
A Novel Dynamic Task Scheduling Algorithm for Grid Networks with Recongurable Processors
10
1 1 2,1 1 1 1 2
Transcript of A Novel Dynamic Task Scheduling Algorithm for Grid Networks with Recongurable Processors

A Novel Dynamic Task Scheduling Algorithm for Grid Networks with
Recon�gurable Processors
M. Faisal Nadeem1, S. Arash Ostadzadeh1, Mahmood Ahmadi2,1, M. Nadeem1 and Stephan Wong1
1Computer Engineering Laboratory, EEMCS Department, Delft University of Technology , The Netherlands2Department of Computer Engineering, Faculty of Engineering, University of Razi, Kermanshah, Iran
Abstract. The incorporation of recon�gurable processors in computational grids promises to provide in-creased performance without compromising �exibility. Consequently, grid networks (such as TeraGrid) areutilizing recon�gurable computing resources next to general-purpose processors (GPPs) in their computingnodes. The near-optimal utilization of resources in a grid network considerably depends on the applicationtask scheduling for the computing nodes. The inclusion of recon�gurable nodes in the computational grids,therefore, requires the rethinking of existing scheduling algorithms in order to take into account recon�g-urable hardware characteristics, e.g., area utilization, performance increase, recon�guration time, and timeto communicate con�guration bitstreams, execution codes, and data. Such characteristics are not taken intoaccount by the traditional grid scheduling algorithms. In this paper, we focus on the design and developmentof a novel and e�cient dynamic scheduling algorithm for application task distribution among di�erent nodesof a recon�gurable computing grid. Furthermore, we developed a simulation framework to implement therequired data structures and scheduling modules. The initial results show an expected trend in the averagenumber of scheduling steps required to accommodate each task.
1 Introduction
Computational grids o�er reliable, pervasive, ordered, and inexpensive access to high-end computational resources[1] that are geographically dispersed over the world. They bene�t from any advancement in high-performancecomputing every time when more capable computing nodes are added to the grid. Examples of worldwide gridprojects are Globus [2], Legion [3], and Unicore [4]. In the past few years, recon�gurable computing is becomingincreasingly more commonly utilized in scienti�c research that requires high-performance computing [5,6], suchas bioinformatics, multimedia processing, and cryptography. The reason is that they provide both increased per-formance without expensing much on �exibility, i.e., allowing quick change between the supported applications.Consequently, grid networks (e.g., TeraGrid [7]) have incorporated recon�gurable computing resources next togeneral-purpose processors (GPPs) in their computing nodes. Proposals to better exploit the characteristicsof recon�gurable computing merged with the requirements of computational grids have been proposed, e.g.,Collaborative Recon�gurable Grid Computing (CRGC) in [8].
The optimal utilization of resources in a grid greatly depends on how applications (and their tasks) arescheduled to be executed in the computing nodes. Various state-of-the-art scheduling algorithms for traditionalgrids were proposed in [9,10,11,12]. Therefore, scheduling algorithms are of paramount importance for any com-putational grid and new ones must be development when the characteristics of the nodes are changed. In theirdevelopment, one must take into consideration the following aspects: static vs. dynamic, centralized vs. de-centralized, and coarse-grained vs. �ne-grained. The inclusion of recon�gurable hardware in the computationalnodes, therefore, requires the rethinking of existing scheduling algorithms in order to take into account recon�g-urable hardware characteristics, such as, area utilization, (possible) performance increase, recon�guration time,and time to communicate con�guration bitstreams, execution codes, and data.
A recent proposal in recon�gurable computing entails the development of a parametrized recon�gurable VLIWprocessor described in [22]. Its bene�ts over other recon�gurable approaches include: programmers do not needto have hardware knowledge to generate code (as existing compilers can be used) and no changes to existingcodes are required to compile for these processors while still able to achieve higher performance in targetedapplications. In addition, the proposal inherently promise the use of parameters (only several) to describe aprocessor design and thereby alleviating the need to communicate large con�guration bitstreams (from severalkilobytes to many (tens of) megabytes). The proposed processor adapts to the application at hand (through thementioned parameters) to provide adequate performance at reasonable costs, e.g., instantiate a 4-way VLIWprocessor organization when the ILP of the application is around 4. The parametrization characteristic can be

exploited by a computational grid by simply attaching to each task the most preferred (desired) con�gurationdescription and sending this information alongside the application code and data to the respective recon�gurablecomputing nodes. The decision whether to accept the task can be left to the node itself or it can be taken bya centralized scheduler. The scheduler must maintain information like recon�gurable hardware size, currentlyrunning con�guration, etc.
In this paper, we focus on the design and development of an e�cient dynamic scheduling algorithm for appli-cation task distribution among di�erent nodes of a recon�gurable computing grid. The mentioned parametrizedrecon�gurable VLIW processor only serves as a case study with concepts such as area utilization, preferredimplementation, and design parameters that can be generalized to the use of any recon�gurable hardware im-plementation of softcores. Furthermore, we developed a simulation framework to implement the required datastructures and scheduling modules. The initial version of the simulator takes into consideration the recon�gura-bility of nodes and their area waste optimization for a given set of tasks and con�gurations. The initial resultsshow an expected trend in the number of scheduling steps required to accommodate each task.
The remainder of the paper is organized as follows: Section 2 presents related work. Section 3 presents theproblem statement. In Section 4, we provide the proposed design by discussing background and scope, ourproposed data structures and scheduling algorithm. Section 5 discusses the simulation framework we developedfor the implementation of the proposed algorithm and data structures. In Section 6, the simulation environmentand results are presented and discussed. Finally, the conclusions and future work are provided in Section 7.
2 Related work
In this section, we describe some previous research in task scheduling on recon�gurable systems and conventionalgrid networks. In recent years, utilization of recon�gurable processors in distributed grid networks has been re-ported in [8,15,7]. These state-of-the-art, however, do not discuss the scheduling of applications (and their tasks)on such networks. As mentioned in previous section, most of the work [9,11,12,10] on scheduling algorithms hasbeen proposed for traditional grid networks with processors of heterogeneous computing capacity, but they arenot recon�gurable processors. There are some task scheduling systems, such as [13,14] for heterogeneous recon-�gurable systems. However, the proposed algorithms only target a single recon�gurable processor and do notconsider them in a distributed environment. Similarly, scheduling algorithms reported in [18,16,19,20] providescheduling solutions, based on real-time constraints, for multiple recon�gurable processors in embedded systemsonly. In addition, the task preferences and advantage of recon�gurability of the processors has not been consid-ered unless a system is partially recon�gurable. In this paper, we propose a dynamic scheduling algorithm forapplication task distribution among di�erent recon�gurable nodes in a computing grid. The proposed algorithmschedule the grid application tasks on the basis of the recon�guration parameters such as, recon�gurability, area,and preferred processor con�guration for the given task. Furthermore a simulation framework is developed toimplement the required data structures and the proposed scheduling algorithm.
3 The Problem Statement
In this section, we formalize the problem statement by discussing the models for task, processor con�gurationand nodes in the grid network. We assume that each task is a part of a large-scale application and is independentof other tasks. Some examples of such applications can be found in [21].
A task is represented by the following tuple:
Taski (TID, trequired, Cpref ) (1)
Where TID represents the task number and trequired is the execution time required by the task i. Cpref is thepreferred processor con�guration required by the task i. This con�guration can be a speci�c processor capableof being implemented on a recon�gurable node.
Subsequently, we represent a general con�guration of processor to be implemented on a recon�gurable node:
Ci (CID,Area, Ctype, parameters) (2)
Where CID represents the con�guration number and Area is the total recon�gurable area needed by thecon�guration i . Ctype represents the type of con�guration of the processor required by tasks in the system.

Typical examples of Ctype are soft-core processors, digital signal processors (DSPs), custom computing units(CCUs) etc., parameters are the attributes of a particular processor which provide the details of the Ctype
processor required by the tasks. For instance, as mentioned earlier, a Ctype can be the soft-core ρ-VEX VLIWprocessor implemented on FPGA, as discussed in [22] and it can adopt to several parameters such as, number ofissue slots, cluster cores, number and types of functional units, number of memory units. Application tasks withpreferred con�guration (Cpref ) are submitted to the grid scheduler, which may de�ne any particular con�gurationof type Ctype with these speci�c parameters.
Similarly, a grid node is represented by the following tuple:
Nodei (NID,Area,Cexisting, state) (3)
Where NID represents node number, Area is the total recon�gurable area of the grid node i and staterepresents state of the node i whether it is currently busy or idle. Furthermore, Cexisting represents the currentcon�guration on the grid node. Initially, no con�guration is assumed on the grid nodes and, therefore, is set toCblank. Based on above de�nitions, we formulate the problem as follows:
Given a set of tasks de�ned by (1) and a set of recon�gurable nodes represented by (3), �nd a dynamicscheduling algorithm to map all tasks to the grid nodes in the following order of preference.
For given set of nodes Nodei and con�gurations Ci, a task with preferred con�guration Cpref is mapped ontoa node in the following order, if the Cpref exists in the con�gurations list on the grid.
1. Each task is mapped onto a node with its preferred con�guration Cpref .2. If Cpref is not available in the grid, then the task is mapped to a blank node after creating its Cpref by either
sending the entire bitstream or the con�guration parameters onto the node. In doing so, the area utilizationis minimized.
3. In case there is no blank node available in the grid, the task is assigned to an idle node whose Cexisting 6= Cpref
of the task. In this case, Cexisting is completely removed from the node and it is recon�gured for the Cpref .
In case, the preferred con�guration Cpref does not exist in con�gurations Ci, the node with the closest-match
con�guration is determined in the grid for a given match criteria and the task is assigned to that grid node.However, if no match is found, the task is discarded.
4 The Proposed Algorithm
In this section, we will discuss the proposed design. First, we discuss background and scope to provide the conceptof recon�gurable grid system. Subsequently, the proposed scheduling algorithm and the required data structuresare explained with the help of an example.
4.1 Background and Scope
A conceptual view of the proposed grid network is depicted in Figure 1a. It can be observed that each gridnode contains a recon�gurable hardware (FPGA) with a �xed area. Each node is con�gured with a speci�ccon�guration of a processor of type Ctype. Furthermore, the network contains a Resource Management System
(RMS) which is capable of sending bitstreams of di�erent Ctype con�gurations on the network. It also implementsa scheduling algorithm by in-taking user tasks and generates task/node mappings as its output. The detailedview of the resource management system is depicted in Figure 1b.
The RMS consists of a Grid Information Service (GIS) which is a dynamically changing module. It implementsdata structures which contain the information about the current states of all the nodes in the grid network. Thisinformation consists of current state of a grid node (whether it is busy or idle), current Ctype con�guration onthe node and available recon�gurable area. The status information of each node is updated each time the currentstate of that node is changed. In addition, the GIS can register new grid nodes in the network. The core of theRMS is a scheduler which implements a task scheduling algorithm to produce task/node mapping decisions. Thedetails of the scheduling algorithm are explained later in this paper. Moreover, the RMS contains a bitstreamlibrary which consists of a set of bitstreams of di�erent con�gurations of Ctype. These bitstreams are alreadysynthesized, implemented and tested on the nodes and can be considered as valid bitstreams for the grid network.

(a)
Grid Information
System
I NP U T
INTERFACE
Scheduler
BitstreamLibrary
OUTP U T
INTERFACE
Tasks Queue
Status Updates from Grid Nodes
User Tasks
New Node Registration
Requests
Scheduling Decisions
Bitstreams
Tasks
(b)
Figure 1: A grid network with recon�gurable nodes. (a) A generalized view. (b) The resource management system.
We assume that each user application task requires a preferred con�guration of a processor of Ctype withspeci�c parameters. The parametrization characteristics of Ctype processor can be exploited by the grid by eithersending the required parameters of the Cpref of a task or by sending the corresponding bitstream of the Cpref tothe respective recon�gurable computing nodes. The decision whether to only send parameters or the bitstreamsdepends on the local availability of corresponding bitstream on grid nodes. For instance, a task may require aCpref as a 4-way VLIW processor with parameters, such as 4×MUL, 4×ALUs, 2 memory units. The RMS willdecide to accomodate the task onto a suitable grid node speci�ed by the scheduler. This approach provides a novelidea of distribution of bitstreams or parameters over a grid network, based on the Cpref of applications task.The grid nodes behave dynamically as they can be recon�gured according to the requirements of an application.
4.2 The Proposed Data Structures
In this section, we discuss the required data structures for our proposed scheduling algorithm. The data structuresare explained with the help of an example. These proposed data structures are used to maintain the states of thegrid nodes in the resource management system and scheduler, depicted in Figure 1b. A grid node can have a stateof being busy or idle and it contains a particular Cexisting. All this information is maintained by using linked listsof busy or idle nodes with the same con�guration and a linked list of blank nodes. This makes it possible to searchthe lists to retrieve state information of the required grid node in a faster manner as compared to a scenario ifall nodes with di�erent states are stored in a linear array. Additionally, it can be signi�cantly time-consumingif the number of grid nodes are very large. The traversal of a linear array to �nd required node(s) takes muchlonger time. The data structures contain the information corresponding to all the nodes in the grid network. Theupdated states of the Ctype con�guration on a particular node, available areas of the nodes, and current busyand idle lists speci�c to each node, are maintained in the de�ned data structures. These lists are implemented aslinked lists which attach nodes of the same con�guration together. List manipulations are detailed through thefollowing example: We assume that we have a grid network with only 3 Ctype con�gurations and 16 grid nodes.Lets assume that the con�gurations are denoted by C2, C3, and C7. The following assumptions are made in thedesign and implementation of the lists:
� A blank node is represented by Φ. A blank node in the grid network is a node which is not yet con�guredwith any con�guration.
� A currently busy node is represented by a +ve sign of the corresponding con�guration number. For instance, acurrently busy node with a con�guration C2 is denoted by +C2 or C2. Similarly, a free node with con�gurationC3 is denoted as −C3.
� When the state of a node is changed from free to busy (or busy to free), its current con�guration is modi�edby a change of sign from -ve to +ve (or +ve to -ve).
� The current busy list represents a linked list of all the nodes with a particular con�guration that are cur-rently busy. For instance, (1 → 8 → 11) shows that node 1, 8 and 11 are busy nodes with same (i.e., C2)con�guration.

� Similarly, the current idle list represents a linked list of all the idle nodes with a particular con�guration.� A blank list is de�ned to link the blank nodes in the grid network. This list uses the current busy list �eld ina similar manner as busy list, but the corresponding nodes do not have any con�guration and are representedby Φ in their current con�guration.
Array Index 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15Current Configuration C3 C2 C-3 C7 Ф C7 C3 C-7 C2 Ф C-3 C2 C-3 Ф C7 Ф
Area A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
Current Busy List 6 8 – 5 9 14 NULL – 11 13 – NULL – 15 NULL NULL
Current Idle List – – 10 – – – – NULL – – 12 – NULL – – –
Fig. 2: The nodes states array.
We explain a state scenario of the lists using an example. Figure 2 depicts the status of nodes in grid network.It maintains the current dynamic state of all the nodes in the following manner:
� Node IDs are represented by the indices of the array.� Current con�guration shows the current con�guration on the node represented by the node ID.� Area shows the total available area of the node.� Current Busy List shows the node ID of the next busy node with the same con�guration as of the currentnode. For example, linked list (1→ 8→ 11) in the Figure 2 shows the list of busy nodes with C2.
� Similarly, Current Idle List shows the node ID of the next idle node with the same con�guration as of thecurrent node. For example, linked list (2 → 10 → 12) in the Figure 2 depicts the list of idle nodes withcon�guration C3.
� A list of blank nodes is maintained by the Current Busy List �eld. For example, (4 → 9 → 13 → 15) is alinked list of all the blank nodes in the grid network.
� A NULL entry indicates the last node of a particular list.� A dash sign in a current busy or idle list indicates that the node does not currently exist in the speci�ed list.For instance, a dash sign in Current Idle List of node 0 shows that the node is currently in the busy list, notin the idle list.
Additionally, we consider that linked lists (0 → 6) and (3 → 5 → 14) show busy nodes with con�gurationsC3 and C7, respectively. All con�gurations are stored in another data structure which is called con�gurationsarray depicted in Figure 3a. Each entry in this array corresponds to the data structure to provide the detailsof Ctype con�guration and its parameters as shown in the tuple 2. Furthermore, it contains two pointers Idlestart and Busy start. Idle start points to the �rst node of the linked list of the idle nodes with the correspondingcon�guration of a particular node. Similarly, the Busy start points to the �rst node of the linked list of busynodes with the corresponding con�guration of a particular node.
Similarly, the Figure 3b depicts the Node data structure which represents a typical grid node. It comprises ofthe current or existing Ctype con�guration of the node, recon�gurable area, pointers to the next node in the idlelist with same con�guration (Inext), pointer to the next node in the busy list with same con�guration (Bnext),and a pointer to the current task being executed on the node (CurTask). The node structure is represented bythe tuple (3). The Current Con�guration �eld of Figure 2 only represents the entry points to the con�gurationsarray. The algorithm to schedule an application task onto a grid node using the above mentioned data structuresis described in the next section .
4.3 The Dynamic Scheduling Algorithm
In this section, we describe the proposed dynamic scheduling algorithm which uses the data structures discussedin Section 4.2.
Intially, the Cpref of the current task (CT) is matched in the con�gurations array depicted in Figure 3a.If the Cpref is found in the array, then the algorithm looks for one or more idle nodes of that con�gurationby traversing the list of idle nodes of that particular con�guration by using the pointer Idle start. If the nodes

(a) (b)
Figure 3: The proposed data structures: (a) The con�gurations array. (b) The nodes array.
Synthetic Task Generator
CoreScheduling
ModuleCurrent Busy ListCurrent Idle List
Suspended Tasks Queue
Configurations Generator
Node Generator
Simulation Report
Generator
rScheduleSim
Configurations Array
Node List
Fig. 4: The simulation framework.
(idle) are available, the CT is allocated to the best-match node to con�gure the Cpref of CT. The node with thebest-match is one which takes minimum recon�guration area among all the nodes in the linked list. On the otherhand, if Cpref is found in the con�gurations array, but there is no idle node available, then the CT searchesfor the list of blank nodes (which are not yet con�gured). If neither idle nor blank nodes are available with theCpref , then the algorithm searches for any idle node with minimum su�cient area and allocates the task to itafter making it a blank node and recon�guring it with Cpref .
In case the Cpref of the CT is not found in the con�gurations array, the algorithm searches for a node withthe closest-match con�guration to Cpref of CT. Once the closest con�guration is found, the algorithm looksfor idle nodes with that con�guration. If not found, it looks for blank nodes with su�cient area to con�gurethem. If blank nodes are also not found, then the algorithm puts the tasks in a suspension queue to wait for anybusy nodes of the required con�guration to set idle. Finally, a task is discarded if no node with su�cient area isavailable to recon�gure its Cpref .
Subsequently, the corresponding busy or idle lists are updated accordingly, after the CT is allocated to acertain node. The node is removed from the blank list and is attached to the start of the list of busy nodes, andthe blank list is updated (at start, because it is fast and easy to do so).
5 The Simulation Framework
Figure 4 depicts our simulation framework designed for the implementation of the proposed task schedulingalgorithm. We developed a simulator in C++ which is capable of generating synthetic tasks, grid nodes, anddi�erent con�gurations. The Synthetic Task Generator generates tasks for given task distribution function. TheNode Generator module generates grid nodes with di�erent recon�gurable area sizes. A user can set the upperand lower area ranges with the nodes for simulation purpose. For a realistic study, these area ranges can be setaccording to the actual area sizes of the recon�gurable devices available. Similarly, the Con�guration Generator
module generates a variety of processor con�gurations for a particular grid node. Again for a realistic case,di�erent con�gurations of Ctype and their the corresponding parameters are set according to the requirements ofthe application tasks. The simulator core module implements the scheduling algorithm proposed in Section 4.3and the data structures provided in Section 4.2. The user-de�ned con�gurations are stored in a Con�guration
Array and the linked lists are implemented accordingly, using node pointers. A Suspension Queue holds TIDs

Table 1: The simulation environment.Parameter Value
Total tasks generated [103...106]Total nodes variable
Total con�gurations variableTasks generation interval [1....50]Task required area range [100...2500]Node available area range [1000...5000]
Task required timeslice range [100...10000]
of the tasks which can not be accommodated by any node. This particular situation occurs, when all the nodeswith Cpref are busy and there are no blank or idle nodes (with su�cient area) available for the current task.The suspension queue is checked automatically after the completion of each running task to �nd the potentialsubstitute for the task. The Core Scheduling Module implements the scheduling algorithm and the methodsrequired to interact with the node and con�guration data structures. Finally, the Simulation Report Generator
module stores the statistics generated by the scheduler. It reports statistics such as the total number of schedulingsteps required per task, average waiting time and average running time of each task. The average number ofscheduling steps required per task, provides the total number of search links explored by the algorithm to mapa task to a proper node in the system. This performance metric is important because scheduling steps areproportional to the system time of a host executing the scheduling algorithm.
6 Simulation Environment and Experimental Results
The main simulation parameters used in our experiments are presented in Table 1. The experiments were con-ducted on di�erent sets of tasks consisting of 103 to 106 tasks. The arrival rates of the tasks follow a uniformdistribution of arrival times within an interval [1 50], whereas, task completion time ranges between 100 and10000. Similarly, the preferred con�guration Cpref for any given task requires area within range between 100to 2500 area units (e.g., area slices or FPGA LUTs). The available recon�gurable hardware area range is setbetween 1000 to 5000 area units. It is assumed that only 10 % of the total tasks do not �nd their Cpref in thecon�gurations array and they always �nd the closest-match con�guration.
6.1 Discussion of the Results
We conducted two sets of simulation experiments in order to compute the average number of scheduling stepsrequired per task. The �rst set of experiments was conducted for variable number of grid nodes, for a �xed setof con�gurations as depicted in Figure 5. The second set of experiments was performed for variable number ofcon�gurations and �xed set of grid nodes, as depicted in Figure 6. The simulations were performed for speci�csets of tasks between 103 to 106. The overall simulation scheduling steps required for all tasks were averaged outfor total number of tasks in each experiment, to estimate the average number of scheduling steps per task. Theoutput results were collected by the output Simulation Report Generator in our simulation framework.
Investigation with variable number of grid nodes, �xed set of con�gurations
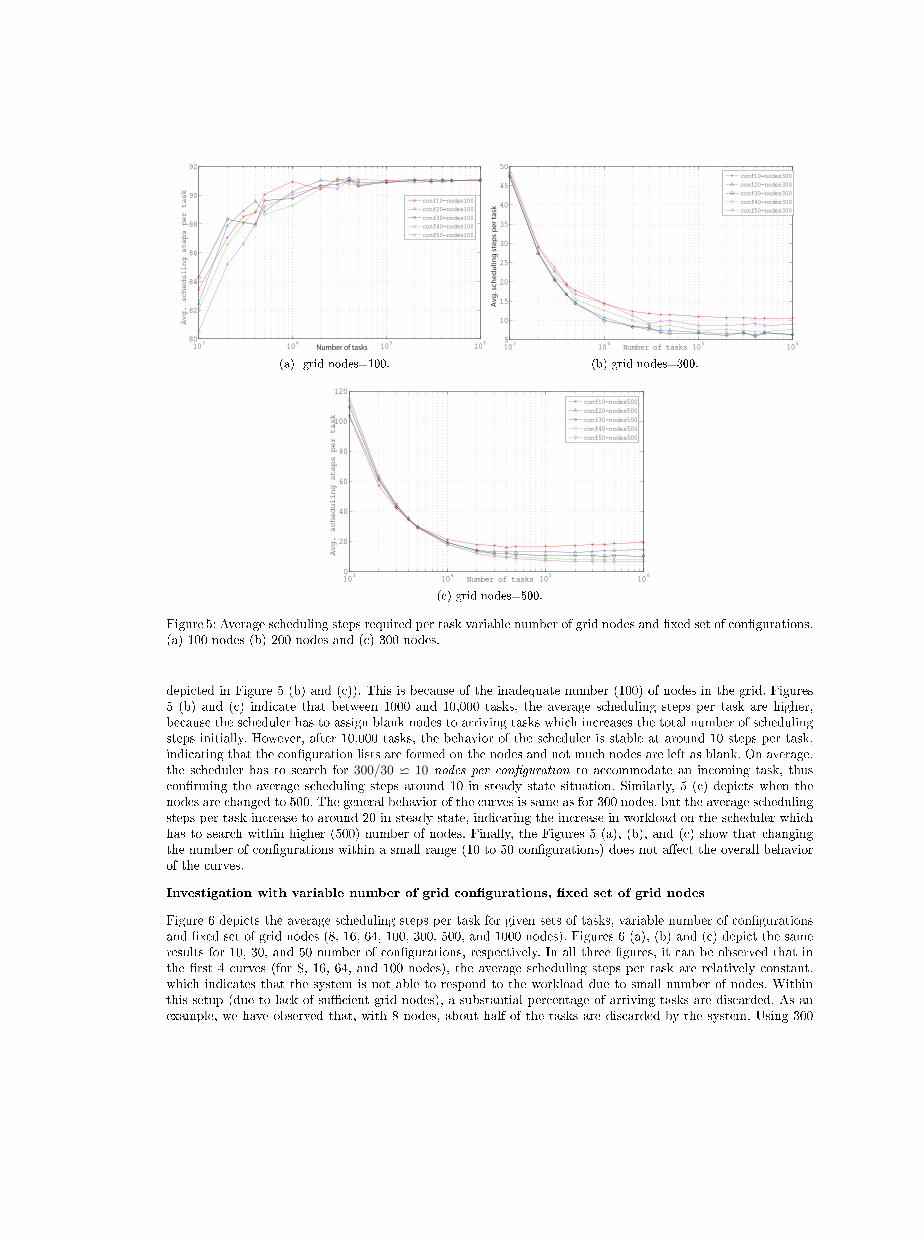
The average number of scheduling steps per task for given sets of tasks, for variable number of grid nodes and�xed set of con�gurations (10, 20, 30, 40, and 50), are depicted in Figure 5. Figures 5 (a), (b), and (c) depictthe same results for 100, 300, and 500 di�erent nodes, respectively. Figure 5 (a) shows that, for a small numberof nodes (100 nodes), an increase is observed in the average scheduling steps required per task, for a speci�crange of tasks between 1000 and 10,000. It is because the system can not accommodate the tasks in a timelymanner due to a small number of nodes and they are frequently put in the suspension list, which imposes a searchburden on the scheduler during the simulation process. For relatively large number of tasks (10,000 and up), theaverage scheduling steps curve tends to be stable, indicating that the system response is predictable for highernumber of tasks, however, still the quantitative value of the average scheduling steps is high. The curves showthat the arrival pattern and rates of the incoming tasks are the same which increases the system response timebut the average scheduling steps per task remain the same. Additionally, it should be noted that the averagescheduling steps per task are higher (around 80 to 92) as compared to a scenario with higher number of nodeswhere average scheduling steps per tasks are lower (approximately 10 for 300 nodes and 20 for 500 nodes as
103 104 105 10680
82
84
86
88
90
92
Number of tasks
Avg. scheduling steps per task
conf10−nodes100conf20−nodes100conf30−nodes100conf40−nodes100conf50−nodes100
(a) grid nodes=100.
103 104 105 1065
10
15
20
25
30
35
40
45
50
Number of tasks
Avg
. sch
edul
ing
step
s p
er ta
sk
conf10−nodes300conf20−nodes300conf30−nodes300conf40−nodes300conf50−nodes300
(b) grid nodes=300.
103 104 105 1060
20
40
60
80
100
120
Number of tasks
Avg. scheduling steps per task
conf10−nodes500conf20−nodes500conf30−nodes500conf40−nodes500conf50−nodes500
(c) grid nodes=500.
Figure 5: Average scheduling steps required per task variable number of grid nodes and �xed set of con�gurations.(a) 100 nodes (b) 200 nodes and (c) 300 nodes.
depicted in Figure 5 (b) and (c)). This is because of the inadequate number (100) of nodes in the grid. Figures5 (b) and (c) indicate that between 1000 and 10,000 tasks, the average scheduling steps per task are higher,because the scheduler has to assign blank nodes to arriving tasks which increases the total number of schedulingsteps initially. However, after 10,000 tasks, the behavior of the scheduler is stable at around 10 steps per task,indicating that the con�guration lists are formed on the nodes and not much nodes are left as blank. On average,the scheduler has to search for 300/30 w 10 nodes per con�guration to accommodate an incoming task, thuscon�rming the average scheduling steps around 10 in steady state situation. Similarly, 5 (c) depicts when thenodes are changed to 500. The general behavior of the curves is same as for 300 nodes, but the average schedulingsteps per task increase to around 20 in steady state, indicating the increase in workload on the scheduler whichhas to search within higher (500) number of nodes. Finally, the Figures 5 (a), (b), and (c) show that changingthe number of con�gurations within a small range (10 to 50 con�gurations) does not a�ect the overall behaviorof the curves.
Investigation with variable number of grid con�gurations, �xed set of grid nodes
Figure 6 depicts the average scheduling steps per task for given sets of tasks, variable number of con�gurationsand �xed set of grid nodes (8, 16, 64, 100, 300, 500, and 1000 nodes). Figures 6 (a), (b) and (c) depict the sameresults for 10, 30, and 50 number of con�gurations, respectively. In all three �gures, it can be observed that inthe �rst 4 curves (for 8, 16, 64, and 100 nodes), the average scheduling steps per task are relatively constant,which indicates that the system is not able to respond to the workload due to small number of nodes. Withinthis setup (due to lack of su�cient grid nodes), a substantial percentage of arriving tasks are discarded. As anexample, we have observed that, with 8 nodes, about half of the tasks are discarded by the system. Using 300

103 104 105 1060
50
100
150
200
250
Number of tasks
Avg. scheduling steps per task
conf10−nodes8conf10−nodes16conf10−nodes64conf10−nodes100conf10−nodes300conf10−nodes500conf10−nodes1000
(a) con�gurations=10.
103 104 105 1060
50
100
150
200
250
Number of tasks
Avg. scheduling steps per task
conf20−nodes8conf20−nodes16conf20−nodes64conf20−nodes100conf20−nodes300conf20−nodes500conf20−nodes1000
(b) con�gurations=20.
103 104 105 1060
50
100
150
200
250
300
Number of tasks
Avg. scheduling steps per task
conf30−nodes8conf30−nodes16conf30−nodes64conf30−nodes100conf30−nodes300conf30−nodes500conf30−nodes1000
(c) con�gurations=30.
Figure 6: Average scheduling steps required per task for variable number of con�gurations and �xed set of gridnodes. (a) 10 con�gurations (b) 20 con�gurations and (c) 30 con�gurations.
grid nodes, the system acts as expected. The average scheduling steps per task are higher for 1000 to 10,000 tasksdue to higher number of scheduling steps required to accommodate tasks to blank nodes at the initial stage ofscheduling which results in higher number of average scheduling steps per task for relatively smaller number oftasks. For higher number of tasks (10,000 and up), the curves become stable with expected number of averagescheduling steps per task for 300, 500, 1000 grid nodes.
From the above mentioned sets of experiments, it can be noticed that the system behavior is similar forvarious number of con�gurations (within reasonably smaller range). However, the number of nodes a�ect theaverage scheduling steps per task for a given set of tasks. For instance, it is observed that the scheduler takesless average scheduling steps per tasks for 300 nodes as compared to 500 or 1000 grid nodes. Subsequently, it isconcluded that the system works optimally at around 300 nodes for given sets of tasks between the range 103 to106.
The proposed simulation framework can be used to investigate the optimal system scenario(s) for a givennumber of tasks, grid nodes, con�gurations, task arrival distributions, area ranges, and task required times, etc.Subsequently, the proposed algorithm can be utilized for implementing di�erent sets of scheduling policies, suchas optimization on waiting times of the tasks, recon�guration and bitstream communication times, etc.
7 Conclusions and Future Work
In this paper, we proposed an e�cient dynamic scheduling algorithm to map application tasks on a grid networkof recon�gurable nodes. We proposed e�cient data structures to search required node(s) within the network.Additionally, we developed a simulation framework to implement the proposed scheduling algorithm based on thedeveloped data structures. The initial simulation results show an expected trend in the average scheduling steps

required to accommodate each task. In our future work, we will extend the simulation framework to investigatedi�erent scheduling strategies and the impact of di�erent con�guration parameters on the average schedulingsteps per task. Furthermore, we will simulate the system for di�erent arrival distribution patterns of workloadsand observe their impacts on the overall simulation and task waiting times of the system. Finally, we will testthe simulation framework for real applications with real-world scenarios.
References
[1] I. Foster and C. Kesselman, �Computational Grids", in Selected Papers and Invited Talks from the 4th InternationalConference on Vector and Parallel Processing (VECPAR), pp. 3�37, 2001.
[2] I. Foster and C. Kesselman, �Globus: A Metacomputing Infrastructure Toolkit", in International Journal of Super-computer Applications, vol. 11, pp. 115�128, 1996.
[3] Steve J. Chapin, et. al, �The Legion Resource Management System", in Proceedings of the 5th Workshop on JobScheduling Strategies for Parallel Processing, pp. 162�178, 1999.
[4] Dietmar Erwin, �UNICORE - A Grid Computing Environment", in Lecture Notes in Computer Science, pp. 825�834,2001.
[5] K.Compton and S. Hauck, �Recon�gurable Computing: A Survey of Systems and Software", in ACM ComputerSurvey, vol.34, no.2, pp. 171�210, 2002.
[6] K. Bondalapati and V. K. Prasanna, �Recon�gurable Computing Systems", in Proceedings of the IEEE, vol. 90, no.7,pp. 1201�1217, 2002.
[7] TeraGrid, �Purdue FPGA Resources for the TeraGrid network", http://www.rcac.purdue.edu/teragrid/userinfo/fpga.[8] S. Wong and M. Ahmadi, �Recon�gurable Architectures in Collaborative Grid Computing: An Approach", in Pro-
ceedings of the 2nd International Conference on Networks for Grid Applications (GridNets), 2008.[9] F. Dong and S. G. Akl, �Scheduling Algorithms for Grid Computing: State of the Art and Open Problems", Technical
Report No. 2006-504, 2006.[10] H. Cao, H. Jin, X. Wu, S. Wu, and X. Shi, �DAGMap: E�cient and Dependable Scheduling of DAG Work�ow Job
in Grid",in Journal of Supercomputing, vol. 51, no. 2, pp. 201�223, 2010.[11] H. Topcuoglu, S. Hariri, and M.-Y. Wu, �Task Scheduling Algorithms for Heterogeneous Processors", in Proceedings
of the 8th Heterogeneous Computing Workshop (HCW), pp. 3, 1999.[12] N. Muthuvelu, J. Liu, N. L. Soe, S. Venugopal, A. Sulistio, and R. Buyya, �A Dynamic Job Grouping-Based Schedul-
ing for Deploying Applications with Fine-grained Tasks on Global Grids", in Proceedings of the 2005 Australasianworkshop on Grid computing and e-research(ACSW Frontiers), pp. 41�48, 2005.
[13] A. Ahmadinia, Christophe Bobda, Dirk Koch, Mateusz Majer, and Jurgen Teich, �Task Scheduling for Heteroge-neous Recon�gurable Computers", in Proceedings of the 17th Symposium on Integrated Circuits and Systems Design(SBCCI), pp. 22�27, 2004.
[14] J. Teller, F. Ozguner, and R. Ewing, �Scheduling Task Graphs on Heterogeneous Multiprocessors with Recon�gurableHardware", in Proceedings of the 2008 International Conference on Parallel Processing - Workshops (ICPPW ), pp.17�24, 2008.
[15] M. Smith and G. D. Peterson. �Parallel Application Performance on Shared High Performance Recon�gurable Com-puting resources". in Performance Evaluation, vol. 60, pp. 107�125, 2005.
[16] O. Diessel, H. ElGindy, M. Middendorf, H. Schmeck, and B. Schmidt, �Dynamic Scheduling of Tasks on PartiallyRecon�gurable FPGAs", in IEEE Proceedings on Computers and Digital Techniques, pp. 181�188, 2000.
[17] Rodolfo Pellizzoni and Marco Caccamo, �Real-Time Management of Hardware and Software Tasks for FPGA-BasedEmbedded Systems", in IEEE Transactions on Computers, vol. 56, no. 12, December 2007.
[18] S. Baruah, �The Non-Preemptive Scheduling of Periodic Tasks upon Multiprocessors", in Real-Time Systems, vol.32, pp. 9�20, 2006.
[19] C. Steiger, H. Walder, and M. Platzner, �Heuristics for Online Scheduling Real-Time Tasks to Partially Recon�gurableDevices", in Proceedings of the 13rd International Conference on Field Programmable Logic and Application (FPL),pp. 575�584, 2003.
[20] D. B. Stewart and P. K. Khosla, �Real-Time Scheduling of Dynamically Recon�gurable Systems", in Proceedings ofInternational Conference on Systems Engineering, pp.139-142, 1991.
[21] D. P. Anderson, �BOINC: A System for Public-Resource Computing and Storage", in 5th IEEE/ACM InternationalWorkshop on Grid Computing, pp. 4�10, 2004.
[22] S. Wong, T. V. As, and G. Brown, �ρ-VEX: A Recon�gurable and Extensible Softcore VLIW Processor", in IEEEInternational Conference on Field-Programmable Technology (ICFPT), 2008.




















