
Data Mining 02- داده کاوی
84
Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University ﭘﻴــﺶ ﭘــﺮدازش داده ﭘﻴــﺶ ﭘــﺮدازش دادهData Preprocessing Data Preprocessing دﻛﺘﺮ ﻣﺤﻤﺪ ﺣﺴﻴﻦ ﻧﺪﻳﻤﻲ داﻧﺸﻜﺪه ﻣﻬﻨﺪﺳﻲ ﻛﺎﻣﭙﻴﻮﺗﺮ داﻧﺸﮕﺎه آزاد اﺳﻼﻣﻲ واﺣﺪ ﻧﺠﻒ آﺑﺎد داده ﻛﺎوي داده ﻛﺎويData Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Transcript of Data Mining 02- داده کاوی

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
پيــش پــردازش داده پيــش پــردازش داده Data PreprocessingData Preprocessing
دكتر محمد حسين نديميدانشكده مهندسي كامپيوتر
دانشگاه آزاد اسالمي واحد نجف آباد
داده كاويداده كاوي
Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
مقدمه
وبرگرفته از منابع مختلف داراي پايگاه داده ها در دنياي امروز ، به علت حجم بسيار باالي داده . دار، گم شده و ناسازگار هستند noiseداده
. تكنيك هاي زيادي در پيش پردازش داده ها وجود دارند تكنيك هاي زيادي در پيش پردازش داده ها وجود دارند تكنيك هاي زيادي در پيش پردازش داده ها وجود دارند تكنيك هاي زيادي در پيش پردازش داده ها وجود دارند
Data Cleaning : براي حذفnoise در داده ها و تصحيح ناسازگاري در داده ها به كار مي رود.Data Integration : داده ها ي منابع مختلف را در يكData store منسجم مانند Data
warehouse ذخيره مي كند .Data Transformation : داده ها نرمالسازي ميشوند .
Data reduction : حجم داده ها را با راهكارهاي تجميع ، حذف افزونگي ياclustering كاهش .مي دهد
2

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
.داده كاوي به عنوان مرحله اي از كشف دانش 3

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
چرا پيــش پردازش داده ؟
Data miningدار و ناسازگار را به كمك تكنيك هاي noiseشما مي خواهيد داده هاي ناكامل ، . آناليز كنيد
هاي مورد عالقه Attributeبه داليل متعددي ايجاد مي شوند ، به عنوان مثال داده هاي ناكامل �
. مانند اطالعات مشتريان در تراكنشهاي فروش . ممكن است بدون مقدار رها شود
.تند ، داده هاي شامل خطا و يا خارج از محدوده ي مورد انتظار داده ها هس دار noiseداده هاي �
داده هايي شامل تناقض در كدهاي مورد استفاده در بخش دسته بندي Inconsistentداده هاي �
. آيتم ها هستند
4

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
داده هاي ناكامل بنا به داليل زيادي ممكن است ايجاد شوند
Attribute اكنش فروش در هاي مورد عالقه، ممكن است مانند اطالعات مشتريان براي داده هاي تر
. دسترس نباشند
كه در زمان ورود در نظر گرفته داده هاي ساده اي نيز ممكن است وجود نداشته باشد تنها به اين دليل
. نشده اند
ممكن است Attributeچندين داده هاي گم شده به ويژه براي تاپل ها با چندين مقدار گم شده براي
. نياز به استنباط داشته باشند
. كردن تجهيزات ثبت نشده باشند برخي داده ها نيز ممكن است به دليل سوء تفاهم و يا به دليل بد عمل
. باشند داده هاي متناقض ممكن است با حذف داده هاي ثبت شده ديگري ايجاد شده
. فته شود عالوه بر اين تاريخچه ي ثبت يا تغييرات داده ها ممكن است ناديده گر
5

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
وجود دارد noisyداليل مختلفي براي داده هاي
. اشندابزارهايي كه براي جمع آوري داده استفاده مي شوند ممكن است معيوب ب. شند ممكن است انسان يا كامپيوتر در هنگام ورود داده ها دچار خطا شده با
. خطاها ممكن است در زمان انتقال داده رخ داده باشند محدويت هاي تكنولوژيكي
كدهاي داده ي استفاده داده هاي نادرست ممكن است نتيجه ي ناسازگاري در قوانين نامگذاري ياشده يا فورمت هاي ناسازگار براي فيلدهاي ورودي
6
Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
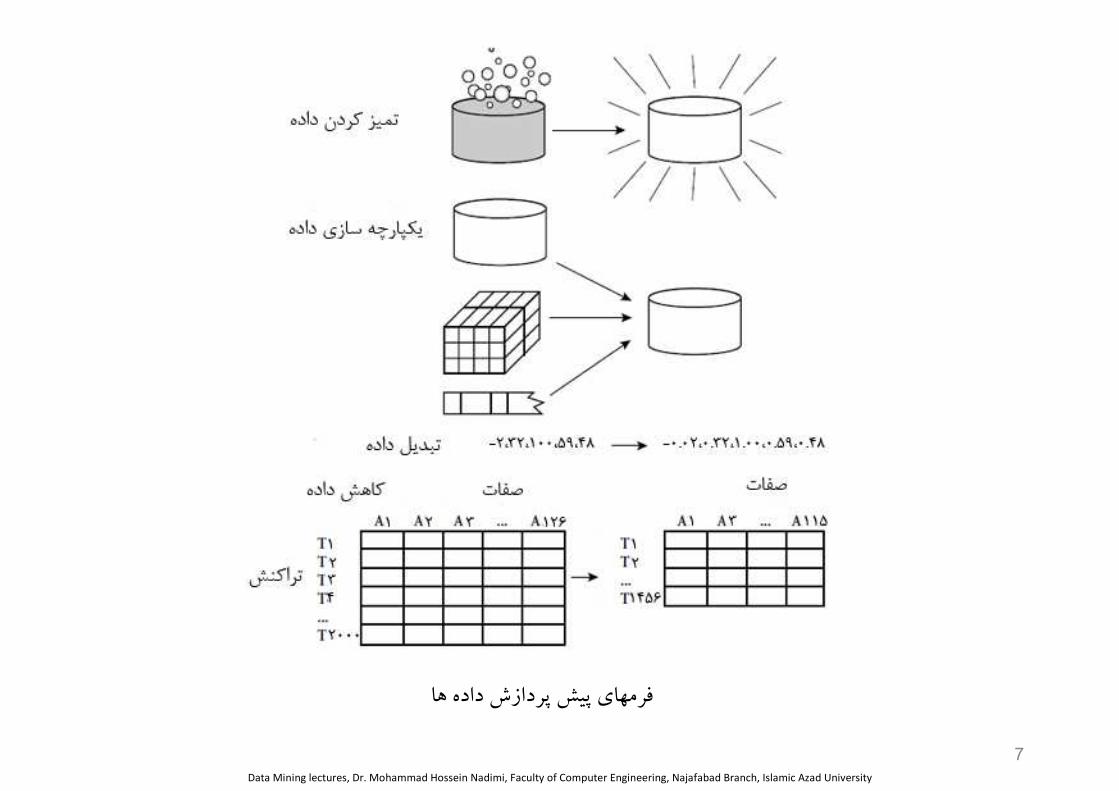
فرمهاي پيش پردازش داده ها
7

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
خالصه سازي داده هاي توصيفي
highlightعمولي داده ها و تكنيك خالصه سازي داده هاي توصيفي ، براي شناسايي ويژگي هاي م. مورد بررسي قرار بگيرند بكار مي رودoutlier يا noiseكردن مقادير داده اي كه بايد به عنوان
يا هاي پيش پردازش داده ،كابران بايستي درموردگرايش داده ها به تمركزTaskدر بسياري از�. پراكندگي اطالع داشته باشند
:اندازه گيري در مورد گرايش داده ها به مركزيت ، شامل �
ميانگين �ميانه �مد �مركزيت دامنه �
8

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
) ادامه(
:اندازه گيري پراكندگي داده ها شامل �
quartileربع يا �
interquartileدامنه ي ميان ربع يا � range
واريانس �
. آمار توصيفي كمك بزرگي در درك پراكندگي داده ها هستند
9

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
)Central Tendency(معيارهاي گرايش مركزي
meanين يا رايجترين و مؤثرترين اندازه گيري عددي مركز يك مجموعه داده ، ميانگ . است
: ميانگين اين مجموعه از مقادير برابراست با
به ( )avg يا()average است كه به صورت SQL اين فرمول مربوط به تابع تجمعي موجو د در .كار مي رود
i=1,2,…N مرتبط باشد كه براي wi در يك مجموعه ممكن است با يك وزن xi گاهي اوقات هر در اين موارد مي توانيم آن را . نشان دهنده ي ارزش ، اهميت يا فراواني وقوع مقادير مرتبط با آنهاست
. به صورت زير محاسبه كنيم
N
xxx
N
xx N
N
ii +++
==∑
= .....211
n
NNN
ii
N
iii
www
xwxwxw
w
xwx
.....
.....
21
2211
1
1
+++++==
∑
∑
=
=
10

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ادامه
. يكي از بزرگترين مشكالت ميانگين ، حساسيت آن به مقادير حداكثري است. استmedianيا براي داده هاي نامتقارن يك معيار مركزيت داده ها استفاده از ميانه
مقدار مجزاي مرتب شده ي عددي داده شده استN با Data setفرض كنيد كه يك اگر تعداد اعداد فرد باشد ميانه مقدار وسط در داده هاست ☯.اگر تعداد اعداد زوج باشد ميانه ، ميانگين دو عدد وسط خواهد بود☯
. براي يك مجموعه داده ، مقدار بيشترين تكرار در مجموعه است مد مختلف وجود داشته باشد كه منجر اين امكان وجود دارد كه براي مقدارِ بيشترين تكرار ، چندين مقدار
.به ارائه بيش از يك نتيجه براي مد خواهد شد Data set هايي با يك يا دو يا سه مد به ترتيب unimodsal، biomodal و trimodal ناميده مي
. شوند
11

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
در مقابل دادهاي اريب مثبت و منفي ميانگين، ميانه و مد داده هاي متقارن
12

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
اندازه گيري پراكندگي داده ها
. يا واريانس آن داده ها مي گويند درجه ي تمايل داده هاي عددي به گسترش را پراكندگي
:رايج ترين معيارهاي اندازه گيري پراكندگي داده ها عبارتند از �
Range ) براساس ربع ( عددي 5خالصه
محدوده ي ميان ربعي انحراف از معيار
13

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Range ،Quartiles ،Outlier و Box plot
�Range: تفاوت بين بزرگترين مقدار )max() ( و كوچكترين مقدار )min() ( در آنمجموعه
�Quartiles : اختيار شامل ميانه ، اطالعاتي در مورد مركزيت ، پراكندگي و شكل توزيع در. ما قرار مي دهد
. به صورت زير شناخته مي شود IQRيا فاصله ميان ربعي ��Boxplot ها يك روش محبوب براي تجسم يك توزيع است .
: عددي به صورت زيراست 5 شامل خالصه سازي Boxplot يك . است IQRبطور معمول جعبه هاي پاياني در ربع ها هستند بطوريكه طول جعبه 1.. نشان گذاري مي شود Boxميانه با يك خط ميان 2. كوچكترين مقدار و بزرگترين مقدار مشاهده شده را نشان مي دهد Boxدو خط خارج شده از 3.
. ناميده مي شودwhiskerكه خطوط
13 QQIQR −=
14

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
شعبه از شركت 4براي كاالهاي فروخته شده unit priceبراي داده Box Plotنمودار Alletectonics طي زمانهاي مشخص
15

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
واريانس و انحراف معيار
: عبارتست از xn,…..x2,x1 داده ي مشاهده شده ي Nواريانس
انحراف معيار . تعريف شد1.2در اينجا مقدار ميانگين مشاهدات است همانطور كه در فرمول )σ ( مشاهدات ، مجذور واريانس)σ2 ( است .
])(1
[1
)(1 222
1
xiN
xN
xxN i
N
ii ∑−∑=−= ∑
=
2σ
16

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
نمايش گرافيكي خالصه سازي داده هاي توزيعي پايه
خطي به كار رفته در اكثر بسته هاي نرم عالوه بر نمودارهاي ميله اي ، نمودارهاي دايره اي و نمودارهايده و آماري داده ها ، انواع خاص ديگري از نمودارها براي نمايش خالصه دا–افزاري نمايش گرافيكي
.توزيعات وجود دارد
: اين روش ها عبارتند از �Histogram
�quantile plot
�q-q plot
�scatter plot
�loess curre
17

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Histogram
�Histogram: يك روش گرافيكي براي خالصه سازي توزيع يك صفت خاص
� )$(وا����
تعداد آيتم فروخته شده
18

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
quantile plot
�quantile plot : روش ساده و مؤثر براي بررسي و ترسيم توزيع داده هاي تك متغيري
quantile plot 1.2را براي داده هاي جدول براي كاالهاي فروخته شده در Unit Priceدادهاي : 1. 2جدول
Alletectonicesيك شعبه از شركت
19

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
q-q plot
�q-q plot : يك وسيلهVisualization يا ( قوي است كه در آن كاربر مي تواند ببيند آيا تغييريshift در رفتن از يك توزيع به توزيع ديگري وجود دارد يا نه) ي.
quantile-quantileيك plotبراي داده ي Unit price از دو شعبه مختلف 20

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
scatter plot
�scatter plot : تمايل بين دو يكي از كارآمدترين متدهاي گرافيكي براي تعيين وجود رابطه ، الگو يا Attribute عددي است .
1.2 جدول Data set براي Scatter plotيك
21

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
loess curre
�loess curre : يك يكي ديگر از روش هاي اكتشافي گرافيكي است كه يك منحني هموار را بهscatter plot براي فراهم آوردن درك بهتري از الگوهاي وابستگي اضافه مي كند .
loess curve برايData set 1.2 جدول22

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Data cleaning
ها را بر طرف كرده ، Noise سعي دارد مقادير مفقود شده را پر كند، Data cleaningروال �. ها را شناسايي و ناسازگاريها را بر طرف مي كندoutlierهمچنين
::::Data cleaningتكنيك هاي پايه اي تكنيك هاي پايه اي تكنيك هاي پايه اي تكنيك هاي پايه اي �Missing value : شيوه هاي كنترل ومهار مقادير مفقود شده
Noisy Data : تكنيك هاي هموارسازي داده هاData cleaningفرايند
23

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Missing value
“ ؟ ها ، مقادير مفقود پيدا كنيد Attributeچگونه شما ميتوانيد براي اين "
:متدهاي زير را داريم
ناديده گرفتن تاپلها پر كردن مقادير مفقود شده بصورت دستي
استفاده از يك ثابت سراسري براي پر كردن مقادير مفقود براي تكميل مقدار مفقود شدهAttributeاستفاده از ميانگين
براي تاپل معين ، استفاده كنيدclass براي تمام نمونه هاي متعلق به يك Attributeاز ميانگين از متحمل ترين ارزش براي تكميل مقدار مفقود استفاده كنيد
24

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Noisy Data
�Noise چيست ؟ ....يك خطاي تصادفي يا تفاوت در متغيرهاي اندازه گيري شده استيك خطاي تصادفي يا تفاوت در متغيرهاي اندازه گيري شده استيك خطاي تصادفي يا تفاوت در متغيرهاي اندازه گيري شده استيك خطاي تصادفي يا تفاوت در متغيرهاي اندازه گيري شده است
، چگونه مي توان داده را براي حذف price عددي مثل Attributeبا در نظر گرفتن يك ”�Noiseهموار كرد؟ ،”
: : : : تكنيك هاي هموار سازي دادهتكنيك هاي هموار سازي دادهتكنيك هاي هموار سازي دادهتكنيك هاي هموار سازي داده Beginning
Regression
Clustering
25

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Beginning
�Beginning : : : : متدهايBeginning همواركردن مقادير يك داده ي مرتب شده را با استنتاج مقادير ، . دهند همسايگان مجاور آن يا به عبارت ديگر با مقادير پيرامون آن انجام مي
Data Smoothing براي Binningمتدهاي 26

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Regression
�Regression : ود داده مي تواند با تناسب داده شده با يك تابع مانند رگرسيون هموار ش .
� Regression Linear شامل يافتن بهترين خط براي fit كردن دو Attribute) يا دو متغير (. ديگري استفاده شودAttribute مي تواند براي پيش بيني Attributeبطوريكه يك . است
�Multiple linear Regression يك گسترش ازlinear Regression است بطوريكه . مي شودfit را شامل و داده در يك سطح چند بعدي Attributeبيش از يك
27

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Clustering
�Clustering :outlier ها ممكن است با clusteringدر اين روش مقادير مشابه . كشف شوندبطور مشهود مقادير خارج از مجموعه هاي . ها سازمان دهي مي شوند cluster و يا Groupدر
cluster ها بعنوان outlierها در نظر گرفته مي شوند .
كه داده ها در سه يك طرح دو بعدي از داده مشتري با توجه به موقعيت مشتري در شهر است Cluster مركز جرم هر . نشان داده شده اندClusterنمايش داده شده كه ميانگين نقاط + با يك
ها قابل شناسايي است Cluster ها با نفاط خارج از Outlier. استClusterدر فضاي آن
28

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Data cleaningفرايند
. كشف اختالف است Data cleaningاولين مرحله فرايند
:عوامل اختالف مي تواند چندين دليل زير باشند . فرم هاي ورود اطالعات باطراحي ضعيف كه فيلدهاي اختياري زيادي دارند
خطاهاي انساني در ورود اطالعات ) ند يعني پاسخ دهندگاني كه نمي خواهند اطالعاتي را در مورد خود افشا كن (خطاهاي سنجش
) مانند آدرس هاي قديمي ( زوال اطالعات
"بنابراين چگونه مي توان كشف خطا را پيشبرد ؟"به چنين دانشي در مورد . ان استفاده كردبه عنوان يك نقطه شروع ، از هر دانش مربوط به ويژگي هاي داده مي تو
. مي گويند Meta dataداده كه در واقع داده اي در مورد داده است
29

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
يكپارچگي وتبديل داده ها
استخراج داده اغلب مستلزم يكپارچگي داده ها هست Data storeيكپارچگي داده ها از چندين
بعالوه الزم است داده به شكلهاي مناسب براي استخراج تبديل شود
: استخراج شامل دو مرحله زير است
فرايند يكپارچه سازي داده ها فرايند تـبديل داده
30

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
فرايند يكپارچه سازي داده ها
ل سازي نمود وتطبيق داد ؟ چگونه مي توان موجوديت هاي دنياي واقعي از چندين منبع داده را معاد
.استشناسايي موجوديتها اولين موضوع
Metadata براي هر Attribute مي تواند شامل اسم ، معني ، نوع داده ، دامنه مقادير مجاز براي . باشد blank براي كنترل مقادير تهي صفر يا Null و قواعد Attributeاين
استفاده هايي مي توانند براي كمك به اجتناب از خطاها در شماي يكپارچه سازيMetadataچنين . شود
31

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ادامه
.است فزونگي ادومين موضوع ☯
Data set ها يا ابعاد نيز مي توانند عامل افزونگي در Attributeناسازگاري هاي در نامگذاري ☯.حاصله باشند
. بعضي افزونگي ها، با آناليز همبستگي قابل كشف هستند☯:فرمول ضريب همبستگي ☯
≥1-دقت كنيد كه☯ Y A,B ≤ به طور B و Aاز صفر بزرگتر باشد ، يعنيYA,Bاگر . است 1+. مثبت به هم وابسته هستند
. ممكن است به عنوان يك افزونگي حذف شود ) Bيا ( Aمقدار باال نشان مي دهدكه
BA
N
i ii
BA
N
i iiBA N
BANba
N
BbAaY
δδδδ∑∑ == =
−−= 11 )())((
,
32

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ادامه
�Scatter plot نيز مي تواند براي مطالعه و بررسي همبستگي بينAttributeها استفاده شود . ، مي تواند B و Attribute ، A، يك رابطه همبستگي بين دو )مجزا( براي داده هاي طبقه بندي �
. كشف شود χ2 (chi-squer)تست با
A(فراواني مشاهده شده ي رويداد مشترك oij در اينجا � i,Bi ( كه تعداد واقعي آن است مي باشد وeij تكرار واقعي )A i,Bj (است ، كه طبق فرمول زير محاسبه مي شود .
�N تعداد تاپل هاي داده است .count(A=ai) تعداد تاپل هاست كه داراي ارزش ai براي A است . است B براي bj تعداد تاپل هاست كه داراي ارزش count(B=bj)و
∑ ∑= =
−= c
i
r
jij
ijij
e
eaX
1 1
22 )(
N
bBcountaAcounte ii
ij
)()( =×==
33

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
:χ2 هاي طبقه بندي با كاربرد Attribute آناليز همبستگي 1.2مثال
از هر فرد در . جنسيت هر فرد نيز ثبت شده است . نفري بررسي شده باشد 1500فرض كنيد يك گروه .واقعي باشد سوال شده است مورد اينكه نوع مطالب مورد عالقه ي آن ها براي مطالعه غيرواقعي يا
براي مطالب ”preferred-reading“ براي جنسيت و ”gender“ داريم، Attributeاز اينرو ما دو �. مورد عالقه
نشان داده شده خالصه 2.2 در جدول احتمال كه در جدول countتكرار مشاهده شده هر رويداد مشترك يا �. اعداد داخل پرانتز تكراري هاي مورد انتظار هستند . مي شود
:عبارتست از ) male ,fiction(براي مثال ، تكرار مورد انتظار براي هر سلول
9001500
45030011 =×=×=
N
Fictioncountmalecounte
)()(
34

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
93/50748/3011/7190/12144/284840
)8401000(
360
)360200(
210
)21050(
90
)90250( 22222
=+++=
−+−+−+−=x
9001500
45030011 =×=×=
N
Fictioncountmalecounte
)()(
2.2جدول
مورد نياز براي رد فرضيه χ2، ارزش 1براي درجات آزادي ) 2-1)(2-1=(1: ، درجات آزادي عبارتند از 2×2براي اين جدول . است828/10 برابر با 001/0در سطح اهميت
ادامه
35

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ادامه
.مقادير داده است هاي conflictكشف و حل سومين موضوع مهم در فرايند يكپارچه سازي داده �
در منابع مختلف، ممكن است Attributeبراي مثال، براي يك موجوديت دنياي واقعي، مقادير �.متفاوت باشد
. كدگذاري باشداين تفاوتها ممكن است نشأت گرفته از تفاوت در نمايش ، درجه بندي يا�
36

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
فرايند تـبديل داده
م هاي مناسب استخراج تثبيت مي شوندم هاي مناسب استخراج تثبيت مي شوندم هاي مناسب استخراج تثبيت مي شوندم هاي مناسب استخراج تثبيت مي شونددر فرايند تبديل داده ، داده ها تغيير شكل داده مي شوند و يا در فردر فرايند تبديل داده ، داده ها تغيير شكل داده مي شوند و يا در فردر فرايند تبديل داده ، داده ها تغيير شكل داده مي شوند و يا در فردر فرايند تبديل داده ، داده ها تغيير شكل داده مي شوند و يا در فر
: فرايند تبديل داده شامل موارد زير است �Smoothing : كه براي حذفNoise از داده بكار مي رود و شامل تكنيكهاي Regression ،
Clustering و binning است .�Aggregation : در اين روش عمليات خالصه سازي يا تجميع داده ها اعمال مي شود .�Generalization: يا سطح پائين با دادهاي سطح باالتر با ) خام (داده ها ، در اين تكنيك داده هاي اوليه
. كاربرد مفاهيم سلسله مراتب جايگزين مي شوند�Normalization :در اين تكنيك داده هايAttribute 1 براي قرار گرفتن در يك دامنه خاص مثل
. درجه بندي مي شوند 1 تا 0 و 1 تا – هاي جديد ايجاد و به مجموعه Attributeدر اين تكنيك : )Attribute )Featureساخت �
Attributeهاي قبلي اضافه مي شوند تا به فرايند استخراج كمك كنند .
37

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ادامه
: ها را بررسي مي كنيم متدهاي زيادي براي نرمالسازي داده وجود دارد ، سه مورد از اين متد
Max-Minنرمالسازي
z-scoreنرمالسازي
Decimal scalingنرمالسازي
38

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Max-Minنرمالسازي
. يك تبديل خطي را روي داده هاي اوليه اجرا مي كند Max-Minنرمالسازي . باشد A مانند Attribute مقادير حداكثر و حداقل يك MinAو MaxAفرض كنيد كه
: ، را به كادر دامنه ي زير نگاشت مي كند با محاسبه A از v ، يك مقدار Max-Minنرمالسازي
[new-minA ,new-maxA]
. روابط بين مقادير داده اوليه را حفظ مي كندMax-Minنرمالسازي
AnewAnewAnewAA
AVV min)min.max.(
minmax
min −+−−
−=′
39

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Max-Min نرمالسازي 2.2مثال
هزار دالر هستند 98 و 12 درآمد به ترتيب Attributeفرض كنيد كه مقادير حداقل وحداكثر �. نگاشت كنيم ] 0.0 و 1. 0[ ما مي خواهيم درآمد را در دامنه �
دالر براي درآمد با فرمول 73600 يك ارزش Max-Min با نرمالسازي
71600001. نگاشت مي شود12000980001200073600
/)/( =+−−−
40

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
z-score نرمالسازي
نرمالسازي A براساس ميانگين و انحراف معيار Attribute ، A مقادير يك z-scoreدر نرمالسازي .مي شوند
نشان داده و به نرمالسازي شده را باA مي ناميم ، مقدار V را A مقدار صفت خاصه �وصورت زير محاسبه مي شود
. هستندA و ميانگين و انحراف معيار صفت خاصه ي در اينجا A
AVV
σ′−=′
V′
Aσ A
41

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
z-score نرمالسازي 3.2مثال
. هزار دالر هستند 16 و 54 در آمد به ترتيب Attributeفرض كنيد ميانگين و انحراف معيار مقادير �
دالر براي درآمد به تبديل73600 مقدار z-score با نرمالسازي �
. مي شود
225116000
540073600/=−
42

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Decimal scalingنرمالسازي با
را نرمالسازي مي A با حركت نقطه اعشار مقادير صفت خاصه Decimal scalingنرمالسازي با . كند
. بستگي داردAميزان حركت نقطه اعشار به ارزش مطلق حداكثري . را با نشان مي دهيم A مي ناميم و مقدار نرمالسازي شده V را Aمقدار صفت خاصه ي
كوچكترين عدد صحيح است وj محاسبه مي كنيم بطوريكه j
VV
10=′
1|)(| <′VMax
V′
43

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Decimal scaling 4.2مثال
. درجه بندي مي شوند 917 تا -986 از Aفرض كنيد كه مقادير ذخيره شده
. است 986 برابر با A حداكثر مقدار مطلق
) j=3يعني( تقسيم مي كنيم 1000 ، هر مقدار را بر Decimal scaling براي نرمالسازي با
. نرمالسازي مي شود 917/0 در 917 نرمالسازي مي شود و -986/0 در -986طوري كه
44

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
كـــــاهش داده
كه حجم كوچكتري Data setتكنيك هاي كاهش داده براي كسب يك نمايش كاهش يافته از �. دارد بكار روند
. يكپارچگيِ داده ي اصلي حفظ مي شود�. هاي كاهش يافته بايد كارآمدتر از توليد نتايج تحليلي مشابه باشدData setاستخراج �
: استراتژي كاهش داده شامل موارد زير است �Data cube Aggregation :
. بكار مي رودData cube در اين استراتژي عمليات تجميع براي ساخت داده ي يك
�Attribute subset selection :. يا ابعاد بي ربط ، ضعيف يا افزونه كشف و حذف ميشوندAttribute در اين استراتژي
45

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ادامه
�Dimensinality Reduction :. استفاده مي شوندData setه در اين استراتژي از مكانيزم هاي كدگذاري براي كاهش انداز
�Numerosity Reduction :. زين مي شونددر اين استراتژي داده ها با نمايش هاي كوچكتر و متنوع از داده جايگ
: مجزا سازي و توليد سلسه مراتب مفهومي �. ها با سطوح مفهومي باالتر يا دامنه ها جايگزين مي شوندAttribute در اين استراتژي مقادير داده ي خام
كاهش data setتخراج اندازه يك زمان محاسباتي صرف شده بر كاهش داده نبايد از زمان صرف شده براي اس.يافته سنگين تر باشد
46

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Data cubeتجميع داده ها
شد و اين داده ها، داده هاي فرض كنيد كه براي انجام يك آناليز ، داده هاي الزم جمع آوري شده باالبته شما به . است 2004 تا 2002درخالل سال هاي AllElectronicsفروش سه ماهه شركت
.تحليل فروش ساالنه به جاي فروش ، سه ماهه عالقه مند هستيد زم براي فرايند آناليز از مجموعه داده هاي حاصله حجم كمتري دارند ، بدون آنكه اطالعات مفيد ال
. دست رفته باشد
AllElectronicsداده هاي فروش براي يك شعبه ي سمت چپ داده هاي فروش به ازاي هر فصل . 2004 تا 2002در خالل سالهاي . ارائه شده است نشان داده شده است و سمت راست داده هاي تجميع شده براي فروش ساالنه
47

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ها Attributeانتخاب زير مجموعه اي از
Data set هاي مورد آناليز ممكن است شامل صدها Attribute باشند ، كه بسياري از آنها ممكن است
.به روال استخراج ربطي نداشته باشند يا اساسا افزونه باشند
: ها Attributeهدف انتخاب زير مجموعه اي از
هاست كه نتيجه ي توزيع احتمال آنها دركالسهاي داده Attributeيافتن مجموعه ي حداقلي از
. اشداي تقريبا نزديك به توزيع احتمال اصلي با استفاده از همه داده ها ب
هايي كه در الگوهاي كشف شده كاهش يافته و باعث فهم آسان الگوها ي Attributeتعداد
.كشف شده مي شود
48

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ها Attributeانتخاب زير مجموعه اي از
: ها شامل تكنيك هاي زير هستند ها شامل تكنيك هاي زير هستند ها شامل تكنيك هاي زير هستند ها شامل تكنيك هاي زير هستند Attributeمتدهاي اكتشافي اصليِ انتخاب زير مجموعه متدهاي اكتشافي اصليِ انتخاب زير مجموعه متدهاي اكتشافي اصليِ انتخاب زير مجموعه متدهاي اكتشافي اصليِ انتخاب زير مجموعه �
�stepwise selection forward :. به عنوان يك مجموعه كاهش يافته شروع مي شود Attribute اين روش با يك مجموعه ي خالي
در هر مرحله يا تكرار بعدي ، . اصلي به مجموعه كاهش يافته اضافه مي شوند Attributeبهترين . اصلي باقي مانده به مجموعه افزوده مي شودAttributeبهترين
�elimination : باقي Attributeدر هر مرحله اين بدترين . ها شروع مي شودAttribute اين روش با كل مجموعه
.مانده در مجموعه را حذف مي كند�of forward selection and backward elimination combination : دو
انتخاب و بدترين Attributeروش قبلي مي توانند طوري تركيب شوند كه در هر مرحله بهترين Attribute حذف شود .
49

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
حريصانه براي انتخاب زيرمجموعه اي از ) اكتشافي(روشهاي Attribute ها
50

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
كــاهش ابــعاد
يافته يا فشرده ي از داده در كاهش ابعاد ، كد گذاري يا تبديل داده براي ايجاد يك نمايش كاهش . اوليه انجام مي شود
ز آن از دست رفته باشد ، باز سازي بطوريكه داده اوليه بتواند از داده ي فشرده ، بدون آنكه اطالعاتي ا . شود
: Lossyدو روش معروف و كارآمد كاهش ابعاد متد
Transformation wavelet آناليز مؤلفه هاي اصلي
51

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Wavelet Transforms
Discrete wavelet Transform) DWT ( يك تكنيك پردازش سيگنال خطي است كه هنگام X' با عنوان wavelet آن را به يك بردار متفاوت عددي ضرايب Xاعمال به يك بردار داده مانند
.اين دو بردار داراي يك طول هستند . تبديل مي كند
waveletاده ي چگونه اين تكنيك مي تواند براي كاهش داده مناسب باشد در صورتي كه د “transformation داراي طول مشابه به داده ي اصلي است ؟ ، ”
. مي تواند مختصر شود wavelet transformationسودمندي اين روش در اين واقعيت است كه داده ي مي حفظwavelet ترين ضرايب يك تقريب فشرده از داده ها مي تواند ، با ذخيره يك كسر كوچك از قوي
.شود
از داده ها بدون هموارسازي ويژگي هاي اصلي داده بكار مي رود noiseاين تكنيك همچنين براي حذف . را كارآمدتري امكان پذير مي كندData cleaningبنابراين
52

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ها Waveletمثالهايي از خانواده ي
53

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Wavelet Transforms
: : : : رايج عبارتند از رايج عبارتند از رايج عبارتند از رايج عبارتند از wavelet تبديالت تبديالت تبديالت تبديالت
.1Harr-2
.2 Dauhechie-4
.3Daubechies-6
سله مراتبي است كه داده را در روش كلي براي اعمال يك تبديل مجزا استفاده از الگوريتم هرمي سل.مي شودهر تكرار نصف مي شوند كه اين استراتژي به سرعت باالي محاسبات منجر
54

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
الگوريتم هرمي سلسله مراتبي
: : : : اين متد بصورت زير است اين متد بصورت زير است اين متد بصورت زير است اين متد بصورت زير است اين حالت مي تواند با پر كردن بردار داده با صفرها در . باشد 2بردار داده ي ورودي بايد يك توان صحيح از
. بدست مي آيد) (صورت نياز
. هر تبديل شامل كاربرد دو تابع است ن دار يا حاصل جمع ، اولين تابع هموارسازي داده ها را انجام مي دهد ، مانند ميانگين وز
.تابع دوم يك تفاضل وزن دار را اجرا مي كند
. اعمال مي شوند xاين دو تابع به جفت هاي نقاط داده اي در مال مي شود تا مجموعه هاي داده ي دو تابع به صورت بازگشتي به مجموعه هاي داده حاصله در حلقه قبلي اع
. باشند2حاصله داراي طول داده تبديل شده wavelet هاي حاصله در تكرارهاي باال به عنوان ضرايب Data setمقادير انتخابي از
. تعيين مي شوند
nL ≥
55

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
آناليز مؤلفه هاي اصلي
، nيل شده باشند كه با فرض كنيد كه داده رو به كاهش از بردارهاي داده اي يا تاپل هايي تشكAttribute كه . يا بعد توصيف مي شوندPrincipal Component Analysis يا PCA )
) نيز ناميده مي شود K-L يا متد Karhunen-Loeveكه ود ، جستجو بعدي را كه به بهترين نحو مي تواند براي نشان دادن داده استفاده شnبردارهاي متعامد
.مي كند بطوريكه باشد ت منجر به كاهش ابعاد بدين ترتيب داده ي اصلي به يك فضاي كوچك تر نگاشت مي شود و در نهاي
. مي شود PCA ذات ، Attribute ها را با ايجاد يك مجموعه كوچكتر و جايگزين متغيرها تركيب مي كند .
. داده ي اوليه نيز مي تواند دراين مجموعه كوچكتر پبش بيني شوند
nk ≤
56

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
PCA
: روال اصلي بصورت زير است . در يك دامنه قرار مي گيردAttributeداده هاي ورودي نرمالسازي مي شوند ، بطوريكه هر
PCA ، 4 بردار orthonormal را محاسبه مي كند كه اساس داده ي ورودي نرمالسازي شده را فراهم مي . كنند
مؤلفه هاي اصلي اساساً به عنوان . مؤلفه هاي اصلي، به ترتيبِ كاهش اهميت يا قدرت طبقه بندي مي شوند در مورد واريانس فراهم ارائه مي يك مجموعه جديد محورها براي داده ها به كار مي روند و اطالعات مهمي
.. كنند هستند را براي يك مجموعه داده ي معين نشان Y2 و Y1 دو مؤلفه اصلي اول را كه 17.2براي مثال شكل
اين اطالعات به شناسايي گروه ها يا الگوها در داده . ترسيم شده اند X2 و X1مي دهد كه در محورهاي . كمك مي كند
م داده ها مي تواند با حذف مؤلفه آز آنجايي كه مؤلفه ها به ترتيب كاهش اهميت طبقه بندي مي شوند ، حج .هاي ضعيف تر كاهش پيدا كند
57

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ادامه
PCA از نظر محاسباتي ارزان است و مي تواند هم براي Attribute هاي مرتب و هم نامرتب . بكار رود و توانايي كنترل داده هاي اسپارس و اريب را دارد
كنترل PCAو بعد با روش داده هاي چند بعدي با بيش از دو بعد را مي توان با كاهش مسئله به د . كرد
. و رگرسيون چندگانه استفاده شوند clusterمؤلفه هاي اصلي مي توانند به عنوان ورودي در آناليز در كنترل داده هاي اسپارس بهتر عمل مي كندwavelet ، PCAدر مقايسه با تبديالت
. دو مولفه اصلي اول براي داده هاي داده شده هستند Y2 و Y1آناليز مولفه هاي اصلي 58

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Numerosity Reduction
....اين تكنيك ها به دو صورت پارامتري يا غير پارامتري هستند اين تكنيك ها به دو صورت پارامتري يا غير پارامتري هستند اين تكنيك ها به دو صورت پارامتري يا غير پارامتري هستند اين تكنيك ها به دو صورت پارامتري يا غير پارامتري هستند
ه تنها پارامترهاي داده در متدهاي پارامتري ، يك مدل براي تخمين داده به كار مي رود بطوريك كه توزيعات احتمال چند Log-Liner مدل هاي .ها به جاي داده ي واقعي ذخيره مي شوند
. بعدي گسسته را تخمين مي زنند ، يك مثال براي متدهاي پارامتري هستند
هيستوگرام ها شامل متدهاي غير پارامتري براي ذخيره سازي نمايش هاي كاهش يافته داده ها ،clustering و sampling استفاده مي شود .
59

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Log-Liner و Regressionمدل
. براي بدست آوردن تقريب از داده استفاده مي شوندLog-linerرگرسيون و مدل هاي
. شونددر رگرسيون خطي ساده ، داده ها متناسب با يك خط مستقيم مدل سازي مي ، با x مي تواند به عنوان يك تابع خطي از متغير تصادفي ديگر به نام y براي مثال متغير تصادفي
:فرمول زير مدل سازي شود
Y=wx+b. توزيعات احتمال چند بعدي گسسته را تخمين مي زنند Log-linerمدلهاي
براي تخمين احتمال هر نقطه در يك فضاي چند بعدي براي يك مجموعه log-linerمدل هاي Attribute د گسسته باعنوان يك زير مجموعه كوچكتر از تركيب ابعاد استفاده مي شو.
. هر دو براي داده هاي پراكنده استفاده مي شوند log-linerرگرسيون و مدل هاي
60

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Histogeram
براي تخمين توزيعات داده ها استفاده مي كنند و يك فرم رايج در binningهيستوگرام ها از متد
. كاهش داده هستند
را به زير مجموعه منفصل يا A ، توزيع داده ، A ، مانندAttributeيك هيستوگرام براي يك
. باكت تقسيم مي كند
باشد ، باكتها، باكتهاي يكتا ”فراواني/Attributeمقدارِ “اگر هر باكت نشان دهنده يك جفت
. ناميده مي شوند
61

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
histogram 5.2مثال
اعداد تا . (هستندAllElectronics داده هاي زير ،ليستي از قيمت هاي اقالم فروخته در شركت : اعداد طبقه بندي شدند) . حد امكان گرد شده اند
1,1,5,5,5,5,5,8,8,10,10,10,10,12,14,14,14,15,15,15,15,15,18,18,18,18,18,18,18,18,20,20,20,20,20,20,20,21,21,21,21,25,25,25,25,25,28,28,3
0,30,30.
براي قيمت با استفاده از باكتهاي يكتا به صـورتي Histogramيك فراواني/ كه هر باكت نشان دهند ي زوج مقدار صفت خاصه
62

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
هيستوگرام
” ها تقسيم مي شوند ؟Attribute ها و مقادير Bucketچگونه “
: چند قاعده براي بخش بندي داده وجود دارد ، از جمله
. استuniform ، عرض هر دامنه باكت Equal-widthدر يك هيستوگرام : پهناي برابر در يك هيستوگرام با فراواني برابر باكت ها طوري توليد مي شوند كه : فراواني برابر يا عمق برابر
. تكرار هر باكت ثابت است V-optional : گيريم ، اگر تمام هيستوگرام هاي ممكن را براي يك تعداد باكت معين در نظر ب
. هيستوگرامي با كمترين واريانس است V-optinalهيستوگرام
63

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
دالر تجميع شده 10با عرض هيستوگرام با عرض برابر براي قيمت بطوريكه براي همه باكتها قيمتها . است
64

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
نمونه برداري را براي كاهش D ي مانند Data setمعمولترين شيوه هايي موجود را بررسي مي كنيم كه توانستند
. داده نمونه برداري كنند :) s) SRSWORنمونه تصادفي ساده بدون جايگزين با اندازه �
D در tuple ايجاد مي شود بطوريكه احتمال ترسيم هر D (s<N) تاپل ازN با s اين روش با ترسيم . است N/1برابر با
: s (SRSWR)نمونه تصادفي ساده با جايگزيني با اندازه �. ترسيم ، ثبت و تعويض مي شودD است ، به جز اينكه هر بار يك تاپل از SRSWORاين مشابه
: نمونه برداري خوشه اي� Sاز خوشه هاي SRS خوشه ي منفصل گروه بندي شوند ، در ادامه يك M در D اگر تاپل ها در
. بدست آيد
: نمونه برداري طبقه اي � با بدست D تقسيم شود ، يك نمونه برادري طبقه اي از strata به بخش هاي منفصل بنام اليه يا Dاگر
. از هر اليه ايجاد مي شود SRSآوردن يك
65

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
نمونه برداري مي تواند براي كاهش داده ها استفاده شود 66

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
مجزا سازي داده و توليد سلسله مراتب مفهوم
: تكنيك هاي مجزاسازي داده به فواصل ، استفاده Attribute پيوسته، با تقسيم دامنه ي Attributeبراي كاهش تعداد مقادير يك
. ميشوند .مي توانند براساس چگونگي اجراي مجزا سازي طبقه بندي شوند
زاسازي تحت نظارت انجام اگر فرآيند مجزاسازي از اطالعات كالس استفاده كند، مي گوييم اين مج. شده است
مفاهيم سطح باالتر سلسله مراتب هاي مفهومي با جمع آوري و تعويض مفاهيم سطح پا ئين با . ميتوانند براي كاهش داده استفاده شوند
. نياز دارداستخراج يك مجموعه داده ي كاهش يافته به عمليات ورودي وخروجي كمتري به عنوان يك مرحله در تكنيك هاي مجزاسازي و سلسله مراتب مفهومي قبل از فرايند داده كاوي
. پيش پردازش بكار مي روند
67

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
.Y$ تا X$ كه از [X.$Y$) با فواصل priceيك سلسله مراتب مفهومي براي صفت خاصه ي
68

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
مجزا سازي و توليد سلسله مراتب مفهومي براي داده هاي عددي
هاي عددي براساس مجزاسازي داده ها انجام Attributeايجاد اتوماتيك سلسله مراتب مفهومي براي . مي شود
: در اين خصوص روشهاي زير در ادامه بررسي مي شود
Binning آناليز هيستوگرام
entropy مجزاسازي مبتني بر آناليز خوشه
χ2 ادغام مجزا سازي با بخش بندي مستقيم
69

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Binning
binning يك روش تقسيم باال به پايين براساس تعداد مشخص Bin است .نيز به كار مي به عنوان روشهاي مجزاسازي داده و توليد خودكار سلسله مراتب مفهومي اين روش
. روند
: مثال
: مي تواند به روشهايAttribute مقادير binningعرض برابر يا فراواني برابر
، مثالً هموارسازي با ميانگين يا bin با ميانه يا ميانگين همان bin جايگزين نمودن مقدار هر هموارسازي با ميانه
. مجزاسازي شوند
70

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Entropyمجزا سازي مبتني بر
Entropy يكي از پر كاربردترين معيارهاي مجزا سازي است .
. يك تكنيك تقسيم بندي باال به پائين تحت نظارت است Entropyمجزا سازي مبتني بر � به صورت Entropy در يك مجموعه مبتني برAttributeروش پايه اي براي مجزا سازي يك �
: زير است در نظر گرفته Aدامنه مي تواند به عنوان يك مرز فاصله ويژه يا نقطه تقسيم ، براي تقسيم Aهر مقدار�
به دو زير مجموعه تقسيم كند D مي تواند تاپل ها را در Aبه عبارت ديگر يك نقطه تقسيم براي . شود ≥ Aكه شرايط split-point و A > split-point را به ترتيب برآورده مي كند ، بدين وسيله يك
.مجزا سازي دودويي ايجاد مي شود
71

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ادامه
. از اطالعات مربوطه برچسب كالس تاپلها استفاده مي كند Entropyمجزاسازي مبتني بر �
≥ A هستند ، كه به ترتيب با شرايط D متناسب با تاپل ها در D2,D1 در اينجا split-point و A > split-point برآورده مي كنند .|D| تعداد تاپل ها در D است و غيره .
سبه مي براي يك مجموعه ي معين ، براساس توزيع كالس تاپل ها در مجموعه محا Entropy تابع شود
: عبارتست از CN,…..C2,C1 ، Entropy ، D1 كالس ، m براي مثال ، با در نظر گرفتن
، تقسيم D1 در ci است كه با تقسيم تعداد تاپل هاي كالس D در ciاحتمال كالس ، Pi در اينجا . تعيين مي شود ) D1كل تعداد تاپل ها در (|D1|بر
)(||
||)(
||
||)( 2
21
1 DentropyD
DDEntropy
D
DDInfoA +=
)(log)( i
N
i i ppDEntropy 211 ∑ =−=
72

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ادامه
رسيدن به معيار پاياني فرآيند تعيين نقطه تقسيم ، بطور بازگشتي در هر بخش بدست آمده ، تا �-spiltمثالً وقتي حداقل اطالعات مورد نياز بر تمام . انجام شود point كانديد از يك آستانه . بزرگتر است ، كمتر است يا وقتي تعداد فاصله ها از يك آستانه فاصله ي حداكثري Űكوچك ،
كه در اينجا توصيف شدند براي درختان تصميم نيز Entropyمعيارهاي بدست آوردن اطالعات و�Decision Tree Induction.استفاده مي شوند
73

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
χ2آناليز اد غام فواصل با
ChiMerge يك روش مجزاسازي مبتني بر χ2 است .
م يك روش پائين به باال است كه با يافتن بهترين فواصل همسايه و ادغاchimergeروش .نظارت است بازگشتي آنها براي ايجاد فواصل بزرگتر كار مي كند و از روشهاي تحت
Chimergeبصورت زير عمل مي كند :تست هاي. بصورت يك فاصله تصور مي شود A عددي مانند Attribute در ابتدا هر مقدار متمايز يك
χ2فاصله ي مجاور اجرا مي شوند فاصله هاي مجاور با حداقل مقادير. براي هر جفتχ2 با هم ادغام مياين فرآيند . پائين براي يك جفت ، توزيعات مشابه كالسها را نشان مي دهند χ2شوند ، زيرا كه مقادير
. تعريف شده برآورد شودادغام به طور بازگشتي پيش مي رود تا يك معيار متوقف كننده از پيش
74

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
مجزا سازي به وسيله پارتيشن بندي مستقيم
كدست كه خواناتر هم بسياري از كاربران ترجيح مي دهند دامنه هاي عددي را در فاصله هاي ي
. هستند تقسيم بندي كنند تا شهودي يا طبيعي به نظر برسند
تقسيم بندي مي شود قطعا از ] $ 60000 و $50000(براي مثال، حقوق ساالنه كه در دامنه اي مانند
كه با آناليز خوشه بندي پيچيده بدست مي آيد ] $6087234 ، $5126393(دامنه ي عددي مانند
. مطلوب تر است
. فاده شود مي تواند براي بخش بندي داده هاي عددي در فواصل يكدست و طبيعي است5-4-3قانون
75

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
3-4-5قانون
: : : : اين قانون به صورت زير است اين قانون به صورت زير است اين قانون به صورت زير است اين قانون به صورت زير است
3 را در مهمترين رقم پوشش دهد بنابراين دامنه را مي توان به 9 يا 7 ،6، 3اگر يك فاصله مقادير مجزاي
) 7 براي 2-3-2 فاصله در گروه بندي 3 و 9 ، 6 ، 3 فاصله عرض برابر براي 3. ( فاصله تقسيم كرد
را در مهمترين رقم پوشش دهد ، بنابراين دامنه را به چهار فاصله 8 يا 4، 2اگر اين قانون مقادير مجزاي
. عرض برابر تقسيم مي كند
فاصله 5 را در مهمترين رقم پوشش دهد ، بنابراين دامنه را به 10 يا 5، 1اگر اين قانون ، مقادير مجزاي
. عرض برابر تقسيم مي كند
76

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
توليد سلسله مراتب مفهوم براي داده هاي طبقه بندي
ه بندي تعدادي محدودي مقادير داده هاي طبقه بندي در واقع داده هاي مجزايي هستند كه براي طبق.، بدون وجود ترتيب بين مقادير استفاده مي شوند) اما احتماال زياد ( مجزا
Item type , job ، category , Geographic location نمونه هايي از اين نوع داده ها هستند .
. . . . ود داردود داردود داردود داردچند متد براي توليد سلسله مراتب مفهومي براي داده هاي طبقه بندي وجچند متد براي توليد سلسله مراتب مفهومي براي داده هاي طبقه بندي وجچند متد براي توليد سلسله مراتب مفهومي براي داده هاي طبقه بندي وجچند متد براي توليد سلسله مراتب مفهومي براي داده هاي طبقه بندي وج ها در سطح شما بوسيله كاربران يا متخصصين Attributeتعيين ترتيب جزئي صريح
تعيين بخشي از يك سلسله مراتب با گروه بندي داده هاي صريح ،البته نه تعيين ترتيب جزيي آن ها Attributeتعيين يك مجموعه
77

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
ها در سطح شما بوسيله Attributeتعيين ترتيب جزئي صريح كاربران يا متخصصين
هاي دسته بندي يا ابعاد معمولي شامل يك گروه Attributeسلسله مراتب مفهومي براي Attribute هستند .
شخص كردن يك ترتيب يك كاربر يا خبره مي تواند به آساني يك سلسله مراتب مفهومي را با م . تعريف كند schema ها در سطح Attributeنسبي يا كلي از
: : : : براي مثال براي مثال براي مثال براي مثال ممكن است شامل گروه هاي data worehouseيك پايگاه داده رابطه اي يا بعد مكاني يك �
Attribute زير باشد :street, city, province or state, and country
78

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
تعيين بخشي از يك سلسله مراتب با گروه بندي داده هاي صريح
ارش مقادير صريح غير واقعي در يك پايگاه داده ي بزرگ ، تعريف يك سلسله مفهوميِ كامل با شمخش كوچك داده در مقابل ، ما مي توانيم به آساني گروه بندي هاي صريح را براي يك ب . است . مياني مشخص كنيم –سطح
: : : : براي مثال براي مثال براي مثال براي مثال يك سلسله مراتب را در سطح شما تشكيل province و country بعد از مشخص كردن اينكه
: تعريف كند مي دهند ، يك كاربر مي تواند به طور دستي سطوح مياني را مانند زير
{Alberta , Saskatchewan , Manitova}Є prairies-canada
{British Columbia , prairies – Canada } Є wastern – Canada
79

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
،البته نه تعيين ترتيب جزيي آن ها Attribute يك مجموعه تعيين
را كه يك سلسله مراتب مفهومي را تشكيل مي Attributeيك كاربر ممكن است يك مجموعه اين سيستم مي تواند به . دهد مشخص كند البته ممكن است براي بيان ، ترتيب جزئي آنها حذف شود
ها را براي ساخت يك سلسله مراتب مفهومي معني دار ايجاد كند Attributeطور اتوماتيك ترتيب . ها Attributeمجموعه بدون دانش معنايي از داده ها ، چگونه يك ترتيب سلسله مراتبي از يك “
”قابل يافت است ؟
:مثال زير را در نظر بگيريد
80

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
Attribute توليد سلسله مراتب مفهوم براساس تعداد مقادير متمايز هر 7.2مثال
يا state , country, street مكاني مانند Attribute فرض كنيد يك كاربر يك مجموعه city , province را از پايگاه داده AllElectronics انتخاب كند ، البته ترتيب سلسله مراتبي
مي تواند به locationيك سلسله مراتب مفهومي براي . ها را مشخص نمي كند Attributeبين . طور اتوماتيك ، طبق شكل ايجاد شود
Attribute مقادير متمايز يك توليد اتوماتيك يك سلسه مراتب مفهومي براي زمان براساس شمارش تعداد 81

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
توليد سلسله مراتب مفهومي با كاربرد اتصاالت معنايي از 8.2مثالپيش مشخص شده
را به هم وصل كرده باشد Attribute ، 5فرض كنيد يك متخصص در داده كاوي تعداد number, street, city, province or state, and country زيرا كه آنها از نظر معنايي
. به هم مرتبط هستندlocationدر زمينه ي است location را براي يك سلسله مراتب كه معرف cityاگر يك كاربر تنها صفت خاصه ي ،
صفت خاصه مرتبط را براي تشكيل يك 5مشخص كند، سيستم مي تواند به طور اتوماتيك تمام ها را مانند Attribute سلسله مراتب واكشي كند ، بعالوه در صورت نياز مي تواند هريك از اين
street , number از سلسله مراتب حذف كند و city را به عنوان پائين ترين سطح مفهومي در . سلسله مراتب حفظ شود
82

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
3تكليف كالسي شماره
مطالعه دو مقاله معتبركه با استفاده از پيش پردازش داده �ها در فرايند داده كاوي يك مشكلي را حل نموده اند
روش استفاده شده برسي و شرح داده شود • اثر استفاده از آن روي نتايج بدست آمده شرح داده شود •به نظر شما روش مذكور در حل چه مشكالت ديگري مي تواند استفاده •
.شود. تاريخ تحويل و ارائه كالسي جلسه هفتم كالس مي باشد � ارسال نماييد و درموضوع آن [email protected]اساليد هاي خود را به آدرس �
را قرار دهيد DM911-A03فقط عنوان
83

Data Mining lectures, Dr. Mohammad Hossein Nadimi, Faculty of Computer Engineering, Najafabad Branch, Islamic Azad University
پرسش و پاسخ
84




















