
An FPGA-based Multi-core Approach for Pipelining Computing Stages
8
An FPGA-based Multi-Core Approach for Pipelining Computing Stages Ali Azarian, João M. P. Cardoso Departamento de Engenharia Informática, Universidade do Porto, Faculdade de Engenharia (FEUP) Porto, Portugal INESC TEC, Porto, Portugal [email protected], [email protected] Stephan Werner, Jürgen Becker Karlsruhe Institute of Technology – KIT Karlsruhe, Germany {stephan.werner, becker} @kit.edu ABSTRACT In recent years, there has been increasing interest on using task-level pipelining to accelerate the overall execution of applications mainly consisting of Producer-Consumer tasks. This paper proposes an approach to achieve pipelining exe- cution of Producer-Consumer pairs of tasks in FPGA-based multi-core architectures. Our approach is able to speedup the overall execution of successive, data-dependent tasks, by using multiple cores and specific customization features pro- vided by FPGAs. An important component of our approach is the use of customized inter-stage buffer schemes to com- municate data and to synchronize the cores associated to the Producer-Consumer tasks. In order to improve performance, we propose a technique to optimize out-of-order Producer- Consumer pairs where the consumer uses more than once each data element produced, a behavior present in many applications (e.g., in image processing). All the schemes and optimizations proposed in this paper were evaluated with FPGA implementations. The experimental results show the feasibility of the approach in both in-order and out-of-order Producer-Consumer tasks. Furthermore, the results using our approach to task-level pipelining and a multi-core ar- chitecture reveal noticeable performance improvements for a number of benchmarks over a single core implementation without using task-level pipelining. Keywords Multi-core processors, task-level pipelining, FPGA, Producer- Consumer data communication. 1. INTRODUCTION Task-level pipelining is an important technique for multi- core based systems [1] [2] especially when dealing with appli- cations consisting of Producer-Consumer computing stages. It provides additional speed-ups over the ones achieved by Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. SAC’13 March 18-22, 2013, Coimbra, Portugal. Copyright 2013 ACM 978-1-4503-1656-9/13/03 ...$10.00. the exploration of other forms of parallelism. The main idea of task-level pipelining is to overlap the execution of data-dependent tasks (computing stages). In the presence of multi-core based systems, task-level pipelining can be achieved by mapping each task to a distinct core and by syn- chronizing their execution using a handshaking based data communication scheme. Inter-task data communication be- tween cores is one of the most important topics in task-level pipelining. A simple data communication model for task- level pipelining can rely in the use of FIFO channels between cores. This is the model used in the presence of Producer- Consumer (P/C) pairs able to communicate efficiently over FIFO channels, such as the cases of P/C pairs with in-order communication patterns. In this model, the Consumer reads data from the FIFO using blocking read and the Producer write data to the FIFO using non-blocking write [3][4]. Although using FIFO channels between Producers and Consumers is an efficient solution for in-order P/C pairs, it may not be efficient or feasible for out-of-order P/C pairs. The use of FIFO channels strictly depends on the communica- tion patterns between Producers and Consumers. A problem appears if the order of data being produced is different from the order of data being consumed. In such case, FIFOs may not be sufficient to synchronize the data communication be- tween Producers and Consumers and it is necessary to use other data communication mechanisms [3]. Most recent studies are based on software approaches to task-level pipelining in the presence of out-of-order Producer- Consumer pairs. In these studies, an extra storage and buffer memory are introduced based on the order of the commu- nication pattern between the Producer and the Consumer, determined at compile time [3]. The data communication in these studies uses unbounded FIFOs which prevents these solutions to be implemented in hardware. The main contribution of this paper is an approach to implement customized multi-core architectures to achieve pipelining execution of P/C pairs without needing to change the order of producer or consumer. An important aspect of our approach is the use of customized inter-stage buffer schemes to communicate data and to synchronize the cores associated with the Producer-Consumer tasks (computing stages). Our approach provides the ability to pipeline the tasks of in-order and out-of-order communication patterns between P/C pairs. 1533
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of An FPGA-based Multi-core Approach for Pipelining Computing Stages

An FPGA-based Multi-Core Approachfor Pipelining Computing Stages
Ali Azarian, João M. P. CardosoDepartamento de Engenharia Informática,
Universidade do Porto, Faculdade deEngenharia (FEUP)
Porto, PortugalINESC TEC, Porto, Portugal
[email protected], [email protected]
Stephan Werner, Jürgen BeckerKarlsruhe Institute of Technology – KIT
Karlsruhe, Germany{stephan.werner, becker} @kit.edu
ABSTRACTIn recent years, there has been increasing interest on usingtask-level pipelining to accelerate the overall execution ofapplications mainly consisting of Producer-Consumer tasks.This paper proposes an approach to achieve pipelining exe-cution of Producer-Consumer pairs of tasks in FPGA-basedmulti-core architectures. Our approach is able to speedupthe overall execution of successive, data-dependent tasks, byusing multiple cores and specific customization features pro-vided by FPGAs. An important component of our approachis the use of customized inter-stage buffer schemes to com-municate data and to synchronize the cores associated to theProducer-Consumer tasks. In order to improve performance,we propose a technique to optimize out-of-order Producer-Consumer pairs where the consumer uses more than onceeach data element produced, a behavior present in manyapplications (e.g., in image processing). All the schemes andoptimizations proposed in this paper were evaluated withFPGA implementations. The experimental results show thefeasibility of the approach in both in-order and out-of-orderProducer-Consumer tasks. Furthermore, the results usingour approach to task-level pipelining and a multi-core ar-chitecture reveal noticeable performance improvements fora number of benchmarks over a single core implementationwithout using task-level pipelining.
KeywordsMulti-core processors, task-level pipelining, FPGA, Producer-Consumer data communication.
1. INTRODUCTIONTask-level pipelining is an important technique for multi-
core based systems [1] [2] especially when dealing with appli-cations consisting of Producer-Consumer computing stages.It provides additional speed-ups over the ones achieved by
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.SAC’13 March 18-22, 2013, Coimbra, Portugal.Copyright 2013 ACM 978-1-4503-1656-9/13/03 ...$10.00.
the exploration of other forms of parallelism. The mainidea of task-level pipelining is to overlap the execution ofdata-dependent tasks (computing stages). In the presenceof multi-core based systems, task-level pipelining can beachieved by mapping each task to a distinct core and by syn-chronizing their execution using a handshaking based datacommunication scheme. Inter-task data communication be-tween cores is one of the most important topics in task-levelpipelining. A simple data communication model for task-level pipelining can rely in the use of FIFO channels betweencores. This is the model used in the presence of Producer-Consumer (P/C) pairs able to communicate efficiently overFIFO channels, such as the cases of P/C pairs with in-ordercommunication patterns. In this model, the Consumer readsdata from the FIFO using blocking read and the Producerwrite data to the FIFO using non-blocking write [3][4].
Although using FIFO channels between Producers andConsumers is an efficient solution for in-order P/C pairs, itmay not be efficient or feasible for out-of-order P/C pairs.The use of FIFO channels strictly depends on the communica-tion patterns between Producers and Consumers. A problemappears if the order of data being produced is different fromthe order of data being consumed. In such case, FIFOs maynot be sufficient to synchronize the data communication be-tween Producers and Consumers and it is necessary to useother data communication mechanisms [3].
Most recent studies are based on software approaches totask-level pipelining in the presence of out-of-order Producer-Consumer pairs. In these studies, an extra storage and buffermemory are introduced based on the order of the commu-nication pattern between the Producer and the Consumer,determined at compile time [3]. The data communication inthese studies uses unbounded FIFOs which prevents thesesolutions to be implemented in hardware.
The main contribution of this paper is an approach toimplement customized multi-core architectures to achievepipelining execution of P/C pairs without needing to changethe order of producer or consumer. An important aspectof our approach is the use of customized inter-stage bufferschemes to communicate data and to synchronize the coresassociated with the Producer-Consumer tasks (computingstages). Our approach provides the ability to pipeline thetasks of in-order and out-of-order communication patternsbetween P/C pairs.
1533

for(i=0; i<N; i++) { for (j=0; j<N; j++) {
out=Fp(i,j); fifoPut(out); }
}
for(i=0; i<N; i++) { for (j=0; j<N; j++) {
in=fifoGet ();Fc(in); }
}
Unbounded(FIFO
Producer Consumer
Figure 1: Example of a simple Producer-Consumerpair using an unbounded FIFO channel.
We analyze different implementations of Inter-Stage Buffers(ISBs) and compare them based on the measurements usingthe FPGA board. In addition, we propose a technique toimprove out-of-order P/C pairs when a consumer uses morethan once a data element produced by a producer (referredherein as single write, multiple reads). The optimizationtechnique provides a reduction of requests from producer byusing a scheme based on shadow memory. The results showthat our custom architecture provides higher speed-ups forin-order and out-of-order.
We evaluate our approach with FPGA implementationsand measurements on a set of benchmarks running on anFPGA board. We compare the execution speed-up ob-tained by our approach to task-level pipelining over theexecution of applications in a single core and without usingtask-level pipelining.
The rest of this paper is organized as follows. Section 2gives an introduction to task-level pipelining. Section 3presents our approach and introduces the inter-stage buffer.Section 4 presents an optimization technique for dealing withP/C pairs with single write, multiple reads behavior. Sec-tion 5 presents the experimental setup and the experimentalresults. Section 6 describes related work related to task-level pipelining. Finally, Section 7 concludes this paper andpresents ongoing and future work.
2. TASK-LEVEL PIPELININGA task is a unit of computation which can be as fine-
grained as an arithmetic operation or as coarse-grained asa procedure that executes thousands of instructions. Manyapplications, such as image/video processing applications,are structured as a sequence of data-dependent computingstages using the P/C pair communication paradigm whichare amendable to pipelined execution [5][6].
Using task-level pipelining, a consumer computing stage(e.g., identifying a loop or a set of nested loops) may startexecution before the end of the producer computing stage,based on data availability. Performance gains can be achievedas the consumer can process data as soon as it becomesavailable. In this fine-grained data synchronization, theProducer and the Consumer may overlap significant parts oftheir execution.
The simplest implementation of task-level pipelining usesa FIFO channel between cores implementing Producer-Consumer pairs. The FIFO can store an array elementor a set of array elements to establish data synchronizationbetween the Producer and Consumer. The FIFO is sufficientwhen the sequence of producing data is the same than thesequence of consuming data (referred herein as in- order datacommunication pattern or simply in-order). In this case,the data communication between the Producer and Con-sumer can be synchronized by using a FIFO storing one data
(0,0)
Producer
Consumer
(0,0) (0,1) (0,2) (1,0) (1,1)
(0,0) (2,0)
(2,0) (2,1)Write
Read
Buffer
(1,0)
(0,1) (0,2) ....... (1,0) (1,1) (2,0) (2,1).......
Wait Wait
Figure 2: A sequence of the producing and consum-ing data for an out-of-order P/C pair.
element in each stage. Fig. 1 shows the simplest instanceof data communication over an unbounded FIFO channel toobtain the fine-grained synchronization between P/C pairs.In this model, the one-dimensional FIFO channel is beingaccessed by means of a non-blocking write from the Producerside and a blocking read from the Consumer side.
Other implementations use bounded FIFOs and block-ing writes from the Producer [7][8]. This is the preferablehardware implementation.
The problem emerges if the data produced is not consumedin the same order (referred herein as out-of-order data com-munication pattern or simply out-of-order). In such case,a simple FIFO is typically not sufficient to implement thecommunication, and a possible solution is to use an extrastorage and control at the consumer side [6][9].
2.1 P/C data communication orderWe show in Fig. 1 two computing stages using nested
loop computations (as an example of data-dependent tasks)for the Producer and Consumer. In each iteration of theProducer, a function Fp is evaluated and the result is sentto the Consumer over the FIFO. Similarly, in each iterationof the Consumer, a value is read from the FIFO. This valueis consumed as an argument of the function Fc.
According to the sequences of data produced and con-sumed, P/C pairs can be classified in two different types:in-order and out-of-order. In in-order P/C pairs, the se-quences of producing and consuming data are the same (seenested-loop computations in Fig. 1). In out-of-order P/Cpairs, the sequences of producing and consuming data aredifferent.
The main idea behind a generic task-level pipelining isto overlap some of the producer-consumer execution steps.Fig. 2 shows the sequence of an out-of-order P/C pair wheresome of the Producer and Consumer steps execute concur-rently (e.g., as soon as data element (0, 0) is produced theconsumer processes it and waits for the data element (1, 0),and after producing data element (0, 0) the producer con-tinues producing other data elements such as (0, 1), (0, 2),etc.). An implementation of out-of-order P/C pairs requiresa synchronization scheme and an inter-stage buffer able toaccommodate the data being communicated between theProducer and the Consumer.
2.2 P/C pairs ratiosThe ratio of the Producer and Consumer defines the num-
ber of times each data element is produced/consumed. Ifthe Producer sends an element to the Consumer just once,the ratio of the Producer is 1. Similarly, if the Consumeruses an element just once, the ratio of the Consumer is 1.
1534

ProducerInter-Stage
BufferConsumer
Shared Main Memory
Figure 3: Target system block diagram consideringan Inter-Stage Buffer (ISB) between the Producerand the Consumer.
Equation (1) shows the general form of P/C pairs ratios.For instance, a P/C pair ratio of (1 : 2) means that dataelements are produced once and there is at least one elementused twice by the consumer. A P/C pair ratio of (2 : 1)means that there is at least one element produced twice andconsumed once.
(Pr : Cr; 1 ≤ Pr ≤ Prmax ; 1 ≤ Cr ≤ Crmax) (1)
P/C pairs can be grouped in four categories: (1 : 1),(1 : Crmax), (Prmax : 1) and (Prmax : Crmax).
In this paper we propose a technique to deal with differentP/C pairs ratios.
3. INTER-STAGE BUFFER APPROACHTo provide task-level pipelining between Producers and
Consumers and to overcome the limitations related to simpleFIFO implementations, we explore an alternative inter-stagescheme. In this scheme, for each data element being com-municated between the Producer and Consumer there is anempty/full flag. We propose a customized multi-core archi-tecture with a flexible Inter-Stage Buffer (ISB) between eachP/C pair (see Fig. 3). As depicted in Fig. 3, the Produceris connected to the ISB using one channel responsible tocommunicate data between the Producer and the ISB. TheConsumer is connected to the ISB by using two channels:Receiving and Sending channel. These channels are simplebounded FIFOs. Our current approach uses blocking writeover the sending channel to the ISB and blocking read fromthe ISB over the receiving channel.
The consumer uses the receiving channel to get data fromthe ISB. The sending channel is used to transmit the requeststo the ISB concurrently. Both Producer and Consumer areconnected to the external shared main memory. Based onthe types of memory which can be used in the ISB (localand/or main memory), we present three possible schemes:using local memory, using main memory, or using both localand main memory (see Fig. 4).
Fig. 4 presents three different possibilities for the ISBin terms of local/main memory interfaces. The scheme (a)presents the situation where the ISB uses only a boundedlocal memory as a buffer. In this case, the Producer sendsdata to the ISB over the sending channel and the ISB writesthe produced data in the local memory. The scheme (b)shows the second scheme of the ISB which uses externalmain memory. The third scheme of the ISB (see (c) in Fig. 4)uses both local memory and external shared main memory.
Rodrigues et al. [5] used a fine-grained synchronizationscheme between Producer and Consumer stages and a hashfunction concept (using zero-cost hash-functions [10]) to re-duce the size of the Inter-Stage Buffers. This synchronizationis similar to the concept of using the empty/full tagged mem-
Inter-Stage Buffer
Main Memory
Local memory
Inter-Stage Buffer
Main Memory
Inter-Stage Buffer
Local memory
(a) (b) (c)
Figure 4: Different possibilities for the inter-stagebuffer (ISB): (a) w/ local memory and w/o access tomain memory; (b) w/o local memory and w/ accessto main memory; (c) w/ local memory and access tomain memory.
ory scheme for multiprocessor architectures using sharedmemory [11].
Our proposed architecture extends the data synchroniza-tion between the Producer and Consumer for in-order andout-of-order P/C pairs using bounded local memory and/ormain memory. Here we explore the mechanism of differentschemes of the ISB. Fig. 5 shows the block diagram of theISB in the context of using different memory types. In thispaper we explore different schemes for the ISB to supporttask-level pipelining in the context of P/C pairs.
3.1 Inter-Stage Buffer using local memoryIn this first scheme, for each array element produced, the
Producer sends its index and value to the ISB. The ISBreceives the index from producer side and maps it to thelocal memory using a simple hash function (e.g., using anumber of least significant bits of the binary representationof the index). The index and value produced are then storedin the ISB local memory location defined by the addressgiven by the hash function. Related to the value stored inthe ISB, there is a flag which indicates if a data element wasproduced and thus can be consumed by the Consumer. Thepath A illustrated in Fig. 5 presents the flow of using an ISBonly using local memory as memory buffer.
In each ISB read by the Producer, the ISB gets the re-quested index from the Consumer side and checks the statusof the respective flag addressed by the hash function. If therequested element is present (if the respective flag bit is full)in the ISB local buffer, it is sent to the Consumer and therespective flag is set to empty. If the requested element bythe consumer is not available in the local memory, the con-sumer will be idle and will wait until the requested elementis ready in the local memory.
Although reading/writing from/to local memory in theISB is fast, the limitation of the size of the local memorymay be a bottleneck to store all produced data in out-of-order P/C pair cases. We may have a deadlock situationas the Producer may stop to produce data if the ISB localmemory is full. To avoid deadlock situations we need todetermine before system deployment the minimum size ofthe local memory needed. Such approach was proposed by [5]in the context of task-level pipelining of application-specificarchitectures, where the buffer size was determined usingRTL simulations.
1535

Figure 5: Inter-Stage Buffer using local and/orShared Main Memory.
3.2 Inter-Stage Buffer using main memoryIn this second scheme, the ISB only uses the main memory
(see path B in Fig. 5). The ISB receives the index and thedata value from the Producer and stores the data in the mainmemory addressed by the index (i.e., without using indexesgiven by hash functions). In this case, we assume that thereis enough space in main memory to store all produced data.An empty/full bit flag table determines the status of storeddata in the main memory. Similarly, the ISB receives therequested index from the Consumer and directly checks theflag status of the requested index in main memory. If theflag status is full means that the data element can be sent tothe consumer (note that in this case we do not need to resetthe respective flag). The main disadvantage of using mainmemory is that the data communication over an externalmain memory is slower than using local memory. However,using external main memory provides enough space to storeall the produced data and to avoid deadlock situations.
3.3 Inter-Stage Buffer using local and mainmemory
A third scheme considers ISBs using both local and mainmemory for storing produced data. In this scheme, the ISBtries to store firstly the produced index and data value intothe local memory by using the hash function in the sameway of first scheme. If the flag bit in the local memory isin full status, the ISB stores the produced data value in themain memory without using the hash function in the sameway of second scheme. If both flag bits of the local and mainmemory are in empty status, the consumer waits until datacorrespondent to the requested index is produced and storedin local or in main memory.
The previous explanations consider (1 : 1) P/C pairs ratios.For (1 : N) P/C pairs we use a similar approach, but insteadof a table of flags in the ISB we use a synchronization tableof numbers where each number represents the number oftimes a data element is requested. For each data producedthe respective table value is set to the number of timesit is requested (N). For each request the respective tablevalue is decremented by one and when it is 0 means that itis empty. In our current approach we are not considering(N : M), being N > 1, P/C pairs. The analysis of many
#define I Window row#define J Window column#define L Image Length#define W Image Widthint Calculate Number of Requests ( int x , int y ){ int m, n ;
i f ( x < I ) m = x ;else i f ( ( x >= I ) && (x <= (L−I ) ) ) m = I ;else m = L − x + 1 ;
i f ( y < J ) n = y ;else i f ( ( y >= J) && (y <= (W−J ) ) ) n = J ;else n = W − y + 1return (m ∗ n) ;
}
Figure 6: Example of a function to compute thenumber of requests for each data element.
applications indicates that the (1 : 1) and (1 : N) P/C pairsare the most common.
4. OPTIMIZING (1:N) P/C PAIRS RATIOSIn many image/video processing computing stages, the
P/C pairs ratios is (1 : N). In such cases, we can use themaximum number of requests per data element (N) for allthe elements. However, in some computing stages this impliesdata elements not being removed from the local memory. Toprevent this situation we can use a function to determine theprecise number of requests for each requested element of theConsumer. In this case the ISB assigns it to the respectiveelement in the synchronization table.
For instance, many image processing applications are basedon calculations (e.g., average, sum) using windows of pixelsof images. By considering the size of the window, we cancompute the number of requests from the Consumer basedon the coordinates of each produced element. For example,in the Edge-Detection kernel used in our experiments, thewindow size is defined as 3×3. It means that in the Consumerstage, all the elements of this window are required to performa specific computation of the algorithm and to store the resultin the output image. For this particular computing stage,we propose the function in Fig. 6 to calculate the numberof requests for each produced element. This function can beimplemented in the Producer or in the ISB. The function usesthe (x, y) of each produced element as an input argumentand returns the number of requests for each element of theConsumer stage.
As an example, consider an image processing applicationwith the image size of 8× 8 and 3× 3 window block depictedin Fig. 7 (a). The window block is moved horizontally to thenext column until it reaches the last column of the imageand then continues vertically considering the next row untilit reaches the last row of the image.
Fig. 7 (b) presents the situation when the window blockmoves to the next column of the image. In the second windowblock, most of the elements are requested in a previouswindow block which is depicted by the light pattern greycolor (see Fig. 7 (b) right). We can see that the number ofrequests for each pixel of the image is not constant. It meansthat based on the x, y of the pixel in the image, the numberof requests is different. For example, the four corners of theimage are requested once, while the pixels in the centre ofthe image are requested 8 times.
1536

A[0,1] A[0,2] ....
A[1,0] A[1,1] A[1,2]
A[2,0] A[2,1] A[2,2]
0
1
2
0 1 2Row
ColWindow block
....
....
....
....
....
7
....
....
....
....
....
....
7
A[0,1] A[0,2] A[0,3]
A[1,1] A[1,2]
A[2,1] A[2,2]
0
1
2
0 1 2
A[1,3]
A[2,3]
....
....
....
7
....
....
....
7
....
....
....
....
....
....
3
Window block
A[0,0]
(a)
A[0,1] A[0,2] ....
A[1,0] A[1,1] A[1,2]
A[2,0] A[2,1] A[2,2]
0
1
2
0 1 2Row
ColWindow block
....
....
....
....
....
7
....
....
....
....
....
....
7
A[0,1] A[0,2] A[0,3]
A[1,1] A[1,2]
A[2,1] A[2,2]
0
1
2
0 1 2
A[1,3]
A[2,3]
....
....
....
7
....
....
....
7
....
....
....
....
....
....
3
New Requests
A[0,0]
Shadow Window
(b)
Figure 7: Example of a P/C pair with ratio of (1 :Crmax): (a) window block movement; (b) reducingthe number of accesses to the ISB by using ashadow memory.
Although this function performs well to set the precisevalue for the synchronization table, it may not free local mem-ory positions as intended when the number of requests is notconstant for each pixel of the image. Thus, we propose an op-timization technique to decrease the number of requests fromthe Consumer by storing the previously requested elementsinto a local shadow memory.
The shadow memory is implemented in the Consumer sideas a simple one dimensional array to store the previouslyrequested elements as shown in Fig. 7 (b). By storing theprevious window block in the shadow memory, the Consumerrequests only the new elements which are not available incurrent shadow memory. As shown, the number of requests insecond window block can be decreased to only three requests.As a result of reducing the number of requests to ISB, wecan achieve higher speed-ups for 1 : N ratio P/C pairs.
5. EXPERIMENTAL SETUP AND RESULTSFor evaluating our task-level pipelining approach we use a
GenesysTM Virtex-5 XC5LX50T FPGA Development Board.The target architecture was developed with Xilinx EDK12.3 tools. For the cores of the architecture we use XilinxMicroBlaze processors (MB) [12] without caches.
Fig. 8 illustrates the target architecture. The MicroBlazeprocessors use the Fast Simplex Link (FSL) Bus in orderto communicate directly to each other [13]. Peripheralsof the system such as the MicroBlaze Debugger Module(MDM), which enables debugging for the MB processors, areconnected to the Processor Local Bus (PLB) of MicroBlazeprocessors. All three MicroBlaze processors directly connectto the shared DDR2-SDRAM memory through the PLB. TheTimer is a 32-bit timer attached to the PLB to measure thenumber of executed MicroBlaze clock cycles. The size of
MicroBlaze+1(MB+1)
MicroBlaze+2(MB+2)
PLB+1
FSL
FSLFSL
DDR26SDRAM
RS232+UART
MDM
Timer
PLB+2
PLB+3
MicroBlaze+3(MB+3)
Figure 8: Block diagram of the target architecture.
Table 1: Benchmarks used in the experiments
BenchmarkData CommunicationOrder
Fast DCT (FDCT) out-of-orderGray-Histogram(RGB2gray+Histogram)
in-order
Wavelet Transforms out-of-orderFIR-Edge (FIR filter +Edge-Detection)
out-of-order
Edge-Detection out-of-order
the local data memory connected to MB2 and used in allexperiments is 1, 024 × 32bit.
In this architecture, MB1 and MB3 are responsible to exe-cute the codes for the Producer and Consumer, respectively.At the moment we use an additional MicroBlaze (MB2 ) andlocal memory to implement the ISB schemes. Although thismay not be the fastest solution (compared to the use of hard-ware implementations of the ISBs), it allows the flexibilityand easy programmability required to explore and evaluatedifferent data communication and synchronization schemes.
To evaluate the impact of our customized multi-core archi-tecture approach with customized ISB schemes to communi-cate data and to synchronize the cores associated with theProducer-Consumer tasks, we compare the execution timeobtained with task-level pipelining and the architecture ofFig. 8 over a fully sequential solution executing in a singleMicroBlaze processor. We also present results of using threeschemes for the ISB.
We measure the execution time for a set of benchmarkswhich are described in Table 1. To provide the Producer-Consumer data communication model, the original sequentialcode of the benchmarks was partitioned in computing stages,being each stage a sequence of loops or nested loops.
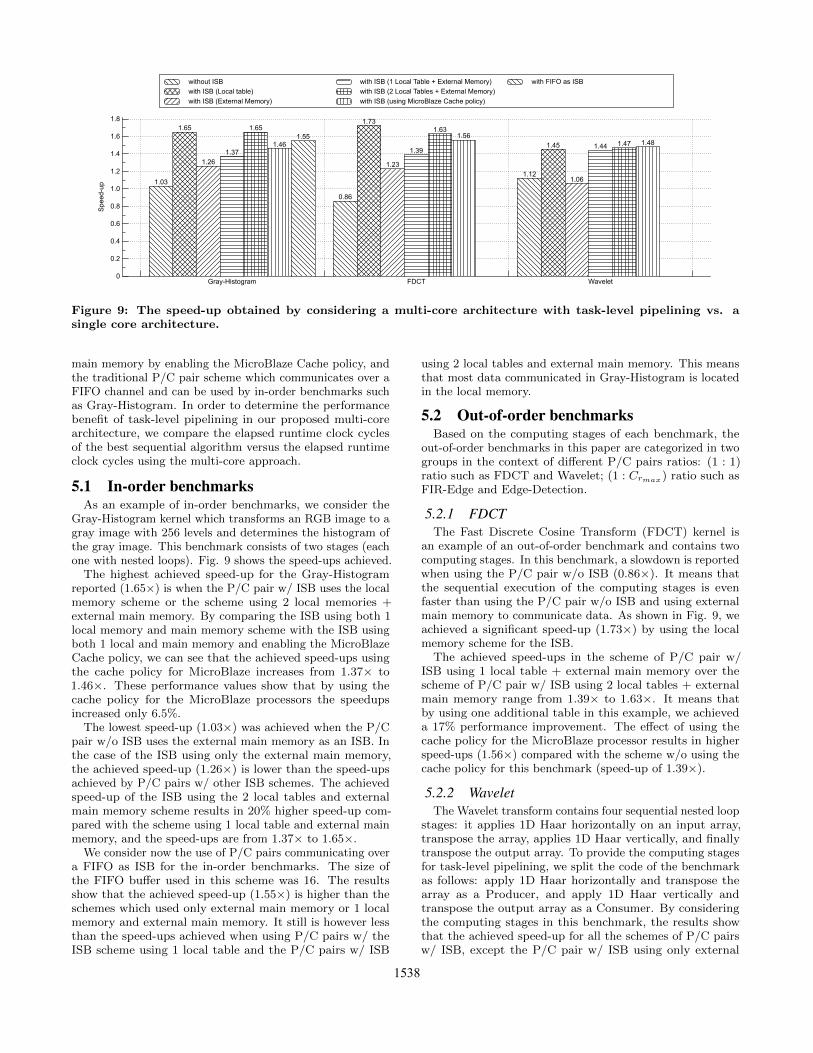
Fig. 9 shows the speed-ups achieved considering the pro-posed multi-core architecture with Producer-Consumer task-level pipelining when comparing the benchmarks with se-quential execution in a single core. As shown, we evaluate thebenchmarks w/ and w/o using ISB. The P/C pair exampleswith ISB consider different categories based on the use ofdifferent memories: w/o ISB and using the external mainmemory as an inter-stage buffer, w/ ISB using one local ta-ble, w/ ISB using only external main memory, w/ ISB usingboth 1 local table and main memory, w/ ISB using both 2local tables and main memory, w/ ISB using both local and
1537
1.03
0.86
1.12
1.651.73
1.45
1.26 1.23
1.06
1.37 1.39 1.44
1.65 1.63
1.471.461.56
1.481.55
Spee
d-up
0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8
Gray-Histogram FDCT Wavelet
without ISBwith ISB (Local table)with ISB (External Memory)
with ISB (1 Local Table + External Memory)with ISB (2 Local Tables + External Memory)with ISB (using MicroBlaze Cache policy)
with FIFO as ISB
Figure 9: The speed-up obtained by considering a multi-core architecture with task-level pipelining vs. asingle core architecture.
main memory by enabling the MicroBlaze Cache policy, andthe traditional P/C pair scheme which communicates over aFIFO channel and can be used by in-order benchmarks suchas Gray-Histogram. In order to determine the performancebenefit of task-level pipelining in our proposed multi-corearchitecture, we compare the elapsed runtime clock cyclesof the best sequential algorithm versus the elapsed runtimeclock cycles using the multi-core approach.
5.1 In-order benchmarksAs an example of in-order benchmarks, we consider the
Gray-Histogram kernel which transforms an RGB image to agray image with 256 levels and determines the histogram ofthe gray image. This benchmark consists of two stages (eachone with nested loops). Fig. 9 shows the speed-ups achieved.
The highest achieved speed-up for the Gray-Histogramreported (1.65×) is when the P/C pair w/ ISB uses the localmemory scheme or the scheme using 2 local memories +external main memory. By comparing the ISB using both 1local memory and main memory scheme with the ISB usingboth 1 local and main memory and enabling the MicroBlazeCache policy, we can see that the achieved speed-ups usingthe cache policy for MicroBlaze increases from 1.37× to1.46×. These performance values show that by using thecache policy for the MicroBlaze processors the speedupsincreased only 6.5%.
The lowest speed-up (1.03×) was achieved when the P/Cpair w/o ISB uses the external main memory as an ISB. Inthe case of the ISB using only the external main memory,the achieved speed-up (1.26×) is lower than the speed-upsachieved by P/C pairs w/ other ISB schemes. The achievedspeed-up of the ISB using the 2 local tables and externalmain memory scheme results in 20% higher speed-up com-pared with the scheme using 1 local table and external mainmemory, and the speed-ups are from 1.37× to 1.65×.
We consider now the use of P/C pairs communicating overa FIFO as ISB for the in-order benchmarks. The size ofthe FIFO buffer used in this scheme was 16. The resultsshow that the achieved speed-up (1.55×) is higher than theschemes which used only external main memory or 1 localmemory and external main memory. It still is however lessthan the speed-ups achieved when using P/C pairs w/ theISB scheme using 1 local table and the P/C pairs w/ ISB
using 2 local tables and external main memory. This meansthat most data communicated in Gray-Histogram is locatedin the local memory.
5.2 Out-of-order benchmarksBased on the computing stages of each benchmark, the
out-of-order benchmarks in this paper are categorized in twogroups in the context of different P/C pairs ratios: (1 : 1)ratio such as FDCT and Wavelet; (1 : Crmax) ratio such asFIR-Edge and Edge-Detection.
5.2.1 FDCTThe Fast Discrete Cosine Transform (FDCT) kernel is
an example of an out-of-order benchmark and contains twocomputing stages. In this benchmark, a slowdown is reportedwhen using the P/C pair w/o ISB (0.86×). It means thatthe sequential execution of the computing stages is evenfaster than using the P/C pair w/o ISB and using externalmain memory to communicate data. As shown in Fig. 9, weachieved a significant speed-up (1.73×) by using the localmemory scheme for the ISB.
The achieved speed-ups in the scheme of P/C pair w/ISB using 1 local table + external main memory over thescheme of P/C pair w/ ISB using 2 local tables + externalmain memory range from 1.39× to 1.63×. It means thatby using one additional table in this example, we achieveda 17% performance improvement. The effect of using thecache policy for the MicroBlaze processor results in higherspeed-ups (1.56×) compared with the scheme w/o using thecache policy for this benchmark (speed-up of 1.39×).
5.2.2 WaveletThe Wavelet transform contains four sequential nested loop
stages: it applies 1D Haar horizontally on an input array,transpose the array, applies 1D Haar vertically, and finallytranspose the output array. To provide the computing stagesfor task-level pipelining, we split the code of the benchmarkas follows: apply 1D Haar horizontally and transpose thearray as a Producer, and apply 1D Haar vertically andtranspose the output array as a Consumer. By consideringthe computing stages in this benchmark, the results showthat the achieved speed-up for all the schemes of P/C pairsw/ ISB, except the P/C pair w/ ISB using only external
1538
1.14 1.141.27 1.27
0.64
1.56
0.95
1.26
0.46
1.64
0.56
1.01
0.55
2.23
0.52
1.14
0.37
2.20
0.52
1.15
0.46
2.38
0.58
1.39
Spee
d-up
0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8
2.0
2.2
2.4
FIR-Edge (Scheme#1) Fir-Edge (Scheme#2) Edge-Detection (Scheme#1) Edge-Detection (Scheme#2)
without ISBwith ISB (Local table)
with ISB (External Memory)with ISB (1 Local Table + External Memory)
with ISB (2 Local Tables + External Memory)with ISB (using MicroBlaze Cache policy)
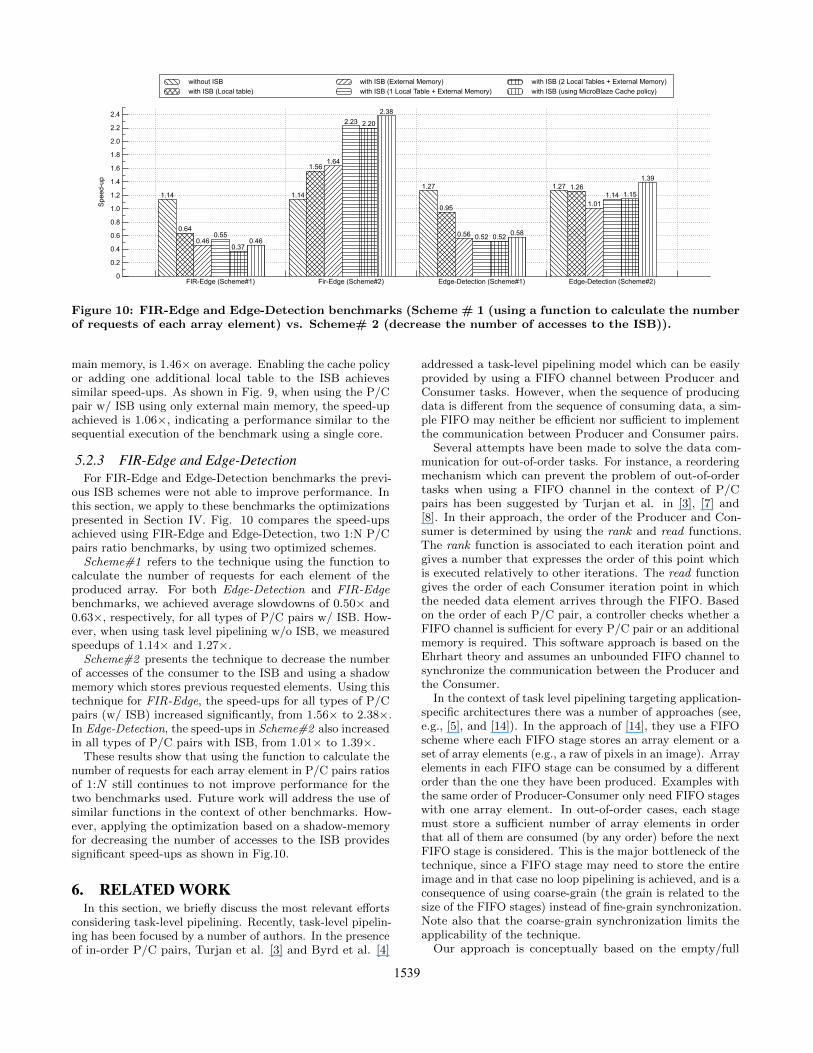
Figure 10: FIR-Edge and Edge-Detection benchmarks (Scheme # 1 (using a function to calculate the numberof requests of each array element) vs. Scheme# 2 (decrease the number of accesses to the ISB)).
main memory, is 1.46× on average. Enabling the cache policyor adding one additional local table to the ISB achievessimilar speed-ups. As shown in Fig. 9, when using the P/Cpair w/ ISB using only external main memory, the speed-upachieved is 1.06×, indicating a performance similar to thesequential execution of the benchmark using a single core.
5.2.3 FIR-Edge and Edge-DetectionFor FIR-Edge and Edge-Detection benchmarks the previ-
ous ISB schemes were not able to improve performance. Inthis section, we apply to these benchmarks the optimizationspresented in Section IV. Fig. 10 compares the speed-upsachieved using FIR-Edge and Edge-Detection, two 1:N P/Cpairs ratio benchmarks, by using two optimized schemes.
Scheme#1 refers to the technique using the function tocalculate the number of requests for each element of theproduced array. For both Edge-Detection and FIR-Edgebenchmarks, we achieved average slowdowns of 0.50× and0.63×, respectively, for all types of P/C pairs w/ ISB. How-ever, when using task level pipelining w/o ISB, we measuredspeedups of 1.14× and 1.27×.
Scheme#2 presents the technique to decrease the numberof accesses of the consumer to the ISB and using a shadowmemory which stores previous requested elements. Using thistechnique for FIR-Edge, the speed-ups for all types of P/Cpairs (w/ ISB) increased significantly, from 1.56× to 2.38×.In Edge-Detection, the speed-ups in Scheme#2 also increasedin all types of P/C pairs with ISB, from 1.01× to 1.39×.
These results show that using the function to calculate thenumber of requests for each array element in P/C pairs ratiosof 1:N still continues to not improve performance for thetwo benchmarks used. Future work will address the use ofsimilar functions in the context of other benchmarks. How-ever, applying the optimization based on a shadow-memoryfor decreasing the number of accesses to the ISB providessignificant speed-ups as shown in Fig.10.
6. RELATED WORKIn this section, we briefly discuss the most relevant efforts
considering task-level pipelining. Recently, task-level pipelin-ing has been focused by a number of authors. In the presenceof in-order P/C pairs, Turjan et al. [3] and Byrd et al. [4]
addressed a task-level pipelining model which can be easilyprovided by using a FIFO channel between Producer andConsumer tasks. However, when the sequence of producingdata is different from the sequence of consuming data, a sim-ple FIFO may neither be efficient nor sufficient to implementthe communication between Producer and Consumer pairs.
Several attempts have been made to solve the data com-munication for out-of-order tasks. For instance, a reorderingmechanism which can prevent the problem of out-of-ordertasks when using a FIFO channel in the context of P/Cpairs has been suggested by Turjan et al. in [3], [7] and[8]. In their approach, the order of the Producer and Con-sumer is determined by using the rank and read functions.The rank function is associated to each iteration point andgives a number that expresses the order of this point whichis executed relatively to other iterations. The read functiongives the order of each Consumer iteration point in whichthe needed data element arrives through the FIFO. Basedon the order of each P/C pair, a controller checks whether aFIFO channel is sufficient for every P/C pair or an additionalmemory is required. This software approach is based on theEhrhart theory and assumes an unbounded FIFO channel tosynchronize the communication between the Producer andthe Consumer.
In the context of task level pipelining targeting application-specific architectures there was a number of approaches (see,e.g., [5], and [14]). In the approach of [14], they use a FIFOscheme where each FIFO stage stores an array element or aset of array elements (e.g., a raw of pixels in an image). Arrayelements in each FIFO stage can be consumed by a differentorder than the one they have been produced. Examples withthe same order of Producer-Consumer only need FIFO stageswith one array element. In out-of-order cases, each stagemust store a sufficient number of array elements in orderthat all of them are consumed (by any order) before the nextFIFO stage is considered. This is the major bottleneck of thetechnique, since a FIFO stage may need to store the entireimage and in that case no loop pipelining is achieved, and is aconsequence of using coarse-grain (the grain is related to thesize of the FIFO stages) instead of fine-grain synchronization.Note also that the coarse-grain synchronization limits theapplicability of the technique.
Our approach is conceptually based on the empty/full
1539

tagged memories which have been described in [11] and [15],both in the context of shared memory multi-threaded/multi-processor architectures. Those memories were used for fine-grained synchronization of data Producer-Consumer by tasksexecuting in distinct processors. They can be seen as theempty/full tables used in the work presented in this paper.In our case we use an inter-stage buffer between cores andlocal tables to communicate as many as possible data el-ements between cores without accessing the main sharedmemory. One important aspect of our hierarchical scheme isthe minimization of conflicts when storing data and indexesin the inter-stage buffer.
Most relevant to our approach is the work presentedin [5] which is a technique for pipelining sequences of data-dependent loops using a fine-grained synchronization scheme.This scheme is implemented using inter-stage buffers tocommunicate data between Producer and Consumer stages(in-order and out-of-order) and the corresponding readyflags. This technique was used in the context of a compilerof software programming languages (e.g., Java) to specificcustomizable architectures suitable for implementation inFPGAs. Note, however, that the approach in [5] did notuse an inter-stage buffer with access to main memory and itrelies on RTL simulations to calculate the minimum size forthe inter-stage buffer.
7. CONCLUSIONSThis paper presented an approach for fine-grained task-
level pipelining in the context of FPGA-based multi-corearchitectures. Our approach is able to provide task-levelpipelining to both in-order and out-of-order computing stages.We analyzed and compared different implementations ofthe inter-stage buffer. In addition, we presented an opti-mization technique to reduce, in out-of-order benchmarks,the number of requests to the same data element (multiplereads) by reusing data through the use of a shadow memorybased scheme.
All the solutions proposed in this paper were implementedusing an FPGA board. Those solutions were evaluated bymeasuring execution times using in-order and out-of-orderbenchmarks. The results show that our task-level pipeliningapproach using a multi-core architecture can achieve sig-nificant speed-ups over the sequential execution of comput-ing stages in a single core. The shadow memory basedoptimization technique proposed in this paper provides highperformance improvements for out-of-order single write, mul-tiple reads producer-consumer behaviors.
Ongoing work is focused on experiments with additionalbenchmarks. Future work will address other schemes forthe inter-stage buffer and additional optimizations. We alsoplan to research hash-functions able to reduce conflicts whenstoring data to the local tables of the inter-stage buffers.
AcknowledgmentThe work presented was partially supported by Fundacaopara a Ciencia e a Tecnologia (FCT) under grant numberSFRH/BD/80481/2011. The authors also acknowledge thepartial support by the European Framework Programme 7(FP7) under contract No. 248976. Any opinions, find-ings, and conclusions or recommendations expressed in thismaterial are those of the author(s) and do not necessarilyreflect the views of the European Commission.
8. REFERENCES[1] G. R. Andrews, Concurrent programming: principles
and practice. Benjamin-Cummings Publishing Co.,Inc., 1991.
[2] D. Kim, K. Kim, J.-Y. Kim, S. Lee, and H.-J. Yoo,“Memory-centric network-on-chip for power efficientexecution of task-level pipeline on a multi-coreprocessor,” Computers Digital Techniques, IET, vol. 3,no. 5, pp. 513–524, september 2009.
[3] A. Turjan, B. Kienhuis, and E. Deprettere, “SolvingOut-of-Order Communication in Kahn ProcessNetworks,” J. VLSI Signal Process. Syst., vol. 40, no. 1,pp. 7–18, May 2005.
[4] G. Byrd and M. Flynn, “Producer-consumercommunication in distributed shared memorymultiprocessors,” Distributed Shared MemoryMultiprocessors, Proceedings of the IEEE, vol. 87, no. 3,pp. 456–466, 1999.
[5] R. Rodrigues, J. M. P. Cardoso, and P. C. Diniz, “AData-Driven Approach for Pipelining Sequences ofData-Dependent Loops,” in Proceedings of the 15thIEEE Symposium on Field-Programmable CustomComputing Machines, ser. FCCM ’07, 2007, pp.219–228.
[6] H. Ziegler, B. So, M. Hall, and P. C. Diniz,“Coarse-Grain Pipelining on Multiple FPGAArchitectures,” in Proceedings of the 10th IEEESymposium on Field-Programmable Custom ComputingMachines, ser. FCCM ’02, 2002, p. 77.
[7] A. Turjan, B. Kienhuis, and E. Deprettere, “Atechnique to determine inter-process communication inthe polyhedral model,” in Proc. Int. Workshop onCompilers for Parallel Computers (CPC’03), 2003, pp.8–10.
[8] A. Turjan, B. Kienhuis, and E. Deprettere, “A compiletime based approach for solving out-of-ordercommunication in kahn process networks,” inProceedings of IEEE 13th International Conference onApplication specific Systems, Architectures andProcessor, 2002, pp. 17–28.
[9] G. Kahn, “The Semantics of a Simple Language forParallel Programming,” in Proceedings of the IFIPCongress, 1974, pp. 471–475.
[10] T. Givargis, “Zero cost indexing for improved processorcache performance,” ACM Transactions on DesignAutomation of Electronic Systems (TODAES), vol. 11,no. 1, pp. 3–25, 2006.
[11] B. Smith et al., “Architecture and applications of theHEP multiprocessor computer system,” Real-Timesignal processing IV, vol. 298, pp. 241–248, 1981.
[12] Xilinx, Inc, MicroBlaze Processor Reference Guidev12.3, 2010.
[13] Xilinx, Inc, LogiCORE IP Fast Simplex Link (FSL)V20 Bus v2.11c, April 2011.
[14] H. Ziegler, M. Hall, and P. Diniz, “Compiler-generatedcommunication for pipelined FPGA applications,” inProceedings of the 40th annual Design AutomationConference. ACM, 2003, pp. 610–615.
[15] B. Smith, “Advanced computer architecture,” D. P.Agrawal, Ed., 1986, ch. A pipelined, shared resourceMIMD computer, pp. 39–41.
1540



















