
Chapter 1 - Introduction
118
3 Chapter 1 - Introduction This study utilises a commercially available tagged corpus of ancient Greek to investigate a group of words that originated in Proto-Indo-European and show a number of interesting and diverse features in the modern descendants of that language, including Greek and English. I establish a statistical method for use in a corpus-linguistic, quantitative approach to the collection and interpretation of data, and use the results to develop and test hypotheses about the nature and cause of language change and to identify variations possibly unobservable by other methods, thus making them available for further study. Why study Greek? Ancient Greek continues to be learnt and studied because of the importance and prestige of Classical Greece and its literature, philosophy and polity to the history of western civilisation. Within Greece it has usually also been a compulsory school subject for reasons of national consciousness and identity. As long as interest in ancient history and the roots of our culture continues, it will be desirable for a linguistic approach to the study of the language to be maintained as one of the necessary tools for understanding ancient documents and culture. But, like Chinese, Greek is a language with a long and near-continuous recorded history, offering a unique source for the study of language change in general. At least in its written form, today’s Greek is recognisable as a version of the language of Homer nearly three thousand years ago. 1 This conservatism is unusual in the world’s languages and deserves investigation, but at the 1 Substantial sound changes are obscured by historical spelling, but there is a high degree of retention of lexical items and of morphology (particularly in the nominal system). Homer is cited as an exemplar of the oldest known form of Greek because the language of the orally transmitted Homeric poems preserves many linguistic features that are thought to be more archaic than the language of the earliest Greek documents, the Linear B tablets dating from approximately 1400 BC.
-
Upload
khangminh22 -
Category
Documents
-
view
11 -
download
0
Transcript of Chapter 1 - Introduction

3
Chapter 1 - Introduction
This study utilises a commercially available tagged corpus of ancient Greek to investigate a
group of words that originated in Proto-Indo-European and show a number of interesting and
diverse features in the modern descendants of that language, including Greek and English. I
establish a statistical method for use in a corpus-linguistic, quantitative approach to the
collection and interpretation of data, and use the results to develop and test hypotheses about
the nature and cause of language change and to identify variations possibly unobservable by
other methods, thus making them available for further study.
Why study Greek?
Ancient Greek continues to be learnt and studied because of the importance and prestige of
Classical Greece and its literature, philosophy and polity to the history of western civilisation.
Within Greece it has usually also been a compulsory school subject for reasons of national
consciousness and identity. As long as interest in ancient history and the roots of our culture
continues, it will be desirable for a linguistic approach to the study of the language to be
maintained as one of the necessary tools for understanding ancient documents and culture. But,
like Chinese, Greek is a language with a long and near-continuous recorded history, offering a
unique source for the study of language change in general. At least in its written form, today’s
Greek is recognisable as a version of the language of Homer nearly three thousand years ago.1
This conservatism is unusual in the world’s languages and deserves investigation, but at the
1 Substantial sound changes are obscured by historical spelling, but there is a high degree of retention
of lexical items and of morphology (particularly in the nominal system). Homer is cited as an exemplar of
the oldest known form of Greek because the language of the orally transmitted Homeric poems preserves
many linguistic features that are thought to be more archaic than the language of the earliest Greek
documents, the Linear B tablets dating from approximately 1400 BC.

4
same time Greek has a history of great variation, both diachronic and synchronic, that can
contribute to our knowledge of how and why languages change. The particular group of words
studied in this thesis, which are interesting for their diverse and little understood behaviour in
many of the related languages of Europe, can be traced back through Greek to their common
origins in Proto-Indo-European.
Greek is one of the foundational languages in the history of linguistics. It was the observation of
similarities and of the regularity of differences between Greek, Latin and Sanskrit that led to the
postulation of family relationships between languages and so allowed the development of the
comparative method of historical linguistics. This method has since been profitably applied to
the identification and study of other language families and sub-families. Nineteenth century
linguistic progress both arose from and stimulated further intensive study of Ancient Greek. The
subsequent decline in classical studies does not diminish the importance of Greek, either as a
vehicle for access to the ancient world or as a rich linguistic resource for the study of language
change.
From the perspective of the modern language, the long continuous history and the relative
accessibility of the written Greek of most earlier periods to the speaker of Modern Greek make it
both a natural and useful area of study.2 For Greeks it is also sometimes a matter of national
pride not only to be familiar with what they regard as their own heritage but also to be active
participants in scholarly debate over issues that concern Greece and Greek, such as the
pronunciation of the ancient language by modern scholars.3
2 This accessibility is due to several sociological factors, including a minimum-hours requirement in
school curricula, general familiarity with the conservative language of the Orthodox liturgy, and a long
history of diglossia in which until the 1970s much education and written communication was conducted in
an archaising form of Greek (known as Katharevousa, ‘purifying’).
3 This remains a contentious issue, and practice differs from country to country. The origins of the
reconstruction of the ancient pronunciation and its introduction into teaching practices in England are

5
Apart from general interest in history, culture and language, there is another reason why Greek
has been studied, and outside Greece it is now the principal cause why Ancient Greek is still
learnt: it is the language of the New Testament. This collection of first-century documents, the
earliest extant Christian writings, has been intensively studied since its beginning and has been
hugely influential as the sacred text of a major world religion. The project of translating these
scriptures into the world’s languages began very early4 and is still in progress, with the Summer
Institute of Linguistics the largest and best-known trainer of translators.5 The majority of recent
linguistic studies of Ancient Greek are contributions to the study of the New Testament and the
world of early Christianity and Second Temple Judaism, although Mycenaean Greek and
dialectology are also popular research areas.
For a number of cultural reasons, then, as well as linguistic ones, study of the Greek language is
rewarding. This study looks at a specific group of words and traces their origin and use in
Homeric and Classical Greek, as detailed in recent studies, with the aim of comparing their use
in the subsequent period of the language known as the Koine, to see whether changes can be
discerned, and if so whether reasons for the changes can be suggested and verified.
outlined by Allen 1987: 140-9. Petrounias 2007: 1266-79 contrasts practices in western countries and in
Greece and lists the advantages and disadvantages of the opposing positions.
4 The first large-scale translation project in history was the translation of the Hebrew scriptures into
Greek, beginning in the early third century BC (Dines 2004). Versions of the New Testament in Latin,
Syriac, Armenian and other languages are known from about AD 180, which is approximately the
beginning of the period of decline of Greek in the western empire (Aland & Aland 1989: 185ff).
5 Many translators work from English or other modern-language versions, but most agencies require
translators to be familiar with Greek; it is also a compulsory subject in many theological colleges.

6
Outline of this study
Chapter 2 surveys the history of the Greek language diachronically from its antecedents in
Proto-Indo-European to the classical period, with particular reference to prepositional and
preverbal particles (‘P-words’).6 After a brief survey of the evidence for Mycenaean Greek, the
earliest attested stage of the language, I review two studies of the P-words in relation to two
synchronic states of the language, Homeric and Classical Greek, and give examples of the
different usages in the two periods.
In Chapter 3 I trace the development of the next stage of the language, the Koine or ‘Common
Language’ of the hellenistic period, and look at the use of prepositions and preverbs in the New
Testament (NT), with particular attention to the problem of developing a method of evaluating
large sets of raw data. Comparisons are made with the data presented in Chapter 2 and in two
other hellenistic Greek corpora, the Septuagint (LXX) and Apostolic Fathers (AF). P-word usage
in the later Koine period, the era of the New Testament writings, is described in the context of
establishing whether significant changes since the classical period can be detected and
accounted for. (The individual documents comprising the three corpora are described in
Appendix A, along with other data sources referred to.)
In Chapter 4 I review the results of the comparisons and statistical tests made and the success
of the methodologies used, and outline areas for further research.
6 Following O’Dowd’s use of the term for English (1998: passim), I call this group ‘P-words’ as a
convenient superordinate term for the group of adverbs, prepositions and preverbs. They are called
‘particles’ by Luraghi when she wants to leave their lexical class unspecified (2003: 76), but this may be
potentially confusing as the term ‘particle’ is used in Greek grammars for other parts of speech, such as
conjunctions (and appears as ‘PTC’ in Luraghi’s morphemic glosses for some non-P-words). The class of
prepositions that are also P-words is known as ‘proper prepositions’, to be distinguished from ‘improper
prepositions’, which have a more restricted functional range; but this terminology fails to capture their
other functions as preverbs and adverbs.

7
Methodology
The basis of this study is the language of the middle Koine period as realised in the New
Testament. Three corpora are used for a quantitative analysis of the usage of the P-word group,
with a view to establishing the degree of variation, if any, in their usage over time and the
statistical probability that such variation is not due to mere chance or insufficient data. Where a
variation is shown to be statistically significant, grammaticalisation theory is used to suggest
hypotheses about the usage of the P-words and the possible paths of change they could be
expected to undergo.
a. Corpus linguistics7
The corpora used for this study are grammatically tagged texts available in a database called
Accordance, Version 7.0.3 of August 2006, produced by OakTree Software, Inc, in Florida.8 The
principal corpus used is the group of 27 New Testament documents, in the most recent edition of
Nestle-Aland known as NA27.9 It is fully tagged at the lexicogrammatical level using the
GRAMCORD system developed by The GRAMCORD Institute of Vancouver, Washington.10
Two other corpora are also used: a selection of texts from the Septuagint (LXX),11 Greek
7 General information about the field of corpus linguistics in this section is drawn from O’Donnell 2005,
which applies corpus linguistics to the study of the NT. The history of the field is described in Kennedy
1998: 1-87, mainly with reference to studies of English but also acknowledging the origins of corpus-
based research in the development of bible concordances from the 18th century on.
8 http://www.accordancebible.com.
9 Two editions were produced by identical editorial committees headed by Kurt Aland for different
institutions. The texts are identical, but the punctuation and apparatus are different because UBS4 is
produced by the United Bible Societies for the use of translators, while NA27 (1991) is a critical edition
with a full apparatus for textual criticism. For the history of editions see Aland & Aland 1987, and for a
critique of UBS4 and its apparatus see Clarke 1997.
10 http://www.gramcord.org
11 The text used in the database is that of Rahlfs 1935.

8
translations of Hebrew scriptures made from the mid-second century BC, and the Apostolic
Fathers,12 a collection of the earliest Christian writings outside the New Testament. Both these
sets of documents are available in searchable tagged form from Accordance. The approximate
time periods of the three corpora are: 3rd to first century BC (LXX), second half of first century
AD (NT) and first half of second century AD (AF).
Statistical information about earlier periods of Greek is much more difficult to obtain. Indexes
and concordances to some classical authors exist, but in book form with data obtained without
computer assistance. A searchable electronic archive of all Greek writing from the earliest
documents and inscriptions to the end of the Byzantine period, the Thesaurus Linguae Graecae
(TLG),13 returns unreliable information for some kinds of search, because it is not grammatically
tagged or even lemmatised (coded so that inflected forms can be retrieved by a search for the
citation form). The online version of the standard lexicon of Ancient Greek, known as LSJ, gives
word counts which sometimes do not resemble those obtained from TLG.14 Online LSJ through
12
The text used is the edition of Holmes 1999.
13 The TLG databank is available to subscribers as a CD and now also online. A free trial version is
available at http://www.tlg.uci.edu/demo.html. The version I have used is the CD, Version E (February
2000). The TLG project is based at the University of California, Irvine; information about the development
of the data bank is given on the project’s website (http://www.tlg.uci.edu) and in Berkowitz & Squitier
1986, which is a list of the authors and works in TLG (a later edition of this reference tool is available with
free search access on the TLG website). Unfortunately the search programs developed to assist users of
TLG have to be acquired separately. The best one is Pandora, for Macintosh, but Fisher Library has a
more primitive search facility and TLG is not available on Macintosh there.
14 The usage counts which LSJ online provides are based on the bank of citations it uses in its
definitions, not on whole texts; sometimes the usage rates may be similar to those obtained by token
counts in TLG (difficult as they are to achieve), but there is no way to guarantee commensurability of the
two sets of results. As an indication of the difficulties of using the LSJ site, consider this comment at
http://www.greek-language.com/lexical.aids: ‘You may access the Liddell-Scott-Jones Lexicon at the
Perseus site. (If response is slow, try the mirror site.) While this electronic edition of LSJ is tremendously
useful, it is not as up-to-date as the ninth edition. For serious lexical study it is still necessary to consult
the paper-and-ink version.’ The site is slow (as is the mirror site!) and cumbersome to use, and certain
words simply do not appear to be retrievable (for example, the preposition katav kata). The Perseus

9
the Perseus Project also offers a collocation tool, and lists words with similar definitions to the
headwords being consulted.
Many older grammars and other studies provide quantitative information, and some of the early
counts, made without the aid of computers, are surprisingly accurate. It is common to find
comments in grammars that presuppose a statistical study of the phenomenon being discussed,
but the actual data is rarely given.15 A partial exception is the vibrant tradition of concordances:
data is presented in such a way that the user can, with some effort, extract quantitative
information as required. For example, a Greek concordance to the New Testament lists every
occurrence of a particular word, and the user can manually retrieve whatever information is
wanted, such as the number of times a given preposition is followed by a particular case.
However, this procedure is very laborious and liable to error. And a concordance is arranged by
words, like a dictionary, so it does not enable the user to retrieve, for example, every instance of
the use of a particular case or tense.
O’Donnell defines corpus linguistics as ‘a series of methodological and theoretical characteristics
guiding the computational investigation of examples of naturally occurring language’ (2005: 1).
The major preliminary requirement is the construction of a representative corpus. The issue is
complicated for the study of any past period of a language by the lack of samples of speech, the
Project, which runs the online LSJ site, is described at www.perseus.tufts.edu and on Wikipedia
(http://en.wikipedia.org/wiki/Perseus_Project).
15 An exception is Moulton, whose qualitative judgments, as for example on the increasing use of
prepositions and the relationship between changing uses of ejn en and eijV eis (1908: 62-3), are based on
his tables in Moulton & Geden 1897. Another exception is Turner 1963, who gives a lot of frequency data
but often in a misleading way: although continuing the descriptive syntax project of Moulton, he has
reversed Moulton’s emphasis on the evidence for NT Greek as normal hellenistic Greek. Turner’s primary
concern is to demonstrate that NT Greek is a peculiar Jewish Greek variety suffering the influence of
Hebrew and Aramaic. See note 19 below for references to this debate.
The fact that older grammars are based on different editions from those regarded as standard today
makes some of the detailed information incompatible with computer-aided searches.

10
frequent lack of situational clues and the impossibility of consulting native-speaker
competence.16 It has to be immediately recognised that any corpus of a dead language will be
limited to written language samples and that production errors and other such phenomena of
natural language may be unidentifiable.17 Ancient Greek is in a more fortunate position than
many other epigraphic languages (such as Latin and Old English) in having a large body of
surviving material, but the texts are neither random nor representative in the sense desired for
corpus study. That is, they survive as accidents of copying and preservation, and some genres
are over-represented (for example, historical narrative) while others may not have survived at all.
Further, our incomplete knowledge of the situations and cultures in which documents were
produced means that some of the social-context-based tools of discourse analysis may be
unavailable.
Criteria for selecting representative corpora depend partly on the use to which they are to be put.
In the case of Ancient Greek, only written texts are available so there is no opportunity to include
samples of spoken language; and we have to make do with a further limitation: the texts are
overwhelmingly the products of rich men and professional scribes. However, a variety of
registers of the written language can be identified and should be included. For the purposes of
linguistic analysis a corpus must be representative in some way relevant to what is being
investigated: representative of the language of the period studied, of different genres and
16
The evaluation of grammaticality of a small group of sentences, as an analytical procedure such as is
usual in generative grammar, would therefore seem to be very difficult for ‘dead’ languages.
Nevertheless, attempts have been made to apply Chomskyan analysis to NT Greek, for example Schmidt
1981. Schmidt 1985 mentions other generative work on the NT and proposes a transformational
grammar. However, the overwhelming majority of recent linguistic work on the NT takes a functional-
based perspective, particularly Hallidayan grammar and systemic discourse analysis.
17 Some corpus-based studies of Greek have treated drama and philosophical dialogue texts as samples
of spoken language (eg Duhoux 1997). While the studies are valid in seeking to compare the usage of
different genres, it cannot be assumed that any such written evidence preserves spoken language in a
way comparable to the data in modern corpora like Cobuild and the British National Corpus (described by
Kennedy 1998: 46-48 and 50-54 respectively) .

11
registers, of different social occasions for writing etc. Data banks like TLG are not corpora in this
sense: they are digital archives from which users can compile corpora according to their own
criteria.18
Small sample sizes are adequate for some kinds of investigation, but in general larger sizes are
preferable, especially for reliable investigations of authorship. Lexical studies require very large
corpora, because significant vocabulary need not have high frequency; morphological
phenomena recur at a much higher rate, allowing use of smaller samples. It is also desirable to
include whole texts and not just extracts, particularly for study of discourse features.
Porter gives the following reasons for regarding the NT as a suitable corpus for linguistic study
(1989: 1):
* It includes a set of texts by at least 8 authors and of several genres.
* It is large enough to compare favourably with corpora used for analysis by others, being
similar in size, for example, to the Iliad and Thucydides (Romans is similar in size to
Plato’s Apology).
* Its language gives a fair representation of the common language variety of the hellenistic
world.19
* Little modern syntactic work has been done on it.
From the perspective of most work on hellenistic Greek, the NT (or NT and LXX) is the focus of
study and other documents are examined for the light they throw on the language of the NT.20
18
Such compilation is facilitated by TLG’s classification scheme, which identifies the genre, date and
geographical location of each text (Berkowitz & Squitier 1986: xiv ff).
19 The long-held and still occasionally repeated belief that the Greek of the NT was a creation of the early
church, influenced by the Semitic background of its authors, resulted from the unrepresentativeness of the
classical corpus being used to assess it. Once the contemporary papyrological evidence was known, it
became clear that the language of the NT was the normal written language of literate speakers of the
time. For evidence and discussions of this debate, see Horsley 1984, Porter 1989: 111-156, Porter 1991
and Horrocks 1997: 92-97. ON LXX Greek as vernacular Koine see Silva 1980 and Lee 1983: 1-30.

12
From a general linguistic perspective, the NT is still an important body of texts representing the
ordinary language of the period and should be incorporated into any large corpus used to
investigate that language. The difference in approach is apparent when compiling the corpus: a
general-purpose corpus need not include the whole NT and might dispense with the shorter
letters as too small to provide reliable results for some purposes. But even within NT studies
some quantitative or stylometric work compiles figures based on larger sections of text and
occasionally ignores or aggregates the smaller documents.21
Computational investigation of language usage has obvious benefits where large data sets are
available. An additional reason for a corpus-linguistic approach to hellenistic Greek is that it can
help to identify patterns and trends that are imperceptible even to close reading.22 This is
particularly important for study of texts produced in bilingual and diglossic situations, as in the
case of Greek, where frequency alone is sometimes the only indication of interference from
another language or of departure from previous usage.23
20
For example, this is the rationale behind the publication of papyrus letters from Egypt in White 1986:
‘The primary purpose of this collection of letters ... is to provide a comparative body of texts for assessing
the epistolary character of the early Christian letter tradition found in the New Testament and the Early
Church Fathers’ (3). Similar statements are found throughtout the book of the same title by Meecham
(1923).
21 For example, Kenny in some tables omits Jude and 1-3 John (eg Table 8.1, 1986: 50), but more often
adds them to James and 1-2 Peter as ‘Catholic Epistles’ (eg Table 5.2, 1986: 26). In my use of the NT as
a corpus I have divided the text into author-groups (with no implication of acceptance or otherwise of the
traditional ascriptions of authorship) for the purpose of creating manageable samples for statistical
analysis.
22 For instance, corpus-linguistic research has been able to identify differences in the practice of native-
and non-native English student writing, so as to help second language learners avoid unnatural-sounding
English; the features so identified are generated subconsciously and are not visible to readers except as
vague impressions. See for example Berglund & Mason 2003 on the successful use of such parameters
as frequency of pronoun use to identify subconscious stylistic features.
23 Hebrew influence on the Jewish and Christian Greek of the hellenistic period may be detected, for
instance, in an increased use of parataxis, which is a natural phenomenon of spoken language but may
also be a result of literal translation of the Hebrew ‘waw-consecutive’ construction (in which the particle

13
The present study is based on the NT as a corpus, totalling 138,167 words. As it is not my
purpose to consider issues of authorship, I have for convenience divided the 27 NT books
according to traditional author, giving 9 samples of varying size. The two other corpora used
have been similarly divided into unequal sized samples. The AF corpus is made up of 8
samples by traditional author, consisting of letters, narrative accounts and theological treatises
similar in genre to the NT writings; its total size is 64,640 words. For the much larger group of
writings in the LXX, I have extracted a corpus of 5 samples of different sizes but comparable
generic features, totalling 204,929 words. For descriptions of the individual texts, including their
date, genre and linguistic register, see Appendix A.
In addition to the generally reliable data extracted from Accordance, I have obtained frequency
counts of some prepositions from TLG and LSJ. Although they return different raw numbers, the
relative figures are in most cases similar, and may be useful where other data is unavailable.
b. Grammaticalisation
The term ‘grammaticalisation’’24 refers to processes of syntactic change and to observed
tendencies of language variation over time. In recent usage it describes not only how lexical
items become grammatical morphemes but more generally how grammatical encoding of
meaning ‘and’ is part of the verb), or in extended use of prepositions in permissible but rare meanings
(such as ejn en used in instrumental PPs). These may be what Moulton calls ‘secondary Semitisms’, the
over-use of good Greek expressions under the influence of Hebrew and Aramaic usage (vol II, p 15).
24 Also know as ‘grammaticisation, ‘grammatisation’, ‘syntacticisation’ and ‘morphologisation’ (each of
these having a variant spelling with ‘z’). In recent publications ‘grammaticalization’ has become the most
common term. The invention of the term is attributed to Antoine Meillet, who defined it as ‘the attribution
of grammatical character to a previously autonomous word’ (Meillet 1912; 385, translated in Brinton &
Traugott 2005: 24). Surveys of recent work on grammaticalisation are provided in Harris & Campbell
1995, Heine 2003 and Hopper & Traugott 2003.

14
meaning emerges from lexical and collocational meanings. Metaphors like bleaching, fading,
weakening and erosion are used to describe processes of change, but without any implication
that language change represents degeneration; it is emphasised that loss in one area through a
grammaticalisation process is always offset by gain in another. For example, in the
development of adpositions from adverbial particles, the loss of lexical content is offset by a gain
in the argument structure of the adpositional phrase.25
Grammaticalisation is often a result of pragmatic inferencing and is typically accompanied by
semantic reduction, phonetic reduction or generalisation of the context in which a meaning can
occur. At the morphosyntactic level the processes of grammaticalisation are reanalysis and
analogy. Reanalysis is the reinterpretation of a surface form that is capable of more than one
analysis. It changes the underlying syntactic structure so that the surface form is understood
differently even though it has not changed. The textbook example of this is the development in
English of ‘be going to’ from a verb expressing directional motion to one expressing purposive
motion and then to an auxiliary verb expressing futurity. These developments are possible
because the pragmatic implications of utterances in context allow the same surface structure to
carry extra meaning, which is reanalysed as inherent in the structure rather than in the context.
In this case, as often, the reanalysis is accompanied by wider contexts of use (for example, ‘be
going to’ is no longer obligatorily accompanied by a locative expression) and phonetic reduction
(‘gonna’ is possible for the auxiliary but not for the motion sense). This process of generalising a
word or rule so that it can be used in more contexts than before is analogy. It involves the
removal of limitations on the environments in which a word or construction can occur. Often
reanalysis and analogy operate together. In the ‘be going to’ development, the extension of the
meaning of the construction was possible because after reanalysis of the surface form, to
include purposive and not simply directional meaning, the environment in which it could occur
25
Vincent 1999.

15
was generalised to include contexts in which no direction was expressed. Reanalysis
reinterprets ambiguous forms, and analogy regularises existing structures.
In Greek the adverbial particles, which originally had full lexical value and unrestricted word
order, came to be reanalysed as grammatical words, through the reinterpretation of surface
structures in which they frequently co-occurred with other content words, particularly nouns and
verbs. This led to their becoming fixed as either prefixes or prepositions. In the case of
prepositions a further development led to their association with one or more case and to the
preposition being eventually interpreted as the determiner of the case of its noun phrase, instead
of the inherent meaning of the case being independent as previously. (For example, the use of
the genitive case to express ablative meaning was replaced by a prepositional phrase: the case-
only means was no longer available. But the two parallel means of expressing locative meaning,
by a noun phrase in the dative case or by a prepositional phrase, co-existed as alternatives
much longer.)
It has long been noticed that there are trends in language change, such that certain types of
development occur often and in unrelated languages. For instance, English is one of many
languages that have formed future markers from a verb of motion.26 The development of Indo-
European adverbial particles to adpositions, apparently independently in its daughter languages,
results from reanalysis of underlying structures and is a very early development of
configurational syntax in the language family.27
Grammaticalisation theory is weakly predictive, in that it suggests possible paths of change
without prescribing which paths a particular language will take or how far along the path a
change will go. In this paper I will bring quantitative data to bear on hypotheses thrown up by
26
Bybee et al 1994.
27 Hewson & Bubenik 2006: 1-27.

16
known trends in grammaticalisation and developments in earlier forms of Greek, in the
expectation that large data samples will reveal trends not visible to the ordinary reading of texts.
c. Statistical analysis28
Much of the quantitative data compiled in this study is in the form of word counts or ratios of
usage (for example, number of preverb forms as a percentage of all verbs). However, for large-
scale comparison of different sample sizes it is desirable to provide more elaborate calculations,
to ensure that differences in raw number counts are really statistically significant and not merely
the result of normal variations in the samples. Significance, as used in this technical sense, is
an indication that the difference or relationship postulated between the samples is not due to
chance.
Because I have used corpora of different sizes, consisting of populations with different numbers
of samples, it is necessary to adjust the counts to allow for the variations caused by these
differences. The procedure I have used to test for significance first calculates the mean and
standard deviation of the samples and uses these to characterise a population of occurrences
that one would normally expect to observe. The mean and standard deviation for each
population are then used to calculate the probability that differences between the two
populations are due to chance. Where more than two populations are being compared, this
calculation has to be made for each pair of populations. The resulting p-value (probability value)
is used to determine which differences can reliably be considered significant. In the physical
sciences a p-value of 0.02 or under is considered conclusive; for most purposes 0.05 or under is
conclusive, 0.10 is reliable and 0.15 is still likely to be significant. Setting the significance level is
a necessary preliminary to reading a p-value. For this study I have chosen the conservative
28
For information on the choice of an appropriate statistical method I am indebted to Dr Simon Angus,
School of Economics, University of NSW (personal communication).

17
option of 0.05; this means that a result is considered significant if there is at least 95%
probability that it is not due to chance.
The t-stat is calculated from the deviations of the samples from the mean and tells how many
standard errors the sample mean (X- bar) is from the hypothesised value for the mean. The
formula for the t-value is Xbar1 - Xbar2 / standard error of the difference among the means:
where Xbar is the mean of the samples and S is the standard deviation, calculated as:
S = square root of the sum of the squares of the deviations from the mean divided by the
number of samples minus one.
The p-value is the area in the two tails that is outside t-stat and minus-t-stat. Where the direction
of divergence of the hypothesised relation is known, a one-tailed test is conducted. (The ‘tail’ is
the portion of the distribution which in a bell curve graph appears as the narrow section to the
right and left of the area of normal distribution.) If the hypothesis merely suggests a difference
without predicting whether it is greater or less than the population being treated as the norm, a
2-tailed test for p-value is used: this divides the p-value between the two tails.
The p-value is not the probability that the null hypothesis is true, but only that obtaining a result
as extreme as the one being considered is the result of chance alone. It is used to test
hypotheses: that is, it calculates the probability that a hypothesised relation is due to chance,
18
with a p-value below the agreed significance level being interpreted as confirming the hypothesis
that the relation is not due to chance.
An example of testing a hypothesis using the t-test and p-value:
Null hypothesis: that the 3 populations LXX, NT and AF are the same with respect to preverb
frequency.
Hypothesis A: that the frequency of preverbs in NT and AF is greater than in LXX
This hypothesis is based on comments by Morgenthaler, cited by Kenny,29 that the absence of
preverbation in Hebrew and Aramaic suggests the possibility of using frequency of preverbation
in individual writers as a diagnostic of their familiarity with Greek. An implication of this
suggestion is that translations from Hebrew to Greek might be likely to show less preverbation
than independent compositions in Greek by native speakers. (This is just a test hypothesis; the
assumption of a relation between the Greek of native-speakers or bilinguals writing translations
and that of writers in Greek with a poor grasp of the language due to their Semitic background is
not a necessary one; nor has it been established that any of the writers of the NT were not
Greek-speakers (whether as first language or not).)
We begin with raw percentages (word counts are unsuitable because the sample sizes are very
different).
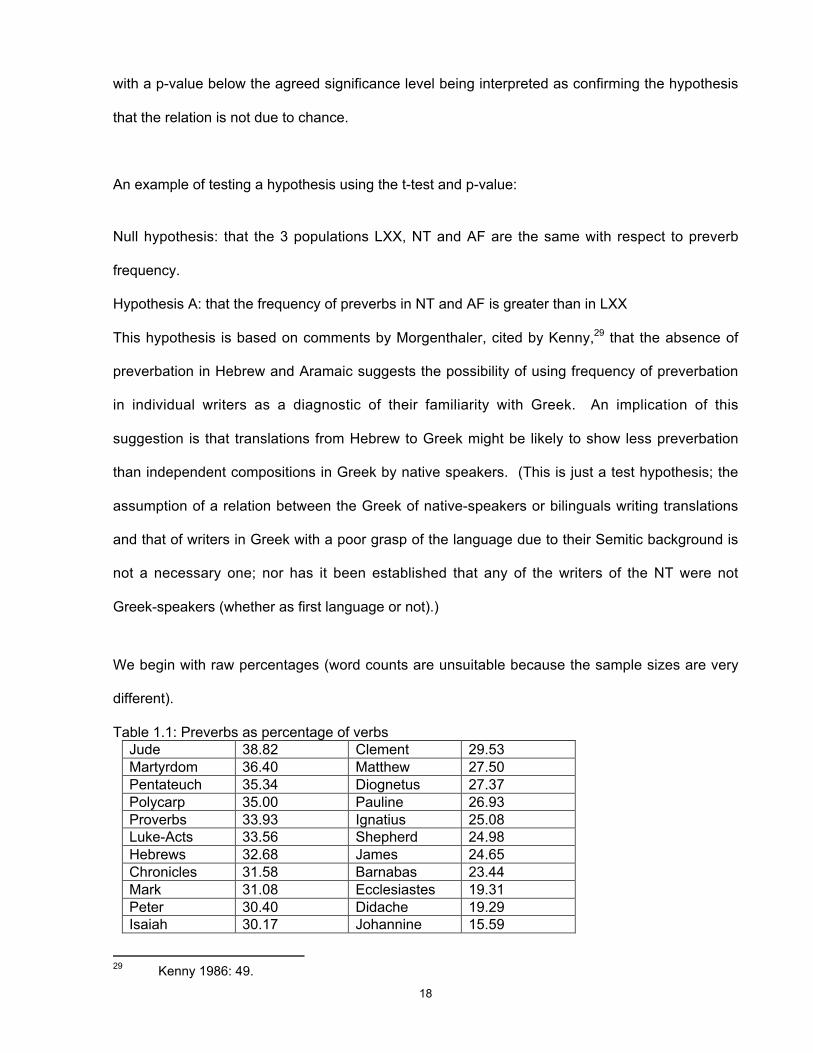
Table 1.1: Preverbs as percentage of verbs
Jude 38.82 Clement 29.53
Martyrdom 36.40 Matthew 27.50
Pentateuch 35.34 Diognetus 27.37
Polycarp 35.00 Pauline 26.93
Proverbs 33.93 Ignatius 25.08
Luke-Acts 33.56 Shepherd 24.98
Hebrews 32.68 James 24.65
Chronicles 31.58 Barnabas 23.44
Mark 31.08 Ecclesiastes 19.31
Peter 30.40 Didache 19.29
Isaiah 30.17 Johannine 15.59
29
Kenny 1986: 49.
19
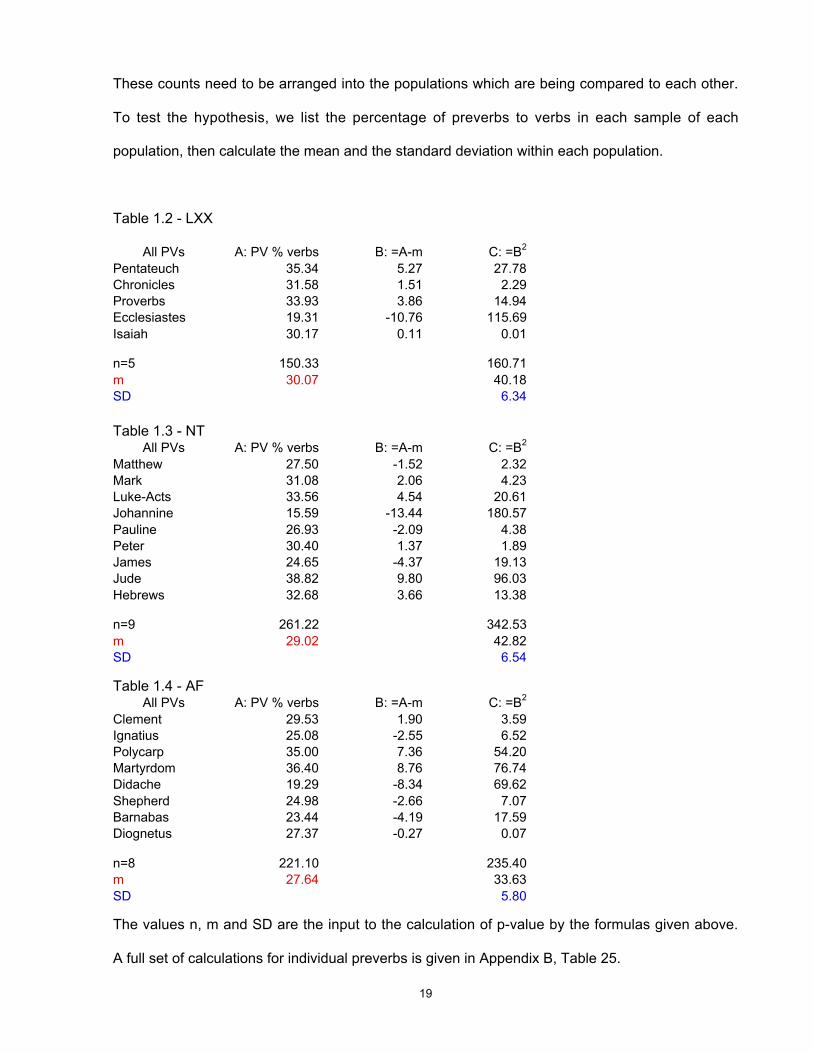
These counts need to be arranged into the populations which are being compared to each other.
To test the hypothesis, we list the percentage of preverbs to verbs in each sample of each
population, then calculate the mean and the standard deviation within each population.
Table 1.2 - LXX
All PVs A: PV % verbs B: =A-m C: =B2
Pentateuch 35.34 5.27 27.78
Chronicles 31.58 1.51 2.29
Proverbs 33.93 3.86 14.94
Ecclesiastes 19.31 -10.76 115.69
Isaiah 30.17 0.11 0.01
n=5 150.33 160.71
m 30.07 40.18
SD 6.34
Table 1.3 - NTAll PVs A: PV % verbs B: =A-m C: =B
2
Matthew 27.50 -1.52 2.32
Mark 31.08 2.06 4.23
Luke-Acts 33.56 4.54 20.61
Johannine 15.59 -13.44 180.57
Pauline 26.93 -2.09 4.38
Peter 30.40 1.37 1.89
James 24.65 -4.37 19.13
Jude 38.82 9.80 96.03
Hebrews 32.68 3.66 13.38
n=9 261.22 342.53
m 29.02 42.82
SD 6.54
Table 1.4 - AFAll PVs A: PV % verbs B: =A-m C: =B
2
Clement 29.53 1.90 3.59
Ignatius 25.08 -2.55 6.52
Polycarp 35.00 7.36 54.20
Martyrdom 36.40 8.76 76.74
Didache 19.29 -8.34 69.62
Shepherd 24.98 -2.66 7.07
Barnabas 23.44 -4.19 17.59
Diognetus 27.37 -0.27 0.07
n=8 221.10 235.40
m 27.64 33.63
SD 5.80
The values n, m and SD are the input to the calculation of p-value by the formulas given above.
A full set of calculations for individual preverbs is given in Appendix B, Table 25.

20
When the t-stat and p-value are calculated for each pair of populations, three results are
obtained, which are conventionally displayed in a grid in which each population is listed twice, in
a row and in a column. To avoid confusion the values are listed only once for each pair, with the
cells that would duplicate this information left empty.
Table 3: One-tailed test
All PVs (as %
of all verbs)
LXX NT AF
LXX
m=30.07
0.29
0.388
0.71
0.245
NTm=29.02
0.460.326
AF
m=27.64
To read this display, begin at the first row (in this case LXX). To see its relation with the other
populations, read across the row to the first filled cell (the cell that redundantly compares LXX to
LXX being left empty): this shows that in relation to LXX, NT has a t-stat of 0.29 and a p-value of
0.388. The t-stat is listed because it shows the direction of any change: a negative value would
show an increase, but here the positive value shows that NT has less preverbation than LXX.
None of the p-values falls under the significance level of 0.05, which means that Hypothesis A of
an increase in preverbation in the original-Greek texts over the translation-Greek texts is not
supported.
Note that the mean as shown is the average of the percentages in each population. Because
the samples are of different sizes, this is not the same as the percentage in the population as a
whole. The overall rate of preverbation in the 3 populations is:
LXX 33.47%, NT 27.33%, 26.22%
The variation here is greater than that listed as the mean in the test above. The purpose of the
test is to reduce the effect of variations in samples of unequal sizes in order to produce a more
reliable estimate of probability. In this case it suggests that the populations show less difference

21
from each other than seems apparent from the raw counts and the overall percentages. This
procedure produces an important caveat: claims about usage must be based on clear standards
and not simply on impressionistic readings.
A hypothesis that the populations are different that does not predict the direction of difference
would produce a different result. In this case, the hypothesis critical p-value is halved, since this
area is now split between the upper and lower tails (or to express it the other way round, the
probability that the null hypothesis is correct is doubled):
Table 4: Two-tailed test
All PVs (as %of all verbs)
LXX NT AF
LXX
m=30.07
0.29
0.775
0.71
0.490
NT
m=29.02
0.46
0.653
AF
m=27.64
Calculation of probability-values by this method is appropriate for the comparison of groups of
data where each group is to be compared to the others and each group consists of several
samples of different sizes. It does not apply to the comparison of single-sample groups; for
example, when considering the usage of tense forms with preverbation in Classical Greek and in
the New Testament, we have insufficient data to obtain p-values, since comparable verb-counts
are not available for different authors (see Chapter 3 on data from the classical author Lysias).
d. Transliteration
The Greek alphabet has a number of characters that do not correspond to roman letters.
Throughout this study I have used a simple transliteration scheme, in which the Greek
characters that represented an aspirated stop are rendered by the roman stop character and ‘h’:
ph, th, kh. Vowels are not distinguished by length even though Greek has separate characters

22
for two of its long vowels (the phonetic distinction maintained in the spelling was lost by the later
Koine period). Where the roman alphabet has a single character that represents a Greek letter,
I use it in preference to a more phonemic spelling; x instead of ks for x, but ps for y which has
no roman equivalent. Iota subscript is written linearly in the roman script. In most places in the
text I give the Greek word followed by a transliteration, but in lists and tables I give just the
transliteration, in order to make the presentation of data less cluttered. I have not usually
reproduced the accent diacritics in the transliterations, except where accent placement is
relevant to the discussion. When giving sample sentences I give the Greek in the first line, then
a transliteration aligned with a gloss and/or morpheme breakdown for each word, and finally a
translation. I have not attempted to provide a phonetic or phonological representation of the
Greek, since the historical spelling conceals significant changes over the long time-span
discussed, and some of the changes are not securely dated.30 The Greek font used in the body
of this study is ‘Galilee’. In Appendix C (where the data is not transliterated), the font is ‘Helena’,
as used in Accordance.
Summary
In this chapter I have offered reasons for continuing to make the Greek language an object of
linguistic investigation and for using the New Testament as a corpus for quantitative study of
hellenistic Greek. I have suggested that a combination of corpus linguistics and
grammaticalisation theory is likely to provide a viable method of discovering facts about the
language that would be difficult to perceive by other forms of analysis, and I have outlined a
basic statistical method that is designed to increase the reliability of quantitative analyses. In the
next chapter I turn to the history of Greek and trace the origins and development of the
prepositions and preverbs that will be studied in Chapter 3.
30
For phonetic transcriptions of Greek texts from all periods, see Horrocks 1997.

23
Chapter 2 – From Proto-Indo-European to Classical Greek
In this chapter I outline what is known of P-words from the earliest period for which there is
evidence, namely the Proto-Indo-European language as it has been reconstructed by historical
linguistics, and trace the changes in their usage, particularly in the development of
configurational syntax, through all attested periods of Greek to the end of the classical period.
The P-words are a distinctive feature of most of the daughter languages of Proto-Indo-European
and offer a rich source of data for cross-linguistic, diachronic and typological studies. Greek with
its three thousand year written history is a unique resource for the study of the origins and
development of this significant and still inadequately understood group of words.
Indo-European and Pre-Greek
Greek is the sole representative of one of the ten branches of Proto-Indo-European (PIE),31 a
language or group of dialects spoken about 4500 BC in an area of eastern Europe to the north
and east of the Black Sea.32 The language as reconstructed by the comparative method is
31
There are ten branches in Fortson’s diagram (2004: 10); Campbell’s has only 8 (2004: 190-1), as he
combines Italic and Celtic as one sub-group and Greek and Armenian as another. If Greek and Armenian
form one sub-group that diverged very early it would mean that the centum-satem phonological divide in
IE languages was to some extent an areal feature and not just a matter of different innovations in different
family groups. There are several known ancient languages that cannot be securely affiliated with any of
the major branches.
32 According to the Kurgan hypothesis of PIE origins, which appears to be the majority view at present.
Other suggested homelands are Anatolia, Armenia, India and even the North Pole (Fortson 2004: 36,
quoting Mallory 1989). Different theories have been proposed on linguistic, archaeological, geographic
and population-genetics grounds; it seems these disciplines rarely point in the same direction. The
Kurgan hypothesis is based on a combination of archaeology and linguistics, principally the nature of the
vocabulary that can be reconstructed for PIE and what this tells us about the culture of its speakers. See
the discussions of Beekes 1995 Chapter 3, Fortson 2004 Chapter 2 and Campbell 2004: 401-2.

24
extensively described by Fortson.33 It had a large inventory of consonants (for example, 15
stops) and at least 8 vowels. Word-roots consisted of a limited number of combinations of
consonants with a fundamental vowel and often other vowels or syllabic consonants.
Polysyllabic words had at least one syllable characterised by a higher pitch. The pitch accent
was mobile and cannot always be reconstructed; it is generally believed that verbs in PIE were
clitics, without their own accent.34 A central feature of morphology was ablaut (usually termed
apophony in relation to Greek), a system of vowel alternations in which different vowels
appeared in roots according to the type of word being derived; inflections and other suffixes
could also ablaut. Words typically consisted of a root, a suffix (or ablaut) and an ending.
Compounding and prefixation also occurred, with reduplication of an initial syllable being
common. PIE was richly inflected, with 8 or 9 cases, three numbers, three persons and several
tenses, all occurring in an older athematic (no vowel) or less archaic thematic (e or o before the
inflection) form.
The word categories that will concern us in our study of Greek prepositions and preverbs are
verbs and adverbs. The PIE verbal system was morphologically complex. It contrasted tense
and aspect, but without a full system in which all tenses occurred in all aspects. Imperfective
present and imperfect tenses existed in aspectual contrast to an always perfective aorist tense,
along with a stative aspect that probably had its own past form (the traditionally termed perfect
and pluperfect);35 there was no future tense. There were two voices (active and middle or
33
Fortson 2004: phonology Ch 3; morphology Ch 4; syntax Ch 8. The following information on the
characteristics of PIE is derived from these chapters. On the comparative method see Beekes 1995 Ch
10, Fortson 2004: Ch 1 and Campbell 2004 Ch 5.
34 Fortson 2004: 99, who notes that in Greek the accent rules for verbs resemble those of clitics rather
than nouns (though of course Greek verbs were no longer clitics as postulated for PIE).
35 This is the view of Jasanoff, who proposes a slightly different reconstruction of the PIE verbal system
from the traditional one on the basis of his investigation of Hittite (the IE language with the earliest
attestation after Vedic Sanskrit) (2001: 215). The view of Porter 1989 that the Greek verbal system was
built around aspect and not tense is incompatible with most reconstructions of the PIE system.

25
perhaps mediopassive; the passive developed from the middle in the daughter branches), four
or five moods, three numbers and three persons with two sets of personal endings. An originally
independent particle became attached to past tense forms as an ‘augment’; it survived in Greek,
Armenian, Phrygian and Sanskrit.36 It bore the stress and in Greek is responsible for a large
amount of allophony in compound verbs, where it comes between the preverb and the root.37
The Greek particles ana, anti, amphi, ek, en, epi, kata, peri, pros, huper, hupo are all reflexes of
known IE adverbial particles.38 In PIE they functioned as independent adverbs, but in collocation
with nouns they were (primarily) postpositions; most of the daughter languages, however, have
prepositional reflexes. These particles could modify verbs without being restricted to the
preverbal position; in some IE descendants the compound verb (combination of preverb and
verb) can have an intervening clitic, or the morphemes can be detached, or the preverb can be
fronted for emphasis.39
We next meet the P-words in Mycenaean Greek, which is chronologically the earliest attested
form of the language. However, there is a three thousand year gap between PIE and
Mycenaean, which can be only partially bridged by reconstruction of Proto-Greek on the basis of
36
Beekes 1995: 226. Phrygian is an IE language spoken in central Asia Minor, with texts from 800 BC to
AD 600; its affiliation if any with other IE languages is not known.
37 The allophony, due to interactions between adjoining vowels and between vowels and aspirates, is
reflected in the spelling; this is one of the reasons the unlemmatised TLG archive is difficult to search.
38 These were not full adverbs of the type commonly formed from adjectives in many IE daughter
languages. In PIE certain case-forms of nouns or adjectives could function adverbially, but the particles
we are considering were mostly independent not derived words (Beekes 1995; 218). It is thought,
however, that even some of these particles can be traced back to case-inflected nouns in an earlier stage
of PIE; for instance, Greek ajntiv anti ‘against’ may come from a word meaning ‘face’ (Hewson & Bubenik
2006: 381).
39 See Fortson 2004: 140 for examples from Old Irish and Gothic, Modern German and Dutch, and
Avestan.

26
comparison of ancient dialects. All such reconstructions remain controversial because of the
difficulty of matching up linguistic and archaeological data.40
Little is known of the migration patterns of the groups of IE speakers into Europe. Greek has
been spoken in the southern Balkan peninsula continuously since the arrival of Proto-Greek
speakers in several waves of migration from approximately the beginning of the second
millennium BC. The earliest documents in Greek date from about 1500 BC (only slightly later
than Old Hittite). Traces of pre-Greek languages remain in some elements of vocabulary,
especially place-names, but substrate influence cannot be identified in phonology or morphology
because of the lack of attestation for the languages. The early, widespread and partly
discontinuous range of dialects confirms the archaeological evidence for a period of mass
migrations, which are not securely datable but may have continued through most of the second
millennium BC; however, it should be noted that the earliest Greek documents do not take us
back as far as a form of Common Greek or Proto-Greek. We still do not know where or when
Greek broke away from IE and how long it existed as a separate language before its speakers
entered the Balkans.
Mycenaean Greek
The earliest Greek documents, palace records preserved on accidentally fired clay tablets and
written in the syllabary known as Linear B, are in a ‘supraregional administrative language’
(Palmer 1980: 57) based on an Arcado-Cyprian dialect. As a chancellery language it is far more
uniform than we might expect from the high level of dialect variation known to have existed, and
so perhaps represents an early Koine.41 The tablets have been found in Crete and in the
40
See Adrados 2005: Chapters 1 & 2 for a contested reconstruction and references to the debate.
41 The Mycenaean documents span several centuries and have been found in diverse areas: the north-
western and eastern Peloponnese and Crete. It was the unanimous opinion of Greeks in antiquity that the
large range of dialects never diverged to the point of mutual unintelligibility. However, it is possible that

27
northeast and southwest Peloponnese, but the language shows little diversity for such a
geographically wide range. The Mycenaean language, so named because the palace of
Mycenae is one of the centres of the civilisation that produced the Linear B tablets, has
preserved some of the phonology of IE not found in later Greek, such as the series of labiovelar
stops; it shares many features otherwise known only from the Homeric writings, and yet is
notably lacking in other features characteristic of Homer.42 The reason for this anomaly is that
the tradition of orally transmitted epic poetry preserved archaic features that were already
obsolete in the spoken language of the Mycenaean civilisation; Homer and the Linear B texts
share some features of early Greek lost by the classical period, but the language of epic is
deliberately archaic and conservative and preserves some even earlier features.43
the continuum of ancient dialects had mutually unintelligible extremities. On the ancient dialect continuum
and what it tells us about population movements of Greek speakers see Finkelberg 1994; see also
Horrocks 1997: 7-16. Dialect diversity was always accompanied by a range of regional Koines that had a
standardising tendency, and frequent and regular interactions between speakers of different dialects was
the norm (Bubenik 1993), with the partial exception of the ‘Dark Ages’ (1200-800 approx).
42 Note that it is conventional to refer to the composer(s) of the Iliad and Odyssey by the name of the
traditional author, Homer, without implication that there was one figure or one stage of composition behind
the poems.
One of the significant features shared by Mycenaean and Homeric Greek is the lack of the definite article,
which developed in Greek (considerably earlier than in any other IE language) only shortly before the
classical period. In the Linear B documents the relative pronoun is rare and may be an adverb (‘thus’)
(Vilborg 1960: 101, 125); in Homer what look like articles are relative and personal pronouns (from which
the article later developed) (Hewson & Bubenik 2006: 3-4, 55-56).
43 On the use of archaic formulas in oral composition of epic poetry see Nagy 1996 and Horrocks 1997:
18. According to the Parry-Lord hypothesis (as presented for instance in Lord 1960), poetry was
composed in performance and employed a stock of key phrases in various metrically useful forms. As
Householder put it: ‘The interplay of formulas ... is ... advantageous to diachronic perspective because of
its conservative effect on the linguistic heritage. Configurations which otherwise would have long ago
become extinct remain embedded in this or that expression preserved by the formulaic structure. It is to
the Epic that we owe the perpetuation of the most archaic words in the Greek repertory, often coexisting
side-by-side in the same line with the most recent.’ (Householder & Nagy 1972: 20-21.) Some of the
poetic formulas are thought to date back to PIE, providing evidence of very early cultural practices such as
myths and religious rituals. See Householder & Nagy 1972: 48-58 for examples of striking parallels in
Homeric, Hittite and Sanskrit verbal collocations.

28
Some of the P-words are attested in Mycenaean but do not exhibit the IE-like behaviour that is
seen in Homer. In the Linear B texts there are prepositions and preverbs but no postpositions or
tmesis (separation of verb and preverb). (See below on Homer’s use of P-words.) In the light of
the development of the P-words in other IE languages, there is no reason to suppose that the
usage in Mycenaean was far different from what became the norm in classical times. Homer,
though intermediate (in terms of when the poems were finally committed to writing) between the
Mycenaean and classical periods, represents an earlier stage of the language in respect to the
usage of the P-words.
The nature of the Linear B documents precludes a full analysis of the Mycenaean language. The
script is inadequate for Greek, as it makes phonetic distinctions Greek does not have and fails to
make others that are significant in Greek. It cannot represent consonant clusters, so either
deletes a consonant or inserts a vowel. Word-final consonants are not shown, which leaves
significant morphology unrepresented. Many words are not securely identified with known
Greek words, as there are often multiple possible conversions to later Greek spelling. The
vocabulary of the tablets consists mostly of personal and place-names, and there are few verbs
and function words and very little clause-level syntax. Nevertheless, the P-words amphi, apo,
epi, sun, meta and para are attested as prepositions; ana, en, peri, pro and huper as preverbs;
and anti and kata as elements of personal names. The only aspect of their usage inconsistent
with classical usage is that hupo is found as an adverb.44
44
This information is from Vilborg 1960: 119-123. A dictionary of Linear B is available on-line at
www.explorecrete.com/archaeology/linearB.pdf. It lists several P-forms, among them the prepositions a-
pu (ajpov apo), e-pi (ejpiv epi), pa-ra (parav para), the adverb u-po (uJpov hupo) and the compound verbs a-pi-
e-ke (ajmfievcei amphiekhei ‘contains’ [hold around]) and e-pi-ko-wo (ejpivkoƒoi epikowoi ‘pay attention’
[look on]). (The conventional transcription of Linear B is to separate syllables by hyphens. Every
character represents a syllable of V or CV type.)

29
The destruction of the centralised Mycenaean civilisation during the twelfth century led to a long
period of population decline, illiteracy, social and linguistic regionalism and economic
depression. There is almost no trace of writing for four centuries. Political and linguistic
unification did not reoccur until the hellenistic period. Alphabetic inscriptions appear from the
early eighth century BC, and shortly after this the Homeric epics reached the form in which they
have been handed down: ‘essentially an archaic eastern Ionic but with an admixture of Aeolic,
and a number of conspicuous archaisms not characteristic of any one historical dialect or region’
(Horrocks 1997:18). The language of epic was thus not an actual spoken dialect but a
conventionalised form that developed in a manner typical of orally transmitted poetry and later
became a prestigious literary variety. Nevertheless, as is clear from comparison with other
ancient IE languages, the peculiarities of the Homeric Dichtersprache are not all merely the
result of its poetic form, and therefore offer some reliable evidence for developments in the
language between PIE and Mycenaean.
Homeric Greek and the P-words
The P-words in Homer have been studied by Horrocks in Space and Time in Homer:
Prepositional and Adverbial Particles in the Greek Epic (1981) and by Luraghi in On the Meaning
of Prepositions and Cases: The Expression of Semantic Roles in Ancient Greek (2003).45
Horrocks begins from the position that:
... the language of the Iliad and Odyssey is regarded as a unitary dialect to be treated
from a synchronic point of view ... despite the chronologically and geographically
disparate origins of vocabulary items, grammatical forms, etc, I take the view,
45
Horrocks 1981 is a type-script with hand-written Greek examples; it gives no transliterations or glosses.
Frequent citations in French are untranslated. There are few headings or breaks in the text, and no index,
making it difficult to go back to sections of interest. Luraghi’s book is explicitly intended for general
linguists with no knowledge of Greek script, and gives all Greek examples in roman transliteration with
lexical glosses and morphemic analysis.

30
consistent with the interpretation of the poems as products of a long and sophisticated
oral tradition, that this amalgam was put to use as a coherent and self-contained
system by individual singers, without assuming knowledge on the part of those singers
of the history and origins of the material employed. (1981: 1)
However, this is to regard the conscious mixture of vernacular and archaic language as
representing a unified linguistic system, whereas no such coexistence is known outside this
literary or performance dialect. Some of Horrocks’ findings regarding the usage and syntactic
character of P-words in Homer depend on this assumption, relying on a spurious synchronic
unity.46 For example, he argues that in Homeric Greek the P-word is an adverbial particle even
where it occurs with a noun phrase in an oblique case, on the grounds that if the P-word is not
always a preposition then it cannot ever be the head of a prepositional phrase. But this
disregards the fact that competing systems were present in the same semi-artificial dialect due
to the deliberate use of older patterns; there is no need to claim that only one system (P as head
of dependent NP, or N as head of NP accompanied by adverb) was synchronically possible in
the language of performance. The older IE system used case to indicate spatial relations, and
any accompanying P-word added meaning without taking over the case function; but both
Mycenaean and classical Greek increasingly used prepositional phrases with the preposition
governing the noun phrase and determining its case, even though (from a diachronic
perspective) it had been the case functions which originally determined what cases a preposition
would govern.47 In Homer both systems (independent case and configurational syntax) are still
present, and to insist that one system is still underlyingly the other is to perform the classical
46
This seems somewhat akin to arguing that the hymn writers of the nineteenth century, who regularly
used obsolete morphology and word order, had only a single underlying synchronic grammar, instead of
recognising that their conscious archaism was a separate system within the genre, which allowed ‘normal’
as well as archaic usage.
47 On case-syncretism in Mycenaean (particularly the fusion of PIE dative and locative) see Horrocks
1981: 128ff: he concludes that prepositional syntax had replaced case as the usual expression of locative
relations.

31
grammarians’ error in reverse: they viewed Homer’s usage as a departure from their own,48
while Horrocks appears to deny that the developments have yet taken place in the epic
language.49 In any case, a different but still strictly synchronic view of the data is possible if the
variation is viewed as the normal outcome of grammaticalisation processes, which typically
generate changes which may coexist with the original constructions. Greek speakers must have
been able to recognise and produce both free and syntactically restricted uses of P-words for
some time while the reanalysis of the constructions was taking place, just as English speakers
can use ‘going to’ in two different syntactic constructions.
Whether Horrocks’ views on the dependency relations of prepositional phrases are accepted or
not, his attempt to find a theoretically rigorous explanation for the variation in Homeric usage is
an improvement on older treatments, which typically are unable to find a unified classification for
the facts of usage.50 However, his analysis is unnecessarily complex. He interprets
independent adverbial uses of particles as ‘implicitly prepositional, since a noun phrase can, in
principle, always be supplied ... adverb phrases consisting of independent particles are
interpreted as pro-forms of full adverb phrases, i.e. as incorporating a covert adverbial element
meaning something like “here”/”there” which is qualified by the particle and construed
anaphorically as co-referential with some previously mentioned adverbial noun phrase (1981:
20). It seems gratuitous to introduce covert elements in this manner. And, like the older
grammarians, he treats differences of positioning of P-words in relation to verbs as different
48
This is clear from their use of the term ‘tmesis’ (‘cutting’) as a description of the phenomenon by which,
as it seemed to them, a preverb became separated from its host verb.
49 He does not of course deny the actual usages, but denies that the configurational patterns in Homer
have syntactic meaning at this stage. He treats the Homeric language in effect as a stage completely
prior to Mycenaean rather than as showing a mixture of older and newer patterns (1981: 18-19). As noted
above in relation to the definite article, there are some features of the two stages which are identical and
do not allow such a complete separation.
50 Horrocks takes Chantraine 1953 as ‘typical of the traditional view of the subject; similar accounts
appear in all the standard grammars and works of reference’ (1981: 10). These accounts note the
differences from classical usage without offering an explanatory account of their development.

32
kinds of syntactic phenomena (phrasal verbs, compound verbs etc), when it accounts for the
facts just as well to regard them as coexisting different stages on the well-known
grammaticalisation path from free lexical items to more restricted function words.51
Horrocks briefly notes that P-words can be associated with verbs in such a way as to make them
transitive (1981: 41). The examples he gives show that the P-word is free to associate with verb
or NP:
(1) a. ton;; d‘ � au\te proseveipe qea; glaukw:piV ‘Aqhvnh
ton d’ aute proseeipe thea glaukopis Athene
PRN.ACC PTC again P towards.spoke goddess gleaming-eyed Name
‘The goddess Athena with gleaming eyes addressed him again’ (A.206)
(1) b. pro;V d’ Eujrukleivan e[eipen
pros d’ Eurykleian eeipen
P towards PTC Name.ACC spoke
‘he addressed Eurykleia’ (u.128)
Here the P-word provides the means to give the verb a direct object (shown in both examples by
the accusative case); normally the verb ‘speak’ can have as an object only words like
‘something’ or ‘a word’. As yet it is still the spatial meaning of the P-word that is doing the work,
rather than a fixed P-word/verb combination where the verb has different properties of
transitivity. The collocation of a verb of speaking with provV pros + ACC as PP remained an
51
It should be noted that Horrocks was writing from a generativist (transformationalist) rather than
functional perspective, before the modern predominantly functionalist renewal of interest in
grammaticalisation.

33
option in classical and later Greek. Nevertheless it is clear how a transitive verb could develop
from this configuration.
Horrocks has a short final section in which he examines the use of the P-words ajpov apo and ejpiv
epi in phrasal and compound verbs. While noting that the meanings of such verb combinations
are typically not compositional, he traces stages in Homeric usage where the parts seem to
retain their separate semantic contributions to the whole, and developments in which the
collocation of verb and particle appears to restrict the options available for accompanying noun
phrases in a way that suggests that the environment in which they are used has changed.
Some uses of the P-words are found to be ‘purely aspectual, with very little of the literal meaning
retained’ (1981: 277). The most common aspectual meanings for ajpov apo are resultative and
intensive, but he finds some examples of inceptives. Interestingly, he finds a difference in the
resultative uses of the PVs ejpiv epi and ajpov apo:
While ajpov is characteristically used in perfective function with the nuance of ‘removal’,
and so tends to appear with destructive verbs, ejpiv is generally associated with
‘creative’ verbs describing an action whose performance ‘to a result’ brings the affected
object ‘onto the scene’ in a state of completion ... availability for some purpose, etc.
(1981: 283-4)
Another resultative sense of ejpiv epi occurs in verbs of ‘urging on’; but it also occasionally has a
durative or repetitive sense. This is consistent with the stronger correlation of the preverb ajpov
apo with perfective aspect, in comparison with ejpiv epi, in verbs in the New Testament (Table
B.23) and suggests that this aspectual correlation will be found throughout the intervening period
(between Homer and late Koine) when data on individual preverb usage becomes available.
On the development of P-words into aspect-related function words Horrocks concludes with a
statement that is entirely consistent with a grammaticalisation approach:

34
... a great many linguistic oppositions to do with notions such as inception, duration,
completion and so on are learned as a kind of analogical extension of oppositions first
learned in connection with concepts such as location, movement and orientation. It
cannot be entirely accidental that the same set of particles are used to express both
types of relationship. (1981: 287)
Horrocks goes on to investigate the semantics of the P-words in relation to their interaction with
case, particularly the originally locative meanings of the cases and their metaphorical
extensions. His componential approach to the semantics of case is expressed in the
terminology later used in Cognitive Linguistics, including the explicitly cognitive approach taken
by Luraghi 2003, who extends the description to include classical Greek usage. Her emphasis is
on establishing the meanings of the preposition-case configurations in Homer, which she argues
are primarily the prototypical spatial meanings, and then showing from a selection of classical
texts how the temporal and other metaphorical extensions of meaning developed from the
spatial ones. Both Horrocks and Luraghi employ the terminology of Source, Path and Goal and
provide plausible reasons for the often slight or apparently imperceptible differences in usage
between prepositions, and between the cases governed by a preposition.
Horrocks’ work is an early attempt to bring current linguistic understanding to bear on issues that
had previously been the domain of philologists and classicists. He rightly rejects approaches
that see the classical language as the standard and earlier stages as merely incomplete
versions of it, an attitude that is implicit in many descriptions of Homeric Greek which fail to
notice that words and constructions that have a surface similarity to classical Greek in fact have
different underlying structures (as in the pronouns that look like articles, and the P-words that
look like preverbs and prepositions). Nevertheless, he overstates the case when he argues that
all the configurational patterns of P-words, for which he has a complex categorisation, are either
merely optional or idiosyncratic collocations and that prepositions are not yet heads of their PPs.

35
The Mycenaean evidence suggests rather that the variety of P-word usage in Homer is due to
the retention of archaisms which can be used simultaneously with more recent systems of
configuration. It is evidence of an earlier form of Greek but exists only in a mixed form of the
language in which older and newer patterns coexist. Horrocks’ work remains valuable for its
general approach and its wealth of examples, but it has now been superseded by Luraghi 2003,
where the data is much more accessible to general linguists and is organised around a more
theoretically consistent approach.
Luraghi begins by stating the theoretical assumptions of Cognitive Linguistics, that grammatical
forms are meaningful and that abstract meaning usually derives from metaphorical extension of
spatial meaning, space being the basic domain of human experience (2003: 11-12). Unlike
Horrocks she considers that this cognitive approach ‘necessarily implies the integration of a
diachronic dimension in the analysis of meaning’, although it does not imply that an original
spatial meaning is synchronically available as a ‘basic’ meaning (2003: 12). She shows however
that in Homer the spatial meaning is still available for almost all the prepositions, whereas by
classical Greek the meanings are less specific and often wholly metaphorical. The prototypically
spatial prepositions en ‘in’ (+dative), ek ‘out of’ (+genitive) and eis ‘into’ (+accusative) are the
most stable and show the least metaphorical extension (2003: 315); they also retain the most
synchronically accessible semantic connection with the locative, ablative and allative functions of
PIE cases.
Luraghi is only incidentally concerned with the P-words’ association with verbs. However, her
summary of Homeric usage is more accessible than Horrocks’, and her wealth of examples of all
the combinations of preposition and case usage is a valuable resource, and includes instances
of all the types of verb and P-word combination found in Homer. Her study is used as the

36
source for Hewson & Bubenik’s discussion of the development of prepositions in Ancient Greek
(2006: Chapters 1 & 3).52
These studies may differ in their reconstructions of the exact paths of change from PIE to Greek,
but they are united in arguing that the traditional classical-oriented view of Homeric usage as an
aberrant one is anachronistic, and that Homer represents an intermediate stage in the
development of P-words from free to configurational elements.
P-words could appear in four configurations in Homer:53
(A) Preposed before a Noun Phrase
(2) ejpi; gai:an ajp’ oujranovqen protravphtai
epí gaian ap’ ouranothen protrapetai
P to earth.ACC P from heaven.[GEN] P.turn.3SG
‘to earth from heaven he turns’
(3) ejpi; cevrsou
epí khersou
P.near shore.GEN
‘near the shore’
(4) ejpi; krotavfoiV ajrarui:a
epí krotaphois araruia
P to temples.DAT.PL suited
‘ f i t t i n g m y h e a d ’
52
In refreshing contrast to Horrocks 1981 and Luraghi 2003, this study always gives the tradtional script
as well as transliterations and glosses, making it convient for both Greek specialists and general linguists.
53 Examples (2) to (13 from the Iliad and Odyssey all show the P-word ejpiv epi and are taken from
Hewson & Bubenik 2006: 4-7. The P-forms are printed in red in the transliterations.

37
In these examples the meaning of the P-word comes from its interaction with the case of the NP.
The accusative case is associated with movement, while the oblique cases are not. In (2) there
are 3 P-words: two preposed to NPs and one preposed to the verb. As in classical Greek ajpov
apo governs the genitive case, but in (2) there is an older genitive morpheme -qen –then instead
of the classical case form oujranou: ouranou.
(B) Postposed after a Noun Phrase
(5) o{ssa te gai:an e[pi pneivei
hossa te gaian épi pneiei
what.NOM.PL and earth P on breathe.3SG54
‘whatever on the earth breathes’
(6) ajletreuvousi muvlh/V e[pi mhvlopa karpovn
aletreuousi muleis épi melopa karpon
grind.3PL millstone.DAT.PL P on yellow grain.ACC
‘they grind the yellow grain on the millstone’
The accent on the first syllable of the P-word indicates that it is not a free adverb or preverb.
This accent placement (termed anastrophe) is of ancient origin, but as accents were not
regularly written until the middle Koine period it cannot be definitely asserted that it represents a
phonetic reality. It is possible, for instance, that it is an early attempt by grammarians conscious
of the anomaly of Homeric usage to differentiate graphically the two types of adposition.
However, Hewson & Bubenik treat the accent placement as genuinely diagnostic: ‘the inner core
prepositions are marked phonologically by lack of accent ... the outer core prepositions are
marked by an accent on the ultimate syllable ... the peripheral prepositions are accented on the
54
The singular verb with a neuter plural subject is normal in Greek, although usually the subject is not
animate. The Greek neuter plural suffix derives from a PIE collective marker (Fortson 2004: 118, 143).

38
antepenultimate’ (2006: xi). The poetic metre is no help here because the pitch accent was only
indirectly related to metre, which was based on syllable quantity.
Note that the P-word with accusative case in (5) cannot have the same meaning as in (2) and
does not mean ‘breathes on the earth’.
(C) Tmesis (belonging with the verb but not preposed)
(7) kai; ejpi; knevfaV iJero;n e[lqh/
kai epí knephas hieron elthe
and P on darkness sacred come.3SG
‘and the sacred darkness closes in’
(8) hjd’ ejpi; sh:m’ e[ceen
ed’ epí sem’ ekheen
and P on barrow heap.IMPF.3SG
‘and heaped a barrow on (him)’
(9) oi|sin ejpi; Zeu;V qh:ke kako;n movron
hoisin epí Zeus theke kakon moron
who.DAT.PL P on Zeus.NOM put.AOR.3SG evil.ACC doom.ACC
‘on whom Zeus put an evil doom’
In (7) the verb is intransitive and there is no oblique NP. In (8) the NP is the direct object of the
verb, and there is no overt locative or indirect object. In (9), it would be unusual to have a P-
word postposed after a prosodically weak word like a pronoun, and the accent supports reading
the P-word as a preverb in tmesis, as it is the usual final accent for the preposition rather than

39
anastrophe as would be required if it collocated with oi|sin hoisin (but note the caveat mentioned
above on example (6) regarding the reliability of accent judgements).
(D) Preverb
(10) kefalh/: d’ ejpevqhke kaluvptrhn
kephale d’ epetheke kaluptren
head.DAT PRT P on.put.AOR.3SG veil.ACC
‘and on her head she put a veil’
(11) puvrgwn hJmetevrwn ejpibhvseai
purgon hemeteron epibeseai
wall.GEN.PL our.GEN.PL P on.mount.FUT.2SG
‘you shall mount upon our walls’
(12) nho;V ejpiqrw/vskwn
neos epithroskon
ship.GEN.SG P on.leap.PRES.PTCP.3MSG
‘as he leapt aboard his ship’
In (9) there is a direct object and an oblique NP that relates semantically to the PV. According to
Hewson & Bubenik the dative in (10) is more closely locative than the genitive in (11) and (12),
where the location is a space that people can move around in; but they do not report whether
this genitive construction can occur where there is a direct object (2006: 8), and it may be that
the difference in case assignment relates to the transitivity of the verb, or to the particular

40
semantics of ejpitivqhmi epitithemi ’put on’, which requires an extra argument (on this verb see
Appendix C).
The following example from Hewson & Bubenik is said to be an example of adverbial usage of
the P-word, but they also call it a post-posed preverb, which seems more likely (notwithstanding
the oxymoron). It is the same verb ejpevlqein epelthein ‘come upon’ as in (7) above.
(13) h[lq’ e[pi yuch; jAgamevmnonoV
elth’ épi psukhe Agamemnonos
come.AOR.3SG P on soul.NOM Name.GEN
‘the soul of Agamemnon approached’
The P-words in classical Greek
This then is the range of usage of P-words in Homer; their position in regard to verbs and noun
phrases is not fixed, and nor is their association with specific cases. By the classical period (the
fifth and fourth centuries BC) they have become much more grammatical, in the sense that their
meaning is more dependent on their syntactic behaviour. Only one P-word, periv peri, retains
the option of being postposed to a noun phrase (a construction called anastrophe; note the
regression of the accent as discussed under example (6)), as in:
(14) a. Homer
Acilleu;V a[stu pevri Priavmoio posi;n tacevessi diwvkei
Achilleus astu péri Priamoio posin
Name.NOM city.N/A P around Name.GEN foot.DAT.PL
takheessi diokei
swift.DAT.PL pursue.PRES.3SG (Iliad 22:172-3, from Luraghi 2003: 273)
‘Achilles is pursuing him with swift feet round the city of Priam’

41
(14) b. classical Greek
dikai:wn pevri kai; ajdivkwn
dikaion péri kai adikon
just.M/N.GEN.PL P about and unjust.M/N.GEN.PL
‘and about the just and the unjust’ (Plato Gorgias 455a (LSJ s.v. peri))
So by the classical period the P-words are restricted to configurational and not independent use.
When associated with verbs they are preverbs, not adverbs, and when associated with NPs they
are prepositions, rarely postpositions and never adverbs. Verbs with preverbation have a
tendency to be associated more strongly with perfective or imperfective aspect, according on the
meaning that the preverb contributes to the collocation. (See below for evidence of the
association of preverbation and aspect in Lysias.) Prepositions, on the other hand, have a much
clearer association with case, although again the semantics of the P-word also contributes to the
formal features of PPs. From the situation in PIE and to a lesser extent in Homer, where case
contributed the distinctions of locative meaning and the P-word modified this meaning as an
optional adjunct, we have arrived at a stage of grammaticalisation where the collocation of P-
word and case is no longer optional, and the preposition is the determiner of the meaning of the
PP, with case as a secondary contributor.
Table 2.1, taken from Luraghi 2005, shows the ‘proper prepositions’ with the cases they govern
in classical Greek. The glosses given are of course over-simplified, but they enable us to
appreciate at a glance the high degree of near-synonymity: some prepositions have nearly the
same meaning when followed by one or another case; and some prepositions have nearly the
same meaning as others.55 For example, periv peri has the same meaning when followed by
accusative as by dative case, and parav para and provV pros with the dative have similar
55
For an extremely fine-tuned analysis of the semantics of each preposition and its case uses, see
Luraghi 2003: 82-313.
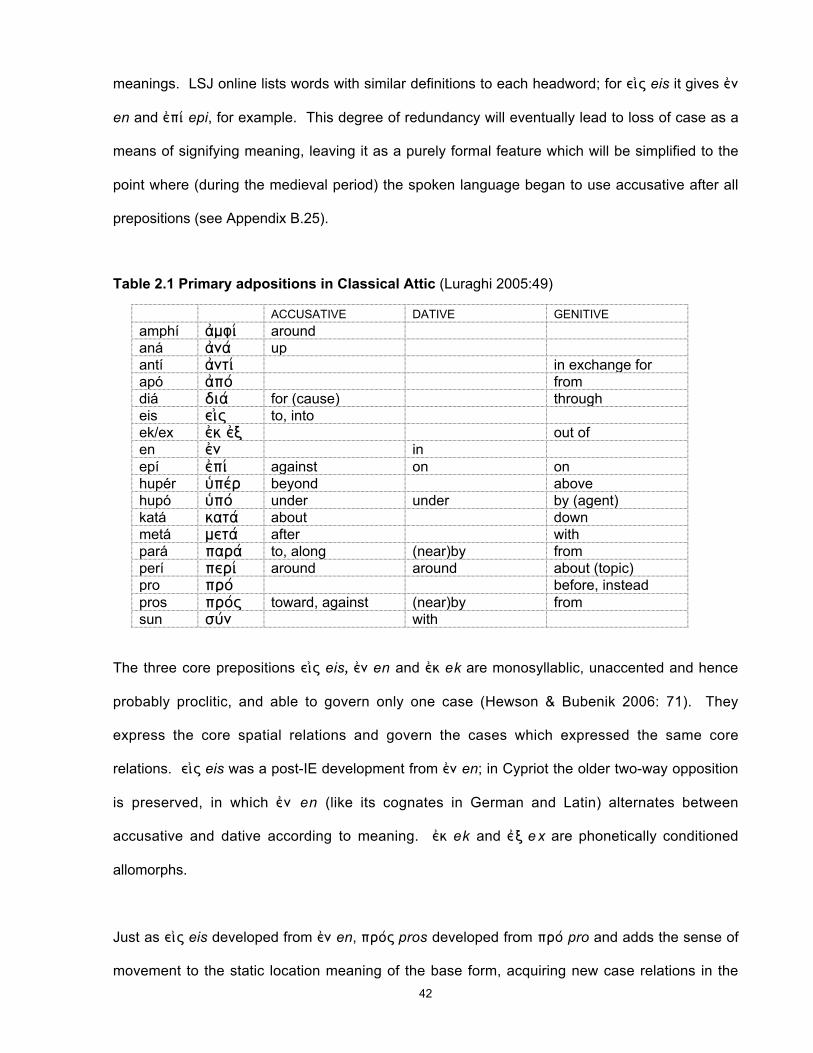
42
meanings. LSJ online lists words with similar definitions to each headword; for eijV eis it gives ejn
en and ejpiv epi, for example. This degree of redundancy will eventually lead to loss of case as a
means of signifying meaning, leaving it as a purely formal feature which will be simplified to the
point where (during the medieval period) the spoken language began to use accusative after all
prepositions (see Appendix B.25).
Table 2.1 Primary adpositions in Classical Attic (Luraghi 2005:49)
ACCUSATIVE DATIVE GENITIVE
amphí ajmfiv around
aná ajnav up
antí ajntiv in exchange for
apó ajpov from
diá diav for (cause) through
eis eijV to, into
ek/ex ejk ejx out of
en ejn in
epí ejpiv against on on
hupér uJpevr beyond above
hupó uJpov under under by (agent)
katá katav about down
metá metav after with
pará parav to, along (near)by from
perí periv around around about (topic)
pro prov before, instead
pros provV toward, against (near)by from
sun suvn with
The three core prepositions eijV eis, ejn en and ejk ek are monosyllablic, unaccented and hence
probably proclitic, and able to govern only one case (Hewson & Bubenik 2006: 71). They
express the core spatial relations and govern the cases which expressed the same core
relations. eijV eis was a post-IE development from ejn en; in Cypriot the older two-way opposition
is preserved, in which ejn en (like its cognates in German and Latin) alternates between
accusative and dative according to meaning. ejk ek and ejx e x are phonetically conditioned
allomorphs.
Just as eijV eis developed from ejn en, provV pros developed from prov pro and adds the sense of
movement to the static location meaning of the base form, acquiring new case relations in the

43
process. Of the non-core prepositions only suvn sun occurs with dative case alone, and only
ajmfiv amphi and ajnav ana with accusative alone, while ajntiv anti, ajpov apo and prov pro take
genitive only.
There is no preposition that governs both dative and genitive but not accusative. This lends
support to Hewson & Bubenik’s conclusion that the primary opposition in the classical
configurational syntax of the PP is between orientation from the landmark (ablative meaning
expressed by genitive case) and orientation towards the landmark, whether static (dative) or
including movement (accusative) (2006: 68-70). However, this distinction by orientation is not
always apparent. As an example of the extremely fine distinction between genitive and dative
with ejpiv epi, Luraghi provides the following minimal pair from a single passage in Herodotus:
(15) a. with dative case
a[ggoV ejpiv th/: kefalh/: e[xousan
angos epi te kephale exousan
vessel.ACC P on ART.DAT head.DAT have.PRTC.F.SG.ACC
‘having a jar on her head’
(15) b. with genitive case
fevrousa to; u{dwr ejpi; th/:V kefalh/:V
pherousa to hudor epi tes kephales
carry.PTCP ART.ACC water.ACC P on ART.GEN head.GEN
‘bearing the water on her head’ (Luraghi 2003: 308)

44
and a similar minimal pair within a sentence, also from Herodotus:
(16) e[cei de; hJ movscoV ou{toV oJ :ApiV kaleovmenoV shmei:a toiavde ejw;n mevlaV, ejpi; me;n
tw/: metwvpw/ leukovn ti trivgwnon, ejpi; de; tou: nwvtou aieto;n eikasmevnon
ekhei de ho moskhos houtos ho Apis
have.PRES.3SG PTC ART.NOM calf.NOM DEM.NOM ART.NOM Name.NOM
kaleomenos semeia toiade eon
call.PRTC.PRES.PASS.M.NOM mark.N/A.PL INDEF.N/A.PL be.PRTC.PRES.NOM
melas epí men toi metopoi leukon ti
black.NOM P on PTC ART.DAT forehead.DAT white.NOM/ACC INDEF.N/A
trigonon epi de tou notou aieton eikasmenon
triangle.N/A P on PTC ART.GEN back.GEN eagle.ACC represent.PRTC.PF.M.PL.ACC
‘this calf called Apis has these marks: he is black, and has on his forehead a three-
cornered white spot, and the likeness of an eagle on his back’
(Luraghi 2003: 309)
Luraghi argues that the uses differ in that the genitive profiles a vertical orientation while the
dative does not specify orientation (2003: 309-10). Hewson & Bubenik on the other hand
consider the difference in the water-jar passage to hinge on whether the empty jar or the (jar full
of) water is being profiled (2006: 75-6). Either or both are possible, even plausible subtleties of
subconscious native-speaker usage, but we are not in a position to judge.
It is likely that quantitative data may provide a means to assess such hypotheses about native-
speaker intuitions, as frequency of use of features that writers and especially speakers are

45
usually unaware of can identify both common patterns and trends, and also anomalous usages
or distinctive stylistic preferences. Without such data for classical Greek we can do no more
than guess at reasons for the variation displayed in (15) and (16).
Table 2.2 shows the frequency of most of the prepositions in Greek. The number given is for
tokens per ten thousand words, and is taken from LSJ online.56 Although incomplete and not
without a significant margin of error, this information may be used as a rough generalisation by
which to compare frequencies at different periods and note any changes. However, in the
absence of a breakdown of these frequencies by case, which is unobtainable with the present
state of grammatical tagging, qualitative analysis must depend on small studies of individual
texts.
Table 2.2 Frequency of prepositions
195.92 eis
89.37 en71.78 pros
65.23 epi
51.33 ek40.49 dia
35.59 hupo
28.67 para28.11 apo
27.80 meta
10.56 huper
5.38 sun4.25 pro
3.48 anti
56
Some prepositions are not listed because faulty links on the Perseus site prevented the searches.
(This is a permanent difficulty with LSJ online.) The counts are for prose texts and refer to the whole of
the data bank used by LSJ: that is, they cover all periods of Greek covered by LSJ, up to early medieval
times, but are drawn from usage citations not whole texts (see Ch 1 note 14); since the citations are
overwhelmingly from the earlier periods of Greek, it is likely that the counts give a rough estimation of
usage over the classical and Koine periods but do not show differences with the periods. For counts
specific to individual authors or periods see Chapter 3.

46
Comparison of this table with the data in Appendix B.8.a (frequency order of prepositions in the
three Koine corpora), shows that eis, en, ek and epi remained in frequent use but pros (possibly
because of its partial synonymy with epi) declined.
Usage counts for preverbs are even harder to obtain than for prepositions, because searches
retrieve many non-verbal P-word compounds and do not retrieve all the possible orthographic
forms of prefixes. The study by Duhoux (1995) which is discussed in the next chapter gives
statistics for preverbs in Lysias but does not break them down into individual preverbs, so that
study of the semantic contribution of each P-word to the aspect of the verb is not possible.
Nevertheless it gives support to the suggestion noted above by Horrocks that P-words in
configuration with verbs contribute aspectual meaning. This correlation will be pursued in
Chapter 3, where the more detailed data on the Koine is studied.
Summary
This chapter has surveyed the development of P-words from free adverbials in PIE to elements
of configurational syntax in classical Greek. By the fifth century BC adpositions have become
fixed as (almost exclusively) prepositions, and free adverbial use of P-words with verbs has all
but disappeared. In the next chapter we survey the post-classical stage of the language, and
look at prepositions and preverbs in the NT corpus and other near-contemporary documents.

47
Chapter 3 - Greek in the hellenistic age
The development of the Koine
The modern Greek language has its origins in the spoken Greek of the hellenistic period,57 the
centuries following the conquests of Alexander the Great, which brought Greek political
domination, administration and education to large areas of the Mediterranean, northern Africa,
the Middle East and as far as northern India.58 Population movements brought about by military
service, centralised administration and colonial and commercial settlements ensured that the
language of Greek-speakers in widely separated areas was continuously exposed to the
levelling effects of a unified administrative language and the need to communicate in a common
dialect. This meant that a renewal of the previous situation of great dialect variety was slow to
come about. The ‘Common Language’ or Koine was thus relatively homogeneous, and, with the
57
There are two principal ways the term ‘hellenistic period’ is used. It refers to the whole period of the
Koine, the koinh; diavlektoV [Koine dialektos] or ‘common language’, from about 300 BC until at least 300
AD and often to 600 or 700 AD (since the end of the reign of Justinian and the Muslim conquests of
substantial parts of the Byzantine empire both form natural historical endpoints). It can also refer to the
first part of the period, from about 300 BC until the Roman occupation of Greece and the eastern
Mediterranean (beginning in the mid-second century BC and complete in 31 BC); the rest of the Koine
period is then known as the Roman period. However, from a linguistic perspective there was no distinct
change. For the purposes of this thesis the period referred to as hellenistic or Koine is approximately 300
BC to 300 AD. This accords with O’Donnell’s definition of the language on which his proposed corpus is
based: ‘Hellenistic Greek can be defined as the extant Greek written by native and non-native language
users throughout the Hellenistic and Roman worlds from approximately the fourth century BCE to the
fourth century CE’ (2006: 2-3). However, my corpora all fall within the period 285 BC to 155 AD.
This account of the development and characteristics of the Koine is based on Horrocks 1997 and
Browning 1987.
58 Although Alexander was Macedonian, his father Philip II had been an admirer of Greek culture and
ensured that Greek was the language of his administration and of his son’s education. After the wars of
succession following Alexander’s death, his conquests were divided among three Greek dynasties, the
Ptolemies, Antigonids and Seleucids. (Whether Macedonian and Greek were related languages is not
known (Horrocks 1997: 32).)

48
exception of an isolated dialect of the Peloponnese, all modern varieties of Greek have
developed from the Koine.59
The basis of the Common Language was a variety of Attic that had been influenced by Ionic, a
closely related dialect which was less conservative than Attic and more accepting of innovation.
Athens’ political dominance had made its dialect prestigious, but it also made Athens and its port
Piraeus centres for large communities of non-Athenians. Already in the writing of classical
authors like Thucydides some concessions were being made to the needs of a wider readership
than just Attic-speakers (Horrocks 1997: 27), and in the following century under Macedonian rule
a ‘Great Attic’ variety was the language of administration and of much prose writing. A more
conservative literary Koine became the spoken language of the educated, a large class of
people in an empire that valued education and provided many opportunities for lucrative careers
that required literacy.
The modern use of the term ‘Koine’ requires comment. The English technical term derives from
the word the Greeks gave their own language. Koineisation is ‘a contact-induced process that
leads to quite rapid, and occasionally dramatic, change’ (Kerswill 2002: 669). A koine is a new
variety of a language brought about by contact between speakers of mutually intelligible varieties
of that language, and typically occurs in new settlements to which people from different parts of
a single language area have migrated. Koineisation is characterised by reduction (loss of
meaningful difference; eg decrease in vocabulary) and simplification (an increase in regularity,
such as loss of irregular case forms). There are two types of koine: regional and immigrant.
The Greek Koine was primarily a regional type, overlaying but not immediately replacing the
local dialects, but in originally non-Greek-speaking areas it was an immigrant koine and became
the vernacular of the colonists. In Palestine and Egypt, for instance, both areas that have
59
Tsakonian retains features of the ancient dialect Laconian, spoken in the area around Sparta. The
modern dialects developed in the medieval period.

49
produced substantial Koine documents, bilingualism was widespread but the indigenous
languages were maintained. However, bilingualism and substrate language influence are not
necessary accompaniments of koineisation, and they appear to have had less effect on Greek
than it had on other languages.
The early period of the Koine was a time of extensive phonological change. Both vowel and
consonant systems underwent restructuring, probably beginning early in the classical period but
obscured by the traditional historical orthography. A significant development was the change of
word-accentuation from pitch to stress. The primary prosodic accent of a word was a raised or
rising pitch on one syllable. When the accent became primarily one of stress (extra loudness
and/or duration), the distinction between long and short vowels could not be maintained. The
invention of accent marks, traditionally dated to about 200 BC at Alexandria, reflects the needs
of the large numbers of Greek-as-a-second-language learners. The change of accent type was
responsible for much homophony, which led to reorganisation of many paradigms, especially in
the verbal system, and along with the loss of some final consonants contributed to the eventual
loss of the dative case.
Restructuring of the consonant system began slightly later. With few exceptions a pronunciation
very like that of Modern Greek was in general use by the sixth century AD, and most of the
changes were current in many regions much earlier. Morphological and syntactic development
was also rapid. Irregular nouns were replaced by synonyms or regular derivatives such as
diminutives. Use of the dative case, especially with prepositions, continued to decline, with the
exception of ejn en, which developed an instrumental sense (Luraghi 2003: 332) and was widely
used in an ‘unclassical’ manner, possibly as a means of reinforcing the dative. ‘A particular
feature of the ordinary Koine in [the Septuagint and] the immediately following period is the
widespread use of ejn [en] + dative as a semantically ‘empty’ means of strengthening the flagging
dative ... however, the accusative is already advancing as the primary prepositional case at the

50
expense of the dative’ (Horrocks 1997: 58-59).60 The bare dative NP survived longest as
indirect object, but genitive pronouns in this function appear from the first century BC and
genitive nouns from about the third century AD (Browning 1983: 37).
In vocabulary there are innovations not only from borrowings but from a distinct increase in the
coining of compound verbs (including verbs with P-words, which were often synonymous with
the simplex form) (Lee 1983: 92). For example, ejxapostevllw ex-apo-stello is formed by adding
ejk ek to an already compound verb, and adds nothing to the meaning (‘send out, send away’):
ek and apo are virtually synonymous here, and the new form, which is frequent from the third
century BC but less so than ajpostevllw apostello, ‘has the same senses as Classical
ajpostevllw, and is clearly just a more vigorous form of the older word’ (Lee 1983: 93).61 The
phenomenon of reinforcing verbs with P-words, which then lost any additional meaning and were
used in the same way as the simple word, is a well-attested grammaticalisation process and has
similarities with the reinforcement of compound verbs with PPs (as in the cooccurrences of
ejpitivqhmi epitithemi with ejpiv epi, on which see Appendix C). Another phenomenon of
preverbation usage is the use of a simplex verb when repeated shortly after its compound:
where the meaning of the two verbs is similar the repetition does not require the complex form,
as in the following example from Mackay 1994: 14:
60
It is also possible that the instrumental use of ejn en in biblical Greek was influenced by the Hebrew
preposition b be in this sense, but this could be an example of increased frequency under Hebrew
influence of an existing feature. Detailed study of the non-literary papyri is required to establish this.
61 In NT there are 132 tokens of ajpostevllw apostello (88 in aorist) and 13 of ejxapostevllw exapostello
(12 aorist). In Luke 20:10 both occur. In the tables of preverb data in Appendix B, all such double
preverbs are counted only once, as tokens of their first P-word.

51
(17) oiJ� i[dioi aujto;n ouj parevlabon. o{soi de;� e[labon aujtovn ...
hoi idioi auton ou parelabon. hosoi de
ART one’s own him not P from/beside.AOR.3PL.take PRN.M.PL.NOM PTC
elabon auton ...
AOR.3PL.take him
‘his own people did not accept him, but as many as did receive him ...’ (John 1:11-12)
Some of our evidence for the changes that took place in the Koine derives from the proscriptions
of grammarians and rhetoricians, who began during the first century BC to reject the common
language and press for a return to the ‘pure’ classical Attic standard. The discrepancy between
the spoken language and the traditional texts that formed the curriculum of Greek education was
becoming a problem for the large class of professional teachers, and Roman occupation
fostered a sense of nostalgia for past glories that often expressed itself in the wish to imitate
classical writers. The Atticist movement called for a return to classical models in preference to
the literature of the intervening period. Their view was that the language of the best classical
writers was the only correct form of Greek, and that change was decay and should be rejected.
They therefore spurned the living spoken language as a basis for literature and tried to imitate
the (sometimes inadequately understood) language of their models. The effect of this was to
maintain in artificial use some moribund features of the language that were dying out naturally,
such as the dative case, and to obscure the evidence for changes in the spoken language,
which is mediated to us almost solely through the distortions of a literacy which could rarely be
obtained except through an Atticist-dominated education. As Browning puts it:
It is very hard to date ... changes, owing to the nature of our evidence, and the inevitable
contamination of any written text by the purist language. In any case many [changes] are
only extensions of features already existing in classical Greek. What is important is not
this or that individual innovation, but the new system. And, as always in language, old
and new systems coexisted side by side in living speech for a long time, until the
distinctive features of the old became ‘desystematised’ and thus condemned to disappear

52
– except in so far as in Greek the prestige of the traditional purist language of writing and
fine speech conferred upon some of them a factitious, zombie-like life. (1983: 35)
At the time the Attic revival was gathering steam, the New Testament and other Christian
literature was being written in a register close to that of contemporary ordinary speech. Such
literature ignored the prescriptions of pagan grammarians for some time, but, just when
Christianity was beginning to become widely accepted and its literature to gain prestige, its
leaders succumbed to the pressure to conform to the by now well-entrenched Atticist standards
of pagan literature. Thus the New Testament did not become the literary model it might have
been, and the chance to limit the growth of the Atticist movement was lost.
This pagan-christian literary alliance, in combination with the changed political conditions which
saw the western Roman empire fall to barbarians and the eastern administration move to
Constantinople, set the direction of Greek literature for a millennium and a half. The style of a
text was no longer a matter of its genre but also reflected the choices and abilities of the writer to
use a more or less archaising form of language, which could range from ordinary Koine with
some ‘Attic’ diagnostic features added (such as a verb in the optative mood)62 to a serious
attempt to recreate the language of Gorgias the rhetorical stylist. Thus the diglossia which had
been a mild feature of Greek education since the adoption of administrative Attic by Philip II was
extended to all spheres of public life, and spoken and written registers increasingly diverged. It
is clear from the non-archaising texts of the Koine period, both literary and non-literary, that the
developments in the spoken language had brought it to the point where it is fair to call it Early
Modern Greek, but all sources for the study of the spoken language are mediated in some way
by the influence of Greek rhetorical education.
62
This is not the function of the optatives in the NT. Of the 68 tokens, almost all occur in formulaic
expressions and prayers where their use is a natural preservation of an older idiom.

53
P-words in New Testament Greek
It is against this background of a recent change in literary standards and practice that we turn to
look at the New Testament. Sources of language data that are early enough to be relatively free
of Atticist influence can contribute valuable information about processes of language change and
about the synchronic state of Greek before diglossia complicates the picture. This study aims to
use quantitative methods to see whether trends can be discerned that would be difficult to
observe or interpret by other methods, as well as to identify areas that would repay a more
qualitative approach.
The data on which the following observations are based can be found in Appendix B. Lists of
word counts and ratios have been compiled for each author-group in each of the three tagged
corpora. In addition, some statistical information from other sources is given so that
comparisons between corpora of different dates can be attempted, though this information is
considered less reliable. The discussion will necessarily focus more on prepositions than on
preverbs, because of the greater accessibility of data on uninflected words through the available
search mechanisms. The purpose of collating quantitative data is to compare large sets of data
from different corpora so as to identify changes in usage that might have been invisible to
language users and therefore reflect natural usage rather than conscious Atticising. Although
the available corpora are in many ways similar in date, genre and register, and so might not
show significant differences, they can with detailed study reveal facts about the synchronic
system under investigation and provide a basis from which to compare other periods and genres
when comparable data is available.
Prepositions
We first notice from Table B.1 that if the preposition ejn en is excepted the dative case has a low
usage compared to the other two cases. This is reported in all accounts of Koine usage. The

54
dative with periv peri and uJpov hupo is no longer used; suvn sun can only take dative, but is
relatively rare; with parav para the case selected depends on the meaning; but with ejpiv epi and
provV pros the dative and accusative have similar meanings, so the case assignment may be a
matter of personal preference of the writer or have some nuance that we can no longer
appreciate. Tables B.2-4 show the usage within each author-group. Only Paul uses epi+DAT
more often than epi+ACC, but the difference (1.70 per thousand words for DAT compared to
1.57 for ACC) is small, and Table B.10 reveals that he uses ejpiv epi less than any other author
except Jude (which is a very small sample). From Table B.1 we also see that avmfiv amphi,
always rare, is not used in NT.
The most striking number in Table B.1 is the high frequency of ejn en. As suggested above, the
decline in the dative case meant that a prepositional configuration was increasingly preferred to
a bare dative. To see whether its increase is real and significant, we can compare token
frequencies obtained from TLG. After obtaining the word counts and calculating probability-
values for each pair of six populations (Classical, Early Koine and Late Koine as well as the
three corpora LXX, NT and AF), Table 3.1 was compiled. It shows that on a hypothesis of an
increase in the use of en (where the null hypothesis is that there was no change), statistically
significant changes have occurred between most pairs of populations, but not in a consistent
direction. The odd population is Later Koine, because of the dating, but the trend is that the TLG
counts are much lower than the Accordance counts.
In view of the unreliable nature of the search method for TLG, it would be unwise to draw firm
conclusions from this. Comparing figures reached by different methods is not recommended but
is difficult to avoid. With this caveat in mind, we can tentatively conclude that the data supports
the trend noted in the literature cited above that en increased significantly in frequency.
However, the decrease in the later Koine period is an oddity.
55
Table 3.1 En: Tokens per 1000 words (from TLG and Accordance)
TLG en Classical EarlyKoine
LXX NT LateKoine
ApostolicFathers
Classical
m=10.24
0.946
0.186
0.372
-3.429
0.003
0.006
-2.712
0.008
0.017
1.854
0.050
0.101
-2.439
0.015
0.030
Early
Koine
m=8.76
-2.948
0.009
0.018
-2.427
0.016
0.032
0.951
0.189
0.378
-2.318
0.020
0.041
LXXm=22.89
0.7170.242
0.485
3.2100.006
0.012
1.5050.078
0.156
NTm=19.81
2.6800.010
0.020
0.8090.215
0.430
Late
Koinem=7.69
-2.648
0.0110.023
Apostolic
Fathers
m=17.11
(Top figure: t-stat, then one-tailed p-value, then 2-tailed p-value. P-values of 0.05 or under are
highlighted.)
The data for the three Accordance corpora is reliable, and Table 3.2 shows the same information
as Table 3.1 just for those three. Table 3.2 shows (as do Tables B.9-11 in Appendix B) that a
slight decrease over time has occurred, with the LXX and AF, as expected from their dates,
having a greater degree of difference; however, the p-values all exceed 0.05, which we have set
as the significance level, leading to the conclusion that the populations do not differ sufficiently to
draw any conclusions about their use of en.
Table 3.2 En: Tokens per 10000 words (from Accordance)
en LXX NT ApostolicFathers
LXX
m=228.9
0.717
0.242
0.485
1.505
0.078
0.156
NT
m=198.06
-0.809
0.215
0.430
ApostolicFathers
m=171.1
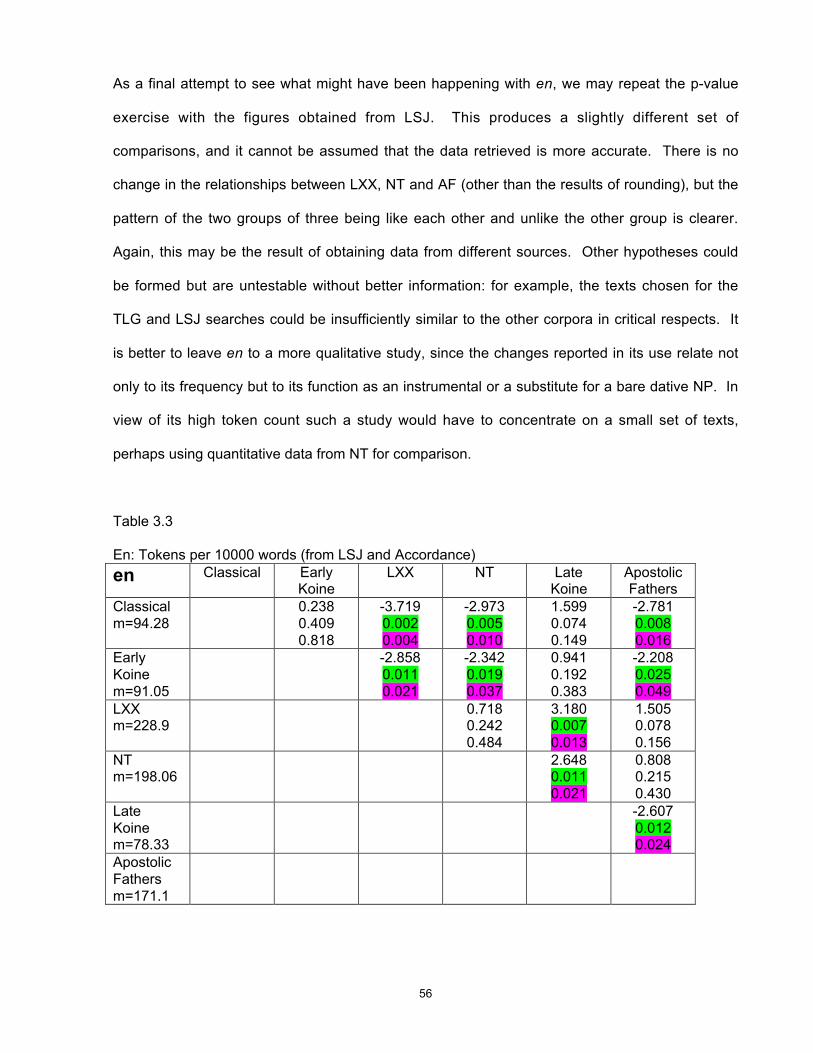
56
As a final attempt to see what might have been happening with en, we may repeat the p-value
exercise with the figures obtained from LSJ. This produces a slightly different set of
comparisons, and it cannot be assumed that the data retrieved is more accurate. There is no
change in the relationships between LXX, NT and AF (other than the results of rounding), but the
pattern of the two groups of three being like each other and unlike the other group is clearer.
Again, this may be the result of obtaining data from different sources. Other hypotheses could
be formed but are untestable without better information: for example, the texts chosen for the
TLG and LSJ searches could be insufficiently similar to the other corpora in critical respects. It
is better to leave en to a more qualitative study, since the changes reported in its use relate not
only to its frequency but to its function as an instrumental or a substitute for a bare dative NP. In
view of its high token count such a study would have to concentrate on a small set of texts,
perhaps using quantitative data from NT for comparison.
Table 3.3
En: Tokens per 10000 words (from LSJ and Accordance)
en Classical EarlyKoine
LXX NT LateKoine
ApostolicFathers
Classical
m=94.28
0.238
0.409
0.818
-3.719
0.002
0.004
-2.973
0.005
0.010
1.599
0.074
0.149
-2.781
0.008
0.016
Early
Koine
m=91.05
-2.858
0.011
0.021
-2.342
0.019
0.037
0.941
0.192
0.383
-2.208
0.025
0.049
LXXm=228.9
0.7180.242
0.484
3.1800.007
0.013
1.5050.078
0.156
NTm=198.06
2.6480.011
0.021
0.8080.215
0.430
Late
Koinem=78.33
-2.607
0.0120.024
Apostolic
Fathers
m=171.1

57
A similar pattern is obtained with the frequency counts of eijV eis (Table 3.4). This preposition
was in the process of replacing ejn +dative in its locative function, although en was not yet
significantly waning in frequency because it was being used in other functions.63 In Table 3.4
there is a statistically significant although small reduction in the frequency of eis between NT and
AF. Tables B.6 and B.7 show the frequencies as 127.9 for NT and 133.0 for AF – which looks
like the reverse of the figures in Table 3.4. This is due to the technique of taking the mean of the
samples in the population rather than the average in the whole population, so as to minimise any
error due to different sample sizes.
Table 3.4 Tokens per 10,000 words (from LSJ)
LSJ eis Classical Early
Koine
LXX NT Late
Koine
Apostolic
Fathers
Classicalm=198.38
-0.0760.470
0.941
3.2810.004
0.008
3.0200.005
0.009
-0.1760.432
0.865
3.0060.005
0.010
Early
Koinem=200.79
6.732
0.0000.000
3.714
0.0010.003
-0.118
0.4550.910
3.767
0.0020.003
LXX
m=116.3
-1.065
0.1520.305
-2.132
0.0330.066
-0.840
0.2080.416
NT
m=132.51
0.201
0.421
0.843
2.149
0.027
0.055
Late
Koine
m=207.45
-2.067
0.012
0.024
ApostolicFathers
m=129.5
So far we have not been able to put much confidence in the result of these probability tests, for
reasons connected with the quality or unavailability of data. In the case of the reliably generated
data from Accordance, there was little significant change to be found. When we apply the same
tests to frequency counts of preverbs, some more interesting changes become visible.
63
For examples of the confusion of eis and en (at least from a purist point of view), see Mk 13:16, Mt
24:18 and Lk17:31, and others cited by Browning 1983: 36.
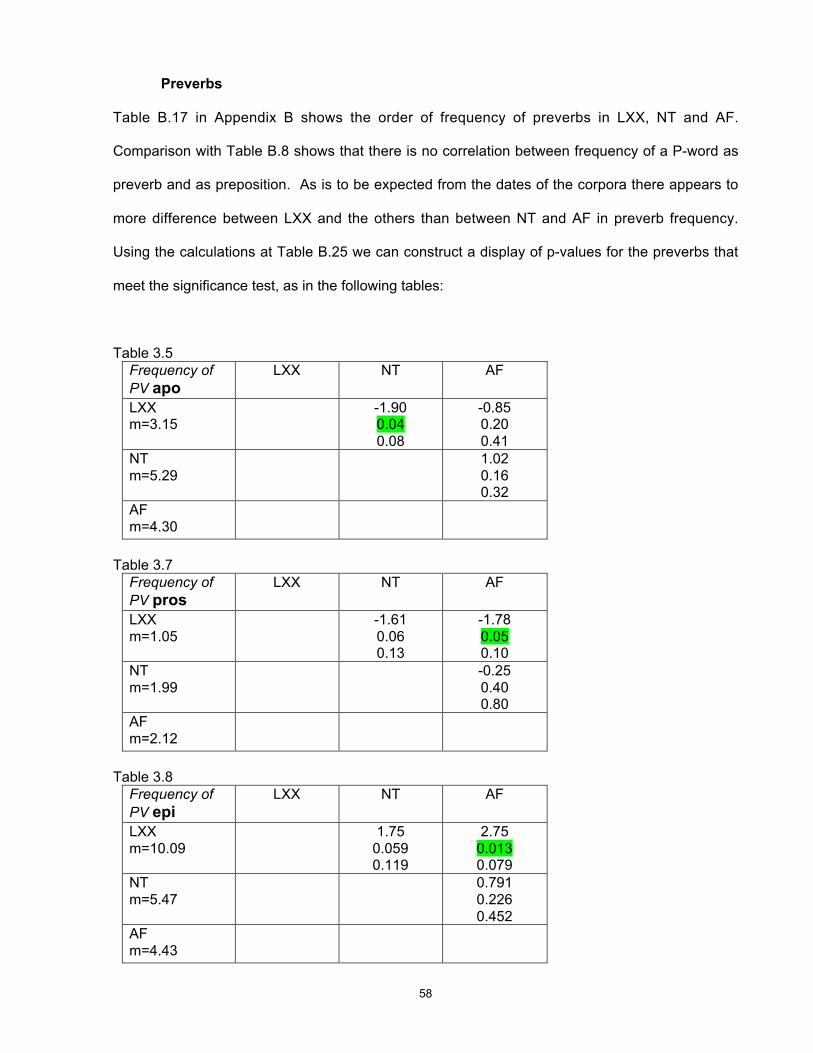
58
Preverbs
Table B.17 in Appendix B shows the order of frequency of preverbs in LXX, NT and AF.
Comparison with Table B.8 shows that there is no correlation between frequency of a P-word as
preverb and as preposition. As is to be expected from the dates of the corpora there appears to
more difference between LXX and the others than between NT and AF in preverb frequency.
Using the calculations at Table B.25 we can construct a display of p-values for the preverbs that
meet the significance test, as in the following tables:
Table 3.5
Frequency of
PV apoLXX NT AF
LXXm=3.15
-1.900.04
0.08
-0.850.20
0.41
NT
m=5.29
1.02
0.160.32
AF
m=4.30
Table 3.7
Frequency of
PV prosLXX NT AF
LXX
m=1.05
-1.61
0.060.13
-1.78
0.050.10
NT
m=1.99
-0.25
0.400.80
AF
m=2.12
Table 3.8
Frequency of
PV epiLXX NT AF
LXX
m=10.09
1.75
0.0590.119
2.75
0.0130.079
NT
m=5.47
0.791
0.226
0.452
AF
m=4.43

59
As this procedure shows, interesting-looking numbers do not always produce statistically
significant results. Only 14 of the 54 preverb/corpus pairs compared in Table 25 show a
significance value of 0.05 or under, and only 7 of these are significant if the direction of change
is unknown (that is, in a two-tailed test). There is no need to present all 19 results as tables
here; the data is easy to read in Table 25 since there are only three corpora to compare. The
preverbs with a p-value of 0.05 or under in a two-tailed test are:
Between LXX and NT: hupo, meta and para
Between LXX and AF: hupo, meta, para and pro.
All of these are statistically significant increases in frequency, as shown by the negative t-stat
value. The only significant decreases in frequency (shown only in the one-tailed tests) are for
ek; this is likely to be associated with the increase of apo with similar meaning. There are no
significant changes from NT to AF, except in the one-tailed test for ek, huper and sun. This data
cannot be interpreted by the figures alone, even where they are judged significant by statistically
appropriate and rigorous methods, but we can use these findings to identify areas that require
further research. In particular, it is likely that the semantics of individual preverbs plays a role in
their frequency, along with their relation to other preverbs of overlapping meaning, and
identifying the areas of interest is a useful step towards organising qualitative research.
So far we have looked at individual preverbs. In the next tables we examine the incidence of
preverbation as a proportion of verb usage.
Table 3.9 Preverb as percentage of all verbs
PVs LXX NT AF
LXX
m=30.07
0.291
0.388
0.775
0.710
0.245
0.490
NTm=29.02
0.4580.326
0.653
Apostolic
Fathersm=27.64
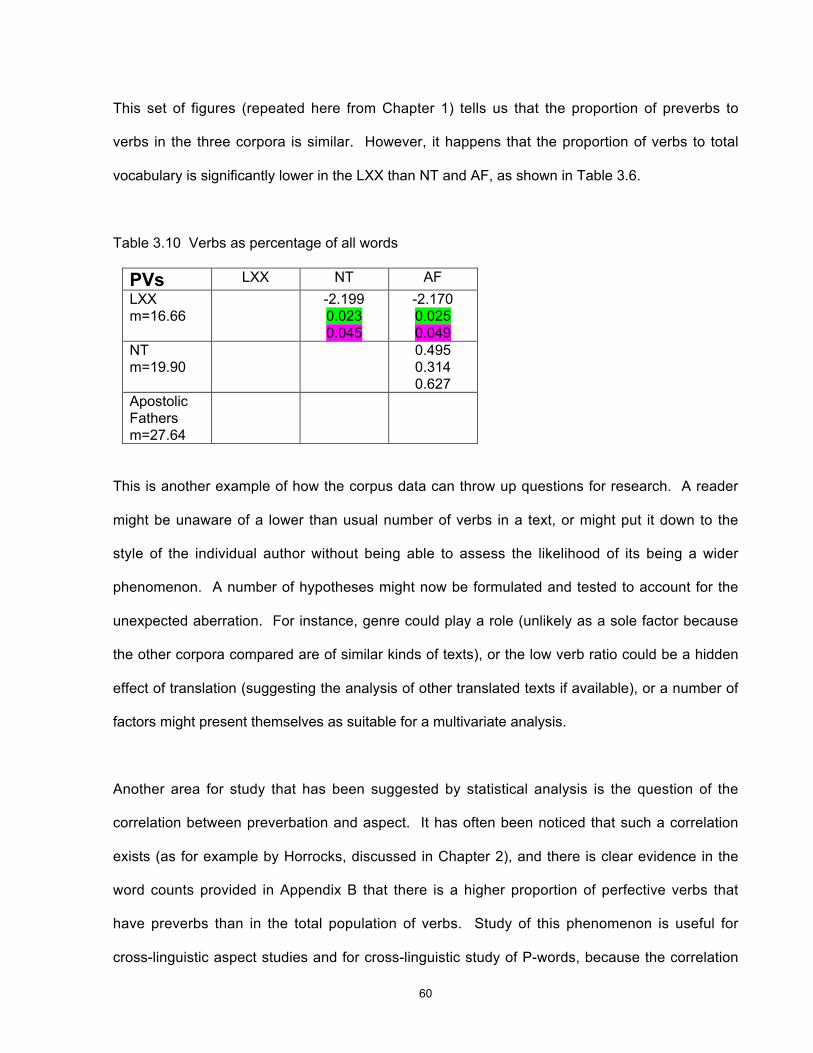
60
This set of figures (repeated here from Chapter 1) tells us that the proportion of preverbs to
verbs in the three corpora is similar. However, it happens that the proportion of verbs to total
vocabulary is significantly lower in the LXX than NT and AF, as shown in Table 3.6.
Table 3.10 Verbs as percentage of all words
PVs LXX NT AF
LXX
m=16.66
-2.199
0.023
0.045
-2.170
0.025
0.049
NT
m=19.90
0.495
0.314
0.627
Apostolic
Fathers
m=27.64
This is another example of how the corpus data can throw up questions for research. A reader
might be unaware of a lower than usual number of verbs in a text, or might put it down to the
style of the individual author without being able to assess the likelihood of its being a wider
phenomenon. A number of hypotheses might now be formulated and tested to account for the
unexpected aberration. For instance, genre could play a role (unlikely as a sole factor because
the other corpora compared are of similar kinds of texts), or the low verb ratio could be a hidden
effect of translation (suggesting the analysis of other translated texts if available), or a number of
factors might present themselves as suitable for a multivariate analysis.
Another area for study that has been suggested by statistical analysis is the question of the
correlation between preverbation and aspect. It has often been noticed that such a correlation
exists (as for example by Horrocks, discussed in Chapter 2), and there is clear evidence in the
word counts provided in Appendix B that there is a higher proportion of perfective verbs that
have preverbs than in the total population of verbs. Study of this phenomenon is useful for
cross-linguistic aspect studies and for cross-linguistic study of P-words, because the correlation

61
between aspect and P-words occurs in many languages but in different ways (O’Dowd 1998:
147-151), but it also has specific application to Koine Greek because it may interact with the
reorganisation of the verbal system in the later Koine period (Browning 1983; 29-34). In
addition, it has been suggested that the aspect-based verbal system of Hebrew may produce in
the Greek translations of the Hebrew scriptures a disproportionate frequency of some verb forms
(this question is discussed in detail in Evans 2001), and statistical analysis of early Koine
documents could address this hypothesis.
In ancient Greek the aspect of verbs was not systematically correlated with tense, so that not
every tense was available in every aspect. As is common cross-linguistically, the present tense
is imperfective and does not have a perfective counterpart (and this is still the case in Modern
Greek). The future tense is built on the perfective stem of the verb, and is sometimes regarded
as an aspect rather than a tense (eg McKay 1994: 8). The past tense has an imperfective
(imperfect) and a perfective (aorist) form, and the stative aspect has three tenses, past, present
and future. By the NT period the aorist and perfect (earlier perfective and stative respectively)
were becoming confused (Browning 1983: 30). Because the aspectual status of future and
perfect tenses is unclear, and they and the imperfect tense are relatively infrequent, I have used
the relative frequencies of present and aorist tenses as a diagnostic of correlation between
preverbation and aspect.
A study of the verbs of the classical orator Lysias (Duhoux 1995) provides data which I have
arranged in a format suitable for comparison with the NT verb data, but being a single-author
study it is not suitable for the sort of comparative exercise that is possible with multiple-author
corpora. A summary of the data given in Appendix B appears in Table 3.7:
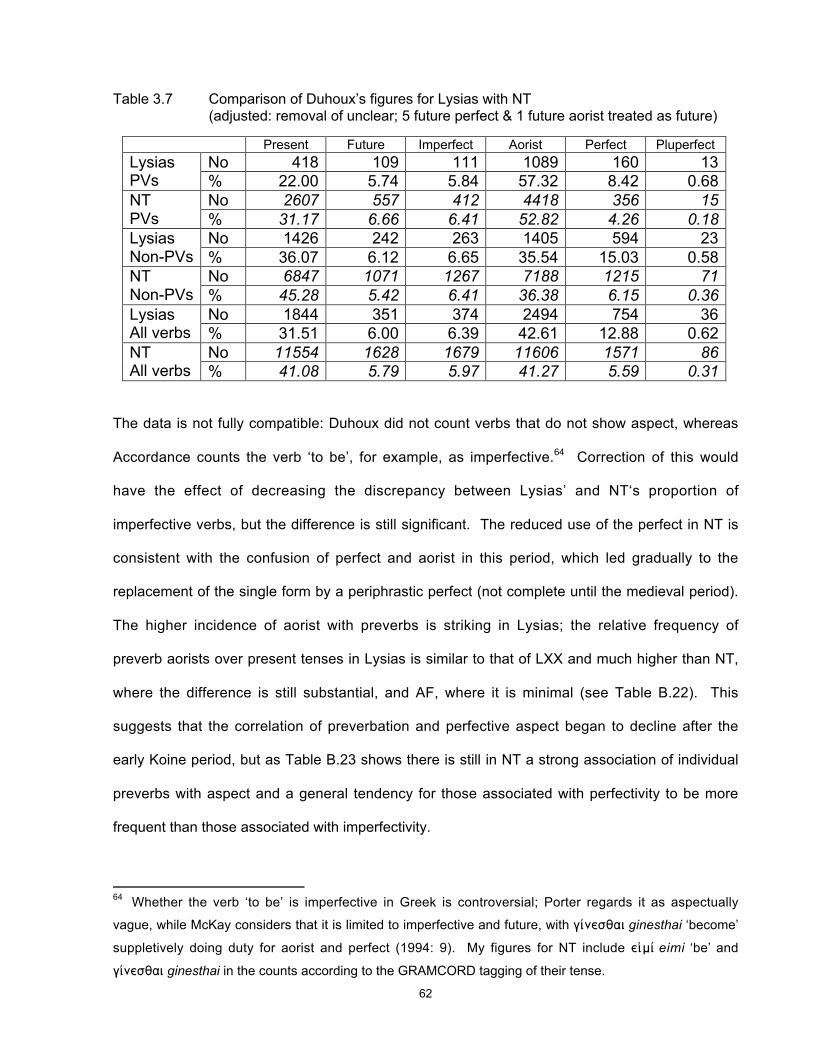
62
Table 3.7 Comparison of Duhoux’s figures for Lysias with NT
(adjusted: removal of unclear; 5 future perfect & 1 future aorist treated as future)
Present Future Imperfect Aorist Perfect Pluperfect
No 418 109 111 1089 160 13LysiasPVs % 22.00 5.74 5.84 57.32 8.42 0.68
No 2607 557 412 4418 356 15NTPVs % 31.17 6.66 6.41 52.82 4.26 0.18
No 1426 242 263 1405 594 23LysiasNon-PVs % 36.07 6.12 6.65 35.54 15.03 0.58
No 6847 1071 1267 7188 1215 71NTNon-PVs % 45.28 5.42 6.41 36.38 6.15 0.36
No 1844 351 374 2494 754 36LysiasAll verbs % 31.51 6.00 6.39 42.61 12.88 0.62
No 11554 1628 1679 11606 1571 86NTAll verbs % 41.08 5.79 5.97 41.27 5.59 0.31
The data is not fully compatible: Duhoux did not count verbs that do not show aspect, whereas
Accordance counts the verb ‘to be’, for example, as imperfective.64 Correction of this would
have the effect of decreasing the discrepancy between Lysias’ and NT‘s proportion of
imperfective verbs, but the difference is still significant. The reduced use of the perfect in NT is
consistent with the confusion of perfect and aorist in this period, which led gradually to the
replacement of the single form by a periphrastic perfect (not complete until the medieval period).
The higher incidence of aorist with preverbs is striking in Lysias; the relative frequency of
preverb aorists over present tenses in Lysias is similar to that of LXX and much higher than NT,
where the difference is still substantial, and AF, where it is minimal (see Table B.22). This
suggests that the correlation of preverbation and perfective aspect began to decline after the
early Koine period, but as Table B.23 shows there is still in NT a strong association of individual
preverbs with aspect and a general tendency for those associated with perfectivity to be more
frequent than those associated with imperfectivity.
64
Whether the verb ‘to be’ is imperfective in Greek is controversial; Porter regards it as aspectually
vague, while McKay considers that it is limited to imperfective and future, with givnesqai ginesthai ‘become’
suppletively doing duty for aorist and perfect (1994: 9). My figures for NT include eijmiv eimi ‘be’ and
givnesqai ginesthai in the counts according to the GRAMCORD tagging of their tense.

63
It is evident that the semantics of individual preverbs is a significant factor in their aspect-linked
behaviour and that the frequency of P-words as preverbs and prepositions does not correlate
strongly (as the tables of order of frequency in Appendix B show). The non-componential
meaning of compound verbs often makes them far less amenable to systematic analysis than
the corresponding preposition, and it cannot be assumed that the two are related. More detailed
study of usages, such as taking account of features not separated in the data collection because
of the limitations of tagging (for instance, case assignment and transitivity), might reveal patterns
of association between preverbs and prepositions that cannot be detected as yet.
Qualitative study of P-words
To turn to a more qualitative approach and continue with a P-word examined in Homer and
classical Greek, let us examine the preposition and preverb epi in the NT. Along with pros, with
which it shares some semantic and functional meanings, it is the most frequent of the non-core
prepositions and is also a common preverb. Although it can take all three cases the dative has
become rare. It continues to show variation of a kind that we saw in earlier Greek (Chapter 2
examples 15 and 16). The New Testament is a rich source of examples of apparently
unmotivated variation, because it has a number of instances of multiple retellings of the same
event. The following minimal pair features the verb ejpitivqhmi epitithemi that we met in Homer
(Example 10 in Chapter 2); the two accounts are of the same incident and they may even have a
common literary source, but they use different strategies to express the locative argument of the
verb, which has the preverb epi. (The collocation of epitihemi with ‘hand’ or ‘hands’ is a common
one in NT; tithemi occurs only once in this sense, in Mark 10:16.)

64
(16) Mt 9:18 with PP
ajlla; ejlqw;n ejpivqeV th;n cei:rav sou ejp’ aujth;n kai; zhvseta
alla elthon epithes ten
but come.PTPL.ACT.M.SG.NOM put.2.SG.AOR.ACT.IMP ART.F.SG.ACC
kheira sou ep’ auten kai zesetai
hand.F.SG.ACC you.SG.GEN on her.ACC and live.3.SG.FUT.MID.IND
‘But come and lay your hand on her, and she will live’
(17) Mk 5:23 with DAT
i{na ejlqw;n ejpiqh:/V ta;V cei:raV aujth/: i{na swqh/: kai; zhvsh/
hina elthon epitheis tas kheiras
CONJ come. P on.put ART.ACC hand.ACC
PART.M.SG.NOM 2.SG.AOR.SUBJ
autei hina sothei kai zesei
her.DAT CONJ .save.3.SG.AOR.PASS.SUBJ and live.3.SG.AOR.SUBJ
‘Come and lay your hands on her, so that she may be made well, and live’
All the NT collocations of epitithemi with epi are set out in Appendix C, along with the far fewer
collocations of tithemi and epi.65 It can be seen that the detailed examination of collocations and
syntactic choices is necessary, and cannot be done without more advanced methods of retrieval
than are currently available in TLG (and in Accordance such searches return many tokens that
do not meet the desired criteria and have to be manually separated from the data to be
assessed). Research is both enabled and limited by the technologies available.
65
This is provided as a sample of the layout and detail of the answers that Accordance gives to queries:
the translation is optional, but the full verse with identifying reference is always given, and the search term
highlighted. It is a much more user-friendly display than traditional corpus outputs and is easily exportable
to other software.

65
Summary
I have shown that the Koine period is a significant one for the development of the Greek
language, both as the source of the modern forms of Greek and as an interesting stage of
linguistic development in itself, including further developments in the usage of P-words. There is
a large body of literature from the period, with diverse genres, from inscriptions and epigraphs,
personal and commercial correspondence and religious tracts to philosophical treatises, novels
and histories; this makes the Koine particularly suitable for corpus studies. However, only a
small part of the material is available in a convenient, accessible digital format that provides
ease of comparison with other research findings.
We have discovered that P-words show interesting changes from previous usages. Prepositions
that governed more than one case now tend to be associated more strongly with certain cases
than others (generally by less frequent use of dative). Preverbation has increased with the use
of compound verbs as synonyms of simplex forms, but the association of preverbs with
perfective aspect has decreased. (Whether these two facts are systematically related cannot be
determined by the statistical analysis used in this study, but is a question for further research.)
Collocation of the same P-word as preposition and preverb is also a feature that suggests that
P-words were continuing a process of grammaticalisation, in which the semantic content of P-
words was decreasing and their collocational significance increasing. All these developments
have implications for corpus study of this and other periods of Greek and for cross-linguistic
comparison of P-words.

66
Chapter 4 - Conclusion
‘The form of criticism that is perhaps the most underutilized and in its most rudimentary form of
development for NT studies is linguistic criticism.’ (McDonald & Porter 2000: 34)
‘...the study of the language of the New Testament ... we find that the basic methodology of longstanding has not been eclipsed significantly by new developments’ (Botha 1991: 71)
Such complaints are commonplace in the field of New Testament studies, which embraces a
large number of specialisms. Linguistics is an obvious component of the intensive scrutiny that
the biblical texts have received, and a necessary perspective. Since the retreat of classical
studies the field of ancient Greek linguistics has been to a large extent populated by scholars
with interests in the New Testament period. This has meant that a number of resources are
available to anyone working on ancient Greek, because of the long tradition of biblical textual
scholarship based on study of the ancient languages and collation of data about them. The
availability of resources like TLG and powerful inexpensive Bible software puts Greek linguists in
an enviable position in comparison with many other languages.
Corpus linguistics is an appropriate tool for studying a language with a large body of texts and
no native speakers. It is particularly suited to probabilistic approaches, but all theories can
benefit from access to reliable data. Much more work needs to be done on designing and
tagging a suitable corpus for study of Greek, and on making any systems accessible, user-
friendly and compatible with the goals of the diverse range of scholars interested in the
hellenistic period.
But the very availability of the corpora I have used makes it tempting to do word counts and
draw conclusions direct from raw numbers. Because of the diverse nature of the material, and
the inherent interest of such diversity, it is imperative that viable methods be established of
assessing the results of corpus searches and displaying them in a manner that does not hide the
complexities and uncertainties involved. As we have seen from the probability-value method of

67
comparing otherwise intractable amounts of data, the results depend not only on the reliability of
the input but also on the ability to ask questions and form testable hypotheses. In spite of the
high level of integrity of the Accordance search facility, the three corpora used have not shown
significant differences in many of the features examined, even though initial number counts
suggested otherwise. This is a healthy corrective to an uncritical use of statistical data. The p-
value method retains its appeal because it partly escapes the need to design corpora of fixed-
length texts or specific genres, an approach that is unlikely to succeed in the field of New
Testament scholarship because of its permanent interest in a specific body of texts. It is a
method that encourages the testing of hypotheses, instead of vague impressionistic
generalisations, and is therefore also a desirable corrective to the tendency (already recognised
and decried by many NT scholars) to give undue weight to non-linguistic (especially tendentious
theological and sociological) evaluations of linguistic data.
Grammaticalisation is one theory that provides hypotheses. Whether something as specific as
how an adverb might become a preposition or case ending, or as general as whether
unidirectionality is a testable claim, it attempts to establish probable or possible paths of
variation and change. Combining a theoretical drive with the means to organise large data sets
and the safeguard of a statistical method that prevents rash judgments is a desirable goal; in the
case of hellenistic Greek much progress has already been made but much more is possible.
This study has identified several areas where quantitative methods have produced unexpected
questions for qualitative research to investigate. Corpus linguistics is not the only appropriate
methodology for studying hellenistic Greek, but when combined with complementary approaches
such as grammaticalisation and discourse analysis (as suggested by O’Donnell 2005) it offers
good prospects for progress. The essential immediate need is for the development of
standardised tagged digital corpora, and the early Christian documents now available are a good
model of what could be done for this and other periods of Greek, and for other languages for
which corpus study is a new direction.

68
Appendices
Appendix A Description of corpora 69
Appendix B Tables of data
Appendix C Case study of a P/PV collocation

69
Appendix A — Composition of the corpora used in this study
LXX66
The Septuagint, from Latin septuaginta ‘seventy’ (abbreviated LXX) (Greek JEbdomhvkonta
hebdomekonta), is so called because of the ancient tradition that the translation was produced
by a committee of 72 scholars. The searchable text in Accordance is the edition of Rahlfs 1935.
1. Pentateuch
From Greek pentateuvcwV pentateukos ‘consisting of 5 books in one volume’. This is the name
traditionally given to the first 5 books of the Hebrew Bible; it is also called the Torah (Hebrew
‘law, teaching’). The Greek translations of the Pentateuch are the earliest of the LXX
translations and were made by different translators. 124,530 words.
a. Genesis Heb tyvarb;; Bereshit ‘in the beginning’ Grk GevnesiV genesis ‘birth’
Probably the first book of the Pentateuch to be translated. Idiomatic Greek with occasional
Hebrew influence. An account of the creation of the world, the lives of the first generations of
humans, the calling of Abraham and the migration of his descendants to Egypt. 32,573 words.
b. Exodus Heb twmv Shemot ‘names’, Grk [ExodoV exodos ‘going out’
Less literal translation than Genesis. An account of the struggles of the people of Israel to
escape from Egypt, the life of Moses and the people’s wandering in the desert of Sinai. 24,818
words.
c. Leviticus Heb arqyw Vayikra’ ‘and he called’, Grk Leui-tikovn leuitikon ‘Levitic’
Idiomatic Greek with creative solutions to translating Hebrew technical terms. Lists of laws and
regulations, especially those relating to personal and communal holiness and to priestly and
other cultic requirements. 19,085 words.
d. Numbers Heb rbdmb Bemidbar ‘in the desert’, Grk jAriqmoiv arithmoi ‘numbers’
Fairly literal. An account of the census of the people at Mt Sinai, their journey to Moab and the
sending of spies into the Promised Land. 25,059 words.
66
The following information about translations is taken from Dines 2004. On the rhetorical style of the
LXX see Lee 1997.

70
LXX continued
e. Deuteronomy Heb Myrbd Devarim ‘things, words’, Grk Deuteronovmion deuteronomion
‘second law’. Also a literal translation. Three sermons by Moses to the people in Moab as they
wait to enter the Promised Land; the death of Moses. 22,995 words.
2. Chronicles Heb Mymyh yrbd Divrey hayyamim ‘events of the days’, Grk
Paraleipomevnwn paraleipomenon ‘things left out, supplements’
Free translation style. Two books of genealogical lists and history of the reigns of David,
Solomon and the kings of Judah to the time of the Babylonian exile. 37,600 words.
3. Proverbs Heb hmlv ylvm Mishley Shelomoh ‘proverbs of Solomon’, Grk Paroimivai
paroimiai ‘proverbs’. Paraphrase style of translation. Proverbs about wisdom and the way to
live according to knowledge of God. 11,166 words.
4. Ecclesiastes Heb tlhq Qohelet ‘assembler’, Grk j Ekklhsiasth vV ecclesiastes
‘assembler’
Very literal translation, probably from 1 BC - 1 AD. Reflections on wisdom and the best way of
life. 4546 words.
5. Isaiah Heb hyovy Yesha‘yah ‘Isaiah’, Grk jHsai-vaV Esaias (personal name)
Free translation, probably later than mid-second century BC. Prophecies of judgments against
the nations persecuting Judah and against Judah, and about the future messiah. 27,087 words.

71
NT
The New Testament is a collection of 27 texts considered scripture in the Christian tradition.
The searchable text in Accordance is the edition of Nestle-Aland 27 (1993). There is no
evidence that any of the books were not written in Greek, though some may have been based
on Aramaic documentary as well as oral traditions. It is probable that all the writers were
bilingual in Aramaic and Greek, and Paul at least was educated in Hebrew. The corpus is
divided into samples by traditional author. 138,167 words.
1. Gospel of Matthew
A narrative of events in the life of Jesus including reported speeches.67 Non-literary language.68
Shares material with Mark and Luke (generally thought that Matthew and Luke independently
used Mark or a common source).
70-80 AD. 18,363 words.
2. Gospel of Mark
A narrative of events in the life of Jesus including reported speeches. Vulgar/non-literary
language. 55-70 AD. Shares material with Matthew and Luke but usually considered prior to
them. 11,313 words.
3. Gospel of Luke and Acts of the Apostles
Luke: narrative of events in the life of Jesus including reported speeches. Non-literary
language.69 75-90 AD. Shares material with Mark and Matthew. 19,496 words.
Acts: history of the origins and growth of the early church, including speeches, first- and third-
person narrative. Non-literary language. 75-90 AD. 18,4471 words.
The common authorship of these two books is relatively uncontroversial.
4. Gospel and Epistles of John, Revelation
Gospel of John: narrative of events in the life of Jesus including reported speeches. Vulgar/non-literary
language. 85-100 AD. 15,675 words.
67
On the generic nature of ‘gospels’ as belonging to the Greek Bios tradition, see Burridge 1997a and
1997b.
68 This categorisation of the language styles of the NT books follows that of O’Donnell 2006 (Chapter 3
Appendix A, 164-5). The dates given are also taken from O’Donnell’s list. (There is great variety of
opinion about dates and authorship: a slightly earlier dating is argued for by Carson & Moo 2005.) The
word counts given here differ from O’Donnell’s and are taken from Accordance’s count of NA27.
69 Luke’s language is usually considered more literary than O’Donnell’s classification suggests. Cf
Browning (1983: 40): ‘St Luke ... has rather more literary pretensions than the other Synoptics [Matthew
and Mark]’. But his ‘pretensions’ are literary rather than purist; his language is Koine not Atticising.

72
NT continued
Epistles of John: 1 John – pastoral letter to a congregation. Vulgar/non-literary language. 85-
100 AD. 2141 words. 2 John: letter to a congregation warning about false teachers. Vulgar/non-
literary language. 85-100 AD. 245 words. 3 John – letter to an individual. Vulgar/non-literary
language. 85-100 AD. 219 words.
Revelation (Apocalypse): A series of visions in the Jewish apocalyptic tradition, prefaced by
seven short letters to churches, traditionally attributed to the apostle John. Vulgar language.
50-90 AD. 9856 words.
5. Epistles of Paul Non-literary language. 32,442 words.
Romans – A theological treatise setting out Paul’s teaching, within a letter to the church in
Rome. 55-50 AD. 7114 words.
1 Corinthians – A letter to the Corinthian church concerning internal problems and answering
questions from them. 55-60 AD. 6842 words.
2 Corinthians – A letter to the Corinthian church defending Paul’s decision to delay his visit to
them and giving teaching on various matters. 55-60 AD. 4488 words.
Galatians – A letter to a church in Asia Minor defending Paul’s status as an apostle and
restating his basic teaching. 50-55 AD. 2233 words.
Ephesians – A letter to a church in Asia Minor about redemption in Christ and what this means
for Christian living. ?55-65 AD. 2423 words.
Philippians – A letter to a church in Macedonia commending certain elders and calling for
perseverance. 55-65 AD. 1631 words.
Colossians – A letter to a church in Asia Minor about the greatness of Christ and the danger of
false teaching. 55-65 AD. 1582 words.
1 Thessalonians – A letter to a church in Macedonia recalling Paul’s stay in Thessaloniki and
exhorting the church to live in light of Christ’s return. 50-55 AD. 1482 words.
2 Thessalonians – A letter to the same church encouraging them to stand firm under
persecution. 50-55 AD. 823 words.
1 Timothy – A letter to a church elder warning against false teachers and explaining how to treat
various groups in the congregation. 60-100 AD. 1591 words.
2 Timothy – A letter to the elder encouraging him to persevere in spite of the fact that Paul is
now in prison facing death. 160-100 AD. 239 words.
Titus – A letter to a church elder in Crete, encouraging him to appoint elders there and
explaining criteria for such service. 60-100 AD. 55-65 AD. 659 words.
Philemon – A letter to a friend encouraging him to treat his slave generously. 55-65 AD. 335
words.

73
NT continued
6. Epistles of Peter
1 Peter – a letter to persecuted Christians in Asia Minor. Non-literary/literary language. 65-90
AD. 1685 words.
2 Peter – a letter warning about false teachers. Includes some borrowing from the letter of Jude
(or possibly vice versa). Non-literary language. 65-95 AD. 1099 words.
7. Epistle of James
A letter to churches in Palestine concerning suffering, the law and good works and dealing with
dissension. Non-literary/literary language. 45-50 or 90-100 AD. 1745 words.
8. Epistle of Jude
A letter warning about false teachers. Shares some material with 2 Peter. Non-literary
language. 70-95 AD. 461 words.
9. Epistle to the Hebrews
A series of homilies on the supremacy of Christ showing how he fulfils various Old Testament
concepts. Non-literary/literary language. 70-95 AD. 4956 words.

74
AF
The Apostolic Fathers is a collection of some of the earliest extant writings of the Christian
church. They were written not long after the New Testament, with a similar range of genres and
topics. The edition used by Accordance is Holmes 1999. 64,640 words.70
1. Letters of Clement Clement was an elder of the church in Rome. 13,182 words.
1 Clement – a letter from the Roman church to the church in Corinth concerning a dispute there,
written in 96 AD. 10127 words.
2 Clement - spuriously attributed to Clement, an anonymous sermon written about 140-160 AD.
3055 words.
2. Letters of Ignatius From Ignatius Theophorus of Antioch (died 107 AD). Seven of the 15
letters attributed to him are considered genuine; they were written to various churches while he
was travelling through Asia Minor. Non-literary language. 7960 words.
Ephesians – A letter from Smyrna about the dangers of docetism. 1822 words.
Magnesians – A letter from Smyrna about the need for unity. 1084 words.
Trallians – A letter from Smyrna about the dangers of docetism. 983 words.
Romans – A letter embracing Ignatius’ approaching martyrdom. 1061 words.
Philadelphians – A letter from Troas urging unity. 1026 words.
Smyrnaeans – A letter from Troas about the dangers of docetism. 1184 words.
Polycarp – A letter of advice from a senior to a junior church leader. 800 words.
3. Letter of Polycarp
Letter from Polycarp of Smyrna (died 155 AD) to the church at Philippi in Macedonia. Non-
literary language. Written after 107 AD. 1146 words.
4. Martyrdom of Polycarp
A letter from the church in Smyrna to a Phrygian church, embodying an eyewitness account of
the death of Bishop Polycarp, written shortly after 155 AD. Literary language. 2733 words.
5. Didache
A treatise or catechism incorporating early Christian and pre-Christian material. Written 70-200
AD, probably 100-120 AD. Non-literary language. 2234 words.
70
The following information about the AF documents is taken from Staniforth 1968.

75
AF continued
6. Shepherd of Hermas
A series of visions and parables. Written in the second century, possibly later than 155 AD.
Vulgar language. 27,869 words.
7. Letter of Barnabas
A theological tract in letter form, written between 70 and 132 AD. 6834 words.
8. Letter to Diognetus
Anonymous treatise in letter form, written 124 AD or later. Literary language. 2682 words.
TLG and LSJ Corpora
In order to put information extracted from the TLG and LSJ databases into a usable form
comparable with the three corpora described above, I have collected data on the following
authors and divided them into three populations based on their dates:
Classical
Herodotus 5 BC 189,489 words history
Thucydides 5 BC 153,260 words history
Plato 5-4 BC 585,531 words philosophy
Lysias 5-4 BC 70,543 words rhetoric
Aristotle 4 BC 1,104,731 words philosophy
Early Koine
Polybius 3-2 BC 331,666 words history
Diodorus Siculus 1 BC 486,054 words history
Strabo 1 BC – AD 1 299,836 words geography
Later Koine
Appian AD 1-2 491,292 words history
Epictetus AD 1-2 233,587 words philosophy
Cassius Dio AD 2-3 88,164 words history
Early Koine is roughly contemporaneous with the Septuagint, and Later Koine with the New
Testament and Apostolic Fathers.

76
Appendix B – index of data tables
B.1. Prepositions in New Testament by case 77
B.2 NT prepositions by author a. 1-case prepositions 78
B.3 NT prepositions by author b. 2-case prepositions 79
B.4 NT prepositions by author c. 3-case prepositions 80
B.5. Prepositions in LXX – frequency by author 81
B.6. Prepositions in NT – frequency by author 82
B.7 Prepositions in AF – frequency by author 83
B.8. Comparison of frequency order of prepositions in each corpus 84
a. Frequency in LXX, NT & AF 84
b. Frequency as tokens per 10,000 words in LSJ and LXX, NT, AF 84
B.9. Prepositions in LXX 85
B.10. Prepositions in NT 86
B.11. Prepositions in AF 88
B.12 Preverbs in Lysias and NT 90
a. Table from Duhoux 1995 90b. Amalgamation of Duhoux’s 6 tables of preverbs 90
c. Equivalent table of NT data 91
d. Comparison of data from Lysias and NT 91
B.13 P-values for comparison of data from TLG and LSJ with NT, LXX & AF 92
a. TLG & Accordance data for frequency of epi 92
b. TLG & Accordance data for frequency of pros 92c. LSJ & Accordance data for frequency of eis 93
d. TLG & Accordance data for frequency of en 93
B.14 Preverbs in LXX: order of frequency 94
B.15 Preverbs in NT: order of frequency 95
B.16 Preverbs in AF: order of frequency 96
B.17 Comparison of frequency order of preverbs in each corpus 97
B.18 Preverbs in NT according to tense 98
B.19 Tenses in LXX, NT, AF 99
B.20 Present and aorist tenses of preverbs in LXX 100
B.21 Present and aorist tenses of preverbs in AF 101
B.22 Summary of PV usage by tense in LXX, NT, AF 102
B.23 Frequencies of PVs in NT accoding to tense 103
B.24 NT usage of PVs by author 104
B.25 Probability-value calculations for preverbs in LXX, NT, AF 107
B.26 Prepositions and preverbs in Modern Greek 109a. Modern Greek reflexes of ancient prepositions 109
b. Katharevousa prepositions in Modern Greek 110
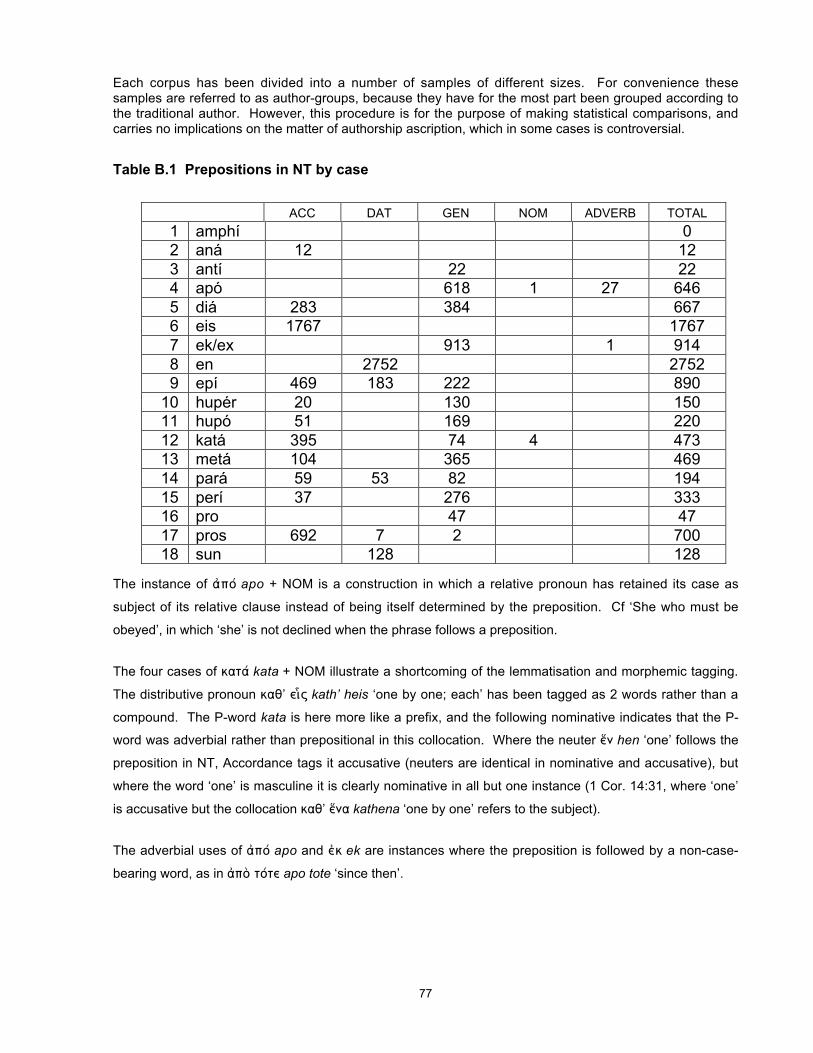
77
Each corpus has been divided into a number of samples of different sizes. For convenience thesesamples are referred to as author-groups, because they have for the most part been grouped according tothe traditional author. However, this procedure is for the purpose of making statistical comparisons, andcarries no implications on the matter of authorship ascription, which in some cases is controversial.
Table B.1 Prepositions in NT by case
ACC DAT GEN NOM ADVERB TOTAL
1 amphí 0
2 aná 12 12
3 antí 22 22
4 apó 618 1 27 646
5 diá 283 384 667
6 eis 1767 1767
7 ek/ex 913 1 914
8 en 2752 2752
9 epí 469 183 222 890
10 hupér 20 130 150
11 hupó 51 169 220
12 katá 395 74 4 473
13 metá 104 365 469
14 pará 59 53 82 194
15 perí 37 276 333
16 pro 47 47
17 pros 692 7 2 700
18 sun 128 128
The instance of ajpov apo + NOM is a construction in which a relative pronoun has retained its case as
subject of its relative clause instead of being itself determined by the preposition. Cf ‘She who must be
obeyed’, in which ‘she’ is not declined when the phrase follows a preposition.
The four cases of katav kata + NOM illustrate a shortcoming of the lemmatisation and morphemic tagging.
The distributive pronoun kaq’ ei|V kath’ heis ‘one by one; each’ has been tagged as 2 words rather than a
compound. The P-word kata is here more like a prefix, and the following nominative indicates that the P-
word was adverbial rather than prepositional in this collocation. Where the neuter e{n hen ‘one’ follows the
preposition in NT, Accordance tags it accusative (neuters are identical in nominative and accusative), but
where the word ‘one’ is masculine it is clearly nominative in all but one instance (1 Cor. 14:31, where ‘one’
is accusative but the collocation kaq’ e{na kathena ‘one by one’ refers to the subject).
The adverbial uses of ajpov apo and ejk ek are instances where the preposition is followed by a non-case-
bearing word, as in ajpo; tovte apo tote ‘since then’.
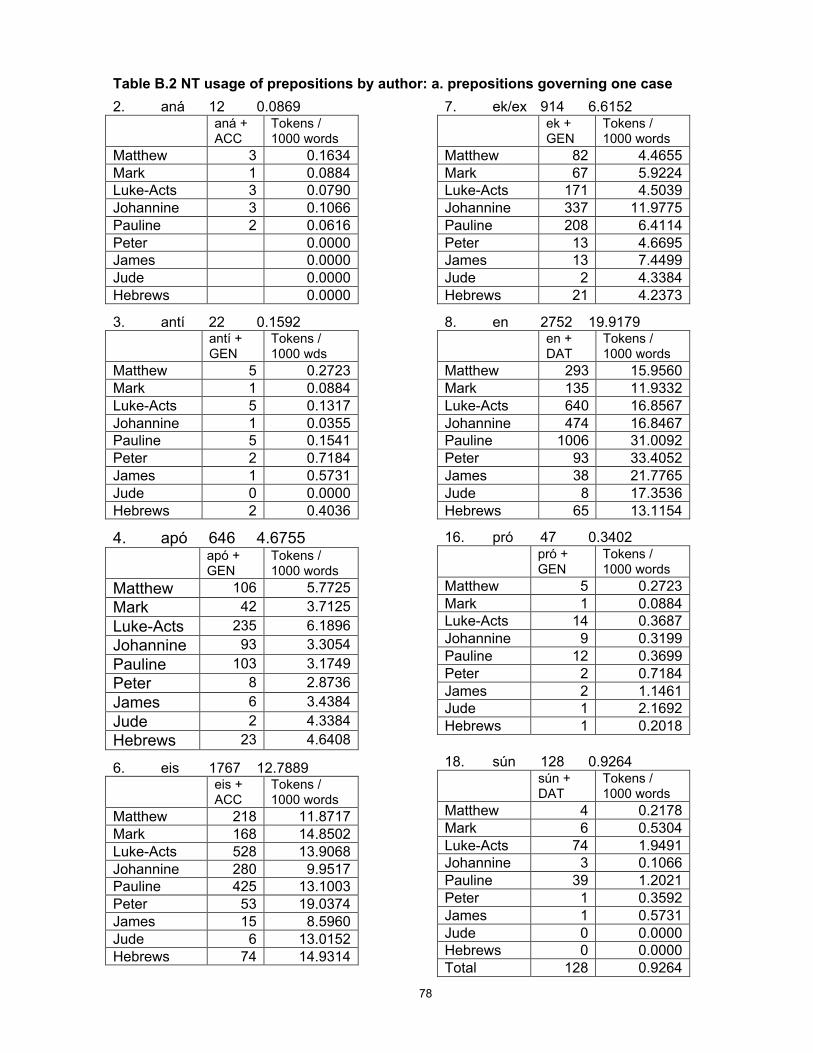
78
Table B.2 NT usage of prepositions by author: a. prepositions governing one case
2. aná 12 0.0869aná +ACC
Tokens /1000 words
Matthew 3 0.1634
Mark 1 0.0884
Luke-Acts 3 0.0790
Johannine 3 0.1066
Pauline 2 0.0616
Peter 0.0000
James 0.0000
Jude 0.0000
Hebrews 0.0000
3. antí 22 0.1592antí +GEN
Tokens /1000 wds
Matthew 5 0.2723
Mark 1 0.0884
Luke-Acts 5 0.1317
Johannine 1 0.0355
Pauline 5 0.1541
Peter 2 0.7184
James 1 0.5731
Jude 0 0.0000
Hebrews 2 0.4036
4. apó 646 4.6755apó +GEN
Tokens /1000 words
Matthew 106 5.7725
Mark 42 3.7125
Luke-Acts 235 6.1896
Johannine 93 3.3054
Pauline 103 3.1749
Peter 8 2.8736
James 6 3.4384
Jude 2 4.3384
Hebrews 23 4.6408
6. eis 1767 12.7889eis +ACC
Tokens /1000 words
Matthew 218 11.8717
Mark 168 14.8502
Luke-Acts 528 13.9068
Johannine 280 9.9517
Pauline 425 13.1003
Peter 53 19.0374
James 15 8.5960
Jude 6 13.0152
Hebrews 74 14.9314
7. ek/ex 914 6.6152ek +GEN
Tokens /1000 words
Matthew 82 4.4655
Mark 67 5.9224
Luke-Acts 171 4.5039
Johannine 337 11.9775
Pauline 208 6.4114
Peter 13 4.6695
James 13 7.4499
Jude 2 4.3384
Hebrews 21 4.2373
8. en 2752 19.9179en +DAT
Tokens /1000 words
Matthew 293 15.9560
Mark 135 11.9332
Luke-Acts 640 16.8567
Johannine 474 16.8467
Pauline 1006 31.0092
Peter 93 33.4052
James 38 21.7765
Jude 8 17.3536
Hebrews 65 13.1154
16. pró 47 0.3402pró +GEN
Tokens /1000 words
Matthew 5 0.2723
Mark 1 0.0884
Luke-Acts 14 0.3687
Johannine 9 0.3199
Pauline 12 0.3699
Peter 2 0.7184
James 2 1.1461
Jude 1 2.1692
Hebrews 1 0.2018
18. sún 128 0.9264sún +DAT
Tokens /1000 words
Matthew 4 0.2178
Mark 6 0.5304
Luke-Acts 74 1.9491
Johannine 3 0.1066
Pauline 39 1.2021
Peter 1 0.3592
James 1 0.5731
Jude 0 0.0000
Hebrews 0 0.0000
Total 128 0.9264
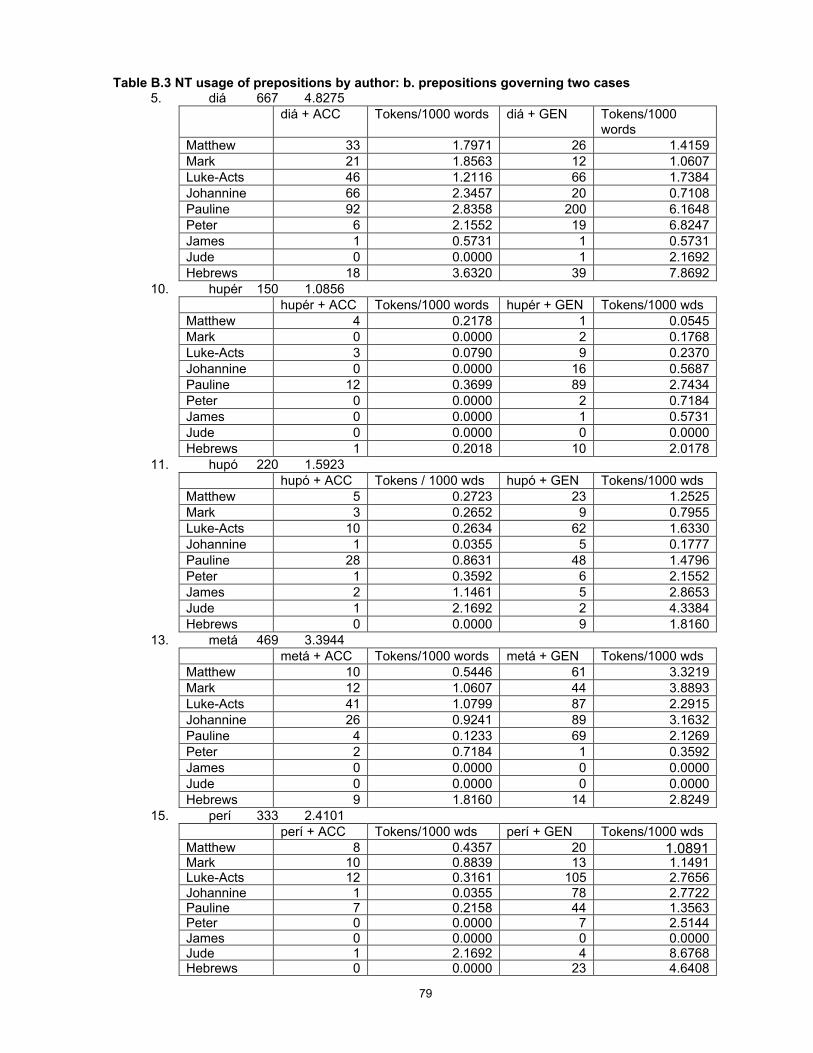
79
Table B.3 NT usage of prepositions by author: b. prepositions governing two cases5. diá 667 4.8275
diá + ACC Tokens/1000 words diá + GEN Tokens/1000words
Matthew 33 1.7971 26 1.4159
Mark 21 1.8563 12 1.0607
Luke-Acts 46 1.2116 66 1.7384
Johannine 66 2.3457 20 0.7108
Pauline 92 2.8358 200 6.1648
Peter 6 2.1552 19 6.8247
James 1 0.5731 1 0.5731
Jude 0 0.0000 1 2.1692
Hebrews 18 3.6320 39 7.8692
10. hupér 150 1.0856
hupér + ACC Tokens/1000 words hupér + GEN Tokens/1000 wds
Matthew 4 0.2178 1 0.0545
Mark 0 0.0000 2 0.1768
Luke-Acts 3 0.0790 9 0.2370
Johannine 0 0.0000 16 0.5687
Pauline 12 0.3699 89 2.7434
Peter 0 0.0000 2 0.7184
James 0 0.0000 1 0.5731
Jude 0 0.0000 0 0.0000
Hebrews 1 0.2018 10 2.0178
11. hupó 220 1.5923
hupó + ACC Tokens / 1000 wds hupó + GEN Tokens/1000 wds
Matthew 5 0.2723 23 1.2525
Mark 3 0.2652 9 0.7955
Luke-Acts 10 0.2634 62 1.6330
Johannine 1 0.0355 5 0.1777
Pauline 28 0.8631 48 1.4796
Peter 1 0.3592 6 2.1552
James 2 1.1461 5 2.8653
Jude 1 2.1692 2 4.3384
Hebrews 0 0.0000 9 1.8160
13. metá 469 3.3944
metá + ACC Tokens/1000 words metá + GEN Tokens/1000 wds
Matthew 10 0.5446 61 3.3219
Mark 12 1.0607 44 3.8893
Luke-Acts 41 1.0799 87 2.2915
Johannine 26 0.9241 89 3.1632
Pauline 4 0.1233 69 2.1269
Peter 2 0.7184 1 0.3592
James 0 0.0000 0 0.0000
Jude 0 0.0000 0 0.0000
Hebrews 9 1.8160 14 2.8249
15. perí 333 2.4101
perí + ACC Tokens/1000 wds perí + GEN Tokens/1000 wds
Matthew 8 0.4357 20 1.0891
0.07080.5718
0.4248
0.23960.0381
0.0000
0.02180.12530
Mark 10 0.8839 13 1.1491Luke-Acts 12 0.3161 105 2.7656Johannine 1 0.0355 78 2.7722Pauline 7 0.2158 44 1.3563Peter 0 0.0000 7 2.5144James 0 0.0000 0 0.0000Jude 1 2.1692 4 8.6768Hebrews 0 0.0000 23 4.6408
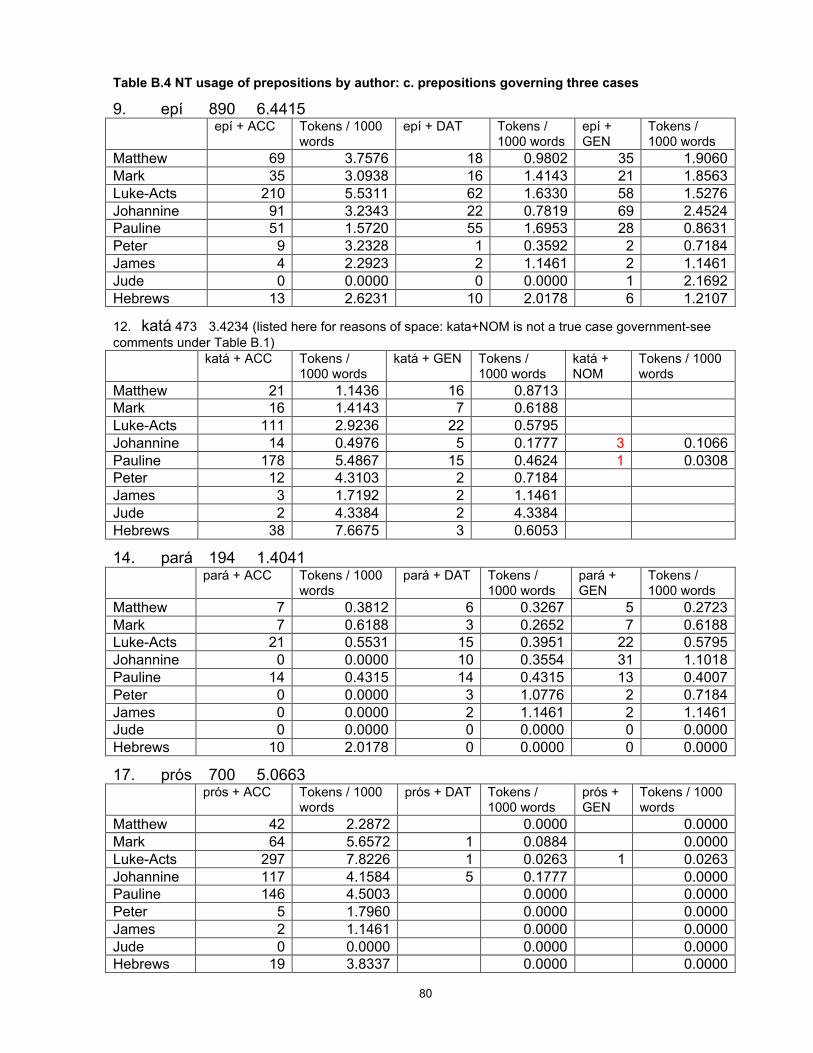
80
Table B.4 NT usage of prepositions by author: c. prepositions governing three cases
9. epí 890 6.4415epí + ACC Tokens / 1000
wordsepí + DAT Tokens /
1000 wordsepí +GEN
Tokens /1000 words
Matthew 69 3.7576 18 0.9802 35 1.9060
Mark 35 3.0938 16 1.4143 21 1.8563
Luke-Acts 210 5.5311 62 1.6330 58 1.5276
Johannine 91 3.2343 22 0.7819 69 2.4524
Pauline 51 1.5720 55 1.6953 28 0.8631
Peter 9 3.2328 1 0.3592 2 0.7184
James 4 2.2923 2 1.1461 2 1.1461
Jude 0 0.0000 0 0.0000 1 2.1692
Hebrews 13 2.6231 10 2.0178 6 1.2107
12. katá 473 3.4234 (listed here for reasons of space: kata+NOM is not a true case government-see
comments under Table B.1)
katá + ACC Tokens /1000 words
katá + GEN Tokens /1000 words
katá +NOM
Tokens / 1000words
Matthew 21 1.1436 16 0.8713
Mark 16 1.4143 7 0.6188
Luke-Acts 111 2.9236 22 0.5795
Johannine 14 0.4976 5 0.1777 3 0.1066
Pauline 178 5.4867 15 0.4624 1 0.0308
Peter 12 4.3103 2 0.7184
James 3 1.7192 2 1.1461
Jude 2 4.3384 2 4.3384
Hebrews 38 7.6675 3 0.6053
14. pará 194 1.4041pará + ACC Tokens / 1000
wordspará + DAT Tokens /
1000 wordspará +GEN
Tokens /1000 words
Matthew 7 0.3812 6 0.3267 5 0.2723
Mark 7 0.6188 3 0.2652 7 0.6188
Luke-Acts 21 0.5531 15 0.3951 22 0.5795
Johannine 0 0.0000 10 0.3554 31 1.1018
Pauline 14 0.4315 14 0.4315 13 0.4007
Peter 0 0.0000 3 1.0776 2 0.7184
James 0 0.0000 2 1.1461 2 1.1461
Jude 0 0.0000 0 0.0000 0 0.0000
Hebrews 10 2.0178 0 0.0000 0 0.0000
17. prós 700 5.0663prós + ACC Tokens / 1000
wordsprós + DAT Tokens /
1000 wordsprós +GEN
Tokens / 1000words
Matthew 42 2.2872 0.0000 0.0000
Mark 64 5.6572 1 0.0884 0.0000
Luke-Acts 297 7.8226 1 0.0263 1 0.0263
Johannine 117 4.1584 5 0.1777 0.0000
Pauline 146 4.5003 0.0000 0.0000
Peter 5 1.7960 0.0000 0.0000
James 2 1.1461 0.0000 0.0000
Jude 0 0.0000 0.0000 0.0000
Hebrews 19 3.8337 0.0000 0.0000
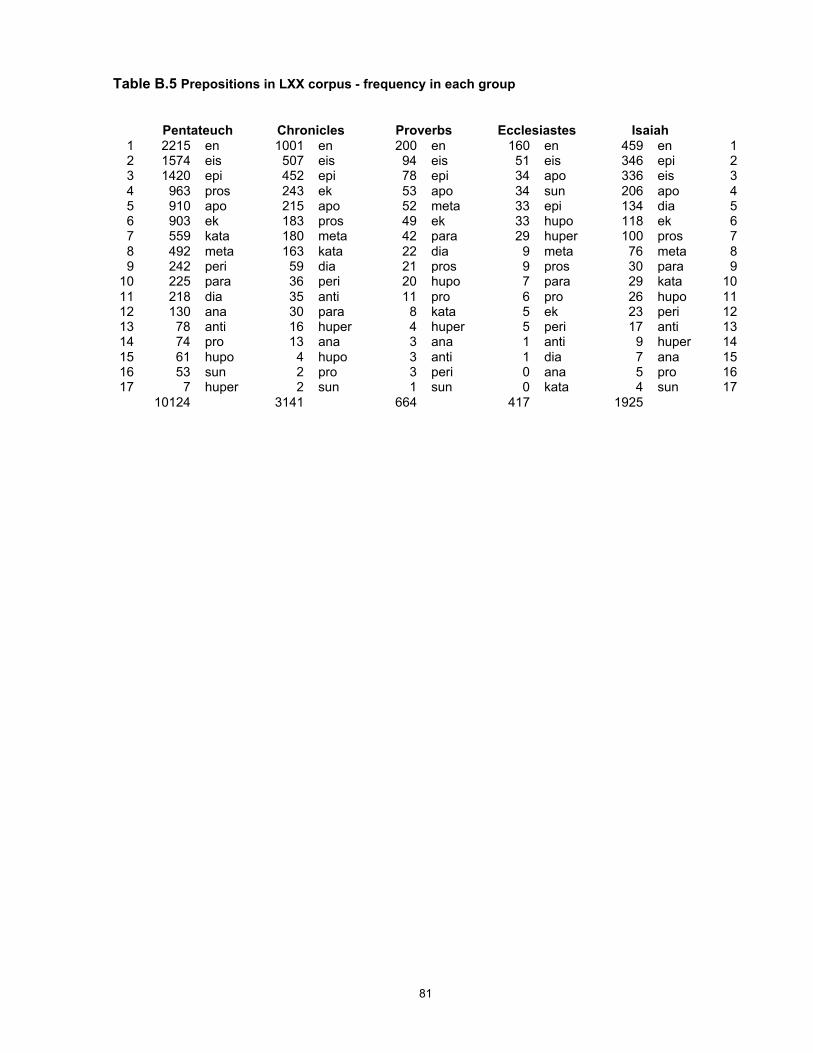
81
Table B.5 Prepositions in LXX corpus - frequency in each group
Pentateuch Chronicles Proverbs Ecclesiastes Isaiah1 2215 en 1001 en 200 en 160 en 459 en 12 1574 eis 507 eis 94 eis 51 eis 346 epi 23 1420 epi 452 epi 78 epi 34 apo 336 eis 34 963 pros 243 ek 53 apo 34 sun 206 apo 45 910 apo 215 apo 52 meta 33 epi 134 dia 56 903 ek 183 pros 49 ek 33 hupo 118 ek 67 559 kata 180 meta 42 para 29 huper 100 pros 78 492 meta 163 kata 22 dia 9 meta 76 meta 89 242 peri 59 dia 21 pros 9 pros 30 para 9
10 225 para 36 peri 20 hupo 7 para 29 kata 1011 218 dia 35 anti 11 pro 6 pro 26 hupo 1112 130 ana 30 para 8 kata 5 ek 23 peri 1213 78 anti 16 huper 4 huper 5 peri 17 anti 1314 74 pro 13 ana 3 ana 1 anti 9 huper 1415 61 hupo 4 hupo 3 anti 1 dia 7 ana 1516 53 sun 2 pro 3 peri 0 ana 5 pro 1617 7 huper 2 sun 1 sun 0 kata 4 sun 17
10124 3141 664 417 1925
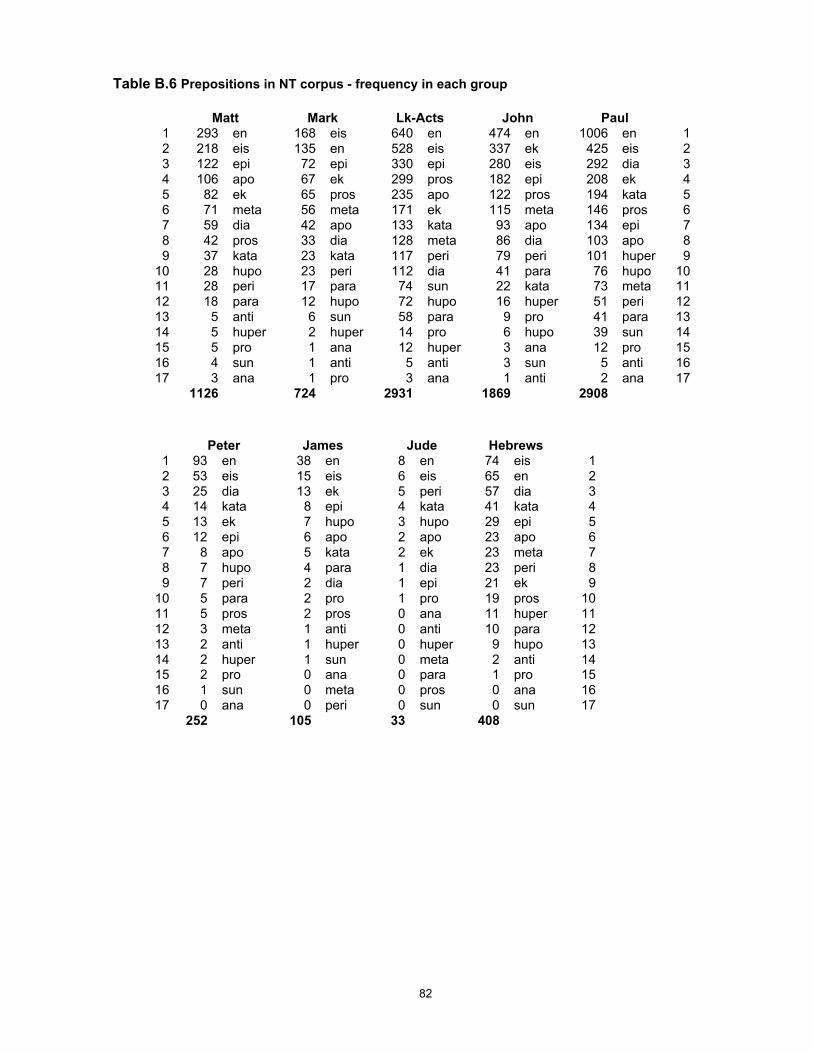
82
Table B.6 Prepositions in NT corpus - frequency in each group
Matt Mark Lk-Acts John Paul1 293 en 168 eis 640 en 474 en 1006 en 12 218 eis 135 en 528 eis 337 ek 425 eis 23 122 epi 72 epi 330 epi 280 eis 292 dia 34 106 apo 67 ek 299 pros 182 epi 208 ek 45 82 ek 65 pros 235 apo 122 pros 194 kata 56 71 meta 56 meta 171 ek 115 meta 146 pros 67 59 dia 42 apo 133 kata 93 apo 134 epi 78 42 pros 33 dia 128 meta 86 dia 103 apo 89 37 kata 23 kata 117 peri 79 peri 101 huper 9
10 28 hupo 23 peri 112 dia 41 para 76 hupo 1011 28 peri 17 para 74 sun 22 kata 73 meta 1112 18 para 12 hupo 72 hupo 16 huper 51 peri 1213 5 anti 6 sun 58 para 9 pro 41 para 1314 5 huper 2 huper 14 pro 6 hupo 39 sun 1415 5 pro 1 ana 12 huper 3 ana 12 pro 1516 4 sun 1 anti 5 anti 3 sun 5 anti 1617 3 ana 1 pro 3 ana 1 anti 2 ana 17
1126 724 2931 1869 2908
Peter James Jude Hebrews1 93 en 38 en 8 en 74 eis 12 53 eis 15 eis 6 eis 65 en 23 25 dia 13 ek 5 peri 57 dia 34 14 kata 8 epi 4 kata 41 kata 45 13 ek 7 hupo 3 hupo 29 epi 56 12 epi 6 apo 2 apo 23 apo 67 8 apo 5 kata 2 ek 23 meta 78 7 hupo 4 para 1 dia 23 peri 89 7 peri 2 dia 1 epi 21 ek 9
10 5 para 2 pro 1 pro 19 pros 1011 5 pros 2 pros 0 ana 11 huper 1112 3 meta 1 anti 0 anti 10 para 1213 2 anti 1 huper 0 huper 9 hupo 1314 2 huper 1 sun 0 meta 2 anti 1415 2 pro 0 ana 0 para 1 pro 1516 1 sun 0 meta 0 pros 0 ana 1617 0 ana 0 peri 0 sun 0 sun 17
252 105 33 408
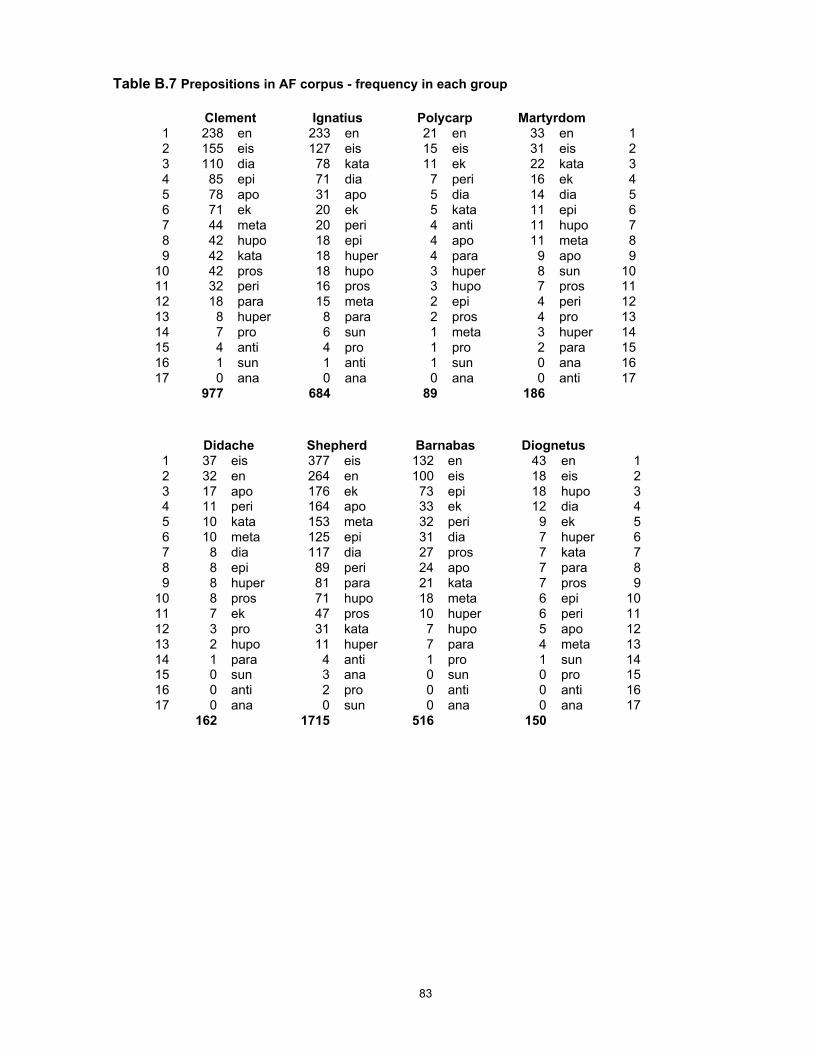
83
Table B.7 Prepositions in AF corpus - frequency in each group
Clement Ignatius Polycarp Martyrdom1 238 en 233 en 21 en 33 en 12 155 eis 127 eis 15 eis 31 eis 23 110 dia 78 kata 11 ek 22 kata 34 85 epi 71 dia 7 peri 16 ek 45 78 apo 31 apo 5 dia 14 dia 56 71 ek 20 ek 5 kata 11 epi 67 44 meta 20 peri 4 anti 11 hupo 78 42 hupo 18 epi 4 apo 11 meta 89 42 kata 18 huper 4 para 9 apo 9
10 42 pros 18 hupo 3 huper 8 sun 1011 32 peri 16 pros 3 hupo 7 pros 1112 18 para 15 meta 2 epi 4 peri 1213 8 huper 8 para 2 pros 4 pro 1314 7 pro 6 sun 1 meta 3 huper 1415 4 anti 4 pro 1 pro 2 para 1516 1 sun 1 anti 1 sun 0 ana 1617 0 ana 0 ana 0 ana 0 anti 17
977 684 89 186
Didache Shepherd Barnabas Diognetus1 37 eis 377 eis 132 en 43 en 12 32 en 264 en 100 eis 18 eis 23 17 apo 176 ek 73 epi 18 hupo 34 11 peri 164 apo 33 ek 12 dia 45 10 kata 153 meta 32 peri 9 ek 56 10 meta 125 epi 31 dia 7 huper 67 8 dia 117 dia 27 pros 7 kata 78 8 epi 89 peri 24 apo 7 para 89 8 huper 81 para 21 kata 7 pros 9
10 8 pros 71 hupo 18 meta 6 epi 1011 7 ek 47 pros 10 huper 6 peri 1112 3 pro 31 kata 7 hupo 5 apo 1213 2 hupo 11 huper 7 para 4 meta 1314 1 para 4 anti 1 pro 1 sun 1415 0 sun 3 ana 0 sun 0 pro 1516 0 anti 2 pro 0 anti 0 anti 1617 0 ana 0 sun 0 ana 0 ana 17
162 1715 516 150
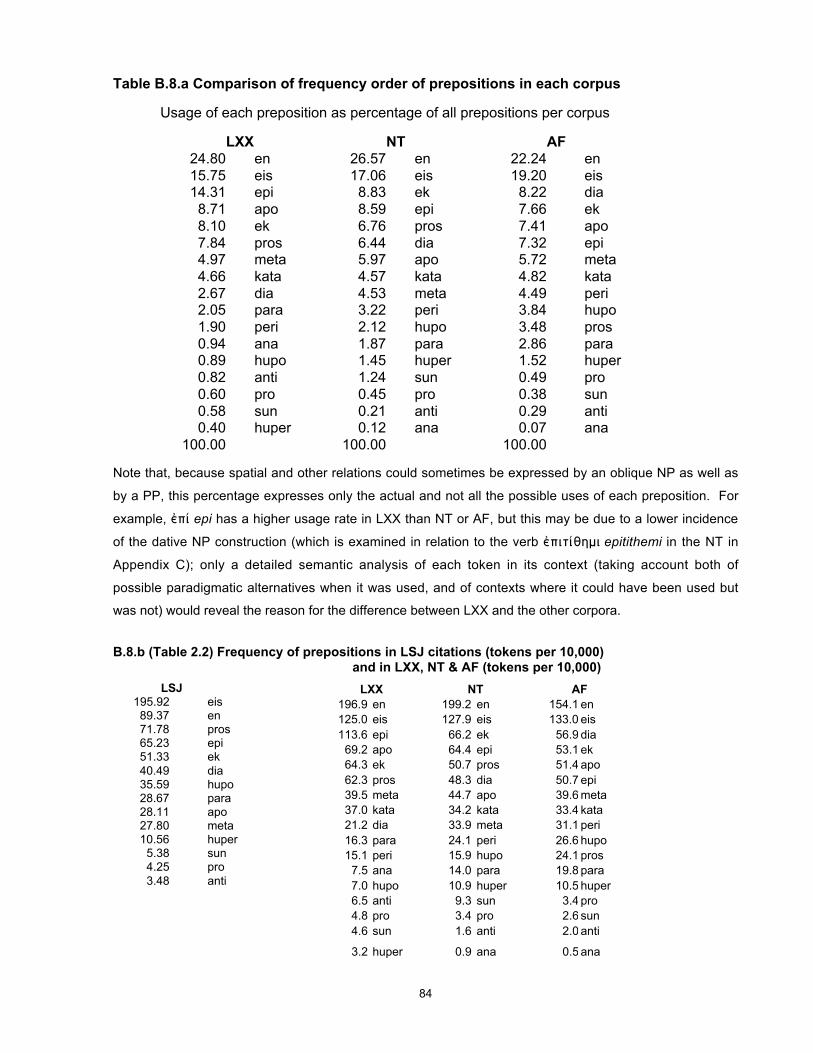
84
Table B.8.a Comparison of frequency order of prepositions in each corpus
Usage of each preposition as percentage of all prepositions per corpus
LXX NT AF
24.80 en 26.57 en 22.24 en
15.75 eis 17.06 eis 19.20 eis14.31 epi 8.83 ek 8.22 dia
8.71 apo 8.59 epi 7.66 ek
8.10 ek 6.76 pros 7.41 apo
7.84 pros 6.44 dia 7.32 epi4.97 meta 5.97 apo 5.72 meta
4.66 kata 4.57 kata 4.82 kata
2.67 dia 4.53 meta 4.49 peri2.05 para 3.22 peri 3.84 hupo
1.90 peri 2.12 hupo 3.48 pros
0.94 ana 1.87 para 2.86 para0.89 hupo 1.45 huper 1.52 huper
0.82 anti 1.24 sun 0.49 pro
0.60 pro 0.45 pro 0.38 sun
0.58 sun 0.21 anti 0.29 anti0.40 huper 0.12 ana 0.07 ana
100.00 100.00 100.00
Note that, because spatial and other relations could sometimes be expressed by an oblique NP as well as
by a PP, this percentage expresses only the actual and not all the possible uses of each preposition. For
example, ejpiv epi has a higher usage rate in LXX than NT or AF, but this may be due to a lower incidence
of the dative NP construction (which is examined in relation to the verb ejpitivqhmi epitithemi in the NT in
Appendix C); only a detailed semantic analysis of each token in its context (taking account both of
possible paradigmatic alternatives when it was used, and of contexts where it could have been used but
was not) would reveal the reason for the difference between LXX and the other corpora.
B.8.b (Table 2.2) Frequency of prepositions in LSJ citations (tokens per 10,000)and in LXX, NT & AF (tokens per 10,000)
LSJ195.92 eis89.37 en71.78 pros65.23 epi51.33 ek
40.49 dia35.59 hupo28.67 para28.11 apo27.80 meta10.56 huper
5.38 sun4.25 pro
3.48 anti
LXX NT AF
196.9 en 199.2 en 154.1 en
125.0 eis 127.9 eis 133.0 eis
113.6 epi 66.2 ek 56.9 dia
69.2 apo 64.4 epi 53.1 ek
64.3 ek 50.7 pros 51.4 apo
62.3 pros 48.3 dia 50.7 epi
39.5 meta 44.7 apo 39.6 meta
37.0 kata 34.2 kata 33.4 kata
21.2 dia 33.9 meta 31.1 peri
16.3 para 24.1 peri 26.6 hupo
15.1 peri 15.9 hupo 24.1 pros
7.5 ana 14.0 para 19.8 para
7.0 hupo 10.9 huper 10.5 huper
6.5 anti 9.3 sun 3.4 pro
4.8 pro 3.4 pro 2.6 sun
4.6 sun 1.6 anti 2.0 anti
3.2 huper 0.9 ana 0.5 ana
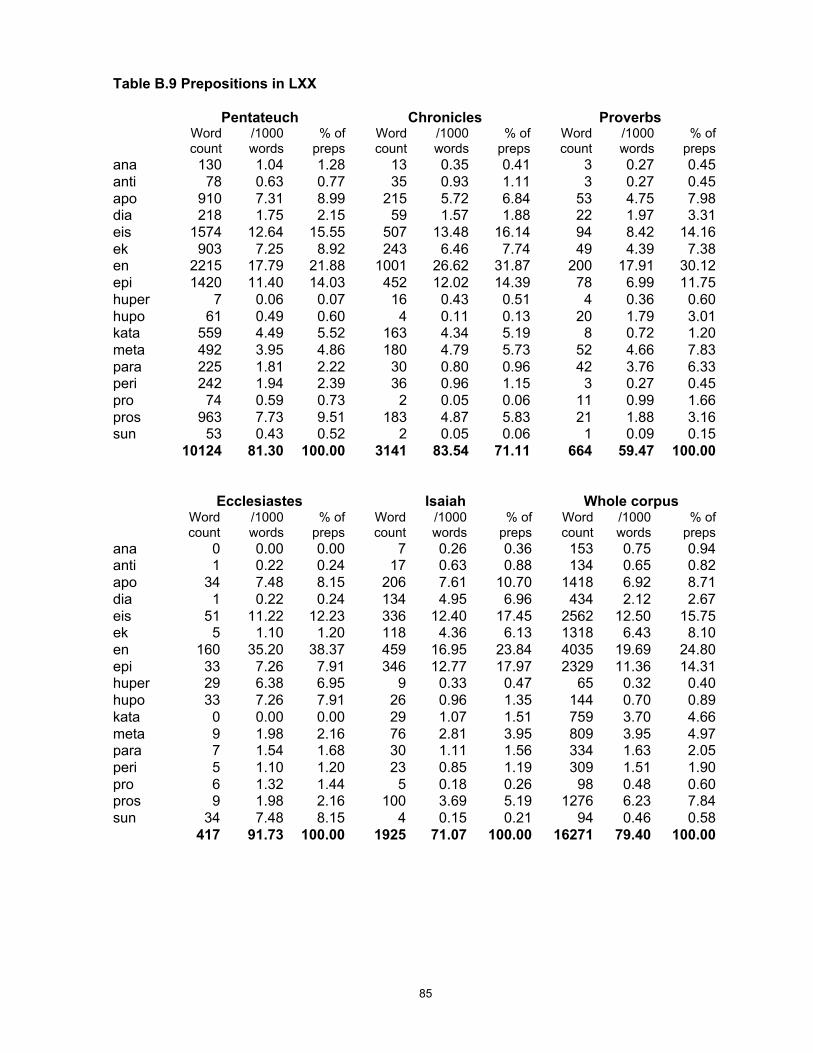
85
Table B.9 Prepositions in LXX
Pentateuch Chronicles ProverbsWordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
ana 130 1.04 1.28 13 0.35 0.41 3 0.27 0.45
anti 78 0.63 0.77 35 0.93 1.11 3 0.27 0.45
apo 910 7.31 8.99 215 5.72 6.84 53 4.75 7.98dia 218 1.75 2.15 59 1.57 1.88 22 1.97 3.31
eis 1574 12.64 15.55 507 13.48 16.14 94 8.42 14.16
ek 903 7.25 8.92 243 6.46 7.74 49 4.39 7.38en 2215 17.79 21.88 1001 26.62 31.87 200 17.91 30.12
epi 1420 11.40 14.03 452 12.02 14.39 78 6.99 11.75
huper 7 0.06 0.07 16 0.43 0.51 4 0.36 0.60
hupo 61 0.49 0.60 4 0.11 0.13 20 1.79 3.01kata 559 4.49 5.52 163 4.34 5.19 8 0.72 1.20
meta 492 3.95 4.86 180 4.79 5.73 52 4.66 7.83
para 225 1.81 2.22 30 0.80 0.96 42 3.76 6.33peri 242 1.94 2.39 36 0.96 1.15 3 0.27 0.45
pro 74 0.59 0.73 2 0.05 0.06 11 0.99 1.66
pros 963 7.73 9.51 183 4.87 5.83 21 1.88 3.16sun 53 0.43 0.52 2 0.05 0.06 1 0.09 0.15
10124 81.30 100.00 3141 83.54 71.11 664 59.47 100.00
Ecclesiastes Isaiah Whole corpusWordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
ana 0 0.00 0.00 7 0.26 0.36 153 0.75 0.94anti 1 0.22 0.24 17 0.63 0.88 134 0.65 0.82
apo 34 7.48 8.15 206 7.61 10.70 1418 6.92 8.71
dia 1 0.22 0.24 134 4.95 6.96 434 2.12 2.67
eis 51 11.22 12.23 336 12.40 17.45 2562 12.50 15.75ek 5 1.10 1.20 118 4.36 6.13 1318 6.43 8.10
en 160 35.20 38.37 459 16.95 23.84 4035 19.69 24.80
epi 33 7.26 7.91 346 12.77 17.97 2329 11.36 14.31huper 29 6.38 6.95 9 0.33 0.47 65 0.32 0.40
hupo 33 7.26 7.91 26 0.96 1.35 144 0.70 0.89
kata 0 0.00 0.00 29 1.07 1.51 759 3.70 4.66
meta 9 1.98 2.16 76 2.81 3.95 809 3.95 4.97para 7 1.54 1.68 30 1.11 1.56 334 1.63 2.05
peri 5 1.10 1.20 23 0.85 1.19 309 1.51 1.90
pro 6 1.32 1.44 5 0.18 0.26 98 0.48 0.60pros 9 1.98 2.16 100 3.69 5.19 1276 6.23 7.84
sun 34 7.48 8.15 4 0.15 0.21 94 0.46 0.58
417 91.73 100.00 1925 71.07 100.00 16271 79.40 100.00
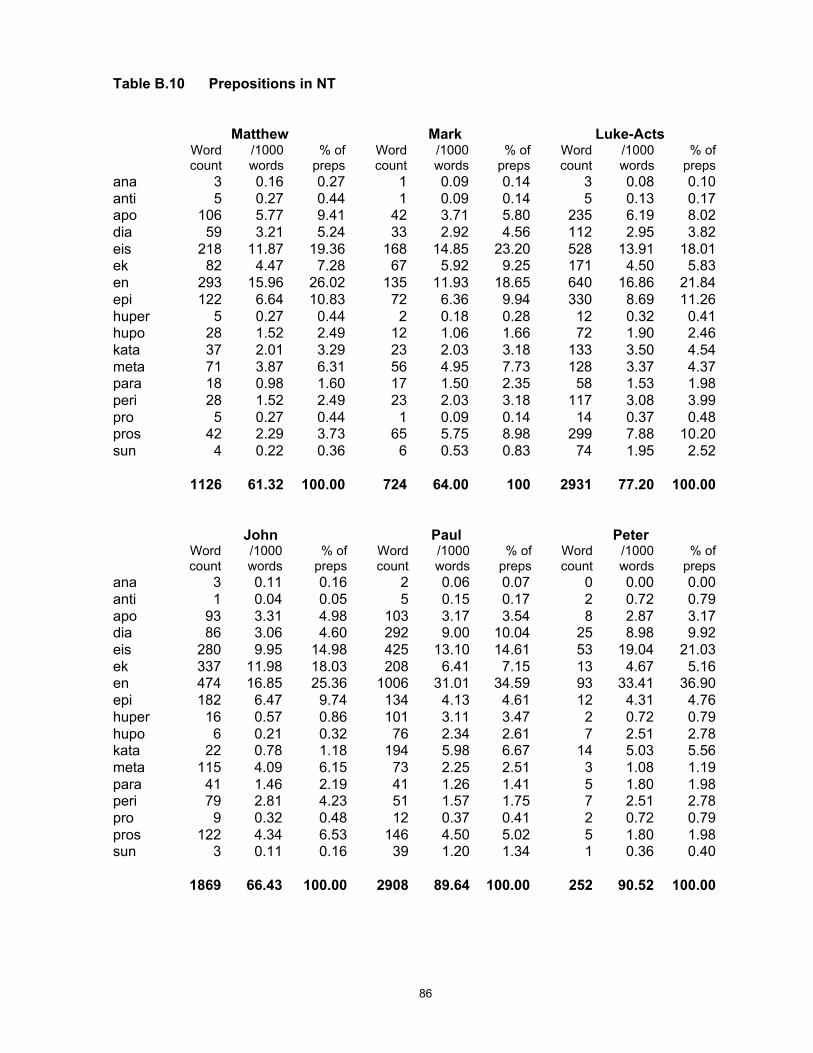
86
Table B.10 Prepositions in NT
Matthew Mark Luke-ActsWordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
ana 3 0.16 0.27 1 0.09 0.14 3 0.08 0.10
anti 5 0.27 0.44 1 0.09 0.14 5 0.13 0.17apo 106 5.77 9.41 42 3.71 5.80 235 6.19 8.02
dia 59 3.21 5.24 33 2.92 4.56 112 2.95 3.82
eis 218 11.87 19.36 168 14.85 23.20 528 13.91 18.01ek 82 4.47 7.28 67 5.92 9.25 171 4.50 5.83
en 293 15.96 26.02 135 11.93 18.65 640 16.86 21.84
epi 122 6.64 10.83 72 6.36 9.94 330 8.69 11.26
huper 5 0.27 0.44 2 0.18 0.28 12 0.32 0.41hupo 28 1.52 2.49 12 1.06 1.66 72 1.90 2.46
kata 37 2.01 3.29 23 2.03 3.18 133 3.50 4.54
meta 71 3.87 6.31 56 4.95 7.73 128 3.37 4.37para 18 0.98 1.60 17 1.50 2.35 58 1.53 1.98
peri 28 1.52 2.49 23 2.03 3.18 117 3.08 3.99
pro 5 0.27 0.44 1 0.09 0.14 14 0.37 0.48pros 42 2.29 3.73 65 5.75 8.98 299 7.88 10.20
sun 4 0.22 0.36 6 0.53 0.83 74 1.95 2.52
1126 61.32 100.00 724 64.00 100 2931 77.20 100.00
John Paul PeterWordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
ana 3 0.11 0.16 2 0.06 0.07 0 0.00 0.00
anti 1 0.04 0.05 5 0.15 0.17 2 0.72 0.79
apo 93 3.31 4.98 103 3.17 3.54 8 2.87 3.17dia 86 3.06 4.60 292 9.00 10.04 25 8.98 9.92
eis 280 9.95 14.98 425 13.10 14.61 53 19.04 21.03
ek 337 11.98 18.03 208 6.41 7.15 13 4.67 5.16en 474 16.85 25.36 1006 31.01 34.59 93 33.41 36.90
epi 182 6.47 9.74 134 4.13 4.61 12 4.31 4.76
huper 16 0.57 0.86 101 3.11 3.47 2 0.72 0.79
hupo 6 0.21 0.32 76 2.34 2.61 7 2.51 2.78kata 22 0.78 1.18 194 5.98 6.67 14 5.03 5.56
meta 115 4.09 6.15 73 2.25 2.51 3 1.08 1.19
para 41 1.46 2.19 41 1.26 1.41 5 1.80 1.98peri 79 2.81 4.23 51 1.57 1.75 7 2.51 2.78
pro 9 0.32 0.48 12 0.37 0.41 2 0.72 0.79
pros 122 4.34 6.53 146 4.50 5.02 5 1.80 1.98sun 3 0.11 0.16 39 1.20 1.34 1 0.36 0.40
1869 66.43 100.00 2908 89.64 100.00 252 90.52 100.00
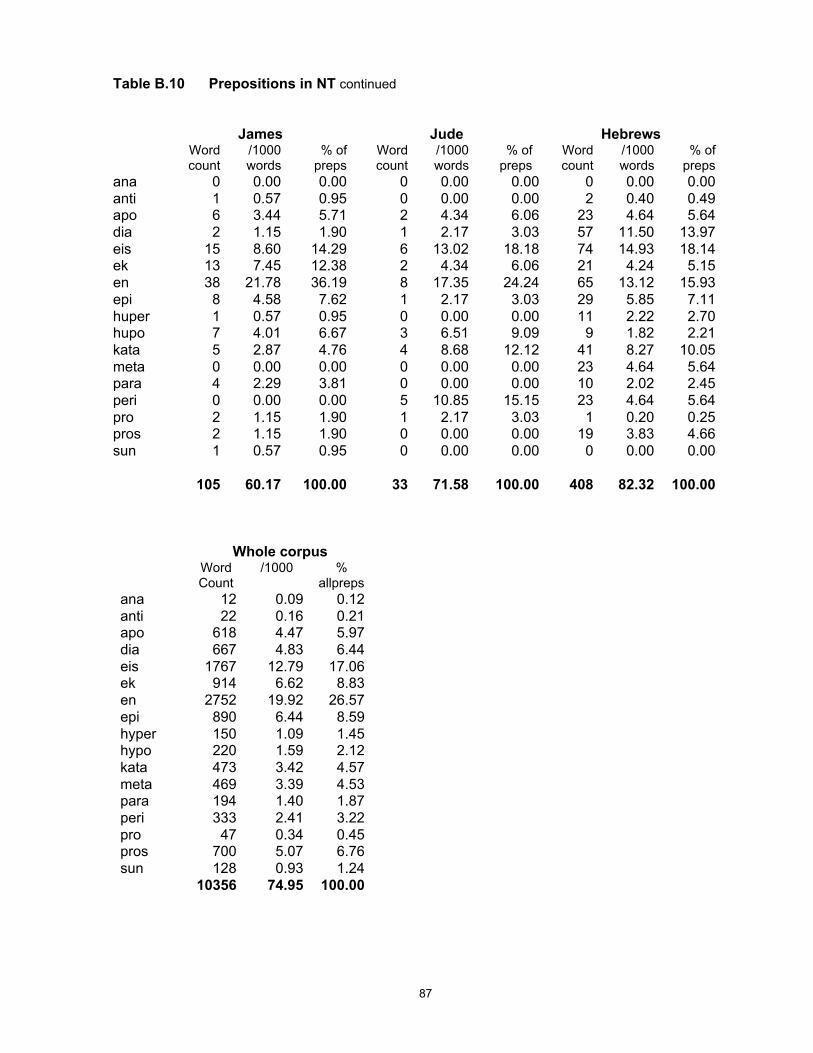
87
Table B.10 Prepositions in NT continued
James Jude HebrewsWordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
Wordcount
/1000words
% ofpreps
ana 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00
anti 1 0.57 0.95 0 0.00 0.00 2 0.40 0.49apo 6 3.44 5.71 2 4.34 6.06 23 4.64 5.64
dia 2 1.15 1.90 1 2.17 3.03 57 11.50 13.97
eis 15 8.60 14.29 6 13.02 18.18 74 14.93 18.14ek 13 7.45 12.38 2 4.34 6.06 21 4.24 5.15
en 38 21.78 36.19 8 17.35 24.24 65 13.12 15.93
epi 8 4.58 7.62 1 2.17 3.03 29 5.85 7.11
huper 1 0.57 0.95 0 0.00 0.00 11 2.22 2.70hupo 7 4.01 6.67 3 6.51 9.09 9 1.82 2.21
kata 5 2.87 4.76 4 8.68 12.12 41 8.27 10.05
meta 0 0.00 0.00 0 0.00 0.00 23 4.64 5.64para 4 2.29 3.81 0 0.00 0.00 10 2.02 2.45
peri 0 0.00 0.00 5 10.85 15.15 23 4.64 5.64
pro 2 1.15 1.90 1 2.17 3.03 1 0.20 0.25pros 2 1.15 1.90 0 0.00 0.00 19 3.83 4.66
sun 1 0.57 0.95 0 0.00 0.00 0 0.00 0.00
105 60.17 100.00 33 71.58 100.00 408 82.32 100.00
Whole corpusWordCount
/1000 %allpreps
ana 12 0.09 0.12
anti 22 0.16 0.21apo 618 4.47 5.97
dia 667 4.83 6.44
eis 1767 12.79 17.06ek 914 6.62 8.83
en 2752 19.92 26.57
epi 890 6.44 8.59
hyper 150 1.09 1.45hypo 220 1.59 2.12
kata 473 3.42 4.57
meta 469 3.39 4.53para 194 1.40 1.87
peri 333 2.41 3.22
pro 47 0.34 0.45pros 700 5.07 6.76
sun 128 0.93 1.24
10356 74.95 100.00
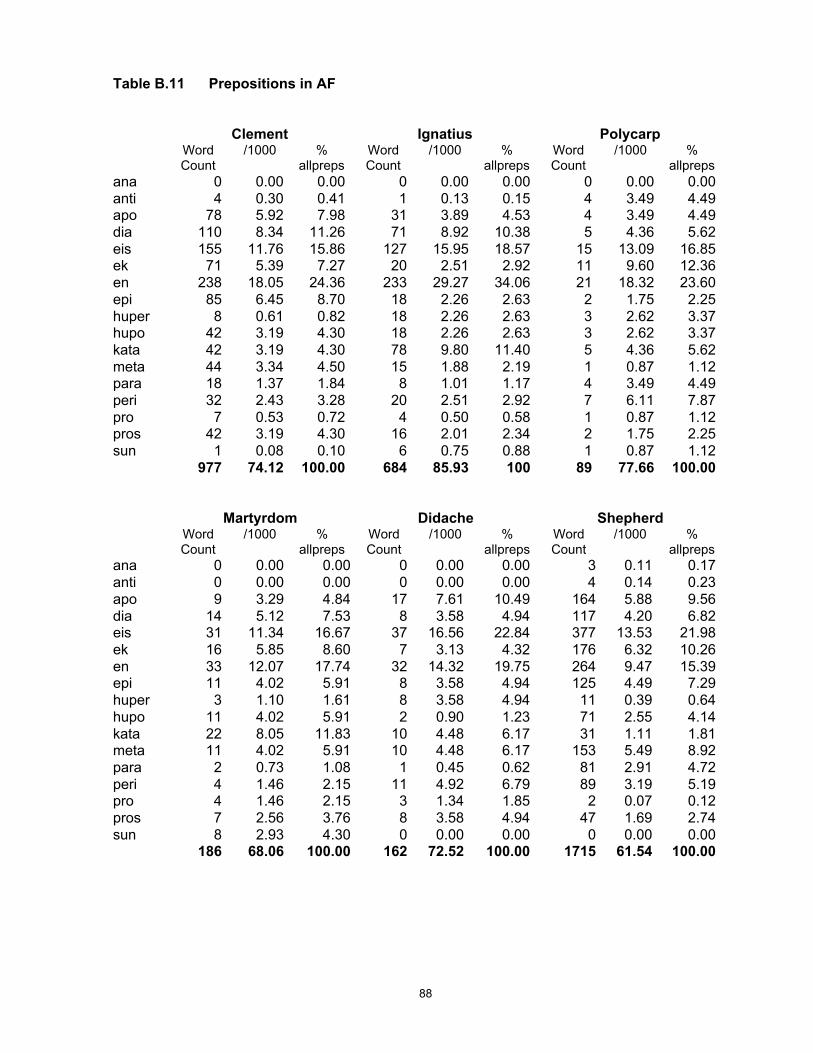
88
Table B.11 Prepositions in AF
Clement Ignatius PolycarpWordCount
/1000 %allpreps
WordCount
/1000 %allpreps
WordCount
/1000 %allpreps
ana 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00
anti 4 0.30 0.41 1 0.13 0.15 4 3.49 4.49apo 78 5.92 7.98 31 3.89 4.53 4 3.49 4.49
dia 110 8.34 11.26 71 8.92 10.38 5 4.36 5.62
eis 155 11.76 15.86 127 15.95 18.57 15 13.09 16.85ek 71 5.39 7.27 20 2.51 2.92 11 9.60 12.36
en 238 18.05 24.36 233 29.27 34.06 21 18.32 23.60
epi 85 6.45 8.70 18 2.26 2.63 2 1.75 2.25
huper 8 0.61 0.82 18 2.26 2.63 3 2.62 3.37hupo 42 3.19 4.30 18 2.26 2.63 3 2.62 3.37
kata 42 3.19 4.30 78 9.80 11.40 5 4.36 5.62
meta 44 3.34 4.50 15 1.88 2.19 1 0.87 1.12para 18 1.37 1.84 8 1.01 1.17 4 3.49 4.49
peri 32 2.43 3.28 20 2.51 2.92 7 6.11 7.87
pro 7 0.53 0.72 4 0.50 0.58 1 0.87 1.12pros 42 3.19 4.30 16 2.01 2.34 2 1.75 2.25
sun 1 0.08 0.10 6 0.75 0.88 1 0.87 1.12
977 74.12 100.00 684 85.93 100 89 77.66 100.00
Martyrdom Didache ShepherdWordCount
/1000 %allpreps
WordCount
/1000 %allpreps
WordCount
/1000 %allpreps
ana 0 0.00 0.00 0 0.00 0.00 3 0.11 0.17
anti 0 0.00 0.00 0 0.00 0.00 4 0.14 0.23
apo 9 3.29 4.84 17 7.61 10.49 164 5.88 9.56
dia 14 5.12 7.53 8 3.58 4.94 117 4.20 6.82eis 31 11.34 16.67 37 16.56 22.84 377 13.53 21.98
ek 16 5.85 8.60 7 3.13 4.32 176 6.32 10.26
en 33 12.07 17.74 32 14.32 19.75 264 9.47 15.39epi 11 4.02 5.91 8 3.58 4.94 125 4.49 7.29
huper 3 1.10 1.61 8 3.58 4.94 11 0.39 0.64
hupo 11 4.02 5.91 2 0.90 1.23 71 2.55 4.14
kata 22 8.05 11.83 10 4.48 6.17 31 1.11 1.81meta 11 4.02 5.91 10 4.48 6.17 153 5.49 8.92
para 2 0.73 1.08 1 0.45 0.62 81 2.91 4.72
peri 4 1.46 2.15 11 4.92 6.79 89 3.19 5.19pro 4 1.46 2.15 3 1.34 1.85 2 0.07 0.12
pros 7 2.56 3.76 8 3.58 4.94 47 1.69 2.74
sun 8 2.93 4.30 0 0.00 0.00 0 0.00 0.00186 68.06 100.00 162 72.52 100.00 1715 61.54 100.00
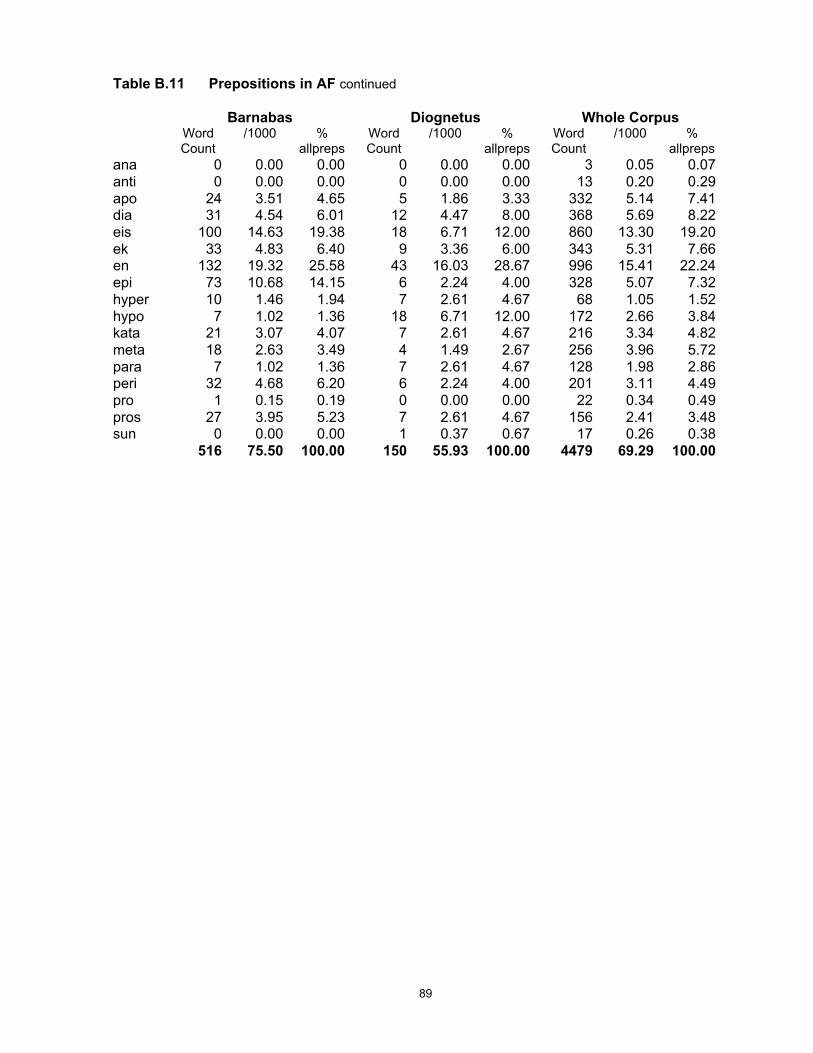
89
Table B.11 Prepositions in AF continued
Barnabas Diognetus Whole CorpusWordCount
/1000 %allpreps
WordCount
/1000 %allpreps
WordCount
/1000 %allpreps
ana 0 0.00 0.00 0 0.00 0.00 3 0.05 0.07
anti 0 0.00 0.00 0 0.00 0.00 13 0.20 0.29
apo 24 3.51 4.65 5 1.86 3.33 332 5.14 7.41dia 31 4.54 6.01 12 4.47 8.00 368 5.69 8.22
eis 100 14.63 19.38 18 6.71 12.00 860 13.30 19.20
ek 33 4.83 6.40 9 3.36 6.00 343 5.31 7.66en 132 19.32 25.58 43 16.03 28.67 996 15.41 22.24
epi 73 10.68 14.15 6 2.24 4.00 328 5.07 7.32
hyper 10 1.46 1.94 7 2.61 4.67 68 1.05 1.52
hypo 7 1.02 1.36 18 6.71 12.00 172 2.66 3.84kata 21 3.07 4.07 7 2.61 4.67 216 3.34 4.82
meta 18 2.63 3.49 4 1.49 2.67 256 3.96 5.72
para 7 1.02 1.36 7 2.61 4.67 128 1.98 2.86peri 32 4.68 6.20 6 2.24 4.00 201 3.11 4.49
pro 1 0.15 0.19 0 0.00 0.00 22 0.34 0.49
pros 27 3.95 5.23 7 2.61 4.67 156 2.41 3.48sun 0 0.00 0.00 1 0.37 0.67 17 0.26 0.38
516 75.50 100.00 150 55.93 100.00 4479 69.29 100.00
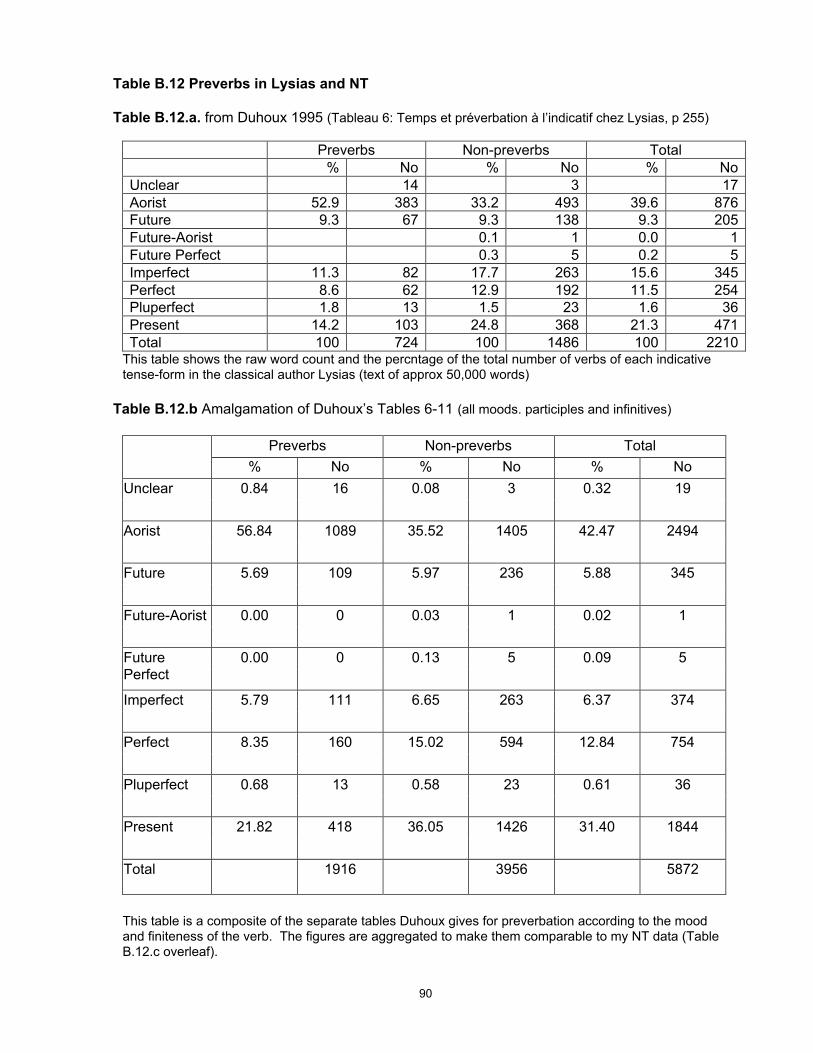
90
Table B.12 Preverbs in Lysias and NT
Table B.12.a. from Duhoux 1995 (Tableau 6: Temps et préverbation à l’indicatif chez Lysias, p 255)
Preverbs Non-preverbs Total
% No % No % No
Unclear 14 3 17
Aorist 52.9 383 33.2 493 39.6 876
Future 9.3 67 9.3 138 9.3 205
Future-Aorist 0.1 1 0.0 1
Future Perfect 0.3 5 0.2 5
Imperfect 11.3 82 17.7 263 15.6 345
Perfect 8.6 62 12.9 192 11.5 254
Pluperfect 1.8 13 1.5 23 1.6 36
Present 14.2 103 24.8 368 21.3 471
Total 100 724 100 1486 100 2210This table shows the raw word count and the percntage of the total number of verbs of each indicativetense-form in the classical author Lysias (text of approx 50,000 words)
Table B.12.b Amalgamation of Duhoux’s Tables 6-11 (all moods. participles and infinitives)
Preverbs Non-preverbs Total
% No % No % No
Unclear 0.84 16 0.08 3 0.32 19
Aorist 56.84 1089 35.52 1405 42.47 2494
Future 5.69 109 5.97 236 5.88 345
Future-Aorist 0.00 0 0.03 1 0.02 1
Future
Perfect
0.00 0 0.13 5 0.09 5
Imperfect 5.79 111 6.65 263 6.37 374
Perfect 8.35 160 15.02 594 12.84 754
Pluperfect 0.68 13 0.58 23 0.61 36
Present 21.82 418 36.05 1426 31.40 1844
Total 1916 3956 5872
This table is a composite of the separate tables Duhoux gives for preverbation according to the moodand finiteness of the verb. The figures are aggregated to make them comparable to my NT data (TableB.12.c overleaf).
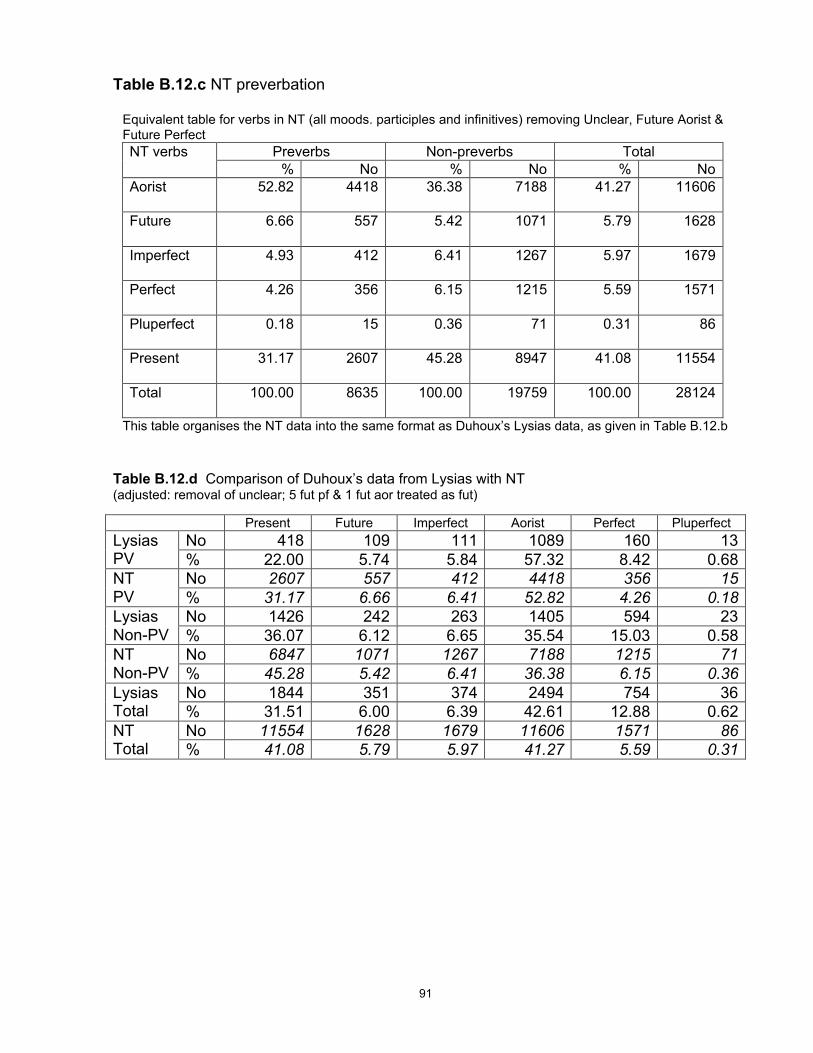
91
Table B.12.c NT preverbation
Equivalent table for verbs in NT (all moods. participles and infinitives) removing Unclear, Future Aorist &Future Perfect
Preverbs Non-preverbs TotalNT verbs
% No % No % No
Aorist 52.82 4418 36.38 7188 41.27 11606
Future 6.66 557 5.42 1071 5.79 1628
Imperfect 4.93 412 6.41 1267 5.97 1679
Perfect 4.26 356 6.15 1215 5.59 1571
Pluperfect 0.18 15 0.36 71 0.31 86
Present 31.17 2607 45.28 8947 41.08 11554
Total 100.00 8635 100.00 19759 100.00 28124
This table organises the NT data into the same format as Duhoux’s Lysias data, as given in Table B.12.b
Table B.12.d Comparison of Duhoux’s data from Lysias with NT(adjusted: removal of unclear; 5 fut pf & 1 fut aor treated as fut)
Present Future Imperfect Aorist Perfect Pluperfect
No 418 109 111 1089 160 13LysiasPV % 22.00 5.74 5.84 57.32 8.42 0.68
No 2607 557 412 4418 356 15NTPV % 31.17 6.66 6.41 52.82 4.26 0.18
No 1426 242 263 1405 594 23LysiasNon-PV % 36.07 6.12 6.65 35.54 15.03 0.58
No 6847 1071 1267 7188 1215 71NTNon-PV % 45.28 5.42 6.41 36.38 6.15 0.36
No 1844 351 374 2494 754 36LysiasTotal % 31.51 6.00 6.39 42.61 12.88 0.62
No 11554 1628 1679 11606 1571 86NTTotal % 41.08 5.79 5.97 41.27 5.59 0.31
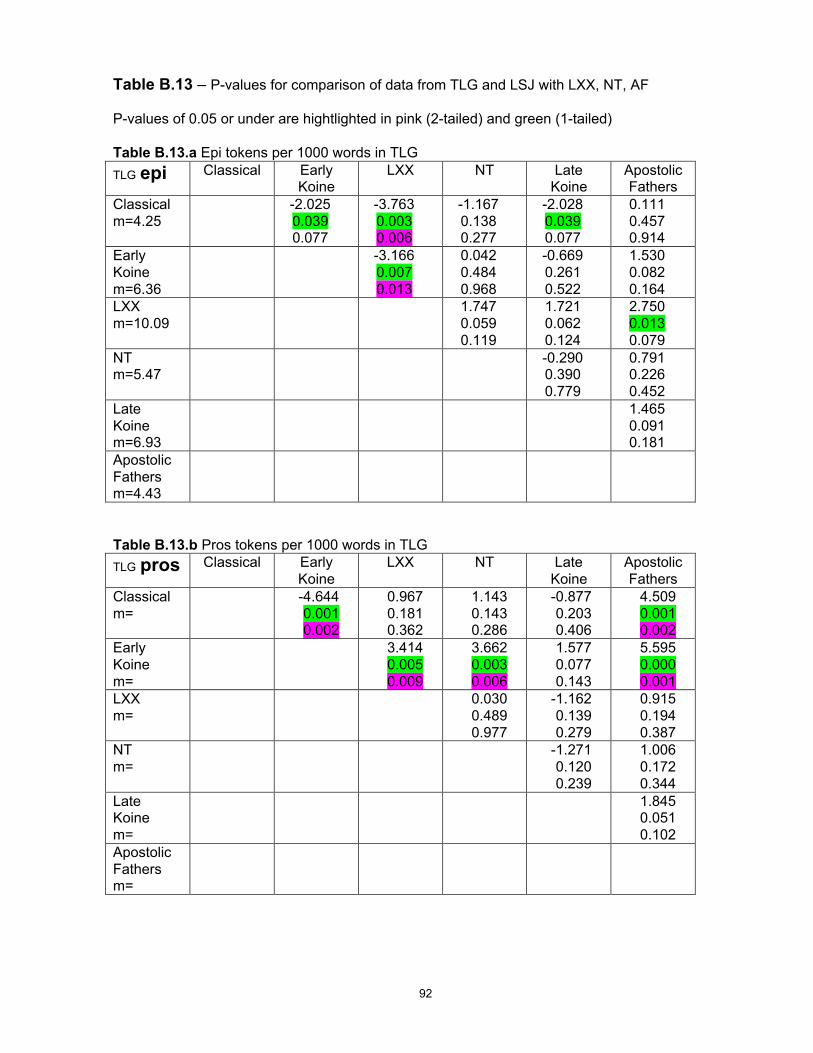
92
Table B.13 – P-values for comparison of data from TLG and LSJ with LXX, NT, AF
P-values of 0.05 or under are hightlighted in pink (2-tailed) and green (1-tailed)
Table B.13.a Epi tokens per 1000 words in TLG
TLG epi Classical EarlyKoine
LXX NT LateKoine
ApostolicFathers
Classical
m=4.25
-2.025
0.0390.077
-3.763
0.0030.006
-1.167
0.1380.277
-2.028
0.0390.077
0.111
0.4570.914
Early
Koine
m=6.36
-3.166
0.007
0.013
0.042
0.484
0.968
-0.669
0.261
0.522
1.530
0.082
0.164
LXX
m=10.09
1.747
0.059
0.119
1.721
0.062
0.124
2.750
0.013
0.079
NTm=5.47
-0.2900.390
0.779
0.7910.226
0.452
Late
Koinem=6.93
1.465
0.0910.181
Apostolic
Fathersm=4.43
Table B.13.b Pros tokens per 1000 words in TLG
TLG pros Classical Early
Koine
LXX NT Late
Koine
Apostolic
Fathers
Classical
m=
-4.644
0.0010.002
0.967
0.1810.362
1.143
0.1430.286
-0.877
0.2030.406
4.509
0.0010.002
Early
Koine
m=
3.414
0.005
0.009
3.662
0.003
0.006
1.577
0.077
0.143
5.595
0.000
0.001
LXX
m=
0.030
0.489
0.977
-1.162
0.139
0.279
0.915
0.194
0.387
NT
m=
-1.271
0.120
0.239
1.006
0.172
0.344
LateKoine
m=
1.8450.051
0.102
Apostolic
Fathersm=
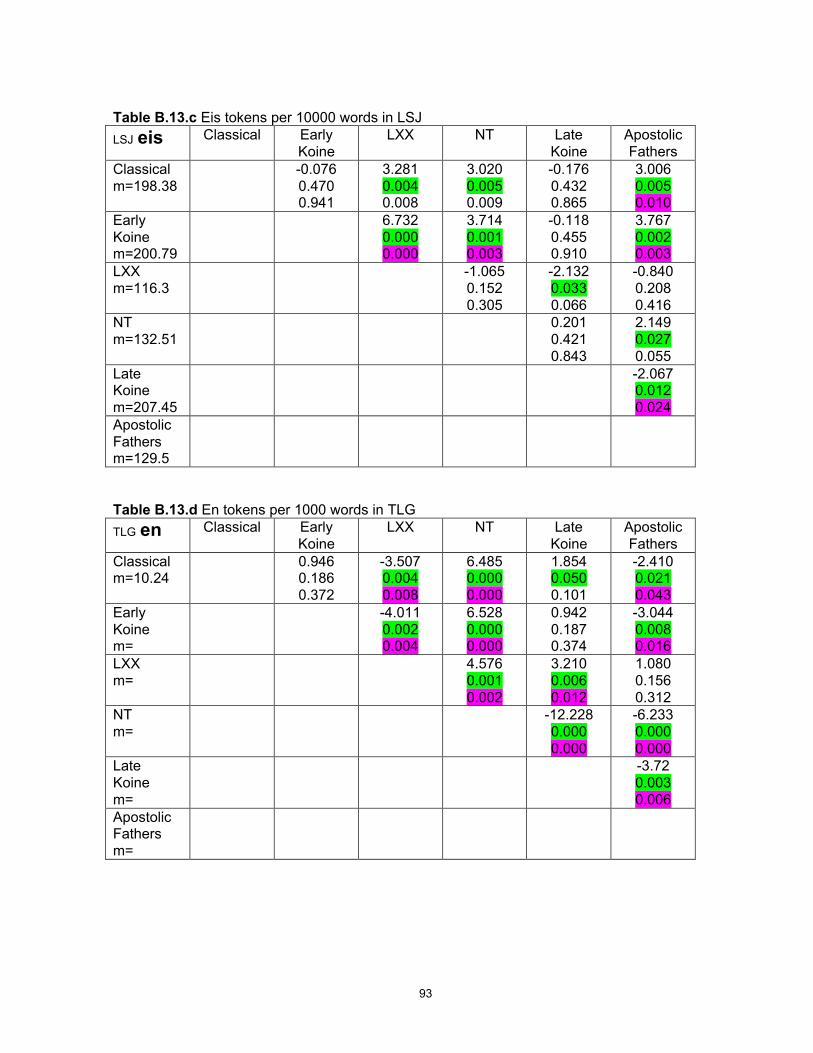
93
Table B.13.c Eis tokens per 10000 words in LSJ
LSJ eis Classical Early
Koine
LXX NT Late
Koine
Apostolic
Fathers
Classical
m=198.38
-0.076
0.4700.941
3.281
0.0040.008
3.020
0.0050.009
-0.176
0.4320.865
3.006
0.0050.010
Early
Koinem=200.79
6.732
0.0000.000
3.714
0.0010.003
-0.118
0.4550.910
3.767
0.0020.003
LXX
m=116.3
-1.065
0.152
0.305
-2.132
0.033
0.066
-0.840
0.208
0.416
NT
m=132.51
0.201
0.421
0.843
2.149
0.027
0.055
LateKoine
m=207.45
-2.0670.012
0.024
Apostolic
Fathersm=129.5
Table B.13.d En tokens per 1000 words in TLG
TLG en Classical Early
Koine
LXX NT Late
Koine
Apostolic
Fathers
Classicalm=10.24
0.9460.186
0.372
-3.5070.004
0.008
6.4850.000
0.000
1.8540.050
0.101
-2.4100.021
0.043
Early
Koinem=
-4.011
0.0020.004
6.528
0.0000.000
0.942
0.1870.374
-3.044
0.0080.016
LXX
m=
4.576
0.001
0.002
3.210
0.006
0.012
1.080
0.156
0.312
NT
m=
-12.228
0.000
0.000
-6.233
0.000
0.000
Late
Koine
m=
-3.72
0.003
0.006
ApostolicFathers
m=

94
Table B.14 Preverbs in LXX - order of frequency in each group
Pentateuch Chronicles Proverbs Ecclesiastes Isaiah1 1115 apo 275 kata 118 apo 29 apo 260 apo 12 1061 ek 224 apo 104 kata 26 ek 236 kata 23 828 kata 208 ek 93 ek 26 epi 209 ana 34 645 epi 137 ana 87 epi 13 kata 188 ek 45 534 ana 120 epi 63 sun 11 sun 131 epi 56 501 pros 73 sun 46 para 9 ana 123 sun 67 412 sun 69 eis 42 dia 9 dia 92 para 78 370 eis 61 pros 35 hupo 9 peri 67 dia 89 361 para 60 dia 33 ana 7 pros 65 en 9
10 284 dia 57 para 33 pros 6 para 58 pros 1011 251 en 41 en 21 en 3 hupo 38 anti 1112 118 peri 19 pro 20 pro 2 anti 35 eis 1213 79 hupo 16 hupo 18 peri 1 eis 24 peri 1314 54 pro 12 anti 14 eis 0 en 15 hupo 1415 40 anti 12 peri 10 meta 0 huper 12 pro 1516 29 meta 9 meta 9 anti 0 meta 11 meta 1617 22 huper 2 huper 9 huper 0 pro 4 huper 1718 0 amphi 0 amphi 0 amphi 0 amphi 0 amphi 18
6704 1395 755 151 1568
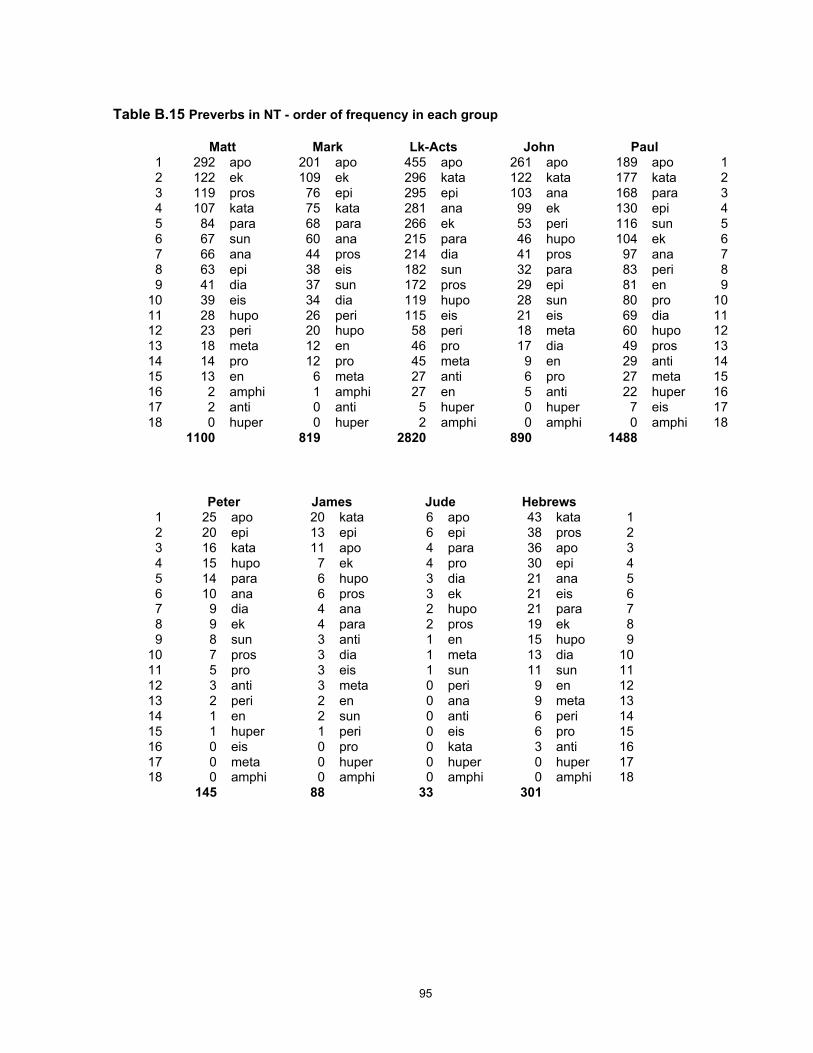
95
Table B.15 Preverbs in NT - order of frequency in each group
Matt Mark Lk-Acts John Paul1 292 apo 201 apo 455 apo 261 apo 189 apo 12 122 ek 109 ek 296 kata 122 kata 177 kata 23 119 pros 76 epi 295 epi 103 ana 168 para 34 107 kata 75 kata 281 ana 99 ek 130 epi 45 84 para 68 para 266 ek 53 peri 116 sun 56 67 sun 60 ana 215 para 46 hupo 104 ek 67 66 ana 44 pros 214 dia 41 pros 97 ana 78 63 epi 38 eis 182 sun 32 para 83 peri 89 41 dia 37 sun 172 pros 29 epi 81 en 9
10 39 eis 34 dia 119 hupo 28 sun 80 pro 1011 28 hupo 26 peri 115 eis 21 eis 69 dia 1112 23 peri 20 hupo 58 peri 18 meta 60 hupo 1213 18 meta 12 en 46 pro 17 dia 49 pros 1314 14 pro 12 pro 45 meta 9 en 29 anti 1415 13 en 6 meta 27 anti 6 pro 27 meta 1516 2 amphi 1 amphi 27 en 5 anti 22 huper 1617 2 anti 0 anti 5 huper 0 huper 7 eis 1718 0 huper 0 huper 2 amphi 0 amphi 0 amphi 18
1100 819 2820 890 1488
Peter James Jude Hebrews1 25 apo 20 kata 6 apo 43 kata 12 20 epi 13 epi 6 epi 38 pros 23 16 kata 11 apo 4 para 36 apo 34 15 hupo 7 ek 4 pro 30 epi 45 14 para 6 hupo 3 dia 21 ana 56 10 ana 6 pros 3 ek 21 eis 67 9 dia 4 ana 2 hupo 21 para 78 9 ek 4 para 2 pros 19 ek 89 8 sun 3 anti 1 en 15 hupo 9
10 7 pros 3 dia 1 meta 13 dia 1011 5 pro 3 eis 1 sun 11 sun 1112 3 anti 3 meta 0 peri 9 en 1213 2 peri 2 en 0 ana 9 meta 1314 1 en 2 sun 0 anti 6 peri 1415 1 huper 1 peri 0 eis 6 pro 1516 0 eis 0 pro 0 kata 3 anti 1617 0 meta 0 huper 0 huper 0 huper 1718 0 amphi 0 amphi 0 amphi 0 amphi 18
145 88 33 301
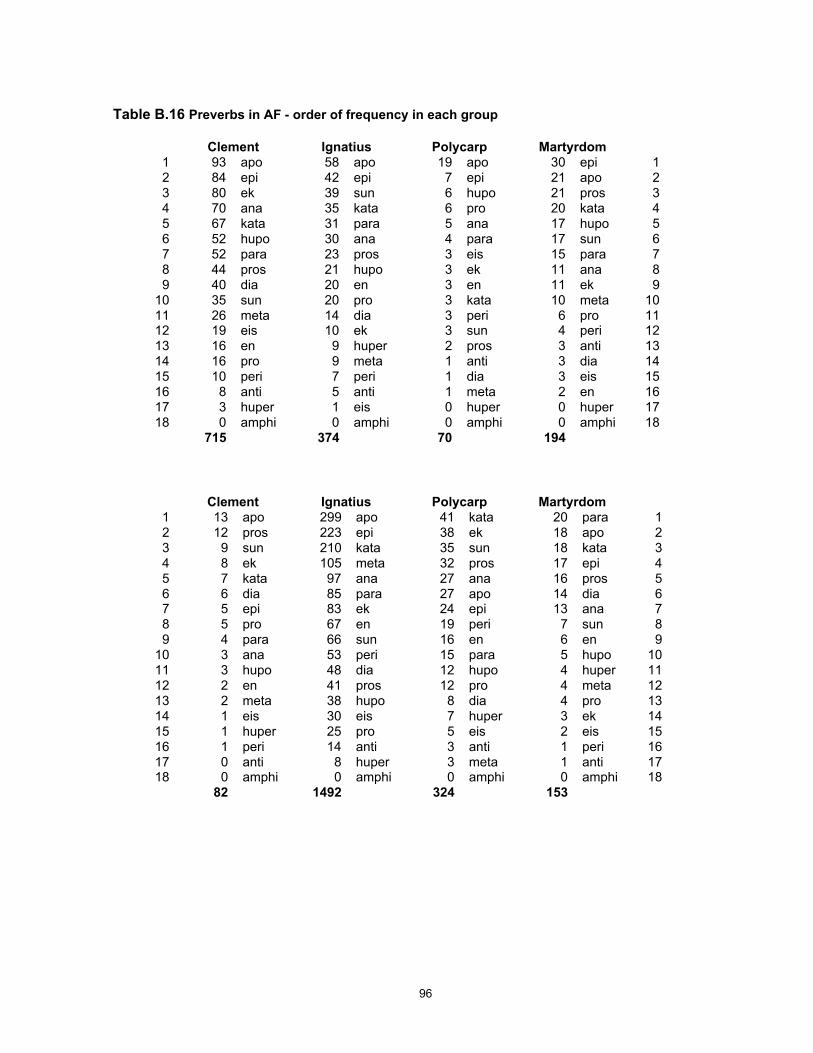
96
Table B.16 Preverbs in AF - order of frequency in each group
Clement Ignatius Polycarp Martyrdom1 93 apo 58 apo 19 apo 30 epi 12 84 epi 42 epi 7 epi 21 apo 23 80 ek 39 sun 6 hupo 21 pros 34 70 ana 35 kata 6 pro 20 kata 45 67 kata 31 para 5 ana 17 hupo 56 52 hupo 30 ana 4 para 17 sun 67 52 para 23 pros 3 eis 15 para 78 44 pros 21 hupo 3 ek 11 ana 89 40 dia 20 en 3 en 11 ek 9
10 35 sun 20 pro 3 kata 10 meta 1011 26 meta 14 dia 3 peri 6 pro 1112 19 eis 10 ek 3 sun 4 peri 1213 16 en 9 huper 2 pros 3 anti 1314 16 pro 9 meta 1 anti 3 dia 1415 10 peri 7 peri 1 dia 3 eis 1516 8 anti 5 anti 1 meta 2 en 1617 3 huper 1 eis 0 huper 0 huper 1718 0 amphi 0 amphi 0 amphi 0 amphi 18
715 374 70 194
Clement Ignatius Polycarp Martyrdom1 13 apo 299 apo 41 kata 20 para 12 12 pros 223 epi 38 ek 18 apo 23 9 sun 210 kata 35 sun 18 kata 34 8 ek 105 meta 32 pros 17 epi 45 7 kata 97 ana 27 ana 16 pros 56 6 dia 85 para 27 apo 14 dia 67 5 epi 83 ek 24 epi 13 ana 78 5 pro 67 en 19 peri 7 sun 89 4 para 66 sun 16 en 6 en 9
10 3 ana 53 peri 15 para 5 hupo 1011 3 hupo 48 dia 12 hupo 4 huper 1112 2 en 41 pros 12 pro 4 meta 1213 2 meta 38 hupo 8 dia 4 pro 1314 1 eis 30 eis 7 huper 3 ek 1415 1 huper 25 pro 5 eis 2 eis 1516 1 peri 14 anti 3 anti 1 peri 1617 0 anti 8 huper 3 meta 1 anti 1718 0 amphi 0 amphi 0 amphi 0 amphi 18
82 1492 324 153
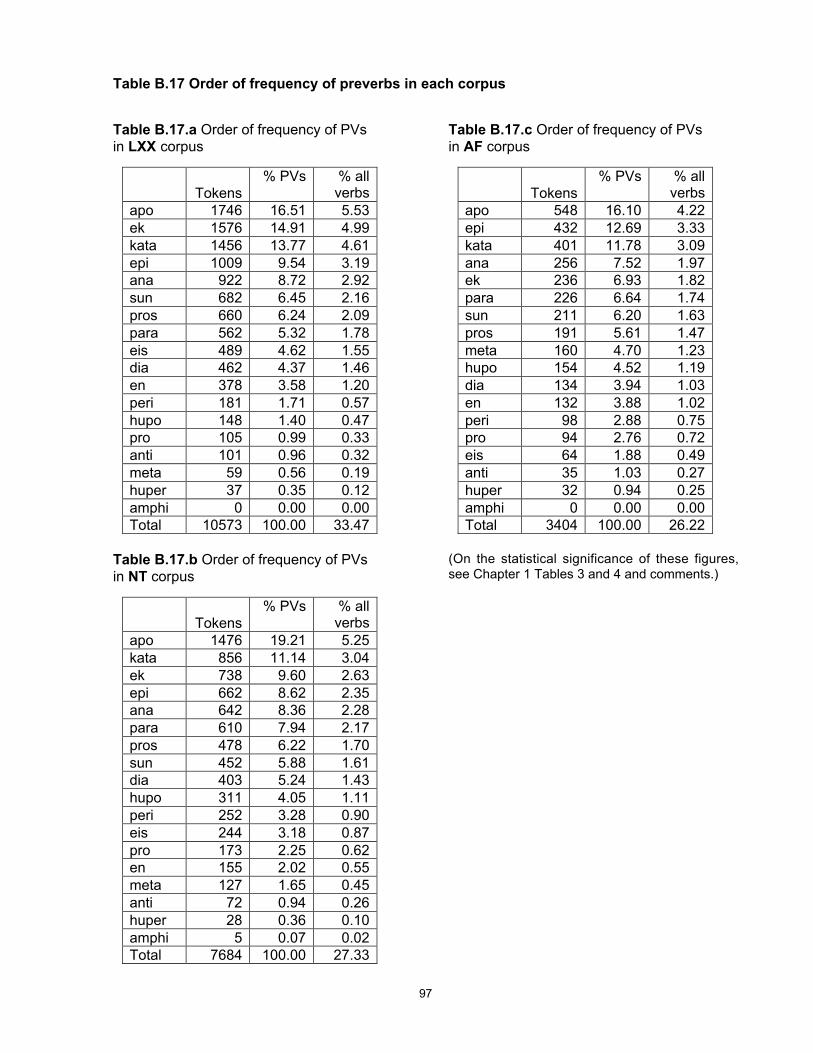
97
Table B.17 Order of frequency of preverbs in each corpus
Table B.17.a Order of frequency of PVs
in LXX corpus
Tokens
% PVs % allverbs
apo 1746 16.51 5.53
ek 1576 14.91 4.99
kata 1456 13.77 4.61
epi 1009 9.54 3.19
ana 922 8.72 2.92
sun 682 6.45 2.16
pros 660 6.24 2.09
para 562 5.32 1.78
eis 489 4.62 1.55
dia 462 4.37 1.46
en 378 3.58 1.20
peri 181 1.71 0.57
hupo 148 1.40 0.47
pro 105 0.99 0.33
anti 101 0.96 0.32
meta 59 0.56 0.19
huper 37 0.35 0.12
amphi 0 0.00 0.00
Total 10573 100.00 33.47
Table B.17.b Order of frequency of PVs
in NT corpus
Tokens
% PVs % allverbs
apo 1476 19.21 5.25
kata 856 11.14 3.04
ek 738 9.60 2.63
epi 662 8.62 2.35
ana 642 8.36 2.28
para 610 7.94 2.17
pros 478 6.22 1.70
sun 452 5.88 1.61
dia 403 5.24 1.43
hupo 311 4.05 1.11
peri 252 3.28 0.90
eis 244 3.18 0.87
pro 173 2.25 0.62
en 155 2.02 0.55
meta 127 1.65 0.45
anti 72 0.94 0.26
huper 28 0.36 0.10
amphi 5 0.07 0.02
Total 7684 100.00 27.33
Table B.17.c Order of frequency of PVs
in AF corpus
Tokens
% PVs % allverbs
apo 548 16.10 4.22
epi 432 12.69 3.33
kata 401 11.78 3.09
ana 256 7.52 1.97
ek 236 6.93 1.82
para 226 6.64 1.74
sun 211 6.20 1.63
pros 191 5.61 1.47
meta 160 4.70 1.23
hupo 154 4.52 1.19
dia 134 3.94 1.03
en 132 3.88 1.02
peri 98 2.88 0.75
pro 94 2.76 0.72
eis 64 1.88 0.49
anti 35 1.03 0.27
huper 32 0.94 0.25
amphi 0 0.00 0.00
Total 3404 100.00 26.22
(On the statistical significance of these figures,see Chapter 1 Tables 3 and 4 and comments.)
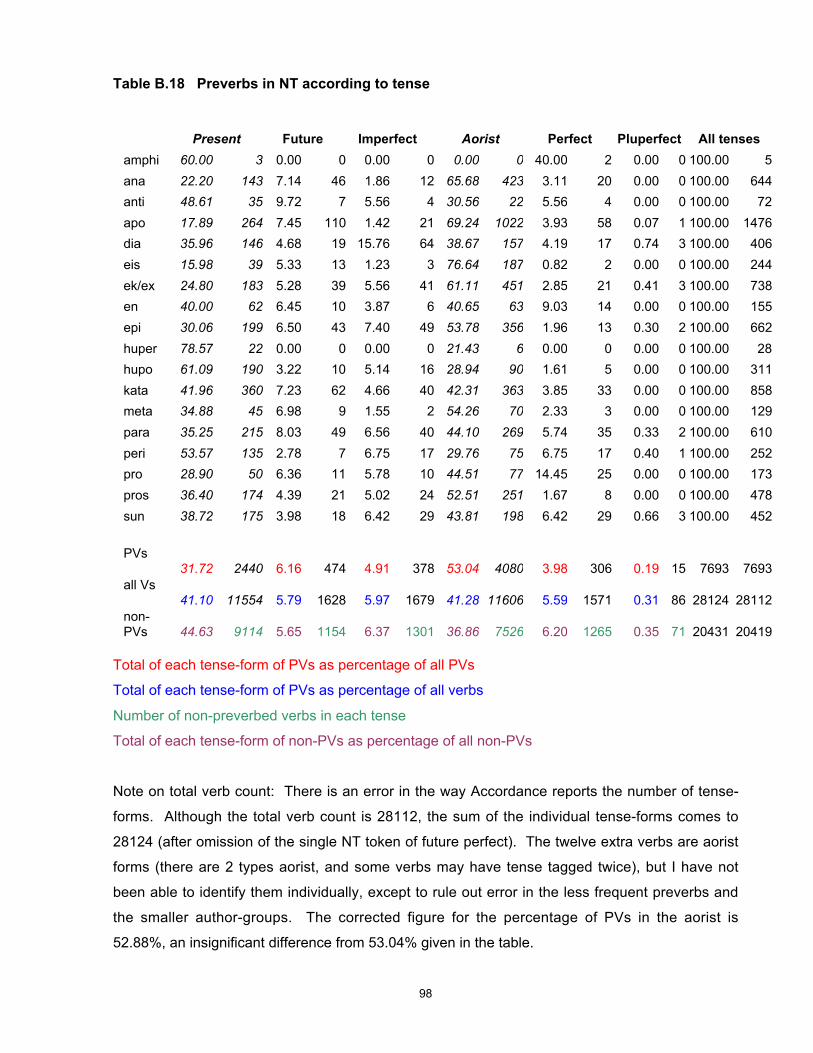
98
Table B.18 Preverbs in NT according to tense
Present Future Imperfect Aorist Perfect Pluperfect All tenses
amphi 60.00 3 0.00 0 0.00 0 0.00 0 40.00 2 0.00 0 100.00 5
ana 22.20 143 7.14 46 1.86 12 65.68 423 3.11 20 0.00 0 100.00 644
anti 48.61 35 9.72 7 5.56 4 30.56 22 5.56 4 0.00 0 100.00 72
apo 17.89 264 7.45 110 1.42 21 69.24 1022 3.93 58 0.07 1 100.00 1476
dia 35.96 146 4.68 19 15.76 64 38.67 157 4.19 17 0.74 3 100.00 406
eis 15.98 39 5.33 13 1.23 3 76.64 187 0.82 2 0.00 0 100.00 244
ek/ex 24.80 183 5.28 39 5.56 41 61.11 451 2.85 21 0.41 3 100.00 738
en 40.00 62 6.45 10 3.87 6 40.65 63 9.03 14 0.00 0 100.00 155
epi 30.06 199 6.50 43 7.40 49 53.78 356 1.96 13 0.30 2 100.00 662
huper 78.57 22 0.00 0 0.00 0 21.43 6 0.00 0 0.00 0 100.00 28
hupo 61.09 190 3.22 10 5.14 16 28.94 90 1.61 5 0.00 0 100.00 311
kata 41.96 360 7.23 62 4.66 40 42.31 363 3.85 33 0.00 0 100.00 858
meta 34.88 45 6.98 9 1.55 2 54.26 70 2.33 3 0.00 0 100.00 129
para 35.25 215 8.03 49 6.56 40 44.10 269 5.74 35 0.33 2 100.00 610
peri 53.57 135 2.78 7 6.75 17 29.76 75 6.75 17 0.40 1 100.00 252
pro 28.90 50 6.36 11 5.78 10 44.51 77 14.45 25 0.00 0 100.00 173
pros 36.40 174 4.39 21 5.02 24 52.51 251 1.67 8 0.00 0 100.00 478
sun 38.72 175 3.98 18 6.42 29 43.81 198 6.42 29 0.66 3 100.00 452
PVs31.72 2440 6.16 474 4.91 378 53.04 4080 3.98 306 0.19 15 7693 7693
all Vs41.10 11554 5.79 1628 5.97 1679 41.28 11606 5.59 1571 0.31 86 28124 28112
non-PVs 44.63 9114 5.65 1154 6.37 1301 36.86 7526 6.20 1265 0.35 71 20431 20419
Total of each tense-form of PVs as percentage of all PVs
Total of each tense-form of PVs as percentage of all verbs
Number of non-preverbed verbs in each tense
Total of each tense-form of non-PVs as percentage of all non-PVs
Note on total verb count: There is an error in the way Accordance reports the number of tense-
forms. Although the total verb count is 28112, the sum of the individual tense-forms comes to
28124 (after omission of the single NT token of future perfect). The twelve extra verbs are aorist
forms (there are 2 types aorist, and some verbs may have tense tagged twice), but I have not
been able to identify them individually, except to rule out error in the less frequent preverbs and
the smaller author-groups. The corrected figure for the percentage of PVs in the aorist is
52.88%, an insignificant difference from 53.04% given in the table.

99
Table B.19.a Tenses in LXX Corpus
Pentateuch Chronicles Proverbs Ecclesiastes Isaiah Total
present 3529 18.60 724 16.39 1233 55.42 248 31.71 1301 25.03 7035 22.27
imperfect 546 2.88 237 5.37 24 1.08 3 0.38 59 1.14 869 2.75
future 4711 24.83 257 5.82 400 17.98 140 17.90 1629 31.35 7137 22.59
aorist 9371 49.39 3052 69.10 487 21.89 360 46.04 1942 37.37 15212 48.15
perfect 775 4.08 143 3.24 79 3.55 31 3.96 257 4.95 1285 4.07
pluperfect 40 0.21 4 0.09 2 0.09 0 0.00 9 0.17 55 0.17
All Vs 18972 100.00 4417 100.00 2225 100.00 782 100.00 5197 100.00 31593 100.00
Table B.19.b Tenses in NT
Matthew Mark Luke-Acts John Paul
present 1420 35.48 977 37.06 2724 32.41 2475 43.31 3057 55.30
imperfect 142 3.55 293 11.12 784 9.33 332 5.81 85 1.54
future 355 8.87 124 4.70 419 4.99 302 5.29 323 5.84
aorist 1964 49.08 1142 43.32 4110 48.90 2094 36.65 1655 29.94
perfect 113 2.82 92 3.49 335 3.99 475 8.31 407 7.36
pluperfect 8 0.20 8 0.30 33 0.39 36 0.63 1 0.02
All Vs 4002 100.00 2636 100.00 8405 100.00 5714 100.00 5528 100.00
Actual Vs 4000 2635 8402 5710 5525
Peter James Jude Hebrews Total
present 238 49.90 197 55.18 41 48.24 425 46.15 11554 41.08
imperfect 11 2.31 3 0.84 2 2.35 27 2.93 1679 5.97
future 27 5.66 26 7.28 1 1.18 51 5.54 1628 5.79
aorist 167 35.01 112 31.37 32 37.65 330 35.83 11606 41.27
perfect 34 7.13 19 5.32 9 10.59 87 9.45 1571 5.59
pluperfect 0 0.00 0 0.00 0 0.00 0 0.00 86 0.31
All Vs 477 100.00 357 100.00 85 100.00 920 99.89 28125 100.00
Actual Vs 477 357 85 920
As noted under Table B.18, there is an error in the tense-counts for NT. The ‘Actual Vs’ lineshows where the error affects each author-group. Ony the larger groups are affected, byovercounting of aorists. The percentage of 99.89 for verbs in Hebrews is due to omission ofa future perfect (the only token of this form in NT).
Table B.19.c Tenses in AF Corpus
Clement Ignatius Polycarp Martyrdom Didache
present 1014 41.88 855 57.34 99 49.50 196 36.77 198 46.59
imperfect 58 2.40 27 1.81 1 0.50 38 7.13 1 0.24
future 214 8.84 41 2.75 12 6.00 6 1.13 95 22.35
aorist 978 40.40 433 29.04 74 37.00 263 49.34 120 28.24
perfect 147 6.07 135 9.05 14 7.00 27 5.07 11 2.59
pluperfect 10 0.41 0 0.00 0 0.00 3 0.56 0 0.00
all Vs 2421 100.00 1491 100.00 200 100.00 533 100.00 425 100.00
Shepherd Barnabas Diognetus Total
present 2899 48.54 638 46.16 335 59.93 6234 48.01
imperfect 286 4.79 30 2.17 8 1.43 449 3.46
future 438 7.33 175 12.66 23 4.11 1004 7.73
aorist 2002 33.52 456 33.00 155 27.73 4481 34.51
perfect 327 5.47 83 6.01 36 6.44 780 6.01
pluperfect 21 0.35 0 0.00 2 0.36 36 0.28
all Vs 5973 100.00 1382 100.00 559 100.00 12984 100.00

100
Table B.20 Present and aorist tenses of PVs in LXX Corpus
Pentateuch Chronicles Proverbs
Present Aorist Present Aorist Present Aorist
ana 5.42 50 36.23 334 2.93 27 9.87 91 1.63 15 0.65 6
anti 4.95 5 11.88 12 0.00 0 10.89 11 3.96 4 0.00 0
apo 5.73 100 37.63 657 0.63 11 10.82 189 2.92 51 2.52 44
dia 12.77 59 27.49 127 1.52 7 9.09 42 4.55 21 1.30 6
eis 12.27 60 42.94 210 1.84 9 8.59 42 0.61 3 1.64 8
ek/ex 6.98 110 37.75 595 1.97 31 10.34 163 2.86 45 1.90 30
en 14.81 56 39.42 149 0.00 0 10.05 38 3.70 14 0.79 3
epi 5.65 57 34.79 351 1.78 18 9.02 91 4.66 47 2.87 29
huper 10.81 4 37.84 14 0.00 0 2.70 1 10.81 4 8.11 3
hupo 20.27 30 25.68 38 4.73 7 5.41 8 14.19 21 6.76 10
kata 9.34 136 28.71 418 3.91 57 13.26 193 3.64 53 1.58 23
meta 1.69 1 37.29 22 0.00 0 15.25 9 10.17 6 5.08 3
para 8.01 45 40.21 226 1.96 11 7.12 40 4.98 28 1.78 10
peri 6.08 11 29.28 53 3.87 7 0.55 1 4.97 9 3.31 6
pro 20.95 22 17.14 18 3.81 4 12.38 13 0.00 0 5.71 6
pros 12.88 85 32.27 213 1.21 8 6.21 41 2.73 18 1.36 9
sun 6.16 42 39.00 266 0.88 6 9.53 65 6.16 42 1.17 8
8.26 873 35.02 3703 1.92 203 9.82 1038 3.60 381 1.93 204
11.17 3529 29.66 9371 2.29 724 9.66 3052 3.90 1233 1.54 487
12.64 2656 26.96 5668 2.48 521 9.58 2014 4.05 852 1.35 283
19.08 80.92 16.36 83.64 65.13 34.87
Ecclesiastes Isaiah Whole Corpus
Present Aorist Present Aorist Present Aorist
ana 0.33 3 0.22 2 2.06 19 89 12.36 114 56.62 522
anti 0.99 1 0.99 1 20.79 21 8.91 9 30.69 31 32.67 33
apo 0.23 4 0.92 16 2.00 35 7.62 133 11.51 201 59.51 1039
dia 0.22 1 0.65 3 4.33 20 4.55 21 23.38 108 43.07 199
eis 0.00 0 0.20 1 0.61 3 4.50 22 15.34 75 57.87 283
ek/ex 0.57 9 0.70 11 1.71 27 6.35 100 14.09 222 57.04 899
en 0.00 0 0.00 0 6.61 25 6.08 23 25.13 95 56.35 213
epi 0.40 4 1.78 18 3.07 31 4.86 49 15.56 157 53.32 538
huper 0.00 0 0.00 0 0.00 0 0.00 0 21.62 8 48.65 18
hupo 1.35 2 1.35 2 4.73 7 4.73 7 45.27 67 43.92 65
kata 0.21 3 0.48 7 3.91 57 6.25 91 21.02 306 50.27 732
meta 0.00 0 0.00 0 0.00 0 6.78 4 11.86 7 64.41 38
para 0.53 3 0.36 2 4.80 27 7.12 40 20.28 114 56.58 318
peri 3.31 6 1.66 3 0.00 0 6.63 12 18.23 33 41.44 75
pro 0.00 0 0.00 0 1.90 2 2.86 3 26.67 28 38.10 40
pros 0.30 2 0.61 4 3.03 20 3.03 20 20.15 133 43.48 287
sun 0.00 0 0.88 6 2.93 20 6.45 44 16.13 110 57.04 389
0.36 38 0.72 76 2.97 314 6.31 667 17.11 1809 53.80 5688
0.78 248 1.14 360 4.12 1301 6.15 1942 22.27 7035 48.15 15212
1.00 210 1.35 284 4.70 987 6.07 1275 24.86 5226 45.31 9524
33.33 66.67 32.01 67.99 24.13 75.87
PV tense-form as percentage of all PVs in whole corpusAll verb tense-forms as percentage of all verbs in whole corpusAll non-PV tense-forms as percentage of all non-PVs in whole corpusEach tense as percentage of sum of present and aorist forms in its group (a ‘two-party-preferred’ rate)

101
Table B.21 Present and aorist tenses of PVs in AF Corpus
Clement Ignatius Polycarp Martyrdom
Present Aor Present Aorist Present Aor Present Aor
ana 10.94 28 12.11 31 3.91 10 7.03 18 0.78 2 1.17 3 0.78 2 3.13 8
anti 14.29 5 2.86 1 8.57 3 5.71 2 5.71 2 0.00 0 5.71 2 2.86 1
apo 4.93 27 9.85 54 2.92 16 6.02 33 0.91 5 1.09 6 0.91 5 2.55 14
dia 9.70 13 14.93 20 3.73 5 5.22 7 0.75 1 0.00 0 0.75 1 0.75 1
eis 1.56 1 21.88 14 1.56 1 0.00 0 1.56 1 4.69 3 1.56 1 3.13 2
ek/ex 2.54 6 2.97 7 3.81 9 0.85 2 0.42 1 0.42 1 0.42 1 0.42 1
en 11.36 15 38.64 51 3.79 5 1.52 2 3.03 4 0.76 1 3.03 4 5.30 7
epi 8.56 37 8.33 36 2.55 11 6.25 27 2.78 12 0.69 3 2.78 12 3.47 15
huper 9.38 3 0.00 0 21.88 7 6.25 2 0.00 0 0.00 0 0.00 0 0.00 0
hupo 20.63 33 9.38 15 9.38 15 3.75 6 3.75 6 2.50 4 3.75 6 5.00 8
kata 3.99 16 9.48 38 2.99 12 3.49 14 1.25 5 0.50 2 1.25 5 3.24 13
meta 2.50 4 10.63 17 1.88 3 3.75 6 1.25 2 0.00 0 1.25 2 5.00 8
para 7.08 16 9.73 22 8.85 20 4.42 10 3.10 7 0.88 2 0.88 2 2.21 5
peri 4.08 4 3.06 3 7.14 7 0.00 0 0.00 0 0.00 0 7.14 7 1.02 1
pro 3.19 3 7.45 7 10.64 10 4.26 4 2.13 2 3.19 3 0.00 0 1.06 1
pros 8.90 17 10.99 21 7.85 15 2.09 4 5.76 11 0.00 0 1.05 2 5.24 10
sun 2.84 6 8.53 18 9.48 20 5.69 12 1.42 3 0.95 2 5.21 11 5.69 12
6.86 234 10.41 355 4.96 169 4.37 149 1.88 64 0.88 30 1.94 66 3.14 107
7.81 1014 7.53 978 6.59 855 3.33 433 1.51 196 0.57 74 1.51 196 2.03 263
8.15 780 6.51 623 7.17 686 2.97 284 1.38 132 0.46 44 1.36 130 1.63 156
39.73 60.27 53.14 46.86 50.82 49.18 37.43 62.57
Didache Shepherd Barnabas Diognetus
Present Aor Present Present Aorist Present Aor Aorist
ana 0.39 1 0.39 1 10.55 27 23.83 61 3.91 10 4.30 11 2.73 7 1.95 5
anti 0.00 0 0.00 0 8.57 3 25.71 9 2.86 1 5.71 2 2.86 1 0.00 0
apo 1.09 6 0.36 2 11.68 64 30.84 169
1.28 7 1.64 9 1.82 10 1.46 8
dia 1.49 2 0.75 1 11.94 16 14.18 19 2.99 4 1.49 2 5.97 8 0.75 1
eis 0.00 0 1.56 1 6.25 4 23.44 15 3.13 2 4.69 3 0.00 0 3.13 2
ek/ex 0.85 2 0.00 0 7.20 17 14.41 34 2.54 6 1.69 4 0.85 2 1.69 4
en 2.27 3 0.76 1 22.73 30 25.76 34 9.09 12 12.88 17 0.76 1 1.52 2
epi 0.23 1 0.23 1 16.44 71 23.15 100
2.31 10 2.31 10 1.62 7 1.85 8
huper 0.00 0 3.13 1 25.00 8 0.00 0 9.38 3 6.25 2 9.38 3 0.00 0
hupo 0.63 1 0.63 1 11.25 18 10.63 17 0.63 1 5.63 9 1.25 2 1.25 2
kata 1.25 5 0.50 2 22.19 89 19.45 78 4.24 17 4.24 17 2.49 10 0.75 3
meta 0.63 1 0.63 1 14.38 23 41.25 66 0.00 0 1.88 3 1.25 2 0.63 1
para 0.00 0 0.88 2 10.18 23 19.47 44 1.33 3 2.65 6 6.19 14 2.21 5
peri 1.02 1 0.00 0 31.63 31 12.24 12 6.12 6 6.12 11 1.02 1 0.00 0
pro 0.00 0 4.26 4 10.64 10 5.32 5 4.26 4 11.70 4 2.13 2 2.13 2
pros 4.19 8 0.52 1 7.85 15 10.99 21 10.47 20 2.09 8 6.28 12 1.57 3
sun 0.95 2 2.37 5 12.80 27 14.22 30 7.11 15 3.79 9 2.84 6 0.00 0
0.97 33 0.70 24 13.96 476 20.94 714
3.55 121 3.72 127 2.58 88 1.35 46
1.52 198 0.92 120 22.33 2899
15.42 2002
4.91 638 3.51 456 2.58 335
1.19 155
1.72 165 1.00 96 25.31 2423
13.45 1288
5.40 517 3.44 329 2.58 247
1.14 109
57.89 42.11 40.00 60.00 48.79 51.21 65.67 34.33
PV tense-form as percentage of all PVs in whole corpusAll verb tense-forms as percentage of all verbs in whole corpusAll non-PV tense-forms as percentage of all non-PVs in whole corpusEach tense as percentage of sum of present and aorist forms in its group (a ‘two-party-preferred’ rate)
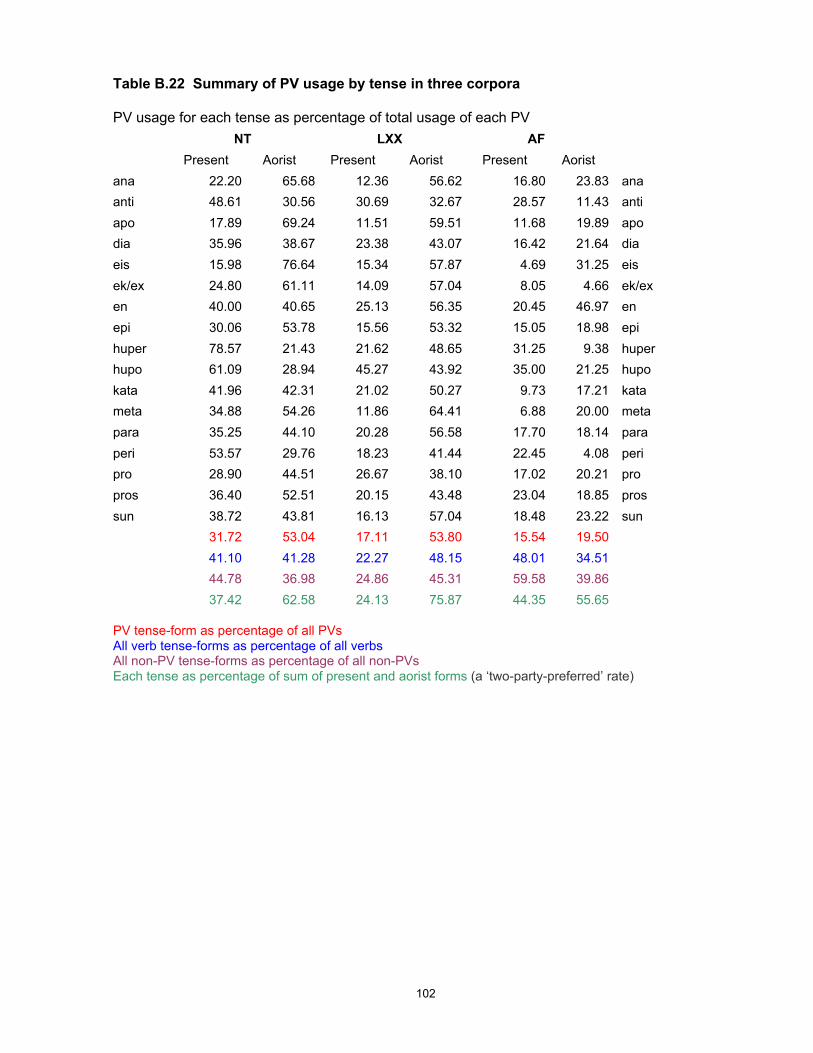
102
Table B.22 Summary of PV usage by tense in three corpora
PV usage for each tense as percentage of total usage of each PV
NT LXX AF
Present Aorist Present Aorist Present Aorist
ana 22.20 65.68 12.36 56.62 16.80 23.83 ana
anti 48.61 30.56 30.69 32.67 28.57 11.43 anti
apo 17.89 69.24 11.51 59.51 11.68 19.89 apo
dia 35.96 38.67 23.38 43.07 16.42 21.64 dia
eis 15.98 76.64 15.34 57.87 4.69 31.25 eis
ek/ex 24.80 61.11 14.09 57.04 8.05 4.66 ek/ex
en 40.00 40.65 25.13 56.35 20.45 46.97 en
epi 30.06 53.78 15.56 53.32 15.05 18.98 epi
huper 78.57 21.43 21.62 48.65 31.25 9.38 huper
hupo 61.09 28.94 45.27 43.92 35.00 21.25 hupo
kata 41.96 42.31 21.02 50.27 9.73 17.21 kata
meta 34.88 54.26 11.86 64.41 6.88 20.00 meta
para 35.25 44.10 20.28 56.58 17.70 18.14 para
peri 53.57 29.76 18.23 41.44 22.45 4.08 peri
pro 28.90 44.51 26.67 38.10 17.02 20.21 pro
pros 36.40 52.51 20.15 43.48 23.04 18.85 pros
sun 38.72 43.81 16.13 57.04 18.48 23.22 sun
31.72 53.04 17.11 53.80 15.54 19.50
41.10 41.28 22.27 48.15 48.01 34.51
44.78 36.98 24.86 45.31 59.58 39.86
37.42 62.58 24.13 75.87 44.35 55.65
PV tense-form as percentage of all PVsAll verb tense-forms as percentage of all verbsAll non-PV tense-forms as percentage of all non-PVsEach tense as percentage of sum of present and aorist forms (a ‘two-party-preferred’ rate)

103
Table B.23 Frequency of PVs in NT according to tense
Present tense - least to mostfrequent
Aorist tense – most to leastfrequent
15.98 eis 76.64 eis
17.89 apo 69.24 apo
22.20 ana 65.68 ana
24.80 ek 61.11 ek
28.90 pro 54.26 meta
30.06 epi 53.78 epi
34.88 meta 52.51 pros
35.25 para 44.51 pro
35.96 dia 44.10 para
36.40 pros 43.81 sun
38.72 sun 42.31 kata
40.00 en 40.65 en
41.96 kata 38.67 dia
48.61 anti 30.56 anti
53.57 peri 29.76 peri
61.09 hupo 28.94 hupo
78.57 huper 21.43 huper
The four preverbs at each end of the table (printed in red) correlate very strongly with one tense
and appear in the same order, while the others are more evenly distributed between the tenses.
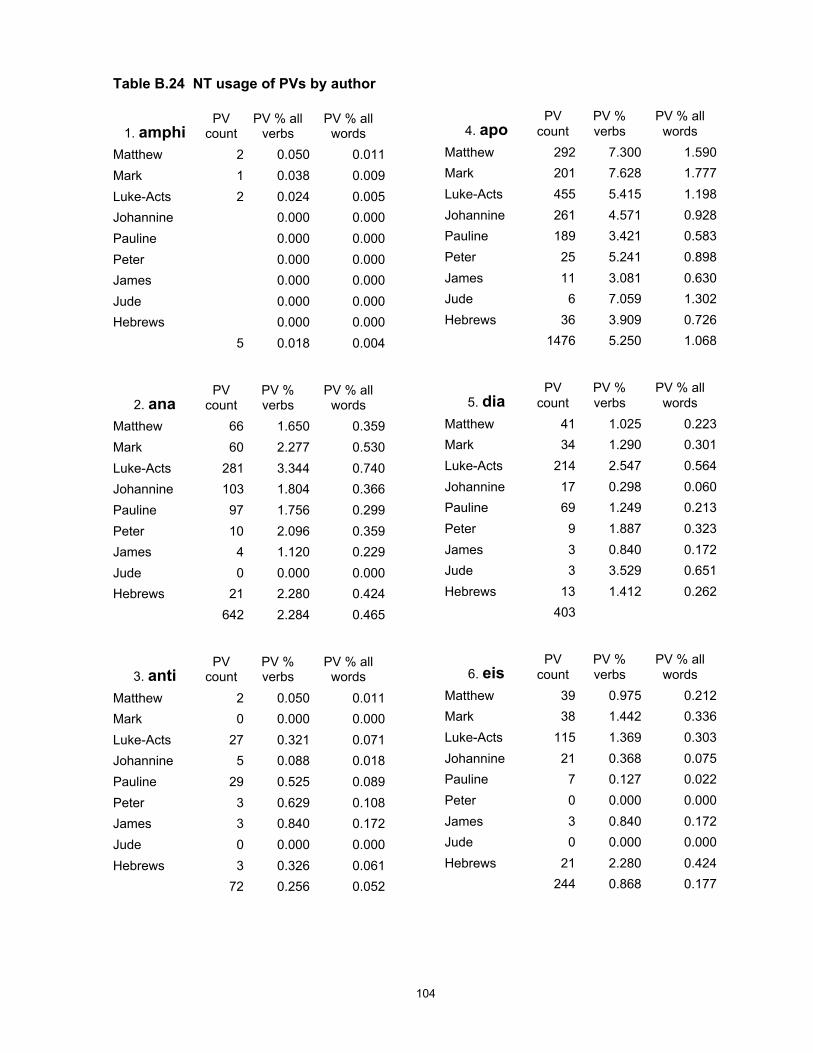
104
Table B.24 NT usage of PVs by author
1. amphiPV
countPV % all
verbsPV % all
words
Matthew 2 0.050 0.011
Mark 1 0.038 0.009
Luke-Acts 2 0.024 0.005
Johannine 0.000 0.000
Pauline 0.000 0.000
Peter 0.000 0.000
James 0.000 0.000
Jude 0.000 0.000
Hebrews 0.000 0.000
5 0.018 0.004
2. anaPV
countPV %verbs
PV % allwords
Matthew 66 1.650 0.359
Mark 60 2.277 0.530
Luke-Acts 281 3.344 0.740
Johannine 103 1.804 0.366
Pauline 97 1.756 0.299
Peter 10 2.096 0.359
James 4 1.120 0.229
Jude 0 0.000 0.000
Hebrews 21 2.280 0.424
642 2.284 0.465
3. antiPV
countPV %verbs
PV % allwords
Matthew 2 0.050 0.011
Mark 0 0.000 0.000
Luke-Acts 27 0.321 0.071
Johannine 5 0.088 0.018
Pauline 29 0.525 0.089
Peter 3 0.629 0.108
James 3 0.840 0.172
Jude 0 0.000 0.000
Hebrews 3 0.326 0.061
72 0.256 0.052
4. apoPV
countPV %verbs
PV % allwords
Matthew 292 7.300 1.590
Mark 201 7.628 1.777
Luke-Acts 455 5.415 1.198
Johannine 261 4.571 0.928
Pauline 189 3.421 0.583
Peter 25 5.241 0.898
James 11 3.081 0.630
Jude 6 7.059 1.302
Hebrews 36 3.909 0.726
1476 5.250 1.068
5. diaPV
countPV %verbs
PV % allwords
Matthew 41 1.025 0.223
Mark 34 1.290 0.301
Luke-Acts 214 2.547 0.564
Johannine 17 0.298 0.060
Pauline 69 1.249 0.213
Peter 9 1.887 0.323
James 3 0.840 0.172
Jude 3 3.529 0.651
Hebrews 13 1.412 0.262
403
6. eisPV
countPV %verbs
PV % allwords
Matthew 39 0.975 0.212
Mark 38 1.442 0.336
Luke-Acts 115 1.369 0.303
Johannine 21 0.368 0.075
Pauline 7 0.127 0.022
Peter 0 0.000 0.000
James 3 0.840 0.172
Jude 0 0.000 0.000
Hebrews 21 2.280 0.424
244 0.868 0.177
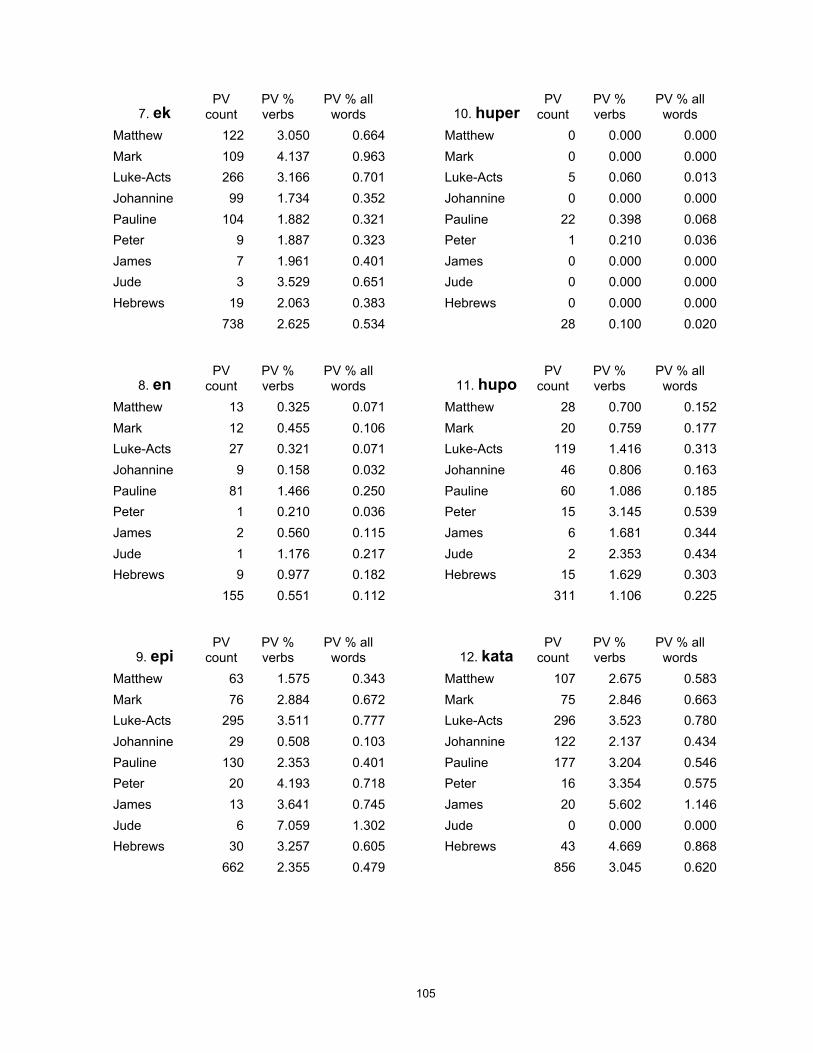
105
7. ekPV
countPV %verbs
PV % allwords
Matthew 122 3.050 0.664
Mark 109 4.137 0.963
Luke-Acts 266 3.166 0.701
Johannine 99 1.734 0.352
Pauline 104 1.882 0.321
Peter 9 1.887 0.323
James 7 1.961 0.401
Jude 3 3.529 0.651
Hebrews 19 2.063 0.383
738 2.625 0.534
8. enPV
countPV %verbs
PV % allwords
Matthew 13 0.325 0.071
Mark 12 0.455 0.106
Luke-Acts 27 0.321 0.071
Johannine 9 0.158 0.032
Pauline 81 1.466 0.250
Peter 1 0.210 0.036
James 2 0.560 0.115
Jude 1 1.176 0.217
Hebrews 9 0.977 0.182
155 0.551 0.112
9. epiPV
countPV %verbs
PV % allwords
Matthew 63 1.575 0.343
Mark 76 2.884 0.672
Luke-Acts 295 3.511 0.777
Johannine 29 0.508 0.103
Pauline 130 2.353 0.401
Peter 20 4.193 0.718
James 13 3.641 0.745
Jude 6 7.059 1.302
Hebrews 30 3.257 0.605
662 2.355 0.479
10. huperPV
countPV %verbs
PV % allwords
Matthew 0 0.000 0.000
Mark 0 0.000 0.000
Luke-Acts 5 0.060 0.013
Johannine 0 0.000 0.000
Pauline 22 0.398 0.068
Peter 1 0.210 0.036
James 0 0.000 0.000
Jude 0 0.000 0.000
Hebrews 0 0.000 0.000
28 0.100 0.020
11. hupoPV
countPV %verbs
PV % allwords
Matthew 28 0.700 0.152
Mark 20 0.759 0.177
Luke-Acts 119 1.416 0.313
Johannine 46 0.806 0.163
Pauline 60 1.086 0.185
Peter 15 3.145 0.539
James 6 1.681 0.344
Jude 2 2.353 0.434
Hebrews 15 1.629 0.303
311 1.106 0.225
12. kataPV
countPV %verbs
PV % allwords
Matthew 107 2.675 0.583
Mark 75 2.846 0.663
Luke-Acts 296 3.523 0.780
Johannine 122 2.137 0.434
Pauline 177 3.204 0.546
Peter 16 3.354 0.575
James 20 5.602 1.146
Jude 0 0.000 0.000
Hebrews 43 4.669 0.868
856 3.045 0.620
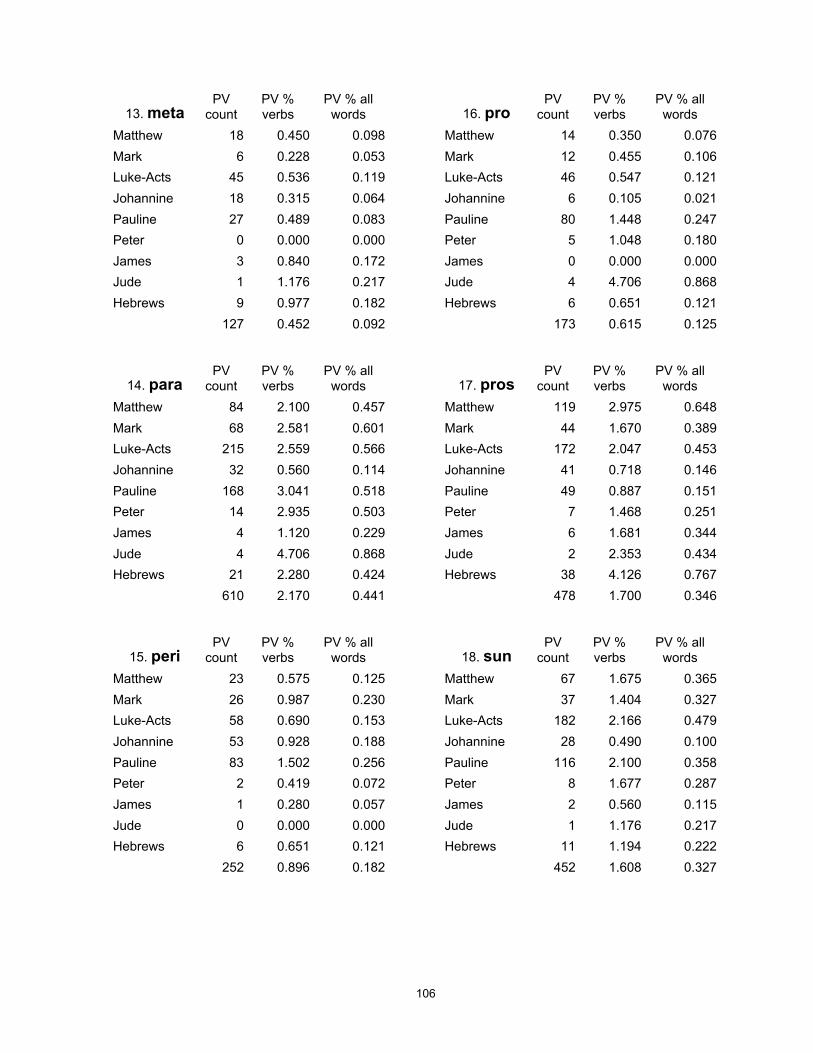
106
13. metaPV
countPV %verbs
PV % allwords
Matthew 18 0.450 0.098
Mark 6 0.228 0.053
Luke-Acts 45 0.536 0.119
Johannine 18 0.315 0.064
Pauline 27 0.489 0.083
Peter 0 0.000 0.000
James 3 0.840 0.172
Jude 1 1.176 0.217
Hebrews 9 0.977 0.182
127 0.452 0.092
14. paraPV
countPV %verbs
PV % allwords
Matthew 84 2.100 0.457
Mark 68 2.581 0.601
Luke-Acts 215 2.559 0.566
Johannine 32 0.560 0.114
Pauline 168 3.041 0.518
Peter 14 2.935 0.503
James 4 1.120 0.229
Jude 4 4.706 0.868
Hebrews 21 2.280 0.424
610 2.170 0.441
15. periPV
countPV %verbs
PV % allwords
Matthew 23 0.575 0.125
Mark 26 0.987 0.230
Luke-Acts 58 0.690 0.153
Johannine 53 0.928 0.188
Pauline 83 1.502 0.256
Peter 2 0.419 0.072
James 1 0.280 0.057
Jude 0 0.000 0.000
Hebrews 6 0.651 0.121
252 0.896 0.182
16. proPV
countPV %verbs
PV % allwords
Matthew 14 0.350 0.076
Mark 12 0.455 0.106
Luke-Acts 46 0.547 0.121
Johannine 6 0.105 0.021
Pauline 80 1.448 0.247
Peter 5 1.048 0.180
James 0 0.000 0.000
Jude 4 4.706 0.868
Hebrews 6 0.651 0.121
173 0.615 0.125
17. prosPV
countPV %verbs
PV % allwords
Matthew 119 2.975 0.648
Mark 44 1.670 0.389
Luke-Acts 172 2.047 0.453
Johannine 41 0.718 0.146
Pauline 49 0.887 0.151
Peter 7 1.468 0.251
James 6 1.681 0.344
Jude 2 2.353 0.434
Hebrews 38 4.126 0.767
478 1.700 0.346
18. sunPV
countPV %verbs
PV % allwords
Matthew 67 1.675 0.365
Mark 37 1.404 0.327
Luke-Acts 182 2.166 0.479
Johannine 28 0.490 0.100
Pauline 116 2.100 0.358
Peter 8 1.677 0.287
James 2 0.560 0.115
Jude 1 1.176 0.217
Hebrews 11 1.194 0.222
452 1.608 0.327

107
Table B.25 Data for calculation of p-values for comparison of
preverb frequency in three corpora
B.25.a Means and standard deviationsMEANS STDEVS
n 5 9 8 5 9 8
A - LXX B - NT C - AF A - LXX B - NT C - AF
ana 1.48 1.81 2.01 1.41 0.91 0.65
anti 0.17 0.31 0.30 0.12 0.30 0.18
apo 3.15 5.29 4.30 2.52 1.71 2.28
dia 0.88 1.57 1.12 0.65 0.97 0.70
eis 0.76 0.82 0.55 0.92 0.89 0.44
ek 2.90 2.60 1.76 2.41 0.88 0.95
en 0.49 0.63 0.96 0.60 0.47 0.41
epi 2.05 3.22 3.14 1.55 1.83 1.35
huper 0.05 0.07 0.29 0.05 0.14 0.28
hupo 0.29 1.51 1.63 0.31 0.82 1.02
kata 2.65 3.11 2.72 2.57 1.57 0.83
meta 0.09 0.56 0.90 0.09 0.38 0.62
para 0.88 2.43 2.01 0.74 1.18 0.88
peri 0.44 0.67 0.73 0.46 0.44 0.50
pro 0.18 1.03 1.17 0.19 1.45 0.80
pros 1.05 1.99 2.12 1.04 1.06 1.08
sun 1.16 1.38 1.97 0.86 0.60 0.76
All PVs 30.07 29.02 27.64 6.34 6.54 5.80
B.25.b Calculation of p-values between LXX & NT
A - LXX B - NT
mean sd mean sd t-stat p-value p-value
n 5 9 1-tailed 2-tailed
ana 1.48 1.41 1.81 0.91 -0.54 0.30 0.60
anti 0.17 0.12 0.31 0.30 -0.99 0.17 0.34
apo 3.15 2.52 5.29 1.71 -1.90 0.04 0.08
dia 0.88 0.65 1.57 0.97 -1.41 0.09 0.18
eis 0.76 0.92 0.82 0.89 -0.13 0.45 0.90
ek 2.90 2.41 2.60 0.88 0.34 0.37 0.74
en 0.49 0.60 0.63 0.47 -0.48 0.32 0.64
epi 2.05 1.55 3.22 1.83 -1.20 0.12 0.25
huper 0.05 0.05 0.07 0.14 -0.37 0.36 0.72
hupo 0.29 0.31 1.51 0.82 -3.18 0.00 0.01
kata 2.65 2.57 3.11 1.57 -0.42 0.34 0.68
meta 0.09 0.09 0.56 0.38 -2.68 0.01 0.02
para 0.88 0.74 2.43 1.18 -2.64 0.01 0.02
peri 0.44 0.46 0.67 0.44 -0.93 0.18 0.37
pro 0.18 0.19 1.03 1.45 -1.29 0.11 0.22
pros 1.05 1.04 1.99 1.06 -1.61 0.06 0.13
sun 1.16 0.86 1.38 0.60 -0.57 0.29 0.58
All PVs 30.07 6.34 29.02 6.54 0.29 0.39 0.78
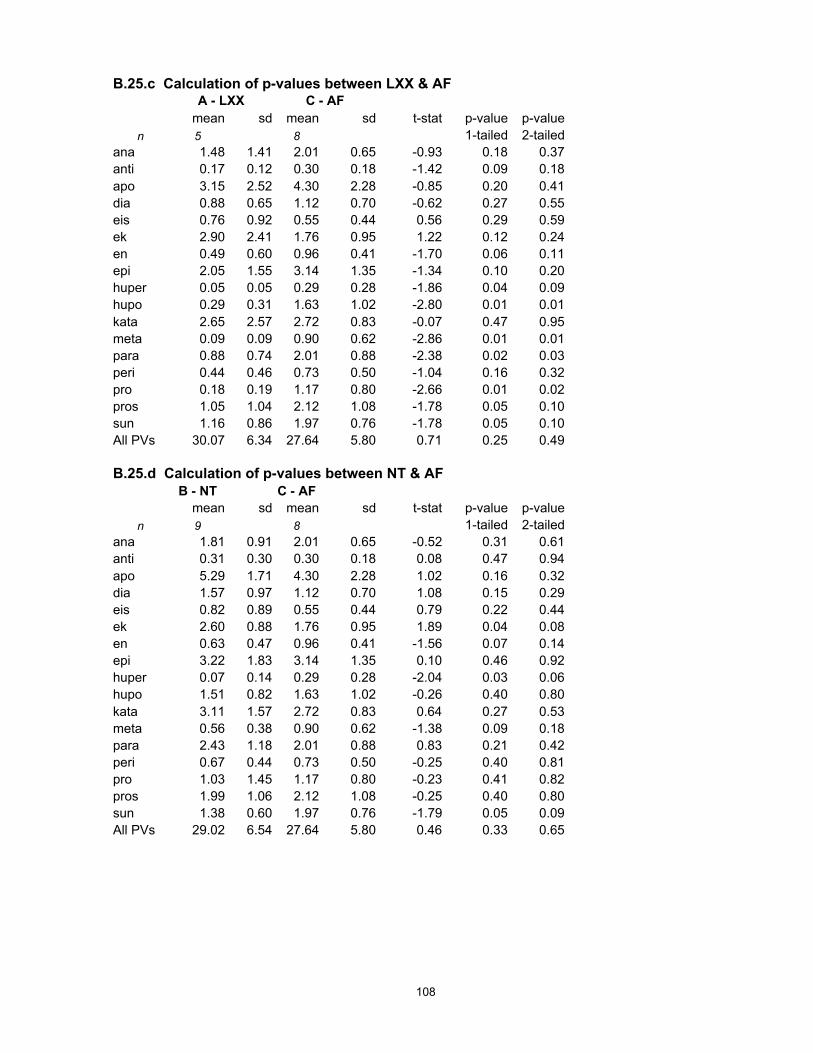
108
B.25.c Calculation of p-values between LXX & AFA - LXX C - AF
mean sd mean sd t-stat p-value p-value
n 5 8 1-tailed 2-tailed
ana 1.48 1.41 2.01 0.65 -0.93 0.18 0.37
anti 0.17 0.12 0.30 0.18 -1.42 0.09 0.18
apo 3.15 2.52 4.30 2.28 -0.85 0.20 0.41
dia 0.88 0.65 1.12 0.70 -0.62 0.27 0.55
eis 0.76 0.92 0.55 0.44 0.56 0.29 0.59
ek 2.90 2.41 1.76 0.95 1.22 0.12 0.24
en 0.49 0.60 0.96 0.41 -1.70 0.06 0.11
epi 2.05 1.55 3.14 1.35 -1.34 0.10 0.20
huper 0.05 0.05 0.29 0.28 -1.86 0.04 0.09
hupo 0.29 0.31 1.63 1.02 -2.80 0.01 0.01
kata 2.65 2.57 2.72 0.83 -0.07 0.47 0.95
meta 0.09 0.09 0.90 0.62 -2.86 0.01 0.01
para 0.88 0.74 2.01 0.88 -2.38 0.02 0.03
peri 0.44 0.46 0.73 0.50 -1.04 0.16 0.32
pro 0.18 0.19 1.17 0.80 -2.66 0.01 0.02
pros 1.05 1.04 2.12 1.08 -1.78 0.05 0.10
sun 1.16 0.86 1.97 0.76 -1.78 0.05 0.10
All PVs 30.07 6.34 27.64 5.80 0.71 0.25 0.49
B.25.d Calculation of p-values between NT & AF
B - NT C - AF
mean sd mean sd t-stat p-value p-value
n 9 8 1-tailed 2-tailed
ana 1.81 0.91 2.01 0.65 -0.52 0.31 0.61
anti 0.31 0.30 0.30 0.18 0.08 0.47 0.94
apo 5.29 1.71 4.30 2.28 1.02 0.16 0.32
dia 1.57 0.97 1.12 0.70 1.08 0.15 0.29
eis 0.82 0.89 0.55 0.44 0.79 0.22 0.44
ek 2.60 0.88 1.76 0.95 1.89 0.04 0.08
en 0.63 0.47 0.96 0.41 -1.56 0.07 0.14
epi 3.22 1.83 3.14 1.35 0.10 0.46 0.92
huper 0.07 0.14 0.29 0.28 -2.04 0.03 0.06
hupo 1.51 0.82 1.63 1.02 -0.26 0.40 0.80
kata 3.11 1.57 2.72 0.83 0.64 0.27 0.53
meta 0.56 0.38 0.90 0.62 -1.38 0.09 0.18
para 2.43 1.18 2.01 0.88 0.83 0.21 0.42
peri 0.67 0.44 0.73 0.50 -0.25 0.40 0.81
pro 1.03 1.45 1.17 0.80 -0.23 0.41 0.82
pros 1.99 1.06 2.12 1.08 -0.25 0.40 0.80
sun 1.38 0.60 1.97 0.76 -1.79 0.05 0.09
All PVs 29.02 6.54 27.64 5.80 0.46 0.33 0.65

109
B.26 Prepositions and Preverbs in Modern Greek
All the ancient P-words which were used as preverbs in ancient Greek are still productive as
preverbs in Modern Greek, in spite of the fact that most are no longer used as prepositions.
Holton et al 1997 provide examples of prefixation for the 12 prepositions most common in
compound formation, along with their current meanings (1997: 179-181).71 amfiv amphi, eiV eis,
en en, epiv epi, periv peri and proV pros are now less productive than the others.
Holton et al 1997 give a checklist of 39 prepositions in Modern Greek, of which 19 are in use in
standard speech, the others being of Katharevousa origin (pp 407-8).72 Of the 19, only 9 are
derived from the ancient proper prepositions (not counting compound prepositions). These are:
Table B.26.a Modern Greek reflexes of the ancient prepositions
MGk AncGk
antiv andi ajntiv antiapov apo ajpov apogia ya diav diakatav kata katav katame me metav metametav meta metav metaparav para parav paraproV pros provV prosse se eijV eis
All these demotic prepositions govern the accusative case. Me me ‘with’ comes from the ancient
metav meta + genitive, while metav meta ‘after’ is from metav + accusative. Both gia ya and se se
exist alongside their ancient forms, which are still available in restricted usages. In Modern
Greek se , apov, gia and me are by far the most frequent prepositions, and se and apov are
particularly common as elements of the many compound prepositions of the modern language.
71
Modern meanings often differ from the ancient meanings of the compound elements, which often
results in Modern Greek words having a meaning unlike that of the equivalent word borrowed from ancient
Greek or constructed from Greek elements in modern European languages (Janni 1993).
72 Katharevousa (‘Purifying [language]’) is the name of the archaising form of Greek developed in the
eighteenth and nineteenth centuries and made the official language of the modern Greek state. It was
formally abandoned in favour of demotic Greek in 1976.

110
The following prepositions derived from the ancient prepositions are available in formal registers
or with specialised meanings in specific fields, and may take the genitive case or even the dative
in fixed expressions (Holton et al 1997: 405-7). (In Modern Greek the dative case survives only
in lexicalised expressions derived from Katharevousa.)
Table B.26.b Katharevousa prepositions in limited use in Modern Greek
MGk AncGk
anav ana ajnav anadiav !ya diav dia
eiV is eijV eisek ek ejk eken en ejn enepiv epi ejpiv epiperiv peri periv peripro pro prov prosun sin suvn sunupevr iper uJJpevr huperupov ipo uJpov hupo

111
Appendix C – NT uses of ejpitivqhmi epitithemi
First column is NT text (NA27), second column is NRSV translation, both from Accordance
Bold: verb epitithemiRed: Accusative direct object Purple: PP with epi + genitiveGreen: PP with epi + accusative Blue: dative NP
(Corresponding words in translation in same colour)
Matt. 9:18 Tauvta aujtouv lalouvntoßaujtoi!ß, i˙dou\ a‡rcwn ei–ß e˙lqw»n proseku/neiaujtwˆ" le÷gwn o¢ti hJ quga¿thr mou a‡rtie˙teleu/thsen: aÓlla» e˙lqw»n e˙pi÷qeß th\ncei!ra¿ sou e˙p# aujth/n, kai« zh/setai.
Matt. 19:13 To/te proshne÷cqhsan aujtwˆ"paidi÷a iºna ta»ß cei!raß e˙piqhØv aujtoi!ß kai«proseu/xhtai: oi˚ de« maqhtai« e˙peti÷mhsanaujtoi!ß.
Matt. 19:15 kai« e˙piqei«ß ta»ß cei!raßaujtoi!ß e˙poreu/qh e˙kei!qen.
Matt. 21:7 h¡gagon th\n o¡non kai« to\npw"lon kai« e˙pe÷qhkan e˙p# aujtw"n ta»i˚ma¿tia, kai« e˙peka¿qisen e˙pa¿nw aujtw"n.
Matt. 23:4 desmeu/ousin de« forti÷a bare÷a[kai« dusba¿stakta] kai« e˙pitiqe÷asin e˙pi«tou\ß w‡mouß tw"n aÓnqrw¿pwn, aujtoi« de« twˆ"daktu/lwˆ aujtw"n ouj qe÷lousin kinhvsaiaujta¿.
Matt. 27:29 kai« ple÷xanteß ste÷fanon e˙xaÓkanqw"n e˙pe÷qhkan e˙pi« thvß kefalhvßaujtouv kai« ka¿lamon e˙n thØv dexiaˆ" aujtouv,kai« gonupeth/santeß e¶mprosqen aujtouve˙ne÷paixan aujtwˆ" le÷gonteß: cai!re, basileuvtw"n #Ioudai÷wn,
Matt. 27:37 Kai« e˙pe÷qhkan e˙pa¿nw thvßkefalhvß aujtouv th\n ai˙ti÷an aujtouvgegramme÷nhn: ou$to/ß e˙stin #Ihsouvß oJbasileu\ß tw"n #Ioudai÷wn.
Mark 3:16 [kai« e˙poi÷hsen tou\ß dw¿deka,]kai« e˙pe÷qhken o¡noma twˆ" Si÷mwni Pe÷tron,17 kai« #Ia¿kwbon to\n touv Zebedai÷ou kai«#Iwa¿nnhn to\n aÓdelfo\n touv #Iakw¿bou kai«e˙pe÷qhken aujtoi!ß ojno/ma[ta] boanhrge÷ß, o¢e˙stin ui˚oi« bronthvß:
Mark 5:23 kai« parakalei! aujto\n polla»le÷gwn o¢ti to\ quga¿trio/n mou e˙sca¿twß e¶cei,iºna e˙lqw»n e˙piqhØvß ta»ß cei!raß aujthØv iºnaswqhØv kai« zh/shØ.
Matt. 9:18 While he was saying thesethings to them, suddenly a leader of the
synagogue came in and knelt before him,saying, “My daughter has just died; but
come and lay your hand on her, and she will
live.”
Matt. 19:13 Then little children were beingbrought to him in order that he might lay his
hands on them and pray. The disciplesspoke sternly to those who brought them;
Matt. 19:15 And he laid his hands on themand went on his way.
Matt. 21:7 they brought the donkey and thecolt, and put their cloaks on them, and he
sat on them.
Matt. 23:4 They tie up heavy burdens, hardto bear, and lay them on the shoulders of
others; but they themselves are unwilling tolift a finger to move them.
Matt. 27:29 and after twisting some thornsinto a crown, they put it on his head. They
put a reed in his right hand and knelt before
him and mocked him, saying, “Hail, King ofthe Jews!”
Matt. 27:37 Over his head they put thecharge against him, which read, “This isJesus, the King of the Jews.”
Mark 3:16 So he appointed the twelve:
Simon (to whom he gave the name Peter);
17 James son of Zebedee and John thebrother of James (to whom he gave the
name Boanerges, that is, Sons of Thunder);
Mark 5:23 and begged him repeatedly, “Mylittle daughter is at the point of death. Come
and lay your hands on her, so that she maybe made well, and live.”

112
Mark 6:5 kai« oujk e˙du/nato e˙kei! poihvsaioujdemi÷an du/namin, ei˙ mh\ ojli÷goißaÓrrw¿stoiß e˙piqei«ß ta»ß cei!raße˙qera¿peusen.
Mark 7:32 Kai« fe÷rousin aujtwˆ" kwfo\n kai«mogila¿lon kai« parakalouvsin aujto\n iºnae˙piqhØv aujtwˆ" th\n cei!ra.
Mark 8:23 kai« e˙pilabo/menoß thvß ceiro\ßtouv tuflouv e˙xh/negken aujto\n e¶xw thvßkw¿mhß kai« ptu/saß ei˙ß ta» o¡mmata aujtouv,e˙piqei«ß ta»ß cei!raß aujtwˆ" e˙phrw¿ta aujto/n:ei¶ ti ble÷peiß;
Mark 8:25 ei•ta pa¿lin e˙pe÷qhken ta»ßcei!raß e˙pi« tou\ß ojfqalmou\ß aujtouv, kai«die÷bleyen kai« aÓpekate÷sth kai« e˙ne÷blepenthlaugw"ß a‚panta.
Mark 16:18 [kai« e˙n tai!ß cersi«n] o¡feißaÓrouvsin ka·n qana¿simo/n ti pi÷wsin ouj mh\aujtou\ß bla¿yhØ, e˙pi« aÓrrw¿stouß cei!raße˙piqh/sousin kai« kalw"ß eºxousin.
Luke 4:40 Du/nontoß de« touv hJli÷oua‚panteß o¢soi ei•con aÓsqenouvntaß no/soißpoiki÷laiß h¡gagon aujtou\ß pro\ß aujto/n: oJde« e˚ni« e˚ka¿stwˆ aujtw"n ta»ß cei!raß e˙pitiqei«ße˙qera¿peuen aujtou/ß.
Luke 10:30 ÔUpolabw»n oJ #Ihsouvß ei•pen:a‡nqrwpo/ß tiß kate÷bainen aÓpo\#Ierousalh\m ei˙ß #Iericw» kai« lhØstai!ßperie÷pesen, oi % kai« e˙kdu/santeß aujto\n kai«plhga»ß e˙piqe÷nteß aÓphvlqon aÓfe÷nteßhJmiqanhv.
Luke 13:13 kai« e˙pe÷qhken aujthØv ta»ßcei!raß: kai« paracrhvma aÓnwrqw¿qh kai«e˙do/xazen to\n qeo/n.
Luke 15:5 kai« euJrw»n e˙piti÷qhsin e˙pi« tou\ßw‡mouß aujtouv cai÷rwn
Luke 23:26 Kai« w�ß aÓph/gagon aujto/n,e˙pilabo/menoi Si÷mwna¿ tina Kurhnai!one˙rco/menon aÓp# aÓgrouv e˙pe÷qhkan aujtw" to\nstauro\n fe÷rein o¡pisqen touv #Ihsouv.
Mark 6:5 And he could do no deed of powerthere, except that he laid his hands on a few
sick people and cured them.
Mark 7:32 They brought to him a deaf manwho had an impediment in his speech; and
they begged him to lay his hand on him.
Mark 8:23 He took the blind man by thehand and led him out of the village; and
when he had put saliva on his eyes and laid
his hands on him, he asked him, “Can you
see anything?”
Mark 8:25 Then Jesus laid his hands onhis eyes again; and he looked intently and
his sight was restored, and he saw
everything clearly.
Mark 16:18 they will pick up snakes in theirhands, and if they drink any deadly thing, it
will not hurt them; they will lay their handson the sick, and they will recover.”
Luke 4:40 As the sun was setting, allthose who had any who were sick with
various kinds of diseases brought them to
him; and he laid his hands on each of themand cured them.
Luke 10:30 Jesus replied, “A man wasgoing down from Jerusalem to Jericho, and
fell into the hands of robbers, who stripped
him, beat him [put blows on him], and wentaway, leaving him half dead.
Luke 13:13 When he laid his hands on her,immediately she stood up straight and
began praising God.
Luke 15:5 When he has found it, he lays iton his shoulders and rejoices.
Luke 23:26 As they led him away, theyseized a man, Simon of Cyrene, who was
coming from the country, and they laid thecross on him, and made him carry it behind
Jesus.

113
John 9:15 pa¿lin ou™n hjrw¿twn aujto\n kai«oi˚ Farisai!oi pw"ß aÓne÷bleyen. oJ de« ei•penaujtoi!ß: phlo\n e˙pe÷qhke÷n mou e˙pi« tou\ßojfqalmou\ß kai« e˙niya¿mhn kai« ble÷pw.
John 19:2 kai« oi˚ stratiw "tai ple÷xanteßste÷fanon e˙x aÓkanqw"n e˙pe÷qhkan aujtouvthØv kefalhØv kai« i˚ma¿tion porfurouvnperie÷balon aujto\n
Acts 6:6 ou§ß e¶sthsan e˙nw¿pion tw"naÓposto/lwn, kai« proseuxa¿menoi e˙pe÷qhkanaujtoi!ß ta»ß cei!raß.
Acts 8:17 to/te e˙peti÷qesan ta»ß cei !raß e˙p#aujtou\ß kai« e˙la¿mbanon pneuvma a‚gion.
Acts 8:19 le÷gwn: do/te kaÓmoi« th\ne˙xousi÷an tau/thn iºna wˆ— e˙a»n e˙piqw! ta»ßcei!raß lamba¿nhØ pneuvma a‚gion.
Acts 9:12 kai« ei•den a‡ndra [e˙n oJra¿mati]ÔAnani÷an ojno/mati ei˙selqo/nta kai«e˙piqe÷nta aujtw" [ta»ß] cei!raß o¢pwßaÓnable÷yhØ.
Acts 9:17 #Aphvlqen de« ÔAnani÷aß kai«ei˙shvlqen ei˙ß th\n oi˙ki÷an kai« e˙piqei«ß e˙p#aujto\n ta»ß cei!raß ei•pen: Saou\l aÓdelfe÷, oJku/rioß aÓpe÷stalke÷n me, #Ihsouvß oJ ojfqei÷ßsoi e˙n thØv oJdwˆ " hØ$ h¡rcou, o¢pwß aÓnable÷yhØßkai« plhsqhØvß pneu/matoß a�gi÷ou.
Acts 13:3 to/te nhsteu/santeß kai«proseuxa¿menoi kai« e˙piqe÷nteß ta»ß cei !raßaujtoi!ß aÓpe÷lusan.
Acts 15:10 nuvn ou™n ti÷ peira¿zete to\n qeo\ne˙piqei"nai zugo\n e˙pi« to\n tra¿chlon tw "nmaqhtw"n o§n ou¡te oi˚ pate÷reß hJmw"n ou¡tehJmei!ß i˙scu/samen basta¿sai;
Acts 15:28 e¶doxen ga»r twˆ" pneu/mati twˆ"a�gi÷wˆ kai« hJmi!n mhde«n ple÷on e˙piti÷qesqaiuJmi!n ba¿roß plh\n tou/twn tw"n e˙pa¿nagkeß,
Acts 16:23 polla¿ß te e˙piqe÷nteß aujtoi !ßplhga»ß e¶balon ei˙ß fulakh\nparaggei÷lanteß twˆ" desmofu/lakiaÓsfalw"ß threi!n aujtou/ß.
Acts 18:10 dio/ti e˙gw¿ ei˙mi meta» souv kai«oujdei«ß e˙piqh/setai÷ soi touv kakw"sai÷ se,dio/ti lao/ß e˙sti÷ moi polu\ß e˙n thØv po/leitau/thØ.
John 9:15 Then the Pharisees alsobegan to ask him how he had receivedhis sight. He said to them, “He put mud on
my eyes. Then I washed, and now I see.”
John 19:2 And the soldiers wove a crown ofthorns and put it on his head, and theydressed him in a purple robe.
Acts 6:6 They had these men stand beforethe apostles, who prayed and laid theirhands on them.
Acts 8:17 Then Peter and John laid theirhands on them, and they received the Holy
Spirit.
Acts 8:19 saying, “Give me also this powerso that anyone on whom I lay my handsmay receive the Holy Spirit.”
Acts 9:12 and he has seen in a vision aman named Ananias come in and lay his
hands on him so that he might regain his
sight.”
Acts 9:17 So Ananias went and entered thehouse. He laid his hands on Saul and said,“Brother Saul, the Lord Jesus, who
appeared to you on your way here, has sent
me so that you may regain your sight and befilled with the Holy Spirit.”
Acts 13:3 Then after fasting and prayingthey laid their hands on them and sent them
off.
Acts 15:10 Now therefore why are youputting God to the test by placing on the
neck of the disciples a yoke that neither our
ancestors nor we have been able to bear?
Acts 15:28 For it has seemed good to theHoly Spirit and to us to impose on you nofurther burden than these essentials:
Acts 16:23 After they had given them asevere flogging, they threw them into prison
and ordered the jailer to keep them securely.
Acts 18:10 for I am with you, and no onewill lay a hand on you to harm you, for thereare many in this city who are my people.”

114
Acts 19:6 kai« e˙piqe÷ntoß aujtoi!ß touvPau/lou [ta»ß] cei!raß h™lqe to\ pneuvma to\a‚gion e˙p# aujtou/ß, e˙la¿loun te glw¿ssaißkai« e˙profh/teuon.
Acts 28:3 Sustre÷yantoß de« touv Pau/loufruga¿nwn ti plhvqoß kai« e˙piqe÷ntoß e˙pi«th\n pura¿n, e¶cidna aÓpo\ thvß qe÷rmhße˙xelqouvsa kaqhvyen thvß ceiro\ß aujtouv.
Acts 28:8 e˙ge÷neto de« to\n pate÷ra touvPopli÷ou puretoi!ß kai« dusenteri÷wˆsuneco/menon katakei!sqai, pro\ß o§n oJPauvloß ei˙selqw»n kai« proseuxa¿menoße˙piqei«ß ta»ß cei!raß aujtwˆ" i˙a¿sato aujto/n.
Acts 28:10 oi% kai« pollai!ß timai!ße˙ti÷mhsan hJma "ß kai« aÓnagome÷noiß e˙pe÷qentota» pro\ß ta»ß crei÷aß.
1Tim. 5:22 cei !raß tace÷wß mhdeni« e˙piti÷qeimhde« koinw¿nei a�marti÷aiß aÓllotri÷aiß:seauto\n a�gno\n th/rei.
Rev. 22:18 Marturw" e˙gw» panti« twˆ"aÓkou/onti tou\ß lo/gouß thvß profhtei÷aß touvbibli÷ou tou/tou: e˙a¿n tiß e˙piqhØv e˙p# aujta¿,e˙piqh/sei oJ qeo\ß e˙p# aujto\n ta»ß plhga»ßta»ß gegramme÷naß e˙n twˆ" bibli÷wˆ tou/twˆ,
Acts 19:6 When Paul had laid his hands onthem, the Holy Spirit came upon them, and
they spoke in tongues and prophesied
Acts 28:3 Paul had gathered a bundle ofbrushwood and was putting it on the fire,
when a viper, driven out by the heat,
fastened itself on his hand.
Acts 28:8 It so happened that the father ofPublius lay sick in bed with fever and
dysentery. Paul visited him and cured him
by praying and putting his hands on him.
Acts 28:10 They bestowed many honors onus, and when we were about to sail, theyput on board all the provisions we needed.
1Tim. 5:22 Do not ordain anyone hastily,and do not participate in the sins of others;
keep yourself pure.
Rev. 22:18 I warn everyone who hears thewords of the prophecy of this book: ifanyone adds to them, God will add to that
person the plagues described in this book;
Configurational syntax of ejpitivqhmi epitithemi:
A. with a PP ejpiv epi + ACC 12
ejpiv epi + GEN 2 (Mt 21:7, 27:29)
+ a different preposition 1 (Mt 27:37)
(ejpavnw epano: compound preposition used only as an
adverb in classical Greek)
B. with accusative NP (direct object) 32
C. with dative NP (locative oblique object) 23
A. and C. never co-occur. They are different strategies for expressing the same meaning.
B and C frequently co-occur (20 times) (and the object is sometimes left unexpressed, as in Jn19:1 and perhaps Ac 18:10)
A. and B. is not uncommon (9 times)
From this brief survey it appears that, although both PP and dative NP are available, the dative
NP is preferrred in a ratio of approximately 2:1.

115
Co-occurrences of tivqhmi tithemi and ejpiv epi in NT
Green: epi with accusativePurple: epi with genitive
Matt. 5:15 oujde« kai÷ousin lu/cnon kai«tiqe÷asin aujto\n uJpo\ to\n mo/dion aÓll# e˙pi«th\n lucni÷an, kai« la¿mpei pa"sin toi!ß e˙n thØvoi˙ki÷aˆ.
Matt. 12:18 i˙dou\ oJ pai!ß mou o§n hØJre÷tisa,oJ aÓgaphto/ß mou ei˙ß o§n eujdo/khsen hJ yuch/mou: qh/sw to\ pneuvma¿ mou e˙p! aujto/n,kai« kri÷sin toi !ß e¶qnesin aÓpaggelei !.
Mark 4:21 Kai« e¶legen aujtoi!ß: mh/tie¶rcetai oJ lu/cnoß iºna uJpo\ to\n mo/dion teqhØvh£ uJpo\ th\n kli÷nhn; oujc iºna e˙pi« th\n lucni÷anteqhØv;
Mark 10:16 kai« e˙nagkalisa¿menoß aujta»kateulo/gei tiqei«ß ta»ß cei!raß e˙p# aujta¿.
Luke 6:48 o¢moio/ß e˙stin aÓnqrw¿pwˆoi˙kodomouvnti oi˙ki÷an o§ß e¶skayen kai«e˙ba¿qunen kai« e¶qhken qeme÷lion e˙pi« th\npe÷tran: plhmmu/rhß de« genome÷nhßprose÷rhxen oJ potamo\ß thØv oi˙ki÷aˆ e˙kei÷nhØ,kai« oujk i¶scusen saleuvsai aujth\n dia» to\kalw"ß oi˙kodomhvsqai aujth/n.
Luke 8:16 Oujdei«ß de« lu/cnon a‚yaßkalu/ptei aujto\n skeu/ei h£ uJpoka¿tw kli÷nhßti÷qhsin, aÓll# e˙pi« lucni÷aß ti÷qhsin, iºna oi˚ei˙sporeuo/menoi ble÷pwsin to\ fw"ß.
Luke 11:33 Oujdei«ß lu/cnon a‚yaß ei˙ßkru/pthn ti÷qhsin [oujde« uJpo\ to\n mo/dion]aÓll# e˙pi« th\n lucni÷an, iºna oi˚ei˙sporeuo/menoi to\ fw"ß ble÷pwsin.
John 19:19 e¶grayen de« kai« ti÷tlon oJPila"toß kai« e¶qhken e˙pi« touv staurouv: h™nde« gegramme÷non: #Ihsouvß oJ Nazwrai!oß oJbasileu\ß tw"n #Ioudai÷wn.
Matt. 5:15 No one after lighting a lamp putsit under the bushel basket, but on the
lampstand, and it gives light to all in the
house.
Matt. 12:18 “Here is my servant, whom Ihave chosen, my beloved, with whom my
soul is well pleased. I will put my Spirit uponhim,
and he will proclaim justice to the Gentiles.
Mark 4:21 He said to them, “Is a lampbrought in to be put under the bushel basket,
or under the bed, and not [put] on thelampstand?
Mark 10:16 And he took them up in hisarms, laid his hands on them, and blessed
them.
Luke 6:48 That one is like a man building ahouse, who dug deeply and laid the
foundation on rock; when a flood arose, the
river burst against that house but could not
shake it, because it had been well built.
Luke 8:16 “No one after lighting a lamphides it under a jar, or puts it under a bed,
but puts it on a lampstand, so that those whoenter may see the light.
Luke 11:33 “No one after lighting a lampputs it in a cellar, but on the lampstand so
that those who enter may see the light.
John 19:19 Pilate also had an inscriptionwritten and put on the cross. It read, “Jesusof Nazareth, the King of the Jews.”

116
Acts 5:15 w‚ste kai« ei˙ß ta»ß platei÷aße˙kfe÷rein tou\ß aÓsqenei!ß kai« tiqe÷nai e˙pi«klinari÷wn kai« kraba¿ttwn, iºna e˙rcome÷nouPe÷trou ka·n hJ skia» e˙piskia¿shØ tini« aujtw"n.
Acts 21:5 o¢te de« e˙ge÷neto hJma"ß e˙xarti÷saita»ß hJme÷raß, e˙xelqo/nteß e˙poreuo/meqapropempo/ntwn hJma"ß pa¿ntwn su\n gunaixi«kai« te÷knoiß eºwß e¶xw thvß po/lewß, kai«qe÷nteß ta» go/nata e˙pi« to\n ai˙gialo\nproseuxa¿menoi
2Cor. 3:13 kai« ouj kaqa¿per Mwu¨shvße˙ti÷qei ka¿lumma e˙pi« to\ pro/swpon aujtouvpro\ß to\ mh\ aÓteni÷sai tou\ß ui˚ou\ß #Israh\lei˙ß to\ te÷loß touv katargoume÷nou.
Rev. 1:17 Kai« o¢te ei•don aujto/n, e¶pesapro\ß tou\ß po/daß aujtouv w�ß nekro/ß, kai«e¶qhken th\n dexia»n aujtouv e˙p# e˙me« le÷gwn:mh\ fobouv: e˙gw¿ ei˙mi oJ prw"toß kai« oJe¶scatoß
Rev. 10:2 kai« e¶cwn e˙n thØv ceiri« aujtouvbiblari÷dion hjnewˆgme÷non. kai« e¶qhken to\npo/da aujtouv to\n dexio\n e˙pi« thvß qala¿sshß,to\n de« eujw¿numon e˙pi « thvß ghvß
Acts 5:15 so that they even carried out thesick into the streets, and laid them on cots
and mats, in order that Peter’s shadow might
fall on some of them as he came by.
Acts 21:5 When our days there were ended,
we left and proceeded on our journey; and allof them, with wives and children, escorted us
outside the city. There we knelt [put knees]
down on the beach and prayed
2Cor. 3:13 not like Moses, who put a veilover his face to keep the people of Israel
from gazing at the end of the glory that wasbeing set aside.
Rev. 1:17 When I saw him, I fell at his feetas though dead. But he placed his right hand
on me, saying, “Do not be afraid; I am the
first and the last,
Rev. 10:2 He held a little scroll open in hishand. Setting his right foot on the sea andhis left foot on the land...
Apart from the double use in Rev. 10:2, only Luke uses PP+GEN, but he also uses (slightly
more often) PP+ACC.
As a verb requiring a locative argument (like English ‘put’), tivqhmi tithemi frequently occurs with
other prepositions (as in Lk 8:16 & 11:33 above); here only the occurrences with ejpiv epi are
considered, because of the variation in case government displayed. Although epi + DAT occurs
in NT almost as often as epi + GEN (but together less than epi + ACC), it never occurs with
tithemi. The variation is only between ACC and GEN: contrast the variation between GEN and
DAT in Chapter 2 examples (14) & (15). Clearly by the middle or later Koine period the
distinction between orientation towards or away from the landmark, which previously
distinguished accusative and genitive cases, is no longer active. Compare the loss of the
distinction between motion and location in the confusion between eijV eis and ejn en.

117
References
ADRADOS 2005 Francisco Rodríguez Adrados, A History of the Greek Language from itsOrigins to the Present (translation by Francisca Rojas del Canto of Adrados,Historia de la lengua griega, Madrid 1999). Leiden: Brill.
ALAND & ALAND
1987Kurt Aland & Barbara Aland, The Text of the New Testament: An Introducion tothe Critical Editions and to the Theory and Practice of Modern Textual Criticism,second edition. Translated by Erroll F Rhodes. Grand Rapids: Eerdmans.
ALLEN 1987 W Sidney Allen, Vox Graeca: A Guide to the Pronunciation of Classical Greek,third edition. Cambridge: Cambridge University Press.
BDAG Bauer, Danker, Arndt, Gingrich, 2000, A Greek-English Lexicon of the NewTestament and Other Early Christian Literature, third edition, ed Frederick WDanker. Chicago: University of Chicago Press.
BEEKES 1995 Robert S P Beekes, Comparative Indo-European Linguistics: An Introduction.Amsterdam: John Benjamins.
BERGLUND & MASON
2003Ylva Berglund & Oliver Mason, ‘”But this formula doesn’t mean anything...!?”’,in Andrew Wilson, Paul Rayson & Tony McEnery (eds), Corpus Linguistics bythe Lune: A Festschrift for Geoffrey Leech. Frankfurt am Main: Peter Lang.
BERKOWITZ &SQUITIER 1986
Luci Berkowitz & Karl A Squitier, Thesurus Linguae Graecae: Canon of GreekAuthors and Works (with technical assistance from William A Johnson), secondedition. Oxford: Oxford University Press.
BOTHA 1991 J Eugene Botha, ‘Style in the New Testament: The Need for SeriousReconsideration’, Journal for the Study of the New Testament 43, 71-87.
BRINTON &TRAUGOTT 2005
Laurel J Brinton & Elizabeth Closs Traugott, Lexicalization and LanguageChange. Cambridge: Cambridge University Press.
BROWNING 1983 Robert Browning, Medieval and Modern Greek, second edition. Cambridge:Cambridge University Press.
BUBENIK 1989 Vit Bubenik, Hellenistic and Roman Greece as a Sociolinguistic Area.Amsterdam: John Benjamins.
BUBENIK 1993 Vit Bubenik, ‘Dialect contact and Koineization: the case of Hellenistic Greek’, inInternational Journal of the Sociology of Language 99 (1993) 9-23.
BURRIDGE 1997a Richard A Burridge, ‘Biography’, pp 371-392 in Stanley E Porter (ed),Handbook of Classical Rhetoric in the Hellenistic Period 330 BC – AD 400.Leiden: Brill.
BURRIDGE 1997b Richard A Burridge, ‘The Gospels and Acts’, pp 507-532 in Stanley E Porter(ed), Handbook of Classical Rhetoric in the Hellenistic Period 330 BC – AD400. Leiden: Brill.
BYBEE ET AL 1994 Joan Bybee, Revere Perkin & William Pagliuca, The Evolution of Grammar:Tense, Aspect and Modality in the Languages of the World. Chicago:University of Chicago Press.
CAMPBELL 2004 Lyle Campbell, Historical Linguistics: An Introduction (second edition).Edinburgh: Edinburgh University Press.
CARSON & MOO
2005D A Carson & Douglas J Moo, An Introduction to the New Testament (secondedition). Grand Rapids: Zondervan.
CHANTRAINE 1953 P Chantraine, Grammaire Homérique, Vol II Syntaxe. Paris: Klincksieck.

118
CHRISTIDIS 2007 A-F Christidis (ed), A History of Ancient Greek: From the Beginnings to lateAntiquity, edited for the Centre for the Greek Language by A-F Christidis withthe assistance of Maria Arapopoulou and Maria Chriti, Cambridge UniversityPress; originally published in Greek, as Istoriva thV ellhnikhvV glwvssaV: ApovtiV arcevV evwV thn uvsterh arcaiovthta, by the Centre of the Greek Languageand the Institute of Modern Greek Studies [Manolis Triandafyllidis Foundation],Thessaloniki, 2001. (Individual articles cited as ‘[Author] in Christidis 2007’.)
CLARKE 1997 Kent D Clarke, Textual Optimism: A Critique of the United Bible Societies’Greek New Testament. Sheffield: Sheffiels Academic Press.
DINES 2004 Jennifer M Dines, The Septuagint. London: T & T Clark.
DUHOUX 1995 Yves Duhoux, ‘Études sur l’aspect verbal en grec ancien 1: présentation d’uneméthode’, Bulletin de la Société de Linguistique de Paris 90.1, 241-99.
DUHOUX 1997 Yves Duhoux, ‘Grec écrit et grec parlé: Une étude contrastive des particulesaux Ve-Ive siècles’, in Albert Rijksbaron (ed), New Approaches to GreekParticles. Amsterdam: Brill.
EVANS 2001 T V Evans, Verbal Syntax in the Greek Pentateuch: Natural Greek Usage andHebrew Interference. Oxford: Oxford University press
FANNING 1990 Buist M Fanning, Verbal Aspect in the New Testament. Oxford: ClarendonPress.
FINKELBERG 1994 Margalit Finkelberg, ‘The dialect continuum of Ancient Greek’, in HarvardStudies in Classical Philology 96 (1994) 1-36.
FORTSON 2004 Benjamin W Fortson IV, Indo-European language and Culture: An Introduction.Oxford: Blackwell Publishing.
FUNK 1973 Robert W Funk, A Beginning-Intermediate Grammar of Hellenistic Greek (3volumes), second edition. Missoula: Society of Biblical Literature.
GIGNAC 1981 Francis Thomas Gignac, A Grammar of the Greek Papyri of the Roman andByzantine Periods, Vol 1 (Phonology) & Vol 2 (Morphology). Milano: IstitutoEditoriale Cisalpino-La Goliardica
HARRIS & CAMPBELL
1995Alice C Harris & Lyle Campbell, Historical Syntax in Cross-LinguisticPerspective. Cambridge: Cambridge University Press.
HEWSON & BUBENIK
2006John Hewson & Vit Bubenik, From Case to Adposition: The Development ofConfigurational Syntax in Indo-European Languages. Amsterdam: JohnBenjamins
HEINE 2003 Bernd Heine, ‘Grammaticalization’, Chapter 18 (575-600) in Brian D Joseph &Richard Janda (eds), Handbook of Historical Linguistics. Oxford: Blackwell
HOLMES 1999 Michael W Holmes (ed), The Apostolic Fathers: Greek Texts and EnglishTranslations, second edition. Grand Rapids: Baker Academic.
HOLTON ET AL 1997 David Holton, Peter Mackridge & Irene Philippaki-Warburton, Greek: AComprehensive Grammar of the Modern Language. London: Routledge.
HOPPER &TRAUGOTT 2003
Paul J Hopper & Elizabeth Closs Traugott, Grammaticalization (second edition).Cambridge: Cambridge University Press.
HORROCKS 1981 Geoffrey C Horrocks, Space and Time in Homer: Prepositional and AdverbialParticles in the Greek Epic. New York: Arno Press
HORROCKS 1997 Geoffrey Horrocks, Greek: A History of the Language and its Speakers.London: Longman.
HOUSEHOLDER &NAGY 1972
Fred W Householder & Gregory Nagy, Greek: A Survey of Recent Work. TheHague: Mouton.
HORSLEY 1984 G H R Horsley, ‘Divergent Views on the Nature of the Greek of the Bible’, inBiblica 65 (1984) 393-403.

119
JANNI 1993 Pietro Janni, ‘On the Treatment of Some Greek Prepositions in ModernLanguage Dictionaries’, in Bela Brogyanyi & Reiner Lipp (eds), Comparative-Historical Linguistics: Indo-European and Finno-Ugric. Amsterdam: JohnBenjamins.
JASANOFF 2001 Jay H Jasanoff, Hittite and the Indo-European Verb. Oxford: Oxford UniversityPress.
KENNEDY 1998 Graeme Kennedy, An Introduction to Corpus Linguistics. London: Longman.
KENNY 1986 Anthony Kenny, A Stylometric Study of the New Testament. Oxford: Clarendon
KERSWILL 2002 Paul Kerswill, ‘Koineization and Accommodation’, Chapter 26 of JK Chambers,Peter Trudgill & Natalie Schilling-Estes (eds), The Handbook of LanguageVariation and Change. Blackwell: Oxford
LEE 1983 John A L Lee, A Lexical Study of the Septuagint Version of the Pentateuch.Chico Ca: Scholars Press
LEE 1997 John A L Lee, ‘Translations of the Old Testament: 1 Greek’, pp 775-783 inStanley E Porter (ed), Handbook of Classical Rhetoric in the Hellenistic Period330 BC – AD 400. Leiden: Brill.
LORD 1960 Albert B Lord, The Singer of Tales. Cambridge Mass: Harvard UniversityPress.
LSJ Henry George Liddell & Robert Scott, A Greek-English Lexicon, revised andaugmented throughout by Sir Henry Stuart Jones, with the assistance ofRoderick McKenzie. 1940. (Oxford: Clarendon). Available online through thePerseus Project at http://www.perseus.tufts.edu. (The Supplements to LSJ of1968 and 1996 are not yet freely available online.)
LURAGHI 2003 Silvia Luraghi, On the Meaning of Prepositions and Cases. Amsterdam: JohnBenjamins.
LURAGHI 2005 Silvia Luraghi, Ancient Greek. Munich: Lincom Europa
MCKAY 1994 K L McKay, A New Syntax of the Verb in New Testament Greek: AnAaspectualApproach. New York: Peter Lang.
MALLORY 1989 J P Mallory, In Search of the Indo-Europeans: Language, Archaeology andMyth. London: Thames and Hudson.
MANDILARAS 1973 Basil G Mandilaras, The Verb in the Greek Non-Literary Papyri. Athens:Hellenic Ministry of Culture and Sciences
MEECHAM 1923 Henry G Meecham, Light from Ancient Letters: Private Corrrespondence in theNonliterary Papyri of Oxyrhincus of the First Four Centuries, and its Bearing onNew Testament Language and Thought. Eugene, Oregon: Wipf and Stock.
MEILLET 1912 Antoine Meillet, ‘L’évolution des formes grammaticales’, Scientia (Rivista diScienza) 12, no.26.6: 384-400.
MORGENTHALER
1958R Morgenthaler, Statistik des neutestamentlichen Wortschatzes. Zurich:Gotthelf Verlag.
MOULTON I & II James Hope Moulton, A Grammar of New Testament Greek, Vol 1:Prolegomena (1908), Vol 2: Accidence and Word Formation (1919).Edinburgh: T & T Clark.
MOULTON & GEDEN
1897William Fiddian Moulton & Alfred Shenington Geden, Concordance to theGreek New Testament according to the Texts of Westcott and Hort. Edinburgh:T&T Clark.
NA 27 Nestle-Aland, Novum Testamentum Graece 27th edition 1993, in the tradition ofEberhard Nestle and Erwin Nestle, edited by Barbara & Kurt Aland, JohannesKaravidopoulos, Carlo M Martini, Bruce M Metxger. Stuttgart: DeutscheBibelgesellschaft.
120
NAGY 1996 Gregory Nagy, Homeric Questions. Austin: University of Texas Press.
O’DONNELL 2005 Matthew Brook O’Donnell, Corpus Linguistics and the Greek of the NewTestament (New Testament Monographs 6). Sheffield: Sheffield Phoenix Press.
O’DOWD 1998 Elizabeth M O’Dowd, Prepositions and Particles in English: A Discourse-functional Account. Oxford: Oxford University Press.
PALMER 1980 Leonard R Palmer, The Greek Language. London: Faber & Faber.
PETROUNIAS 2007 E B Petrounias, ‘The pronunciation of Ancient Greek in modern times’(translated by Andry Hendry), in Christidis 2007.
PORTER 1989 Stanley E Porter, Verbal Aspect in the Greek of the New Testament, withReference to Tense and Mood. New York: Peter Lang
PORTER 1991 Stanley E Porter (ed), The Language of the New Testament: Classic Essays.Sheffield: Sheffield Academic Press.
PORTER & CARSON
1993Stanley E Porter & D A Carson (eds), Biblical Greek Language and Linguistics:Open Questions in Current Research (JSNT SS 80). Sheffield: SheffieldAcademic Press.
RAHLFS 1935 A Rahlfs (ed), Septuaginta, id est Vetus Testamentum Graece iuxta LXXinterpretes, 2 vol. Stuttgart.
SCHMIDT 1981 Daryl Schmidt, Hellenistic Greek Grammar and Noam Chomsky: NominalizingTransformations. Chico CA: Scholars Press.
SCHMIDT 1985 Daryl Schmidt, ‘The Study of Hellenistic Greek Grammar in the Light ofContemporary Linguistics’, in Charles H Talbert (ed), Perspectives on the NewTestament: Essays in Honor of Frank Stagg. Macon: Mercer University Press.
SILVA 1980 Moises Silva, ‘Bilingulaism and the Character of Palestinian Greek’, in Biblica61 (1980) 198-219.
STANIFORTH 1968 Maxwell Staniforth (translator), Early Christian Writings: The Apostolic Fathers,Harmondsworth: Penguin.
TLG Thesaurus Linguae Graecae: data bank of Greek texts available bysubscription from University of California, Irvine.
TURNER 1963 Nigel Turner, A Grammar of New Testament Greek, Vol III: Syntax, by J HMoulton. Edinburgh: T & T Clark
VILBORG 1960 Ebbe Vilborg, A Tentative Grammar of Mycenaean Greek. Göteborg: ElandersBoktryckeri Aktiebolag.
VINCENT 1999 Nigel Vincent, ‘The evolution of c-structure: prepositions and PPs from Indo-European to Romance’, Linguistics 37.6:111-115.
WHITE 1986 John L White, Light from Ancient Letters. Philadelphia: Fortress Press.
WEBSITES:
ACCORDANCE www.accordancebible.com
GRAMCORD www.gramcord.org
LINEAR B www.explorecrete.com/archaeology/linearB.pdf
LSJ http://www.perseus.tufts.edu
PERSEUS PROJECT www.perseus.tufts.edu, en.wikipedia.org/wiki/Perseus_Project
TLG www.tlg.uci.edu, www.tlg.uci.edu/demo.html




















