
A Methodology for Validating Large Knowledge Bases
11
Int. J. Man-Machine Studies (1990) 33, 361-371 A methodology for validating large knowledge bases RAJIV ENAND AND GARY S. KAtlN Carnegie Group Inc., Five PPG Place, Pittsburgh, PA 15222, USA AND ROBERT A. MILLS Ford Motor Co., Dearborn, MI, USA (Based on a paper presented at the AAAI Knowledge Acquisition for Knowledge- Based Systems Workshop, Banff, November 1988) Knowledge acquisition is not complete until a knowledge base is fully verified and validated. During verification and validation, knowledge bases are substantially refined and corrected. This paper offers a methodology for verification and validation that focuses knowledge acquisition on a progressively deeper set of issues related to knowledge base correctness. These are knowledge base verification, domain validation, procedural validation, and procedural optimization. This metho- dology has been developed in the course of using the TESTBENCHdiagnostic shell to build a large system. 1. Overview As expert systems approach deployment, validation becomes the critical issue. Undiscovered errors that show up in the production environment can cause severe problems. Depending on the domain in which the sYstem is installed, the ramifications of incorrect conclusions can vary from minor irritation to catastrophe (Geissmann & Schultz, 1988). The validation process is designed to give a developer the confidence to deploy a system into a target domain. Benbasat and Dhaliwal (1988) state that the validity of the KA process is the degree of homomorphism between the representation system, i.e. knowledge base, and the system that it is supposed to represent, i.e. the expert source. However, the validity of any complex deployed knowledge based system must also encompass inconsistencies between the expert source and domain. In small knowledge bases, it is practical ,to test exhaustively all assertions. Therefore, a straightforward exhaustive validation strategy can be employed to giye the necessary level of confidence. However, as these knowledge bases grow in size, exhaustive testing becomes impractical. Alternative validation approaches which can meet system requirements must be evaluated. Each approach must be evalutated in terms of cost (knowledge engineering resources, domain expert resources, machine resources, etc.) and expected system coverage'. In the following, a four-phase aigproach to verification and validation is outlined and discussed. The characteristics of each phase are discussed using experience gained through TESTBENCH applicationst. This paper extends a body of recent t TF.~TBENCH is an application shell developed at Carnegie Group Inc. It is based on the TEST architecture (Kahn, 1987). 361 0020-7373/90/040361 + 11503.00/0 t~) 1990 Academic Press Limited
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of A Methodology for Validating Large Knowledge Bases

Int. J. Man-Machine Studies (1990) 33, 361-371
A methodology for validating large knowledge bases RAJIV ENAND AND GARY S. KAtlN
Carnegie Group Inc., Five PPG Place, Pittsburgh, PA 15222, USA
AND
ROBERT A. MILLS
Ford Motor Co., Dearborn, MI, USA
(Based on a paper presented at the A A A I Knowledge Acquisition for Knowledge- Based Systems Workshop, Banff, November 1988)
Knowledge acquisition is not complete until a knowledge base is fully verified and validated. During verification and validation, knowledge bases are substantially refined and corrected. This paper offers a methodology for verification and validation that focuses knowledge acquisition on a progressively deeper set of issues related to knowledge base correctness. These are knowledge base verification, domain validation, procedural validation, and procedural optimization. This metho- dology has been developed in the course of using the TESTBENCHdiagnostic shell to build a large system.
1. Overview
As expert systems approach deployment, validation becomes the critical issue. Undiscovered errors that show up in the production environment can cause severe problems. Depending on the domain in which the sYstem is installed, the ramifications of incorrect conclusions can vary from minor irritation to catastrophe (Geissmann & Schultz, 1988).
The validation process is designed to give a developer the confidence to deploy a system into a target domain. Benbasat and Dhaliwal (1988) state that the validity of the KA process is the degree of homomorphism between the representation system, i.e. knowledge base, and the system that it is supposed to represent, i.e. the expert source. However, the validity of any complex deployed knowledge based system must also encompass inconsistencies between the expert source and domain.
In small knowledge bases, it is practical ,to test exhaustively all assertions. Therefore, a straightforward exhaustive validation strategy can be employed to giye the necessary level of confidence. However, as these knowledge bases grow in size, exhaustive testing becomes impractical. Alternative validation approaches which can meet system requirements must be evaluated. Each approach must be evalutated in terms of cost (knowledge engineering resources, domain expert resources, machine resources, etc.) and expected system coverage'.
In the following, a four-phase aigproach to verification and validation is outlined and discussed. The characteristics of each phase are discussed using experience gained through TESTBENCH applicationst. This paper extends a body of recent
t TF.~TBENCH is an application shell developed at Carnegie Group Inc. It is based on the TEST architecture (Kahn, 1987).
361 0020-7373/90/040361 + 11503.00/0 t~) 1990 Academic Press Limited

362 R. ENAND ET AL.
work on verification and validation (Marcot, 1987; Nguyen, Perkins, Laffey & Pecora, 1987; Benbasat & Dhaliwal, 1988; Geissmann & Schultz, 1988), by articulating a broadly applicable methodology and identifying architectural require- ments for systems which the methodology can be applied.
1.I. TESTBENCH
TESTBENCH is an application shell that provides a domain-independent diagnostic problem-solver together with a library of schematic prototypes (Kahn, 1987). These prototypes constitute the object types and the structure required by each domain- specific knowledge base. The knowledge base structure is based on a weak causal model of domain-specific failure-modes (Figure 1). The model begins with objects which define reported problems with the unit being diagnosed (concerns) and terminates with leaf failures, which are repairable.
The diagnostic strategy for a concern is based primarily on a failure-mode object. Failure-mode objects contain links to related objects which define various aspects of the behavior of the node (tests, repairs, e t c . . . ) . Failure-modes are linked to other failure-modes via cAUSED-BY relations, therefore creating a network of causal relationships between failure-modes. Pattern matching rule objects can be linked at any point within the network to dynamically modify the definition of the knowledge base when exceptions to the diagnosis are found.
The TESTBENCH problem solver employs an opportunistic refocusing strategy to traverse the search space until a terminal failure-mode (one with no CAUSED-BY list) is found. At that point, repairs to correct the problem in the terminal node are recommended (Pepper & Khan, 1987).
C Concern failure-mode )
C A U S E D - B Y ~ ~ CAUSED-BY \ r y
~ ~ ~ A LWAYS- L E A ~ CAUSED-BY ( Functional ~ ( Functional ~ Functional ~
fai, ure-modeJ ~fai,ure-modeJ C falture-modeJ
CAUSED-BY S ~ C A U S E D ' B Y ~ CAUSED-BY r r .o-.oo., ~ fai~,,.-~o~e j ~. failure-mode)
CAUSED-BY ~ ~ ALWAYS- LEA DS'TO ALWAYS" LEADS'TO B~ CAUSED" BY ( Com.o.o, ( Co o~
failure-mode ) ~.failure-mode J FmURE 1. Structure of a TESTBENCH knowledge base. Any two schemata connected by an
ALWAYS-LEADS-TO relation must have a CAUSED-BY relationin the opposite direction.

VALIDATING KNOWLEDGE BASES 363
2. Validation strategy
Correctness of a diagnostic knowledge base is evaluated in two dimensions: accuracy and efficiency. Performing the fewest number of steps in a given diagnostic session is just as important as identifying the correct underlying fault. If the system recommends any extra steps that a human diagnostician would not normally perform, acceptance of the system will be greatly hindered. Also, the additional time spent in the diagnosis can lead to additional labor and equipment costs when the system is deployed. However, achieving the optimal diagnosis in all cases in any medium to large size domain is seen as an unattainable goal.
Therefore, it is important to understand and state the goal of a validation process prior to its formation. An initial goal of a diagnostic system might be accuracy in all cases while allowing a certain level of sub-optimal diagnosis. The level of sub-optimal diagnosis would again depend on the domain in which the system is to be deployed. In the following section, we describe a validation strategy which achieves this goal.
2.1. STRATEGY OVERVIEW
In most medium to large knowledge bases, exhaustive validation is impractical. For example, in a medium to large scale application that was undertaken using the TESTBENCH architecture, estimates were made as to the different number of dynamic paths. The knowledge base consisted of a moderate amount of complexity within the diagnosis and contained roughly two hundred terminal failures, which could cause a given concern. Since there is a great amount of overlap between intermediate failures within the hierarchy, the total number of unique paths grows quickly. Early estimates of this knowledge base yielded over 10,000 paths for each of the concerns. It became obvious fairly early that an exhaustive validation of the network would require a much greater effort and resource than was available.
Validation of knowledge bases of this scale must be broken up into manageable sections. These sections must each validate an aspect of the correctness of the knowledge base. The collective sections should then validate every desired aspect of the knowledge base. In diagnostic knowledge bases, validation can be broken down into four phases.
�9 Knowledge base verification--Ensure the knowledge base has captured the intent of the expert;
�9 Domain validation--Ensure the correctness of the expert's knowledge of the target domain;
�9 Procedural validation--Ensure the procedure represented in the knowl- edge base leads to a valid conclusion;
�9 Procedure optimization--Ensure the procedure represented in the knowl- edge base is acceptable (achieves the criteria of optimality that is desired).
Each of the phases listed above are designed to bring the knowledge base an incremental step closer to achieving the stated goal of correct diagnosis. Although inherently sequential, a moderate amount of overlap between steps is allowed. In

364 R. ENAND ET AL.
the following sections, we discuss each of these phases in detail and show how they were applied in a knowledge base built using the TESTBENCH architecture.
2.2. KNOWLEDGE BASE VERIFICATION
The process of interviewing experts and subsequently building knowledge bases from the knowledge acquired in the session is a complicated and lengthy task. However, because most of the information is communicated verbally, inaccuracies will appear in the implementation of the knowledge. A skilled knowledge engineer will, however, implement some form of written feedback to the domain expert to ensure the concepts conveyed in the interview session were as intended by the expert. Depending on the constraints on domain expert time, rapid prototyping techniques can also help to verify communication. However, it is quite often impossible to verify every piece of knowledge that is acquired during a knowledge acquisition session.
2. 2.1. Goal Since several discrepancies are anticipated in the knowledge base after completion of the build phase, the goal of the first step in the validation process is to ensure that the knowledge in the knowledge base is consistent with the intent of the domain expert. Only after these inconsistencies are removed, should the knowledge base be tested in the target .domain. Therefore, verification gives the developer a certain level of confidence that the system will behave reasonably under target conditions.
Z2 .2 Application in TESTBENCH knowledge bases Ensuring that a TESTBENCH knowledge base's contents are consistent with the expert's view can be a rather lengthy task. It is important to traverse as much of the knowledge base as possible within the allowed time and resources. During this process, the knowledge engineer and the expert run the system together to ensure paths in the knowledge base operate as the expert desires. A path is defined to be all the objects used by the system to get from a concern to the terminal failure-mode (Figure 2).
In order to expedite traversal of paths, this step may be performed in a laboratory environment without the use of the target equipment. The issue of exhaustive VS selective validation is important to resolve prior to this phase. As mentioned earlier, exhaustive validation in a knowledge base of moderate size will require more resources than are probably available. Therefore, selective validation becomes an attractive alternative. In TESTBENCH knowledge bases, selective validation is aided by building three characteristics into the knowledge base (Figure 2): structure, modularity and independence.
Since TESTBENCH knowledge bases exist to pre-defined structure, an analysis of their structure can identify the various nodes that will require traversal. This can easily be done by identification of all possible causal paths through the diagnostic tree. These paths can provide significant guidance to knowledge engineers involved in the process. Additionally, if the structure is fixed, tools can easily be written to track the progress of the verification and validation process.
Modularity is built into the knowledge base by introducing structure into the failure-mode network, potentially beyond the requirements of the current diagnosis.

VALIDATING KNOWLEDGE BASES 365
I CONCERN 1 FAILURE- MODE MODUiARITY (COMPONENT ~ ~ F U NCTIONAL~~ FAILURE -MODE '
~ COMPONENT ~ I COMPONENT ~I~,,~INDEPENDENCE FAILURE-MODE FAILURE-MODE FIGURE 2. Validation aids in TESTBENCH.
1
In TESTBENCH terminology, failure-mode-class objects are-used to group and classify related sets of failures. For example, the top level diagnosis of the failure of an engine may contain classes of electrical, mechanical, fluid, etc. failures. In this manner, each group of related failures can be verified independently.
Independence, in this sense, states that no assumptions about machine state or the path traversed may be built into objects implicitly. If any are made, they must be made explicit in the form of rule objects. For example, in an engine, correctness of a starter motor function depends on a good source of energy from the battery, as well proper function of the motor. In this case, that assumption must be made explicitly in the starter motor failure object. These rule objects explicitly verify desired conditions prior to specifying the behavior of any failure or test node. Aspects of the behavior of the node such as removal from consideration, possible results of a test, etc. can be modified dynamically by rule objects.
TESTBENCH knowledge base construction principles require independence to be built into each object. This property can therefore yield a conclusion that any given object needs to be validated only in a single context o r usage. If the node is independent, then its behavior will be consistent between several different uses. This results i na more easily maintainable knowledge base.
Under the independence property, if all the children failure-modes of an individual failure-mode are verified, then it can be considered verified. A terminal failure-mode (one with no childern) can be considered verified if it lies on a complete path (Figure 3) which has domain expert approval. Therefore, if an entire sub-tree of the diagnostic tree is verified, it will not require re-verification. However, it is a good practice to examine the entry point failure of a verified sub-tree from at least two different parents to verify independence. A verified knowledge base would then be one in which all failure-mode objects are individually verified.
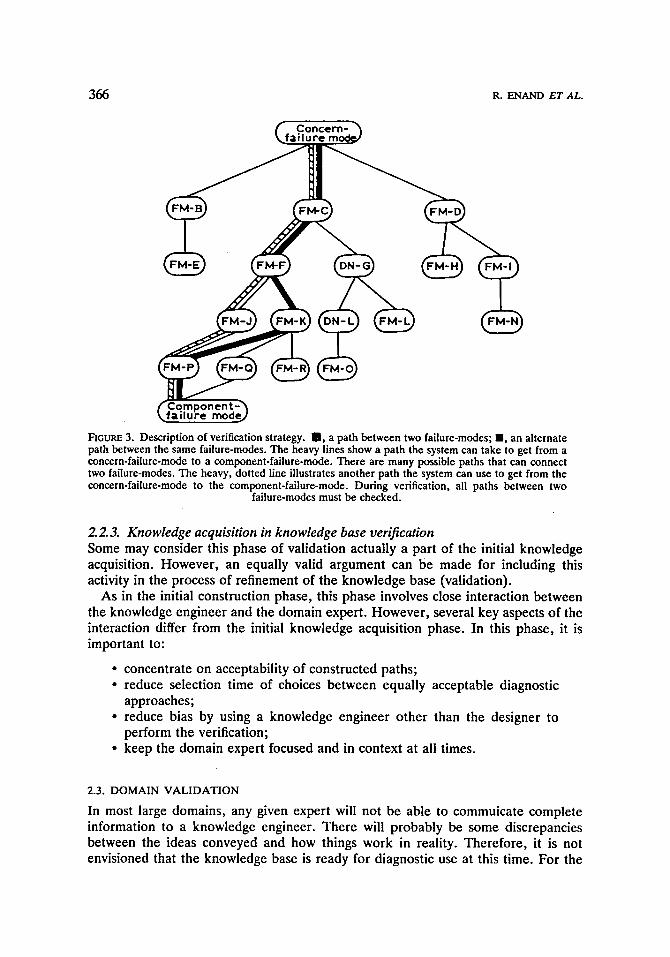
366 R. ENAND E T AL.
FIGURE 3. Description of verification strategy. S , a path between two failure-modes; II, an alternate path between the same failure-modes. The heavy lines show a path the system can take to get from a concern-failure-mode to a component-failure-mode. There are many possible paths that can connect two failure-modes. The heavy, dotted line illustrates another path the system can use to get from the concern-failure-mode to the component-failure-mode. During verification, all paths between two
failure-modes must be checked.
2.2. 3. Knowledge acquisition in knowledge base verification Some may consider this phase of validation actually a part of the initial knowledge acquisition. However, an equally valid argument can be made for including this activity in the process of refinement of the knowledge base (validation).
As in the initial construction phase, this phase involves close interaction between the knowledge engineer and the domain expert. However, several key aspects of the interaction differ from the initial knowledge acquisition phase. In this phase, it is important to"
�9 concentrate on acceptability of constructed paths; �9 reduce selection time of choices between equally acceptable diagnostic
approaches; �9 reduce bias by using a knowledge engineer other than the designer to
perform the verification; �9 keep the domain expert focused and in context at all times.
2.3. DOMAIN VALIDATION
In most large domains, any given expert will not be able to commuicate complete information to a knowledge engineer. There will probably be some discrepancies between the ideas conveyed and how things work in reality. Therefore, it is not envisioned that the knowledge base is ready for diagnostic use at this time. For the

VALIDATING KNOWLEDGE BASES 367
sake of expediency in the build and verification procedures, a large knowledge base will probably not be completely exercised outside of a laboratory environment. It is important that any initial testing of the knowledge base in a target domain be in a fully controlled environment. As testing proceeds, the amount of control exercised over the environment can be reduced, until final pilot testing, which should take place in as close to a target domain as possible. This step begins the process of testing the system in a controlled environment.
2.3.1. Goa l Because some discrepancy between the expert's view of the domain and reality are expected, a phase of validation must be performed to identify and resolve them. The goal of this phase of the validation process is to remove obvious discrepancies between an expert's view of the domain and reality. It is assumed that after this phase, the knowledge base is free of any gross inconsistencies with reality.
2.3.2 Application in TESTBENCH knowledge bases In TESTBENCH knowledge bases, a major discrepancybetween the expert's view and reality is noted by an incorrect causal representation between a concern failure-mode and a terminal failure-mode. All links between the two that are built into the knowledge base should be checked for accuracy. In order to accomplish this, a list of all terminal failure-modes is generated showing which concerns it is linked to. The failure is induced in the target equipment and the concerns that are observed are recorded. The list of recorded concerns are compared with the expected list and discrepancies are noted.
Because there are many parameters on how the failure is induced and how it occurs in the real world, discrepancies cannot automatically be removed from the knowledge base. For example, factors such as age of equipment and interactions between multiple failures are difficult to introduce in a controlled environment. Inducement of these failures in a controlled environment may not produce the expected result, whereas it may in a real world situation. Therefore, failures which do not cause the expected noticeable concern are indicated as suspect and require review by a domain expert other than the original knowledge source. The new domain expert is responsible for verifying the accuracy of diagnosis based on experience and understanding of the domain.
In most domains some failures are too difficult or too expensive to induce. These links are validated by using the knowledge of a different expert. If the second expert concurs that there is a link between the two, then it can be assumed that one exists. If the link is questionable, an alternate means of checking the validity of the link should be established. If the new domain expert does not believe that a link could occur, then the path is marked for removal. The list of concern/terminal failure pairs is fed back to the knowledge engineer for removal at some later point.
23.3. Knowledge acquisition in domain validation Knowledge bases constructed for the purposes of diagnosis do not necessarily contain adequate information on how to induce the terminal failure diagnosed by the system. Quite often, for instance, the ways in which a component can fail need

368 R. ENAND ET AL.
not be distinctly represented in a diagnostic knowledge base--rather a generaliza- tion at the component failure level is sufficient. For example, there are several ways in which a water pump can fail (bad motor, broken part within pump, corroded connections, etc.). All the failures may lead to the same repair: Replace the pump. Using a water-pump-failure to represent any of the failures is thus sufficient to getting correct diagnostic and repair behavior.
To induce a failure, however, one must induce a particular type of fault, e.g. a bad motor. So doing can cause a great degree of confusion in domain validation, as this fault may only lead to a subset of the symptoms related to the generic water pump failure. As a result, persons involved in validation could believe that the original knowledge source erred in identifying some non-occurring symptoms.
To prevent this, it is important to complete knowledge bases to the degree required by the domain validation procedures used. This additional information is made available to those who induce or simulate failures. Data used to fully complete the specification of the terminal failure modes can come from a variety of sources:
�9 non-diagnostic data added in the build process for purposes of testing; �9 review of path by domainexpert used to model the knowledge base; �9 a listing of the intermediate failures which are caused by the terminal.
Each source should be explored thoroughly, prior to actual testing.
2.4. PROCEDURAL VALIDATION
Upon successful completion of domain validation, causal relationships between top level concerns and their root level failure have been established. However, the diagnostic path used to traverse the knowledge base between symptoms, intermedi- a te faults or fault classifications, and terminal faults has not been validated. This phase will validate that a path does exist within the knowledge base and that, when run with against real-world data, a valid conclusion is reached.
2. 4.1. Goal Because some level of incorrectness of the paths represented in the knowledge base is expected, the goal of this phase of the validation process is to ensure that the procedure that the expert system uses leads to a valid conclusion. The path used must also meet certain obvious levels of reasonableness. The end result of this process will be a procedurally valid knowledge base: one which reaches the proper conclusions and recommended repairs, but which may, in some cases, lead to a sub-optimal diagnosis.
2. 4.2. Application in TESTBENCH knowledge bases For a diagnostic path to be procedurally valid, it must reach the proper conclusion and recommend the proper repair. Also, the intermediate conclusions reached by the system should be correct. In TESTBENCH knowledge bases, this is accom- plished by using the list of terminal failures which correctly caused observable failures in the previous phase. Each of these terminal failures is re-introduced into the equipment at this time and the system is used to diagnose the fault. The technician performs each test, as indicated by the system and gives the response indicated as a result of executing the requested test.

VALIDATING KNOWLEDGE BASES 369
If the system fails to achieve the desired conclusions, based on the data received from the tests, the path is analysed to find the point of divergence. The knowledge base must then be fixed to yield a valid diagnosis. At some later point, this phase will be attempted again, with an updated knowledge base. Also, if obvious flaws in the optimization of the path are noted by the technician, they are analysed as well.
2. 4. 3. Knowledge acquisition in procedural validation The knowledge engineer is responsible for responding to each of the notes returned from the technician that used the system. Quite often, this involves taking the problem noted, a hardcopy of the path in question, and any additional data to the domain expert for review.
In this and all phases, it is important to fully understand the implications of making a change in the knowledge base. Due to the network architecture of the system, a change to a single object could potentially invalidate the testing done on several paths. Each change to an object must be evaluated with respect to the extent of dynamic path change. Changes which affect the strategy of the diagnosis must be taken through the multi-step validation process. However, changes which are either "cosmetic" or limited in range can be validated locally.
2.5. PROCEDURAL OPTIMIZATION
It is assumed that some level of sub-optimal diagnosis exists in a procedurally valid knowledge base. Since optimality was not a criterion for success in previoussteps, the level of sub-optimal diagnosis is assumed to be beyond the threshold of tolerance. Prior to introducing the system into the field, it is important to bring the diagnostic paths to the desired level of optimality. When this level is met, the paths can be said to be procedurally correct.
One of the most difficult issues to resolve in achieving procedural correctness is the definition of the criteria for measurement of optimality, e.g. number of questions asked, cost of testing, etc. It is important to define, early on, under what criteria the system will be measured. After this is done, a system can be installed to ensure that the desired level of optimality has been achieved. One problem in doing this, however, is the availability of benchmarks for acceptable performance. Depending on the domain, this may be available in different forms. In some cases, it may end up being a qualitative judgement made by experts, based on a defined set of criteria.
2.5.1. Goal Because a certain level of sub-optimal diagnosis is expected at this time, effort must be expended to remove it. The goal of this phase of the validation is to bring the knowledge base up to the desired level of optimal diagnosis. The end result is a procedurally correct knowledge base, which is ready for deployment in the field. Depending on domain requirements or an artifically set tolerance of sub-optimality, this phase could be anywhere from a trivial to a major effort.
2.5.2. Application in TESTBENCH knowledge bases Optimality of diagnosis in a TESTBENCH knowledge base can be defined in two dimensions: the fewest number of tests executed and the lowest total cost of a

370 R. E N A N D E T A L .
diagnosis (defined as the sum of the costs of each of the tests performed). Depending on the domain, this measure can be either quantitative or qualitative.
If technician intervention in the diagnostic process is considered an expense, then optimality can be measured by the number of technician interventions required to recommend a repair. In a simplistic view, a goal might be to achieve a pre-defined system with an average number of interventions. The average number of interventions in a diagnostic session can be calculated by an analysis based on the depth of the diagnostic tree below a given concern.
If technician intervention is not seen as a great expense, then the previous definition of optimality cannot be used. An alternative goal might be to reduce the cost of the average diagnosis. It can be assumed, in most domainsl that different tests that are performed each come with their own cost. This cost may be in terms of time to perform the test, availability of test equipment, expense of parts used, etc. In this case, a cost factor must be associated with each test. This way, the total cost can be summed by reviewing each test performed in the course of every diagnosis.
In reality, the goal of most systems is a combination of the two goals stated earlier. In the diagnosis of obvious failures, the goals may be to reduce the number of technician interventions. In the diagnosis of more difficult failures, cost may play a more important factor.
2 5. 3. Knowledge acquisition in procedural optimization Depending on the stated goal of optimality, this process can have varying degrees of interaction with domain experts. If the goal can be quantified algorithmically, then the identification of suspect sections of the knowledge base can be identified by the knowledge engineer.
However, if such a quantifiable measure cannot be identified, various techniques such as sampling can be employed. An effective technique in inventory control systems involves an ABC sampling comparison of reported and actual inventories. In this method, critical parts are labeled as A parts, and are tracked much more closely than less critical B and C parts. In a diagnostic knowledge base, terminal failures can be classified in such a scheme as well. The criteria for classification is based on probability of occurrence in the field, as measured against history data. In this manner, a sampling of the paths associated with all three classes of failures can be made and a weighted average of the acceptability factor of each path can be computed. The acceptability factor is likely to be a qualitative measure given by an expert or an end user. This weighted average can be compared against a threshold for evaluation.
3. Conclusions
Knowledge acquisition is not complete until a knowledge base is fully verified and validated. During verification and validation, knowledge bases are substantially refined and corrected. This paper has described a four phase methodology. Knowledge base verification ensures that the knowledge base captures the intent of the domain expert. Domain validation ensures that domain expert's factual model of the domain is correct. Procedural validation ensures that the expert system will arrive at a correct conclusion given accurate data at run time. Procedural

VALIDATINO KNOWLEDGE BASES 371
optimization ensures that the system performs successfully with respect to defined optimality criteria.
Architectures, like TESTBENCH, which distinguish factual domain models from problem-solving procedures, facilitate a distinction between domain validation and procedural validation. This distinction facilitates the development of a testing program by allowing the validation team to develop test procedures appropriate to each set of issues.
We have shown, by example, that modularity and independence in a knowledge base aids the verification and validation process. When knowledge bases can be effectively partitioned, validation costs drop significantly. Also, it has been shown that knowledge base completeness must be understood not just in terms of the problem-solving task, but also in terms of validation requirements.
While we have not demonstrated that our methodology has broad applicability, the distinctions made are intuitively general. We have attempted to present the methodology in a manner that will encourage other system developers to apply it to other domains.
As inany testing process, a various number of groups and individuals provide critical input for success. We would like to recognize the efforts of James D. Wells and Jeff Pepper in the formulation and documentation of this work. Various other groups of individuals including a skilled group of Ford knowledge engineers, the Quality Assurance Group within Carnegie Group, numerous engineers in diagnostic applications at Carnegie Group, and the contribu- tions of engineers and technicians from Intelligent Controls, Inc. are especially recognized for their input.
References
BENBASAT, I. & DHALIWAL, J. (1988). A framework for the validation of knowledge acquisition. Proceedings of the Third Knowledge Acquisition for Knowledge-Based systems workshop. Banff, Canada.
GEmSMAr~,q J. & SCHULTZ, R. (1988). Verification and validation of expert systems. AI Expert, February, 26-33.
GREEN, C. J. R. & KEYES, M. M. (1987). Verification and validation of expert systems, Proceedings of Western Conference on Expert Systems, Anaheim CA: June 2-4.
KAHN, G. S. (1987). TEST: a model-driven application shell. Proceedings of AAAI-87, pp. 814-818, Los Altos, CA: William Kaufmann.
MARCOT, B. (1987). Testing your knowledge base. AI Expert, August. NGUYEN, T. A., PERKINS, W. A., LAFFEY, T. J. & PECORA, D. (1987). Knowledge base
verification. AI Magazine. PEPPER, J. & KAHN, G. S. (1987). Repair strategies in a diagnostic expert system.
Proceedings of the Tenth International Joint Conference on Artificial Intelligence, August, 1987.




















