Development of Speech Input Method for Interactive VoiceWeb Systems
10
J.A. Jacko (Ed.): Human-Computer Interaction, Part II, HCII 2009, LNCS 5611, pp. 710–719, 2009. © Springer-Verlag Berlin Heidelberg 2009 Development of Speech Input Method for Interactive VoiceWeb Systems Ryuichi Nisimura 1 , Jumpei Miyake 2 , Hideki Kawahara 1 , and Toshio Irino 1 1 Wakayama University, 930 Sakaedani, Wakayama-shi, Wakayama, Japan 2 Nara Institute of Science and Technology, 8916-5 Takayama-cho, Ikoma-shi, Nara, Japan [email protected] Abstract. We have developed a speech input method called “w3voice” to build practical and handy voice-enabled Web applications. It is constructed using a simple Java applet and CGI programs comprising free software. In our website (http://w3voice.jp/), we have released automatic speech recognition and spoken dialogue applications that are suitable for practical use. The mechanism of voice-based interaction is developed on the basis of raw audio signal transmis- sions via the POST method and the redirection response of HTTP. The system also aims at organizing a voice database collected from home and office envi- ronments over the Internet. The purpose of the work is to observe actual voice interactions of human-machine and human-human. We have succeeded in ac- quiring 8,412 inputs (47.9 inputs per day) captured by using normal PCs over a period of seven months. The experiments confirmed the user-friendliness of our system in human-machine dialogues with trial users. Keywords: Voice-enabled Web, Spoken interface, Voice collection. 1 Introduction We have developed a speech input method for interactive voice-enabled Web system. The proposed system is constructed using a simple Java applet and CGI programs. It would serve as a practical speech interface system comprising only free software. The World Wide Web has become an increasingly more popular system for finding information on the Internet. At present, nearly every computer-based communication service is developed on the Web framework. Further, Internet citizens have begun to benefit significantly from transmitting multimedia data over Web 2.0, which refers to second-generation Internet-based Web services such as video upload sites, social networking sites, and Wiki tools. To increase the use of speech interface technologies in everyday life, it is necessary to use a speech input method for Web systems. A large-scale collection of voice database is indispensable for the study of voice interfaces. We have been collecting voices in cases such as simulated scenarios, WOZ (Wizard of Oz) dialogue tests[1], telephone-based system[2,3], and public space tests[4]. However, an evaluation of voices captured by normal PCs is still insufficient to organize a voice database. To develop and utilize the speech interface further, it is important to know the recording conditions prevalent in home and office environ- ments [5]. Further, it is also important to know the configurations of the PCs used for
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Development of Speech Input Method for Interactive VoiceWeb Systems

J.A. Jacko (Ed.): Human-Computer Interaction, Part II, HCII 2009, LNCS 5611, pp. 710–719, 2009. © Springer-Verlag Berlin Heidelberg 2009
Development of Speech Input Method for Interactive VoiceWeb Systems
Ryuichi Nisimura1, Jumpei Miyake2, Hideki Kawahara1, and Toshio Irino1
1 Wakayama University, 930 Sakaedani, Wakayama-shi, Wakayama, Japan 2 Nara Institute of Science and Technology, 8916-5 Takayama-cho, Ikoma-shi, Nara, Japan
Abstract. We have developed a speech input method called “w3voice” to build practical and handy voice-enabled Web applications. It is constructed using a simple Java applet and CGI programs comprising free software. In our website (http://w3voice.jp/), we have released automatic speech recognition and spoken dialogue applications that are suitable for practical use. The mechanism of voice-based interaction is developed on the basis of raw audio signal transmis-sions via the POST method and the redirection response of HTTP. The system also aims at organizing a voice database collected from home and office envi-ronments over the Internet. The purpose of the work is to observe actual voice interactions of human-machine and human-human. We have succeeded in ac-quiring 8,412 inputs (47.9 inputs per day) captured by using normal PCs over a period of seven months. The experiments confirmed the user-friendliness of our system in human-machine dialogues with trial users.
Keywords: Voice-enabled Web, Spoken interface, Voice collection.
1 Introduction
We have developed a speech input method for interactive voice-enabled Web system. The proposed system is constructed using a simple Java applet and CGI programs. It would serve as a practical speech interface system comprising only free software.
The World Wide Web has become an increasingly more popular system for finding information on the Internet. At present, nearly every computer-based communication service is developed on the Web framework. Further, Internet citizens have begun to benefit significantly from transmitting multimedia data over Web 2.0, which refers to second-generation Internet-based Web services such as video upload sites, social networking sites, and Wiki tools. To increase the use of speech interface technologies in everyday life, it is necessary to use a speech input method for Web systems.
A large-scale collection of voice database is indispensable for the study of voice interfaces. We have been collecting voices in cases such as simulated scenarios, WOZ (Wizard of Oz) dialogue tests[1], telephone-based system[2,3], and public space tests[4]. However, an evaluation of voices captured by normal PCs is still insufficient to organize a voice database. To develop and utilize the speech interface further, it is important to know the recording conditions prevalent in home and office environ-ments [5]. Further, it is also important to know the configurations of the PCs used for

Development of Speech Input Method for Interactive VoiceWeb Systems 711
recording voices through the use of field tests. The proposed system is designed to collect actual voices in homes and offices through the Internet.
2 Related Works
Advanced Web systems that enable voice-based interactions have been proposed, such as the MIT WebGalaxy system[6][7]. Voice Extensible Markup Language (VoiceXML)1, which is the W3C2 standard XML format, can be used to develop a spoken dialogue interface with a voice browser[8]. SALT (Speech Application Lan-guage Tags) is an other extension of HTML (Hypertext Markup Language) that adds a speech interface to Web systems[9]. They require special add-on programs or customized Web browsers: therefore, users must preinstall a speech recognition and synthesis engine and prepare nonstandard programs for voice recording. However, complicated setups make it difficult for users to access voice-enabled websites.
Adobe Flash, which is a popular animation player for the Web environment, can be used for voice recording using generic Web browsers. However, a rich development tool that is not freely available is required to produce Flash objects containing a voice recording function. Moreover, the system might require a custom-built Web server to serve websites with a voice recording facility. Hence, developments of a voice-enabled Web system by Flash are not necessarily an easy process.
3 Overview
Figure 1 shows a screen shot of the proposed Web system. The website features an online fruit shop. In this site, users can use our spoken dialogue interface.
The Web browser displays normal HTML documents, Flash movies, and a recording panel. An HTML document that contains text, images, etc., provides instructions on how to use this Web site. One of the HTML documents also presents the results of an
Flash Movie
Recording Panel
Fig. 1. Screen shot of voice-enabled website
1 http://www.voicexml.org/ 2 http://www.w3.org/

712 R. Nisimura et al.
order placed by a user. The Flash movie provides an animated agent to realize signifi-cant visual interactions between the system and the user. The synthetic voice of the agent produced by dialogue processing would be sounded by embedding a Flash movie.
Figure 2 shows a close-up of the re-cording panel in the Web interface. The recording panel is the most important component of our voice-enabled Web framework. It is a pure Java applet (using Java Sound API of standard Java APIs) that records the voice of a user and trans-mits it to a Web server.
When the recording panel is activated by pressing the button, the voice of the user is recorded through the microphone
of the client PC. After the button is released, the panel begins to upload the recorded signals to the Web server.
The recording panel also provides visual feedback to the user, as shown in Fig-ure2. During voice recording, a bar of the panel acts as a power-level meter. Users can monitor their voice signal level by observing the red bar (Figure 2 - 2). The message “under processing now” is displayed on the bar while the recorded signals are transmitted to the Web server and processed in a dialogue sequence (Figure 2 -3). Subsequently, browser shows processing a result after the transmis-sion is completed.
We designed the proposed w3voice system to actualize the following concepts:
1. Users can use our voice-enabled web system with easy setup procedures without any add-on program pre-installations on the client PC.
2. Web developers can develop their original voice-enabled web pages by using our free development tool kits with existing technologies (CGI programs and standard Web protocols), and open-source software. We have released the development tool kits in our website, http://w3voice.jp/skeleton/.
3. Our system can run identically on all supported platforms, including all major operating systems such as Windows (XP and Vista), MacOS X, and Linux. Users can use their preferred Web browsers such as Internet Explorer, Mozilla, Firefox, and Safari.
4. Our system can provide practicable and flexible framework that enables a wide variety of speech applications. To realize them, we have adopted server-side archi-tecture in which the major processing sequences (speech recognition, speech syn-thesis, contents output) are performed on the Web server.
4 Program Modules
Figure 3 shows an outline of the architecture of the w3voice system. The system con-sists of two program modules – a client PC module and a Web server module.
(Windows)(Mac OS X)
(1) On mouse
(2) Recording
(3) Data Transmitting,and Processing
Fig. 2. Recording panel

Development of Speech Input Method for Interactive VoiceWeb Systems 713
4.1 Client PC Module
As mentioned earlier, the client PC module is a Java applet that is launched automati-cally by HTML codes as follows.
<applet code="w3voice.class" code-base="http://w3voice.jp/" archive="w3voice.jar">
<param name="SamplingRate" value="44100">
<param name="UploadURL" value="http://w3voice.jp/shop/upload.cgi">
</applet>
Fig. 3.
The applet runs on the Java VM of the Web browser and it records the user’s voice and transmits the signals to the Web server. The POST method of HTTP is used as the signal transmission protocol. The applet has been implemented such that it functions as an upload routine similar to a Web browser program. Thus, our system can operate on broadband networks developed for Web browsing because the POST method is a standard protocol used to upload images and movie files.
In this HTML code, Website developer can specify the sampling rate for recording voice by assigning a value to the parameter “SamplingRate.” The URL address of the site to which the signals must be uploaded must be defined in “UploadURL.”
4.2 Web Server Module
We have designed a server-side architecture in which the processing sequence of the system is performed on the Web server.
As shown in Figure 4, the CGI program forked from a Web server program (httpd) comprises two parts. One part receives the sig-nals from the applet and stores them in a file. The other part consists of the main program that processes the signals, recognizes voices, and produces outputs.
The recorded signals transmitted by the app-let are captured in “upload.cgi,” which is assigned in UploadURL (Section 4.1). It creates a unique ID number for the stored data.
Then, the main program, e.g., “shop.cgi” in the case of the online fruit shop, is called by the Web browser. The address (URL) of the main program is provided to the browser through the HTTP redirect response outputted by upload.cgi as follows. HTTP/1.1 302 Date: Sun, 18 Mar 2007 13:15:42 GMT Server: Apache/1.3.33 (Debian GNU/Linux) Location: http://w3voice.jp/shop/shop.cgi?q=ID Connection: close Content-Type: application/x-perl
Web server
upload.cgi(Receiver)
shop.cgi(Main)
HTTP Redirectwith Data ID
Fig. 4. CGI processes

714 R. Nisimura et al.
The “Location:” field contains the URL of the main program identifying the stored data by its ID number.
Thus, our system does not require any special protocol to realize a practical voice-enabled Web interface. The CGI programs can be written in any programming lan-guage such as C/C++, Perl, PHP, Ruby, and Shell script.
5 Applications
Original and novel voice-enabled Web applications using the w3voice system have been released. In this section, we would like to make a brief presentation of these applications. They are readily available at the following Web site3:
http://w3voice.jp/
5.1 Speech Recognition and Dialogue (Figure 5)
As shown in Section 3 (online fruit shop), the w3voice system can provide speech recognition and dialogue services.
Web Julius is a Web-based front-end in-terface for Julius4, which is an open source speech recognition engine[10]. This appli-cation realizes quick-access interface for a dictation system without requiring the installation of any speech recognition pro-grams on the client PC. The HTML text shows the recognized results outputted by Julius for an input voice. Users can quickly change the decoding parameters of N-best and a beam search through a Web-based interface. We have prepared many built-in language and acoustic models to adapt to the linguistic and acoustic parameters of the input voice.
Web Takemaru-kun system is our Japanese spoken dialogue system, which has been developed on the basis of an existing system[4, 11] with the w3voice system. The original Takemaru-kun system has been permanently installed in the entrance hall of the Ikoma Community Center in order to provide visitors with information on the center and Ikoma City. The authors have been examining the spoken dialogue inter-face with a friendly animated agent through a long-term field test that commenced in November 2002. Our analysis of user voices recorded during this test shows that many citizens approve of the Takemaru-kun agent. The w3voice system allows users to readily interact with the Takemaru-kun agent through the Internet and also makes the interaction a pleasant experience.
3 It should be noted that the content on our website is currently in Japanese because our speech
recognition program can accept inputs only in Japanese. However the proposed framework of w3voice system does not depend on the language of the speaker.
4 http://julius.sourceforge.jp/
Fig. 5. Left: Speech Recognizer Web Julius. Right: Web Takemaru-kun, Japa-nese spoken dialogue system.

Development of Speech Input Method for Interactive VoiceWeb Systems 715
5.2 Speech Analysis and Synthesis
Because the w3voice system processes raw audio signals transmitted by the client PC, any post signal processing technique can be adopted.
The spectrogram analyzer (Figure 6) is a simple signal analyzer that shows a sound spectrogram produced by MATLAB, which is a numerical computing environment distributed by The MathWorks5. The analyzer is beneficial to students learning about signal processing, although this content is very simple.
w3voice.jp provides a voice-changer application to en-sure user privacy (Figure 7). An uploaded signal is
decomposed into source information and resonator information by STRAIGHT[12]. In addition, the users can also reset the vocal parameters. By applying dynamic Web programming techniques using Ajax (Asynchronous JavaScript and XML), a synthe-sized voice is reproduced by a single click in real time. The vocal parameters are preserved as HTTP cookies by the Web browser, which are referred by the voice conversion routines of other applications.
5.3 Web Communication
Our system can be used to build new Web-based communication tools using which the uploaded voices can be shared by many users.
As for an example, we have introduced a speech-oriented interface onto a Web-based online forum system6. Anchor tags linking to transmitted voice files are
5 http://www.mathworks.com/ 6 http://w3voice.jp/keijiban/
Fig. 6. Web-base sound spectrogram analyzer
Fig. 7. Screen shot of the STRAIGHT voice changer. A synthesized voice would be played by clicking a point on the grid. User can control the pitch stretch of changed voices by the x-coordinate of mouse cursor. The spectrum stretch is represented by the y-coordinate.
716 R. Nisimura et al.
provided by the forum system to users who enjoy chatting using natural voices. A conventional online forum system allows users to use text-based information to com-municate with each other. The source code of the voice-enabled forum system, which includes only 235 lines of the Perl script, demonstrates the ease with which voice applications based on the w3voice system can be developed.
Voice Photo7 can be used to create speaking photo albums on the Web. It is a free service that integrates uploaded voice recordings with JPEG files and generates an object file in Flash. When the user moves the mouse cursor over the Flash file, the embedded voice is played. The file generated by this service can be downloaded as a simple Flash file. Thus, webmasters can easily place them on their blogs or home-pages.
6 Experiments
6.1 Data Collection
The operation of “w3voice.jp” began on March 9, 2007. Internet users can browse to our site and try out our voice-enabled Web at anytime and from anywhere.
All voices transmitted from the client PC are stored on our Web server. We are investigating access logs containing recorded user voices and their PC configu-rations.
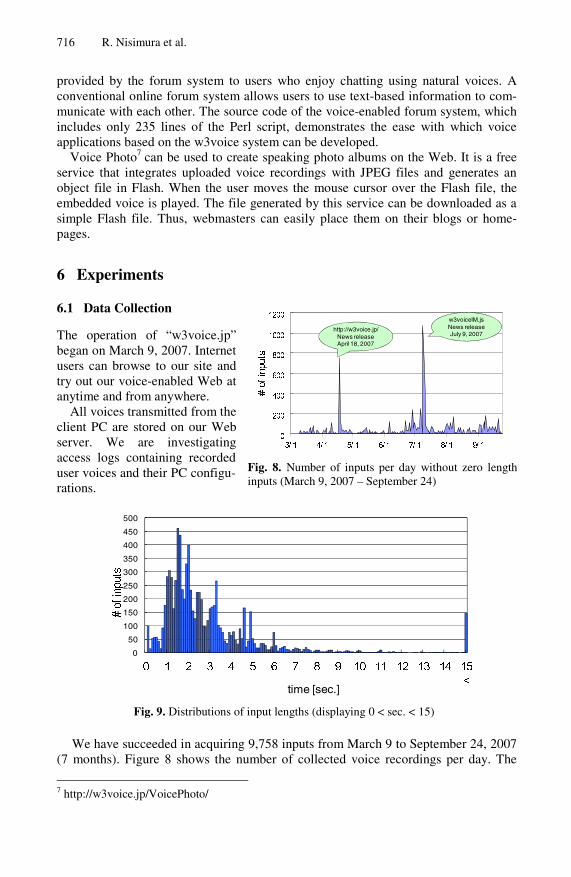
We have succeeded in acquiring 9,758 inputs from March 9 to September 24, 2007 (7 months). Figure 8 shows the number of collected voice recordings per day. The
7 http://w3voice.jp/VoicePhoto/
0
200
400
600
800
1000
1200
3/ 1 4/ 1 5/ 1 6/ 1 7/ 1 8/ 1 9/ 1
Month
# of inputs
http://w3voice.jp/News releaseApril 18, 2007
w3voiceIM.jsNews releaseJuly 9, 2007
Fig. 8. Number of inputs per day without zero length inputs (March 9, 2007 – September 24)
Fig. 9. Distributions of input lengths (displaying 0 < sec. < 15)
0
50
100
150
200
250
300
350
400
450
500
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
<
# of inputs
time [sec.]

Development of Speech Input Method for Interactive VoiceWeb Systems 717
number of the averaged input per day was 47.6 since August when the access became regular. They were obtained from 1,179 unique IP addresses. We have acquired in-formative successes by public testing the system with consecutive and extensive uses from users.
Figure 9 shows distributions of utterance lengths, where the horizontal axis indi-cates the lengths of the inputs (sec.). There were 1,346 (13.8%) inputs of zero length, which occurred due to a single click of the recording panel. The majority were per-formed to check the responses against the click of the panel. Although some users had misconceptions regarding the use of the panel in recording voices, they recorded their voices correctly after the second attempt. Meanwhile, the longest recorded input was a discourse speech with 6286.3 s.
Table 1. Configurations of computing environments in the experiments
Operating system Web browser # Windows XP Internet Explorer 8 Windows XP FireFox 1 MacOS X Safari 3
Total 12
6.2 Evaluation
An evaluation was conducted to investigate the user-friendliness of our system with regard to human-machine dialogues. Our aim was to observe the occurrences of prob-lems caused by programming bugs and human error.
Twelve students from our laboratory served as the trial users. Their task was to ac-cess the Web Takemaru-kun system and have conversations by using their office PCs. Ten trials were conducted by each user. Table 1 shows the computing environments of each user who evaluated our system.
The results revealed that all but one trial user could interact with the Takemaru-kun agent. The operating system of the user who could not interact was MacOS X. His Macintosh computer contained more than one audio device. He had changed a setting for the microphone lines in the control panel of MacOS X before testing the system. However, the Web browser was not restarted after changing the microphone line. Hence, silent signals were captured in his trials.
7 Conclusions
This paper proposes a speech input method to develop practical and handy voice-enabled Web applications. It is constructed using a simple Java applet and CGI pro-grams based on free software. The proposed system does not require the installation of any special add-on programs, which can be a difficult process, for using spoken interface applications. We have named this system “w3voice.”
This paper explains the mechanism of voice-based interactions based on the HTTP POST method and the HTTP redirect response in detail.
Examples of voice-enabled Web applications such as a speech recognizer, spoken dialogue system, spectrogram analyzer, voice changer, and an online forum are

718 R. Nisimura et al.
introduced in this paper. Indeed, all users having an Internet connection can use these applications on our Web site.
Further, web developers can build voice applications easily by using the w3voice system. To induce the Web developers to start voice Web systems, we have begun to distribute a set of sample source codes of the w3voice system under an open-source license. It also contains key-signed Java applet and short English documents. You can download it from our website8.
The system also aims at organizing a voice database using the voices recorded in home and office environments. We have succeeded in acquiring 8,412 inputs (47.9 inputs per day) captured by normal PCs over a period of seven months.
The user-friendliness of our system in human-machine dialogues is confirmed by the results of experiments in which several students evaluated the system as trial users.
7.1 Future Work
Technical improvements for the next version of the w3voice system are planned. To reduce the network load, it is important to compress the data stream transmitted from the applet to the Web server. Further, it is necessary to investigate the robustness of our system against simultaneous multiple access. We are also considering the exami-nation of automatic speech segmentation without requiring mouse operations. How-ever, the introduction of automatic recording involves some awkward problems that involve securing user privacy. In the feedback we received for our users, the uneasi-ness of an electrical interception in using an automatic voice recording program was pointed out. The tapping act without careful consideration might lack the reliability of the users.
We consider that the most important element in our work is the continuation of testing the system. We have been performing detailed analysis of the collected voice recordings. This project would contribute to improving the human-machine and hu-man-human communications.
References
1. Kawaguchi, N., et al.: Multimedia Corpus of In-Car Speech Communication. Journal of VLSI Signal Processing-Systems for Signal, Image, and Video Technology 36, 153–159 (2004)
2. Raux, A., et al.: Doing Research on a Deployed Spoken Dialogue System: One Year of Let’s Go! Experience. In: Proc. Interspeec 2006, pp. 65–68 (2006)
3. Turunen, M., et al.: Evaluation of a Spoken Dialogue System with Usability Tests and Long-term Pilot Studies: Similarities and Differences. In: Proc. Interspeec 2006, pp. 1057–1060 (2006)
4. Nisimura, R., et al.: Operating a Public Spoken Guidance System in Real Environment. In: Proc. Interspeec 2005, pp. 845–848 (2005)
5. Hara, S., et al.: An online customizable music retrieval system with a spoken dialogue in-terface. The Journal of the Acoustical Society of America (4th Joint Meeting of ASA/ASJ) 120(5) Pt. 2, 3378–3379 (2006)
8 http://w3voice.jp/skeleton/

Development of Speech Input Method for Interactive VoiceWeb Systems 719
6. Lau, R., et al.: WebGalaxy - Integrating Spoken Language and Hypertext Navigation. In: Proc. EUROSPEEC 1997, pp. 883–886 (1997)
7. Gruenstein, A., et al.: Scalable and Portable Web-Based Multimodal Dialogue Interaction with Geographical Database. In: Proc. Interspeech 2006, pp. 453–456 (2006)
8. Oshry, M., et al.: Voice Extensible Markup Language (VoiceXML) Version 2.1, W3C Recommendation, W3C (2007)
9. The SALT Forum, SALT: Speech Application Tags (SALT) 1.0 Specification (2002) 10. Lee, A., et al.: Julius – An Open Source Real-Time Large Vocabulary Recognition Engine.
In: Proc. EUROSPEEC 2001, pp. 1691–1694 (2001) 11. Nisimura, R., et al.: Public Speech-Oriented Guidance System with Adult and Child Dis-
crimination Capability. In: Proc. ICASSP 2004, vol. 1, pp. 433–436 (2004) 12. Banno, H., et al.: Implementatioin of realtime STRAIGHT speech manipulation system:
Report on its first implementation. Acoustic Science and Technology 28(3), 140–146 (2007)