
Efficient Algorithm for Discovering Potential Interesting Patterns with Closed Itemsets

Int. J. Granular Computing, Rough Sets and Intelligent Systems, Vol. 2, No. 2, 2011 107
Copyright © 2011 Inderscience Enterprises Ltd.
Algorithms for discovering potentially interesting patterns
Raj Singh* School of Science and Computer Engineering, University of Houston Clear Lake, Houston, TX 77058, USA E-mail: [email protected] *Corresponding author
Tom Johnsten School of Computer and Information Sciences, University of South Alabama, Mobile, AL 36688, USA E-mail: [email protected]
Vijay V. Raghavan Center of Advanced Computer Studies, University of Louisiana, Lafayette, LA 70504, USA E-mail: [email protected]
Ying Xie Deptartment of Computer Science and Information Systems, Kennesaw State University, Kennesaw, GA 30144, USA E-mail: [email protected]
Abstract: A pattern discovered from a collection of data is usually considered potentially interesting if its information content can assist the user in their decision making process. To that end, we have defined the concept of potential interestingness of a pattern based on whether it provides statistical knowledge that is able to affect one’s belief system. In this paper, we introduce two algorithms, referred to as All-Confidence based Discovery of Potentially Interesting Patterns (ACDPIP) and ACDPIP-Closed, to discover patterns that qualify as potentially interesting. We show that the ACDPIP algorithm represents an efficient alternative to an algorithm introduced in our earlier work, referred to as Discovery of Potentially Interesting Patterns (DAPIP). However, results of experimental investigations also show that the application of ACDPIP is limited to sparse datasets. In response, we propose the algorithm ACDPIP-Closed designed to effectively discover potentially interesting patterns from dense datasets.

108 R. Singh et al.
Keywords: data mining; potential interesting patterns; positive patterns; negative patterns; association rules; closed frequent itemsets.
Reference to this paper should be made as follows: Singh, R., Johnsten, T., Raghavan, V.V. and Xie, Y. (2011) ‘Algorithms for discovering potentially interesting patterns’, Int. J. Granular Computing, Rough Sets and Intelligent Systems, Vol. 2, No. 2, pp.107–122.
Biographical notes: Raj Singh is an Adjunct Faculty at the University of Houston Clear Lake. He has over ten year’s corporate and industrial-based experience. His research interests are in areas of data mining, biomedical data mining, web data mining, and soft-ware development.
Tom Johnsten is an Associate Professor at the University of South Alabama. His research interests include data mining, text mining, data warehousing, and medical informatics. His work has been presented at various internal conferences.
Vijay V. Raghavan is a Distinguished Professor at the University of Louisiana. He is an expert in information retrieval and data mining, with over 170 publications. His research activities address various approaches to designing effective retrieval systems and he has contributed efficient algorithms for data analysis tasks, such as predictive modelling, database segmentation and link analysis, in the context of knowledge discovery in databases (KDD). He co-chaired the NSF Workshop on Future Directions in Information Retrieval in 1991, which led to the multi-agency-sponsored, Digital Library Initiative. He received the IEEE/ICDM 2005 Outstanding Service award, served on the NSF/CISE Advisory Committee (2008–2010), and serves on the Executive Committee of IEEE TC on Intelligent Informatics.
Ying Xie is an Associate Professor of Computer Science at the Kennesaw State University. His research interests include information retrieval, data mining, computational intelligence, granular computing, and bioinformatics. His research was sponsored by NSF and a couple of US companies. He holds several pending US patents.
This paper is a revised and expanded version of a paper entitled ‘Efficient algorithm for discovering potential interesting patterns with closed itemsets’ presented at 2010 IEEE International Conference on Granular Computing, San Jose, CA, 14–16 August 2010.
1 Introduction
Knowledge discovery in databases (KDD) is defined to be the non-trivial process of identifying valid, novel, potentially interesting, and ultimately understandable patterns in data. We define the potential interestingness of a pattern based on whether it provides statistical knowledge that is able to affect one’s belief system (Agrawal and Srikant, 1994).
There are numerous applications in which the discovery of such potentially interesting patterns is particularly significant. For example, in Chen et al. (2007), the authors propose a data mining technique to discover the side effects of drugs on preterm

Algorithms for discovering potentially interesting patterns 109
births. According to the authors, their technique discovered that the combined exposure to citalopram and alcohol leads to increased risk of preterm birth. This pattern was considered potentially interesting because the difference in the confidence between (citalopram ∧ alcohol) ⇒ preterm-birth and citalopram ⇒ preterm-birth was significant. The primary challenge in automating the discovery process for the patterns described above is that these potentially interesting patterns may have very low support. On the one hand, traditional, association mining algorithms may not discover rules like (citalopram ∧ alcohol) ⇒ preterm-birth as a result of having insufficient support. On the other hand, association mining algorithms may unnecessarily report some potentially interesting rules redundantly – both rules citalopram ⇒ preterm-birth and (citalopram ∧ alcohol) ⇒ preterm-birth – even when they have nearly the same confidence level. This form of redundancy has been previously evaluated using a measure called improvement (Bayardeo et al., 1999). Informally, the improvement of a pattern is defined as the minimum difference between its confidence and the confidence of any of its sub-patterns having the same consequent. We believe that a rigorous approach, one in which the discovery process is based on a comparison of confidence values among ‘closely’ related patterns, is needed in order to allow for the efficient discovery of potentially interesting patterns.
To that end, we have formally defined two such classes of patterns, referred to as positive and negative, and have developed an algorithm, Discovering of Potentially Interesting Patterns (DAPIP), to discover them from a collection of data (Saquer and Deogun, 2000). We will show in Section 2 that DAPIP ensures the discovery of all positive and negative patterns satisfying a set of user-defined input parameters. Unfortunately, the application of DAPIP requires generating itemsets based on small support thresholds, and thus its application is limited to relatively small, sparse datasets.
As a result, in this paper, we investigate two new algorithms designed to effectively discover positive and negative patterns. The first algorithm, referred to as All-Confidence-based Discovery of Potentially Interesting Patterns (ACDPIP), generates itemsets based on an all-confidence threshold instead of a support threshold. The all-confidence value of an itemset, I, represents the minimum confidence of a rule (pattern) that can be generated from the itemsets in I (Omiecinski, 2003). This measure has the desirable anti-monotonic property: if an itemset I does not satisfy a given all-confidence threshold, then no super itemset of I will satisfy the threshold. Results of experimental investigations show that ACDPIP provides adequate levels of coverage in discovering of positive and negative patterns. Unfortunately, the investigations also show that its application is limited to sparse datasets.
The ACDPIP-Closed algorithm is designed to discover maximal non-redundant positive patterns from a set of frequent closed itemsets. This algorithm is an extension of the ACDPIP algorithm. We will show empirically that ACDPIP-Closed can successfully discover maximal non-redundant positive patterns from both sparse and dense datasets.
The rest of this paper is organised as follows: Section 2 highlights the unique contributions of our work by comparing it to related work. Sections 3 and 4 present the details of the two algorithms, ACDPIP and ACDPIP-Closed, respectively. Section 5 presents results of experiments conducted in order to assess the performance of the two algorithms. Section 6 provides a summary of the work.

110 R. Singh et al.
2 Related work
Several published papers have reported on work related to the discovery of potentially interesting, descriptive rules from a collection of data. The previous work most closely related to the work presented in this paper includes the notion of exception rules (Hussain et al., 2000; Suzuki, 2002), peculiarity rules (Zhong et al., 2003), and negative association rules (Savasere et al., 1998), and imperfectly sporadic rules (Koh and O’Keefe, 2008).
A rule A ∧ B → C is an exception rule if A → C and B → C are common sense rules (i.e., high support and high confidence). Although similar in form, the concept of our negative pattern is more inclusive in the sense that the reference rules A → C and B → C may not necessarily be common sense rules in order for A ∧ B → C to be a negative pattern. As long as the combination of A ∧ B introduces sufficient negative change in the confidence of implying C, then A ∧ B → C is considered to be a negative pattern. Therefore, the exception rule can be viewed as a special case of our negative pattern.
A peculiarity rule is characterised by having a low support value, a high confidence value, and a high change in support. The change in support of a rule is defined as the difference in a rule’s confidence value and its support value. For a given rule, A → B, the change in support can be interpreted as the difference between the posterior probability of A given B and the prior probability of B. A high change in support is also the necessary requirement for a positive pattern in which the antecedent is an atomic concept. The discovery of positive patterns, however, is not limited to peculiar data objects.
A negative association rule of the form, A → B, states that within a transaction the set of items A frequently occurs in the absence of the set of items B. Given that the number of rules of the form A → B can be overwhelmingly large, extra semantic constraints are needed for mining negative association rules.
An imperfectly sporadic rule, A → B, is characterised as having a relatively high degree of confidence and a support value less than a user specified threshold, maxsup. In order to facilitate the discovery of such rules the authors in Koh and O’Keefe (2008) limit the rules of interest to those having a single item consequent and require the inclusion of an itemset with support greater than or equal to maxsup. A potentially interesting imperfectly sporadic rule would consist of items that individually have high support, but the set of items comprising the antecedent has low support. Such rules might not be discovered through the application of an association rule mining algorithm. A shortcoming of the rule definition in Koh and O’Keefe (2008) is the potential to generate a rule set containing redundant rules, i.e., ‘closely’ related rules having nearly the same confidence level.
In Xie et al. (2006), we have considered the problem of discovering potentially interesting patterns (rules) from a dataset D consisting of N transactions {t1, t2,…,tN}, where each transaction ti ⊆ I and I is a set of items {i1, i2,…,ik} over which the transactions are defined. We assume the standard definition for the support (supp) of an itemset and for the confidence (conf) of a rule.
We define a binary relation ≤ on I, such that for any pair of itemsets P*, P ⊆ I, we have P* ≤ P ↔ P = P* ∪ {i}, where i ∈ I. The itemset P* is referred to as a parent of P whenever P* ≤ P. Finally, given a rule P → Q where P ⊆ I, Q ⊆ I, we define the noise control threshold, n, to represent the minimum required support of P.

Algorithms for discovering potentially interesting patterns 111
Definition 2.1: potentially interesting positive pattern: Let P ⊆ I, Q ⊆ I and P ∩ Q = Ø. A rule P → Q is called a positive pattern if one of the following two conditions holds:
1 (conf(P → Q) – supp(Q)) ≥ s, given: P ∈ I (P is an atomic itemset), supp(P) ≥ n, and 0 ≤ s ≤ 1
2 (conf(P → Q) – MAX1 ≤ i ≤ j {conf(Pi → Q)}) ≥ s, given: P ⊆ I (P is composite itemset), supp(P) ≥ n, itemsets {P1, P2,…,Pj} are all the parent itemsets of P, and 0 ≤ s ≤ 1.
Definition 2.2: potentially interesting negative pattern: Let P ⊆ I, Q ⊆ I and P ∩ Q = Ø. A rule P → Q is called a negative pattern if one of the following two conditions holds:
1 (supp(Q) – conf(P → Q) ≥ s), given: P ∈ I (P is an atomic itemset), supp(P) ≥ n, and 0 ≤ s ≤ 1
2 (MIN1 ≤ i ≤ j {conf(Pi → Q)} – conf(P → Q)) ≥ s, given: P ⊆ I (P is a composite itemset), supp(P) ≥ n, itemsets {P1, P2,…,Pj} are all the parent itemsets of P, and 0 ≤ s ≤ 1.
The parameter s is called the significance controller and it intuitively represents the minimum degree of statistical change that a pattern must provide in order for it to be classified as potentially interesting. Both positive and negative patterns represent potentially interesting information. For example, a pattern with confidence of 30% will typically be deemed uninteresting. However, consider the following situation: the conf(B → A) is 1% or 80% and conf(B ^ C → A) is 30%, where A is some kind of disease; B denotes some population and B ^ C is a subpopulation of B. Now one may conclude that the latter pattern is potentially useful.
In Xie et al. (2006), two lemmas were given that guarantee the existence of an algorithm for DAPIP. One of the two lemmas, which we will refer to as Lemma 1, states that if the rule P → Q is a positive pattern, then its confidence value is greater than or equal to s and its support is greater than or equal to n*s, where n is the noise control threshold and s is the significance threshold. The other lemma, which we will refer to as Lemma 2, states that if the rule P → Q is a negative pattern and P is a composite itemset, then the confidence and support values associated with a pattern Pi → Q, where Pi is the parent of P in the rule P → Q, is greater than or equal to s and n*s, respectively.
The terminology used to describe the proposed DAPIP algorithm is given below and the algorithm itself is shown in Figure 1.
• R = (P → Q) is a rule, where 1 ,Mj jP a== ∧ aj ∈ {a1, a2,…,aM} ⊆ I; 1 ,N
k kQ b== ∧
bk ∈ {b1, b2,…,bN} ⊆ (I – P); antecedent (R) is P; consequent (R) is { }{ }1 1 2( ) : , , , .M
l l l Mparents P c c a a a== ∧ ∈ … Assume {P1, P2,…,Pj} denotes all
parent itemsets of itemset P.
• FIs is the set of concepts, such that, for any concept P ∈ FIs ⇔ supp(P) ≥ n*s.
• AP is the set of all strong association rule patterns.
• APk is the set of association rule patterns such that, for all Pai ∈ APk, length (antecedent (R)) = k.
• APkl is a subset of APk such that

112 R. Singh et al.
1 for any Pai, Paj ∈ APkl, consequent (Pai) = consequent (Paj) 2 for any APkm, (m ≠ l) for any Pai ∈ APkl, and any Paj ∈ APkl, then
consequent (Pai) ≠ consequent (Paj).
• PP is the set of positive patterns.
• NP is the set of negative patterns.
• CNPk is the set of candidate negative patterns such that for all Pai ∈ CNPk length(antecedent (Pai)) = k.
Figure 1 Algorithm DAPIP
Algorithm DAPIP: Input: significance controller s, noise controller n, Output: All positive patterns PP and negative patterns NP. [1] Generate all frequent itemsets FI with support ≥ n*s with an apriori-like algorithm. [2] Generate all association rule patterns with confidence ≥ s from FI and put them into set AP. [3] for each R ∈ AP (assuming R = P → Q) //When P ∈ I (P is an atomic itemset; that is, P is a 1-itemset) [4] if (((conf(P → Q) – supp(Q)) ≥ s) & (supp(P) ≥ n)) [5] add R to PP //When P ⊆ I (P is composite itemset; that is, P is a k-itemset, for k > 1) [6] if (((conf (P → Q) – MAX1 ≤ i ≤ j {conf(Pi → Q)}) ≥ s) & supp(P) ≥ n) ∀Pi ∈ Parents(P) [7] add R to PP //When P ∈ I (P is an atomic itemset; that is, P is a 1-itemset) [8] if (((supp(Q) – (conf(P → Q) ) ≥ s) & (supp(P) ≥ n)) [9] add R to NP //When P ⊆ I (P is composite itemset; that is, P is a k-itemset, for k > 1) [10] let AP = AP1 ∪ AP2 ∪…∪ APT [11] for k = 1 to T, [12] let APk = APk1 ∪ APk2 ∪…∪ APkX [13] for l = 1 to X, [14] generate candidate negative patterns Rn from APkl and put them in CNPk + 1 [15] for each pattern Rn ∈ CNPk + 1 [16] if (((MIN1 ≤ i ≤ j{conf(Pi → Q)} – conf(P → Q)) ≥ s) & supp(P) ≥ n) ∀Pi ∈ Parents(P) [17] add Rn to NP
The first step of DAPIP requires the generation of itemsets satisfying a support threshold equal to n*s, where n is the noise control threshold and s is the significance threshold. A support threshold equal n*s may be a relatively small quantity for reasonably selected values of n and s. A possible solution is to increase the support threshold above n*s. The use of an increased support threshold violates the conditions set forth by Lemmas 1 and 2, and thus there is no longer an assurance that the resulting algorithm will discover all

Algorithms for discovering potentially interesting patterns 113
positive and negative patterns. In addition, as the support threshold increases so does the implicit minimum noise and confidence requirements of both positive patterns and the parents of negative patterns. This fact has a damaging effect on the algorithm’s ability to discover positive and negative patterns.
3 ACDPIP algorithm
To address the shortcomings related to the use of a support threshold mentioned above, we have developed an algorithm, referred to as ACDPIP. The difference between DAPIP and ACDPIP is the latter algorithm generates itemsets based on an all-confidence threshold instead of a support threshold.
The use of an all-confidence threshold allows for the explicit generation of itemsets containing patterns having a confidence value greater than or equal to s. Unfortunately, the use of an all-confidence threshold does not necessarily ensure the discovery of all patterns with a confidence value greater than or equal to s. This fact raises the following question: Is it possible to design an algorithm that will ensure the discovery of all qualified positive and negative patterns based on an all-confidence threshold value? The following theorem proves the answer to this question is yes.
Theorem 3.1: Let T be a transaction table with N transactions. The value n*s is the lower bound for the threshold on the all-confidence measure to ensure that ‘frequent’ itemsets so generated are sufficient to compute all positive and negative interesting patterns in T, where n and s are, respectively, noise and significance threshold values.
Proof: Based on Lemmas 1 and 2, we need only to show that all itemsets which satisfy the support threshold n*s also satisfy the all-confidence threshold n*s. Suppose an itemset I = {i1, i2,…,ij} has a support value greater than or equal to n*s. It follows that the all-conf(I) = | {i1, i2,…,ij}| / MAX{| {i1} |, | {i2} |,…,| {ij} |} ≥ supp(I) = | {i1, i2,…,ij} | / N since MAX{| {i1} |, | {i2} |,…,| {ij} |} ≤ N. �
In spite of Theorem 3.1, we consider ACDPIP to be a heuristic search algorithm because its ability to discover positive and negative patterns is maximised with respect to its efficiency and quantity of discovered patterns (i.e., coverage level) when executed with an all-confidence threshold value t greater than n*s (Singh et al., 2009).
The ACDPIP algorithm is shown in Figure 2 and it consists of the following general steps:
• Generate all frequent itemsets FI from a given dataset D using a minimum all-confidence > t.
• For each frequent itemset, generate all possible association rules.
• For each association rule determine if it represents either a positive or a negative pattern.
We have shown empirically in Singh et al. (2009) that ACDPIP, for various all-confidence threshold values t, represents an efficient alternative to DAPIP when applied to sparse datasets. When applied to dense datasets the performance of algorithm declines due to the generation of a large number of redundant itemsets. This fact has

114 R. Singh et al.
resulted in the design an algorithm to reduce the redundancy without losing non-redundant itemsets and patterns in return.
Figure 2 Algorithm ACDPIP
Algorithm ACDPIP: Input: significance controller s, noise controller n, all-confidence threshold t. Output: set of positive patterns PP and the set of negative patterns NP. [1] Generate all frequent itemsets FI with all-confidence ≥ t with modified apriori algorithm. [2] for each itemset fin ∈ FI generate all possible rules from fin and place in AP [3] for each R ∈ AP (assuming R = P → Q) //When P ∈ I (P is an atomic itemset; that is, P is a 1-itemset) [4] if (((conf (P → Q) – supp(Q)) ≥ s) & (supp(P) ≥ n)) [5] add R to PP [6] elseif (((supp(Q) – conf(P → Q)) ≥ s) & (supp(P) ≥ n)) [7] add R to NP //When P ⊆ I (P is composite itemset; that is, P is a k-itemset, for k > 1) [8] if (((conf(P → Q) – MAX1 ≤ i ≤ j {conf(Pi → Q)}) ≥ s) & supp(P) ≥ n) ∀Pi ∈ Parents(P) [9] add R to PP [10] elseif (((MIN1 ≤ i ≤ j{conf(Pi → Q)} – conf(P → Q)) ≥ s) & supp(P) ≥ n) ∀Pi ∈ Parents(P) [11] add R to NP
4 ACDPIP-Closed algorithm
Researchers have improved the efficiency of discovering association rules through the use of frequent closed itemsets. Specifically, the concept of frequent closed itemsets to generate association rules has been studied by a number of researchers (Bastide et al., 2000; Pasquier et al., 2000; Saquer and Deogun, 2000; Zaki, 2000). The primary focus of their work has been to use frequent closed itemsets to produce generating sets of association rules. A generating set represents a non-redundant collection of interesting association rules from which all other interesting rules can be derived.
As described in Section 2, the discovery of positive and negative patterns is limited when itemsets are generated based on a support threshold. This fact motivated the design of the ACDPIP algorithm which generates itemsets based on a given all-confidence threshold. Hence, another interesting research question is the following: Can the efficiency of ACDPIP be improved, without sacrificing its effectiveness, through the use closed itemsets? The answer to this question is yes in the context of positive patterns and the explanation is provided in this section. To that end, we present a set of formal definitions, an important theorem, and the design of an efficient algorithm that discovers positive patterns (rules) through the generation of all-confidence-based frequent closed itemsets.
Previous work has defined a frequent closed itemset based on the measure of support.

Algorithms for discovering potentially interesting patterns 115
Definition 4.1: frequent closed itemset (support-based): An itemset X is called a closed itemset if there exists no itemset X′ such that
1 X′ is a proper superset of X
2 supp(X′) = supp(X).
If condition 1 and 2 hold for X′, then X′ can be a closed itemset. A closed itemset X is a closed frequent itemset (CFI) if it is frequent; that is, if supp(X) ≥ minimum support threshold.
We have modified the above definition to specify frequent closed itemsets based on an all-confidence threshold.
Definition 4.2: all-confidence-based frequent closed itemset: An itemset X is called a closed itemset if there exists no itemset X′ such that
1 X′ is a proper superset of X
2 all-conf(X′) = all-conf(X).
If condition 1 and 2 hold for X′, then X′ can be a closed itemset. A closed itemset X is an all-confidence closed frequent itemset (ACFI) if it is frequent according to a minimum all-confidence threshold; that is, if all-conf(X) ≥ all-conf-supp.
The notion of a frequent closed itemset based on all-confidence allows for the discovery of maximal non-redundant positive patterns (rules) satisfying a given significance threshold. The importance of which is not only a reduction in the time required to generate such rules, but also the generated rules are non-redundant.
Definition 4.3: descendant rule: If X ^ Y → W and X ^ Y → Z are interesting rules then X ^ Y → W ^ Z is a descendant of the rules X ^ Y → W and X ^ Y → Z.
Definition 4.4: positive redundancy: A rule P is a positive redundant rule if its level of significance (s) is less than or equal to the significance level of a descendant rule; otherwise, a rule P is said to be a maximal non-redundant positive rule.
The following example illustrates the concept of a maximal non-redundant positive rule.
Example 4.1: Given an itemset {A, B, C, D} is not closed (support-based). There must exist a super itemset, such as {A, B, C, D, E}, that contains {A, B, C, D} and has a support value equal to the support of {A, B, C, D}. Assume the rule A ^ B → C ^ D (generated from the itemset {A, B, C, D}) is a positive rule. It follows that the positive rule A ^ B → C^D is redundant with respect to the descendant rule A ^ B → C ^ D ^ E (generated from the closed itemset {A, B, C, D, E}):
• conf((A ^ B → C ^ D)) – MAX(conf(A → C ^ D); conf(B → C ^ D)) = s1
• conf((A ^ B → C ^ D ^ E)) – MAX(conf(A → C ^ D^E); conf(B → C ^ D ^ E)) = s2
It follows that s1 ≤ s2 as a result of:
• conf((A ^ B → C ^ D)) = conf((A ^ B → C ^ D ^ E)) since supp ({A, B, C, D, E}) = supp({A, B, C, D})

116 R. Singh et al.
• assume, without loss of generality, that MAX(conf(A → C ^ D); conf(B → C ^ D)) = conf(A → C ^ D) and MAX(conf(A → C ^ D ^ E); conf(B → C ^ D ^ E)) = conf(A → C ^ D ^ E). It follows that conf(A → C ^ D) ≥ conf(A → C ^ D^E).
Hence, if {A, B, C, D, E} is not closed then the positive rule A ^ B → C ^ D ^ E is positive redundant with respect to a descendant rule derived from a longer itemset (e.g., {A, B, C, D, E, F}).
The ideas presented in the above example can be stated formally.
Theorem 4.1: If a positive rule P is generated from a frequent non-closed itemset I, then P is redundant.
Proof: Let I1 be a frequent non-closed itemset and R1: X → W be a positive rule generated from I1 satisfying a significance threshold s1. Since I1 is a non-closed itemset, there must exist an itemset I2 such that I1 ⊂ I2 and supp(I1) = supp(I2). A descendant rule R2 of R1 can be generated from I2. Without loss of generality, assume R2 is X → W ^ Z and R2 has a significance value s2. It follows directly from the definitions of rule support and positive pattern that s2 ≥ s1 (i.e., conf(R2) = conf(R1) since supp(R2) = supp(R1) and the antecedent of R2 and R1 are equivalent; and, the maximum confidence of the parent rules associated with R2 will be less than or equal to the maximum confidence of the parent rules associated with R1 since support of a parent rule of R2 will less than or equal to support of a parent rule of R1, for a given parent rule antecedent). Therefore, R1 is a positive redundant rule. �
Example 4.1 and Theorem 4.1 are based on closed itemsets defined in terms of support. Fortunately, we have constructed the following theorem that establishes an equivalence relationship between support-based closed itemsets and all-confidence-based closed itemsets.
Theorem 4.2: Suppose that the items in I are ordered such that supp(ij) ≥ supp(ik), for 1 ≤ j ≤ k ≤ n. Then, an itemset is all-confidence-based closed if it is support-based closed.
Proof: Let T is a transaction table with N transactions.
• Only if-part: Let X = {i1, i2,…,ij} be an all-confidence-based frequent itemset and there exist an all-confidence-based closed frequent itemset X′ = {i1, i2,…,ik}, where 1 < j < k.
We know from Definition 4.2, if X′ all-confidence-based closed then,
- ( ) - ( )all conf X all conf X′ = (1)
and is proper superset of X X′ (2)
Now from all-confidence definition (Chen et al., 2007),
( ){ }( )- ( )j j
Supp Xall conf XMAX Supp i i X
=∀ ∈
(3)
( ){ }( )- ( )k k
Supp Xall conf XMAX Supp i i X
′′ =
′∀ ∈ (4)

Algorithms for discovering potentially interesting patterns 117
From the fact that MAX is monotonically non-decreasing function, with the addition of another item, it must be true that,
{ } { } { }{ } { } { } { }{ }1 2 1 2, , , , , , .j kMAX i i i MAX i i i≤… …
From (1) and (2), we obtain supp(X) has to ≥ supp(X′) and that the all-confidence values are equal, which imply that,
{ } { } { }{ } { } { } { }{ }1 2 1 2, , , , , , .j kMAX i i i MAX i i i≥… …
Therefore, we can conclude that,
{ } { } { }{ } { } { } { }{ }1 2 1 2, , , , , , .j kMAX i i i MAX i i i=… …
Thus,
( ) ( )supp X supp X ′= (5)
(2) and (5) satisfies the Definition 3.2 and thus X′ is support-based closed.
• If-part: From the fact that MAX is monotonically non-decreasing function, with the addition of another item, it must be true that,
{ } { } { }{ } { } { } { }{ }1 2 1 2, , , , , , .j kMAX i i i MAX i i i≤… …
From the assumption that items in I are ordered in non-increasing value of their supports, we conclude,
{ } { } { }{ } { } { } { }{ }1 2 1 2, , , , , , ,j kMAX i i i MAX i i i≥… …
implying that the denominators in (3) and (4) are equal.
Since we are given supp(X) = supp(X′), we conclude that,
( ){ } ( ){ }( ) ( )
j j k k
Supp X Supp XMax Supp i i X MAX Supp i i X
′=
′∀ ∈ ∀ ∈
Thus, we conclude that,
- ( ) - ( ).all conf X all conf X′ = �
Based on the above theorem redundant positive patterns can be eliminated through the generation of all-confidence-based frequent closed itemsets.
We have extended the ACDPIP algorithm to discover maximal non-redundant positive rules from all-confidence-based frequent closed itemsets. The resulting algorithm, called ACDPIP-Closed, is shown in Figure 3.

118 R. Singh et al.
Figure 3 Algorithm ACDPIP-Closed
Algorithm ACDPIP-Closed:
Input: dataset D; significance controller s, noise controller n, all-confidence threshold t.
Output: maximal non-redundant positive patterns PP satisfying s.
[1] Generate closed frequent itemsets ACFCIt with all_conf > t using modified apriori algorithm.
[2] for each itemset fi ∈ ACFCIt generate all possible rules from fi and place in AP
[3] for each R ∈ AP (assuming R = P → Q)
//When P ∈ I (P is an atomic itemset; that is, P is a 1-itemset)
[4] if (((conf(P → Q) – supp(Q)) ≥ s) & (supp(P) ≥ n))
[5] add R to PP
//When P ⊆ I (P is composite itemset; that is, P is a k-itemset, for k > 1)
[6] if (((conf (P → Q) – MAX1 ≤ i ≤ j {conf(Pi → Q)}) ≥ s) & supp(P) ≥ n) ∀Pi ∈ Parents(P)
[7] add R to PP
Some of the terminology used in the algorithm is given below.
• ACFCIt is the set of all-confidence-based frequent closed itemsets, such that, for any itemset P ∈ ACFCIt ⇔ all-conf(P) ≥ t
• AP is a set of association rule patterns
• PP is a set of non-redundant LHS positive patterns.
The steps of the algorithm are as follows:
• Generate all frequent closed itemsets ACFIt from a given dataset D using a minimum all-confidence > t.
• For each frequent closed itemset, generate all possible association rules.
• For each association rule determine if it represents either a positive pattern. In particular, if a rule satisfies the definition of a positive pattern then evaluate the next rule.
• All discovered rules will represent maximal non-redundant positive rules.
We have modified the Apriori algorithm (Agrawal and Srikant, 1994) to generate all-confidence-based frequent closed itemsets from a dataset D. Specifically, the algorithm finds frequent closed itemsets using a bottom-up procedure in which candidate itemsets of size k are generated by joining the frequent itemsets of size k – 1. If any superset of an itemset I has an all-confidence equal to the all-confidence of I then it is not returned as part of the result set. The algorithm terminates when the frequent closed itemsets of a given size is equal to zero.

Algorithms for discovering potentially interesting patterns 119
5 Experiments
We compared the performance of ACDPIP and ACDPIP-Closed. In our previous work, we experimentally showed that overall performance of algorithm ACDPIP is promising and it has improved interesting pattern discovery but there is requirement for improvement when dataset is dense. The specific objectives of these experiments were to compare the coverage level and execution time of both algorithms for dense datasets.
5.1 Experimental setup
The experiments were performed on a PC with Intel(R) Core(TM) Duo CPU, E6750 @ 2.66 GHz, and 3 GB of RAM. The noise control threshold, n, and the significance threshold, s, used in all experiments were .02, and 0.1, respectively. Three real-life dense datasets, chess, mushroom, and adult were used in the experimental investigation. These datasets were obtained from the UCI ML repository (Asuncion and Newman).
5.2 Results and discussion
The experimental results demonstrate that ACDPIP-Closed outperformed ACDPIP on the selected datasets. The changes implemented to ACDPIP improved the performance of the algorithm. Specifically, ACDPIP-Closed outperformed ACDPIP with respect to the number of generated itemsets, the number of generated redundant patterns, and the execution time.
Figure 4 shows the number of itemsets generated by ACDPIP and ACDPIP-Closed with an all-confidence threshold value equal to 0.06. It demonstrates that the redundant itemset reduction obtained by ACDPIP-Closed for the chess dataset was approximately 27%, for the mushroom dataset it was 48%, and approximately 33% for the adult dataset.
Figure 4 Redundant itemset reduction with closed itemsets (see online version for colours)
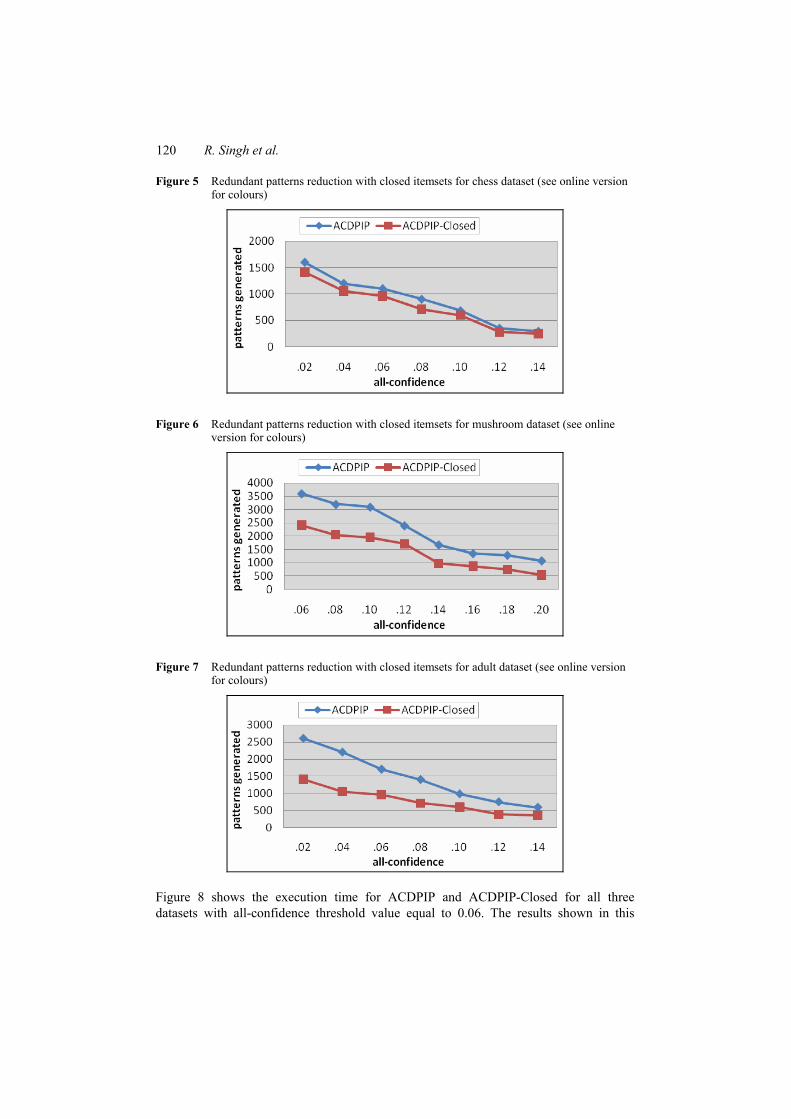
Figures 5–7 provide a comparison of the number of patterns discovered by ACDPIP and ACDPIP-Closed with respect to the chess, mushroom, and adult datasets, respectively. The additional patterns discovered by ACDPIP represent redundant patterns. The level of redundancy in the context of the chess datasets is approximately 13%, 37% in the context of the mushroom dataset, and 28% in the context of the adult dataset.
120 R. Singh et al.
Figure 5 Redundant patterns reduction with closed itemsets for chess dataset (see online version for colours)
Figure 6 Redundant patterns reduction with closed itemsets for mushroom dataset (see online version for colours)
Figure 7 Redundant patterns reduction with closed itemsets for adult dataset (see online version for colours)
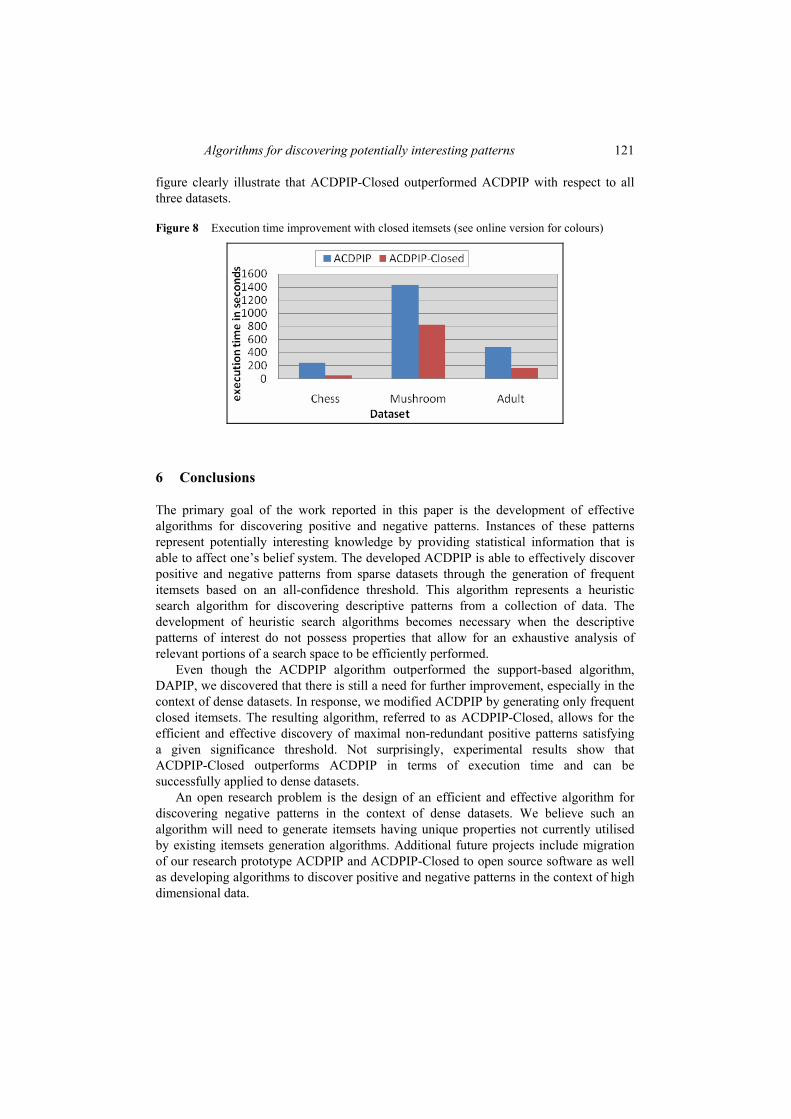
Figure 8 shows the execution time for ACDPIP and ACDPIP-Closed for all three datasets with all-confidence threshold value equal to 0.06. The results shown in this
Algorithms for discovering potentially interesting patterns 121
figure clearly illustrate that ACDPIP-Closed outperformed ACDPIP with respect to all three datasets.
Figure 8 Execution time improvement with closed itemsets (see online version for colours)
6 Conclusions
The primary goal of the work reported in this paper is the development of effective algorithms for discovering positive and negative patterns. Instances of these patterns represent potentially interesting knowledge by providing statistical information that is able to affect one’s belief system. The developed ACDPIP is able to effectively discover positive and negative patterns from sparse datasets through the generation of frequent itemsets based on an all-confidence threshold. This algorithm represents a heuristic search algorithm for discovering descriptive patterns from a collection of data. The development of heuristic search algorithms becomes necessary when the descriptive patterns of interest do not possess properties that allow for an exhaustive analysis of relevant portions of a search space to be efficiently performed.
Even though the ACDPIP algorithm outperformed the support-based algorithm, DAPIP, we discovered that there is still a need for further improvement, especially in the context of dense datasets. In response, we modified ACDPIP by generating only frequent closed itemsets. The resulting algorithm, referred to as ACDPIP-Closed, allows for the efficient and effective discovery of maximal non-redundant positive patterns satisfying a given significance threshold. Not surprisingly, experimental results show that ACDPIP-Closed outperforms ACDPIP in terms of execution time and can be successfully applied to dense datasets.
An open research problem is the design of an efficient and effective algorithm for discovering negative patterns in the context of dense datasets. We believe such an algorithm will need to generate itemsets having unique properties not currently utilised by existing itemsets generation algorithms. Additional future projects include migration of our research prototype ACDPIP and ACDPIP-Closed to open source software as well as developing algorithms to discover positive and negative patterns in the context of high dimensional data.

122 R. Singh et al.
References Agrawal, R. and Srikant, R. (1994) ‘Fast algorithms for mining association rules’, Paper presented
at the 20th International Conference on Very Large Databases, Santiago de Chile, Chile. Asuncion, A. and Newman, D.J. (2007) UCI Machine Learning Repository, University of
California Irvine, available at http://www.ics.uci.edu/~mlearn/MLRepository.html (accessed on 14–16/08/10).
Bastide, Y., Pasquier, N., Taouil, R., Stumme, G. and Lakhal L. (2000) ‘Mining minimal non-redundant association rules using frequent closed itemsets’, Paper presented at the 1st International Conference on Computational Logic, London, UK.
Bayardeo, R., Agrawal, R. and Gunopulos, D. (1999) ‘Constraint-based rule mining in large, dense databases’, Paper presented at the 15th International Conference on Data Engineering, Sydney, Australia.
Chen, Y., Pedersen, L., Chu, W. and Olsen, J. (2007) ‘Drug exposure side effects from mining pregnancy data’, SIGKDD Explorations, Vol. 9, No. 1, pp.22–29.
Hussain, F., Liu, H., Suzuki, E. and Lu, H. (2000) ‘Exception rule mining with a relative interestingness measure’, Paper presented at the 4th Pacific-Asia Conference on Knowledge Discovery and Data Mining, Kyoto, Japan.
Koh, Y. and O’Keefe, R. (2008) ‘Mining interesting imperfectly sporadic rules’, Knowledge and Information Systems, Vol. 14, No. 2, pp.179–196.
Omiecinski, E.R. (2003) ‘Alternative interest measures for mining associations’, IEEE Transaction on Knowledge and Data Engineering, Vol. 15, No. 1, pp.57–69.
Pasquier, N., Bastide, Y., Taouil, R. and Lakhal, L. (2000) ‘Closed set based discovery of small covers for association rules’, Networking and Information Systems Journal, Vol. 3, pp.349–377.
Saquer, J. and Deogun, J. (2000) ‘Using closed itemsets for discovering representative association rules’, Paper presented at the International Symposium on Foundations of Intelligent Systems, Charlotte, NC, USA.
Savasere, A., Savasere, E. and Navathe, S. (1998) ‘Mining for strong negative associations in a large database of customer transactions’, Paper presented at the 14th International Conference on Data Engineering, Orlando, FL, USA.
Singh, R., Johnsten, T., Raghavan, V.V. and Xie, Y. (2009) ‘An efficient algorithm for discovering positive and negative patterns’, Paper presented at the 2009 IEEE International Conference on Granular Computing, Nanchang, China.
Suzuki, E. (2002) ‘Undirected discovery of interesting exception rules’, International Journal of Pattern Recognition and Artificial Intelligence, Vol. 16, No. 8, pp.1065–1086.
Xie, Y., Johnsten, T., Raghavan, V.V. and Ramachandran, K. (2006) ‘On discovering potentially useful patterns from databases’, Paper presented at the 2006 IEEE International Conference on Granular Computing, Atlanta, GA, USA.
Zaki, M. (2000) ‘Generating non-redundant association rules’, Paper presented at the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Boston, MA, USA.
Zhong, N., Yao, Y.Y. and Ohshima, M. (2003) ‘Peculiarity oriented multidatabase mining’, IEEE Transactions on Knowledge and Data Engineering, Vol. 15, pp.952–960.
Copyright © 2022 FDOKUMEN




















