
Copia de ANALISIS DE CORRESPONDENCIA
26
ANALISIS DE ANALISIS DE CORRESPONDENCIA CORRESPONDENCIA
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Copia de ANALISIS DE CORRESPONDENCIA

ANALISIS DE ANALISIS DE CORRESPONDENCIACORRESPONDENCIA

El análisis de correspondencia es una técnica de análisis exploratorio de datos diseñado para tablas de doble entrada (correspondencia simple) y tablas de múltiples entradas (correspondencia múltiple) que presentan algún tipo de relación entre las filas y las columnas. Al mismo tiempo es una técnica descriptiva de análisis multivariable de datos usada para la simplificación de datos que presentan dificultad para su descripción o comprensión.
Es de útil aplicación en trabajos exploratorios donde son pocas o inexistentes las hipótesis previas del comportamiento de la población, tanto en las vertientes correlaciones como experimentales.
INTRODUCCION

El nombre de análisis de correspondencia es una traduccion del francés "Analyse des correspondances", el cual fue propuesto en los años 60’ por el físico-matemático francés Benzécri, con el fin de definir, describir e interpretar el análisis a través de un gráfico geométrico.Esta técnica analiza los datos tal como fue diseñado por algunos precursores de la estadística entre los que se destacan Pearson, Guttman, Fisher, los cuales, sin embargo no pudieron llevar a cabo los cálculos por la carencia de instrumentos que permitiesen cálculos matemáticos tan complejos como los que puede hoy en día realizar las computadoras y los software existentes en el mercado.
HISTORIA

Dada una tabla de observaciones correspondiente a dos variables
cualitativas, el análisis de correspondencias simples es una técnica para
representar las categorías de las dos variables en un espacio de
pequeña dimensión que permita interpretar, por un lado, las similitudes
entre las categorías de una variable respecto a las categorías de la otra,
y por otro, las relaciones entre las categorías de cada una de las
variables por separado.Así al analizar el cruce entre dos variables se
pretende:
• Reducir la información de la que disponemos a factores que permitan
explicarla de modo más resumido y sencillo.
• Crear un espacio factorial en el que ubicar las variables y sujetos para
poder establecer grados de semejanza y diferencia entre ellos.
ANÁLISIS DE CORRESPONDENCIA SIMPLE

Tabla de contingencia de diTabla de contingencia de dimmension Iension I*J*J
fi fijj1
J
f j fiji1
I
n f fij fjj1
J
j1
J
i1
I fi
i1
I

Perfil de la fila i-ésima es la proporción (la parte) de cada categoría de la variable j en (que contiene) la fila i. rij=fij/fi.
También encontramos el perfil de los totales de cada columna de la tabla (perfil de los marginales de columna), que es lo mismo que decir que es el perfil medio de las filas. (Divido el total de cada columna sobre n)
PERFILES FILAS
PERFILES COLUMNAS
Perfil de la columna j-ésima es la proporción (la parte) de cada categoría de la variable i en (que contiene) la columna j.
Además encontramos el perfil de los totales de cada fila de la tabla (perfil de los marginales de filas).
También es el perfil medio de las columnas

REPRESENTACIÓN DE LOS PERFILES FILAREPRESENTACIÓN DE LOS PERFILES FILA
TABLA DE PERFILES FILA
Perfil de la i-ésimacategoría de la variable i
Cada fila de esta matriz representa la distribución de la variable en columnas condicionada al atributo que representa la fila.
R (rij)
ri'(ri1,ri2,,riJ)
rij fij fi
rijj1
J (fij fi)
j1
J fi fi 1
r'(r1,r2,,rI)
rii1
I (fi n)
i1
I n n1
Perfil de los totales por filas= Perfil medio de las columnas
IxJ

REPRESENTACIÓN DE LOS PERFILES COLUMNAREPRESENTACIÓN DE LOS PERFILES COLUMNA
TABLA DE PERFILES COLUMNA
Perfil de la j-ésimacategoría de la variable j
Cada columna de esta matriz representa la distribución de la variable en filas condicionada al atributo que representa la columna.
C (cij )
ciji1
I (fij f j)
i1
I f j f j 1
cj'(c1j ,c2j ,,cIj)
c'(c1,c2,,cJ )
cjj1
J (f j n)
j1
J n n1
Perfil de los totales por columnas =Perfil medio de las filas
IxJ
cij fij f j

En el espacio RJ (espacio de las filas)
-Tenemos una nube de I puntos [N(I)] que representan a las I filas
-Las J coordenadas del punto fila i-ésimo serán :
-El vector que lo representa será, por tanto:
ri'(ri1,ri2,,riJ)
rij
En el espacio RI (espacio de las columnas)
-Tenemos una nube de J puntos [N(J)] que representan a las J columnas
-Las I coordenadas del punto columna i-ésimo serán :
- El vector que lo representa será, por tanto:
cij
cj'(c1j ,c2j ,,cIj)
…
…

DISTANCIA JI-CUADRADO
El estadístico ji-cuadrado χ² es una medida global de las diferencias entre las frecuencias observadas y las frecuencias esperadas de una tabla de contingencia. Calculamos las frecuencias esperadas mediante la hipótesis de homogeneidad de los perfiles fila (o de los perfiles columna) . Se multiplican las marginales y se divide por n para ello.Las frecuencias observadas siempre serán distintas de las frecuencias esperadas. Sin embargo, en estadística queremos saber si estas diferencias son suficientemente grandes como para contradecir la hipótesis de que las filas son homogéneas. Es decir, queremos saber si es poco probable que las discrepancias entre las frecuenciasobservadas y las frecuencias esperadas se deban sólo al azar. Para responder a esta pregunta calcularemos una medida de discrepancia entre las frecuencias observadas y las frecuencias esperadas. Concretamente, calcularemos las diferencias entre cada par de frecuencias observadas y esperadas, las elevaremos al cuadrado, lasdividiremos por las frecuencias esperadas e iremos acumulando los resultados hasta llegar a un valor final —el estadístico ji-cuadrado, que simbolizaremos por χ² — :

Entonces la formula correspondiente es:
Se contrasta de esta manera la Hipótesis Nula, H0, de Homogeneidad contra la Hipótesis Alternativa, H1, de No Homogeneidad
Para corroborar esto el valor del χ² observado se compara con el valor de la tabla de la distribución Ji-Cuadrado calculando los Grados de Libertad como (Cantidad de Filas - 1) * (Cantidad de Columnas - 1) con significación 1-α.
Si χ² observado >= χ² (r-1) (c-1) (1- α) entonces Se rechaza H0 y por lo tanto no habrá Homogeneidad entre las categorías de las variables, es decir habrá diferencias.

Si la inercia es baja, habrá poca asociación entre la variable fila y la variable columna.
Si la inercia es alta habrá una alta asociación entre ellas.
INERCIA
En el Análisis de Correspondencia, llamamos inercia total, o simplemente inercia, al valor χ2/n donde n es el total de la tabla. Este valor es una medida de la varianza total de la tabla independiente de su tamaño. En estadística, este valor recibe diferentes nombres, uno de ellos es el de «coeficiente medio cuadrático de contingencia». A su raíz cuadrada la denominamos «coeficiente Phi» (φ); por tanto, podemos expresar la inercia como φ2.

DISTANCIA EUCLIDIA
Es el cuadrado de la distancia «directa» entre el perfil fila y el perfil fila medio en un espacio físico tridimensional
Se representa como :
Raiz { ∑ [ (Valor Observado / Total de la fila ) – (Total de la Columna / n) ]2 }
DISTANCIA EUCLIDIA PONDERADARaiz {∑ [ (Valor Observado / Total de la fila ) – (Total de la Columna / n) ]2 }
(Total de la Columna / n)

La masa asociada a cada elemento (categoría de la variable fila o de la variable columna) mide la importancia relativa de dicho elemento.La masa que corresponde a cada perfil será su total marginal divido por el gran total (n)
Por tanto, la masa de cada perfil fila, será el correspondiente elemento del perfil medio de columnas (ri), mientras que la masa de cada perfil columna, será el correspondiente elemento del perfil medio de las filas (cj)
ri fin
cj fj
nMasa del i-ésimoperfil fila
Masa del j-ésimoperfil columna
Mientras que el perfil que representa a una fila/columna es independiente del total marginal correspondiente, este total lo vamos a utilizar para medir la importancia del perfil en el análisis.
MASA (PESO)

MAPAS PERCEPTUALES
Se puede evidenciar de manera más perceptible el grado de relación entre las categorías de cada variable por eso surge el nombre de mapas perceptuales. Cuando el grado de asociación es alto, éstas parecerán en el diagrama relativamente juntas.
El mapa perceptual muestra los puntos (categorías de las variables observadas) que indican la relación o correspondencia que pudiera existir entre las variables de estudio.
Interpretación: El mapa se interpreta por la cercanía de las marcas/productos/servicios a los atributos.
Observaremos un ejemplo en la diapositiva siguiente

En el mapa de posicionamiento podemos ver un plano dividido por dos ejes y la representación, al mismo tiempo, de productos y atributos. Observamos distintos tipos de cereales y diferentes atributos
El eje horizontal o Dimensión 1, esta claramente definido a la izquierda por atributos tales como lo alimenticio, lo sabroso que resulta para el niño y el contenido de fibra del cereal. A la derecha, por atributos tales como la falta de vitaminas y el ser una golosina mas que un alimento. Este nuevo factor podría entonces llamarse el factor “nutricional”. El eje vertical o Dimensión 2, se presenta definido por la parte superior por atributos tales como el rendimiento y su facilidad para ser servido y por su lado inferior por lo caro y lo útil que resulta para salir de apuros. Un factor así conformado puede denominarse como el factor de “La practicidad”.

El análisis de correspondencia múltiple es una generalización del análisis de correspondencia simple (ACS), es decir en este análisis se involucran a 3 o más variables categóricas o cualitativas seleccionadas en un espacio perceptual común. Se trata de un análisis multidimensional de tipo factorial que presenta un alcance eminentemente descriptivo, basándose en el diferencial semántico, se selecciona una serie de palabras, estímulos, atributos que aluden al objeto social a indagar. La diferencia con el Análisis de Correspondencia Simple es que en el Análisis de Correspondencia Múltiple se utilizan tablas disyuntivas completas y no tablas de contingencia, lo cual nos permite tener cálculos e interpretaciones más específicas.
Debido a que en varias ocasiones tratamos de medir una serie de variables cualitativas las cuales deben comprobar dos características:
• Que las modalidades de cada variable sea mutuamente excluyentes.
• Que las modalidades de cada variable son exhaustivas, es decir todo individuo presente una de ellas obligatoriamente.
ANÁLISIS DE CORRESPONDENCIA MÚLTIPLE

La información obtenida para el análisis de correspondencias La información obtenida para el análisis de correspondencias múltiple la obtenemos de una tabla de datos donde consta por un lado múltiple la obtenemos de una tabla de datos donde consta por un lado los individuos y por el otro las variables cualitativas a analizar, los individuos y por el otro las variables cualitativas a analizar, pero esta tabla no es muy conveniente, debido a que la suma de filas pero esta tabla no es muy conveniente, debido a que la suma de filas y columnas no es conveniente. y columnas no es conveniente. Por tal razón se elabora la recodificación de esta tabla en la Por tal razón se elabora la recodificación de esta tabla en la denominada denominada Tabla Disyuntiva Completa,Tabla Disyuntiva Completa, que es una tabla lógica en otras que es una tabla lógica en otras palabras está compuesta de ceros y unos, como se puede observar a palabras está compuesta de ceros y unos, como se puede observar a continuación:continuación:
En pocas palabras partimos de la tabla R para construir la tabla Z, En pocas palabras partimos de la tabla R para construir la tabla Z, que esta formada de n filas y p columnas representadas por una que esta formada de n filas y p columnas representadas por una codificación lógica que identifican a los individuos y donde el codificación lógica que identifican a los individuos y donde el total del tamaño de la tabla es igual: total del tamaño de la tabla es igual:
1 2 2 4 0 1 0 0 1 0 0 0 12 1 3 0 1 0 1 0 0 0 1 03 1 2 0 0 1 1 0 0 1 0 0
R = 1 2 4 Z= 1 0 0 0 1 0 0 0 11 2 3 1 0 0 0 1 0 0 1 03 2 3 0 1 0 0 1 0 0 1 03 1 1 0 0 1 1 0 1 0 0 0
n 1 1 1 1 0 0 1 0 1 0 0 0
p = 9s = 3
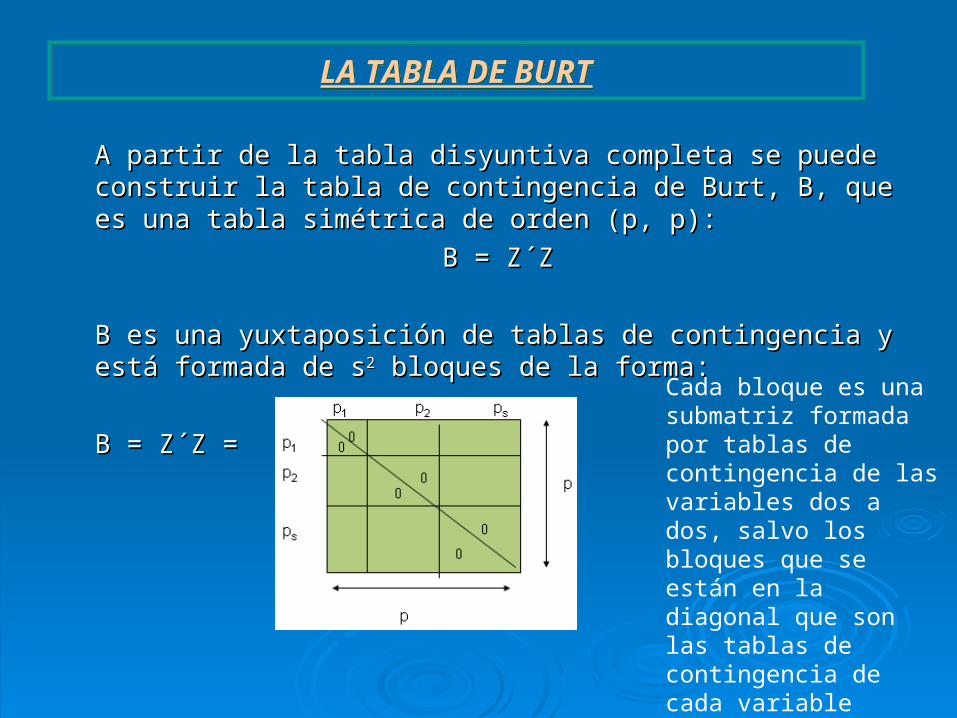
A partir de la tabla disyuntiva completa se puede A partir de la tabla disyuntiva completa se puede construir la tabla de contingencia de Burt, B, que construir la tabla de contingencia de Burt, B, que es una tabla simétrica de orden (p, p):es una tabla simétrica de orden (p, p):
B = Z´ZB = Z´Z
B es una yuxtaposición de tablas de contingencia y B es una yuxtaposición de tablas de contingencia y está formada de sestá formada de s22 bloques de la forma: bloques de la forma:
B = Z´Z = B = Z´Z =
LA TABLA DE BURT
Cada bloque es una submatriz formada por tablas de contingencia de las variables dos a dos, salvo los bloques que se están en la diagonal que son las tablas de contingencia de cada variable consigo misma.

EjemploEjemplo::
Se trabajara con la base de datos acm.sav vista en Se trabajara con la base de datos acm.sav vista en claseclase

Se realizara el Análisis de correspondencia con la Se realizara el Análisis de correspondencia con la variable Volveria ingresada como Fila y la variable Volveria ingresada como Fila y la variable bienvenida como columna con los rangos variable bienvenida como columna con los rangos correspondientes como se observacorrespondientes como se observa


En la diapositiva anterior observamos 3 cuadros.En la diapositiva anterior observamos 3 cuadros.El primero corresponde al cruce de las dos variables El primero corresponde al cruce de las dos variables
con los con los datos observados y las marginales de filas y datos observados y las marginales de filas y
columnas, que es columnas, que es la tabla de correspondencias.la tabla de correspondencias.Luego observamos el perfil fila es decir cada Luego observamos el perfil fila es decir cada
elemento de la fila elemento de la fila sobre el total de la misma.sobre el total de la misma.El tercer cuadro corresponde al perfil columna.El tercer cuadro corresponde al perfil columna.Luego a continuación figura el resumen del Luego a continuación figura el resumen del
estadístico Chi – estadístico Chi – Cuadrado observado y el valor del PV y la inerciaCuadrado observado y el valor del PV y la inercia
Resumen
,671 ,451 ,983 ,983 ,114 ,046,089 ,008 ,017 1,000 ,206
,459 12,841 ,117a 1,000 1,000
Dimensión12Total
Valor propio Inercia Chi-cuadrado Sig. Explicada Acumulada
Proporción de inercia
Desviacióntípica 2
Correlación
Confianza para el Valorpropio
8 grados de libertada.

Por lo cual No Rechazamos la Homogeneidad de la Por lo cual No Rechazamos la Homogeneidad de la tabla, es decirtabla, es decir
que es muy probable que haya similitudes entre las que es muy probable que haya similitudes entre las variables.variables.
El valor del El valor del χ2 –Obs es de 12,841 que es menor al χ2 –Obs es de 12,841 que es menor al valor del χ2 de la valor del χ2 de la
tabla que vale 15,507 con 8 GL al 95% de confianza.tabla que vale 15,507 con 8 GL al 95% de confianza.Se corrobora con el PV que tiene un valor de 0,117 Se corrobora con el PV que tiene un valor de 0,117
mayor a 0,05.mayor a 0,05.
A continuación observamos el cuadro puntos-filas.A continuación observamos el cuadro puntos-filas.Se puede apreciar que el factor más predominante es No Se puede apreciar que el factor más predominante es No
sabe sisabe siVolvería (Masa = 0.464)Volvería (Masa = 0.464)

Ahora vemos el cuadro puntos-columnas donde las Ahora vemos el cuadro puntos-columnas donde las categorías categorías
predominantes son Ni calidad ni no cálida y bastante predominantes son Ni calidad ni no cálida y bastante calidad.calidad.
(Masa = 0.250)(Masa = 0.250)

A continuación aparece el grafico respectivo:




















