
thesis.pdf - Nemertes
98
Πολυτεχνική Σχολή Τμήμα Μηχανικών Η/Υ και Πληροφορικής Διπλωματική Εργασία Σχεδιασμός και ανάπτυξη παράλληλου αλγόριθμου συσταδοποίησης στο Apache Spark Παναγιώτης Κεχαγιάς ΑΜ: 235792 Επιβλέπων: Χρήστος Μακρής Αν. Καθηγητής Πάτρα, [Ιούλιος] [2020]
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of thesis.pdf - Nemertes

Πολυτεχνική Σχολή
Τμήμα Μηχανικών Η/Υ και Πληροφορικής
Διπλωματική Εργασία
Σχεδιασμός και ανάπτυξη παράλληλου αλγόριθμου συσταδοποίησης στο Apache
Spark
Παναγιώτης Κεχαγιάς
ΑΜ: 235792
Επιβλέπων:
Χρήστος Μακρής
Αν. Καθηγητής
Πάτρα, [Ιούλιος] [2020]


Ευχαριστίες
Η διπλωματική εργασία υλοποιήθηκε υπό την επίβλεψη του Αναπληρωτή Καθηγητή
κ. Χρήστου Μακρή, καθηγητή του τμήματος Μηχανικών Ηλεκτρονικών Υπολογιστών
και Πληροφορικής του Πανεπιστημίου Πατρών. Θα ήθελα να ευχαριστήσω τόσο το
Τμήμα όσο και τον ίδιο για την εμπιστοσύνη που μου έδειξε με την ανάθεση του
θέματος και για την άριστη συνεργασία που είχαμε στο διάστημα εκπόνησης της
εργασίας. Επιπλέον, ευχαριστίες θα επιθυμούσα να απευθύνω και στον κύριο
Αγοράκη Μπομπότα, τον συνεπιβλέποντα της εργασίας, που με τη συνεχή
καθοδήγηση και την προθυμία του αποτέλεσε καταλυτικό παράγοντα στην
εκπόνησή της.


i
ΠΙΝΑΚΑΣ ΠΕΡΙΕΧΟΜΕΝΩΝ
Πίνακας περιεχομένων ....................................................................................................................... i
Πίνακας εικόνων............................................................................................................................... iii
Περίληψη .......................................................................................................................................... v
Abstract ........................................................................................................................................... vii
1 Εισαγωγή ................................................................................................................................... 1
1.1 Σημασία του προβλήματος ..................................................................................................... 1
1.2 Συνεισφορά της Διπλωματικής Εργασίας ............................................................................... 1
1.3 Διάρθρωση της Διπλωματικής Εργασίας ............................................................................... 1
2 Θεωρητικό υπόβαθρο ............................................................................................................... 3
2.1 Ανακάλυψη γνώσης από βάσεις δεδομένων .......................................................................... 3 2.1.1 Τι είναι η ανακάλυψη γνώσης από βάσεις δεδομένων ..................................................... 3 2.1.2 Τα βασικά στάδια ανακάλυψης γνώσης από βάσεις δεδομένων ...................................... 4
2.2 Εξόρυξη Δεδομένων - Τύποι Μοντέλων.................................................................................. 6 2.2.1 Προβλεπτικά μοντέλα ........................................................................................................ 7 2.2.2 Περιγραφικά μοντέλα ........................................................................................................ 9
2.3 Εξόρυξη Δεδομένων - Εφαρμογές ......................................................................................... 10
3 Συσταδοποίηση ....................................................................................................................... 13
3.1 Κατηγορίες συσταδοποίησης ................................................................................................ 14 3.1.1 Μέτρα απόστασης ............................................................................................................ 16 3.1.2 Εγκυρότητα συσταδοποίησης .......................................................................................... 17
3.2 Birch ...................................................................................................................................... 21 3.2.1 Βασικά χαρακτηριστικά .................................................................................................... 21 3.2.2 Περιγραφή αλγορίθμου ................................................................................................... 23 3.2.3 Η αποδοτικότητα του αλγορίθμου. .................................................................................. 25
3.3 K-MEANS ............................................................................................................................... 25 3.3.1 Πλεονεκτήματα και μειονεκτήματα του k-means ............................................................ 27
3.4 DBSCAN ................................................................................................................................. 29 3.4.1 Βασικά χαρακτηριστικά .................................................................................................... 29 3.4.2 Περιγραφή αλγορίθμου ................................................................................................... 32 3.4.3 Πλεονεκτήματα και μειονεκτήματα του DBSCAN ............................................................ 34 3.4.4 Εκτίμηση παραμέτρων ..................................................................................................... 36 3.4.5 Υλοποιήσεις του DBSCAN ................................................................................................. 37
4 Κατανεμημένα Περιβάλλοντα Επεξεργασίας Δεδομένων Μεγάλου Ογκου ............................ 39
4.1 Το μοντέλο MapReduce ........................................................................................................ 39 4.1.1 Τι είναι το MapReduce ..................................................................................................... 39 4.1.2 MapReduce Βασικά στάδια .............................................................................................. 40 4.1.3 Πλεονεκτήματα του μοντέλου Hadoop MapReduce ........................................................ 43

ii
4.2 Apache Hadoop 2.0 ............................................................................................................... 45 4.2.1 YARN (Yet Another Resource Negotiator) ........................................................................ 46 4.2.2 HDFS (Hadoop Distributed File System) ........................................................................... 48
4.3 Apache Spark ........................................................................................................................ 49 4.3.1 Apache Spark RDD ............................................................................................................ 52 4.3.2 Apache Spark Data frames................................................................................................ 56 4.3.3 Apache Spark Machine Learning Library (MLLib) ............................................................. 56
5 Τεχνική Περιγραφή Υλοποίησης ............................................................................................. 59
5.1 Παραλληλοποιηση DBSCAN με χρήση πλέγματος. ............................................................... 59 5.1.1 MR-DBSCAN ...................................................................................................................... 59 5.1.2 DBSCAN μέσω πλέγματος ................................................................................................. 60 5.1.3 Παραλληλοποίηση Αλγόριθμου DBSCAN ......................................................................... 66
6 Πειραματική Αξιολόγηση ........................................................................................................ 75
6.1 Δημιουργία συνθετικών βάσεων δεδομένων ....................................................................... 75
6.2 Μετρικές που χρησιμοποιήθηκαν ........................................................................................ 76
6.3 Αποτελέσματα σύγκρισης του υλοποιημένου αλγορίθμου. ................................................. 77 6.3.1 DBSCAN του sklearn ......................................................................................................... 77 6.3.2 K-means Apache Spark ..................................................................................................... 79
6.4 Αξιολόγηση αλγορίθμου πάνω σε πραγματικά δεδομένα ................................................... 80
7 Επίλογος .................................................................................................................................. 83
7.1 Συμπεράσματα ...................................................................................................................... 83
7.2 Μελλοντικές επεκτάσεις ....................................................................................................... 83
8 Βιβλιογραφία .......................................................................................................................... 85

iii
ΠΙΝΑΚΑΣ ΕΙΚΟΝΩΝ
Εικόνα 2.1 Τα βασικά στάδια ανακάλυψης γνώσης από βάσεις δεδομένων .............. 4
Εικόνα 2.2: Είδη μοντέλων εξόρυξης δεδομένων ......................................................... 7
Εικόνα 2.3: Η κατηγοριοποίηση μπορεί να αναπαρασταθεί με διαφορετικούς
τρόπους: (α) IF-THEN rules,(b) Δένδρα αποφάσεων,(c) Νευρωνικά Δίκτυα ................ 8
Εικόνα 2.4: Γραμμική Παλινδρόμηση ............................................................................ 9
Εικόνα 3.1: Ο τελικός αριθμός των συστάδων μπορεί να είναι είτε 2 (κίτρινοι κύκλοι)
είτε 6 (πράσινοι κύκλοι) .............................................................................................. 13
Εικόνα 3.2: Εκτέλεση ιεραρχικού αλγορίθμου ............................................................ 15
Εικόνα 3.3: Αριστερά τα αρχικά στοιχεία & δεξιά ο τρόπος καθορισμού των
συστάδων μέσω της διαμεριστικής συσταδοποίησης ................................................ 15
Εικόνα 3.4: Δομή του CF-TREE. B είναι ο συντελεστής διακλάδωσης & κάθε φύλλο
έχει το πολύ L «CF» που πληρούν το κατώφλι Τ ......................................................... 23
Εικόνα 3.5: Διάγραμμα ροής του BIRCH ...................................................................... 24
Εικόνα 3.6: Διαφορετικές αρχικοποιήσεις των κεντροειδών ...................................... 27
Εικόνα 3.7: Διαφορετικά αποτελέσματα του k-means πάνω στα ίδια δεδομένα (κ =2,
κ = 3) ............................................................................................................................. 28
Εικόνα 3.8: Ορισμένες περιπτώσεις αδυναμίας ομαδοποίησης μέσω του k-means . 28
Εικόνα 3.9: Παράδειγμα DBSCAN με MinPts = 7. Το σημείο C είναι θόρυβος, το B
οριακό σημείο (του Α), και το Α βασικό σημείο .......................................................... 30
Εικόνα 3.10: Αριστερά φαίνεται η ΣΥΣΤΑΔΟΠΟΙΗΣΗ μέσω του K-means και δεξιά μέσω
του DBSCAN ................................................................................................................. 34
Εικόνα 3.11: Εκτέλεση του DBSCAN στην ίδια βάση δεδομένων με Eps:0.15
(αριστερά) & Eps:0.25 (δεξιά) ..................................................................................... 35
Εικόνα 3.12: Εκτέλεση του DBSCAN στην ίδια βάση δεδομένων, (αριστερά) χωρίς να
έχει γίνει προεπεξεργασία των δεδομένων, (δεξιά) μέσω Standardization ............... 36
Εικόνα 4.1: Το μοντέλο MapReduce ............................................................................ 41
Εικόνα 4.2: Παράδειγμα εκτέλεσης του MapReduce για τον υπολογισμό του
αριθμού των συμβόλων .............................................................................................. 43
Εικόνα 4.3: Αρχιτεκτονική Hadoop 2.0 [21]................................................................. 45
Εικόνα 4.4: Αρχιτεκτονική YARN .................................................................................. 47
Εικόνα 4.5: Οι βιβλιοθήκες του Spark ......................................................................... 50
Εικόνα 4.6: Η αρχιτεκτονική του Spark Streaming ...................................................... 51
Εικόνα 4.7: Το διάγραμμα ροής του RDD .................................................................... 53
Εικόνα 4.8: Narrow Transformations (αριστερά) και Wide Transformations (δεξιά).Σε
λειτουργίες που χρησιμοποιούν wide transformations χρησιμοποιείται το data
shuffling ....................................................................................................................... 54
Εικόνα 4.9: Ο catalyst/optimizer του Apache Spark SQL ............................................. 56
Εικόνα 5.1: MR-DBSCAN flow chart [33] ..................................................................... 60
Εικόνα 5.2: Διαχωρισμός των δεδομένων σε 3 τμήματα S1,S2 και S3 ....................... 61
Εικόνα 5.3: Τα τμήματα S12. S23 είναι τα τμήματα S1 και S2 ολισθημένα κατά Eps 63
Εικόνα 5.4: Δημιουργία πλέγματος και partitioning flow chart .................................. 65
Εικόνα 5.5: Καρτεσιανό σύστημα ................................................................................ 68

iv
Εικόνα 5.6: Η εύρεση των γειτονικών στοιχείων μέσω DataFrames .......................... 69
Εικόνα 5.7: Η εύρεση των γειτονικών στοιχείων μέσω DataFrames .......................... 70
Εικόνα 5.8: DBSCAN Flow chart .................................................................................. 72
Εικόνα 5.9 local DBSCAN & run connected component Flow chart .......................... 73
Εικόνα 6.1: Οι βάσεις δεδομένων που χρησιμοποιήθηκαν για την αξιόλογη του
αλγορίθμου .................................................................................................................. 75
Εικόνα 6.2: Αποτελέσματα συγκρίσεων με τον sklearn DBSCAN ................................ 78
Εικόνα 6.3: Αποτελέσματα συγκρίσεων με τον Apache Spark K-means ..................... 79
Εικόνα 6.4: Αριστερά είναι οι πραγματικές συστάδες και δεξιά τα αποτελέσματα του
κάθε αλγορίθμου. ........................................................................................................ 82
Εικόνα 6.5: classification report................................................................................... 82

v
ΠΕΡΙΛΗΨΗ
Η συσταδοποίηση είναι μια κοινή τεχνική για την ανάλυση δεδομένων, η οποία
χρησιμοποιείται σε πολλούς τομείς, όπως είναι η μηχανική μάθηση, η εξόρυξη
δεδομένων, η αναγνώριση προτύπων, η ανάλυση εικόνας και η βιοπληροφορική. Η
συσταδοποίηση είναι η διαδικασία ομαδοποίησης παρόμοιων αντικειμένων σε
διαφορετικές ομάδες. Ένα από τα μεγαλύτερα προβλήματα σήμερα είναι ο
αυξανόμενος αριθμός δεδομένων που πρέπει να αναλύσουμε. Με αυτήν τη
διπλωματική εργασία, επιχειρείται να υλοποιηθεί ο DBSCAN, ένας γνωστός
αλγόριθμος συσταδοποίησης, στην πλατφόρμα Apache Spark ώστε να είναι δυνατή
η εκτέλεσή του σε ένα κατανεμημένο σύστημα με σκοπό να υπερκεραστούν τα
προβλήματα των υπαρχόντων υλοποιήσεων όταν αυτές εφαρμόζονται σε δεδομένα
μεγάλου όγκου. Αναλύονται οι αρχές λειτουργίας του DBSCAN και οι τροποποιήσεις
που έγιναν καθώς και οι λόγους για τους οποίους ήταν απαραίτητες. Τέλος,
εκτελείται μια σειρά πειραμάτων για την αξιολόγηση της απόδοσης του σε
σύγκριση με άλλους αλγορίθμους συσταδοποίησης που παρέχονται από το Apache
Spark όπως o GMM και ο K-means. Αναφέρονται επίσης οι περιορισμοί της
προτεινόμενης προσέγγισής.

vi

vii
ABSTRACT
Clustering is a common technique for data analysis, which is used in many fields,
including machine learning, data mining, pattern recognition, image analysis and
bioinformatics. Clustering is the process of grouping similar objects into different
groups. One of the biggest problems nowadays is the increasing volume of data
which must be analyzed. This thesis addresses the problem by implementing
DBSCAN, a well-known clustering algorithm, using the Apache Spark framework in
order to allow its execution on a computer cluster. This approach aims to overcome
the issues state of the art implementations face when they deal with high volumes
of data. The basic ideas of how DBSCAN works are presented and the proposed
modifications are thoroughly explained along with the reasons they were necessary.
Furthermore, a series of experiments are executed to evaluate the performance of
the algorithm in comparison to other clustering algorithms which are provided by
Spark such as GMM and K-means. Limitations of our approach are also discussed.

viii

1
1 ΕΙΣΑΓΩΓΗ
Στο κεφάλαιο αυτό γίνεται μια εισαγωγή στη διπλωματική εργασία. Παρουσιάζεται
η δομή της και αναφέρονται οι στόχοι που τέθηκαν στο ξεκίνημα και κατά τη
διάρκεια της υλοποίησής της.
1.1 ΣΗΜΑΣΙΑ ΤΟΥ ΠΡΟΒΛΗΜΑΤΟΣ Στις μέρες μας, οι περισσότερες από τις δραστηριότητες που κάνουμε καθημερινά,
όπως η χρήση του Google, Facebook, Twitter αλλά και άλλων διαδικτυακών μέσων
παράγουν τεράστιο όγκο δεδομένων γνωστών και ως big data.
Για τον λόγο αυτό, η έρευνα διεθνώς προσανατολίζεται στην αναζήτηση τρόπων
ασφαλούς διαχείρισης, αποθήκευσης και ανάλυσης των συγκεκριμένων δεδομένων.
Αυτό επιτυγχάνεται μέσω της εξόρυξη δεδομένων ή αλλιώς data mining.
Μια από τις τεχνικές που χρησιμοποιούνται στην εξόρυξη δεδομένων είναι αυτή της
Συσταδοποίησης, η οποία είναι η διαδικασία ανακάλυψης ομάδων και δομών στα
δεδομένα που είναι «παρόμοια» κατά κάποιο τρόπο, χωρίς όμως να
χρησιμοποιούνται γνωστές δομές στα δεδομένα.
Για τη γρήγορη και αποδοτική διαχείριση του μεγάλου όγκου δεδομένων είναι
απαραίτητη η χρήση κατανεμημένων συστημάτων τα οποία επιτρέπουν την
ταυτόχρονη εκτέλεση πολλαπλών συνεργαζόμενων προγραμμάτων σε μία ή
περισσότερες επεξεργαστικές μονάδες.[4]
1.2 ΣΥΝΕΙΣΦΟΡΑ ΤΗΣ ΔΙΠΛΩΜΑΤΙΚΗΣ ΕΡΓΑΣΙΑΣ Μέσω της συγκεκριμένης μελέτης που αναπτύσσεται στη διπλωματική εργασία,
επιδιώκεται η αποτελεσματική ανάλυση και συσταδοποίηση των δεδομένων (data
clustering) μέσω του Apache Spark. Πιο συγκεκριμένα, δοκιμάζονται αρχικά
ορισμένες υλοποιημένες τεχνικές όπως ο αλγόριθμος K-means και έπειτα
ακολουθεί η αξιολόγησή τους με ένα συγκεκριμένο σετ δεδομένων. Στη συνέχεια,
δημιουργείται μια νέα τεχνική από τη μεριά μας, η οποία αναλύεται παρακάτω.
Μέσω της πειραματικής ανάλυσης γίνονται εμφανή τα σημεία αδυναμίας των
υπαρχόντων μεθόδων και κατά συνέπεια η συνεισφορά της νέας τεχνικής στο
μείζον πρόβλημα της συσταδοποίησης των δεδομένων πάνω στα big data.
1.3 ΔΙΑΡΘΡΩΣΗ ΤΗΣ ΔΙΠΛΩΜΑΤΙΚΗΣ ΕΡΓΑΣΙΑΣ Η διπλωματική εργασία αποτελείται από 7 κεφάλαια και είναι οργανωμένα ως εξής.
Στο κεφάλαιο 2 γίνεται μια εισαγωγή στην έννοια της εξόρυξης δεδομένων, των
διαφορετικών μοντέλων και των διαφορών τους. Στο κεφάλαιο 3 αναλύονται 3
αλγόριθμοι συσταδοποίησης (K-Means/DBSCAN/BIRCH), γίνεται μια αναφορά στις
περιπτώσεις κατά τις οποίες εφαρμόζεται καθένας από αυτούς, καθώς και στα
πλεονεκτήματα/μειονεκτήματά τους. Επίσης αναφέρονται οι τρόποι αξιολόγησης
των αλγορίθμων συσταδοποίησης όπως και τρόποι βελτιστοποίησής τους.

2
Στο κεφάλαιο 4 γίνεται αναφορά σε διαφορετικές πλατφόρμες που
χρησιμοποιούνται σε κατανεμημένα συστήματα και στις τεχνικές που
χρησιμοποιούν. Αρχικά, παρατίθεται το κλασικό μοντέλο MapReduce, καθώς και
άλλα που οδήγησαν στις επεκτάσεις του (Apache Hadoop και Apache Spark). Τέλος,
αναλύονται οι βιβλιοθήκες του Apache Spark και η αρχιτεκτονική του, πάνω στην
οποία υλοποιήθηκε ο αλγόριθμος που προτείνεται.
Στο κεφάλαιο 5 παρουσιάζεται ένας νέος αλγόριθμος βασισμένος στο DBSCAN με τη
χρήση πλέγματος. Βασικός στόχος της συγκεκριμένης υλοποίησης είναι η
συσταδοποίηση μεγάλου όγκου δεδομένων μέσω του Apache Spark
χρησιμοποιώντας τις βιβλιοθήκες Spark SQL και DataFrames.
Στο κεφάλαιο 6 παρουσιάζονται τα αποτελέσματα της πειραματικής αξιολόγησης
που πραγματοποιήθηκε για τη σύγκριση του νέου αλγόριθμου με υπάρχουσες
υλοποιήσεις (sklearn DBSCAN) αλλά και αλγορίθμων όπως ο K-means τόσο πάνω σε
συνθετικά αλλά και σε πραγματικά δεδομένα.
Στο κεφάλαιο 7 καταγράφονται τα συμπεράσματα και αναφέρονται οι επεκτάσεις
που μπορούν να γίνουν. Τέλος, στο κεφάλαιο 8 παρουσιάζεται η βιβλιογραφία που
αξιοποιήθηκε κατά την εκπόνηση της συγκεκριμένης διπλωματικής εργασίας.

3
2 ΘΕΩΡΗΤΙΚΟ ΥΠΟΒΑΘΡΟ
Στόχος αυτού του κεφαλαίου είναι να αναλυθούν οι έννοιες της εξόρυξης
δεδομένων. Πιο συγκεκριμένα, γίνεται μια αναφορά στην ανακάλυψη γνώσης από
βάσεις δεδομένων και στις διαφορές που έχει από την εξόρυξη δεδομένων. Στη
συνέχεια, καταγράφονται οι διαφορετικοί τύποι των μοντέλων εξόρυξης δεδομένων
και τέλος η συμβολή που έχει η εξόρυξη δεδομένων σε αρκετούς τομείς.
2.1 ΑΝΑΚΑΛΥΨΗ ΓΝΩΣΗΣ ΑΠΟ ΒΑΣΕΙΣ ΔΕΔΟΜΕΝΩΝ
Τι είναι η ανακάλυψη γνώσης από βάσεις δεδομένων 2.1.1Πολλές φορές οι έννοιες της εξόρυξης δεδομένων και της ανακάλυψης γνώσης
θεωρούνται το ίδιο. Η πρακτική αυτή ακολουθείται χάριν ευκολίας, γιατί ο όρος
«Ανακάλυψη Γνώσης σε Βάσεις Δεδομένων» είναι δύσχρηστος.
Οι Frawley, Piatesky-Shaphiro and Matheus, ορίζουν ως ανακάλυψη γνώσης από
βάσεις δεδομένων μια ντετερμινιστική διαδικασία αναγνώρισης έγκυρων,
καινοτόμων, ενδεχομένως χρήσιμων και εντέλει κατανοητών προτύπων στα
δεδομένα.
Η εξόρυξη δεδομένων αποτελεί ένα μόνο από τα βασικά στάδια που εκτελούνται
κατά την ανακάλυψη γνώσης από βάσεις δεδομένων, καθώς η ανακάλυψη γνώσης
είναι μια ευρύτερη διαδικασία η οποία συμπεριλαμβάνει αρκετά στάδια πέραν της
εξόρυξης δεδομένων.
Τα δεδομένα στην απλή τους μορφή δεν είναι πάρα μια απλή συλλογή
διαφορετικών στοιχείων από τα οποία όμως λίγη πληροφορία μπορεί να εξαχθεί.
Μαζί όμως με την ανάπτυξη των μεθόδων ανακάλυψης γνώσης (data mining & KDD)
η αξία της πληροφορίας έχει βελτιωθεί.
Η ανακάλυψη γνώσης από βάσεις δεδομένων (KDD) είναι μια διαδικασία η οποία
αποτελείται από πολλά στάδια. Πιο συγκεκριμένα, είναι η παραγωγή λειτουργικής
γνώσης η οποία προκύπτει από την επεξεργασία και ανάλυση των δεδομένων που
δίνονται. Αναφέρεται σε ολόκληρη τη διαδικασία, η οποία αρχίζει με τη συλλογή
των απαιτούμενων δεδομένων, την επεξεργασία τους σε κατάλληλη μορφή και
συνεχίζει με τη χρήση των κατάλληλων αλγορίθμων, όπως φυσικά και με την
αξιολόγηση (evaluation) των αποτελεσμάτων.
Τα βασικά στάδια της ανακάλυψης γνώσης από βάσεις δεδομένων είναι (Σχήμα
1.1):
i. Συλλογή δεδομένων (data collection)
ii. Προεπεξεργασία δεδομένων (preprocessing)
iii. Μετασχηματισμός δεδομένων (transformation)
iv. Εξόρυξη δεδομένων (data mining)
v. Διερμηνεία και Αξιολόγηση (interpretation /evaluation)

4
Εικόνα 2.1 Τα βασικά στάδια ανακάλυψης γνώσης από βάσεις δεδομένων
Τα βασικά στάδια ανακάλυψης γνώσης από βάσεις δεδομένων 2.1.2
Συλλογή δεδομένων (Data Collection)
Αρχικά, στη διαδικασία ανακάλυψης γνώσης από βάσεις δεδομένων γίνεται μια
συλλογή όλων των απαιτούμενων δεδομένων και φυσικά η αποθήκευσή τους. Η
συλλογή αυτών των δεδομένων μπορεί να πραγματοποιηθεί είτε με αυτόματο
τρόπο, όπως για παράδειγμα μετρήσεις από έναν μετεωρολογικό σταθμό, είτε
χειροκίνητα π.χ. βαθμολογία φοιτητών ανά εξεταστική. Λανθασμένες μετρήσεις
από τον μετεωρολογικό σταθμό λόγω βλάβης θα δημιουργήσουν ελλιπή ή
λανθασμένα δεδομένα. Όμοια η «δειγματοληψία» των φοιτητών ανά εξεταστική
και όχι όλο το σύνολο των φοιτητών (για μείωση του όγκου των δεδομένων) θα έχει
ως αποτέλεσμα τα δεδομένα να μην είναι τα αναμενόμενα, αν δεν έχει γίνει με
σωστό τρόπο. Την επίλυση τέτοιων προβλημάτων αναλαμβάνει το επόμενο στάδιο,
το οποίο είναι η προεπεξεργασία των δεδομένων. Επειδή αυτό το στάδιο είναι ίσως
το πιο χρονοβόρο, είναι σημαντικό η συλλογή των δεδομένων να γίνει με τρόπο
τέτοιο, ώστε να μην είναι απαραίτητο να γίνουν πολλές ενέργειες στα επόμενα
στάδια. Αυτό θα έχει ως αποτέλεσμα να μειωθεί σημαντικά ο χρόνος εκτέλεσης
αλλά και η ποιότητα του τελικού αποτελέσματος.

5
Προεπεξεργασία δεδομένων (Preprocessing)
Αφότου έχει ολοκληρωθεί η συλλογή των δεδομένων, ακολουθεί το στάδιο της
προεπεξεργασίας των δεδομένων αυτών. Σε αυτό το στάδιο ουσιαστικά
«αφαιρούνται» ελλιπή δεδομένα που έχουν προκύψει ή λανθασμένες τιμές. Ως
παράδειγμα θα μπορούσαμε να αναφέρουμε τα διπλότυπα (δύο ή περισσότερες
φορές η ίδια ακριβώς μέτρηση) ή ελλιπή δεδομένα.
Η προεπεξεργασία των δεδομένων μπορεί να απαιτήσει έως και το 60% της
συνολικής εκτέλεσης σε περιπτώσεις που τα δεδομένα έχουν σε μεγάλο βαθμό
«θόρυβο», γι’ αυτό είναι σημαντικό να γίνει σωστή συλλογή των δεδομένων στο
πρώτο βήμα.
Μετασχηματισμός δεδομένων (Transformation)
Η αξιοπιστία των δεδομένων έχει βελτιωθεί αρκετά μετά την ολοκλήρωση της
προεπεξεργασίας τους. Παρ’ όλα αυτά σε αρκετές περιπτώσεις είναι αναγκαίο να
εφαρμοστεί ένας μετασχηματισμός, ώστε να μπορέσει στη συνέχεια να εφαρμοστεί
ένας αλγόριθμος. Στόχος του μετασχηματισμού των δεδομένων είναι η μετατροπή
τους σε μια διαφορετική μορφή. Δύο από τις πιο συνηθισμένες τεχνικές είναι αυτή
της διακριτοποίησης, κατά την οποία οι αριθμητικές τιμές μετατρέπονται σε
ονομαστικές, και αυτή της κανονικοποίησης (normalization), κατά την οποία γίνεται
αναγωγή των αριθμητικών τιμών σε άλλες αριθμητικές τιμές, που κυμαίνονται
εντός των ορίων μιας επιθυμητής περιοχής. Αφότου έχει ολοκληρωθεί ο
μετασχηματισμός των δεδομένων, τα δεδομένα είναι πλέον στην κατάλληλη μορφή
ώστε να εφαρμοστεί κάποιος αλγόριθμος εξόρυξης δεδομένων.
Εξόρυξη Δεδομένων
Σε αυτό το στάδιο έχουν πλέον εκτελεστεί όλες οι απαραίτητες ενέργειες για τον
καθορισμό και τον μετασχηματισμό των δεδομένων. Το επόμενο στάδιο είναι η
εφαρμογή κάποιου αλγορίθμου για τη δημιουργία ενός μοντέλου. Οι αλγόριθμοι
που μπορούν να χρησιμοποιηθούν σε αυτό το στάδιο ποικίλλουν ανάλογα με τις
ανάγκες και τους τελικούς στόχους, αλλά και τις γνώσεις που έχουμε πάνω στα
δεδομένα. Ο στόχος σε αυτό το στάδιο εξαρτάται από τις ανάγκες μας. Για
παράδειγμα, ας υποθέσουμε ότι έχουμε μετρήσεις των θερμοκρασιών και των
ακραίων φαινομένων του περασμένου χρόνου στην Ελλάδα. Αν ο στόχος είναι να
βρεθεί η πιθανότητα να συμβούν ξανά ακραία καιρικά φαινόμενα, τότε σ’ αυτό το
στάδιο θα εφαρμοστεί κάποιο «προβλεπτικό μοντέλο». Αν αντίθετα στόχος είναι να
βρεθούν συσχετίσεις μεταξύ των δεδομένων, τότε θα εφαρμοστεί κάποιο
«περιγραφικό μοντέλο». Τα είδη των μοντέλων που προκύπτουν ανάλογα με τους
αλγορίθμους που εφαρμόζονται σε αυτό το στάδιο αναλύονται με λεπτομέρειες
στην ενότητα 2.2.

6
Διερμηνεία και Αξιολόγηση
Το τελευταίο στάδιο είναι η αξιολόγηση των δεδομένων που έχουν προκύψει. Η πιο
συνηθισμένη τεχνική για περιγραφικά μοντέλα είναι αυτή της οπτικοποίησης, κατά
την οποία τα αποτελέσματα εμφανίζονται με τη μορφή κάποιου «πίνακα» ή
«σχήματος».
2.2 ΕΞΟΡΥΞΗ ΔΕΔΟΜΕΝΩΝ - ΤΥΠΟΙ ΜΟΝΤΕΛΩΝ
Ο στόχος της εξόρυξης δεδομένων είναι να προσδιοριστούν έγκυροι, νέοι, δυνητικά
χρήσιμοι και κατανοητοί συσχετισμοί και πρότυπα σε υπάρχοντα δεδομένα (Chang
& Hsu, 2005). Τα καθήκοντα της εξόρυξης δεδομένων μπορούν να διαμορφωθούν
είτε ως προβλεπτικά είτε ως περιγραφικά (Dunham, 2003).
Τα μοντέλα που παράγονται από το στάδιο της εξόρυξης δεδομένων διακρίνονται
σε δύο βασικούς τύπους:
Προβλεπτικό (predictive): Τα προβλεπτικά μοντέλα εξόρυξης δεδομένων
παρουσιάζουν ένα μοντέλο από το διαθέσιμο σύνολο δεδομένων που είναι
χρήσιμο για την πρόβλεψη άγνωστων ή μελλοντικών τιμών ενός άλλου συνόλου
δεδομένων. Ουσιαστικά κάνουν μια πρόβλεψη των μελλοντικών δεδομένων. Για
παράδειγμα ένας γιατρός που προσπαθεί να διαγνώσει μια ασθένεια με βάση
τα αποτελέσματα των ιατρικών εξετάσεων ενός ασθενούς. Ορισμένες από τις
εργασίες για τη δημιουργία ενός προβλεπτικού μοντέλου είναι η
κατηγοριοποίηση & πρόβλεψη, η ανάλυση χρονοσειρών και η παλινδρόμηση.
Περιγραφικό (descriptive): Στα περιγραφικά μοντέλα συνήθως η προσπάθεια
στοχεύει στην εύρεση δεδομένων που περιγράφουν πρότυπα ή σχέσεις, τα
οποία παρουσιάζουν νέες σημαντικές πληροφορίες από το διαθέσιμο υπάρχον
σύνολο δεδομένων. Σε αντίθεση με τα προβλεπτικά μοντέλα, ένα περιγραφικό
μοντέλο χρησιμεύει ως ένας τρόπος για να εξερευνηθούν οι ιδιότητες του
συνόλου δεδομένων που δόθηκαν ως είσοδος.
Για παράδειγμα, μια διαφημιστική εταιρία θα μπορούσε να αναλύσει έναν
γενικό πληθυσμό, προκειμένου να ταξινομήσει τους πιθανούς πελάτες σε
διαφορετικά συμπλέγματα και στη συνέχεια να αναπτύξει ξεχωριστές
διαφημιστικές καμπάνιες που στοχεύουν σε κάθε ομάδα. Στην ανίχνευση της
ηλεκτρονικής απάτης γίνεται επίσης χρήση της ομαδοποίησης για τον εντοπισμό
ομάδων ατόμων με παρόμοια πρότυπα αγορών.
Οι πιο γνωστές εργασίες για τη δημιουργία ενός περιγραφικού μοντέλου είναι η
συσταδοποίηση, η παρουσίαση συνόψεων, οι κανόνες συσχέτισης και η
ανακάλυψη ακολουθιών.

7
Εικόνα 2.2: Είδη μοντέλων εξόρυξης δεδομένων
Προβλεπτικά μοντέλα 2.2.1
Μέσω των προβλεπτικών μοντέλων είναι δυνατό να γίνει μια «πρόβλεψη» για το
μέλλον. Μια κλασική εφαρμογή των μοντέλων αυτών είναι στη Μετεωρολογία,
όπου είναι επιθυμητή η πρόβλεψη της θερμοκρασίας των επόμενων ημέρων με όσο
το δυνατόν μεγαλύτερη ακρίβεια. Παρ’ όλα αυτά υπάρχουν αρκετοί άλλοι τομείς
στους οποίους μπορούν να χρησιμοποιηθούν τέτοια μοντέλα, όπως το φιλτράρισμα
«spamming e-mails». Είναι σημαντικό να αναφερθεί ότι η πρόβλεψη δεν είναι
πάντα σωστή. Για τη βελτίωση της ακρίβεια είναι αναγκαία η αύξηση των
δειγμάτων (training set), γεγονός που έχει ως αποτέλεσμα τη σημαντική αύξηση του
κόστους υπολογισμού.
Θα μπορούσε να ειπωθεί με απλά λόγια ότι τα προβλεπτικά μοντέλα απαντάνε στην
ερώτηση «Τι θα γίνει».
Ορισμένες από τις εργασίες για τη δημιουργία ενός προβλεπτικού μοντέλου είναι η
κατηγοριοποίηση & πρόβλεψη, η ανάλυση χρονοσειρών και η παλινδρόμηση.
Κατηγοριοποίηση (Classification)
Η Κατηγοριοποίηση χρησιμοποιείται για να κατηγοριοποιήσει κάθε στοιχείο από
ένα σύνολο δεδομένων σε ένα από τα προκαθορισμένα σύνολα κατηγοριών ή
ομάδων. Η μέθοδος κατηγοριοποίησης χρησιμοποιεί μαθηματικές τεχνικές όπως
Bayes, Δέντρα Αποφάσεων, Νευρωνικά Δίκτυα και στατιστικά στοιχεία. Κατά την
κατηγοριοποίηση, αναπτύσσουμε το λογισμικό που μπορεί να μάθει πώς να
κατηγοριοποιεί τα στοιχεία σε ομάδες. Ένα απλό παράδειγμα κατηγοριοποίησης
είναι να γίνει πρόβλεψη αν βρέχει ή όχι βάσει των δεδομένων που έχουν
κατηγοριοποιηθεί (training sample). Η απάντηση μπορεί να είναι είτε ναι είτε όχι.
Έτσι, υπάρχει ένας συγκεκριμένος αριθμός επιλογών. Οι επιλογές μπορεί να είναι
περισσότερες από 2 και σ’ αυτή την περίπτωση υπάρχει κατηγοριοποίηση
πολλαπλών κατηγοριών.

8
Ο όρος της κατηγοριοποίησης συχνά συγχέεται με τον όρο της συσταδοποίησης. Η
πιο σημαντική διαφορά τους είναι ότι στη συσταδοποίηση δεν υπάρχει καθόλου ή
υπάρχει ελάχιστη γνώση πάνω στα δεδομένα και γίνεται προσπάθεια με κάποιο
αλγόριθμο να παραχθεί «χρήσιμη» πληροφορία.
Εικόνα 2.3: Η κατηγοριοποίηση μπορεί να αναπαρασταθεί με διαφορετικούς τρόπους: (α) IF-THEN rules,(b) Δένδρα αποφάσεων,(c) Νευρωνικά Δίκτυα
Κατηγοριοποίηση & Πρόβλεψη (Classification)
Η κατηγοριοποίηση συχνά συγχέεται με τον γενικό όρο της πρόβλεψης. Στην
κατηγοριοποίηση το αποτέλεσμα που επιδιώκεται είναι η πρόβλεψη της κλάσης
των δειγμάτων. Η κλάση μπορεί να πάρει διακριτές τιμές από ένα πεπερασμένο
σύνολο. Αντίθετα, κατά την πρόβλεψη, με χρήση τεχνικών όπως η παλινδρόμηση, η
μεταβλητή-στόχος μπορεί να είναι οποιοσδήποτε πραγματικός αριθμός.
Παλινδρόμηση (Regression)
Πρόκειται για την πιο απλή μορφή παλινδρόμησης. Παλινδρόμηση είναι η μέθοδος
εξόρυξης δεδομένων για τον προσδιορισμό και την ανάλυση της σχέσης μεταξύ των
μεταβλητών μέσω της εύρεσης μιας συνάρτησης που διαμορφώνει τα δεδομένα
χρησιμοποιώντας σφάλματα. Χρησιμοποιείται για τον προσδιορισμό της
πιθανότητας μιας συγκεκριμένης μεταβλητής, δεδομένης της παρουσίας άλλων
μεταβλητών. Αν το αποτέλεσμα αυτό είναι ευθεία τότε θεωρείτε liner μοντέλο, αν
είναι καμπύλη τότε είναι μη ευθύγραμμο μοντέλο. Η σχέση μεταξύ εξαρτημένης
μεταβλητής δίνεται από την ευθεία γραμμή αν έχει μόνο μία εξαρτημένη
μεταβλητή:
𝛶 = 𝛼 + 𝛽𝛸
Το μοντέλο Υ, η γραμμική συνάρτηση του Χ

9
Εικόνα 2.4: Γραμμική Παλινδρόμηση
Ανάλυση χρονοσειρών (Time series analysis)
Μια χρονοσειρά είναι μια ακολουθία σημείων που καταγράφονται σε συγκεκριμένα
χρονικά σημεία συνήθως σε σταθερά χρονικά διαστήματα (λεπτά/ώρες/μέρες). Ο
αριθμός των δεδομένων που παράγονται ειδικά σε βάθος χρόνου είναι τεράστιος,
οπότε η ανάλυσή τους δεν είναι εύκολη. Η αποδοτική ανάλυσή τους είναι ένα
κομμάτι της εξόρυξης δεδομένων. Ως παράδειγμα θα μπορούσε να αναφερθεί ο
δείκτης των τιμών στο χρηματιστήριο. Μέσω της ανάλυσης μπορούν να γίνουν
ορισμένες προβλέψεις σχετικά με τη διακύμανση των τιμών.
Περιγραφικά μοντέλα 2.2.2
Σε αντίθεση με τα προβλεπτικά μοντέλα όπου επιδιώκεται η πρόβλεψη του «τι θα
συμβεί», στα περιγραφικά μοντέλα στόχος είναι η ανάλυση των δεδομένων που
είναι διαθέσιμα με όσο το δυνατόν πιο αποτελεσματικό τρόπο. Τα περιγραφικά
μοντέλα δίνουν απάντηση στο «τι έγινε».

10
Συσταδοποίηση
Η συσταδοποίηση δεδομένων (data clustering) είναι η εργασία του καταμερισμού
ενός ετερογενούς πληθυσμού σε ένα σύνολο συστάδων (clusters). Στη
συσταδοποίηση δεν υπάρχουν προκαθορισμένες κατηγορίες. Οι εγγραφές
ομαδοποιούνται σε σύνολα με βάση την ομοιότητα που παρουσιάζουν μεταξύ τους.
Επαφίεται σε εμάς να καθορίσουμε τη σημασία που θα έχει κάθε μία από τις
ομάδες που προκύπτουν. Για παράδειγμα, ομάδες που περιλαμβάνουν τα
χαρακτηριστικά που σχετίζονται με τα φύλλα και τον καρπό φυτών μπορεί να
υποδεικνύουν διαφορετικές ποικιλίες ενός φυτού.
Στην ενότητα 2.3 γίνεται μια πιο αναλυτική αναφορά σχετικά με τους αλγορίθμους
και τις αποδόσεις που έχουν.
Κανόνες Συσχέτισης
Η εξαγωγή κανόνων συσχέτισης (Mining Association Rules) θεωρείται μια από τις
σημαντικότερες διεργασίες εξόρυξης δεδομένων. Έχει προσελκύσει ιδιαίτερο
ενδιαφέρον, καθώς οι κανόνες συσχέτισης παρέχουν έναν συνοπτικό τρόπο για να
εκφραστούν οι ενδεχομένως χρήσιμες πληροφορίες που γίνονται εύκολα
κατανοητές από τους τελικούς χρήστες. Οι κανόνες συσχέτισης ανακαλύπτουν
κρυμμένες «συσχετίσεις» μεταξύ των γνωρισμάτων ενός συνόλου των δεδομένων.
Αυτοί οι συσχετισμοί παρουσιάζονται στην ακόλουθη μορφή: Α→Β όπου το Α και το
Β αναφέρονται στα σύνολα γνωρισμάτων που υπάρχουν στα υπό ανάλυση
δεδομένα.
2.3 ΕΞΟΡΥΞΗ ΔΕΔΟΜΕΝΩΝ - ΕΦΑΡΜΟΓΕΣ
H εξόρυξη δεδομένων, όπως αναφέρθηκε, είναι μια διαδικασία για την εξαγωγή
χρήσιμων γνώσεων από μεγάλες βάσεις δεδομένων. Η συνεχιζόμενη αύξηση των
δεδομένων έχει ως αποτέλεσμα να χρησιμοποιείται ως λύση σε πολλά προβλήματα.
Η απόκτηση σημαντικών γνώσεων από έναν πολύ μεγάλο όγκο δεδομένων βρίσκει
εφαρμογή σε αρκετούς τομείς, μερικοί από τους οποίους αναλύονται στη
συγκεκριμένη υποενότητα όπως το μάρκετινγκ, η εκπαίδευση κτλ.

11
Μάρκετινγκ
Η διαδικασία εξόρυξης δεδομένων εξάγει πληροφορίες από διάφορες πηγές
δεδομένων που είναι πολύ χρήσιμες στη διαδικασία σχεδιασμού, οργάνωσης,
διαχείρισης και προώθησης νέου προϊόντος με οικονομικά αποδοτικό τρόπο. Η
τεχνική εξόρυξης δεδομένων μάς βοηθά στην κατανόηση της αγοραστικής
συμπεριφοράς ενός αγοραστή όπως, το πόσο συχνά αγοράζει ένα προϊόν, τη
συνολική αξία όλων των αγορών και πότε ήταν η τελευταία αγορά που
πραγματοποίησε. Με την εξόρυξη δεδομένων γίνονται κατανοητές οι ανάγκες του
καταναλωτή και είναι δυνατό να παραχθούν προϊόντα και να προσφερθούν
υπηρεσίες σύμφωνα με την απαίτηση του καταναλωτικού κοινού. Οι βάσεις
δεδομένων μάρκετινγκ είναι μία από τις πιο δημοφιλείς εφαρμογές της εξόρυξης
δεδομένων.
Ιατροφαρμακευτική περίθαλψη
Η εξόρυξη δεδομένων μπορεί να είναι πολύ χρήσιμη για τη βελτίωση του
συστήματος ιατροφαρμακευτικής περίθαλψης. Με την εξόρυξη δεδομένων είναι
δυνατό να προβλεφθεί ο αριθμός των ασθενών, γεγονός που θα βοηθήσει το
σύστημα υγείας να ανταποκριθεί στην απαίτηση όλων των ασθενών να λάβουν την
κατάλληλη φροντίδα τη σωστή στιγμή και στη σωστή θέση. Η εξόρυξη δεδομένων
μπορεί να βοηθήσει όλους τους κλάδους που εμπλέκονται στην ιατροφαρμακευτική
περίθαλψη. Για παράδειγμα, η εξόρυξη δεδομένων μπορεί να βοηθήσει τους
ασφαλιστές στην ιατροφαρμακευτική περίθαλψη να ανιχνεύσουν απάτες και
καταχρήσεις, οι οργανώσεις ιατροφαρμακευτικής περίθαλψης μπορούν να
βελτιώσουν τη λήψη αποφάσεων χρησιμοποιώντας τις γνώσεις που παρέχει η
εξόρυξη δεδομένων κτλ.
Εκπαίδευση
Η Εκπαιδευτική Εξόρυξη Δεδομένων (EDM) είναι ένας νέος αναδυόμενος τομέας
που χρησιμοποιείται για την αντιμετώπιση των προκλήσεων των μαθητών και
βοηθά στην κατανόηση του «πώς μαθαίνουν οι μαθητές» δημιουργώντας μοντέλα
σπουδαστών. Ο κύριος στόχος της εξόρυξης δεδομένων είναι η πρόβλεψη των
μελλοντικών μαθησιακών συμπεριφορών των μαθητών. Η εξόρυξη δεδομένων
χρησιμοποιείται επίσης για να προβλέψει τα αποτελέσματα του σπουδαστή.
Διαδικτυακό εμπόριο
Οι διαδικτυακές πλατφόρμες που σχετίζονται με αγορές όπως το e-Bay, Amazon
κτλ. συλλέγουν μεγάλο όγκο δεδομένων σχετικά με τις πωλήσεις και το ιστορικό
αγορών πελατών. Η εξόρυξη δεδομένων βοηθά στην ανάλυση της συμπεριφοράς
των πελατών, των προτύπων και των τάσεων αγοράς τους και οδηγεί σε καλύτερη
εξυπηρέτηση και ικανοποίησή τους, καθώς και σε ελαχιστοποίηση του κόστους των
επιχειρήσεων.

12
Τραπεζικός τομέας
Ο τραπεζικός κλάδος έχει ωφεληθεί σημαντικά από τις εξελίξεις στην ψηφιακή
τεχνολογία. Η εξόρυξη δεδομένων γίνεται στρατηγικά σημαντικός τομέας για
πολλές επιχειρηματικές οργανώσεις, συμπεριλαμβανομένου του τραπεζικού τομέα.
Η εξόρυξη δεδομένων χρησιμοποιείται στον χρηματοπιστωτικό και τον τραπεζικό
τομέα για ανάλυση πιστώσεων, δόλιες συναλλαγές, διαχείριση μετρητών και
πρόβλεψη πληρωμής.

13
3 ΣΥΣΤΑΔΟΠΟΙΗΣΗ
Η συσταδοποίηση είναι η διαδικασία εκείνη κατά την οποία ένα σύνολο από
αντικείμενα διαχωρίζονται σε ένα σύνολο από λογικές ομάδες. Η καταχώριση
αντικειμένων σε ίδια ομάδα μεταφράζεται ως ομοιότητα των αντικειμένων αυτών
και αντίστροφα (αντικείμενα που ανήκουν σε διαφορετικές ομάδες είναι ανόμοια).
Η ομοιότητα ή μη, μεταξύ των αντικειμένων, εξαρτάται από το συγκεκριμένο
πρόβλημα και τη μορφή των αντικειμένων [3]. Η συσταδοποίηση ανήκει στα
περιγραφικά μοντέλα, δηλαδή οι «γνώσεις» που έχουμε σχετικά με δεδομένα
εισόδου είναι στην καλύτερη περίπτωση ελάχιστες. Στόχος μας είναι η
ομαδοποίηση των αντικειμένων σε συστάδες. Οι συστάδες που δημιουργούνται
θέλουμε να διαχωρίζουν ορθά τα δεδομένα. Αυτό πρακτικά σημαίνει ότι μια
συστάδα θέλουμε να απαρτίζεται από αντικείμενα, όπου κάθε αντικείμενο είναι πιο
κοντά σε κάθε άλλο αντικείμενο της ίδιας συστάδας απ’ ό,τι σε κάποιο άλλο
αντικείμενο διαφορετικής συστάδας.
Στο πρόβλημα της συσταδοποίησης είναι σημαντικό να αναφερθεί ότι η έννοια της
συστάδας είναι «διφορούμενη» από την άποψη ότι σε ορισμένες περιπτώσεις ο
τελικός αριθμός των συστάδων μπορεί να διαφέρει ανάλογα με τον βαθμό
«ομοιότητας» που θέλουμε να έχουν οι συστάδες μεταξύ τους. Ένα τέτοιο
παράδειγμα φαίνεται στην ακόλουθη εικόνα όπου ο επιθυμητός αριθμός των
συστάδων μπορεί να είναι είτε 2 είτε 6.
Εικόνα 3.1: Ο τελικός αριθμός των συστάδων μπορεί να είναι είτε 2 (κίτρινοι κύκλοι) είτε 6 (πράσινοι
κύκλοι)

14
3.1 ΚΑΤΗΓΟΡΙΕΣ ΣΥΣΤΑΔΟΠΟΙΗΣΗΣ
Η επιλογή του αλγορίθμου συσταδοποίησης είναι ένα πολύ σημαντικό κομμάτι για
την αποτελεσματική και γρήγορη ομαδοποίηση των δεδομένων εισόδου. Όπως
αναφέρθηκε πριν, ο βασικός μας στόχος είναι ο διαχωρισμός των δεδομένων σε
ομάδες που έχουν κοινά χαρακτηριστικά. Η συσταδοποίηση δεν είναι ένας
συγκεκριμένος αλγόριθμος, αλλά το γενικό πρόβλημα που πρέπει να επιλυθεί.
Μπορεί να επιτευχθεί με διαφορετικά μοντέλα, τα οποία χωρίζονται σε κατηγορίες
ανάλογα με τον τρόπο με τον οποίο επιλύουν το πρόβλημα και διαφέρουν
σημαντικά τόσο στη λογική που ακολουθούν όσο και στα αποτελέσματα [28].
Υπάρχουν πάνω από 100 δημοσιευμένοι αλγόριθμοι συσταδοποίησης και η
κατηγοριοποίησή τους δεν είναι εύκολη, καθώς για αρκετούς από αυτούς τους
αλγορίθμους δεν υπάρχει κάποιο σχετικό μοντέλο.
Ιεραρχική συσταδοποίηση
Οι αλγόριθμοι αυτής της κατηγορίας δημιουργούν μια ιεραρχία εμφωλευμένων
συσταδοποιήσεων. Αυτό σημαίνει ότι οι συστάδες περιέχουν εσωτερικά στοιχεία
από μια διαφορετική συστάδα, γεγονός που συμβαίνει αναδρομικά, υπό την έννοια
ότι και αυτές οι συστάδες με τη σειρά τους περιέχουν στοιχεία από άλλες
μικρότερες συστάδες. Με αυτόν τον τρόπο δημιουργούνται τα επίπεδα της
ιεραρχίας όπως φαίνεται στην εικόνα 3.2. Οι αλγόριθμοι αυτοί μπορούν να
αναπαρασταθούν μέσω δένδρων γνωστών και ως dendrograms. Ένα πλεονέκτημα
αυτών των αλγορίθμων είναι το γεγονός ότι δεν χρειάζονται ως είσοδο από τον
χρήστη τον αριθμό των τελικών συστάδων, μιας και όλα τα πιθανά αποτελέσματα
υπολογίζονται και η επιλογή γίνεται απλά «κόβοντας» το δενδρόγραμμα στο
επιθυμητό επίπεδο.
Υπάρχουν δύο βασικές υποκατηγορίες:
Οι συσσωρευτικοί ιεραρχικοί αλγόριθμοι, στους οποίους έχουμε μια
προσέγγιση «από τη βάση προς την κορυφή», δηλαδή κάθε παρατήρηση
ξεκινά από τη δική της συστάδα και ζευγάρια ομάδων συγχωνεύονται καθώς
κάποιος μετακινεί την ιεραρχία.
Οι διαιρετικοί ιεραρχικοί αλγόριθμοι, στους οποίους έχουμε μια προσέγγιση
«από την κορυφή προς τη βάση», δηλαδή όλες οι παρατηρήσεις αρχίζουν σε
μία συστάδα και οι διαχωρισμοί εκτελούνται αναδρομικά, καθώς
μετακινείται προς τα κάτω στην ιεραρχία.

15
Εικόνα 3.2: Εκτέλεση ιεραρχικού αλγορίθμου
Διαμεριστική συσταδοποίηση
Σε αυτή την κατηγορία τα δεδομένα χωρίζονται σε ομάδες. Η βασική διαφορά τους
με τους ιεραρχικούς αλγορίθμους είναι ότι ο διαχωρισμός των στοιχείων γίνεται με
τρόπο τέτοιο, ώστε να έχουμε μη επικαλυπτόμενες συστάδες (ομάδες), δηλαδή
κάθε στοιχείο να ανήκει αποκλειστικά σε μία μόνο υποσυστάδα (Εικόνα 3.3).
Συνήθως ο τελικός αριθμός των συστάδων δίνεται από τον χρήστη, κάτι που
καθιστά αυτά τα μοντέλα σχετικά αδύναμα σε περιπτώσεις που δεν υπάρχει αρκετή
γνώση πάνω στα δεδομένα που είναι προς ομαδοποίηση. Χαρακτηριστικός
αλγόριθμος αυτής της κατηγορίας είναι ο K-means. Βασικό μειονέκτημα όλων των
αλγορίθμων αυτής της κατηγορίας είναι πως η βελτιστοποίησή τους είναι ένα
πρόβλημα NP-HARD οπότε τα αποτελέσματα που δίνουν είναι προσεγγιστικά σε
αρκετές περιπτώσεις.
Εικόνα 3.3: Αριστερά τα αρχικά στοιχεία & δεξιά ο τρόπος καθορισμού των συστάδων μέσω της διαμεριστικής συσταδοποίησης

16
Βασισμένη στην πυκνότητα
Σε αυτή την κατηγορία οι συστάδες ορίζονται ως περιοχές υψηλότερης πυκνότητας
από το υπόλοιπο του συνόλου δεδομένων. Τα δεδομένα/σημεία σε περιοχές που
δεν έχουν υψηλή πυκνότητα (αραιές περιοχές) συνήθως θεωρούνται θόρυβος. Ο
πιο γνωστός αλγόριθμος που βασίζεται στην πυκνότητα είναι ο DBSCAN με βασικό
πλεονέκτημα τη δυνατότητά του να βρίσκει αυθαίρετα σχήματα με προϋπόθεση ότι
υπάρχουν «πυκνές και αραιές» περιοχές. Ο OPTICS είναι μια γενίκευση του DBSCAN
με βασικό πλεονέκτημα ότι απαιτεί λιγότερες παραμέτρους από τον χρήστη (μία
παράμετρο αντί για δύο). Το κύριο μειονέκτημα τέτοιων μεθόδων είναι καταρχάς το
υψηλό υπολογιστικό κόστος Ο(n2) και το γεγονός ότι για να μπορέσουν να «βρουν»
τις συστάδες πρέπει να υπάρχουν διαφορετικές πυκνότητες στην κατανομή των
δειγμάτων. Σε περιπτώσεις που υπάρχουν επικαλυπτόμενες gaussian κατανομές ο
EM (ή γενικότερα οι αλγόριθμοι που βασίζονται σε κατανομές) έχει πάντα καλύτερα
αποτελέσματα. Επίσης, αν οι συστάδες έχουν «σφαιρικό» σχήμα τότε οι αλγόριθμοι
που βασίζονται στη διαμεριστική συσταδοποίηση έχουν τα ίδια αποτελέσματα με
λιγότερο υπολογιστικό κόστος. Τέλος, ο παραλληλισμός τέτοιων αλγορίθμων είναι
σχετικά δύσκολος αλλά παρ’ όλα αυτά εφικτός.
Μοντέλα κατανομών
Σε αυτά τα μοντέλα ορίζουμε ως συστάδα ένα σύνολο σημείων που ανήκουν στην
ίδια κατανομή. Επειδή πολλές φορές τα δεδομένα προς συσταδοποίηση
προκύπτουν με δειγματοληψία τυχαίων αντικειμένων από μια κατανομή, τέτοια
μοντέλα έχουν αρκετά καλή απόδοση. Αν και θεωρητικά η απόδοσή τους είναι
πάρα πολύ καλή, ένα σημαντικό μειονέκτημά τους είναι η πολυπλοκότητα, η οποία
διαφέρει ανάλογα με την κατανομή των δεδομένων (θεωρείται ως ένα NP-HARD
πρόβλημα), και το overfitting. Ένας από τους συνηθισμένους αλγορίθμους για την
εύρεση των παραμέτρων των GMM μοντέλων είναι ο EM. Σε αυτόν τον αλγόριθμο ο
αριθμός των τελικών συστάδων (ο αριθμών των gaussian κατανομών) δίνεται από
τον χρήστη ως είσοδος, έτσι ώστε να αποφευχθεί η υπερφόρτωση.
Μέτρα απόστασης 3.1.1Η επιλογή των μέτρων απόστασης είναι ένα κρίσιμο βήμα στη συσταδοποίηση.
Καθορίζει τον τρόπο με τον οποίο υπολογίζεται η ομοιότητα δύο στοιχείων (x, y) και
επηρεάζει το τελικό σχήμα και μέγεθος των συστάδων.
Τόσο οι διαμεριστικοί αλγόριθμοι, όπως ο K-means, όσο και οι αλγόριθμοι που
βασίζονται στην πυκνότητα, όπως ο DBSCAN, χρησιμοποιούν την απόσταση για τον
καθορισμό των τελικών συστάδων.
Ευκλείδεια απόσταση
Η πιο διαδεδομένη μέθοδος υπολογισμού απόστασης μεταξύ σημείων είναι η
ευκλείδεια απόσταση γνωστή και ως νόρμα 2:

17
d(p,q)=√∑(pi-qi)2
n
i=0
όπου q = (q1, 𝑞2, … . , q𝑛) & p = (p1, p2, . , p𝑛)
Βασικό μειονέκτημα της ευκλείδειας απόστασης είναι ότι δεν μπορεί να υπολογίσει
με αποδοτικό τρόπο τις αποστάσεις σε περιπτώσεις που τα δείγματα δεν είναι
κανονικοποιημένα και όταν ο αριθμός των διαστάσεων είναι μεγαλύτερος από 3
(n >3). Η πολυπλοκότητα χρόνου είναι Ο(n).
Υπολογισμός μέσω Manhattan.
Σε αυτή την περίπτωση η απόσταση μεταξύ 2 σημείων ισούται με τις απόλυτες
διάφορες των συντεταγμένων, γνωστή και ως νόρμα 1:
d(p,q)= ∑ |𝑝𝑖
𝑛
𝑖=0
+ 𝑞𝑖| όπου q = (q1, 𝑞2, … . , q𝑛) & p = (p1, p2, . , p𝑛)
Τέλος, μια μετρική που πρέπει να αναφερθεί είναι η Minkowski η οποία είναι η
γενικευμένη μετρική απόσταση. Όπου μ = η νόρμα που χρησιμοποιούμε.
d(p,q)= (∑ |𝑝𝑖 + 𝑞𝑖 |𝑚
𝑛
𝑖=0
)
1/𝑚
όπου q = (q1, 𝑞2, … . , q𝑛) & p = (p1, p2, . , p𝑛)
Για m = 1 έχουμε την απόσταση Manhattan και για m = 2 την ευκλείδεια απόσταση.
Εγκυρότητα συσταδοποίησης 3.1.2Ένα από τα πιο σημαντικά θέματα της συσταδοποίησης είναι η αξιολόγηση των
αποτελεσμάτων της ώστε να βρεθούν οι κατάλληλες παράμετροι για τα
συγκεκριμένα δεδομένα.
Ο στόχος των μεθόδων συσταδοποίησης είναι να ανακαλύψουν ομάδες που
υπάρχουν σε ένα σύνολο δεδομένων. Σε γενικές γραμμές, θα πρέπει να βρεθούν
συστάδες των οποίων τα σημεία είναι κοντά μεταξύ τους (δηλαδή έχουν υψηλό
βαθμό ομοιότητας) και είναι καλά διαχωρισμένες. Ένα πρόβλημα που
αντιμετωπίζουμε είναι η επιλογή του βέλτιστου αριθμού συστάδων που ταιριάζει
σε ένα σύνολο δεδομένων.

18
Στις πειραματικές αξιολογήσεις των περισσότερων αλγορίθμων χρησιμοποιούνται
σύνολα δεδομένων 2 διαστάσεων (2-D), προκειμένου ο αναγνώστης να είναι σε
θέση να επαληθεύσει οπτικά την εγκυρότητα των αποτελεσμάτων (δηλαδή πόσο
καλά ο αλγόριθμος ομαδοποίησης ανακάλυψε τις συστάδες του συνόλου
δεδομένων). Είναι σαφές ότι η απεικόνιση των δεδομένων είναι μια κρίσιμη
επαλήθευση των αποτελεσμάτων της ομαδοποίησης.
Τα περισσότερα προβλήματα όμως αφορούν σύνολα δεδομένων που είναι
πολλαπλών διαστάσεων. Σε αυτά τα προβλήματα τόσο η αποτελεσματική
απεικόνισή τους όσο και η κατανόηση των συστάδων, χρησιμοποιώντας τα
διαθέσιμα εργαλεία απεικόνισης, είναι δύσκολη για άτομα που δεν είναι
εξοικειωμένα με χώρους υψηλότερων διαστάσεων.
Οι διάφοροι αλγόριθμοι συσταδοποίησης συμπεριφέρονται με διαφορετικό τρόπο
ανάλογα με:
i) τα χαρακτηριστικά του συνόλου δεδομένων (γεωμετρία και κατανομή πυκνότητας
ομάδων),
ii) τις τιμές παραμέτρων εισόδου.
Για παράδειγμα, στους διαμεριστικούς αλγορίθμους συσταδοποίησης (k-means)
είναι αναγκαίο οι συστάδες να είναι καλά διαχωρισμένες ή να έχουν σφαιρικό
σχήμα, ενώ στους αλγορίθμους βασισμένους στην πυκνότητα είναι σημαντικό να
υπάρχουν περιοχές με υψηλή πυκνότητα (δηλαδή πολλά σημεία) ώστε να
δημιουργηθούν οι συστάδες.
Η εγκυρότητα συσταδοποίησης είναι η διαδικασία κατά την οποία εκτιμάται ότι η
έξοδος του αλγόριθμου είναι ένα σύνολο από ομάδες διανυσμάτων, οι οποίες
πληρούν τον ορισμό της συσταδοποίησης καθώς και ορισμένα επιπλέον κριτήρια.
Υπάρχουν τρεις προσεγγίσεις για τη διερεύνηση της εγκυρότητας των συστάδων
[32].
Οι δύο πρώτες προσεγγίσεις (βασιζόμενα σε εξωτερικά & βασιζόμενα σε εσωτερικά
κριτήρια) στηρίζονται σε στατιστικές δοκιμές και το κύριο μειονέκτημά τους είναι το
υψηλό υπολογιστικό κόστος τους. Επιπλέον, οι δείκτες που σχετίζονται με αυτές τις
προσεγγίσεις αποσκοπούν στη μέτρηση του βαθμού στον οποίο ένα σύνολο
δεδομένων επιβεβαιώνει ένα προκαθορισμένο σχήμα. Από την άλλη πλευρά, η
τρίτη προσέγγιση στοχεύει στην εξεύρεση του καλύτερου σχήματος ομαδοποίησης,
στο οποίο μπορεί να οριστεί ένας αλγόριθμος ομαδοποίησης σε ορισμένες
παραδοχές και παραμέτρους.[32]

19
Βασιζόμενα σε εξωτερικά κριτήρια
Στη συγκεκριμένη μελέτη τα αποτελέσματα της ομαδοποίησης αξιολογούνται βάσει
δεδομένων που δεν χρησιμοποιήθηκαν για ομαδοποίηση. Αυτά τα σημεία
αποτελούνται από ένα σύνολο προ-ταξινομημένων αντικειμένων και αυτά τα
σύνολα συχνά δημιουργούνται από ανθρώπους (ειδικούς). Αυτοί οι τύποι μεθόδων
αξιολόγησης υπολογίζουν πόσο κοντά είναι η ομαδοποίηση στις προκαθορισμένες
τάξεις αναφοράς. Ωστόσο, το αρνητικό χαρακτηριστικό των συγκεκριμένων
μεθόδων είναι το γεγονός ότι πρέπει να έχουμε «γνώση» σχετικά με τα δεδομένα
που είναι προς ομαδοποίηση. Αν χρησιμοποιηθούν πραγματικά δεδομένα και όχι
συνθετικά, τότε θα προκύψει πρόβλημα αν η προ-ταξινόμηση δεν έχει γίνει με
σωστό τρόπο.
Υπάρχουν διάφορα μέτρα εξωτερικής αξιολόγησης. Για τον υπολογισμό τους
ορίζονται οι εξής μεταβλητές:
Έστω C = { c1, c2… ck} είναι μια δομή συσταδοποίησης ενός συνόλου δεδομένων X με
την έξοδο του αλγορίθμου P = { P1, P2… Pk}.
Τότε ορίζουμε τις μεταβλητές TP, TN,FN,FP ως εξής:
TP = το πλήθος των διανυσμάτων που ανήκουν σε ίδια ομάδα κατά τη
συσταδοποίηση C και P
TN = το πλήθος των διανυσμάτων που ανήκουν σε διαφορετική ομάδα κατά τη
συσταδοποίηση C και P
FN = το πλήθος των διανυσμάτων που ανήκουν σε διαφορετική ομάδα κατά τη
συσταδοποίηση C, ενώ ανήκουν στην ίδια ομάδα κατά την P
FP = το πλήθος των διανυσμάτων που ανήκουν στην ίδια ομάδα κατά τη
συσταδοποίηση C, ενώ ανήκουν σε διαφορετικές ομάδες κατά την P
RI (Rand Index): μέσω του οποίου μπορούμε να μετρήσουμε το ποσοστό της
σωστής συσταδοποίησης.
RI = 𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝑇𝑁 + 𝐹𝑁 + 𝐹𝑃
Οπού TP είναι ο αριθμός των πραγματικών θετικών, TN είναι ο αριθμός των
πραγματικών αρνητικών, FP είναι ο αριθμός των ψευδών θετικών, και FN είναι ο
αριθμός των ψευδών αρνητικών. Ένα ζήτημα με τον δείκτη RI είναι ότι τα ψευδώς
θετικά και τα ψεύτικα αρνητικά είναι εξίσου σταθμισμένα. Αυτό μπορεί να είναι ένα
ανεπιθύμητο χαρακτηριστικό για ορισμένες εφαρμογές ομαδοποίησης.
F-Measure: Το μέτρο F μπορεί να χρησιμοποιηθεί για να εξισορροπηθεί η συμβολή
των ψευδών αρνητικών με τη στάθμιση της ανάκλησης (recall) μέσω μιας
παραμέτρου β≥1

20
Recall= 𝑇𝑃
𝑇𝑃 + 𝐹𝑁
Precision = 𝑇𝑃
𝑇𝑃 +𝐹𝑃
Μπορούμε να υπολογίσουμε το F-measure ως εξής:
𝐹𝛽 =(𝛽2 + 1) ∗ 𝑅𝑒𝑐𝑎𝑙𝑙 ∗ 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛
𝛽2 ∗ 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑅𝑒𝑐𝑎𝑙𝑙
Όταν 𝛽 = 0 τότε F0 = P. Με άλλα λόγια, η ανάκληση δεν επηρεάζει το F-measure
όταν 𝛽 = 0 και η αύξηση του β κατανέμει μια αυξανόμενη ποσότητα βάρους για
ανάκληση στο τελικό F-measure.
Υπάρχουν διάφοροι άλλοι δείκτες, οι περισσότεροι από τους οποίους βασίζονται
στους παραπάνω τέσσερις πληθάριθμους συνόλων.
Βασιζόμενα σε εσωτερικά κριτήρια
Η δεύτερη προσέγγιση βασίζεται σε εσωτερικά κριτήρια. Μπορούμε να
αξιολογήσουμε τα αποτελέσματα ενός αλγόριθμου ομαδοποίησης σε όρους
ποσοτήτων που περιλαμβάνουν τους ίδιους τους φορείς του συνόλου δεδομένων.
Ένα μειονέκτημα της χρήσης εσωτερικών κριτηρίων στην αξιολόγηση συμπλέγματος
είναι ότι οι υψηλές βαθμολογίες σε ένα εσωτερικό μέτρο δεν οδηγούν αναγκαστικά
σε αποτελεσματικές εφαρμογές ανάκτησης πληροφοριών. Επιπλέον, αυτή η
αξιολόγηση είναι προκατειλημμένη προς αλγορίθμους που χρησιμοποιούν το ίδιο
μοντέλο συσταδοποίησης.
Ένας αλγόριθμος που έχει σχεδιαστεί για κάποια συγκεκριμένα μοντέλα δεν έχει
καμία πιθανότητα εάν το σύνολο δεδομένων περιέχει ένα ριζικά διαφορετικό
σύνολο μοντέλων ή αν η αξιολόγηση μετράει ένα ριζικά διαφορετικό κριτήριο. Για
παράδειγμα, η ομαδοποίηση k-means μπορεί να βρει μόνο καλά διαχωρισμένες
συστάδες. Σε ένα σύνολο δεδομένων με μη διαχωρισμένες συστάδες δεν έχουν
νόημα ούτε η χρήση του k-means ούτε κριτήριο αξιολόγησης που υποθέτει ότι οι
συστάδες είναι καλά διαχωρισμένες.
Σχετικά κριτήρια
Η τρίτη προσέγγιση βασίζεται σε σχετικά κριτήρια. Στη συγκεκριμένη περίπτωση
γίνονται αλλαγές των παραμέτρων εισόδου του αλγορίθμου και εκτιμάται η νέα
συσταδοποίηση C'. Αυτό μπορεί να γίνει επαναληπτικά έτσι ώστε να καταλήξουμε
στην καλύτερη δυνατή συσταδοποίηση. Για παράδειγμα, μπορούμε να θέσουμε
στον K-means την παράμετρο k=2 και μετέπειτα k=3 ή (αν είναι εφικτό) διαφορετικό
μετρό απόστασης, δηλαδή, αντί για ευκλείδεια απόσταση να χρησιμοποιήσουμε
την απόσταση Manhattan.

21
3.2 BIRCH
Ο BIRCH είναι ένας αλγόριθμος εξόρυξης δεδομένων που χρησιμοποιείται για την
πραγματοποίηση ιεραρχικής ομαδοποίησης σε ιδιαίτερα μεγάλα σύνολα
δεδομένων. Ένα πλεονέκτημα του BIRCH είναι η ικανότητά του να συγκεντρώνει
σταδιακά και δυναμικά εισερχόμενα, πολυδιάστατα σημεία μετρικών δεδομένων σε
μια προσπάθεια να παράγει την ομαδοποίηση καλύτερης ποιότητας για ένα
δεδομένο σύνολο πόρων (μνήμη και χρονικοί περιορισμοί).
Στις περισσότερες περιπτώσεις, ο BIRCH απαιτεί μόνο μία σάρωση της βάσης
δεδομένων. Οι εφευρέτες του ισχυρίζονται ότι το BIRCH είναι ο «πρώτος
αλγόριθμος ομαδοποίησης που προτείνεται στην περιοχή της βάσης δεδομένων για
να χειρίζεται θόρυβο αποτελεσματικά». [28]
Βασικά χαρακτηριστικά 3.2.1
Ο αλγόριθμος BIRCH χρησιμοποιεί δύο δομές (CF & CF-tree) μέσω των οποίων
επιτυγχάνεται γρήγορη συσταδοποίηση και λιγότερες ανάγκες όσον αφορά τη
μνήμη που θα χρησιμοποιηθεί.
Ορισμός: Clustering feature (CF)
_____________________________________________________________________
Για ένα σύνολο δεδομένων Ν στοιχείων d διαστάσεων το χαρακτηριστικό
συστάδας (CF) της συστάδας είναι ένα 3-D διάνυσμα : CF =[N,LS,SS] όπου LS
είναι το γραμμικό άθροισμα των σημείων δεδομένων, δηλαδή:
LS= ∑ 𝑋𝑖𝑁𝑖=1
SS είναι το τετραγωνικό άθροισμα των σημείων δεδομένων, δηλαδή:
SS= ∑ (𝑋𝑖) 2𝑁𝑖=1
Χρησιμοποιώντας το CF, μπορούμε εύκολα να υπολογίσουμε πολλά χρήσιμα
στατιστικά στοιχεία σε μια συστάδα. Για παράδειγμα, το κεντροειδές της συστάδας,
την ακτίνα, και τη διάμετρο:

22
Ορισμός: Clustering feature (CF) ιδιότητες
_____________________________________________________________________
Για ένα σύνολο δεδομένων Ν στοιχείων d διαστάσεων όπου CF =[N,LS,SS]
έχουμε ότι:
Κεντροειδές: C = ∑ 𝑋𝑖
𝑁𝑖=1
𝑁 =
𝐿𝑆
𝑁
Ακτίνα: R =√∑ (𝑋𝑖−𝐶)2𝑁𝑖=1
𝑁 = √
𝑆𝑆
𝑁− (
𝐿𝑆
𝑁)
2
Διάμετρος: D = √∑ ∑ (𝑥𝑖+𝑥𝑗 )
2𝑁𝑖=1
𝑁𝑗=1
𝑛(𝑛−1) = √
2𝑛𝑆𝑆− 2𝐿𝑆2
𝑛(𝑛−1)
Λαμβάνοντας αυτές τις ιδιότητες υπόψη μπορούμε εύκολα να δούμε ότι ως R
ορίζεται η μέση απόσταση από τα σημεία ως προς το κέντρο μιας συστάδας και ως
D ο μέσος ορός των ζευγών απόστασης μέσα σε μια συστάδα. Οι δύο συγκεκριμένες
τιμές μάς δείχνουν πόσο «πυκνά» βρίσκονται τα σημεία σε μια συστάδα γύρω από
το κεντροειδές. Οπότε μέσω του CF δεν χρειάζεται να αποθηκεύονται πληροφορίες
σχετικά με τα μεμονωμένα αντικείμενα. Αντίθετα χρειαζόμαστε μόνο ένα σταθερό
μέγεθος μνήμης για την αποθήκευση του διανύσματος CF =[N,LS,SS]. Αυτό είναι το
ιδιαίτερο χαρακτηριστικό στην αποτελεσματικότητα του BIRCH όσον αφορά
την ανάγκη σε μνήμη σε αντίθεση με άλλους αλγορίθμους.
Επιπλέον, τα χαρακτηριστικά συστάδας (CF) είναι προσθετικά. Δηλαδή, για δύο
διαφορετικές συστάδες, C1 και C2, με CF1 =[N1,LS1,SS1] και CF2 =[N2,LS2,SS2]
αντίστοιχα, το CF που δημιουργείται από την ένωση των δύο συστάδων C1 και C2
θα είναι: CF1 + CF1 = [N1+ N2, LS1 + LS2, SS1 +SS2].
Το CF-tree είναι μια δομή δέντρου που αποθηκεύει τα χαρακτηριστικά συστάδας
(CF) για την ιεραρχική συσταδοποίηση. Εξ ορισμού, ένας κόμβος μη τερματικός
(φύλλο) σε ένα δέντρο έχει «παιδιά». Οι κόμβοι εκτός των τερματικών (φύλλων)
αποθηκεύουν τα CFs των παιδιών τους και έτσι συνοψίζουν τις συγκεντρωτικές
πληροφορίες για αυτά.
Ένα δέντρο CF έχει δύο παραμέτρους:
τoν συντελεστή διακλάδωσης Β και
το κατώφλι Τ.
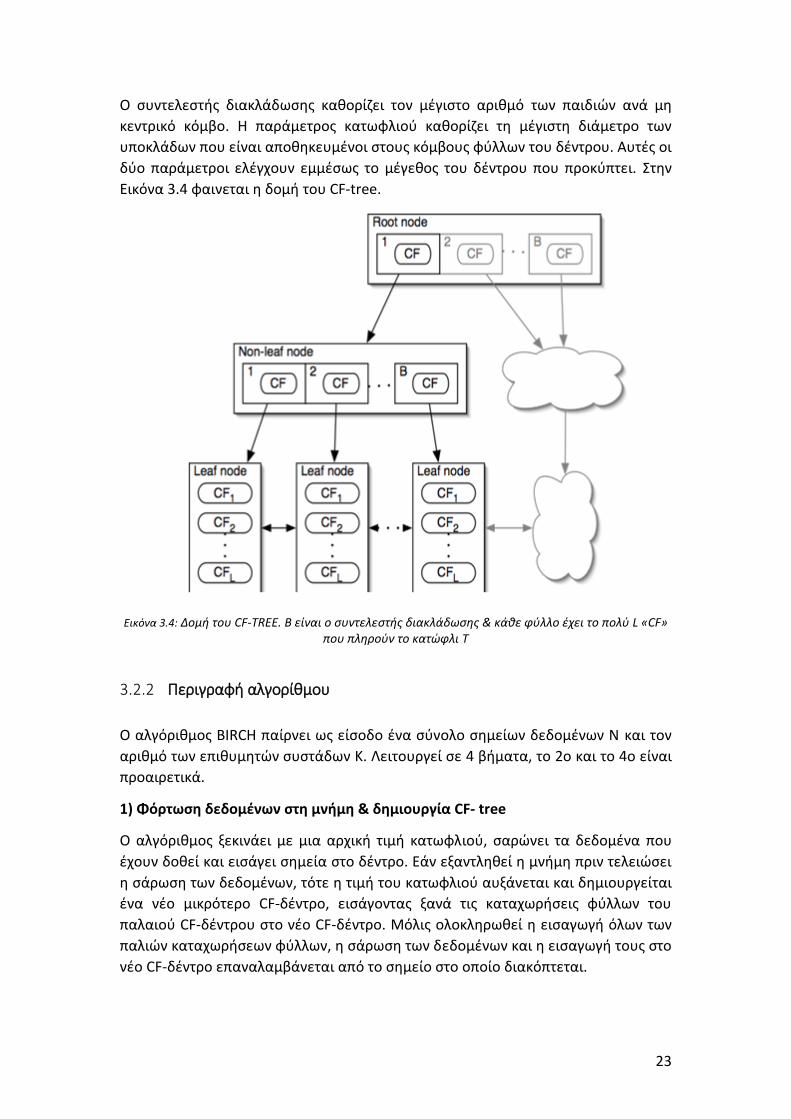
23
Ο συντελεστής διακλάδωσης καθορίζει τον μέγιστο αριθμό των παιδιών ανά μη
κεντρικό κόμβο. Η παράμετρος κατωφλιού καθορίζει τη μέγιστη διάμετρο των
υποκλάδων που είναι αποθηκευμένοι στους κόμβους φύλλων του δέντρου. Αυτές οι
δύο παράμετροι ελέγχουν εμμέσως το μέγεθος του δέντρου που προκύπτει. Στην
Εικόνα 3.4 φαινεται η δομή του CF-tree.
Εικόνα 3.4: Δομή του CF-TREE. B είναι ο συντελεστής διακλάδωσης & κάθε φύλλο έχει το πολύ L «CF» που πληρούν το κατώφλι Τ
Περιγραφή αλγορίθμου 3.2.2
Ο αλγόριθμος BIRCH παίρνει ως είσοδο ένα σύνολο σημείων δεδομένων Ν και τον
αριθμό των επιθυμητών συστάδων Κ. Λειτουργεί σε 4 βήματα, το 2ο και το 4ο είναι
προαιρετικά.
1) Φόρτωση δεδομένων στη μνήμη & δημιουργία CF- tree
Ο αλγόριθμος ξεκινάει με μια αρχική τιμή κατωφλιού, σαρώνει τα δεδομένα που
έχουν δοθεί και εισάγει σημεία στο δέντρο. Εάν εξαντληθεί η μνήμη πριν τελειώσει
η σάρωση των δεδομένων, τότε η τιμή του κατωφλιού αυξάνεται και δημιουργείται
ένα νέο μικρότερο CF-δέντρο, εισάγοντας ξανά τις καταχωρήσεις φύλλων του
παλαιού CF-δέντρου στο νέο CF-δέντρο. Μόλις ολοκληρωθεί η εισαγωγή όλων των
παλιών καταχωρήσεων φύλλων, η σάρωση των δεδομένων και η εισαγωγή τους στο
νέο CF-δέντρο επαναλαμβάνεται από το σημείο στο οποίο διακόπτεται.

24
Είναι σημαντικό η επιλογή του κατωφλιού να γίνει με τρόπο τέτοιο ώστε να
αποφευχθούν πολλαπλές ανακατασκευές σε αυτό το βήμα. Μια μικρή τιμή θα
οδηγήσει σε υψηλό υπολογιστικό κόστος, ενώ μια υψηλή θα έχει ως αποτέλεσμα
ένα λιγότερο λεπτομερές CF-δέντρο απ’ ό,τι είναι εφικτό με τη διαθέσιμη μνήμη.
2) (Προαιρετικό) Δημιουργία μικρότερου CF-tree
Το συγκεκριμένο βήμα είναι προαιρετικό αλλά μπορεί να χρησιμοποιηθεί για να
βελτιωθεί η αποδοχή του αλγορίθμου.
Αρκετοί αλγόριθμοι συσταδοποίησης λειτουργούν καλύτερα όταν τα δεδομένα
είναι μέσα σε ένα συγκεκριμένο εύρος τιμών, οπότε μπορούμε να κάνουμε μια
«σύνοψη των δεδομένων» δημιουργώντας ένα μικρότερο CF-tree αφαιρώντας
ορισμένες τιμές ή συγχωνεύοντας υποκλάσεις που προέκυψαν από το
προηγούμενο βήμα.
3) Συσταδοποίηση μέσω γνωστού αλγορίθμου
Σε αυτό το βήμα εφαρμόζεται κάποιος γνωστός αλγόριθμος συσταδοποίησης.
Οποιοσδήποτε αλγόριθμος θα μπορούσε να προσαρμοστεί για να
κατηγοριοποιήσει τα CF (χαρακτηριστικά συστάδας) αντί για τα σημεία
δεδομένων. Ένας από τους αλγορίθμους που μπορεί να χρησιμοποιηθεί είναι ο K-
MEANS.
Το βασικό όφελος είναι ότι ελαχιστοποιούνται οι λειτουργίες I/O λόγω του BIRCH.
4) (Προαιρετικό) Βελτίωση συσταδοποίησης
Τα αρχικά δεδομένα έχουν σαρωθεί μόνο μία φορά. Το τελευταίο βήμα
περιλαμβάνει επιπρόσθετα περάσματα πάνω στα δεδομένα για να διορθωθούν οι
ανακρίβειες που μπορεί να υπάρχουν. Σε αυτό το βήμα γίνεται επίσης επιλογή της
απόρριψης ή όχι των ακραίων τιμών.
Στο παρακάτω σχήμα φαίνεται το διάγραμμα ροής του αλγορίθμου.
Εικόνα 3.5: Διάγραμμα ροής του BIRCH

25
Η αποδοτικότητα του αλγορίθμου. 3.2.3
Η χρονική πολυπλοκότητα του αλγορίθμου είναι O(n), όπου n ο αριθμός σημείων
προς συσταδοποίηση.
Τα πειράματα έχουν δείξει τη γραμμική επεκτασιμότητα του αλγόριθμου σε σχέση
με τον αριθμό των δεδομένων και την καλή ποιότητα της συσταδοποίησης των
δεδομένων. Ωστόσο, δεδομένου ότι κάθε κόμβος σε ένα CF-δέντρο μπορεί να
κρατήσει μόνο έναν περιορισμένο αριθμό εγγραφών λόγω του μεγέθους του, ένας
κόμβος CF-δέντρου δεν αντιστοιχεί πάντα σε αυτό που ένας χρήστης μπορεί να
θεωρήσει ως συστάδα. Επιπλέον, εάν οι συστάδες δεν έχουν σφαιρικό σχήμα, το
BIRCH δεν έχει καλές επιδόσεις επειδή χρησιμοποιεί την έννοια της ακτίνας ή της
διαμέτρου για να ελέγξει το όριο κάθε συστάδας. Σε περιπτώσεις που έχουμε
αυθαίρετα σχήματα είναι προτιμότερο να επιλεχθεί ένας διαφορετικός αλγόριθμος
(π.χ. DBSCAN).
Οι ιδέες των CF και των CF-δέντρων έχουν εφαρμοστεί πέραν του BIRCH.
Χρησιμοποιούνται από διαφορετικούς αλγορίθμους ως τρόπος αντιμετώπισης
προβλημάτων που αφορούν τα δυναμικά δεδομένα και το clustering Streaming.[31]
3.3 K-MEANS
Ο όρος «K-means» χρησιμοποιήθηκε αρχικά από τον MacQueen το 1967 αν και ο
αλγόριθμος προτάθηκε από τον Stuart Lloyd το 1957. Ο συγκεκριμένος αλγόριθμος
που εντάσσεται στη διαμεριστική συσταδοποίηση είναι από τους πιο γνωστούς και
είναι η ρίζα για πολλούς άλλους. Βασίζεται στην άμεση αποσύνθεση του συνόλου
των δεδομένων σε ένα σύνολο ασυσχέτιστων ομάδων. Ως είσοδος στον αλγόριθμο
ορίζεται ο επιθυμητός αριθμός ομάδων που αποτελεί την παράμετρο k.
O αλγόριθμος K-Means αρχικά επιλεγεί τυχαία k σημεία τα οποία θεωρούνται ως το
κέντρο μιας συστάδας και ονομάζονται κεντροειδή. Η τιμή της παραμέτρου k είναι ο
αριθμός των συστάδων που θέλουμε ο αλγόριθμος να μας εμφανίσει και γι’ αυτόν
τον λόγο η επιλογή του πρέπει να γίνει με μεγάλη ακρίβεια. Σε περίπτωση
αδυναμίας γνώσης του αριθμού των συστάδων θα πρέπει να εκτελέσουμε τον
αλγόριθμο περισσότερες από μία φορές. Ο αλγόριθμος εκτελεί επαναληπτικά δύο
βήματα.
Το πρώτο βήμα αφορά την κατάταξη σε κάποια συστάδα, ενώ το δεύτερο βήμα
αφορά τον επαναπροσδιορισμό και τη μετατόπιση του κεντροειδούς κάθε
συστάδας. Πιο αναλυτικά, όσον αφορά το πρώτο βήμα, δηλαδή την κατάταξη σε
κάποια συστάδα, ο αλγόριθμος εξετάζει κάθε δείγμα σε σχέση με τα κεντροειδή των
συστάδων. Με χρήση κάποιου μέτρου απόστασης, κατατάσσει το εξεταζόμενο
δείγμα στη συστάδα της οποίας το κεντροειδές είναι το πλησιέστερο ως προς το
συγκεκριμένο δείγμα.

26
Στο δεύτερο βήμα, παίρνοντας τον μέσο όρο των δειγμάτων κάθε συστάδας,
επαναϋπολογίζονται τα κεντροειδή της καθεμιάς, ώστε το κεντροειδές να είναι πιο
αντιπροσωπευτικό στην πρόσφατα διαμορφωμένη συστάδα.
Τα συγκεκριμένα 2 βήματα εκτελούνται επαναληπτικά μέχρις ότου τα κέντρα των
συστάδων να μην αλλάζουν ή να αλλάζουν ελάχιστα βάσει μιας τιμής απόστασης
που έχει δοθεί από τον χρήστη. Μια άλλη περίπτωση τερματισμού του αλγορίθμου
είναι αν έχει ξεπεραστεί ένας συγκεκριμένος αριθμός επαναλήψεων.
Η συνάρτηση του τετραγωνικού λάθους (όταν χρησιμοποιείται η Ευκλείδεια
απόσταση) δίνεται από τον τύπο:
όπου E είναι το άθροισμα του τετραγωνικού λάθους για όλα τα αντικείμενα στο
σύνολο δεδομένων, p είναι το σημείο στον χώρο που υποδηλώνει ένα αντικείμενο
και mi είναι το κέντρο της ομάδας.
Ο αλγόριθμος έχει ως εξής:
Αλγόριθμος K-means
_____________________________________________________________________
1) Είσοδος από χρήστη (αριθμός συστάδων) & δεδομένα
2) Τυχαία αρχικοποίηση των k κεντροειδών
3) Επανάλαβε τα βήματα 4-5 μέχρι να μην αλλάζουν τα κέντρα ή προελεγμένο
αριθμό επαναλήψεων.
4) Για κάθε σημείο i:
Βρες το κοντινότερο κέντρο.
Όρισε το σημείο σε αυτή τη συστάδα.
5) Για κάθε συστάδα j:
Υπολογισμός νέων κεντρων.*
*Ο μέσος όρος όλων των σημείων που ανήκουν στη συστάδα j.
27
Πλεονεκτήματα και μειονεκτήματα του k-means 3.3.1
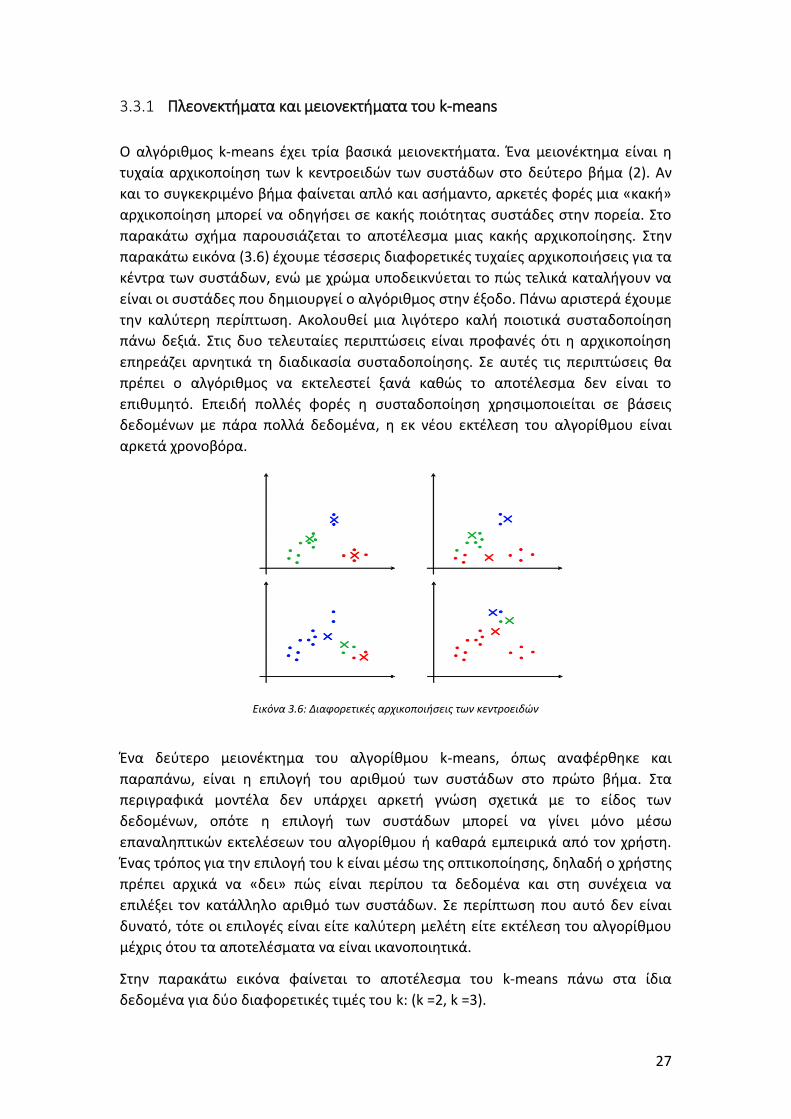
Ο αλγόριθμος k-means έχει τρία βασικά μειονεκτήματα. Ένα μειονέκτημα είναι η
τυχαία αρχικοποίηση των k κεντροειδών των συστάδων στο δεύτερο βήμα (2). Αν
και το συγκεκριμένο βήμα φαίνεται απλό και ασήμαντο, αρκετές φορές μια «κακή»
αρχικοποίηση μπορεί να οδηγήσει σε κακής ποιότητας συστάδες στην πορεία. Στο
παρακάτω σχήμα παρουσιάζεται το αποτέλεσμα μιας κακής αρχικοποίησης. Στην
παρακάτω εικόνα (3.6) έχουμε τέσσερις διαφορετικές τυχαίες αρχικοποιήσεις για τα
κέντρα των συστάδων, ενώ με χρώμα υποδεικνύεται το πώς τελικά καταλήγουν να
είναι οι συστάδες που δημιουργεί ο αλγόριθμος στην έξοδο. Πάνω αριστερά έχουμε
την καλύτερη περίπτωση. Ακολουθεί μια λιγότερο καλή ποιοτικά συσταδοποίηση
πάνω δεξιά. Στις δυο τελευταίες περιπτώσεις είναι προφανές ότι η αρχικοποίηση
επηρεάζει αρνητικά τη διαδικασία συσταδοποίησης. Σε αυτές τις περιπτώσεις θα
πρέπει ο αλγόριθμος να εκτελεστεί ξανά καθώς το αποτέλεσμα δεν είναι το
επιθυμητό. Επειδή πολλές φορές η συσταδοποίηση χρησιμοποιείται σε βάσεις
δεδομένων με πάρα πολλά δεδομένα, η εκ νέου εκτέλεση του αλγορίθμου είναι
αρκετά χρονοβόρα.
Εικόνα 3.6: Διαφορετικές αρχικοποιήσεις των κεντροειδών
Ένα δεύτερο μειονέκτημα του αλγορίθμου k-means, όπως αναφέρθηκε και
παραπάνω, είναι η επιλογή του αριθμού των συστάδων στο πρώτο βήμα. Στα
περιγραφικά μοντέλα δεν υπάρχει αρκετή γνώση σχετικά με το είδος των
δεδομένων, οπότε η επιλογή των συστάδων μπορεί να γίνει μόνο μέσω
επαναληπτικών εκτελέσεων του αλγορίθμου ή καθαρά εμπειρικά από τον χρήστη.
Ένας τρόπος για την επιλογή του k είναι μέσω της οπτικοποίησης, δηλαδή ο χρήστης
πρέπει αρχικά να «δει» πώς είναι περίπου τα δεδομένα και στη συνέχεια να
επιλέξει τον κατάλληλο αριθμό των συστάδων. Σε περίπτωση που αυτό δεν είναι
δυνατό, τότε οι επιλογές είναι είτε καλύτερη μελέτη είτε εκτέλεση του αλγορίθμου
μέχρις ότου τα αποτελέσματα να είναι ικανοποιητικά.
Στην παρακάτω εικόνα φαίνεται το αποτέλεσμα του k-means πάνω στα ίδια
δεδομένα για δύο διαφορετικές τιμές του k: (k =2, k =3).
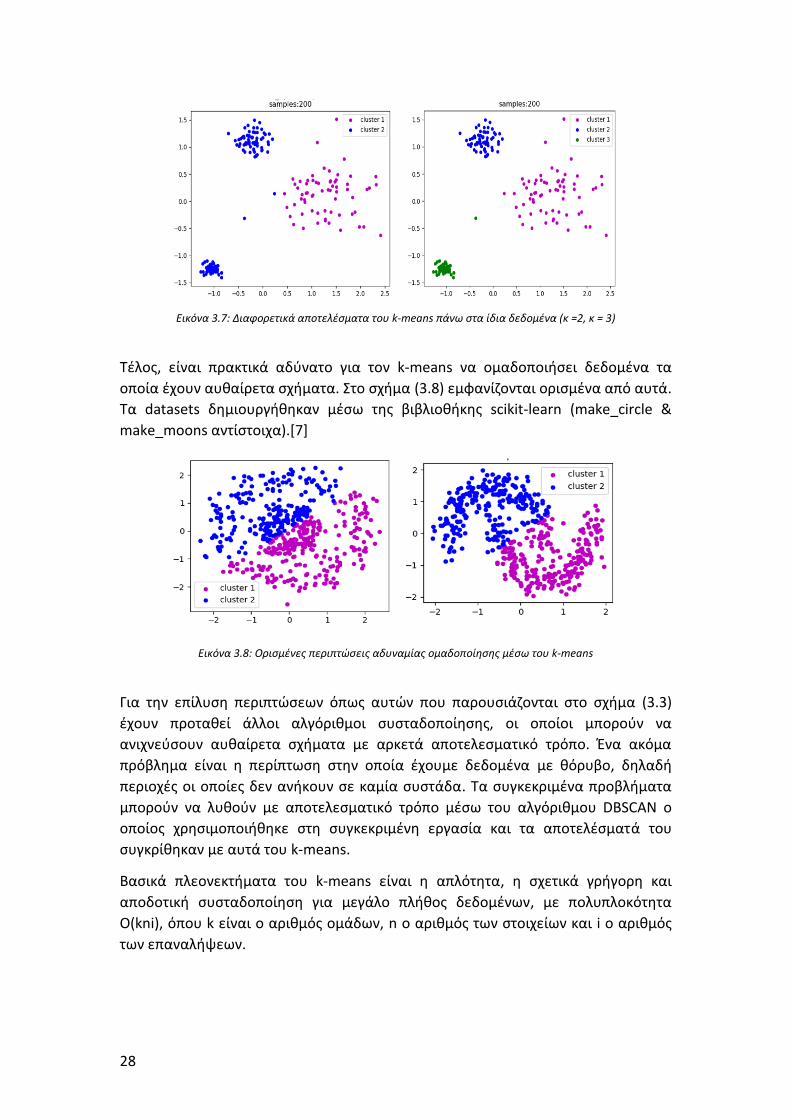
28
Εικόνα 3.7: Διαφορετικά αποτελέσματα του k-means πάνω στα ίδια δεδομένα (κ =2, κ = 3)
Τέλος, είναι πρακτικά αδύνατο για τον k-means να ομαδοποιήσει δεδομένα τα
οποία έχουν αυθαίρετα σχήματα. Στο σχήμα (3.8) εμφανίζονται ορισμένα από αυτά.
Τα datasets δημιουργήθηκαν μέσω της βιβλιοθήκης scikit-learn (make_circle &
make_moons αντίστοιχα).[7]
Εικόνα 3.8: Ορισμένες περιπτώσεις αδυναμίας ομαδοποίησης μέσω του k-means
Για την επίλυση περιπτώσεων όπως αυτών που παρουσιάζονται στο σχήμα (3.3)
έχουν προταθεί άλλοι αλγόριθμοι συσταδοποίησης, οι οποίοι μπορούν να
ανιχνεύσουν αυθαίρετα σχήματα με αρκετά αποτελεσματικό τρόπο. Ένα ακόμα
πρόβλημα είναι η περίπτωση στην οποία έχουμε δεδομένα με θόρυβο, δηλαδή
περιοχές οι οποίες δεν ανήκουν σε καμία συστάδα. Τα συγκεκριμένα προβλήματα
μπορούν να λυθούν με αποτελεσματικό τρόπο μέσω του αλγόριθμου DBSCAN ο
οποίος χρησιμοποιήθηκε στη συγκεκριμένη εργασία και τα αποτελέσματά του
συγκρίθηκαν με αυτά του k-means.
Βασικά πλεονεκτήματα του k-means είναι η απλότητα, η σχετικά γρήγορη και
αποδοτική συσταδοποίηση για μεγάλο πλήθος δεδομένων, με πολυπλοκότητα
Ο(kni), όπου k είναι ο αριθμός ομάδων, n ο αριθμός των στοιχείων και i ο αριθμός
των επαναλήψεων.

29
Σε περίπτωση που οι συστάδες έχουν σφαιρικό σχήμα, η ακρίβεια του k-means
μεγιστοποιείται με την προϋπόθεση πάντα ότι έχει δοθεί σωστή είσοδος από τον
χρήστη όσον αφορά τον αριθμό των συστάδων.
3.4 DBSCAN
Ο αλγόριθμος DBSCAN (Density-based spatial clustering of applications with noise)
του 1996, όπως φαίνεται και από το όνομά του, ανήκει στη συσταδοποίηση που
είναι βασισμένη στην πυκνότητα. Οι αλγόριθμοι αυτής της κατηγορίας
ομαδοποιούν τα στοιχεία που είναι πολύ κοντά μεταξύ τους (υψηλή πυκνότητα),
ενώ χαρακτηρίζουν ως ακραία (θόρυβος) τα στοιχεία που οι κοντινοί τους γείτονες
είναι αρκετά μακριά (χαμηλή πυκνότητα). Ο DBSCAN είναι ένας από τους πιο
συνηθισμένους αλγορίθμους συσταδοποίησης[6]. Αλγόριθμοι όπως ο k-means είναι
ελκυστικοί, ωστόσο, η εφαρμογή σε μεγάλες βάσεις δεδομένων αυξάνει τις
ακόλουθες απαιτήσεις για τους αλγόριθμους ομαδοποίησης. Πιο συγκεκριμένα,
αυξάνει τις ελάχιστες απαιτήσεις της γνώσης τομέα για τον προσδιορισμό των
παραμέτρων εισόδου, επειδή οι κατάλληλες τιμές (αριθμός συστάδων) συχνά δεν
είναι γνωστές εκ των προτέρων. Όταν ασχολούνται με μεγάλες βάσεις δεδομένων, ο
k-means δεν είναι σε θέση να ικανοποιήσει αυτόν τον περιορισμό με αρκετά
αποδοτικό τρόπο (Εικόνα 3.7). Η ανακάλυψη των συστάδων με αυθαίρετο σχήμα,
όπως παρουσιάστηκε στην Εικόνα 3.8, είναι συχνό φαινόμενο. Ο k-means
αποτυγχάνει σχεδόν πάντα στη συσταδοποίηση τέτοιων συνόλων (μη σφαιρικό
σχήμα) ή ο τρόπος, έτσι ώστε να μπορέσει να γίνει εφικτή η ομαδοποίηση αυτών
των δεδομένων, είναι πάρα πολύ δύσκολος.
Βασικό πλεονέκτημα του DBSCAN είναι η δυνατότητα να προσφέρει αποδοτική
συσταδοποίηση (με ένα σχετικά υψηλό υπολογιστικό κόστος στην παραδοσιακή του
υλοποίηση). Παρ’ όλα αυτά χρειάζεται δύο παραμέτρους (τρεις αν λάβουμε υπόψη
και το μετρό απόστασης), ο καθορισμός των οποίων έχει σημαντικό αντίκτυπο στην
τελική έξοδο.
Βασικά χαρακτηριστικά 3.4.1
Ο αλγόριθμος DBSCAN χρησιμοποιεί δυο βασικές παραμέτρους Eps & MinPts.
Δύο σημεία θεωρούνται γείτονες αν η απόσταση αυτών είναι μικρότερη από την
τιμή του Eps.
Ο τρόπος υπολογισμού της απόστασης δεν είναι πάντα η ευκλείδεια απόσταση
οπότε μπορεί να θεωρηθεί ως μια τρίτη παράμετρος. Ως παράδειγμα μπορεί να
θεωρηθεί η περίπτωση που έχουμε γεωγραφικά σημεία.

30
Εναλλακτικά αν χρησιμοποιούμε την ευκλείδεια απόσταση τότε η απόσταση μεταξύ
2 σημείων q, p n διαστάσεων υπολογίζεται από τον τύπο:
d (p, q) =√∑ (𝑝𝑖 − 𝑞𝑖)2𝑛𝑖=0 , όπου q = (q1, q2,….,qn) & p = (p1, p2,.,pn)
MinPts: Ο ελάχιστος αριθμός σημείων που απαιτούνται για τη δημιουργία μιας
πυκνής περιοχής.
Ορισμός 3.1:
_____________________________________________________________________
ε-συστάδα ενός σημείου, ως ε-συστάδα ενός σημείου p ορίζεται το σύνολο:
𝑁𝜀 (𝑝) = {𝑞 ∈ 𝐷|𝑑(𝑝, 𝑞) ≤ 𝐸𝑝𝑠}, όπου D η βάση δεδομένων και d (p, q) η
απόσταση.
Ένα σημείο p διαχωρίζεται σε:
Βασικά (Core point): ένα σημείο για το οποίο υπάρχουν περισσότεροι από
ένας προκαθορισμένοι αριθμοί (MinPts), σημεία σε ακτίνα eps. Αυτά είναι
τα σημεία που είναι στο εσωτερικό μιας συστάδας.
Οριακά (border point): ένα σημείο για το οποίο υπάρχουν λιγότεροι από
ένας προκαθορισμένοι αριθμοί (MinPts), σημεία σε ακτίνα eps, αλλά είναι
στη γειτονιά ενός βασικού σημείου.
Θόρυβο (noise): ένα σημείο που δεν είναι ούτε βασικό ούτε οριακό.
Εικόνα 3.9: Παράδειγμα DBSCAN με MinPts = 7. Το σημείο C είναι θόρυβος, το B οριακό σημείο (του Α), και το Α βασικό σημείο

31
Ορισμός 3.2: (directly density-reachable)
_____________________________________________________________________
Ένα σημείο p είναι directly density-reachable από ένα σημείο q σε σχέση µε τις
παραμέτρους Eps και MinPts, αν
1. p ∈ N_(ε) (q) και
2. |N_(ε) (q) | ≥ MinPts
Η ιδιότητα directly density-reachable είναι συμμετρική για δύο βασικά (core)
σημεία, αλλά όχι για δύο σημεία, από τα οποία το ένα είναι οριακό (boarder). Η
έννοια του directly density-reachable μπορεί να γενικευτεί στην density-reachable
που ορίζει μια πεπερασμένη ακολουθία σημείων τα οποία ανά δύο είναι directly
density-reachable.
Ορισμός 3.3: (density-reachable)
_____________________________________________________________________
Ένα σημείο p είναι density-reachable από ένα σημείο q µε τις παραμέτρους Eps και
MinPts, αν υπάρχει μια αλυσίδα των σημείων P1,P2,.., Pn όπου P1 = q, Pn = P έτσι
ώστε το Pi+1 να είναι άμεσα directly density-reachable από το Pi.
Αυτή η σχέση είναι μεταβατική, αλλά δεν είναι συμμετρική, είναι συμμετρική για τα
Βασικά (Core point).
Ορισμός 3.4: (density-connected)
_____________________________________________________________________
Ένα σημείο p είναι density-connected µε ένα σημείο q σε σχέση µε τις παραμέτρους
Eps και MinPts, αν υπάρχει σημείο k τέτοιο ώστε τα p και q να είναι density-
reachable από το σημείο k σε σχέση µε τις παραμέτρους Eps και MinPts.
Η ιδιότητα density-connected είναι συμμετρική για όλα τα σημεία μιας ομάδας
ανεξάρτητα από το αν είναι ή όχι οριακά.
Με βάση τους παραπάνω ορισμούς μπορεί να γίνει πιο εύκολη η περιγραφή του
αλγορίθμου ορίζοντας τις έννοιες της συστάδας και του θορύβου.

32
Ορισμός 3.5: (συστάδα)
_____________________________________________________________________
Έστω D η συλλογή όλων των δεδομένων και οι παράμετροι Eps & MinPts.
Μια συστάδα C είναι ένα υποσύνολο του D με τους εξής περιορισμούς:
1) Για κάθε p, q: Εάν p ∈ C και q είναι density-reachable από το p τότε q ∈ C
2) Για κάθε p, q p ∈ C: To p είναι density-connected στο q.
Ορισμός 3.6: (Θόρυβος)
_____________________________________________________________________
Έστω C1,C2,..,Cn οι συστάδες από τη συλλογή δεδομένων D. Ως θόρυβος ορίζονται τα
σημεία εκείνα που δεν ανήκουν σε καμία συστάδα Ci όπου i = 1, 2..., n.
Περιγραφή αλγορίθμου 3.4.2
Αρχικά όλα τα σημεία «μαρκάρονται» ως «μη επισκέψιμα». Ο αλγόριθμος ξεκινάει
με ένα τυχαίο σημείο p «μη επισκέψιμο». Γίνεται σύγκριση με όλα τα υπόλοιπα
σημεία ώστε να βρεθούν ποια είναι density-reachable από το p, με βάση τις
παραμέτρους Eps και MinPts. Αν ο αριθμός των «γειτόνων» είναι μεγαλύτερος από
MinPts, δηλαδή το σημείο p είναι «βασικό», τότε δημιουργείται μια ε-συστάδα,
διαφορετικά το συγκεκριμένο σημείο μαρκάρεται ως θόρυβος. Το συγκεκριμένο
σημείο μπορεί αργότερα να βρεθεί ότι ανήκει σε κάποια διαφορετική συστάδα[4].
Όλα τα σημεία μιας ε-συστάδας μαρκάρονται με μια διακριτή τιμή. Εάν ένα σημείο
βρίσκεται ως βασικό σε κάποια άλλη ε-συστάδα, τότε τα σημεία εντός της ε-
συστάδας είναι επίσης μέρος τελικής συστάδας. Με αυτό τον τρόπο και μέσω του
ορισμού 3.5 επιτυγχάνεται η συγχώνευση των ε-συστάδων. Η παραπάνω
διαδικασία συνεχίζεται μέχρι να βρεθούν πλήρως οι «τελικές» συστάδες.
Η διαδικασία επανεκκινείται με ένα νέο σημείο το οποίο μπορεί να είναι μέρος ενός
νέου συμπλέγματος ή να χαρακτηριστεί ως θόρυβος.

33
Αλγόριθμος DBSCAN
_____________________________________________________________________
1) Είσοδος από χρήστη (MinPts,Eps) & δεδομένα (D)
2) label(p) = «μη επισκέψιμο»
3) C = 0
4) Για κάθε σημείο p στα δεδομένα (D) επανάλαβε:
ΑΝ label(p) != επισκέψιμο:
Βρες όλα τα σημεία που ανήκουν στην ε-συστάδαi του p
ΑΝ ε-συστάδαi < MinPts
label(p) = θόρυβος
ΑΛΛΙΩΣ
Επέκταση Συστάδας (p, ε-συστάδαi, C, Εps, MinPts)
Επέκταση Συστάδας (p, ε-συστάδα, C, eps, MinPts)
1) C = C+ 1
2) label(p) = C
3) Για κάθε σημείο στην k στην ε-συστάδα:
Αν το σημείο label(p) != επισκέψιμο
label(p) = C
Βρες όλα τα σημεία που ανήκουν στην ε-συστάδαk του pk
ΑΝ ε-συστάδα >= MinPts
ε-συστάδα = ε-συστάδα U ε-συστάδαk
Η πολυπλοκότητα του αλγορίθμου είναι στη χειρότερη περίπτωση O(n2). Αυτό
συμβαίνει καθώς το ίδιο σημείο μπορεί να συγκριθεί πολλές φορές κατά τη
διάρκεια εκτέλεσης του αλγορίθμου.
Πιο συγκεκριμένα, η «εύρεση όλων των ε-συστάδων ενός σημείου» έχει
πολυπλοκότητα Ο(n) σε περίπτωση που δεν χρησιμοποιείται κάποια μέθοδος,
καθώς πρέπει να ελέγξει αν όλα τα υπόλοιπα σημεία είναι εντός της ακτίνας του Eps
(ορισμός 2.1). Η συγκεκριμένη διαδικασία καλείται για κάθε στοιχείο, οπότε έχουμε
O(n2). Βασικό πρόβλημα σε αυτή την υλοποίηση του αλγορίθμου είναι αφενός το
υψηλό υπολογιστικό κόστος λόγω των περιττών συγκρίσεων που γίνονται και
αφετέρου το γεγονός ότι η παραλληλοποίησή του είναι δύσκολη. Για την επίτευξη
παραλληλοποίησης του DBSCAN έχουν προταθεί αρκετοί αλγόριθμοι όπως οι MR-
DBSCAN, HDBSCAN. Οπότε μπορεί να πραγματοποιηθεί μια σημαντική βελτίωση
του αλγορίθμου, αν μειωθεί ο αριθμός των συγκρίσεων που πρέπει να γίνουν.
Περισσότερη ανάλυση πάνω σε αυτές τις τεχνικές δίνεται στο κεφάλαιο 5.

34
Πλεονεκτήματα και μειονεκτήματα του DBSCAN 3.4.3Ένα από τα πλεονεκτήματα του DBSCAN είναι η δυνατότητά του να βρίσκει τα
«αυθαίρετα» σχήματα σε βάσεις δεδομένων κάτι που δεν είναι εφικτό με τη χρήση
του k-means.
Εικόνα 3.10: Αριστερά φαίνεται η ΣΥΣΤΑΔΟΠΟΙΗΣΗ μέσω του K-means και δεξιά μέσω του DBSCAN
Για παράδειγμα, μπορεί να εντοπίσει μια συστάδα η οποία εκτείνεται γύρω από μια
άλλη συστάδα. Το γεγονός αυτό συμβαίνει λόγω της παραμέτρου MinPts, η οποία
ελαττώνει το φαινόμενο της αλυσίδας των συστάδων. Το φαινόμενο της αλυσίδας
των συστάδων συμβαίνει όταν διαφορετικές συστάδες συνδέονται με μια λεπτή
γραμμή σημείων. Επιπλέον, ένα ακόμα θετικό στοιχείο για τον αλγόριθμο DBSCAN
είναι ότι χαρακτηρίζεται από καλή ευαισθησία στον θόρυβο και δεν επηρεάζεται
από ακραίες τιμές. Για την υλοποίηση του αλγορίθμου χρειάζονται μόνο δύο
παράμετροι, (MinPts, ε), των οποίων ο προσδιορισμός κρίνεται εύκολος μετά από
σωστή αξιολόγηση και παρατήρηση των δεδομένων.
Βασικό μειονέκτημα του DBSCAN είναι το γεγονός ότι τα αποτελέσματα μπορεί να
αλλάξουν σε μεγάλο βαθμό ανάλογα με τις τιμές εισόδου (MinPts & Eps). Είναι
σημαντικό να έχει γίνει σωστή προεπεξεργασία των δεδομένων, καθώς σε αντίθετη
περίπτωση είναι πιθανόν τα αποτελέσματα να μην είναι τα αναμενόμενα.
Ένας τρόπος επίλυσης αυτού του προβλήματος είναι μέσω της κανονικοποίησης ή
Standardization, δηλαδή όλα τα δεδομένα να «τροποποιηθούν» πριν αρχίσει η
εκτέλεση του αλγορίθμου.
Επίσης σε περίπτωση που τα δεδομένα είναι σε αραιή μορφή είναι πιθανόν να μην
είναι εφικτή η σωστή συσταδοποίηση ή να μην είναι αποδοτική. Στην επόμενη
εικόνα (3.11) φαίνεται ένα τέτοιο παράδειγμα. Η επιλογή του Eps πρέπει να γίνει με
πολύ μεγάλη ακρίβεια, ώστε τα σημεία που είναι απομακρυσμένα από τη «μπλε»
συστάδα να μην ανιχνευθούν ως θόρυβος.
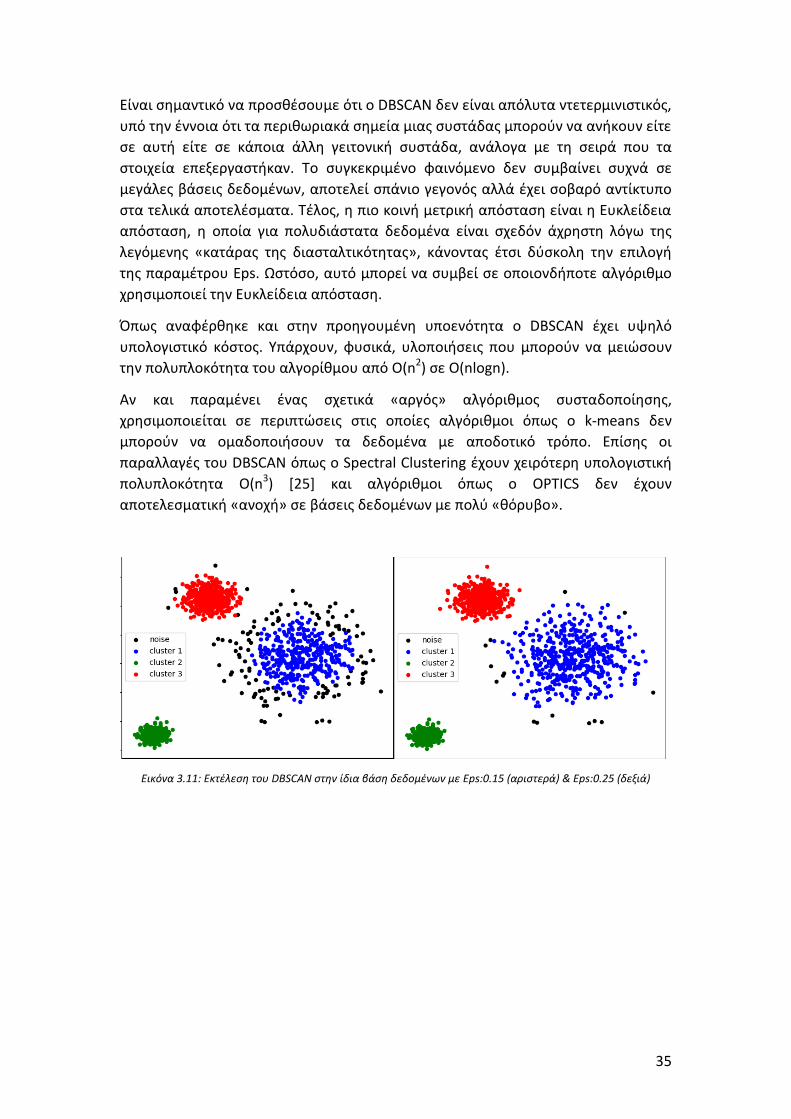
35
Είναι σημαντικό να προσθέσουμε ότι ο DBSCAN δεν είναι απόλυτα ντετερμινιστικός,
υπό την έννοια ότι τα περιθωριακά σημεία μιας συστάδας μπορούν να ανήκουν είτε
σε αυτή είτε σε κάποια άλλη γειτονική συστάδα, ανάλογα με τη σειρά που τα
στοιχεία επεξεργαστήκαν. Το συγκεκριμένο φαινόμενο δεν συμβαίνει συχνά σε
μεγάλες βάσεις δεδομένων, αποτελεί σπάνιο γεγονός αλλά έχει σοβαρό αντίκτυπο
στα τελικά αποτελέσματα. Τέλος, η πιο κοινή μετρική απόσταση είναι η Ευκλείδεια
απόσταση, η οποία για πολυδιάστατα δεδομένα είναι σχεδόν άχρηστη λόγω της
λεγόμενης «κατάρας της διασταλτικότητας», κάνοντας έτσι δύσκολη την επιλογή
της παραμέτρου Eps. Ωστόσο, αυτό μπορεί να συμβεί σε οποιονδήποτε αλγόριθμο
χρησιμοποιεί την Ευκλείδεια απόσταση.
Όπως αναφέρθηκε και στην προηγουμένη υποενότητα ο DBSCAN έχει υψηλό
υπολογιστικό κόστος. Υπάρχουν, φυσικά, υλοποιήσεις που μπορούν να μειώσουν
την πολυπλοκότητα του αλγορίθμου από O(n2) σε Ο(nlogn).
Αν και παραμένει ένας σχετικά «αργός» αλγόριθμος συσταδοποίησης,
χρησιμοποιείται σε περιπτώσεις στις οποίες αλγόριθμοι όπως ο k-means δεν
μπορούν να ομαδοποιήσουν τα δεδομένα με αποδοτικό τρόπο. Επίσης οι
παραλλαγές του DBSCAN όπως ο Spectral Clustering έχουν χειρότερη υπολογιστική
πολυπλοκότητα O(n3) [25] και αλγόριθμοι όπως ο OPTICS δεν έχουν
αποτελεσματική «ανοχή» σε βάσεις δεδομένων με πολύ «θόρυβο».
Εικόνα 3.11: Εκτέλεση του DBSCAN στην ίδια βάση δεδομένων με Eps:0.15 (αριστερά) & Eps:0.25 (δεξιά)
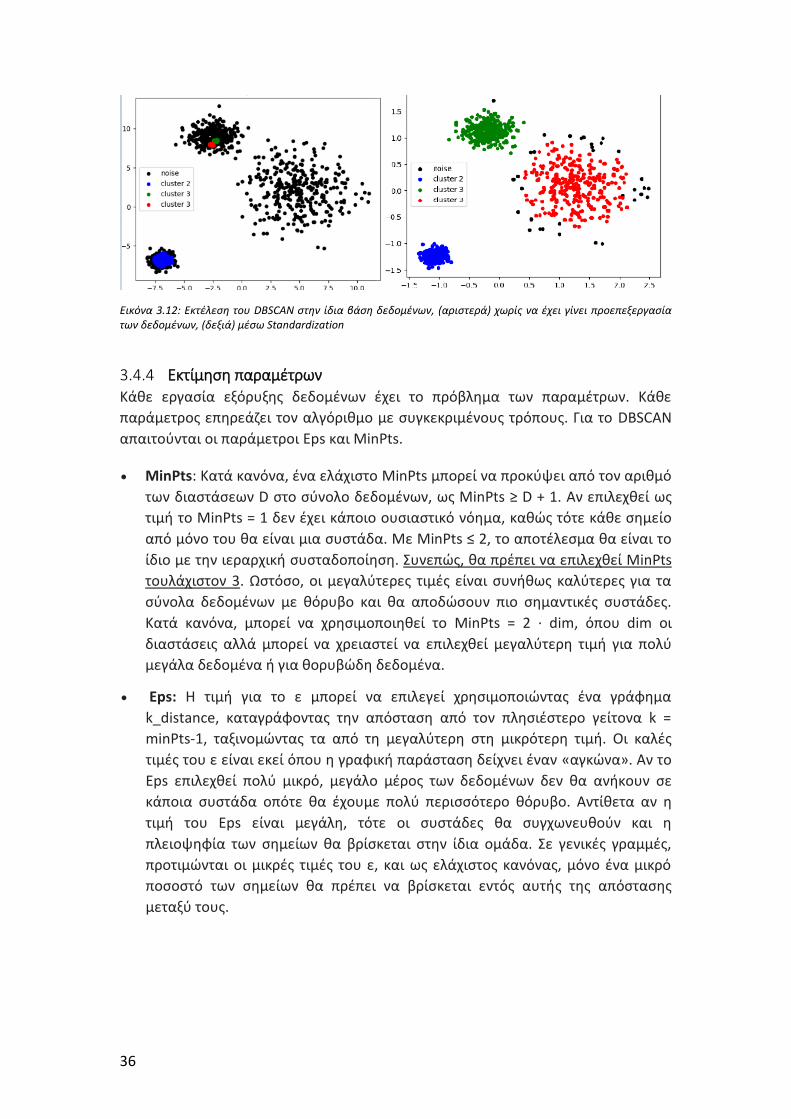
36
Εικόνα 3.12: Εκτέλεση του DBSCAN στην ίδια βάση δεδομένων, (αριστερά) χωρίς να έχει γίνει προεπεξεργασία των δεδομένων, (δεξιά) μέσω Standardization
Εκτίμηση παραμέτρων 3.4.4Κάθε εργασία εξόρυξης δεδομένων έχει το πρόβλημα των παραμέτρων. Κάθε
παράμετρος επηρεάζει τον αλγόριθμο με συγκεκριμένους τρόπους. Για το DBSCAN
απαιτούνται οι παράμετροι Eps και MinPts.
MinPts: Κατά κανόνα, ένα ελάχιστο MinPts μπορεί να προκύψει από τον αριθμό
των διαστάσεων D στο σύνολο δεδομένων, ως MinPts ≥ D + 1. Αν επιλεχθεί ως
τιμή το MinPts = 1 δεν έχει κάποιο ουσιαστικό νόημα, καθώς τότε κάθε σημείο
από μόνο του θα είναι μια συστάδα. Με MinPts ≤ 2, το αποτέλεσμα θα είναι το
ίδιο με την ιεραρχική συσταδοποίηση. Συνεπώς, θα πρέπει να επιλεχθεί MinPts
τουλάχιστον 3. Ωστόσο, οι μεγαλύτερες τιμές είναι συνήθως καλύτερες για τα
σύνολα δεδομένων με θόρυβο και θα αποδώσουν πιο σημαντικές συστάδες.
Κατά κανόνα, μπορεί να χρησιμοποιηθεί το MinPts = 2 · dim, όπου dim οι
διαστάσεις αλλά μπορεί να χρειαστεί να επιλεχθεί μεγαλύτερη τιμή για πολύ
μεγάλα δεδομένα ή για θορυβώδη δεδομένα.
Eps: Η τιμή για το ε μπορεί να επιλεγεί χρησιμοποιώντας ένα γράφημα
k_distance, καταγράφοντας την απόσταση από τον πλησιέστερο γείτονα k =
minPts-1, ταξινομώντας τα από τη μεγαλύτερη στη μικρότερη τιμή. Οι καλές
τιμές του ε είναι εκεί όπου η γραφική παράσταση δείχνει έναν «αγκώνα». Αν το
Eps επιλεχθεί πολύ μικρό, μεγάλο μέρος των δεδομένων δεν θα ανήκουν σε
κάποια συστάδα οπότε θα έχουμε πολύ περισσότερο θόρυβο. Αντίθετα αν η
τιμή του Eps είναι μεγάλη, τότε οι συστάδες θα συγχωνευθούν και η
πλειοψηφία των σημείων θα βρίσκεται στην ίδια ομάδα. Σε γενικές γραμμές,
προτιμώνται οι μικρές τιμές του ε, και ως ελάχιστος κανόνας, μόνο ένα μικρό
ποσοστό των σημείων θα πρέπει να βρίσκεται εντός αυτής της απόστασης
μεταξύ τους.

37
Υλοποιήσεις του DBSCAN 3.4.5Ο DBSCAN είναι ένας αλγόριθμος ο οποίος δεν υποστηρίζεται επίσημα από το
Apache Spark (πιο συγκεκριμένα από τη βιβλιοθήκη MLLib) που είναι ο στόχος της
συγκεκριμένης διπλωματικής εργασίας. Παρόλο που υπάρχουν υλοποιήσεις σε
άλλες πλατφόρμες, η απόδοση μπορεί να διαφοροποιείται σε μεγάλο βαθμό,
ανάλογα με την ποιότητα υλοποίησης, στις διαφορές γλώσσες προγραμματισμού
που χρησιμοποιούνται και στον τρόπο που γίνεται η μεταγλώττιση.
Ορισμένες από τις πιο γνωστές είναι:
H υλοποίηση από την Python του DBSCAN μέσω της βιβλιοθήκης scikit-learn.
Η συγκεκριμένη υλοποίηση χρησιμοποιεί k-d tree και ball tree για τη
βελτίωση της ταχύτητας εκτέλεσης του αλγορίθμου αλλά μπορεί να
χρησιμοποιηθεί n2 μνήμη στη χειρότερη περίπτωση.
Η βιβλιοθήκη pyclustering περιλαμβάνει μια υλοποίηση σε Python και σε
C++ του DBSCAN για ευκλείδεια απόσταση μόνο.
Το SPMF περιλαμβάνει μια υλοποίηση του αλγορίθμου DBSCAN μέσω της
χρήσης k-d tree αλλά υποστηρίζει μόνο την ευκλείδεια απόσταση.
Η Weka περιέχει (ως προαιρετικό πακέτο στις πιο πρόσφατες εκδόσεις) μια
βασική υλοποίηση του DBSCAN που εκτελείται σε τετραγωνικό χρόνο και
γραμμική μνήμη.
Η ELKI προσφέρει μια εφαρμογή του DBSCAN καθώς και του GDBSCAN και
άλλων παραλλαγών.

38

39
4 ΚΑΤΑΝΕΜΗΜΕΝΑ ΠΕΡΙΒΑΛΛΟΝΤΑ ΕΠΕΞΕΡΓΑΣΙΑΣ ΔΕΔΟΜΕΝΩΝ
ΜΕΓΑΛΟΥ ΟΓΚΟΥ
4.1 ΤΟ ΜΟΝΤΕΛΟ MAPREDUCE
Η αύξηση των δεδομένων στις μέρες μας έχει ως αποτέλεσμα οι βάσεις δεδομένων
να έχουν αυξηθεί σε terabytes (1012 bytes) και petabytes (1015 bytes). Ένας τρόπος
επεξεργασίας τόσο μεγάλων βάσεων δεδομένων είναι με τη χρήση ενός μοντέλου
παράλληλης επεξεργασίας γνωστό και ως MapReduce, το οποίο διακρίνεται για την
απλοϊκότητα και την αξιοπιστία του. Το μοντέλο MapReduce αρχικά αναπτύχθηκε
από την Google[12]. Τo Hadoop είναι μια open source έκδοση του MapReduce η
οποία χρησιμοποιείται σε μεγάλο βαθμό τόσο από την ακαδημαϊκή κοινότητα όσο
και από εταιρίες για την ανάλυση μεγάλου όγκου δεδομένων[17].
Πάνω από 70 εταιρίες χρησιμοποιούν το Hadoop συμπεριλαμβανομένων γνωστών
ομίλων όπως Facebook, Yahoo!, Adobe και IBM.
Τι είναι το MapReduce 4.1.1
Το MapReduce είναι ένα προγραμματιστικό μοντέλο για την επεξεργασία πολύ
μεγάλων σετ δεδομένων με παράλληλο και κατανεμημένο τρόπο χρησιμοποιώντας
μια ομάδα υπολογιστών[16]. Αποτελείται από μια διαδικασία (ή μέθοδο) map, η
οποία εκτελεί φιλτράρισμα και ταξινόμηση (π.χ. ταξινόμηση των ατόμων με βάση
την ηλικία τους, ταξινόμησή τους σε ουρές, μία ουρά για κάθε ηλικία) και μια
μέθοδο reduce, η οποία εκτελεί μια συνοπτική λειτουργία (π.χ. ο αριθμός των
ατόμων σε κάθε ουρά, αποδίδοντας συχνότητες ηλικιών).
Το σύστημα MapReduce (που ονομάζεται επίσης " infrastructure" ή " framework")
χρησιμοποιείται για την επεξεργασία πολύ μεγάλων σετ δεδομένων με παράλληλο
και κατανεμημένο τρόπο χρησιμοποιώντας μια ομάδα υπολογιστών.
Το μοντέλο είναι μια εξειδίκευση της στρατηγικής split-apply-combine για την
ανάλυση δεδομένων. Είναι εμπνευσμένο από τις διεργασίες map & reduce, που
χρησιμοποιούνται συνήθως στον λειτουργικό προγραμματισμό, αν και ο σκοπός
τους στο MapReduce δεν είναι ο ίδιος όπως στις αρχικές τους μορφές.

40
Οι βασικές συνεισφορές του MapReduce δεν είναι οι map & reduce λειτουργίες,
αλλά η επεκτασιμότητα και η ανοχή σφάλματος που επιτυγχάνεται για διάφορες
εφαρμογές, βελτιστοποιώντας τον μηχανισμό εκτέλεσης. Ως εκ τούτου, η
υλοποίηση του MapReduce σε έναν υπολογιστή συνήθως δεν είναι ταχύτερη από
μια παραδοσιακή (μη MapReduce) υλοποίηση. Οποιαδήποτε κέρδη συνήθως
φαίνονται μόνο με εφαρμογές πολλαπλών νημάτων σε υλικό πολλαπλών
επεξεργαστών, δηλαδή σε κατανεμημένα συστήματα. Η χρήση αυτού του μοντέλου
είναι επωφελής μόνο όταν αρχίσει να παίζει η βελτιστοποιημένη λειτουργία
κατανομής ανακατασκευών (η οποία μειώνει το κόστος επικοινωνίας δικτύου) και
τα χαρακτηριστικά ανοχής σφάλματος του πλαισίου MapReduce. Η βελτιστοποίηση
του κόστους επικοινωνίας είναι απαραίτητη για έναν καλό αλγόριθμο
MapReduce.[18]
Οι βιβλιοθήκες MapReduce έχουν γραφτεί σε πολλές γλώσσες προγραμματισμού,
όπως java, με διαφορετικά επίπεδα βελτιστοποίησης. Το όνομα MapReduce
αναφέρεται αρχικά στην ιδιόκτητη τεχνολογία Google, αλλά από τότε έχει
γενικευτεί.
MapReduce Βασικά στάδια 4.1.2
Στο παράδειγμα προγραμματισμού MapReduce, η βασική μονάδα πληροφοριών
είναι ένα «ζεύγος» <key;value> όπου κάθε key και κάθε value είναι δυαδικές
συμβολοσειρές. Η είσοδος σε οποιοδήποτε MapReduce αλγόριθμο είναι ένα σετ
από <key;value> «ζεύγη». Υπάρχουν τρία βασικά στάδια: Μap, Shuffle και Reduce.
Στο Map stage, μη αλληλεπικαλυπτόμενα κομμάτια από τα δεδομένα εισόδου που
είναι «ζεύγη» <key;value> ανατίθενται σε διαφορετικές m διεργασίες (mappers), οι
οποίες βγάζουν ένα σετ από ενδιάμεσα <key;value> αποτελέσματα. Είναι πολύ
σημαντικό η λειτουργία του map να λειτουργεί σε ένα ζεύγος τη φορά. Αυτό
επιτρέπει τον εύκολο παραλληλισμό, καθώς διαφορετικές είσοδοι για το map
μπορούν να υποβληθούν σε επεξεργασία από διαφορετικά μηχανήματα.
Κατά τη διάρκεια του shuffle stage, το σύστημα που εφαρμόζει MapReduce
αποστέλλει όλες τις τιμές που σχετίζονται με ένα μεμονωμένο κλειδί στο ίδιο
μηχάνημα. Αυτό συμβαίνει αυτόματα. Το shuffle stage ουσιαστικά μεταφέρει τα
δεδομένα από τους mappers στους reducers, το οποίο είναι απαραίτητο, καθώς
διαφορετικά δεν θα μπορούσαν να έχουν οποιαδήποτε είσοδο (ή είσοδο από κάθε
mapper). Το shuffling μπορεί να ξεκινήσει πριν ακόμα ολοκληρωθεί το map stage
και με αυτόν τον τρόπο βελτιώνεται η ταχύτητα εκτέλεσης [17].

41
Στο reduce stage, ο reducer ρ λαμβάνει όλες τις τιμές που σχετίζονται με ένα μόνο
κλειδί k και εξάγει μια πολλαπλή ομάδα ζευγών <key;value> με το ίδιο κλειδί k.
Αυτό υπογραμμίζει μία από τις διαδοχικές πλευρές της υπολογιστικής απεικόνισης
MapReduce: Όλες οι διεργασίες map πρέπει να ολοκληρωθούν πριν αρχίσει το stag
reduce. Ομοίως, ο reducer έχει πρόσβαση σε όλες τις τιμές με το ίδιο κλειδί και
μπορεί να πραγματοποιήσει διαδοχικούς υπολογισμούς σε αυτές τις τιμές. Ο
τρόπος μέσω του οποίου επιτυγχάνεται ο παραλληλισμός είναι το γεγονός ότι οι
reducers που λειτουργούν σε διαφορετικά keys μπορούν να εκτελούνται
ταυτόχρονα. Συνολικά, ένα προγραμματιστικό μοντέλο MapReduce μπορεί να
αποτελείται από πολλούς γύρους διαφορετικών map και reduce διεργασιών, οι
οποίες εκτελούνται η μία μετά την άλλη.
Εικόνα 4.1: Το μοντέλο MapReduce
Ορισμός 4.1: mapper
_____________________________________________________________________
Ένας mapper είναι μια (ενδεχομένως τυχαία) συνάρτηση που παίρνει σαν είσοδο
ένα <key;value> ζεύγος δυαδικών συμβολοσειρών. Ως έξοδος ο mapper παράγει
ένα πεπερασμένο σύνολο πολλαπλών νέων <key;value> ζευγών. Είναι σημαντικό ο
mapper να λειτουργεί σε ένα <key;value> ζεύγος κάθε φορά. Η λογική για αυτήν την
ενδιάμεση έξοδο ορίζεται στη μέθοδο Map() της εφαρμογής.
Ορισμός 4.2: reducer
_____________________________________________________________________
Ένας reducer είναι μια (ενδεχομένως τυχαία) συνάρτηση που παίρνει σαν είσοδο
μια δυαδική συμβολοσειρά k που είναι το κλειδί και μια ακολουθία τιμών v1, v2, ...,
vn που είναι επίσης δυαδικές συμβολοσειρές. Ως έξοδος, ο reducer παράγει ένα
πολλαπλό σύνολο ζευγών δυαδικών συμβολοσειρών <k;vk,1>, <k; vk,2>,. ., <k;
vk,n>. Το κλειδί στην πλειάδα εξόδου είναι το ίδιο με το κλειδί στην πλειάδα
εισόδου.

42
Μια απλή συνέπεια αυτών των δύο ορισμών είναι ότι οι mappers μπορούν να
χειριστούν τα κλειδιά αυθαίρετα, αλλά οι reducers δεν μπορούν να αλλάξουν τα
κλειδιά καθόλου.
Ένας άλλος τρόπος να εξετάσουμε το MapReduce είναι ως ένας παράλληλος και
κατανεμημένος υπολογισμός 5 βημάτων:[19]
1 Προετοιμασία της εισόδου στην Map ().
2 Εκτέλεση του κώδικα Map () που παρέχεται από τον χρήστη.
3 "Shuffle" των εξόδων των Maps() στους επεξεργαστές Reduce.
4 Εκτέλεση του κώδικα Reduce () που παρέχεται από τον χρήστη.
5 Δημιουργία τελικής εξόδου.
Στο πρώτο βήμα, κάθε μπλοκ ανατίθεται σε ένα mapper και κάθε mapper
αποτελείται από μια διεργασία mapper, η οποία αναθέτει το κλειδί στο μπλοκ, το
οποίο θα προσδιορίζει τα δεδομένα μεταξύ διαφόρων επεξεργαστών.
Στη συνέχεια η map () εκτελείται ακριβώς μία φορά για κάθε κλειδί K1,
δημιουργώντας έξοδο που οργανώνεται από το κλειδί K2 (βήμα 2).
Οι έξοδοι από τις Map() διεργασίες πρέπει να διατεθούν σε κάθε reduce διεργασία.
Αυτό γίνεται μέσω του shuffling το οποίο εξασφαλίζει ότι κάθε reduce εκχωρείται
σε όλες τις εξόδους της Map() διεργασίας και ότι κάθε έξοδος από τη Map()
διεργασία έχει διατεθεί σε κάθε reducer.
Εκτέλεση του κώδικα Reduce () που παρέχεται από τον χρήστη: Το Reduce ()
εκτελείται για μια φορά για κάθε αποτέλεσμα από τη Map.
Δημιουργία τελικής εξόδου συλλέγοντας όλα τα αποτελέσματα από τους reducers
και ταξινομώντας τους.

43
Εικόνα 4.2: Παράδειγμα εκτέλεσης του MapReduce για τον υπολογισμό του αριθμού των συμβόλων
Πλεονεκτήματα του μοντέλου Hadoop MapReduce 4.1.3
Τα βασικά πλεονεκτήματα του μοντέλου Hadoop MapReduce είναι:
Επεκτασιμότητα: H πλατφόρμα Hadoop MapReduce είναι εξαιρετικά επεκτάσιμη.
Αυτό οφείλεται σε μεγάλο βαθμό στην ικανότητα να αποθηκεύει καθώς και να
διανέμει μεγάλα σύνολα δεδομένων σε πλήθος εξυπηρετητών. Αυτοί οι διακομιστές
μπορούν να είναι χαμηλού κόστους και μπορούν να λειτουργούν παράλληλα. Με
κάθε προσθήκη διακομιστών αυξάνεται περαιτέρω η απόδοση. Αντίθετα με τα
παραδοσιακά συστήματα διαχείρισης σχεσιακών βάσεων δεδομένων (RDMS) που
δεν μπορούν να κλιμακωθούν για να επεξεργαστούν τεράστια ποσά δεδομένων, ο
προγραμματισμός Hadoop MapReduce επιτρέπει στους επιχειρηματικούς
οργανισμούς να εκτελούν εφαρμογές από έναν τεράστιο αριθμό δεδομένων που θα
μπορούσε να περιλαμβάνει τη χρήση χιλιάδων terabytes. [20]
Απλοϊκότητα: Tο Hadoop MapReduce, όπως αναφέρθηκε πιο πάνω, είναι ένα απλό
μοντέλο προγραμματισμού. Αυτό βασικά επιτρέπει στους προγραμματιστές να
αναπτύξουν προγράμματα MapReduce που μπορούν να χειριστούν εργασίες με
περισσότερη ευκολία και αποτελεσματικότητα. Τα προγράμματα για MapReduce
μπορούν να γραφτούν χρησιμοποιώντας τη Java, μια γλώσσα που δεν είναι πολύ
δύσκολη και χρησιμοποιείται σε μεγάλη κλίμακα. Έτσι, είναι εύκολο για τους
προγραμματιστές να μαθαίνουν και να γράφουν προγράμματα που ικανοποιούν
επαρκώς τις ανάγκες επεξεργασίας δεδομένων.

44
Ευελιξία: Οι επιχειρήσεις μπορούν να χρησιμοποιήσουν το προγραμματιστικό
μοντέλο Hadoop MapReduce για να αποκτήσουν πρόσβαση σε διάφορες νέες πηγές
δεδομένων και επίσης να λειτουργούν με διαφορετικούς τύπους δεδομένων,
ανεξάρτητα από το εάν είναι δομημένες ή μη δομημένες. Αυτό τους επιτρέπει να
παράγουν αξία από όλα τα δεδομένα που μπορούν να προσεγγιστούν από αυτά. Σε
αυτές τις γραμμές, η Hadoop προσφέρει υποστήριξη σε πολλές γλώσσες που
μπορούν να χρησιμοποιηθούν για επεξεργασία και αποθήκευση δεδομένων. Είτε η
πηγή δεδομένων είναι κοινωνικά μέσα, ηλεκτρονικό ταχυδρομείο, είτε clickstream,
το MapReduce μπορεί να λειτουργήσει σε όλα αυτά. Επίσης, το Hadoop MapReduce
επιτρέπει πολλές εφαρμογές, όπως συστήματα συστάσεων, επεξεργασία αρχείων
καταγραφής, ανάλυση μάρκετινγκ, αποθήκευση δεδομένων και ανίχνευση απάτης.
Παράλληλη επεξεργασία: Μια από τις κύριες πτυχές της λειτουργίας του
προγραμματισμού MapReduce είναι ότι χωρίζει τις εργασίες με τρόπο που
επιτρέπει την εκτέλεσή τους παράλληλα. Η παράλληλη επεξεργασία επιτρέπει σε
πολλούς επεξεργαστές να αναλάβουν αυτές τις διαιρεμένες εργασίες, έτσι ώστε να
τρέχουν ολόκληρα προγράμματα σε λιγότερο χρόνο.
Ασφάλεια: Η ασφάλεια είναι μια ζωτικής σημασίας πτυχή κάθε εφαρμογής. Αν
κάποιος παράνομος χρήστης ή οργανισμός αποκτήσει πρόσβαση σε πολλαπλά
petabytes δεδομένων ενός οργανισμού, μπορεί να προκαλέσει μαζική βλάβη από
πλευράς επιχειρηματικών συναλλαγών και επιχειρήσεων. Από την άποψη αυτή, το
MapReduce συνεργάζεται με την ασφάλεια HDFS και HBase που επιτρέπει μόνο σε
εγκεκριμένους χρήστες να λειτουργούν σχετικά με τα δεδομένα που είναι
αποθηκευμένα στο σύστημα.
Ταχύτητα: Το Hadoop χρησιμοποιεί μια μέθοδο αποθήκευσης γνωστή ως
κατανεμημένο σύστημα αρχείων, το οποίο βασικά εφαρμόζει ένα σύστημα mapping
για τον εντοπισμό δεδομένων σε ένα cluster. Τα εργαλεία που χρησιμοποιούνται
για την επεξεργασία δεδομένων, όπως ο προγραμματισμός MapReduce, είναι
επίσης γενικά τοποθετημένα στους ίδιους διακομιστές, πράγμα που επιτρέπει την
ταχύτερη επεξεργασία των δεδομένων. Ακόμη και αν τυχαίνει να αντιμετωπίζονται
μεγάλες ποσότητες δεδομένων που δεν είναι δομημένες, το Hadoop MapReduce
χρειάζεται λεπτά για να επεξεργαστεί terabytes των δεδομένων και ώρες για
petabytes δεδομένων.
Ανοχή στα σφάλματα: Όταν αποστέλλονται δεδομένα σε έναν μεμονωμένο κόμβο
σε ολόκληρο το δίκτυο, το ίδιο σύνολο δεδομένων διαβιβάζεται επίσης στους
άλλους πολυάριθμους κόμβους που αποτελούν το δίκτυο. Έτσι, αν υπάρχει κάποια
βλάβη που επηρεάζει έναν συγκεκριμένο κόμβο, υπάρχουν πάντα άλλα αντίγραφα
που μπορούν ακόμα να προσαρμοστούν όποτε μπορεί να προκύψει η ανάγκη. Αυτό
εξασφαλίζει πάντα τη διαθεσιμότητα δεδομένων. Ένα από τα μεγαλύτερα
πλεονεκτήματα που προσφέρει ο Hadoop είναι αυτό της ανοχής του σφάλματος. Το
Hadoop MapReduce έχει τη δυνατότητα να αναγνωρίζει γρήγορα τα σφάλματα που
εμφανίζονται και στη συνέχεια να εφαρμόζει μια γρήγορη και αυτόματη λύση
αποκατάστασης.

45
4.2 APACHE HADOOP 2.0
Το MapReduce είναι ιδανικό για πολλές εφαρμογές, αλλά όχι για όλα. Άλλα μοντέλα
προγραμματισμού εξυπηρετούν καλύτερα τις απαιτήσεις όπως η επεξεργασία
γραφημάτων (π.χ. Google Pregel / Apache Giraph) και η επαναληπτική
μοντελοποίηση χρησιμοποιώντας τη διεπαφή μετάδοσης μηνυμάτων (MPI). Όπως
συμβαίνει συχνά, μεγάλο μέρος από τα επιχειρησιακά δεδομένα είναι ήδη
διαθέσιμα στο Hadoop HDFS και έχουν πολλαπλές διαδρομές για επεξεργασία.
Επιπλέον, δεδομένου ότι το MapReduce είναι ουσιαστικά προσανατολισμένο σε
παρτίδες, η υποστήριξη για επεξεργασία σε πραγματικό χρόνο ή σχεδόν σε
πραγματικό χρόνο έχει γίνει ένα σημαντικό ζήτημα για τον χρήστη βάση. Ένα πιο
ισχυρό περιβάλλον υπολογιστών εντός του Hadoop επιτρέπει στους οργανισμούς
να βλέπουν την αύξηση της απόδοσης Hadoop με τη μείωση του λειτουργικού
κόστους για τους διαχειριστές, μειώνοντας την ανάγκη μετακίνησης δεδομένων
μεταξύ του Hadoop HDFS και άλλων συστημάτων αποθήκευσης, παρέχοντας άλλες
τέτοιες βελτιώσεις.
Το Apache Hadoop 2.0 είναι ένα από τα πιο ευρέως χρησιμοποιούμενα εργαλεία
ανοιχτού κώδικα για την κατανόηση των Big Data. Το Hadoop αποτελείται από ένα
σύνολο εργαλείων και τεχνολογιών που σχετίζονται με τα Big Data. Χρησιμοποιείται
συχνά σε συνδυασμό με τις βάσεις δεδομένων Apache Spark και NoSQL για την
αποθήκευση και τη διαχείριση δεδομένων pipeline τύπου Spark.
Εικόνα 4.3: Αρχιτεκτονική Hadoop 2.0 [21]

46
Το Hadoop χωρίζει τα αρχεία σε μεγάλα μπλοκ και τα διανέμει σε κόμβους σε ένα
cluster. Στη συνέχεια μεταφέρει τον συσκευασμένο κώδικα σε κόμβους για να
επεξεργαστεί τα δεδομένα παράλληλα. Αυτή η προσέγγιση εκμεταλλεύεται την
τοποθεσία των δεδομένων, όπου οι κόμβοι χειρίζονται τα δεδομένα στα οποία
έχουν πρόσβαση. Αυτό επιτρέπει την επεξεργασία του συνόλου δεδομένων
γρηγορότερα και αποτελεσματικότερα απ’ ό,τι θα ήταν σε μια συμβατικότερη
αρχιτεκτονική υπερυπολογιστών, που βασίζεται σε ένα παράλληλο σύστημα
αρχείων όπου οι υπολογισμοί και τα δεδομένα διανέμονται μέσω δικτύων υψηλής
ταχύτητας [22].
Το βασικό πλαίσιο Apache Hadoop 2.0 αποτελείται από τις ακόλουθες ενότητες:
Hadoop Common - περιέχει βιβλιοθήκες και βοηθητικά προγράμματα που
απαιτούνται από άλλες ενότητες Hadoop.
Hadoop Distributed File System (HDFS) - ένα κατανεμημένο σύστημα αρχείων που
αποθηκεύει δεδομένα σε μηχανές βασικών προϊόντων, παρέχοντας πολύ υψηλό
συνολικό εύρος ζώνης σε όλο το σύμπλεγμα.
Hadoop YARN - (εισήγαγε το 2012) μια πλατφόρμα υπεύθυνη για τη διαχείριση των
πόρων πληροφορικής σε ομάδες και τη χρήση τους για τον προγραμματισμό των
εφαρμογών των χρηστών [23].
Hadoop MapReduce - εφαρμογή του μοντέλου προγραμματισμού MapReduce για
επεξεργασία δεδομένων μεγάλης κλίμακας. Το μοντέλο Hadoop MapReduce
βασίζεται σε αυτό που δημιουργήθηκε από την google και αναλύθηκε στην
προηγουμένη υποενότητα.
YARN (Yet Another Resource Negotiator) 4.2.1
Το Apache YARN είναι το επίπεδο διαχείρισης πόρων του Hadoop. Το YARN εισήχθη
στο Hadoop 2.x. Το YARN επιτρέπει αποδοτική επεξεργασία δεδομένων, όπως
επεξεργασία γραφημάτων, διαλογική επεξεργασία, stream processing, καθώς και
επεξεργασία παρτίδων για την εκτέλεση και την επεξεργασία δεδομένων που είναι
αποθηκευμένα σε HDFS (Hadoop Distributed File System). Εκτός από τη διαχείριση
των πόρων, το YARN επίσης κάνει την εργασία προγραμματισμού. Το YARN
επεκτείνει την ισχύ του Hadoop σε άλλες εξελισσόμενες τεχνολογίες, ώστε να
μπορούν να επωφεληθούν από το HDFS (το πιο αξιόπιστο και δημοφιλές σύστημα
αποθήκευσης στον πλανήτη) και το οικονομικό cluster.

47
Η θεμελιώδης ιδέα του YARN είναι να χωρίσει τις δύο μεγάλες ευθύνες του
JobTracker (έκδοση Hadoop 1.0), δηλαδή τη διαχείριση πόρων και τον
προγραμματισμό της εργασίας, σε ξεχωριστά προγράμματα που εκτελούνται στο
υπόβαθρο: ένα κοινό ResourceManager και για κάθε εφαρμογή ένα
ApplicationMaster (AM). Το ResourceManager και όλα τα NodeManager (NM),
αποτελούν το νέο και γενικό λειτουργικό σύστημα για τη διαχείριση εφαρμογών με
κατανεμημένο τρόπο (έκδοση 2.0).
Ένα κοινό ResourceManager και για κάθε εφαρμογή ένα ApplicationMaster (AM). Το
ResourceManager(RM) και όλα τα NodeManager (NM),
Πιο συγκεκριμένα ο RM είναι υπεύθυνος για την κατανομή πόρων μεταξύ όλων των
εφαρμογών. Κάθε φορά που λαμβάνει μια αίτηση επεξεργασίας (από τον ΑΜ), το
διαβιβάζει στον αντίστοιχο NM και κατανέμει τους πόρους για την ολοκλήρωση της
αίτησης ανάλογα. Αποτελείται από δύο βασικά στοιχεία, τον Scheduler, ο οποίος
εκτελεί προγραμματισμό με βάση την παραχωρηθείσα εφαρμογή και τους
διαθέσιμους πόρους, και τον AM, οποίος διαχειρίζεται την εκτέλεση των AM στο
cluster. Είναι σημαντικό να αναφερθεί ότι ο Scheduler δεν εκτελεί άλλες εργασίες,
όπως παρακολούθηση, και δεν εγγυάται την επανεκκίνηση σε περίπτωση αποτυχίας
μιας εργασίας.
Αντίστοιχα, κάθε κόμβος του cluster διαθέτει ένα NM που η κύρια ευθύνη του είναι
η παρακολούθηση και η χρήση των πόρων. Ουσιαστικά «ελέγχει» τους ‘Containers’
(μια συλλογή από φυσικούς πόρους, όπως RAM, πυρήνες CPU και δίσκο σε έναν
μόνο κόμβο) και δημιουργεί ή ξεκινάει διεργασίες μετά από αίτημα του AM[28].
Εικόνα 4.4: Αρχιτεκτονική YARN

48
HDFS (Hadoop Distributed File System) 4.2.2
Όταν ένα σύνολο δεδομένων ξεπερνά τη χωρητικότητα αποθήκευσης ενός και μόνο
υπολογιστή, καθίσταται αναγκαίο να κατακερματιστεί σε ένα σύνολο από
υπολογιστές. Τα συστήματα αρχείων, που διαχειρίζονται την αποθήκευση σε ένα
δίκτυο υπολογιστών, ονομάζονται κατανεμημένα συστήματα αρχείων. Δεδομένου
ότι αυτά βασίζονται σε κάποιο δίκτυο δεδομένων, υπεισέρχονται όλες οι επιπλοκές
του προγραμματισμού μέσω δικτύου, καθιστώντας έτσι τα κατανεμημένα
συστήματα αρχείων πιο περίπλοκα απ’ ό,τι τα συστήματα αρχείων σε έναν μόνο
σκληρό δίσκο. Για παράδειγμα, μία από τις μεγαλύτερες προκλήσεις είναι το
κατανεμημένο σύστημα αρχείων να αντιμετωπίζει βλάβες σε υπολογιστικούς
κόμβους, χωρίς να υποστεί απώλεια δεδομένων. Το Hadoop έχει ένα νέο
κατανεμημένο σύστημα αρχείων, που ονομάζεται HDFS (Hadoop Distributed File
System).
Το HDFS είναι ένα σύστημα αρχείων σχεδιασμένο για την αποθήκευση πολύ
μεγάλων αρχείων, με υποστήριξη για πρότυπα προσπέλασης σε δεδομένα συνεχούς
ροής (streaming data access patterns) σε cluster.
Βασικά πλεονεκτήματα θα που μπορούσαν να αναφερθούν είναι, αρχικά, το
γεγονός ότι οι εφαρμογές που τρέχουν σε HDFS χειρίζονται δεδομένα πολύ μεγάλου
όγκου. Ένα συνηθισμένο αρχείο στο HDFS έχει μέγεθος της τάξης Gigabyte έως και
Terabyte. Το HDFS δίνει τη δυνατότητα:
(α) παροχής υπηρεσιών με υψηλό όγκο πληροφορίας, που μπορεί να μεταδοθεί
μέσω διαδικτύου σε δεδομένο χρόνο (bandwidth) και
(β) ύπαρξης εκατοντάδων κόμβων σε ένα ενιαίο cluster.
Επίσης το HDFS είναι σχεδιασμένο περισσότερο για batch processing παρά για
διαδραστική χρήση από τους χρήστες. Το POSIX (Portable Operating System
Interface for Unix) θέτει πολλές απαιτήσεις που δεν χρειάζονται στις εφαρμογές
που εκτελούνται στο HDFS. Ένα ακόμα πλεονέκτημα είναι η δυνατότητα του HDFS
να ερευνά λάθη που οφείλονται σε αποτυχίες στο hardware, και αυτόματα να
ανακτά τα δεδομένα σε τέτοιες περιπτώσεις. Αυτό είναι αρκετά σημαντικό αν
ληφθεί υπόψιν το γεγονός ότι το HDFS χειρίζεται τεράστιο όγκο δεδομένων, οπότε
είναι αρκετά πιθανό φαινόμενο. Τέλος το HDFS χαρακτηρίζεται από την
απλοϊκότητά του καθώς και τη δυνατότητα να είναι εύκολα φορητό από μία
πλατφόρμα σε μία άλλη[4].

49
4.3 APACHE SPARK
Οι βιομηχανίες χρησιμοποιούν εκτεταμένα το Hadoop για να αναλύσουν τα σύνολα
δεδομένων τους. Ο λόγος είναι ότι το framework Hadoop βασίζεται σε ένα απλό
μοντέλο προγραμματισμού (MapReduce) και επιτρέπει μια υπολογιστική λύση που
είναι κλιμακωτή, ευέλικτη, ανεκτική σε λάθη και οικονομικά αποδοτική. Εδώ, η
κύρια ανησυχία είναι να διατηρηθεί η ταχύτητα επεξεργασίας μεγάλων συνόλων
δεδομένων, από την άποψη του χρόνου αναμονής μεταξύ των ερωτημάτων και του
χρόνου αναμονής για την εκτέλεση του προγράμματος. Το Spark εισήχθη από το
Apache Software Foundation για την επιτάχυνση της διαδικασίας υπολογιστικού
λογισμικού Hadoop. Σε αντίθεση με μια κοινή πεποίθηση, το Spark δεν είναι μια
τροποποιημένη έκδοση του Hadoop και δεν εξαρτάται, πραγματικά, από αυτό
επειδή έχει τη δική του διαχείριση cluster. Το Hadoop είναι ένας από τους τρόπους
υλοποίησης του Spark. Το Spark χρησιμοποιεί το Hadoop με δύο τρόπους: το ένα
είναι αποθήκευση και το δεύτερο επεξεργασία. Δεδομένου ότι ο Spark έχει δικό του
υπολογισμό διαχείρισης συμπλεγμάτων, χρησιμοποιεί το Hadoop μόνο για σκοπούς
αποθήκευσης[10].
Το MapReduce και οι παραλλαγές του έχουν μεγάλη επιτυχία στην εφαρμογή
μεγάλων εφαρμογών δεδομένων (big data). Ωστόσο, τα περισσότερα από αυτά τα
συστήματα είναι χτισμένα γύρω από ένα κυκλικό μοντέλο ροής δεδομένων που δεν
είναι κατάλληλο για άλλες δημοφιλείς εφαρμογές, ένα λειτουργικό σύνολο
δεδομένων σε πολλαπλές παράλληλες λειτουργίες, συμπεριλαμβανομένων πολλών
επαναληπτικών αλγορίθμων μηχανικής μάθησης, καθώς και διαδραστικών
εργαλείων ανάλυσης δεδομένων. Το Spark είναι ένα νέο flamework που
υποστηρίζει αυτές τις εφαρμογές διατηρώντας παράλληλα την επεκτασιμότητα και
την ανοχή σφάλματός του. Για την επίτευξη αυτών των αναγκών, το Spark εισήγαγε
τα RDDs (resilient distributed datasets).
Το Spark παρουσιάστηκε από το Apache Software Foundation για την επιτάχυνση
της διαδικασίας προγραμματισμού του Hadoop και την υπέρβαση των περιορισμών
του. Παρ’ όλα αυτά το Apache Spark βασίζεται στο Hadoop για σκοπούς
αποθήκευσης. Σε αρκετές περιπτώσεις το Spark μπορεί να ξεπεράσει τον Hadoop
κατά 10 φορές σε ταχύτητα[24]. Το Spark έχει υλοποιηθεί στη γλώσσα
προγραμματισμού Scala, μια στατική γλώσσα προγραμματισμού υψηλού επιπέδου
για το Java VM που εκθέτει ένα λειτουργικό περιβάλλον προγραμματισμού
παρόμοιο με το DryadLINQ. Το Spark υποστηρίζεται από άλλες γλώσσες
προγραμματισμού όπως η java/Python/R, γεγονός που δίνει μεγάλη ευελιξία στους
προγραμματιστές.

50
Τα βασικά στοιχεία του Spark
Το Spark αποτελείται από 6 βασικά στοιχεία: Spark Core, Spark SQL, Spark
Streaming, Spark MLLib, Spark GraphX.
Εικόνα 4.5: Οι βιβλιοθήκες του Spark
Spark Core
Όλες οι λειτουργίες που παρέχονται από το Apache Spark είναι χτισμένες στην
κορυφή του Apache Spark Core. Παρέχει υπολογισμούς In-Memory, βασικές
λειτουργικότητες I/O και κατανεμημένο διαμοιρασμό και χρονοδρομολόγηση των
tasks και τη δυνατότητα προγραμματισμού εφαρμογών σε διάφορες γλώσσες
προγραμματισμού όπως Java, Python, Scala και R. Για την επίτευξη αυτών το Apache
Spark ενσωματώνεται σε μια ειδική συλλογή που ονομάζεται RDD, η οποία
αναλύεται στην επόμενη υποενότητα.
Spark SQL
Το Spark SQL είναι ένα κατανεμημένο πλαίσιο για τη δομημένη επεξεργασία
δεδομένων. Προσφέρει μια καινούργια δομή, η οποία είναι τα DataFrames μέσω
των οποία μπορούμε να επεξεργαστούμε με πιο αποδοτικό τρόπο δομημένα
δεδομένα. Μέσω του Spark SQL, το Spark μπορεί να κάνει επιπλέον
βελτιστοποιήσεις που είναι αδύνατες μέσω των RDD. Δυνατότητα χρήσης του Spark
SQL δίνεται είτε μέσω SQL είτε μέσω των DataFrames. Στη συγκεκριμένη
διπλωματική εργασία χρησιμοποιήθηκε κυρίως η συγκεκριμένη βιβλιοθήκη.

51
Spark steaming
Το Spark Streaming είναι μια επέκταση του Spark μέσω του οποίου μπορούν να
εκτελεστούν ερωτήματα και γίνεται επεξεργασία ροών δεδομένων. Τα δεδομένα
μπορούν να ληφθούν από πολλές πηγές, όπως οι υποδοχές Kafka, Flume, Kinesis ή
TCP, και μπορούν να επεξεργαστούν με σύνθετους αλγορίθμους που εκφράζονται
με λειτουργίες υψηλού επιπέδου όπως map, reduce, join και window. Στη συνέχεια
τα δεδομένα μπορούν να αποθηκευτούν σε συστήματα αρχείων και βάσεις
δεδομένων όπως το HDFS.
Εικόνα 4.6: Η αρχιτεκτονική του Spark Streaming
Apache Spark GraphX
Το GraphX στο Spark είναι μια επέκταση πάνω στα RDD προσφέροντας μια νέα
δομή για τη δημιουργία και την παράλληλη εκτέλεση γραφημάτων. Πολλές τεχνικές
της εξόρυξης δεδομένων όπως η συσταδοποίηση και η κατηγοριοποίηση μπορούν
να υλοποιηθούν μέσω γραφημάτων.
Αν και η βιβλιοθήκη GraphX υποστηρίζεται μόνο από την Scala & java, υπάρχει μια
παρόμοια βιβλιοθήκη (graph frames) η οποία προσφέρει API για python & R.
Apache Spark ΜLlid
H Βιβλιοθήκη Apache Spark ΜLlid παρέχει αρκετούς αλγορίθμους machine learning
υλοποιημένους με τρόπο τέτοιο ώστε να τρέχουν αποδοτικά σε κατανεμημένα
συστήματα. Περισσότερες πληροφορίες δίνονται στην υποενότητα 4.3.3.

52
Apache Spark RDD 4.3.1
Η κύρια αφηρημένη δομή στο Spark είναι αυτή του RDD. Ένα RDD είναι μια συλλογή
αντικειμένων μόνο για ανάγνωση σε ένα σύνολο υπολογιστών (cluster) που
μπορούν να ξαναδημιουργηθούν εάν χαθεί κάποιο τμήμα. Οι χρήστες μπορούν να
αποθηκεύσουν προσωρινά ένα RDD στη μνήμη (ή στον δίσκο) μεταξύ μηχανών και
να την επαναχρησιμοποιήσουν σε πολλαπλές παράλληλες λειτουργίες τύπου
MapReduce. Παρόλο που τα υπάρχοντα frameworks όπως το MapReduce()
παρέχουν πολλές αφαιρέσεις για την πρόσβαση σε υπολογιστικούς πόρους ενός
cluster, δεν μπορούν να διαχειριστούν καταλληλά αφαιρέσεις σε συστήματα
υπολογιστών τα οποία δεν διαμοιράζονται τη μνήμη. Αυτό το καθιστά
αναποτελεσματικό για μια σημαντική τάξη αναδυόμενων εφαρμογών: εκείνες που
επαναχρησιμοποιούν ενδιάμεσα αποτελέσματα σε πολλαπλούς υπολογισμούς. H
επαναχρησιμοποίηση δεδομένων είναι συχνό φαινόμενο σε πολλές επαναληπτικές
μηχανές μάθησης και αλγόριθμους γραφημάτων, συμπεριλαμβανομένων των
PageRank K-means clustering, DBSCAN και της παλινδρόμησης.
Μια άλλη περίπτωση χρήσης είναι στην εξόρυξη δεδομένων, όπου ένας χρήστης
εκτελεί πολλαπλά ερωτήματα στο ίδιο υποσύνολο των δεδομένων. Δυστυχώς, στα
frameworks που αναλύθηκαν πιο πάνω, ο μόνος τρόπος για να
επαναχρησιμοποιηθούν τα δεδομένα μεταξύ υπολογισμών (π.χ. μεταξύ δύο
εργασιών MapReduce) είναι η εγγραφή τους σε ένα εξωτερικό σταθερό σύστημα
αποθήκευσης, π.χ. ένα κατανεμημένο σύστημα αρχείων (HDFS). Αυτό αυξάνει
σημαντικά τον χρόνο υπολογισμού λόγω της αναπαραγωγής δεδομένων και της
σειριακής εκτέλεσης[27].
Είναι σημαντικό να αναφερθεί ότι το Apache Spark είναι «φιλικό» προς τον χρήστη,
καθώς προσφέρει αρκετές έτοιμες και απλές εντολές. Με αυτόν τον τρόπο
επιτυγχάνεται εύκολη και αποτελεσματική παραλληλοποίηση χωρίς ιδιαίτερη
δυσκολία, σε αντίθεση με τις προηγούμενες μεθόδους όπως το MapReduce() όπου
η ανάπτυξη ενός κώδικα ήθελε ιδιαίτερη προσοχή για αποφυγή «σειριακής»
εκτέλεσης.
Τα βασικά χαρακτηριστικά ενός RDD είναι τα γράμματα του ονόματός του, δηλαδή:
i) Resilient: Τα RDDs επιτυγχάνουν ανοχή σφάλματος μέσω της «έννοιας της
καταγωγής»: Δηλαδή αν χαθεί ένα τμήμα ενός RDD, το RDD έχει αρκετές
πληροφορίες για το πώς προέρχεται από άλλα RDD ώστε να μπορεί να
ξαναδημιουργηθεί μόνο αυτό το τμήμα. [24]
ii) Distributed: Τα δεδομένα βρίσκονται κατανεμημένα σε πολλούς κόμβους ενός
cluster.
iii) Dataset: Είναι μια συλλογή δεδομένων που έχει διασπαστεί σε μικρότερες
μονάδες.

53
Στο Spark, κάθε RDD αντιπροσωπεύεται από ένα Scala object. Το Spark επιτρέπει
στους προγραμματιστές να κατασκευάσουν RDD με τρεις τρόπους:
• Από ένα αρχείο που βρίσκεται σε ένα κοινό σύστημα αρχείων, όπως το Hadoop
Distributed File System (HDFS).
• Με τον "παραλληλισμό" μιας συλλογής Scala (π.χ. ένας πίνακας ή μια λίστα) στο
πρόγραμμα οδήγησης, που σημαίνει ότι θα διαιρεθεί σε ένα αριθμό κομματιών που
θα αποσταλούν σε πολλαπλούς κόμβους.
• Με τη μετατροπή ενός υπάρχοντος RDD. Ένα σύνολο δεδομένων με στοιχεία
τύπου Α μπορεί να μετατραπεί σε σύνολο δεδομένων με στοιχεία τύπου Β
χρησιμοποιώντας μια λειτουργία που ονομάζεται flatMap, η οποία περνά κάθε
στοιχείο μέσω μιας λειτουργίας που παρέχεται από τον χρήστη τύπου A ⇒ Λίστα
[B]. Άλλοι μετασχηματισμοί μπορούν να εκφραστούν χρησιμοποιώντας το flatMap,
συμπεριλαμβανομένου του map (τα στοιχεία μετασχηματίζονται μέσω μιας
συνάρτησης τύπου A ⇒ B) και του filter (επιλέγονται στοιχεία βάσει μιας συνθήκης)
[24].
Εικόνα 4.7: Το διάγραμμα ροής του RDD
Μέσω των RDDs, μπορούν να εκτελεστούν δύο λειτουργίες:
Μετασχηματισμοί (transformations): Πρόκειται για τις λειτουργίες που
εφαρμόζονται για τη δημιουργία ενός νέου RDD. Tα δεδομένα στα RDD στο Spark
δεν αλλάζουν, καθώς είναι αμετάβλητα. Όλοι οι μετασχηματισμοί που γίνονται σε
ένα RDD είναι lazy evaluation, δηλαδή δεν εκτελούνται μέχρι να «ζητήσει» ο
χρήστης τα αποτελέσματα μέσω κάποιας ενέργειας (action).

54
Οι μετασχηματισμοί μπορούν να χωριστούν σε δύο κατηγορίες:
• ArrowNW Transformations: Όλα τα στοιχεία που απαιτούνται για τον υπολογισμό
των εγγραφών σε ένα ενιαίο partition, υπάρχουν σε ένα ενιαίο partition του
γονικού RDD (no partitioning). Οι Narrow Transformations είναι το αποτέλεσμα
λειτουργιών όπως map(), filter().
• Wide Transformations: Όλα τα στοιχεία που απαιτούνται για τον υπολογισμό των
εγγραφών στο ενιαίο partition μπορεί να υπάρχουν σε πολλά partition του γονικού
RDD. Οι ευρείς μετασχηματισμοί είναι το αποτέλεσμα των groupByKey ().
Εικόνα 4.8: Narrow Transformations (αριστερά) και Wide Transformations (δεξιά).Σε λειτουργίες που χρησιμοποιούν wide transformations χρησιμοποιείται το data shuffling
Ορισμένες από τις λειτουργίες μετασχηματισμού παρέχονται στον παρακάτω
πίνακα:
Function Περιγραφή
map() Επιστρέφει ένα νέο RDD εφαρμόζοντας μια συνάρτηση σε κάθε
στοιχείο αυτού του RDD.
filter() Επιστρέφει ένα νέο RDD που περιέχει μόνο τα στοιχεία που
ικανοποιούν μια συνθήκη (π.χ. μη-αρνητικές τιμές).
groupByKey() Μετατρέπει ζεύγος (key, value) σε ζεύγος (key, <iterable value>).
union() Επιστρέφει ένα νέο RDD που περιέχει όλα τα στοιχεία από δύο
RDDs. Τα διπλότυπα δεν καταστρέφονται.

55
Ενέργειες (actions): Εφαρμόζονται σε ένα RDD για να καθοδηγήσουν τον Apache
Spark να εφαρμόσει τον υπολογισμό και να περάσει το αποτέλεσμα. Για να
εκτελεστεί μια ενέργεια πρέπει πρώτα όλοι οι μετασχηματισμοί να ολοκληρωθούν.
Ορισμένες από τις ενέργειες που χρησιμοποιούνται στο Spark δίνονται παρακάτω:
Function Περιγραφή
count() Λαμβάνει τον αριθμό στοιχείων δεδομένων σε RDD.
collect() Επιστρέφει όλα τα στοιχεία του RDD στο πρόγραμμα οδήγησης
σε μία μόνο λίστα.
reduce() Συγκεντρώνει όλα τα στοιχεία του RDD εφαρμόζοντας μια
συνάρτηση και επιστρέφει ένα αποτέλεσμα.
Foreach
(operation)
Εκτελεί το operation για κάθε στοιχείο δεδομένων σε RDD
first() Ανακτά το πρώτο στοιχείο δεδομένων ενός RDD
Οι περιορισμοί των RDDs
Τα RDDs κατάφεραν να λύσουν αρκετά προβλήματα που είχαν τα προηγούμενα
κατανεμημένα περιβάλλοντα επεξεργασίας δεδομένων. Παρ’ όλα αυτά έχουν
ορισμένους σημαντικούς περιορισμούς στο Apache Spark.
Στα RDDs δεν υπάρχει κάποιος μηχανισμός ώστε να γίνει βελτιστοποίηση της
εισόδου με αυτόματο τρόπο. Οποιαδήποτε βελτιστοποίηση πρέπει να γίνει
«χειροκίνητα» κάτι το οποίο πολλές φορές είναι δύσκολο ή απαιτεί αρκετή
εμπειρία.
Αν και τα RDDs μπορούν να «ξαναδημιουργηθούν» σε περίπτωση που χαθεί κάποιο
τμήμα, η απόδοσή τους υποβαθμίζεται σε πολύ μεγάλο βαθμό σε περίπτωση που
δεν υπάρχει αρκετός χώρος αποθήκευσης στη μνήμη (RAM) ή στον δίσκο. Με την
αύξηση του μεγέθους της μνήμης RAM και του δίσκου είναι δυνατό να ξεπεραστεί
αυτό το ζήτημα. Επίσης τα RDDs δεν μπορούν να διαχειριστούν δομημένα δεδομένα
όπως αλλά APIs. Τέλος τα RDDs δεν υποστηρίζουν επεξεργασία δεδομένων σε
πραγματικό χρόνο.
Για αυτούς τους λόγους, δηλαδή την αποδοτική διαχείριση μνήμης και τη λήψη ενός
βελτιστοποιημένου σχεδίου εκτέλεσης, το Apache Spark εισήγαγε τα DataFrames
στην έκδοση1.3.0.

56
Apache Spark DataFrames 4.3.2Τα Data frames προστέθηκαν στο Apache Spark μέσω της βιβλιοθήκης Spark SQL.
Βασικό μειονέκτημα των RDDs είναι η αδυναμία τους να χειρίζονται δομημένα
δεδομένα κάτι που είναι αρκετά συνηθισμένο σε αλγορίθμους machine learning.
Μέσω της βιβλιοθήκης Spark SQL παρέχονται περισσότερες πληροφορίες σχετικά
με τη δομή των δεδομένων. Το Spark SQL χρησιμοποιεί αυτές τις επιπλέον
πληροφορίες για να πραγματοποιήσει επιπλέον βελτιστοποιήσεις.
Τα DataFrames είναι μια επέκταση των RDDs. Αν και έχουν βασικές διαφορές, οι
οποίες θα αναλυθούν στη συνέχεια, έχουν αρκετές ομοιότητες όπως την ανοχή στα
σφάλματα.
Στα DataFrames τα δεδομένα αναπαρίστανται ως μια κατανεμημένη συλλογή
δεδομένων που οργανώνονται σε ονομαστικές στήλες, δηλαδή ένας πίνακας σε μια
σχεσιακή βάση δεδομένων. Επίσης το API του Apache Spark SQL επιτρέπει την
επεξεργασία δεδομένων σε διάφορες μορφές (AVRO, CSV, JSON και συστήματα
αποθήκευσης HDFS, πίνακες HIVE, MySQL).
Το βασικότερο πλεονέκτημα των DataFrames τους σε σχέση με τη δομή των RDDs
είναι η βελτιστοποίηση που πραγματοποιείται με χρήση του catalyst.
Εικόνα 4.9: Ο catalyst/optimizer του Apache Spark SQL
Ο βελτιστοποιητής μπορεί να πάρει μερικές αποφάσεις που συμβάλλουν στη
μείωση του χρόνου εκτέλεσης.
Όπως και στα RDDs έτσι και στα DataFrames όλες οι λειτουργίες γίνονται με τον ίδιο
τρόπο (δηλαδή σε transformations και actions).
Apache Spark Machine Learning Library (MLLib) 4.3.3
Η Apache Spark MLLib είναι μια βιβλιοθήκη του Apache Spark για την ανάλυση
μεγάλων δεδομένων περιέχοντας περισσότερους από 55 αλγορίθμους machine
learning. Μέσω της MLLib οι αλγόριθμοι επωφελούνται τόσο από τον
παραλληλισμό των διαδικασιών όσο και των δεδομένων.

57
Η βιβλιοθήκη περιλαμβάνει αλγορίθμους διαφορετικών μεθόδων που
χρησιμοποιούνται στην εξόρυξη δεδομένων όπως η ταξινόμηση, η ομαδοποίηση, η
παλινδρόμηση και η εξαγωγή κανόνων, η οποία επιτρέπει την εύκολη και γρήγορη
ανάπτυξη πρακτικών εφαρμογών μεγάλης κλίμακας μηχανικής μάθησης[29].
Όσον αφορά τους αλγορίθμους συσταδοποίησης, η βιβλιοθήκη δεν περιλαμβάνει
μεγάλο αριθμό αλγόριθμων (οι μόνοι αλγόριθμοι είναι ο k-Means, o GMM και ο
LDA) αλλά επεκτείνεται συνέχεια. Έχουν γίνει αρκετές δημοσιεύσεις σχετικά με την
υλοποίηση αλγορίθμων συσταδοποίησης χρησιμοποιώντας το Apache Spark, όπως
παραλλαγές του DBSCAN και του BIRCH.
Αν και η βιβλιοθήκη υποστηρίζει τόσο RDD API όσο και DataFrames API, μετά την
έκδοση 2.0, το API που βασίζεται σε RDD βρίσκεται πλέον σε λειτουργία
συντήρησης[30].
Για να γίνει δυνατό να χρησιμοποιηθεί η συγκεκριμένη βιβλιοθήκη είναι
απαραίτητο να υπάρχουν ορισμένες άλλες βιβλιοθήκες (πέρα από την πλατφόρμα
του Apache Spark). Πιο συγκεκριμένα σε περίπτωση που χρησιμοποιείται η γλώσσα
προγραμματισμού Python η οποία υποστηρίζεται, θα πρέπει να είναι
εγκατεστημένη η βιβλιοθήκη NumPy 1.4.0.

58

59
5 ΤΕΧΝΙΚΗ ΠΕΡΙΓΡΑΦΗ ΥΛΟΠΟΙΗΣΗΣ
5.1 ΠΑΡΑΛΛΗΛΟΠΟΙΗΣΗ DBSCAN ΜΕ ΧΡΗΣΗ ΠΛΕΓΜΑΤΟΣ. Η παραδοσιακή υλοποίηση του DBSCAN έχει, όπως αναφέρθηκε παραπάνω, δύο
βασικά προβλήματα. Αρχικά η παραλληλοποίησή του είναι δύσκολη και έπειτα ο
αριθμός των συγκρίσεων που πραγματοποιούνται σε μεγάλες βάσεις δεδομένων
κατά την εκτέλεση του αλγορίθμου είναι υψηλός.
Η συγκεκριμένη διπλωματική εργασία βασίστηκε σε μια υλοποίηση του DBSCAN η
οποία προτάθηκε από τους Yaobin HE, Haoyu TAN, Wuman LUO, Shengzhong FENG,
Jianping FAN γνωστός και ως MR-DBSCAN [33].
MR-DBSCAN 5.1.1Ο MR-DBSCAN είναι ένας αλγόριθμος συσταδοποίησης που σχεδιάστηκε πάνω στο
μοντέλο MapReduce και πρόκειται για μια επέκταση του DBSCAN.
Η βασική διαφορά του MR-DBSCAN με τον παραδοσιακό DBSCAN είναι πως
επιτυγχάνει τη συσταδοποίηση εκτελώντας τα δύο παραπάνω βήματα. Πιο
συγκεκριμένα ο αλγόριθμος μπορεί να χωριστεί στα εξής βήματα: data partitioning,
local clustering(DBSCAN), global merging.
Data partitioning: Σε αυτό το βήμα γίνεται ένας διαχωρισμός της βάσης δεδομένων
σε ομάδες, δημιουργώντας με αυτό τον τρόπο ένα είδος πλέγματος. Η
συγκεκριμένη τεχνική με ορισμένες διαφοροποιήσεις αναλύεται στην υποενότητα
5.1.1. όπου αναφέρονται τα προβλήματα που παρουσιάζονται στη δημιουργία του
πλέγματος.
Local clustering: Σε αυτό το βήμα εκτελέστηκε ο DBSCAN σε καθεμιά από τις
ομάδες που δημιουργήθηκαν στο προηγούμενο βήμα. Ως έξοδο παίρνουμε τις
«τοπικές» συστάδες οι οποίες στη συνέχεια συγχωνεύονται. Είναι σημαντικό να
αναφερθεί ότι ο DBSCAN έχει υλοποιηθεί με διαφορετικό τρόπο ώστε να βελτιωθεί
η ταχύτητα εκτέλεσης του μέσω του μοντέλου MapReduce. Στην υποενότητα 5.1.2
προτείνεται ένας διαφορετικός τρόπος υλοποίησης του DBSCAN μέσω τoυ API που
παρέχεται από το Apache Spark, SQL Apache Spark.
Global merging: Συγχώνευση όλων των συστάδων που προέκυψαν.

60
Εικόνα 5.1: MR-DBSCAN flow chart [33]
Ο MR-DBSCAN μπορεί να θεωρηθεί ως ένας αλγόριθμος που συνδυάζει τη
διαμεριστική συσταδοποίηση και την πυκνότητα. Αυτό συμβαίνει καθώς στο πρώτο
βήμα του αλγορίθμου τα δεδομένα χωρίζονται σε ομάδες και στη συνέχεια
εκτελείται ο DBSCAN αλγόριθμος «τοπικά» σε κάθε ομάδα.
Προφανώς το πιο δύσκολο κομμάτι είναι τα κριτήρια αλλά και ο τρόπος μέσω των
οποίων θα δημιουργηθούν οι ομάδες στο πρώτο στάδιο (data partitioning), έτσι
ώστε να επιτευχθεί σωστή συσταδοποίηση και όσο το δυνατόν καλύτερη
παραλληλοποίηση στο επόμενο βήμα.
DBSCAN μέσω πλέγματος 5.1.2Ένα βασικό κομμάτι της συσταδοποίησης μέσω του DBSCAN είναι ο υπολογισμός
της απόστασης των σημείων μεταξύ τους. Το βασικό αρνητικό σε αυτή την τεχνική
είναι ότι υπάρχουν σημεία για τα οποία είναι βέβαιο ότι η ευκλείδεια απόστασή
τους είναι μεγαλύτερη από Eps οπότε ο υπολογισμός τους εξαρχής είναι άσκοπος.
Επίσης, ο τρόπος με τον οποίο τα δεδομένα θα σταλούν σε κάθε μονάδα του
κατανεμημένου συστήματος δεν έχει καθοριστεί.
Ένας τρόπος για την επίλυση αυτών των προβλημάτων είναι διασπάζοντας την
αρχική βάση δεδομένων σε μικρότερες, δημιουργώντας ουσιαστικά ένα πλέγμα
μέσω του οποίου επιτυγχάνεται μια σημαντική μείωση των συγκρίσεων όπως
φαίνεται στο σχήμα 5.1.

61
Εικόνα 5.2: Διαχωρισμός των δεδομένων σε 3 τμήματα S1,S2 και S3
Υπάρχουν διαφορετικοί τρόποι διάσπασης των αρχικών δεδομένων σε μικρότερα
μέσω της χρήσης πλέγματος. Στη συγκεκριμένη διπλωματική εργασία προτείνονται
2 διαφορετικές τεχνικές.
Δημιουργία επικαλυπτόμενων και μη-επικαλυπτόμενων τμημάτων.
Δημιουργία συγχωνευμένων τμημάτων.
o Δημιουργία διευρυμένων τμημάτων.
Για τηρν πρώτη τεχνική η δημιουργία του πλέγματος χωρίζεται σε τρεις φάσεις:
Στην πρώτη φάση γίνεται ένα πέρασμα όλων των στοιχείων έτσι ώστε να βρεθεί η
μέγιστη και η ελάχιστη τιμή της μεταβλητής x. Η εύρεση της συγκεκριμένης τιμής
είναι απαραίτητη για τη δημιουργία των ορθογωνίων στη δεύτερη φάση.
Η δεύτερη φάση είναι η διάσπαση της αρχικής βάσης δεδομένων σε μικρότερες
λαμβάνοντας υπόψιν τον εξής περιορισμό:
Κάθε τμήμα πρέπει να είναι διαστάσεων ίσων τουλάχιστον με 2*Eps όπου Eps είναι
η παράμετρος που δίνεται από τον χρήστη ως κατώφλι απόστασης (σχήμα 5.1).

62
Η τρίτη φάση είναι η δημιουργία n-1 τμημάτων που είναι επικαλυπτόμενα με αυτά
που δημιουργήθηκαν στη δεύτερη φάση (Εικόνα 5.2 Τα S12, S23). Tα
επικαλυπτόμενα τμήματα που δημιουργούνται σε αυτή τη φάση είναι ουσιαστικά
τα τμήματα S1 και S2 ολισθημένα κατά Eps.
Μπορούμε να εκτελέσουμε μια ακόμα φάση που είναι η ένωση των τμημάτων που
δημιουργήθηκαν στη φάση 2 και των επικαλυπτόμενων που δημιουργήθηκαν στη
φάση 3.
Αλγόριθμος δημιουργίας πλέγματος(1 &2 ):
1) Σάρωσε όλα τα δεδομένα και βρες την ελάχιστη τιμή και τη μέγιστη τιμή του x.
2) Υπολόγισε τον αριθμό των τμημάτων n = | 𝑥𝑚𝑎𝑥 − 𝑥𝑚𝑖𝑛|
2∗Eps
2) Δημιούργησε n τμήματα στο διάστημα [xmin¸, xmax] μη επικαλυπτόμενα δηλαδή
[xmin, xmin +2*Eps ],[ xmin +2*Eps, xmin +4*Eps] …
3) Δημιούργησε n-1 τμήματα τα οποία είναι η ολίσθηση των πρώτων n-1 τμημάτων
που προέκυψαν δηλαδή [xmin + Eps, xmin +3*Eps ],[ xmin +3*Eps, xmin +5*Eps] …
4) Συγχώνευσε τα n τμήματα (βήμα 2) με τα n-1 τμήματα (βήμα 3) και δημιούργησε
τα τελικά n τμήματα:
Αν Q ={q1,q2,..,qn} τα τμήματα του βήματος 2 & S= {s1, s2, sn-1} τα ολισθημένα τότε
R = {q1∪ s1, q2∪ s2, qn∪ sn-1, qn}
Σε κάθε ένα από τα τμήματα που δημιουργήθηκαν (S1, S2, S3, S12, S23) μπορεί να
εφαρμοστεί ο DBSCAN και να έχουμε μια «τοπική» συσταδοποίηση.
Το πλεονέκτημα αυτής της τεχνικής είναι ότι μπορούμε ευκολά να εκτελέσουμε
παράλληλα τον DBSCAN σε διαφορετικές μονάδες (δηλαδή σε ένα κατανεμημένο
σύστημα).
Η βασική διαφορά μεταξύ των δύο αυτών τεχνικών είναι πως στην πρώτη
περίπτωση η τμηματοποίηση γίνεται σε μεγαλύτερο βαθμό πριν σταλούν τα
δεδομένα σε κάθε μονάδα του κατανεμημένου συστήματος. Επειδή οι απαιτήσεις
σε μνήμη είναι λιγότερες, μπορεί σε περίπτωση που δεν υπάρχει αρκετή μνήμη να
εφαρμοστεί ο αλγόριθμος DBSCAN σε ένα μόνο τμήμα και αφότου έχει
ολοκληρωθεί η εκτέλεση του να μεταβεί στο επόμενο.
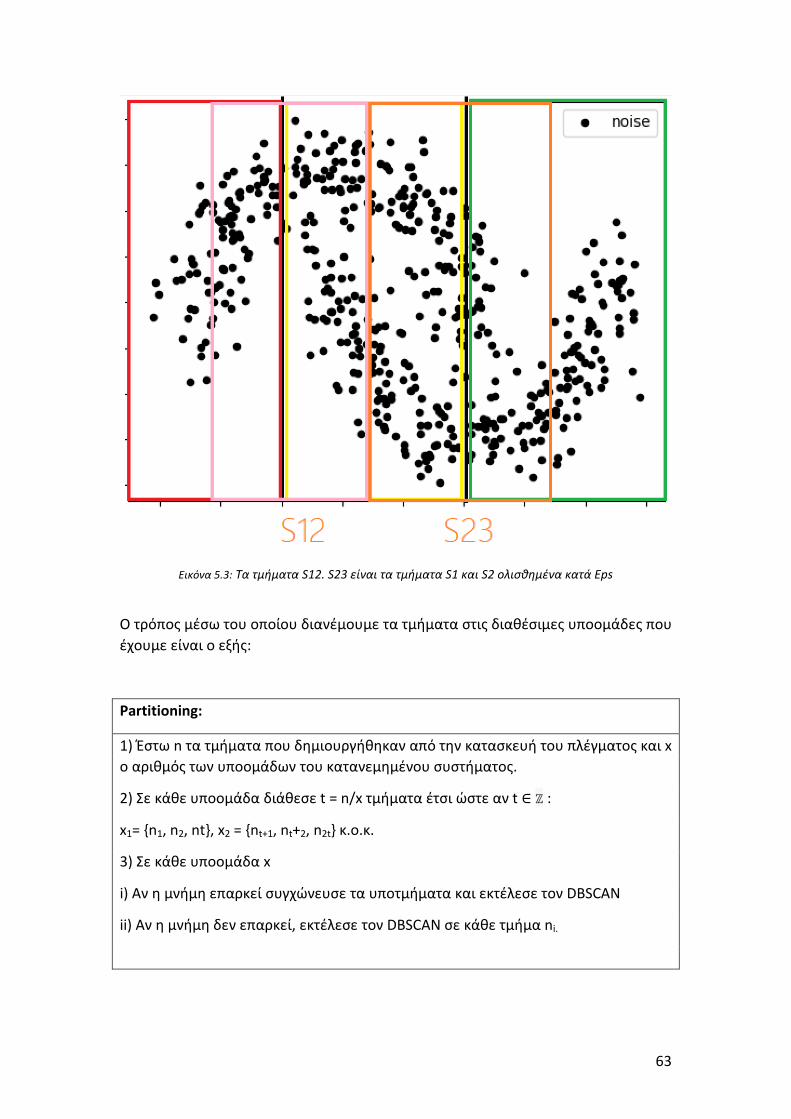
63
Εικόνα 5.3: Τα τμήματα S12. S23 είναι τα τμήματα S1 και S2 ολισθημένα κατά Eps
Ο τρόπος μέσω του οποίου διανέμουμε τα τμήματα στις διαθέσιμες υποομάδες που
έχουμε είναι ο εξής:
Partitioning:
1) Έστω n τα τμήματα που δημιουργήθηκαν από την κατασκευή του πλέγματος και x
ο αριθμός των υποομάδων του κατανεμημένου συστήματος.
2) Σε κάθε υποομάδα διάθεσε t = n/x τμήματα έτσι ώστε αν t ∈ ℤ :
x1= {n1, n2, nt}, x2 = {nt+1, nt+2, n2t} κ.ο.κ.
3) Σε κάθε υποομάδα x
i) Αν η μνήμη επαρκεί συγχώνευσε τα υποτμήματα και εκτέλεσε τον DBSCAN
ii) Αν η μνήμη δεν επαρκεί, εκτέλεσε τον DBSCAN σε κάθε τμήμα ni.

64
Ένα ακόμα πλεονέκτημα αυτής της τεχνικής είναι η επίλυση του προβλήματος ότι οι
παράμετροι Eps & MinPts είναι «μη μεταβλητές». Μπορεί αν είναι απαραίτητο να
χρησιμοποιηθούν διαφορετικές παράμετροι για κάθε τμήμα για τη βελτίωση της
συσταδοποίησης ή ακόμα και συνδυασμός αλγορίθμων.
Το μειονέκτημα είναι η εύρεση και η αποδοτική «διάσπαση» της αρχικής βάσης
δεδομένων. H επιλογή του 2*Eps για το εύρος του κάθε διαστήματος είναι η
ελάχιστη που προέκυψε χωρίς απώλειες αλλά δεν είναι η βέλτιστη τιμή.
Αν επιλεχθεί πολύ μικρό Eps τότε τα τμήματα θα συγχωνευθούν ξανά στο
partitioning stage (λόγω του μικρού όγκου και για την επίτευξη καλύτερης
παραλληλοποίησης). Αν επιλεχθεί μεγάλη τιμή στο Eps, δηλαδή λίγα τμήματα, τότε
είναι πιθανόν να μην επωφελούμαστε από όλες τις υποομάδες.
Μια εναλλακτική είναι αυτή των «διευρυμένων τμημάτων», δηλαδή να
δημιουργήσουμε n τμήματα, όσες και οι μονάδες που έχει το κατανεμημένο
σύστημα, και στη συνέχεια να «επεκτείνουμε» τα τμήματα ώστε να είναι
επικαλυπτόμενα. Οι απαιτήσεις σε μνήμη είναι περισσότερες, οπότε η
συγκεκριμένη τεχνική δεν είναι πάντα αποδοτική αλλά έχει το πλεονέκτημα ότι
είναι απλοϊκή (Εικόνα 5.3).
Αλγόριθμος δημιουργίας πλέγματος(3):
1) Σάρωσε όλα τα δεδομένα και βρες την ελάχιστη τιμή και τη μέγιστη τιμή του x
2) O αριθμός των τμημάτων είναι όσες και οι μονάδες που έχουμε (είσοδος από τον
χρήστη)
2)d =| 𝑥𝑚𝑎𝑥 − 𝑥𝑚𝑖𝑛|
n, όπου n ο αριθμός των μονάδων του κατανεμημένου συστήματος
2) Δημιούργησε n τμήματα στο διάστημα [xmin¸, xmax] μη επικαλυπτόμενα δηλαδή
[xmin, xmin + d ],[ xmin + d, xmin +2* d] …[ x max – *d, xmax ]
3) Επέκτεινε τα όρια κάθε τμήματος κατά 2*Eps :
[xmin, xmin + d] > [xmin -2*Eps, xmin + d +2*Eps]
[ xmin + d, xmin +2* d] > [ xmin + d - 2*Eps, xmin +2* d +2*Eps]
4) Εκτέλεσε τον DBSCAN σε κάθε υποομάδα

65
Στην Εικόνα 5.3 φαίνονται σχηματικά οι τρεις τρόποι που προτείνονται για τη
δημιουργία του πλέγματος και τον τρόπο με τον οποίο επιτυγχάνεται η
παραλληλοποίηση του DBSCAN. Κάθε μέθοδος έχει τα πλεονεκτήματά της και η
επιλογή εξαρτάται από τον όγκο των δεδομένων και τους διαθέσιμους
υπολογιστικούς πόρους που έχουμε.
Εικόνα 5.4: Δημιουργία πλέγματος και partitioning flow chart
Σε περίπτωση που δεν έχουμε αρκετή μνήμη, το Spark αυτόματα θα μεταφέρει τα
δεδομένα στον δίσκο, οπότε η εκτέλεση του αλγορίθμου θα πραγματοποιηθεί αλλά
με υψηλό υπολογιστικό κόστος.
Για την εύρεση του x_min & του x_max χρησιμοποιήθηκαν οι εντολές που
παρέχονται από στο Spark RDD.max(), RDD.min().

66
Τέλος, είναι σημαντικό να αναφερθεί πως η τοπική συσταδοποίηση, ανεξάρτητα της
τεχνικής που θα ακολουθήσουμε κατά τη δημιουργία του πλέγματος,
ολοκληρώνεται όταν η πιο «αργή» υποομάδα ολοκληρώσει την εκτέλεση του
«τοπικού» DBSCAN. Αυτό σημαίνει ότι αν τα δεδομένα προς επεξεργασία είναι
συγκεντρωμένα σε ένα μικρό διάστημα η συγκεκριμένη τεχνική δεν θα είναι
ιδιαίτερα αποδοτική μιας και ο αλγόριθμος θα εκτελεστεί σχεδόν σειριακά.
Γι’ αυτό τον λόγο έγινε μια τροποποίηση στη «σειριακή» εκτέλεση του DBSCAN η
οποία αναλύεται στην επόμενη υποενότητα.
Παραλληλοποίηση Αλγόριθμου DBSCAN 5.1.3Η υλοποίηση του DBSCAN μέσω Apache Spark διαφέρει σε ένα σημαντικό βαθμό σε
σχέση με την κλασική του υλοποίηση. Αυτό συμβαίνει επειδή βασικός στόχος είναι
να εκμεταλλευτούμε την «παραλληλία» που μας προσφέρει το Apache Spark.
Η γλώσσα προγραμματισμού που χρησιμοποιήθηκε ήταν η python για την οποία τo
Spark προσφέρει API. Χρησιμοποιήθηκαν επίσης τα Spark DataFrames που
προσφέρονται μέσω της βιβλιοθήκης Spark SQL. Ωστόσο σε ορισμένα σημεία η
χρήση των RDDs ήταν απαραίτητη για την περαιτέρω βελτίωση της απόδοσης του
αλγορίθμου.
Για την πλήρη λειτουργικότητα του αλγορίθμου πρέπει να είναι εγκατεστημένες οι
παρακάτω βιβλιοθήκες:
Python 3.7
PySpark 2.4
Graphframes 0.6
NumPy 1.84
Ο αλγόριθμος ως είσοδο δέχεται τις εξής παραμέτρους:
Παράμετροι περιγραφή Default
value
dim Αριθμός διαστάσεων Null
Min-pts Βλ. DBSCAN 3
Eps Βλ. DBSCAN 0.3
type_of_r Τρόπος δημιουργίας του πλέγματος 3
partition Καθορισμός αριθμού τμημάτων χρησιμοποιείται
μόνο αν type_of_r =3
8
graphs Χρήση γραφημάτων 1
67
Η παράμετρος type_of_r αφορά τον τρόπο δημιουργίας του πλέγματος, ο οποίος
αναλύθηκε στην προηγουμένη υποενότητα, και η επιλογή της είναι για
πειραματικούς σκοπούς.
Η παράμετρος partition έχει νόημα μόνο αν θέλουμε να χρησιμοποιήσουμε την
τεχνική διευρυμένων τμημάτων ή αν δεν θέλουμε να χρησιμοποιήσουμε καθόλου
πλέγμα (partition = 1).
type_of_rectangles output
1 Δημιουργία επικαλυπτόμενων & μη επικαλυπτόμενων
τμημάτων
2 Δημιουργία συγχωνευμένων τμημάτων
3 Δημιουργία διευρυμένων τμημάτων (προκαθορισμένος
αριθμός βάσει της παραμέτρου partition).
Η παράμετρος graphs αφορά τη χρήση ή όχι γραφήματος για τη συγχώνευση των
τελικών συστάδων μέσω της βιβλιοθήκης graph frames.
Ο αλγόριθμος μπορεί να χωριστεί στα εξής 7 βήματα:
Βήμα 1: Προεπεξεργασία δεδομένων
Αρχικά δημιουργείται ένα DataFrames με όλα τα δεδομένα, αφαιρούνται όλα τα
ελλιπή δεδομένα (null values) και μετατρέπονται σε float αν είναι ακαριαίοι
αριθμοί. Στη συνέχεια καταχωρείται ένα «μοναδικό ID» για κάθε σημείο. Θεωρούμε
πως τα δεδομένα εισόδου είναι όλα αριθμοί και δεν έχουμε ελλιπή δεδομένα από
αυτό το σημείο και μετά.
Βήμα 2: Χρήση πλέγματος
Το συγκεκριμένο βήμα θα μπορούσε να είναι προαιρετικό, αλλά σε περίπτωση που
δεν εκτελεστεί δεν εκμεταλλευόμαστε σε αρκετά ικανοποιητικό βαθμό την
παραλληλία που προσφέρει το Spark όταν έχουμε μεγάλο όγκο δεδομένων. Αν
επιθυμούμε να μη δημιουργηθεί πλέγμα, τότε ως είσοδο στον αλγόριθμο θέτουμε
type_of_rectangles = 3, partition = 1Σε αυτό το βήμα δημιουργείται το πλέγμα που
αναλύθηκε στην προηγουμένη υποενότητα. Ανεξάρτητα από την τεχνική που θα
ακολουθήσουμε ως έξοδο, θα έχουμε ένα σύνολο από DataFrames ιδίας μορφής με
αυτά που προέκυψαν στο βήμα 1, αλλά μικρότερου όγκου. Τα βήματα 3,4,5 θα
εκτελεστούν σε κάθε ένα από τα DataFrames που θα προκύψουν.

68
Βήμα 3: Δημιουργία καρτεσιανού συστήματος & υπολογισμός απόστασης
Σε κάθε ένα από αυτά τα DataFrames πλέον μπορεί να εφαρμοστεί ο DBSCAN με
ορισμένες τροποποιήσεις. Πιο συγκεκριμένα, έχοντας μειώσει τον όγκο των
δεδομένων, μπορεί πλέον να εφαρμοστεί ο μετασχηματισμός «cross join» για τη
δημιουργία του καρτεσιανού συστήματος διαστάσεων n*n, το οποίο περιέχει όλους
του πιθανούς συνδυασμούς, όπως φαίνεται στην Εικόνα 5.5.
Εικόνα 5.5: Καρτεσιανό σύστημα
Η δομή που χρησιμοποιείται είναι αυτή των DataFrames. Ο υπολογισμός της
απόστασης μεταξύ δύο σημείων μπορεί να υπολογιστεί με τη χρήση των UDFs
(User-Defined Function). Ως είσοδο η συγκεκριμένη συνάρτηση δέχεται τις
συντεταγμένες των δύο σημείων και επιστρέφει την απόσταση (Εικόνα 5.6) ή
εκτελείται παράλληλα σε κάθε γραμμή του DataFrames.
Η ευκλείδεια απόσταση υπολογίζεται από τον τύπο:
d (p, q) =√∑ (𝑝𝑖 − 𝑞𝑖)2𝑛𝑖=0 , οπού q = (q1, q2,….,qn) & p = (p1, p2,.,pn)
Ή πιο απλά αν έχουμε δύο διαστάσεις: d (x, y) = √(𝑥_1 − 𝑥_2) 2 + (𝑦_1 – 𝑦_2) 2
Έχοντας υπολογίσει όλες τις αποστάσεις, μπορούν πλέον, εφαρμόζοντας τους
κατάλληλους μετασχηματισμούς, να αφαιρεθούν όλα τα σημεία τα οποία δεν
υποκύπτουν στον περιορισμό d(x,y) ≤ eps.
Αυτό μπορεί να υλοποιηθεί με δύο τρόπους:
1) Τη χρήση της εντολής filter() δηλαδή filter(df.distance<eps) η οποία έχει σχετικά
υψηλό υπολογιστικό κόστος.
2) Η udf να τροποποιηθεί έτσι ώστε να ελέγχει τη συνθήκη d(x,y) ≤ eps. Αυτό μπορεί
να επιτευχθεί αν ως έξοδο η udf συνθήκη d(x,y) ≤ eps επιστρέφει το ID του σημείου
που συγκρίνεται αν είναι εντός της ακτίνας eps, ενώ σε αντίθετη περίπτωση null.

69
Στην Εικόνα 5.6 φαίνεται σχηματικά πώς λειτουργεί ο συγκεκριμένος
μετασχηματισμός.
Εικόνα 5.6: Η εύρεση των γειτονικών στοιχείων μέσω DataFrames
Ο λόγος που επιλέχθηκε να μη χρησιμοποιηθεί η εντολή filter() είχε να κάνει με το
γεγονός ότι στο επόμενο βήμα εκτελείται το reduce stage, δηλαδή όλα τα στοιχεία
συγχωνεύονται σε λίστες βάσει του ID. Με άλλα λόγια, όλα τα στοιχεία που
ικανοποιούν τη συνθήκη (1) συγχωνεύονται σε μια λίστα.
Βήμα 5: Εύρεση των γειτονικών στοιχείων
Tο επόμενο βήμα είναι να διατηρηθούν τα σημεία στα οποία ο αριθμός των
γειτόνων τους είναι ίσος ή μεγαλύτερος της παραμέτρου MinPts.
Αρχικά εφαρμόζουμε τον μετασχηματισμό “groupby” μέσω του οποίου
συγχωνεύουμε όλα τα γειτονικά στοιχεία που έχει το κάθε σημείο σε μια λίστα. Για
να βρεθούν τα βασικά σημεία, πρέπει να «διαγράψουμε» όλες τις λίστες με μήκος
λιγότερο από MinPts χρησιμοποιώντας την εντολή που παρέχεται από τη
βιβλιοθήκη του Spark SQL: filter(size(“column”)<MinPts. Όπου size(“column”)
επιστρέφει το μήκος της κάθε λίστας.

70
Εικόνα 5.7: Η εύρεση των γειτονικών στοιχείων μέσω DataFrames
Βήμα 6: Δημιουργία τελικών συστάδων
To τελευταίο στάδιο είναι να συγχωνευτούν οι λίστες που έχουν τουλάχιστον ένα
κοινό σημείο. Αν έχουμε χρησιμοποιήσει την τεχνική του πλέγματος (δηλαδή
έχουμε μόνο 1 DataFrames) τότε συγχωνεύουμε όλα τα DataFrames που έχουν
προκύψει εναλλακτικά εφαρμόζουμε την ακόλουθη τεχνική σε κάθε ένα από
DataFrames που έχουμε.
Για την εκτέλεση της συγχώνευσης των λιστών μπορούμε να ακολουθήσουμε δύο
διαφορετικές τεχνικές (η επιλογή χρήσης ή όχι γραφημάτων μπορεί να καθοριστεί
από τον χρήστη).
Η πρώτη τεχνική χρησιμοποιεί την εκτέλεση ενός σειριακού αλγορίθμου (μέθοδος
Recursion) σε κάθε DataFrames. Κάτι τέτοιο, όμως, δεν είναι αποτελεσματικό σε
περιπτώσεις που πρέπει να επεξεργαστούν μεγάλοι όγκοι δεδομένων καθώς δεν
γίνεται εκμεταλλεύσιμη σε κανένα βαθμό η παραλληλία που προσφέρει το Apache
Spark.
Η δεύτερη τεχνική χρησιμοποιεί ένα γράφημα που δημιουργήθηκε μέσω της
βιβλιοθήκης που παρέχεται από το Apache Spark γνωστή και ως graph frames. Το
γράφημα δημιουργήθηκε ως εξής:
1) Κάθε σημείο είναι μια κορυφή
2) Για κάθε γραμμή του DataFrames, δημιουργήθηκαν τόσες ακμές όσα και στοιχεία
στη λίστα (ID_neighbor) μεταξύ του κάθε στοιχείου της λίστας και το ID (βασικό
σημείο).
Στη συνέχεια εκτελέστηκε ο αλγόριθμος connected component μέσω του οποίου
βρέθηκαν οι τελικές συστάδες.
Ο αλγόριθμος connected component παρέχεται μέσω της βιβλιοθήκης graph frames
του Spark και ουσιαστικά βρίσκει όλα τα «μη συνεκτικά» γραφήματα, τα οποία στη
συγκεκριμένη περίπτωση είναι οι τελικές μας συστάδες.

71
Αν έχουμε πολλαπλά DataFrames τότε συγκεντρώνουμε όλα τα αποτελέσματα και
συγχωνεύουμε για μια ακόμα ακόμα φορά τις λίστες, κάθε λίστα είναι η τοπική
συστάδα που προέκυψε από την διάσπαση του αρχικού DataFrames.
Βήμα 7: Καθορισμός ετικετών στα δεδομένα
Ως έξοδο ο αλγόριθμος επιστρέφει ένα διάνυσμα μήκους n (όσα και τα στοιχεία που
έχουμε), στο οποίο κάθε στοιχείο έχει τιμή 0 αν είναι θόρυβος και C αν ανήκει σε
κάποια συστάδα. Δηλαδή τα στοιχεία της πρώτης συστάδας έχουν τιμή C= 1, της
δεύτερης C =2 κ.ο.κ.
Στην εικόνα 5.8 φαίνεται το flow chart του αλγορίθμου που υλοποιήθηκε και 5.9 οι
υπό ρουτίνας local DBSCAN & Run connected component
Ο ψευδοκώδικας έχει ως εξής:
Παραλληλοποίηση Αλγόριθμου DBSCAN
_____________________________________________________________________
1) Είσοδος από χρήστη (MinPts,Eps) & δεδομένα (D)
2) label (Di) = unique_ID // 0,1, 2. n-1
3) Χρήση πλέγματος
a) Δημιούργησε ένα καρτεσιανό σύστημα μεταξύ όλων των σημείων n*n
b) Αφαίρεσε όλα τα σημεία για τα οποία dist <eps *
c) Συγχώνευσε όλα τα σημεία σε λίστες // n λίστες
d) Αφαίρεσε όλες τις λίστες όπου len(list) <Min_pts
e**) Συγχώνευσε τις λίστες που έχουν κοινά στοιχεία //δημιουργία τοπικών
συστάδων
5)Συγχώνευσε όλα τα DataFrames.
6) Συγχώνευσε τις λίστες που έχουν κοινά στοιχεία //δημιουργία τελικών συστάδων
7) Κάθε λίστα είναι μια τελική συστάδα & τα υπόλοιπα στοιχεία θόρυβος
*Η αφαίρεση των στοιχείων γίνεται χωρίς τη χρήση της εντολής filter() για βελτίωση
της ταχύτητας εκτέλεσης του αλγορίθμου.
**
i) Δημιούργησε ένα γράφημα με ακμές τα στοιχεία κάθε λίστας
ii) Εφάρμοσε τον αλγόριθμο connected component για την εύρεση των μη
συνεκτικών γραφημάτων (τα συγκεκριμένα γραφήματα είναι οι τελικές συστάδες)
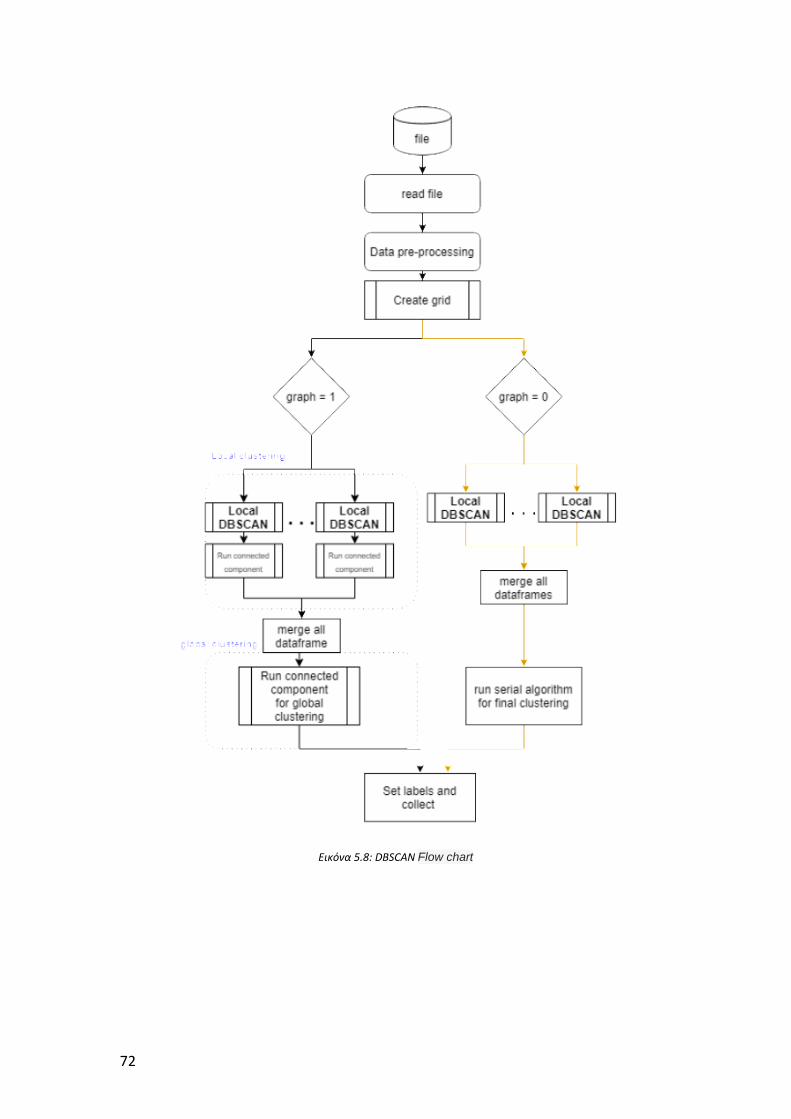
72
Εικόνα 5.8: DBSCAN Flow chart
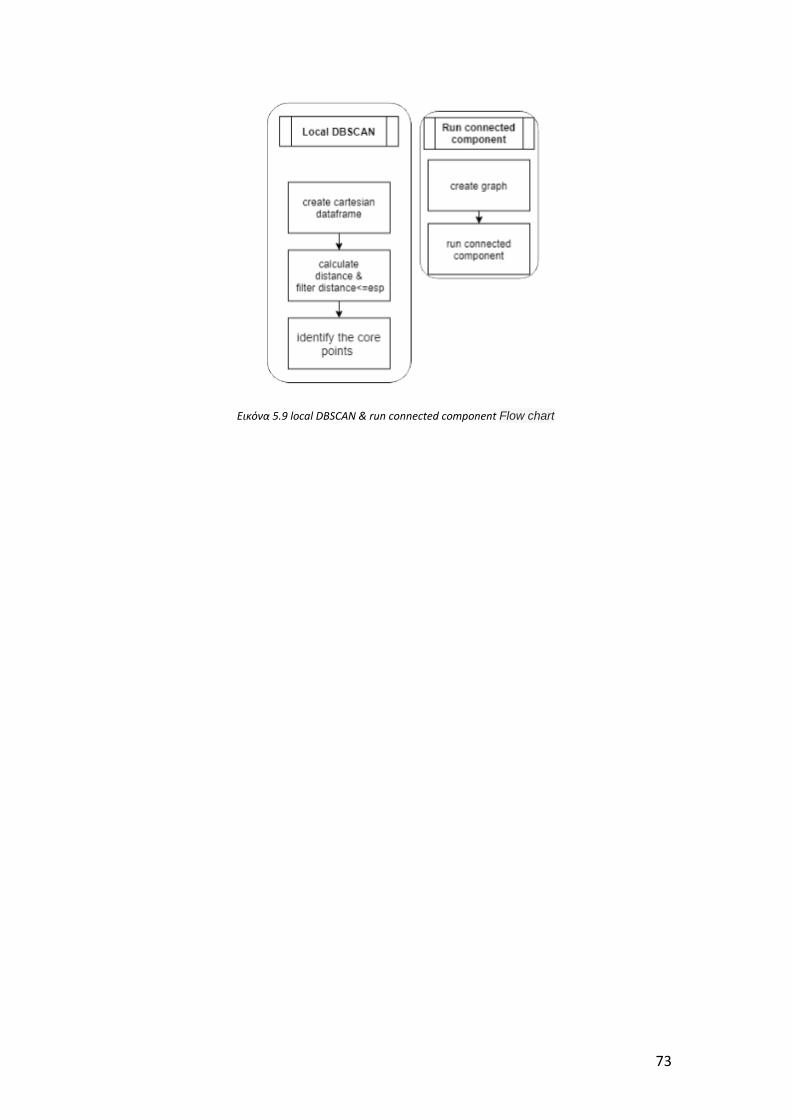
73
Εικόνα 5.9 local DBSCAN & run connected component Flow chart

74

75
6 ΠΕΙΡΑΜΑΤΙΚΗ ΑΞΙΟΛΟΓΗΣΗ
6.1 ΔΗΜΙΟΥΡΓΙΑ ΣΥΝΘΕΤΙΚΩΝ ΒΑΣΕΩΝ ΔΕΔΟΜΕΝΩΝ
Για την αξιολόγηση του αλγορίθμου που υλοποιήθηκε δημιουργήθηκαν συνθετικές
βάσεις δεδομένων μέσω της βιβλιοθήκης sklearn χρησιμοποιώντας τη γλώσσα
python. Πιο συγκεκριμένα, δοκιμάστηκαν 6 datasets (5 συνθετικά και 1 με
πραγματικά δεδομένα) μέσω των οποίων μπορεί να γίνει εύκολα αντιληπτή η
αποδοτικότητα του DBSCAN που υλοποιήθηκε στη συγκεκριμένη διπλωματική
εργασία και να συγκριθεί με υπάρχουσες υλοποιήσεις.
Μορφή Διαστάσεις Αλγόριθμοι που συγκρίθηκαν
Dataset_1 3 διαχωρισμένες συστάδες 2 έως 4 K-means (Apache Spark)
Dataset_2 2 διαχωρισμένες συστάδες
1 με αραιά σημεία
2 έως 4 K-means (Apache Spark), DBSCAN
(sklearn)
Dataset_3 Αυθαίρετο σχήμα (2 συστάδες) 2 DBSCAN (sklearn)
Dataset_4 Αυθαίρετο σχήμα (2 συστάδες) 2 DBSCAN (sklearn)
Dataset_5 Ανισοτροπικά κατανεμημένα
δεδομένα (2 συστάδες)
2 DBSCAN (sklearn)
Εικόνα 6.1: Οι βάσεις δεδομένων που χρησιμοποιήθηκαν για την αξιόλογη του αλγορίθμου

76
Στην Εικόνα 7.1 φαίνεται η μορφή που έχουν τα συγκεκριμένα datasets (αν οι
διαστάσεις είναι δύο). Δεν κρίνεται αναγκαίο να γίνει μια σύγκριση μεταξύ του K-
Means και του DBSCAN στις περιπτώσεις 3, 4 και 5, αφού ο k-means αποτυγχάνει
πλήρως να ομαδοποιήσει δεδομένα που έχουν αυτή τη μορφή.
Για τον λόγο αυτό η σύγκριση του DBSCAN και του k-means περιορίστηκε σε
δεδομένα για τα οποία ξέρουμε ότι οι συστάδες είναι καλά διαχωρισμένες
(περιπτώσεις 1 και 2).
6.2 ΜΕΤΡΙΚΕΣ ΠΟΥ ΧΡΗΣΙΜΟΠΟΙΗΘΗΚΑΝ Για την αξιολόγηση του αλγορίθμου που υλοποιήθηκε χρησιμοποιήθηκαν δύο
μετρικές που παρέχονται από τη βιβλιοθήκη sklearn. Το F-measure (Fowlkes-
Mallows scores), το οποίο αναλύθηκε στην υποενότητα 3.1.2, και το ΜΙ (Mutual
Information).
Βασικό αρνητικό των συγκεκριμένων μετρικών είναι ότι πρέπει να υπάρχει «γνώση»
όσον αφορά το αποτέλεσμα που αναμένουμε. Η σύγκριση των αποτελεσμάτων δύο
αλγορίθμων μέσω του FMI δεν έχει κάποιο σημαντικό αποτέλεσμα, καθώς είναι
πιθανόν κανένας από τους δύο να μην επιτυγχάνει αποτελεσματική
συσταδοποίηση.
Για παράδειγμα, αν συγκρίνουμε τον DBSCAN και τον k-Means για ένα dataset που
αποτελείται από αυθαίρετα σχήματα, τότε η μετρική είναι εντελώς λανθασμένη.
Επίσης, ο DBSCAN αναγνωρίζει σημεία ως «θόρυβο», γεγονός που είναι ανέφικτο
για τον k-means και για άλλους αλγόριθμους (GMM). Αυτό έχει ως αποτέλεσμα οι
μετρικές να μη δείχνουν την πραγματικότητα, καθώς η εύρεση του θορύβου και η
αφαίρεσή του από τα δεδομένα είναι ένα από τα βασικά πλεονεκτήματα του
DBSCAN σε σχέση με τους υπόλοιπους αλγορίθμους συσταδοποίησης. Στα
συγκεκριμένα πειράματα θεωρήσαμε ότι ο θόρυβος είναι μια «ανεξάρτητη»
συστάδα. Στις περιπτώσεις που υπήρχε ασυμφωνία αποτελεσμάτων
χρησιμοποιήθηκε η τεχνική της οπτικοποίησης (για dataset έως δύο διαστάσεων).

77
Γι’ αυτόν τον λόγο οι συγκεκριμένες μετρικές χρησιμοποιήθηκαν μόνο στην
περίπτωση που δόθηκε ως είσοδος ένα dataset, για το οποίο γνωρίζαμε τον ακριβή
αριθμό των συστάδων και τα σημεία που ανήκαν σε κάθε συστάδα (υποενότητα
6.4). Στα τεχνικά dataset χρησιμοποιήθηκε η τεχνική της οπτικοποίησης
χρησιμοποιώντας τη βιβλιοθήκη matplotlib.
6.3 ΑΠΟΤΕΛΕΣΜΑΤΑ ΣΥΓΚΡΙΣΗΣ ΤΟΥ ΥΛΟΠΟΙΗΜΕΝΟΥ ΑΛΓΟΡΙΘΜΟΥ.
DBSCAN του sklearn 6.3.1Η σύγκριση του DBSCAN η οποία παρέχεται από τις βιβλιοθήκες του SKLEARN με
τον DBSCAN που υλοποιήθηκε στο Apache Spark (με χρήση συγχωνευμένων
τμημάτων) δεν είναι εφικτή για μεγάλο όγκο δεδομένων. Αυτό συμβαίνει επειδή το
pandas δεν μπορεί να υποστηρίξει επεξεργασία πάνω σε μεγάλο όγκο δεδομένων
σε αντίθεση με το Apache Spark.
Παρ’ όλα αυτά μια σύγκριση μεταξύ του sklearn DBSCAN και των δύο υλοποιήσεων
που προτείνονται (με χρήση γραφημάτων και χωρίς) μπορεί να δείξει την
αποδοτικότητα του κάθε αλγορίθμου.
Για κάθε dataset οι αλγόριθμοι συγκρίθηκαν με Min_pts =15 και eps με
διαφορετικές τιμές ώστε να παρατηρούνται οι περιπτώσεις ασυμφωνίας. Σε όλες τις
περιπτώσεις οι αλγόριθμοι βρήκαν τον ίδιο αριθμό συστάδων αλλά είχαν
διαφορετική ευαισθησία στον θόρυβο.
Dataset 2 (3 συστάδες, 1 με μικρή πυκνότητα): Για Eps. ∈ [0.14, 0.24] η
συσταδοποίηση ήταν αποτελεσματική και οι δύο αλγόριθμοι είχαν τα ίδια
αποτελέσματα με τον DBSCAN του sklearn.
Dataset 3 (2 συστάδες αυθαίρετο σχήμα): Για Eps. ∈ [0.22, 0.24] η συσταδοποίηση
ήταν αποτελεσματική και οι δύο αλγόριθμοι είχαν τα ίδια αποτελέσματα με τον
DBSCAN του sklearn.
Dataset 4 (2 συστάδες αυθαίρετο σχήμα): Για Eps. ∈ [0.22, 0.24] η συσταδοποίηση
ήταν αποτελεσματική και οι δύο αλγόριθμοι είχαν τα ίδια αποτελέσματα με τον
DBSCAN του sklearn.
Dataset 5 (2 συστάδες με Ανισοτροπικά κατανεμημένα δεδομένα): Για Eps. ∈ [0.1,
0.28] η συσταδοποίηση δεν ήταν αποτελεσματική και οι δύο αλγόριθμοι είχαν τα
ίδια αποτελέσματα με τον DBSCAN του sklearn, αλλά αναγνώρισαν τρεις αντί για
δύο συστάδες. Η επιλογή του DBSCAN σε δεδομένα που είναι κατανεμημένα
Ανισοτροπικά δεν είναι αποτελεσματική. Για την αποτελεσματική συσταδοποίηση
πρέπει να εφαρμοστεί διαφορετικός αλγόριθμος όπως ο GMM(EM).
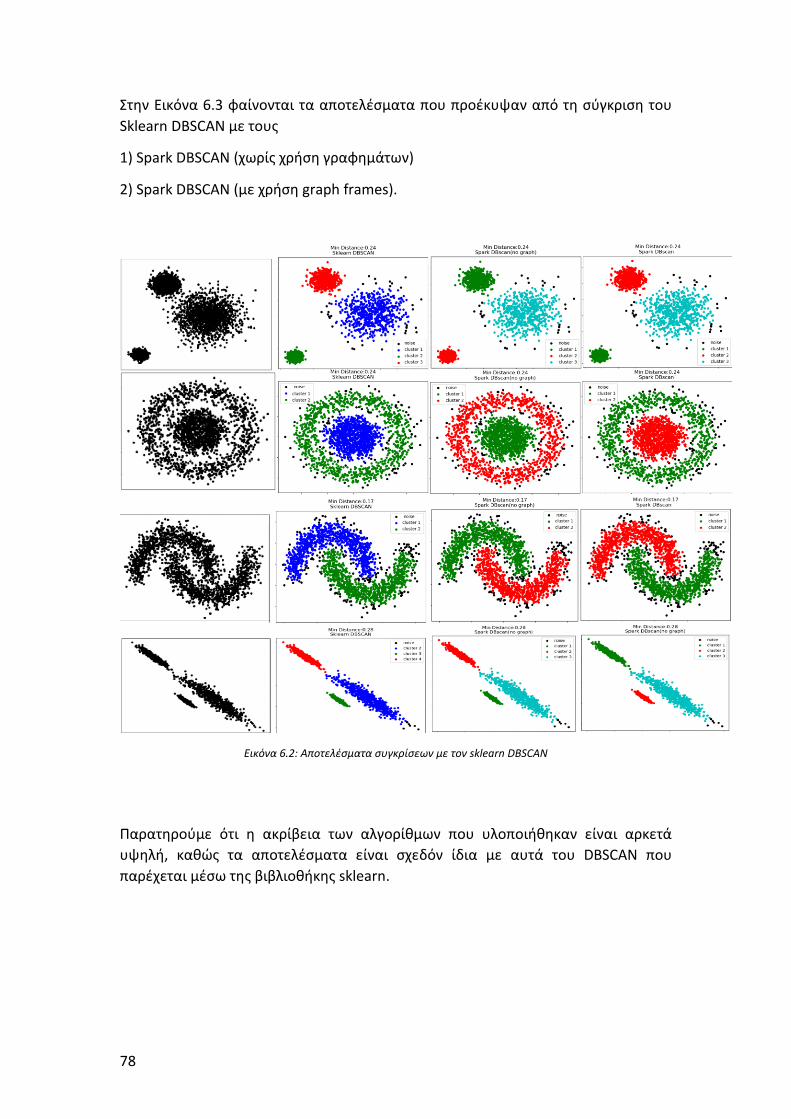
78
Στην Εικόνα 6.3 φαίνονται τα αποτελέσματα που προέκυψαν από τη σύγκριση του
Sklearn DBSCAN με τους
1) Spark DBSCAN (χωρίς χρήση γραφημάτων)
2) Spark DBSCAN (με χρήση graph frames).
Εικόνα 6.2: Αποτελέσματα συγκρίσεων με τον sklearn DBSCAN
Παρατηρούμε ότι η ακρίβεια των αλγορίθμων που υλοποιήθηκαν είναι αρκετά
υψηλή, καθώς τα αποτελέσματα είναι σχεδόν ίδια με αυτά του DBSCAN που
παρέχεται μέσω της βιβλιοθήκης sklearn.

79
K-means Apache Spark 6.3.2Η σύγκριση του DBSCAN, που υλοποιήθηκε στο Apache Spark (με χρήση
συγχωνευμένων τμημάτων), και του αλγορίθμου k-means, που παρέχεται μέσω της
βιβλιοθήκης MLLib Apache Spark, περιορίστηκε στα δύο πρώτα datasets στα οποία
οι συστάδες ήταν καλά διαχωρισμένες. Αυτό έγινε καθώς στα υπόλοιπα datasets ο
k-means αλγόριθμος αποτυγχάνει πλήρως να ομαδοποιήσει τα δεδομένα (λόγω του
αυθαίρετου σχήματος που έχουν).
Για κάθε dataset οι αλγόριθμοι συγκρίθηκαν με Min_pts =4 και eps = 0.3.
Dataset 1 (3 συστάδες): Η συσταδοποίηση ήταν αποτελεσματική και οι δύο
αλγόριθμοι είχαν τα ίδια αποτελέσματα με τον k-means του Apache Spark.
Αυτό είναι και το αναμενόμενο αποτέλεσμα, καθώς όλες οι συστάδες έχουν
«υψηλή» πυκνότητα και είναι καλά διαχωρισμένες (διακριτές). Φυσικά, αν
δοκιμάσουμε διαφορετικές τιμές στην παράμετρο Eps, τότε τα αποτελέσματα θα
διαφέρουν.
Dataset 2 (2 διαχωρισμένες συστάδες, 1 με αραιά σημεία): Η συσταδοποίηση ήταν
αποτελεσματική αλλά λόγω της μικρής πυκνότητας της μιας συστάδας ορισμένα
σημεία ανιχνευθήκαν ως θόρυβος, το οποίο βεβαία δεν είναι απαραίτητα λάθος.
Στην Εικόνα 6.4 φαίνονται τα αποτελέσματα που προέκυψαν από τη σύγκριση του
Apache Spark K-means με τους
1) Spark DBSCAN (χωρίς χρήση γραφημάτων)
2) Spark DBSCAN (με χρήση graph frames).
Εικόνα 6.3: Αποτελέσματα συγκρίσεων με τον Apache Spark K-means

80
Παρατηρούμε ότι η ακρίβεια των αλγορίθμων που υλοποιήθηκαν είναι αρκετά
υψηλή, καθώς τα αποτελέσματα είναι σχεδόν ίδια με αυτά του k-means που
παρέχεται μέσω της βιβλιοθήκης MLLib Apache Spark.
6.4 ΑΞΙΟΛΟΓΗΣΗ ΑΛΓΟΡΙΘΜΟΥ ΠΑΝΩ ΣΕ ΠΡΑΓΜΑΤΙΚΑ ΔΕΔΟΜΕΝΑ Οι τεχνικές βάσεις δεδομένων μπορούν να μας δώσουν απαντήσεις όσο αναφορά
την αποτελεσματικότητα ενός αλγορίθμου σε σύγκριση με κάποια άλλη γνωστή
υλοποίηση παρόλα αυτά δεν είναι σε θέση να «λύσουν» κάποιο ουσιαστικό
πρόβλημα που είναι και ο βασικός σκοπός της συσταδοποίησης. Επίσης στις
τεχνικές βάσεις δεδομένων δεν μπορούμε με ευκολία να αξιολογήσουμε τα
αποτελέσματα όταν έχουμε παραπάνω από 3 διαστάσεις.
Για τους λογούς αυτούς κρίθηκε απαραίτητο να εκτελεστεί ο αλγόριθμος σε ένα
dataset με πραγματικά δεδομένα. Πιο συγκεκριμένα το dataset που
χρησιμοποιήσαμε αφορούσε ένα σύνολο αστεριών για την πρόβλεψη τύπων
αστεριών στο οποίο οι τύποι όλοι των αστερίων ήταν γνωστοί εξαρχής[36].
Οπότε η αξιολόγηση όλων των αλγορίθμων που συγκρίθηκαν ήταν σε βάση ποσό
αποτελεσματικά μπορέσαν να ομαδοποιήσουν τα δεδομένα.
Περιλαμβάνει συνολικά 240 records 5 διαστάσεων διαχωρισμένοι σε 6 συστάδες το
CSV file είναι δομημένο ως εξής:
Θερμοκρασία(K) Φωτεινότητα Ακτίνα Απόλυτη
λαμπρότητα
τύπος
Οι αλγόριθμοι που συγκρίθηκαν ήταν ο Spark K-means, Spark GMM(EM), DBSCAN
(με χρήση πλέγματος & γράφων).
Για την εκτέλεση του K-means δοκιμαστήκαν ως είσοδοι k ∈[2,40]. Αν και
γνωρίζουμε εξ’ αρχής ότι το dataset αποτελείτε από 6 συστάδες θεωρούμε ότι η
συγκεκριμένη πληροφορία δεν είναι γνωστή. Ο K-means σε καμία περίπτωση δεν
είναι η σωστή επιλογή. Αυτό συμβαίνει επειδή το σχήμα των συστάδων είναι
αυθαίρετο με αποτέλεσμα η αποτελεσματικότητα του k-means να είναι πολύ
χαμηλή. Για k =6 το FMI είναι περίπου 0.428 ± 0.002 και με την καλύτερη ακρίβεια
να την έχουμε για k= 12 οπού FMI = 0.430 ± 0.001.
Όμοια για την εκτέλεση του GMM δοκιμαστήκαν ως είσοδοι k ∈[2,40]. Η
αποτελεσματικότητα της συσταδοποίηση μέσο του GMM ήταν παρόμοια με αυτή
του K-means. Για k=6 FMI:0.45± 0.004.
Για την εκτέλεση του DBSCAN (με χρήση πλέγματος & γράφων) δοκιμαστήκαν ως
είσοδοι eps = 0.3 & Min_pts =5 (graph = 0,1, type_of_rectangles = 1 ).

81
Ο DBSCAN όπως αναφέρθηκε και πιο πριν βασίζεται στην πυκνότητα δηλαδή
διαχωρίζει τις συστάδες ανάλογα με το ποσό πυκνές είναι. Επειδή οι συστάδες
έχουν αυθαίρετο σχήμα η αποτελεσματικότητα του DBSCAN είναι αρκετά καλύτερη
σε σχέση με τον K-means και του GMM. Φυσικά η αποτελεσματικότητα του
αλγορίθμου θα είναι διαφορετική αν έχουμε γνώση πάνω στα δεδομένα που
επεξεργαζόμαστε.
Για eps = 0.3 & Min_pts =5 το FMI είναι περίπου 0.691 ± 0.004 όταν
χρησιμοποιούμε γράφημα και 0.690± 0.003 χωρίς. Αν κάνουμε την υπόθεση ότι
αναμένουμε 6 συστάδες η ότι κάθε συστάδα δεν έχει περισσότερα από 1/6 των
συνολικών στοιχείων τότε μπορούμε να εκτελέσουμε τον DBSCAN ξανά (σε αυτή την
περίπτωση θα έχουμε FMI = 0.856.
* Σε περίπτωση που εκτελεστεί ο DBSCAN δεύτερη φορά τοπικά στην συστάδα με τα περισσότερα
σημεία (25% των συνολικών σημείων) για eps =0.1 & Min_pts = 3 τότε το FMI = 0.856.
Για να γίνουν πιο ευκολά κατανοητά τα αποτελέσματα στην εικόνα 6.4 φαίνονται τα
αποτέλεσμα των αλγορίθμων όταν εκτελεστήκαν χρησιμοποιώντας τις 4 διαστάσεις
αλλά χρησιμοποιώντας μόνο την «Θερμοκρασία» και την «Απόλυτη λαμπρότητα».
Επίσης στην εικόνα 6.5 φαίνονται πιο αναλυτικά οι μετρήσεις που έγιναν .
Παρατηρούμε ότι το αποτέλεσμα τόσο του GMM όσο και του K-means δεν μπορεί
να αξιοποιηθεί σε μεγάλο βαθμό διότι όλες οι συστάδες έχουν σημεία που δεν θα
έπρεπε να ανήκουν σε αυτές. Αντίθετα ο DBSCAN αν και δεν καταφέρνει σε
απολυτό βαθμό να βρει τον τύπο των αστερίων, είναι σε θέση να δώσει μερικές
χρήσιμες πληροφορίες (συστάδα 2, 3 ) επίσης οι συστάδες 1 & 2 είναι όμοιες οπότε
ο διαχωρισμός τους μπορεί να γίνει μόνο αν εκτελέσουμε ξανά τον DBSCAN
περιορίζοντας τον σε αυτά τα δεδομένα και εφαρμόζοντας μικρότερη τιμή
απόσταση (Eps =0.1 & MinPts = 3).
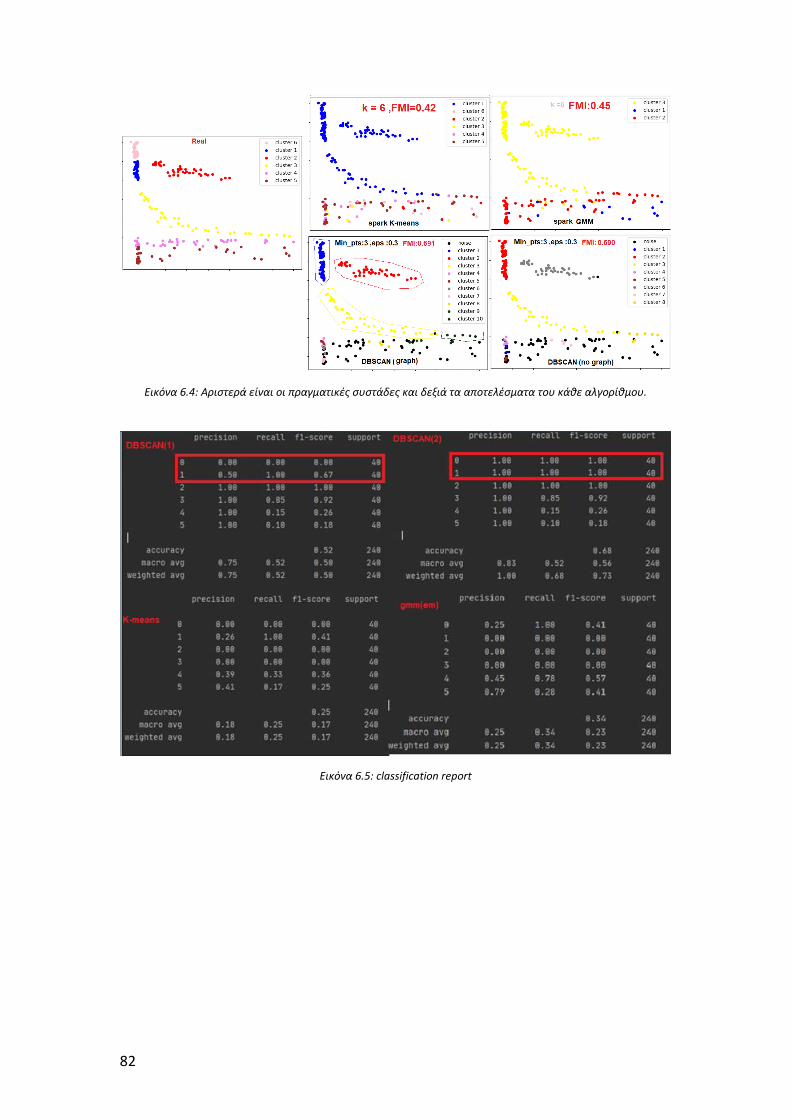
82
Εικόνα 6.4: Αριστερά είναι οι πραγματικές συστάδες και δεξιά τα αποτελέσματα του κάθε αλγορίθμου.
Εικόνα 6.5: classification report

83
7 ΕΠΙΛΟΓΟΣ
7.1 ΣΥΜΠΕΡΑΣΜΑΤΑ
Μέσω της συγκεκριμένης διπλωματικής εργασίας υλοποιήθηκε ένας αλγόριθμος
συσταδοποίησης βασισμένος στο DBSCAN χρησιμοποιώντας το Apache Spark. Η
συγκεκριμένη υλοποίηση μπορεί να ξεπεράσει τα μειονεκτήματα παρόμοιων
υλοποιήσεων, όπως αυτή που παρέχεται μέσω της βιβλιοθήκης sklearn, όσον
αφορά την επεξεργασία μεγάλου όγκου δεδομένων. Το Apache Spark λόγω της
αρχιτεκτονικής του (RDDs) μπορεί να διαχειριστεί χωρίς πρόβλημα δεδομένα
μεγάλου όγκου κάτι που είναι αρκετά συχνό φαινόμενο στη συσταδοποίηση.
Ο αλγόριθμος που υλοποιήθηκε είχε αρκετά καλά αποτελέσματα σε σύγκριση με
άλλες υλοποιήσεις σχετικά με την ακρίβεια. Ωστόσο, λόγω περιορισμών η εκτέλεσή
του σε κατανεμημένο σύστημα, ώστε να γίνουν μετρήσεις της ταχύτητας εκτέλεσης,
δεν ήταν εφικτή.
7.2 ΜΕΛΛΟΝΤΙΚΕΣ ΕΠΕΚΤΑΣΕΙΣ
Ο αλγόριθμος που υλοποιήθηκε στα πλαίσια της διπλωματικής εργασίας μπορεί να
αποτελέσει βάση για νέες έρευνες και εργασίες.
Πιο συγκεκριμένα, ο υπολογισμός της απόστασης που χρησιμοποιήθηκε ήταν αυτός
της ευκλείδειας απόστασης (νόρμα 2). Μια απλή αλλά σημαντική επέκταση θα ήταν
η προσθήκη διαφορετικών τροπών υπολογισμού (π.χ. απόσταση Μανχάταν).
Επίσης, η χρήση R-trees ή κάποιας διαφορετικής δομής δεδομένων για την
εξοικονόμηση χώρου στη μνήμη ή ακόμα και η βελτίωση της ταχύτητας εκτέλεσης
του αλγορίθμου αποτελούν σημαντικές παραμέτρους.
Μια μελέτη που κρίνεται απαραίτητη είναι αυτή που θα σχετίζεται με τη δοκιμή του
αλγόριθμου σε κατανεμημένο σύστημα. Δυστυχώς λόγω περιορισμών αυτό δεν
κατέστη εφικτό και η συγκεκριμένη διπλωματική εργασία υπολόγισε μόνο την
ακρίβεια του αλγορίθμου και όχι την ταχύτητα εκτέλεσής του, διότι όλα τα
πειράματα έγιναν σε έναν υπολογιστή. Επιπλέον η χρήση μεγαλύτερων datasets με
πραγματικά δεδομένα είναι σημαντική για την περεταίρω αξιολόγηση του
αλγορίθμου.
Τέλος ο τρόπος δημιουργίας του πλέγματος μπορεί βελτιωθεί περεταίρω πιθανός
λαμβάνοντας με κάποιο αποδοτικό τρόπο την «πυκνότητα» των σημείων.

84

85
8 ΒΙΒΛΙΟΓΡΑΦΙΑ
[1] https://www.britannica.com/technology/data-mining
[2] https://nocodewebscrAPIng.com/difference-data-mining-kdd/
[3] Mining Enrolment Data Using Predictive and Descriptive Approaches Fadzilah
Siraj and Mansour Ali Abdoulha Applied Sciences, College of Arts & Sciences,
University Utara Malaysia Malaysia
[4] Βερύκιος, Β., Καγκλής, Β., Σταυρόπουλος, Η. 2015. Η επιστήμη των δεδομένων
μέσα από τη γλώσσα R. [ηλεκτρ. βιβλ.]
[5]http://www.hypertextbookshop.com/dataminingbook/public_version/contents/c
hapters/chapter004/section004/blue/page003.html
[6] Ester, M., Kriegel, H.-P., Sander, J., Xu, X.W. A density-based algorithm for
discovering clusters a density-based algorithm for discovering clusters in large spatial
databases with noise. In Proceedings of the Second International Conference on
Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp.
226–231
[7]https://scikitlearn.org/stable/auto_examples/cluster/plot_cluster_comparison.ht
ml#sphx-glr-auto-examples-cluster-plot-cluster-comparison-py
[8] https://www.tutorialspoint.com/hadoop/hadoop_mapreduce.htm
[9] https://databricks.com/
[10] https://Apache Spark.Apache.org/
[11] https://www.jetbrains.com/pycharm/
[11] A Model of Computation for MapReduce
[12] J. Dean and S. Ghemawat. MapReduce: simplified data processing on large
clusters. In Proceedings of OSDI, pages 137–150, 2004
[13] J. Dean and S. Ghemawat. MapReduce: simplified data processing on large
clusters. Commun. ACM, 51(1):107–113, 2008
[14] Yahoo! partners with four top universities to advance cloud computing systems
and applications research. Yahoo! Press Release, 2009. http://research.yahoo.
com/news/2743.
[15] U. Kang, C. Tsourakakis, A. Appel, C. Faloutsos, and J. Leskovec. HADI: Fast
diameter estimation and mining in massive graphs with hadoop. Technical Report
CMU-ML-08-117, CMU, December 2008
[16] https://www.talend.com/resources/what-is-mapreduce/

86
[17] https://stackoverflow.com/questions/22141631/what-is-the-purpose-of-shuffling-and-
sorting-phase-in-the-reducer-in-map-reduce
[18] https://en.wikipedia.org/wiki/MapReduce
[19] Hadoop BIG DATA Interview Questions You'll Most Likely Be Asked
[20] https://www.tutorialspoint.com/advantages-of-hadoop-mapreduce-programming
[21] https://data-flair.training/blogs/hadoop-architecture/
[22] https://en.wikipedia.org/wiki/Apache_Hadoop
[23] https://blog.cloudera.com/Apache-hadoop-yarn-concepts-and-applications/
[24] Spark: Cluster Computing with Working Sets Matei Zaharia, Mosharaf
Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica University of California,
Berkeley
[25] Fast Approximate Spectral Clustering Donghui Yan Ling Huang Michael I. Jordan
[26] Relative Density Clustering Algorithm Based on Density Fluctuation Cai Zhao
GAN, Hong Bin HUANG
[27] Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory
Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave,
Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica
University of California, Berkeley
[28] https://en.wikipedia.org/wiki/Hierarchical_clustering
[29] Big Data Machine Learning using Apache Spark MLLib Mehdi Assefi1, Ehsun
Behravesh2, Guangchi Liu3, and Ahmad P. Tafti4 1Department of Computer Science,
University of Georgia
[30] https://Apache Spark.Apache.org/docs/latest/ml-guide.html
[31] Data Mining: Concepts and Techniques Third Edition Jiawei Han University of
Illinois at Urbana–Champaign Micheline Kamber Jian Pei Simon Fraser University.
[32] Theodoridis, S. & Koutroubas, K. (1999). Pattern Recognition. Academic Press.
[33] MR-DBSCAN: a scalable MapReduce-based DBSCAN algorithm for heavily
skewed data Yaobin HE 1,3, Haoyu TAN2, Wuman LUO2, Shengzhong FENG1,
Jianping FAN1
[34] Research on the Parallelization of the DBSCAN Clustering Algorithm for Spatial
Data Mining Based on the Spark Platform
[35] https://www.kaggle.com/deepu1109/star-dataset




















