
Using Ant Colony System to Consolidate VMs for Green Cloud Computing
14
Copyright Notice The document is provided by the contributing author(s) as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. This is the author’s version of the work. The final version can be found on the publisher's webpage. This document is made available only for personal use and must abide to copyrights of the publisher. Permission to make digital or hard copies of part or all of these works for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage. This works may not be reposted without the explicit permission of the copyright holder. Permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works must be obtained from the corresponding copyright holders. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each copyright holder. IEEE papers: © IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. The final publication is available at http://ieeexplore.ieee.org ACM papers: © ACM. This is the author's version of the work. It is posted here by permission of ACM for your personal use. Not for redistribution. The final publication is available at http://dl.acm.org/ Springer papers: © Springer. Pre-prints are provided only for personal use. The final publication is available at link.springer.com
Transcript of Using Ant Colony System to Consolidate VMs for Green Cloud Computing

Copyright Notice
The document is provided by the contributing author(s) as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. This is the author’s version of the work. The final version can be found on the publisher's webpage.
This document is made available only for personal use and must abide to copyrights of the publisher. Permission to make digital or hard copies of part or all of these works for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage. This works may not be reposted without the explicit permission of the copyright holder.
Permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works must be obtained from the corresponding copyright holders. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each copyright holder.
IEEE papers: © IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. The final publication is available at http://ieeexplore.ieee.org
ACM papers: © ACM. This is the author's version of the work. It is posted here by permission of ACM for your personal use. Not for redistribution. The final publication is available at http://dl.acm.org/
Springer papers: © Springer. Pre-prints are provided only for personal use. The final publication is available at link.springer.com

1
Using Ant Colony System to Consolidate VMsfor Green Cloud Computing
Fahimeh Farahnakian, Adnan Ashraf, Tapio Pahikkala, Pasi Liljeberg, Juha Plosila,Ivan Porres, and Hannu Tenhunen
Abstract—High energy consumption of cloud data centers is a matter of great concern. Dynamic consolidation of VirtualMachines (VMs) presents a significant opportunity to save energy in data centers. A VM consolidation approach uses livemigration of VMs so that some of the under-loaded Physical Machines (PMs) can be switched-off or put into a low-powermode. On the other hand, achieving the desired level of Quality of Service (QoS) between cloud providers and their users iscritical. Therefore, the main challenge is to reduce energy consumption of data centers while satisfying QoS requirements. Inthis paper, we present a distributed system architecture to perform dynamic VM consolidation to reduce energy consumptionof cloud data centers while maintaining the desired QoS. Since the VM consolidation problem is strictly NP-hard, we use anonline optimization metaheuristic algorithm called Ant Colony System (ACS). The proposed ACS-based VM Consolidation (ACS-VMC) approach finds a near-optimal solution based on a specified objective function. Experimental results on real workloadtraces show that ACS-VMC reduces energy consumption while maintaining the required performance levels in a cloud datacenter. It outperforms existing VM consolidation approaches in terms of energy consumption, number of VM migrations, andQoS requirements concerning performance.
Index Terms—Dynamic VM consolidation, ant colony system, cloud computing, green computing, energy-efficiency, SLA
F
1 INTRODUCTION
C LOUD computing is a relatively new computingparadigm. It leverages several existing concepts
and technologies, such as data centers and hardwarevirtualization, and gives them a new perspective.Cloud computing provides three service models andfour deployment models [1]. The three service modelsare Infrastructure as a Service (IaaS), Platform asa Service (PaaS), and Software as a Service (SaaS).Similarly, the four deployment models are privatecloud, community cloud, public cloud, and hybridcloud [2], [3]. With its pay-per-use business modelfor the customers, cloud computing shifts the capitalinvestment risk for under or over provisioning to thecloud providers [4], [5]. Therefore, several public IaaS,PaaS, and SaaS cloud providers, such as Amazon,Google, and Microsoft, operate large-scale cloud datacenters around the world. Moreover, due to the ever-increasing cloud infrastructure demand, there hasbeen a significant increase in the size and energy con-sumption of the cloud data centers [6]. High energyconsumption not only translates to a high operatingcost, but also leads to higher carbon emissions. There-fore, energy-related costs and environmental impacts
• F. Farahnakian, T. Pahikkala, P. Liljeberg, J. Plosila, and H. Tenhunenare with the Department of Information Technology, University ofTurku, Turku, Finland.E-mail: [email protected], [email protected], [email protected], [email protected],[email protected]
• A. Ashraf and I. Porres are with Department of Information Technolo-gies, Abo Akademi University, Turku, Finland.E-mail: [email protected], [email protected]
of data centers have become major concerns andresearch communities are being challenged to find ef-ficient energy-aware resource management strategies.On the other hand, achieving the desired level ofQuality of Service (QoS) between cloud providers andtheir users is critical for satisfying customers’ expecta-tions concerning performance. The QoS requirementsare formalized via Service Level Agreements (SLAs)that describe the required performance levels, such asminimal throughput and maximal response time orlatency of the system. Therefore, the main challengeis to reduce energy consumption of data centers whilesatisfying QoS requirements.
Over the past few years, there have been severalattempts to reduce energy consumption of data cen-ters. Currently, the two widely-used techniques aredynamic server provisioning and Virtual Machine(VM) consolidation. Dynamic server provisioning ap-proaches [7] save energy by using a reduced amountof resources needed to satisfy the workload require-ments. Therefore, unnecessary servers are switched-off or put into a low-power mode when the work-load demand decreases. Similarly, when the demandincreases, additional servers are switched-on or putback into a high-power mode. Dynamic VM consoli-dation is another effective way to improve the utiliza-tion of resources and their energy-efficacy [6], [8]. Itleverages the hardware virtualization technology [9],which shares a Physical Machine (PM) among multi-ple performance-isolated platforms called VMs, whereeach VM runs one or more application tasks. Thesharing of the PM resources among multiple VMs

2
is handled by the Virtual Machine Monitor (VMM).Therefore, virtualization takes dynamic server pro-visioning one step further and allows different ap-plications to be allocated on the same PM to im-prove the resource utilizations. Moreover, it allowslive VM migration and consolidation to pack VMson a reduced number of PMs, reducing the energyconsumption [10]. However, in order to maximizeresource utility, it is essential to manage PM resourcesin an adequate manner. Therefore, one of the mostimportant optimization problems concerning VM con-solidation is energy-efficient placement of VMs onPMs. Furthermore, to be able to cope with the work-load variability of different types of applications, theVM consolidation should be performed in an onlinemanner.
In this paper, we address the VM consolidationproblem with the objective to reduce energy con-sumption of data centers while satisfying QoS require-ments. We present a distributed system architectureto perform dynamic VM consolidation to improveresource utilizations of PMs and to reduce their en-ergy consumption. We also propose a dynamic VMconsolidation approach that uses a highly adaptiveonline optimization metaheuristic algorithm calledAnt Colony System (ACS) [11], [12] to optimize VMplacement. The proposed ACS-based VM Consoli-dation (ACS-VMC) approach uses artificial ants toconsolidate VMs into a reduced number of activePMs according to the current resource requirements.These ants work in parallel to build VM migrationplans based on a specified objective function. Theperformance of the proposed ACS-VMC approach isevaluated by using CloudSim [13] simulations on realworkload traces, which were obtained from more thana thousand VMs running on servers located at morethan 500 places around the world. The simulationresults show that ACS-VMC maintains the desiredQoS while reducing energy consumption in a clouddata center. It outperforms existing VM consolidationapproaches in terms of energy consumption, numberof VM migrations, and number of SLA violations.
The remainder of this paper is organized as follows.Section 2 discusses some of the most important relatedworks and briefly reviews the Ant Colony Optimiza-tion (ACO) metaheuristic. Section 3 and Section 4present the system architecture and the proposed dy-namic VM consolidation approach, respectively. Sec-tion 5 describes the experimental design and setup.Finally, we present the experimental results in Sec-tion 6 and our conclusions in Section 7.
2 BACKGROUND AND RELATED WORK
The existing VM consolidation approaches, suchas [14], [15], [16], [17] are used in data centers toreduce under-utilization of PMs and to optimize theirenergy-efficiency. The main idea in these approaches
is to use live VM migration [10] to periodically consol-idate VMs so that some of the under-loaded PMs canbe released for termination. Determining when it isbest to reallocate VMs from an overloaded PM is animportant aspect of dynamic VM consolidation thatdirectly influences the resource utilization and QoS.In [18], two static thresholds were used to indicatethe time of VM reallocation. This approach keepsthe total Central Processing Unit (CPU) utilizationof a PM between these thresholds. However, settingstatic thresholds is not efficient for an environmentwith dynamic workloads. Therefore, Beloglazov andBuyya [19] presented adaptive thresholds that canbe derived based on the statistical analysis of thehistorical data.
Another important aspect of dynamic VM consol-idation concerns load prediction on a PM. Using aprediction of the future load enables proactive con-solidation of VMs on the overloaded and under-loaded PMs. Therefore, in our previous works [20],[21], we proposed two regression methods to predictCPU utilization of a PM. These methods use the lin-ear regression and the K-nearest neighbor regressionalgorithms, respectively, to approximate a functionbased on the data collected during the lifetimes ofthe VMs. Therefore, we used the function to predictan overloaded or an under-loaded PM for reducingthe SLA violations and energy consumption.
The VM consolidation problem is known to be NP-hard [15], [22]. Therefore, it is expensive to find an op-timal solution with a large number of PMs and VMs.In some of the existing approaches, VM consolidationhas been formulated as an optimization problem withthe objective to find a near optimal solution by using agreedy approach [22], [23], [24]. Since an optimizationproblem is associated with constraints, such as datacenter capacity and SLA, these works use a heuristicto consolidate workload in a multi-dimensional binpacking problem. The PMs are assumed to be thebins and the VMs are considered as the objects. Theobjective of bin packing is to minimize the numberof bins while packing all the objects. Wood et al. [22]used a greedy algorithm to determine a sequence ofmoves to migrate overloaded VMs to under-loadedPMs. Ajiro and Tanaka [23] used a load balancingalgorithm called least-loaded (LL) to balance the loadamong PMs. Wang et al [24] formulated the VMconsolidation problem as a stochastic bin packingproblem and used an online packing algorithm toconsolidate VMs with dynamic bandwidth demands.
In this paper, we formulate energy-efficient VMconsolidation as a multi-objective combinatorial opti-mization problem and apply a highly adaptive onlineoptimization [25] metaheuristic called Ant ColonyOptimization (ACO) [11] to find a near-optimal solu-tion. ACO is a multi-agent approach to difficult com-binatorial optimization problems, such as travelingsalesman problem (TSP) and network routing [12].

3
It is inspired by the foraging behavior of real antcolonies. While moving from their nest to a foodsource and back, ants deposit a chemical substanceon their path called pheromone. Other ants can smellpheromone and they tend to prefer paths with ahigher pheromone concentration. Thus, ants behaveas agents who use a simple form of indirect commu-nication called stigmergy to find better paths betweentheir nest and the food source. It has been shownexperimentally that this simple pheromone trail fol-lowing behavior of ants can give rise to the emergenceof the shortest paths [12]. It is important to note herethat although each ant is capable of finding a completesolution, high quality solutions emerge only from theglobal cooperation among the members of the colonywho concurrently build different solutions. Moreover,to find a high quality solution, it is imperative toavoid stagnation, which is a premature convergence toa suboptimal solution or a situation where all ants endup finding the same solution without sufficient explo-ration of the search space [12]. In ACO metaheuristic,stagnation is avoided mainly by using pheromoneevaporation and stochastic state transitions.
There are a number of ant algorithms, such asAnt System (AS), Max-Min AS (MMAS), and AntColony System (ACS) [11], [12]. ACS was introducedto improve the performance of AS and it is cur-rently one of the best performing ant algorithms. Theexisting ACO-based resource allocation and serverconsolidation approaches include [15], [26], [27], [28].Yin and Wang [26] applied ACO to the nonlinearresource allocation problem, which seeks to find anoptimal allocation of a limited amount of resourcesto a number of tasks to optimize their nonlinearobjective function. Feller et al. [15] applied MMASto the VM consolidation problem in the context ofcloud computing. A recent paper by Ferdaus et al. [27]integrated ACS with a vector algebra-based serverresource utilization capturing technique [29]. Anotherrecent work by Ashraf and Porres [28] used ACSto consolidate multiple web applications in a cloud-based shared hosting environment.
In this paper, we apply ACS to the VM consolida-tion problem. Our main contributions are as follows:• We formulate energy-efficient VM consolidation
as a multi-objective combinatorial optimizationproblem to optimize three conflicting objectivessimultaneously. The objectives include reducingenergy consumption, minimizing the number ofVM migrations, and avoiding SLA violations.
• We present a distributed multi-agent system ar-chitecture for dynamic VM consolidation. In ourapproach, a local agent detects PM status: nor-mal, overloaded, predicted overloaded, or under-loaded. We use the LiRCUP method [20] to pre-dict an overloaded PM for avoiding SLA vio-lations, as described in Section 3. Moreover, aglobal agent dynamically consolidates VMs into
a reduced number of PMs by using our proposedACS-based VM Consolidation (ACS-VMC) algo-rithm, which is presented in Section 4.
• We take into account the multi-dimensional re-source utilizations of a PM. Therefore, VM con-solidation in ACS-VMC is based on three re-source dimensions: CPU, memory, and networkInput/Output (I/O).
• The performance of the proposed ACS-VMC ap-proach is evaluated by CloudSim simulation onreal workload traces. We compared our proposedapproach with the existing dynamic VM consol-idation approaches in the CloudSim toolkit andwith the ACS-based VM consolidation approachin [27]. The results show that ACS-VMC out-performs existing VM consolidation approachesin terms of energy consumption, number of VMmigrations, and number of SLA violations.
3 SYSTEM ARCHITECTURE
A cloud data center consists of m heterogeneousPMs that have different resource capacities. Each PMcontains a CPU, which is often a multi-core. The CPUperformance can be defined in terms of Millions ofInstructions Per Second (MIPS). In addition, a PM isalso characterized by the amount of memory, networkI/O, and storage capacity. At any given time, a clouddata center usually serves many simultaneous users.Users submit their requests for provisioning of n VMs,which are allocated to the PMs. The length of eachrequest is specified in millions of instructions (MI). Inour proposed approach, the VMs are initially allocatedto PMs based on the Best Fit Decreasing (BFD) algo-rithm, which is one of the best known heuristics forthe bin-packing problem [16]. BFD first sorts all VMsby their utilization weights in the decreasing order.Then, it starts with the VMs that require the largestamount of resources. The BFD algorithm allocatesVMs in such a way that the unused capacity in thedestination PMs is minimized. Thus, it selects a PMfor which the amount of available resources is closestto the requested amount of resources by the VM.Therefore, BFD algorithm provides an initial efficientallocation of VMs. However, due to dynamic work-loads, the resource utilizations of VMs continue tovary over time. Therefore, an initial efficient allocationapproach needs to be augmented with a VM consol-idation algorithm that can be applied periodically. Inour proposed approach, the ACS-VMC algorithm isapplied periodically in order to adapt and optimizethe VM placement according to the workload.
Figure 1 depicts the proposed system model thatconsists of two types of agents: local and global agent.A Local Agent (LA) resides in a PM to solve thePM status detection sub-problem by observing thecurrent resource utilizations of the PM. The GlobalAgent (GA) acts as a supervisor and optimizes the

4
Global Agent
Local
Agent
PM
2
VMM
4
3
1
VM VM VM
PM
Local
AgentVMM
4
1
VM VM VM
...
Fig. 1: The system architecture
VM placement by using the proposed ACS-VMC algo-rithm. The task sequence of these agents is describedas follows:
1) Each LA monitors the CPU utilization andcategorizes the PM into one of the four setsPnormal, Pover, Pover, and Punder. Respectively,these sets represent the normal, overloaded, pre-dicted overloaded, and under-loaded PMs basedon the following conditions:• If the current CPU utilization exceeds PM
capacity, the PM is considered as a memberof Pover.
• If the predicted utilization value is largerthan the available CPU capacity, the PMis considered as a member of Pover. Weuse LiRCUP [20] to forecast the short-termCPU utilization of a PM based on the linearregression technique. In LiRCUP, the linearregression approximates the utilization func-tion according to the past utilization valuesin a PM.
• If the current CPU utilization is less than athreshold of the total CPU utilization, thePM is categorized as a member of Punder.We performed a series of preliminary exper-iments to estimate the threshold. Based onour analysis, in general, the best results areobtained when the threshold is set to 50%.
• All remaining PMs belong to Pnormal.2) The GA collects the status of individual PMs
from the LAs and builds a global best migrationplan by using the proposed ACS-VMC algo-rithm, which is described in the next section.
3) The GA sends commands to VMMs for per-forming VM consolidation task. The commandsdetermine which VMs on a source PM shouldbe migrated to which destination PMs.
4) The VMMs perform actual migration of VMsafter receiving the commands from the GA.
4 ACS-BASED VM CONSOLIDATIONThe pseudocode of the proposed ACS-based VM Con-solidation (ACS-VMC) algorithm is given as Algo-rithm 1. For the sake of clarity, the concepts used
in the proposed algorithm and their notations aretabulated in Table 1. Each PM p ∈ P hosts one or moreVMs from the set of VMs V . Moreover, in the contextof VM migration, each PM is a potential source PM forthe VMs already residing on that PM. Both the sourcePM and the VM are characterized by their resourceutilizations, such as CPU, memory and network I/O.Likewise, a VM can be migrated to any other PM.Therefore, any other PM is a potential destination PM,which is also characterized by its resource utilizations.Thus, the proposed ACS-VMC algorithm creates a setof tuples T , where each tuple t ∈ T consists of threeelements: the source PM pso, the VM to be migratedv, and the destination PM pde as given in (1)
t = (pso, v, pde) (1)
The PMs in the VM consolidation problem are anal-ogous to the cities in the TSP, while the tuples areanalogous to the edges that connect the cities. Due toobvious reasons, it is imperative to reduce the com-putation time of the consolidation algorithm, whichis primarily based on the number of tuples |T |. Thus,when making the set of tuples T , the algorithm ap-plies two constraints, which result in a reduced set oftuples by removing some least important and obsoletetuples. The first constraint is given as
pso ∈ Pover ∨ pso ∈ Pover ∨ pso ∈ Punder (2)
It ensures that only a predicted overloaded, an over-loaded, or an under-loaded PM is used as a sourcePM pso. The rationale of including a predicted over-loaded PM as a source PM is to prevent the PMfrom becoming overloaded. Similarly, the amount ofSLA violations are reduced by migrating some VMsfrom an overloaded PM. In addition, migrations froman under-loaded PM are more likely to result inswitching of the PM to the sleep mode, which wouldreduce the energy consumption by minimizing thenumber of active PMs.
The second constraint further restricts the size ofthe set of tuples |T | by ensuring that none of theoverloaded Pover and predicted overloaded Pover PMsbecome a destination PM pde
pde /∈ Pover ∧ pde /∈ Pover (3)
By applying these two simple constraints in a seriesof preliminary experiments, we observed that thecomputation time of the algorithm was significantlyreduced without compromising the quality of thesolutions.
The output of the VM consolidation algorithm is amigration plan, which, when enforced, would resultin a minimal set of active PMs needed to host all VMswithout compromising their performance. Thus, theobjective function of the proposed algorithm is
f(M) = |Ps|γ +1
|M |(4)

5
TABLE 1: Summary of concepts and their notations
P set of physical machines (PMs)Pnormal set of PMs on a normal load levelPover set of overloaded PMsPover set of predicted overloaded PMsPs set of sleeping PMsPunder set of under-loaded PMsVp set of VMs running on a PM pMS set of migration plansT set of tuplesTk set of tuples not yet traversed by ant kV set of VMsv VM in a tupleCpde total capacity vector of the destination PM pdeM a migration planM+ the global best migration planMk ant-specific migration plan of ant kMmk ant-specific temporary migration plan of ant k
q a uniformly distributed random variableS a random variable selected according to (7)Scrk thus far best score of ant kUv used capacity vector of the VM vUpde used capacity vector of the destination PM pdeUpso used capacity vector of the source PM psopde destination PM in a tuplepso source PM in a tupleη heuristic valueτ amount of pheromoneτ0 initial pheromone level∆+τs additional pheromone amount given to the tu-
ples in M+
q0 parameter to determine relative importance ofexploitation
α pheromone decay parameter in the global up-dating rule
β parameter to determine the relative importanceof η
γ parameter to determine the relative importanceof |Ps|
ρ pheromone decay parameter in the local updat-ing rule
nA number of ants that concurrently build theirmigration plans
nI number of iterations of the main, outer loop inthe algorithm
where M is the migration plan and Ps is the set ofPMs that will be switched to the sleep mode when Mis enforced. The parameter γ determines the relativeimportance of |Ps| with respect to |M |. Since theultimate objective in the dynamic VM consolidationalgorithm is to minimize the number of active PMs,the objective function is defined in terms of numberof sleeping PMs |Ps|. Moreover, it prefers smallermigration plans because live migration is a resource-intensive operation.
At the end of the ACS-VMC algorithm, when theselected migration plan is enforced, our approach fur-ther restricts the number of active PMs by preferringVM migrations to the already active PMs. Thus, a PMin the sleep mode is switched on only when it is notpossible to migrate a VM to an already active PM.
Moreover, a PM can only be switched to the sleepmode when all of its VMs migrate from it, that is,when the PM no longer hosts any VMs. Thus, the set
of sleeping PMs Ps is defined as
Ps = {∀p ∈ P | Vp = ∅} (5)
where Vp is the set of VMs running on a PM p.Unlike the TSP, there is no notion of a path in
the VM consolidation problem. Therefore, in our ap-proach, the pheromone is deposited on the tuples de-fined in (1). Each of the nA ants uses a stochastic statetransition rule to choose the next tuple to traverse. Thestate transition rule in ACS is called pseudo-random-proportional-rule [11]. According to this rule, an antk chooses a tuple s to traverse next by applying
s =
{arg maxu ∈ Tk{[τu] · [ηu]β}, if q ≤ q0S, otherwise
(6)
where τ denotes the amount of pheromone and ηrepresents the heuristic value associated with a partic-ular tuple. β is a parameter to determine the relativeimportance of the heuristic value with respect to thepheromone value. Tk ⊂ T is the set of tuples thatremain to be traversed by ant k. q ∈ [0, 1] is a uni-formly distributed random variable and q0 ∈ [0, 1] isa parameter. S is a random variable selected accordingto the probability distribution given in (7), where theprobability ps of an ant k to choose tuple s to traversenext is defined as
ps =
[τs]·[ηs]β∑
u ∈ Tk
[τu]·[ηu]β, if s ∈ Tk
0, otherwise(7)
The heuristic value ηs of a tuple s is defined in asimilar fashion as in [15] and [28] as
ηs =
{(|Cpde − (Upde + Uv)|1)−1, if Upde + Uv ≤ Cpde0, otherwise
(8)where Cpde is the total capacity vector of the destina-tion PM pde, Upde is the used capacity vector of pde,and likewise Uv is the used capacity vector of the VMv in tuple s. The heuristic value η is based on themultiplicative inverse of the scalar-valued differencebetween Cpde and Upde +Uv . It favors VM migrationsthat result in a reduced under-utilization of PMs.Moreover, the constraint Upde + Uv ≤ Cpde preventsmigrations that would result in the overloading ofthe destination PM pde. In the proposed algorithm, weassumed three resource dimensions, which representCPU, memory and network I/O utilization.
The stochastic state transition rule in (6) and (7)prefers tuples with a higher pheromone concentrationand which result in a higher number of released PMs.The first case in (6) where q ≤ q0 is called exploita-tion [11], which chooses the best tuple that attains themaximum value of [τ ] · [η]β . The second case, calledbiased exploration, selects a tuple according to (7).The exploitation helps the ants to quickly convergeto a high quality solution, while at the same time, the

6
biased exploration helps them to avoid stagnation byallowing a wider exploration of the search space. Inaddition to the stochastic state transition rule, ACSalso uses a global and a local pheromone trail evap-oration rule. The global pheromone trail evaporationrule is applied towards the end of an iteration afterall ants complete their migration plans. It is definedas
τs = (1− α) · τs + α ·∆+τs (9)
where ∆+τs is the additional pheromone amount that
is given only to those tuples that belong to the globalbest migration plan in order to reward them. It isdefined as
∆+τs =
{f(M+), if s ∈ M+
0, otherwise(10)
α ∈ (0, 1] is the pheromone decay parameter, and M+
is the global best migration plan from the beginningof the trial.
The local pheromone trail update rule is applied ona tuple when an ant traverses the tuple while makingits migration plan. It is defined as
τs = (1− ρ) · τs + ρ · τ0 (11)
where ρ ∈ (0, 1] is similar to α and τ0 is the initialpheromone level, which is computed as the multi-plicative inverse of the product of the approximateoptimal |M | and |P |
τ0 = (|M | · |P |)−1 (12)
One way to estimate optimal |M | is to use the nearestneighborhood heuristic [11]. We use the K-nearestneighbor (KNN) heuristic [30] to estimate the optimal|M | by using a training data set. The data set has msamples, where each sample xi is described by threeinput variables (xi1, xi2, xi3) and an output variableyi, that is, xi = {xi1, xi2, xi3, yi}. The goal is to finda relationship between the input variables and theoutput variable. Therefore, we choose the number ofunder-loaded PMs, the number of overloaded PMs,and the number of VMs as the three input variables(xi1, xi2, xi3) and the migration plan size as the outputvariable (yi).
The KNN heuristic estimates the output by takinga local average of the training data set. Moreover, thelocality is defined in terms of the K samples nearestto the estimation sample. We use Euclidean distanceto measure the distance metric between new sampleand other samples.
The pseudo-random-proportional-rule in ACS andthe global pheromone trail update rule are intendedto make the search more directed. The pseudo-random-proportional-rule prefers tuples with a higherpheromone level and a higher heuristic value. There-fore, the ants try to search other high quality solutionsin a close proximity of the thus far global best so-lution. On the other hand, the local pheromone trail
Algorithm 1 ACS-based VM consolidation
1: M+ = ∅, MS = ∅2: ∀t ∈ T |τt = τ03: for i ∈ [1, nI] do4: for k ∈ [1, nA] do5: Mm
k = ∅,Mk = ∅, Scrk = 06: for t ∈ T do7: generate a random variable q with a uni-
form distribution between 0 and l8: if q > q0 then9: compute ps ∀s ∈ T by using (7)
10: end if11: choose a tuple t ∈ Tk to traverse by
using (6)12: Mm
k = Mmk ∪ {t}
13: apply local update rule in (11) on t14: update used capacity vectors Upso and Upde
in t15: if f(Mm
k ) > Scrk then16: Scrk = f(Mm
k )17: Mk = Mk ∪ {t}18: else19: Mm
k = Mmk \ {t}
20: end if21: end for22: MS = MS ∪ {Mk}23: end for24: M+ = arg maxMk ∈MS{f(Mk)}25: apply global update rule in (9) on all s ∈ T26: end for
update rule complements exploration of other highquality solutions that may exist far from the best-so-far global solution. This is because whenever an anttraverses a tuple and applies the local pheromone trailupdate rule, the tuple looses some of its pheromoneand becomes less attractive for other ants. Therefore,it helps in avoiding stagnation where all ants end upfinding the same solution or where they prematurelyconverge to a suboptimal solution.
The pseudocode in Algorithm 1 creates a set oftuples T using (1) and sets the pheromone valueof each tuple to the initial pheromone level τ0 byusing (12) (line 2). The algorithm iterates over nI iter-ations (line 3). In each iteration, nA ants concurrentlybuild their migration plans (lines 4–23). Each antiterates over |T | tuples (lines 76–21). It computes theprobability of choosing the next tuple to traverse byusing (7) (line 9). Afterwards, based on the computedprobabilities and the stochastic state transition rulein (6), each ant chooses a tuple t ∈ Tk to traverse(line 11) and adds t to its temporary migration planMmk (line 12). The local pheromone trail update rule
in (11) and (12) is applied on t (line 13) and theused capacity vectors at the source PM Upso andthe destination PM Upde in t are updated to reflect

7
the impact of the migration (line 15). The objectivefunction in (4) is applied on Mm
k , and if it yields ascore higher than the ant’s best score Scrk (line 16), t isadded to the ant-specific migration plan Mk (line 17).Otherwise, the tuple t is removed from the temporarymigration plan Mm
k (line 19). Then, towards the endof an iteration when all ants complete their migrationplans, all ant-specific migration plans are added tothe set of migration plans MS (line 22). Each migra-tion plan Mk ∈ MS is evaluated by applying theobjective function in (4), the global best applicationmigration plan M+ is selected (line 24), and the globalpheromone trail update rule in (9) and (10) is appliedon all tuples (line 25). Finally, when all iterations ofthe main outer loop complete, the algorithm outputsthe global best migration plan M+.
5 EXPERIMENTAL DESIGN AND SETUP
To evaluate the efficiency of our proposed ap-proach, we set up experimental environment usingthe CloudSim toolkit [13]. CloudSim is a discreteevent simulator for implementation and evaluationof resource provisioning and VM consolidation tech-niques for different applications. We simulated a datacenter comprising 800 heterogeneous PMs and se-lected two server configurations in CloudSim: HPProLiant ML110 G4 (Intel Xeon 3040, 2 cores×1860MHz, 4 GB), and HP ProLiant ML110 G5 (Intel Xeon3075, 2 cores×2660 MHz, 4 GB). Dual-core CPUs aresufficient to evaluate resource management methodsthat are designed for multi-core CPU architectures.Moreover, it is important to simulate a large num-ber of servers for performance evaluation of VMconsolidation methods. To evaluate the efficiency ofour proposed approach, we measured four metrics:SLA violations, energy consumption, number of mi-grations, and energy-SLA violations. The results arebased on two different workloads: a random work-load and a real workload. In the random workload,the users submit requests for the provisioning of 800heterogeneous VMs. In the real workload, the numberof VMs on each day is specified in Table 2. The ACSparameters that were used in the proposed approachare tabulated in Table 3. These parameter values wereobtained in a series of preliminary experiments.
5.1 SLA ViolationsMaintaining the desired QoS is an important require-ment for cloud data centers. QoS requirements arecommonly formalized in the form of SLAs, whichspecify enterprise service-level requirements for datacenter in terms of minimum latency or maximumresponse time. Beloglazov and Buyya [19] proposeda workload independent metric called SLAV (SLAViolations) to evaluate the SLA delivered by a VMin an IaaS cloud. It represents both the SLA Vi-olations due to Over-utilization (SLAVO) and SLA
TABLE 2: Number of VMs in the real workload
Date Number of VMs3 March 10526 March 8989 March 1061
22 March 151625 March 10783 April 14639 April 1358
11 April 123312 April 105420 April 1033
TABLE 3: ACS parameters in the proposed approach
α β γ ρ q0 nA nI w0.1 0.9 5 0.1 0.9 10 2 2−7
Violations due to Migrations (SLAVM). The SLAVOand SLAVM metrics independently and with equalimportance characterize the level of SLA violationsby the infrastructure. Therefore, a combined metric(SLAV) describes performance degradations due tothe overloading of the host PMs as well as thosecaused by VM migrations, as
SLAV = SLAV O × SLAVM (13)
SLAVO indicates the percentage of time, during whichactive PMs have experienced the CPU utilization of100%. It is defined as
SLAV O =1
M
M∑i=1
Tsi
Tai(14)
where M is the number of PMs; Tsi is the total timethat the PM i has experienced the utilization of 100%leading to an SLA violation. Tai is the total durationof the PM i being in the active state. SLAVM showsthe overall performance degradation by VMs due tomigrations. It is computed as
SLAVM =1
N
N∑j=1
Cdj
Crj(15)
where N is the number of VMs; Cdj is the estimate ofthe performance degradation of the VM j caused bymigrations; Crj is the total CPU capacity requested bythe VM j during its lifetime. Based on our preliminaryexperiments, we estimated Cdj as 10% of the CPUutilization in MIPS during all migrations of the VMj.
5.2 Energy ConsumptionWe consider the total energy consumption of thephysical resources in a data center that is requiredto handle the application workloads. The energy con-sumption of a PM depends on the utilization of itsCPU, memory, disk, and network card. Most stud-ies [19], [31] show that CPU consumes more powerthan memory, disk storage, and network interface.

8
Therefore, the resource utilization of a PM is usuallyrepresented by its CPU utilization. Instead of usingan analytical model of energy consumption, we usedthe real data in the SPECpower benchmark1. Table 4illustrates the amount of energy consumption of HPG4 and G5 servers at different load levels.
5.3 Number of VM MigrationsLive VM migration is a costly operation that includessome amount of CPU processing on the source PM,the link bandwidth between the source and desti-nation PMs, the downtime of the services on themigrating VM, and the total migration time [16].Therefore, one of our objectives was to minimize thenumber of migrations. The length of a VM migrationin CloudSim takes as long as it needs to migratethe memory assigned to the VM over the networkbandwidth link between source and destination PMs.In our simulations, we used 1Gbps network links.
5.4 Energy and SLA ViolationsThe objective of the proposed VM consolidation ap-proach is to minimize both energy and SLA violations.Since there is a trade-off between performance andenergy consumption, we measured a combined metriccalled ESV (Energy and SLA Violations) that capturesboth the Energy Consumption (EC) and the SLAViolations (SLAV) as
ESV = EC × SLAV (16)
6 EXPERIMENTAL RESULTS
In this section, we compare the proposed ACS-VMCapproach with an ACS based VM consolidation al-gorithm in [27] and four heuristic algorithms fordynamic reallocation of VMs in [19]. The AVVMCconsolidation scheme [27] proposes the ant colonyoptimization with balanced usage of computing re-sources based on vector algebra. Moreover, the mainidea of these algorithms [19] is to set upper andlower utilization thresholds and keep the total CPUutilization of a node between them. When the upperthreshold is exceeded, VMs are reallocated for loadbalancing and when the utilization of a PM dropsbelow the lower threshold, VMs are reallocated forconsolidation. The algorithms adapt the utilizationthreshold dynamically based on the Median AbsoluteDeviation (MAD), the Interquartile Range (IQR), andLocal Regression (LR) approach to estimate the CPUutilization. Moreover, a static threshold method (THR)is proposed in [19] that monitors the CPU utiliza-tion and migrates a VM when the current utilizationexceeds 80% of the total amount of available CPUcapacity on the PM. In our experiments, we considertwo type of workloads:
1. http : //www.spec.org/power ssj2008/
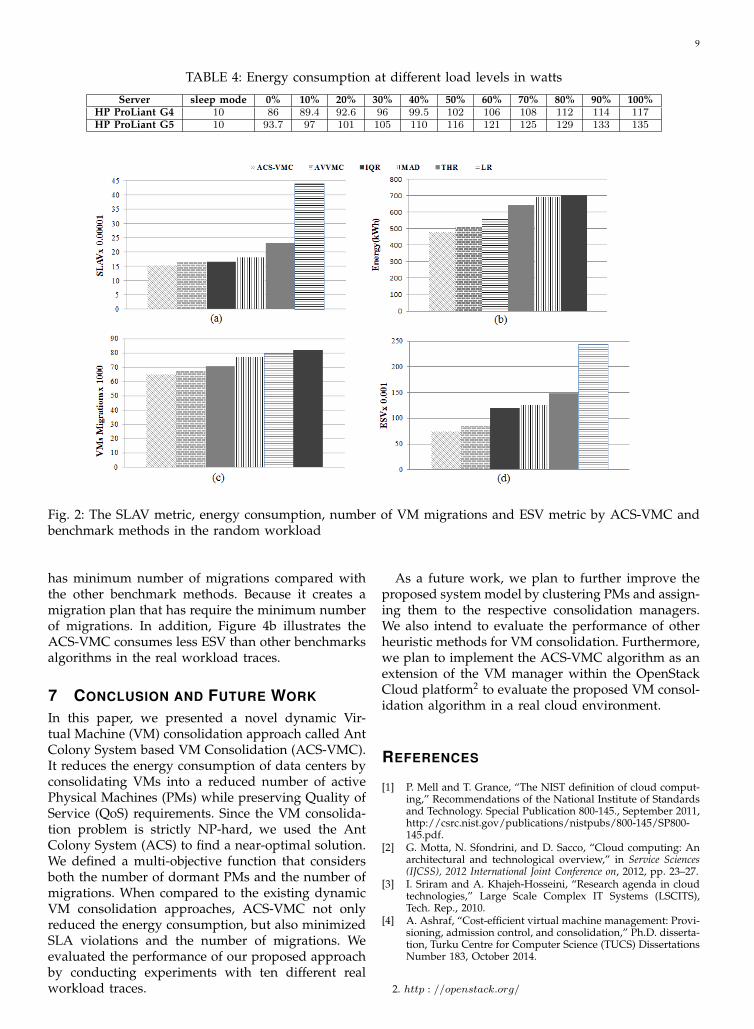
6.1 Random WorkloadIn the random workload, each VM runs an appli-cation with a variable utilization of CPU, which isgenerated with a uniform distribution. Figure 2(a)presents the SLA violation levels caused by the ACS-VMC, AVVMC, THR, MAD, IQR, and LR methods inthe random workload. The results indicate that ACS-VMC reduced the SLA violations more efficiently thanthe other approaches. This is due to the fact thatACS-VMC prevents SLA violations by using a pre-diction of the overloaded PMs and that the heuristicvalue in (8) ensures that the destination PM doesnot become overloaded when a VM migrates on it.Figure 2(b)shows that the proposed dynamic VMconsolidation approach, ACS-VMC, brought higherenergy savings in comparison to the other approachesin the random workload. In ACS-VMC, a signicantreduction of the energy consumption of 7.3%, 16.4%,45.2%, 34.5%, and 47.7% was achieved when com-pared to AVVMC, LR, MAD, THR, and IQR, respec-tively. In addition, the trade-off between maximizingthe QoS and minimizing the energy consumption ofdata center is demonstrated in Figure 2(c). Figure 2(d)depicts the total number of VMs migration duringthe VM consolidation in the random workload. TheACS-VMC outperforms the AVVMC and adaptive-threshold based algorithms due to predictions of uti-lization, and therefore decreased the number of VMmigrations.
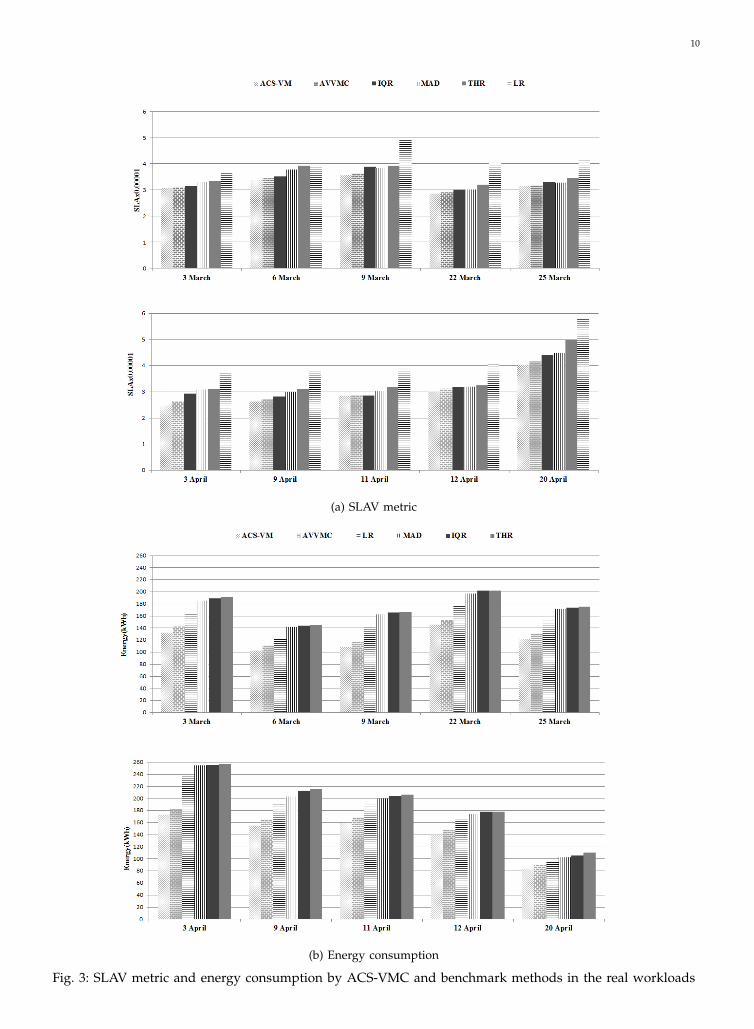
6.2 Real WorkloadReal workload data is provided as a part of theCoMon project, a monitoring infrastructure for Plan-etLab [32]. In this project, the CPU usage data iscollected every five minutes from more than a thou-sand VMs and is stored in different files. The VMsare allocated on servers that are located at more than500 places around the world. In fact, the workload isrepresentative of an IaaS cloud environment such asAmazon EC2, which several independent users createand manage VMs. Figure 3a shows that ACS-VMC ledto significantly less SLA violations than the other fourbenchmark algorithms. The main reason is that ACS-VMC employs measures to prevent VM migrationsthat would result in the overloading of the destina-tion PM. Moreover, it preemptively reallocates VMsfrom a predicted overloaded PM. Figure 3b showsthat ACS-VMC consumed less power than the otherbenchmark algorithms in the real workload traces. ourproposed VM consolidation approach reduces energyconsumption by up to 53.4% with desirable systemperformance in March 2011 load traces. This is be-cause, the defined objective function tries to maximizethe number of dormant PMs by packing VMs intothe PMs that have enough capacity. The number ofVM migrations in the real workload are shown inFigure 4a. As observed from the results, ACS-VMC
9
TABLE 4: Energy consumption at different load levels in watts
Server sleep mode 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%HP ProLiant G4 10 86 89.4 92.6 96 99.5 102 106 108 112 114 117HP ProLiant G5 10 93.7 97 101 105 110 116 121 125 129 133 135
Fig. 2: The SLAV metric, energy consumption, number of VM migrations and ESV metric by ACS-VMC andbenchmark methods in the random workload
has minimum number of migrations compared withthe other benchmark methods. Because it creates amigration plan that has require the minimum numberof migrations. In addition, Figure 4b illustrates theACS-VMC consumes less ESV than other benchmarksalgorithms in the real workload traces.
7 CONCLUSION AND FUTURE WORK
In this paper, we presented a novel dynamic Vir-tual Machine (VM) consolidation approach called AntColony System based VM Consolidation (ACS-VMC).It reduces the energy consumption of data centers byconsolidating VMs into a reduced number of activePhysical Machines (PMs) while preserving Quality ofService (QoS) requirements. Since the VM consolida-tion problem is strictly NP-hard, we used the AntColony System (ACS) to find a near-optimal solution.We defined a multi-objective function that considersboth the number of dormant PMs and the number ofmigrations. When compared to the existing dynamicVM consolidation approaches, ACS-VMC not onlyreduced the energy consumption, but also minimizedSLA violations and the number of migrations. Weevaluated the performance of our proposed approachby conducting experiments with ten different realworkload traces.
As a future work, we plan to further improve theproposed system model by clustering PMs and assign-ing them to the respective consolidation managers.We also intend to evaluate the performance of otherheuristic methods for VM consolidation. Furthermore,we plan to implement the ACS-VMC algorithm as anextension of the VM manager within the OpenStackCloud platform2 to evaluate the proposed VM consol-idation algorithm in a real cloud environment.
REFERENCES
[1] P. Mell and T. Grance, “The NIST definition of cloud comput-ing,” Recommendations of the National Institute of Standardsand Technology. Special Publication 800-145., September 2011,http://csrc.nist.gov/publications/nistpubs/800-145/SP800-145.pdf.
[2] G. Motta, N. Sfondrini, and D. Sacco, “Cloud computing: Anarchitectural and technological overview,” in Service Sciences(IJCSS), 2012 International Joint Conference on, 2012, pp. 23–27.
[3] I. Sriram and A. Khajeh-Hosseini, “Research agenda in cloudtechnologies,” Large Scale Complex IT Systems (LSCITS),Tech. Rep., 2010.
[4] A. Ashraf, “Cost-efficient virtual machine management: Provi-sioning, admission control, and consolidation,” Ph.D. disserta-tion, Turku Centre for Computer Science (TUCS) DissertationsNumber 183, October 2014.
2. http : //openstack.org/
10
(a) SLAV metric
(b) Energy consumption
Fig. 3: SLAV metric and energy consumption by ACS-VMC and benchmark methods in the real workloads

11
(a) Number of VM migrations
(b) ESV metric
Fig. 4: Number of VM migrations and ESV metric by ACS-VMC and benchmark methods in the real workloads

12
[5] A. Ashraf, M. Hartikainen, U. Hassan, K. Heljanko, J. Lilius,T. Mikkonen, I. Porres, M. Syeed, and S. Tarkoma, “Introduc-tion to cloud computing technologies,” in Developing CloudSoftware: Algorithms, Applications, and Tools, I. Porres, T. Mikko-nen, and A. Ashraf, Eds. Turku Centre for Computer Science(TUCS) General Publication Number 60, October 2013, pp. 1–41.
[6] A. Beloglazov, R. Buyya, Y. C. Lee, and A. Zomaya, “Ataxonomy and survey of energy-efficient data centers andcloud computing systems,” Advances in Computers, vol. 82, pp.47–111, 2011.
[7] A. Gandhi, M. Harchol-Balter, R. Raghunathan, and M. A.Kozuch, “AutoScale: Dynamic, robust capacity managementfor multi-tier data centers,” ACM Transactions on ComputerSystems, vol. 30, no. 4, pp. 14:1–14:26, 2012.
[8] L. Deboosere, B. Vankeirsbilck, P. Simoens, F. Turck, B. Dhoedt,and P. Demeester, “Efficient resource management for virtualdesktop cloud computing,” The Journal of Supercomputing,vol. 62, no. 2, pp. 741–767, 2012.
[9] P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho,R. Neugebauer, I. Pratt, and A. Warfield, “Xen and the artof virtualization,” SIGOPS Oper. Syst. Rev., vol. 37, no. 5, pp.164–177, 2003.
[10] C. Clark, K. Fraser, S. Hand, J. G. Hansen, E. Jul, C. Limpach,I. Pratt, and A. Warfield, “Live migration of virtual machines,”in Proceedings of the 2Nd Conference on Symposium on NetworkedSystems Design & Implementation, ser. NSDI’05, vol. 2, 2005, pp.273–286.
[11] M. Dorigo and L. Gambardella, “Ant colony system: a coop-erative learning approach to the traveling salesman problem,”Evolutionary Computation, IEEE Transactions on, vol. 1, no. 1,pp. 53–66, 1997.
[12] M. Dorigo, G. Di Caro, and L. M. Gambardella, “Ant algo-rithms for discrete optimization,” Artif. Life, vol. 5, no. 2, pp.137–172, Apr. 1999.
[13] R. N. Calheiros, R. Ranjan, A. Beloglazov, C. A. F. De Rose, andR. Buyya, “CloudSim: a toolkit for modeling and simulationof cloud computing environments and evaluation of resourceprovisioning algorithms,” Software: Practice and Experience,vol. 41, no. 1, pp. 23–50, 2011.
[14] W. Vogels, “Beyond server consolidation,” ACM Queue, vol. 6,no. 1, pp. 20–26, 2008.
[15] E. Feller, C. Morin, and A. Esnault, “A case for fully decentral-ized dynamic VM consolidation in clouds,” in Cloud ComputingTechnology and Science (CloudCom), 2012 IEEE 4th InternationalConference on, December 2012, pp. 26–33.
[16] A. Murtazaev and S. Oh, “Sercon: Server consolidation al-gorithm using live migration of virtual machines for greencomputing,” IETE Technical Review, vol. 28, no. 3, pp. 212–231,2011.
[17] M. Marzolla, O. Babaoglu, and F. Panzieri, “Server consolida-tion in clouds through gossiping,” in World of Wireless, Mobileand Multimedia Networks (WoWMoM), 2011 IEEE InternationalSymposium on a, 2011, pp. 1–6.
[18] A. Beloglazov, J. Abawajy, and R. Buyya, “Energy-aware re-source allocation heuristics for efficient management of datacenters for cloud computing,” Grid Computing and eScience,Future Generation Computer Systems (FGCS), vol. 28, pp. 755–768, 2012.
[19] A. Beloglazov and R. Buyya, “Optimal online deterministicalgorithms and adaptive heuristics for energy and perfor-mance efficient dynamic consolidation of virtual machines incloud data centers,” Concurrency and Computation: Practice andExperience, vol. 24, no. 13, pp. 1397–1420, 2012.
[20] F. Farahnakian, P. Liljeberg, and J. Plosila, “LiRCUP: Linearregression based CPU usage prediction algorithm for livemigration of virtual machines in data centers,” in SoftwareEngineering and Advanced Applications (SEAA), 2013 39th EU-ROMICRO Conference on, 2013, pp. 357–364.
[21] F. Farahnakian, T. Pahikkala, P. Liljeberg, and J. Plosila, “En-ergy aware consolidation algorithm based on K-nearest neigh-bor regression for cloud data centers,” in Utility and CloudComputing (UCC), 2013 IEEE/ACM 6th International Conferenceon, Dec 2013, pp. 256–259.
[22] T. Wood, P. Shenoy, A. Venkataramani, and M. Yousif, “Sand-piper: Black-box and gray-box resource management for vir-
tual machines,” Computer Networks, vol. 53, pp. 2923–2938,2009.
[23] Y. Ajiro and A. Tanaka, “Improving packing algorithms forserver consolidation,” in Proceedings of the International Con-ference for the Computer Measurement Group (CMG), 2007, pp.399–407.
[24] M. Wang, X. Meng, and L. Zhang, “Consolidating virtualmachines with dynamic bandwidth demand in data centers,”in INFOCOM, 2011 Proceedings IEEE, 2011, pp. 71–75.
[25] M. Harman, K. Lakhotia, J. Singer, D. R. White, and S. Yoo,“Cloud engineering is search based software engineering too,”Journal of Systems and Software, vol. 86, no. 9, pp. 2225–2241,2013.
[26] P.-Y. Yin and J.-Y. Wang, “Ant colony optimization for thenonlinear resource allocation problem,” Applied Mathematicsand Computation, vol. 174, no. 2, pp. 1438–1453, 2006.
[27] M. Ferdaus, M. Murshed, R. Calheiros, and R. Buyya, “Vir-tual machine consolidation in cloud data centers using ACOmetaheuristic,” in Euro-Par 2014 Parallel Processing, ser. LectureNotes in Computer Science, F. Silva, I. Dutra, and V. San-tos Costa, Eds. Springer International Publishing, 2014, vol.8632, pp. 306–317.
[28] A. Ashraf and I. Porres, “Using ant colony system to consol-idate multiple web applications in a cloud environment,” in22nd Euromicro International Conference on Parallel, Distributedand Network-based Processing (PDP), 2014, pp. 482–489.
[29] M. Mishra and A. Sahoo, “On theory of VM placement:Anomalies in existing methodologies and their mitigationusing a novel vector based approach,” in Cloud Computing(CLOUD), 2011 IEEE International Conference on, July 2011, pp.275–282.
[30] T. Cover and P. Hart, “Nearest neighbor pattern classification,”Information Theory, IEEE Transactions on, vol. 13, no. 1, pp. 21–27, 1967.
[31] D. Kusic, J. Kephart, J. Hanson, N. Kandasamy, and G. Jiang,“Power and performance management of virtualized com-puting environments via lookahead control,” in AutonomicComputing, 2008. ICAC ’08. International Conference on, 2008,pp. 3–12.
[32] K. Park and V. Pai, “CoMon: a mostly-scalable monitoring sys-tem for PlanetLab,” ACM SIGOPS Operating Systems Review,vol. 40, pp. 65–74, 2006.
Fahimeh Farahnakian received M.S degreein Computer Engineering from the Universityof Science and Technology, Tehran, Iran, in2009. She is currently pursuing her Ph.D.in Embedded Computer and Electronic Sys-tems Laboratory, University of Turku, Fin-land and from May 2011 she is a doc-toral candidate of Graduate School in Elec-tronics, Telecommunications and Automation(GETA). In addition Her research interests in-clude cloud computing, energy efficient data
center, network on- chips, machine learning, pattern recognitionand fuzzy control. She is a member of IEEE and is a frequentreviewer for research journals, such as Journal of Circuits, Systemsand Computers (JCSC), International Journal of High PerformanceSystems Architecture (IJHPSA), Journal of Low Power Electronics(JOLPE) and Journal of Supercomputing.

13
Adnan Ashraf received his M.Sc and MS de-grees in Computer Science from MohammadAli Jinnah University, Islamabad, Pakistan in2003 and 2006, respectively, and receivedhis PhD degree in Software Engineering fromAbo Akademi University, Turku, Finland in2014. He is currently working as a postdoc-toral researcher in the Software EngineeringLaboratory at Abo Akademi University. Hisresearch interests include cloud computing,energy-efficient data centers, cost-efficient
virtual machine management, admission control, server consolida-tion, and search based software engineering.
Tapio Pahikkala currently acts as a profes-sor of intelligence systems in University ofTurku, Finland. He received Ph.D degree incomputer science from University of Turkuin 2008 an d held an Academy of Finlandpostdoctoral position during 2010-2012. Hisresearch focuses on machine learning, pat-tern recognition, algorithmic, and computa-tional intelligence. He has authored morethan 80 peer-reviewed scientific publicationsand served in program committees of numer-
ous scientific conferences. He is a member of both ACM and IEEE,and he served as member in several committees of IEEE societies.
Pasi Liljeberg received his M.Sc. and Ph.D.degrees in electronics and information tech-nology from the University of Turku, Turku,Finland, in 1999 and 2005, respectively. Heis an Associate Professor in Embedded Elec-tronics laboratory and an Adjunct Profes-sor in embedded computing architecturesat the University of Turku, Embedded Com-puter Systems laboratory. During the period20072009 he held an Academy of Finlandresearcher position. Adj.Prof. Liljeberg is the
author of over 150 peer- reviewed publications, has supervised9 PhD theses. His current research interests include parallel anddistributed systems, Internet-of-Things, embedded computing archi-tecture, fault tolerant and energy aware system design, 3D multi-processor system architectures, dynamic power management, cyberphysical systems, intelligent network-on-chip communication archi-tectures and reconfigurable system design.
Juha Plosila is an Associate Professor inEmbedded Computing and an Adjunct Pro-fessor in Digital Systems Design at the Uni-versity of Turku (UTU), Department of In-formation Technology, Finland. He receiveda PhD degree in Electronics and Commu-nication Technology from UTU in 1999. Dr.Plosila is the leader of the Embedded Com-puter and Electronic Systems (ECES) re-search unit and a co-leader of the ResilientIT Infrastructures (RITES) research program-
mer at Turku Centre for Computer Science (TUCS). He leads theEmbedded Systems masters program at the EIT ICT Labs MasterSchool and is a management committee member of the EU COSTActions IC1103 (MEDIAN: Manufacturable and Dependable Multi-core Architectures at Nanoscale) and IC1202 (TACLe: Timing Analy-sis on Code Level). Dr. Plosila is an Associate Editor of InternationalJournal of Embedded and Real-Time Communication Systems (IGIGlobal).
Ivan Porres is a professor in Software Engi-neering, head of the Computer Engineeringeducation, and vice-head of the Departmentof Information Technologies at Abo AkademiUniversity. He is the leader of the Soft-ware Engineering Laboratory at the TurkuCentre for Computer Science (TUCS) andprincipal investigator at Abo Akademi forthe Cloud Software Finland (2009-2013) andN4S (2014-2017) projects at the DIGILE, theFinnish Strategic Centre for Science, Tech-
nology and Innovation in the Field of ICT. He has received the Ten-Year Most Influential Paper Award at the ACM/IEEE Conference onModel Driven Engineering Languages and Systems in two occasionsand has participated in many review appointments and the organiza-tion of research events.
Hannu Tenhunen received the Diplomasfrom the Helsinki University of Technology,Finland, 1982, and the PhD degree fromCornell University , Ithaca, New York, 1986.In 1985, the join ed the Signal ProcessingLaboratory , Tampere University of Technol-ogy, Finland, as an associate professor andlater served as a professor and departmentdirector. Since 1992, ha has been a professorat the Royal Institute of Technology (KTH),Sweden, where he also served as dean. He
is currently the director of Turku Center for Computer Science , Fin-land, and at the University of Turku. He has more than 600 reviewedpublications and 16 patents internationality. He is a member of theIEEE.




















