
The pitfalls of deploying solid-state drive RAIDs
13
The Pitfalls of Deploying Solid-State Drive RAIDs Nikolaus Jeremic 1 , Gero Mühl 1 , Anselm Busse 2 , Jan Richling 2 1 Architecture of Application Systems Group, University of Rostock, Germany 2 Communication and Operating Systems Group, Berlin University of Technology, Germany {nikolaus.jeremic,gero.muehl}@uni-rostock.de, {abusse,richling}@cs.tu-berlin.de ABSTRACT Solid-State Drives (SSDs) are about to radically change the way we look at storage systems. Without moving mechanical parts, they have the potential to supplement or even replace hard disks in performance-critical applications in the near future. Storage systems applied in such settings are usu- ally built using RAIDs consisting of a bunch of individual drives for both performance and reliability reasons. Most existing work on SSDs, however, deals with the architecture at system level, the flash translation layer (FTL), and their influence on the overall performance of a single SSD device. Therefore, it is currently largely unclear whether RAIDs of SSDs exhibit different performance and reliability character- istics than those comprising hard disks and to which issues we have to pay special attention to ensure optimal operation in terms of performance and reliability. In this paper, we present a detailed analysis of SSD RAID configuration issues and derive several pitfalls for deploying SSDs in common RAID level configurations that can lead to severe performance degradation. After presenting potential solutions for each of these pitfalls, we concentrate on the particular challenge that SSDs can suffer from bad random write performance. We identify that over-provisioning offers a potential solution to this problem and validate the effec- tiveness of over-provisioning in common RAID level configu- rations by experiments whose results are compared to those of an analytical model that allows to approximately predict the random write performance of SSD RAIDs based on the characteristics of a single SSD. Our results show that over- provisioning is indeed an effective method that can increase random write performance in SSD RAIDs by more than an order of magnitude eliminating the potential Achilles heel of SSD-based storage systems. Categories and Subject Descriptors B.8.2 [Performance and Reliability]: Performance Anal- ysis and Design Aids; D.4.2 [OPERATING SYSTEMS]: Storage Management—Secondary storage Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. SYSTOR’11, May 30 - Jun 01 2011, Haifa, Israel Copyright 2011 ACM 978-1-4503-0773-4/11/05 ...$10.00. General Terms Performance, Measurement, Experimentation Keywords Storage systems, Solid-state drives, RAID 1. INTRODUCTION Flash memory based storage devices are considered as promising mean to narrow the gap between the access time of main memory and mass storage based on mechanical hard disk drives. These new kind of devices, which are referred to as solid-state drives (SSDs), have the potential to replace magnetic disk storage for performance-critical applications, because they are largely superior in the maximal number of in-/output operations per second (IOPS). This advantage stems from the fact that, in contrast to hard disks (HDDs), SSDs have no moving mechanical parts. Unfortunately, cur- rent SSDs have a lower capacity and a much higher cost per gigabyte preventing them from replacing hard disks in all application areas now. However, the price and capacity gap is expected to narrow substantially in the future. To allow for a seamless and easy replacement of HDDs, SSDs intended to be used in desktop, workstation and server systems usually offer a standard mass storage interface like SATA or SAS to the host system. While this allows SSDs to enter this market without barriers, it is important to under- stand that internally an SSD works totally different than a HDD. The main difference is that due to the inherent char- acteristics of flash memory, it is not feasible to update data in place. Consequently, overwriting data requires a physi- cal relocation instead. Furthermore, flash cells can only be erased a finite and rather low number of times raising the need for wear leveling that aims at distributing erase cycles as uniformly as possible to avoid that areas of flash memory wear out too early. To hide this peculiarities from the host system and support transparency with respect to applica- tions, usually a Flash Translation Layer (FTL) is employed allowing to use the SSD like a normal block device. For the SSDs that we consider in this paper, the FTL is realized in- side the SSD controller that is part of the SSD package and also offers the standard mass storage interface to the host system. In this setting, the details of the FTL are hidden from the host’s operating system. The FTL can, however, also be part of an operating system driver, e.g., in embed- ded systems or when SSDs are attached to the host system directly by PCI-Express.
Transcript of The pitfalls of deploying solid-state drive RAIDs

The Pitfalls of Deploying Solid-State Drive RAIDs
Nikolaus Jeremic1, Gero Mühl1, Anselm Busse2, Jan Richling2
1 Architecture of Application Systems Group, University of Rostock, Germany2 Communication and Operating Systems Group, Berlin University of Technology, Germany
{nikolaus.jeremic,gero.muehl}@uni-rostock.de, {abusse,richling}@cs.tu-berlin.de
ABSTRACTSolid-State Drives (SSDs) are about to radically change theway we look at storage systems. Without moving mechanicalparts, they have the potential to supplement or even replacehard disks in performance-critical applications in the nearfuture. Storage systems applied in such settings are usu-ally built using RAIDs consisting of a bunch of individualdrives for both performance and reliability reasons. Mostexisting work on SSDs, however, deals with the architectureat system level, the flash translation layer (FTL), and theirinfluence on the overall performance of a single SSD device.Therefore, it is currently largely unclear whether RAIDs ofSSDs exhibit different performance and reliability character-istics than those comprising hard disks and to which issueswe have to pay special attention to ensure optimal operationin terms of performance and reliability.
In this paper, we present a detailed analysis of SSD RAIDconfiguration issues and derive several pitfalls for deployingSSDs in common RAID level configurations that can lead tosevere performance degradation. After presenting potentialsolutions for each of these pitfalls, we concentrate on theparticular challenge that SSDs can suffer from bad randomwrite performance. We identify that over-provisioning offersa potential solution to this problem and validate the effec-tiveness of over-provisioning in common RAID level configu-rations by experiments whose results are compared to thoseof an analytical model that allows to approximately predictthe random write performance of SSD RAIDs based on thecharacteristics of a single SSD. Our results show that over-provisioning is indeed an effective method that can increaserandom write performance in SSD RAIDs by more than anorder of magnitude eliminating the potential Achilles heel ofSSD-based storage systems.
Categories and Subject DescriptorsB.8.2 [Performance and Reliability]: Performance Anal-ysis and Design Aids; D.4.2 [OPERATING SYSTEMS]:Storage Management—Secondary storage
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.SYSTOR’11, May 30 - Jun 01 2011, Haifa, IsraelCopyright 2011 ACM 978-1-4503-0773-4/11/05 ...$10.00.
General TermsPerformance, Measurement, Experimentation
KeywordsStorage systems, Solid-state drives, RAID
1. INTRODUCTIONFlash memory based storage devices are considered as
promising mean to narrow the gap between the access timeof main memory and mass storage based on mechanical harddisk drives. These new kind of devices, which are referredto as solid-state drives (SSDs), have the potential to replacemagnetic disk storage for performance-critical applications,because they are largely superior in the maximal numberof in-/output operations per second (IOPS). This advantagestems from the fact that, in contrast to hard disks (HDDs),SSDs have no moving mechanical parts. Unfortunately, cur-rent SSDs have a lower capacity and a much higher cost pergigabyte preventing them from replacing hard disks in allapplication areas now. However, the price and capacity gapis expected to narrow substantially in the future.
To allow for a seamless and easy replacement of HDDs,SSDs intended to be used in desktop, workstation and serversystems usually offer a standard mass storage interface likeSATA or SAS to the host system. While this allows SSDs toenter this market without barriers, it is important to under-stand that internally an SSD works totally different than aHDD. The main difference is that due to the inherent char-acteristics of flash memory, it is not feasible to update datain place. Consequently, overwriting data requires a physi-cal relocation instead. Furthermore, flash cells can only beerased a finite and rather low number of times raising theneed for wear leveling that aims at distributing erase cyclesas uniformly as possible to avoid that areas of flash memorywear out too early. To hide this peculiarities from the hostsystem and support transparency with respect to applica-tions, usually a Flash Translation Layer (FTL) is employedallowing to use the SSD like a normal block device. For theSSDs that we consider in this paper, the FTL is realized in-side the SSD controller that is part of the SSD package andalso offers the standard mass storage interface to the hostsystem. In this setting, the details of the FTL are hiddenfrom the host’s operating system. The FTL can, however,also be part of an operating system driver, e.g., in embed-ded systems or when SSDs are attached to the host systemdirectly by PCI-Express.

The seamless compatibility to existing HDDs allows touse SATA and SAS SSDs not only as individual devices butalso in RAID configurations without requiring any changeson the host side. However, since SSDs have different per-formance and reliability characteristics and work internallyin a different way compared to HDDs, it is difficult to pre-dict the behavior of SSDs in a RAID setup. Furthermore,it is unclear if the full potential of SSDs can be exploitedusing existing hardware and software RAID infrastructures.Therefore, it is currently largely an open question whetherRAID arrays of SSDs exhibit different performance and re-liability characteristics than those comprising HDDs and towhich issues we have to pay special attention to ensure op-timal operation in terms of performance and reliability.
In this paper, we present the general challenges and pit-falls that exist when deploying SSDs in a RAID configura-tion and discuss how to avoid them. Among these pitfalls,we select the problem that SSDs and, especially, RAIDsbased on SSDs, suffer from bad random write performanceas the main objective of our research presented here. Forsingle SSDs, this problem can be addressed by means ofover-provisioning, i.e., increasing spare capacity. We inves-tigate the applicability of this solution to all commonly usedRAID level configurations such as RAID 0, RAID 1, RAID 5,RAID 6, and RAID 10 by deriving mathematical modelsthat we evaluate based on experiments. Our results indi-cate that over-provisioning can improve the random writeperformance of SSD RAIDs substantially.
The remainder of the paper is organized as follows: Westart by introducing the background of SSDs and RAIDs inSect. 2. Then, we discuss the pitfalls of deploying SSDs inRAID configurations and how to avoid them in Sect. 3. InSect. 4, we analyze the impact of workload history on SSDrandom write performance in RAID configurations and eval-uate over-provisioning as a mean to improve performance.Finally, the paper is wrapped up in Sect. 5.
2. TECHNICAL BACKGROUND
2.1 Solid State DrivesSSDs usually comprise multiple NAND-flash chips, a flash
controller, a SRAM-based buffer, a host interface, and an op-tional DRAM-based cache. Most flash chips are organizedin blocks consisting of multiple pages. A page is the smallestdata unit for read and write operations, while a block is thesmallest data unit for erasing. However, flash blocks shouldnot be confused with filesystem blocks. The storage capac-ity per flash page ranges between 512 bytes and multiplekilobytes, while one block includes usually 64 or 128 pages.One key property of flash memory is that its cells have tobe erased before data can be written to them. Due to thelack of ability to override data, modification of page contentresults in relocation of the related page. The data within theold page will then be considered as invalid. To avoid runningout of free pages, invalidated pages have to be reclaimed ontime. Since a block can contain pages with valid and invaliddata, the content of pages with valid data has to be copiedinto another block before erasing a particular block. Thistask is called garbage collection. Relocating the contents ofpages leads to more pages being written inside the SSD aspage writes issued by the host. This is known as write am-plification [5]. As flash blocks can only be erased a finitenumber of times, ranging from less than 5,000 writes per
block on a consumer device to 100,000 writes on an enter-prise device, wear leveling has to ensure that erases spreadover all blocks as uniformly as possible.
An effective approach to reduce write amplification thatis applied by almost any SSD is to use spare capacity alsoknown as over-provisioning area. This capacity is a part ofthe SSD physical flash storage capacity that is not advertisedby the device to the host’s operating system. For example,the Intel X25-M has a physical capacity of 80 GiB = 80 · 230
bytes, but a logical capacity of only 80 GB = 80 · 109 bytesis advertised to the host system, hence the user capacity is93.1% and the spare capacity 6.9% of the total capacity. Tounderstand the crucial role of spare capacity, consider anSSD whose physical capacity is completely filled with data.If a data page shall be overwritten in this situation, it isnecessary to read the whole block containing this page intothe controller’s cache, to erase this block, and to write thenew version of the block back to drive. This would result inthe maximal possible write amplification. For example, if ablock consists of 128 pages, writing a single page of a blockwould lead to writing 128 pages instead of one, i.e., a writeamplification factor of 128. If several pages of a block wouldbe overwritten in this way simultaneously, the write amplifi-cation factor would decrease, but still performance would bepoor. Maintaining spare capacity permits reclaiming blockswith a certain number of invalid pages more efficiently anddecreases write amplification.
In practice, write amplification leads to performance de-gradation on writes, especially on random writes with smallrequest sizes. However, spare capacity is not the only fac-tor of impact for write amplification. It is also affected bywear leveling, data placement and the applied reclaimingpolicy [5]. Enterprise and mainstream SSDs usually exhibita considerably different amount of spare capacity. Whileenterprise SSDs posses larger spare capacity and offer ran-dom write rates much higher than mechanical hard disks,mainstream SSDs can, due to low spare capacity, exhibit avery low random write performance [12] that can even belower than that of conventional HDDs. A further cause ofthis difference is that enterprise SSDs are usually equippedwith singe-level cell (SLC) flash that allows a higher writespeed than the cheaper multi-level cell (MLC) flash mostlyused for mainstream SSDs.
A related potential problem is caused by the file deletionmethod of current filesystems: when a file is deleted, thisonly leads to changes of the data structure (usually, thedirectory of the filesystem is updated and the clusters pre-viously occupied by the file are marked as free within thedata structure of the filesystem). From the viewpoint of theSSD, this is only a change in data, it does not announce thefact that this data is no longer relevant and the appropriatepages can be treated as empty. Therefore, the SSD controllerstill treats the respective pages as being occupied until thepages are explicitly overwritten by new data. Making theSSD controller aware of this new free space would highly beappreciated since this space would have the same positive ef-fect as the always maintained spare capacity. This problemis tackled by TRIM support, which tells the SSD controllerexplicitly that some area is now free. It enables the SSDcontroller to garbage collect those flash pages whose contentis regarded as unnecessary by the filesystem. TRIM supportis currently being incorporated into filesystem drivers. Priorto SSDs, there has simply been no need for this mechanism

since hard disks are capable of updating data in place. Foran SSD, however, freeing unused space is highly beneficialas each flash page freed potentially improves the efficiencyof garbage collection and lowers the write amplification.
2.2 RAIDsThe RAID (Redundant Array of Independent Disks) tech-
nique was introduced by Patterson et al. [10]. A RAID in-volves multiple devices which are grouped together to in-crease the reliability, the performance, or both characteris-tics of storage compared to a single drive. This is achievedby the concepts of data striping and data redundancy or acombination of both. Data striping places different portionsof the data on different drives, e.g., in a round-robin fash-ion. The size of each portion is often referred to as stripesize, while the parts are termed stripe units or chunks [8,section 24.1]. The effect of data striping is that randomaccesses are distributed to the available drives and that se-quential accesses are divided into portions that are similarlydistributed. This way, more random accesses can be exe-cuted and the speed of sequential accesses increases. Whiledata striping increases performance, data redundancy im-proves reliability by storing data on multiple drives (datamirroring) or by protecting data stripes with additional par-ity information stored in stripe units to mask drive failures.
RAID configurations can be categorized into RAID levelswith the most common RAID levels being 0, 1, 10, 5 and6. In a RAID 0 setup, the chunks are simply interleavedon different drives of the RAID. This configuration requiresat least two drives. The RAID 0 setup has the benefit of ahigher throughput compared to a single drive, but reducesthe reliability of the RAID significantly since data loss oc-curs when one drive fails. A RAID 1 setup also needs atleast two drives. Here, data is mirrored such that it can beread from any of the drives. Thus, data loss only occurswhen all drives fail increasing reliability substantially at theexpense of storage space. Besides increasing reliability, aRAID 1 also increases the read performance since reads canbe distributed to all drives. RAID 10 is a nested RAID levelthat combines RAID 0 and RAID 1 by running a RAID 0on top of two or more RAID 1. Thus, it realizes a stripeset of mirrors. Data loss occurs in a RAID 10 only when alldisks of a mirror set fail simultaneously.
A RAID 5 setup consists of at least three drives and com-bines interleaving of data stripes as in case of a RAID 0with block-wise parity calculations for the interleaved stripeunits. The parity stripe units are rotated among the drivesfor load balancing. If a single drive fails, each of its datastripe units can be reconstructed using the remaining datastripe units within a stripe and the corresponding paritystripe unit residing on the other drives. In a RAID 5 onlyone drive may fail without data loss. If more than one drivefails, e.g., during reconstruction of the RAID, data loss isalmost certain. Furthermore, a RAID 5 in degraded modehas a similar low reliability as a RAID 0. A RAID 6 setuptackles these problems by adding a second, orthogonal par-ity. This permits the failure of up to two drives, but alsoincreases the number of necessary drives to at least four.For both RAID levels, accesses are distributed among thedrives. That increases performance especially for read ac-cesses while write operations suffer from the necessity to up-date the parity information (for random writes this requiresadditional read operations). Nevertheless, random accesses
profit from the inherent parallelism. RAID 5 and 6 are alsocalled parity-based RAID levels, while RAID 0, 1, and 10belong to parity-less RAID levels.
There are two basic approaches to implement RAIDs. Inthe first approach called software RAID, the RAID device isrealized by the operating system and the RAID algorithm isexecuted on the host processor. With the second approachcalled hardware RAID, the drives are attached to a hardwareRAID controller that realizes the RAID by executing theRAID algorithm on its own processor and presenting thewhole array as one large device to the host machine. Bothapproaches allow applications to access the RAID in thesame way as a single drive, but if a hardware RAID is used,the operating system is not aware of the individual drives.
2.3 SSD RAIDsOne might think that the RAID technology is now becom-
ing obsolete with the emergence of high performance SSDs,because a single SSD seems to more reliable than a singleHDD due to the lack of moving parts and can offer higherperformance than a HDD RAID. However, if we look intothis in more detail, it becomes clear that this applies onlyto a subset of applications. Considering performance, thereare many applications that can benefit from a much higherperformance than can be achieved using only a single SSD.Examples are on-line transaction processing (OLTP), wherethe number of transactions that can be executed per secondis often limited by the performance of persistent storage,and cloud computing, where the number of virtual machinesthat can be run on a physical server heavily depends on howfast memory pages can be swapped out to and read backfrom secondary storage.
Considering reliability, there are also many applicationswhose requirements cannot be satisfied using a single SSD.Comparing the MTBF of an enterprise hard disk of 1,600,000hours [13] to the MTBF of an enterprise SSD of 2,000,000hours [7] shows that there is no dramatic difference. Hence,a single SSD cannot replace a RAID with its data redun-dancy considering reliability. A final reason why SSD RAIDsare needed is capacity: SSDs exhibit currently a capacitythat is about an order of magnitude smaller than that ofHDDs. Summarizing, it can be concluded that even in theera of high performance SSDs, the aggregation of drives intoRAIDs remains beneficial for performance, reliability andcapacity reasons. Thus, analyzing such SSD RAID configu-rations is an important issue.
3. PITFALLS OF SSD RAIDSAfter introducing the technology of SSDs and RAIDs,
we now discuss a number of pitfalls that may lead to se-vere problems in terms of performance and reliability whendeploying SSDs in RAID configurations. For each pitfall,we propose solutions including those known from relatedwork and depict future research directions. Besides dis-cussing the pitfalls and potential solutions, we finally in-troduce the main objective of this paper, the problem ofworkload history dependency and the corresponding solutionby over-provisioning in the context of SSD RAIDs. Over-provisioning already proved promising for single SSDs.
3.1 I/O Topology and I/O BottlenecksSSDs are able to deliver very high data rates. In con-
figurations using only a single SSD this is not a problem

because usually all elements (SATA/SAS controllers, PCI-Express links, HyperTransport, QPI or DMI/ESI links) onthe path between the drive and the processor cores are faster.In a RAID setup, however, this changes as the system hasnow to deal with the combined data rates of several drivesthat are accessed in parallel. Therefore, it is essential for anSSD RAID setup that there is no bottleneck with respect toavailable data rate on the path between the drives and theprocessor cores. This should be assured by a careful evalua-tion of the I/O topology of the machine and an appropriatemapping of the SSDs to available controllers and/or addi-tional controllers to distribute data rate demands properly.
To give an example: The Intel ICH10R used in our ex-periments (cf. Sect. 4.1) offers 6 SATA-2 ports (300 MB/seach) and is connected to the Intel 5520 chipset using Intel’sEnterprise Southbridge Interface (ESI) that offers 1 GB/sper direction. The Intel 5520 is attached to each of the twoquad-core processors using a dedicated QPI link offering atotal bandwidth of 12.8 GB/s per direction and per proces-sor. Furthermore, these are the theoretical maximum valuesso in practice the data rates are lower due to protocol over-head. Therefore, the ESI link might become a bottleneck ina 3 SSD RAID setup already.
3.2 RAID ImplementationEnsuring sufficient interconnection data rates may not be
enough in RAID configurations where SSDs are attached tohardware RAID controllers. These do not only offer theinterfaces to attach drives but also execute the RAID algo-rithm (including parity calculations for parity-based RAIDconfigurations) using a dedicated processor. Since the con-trollers that are currently available target magnetic disks,which exhibit a much lower maximal number of IOPS, thedesign of these controllers may introduce an additional bot-tleneck. Even current enterprise-class RAID controllers canget saturated with a rather small number of SSDs [4, 11].Therefore, it can be more advantageous to attach SSDs tosimpler controllers and use software RAID implementationsthat are often provided by the operating system, as in caseof Linux or Windows 2008 Server. However, further investi-gations are needed to verify whether current software RAIDimplementations are capable of dealing with SSD RAIDscomprising many devices. It may turn out that the soft-ware RAID implementations must be improved to becomesuitable for this purpose.
3.3 Stripe SizeChoosing the proper stripe size in a RAID system is not
a simple task since data striping aims at two effects: (a)acceleration of larger requests (e.g., sequential accesses) bysplitting them to be able to serve a request by reading fromor writing to at best all drives in parallel and (b) distributingsmaller requests (e.g., random accesses) to all drives. If thechosen stripe size is too large, splitting of larger requests isnot effective anymore causing a drop in data rate. Further-more, hotspots may arise leading to an uneven distributionof the load to the drives if the stripe size is too high. If thechosen stripe size is too small, the number of requests to beserved by the drives increases because even rather small re-quests are split up. This can lead to decreased performancebecause larger requests are served less efficiently and a drivehas a limited number of IOPS it can execute.
Considering parity-based RAID configurations, a too largestripe size can have an additional negative effect on writerequests [8, section 24.3.2] since writing a whole stripe be-comes less probable. Writing a whole stripe (i.e., all datastripe units of a stripe) is preferable as the parity data canbe computed solely from the data that has to be written. Incontrast to that, data has to be read from the other drivesto be able to calculate the parity information in case thatless than a stripe is written. If less than half of a stripe hasto be updated, the old version of the data and the parity areusually read. Similarly, when more than half of a stripe hasto be written, the remaining data of the stripe is read. Thus,writing less data than a full stripe yields read-modify-writeoperations resulting in additional overhead.
So far, everything said about the potential effects of vary-ing stripe sizes applies to SSDs as well as to HDDs. In thefollowing, we discuss the main differences between SSDs andHDDs that might have an effect on the optimal stripe size.The first difference is that SSDs are able to execute a muchhigher number of IOPS than HDDs and that the perfor-mance penalty of executing small requests compared to largerequests on a HDD is much higher than on an SSD. This es-pecially holds for reads, but usually also for writes. Thedisproportionate performance penalty of executing small re-quests on a HDD stems from the fact that the time neededto position the head dominates the execution time of theoperation in this case. Reading or writing more data fromthe same position increases this time only slightly. The sec-ond difference is that SSDs usually have multiple flash chipsthat are connected to the controller by separate channels.Thus, choosing too small stripes may hinder requests fromexploiting the internal parallelism of an SSD. However, sincea request is then split up and served by multiple SSDs, theeffect on performance is attenuated.
Petrov et al. [11] investigated the effect of varying stripesizes on the performance of random as well as sequentialread and write operations in SSD RAIDs. Their results con-firm our conjecture that too small stripe sizes should beavoided because of the negative effect on large sequentialwrites. They also show that a stripe unit size of 64 KiBperforms better than a stripe size of 16 KiB for a RAID 0comprising Intel X25-E drives. This goes in line with ourthoughts about internal SSD parallelism. Nevertheless, wethink that further investigations are needed to get betterinsights into what stripe size should be chosen for a SSDRAID configuration and workload, and consider this issueas future work.
3.4 Alignment IssuesNext, we consider all reasons for degrading performance
due to operations issued on the host side leading to un-necessarily inefficient operations being executed on the SSDdevices because of a missing or wrong alignment.
The first issue is caused by the fact that data can onlybe read and written to an SSD in multiple of a flash page(usually 2 or 4 KiB) because flash pages are the atomic datatransfer units from the perspective of flash chips and theSSD controller. However, most operating systems work with512 byte sectors as atomic unit because hard disks used tohave sectors of this size for several decades. While issuing aread command for less than a flash page results in fetchingthe whole page into the SSD controller’s cache, writing lessthan a flash page can cause performance degrading read-

modify-write operations that also raise write amplification.Thus, writing less data to an SSD than its page size shouldbe avoided in any case. Moreover, for the same reasons,requests should be aligned to flash page boundaries, i.e.,start and end at addresses should match flash page bound-aries. Similarly, writing less than 4 KiB should be avoidedon newer hard disks featuring 4 KiB sectors and accesses tothese devices should also be aligned to match sectors.
Although some SSDs (e.g., Intel’s X25 drives) seem tobe capable of handling unaligned writes better than otherdrives, the best strategy is to avoid the described problemby adapting the logical configuration to the physical setup.In case of a single disk, this can be achieved by aligningpartitions such that they start at addresses correspondingto a flash page boundary and by setting the cluster size ofthe filesystem to the flash page size or multiples thereof.
In a RAID configuration, besides partition alignment andfilesystem cluster size an additional issue must be consid-ered: A RAID could start – like a partition – somewherebeyond the first SSD page because it may need to storesome metadata. In this case, the resulting offset has to beconsidered when creating aligned partitions.
3.5 Asymmetric Read and Write SpeedMost SSDs have a significantly higher read than write
speed. This applies especially for random accesses, but holdsin moderate form for sequential accesses as well. For ex-ample, according to the product manual of the Intel X25-M G2 [6], these drives have a sequential read throughput of250 MB/s and a sequential write throughput of 70–100 MB/sdepending on the model. Random read speed is rated upto 35,000 IOPS, while random write speed is rated up to3,300 IOPS for 4 KiB requests. When deploying SSDs inRAID configurations, it has to be taken into considerationthat some RAID levels (e.g., 1, 5 and 6) exhibit similardeficits as SSDs, namely a notable better read than writeperformance (cf. [3, table 3]). If SSDs are used in one ofthese RAID configurations, both effects will accumulate re-sulting in better read but worse write performance. De-pending on the workload, an SSD RAID might not reachthe expected performance goals.
There are also some fundamental differences between SSDsand HDDs that can aggravate this asymmetry. For exam-ple, consider a sequential read access in a RAID 1 configu-ration. Reading in parallel from several HDDs usually doesnot improve performance except for very large requests con-siderably exceeding track size. This is because the disk headmoves over succeeding data anyway, while the head of an-other drive would have to be positioned first. Thus, readingin parallel will normally only pay off for concurrent requests.
The picture is completely different for SSDs where readingin parallel from several mirrors in order to serve one requestwill usually decrease the response time substantially pro-vided the RAID controller or software RAID driver is awareof this potential. We performed a sequential read test ona RAID 1 array consisting of 2 SSDs to investigate the be-havior of the current Linux software RAID implementation.The measured throughput of about 250 MB/s was approx-imately the same as for a single SSD, so the current Linuxsoftware RAID seems not to be aware of the mentioned po-tential.
In contrast to this, the random read performance of thesame RAID 1 setup nearly doubles to 76, 200 IOPS com-
pared to a single SSD according to our measurements. Asa result, the current Linux software RAID implementationcan be optimized for mirrored SSD RAIDs to benefit fromthe fact that SSDs do not suffer from delays due to head po-sitioning. In summary, the mentioned problems have to bekept in mind when designing and evaluating RAID setupswith SSDs, as there is no simple way to avoid them. How-ever, it may turn out that this asymmetry favors non-parityRAID configuration such as RAID 10 instead of parity-basedlike RAID 5 or RAID 6. We will further discuss these issuesin Sect. 4 based on the results of our experiments.
3.6 Synchronous SSD AgingDue to the limited number of erasure cycles that flash
can cope with, SSDs wear out and eventually fail. How fastthe erase cycles of a single drive are consumed depends onthe workload the drive is faced with. Since the conventionalRAID levels we discussed (i.e., RAID 0, 1, 10, 5, and 6)tend to distribute writes evenly to the available drives, theindividual SSDs age at similar speeds raising the risk thatseveral drives wear out at the same time. This may cause si-multaneous drive failures and, thus, data loss. Furthermore,this effect is amplified by the common habit to use the samedrive model for every drive in the RAID and that all drivesare usually deployed at the same time.
To cope with the problem of simultaneous aging of SSDsproceeding at the same pace, Balakrishnan et al. [2, 9] sug-gest to adapt the parity-based RAID levels 5 and 6 suchthat the parity information is distributed unevenly to theavailable drives. The skew of the parity distribution can beconfigured between two extremes: a conventional RAID 5and 6, which distribute parity evenly, and a RAID 4 and itsequivalent with two parities, which store the parity infor-mation on one and two dedicated drives, respectively. As aresult, the more the distribution is skewed, the more perfor-mance is affected.
However, while the approach of Balakrishnan et al. accom-plishes that the drives use up their erasure cycles at differentspeeds, it is still not clear whether it really increases the reli-ability of SSD RAIDs or if some other approach (e.g., usingmore parities) might be a better choice. Our main concern isthat while drives may have the same number of guaranteedor expected erasure cycles, a particular drive can neverthe-less fail with a much lower or higher erasure cycle count.
3.7 Workload History DependencyThe main factors determining the performance of a HDD
are its average seek time, its average rotational delay and itsmedia data rate. Due to its mechanically moving parts, aHDD can only process at most a few hundred operations persecond. The main advantage of HDDs, however, is that theirperformance is well predictable and depends only on the cur-rent workload to be handled by the device. This observa-tions are based on the behavior at block level, i.e., belowthe filesystem layer. The situation is different at filesystemlayer, where a HDD is also a subject to workload historydependency caused by file fragmentation. This, however, isunder control of operating systems file system driver and de-pends on the actual implementation of a filesystem. In thispaper, we concentrate on the block layer to eliminate thedependency on filesystems and to improve the generality ofour findings.

The performance of SSDs does not only depend on thecurrent workload but also on the workload history makingtheir performance much less predictable. If a workload witha high portion of random writes is applied to an SSD for alonger time, the write performance of the SSD starts to sufferand the longer this type of load is applied, the worse thewrite performance of the SSD gets until it reaches its worst-case performance. The reason for this behavior is internalfragmentation of the flash blocks caused by random writes.On the other hand, sequential writes improve the conditionof an SSD allowing it to recover, because sequential writesdecrease internal fragmentation.
Our experiments using Intel X25-M drives showed thatwhile neither sequential nor random read performance aresignificantly affected by internal fragmentation, sequentialand random write performance can greatly suffer. To deter-mine the variation range of random and sequential writespeeds for Intel X25-M drives, we performed short mea-surements with different drive conditions. Directly after asecure erase, which ensures that every block of a SSD isempty, the random write performance was 19,816 IOPS, af-ter the drive has been filled with data sequentially, it was1,338 IOPS, and after the capacity of the drive has beenwritten using random writes, performance of random writeswas 587 IOPS. Thus, in normal operation, it will vary be-tween 587 and 1,338 IOPS. Similarly, immediately after asecure erase, sequential write performance was 85 MB/s, af-ter the drive has been filled with data sequentially, it was74 MB/s, and after the physical drive capacity has beenwritten using random writes, sequential write throughputwas only 45 MB/s. Thus, in normal operation, it will varybetween 45 and 74 MB/s.
The workload history is, thus, an important issue affect-ing the performance of an SSD, especially with respect torandom writes, and it affects both a single SSD as well as aRAID comprising multiple SSDs. Compared to the pitfallsdiscussed so far, there is not much research on the effectof workload history on the performance of single SSDs andSSD RAIDs. Therefore, we decided to investigate this effectin more detail in the following section.
4. ANALYSIS OF SSD RAID BEHAVIORThe main concern of this section is to understand the im-
pact of workload history dependency on SSD RAIDs and toconsider approaches do deal with it. Despite the fact thatthe workload history does not only affect random writes butalso sequential writes, we will focus on the random writes,because the impact to those is much higher as shown in theprevious section. Additionally, the approaches to deal withworkload history regarding random writes will also work forsequential writes. In order to address the workload historydependency of SSD RAIDs, we first consider in Sect. 4.2 asingle SSD without RAID. Next, we analyze in Sect. 4.3 howcan the insights gained from that considerations be appliedto RAIDs based on SSDs. All considerations are based ontheoretical models describing the behavior of SSDs as wellas experiments conducted on real hardware.
4.1 Experimental SetupAll experiments described in this paper were run on a
server machine equipped with two Intel Xeon X5550 2.67GHz processors, 48 GiB RAM and the Intel 5520 chipset.This machine offers two on-board mass storage controllers,
Figure 1: Average random write IOPS in RAID 0configurations with a spare capacity of 77% on vary-ing queue depth.
namely a LSI 1068E with eight SAS ports and an IntelICH10R with six SATA-2 ports. The ICH10R was set tooperate in AHCI mode in order to use Native CommandQueuing (NCQ) that enables issuing up to 31 requests at atime. This permits to utilize more than one flash chip of anSSD on random workloads. We used a bunch of Intel X25-MPostville G2 80 GB SSDs in our experiments.
On the software side, we used Gentoo Linux with ker-nel version 2.6.36 as operating system. Presented bench-mark results were obtained from the tool Flexible I/O tester(fio) version 1.43.2 [1], which supports Linux native asyn-chronous I/O (AIO). All experiments were conducted usingnon-buffered direct I/O (to minimize cache effects) and thenoop I/O scheduler (to avoid unnecessary reordering of re-quests to optimize the non-existing seek time and the po-tential interference with NCQ operation).
In order achieve a good scalability for random write per-formance in SSD RAIDs, first we had to choose an appropri-ate degree of parallelism, which corresponds to the numberof outstanding requests or the queue depth as we use asyn-chronous I/O. The used queue depth of 248 was obtainedby experiments with different number of SSDs in a RAID 0configuration. The results of corresponding experiments areillustrated in Fig. 1 and indicate that a queue depth of 248is a good choice as higher values do not lead to a substantialincrease of throughput in most of the examined setups.
During our evaluation, we cope with the long-term work-load dependency of SSD performance (pitfall 3.7) by doingall measurements with the worst practicable workload his-tory which is a purely random workload with small requestsconsisting of a single page. This is achieved by preparingthe SSDs with a secure erase followed by purely randomlywriting an amount of data to a single SSD or the RAID de-vice, which covers the physical capacity of all used SSDs.As an example, during each run 240 GiB of data would bewritten in portions of 4 KiB to an RAID 0 array composedof 80 GiB SSDs. After establishing this workload history,the measurements of the random write performance in SSDRAIDs were repeated two times. These two runs suffice asthe average write speed shows almost no difference betweenthe repetitions.
To avoid a performance bottleneck due to a hardwareRAID controller (pitfall 3.2) in combination with SSDs,we decided to skip hardware RAID setups and rely on theLinux software RAID implementation. As our test systemincludes two mass storage controllers, we ran comparison

benchmarks with a single SSD to verify whether a single SSDdelivers the nominal performance according to the specifica-tion. Our benchmarks revealed that the random read perfor-mance is not comparable. While a single X25-M deliveredonly about 27, 000 IOPS with the LSI 1068E, it exceededthe expectations with about 40, 000 IOPS in combinationwith the ICH10R. By specification, one X25-M reaches upto 35, 000 IOPS for random reads. The remaining tests gavemostly equivalent results and hence we preferred to use theIntel ICH10R for further benchmarks.
Considering the I/O topology of our test system (pit-fall 3.1), the path between the CPUs and the mass storagecontroller (weakest element: ESI, 1 GB/s) might becomea bottleneck in a 3 SSD RAID setup already consideringthe sequential read performance. On the other hand, ran-dom reads and writes up to 5 SSDs might be served as thedata rates are considerably lower (approx. 140 MB/s forrandom reads). To determine the real performance, bench-marks were accomplished with up to 5 SSDs connected tothe ICH10R. According to the results in Fig. 2, the ICH10Rgets saturated with three SSDs on sequential reads and fiveSSDs on random reads with respect to the nominal perfor-mance of up to 35, 000 IOPS per SSD. Writes are non-criticaldue to the overall lower data rates. All of these results wereobtained by a performance maximizing configuration withrespect to spare capacity (cf. Sect. 4.2).
Despite the fact that our controller becomes a bottleneckwith more than 4 SSDs on random reads, this should notaffect the random write performance of SSD RAID con-figurations comprising 5 SSDs. The reason is that evenparity-based RAID configurations, where writes can incurreading old data and parity, do not require reading from alldevices at once. The examination of the random write per-formance showed that although a single SSD reaches about11, 500 IOPS, attaching more than one SSD to the IntelICH10R leads to a throughput decrease to approximately8, 900 IOPS for each drive. This seems not to be an is-sue of too low number of outstanding requests compared toour RAID measurements, where the number of outstand-ing requests was higher, namely 248/n for each of n drives.However, the throughput of about 8, 900 IOPS for each SSDpersists up to 5 SSDs as Fig. 2 shows. Further measure-ments with lower spare capacities indicate that the problemdoes not arise when each SSD is only capable of a lowerrandom write throughput. This observation supports thefact that this behavior is caused by a controller or driver re-lated bottleneck. Finally, using the Linux software RAIDimplementation involves partitioning the used SSDs. Toavoid alignment issues (pitfall 3.4), partitions were alignedto flash pages (4 KiB). Furthermore, the stripe size was setto 64 KiB, which is a multiple of page size (pitfall 3.3) andfollows the suggestions given by Petrov et al. [11].
4.2 Random write performance of a single SSDSequential and random write speed of an SSD can both
be affected by fragmentation. The effect is similar becausein both cases the pages are sequentially written to newlyerased flash blocks. What causes the degradation is not thewriting itself, but the inefficient garbage collection neededto prepare empty blocks for writing. The high write ampli-fication is caused by the fact that random workloads leadto an unfavorable distribution of invalid pages to blocks ap-proaching equal distribution in the worst case.
Figure 2: Average performance of independentSSDs attached to Intel ICH10R. Left y-axis: Ran-dom access throughput with 31 outstanding re-quests, right y-axis: sequential access throughput.
Overall, there are three possible directions to deal with thewrite performance problems caused by fragmentation: First,anticipatory garbage collection could be used in a way that itis executed in idle periods of the drive. However, this wouldincrease write amplification at least slightly because garbagecollecting a block at the latest possible time maximizes theexpected number of invalid pages the block contains at thistime. Additionally, this has to be done inside the SSD con-troller and is therefore no option for existing SSDs. Second,nearly all newer SSDs support TRIM (cf. Sec. 2.1) enablingthe SSD controller to be aware of erased pages. Most SSDmanufacturers work against low random write performanceby over-provisioning. As mentioned in Sect. 2, each SSDhas to maintain some spare capacity in order to facilitategarbage collection. Therefore, the third option is increasingthe spare capacity to ensure that a sufficient number of freeblocks is always available. While the FTL does not explic-itly offer user adjustable parameters in current SSDs, it ispossible to adjust the spare capacity indirectly. This can beachieved by leaving parts of an SSD unused, i.e., by neverwriting to some parts of the logical address space. As a con-sequence, the partitioned space has to be smaller than theadvertised capacity of the SSD. Results reported by Hu etal. [5] suggest that leaving about 30% of physical capacity asspare can reduce extra page writes to about one additionalpage write for each host-side page write, limiting the writeamplification to a factor of 2.
The spare capacity cs is the portion of the physical ca-pacity cp of an SSD that is not offered as logical capacitycl to the host’s operating system, i.e., cl = cp − cs. Theworst-case write amplification occurs when the flash pagescurrently not containing valid file data are evenly distributedover all physical blocks. In that case, when a drive has aspare capacity cs, the worst-case write amplification equalsawc = cp/cs = cp/(cp− cl). This also means that the worst-case write speed is a factor of awc lower than the optimalwrite speed. Spare capacity also largely effects workloadswith a large portion of random writes but it can be expectedthat the random write speed in practice is better than theworst-case write speed as calculated above because in theformer case the pages not containing valid file data are notevenly spread over all blocks. The reason is that blocks thathave been erased longer ago will probably contain more ofthese pages than blocks erased recently. For garbage col-lection, then, those block containing the maximum number
0
5
10
15
20
5 10 15 20 25 30
Wri
teA
mpl
ifica
tion
Spare Capacity in Percent of Physical Capacity
Worst-Case Write Amplification0% random, 100% sequential10% random, 90% sequential30% random, 70% sequential60% random, 40% sequential100% random, 0% sequential
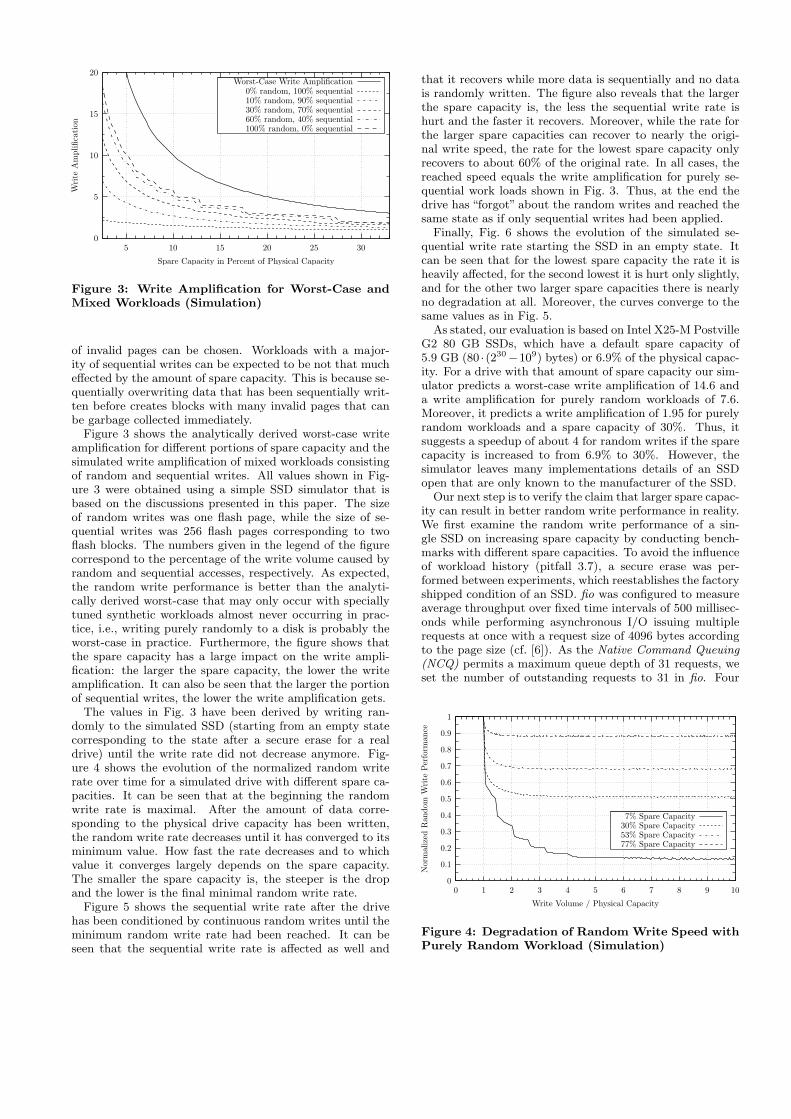
Figure 3: Write Amplification for Worst-Case andMixed Workloads (Simulation)
of invalid pages can be chosen. Workloads with a major-ity of sequential writes can be expected to be not that mucheffected by the amount of spare capacity. This is because se-quentially overwriting data that has been sequentially writ-ten before creates blocks with many invalid pages that canbe garbage collected immediately.
Figure 3 shows the analytically derived worst-case writeamplification for different portions of spare capacity and thesimulated write amplification of mixed workloads consistingof random and sequential writes. All values shown in Fig-ure 3 were obtained using a simple SSD simulator that isbased on the discussions presented in this paper. The sizeof random writes was one flash page, while the size of se-quential writes was 256 flash pages corresponding to twoflash blocks. The numbers given in the legend of the figurecorrespond to the percentage of the write volume caused byrandom and sequential accesses, respectively. As expected,the random write performance is better than the analyti-cally derived worst-case that may only occur with speciallytuned synthetic workloads almost never occurring in prac-tice, i.e., writing purely randomly to a disk is probably theworst-case in practice. Furthermore, the figure shows thatthe spare capacity has a large impact on the write ampli-fication: the larger the spare capacity, the lower the writeamplification. It can also be seen that the larger the portionof sequential writes, the lower the write amplification gets.
The values in Fig. 3 have been derived by writing ran-domly to the simulated SSD (starting from an empty statecorresponding to the state after a secure erase for a realdrive) until the write rate did not decrease anymore. Fig-ure 4 shows the evolution of the normalized random writerate over time for a simulated drive with different spare ca-pacities. It can be seen that at the beginning the randomwrite rate is maximal. After the amount of data corre-sponding to the physical drive capacity has been written,the random write rate decreases until it has converged to itsminimum value. How fast the rate decreases and to whichvalue it converges largely depends on the spare capacity.The smaller the spare capacity is, the steeper is the dropand the lower is the final minimal random write rate.
Figure 5 shows the sequential write rate after the drivehas been conditioned by continuous random writes until theminimum random write rate had been reached. It can beseen that the sequential write rate is affected as well and
that it recovers while more data is sequentially and no datais randomly written. The figure also reveals that the largerthe spare capacity is, the less the sequential write rate ishurt and the faster it recovers. Moreover, while the rate forthe larger spare capacities can recover to nearly the origi-nal write speed, the rate for the lowest spare capacity onlyrecovers to about 60% of the original rate. In all cases, thereached speed equals the write amplification for purely se-quential work loads shown in Fig. 3. Thus, at the end thedrive has “forgot” about the random writes and reached thesame state as if only sequential writes had been applied.
Finally, Fig. 6 shows the evolution of the simulated se-quential write rate starting the SSD in an empty state. Itcan be seen that for the lowest spare capacity the rate it isheavily affected, for the second lowest it is hurt only slightly,and for the other two larger spare capacities there is nearlyno degradation at all. Moreover, the curves converge to thesame values as in Fig. 5.
As stated, our evaluation is based on Intel X25-M PostvilleG2 80 GB SSDs, which have a default spare capacity of5.9 GB (80 · (230−109) bytes) or 6.9% of the physical capac-ity. For a drive with that amount of spare capacity our sim-ulator predicts a worst-case write amplification of 14.6 anda write amplification for purely random workloads of 7.6.Moreover, it predicts a write amplification of 1.95 for purelyrandom workloads and a spare capacity of 30%. Thus, itsuggests a speedup of about 4 for random writes if the sparecapacity is increased to from 6.9% to 30%. However, thesimulator leaves many implementations details of an SSDopen that are only known to the manufacturer of the SSD.
Our next step is to verify the claim that larger spare capac-ity can result in better random write performance in reality.We first examine the random write performance of a sin-gle SSD on increasing spare capacity by conducting bench-marks with different spare capacities. To avoid the influenceof workload history (pitfall 3.7), a secure erase was per-formed between experiments, which reestablishes the factoryshipped condition of an SSD. fio was configured to measureaverage throughput over fixed time intervals of 500 millisec-onds while performing asynchronous I/O issuing multiplerequests at once with a request size of 4096 bytes accordingto the page size (cf. [6]). As the Native Command Queuing(NCQ) permits a maximum queue depth of 31 requests, weset the number of outstanding requests to 31 in fio. Four
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 1 2 3 4 5 6 7 8 9 10
Nor
mal
ized
Ran
dom
Wri
tePer
form
ance
Write Volume / Physical Capacity
7% Spare Capacity30% Spare Capacity53% Spare Capacity77% Spare Capacity
Figure 4: Degradation of Random Write Speed withPurely Random Workload (Simulation)

0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 1 2 3 4 5 6 7 8 9 10
Nor
mal
ized
Sequ
enti
alW
rite
Per
form
ance
Write Volume / Physical Capacity
7% Spare Capacity30% Spare Capacity53% Spare Capacity77% Spare Capacity
Figure 5: Recovery of Sequential Write Speed afterPurely Random Workload (Simulation)
different amounts of spare capacity, namely 7%, 30%, 53%and 77% were chosen by reducing the nominal user capacityof 80 GB in steps of 20 GB.
The results in Fig. 7 confirm that the average randomwrite performance of a single SSD could be remarkably im-proved with increasing spare capacity. This correlation isnumerically expressed by the speedup factors illustrated inFig. 8, showing that increasing the spare capacity to 30%triggers about 700% rise in average number of IOPS. Fur-thermore, the use of a spare capacity of 77% can increase theaverage throughput by more than 19 times. For larger sparecapacities, even higher speedups may be possible. However,the achievable speedup will be smaller than 34 since writingrandomly to an SSD, to that a secure erased has been ap-plied, is 34 times faster than in the worst-case (cf. Sect.3.7).
Next, we take a look to the empirical distribution of themeasurements in the first row of the histograms in Fig. 9.These histograms show that the whole variation range of theaverage throughput values narrows and shifts into the rangebetween 1,000 and 10,000 IOPS with increasing spare ca-pacity. This is most evident in the transition from the sparecapacity of 7% to 30%. Moreover, narrowing the variationmakes the storage device more predictable and together withincreased minimal performance more suitable for demand-ing applications. Summarizing, our results for a single SSD
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 1 2 3 4 5 6 7 8 9 10
Nor
mal
ized
Sequ
enti
alW
rite
Per
form
ance
Write Volume / Physical Capacity
7% Spare Capacity30% Spare Capacity53% Spare Capacity77% Spare Capacity
Figure 6: Degradation of Sequential Write Speed(Simulation)
demonstrate that increasing the spare capacity improves theaverage random write performance substantially.
4.3 Random write performance of SSD RAIDsWith respect to the random write performance of SSD
RAIDs, there are the same three options as for single SSDs.We skip anticipatory garbage collection here as this increaseswrite amplification and, more important, this is only possi-ble for the manufacturer of SSDs. The second possibilitydeals with announcing erased blocks to the SSDs. In case ofa RAID implementation, this requires the mapping of TRIMrequests originating from the filesystem to TRIM commandsthat are sent to the SSDs in the array. In case of a parity-less RAID setup, this is simple because every erase opera-tion at filesystem level maps to one corresponding page onone (RAID 0) or more (in case of mirrors, i.e., RAID 1 orRAID 10) of the SSDs with no dependencies regarding otherpages. Therefore, this could be implemented straightforwardin a software RAID implementation or within the firmwareof a hardware RAID controller. For a parity-based RAID,the situation is different because writes and, therefore, alsoerase operations additionally lead to updates on other disks.Therefore, the mapping of TRIM commands is tricky andrequires special handling of, e.g., cases such as partly emptystripes. Thus, in this paper we concentrate on the third op-tion, that is over-provisioning. However, we consider TRIMsupport in SSD RAIDs for future work.
At first glance, it would be obvious that the random writethroughput of RAID arrays comprising SSDs grows with in-creasing spare capacity in the same way as for a single SSD.However, there are indications that the situation might bedifferent for SSD RAIDs. First, parity-based RAID levelsincur read operations interleaved with writes that may in-fluence each other. Second, employing an RAID implemen-tation extends the I/O path and adds complexity. In ourcase, it introduces a further software layer, as we use Linuxsoftware RAID. This has the potential to influence the per-formance scale-up with increasing number of drives. How-ever, the problem itself also applies to a hardware RAID(cf. Sect. 3.2). Hence, the influence of spare capacity in SSDRAIDs might turn out to be different to that of a single SSD.
Our analysis is subdivided into parity-less (Sect. 4.3.1)and parity-based (Sect. 4.3.2) RAID setups as these featuresignificant differences with regard to write operations (e.g.,writing to a parity-based RAID leads to reads and writes atdevice levels, while parity-less RAIDs yield only writes).
4.3.1 Parity-less SSD RAIDsIn parity-less SSD RAIDs, the expected random write per-
formance can be calculated similarly as for hard disks: Forconfigurations with n disks, a random write on the RAIDdevice results in an overall number of m random writes onthe individual SSD devices, where m is the number of mir-rors. Since we issue random writes on the RAID device, theresulting write operations spread uniformly over the individ-ual drives. Thus, if a single SSD is capable of executing wrandom writes per second, we can expect the RAID deviceto be capable of executing z = n
m· w random writes per
second. The result would be a speedup of nm
for RAID 10,a speedup of 1 for RAID 1 (since n = m), and a speedup ofn for RAID 0 (due to m = 1). Consequently, the speedupfactor, which arises when w is growing due to an increasedspare capacity, should equal to that of a single SSD.

Figure 7: Average random write IOPS in RAID configurations on varying spare capacities.
Figure 8: Speedup factor for random writes in RAID configurations on varying spare capacities.
To provide support for this theoretical considerations, weperformed random write benchmarks of common parity-lessRAID configurations (RAID 0, RAID 1 and RAID 10) withdifferent spare capacities. Our analysis includes the averagerandom write throughput and a closer look at the empiricaldistribution of the measurements.
Taking a look at the average random write performance ofthe tested RAID 0 configurations (Fig. 7), it can be noticedthat RAID 0 scales linearly up to 3 drives for spare capaci-ties of 7% and 30%, while this holds only for 2 drives whenthe spare capacity is increased even further. Consequently,the speedup factors of the mentioned configurations, whichare depicted in Fig. 8, decrease with growing spare capac-ity in comparison to the speedup factors of a single SSD.The problem is not rooted in a general upper limit of thetotal number of IOPS as the measurements of the RAID 0with 5 SSDs and a spare capacity of 77% show. In fact, thethroughput scale-up worsens when writes can be performedfaster due to increased spare capacity. This claim is sup-
ported by the results for RAID 1 with 2 SSDs and RAID 10with 4 SSDs. The speedup factor of the former grows almostas for a single SSDs with increasing spare capacity, while forthe latter this applies only for spare capacities of 7% and30%. Because the effect is not only correlated with spare ca-pacity but also with the number of drives, we suspect someother limitation, e.g., in the Linux RAID implementation.
Concerning the distribution of the throughput values forRAID 0 and RAID 10 shown in the second and third row ofFig. 9, a similar effect like for a single SSD (first row) can beobserved. The extent of variations declines and the through-put grows by at least ten times. Despite all, the scale-up fac-tor of the average throughput decreases with higher writeperformance and growing number of drives. Nevertheless,increasing spare capacity still remains beneficial.
4.3.2 Parity-based SSD RAIDsIn contrast to parity-less RAID configurations, the speed-
up factor in parity-based RAIDs depends on the ratio be-

Figure 9: Logarithmic scale histograms of random write throughput values in SSD RAID configurations onvarying spare capacities. Throughput in IOPS is shown on the x-axis, while relative frequencies are shownon the y-axis.

tween the read and the write performance as well as on theinfluence that reads and writes can have on each other. Thisis due to the fact that a write request to a parity-based RAIDresults not only in writes to the underlying drives, but alsoin additional read requests. Consequently, our next step isan analytical determination of this scalability factor, whichwould equal to 1 in parity-less RAID configurations resultingin the same speedup factors as of a single SSD.
First, we determine the expected number of random writesper second that a parity-based RAID configuration of nSSDs with p rotating parities can execute. A random writeon the RAID device results in p + 1 random reads, to readthe old version of the data stripe and the p parity stripes,and the same number of random writes to write the newversion of the data stripe and the parity stripes. An ex-ception to this are RAID setups with p + 2 ≤ n ≤ 2p + 1drives (e.g., RAID 5 with three and RAID 6 with four or fivedrives). In these cases, a random write to the RAID devicecan be achieved with n− (p + 1) random reads to read theremaining data stripes, and p + 1 random writes in order towrite the new data stripe and the new parity stripes. Thus,in these cases, the number of necessary random reads variesbetween 1 and p. In case of Linux, the software RAID im-plementation always uses the strategy that is more efficient,i.e., involves less read operations.
Since we issue random writes on the RAID device, the re-sulting write and read operations spread uniformly over theindividual drives. Consequently, the maximum throughputis achieved when all drives are saturated with write and readoperations. Let wmax and rmax be the maximum number ofrandom writes respectively random reads per second thatcan be executed on a single SSD for some spare capacity.Then, we assume that
w
wmax+
r
rmax= 1
holds for a single saturated drive, where w and r are thenumber of random writes and reads actually executed persecond, respectively.
First, we assume that n > 2p + 1 and, thus, the numberof random reads equals the number of random writes, i.e.,w = r. It follows that
w = r =1
(w−1max + r−1
max)=
wmax
(1 + f)
with f = wmax/rmax. If we assume that the write per-formance of an SSD cannot exceed the read performance(0 < f ≤ 1), it follows that 0.5 · wmax ≤ w < wmax, wherethe actual value of w depends on f and, thus, on the sparecapacity of the individual SSDs.
Now, we consider the case that p + 2 ≤ n ≤ 2p + 1. Then,
w =p + 1
n− (p + 1)· r
and, thus, for a saturated drive
w =1
w−1max + n−(p+1)
p+1· r−1
max
.
From this follows that
w =wmax
1 + n−(p+1)p+1
· f=
(p + 1) · wmax
p + 1 + f · (n− (p + 1)).
Thus, p+1n
≤ w < wmax since 0 < f ≤ 1. Therefore, the
lower bound for w is 23· wmax for a RAID 5 with 3 drives,
and 34· wmax and 4
5· wmax for a RAID 6 with four and five
drives, respectively. Again, the actual value of w dependson f and, thus, on the spare capacity.
From the derivation above, we know that a single drive(with a certain spare capacity) that can execute at mostwmax random writes in isolation can contribute w randomwrites to the performance of the RAID set if used in a parity-based raid configuration. Since one random write to theRAID device results in p + 1 random writes being executedon the n drives, we can execute z = n
p+1· w random writes
on the RAID device.Now, we can determine the expected speedup of a RAID
device whose write/read throughput ratio has been increasedfrom f1 to f2 by extending the spare capacity. This speedupis not equal to that of a single SSD because the speed ofrandom writes is increased by extending the spare capacity,while the speed of random reads is unaffected by this. Toderive the speedup of the RAID device, the speedup of thesingle drive has to be multiplied by the scalability factor sf .If n > 2p + 1, then
sf =w2
w1/wmax2
wmax1
=1 + f1
1 + f2
and if p + 2 ≤ n ≤ 2p + 1, then
sf =p + 1 + f1[n− (p + 1)]
p + 1 + f2[n− (p + 1)].
The speedup factor values for tested RAID 5 and RAID 6configurations with spare capacity increased from 7% to 77%attract attention due to a declining trend as illustrated inFig. 8. Thus, we compare them with the expected valuesderived from our model and a single SSD. For parity-basedRAID configurations the analytical speedup values derivedfrom our model are also denoted in Fig. 8. ConsideringRAID 5 configurations with 3 to 5 drives, the measured val-ues are about 20% lower for 3 and 4. However, for 5 SSDsthe measured value is about 43% lower indicating a scalingissue similarly to the RAID 0 configuration with 5 drivesas discussed in Sec 4.3.1. If we consider the lower sparecapacity expansions to 30% or 53% the difference betweenmeasured and derived values is significantly lower, lying be-tween 10% and 20%. Taking a look at the RAID 6 resultsfor configurations with 4 and 5 drives shown in Fig. 8, themeasured values are still about 20% and 31% lower than theexpected values for a spare capacity increase to 77%. Similarto the RAID 5 speedup values, the difference between calcu-lated and measured values is considerably lower for smallerspare capacities (30% and 53%), ranging from to 16% and19%. This supports the claim about scaling problems with5 drives in combination with high random write throughputof each SSD, when the spare capacity increased to 77%.
Summarizing, the results of the parity-based RAID mea-surements are about 20% lower than in our model, except forconfigurations with 5 drives in combination with the high-est spare capacity increase. The cause of the deviation canbe a negative interaction between reads and writes, whichis currently not considered in our model. Similarly as withparity-less RAID configurations with 5 drives, the parity-based RAID configurations exhibit scaling issues in combi-nation with high random write speeds.

Next, we take a look at the distribution of the through-put values for RAID 5 and RAID 6 shown in the histogramsin the fourth and fifth row in Fig. 9. It can be observedthat the whole variation range narrows reaching from about1,000 to tens of thousands IOPS, if we increase the spare ca-pacity up to 77%. This is analogous to the observations fora single SSD and the two parity-less RAID configurations,and, again, makes such setups more suitable for demand-ing scenarios requiring more predicable and higher mini-mum performance. Consequently, the results indicate thathigher over-provisioning positively affects random write per-formance of parity-based SSD RAIDs as well.
5. CONCLUSIONSIn this paper, we have discussed the pitfalls of SSD RAIDs.
The effort required to avoid each of them is very different.Some pitfalls like those related to cluster and stripe unitsize can easily be overcome by choosing appropriate values.The same is true for partition alignment and RAID align-ment. Other pitfalls can only be overcome by increasingcosts, e.g., to ensure the required capabilities of the hosthardware. Finally, there are pitfalls such as the asymmetricread/write performance of SSDs that cannot be avoided, butonly limited in impact by, e.g., using parity-less instead ofparity-based RAID setups or by increasing spare capacity.
We investigated the problem of workload history depen-dency in depth and analyzed the applicability of over-pro-visioning that is promising for single SSDs to SSD RAIDs.Based on models and experiments, our research confirmsthat increasing the spare capacity significantly increases theguaranteed random write performance of SSD RAIDs. Whileevaluating the performance characteristics of a single SSDis time consuming, evaluating a RAID or even different po-tential RAID setups is even more complex. The model thatwe developed allows to approximately predict the randomwrite performance of a parity-based SSD RAID based onmeasurements of a single SSD helping to reduce or even toavoid time consuming measurements.
As our next steps, we want to extend this model to a moreholistic approach that takes further parameters such as theinteraction between reads and writes in parity-based RAIDconfigurations, sequential write performance, read perfor-mance, stripe unit size and I/O topology into account. Ourfinal goal is to derive a detailed model that can be used todecide on suitable SSD RAID configurations based on givenperformance targets. On the practical side, we intend to in-vestigate the performance gaps that seem to be caused bythe current Linux software RAID implementation (Sect. 4.3)by comparing it to other RAID implementations such as thesoftware RAID of Windows Server 2008 or a Device Mapper-based RAID implementation under Linux. This will includea deeper analysis of the internal behavior and the bottle-necks of software RAID implementations. Another area offuture research is related to TRIM support in RAID sys-tems. While this seems to be straightforward for parity-lesssetups, parity-based RAIDs require more research especiallyfor TRIM in stripes that are only partly erased.
Finally, we want to explore the properties of hybrid RAIDsetups containing SSDs and HDDs. Currently, some RAIDconfigurations like RAID 4 are not widely used because thisRAID levels impose a larger workload to one or more drivesthan to the other drives in the RAID constituting bottle-necks. Replacing those drives by SSDs may result in a high-
performance but still cost-efficient RAID setup. Similarly,it seems possible to setup a hybrid SSD RAID composed ofa small number of enterprise SSDs and a larger number oflow-cost consumer SSDs. Overall, we believe that RAIDsconsisting of SSDs will be an essential part of the futurestorage systems and that further research is still needed toexploit the full potential of these devices.
6. REFERENCES[1] Axboe, J. Flexible i/o tester. Freshmeat project
website (2010). http://freshmeat.net/projects/fio/.
[2] Balakrishnan, M., Kadav, A., Prabhakaran, V.,and Malkhi, D. Differential raid: Rethinking raid forssd reliability. Trans. Storage 6 (July 2010), 4:1–4:22.
[3] Chen, P. M., Lee, E. K., Gibson, G. A., Katz,R. H., and Patterson, D. A. Raid:high-performance, reliable secondary storage. ACMComput. Surv. 26 (June 1994), 145–185.
[4] He, J., Bennett, J., and Snavely, A. Dash-io: anempirical study of flash-based io for hpc. InProceedings of the 2010 TeraGrid Conference (NewYork, NY, USA, 2010), TG ’10, ACM, pp. 10:1–10:8.
[5] Hu, X.-Y., Eleftheriou, E., Haas, R., Iliadis, I.,and Pletka, R. Write amplification analysis inflash-based solid state drives. In SYSTOR ’09:Proceedings of SYSTOR 2009: The IsraeliExperimental Systems Conference (New York, NY,USA, 2009), ACM, pp. 1–9.
[6] Intel Corporation. Intel x18-m/x25-m sata solidstate drive – product manual. Tech. rep., IntelCorporation, May 2009.http://download.intel.com/design/flash/nand/mainstream/mainstream-sata-ssd-datasheet.pdf.
[7] Intel Corporation. Intel x25-e sata solid state drive– product manual. Tech. rep., Intel Corporation, May2009. http://download.intel.com/design/flash/nand/extreme/319984.pdf.
[8] Jacob, B. L., Ng, S. W., and Wang, D. T.Memory Systems: Cache, DRAM, Disk. MorganKaufmann, 2008.
[9] Kadav, A., Balakrishnan, M., Prabhakaran, V.,and Malkhi, D. Differential raid: rethinking raid forssd reliability. SIGOPS Oper. Syst. Rev. 44, 1 (2010),55–59.
[10] Patterson, D. A., Gibson, G., and Katz, R. H. Acase for redundant arrays of inexpensive disks (raid).SIGMOD Rec. 17 (June 1988), 109–116.
[11] Petrov, I., Almeida, G., Buchmann, A., andGraf, U. Building large storage based on flash disks.In In Proceedings of ADMS 2010 (September 2010).
[12] Polte, M., Simsa, J., and Gibson, G. Enablingenterprise solid state disks performance. In 1stWorkshop on Integrating Sold-state Memory into theStorage Hierarchy (March 2009), Department ofComputer Science and Engineering. The PennsylvaniaState University, pp. 1–7.
[13] Seagate Technology. Seagate cheetah 15k.7 sas –product manual. Tech. rep., Seagate Technology,November 2010.http://www.seagate.com/staticfiles/support/disc/manuals/enterprise/cheetah/15K.7/SAS/100516226d.pdf.




















