24
.,
,
,,
,
= = =
= = =
Organizando estes resultados no Quadro da ANAVA, temos:
Fontes de Variação G. L. S. Q. Q. M. Fc Tratamentos Blocos
2 3
66,06 11,07
33,03 3,69
26,64** 2,99
Resíduo 6 7,41 1,24 Total 11 84,54
Das tabelas das distribuições F, temos que F(2,6.0,05) = 5,14 e F(2,6;0,01) = 10,92.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
115
O valor FcTr = 26,64 é maior do que estes valores tabelados, então rejeitamos a
hipótese
nula H0 para um nível α = 0,01, ou 1% de probabilidade (se é significativo a 1%, também
é significativo a 5%), e concluímos que existe uma diferença entre as três dietas. As
conclusões sobre ás diferenças entre os efeitos de ninhadas (blocos) podem ser
baseadas no Fc para blocos (FcBl = 2,98 com p=0,118). Parece que não existe uma
variação significativa entre as ninhadas nos ganhos de peso. O teste F da ANOVA para
os blocos é um teste aproximado mesmo quando as suposições são satisfeitas.
Alguns pesquisadores sugerem que não se considere o efeito colocado nos blocos em
futuros estudos similares, somente se o valor mínimo significativo (valor de p) associado
à estatística calculada for maior ou igual a 0,25 ( p ³ 0,25 ) . Para estes dados, FcBl =
2,99 tem um p = 0,118. Portanto, mesmo que existe insuficientes evidências para rejeitar
H 0 0 : b j = , ou seja, não existe efeito de ninhada, não é uma boa idéia ignorar os efeitos
de ninhada em futuros estudos.
6.12. O problema da perda de parcela
Embora não seja desejável, a perda de parcelas faz parte do cotidiano do
experimentador e precisa ser superada. Na experimentação com animais, isso ocorre
devido a doenças durante a realização do experimento ou até mesmo no caso de morte
de um animal. Em agronomia isso pode ocorrer devido a problemas de execução do
experimento, morte ou doença das plantas, extravio de fichas onde os dados são
registrados, registro de um valor superestimado (absurdo) ou duvidoso.
De qualquer forma a experimentação é um processo que exige muita sensibilidade por
parte do pesquisador, o que torna aqueles com mais experiência, verdadeiros consultores
em caso de dúvidas ou fenômenos inesperados. De qualquer forma essa experiência e
também sensibilidade só é adquirida com o tempo e após a execução de vários
experimentos. Portanto, sempre que houver dúvidas, é recomendável recorrer a um
estatístico, ou mesmo a algum profissional da área que tenha experiência e familiaridade
com a experimentação.
Os experimentos que contém perda de parcelas são denominados “não balanceados”. No
caso de um DIC isso é facilmente realizado com a aproximação de algumas fórmulas da
Análise de Variância. No caso de um DBC apresentaremos uma alternativa bastante
simples para a superação deste problema. A alternativa seria a utilização de métodos de
Análise Multivariada, que na verdade se trata de uma estatística bastante avançada que

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
116
é vista em cursos de pós-graduação em estatística, e, portanto foge do escopo deste
curso. O caminho a ser seguido em nosso caso consiste inicialmente em estimar o valor
da parcela que foi perdida por meio da fórmula:.
Vamos considerar o seguinte exemplo:
Exemplo:
Tratamentos
Classe de idade (Blocos)
1 2 3 4
Total
A 15 11 20 18 64
B 22 31 45 26 124
C 33 37 * 30 100
D 44 31 49 34 158
E 37 30 36 21 124
Total 151 140 150 129 570
A generalização destes dados pode ser representada no quadro abaixo
Blocos Tratamentos 1 2 3 … j r Total
1 y11 Y12 y13 … .… y1r 1 Y +
2 y12 y22 y32 … … y2r 2 Y +
3 i
y13
y23 y33 … …
ij Y
y3r 3 Y +
… k
…
yk1
…
yk2
…
yk3
… …
ykr
4 Y+
Total 1 Y + 2 Y + 3 Y +
5 Y + Y++
sendo:
ij Y a estimativa da parcela perdida;
k o número de tratamentos e r o número de blocos;
Y++ o total das parcelas disponíveis;
Yi+ o total das parcelas restantes no bloco onde ocorreu a parcela perdida;
Y+j o total das parcelas res tes no tratamento onde ocorreu a parcela perdida.
Uma solução interessante para o caso da perda de uma parcela consiste em estimar seu
valor usando a fórmula:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
117
( ) ( )kY rY Yi j
yijk 1 r 1
´ ´ ´ˆ
−+ + ++=
− −
No exemplo acima, temos uma parcela perdida no tratamento C no bloco 3 (classe de
idade). Nestes dados temos:
• k= 5, r= 4 Y 3´+ = 150 Y3
´+=100 e Y
´++ = 570
•a estimativa da parcela é dada por ( ) ( )
5 100 4 150 570y 44 17ij
5 1 4 1
( ) ( )ˆ ,
+ −= =
− −
Este valor deve ser substituído no lugar do dado perdido e a análise é feita como
anteriormente. A única diferença é que se perde um grau de liberdade no resíduo,
obtendo-se o seguinte quadro de análise de variância:
Fontes de Variação G. L. S. Q. Q. M. Fc Tratamentos Blocos
4 3
1289,00 488,56
322,25 162,86
10,21**
Resíduo 11 347,18 31,56 Total 18 2124,75 F(4; 11; 0,05) = 3,36; F(4; 11; 0,01) = 5,67; F(3; 11; 0,05) = 3,59 ; F(3; 11; 0,01) = 6,62
Observação: Nessa última análise, o quadrado médio do resíduo está corretamente
estimado, mas aquele correspondente a tratamento está ligeiramente exagerado. Para
corrigi-lo, basta subtrair da SQTr a seguinte quantidade:
2Yk 1 j
U Yijk k 1
ˆ − +
= − −
Então, temos: 2
5 1 150U 44 17 35 59
5 5 1, ,
− = − = −
, logo a SQTr correta fica igual a SQTr =
1289,00 – 35,59 = 1253,41 e a _QMTr = 313,35.
FC = 9,93. Como o valor de FC> F ( 4,11: 0,05 ) a conclusão sobre a presença de pelo menos
um efeito de tratamento não nulo, continua valendo.
OBS: Muitas vezes, dispensa-se o uso dessa correção, já que nem sempre ela
altera os resultados. Entretanto, na dúvida, devemos aplicar essa correção.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
118
6.13 Análise de variância de medidas repetidas
Um delineamento experimental de medidas repetidas é aquele no qual, várias medidas
são feitas na mesma unidade experimental (geralmente animal), e estas medidas
repetidas constituem as repetições. Para ilustrar melhor esta característica vamos
considerar o exemplo 2, item 11 da Aula 3 , pg 35. Neste exemplo tínhamos 4 amostras
independentes de animais e todos os animais de cada grupo foram alimentados, depois
do sorteio, com uma das 4 dietas. Nos delineamentos de medidas repetidas não existe
amostras independentes de animais; ao contrário, cada um dos 5 animais
terão seus pesos medidos depois que foram submetidos a uma determinada dieta, depois
de um certo período de tempo, os mesmos cinco animais terão seus pesos avaliados
depois de terem sidos submetidos a outra dieta, e assim sucessivamente, até serem
submetidos a todas as dietas. A tabulação dos dados pode ser bem parecida com a
representação dos dados do DBC. Neste exemplo podemos ter:
Animais Dietas 1 2 3 4 5 Total
1 y11 y21 y31 y41 y51 1 Y+
2 y12 y22 y32 y42 y52 2 Y+
3 y13 y23 y33 y43 y53 3 Y+
4 y14 y24 y34 y44 y54 4 Y+
Total 1 Y + 2 Y + 3 Y + 4 Y + 5 Y + Y++
Os resultados dos cálculos da ANOVA de um delineamento de medidas repetidas são os
mesmos de uma análise de um DBC. A grande vantagem deste tipo de delineamento é o
seu econômico requerimento de unidades experimentais (animais).
Este delineamento tem desvantagens se existe um efeito por causa da seqüência em que
os tratamentos são administrados (dietas no presente exemplo) aos animais. Uma outra
desvantagem surge se o tempo entre a aplicação de diferentes tratamentos é insuficiente
para evitar a sobreposição de efeitos do tratamento anterior.
EXEMPLO. Considere o conjunto de dados abaixo os quais se referem a níveis de
concentração de colesterol (mg/dl) em sangue de 7 animais experimentais, depois que
foram tratados cada um com uma das três drogas, com suficiente tempo entre as
aplicações das drogas para que seu efeito desaparecesse do animal.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
119
Drogas Animais 1 2 3 Total
1 164 152 178 494 2 202 181 222 605 3 143 136 132 411 4 5 6 7
210 228 173 161
194 219 159 157
216 245 182 165
620 692 514 483
Total 1281 1198 1340 3819
Faça os cálculso e apresente os resultados

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
120
Exercícios 1. Os dados abaixo, se referem a um experimento instalado segundo o DBC, em que os
tratamentos, 5 produtos comerciais para suprir deficiência de micronutriente em caprinos,
foram fornecidos aos animais os quais foram separados em 3 grupos segundo a idade.
Os resultados obtidos, expressos em ppm de micronutriente/ml de sangue, foram os
seguintes:
Produtos comerciais Bloco 1 2 3 4 5 Totais
1 83 86 103 116 132 520 2 63 69 79 81 98 390 3 55 61 79 79 91 365
Totais 201 216 261 276 321 1275
Pede-se proceder a ANOVA e aplicar o teste Tukey e Duncan, usando o nível de 5% de
probabilidade.
2. Com a finalidade de aumentar a produção de lã de suas ovelhas, por meio de uma
alimentação mais apropriada um criador separou 28 ovelhas de sua criação. Como as
ovelhas eram de idades diferentes, dividiu-as em 7 grupos, sendo que dentro de cada um
destes grupos havia 4 ovelhas de mesma idade e homogeneidade para as demais
características. Dentro de cada grupo foi realizado um sorteio para distribuir ao acaso, os
4 Tipos de Alimentação (TA) às ovelhas do grupo. O experimento se iniciou logo após as
ovelhas terem sido submetidas a uma tosquia e se encerrou quando já era o momento de
se realizar uma nova tosquia da qual foram obtidos os seguintes resultados, expressos
em unidade de medida de lã por animal:
grupos Bloco 1 2 3 4 5 6 7 Totais
1 30 32 33 34 29 30 33 221 2 29 31 34 31 33 33 29 220 3 43 47 46 47 48 44 47 322 4 23 25 21 19 20 21 22 151
Totais 125 135 134 131 130 128 131 914
Com base nas informações anteriores, pede-se (α = 1%):
a) Qual o tipo de delineamento experimental que o criador utilizou? Justifique sua

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
121
resposta.
b) Existe diferença entre os tipos de alimentação fornecidos às ovelhas com
relação a produção de lã?
c) Com base no teste Tukey, qual(is) seria(m) o(s) tipo(s) de alimentação a ser(em)
recomendada(s) às ovelhas?
3. Um experimento no DBC com 4 repetições forneceu os dados abaixo:
Blocos Tratamentos 1 2 3 4 Totais
1 142,36 144,78 145,19 138,88 571,21 2 139,28 137,77 144,44 130,61 552,10 3 140,73 134,06 136,07 144,11 554,97 4 150,88 135,83 136,97 136,36 560,04 5 153,49 165,02 151,75 150,22 620,48
Totais 726,74 717,46 714,42 700,18 2858,8
Para o nível de 5% de significância, pede-se:
a) ANOVA
b) Teste Tukey
c) Teste Duncan
d) Aplicar o teste Scheffé ao contraste C = m1 + m2 − 2m5
e) Aplicar o teste t aos contrastes
C1 = m1 + m2 - 2m5
C2 = m2 + m3 – m1 - m4
C3 = m1 – m4
4. O resumo da Análise de Variância de um experimento instalado segundo o
Delineamento em Blocos Casualizados, para verificar se existe diferença entre 5 tipos de
Levedura na produção de cerveja, é fornecido a seguir:
FV GL QM F Blocos 3 Tratamentos Resíduo 4,895 Total
Totais de Tratamentos:
T1 = 12,0 T2 = 25,2 T3 = 22,0 T4 = 24,0 T5 = 45,6

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
122
Ao nível de 5% de probabilidade, pede-se:
a) Existe diferença entre os 5 tipos de Levedura, na produção de cerveja?
b) Pelo teste Tukey, qual(is) o(s) tipo(s) de Levedura que apresentou(aram) maior
produção?
c) Pelo teste Duncan, qual(is) o(s) tipo(s) de Levedura que apresentou(aram) menor
produção?
5. Um Engenheiro-Agrícola, com o objetivo de verificar qual tipo de pneu que proporciona
menor consumo de combustível, para trabalhar em terrenos encharcados,
testou 4 diferentes tipos de pneus. Como a área que dispunha para realizar o
experimento era heterogênea com relação à declividade, ele subdividiu a área total em 3
sub-áreas de tal forma que dentro de cada uma delas existia uniformidade com relação à
declividade.
Após isto, dentro de cada sub-área realizou um sorteio ao acaso, dos tipos de pneus às
unidades experimentais. Com a realização da pesquisa, obteve-se os seguintes
resultados de consumo expressos em litros/hora trabalhada.
Pneu Sub-áreas Tipo 1 Tipo 2 Tipo 3 Tipo 4 Totais
1 30 32 33 35 130 2 29 30 31 33 123 3 25 26 30 31 112
Totais 84 88 94 99 365
Por meio das informações fornecidas acima, pede-se (use o nível de 5% designificância,
quando necessário).
a) Quais foram os Princípios Básicos da Experimentação utilizados neste experimento?
Justifique sua resposta.
b) Qual foi o tipo de delineamento experimental utilizado pelo Engenheiro-Agrícola?
Justifique sua resposta.
c) Em termos do consumo, conclua com relação aos tipos de pneus, por meio de uma
análise de variância.
d) Qual tipo de pneu que proporciona o pior consumo? Use o teste Duncan, se
necessário

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
123
6. Suponha que alguém solicite sua ajuda, na aplicação de testes de médias aos dados
de um experimento, instalado segundo o DBC com 4 repetições, para o qual o F da
Análise de Variância para tratamentos foi significativo. Para tanto você recebe as
seguintes informações:
Tratamentos 1 2 3 Totais 400 440 360
SQResíduo = 360 α = 5%
C1 = 3m1 − 2m2 − 2m3 C2 = m1 − 2m2 + m3 C3 = m1 – m2
a) Obtenha a V(C2)
b) Admita que ele deseja aplicar o teste de Scheffé em C1 e C2. Proceda a aplicação
do teste Scheffé de maneira adequada conforme visto em sala de aula.
c) Admita que ele deseja aplicar o teste t em C2 e C3. Proceda a aplicação do teste t
de maneira adequada conforme visto em sala de aula.
d) Obtenha um grupo de contrastes ortogonais a partir apenas de C3, usando o método
do sistema de equações lineares.
7. Um pesquisador foi encarregado de verificar se havia diferença de durabilidade entre 4
tipos de microaspersores presentes no mercado, produzidos por duas fábricas diferentes,
conforme quadro abaixo:
Tratamentos Microaspersor Fabricado por 1 Tipo A Água Boa S.A. 2 Tipo B Água Boa S.A. 3 Tipo C Água Boa S.A. 4 Tipo Único Água Ardente Ltda

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
124
Desconsiderando como o experimento foi conduzido, bem como o tipo de informação
usado na avaliação, considere os seguintes dados, após uma análise parcial dos
mesmos:
FV GL SQ QM F Blocos 3 1760 35,2 Tratamentos 4 Resíduo 12 4,895 50 Total 19
Com base nas informações acima pede-se: (use α=5%)
a) Cada tratamento foi repetido quantas vezes? Justifique sua resposta.
b) Que hipótese estaríamos testando pela ANOVA? Qual a sua conclusão no presente
caso?
c) Para responder qual é o melhor microaspersor, o que deveríamos fazer? Apenas
comente rapidamente.
d) Faça um teste (à sua escolha) para saber se há diferença entre os resultados médios
apresentados pelos microaspersores da fábrica Água Boa S.A. com o apresentado pelo
microaspersor da fábrica Água Ardente Ltda.
Médias dos Tratos m =1 36
m =2 40
m =3 60
m =4 40

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
125
C A P Í T U L O 7
DELINEAMENTO EM QUADRADO LATINO (DQL)
7.1 Introduão
Vimos que o Delineamento em Bloco Casualizado (DBC) é um delineamento
experimental simples que permite fazer comparações entre as respostas esperadas dos
tratamentos depois da eliminação (do ajuste) do efeito de uma variável de confundimento.
O delineamento utiliza os níveis desta variável de confundimento para formar blocos de
unidades experimentais. Pela imposição da restrição de que todos os tratamentos devam
ser aplicados a exatamente uma unidade experimental em cada bloco, podemos
assegurar que o delineamento eliminará os efeitos de bloco quando da comparação dos
efeitos dos tratamentos. Delineamentos simples para a eliminação dos efeitos de mais de
uma variável de confundimento pode ser construída analogamente ao DBC. Em
particular, o Delineamento Quadrado Latino (DQL) pode ser usado para ajustar os efeitos
de duas variáveis de confundimento.
A estrutura de um DQL para comparar k tratamentos pode ser visualizada em um arranjo
de k2 unidades experimentais em um quadrado de k linhas e k colunas. As respostas das
unidades experimentais em uma mesma linha são afetadas por um efeito comum de
confundimento denominado efeito da linha. Similarmente, as respostas das unidades
experimentais na mesma coluna são afetadas por um efeito comum de confundimento
denominado efeito da coluna. Os k tratamentos são aplicados às k2 unidades
experimentais de tal maneira que todo tratamento
aparece exatamente uma única vez em cada linha e uma em cada coluna.
Considere o seguinte exemplo, extraído de Rao, P.V. Statistical research methods in the
life science, pg 727: Em um estudo para comparar as tolerâncias de gatos a quatro
substâncias cardíacas (A, B, C, D) foi conduzida utilizando-se um DQL , no qual as linhas
representavam quatro combinações de dois períodos (A.M. , P.M.)

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
126
Dias
1 2 3 4 Yi.. i Y ++ I,AM Y11(D)
3,26
Y12(B) 4,15
Y13(A) 3,02
Y14(C) 3,67
Y1++
14,10
1 Y ++
I,PM Y21(B) 2,73
Y22(D) 3,38
Y23(C) 3,29
Y24(A) 4,50
Y2++
13,90 2 Y ++
II,AM Y31(A) 3,45
Y32(C) 4,09
Y33(B) 2,66
Y34(D) 3,51
Y3++
13,71 3 Y ++
II,PM Y41(C) 3,20
Y42(A) 3,14
Y43(D) 3,48
Y44(B) 3,40
Y4++
13,22 4 Y ++
Y+j+ Y+1+
12,64 Y+2+
14,76 Y+3+
12,45 Y+4+
15,08 Y+++
54,93
1 Y+ + 2 Y+ + 3 Y+ + 4 Y+ + Y+j+
Combinações de tempo e técnicas Totais dos tratamentos:
Y++( A)= Y13( A)+ Y24( A)+ Y31( A)+ Y42( A) = 3,02+ 4,50+ 3,45+ 3,14 = 14,11
Y++(B)= Y12( B)+ Y21( B)+ Y33( B)+ Y44( B) = 4,15+ 2,73+ 2,66+ 3,40 = 12,94
Y++( C)= Y14( C)+ Y23( C)+ Y32( C)+ Y41( C) = 3,67+ 3,29+ 4,09+ 3,20= 14,25
Y++( D)= Y11( D)+ Y22( D)+ Y34( D)+ Y43( D) = 3,26+ 3,38+ 3,51+ 3,48= 13 63
Notação:
• Y++i = soma das observações da i-ésima linha (i = 1, 2,..., k);
• Y+i+ = soma das observações da j-ésima coluna (j=1,2, ..., k);
• Y++(t) = soma das observações do t-ésimo tratamento
7.2 Modelo Matemático. Hipóteses
O modelo matemático de um experimento em quadrado latino é:
y l c t E i j k t n ti j k i j k i jk==== ++++ ++++ ++++ ++++ ==== ====µµµµ ( ) ( , , , , . . . , ; )1 2 2
onde:
yi j k = valor da parcela que recebeu o tratamento k na linha i e coluna j;
µµµµ = média geral do experimento;
li = efeito da linha i (1a variável de controle);
cj = efeito da coluna j (2a variável de controle);
tk = efeito do tratamento k;
E(i j k) = erro da parcela que recebeu o tratamento k, na linha i e coluna j.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
127
Observação: Como existe apenas uma observação por parcela, somente 2 dos 3 índices são necessários para identificar a parcela. Basta conhecer i e j para você saber qual é o tratamento k envolvido. - Tipos de Modelo
Fixo, aleatório ou misto.
- Hipóteses do Modelo
a) Aditividade
Não pode haver interação entre as variáveis de controle e tratamento.
b) Homogeneidade de variâncias
c) Normalidade e Independência de Erros
7.3 Objetivo do Controle em 2 Direções
O objetivo do controle é remover a variabilidade do material experimental ou do ambiente
em 2 direções. As variações entre blocos horizontais e verticais, que esperamos serem
grandes, são eliminadas do erro experimental.
7.4 Caracterização do Quadrado Latino
Cada tratamento aparece uma única vez em cada linha (bloco horizontal) e em cada
coluna (bloco vertical). A exigência principal do quadrado latino é que o número de
repetições seja igual ao número de tratamentos. Quando este número for muito grande, o
DQL é impraticável.
É um delineamento bem menos flexível que o DBC e, como este, o erro experimental
pode aumentar com o tamanho do quadrado. Os quadrados latinos mais usados são
aqueles com 5 a 8 tratamentos. O QL 2 x 2 não é usado isoladamente, pois o erro fica
com zero grau de liberdade, o que é inviável; os QL’s 3 x 3 e 4 x 4 já são bem usados,
porém repetidos várias vezes. Os tipos 5 x 5 a 8 x 8 são usados sem repetição.
Os quadrados latinos recebem este nome porque o número de parcelas totais do
experimento corresponde ao quadrado do número de tratamentos (n = t2) e por terem
sido, originalmente, representados por letras latinas.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
128
7.5 Partição da soma de quadrados
Do quadro de representação das observações no DQL, podemos notar as seguintes
desvios:
Podemos identificar os seguintes desvios:
• ijt Y – Y+++ , como o desvio de uma observação em relação à média geral;
• ijtY - Y+++ t , como o desvio da média do t-ésimo tratamento em relação à média geral;
• iY ++ - Y+++ , como o desvio da média da i-ésimo linha em relação á média geral;
• jY+ + - Y+++ , como o desvio da média da j-ésima coluna em relação á média
geral;
Então, podemos escrever a igualdade:
( ) ( ) ( ) ( ) ( ) ( )Y Y Y Y Y Y Y Y Y Y Y 2Yijt i j t ijt i j ij Y − = − + − + − + − − − ++++ ++ +++ + + +++ ++ +++ ++ + + + +++ a qual representa a “ a variação de uma observação em relação à média geral amostral
como uma soma da variação da média da i-ésima linha em relação à média geral, com a
variação da média da j-ésima coluna em relação à média geral, com a variação da média
da j-ésima coluna em relação à média geral, com a variação da média do k-ésima
tratamento em relação à média geral, com a variação do erro experimental “. Elevando-se
ao quadrado os dois membros da identidade acima e somando em relação aos índices i e
j, obtemos:
( ) ( ) ( ) ( )
( )
Y Y Y Y Y Y Y k Y
Y Y Y Y 2Y
k k k k k2 22 2ijk i j i
i 1 j 1 i 1 i 1 i 1
k k k 2ijk i j ij
i 1 j 1t 1
− = − + − + −
+ − − − +
∑ ∑ ∑ ∑ ∑+++ ++ +++ + + +++ + +++= = = = =
∑ ∑ ∑ ++ + + + +++= = =
Ou seja, a “ Soma de quadrados do Total (SQT) é igual à Soma de Quadrados do efeito
colocado nas linhas (SQL), mais a Soma de Quadrados do efeito colocado nas colunas
(SQC), Mais a Soma de Quadrados dos tratamentos (SQTr), mais a Soma de Quadrados
dos resíduos (SQR). Notem que existe k2 observações, então a SQT tem k2 -1 graus de
liberdade. Existe k – linhas, k – colunas e k – tratamentos, tal que cada uma das três

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
129
soma de quadrados SQL, SQC e SQTr têm k-1 graus de liberdade. Finalmente, os graus
de liberdade para SQR pode ser
calculado pela diferença entre os graus de liberdade entre a SQT e soma dos graus de
liberdade para linhas, colunas e tratamentos. ((k2-1)-(k-1)-k-1)-(k-1)=(k-1)(k-2)).
Assim, os graus de liberdade associados a cada membro da equação acima fica
Total Linhas Colunas Tratamentos Resíduo ( k2 -1) = (k-1) + (k-1) + (k-1) + (k-1)(k-2)
7.6. Quadrados médios
Dividindo a SQL, SQC, SQTr e SQR pelos correspondentes graus de liberdade,
obtemos, respectivamente o Quadrado Médio das Linhas (QML), o Quadrado Médio
das Colunas (QMC) , o Quadrado Médio de Tratamentos (QMTr) e o Quadrado
Médio Resíduo (QMR), isto é,
( ) ( )
SQLQML
k 1
SQCQMC
k 1
SQTrQMTr
k 1
SQRQMR
k 1 k 2
=−
=−
=−
=− −
7.7 Eestatística e região crítica do teste A estatística para o teste é
QMTrF
QMRc =
a qual, deve ser próximo de 1 se H0 for verdadeira, enquanto que valores grandes dessa
estatística são uma indicação de que H0 é falsa. A teoria nos assegura que Fc tem, sob
H0 distribuição F – Snedecor com (k -1) e (k-1)(k-2) graus de liberdade no numerador e
no denominador, respectivamente. Resumidamente, indicamos:
c k 1 k 1 k 2 0 FC ~ F( ( k- 1,( k- 1)( k 2 ),α ) , sob H0 .
Rejeitamos H0 para o nível de significância α se
FC > F( ( k- 1,( k- 1)( k 2 ),α ) ,
sendo, F( ( k- 1,( k- 1)( k 2 ),α ) o quantil de ordem (1 −α ) da distribuição F-Snedecor com (k -1)
e (k-1)(k-2) graus de liberdade no numerador e no denominador

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
130
7.8 Quadro da análise de variância (ANAVA)
Dispomos as expressões necessárias ao teste na Tabela abaixo, denominada de Quadro
de Análise de Variância (ANAVA).
Fontes de Variação G. L. S. Q. Q. M. F Tratamentos
k - 1 ( )Y Y
kk
2 2kt
2i 1
− +++++∑=
SQTr
k 1−
QMTr
QMR
Linhas
k - 1 ( )Y Y
kk
2 2ki
2i 1
− +++++∑=
SQL
k 1−
QML
QMR
Colunas Resíduo
k - 1
(k-1)(k-2)
( )YY
kk
2 2k j
2i 1
−+ + +++∑
=
≠
SQC
k 1−
SQL
k 1−
QMC
QMR
Total kr - 1 ( )2k k Y2Yijt 2ki 1 j 1
+++−∑ ∑= =
Pode-se provar que:
• E(QMR) = σ2 , ou seja, QMR é um estimador não viesado da variância σ2 ;
• E( QM)r) σ2 +( )
krti
k 1 i 1∑
− =, ou seja, QMTr é um estimador não viesado da variância σ2
se a hipótese H0 : t1 =t2 =... =tk = é verdadeira.
7.9 Detalhes computacionais
Apresentaremos alguns passos que facilitam os cálculos das somas de quadrados da
ANAVA.
• Calcule a correção para a média ( )+++=
2
2
YC M
k
• Calcule a Soma de Quadrados dos Totais (SQT)
= =
= −∑∑2
1 1
k k
i j ti j
S Q T Y C M
• Calcule a Soma de Quadrados Entre os Tratamentos (SQTr)
++= −
2t
YS Q T r C Mk

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
131
• Calcule a Soma de Quadrados das Linhas (SQL) ++
=
= −∑2
1
ki
j
YS Q L C Mk
• Calcule a Soma de Quadrados dasColunas (SQC) + +
=
= −∑2
1
kj
j
YS Q C C M
k
• Calcule a Soma de Quadrados Residual (SQR) pela diferença, isto é,SQR = SQT –
SQTr – SQL - SQC ;
• Calcule os Quadrados Médios Entre os Tratamentos (QMTr), o Quadrado Médio
Residual (QMR) o Quadrado Médio de Linhas (QML) e o Quadrado Médio de Colunas
(QMC)
=−
1S Q T rQ M T rk ,
( ) ( )=
− −1 2S Q RQ M R
k k , =−
1S Q LQ M Lk e =
−1
S Q CQ M Ck
• Calcule Fc para tratamentos, FC para Linhas e FC para Colunas
=C T r
Q M T rFQ M R =C L
Q M LFQ M R =C C
Q M CFQ M R
EXEMPLO 1: Vamos considerar os dados do exemplo apresentado no item1.
Os cálculos para montar-mos o quadro da ANAVA são:
k = 4, e k2 = N =16. Então
• Graus de liberdade:
Total= k2 - 1 = N - 1 = 16 - 1 = 15; Trat = k – 1 = 4 - 1 = 3
Linhas = k - 1 = 4 - 1 = 3 Colunas = k - 1 = 4 - 1 = 3 e
Res. = (k-1) (k-2) = (4)(2) = 8
• ( )
= =
25 4 , 9 31 8 8 , 5 8 1 6
1 6C M
• SQT = (3,26)2+ (4,15)2 +...+ (3,40)2 – CM = 192,1871 – 188,5816 =3,6055
• ( ) ( ) ( ) ( )++= − = + + + −
=
2 2 2 22 1 4 , 1 1 1 2 , 9 4 1 4 , 2 5 1 3 , 6 34 4 4 4
1 8 8 , 8 4 3 8 - 1 8 8 , 5 8 1 6 = 0 , 2 6 2 2
tYS Q T r C M C M
kS Q T r
• ( ) ( ) ( ) ( )++
=
= − = + + + −
=
∑
2 2 2 22
1
1 4 , 1 0 1 3 , 9 0 1 3 , 7 1 1 3 , 2 24 4 4 4
1 8 8 , 6 8 8 1 - 1 8 8 , 5 8 1 6 = 0 , 1 0 6 5
ki
j
YS Q L C M C Mk
S Q L

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
132
• ( ) ( ) ( ) ( )+ +
=
= − = + + + −
=
∑
2 2 2 22
1
1 2 , 6 4 1 4 , 7 6 1 2 , 4 5 1 5 , 0 84 4 4 4
1 9 0 , 0 0 9 0 - 1 8 8 , 5 8 1 6 = 1 , 4 2 7 4
kj
j
YS Q C C M C M
kS Q C
• SQR = SQT − SQTr − SQL −SQC = 3,6055 − 0,2622 −0,1065 −1,4274 =1,8094
• = = =−
0 , 2 6 2 2 0 , 0 8 7 41 3
S Q T rQ M T rk
• = = =−
0 , 1 0 6 5 0 , 0 3 5 51 3
S Q LQ M Lk
• = = =−
1 , 4 2 7 4 0 , 4 7 5 81 3
S Q CQ M Ck
• ( ) ( )
= = =− −
1 , 8 0 9 4 0 , 3 0 1 661 2
S Q RQ M Rk k
• = = =
0 , 0 8 7 4 0 , 2 8 9 80 , 3 0 1 6C T r
Q M T rFQ M R
• = = =
0 , 0 3 5 5 0 , 1 1 7 70 , 3 0 1 6C L
Q M LFQ M R
• = = =
0 , 4 7 5 8 1 , 5 7 7 60 , 3 0 1 6C C
Q M CFQ M R
Organizando estes resultados no Quadro da ANAVA, temos: Fontes de Variação G. L. S. Q. Q. M. F Tratamentos 3 0,2622 0,0874 0,2898 Linhas 3 0,1065 0,0355 Colunas Resíduo
3 6
1,4274 1,8094
0,4758 0,3016
Total 15 3,6055 Das tabelas das distribuições F, temos que F(3,6;0,05)= 4,76 e F(3,6;0,01)= 9,78.
O valor FcTr = 0,2898 é menor do que estes valores tabelados, então não rejeitamos a
hipótese nula H0 para um nível a = 0,05, ou5% de probabilidade e concluímos que os
dados não evidenciam uma diferença significativa entre as quatros drogas. Os dados
também não evidenciam uma variação significativa entre os efeitos colocados nas linhas
(p=0,946) e nas colunas (p=0,290). Seguindo o que alguns pesquisadores sugerem não

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
133
consideraríamos os efeitos de linhas e colunas em futuros experimentos, tendo em vista
que o valor do nível de significância para linhas e colunas é superior a 0,25.
Exemplo 2. Com o objetivo de estudar o efeito da idade da castração no
desenvolvimento e produção de suínos, foi utilizado um delineamento em quadrado latino
com 4 tratamentos envolvendo a castração aos 7 dias (C); aos 21 dias (D); aos 56 dias
(A) e suínos inteiros (B). A variação existente entre as leitegadas foi controlada pelas
linhas do quadrado e a variação dos pesos dos leitões dentro das leitegadas foi isolada
pelas colunas. Os ganhos de peso, em kg, ao final do experimento (252 dias) estão
apresentados no quadro a seguir:
Leitegada Pesos dos leitões dentro das leitegadas
1 2 3 4 Totais
1 93,0 (A) 108,6 (B) 108,9 (C) 102 (D) 412,5
2 115,4 (B) 96,5 (D) 77,9 (A) 100,2 (C) 390,0
3 102,1 (C) 94,9 (A) 116,9 (D) 96,0 (B) 409,9
4 117,6 (D) 114,1 (C) 118,7 (B) 97,6 (A) 448,0
Totais 428,1 414,1 422,4 395,8 1660,4
Organizando estes resultados no Quadro da ANAVA, temos: Fontes de Variação G. L. S. Q. Q. M. F Tratamentos 3 913,57 304,52 4,42 Linhas 3 436,55 145,52 2,11 Colunas Resíduo
3 6
148,95 413,00
49,65 68,83
0,72
Total 15 1912,07 Das tabelas das distribuições F, temos que F(3,6;0,05)= 4,76 e F(3,6;0,01)= 9,78.
O valor FcTr = 4,42 é menor do que estes valores tabelados, então não rejeitamos a
hipótese nula H0 para um nível a = 0,05, ou5% de probabilidade e concluímos a hipótese
de que os efeitos de tratamento são todos nulos não é rejeitada, ou seja, os ganhos de
peso dos leitões submetidos às diferentes idades de castração são todos iguais a 103,78.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
134
7.10 Como contornar o problema de pequeno número de graus de liberdade para o
resíduo ?
Um problema que aparece quando usamos o delineamento em quadrado latino com um
número pequeno de tratamentos, é que o resíduo passa a ser estimado com um número
pequeno de graus de liberdade. No quadro a seguir, apresentamos o número de graus de
liberdade do resíduo no DQL para diferentes números de tratamentos:
Número de tratamentos g.l. do resíduo 3 2 4 6 5 12 6 20 7 30 8 42
RESPOSTA: Planejar mais de uma repetição do quadrado latino para conseguir
um número satisfatório de graus de liberdade para o resíduo. Por exemplo, se k = 4
tratamentos e queremos um número de g.l. para o resíduo superior a 12, devemos
fazer pelo menos r = 2 repetições do Q.L. original.
Solução 1: usar as mesmas linhas e mesmas colunas;
QL1 C1 C2 C3 C4 QL1 C1 C2 C3 C4 L1 A B C D L1 D A B C L2 B C D A L2 C C D A L3 C D A B L3 B C D A L4 D A B C L4 A B C D
Quadro da ANAVA resultante
Causas de variação gl QL r – 1 = 2
Tratamentos k – 1 = 3 Linhas k – 1 = 3
Colunas k – 1 = 3 Resíduo (k – 1)[ r (k + 1) – 3] = 21
Total r (k2 – 1 ) = 31
Solução 2: usar as mesmas linhas com as colunas diferentes (ou mesmas colunas
com linhas diferentes);

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
135
QL1 C1 C2 C3 C4 QL1 C5 C6 C7 C8 L1 A B C D L1 D A B C L2 B C D A L2 C D A B L3 C D A B L3 B C D A L4 D A B C L4 A B C D
Quadro da ANAVA resultante Causas de variação gl
QL r – 1 = 2 Tratamentos k – 1 = 3
Linhas k – 1 = 3 Colunas (QL) r ( k – 1 ) = 6
Resíduo (k – 1)(r k – 2 )= 18 Total r (k2 – 1 ) = 31
Solução 3: usar linhas e colunas diferentes.
QL1 C1 C2 C3 C4 QL1 C5 C6 C7 C8 L1 A B C D L5 D A B C L2 B C D A L6 C D A B L3 C D A B L7 B C D A L4 D A B C L8 A B C D
Quadro da ANAVA resultante
Causas de variação gl QL r – 1 = 2
Tratamentos k – 1 = 3 Linhas(QL)* r ( k - 1) = 6
Colunas (QL)** r ( k – 1 ) = 6 Resíduo (k – 1) [ k (k – 1) –1]=15
Total r (k2 – 1 ) = 31 (*) lê-se “Efeito de linhas dentro de quadrado latino”
(**) lê-se “Efeito de colunas dentro de quadrado latino” Suponha que um experimentador esteja interessado em estudar os efeitos da atividade
da estimulação hormonal folicular (follicle-stimulation hormone - FSH) em vacas é medido
em bioensaios pesando-se o ovário (mg) de ratos imaturos. Duas variáveis conhecidas
que influenciam o peso de ovários de ratos são: a constituição genética e o peso
corporal. Acredita-se que o peso corporal é independente das diferenças genéticas,
assim o delineamento quadrado latino (DQL) é adequado.
Dois quadrados latinos 4 x 4 foram usados com as linhas = ninhadas de ratos e colunas =
classes de peso corporal. O pesquisador considerou a diferença nos pesos corporais nos
dois quadrados para preservar os graus de liberdade do erro experimental, dado que a

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
136
amplitude do peso corporal era consistente de ninhada para ninhada, ou seja, o
pesquisador repetiu o experimento considerando as mesmas classes de peso corporal
(Solução 2).
QL1 C1 C2 C3 C4 totais QL1 C5 C6 C7 C8 Totais L1 (D) 44 (C) 39 (B) 52 (A) 73 208 L5 (B) 51 (C) 74 (A) 74 (D) 82 270 L2 (B) 26 (A) 45 (D) 49 (C) 58 178 L6 (D) 62 (A) 74 (C) 75 (B) 79 290 L3 (C) 67 (D) 71 (A) 41 (B) 76 295 L7 (A) 71 (D) 67 (B) 60 (C) 74 272 L4 (A) 77 (B) 74 (C) 88 (D) 100 339 L8 (C) 49 (B) 47 (D) 58 (A) 68 222
Totais 214 229 270 307 1020 Totais 233 251 267 303 1054
Totais dos tratamentos: 563 (A), 465 (B), 513 (C), 533 (D)
Cálculos:
• ( )++ +
= − =
22 2 1 0 2 0 1 0 5 44 4 . . . 6 8 7 7 1 0
8 3 2S Q T
• ( )++ +
= − =
22 2 1 0 2 0 1 0 5 45 6 3 . . . 5 3 3 6 3 5
8 3 2S Q T r
• ( )++ + +
= − =
22 2 2 1 0 2 0 1 0 5 42 0 8 1 7 8 . . . 2 2 2 4 8 8 9
4 3 2S Q L
• ( ) ( ) ( )+ + + +
= − =
2 2 22 1 4 2 2 3 . . . 3 0 7 + 3 0 3 1 0 2 0 1 0 5 41 9 1 4
8 3 2S Q C
Quadro da ANAVA resultante Fontes de variação gl SQ QM F
QL 1 20 20 Tratamentos 3 635 221,67 13,05
Linhas 6 4889 814,83 50,24 Colunas * 3 1914 638,00 39,33 Resíduo 18 292 16,22
Total 31 7730
Das tabelas das distribuições F, temos que F(3,18;0,05) =3,16 e F(3,18;0,05) = 5,09 . O valor
FcTr = 13,05 é maior que estes valores tabelados, então rejeitamos a hipótese nula H0
para um nível a = 0,01, ou1% de probabilidade e concluímos que a hipótese de que os
efeitos de tratamento são todos nulos é rejeitada, ou seja, os pesos dos ovários de ratos
imaturos (bioensaio para vacas) existe pelo menos dois tratamentos que diferem entre si
no peso de ovários.
Podemos usar o teste de Tukey para compararmos as médias dos tratamentos (note que
temos 4 tratamentos e cada um deles aparece 8 vezes). Então,

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
137
( )= = =8 ,1 8 ; 0 , 0 5
1 6 , 2 24 , 0 8 8 , 2 7 2 28
Q M Rd m s qr k
Drogas Peso médio* (mg)
A 70,4 a D 66,6 a C 64,1 ab B 58,1 b
* Médias seguidas pelas mesmas letras na coluna não diferem entre si pelo teste de Tukey a 5%.
Baseado nos resultados apresentados na tabela anterior pode-se afirmar que os pesos
de ovários tratados com as drogas A, D e C não diferem entre si e os pesos dos ovários
tratados com as drogas C e B também não diferem entre si. As diferenças nos pesos de
ovários estão entre as drogas A e D quando comparadas, individualmente, com a droga
B.
7.11 Casualização dos tratamentos
Suponha que queremos dispor os tratamentos A, B, C, e D sobre um quadrado latino 4 x
4 • escolhemos aleatoriamente um dos quadrados padrões de tamanho 4.
Suponha
1 2 3 4
1 A B C D
2 B C D A
3 C D A B
4 D A B C
• selecionemos uma das permutações de 1, 2, 3, e 4. suponha 2, 4, 1, 3.
então
1 2 3 4
2 B C D A
4 D A B C
1 A B C D
3 C D A B

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
138
• selecionemos uma outra das permutações de 1, 2, 3, e 4. suponha 1, 3, 4, 2.
então
1 2 3 4
2 B D A C
4 D B C A
1 A C D B
3 C A B D
Este é o delineamento escolhido.
7.12. Exemplos em que as unidades experimentais são animais ou pessoas
Neste tipo de experimento os próprios animais ou pessoas servem como um critério de
classificação (linhas) e o tempo (colunas) é o outro, ou seja, medidas repetidas não
aleatórias são obtidas de cada animal (pessoa) distribuídos a uma seqüência de
tratamentos.
Exemplo1
Por exemplo,
• avaliação da digestibilidade total aparente em cinco rações calculadas para conter : 7,0;
9,5; 12,0; 14,5 e 17,0 % de proteína bruta com base na matéria seca, tendo como
ingredientes feno de capim elefante, fubá de milho, farelo de soja e mistura mineral;
• a condução do experimento exige gaiolas metabólicas individuais para medir o consumo
da ração, coleta de fezes, urina, etc. cada gaiola conterá um novilho zebu com peso em
torno de 280 kg;
• o processo de digestão permite a obtenção de resposta no tempo. Assim sendo definiu-
se por cinco períodos sequênciais de 21 dias cada, nos quais 14 dias iniciais seriam
considerados de adaptação à ração e os 7 dias finais para o registro de resultados;
• cada período experimental deveria conter as cinco rações, testadas uma em cada
animal. o efeito do período deve ser blocado porque condições climáticas variáveis entre
os períodos podem afetar o consumo e a digestibilidade;
• o efeito dos cinco novilhos deve ser blocado;
• o delineamento escolhido é o D.Q.L 5 x 5;

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
139
• a resposta medida foi a digestibilidade aparente de carboidratos totais (%).
Novilho PERÍODOS
1 2 3 4 5 Totais
B246 46 (A) 60 (B) 62 (C) 69 (D) 65 (E) 302
AT14 65 (E) 69 (A) 72 (D) 64 (B) 60 (C) 330
NN89 54 (C) 80 (D) 67 (A) 71 (E) 63 (B) 335
AG90 63 (B) 72 (C) 74 (E) 66 (A) 64 (D) 339
SS45 69 (D) 85 (E) 74 (B) 72 (C) 70 (A) 370
Totais 297 366 349 342 322 1676
(COMO EXERCÍCIO, OBTENHA A ANÁLISE DE VARIÂNCIA PARA ESTE
EXPERIMENTO)
Exemplo 2:
• avaliação do efeito de anestésicos sobre o metabolismo animal é imprescindível ao
cirurgião;
• vamos considerar 5 anestésicos e analisar variáveis como: frequência
cardíaca,respiratória, pressão sanguínea, tempo efetivo de anestesia. Estas variáveis são
muito instáveis com c.v. > 35,0 %. Existe uma reação muito diferente de animal para
animal o que exigiria um número muito grande destes ( de 13 a 49 animais) para cada
anestésico.
• por outro lado estas respostas são de fluxo contínuo. Podemos testar todos os
anestésicos, em ocasiões diferentes com intervalos de 2 a 3 dias, no mesmo animal.
• se um animal recebe todos os anestésicos , em sequência controlada, todos os demais
deverão também recebê-los, mas cada um dos cachorros deverá estar submetido a um
anestésico diferente, de modo que , em um mesmo dia, todos os cães e todos os
anestésicos estejam sendo testados. Com este procedimento, o eventual efeito de dia
poderá estar controlado.
• a maneira mais simples de se controlar o efeito de dia de experimentação (ou período) e
o efeito de cães, é o efeito de controle local (blocos);
• uma solução prática que leva em conta os dois tipos de blocagem (período e animal) é o
croqui do delineamento quadrado latino (D.Q.L.) onde as letras representam um
anestésico específico.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
140
PERÍODO
ANIMAL 1 2 3 4 5
1 A E B D C
2 D B A C E
3 C A E B D
4 E C D A B
5 B D C E A
Resumo

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
141
Exercícios 1. Um pesquisador instalou um experimento para comparar 5 tipos de bacilos (A, B, C,D,
e E) usados para produção de iogurte. No momento da instalação do experimento, o
pesquisador verificou que o material experimental disponível (25 unidades de 1 litro de
leite) não era completamente homogêneo entre si, pois apresentavam variação quanto ao
teor de gordura e grau de acidez. Para controlar estas duas fontes de variação, o
pesquisador distribuiu os bacilos ao acaso às amostras de leite de tal forma que cada
bacilo pudesse ser testado em todas as condições de teor de gordura e grau de acidez. O
quadro dado a seguir ilustra a distribuição dos bacilos às amostras de leite bem como o
volume (em ml) de iogurte produzido:
Grau de Acidez
Totais Teor de Gordura 1 2 3 4 5
1 450 A
620 E
680 C
620 D
780 B
3150
2 750 C
990 B
750 E
660 A
830 D
3980
3 750 D
910 C
690 A
990 B
760 E
4100
4 650 E
890 C
835 B
850 C
875 A
4100
5 750 B
720 A
850 D
770 E
890 C
3980
Totais 3350 4130 3805 3890 4135 19310
Com base nas informações fornecidas, pergunta-se:
1. Qual foi a unidade experimental utilizada?
2. Quais foram os tratamentos em teste?
3. Quantas vezes o princípio do controle local foi utilizado neste experimento?
4. Qual foi o Delineamento experimental utilizado nesta pesquisa?
5. Usando os dados experimentais fornecidos anteriormente e o teste F para testar a
fonte de variação bacilos, pode-se concluir que ao nível de 5% de probabilidade que a)
existe pelo menos um contraste entre médias de bacilos estatisticamente diferente de
zero
b) todos os possíveis contrastes entre médias de bacilos são estatisticamente nulos
c) o bacilo A é o melhor
d) o bacilo B é o melhor
e) o bacilo C é o melhor

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
142
f) nenhuma das alternativas anteriores
6. O teste de Tukey indica que o(s) bacilo(s) que proporciona(m) maior(es) média(s)
de produção de iogurte é (são) (use o nível de 5% de significância) foi(ram)
a) o bacilo A
b) o bacilo B
c) o bacilo C
d) o bacilo D
e) o bacilo E
f) os bacilos A, B e C
g) os bacilos B, C e D
h) os bacilos C, D e E
i) os bacilos A, D e E
j) nenhuma das alternativas anteriores
2. Um experimento foi conduzido numa região do Pantanal com o objetivo de selecionar
forrageiras que garantissem uma maior produção de matéria seca. Foi utilizado o
delineamento em quadrado latino, buscando controlar diferenças de fertilidade em duas
direções, sendo avaliadas 7 forrageiras (A, B, C, D, E, F, G). Foram obtidos os seguintes
resultados parciais com a realização do experimento:
Tratamentos A B C D E F G
Totais 30,8 25,2 19,6 14 13,3 9,8 8,4
Linhas 1 2 3 4 5 6 7
Totais 18,9 19,9 14,5 18,1 15,6 17,4 16,7
SQTotal = 72,36 SQColunas = 1,27
Verificar se existe efeito significativo de forrageiras, pelo teste F, e concluir para α=1%.
3. Num experimento de competição de variedades de cana forrageira foram usadas 5
variedades: A=CO290; B=CO294; C=CO297; D=CO299 e E=CO295, dispostas em um
quadrado latino 5x5. O controle feito através de blocos horizontais e verticais teve por
objetivo eliminar influências devidas a diferenças de fertilidade em duas direções. As
produções, em kg/parcela, foram as seguintes:
Colunas

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
143
Linhas 1 2 3 4 5 Totais
1 432(D) 518(A) 458(B) 583(C) 331(E) 2322
2 724(C) 478(E) 524(A) 550(B) 400(D) 2676
3 489(E) 384(B) 556(C) 297(D) 420(A) 2146
4 494(B) 500(D) 313(E) 486(A) 501(C) 2294
5 515(A) 660(C) 438(D) 394(E) 501(C) 2325
Totais 2654 2540 2289 2310 1970 11763
Considerando α = 5% , pede-se:
a. Análise de Variância
b. Qual a variedade a ser recomendada? Utilize teste de Tukey, se necessário
4. Aplicar o teste de Tukey para comparar as médias de tratamentos, relativos ao
Quadrado Latino 5x5, dados:
SQResiduo = 34116,0 α = 5%
T1 = 3024,0; T2 = 2549,0; T3 = 2349,0; T4 = 1970,0; T5 = 1734,0

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
144
C A P Í T U L O 8
EXPERIMENTOS FATORAIS
8.1 Introdução
Experimentos fatoriais são aqueles em que se estudam simultaneamente dois ou mais
fatores, cada um deles com dois ou mais níveis. O fatorial é um tipo de esquema, ou seja,
uma das maneiras de organizar os tratamentos e não um tipo de delineamento, que
representa a maneira pela qual os tratamentos são distribuídos às unidades
experimentais. Na verdade, os experimentos fatoriais são montados segundo um tipo de
delineamento experimental, como por exemplo: o DIC e o DBC.
Nos experimentos fatoriais, os tratamentos são obtidos pelas combinações dos níveis dos
fatores. Num experimento fatorial completo, cada nível de um fator combina com todos os
níveis dos outros fatores. A principal aplicação de experimentos fatoriais é quando se
quer saber sobre o efeito de diversos fatores que influenciam na variável em estudo e o
relacionamento entre eles.
A simbologia comumente utilizada, para experimentos fatoriais é indicar o produto dos
níveis dos fatores em teste. Por exemplo: Experimento Fatorial 2x4x6. O produto 2x4x6
informa que no experimento foram testados simultaneamente 3 fatores. O primeiro possui
2 níveis, o segundo 4 níveis e o terceiro 6 níveis. Quando o número de níveis é igual para
todos os fatores, pode-se utilizar a seguinte simbologia: nF, em que F é o número de
fatores n é o número de níveis de cada fator. Por exemplo: Experimento Fatorial 43. A
potência 43 informa que o experimento tem 3 fatores com 4 níveis cada um.
8.2. Tipos de efeitos avaliados em um experimento fatorial Nos experimentos fatoriais, podem ser estudados os seguintes efeitos:
8.2.1. Efeito simples de um fator
como a medida da variação que ocorre com a característica em estudo (ganho de peso,
neste exemplo) correspondente às variações nos níveis desse fator, em cada um dos
níveis do outro fator.
• Efeito simples do antibiótico no nível 0 de vitamina B12 :

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
145
A(dentro de b0) = a1 b0 - a0 b0= 32 – 14 = 18 0
• Efeito simples do antibiótico no nível 1 de vitamina B12:
A(dentro de b1) = a1 b1- a0 b1= 53 - 23 = 30
• Efeito simples da vitamina B12 no nível 0 de antibiótico :
B(dentro de a0)= a0 b1 – a0 b0 = 23 - 14 =9
• Efeito simples da vitamina B12 no nível 1 de antibiótico :
B(dentro de a1)= a1 b1 - a0 b0 = 53 - 32 = 21
8.2.2. Efeito principal de um fator
é uma medida da variação que ocorre com a característica em estudo, correspondente
às variações nos níveis desse fator, em média, de todos os níveis do outro fator.
( ) ( )
( ) ( )
18 3024
2
B9 21
152
A Adentro de b dentro de b0 1Efeito principal de A=
2B
dentro de a dentro de a0 1Efeito principal de B=2
++
= =
++
= =
8.2.3. Efeito de interação entre os dois fatores
é uma medida da variação que ocorre com a característica em estudo, correspondente às
variações nos níveis de um fator, ao passar de um nível a outro do outro fator.
( ) ( )
( ) ( )
30 186
2
B21 9
62
A - Adentro de b dentro de b0 1Efeito da interação de AxB=
2B
dentro de a dentro de a0 1Efeito da interação de BxA=2
−= =
−−
= =
isto é, tanto faz calcular a interação A x B como a interação B x A - Efeito de Interação: é o efeito simultâneo dos fatores sobre a variável em estudo.
Dizemos que ocorre interação entre os fatores quando os efeitos dos níveis de um fator
são modificados pelos níveis do outro fator.
O efeito da interação pode ser mais facilmente compreendido por meio de gráficos. Para
ilustrar o efeito da interação, considere um experimento fatorial 3x2, em que os fatores
em testes são Variedade (V) e Espaçamento (E). Os tratamentos para este experimento
são os seguintes:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
146
V1E1 V2E1 V3E1
V1E2 V2E2 V3E2
Suponha os seguintes resultados fictícios, para a variável altura de plantas (cm), deste
experimento, nas seguintes situações:
1) Não há interação
Variedades Espaçamento V1 V2 V3
E1 8 10 12 E2 6 8 10
Quando não há interação as diferenças entre os resultados dos níveis de um fator são
estatisticamente iguais para todos os níveis do outro fator.
2) Há interação Variedades Espaçamento V1 V2 V3
E1 2 4 6 E2 5 10 2

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
147
8.3. Quadro de tabulação de dados Uma maneira de tabular os dados de um experimento fatorial, com dois fatores A e B,
com I e níveis, respectivamente, instalados segundo o DIC, com K repetições, é fornecida
a seguir:
A1 A2 A3 Repetição B1 B2 ... BJ B1 B2 ... BJ ... B1 B2 ... BJ
Y111 Y121 Y1J1 Y211 Y221 Y2J1 Yi11 YI21 YIJ1 Y112 Y122 Y1J2 Y212 Y222 Y2J2 YI12 YI22 YIJ2 ... ... ... ... ... ... ... ... ... ... ... ... Y11K Y12K Y1JK Y21K Y22K Y2JK YI1K YI2K YIJK Total Y11• Y12• Y1J• Y21• Y22• Y2J• YI1• YI2• YIJ•
Deste quadro, pode-se tirar algumas informações que posteriormente serão úteis na
análise de variância:
Total do ij-ésimo tratamento: ( )K
IJK IJIJk
AB Y Y •=
= =∑1
Total do i-ésimo nível do fator A: J ,K
I IJK I
j ,k
A Y Y ••= =
= =∑1 1

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
148
Total do j-ésimo nível do fator B: J ,K
J IJK J
j ,k
B Y Y• •= =
= =∑1 1
Total Geral: I ,J,K I J
IJK I J
I , j ,k i i j
G Y A B Y= = = = =
= = = =∑ ∑ ∑1 1 1 1 iii
Média do i-ésimo nível do fator A: i
iA
Am
JK=
Média do j-ésimo nível do fator B: J
j
B
Bm
IK=
Média geral: G
mN
=
Número total de parcelas: N=IJK
Pode-se montar um quadro auxiliar contendo os totais de tratamentos, cujos valores são
obtidos pela soma de todas as repetições para o tratamento em questão. Este quadro
facilita o cálculo das somas de quadrados devido aos fatores A e B, e da interação entre
eles. Para a situação citada, o quadro de totais de tratamentos é do seguinte tipo:
Fator A Fator B
B1 B2 ... BJ Totais A1 Y111 Y121 Y1J1 A1
A2 Y112 Y122 Y1J2 A2
... ... ... ... ... ... AI YI1. YI2. YIj. AI
Totais B1 B2 Bj G
8.4. Modelo matemático de um experimento fatorial
O modelo de um experimento fatorial com dois fatores, num delineamento inteiramente
casualizado com r repetições, pode ser escrito como:
yijk i j ij ijkµ α β (αβ) ε= + + + +
Sendo:
• yijk é a k ésima resposta que recebeu o i ésimo nível do fator α e o j ésimo nível do fator
β
• µ é uma constante (média ) comum a todas as observações;
• αi é o efeito do i ésimo nível do fator com i 1,...,a;
• βj é o efeito do j ésimo nível do fator com j 1, ...,b;

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
149
(αβ)ij é o efeito da interação do i- ésimo nível do fator α com o efeito do j- ésimo nível do
fator β
• εijk é o erro experimental associado à observação yijk com k 1... r,
8.5. Análise de Variância
A análise de variância de um experimento fatorial é feita desdobrando-se a soma de
quadrados de tratamentos nas partes devido aos efeitos principais de cada fator e na
parte devido à interação entre os fatores. O quadro a seguir apresenta como seria a
análise de um experimento fatorial, com 2 fatores A e B, com I e J níveis,
respectivamente, e K repetições, instalado segundo o DIC.
FV GL SQ QM F A (I-1) SQA ( )SQA I −
1
B (J-1) SQB ( )SQB J −1
A x B (I-1)(J-1) SQAxB ( )( )SQAxB I J− −1 1
Tratamentos (IJ-1) (SQTrat) ( )SQTrat IJ −1
Residuo n2=IJ(K-1) SQRes Total IJK – 1 SQTotal
As fórmulas para a obtenção das somas de quadrados são as seguintes:
I,J ,K
ijk
i ,j ,k
SQTotal Y C= = =
= −∑2
1 1 1 I,J
ij
i ,j
YSQTrat C
K= =
= −∑2
1 1
Jj
j
BSQB C
IK=
= −∑2
1
I,J ,K
ijk
i ,j ,k
Y
CIJK
= = =
=∑
2
1 1 1
Ii
i
ASQA C
Jk=
= −∑2
1 J
j
j
BSQB C
ik=
= −∑2
1
SQResíduo = SQTotal – SQTrat SQAxB = SQTrat – SQA – SQB
O quadro abaixo apresenta como seria a análise de um experimento fatorial, com 2
fatores A e B, com I e J níveis, respectivamente, e K repetições (ou blocos), instalado
segundo o DBC.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
150
FV GL SQ QM F A (I-1) SQA ( )SQA I −
1
B (J-1) SQB ( )SQB J −1
A x B (I-1)(J-1) SQAxB ( )( )SQAxB I J− −1 1
Tratamentos (IJ-1) (SQTrat) ( )SQTrat IJ −1
Blocos K-1 SQBlocos Residuo n2=(IJ-1)(K-1) SQRes Total IJK – 1 SQTotal
Nesta situação
Kk
k
WSQBlocos C
IJ=
= −∑2
1
em que,
→ Total do k-ésimo bloco:Wk=I ,J
k ijk k
i , j
W Y Y= =
= =∑1 1 iii
Conforme apresentado nas duas tabelas anteriores, na análise dos dados oriundos de
um experimento fatorial, para os dois tipos de delineamentos, deve-se inicialmente
proceder ao teste F para a interação entre os fatores. As hipóteses para o teste F da
interação são:
H0: Os fatores A e B atuam independentemente sobre a variável resposta em estudo.
Ha: Os fatores A e B não atuam independentemente sobre a variável resposta em estudo.
O resultado deste teste F para a interação indica como as comparações dos níveis de um
fator devem ser realizadas. Temos dois resultados possíveis para o teste F da interação
os quais serão apresentados a seguir.
8.5.1 Interação não-significativa Este caso ocorre quando a hipótese H0 para a interação entre os fatores não é rejeitada.
Este resultado implica que os efeitos dos fatores atuam de forma independente.
Portanto recomenda-se que as comparações dos níveis de um fator sejam feitas de
forma geral em relação ao outro fator, ou seja, independente dos níveis outro fator. O
passo seguinte na análise estatística dos dados experimentais é proceder ao
teste F para cada fator como ilustrado na tabela apresentada a seguir para o caso
do DBC.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
151
FV GL SQ QM F A (I-1) SQA ( )SQA I −
1
B (J-1) SQB ( )SQB J −1
A x B (I-1)(J-1) SQAxB ( )( )SQAxB I J− −1 1
Não significativo
Tratamentos (IJ-1) (SQTrat) ( )SQTrat IJ −1
Blocos K-1 SQBlocos Residuo n2=(IJ-1)(K-1) SQRes Total IJK – 1 SQTotal
As hipóteses para realizar o teste F para os efeitos principais são:
Fator A
H0: mA1 = mA2 =...= mAI ou seja, todos os possíveis contrastes entre as médias dos
níveis do fator A, são estatisticamente nulos, ao nível de probabilidade em que foi
executado o teste.
Ha:não H0 ou seja, existe pelo menos um contraste entre as médias dos níveis do fator A,
que é estatisticamente diferente de zero, ao nível de probabilidade em que foi executado
o teste. Fator B
H0: mB1 = mB2 =... = mBJ ou seja, todos os possíveis contrastes entre as médias dos
níveis do fator B, são estatisticamente nulos, ao nível de probabilidade em que foi
executado o teste.
Ha:não H0 ou seja, existe pelo menos um contraste entre as médias dos níveis do fator B,
que é estatisticamente diferente de zero, ao nível de probabilidade em que foi executado
o teste.
Se os fatores A e B forem qualitativos, e o teste F para A e/ou B, for não significativo, a
aplicação do teste de médias é desnecessária. Se o teste F for significativo, para A e/ou
B, aplica-se um teste de médias para comparar os níveis do fator. As estimativas das
médias dos níveis dos fatores são obtidas por
i
iA
AFator A m
JK→ =
i
j
B
BFator B m
IK→ =

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
152
Para realizar o teste de Tukey para comparar as medias dos níveis dos fatores em teste
temos que usar
∆ qα
A QMRes
qJK
(I;n2)
B QMResq
IK (J;n2)
Para o teste de Duncan temos que usar
∆ qα
A i
QMResZ
JK (nA;n2)
B i
QMResZ
IK (nB;n2)
Em que nA e nB são os números de médias ordenadas abrangidas pelo contraste sendo
testados.
As hipóteses para os testes Tukey e Duncan para comparar as médias dos níveis dos
fatores são
Fator A → H0 : mAi = mAu versus Ha : mAi ≠ mAu para i ≠ u = 1, 2, 3, ... , I
Fator B → H0 : mBj = mBu versus Ha : mBj ≠ mBu para j ≠ u = 1, 2, 3, ... , J
Para a aplicação do teste t temos que usar

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
153
t tα
A A A
I
i
i
C C
QMResa
JK =
−
∑2
1
tα (n2)
B B B
I
i
i
C C
QMResb
IK =
−
∑2
1
tα (;n2)
Em que
CA = a1mA1 + a2mA2 + ... + aImAI e
CB = b1mB1 + b2mB2 + ... + bImBJ
Para a aplicação do teste Scheffé para testar os contrastes YA e YB temos que usar
S Ftab
A ( )I
TAB i
i
QMResS I F a
JK =
= − ∑2
1
1 Ftα [(I-1);n2]
B ( )J
TAB j
j
QMResS J F b
IK =
= − ∑2
1
1 Fα [(J-1);n2]
As hipóteses para os testes de Scheffé e t para testar os contrastes são
Fator A → H0 : CA = 0 versus Ha : CA ≠ 0
Fator B → H0 : CB = 0 versus Ha : CB ≠ 0
Exemplo Fatorial 2 x 3 (com interação não significativa):
O crescimento do conteúdo de água em tecidos de lesmas sob 6 diferentes condições
experimentais foi avaliada. As 6 condições foram obtidas combinado-se os dois níveis de
temperatura (fator A) com três níveis de umidade (fator B) com.
Foram feitas 4 repetições para cada combinação de tratamento. Os resultados, em
porcentagem, foram :

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
154
Fator umidade (%) Fator temperatura(0C) 45 75 100
20 76 64 72 82 100 96 79 71 86 86 92 100
30 72 72 72 75 100 94
64 70 82 84 98 99
Os totais das 4 repetições para o fatorial A x B = (2)(3)= 6 tratamentos são os
seguintes:
(4) Níveis de A (Temperatura
ºC))
Níveis de B (Umidade (%)) Total
b1 = 45 % b2 = 75 % b3 = 100 %
a1 = 20 ºC 290 326 388 1004 a2 = 30 ºC 278 313 391 982 Total 568 639 779 1986
( )2 2Y 19862 2 2 2
SQ Y Y 76 99 3386 5T 111 222 a b r 2 3 4
2 2 2 2 2 2 2 2 2Y Y Y Y Y 290 326 391 198611 12 21 22SQ 2922TRr r r r a b r 4 4 4 2 3 4
22 2 2YY Y Y1 2 iSQ Abr br br a b
... ( ... ) ,( )( )( ) ( )( )( )
...( )( )( ) ( )( )( )
( ) ...( )(
+++= + + − = + + − =+
+++= + + + − = + + + − =
++ ++ ++ +++= + + + −
( )
2 2 21004 982 1986
20 17r 3 4 3 4 2 3 4
22 2 2 2 2 2YY Y Y 568 779 19861 2 iSQ B 2881 75ar ar ar a b r 2 4 2 4 2 3 4
SQ SQ SQ A SQ B 2922 20 17 2881 75 20 8TRA x B
,)( ) ( )( ) ( )( ) ( )( )( )
( ) ... ,( )( )( ) ( )( ) ( )( ) ( )( )( )
( ) ( ) , , ,
= + − =
+ + + + + + +++= + + + − = + − =
= − − = − − =Quadro da ANAVA no DIC
Fonte de variação gl SQ QM Fc Temperatura (A) 1 20,17 20,17 0,78 ns
Umidade (B) 2 2881,75 1440,88 55,85**
Int. AxB 2 20,08 10,04 0,39 ns
Tratamentos (5) 2922,00 Resíduo 18 464,5 25,81 Total 23 3386,5 F(1, 18; 0,05) = 4,41 F(1, 18, 0,01)= 8,29 F(2, 18; 0,05)= 3,55 F(2, 18, 0,01)= 6,01 F(5, 18; 0,05) = 2,77 F(5, 18, 0,01)= 4,25 Do quadro acima, observamos que o teste da interação entre a temperatura e umidade
não é significativa (p>0,05), e concluímos que os dados não suportam a hipótese de uma

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
155
interação entre temperatura e umidade. Dado que a interação não foi significativa, a
análise prossegue analisando-se os efeitos principais da temperatura e da umidade
isoladamente. Isto pode ser feito analisando-se os dois tipos de diferenças:
• as diferenças entre os conteúdos médios da água nos tecidos nos dois níveis de A
(temperatura).
• as diferenças entre os conteúdos médios da água nos tecidos nos três níveis de B
(umidade).
O teste F para o efeito principal A é não significativo (p>0,05), e portanto não existe
evidências suficientes para concluir que os valores médios do conteúdo da água nos
tecidos são diferentes nos dois níveis de temperatura, entretanto, o teste F para o efeito
principal da umidade é altamente significativo (p<0,01), o que implica que os dados
suportam a conclusão de que os valores médios do conteúdo da água nos tecidos não
são os mesmos nos três níveis da umidade. Isto pode ser visualizado na tabela de
médias abaixo (última linha):
(4) Níveis de A
(Temperatura ºC))
Níveis de B (Umidade (%)) Médias de A Temperatura
b1 = 45 % b2 = 75 % b3 = 100 %
a1 = 20 ºC
a2 = 30 ºC
72,5 81,5 97,00
69,5 78,25 97,75
83,67 A
81,83 A
Médias de B
Umidade
71,00 a 79,88 b 97,38 c 82,75
Médias com a mesma letra maiúscula nas colunas não diferem entre si pelo teste de Tukey a 5% Médias com a mesma letra minúscula nas linhas não diferem entre si pelo teste de Tukey a 5%
Cálculos do teste de Tukey:
• para o efeito principal A (temperatura):
q(2;18;0,05) = 2,97
25 81dms 2 97 4 36A
12
,, ,= =
• para o efeito principal de B (Umidade):
q(2;18;0,05) = 3,63
25 81dms 3 63 6 52B
8
,, ,= =

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
156
O gráfico das médias dos tratamentos fornece um conveniente método de mostrar os
resultados. As linhas sólidas no gráfico da interação são praticamente paralelas; isto
confirma o resultado do teste F para a interação entre temperatura e umidade.
Mais ainda, a proximidade das duas linhas sólidas indicam que a diferença entre as
respostas médias observadas nas duas temperaturas são não significativas; esta
conclusão é confirmada pelo teste F do efeito principal da temperatura. Uma checagem
gráfica para presença do efeito principal da umidade é dada pela orientação da linha
pontilhada. Se o efeito principal de tal efeito não estivesse presente, então a linha
pontilhada deveria estar paralela ao eixo x. O gráfico mostra que não é este o caso. O
teste F para o efeito principal de B (umidade) suporta esta conclusão.
Outra forma de explicar a significância do fator B é por meio da regressão polinomial
Umidade (%)
Média obs
ervada
do conteú
do da águ
a (%)

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
157
Gráfico das médias do fator B Equação ajustada
y=82.471-0.585*x+0.007*x^2+eps
8.5.2 Interação significativa
Este caso ocorre quando a hipótese H0 para a interação entre os fatores é rejeitada. Este
resultado implica que os efeitos dos fatores atuam de forma dependente. Neste caso as
comparações entre os níveis de um fator levam em consideração o nível do outro fator,
pois o resultado significativo para a interação indica que o efeito de um fator depende do
nível do outro fator.
Portanto, não é recomendado realizar o teste F para cada fator isoladamente tal como foi
apresentado para o caso da interação nãosignificativa.
O procedimento recomendado é realizar o desdobramento do efeito da interação.
Para realizar este desdobramento deve-se fazer uma nova análise de variância em que
os níveis de um fator são comparados dentro de cada nível do outro fator, tal como
apresentado nas tabelas a seguir.
40 45 50 55 60 65 70 75 80 85 90 95 100 105
Média obs
ervada
do conteú
do da águ
a (%)
100 96 92 88 84 80 76 72 68
Umidade (%)

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
158
Desdobramento para comparar os níveis de A dentro de cada nível de B, ou seja, estudar
A/B
FV GL SQ QM F A/B1 (I-1) SQA/B1
( )SQA / B
I −
11
QMA / B
QMRes
1
A/B2 (I-1) SQA/B2
( )SQA / B
I −
21
QMA / B
QMRes
2
... ... ... ... A/BJ (I-1) SQA/BJ
( )SQA / BJ
I −1
QMA / BJ
QMRes
Residuo n2 SQRes Total IJK – 1 SQTotal
As hipóteses para testar as fontes de variação da tabela acima, para j=1, 2, 3, ..., J, são
H0 : mA1/Bj = mA2/Bj = ... = mAI/Bj
Ha:não H0
Desdobramento para comparar os níveis de B dentro de cada nível de A, ou seja estudar
B/A
FV GL SQ QM F B/A1 (J-1) SQA/A1
( )SQA / A
J −
11
QMB / A
QMRes
1
B/A2 (J-1) SQA/A2
( )SQA / A
J −
21
QMB / A
QMRes
2
... ... ... ... B/AI (J-1) SQA/AI
( )SQA / AI
J −1
QMB / AI
QMRes
Residuo n2 SQRes Total IJK – 1 SQTotal
As hipóteses para testar as fontes de variação da tabela acima, para i=1, 2, 3, ..., I, são
H0 : mB1/Ai = mB2/Ai = ... = mBJ/Ai
Ha:não H0
Em que as SQA/Bj e SQB/Ai podem ser obtidas usando a fórmula geral para a soma de
quadrados dada por

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
159
k
ikii
ki i
i
i
Xx
SQr
r
=
=
=
= −∑
∑∑
2
21
1
1
Se os fatores forem qualitativos, procede-se ao teste F para cada fonte de variação do
desdobramento. Nas fontes de variação em que o teste F foi significativo e o fator tem
mais de dois níveis, recomenda-se a aplicação de um teste de médias. As estimativas
das médias dos níveis dos fatores são obtidas por
Fator A → iAi
Am
K=
Fator B → j
Bj
Bm
K=
Para realizar o teste de Tukey para comparar as médias dos níveis dos fatores em teste
temos que usar
∆ qα
A QMRes
qK
(I;n2)
B QMResq
K (J;n2)
Para o teste de Duncan temos que usar
∆ qα
A i
QMResZ
K (nA;n2)
B i
QMResZ
K (nB;n2)
Em que nA e nB são os números de médias ordenadas abrangidas pelo contraste sendo
testados.
As hipóteses para os testes Tukey e Duncan para comparar as médias dos níveis dos
fatores são

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
160
Fator A → H0 : mAi/Bj = mAu/Bj versus Ha : mAi/Bj ≠ mAu/Bj para i ≠ u = 1, 2, 3, ..., I e j = 1,
2, ... , J
Fator B → H0 : mBj/Ai = mBu/Ai versus Ha : mBj/Ai ≠ mBu/Ai para j ≠ u = 1, 2, 3, ., J e i = 1,
2, ... , I
Para a aplicação do teste t temos que usar
t tα
A A A
I
i
i
C C
QMResa
K =
−
∑2
1
tα (n2)
B B B
I
i
i
C C
QMResb
K =
−
∑2
1
tα (;n2)
Em que
CA = a1mA1/Bj + a2mA2/Bj + ... + aImAI/Bj para j = 1, 2, ..., J e
CB = b1mB1/Ai + b2mB2/Ai + ... + bImBJ/Ai para i = 1, 2, ... , I
Para a aplicação do teste Scheffé para testar os contrastes CA e CB temos que usar
S Ftab
A ( )I
TAB i
i
QMResS I F a
K =
= − ∑2
1
1 Ftα [(I-1);n2]
B ( )J
TAB j
j
QMResS J F b
K =
= − ∑2
1
1 Fα [(J-1);n2]
As hipóteses para os testes de Scheffé e t para testar os contrastes são
Fator A → H0 : CA = 0 versus Ha : CA ≠ 0
Fator B → H0 : CB = 0 versus Ha : CB ≠ 0

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
161
Exemplo:
considere o esquema fatorial 2 x 2 ( dois níveis de antibiótico, dois níveis de vitamina
B12) para estudar o aumento de peso (Kg) diário em suínos.
a0 – sem antibiótico; a1 – com 40 mg de antibiótico
b0 – sem vitamina B12 ; b1 – com 5 mg de vitamina B12
Repetição a0 a1 b0 b1 b0 b1
1 1,30 1,26 1,05 1,52 2 1,19 1,21 1,00 1,56 3 1,08 1,19 1,05 1,55
Total 3,57 3,66 3,10 4,66
OBS: neste caso o delineamento experimental foi o inteiramente casualizado com os
tratamentos num esquema fatorial 2 x 2, com 3 repetições Outra forma de apresentação
dos dados
Tratamento Repetição Total a0b0
a0b1
a1b0
a1b1
1,30 1,19 1,08 1,26 1,21 1,19 1,05 1,00 1,05 1.52 1,56 1,55
3,57 3,66 3,10 4,63
14,96
Calculo das Soma de Quadrados: SQT= (1,302 +1,192+1,082+1,262+1,212+1,192+1,052+1,002+1,052+1,522+1,562+1,552) -
( )214 99
12
,
SQT = 0,4418
SQTrat= ( ) ( )214 961 2 2 2 23 57 3 66 3 10 4 633 12
,, , , ,+ + + −
SQtrat=0,4124
SQResiduo = SQT – SQTrat = 0,4418 – 0,4124
SQResiduo = 0,0294

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
162
e então, podemos construir um primeiro quadro de análise de variância: Fonte de variação gl SQ QM F Tratamentos 3 0,4124 0,1375 37,16**
Resíduo 8 0,0294 0,0037 Total 11 Como F(3,8;0,01)= 7,59 podemos concluir que pelo menos duas médias de tratamentos
diferem significativamente (p<0,01) entre si quanto ao ganho de peso diário de suínos. A
continuação da análise pode envolver a comparação das médias dos tratamentos por
meio de um dos procedimentos de comparações múltiplas conhecidos, como os testes de
Tukey, Duncan, t-Student, Scheffé etc.
Uma alternativa de análise mais simples e mais informativa, está baseada no esquema
fatorial dos tratamentos. Utilizando o quadro com os totais das combinações dos níveis
dos fatores A e B e as fórmulas apresentadas anteriormente, podemos construir um novo
quadro de análise de variância que permitirá testar se existe interação entre os dois
fatores e se cada um dos fatores tem efeito significativo sobre o desenvolvimento dos
suínos.
Quadro auxiliar com os totais das combinações dos níveis de antibióticos (a0, a1) e vitamina B12
(3) b0 b1 Totais a0
a1
3,57 3,66 3,10 4,63
7,23 7,76
Totais 6,67 8,29 14,99 Assim
( ) ( )
( ) ( )
214 961 2 2SQ A 7 32 7 76 0 02097
6 12
214 961 2 2SQ B 6 67 8 29 0 21883
6 12
SQ AxB SQTrat SQ A SQ B
SQ AxB 0 4124 0 02097 0 21883
SQ AxB 0 1723
,( ) , , ,
,( ) , , ,
( ) ( ( ) ( ))
( ) , ( , , )
( ) ,
= + − =
= + − =
= − +
= − +
=
SQT= (1,302 +1,192+1,082+1,262+1,212+1,192+1,052+1,002+1,052+1,522+1,562+1,552) -
( )214 99
12
,
SQT = 0,4418 O novo quadro da ANAVA fica:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
163
FV GL SQ QM F
Antibiótico (A) 1 0,02097 0,02097 5,67*
Vitamina B12 (B) 1 0,21883 0,2183 59**
Int. AxB 1 0,1723 0,1723 46,57**
Tratamentos (3) 0,4124
Resíduo 8 0,0294 0,0037
Total 11
Da tabela apropriada, temos F(3, 8; 0,01) = 7,59; F(1, 8, 0,05) = 5,32 ; F(1, 8 ; 0,01) =
11,26 Comparando os valores calculados das estatísticas F, podemos concluir que:
• o teste para a interação AxB foi significativo (p < 0,01), indicando que o efeito da
vitamina B12 na presença ou ausência de antibiótico é significativamente diferente.
1,8 Níveis de antibiótico 1,7 1,6 1,5 Peso diário (kg) 1,4 1,3 1,2 1,1 1,0 b0 b1
Níveis de vitamina B12 Gráfico das médias de ganho de peso dos níveis de vitamina B12 por nível de antibiótico
Como a interação AxB resultou significativa (veja o gráfico apresentado acima), as
interpretações dos testes dos efeitos simples de Antibiótico (A) e de Vitamina B12 (B)
perdem o significado. Precisamos estudar a interação fazendo os seguintes
desdobramentos:
a) Desdobramento da interação AxB para estudar o comportamento dos fator A dentro
de cada nível de vitamina B12 (b0 e b1) :

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
164
( ) ( ) ( )2 2Y1 1 6 672 2 2 2SQ A Y Y 3 57 3 10 0 0368
11 21r 2 r 3 2 3dentro de b0
( , ). , ,
( ) ( )+++= + − = + − =
( ) ( ) ( )2 2Y1 1 8 292 2 2 2SQ A Y Y 3 66 4 63 0 1568
12 22r 2 r 3 2 3dentro de b1
( , ). , ,
( ) ( )+++= + − = + − =
Assim, monta-se a seguinte análise de variância do desdobramento dos graus de
liberdade da interação A x B para se estudar o efeito do antibiótico no ganho de peso
diário de suínos na ausência e na presença da vitamina B12.
Fonte de variação GL SQ QM F A dentro de b0 1 0,0368 0,0368 10,03
**
A dentro de b1 1 0,1568 0,1568 42,73**
Resíduo 8 0,0294 0,0037
A linha do resíduo é a mesma da ANOVA anterior.
Comparando os valores calculados da estatística F com o valor tabelado F(1;8;0,05) = 5,32 e
F(1;8;0,01) =11,3, conclui-se que o efeito do fator antibiótico no peso diário de suínos no
nível b0 de vitamina B12 é significativo (p<0,05) e significativo (p<0,01) no nível b1 da
vitamina B12. Ou então, que:
• Quando se utiliza a dose b0 de vitamina B12 existe uma diferença no peso diário dos
suínos. A estimativa desta diferença é dado por A(dentro de b0) a1 b0 – a0 b0 = 3,10 - 3,57 =
0,47 Kg E ela é significativa pelo teste F da ANOVA do desdobramento, indicando que
somente o efeito somente do antibiótico prejudica o peso diário dos suínos.
• Quando se utiliza a dose b1 de vitamina B12 existe uma diferença no peso diário dos
suínos. A estimativa desta diferença é dada por A(dentro de b1) = a b1 – a0 b1 = 4,63 – 3,66
=0, 97 Kg
E ela é significativa pelo teste F da ANOVA do desdobramento, indicando que a
combinação dos níveis a1 do antibiótico e b1 da vitamina B12 favorece o peso diário dos
suínos.
a) Desdobramento da interação AxB para estudar o comportamento dos fator B dentro
de cada nível de antibiótico A (a0 e a1) (preencher os espaços)
( ) ( )2 2Y1 12 2SQ B Y Y
11 21r 2 r 3
( )( )dentro de a0 ( )
+++= + − = − =

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
165
( ) ( )2 2Y1 12 2SQ B Y Y
21 22r 2 r 3
( )( )dentro de a1 ( )
+++= + − = − =
Assim, monta-se a seguinte análise de variância do desdobramento dos graus de
liberdade da interação A x B para se estudar o efeito da vitamina B12 no ganho de peso
diário de suínos na ausência e na presença de antibiótico:
Fonte de variação gl SQ QM F B dentro de a0
*
B dentro de a1
Resíduo
Concluir como no desdobramento anterior
Podemos comparar as médias de peso diário de suínos dos antibióticos , para cada uma
dos níveis de vitamina B12 , utilizando o Teste de Tukey (a = 5%). Para tanto,
calculamos:
( ) ( )QM QM 0 00367R Rd m s q q 3 26 0 1140a g l 2 8 0 05r 3 3do resíduo 0,05
,. . . , ,. . . ; ; ,= = = = =
Quadro auxiliar com as médias dos antibióticos para cada um dos níveis da
vitamina B12
b0 b1
a0 3,57 A 3,66 A
a1 3,10 B 4,63 B
Obs.: médias seguidas pelas mesmas letras maiúsculas, nas colunas, não diferem entre si a 5% de probabilidade, pelo Teste de Tukey
(fazer como exercício o teste de Tukey a 5%, para as linhas)
Notação geral dos totais de um esquema fatorial 2 x 2 organizados em uma tabela 2x2,
do tipo:
r b0 b1 Total
a0 Y11+ Y12+ Y1++
a1 Y21+ Y22+ Y2++
Total Y+1+ Y+2+ Y+++
As fórmulas das Soma de Quadrados podem ser escritas de uma forma geral:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
166
( )
( )
( )
( )( )
2Y2 2SQ Y YT 111 222 a b r
2Y1 2 2 2 2SQ Y Y Y YTR 11 12 21 22r a b r
2Y1 2 2SQ A Y Y1 22r a b r
2Y1 2 2SQ B Y Y1 22r a b r
SQ SQ SQ A SQ BTRA x B
...( )( )( )
( )( )( )
( )( )( )( )
( )( )( )( )
( ) ( )
+++= + + −+
+++= + + + −
+++= + −++ ++
+++= + −+ + + +
= − −
8.6. Vantagens e desvantagens de um experimento fatorial
Vantagens
a. Permite o estudo dos efeitos principais e o efeito da interação entre os fatores.
b. O no de graus de liberdade associado ao resíduo é alto quando comparado com os
experimentos simples dos mesmos fatores, o que contribui para diminuir a variância
residual, aumentando a precisão do experimento.
c. todas as parcelas são utilizadas no calculo dos efeitos principais dos fatores e dos
efeitos das interações, a razão pela qual o número de repetições é elevado
Desvantagem
a. sendo os tratamentos constituídos por todas as combinações possíveis entre os níveis
dos diversos fatores, o número de tratamento aumenta muito e, muitas vezes não
podemos distribuí-los em blocos casualizados devido à exigência da homogeneidade das
parcelas dentro de cada bloco.
b. a análise estatística é mais trabalhosa que nos experimentos simples, e a interpretação
dos resultados tornam mais difíceis à medida que aumentamos oi número de níveis no
experimento
c. Requer maior número de unidades experimentais em relação aos experimentos
simples.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
167
Exercícios
1. Seja um experimento fatorial instalado no DIC, com dois fatores: Irrigação (A) e
Calagem (B), cada um deles com dois níveis: presença (A1 B1 ) A e B e ausência (A0,B0 ).
Os dados obtidos (kg de planta/parcela) para cada tratamento são fornecidos abaixo.
Pede-se realizar a ANOVA e obter as conclusões sobre os fatores. Use α = 5%.
A0B0 A0B1 A1B0 A1B1
25 35 41 60
32 28 35 67
27 33 38 59
2. Em um experimento fatorial no DIC em que foram combinadas duas doses de N e duas
doses de fósforo, com 5 repetições, são dados:
P0
P1
N0 10,5 11 9,8 11,2 9,9 11,2 11 10,4 13,1 10,6
N1 11,5 12,4 10,2 12,7 10,4 14 14,1 13,8 13,5 14,2
Considerando o nível de significância de 5%, concluir sobre os efeitos dos fatores.
3. Suponha que você esteja participando de uma seleção para um emprego numa
empresa de pesquisa. Dentre as várias áreas em avaliação, consta a área de Estatística,
que objetiva avaliar seus conhecimentos na área, não simplesmente pedindo-lhe para
fazer "contas" (o que eles acham ser de menor importância), mas sim com respeito à
estratégia de análise, interpretação, discussão e tomada de decisão.
São feitas as seguintes perguntas:
a) Como você faria um "leigo" entender o que vem a ser INTERAÇÃO ENTRE DOIS
FATORES A e B. Para explicar você pode usar exemplos, gráficos, tabelas, etc, à sua
escolha.
b) Qual a estratégia de análise a ser efetuada (ou os passos da análise subseqüente) nos
seguintes casos de um fatorial com dois fatores A e B:
b.1) INTERAÇÃO NÃO SIGNIFICATIVA;
b.2) INTERAÇÃO SIGNIFICATIVA.
4. Num experimento com suínos foram comparadas três rações (A, B, C) e dois níveis de
proteína (1-Alto, 2-Médio), utilizando um delineamento inteiramente casualizado num

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
168
esquema fatorial com 5 repetições. Ao final do experimento, obteve-se o seguinte quadro
de interação para os totais de tratamentos:
Rações
Proteína A B C Totais
1 498 428 477 1403
2 469 350 406 1225
Totais 967 778 883 2628
Ao nível de 5% de probabilidade, pede-se:
a. Complete o quadro da ANOVA e verifique se os fatores rações e níveis de proteína
atuam independentemente.
FV GL SQ QM F
Ração Proteína Interação 2 140,4667 0,34
(Tratamentos) Resíduo 4957,20 Total
b. Qual seria a ração a ser recomendada? (Use o teste de Duncan se necessário)
c. Qual seria o nível de proteína a ser recomendado? (Use o teste de Duncan se
necessário).
5. Com os dados do quadro de interação do fatorial 2x6, no delineamento em Blocos
Casualizados com 2 repetições, e considerando α = 5% com os fatores A e B atuando
dependentemente, pede-se :
a) testar e concluir a respeito do fator A dentro do nível B4
b) Fazer o estudo do fator B dentro dos níveis de A procedendo a análise de variância e o
teste de Tukey se necessário
B1 B2 B3 B4 B5 B6 Totais
A1 46,8 48,2 47,3 49 48,5 46,9 286,7
A2 47,2 60,8 69,3 71,6 61,5 46,8 357,2
Totais 94 109 116,6 120,6 110 93,7 643,9
SQResíduo = 120,8325

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
169
6. Em um experimento de substituição do farelo de soja pelo farelo de girassol na ração
de suínos, montou-se um experimento fatorial 2x5, com os fatores Sexo (machos e
fêmeas) e Ração com substituição de farelo de soja por farelo de girassol (0%, 25%,
50%, 75% e 100%), utilizando-se 30 suínos (15 machos e 15 fêmeas) castrados da raça
Duroc-Jersey, num delineamento em blocos casualizados com 3 repetições, de acordo
com os grupos de pesos iniciais. Os resultados de ganho de peso dos animais aos 112
dias de experimento estão apresentados na tabela a seguir:
Bloco Machos Fêmeas
G0 G25 G50 G75 G100 G0 G25 G50 G75 G100
1 85,0 94,5 99,5 93,0 83,0 77,9 71,5 67,5 71,5 89,5
2 86,0 96,0 98,0 96,0 80,0 83,2 73,5 63,5 70,8 91,8
3 84,0 95,8 104,0 90,5 78,5 83,5 70,5 65,0 72,9 92,9
Total 255,0 286,3 301,5 279,5 241,5 244,6 215,5 196,0 214,8 274,2
Pede-se:
a. Montar o esquema da Análise de Variância e fazer os testes convenientes;
b Comparar as médias dos níveis do fator G dentro de cada um dos níveis do fator S;
c. Construir gráficos para estudar o comportamento das respostas médias dos níveis de
G para cada um dos níveis de S.
7. O rendimento de um processo químico está sendo estudado. As duas variáveis mais
importantes acreditam-se ser a pressão e a temperatura. Três níveis de cada fator são
selecionados, e um experimento fatorial com duas repetições é realizado. Os dados de
rendimento seguem:
Pressão (Psig)
Temperatura (ºC)
200 215 230
150 90,4 90,7 90,2
90,2 90,6 90,4 160 90,1 90,5 89,9 90,3 90,6 90,1
170 90,5 90,8 90,4 90,7 90,9 90,1

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
170
a) Faça a análise de variância do fatorial completo e escreva as conclusões. Use α = 0,05.
b) Prepare gráficos de resíduos apropriados e comente sobre a adequação do modelo.
c) Obtenha os efeitos lineares e quadráticos de temperatura e pressão.
d) Ajuste um modelo de regressão apropriado para os dados de resposta (rendimento).
Use este modelo para prover conselhos a respeito das condições de operação para o
processo.
8. A percentagem de madeira em polpa fina, a pressão da cuba e o tempo de cozimento
da polpa estão sendo investigados sobre seus efeitos na resistência do papel. Três
níveis de concentração de madeira, três níveis de pressão, e dois tempos de cozimento
são selecionados. Um experimento fatorial com duas repetições é conduzido, e os
seguintes dados são obtidos:
Percentagem de concentração de madeira (%)
Tempo de Cozimento 3.0 Horas Tempo de Cozimento 4.0 Horas Pressão Pressão
400 500 650 400 500 650 2 196,6 197,7 199,8 198,4 199,6 200,6 196,0 196,0 199,4 198,6 200,4 200,9 4 198,5 196,0 198,4 197,5 198,7 199,6 197,2 196,9 197,6 198,1 198,0 199,0 8 197,5 195,6 197,4 197,6 197,0 198,5 196,6 196,2 198,1 198,4 197,8 199,8
a) Analise os dados (fazer a anava do modelo fatorial) e tire suas conclusões. Use α
= 0,05.
b) Prepare gráficos de resíduos apropriados e comente sobre a adequação do
modelo.
c) Ajuste um modelo de regressão para os dados.
d) Sobre que conjunto de condições você gostaria de operar esse processo? Por
quê?

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
171
9. Um experimento foi conduzido no delineamento de blocos casualizados, com três
repetições, com a finalidade de estudar o efeito de matéria orgânica e calagem no
desenvolvimento de mudas de café. Os tratamentos foram dispostos num esquema
fatorial 3x2, sendo três tipos de matéria orgânica (esterco de aves, esterco bovino e
composto orgânico) e dois níveis de calagem (60 e 120 kg de calcáreo/m3 de terra). Os
valores obtidos de altura das mudas (cm) foram:
Blocos Teste- 60 120 Total
munha Aves Bovino Orgânico Aves Bovino Orgânico
I 17 25 26 28 30 33 37 II 16 25 24 26 29 32 36 II 14 21 23 25 27 30 34
a) Fazer a análise de variância completa, com desdobramento de graus de liberdade e
comparações múltiplas quando pertinentes
10. Uma pesquisa está estudando o efeito da lidocaína no nível de enzima do músculo
cardíaco de cães da raça beagle. No experimento foram testadas três diferentes marcas
de lidocaína (A), três níveis de dosagem (B), e 3 cães diferentes (C). O experimento é um
fatorial 33, com 2 repetições. Os dados abaixo se referem aos níveis de enzima
observados no estudo.
Marcas de
lidocaína Dosagem
Repetição 1 Repetição 2 Cão Cão
1 2 3 1 2 3
1 1 86 84 85 84 85 86 2 94 99 98 95 97 90 3 101 106 98 105 104 103
2 1 85 84 86 80 82 84 2 95 98 97 93 99 95 3 108 114 109 110 102 100
3 1 84 83 81 83 80 79 2 95 97 93 92 96 93 3 105 100 106 102 111 108
Faça a análise de variância e conclua sobre os resultados

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
172
C A P Í T U L O 9
EXPERIMENTOS EM PARCELAS SUBDIVIDIDAS
9.1 Introdução
Vimos que nos experimentos fatoriais ou esquemas fatoriais, os tratamentos gerados
pelas combinações dos níveis dos fatores são designados às unidades experimentais de
acordo com o procedimento de aleatorização do delineamento inteiramente casualizado
(DIC), ou do delineamento em blocos casualizados (DBC), ou do delineamento em
quadrado latino (DQL). Entretanto, outros tipos de aleatorização são possíveis. O
delineamento em parcelas subdivididas surge de uma destas aleatorizações alternativas.
O princípio básico deste delineamento é: parcelas ou unidades inteiras que recebem os
níveis de um dos fatores são subdivididas em subparcelas, às quais os níveis de um fator
adicional são aplicados. Assim cada parcela funciona como um bloco para as
subparcelas. Os níveis do fator colocados nas parcelas são denominados de tratamentos
principais e os níveis do fator sorteados nas subparcelas são denominados de
tratamentos secundários. O Delineamento em Parcelas Subdivididas é freqüentemente
usado com experimentos fatoriais e tem muito em comum com delineamentos
parcialmente hierárquico. O termo "PARCELA SUBDIVIDIDA" surgiu na experimentação
agronômica onde um único nível de um fator (ou tratamento)‚ aplicado a uma parcela
relativamente grande de terra (whole plot), mas todos os níveis de um segundo fator são
aplicados às subparcelas (split-plots) dessa parcela maior. Os tratamentos primários são
distribuídos às parcelas de acordo com um delineamento especificado (DIC, DBC, DQL
etc.) e os tratamentos secundários são distribuídos aleatoriamente às subparcelas de
cada parcela.
EXEMPLO 1: A seguir apresentamos o croqui de um experimento em parcelas
subdivididas com o Fator A com 2 níveis (tratamentos primários) aplicados às parcelas de
acordo com um delineamento em blocos
casualizados com 3 repetições e o Fator B com 3 níveis (tratamentos secundários)
aplicados às subparcelas. Vale notar que os níveis de A são sorteados entre as duas
parcelas de cada bloco e os níveis de B são sorteados entre as três subparcelas de cada
parcela

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
173
ou seja, o delineamento em parcelas subdivididas representa uma restrição à
casualização completa existente em um ensaio fatorial envolvendo o mesmo número de
fatores e de níveis.
Na análise estatística desses experimentos, as Fontes de Variação que fazem parte da
variação entre as parcelas (Fator-A e Blocos, por exemplo) são usualmente agrupadas
separadamente daquelas que fazem parte da variação dentro das parcelas ou entre as
subparcelas (Fator-B e interação AxB). Neste caso, temos dois resíduos distintos:
um referente às parcelas e outro referente às subparcelas.
O uso em parcelas subdivididas é desejável quando:
• os tratamentos associados com os níveis de um ou mais fatores exigem maiores
quantidades de material experimental em uma mesma unidade experimental (ou parcela)
que outros tratamentos;
• um fator adicional vai ser incorporado ao experimento para aumentar a sua
abrangência;
• uma maior precisão é desejada para comparações entre os níveis de alguns fatores.
Parcelas
Subparcelas
Bloco I Bloco II Bloco III
A1 A2
B1 B2 B3 B3
B2 B1
A2 A1
B3 B2 B2 B3
B1 B1
B1 B2 B3 B3
B2 B1
A2 A1
BLOCO 1
A1B1 A1B2
A2B3 A1B3
A2B2 A2B1
BLOCO 2
A1B3 A2B2
A2B2 A1B3
A2B1 A1B1
BLOCO 3
A1B1 A2B2
A2B3 A1B3
A1B2 A2B1

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
174
9.2 Vantagem e desvantagem de um experimento em parcelas subdividas
Vantagem
• permite utilizar fatores que requerem quantidades relativamente grandes de material
experimental e outros fatores que requerem quantidades pequenas, combinados num
mesmo experimento.
Desvantagens
• geralmente, o erro associado às parcelas é muito maior que o erro associado às
subparcelas. Desse modo, os efeitos de tratamentos primários, ainda que notáveis
(grandes), podem não ser significativos, enquanto que os efeitos de tratamentos
secundários, ainda que muito pequenos, podem ser estatisticamente significativos.
• para diferentes comparações entre médias de tratamentos existem diferentes variâncias
9.3. Análise de variância (ANAVA)
A análise de variância de um experimento em parcelas subdivididas é feita desdobrando
os efeitos das parcelas e das subparcelas nas partes que as compõem. Para cada um
destes desdobramentos, existe um resíduo, o qual é utilizado para testar o efeito das
fontes de variação pertinentes.
No quadro a seguir, apresentamos a partição dos graus de liberdade de um experimento
em parcelas subdivididas com “a” tratamentos primários, “b” tratamentos secundários, “r”
repetições e diferentes delineamentos para os tratamentos aplicados às parcelas.
D.I.C. (“r” repetições) D.B.C.(“r” blocos) D.Q.L. (“a” repetições)
Fonte de Variação g.l. Fonte de Variação g.l. Fonte de Variação g.l. Linhas (a-1)
Blocos (r-1) Colunas (a-1) A (a-1) A (a-1) A (a-1)
Resíduo (a) a(r-1) Resíduo (a) a(r-1) Resíduo (a) a(r-1) (Parcelas) (ar-1) (Parcelas) (ar-1) (Parcelas) (ar-1)
B (b-1) B (b-1) B (b-1) AxB (a-1)(b-1) AxB (a-1)(b-1) AxB (a-1)(b-1)
Resíduo (b) a(r-1)(b-1) Resíduo (b) a(r-1)(b-1) Resíduo (b) a(r-1)(b-1) Total abr-1 Total abr-1 Total abr-1
9.4 Modelo matemático e suposições
Considerando um experimento em parcelas subdivididas envolvendo “a” tratamentos
primários arranjados em um DIC com “r” repetições e “b” tratamentos secundários, o
modelo pode ser escrito como:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
175
yijk = µ + αi +Sik + βj + (αβ)ij +εijk, com k = 1,...,r1; i = 1,...,a; j = 1,...,b sendo: µ: a média geral;
αi: o efeito do i ésimo nível de A;
Sik: efeito da k ésima parcela recebendo o i ésimo nível de A~ N(0,σ2), erro(a);
βj : o efeito do j ésimo nível de B;
(αβ)ij : o efeito conjunto de i ésimo nível de A e j ésimo nível de B;
εijk: efeito do erro aleatório ~N(0,σ2)
Considerando agora, um experimento em parcelas subdivididas envolvendo “a”
tratamentos primários arranjados em “r” blocos casualizados e “b” tratamentos
secundários, o modelo pode ser escrito como:
yijk = µ + αi +Sik + Rk + (SR)ik βj + (αβ)ij + εijk, com k = i 1,...,r1 ; i =1,...,a; j = 1,...,b
sendo: µ: a média geral;
αi: o efeito do i ésimo nível de A;
Sik: efeito da k ésima parcela recebendo o i ésimo nível de A~ N(0,σ2), erro(a);
Rk:efeito do k ésimo bloco;
(SR)ik: o efeito conjunto de i ésimo nível de A e o k ésimo bloco
βj : o efeito do j ésimo nível de B;
(αβ)ij : o efeito conjunto de i ésimo nível de A e j ésimo nível de B;
εijk: efeito do erro aleatório ~N(0,σ2)
9.5 Hipótese estatística
As seguintes hipóteses podem ser testadas nos experimentos em parcelas subdivididas.
• A hipótese de que não existe ou existe interação AB é equivalente às hipóteses
H0AB: (αβ)ij vs H1AB: (αβ)ij ≠ 0 com i = 1,..., a e j = 1,...,b;
usamos a estatística FAB = QM(AxB)/QMRes(b), que sob H0, tem distribuição F-
Snedecor com graus de liberdade da interação no numerador e graus de liberdade do
resíduo (b) no denominador.
• as hipóteses de que não existe efeito principal do fator A é

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
176
H0AB:αi vs H1AB αi ≠ 0 com i = 1,..., a e j = 1,...,b usamos a estatística FA =
QMA/QMRes(a), que sob H0, tem distribuição F-Snedecor com graus de liberdade do
fator A no numerador e graus de
liberdade do erro (a) no denominador.
• as hipóteses de que não existe efeito principal do fator B é
H0AB: βj vs H1AB βj ≠ 0 com i = 1,..., a e j = 1,...,b, usamos a estatística FB =
QMB/QMRes(b), que sob H0, tem distribuição F-Snedecor com graus de liberdade do
fator B no numerador e graus de liberdade do erro (b) no denominador.
9.6 Somas de quadrados
Apresentaremos alguns passos que facilitam os cálculos das somas de quadrados da
ANAVA.
No DIC:
• Soma de Quadrados do Total (SQT)
( ) ( )2 2r a b y y2SQ yT ijk abr abrk 1i 1 j 1
sendo C =,+++ +++= −∑ ∑ ∑= = =
• Soma de Quadrados do fator A, SQ(A) a1 2SQ A Y C
ibr i 1
( ) = −∑ ++=
• Soma de Quadrados da Parcelas, SQ(Parc) ( )a b1 2SQ Parcelas Y C
ijb i j
,
,= −∑ +
• SQRes(a) = SQ(Parc) – SQ(A);
• Soma de Quadrados do fator B, SQ(B) b1 2SQ B Y C
iar i 1
( ) = −∑ + +=
• Soma de Quadrados da interação AxB, SQ(AxB)=SQ(A,B)- SQ(A)-SQ(B)
ou a b1 2SQ AxB Y C
ijr i 1 j 1
( ) = −∑ ∑ += =
,sendo a SQ(A,B) a soma de quadrado conjunta, a qual
nos fatoriais a a x b é igual à soma de quadrados dos tratamentos (SQTr).
Para calcular os coeficientes de variação para as parcelas e para as subparcelas
usamos, respectivamente:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
177
QM QMR a R bCV a x100 CV b x100
Y Y
( ) ( )( ) ; ( )= =
+++ +++
SQ2 ModeloR x100
SQT= , sendo que SQModelo = SQ(Parc ) + SQ(B) + SQ( AxB)
Dos testes de hipóteses sugeridos anteriormente, se ocorrer interação AxB significativa,
torna-se imprescindível fazer o desdobramento SQ B(Dentro de A) , para i = 1, 2, ..., a ou SQ
A(Dentro de B) , para j = 1, 2, ..., b.
Para testar se “as médias de B são iguais, dentro de cada nível de A” usaremos como
denominador da estatística F, 2sB QMRes(b), com seus a(r-1)(b-1) graus de liberdade.
Para testar se “as médias de A são iguais, dentro de cada nível de B” usaremos como
denominador da estatística F, o valor obtido de Re (*) [(QMRes(a)+ ( b 1)QMRe s( b)]b ,
que tem n’ graus de liberdade, o qual é calculado pela Fórmula de Sattertwait:
[ ]( )
ba
ba
b
bVb
n
V
VbVn
222
2
'
1
)1(
−+
−+=
9.7 Comparações múltiplas entre mádias de tratamentos
Após tirarmos as conclusões sobre os testes de hipóteses da Análise de Variância,
poderemos estar interessados em comparar as médias dos tratamentos primários (A),
dos secundários (B) ou da interação (AxB). Daí, o problema consiste em usar a
estimativa da variância (s2) apropriada. A seguir, resolvemos esses problemas para os
casos mais freqüentes.
1º Caso: Entre médias de tratamento primário
• Para testar um contraste escolhido a priori,
Y = c1 µ1 + c2 µ2 + ... + ca µa , onde i =1, 2,..., a i são as médias dos tratamentos primários
usamos a estatística t-Student
YitQMR a 2
cir i
ˆ
( )=
∑
com graus de liberdade do Res(a)
• Para testar um contraste entre duas médias de A, Y = µi − µj, usamos a estatística t-
Student

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
178
Yit2
QM abr
ˆ
(R( )
=
• Para os testes de Tukey e de Duncan usamos, respectivamente,
( )
( )
QMR adms q eA a gl brs a
QMR adms zB a gl brs a
( ); Re ( )
( ); Re ( )
= =
= =
Sendo, que “q” e “z” correspondem aos valores tabelados da distribuição de Tukey e
Duncan.
20 Caso: Entre média de tratamento secundário
• Para testar um contraste escolhido a priori,
Y = c1 µ1 + c2 µ2 + ... + ca µa , onde i =1, 2,..., b, são as médias dos tratamentos
secundários, usamos a estatística t-Student
• Para testar um contraste entre duas médias de B, Y = µi − µj, usamos a estatística t-
Student
Yit2QM b
ar
ˆ
(R( )
=
• Para os testes de Tukey e de Duncan usamos, respectivamente,
( )
( )
QMR bdms q eA a gl ars a
QMR bdms zB a gl ars a
( ); Re ( )
( ); Re ( )
= =
= =
Sendo, que “q” e “z” correspondem aos valores tabelados da distribuição de Tukey e
Duncan.
30 Caso: Entre médias do tratamento secundário num mesmo nível de i de A
• Para testar um contraste escolhido a priori,

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
179
Y = c1 µi1 + c2 µi2 + ... + ca µib , onde µij j =1, 2,..., b, são as médias dos tratamentos
secundários num mesmo nível “i” de A, usamos a estatística t-Student
• Para testar um contraste entre duas médias de B, Y = µi − µj, usamos a estatística t-
Student
YitQM R b 2
cir i
ˆ
( ( ))=
∑
, com os graus de liberdade do QMRes(b).
• Para testar um contraste entre duas médias de B num mesmo nível de A, Y = µij − µij,
usamos a estatística t-Student
Yit2QM b
r
ˆ
(R( )
= ,com os graus de liberdade do QMRes(b).
• Para os testes de Tukey e de Duncan usamos, respectivamente,
( )
( )
QMR bdms q eA b gl rs a
QMR bdms zB b gl rs a
( ); Re ( )
( ); Re ( )
= =
= =
Sendo, que “q” e “z” correspondem aos valores tabelados da distribuição de Tukey e
Duncan.
40 Caso: Entre médias do tratamento primário num mesmo nível de B
• Para testar um contraste escolhido a priori,
Y = c1 µ1j + c2 µ2j + ... + ca µaj , sendo µij 1 =1,2, ..., a as médias dos tratamentos
primários num mesmo nível “j” de B, usamos a estatística t-Student
YitQMR a b 1 QMR b 2c
ibr i
ˆ
( ) ( ) ( )
=+ −
∑
com n’ graus de liberdade calculados pela Fórmula de
Sattertwait
• Para testar um contraste entre duas médias de A num mesmo nível de B,YI = µij − µij,
usamos a estatística t-Student

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
180
Yit2
QM b 1 QMa R bbr
ˆ
( )(R( ) ( )
= + −
, com n’ graus de liberdade calculados pela Fórmula
de Sattertwait
Para os testes de Tukey e de Duncan usamos, respectivamente
( )
( )
1dms q QM QMR a b 1 R bb n br
1dms z QM QMB R a b 1 R bb n br
( ) ( ) ( ); '
( ) ( ) ( ); '
= = + −
= = + −
sendo os valores de “q” e “z” correspondem a “b” tratamentos e n’ graus de liberdade
para o resíduo (calculados pela Fórmula de Sattertwait) e são encontrados em tabelas
próprias.
EXEMPLO: supor um experimento com três rações A, B e C em seis blocos
casualizados, sendo cada parcela constituída de dois bovinos de corte. Em uma
determinada fase do experimento, os bovinos dentro de cada parcela, passaram a
receber, por sorteio, um dos dois tipos de suplementos minerais M e P.
Croqui do experimento em parcelas subdivididas em blocos casualizados:
Bloco I
B A C P M M P P M
Bloco II
A C B P M M P P M
Bloco III
B C A P M M P M P
Bloco IV
A B C M P M P P M
Bloco V
C A B P M M P P M
Bloco VI
C B A M P M P P M

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
181
1ª letra fator ração
2ª letra fator suplemento mineral
Blocos
I II III IV V VI
BP AM BP AM CP CM
BM AP BM AP CM CP
AM CM CM BM AM BM
AP CP CP BP AP BP
CP BP AM CP BP AP
CM BM AP CM BM AM
Esquema da análise de variância
Fonte de variação gl Blocos) 5
Ração (Trat. principal) A 2 Erro (a) 10
Parcelas (17) Suplemento mineral (Trat. Secundário) B 1 Ração x Suplemento 2 Erro (b) 15 Total 35 Os ganhos individuais ao final do experimento foram:
Blocos Ração A Ração B Ração C Total M P M P M P
I II III IV V VI
107 89 117 101 122 98 111 101 90 95 116 90
116 101 136 110 130 104 122 91 117 100 114 94
90 96 112 89
99 92 105 78 110 90 114 93
599 665 645 608 602 621
Total 663 574 735 600 630 538 3.740
Quadro de Totais I
Blocos(2)*
Ração A Ração B Ração C Total
I II III IV V VI
196 218 220 212 185 206
217 246 234 213 217 208
186 201 191 183 200 207
599 665 645 608 602 621
Total 1.237(12) 1.335(12) 1.168(12) 3.740(36)

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
182
(*) Os números entre parênteses representam o total de parcelas somadas para se obter os
valores observados da tabela.
Cálculos:
( )2
3 7402 2 2SQ 107 2 89 93 388 544 44T3 2 6
., ... . ,
( )( )( )= + + + − =
( )2
1 3 7402 2 2SQ 599 665 621 588 22Bloc6 2 3 6
.... ,os ( )( )( )
= + + + − =
Para obtermos a soma de quadrados das parcelas usamos o quadro auxiliar I com os
totais de cada parcela. Como temos duas subparcelas em cada parcela temos
( )2
1 3 7402 2 2SQ 196 217 207 2 377 56Parcelas2 2 3 6
.... . ,
( )( )( )= + + + − =
Para as demais SQ, organizamos o seguinte quadro de totais II que relaciona os níveis
dos dois fatores entre si:
SUPLEMENTOS
(6)
RAÇÃO
Totais
A B C
M
P
663
574
735
600
630
538
2.028
1.712
Totais 1.237 1.335 1.168 3.740
( )2
1 3 7402 2 2SQ 1 237 1 335 1 168 1 173 73Rações12 2 3 6
.. . . . ,
( )( )( )= + + − =
SQ =SQ -SQ -SQ =2.377,56-582,22-1.173,73=621,61 (Res(a)) Parcelas Blocos Rações
( )2
1 3 7402 2SQ 2 028 1 712 2 773 83Supl18 2 3 6
.. . . ,. ( )( )( )
= + − =
( )2
1 3 7402 2 2SQ 663 574 538 4 057 89R S6 2 3 6
.... . ,( , ) ( )( )( )
= + + + − =
( )SQ SQ SQ SQ 4 057 89 1 173 73 2 773 78 110 38R S R SRxS . , . , . , ,( , )= − − = − − =
( )SQ =SQ -SQ -SQ -SQ =6.061,56-2.377,56-2.773,78-110,38=799,84(Res(b)) T Parcelas Supl. RxC

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
183
Quadro da ANAVA
FV GL SQ QM F Blocos 5 588,22 117,644 2,21 Ração (Trat. principal) A 2 1173,73 586,865 11,01 Erro (a) 10 621,61 62,161 1,17 Parcelas 17 2377,56 139,857 2,62 Suplemento mineral (Trat. Secundário) B 1 2773,78 2773,78 52,02 Ração x Suplemento 2 110,38 55,19 1,04 Erro (b) 15 799,84 53,3227 Total 35 8445,12
Obs. Os efeitos das rações e dos blocos são testados usando o resíduo (a). Os efeitos
dos suplementos e da interação são testados usando o resíduo b.
F(5,10; 0,05)=3,33 ; F(5,10; 0,01)= 5,64; F(2,10; 0,05)= 4,10; F(2,10; 0,01)= 7,56; F(1,15;
0,05)= 4,54
F(1,15; 0,01)= 8,86; F(2,15; 0,05)= 3,68; F(2,15; 0,01)= 6,36
Conclusão: como a interação não foi significativa (p>0,05) devemos interpretar as
diferenças significativas dos efeitos principais da ração e do suplemento.
QMR a 62 16CV a x100 x100 7 59
Y 103 89
QMR b 53 32CV b x100 x100 7 03
Y 103 89
( ) ,( ) , %
,
( ) ,( ) , %
,
= = =
= = =
Teste de Tukey:
• duas médias de A
( )
2E adms qA a glE rba
124 32dms 3 88 12 44A
12
sendo E(a) = QM(R(a))( )
,; ( )
,, ,
= =
= =
• duas médias de B
( )2E b
dms qB a glE rab
106 64dms 3 01 7 33B
18
sendo E(b) = QM(R(b))( )
,; ( )
,, ,
= =
= =
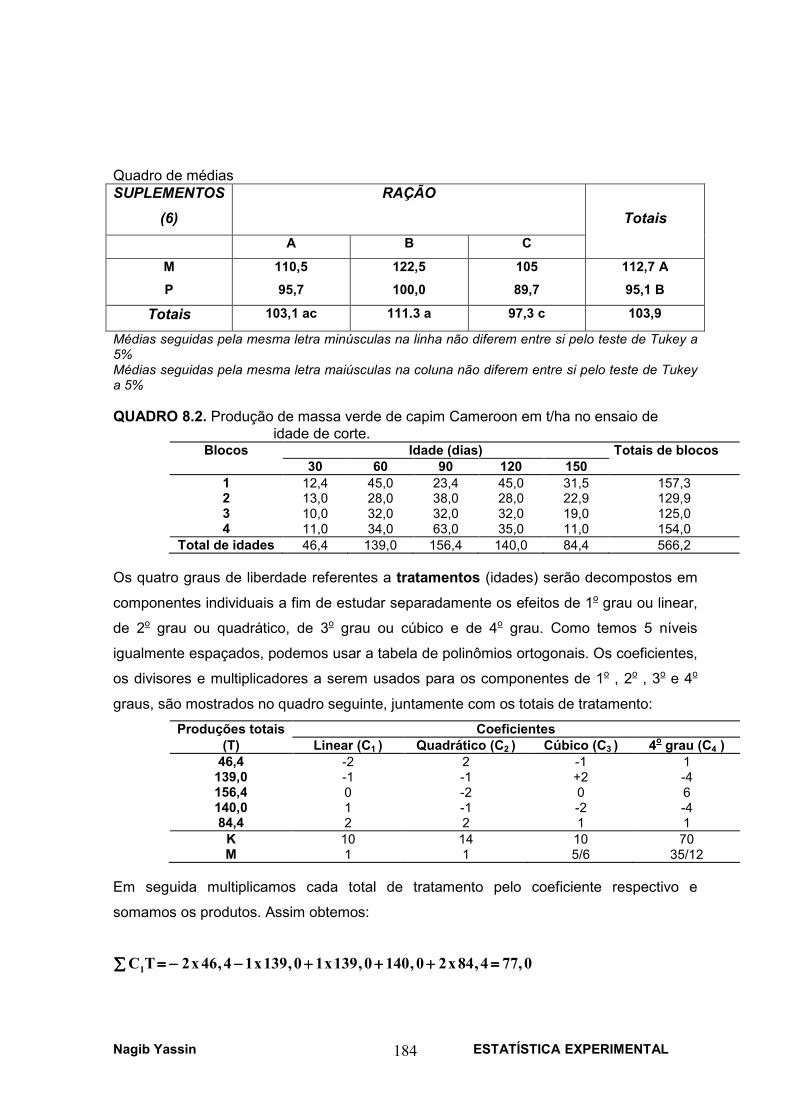
Nagib Yassin ESTATÍSTICA EXPERIMENTAL
184
Quadro de médias SUPLEMENTOS
(6)
RAÇÃO
Totais
A B C
M
P
110,5
95,7
122,5
100,0
105
89,7
112,7 A
95,1 B
Totais 103,1 ac 111.3 a 97,3 c 103,9
Médias seguidas pela mesma letra minúsculas na linha não diferem entre si pelo teste de Tukey a 5% Médias seguidas pela mesma letra maiúsculas na coluna não diferem entre si pelo teste de Tukey a 5%
QUADRO 8.2. Produção de massa verde de capim Cameroon em t/ha no ensaio de idade de corte.
Blocos Idade (dias) Totais de blocos 30 60 90 120 150 1 12,4 45,0 23,4 45,0 31,5 157,3 2 13,0 28,0 38,0 28,0 22,9 129,9 3 10,0 32,0 32,0 32,0 19,0 125,0 4 11,0 34,0 63,0 35,0 11,0 154,0
Total de idades 46,4 139,0 156,4 140,0 84,4 566,2 Os quatro graus de liberdade referentes a tratamentos (idades) serão decompostos em
componentes individuais a fim de estudar separadamente os efeitos de 1o grau ou linear,
de 2o grau ou quadrático, de 3o grau ou cúbico e de 4o grau. Como temos 5 níveis
igualmente espaçados, podemos usar a tabela de polinômios ortogonais. Os coeficientes,
os divisores e multiplicadores a serem usados para os componentes de 1o , 2o , 3o e 4o
graus, são mostrados no quadro seguinte, juntamente com os totais de tratamento:
Produções totais Coeficientes (T) Linear (C1 ) Quadrático (C2 ) Cúbico (C3 ) 4o grau (C4 )
46,4 -2 2 -1 1 139,0 -1 -1 +2 -4 156,4 0 -2 0 6 140,0 1 -1 -2 -4 84,4 2 2 1 1 K 10 14 10 70 M 1 1 5/6 35/12
Em seguida multiplicamos cada total de tratamento pelo coeficiente respectivo e
somamos os produtos. Assim obtemos:
C T x x x x1 2 46 4 1 139 0 1 139 0 140 0 2 84 4 77 0==== −−−− −−−− ++++ ++++ ++++ ====∑∑∑∑ , , , , , ,

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
185
A soma de quadrados para o componente linear é dada por:
SQRLinearC T
rK====
∑∑∑∑( )1
2
1
onde r é o número de parcelas (repetições) em cada total e K1 é a soma dos quadrados
dos coeficientes. Como r = 4 e K1 = 10, obtemos:
SQR Linearx
==== ====( , )
,77 0
4 10148 2250
2
Para os componentes quadráticos, cúbicos e de 4o grau obtemos:
∑∑∑
−=
=
−=
8,46
0,36
2,330
4
3
2
TC
TC
TC
com as seguintes somas de quadrados:
SQRQuadráticaC T
rK x
SQRCúbicaC T
rK x
====∑∑∑∑ ====
−−−−====
====∑∑∑∑
==== ====
( ) ( , ),
( ) ( ),
2
2
2 2
3
2
3
2
330 2
4 141947 0007
36
4 1032 4000
SQR 4O grau = ( ) ( , )
,C T
rK x
4
2
4
246 8
4 707 8223
∑∑∑∑ ====−−−−
====
Como a decomposição em componentes linear, quadrático, cúbico e 4o grau é ortogonal,
a soma de suas somas de quadrado é igual à soma de quadrados de tratamentos (idades
de corte), ou seja:
SQIdadesdecorte
SQIdadesdecorte
==== ++++ ++++ ++++ ++++ −−−−
====
46 4
4
139 0
4
156 4
4
140 0
4
84 4
4
566 2
20
2135 4480
2 2 2 2 2 2, , , , , ,
,
SQQL + SQRQ + SQRC + SQR4O grau = 148,2250 + 1947,0007 + 32,4000 + 7,8223 =
2135,4480 = SQIdades de corte

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
186
As outras variações isoladas pelo experimento são calculadas como segue:
SQTotal
SQBloco
SQErro SQTotal SQIdades SQBlo
==== ++++ ++++ ++++ −−−− ====
==== ++++ ++++ ++++ −−−− ====
==== −−−− −−−−
12 4 45 0 11 0566 2
203544 8580
157 3
5
129 9
5
125 0
5
154 0
5
566 2
20162 5380
2 2 22
2 2 2 2 2
, , . . . ,,
,
, , , , ,,
cos
= 3544,8580 - 2135,4480 - 162,5380 = 1246,8720 O quadro de análise de variância tem a seguinte forma: Causas de variação G. L. S. Q. Q. M. F Regressão linear 1 148,2250 148,2250 1,43 Regressão quadrática 1 1947,0007 1947,0007 18,74 ∗ ∗ Regressão cúbica 1 32,4000 32,4000 < 1 Regressão de 4o grau 1 7,8223 7,8223 < 1 Blocos 3 162,5380 54,1793 < 1 Erro 12 1246,8720 103,9060 Total 19 3544,8580
∗ ∗ Significativo ao nível de 1% de probabilidade. Cada um dos quadrados médios é testado por meio do erro e a hipótese de nulidade é a
de que a média de população para a comparação é zero. Se somente o efeito linear é
significativo, conclui-se que o aumento na resposta para níveis sucessivos do fator é
constante. A resposta pode ser negativa ou positiva quer ela diminua ou aumente com os
aumentos do nível do fator. Um efeito quadrático significativo indica que uma equação de
regressão de 2o grau ajusta melhor os dados, isto é, o aumento ou decréscimo para cada
aumento de nível do fator não é constante mas muda progressivamente.
Para o nosso exemplo a análise mostra efeito quadrático altamente significativo para as
idades de corte do capim Cameroom. Observando nossos dados, vemos que as
produções médias aumentam até a idade de 50 dias e a partir daí começam a decrescer;
verifica-se, também, que os aumentos e os decréscimos não são constantes. Os
componentes de 3o e 4o graus não significativos indicam que não trariam melhora alguma
ao ajustamento.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
187
Exercícios
1. Um experimento foi conduzido para avaliar o comportamento de diferentes cultivares
de soja em diversas épocas de semeadura. Os tratamentos épocas foram sorteados nas
parcelas e os cultivares nas subparcelas, utilizando-se o delineamento em blocos
casualizados com três repetições. Os resultados obtidos da porcentagem de germinação
foram:
Época de Blocos Cultivar Total das Parcelas
Média
Semeadura E316 Emb1 Rai Iti
Outubro 1 81 60 94 57 292(4) 2 77 56 90 53 276 3 85 64 97 61 307
Novembro 1 90 92 96 90 368 2 94 96 99 94 383 3 86 88 92 86 352
Dezembro 1 86 90 90 91 357 2 82 94 94 95 365 3 90 86 86 87 349
Total 771(9) 726 838 714 3049(36)
Fonte: Dados adaptados de Pereira (1998).
a) Faça a análise de variância e interpretar os resultados;
b) Identifique qual o melhor cultivar em de cada época;
c) Identifique qual a melhor época para cada cultivar.
d) Para os itens (b) e (c) faça o desdobramento da interação e aplique o SNK para
comparar os tratamentos.
2. Um experimento foi realizado para avaliar o comportamento de três cultivares de trigo
submetido a três níveis de irrigação. O fator irrigação foi casualizado nas parcelas e os
cultivares nas subparcelas utilizando-se o delineamento em blocos casualizados com três
repetições. Os valores de índice de glúten (em %) foram:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
188
Cultivar Irrigação Blocos 1 2 3 A 0 75 83 74 40 81 85 80 80 84 90 85 B 0 80 82 80 40 84 89 83 80 90 93 89 C 0 79 82 78 40 87 93 88 80 96 97 95
a) Faça a análise de variância, interprete os resultados obtidos;
b) Faça o desdobramento da interação para comparar os cultivares em cada nível de irrigação e aplique o teste de Tukey (%) para avaliar os cultivares;
c) Faça o desdobramento da interação para comparar os níveis de irrigação em cada cultivar e use a análise de regressão para descrever o efeito da irrigação;
3. Valores da enzima PFO em função do tipo de colheita e da época de colheita de
cafeeiro cultivar mundo novo em experimento em blocos casualizados, com três
repetições e tratamentos dispostos em parcelas subdivididas. As épocas de colheitas
constituem o fator das parcelas. Fazer a análise de variância completa, com aplicação de
teste de comparação múltipla e desdobramento de interação, se for necessário.
Tipo de Colheita
Bloco Época de Colheita 31-05 14-06 28-06 12-07 26-07 10-08
Pano 1 58 61 66 68 67 70 2 57 63 67 66 69 72 3 59 59 65 69 65 68
Chão 1 56 59 60 61 62 63 2 57 58 59 63 61 61 3 54 61 61 59 63 63
4. Um pesquisador pretende instalar um experimento para avaliar o efeito dos fatores
temperatura de armazenamento (ambiente, resfriado e congelado) e soluções de cálcio
(0%, 1%, 2% e 3%) em maças, visando a conservação de frutos de maça com boa
qualidade. Como o pesquisador poderá instalar esse experimento? Justifique o uso dos
delineamentos experimentais (DIC, DBC ou QL), o número de repetições (quatro?), o que
será a unidade experimental? Apresente o esquema de análise de variância

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
189
considerando que os tratamentos podem ser dispostos, na sua instalação, nos esquemas
em fatorial e em parcela subdividida. Comente qual poderá ser a melhor opção para o
pesquisador.
5. Um experimento foi conduzido para avaliar condições de armazenamento para
conservação de banana prata. Os tratamentos primários foram duas temperaturas (120C
e 250C) e os tratamentos secundários (AR, AR+AE, AM, e AM+AE) constituídos pelo
armazenamento refrigerado (AR), atmosfera modificada (AM) pelo uso de filme de
polietileno de baixa densidade associados com a absorção de etileno (AE). Utilizou-se o
delineamento em blocos casualizados, com duas repetições. Os resultados obtidos para
firmeza da polpa (N) foram:
Temperatura Blocos Tratamentos
AR AR+AE AM AM+AE
120C 1 7,0 7,0 5,7 6,6
2 6,5 6,7 5,4 6,9
250C 1 6,2 9,4 7,1 10,5
2 5,8 8,9 6,5 9,6
a) Faça a análise de variância, interprete os resultados obtidos;
b) Faça o desdobramento da interação para comparar os tipos de armazenamentos em cada nível de temperatura e aplique o teste de Tukey (%) para avaliar os tipos de armazenamentos;
c) Faça o desdobramento da interação para comparar os níveis de temperaturas em cada tipo de armazenamento e use o teste F para comparar os efeitos das temperaturas.
6. Um experimento foi realizado com o objetivo de comparar sistemas de preparo de solo
na cultura do milho, bem como determinar a melhor cultivar. O delineamento
experimental foi o blocos casualizado com quatro repetições, com os tratamentos
dispostos no esquema de parcelas subdivididas. Os valores de produção de grãos (t/ha)
obtidos foram:

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
190
Sistema de Cultivar Blocos Total
Preparo Solo I II III IV
Aração A 4,2 4,6 4,5 4,4 B 4,5 4,7 4,3 4,7 C 5,2 5,0 6,8 5,8
Aração+Gradagem A 3,8 4,4 4,8 3,9 B 3,7 3,5 3,1 3,7 C 3,5 3,1 3,4 3,3
Subsolagem A 4,2 4,2 5,2 5,1 B 4,0 3,8 3,7 4,1 C 3,9 3,9 3,7 4,0
a) Faça a análise de variância completa, incluindo todos os desdobramentos e interpretações; 7. Um experimento foi conduzido no delineamento inteiramente casualizado com duas
repetições, com o objetivo de controlar ninfas (formas jovens) de cigarrinhas (Deois
flavopicta) das pastagens através do uso de inseticidas e do manejo (modos de
aplicação, em tempo após corte). Os valores obtidos da porcentagem de eficiência do
controle químico foram:
Manejo Repetição Inseticidas
(Dias após corte)
Decis FW Mipcin 4G Mipcin 2GF
Toxafeno Lorsban
1 dia 1 53 58 80 28 25 2 57 64 84 32 29
8 dias 1 55 28 47 58 33 2 66 32 51 64 37
15 dias 1 35 77 55 68 40 2 37 71 53 64 42
a) Faça a análise de variância com desdobramento de interação e interpretação dos
resultados.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
191
C A P Í T U L O 10 Regressão na análise de variância
10.1. Introdução
Um fator em estudo num experimento pode ser classificado como qualitativo ou
quantitativo. Um fator qualitativo é aquele onde os seus níveis diferem por algum atributo
qualitativo. Como exemplos têm-se variedades, tipos de defensivos, métodos de conduzir
uma determinada tarefa, etc. Por outro lado, um fator quantitativo é aquele onde os níveis
se diferem com relação a quantidade do fator. Como exemplos têm-se temperatura,
umidade, concentração de um princípio ativo, níveis de insumo, pH, etc.
Quando o fator é qualitativo, deve-se proceder à análise de variância dos dados e às
comparações entre médias dos níveis do fator usando algum dos procedimentos para
comparações múltiplas, quando o F for significativo. Para o caso de um fator quantitativo,
deve-se estudar o efeito do fator quantitativo pó r meio de uma relação funcional entre o
mesmo e a variável resposta. A técnica indicada neste caso é a análise de regressão.
A análise de regressão consiste na realização de uma análise estatística com o objetivo
de verificar se a relação funcional estabelecida entre um fator quantitativo e uma variável
resposta é significativa. Em outras palavras, consiste na obtenção de uma equação que
tenta explicar a variação significativa de uma variável resposta em função da variação
dos níveis de um ou mais fatores quantitativos.
10.2. Escolha do modelo para equacionar o fenômeno em estudo
Para tentar estabelecer uma equação que representa o fenômeno em estudo, pode-se
plotar um diagrama de dispersão para verificar como se comportam os valores da
variável resposta (Y) em função da variação dos níveis do fator quantitativo (X).
O comportamento de Y em relação a X, pode se apresentar de diversas maneiras:
linear, quadrático, cúbico, exponencial, logarítmico, etc... . Para se estabelecer o modelo
para explicar o fenômeno, deve-se verificar qual tipo de curva e equação de um modelo
matemático que mais se aproxime dos pontos plotados no diagrama de dispersão.
Contudo, pode-se verificar que os pontos do diagrama de dispersão, não vão se ajustar
perfeitamente à curva do modelo matemático proposto. Haverá na maioria dos pontos,
uma distância entre os pontos do diagrama e aqueles obtidos quando a curva do modelo

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
192
proposto é traçada. Isto acontece, devido ao fato do fenômeno que está em estudo, não
ser um fenômeno matemático e sim um fenômeno que está sujeito a influências de
inúmeros fatores. Assim, o objetivo da regressão é obter um modelo matemático que
melhor se ajuste aos valores observados de Y em função da variação dos níveis da
variável X.
O modelo matemático que irá ser ajustado deve satisfazer as seguintes condições:
- Modelo selecionado deve ser coerente para representar em termos práticos, o
fenômeno em estudo;
- Modelo deve conter apenas as variáveis que são relevantes para explicar o fenômeno.
10.3. Método para obter a equação estimada
Como foi dito anteriormente, os pontos do diagrama de dispersão ficam um pouco
distantes da curva do modelo matemático escolhido. Um dos métodos que se pode
utilizar para obter a relação funcional, se baseia na obtenção de uma equação estimada
de tal forma que as distâncias entre os pontos do diagrama e os pontos da curva do
modelo matemático, no todo, sejam as menores possíveis. Este método é denominado
de Método dos Mínimos Quadrados (MMQ). Em resumo por este método a soma de
quadrados das distâncias entre os pontos do diagrama e os respectivos pontos na
curva da equação estimada é minimizada, obtendo-se, desta forma, uma relação
funcional entre X e Y, para o modelo escolhido, com um mínimo de erro possível.
10.3.1. Modelo linear de 1º grau O modelo estatístico para esta situação seria:
Yi = β0 + β1 Xi + ei
em que
Yi é o valor observado para a variável dependente Y no i-ésimo nível da variável
independente X;
β0 é a constante de regressão. Representa o intercepto da reta com o eixo dos Y;
β1 é o coeficiente de regressão. Representa a variação de Y em função da variação de
uma unidade da variável X;
Xi é o i-ésimo nível da variável independente X (i = 1,2,K,n); e
ei é o erro que está associado à distância entre o valor observado Yi e o correspondente
ponto na curva, do modelo proposto, para o mesmo nível i de X.
Para se obter a equação estimada, vamos utilizar o MMQ, visando a minimização

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
193
dos erros. Assim, tem-se que:
ei = β0 + β1 Xi
elevando ambos os membros da equação ao quadrado
[ ]i 1 ie β β X= +22
0
aplicando o somatório,
[ ]i 1 ie β β X= +∑ ∑22
0
Por meio da obtenção de estimadores de β0 e β1, que minimizem o valor obtido na
expressão anterior, é possível alcançar a minimização da soma de quadrados dos erros.
Sabemos do Cálculo que para se encontrar o mínimo de uma equação deve-se derivar a
equação em relação à variável de interesse, e igualar a derivada resultante ao valor zero.
Portanto, derivando a expressão (1) em relação a 0 1 β e β e igualando-as a zero, obtém-
se:
( )
( ) ( )
n
i n ni
i i
i i
n
i n ni
i i i i
i i
eˆ ˆ ˆ ˆY β β X Y β β X
β
eˆ ˆ ˆ ˆY β β X X Y β β X X
β
=
= =
=
= =
∂
= ⇒ − = − = ⇒ − = = ∂∂ = ⇒ − = − = ⇒ − = = ∂
∑∑ ∑
∑∑ ∑
2
11 0 1 1 0 1
1 10
2
11 0 1 1 0 1
1 11
0 2 1 0 0
0 2 0 0
n n n n n
i i i i
i i i i i
n n n n n n
i i i i i i i i
i i i i i i
ˆ ˆ ˆ ˆY β β X Y nβ β X
ˆ ˆ ˆ ˆYX β X β X YX β X β X
= = = = =
= = = = = =
− − = ⇒ − − =
− − = ⇒ − − =
∑ ∑ ∑ ∑ ∑
∑ ∑ ∑ ∑ ∑ ∑
0 1 0 11 1 1 1 1
2 20 1 0 1
1 1 1 1 1 1
0 0
0 0
n n
i i
i i
n n
i i i
i i
ˆ ˆY nβ β X
ˆ ˆYX β β X
= =
= =
= +
= +
∑ ∑
∑ ∑
0 11 1
20 1
1 1
Este é o sistema de equações normais, que permite a obtenção de estimativas de
β0 e β1, que minimizam a soma de quadrados dos erros.
Uma vez obtidas estas estimativas, podemos escrever a equação estimada:
î iˆ ˆY β β X= +0 1

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
194
10.3.2. Modelo linear de 2º grau O modelo estatístico para esta situação seria:
Yi = β0 + β1 Xi + β2i
X2
+ ei
em que,
Yi é o valor observado para a variável dependente Y no i-ésimo nível da variável
independente X;
β0 é a constante de regressão;
β1 é o coeficiente de regressão;
Xi é o i-ésimo nível da variável independente X (i = 1,2,K,n);
Β2 é o coeficiente de regressão;
iX
2
é o i-ésimo nível da variável independente X, elevado ao quadrado;
ei é o erro que está associado à distância entre o valor observado Yi e o correspondente
ponto na curva para o mesmo nível i de X.
Utilizando o MMQ, no modelo de 2º grau, chegar-se-á ao seguinte sistema de equações
normais, para se obter as estimativas de β0, β1 e β2 :
n n
i i
i i
n n n n
i i i i
i i i i
n n n n
i i i i i
i i i i
ˆ ˆY nβ β β X
ˆ ˆ ˆYX β X β X β X
ˆ ˆ ˆYX β X β X β X
= =
= = = =
= = = =
= + +
= + +
= + +
∑ ∑
∑ ∑ ∑ ∑
∑ ∑ ∑ ∑
20 1 2
1 1
2 30 0 1 2
1 1 1 1
2 2 3 40 1 3
1 1 1 1
Uma vez obtidas estas estimativas, podemos escrever a equação estimada:
îˆ ˆ ˆY β β X β X= + +0 1 1 2 2
10.4. Análise de variância da regressão A equação estimada obtida, apenas estabelece uma relação funcional, entre a variável
dependente e a variável independente, para representar o fenômeno em estudo.
Portanto a simples obtenção da equação estimada não responde ao pesquisador se a
variação da variável independente influencia significativamente na variação da variável
dependente.
Para se responder a esta pergunta, é necessário realizar um teste estatístico para as
estimativas dos coeficientes da equação de regressão estimada. Um teste que pode ser

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
195
realizado para verificar tal fato é o teste F da análise de variância. Portanto, é necessário
realizar uma análise de variância dos dados observados, em função do modelo proposto.
Contudo, a estratégia da análise de variância depende se houve ou não repetições no
experimento.
10.4.1. Apenas um único valor observado para cada nível da variável
independente
Nesta situação não existe repetição. A única estimativa da variância residual é aquela
dada pela falta de ajuste dos valores observados ao modelo ajustado. O quadro para a
análise de variância para a regressão para esta situação é do seguinte tipo:
FV GL SQ QM F
Regressão p SQReg SQReg
p
QMReg
QMInd
Independente da Regressão
n-1-p SQInd SQInd
n p− −1
Total n-1 SQTotal
em que,
p = no de coeficientes de regressão (não inclui o β0)
n = no de observações.
As fórmulas para a obtenção das somas de quadrados total e da soma de quadrados do
independente da regressão são as mesmas, tanto para o modelo linear de 1o grau
quanto para o de 2o grau, as quais são dadas a seguir:
n
ini
i
i
Y
SQTotal Yn
=
=
= −∑
∑
2
12
1 SQInd = SQTotal – SQRegressão
Já a soma de quadrados para a regressão varia de acordo com o modelo em teste
1º grau 2º grau
n
in ni
i i i
i i
Yˆ ˆSQRegressão β Y β YX
n
=
= =
= +∑
∑ ∑
2
10 1
1 1
n
in n ni
i i i i i
i i i
Yˆ ˆ ˆSQRegressão β Y β YX β YX
n
=
= = =
= + +∑
∑ ∑ ∑
2
120 1 2
1 1 1
As hipóteses estatísticas para o teste F são as seguintes:
H0 : β1 = β2 = .... = βp = 0 , o que significa dizer que as p variáveis independentes não

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
196
exercem influência na variável dependente, segundo o modelo proposto.
Ha: βi ≠ β0 , para pelo menos um i, o que significa dizer que pelo menos uma das p
variáveis independentes exerce influência na variável dependente, segundo o modelo
proposto.
O valor de F da análise de variância, deve ser comparado, com o valor de F tabelado
(Ftab) , o qual se obtém na tabela da distribuição F de acordo com o nível de significância
do teste, e o número de graus de liberdade para a regressão e independente da
regressão, ou seja:
Ftab = Fα (p;n 1 p) .
A regra decisória para o teste F é:
- Se F ≥ ⇒ Ftab Rejeita-se 0 H0 ao nível de significância que foi realizado o teste. Podese
inferir que a variável independente influência significativamente a
variável dependente Y.
- Se F < ⇒ FTab Não rejeita-se H0 ao nível de significância que foi realizado o teste.
Pode-se inferir que a variável independente não influência significativamente a variável
dependente Y.
10.4.2. Mais de um valor observado para cada nível da variável independente
Nesta situação, existe mais de um valor observado para cada nível da variável
independente. Assim é possível obter uma estimativa da variância residual tal como
aquela obtida em modelos de delineamento, o que não é possível quando se tem uma
única observação para cada nível da variável independente.
Normalmente o que se faz numa situação como esta é inicialmente proceder a uma
análise de variância usual considerando o efeito do fator quantitativo como se fosse a
fonte de variação tratamentos numa análise de variância usual. Isto é realizado para que
se quantifique a variância residual. Posteriormente, o efeito de tratamentos é desdobrado
nos efeitos associado a um ajuste de um modelo de regressão e também a falta de ajuste
deste modelo. A escolha do modelo de regressão a ser ajustado é aquele que mais se
aproxima dos pontos médios observados para cada nível da variável independente. O
quadro abaixo resume o que acabou de ser descrito, para uma situação geral em que se
está testando I níveis da variável independente em um experimento instalado segundo o
delineamento inteiramente casualizado com K repetições. Pressupõe-se também que se
está testando um modelo de regressão com p coeficientes de regressão. O total de
observações neste experimento é igual a N=IK.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
197
FV GL SQ QM F
Regressão p SQReg SQReg
p
QMReg
QMRes
Falta de Ajustamento I-1-p SQFalta SQFalta
I −1
(Tratamentos) I-1 SQTrat ___
Resíduo I(K – 1) SQRes
( )SQRes
I J −1 QMFalta
QMRes
Total IK – 1 SQTotal ___
O teste F para a falta de ajustamento é realizado para verificar se o modelo adotado está
se ajustando bem aos dados. Se o teste F para a falta de ajustamento for significativo,
indica que o modelo ajustado não é apropriado e um novo modelo que se ajuste melhor
aos dados deve ser testado. Se por outro lado, a falta de ajustamento for não-significativa
indica que o modelo adotado se ajusta bem aos dados.
Conseqüentemente faz sentido analisar o teste F para a fonte de variação regressão para
saber se a variável independente tem influência significativa sobre a variável dependente.
No caso de falta de ajustamento significativa não faz sentido realizar o teste para a
regressão, pois o modelo de regressão não se ajustou significativamente aos dados.
As hipóteses para a falta de ajustamento são:
H0: a falta de ajustamento não é significativa
Ha: a falta de ajustamento é significativa
O valor tabelado de F para a falta de ajustamento é encontrado usando
FTab = Fα (p; I 1 p)
A regra decisória para o teste F para a falta de ajustamento é:
Se F ≥ ⇒ Ftab Rejeita-se H0 ao nível de significância que foi realizado o teste. O modelo
adotado não se ajusta bem aos dados. Um novo modelo deve ser testado.
Se F < ⇒ FTab Não rejeita-se H0 ao nível de significância que foi realizado o teste. O
modelo adotado se ajusta bem aos dados. Não há necessidade de se testar um novo
modelo. Procede-se ao teste F para regressão.
O teste F para a regressão é idêntico ao caso anterior, ou seja, com apenas uma
observação para cada nível da variável independente.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
198
10.5. Coeficiente de determinação (R2)
O coeficiente de determinação fornece uma informação auxiliar ao resultado da análise
de variância da regressão, para verificar se o modelo proposto é adequado ou não para
descrever o fenômeno.
Para o caso em que se tem uma única observação para cada nível da variável
independente , o R2 é obtido por:
SQRegR
SQTotal=
2
Já para o caso em que se tem mais de um valor observado para cada nível da variável
independente, o valor de R2 é obtido por:
SQRegR
SQTrat=
2
O valor de R2 varia no intervalo de 0 a 1. Valores próximos de 1 indicam que o modelo
proposto é adequado para descrever o fenômeno.

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
199
Exercícios
1. Verificar, utilizando os dados amostrais fornecidos abaixo, se a temperatura tem
influência significativa sobre o comprimento de uma barra de aço. Utilize o modelo linear
de 1º grau e o nível de 5% de significância.
Temperatura (ºC) 10 15 20 25 30
Comprimento (mm) 1003 1005 1010 1011 1014
2. Para verificar se existe uma relação linear de 1º grau entre Umidade Relativa (UR) do
ar da secagem de sementes e a germinação das mesmas, um pesquisador realizou um
teste com 4 diferentes valores para a % de UR do ar que atravessava as sementes
armazenadas, obtendo-se os seguintes valores amostrais:
UR (%) 20 30 40 50
Germinação (%) 94 96 95 97
Ao nível de 5% de probabilidade, qual seria a conclusão do pesquisador? Qual seria a
equação estimada?
3. Para o seguinte conjunto de valores de X (variável independente) e Y (variável
dependente), faça a análise de regressão segundo o modelo linear de 1º grau e obtenha
a equação de regressão estimada. Use o nível de significância de 5%.
X 2 4 6 8 10 12 14 16 18 20
Y 10,3 18,2 25,1 35,6 43 50 59,1 67,8 75,2 85
4. De acordo com os dados fornecidos abaixo para a variável X (dose do micronutriente
Zn em ppm) e a variável Y (matéria seca em g/planta), verifique, usando o nível de 5% de
probabilidade e o modelo linear de 2º grau, se a relação entre as variáveis X
(independente) e Y (dependente) é significativa.
X 1 2,5 4 5,5 7 8,5
Y 20,3 31,3 34,6 35,1 30,2 19,7
5. O modelo linear abaixo foi proposto para explicar a relação entre a quantidade de
ração fornecida e produção de leite por cabras:
Yi = a + bXi + ei Pede-se por meio dos dados abaixo, verificar se a ração influencia
significativamente a produção de leite (α = 5%):

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
200
Níveis de Ração (g) 50 75 100 125 150
Produção de leite (l/dia) 1,2 1,7 2 2,1 2,5
6. Para se avaliar o efeito de diferentes dosagens de um micronutriente no
desenvolvimento de duas espécies vegetais, foi realizado em experimento fatorial 4x2 no
D.B.C. com 5 repetições. Após a coleta e tabulação dos dados (em produção de matéria
verde por determinada unidade de área) foi montado o seguinte quadro de totais de
tratamentos:
Dose 1 Dose 2 Dose 3 Dose 4 Totais
Espécie 1 60 52 60 90 262
Espécie 2 56 50 40 40 186
Totais 116 102 100 130 448
A análise de variância dos dados no computador forneceu o seguinte quadro (incompleto)
da ANAVA:
FV GL SQ QM F
Fator A Fator B 58,2 Int. AxB 49,2 (Trat.) Blocos Resíduo 10 Total
Com base nos dados apresentados acima, pede-se: (obs.: use α = 5%):
a) Obtenha a soma de quadrados para o fator A. Apresente os cálculos.
b) Os fatores em estudo atuam independentemente na variável em análise?
JUSTIFIQUE.
c) Qual espécie deveria ser usada de modo a termos uma maior produção de massa
verde, quando for usada a dose 3 do micronutriente? JUSTIFIQUE.
d) Como deveríamos continuar a análise caso fosse de nosso interesse determinar a
melhor dose do micronutriente? Descreva a estratégia de análise de maneira resumida,
apresentando a seqüência dos procedimentos a serem realizados juntamente com
algumas discussões, mas sem precisar fazer nenhum tipo de cálculo

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
201
7. Suponha que um colega seu tenha usado um programa de computador para realizar a
análise de regressão de um experimento no DIC com 4 repetições, no qual foi avaliado o
efeito de 5 níveis de adubo na produção de soja. O orientador desse seu colega pediu
que ele testasse três modelos. Como seu colega "matou" todas as aulas de estatística,
ele foi pedir sua ajuda para a escolha do melhor modelo a partir dos dados abaixo,
referentes à análise de cada modelo. Baseado no quadro fornecido abaixo, pede-se
escolher o melhor modelo. Explique, para cada modelo, a razão dele ter sido selecionado
ou eliminado. Use α = 5%.
MODELO 1
FV GL SQ QM
Regressão 1 36 36 Falta de Ajust. 3 60 20 (Trat.) (4) 96 Resíduo 15 75 5 Total 19 171
MODELO 2
FV GL SQ QM
Regressão 2 66 33 Falta de Ajust. 2 30 15 (Trat.) (4) 96 Resíduo 15 75 5 Total 19 171
MODELO 3
FV GL SQ QM
Regressão 3 76 25,3 Falta de Ajust. 1 20 20 (Trat.) (4) 96 Resíduo 15 75 5 Total 19 171
O gráfico de dispersão dos valores médios de produção em função das doses de adubo
obtido pelo seu colega foi

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
202
8. Com o objetivo de estudar o efeito da temperatura no ganho de peso de determinada
espécie de animal de pequeno porte, foi realizado um estudo em que alguns animais
foram submetidos a diferentes temperaturas no local em que eram confinados.
Com base nos dados de ganho de peso, obtidos depois de determinado período,
ajustouse a seguinte equação de regressão:
Y = - 6,89 + 0,93X – 0,02X2
Considerando que a análise de variância da regressão resultou em F significativo para
regressão, pede-se:
a) Qual seria o ganho de peso (em quilos) esperado, se fosse mantida constante, no local
de confinamento do animal em questão, a temperatura de 23 oC?
b) Qual seria a temperatura a ser usada para que fosse obtido o máximo de ganho de
peso?
9. Suponha que tenha sido realizada uma pesquisa a respeito da influência do tempo de
estudo na nota da prova de determinada disciplina. Os dados obtidos com respeito a
cinco alunos aleatoriamente entrevistados são dados abaixo:
Xi = Tempo de estudo (em horas) 2 3 4 5 6
Y = Nota obtida (em 10) 3 5 6 8 9
20 40 60
Doses (kg/ha)
Produçã
o – kg/unid
25 20 15 10 5

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
203
iX =∑2 0 iX =∑
2 9 0 iY =∑
3 1 i iX Y =∑
1 3 9 iY =∑
2 2 1 5
Pede-se:
a) Ajuste um modelo de regressão linear de 1o grau para tentar explicar a variação na
nota do aluno em função do tempo de estudo.
OBS.: Indique a resolução, inclusive apresentando o sistema de equações normais.
b) Poderíamos dizer que o tempo de estudo influencia significativamente a nota obtida?
(use α = 5%).
10. Suponha que um pesquisador, tendo como objetivo desenvolver uma bebida Láctea
com sabor natural de laranja e temendo que o uso do suco natural resultasse em elevada
acidez, resolveu testar 10 dosagens de suco natural (10, 15, 20, 25, 30, 35, 40, 45, 50 e
55 ml) com relação ao ph da bebida Láctea. Para tanto preparou um lote da fórmula
básica da bebida Láctea. A fórmula básica é aquela que contém todos os ingredientes da
bebida Láctea, exceto o suco de laranja. Como o lote era completamente homogêneo,
dividiu o lote em 30 amostras. Procedeu-se então a distribuição inteiramente ao acaso
das dosagens de suco de laranja às amostras. Ao final, cada dosagem foi designada a 3
amostras. Após a mistura do suco de laranja às amostras, o pH da bebida Láctea foi
medido. Um gráfico de dispersão da dosagem versus pH, mostrou que o modelo linear de
1o grau era indicado para estudar o fenômeno. Com base nos dados, as seguintes
informações foram obtidas
Quadro da ANAVA da Regressão
FV GL SQ QM F
Regressão 237,692
Falta de Ajust.
(Trat.) (23,372)
Resíduo
Total 25,1520
Equação da regressão ajustada: î
Y = 0,063 – 0,08Xi
Com base nas informações fornecidas acima e usando o nível de 5% de significância,
pede-se:
OBSERVAÇÃO: UTILIZAR QUATRO DECIMAIS NOS CÁLCULOS
a. O modelo ajustado é adequado para descrever o fenômeno?

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
204
b. A dosagem do suco de laranja tem efeito significativo na acidez da bebida Láctea?
c. Quanto se espera que varie o pH da bebida Láctea em função da variação de 1
ml de suco de laranja?

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
205
Tabela 1, Distribuição t de Student
Teste Unilateral
gl
15% 10% 5% 2,5% 2% 1% 0,5% 0,1% 0,05%
Teste Bilateral
30% 20% 10% 5% 4% 2% 1% 0,2% 0,1%
1 1,9626 3,0777 6,3137 12,7062 15,8945 31,8210 63,6559 318,2888 636,5776
2 1,3862 1,8856 2,9200 4,3027 4,8487 6,9645 9,9250 22,3285 31,5998
3 1,2498 1,6377 2,3534 3,1824 3,4819 4,5407 5,8408 10,2143 12,9244
4 1,1896 1,5332 2,1318 2,7765 2,9985 3,7469 4,6041 7,1729 8,6101
5 1,1558 1,4759 2,0150 2,5706 2,7565 3,3649 4,0321 5,8935 6,8685
6 1,1342 1,4398 1,9432 2,4469 2,6122 3,1427 3,7074 5,2075 5,9587
7 1,1192 1,4149 1,8946 2,3646 2,5168 2,9979 3,4995 4,7853 5,4081
8 1,1081 1,3968 1,8595 2,3060 2,4490 2,8965 3,3554 4,5008 5,0414
9 1,0997 1,3830 1,8331 2,2622 2,3984 2,8214 3,2498 4,2969 4,7809
10 1,0931 1,3722 1,8125 2,2281 2,3593 2,7638 3,1693 4,1437 4,5868
11 1,0877 1,3634 1,7959 2,2010 2,3281 2,7181 3,1058 4,0248 4,4369
12 1,0832 1,3562 1,7823 2,1788 2,3027 2,6810 3,0545 3,9296 4,3178
13 1,0795 1,3502 1,7709 2,1604 2,2816 2,6503 3,0123 3,8520 4,2209
14 1,0763 1,3450 1,7613 2,1448 2,2638 2,6245 2,9768 3,7874 4,1403
15 1,0735 1,3406 1,7531 2,1315 2,2485 2,6025 2,9467 3,7329 4,0728
16 1,0711 1,3368 1,7459 2,1199 2,2354 2,5835 2,9208 3,6861 4,0149
17 1,0690 1,3334 1,7396 2,1098 2,2238 2,5669 2,8982 3,6458 3,9651
18 1,0672 1,3304 1,7341 2,1009 2,2137 2,5524 2,8784 3,6105 3,9217
19 1,0655 1,3277 1,7291 2,0930 2,2047 2,5395 2,8609 3,5793 3,8833
20 1,0640 1,3253 1,7247 2,0860 2,1967 2,5280 2,8453 3,5518 3,8496
21 1,0627 1,3232 1,7207 2,0796 2,1894 2,5176 2,8314 3,5271 3,8193
22 1,0614 1,3212 1,7171 2,0739 2,1829 2,5083 2,8188 3,5050 3,7922
23 1,0603 1,3195 1,7139 2,0687 2,1770 2,4999 2,8073 3,4850 3,7676
24 1,0593 1,3178 1,7109 2,0639 2,1715 2,4922 2,7970 3,4668 3,7454
25 1,0584 1,3163 1,7081 2,0595 2,1666 2,4851 2,7874 3,4502 3,7251
26 1,0575 1,3150 1,7056 2,0555 2,1620 2,4786 2,7787 3,4350 3,7067
27 1,0567 1,3137 1,7033 2,0518 2,1578 2,4727 2,7707 3,4210 3,6895
28 1,0560 1,3125 1,7011 2,0484 2,1539 2,4671 2,7633 3,4082 3,6739
29 1,0553 1,3114 1,6991 2,0452 2,1503 2,4620 2,7564 3,3963 3,6595
30 1,0547 1,3104 1,6973 2,0423 2,1470 2,4573 2,7500 3,3852 3,6460
35 1,0520 1,3062 1,6896 2,0301 2,1332 2,4377 2,7238 3,3400 3,5911
40 1,0500 1,3031 1,6839 2,0211 2,1229 2,4233 2,7045 3,3069 3,5510
50 1,0473 1,2987 1,6759 2,0086 2,1087 2,4033 2,6778 3,2614 3,4960
60 1,0455 1,2958 1,6706 2,0003 2,0994 2,3901 2,6603 3,2317 3,4602
12
0
1,0409 1,2886 1,6576 1,9799 2,0763 2,3578 2,6174 3,1595 3,3734
+∞∞∞∞ 1,0364 1,2816 1,6449 1,9600 2,0537 2,3264 2,5758 3,0902 3,2905

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
206
F
TABELA 2 Distribuição
F de Snedecor
α = 0,05
GL
denom.- n2 GL no numerador – n1
1 2 3 4 5 6 7 8 9 10 1 161,45 199,50 215,71 224,58 230,16 233,99 236,77 238,88 240,54 241,88 2 18,51 19,00 19,16 19,25 19,30 19,33 19,35 19,37 19,38 19,40 3 10,13 9,55 9,28 9,12 9,01 8,94 8,89 8,85 8,81 8,79 4 7,71 6,94 6,59 6,39 6,26 6,16 6,09 6,04 6,00 5,96 5 6,61 5,79 5,41 5,19 5,05 4,95 4,88 4,82 4,77 4,74 6 5,99 5,14 4,76 4,53 4,39 4,28 4,21 4,15 4,10 4,06 7 5,59 4,74 4,35 4,12 3,97 3,87 3,79 3,73 3,68 3,64 8 5,32 4,46 4,07 3,84 3,69 3,58 3,50 3,44 3,39 3,35 9 5,12 4,26 3,86 3,63 3,48 3,37 3,29 3,23 3,18 3,14 10 4,96 4,10 3,71 3,48 3,33 3,22 3,14 3,07 3,02 2,98 11 4,84 3,98 3,59 3,36 3,20 3,09 3,01 2,95 2,90 2,85 12 4,75 3,89 3,49 3,26 3,11 3,00 2,91 2,85 2,80 2,75 13 4,67 3,81 3,41 3,18 3,03 2,92 2,83 2,77 2,71 2,67 14 4,60 3,74 3,34 3,11 2,96 2,85 2,76 2,70 2,65 2,60 15 4,54 3,68 3,29 3,06 2,90 2,79 2,71 2,64 2,59 2,54 16 4,49 3,63 3,24 3,01 2,85 2,74 2,66 2,59 2,54 2,49 17 4,45 3,59 3,20 2,96 2,81 2,70 2,61 2,55 2,49 2,45 18 4,41 3,55 3,16 2,93 2,77 2,66 2,58 2,51 2,46 2,41 19 4,38 3,52 3,13 2,90 2,74 2,63 2,54 2,48 2,42 2,38 20 4,35 3,49 3,10 2,87 2,71 2,60 2,51 2,45 2,39 2,35 21 4,32 3,47 3,07 2,84 2,68 2,57 2,49 2,42 2,37 2,32 22 4,30 3,44 3,05 2,82 2,66 2,55 2,46 2,40 2,34 2,30 23 4,28 3,42 3,03 2,80 2,64 2,53 2,44 2,37 2,32 2,27 24 4,26 3,40 3,01 2,78 2,62 2,51 2,42 2,36 2,30 2,25 25 4,24 3,39 2,99 2,76 2,60 2,49 2,40 2,34 2,28 2,24 26 4,23 3,37 2,98 2,74 2,59 2,47 2,39 2,32 2,27 2,22 27 4,21 3,35 2,96 2,73 2,57 2,46 2,37 2,31 2,25 2,20 28 4,20 3,34 2,95 2,71 2,56 2,45 2,36 2,29 2,24 2,19 29 4,18 3,33 2,93 2,70 2,55 2,43 2,35 2,28 2,22 2,18 30 4,17 3,32 2,92 2,69 2,53 2,42 2,33 2,27 2,21 2,16 35 4,12 3,27 2,87 2,64 2,49 2,37 2,29 2,22 2,16 2,11 40 4,08 3,23 2,84 2,61 2,45 2,34 2,25 2,18 2,12 2,08 45 4,06 3,20 2,81 2,58 2,42 2,31 2,22 2,15 2,10 2,05 50 4,03 3,18 2,79 2,56 2,40 2,29 2,20 2,13 2,07 2,03 100 3,94 3,09 2,70 2,46 2,31 2,19 2,10 2,03 1,97 1,93 120 3,92 3,07 2,68 2,45 2,29 2,17 2,09 2,02 1,96 1,91 ∞ 3,84 3,00 2,60 2,37 2,21 2,10 2,01 1,94 1,88 1,83
área = = 0,05
(valor tabulado)

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
207
F
TABELA 3 Distribuição
F de Snedecor
α = 0,01
GL
denom n2 GL no numerador – n1
1 2 3 4 5 6 7 8 9 10 1 4052,2 4999,3 5403,5 5624,3 5764,0 5859,0 5928,3 5981,0 6022,4 6055,9 2 98,50 99,00 99,16 99,25 99,30 99,33 99,36 99,38 99,39 99,40 3 34,12 30,82 29,46 28,71 28,24 27,91 27,67 27,49 27,34 27,23 4 21,20 18,00 16,69 15,98 15,52 15,21 14,98 14,80 14,66 14,55 5 16,26 13,27 12,06 11,39 10,97 10,67 10,46 10,29 10,16 10,05 6 13,75 10,92 9,78 9,15 8,75 8,47 8,26 8,10 7,98 7,87 7 12,25 9,55 8,45 7,85 7,46 7,19 6,99 6,84 6,72 6,62 8 11,26 8,65 7,59 7,01 6,63 6,37 6,18 6,03 5,91 5,81 9 10,56 8,02 6,99 6,42 6,06 5,80 5,61 5,47 5,35 5,26 10 10,04 7,56 6,55 5,99 5,64 5,39 5,20 5,06 4,94 4,85 11 9,65 7,21 6,22 5,67 5,32 5,07 4,89 4,74 4,63 4,54 12 9,33 6,93 5,95 5,41 5,06 4,82 4,64 4,50 4,39 4,30 13 9,07 6,70 5,74 5,21 4,86 4,62 4,44 4,30 4,19 4,10 14 8,86 6,51 5,56 5,04 4,69 4,46 4,28 4,14 4,03 3,94 15 8,68 6,36 5,42 4,89 4,56 4,32 4,14 4,00 3,89 3,80 16 8,53 6,23 5,29 4,77 4,44 4,20 4,03 3,89 3,78 3,69 17 8,40 6,11 5,19 4,67 4,34 4,10 3,93 3,79 3,68 3,59 18 8,29 6,01 5,09 4,58 4,25 4,01 3,84 3,71 3,60 3,51 19 8,18 5,93 5,01 4,50 4,17 3,94 3,77 3,63 3,52 3,43 20 8,10 5,85 4,94 4,43 4,10 3,87 3,70 3,56 3,46 3,37 21 8,02 5,78 4,87 4,37 4,04 3,81 3,64 3,51 3,40 3,31 22 7,95 5,72 4,82 4,31 3,99 3,76 3,59 3,45 3,35 3,26 23 7,88 5,66 4,76 4,26 3,94 3,71 3,54 3,41 3,30 3,21 24 7,82 5,61 4,72 4,22 3,90 3,67 3,50 3,36 3,26 3,17 25 7,77 5,57 4,68 4,18 3,85 3,63 3,46 3,32 3,22 3,13 26 7,72 5,53 4,64 4,14 3,82 3,59 3,42 3,29 3,18 3,09 27 7,68 5,49 4,60 4,11 3,78 3,56 3,39 3,26 3,15 3,06 28 7,64 5,45 4,57 4,07 3,75 3,53 3,36 3,23 3,12 3,03 29 7,60 5,42 4,54 4,04 3,73 3,50 3,33 3,20 3,09 3,00 30 7,56 5,39 4,51 4,02 3,70 3,47 3,30 3,17 3,07 2,98 35 7,42 5,27 4,40 3,91 3,59 3,37 3,20 3,07 2,96 2,88 40 7,31 5,18 4,31 3,83 3,51 3,29 3,12 2,99 2,89 2,80 45 7,23 5,11 4,25 3,77 3,45 3,23 3,07 2,94 2,83 2,74 50 7,17 5,06 4,20 3,72 3,41 3,19 3,02 2,89 2,78 2,70 100 6,90 4,82 3,98 3,51 3,21 2,99 2,82 2,69 2,59 2,50 120 6,85 4,79 3,95 3,48 3,17 2,96 2,79 2,66 2,56 2,47 ∞ 6,63 4,61 3,78 3,32 3,02 2,80 2,64 2,51 2,41 2,32
área = = 0,01
(valor tabulado)

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
208
Tabela 4 - Valores da amplitude total estudentizada (q), para uso no teste de Tukey, ao
nível de 5% de probabilidade
GL k= Número e tratamentos
2 3 4 5 6 7 3 9 10
1 17,97 90,03
26,98 135,00
32,82 164,30
37,08 185,60
40,41 202,20
43,12 215,80
45,40 227,20
47,36 237,00
49,07 245,6
2 6,09 14,04
8,33 19,02
9,80 22,29
10,88 24,72
11,74 26,63
12,44 28,20
13,03 29,53
13,54 30,68
13,99 31,69
3 4,50 8,26
5,91 10,62
6,83 12,17
7,50 13,33
8,04 14,24
8,48 15,00
8,85 15,64
9,18 16,20
9,46 16,69
4 3,93 6,51
5,04 8,12
5,76 9,17
6,29 9,96
6,71 10,58
7,05 11,10
7,35 11,55
7,60 11,93
7,83 12,27
5 3,64 5,70
4,60 6,98
5,22 7,80
5,67 8,42
6,03 8,91
6,33 9,32
6,58 9,67
6,80 9,97
6,99 10,24
6 3,46 5,24
4,34 6,33
4,90 7,03
5,30 7,56
5,63 7,97
5,90 8,32
6,12 8,61
6,32 8,87
6,49 9,10
7 3,34 4,95
4,16 5,92
4,68 6,54
5,06 7,01
5,36 7,37
5,61 7,68
5,82 7,94
6,00 8,17
6,16 8,37
8 3,26 4,75
4,04 5,64
4,53 6,20
4,89 6,62
5,17 6,96
5,40 7,24
5,60 7,47
5,77 7,68
5,92 7,86
9 3,20 4,60
3,95 5,43
4,41 5,96
4,76 6,35
5,02 6,66
5,24 6,91
5,43 7,13
5,59 7,33
5,74 7,49
10 3,15 4,48
3,88 5,27
4,33 5,77
4,65 6,14
4,91 6,43
5,12 6,67
5,30 6,87
5,46 7,05
5,60 7,21
11 3,11 4,39
3,82 5,15
4,26 5,62
4,57 5,97
4,82 6,25
5,03 6,48
5,20 6,67
5,35 6,84
5,49 6,99
12 3,08 4,32
3,77 5,05
4,20 5,50
4,51 5,84
4,75 6,10
4,95 6,32
5,12 6,51
5,27 6,67
5,39 6,81
13 3,06 4,26
3,73 4,96
4,15 5,40
4,45 5,73
4,69 5,98
4,88 6,19
5,05 6,37
5,19 6,53
5,32 6,67
14 3,03 4,21
3,70 4,89
4,11 5,32
4,41 5,63
4,64 5,88
4,83 6,08
4,99 6,26
5,13 6,41
5,25 6,54
15 3,01 4,17
3,67 4,84
4,08 5,25
4,37 5,56
4,59 5,80
4,78 5,99
4,94 6,16
5,08 6,31
5,20 6,44
16 3,00 4,13
3,65 4,79
4,05 5,19
4,33 5,49
4,56 5,72
4,74 5,92
4,90 6,08
5,03 6,22
5,15 6,35
17 2,98 4,10
3,63 4,74
4,02 5,14
4,30 5,43
4,52 5,66
4,70 5,85
4,86 6,01
4,99 6,15
5,11 6,27
18 2,97 4,07
3,61 4,70
4,00 5,09
4,28 5,38
4,49 5,60
4,67 5,79
4,82 5,94
4,96 6,08
5,07 6,20
19 2,96 4,05
3,59 4,67
3,98 5,05
4,25 5,33
4,47 5,55
4,65 5,73
4,79 5,89
4,92 6,02
5,04 6,14
20 2,95 4,02
3,58 4,64
3,96 5,02
4,23 5,29
4,45 5,51
4,62 5,69
4,77 5,84
4,90 5,97
5,01 6,09
24 2,92 3,96
3,53 4,55
3,90 4,91
4,17 5,17
4,37 5,37
4,54 5,54
4,68 5,69
4,81 5,81
4,92 5,92
30 2,89 3,89
3,49 4,45
3,85 4,80
4,10 5,05
4,30 5,24
4,46 5,40
4,60 5,54
4,72 5,65
4,82 5,76
40 2,86 3,82
3,44 4,37
3,79 4,70
4,04 4,93
4,23 5,11
4,39 5,26
4,52 5,39
4,63 5,50
4,73 5,60
60 2,83 3,76
3,40 4,28
3,74 4,59
3,98 4,82
4,16 4,99
4,31 5,13
4,44 5,25
4,55 5,36
4,65 5,45
120 2,80 3,70
3,36 4,20
3,68 4,50
3,92 4,71
4,10 4,87
4,24 5,01
4,36 5,12
4,47 5,21
4,56 5,30
∞ 2,77 3,64
3,31 4,12
3,63 4,40
3,86 4,60
4,03 4,76
4,17 4,88
4,29 4,99
4,39 5,08
4,47 5,16

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
209
Tabela 5. Teste de Dunnett
GL (N-k) αααα
k níveis
2 3 4 5 6 7 8 9 10
5
0,05 2,57 3,03 3,29 3,48 3,62 3,73 3,82 3,9 3,97
0,01 4,03 4,63 4,98 5,22 5,41 5,56 5,69 5,8 5,89
6
0,05 2,45 2,86 3,1 3,26 3,39 3,49 3,57 3,64 3,71
0,01 3,71 4,21 4,51 4,71 4,87 5 5,1 5,2 5,28
7
0,05 2,36 2,75 2,97 3,12 3,24 3,33 3,41 3,47 3,53
0,01 3,5 3,95 4,21 4,39 4,53 4,64 4,74 4,82 4,89
8
0,05 2,31 2,67 2,88 3,02 3,13 3,22 3,29 3,35 3,41
0,01 3,36 3,77 4 4,17 4,29 4,4 4,48 4,56 4,62
9
0,05 2,26 2,61 2,81 2,95 3,05 3,14 3,2 3,26 3,32
0,01 3,25 3,63 3,85 4,01 4,12 4,22 4,3 4,37 4,43
10
0,05 2,23 2,57 2,76 2,89 2,99 3,07 3,14 3,19 3,24
0,01 3,17 3,53 3,74 3,88 3,99 4,08 4,16 4,22 4,28
11
0,05 2,2 2,53 2,72 2,84 2,94 3,02 3,08 3,14 3,19
0,01 3,11 3,45 3,65 3,79 3,89 3,98 4,05 4,11 4,16
12
0,05 2,18 2,5 2,68 2,81 2,9 2,98 3,04 3,09 3,14
0,01 3,05 3,39 3,58 3,71 3,81 3,89 3,96 4,02 4,07
13
0,05 2,16 2,48 2,65 2,78 2,87 2,94 3 3,06 3,1
0,01 3,01 3,33 3,52 3,65 3,74 3,82 3,89 3,94 3,99
14
0,05 2,14 2,46 2,63 2,75 2,84 2,91 2,97 3,02 3,07
0,01 2,98 3,29 3,47 3,59 3,69 3,76 3,83 3,88 3,93
15
0,05 2,13 2,44 2,61 2,73 2,82 2,89 2,95 3 3,04
0,01 2,95 3,25 3,43 3,55 3,64 3,71 3,78 3,83 3,88
16
0,05 2,12 2,42 2,59 2,71 2,8 2,87 2,92 2,97 3,02
0,01 2,92 3,22 3,39 3,51 3,6 3,67 3,73 3,78 3,83
17
0,05 2,11 2,41 2,58 2,69 2,78 2,85 2,9 2,95 3
0,01 2,9 3,19 3,36 3,47 3,56 3,63 3,69 3,74 3,79
18
0,05 2,1 2,4 2,56 2,68 2,76 2,83 2,89 2,94 2,98
0,01 2,88 3,17 3,33 3,44 3,53 3,6 3,66 3,71 3,75
19
0,05 2,09 2,39 2,55 2,66 2,75 2,81 2,87 2,92 2,96
0,01 2,86 3,15 3,31 3,42 3,5 3,57 3,63 3,68 3,72
20
0,05 2,09 2,38 2,54 2,65 2,73 2,8 2,86 2,9 2,95
0,01 2,85 3,13 3,29 3,4 3,48 3,55 3,6 3,65 3,69
24
0,05 2,06 2,35 2,51 2,61 2,7 2,76 2,81 2,86 2,9
0,01 2,8 3,07 3,22 3,32 3,4 3,47 3,52 3,57 3,61
30
0,05 2,04 2,32 2,47 2,58 2,66 2,72 2,77 2,82 2,86
0,01 2,75 3,01 3,15 3,25 3,33 3,39 3,44 3,49 3,52
40
0,05 2,02 2,29 2,44 2,54 2,62 2,68 2,73 2,77 2,81
0,01 2,7 2,95 3,09 3,19 3,26 3,32 3,37 3,41 3,44
60
0,05 2 2,27 2,41 2,51 2,58 2,64 2,69 2,73 2,77
0,01 2,66 2,9 3,03 3,12 3,19 3,25 3,29 3,33 3,37

Nagib Yassin ESTATÍSTICA EXPERIMENTAL
210
Tabela 6 - Valores da amplitude total estudentizada (z), para uso no teste de Duncan, ao
nível de 5% de probabilidade
n2 2 3 4 5 6 7 8 9 10
1 18,00 18,00 18,00 18,00 18,00 18,00 18,00 18,00 18,00
2 6,09 6,09 6,09 6,09 6,09 6,09 6,09 6,09 6,09
3 4,50 4,50 4,50 4,50 4,50 4,50 4,50 4,50 4,50
4 3,93 4,01 4,02 4,02 4,02 4,02 4,02 4,02 4,02
5 3,64 3,74 3,79 3,83 3,83 3,83 3,83 3,83 3,83
6 3,46 3,58 3,64 3,68 3,68 3,68 3,68 3,68 3,68
7 3,35 3,47 3,54 3,58 3,60 3,61 3,61 3,61 3,61
8 3,26 3,39 3,47 3,52 3,55 3,56 3,56 3,56 3,56
9 3,20 3,34 3,20 3,34 3,41 3,52 3,52 3,52 3,52
10 3,15 3,30 3,15 3,30 3,37 3,47 3,47 3,47 3,47
11 3,11 3,27 3,35 3,39 3,43 3,44 3,45 3,46 3,46
12 3,08 3,23 3,33 3,36 3,40 3,42 3,44 3,44 3,46
13 3,06 3,21 3,30 3,35 3,38 3,41 3,42 3,44 3,45
14 3,03 3,18 3,27 3,33 3,37 3,39 3,41 3,42 3,44
15 3,01 3,16 3,25 3,31 3,36 3,38 3,40 3,42 3,43
16 3,00 3,15 3,23 3,30 3,34 3,37 3,39 3,41 3,43
17 2,98 3,13 3,22 3,28 3,33 3,36 3,38 3,40 3,42
18 2,97 3,12 3,21 3,27 3,32 3,35 3,37 3,39 3,41
19 2,96 3,11 3,19 3,26 3,31 3,35 3,37 3,39 3,41
20 2,95 3,10 3,18 3,25 3,30 3,34 3,36 3,38 3,40
22 2,93 3,08 3,17 3,24 3,29 3,32 3,35 3,37 3,39
24 2,92 3,07 3,15 3,22 3,28 3,31 3,34 3,37 3,38
26 2,91 3,06 3,14 3,21 3,27 3,30 3,34 3,36 3,38
28 2,90 3,04 3,13 3,20 3.26 3,30 3,33 3,35 3,37
30 2,89 3,04 3,12 3,20 3,25 3,29 3,32 3,35 3,37
40 2,86 3,01 3,10 3,17 3,22 3,27 3,30 3,33 3,35
60 2,83 2,98 3,08 3,14 3,20 3,24 3,28 3,31 3,33
100 2,80 2,95 3,05 3,12 3,18 3,22 3,26 3,29 3,32
∞ 2,77 2,92 3,02 3,09 3,15 3,19 3,23 3,26 3,29
n = nº de médias ordenadas abrangidas pelo contraste n2 = nº de graus de liberdade do resíduo




















