Fault Tolerant Task Scheduling on Computational Grid Using Checkpointing Under Transient Faults
17
Arab J Sci Eng (2014) 39:8775–8791 DOI 10.1007/s13369-014-1455-2 RESEARCH ARTICLE - COMPUTER ENGINEERING AND COMPUTER SCIENCE Fault Tolerant Task Scheduling on Computational Grid Using Checkpointing Under Transient Faults Ritu Garg · Awadhesh Kumar Singh Received: 3 June 2014 / Accepted: 30 September 2014 / Published online: 12 November 2014 © King Fahd University of Petroleum and Minerals 2014 Abstract Application scheduling is crucial for grid com- puting environment. The failure of grid resources poses a great challenge to it. Most existing application scheduling algorithms deal with resource failures by employing reli- ability-aware scheduling without considering performance and do not adequately provide fault tolerance to them. In this paper, we proposed a fault tolerant task scheduling algorithm for independent and dependent (workflows) tasks consider- ing reliability as well as the performance of grid resources. We focused on the Weibull distributed failures of grid resour- ces in spite of commonly adopted assumption of Poisson fail- ure distribution. To handle such failures, rollback recovery via checkpoint/restart is used for improving system depend- ability and reliability. The optimal checkpointing frequency is used with the goal to minimize the fault tolerance over- head (expected waste time). Based on minimal wasted time, a new factor known as capacity decreasing factor is generated. It considers both the performance and failure characteristics of the resources. Finally, the efficient scheduling decision is made using genetic algorithm considering the capacity decreasing factor by generating the new computing capac- ity of the resources in the presence of failures. The efficient scheduling solution is generated having both optimal perfor- mance (makespan) and reliability (i.e., the lowest tendency to fail). Further, precedence constraint of sub-tasks is also considered, where ordering of tasks is performed consider- ing the precedence relationship and fault tolerance overhead. The simulation results show that our proposed fault tolerant scheduling algorithm achieves better performance and execu- R. Garg (B ) · A. K. Singh Computer Engineering Department, National Institute Of Technology, Kurukshetra, Haryana, India e-mail: [email protected] A. K. Singh e-mail: [email protected] tion reliability than other previous algorithms in the presence of failures. Keywords Grid computing · Task scheduling · Fault tolerance · Checkpointing · Weibull failure distribution · Genetic algorithm 1 Introduction With the rapid development of networking technology, grid computing [1] has emerged as a promising distributed 123
Transcript of Fault Tolerant Task Scheduling on Computational Grid Using Checkpointing Under Transient Faults

Arab J Sci Eng (2014) 39:8775–8791DOI 10.1007/s13369-014-1455-2
RESEARCH ARTICLE - COMPUTER ENGINEERING AND COMPUTER SCIENCE
Fault Tolerant Task Scheduling on Computational GridUsing Checkpointing Under Transient Faults
Ritu Garg · Awadhesh Kumar Singh
Received: 3 June 2014 / Accepted: 30 September 2014 / Published online: 12 November 2014© King Fahd University of Petroleum and Minerals 2014
Abstract Application scheduling is crucial for grid com-puting environment. The failure of grid resources poses agreat challenge to it. Most existing application schedulingalgorithms deal with resource failures by employing reli-ability-aware scheduling without considering performanceand do not adequately provide fault tolerance to them. In thispaper, we proposed a fault tolerant task scheduling algorithmfor independent and dependent (workflows) tasks consider-ing reliability as well as the performance of grid resources.We focused on the Weibull distributed failures of grid resour-ces in spite of commonly adopted assumption of Poisson fail-ure distribution. To handle such failures, rollback recoveryvia checkpoint/restart is used for improving system depend-ability and reliability. The optimal checkpointing frequencyis used with the goal to minimize the fault tolerance over-head (expected waste time). Based on minimal wasted time, anew factor known as capacity decreasing factor is generated.It considers both the performance and failure characteristicsof the resources. Finally, the efficient scheduling decisionis made using genetic algorithm considering the capacitydecreasing factor by generating the new computing capac-ity of the resources in the presence of failures. The efficientscheduling solution is generated having both optimal perfor-mance (makespan) and reliability (i.e., the lowest tendencyto fail). Further, precedence constraint of sub-tasks is alsoconsidered, where ordering of tasks is performed consider-ing the precedence relationship and fault tolerance overhead.The simulation results show that our proposed fault tolerantscheduling algorithm achieves better performance and execu-
R. Garg (B) · A. K. SinghComputer Engineering Department, National InstituteOf Technology, Kurukshetra, Haryana, Indiae-mail: [email protected]
A. K. Singhe-mail: [email protected]
tion reliability than other previous algorithms in the presenceof failures.
Keywords Grid computing · Task scheduling · Faulttolerance · Checkpointing · Weibull failure distribution ·Genetic algorithm
1 Introduction
With the rapid development of networking technology, gridcomputing [1] has emerged as a promising distributed
123

8776 Arab J Sci Eng (2014) 39:8775–8791
computing paradigm that enables large-scale resource shar-ing and collaboration. To achieve the promising potential ofdistributed resources, effective and efficient scheduling algo-rithm is important. The grid scheduling problem is to coordi-nate and allocate the resources to grid applications in order toefficiently execute them. Many important grid applicationsin e-science and e-business fall in the category of workflowapplications, which have task dependencies among them.The optimization of scheduling problem is NP-complete, sonumerous heuristic algorithms have been proposed. Presentheuristics such as minimum completion time (MCT), max–min, min–min, suffrage [2] for independent tasks and het-erogeneous earliest finish time (HEFT) [3], critical path ona processor (CPOP) [3], and path clustering heuristic [4] forworkflow tasks aims to achieve the minimum execution timeonly. But all these heuristics rarely consider the failure anderror conditions in the grid.
However, the grid resources are normally highly dynamic,geographically distributed, and heterogeneous. These char-acteristics often lead to variability in grid availability due tothe failure or error conditions that are either permanent ortransient. Permanent failures are caused by physical defects,while transient failures are generally caused by temporarychanges such as environmental changes, rebooting of sys-tem. Transient failures disappear after a short period of timeand the node resume task processing. Due to the developmentof hardware technology, nowadays, transient failures are themain reasons for the system failures and it is the focus of ourresearch. The failures of the grid resources affect the taskexecution fatally, especially for long running tasks (that runsfrom hours to weeks). This may lead to task failures, violatingtiming deadlines and service level agreements, denials of ser-vice, degraded user-expected quality of service, etc., whichis not acceptable, and it increases the importance of fault tol-erance in grid scheduling. Recently, several fault avoidanceand fault removal algorithms [5,6] have been proposed in theliterature to maximize the reliability of the application. Theseschedulers normally provide the reliability-aware schedulingwithout considering performance and do not provide faulttolerance to them. In this paper, we schedule the tasks to thegrid resources considering reliability and performance alongwith applying the fault tolerance, so that we are able to pre-vent task failures resulting from the failures of grid resources.Here, fault tolerance is applied considering performance fac-tors and the failure characteristics of the resources in order toachieve optimal execution performance (i.e., minimum exe-cution time) and maintaining high task reliability.
Providing fault tolerance in the grid while optimizing per-formance in terms of execution time is a challenging task.Checkpoint recovery and job replication are two primarilyused fault tolerance techniques in the literature [7–9]. Thefirst approach depends on the system’s MTTR, while thelatter depends on the availability of alternative sites to run
replicas. The rollback recovery via checkpoint/restart mecha-nism has been popular technique [10,11] for fault tolerance indistributed computing systems, where many real-time appli-cations are running. It is resource-efficient way to handlefailures in comparison with replication. Further according toGuo et al. [12], local node fault recovery (LNFR) is efficientto achieve fault tolerance by resuming the task executionon failed node after node recovery, especially for the longrunning computations. Hence, in this paper, we applied thelocal node recovery by checkpoint/restart approach consider-ing the transient (recoverable) failures. It periodically savesa snapshot of the system to the local disk and uses it forrecovery considering recoverable failures.
Most prior work on fault tolerance in grid [7,9,13] assumesPoisson distributed failures where the processor failure rate isindependent of their usage. This assumption can be acceptedfor random soft errors, but it is inaccurate for the currentstudy, as the system follows the wear-out-related hard errorsalso. Based on recent studies [14–18] with the distributionfitting to the failure data show that the mean time betweenfailures (MTBF) on modern high-performance computingsystems is best modeled by Weibull distribution. Some ofthem find decreasing hazard rates, while others find that haz-ard rates are flat or increasing [18]. Further, [19] illustratesthat most failures are transient and are recoverable. Thus, weassume that arrival of failure is independent and follows theWeibull distribution with decreasing hazard rate. Due to itsvarying rate, techniques to provide fault tolerance for Pois-son distributed failures in the literature are not suitable forhandling Weibull failures.
Thus, our contribution in this work is to design the faulttolerant task scheduling (FTTS) algorithm for independent aswell as dependent tasks grid applications that takes the failurerate and computing capacity of resources into considerationwhile scheduling rather than considering only time optimiza-tion [20] or reliability optimization [5]. Based on the abilityto preemptively know about the faults and to provide ade-quate fault tolerance, allows the new class of task schedulingwhere fault tolerance overhead as well as performance of gridresources is considered at the time of scheduling. We sched-ule the tasks to grid resources with the aim to achieve optimalperformance and reliability of task execution. To the best ofour knowledge, it is the only algorithm which considers faulttolerance along with the performance at the time of schedul-ing, while most existing scheduling algorithms consider faulttolerance at the time of execution. Experimental results haveshown that the performance of the proposed algorithm isbetter compared with time optimization (speed aware) andreliability optimization (reliability aware) strategy, due toconsideration of fault tolerance overhead and performanceof grid resources.
The rest of the paper is organized as follows. Section 2includes the related work. Section 3 briefly specifies the
123

Arab J Sci Eng (2014) 39:8775–8791 8777
proposed FTTS, its architecture and framework of the gridcomputing system, and the task model. Section 4 specifiesthe description of checkpoint/restart model used for provid-ing fault tolerance. Further, Sect. 5 describes the proposedFTTS algorithm for independent and dependent task applica-tions. Section 6 discusses the simulation and result analysis.Finally, Sect. 7 gives the conclusion.
2 Related Work
Noticeable research and practice have been made in the lit-erature [15–17] which reveals that grid environment is morefailure prone than general distributed systems. Thus, faulttolerance is the critical activity for the applications runningin the grid computing system.
Handling of failure before job scheduling is very impor-tant and is called proactive fault tolerance. Reference [21]suggests that the proactive failure handling improves the sys-tem availability. Fault tolerance in the grid has traditionallyfocused on recovery strategies implemented through proac-tive failure handling techniques like job checkpointing andreplication. Further, in papers [10,22–24], genetic algorithm-based approaches are used to provide fault tolerance to thesystem. They considered different fault tolerance schemeslike checkpointing and replication.
In the research paper [20], the author introduced the adap-tive task checkpointing-based fault tolerant job schedulingstrategy for economic grids. It maintains the fault index ofgrid resources. The scheduler makes scheduling decisionsaccording to the fault index and response time of the resources.In [25], fault tolerance is achieved by dynamically adapt-ing the frequency of checkpoints and a history of failureinformation about a resource is used to increase the through-put. Whenever a resource failure occurs, the proposed faultindex-based rescheduling (FIBR) algorithm reschedules thejob from failed resource to some other available resource,and then, the job is executed from the last saved checkpoint.The major drawback of these studies is the use of fault index,which is not a better indicator of resource failure tendencyin comparison with failure rate.
In [26], scheduling system is proposed based on schedul-ing indicator (SI), a new factor considering response time,and failure rate of the resources. Here, it schedules the inde-pendent tasks to the resources with least value of SI with theaim to avoid resources that frequently fails. Here, the failure-aware scheduling is proposed without considering fault tol-erance to the failed tasks.
Last failure time-based checkpoint adaptation and meanfailure time-based checkpoint adaptation algorithm are dis-cussed in [15]. Reference [27] assumed that short runningjobs can be resubmitted from scratch if they failed and pre-sented a fault tolerant scheme that should apply to long
running jobs using checkpointing. In paper [28], author hasintroduced a cooperative checkpointing scheme using run-time decision concept, allowing checkpoint requests to bedynamically skipped at runtime to reduce checkpoint over-head. Reference [29], in turn, considers dynamic checkpoint-ing interval reduction; in case, it leads to computational gain,which is measured by the sum of the differences between themeans for fault-affected and fault-unaffected job responsetimes. In [30], (FT-Pro) another adaptive fault managementscheme is proposed. Here, optimal checkpointing schemesare introduced to provide fault tolerance but without consid-ering the scheduling issues.
Most research on proactive failure handling considers thefault index of the resources which may not be the effec-tive indicator of the failure history. Some of the work whichconsiders failure rate for indicating failure tendency consid-ers the Poisson failure distribution (constant failure). How-ever, in the grid computing systems [16,17,31,32], the timebetween failures follows the Weibull distribution. So, in thispaper, we considered the checkpointing approach for faulttolerance considering Weibull failure distribution. Finally, anefficient scheduling solution is generated using genetic algo-rithm considering the failure information (in terms of faulttolerance overhead) along with performance characteristicsof the resources.
3 The Proposed Fault Tolerant Task Scheduler
The proposed FTTS algorithm schedules the application taskswith the aim to minimize the execution time along with han-dling faults by adding fault tolerance. Here, fault tolerance isprovided to the system with the help of checkpointing/restartmechanism considering the recoverable or transients faults.In case of a failure, the saved state is restored and processstarts re-execution from the last checkpoint. Here, in thisstudy, first, we calculate the optimal checkpointing frequencyfor local checkpointing with the aim to minimize expectedwasted time (or fault tolerance overhead) based on the tran-sient failure rates of resources. Depending upon the expectedwasted time, capacity decreasing factor is calculated whichis then used to estimate the available computing capacity ofthe resources in the presence of failures. Finally, the efficientscheduling decision is made considering the new availablecomputing capacity of the resources based on the geneticalgorithm.
3.1 FTTS Architecture and Its Components
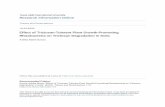
Figure 1 shows the architecture of proposed fault tolerant taskscheduling algorithm. It consists of mainly five components:task scheduler, execution manager, failure event producer,grid information server, and grid resources.
123

8778 Arab J Sci Eng (2014) 39:8775–8791
Fig. 1 Fault tolerance-basedtask scheduling architecture
User
Grid Information
ServerTask Scheduler
Execution Manager
Submits Application tasks
Result
Failure Event Producer Failure History
Archive
Grid resources
Group A(CR's)
CM FD
Group C(CR's)
CM FD
Grid resources are the computing nodes present in the gridcomputing system. Grid resources register themselves to thegrid information server (GIS), which maintains the infor-mation about all the resources including their computationalspeed, existing load, memory availability, and so on. All theresources that join or leave the system are monitored by GIS.The failure detector (FD) and checkpoint manager (CM) runon each computing group. Failure detector detects the occur-rence of failure at the resources and sends the informationto the failure event producer. Checkpoint manager receivesthe partially executed result of the task after specific inter-val specified by the execution manager and saves it to thelocal stable storage. It responds to task failure or completionmessage by passing the saved data for resuming the task orremoving the data after completion, respectively.
Failure event producer aggregates the information aboutfailures of the resources at different sites (groups) and passesit to failure history archive. There it stores information likewhen failure occurs, types of failure, and recovery time offailure. After statistical analysis over the failure history arc-hive data, failure rate and mean recovery time of the resourcesare generated by the GIS when required.
Task scheduler is an important component in grid comput-ing architecture. User first submits the application task to thetask scheduler along with its Qos requirements. Task sched-uler then contacts the GIS for collecting information regard-ing the available resources, their computation capacity, andfailure rate, etc. Depending upon the failure rate of resources,the task scheduler estimates the optimal checkpointing fre-quency by minimizing the expected wasted time (or fault tol-erance overhead) to provide fault tolerance to the executionof task as described in Sect. 4. Considering expected wastedtime, it generates the capacity decreasing factor, which isthen used to estimate the new available computing capacityof the resources in the presence of faults. It then schedules thetasks to the appropriate resources based on the genetic algo-rithm considering application tasks requirements and esti-mated available computing capacity of the resources. Usingavailable computing capacity of the resources, task sched-
LANPC
ClusterLAN
Fig. 2 Example of grid computing system model
uler is able to schedule the tasks considering performancecharacteristics as well as failure information of the resourcesapart from the time optimization or reliability optimizationtechniques which considers only performance characteristicsor failure information, respectively.
The execution manager then dispatches the ready tasks tothe appropriate resources as scheduled by the GA-based taskscheduler. It further passes the optimal checkpointing infor-mation to the checkpoint manager residing at the respectivecomputing sites.
3.2 FTTS Framework
In this section, we describe the formal definitions for gridresources, application tasks used in this study.
System Model In our grid computing system model, weconsidered the groups of interconnected geographical dis-tributed resources, where groups may be LANs, clusters, orindividual nodes as shown in Fig. 2. Here, each resource in the
123

Arab J Sci Eng (2014) 39:8775–8791 8779
group is autonomous and associated with different processingcapabilities. Further, there is a global task scheduler respon-sible for distributing the tasks to the available computingresources among the different groups with the help of (GIS).
We consider the grid network consisting of m numberof heterogeneous and dynamic computing resources repre-sented as set R = {r1, r2, . . ., rm}, which are interconnectedby fully connected communication links with equal band-width(unity), and communication is assumed to be performedwithout contention. Further, it is assumed that the network isfully reliable and failure occurs only at computing resources.Each resource has computational rate which is denoted byN ( j), j ∈ {1, 2, . . ., m} and represents the computing speedof the resource to perform specific operations in a given time(millions of instructions per second). The terms node, host,and processor within this article represent the computingresource and are used interchangeably.
Further, each resource has different failure characteristics.Several studies analyze the time between failures [13–15] fordistributed systems and find that the Weibull distribution tobe a good fit. In the Weibull failure distribution, there aretwo parameters—scale parameter (α) and shape parameter(β). When β = 1 means that failure rate is constant withtime, β > 1 means that failure rate increases with time, andβ < 1 means that failure rate decreases with time. Here, inthis study, the time between failures is assumed to follow theWeibull failure distribution with decreasing hazard rate.
Task Model We consider the set of n tasks (independentbatch tasks as well as dependent tasks) represented as vi , i ∈{1, 2, . . ., n} which are to be assigned to grid resources forexecution. Each task is associated with the workload w(vi )
which represents the size/computing demand of i th task andexpressed as the number of instructions (MI) to be executedby the task.
A parallel application with dependent tasks (or precedenceconstraint tasks) is represented by an acyclic directed graph(DAG) G = (V, E) where V is the set of vertices represent-ing n different tasks vi . E is the set of edges representingdependencies among the tasks. An edge ei j = (vi , v j ) ∈E, 1 ≤ i ≤ n, 1 ≤ j ≤ n, i �= j represents the precedenceconstraint such that task v j cannot start its execution beforecompletion of task vi . The weight w(ei j ) assigned to edge ei j
represents the amount of data required to be transfer from taskvi to v j if they are not executed on the same resource. In theset {vx ∈ V : exi ∈ E}, predecessor of task vi is representedas pred(vi ) and all the successors are denoted by succ(vi ). Atask without any predecessor, i.e., pred(vi ) = φ is called anentry task, and a task without any successor succ(vi ) = φ iscalled an exit task. In general, we consider that the DAG hasone entry task and one exit task. Figure 3 shows an exampleof the dependent task application represented as DAG.
Based on the information of application tasks and systemresources, task scheduler schedules the tasks to the appropri-
T2 T3
T4 T5
T6
T1
Fig. 3 Dependent task application represented as DAG
ate resources. Let S : V → R denotes the task mapping/taskassignment string, where S(i) = r j means that task vi isassigned to the resource r j . The detail of scheduling algo-rithm is introduced in Sect. 5.
4 Description of Checkpoint/Restart Model
In this paper, we considered the use of fault tolerant schemebased on checkpointing that is one of the most popular tech-niques to provide fault tolerance in high end computing.It stores the status of current application state in order torestart the application after the occurrence of any failureavoiding the job to start from scratch. Conversely, it requiresadditional time to save the application states known as thecheckpointing overhead. The efficiency of the checkpointingmechanism is strongly dependent on the length of the check-pointing interval. Frequent checkpointing may enhance theoverhead, while lazy checkpointing may lead to loss of sig-nificant computation, thereby increasing the application re-computing time. Hence, we focus on how to determine thesize of the checkpointing interval that minimizes waste timebased upon the knowledge about the application as well asthe system characteristics.
Here, we applied the checkpoint/restart mechanism (shownin Fig. 4) for fault tolerance under Weibull failure distribu-tion since it effectively represents the machine availability ina large-scale computing environment such as grid.
The mathematical derivation of checkpoint/restart modelis based on the following assumptions [14,32,33]:
• Assumption 1 The application is interrupted by a series ofrandom transient failures where the time between failureshas a certain probability density function f (t). The systemfailure can be detected by a monitoring mechanism andrecovery phase is then invoked, and we assume that there isno failure during the checkpointing and rollback recovery.
• Assumption 2 C is defined as the mean checkpoint over-head, i.e., the overhead in the execution time of the appli-
123

8780 Arab J Sci Eng (2014) 39:8775–8791
Fig. 4 Checkpoint/restartmodel
tfi-1
i-1th failure tfi
ith failure
Ti
Recovery t1 t2 tk-1 tk
C
Variable Checkpoint
Interval
TRe RRecovery Phase
Full Checkpoint
cation caused by a checkpointing operation. Every check-point overhead C is constant.
• Assumption 3 The re-computing time (TRe) is time inter-val between the latest checkpoint and the present failureevent. It represents the time lost due to failure.
• Assumption 4 Trec is defined as the mean recovery over-head, which includes the mean repair time or downtimeof the system followed by reload overhead (R).
The checkpoint/restart model considered here allows morethan one failure during the lifetime of the application. Aftereach failure, application restarts from the latest checkpointas shown in Fig. 4 and the period between two consecutivefailures is known as failure cycle. The I th failure cycle (Ti )
starts from I − 1th failure (except the initial cycle) followedby rollback recovery phase, task execution with checkpoint-ing after some checkpointing intervals and finally end withI th failure. Ti here represents the random variable of timeto failure of the i th failure. Hence, the sequence Ti |i ≥ 1can be treated as a renewal reward process. Therefore, bymean of the calculus of variations, our aim is to determinethe optimal sequence of checkpoints by minimizing the totalexpected waste time that includes checkpointing overhead,re-computing time, and recovery overhead for Weibull failuredistribution.
4.1 Checkpointing Overhead
Checkpointing overhead is given by number of checkpointsduring failure-free interval of consecutive checkpoints andoverhead of each checkpoint (C).
Let us consider, a continuous checkpointing frequencyfunction n(t) with sequence of discrete checkpointing timeinstants, t0, t1, t2, . . ., tn such that
∫ ti
ti−1
n(t)dt = 1, ∀i = 1 (1)
where ti (i =1, 2, . . .) is i th checkpoint placement and t0 =0
CheckpointCheckpoint
Failure
tk+1 tk
tfI
1\n(t)
TRe
Fig. 5 Relationship between re-computing time (TRe) and checkpoint-ing frequency function n(t)
Let N0,Ti represents the number of checkpoints in the timeinterval [0, Ti ] and is given by of the integral of checkpointfrequency function n(t) over the time interval [0, Ti ], so thenumber of checkpoints will be given by Eq. (2)
N0,Ti =∫ Ti
0n(t)dt (2)
So, checkpointing overhead is
Checkpointing overhead = C · N0,Ti = C∫ Ti
0n(t)dt (3)
4.2 Re-computing Time
When a failure event occurs at the system, then system has torecover from latest checkpoint. So, amount of lost operationsneeds to be recomputed. Here, the re-computing time (TRe)
denotes the time interval between failure occurrence time(t fi ) and the latest checkpoint (tk) as shown in Fig. 5. It canbe estimated by using the checkpointing frequency function.
By mean value theorem, TRe can be approximatelyexpressed as a function of the reciprocal of n(t) (see [14]).Therefore, TRe can be approximated by the Eq. (4).
TRe ≈ k
n(t)(4)
123

Arab J Sci Eng (2014) 39:8775–8791 8781
where k represents the re-computing time coefficient and it isthe ratio of the re-computing time and checkpointing intervalin which failure event occurs as shown in Fig. 4 and its valuelies between (0,1).
k = TRe
tk+1 − tk= t fi − tk
tk+1 − tk(5)
4.3 Recovery Overhead
The recovery overhead (Trec) represents the time needed forthe system to recover from failure. It includes the systemdown time followed by latest checkpoint reload time (R).Here, we considered the down time to be negligible in case oftransient failures and R is the time required to reload the latestcheckpoint during the rollback recovery phase and assumedto be constant.
Trec = R (6)
4.4 Total Wasted Time
The total wasted time (WTi ) in a given i th failure cycle (Ti )
is the sum of the checkpointing overhead, re-computing time(TRe), and recovery time (Trec) as shown in Fig. 4. So, totalwasted time (WTi ) is expressed as
WTi = Checkpointing Overhead + Re-computing Time
+ Recovery Time
According to Eqs. (3), (4), and (6)
WTi = C∫ Ti
0n(t)dt + k
n(t)+ R (7)
There can be more than one failure during the lifetime ofa running application. The checkpointing process followsa renewal reward process in which WTi denotes the wastedtime from the starting or restarting point to the i th failure. LetN (t) be the number of system failures in the interval [0, t].So, mean wasted time of the application can be expressed as
E(∑N (t)
i=1 WTi
)
t(8)
Denoting the first time to failure as T1, the theorem of renewalreward process can be given as:
limt→∞
E(∑N (t)
i=1 WTi
)
t= E[WT1]
E[T1] (9)
The Eq. (8) suggests that minimizing the overall expectedwasted time is equivalent to minimizing the wasted time fromthe starting point to the first failure. Now, we concentrate onwasted time due to first failure and denote it as WT and timeto failure denoted by T .
Let f (t) is the probability density function of time to fail-ure random variable and F(t) is the cumulative distributionfunction. Then, the expected wasted time distribution can becalculated by (10)
E[WT] =∫ ∞
0(WT) · f (t) dt (10)
By using Eqs. (7) and (10) becomes
E[WT] =∫ ∞
0
[C
∫ t
0n(t) · dt + k
n(t)+ R
]· f (t) dt (11)
4.5 The Optimal Checkpoint Frequency n*(t)
The optimum checkpointing frequency can be obtained byminimizing the expected waste time E[WT] and can be expre-ssed as follows
n∗(t) =√
k
C
√f (t)
1 − F(t)(12)
Proof Minimizing expected wasted timeE[WT] is equiva-lent to
min
([C
∫ t
0n(t)dt + k
n(t)+ R
]. f (t)
)
Let ξ(t) = ∫ t0 n(t)dt and ξ ′(t) = n(t) then
�(ξ, ξ ′, t) =(
C.ξ(t) + k
ξ ′(t)+ R
)· f (t)
For to get extreme values, the function must satisfy
∂�
∂ξ− d
dt· ∂�
∂ξ ′ = 0
where
∂�
∂ξ= C · f (t)
and
∂�
∂ξ ′ = − k
(ξ ′(t))2 · f (t)
So,
∂�
∂ξ− d
dt· ∂�
∂ξ ′ = C · f (t) +d
dt
(k
(ξ ′(t))2 · f (t)
)= 0
After taking integral from 0 to t , we get
n(t) =√
k
C
√f (t)
1 − F(t)
Here, n(t) represents the optimal checkpointing frequencyfunction [represented by n*(t)] for which expected wastedtime is minimum.
Proof is complete. �
123

8782 Arab J Sci Eng (2014) 39:8775–8791
We considered the failure distribution as Weibull distrib-ution, so failure density function f (t) is defined as
f (t) = β
α
(t
α
)β−1
e−(t/α)β (13)
with scale parameter α > 0 and shape parameter β < 1. Incase β = 1, the Weibull distribution is identical to the expo-nential distribution. And cumulative density function F(t)is
F(t) = 1 − e−(t/α)β (14)
Using Eqs. (13) and (14), Eq. (12) becomes
n∗(t) =√
k
C·(
t
α
) β−12
√β
α(15)
4.6 The Optimal Checkpoint Placements
Let ti is the i th optimal checkpoint placement for i = 1, 2, . . ..Using optimal checkpointing frequency (n*(t)) in Eq. (1), tican be expressed as
ti =(
i · β + 1
2A
) 2β+1
(16)
where
A =√
k
C·(
1
α
) β−12
√β
α
Proof As per Eq. (1),∫ ti
ti−1
n(t)dt = 1 =∫ ti
ti−1
A · tβ−1
2 dt = 2A
β + 1
(t
β+12
)ti
ti−1
ti =(
β + 1
2A+ t
β+12
i−1
) 2β+1
Finally, by applying induction, we get
ti =(
i · β + 1
2A
) 2β+1
Proof is complete. � Finally, the minimum expected waste time can be cal-
culated as Eq. (11) by considering the optimal checkpointfrequency function n*(t) and is expressed as
E[WT] =∫ ∞
0
[C
∫ t
0n∗(t) · dt + k
n(t)+ R
]· f (t) · dt
(17)
5 Fault Tolerant Task Scheduling
Given a grid computing system, application tasks, and check-point restart model described above, we define fault tolerant
grid scheduling as the problem of assigning application tasks(independent or dependent) to the available grid resources,so that the makespan is minimized while maintaining hightask reliability.
The notion of checkpointing induces overhead to total exe-cution time, but allows recovering from current state in caseof failures. Optimal sequence of checkpoints is placed as perEq. (16) in order to minimize the expected wasted time. Theidea is to recalculate the computing capacity (computationalrate) of each resource in the grid environment after consid-ering its failure characteristics. Based on the failure infor-mation collected from the GIS, we calculate the expectedwasted time (E[WT]) due to fault tolerance for each task oneach resource as mentioned in the Eq. (17). After that, thetotal execution time (TET) of each task over different proces-sors is calculated by adding expected wasted time E[WT] tothe execution time without failure (ET). We then calculatecapacity decreasing factor (CDF) by dividing the TET byET. Finally, the node’s available computing capacity is esti-mated by dividing the given node computing capacity withoutfailure to the capacity decreasing factor.
Let TET [vi , r j ] represents the total execution time of i thtask over j th resource including fault tolerance overhead &ET [vi , r j ] is the execution time without failure. CDF[i, j]represents capacity decreasing factor. Then, we can calculatethe capacity decreasing factor according to Eq. (18).
CDF[i, j] = TET[vi , r j
]ET
[vi , r j
] (18)
Using CDF[i, j] as a capacity decreasing factor, the avail-able computing capacity of the resources is calculated in thepresence of failures. Let, NC[ j] represents the available com-puting capacity considering fault tolerance in the presence offailures and N [ j] is the initial computing capacity withoutconsidering failure corresponding to the j th resource. So,NC[ j] is expressed as:
NC[ j] = N [ j]CDF[i, j] (19)
Based upon NC[ j], task scheduling is performed using gene-tic algorithm in order to achieve minimal makespan and hightask reliability. The important parameters and notations usedfor fault tolerant task scheduling (inspired by our previouswork [34,35]) are formally defined as follows:
• Computation cost/execution time represents the executiontime of i th task over j th resource
ET[vi , r j ] = w(vi )
N ( j)(20)
• Communication cost represents the communication timerequired to transfer output data from task vp to vi if they
123

Arab J Sci Eng (2014) 39:8775–8791 8783
are scheduled on resource rs and r j , respectively, consid-ering the available bandwidth (Bs, j ) of the link betweenthem (for simplicity, unit bandwidth is considered overhere). The communication time between two tasks is con-sidered to be zero if they are mapped to the same resource.
Cs, jp,i
= w(epi )
Bs, j(21)
• Estimated start time of tasks vi on resource r j .
EST[vi , r j
] =
⎧⎪⎨⎪⎩
max
{Avail[r j ], max
vp ∈pred(vi )
{EST[vp, rs] + Cs, j
p,i
}}for dependent task
max{Avail[r j ]} for independent task
⎫⎪⎬⎪⎭ (22)
where Avail[r j ] is the available time of resource noder j . And pred(vi ) is the set of immediate predecessor tasksof task vi in case of dependent tasks. For the entry taskventr y , the EST is zero.
• Estimated finish time of a task vi on some resource r j .
EFT[vi , r j
] = EFT[vi , r j
] + ET[vi , r j
](23)
• Overall makespan of grid application represents the esti-mated finish time of the last completed task on any proces-sor. Let, S(i) represents the resource to which task vi
is assigned as per scheduling solution S, then overallmakespan is
makespan(S) = maxr j ∈R
{max
i |S(i)=r j
{EFT
[vi , r j
]}}(24)
5.1 Fault Tolerant Task Scheduling Using GA
Genetic algorithms (GA) are the large class of evolution-ary algorithms based on the Darwin’s theory [36] of sur-vival. Recently, it is widely recognized as a domain indepen-dent powerful meta-heuristic used to search global optimain multidimensional search space. Thus, it is used to solvevarious optimization problems in the literature [37,38]. Fur-ther, GA shows robust performance with scheduling prob-lems and is able to produce several satisfying solutions byiterative evolutions over generations of scheduling solutions.General procedure for GA is as follows: (i) create an initialpopulation of solutions also called chromosomes which rep-resents the candidate solutions to the optimization problem.(ii) Evaluate the fitness of the solution and select the optimalchromosome with best fitness value for next population. (iii)Generate new population of solutions by applying geneticoperators of crossover and mutation. (iv) Repeat step 2 and 3
until predefine number of evaluations is reached or the pop-ulation converges. Each step of GA is explained further asfollows:
A. Problem Encoding In our work, the scheduling solutionis represented as the task assignment string S, which is theallocation of each task vi to the available time slot of theresource r j capable of executing the task. Figure 6a showsa feasible task assignment string corresponding to DAG (inFig. 3) by assuming availability of 3 resources.
B. Crossover Crossovers are used to generate better solu-tions by rearranging the part of existing fittest solutions. Wehave used one-point crossover for task assignment string.Our crossover operation first selects some pairs of solu-tions with probability of crossover (pc) set to 0.8. Fromeach pair of solutions, it randomly generates a cutoff point,which divides the strings into two parts: left and right. Theright parts are then exchanged to generate new solutions.The process of crossover on two task mapping strings isdescribed in Fig. 6b.
C. Mutation Further, mutation operator is used to explorenew things that could not be exploited by crossover operator.For mutation, single chromosome is selected to generate newchromosome which possibly is genetically better. Here, anindividual’s task is reassigned on another resource randomly.As depicted in Fig. 6c, a task v5 is reassigned on resourcer3 which earlier was assigned on r2. We used the replacingmutation operator with the probability of mutation set to 0.5.In general, mutation should be applied with significant lowrate, but we have applied it with high rate because it showseffective results in grid environment as shown by Yu andBuyya [39].
D. Fitness evaluation In order to evaluate the individuals, thefitness function makespan corresponding to scheduling solu-tion S is used after considering the fault tolerance overhead.In our evaluation operation, we first estimate the CDF[i, j]as a capacity decreasing factor of resource r j correspond-ing to the i th task as per Eq. (17) considering the expectedwasted time (fault tolerance overhead). Then, available com-puting capacity of the resources NC[ j] is calculated in thepresence of failures. Using NC[ j] instead of N[ j], we cal-culate the computation cost (as per Eq. 20) of task vi onresource r j , which represents the execution time consider-ing fault tolerance overhead. Using this computation cost,
123

8784 Arab J Sci Eng (2014) 39:8775–8791
Fig. 6 Genetic operators ofcrossover and mutation on taskassignment string
(a) Task Assignment String
(b) Crossover Operation on two task assignment strings
(c) Mutation Operation
{r3, r1, r3, r2, r1, r3}
{r3, r1, r3, r2, r1, r3}
Crossover Point
{r2, r3, r1, r3, r2, r1}
{r3, r1, r1, r3, r2, r1}
{r2, r3, r3, r2, r1, r3}
A�er Crossover
Before Crossover
{r3, r1, r1, r3, r2, r1}
{r3, r1, r1, r3, r3, r1}
Before Muta�on
A�er Muta�on
the fitness function makespan is calculated as per Eq. (24)and the individuals with minimum makespan are selected.The pseudocode of our evaluation algorithm is shown inAlgorithm 1 and Algorithm 2 for independent tasks anddependent tasks applications, respectively.
5.1.1 For Independent Tasks
For batch jobs (independent tasks), the pseudocode of ourevaluation algorithm is shown below:
Here, Algorithm 1 describes the evaluation of the taskassignment string corresponding to scheduling solution Sbased on the fitness function (makespan) for independenttask application. Firstly, execution time (ET) of each taskover each resource is estimated without considering the fail-ure of the resources. Based upon ET and considering failure
characteristics of resources, the n*(), E[WT], and CDF[i, j]are calculated represented in step 2. Then, in step 3, tasks arearranged in non-increasing order of their workload in order toprioritize the tasks based on their size. Finally, in step 4, thescheduling solution S is evaluated. In order to do so, NC[ j]of the resource is calculated considering the CDF[i, j] fromstep 2 corresponding to i th task over j th resource in S. UsingNC[ j], the important parameters like EST and EFT are calcu-lated, and finally, makespan in the presence of fault toleranceis calculated corresponding to scheduling solution S.
5.2 For Dependent (DAG-based) Tasks
This section presents the fault tolerant scheduling algorithmfor dependent task application (precedence constraint tasks)with the aim to reduce the makespan considering the failure
123

Arab J Sci Eng (2014) 39:8775–8791 8785
information. The algorithm consists of two phases, first is togenerate the optimized execution order of the tasks accordingto the modified version of HEFT [3] called task priority phaseand second is to evaluate the mapping string using max_minstrategy.
Task Priority Phase Tasks are ordered to generate theschedule as per their scheduling priorities based on the rank-ing. Our fault tolerant scheduling algorithm will use faulttolerant rank (FT_rank) attribute to compute the priorities ofthe tasks. FT_rank is explained as below.
For a given set of tasks modeled by DAG, the FT_rankrepresents the rank of the task from the exit node to itself. It iscomputed as the sum of average computation cost of the task,communication cost of edges, and average fault toleranceoverhead of task over all the resources. The communicationcost for the tasks allocated to the same resource is assumedto be zero. Thus, FT_rank of task vi is recursively definedas
FT_rank(vi ) = ET(vi ) + maxv j ∈succ(vi )
{Ci, j + FT_rank(v j )} + CPvi
(25)
where succ(vi ) is the set of the immediate successors oftask vi , ET(vi ) is the average computational cost, Ci, j is theaverage communication cost of edge ei j , and CPvi is theaverage fault tolerance overhead of task vi . Further, CPvi canbe computed by taking the average wasted time correspondto tasks over each resource and can be expressed as
CPvi =m∑
j=1
E[WTi ] j/m (26)
FT_rank is computed recursively by traversing the task graphupward, starting from exit node. For the exit node, the rankcan be computed as
FT_rank(vexit) = ET(vexit) + CPvexit (27)
Basically, the FT_rank(vi ) is the length of the critical pathfrom task vi to exit node, including fault tolerance overhead.
Based on the task priority phase, pseudocode of our eval-uation algorithm is shown below. Here, we first select thetasks in the order of their priority; then, as per task assign-ment/mapping string, the schedule S is evaluated based onits fitness function (makespan).
Algorithm 2 describes the procedure for evaluation of taskassignment string corresponding to solution S for dependenttask application based on makespan as the fitness function.Here, tasks are prioritized based on their FT_rank calculatedby step 3, 4, and 5 instead of size as in algorithm 1. Afterordering the tasks, the evaluation of solution S is performedin step 6 similar to algorithm 1.
The time complexity of our evaluation algorithm is dom-inated by the basic operations of: (1) calculating expected
wasted time of each task over each processor O(nm), wheren is the number of tasks and m is the number of processors.(2) Calculating priority of the tasks O(mn) and sorting thetask based on their priority O(log n). (3) Calculating theestimated start time of the tasks over each processor O(d),where d is the number of directed edges in case of depen-dent task application. Therefore, the overall complexity ofthe proposed algorithm is O(mn + log n + d).
6 Simulation Strategy
In this section, we present the experiments for evaluating theperformance of the proposed FTTS algorithm for the varietyof applications in the simulated grid environment. Here, first,we described the simulation model, followed by the perfor-mance metrics used to compare the algorithms. Finally, theresults of the simulation experiments are provided.
6.1 Simulation Model
To verify the correctness and effectiveness of the proposedFTTS algorithm, we have conducted extensive experimentsand simulation. Our simulated research environment com-prises 64 processors with different computational power dis-tributed over eight clusters. We generated failure models foreach of the eight clusters based on the Weibull distributionsfor MTBF with decreasing hazard rate. So, we consideredshape parameter (β) varies from 0.2 (low failure rate) to 0.8(high failure rate). The value of scale parameter α =13,200.The re-computing time coefficient is 0.5; checkpoint storagecost and recovery time (including average down time) is 2minutes.
First, we run the grid application with independent tasks(batch jobs) where numbers of tasks vary from [20,100]. Fur-ther, we conducted experiments with precedence constrainttasks (dependent tasks or workflows) in the grid. We usedthe workflow models represented by a random task graph,where the numbers of tasks vary from [20,100]. The meanout degree of the node is 2. The computation cost of each taskvi on resource r j is selected randomly by the uniform distri-bution with the mean equal to the twice of specified averagecomputation cost. The cost of each edge was selected ran-domly from the uniform distribution across the mean equal tothe product of average computation cost and the communica-tion to computation ratio (CCR). Here, CCR is taken as 0.5 torepresent the computation intensive application. Other para-meters corresponding to GA are as follows: population size= twice the number of tasks, crossover rate = 0.8, mutationrate = 0.5.
To compare the efficiency of the proposed FTTS algo-rithm, we have implemented the time-optimized scheduling
123

8786 Arab J Sci Eng (2014) 39:8775–8791
algorithm with checkpointing [20], time-optimized schedul-ing algorithm only (similar to max–min [2] for independentjobs and HEFT [3] for dependent jobs), and reliability opti-mized (or reliability aware) scheduling algorithm [5].
In time-optimized (speed aware) scheduling algorithm,only task allocation is done on the basis of speed (computa-tional capacity) of the node, i.e., a task is assigned to a nodewhose original computational capacity is highest among theavailable nodes without considering the failure informationof the node. Further, in case of time-optimized schedulingwith checkpointing, first, task allocation is done based ontime optimization strategy (computing speed), and then, thefault tolerance is provided with the help of checkpointingbased on failure information of the nodes.
In reliability-aware scheduling, availability of each node ispredicted and then task is allocated to the node with minimumreliability cost. In case of node failure, task is rescheduledto the other node based on reliability cost. Here, it tries toavoid the faults rather than providing fault tolerance apartfrom the proposed algorithm, which performs both: first faultavoidance and then fault tolerance.
6.2 Performance Metrics
To evaluate the performance of the proposed approach ofFTTS in grid, we considered different application centricparameters as performance improvement rate (PIR), failureratio (FR), and system centric parameters such as failure slowdown (FSD).
• Performance Improvement Rate (PIR) It specifies the per-centage of performance improvement (or reduction inmakespan) for the proposed FTTS algorithm with respectto other algorithms and is measured as follows:
PIR(%) = makespan (other) − makespan (FTTS)
makespan (FTTS)× 100
(28)
• Failure Ratio (FR) It is the ratio of total number of failuresin the proposed algorithm to the total number of failuresin the other scheduling algorithm. The proposed FTTSalgorithm will be better if the value of FR comes out tobe less than 1.
123

Arab J Sci Eng (2014) 39:8775–8791 8787
Failure Ratio (FR)
= Total Number of Failures (FTTS Algorithm)
Total Number of Failures (other Algorithm)(29)
• Failure Slow down (FSD) FSD is defined as the ratio oftime delay caused by failure-to-failure-free job executiontime, average over the total number of jobs. The FSD ofthe fault tolerant task scheduling algorithm should be lessthan that of other scheduling algorithms considered.
6.3 Simulation Results and Analysis
Here, we present the results of the simulations described inSect. 6.1.
Test Suit1: First, we considered the independent task appli-cation by varying the number of tasks (as in [40–43]). Resultscorresponding to different performance metrics consideredare shown in Fig. 7. Figure 7a shows the results of per-formance improvement rate (PIR) of the proposed FTTSalgorithm with respect to the other algorithms considered.Results clearly show that PIR increases as number of tasksis increasing. Compared to time-optimized scheduling withcheckpointing, FTTS provides improvement of 9–17 %. Thisis due to the fact that here the resources are selected with min-imum execution time without considering their failure char-acteristics, which may be more prone to failures. Hence, largenumber of tasks may fail which are then handled by check-point restart mechanism, ultimately increasing the overallmakespan of the schedule. Compared to time-optimized sche-duling only, FTTS reports the improvement rate of 15–34 %,and this is due to restarting the execution of the failed taskfrom the scratch, which may fail again. Further, there isimprovement of 7–12 % compared to reliability-aware sche-duling. In reliability-aware scheduling, the task is scheduledover reliable node which may not provide minimum execu-tion time. Further, in case of failure, it reschedules the failedtask to other reliable node and start the task execution fromscratch, which increases the overall makespan of the appli-cation.
Figure 7b shows the failure ratio of the proposed FTTSalgorithm to the other algorithms and is always coming out tobe less than 1. It clearly shows that FTTS algorithm performsbetter in terms of FR. For time-optimized scheduling withcheckpointing, FR varies from 0.84 to 0.62 as the numbersof tasks are increasing. While in time-optimized scheduling,only FR varies from 0.7 to 0.44. Here, numbers of failuresare large, due to the fact that without fault tolerance (check-pointing) failed tasks have to restart from scratch with morechances of failures again. In reliability-aware scheduling, FRvaries from 0.92 to 0.75 only.
Figure 7c represents that the failure slow down (FSD)corresponding to different algorithms considered. In case of
proposed algorithm, FSD varies from 1.2 to 2.4 for differentnumber of tasks. Here, small delay incurs due to handling ofsmall number of failures. While in case of time-optimizedscheduling with checkpointing and time-optimized schedul-ing only, FSD lies between 2.3 to 3.7 and 5.8 to 6.9, respec-tively. As the number of failures is more, here, so delayincurred will be more. In reliability-aware scheduling, FSDvaries from 3.3 to 4.6, because no fault handling is providedhere even in the presence of small number of failures. Over-all, the results clearly manifest that our proposed FTTS algo-rithm performs better as compared to the other schedulingalgorithms.
Test Suit2: Second set of experiments is performed fordependent tasks (workflow) applications represented by ran-dom task graphs with different number of tasks (as takenin [44,45]), and the results corresponding to different perfor-mance metrics are shown in Fig. 8. The results trends are sim-ilar to test suit1. Figure 8a shows the performance improve-ment rate of the proposed FTTS algorithm to the other algo-rithms. Compared to time-optimized scheduling with check-pointing, time-optimized scheduling only, and reliability-aware scheduling, FTTS provides PIR from 11 to 19, 21 to37, and 8 to 16 %, respectively. Figure 8b shows the failureratio of the proposed algorithm to the other algorithms andis always coming out to be less than 1. Hence, the proposedalgorithm performs better than other algorithms in terms ofFR. Figure 8c shows the failure slow down (FSD) for depen-dent tasks represented by random task graphs. The resultsclearly show that our proposed FTTS algorithm is havingless FSD as compared to the other scheduling algorithms.
It can be seen that the proposed FTTS performs better incomparison with other algorithms, not only for independenttasks but also for dependent task applications and achieveefficient scheduling in the presence of fault tolerance.
7 Conclusion
Grid scheduler is one of the key components of the grid com-puting environment. Estimating the performance of the sys-tem is the key responsibility of the scheduler. In this paper,a FTTS algorithm is proposed to increase the execution per-formance while maintaining high task reliability even in thepresence of resource failures.
Here, the solution includes (1) efficient fault tolerant envi-ronment, i.e., optimal checkpoint placement. (2) Design ofoptimal task scheduling. We first introduced the checkpointand recovery mechanism to handle the Weibull distributedfailures. Based on the calculation of expected waste time (orfault tolerance overhead) due to failure handling, we derivethe capacity decreasing factor, which is then used to esti-mate the new computing capacity of the resources. The taskscheduling decision is then made using genetic algorithm
123

8788 Arab J Sci Eng (2014) 39:8775–8791
Fig. 7 Comparison betweenresults for proposed FTTS andother algorithms forindependent tasks applicationwith different number of tasks
(b) Failure ratio (FR) of FTTS algorithm over other algorithms considered
(c) Failure slow down (FSD) of FTTS algorithm over other algorithms considered
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
20 40 60 80 100
Failu
re R
a�o
Number of Tasks
Time op�mized scheduling with checkpoin�ngTime op�mized scheduling onlyReliability aware scheduling
0123456789
10
20 40 60 80 100
Failu
re S
low
Dow
n
Number of Tasks
Proposed AlgorithmTime op�mized scheduling with checkpoin�ngTime op�mized scheduling onlyReliability aware scheduling
(a) PIR (%) of FTTS algorithm over other algorithms considered
0
5
10
15
20
25
30
35
40
45
20 40 60 80 100Perf
orm
ance
Impr
ovem
ent r
ate
(%)
Number of Tasks
Time op�mized scheduling with checkpoin�ngTime op�mized scheduling onlyReliability Aware scheduling
123

Arab J Sci Eng (2014) 39:8775–8791 8789
Fig. 8 Comparison betweenresults for proposed FTTS andother algorithms for dependenttasks application (represented asa random task graph) withdifferent number of tasks
(a) PIR (%) of FTTS algorithm over other algorithms considered
(b) Failure ratio (FR) of FTTS algorithm over other algorithms considered
0
5
10
15
20
25
30
35
40
45
20 40 60 80 100Pe
rfor
man
ce Im
prov
emen
t rat
e (%
)Number of Tasks
Time op�mized scheduling with checkpoin�ngTime op�mized scheduling onlyReliability Aware scheduling
00.10.20.30.40.50.60.70.80.9
1
20 40 60 80 100
Failu
re R
a�o
Number of Tasks
Time op�mized scheduling with checkpoin�ngTime op�mized scheduling onlyReliability aware scheduling
(c) Failure slow down (FSD) of FTTS algorithm over other algorithms considered
0123456789
10
20 40 60 80 100
Failu
re S
low
Dow
n
Number of Tasks
Proposed AlgorithmTime op�mized scheduling with checkpoin�ngTime op�mized scheduling onlyReliability aware scheduling
123

8790 Arab J Sci Eng (2014) 39:8775–8791
according to this new computing capacity considering bothtime and failure information of resources. We presented thefault tolerant task scheduling for independent and dependenttask applications with the aim to minimize both executiontime and the number of faults. Simulation evaluation showsthat the FTTS algorithm is better than other algorithms interms of performance (i.e., minimum execution time) andtask reliability.
References
1. Buyya, R.; Venugopal, S.: A gentle introduction to grid computingand technologies. CSI Commun. 29, 9–19 (2005)
2. Braun, T.D.; Siegal, H.J.; Beck, N.: A comparison of eleven staticheuristics for mapping a class of independent tasks onto hetero-geneous distributed computing systems. J. Parallel Distrib. Com-put. 61, 810–837 (2001)
3. Haluk, T.; Hariri, S.; Wu, M.Y.: Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEETrans. Parallel Distrib. Syst. 13, 260–274 (2002)
4. Bittencourt, L.F.; Madeira, E.R.M.; Cicerre, F.R.L.; Buzato, L.E.:A path clustering heuristic for scheduling task graphs onto a grid.In: Proceedings of the 3rd ACM International Workshop on Mid-dleware for Grid Computing, Grenoble, France (2005)
5. Tao, Y.; Jin, H.; Wu, S.; Shi, X.; Shi, L.: Dependable grid work-flow scheduling based on resource availability. J. Grid Com-put. 11(1), 47–61 (2013)
6. Wang, X.; Buyya, R.; Su, J.: Reliability-oriented genetic algo-rithm for workflow applications using max–min strategy. In: 9thIEEE/ACM International Symposium on Cluster Computing andthe Grid, CCGRID’09, pp. 108–115 (2009)
7. Buntinas, D.; Coti, C.; Herault, T.; Lemarinier, P.; Pilard, L.;Rezmerita, A.; Rodriguez, E.; Cappello, F.: Blocking vs. non-blocking coordinated checkpointing for large-scale fault tolerantMPI. Future Gener. Comput. Syst. 24(1), 73–84 (2008)
8. Bouteiller, A.; Herault, T.; Krawezik, G.; Cappello, F.: MPICH-V:a multiprotocol fault tolerant MPI. Int. J. High Perform. Comput.Appl. 20(3), 319–333 (2006)
9. Hwang, S.; Kesselman, C.: Grid workflow: A flexible failure han-dling framework for the grid. In: Proceedings of 12th IEEE Inter-national Symposium on High Performance Distributed Computing(2003)
10. Wu, C.C.; Lai, K.C.; Sun, R.Y.: GA-based job scheduling strategiesfor fault tolerant grid systems. In: Asia-Pacific Services ComputingConference, APSCC’08, pp. 27–32, IEEE (2008)
11. Robert, Y.; Vivien, F.; Zaidouni, D.: On the complexity of schedul-ing checkpoints for computational workflows. In IEEE/IFIP 42ndInternational Conference on Dependable Systems and NetworksWorkshops (DSN-W), pp. 1–6, IEEE (2012)
12. Guo, S.; Huang, H.Z.; Wang, Z.; Xie, M.: Grid service reliabil-ity modeling and optimal task scheduling considering fault recov-ery. IEEE Trans. Reliab. 60(1), 263–274 (2011)
13. Cappello, F.: Modeling and tolerating heterogeneous failures inlarge parallel systems. In: Proceedings of the SC’2011 Interna-tional Conference for High Performance Computing, Networking,Storage and Analysis, ACM Press (2011)
14. Liu, Y.; Nassar, N.; Leangsuksun, C.; Nichamon, N.; Paun, M.;Scott, S.: An optimal checkpoint/restart model for a large scalehigh performance computing system. In: IEEE International Sym-posium on Parallel and Distributed Processing (IPDPS 2008),pp. 1–9 (2009)
15. Schroeder, B.; Gibson, G.A.: A large-scale study of failures in high-performance computing system. IEEE Trans. Dependable Secur.Comput. 7(4), 337–350 (2010)
16. Sangrasi, A.; Djemame, K.: Component level risk assessment ingrids: a probabilistic risk model and experimentation. In: IEEEInternational Conference on Digital Ecosystem and Technology(2011)
17. Linping, W.; Dan, M.; Zhan, J.; Lei, W.; Bibo, T.: A failure-awarescheduling strategy in large-scale cluster system. In: Proceedingsof the Sixth IEEE International Symposium on Cluster Computingand the Grid (2006)
18. Iosup, A.; Jan, M.; Sonmez, O.; Epema, D.H.J.: On the dynamicresource availability in grids. In: IEEE/ACM International Confer-ence on Grid Computing 2007, pp. 26–33 (2007)
19. Tao, Y.; Wu, S.; Shi, L.: Performance modeling of resource failuresin grid environments. In: Fifth International Conference on Frontierof Computer Science and Technology (FCST), pp. 65–71, IEEE(2010)
20. Nazir, B.; Qureshi, K.; Manuel, P.: Adaptive checkpointing strategyto tolerate faults in economy based grid. J. Supercomput. 50(1), 1–18 (2009)
21. Salfner, F.; Malek, M.: Reliability modeling of proactive fault han-dling. Department of Computer Science, Humboldt-Universität zuBerlin, Germany, Tech. Rep. 209 (2005)
22. Upadhyay, N.; Misra, M.: Incorporating fault tolerance in GA-based scheduling in grid environment. In: 2011 World Congress onInformation and Communication Technologies (WICT), pp. 772–777, IEEE (2011)
23. Priya, S.B.; Prakash, M.; Dhawan, K.K.: Fault tolerance-geneticalgorithm for grid task scheduling using check point. In: Sixth Inter-national Conference on Grid and Cooperative Computing, GCC2007, pp. 676–680, IEEE (2007)
24. Alfoly, A.I.; Abdelhalim, M.B.; Senbel, S.: Economic grid faulttolerance scheduling using modified genetic algorithm. In: 9thIEEE/ACS International Conference on Computer Systems andApplications (AICCSA 2011), pp. 1–8, IEEE (2011)
25. Therasa, S.; Sumathi, G.; Antony Dalya, S.: Dynamic adaptationof checkpoints and rescheduling in grid computing. Int. J. Comput.Appl. 2(3), 95–99 (2010)
26. Amoon, M.: A fault-tolerant scheduling system for computationalgrids. J. Comput. Electr. Eng. 38, 399–412 (2012)
27. Mehta, J.; Chaudhary, S.: Checkpointing and recovery mecha-nism in grid. In: Proceeding of 16th International Conference onAdvanced Computing and Communication (Dec. Chennai), pp.131–140 (2007)
28. Oliner, A.J.; Rudolph, L.; Sahoo, R.K.: Cooperative checkpointing:a robust approach to large-scale systems reliability. In: Proceedingsof the 20th Annual International Conference on Supercomputing(ICS), Australia, pp. 14–23 (2006)
29. Katsaros, P.; Angelis, L.; Lazos, C.: Performance and effective-ness trade-off for checkpointing in fault-tolerant distributed sys-tems. Concurr. Comput. Pract. Exp. 19(1), 37–63 (2007)
30. Li, Y.; Lan, Z.: Using adaptive fault tolerance to improve applica-tion robustness on the Teragrid. In: Proceedings of TeraGrid, 322(2007)
31. Ming, W.; Xian, H.S.; Hui, J.: Performance under failure ofhigh-end computing. In: ACM/IEEE Supercomputing Conference(2007)
32. Naksinehaboon, N.; Paun, M.; Nassar, R.; Leangsuksun, B.; Scott,S.: High performance computing systems with various check-pointing schemes. Int. J. Comput. Commun. Control 4(4), 386–400 (2009)
33. Ling, Y.; Mi, J.; Lin, X.: A variational calculus approach to opti-mal checkpoint placement. IEEE Trans. Comput. 50(7), 699–707 (2001)
123

Arab J Sci Eng (2014) 39:8775–8791 8791
34. Garg, R.; Singh, A.K.: Reference point based multi-objective opti-mization to workflow grid scheduling. Int. J. Appl. Evol. Comput.(IJAEC) 3(1), 80–99 (2012)
35. Garg, R.; Singh, A.K.: Multi-objective workflow grid schedulingusing ε-fuzzy dominance sort based discrete particle swarm opti-mization. Int. J. Supercomput. 68(2), 709–732 (2014)
36. Goldberg, D.E.: Genetic Algorithm in Search, Optimization, andMachine Learning. Pearson Education, India (2006)
37. Sadrzadeh, A.: Knowledge-based genetic algorithm for dynamicmachine–tool selection and operation allocation. Arab. J. Sci.Eng. 39(5), 4315–4323 (2014)
38. Abusorrah, A.M.: The application of the linear adaptive geneticalgorithm to optimal power flow problem. Arab. J. Sci. Eng. 39,4901–4909 (2014)
39. Yu, J.; Buyya, R.: Scheduling scientific workflow applications withdeadline and budget constraints using genetic algorithms. Sci. Pro-gram. J. 14(1), 217–230 (2006)
40. Do, T.; Nguyen, T.; Nguyen, D.T.; Nguyen, H.C.; Le, T.: Failure-aware scheduling in grid computing environments. In: GCA,pp. 40–46 (2009)
41. Samal, A.K.; Mall, R.; Tripathy, C.: Fault tolerant schedulingof hard real-time tasks on multiprocessor system using a hybridgenetic algorithm. Swarm Evol. Comput. 14, 92–105 (2014)
42. Qureshi, K.; Khan, F.G.; Manuel, P.; Nazir, B.: A hybrid faulttolerance technique in grid computing system. J. Supercom-put. 56(1), 106–128 (2011)
43. Tao, Y.; Jin, H.; Wu, S.; Shi, X.: An optimistic checkpoint mech-anism based on job characteristics and resource availability fordynamic grids. Wuhan Univ. J. Nat. Sci. 16(3), 213–222 (2011)
44. Cao, H.; Jin, H.; Wu, X.; Wu, S.; Shi, X.: DAGMap: efficient anddependable scheduling of DAG workflow job in Grid. J. Super-comput. 51(2), 201–223 (2010)
45. Zhao, L.; Ren, Y.; Sakurai, K.: Reliable workflow schedulingwith less resource redundancy. Parallel Comput. 39(10), 567–585 (2013)
123