

آزمون فرضيه در علوم اجتماعی
26
کم ؛ نسخه الکترونيکی ويرايش ي ی ع ما جت وم ا عل ه ضي ر ف ون م آز رمان قه آرش [email protected] 21903182190
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of آزمون فرضيه در علوم اجتماعی

9

0
فهرست مطالب
3 .............................................................................................................. پيشگفتار: أ
4 .............................................................................. یآمار فرضيات در پايه مفاهيم: ب
5 ................................................................................ یآمار فرضيات یبند صورت: ج
7 .................................. مستقل یگروهها در یتطبيق تحليل يا محور گروه فرضيات آزمون: د
33 ................................. ثابت یگروهها در یتطبيق تحليل يا محور تکرار فرضيات آزمون: ه
35 ............................................. ها متغير دوگانه یستگهمب يا محور متغير فرضيات آزمون: و
37 ........................................................ رگرسيون تحليل يا محور مدل فرضيات آزمون: ز
55 ...................................................................................................... آخر سخن :ح

8
پيشگفتار:أ
مجموعه يادداشتهای ذيل حاصل گزاره نويسی بخشی از درسهای ارائه شده
ل آقای دکتر هادی جباری در نيمسااستاد ارجمند جناب آمار پيشرفته توسط
و در قالب درس آمار پيشرفته دوره دکتری 3333-3335دوم سال تحصيلی
است . اگر چه مطالب ارائه شده توسط رشته جامعه شناسی اقتصادی و توسعه
يد رس ايشان فرا تر از يادداشتهای ذيل است ، اما پس از پايان دوره به نظر
«آزمون فرضيه در علوم اجتماعی»وان تحت عنوان مطالب را می تاين امهات
اين مجموعه به زبان يک دانشجوی علوم اجتماعی نگاشته هرچندتنظيم کرد.
مار فاصله دارد . ولی سعی شده است به آشده و از ترمينولوژی دقيق علم
در حوزه آزمون امهات ابهامات پژوهشگران در بخشهای آماری تحقيقاتشان
نسخه پيش رو ، ويرايش يکم اين بپردازد. گزاره اصلی ، 77 در قالب فرضيه
ود. باشد محدود توزيع ميش یمجموعه است که به شکل الکترونيکی و در سطح
به مدد راهنمايی وارشاد شما دوستان بزرگوار، ويرايش های بعدی اين
من ض ايشان به رسم ادب بوسه می زنم . دست هبمجموعه کاملتر منتشر شود .
مرهون آموزشهای دوست ود راخ اينجانب ؛تشکر از اين استاد ارجمند
آماری. که تجارب ميدانم ارجمند جناب آقای دکتر مجيد حيدری چروده
خود را بی دريغ در اختيار همکارانشان قرار می دهند. نام و ياد اين بزرگان
گرامی باد .

4
فرضيات آماری در مفاهيم پايه :ب
محقق دچار خطا می شود. يعنی يکی از اين دو ـ H1و H0فرضيه ـ گاهی در بررسی اين دو فرضيه .1
فرضيه ممکن است به خطا رد شود .که از آن به خطای نوع اول و خطای نوع دوم تعبير می شود .
شود ؛ رد به خطا H1به خطا رد شود ؛ از آن تعبير به خطای نوع اول می شود . و اگر فرضيه H0اگر فرضيه .2
دوم می شود .از آن تعبير به خطای نوع
نمايش دهند . βو احتمال خطای نوع دوم را αاحتمال خطای نوع اول را با .3
ـ هردو و همزمان ـ در آن کم باشد . آزمون خوب آزمونی است که خطای نوع اول و دوم .4
1توان آزمون را با .5 − β و آن قدرت تمايز بين فرضيه نمايش می دهند .H0 وH1 . است
يعنی حداکثر %5و اين يعنی خطای نوع اول %5)يا سطح خطا %55در اصل يعنی حداقل %55سطح اطمينان .6
55بار نمونه از همان جامعه انتخاب کنيم در 100( و اين به اين معنا است که اگر با شرايط مساوی 5%
μمورد آن نتيايج تکرار می شود . ∈ (11,11)
ورد فاصله ای و آزمون فرضيات آبزار داريم : برآورد نقطه ای ، بردر آمار استنباطی ما سه ا .1
stبرآورد نقطه ای در قالب .1 at i st i cs است که مهمترين شاخص آن ميانگين است .
درصد ميانگين بين 55برآورد فاصله ای چيست؟ با اطمينان برآورد فاصله ای در قالب فاصله اطمينان است . .5
است . اگر اين فاصله را زيادکنيم يا حد اطمينان را کم نماييم می توانيم فرضيه را تاييد يا رد 1.1. و 5
نماييم.
p-valآزمون فرضيه در قالب .10 ue . است
P-valنکته .11 ue راp - نه مقدار ،مقدار ترجمه نماييدp
رای يک تصميم گيری درست در حوزه آزمون فرضيه احتياج به هر سه شاخص داريم . ب .12
روابط بين دو متغيراگرآن دو مربوط به دوجامعه مستقل باشند متفاوت از اين است که متعلق به بيان برای .13
يک جامعه در دو يا چند مقطع زمانی باشند
correl واژگانبرای بيان رابطه دو متغير در دو جامعه مستقل از .14 at i on و Rel at i on استفاده می
کنيم با اين توضيح که : اگر هدف بيان همبستگی بين دو متغير ـ بدون درنظر گرفتن تقدم وتاخر باشد بايد
correlاز واژه at i on ولی اگر قالب اظهاری در شکل تاثير يک متغير بر متغير ديگرباشد؛ بايد از واژه
Rel at i on د .استفاده نمو

0
برای بيان تغيرات دو متغير در دو جامعه وابسته )در اصل دو متغير نيست بلکه نوسانات يک متغير در چند .15
Associمقطع زمانی است و بنابراين هبستگی آنها درونی محسوب ميشود. ( از واژگان at i on و
Aut ocorrel at i on .استفاده می شود
آماری فرضيات بندی صورت:ج
مورد استفاده و استناد يک محقق يا از نظر او پذيرفته شده است يا مورد ترديدگزاره های .16
Assumptگزاره های پذيرفته شده را پذيره ، فرض يا .11 i on . می نماند
گزارش گزاره های پذيرفته شده در قالب آمار توصيفی است :توصيف وضعيت موجود ، پس در آمار .11
داريم. که هر کدام کارايی خودش را دارد .توصيفی ما جدول ، نمودار و شاخص
Hypotگزاره های مورد ترديد را فرضيه يا .15 hesi s می نماند . برای کاهش ترديد ، الزم است محقق
فرضيات را بيازمايد . ارزيابی گزاره های مورد ترديد در قالب آمار استنباطی است . البته بايد به اين نکته نيز
رضيات آنگاه درآمار استنباطی قرار می گيرد که تحليل داده ها بر اساس نمونه باشد . توجه نمود که آزمون ف
به عبارت ديگر اگر تمام شماری صورت پذيرفته باشدازمون فرضيات باز هم در قالب آمار توصيفی است و
ان هم از طريق مقايسه ميانگين ها
. هدف اصلی ، پيش بينی وضعيت آينده بر اساس نمونه است .20
برای آزمون فرضيات گام نخست صورت بندی دقيق فرضيه است . .21
است . در آزمون فرضيه اگر بخواهيم آن را با زبان آماری H1و H0صورت بندی فرضيه در قالب فرضيات .22
دقيق صورت بندی نماييم . در واقع بايد هر فرضيه را در قالب دو فرضيه منشق نماييم .
23. H0 : Nul l Hypot hesi s فرضيه صفر يا اوليه يا خنثی ، صورت بندی فرضيه صفر بايد به گونه ای
باشد که هيچ تفاوت يا رابطه ای را بيان ندارد. به بيان ديگر دارای معنای ضمنی مساوی است .
24. H1 : Al t ernat i ve Hypot hesi s فرضيه مقابل
. H1 و H0 آزمون آ ماری : در اصل دستورالعملی است برای بررسی دو فرضيه .25
رد نمايد . اگر اين تالش به ثمر H1را به نفع H0آنچه محقق بايد انجام دهد آن است که تالش نمايد تا .26
به اين صورت H0 نيست . مثال اگر H1رد شده است . ولی اين به معنای تاييد H0رسيد در واقع فرضيه
است 11دارد يکی اينکه ميانگين بزرگتر از است و رد شود . خودش چند حالت 11است که ميانگين برابر

6
H1و گاهی در قالب H0است. گاهی ادعای محقق در قالب 11و يک حالت هم اين است که کوچکتر از
است .
« .يافتيمدليلی برای رد کردن ن» عبارت دقيقتر برای زمانی که فرضيه ای تاييد شود اين است که بگوييم .21
د. باش )باال( ضريب اطمينان مطلوبثانيا باشد و )کم (مطلوب طول اوال فاصله اطمينان خوب يعنی .21
هر دو کوچک باشد . مقادير β و α آزمون مناسب آزمونی است که .25
يعنی دارای توان باال 1 آزمون پرتوان .30
31. 1 − β را توان آزمون می نامند.
.را ضريب اطمينان می نامند ∝−1 .32
صدم بيشتر نشود . ب: توان از همه بيشتر 5تجاوز نکند. مثال از ∝قاعده پرتوان :الف : خطای نوع اول از .33
باشد
دارای بيشترين توان ∝آزمون پرتوان : آزمونی است که در بين همه آزمونها با سطح خطای نوع اول .34
)کمترين احتمال خطای نوع دوم ( باشد .
آزمون نيست . مگر اينکه حجم نمونه مناسب باشد. بی خوآزمون پرتوان دليلی بر .35
tآزمونهای توصيفی احتياج به آزمون .36 -t est براساس يک ميزان استاندارد دارد .
باشد يافته اگر حجم نمونه کمپايين بودن حجم نمونه الزاما به معنای غير نرمال بودن توزيع پراکندگی نيست . .31
ها قابل تعميم نيست و اگر زياد باشد تفاوت های کم در ميانگين ها بزرگ جلوه داده می شود )به زبان ساده
سبب پذيرش فرضيه می شود (مثال اگر ما دو دسته دانشجوی پسر و دختر داشته باشيم که در دسته اول ميانگين
45دانشجو و در دسته دختران 30شد .چنانچه حجم نمونه در دسته پسران با 11.1و در دسته دوم 11نمرات
باشد 45000و حجم نمونه دختران 30000دانشجو باشد، فرضيه تاييد نمی شود . ولی اگر حجم نمونه پسران
همين تفاوت يک دهم را آزمون به عنوان تفاوت معنادار نشان می دهد.
Shapiآزمون نيکويی برازش برای بررسی نرمال بودن يک توزيع .31 ro wi l k دارای قدرت بيشتری از
one samplآزمون e kol mogrov smi rnov است . روش تفسير اين دو آزمون مانند هم است
anal اين آزمون را می توان در مسير ذيل دنبال نمود . .35 yze/
descri pt i ve/expl ore/normal i t y pl ot
1 MP

7
Q-Q Plدر آن نمودار اين مسير دارای اين حسن است که .40 ot را می توان دريافت که دارای توانی برای
در اين نمودار توزيع داده ها پيرامون خط ترسيم شده است .توصيف وضعيت نرماليته متغير است .
. باشد« نامساوی است ».....................آزمونهای دو دامنه برای مواقعی است صورت بندی فرضيه به شکل .41
ر است کوچکت».................يا به صورت « بزرگتر است ».................اگر صورت بندی فرضيه به صورت ولی
p-valباشد . نتايج « ue که همانsi gn نمود. و در هر حال آزمون يک دامنه 2است را بايد تقسيم بر
P-Valباشد يا دو دامنه در پايان ميزان ue را بايد با ميزانα قايسه نمود . و بايد ازآن کمتر يا مساوی باشد م
ل . نکته قابل ذکر آنکه در ازمون تک دامنه اگرفرضيه ما به شکصدم باشد يا بيشتر يا کمتر 5حال می خواهد
P-Valمعکوس تاييد شد . بايد مقدار ue .را ابتدا از يک کم نمود سپس تقسيم بر دو نماييم
α ≥ P-Valueآزمون دو دامنه : رضايت به تحصيالت بستگی دارد
α ≥ P−Value استبيشتر ازمون تک دامنه مستقيم : هر چه تحصيالت بيشتر باشد رضايت آ
2
α ≥ 1−(P−Value ) آزمون تک دامنه معکوس : هرچه تحصيالت بيشتر رضايت کمتر است
2
استفاده از آزمونهای تک دامنه زمانی قابل طرح است که فرضيه از مبنای نظری قوی برخوردار باشد . .42
سبت به تقارن در نآنها نسبت به نرمال بودن توزيع متغير خيلی حساس نيستند . بلکه حساسيت آزمونها برخی .43
T-Testتوزيع است . مانند آزمون
درصد از بيشترين و 5است که با حذف 2شاخصی رساتر از ميانگين وجود دارد به نام ميانگين پيراسته .44
کمترين داده ها به محاسبه ميانگين می پردازد . به اين وسيله ميانگين فارغ از داده هايی که ايجاد اوريب می
Anal . نماييد دنبال را ذيل مسير منظور اين به. کند حذف می شود yze/ descri pt i ve/expl ore
T-Testآزمون در .45 نمونه باشد . نه 30وقتی می گوييم حجم نمونه باال باشد يعنی هر دو باالتر يا مساوی
برسد . 30اينکه مجموعا به
يا تحليل تطبيقی در گروههای مستقل گروه محور آزمون فرضيات:د
در براوردحجم نمونه يکی باشد αبايد با ميزان α ميزاندر ازمون فرضيات يا مقايسه ميانگين ها، فرض اول: .46
و .اگر دو بعدی باشد بايد از تحليل واريانس دوطرفهآن است که متغير وابسته ما يک بعدی باشد فرض دوم
2 Trimmed Mean

3
اگر بيش از دو بعد باشد از تحليل واريانس چند طرفه بايد استفاده نمود .فرض سوم آن است که قصد کنترل
متغير ها را نداريم . اگر چنين قصدی داشته باشيم بايد از تحليل کواريانس استفاده نمود روابط بين
است مبنا دو اساس بر حالت چهار اين : است حالت 4 یدارا هم از مستقل جامعه دو ميانگين مقايسه آزمون .41
یواريانسها یرنابراب يا یبرابر دوم و. است نبودن يا بودن نرمال لحاظ به یاصل متغير توزيع وضعيت یيک که
بارتع به. کند یم مشخص را یپراکندگ عوامل سهم که است اين در واريانس آناليز فلسفه. است جوامع
به انسهاواري تفاوت اين آيا چيست؟ یگروه درون واريانس به یگروه ميان واريانس نسبت گويد یم ديگر
بر اساس قضيه حد مرکزی وقتی جامعه ( اند نيامده معادله اين در که) عوامل ساير يا است یاصل متغير خاطر
واحد افزايش می يابد توزيع نمونه به سمت نرمال بودن پيش می رود . 30بزرگ باشد يعنی حجم آن از
واحد باشد احتياج به بررسی نرمال بودن توزيع نيست ولی برای نمونه های 30بنابراين اگر حجم نمونه باالی
Iدر عين حال در آزمون واحد الزم است بررسی شود . 30زير ndependent Sampl es T Test
حوهناگر توزيع دو جامعه نرمال نباشد ولی تفاضل دو جامعه نرمال باشد ، می توان به حساب نرمال گذاشت .
بهره توان یم مسير چند از واريانسها ینابرابر يا یبرابر یبررس یبرا یول شد گفته که بودن نرمال یبررس
Levene st يا لون آزمون از یيک: جست at i st i c دوم و. نمود استفاده Two-Sampl e
Kol mogorov-Smi rnov Test ميزان که نبريم خاطر از را نکته اين. است P-Val ue یهردو در
بيشتر شرح اما و. باشد صدم پنج یمساو يا بزرگتر بايد آنها
از تاينصور در باشند برابر یواريانسها یدارا و باشد نرمال پاسخ یهامتغير توزيع اگر .41.1
I ndependent Sampl es T Test واريانسها یبرابر پذيرش بر یمبتن که آن جدول نخست سطر از و
است ان یها یخروج جز لون آزمون . شود یم استفاده است
از ورتاينص در نباشند برابر یواريانسها یدارا یول باشد نرمال پاسخ متغير توزيع اگر .41.2
I ndependent Sampl es T Test واريانسها یبرابر پذيرش عدم بر یمبتن که آن جدول دوم سطر از و
. شود یم استفاده است
آزمون از اينصورت در. باشد برابر نيز جامعه واريانس و نباشد نرمال پاسخ متغير توزيع اگر .41.3
Mann-Whi t ney Test یبرابر فرض پيش یدارا یويتن مان آزمون ديگر عبارت به شود یم استفاده
Two-Sampl آزمون به احتياج یپراکندگ ميزان یبررس یبرا. است جامعه دو یپراکندگ e Kol mogorov-
Smi rnov Test آزمون با را آزمون اين که شود دقت. دارد وجود صفحه همان در که است One-Sampl e
Kol mogorov-Smi rnov Test P-Val ميزان صورت هر در نگيريم اشتباه ue يا بزرگتر بايد ان در
. باشد صدم پنج یمساو

1
از ورتاينص در. نباشد برابر نيز جامعه واريانس یول نباشد نرمال پاسخ متغير توزيع اگر .41.4
؛ باشد جامعه دو یپراکندگ ینابرابر از حکايت زمونآ اين نتايج اگر ديگر بيان به. شود یم استفاده ميانه آزمون
است ذيل شرح به آن درسآ که. نماييم استفاده Median Test ها ميانه مقايسه آزمون از بايد صورت اين درAnalyze/ nonparametric tests/legacy dialogs/k independent sample T-Test /kruskal wallis H
مبنا دو اساس بر حالت چهار اين : است حالت 4 یدارا نيز هم از مستقل جامعه چند ميانگين مقايسه آزمون .41
یابرابرن يا یبرابر دوم و. است نبودن يا بودن نرمال لحاظ به یاصل متغير توزيع وضعيت یيک که است
. است جوامع یواريانسها
يک انسواري آناليز از اينصورت در. باشد برابر نيز جامعه واريانس و باشد نرمال پاسخ متغير توزيع اگر .41.1
است ذيل شرح به آن آدرس . شود یم استفاده یپارامتر طرفه
Analyze/ Compare Mean /One Way ANOVA /Option/ Homogeneity of Variances
ی آزمون ولچ يک طرفه پارامتراگر توزيع متغير پاسخ نرمال باشد ولی واريانس جامعه نيز برابر نباشد .در اينصورت از .41.2
استفاده می شود .
Analyze/ Compare Mean /One Way ANOVA /Option/ Welch
ک طرفه ي کروسکال واليس اگر توزيع متغير پاسخ نرمال نباشد و واريانس جامعه نيز برابر باشد .در اينصورت از آزمون .41.3
پارامتری استفاده می شود . نانپارامتريک
متغير پاسخ نرمال نباشد و واريانس جامعه نيز برابر نباشد .در اينصورت از آزمون نانپارامتريک ميانه استفاده می اگر توزيع .41.4
شود .
Analyze/ nonparametric tests/legacy dialogs/k independent sample T-Test /Median
ای کمی ـ است و حالت خاصی از مفهوم کواريانس و واريانس : کواريانس بيانگر هم تغيری ـ در متغير ه .45
آن واريانس نام دارد
𝑆𝑋,𝑌 =1
𝑛 − 1∑(𝑥𝑖
𝑛
𝑖=1
− �̅�)(𝑦𝑖 − �̅�)
𝑆𝑥,𝑥 = 𝑆𝑋2 =
1𝑛 − 1
∑(𝑥𝑖−�̅�)2𝑛
𝑖=1

92
ر به منظور بررسی ميزان تاثير عوامل کيفی روی يک متغير پاسخ کمی با کنترل اثر متغيآناليز کواريانس : .50
های مستقل کمی ديگر به کار می رود . به اين متغير های مستقل کمی ـ که خود روی متغير پاسخ تاثير داردـ
covariکوريته at e يا ANCOVA ل کواريانس، يا هم عامل می گويند . شايان توجه است که در تحلي
نرمال بودن متغيرهای مستقل اهميتی ندارد.
ص ()با کنترل متغير های مشخ ل : بررسی تاثير روش آموزشی )متغير در سطح سنجش اسمی ( بر روی ميزان يادگيریمثا
در اين جا ذکر اين نکته حائز اهميت بسيار است که پاسخ به اين سوال مستلزم استفاده از روش آزمايشی و با :أ
تکنيک همتا سازی است . ولی در همتا سازی اگر تعداد متغير هايی که الزم است کنترل شود زياد باشد عمال
غير ممکن می شود . بنابراين بايد با کمک تکنيک آناليز کواريانس به کنترل متغير ها بپردازيم.
ل تاثير آن تقل اصلی ـ که در اصدر آناليز کواريانس متغير های مستقل به دو دسته تقسيم می شوند. متغير مس :ب
را می خواهيم بسنجيم ـ و در سطح سنجش اسمی است. را همان متغير مستقل يا فاکتور می نامند و ساير
Covariمتغير های مستقل را که در اصل حکم متغير کنترلی را دارند هم عامل يا at e می نامند . برای
analل نماييد:انجام تحليل کواريانس مسير ذيل را دنبا yze\general l i near
model \uni vari at e

99
نجش فاصله ای در سطح سدو بعدی هنگامی که قصد تبيين يک متغير وابسته آناليز واريانس دو طرفه : .51
به وسيله چند متغير مستقل که در سطح سنجش غير فاصله ای باشند) متغير های کيفی مانند جنس ، شغل و...(
شيم . مسير ذيل را دنبال نماييد را داشته با
Analyze/ General Linear Model/Univariate
هنگامی که قصد تبيين يک متغير وابسته چند بعدی )بيش از دو بعد(و در : طرفه چند واريانس آناليز .52
ای کيفی هسطح سنجش فاصله ای به وسيله چند متغير مستقل که در سطح سنجش غير فاصله ای باشند) متغير
مانند جنس ، شغل و...( را داشته باشيم . مسير ذيل را دنبال نماييد
Analyze/ General Linear Model/Multivariate
در آناليز واريانس بايد به اين نکته توجه داشت که نمونه گيری بايد طبقه ای و بر اساس تمام متغير های نکته: .53
دو يا چند آناليز واريانس»کيفی يا مستقل ـ که عامل نام می گيرند ـ باشد . اگر اين پيش فرض محقق باشد
د طرفه ناقص می گويند. در حالت اول می گويند و در غير اينصورت آناليز واريانس دو يا چن« طرفه کامل
modelمنطبق بر پيش فرض سيستم است ولی اگر حالت دوم رخ داد بايد بايد درگزينه وارد شويم و گزينه
cust om را فعال نماييم . ودرآنجا صرفا متغير هايی که بر مبنای آن نمونه گيری انجام شده است را وارد
جعبه مربوطه نماييم.
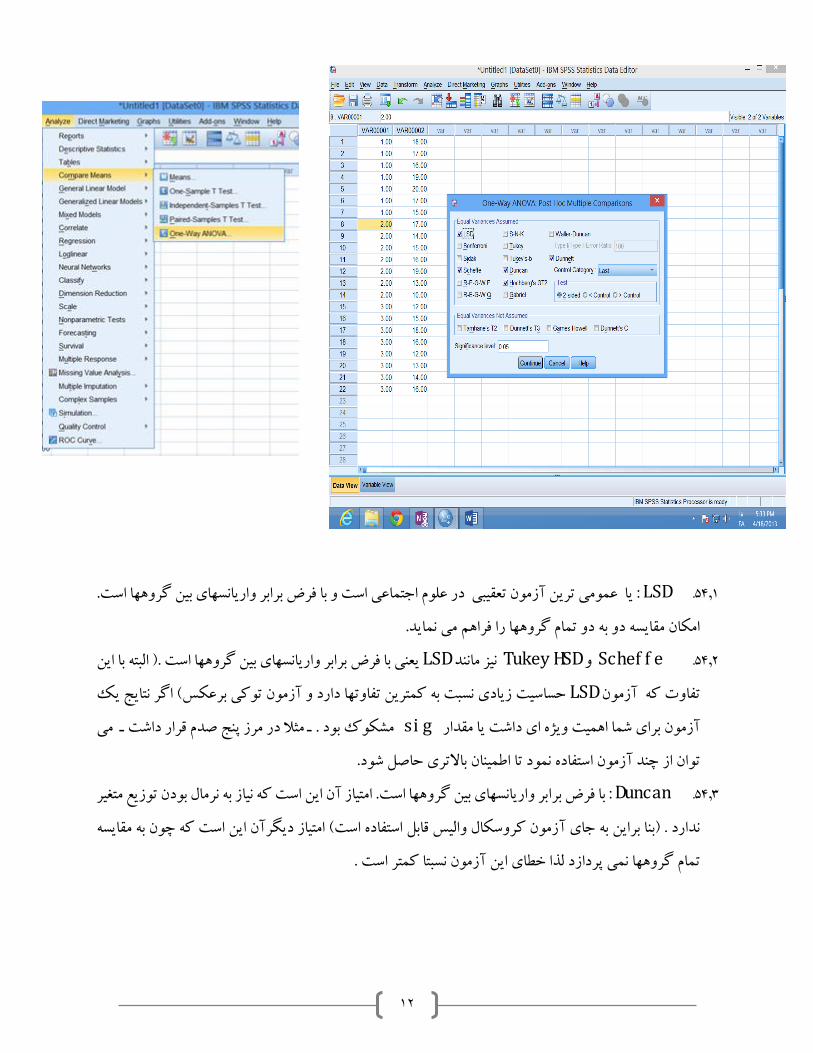
دنمعناداربو زمونهايی هستند کهآدر بحث مقايسه ميانگين ها ، آزمونهای تعقيبی : 3تعقيبی آزمونهای .54
ـ زان تفاوت را در درون طبقاتيم زمون آبررسی می کنند . به بيان ديگر به صرف اجرای ـ به صورت دو به دو
درج در خروجی مننتايج توصيفی مقايسه ميانگينها و معنا دار بودن تفاوت بين طبقات ، نمی توان بر اساس
انگين ها يمقايسه مآزمون زيرا نتايج . با طبقه ای ديگر است تفاوت معنا دارگفت کدام طبقه دارای آن ،
اجرای آزمونهای تعقيبی ضرورت دارد .دار را به صورت کلی بيان می دارد . لذا معنا وجود يا عدم تفاوت
دارای ارزش مساوی تقريبامده است وآآزمونهای تعقيبی دارای انواع متعددی هستند که در جعبه مذکور
است . البته به اقتضای شرايط کار بهتر است از نوعی خاص از آنها استفاده نمود . مثال
8 Post Hoc Tests
90
54.1. LSD :ت. واريانسهای بين گروهها اسفرض برابر ماعی است و با تدر علوم اج تعقيبی عمومی ترين آزمون ا ي
امکان مقايسه دو به دو تمام گروهها را فراهم می نمايد.
54.2. Schef f e وTukey HSD نيز مانندLSD ا اين ) البته ب. يعنی با فرض برابر واريانسهای بين گروهها است
تايج يک اگر ن (حساسيت زيادی نسبت به کمترين تفاوتها دارد و آزمون توکی برعکس LSDآزمون تفاوت که
si برای شما اهميت ويژه ای داشت يا مقدارآزمون g . می ـ مرز پنج صدم قرار داشت درمثال ـ مشکوک بود
حاصل شود.زمون استفاده نمود تا اطمينان باالتری آتوان از چند
54.3. Duncan بر واريانسهای بين گروهها است. امتياز آن اين است که نياز به نرمال بودن توزيع متغير : با فرض برا
زمون کروسکال واليس قابل استفاده است( امتياز ديگرآن اين است که چون به مقايسه آندارد . )بنا براين به جای
است . ترزمون نسبتا کمآتمام گروهها نمی پردازد لذا خطای اين

98
54.4. Dunnet t : با فرض برابر واريانسهای بين گروهها است . بيشتر برای مطالعاتی مناسب است که در قالب
يا ن اين است که گروه گواهآن پيش فرض آاست . که در 4کنترلگروه آزمون و گروه گواه است . دارای جعبه
.اييمنم مجدد بايد آن را تنظيمنباشد خر آخرين گروه است . بنابراين اگر گروه آ کنترل
ست به لحاظ بهتر انداشته باشد ، در آزمونهای مقايسه ميانگينها وقتی بين دو گروه تفاوت معناداری وجود نکته :
« از اين حيث مشابهت برقراراست» اظهاری اين گونه بيان شود که
يا تحليل تطبيقی در گروههای ثابت تکرار محورآزمون فرضيات :ه
ا ت اگر يک متغير پاسخ دردو يا چند مقطع زمانی، مکرر اندازه گيری شود اندازه گيريهای تکراری: .55
برای بررسی تاثير آن عامل ـ که اصطالحا؛ مشخصی بر آن تاثير گذار بوده است يا خيرمشخص شود عامل
درون گروهی است ـ بايد از طرح اندازه های تکراری استفاده کنيم. در اين طرح عامل درون گروهی حالت
خاصی از اندازه های تکراری است. و به فراخور نرمال بودن يا نبودن متغير اصلی )پاسخ ( دو حالت اصلی
و بار يا بيش از دو بار( نيز دو حالت دارد . پس در مجموع مقايسه ميانگينها همچنين به لحاظ تکرار )ددارد
در اندازگيريهای تکراری چهار حالت دارد .
با دو نوبت تکرار و برخورداری از توزيع نرمال .55.1
Analyze / Compare means / Paired samples t-test به اين منظور اين مسير را دنبال می کنيم:
نوبت تکرار و برخورداری از توزيع غير نرمالبا دو .55.2
می هاستفاد وابسته جامعه دو های آزمون از باشد باشد شده اجرا مقطع دو در ما پاسخ متغير که صورتی در
Wi ويلکاکسون آزمون آنها ترين عمومی و معروفترين که. کنيم l coxon مک آزمون از بين اين در. است
McNemar نما باشد 1و0 قالب در حالتی ودو اسمی ما اصلی متغير که کنيم می استفاده زمانی
با بيش از دو نوبت تکرار و برخورداری از توزيع نرمال .55.3
اگر دارای توزيعی نرمال باشندو تعدا تکرار ها بيشتر از دو متغير باشد
استفاده خواهيم نمود که از آن به تحليل واريانس General Linear Model / Repeated Measureاز
زمانی مقطع( ات دو از بيش) چند در کمی پاسخ متغير يک اگردرون گروهی تعبير می شود. اما توضيح بيشتر :
4 control category

94
های هانداز طرح از بايد ـ است گروهی درون اصطالحا که ـ عامل آن تاثير بررسی برای. شود گيری اندازه مکرر
بردار اگر. است تکراری های اندازه از خاصی حالت گروهی درون عامل طرح اين در. کنيم استفاده تکراری
يک با تکراری های اندازه طرح از حاصل های داده تحليل برای باشد متغير k نرمال توزيع دارای وابسته متغير
معنا ناي به اين و. کنيم می استفاده پارامتريک تکراری های اندازه طرح آناليز از سطحی k گروهی درون عامل
نيست پذير امکان Spss محيط در مذکور بردار محاسبه. باشد نرمال توزيعی دارای بايد متغيره سه بردار که است
. کنيم یم بررسی را آن بودن نرمال وضعيت يک به يک صورت به را مذکور وابسته های متغير تسامح به ولذا.
های درخروجی . باشد نرمال توزيعی مذکور زمانی مقاطع تمام در اصلی متغير توزيع که است الزم ديگر بيان به
Subjects -Within ابتدا در Spss خروجی. باشد دار معنا 5کرويت فرض که نمود دقت بايد شده گرفته درنظر
Factors است دهش گيری اندازه مختلف مراحل در که است وابسته متغير همان از حکايت که کند می معرفی را
متغير آن از حکايت اصل در که پردازد می Between-Subjects Factors معرفی و ارائه به آن از پس.
سيستم ديگر خروجی. گردد می ارائه افزار نرم توسط بيشتری تفکيکی های خروجی آن اساس بر که است کيفی
يا بودن دار معنا اصل در که است Effect و Multivariate Tests است سيستم اصلی خروجی اصل در که
که است اين ديگر کرذ قابل نکته. است کيفی متغير گرفتن نظر در با و نظرگرفتن در بدون تغييرات متغير نبودن
استفاده Bonferroni آزمون از که است اين بهتر Optionدر قسمت گروهی درون تاثيرات بررسی برای
دوی به دو تفاوتهای تا کنيم می استفاده Post hoc tests گزينه از گروهی ميان تاثيرات بررسی وبرای. شود
متغير مقوالت عدادت که باشيم داشته توجه نکته اين به البته. نماييم مالحظه نظر مورد کيفی متغير اساس بر را آنها
باشد بيشتر يا سه بايد کيفی
با بيش از دو نوبت تکرار و برخورداری از توزيع غير نرمال .55.4
NPar Tests پارامتريک غير آزمونهای از بودن نرمال غير صورت در و باشد متغير دو از بيشتر ها تکرار تعدا اگر
درون) تکراری های اندازه با ای رتبه واريانس تحليل به آن از که. نمود خواهيم استفاده( من فريد آزمون مانند)
بردار يا( باشد اسمی يا ای ازرتبه اعم ای رتبه کيفی) نباشد کمی پاسخ متغير که صورتی در. شود می تعبير( گروهی
y من فريد آزمون از وابسته جامعه چند ميانه مقايسه برای بايد. نباشد متغيره چند نرمال توزيع دارای Friedman
هنگامی آن و است من فريد آزمون از خاصی حالت Cochran Test کوکران آزمون ميان اين در .نماييم استفاده
باشد 1 و 0 و ای مقوله دو ما اصلی متغير که است
5 Sphericity Assumed
90
متغير ها دوگانه همبستگی فرضيات متغير محور يا آزمون:و
برای بررسی هبستگی بين دو متغير از نمودار اسکترگراف به آدرس ذيل می توان استفاده لحاظ توصيفی ، به .56
نمود.
graph//legacy dialog /scatter graph
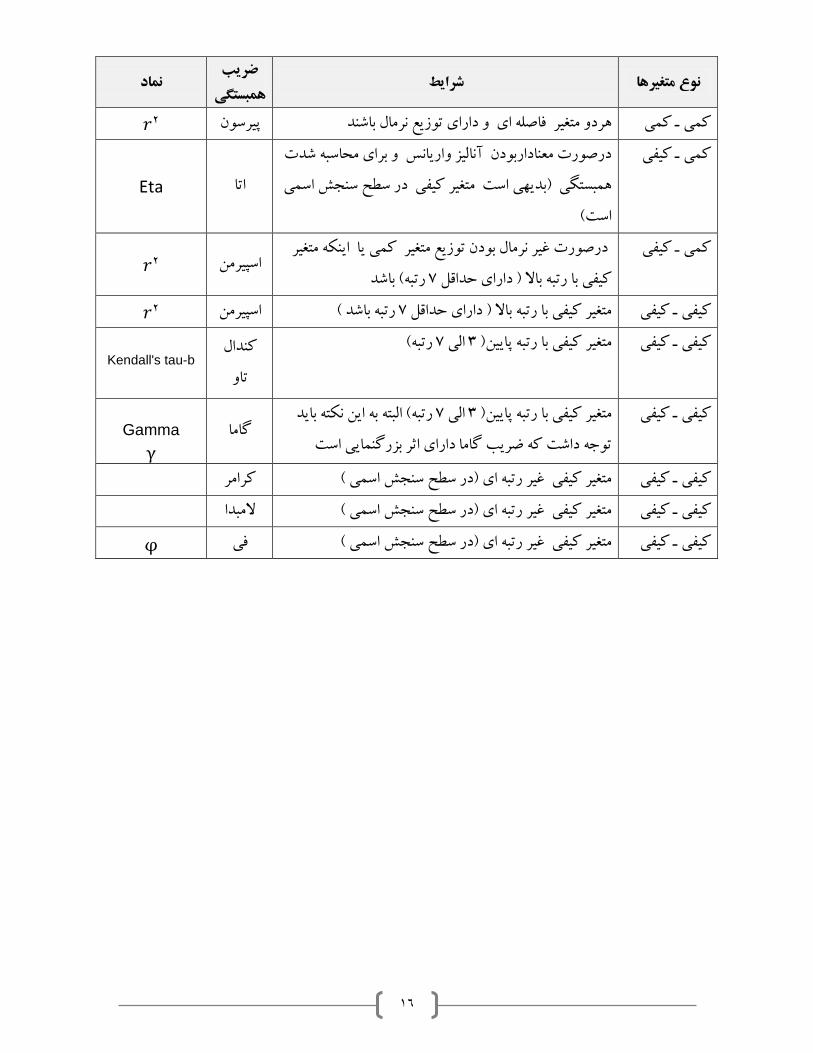
ولی .را تا حد خوبی نشان می دهد ( خطی يا غير خطی بودن نوع رابطه ) اين نمودار ها وجود رابطه ، جهت رابطه و
)بخوانيم رو( ρبرای پيدا نمودن شدت همبستگی احتياج به ضريب همبستگی داريم . ضريب همبستگی جامعه را با
نمايش می دهند . rو ضريب همبستگی نمونه را با
96
شرايط هانوع متغيرضريب
همبستگی نماد
𝑟2 پيرسون دارای توزيع نرمال باشند فاصله ای و هردو متغير کمی ـ کمی
درصورت معناداربودن آناليز واريانس و برای محاسبه شدت کيفی ـ کمی
همبستگی )بديهی است متغير کيفی در سطح سنجش اسمی
است(
Eta اتا
تغير ماينکه درصورت غير نرمال بودن توزيع متغير کمی يا کمی ـ کيفی
باشد رتبه( 1کيفی با رتبه باال ) دارای حداقل 𝑟2 اسپيرمن
𝑟2 اسپيرمن رتبه باشد ( 1متغير کيفی با رتبه باال ) دارای حداقل کيفی ـ کيفیکندال رتبه( 1الی 3متغير کيفی با رتبه پايين) کيفی ـ کيفی
تاو
Kendall's tau-b
البته به اين نکته بايد رتبه( 1الی 3متغير کيفی با رتبه پايين) کيفی ـ کيفی
توجه داشت که ضريب گاما دارای اثر بزرگنمايی است گاما
Gamma γ
کرامر متغير کيفی غير رتبه ای )در سطح سنجش اسمی ( کيفی ـ کيفی
المبدا متغير کيفی غير رتبه ای )در سطح سنجش اسمی ( کيفی ـ کيفی
φ فی سطح سنجش اسمی (متغير کيفی غير رتبه ای )در کيفی ـ کيفی
97
آزمون فرضيات مدل محور يا تحليل رگرسيون :ز
اگر بخواهيم مقادير يک متغير را از روی چند متغير ديگر پيش بينی نماييم . يکی از روشهای برآورد ،استفاده .51
از تحليل رگرسيون است .
يل در تحل نوعی رگرسيون است که يک متغير مستقل و يک متغير وابسته دارد . 6ساده یخط رگرسيون .51
spssرگرسيون قبل از اجرای داده ها بر روی نرم افزار به اين نکته بايد دقت داشت پيش فرض اين است
که اگر پاسخگويی حتی برای يک متغير داده مفقوده داشته باشد ؛ آن پاسخگو حذف می شود . بنابراين
بازسازی داده های مفقوده ـ به ويژه اگر تعداد کل مشاهدات کم باشد ـ از اهميت شايانی برخوردار است .
6 Simple Linear Regression

93
نوع غالب تحليلهای رگرسيون از اين نوع است و ان رگرسيونی است که مجموعه ای از 1چندگانه یخط رگرسيون
متغير های مستقل و يک متغير وابسته دارد.
:اهداف تحليل رگرسيون .55
تعين اثر متغير های کمی بر روی يک متغير وابسته کمی (1
پيش بينی متغير وابسته کمی بر اساس متغير های مستقل کمی (2
يکی از مسائل مهم در رگرسيون خطی چند گانه يافتن زير مجموعه ای از متغير های مستقل است که نقش .60
ها ،روش جستجوی اتومات است. در اين روشمهمی در پيش بينی متغير وابسته دارند . يکی از بهترين روش
ـ که در واقع به دنبال ساختن مدل هستيم ـ کليه مدلهای رگرسيون ممکن برازش می شوند و بر اساس چند
معيار ، بهترين مدل رگرسيون انتخاب می شود.
برای انجام تحليل رگرسيونپيش فرض های الزم .13
.باشند یکم ها متغير (1
.باشد مشخص مستقل و وابسته متغير (2
يل سوال : يعنی تحل.) به عبارت ديگر تمام شماری نباشد( باشد موجود جامعه از ساده یتصادف نمونه يک (3
رگرسيون پيش فرض ان اين است که نمونه گيری تحقيق خوشه ای و يا طبقه ای نباشد؟
يل واريانسمدل رگرسيون برآورد شده از روی نمونه برای جامعه معتبر باشد .)معناداربودن تحل (4
( spssدرخروجی
ترسيم نمودار باقيمانده ها بر حسب روش ترين ساده يا نخست روش شناسايی راه. باشد خط شيب یدارا مدل (5
ين معنی که چنانچه بين مقادير پيش بينی شده و مقادير باقيمانده استاندارد ه امقادير پيش بينی شده است. ب
باشد، می توان به وجود رابطه خطی بين متغيرهای مستقل و وابسته شده، الگو يا رابطه مشخصی وجود نداشته
Graph/scatترسيم نمودار پراکنش )از طريق دستور دوم شناسايی روشاطمينان داشت. t erpl ot )
باقيمانده ها بر حسب يکايک متغيرهای مستقل وارد شده در معادله است. چنانچه بين متغيرهای مستقل و
در عمليات رگرسيون اعتماد کرد. ،پيشفرض اين ای مشاهده نشود، می توان به رعايتباقيمانده ها رابطه
متغير باقيمانده استاندارد saveالزم به ذکر است که برای انجام اين دستور، ابتدا بايد با کليک بر روی دستور
جام نمود. . و سپس مراحل فوق الذکر را انشده يا خام را به انتهای فايل داده ها اضافه نمود
باشد صفر خطاها، ميانگين (6
7 Multiple Linear Regression

91
Durbiاستفاده از آماره شناسايی راه.باشند يا مستقل همبسته ناخود خطاها، (1 n-Wat son است. اين
1.5حالت مطلوب آن بين (Heung & Gu, 2012, p. 1113)قابل پذيرش است . 3الی 1شاخص در بازه
است 2باشد .و حالت ايده ال آن 2.5الی
plاينکه وارد قسمت نخست راه شناسايی راه باشند ثابت واريانس یدارا خطاها، (1 ot شد و در انجا
zpred را در قسمتx وzresi du را در قسمت y وارد نماييم . خروجی حاصل در صورتی که شکل
ست که اين ا دومشناسايی راه. قيف نداشته باشد به اين معنا است که خطاها دارای واريانس ثابت هستند
prediوارد ميشويم در قسمت saveدر قسمت ct val ues stگزينه andardi zed را انتخاب
ن فايل داده ها يک متغير جديد ايجاد می شود. می توان درقسمت می نماييم .اين سبب می شود که در پايا
graph گزينهscat t er pl ot را انتخاب نمود . آنجا نيز اگر قيفی شکل نباشد حکايت از آن دارد که
پيش فرض ثابت بودن خطای واريانس ها، محقق شده است .
pl وارد قسمت شناسايی راه باشد نرمال خطاها توزيع (5 ot می شويم و در کادر مستطيلی پايين گزينه
Hi st ogram و نيز گزينهNormal probabi l i t y pl ot نماييم یم انتخاب را .
کامل يعنی .هم خطیباشند نداشته یخط هم یتوزيع مستقل یمتغيرها بايد باشد گانه چند رگرسيون اگرمدل (10
گر به در سنجش رضايت شغلی ا يکی دقيقا رابطه خطی با متغيرهای مستقل داشته باشد. مثال از هم خطی :
کی از ابعاد رضايت ياشتباه يکی از ابعاد رضايت شغلی را به عنوان متغير مستقل در نظر بگيريم ؛ در اينصورت
اندازه اخصیش توسط مستقل متغيرهای بين خطی رابطه قدرت»شناسايی راه .پيدا می نمايد رابطه با رضايت
متغير آن پراکندگی از نسبتی1تولرانس مستقل، متغير هر برای. شود می ناميده تولرانس که شود می گيری
بين مقدار ناي. شود نمی توجيه مدل در موجود مستقل متغيرهای ساير با متغير آن خطی رابطه توسط که است
زا کوچکی بخش مستقل متغير يک در که است معنی به اين 1 به نزديک مقدار. است نوسان در 1 تا صفر
يک که است یمعن اين به صفر به نزديک مقدار. شود می توجيه مستقل متغيرهای ساير توسط آن پراکندگی
ترکمش خطی رابطه دارای ها داده اين. است مستقل متغيرهای ساير از خطی ترکيب يک تقريبا متغير
(.SPSS11، 516 اصغری، و فتوحی) «هستند 5چندگانه
می باشد و تفسير آن به اين صورت است که اگر متغير ]0 -1[برای هر متغير در بازهء Toleranceآمارهء
ل را را متغير وابسته فرض کنيم و ساير متغيرهای مستق -که در واقع يکی از متغيرهای مستقل مدل است-مفروض
8 Tolerance 9 Multicolinear

02
که در واقع ميزان تبيين آن متغير به وسيله ساير متغيرهای -آن متغير 2Rمتغيرهای پيش بينی کنندهء او بدانيم؛ ميزان
مربوط به آن متغير بدست می آيد. Toleranceکم نماييم ميزان « 1»را از عدد -مستقل است
گردد. = 1Tolerance مقدار و 2R =0در حالت ايده آل بايد = 2R – 1Toleranceبه عبارت ديگر
نزديکتر شود؛ نشان از استقالل « 1»به عدد Toleranceليکن در عمل اين امر غير ممکن است. اما هر قدر ميزان
در مجموع تولرانس اگر بزرگتر از يک دهم باشد قابل پذيرش است . شاخص بيشتر متغيرهای مستقل است.
𝑇𝑜𝑙𝑒𝑟𝑎𝑛𝑐𝑒.که ميزان آن عکس تولرانس است : است VIFديگر در همين زمينه شاخص =1
𝑉𝐼𝐹
مفهوم خطا .15
براورد شده ازروی معادله Yواقعی و yنمايش می دهند عبارت است از تفاضل بين eرا با آن خطا يا مانده ها که
نند(بنابراين هم را خنثی ميکثابت ميشود که مجموع خطاها معادل صفر است .)زيرا مقادير مثبت و منفی به لحاظ رياضی
معموال ذا لبرای بررسی ميزان خطا و می نيمم نمودن آن بايد مجموع مربعات خطا را به شکل مينيمم محاسبه نماييم. .
از روش کمترين می نيمم خطاها استفاده می شود.
5Adj با 5R تفاوت .13 usted R
برای؛ با افزايش متغيرهای مستقل افزايش می يابد 2R دراين است که چون ميزان 2Adjusted R با 2R تفاوت
که دراصل مستقل از تعداد متغيرهای 2Adjusted Rمقايسه چند مدل با تعداد متغيرهای مستقل متفاوت از ميزان
مستقل است استفاده می نماييم.
ای متغيرهای مستقل کمتری متغير وابسته را تبيين نمايد.و در ضمن خطدر مقايسه دو مدل ، مدلی بهتر است که با تعداد
استاندارد برآورد هم کمتر باشد .
: مدل بهترين تعيين یها معيار .14
(کمتر است . Pتعدا پارامتر ها يا متغير ها ) (1
نزديکتر است . 1به 10ضريب تعيين تصحيح شده (2
3) P ͠ CP ی در مهم متغير تاثير کاهشو به اين معنا است که يک مدل خوب مدلی است اضافه شدن يا2R نداشته باشد
10 Adjusted R2

09
spss)در .: هرقدر کوچکتر باشد ؛ بهتر است 11شاخص آکائيک (4 قابل سنجش نيست (
BIشاخص (5 C هرقدر کوچکتر باشد ، بهتر است . )درspss قابل سنجش نيست (
واحد 1حجم نمونه به اندازه شدن کمبر اين اساس مدلی خوب است که با افزوده شدن يا PRESSشاخص (6
spssآن ايجاد نشود. )در 2Rتغييری در قابل سنجش نيست (
خطای استاندارد برآورد: هرقدر کوچکتر باشد ، بهتر است . (1
تکنيک های جستجوی گام به گام .15
پسرو ياBack ward در اين تکنيک ابتدا همه متغير ها وارد می شوند. و سپس در هر مرحله ـ به تدريج :
و از ضعيف ترين متغيرـ حذف می کند. . در اين تکنيک آخرين مدل ، بهترين مدل است .
پيشرو ياForward بر خالف روش قبل ، در اين تکنيک متغير ها به تدريج و بر حسب اهميت از قويترين :
غير وارد مدل می شوند.مت
قدم به قدم St ep wi se . ترکيب اولی و دومی است
در مجموع می توان گفت از بين تکنيک های مختلف مناسبترين تکنيک درمطالعات اجتماعی عموما پسرو
است Back wardيا
اعتبار يابی مدل
مبانی نظری و تجارب پژوهشی ديگراناعتبار يابی نظری: به اين منظور الزم است ضرايب بتای مدل را با .66
تطبيق دهيم . هرقدر هماهنگ تر بود نشانه آن است که اعتبار نظری مدل بهتر است .
اعتبار يابی آماری : به اين منظور داده ها را به دو دسته تقسيم می کنيم . با اين توضيح که دسته نخست ـ که .61
درصد داده 20ربوط به مدل سازی است . و دسته دوم ـ که درصد داده ها را تشکيل می دهد ـ داده های م 10
ها را تشکيل می دهد ـ داده های مربوط به اعتبار سازی است . برای اعتبار يابی آماری مدل، الزم است داده
درصدی قرار داد. به اين 10درصدی بخش اعتبار سازی را در مدل ساخته شده بر اساس داده های 20های
. به اين ترتيب در پايان فايل داده ها متغير 12مدل مذکور را ـ که به مثابه يک تابع است ـ بسازيم منظور بايد
پيش بينی شده بر اساس مدل است . سپس الزم است ميزان Yجديدی ايجاد می شود که در اصل مقدار
يشتر اعتبار آماری مدل ب واقعی را محاسبه نمود . هرقدر اين همبستگی بيشتر باشد yمشاهده شده با Y هبستگی
درصد از مدل نبايد در اصل از حجم نمونه واقعی پژوهش 20است . نکته قابل ذکر اين است که کاهش حجم
99 AIC
استفاده نمود computeبرای اين منظور می توان از فرمان 90

00
درصد بايد نمونه ای متمم و جداگانه باشد.) هرچند 20کسر گردد. به عبارت ديگر و به لحاظ تئوريک اين
مستلزم هزينه اضافی برای پروژه است . بنابراين در عمل اين عمل به شکل ناب آن تقريبا غير ممکن است و
از همان حجم نمونه اصلی کسر می شود.(
نحوه ورود متغير مستقل کيفی در معادله رگرسيون معمولی .16
: اگر متغير کيفی دو سطحی باشد . با تعريف متغير نشانگر )صفر و يک ( کمی شده و به معادله اضافه ميشود.الف
رتبه ای و غير رتبه ایاگر متغير کيفی چند سطحی باشد خود دو حالت دارد . ب:
سطح ، متغير نشانگر يا تصنعی ايجاد نماييم. K-1بايد به تعداد غير رتبه ایدر حالت
تيجه دو مبنا قرار داد .و درن را بيکارمثال اگر متغير شغل، سه مقوله ای باشد و شامل بيکار ، آزاد و کارمند ،می توان
شاغل و آن هنگامی است که مورد ما 1متغير ايجاد نمود . يک متغير شاغل با کار آزاد است که دو مقوله دارد يکی
. شاغل و با کار آزاد نباشدوديگری صفر و آن هنگامی است که مورد ما و با کار آزاد باشد
شاغل و کارمند و آن حالتی است که 1ست و آن نيز دو حالت دارد . يکی متغير دوم ما هم شاغل با کار کارمندی ا
. شاغل و کارمند نباشدو حالت دوم صفر است و آن حالتی است که باشد
باشد بايد به صورت متقارن کدگذاری شود . مثال اگر رضايت و در سه مقوله کم ، کيفی و رتبه ایاما اگر متغير ما
( کد گذاری نماييم.1+( زيادبا کد )0متوسط با کد ) (1-د به صورت : کم با کد )متوسط و زياد است باي
نحوه ورود متغير وابسته کيفی در معادله رگرسيون معمولی .13
چند حالت برای اين منظور قابل تصور است:
يفی باشد ک در حالتی که متغير وابسته کيفی باشد و تعداد متغير های مستقل يکی باشد وآن متغير مستقل هم
و نياز به پيش بينی نداشته باشيم در اين صورت نياز به تحليل رگرسيون نداريم.
در :الف است همقول دو دارای که انتخاباتی کنش وابسته متغيررابطه بين جنسيت و کنش انتخاباتی : :مثال
متغير مستقل جنس با دو مقوله مرد و زن و کنم نمی شرکت انتخابات در: ب کنم می شرکت انتخابات
: در اينجا احتياج به تحليل رگرسيون نداريم.برای بررسی رابطه جنسيت و کنش انتخاباتی می توان از آزمون کی دو
و وی کرامر يا المدا استفاده می کنيم.

08
تقل هم کمی باشد ير مسدر حالتی که متغير وابسته کيفی باشد و تعداد متغير های مستقل يکی باشد وآن متغ
در اين صورت نياز به تحليل رگرسيون داريم.
: الف است مقوله دو دارای که انتخاباتی کنش وابسته متغيررابطه بين رضايت اجتماعی و کنش انتخاباتی ، :مثال
احتياج ينجاا در اجتماعی رضايت: مستقل متغير کنم نمی شرکت انتخابات در: ب کنم می شرکت انتخابات در
. است باينری لجستيک نوع از رگرسيون نوع. داريم رگرسيون تحليل به
) در حالتی که متغير وابسته کيفی باشد و تعداد متغير های مستقل چند تا باشند وآنها )يعنی متغيرهای مستقل
اعم از اينکه کمی يا کيفی باشند در اين صورت نياز به تحليل رگرسيون داريم.
وابسته تغيرمرابطه بين مجموعه متغير های مستقل ) رضايت اجتماعی ، جنسيت و...( و کنش انتخاباتی ؛ :مثال
کنم مین شرکت انتخابات در: ب کنم می شرکت انتخابات در الف است مقوله دو دارای که انتخاباتی کنش
. داريم رگرسيون تحليل به احتياج اينجا در...... و جنسيت و اجتماعی رضايت: مستقل متغير
رسيون رتبه ای از رگاگر متغير وابسته در سطح سنجش رتبه ای باشد لجستيک:و رگرسيون رتبه ای .10
.استفاده می شود
ن لجستيک از رگرسيو )و تحقيق از نوع غير آزمايشی باشد ( اگر متغير وابسته در سطح سنجش اسمی باشد
Biاستفاده می شود با اين توضيح که ، اگرمتغير وابسته دو مقوله ای باشداز nary l ogi st i c واگر چند
Mulمقوله ای باشد t i nomi nal l ogi st i c .استفاده می شود
استفاده تاگر متغير وابسته در سطح سنجش اسمی باشد )و تحقيق از نوع آزمايشی باشد ( از رگرسيون پروبي
می شود
( در رگرسيون لجستيک بايد به سراغ آخرين گامst ep) رفت . در اين گام چندين جدول داريم که
Clمهمترين انها دو جدول است يکی جدول assi f i cat i on Tabl e که در آن شاخصOveral l
Percent age لمی آيد . و ديگری جدو Vari abl es i n t he Equat i on
تحليل عاملی .73
در تحليل عاملی محقق دو هدف عمده را دنبال می نمايد:
ها( فرضی. )بر اساس بارگويه گويه ها درتبيين متغير پنهانيا بررسی ميزان نقش متغير های آشکار الف:

04
که يک يا چند متغير پنهان را اندازه گيری می نمايد. ما به کمک تحليل وجود دارد چند متغير قابل مشاهده
عاملی می توانيم عالوه بر دسته بندی متغير های قابل مشاهده به بررسی ميزان نقش آنها درتبيينمتغير پنهان)فرضی(
)بر اساس بارگويه ها(بپردازيم .
ام . مستقل بودن اين ابعاد سبب می شود که برای انجيگر ب: خالصه نمودن متغير ها در قالب ابعاد مستقل از يکد
تحليل رگرسيون پيش فرض استقالل متغير های مستقل بدون هيچ دردسری محقق شود.
ارد نه دهايی در سطح سنجش فاصله ای نبايد از اين نکته غافل شد که تحليل عاملی اختصاص به متغير : 1نکته
. بنابراين بر اساس منطق آن ، برای گويه های پنج قسمتی طيف ليکرت ترتيبی هايی در سطح سنجش متغير
مناسب نيست .
دوران دادن در اصل برای تصريح مرزهای بين عاملها است تا به اين وسيله تفسير راحتتر انجام شود. : 2نکته
مشاهدات به یده وزن .75
به weight casesاگر در مجموعه داده های ما وزن داده ها يا مشاهدات يکسان نباشد ، می توان با فرمان
وزن دهی داده ها پرداخت . مکانيزم اين فرمان اين است که تعداد مشاهداتی را که دارای وزن بيشتری است
ه ها ديده نمی شود ولی اگر از داده ها يک صفحه دادمتناسب با وزن آن تکرار می نمايد . البته اين تکرار در
فراوانی بگيريم در جدول فراوانی قابل رويت است . مسير آن هم به صورت ذيل است

00
سخن آخر:ح
درپايان ضمن پذيرش محدوديت ها و نواقص اثر موجود ، از دوستان
ارجمندی که نظرات و پيشنهادات خود را برای اينجانب ارسال مينمايند ،
نه انشاهلل ويرايش های کاملتر اين مجموعه درآينده ای. پيشاپيش تشکر ميشود
چندان دور تقديم به جامعه پژوهشگران اجتماعی شود .
21903182190




















