
Lecture 16 - Encoder Decoder Models, Attention Mechanism
311
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1/60 CS7015 (Deep Learning) : Lecture 16 Encoder Decoder Models, Attention Mechanism Mitesh M. Khapra Department of Computer Science and Engineering Indian Institute of Technology Madras Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of Lecture 16 - Encoder Decoder Models, Attention Mechanism

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.1/60
CS7015 (Deep Learning) : Lecture 16Encoder Decoder Models, Attention Mechanism
Mitesh M. Khapra
Department of Computer Science and EngineeringIndian Institute of Technology Madras
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.2/60
Module 16.1: Introduction to Encoder Decoder Models
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modeling
Informally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth word
More formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNN
We will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.3/60
<GO>
U
s0
V
I
I
U
W
P(yt = j|yt−11 )yt
V
am
P(yt = j|yt−11 )yt
am
U
V
W
at
P(yt = j|yt−11 )yt
at
U
V
W
home
P(yt = j|yt−11 )yt
home
U
V
W
today
P(yt = j|yt−11 )yt
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We will start by revisiting theproblem of language modelingInformally, given ‘t − i’ words we areinterested in predicting the tth wordMore formally, given y1, y2, ..., yt−1 wewant to find
y∗ = argmax P(yt|y1, y2, ..., yt−1)
Let us see how we modelP(yt|y1, y2...yt−1) using a RNNWe will refer to P(yt|y1, y2...yt−1) byshorthand notation: P(yt|yt−1
1 )
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.4/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We are interested in
P(yt = j|y1, y2...yt−1)
where j ∈ V and V is the set of allvocabulary words
Using an RNN we compute this as
P(yt = j|yt−11 ) = softmax(Vst + c)j
In other words we compute
P(yt = j|yt−11 ) = P(yt = j|st)
= softmax(Vst + c)j
Notice that the recurrent connectionsensure that st has information aboutyt−11
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.4/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We are interested in
P(yt = j|y1, y2...yt−1)
where j ∈ V and V is the set of allvocabulary wordsUsing an RNN we compute this as
P(yt = j|yt−11 ) = softmax(Vst + c)j
In other words we compute
P(yt = j|yt−11 ) = P(yt = j|st)
= softmax(Vst + c)j
Notice that the recurrent connectionsensure that st has information aboutyt−11
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.4/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We are interested in
P(yt = j|y1, y2...yt−1)
where j ∈ V and V is the set of allvocabulary wordsUsing an RNN we compute this as
P(yt = j|yt−11 ) = softmax(Vst + c)j
In other words we compute
P(yt = j|yt−11 ) = P(yt = j|st)
= softmax(Vst + c)j
Notice that the recurrent connectionsensure that st has information aboutyt−11
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.4/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
We are interested in
P(yt = j|y1, y2...yt−1)
where j ∈ V and V is the set of allvocabulary wordsUsing an RNN we compute this as
P(yt = j|yt−11 ) = softmax(Vst + c)j
In other words we compute
P(yt = j|yt−11 ) = P(yt = j|st)
= softmax(Vst + c)j
Notice that the recurrent connectionsensure that st has information aboutyt−11
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.5/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
Data:
India, officially the Republicof India, is a country in SouthAsia. It is the seventh-largestcountry by area, .....
Data: All sentences from any largecorpus (say wikipedia)
Model:
st = σ(Wst−1 + Uxt + b)P(yt = j|yt−1
1 ) = softmax(Vst + c)j
Parameters: U,V,W, b, cLoss:
L (θ) =
T∑t=1
Lt(θ)
Lt(θ) = − log P(yt = ℓt|yt−11 )
where ℓt is the true word at time stept
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.5/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
Data:
India, officially the Republicof India, is a country in SouthAsia. It is the seventh-largestcountry by area, .....
Data: All sentences from any largecorpus (say wikipedia)Model:
st = σ(Wst−1 + Uxt + b)P(yt = j|yt−1
1 ) = softmax(Vst + c)j
Parameters: U,V,W, b, cLoss:
L (θ) =
T∑t=1
Lt(θ)
Lt(θ) = − log P(yt = ℓt|yt−11 )
where ℓt is the true word at time stept
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.5/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
Data:
India, officially the Republicof India, is a country in SouthAsia. It is the seventh-largestcountry by area, .....
Data: All sentences from any largecorpus (say wikipedia)Model:
st = σ(Wst−1 + Uxt + b)P(yt = j|yt−1
1 ) = softmax(Vst + c)j
Parameters: U,V,W, b, cLoss:
L (θ) =
T∑t=1
Lt(θ)
Lt(θ) = − log P(yt = ℓt|yt−11 )
where ℓt is the true word at time stept
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.5/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
Data:
India, officially the Republicof India, is a country in SouthAsia. It is the seventh-largestcountry by area, .....
Data: All sentences from any largecorpus (say wikipedia)Model:
st = σ(Wst−1 + Uxt + b)P(yt = j|yt−1
1 ) = softmax(Vst + c)j
Parameters: U,V,W, b, c
Loss:
L (θ) =
T∑t=1
Lt(θ)
Lt(θ) = − log P(yt = ℓt|yt−11 )
where ℓt is the true word at time stept
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.5/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
Data:
India, officially the Republicof India, is a country in SouthAsia. It is the seventh-largestcountry by area, .....
Data: All sentences from any largecorpus (say wikipedia)Model:
st = σ(Wst−1 + Uxt + b)P(yt = j|yt−1
1 ) = softmax(Vst + c)j
Parameters: U,V,W, b, cLoss:
L (θ) =
T∑t=1
Lt(θ)
Lt(θ) = − log P(yt = ℓt|yt−11 )
where ℓt is the true word at time stept
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.5/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
Data:
India, officially the Republicof India, is a country in SouthAsia. It is the seventh-largestcountry by area, .....
Data: All sentences from any largecorpus (say wikipedia)Model:
st = σ(Wst−1 + Uxt + b)P(yt = j|yt−1
1 ) = softmax(Vst + c)j
Parameters: U,V,W, b, cLoss:
L (θ) =
T∑t=1
Lt(θ)
Lt(θ) = − log P(yt = ℓt|yt−11 )
where ℓt is the true word at time stept
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?
It is simply the word that wepredicted at the previous time stepIn general
st = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?
It is simply the word that wepredicted at the previous time stepIn general
st = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?It is simply the word that wepredicted at the previous time step
In generalst = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?It is simply the word that wepredicted at the previous time step
In generalst = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?It is simply the word that wepredicted at the previous time step
In generalst = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?It is simply the word that wepredicted at the previous time step
In generalst = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?It is simply the word that wepredicted at the previous time step
In generalst = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?It is simply the word that wepredicted at the previous time stepIn general
st = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?It is simply the word that wepredicted at the previous time stepIn general
st = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?It is simply the word that wepredicted at the previous time stepIn general
st = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabulary
In practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.6/60
<GO>
o/p: I
00001
am
00100
at
01000
home
00001
today
00010
<stop>
01000
st
What is the input at each time step?It is simply the word that wepredicted at the previous time stepIn general
st = RNN(st−1, xt)
Let j be the index of the wordwhich has been assigned the maxprobability at time step t − 1
xt = e(vj)
xt is essentially a one-hot vector(e(vj))representing the jth word in thevocabularyIn practice, instead of one hotrepresentation we use a pre-trainedword embedding of the jth word
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.7/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
Notice that s0 is not computed butjust randomly initialized
We learn it along with the otherparameters of RNN (or LSTM orGRU)We will return back to this later
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.7/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
Notice that s0 is not computed butjust randomly initializedWe learn it along with the otherparameters of RNN (or LSTM orGRU)
We will return back to this later
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.7/60
<GO>
U
s0
V
I
I
U
W
V
am
am
U
V
W
at
at
U
V
W
home
home
U
V
W
today
today
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
Notice that s0 is not computed butjust randomly initializedWe learn it along with the otherparameters of RNN (or LSTM orGRU)We will return back to this later
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.8/60
st = σ(U xt + Wst−1 + b)st
ht
ht
st = RNN( st−1, xt)
st = σ(W(ot ⊙ st−1) + Uxt + b)st = it ⊙ st−1 + (1− it)⊙ st
ht
st = GRU( st−1, xt)
st = σ(W ht−1 + Uxt + b)st = ft ⊙ st−1 + it ⊙ st
ht = ot ⊙ σ(st)
ht, st = LSTM( ht−1, st−1, xt)
Before moving on we will see a compact way of writing the function computedby RNN, GRU and LSTM
We will use these notations going forward
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.8/60
st = σ(U xt + Wst−1 + b)st
ht
ht
st = RNN( st−1, xt)
st = σ(W(ot ⊙ st−1) + Uxt + b)st = it ⊙ st−1 + (1− it)⊙ st
ht
st = GRU( st−1, xt)
st = σ(W ht−1 + Uxt + b)st = ft ⊙ st−1 + it ⊙ st
ht = ot ⊙ σ(st)
ht, st = LSTM( ht−1, st−1, xt)
Before moving on we will see a compact way of writing the function computedby RNN, GRU and LSTM
We will use these notations going forward
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.8/60
st = σ(U xt + Wst−1 + b)st
ht
ht
st = RNN( st−1, xt)
st = σ(W(ot ⊙ st−1) + Uxt + b)st = it ⊙ st−1 + (1− it)⊙ st
ht
st = GRU( st−1, xt)
st = σ(W ht−1 + Uxt + b)st = ft ⊙ st−1 + it ⊙ st
ht = ot ⊙ σ(st)
ht, st = LSTM( ht−1, st−1, xt)
Before moving on we will see a compact way of writing the function computedby RNN, GRU and LSTM
We will use these notations going forward
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.8/60
st = σ(U xt + Wst−1 + b)st
ht
ht
st = RNN( st−1, xt)
st = σ(W(ot ⊙ st−1) + Uxt + b)st = it ⊙ st−1 + (1− it)⊙ st
ht
st = GRU( st−1, xt)
st = σ(W ht−1 + Uxt + b)st = ft ⊙ st−1 + it ⊙ st
ht = ot ⊙ σ(st)
ht, st = LSTM( ht−1, st−1, xt)
Before moving on we will see a compact way of writing the function computedby RNN, GRU and LSTM
We will use these notations going forward
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.8/60
st = σ(U xt + Wst−1 + b)st
ht
ht
st = RNN( st−1, xt)
st = σ(W(ot ⊙ st−1) + Uxt + b)st = it ⊙ st−1 + (1− it)⊙ st
ht
st = GRU( st−1, xt)
st = σ(W ht−1 + Uxt + b)st = ft ⊙ st−1 + it ⊙ st
ht = ot ⊙ σ(st)
ht, st = LSTM( ht−1, st−1, xt)
Before moving on we will see a compact way of writing the function computedby RNN, GRU and LSTM
We will use these notations going forward
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.8/60
st = σ(U xt + Wst−1 + b)st
ht
ht
st = RNN( st−1, xt)
st = σ(W(ot ⊙ st−1) + Uxt + b)st = it ⊙ st−1 + (1− it)⊙ st
ht
st = GRU( st−1, xt)
st = σ(W ht−1 + Uxt + b)st = ft ⊙ st−1 + it ⊙ st
ht = ot ⊙ σ(st)
ht, st = LSTM( ht−1, st−1, xt)
Before moving on we will see a compact way of writing the function computedby RNN, GRU and LSTM
We will use these notations going forward
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.8/60
st = σ(U xt + Wst−1 + b)st
ht
ht
st = RNN( st−1, xt)
st = σ(W(ot ⊙ st−1) + Uxt + b)st = it ⊙ st−1 + (1− it)⊙ st
ht
st = GRU( st−1, xt)
st = σ(W ht−1 + Uxt + b)st = ft ⊙ st−1 + it ⊙ st
ht = ot ⊙ σ(st)
ht, st = LSTM( ht−1, st−1, xt)
Before moving on we will see a compact way of writing the function computedby RNN, GRU and LSTM
We will use these notations going forward
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.8/60
st = σ(U xt + Wst−1 + b)st
ht
ht
st = RNN( st−1, xt)
st = σ(W(ot ⊙ st−1) + Uxt + b)st = it ⊙ st−1 + (1− it)⊙ st
ht
st = GRU( st−1, xt)
st = σ(W ht−1 + Uxt + b)st = ft ⊙ st−1 + it ⊙ st
ht = ot ⊙ σ(st)
ht, st = LSTM( ht−1, st−1, xt)
Before moving on we will see a compact way of writing the function computedby RNN, GRU and LSTMWe will use these notations going forward
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?We are now interested in P(yt|yt−1
1 , I)instead of P(yt|yt−1
1 ) where I is animageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswords
What if we want to generate asentence given an image?We are now interested in P(yt|yt−1
1 , I)instead of P(yt|yt−1
1 ) where I is animageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?
We are now interested in P(yt|yt−11 , I)
instead of P(yt|yt−11 ) where I is an
imageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?
We are now interested in P(yt|yt−11 , I)
instead of P(yt|yt−11 ) where I is an
imageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?
We are now interested in P(yt|yt−11 , I)
instead of P(yt|yt−11 ) where I is an
imageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?
We are now interested in P(yt|yt−11 , I)
instead of P(yt|yt−11 ) where I is an
imageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?
We are now interested in P(yt|yt−11 , I)
instead of P(yt|yt−11 ) where I is an
imageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?
We are now interested in P(yt|yt−11 , I)
instead of P(yt|yt−11 ) where I is an
imageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?
We are now interested in P(yt|yt−11 , I)
instead of P(yt|yt−11 ) where I is an
imageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?
We are now interested in P(yt|yt−11 , I)
instead of P(yt|yt−11 ) where I is an
imageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?We are now interested in P(yt|yt−1
1 , I)instead of P(yt|yt−1
1 ) where I is animage
Notice that P(yt|yt−11 , I) is again a
conditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.9/60
A man throwinga frisbee in a park
<Go>
U
s0
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 )
So far we have seen how to model theconditional probability distributionP(yt|yt−1
1 )
More informally, we have seen howto generate a sentence given previouswordsWhat if we want to generate asentence given an image?We are now interested in P(yt|yt−1
1 , I)instead of P(yt|yt−1
1 ) where I is animageNotice that P(yt|yt−1
1 , I) is again aconditional distribution
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.10/60
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Earlier we modeled P(yt|yt−11 ) as
P(yt|yt−11 ) = P(yt = j|st)
Where st was a state capturing all theprevious wordsWe could now model P(yt = j|yt−1
1 , I)as P(yt = j|st, fc7(I))where fc7(I) is the representationobtained from the fc7 layer of animage
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.10/60
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Earlier we modeled P(yt|yt−11 ) as
P(yt|yt−11 ) = P(yt = j|st)
Where st was a state capturing all theprevious words
We could now model P(yt = j|yt−11 , I)
as P(yt = j|st, fc7(I))where fc7(I) is the representationobtained from the fc7 layer of animage
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.10/60
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Earlier we modeled P(yt|yt−11 ) as
P(yt|yt−11 ) = P(yt = j|st)
Where st was a state capturing all theprevious wordsWe could now model P(yt = j|yt−1
1 , I)as P(yt = j|st, fc7(I))
where fc7(I) is the representationobtained from the fc7 layer of animage
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.10/60
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Earlier we modeled P(yt|yt−11 ) as
P(yt|yt−11 ) = P(yt = j|st)
Where st was a state capturing all theprevious wordsWe could now model P(yt = j|yt−1
1 , I)as P(yt = j|st, fc7(I))where fc7(I) is the representationobtained from the fc7 layer of animage
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.11/60
There are many ways of making P(yt = j) conditional on fc7(I)
Let us see two such options
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.11/60
There are many ways of making P(yt = j) conditional on fc7(I)Let us see two such options
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.12/60
Option 1
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xT
sT
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Option 1: Set s0 = fc7(I)
Now s0 and hence all subsequent st’sdepend on fc7(I)We can thus say that P(yt = j)depends on fc7(I)In other words, we are computingP(yt = j|st, fc7(I))
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.12/60
Option 1
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xT
sT
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Option 1: Set s0 = fc7(I)Now s0 and hence all subsequent st’sdepend on fc7(I)
We can thus say that P(yt = j)depends on fc7(I)In other words, we are computingP(yt = j|st, fc7(I))
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.12/60
Option 1
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xT
sT
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Option 1: Set s0 = fc7(I)Now s0 and hence all subsequent st’sdepend on fc7(I)We can thus say that P(yt = j)depends on fc7(I)
In other words, we are computingP(yt = j|st, fc7(I))
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.12/60
Option 1
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xT
sT
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Option 1: Set s0 = fc7(I)Now s0 and hence all subsequent st’sdepend on fc7(I)We can thus say that P(yt = j)depends on fc7(I)In other words, we are computingP(yt = j|st, fc7(I))
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.13/60
Option 2
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Option 2: Another more explicitway of doing this is to compute
st = RNN(st−1, [xt, fc7(I))]
In other words we are explicitly usingfc7(I) to compute st and henceP(yt = j)You could think of other ways ofconditioning P(yt = j) on fc7
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.13/60
Option 2
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Option 2: Another more explicitway of doing this is to compute
st = RNN(st−1, [xt, fc7(I))]
In other words we are explicitly usingfc7(I) to compute st and henceP(yt = j)
You could think of other ways ofconditioning P(yt = j) on fc7
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.13/60
Option 2
CNN
s0 = fc7(I)
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Option 2: Another more explicitway of doing this is to compute
st = RNN(st−1, [xt, fc7(I))]
In other words we are explicitly usingfc7(I) to compute st and henceP(yt = j)You could think of other ways ofconditioning P(yt = j) on fc7
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.14/60
Encoder
CNN
h0
Decoder
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Let us look at the fullarchitecture
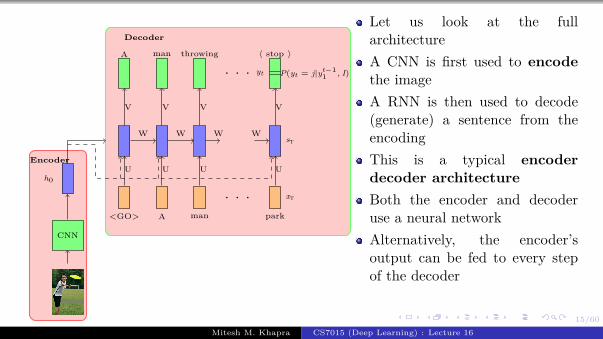
A CNN is first used to encodethe imageA RNN is then used to decode(generate) a sentence from theencodingThis is a typical encoderdecoder architectureBoth the encoder and decoderuse a neural network
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.14/60
Encoder
CNN
h0
Decoder
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Let us look at the fullarchitectureA CNN is first used to encodethe image
A RNN is then used to decode(generate) a sentence from theencodingThis is a typical encoderdecoder architectureBoth the encoder and decoderuse a neural network
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.14/60
Encoder
CNN
h0
Decoder
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Let us look at the fullarchitectureA CNN is first used to encodethe imageA RNN is then used to decode(generate) a sentence from theencoding
This is a typical encoderdecoder architectureBoth the encoder and decoderuse a neural network
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.14/60
Encoder
CNN
h0
Decoder
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Let us look at the fullarchitectureA CNN is first used to encodethe imageA RNN is then used to decode(generate) a sentence from theencodingThis is a typical encoderdecoder architecture
Both the encoder and decoderuse a neural network
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.14/60
Encoder
CNN
h0
Decoder
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Let us look at the fullarchitectureA CNN is first used to encodethe imageA RNN is then used to decode(generate) a sentence from theencodingThis is a typical encoderdecoder architectureBoth the encoder and decoderuse a neural network
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.15/60
Encoder
CNN
h0
Decoder
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing
. . .
W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , I)
Let us look at the fullarchitectureA CNN is first used to encodethe imageA RNN is then used to decode(generate) a sentence from theencodingThis is a typical encoderdecoder architectureBoth the encoder and decoderuse a neural networkAlternatively, the encoder’soutput can be fed to every stepof the decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.16/60
Module 16.2: Applications of Encoder Decoder models
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.17/60
For all these applications we will try to answer the following questions
What kind of a network can we use to encode the input(s)? (What is anappropriate encoder?)What kind of a network can we use to decode the output? (What is anappropriate decoder?)What are the parameters of the model ?What is an appropriate loss function ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.17/60
For all these applications we will try to answer the following questionsWhat kind of a network can we use to encode the input(s)? (What is anappropriate encoder?)
What kind of a network can we use to decode the output? (What is anappropriate decoder?)What are the parameters of the model ?What is an appropriate loss function ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.17/60
For all these applications we will try to answer the following questionsWhat kind of a network can we use to encode the input(s)? (What is anappropriate encoder?)What kind of a network can we use to decode the output? (What is anappropriate decoder?)
What are the parameters of the model ?What is an appropriate loss function ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.17/60
For all these applications we will try to answer the following questionsWhat kind of a network can we use to encode the input(s)? (What is anappropriate encoder?)What kind of a network can we use to decode the output? (What is anappropriate decoder?)What are the parameters of the model ?
What is an appropriate loss function ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.17/60
For all these applications we will try to answer the following questionsWhat kind of a network can we use to encode the input(s)? (What is anappropriate encoder?)What kind of a network can we use to decode the output? (What is anappropriate decoder?)What are the parameters of the model ?What is an appropriate loss function ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.18/60
Encoder
Decoder Lt(θ) = − log P(yt = j|yt−11 , fc7 )
CNN
h0
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing . . .
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , fc7 )
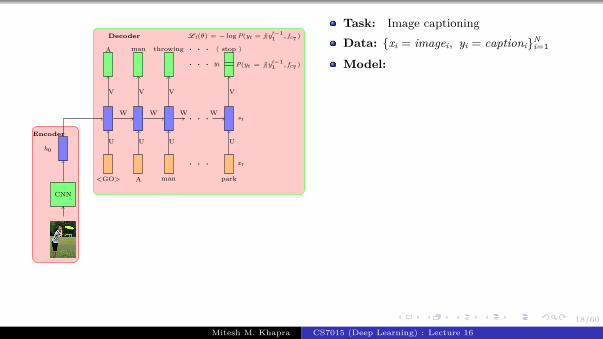
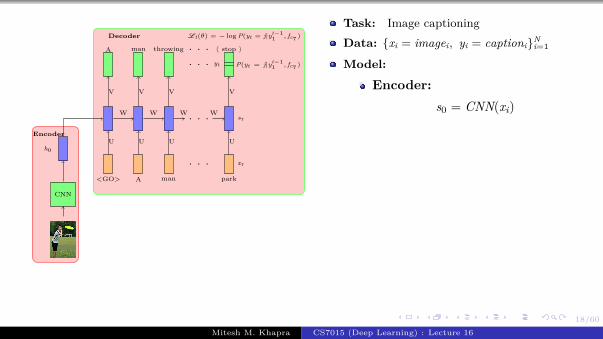
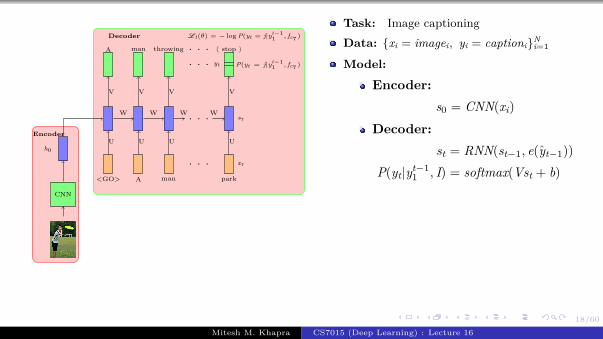
Task: Image captioning
Data: {xi = imagei, yi = captioni}Ni=1
Model:
Encoder:s0 = CNN(xi)
Decoder:st = RNN(st−1, e(yt−1))
P(yt|yt−11 , I) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Wconv, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , I)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.18/60
Encoder
Decoder Lt(θ) = − log P(yt = j|yt−11 , fc7 )
CNN
h0
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing . . .
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , fc7 )
Task: Image captioningData: {xi = imagei, yi = captioni}N
i=1
Model:
Encoder:s0 = CNN(xi)
Decoder:st = RNN(st−1, e(yt−1))
P(yt|yt−11 , I) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Wconv, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , I)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.18/60
Encoder
Decoder Lt(θ) = − log P(yt = j|yt−11 , fc7 )
CNN
h0
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing . . .
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , fc7 )
Task: Image captioningData: {xi = imagei, yi = captioni}N
i=1
Model:
Encoder:s0 = CNN(xi)
Decoder:st = RNN(st−1, e(yt−1))
P(yt|yt−11 , I) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Wconv, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , I)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.18/60
Encoder
Decoder Lt(θ) = − log P(yt = j|yt−11 , fc7 )
CNN
h0
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing . . .
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , fc7 )
Task: Image captioningData: {xi = imagei, yi = captioni}N
i=1
Model:Encoder:
s0 = CNN(xi)
Decoder:st = RNN(st−1, e(yt−1))
P(yt|yt−11 , I) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Wconv, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , I)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.18/60
Encoder
Decoder Lt(θ) = − log P(yt = j|yt−11 , fc7 )
CNN
h0
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing . . .
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , fc7 )
Task: Image captioningData: {xi = imagei, yi = captioni}N
i=1
Model:Encoder:
s0 = CNN(xi)
Decoder:st = RNN(st−1, e(yt−1))
P(yt|yt−11 , I) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Wconv, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , I)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.18/60
Encoder
Decoder Lt(θ) = − log P(yt = j|yt−11 , fc7 )
CNN
h0
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing . . .
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , fc7 )
Task: Image captioningData: {xi = imagei, yi = captioni}N
i=1
Model:Encoder:
s0 = CNN(xi)
Decoder:st = RNN(st−1, e(yt−1))
P(yt|yt−11 , I) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Wconv, b
Loss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , I)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.18/60
Encoder
Decoder Lt(θ) = − log P(yt = j|yt−11 , fc7 )
CNN
h0
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing . . .
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , fc7 )
Task: Image captioningData: {xi = imagei, yi = captioni}N
i=1
Model:Encoder:
s0 = CNN(xi)
Decoder:st = RNN(st−1, e(yt−1))
P(yt|yt−11 , I) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Wconv, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , I)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
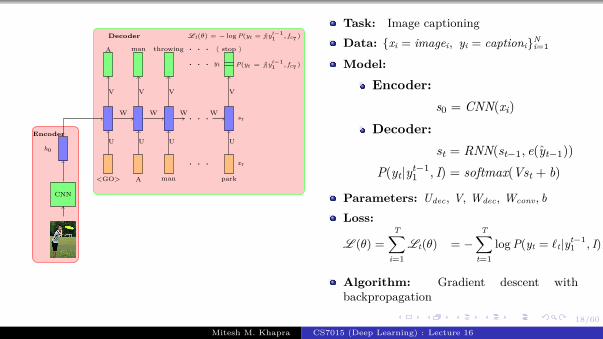
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.18/60
Encoder
Decoder Lt(θ) = − log P(yt = j|yt−11 , fc7 )
CNN
h0
<GO>
U
V
A
A
U
V
W
man
man
U
V
W
throwing . . .
. . .
. . .W
. . .
park
U
V
W
xt
st
yt
⟨ stop ⟩
P(yt = j|yt−11 , fc7 )
Task: Image captioningData: {xi = imagei, yi = captioni}N
i=1
Model:Encoder:
s0 = CNN(xi)
Decoder:st = RNN(st−1, e(yt−1))
P(yt|yt−11 , I) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Wconv, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , I)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailment
Data: {xi = premisei, yi = hypothesisi}Ni=1
Model (Option 1):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b
Loss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.19/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.20/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailment
Data: {xi = premisei, yi = hypothesisi}Ni=1
Model (Option 2):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, [hT, e(yt−1)])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.20/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 2):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, [hT, e(yt−1)])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.20/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 2):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, [hT, e(yt−1)])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.20/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 2):Encoder:
ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, [hT, e(yt−1)])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.20/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 2):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, [hT, e(yt−1)])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.20/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 2):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, [hT, e(yt−1)])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b
Loss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.20/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 2):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, [hT, e(yt−1)])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.20/60
i/p : It is raining outside
o/p : The ground is wet
x1
Iti/p:
x2
is
x3
raining
x4
outside
ht
<Go>
o/p:The
00001
The
ground
00100
ground
is
01000
is
wet
00001
wet
<STOP>
00010
st
Task: Textual entailmentData: {xi = premisei, yi = hypothesisi}N
i=1
Model (Option 2):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, [hT, e(yt−1)])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translation
Data: {xi = sourcei, yi = targeti}Ni=1
Model (Option 1):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b
Loss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
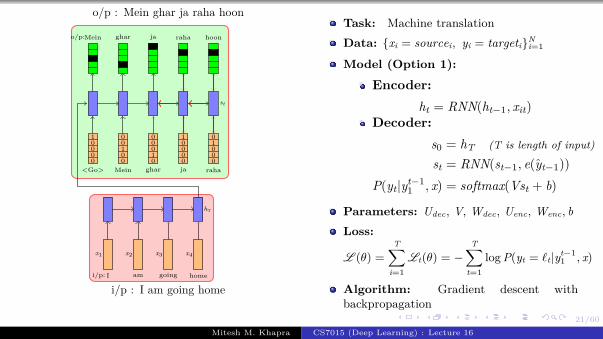
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
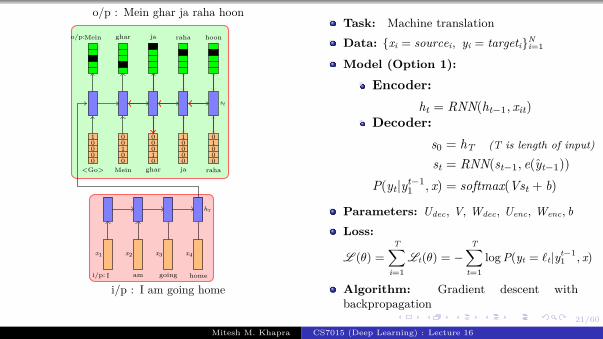
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
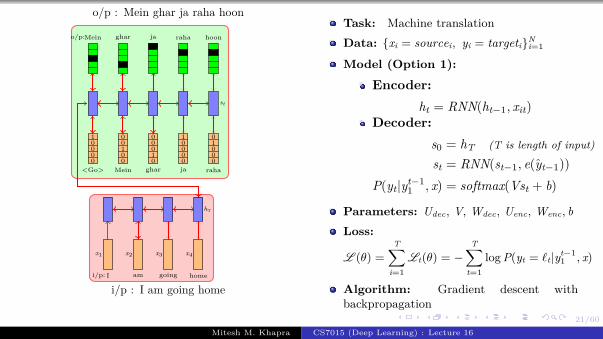
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.21/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.22/60
i/p : I am going home
o/p : Mein ghar ja raha hoon
x1
Ii/p:
x2
am
x3
going
x4
home
ht
<Go>
o/p:Mein
00001
Mein
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
st
Task: Machine translationData: {xi = sourcei, yi = targeti}N
i=1
Model (Option 2):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, [hT, e(yt−1)])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.23/60
i/p : I N D I A
o/p : š ' @ i y a
x1
Ii/p:
x2
N
x3
D
x4
I
x5
A
ht
<Go>
o/p: š
00001
š
'
00100
'
@
01000
@
i
00001
i
y
00010
y
a
00010
st
Task: Transliteration
Data: {xi = srcwordi, yi = tgtwordi}Ni=1
Model (Option 1):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.23/60
i/p : I N D I A
o/p : š ' @ i y a
x1
Ii/p:
x2
N
x3
D
x4
I
x5
A
ht
<Go>
o/p: š
00001
š
'
00100
'
@
01000
@
i
00001
i
y
00010
y
a
00010
st
Task: TransliterationData: {xi = srcwordi, yi = tgtwordi}N
i=1
Model (Option 1):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.23/60
i/p : I N D I A
o/p : š ' @ i y a
x1
Ii/p:
x2
N
x3
D
x4
I
x5
A
ht
<Go>
o/p: š
00001
š
'
00100
'
@
01000
@
i
00001
i
y
00010
y
a
00010
st
Task: TransliterationData: {xi = srcwordi, yi = tgtwordi}N
i=1
Model (Option 1):
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.23/60
i/p : I N D I A
o/p : š ' @ i y a
x1
Ii/p:
x2
N
x3
D
x4
I
x5
A
ht
<Go>
o/p: š
00001
š
'
00100
'
@
01000
@
i
00001
i
y
00010
y
a
00010
st
Task: TransliterationData: {xi = srcwordi, yi = tgtwordi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.23/60
i/p : I N D I A
o/p : š ' @ i y a
x1
Ii/p:
x2
N
x3
D
x4
I
x5
A
ht
<Go>
o/p: š
00001
š
'
00100
'
@
01000
@
i
00001
i
y
00010
y
a
00010
st
Task: TransliterationData: {xi = srcwordi, yi = tgtwordi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.23/60
i/p : I N D I A
o/p : š ' @ i y a
x1
Ii/p:
x2
N
x3
D
x4
I
x5
A
ht
<Go>
o/p: š
00001
š
'
00100
'
@
01000
@
i
00001
i
y
00010
y
a
00010
st
Task: TransliterationData: {xi = srcwordi, yi = tgtwordi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b
Loss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.23/60
i/p : I N D I A
o/p : š ' @ i y a
x1
Ii/p:
x2
N
x3
D
x4
I
x5
A
ht
<Go>
o/p: š
00001
š
'
00100
'
@
01000
@
i
00001
i
y
00010
y
a
00010
st
Task: TransliterationData: {xi = srcwordi, yi = tgtwordi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.23/60
i/p : I N D I A
o/p : š ' @ i y a
x1
Ii/p:
x2
N
x3
D
x4
I
x5
A
ht
<Go>
o/p: š
00001
š
'
00100
'
@
01000
@
i
00001
i
y
00010
y
a
00010
st
Task: TransliterationData: {xi = srcwordi, yi = tgtwordi}N
i=1
Model (Option 1):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
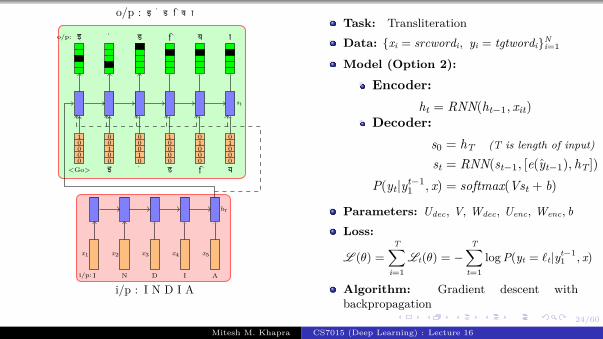
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.24/60
i/p : I N D I A
o/p : š ' @ i y a
x1
Ii/p:
x2
N
x3
D
x4
I
x5
A
ht
<Go>
o/p: š
00001
š
'
00100
'
@
01000
@
i
00001
i
y
00010
y
a
00010
st
Task: TransliterationData: {xi = srcwordi, yi = tgtwordi}N
i=1
Model (Option 2):Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, [e(yt−1), hT])
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.25/60
Question: Whatis the bird’s color
O/p: White
What is the bird’s color
CNN
s
ht hI
White
Task: Image Question Answeing
Data: {xi = {I, q}i, yi = Answeri}Ni=1
Model:
Encoder:hI = CNN(I), ht = RNN(ht−1, qit)
s = [hT; hI]
Decoder:P(y|q, I) = softmax(Vs + b)
Parameters: V, b, Uq, Wq, Wconv, bLoss:
L (θ) = − log P(y = ℓ|I, q)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.25/60
Question: Whatis the bird’s color
O/p: White
What is the bird’s color
CNN
s
ht hI
White
Task: Image Question AnsweingData: {xi = {I, q}i, yi = Answeri}N
i=1
Model:
Encoder:hI = CNN(I), ht = RNN(ht−1, qit)
s = [hT; hI]
Decoder:P(y|q, I) = softmax(Vs + b)
Parameters: V, b, Uq, Wq, Wconv, bLoss:
L (θ) = − log P(y = ℓ|I, q)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.25/60
Question: Whatis the bird’s color
O/p: White
What is the bird’s color
CNN
s
ht hI
White
Task: Image Question AnsweingData: {xi = {I, q}i, yi = Answeri}N
i=1
Model:
Encoder:hI = CNN(I), ht = RNN(ht−1, qit)
s = [hT; hI]
Decoder:P(y|q, I) = softmax(Vs + b)
Parameters: V, b, Uq, Wq, Wconv, bLoss:
L (θ) = − log P(y = ℓ|I, q)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.25/60
Question: Whatis the bird’s color
O/p: White
What is the bird’s color
CNN
s
ht hI
White
Task: Image Question AnsweingData: {xi = {I, q}i, yi = Answeri}N
i=1
Model:Encoder:hI = CNN(I), ht = RNN(ht−1, qit)
s = [hT; hI]
Decoder:P(y|q, I) = softmax(Vs + b)
Parameters: V, b, Uq, Wq, Wconv, bLoss:
L (θ) = − log P(y = ℓ|I, q)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.25/60
Question: Whatis the bird’s color
O/p: White
What is the bird’s color
CNN
s
ht hI
WhiteTask: Image Question AnsweingData: {xi = {I, q}i, yi = Answeri}N
i=1
Model:Encoder:hI = CNN(I), ht = RNN(ht−1, qit)
s = [hT; hI]
Decoder:P(y|q, I) = softmax(Vs + b)
Parameters: V, b, Uq, Wq, Wconv, bLoss:
L (θ) = − log P(y = ℓ|I, q)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
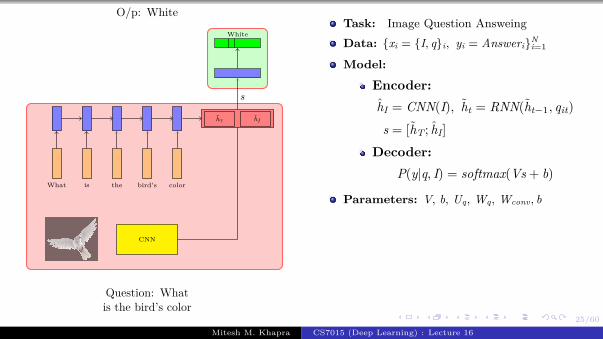
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.25/60
Question: Whatis the bird’s color
O/p: White
What is the bird’s color
CNN
s
ht hI
WhiteTask: Image Question AnsweingData: {xi = {I, q}i, yi = Answeri}N
i=1
Model:Encoder:hI = CNN(I), ht = RNN(ht−1, qit)
s = [hT; hI]
Decoder:P(y|q, I) = softmax(Vs + b)
Parameters: V, b, Uq, Wq, Wconv, b
Loss:L (θ) = − log P(y = ℓ|I, q)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.25/60
Question: Whatis the bird’s color
O/p: White
What is the bird’s color
CNN
s
ht hI
WhiteTask: Image Question AnsweingData: {xi = {I, q}i, yi = Answeri}N
i=1
Model:Encoder:hI = CNN(I), ht = RNN(ht−1, qit)
s = [hT; hI]
Decoder:P(y|q, I) = softmax(Vs + b)
Parameters: V, b, Uq, Wq, Wconv, bLoss:
L (θ) = − log P(y = ℓ|I, q)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
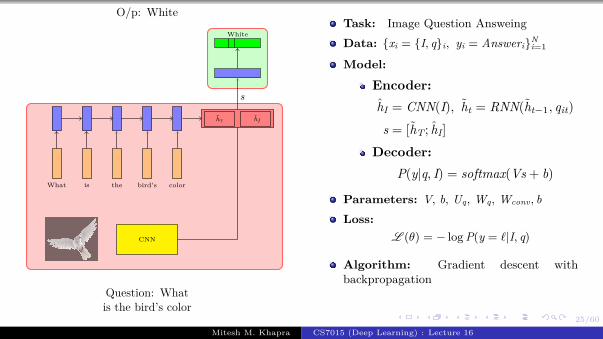
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.25/60
Question: Whatis the bird’s color
O/p: White
What is the bird’s color
CNN
s
ht hI
WhiteTask: Image Question AnsweingData: {xi = {I, q}i, yi = Answeri}N
i=1
Model:Encoder:hI = CNN(I), ht = RNN(ht−1, qit)
s = [hT; hI]
Decoder:P(y|q, I) = softmax(Vs + b)
Parameters: V, b, Uq, Wq, Wconv, bLoss:
L (θ) = − log P(y = ℓ|I, q)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.26/60
i/p : India beats Srilanka to win ICC WC 2011.Dhoni and Gambhir’s half centuries help beat SL
o/p : India wonthe world cup
Indiai/p: beats
. . .
. . .
. . .
. . .
. . .
. . . Srilanka
ht
c
<Go>
o/p:India
00001
India
won
00100
won
the
01000
the
world
00001
world
cup
00010
cup
<STOP>
00010
st
Task: Document Summarization
Data: {xi = Documenti, yi =Summaryi}N
i=1
Model:
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.26/60
i/p : India beats Srilanka to win ICC WC 2011.Dhoni and Gambhir’s half centuries help beat SL
o/p : India wonthe world cup
Indiai/p: beats
. . .
. . .
. . .
. . .
. . .
. . . Srilanka
ht
c
<Go>
o/p:India
00001
India
won
00100
won
the
01000
the
world
00001
world
cup
00010
cup
<STOP>
00010
st
Task: Document SummarizationData: {xi = Documenti, yi =Summaryi}N
i=1
Model:
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.26/60
i/p : India beats Srilanka to win ICC WC 2011.Dhoni and Gambhir’s half centuries help beat SL
o/p : India wonthe world cup
Indiai/p: beats
. . .
. . .
. . .
. . .
. . .
. . . Srilanka
ht
c
<Go>
o/p:India
00001
India
won
00100
won
the
01000
the
world
00001
world
cup
00010
cup
<STOP>
00010
st
Task: Document SummarizationData: {xi = Documenti, yi =Summaryi}N
i=1
Model:
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
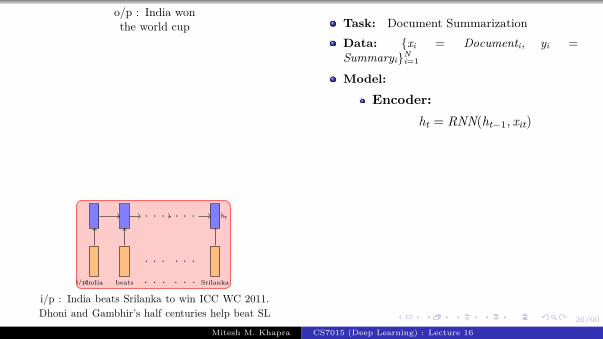
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.26/60
i/p : India beats Srilanka to win ICC WC 2011.Dhoni and Gambhir’s half centuries help beat SL
o/p : India wonthe world cup
Indiai/p: beats
. . .
. . .
. . .
. . .
. . .
. . . Srilanka
ht
c
<Go>
o/p:India
00001
India
won
00100
won
the
01000
the
world
00001
world
cup
00010
cup
<STOP>
00010
st
Task: Document SummarizationData: {xi = Documenti, yi =Summaryi}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)
Decoder:s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
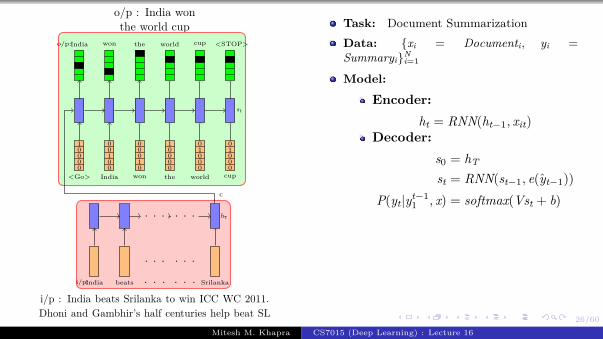
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.26/60
i/p : India beats Srilanka to win ICC WC 2011.Dhoni and Gambhir’s half centuries help beat SL
o/p : India wonthe world cup
Indiai/p: beats
. . .
. . .
. . .
. . .
. . .
. . . Srilanka
ht
c
<Go>
o/p:India
00001
India
won
00100
won
the
01000
the
world
00001
world
cup
00010
cup
<STOP>
00010
st
Task: Document SummarizationData: {xi = Documenti, yi =Summaryi}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
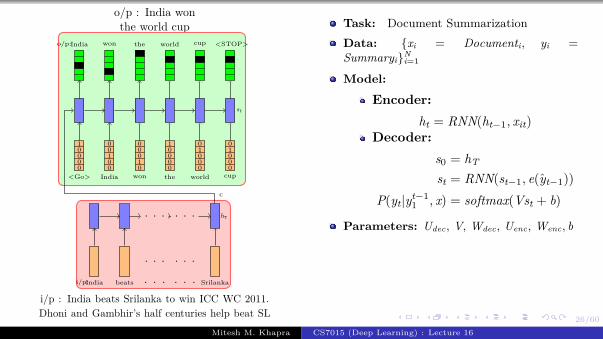
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.26/60
i/p : India beats Srilanka to win ICC WC 2011.Dhoni and Gambhir’s half centuries help beat SL
o/p : India wonthe world cup
Indiai/p: beats
. . .
. . .
. . .
. . .
. . .
. . . Srilanka
ht
c
<Go>
o/p:India
00001
India
won
00100
won
the
01000
the
world
00001
world
cup
00010
cup
<STOP>
00010
st
Task: Document SummarizationData: {xi = Documenti, yi =Summaryi}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b
Loss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.26/60
i/p : India beats Srilanka to win ICC WC 2011.Dhoni and Gambhir’s half centuries help beat SL
o/p : India wonthe world cup
Indiai/p: beats
. . .
. . .
. . .
. . .
. . .
. . . Srilanka
ht
c
<Go>
o/p:India
00001
India
won
00100
won
the
01000
the
world
00001
world
cup
00010
cup
<STOP>
00010
st
Task: Document SummarizationData: {xi = Documenti, yi =Summaryi}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.26/60
i/p : India beats Srilanka to win ICC WC 2011.Dhoni and Gambhir’s half centuries help beat SL
o/p : India wonthe world cup
Indiai/p: beats
. . .
. . .
. . .
. . .
. . .
. . . Srilanka
ht
c
<Go>
o/p:India
00001
India
won
00100
won
the
01000
the
world
00001
world
cup
00010
cup
<STOP>
00010
st
Task: Document SummarizationData: {xi = Documenti, yi =Summaryi}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.27/60
. . .
o/p : A man walking on a rope
CNN CNN
. . .
. . .
. . .
. . .
CNN
A man walking on a rope
Task: Video Captioning
Data: {xi = videoi, yi = desci}Ni=1
Model:
Encoder:ht = RNN(ht−1,CNN(xit))
Decoder:s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, Wdec, V, b, Wconv, Uenc,Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.27/60
. . .
o/p : A man walking on a rope
CNN CNN
. . .
. . .
. . .
. . .
CNN
A man walking on a rope
Task: Video CaptioningData: {xi = videoi, yi = desci}N
i=1
Model:
Encoder:ht = RNN(ht−1,CNN(xit))
Decoder:s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, Wdec, V, b, Wconv, Uenc,Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.27/60
. . .
o/p : A man walking on a rope
CNN CNN
. . .
. . .
. . .
. . .
CNN
A man walking on a rope
Task: Video CaptioningData: {xi = videoi, yi = desci}N
i=1
Model:
Encoder:ht = RNN(ht−1,CNN(xit))
Decoder:s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, Wdec, V, b, Wconv, Uenc,Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.27/60
. . .
o/p : A man walking on a rope
CNN CNN
. . .
. . .
. . .
. . .
CNN
A man walking on a rope
Task: Video CaptioningData: {xi = videoi, yi = desci}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))
Decoder:s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, Wdec, V, b, Wconv, Uenc,Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
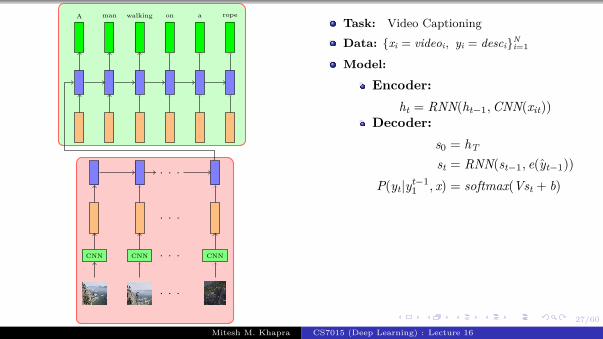
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.27/60
. . .
o/p : A man walking on a rope
CNN CNN
. . .
. . .
. . .
. . .
CNN
A man walking on a ropeTask: Video CaptioningData: {xi = videoi, yi = desci}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))Decoder:
s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, Wdec, V, b, Wconv, Uenc,Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.27/60
. . .
o/p : A man walking on a rope
CNN CNN
. . .
. . .
. . .
. . .
CNN
A man walking on a ropeTask: Video CaptioningData: {xi = videoi, yi = desci}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))Decoder:
s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, Wdec, V, b, Wconv, Uenc,Wenc, b
Loss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
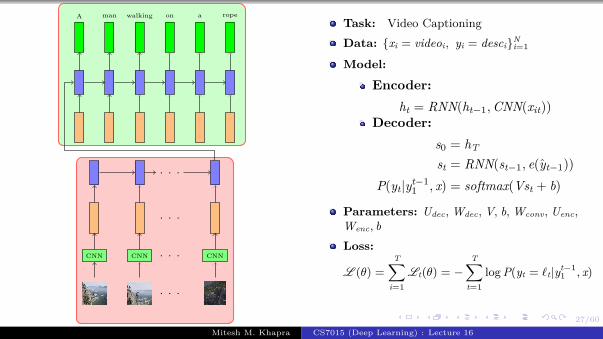
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.27/60
. . .
o/p : A man walking on a rope
CNN CNN
. . .
. . .
. . .
. . .
CNN
A man walking on a ropeTask: Video CaptioningData: {xi = videoi, yi = desci}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))Decoder:
s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, Wdec, V, b, Wconv, Uenc,Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.27/60
. . .
o/p : A man walking on a rope
CNN CNN
. . .
. . .
. . .
. . .
CNN
A man walking on a ropeTask: Video CaptioningData: {xi = videoi, yi = desci}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))Decoder:
s0 = hT
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, Wdec, V, b, Wconv, Uenc,Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.28/60
. . .
o/p: Surya Namaskar
CNN CNN
. . .
. . .
. . .
. . .
CNN
Suryanamaskar
Task: Video Classification
Data: {xi = Videoi, yi = Activityi}Ni=1
Model:
Encoder:ht = RNN(ht−1,CNN(xit))
Decoder:s = hT
P(y|I) = softmax(Vs + b)
Parameters: V, b, Wconv, Uenc, Wenc, bLoss:
L (θ) = − log P(y = ℓ|Video)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.28/60
. . .
o/p: Surya Namaskar
CNN CNN
. . .
. . .
. . .
. . .
CNN
Suryanamaskar
Task: Video ClassificationData: {xi = Videoi, yi = Activityi}N
i=1
Model:
Encoder:ht = RNN(ht−1,CNN(xit))
Decoder:s = hT
P(y|I) = softmax(Vs + b)
Parameters: V, b, Wconv, Uenc, Wenc, bLoss:
L (θ) = − log P(y = ℓ|Video)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.28/60
. . .
o/p: Surya Namaskar
CNN CNN
. . .
. . .
. . .
. . .
CNN
Suryanamaskar
Task: Video ClassificationData: {xi = Videoi, yi = Activityi}N
i=1
Model:
Encoder:ht = RNN(ht−1,CNN(xit))
Decoder:s = hT
P(y|I) = softmax(Vs + b)
Parameters: V, b, Wconv, Uenc, Wenc, bLoss:
L (θ) = − log P(y = ℓ|Video)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
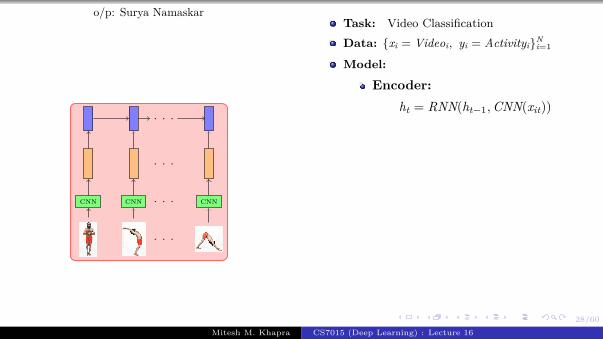
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.28/60
. . .
o/p: Surya Namaskar
CNN CNN
. . .
. . .
. . .
. . .
CNN
Suryanamaskar
Task: Video ClassificationData: {xi = Videoi, yi = Activityi}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))
Decoder:s = hT
P(y|I) = softmax(Vs + b)
Parameters: V, b, Wconv, Uenc, Wenc, bLoss:
L (θ) = − log P(y = ℓ|Video)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.28/60
. . .
o/p: Surya Namaskar
CNN CNN
. . .
. . .
. . .
. . .
CNN
SuryanamaskarTask: Video ClassificationData: {xi = Videoi, yi = Activityi}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))Decoder:
s = hT
P(y|I) = softmax(Vs + b)
Parameters: V, b, Wconv, Uenc, Wenc, bLoss:
L (θ) = − log P(y = ℓ|Video)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.28/60
. . .
o/p: Surya Namaskar
CNN CNN
. . .
. . .
. . .
. . .
CNN
SuryanamaskarTask: Video ClassificationData: {xi = Videoi, yi = Activityi}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))Decoder:
s = hT
P(y|I) = softmax(Vs + b)
Parameters: V, b, Wconv, Uenc, Wenc, b
Loss:L (θ) = − log P(y = ℓ|Video)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.28/60
. . .
o/p: Surya Namaskar
CNN CNN
. . .
. . .
. . .
. . .
CNN
SuryanamaskarTask: Video ClassificationData: {xi = Videoi, yi = Activityi}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))Decoder:
s = hT
P(y|I) = softmax(Vs + b)
Parameters: V, b, Wconv, Uenc, Wenc, bLoss:
L (θ) = − log P(y = ℓ|Video)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.28/60
. . .
o/p: Surya Namaskar
CNN CNN
. . .
. . .
. . .
. . .
CNN
SuryanamaskarTask: Video ClassificationData: {xi = Videoi, yi = Activityi}N
i=1
Model:Encoder:
ht = RNN(ht−1,CNN(xit))Decoder:
s = hT
P(y|I) = softmax(Vs + b)
Parameters: V, b, Wconv, Uenc, Wenc, bLoss:
L (θ) = − log P(y = ℓ|Video)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.29/60
i/p: How are you
o/p: I am fine
x1
Howi/p:
x2
are
x3
you
ht
c
<Go>
o/p: I
00001
I
am
00100
am
fine
01000
fine
<STOP>
st
00001
Task: Dialog
Data: {xi = Utterancei, yi =Responsei}N
i=1
Model:
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.29/60
i/p: How are you
o/p: I am fine
x1
Howi/p:
x2
are
x3
you
ht
c
<Go>
o/p: I
00001
I
am
00100
am
fine
01000
fine
<STOP>
st
00001
Task: DialogData: {xi = Utterancei, yi =Responsei}N
i=1
Model:
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.29/60
i/p: How are you
o/p: I am fine
x1
Howi/p:
x2
are
x3
you
ht
c
<Go>
o/p: I
00001
I
am
00100
am
fine
01000
fine
<STOP>
st
00001
Task: DialogData: {xi = Utterancei, yi =Responsei}N
i=1
Model:
Encoder:ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
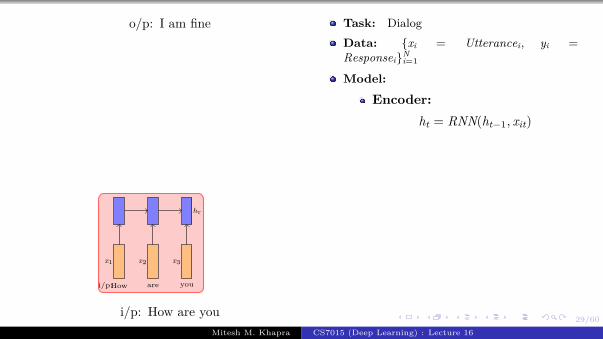
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.29/60
i/p: How are you
o/p: I am fine
x1
Howi/p:
x2
are
x3
you
ht
c
<Go>
o/p: I
00001
I
am
00100
am
fine
01000
fine
<STOP>
st
00001
Task: DialogData: {xi = Utterancei, yi =Responsei}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)
Decoder:s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.29/60
i/p: How are you
o/p: I am fine
x1
Howi/p:
x2
are
x3
you
ht
c
<Go>
o/p: I
00001
I
am
00100
am
fine
01000
fine
<STOP>
st
00001
Task: DialogData: {xi = Utterancei, yi =Responsei}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.29/60
i/p: How are you
o/p: I am fine
x1
Howi/p:
x2
are
x3
you
ht
c
<Go>
o/p: I
00001
I
am
00100
am
fine
01000
fine
<STOP>
st
00001
Task: DialogData: {xi = Utterancei, yi =Responsei}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b
Loss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.29/60
i/p: How are you
o/p: I am fine
x1
Howi/p:
x2
are
x3
you
ht
c
<Go>
o/p: I
00001
I
am
00100
am
fine
01000
fine
<STOP>
st
00001
Task: DialogData: {xi = Utterancei, yi =Responsei}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
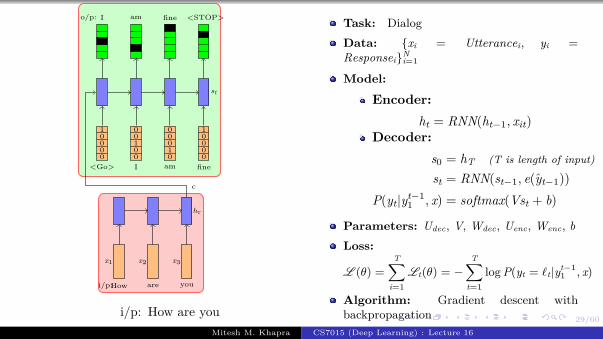
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.29/60
i/p: How are you
o/p: I am fine
x1
Howi/p:
x2
are
x3
you
ht
c
<Go>
o/p: I
00001
I
am
00100
am
fine
01000
fine
<STOP>
st
00001
Task: DialogData: {xi = Utterancei, yi =Responsei}N
i=1
Model:Encoder:
ht = RNN(ht−1, xit)Decoder:
s0 = hT (T is length of input)
st = RNN(st−1, e(yt−1))
P(yt|yt−11 , x) = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, bLoss:
L (θ) =
T∑i=1
Lt(θ) = −T∑
t=1
log P(yt = ℓt|yt−11 , x)
Algorithm: Gradient descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.30/60
And the list continues ...
Try picking a problem from your domain and see if you can model it using theencoder decoder paradigmEncoder decoder models can be made even more expressive by adding an“attention” mechanismWe will first motivate the need for this and then explain how to model it
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.30/60
And the list continues ...Try picking a problem from your domain and see if you can model it using theencoder decoder paradigm
Encoder decoder models can be made even more expressive by adding an“attention” mechanismWe will first motivate the need for this and then explain how to model it
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.30/60
And the list continues ...Try picking a problem from your domain and see if you can model it using theencoder decoder paradigmEncoder decoder models can be made even more expressive by adding an“attention” mechanism
We will first motivate the need for this and then explain how to model it
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.30/60
And the list continues ...Try picking a problem from your domain and see if you can model it using theencoder decoder paradigmEncoder decoder models can be made even more expressive by adding an“attention” mechanismWe will first motivate the need for this and then explain how to model it
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.31/60
Module 16.3: Attention Mechanism
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.32/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us motivate the task of attention withthe help of MT
The encoder reads the sentences only onceand encodes itAt each timestep the decoder uses thisembedding to produce a new wordIs this how humans translate a sentence ?
Not really!
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.32/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us motivate the task of attention withthe help of MTThe encoder reads the sentences only onceand encodes it
At each timestep the decoder uses thisembedding to produce a new wordIs this how humans translate a sentence ?
Not really!
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
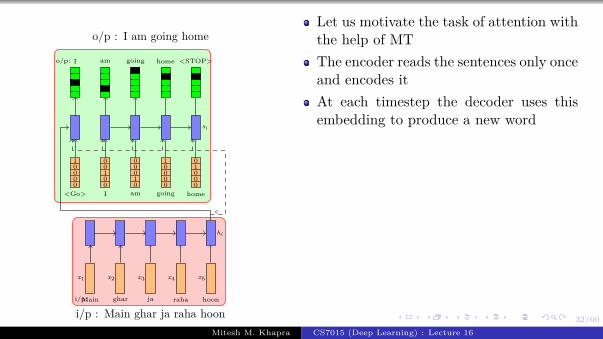
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.32/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us motivate the task of attention withthe help of MTThe encoder reads the sentences only onceand encodes itAt each timestep the decoder uses thisembedding to produce a new word
Is this how humans translate a sentence ?
Not really!
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
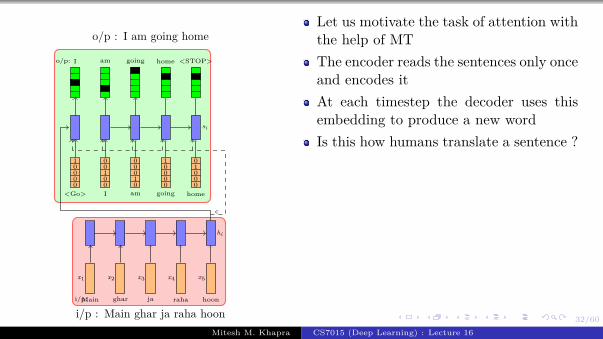
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.32/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us motivate the task of attention withthe help of MTThe encoder reads the sentences only onceand encodes itAt each timestep the decoder uses thisembedding to produce a new wordIs this how humans translate a sentence ?
Not really!
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.32/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us motivate the task of attention withthe help of MTThe encoder reads the sentences only onceand encodes itAt each timestep the decoder uses thisembedding to produce a new wordIs this how humans translate a sentence ?Not really!
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.33/60
o/p : I am going home
t1 : [ 1 0 0 0 0 ]t2 : [ 0 0 0 0 1 ]t3 : [ 0 0 0.5 0.5 0 ]t4 : [ 0 1 0 0 0 ]
i/p : Main ghar ja raha hoon
Humans try to produce each word inthe output by focusing only on certainwords in the input
Essentially at each time step we comeup with a distribution on the inputwordsThis distribution tells us how muchattention to pay to each input wordsat each time stepIdeally, at each time-step we shouldfeed only this relevant information(i.e. encodings of relevant words) tothe decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.33/60
o/p : I am going home
t1 : [ 1 0 0 0 0 ]t2 : [ 0 0 0 0 1 ]t3 : [ 0 0 0.5 0.5 0 ]t4 : [ 0 1 0 0 0 ]
i/p : Main ghar ja raha hoon
Humans try to produce each word inthe output by focusing only on certainwords in the inputEssentially at each time step we comeup with a distribution on the inputwords
This distribution tells us how muchattention to pay to each input wordsat each time stepIdeally, at each time-step we shouldfeed only this relevant information(i.e. encodings of relevant words) tothe decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.33/60
o/p : I am going homet1 : [ 1 0 0 0 0 ]
t2 : [ 0 0 0 0 1 ]t3 : [ 0 0 0.5 0.5 0 ]t4 : [ 0 1 0 0 0 ]
i/p : Main ghar ja raha hoon
Humans try to produce each word inthe output by focusing only on certainwords in the inputEssentially at each time step we comeup with a distribution on the inputwords
This distribution tells us how muchattention to pay to each input wordsat each time stepIdeally, at each time-step we shouldfeed only this relevant information(i.e. encodings of relevant words) tothe decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.33/60
o/p : I am going homet1 : [ 1 0 0 0 0 ]t2 : [ 0 0 0 0 1 ]
t3 : [ 0 0 0.5 0.5 0 ]t4 : [ 0 1 0 0 0 ]
i/p : Main ghar ja raha hoon
Humans try to produce each word inthe output by focusing only on certainwords in the inputEssentially at each time step we comeup with a distribution on the inputwords
This distribution tells us how muchattention to pay to each input wordsat each time stepIdeally, at each time-step we shouldfeed only this relevant information(i.e. encodings of relevant words) tothe decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.33/60
o/p : I am going homet1 : [ 1 0 0 0 0 ]t2 : [ 0 0 0 0 1 ]t3 : [ 0 0 0.5 0.5 0 ]
t4 : [ 0 1 0 0 0 ]
i/p : Main ghar ja raha hoon
Humans try to produce each word inthe output by focusing only on certainwords in the inputEssentially at each time step we comeup with a distribution on the inputwords
This distribution tells us how muchattention to pay to each input wordsat each time stepIdeally, at each time-step we shouldfeed only this relevant information(i.e. encodings of relevant words) tothe decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.33/60
o/p : I am going homet1 : [ 1 0 0 0 0 ]t2 : [ 0 0 0 0 1 ]t3 : [ 0 0 0.5 0.5 0 ]t4 : [ 0 1 0 0 0 ]
i/p : Main ghar ja raha hoon
Humans try to produce each word inthe output by focusing only on certainwords in the inputEssentially at each time step we comeup with a distribution on the inputwords
This distribution tells us how muchattention to pay to each input wordsat each time stepIdeally, at each time-step we shouldfeed only this relevant information(i.e. encodings of relevant words) tothe decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.33/60
o/p : I am going homet1 : [ 1 0 0 0 0 ]t2 : [ 0 0 0 0 1 ]t3 : [ 0 0 0.5 0.5 0 ]t4 : [ 0 1 0 0 0 ]
i/p : Main ghar ja raha hoon
Humans try to produce each word inthe output by focusing only on certainwords in the inputEssentially at each time step we comeup with a distribution on the inputwordsThis distribution tells us how muchattention to pay to each input wordsat each time step
Ideally, at each time-step we shouldfeed only this relevant information(i.e. encodings of relevant words) tothe decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.33/60
o/p : I am going homet1 : [ 1 0 0 0 0 ]t2 : [ 0 0 0 0 1 ]t3 : [ 0 0 0.5 0.5 0 ]t4 : [ 0 1 0 0 0 ]
i/p : Main ghar ja raha hoon
Humans try to produce each word inthe output by focusing only on certainwords in the inputEssentially at each time step we comeup with a distribution on the inputwordsThis distribution tells us how muchattention to pay to each input wordsat each time stepIdeally, at each time-step we shouldfeed only this relevant information(i.e. encodings of relevant words) tothe decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.34/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us revisit the decoder that we haveseen so far
We either feed in the encoder informationonly once(at s0)Or we feed the same encoder informationat each time stepNow suppose an oracle told you whichwords to focus on at a given time-step tCan you think of a smarter way of feedinginformation to the decoder?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.34/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us revisit the decoder that we haveseen so farWe either feed in the encoder informationonly once(at s0)
Or we feed the same encoder informationat each time stepNow suppose an oracle told you whichwords to focus on at a given time-step tCan you think of a smarter way of feedinginformation to the decoder?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
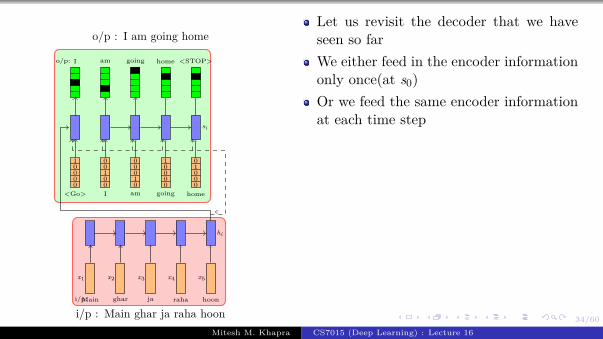
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.34/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us revisit the decoder that we haveseen so farWe either feed in the encoder informationonly once(at s0)Or we feed the same encoder informationat each time step
Now suppose an oracle told you whichwords to focus on at a given time-step tCan you think of a smarter way of feedinginformation to the decoder?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.34/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us revisit the decoder that we haveseen so farWe either feed in the encoder informationonly once(at s0)Or we feed the same encoder informationat each time stepNow suppose an oracle told you whichwords to focus on at a given time-step t
Can you think of a smarter way of feedinginformation to the decoder?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.34/60
Option 2
i/p : Main ghar ja raha hoon
o/p : I am going home
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
c
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
si
Let us revisit the decoder that we haveseen so farWe either feed in the encoder informationonly once(at s0)Or we feed the same encoder informationat each time stepNow suppose an oracle told you whichwords to focus on at a given time-step tCan you think of a smarter way of feedinginformation to the decoder?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
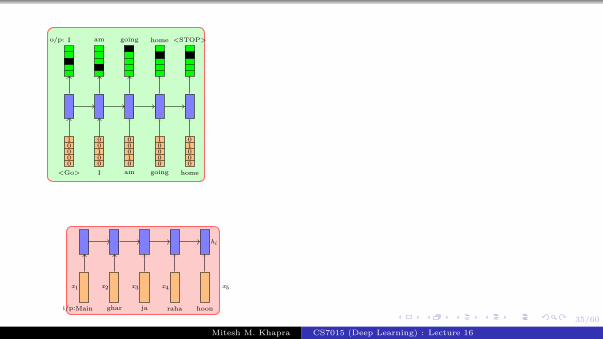
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.35/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
We could just take a weighted averageof the corresponding word representationsand feed it to the decoderFor example at timestep 3, we canjust take a weighted average of therepresentations of ‘ja’ and ‘raha’Intuitively this should work betterbecause we are not overloading thedecoder with irrelevant information(about words that do not matter at thistime step)How do we convert this intuition into amodel ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.35/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
We could just take a weighted averageof the corresponding word representationsand feed it to the decoder
For example at timestep 3, we canjust take a weighted average of therepresentations of ‘ja’ and ‘raha’Intuitively this should work betterbecause we are not overloading thedecoder with irrelevant information(about words that do not matter at thistime step)How do we convert this intuition into amodel ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.35/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
We could just take a weighted averageof the corresponding word representationsand feed it to the decoderFor example at timestep 3, we canjust take a weighted average of therepresentations of ‘ja’ and ‘raha’
Intuitively this should work betterbecause we are not overloading thedecoder with irrelevant information(about words that do not matter at thistime step)How do we convert this intuition into amodel ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.35/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4
+
α1,5 α2,5α3,5α4,5 α5,5
c5
We could just take a weighted averageof the corresponding word representationsand feed it to the decoderFor example at timestep 3, we canjust take a weighted average of therepresentations of ‘ja’ and ‘raha’Intuitively this should work betterbecause we are not overloading thedecoder with irrelevant information(about words that do not matter at thistime step)
How do we convert this intuition into amodel ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.35/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4
+
α1,5 α2,5α3,5α4,5 α5,5
c5
We could just take a weighted averageof the corresponding word representationsand feed it to the decoderFor example at timestep 3, we canjust take a weighted average of therepresentations of ‘ja’ and ‘raha’Intuitively this should work betterbecause we are not overloading thedecoder with irrelevant information(about words that do not matter at thistime step)How do we convert this intuition into amodel ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.36/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Of course in practice we will not have thisoracleThe machine will have to learn this fromthe dataTo enable this we define a function
ejt = fATT(st−1, cj)
This quantity captures the importance ofthe jth input word for decoding the tth
output word (we will see the exact formof fATT later)We can normalize these weights by usingthe softmax function
αjt =exp(ejt)
M∑j=1
exp(ejt)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
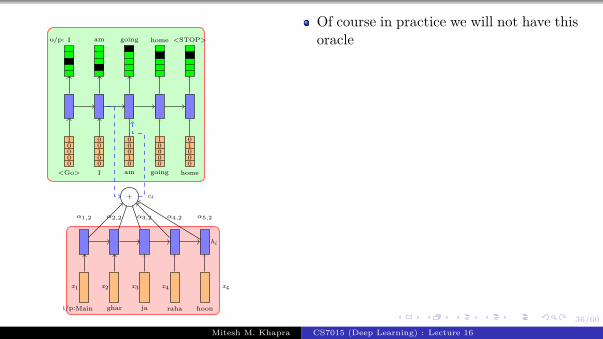
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.36/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Of course in practice we will not have thisoracle
The machine will have to learn this fromthe dataTo enable this we define a function
ejt = fATT(st−1, cj)
This quantity captures the importance ofthe jth input word for decoding the tth
output word (we will see the exact formof fATT later)We can normalize these weights by usingthe softmax function
αjt =exp(ejt)
M∑j=1
exp(ejt)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.36/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Of course in practice we will not have thisoracleThe machine will have to learn this fromthe data
To enable this we define a function
ejt = fATT(st−1, cj)
This quantity captures the importance ofthe jth input word for decoding the tth
output word (we will see the exact formof fATT later)We can normalize these weights by usingthe softmax function
αjt =exp(ejt)
M∑j=1
exp(ejt)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
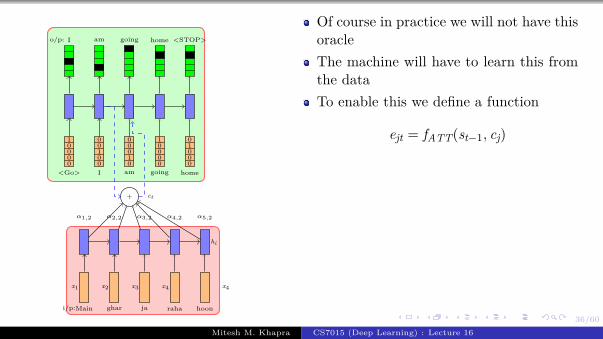
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.36/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Of course in practice we will not have thisoracleThe machine will have to learn this fromthe dataTo enable this we define a function
ejt = fATT(st−1, cj)
This quantity captures the importance ofthe jth input word for decoding the tth
output word (we will see the exact formof fATT later)We can normalize these weights by usingthe softmax function
αjt =exp(ejt)
M∑j=1
exp(ejt)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.36/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Of course in practice we will not have thisoracleThe machine will have to learn this fromthe dataTo enable this we define a function
ejt = fATT(st−1, cj)
This quantity captures the importance ofthe jth input word for decoding the tth
output word (we will see the exact formof fATT later)
We can normalize these weights by usingthe softmax function
αjt =exp(ejt)
M∑j=1
exp(ejt)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.36/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Of course in practice we will not have thisoracleThe machine will have to learn this fromthe dataTo enable this we define a function
ejt = fATT(st−1, cj)
This quantity captures the importance ofthe jth input word for decoding the tth
output word (we will see the exact formof fATT later)We can normalize these weights by usingthe softmax function
αjt =exp(ejt)
M∑j=1
exp(ejt)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.37/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
αjt =exp(ejt)
M∑j=1
exp(ejt)
αjt denotes the probability of focusing onthe jth word to produce the tth outputwordWe are now trying to learn the α’s insteadof an oracle informing us about the α’sLearning would always involve someparametersSo let’s define a parametric form for α’s
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.37/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
αjt =exp(ejt)
M∑j=1
exp(ejt)
αjt denotes the probability of focusing onthe jth word to produce the tth outputwordWe are now trying to learn the α’s insteadof an oracle informing us about the α’sLearning would always involve someparametersSo let’s define a parametric form for α’s
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.37/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
αjt =exp(ejt)
M∑j=1
exp(ejt)
αjt denotes the probability of focusing onthe jth word to produce the tth outputword
We are now trying to learn the α’s insteadof an oracle informing us about the α’sLearning would always involve someparametersSo let’s define a parametric form for α’s
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.37/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
αjt =exp(ejt)
M∑j=1
exp(ejt)
αjt denotes the probability of focusing onthe jth word to produce the tth outputwordWe are now trying to learn the α’s insteadof an oracle informing us about the α’s
Learning would always involve someparametersSo let’s define a parametric form for α’s
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.37/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
αjt =exp(ejt)
M∑j=1
exp(ejt)
αjt denotes the probability of focusing onthe jth word to produce the tth outputwordWe are now trying to learn the α’s insteadof an oracle informing us about the α’sLearning would always involve someparameters
So let’s define a parametric form for α’s
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.37/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
αjt =exp(ejt)
M∑j=1
exp(ejt)
αjt denotes the probability of focusing onthe jth word to produce the tth outputwordWe are now trying to learn the α’s insteadof an oracle informing us about the α’sLearning would always involve someparametersSo let’s define a parametric form for α’s
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.38/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
From now on we will refer to the decoderRNN’s state at the t-th timestep as st andthe encoder RNN’s state at the j-th timestep as cj
Given these new notations, one (amongmany) possible choice for fATT is
ejt = VTatt tanh(Uattst−1 + Wattcj)
Vatt ∈ Rd , Uatt ∈ Rd×d, Watt ∈ Rd×d areadditional parameters of the modelThese parameters will be learned alongwith the other parameters of the encoderand decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
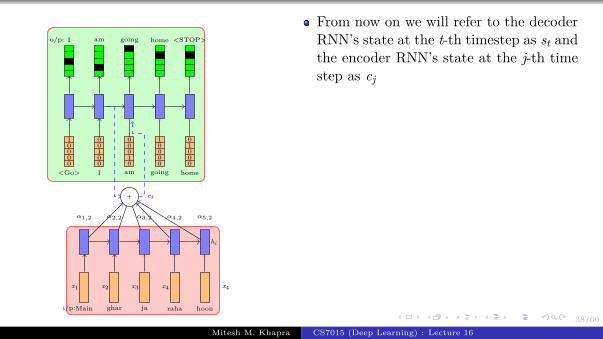
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.38/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
From now on we will refer to the decoderRNN’s state at the t-th timestep as st andthe encoder RNN’s state at the j-th timestep as cj
Given these new notations, one (amongmany) possible choice for fATT is
ejt = VTatt tanh(Uattst−1 + Wattcj)
Vatt ∈ Rd , Uatt ∈ Rd×d, Watt ∈ Rd×d areadditional parameters of the modelThese parameters will be learned alongwith the other parameters of the encoderand decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.38/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
From now on we will refer to the decoderRNN’s state at the t-th timestep as st andthe encoder RNN’s state at the j-th timestep as cj
Given these new notations, one (amongmany) possible choice for fATT is
ejt = VTatt tanh(Uattst−1 + Wattcj)
Vatt ∈ Rd , Uatt ∈ Rd×d, Watt ∈ Rd×d areadditional parameters of the modelThese parameters will be learned alongwith the other parameters of the encoderand decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.38/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
From now on we will refer to the decoderRNN’s state at the t-th timestep as st andthe encoder RNN’s state at the j-th timestep as cj
Given these new notations, one (amongmany) possible choice for fATT is
ejt = VTatt tanh(Uattst−1 + Wattcj)
Vatt ∈ Rd , Uatt ∈ Rd×d, Watt ∈ Rd×d areadditional parameters of the model
These parameters will be learned alongwith the other parameters of the encoderand decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.38/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
From now on we will refer to the decoderRNN’s state at the t-th timestep as st andthe encoder RNN’s state at the j-th timestep as cj
Given these new notations, one (amongmany) possible choice for fATT is
ejt = VTatt tanh(Uattst−1 + Wattcj)
Vatt ∈ Rd , Uatt ∈ Rd×d, Watt ∈ Rd×d areadditional parameters of the modelThese parameters will be learned alongwith the other parameters of the encoderand decoder
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.39/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Wait a minute !This model would make a lot of sense ifwere given the true α’s at training time
αtruetj = [0, 0, 0.5, 0.5, 0]
αpredtj = [0.1, 0.1, 0.35, 0.35, 0.1]
We could then minimize L (αtrue, αpred)in addition to L (θ) as defined earlierBut in practice it is very hard to get αtrue
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.39/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Wait a minute !
This model would make a lot of sense ifwere given the true α’s at training time
αtruetj = [0, 0, 0.5, 0.5, 0]
αpredtj = [0.1, 0.1, 0.35, 0.35, 0.1]
We could then minimize L (αtrue, αpred)in addition to L (θ) as defined earlierBut in practice it is very hard to get αtrue
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.39/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Wait a minute !This model would make a lot of sense ifwere given the true α’s at training time
αtruetj = [0, 0, 0.5, 0.5, 0]
αpredtj = [0.1, 0.1, 0.35, 0.35, 0.1]
We could then minimize L (αtrue, αpred)in addition to L (θ) as defined earlierBut in practice it is very hard to get αtrue
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
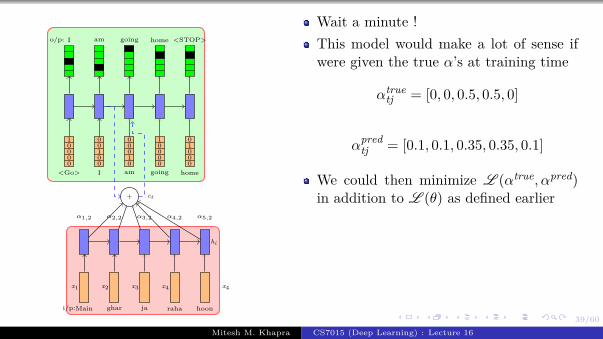
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.39/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Wait a minute !This model would make a lot of sense ifwere given the true α’s at training time
αtruetj = [0, 0, 0.5, 0.5, 0]
αpredtj = [0.1, 0.1, 0.35, 0.35, 0.1]
We could then minimize L (αtrue, αpred)in addition to L (θ) as defined earlier
But in practice it is very hard to get αtrue
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.39/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
Wait a minute !This model would make a lot of sense ifwere given the true α’s at training time
αtruetj = [0, 0, 0.5, 0.5, 0]
αpredtj = [0.1, 0.1, 0.35, 0.35, 0.1]
We could then minimize L (αtrue, αpred)in addition to L (θ) as defined earlierBut in practice it is very hard to get αtrue
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.40/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
For example, in our translation examplewe would want someone to manuallyannotate the source words whichcontribute to every target word
It is hard to get such annotated dataThen how would this model work in theabsence of such data ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.40/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
For example, in our translation examplewe would want someone to manuallyannotate the source words whichcontribute to every target wordIt is hard to get such annotated data
Then how would this model work in theabsence of such data ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
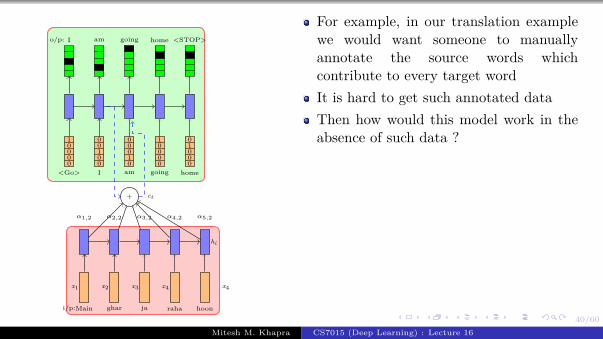
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.40/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
For example, in our translation examplewe would want someone to manuallyannotate the source words whichcontribute to every target wordIt is hard to get such annotated dataThen how would this model work in theabsence of such data ?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.41/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
It works because it is a better modelingchoiceThis is a more informed modelWe are essentially asking the model toapproach the problem in a better (morenatural) wayGiven enough data it should be ableto learn these attention weights just ashumans doThat’s the hope (and hope is a goodthing)And in practice indeed these models workbetter than the vanilla encoder decodermodels
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.41/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
It works because it is a better modelingchoice
This is a more informed modelWe are essentially asking the model toapproach the problem in a better (morenatural) wayGiven enough data it should be ableto learn these attention weights just ashumans doThat’s the hope (and hope is a goodthing)And in practice indeed these models workbetter than the vanilla encoder decodermodels
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
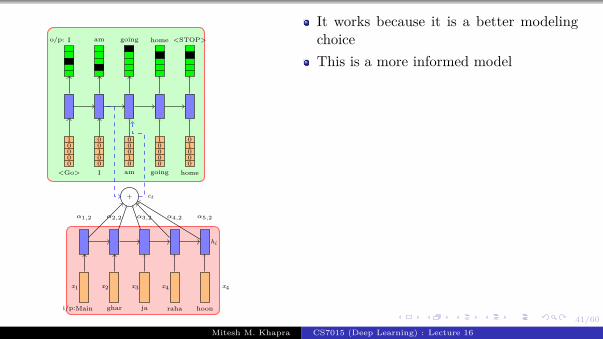
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.41/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
It works because it is a better modelingchoiceThis is a more informed model
We are essentially asking the model toapproach the problem in a better (morenatural) wayGiven enough data it should be ableto learn these attention weights just ashumans doThat’s the hope (and hope is a goodthing)And in practice indeed these models workbetter than the vanilla encoder decodermodels
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.41/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
It works because it is a better modelingchoiceThis is a more informed modelWe are essentially asking the model toapproach the problem in a better (morenatural) way
Given enough data it should be ableto learn these attention weights just ashumans doThat’s the hope (and hope is a goodthing)And in practice indeed these models workbetter than the vanilla encoder decodermodels
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.41/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
It works because it is a better modelingchoiceThis is a more informed modelWe are essentially asking the model toapproach the problem in a better (morenatural) wayGiven enough data it should be ableto learn these attention weights just ashumans do
That’s the hope (and hope is a goodthing)And in practice indeed these models workbetter than the vanilla encoder decodermodels
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.41/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
It works because it is a better modelingchoiceThis is a more informed modelWe are essentially asking the model toapproach the problem in a better (morenatural) wayGiven enough data it should be ableto learn these attention weights just ashumans doThat’s the hope (and hope is a goodthing)
And in practice indeed these models workbetter than the vanilla encoder decodermodels
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
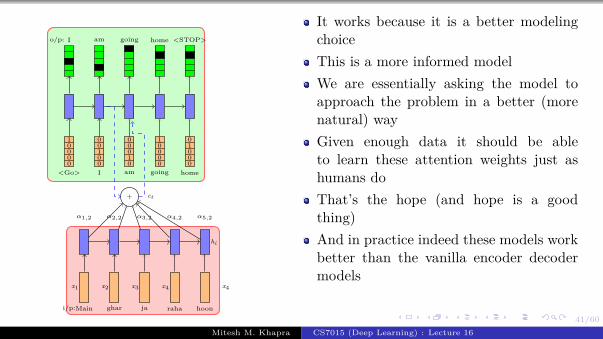
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.41/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x4
hoon
hi
+ ct
α1,2 α2,2 α3,2 α4,2 α5,2
It works because it is a better modelingchoiceThis is a more informed modelWe are essentially asking the model toapproach the problem in a better (morenatural) wayGiven enough data it should be ableto learn these attention weights just ashumans doThat’s the hope (and hope is a goodthing)And in practice indeed these models workbetter than the vanilla encoder decodermodels
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.42/60
Let us revisit the MT model that we saw earlier and answer the same set ofquestions again (data, encoder, decoder, loss, training algorithm)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine Translation
Data: {xi = sourcei, yi = targeti}Ni=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:
ejt = VTattntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
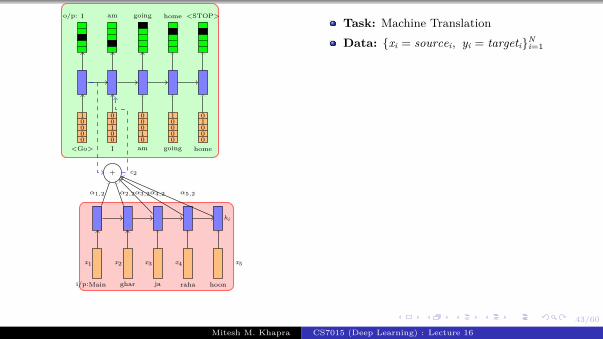
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine TranslationData: {xi = sourcei, yi = targeti}N
i=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:
ejt = VTattntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine TranslationData: {xi = sourcei, yi = targeti}N
i=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:
ejt = VTattntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4
+
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine TranslationData: {xi = sourcei, yi = targeti}N
i=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:
ejt = VTattntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4
+
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine TranslationData: {xi = sourcei, yi = targeti}N
i=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:ejt = VT
attntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine TranslationData: {xi = sourcei, yi = targeti}N
i=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:ejt = VT
attntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine TranslationData: {xi = sourcei, yi = targeti}N
i=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:ejt = VT
attntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine TranslationData: {xi = sourcei, yi = targeti}N
i=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:ejt = VT
attntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
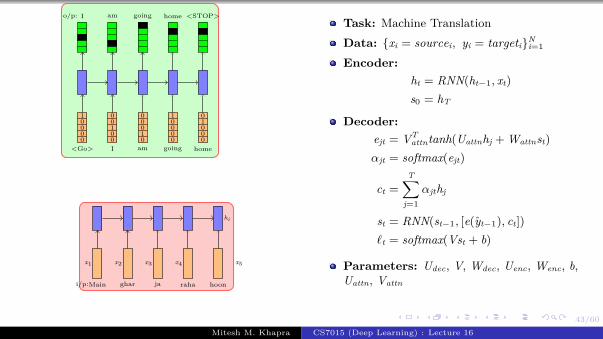
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine TranslationData: {xi = sourcei, yi = targeti}N
i=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:ejt = VT
attntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.43/60
<Go>
o/p: I
00001
I
am
00100
am
going
01000
going
home
00001
home
<STOP>
00010
x1
Maini/p:
x2
ghar
x3
ja
x4
raha
x5
hoon
hi
+ c3
α1,3 α2,3 α3,3 α4,3 α5,3
+ c2
α1,2 α2,2α3,2α4,2 α5,2
+
α1,4α2,4α3,4 α4,4 α5,4
c4 +
α1,5 α2,5α3,5α4,5 α5,5
c5
Task: Machine TranslationData: {xi = sourcei, yi = targeti}N
i=1
Encoder:ht = RNN(ht−1, xt)
s0 = hT
Decoder:ejt = VT
attntanh(Uattnhj + Wattnst)
αjt = softmax(ejt)
ct =T∑
j=1
αjthj
st = RNN(st−1, [e(yt−1), ct])
ℓt = softmax(Vst + b)
Parameters: Udec, V, Wdec, Uenc, Wenc, b,Uattn, Vattn
Loss and Algorithm remains same
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.44/60
You can try adding an attention component to all the other encoder decodermodels that we discussed earlier and answer the same set of questions (data,
encoder, decoder, loss, training algorithm)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.45/60
Can we check if the attention model actually learns something meaningful ?
In other words does it really learn to focus on the most relevant words in theinput at the t-th timestep ?We can check this by plotting the attention weights as a heatmap (we will seesome examples on the next slide)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.45/60
Can we check if the attention model actually learns something meaningful ?In other words does it really learn to focus on the most relevant words in theinput at the t-th timestep ?
We can check this by plotting the attention weights as a heatmap (we will seesome examples on the next slide)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.45/60
Can we check if the attention model actually learns something meaningful ?In other words does it really learn to focus on the most relevant words in theinput at the t-th timestep ?We can check this by plotting the attention weights as a heatmap (we will seesome examples on the next slide)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.46/60
Figure: Example output of attention-basedsummarization system [Rush et al. 2015.]
Figure: Example output of attention-basedneural machine translation model [Cho et al.2015].
The heat map shows a soft alignment between the input and the generatedoutput.Each cell in the heat mapsssss corresponds to αtj (i.e., the importance of thejth input word for predicting the tth output word as determined by the model)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.46/60
Figure: Example output of attention-basedsummarization system [Rush et al. 2015.]
Figure: Example output of attention-basedneural machine translation model [Cho et al.2015].
The heat map shows a soft alignment between the input and the generatedoutput.Each cell in the heat mapsssss corresponds to αtj (i.e., the importance of thejth input word for predicting the tth output word as determined by the model)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
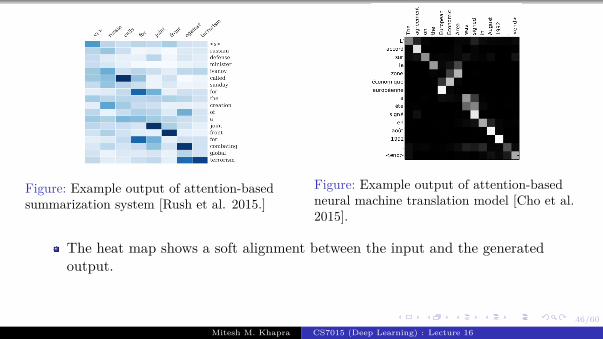
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.46/60
Figure: Example output of attention-basedsummarization system [Rush et al. 2015.]
Figure: Example output of attention-basedneural machine translation model [Cho et al.2015].
The heat map shows a soft alignment between the input and the generatedoutput.
Each cell in the heat mapsssss corresponds to αtj (i.e., the importance of thejth input word for predicting the tth output word as determined by the model)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.46/60
Figure: Example output of attention-basedsummarization system [Rush et al. 2015.]
Figure: Example output of attention-basedneural machine translation model [Cho et al.2015].
The heat map shows a soft alignment between the input and the generatedoutput.Each cell in the heat mapsssss corresponds to αtj (i.e., the importance of thejth input word for predicting the tth output word as determined by the model)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.47/60Figure: Example output of attention-based video captioning system [Yao et al. 2015.]
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.48/60
Module 16.4: Attention over images
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.49/60
A man throwinga frisbee in a park
How do we model an attention mechanismfor images?
In the case of text we have arepresentation for every location (timestep) of the input sequenceBut for images we typically userepresentation from one of the fullyconnected layersThis representation does not contain anylocation informationSo then what is the input to the attentionmechanism?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.49/60
<Go>
o/p:main
00001
main
ghar
00100
ghar
ja
01000
ja
raha
00001
raha
hoon
00010
hoon
<STOP>
00010
hi
x1
Ii/p:
x2
am
x3
going
x4
home
hi
+ ct
α1 α2 α3 α4
How do we model an attention mechanismfor images?In the case of text we have arepresentation for every location (timestep) of the input sequence
But for images we typically userepresentation from one of the fullyconnected layersThis representation does not contain anylocation informationSo then what is the input to the attentionmechanism?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.49/60
Encoder
CNN
h0
How do we model an attention mechanismfor images?In the case of text we have arepresentation for every location (timestep) of the input sequenceBut for images we typically userepresentation from one of the fullyconnected layers
This representation does not contain anylocation informationSo then what is the input to the attentionmechanism?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
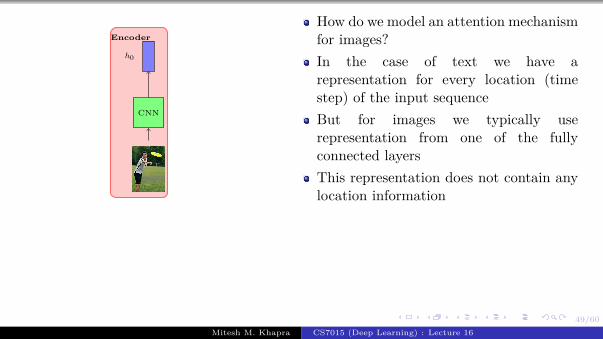
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.49/60
Encoder
CNN
h0
How do we model an attention mechanismfor images?In the case of text we have arepresentation for every location (timestep) of the input sequenceBut for images we typically userepresentation from one of the fullyconnected layersThis representation does not contain anylocation information
So then what is the input to the attentionmechanism?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.49/60
Encoder
CNN
h0
How do we model an attention mechanismfor images?In the case of text we have arepresentation for every location (timestep) of the input sequenceBut for images we typically userepresentation from one of the fullyconnected layersThis representation does not contain anylocation informationSo then what is the input to the attentionmechanism?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
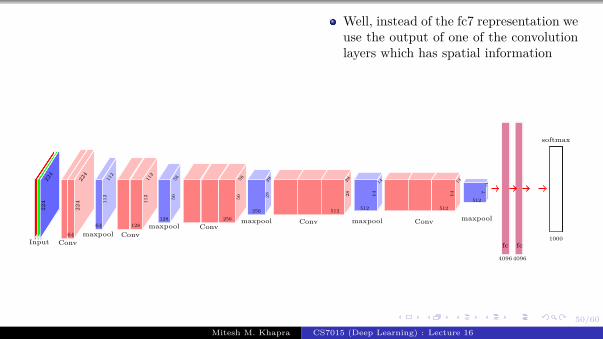
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.50/60
Input
224
224
Conv
224
224
64 maxpool
112
112
64Conv
112
112
128 maxpool
5656
128
Conv56
56
256 maxpool
2828
256
Conv
2828
512
maxpool
14
14
512
Conv
14
14
512
maxpool
7
7
512
fc fc
4096 4096
softmax
1000
Well, instead of the fc7 representation weuse the output of one of the convolutionlayers which has spatial information
For example the output of the 5th
convolutional layer of VGGNet is a 14×14× 512 size feature mapWe could think of this as 196 locations(each having a 512 dimensionalrepresentation)The model will then learn an attentionover these locations (which in turncorrespond to actual locations in theimages)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
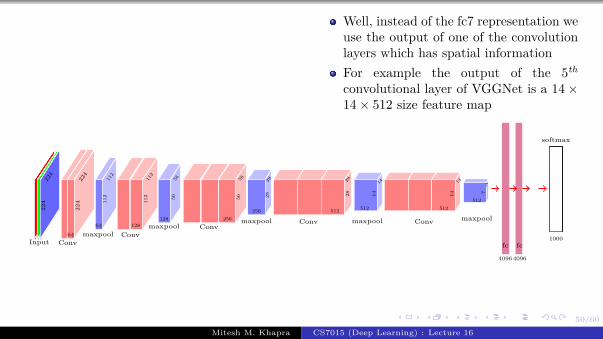
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.50/60
Input
224
224
Conv
224
224
64 maxpool
112
112
64Conv
112
112
128 maxpool
5656
128
Conv56
56
256 maxpool
2828
256
Conv
2828
512
maxpool
14
14
512
Conv
14
14
512
maxpool
7
7
512
fc fc
4096 4096
softmax
1000
Well, instead of the fc7 representation weuse the output of one of the convolutionlayers which has spatial informationFor example the output of the 5th
convolutional layer of VGGNet is a 14×14× 512 size feature map
We could think of this as 196 locations(each having a 512 dimensionalrepresentation)The model will then learn an attentionover these locations (which in turncorrespond to actual locations in theimages)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.50/60
…1 2 196
512
14
14
512
Well, instead of the fc7 representation weuse the output of one of the convolutionlayers which has spatial informationFor example the output of the 5th
convolutional layer of VGGNet is a 14×14× 512 size feature mapWe could think of this as 196 locations(each having a 512 dimensionalrepresentation)
The model will then learn an attentionover these locations (which in turncorrespond to actual locations in theimages)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.50/60
…1 2 196
512
+
αt1 αt196
14
14
512
Well, instead of the fc7 representation weuse the output of one of the convolutionlayers which has spatial informationFor example the output of the 5th
convolutional layer of VGGNet is a 14×14× 512 size feature mapWe could think of this as 196 locations(each having a 512 dimensionalrepresentation)The model will then learn an attentionover these locations (which in turncorrespond to actual locations in theimages)
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.51/60
Let us look at some examples of attention over images for the task of imagecaptioning
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.52/60
Figure: Examples of the attention-based model attending to the correct object (whiteindicates the attended regions,underlines indicates the corresponding word) [KyunghyunCho et al. 2015.]
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.53/60
Module 16.5: Hierarchical Attention
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.54/60
ContextU: Can you suggest a good movie?B: Yes, sure. How about Logan?U: Okay, who is the lead actor?
ResponseB: Hugh Jackman, of course
Consider a dialog between a user (u)and a bot (B)
The dialog contains a sequence ofutterances between the user and thebotEach utterance in turn is a sequenceof wordsThus what we have here is a“sequence of sequences” as inputCan you think of an encoder for sucha sequence of sequences?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.54/60
ContextU: Can you suggest a good movie?B: Yes, sure. How about Logan?U: Okay, who is the lead actor?
ResponseB: Hugh Jackman, of course
Consider a dialog between a user (u)and a bot (B)The dialog contains a sequence ofutterances between the user and thebot
Each utterance in turn is a sequenceof wordsThus what we have here is a“sequence of sequences” as inputCan you think of an encoder for sucha sequence of sequences?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.54/60
ContextU: Can you suggest a good movie?B: Yes, sure. How about Logan?U: Okay, who is the lead actor?
ResponseB: Hugh Jackman, of course
Consider a dialog between a user (u)and a bot (B)The dialog contains a sequence ofutterances between the user and thebotEach utterance in turn is a sequenceof words
Thus what we have here is a“sequence of sequences” as inputCan you think of an encoder for sucha sequence of sequences?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.54/60
ContextU: Can you suggest a good movie?B: Yes, sure. How about Logan?U: Okay, who is the lead actor?
ResponseB: Hugh Jackman, of course
Consider a dialog between a user (u)and a bot (B)The dialog contains a sequence ofutterances between the user and thebotEach utterance in turn is a sequenceof wordsThus what we have here is a“sequence of sequences” as input
Can you think of an encoder for sucha sequence of sequences?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.54/60
ContextU: Can you suggest a good movie?B: Yes, sure. How about Logan?U: Okay, who is the lead actor?
ResponseB: Hugh Jackman, of course
Consider a dialog between a user (u)and a bot (B)The dialog contains a sequence ofutterances between the user and thebotEach utterance in turn is a sequenceof wordsThus what we have here is a“sequence of sequences” as inputCan you think of an encoder for sucha sequence of sequences?
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.55/60
<Go>
o/p:Hugh
00001
I
Jackman
00100
am
of
01000
going
course
00001
home
<STOP>
00010
Can you…
movie? Yes sure…Logan? Okay who
…
actor?
We could think of a two levelhierarchical RNN encoder
The first level RNN operates on thesequence of words in each utteranceand gives us a representationWe now have a sequence of utterancerepresentations (red vectors in theimage)We can now have another RNNwhich encodes this sequence andgives a single representations for thesequences of utterancesThe decoder can then produce anoutput sequence conditioned on thisutterance
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.55/60
<Go>
o/p:Hugh
00001
I
Jackman
00100
am
of
01000
going
course
00001
home
<STOP>
00010
Can you…
movie? Yes sure…Logan? Okay who
…
actor?
We could think of a two levelhierarchical RNN encoderThe first level RNN operates on thesequence of words in each utteranceand gives us a representation
We now have a sequence of utterancerepresentations (red vectors in theimage)We can now have another RNNwhich encodes this sequence andgives a single representations for thesequences of utterancesThe decoder can then produce anoutput sequence conditioned on thisutterance
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.55/60
<Go>
o/p:Hugh
00001
I
Jackman
00100
am
of
01000
going
course
00001
home
<STOP>
00010
Can you…
movie? Yes sure…Logan? Okay who
…
actor?
We could think of a two levelhierarchical RNN encoderThe first level RNN operates on thesequence of words in each utteranceand gives us a representationWe now have a sequence of utterancerepresentations (red vectors in theimage)
We can now have another RNNwhich encodes this sequence andgives a single representations for thesequences of utterancesThe decoder can then produce anoutput sequence conditioned on thisutterance
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.55/60
<Go>
o/p:Hugh
00001
I
Jackman
00100
am
of
01000
going
course
00001
home
<STOP>
00010
Can you…
movie? Yes sure…Logan? Okay who
…
actor?
We could think of a two levelhierarchical RNN encoderThe first level RNN operates on thesequence of words in each utteranceand gives us a representationWe now have a sequence of utterancerepresentations (red vectors in theimage)We can now have another RNNwhich encodes this sequence andgives a single representations for thesequences of utterances
The decoder can then produce anoutput sequence conditioned on thisutterance
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.55/60
<Go>
o/p:Hugh
00001
I
Jackman
00100
am
of
01000
going
course
00001
home
<STOP>
00010
Can you…
movie? Yes sure…Logan? Okay who
…
actor?
We could think of a two levelhierarchical RNN encoderThe first level RNN operates on thesequence of words in each utteranceand gives us a representationWe now have a sequence of utterancerepresentations (red vectors in theimage)We can now have another RNNwhich encodes this sequence andgives a single representations for thesequences of utterancesThe decoder can then produce anoutput sequence conditioned on thisutterance
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.56/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Let us look at another example
Consider the task of documentclassification or summarizationA document is a sequence of sentencesEach sentence in turn is a sequence ofwordsWe can again use a hierarchical RNNto model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.56/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Let us look at another exampleConsider the task of documentclassification or summarization
A document is a sequence of sentencesEach sentence in turn is a sequence ofwordsWe can again use a hierarchical RNNto model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.56/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Let us look at another exampleConsider the task of documentclassification or summarizationA document is a sequence of sentences
Each sentence in turn is a sequence ofwordsWe can again use a hierarchical RNNto model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.56/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Let us look at another exampleConsider the task of documentclassification or summarizationA document is a sequence of sentencesEach sentence in turn is a sequence ofwords
We can again use a hierarchical RNNto model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.56/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Let us look at another exampleConsider the task of documentclassification or summarizationA document is a sequence of sentencesEach sentence in turn is a sequence ofwordsWe can again use a hierarchical RNNto model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.56/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Let us look at another exampleConsider the task of documentclassification or summarizationA document is a sequence of sentencesEach sentence in turn is a sequence ofwordsWe can again use a hierarchical RNNto model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.56/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Let us look at another exampleConsider the task of documentclassification or summarizationA document is a sequence of sentencesEach sentence in turn is a sequence ofwordsWe can again use a hierarchical RNNto model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.56/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Let us look at another exampleConsider the task of documentclassification or summarizationA document is a sequence of sentencesEach sentence in turn is a sequence ofwordsWe can again use a hierarchical RNNto model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.57/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Data: {Documenti, classi}Ni=1
Word level (1) encoder:h1
ij = RNN(h1ij−1,wij)
si = h1iTi [T is length of sentence i]
Sentence level (2) encoder:h2
i = RNN(h2i−1, si)
s = h2K [K is number of sentences]
Decoder:P(y|document) = softmax(Vs + b)
Params: W1enc, U1
enc, W2enc, U2
enc, V, bLoss: Cross EntropyAlgorithm: Gradient Descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.57/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Data: {Documenti, classi}Ni=1
Word level (1) encoder:h1
ij = RNN(h1ij−1,wij)
si = h1iTi [T is length of sentence i]
Sentence level (2) encoder:h2
i = RNN(h2i−1, si)
s = h2K [K is number of sentences]
Decoder:P(y|document) = softmax(Vs + b)
Params: W1enc, U1
enc, W2enc, U2
enc, V, bLoss: Cross EntropyAlgorithm: Gradient Descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.57/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Data: {Documenti, classi}Ni=1
Word level (1) encoder:h1
ij = RNN(h1ij−1,wij)
si = h1iTi [T is length of sentence i]
Sentence level (2) encoder:h2
i = RNN(h2i−1, si)
s = h2K [K is number of sentences]
Decoder:P(y|document) = softmax(Vs + b)
Params: W1enc, U1
enc, W2enc, U2
enc, V, bLoss: Cross EntropyAlgorithm: Gradient Descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.57/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Data: {Documenti, classi}Ni=1
Word level (1) encoder:h1
ij = RNN(h1ij−1,wij)
si = h1iTi [T is length of sentence i]
Sentence level (2) encoder:h2
i = RNN(h2i−1, si)
s = h2K [K is number of sentences]
Decoder:P(y|document) = softmax(Vs + b)
Params: W1enc, U1
enc, W2enc, U2
enc, V, bLoss: Cross EntropyAlgorithm: Gradient Descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.57/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Data: {Documenti, classi}Ni=1
Word level (1) encoder:h1
ij = RNN(h1ij−1,wij)
si = h1iTi [T is length of sentence i]
Sentence level (2) encoder:h2
i = RNN(h2i−1, si)
s = h2K [K is number of sentences]
Decoder:P(y|document) = softmax(Vs + b)
Params: W1enc, U1
enc, W2enc, U2
enc, V, b
Loss: Cross EntropyAlgorithm: Gradient Descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
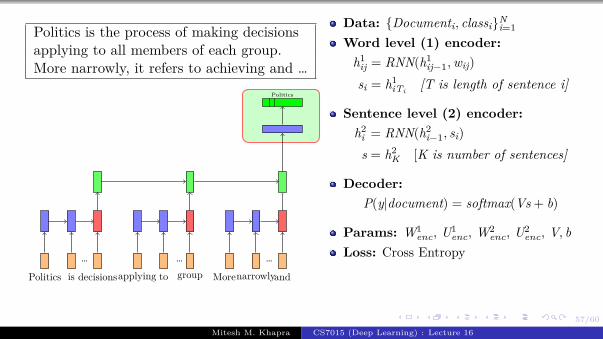
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.57/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Data: {Documenti, classi}Ni=1
Word level (1) encoder:h1
ij = RNN(h1ij−1,wij)
si = h1iTi [T is length of sentence i]
Sentence level (2) encoder:h2
i = RNN(h2i−1, si)
s = h2K [K is number of sentences]
Decoder:P(y|document) = softmax(Vs + b)
Params: W1enc, U1
enc, W2enc, U2
enc, V, bLoss: Cross Entropy
Algorithm: Gradient Descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.57/60
Politics is the process of making decisionsapplying to all members of each group.More narrowly, it refers to achieving and …
Politics is
…
decisionsapplying to
…group Morenarrowly
…
and
Politics
Data: {Documenti, classi}Ni=1
Word level (1) encoder:h1
ij = RNN(h1ij−1,wij)
si = h1iTi [T is length of sentence i]
Sentence level (2) encoder:h2
i = RNN(h2i−1, si)
s = h2K [K is number of sentences]
Decoder:P(y|document) = softmax(Vs + b)
Params: W1enc, U1
enc, W2enc, U2
enc, V, bLoss: Cross EntropyAlgorithm: Gradient Descent withbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.58/60
Figure: Hierarchical Attention Network[Yang et al.]
How would you model attention insuch a hierarchical encoder decodermodel ?
We need attention at two levelsFirst we need to attend to important(most informative) words in asentenceThen we need to attend to important(most informative) sentences in adocumentLet us see how to model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.58/60
Figure: Hierarchical Attention Network[Yang et al.]
How would you model attention insuch a hierarchical encoder decodermodel ?We need attention at two levels
First we need to attend to important(most informative) words in asentenceThen we need to attend to important(most informative) sentences in adocumentLet us see how to model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.58/60
Figure: Hierarchical Attention Network[Yang et al.]
How would you model attention insuch a hierarchical encoder decodermodel ?We need attention at two levelsFirst we need to attend to important(most informative) words in asentence
Then we need to attend to important(most informative) sentences in adocumentLet us see how to model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.58/60
Figure: Hierarchical Attention Network[Yang et al.]
How would you model attention insuch a hierarchical encoder decodermodel ?We need attention at two levelsFirst we need to attend to important(most informative) words in asentenceThen we need to attend to important(most informative) sentences in adocument
Let us see how to model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.58/60
Figure: Hierarchical Attention Network[Yang et al.]
How would you model attention insuch a hierarchical encoder decodermodel ?We need attention at two levelsFirst we need to attend to important(most informative) words in asentenceThen we need to attend to important(most informative) sentences in adocumentLet us see how to model this
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.59/60
Figure: Hierarchical Attention Network[Yang et al.]
Data: {Documenti, classi}Ni=1
Word level (1) encoder:hij = RNN(hij−1,wij)
uij = tanh(Wwhij + bw)
αij =exp(uT
ij uw)∑t exp(uT
ituw)
si =∑
jαijhij
Sentence level (2) encoder:
hi = RNN(hi−1, si)
ui = tanh(Wshi + bs)
αi =exp(uT
i us)∑i exp(uT
i us)
s =∑
iαihi
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.59/60
Figure: Hierarchical Attention Network[Yang et al.]
Data: {Documenti, classi}Ni=1
Word level (1) encoder:hij = RNN(hij−1,wij)
uij = tanh(Wwhij + bw)
αij =exp(uT
ij uw)∑t exp(uT
ituw)
si =∑
jαijhij
Sentence level (2) encoder:
hi = RNN(hi−1, si)
ui = tanh(Wshi + bs)
αi =exp(uT
i us)∑i exp(uT
i us)
s =∑
iαihi
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.59/60
Figure: Hierarchical Attention Network[Yang et al.]
Data: {Documenti, classi}Ni=1
Word level (1) encoder:hij = RNN(hij−1,wij)
uij = tanh(Wwhij + bw)
αij =exp(uT
ij uw)∑t exp(uT
ituw)
si =∑
jαijhij
Sentence level (2) encoder:
hi = RNN(hi−1, si)
ui = tanh(Wshi + bs)
αi =exp(uT
i us)∑i exp(uT
i us)
s =∑
iαihi
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.60/60
Figure: Hierarchical Attention Network[Yang et al..]
Decoder:
P(y|document) = softmax(Vs + b)
Parameters:Ww,Ws,V, bw, bs, b, uw, us
Loss: cross entropyAlgorithm: Gradient Descent andbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.60/60
Figure: Hierarchical Attention Network[Yang et al..]
Decoder:
P(y|document) = softmax(Vs + b)
Parameters:Ww,Ws,V, bw, bs, b, uw, us
Loss: cross entropyAlgorithm: Gradient Descent andbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16
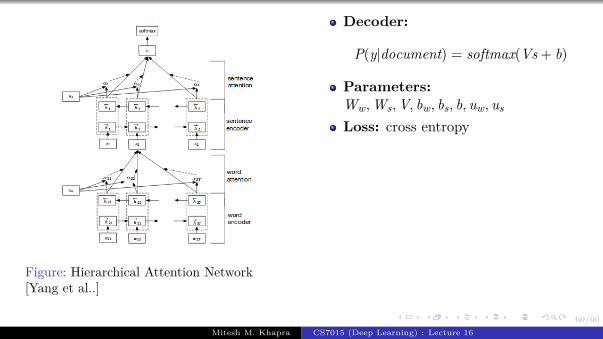
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.60/60
Figure: Hierarchical Attention Network[Yang et al..]
Decoder:
P(y|document) = softmax(Vs + b)
Parameters:Ww,Ws,V, bw, bs, b, uw, us
Loss: cross entropy
Algorithm: Gradient Descent andbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16

...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.
...
.60/60
Figure: Hierarchical Attention Network[Yang et al..]
Decoder:
P(y|document) = softmax(Vs + b)
Parameters:Ww,Ws,V, bw, bs, b, uw, us
Loss: cross entropyAlgorithm: Gradient Descent andbackpropagation
Mitesh M. Khapra CS7015 (Deep Learning) : Lecture 16




















