
An interface for melody input
17
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of An interface for melody input

An Interface for Melody InputLutz Prechelt and Rainer TypkeUniversity of KarlsruheWe present a software system, called Tuneserver, which recognizes a musical tune whistled by theuser, �nds it in a database, and returns its name, composer, and other information. Such a serviceis useful for track retrieval at radio stations, music stores, etc., and is also a step towards the long-term goal of communicating with a computer much like one would with a human being. Tuneserveris implemented as a public Java-based WWW service with a database of approximately 10,000motifs. Tune recognition is based on a highly error-resistant encoding, proposed by Parsons, thatuses only the direction of the melody, ignoring the size of intervals as well as rhythm. We presentthe design and implementation of the tune recognition core, outline the design of the web service,and describe the results obtained in an empirical evaluation of the new interface, including thederivation of suitable system parameters, resulting performance �gures, and an error analysis.Categories and Subject Descriptors: E.4 [Data]: Coding and Information Theory|Error Con-trol Codes; H.1.2 [Models and Principles]: User/Machine Systems|Human Information Pro-cessing; H.3.3 [Information Storage and Retrieval]: Information Search and Retrieval|Se-lection Process; H.3.5 [Information Storage and Retrieval]: Online Information Services;H.5.4 [Information Interfaces and Presentation]: User Interfaces|Interaction styles; I.2.m[Arti�cial Intelligence]: Miscellaneous; I.5.4 [Pattern Recognition]: Applications|SignalProcessing; K.4.m [Computers and Society]: MiscellaneousGeneral Terms: Algorithms, Human Factors, PerformanceAdditional Key Words and Phrases: input mode, melody, motif, recognition, theme, tune1. ON INPUT MODESDesigning computer interactions so that they become human-like is one challengeof computer science research. We call this problem the interaction challenge andshall view it from the input perspective. Although most human interaction usesonly two input channels, namely the auditory and the optical systems, a wide rangeof types of information is transmitted through them: the channels are used in manydi�erent modes . The support of all the various input modes of human interaction isone aspect of the interaction challenge. This article contributes to the set of inputmodes available for use with computers by presenting the design, implementation,and evaluation of Tuneserver, a melody recognition system that acts as a robustlistening expert for musical themes.1.1 Current input modesCurrent research on direct human input (i.e., input not involving the explicit op-eration of hardware such as a keyboard or mouse or special-purpose devices [Jacob1996]) focuses on input modes that have relatively broad applicability in business,Address: Fakult�at f�ur Informatik, Universit�at Karlsruhe, D-76128 Karlsruhe, GermanyE-mail: [email protected], [email protected],http://wwwipd.ira.uka.de/Tichy/

2 � Lutz Prechelt and Rainer Typkeengineering, or general computer use contexts. Some of them have already maturedinto commercial applications, while research on others has just begun.The oldest direct input mode is probably speech recognition [Cole et al. 1995].Attempts to boost the performance of speech recognition by using additional tech-niques like lip-reading [Stork and Hennecke 1996] have been under way for sometime. For di�cult words, such as special names, oral spelling or online handwriting[Manke et al. 1995] might prove helpful.Gesture, posture, and detection of gaze-direction are used to identify the targetsof a verbal (or other) utterance or the focus of attention [Stiefelhagen et al. 1997].Detection of emotions in verbal utterances [Dellaert et al. 1996] or in mimics ac-companying them allows for more accurate interpretation and reaction. Generalhandwriting, sketching, and screen gestures are further input modes already beingapplied, e.g., in palmtop computers.The user should be able to choose and mix these input modes as he sees �t,resulting in multi-modal input , which will become increasingly important in thefuture [Myers et al. 1996]; see [Benoit et al. 1999] for an overview. For achievinghuman-like interaction with a computer, the raw input processing should be sup-ported by appropriate understanding and control intelligence. However, the timewhen computers will interact in a truly human way with their users is still in thefuture. For instance, Reddy [Reddy 1995] considers a translating telephone to be a\Grand Challenge in AI Megaproject".1.2 Melody inputThe research work we present here adds another channel of computer-human inter-action that may help with quick track retrieval at radio stations, make audio-on-demand WWW services easier to use, improve service at audio media stores or, inthe far future, serve as another part of the human-like interaction capabilities ofcommodity computers.The purpose is to process audio input signals (such as singing, humming, orwhistling) that represent a melody, and to use a robust approximate representationof the input melody as a search key for retrieving whatever information is connectedto it in a database. We call our implementation \Tuneserver". See Section 4 for adiscussion of related work.Melody recognition is super�cially similar to speech recognition, but there areimportant di�erences. On one hand, the signal structure is simpler, since there areno phonemes. At later stages, the information processed in melody input is far lessambiguous and, again, simpler in structure. On the other hand, melody recognitionis also quite di�cult, because, as we will see below, average humans are not verygood at providing accurate input.1.3 Usage scenariosThe most important obstacle towards wide deployment and use of Tuneserver func-tionality is the availability of the database contents required for �nding a tune.As described in Section 2.2, a few bytes of special encoding describing the melodymust be stored there for identifying a tune, linked to whatever shall be retrieved:the actual audio signal of a recording, audiographic information such as title, per-former, duration, composer, publisher, ordering information etc. However, once

An Interface for Melody Input � 3Tuneserver technology is reliable, it may become popular enough for music pub-lishers to include this information on a small data track on each CD, and serviceproviders might provide databases covering older music titles.Given such infrastructural support, one can imagine the following scenarios:Adam has heard an old tune on the radio and wants to buy it on CD. In ear-lier days, he wouldn't even have tried, because, like most people, he is much tooshy to sing, hum, or whistle the melody to a salesperson in a music store (andeven people who dared often ended up with just a shrug). Today, he walks to thestore, goes to the \Find your music" box in a quiet corner (much like a phonebooth), hums secretly into a microphone, and is presented with a list of 27 possiblerecordings. To reduce the selection, he enters additional information from menus:\single female singer" and \recording is older than 5 years". Two titles remain,and he listens to each of them. He ends up buying both of them; one is what hewas looking for, and the other one he likes as well.Carla is a radio moderator. She routinely uses Tuneserver to retrieve titles thatare stored in the online digital music archive. Since pure speech recognition inputhas been tried before by her radio station, and has proven to be too ine�cient formusic track retrieval, the station now uses Tuneserver in combination with a rathersimple and robust speech recognition engine. Hence, she can select and play a titleon the air purely by voice command, without handling a CD or a keyboard. Atone point, she uses the keyboard for a text-based search for a speci�c cover versionof \With a little help from my friends" that she knows her station has on a vinylrecord, but none of her database queries leads to the desired result. Frustratedand ready to give up, she decides to try Tuneserver. She hums the melody, obtains14 tracks, and among them �nds the one she wanted: It is stored as \Help fromfriends"! Later she �nds that this is indeed the title printed on the record for thistrack.1.4 Article overviewIn the following section, we will describe the overall system architecture of Tune-server and the design and implementation issues that arise. In particular, we willdescribe the recognition algorithms and the optimization of their adjustable pa-rameters. Section 3 presents and analyzes the results of an empirical study basedon over 100 recordings from 24 di�erent persons. We identify the factors that limitTuneserver's performance and analyze their contributions. Subsequent sections dis-cuss closely related work and possible future system improvements.2. DESIGN AND TECHNIQUESWe �rst provide an overview of the system parts and how they interact. Then wedescribe the melody encoding, called Parsons code [Parsons 1975], that underliesTuneserver. The core procedure, converting the sound signal into the Parsons code,is described in Section 2.3, and values for its parameters are derived in Section 2.4.Finally, a derivation of the distance function used to rank the database entriesduring the search process follows in Section 2.5, followed by a discussion of itsparameters in Section 2.6. Readers not interested in the technical details may wantto skip the later subsections and only read 2.1 and 2.2.

4 � Lutz Prechelt and Rainer Typke
symphony/8 in F, 1st movement, 1st themeBeethoven, Ludwig van:Display:6� Calculation of the editing distances to all list entries� Compilation of a list of the closest matches'& $%Server HTTP connection Parsons CodeList of possible tunes
Wave �leRecording with microphone/sound card'&
$%
Applet (Client) Spectrum analysis (FFT)?DUUDDDURDRUUUUCalculation of the Parsons code:???List of notes (pitch and duration)
-1 234 5867Fig. 1. Overview of the system architecture and the querying process. The large bottom boxrepresents the server, the large middle box represents the client applet. The small boxes containingnumbers indicate the sequence of events, arrows indicate data ow.2.1 System architecture overviewTuneserver is split into a client, implemented as a Java applet, and a web server.The latter is also written in Java, taking advantage of the language's internetfeatures, but uses a core written in C++.The main routine that converts sound into the Parsons code (described below)is located in the client. Hence, only a few bytes of Parsons code (typically about 5to 30) need to be transfered to the server instead of an actual audio �le of possiblyseveral hundred kilobytes.The web server accepts Parsons code from a client and responds with a rankedlist of those musical themes from its database whose Parsons codes are most similaraccording to an appropriate distance function. See also Figure 1 for an overview.Tuneserver's database consists of 10,370 entries of classical music from the collectionof themes published in Parsons's book [Parsons 1975]. Tuneserver can be found athttp://wwwipd.ira.uka.de/tuneserver/.2.2 Error-resistant encoding: The Parsons codeTuneserver should work for everybody. However, especially with untrained users,there is the problem of input inaccuracies. Most people tend to whistle out of tune,some change key in the middle of a theme, and many use inaccurate rhythm. Asa result, a system that uses rhythm and note intervals for analyzing the user input

An Interface for Melody Input � 5would have to deal with many potential problems.Parsons showed that a simple encoding of tunes that ignores most of the infor-mation in the musical signal can still provide enough information for distinguishingbetween a large number of tunes. The Parsons code re ects only the directionsof melodies. Each pair of consecutive notes is coded as \U" (\up") if the secondnote is higher than the �rst note, \R" (\repeat") if the pitches are equal, and \D"(\down") otherwise. Rhythm is completely ignored. Thus, the �rst theme fromthe last movement of Beethoven's 9th symphony (Ode to Joy) would be codedRUURDDDDRUURDR.1 Note that the �rst note of any tune is used only as areference point and does not show up explicitly in the Parsons code at all.We use the Parsons code for representing tunes, thus ignoring all sound infor-mation except for the directional pattern. This approach makes our system error-tolerant with respect to both time and frequency. What remains is the problem ofdeciding where notes start and end, and whether a given pair of notes should beconsidered equal or not.The following subsections cover technical details of the recognition mechanism.If you are not interested in these, just skip to Section 3.2.3 Converting sound into the Parsons codeWe decided to focus on whistled input (as opposed to singing or humming) becausethe sound of whistling varies much less among people than singing; it is unrelatedto gender, for example. Furthermore, the frequency spectrum of whistling is farsimpler than that of other vocal emissions, which makes analysis easier.We �rst make a digital recording, sampled with 8 bit at 11 kHz. Higher resolutionis not required, because, as we will see below, we will use only very little of theactual acoustic information. We group the sequence of samples into overlappingwindows, ignoring the very �rst tskip milliseconds to eliminate start noises (seeTable 1 for tskip and other user-adjustable parameters of the system). The windowsize is 46 ms and each window overlaps half of the previous one and half of thenext one. We smooth the window margins using a cosine function. There are othercommon smoothing functions that would work just as well, because only coarsespectrum di�erences are relevant for the Parsons code. Then we apply a FastFourier Transform to obtain frequency spectrum samples, one per window.The next step is to take the maximum amplitude (the peak) from each spectrum;we regard the associated frequency as the pitch whistled during this window andthe associated amplitude as the volume of the window. If, however, the maximumis not signi�cantly higher than the rest of the spectrum, we mark the window as\silence" by setting the volume to zero. To decide this, we compare the quotient ofthe highest peak and second highest peak to the �xed threshold rpeaks. Thus, weobtain a sequence of frequency-volume pairs, one per FFT window. This relativelysimple approach is su�cient for pitch determination, because a whistling signalcontains only one single base frequency plus overtones, and hence a unique pitch.1More than fault tolerance, the aim was to enable people who cannot read notes and do not knowmuch about music to �nd the title of a given theme. Before Parsons's book had been published,the easiest way of doing this was to transpose the theme into the key of C and then write downthe actual notes and look them up in the dictionary of Barlow and Morgenstern [Barlow andMorgenstern 1948].

6 � Lutz Prechelt and Rainer Typkeparameter meaning valuetskip Skip the �rst 10msrvolmin Ignore everything below 5% of rec. max. volumefmin Ignore notes below 400 Hzrpeaks Ignore spectra w. 1st2nd peak ratio below 2rvolmin;note Split note if volume drops below 18% of local avg. volumetrvolmin;note Local avg. volume covers 253 mstmin;note Ignore notes shorter than 46 msrf;note Di�erent notes threshold quotient is 1.03Dins(R) Penalty for inserting/deleting an R is 1Dins(DU) Penalty for inserting/del. a D or U is 2DR$DU ;DD$U Penalty for confusing any of R,D,U is 1Table 1. User-selectable parameters and their settings used in the empirical evaluation. The lastthree lines will be explained in Section 2.5.It is then necessary to group these pairs into notes. As an indicator for noteboundaries we use (1) the silence windows and (2) sudden changes in frequency. Ifthe quotient of consecutive frequency values exceeds a user-de�ned threshold rf;note,we insert an arti�cial silence window to mark the end of the note. Afterwards, wecombine all windows between any two silence windows into a single note with thecorresponding duration and remove the silence windows. The result is a sequenceof notes with certain frequencies and durations.The steps in this process, starting with the frequency-volume pairs, are:|Set all windows where the volume, the frequency, or the peak amplitude ratioare below the user-de�ned thresholds rvolmin, fmin, or rpeaks , respectively, to\silence". This avoids erroneous interpretation of unclear input signals.|If the volume drops below a user-speci�ed threshold rvolmin;note in relation tothe average volume of the surrounding trvolmin;note milliseconds, it is assumedthat the whistler repeated a note without a proper break. Insert an arti�cialsilence window in all such positions.|If the predecessor and successor of a window have the same frequency, but di�erfrom the current window's frequency, set the current window's frequency to thatof its neighbors. This smoothes the frequency curve.|Combine consecutive non-silence windows into one note if the frequency ratio ofall these windows is below rf;note. Calculate the average of the frequency andthe sum of the durations of the windows.|Delete silence windows and delete notes that are shorter than the user-speci�edminimum length tmin;note.The resulting list of notes is later displayed together with the search result, aidingthe user in �nding technical parameter changes needed to enhance the recognition.2.4 Parameter values for Parsons code conversionAs described earlier, the algorithm for the conversion is constructed in a relativelystraightforward way. However, to complete the contribution, we must explain howwe obtained the values for the parameters that are listed in Table 1.

An Interface for Melody Input � 7For three of these parameters, namely rvolmin, rvolmin;note, and fmin, we per-formed a thorough search of the parameter space, together with the four parametersof the distance function discussed in Section 2.5. For this search we used the datarecorded for the empirical evaluation as described in Section 3.1. We used half of thedata for �nding good parameters and the other half for validating that these valuesdid not over�t these particular recordings (and would hence not be good values forother recordings). We found that Tuneserver was generally not prone to parameterover�tting, which is not surprising given that we �t only seven parameters to morethan 1600 notes.The 7-dimensional search worked by multiple discrete descent. From each of alarge number of random starting points in the parameter space, the recognitionperformance at that point was compared to each of two neighboring points alongeach of the seven axes. The best of these was taken as the next reference point,until a local minimum was reached. Then a new random starting point was chosen.As search step size, we used �5% for rvolmin, �3% for rvolmin;note, and multipli-cation/division by 1.1 for fmin. The performance was measured by determining therank of the intended tune in Tuneserver's result list for every recording. For tuneswhich did not appear among the �rst 100 results, a rank of 200 was counted.We obtained performance data for about 5000 parameter sets, using several weeksof CPU time. This performance data was then analyzed to �nd, from the mostsuccessful parameter sets, those parameters that exhibited optimum performancerobustness, i.e., best performance stability in the parameter neighborhood.We found that the global silence threshold rvolmin should be 5 percent, muchlower than what we had initially thought. The optimum note-local volume thresholdrvolmin;note turned out to be 18 percent, also lower than expected. We foundthat the lower cuto� frequency fmin has only little in uence on performance, goodperformance was obtained in the range 300 Hz to 800 Hz.Early trial-and-error investigations with a few recordings had shown that theother parameters mentioned in the top part of Table 1 are even less sensitive tochanges than fmin. Therefore, we chose them based on a few trials alone. Forrf;note, the obvious choice is a quarter tone, which is half of a twelvth octave ora frequency ratio of 2�12p2 or 1.03. We found that this works as well as expected.The times used for initial cuto� (tskip), minimum note duration (tmin;note), anddetermining local volume (trvolmin;note) are not very critical. 10ms, 40ms, and110ms, respectively, work well. Note that for whistlers producing highly uctuatingtones, tmin;note and trvolmin;note could in principle be quite important, but it turnsout that such tones are usually so unstable that even the best parameter values donot help.2.5 Search processThe server's task is to create a list of pieces whose Parsons codes are most similarto the code that was provided by the applet. To accomplish this, we used theconcept of editing distance [Ukkonen 1985]. In essence, we calculate the numberof insertions, deletions, and replacements of single characters that are necessaryfor converting one given code string into the other one. The minimum weightedsum of these elementary steps is the editing distance. It is computed by dynamicprogramming with �xed weights.

8 � Lutz Prechelt and Rainer TypkeThe user usually does not provide the same number of notes that are encodedfor the tune in the database. Since we do not want this di�erence to in uence ourdistance measurements, we have to avoid adding or deleting notes that are missingat the end of one of the two strings and counting these steps for the editing distance.To accomplish this, we cut o� additional characters, comparing two strings of equallength.For our problem of comparing Parsons codes, we should distinguish betweendi�erent classes of replace, delete, and insert operations. Unlikely distortions of theParsons code should lead to bigger di�erences. Here are the considerations:|It is probably less likely that a user omits or adds a note that goes up or down(leading to a D or U), compared to a repetition (leading to an R). Our systemalso detects boundaries between di�erent notes more reliably than boundariesbetween repeated notes. Hence inserting an R should have a weight di�erentfrom (presumably smaller than) the weight associated with inserting a D or U.|For replacement, the distance for R-to-D or R-to-U should obviously be smallerthan the distance for D-to-U or U-to-D.|Replacing R with U should have the same weight as replacing R with D, becauseotherwise the distance function would be sensitive to melodic inversion, whichseems inappropriate.|Insertions and the corresponding deletions must have the same weight, becausea distance function must always be symmetric.Applying these rules, we arrive at the following set of four di�erent weights forthe various editing operations:|DD$U for replacing a D with a U, or vice versa,|Dins(DU) for inserting or deleting a D or a U,|DR$DU for replacing an R with a D or a U, or vice versa,|Dins(R) for inserting or deleting an R.The server performs an exhaustive search by comparing the query string sepa-rately to each database entry. The closest matches are returned, sorted by theirediting distance. Note that only the ratio of the editing weights is important forthe ordering of results, not their absolute values, so there are e�ectively only threedegrees of freedom in the four parameters. An exhaustive search is hardly a per-formance problem for the 10,000 entries that we have | it can be done in abouta second on our 167 MHz UltraSparc1. (The initial Java implementation of theserver using JDK 1.1.5, however, took about 30 times as long.)2.6 Parameter values for distance functionWhen we designed the distance function, we originally believed that the weightsshould be chosen so thatDins(R) < DR$DU < Dins(DU) < DD$U < 2Dins(R)However, during the parameter optimization as described in Section 2.4, we foundthat this was a bad choice. For all four parameters, we investigated random start-ing points in the range 1. . . 40, with search steps of size 1. The results indicated

An Interface for Melody Input � 9that direct replacements in the Parsons code should be forbidden by the distancefunction, that is, the weights DR$DU and DD$U could both be in�nitely large!Note that this is equivalent to setting DR$DU to Dins(R) +Dins(DU) and settingDD$U to 2Dins(DU), because a replacement can always be performed by a deletionplus an insertion.For the remaining parameters, our optimization suggests Dins(DU) = 2Dins(R)to be the best choice. Dins(R) should be smaller because, as mentioned above,determining the correct number of Rs is often di�cult for the recognition system.3. RESULTS AND DISCUSSIONWe now describe an empirical evaluation of Tunserver, based on 110 recordingsthat were made under adverse real-world conditions. We begin with a descriptionof the design and participants of the study and give de�nitions of important terms.In section 3.3 through 3.6, we describe Tuneserver's recognition performance andanalyze the factors contributing to recognition errors. The analyses are based onthe individual recordings, on recordings grouped by tune or by person, and onthe types of individual notes in the recording. Finally, we report on the speed ofTuneserver. The statistical evaluation was performed with S-Plus 3.4 on Solaris.For a summary of the results, you may want to peek into the conclusion section(Section 5). As for usability and qualitative aspects of Tuneserver performance, wedescribe some user reactions in Section 3.8.3.1 Design and subjects of the empirical evaluationThe recordings stem from 24 di�erent persons and were made in various live envi-ronments using a laptop computer. The recordings thus re ect di�erent sorts andlevels of background noise, various kinds of acoustic environment, di�erent mindsetsof the subjects, etc. The evaluation uses the parameter settings given in Table 1.Of the 24 subjects, 18 were computer scientists, and a few were musicians. Thedata of subject 13 was ignored in the analysis, as this person brought out only thesame note over and over, and even that was hardly a whistled tone at all.Every subject was asked to �rst whistle two themes of his or her own choice, thenthe theme from Haydn's Kaiserquartett (Emperor's quartet) which is used as theGerman national anthem, and �nally the opening theme of Mozart's \Eine kleineNachtmusik". Due to the circumstances there are a few exceptions to this rule,e.g., 3 persons whistled less than four themes while 2 whistled more than four. Ifimmediately after a recording (and before the Tuneserver query results were known)a subject wanted to repeat the recording, such a repetition was performed, but stillboth recordings are included in the evaluation. Overall, there are 13 repetitionsplus 2 second repetitions within the 106 valid recordings.3.2 De�nitionsIf, in the Tuneserver output for a recording of theme t, there are n other themeswith a distance smaller than t, we call n+1 the rank of the recording. We call therecording a hit if its rank is 1 and found if its rank is 40 or better. A recording maynot be found either because Tuneserver did not decode it properly or because it isnot known, i.e., the theme is not in Tuneserver's database at all. A recording is�nal if it was not repeated by the subject. We distinguish between three di�erent

10 � Lutz Prechelt and Rainer TypkeParsons codes for each recording. The recognized code is what Tuneserver actuallyproduces from the input, the intended code is the code of the tune stored in thedatabase and the whistled code is what the subject actually did input, as judged bya human expert. The whistled code is usually \in between" the other two and allowsto separate recognition errors made by the system from recognition errors provokedby incorrect input. For each recording, we subjectively evaluated several conditionsthat might make recognition more di�cult; for each we use a four-point ordinal scale(none, little, some, much): Noise is the presence of background sounds, usuallywind, sometimes other voices. Breath characterizes the average lack of clarity ofthe whistled tones, which usually stems from additional air sounds. Vibrato refersto frequency oscillation within the individual notes, and glissando describes howmuch the tones were \smeared" into one another with respect to their frequencychanges. The error density of a recording is the editing distance from recognizedto whistled Parsons code divided by the length of the whistled Parsons code. Thelatter will also be called the number of notes or the recording length.3.3 Results by recordingTwelve recordings were not known, we ignore them for the rest of this subsection.The overall found rate is 77%, the overall hit rate is 44%. If Tuneserver's noterecognition were perfect, that is, if the database could be queried with the Parsonscode of what was actually whistled (without any recognition errors), the found ratewould be 95% and the hit rate 94%. The remaining 6% mistakes are due to melodiesthat were whistled so wrongly by the subjects that even their accurate Parsons codebecame incorrect. We can correct for these mistakes that are not recognition errorsby dividing the actual found rate of 77% by the optimal found rate of 95% andobtain a corrected found rate of 81%. The correspondingly corrected hit rate is47%. Considering only �nal recordings, these numbers improve to 84% and 49%,respectively.What causes the remaining misses? We will analyze misses by several factors:�rst by the conditions noise, breath, vibrato, and glissando, and then by the numberof notes whistled.Breath is a signi�cant predictor for di�erences in the error density; a statisticaltest (one-sided Wilcoxon rank sum test with Lehmann correction for ties) showedthat the median error density was signi�cantly larger when there was some ormuch breath compared to recordings with none or little breath (p = 0:0008)2. Theproblem areas glissando (p = 0:597), vibrato (p = 0:773), and noise (p = 0:485)were found to be insigni�cant. Recordings with vibrato actually tend to have lesserrors, probably because vibrato was typically used by the more capable whistlers.Finding noise to be insigni�cant means that our recognition is almost immune tothe sometimes substantial amounts of background noise that were present duringour recordings | at least with the relatively insensitive type of microphone weused.If we restrict the set of recordings to the 62 known �nal recordings with breath2This p value means the following: It seems as if one can use the breath level for improvingpredictions of error density. However, this apparent connection might be purely incidental. Butthe chances that it actually is purely incidental are only 0.0008 (that is, about 1 in 1200).

An Interface for Melody Input � 11level \none", the corrected found ratio improves to 86%, the corrected hit ratio to59%. See also Figure 2 for an overview of these results.0
2040
6080
100
foun
d
hit
known corrected correctedfinal
correctedno breath
perc
ent
Fig. 2. Found rates and hit rates for various subsets of the known recordings from the empiricalevaluation, see the discussion in the text.The recordings consisted of between 3 and 39 notes, with a median of 16. Thefound rate increases for longer recordings, e.g., from about 70% to about 80% whenthe number of whistled notes increases from 8 to 16. This is not surprising becausethe number of exact matches in the data base can be quite large for short Parsonscodes, but we allow at most 100 matches. Note that input far beyond 15 notes isnot useful because no database entry covers more than 15 notes.Summarizing, we can state that Tuneserver successfully recognizes about four outof any �ve tunes. The analysis of entire recordings reveals two conditions underwhich Tuneserver tends to make mistakes: too much breathing noise in the input,or an insu�cient number of notes supplied for proper discrimination of multipletunes.3.4 Results by personEach subject made between 2 and 7 �nal recordings of known tunes, on average 3.5.During the process of making these recordings, we found that some persons werehighly capable of producing nice-sounding, accurate input that was presumablyeasy to process for Tuneserver, while others were bad whistlers who we expected toproduce lots of failures. Looking at the results, there are indeed large di�erencesbetween the success rates of the individual subjects. The most successful quarterof our subjects has a found rate of 100% and a hit rate of 67% or better, while theleast successful quarter has a found rate at or below 67% and a hit rate at or below25%. See also Figure 3.However, although there de�nitely are good and bad whistlers, this distributionof found and hit rates is not signi�cantly di�erent from the distribution one wouldget if the rates were completely independent of the person. Hence, the available

12 � Lutz Prechelt and Rainer TypkeM
oo ooo ooo o oooo ooo ooo o ooo
Moooo o oooooooo ooo oo o o ooo
hit
found
0 20 40 60 80 100
found and hit rates by person [percent]Fig. 3. Distributions of found and hit rates over the subjects. The whiskers indicate the topand bottom 10 percent, the box edges indicate the top and bottom 25 percent, the fat dot is themedian, the M-line marks the mean and its standard error.data is insu�cient for measuring how much the individual whistling capabilitiesin uence Tuneserver's recognition performance.3.5 Results by tuneAs one might expect, not all tunes are created equal with respect to their probabilityof being successfully recognized by Tuneserver. Plotting the found rates and hitrates separately for the di�erent tunes, we �nd clear di�erences; see Figure 4. The0
2040
6080
100
foun
d
hit
Mozart Haydn other Mozartcorrected
perc
ent
Fig. 4. Found rates and hit rates by tune whistled.found and hit rates for the Mozart theme are close to the average; the successfor the Haydn theme is clearly higher (two combined Fisher exact p tests indicatep = 0:028 that the corrected found and hit rates are in fact not di�erent). Thisdi�erence is a result of the musical di�culty of the themes: The Haydn theme hasall long notes, with modest intervals in between. In contrast, the Mozart themealso contains shorter notes and larger intervals; it also covers a greater frequencyrange. We cannot say anything speci�c about any of the other themes here, sincenone of them was chosen often enough (only one was chosen more than twice), butapparently the whistlers often picked themes that they did not know well enough or

An Interface for Melody Input � 13that were di�cult. As a result, the success rates for the arbitrarily chosen themesare distinctly lower than the rest. However, the Mozart theme was much moreoften whistled wrongly than the others: even with perfect recognition, the foundrate would have been only 89%. As a consequence, for the Mozart recordings, thedi�erence between corrected found and hit rate and the uncorrected rates are aboveaverage.3.6 Results by noteOne other analysis that helps understand Tuneserver's performance is based on thedi�erent types of notes (up, down, or repeat). Figure 5 shows that the performancedecreases with an increasing number of R notes that need to be recognized. Thisindicates that R notes actually cause more di�culties than U and D notes, because,as mentioned above in Section 3.3, the performance is generally expected to be betterfor longer recordings, not worse.ooooooooooooooooooooooooooooooooooooooooooooooooooo
ooo
ooooo oo
o
ooooo
ooooo
oo
oo
oo
o
o
o
least squares fitL1 (least distance) fitleast trimmed sq. fit
0
20
40
60
80
100
0 5 10 15
number of Rs in whistled code
hit r
ate
[per
cent
]
Fig. 5. Average hit rate depending on the number of Rs in the whistled Parsons code. The plotalso shows a standard regression line and two kinds of robust regression lines.We may understand the e�ect better by looking at the individual recognitionerrors. Figure 6 compares the number of R characters in the recognized code andthe whistled code. The plot shows the di�erences of these numbers, separately forthe Mozart and the Haydn theme; it also contains the same comparisons for theD and U characters. Ideally, the di�erence should always be zero; anything elseindicates recognition errors.We see that R is more prone to errors than D or U and that the R errors arealways insertions. One could reduce the number of R insertions by decreasing thervolmin;note or rpeaks parameters or by increasing the tmin;note parameter, but bothwould produce more mistakes elsewhere than could be avoided here. The di�cultyof correctly recognizing R notes is inherent in the task and Tuneserver actuallyperforms quite well on it.
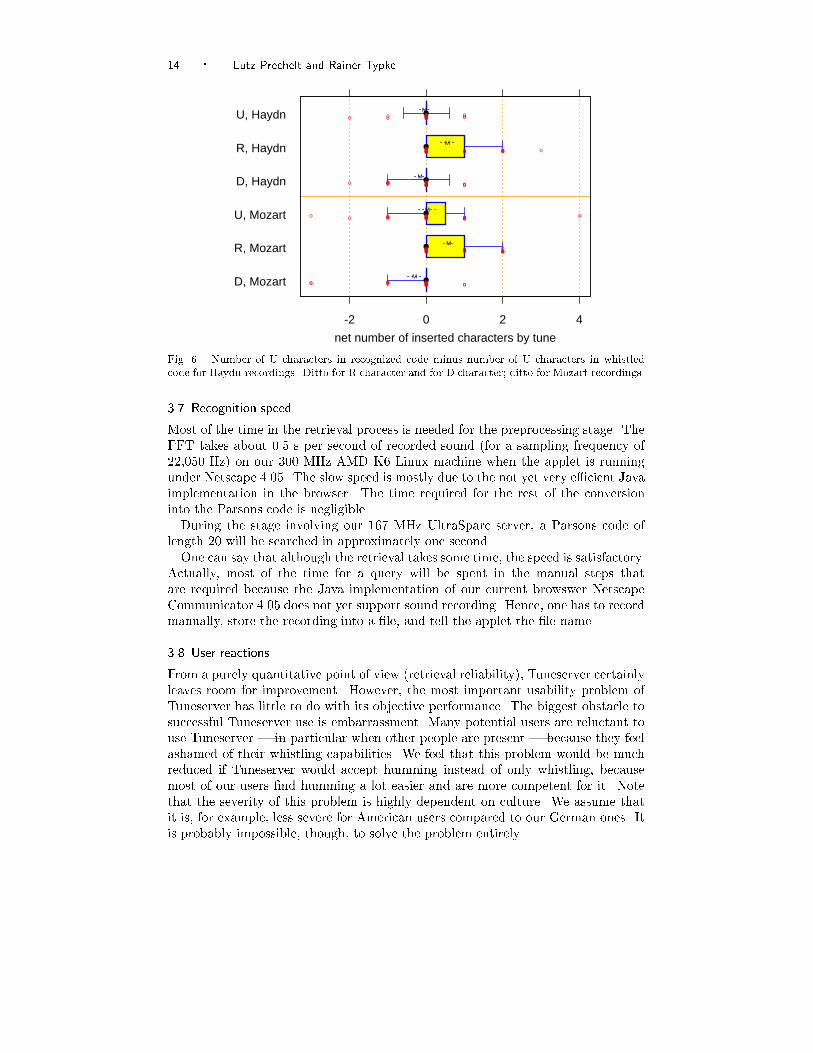
14 � Lutz Prechelt and Rainer Typke
Mooooo oo ooooooo oooo oooooooo
Mo oo o oo ooo oo ooooo ooooo oooo o
Mo oooo oo oooo oooo ooo oooo ooo oo
Mooo oo oo ooo oooooooooo o ooo
Mooooo ooo oo oo oooooooo oo oo o
Mooooooo o oooooo ooooooo o
D, Mozart
R, Mozart
U, Mozart
D, Haydn
R, Haydn
U, Haydn
-2 0 2 4
net number of inserted characters by tuneFig. 6. Number of U characters in recognized code minus number of U characters in whistledcode for Haydn recordings. Ditto for R character and for D character; ditto for Mozart recordings.3.7 Recognition speedMost of the time in the retrieval process is needed for the preprocessing stage. TheFFT takes about 0.5 s per second of recorded sound (for a sampling frequency of22,050 Hz) on our 300 MHz AMD K6 Linux machine when the applet is runningunder Netscape 4.05. The slow speed is mostly due to the not yet very e�cient Javaimplementation in the browser. The time required for the rest of the conversioninto the Parsons code is negligible.During the stage involving our 167 MHz UltraSparc server, a Parsons code oflength 20 will be searched in approximately one second.One can say that although the retrieval takes some time, the speed is satisfactory.Actually, most of the time for a query will be spent in the manual steps thatare required because the Java implementation of our current browswer NetscapeCommunicator 4.05 does not yet support sound recording. Hence, one has to recordmanually, store the recording into a �le, and tell the applet the �le name.3.8 User reactionsFrom a purely quantitative point of view (retrieval reliability), Tuneserver certainlyleaves room for improvement. However, the most important usability problem ofTuneserver has little to do with its objective performance. The biggest obstacle tosuccessful Tuneserver use is embarrassment. Many potential users are reluctant touse Tuneserver | in particular when other people are present | because they feelashamed of their whistling capabilities. We feel that this problem would be muchreduced if Tuneserver would accept humming instead of only whistling, becausemost of our users �nd humming a lot easier and are more competent for it. Notethat the severity of this problem is highly dependent on culture. We assume thatit is, for example, less severe for American users compared to our German ones. Itis probably impossible, though, to solve the problem entirely.

An Interface for Melody Input � 15This issue set aside, most of our users reacted very positively. We quote onee-mail sent to us in verbatim. It combines several of the more frequent types ofcomments:Brilliant applet! It got all the tunes I tried except for the famous MozartHorn Concerto KV495 rondo theme, which didn't seem to be in thedatabase! I was particularly impressed when it got the national Aus-tralian anthem, even though I remembered it wrong!4. RELATED WORKWe know of four published attempts at tune recognition. The �rst one is Queryby Humming (QbH) by Ghias, Chamberlin and Smith [Ghias et al. 1995]. QbH issimilar to the core of TuneServer (without the web service) and also uses Parsonscoding. The major technical di�erence is that QbH uses autocorrelation instead ofspectrum analysis for determining the pitch, allowing humming to be input insteadof whistling. Unfortunately, the article provides only very vague information on theactual retrieval performance obtained, allowing no direct comparison of the systemcapabilities. The QbH database contains 183 songs; the data were extracted fromMIDI �les. The search implementation does not scale well as it is more than 30times slower compared to ours: it searches about 30 songs per second on a SunSparcStation 2.The QbH article mentions similar work by Kageyama and Takashima that wasapparently published only in Japanese.Query by Humming also inspired a module of the same name in the WorldBeatsystem [Borchers 1997]. In that implementation, the pitch tracking is done byspecial-purpose hardware, a Roland GI-10 Guitar-to-MIDI converter. Again, noserious empirical evaluation of the performance is available. The database consistsof 20 Beatles songs.3Finally, the New Zealand Digital Library project [Witten et al. 1998] contains atune recognition module called MELDEX [McNab et al. 1997]. It has an extensivedatabase of 9,400 tunes (mostly folk songs, including 2,100 chinese songs), but arather simple front-end, requiring the individual notes to be clearly separated by theuser. Pitch determination is based on �ltering for obtaining the base frequency andis fast in MELDEX, but the approximate code matching for database recall is almost10 times slower than in Tuneserver. The article claims that input can be \sung,hummed, or otherwise entered", but no data on actual recognition performanceis presented at all. However, the article presents a nice investigation comparingdi�erent encoding methods that either use or ignore rhythmic information andeither use note intervals or the ternary R-D-U code only. The results indicate, forinstance, that for the given database of 9400 tunes, an average of about 8 notes arerequired to reduce the number of matchings songs to just one if only the Parsonscode is used,4 about 4 notes if full melodic information (rhythm and intervals) isprocessed, assuming perfect quality of the user's input.3Jan Borchers, personal communication, June 1998.4The value is surprising, as 8-note Parsons codes can discriminate only 6,561 di�erent tunes, butis plausible as an average.

16 � Lutz Prechelt and Rainer Typke5. CONCLUSIONS AND FUTURE WORKMelody input is viable. We presented a design and implementation of a tune recog-nition system that is fast enough for interactive use and provided parameters withwhich its recognition accuracy is good enough for practical application. Our empir-ical evaluation found that Tuneserver lists the intended tune, if it is known, amongthe 40 most probable ones 77% of the time | despite di�cult real-world conditionssuch as background noise, subjects who cannot whistle well, and subjects providingtoo few notes for proper recognition or providing entirely incorrect melodies. Weconsider this performance quite satisfying. The success rate will be even higher ifthe input is whistled cleanly and if it is su�ciently long (about 15 notes).We see the following desirable extensions of this work:|More powerful front end: A more elaborate analysis of the audio signal shouldallow for singing or humming in addition to whistling. This will make it subjec-tively and objectively easier for most users to provide input that is accurate andclear enough for an error-free analysis.|Learning from frequent mistakes: The search machinery should learn from userfeedback and automatically build and employ a model of typical user input errors.This could improve the precision and recall of the retrieval for incorrect inputs.|Learning new melodies: It should be possible to incorporate new melodies intothe database automatically. This could best be done by analysis of full musicalaudio signals. Alternatively, techniques such as those used (but not published)by [Ghias et al. 1995] could be used to extract melodies from MIDI �les.ACKNOWLEDGMENTSWe thank those who participated in the empirical study and all other Tuneserverusers who gave us feedback. Thanks also to Michael Philippsen, Agatha Walczak,D�orte Neundorf, and Bernhard Haumacher for commenting on drafts of this arti-cle. Thanks to our reviewers for suggesting to put in some more qualitative andspeculative information.REFERENCESBarlow, H. and Morgenstern, S. 1948. A directory of musical themes. Crown Publishers,New York, NY.Benoit, C., Pelachaud, C., and Suhm, B. 1999. Multimodal speech systems. In D. Gib-bons, R. Moore, and R. Winski Eds., Handbook of Standards and Resources in Spo-ken Language Systems, Volume supplement. Berlin: Mouton de Gruyter. to appear,http://werner.ira.uka.de/~bsuhm/.Borchers, J. 1997. Worldbeat: Designing a baton-based interface for an interactive musicexhibit. In Proc. ACM Intl. Conf. on Computer-Human Interaction (CHI97) (Atlanta,GA, March 1997), pp. 131{138. acm press.Cole, R. A., Mariani, J., Uszkoreit, H., Zaenen, A., and Zue, V. 1995. Survey of theState of the Art in Human Language Technology. Center for Spoken Language Understand-ing CSLU, Carnegie Mellon University, Pittsburgh, PA.Dellaert, F., Polzin, T., and Waibel, A. 1996. Recognizing emotion in speech. In Proc.Intl. Conf. on Spoken Language Processing (Philadelphia, Oct. 1996), pp. 1970{1973.Ghias, A., Logan, J., Chamberlin, D., and Smith, B. C. 1995. Query by humming {musical information retrieval in an audio database. In ACM Multimedia (San Francisco,CA, Nov. 1995).

An Interface for Melody Input � 17Jacob, R. J. 1996. Human-computer interaction input devices. ACM Computing Sur-veys 28, 1 (March), 177{179.Manke, S., Finke, M., and Waibel, A. 1995. Npen++: A writer independent, large vo-cabulary on-line cursive handwriting recognition system. In Proc. Intl. Conf. on DocumentAnalysis and Recognition (Montreal, Canada, Aug. 1995). IEEE CS press.McNab, R. J., Smith, L. A., Bainbridge, D., and Witten, I. H. 1997. The New Zealanddigital library MELody inDEX. D-Lib magazine 3, 5 (May). www.dlib.org, ISSN 1082-9873.Myers, B., Hollan, J., Cruz, I., Bryson, S., Bulterman, D., Catarci, T., Citrin, W.,Glinert, E., Grudin, J., and Ioannidis, Y. 1996. Strategic directions in human-computer interaction. ACM Computing Surveys 28, 4 (Dec.), 794{809.Parsons, D. 1975. The Directory of Tunes and Musical Themes. Spencer Brown.Reddy, R. 1995. Grand challenges in AI. ACM Computing Surveys 27, 3 (Sept.), 301{303.Stiefelhagen, R., Yang, J., and Waibel, A. 1997. A model-based gaze tracking system.Intl. Journal of Arti�cial Intelligence Tools 6, 2, 193{209.Stork, D. G. and Hennecke, M. E. 1996. Speechreading: An overview of image pro-cessing, feature extraction, sensory integration and pattern recognition techniques. In Intl.Conf. on Automatic Face and Gesture Recognition (Killington, VT, Oct. 1996), pp. xvi{xxvi. IEEE CS press.Ukkonen, E. 1985. Finding approximate patterns in strings. Journal of Algorithms 6, 132{137.Witten, I. H., Nevill-Manning, C., McNab, R., and Cunningham, S. J. 1998. A publiclibrary based on full-text retrieval. Communications of the ACM 41, 4 (April), 71{75.




















