
Flexible scalable digital video coding
16
Signal Processing: Image Communication 5 (1993) 5 20 5 Elsevier Flexibly scalable digital video coding Cesar Gonzales and Eric Viscito IBM T. J. Watson Research Center, P.O. Box 704, Yorktown Heights, NY10598. USA Abstract. In this paper, we describe a video coding algorithm which combines the high visual quality of hybrid motion- compensated transform-based video coding techniques with the functional advantages of scalable, multi-resolution video. The technique produces a hierarchical video data representation by incorporating a simple frequency domain pyramid in a hybrid motion-compensated prediction/discrete cosine transform video coding algorithm. Compared to a single-layer hybrid scheme, this method has a very low penalty in coding efficiencyand codec complexity. Keywords. Video coding algorithm; scalable digital video; frequency domain pyramid. 1. Introduction The ISO MPEG Committee is responsible for creating standards for the coded digital representation of video and associated audio. In the first phase of MPEG activity, known as MPEG-1, a coding standard was developed for applications requiring video resolutions of approximately 360 x 240 pixels at picture rates of 24-30 pictures/sec and bit-rates up to about 1.5 Mbits/sec [3, 10]. Work is currently underway on MPEG-2, a standard for coding of video at CCIR 601 resolutions with nominal bit-rates in the range of 4-10 Mbits/sec. A large and diverse group of industries, including computer, consumer electronic, communications and broadcast television companies, is participating in the development of the MPEG-2 standard, and it is expected to be widely used. Because of this broad interest in MPEG-2, there are conflicting requirements from different applications in terms of features and functions, including compatibility, encoder and decoder implementation complex- ity, bit error and cell loss resilience, multi-resolution video, and image quality, among other things. It is unlikely that these conflicting requirements can be satisfied by a single, inflexible coding algorithm. Instead, a flexible algorithm is required, which can be matched to the requirements of the specific application. A properly designed algorithm will satisfy many of these requirements, while still preserving a great deal of commonality among the different manifestations of the algorithm. In this paper, we describe a video coding algorithm which has the potential to satisfy this need. We have proposed this algorithm for MPEG-2 [11]. The algorithm is a straight-forward extension of the MPEG-1 draft standard. The main extension, which involves the use of a frequency domain pyramid inside of a motion-compensated/DCT based coding scheme, enables the encoding of video that is scalable. By scal- ability [4], we mean the ability to have more than one image resolution and/or quality level readily available in the bit-stream.~ We distinguish among three types of scales: spatial, temporal and amplitude. The three types of scales are briefly defined below. Scalabilty is difficult to define precisely: it is not itself a function or functionality; rather it is a property of a video data representation that enables applications to support certain functions. A key property is that more than one version of the video signal can be reconstructed from the data representation, with the different versions differing in resolution or visual quality. 0923-5965/93/$06.00 ~, 1993 Elsevier Science Publishers B.V. All rights reserved
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Flexible scalable digital video coding

Signal Processing: Image Communication 5 (1993) 5 20 5 Elsevier
Flexibly scalable digital video coding
Cesar Gonzales and Eric Viscito IBM T. J. Watson Research Center, P.O. Box 704, Yorktown Heights, NY10598. USA
Abstract. In this paper, we describe a video coding algorithm which combines the high visual quality of hybrid motion- compensated transform-based video coding techniques with the functional advantages of scalable, multi-resolution video. The technique produces a hierarchical video data representation by incorporating a simple frequency domain pyramid in a hybrid motion-compensated prediction/discrete cosine transform video coding algorithm. Compared to a single-layer hybrid scheme, this method has a very low penalty in coding efficiency and codec complexity.
Keywords. Video coding algorithm; scalable digital video; frequency domain pyramid.
1. Introduction
The ISO M P E G Commit tee is responsible for creating standards for the coded digital representation o f video and associated audio. In the first phase o f M P E G activity, known as MPEG-1 , a coding s tandard was developed for applications requiring video resolutions o f approximately 360 x 240 pixels at picture
rates o f 24-30 pictures/sec and bit-rates up to about 1.5 Mbits /sec [3, 10]. W o r k is currently underway on
MPEG-2 , a s tandard for coding of video at C C I R 601 resolutions with nominal bit-rates in the range
o f 4-10 Mbits/sec. A large and diverse group of industries, including computer , consumer electronic,
communica t ions and broadcas t television companies, is participating in the development o f the M P E G - 2
standard, and it is expected to be widely used. Because o f this broad interest in MPEG-2 , there are conflicting requirements f rom different applications
in terms of features and functions, including compatibility, encoder and decoder implementat ion complex- ity, bit error and cell loss resilience, multi-resolution video, and image quality, among other things. It is
unlikely that these conflicting requirements can be satisfied by a single, inflexible coding algorithm. Instead, a flexible algori thm is required, which can be matched to the requirements o f the specific application. A
properly designed algori thm will satisfy m a n y of these requirements, while still preserving a great deal o f
commonal i ty a m o n g the different manifestat ions o f the algorithm. In this paper, we describe a video coding algori thm which has the potential to satisfy this need. We have
proposed this algori thm for M P E G - 2 [11]. The algori thm is a s traight-forward extension of the MPEG-1
draft standard. The main extension, which involves the use o f a frequency domain pyramid inside o f a
m o t i o n - c o m p e n s a t e d / D C T based coding scheme, enables the encoding of video that is scalable. By scal-
ability [4], we mean the ability to have more than one image resolution a n d / o r quality level readily available
in the bit-stream.~ We distinguish among three types o f scales: spatial, temporal and amplitude. The three types o f scales are briefly defined below.
Scalabilty is difficult to define precisely: it is not itself a function or functionality; rather it is a property of a video data representation that enables applications to support certain functions. A key property is that more than one version of the video signal can be reconstructed from the data representation, with the different versions differing in resolution or visual quality.
0923-5965/93/$06.00 ~, 1993 Elsevier Science Publishers B.V. All rights reserved

C. Gonzales, E. Viscito / Flexibly scalable digital video coding
Spatial scaling: a multiplicity of spatial resolutions in the video hierarchy. Rate scaling." a multiplicity of picture rates in the video hierarchy. This feature is inherent in the MPEG-
1 algorithm, and therefore in the proposed architecture. By proper choice of the MPEG-1 M-parameter, and by selectively skipping over one or more of the B-pictures, the MPEG-1 syntax can permit decoding at a multiplicity of temporal resolutions.
Amplitude scaling: more than one version of the video at the same spatial and temporal resolutions. The difference among the layers is fidelity.
Bit-stream scalability is useful in numerous scenarios, including network environments with video servers and multiple decoding platforms of varying costs and capabilities. Another application is for channel error resilience in broadcast. Lower layers of a scalable bit-stream can be error-protected to a greater degree than higher layers, causing most errors to result in slight degradation in picture quality rather than severe impairments. These are just two application areas; one purpose of this paper is to explore scalability requirements of other applications. 2
An important aspect of the proposed algorithm is that the scability is flexible. At its simplest, the algorithm produces a single-layer bit-stream, syntax-compatible with MPEG-1. A slight extension, which is compatible with MPEG-1 syntax, permits the coding of single-layer interlaced video. Finally, in its most developed manifestation, a multi-layer video hierarchy can be supported in a manner that retains a great deal of commonality with MPEG-1 syntax and core technology. A device capable of decoding a scalable bit-stream with several layers would be just slightly more complex than a single-layer decoder operating at the highest resolution layer.
The paper is organized as follows. Section 2 examines some of the many applications for which the MPEG-2 algorithm may be used, to underscore the motivation for scalable video. It emphasizes the features and functions of those algorithms which are potentially enabled by scalability. Section 3 describes the proposed scalable algorithm, with its frequency domain pyramid. Section 4 is a evaluation of the frequency domain pyramid approach described in this paper from the point of view of complexity and coding efficiency.
2. Application requirements analysis
We take the following approach to the analysis of the requirements of various applications as they concern scalability. A list of potential applications or application classes is described. A second list of application features and functions is also described. Finally, for each, application, each feature or function is rated as to its desirability or necessity.
2.1. Scalable application features and functions
We first describe the features and functions against which the applications will be assessed. For each application, a different set of operational characteristics is necessary. The list below consists of only those that relate to scalability, either because they are made possible by it or because they are influenced (positively or negatively) by it. Each of these items represents a column in the matrix.
2 When we refer to a 'low' or 'lower' layer in this paper, we mean a layer at a lower spatial, temporal or amplitude resolution than a 'higher' layer. Signal Processing: Image Communication

c. Gonzales, E. Viscito / Flexibly scalable digital video coding
1. Picture quality Picture quality is almost always one of the most important considerations in a video service. In scalable
applications, each scale can have a distinct picture quality requirement. It is difficult to assess required or acceptable picture quality in several layers of scalable video hierarchy. Hence, we consider only two quality parameters: the quality of the highest scale and the quality of the other scales.
We suggest three categories: 'critical', 'primary', 'secondary'. The picture quality is 'critical' in an applica- tion if high quality is by far the most important requirement, and economic viability of the application is jeopardized by any significant degradation. Picture quality is 'primary' if it is very important, but not the single dominating feature. A picture quality requirement designation of 'secondary' applies when quality is not the primary concern. The 'secondary' designation may only apply to lower scales.
2. Type and degree of scaling One of the most important aspects of a scalable application is the underlying video hierarchy, as reflected
in the type of scales needed and the number of each type required. One way to characterize this hierarchy is to designate how many layers are required, and what the relation of the spatial, temporal and amplitude resolutions of each scale are to those of the highest scale.
For example, suppose an application required CCIR 601 704 × 480 resolution at 30 pictures/sec and 5 Mbits/sec at the highest layer, and in addition, a second layer with the same spatio-temporal resolution but half the bit-rate, and a third layer with half resolution both spatially and temporally (i.e. 352 × 240 at 15 pictures/sec), but with an unconstrained bit-rate. This can be described concisely by
Layer number Resolution Picture rate Bit-rate
Layer 1 704 x 480 30 5.0 Layer 2 1.0 1.0 0.5 Layer 3 0.5 0.5
The information for layer 1 (the highest resolution layer) is given in absolute terms. The other layers are described with reference to layer 1. Therefore, layer 2 has a picture resolution of 704 × 480, a picture rate of 30 pictures/sec, and a bit-rate of 2.5 Mbits/sec. Layer 3 has resolution 352 × 240, picture rate of 15 pictures/sec and an unconstrained bit-rate (but clearly lower than 2.5 Mbits/s).
The number of layers required is a key element of this feature. Note that this method of characterizing applications regarding type and number of layers describes amplitude scale relationship between them. This
may not be the only or best way. For instance, it could be that the relative quality between layers is important in an application, and whatever bit-rate allocation among layers is needed to achieve that quality would be acceptable. In this case, a designation of picture quality in the individual layers would be necessary to characterize the amplitude scaling.
We must maintain a distinction between application requirements for .layers and the means of imple- menting those requirements. For example, an application requiring bit error resilience may require several layers of amplitude scaling (with decreasing amounts of coding noise at the same spatio-temporal resolu- tion). In practice, this may be implemented with spatial scaling, or even some form of temporal scaling.
Vol, 5, Nos. I 2. February 1993

C. Gonzales, E. Viscito / Flexibly scalable digital video coding
3. Layer bandwidth control Whereas most applications of scalable video will require constraints in overall peak and average bit-
rates, the issue of whether the fractional bit-rates of the lower layers can be left unconstrained, or whether they should be fixed is still open. There is Usually a trade-off between the degree of bandwidth control of the lower layers and the resulting image quality. Some applications may require well-defined bit-rates in lower layers even if that means a lower quality for the full resolution video. Other applications will tolerate unconstrained bit-rates for its lower layers as long as the quality of the full resolution video is very high. These contrasting requirements are indicated in the notation of the previous section: the third entry in the description of each layer is a fractional bit-rate, or a ' - - ' for 'don't care'. It should be noted that it is unlikely that arbitrary specifications for layer picture qualities and bandwidths can be achieved with any approach to scalability. Instead a compromise will almost always be required of the application developer.
4. Complexity scaling One attractive feature of scalable video is the possibility that the decoding of lower layers can be done
using less complex hardware or even software. We indicate for each application that decoder complexity scaling takes on one of three degrees of importance: necessary, important or unnecessary.
Applications which can benefit from encoder complexity scalability can be envisioned. The usefulness of encoder scalability needs more study.
2.2. Scalable applications
What follows is a list of sample applications we have generated for CCIR 601 resolution video, charac- terized against the above requirements. The designations represent our own initial attempts to understand the problem of characterizing applications for scalability requirements.
1. High-quality CCIR 601 single-resolution video This application, which from the description does not require scalability, is included as a benchmark.
High layer quality: Lower layer quality: Number of scales : Scale bandwidth control: Complexity scaling:
CRITICAL
1 704x480 30 4 9
2. Error-resilient single-resolution video Some broadcast applications must contend with serious channel impairments in the form of bit errors,
cell loss or other degradations. Prime examples are terrestrial broadcast, satellite broadcast and ATM network transmission. Protection against such errors through multi-priority error protection or transmission schemes can be made possible by a scalable representation of the video signal. For example, a two-layer dynamically scalable video hierarchy based directly on the MPEG-1 standard has already been implemented in a proposal for High Definition Television before the Federal Communications Commission [8].
At least two layers are needed, with all of them targeted to the same spatio-temporal resolution. We emphasize that this does not imply that all the layers must necessarily be at the target resolution. Signal Processing: Image Communication

C. Gonzales, E. Viscito / Flexibly scalable digital video coding 9
High layer quality: CRITICAL Lower layer quality: SECONDARY Number of scales: > 1
Scale bandwidth control:
Complexity scaling:
Most likely necessary within preset ranges which are medium- or channel-dependent. Unimportant
704 × 480 30 3 9 1.0 1.0 ?
3. Multi-platform decoding
This application group addresses the need to produce video that can be decoded by a range o f platforms
of different capabilities. This capability has potential usefulness in a variety o f scenarios. It includes applica- tions in which backward compatibil i ty with another s tandard is necessary, but extends to many applications
outside that limited set. One example is a video server on a heterogeneous digital network. Another example
is multi-resolution television broadcast . We outline the case o f three spatial layers for a heterogeneous
network.
High layer quality: CRITICAL/PRIMARY Lower layer quality: PRIMARY Number of scales: >2
Scale bandwidth control: Complexity scaling :
Unnecessary within a range Necessary
704 x 480 30 4 9 0.5 1.0 - - 0.25 1.0 - -
4. Multi-window, multi-source decoding
One example o f this type o f application is mult i-party video-conferencing. Certain surveillance applica-
tions could also qualify. Critical is the ability to have several sources displayed in different windows
simultaneously with the size o f each source independently selectable at the decoder. Besides being able to
display multiple video windows within a single viewing screen (thus saving processing resources for re-
sizing to the target window sizes), there is a savings in processing resources in decoding the multiple video
streams. In the op t imum case, a single decoding engine could multiplex itself a m o n g the incoming bit- streams operat ing only on the port ions that are necessary to reconstruct the target window resolution.
High layer quality: Lower layer quality: Number of scales :
Scale bandwidth control: Complexity scaling:
CRITICAL/PRIMARY SECONDARY >2
Unnecessary within a range Necessary
640 × 480 30 1.5 3 0.5 1.0 0.25 1.0 - -
5. Multi-scan-rate serial storage
By decoding diminishing port ions o f a scalable bit-stream, it is possible to implement video playback at increasing speeds while maintaining reasonable processing requirements. Precise details o f the scalability requirements in this application are dependent on the specific storage or communica t ion medium. Neverthe- less, it seems that some form of scalability is essential to it.
Vol. 5, Nos. I 2, February 1993

10 C. Gonzales, E. Viscito / Flexibly scalable digital video coding
High layer quality: CRITICAL Lower layer quality: SECONDARY Number of scales: >4
Scale bandwidth control: Complexity scaling :
Medium-dependent Necessary
740 x 480 30 4 9 ? ? ?
The above applications are a subset among others that have been proposed by our MPEG colleagues, but it is already clear from the above that the type and degree of scalability needed depends to a great degree on the particulars of each application. This is why we feel it is essential to provide flexible scalability. The important features of an application should not be diminished because of the need to include a number of scales that are not useful to the application. This applies to high quality single-resolution television in particular, but to all applications as well.
3. Flexibly scalable video coding algorithm
3.1. MPEG-1 background
Since this video coding algorithm is based fundamentally on the MPEG-1 draft standard, we will briefly describe the relevant aspects of that algorithm. However, to avoid an overly lengthy description, we assume that the reader has a basic understanding of that standard. A more complete overview can be found in [3], and a detailed description in the informative annex of the video section of the Standard Committee Draft [10]. In MPEG-1, the pixel data is organized in a hierarchical fashion as follows. A sequence of pictures is divided into distinct sets known as Groups of pictures (GOPs). Within a GOP, there are three types of pictures: Intra-pictures (I-pictures), predicted pictures (P-pictures) and interpolated pictures (B-pictures). I-pictures are coded independently, without reference to other pictures. P-pictures are coded using motion compensated prediction from the most recent I- or P-picture. Typically, a P-picture is separated in time by more than one picture interval from the predicting picture. I- and P-pictures are known collectively as anchor pictures. The pictures which lie between anchor pictures are the B-pictures and are coded using motion compensated prediction from the past or future anchor picture or an average of them (The 'B' is for bidirectionally predicted). A typical arrangement of I-, P- and B-pictures is shown in Fig. 1.
Each picture is subdivided into units called slices. Each slice consists of a series of Macroblocks, which consist themselves of 16 x 16 regions of luminance and the spatially co-located 8 × 8 regions of the chromin- ance images. Macroblocks (MBs) are ordered sequentially in lexicographic order, and a slice consists of a
Signal Processing: Image Communication
I B B P B B P B B I
Fig. 1. Typical MPEG motion compensation structure.

C. Gonzales, E. Viscito / Flexibly scalable digital video coding 11
Input Picture
VLC Compressed
I and D~ta
a) Encoder
Reconstructed
C o m p r e s s e d ~
Data DVLCe ~do.~i~!vrm~ n : ~:~fiomlOu~it ~_J
b)Decoder
Fig. 2. Prototype MPEG-I: (a) encoder and (b) decoder.
variable number of Macroblocks in that order. A slice may contain exactly one row of macroblocks. Within the macroblock, the luminance region is further subdivided into 8 × 8 regions known as blocks.
Motion compensated prediction is done on a macroblock basis. The discrete cosine transform is taken on each of the 8 x 8 blocks within a macroblock. DCT coefficients are quantized, ordered according to a zig-zag scan, and grouped into combined (run, amplitude) events. The quantization involves a quantizer scale factor QP that helps control the bit-rate, among other things. The (run, amplitude) events are VLC coded, along with all other side information from the macroblock and multiplexed into a single bit-stream. All data for a macroblock are multiplexed in the same location in the bit-stream. Block diagrams of a prototypal MPEG-1 encoder and decoder are shown in Fig. 2.
Many details of MPEG-1 have been omitted here, including the discretionary aspects of encoder opera- tion. Information on these issues can be found in [2, 5, 6].
3.2. Sealable video architecture overview
The key difference of this algorithm from MPEG-1 is that a family of hierarchical video representations can be generated. The simplest member of the family is a single-layer bit-stream which is fully MPEG-1 compatible. One or more lower layers can be added to this layer. Each layer can have a spatial resolution equal to or less than the next higher layer. The possible spatial resolutions of a layer are 1/2, 1/4 and 1/8 the resolution (in each dimension) of the highest layer. If the spatial resolution of two layers are the same, then the layers differ in the fidelity at that resolution. This fidelity difference is achieved by using different quantizer scale factors in the layers.
This resolution hierarchy is achieved by a pyramid in the DCT coefficient domain. Figure 3 depicts the DCT coefficients that reside in each of the four possible spatial scales. The highest scale (scale-8) has a full 8 x 8 DCT block. Scale-4 has a 4 x 4 DCT block, and its coefficients correspond to the upper left, or low frequency, coefficients of scale-8. Similarly, scale-2 consists of a 2 x 2 block, and scale-1 consists of simply
Vol. 5, Nos. 1 2, February 1993

12 C. Gonzales, E. Viscito / Flexibly scalable digital video coding
Ct [] 1/64 Resolution m Predicted DCT coefficient
C2 ~ 1/16 Resolution D Non-predicted DCT coefficient
C 4 ~ 1/4 Resolution
C s Full Resolution
i
Fig. 3. Hierarchical scales in the DCT domain.
the DC coefficient. In the scalable video hierarchy, the DCT coefficients of each layer are used to predict the corresponding coefficients of the next higher layer, as described in more detail in Section 3.4. This is true even if the two layers are at the same scale. To decode to a target scale (say scale-N), appropriately
normed transforms of size N × N are used. Decoding to a target scale involves an MPEG-l-l ike decoder operating at that scale, plus additional VLC decoding, partial dequantization and addition of DCT coefficient data from lower layers.
We emphasized that not all of the above scales must appear in a scalable bit-stream. A bit-stream can be constructed with just those scales which are necessary for the application at hand. Information pertaining to which scales are present in a bit-stream is transmitted in the MPEG-1 sequence layer.
It should also be noted that there is no technical impediment to having 8 scales, from 1 through 8, each corresponding to a different sized square region of the 8 × 8 DCT block. However, we have restricted the scalable system to factors of 2 to simplify the computations for motion-compensation as described in Section 3.8.
The frequency pyramid proposed in this paper has elements in common with several types of compression for progressive image transmission. One such technique is the spectral selection as described in the JPEG image compression standard [9]. In that approach, different subsets of the DCT coefficients are encoded in different scans over the image. There is considerable flexibility in how many scans are used and how the DCT coefficients are apportioned among the bands. This is analogous to the different scales in our approach. Other approaches to transform domain progressive image coding have involved repetitive quantization of each DCT coefficient [7]. A similar effect can be achieved in our approach by using different values of the quanitizer scale parameter QP in multiple layers at the same resolution or at different resolutions. Note that JPEG also has a successive approximation mode, in which each coefficient is refined in several passes. However, this refinement can take place only one bit at a time.
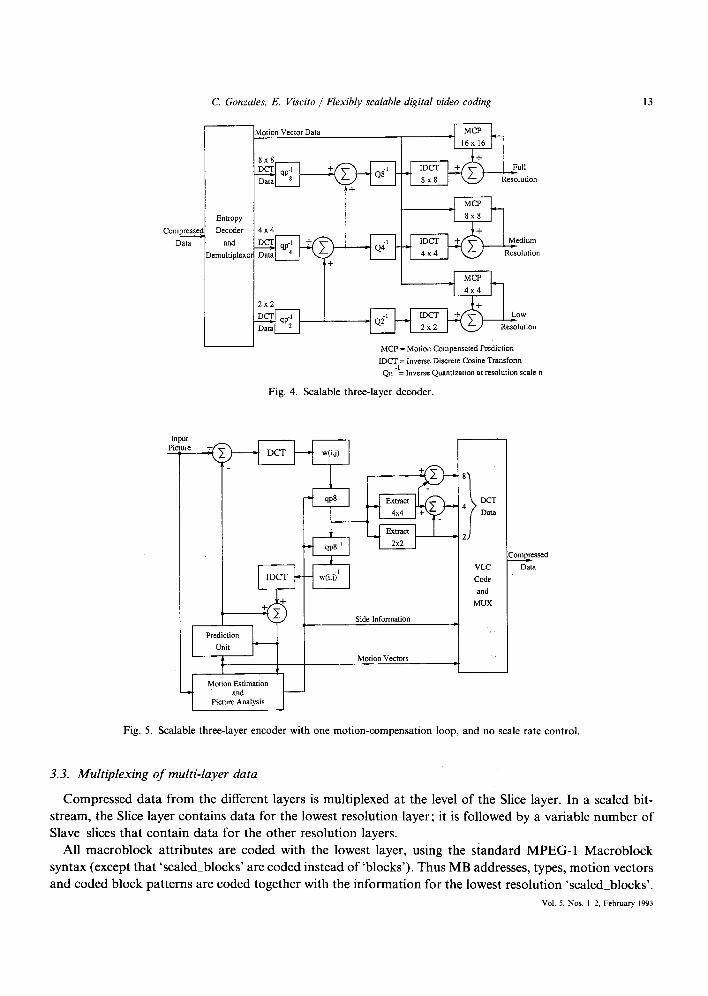
In the remainder of this section, we look at specific aspects of the video coding scheme in more detail. As specific examples, Fig. 4 shows a three-layer scalable decoder and Fig. 5 shows the simplest three-layer scalable encoder. In addition, Fig. 6 shows a slightly more complex encoder capable of controlling the bit- rate of the individual scales. We refer to these examples throughout most of the course of the discussion. Signal Processing: Image Communication
C. Gonzales, E. Viscito / Flexibly scalable digital video coding
Motion Vector Data •
- - T T - . I I 8x8
~ q 8x8 F- ~v,.~ Resolution
~ntfopy I "~ Compressed Decoder 4 x 4
Data and D ~ + ~ ~ ~ ~ ~ I Mediurn
Demultiplexor Deta[.._.~ k ~ ~ ~] 4x4 I - ~ , ~ , '/ Resolution
2 x 2 I ~'+ I
Dat;L.2._] [_LL_I I 2~2 I ~ Resol~t,on
MCP = Motion Compensated Prediction
IDCT = Inverse Discrete Cosine Transform -1 Qn = Inverse Quantizafion at resolution scale n
Fig. 4. Scalable three-layer decoder.
13
Input Pi....~cture < ~
Picture Analysis
4 Data
-7 ~x2 ~ 2 Co~p:essed VLC Data
" Code and
MUX
Side Information m.
Motion Vectors ~,
Fig. 5. Scalable three-layer encoder with one motion-compensation loop, and no scale rate control.
3.3. Multiplexing of rnulti-layer data
Compressed data from the different layers is multiplexed at the level o f the Slice layer. In a scaled bit- stream, the Slice layer contains data for the lowest resolution layer; it is fol lowed by a variable number o f Slave slices that contain data for the other resolution layers.
All macroblock attributes are coded with the lowest layer, using the standard MPEG-1 Macroblock syntax (except that 'scaled_blocks' are coded instead of'blocks') . Thus MB addresses, types, mot ion vectors and coded block patterns are coded together with the information for the lowest resolution 'scaled_blocks'.
Vol. 5, Nos. 1-2, February 1993

14 c. Gonzales, E. Viscito / Flexibly scalable digital video coding
Input
~ + 2JData Compressed ] ~ VLC Data
Code and
MUX Side Information
Prediction Unit ~ t Motion Vectors
_~ Motion Estimation I and Picture Analysis
Fig. 6. Three-layer, one-loop encoder with scale rate control.
The low resolution 'scaled_blocks' contain only the appropriate D C T coefficients and are coded using a modification of the usual 'block' syntax, as discussed in Section 3.8.
The Macroblock attributes coded in the Slice layer are inherited by the higher layers, and therefore do not need to be coded in the Slave_slices. The Slave_slices contain Slave_macroblock data which, in turn, contain DCT coefficient data which augments that in the lowest layer. These data increase the resolution or amplitude-precision of the scaled blocks. Because the macroblock attributes of the Slice layer are inherited by the Slave_macroblocks, only DCT data appears in Slave_slices. In fact, data appears only for those blocks indicated by the MPEG-1 Coded block pattern (CBP) in the Slice layer.
3.4. Hierarchical D C T coefficient prediction
DCT coefficients in a lower layer are used to predict the corresponding coefficients in the next higher layer, as depicted in Fig. 3. After computing the prediction differences, these differences together with the new (not predicted) coefficient data are converted to (run, amplitude) events using the standard MPEG-1 zig-zag scan pattern.
3.5. D C T and I D C T definitions for low resolution scales
DCT transforms with non-standard normalization factors are used to simplify the process of quantization and inverse quantization. The following definitions are used:
SCALE FDCT IDCT
8 x 8 DCT(8 x 8) IDCT(8 x 8) 4 x 4 2*DCT(4 x 4) IDCT(4 x 4)/2 2 x 2 4*DCT(2 x 2) IDCT(2 x 2)/4
Signal Processing: Image Communication

C. Gonzales, E. Viscito / Flexibly scalable digital video coding 15
where D C T ( N x N) and IDCT(N × N) are the standard definitions for the 2-dimensional transform of size N x N. 3
The advantage gained by using this approach is that the same quantization matrix (see Section 3.6) can be used at all scales, resulting in very simple procedures for reconstructing DCT coefficients. An alternative implementation would use the standard DCT definitions and instead re-normalize the quantization matrix at each scale.
Note that it is not necessary to actually employ DCTs of size other than 8 × 8 in an encoder. For instance, Fig. 5 shows an encoder in which the lower scale DCT coefficients are obtained by extracting the corresponding coefficients from the highest layer. Similarly, a decoder operating at a particular target resolution needs, for each block, only one DCT of the size appropriate to that resolution. This is illustrated in Fig. 4. It should be noted that Fig. 4 actually has three decoders, one for each resolution scale. However, it can be easily seen from the figure that decoding for one target scale requires only one size DCT.
3.6. Quantization
Quantization in the MPEG-1 standard consists essentially of dividing each DCT coefficient by a number which is the product of an entry from a quantization matrix w ( i , j ) and a scale factor QP. The quantization matrix value can be different for each of the 64 DCT coefficients. There can be two different matrices, one for macroblocks coded without prediction (intra MBs), and another for predicted MBs. The QP value is the same for all coefficients in a macroblock, and can take any integer value from 1 to 31. 4 The QP parameter, which can change from MB to MB, has the joint purposes of permitting bit-rate control and space-varying quantization.
In the scalable system, we have chosen to use the same MPEG-1 quantization matrices for all resolution scales. Hence, for the 2 x 2 hierarchical layer, the upper left 2 x 2 elements of the 8 x 8 quantization matrices are used, and so on. This leads to a very simple means of dequantizing DCT coefficients. In general, to rebuild the DCT coefficients for a target scale, the following steps are needed: 1. partial inverse quantization of the DCT coefficients of the target scale and all lower scales by the
appropriate quantizer scale factor QP, (QP2 for scale 2 × 2, QP4 for scale 4 × 4 and QP8 for scale 8 x 8), 2. where appropriate, summation of the results of the previous step (hierarchical prediction), 3. final inverse quantization of the DCT coefficients of the target scale using the appropriate quantization
matrix w (intra or non-intra). These operations are depicted in Fig. 4. Except for DC coefficients in intra blocks, partial inverse quantiza- tion is defined by
~0 if QAC(i, j ) = 0, partial_inv(i, J)
(2QAC(i , j ) +k )QP , otherwise,
where QAC(i , j ) is the ( i , j ) - th quantized DCT coefficient of a block, partial_inv is the result of partial dequantization, k = 0 for intra and k = 1 for non-intra macroblocks. Final inverse quantization is defined by
part ial_inv(i , j)w(i , j)) rec(i, j ) -
16
3 That is, where the underlying DCT matrix is orthogonal. 4 The sole exception to this two-component quantization is that the DC coefficient of intra MBs is quantized with a fixed value
of 8. Vol. 5, Nos. 1 2, February 1993

16 C. Gonzales, E. Viscito / Flexibly scalable digital video coding
where w is the quantization matrix for intra MBs, and w is the non-intra matrix for non-intra macroblocks. For the DC value of intra blocks, the reconstruction is obtained by calculating 8QDC, for all scaling layers, where QDC is the quantized DC coefficient.
3.7. Provision for layer bandwidth control
The purpose of allowing different QP values in different scales is to permit bit-rate control of the individual scales. To implement this, the Slaveslice layer specification includes a quantizer delta parameter AQP,. This delta is always specified with reference to the corresponding quantizer scale factor used in the Slice layer. This parameter is used to derive QPn values used in the slave layers according to
QPn = clip_ 1_31 [QPlow + AQPn],
where QPlow is the QP value transmitted in the Slice layer for the MB under consideration, and the function 'clip_l_31' sets values exceeding 31 to 31, and values less than 1 to 1.
Although the ability to control the bit-rate of the individual layers exists, an encoder does not necessarily have to use different QPn values in different scales. Figure 5 is an example of an encoder that simply extracts the appropriate DCT coeffients from the highest scale to obtain those of the lower scales.
3.8. Coding of motion vector data
Motion vector data are part of the MB attributes which are coded in the Slice layer. Regardless of the resolution associated with the pixel data of the Slice layer, the motion vector data are generated so as to apply to the full resolution video, and therefore they are the same as those that would be derived for a non-scalable bit-stream. This means that, to reconstruct motion vectors for resolution scales other than full resolution, these data must be scaled appropriately. This scaling is achieved for scale-n by multiplying the full-resolution motion vector by n/8, rounding away from zero to a resolution of 1/2 pixel. For example, the x- and y-motion-vector components at scale-4 are 1/2 the corresponding full resolution scale-8 components. Similarly the scale-2 vector components are 1/4 the corresponding scale-8 components.
3.9. DCT coefficient VLC coding
For each scale, a two-dimensional VLC table is used to code the DCT coefficients. Coding of 2 x 2 and 4 × 4 DCT coefficients is through a set of new VLC tables, described below. For the final 8 × 8 layer, coefficients are coded (intra macroblocks included) by using the standard MPEG-1 tables, without the special-case treatment of the first run/amplitude event. A difference from MPEG-1 is that, in slave_slices, there may be blocks in a particular layer for which all prediction differences and all unpredicted coefficients are zero, but which are coded anyway. This happens because there is non-zero data for the block in one or more of the other layers. In such cases, an end-of-block (EOB) is the first and only event coded.
The variable-length coding scheme used for coding of DCT coefficients in the lower scales is a modified JPEG-style. In the JPEG scheme [9], VLC codes are assigned to RUNS and LOG-MAGNITUDE combina- tions; followed by a number of bits, equal to the log-magnitude, that specify the exact amplitude. The entire (RUN, LOG_MAG) codeword table can be constructed from knowledge of the number of codewords of each length, and an ordered list of (RUN, LOG_MAG) pairs. The complete specification for these tables appears in [ 11 ]. Signal Processing: Image Communication

C. Gonzales, E. Viscito / Flexibly scalable digital video coding 17
We are still studying the issue of DCT coefficient coding, and expect to improve upon the above method in the near future.
4. Impact of scalability on complexity and visual quafity
The introduction of increased functionality in the form of a video hierarchy brings an increase in codec complexity and a reduction of visual quality. It is important to assess the value of the functionality added by the hierarchy against these drawbacks. We cannot assess the performance of the frequency domain pyramid approach without an understanding of the requirements for scalability. We have discussed in Section 2 a set of prototypal applications that benefit from scalability, and a set of functionalities or features that scalability would provide for these applications. This can be used to begin a study of the merits of the approach.
4.1. Picture quality
Picture quality is usually one of the most important considerations in a video service. In scalable applica- tions, each scale can have a distinct picture quality requirement. Generally speaking, there will be a trade- off between the quality of the highest scale (full resolution) and the quality of the lower scales. Some applications require that the quality of the highest scale be the best possible even if that means degraded lower resolution scales.
A frequency pyramid is capable of providing a hierarchical video representation with little degradation in picture quality because the bit-rate overhead of sending additional scales can be made minimal. This is true because in the simplest case, the lower layers are derived by extracting the appropriate set of DCT coefficients from the higher layer. In this scenario, experiments have demonstrated that very little is lost in coding efficiency as compared to a single-layer approach. Specifically, we have run experiments in which a single-layer and a three-layer bit-stream (with scales 8, 4 and 2) have been produced in parallel by a single encoder. All coding operations except the coding of DCT coefficients and data multiplexing were identical, including rate control and quantization rules. This ensures that the highest layer reconstructed pictures provided by the two approaches are identical. In this experiment, the three-layer coder produced only 8- 20% more compressed data than the single layer coder.
The experiment was conducted as follows. The first 61 pictures of the MPEG-2 test sequences Flower garden, Mobile and calendar and Table tennis were coded using the single-layer encoder which we proposed for the MPEG-2. During this run, histogram data were collected for the three-layer statistics, assuming that the lower layers are formed by extracting the appropriate DCT coefficients directly from the highest layer. These histograms were used to design JPEG-style two-dimensional VLC tables, which were then used to code the three-layer version using an otherwise identical encoder, as described above. Two variations of the three-layer scheme were produced; one used the MPEG-1 VLC table in scale-8, and the other used the optimized JPEG-style table produced from the statistics. Table 1 shows the coding efficiency results of this experiment.
There are several effects to consider in this type of experiment, including the different style of tables, the fact that the JPEG-style tables were optimized for the limited data set of 183 pictures, rather than a wider data base, and the fact that predicted coefficients in the higher layers are guaranteed to be zero in this encoder, but not in the general case. On the other hand, a single table was used for each scale for all pictures in all three sequences. We are in the process of conducting more thorough experiments to address the entire
Vol. 5, NOS. 1 2, February 1993

18 C. Gonzales, E. Viscito / Flexibly scalable digital video coding
Table 1 Cumulative byte counts over the first sixty-one pictures of three sequences for three encoders: l-layer MPEG-I, 3-layer with MPEG-1 in scale-8, and 3-layer with JPEG-style in all three layers
(a) Table tennis
Encoder Byte count Penalty
l-layer 1,028,726 - - 3-layer (M) 1,213,845 18.0% 3-layer (J) 1,110,206 7.9%
(c) Mobile and calendar
Encoder Byte count Penalty
l-layer 1,052,638 - - 3-layer 1,260,880 19.8% 3-layer (J) 1,199,093 13.9%
(b) Flower garden
Encoder Byte count Penalty
l-layer 1,038,325 - - 3-layer (M) 1,241,375 20.2% 3-layer (J) 1,158,447 11.6%
problem of VLC coding for flexibly scalable video. Nonetheless, the results do indicate that potentially very small penalties can be incurred for the introduction of layers.
4.2. Type and degree o f scaling
One of the most important aspects of a scalable application is the underlying video hierarchy, as reflected in the type of scales needed and the number of each type required. The three types of scales are spatial, temporal and amplitude. The number of scalable layers and their types is a subject of debate, and is most likely application-dependent. For reasons addressed below, we feel that a frequency pyramid approach can provide a good solution.
4.3. Scale bandwidth control
Whereas most applications of scalable video will require constraints in overall peak and average bit- rates, the issue of whether the fractional bit-rates of the scaling layers can be left 'unconstrained' or whether they should be fixed will depend on the application. In applications where the fractional rates can be left unconstrained, the above experiment shows that the frequency pyramid can be quite efficient. We also believe that for a range of 'limited bandwidth constraints' , the frequency pyramid will perform well. When fixed low-bandwidths are needed for each of the scales, other techniques, including a spatial pyramid may be competitive. In extreme cases for which a single low-bandwidth lower layer is needed, a parallel, independent bit-stream (simulcast) may even be sufficient.
4.4. Decoder complexity
From the description of the video architecture in Section 3, the additional operations (over those of a single-layer decoder) required to decode the full-resolution layer can be described. Referring to Fig. 4, it can be seen that additional data demultiplexing and buffering is necessary to access the layers. In our three-layer software simulations, we have used three software pointers that traverse the MBs in a slice simultaneously in the process of VLC decoding. This approach requires pointer set-up at the start of every slice (which in turn requires searching for Slave slice Start Codes) and multiplexing among multiple VLC Signal Processing : Image Communication

C. Gonzales, E. Viscito / Flexibly scalable digital video coding 19
decoders on an MB basis, but avoids the need to partially decode and store an entire slice at the lower layers. On a fundamental level, most of the decoding operations can be easily parallelized in hardware.
The other additional function required in the frequency pyramidal hierarchical approach is to combine the VLC-decoded DCT data from all layers below and including the layer being decoded. This is described in Section 3.6.
It is also useful to make comparative statements regarding the complexity of two approaches to the same problem. We consider briefly the steps involved in a hierarchical scheme based on a spatial pyramid with MPEG-like layers. Here, each layer below the target layer must be entirely VLC-decoded, dequantized, inverse transformed and motion-compensated. In addition, some up-sampling and filtering is usually used in preparing a lower layer to be used as a prediction for a higher layer. Even if the lower layer is used as the prediction only in a small percentage of each picture, it may be necessary to fully decode the lower layers because it is not known a priori which regions are needed for prediction of the higher layer or for motion-compensated prediction of necessary regions of future pictures at the lower layer. From this point of view, the frequency pyramid seems to be clearly superior to the spatial pyramid.
4.5. Encoder complexity
As with MPEG-l , the complexity of an encoder implementation in the scalable scheme is quite dependent on discretionary choices, and dictated to a more limited extent be the nature of the video data representation. In the simple case in which lower layer DCT coefficients are formed by extracting the corresponding ones from higher layers, the additional complexity is quite analogous to that described for the decoder above. However, other more complex possibilities exist. One possibility is an encoder in which each layer contains a complete motion-compensated prediction loop, with DCTs of the appropriate size and independent quantization. Note that the motion estimation is still shared among the layers. We have implemented a simulation of this encoder and performed some preliminary experiments to test the effects of the lower layer prediction error build-up which occurs in the simplest encoder. In the more complex three-loop encoder, some of the predicted coefficients in higher layers are non-zero (where in the simpler encoder, they are guaranteed to be zero), which results in less efficient coding. Thus, while motion-related artifacts were reduced, overall coding noise increased slightly.
4.6. Complexity scaling
Some of the applications in which we are interested require decoding complexity scaling. While virtually any hierarchical scheme will yield complexity scaling by virtue of the fact that fewer bits and pixels must be processed in lower layers, there are other factors that favor a frequency pyramid.
For example, one key difference between the frequency and spatial pyramids is that smaller DCTs are used in lower layers in the frequency pyramid. Based on a straight-forward analysis assuming that the cost of a fast N x N DCT is proportional to N 2 log(N2), a 4 x 4 inverse DCT is 2/3 as costly on a per-pixel basis as an 8 x 8. Similarly, a 2 x 2 is 1/3 as costly as an 8 × 8. A more careful analysis of IDCT algorithms geared to non-multiply/add architectures shows that the 4 × 4 requires roughly 45% the multiplies and 70% of the adds of the 8 × 8. For multiply/add architectures, the 4 × 4 operation count is 77% that of the 8 × 8 [1]. Thus the cost of DCTs scales more in the frequency approach than in the spatial pyramid approach, which is a clear advantage for software decoding and may also represent one for hardware. This advantage for the frequency approach must be weighed against the fact that most likely less side information needs to be decoded in lower layers when 8 × 8 blocks are used. Clearly, more work is needed to evaluate the relative merits of these approaches.
Vol. 5, Nos. 1 2, February 1993

20 C. Gonzales, E. Viscito / Flexibly scalable digital video coding
5. Conclusion
We believe that a set o f real applications exists that requires a scalable video data representation.
Furthermore, we also believe that several o f these applications require a set o f functionalities which are
well supported by a frequency pyramid approach to scalability. We have described a flexible method for
scalable digital video using a frequency domain pyramid. This approach has advantages bo th in terms of
visual quality and complexity. However, some aspects o f the system are still under study. It may be possible to improve the post-quant izat ion processing of D C T coefficient data (scanning and coding) to make it
more efficient over the b road range of applications. The approach can also be extended in several ways.
One possibility is to include a larger choice o f scales, rather than only 1, 2, 4 and 8, as discussed in Section
3.2. It is also possible that the current highest scale (scale-8) could serve as a lower scale o f a high
definition system using 16 × 16 D C T s as the new highest scale. With these possibilities comes the prospect o f
compatibility, commonal i ty and interoperability across a wide spectrum of future video services.
Acknowledgments
We would like to thank our colleagues Lascoe Allman, Thomas McCar thy , Keith Pennington and Dov R a m m for their contr ibut ions to this effort.
References
[1] E. Feig and S. Winograd, "Fast algorithms for the discrete cosine transform", IEEE Trans. Signal Process., Vol. 40, September 1992.
[2] C. Gonzales and E. Viscito, "Motion video adaptive quantization in the transform domain", IEEE Trans. Circuits Systems for Video Technology, Vol. 1, December 1991, pp. 374 378.
[3] D. LeGall, "MPEG: A video compression standard for multimedia applications", Comm. ACM, Vol. 34, April 1991. [4] A. Lippman, "Feature sets for interactive images", Comm. ACM, Vol. 34, April 1991, pp. 93-101. [5] A. Puri and R. Aravind, "Motion-compensated video coding with adaptive perceptual quantization", IEEE Trans. Circuits
Systems for Video Technology, Vol. 1, December 1991, pp. 351 361. [6] E. Viscito and C. Gonzales, "A video compression algorithm with adaptive bit allocation and quantization", SPIE Visual Comm.
Image Process., Vol. 1605, November 1991, pp. 58-71. [7] L. Wang and M. Goldberg, "Progressive image transmission by transform coefficient residual error quantization", IEEE Trans.
Comm., Vol. 36, January 1988, pp. 75-87. [8] Advanced Television Research Consortium, Advanced Digital Television System Description, 1992. [9] ISO-IEC JTC1/SC29/WG8, JPEG Draft International Standard 10918-1, 1992.
[ 10] ISO-IEC JTCI/SC29/WG11, MPEG Committee draft CD 11172, Rev 1, 1991. [11] ISO-IEC JTC1/SC29/WG11 91/212, A Proposal for MPEG-I coding with scalable extensions, 1991.
Signal Processing: Image Communication




















