
TEI and Linguistics - OpenEdition Journals
163
Journal of the Text Encoding Initiative Issue 3 | November 2012 TEI and Linguistics Piotr Bański, Eleonora Litta Modignani Picozzi and Andreas Witt (dir.) Electronic version URL: http://journals.openedition.org/jtei/475 DOI: 10.4000/jtei.475 ISSN: 2162-5603 Publisher TEI Consortium Electronic reference Piotr Bański, Eleonora Litta Modignani Picozzi and Andreas Witt (dir.), Journal of the Text Encoding Initiative, Issue 3 | November 2012, « TEI and Linguistics » [Online], Online since 05 November 2012, connection on 13 April 2020. URL : http://journals.openedition.org/jtei/475 ; DOI : https://doi.org/ 10.4000/jtei.475 This text was automatically generated on 13 April 2020.
-
Upload
khangminh22 -
Category
Documents
-
view
3 -
download
0
Transcript of TEI and Linguistics - OpenEdition Journals

Journal of the Text Encoding Initiative
Issue 3 | November 2012TEI and LinguisticsPiotr Bański, Eleonora Litta Modignani Picozzi and Andreas Witt (dir.)
Electronic versionURL: http://journals.openedition.org/jtei/475DOI: 10.4000/jtei.475ISSN: 2162-5603
PublisherTEI Consortium
Electronic referencePiotr Bański, Eleonora Litta Modignani Picozzi and Andreas Witt (dir.), Journal of the Text EncodingInitiative, Issue 3 | November 2012, « TEI and Linguistics » [Online], Online since 05 November 2012,connection on 13 April 2020. URL : http://journals.openedition.org/jtei/475 ; DOI : https://doi.org/10.4000/jtei.475
This text was automatically generated on 13 April 2020.

TABLE OF CONTENTS
Editorial Introduction to the Third IssuePiotr Bański, Eleonora Litta Modignani Picozzi and Andreas Witt
The TEI and Current Standards for Structuring Linguistic DataAn OverviewMaik Stührenberg
A TEI P5 Document Grammar for the IDS Text ModelHarald Lüngen and C. M. Sperberg-McQueen
Creating Lexical Resources in TEI P5A Schema for Multi-purpose Digital DictionariesGerhard Budin, Stefan Majewski and Karlheinz Mörth
Consistent Modeling of Heterogeneous Lexical StructuresLaurent Romary and Werner Wegstein
A TEI Schema for the Representation of Computer-mediated CommunicationMichael Beißwenger, Maria Ermakova, Alexander Geyken, Lothar Lemnitzer and Angelika Storrer
Building and Maintaining the TEI LingSIG BibliographyUsing Open Source Tools for an Open Content InitiativePiotr Bański, Stefan Majewski, Maik Stührenberg and Antonina Werthmann
Journal of the Text Encoding Initiative, Issue 3 | November 2012
1

Editorial Introduction to the ThirdIssuePiotr Bański, Eleonora Litta Modignani Picozzi and Andreas Witt
1 Linguistics had a strong presence at the TEI’s beginnings, being represented by names
as significant as those of Nancy Ide, Donald E. Walker, and Antonio Zampolli.
Linguistics was mentioned explicitly in the names of two of its three founding
organizations: Association for Computers and the Humanities, Association for
Computational Linguistics, and Association for Literary and Linguistic Computing. It
was the main focus of one of the four initial committees (http://www.tei-c.org/Vault/
AB/abj01.txt) and, within several years of the inception of the work on the TEI
Guidelines, the British National Corpus clearly demonstrated the TEI’s usefulness for
encoding language resources.
2 While the TEI proved successful in annotating basic grammatical information in an in-
line fashion, by the time the BNC was compiled there was a rapid development in
corpus studies, directed not only at the volume of primary data but also at annotations
that gradually began to provide information beyond part-of-speech categorization and
lemmatization. Architectures were needed which would provide simple and fast
deployment, describing exactly the information that was needed without the overhead
of extra markup and using a flatter metadata structure. This is how specifications such
as CES (primarily for morphosyntactic and alignment annotation) and TigerXML (for
syntactic annotation, both hierarchical and relational) were developed and began to be
adopted by the linguistic community.
3 The early 2000s saw rapid development of language resources encoded in CES (Corpus
Encoding Standard) developed from TEI P3, and then XCES, as well as Tiger XML, both
of which exceeded the TEI in their popularity within tightly focused linguistic circles. It
should also be pointed out that, while the robust stand-off mechanisms of the TEI are
still being refined, CES and then XCES provided basic reference mechanisms which
proved extremely popular among corpus creators. Similar is the case of feature
structure markup: while the ISO/TEI feature structure schema offers numerous ways to
encode linguistic information (Witt et. al. 2009), in the absence of the feature structure
validation mechanisms, corpus builders adopted much simpler solutions.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
2

4 This state of affairs has gradually been changing: TEI P5, as a mature XML-based toolkit
that supports all the newest XML technologies, once again could be an important
player in the market of annotation standards (in the case of the TEI, a more precise
phrase could be annotation standard toolkits) and has recently been applied to encode
major linguistic enterprises such as the National Corpus of Polish, with its impressive
stand-off architecture featuring a number of separate annotation layers
(Przepiórkowski and Bański 2010).
5 The TEI special interest group for linguists (LingSIG), founded in 2010, has as its aim
making the TEI even more competitive in the area of linguistic annotation frameworks,
while maintaining close connections with the work performed at ISO TC37 SC4, the ISO
committee devoted to the management of language resources.
6 At the time of writing, the SIG has met twice (at the TEI conferences in Zadar and in
Würzburg) where a series of micropresentations were offered on various topics
connecting the TEI and linguistics. It was also from the participants of the Würzburg
meeting that most submissions for the present issue were received.
7 This issue begins with an overview of the current annotation standards landscape. “The
TEI and Current Standards for Structuring Linguistic Data: An Overview,” by Maik
Stührenberg, provides a remarkable summary of the most recent efforts to create
international standards for the annotation of linguistic corpora, developed by the ISO
technical committee for Terminology and other Language and Content Resources (ISO/
TC 37). This article opens a window onto the world of standards creation, detailing the
steps necessary for a set of protocols to become a standard, contrasting that with
community discussion-based specifications such as the TEI Guidelines, and showing
how the latter have been influential in the creation of de facto standards.
8 The second paper, “A TEI P5 Document Grammar for the IDS Text Model,” by corpus
linguistics specialist Harald Lüngen and a veteran of both TEI and XML, C.M. Sperberg-
McQueen, presents the process of making the legacy data of DeReKo (Deutsches
Referenzkorpus, the largest archive of German written text, collected at the IDS
Mannheim since 1964) compatible with the current version of TEI P5. The paper
describes the steps taken to encode the corpus since the early 1990s through a detailed
analysis of the way the IDS text model evolved to ultimately include the preparation of
an ODD file which, in turn, documents the model.
9 Gerhard Budin, Stefan Majewski, and Karlheinz Mörth write about a similar effort in
the area of dictionary encoding. Their paper describes the work of the Institute for
Corpus Linguistics and Text Technology (ICLTT) of the Austrian Academy of Sciences in
a number of projects involving both the digitisation of print dictionaries and the
creation of new born-digital lexicographical data. The article explores how even within
the restrictions imposed by the TEI dictionary module, an attentive customisation with
an eye to interoperability with other standards and digital NLP tools makes TEI P5 a
model that can be applied over a variety of digitisation projects. The article touches on
issues of hierarchies, polyfunctionality of certain elements in the dictionary module,
word-class information, and interoperability of the markup schema with other digital
frameworks. The authors present the project’s experience in encoding
morphosyntactic information, linguistic varieties and writing systems, etymology,
semantics, and specific production metadata, ultimately proving the value of the
customised TEI P5 dictionary module both in the representation of digital dictionaries
and the potential for use in NLP related applications.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
3

10 “Consistent Modeling of Heterogeneous Lexical Structures” by Laurent Romary and
Werner Wegstein highlights issues concerning the interoperability of a variety of data
sources in lexical data modelling. This article starts by underlining the difficulties
arising from building ad hoc data models from the TEI Guidelines’ Dictionaries chapter,
which inevitably leads to poor accessibility. The authors focus on lexical structures and
propose a more generic methodology based on the concept of crystals, the smallest
units in a construct that can help divide a document into regular chunks of information
that can be processed more easily by external tools.
11 Michael Beißwenger, Maria Ermakova, Alexander Geyken, Lothar Lemnitzer, and
Angelika Storrer present a novel application of TEI P5 in the description of computer-
mediated communication. Their paper, “A TEI Schema for the Representation of
Computer-mediated Communication,” introduces an XML schema which provides a
structure for the encoding of the structural units of communication in not only forums,
blogs, and bulletin boards but also instant messaging, wikis, and twitter feeds, as well
as the annotation of these units. The paper offers an interesting view on the processing
of a new literary genre characterised by precise interaction features such as emoticons,
interaction words, acronyms, and so on, and on the need for TEI P5 to cater for such
forms of text.
12 Piotr Bański, Stefan Majewski, Maik Stührenberg, and Antonina Werthmann take on a
more general issue relating to the social and infrastructural aspect of the SIG, and
present a proposal for integrating a TEI markup exporter into the general-purpose
citation manager Zotero. The paper provides a glimpse into the origins of the SIG’s
online presence and articulates a proposal for specific choices within TEI bibliographic
elements to suggest a coherent and interchangeable way of sharing and maintaining
bibliographic reference stores.
13 The guest editors of the volume wish to express their thanks to the authors and the
reviewers, and acknowledge the work by the Journal of the Text Encoding Initiative regular
editors, Susan Schreibman and Kevin Hawkins, in bringing the issue into uniform
shape.
BIBLIOGRAPHY
Przepiórkowski, Adam and Piotr Bański. 2011. “XML Text Interchange Format in the National
Corpus of Polish.” In Explorations across Languages and Corpora, edited by Stanisław Góźdź-
Roszkowski, 55–65. Frankfurt am Main: Peter Lang.
Witt, Andreas, Georg Rehm, Erhard Hinrichs, Timm Lehmberg, and Jens Stegmann. 2009.
“SusTEInability of linguistic resources through feature structures.” Literary & Linguistic Computing
24 (3): 363–372. doi:10.1093/llc/fqp024.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
4

The TEI and Current Standards forStructuring Linguistic DataAn Overview
Maik Stührenberg
1. Introduction
1 During the last decade linguistic annotation of corpora has undergone a substantial
change. While in the late 20th century annotation formats were developed and used
exclusively for projects or within small communities, we now have a large number of
standardization efforts carried out by the International Organization for
Standardization (ISO), addressing, in particular, new advancements in technology such
as very large and multiply annotated corpora. An overview is given by Ide and Romary
(2007) and Declerck et al. (2007).
2 In addition, these standardization efforts are increasingly adopted in international
projects such as CLARIN (Common Language Resources and Technology Infrastructure)
and FLARENET (Fostering Language Resources Network).1 Both projects involve
harmonization of formats and standards for language resources and technology with
the goal of making these much more accessible to researchers via component metadata
registries (see Broeder et al. 2011) and by providing guidelines to choose particular
specifications (see Monachini et al. 2011).
3 Of course, international standards are not developed in isolation, without any reference
to established de facto standards such as the TEI Guidelines. However, there are some
differences that can be observed when comparing the TEI Guidelines to these
specifications with respect to various aspects of markup languages such as the formal
model, the notation, and the annotation model.
4 After a short overview of the process of standardization of international standards, we
will contrast this process with the development of community-based specifications,
such as the TEI Guidelines. After this introduction, a number of ISO standards that deal
with the annotation of language corpora will be examined. The TEI’s influence on the
Journal of the Text Encoding Initiative, Issue 3 | November 2012
5

development of these standards will then be discussed. This paper will conclude with recommendations for scholars and researchers that deal
with linguistically annotated corpora.
2. Current International Standards
2.1. International Standardization
5 The term standard can have two meanings. On the one hand, the term can depict
international (or national) industry norms and standards—that is, specifications
developed by organizations that have been assigned to this task, such as ANSI
(American National Standards Institute) in the USA or DIN (Deutsches Institut für
Normung) in Germany. Such standards are called de jure standards.On the other hand, there are also de facto (or market-driven) standards, i.e., specifications
that are not endorsed by a standards organization but have achieved a greater
popularity compared to similar specifications. An obvious example of such a de facto
standard is the original file format of Microsoft Word: the ubiquitous “doc” format. In
this case, the status of the specification is based on the dominant market position of the
respective company. Another example is the tagset of the TEI Guidelines, the status of
which can be explained by its broad acceptance by scholars around the world.
6 De jure standards are developed by international committees, usually under the
auspices of the International Organization for Standardization (ISO) and comprising
members from various national standards bodies. ISO, for example, has technical
committees (TC), divided into subcommittees (SC) and then into working groups (WG)
chartered to work on a distinctive topic. But the work of developing a standard often
begins in one or more national bodies, since technical committees are made up of
national representatives of various stakeholders such as industry, NGO, government or
academia. Therefore, each national organization for standardization (a member body)
decides to participate in a number of technical committees. These national bodies often
reflect the structure of ISO, allowing for straightforward collaboration between
corresponding committees in different countries.
7 A relevant ISO subcommittee in the field of linguistic annotation is ISO/TC 37/SC 4 (in
this case, “SC” is for subcommittee 4) called “Language Resource Management”, of the
technical committee “Terminology and other Language and Content Resources”. It is
divided into six working groups (WG):
WG 1: Basic descriptors and mechanisms for language resources
WG 2: Annotation and representation schemes
WG 3: Multilingual information representation
WG 4: Lexical resources
WG 5: Workflow of language resource management
WG 6: Linguistic annotation.2
8 These working groups develop relevant specifications for the field of linguistic
annotation.
9 ISO has a protocol for the proposal process (International Organization for
Standardization/International Electrotechnical Commission 2012) in which proposals
•
•
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
6

must pass through seven stages, each of which takes some time, before becoming
official standards:
Preliminary stage
Proposal stage
Preparatory stage
Committee stage
Enquiry stage
Approval stage
Publication stage
10 The first stage marks the introduction of a Preliminary Work Item (PWI), which can be
introduced by members of the working group or by outside interested parties. After a
positive internal review, it becomes a New Work Item Proposal (NP). At that time it
reaches the proposal stage, in which the so-called P-members (“participating
members”) of the respective committee (or sub-committee) have to vote in favor or
against the further pursuit of this item.3 If the majority of the P-members cast a
positive vote and at least five P-members signal a willingness to participate in the
standardization process, the NP is added as a new project of the WG, reaching the
beginning of the preparatory stage.
11 In each of the following stages the status of the proposal changes according to
substantial improvements that have been made. The committee stage is the first stage
at which the Committee Draft (CD), as it’s then called, is commented on by national
bodies of the TC/SC. This stage ends when all technical issues have been resolved. In
that case the CD is transformed into a Draft International Standard (DIS) and enters the
enquiry stage.
12 At this stage the DIS will be circulated to all national bodies for a ballot. A vote can be
either positive, negative, or an abstention; in the two former cases the vote may be
accompanied by editorial or technical comments. The DIS is approved if a two-thirds
majority of the P-members’ votes are in favor and not more than one-quarter of the
total votes cast are negative. In that case it will be registered as a Final Draft
International Standard (FDIS), proceeding to the approval stage.4
13 From this point onwards the text of the FDIS is usually not publicly available for free
(although there are exceptions to this rule). As a result, researchers often consult and
cite Committee Drafts or Draft International Standards in their work. However, such a
time-consuming and consensus-driven process means that major changes often exist
between draft versions and the final International Standard. In contrast, openly
developed standards such as the TEI Guidelines are often publicly available both as
drafts and final versions, which eases the adoption of changes between different
versions.
14 The boundaries between de facto and de jure standards can be very weak; in fact,
sometimes de facto standards became de jure standards. For example, Simons (2007)
explains the long process of developing a standard for describing language codes,
starting from Ethnologue and ending with the International Standard ISO 639-3:2007.5
15 In the next section we will discuss some de jure standards that have been developed in
ISO/TC 37/SC 4 that may affect the work of current and future linguists.6
•
•
•
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
7

2.2. Feature Structures (FS)
16 Feature Structures are general-purpose data structures consisting of a named feature
and its value (or values). Complex feature structures contain a group of individual
features allowing for a representation of various kinds of information. In linguistics, feature structures are best known as part of Head-driven Phrase
Structure Grammar (HPSG).7
17 Feature structure representations have been a part of the TEI Guidelines from the very
beginning.8 However, during the transition from P4 to P5 a substantial amount of work was
undertaken to improve the tag set and to clarify its underlying formal logic.
18 The following is an example of a TEI-based linguistic feature structure:
<fs>
<f name="CAT">
<symbol value="np" />
</f>
<f name="AGR">
<fs>
<f name="NUM">
<symbol value="sing" />
</f>
<f name="PER" />
<symbol value="third" />
</f>
</fs>
</f>
</fs>
Figure 1: TEI-based feature structure for a linguistic annotation (from Stegmann and Witt 2009).
19 This feature structure consists of two features. The first, named “CAT”, is a simple
feature that has the atomic feature value “np”. The second, named “AGR” is a complex
feature (that is, its value consists of other feature structures), containing the features
“NUM” and “PER”.
20 A few key players in the TEI community submitted the P5 revision of the feature
structure annotation format for standardization as the two-part ISO standard 24610.
While the first part, ISO 24610-1:2006, describes feature structures (including the
representation format shown in the example above and an informal overview of the
basic characteristics of feature structures), the second part, ISO 24610-2:2011, discusses
feature system declaration described in Chapter 18.11 of the TEI Guidelines.
21 Both parts of ISO 24610 use a RELAX NG grammar that is a subset of the TEI’s P5
document grammar with only slight changes (for example, a different root element). As
one may observe, there is a five-year gap between the two parts of ISO 24610. In
addition, ISO 24610-1 was scheduled for a regular revision that should have been
Journal of the Text Encoding Initiative, Issue 3 | November 2012
8

finished in early 2012. However, due to time constraints on the part of the involved
experts, work on the Committee Draft for the revision has been put on hold, leaving ISO
24610-1:2006 as the current version.
2.3. The Linguistic Annotation Framework (LAF)
22 Development of the Linguistic Annotation Framework began in 2005, and it became an
approved standard in 2012 (ISO 24612). Its goal is to establish a definitive standard
based on widely used de facto standards such as the TEI, the Corpus Encoding Standard
(CES, see Ide 1998), and its successor XCES (Ide et al. 2000).
23 LAF provides a framework for representing linguistic annotation of various kinds. It
includes an abstract data model for general-purpose linguistic annotation (in contrast
to more specific annotation formats such as the Morpho-Syntactic Annotation
Framework discussed in the next section) and an XML serialization format called Graph
Annotation Format (GrAF), which serves as a pivot format for mapping between user-
defined annotation formats. The data model consists of three parts: (1) anchors that
define regions by referencing locations in the primary data (that is, the data to be
annotated); (2) a graph structure, consisting of nodes, edges and links to the before-
mentioned regions; and (3) an annotation structure comprising a directed graph
referencing regions or other annotations. The nodes in this graph are associated with
feature structures providing the annotation content. LAF does not include data
categories but instead relies on ISO 12620:2009, the International Standard for
describing data categories, and on ISOcat, an implementation of ISO 12620:2009
developed in ISO/TC 37/SC 3.9
24 A language resource conforming to LAF consists of the primary data; a base
segmentation (that is, at least one document that provides anchors and therefore
defines regions of the primary data); a number of annotation documents containing
nodes, edges and feature structures; and a set of header files (metadata). By storing
primary data and annotation in separate files, LAF uses stand-off annotation (see
Thompson and McKelvie 1997), similar to CES and XCES, to more easily encode
overlapping and discontiguous regions than if these were encoded in a single file. The
anchors are nodes that are located between base units of the primary data. Depending
on the type of primary data (text, audio, video, or other) the base unit can be a
character, a segment of time, or another useful unit of segmentation. An annotation
document contains annotations associated with the nodes in the graph that reference
regions of the primary data. While stand-off annotation would allow the combination of
several linguistic annotation layers into a single annotation document (see Stührenberg
and Jettka 2009), the standard recommends the use of separate annotation files for the
purpose of exchange.
25 Figure 2 shows a fragment of an example annotation document containing both a
header, nodes, edges and annotations (taken from ISO/FDIS 24612).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
9

<?xml version="1.0" encoding="UTF-8"?>
<graph xmlns="http://www.xces.org/ns/GrAF/1.0/">
<graphHeader>
<labelsDecl>
<labelUsage label="fullTextAnnotation" occurs="1"/>
<labelUsage label="Target" occurs="171"/>
<labelUsage label="FE" occurs="372"/>
<labelUsage label="sentence" occurs="32"/>
<labelUsage label="annotationSet" occurs="171"/>
<labelUsage label="NamedEntity" occurs="32"/>
</labelsDecl>
<dependencies>
<dependsOn type="fntok"/>
</dependencies>
<annotationSpaces>
<annotationSpace as.id="FrameNet" default="true"/>
</annotationSpaces>
</graphHeader>
<node xml:id="fn-n156"/>
<a label="FE" ref="fn-n156">
<fs>
<f name="FE" value="Speaker"/>
<f name="rank" value="1"/>
<f name="GF" value="Ext"/>
<f name="PT" value="NP"/>
</fs>
</a>
<!-- [...] -->
<edge xml:id="e233" from="fn-n156" to="fn-n133"/>
<!-- [...] -->
<region xml:id="r1" anchors="980 9190"/>
<region xml:id="r2" anchors="980 993"/>
<!-- [...] -->
<node xml:id="a232">
<link targets="r1"/>
</node>
<node xml:id="a233">
<link targets="r2"/>
</node>
<!-- [...] -->
<a label="R Gesture Units 1" ref="a232"/>
<a label="preparation" ref="a233"/>
</graph>
Figure 2: An example annotation document using the Graph Annotation Format (GrAF).
26 LAF takes input from several other specifications: the header files resemble the ones
used in CES, which in turn are based on TEI headers. ISO 24610-1:2006 can be used for
Journal of the Text Encoding Initiative, Issue 3 | November 2012
10

these feature structures. However, the standard recommends its own representation
format shown in figure 2 as a more concise notation.
27 What is somewhat disturbing is the fact that a document grammar for the Graph
Annotation Format was removed when the draft standard moved from from DIS to
FDIS. The DIS version contained an XML schema file in the informative annex of the
specification while the FDIS contains only fragments of a RELAX NG document
grammar. Since the FDIS was approved as International Standard in 2012 without any
comments regarding this topic, we assume that this is also the case for the final
version.
2.4. The Syntactic Annotation Framework (SynAF)
28 The Syntactic Annotation Framework (SynAF, ISO 24615:2010) pursues the goal of
defining both a meta-model for syntactic annotation and a set of data categories. In
contrast to the more specific Morpho-Syntactic Annotation Framework (MAF), which is
discussed in the next subsection, SynAF had already been published as an International
Standard in 2010. The latest version that is publicly available for free is ISO/FDIS 24615,
but an early version is discussed by Declerck (2006). SynAF is based on the Penn
Treebank initiative, the Negra/Tiger initiative, and the ISST initiative and has been
developed mainly by the LIRICS Consortium. While MAF deals with part of speech,
morphological and grammatical features, SynAF deals with the annotation of syntactic
constituency of groups of MAF word forms in sentence boundaries.
29 The meta-model for SynAF contains the generic class of Syntactic Nodes and Syntactic
Edges, which together form a Syntactic Graph. Syntactic Nodes can be differentiated
into T_Nodes (terminal nodes)—that is, the morpho-syntactic annotated word forms of
MAF, defined over one or more spans—and NT_Nodes (non-terminal nodes of a syntax
tree). The T_Nodes are annotated with syntactic data categories according to the word
level, whereas the NT_Nodes are annotated with syntactic categories according to the
phrase, clause, or sentence level.
30 Syntactic Edges are used to represent relations between Syntactic Nodes, such as
dependency relations. The edges can be specified as primarySyntacticEdge (expressing
the constituency relationship) or secondarySyntacticEdge, which “may be used to
express the relationship between a head and a coreferent of its omitted dependent”
(ISO/FDIS 24615, 14). Since the standard does not propose a specific tag set but only
generic classes and specific data categories, there are several possible serialization
formats. Romary et al. (2011) propose the <tiger2> XML format; another natural
selection would be the Graph Annotation Format defined in LAF.
2.5. The Morpho-Syntactic Annotation Framework (MAF)
31 The Morpho-Syntactic Annotation Framework is closely connected to the Syntactic
Annotation Framework (SynAF) discussed in the previous section. MAF is not yet an
International Standard but is in the stage of an FDIS (ISO/FDIS 24611). The last version
freely available to the public is ISO/CD 24611. However, the basic concepts of the
specification such as the two-level structuring for tokens and word forms, and the
ambiguity handling are discussed by Clément and de la Clergerie (2005).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
11

32 MAF uses stand-off annotation as well and represents an annotated document as the
primary data (called a “raw document” by Clément and de la Clergerie 2005) and a set
of annotations. An input document can be divided into tokens, which can be used as
anchors for word forms. Tokens resemble the regions in LAF—that is, they represent
segments of the primary data. MAF does not provide an addressing schema used to
refer to positions but instead relies on externally defined addressing schemas.10
33 Similar to LAF, these tokens can be organized in a directed acyclic graph (DAG) called a
token lattice. Word forms carry the annotation by using feature structure
representations and refer to tokens in an m:n-relation (where one or more tokens
anchors one or more word forms). Word forms, too, can be organized—in a word form
lattice. Figure 3 shows an example annotation of the sentence “I wanna put up new
wallpaper.”11
Journal of the Text Encoding Initiative, Issue 3 | November 2012
12

<maf xmlns="http://www.iso.org/ns/MAF" document="sample.txt"
addressing="char_offset">
<olac:olac
xmlns:olac="http://www.language-archives.org/OLAC/1.0/"
xmlns="http://purl.org/dc/elements/1.1/">
<creator>Maik Stührenberg</creator>
</olac:olac>
<token xml:id="t1" form="I" from="0" to="1"/>
<token xml:id="t2" join="right" form="wan" from="2" to="5"/>
<token xml:id="t3" join="left" form="na" from="5" to="7"/>
<token xml:id="t4" form="put" from="8" to="11"/>
<token xml:id="t5" form="up" from="12" to="14"/>
<token xml:id="t6" form="new" from="15" to="18"/>
<token xml:id="t7" form="wall" from="19" to="23"/>
<token xml:id="t8" form="paper" from="23" to="28"/>
<token xml:id="t9" form="." from="28" to="29">.</token>
<wordForm lemma="I" tokens="#t1">
<fs>
<f name="pos">
<symbol value="PP"/>
</f>
</fs>
</wordForm>
<wordForm lemma="want" tokens="#t2">
<fs>
<f name="pos">
<symbol value="VBP"/>
</f>
</fs>
</wordForm>
<wordForm lemma="to" tokens="#t3">
<fs>
<f name="pos">
<symbol value="TO"/>
</f>
</fs>
</wordForm>
<wordForm tokens="#t2 #t3"/>
<wordForm lemma="put" tokens="#t4"/>
<wordForm lemma="up" tokens="#t5"/>
<wordForm lemma="put_up" tokens="#t4 #t5">
<fs>
<f name="pos">
<symbol value="VB"/>
</f>
</fs>
</wordForm>
<wordForm lemma="new" tokens="#t6">
<fs>
Journal of the Text Encoding Initiative, Issue 3 | November 2012
13

<f name="pos">
<symbol value="JJ"/>
</f>
</fs>
</wordForm>
<wordForm lemma="wallpaper" tokens="#t7 #t8">
<fs>
<f name="pos">
<symbol value="NN"/>
</f>
</fs>
</wordForm>
</maf>
Figure 3: Example annotation using MAF’s current serialization format.
34 Instead of stand-off annotation, it is possible to use inline annotation for the token
content; in fact, most examples in ISO/CD 24611 use this notation. In this case the value
of the @from attribute would be used as element content of the <token> element and
the @from and @to attributes would be omitted. However, following the standard, this
is not recommended since it may conflict with other annotations.
35 The morpho-syntactic content is represented by feature structures: ISO/CD 24611
directly refers to ISO 24610-1:2006. Metadata may be included according to the OLAC
metadata specification (Simons and Bird 2008) using the OLAC namespace as seen in
figure 3.
36 In addition, ISO/FDIS 24611 contains a RELAX NG-like specification, some annotated
examples and a list of morpho-syntactic data categories as part of its appendixes.
3. The Relation of the TEI to the Current de jureStandards
37 In this section the relation between the TEI and the previously mentioned standards
will be discussed, focusing on aspects of their notation format and annotation models.
Bański and Przepiórkowski have already stated the fact that the TEI is a direct ancestor
of these standards:
The current standards that have been or are being established by ISO TC 37 SC 4committee …, known together as the LAF (Linguistic Annotation Framework) familyof standards, … descend in part from an early application of the TEI, back when theTEI was still an SGML-based standard. That application was the Corpus EncodingStandard …, later redone in XML and known as XCES …. XCES was a conceptualpredecessor of the current ISO LAF pivot format for syntactic interoperability ofannotation formats, GrAF (Graph Annotation Framework) …. GrAF defines an XMLserialization of the LAF data model consisting of directed acyclic graphs withannotations (also expressible as graphs), attached to nodes. This basic data model isin fact common to the TEI formats defined for the NCP, the LAF family of standards,and the other standards and best practices …. (2010b, 36)
Journal of the Text Encoding Initiative, Issue 3 | November 2012
14

3.1. Influence on the Data Model
38 In the field of Digital Humanities there has been the assumption that text is
hierarchically structured (see, for example, Coombs et al. 1987 or the OHCO thesis
postulated by DeRose et al. 1990 and Renear et al. 1996, stating that a text is an Ordered
Hierarchy of Content Objects), and therefore markup languages which were developed
to annotate mainly textual content use the formal model of a tree.
39 But in fact, there are several authors that tend to agree that the formal model of XML
instances is that of a graph: Abiteboul et al. 2000, Polyzotis and Garofalakis 2002, Gou
and Chirkova 2007, Møller and Schwartzbach 2011, and Jettka and Stührenberg 2011. In
particular, the use of the XML-inherent integrity constraints—that is, ID/IDREF/
IDREFS token-type attributes (in XML DTD syntax) or xs:ID/xs:IDREF/
xs:IDREFS and xs:key/xs:keyref (in XSD syntax), respectively, which are
supported by document grammar formalisms—can be used to represent graph
structures in XML. An example for such an XML serialization of a graph can be
observed in the way in which an edge in GrAF is constructed by referring to the IDs of
already established nodes via the @from and @to attributes. Similar examples can be
found in the XStandoff format (Stührenberg and Jettka 2009; Witt et al. 2011; Jettka and
Stührenberg 2011).
40 Apart from a representation format for graphs, networks, and trees found in TEI since
P3, the refined and enhanced feature structure representation format of TEI P5 has
been a great step in establishing a more expressive formal model. In addition, other
specifications developed for various projects, such as XStandoff, NITE (Carletta et al.
2005), or the Potsdamer Austauschformat für linguistische Annotation12 (PAULA, Dipper
et al. 2007), propagate graph-based formal models.
41 Therefore, the TEI cannot be seen as the direct or single ancestor of the current
standards in development. However, it seems that this newer graph-based formal
model (that is dependent on the existence of a document grammar using the
aforementioned integrity constraints) may play a greater part in future XML formats
(especially those for structuring multiply annotated data), and one may argue that the
TEI has accompanied this change from a strictly hierarchical to a graph-based formal
model.
3.2. Influence on Notation Format
42 The notation format that is used by all standards discussed here is stand-off
annotation. Although stand-off annotation is not a generic TEI concept, the TEI
Guidelines have long included mechanisms to deal with overlapping markup, namely
milestone elements, fragmentation and reconstruction, and multiple encodings of the
same information.13 Moreover, it was the previously mentioned Corpus Encoding
Standard (CES), a modification of TEI P3 that made stand-off annotation the default
model for linguistic corpora. In the current version of the TEI (P5) the term “stand-off
markup” is discussed in Chapters 16.9 and 20.4, firmly establishing the concept of
separating primary data and markup in the wider text encoding community. This
support for stand-off annotation is rated as a crucial point by Bański and
Przepiórkowski: “Any standards adopted for these levels should allow for stand-off
Journal of the Text Encoding Initiative, Issue 3 | November 2012
15

annotation, as is now common practice and as is virtually indispensable in the case of
many levels of annotation, possibly involving conflicting hierarchies” (2010a, 98).
43 Although stand-off annotation can still be cumbersome to manage (especially when
positions in the primary data are used to establish anchors and regions), some software
products have been developed during the past years to support this notation—for
example, the web-based annotation platform “Serengeti” (which uses XStandoff—see
Stührenberg et al. 2007; Poesio et al. 2011) or the “Glozz Annotation Platform”
(Widlöecher and Mathet 2009). Among the various candidates for dealing with multiple
(and possibly overlapping) annotations, stand-off markup seems to be the most
promising. (See Bański 2010 for a discussion of advantages and disadvantages of using
TEI stand-off annotation.)
3.3. Influence on the Annotation Model
44 One of the building blocks of the TEI’s success among various scholars is the fact that it
does not define a normative standard but rather guidelines. These recommendations
try to not constrain the user to a single way of encoding but leave a large amount of
personal freedom (and responsibility) to the user, while other annotation formats try
to be as strict as possible to reflect a certain annotation model and theory.
45 The generic markup that is manifested in the TEI’s feature structure representation is
informed by this permissive attitude. As a consequence, all current International
Standards for linguistic data use generic elements and attributes (and especially
feature structures) to store annotation information. The use of such generic markup
has both advantages and disadvantages. On the one hand it helps to separate the
meaning (the concept) of an annotation from its serialization (a separation introduced
by Bayerl et al. 2003 and Witt 2004), establishing a basis for multiply annotated corpora.
But on the other hand, a generic annotation format is generally more verbose and
makes only little use of the hierarchical relations between elements inherent in XML.
In addition, it relies heavily on a given set of standardized data categories to assure the
comparability of annotation.
4. Conclusion
46 A comparison of the TEI Guidelines with the International Standards discussed in the
previous sections leaves us with mixed results. On the one hand, the ISO specifications
have the advantage of being de jure standards (at least if the standardization process
will be finished for MAF). On the other hand, this status is a mixed blessing. Since
International Standards are the outcome of a procedure relying on consensus, the
results are often compromise-ridden. Moreover, specifications can get mired in long
approval processes: LAF is a case in point, since it took so many years to reach the
status of an International Standard. This long gestation raised problems for other
standards, such as MAF, that refer to LAF’s components even before the standard was
finalized. In addition, users not familiar with the relationships between the different
standards may find it difficult to keep track of specification status and dependencies.
To help such users, we have developed a web-based information system presenting an
overview of these relations (Stührenberg et al. 2012).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
16

47 In contrast, the TEI Guidelines represent a stable and mature representation format for
annotation. Although it is also based on consensus, by maintaining a greater variety of
possible annotation solutions it is less prone to compromise.14 Another advantage over
the standards discussed in this article is that the TEI can be used as is without the need
to add further specifications, such as an external metadata format. In addition, the TEI
tag set is highly modular and can be modified easily by using the web-based “Roma”
tool, resulting in a strict or rich feature set depending on one’s own needs. The
comprehensive Guidelines themselves and a large helpful community complement
these benefits. Therefore, it should not be surprising that the TEI remains a
recommended annotation format for encoding linguistic corpora, following
Przepiórkowski and Bański: “We conjecture that—given the stability, specificity and
extensibility of TEI P5 and the relative instability and generality of some of the other
proposed standards—this approach is currently the optimal way of following corpus
encoding standards.” (2009, 250).
48 However, with International Standards such as the Linguistic Annotation Framework,
the Morpho-Syntactic Annotation Framework, and the Syntactic Annotation
Framework, normative efforts to ease the exchange of linguistically annotated data are
finally emerging. It will be interesting to observe the final version of MAF and
especially the application of LAF and MAF in the wild.
49 Regarding the relationship between the TEI Guidelines and the discussed de jure
standards, one can observe that the former may have influenced current specifications
in many ways. However, especially for the data model and notation format, other
projects and specifications played important roles as well.
5. Recommendations
50 Current linguistic researchers are spoiled for choice: in addition to well-established de
facto standards such as the TEI, international de jure standards are on the rise. Projects
such as CLARIN or FLARENET promise to help users choose among them by providing
recommendations and guidelines as the aforementioned web-based information
system. Apart from that, it seems that the combination of generic annotation formats
such as the feature structure representation format present in the TEI P5, ISO
24610-1:2006, and ISO 24610-2:2011 and respective data category sets will be a valid
candidate for a sustainable annotation format. Data categories should be registered via
the official implementation of ISO 12620:2009, ISOcat, available at http://
www.isocat.org.
51 A practical additional interim solution could be the setup of an ISOcat TEI data category
set providing all of the elements and attributes in P5. In conjunction with a stylesheet
transforming inline TEI to a stand-off TEI feature structure representation (with the
respective ISOcat references), the resulting output format should be compatible with
ISO 24610-1:2006 and could be used as a starting point for LAF-based annotations.
52 As a side-effect, users familiar with the TEI could use their existing annotation tool
chain. Future versions of the TEI Guidelines should further embrace the noticeable
trend of using stand-off notation, possibly introducing it to a broader range of
linguistic researchers and even for other non-linguistic uses of the TEI.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
17

BIBLIOGRAPHY
Abiteboul, Serge, Peter Buneman, and Dan Suciu. 2000. Data on the Web: From Relations to
Semistructured Data and XML. San Francisco: Morgan Kaufman.
Piotr Bański. 2010. “Why TEI standoff annotation doesn’t quite work: and why you might want to
use it nevertheless.” In Proceedings of Balisage: The Markup Conference, 2010. Vol. 5 of Balisage
Series on Markup Technologies. doi:10.4242/BalisageVol5.Banski01.
Bański, Piotr, and Adam Przepiórkowski. 2010a. “TEI P5 as a Text Encoding Standard for
Multilevel Corpus Annotation.” In Digital Humanities 2010 Conference Abstracts, 98–100. http://
dh2010.cch.kcl.ac.uk/academic-programme/abstracts/papers/pdf/ab-616.pdf.
———. 2010b. “The TEI and the NCP: the Model and its Application.” In Proceedings of LREC 2010
Workshop on Language Resources: From Storyboard to Sustainability and LR Lifecycle Management, 34–
38. http://www.lrec-conf.org/proceedings/lrec2010/workshops/W20.pdf.
Bayerl, Petra Saskia, Harald Lüngen, Daniela Goecke, Andreas Witt, and Daniel Naber. 2003.
“Methods for the Semantic Analysis of Document Markup.” In Proceedings of the 2003 ACM
Symposium on Document Engineering, 161–170. New York: ACM.
Broeder, Daan, Oliver Schonefeld, Thorsten Trippel, Dieter van Uytvanck, and Andreas Witt. 2011.
“A Pragmatic Approach to XML Interoperability – the Component Metadata Infrastructure
(CMDI).” In Proceedings of Balisage: The Markup Conference 2011. Vol. 7 of Balisage Series on Markup
Technologies. doi:10.4242/BalisageVol7.Broeder01.
Carletta, Jean, Stefan Evert, Ulrich Heid, and Jonathan Kilgour. 2005. “The NITE XML toolkit: data
model and query language.” Language Resources and Evaluation 39 (4): 313–334.
Clément, Lionel, and Èric Villemonte de la Clergerie. 2005. “MAF: A Morphosyntactic Annotation
Framework.” In Proceedings of the 2nd Language & Technology Conference: Human Language
Technologies as a Challenge for Computer Science and Linguistics, 90–94. Poznań, Poland:
Wydawnictwo Poznańskie.
Coombs, James H. Allen H. Renear, and Steven J. DeRose. 1987. “Markup Systems and the Future
of Scholarly Text Processing.” Communications of the ACM 30 (11): 933–947.
Dalby, David, Lee Gillam, Christopher Cox, and Debbie Garside. 2004. “Standards for Language
Codes: Developing ISO 639.” In LREC 2004: Fourth International Conference on Language Resources and
Evaluation, 127–130. Paris: ELRA.
Declerck, Thierry. 2006. “SynAF: Towards a Standard for Syntactic Annotation.” In Book of
Abstracts [conference abstracts from LREC 2006], 229–232. Paris: ELRA.
Declerck, Thierry, Nancy Ide, and Thorsten Trippel. 2007. “Interoperable Language Resources.”
SDV – Sprache und Datenverarbeitung 31 (01/02): 101–113.
DeRose, Steven J., David G. Durand, Elli Mylonas, and Allen H. Renear. 1990. “What is text,
really?” Journal of Computing in Higher Education 1 (2): 3–26.
Dipper, Stefanie, Michael Götze, Uwe Küssner, and Manfred Stede. 2007. “Representing and
Querying Standoff XML.” In Datenstrukturen für linguistische Ressourcen und ihre Anwendungen. Data
Structures for Linguistic Resources and Applications, edited by Georg Rehm, Andreas Witt, and Lothar
Lemnitzer, 337–346. Tübingen: Gunter Narr.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
18

Gou, Gang, and Rada Chirkova. 2007. “Efficiently Querying Large XML Data Repositories: A
Survey.” IEEE Transactions on Knowledge and Data Engineering 19 (10): 1381–1403.
Ide, Nancy, Patrice Bonhomme, and Laurent Romary. 2000. “XCES: An XML-based Encoding
Standard for Linguistic Corpora.” In Second International Conference on Language Resources and
Evaluation, 825–830. Paris: European Language Resources Association.
Ide, Nancy. 1998. “Corpus Encoding Standard: SGML Guidelines for Encoding Linguistic Corpora”.
In First International Conference on Language Resource and Evaluation, 463–470. Paris: ELRA.
Ide, Nancy, and Laurent Romary. 2007. “Towards International Standards for Language
Resources.” In Evaluation of Text and Speech Systems, edited by Laila Dybkjaer, Holmer Hemsen, and
Wolfgang Minker, 263–284. Dordrecht: Springer.
International Organization for Standardization/International Electrotechnical Commission. 2012.
“ISO/IEC Directives, Part 1: Procedures for the technical work.” 9th Edition, March 8, 2012.
http://isotc.iso.org/livelink/livelink?
func=ll&objId=10563026&objAction=Open&nexturl=%2Flivelink%2Flivelink%3Ffunc%3Dll%26objId%3D4230455%26objAction%3Dbrowse%26sort%3Dsubtype
Jettka, Daniel, and Maik Stührenberg. 2011. “Visualization of concurrent markup: From trees to
graphs, from 2D to 3D.” In Proceedings of Balisage: The Markup Conference 2011. Vol. 7 of Balisage
Series on Markup Technologies. doi:10.4242/BalisageVol7.Jettka01.
Langendoen, D. Terence, and Gary F. Simons. 1995. “A Rationale for the TEI Recommendations for
Feature-Structure Markup.” Computers and the Humanities 29 (3): 191–209.
Monachini, Monica, Valeria Quochi, Nicoletta Calzolari, Núria Bel, Gerhard Budin, Tommaso
Caselli, Khalid Choukri, Gil Francopoulo, Erhard Hinrichs, Steven Krauwer, Lothar Lemnitzer,
Joseph Mariani, Jan Odijk, Stelios Piperidis, Adam Przepiorkowski, Laurent Romary, Helmut
Schmidt, Hans Uszkoreit, and Peter Wittenburg. 2011. “The Standards’ Landscape Towards an
Interoperability Framework: The FLaReNet proposal Building on the CLARIN Standardisation
Action Plan.” http://www.flarenet.eu/sites/default/files/FLaReNet_Standards_Landscape.pdf.
Møller, Anders, and Michel I. Schwartzbach. 2011. “XML Graphs in Program Analysis.” Science of
Computer Programming 76 (6): 492–515.
Poesio, Massimo, Nils Diewald, Maik Stührenberg, Jon Chamberlain, Daniel Jettka, Daniela
Goecke, and Udo Kruschwitz. 2011. “Markup Infrastructure for the Anaphoric Bank: Supporting
Web Collaboration.” In Modeling, Learning and Processing of Text Technological Data Structures, edited
by Alexander Mehler, Kai-Uwe Kühnberger, Henning Lobin, Harald Lüngen, Angelika Storrer, and
Andreas Witt, 197–218. Berlin: Springer.
Pollard, Carl, and Ivan A. Sag. 1987. Information-based Syntax and Semantics. Menlo Park: CSLI.
Pollard, Carl, and Ivan A. Sag. 1994. Head-Driven Phrase Structure Grammar. Chicago: The University
of Chicago Press.
Polyzotis, Neoklis, and Minos Garofalakis. 2002. “Statistical Synopses for Graph-Structured XML
Databases.” In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data,
358–369. New York: ACM.
Przepiórkowski, Adam, and Piotr Bański. 2009. “Which XML Standards for Multilevel Corpus
Annotation?“ http://bach.ipipan.waw.pl/~adamp/Papers/2009-ltc-tei/ltc-030-
przepiorkowski.pdf.
Renear, Allen H., Mylonas, Elli, and David D. Durand. 1996. “Refining Our Notion of What Text
Really Is: The Problem of Overlapping Hierarchies.” Selected Papers from the ALLC/ACH Conference,
Christ Church, Oxford, April 1992. Vol. 4 of Research in Humanities Computing. 263–280.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
19

Romary, Laurent, Amir Zeldes, and Florian Zipser. 2011. “<tiger2/> – Serialising the ISO SynAF
Syntactic Object Model.” Computing Research Repository (CoRR). http://arxiv.org/pdf/1108.0631v1.
Simons, Gary F. 2007. “Linguistics as a community activity: The paradox of freedom through
standards.” In Time and Again: Theoretical and Experimental Perspectives on Formal Linguistics: Papers
in Honor of D. Terence Langendoen, edited by William D. Lewis, Simin Karimi, Heidi Harley, and Scott
Farrar, 235–250. Amsterdam: John Benjamins.
Simons, Gary F., and Steven Bird. 2008. “OLAC Metadata.” Open Language Archives Community
Standard. http://www.language-archives.org/OLAC/metadata-20080531.html.
Stegmann, Jens, and Andreas Witt. 2009. “TEI Feature Structures as a Representation Format for
Multiple Annotation and Generic XML Documents.” Proceedings of Balisage: The Markup Conference.
Balisage Vol. 3 of Series on Markup Technologies. doi:10.4242/BalisageVol3.Stegmann01.
Stührenberg, Maik, Daniela Goecke, Nils Diewald, Irene Cramer, and Alexander Mehler. 2007.
“Web-based Annotation of Anaphoric Relations and Lexical Chains.” In Proceedings of the Linguistic
Annotation Workshop, 140–147. http://www.aclweb.org/anthology/W/W07/W07-1523.pdf.
Stührenberg, Maik, and Daniel Jettka. 2009. “A Toolkit for Multi-dimensional Markup: The
Development of SGF to XStandoff.” Proceedings of Balisage: The Markup Conference 2009. Vol. 3 of
Balisage Series on Markup Technologies. doi:10.4242/BalisageVol3.Stuhrenberg01.
Stührenberg, Maik, Antonina Werthmann, and Andreas Witt. 2012. “Guidance through the
Standards Jungle for Linguistic Resources.” In Proceedings of the LREC 2012 Workshop on Collaborative
Resource Development and Delivery, 9–13.
Thompson, Henry S., and David McKelvie. 1997. “Hyperlink Semantics for Standoff Markup of
Read-only Documents.” In Proceedings of SGML Europe ’97: The next decade – Pushing the Envelope,
227–229.
Widlöcher, Antoine, and Yann Mathet. 2009. “La plate-forme Glozz : environnement d’annotation
et d’exploration de corpus”. In Actes de la 16e conférence sur le Traitement Automatique des Langues
Naturelles (TALN 2009) – Session posters. http://www-lipn.univ-paris13.fr/taln09/pdf/
TALN_120.pdf.
Witt, Andreas. 2004. “Multiple Hierarchies: New Aspects of an Old Solution.” Proceedings of
Extreme Markup Languages, Montréal.http://conferences.idealliance.org/extreme/html/2004/Witt01/EML2004Witt01.html.
Witt, Andreas, Daniela Goecke, Maik Stührenberg, and Dieter Metzing, 2011. “Integrated
Linguistic Annotation Models and Their Application in the Domain of Antecedent Detection”. In
Modeling, Learning and Processing of Text Technological Data Structures, edited by Alexander Mehler,
Kai-Uwe Kühnberger, Henning Lobin, Harald Lüngen, Angelika Storrer, and Andreas Witt, 197–
218. Berlin: Springer.
NOTES
1. See the projects’ websites at http://www.clarin.eu/ and http://www.flarenet.eu/,
respectively, for further information.
2. The website located at http://www.tc37sc4.org/ provides some further information.
3. P-members are contrasted with O-members, who only observe but still have the right
to comment on the process.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
20

4. If no negative votes are cast the DIS proceeds to the publication stage immediately.
5. See Dalby et al. (2004) for further details about the design philosophy of this special
standard.
6. Apart from the specifications discussed in this section there are of course other
standards that may be of interest, such as the Lexical Markup Framework (LMF, ISO
24613:2008). However, due to space restrictions we limit the discussion to the
annotation formats described in this article. We will not discuss in detail any metadata
standards, such as ISO 12620:2009 (Data Category Registry, DCR), which can be used
together with generic annotation formats to provide further semantics for a
linguistically encoded text.
7. For an overview of HPSG, see Pollard and Sag (1987, 1994).
8. See Langendoen et. al (1995) for a discussion of the TEI recommendations for feature
structure markup.
9. See http://www.isocat.org for more information about both ISO 12620:2009 and
about the ISOcat registry.
10. The current version of MAF includes the notion, that “character offsets may be
sufficient” in the simplest case.
11. The original example was taken from http://korpling.german.hu-berlin.de/tiger2/
homepage/tiger1.html and was adapted to meet further MAF requirements.
12. Potsdam Interchange Format for Linguistic Annotation.
13. Early usage of stand-off annotation can be found in the second phase of the TIPSTER
project in 1996. A discussion of the concept can be found in Thompson and McKelvie
(1997). The P3 version of the TEI did not include the term stand-off as such but
supported the connection of analytic and interpretive markup outside of textual
markup and embedded markup (Chapter 14.9). The current P5 includes a whole chapter
dealing with stand-off markup (Chapter 16.9).
14. One has to admit that one of the disadvantages of the TEI is the fact that it
frequently allows too many ways of annotating a certain text feature. This can also be
seen as a limiting compromise.
ABSTRACTS
The TEI has served for many years as a mature annotation format for corpora of different types,
including linguistically annotated data. Although it is based on the consensus of a large
community, it does not have the legal status of a standard. During the last decade, efforts have
been undertaken to develop definitive de jure standards for linguistic data that not only act as a
normative basis for the exchange of language corpora but also address recent advancements in
technology, such as web-based standards, and the use of large and multiply annotated corpora.
In this article we will provide an overview of the process of international standardization and
discuss some of the international standards currently being developed under the auspices of ISO/
TC 37, a technical committee called “Terminology and other Language and Content Resources”.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
21

After that the relationship between the TEI Guidelines and these specifications, according to
their formal model, notation format, and annotation model, will be discussed. The conclusion of
the paper provides recommendations for dealing with language corpora.
INDEX
Keywords: feature structures, ISO/TC 37/SC 4, Linguistic Annotation Framework (LAF), Morpho-
Syntactic Annotation Framework (MAF), standards, Syntactic Annotation Framework (SynAF)
AUTHOR
MAIK STÜHRENBERG
Maik Stührenberg received his Ph. D. in Computational Linguistics and Text Technology from
Bielefeld University in 2012. After graduating in 2001, he worked on various projects at Justus-
Liebig-Universität Gießen, Bielefeld, and at the Institut für Deutsche Sprache (IDS, Institute for
the German Language) in Mannheim. He is currently employed as a research assistant at Bielefeld
University and is involved in NA 105-00-06 AA, the German mirror committee of ISO TC37 SC4.
His main research interests include specifications for structuring multiply annotated data
(especially linguistic corpora), query languages, and query processing.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
22

A TEI P5 Document Grammar for theIDS Text ModelHarald Lüngen and C. M. Sperberg-McQueen
1. Introduction
1 The Institut für Deutsche Sprache (IDS) in Mannheim, Germany, hosts the German
Reference Corpus (DEREKO), the largest archive in the world of corpora of contemporary
written German. With over 5 billion word tokens,1 DEREKO contains fiction, scientific
texts, newspaper articles, and a wide variety of other text types. The corpora in DEREKO
have been collected since 1964 and are licensed for academic use via the IDS corpus
access platform COSMAS II.2 They are used by linguistics researchers at the IDS and at
other institutions around the world.
2 All corpora within DEREKO are marked up with metadata and annotations according to
the IDS text model, which is currently realized in IDS-XCES, an IDS-specific adaptation
of the XCES corpus encoding standard (Ide et al. 2000). This paper describes the
features of the IDS text model and our ongoing project, named I5 (short for “IDS-TEI P5
”), in which we are preparing a TEI P5 ODD document for this text model. Since DEREKO
is not available for direct download, a migration to TEI P5 had not been highly
prioritized (since no one outside the IDS would directly benefit from such a
conversion). However, it is hoped that a TEI P5 document grammar for the IDS text
model will facilitate the building and maintenance of quality assurance tools, will
enable the IDS to abandon the older in-house annotation format and therefore enable
new project members to familiarize themselves more quickly and easily with the
model. In the long run, we hope that the migration to TEI P5 will contribute to a
harmonization and standardization process in which tools will be produced that are
able to deal with large-scale TEI data (cf. Kupietz et al. 2010).
3 This paper begins with background on the nature and purposes of the corpora collected
at IDS and the motivation for the I5 project (section 1). It continues with a description
of the origin and history of the IDS text model (section 2), and a description (section 3)
Journal of the Text Encoding Initiative, Issue 3 | November 2012
23

of the techniques used to automate, as far as possible, the preparation of the ODD file
documenting the IDS text model. It ends with some concluding remarks (section 4). A
survey of the additional features of the IDS-XCES realization of the IDS text model is
given in an appendix.3
2. Origin and History of the IDS Text Model
4 IDS researchers at different locations in Germany initially created corpora for specific
research purposes, each encoded using a home-grown encoding scheme. Examples of
these early corpora are the Wendekorpus,4 the Bonner Zeitungskorpus,5 and the
Mannheimer Korpora 1 and 2,6 all of which are available to this day as part of the German
Reference Corpus, DEREKO. A unified text and annotation format for all IDS corpus texts
was first introduced in 1991.
2.1. BOT
5 The first attempt at a unified pivot format for IDS corpora was called BOT (an acronym
formed out of the initials of “Beginning of text”). It grew out of the COSMAS (Corpus
Search, Management and Analysis System, later known as COSMAS I) project, which lasted
from 1991 to 2003. Among its goals were the integration of the various existing single
corpora into a common representation format, the centralization of corpus acquisition
and encoding activities at the IDS, and the development of corpus access software for
linguistic research. The first version of BOT was defined by Cyril Belica of IDS in 1992
and remains the basis of the IDS text model. It is a character-based format, of which the
header part contains bibliographic metadata expressed in seven data fields (see table 1
and the example below it), which form the minimum of bibliographic data. Each field is
represented in a single line in the file and exhibits a binary structure (field_name:
value_string).
Field name Semantics
BOTC corpus identifier
BOTD document identifier
BOTT text identifier
BOTd resolved document identifier
BOTt elaborated bibliographic reference
BOTi reduced bibliographic reference
BOTP processing information: is page numbering encoded in the corpus text as in the source or not?
Journal of the Text Encoding Initiative, Issue 3 | November 2012
24

Table 1: The seven fields of the BOT minimum
BOTC:DIV
BOTD:WC4
BOTT:WC4.04004
BOTd:Christa Wolf: Essays/Gespräche/Reden/Briefe
1959-1974
BOTt:DIV/WC4.04004 Wolf, Christa: Das siebte Kreuz,
[Nachwort], (Entstehung: 1963), In: Wolf, Christa:
Werke, Bd. 4, Essays/Gespräche/Reden/Briefe 1959-
1974, Hrsg.: Hilzinger, Sonja. - München:
Luchterhand Literaturverlag, 1999, S. 24-41
BOTi:DIV/WC4.04004 Wolf, Christa: Das siebte Kreuz,
[Nachwort], (Entstehung: 1963), In: Wolf, Christa:
Werke, Bd. 4, Essays/Gespräche/Reden/Briefe 1959-
1974, Hrsg.: Hilzinger, Sonja. - München:
Luchterhand Literaturverlag, 1999, S. 24-41
BOTP:1
Example of corpus text header as BOT minimum. The line breaks within the fields are not present inthe original.
6 The fields BOTC, BOTD, and BOTT reflect a three-level hierarchical structure in this
model: corpus, document, and text. A corpus contains one or more documents, and a
document contains one or more texts, and each corpus, document, or text would have
such a header. In the model, a text is defined as a relatively independent, coherent sequence
of natural language utterances that has emerged from natural communicative situations.7 A
text may comprise, for example, one or sometimes several newspaper articles, a journal
article, a short story, or an extract of a literary work. Texts are combined to form a
document according to certain aspects such as source, chronological sequence, topic, or
text type—for example, texts from one edition of a particular day’s newspaper would
form one document. However, not every document contains more than one text: a
corpus of the collected works of one author would contain one document per novel,
each of which would include a single text.
7 The fields BOTd, BOTt, and BOTi contain the bibliographic reference in different
degrees of detail,8 each of which was needed for different presentation modes (for
example, as part of a corpus overview or of a KWIC view of query results).
8 Later, the field BOT+ent (for “Entstehungszeit”, the time of creation, if known, or
otherwise of the first edition) was also included in the BOT minimum because the
(approximate) year when a literary work was actually written can differ considerably
from the year of publication of the source used in the composition of the corpus. The
collected works of Thomas Mann, for instance, all have 1960 as their year of
publication, while his first novel, Buddenbrooks, first appeared in 1901. If only the date
of publication were recorded, discrepancies between the date of composition and the
date of publication would distort linguistic analyses of language variation over time.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
25

9 BOT also included a number of “surrounding tags” for inline annotations such as b+…
+b for a caption or u+…+u for a heading, using what is sometimes known as the
“Mannheim Conventions” (“Mannheimer Konvention”, MK). This convention was based
on markup as used in several of the earlier corpora (see, for example, Kolvenbach
1989).
10 Within the COSMAS project, all existing IDS corpora (about 28 million tokens) were
converted into the BOT/MK format using a set of conversion scripts,9 by 1993 they were
accessible via the new corpus research system, also named COSMAS, to researchers at
the IDS, and by 1996 to researchers all over the world via a web interface.
11 While the P2 version of the TEI Guidelines had been published in 1992, IDS staff chose
not to adopt the TEI at that time, both because the IDS was not yet receiving any text
data in SGML and because COSMAS had already been designed to use BOT/MK syntax.
12 Many useful types of information were only implicit in BOT/MK or were missing
entirely and therefore unavailable for researchers to use in queries. Moreover, the
follow-up project COSMAS II had started in 1995, and one of its goals was to allow the
creation of virtual corpora (cf. Kupietz and Keibel 2009), but the original BOT/MK
format did not contain all the fields necessary to do this. Consequently, in the years
1993–1998 many more fields were added to the BOT header, in particular new fields for
the components of bibliographic information (this information had been included as an
unparsed string in the first version of BOT). The more recent field names all start with
‘BOT+’, e.g. BOT+a (author), BOT+ti (title), BOT+u (subtitle), BOT+X (text type), BOT+b
(volume), BOT+in (title of a collection in which the document or text was contained),
and the above-mentioned BOT+ent. Altogether the revised BOT header has 38 fields
available. Moreover, two basic templates of a BOT header were defined, each specifying
a subset of the full set of BOT fields: Template 1 was used for independent works and
dependent works contained in collections, and Template 2 was used for newspaper and
journal articles.10
13 New texts to be added to the corpora were encoded according to the new version of
BOT/MK. The values of the fields BOTd, BOTt, and BOTi, which contained the various
versions of a bibliographic text string, were now automatically assembled at a later
stage of the conversion from the fields that contained the components. By 1998, the IDS
corpora comprised approximately 260 million tokens.
2.2. Conversion to IDS-CES
14 The year 1999 saw the start of DEREKO, a project for the acquisition and annotation of a
German Reference Corpus (Deutsches Referenzkorpus),11 conducted in cooperation with
the universities of Stuttgart and Tübingen and lasting until 2002, when it reached 1.8
billion tokens.12 Two important goals of DEREKO were, first, mass acquisition of texts by
obtaining licenses from publishing houses and individuals, and, second, the use of CES,
a new corpus encoding standard (Ide 1998) based on TEI. Between 1998 and 2003, a
mapping of all BOT/MK fields and inline markup into the CES structure of elements and
attributes was specified. Certain features of the BOT/MK markup, however, could not
be rendered within the CES markup; therefore, additional elements and attributes were
defined on top of CES, yielding IDS-CES, the IDS-specific adaptation of CES. As far as
possible, the additional elements and attributes were taken from the TEI P3 Guidelines
(ACH/ACL/ALLC 1994), but several had to be defined totally outside CES and TEI, with
Journal of the Text Encoding Initiative, Issue 3 | November 2012
26

care taken to name and define them in the style of CES. In particular, it was decided
that the three-way hierarchical structure with the units corpus, document, and text
should be retained, although CES/TEI provided only <cesCorpus> and <cesDoc>.
Hence, <idsCorpus>, <idsDoc>, and <idsText> were defined to replace these.
Another element that was newly introduced in IDS-CES is <creatDate> for the time
of creation, i.e. for the value of the field BOT+ent.13 Initially, IDS-CES was used as an
exchange format only, as COSMAS still employed BOT/MK internally. Newly acquired
texts (some of which arrived in SGML) were first encoded in BOT/MK, and a converter
(TRADUCES14) was developed to transform the new and old BOT texts into IDS-CES.
15 Starting in 2001, the BOT/MK format was extended again, this time under the name
“BOTX”. For BOTX, new markup was defined: u+zz+, u+zzz+, etc. for sub-headings at
different levels, li+ for list items, and other tags for tables, preface, table of contents,
footnotes (which had previously not been marked up or had even been removed), and
more textual features. The idea behind this extension was that all the features of a
document—including not only previously unrepresented layout features but also tables
of contents and imprint information—should be representable within the IDS text
model so that the source document’s layout would be reconstructible. The endeavor
was also inspired by the many elements and attributes offered by CES for document
features that were not captured by BOT/MK. Many of these features were in fact
already marked up in the SGML source documents that the IDS received but then
dropped in the BOT/MK representation, so it seemed worthwhile to make an effort to
retain them. For some time, all incoming texts were converted to BOTX using small
specialized programming routines that a programmer designed by checking the
original layout in the corresponding hardcopy edition of the text. Since all the older
corpus texts remained in plain BOT/MK, all BOTX texts first had to be converted to
BOT/MK (that is, some markup had to be removed automatically) for their integration
in COSMAS I.
16 BOTX and BOT/MK still had some flaws. For instance, the order of MK annotations (the
inline annotations) is not fixed and was sometimes unclear—for example, when a
passage is in a foreign language, is a quotation, and is printed in italics. Moreover, some
tags are ambiguous character sequences that happen to appear in the source text, so
since around 2004 several alternative tags taken from the TEI have been introduced in
BOT/MK, such as <line>...</line> instead of ‘…/’. Incoming texts were marked
up with the new tags and then converted to IDS-CES, but the existing corpora were not
retroactively changed.
17 For completeness, we would like to mention that around 2007, some more new markup
was added to BOT/MK only, namely the three fields BOT+D, BOT+V, and BOT+R for
specifying the results of the IDS duplicate detection module, and the field BOT+th for
results from the IDS thematic classification module.15 These fields are mapped to
<classDecl> and sub-elements in IDS-CES.
18 IDS-CES was introduced as the internal corpus representation format in COSMAS II, the
successor of the research software COSMAS I, which was finally taken out of service in
2003. Under COSMAS II, the BOTX texts were directly converted to IDS-CES without loss
of information.16
Journal of the Text Encoding Initiative, Issue 3 | November 2012
27

2.3. Conversion to IDS-XCES
19 In 2000, the first XCES specification was released (Ide, Bonhomme, and Romary 2000),
in which the SGML-based Corpus Encoding Standard was redefined on an XML basis. In
2006, an IDS-XCES DTD was developed, consisting of the XCES DTD with the addition of
those elements and attributes that had already been added to CES to form IDS-CES.
20 The corpus archive (containing around 2.4 billion tokens at that time) was converted in
2006. The mapping from IDS-CES to IDS-XCES was entirely automated using XSLT.17
(The differences between XCES and IDS-XCES are described in the appendix.) In 2008,
IDS-XCES was introduced as the internal corpus data format in COSMAS.
21 All incoming texts are still initially encoded in the IDS pivot format BOT/MK or its
extension BOTX. So the chain of conversions for new text data to be integrated in
COSMAS II is currently original format → BOT(X) → IDS-CES → IDS-XCES.
22 The following diagram illustrates the long and complex development of IDS-XCES
described above, by which this format was derived from TEI P3 and TEI P4 (TEI
Consortium 2001), through CES and XCES and the local changes at IDS. As a result of the
long chain of derivation, the relationship between the text model of the TEI Guidelines
and the IDS text model (and the corresponding differences between the two markup
systems) are hard to take in at a glance.
Figure 1: Development of the IDS-XCES DTD
23 In fact, one motivation for preparing a TEI P5-based ODD file for the IDS text model is to
make the relation between the two text models simpler and clearer.
24 The Appendix gives a brief account of IDS-XCES, mainly by specifying its differences to
the original XCES.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
28

3. Preparation of an ODD File
25 As the summary above has made clear, elements and attributes from TEI P3 and TEI P4
come into IDS-XCES through two channels: some are inherited through XCES, while
others are retroactively added in IDS-XCES.
26 The goal of the I5 project is to reorganize the definition of the IDS vocabulary as a
single set of modifications taking TEI P5 as its base and using the new customization
mechanism specified in TEI P5, which uses an ODD (“one document does it all”) file to
specify a particular customization instead of relying on the customization mechanisms
built into a particular schema language. TEI P5 defines a specific XML tag set for use in
ODD files and prescribes an algorithm for processing ODD files to generate customized
versions of the TEI encoding scheme. This prescribed algorithm is implemented by
software available from the TEI Consortium under the name Roma. As indicated in the
diagram below, Roma reads the TEI P5 specification of the vocabulary and the ODD file
provided by the user and generates on demand from them a DTD, a schema document
in Relax NG or XSD notation, or reference documentation for the elements and
attributes included in the specified customization.
Figure 2: Generating document grammars and documentation using Roma
27 The immediate concrete goal of the I5 project, therefore, is to prepare an ODD file
which will, when processed by Roma, produce document grammars suitable for use by
IDS in processing the DEREKO archive.
3.1. Conditions for the Language as a Set of Documents
28 What language should those document grammars describe? The core requirements for
the language to be defined can be summarized schematically in this way:
I5 : P5 ≃ IX : P3
L(I5) ±⊆ L(P5)
L(I5) ≡ L(IX)
29 In these and subsequent formulae, the following abbreviations are used for brevity:
P3, P4, and P5 denote the document grammars (or in some cases the languages defined by
those grammars) of TEI P3, TEI P4, and TEI P5 respectively.
CES and XCES denote the document grammars of the original Corpus Encoding Standard and
its XML revision.
•
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
29

IX denotes the document grammar of the current IDS-XCES DTD (as realized in file ids-
xces.dtd).
I5 denotes the grammar developed by this project.
For any document grammar x, L(x) denotes the language recognized (or defined) by x.
E(x) denotes the set of elements defined in an XML vocabulary or document grammar x.
DRK denotes the German Reference Corpus (Deutsches Referenzkorpus) DEREKO, viewed as a
set of documents (and thus as a language defined by enumeration of its sentences).
30 With these notational conventions in place, we can reformulate the core requirements
for the I5 project.
31 First, the I5 vocabulary should stand in roughly the same relation to TEI P5 as the
current IDS-XCES vocabulary stands to TEI P3 (or TEI P4):
I5 : P5 ≃ IX : P3
32 Second, the language should be (more or less) a subset of the language defined by TEI
P5:
L(I5) ±⊆ L(P5)
33 Third, the language defined by the I5 document grammar should at least in principle be
equivalent, or nearly equivalent, to that defined by IDS-XCES:
L(I5) ≡ L(IX) (?)
34 Since one goal of the project is to incorporate in I5 the improvements on TEI P3
incorporated in TEI P5, absolute equivalence in all details is probably not in fact
desirable (hence the addition of the question mark vis-à-vis the initial formulation).
35 Some further requirements or desiderata can also be identified and expressed
formulaically. If absolute equivalence is not the goal, then the language of I5 needs to
be constrained in other ways. The language of I5 should be similar to that of IDS-XCES,
even if not absolutely equivalent. That is, perhaps strict equivalence (≡) should be
replaced by similarity (≃):
L(I5) ≃ L(IX)
36 Every document in DEREKO should be legal against the new document grammar:
DRK ⊆ L(I5)
37 Empirically, it can be observed that DEREKO exercises only a proper subset of the current
document grammar IDS-XCES: for example, there are a number of attributes defined in
the grammar which do not in fact occur in the corpus. It is a design decision (still being
considered) whether to retain such currently unused constructs, in the expectation
that they may be used later, or to eliminate them so as to make the language of I5 be
more nearly equivalent to that of DEREKO:
DRK ⊊ L(I5) ?
DRK = L(I5) ?
3.2. Realization of a Grammar in ODD
38 To specify a particular customization of the TEI vocabulary, an ODD file must specify
the inclusion or exclusion of individual:
TEI modules
elements within a module
attributes within a module
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
30

39 Some examples may help make it clear how this is done.
40 For example, the following ODD-file fragment includes the tei and core modules in a
customization:
<TEI ...> ...
<specGrp xml:id="specgroup-core">
<moduleRef key="tei"/><!-- required -->
<moduleRef key="core"/>
<!--* abbr address analytic author bibl biblScope biblStruct
* corr date distinct editor foreign gap gloss head
* hi imprint item l label lb lg list measure mentioned
* monogr name note num orig p pb ptr pubPlace publisher
* q quote ref reg respStmt sp speaker stage term time title
*-->
<p>Delete unneeded elements.</p>
<specGrpRef target="#specgroup-core-deletions"/>
<p>Rename some elements.</p>
<specGrpRef target="#specgroup-core-renamings"/>
</specGrp>
...
</TEI>
41 Individual elements may be excluded by specifying mode="delete" on an
appropriate <elementSpec> element:
<elementSpec ident="add" module="core" mode="delete"/>
<elementSpec ident="addrLine" module="core" mode="delete"/>
<elementSpec ident="binaryObject" module="core" mode="delete"/>
<elementSpec ident="cb" module="core" mode="delete"/>
<elementSpec ident="choice" module="core" mode="delete"/>
42 I5 must deal with several different sets of elements:
Some elements should be incorporated from TEI P5. TEI P5 elements not present in IDS-
XCES, on the other hand, should be excluded.
Elements present in XCES but not present in TEI P5 must be defined. (They could be taken
over from an XCES ODD file, if one existed, but there is not currently any ODD-defined
version of XCES.)
Additional elements found in IDS-XCES but not in XCES or TEI P5 must be defined.
43 That is, E(I5) =
(E(IX) ∩ E(P5))
∪ (E(IX) ∩ (E(XCES) ∖ E(P5))
∪ (E(IX) ∖ (E(XCES) ∪ E(P5))
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
31

44 Note that the elements in the last group are not necessarily IDS extensions to XCES:
they may also include elements in TEI P3 which are inherited by IDS-XCES from TEI P3,
but which are no longer included in the TEI vocabulary in version P5.
45 It is possible to identify the elements which belong in each of the subsets described
manually, given sufficient patience and capacity for tedious detail. It is significantly
more convenient, however, to make the machine help us in the task. This can be done
in a three-step process:
Encode the relevant document grammars as XML documents.
Compare them using XQuery.
Generate the appropriate ODD declarations automatically.
46 A number of tools exist which can provide XML representations of DTDs. For the work
described here, we have used a simple application based on SWI Prolog (Wielemaker
n.d.), which loads a DTD and emits an XML representation of the DTD. The following
example shows a fragment of the IDS-XCES document grammar in this representation:
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
32

<dtd>
<desc>This document
(<code>2011/blackmesatech/IDS/interim/ids_xces_onefile.v3.xml</code>)
is an XML representation of
<code>2011/blackmesatech/IDS/interim/onefile.dtd</code> made by
dtdxml.pl on <date value="2011-09-11">2011-09-11</date></desc>
<elemdecl gi="gloss">
<star>
<or>
<elem>#pcdata</elem>
<or>
<elem>abbr</elem>
<or>
<elem>date</elem>
<or>
<elem>num</elem>
<or>
<!--* ... *-->
</or>
</or>
</or>
</or>
</or>
</star>
</elemdecl>
<attlist gi="gloss">
<att>
<name>id</name>
<type>id</type>
<dft>
<implied/>
</dft>
</att>
<att>
<name>n</name>
<type>cdata</type>
<dft>
<implied/>
</dft>
</att>
<att>
<name>xml:lang</name>
<type>cdata</type>
<dft>
<implied/>
</dft>
Journal of the Text Encoding Initiative, Issue 3 | November 2012
33

</att>
<!--* ... *-->
</attlist>
</dtd>
47 It is then a straightforward task to use XQuery to identify the first set of elements: IDS
elements which appear in TEI P5:
(: find the IDS elements that appear in the TEI Guidelines :)
declare namespace TEI = "http://www.tei-c.org/ns/1.0";
declare variable $dir.TEI := "file:/home/TEI";
declare variable $dir.IDS := "file:/Users/cmsmcq/2011/blackmesatech/IDS";
declare variable $P5 := doc(
concat($dir.TEI,
"/P5/Source/Guidelines/en/guidelines-en.xml"
));
declare variable $ids-xces := doc(
concat($dir.IDS,
'/interim/ids_xces_onefile.v3.xml'
));
<elements>{
for $e in $ids-xces/dtd/elemdecl
let $gi := string($e/@gi),
$elemspec := $P5//TEI:elementSpec
[@ident = $gi]
where $elemspec
order by $gi
return <e gi="{$gi}" module="{$elemspec/@module}"/>
}</elements>
48 After setting up variables for the text of TEI P5 and the XML encoding of the IDS-XCES
DTD ($P5 and $ids-xces, respectively), the query identifies each element name in
the IDS-XCES DTD ($gi, for generic identifier) and then finds ($elemspec) the
specification for that element in TEI P5, if there is one. If such an element specification
exists in TEI P5, then an XML element is returned giving the name of the element and
its module.
49 Once the basic query is formulated, it is simple to modify the return statement to
return instead the appropriate ODD declaration for the element:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
34

(: ... :)
return <elementSpec module="{$module}"
ident="{$teigi}" mode="change">
<altIdent>{$idsgi}</altIdent>
</elementSpec>
(: ... :)
50 Similar queries can be constructed to generate appropriate ODD declarations for
elements to be suppressed from TEI P5 or added to it.
3.3. Documentation
51 The ODD file is designed as a form of literate program which allows us to embed the
formal declarations of the document grammar in a human-readable document and
intertwine the schema with the documentation. The I5 project endeavors to make the
relation of TEI P5 to the IDS customization of TEI P5 easier to understand by treating
the ODD file itself not, as is sometimes done, primarily as input to Roma but primarily
as a document intended for human readers. The screen shot below illustrates the
principle: it shows the part of the document beginning with the ODD fragment given
above, which embeds the tei and core modules of TEI P5, in a style derived from the
IDS house style for Web pages.
52 A significant part of the effort in the I5 project is the preparation of appropriate tag-set
documentation for IDS-specific elements and attributes and for IDS-specific usages for
Journal of the Text Encoding Initiative, Issue 3 | November 2012
35

standard TEI and XCES constructs. Descriptions of the elements and attributes of the
document grammar are taken in part from TEI P5, in part transcribed from the XCES
documentation, and in part written from scratch. The individual element specifications
are embedded in the ODD file, as can be seen in the screen shot below; they can also be
extracted by Roma and integrated with documentation for standard TEI elements in the
form of reference documentation.
4. Conclusions
53 The history of the IDS text model and its markup reflects, in its individual way, several
important trends in the processing of natural language data generally and in corpus
linguistics more particularly.
54 From the earliest beginnings, corpus data at IDS used markup to record important
information about the text and to make explicit certain information within the text
which would otherwise have been inaccessible to automatic processing. The early
collections, however, all used idiosyncratic markup. Because of the large (for the times)
volume of data it had collected, IDS became convinced earlier than some projects of the
need to develop a standardized system of text representation. Like many who are early
to perceive the need for standardization, IDS developed its own standard format, in the
form of BOT. This standardization effort paid off: it made feasible the significant
investment in infrastructure represented by the COSMAS I project.
55 During COSMAS II, TEI markup was introduced in the form of CES. The broad coverage,
non-prescriptive approach, and sheer size of TEI P2, P3, and P4 made them daunting to
many prospective users: hard to understand and thus hard to adopt. CES and XCES,
which took a more focused, domain-specific approach, were more prescriptive, smaller,
and easier to understand; in consequence, they were easier for IDS to adopt as the basis
Journal of the Text Encoding Initiative, Issue 3 | November 2012
36

for its SGML and XML formats. Experience showed, however, that some TEI constructs
omitted from CES as unnecessary for corpus-linguistic work were needed, after all, to
handle the broad variety of texts and textual constructs which turn up in large corpora
like DEREKO. So IDS-CES and IDS-XCES found it necessary to bring some elements and
attributes back from TEI P3 and P4.
56 With I5, the IDS text model is directly derived from the TEI text model; the relation of
I5 to TEI, defined as it is by a single ODD file, will be somewhat easier to discern than
the relation of IDS-CES to TEI P3 or of IDS-XCES to TEI P4. The relation to XCES will still
be relatively easy to identify: by comparing the I5 ODD file to the extension files of
XCES, any reader will be able to see which TEI elements are retained in one
customization but not the other, and which additional elements and attributes are
common to the two.
Appendix: Features of IDS-XCES
57 As indicated in Section 2.3, the format IDS-XCES is based on the XCES document
grammar as defined in Ide, Bonhomme, and Romary (2000) and the XCES DTD files.18
These DTD files have been taken and modified as necessary for the IDS text model as
described below. The IDS-XCES document grammar comprises the files ids-xcesdoc.dtd, ids-lat1.ent, ids.xcustomize.ent, and
ids.xheader.elt;19 the XCES DTD files xcesAlign.dtd and xcesAna.dtd have
no equivalents among the IDS-XCES DTD source files. The former file has no equivalent
because there is no need to align corpus data in the monolingual German reference
corpus. The latter has no equivalent because linguistic annotations, apart from the
sentence segmentation, play (almost) no role in the IDS text model. Instead, several
layers of linguistic markup are provided as standoff annotation in separate files.20 Still,
IDS-XCES allows the specification of morphosyntactic annotations in attributes of the
<w> element: for a small number of corpora, there are versions of IDS-XCES documents
with inline linguistic annotations added to the element <w>.
58 In IDS-XCES, some IDS-specific elements and attributes have been added to the original
XCES, and in doing so, some of the XCES content models have been modified. These
additional elements and attributes can be grouped into those that are essentially
(context-dependent) renamings of XCES elements, those that have been taken from the
TEI P3 (or P4) specification (such as <textDesc> and <front>) and those that are
neither in XCES nor in TEI P3 (or P4).
59 In the following sections, we will give a summary of the most important features of IDS-
XCES compared with XCES. We give examples of elements and their characteristics,
without presenting complete content models including all attributes. The complete
changes are documented formally in a synopsis at http://www.ids-mannheim.de/kl/
projekte/korpora/idsxces.html.
A.1. Corpus Structure and Header
Element name Possible parents Modeled on Meaning Example
<idsCorpus> xml document rootXCES:
cesCorpuscorpus
Journal of the Text Encoding Initiative, Issue 3 | November 2012
37

<idsDoc> <idsCorpus> XCES: cesDoc document
<idsText> <idsDoc> XCES: cesDoc text
<idsHeader>
<idsCorpus>,
<idsDoc>,
<idsText>
XCES:
cesHeaderheader
<korpusSigle> <titleStmt> IDS-specific
corpus ID
(formerly
BOTC)
<korpusSigle>DIV</
korpusSigle>
<dokumentSigle> <titleStmt> IDS-specific
document
ID
(formerly
BOTD)
<dokumentSigle>DIV/
SGP </
dokumentSigle>
<textSigle> <titleStmt> IDS-specific
text ID
(formerly
BOTT)
<textSigle>DIV/SGP.
00000 </textSigle>
<c.title> <titleStmt> IDS-specific corpus title
<d.title> <titleStmt> IDS-specificdocument
title
<t.title> <titleStmt> IDS-specific text title
<pagination> <editorialDecl> IDS-specific
whether
page
numbering
is present
or not
(processing
info;
formerly
BOTP)
<pagination
type="yes"/>*
* Pagination information is included in a @type attribute, which is available for many elements in bothXCES and TEI.
Table 2: Examples of elements added for the description of the corpus structure and header
60 Those elements that are essentially renamings of XCES elements are the high-level
components <idsCorpus>, <idDoc>, and <idsText>—representing the three-
level corpus structure of the IDS text model (from <cesCorpus> and <cesDoc>)—
and <idsHeader> (from <cesHeader>).
61 In the content model for the <idsHeader>, the CES element <titleStmt> has been
substantially revised to contain one of <korpusSigle>, <dokumentSigle>, or
<textSigle> and one of <c.title>, <d.title>, or <t.title> to mark the ID
and title of a corpus, document, or text (respectively).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
38

A.2. Front and Back Matter
Element namePossible
parentsModeled on Meaning Example
<front> <text>TEI P3/P4:
<front>
front
matter
<back> <text> TEI P3/P4: <back>back
matter
<titlePage> <front>TEI P3/P4:
<titlePage>title page
<docTitle> <titlePage>TEI P3/P4:
<docTitle>
document
title as
part of
the
source
<docTitle><titlePart
type="main"><s>Jacques
Hilarius Sandsacks
Psychoschmarotzer</
s></
titlePart><titlePart
type="desc"><s>Roman</
s></titlePart></
docTitle>*
<docImprint> <front>TEI P3/P4:
<docImprint>imprint
<docImprint>Aufbau-
Verlag</docImprint>
* Since <docTitle> contains the title as it occurs printed in the source, it is part of the object text,and can be divided into sentence-like divisions marked by <s>.
62 One group of non-XCES elements found in IDS-XCES includes <front> and <back>
and their child elements, all of which were taken from the TEI P3 (or P4) specifications.
A.3. Drama
Element
name
Possible
parentsModeled on Meaning Example
<stage>
<div>,
<sp>,
<s>
TEI P3/P4:
<stage>
stage direction or
extra-linguistic
event in debate
<stage>(Beifall bei der
CDU/CSU und der FDP)</
stage>
63 For the encoding of drama and records of parliamentary debates, the element
<stage> (for stage directions) was adopted from TEI P3 (or P4).
A.4. Page Breaks and Pointers
Element
name
Possible
parentsModeled on Meaning Example
<pb>non-header
elements
with mixed
content
TEI P3/P4:
<pb>page break <pb n="38" TEIform="pb"/>
Journal of the Text Encoding Initiative, Issue 3 | November 2012
39

<lb>TEI P3/P4:
<lb>line break <lb TEIform="pb"/>
<ptr>TEI P3/P4:
<ptr>
pointer to
xml id
<ptr rend="number"
targType="note" targOrder="u"
target="shs.00000-n2-f2"/>
<xptr>TEI P3/P4:
<xptr>
<xptr targType="pb"
targOrder="u" doc="korpref.mk2"
from="WF1.00004-168-PB168"
to="DITTO" TEIform="xptr"/>
64 A group of “milestone” elements—<pb>, <lb>, <ptr>, and <xptr>—has been added
to IDS-XCES as part of almost all mixed content models. They are adopted from the TEI
P3 (or P4) to mark page breaks, line breaks, and references to other corpora,
documents, texts (e.g. from a bibliography section), sections, pages etc.
A.5. Corrections and Completions
Element
name
Possible
parentsModeled on Meaning Example
<orig>
non-header
elements
with mixed
content
TEI P3/P4:
<orig>
spelling variant
or morphological
ellipsis
<orig
reg="Ferienheime">Ferien-</
orig> und Kinderheime
65 The <orig> element with its attribute @reg has also been adopted from the TEI P3 (or
P4). In some corpora it is used to mark and complete morphological ellipsis and
sometimes used to mark spelling variants.
A.6. Morphosyntactic Inline Annotations
Element
namePossible parents
Modeled
onMeaning Example
<w>non-header elements
with mixed content
TEI P3/P4:
<w>wordform
<w ana="NOU com sg n
dat">Telefon</w>
66 The <w> element with its attribute @ana has been adopted from the TEI P3 (or P4) to
mark word forms and to provide morphosyntactic analyses for them. Only a handful of
the IDS corpora, however, contain such inline annotations.
A.7. Time of Creation
Element namePossible
parents
Modeled
onMeaning Example
Journal of the Text Encoding Initiative, Issue 3 | November 2012
40

<creatDate> <creation>IDS-
specific
time of
creation
and
(short
version
of)
reference
to first
edition
<creation><creatDate>2001</
creatDate><creatRef>(Erstveröffentlichung:
Frankfurt a.M., 2001)</
creatRef><creatRefShort>(Erstv. 2001)</
creatRefShort></creation>
<creatRef> <creation>IDS-
specific
<creatRefShort> <creation>IDS-
specific
67 The elements under <creation> are used to encode available information about the
time of creation of a text and the publication date of the first edition, if known. In TEI
P3 and P4, the contents of <creation> can be marked up using generic <bibl> and
<date> elements, but TEI does not provide an unambiguous way to indicate that a
particular bibliographic reference and date inside a <creation> element are for the
first edition. In CES and XCES, <creation> contains only character data with no
substructure at all.
A.8. Text Description
Element name Possible parents Modeled on Meaning Example
<textDesc> <profileDesc>TEI P3/P4:
<textDesc>
wrapper for
text
description
<textType> <textDesc> IDS-specific
text type
according to
type
inventory
(BOT+x)
<textType>Roman</textType>
<textTypeRef> <textDesc> IDS-specific
text type as
to appear in
bibliographic
string
(BOT+X)
<textTypeRef>Tageszeitung</
textTypeRef>
<textTypeArt> <textDesc> IDS-specific
text type of a
specific
article
(BOT+xa)
<textTypeArt>Interview</
textTypeArt>
<textDomain> <textDesc> IDS-specificsubject area
(BOT+r)
<textDomain>Regionales /
Unterhaltung/Kultur</
textDomain>
<column> <textDesc> IDS-specific
original label
of newspaper
section as in
the source
(BOT+ress)
<column>FERNSEHEN</column>
Journal of the Text Encoding Initiative, Issue 3 | November 2012
41
68 IDS-specific elements under <textDesc> are used to encode genre, text type,
newspaper section or subject area according to different classification schemes.
A.9. Edition Information
Element namePossible
parents
Modeled
onMeaning Example
<further>
<edition>
IDS-
specific
further edition
of the same
source with
year (BOT+gg)
<further>5. Auflage 1998
(1. Auflage 1997)</further>
<kind>IDS-
specific
kind of edition
of the source
(BOT+g)
<kind>Taschenbuch</kind>
<appearance>IDS-
specific
“physical”
appearance of
the source
(BOT+e)
<appearance>Microfiche</
appearance>
69 IDS-specific elements under <edition> are used to encode information about other
existing editions or the range of existing editions, the kind of edition (paperback,
special edition etc.), and the kind of object that was used as the source (photocopy,
microfiche, etc.).
A.10. Bibliographic Reference
Element namePossible
parents
Modeled
onMeaning Example
<reference> <sourceDesc>IDS-
specific
bibliographic
reference
string
<reference type="short"
assemblage="regular">DIV/
SGP.00000 Szendrödi:
Jacques Hilarius Sandsacks
Psychoschmarotzer, 2001</
reference>
70 The element <reference> may appear multiple times under <sourceDesc>, with
different values of its @type attribute specifying various versions of the bibliographic
reference string required for different modes of display and information in the
@assemblage attribute about whether it has been automatically assembled from
other elements or not.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
42

BIBLIOGRAPHY
Association for Computers and the Humanities (ACH), Association for Computational Linguistics
(ACL), and Association for Literary and Linguistic Computing (ALLC). 1999. Guidelines for Electronic
Text Encoding and Interchange (TEI P3), edited by C. M. Sperberg-McQueen and Lou Burnard.
Chicago and Oxford: Text Encoding Initiative. First published 1993. http://www.tei-c.org/Vault/
GL/P3/index.htm.
al-Wadi, Doris and Irmtraud Jüttner. 1996. “Textkorpora des Instituts für Deutsche Sprache: Zur
einheitlichen Struktur der bibliographischen Beschreibung der Korpustexte.” In LDV-INFO 8.
Informationsschrift der Arbeitsstelle Linguistische Datenverarbeitung, edited by IDS, 1–85. Mannheim.
Belica, Cyril, Marc Kupietz, Andreas Witt, and Harald Lüngen. 2011 “The Morphosyntactic
Annotation of DEREKO: Interpretation, Opportunities, and Pitfalls.” In Grammatik und Korpora 2009.
Dritte Internationale Konferenz. Mannheim, 22.4.–24.9.2009, edited by Marek Konopka, Jacqueline
Kubczak, Christian Mair, František Šticha, and Ulrich Hermann Waßner, 451–469.
Korpuslinguistik und interdisziplinäre Perspektiven auf Sprache 1. Tübingen: Narr.
Ide, Nancy. 1998. “Corpus Encoding Standard: SGML Guidelines for Encoding Linguistic Corpora.”
Proceedings of the First International Language Resources and Evaluation Conference, 463–470.
Grananda, Spain.
Ide, Nancy, Patrice Bonhomme, and Laurent Romary. 2000. “XCES: An XML-based Standard for
Linguistic Corpora.” In Proceedings of the Second Language Resources and Evaluation Conference (LREC),
825–830. Athens, Greece.
Kolvenbach, Monika. 1988/1989. “Schreibkonventionen für IDS-Korpora.” In LDV-INFO 7.
Informationsschrift der Arbeitsstelle Linguistische Datenverarbeitung. Edited by Tobias Brückner.
Kupietz, Marc. 2005. Near-Duplicate Detection in the IDS Corpora of Written German. Technical Report
KT-2006-01. Institut für Deutsche Sprache, Mannheim.
Kupietz, Marc and Holger Keibel. 2009. “The Mannheim German Reference Corpus (DEREKO) as a
basis for empirical linguistic research.” Working Papers in Corpus-based Linguistics and Language
Education 3, edited by Makoto Minegishi and Yuji Kawaguchi, 53–59. Tokyo: Tokyo University of
Foreign Studies (TUFS).
Kupietz, Marc, Oliver Schonefeld, and Andreas Witt. 2010. “The German Reference Corpus: New
developments building on almost 50 years of experience.” In Language Resources: From Storyboard
to Sustainability and LR Lifecycle Management, edited by Victoria Arranz and Laura van Eerten.
http://www.lrec-conf.org/proceedings/lrec2010/workshops/W20.pdf
Perkuhn, Rainer, Cyril Belica, Doris al-Wadi, Meike Lauer, Kathrin Steyer, and Christian Weiß.
2005. “Korpustechnologie am Institut für Deutsche Sprache.” In Korpuslinguistik deutsch: synchron
– diachron – kontrastiv, edited by Johannes Schwitalla and Werner Wegstein, 57–70. Tübingen,
Germany.
TEI Consortium. 2001. TEI P4: Guidelines for Electronic Text Encoding and Interchange: XML-Compatible
Edition, edited by C. M. Sperberg-McQueen and Lou Burnard. N.p.: TEI Consortium. http://
www.tei-c.org/release/doc/tei-p4-doc/html/.
TEI Consortium. 2012. TEI P5: Guidelines for Electronic Text Encoding and Interchange. Version 2.1.0.
Last updated June 17. N.p.: TEI Consortium. http://www.tei-c.org/release/doc/tei-p5-doc/en/
html/index.html.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
43

Wielemaker, Jan. n.d. “SWI-Prolog SGML/XML parser.” SWI-Prolog. http://www.swi-prolog.org/
pldoc/package/sgml.html.
NOTES
1. http://www.ids-mannheim.de/kl/projekte/korpora/
2. http://www.ids-mannheim.de/cosmas2/
3. We would like to thank Doris al-Wadi, Cyril Belica, Marc Kupietz, and Eric Seubert for their
enormous help regarding our questions about the history of the IDS text model.
4. Texts from 1989–1990 that document the political change that led to reunification, prepared
by the IDS and the former Zentralinstitut für Sprachwissenschaft.
5. Bonn newspaper corpus, from various years between 1949 and 1974, prepared in the 1970s.
6. Mannheim corpus 1 and 2, with texts from 1949 to 1974.
7. Cf. Perkuhn 2005 et al., p. 61 (our translation).
8. Since the document identifier consists of three capital letters usually derived from
the initials of the author and/or initials of content words from the title of the
document, the resolved document identifier (field BOTd) also corresponds to an
abbreviated version of the bibliographic reference.
9. Like BOT itself, the conversion scripts were prepared by Cyril Belica.
10. The many additional BOT fields and the two basic templates were all specified by
Doris al-Wadi and Irmtraud Jüttner (al-Wadi and Jüttner 1996).
11. The name DEREKO (Deutsches Referenzkorpus) has been in use since then for the
archive of contemporary written-language corpora at the IDS.
12. The project would later be called DEREKO-I.
13. The specification of the mapping and the definition of IDS-specific elements were
prepared by Doris al-Wadi of IDS.
14. TRADUCES was developed by Eric Seubert of IDS.
15. These fields were added by Marc Kupietz of IDS (Kupietz 2005).
16. BOTX was defined by Eric Seubert.
17. The specification of the mapping and the conversion script were prepared by Marc
Kupietz.
18. These may be downloaded from http://www.xces.org/dtds.html.
19. These files may be downloaded from http://corpora.ids-mannheim.de/idsxces1/
DTD/.
20. See Belica et al. 2011.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
44

ABSTRACTS
This paper describes work in progress on I5, a TEI-based document grammar for the corpus
holdings of the Institut für Deutsche Sprache (IDS) in Mannheim and the text model used by IDS
in its work. The paper begins with background information on the nature and purposes of the
corpora collected at IDS and the motivation for the I5 project (section 1). It continues with a
description of the origin and history of the IDS text model (section 2), and a description (section
3) of the techniques used to automate, as far as possible, the preparation of the ODD file
documenting the IDS text model. It ends with some concluding remarks (section 4). A survey of
the additional features of the IDS-XCES realization of the IDS text model is given in an appendix.
INDEX
Keywords: corpora, ODD, DTD, CES, XCES
AUTHORS
HARALD LÜNGEN
Harald Lüngen has been a researcher in the area of corpus linguistics at the Institut für Deutsche
Sprache in Mannheim, Germany, since 2011, specialising in the construction and maintenance of
the German Reference Corpus DEREKO and in methods of corpus analysis. Before that, he worked
as a computational linguist and project scientist in the fields of computational lexicology and
morphology, text parsing, and text technology.
C. M. SPERBERG-MCQUEEN
C. M. Sperberg-McQueen (Black Mesa Technologies LLC) is a consultant specializing in helping
memory institutions solve information management problems and preserve cultural heritage
information for the future by using descriptive markup: XML, XSLT, XQuery, XML Schema, and
related technologies. He co-edited the XML 1.0 specification and the first versions of the TEI
Guidelines.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
45

Creating Lexical Resources in TEI P5A Schema for Multi-purpose Digital Dictionaries
Gerhard Budin, Stefan Majewski and Karlheinz Mörth
AUTHOR'S NOTE
This paper is based on a presentation given at the TEI Members’ Meeting 2011 in
Würzburg, Germany.
1. Background
Lexicography, the art of compiling dictionaries, is one of the oldest branches of
linguistics. All remnants of early lexicographic writings stem from Asia, and the oldest
extant precursors of modern dictionaries were Sumerian/Akkadian clay tablets dating
from the second millennium BC; these early lexicographic endeavours represent a very
modern type of text—a bilingual dictionary (Snell-Hornby 1986, 208) which, in most
areas of the world, would not emerge until at least 2,000 years later.
In contrast to the Sumerian clay tablets, most other early testimonies of this academic
tradition were monolingual in nature. The Sanskrit grammarian Yāska1 is regarded by
many as the earliest known Indian lexicographer; his Nirukta was a treatise on
etymology and semantics, containing a glossary of irregular verbs. Chinese
lexicography is some centuries younger: the Erya (author unknown) is the most ancient
Chinese writing that falls into the broader category of dictionaries (Wilkinson 2000, 62).
Although the creation of modern dictionaries is considered to have begun in Europe
with the rise of national languages, there is no clearly discernible demarcation line
between pre-modern and modern dictionary production. Some outstanding works
emerged in the 17th and 18 th centuries. Jean Nicot’s Trésor de la langue Française was
printed in 1606, Agnolo Monosini’s Vocabulario della lingua italiana appeared in 1612,
Johann Christoph Adelung’s Grammatisch-kritisches Wörterbuch der Hochdeutschen
Mundart followed in 1781, and Samuel Johnson finished his Dictionary of the English
Journal of the Text Encoding Initiative, Issue 3 | November 2012
46

Language in 1755.2 The first large-scale Chinese dictionary from this time period, the
Kangxi zidian, dates from 1716 (Wilkinson 2000, 64).
The latest step in this long history is being constituted by the transition towards digital
methods. Today, digital technology is not only used to produce print dictionaries;
rather, many dictionaries exist solely in digital form. Information and communication
technology has become pervasive in all stages of the modern dictionary creation
process: both data acquisition and representation of lexical knowledge rely heavily on
this technology. Furthermore, dictionary makers have shifted from traditional methods
such as introspection and interviews of competent speakers towards more empirical
methods based on lexicographic research using increasingly sophisticated digital
resources such as corpora (large digital text collections that reflect real-world language
usage).
2. The ICLTT’s Dictionaries
The Institute for Corpus Linguistics and Text Technology (ICLTT) of the Austrian
Academy of Sciences has been conducting a number of lexicographic projects,
including both digitizing print dictionaries and creating born-digital lexicographic
data. The lexicographic data produced in these projects are designed to serve a variety
of purposes for both linguistic research and lexicography. To ensure that NLP tools
available at the institute would work with all the data, a uniform encoding system for
all projects was needed. The integration of digital corpus data with the lexicographic
infrastructure has been an important goal and plays an important role in all these
efforts.
The ICLTT as an institution has grown out of several projects. One of the best known
results of these projects is probably the Austrian Academy Corpus (AAC), a digital
collection of German language texts stemming from the 19th and 20 th centuries. The
digital texts contained in the AAC were collected with a literary, a socio-historic and a
lexicographic perspective in mind, but in spite of the literary and historical focus in
setting up the corpus, it is increasingly used by linguists (Moerth 2002).
2.1. Print Dictionaries
The main motive behind setting up the corpus was the institute’s involvement in a
longstanding text-lexicographic project which produced two dictionaries designed to
ease access to one of Austria’s most important works of twentieth-century literature,
Karl Kraus’ magazine Die Fackel. The first volume was a dictionary of idioms and
idiomatic expressions; the second one a comprehensive listing and documentation of
insults and invective terms.
In recent years, the institute has shifted from addressing the needs of literary scholars
by focusing on particular works of literature to catering to the needs of linguists by
devoting resources to smaller and more diverse projects. The ICLTT has also
contributed to the production of the largest German-Russian dictionary ever produced
(Dobrovolsky 2008–2010), which was published as a cooperative project of the Austrian
and the Russian Academies of Sciences.
In addition to creating new print dictionaries, the institute has also digitized historical
dictionaries and even incorporated them into the AAC in order to extend the collection
Journal of the Text Encoding Initiative, Issue 3 | November 2012
47

of texts to as many types of written language as possible. Currently, efforts are being
made to make this data TEI P5 compliant.
2.2. Born-digital Dictionaries
Dictionaries are increasingly created in and for the digital world. Apart from digitizing
paper dictionaries, the ICLTT has also started to create new digital lexical resources,
some of which build on the department’s digital text collections. These include
dictionaries for doing variational linguistics on German as written and spoken in
Austria, Early Modern German, and Arabic; a GUI tool for converting German
Wiktionary data to TEI P5;3 and a comprehensive Dictionary of Modern Persian Single Word
Verbs to be used as the basis for a morphological analyzer. The variation among these
projects has been brought about to a certain degree by the ICLTT’s role as Austria’s
CLARIN and DARIAH coordinator.
3. Data Formats
In choosing a uniform encoding system for all ICLTT data, the department’s staff
surveyed data formats in use. Although most of the relevant dictionary productions of
the recent past have relied on digital data and methods, there is little consensus on
standards. A great number of divergent formats have coexisted: MULTILEX and GENELEX
(GENEric LEXicon) are systems that are associated with the Expert Advisory Group on
Language Engineering Standards (EAGLES).4 Other formats used in digital dictionary
projects are OLIF (Open Lexicon Interchange Format),5 MILE (Multilingual ISLE Lexical
Entry),6 LIFT (Lexicon Interchange Format),7 OWL (Web Ontology Language)8 and DICT
(Dictionary Server Protocol),9 the latter being an important dictionary delivery format
(Faith 1997).
Another standard considered was ISO 1951 (“Presentation/representation of entries in
dictionaries – requirements, recommendations and information”). Although this
standard focuses on encoding the presentation of lexicographical data in dictionaries
for human use in what is called LEXml (Lexicographical Markup Language), it seems
that after a few years of existence only few publishing houses have been using this
format (such as Langenscheidt, Munich) for their dictionary production line.
Last but not least, when looking for an encoding standard for machine readable
dictionaries, ISO 24613:2008 (“Language resource management – Lexical markup
framework (LMF)”), the ISO standard for natural language processing (NLP) and
machine-readable dictionaries (MRD), must be considered. Recently, there have been
discussions about the possibility of creating a TEI serialization of LMF (Romary 2010).
In modeling lexicographic data, it has become common practice to conceptualize the
underlying structures as tree-like constructs, which makes XML an ideal syntax for
expressing the data. Another option, from software engineering, is UML (Unified
Modeling Language)10 which in turn can easily be serialized into an XML vocabulary.
This approach was taken by the authors of LMF.
For our projects, the final “short list” contained ISO 1951, LMF and the TEI dictionary
module. ISO 1951 was eschewed from the very beginning, among other reasons for lack
of support in the community. LMF in turn has gained more support in the dictionary-
producing community. Given the still small amount of available data using LMF and
Journal of the Text Encoding Initiative, Issue 3 | November 2012
48

ongoing discussions, the decision was made to move towards TEI and keep an eye on
the LMF specification as it develops.11
4. TEI Dictionary Module
The TEI dictionary module appears to be the de facto encoding standard for
dictionaries digitized from print sources. As such, “TEI for dictionaries” has a
longstanding tradition. Interestingly, the most recent versions of the TEI Guidelines
contain a passage that indicates that the authors had in mind a much wider range of
dictionaries:
... The elements described here may also be useful in the encoding of computationallexica and similar resources intended for use by language-processing software; theymay also be used to provide a rich encoding for word lists, lexica, glossaries, etc.included within other documents. (TEI Consortium P5 2012, 247)
This passage reflects a considerable conceptual extension of the initial purpose of the
module.12 However, the idea of extending the scope of the TEI dictionary module for use
by language-processing software is not at all as far-fetched as it may seem at first
glance. The fact that there are people interested in the issue has been documented by
the large audience of the workshop “Tightening the Representation of Lexical Data: A
TEI Perspective,” held at the 2011 Annual Conference and Members’ Meeting of the TEI
Consortium (Würzburg, Germany). Actually, the TEI’s ability to adapt to many types of
dictionaries makes it an ideal candidate for such an endeavor.
A fundamental problem we came up against when we started to model our dictionary
data was the lack of available examples against which we could compare our data. It
would have been beneficial if more projects had made at least samples of their data
publicly accessible.13 Many of the examples which can be found on the TEI website are
repetitive and are by no means exhaustive.14 However, getting hold of examples in
other encoding languages is not easy either: ISO 1951 seems to be used by a single
publishing house and LMF has not won much ground in the field, though there are
some data available for the latter.15
5. ICLTT’s TEI Schema
The following sections outline selected features of the ICLTT’s customization of the TEI
P5 dictionary module. The system has been used successfully for lexicographic data
encoding at the department, where it is meant to be a multi-purpose system targeting
both human users and software applications. The following four requirements had
featured strongly in our decision in favor of TEI encoding:
Acquaintance with the overall TEI system: as the department has been working with TEI on
text encoding projects, a number of colleagues are conversant with TEI and have used it
from the very beginning of our dictionary projects;
Intuitiveness of the TEI system: the concise and yet expressive set of elements is definitely
more easily readable to human lexicographers working on the XML source than for instance
the LMF serialization proposed in ISO 24613:2008;
Consistency with other language resources contained in the same collection: the intention
was to keep the encoding system of the dictionary resources in line with other textual data
to be integrated with these lexicographic resources.
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
49

Adaptability to the needs of dictionaries to be used in natural language processing (NLP).
In order to make the TEI dictionary module usable for NLP purposes, it has been
necessary to tighten the many combinatorial options of TEI P5—that is, to constrain the
content models of various elements.
5.1. Representing Lemmas
In TEI, dictionaries are a specific type of text and are therefore encoded with <text>elements, which are made up of optional <front> and <back> matter. The
dictionary entries are placed in a <body> element.
<TEI>
<teiHeader>
...
</teiHeader>
<text>
<front>...</front>
<body>
<entry>...</entry>
<entry>...</entry>
<entry>...</entry>
...
...
...
</body>
<back>...</back>
</text>
</TEI>
Individual entries may be seen as the core of all lexicographic encoding; the structure
of dictionary entries can display a great variety of different forms.16 This also accounts
for the fact that the P5 version of the Guidelines (250) offer three elements to encode
this type of microtexts: <entry>, <entryFree>, and <superEntry>.
The <superEntry> element can be used to group entries together and is not used in
our schema. As the name implies, <entryFree> contains a single <entry> with a
comparatively large number of acceptable elements that may be arranged in many
different ways. In TEI P5, <entryFree> can contain 30 different elements from the
dictionary module alone.17 The great flexibility of this element makes it suitable for
digitizing print dictionaries, but in creating strictly defined dictionary structures to be
used by software, this flexibility is of lesser value.
In contrast to <entryFree>, the <entry> element allows for only ten sub-elements:
<case>, <def>, <etym>, <form>, <gramGrp>, <hom>, <sense>, <usg>, <xr>,
and <dictScrap>. The dictionary schema described in this paper only contains the
simple <entry> element (combinatorial options were further restricted by excluding
both <dictScrap> and <hom> elements from the list of possible child elements).
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
50

Simple dictionary entries invariably start with a lemma. Optionally, entries contain an
indication of the word class of the lemma and one or more <sense> elements. A
typical entry has a structure like this:
<entry>
<form type="lemma">
...
</form>
<gramGrp>
<gram type="pos">...</gram>
</gramGrp>
<sense>
...
</sense>
...</entry>
In many cases, it is difficult for lexicographers to decide whether to integrate lexical
items into one single entry or rather to make two or more entries. Lexical homonymy
in TEI dictionaries is often encoded using the <hom> element, as in the following
abridged example.
<entry>
<form type="lemma"><orth>Schloss</orth></form>
<hom>
<sense>
<cit type="translation" xml:lang="en">
<quote>castle, palace</quote></cit>
</sense>
</hom>
<hom>
<sense>
<cit type="translation" xml:lang="en">
<quote>(pad)lock</quote></cit>
</sense>
</hom>
</entry>
As a basic principle, we have attempted to keep hierarchies in our encoding system as
flat as possible. This is why the <hom> element has been excluded from the set of
Journal of the Text Encoding Initiative, Issue 3 | November 2012
51

possible elements. That is, in cases of homonymy, lexicographers have to either work
with entries that contain several senses or to create separate entries, which would be
encoded in TEI as follows:
<entry>
<form type="lemma"><orth>Schloss</orth></form>
<sense>
<cit type="translation" xml:lang="en">
<quote>castle, palace</quote></cit>
</sense>
</entry>
<entry>
<form><orth>Schloss</orth></form>
<sense>
<cit type="translation" xml:lang="en">
<quote>(pad)lock</quote></cit>
</sense>
</entry>
The same encoding pattern is applied to grammatical homonyms and polyfunctional
items—that is, homographs that are semantically related but have different word classes.
However, encoding homonyms in separate <entry> elements can be problematic,
especially when lexical items belong to different word classes and need to be
distinguished (consider an example from English: “talk” as a verb versus as a noun). For
us, the deciding factor was whether the word class difference manifests itself in the
semantic description, the <sense> block in TEI nomenclature. Whenever different
part-of-speech labels would need to be assigned to <sense> elements (such as with all
grammatical homonyms), the lexical items were encoded in separate <entry>elements rather than in one.
Polyfunctionality is a very common phenomenon and has posed problems in almost all
our projects. Our approach, as detailed above, has pros and cons. However, our main
argument in favor of splitting entries—putting each homonym into a separate
<entry>—is that it makes access to the particular lexical items more straightforward.
Working along these lines, part-of-speech labels only appear on the top-most level of
the entry together with the lemma, not within <sense> elements. If necessary, the
relation between entries could be made explicit by <re> (related entry) elements or
some system of links.
It is obvious that the decision of whether to split entries also depends on what one
plans to do with a particular set of data. For some of our projects, we have plans to
enrich lexical data using corpora: looking for new, hitherto unregistered word forms,
doing statistics on word forms, etc.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
52

5.2. Encoding Word Class Information
A fixed component of all single-word dictionary entries is a block containing word-class
information. In early experiments, we encoded this information within the <form>element representing the lemma. While TEI allows word-class information to appear in
various locations within an <entry> element, the motivation behind putting it within
<form> was that it seemed to be more consistent to say that the lemma, rather than
the entry, belongs to a particular word class. In addition, putting the <gramGrp>element in the lemma’s <form> element allowed <gramGrp> elements containing
part-of-speech information to appear inside <form> elements, yielding an additional
simplification of the schema.
Over time, we have come back to a more canonical TEI encoding, abandoning this
rather atypical practice. This change of attitude was, among other things, motivated by
experiments of converting our data into an LMF-conformant XML serialization: in LMF,
@part-of-speech is defined as an attribute of the element <LexicalEntry>.18
Practical experience has also led us to change usage of elements inside the <gramGrp>element. Initially, word-class information was encoded using the <gramGrp> element,
which can contain a number of other elements such as <case>, <gen>, <mood>,
<pos>, and <tns>. For example:
...
<gramGrp>
<pos>noun</pos>
</gramGrp>
...
We now only allow the <gram> element within <gramGrp>, using attributes to
distinguish various word-class categories. The above example can be rewritten to its
<gram> equivalent like this:
...
<gramGrp>
<gram type="pos">noun</gram>
</gramGrp>
...
Choice of appropriate terminology is important when labeling lemmas with word
classes. Scholars working on digital resources have long needed to maintain
consistency both within a project and one agreed upon by the community at large.
Nowadays, it also involves interoperability with other digital resources, especially by
referring to publicly accessible frameworks (concept repositories) to make the
linguistic terminology explicit. In the field of linguistics, two such frameworks play an
Journal of the Text Encoding Initiative, Issue 3 | November 2012
53

increasingly important role: the so-called GOLD Standard, the General Ontology of
Linguistics Descriptions (Farrar and Langendoen 2003) and ISOcat, the ISO TC37/SC4
Data Category Registry (Kemps-Snijders et al. 2009). The most important feature of the
web-based ISOcat registry is that it provides persistent identifiers (PIDs) for all the
concepts registered in the database, allowing for explicit reference to terms used.
So far, we have attempted to make use of ISOcat terminology in the ICLTT
customization without explicitly referring to the ISOcat terms in the encoding of the
entries. However, we have started to experiment with an alternative way of marking up
word-class information that makes explicit reference to the concept repository which
is exemplified in the following excerpts:
...
<gramGrp>
<gram type="pos" corresp="#vrbNoun"/>
</gramGrp>
...
The label of the @corresp attribute above refers to a feature structure that, in turn,
provides an explicit reference to the particular entry in the ISOcat database:
<fs type="partOfSpeech">
<f xml:id="vrbNoun" name="verbalNoun" fVal="http://www.isocat.org/
datcat/DC-3858"/>
<f xml:id="comNoun" name="commonNoun" fVal="http://www.isocat.org/
datcat/DC-385"/>
<f xml:id="prNoun" name="properNoun" fVal="http://www.isocat.org/datcat/
DC-384"/>
</fs>
5.3. Morphosyntactic Information
Dictionary entries often contain more grammatical forms of the headword. In
traditional lexicography, particular word forms are usually given in order to point the
user to irregularities in inflectional paradigms. In a digital dictionary, which does not
have any spatial limitations, it is not uncommon to have more comprehensive lists of
word forms.
5.3.1. <gramGrp> vs. Feature Structures
The ICLTT has experimented with entries giving only inflectional irregularities and also
those giving complete paradigms; in either case, each word form is encoded with a
<form> element. Whatever the intended use of these word forms, a system is needed
Journal of the Text Encoding Initiative, Issue 3 | November 2012
54

to identify their function. The traditional TEI way to do this would be to enter the
morphosyntactic details of a <form> in a <gramGrp> element:
...
<form type="inflected">
<gramGrp>
<pos value="verb"/>
<tns value="present"/>
<number value="singular"/>
<mood value="indicative"/>
<per value="2"/>
</gramGrp>
<orth>gehst</orth>
</form>
...
In search of a more generic approach, we resorted to a system combining feature
structures19 and ISOcat grounded values. Instead of using the <gramGrp> element as a
child of <form>, the @ana (analytic) attribute is added to the <form> element.
...
<form type="inflected" ana="#v_pres_ind_sg_p2">
<orth>gehst</orth>
</form>
...
The labels used to construct the pointers in the @ana attribute are human-readable
abbreviations. In this part of the system, we have attempted to proceed in line with the
ISO TC37/SC4–related MAF (Morphosyntactic Annotation Framework) draft
specification, in particular Chapter 8 on morpho-syntactic content (ISO 24611 2008, 21).
The components of the value of the @ana attribute are resolved in a feature structure
library:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
55

<fvLib>
...
<fs xml:id="v_pres_ind_sg_p2" name="v_pres_ind_sg_p2"
feats="#pos.verb #tns.pres #mood.ind #num.pl #pers.2">
...
</fvLib>
<fLib>
<f xml:id="pos.verb" name="pos"><symbol value="verb"/></f>
...
<f xml:id="tns.pres" name="tense"><symbol value="present"/></f>
...
<f xml:id="mood.ind" name="mood"><symbol value="indicative"/></f>
...
<f xml:id="num.pl" name="number"><symbol value="plural"/></f>
...
<f xml:id="pers.2" name="person"><symbol value="2nd"/></f>
...
</fLib>
This method of annotating morphosyntactic phenomena is not only extremely concise
(the information is only referenced through links), it also allows for the assignment of
multiple interpretations of the content of the <orth> element. The attribute @anacan contain an open number of so-called data.pointers, each separated by
whitespace:
...
<form type="inflected" ana="#v_pres_ind_pl_p1 #v_pres_ind_pl_p3 ">
<orth>gehen</orth>
</form>
...
5.3.2. A Particular Case: Encoding Roots of Semitic Words
Any general-purpose system such as the TEI is bound to have conceptual gaps. A
particular problem of our projects involving Semitic languages was how to deal with
what in Semitic studies is commonly referred to as a root. In Semitic morphology, word
forms are constructed on top of two, three, or four consonants. These consonants,
which function as abstract linguistic units, form what is commonly called “the root”,
i.e. the semantic skeleton of all morphologically derived forms. The scholars working
with and on the described encoding system were very reluctant to use the TEI element
<form> for the particular purpose, as this would have meant stretching the semantics
of the element too much. Roots are neither word forms nor stems. In order to avoid “tag
Journal of the Text Encoding Initiative, Issue 3 | November 2012
56

abuse”, we first experimented with the TEI’s feature-structure capabilities. Here is an
example taken from our Colloquial Cairene Arabic Dictionary (safar is Arabic for ‘journey’).
...
<form type="lemma">
<form type="lemma"><orth>safar</orth></form>
<fs><f name="root"><string>sfr</string></f></fs>
...
However, our current practice is to encode the root of each lemma by means of the
<gramGrp> element holding the word-class information. Adding an additional
<gram> element to <gramGrp> appears to be a both concise and conceptually
consistent solution to the problem:
...
<gramGrp>
<gram type="pos">noun</gram>
<gram type="root">sfr</gram>
</gramGrp>
...
5.4. Identifying Linguistic Varieties and Writing Systems
When encoding digital texts, linguistic varieties are usually identified using so-called
language codes, of which there are several systems. An older (yet very versatile) system
is Verbix Language Codes, which makes use of the old SIL codes.20 LS-2010
(Linguasphere language codes) is a rather recent system which was published in 2000
and updated in 2010. It contains over 32,000 codes. The most widely used standard is
ISO 639.
All these systems are incomplete and, if still being maintained, continue to evolve. A
downside to all of them is the lack of support coming from the many scholarly
disciplines involved in their use. In addition to the high (and ever changing) number of
linguistic varieties on our globe, one additional aspect has to be taken into
consideration: many linguists also need codes for historic linguistic varieties as well as
for living varieties.
In TEI encoding, it has become common practice to make use of the global21 attribute
@xml:lang, incorporated into the TEI from the World Wide Web Consortium’s XML
Specification. TEI prescribes this attribute to identify both linguistic varieties and
writing systems. In this hybrid approach, the value of the attribute should be
constructed in accordance with Best Current Practice 47 (BCP 47)22 which in turn refers to
and aggregates a number of ISO standards (639-1, 639-2, ISO 15924, ISO 3166).23
Journal of the Text Encoding Initiative, Issue 3 | November 2012
57

BCP 47 defines an extensible system that is sufficiently expressive to identify most
standard linguistic varieties. Language tags are assembled from a sequence of
components (which are also called subtags), each separated by a hyphen. All subtags
except for the first one are optional and have to be arranged in a particular order. The
first subtag is usually an ISO 639-2 value and indicates the linguistic variety; the second
one is an ISO 3166-1 region code. For example, es-MX stands for Spanish as spoken in
Mexico, es-419 for Spanish as spoken in Latin America. In addition, the ISO 639-3 three-
letter language codes and ISO 15924 codes are used. One can specify, for instance, that
the language being used in a particular encoded element is in the Cantonese dialect
(gan) of Chinese (zh) as spoken in Hongkong (HK) and written in Latin characters
(Latn): these subtags have to be arranged in the proper order: zh-gan-Latn-HK.
While identifiers for standard linguistic varieties are adequate for many text encoding
projects, some of our projects in variational linguistics, especially dialectology, need to
provide locational granularity beyond what is specified in the second subtag. To solve
this problem, ICLTT staff make use of private use subtags (which, according to BCP 47,
must be introduced with an x singleton). They help to indicate particular geographical
locations and writing systems that cannot be identified by one of the standards
referenced by BCP 47. Consider the following case of the representation of the lemma
for Egyptian Arabic book:
...
<form type="lemma">
<orth xml:lang="ar-arz-x-cairo-vicav">kitāb</orth> </form>
...
In constructing these labels, ISO standards have been applied wherever possible. The
value of the BCP 47 language tag (that is, the value of the @xml:lang attribute) starts
with the shortest available ISO 639 code: ar stand for Arabic. This is followed by an
extended language subtag. ISO 639-3 provides 30 identifiers for what in the
specification is called individual languages, which all belong to the macrolanguage
Arabic.24 The three-letter subtag arz translates into Egyptian Arabic. 25 Unfortunately,
this is not precise enough for purposes of dialectology, as the dialects spoken in Egypt
are subdivided into a great number of quite divergent dialects, which our system has to
accommodate (with private use subtags, as explained above). The schema we are using
constructs these subtags from two components: location and writing system. The first
component (location) does not require further explanation, whereas the second
component (writing system) in this example is vicav, which stands for Viennese Corpus of
Arabic Varieties (transcription), a hybrid system for transcription that attempts to
represent the most common current usage in the community. While this system of
constructing language labels has served our purposes very well, for documentary
purposes it is still recommended to specify the exact meaning of the toponym (the first
component of our private use subtag) in the <teiHeader> of the dictionary. 26 We
hope that future standards for language tags will allow for geo-spatial references with
much finer granularity.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
58

The following example is taken from a Modern Persian dictionary entry, the English
translation of the lemma is ‘to go, to walk’.
...
<form type="lemma">
<orth xml:lang="fa-Arab"> نتفر </orth>
<orth xml:lang="fa-x-modDMG">raftan</orth>
</form>
...
The two letters fa identify the language (Modern Persian, ISO 639-2), and Arab indicates
the writing system (ISO 15924).27 The private use subtag indicates the system used to
transcribe the Arabic characters. In this particular case, modDMG is a modified version of
the system of the Deutsche Morgenländische Gesellschaft. Documentation of the system and
the applied modifications are explained in the dictionary’s <teiHeader>.
5.5. Etymologies
The encoding of etymologies is straightforward in TEI. As in canonical TEI, our schema
allows the <etym> element as a child of entry. <etym> in turn contains one or more
<lang> elements. To make the information inside the <lang> element explicit, a
@sameAs attribute is added whose value points to feature structures referring to an
ISO 639-2 value.
...
<etym><lang sameAs="#iso2_la">Latin</lang></etym>
...
5.6. Adding Semantics
So far, we have discussed phenomena pertaining to orthography and morphology, but
we have not yet touched on equivalents or translations of the lemmas. All of this kind
of information is placed in one or more <sense> elements. In monolingual
dictionaries, equivalents of the lemma are encoded as <def> elements. Definition in
this particular sense implies synonym or paraphrase. When working on bi- and multi-
lingual data, translations are encoded as <cit> elements, and the content proper is
placed in <quote> elements within these.28 Translations in more than one language
are encoded by means of several <cit> elements.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
59

<entry>
<form type="lemma"><orth>Schloss</orth></form>
<sense>
<cit type="translation" xml:lang="en">
<quote>castle, palace</quote></cit>
<cit type="translation" xml:lang="fr">
<quote>château, palais</quote></cit>
</sense>
...
In addition to the <def> and <cit> elements, our schema only allows <gramGrp>and <usg> inside the <sense> element.
...
<sense>
<usg type="dom">colour</usg>
<cit type="translation" xml:lang="en">
<quote>black</quote></cit>
</sense>
...
5.6.1. Grammatical Valency
The appropriate encoding of grammatical phenomena often called valency or
government is still not entirely resolved in the TEI Guidelines. The Guidelines provide
only two examples for the <colloc> element; both are encoded with a @typeattribute that has the value prep (for preposition). One is an entry for French médire de,
which in English translates as “to speak ill of”.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
60

<entry>
<form>
<orth>médire</orth>
</form>
<gramGrp>
<pos>v</pos>
<subc>t ind</subc>
<colloc type="prep">de</colloc>
</gramGrp>
</entry>
The second example is an entry with Chinese shuō “to speak” as lemma, followed here
by the resultative particle dào, which can be rendered in this context as of or about.
<entry>
<form>
<orth>說</orth> </form>
<gramGrp>
<colloc type="prep">到</colloc>
</gramGrp>
</entry>
The solution we had in mind was something that would reach beyond what, to a
majority of linguists, would be acceptable as collocate. For this reason, we decided to
consider other encoding options.
A uniform system for specifying a lexical item’s main complements (arguments in
linguistic nomenclature) was needed. Note that this part of our encoding system is still
in its infancy. However, it is important to mention that this kind of information is
invariably marked up within the <sense> element. Our current encoding is illustrated
by the following excerpt:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
61

...
<sense>
<gramGrp>
<gram type="argument">in</gram>
</gramGrp>
<cit type="translation" xml:lang="en">
<quote>sich interessieren (für)</quote></cit>
</sense>
...
In our customization, the <gram> element is used to list selected arguments relevant
to the material of a specific project. None of the projects aims at the exhaustive
coverage of arguments. We have also been thinking about making use of feature
structures, as in the following example:
...
<fs type="syntacticBehaviour">
<f name="coreArguments" feats="#optSubj #oblPrepObj "/>
</fs>
...
The above structure will appear very familiar to readers conversant with LMF (Lexical
Markup Framework). With a generic solution designed along these lines, a precise
expression of valency or government is achievable. It would also be feasible to
differentiate between mandatory and optional arguments.
5.6.2. Dictionary Examples
As explained above, all ICLTT dictionary projects are tightly interlinked with corpus-
building activities. For this reason, the encoding of examples in dictionary entries
requires particular attention. The relation between dictionary and corpus has to be
seen as bidirectional: on the one hand, lexicographic data are designed to be used in
the analysis of corpora, yet on the other hand, corpora are used to enhance and refine
dictionaries.
One important requirement was identified at the outset of our work: dictionary
examples must be reusable in different entries of a dictionary. As we did not want to
duplicate data in the dictionary, the natural choice was to work with <ptr> elements
to reference examples.
In TEI P5, dictionary examples are encoded as <cit> elements with @type attributes.
Except for the value of the @type attribute, they look exactly like translations. The
following example is taken from an isiZulu-English glossary:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
62

...
<cit type="exampleSentence" xml:id="amanzi_ayabanda_01">
<quote>Amanzi ayabanda.</quote>
<cit type="translation" xml:lang="en">
<quote>The water is cold.</quote>
</cit>
</cit>
...
In our TEI-encoded dictionaries, examples such as the one above are children of the
<body> element. Our dictionary editing program organizes dictionaries into three
basic units—one metadata record (a <teiHeader> element) for the whole dictionary,
an open number of entries, and dictionary examples (which can either be multi-word
expressions, phrases or sentences with respective translations)—each of which are
stored as separate database entries. Examples can then be linked to particular
<sense> elements through a unique identifier which is referenced via the @targetattribute of a <ptr> element:
<entry xml:id="amanzi_01">
<form type="lemma">
<orth>amanzi</orth>
</form>
...
<sense>
<cit type="translation" xml:lang="en">
<quote>water</quote>
</cit>
<ptr type="exampleSentence" target="#amanzi_ayabanda_01"/>
</sense>
</entry>
Usually, one example <cit> element contains a single <quote> element.
Nevertheless, in some cases multiple <quote> elements might be required, such as to
give the example in several orthographic representations (with the @xml:langattribute differentiating them). The following example is again taken from the
Colloquial Cairene Arabic dictionary:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
63

...
<cit type="exampleSentence" xml:id="id_dinya_harr_01">
<quote xml:lang="ar-arz-x-cairo-vicav">id-dinya ḥarrᴵ ʡawi in-nahar-da.</quote>
<quote xml:lang="ar-arz-x-cairo-modDMG">id-dinyaᴵ ḥarr ’awi in-nahar-da.</quote>
<quote xml:lang="ar-arz-x-cairo-IPA">id-dinya ḥarrᴵ ’awi in-nahar-da.</quote>
<quote xml:lang="ar-arz-Arab-x-cairo">. هدراهنلا یوق رح ایندلا </quote>
<cit type="translation" xml:lang="en">
<quote>It’s very hot today.</quote>
</cit>
</cit>
...
5.7. Metadata at the Level of the Dictionary Entry
Recording production metadata has been a recurring issue in many of the ICLTT’s
encoding projects, and the lexicographic work is no exception. It is common knowledge
that the TEI provides very efficient mechanisms to make statements about all kinds of
responsibility in the <teiHeader> element. However, problems arise when such
statements are needed on a more granular level than the whole TEI document.29 In
parts of our lexicographic work, we need to make responsibility statements not only
about the whole dictionary but also about particular entries.
In everyday lexicographic work, it is not enough to assign the ID of one single
lexicographer to an entry; one might want to trace who did what and at what time. As
neither <revisionDesc> nor <change> may be used as child elements of
<entry>, we considered various options to accommodate this information in our TEI
structures. The intention was not to store production-related metadata only as a
separate field in the database but to preserve this data in a self-contained manner as
part of the entries so that this data would be passed on whenever a digital dictionary
gets distributed.
Two elements were singled out which appeared to be plausible candidates to handle
metadata about revisions of entries: <div> and <note>. These elements both have
sufficiently generic semantics and, most importantly, may be used as children of the
<entry> element. We first tried to encode metadata on revisions like this:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
64

...
<note type="revisionDesc">
<list>
<item><date when="2011-10-11"/>charly, added POS</item>
</list>
</note>
...
We wanted to stay as close as possible to comparable TEI structures without bending
the semantics of particular elements. We decided in favor of a <div> element for
revisions, containing a feature structure. This <div> element is inserted as the last
element at the end of the entry. Each modification of the entry is registered by means
of an <fs> element:
...
<div type="revisionDesc">
<fs type="change">
<f name="who">charly</f>
<f name="when">2011-10-15</f>
<f name="what">added POS</f>
</fs>
...
</div>
...
The <fs> element corresponds to the TEI <change> element, and the single features
(<f> elements) correspond to the attributes of @change. Such constructs can also be
used to register status information: labels carrying values such as proposal, draft, and
approved can be used to control release of selected entries to the public.
6. Tools
So far, work on these digital lexical resources has been accomplished using a software
application developed in-house. The program was initially used in collaborative
glossary editing projects carried out as part of language courses at the University of
Vienna. As it proved to be flexible and adaptable enough, it has been put to use in the
ICLTT’s dictionary projects.
At the heart of the software application is the dictionary editing client, a standalone
application temporarily dubbed the Viennese Lexicographic Editor (VLE). It supports web-
based editing and dictionary entries are stored on a web server. All additional software
components (PHP and MySQL) are open-source and freely available. Communication
Journal of the Text Encoding Initiative, Issue 3 | November 2012
65

between the dictionary client (VLE) and the server has been implemented as a RESTful
web service.
While the dictionary editor is geared towards general use with XML data, it is
particularly suitable and customized for the use with TEI-encoded data. In addition to
fully customizable XSLT stylesheets, the tool includes a number of helpful built-in
features described in brief below.
Configurable keyboard layouts are designed to support the input of Unicode characters
usually not available in standard key assignments. Recent VLE versions allow the
automatic assignment of a keyboard to particular @xml:lang attributes to spare users
of manual switching between keyboard layouts. For example, when the user works on
contents of an element provided with an @xml:lang="ru" attribute, VLE
automatically activates the Russian keyboard layout; on entering an element with the
attribute @xml:lang="de", it switches back to the German layout.
Entry-specific metadata can be generated automatically whenever an entry is saved.
IDs of both entries and examples are created automatically on the basis of the contents
of the respective items.
Another feature of the dictionary editor is a special module that assists with the
integration of corpus examples into dictionaries. The principal idea behind this module
was optimizing access to digital corpora: the corpus interface of the dictionary writing
application enables lexicographers to launch corpus queries and insert them into
existing dictionary entries without using the clipboard to copy-and-paste, which would
inevitably result in a lot of inefficient typing or clicking.30
The validation of our dictionary data currently uses XML Schema, but the most recent
versions of VLE have been delivered with a newly integrated library that is also capable
of validating the data against RelaxNG schemas.
7. Conclusion
The heterogeneity of linguistic annotation has been and will remain a major obstacle
for interoperability and reusability of language resources. Over the past few years,
there has been increased awareness among developers and users of the need to achieve
a higher degree of convergence in many parts of their encoding systems. ICLTT staff
members’ previous experiences with LMF have shaped the TEI customization, and the
draft MAF specification is significantly influencing linguistically motivated TEI
applications. In creating digital dictionaries, both of these ISO specifications (and
others referenced by them) will continue to complement the work with the TEI
Guidelines.
All of our lexicographic endeavors have been guided by a vision of an ever more
densely knit web of dictionaries and more reusable, standards-based, and ideally
publicly available language resources. Such resources and the respective tools for
creation and access form an integral part of state-of-the-art ICT infrastructures. The
ICLTT’s interest in furthering the outreach of the TEI and integrating the Guidelines
into the newly evolving digital infrastructures has, among others reasons, been
motivated by their strong commitment to the European infrastructure projects CLARIN
and DARIAH.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
66

In conclusion, we would like to emphasize that our customization of the TEI P5
dictionary module has proved to be a solid foundation for new lexicographic projects.
While there is no doubt that much work remains to be done, we strongly believe that
the results of our experiments furnish ample evidence that TEI P5 can not only be used
to represent digitized print dictionaries but also for NLP purposes.
BIBLIOGRAPHY
Atkins, Beryl T.S., and Michael Rundell. 2008. The Oxford Guide to Practical Lexicography. Oxford;
New York: Oxford University Press.
Banski, Piotr, and Beata Wójtowicz. 2009. “FreeDict: An Open Source Repository of TEI-encoded
Bilingual Dictionaries”. Paper presented at the 2009 Conference and Members’ Meeting of the TEI
Consortium, Ann Arbor, Michigan, November 9–15, 2009. http://www.tei-c.org/Vault/
MembersMeetings/2009/files/Banski+Wojtowicz-TEIMM-presentation.pdf.
Bel, Nuria, Nicoletta Calzolari, and Monica Monachini, eds. 1995. “Common Specifications and
Notation for Lexicon Encoding and Preliminary Proposal for the Tagsets”. MULTEXT Deliverable
D1.6.1B. Pisa.
Budin, Gerhard, Heinrich Kabas, and Karlheinz Moerth. 2012. “Towards Finer Granularity in
Metadata: Analysing the Contents of Digitised Periodicals”. In Journal of the Text Encoding Initiative
2. doi: 10.4000/jtei.416.
Budin, Gerhard, and Karlheinz Mörth. 2011. “Hooking up to the Corpus: the Viennese
Lexicographic Editor’s Corpus Interface”. In Electronic Lexicography in the 21st Century: New
Applications for New Users: Proceedings of eLex 2011, Bled, 10–12 November 2011, edited by Iztok Kosem
and Karmen Kosem. Ljubljana: Trojina, 52–59. Institute for Applied Slovene Studies.
Dobrovolsky, Dmitry O. 2008–2010. Neues Deutsch-Russisches Grosswörterbuch. 3 vols. Moscow: AST.
Faith, R. 1997. A Dictionary Server Protocol. http://www.rfc-editor.org/rfc/rfc2229.txt.
Farrar, Scott, and D. Terence Langendoen. 2003. “A Linguistic Ontology for the Semantic Web”.
GLOT International 7 (3): 97–100.
Hass, Ulrike, ed. 2005. Grundfragen der elektronischen Lexikographie: Elexiko, das Online-
Informationssystem zum deutschen Wortschatz. Berlin; New York: W. de Gruyter.
Hausmann, Franz Joseph, Oskar Reichman, Herbert Ernst Wiegand, and Ladislav Zgusta, eds.
1989–1991. Dictionaries. An International Encyclopedia of Lexicography. 3 vols. Berlin; New York: W. de
Gruyter.
Ide, Nancy, Adam Kilgarriff, and Laurant Romary. 2000. “A Formal Model of Dictionary Structure
and Content”. In Proceedings of the Ninth EURALEX International Congress: EURALEX 2000: Stuttgart,
Germany, August 8th–12th, 2000, 113–126. Stuttgart: Universität Stuttgart, Institut für
maschinelle Sprachverarbeitung.
Ide, Nancy, Jean Veronis, Susan Warwick-Amstrong, and Nicoletta Calzolari. 1992. “Principles for
Encoding Machine Readable Dictionaries”. In EURALEX ’92 Proceedings: Papers Submitted to the 5th
Journal of the Text Encoding Initiative, Issue 3 | November 2012
67

EURALEX International Congress on Lexicography in Tampere, Finland. Tampere, Finland: Tampereen
Yliopisto.
ISO-24611 (Draft). 2008. Language resource management — Morpho-syntactic annotation framework.
ISO-24613. 2008. Language resource management – Lexical markup framework (LMF).
Kemps-Snijders, Marc, Menzo Windhouwer, Peter Wittenburg, and Sue Ellen Wright. 2009.
“ISOcat: Remodelling Metadata for Language Resources”. In International Journal on Metadata,
Semantics and Ontologies 4: 261–276.
Mörth, Karlheinz. 2002. “The Representation of Literary Texts by Means of XML: Some
Experiences of Doing Markup in Historical Magazines.” In Digital Evidence. Selected Papers from DRH
2000, Digital Resources for the Humanities Conference, edited by Michael Fraser, Nigel Williamson, and
Marilyn Deegan, 17–32. London: Office for Humanities Communication.
Romary, Laurent, Susanne Salmon-Alt, and Gil Francopoulo. 2004. “Standards Going Concrete:
From LMF to Morphalou”. In Workshop on Enhancing and Using Electronic Dictionaries. Geneva:
Coling.
Romary, Laurent. 2010. “Standardization of the Formal Representation of Lexical Information for
NLP”. In Dictionaries: An International Encyclopedia of Lexicography. Supplementary Volume: Recent
Developments with Special Focus on Computational Lexicography. http://arxiv.org/abs/0911.5116.
Romary, Laurent. 2010. “Using the TEI Framework as a Possible Serialization for LMF”. Paper
presented at RELISH workshop, August 4–5, 2010, Nijmegen, Netherlands. http://hal.archives-
ouvertes.fr/docs/00/51/17/69/PDF/NijmegenLexicaAugust2010.pdf.
Sarup, Lakshman. 1920–27. The Nighantu and the Nirukta: The Oldest Indian Treatise on Etymology,
Philology and Semantics. Delhi.
Snell-Hornby, Mary. 1986. “The Bilingual Dictionary: Victim of its own Tradition?” In The History
of Lexicography, edited by Reinhard Hartmann, 207–218. Amsterdam: John Benjamins.
TEI Consortium. 2012. TEI P5: Guidelines for Electronic Text Encoding and Interchange. Version 2.1.0.
Last updated June 17. N.p.: TEI Consortium. http://www.tei-c.org/release/doc/tei-p5-doc/en/
html/index.html.
Wegstein, Werner, Mirjam Blümm, Dietmar Seipel, and Christian Schneiker. 2009.
“Digitalisierung von Primärquellen für die TextGrid-Umgebung: Modellfall Campe-Wörterbuch“.
http://www.textgrid.de/fileadmin/TextGrid/reports/TextGrid_R4_1.pdf.
Wilkinson, Endymion. 2000. Chinese History. A Manual. Cambridge, Mass.: Harvard University Asia
Center.
NOTES
1. There is no reliable information available as to his date of birth. Tradition assumes
the 5th or 6th century BC. See Sarup (1920–27, 54).
2. While none of these works can be regarded as an absolute first, they can all be seen
as important milestones in their respective traditions.
3. A project working on Russian Wiktionary versions is the Wiktionary-Export project
which also produces TEI versions (http://wiktionary-export.nataraj.su/en/about.html).
4. http://www.ilc.cnr.it/EAGLES96/home.html
Journal of the Text Encoding Initiative, Issue 3 | November 2012
68

5. http://www.olif.net/
6. http://www.w3.org/2001/sw/BestPractices/WNET/ISLE_D2.2-D3.2.pdf
7. http://code.google.com/p/lift-standard/
8. http://www.w3.org/TR/owl-ref/
9. http://tools.ietf.org/html/rfc2229
10. A standardized object-oriented modeling language.
11. The ICLTT’s dictionary editor VLE provides a tool to convert some of the TEI
encoded dictionary data into LMF. This end is achieved by making use of XSLT
stylesheets to transform the TEI data into an XML format that looks very much like the
XML serialization as it can be found in the ISO specification.
12. This also shows in the fact that the P4 chapter was titled “Print dictionaries”,
whereas the current P5 version bears the title “Dictionaries”.
13. An example of what we would like to see more of can be found on the ICLTT’s
experimental Showcase website: http://corpus3.aac.ac.at/showcase/index.php/
dictionary. In this dictionary interface, each entry can also be viewed with its TEI
encoding.
14. Among the well-documented examples of TEI P5 encoded dictionaries, there is the
CAMPE dictionary, a product of the TextGrid project (Wegstein 2009). While most data
in the field are not easily available, let alone for reusing or further development, a
number of P5-compliant dictionaries were made freely available by the FreeDict project
(Banski 2009).
15. See the LMF website: http://www.lexicalmarkupframework.org/.
16. The general structure of these items of lexicographic information has been
discussed in various publications before. See Ide et al. (1992), Ide et al. (2000), and
Romary (2011).
17. These are <case>, <colloc>, <def>, <etym>, <form>, <gen>, <gramGrp>,
<hom>, <hyph>, <iType>, <lang>, <lbl>, <mood>, <number>, <oRef>,
<oVar>, <orth>, <pRef>, <pVar>, <per>, <pos>, <pron>, <re>, <sense>,
<subc>, <superEntry>, <syll>, <tns>, <usg>, and <xr>.
18. ISO-24613:2008(E), 39.
19. Feature structures are a general-purpose data structure that have become a widely
used means of representation in linguistics. They have a longstanding tradition in the
TEI. A chapter on the topic in the TEI Guidelines goes back to P3 (Sperberg-McQueen
and Burnard 1994, 394–431).
20. http://wiki.verbix.com/Documents/VerbixLanguageCodes
21. Global attributes can be used on all elements of the TEI encoding scheme.
22. BCPs are published by the Internet Engineering Task Force together with RFC
(request for comments) documents.
23. BCP 47 is made up of two IETF documents: RFC 4646 and RFC 4647. A good overview
is given in TEI Consortium 2012, liv.
24. The registration authority for ISO 639-3 is SIL International (http://www.sil.org/
iso639-3/codes.asp).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
69

25. It is interesting that W3C discourages the use of macrolanguage subtags (http://
www.w3.org/International/questions/qa-choosing-language-tags.en#langsubtag). The
label arz-x-cairo-vicav would be as clear as ar-arz-x-cairo-vicav.
26. While Cairo, Illinois (USA), will probably not be confused with the Egyptian capital
in this context, other ambiguities will definitely occur.
27. The language identifier fa has the “Suppress-Script: Arab” entry set in the IANA
registry. That means that it is the default and should be omitted. However, we decided
to be more explicit in such cases as the different <orth> elements are being used in
our markup scheme exactly for the purpose of representing different writing systems.
28. The structure of the <sense> block has been heavily affected by the transition
from P4 to P5. The <trans> and <tr> elements have been removed from P5.
29. In a paper presented at the TEI Members’ Meeting last year, we discussed the
possibility of assigning TEI headers through links to particular divisions of text
documents (Budin and Moerth 2011).
30. See Budin 2011.
ABSTRACTS
Although most of the relevant dictionary productions of the recent past have relied on digital
data and methods, there is little consensus on formats and standards. The Institute for Corpus
Linguistics and Text Technology (ICLTT) of the Austrian Academy of Sciences has been
conducting a number of varied lexicographic projects, both digitising print dictionaries and
working on the creation of genuinely digital lexicographic data. This data was designed to serve
varying purposes: machine-readability was only one. A second goal was interoperability with
digital NLP tools. To achieve this end, a uniform encoding system applicable across all the
projects was developed. The paper describes the constraints imposed on the content models of
the various elements of the TEI dictionary module and provides arguments in favour of TEI P5 as
an encoding system not only being used to represent digitised print dictionaries but also for NLP
purposes.
INDEX
Keywords: P5, dictionaries, digital lexicography, NLP
AUTHORS
GERHARD BUDIN
Gerhard Budin is full professor for terminology studies and translation technologies at the
Centre of Translation Studies at the University of Vienna, director of the Institute for Corpus
Linguistics and Text Technology of the Austrian Academy of Sciences, member (kM) of the
Journal of the Text Encoding Initiative, Issue 3 | November 2012
70

Austrian Academy of Sciences, and holder of the UNESCO Chair for Multilingual, Transcultural
Communication in the Digital Age. He also serves as vice-president of the International Institute
for Terminology Research and Chair of a technical sub-committee in the International Standards
Organization (ISO) focusing on terminology and language resources (ISO/TC 37/SC 2 2001–2009,
SC 1 2009-present). His main research interests are language technologies, corpus linguistics, and
knowledge engineering, E-Learning technologies and collaborative work systems, distributed
digital research environments, terminology studies, ontology engineering, cognitive systems,
cross-cultural knowledge communication and knowledge organization, philosophy of science,
and information science.
STEFAN MAJEWSKI
Stefan Majewski studied English Language and Literature as well as Sociology at the University of
Vienna and Electronics at the Vienna University of Technology. He graduated in English
Linguistics with a focus on research infrastructures for corpus linguistics. Currently, he is
working at the Austrian Academy of Sciences, where he coordinates and works for the “Data
Service Infrastructure for the Social Sciences and Humanities” (DASISH) project. He is also
employed by the Göttingen State and University Library, where he works for the “TextGrid”
project in research and development. His current interests focus on research infrastructures and
annotation systems.
KARLHEINZ MÖRTH
Karlheinz Mörth is senior researcher and project leader at the Institute for Corpus Linguistics
and Text Technology (ICLTT) of the Austrian Academy of Sciences, lecturer at the University of
Vienna and co-head of the DARIAH Virtual Competency Centre 1 (eInfrastructure). Proceeding
from a broad background in cultural, literary and linguistic studies, he has been working on a
number of scholarly digital projects. He has contributed to the design and creation of the
Austrian Academy Corpus (AAC), taking responsibility for text encoding and software
development. His current research activities focus on eLexicography and text technology for
linguistic research.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
71

Consistent Modeling ofHeterogeneous Lexical StructuresLaurent Romary and Werner Wegstein
AUTHOR'S NOTE
The authors would like to thank the reviewers of earlier versions of this paper,
especially reviewer A, for their very detailed analysis and constructive criticism that
contributed to the profile of our paper.
1. Pooling Lexical Sources: A Digital HumanitiesPerspective
1 Our paper addresses the problem of interoperability between heterogeneous data
sources, an issue that has regularly been the object of many debates within the Text
Encoding Initiative (TEI) community and in general within many standardization
groups providing models or formats for data interchange. At the core of the problem is
the trade-off between expressivity—offering a flexible platform for representing a
variety of possible structures—and processability—being able to predict under which
conditions some data can be the object of a blind interchange, in particular in the
context of them being processed randomly by a generic tool.
2 This trade-off has no generic solution, but it regularly arises in defining the
components of such an expansive modeling platform as the TEI Guidelines. The TEI
specifications are an expression of a balance of interests between the many, varied use
cases from the community and the need to abstract away from such examples in order
to design recommendations that new users can easily understand and apply in the
context of their own encoding endeavours.
3 Throughout the TEI Guidelines one finds a stratification of corrections, constraints, and
new features added over time, which have left some constructs as hybrid data models
Journal of the Text Encoding Initiative, Issue 3 | November 2012
72

and which leave the user wondering which representation is the “optimal” one in a
given context, leading to heterogeneous encoding practice in the global data space of
existing TEI documents. Over the years, this has become more and more an issue as
documents are increasingly accessible online and scholars increasingly collaborate on
projects using TEI documents. That is, the “stratification” of the Guidelines has
worsened the problem of interoperability.
4 In this paper we will focus on lexical structures, which we believe represent a typical
case of the interoperability problem in terms of pooling data from heterogeneous
sources. We have asked ourselves whether the TEI chapter dedicated to lexical data,
simply entitled “Dictionaries,” should not be revised or at least be accompanied by
further constraints on its usage so that basic operations related to the querying,
displaying, or merging of lexical information could be made more straightforward.
5 From a digital humanities perspective, we want to understand if it is possible to find a
balance between expressing precise constraints on the encoding of a primary source
and leaving some freedom to the scholar who will see the encoding activity as a step in
his research process. This is why we have made an attempt to identify a generic
methodology for expressing encoding constraints on source texts based on the idea of
local representation or crystals (Romary 2009). These crystals correspond to elementary
constructs at a low level of granularity in a document, which, independently of the
broader organization of the document itself, can be used to express a certain concept in
an extremely regular way, thus making the further reuse of this information chunk
easier. In this context, interoperability is related to the capacity of a person or a tool to
process encoded crystals within a document independently of its origin.
6 After presenting the general background for modeling and representing lexical
sources, we give an overview of the various crystals that form the basis of most existing
types of lexical entries. For each of these crystals we make systematic
recommendations with corresponding supporting arguments. In the second part of the
paper we illustrate our proposals with concrete cases taken from various dictionary
and lexical database projects.
2. Modeling Tools for Lexical Resources
7 The case of lexical data as presented in a dictionary offers an interesting experimental
setting for studying interoperability in the context of standardisation. It is complex
enough to reflect the variability which is intrinsic to the TEI Guidelines while providing
a limited observational setting for studying the granular structure of lexical entries as
well as the rather high internal coherence that one specific lexical source usually has.
Lexical resources also reflect the variety of analytical points of view that one may have
on linguistic information, ranging from quite descriptive and verbose objects in the
domain of standard human-oriented dictionaries to fully structured databases like
those developed in the natural language processing domain.
8 In this paper we consider only lexical resources that are encoded semasiologically—
where entries are determined according to the forms found in a language and further
refined into the different senses that have been deemed relevant for this form. This
word-to-sense organization is usually seen as the most appropriate for the
representation of large coverage lexica, as opposed to onomasiological representations
(concept-to-term), which better take into account the organization of domain-specific
Journal of the Text Encoding Initiative, Issue 3 | November 2012
73

vocabularies (terminologies). The semasiological perspective is usually the underlying
model for traditional print dictionaries as well as for large-scale lexica in the natural-
language-processing domain (Halpern 2006; Atkins et al. 2002).
9 There are two main international standardization activities that are relevant for the
modeling and the representation of semasiological resources: the Lexical Markup
Framework (LMF) and TEI. In accordance with the modeling strategy of ISO committee
TC 37, LMF (which has been standardised as ISO 24613:2008) provides a group of meta-
models that can be combined to produce specific data models applicable to a wide
range of lexical types or components including machine readable lexica, morphology,
syntax, semantics, and multi-word expression. Even when the LMF specification
provides a possible XML serialisation, it tends to be agnostic as to the actual
implementation of the models it allows one to describe. On the other hand, the TEI has
been seminal in offering a reference XML vocabulary for the representation of
dictionaries, which is mostly compliant with LMF principles.1 However, the variety of
constructions that the TEI actually allows for the representation of the same lexical
phenomenon could possibly be seen as a hindrance to the achievement of deep
interoperability across heterogeneous lexical resources.
10 In this paper we take as a starting point the positions described by LMF and the latest
release of the TEI Guidelines2 in order to provide further insights into how to build
lexical resources or dictionaries relying on a systematic use of standardised constructs.
The work presented here is also based upon some core principles that have
systematically guided our work, both theoretically but also practically, through the in-
depth presentation of examples that have served as experimental background for
testing our proposals. Even though the present work is not about modeling XML
structures at large, several of these principles are derived from a more global concept
of the kind of semantics that XML constructs convey and the way to actually reflect this
in the design of XML formats.
11 With this perspective in mind, two generic constraints that affect the organization and
semantics of lexical structures can be stated:
Semantic grouping: Features that jointly convey a given meaning in a lexical entry should be
systematically grouped together, even when only one such feature occurs and even at the
cost of favoring more deeply-structured representations.
Hierarchical dependency: Features, or groups thereof, which qualify a given level (for
instance, an entry), are considered to be inherited by subcomponents (typically the senses)
of the lexical entry unless otherwise stated (Ide, Kilgarriff, and Romary 2000). (Here and
below, we use “level” to refer to a hierarchical relationship within the data structure.)
12 From these constraints we will progressively derive specific recommendations for the
local organization of lexical entries as guided by a crystal-based analysis. Comparing
these with real data, and in particular with legacy dictionaries, we will try to
understand possible transition schemes from weakly structured data to more
standardized constructs.
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
74

3. Core Proposals: Towards a Systematic Descriptionof Lexical Crystals
3.1. Crystals as Coherent Sub-structures
13 Introducing the concept of crystals in data modeling in general and in the TEI
Guidelines in particular reflects the need to describe data structures that act as
scaffolding for a coherent group of components (or elements in XML terminology).
More precisely, a crystal can be defined as an independent group of connected elements (a
clique) with semantic coherence. A typical example of a crystal is a structured
bibliographical entry using the TEI’s <biblStruct> element. This element contains
internal structure (comprising <analytic>, <monogr> with <imprint>, and
<series>), can be inserted at various places within the TEI architecture, and can be
further expanded by other components or crystals (for example, <author>).
14 Without introducing any specific formalism here, we might define a crystal by:
The set of mandatory and optional components that may occur in the crystal
The structural organization of the crystal, stating in particular the hierarchical relations
between components
The anchor points of the crystal (<analytic>, <monogr> with <imprint>, and
<series>), where it can be further expanded
The global semantics of the crystal, in complement to the specific semantics of its
component elements
15 A crystal is thus a modeling tool that can be used to provide a coherent description of a
subset taken from a more complex data model (as is typically the case with the TEI
Guidelines). To illustrate this, we will briefly demonstrate how the TEI Guidelines
chapter on dictionaries can serve as a basis for implementing LMF, and point out some
consequences this could have on the data architecture that we recommend for certain
TEI elements.
16 As a starting point, let us consider the LMF subset depicted in figure 1, which
implements the semasiological view of a lexical entry. This UML diagram states that a
Lexical Entry is characterised by at least one Form component to which a hierarchically
embedded series of Sense components may be associated. The Form component is
further refined by means of an optional Form Representation component, which can be
used to represent the various concrete implementations of a lexical form (e.g. phonetic,
graphical, etc.). Finally, each component of the meta-model (corresponding here to a
UML class) can be further characterised by properties attached to each of them.
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
75

Figure 1: The Lexical Entry sub-structure of the LMF core package
17 Transposed to the TEI world, the LMF metamodel can be expressed as a TEI crystal
rooted on the <entry> element. This crystal, depicted in figure 2, states that the
minimal lexical entry in a sense as defined by TEI uses the <entry>, <form> and
<sense> elements, with <form> being further decomposed by means of a series of
elements implementing the Form Representation component of LMF.3 The picture also
introduces three new classes, which could gather up all further descriptive elements
needed to refine <entry>, <form>, and <sense>: model.entryDesc,
model.formDesc, and model.senseDesc.
18 This first presentation of the TEI lexical entry as a crystal illustrates how this concept
may help in describing complex structures that rely on constraints that go beyond (and
deeper) than what we normally express by means of DTDs or schemas. Even though we
do not systematically analyze the equivalences between LMF and the TEI in the
following section, we hope that the preceding explanation will help the reader
understand the logic behind the various constraints explained in subsequent sections.
In a pattern analogous to the internal structure of the <cit> element, we see the
organization of the various elements of this lexical entry crystal as a combination of a
structural description (direct dependency of one element on another) and a descriptive
dimension (further constraints applicable to the group of elements).
Figure 2: The ideal element-class organization of a TEI lexical entry
3.2. Morphographical Descriptions
19 In a semasiologically structured lexical entry, form information gives one or more
realizations of a word—whether graphical, phonetical or iconical (by means of a picture
or drawing)—which can be used to find the corresponding lexical unit. Such
Journal of the Text Encoding Initiative, Issue 3 | November 2012
76

information may comprise abstract identifiers for the headword, namely the lemma,
morphological components or categories (such as the consonantal pattern in Arabic),
or any inflectional variant that can be associated with the entry.
20 The central issue in describing the corresponding morphographical crystal is that it
should be based upon an abstract representation of Form as a component, which in turn
groups together all the possible realizations of the corresponding form (the Form
Representation component in LMF), as well as the associated constraints. In terms of
good practices, one should thus refrain from providing a form representation
(realization) in isolation and always include it within an embedding <form> element.4
Unless there is only one form associated with a given lexical entry, the form type (such
as a lemma or inflected form) should be provided to ensure its univocal identification.
21 As a consequence, the minimal structure associated with a TEI-encoded lexical entry—
where the only information given is that of a lemma (here, the French word chat; (en)
cat)—should be encoded as follows:
<entry>
<form type="lemma">
<orth>chat</orth>
</form>
</entry>
22 On this basis, additional variants of the form (such as pronunciation) can be added to
the same form container, together with complementary information characterizing
them. For instance, when more than one orthography is used to provide the form, the
appropriate @type attribute should be used to qualify the corresponding orthography.
In the following example, the lemma for the Korean word “치다” (chida; (en) to hit) is
provided in Hangul orthography ((ko) 한글) orthography together with a Romanized
form.
<form type="lemma">
<orth type="한글">치다</orth>
<orth type="romanized">chida</orth>
</form>
23 As a next step, we advocate the definition of stable values for the @type attribute on
<orth>, adopting ISO 15924 to refer to the script.
24 When alternative forms are provided, indicating, for example, inflectional variation,
then the variants should be encoded in full in order to reflect linguistic differences. For
instance, the example provided in Annex B of LMF (clergyman) is reformulated in TEI as
follows:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
77

<entry>
<gramGrp>
<pos>commonNoun</pos>
</gramGrp>
<form type="lemma">
<orth>clergyman</orth>
</form>
<form type="inflected">
<orth>clergyman</orth>
<gramGrp>
<number>singular</number>
</gramGrp>
</form>
<form type="inflected">
<orth>clergymen</orth>
<gramGrp>
<number>plural</number>
</gramGrp>
</form>
</entry>
3.3. Grammatical Information
25 Grammatical information may appear at various points within a dictionary entry; it is
there to provide additional information about the core objects comprising the entry. In
the lexicographic tradition grammatical information qualifies the lemma, or rather,
since the lemma is just a code representing the entry as a whole, syncretizes the
grammatical features that apply by default to all possible occurrences of the word.
However, the grammatical information can also occur at many other possible levels of
the entry, qualifying inflected forms in a more precise way (as in the “clergyman”
example above), indicating specific constraints associated to a sense, or even qualifying
the occurrence within an example of phrasal expression. As a whole, a grammatical
crystal defined according to these principles may be used at any place where the usage
of a word is described.
26 The notation for grammatical features within human-oriented dictionaries varies
greatly: a given grammatical constraint can, for instance, be represented by a
prototypical morpheme (e.g. der / die / das to indicate grammatical gender in German)
or by means of a descriptive phrase (used in the plural form). At best, idiosyncratic codes
are used (e.g. masc., fém.), though they are not always consistently applied within a
single dictionary, let alone across dictionaries. There is no doubt that such a situation
prevents one from querying lexical entries that include grammatical constraints in a
coherent way. It is therefore a priority to establish requirements for the representation
of grammatical features in a way that is both standard and yet preserves the initial
editorial choices. As a basis for such recommendations we recommend that TEI-based
Journal of the Text Encoding Initiative, Issue 3 | November 2012
78

encoding of dictionary entries should be in keeping with the following elementary
principles:
Grammatical features should systematically be embedded within a <gramGrp> container
element, even if only one feature is present and even if the grammatical information is split
up so that more than one <gramGrp> container may be necessary.
Whereas one should be flexible with the textual content of a grammatical descriptor, it is of
utmost importance to normalize the intended value by means of a @norm attribute.
27 For instance, when a value for the grammatical gender is given by means of a
determiner, the @norm attribute will provide the reference value (e.g. as a code from
the ISOcat data category registry).5 Depending on the encoder’s editorial choices, a
minimal encoding might look like the following example:
<form type="lemma">
<gramGrp>
<gen norm="feminine">die</gen>
</gramGrp>
<orth>Katze</orth>
</form>
28 A more elaborate encoding scheme could lead to the following lemma structure:
<form type="lemma">
<form type="marker">
<gramGrp>
<pos norm="determiner"/>
<gen norm="feminine"/>
</gramGrp>
<orth>die</orth>
</form>
<form type="head">
<gramGrp>
<pos norm="noun"/>
<gen norm="feminine"/>
</gramGrp>
<orth>Katze</orth>
</form>
</form>
29 In general, such grammatical descriptions should be thought of as being equivalent to
the provision of feature structures and thus mappable onto an <fs> element. For
instance, the preceding minimal encoding example (omitting the orthographic form) is
equivalent to:
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
79

<fs>
<f name="gender"><symbol value="feminine"/></gen>
</fs>
30 The next stage in providing a recommendation is to make sure that values for the
@norm attribute are stable within a project and, when possible, across projects. We
recommend two complementary strategies:
For a given project, document and publicize the values used for the norm attribute so that
the community may be aware of possible discrepancies
Relate such values to entries in the ISOcat data category registry so that they are mapped
onto standardized conceptual references.
31 It should be noted that at the time of writing, there is an item on the TEI Council
agenda to better integrate mechanisms available in ISO 12620:2009 (the standard which
defines the structure of ISOcat) within the TEI architecture to facilitate such mappings.
We can thus expect that these recommendations may become in due course standard
practice within the TEI community.
3.4. Senses as Systematic Entry Points
32 The representation level introduced by the Sense component in LMF and its
counterpart <sense> in the TEI Guidelines is an essential concept implementing the
semasiological perspective of a dictionary. Still, a “lazy” encoding style for dictionary
entries could lead to the idea that such a structure is superfluous when, for instance, a
word can directly be described at the same level as the morphological and grammatical
information by a simple definition or a translation that is a child of <entry>. Indeed,
it is often the case in the simplest forms of legacy lexical structures that senses are not
explicitly separated out in the microstructure of the entry. We consider this bad
practice and recommend that <sense> be used to enclose all descriptors that describe
the signified (as opposed to the signifier, that is the <form>, in the Saussurian sense).
33 As can be observed from the variety of constraints that may apply to a <sense>
element within a lexical entry, the underlying understanding of the semasiological
model extends to the organization of senses that do not rely on strict semantic criteria
(Ide, Kilgarriff, and Romary 2000). This is not so much of a paradox when we think of
the numerous ways by which semantic variation may be observed, among which we can
include pure morpho-syntactic or syntactic markers. As a result, we consider that
<sense> should be used to describe any subdivision reflecting a variation in usage for
a given word. In an extreme case, applying automatic collocation extraction tools
(Kilgarriff and Tugwell 2002) may result in generating lexical entries automatically
where senses correspond to the various collocation classes that the tool has
determined.
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
80

34 We thus see the sense component in LMF and the <sense> element in TEI as a generic
container organizing the further description of a signifier, which may contain
information related to:
The actual syntactico-semantic restriction applicable to the sense being described, for
instance by means of further grammatical constraints, a definition, or some usage
restriction
The provision of further illustrative information, in particular contextualized examples or
translations (see the section on the <cit> element below)
Relational information referring to external information expressing the same meaning,
either within another lexical entry or an external ontological reference (such as in the
lexical database project WordNet, described by Miller and Fellbaum [2007]).
35 In order to actually facilitate further querying, it is important that each feature
intended to be associated with a sense shall be precisely typed. Precise typing requires
that clearly defined typologies be associated with elements such as <usg> and <cit>.
Furthermore, dictionary projects should be able to document precisely how much
restrictive or illustrative information is inherited along embedded senses. For instance,
a clear editorial strategy should state whether grammatical constraints replace or
complete existing ones at a higher level of a sense hierarchy.
3.5. <cit>: A Generic Linguistic Quotation Tool
36 The <cit> element in TEI P5 is the result of a merger of several constructs from
former editions of the TEI chapter on dictionaries that had been created to handle
examples and translations in dictionary entries. The underlying aim of the new
framework was twofold. On the one hand, the objective was to provide greater
coherence to the way language excerpts appear not only in dictionaries but in textual
content in general. On the other hand, the TEI Council wanted to design a sound
framework for dealing with additional references or constraints provided in a lexical
entry to compliment the quoted object itself, taking into account that such refinements
may lead to recursive constructs. In terms of interoperability across TEI-based
applications, the main vision behind the <cit> element, and the crystal it shapes, is to
provide entry points for generic searches for quoted language in texts, from the point
of view both of the full-text content and of providing a systematized representation of
constraints associated with the full text.
37 Language quotations in text may indeed take many different forms. In dictionaries the
most basic quotation is simply a phrase or sentence exemplifying the headword. Most
of the times, this quotation does not appear alone but is refined according to two main
axes:
Indication of the source of the quotation, for instance the following from P5 2.0.0: ‘La valeur
n’attend pas le nombre des années’ (Corneille)
Provision of usage information, stating constraints that the example is bound by, such as
domain or pronunciation, as in the following from P5 2.0.0: some … 4. (S~ and any are used
with more): Give me ~ more/s@'mO:(r)/
38 In the case of multilingual dictionaries, language quotations are similarly used to
provide equivalences for the entry (or sub-sense thereof) in the target language. In a
way that is similar to the monolingual case, further refinement of the encoding
structure of a quotation may indicate some source or usage information, but it may also
•
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
81

document the target language proper. A usual case here is the indication of the
grammatical gender of a noun equivalent in the target language.
39 Quotation constructs are not covered in LMF but can easily be modeled as an extension
to the LMF core packages. Figure 3 is a simple representation for such an extension.
The approach is similar to the one we advocate above for grammatical information in
relation to senses, in which the quoted text is embedded in a quotation construct even
if no refinement is actually stated.
Figure 3: An LMF extension for quotations represented in a dictionary
40 In the TEI Guidelines, the quotation construct is implemented by means of the <cit>
element, which has the following characteristics:
The quoted object may be realized not only by means of a <quote> or <q> (both from the
model.qLike class) but also as a more elaborated construct such as an XML object
(<egXML>, a member of model.egLike).
The refinement of a quotation can be instantiated as a bibliographic reference (using an
element from model.biblLike), as a pointer or external reference to a constraint (using
an element from model.ptrLike), as specific lexicographic features such as grammatical
constraints (using an element from model.entryPart), or through the inclusion of
feature structures in <cit>—accidental by design—which are part of model.global. It
should be noted that a refinement can actually be an embedded <cit> (by virtue of the
inclusion of model.entryPart in the content model of <cit>), thus offering, for
example, a natural way to provide a translation of a quotation.
41 Note that the TEI Guidelines already systematize the values of the @type attribute to
“example” and “translation” for use in dictionaries.
42 Given the variety of possible cases where <cit> may be used and the potentially
infinite combinations of refinement, it may be difficult to provide clear requirements
for its application. Basically a proper usage of <cit> should allow a human reader or a
processor to identify one quoted object and treat all other components as refinements
in which semantics are understood in a conjunctive way (in other words, all
refinements apply en bloc to the quoted object). By default, the quoted object should be
the first child of the <cit> element or, in general, the first child that is a member of
either model.qLike or model.egLike.
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
82

43 Although the second part of this paper provides several applications of <cit> in the
context of our observational corpus, we can illustrate here some basic usages of this
element from examples available in the TEI Guidelines.
44 In the following prototypical case, a simple example for the headword is associated
with a refinement giving the pronunciation of part of the quoted text:
<cit type="example">
<quote>Give me <oRef/> more</quote>
<pron extent="part">s@'mO:(r)</pron>
</cit>
45 The next example illustrates the representation of a translation refined with a
grammatical feature:
<cit type="translation" xml:lang="fr">
<quote>habilleur</quote>
<gramGrp>
<gen>m</gen>
</gramGrp>
</cit>
46 Finally, we cannot resist presenting a recursive case where the embedded <cit> is
used as an additional descriptive element for the quoted text at the higher level:
<cit type="example">
<quote>she was horrified at the expense.</quote>
<cit type="translation" xml:lang="fr">
<quote>elle était horrifiée par la dépense.</quote>
</cit>
</cit>
4. Illustrated Guidelines for Early Printed Dictionaries
4.1. Lexicographical Justification
47 We tested our encoding concepts using printed dictionaries from the second half of the
18th century for two reasons. First, in the history of English lexicography the early 18th
century marks the beginning of modern dictionary practice (Landau 2001, 60–66).
Samuel Johnson’s Dictionary of the English Language, first published in 1755, perfectly
Journal of the Text Encoding Initiative, Issue 3 | November 2012
83

embodies these advances in lexicography. Johnson is the first English lexicographer to
include thousands of other quoted “‘authorities’ within his text as illustrations of word
use” (Reddick 1996, 9). His dictionary also brought together “for the first time key
conventions for future dictionary presentation: the folio6 design is a system of
typography that displays the structure of each entry, though there are inconsistencies
of abbreviation and ambiguities” (Luna 2005, 193). Thus this dictionary offers an ideal
test bed to study problems in providing a consistent encoding in P5 of a source
document that offers notational inconsistencies. Second, because Johann Christoph
Adelung7 translated Samuel Johnson’s dictionary into German (Adelung 1783–1796),
Johnson’s dictionary opens up additional perspectives for the study of bilingual
lexicographical resources in the 18th century and research into the history of revision
and the reuse of dictionaries.
48 We test our modeling of lexicographic structures with three samples from Johnson’s
monolingual dictionary representing the most frequent word-classes: the adjective
ABLE, the verb To APPLAUD, and all entries for the noun APPLE (the use of all caps
versus small caps by Johnson is explained below). We further compare Johnson’s apple
entries with the section of apple entries in Adelung’s bilingual English-German
translation of Johnson’s dictionary. To illustrate the differing encoding structures of
bilingual German-English dictionaries we use Eber’s entry FÄHIG, the equivalent of
ABLE. As a source for this entry, Ebers obviously used only the German-French
dictionary of Christian Friedrich Schwan (Schwan 1782), so we include Schwan’s entry
FÆHIG in order to illustrate dictionary reuse across languages in the 18th century. The
images of the encoded pages are given as a supplement to this article.
4.2. Typographic Analysis and Text Encoding
49 Luna begins his essay on the typographic design of Johnson’s dictionary with some
reflexions on how a typographer would analyze a dictionary: “In particular, how does a
typographer look at a dictionary that is also a cultural artifact, as Samuel Johnson’s
Dictionary of the English Language undoubtedly is?” (2005, 175). Building on a more wide-
ranging definition of typography as “configuration of verbal graphic language,” Luna
concludes, “the main concern of this essay is not the quality of the printing, nor the
nature of the paper, nor even the origin of the founts of type used to compose the
Dictionary, but how its visual presentation reflects the structure of the text, its usability,
and perhaps even its compiler’s intentions” (2005, 175).
50 This concept comes very close to what a TEI encoding of a dictionary in an adequate
granularity should achieve: reflecting the structure of the encoded text, facilitating re-
usability in electronic form and—at its best—assisting in the detection of the author’s
intentions. In order to put our aim of a consistent modeling of heterogeneous
structures into practice, we follow some basic principles.
51 We adopt a conservative editorial view for our literal transcription (see section 9.5.1 of
P5) and try to keep the latter close to the printed original: we do not add any character
to the original text or delete it, we transcribe the text in the order in which it appears
in the source, we preserve the linear structures of the text with <pb>, <cb> and <lb>,
and we retain the end-of-line hyphenation (see section 3.2.2 of P5). With such
orthographical variation within the texts of the dictionaries, this makes transcription
much easier. For clarity and to ensure a consistent encoding we encode only a few
Journal of the Text Encoding Initiative, Issue 3 | November 2012
84

structurally important typographic features (significant use of typeface and italics) at
the level of the lexical entry.8
4.3. Encoding Practice at the <entry> Level
52 With re-usability, interoperability, and sustainability of the dictionary entries in mind,
we use two attributes to refine the <entry> element: @xml:id to guarantee a robust
and reliable non-ambiguous identification and @type for classification of the entries.
53 The @xml:id attribute is composed of four parts, each separated by a dot:
two initials of the author’s name and a combination of six letters or numbers to identify the
encoded edition precisely
four digits for the year of publication
six digits for the running number of the entry (given as a random value in the examples)
the lemma, transcribed in lower case only and with any incidental spaces replaced by
underlines.
54 Thus our sample entry ABLE in Samuel Johnson’s dictionary is assigned the @xml:id
'sjdict1f.1755.000123.able'. In the first part, “sj” is taken from Samuel Johnson, “dict”
reflects the title Dictionary of the English Language, and “1” indicates the edition and “f”
the format folio (because edition and format are both rather important for a precise
identification of the different printed editions of Johnson’s dictionary). They are not
necessary for Adelung (Henne 2001, 170), Ebers (Lewis 2012), and Schwan.
55 We use the TEI @type attribute of <entry> to distinguish typographically or verbally
marked types of entries and map them onto corresponding identifiers of the ISOcat
data category registry. The @type attribute used on <entry> belongs to the attribute
class att.entryLike, which includes a list of suggested values for @type. For the
entries in Johnson’s Dictionary we had to add some more fine-grained distinctions to the
list of suggested values.
56 An occasional user of Johnson’s Dictionary may be puzzled about the typesetting of
entry headwords. Thus APPLAUD and APPLE are in full caps, while APPLAUSE and APPLE
TREE are in small caps. Now and then, however, entries appear typeset in italic capital
letters, e.g. ABORIGINES and ABRACADABRA. In his preface, Johnson explains the
background for these marked differences, which for him reflect basic lexicographical
distinctions: “In the investigation both of the orthography and signification of words,
their ETYMOLOGY was necessarily to be considered, and they were therefore to be divided
into primitives and derivatives. A primitive word, is that which can be traced no
further to any English root; . . . Derivatives, are all those that can be referred to any
word in English of greater simplicity” (1755, 3f). Thus primitives or roots are marked by
full caps and the derivatives by small caps. Furthermore, the entries in italic capital
letters indicate foreign words used in the English language (Luna 2005, 181).
57 As Luna notices (2005, 196 fn. 24), this distinction of entries echoes a completely
different way of organizing a dictionary: word-families, represented by roots (in
alphabetical order), followed by their derivatives (ordered non-alphabetically into
morphological or etymological groups). Since Johnson used a single alphabetical order
for all entries, this organizing principle is no longer clearly visible. It is only faintly
reflected in the differentiation of the lemmas. But it is still implicit and that is why we
think it should be encoded explicitly as a significant feature of the dictionary structure.
1.
2.
3.
4.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
85

Accordingly, we map the entries representing lexical units in Johnson’s Dictionary onto
the ISOcat identifiers root or derivation and use foreign to indicate foreign words
respectively. Two examples: ABLE and APPLE of Love.
<entry xml:id="sjdict1f.1755.000123.able" type="Root">
<form type="lemma" norm="able">
<lb/><orth rend="allcaps">A'BLE</orth><pc>.</pc>
<gramGrp><pos norm="adjective">adj.</pos></gramGrp>
</form>
<entry xml:id="sjdict1f.1755.000346.apple_of_love" type="Phrase">
<form type="lemma" norm="apple of love">
<lb/><orth><hi rend="smallcaps">APPLE</hi> <hi rend="italics">of
Love</hi></orth><pc>.</pc>
<gramGrp><pos norm="noun"/></gramGrp>
</form>
<sense>
<cit type="Encyclopedic_Information">
<quote><lb/>Apples of love are of three sorts; ...
<bibl><author>Mortimer</author>’s <title>Husbandry</title>.</bibl>
</cit>
</sense>
</entry>
58 The typography of the entry APPLE of Love―small caps for apple though belonging to the
root entries, italics for of love, and the word class information missing from the source
(though supplied in the encoding)―indicates uncertainty about the word status of the
entry. Furthermore, the classification as type phrase may require some explanation.
Valerie Adams comments in her introduction to word-formation on the distinction
between words and phrases: “Certain noun-preposition-noun phrases also show their
incomplete unification by the possibility of pluralizing the first noun” (1976, 9). Since
the illustrative quotation of Mortimer’s book on Husbandry starts with the plural form
“apples”, we regard the type “Phrase” here as justified and did not consider alternative
ISOcat options.
4.4. The <form> Block
59 The <form> element is designed to contain information on the written form (encoded
using <orth>) and, if present, the spoken form (encoded using <pron>) of one
lemma. We use <form> with two attributes: a @type attribute to distinguish the
lemma from any given inflected forms and a @norm attribute to even out any
orthographic variation, such as the use of upper or lower case, hyphenation, or special
markers to indicate the stress position within the orthographic representation of the
lemma. The <form> block contains a number of elements including <orth> and
<gramGrp>; the TEI <stress> element, designed for stress patterns given
Journal of the Text Encoding Initiative, Issue 3 | November 2012
86

separately, is not applicable here, apart from the fact that we did not want to split up
the orthographic representation any further or change it.
60 Within <orth>, typographic details are stored in a @rend attribute. In Johnson’s
Dictionary we use it to store his typographic differentiation of the printed entries: that
is, his distinction between all caps and small caps. In Schwan’s dictionary it is used to
distinguish two different orthographic representations of the German lemma, the first
with Antiqua capital letters only, the second with upper and lower case, depending on
the German orthography, and using a Fraktur typeface.
61 We use <gramGrp> to collect grammatical information such as part-of-speech (in a
<pos> element) or gender (in a <gen> element). Quite often, grammatical
information precedes or follows the orthographic representation of the entry, such as
the infinitive marker To in entries for verbs in Johnson’s dictionary or the determiner
der, die, das in German noun entries. We capture this information with a <gram>element and a @type attribute containing the appropriate ISOcat value. Without
exception, we store all elements that interpret grammatical features like <pos>,
<gen>, or <gram> within a <gramGrp> element, once again using a @norm attribute
to map the different grammatical descriptions given in the dictionaries to an ISOcat
entry. This way, we avoid conflicts with the order of text on the printed page and can
adjust inconsistencies like missing word class information, such as by adding an empty
<pos> element with a @norm attribute based on information collected elsewhere in
the entry. One example is Johnson’s entry APPLAUD that requires two <gramGrp>elements to capture the grammatical information:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
87

<pb n="148"/><cb n="APP"/>
<entry xml:id="sjdict1f.1755.000234.applaud" type="Root">
<lb/><form type="lemma" norm="applaud">
<gramGrp><gram type="infinitiveParticle">To</gram></gramGrp>
<orth rend="allcaps">APPLA'UD</orth><pc>.</pc>
<gramGrp><pos norm="verb">v.a.</pos></gramGrp>
</form>
<etym>
<pc>[</pc><mentioned xml:lang="la">applaudo</mentioned><pc>,</pc>
<lang><abbr>Lat.</abbr></lang><pc>]</pc>
</etym>
<lb/><sense>
<num>1.</num>
<def>To praise by clapping the hand.</def>
</sense>
<lb/><sense>
<num>2.</num>
<def>To praise in general.</def>
</sense>
<cit type="example">
<lb/><quote>I would applaud thee to the very echo,
<lb/>That should applaud again.</quote>
<bibl><author><abbr>Shakesp.</abbr></author><title>Macbeth</title>.</
bibl>
</cit>
<cit type="example">
<lb/><quote>Nations unborn your mighty names shall sound,
<lb/>And worlds applaud that must not yet be found!</quote>
<bibl><author>Pope</author>.</bibl>
</cit>
</entry>
62 Our use of <pc> is governed by the principle that we avoid punctuation marks as
delimiters of text in elements within <form> and within <etym>; this is for ease of
reusability and searching.
63 In testing our encoding concept we encountered some phenomena―word class in
grammar and hyphenation in orthography―which prompted us to reinforce our aim of
consistently modeling heterogeneous lexicographical data through normalization. The
first case has to do with an old problem of word classes: the categories of adjective and
adverb in German. Ebers defines the part-of-speech information in his entry fähig with
the abridged terms in Latin adj. et adv. This concept—one word, two word classes—is not
compatible with the present-day understanding of word classes in German: since
adverbs in German are never inflected and fähig is capable of inflection, this word is
generally regarded as an adjective in any present-day dictionary of German. Of course,
we do not alter Ebers’ word class definition, but we suggest resolving the word class
conflict in this and in comparable cases by standardizing the value of the @norm
Journal of the Text Encoding Initiative, Issue 3 | November 2012
88

attribute on <pos>, using the ISOcat value adjective only. Ebers’ example entry fähig in
abridged form:
<entry xml:id="jedictge.1796.000999.fähig" type="main">
<form xml:lang="de" type="lemma" norm="fähig">
<lb/><orth>Fähig</orth><pc>,</pc>
<gramGrp>
<pos norm="adjective" xml:lang="la">adj. et adv.</pos>
</gramGrp>
</form>
<sense> ... </sense>
</entry>
64 The second phenomenon has to do with hyphenation, an old problem primarily but not
only in the English language. First, consider Johnson’s noun compounds with apple in
abridged form:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
89

<entry xml:id="sjdict1f.1755.000347.apple-graft" type="derivation">
<form type="lemma" norm="apple graft">
<lb/><orth rend="smallcaps">APPLE-GRAFT</orth><pc>.</pc>
<gramGrp><pos norm="noun">n.s.</pos></gramGrp>
</form>
<etym><pc>[</pc>from
<mentioned corresp="#sjdict1f.1755.000345.apple">apple</mentioned
<lbl>and</lbl>
<mentioned corresp="#sjdict1f.1755.009999.graft">graft</mentioned>
<pc>.]</pc>
</etym>
<sense> ... </sense>
</entry>
<entry xml:id="sjdict1f.1755.000348.apple-tart" type="derivation">
<form type="lemma" norm="apple tart">
<lb/><orth rend="smallcaps">APPLE-TART</orth><pc>.</pc>
<gramGrp><pos norm="noun"/></gramGrp>
</form>
<etym><pc>[</pc>from
<mentioned corresp="#sjdict1f.1755.000345.apple">apple</mentioned>
<lbl>and</lbl>
<mentioned corresp="#sjdict1f.1755.029999.tart">tart</mentioned>
<pc>.]</pc>
</etym>
<sense> ... </sense>
</entry>
<entry xml:id="jdict1f.1755.000349.apple_tree" type="derivation">
<form type="lemma" norm="apple tree">
<lb/><orth rend="smallcaps">APPLE TREE</orth><pc>.</pc>
<gramGrp><pos norm="noun"><abbr>n.s.</abbr></pos></gramGrp>
</form>
<etym><pc>[</pc>from
<mentioned corresp="#sjdict1f.1755.000345.apple">apple</mentioned>
<lbl>and</lbl>
<mentioned corresp="#sjdict1f.1755.039999.tree">tree</mentioned>
<pc>.]</pc>
</etym>
<sense> ... </sense>
</entry>
<entry xml:id="jdict1f.1755.000350.apple_woman" type="derivation">
<form type="lemma" norm="apple woman">
<lb/><orth rend="smallcaps">APPLE WOMAN</orth><pc>.</pc>
<gramGrp><pos norm="noun"><abbr>n.s.</abbr></pos></gramGrp>
</form>
<etym><pc>[</pc>from
<mentioned corresp="#sjdict1f.1755.000345.apple">apple</mentioned>
Journal of the Text Encoding Initiative, Issue 3 | November 2012
90

<lbl>and</lbl>
<mentioned corresp="#sjdict1f.1755.049999.woman">woman</mentioned>
<pc>.]</pc>
</etym>
<sense> ... </sense>
</entry>
65 Apart from the special case “APPLE of love,” both “APPLE-GRAFT” and “APPLE-TART” are
hyphenated, whereas “APPLE TREE” and “APPLE WOMAN” are spelled as two separate words.
There is no consistent distinction here between open (word-spaced) and hyphenated
compounds. Noel Osselton gives a compact résumé of “variation of hyphenated
compounds” in entries and their steady downgrading in the second half of the
dictionary from the letter M onwards (2005). Against this background we have used the
@norm attribute of <form> in order to provide the best support for search
procedures: we have retained the original hyphenated and open compound spellings
from Johnson’s text but have encoded the open or word-spaced form on the @normattribute as the standardized form.
66 In his translation of Johnson’s apple entries, Adelung takes a different view. He unifies
the hyphenated spelling for all the apple compounds, downgrades the hybrid entry
Apple of love to appear as a form mentioned within the base entry apple, and adds more
compounds, taken from other sources mentioned in the introduction:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
91

<entry xml:id="jagkwbed.1783.000999.apple" type="main">
<form xml:lang="en" type="lemma" norm="apple">
<lb/><orth>'Apple</orth><pc>,</pc>
<gramGrp>
<pos norm="noun" xml:lang="la">subst.</pos>
</gramGrp>
<pc>(</pc><pron >äpp'l</pron><pc>,</pc>
</form>
<etym><mentioned><lang xml:lang="ang">angels.</lang>
<lang xml:lang="nds">niederd.</lang>aep- <lb/>pel</mentioned>
<pc>,</pc> <mentioned><lang xml:lang="de">deutsch</lang> Apfel</
mentioned>
<pc>.</pc><pc>)</pc>
</etym>
<sense xml:lang="de">
<num>1)</num>
<def>Die Frucht des <lb/>Apfelbaumes,</def>
<cit type="translation"><quote>der Apfel.</quote></cit>
</sense>
<sense xml:lang="de">
<num>2)</num>
<cit type="Encyclopedic_Information">
<quote>Wegen eini-<lb/>ger Ähnlichkeit in der Gestalt ...</quote>
</cit>
<cit type="Encyclopedic_Information">
<quote><mentioned xml:lang="en">The Apple of love, Love-apple</
mentioned>
o-<lb/>der <mentioned xml:lang="en">Wolf's Peach</mentioned>,
<cit type="translation" xml:lang="de"><quote>Liebesapfel</quote>
</cit>
<term xml:lang="la">Lycoper-<lb/>sicon<name nymRef="Linné">Linn.</
name>
</term>auch wohl eine Art des <term xml:lang="la">Sola-<lb/>num</
term>;
<mentioned xml:lang="en">the Mad-apple</mentioned>,
</sense>
<sense xml:lang="de">
<num>3)</num>
<usg>Figürlich,</usg><def>die Pupille in dem Auge,</def>
<cit type="translation"><quote>der <lb/>Augapfel,</quote></cit>
<xr type="synonym "><lbl>welcher wohl auch
<ref xml:lang="en" target="#adwbeng1.1783.009999.eye-ball">
Eye-ball</ref> ge-<lb/>nannt wird.</lbl>
</xr>
</sense>
</entry>
<entry xml:id="jagkwbed.1783.001000.apple-coar" type="main">
<form xml:lang="en" type="lemma" norm="apple coar">
Journal of the Text Encoding Initiative, Issue 3 | November 2012
92

<lb/><orth>'Apple-coar</orth><pc>,</pc>
<gramGrp<pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<etym><lbl>von</lbl>
<mentioned xml:lang="en" corresp="#jagkwbed.1783.000999.apple">
apple 1)</mentioned>
</etym>
<sense>
<def>der Griebs oder Gröbs in dem Apfel.</def>
</sense>
</entry>
<entry xml:id="jagkwbed.1783.001001.apple-graft" type="main">
<form xml:lang="en" type="lemma" norm="apple graft">
<lb/><orth>'Apple-graft</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
<entry xml:id="jagkwbed.1783.001002.apple-loft" type="main">
<form xml:lang="en" type="lemma" norm="apple loft">
<lb/><orth>'Apple-loft</orth><pc>,</pc>
<gramGrp<pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
<entry xml:id="jagkwbed.1783.001003.apple-monger" type="main">
<form xml:lang="en" type="lemma" norm="apple monger">
<lb/><orth>'Apple-monger</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
<entry xml:id="jagkwbed.1783.001004.apple-paring" type="main">
<form xml:lang="en" type="lemma" norm="apple paring">
<lb/><orth>'Apple-paring</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
<entry xml:id="jagkwbed.1783.001005.apple-roaster" type="main">
<form xml:lang="en" type="lemma" norm="apple roaster">
<lb/><orth>'Apple-roaster</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
Journal of the Text Encoding Initiative, Issue 3 | November 2012
93

<entry xml:id="jagkwbed1.1783.001006.apple-squire" type="main">
<form xml:lang="en" type="lemma" norm="apple squire">
<lb/><orth>'Apple-squire</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
<entry xml:id="jagkwbed.1783.001007.apple-tart" type="main">
<form xml:lang="en" type="lemma" norm="apple tart">
<lb/><orth>'Apple-tart</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
<entry xml:id="jagkwbed.1783.001008.apple-thorn" type="main">
<form xml:lang="en" type="lemma" norm="apple thorn">
<lb/><orth>'Apple-thorn</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
<entry xml:id="jagkwbed.1783.001009.apple-tree" type="main">
<form xml:lang="en" type="lemma" norm="apple tree">
<lb/><orth>'Apple-tree</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
<entry xml:id="jagkwbed.1783.001010.apple-woman" type="main">
<form xml:lang="en" type="lemma" norm="apple woman">
<lb/><orth>'Apple-woman</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense>...</sense>
</entry>
67 These examples illustrate that, despite differences in detail, the <entry> and <form>
information can be encoded using the same pattern. Missing standard information (like
word class) can be supplied without modification of the transcription of the printed
text. Even if the encoding cuts into typographical structures (such as <pron> in
Adelung’s dictionary), it does not corrupt the transcription.
4.5. <etym>: Between Etymology and Word-Formation
68 As noted above, Johnson emphasized the importance of etymology in his preface.
Accordingly, he opens his dictionary with a grammar, and, in the introduction to the
Journal of the Text Encoding Initiative, Issue 3 | November 2012
94

chapter “Of DERIVATION”, explains: “That the English language may be more easily made
understood, it is necessary to enquire how its derivative words are deduced from their
primitives, and how the primitives are borrowed from other languages” (1755, 47). In
compound word entries, he uses square brackets following the part-of-speech
information to mark the root components of the compound—his derivatives (for
example, in APPLE-GRAFT: [from apple and graft]); for root entries, he provides
information about related words in Indo-European, Romance or Germanic languages, if
necessary with an English translation (for example, in ABLE: [habile, Fr. habilis, Lat.
Skilful, ready.]). In accordance with Johnson’s method, we use the <etym> element for
both cases. The <etym> element requires no additional attribute to distinguish these
two cases since its content structure clearly indicates to what type of entry a given
<etym> belongs and how it is to be interpreted:
<entry xml:id="sjdict1f.1755.000123.able" type="Root">
<form>...</form>
<etym><pc>[</pc>
<mentioned xml:lang="fr" >habile</mentioned><pc>,</pc>
<lang><abbr>Fr.</abbr> </lang>
<mentioned xml:lang="la">habilis</mentioned><pc>,</pc>
<lang><abbr>Lat.</abbr></lang>
<lb/><gloss xml:lang="en">Skilful<pc>,</pc> ready<pc>.</pc>
</gloss><pc>]</pc>
</etym>
69 In the encoding of the entry ABLE above, the content of <etym> consists of two
<mentioned> elements, each with a <lang> and possibly a <gloss>, meaning it
must be a root entry.
<entry xml:id="sjdict1f.1755.000347.apple-graft" type="derivation">
<form>...</form>
<etym><pc>[</pc>from
<mentioned corresp="#sjdict1f.1755.000345.apple">apple</mentioned
<lbl>and</lbl>
<mentioned corresp="#sjdict1f.1755.009999.graft">graft</mentioned>
<pc>.]</pc>
</etym>
70 In the encoding of the entry APPLE-GRAFT, the content of <etym> consists of two
<mentioned> elements, each with a @corresp attribute that points to other entries
within the same dictionary, indicating a derivation. While the effort of identifying the
target entry and inserting the corresponding @xml:id attribute is not insignificant,
from our point of view the resulting network of linked entries is worth the effort.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
95

4.6. Stepwise Refinement of <sense>: <num>, <def>, and
<gramGrp> with <gram>
71 The function of <sense> as a container for the semasiological information of
dictionary entries was explained the first half of this paper. Some sections of the
encoding of ABLE can illustrate the flexibility of the concept of crystals for the
encoding of complex semantic structures. The first step of refinement adds <num>elements to label the different <sense>s.
<entry xml:id="sjdict1f.1755.000123.able" type="Root">
<form> ... </form>
<etym> ... </etym>
<sense>
<lb/><num>1.</num>
<def>...</def><cit>...</cit><cit>...</cit>
</sense>
<sense>
<lb/><num>2.</num>
<def>Having power sufficient; enabled.</def>
<cit type="example">
<lb/><quote>All mankind acknowledge themselves able and
sufficient to <lb/> do many things, which actually they never do.
</quote>
<bibl><author>South</author>’s <title>Serm.</title></bibl>
</cit>
</sense>
<sense>
<lb/><num>3.</num>
<gramGrp>
<gram type="syntax">Before a verb, with the participle
<hi rend="italics">to</hi></gram>
</gramGrp>,
<def>it signifies generally hav-<lb/>ing the power</def>;
<gramGrp>
<gram type="syntax">before a noun, with <hi rend="italics">for</
hi></gram>
</gramGrp>,
<def> it means <hi>qualified</hi></def>.
<!-- instances of <cit type="example"> omitted for brevity -->
</sense>
72 In a second step—<num>3.</num>—one <sense> element is used to combine the
morpho-syntactic features “able + to before a verb” in the <gramGrp> container with
the semasiological definition “signifies generally having the power” contained in the
<def> element. In a different construction with able, the morpho-syntactic feature
“before a noun, with for” in <gramGrp> and <gram> is connected with the definition
Journal of the Text Encoding Initiative, Issue 3 | November 2012
96

‘it means qualified’ in <def>. Usually we find grammatical information in a kind of
shorthand in the source, which is likewise encoded briefly:
<gramGrp><pos norm="noun">n.s.</pos></gramGrp>
73 For ABLE, we have a discursive example, which as such is interesting not only in its own
right but also because it combines two clearly distinct syntactic structures and
divergent semantic paraphrases into one sense. The <cit> examples that follow in
sense number 3 repeat the structures and illustrate both usages:
<cit type="example">
<lb/><quote>Wrath is cruel, and anger is outrageous; but who is
able <lb/> to stand before envy?</quote>
<bibl><title>Prov.</title>
<biblScope type="part">xxvii.</biblScope>
<biblScope type="ll">4.</biblScope>
</bibl>
</cit>
<cit type="example">
<lb/><quote>There have been some inventions also, which have been
<lb/>able for the utterance of articulate sounds,
as the speaking of <lb/>certain words.</quote>
<bibl><author>Wilkin</author>’s <title>Mathematical Magic</title>.
</bibl>
</cit>
74 The phrases able to and able for are marked by italics in the print dictionary, but this
was not captured in the encoding. Furthermore, while the refinement of the encoding
could be extended to word level and features of a fine-grain morpho-syntactical
analysis, this is beyond what we want to illustrate in this paper. Therefore we have just
encoded to support analysis of syntax.
4.7. Bilingual Dictionaries: A Shift of Perspective
75 The consistent modeling of heterogeneous lexical structures can be extended to the
more complex structures we find in the two bilingual dictionaries, Adelung’s English-
German translation of Johnson’s dictionary (1783–1796) and Ebers’ New and Complete
Dictionary of the German and English Languages (1796), compiled using Adelung’s and
Schwan’s lexicographical materials. Nevertheless a comparable precision in the
encoding can be achieved. Let us first compare the entry Apple-tart in Johnson’s
dictionary and Adelung’s translation:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
97

<entry xml:id="sjdict1f.1755.000348.apple-tart" type="derivation">
<form type="lemma" norm="apple tart">
<lb/><orth rend="smallcaps">APPLE-TART</orth><pc>.</pc>
<gramGrp><pos norm="noun"/></gramGrp>
</form>
<etym><pc>[</pc>from
<mentioned corresp="#sjdict1f.1755.000345.apple">apple</mentioned>
<lbl>and</lbl>
<mentioned corresp="#sjdict1f.1755.029999.tart">tart</mentioned>
<pc>.]</pc>
</etym>
<sense>
<def>A tart made of apples.</def>
<cit type="example">
<lb/><quote>What, up and down carv’d like an apple-tart.</quote>
<lb/><bibl><author>Shakespeare</author>'s
<title>Taming of the Shrew</title>.
</bibl>
</cit>
</sense>
</entry>
<entry xml:id="jagkwbed.1783.001007.apple-tart" type="main">
<form xml:lang="en" type="lemma" norm="apple tart">
<lb/><orth>'Apple-tart</orth><pc>,</pc>
<gramGrp><pos norm="noun" xml:lang="la">subst.</pos></gramGrp>
</form>
<sense xml:lang="de">
<def>eine Torte von Ä-<lb/>pfeln,</def>
<cit type="translation"><quote>eine Äpfeltorte.</quote></cit>
</sense>
</entry>
76 In contrast to Johnson, Adelung, meeting the requirements of an English-German
dictionary, left out the <etym> element on word-formation and the Shakespeare
quotation and added the word-class information. He translated Johnson’s definition of
apple-tart almost literally into German and then added the slightly strange German
compound Äpfeltorte.
77 The encoding of the translation becomes more complex because of the mix of two
languages which requires an additional control of the extension and inheritance of the
@xml:lang attribute. The use of the German plural form Äpfel in Äpfeltorte may have
been inspired by Johnson’s plural definition and the fact that a decent apple-tart
requires more than one apple. Ten years later, in Adelung’s monolingual German
dictionary, the entry shows no umlaut and the definition is derived from a recipe that
puts the sliced apples on top (1793–1801, vol. 1, 412).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
98

78 In a final look at Ebers’ German-English dictionary, the randomly chosen sample entry
fähig shows the problems in encoding bilingual dictionaries when translation from
mother-tongue into a foreign language is involved.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
99

<entry xml:id="jedictge.1788.000999.fähig" type="main">
<form xml:lang="de" type="lemma" norm="fähig">
<lb/><orth>Fähig</orth><pc>,</pc>
<gramGrp><pos xml:lang="la"norm="adjective">adj. et adv.</pos>
</gramGrp>
</form>
<sense>
<def xml:lang="de">tüchtig, geschickt</def>
<cit type="translation" xml:lang="en">
<quote>capable, able, apt, fit, proper.</quote>
</cit>
<cit type="example" xml:lang="de">
<quote>zu etwas fähig seyn,</quote></cit>
<cit type="translation" xml:lang="en">
<quote>to be capable or <lb/>fit for a Thing.</quote></cit>
<lb/><cit type="example" xml:lang="de">
<quote>sie ist des Erbrechts nicht fähig</quote></cit>
<cit type="translation" xml:lang="en">
<quote>she is <lb/>incapable for Succession.</quote></cit>
</sense>
<sense>
<def xml:lang="de">fähig, lehrsam, gelehrig,</def>
<cit type="translation" xml:lang="en">
<quote>docile, teach- <lb/>able.</quote></cit>
<lb/><cit type="example" xml:lang="de">
<quote>fähig etwas zu erfinden</quote></cit>
<cit type="translation" xml:lang="en">
<quote>inventive.</quote></cit>
<cit type="example" xml:lang="de">
<quote>der Unterweisung fähig</quote></cit>
<cit type="translation" xml:lang="en">
<quote>susceptible of <lb/>Discipline, of Instruction</quote></
cit>
<lb/><cit type="example" xml:lang="de">
<quote>er ist fähig alles zu unternehmen</quote></cit>
<cit type="translation" xml:lang="en">
quote>he <lb/>is a Man that will undertake any <lb/>Thing</
quote></cit>
</sense>
<sense>
<def xml:lang="de">fähig machen,</def>
<cit type="translation" xml:lang="en">
<quote>to enable or fit, to in- <lb/>capacitate, to habilitate.</
quote>
</cit>
<lb/><cit type="example" xml:lang="de">
<quote>der Hunger macht einen zu allem fähig,</quote></cit>
Journal of the Text Encoding Initiative, Issue 3 | November 2012
100

<lb/><cit type="translation" xml:lang="en">
<quote>Hunger breaks through Stone-<lb/>Walls, or Hunger drives
the Wolf <lb/>out of the Forest.</quote></cit>
<lb/><cit type="example" xml:lang="de">
<quote>einen wieder fähig machen,</quote></cit>
<cit type="translation" xml:lang="en">
<quote>to rehabi-<lb/>litate, re-enable, re-instate, re- <lb/
>store,
or re-establish one</quote></cit>
</sense>
</entry>
79 At first glance the main lexicographical problem here is to specify the different senses
of fähig, first in German (with a separate <sense>, each containing a <def>, for each
sense), then in translating the German adjectives into the English equivalents (using
<cit type="translation">), and finally in adding English translations (in <cittype="translation">) of German example phrases (in <cittype="example">) containing the adjective. Unlike in Johnson’s dictionary, the
senses are not numbered and the principle of their order is not quite clear.
80 Recalling the longish title of Ebers’ dictionary, New and Complete Dictionary of the German
and English Languages Composed Chiefly After the German Dictionaries of Mr. Adelung and of
Mr. Schwan, it is worthwhile taking a closer look at Ebers’ possible sources. The entry
fähig in Adelung’s dictionaries (1774–1786, vol. 2; 1793–1801, vol. 2) is built around two
numbered senses and looks completely different. But checking Christian Friedrich
Schwan’s Nouveau dictionnaire de la langue allemande et françoise: Composé sur les
dictionnaires de M. Adelung et de l’Acad. Françoise (1782, 519) shows clearly how Ebers had
compiled this entry of his dictionary:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
101

<entry xml:id="csdictaf.1782.000999.fähig" type="main">
<form xml:lang="de" rend="iso15924:Latn" type="lemma" norm="fähig">
<lb/><orth>FÆHIG</orth><pc>,</pc>
<pc>(</pc><orth rend="iso15924:Latf">fähig</orth><pc>)</pc>
<gramGrp>
<pos xml:lang="fr" norm="adjective">adj. & adv.</pos>
</gramGrp>
</form>
<sense rend="iso15924:Latn">
<def xml:lang="de">tüchtig, geschikt;</def>
<cit type="translation" xml:lang="fr">
<quote>Capable, habile, propre.</quote></cit>
<cit type="example" xml:lang="de"><quote>Zu etwas fähig seyn;</
quote></cit>
<lb/><cit type="translation" xml:lang="fr">
<quote>être capable de qq. ch. être propre à une chose.</quote></
cit>
<lb/><cit type="example" xml:lang="de">
<quote>Sie ist des Erbrechts nicht fähig;</quote></cit>
<cit type="translation" xml:lang="fr">
<quote>elle n'est pas <lb/>habile à succéder.</quote></cit>
</sense>
<sense rend="iso15924:Latn">
<abbr>It.</abbr><def xml:lang="de">Fähig, lehrsam, geleh-<lb/>rig</
def>
<cit type="translation" xml:lang="fr"><quote>docile.</quote></cit>
<cit type="example" xml:lang="de">
<quote>Fähig etwas zu erfinden;</quote></cit>
<cit type="translation" xml:lang="fr"><quote>inven-<lb/>tif.</quote></
cit>
<cit type="example" xml:lang="de">
<quote>Der Unterweisung fähig;</quote></cit>
<cit type="translation" xml:lang="fr">
<quote>susceptible de di-<lb/>scipline.</quote></cit>
<cit type="example" xml:lang="de">
<quote>Er ist fähig alles zu unternèhmen;</quote></cit>
<lb/><cit type="translation" xml:lang="fr">
<quote>il est homme à tout entreprendre.</quote></cit>
<cit type="example" xml:lang="de">
<quote>Dinge, die<lb/>nicht jedermann zu verstehen fähig ist;</
quote>
</cit>
<cit type="translation" xml:lang="fr">
<quote>des <lb/>choses qui ne sont pas à la portée de tout
le mon-<lb/>de</quote></cit>
<cit type="example" xml:lang="de">
<quote>Er ist nicht fähig, euch in geringsten zu<lb/>schaden</
quote></cit>
<cit type="translation" xml:lang="fr">
Journal of the Text Encoding Initiative, Issue 3 | November 2012
102

<quote>il est incapable de vour nuire aucunement.</quote></cit>
<lb/><cit type="example" xml:lang="de"><quote>Fähig machen</quote></
cit>
<cit type="translation" xml:lang="fr"><quote>habiliter.</quote></cit>
<cit type="example" xml:lang="de">
<quote>Der Hunger macht <lb/>einen zu allem fähig;</quote></cit>
<cit type="translation" xml:lang="fr">
<quote>la faim chasse le loup hors<lb/>du bois.</quote></cit>
<cit type="example" xml:lang="de">
<quote>Einen wieder fähig machen;</quote></cit>
<cit type="translation" xml:lang="fr">
<quote>réhabi-<lb/>liter qq. un.</quote></cit>
</sense>
</entry>
81 With the exception of two phrases—“Dinge, die nicht jedermann zu verstehen fähig ist”
and “Er ist nicht fähig euch in geringsten zu schaden”—Ebers has copied the German
text of Schwan’s dictionary and replaced the French translation equivalents by English
ones. The encoding problems remain the same and we think that the solution we
propose is adequate.
5. Conclusion
82 Above we applied our encoding suggestions for the <form> block to Johnson’s entry To
APPLAUD but did not comment on the unusual structure of the elements <sense> and
<cit>: two numbered senses, followed by two quotations. A look at the last edition
(the fourth folio edition of 1773), which was considerably revised and prepared for
publication by Johnson himself, can make the author’s original intentions clearer.
Thanks to Anne McDermott’s excellent CD-ROM edition, published in 1996, we have
access to an SGML encoding of the texts of both the first and fourth folio editions and
can not only compare the texts themselves but also the change over the years from TEI
P3 SGML of 1994 to the current P5 using XML Schema:
83 First folio edition [TEI P5]:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
103

<entry xml:id="sjdict1f.1755.000234.applaud" type="Root" >
<lb/><form type="lemma" norm="applaud">
<gram type="infinitiveParticle">To</gram>
<orth rend="allcaps">APPLA'UD</orth><pc>.</pc>
<gramGrp><pos norm="verb">v.a.</pos></gramGrp>
</form>
<etym>
<pc>[</pc><mentioned xml:lang="la">applaudo</mentioned><pc>,</pc>
<lang><abbr>Lat.</abbr></lang><pc>]</pc>
</etym>
<lb/><sense>
<num>1.</num>
<def>To praise by clapping the hand.</def>
</sense>
<lb/><sense>
<num>2.</num>
<def>To praise in general.</def>
</sense>
<cit type="example">
<lb/><quote>I would applaud thee to the very echo,
<lb/>That should applaud again.</quote>
<bibl><author><abbr>Shakesp.</abbr></author><title>Macbeth</title>.</
bibl>
</cit>
<cit type="example">
<lb/><quote>Nations unborn your mighty names shall sound,
<lb/>And worlds applaud that must not yet be found!</quote>
<bibl><author>Pope</author>.</bibl>
</cit>
</entry>
84 Ann McDermott Fourth folio edition [TEI P3 SGML]:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
104

<ENTRYFREE ID="J4APPLAUD-1" N="1999" TYPE="4">IV
<FORM>
<HI REND="ital">To</HI> <HI REND="acp">APPLA'UD.</HI>
</FORM>
<PB SIG="Bb2r" MACFILE=":4:100:148.CAL" PCFILE="4100148.CAL">
<POS><HI REND="ital">v.a.</HI></POS>
<ETYM>[<HI REND="ital">applaudo,</HI> Lat.]</ETYM>
<SENSE N="1">
<DEF>
<NUM>1.</NUM> To praise by clapping the hand.
</DEF>
<EG TYPE="verse">
<QUOTE>
<L>I would <HI REND="ital">applaud</HI> thee to the very echo,</L>
<L>That should <HI REND="ital">applaud</HI> again.</L>
</QUOTE>
<AUTHOR><HI REND="ital">Shakesp.</HI></AUTHOR>
<TITLE><HI REND="ital">Macbeth.</HI></TITLE>
</EG>
</SENSE>
<SENSE N="2">
<DEF>
<NUM>2.</NUM> To praise in general.
</DEF>
<EG TYPE="verse">
<QUOTE>
<L>Nations unborn your mighty names shall sound,</L>
<L>And worlds <HI REND="ital">applaud</HI> that must
not yet be sound!</L>
</QUOTE>
<AUTHOR><HI REND="ital">Pope.</HI>
</AUTHOR>
</EG>
</SENSE>
</ENTRYFREE>
85 We can conclude:
The transcription of the entry APPLAUD in the SGML version of the fourth folio edition
shows clearly that Johnson had intended to illustrate each definition with an illustrative
quotation, as elsewhere in the dictionary, and that the unusual structure of the first folio
text—two numbered senses, followed by two quotations—is simply a typesetting error.
Both encodings have many structural features in common: with the exception of <cit> and
<pc>, all elements used in our encoding were available in TEI P3, whereas the mechanisms
usable at the attribute level are not comparable. But the main difference is the style of the
encoding: although the SGML version is very close to the typography of the text, our
encoding, using crystals, aims more at interpreting typographical detail in order to capture
1.
2.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
105

lexicographic and linguistic data and to constrain encoding options in favor of robust
interoperability and reusability of resources.
A. Appendix: Facsimiles
A.1. Johnson, Entry “ABLE”
Facsimile A.1.: Page with entry “ABLE” from Johnson (1755).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
106

A.2. Johnson, Entries “To APPLAUD” and “APPLE”
Facsimile A.2.: Page with entries “To APPLAUD” and “APPLE” from Johnson (1755).
A.3. Adelung, Entry “Apple”
Facsimile A.3.: Page with entry “Apple” from Adelung (1783–1796).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
107

A.4. Ebers, Entry “FÄHIG”
Facsimile A.4.: Page with entry “FÄHIG” from Ebers (1796).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
108

A.5. Schwan, Entry “FÆHIG”
Facsimile A.5.: Page with entry “FÆHIG” from Schwan (1782).
BIBLIOGRAPHY
Adams, V. 1976. An Introduction to Modern English Word-Formation. London: Longman.
Adelung, J. C. 1774–1786. Versuch eines vollständigen grammatisch-kritischen Wörterbuches Der
Hochdeutschen Mundart, mit beständiger Vergleichung der übrigen Mundarten, besonders aber der
Oberdeutschen. 5 vols. Leipzig: Breitkopf.
Adelung, J. C. 1783–1796. Neues grammatisch-kritisches Wörterbuch der Englischen Sprache für die
Deutschen; vornehmlich aus dem größern englischen Werke des Hrn. Samuel Johnson nach dessen vierten
Ausgabe gezogen und mit vielen Wörtern, Bedeutungen und Beyspielen vermehrt. 2 vols. Leipzig: im
Schwickertschen Verlage.
Adelung, J. C. 1793–1801. Grammatisch-kritisches Wörterbuch der Hochdeutschen Mundart, mit
beständiger Vergleichung der übrigen Mundarten, besonders aber der Oberdeutschen, von Johann
Christoph Adelung, Churfürstl. Sächs. Hofrathe und Ober-Bibliothekar . . . . 4 vols. Leipzig: Breitkopf.
Atkins, S., N. Bel, F. Bertagna, P. Bouillon, N. Calzolari, C. Fellbaum, R. Grishman, R. Lenci, C.
MacLeod, M. Palmer, G. Thurmair, M. Villegas, and A. Zampolli. 2002. “From Resources to
Applications. Designing the Multilingual ISLE Lexical Entry.” In Proceedings of the 3rd International
Conference on Language Resources and Evaluation, 687–693.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
109

Ebers, J. 1796. New and Complete Dictionary of the German and English Languages composed chiefly after
the German Dictionaries of Mr. Adelung and of Mr. Schwan. . . . Vol. 1. Leipzig: Breitkopf and Haertel.
Halpern, J. 2006. “The role of lexical resources in CJK natural language processing.” In Proceedings
of the Workshop on Multilingual Language Resources and Interoperability, 9–16.
Henne, H., ed. 2001. Deutsche Wörterbücher des 17. und 18. Jahrhunderts. Einführung und Bibliographie.
Hildesheim/Zürich/New York: Olms.
Ide, N., A. Kilgarriff, and L. Romary. 2000. “A Formal Model of Dictionary Structure and Content.”
In Proceedings of Euralex 2000. Stuttgart, 113-126. http://hal.archives-ouvertes.fr/hal-00164625.
Johnson, S. 1755. A Dictionary of the English Language . . . . 2 vols. London: W. Strahan.
Kilgarriff, A. and D. Tugwell. “Sketching Words.” Lexicography and Natural Language Processing: A
Festschrift in Honour of B. T. S. Atkins, ed. Marie-Hélène Corréard. Stuttgart: EURALEX. 125–137.
http://www.kilgarriff.co.uk/Publications/2002-KilgTugwell-AtkinsFest.pdf.
Landau, S. I. 2001. Dictionaries. The Art and Craft of Lexicography. 2nd ed. Cambridge: Cambridge
University Press.
Lewis, D. 2012. Die Wörterbücher von Johannes Ebers. Studien zur frühen englisch-deutschen
Lexikographie. PhD diss., University of Würzburg (in print).
Luna, P. 2005. “The typographic design of Johnson’s Dictionary.” In Anniversary Essays on Johnson’s
Dictionary, ed. Jack Lynch and Anne McDermott, 175–197. Cambridge: Cambridge University Press.
McDermott, A. ed. 1996. Samuel Johnson, A Dictionary of the English Language, on CD-ROM. The First
and Fourth Editions. Cambridge: Cambridge University Press.
Miller George A. and Christiane Fellbaum. 2007. “WordNet Then and Now.” In Language Resources
and Evaluation 41: 209–214, doi:10.1007/s10579-007-9044-6.
Osselton, N. E. 2005. “Hyphenated Compounds in Johnson’s Dictionary.” Anniversary Essays on
Johnson’s Dictionary, eds. Jack Lynch and Anne McDermott, 160–174. Cambridge: Cambridge
University Press.
Reddick, A. 2006. The Making of Johnson’s Dictionary 1746–1773. Rev. ed. Cambridge: Cambridge
University Press.
Romary, L. 2009. “ODD as a generic specification platform.” Paper presented at Text Encoding in
the Era of Mass Digitization: Conference and Members’ Meeting of the TEI Consortium. http://
hal.inria.fr/inria-00433433.
Schwan, C. F. 1782. Nouveau Dictionnaire de la Langue Allemande et Françoise . . . . Vol. 1. Mannheim:
Chez C.F. Schwan et M. Fontaine.
TEI Consortium. 2012. TEI P5: Guidelines for Electronic Text Encoding and Interchange. Version 2.0.2.
Last updated February 2. TEI Consortium. http://www.tei-c.org/Guidelines/P5/.
NOTES
1. Some LMF packages, such as the description of subcategorization frames, do not yet
have any equivalence in the TEI vocabulary, but the TEI extension mechanisms do
facilitate the description of such extensions.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
110

2. Note that some of the changes proposed in this paper (in particular regarding the
systematic use of <sense>) have already been integrated into the December 2011
release (2.0.0, Laurentian).
3. Ideally, this should correspond to model.formPart, but in the current version of
the TEI Guidelines this class is cluttered with other components which are there for
purely syntactic (practical) reasons. We would limit this class to form <orth>,
<pron>, <hyph>, <syll>, and <stress>.
4. Even if this is not allowed in the <entry> element, form representations still
appear in: <cit>, <dictScrap>, <entryFree>, and <nym>, because of their
membership to model.entryPart.
5. http://www.isocat.org/
6. Paul Luna’s analyses here the typography of Johnson’s folio edition of his dictionary
(in opposition to different typography and text structure in the quarto and octavo
editions). Folio is the old measure of size of a book and an indispensable term for
research on Johnson’s dictionaries.
7. Since Adelung’s name does not appear on the title page nor elsewhere in the front
matter, his role as a translator is little known. It is worth mentioning the publication
context. Adelung studied and translated Johnson’s dictionary while working on the two
editions of his own German dictionaries. The first volume of his translation, containing
the letters A to J, was published in 1783. This was after nearly three years of work—
according to his preface (p. xii)—and before he finished the fifth and last volume of the
first edition of his German dictionary which he had started in 1773 (Adelung 1774–
1786). Thirteen years later, in 1796, he published the second volume of his translation
with the letters K to Z, after having finished the first two volumes of the second and
final edition of his German dictionary (Adelung 1793–1801). Against this background,
future research into structural relations between Johnson’s Dictionary of the English
Language and Adelung’s German dictionaries looks promising.
Almost at the same, time Johannes Ebers used Adelung’s lexicographical materials to
compile a German-English counterpart in three volumes with a very elaborate title New
and Complete Dictionary of the German and English Languages composed chiefly after the
German Dictionaries of Mr. Adelung and of Mr. Schwan ... (Ebers 1796).
8. We do not encode the two typefaces for Latin script used by German printers of
Adelung’s and Ebers’ dictionaries because there is a fixed relation between language
(encoded using @xml:lang) and the typeface: for German texts the Fraktur variant is
used, whereas for other languages Antiqua is used. We only encode exceptions to this
rule, such as in Schwan’s German-French dictionary, where ISO 15924 codes are used
for the representation of names of scripts. We do not encode the indentation and
alignment structure, nor do we encode italics in the contexts of part-of-speech labels
(in a <pos> element), of cited forms in <etym> (if printed in italics), of the lemmata
used in illustrative quotations (in a <cit> element), or of the names of authors and
their works in the sources for the illustrative quotations (in a <bibl> element).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
111

ABSTRACTS
Our paper outlines a proposal for the consistent modeling of heterogeneous lexical structures in
semasiological dictionaries, based on the element structures described in detail in chapter 9
(Dictionaries) of the TEI Guidelines. The core of our proposal describes a system of relatively
autonomous lexical “crystals” that can, within the constraints of the relevant element’s
definition, be combined to form complex structures for the description of morphological form,
grammatical information, etymology, word-formation, and meaning for a lexical structure.
The encoding structures we suggest guarantee sustainability and support re-usability and
interoperability of data. This paper presents case studies of encoding dictionary entries in order
to illustrate our concepts and test their usability.
We comment on encoding issues involving <entry>, <form>, <etym>, and on refinements to
the internal content of <sense>.
INDEX
Keywords: dictionary encoding, semasiological dictionary, entry, form, sense, Samuel Johnson,
Dictionary of the English Language
AUTHORS
LAURENT ROMARY
Laurent Romary is Directeur de Recherche for INRIA (France) and guest scientist at Humboldt
University (Berlin, Germany). He carries out research on the modeling of semi-structured
documents, with a specific emphasis on texts and linguistic resources. He received a PhD degree
in computational linguistics in 1989 and his Habilitation in 1999. During several years he launched
and directed the Langue et Dialogue team at Loria (Nancy, France) and participated in several
national and international projects related to the representation and dissemination of language
resources and on man-machine interaction, coordinating the MLIS/DHYDRO, IST/MIAMM, and
eContent/Lirics projects. He has been the editor of ISO standard 16642 (TMF – Terminological
Markup Framework) and is the chairman of ISO committee TC 37/SC 4 on Language Resource
Management, as well as member (2001–2007) then chair (2008–2011) of the TEI Council. In the
recent years, he led the Scientific Information directorate at CNRS (2005–2006) and established
the Max-Planck Digital Library (Sept. 2006–Dec. 2008). He currently contributes to the
establishment and coordination of the DARIAH infrastructure in Europe as transitional director.
WERNER WEGSTEIN
Werner Wegstein is a professor emeritus of German Linguistics and Computational Philology. His
publications include a scholarly edition of an Old-High German Glossary (Ph.D. 1985), the first
complete reverse index to a Middle High German dictionary (1990, together with E. Koller and
N.R. Wolf), a Habilitation on computer-based philology (1995), conference papers on the
application of IT to medieval German (2001), and a recently co-authored work on corpus
linguistics (Korpuslinguistik deutsch: synchron, diachron, kontrastiv, 2005). He hosted the TEI
workshops in Würzburg; is a founding member of TextGrid, the humanities partners of the
Journal of the Text Encoding Initiative, Issue 3 | November 2012
112

German D-Grid initiative; and at present is active in a project researching the interaction
between the sciences and humanities in the field of variation.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
113

A TEI Schema for theRepresentation of Computer-mediated CommunicationMichael Beißwenger, Maria Ermakova, Alexander Geyken, Lothar Lemnitzerand Angelika Storrer
1. Introduction
1 In the past three decades, computer networks and especially the Internet have brought
forth new and emerging genres of interpersonal communication which are the subject
of research in the field of “computer-mediated communication” (henceforth CMC). In
general, genres such as e-mail, online forums, chats, instant messaging, or weblogs
stand in the tradition of well-known genres such as spoken conversations or written
letters. On the other hand, they display linguistic and structural features which differ
from both speech and written text (see below for details) and which can be traced back
to the ways in which interlocutors adapt to the technical potentials and limitations of
computer-mediated communication.
2 Recent surveys on the use of the Internet (such as “ARD/ZDF-Onlinestudie”,1 conducted
annually in Germany) show that use of CMC applications is an important part of
everyday communication. To gain a better understanding of these new forms of
mediated communication and their linguistic peculiarities, we need tools and models
that allow one to analyze them on a broad empirical basis and with the help of corpus
technology and methods from computational linguistics. One important prerequisite
for that would be a common format for the representation and exchange of CMC
resources. Even though CMC phenomena are no longer a completely new field of
research within the humanities, such a format still does not exist.
3 In this paper, we present an XML schema for the representation of genres of computer-
mediated communication that is conformant with the encoding framework defined by
the TEI. Up to now, the encoding of CMC genres and document types has not been a
focus of the TEI. Our schema takes the modules as well as the element and attribute
Journal of the Text Encoding Initiative, Issue 3 | November 2012
114

classes of the P5 version of the TEI Guidelines (released on November 1, 2007) as a
starting point and uses the TEI customization mechanism to extend support to these
genres and document types. The focus of the schema is on those CMC genres which are
written and dialogic―threads in forums and bulletin boards, chat and instant messaging
conversations, wiki talk pages, weblog discussions, microblogging on Twitter, and
conversations on “social network” sites. The schema has been developed in the context
of the project “Deutsches Referenzkorpus zur internetbasierten Kommunikation”
(DeRiK, Beißwenger et al. 2012),2 which is a joint initiative of TU Dortmund University
and the Berlin-Brandenburg Academy of Sciences and the Humanities (BBAW). The
project is embedded in the scientific network Empirische Erforschung internetbasierter
Kommunikation ( http://www.empirikom.net/), funded by the Deutsche
Forschungsgemeinschaft (DFG). The aim of the project is to build a corpus on language
use in the German-speaking Internet which covers the most popular CMC genres. The
corpus is designed to be integrated into the corpora and lexical resource framework
provided by the project “Digitales Wörterbuch der deutschen Sprache” (DWDS)3 at the
BBAW “Zentrum Sprache”.
4 Since all corpus resources of the DWDS project are already encoded according to the
TEI encoding framework, and since there is not yet a common standard for an XML/TEI
representation of the structural and linguistic properties of CMC resources, the project
group decided that the TEI would be an optimal basis for the annotation of the DeRiK
data—assuming that the encoding framework of the TEI would prove to be flexible
enough to be adapted to the particularities of CMC discourse. In particular, we
formulated the following requirements for our schema:
It should provide a model that is adapted to the structural particularities of CMC discourse;
especially that the interlocutors’ contributions to conversations in forums, chats, wiki and
weblog discussions, etc. can neither be adequately described as utterances in speech nor as
paragraphs in traditional writing.
It should provide elements for the annotation of units which are often regarded as “typical”
for language use on the web and which are of special interest to anyone who wants to
compare linguistic features of CMC discourse with the language documented in text corpora
(such as the DWDS corpora); in the DeRiK context, a special focus lies on units which we
subsume under the category interaction signs (including emoticons, interaction words, and
addressing terms).
It should be open to extensions by other researchers in the field of empirical CMC research
or by corpus designers who want to adapt the schema for their own project purposes
(especially on the microlevel, which―in the terminology of our project―is the level below
the individual user contribution).
On the macrolevel (the level above the individual user contributions), its structure should be
oriented toward surface phenomena and thus be as independent as possible from any
specific theory of CMC discourse; this will allow use of the macrostructure model of the
schema as a basic document structure in as many projects as possible; in addition, it will
allow automation of the generation of the basic TEI structure of CMC documents (which is an
important requirement, especially in projects that aim at building large corpora).
It should allow for an easy (but reversible) anonymization of CMC data for purposes in which
the annotated data should be made available as a resource for other researchers or for the
public (as is intended with the DeRiK corpus as part of the DWDS framework).
•
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
115

It should provide all information and metadata which are necessary for using and
referencing random excerpts from the data as references in a general language dictionary as
well as in the results of a corpus query (as is the case in the DWDS online portal).
5 First we will give an outline of the motivation and context of the project. We then will
describe the design of our schema in detail and illustrate some of our basic modeling
decisions with the help of examples from our data.4 The schema itself, its
documentation, and some encoded example documents can be found online.5
6 The current version of the schema will form the foundation of the annotation of CMC
documents in the DeRiK context. Since it is meant to be a core model for representing
CMC, it can be modified and extended by others according to their own specific
perspectives on CMC data. It will have to prove its adequacy for the resource types in
focus by being used and analyzed by more researchers and corpus builders than just its
authors. The schema and its further discussion could be a first step towards an
integration of features for the representation of CMC genres into a future version of the
TEI Guidelines.
2. Motivation and Project Background
2.1. Motivation
7 The motivation for building a corpus of German CMC is to close a gap in the range of
corpora currently available for the study of CMC and contemporary German in general.
Hardly any annotated specialized corpora of CMC exist, and general corpora of
contemporary German do not systematically include language as used on the Internet
(Beißwenger and Storrer 2008). This poses a blatant gap since online communication
has become an important part of everyday communication and can no longer be
ignored when documenting contemporary everyday language use. The field of corpus
linguistics is aware of that gap. In addition to the DeRiK project, which aims to build a
German CMC corpus and integrate it into the DWDS general language corpora, there
are similar ideas or projects for other languages as well. One example is the SoNaR
project which aims at building a balanced reference corpus of contemporary Dutch
including a subcorpus of CMC (Reynaert et al. 2010).
8 Due to a lack of standards for representing CMC, up to now corpus-based research
projects focusing on features of CMC discourse have typically developed their own,
project-specific encoding schemas (see, for example, the XML encoding for chats that
has been designed for the resources included in the Dortmund Chat Corpus, 2003–2009).6
This complicates, maybe even makes impossible, the sharing of this data across
projects, which is all the more regrettable because the individual projects add valuable
structural and semantic information to their data through their annotations (not to
mention the time and person hours required to annotate the data). The potential for
sharing, merging, and comparing corpora, particularly in contrastive linguistic
research, calls for a basic schema which suits the needs of various projects and which is
easy to handle and extend.
9 In addition, such a schema should be compliant with encoding frameworks already
widely used in existing text and speech corpora. This would allow the schema to not
only meet the needs of scholars interested in CMC but also those interested in
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
116

phenomena of contemporary language in general or in comparative analyses of
linguistic phenomena in CMC corpora or corpora of “traditional” text or speech genres.
10 Since many resources within the humanities are already using the encoding framework
provided by the Text Encoding Initiative (TEI), a basic schema for CMC would ideally
comply with this. As will be shown in section 3 of this paper, TEI has the power and
flexibility to describe CMC structures and features even though modules and elements
covering the particularities of CMC discourse are not yet implemented in the TEI.
Therefore, a TEI-compliant XML schema for CMC discourse requires additional
modules. Considering the relevance of the Internet as a communication medium, a
separate module for CMC document types and features could be an important
extension for a future version of the TEI Guidelines.
2.2. The DeRiK Corpus in the Context of the DWDS System
11 Designers of balanced corpora representing the current state of a language should be
sure to include all relevant types of genres in which the contemporary use of this
language is embodied. Nowadays, for a language like German with a strong online
presence, this should include genres of computer-mediated communication. In the
project Deutsches Referenzkorpus zur internetbasierten Kommunikation (DeRiK), 7 we are
aiming to build a corpus of German CMC covering data from the most popular CMC
genres. Data sampling is guided by the findings of the ARD/ZDF-Onlinestudie, which
shows the popularity of various genres among German online users. For practical
reasons, though, the project will sample only those domains and genres that are
cleared from intellectual property rights. The data will be integrated in and presented
through the DWDS, a digital lexical system developed by and hosted at the BBAW. The
system offers one-click access to three different types of resources (Geyken 2007):
Lexical resources: a common language dictionary,8 an etymological dictionary, and a
thesaurus;
Corpus resources: a balanced reference corpus (called the “DWDS core corpus”) of German
from 1900 to the present. The corpus is balanced among nearly equal shares of journalistic
texts, scientific prose, functional texts, and fiction. Until recently, CMC did not play a role
either as an independent text genre or as part of one or more of these genres; additionally, a
set of newspaper corpora and specialized corpora that are not part of the DWDS core corpus
(such as German newspapers from Jewish communities edited in the first decades of the 20th
century);
Statistical resources for words and word combinations.
12 In the web interface, these resources are displayed alongside one another in separate
panels (see fig. 1). Information in all corpus panels can be retrieved through a linguistic
search engine which allows the user to search for patterns of single words,
combinations of words, combinations of words and part-of-speech patterns, and more.
It is thus possible to retrieve examples for multi-word phrases (e.g., collocations) and
grammatical constructions (such as a verb used in the passive voice).
1.
2.
3.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
117

Figure 1: Web interface of the DWDS system
13 The DeRiK corpus will be integrated into this framework as an independent panel as
well as a subcorpus of the DWDS core corpus and, thus, fill the “CMC gap” in the
current version of the corpus.
14 The integration of a CMC reference corpus into the DWDS system will be valuable for
various research and application fields, for example:
Lexicology and lexicography: Besides genre-specific discourse markers and Internet jargon
(like “lol”), new vocabulary is characteristic of CMC discourse. For example, “gruscheln”, a
form describing the virtual approaching of another person in the German social network
StudiVZ (English paraphrase: “to poke”). Furthermore, the disembodiment of synchronous
written communication leads to a metaphorical usage of verbs like “knuddeln” (en: “to hug
[somebody]”). These features should be documented and described in lexical resources.
Language variation and stylistics: The linguistic peculiarities and the stylistic aspects of CMC
are described in the CMC-related literature.9 However, most empirical studies on the matter
have been based upon small and project-related datasets. The DeRiK corpus will provide a
broader basis for qualitative and quantitative investigations on linguistic features and
linguistic variation in German CMC. The DWDS framework will facilitate the comparison of
CMC genres with corpora of other written genres; it will, thus, be easier to investigate how
new patterns and genres emerge.
Language teaching: Internet communication has become an important part of everyday
communication. Thus, language- and culture-specific properties of CMC should also be
regarded in communicative approaches to Second Language Teaching. In this context, the
DeRiK corpus and the lexicographic documentation of CMC vocabulary in the DWDS
dictionary may be useful resources. In school teaching, German native pupils may use the
DWDS system to compare written language and CMC corpora and to explore how style varies
across different genres (Beißwenger and Storrer 2011).
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
118

3. Specification of the Schema
3.1. CMC Genres, Document Types, and Features Covered by the
Schema
15 In a broader sense, computer-mediated communication comprises all communication
“that takes place between human beings via the instrumentality of computers”
(Herring 1996, 1). In a narrower sense, the term “computer-mediated communication”
is used for such forms of communication that are based on computer networks (usually
the Internet). According to John December 1996, those forms of computer-mediated
communication can also be subsumed under the category “Internet-based
communication,” including all communication that “takes place on the global
collection of networks that use the TCP/IP protocol suite for data exchange”. Internet-
based communication can be accessed using client software on desktop or mobile
computers or through applications for the use of online services on mobile
communication devices such as mobile and smart phones.
16 Taking into account the focus of the DeRiK project, we restrict the focus of our schema
to forms of communication which are (i) based on the TCP/IP protocol suite for data
exchange, (ii) dialogic (with all participating users being able to switch between the
role of a recipient/reader and the role of a producer/author of messages), and (iii)
based on writing as the main encoding medium for the users’ dialogue contributions
(that is, the verbal parts of the contributions must be encoded using writing, though
they may also include graphics, embedded audio, or video files). Thus, the present
version of our schema does not cover communication which is mediated via computers
while not being Internet-based (such as SMS communication), monologic forms of
Internet-based communication (such as static webpages), or spoken online
communication using audio or video conferencing software (such as Skype or
Teamspeak).
17 Our schema focuses on those forms of computer-mediated communication in which
written dialogue contributions of more than one interlocutor are displayed in the same
document. In its present version, the schema excludes communication via e-mail and
on Usenet in which each user contribution is stored in a separate (e-mail) document. In
our opinion, the representation of documents that render only one text message
(which, in addition, may have other documents in a vast range of file formats as
attachments) demands a different base structure than documents which preserve
sequences of contributions by two or more users. We do not exclude e-mail and Usenet
conversations from the DeRiK project in general; we simply do not claim that the
schema we describe below is able to adequately cover their features.
18 The schema draft that we describe in the following sections gives a core model for the
representation of the following types of CMC documents:
threads in online forums and in bulletin boards;
discussion threads on talk pages in wikis;
logfiles of conversations in webchats, on Internet Relay Chat (IRC), and in instant messaging
applications;
sequences of user postings in online guestbooks (which have a structure similar to chat or
instant-messaging logfiles);
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
119

sequences of postings and threads on profile pages and in discussion sections of social
network sites;
sequences of user postings on Twitter (such as “timelines” of postings that include the same
thematic hashtag);
discussion threads in weblogs;
sequences of review postings for products presented on online shopping sites;
threads and sequences of “private messages” preserved in users’ individual mailboxes on
social network sites or learning platforms.
19 The status of our schema is that of a core model for the representation of CMC. This
means that the schema is meant to provide elements for the representation of the basic
structural peculiarities on the macrolevel and of some prominent linguistic features
that can be found on the microlevel of CMC discourse. The structural elements on the
microlevel are those elements that can be found in the content of individual users’
contributions to CMC conversations, while the constituting structural elements of the
macrolevel are the users’ contributions themselves. Structures on the microlevel (or
microstructures) are made of linguistic units, punctuation, media objects, and
hyperlinks. The current version of our schema confines itself to those microstructural
elements that can be regarded as typical for CMC―especially the CMC-specific
interaction signs (section 3.5 below). The schema could be extended in such a way that it
covers further linguistic and structural phenomena of CMC discourse (for an overview
of linguistic features in German CMC discourse, see, for example, Runkehl et al. [1998]
and Storrer [2009]; for English, see, for example, Crystal [2001] and the contributions in
Herring [1996]). The schema presented in the following sections is open to such
extensions.
3.2. Basic Modeling Decision: Customizing TEI’s Basic Formats for
the Representation of Text Structure
20 None of the modules in the current version of the TEI Guidelines can be adopted “as is”
for creating a model for the representation of CMC. There are many elements in the
default text structure module which are useful for describing the structure of individual
users’ contributions to CMC discourse, but CMC documents can be regarded as text
documents only in a very technical sense since they include stretches of written
language which, due to their separation through line-breaks, appear paragraph-like. On
the other hand, the dialogic structure of CMC discourse appears similar to the structure
of spoken conversations (covered by the transcribed speech module), but the production
of the users’ contributions to CMC dialogues is a monologic activity and, thus, more
text-like than speech, in which the interlocutor perceives and processes the verbal
utterance nearly simultaneously with its production by the speaker. Therefore, neither
of these modules, nor any other module in P5, provides a model of interpersonal
communication that fits the particularities of the main constituting elements of CMC
discourse. These are the stretches of text that an individual user produces in private
and then passes on to the server through performing a “posting” action (usually by
hitting the [ENTER] key on the keyboard or by clicking on a [SEND] or [SUBMIT] button on
the screen).
21 The commonalities and differences of CMC discourse with text and speech have been
widely addressed in the CMC literature. CMC can best be described as (synchronous or
•
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
120

asynchronous) written or typed conversation (Werry 1996; Storrer 2001; Beißwenger
2002) or as interactive written discourse (Ferrara et al. 1991; Werry 1996), which has to be
regarded as crucially different from spoken conversation as well as from texts since it
uses features of textuality for the purpose of dialogic exchange (see also, for example,
Crystal 2001, 25–48; Hoffmann 2004; Zitzen and Stein 2005): Just like text, CMC is
written. In some CMC genres, the users can apply text formatting features and
paragraph structuring to their contributions. In contrast to texts and similar to spoken
conversation, CMC discourse is dialogic, while the users’ contributions to CMC
dialogues are being composed in a private activity, then sent to the server, then
displayed on the screens; it is not until then that they can be read by other users
(Beißwenger 2003, 2007). This “pre-transmission composition” protocol for the
production of dialogue contributions in CMC is text-like, not speech-like. Accordingly,
even in synchronous modes of CMC (chat and instant messaging), the users lack the
possibility to provide simultaneous feedback or to perceive and process the
contributions of their interlocutors simultaneously with their verbalization (which has
crucial consequences for the interactional management layer, especially turn-taking in
conversation; see, for example, Garcia and Jacobs 1998, 1999; Herring 1999; Beißwenger
2003, 2007; Schönfeldt and Golato 2003; Ogura and Nishimoto 2004; Zitzen and Stein
2005). As can be seen by observing message composition in chat sessions, the message
production includes subprocesses of evaluation and revision (re-writing) which are
particular to the production of text (see, for example, the findings on message
production in chats in Beißwenger [2007, 2010]). All in all, CMC can thus be considered
as more than just a hybrid of text and speech (Crystal 2001, 48). Therefore, neither text
nor speech provides an adequate model for its description. But considering the form
and production of user contributions to CMC conversations, a text model seems to be a
better starting point for practical modeling purposes than a speech model. Or, in
Crystal’s words, “[o]n the whole, Internet language is better seen as writing which has
been pulled some way in the direction of speech rather than as speech which has been
written down” (2011, 21). Still, this does not mean that written language is a good
model for CMC per se; but certain structural features specific to written language can
also be found in CMC, and therefore, a model for the description of text can provide
more elements that can be adopted for the description of written CMC than a model for
speech which is bound to completely different conditions of verbalization and mutual
perception.
22 For our schema, we decided to use the TEI header module in P5 as the basis for the
representation of metadata in CMC documents (with some minor customizations which
will be described in section 3.5 below). For the representation of the document
structure, we decided to tailor a customized version of the TEI default text structure
module and, additionally, of some elements from the common core module (especially
the <p> element for the annotation of paragraphs). The main issues that we had to deal
with while customizing the respective TEI modules for the representation of CMC were
(i) the question of how to represent the users’ written contributions as the main
constituting elements of CMC conversations, (ii) the question of how to represent CMC-
specific types of grouping sequences of users’ contributions to larger units (threads and
logfiles), and (iii) the question of how to differentiate between the inner structure of the
individual users’ contribution and the structure of the CMC discourse (the first being
controlled by the user, the second being the result of an interactional achievement of
Journal of the Text Encoding Initiative, Issue 3 | November 2012
121

all participating users and/or of a certain server routine for ordering incoming user
postings).
23 Regarding (i), we decided to introduce a new element <posting> and assign it to the
divLike class of elements (section 3.3.1 below). Regarding (ii), we decided to
introduce two new <div> types and name them thread and logfile (section 3.3.2 below).
Regarding (iii), we decided to use the <p> element for segmentations in the content of
postings (CMC microstructure) and to use <div> elements for segmentations above the
posting level (CMC macrostructures).
3.3. Elements of the Document Macrostructure
3.3.1. The <posting> Element
24 The element <posting> is the basic CMC-specific element in our schema. In CMC
documents it represents the largest structural unit that can be assigned to one author
and one point in time. The category posting is defined as a content unit that has been
sent to the server “en bloc”. Its function is to make a (written) contribution to the
ongoing dialogue. After being sent (“posted”) to the server, the submitted unit is
displayed in the CMC document as one continuous stretch of content (text plus
embedded media objects such as graphics or video files, etc.). It is usually assigned to
the user name of its author (the user who has sent the unit to the server) and often also
to a certain point in time (indicated through a timestamp). Therefore, postings can be
recognized by their formal structure and, thus, be annotated automatically, even if
they may have different forms and structures in different CMC genres or applications.
Figure 2: Macrostructure of a Wikipedia talk page (excerpt)
25 The example given in figure 2 shows an excerpt from a Wikipedia talk page. Individual
user postings all end with a signature that gives the author’s name and a timestamp.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
122

For example, the signature of posting 1 assigns the posting to an author named Netpilots
and indicates that it was received by the server at 10:36, July 28, 2011 (CEST). More
information about the author can be found on the author’s profile page, which can be
accessed through the hyperlink underlying the name.
26 In a Wikipedia talk page, there is a convention to use a paragraph break to separate
each author’s posting. This makes the sequence of postings in the document appear like
a sequence of paragraphs in a text document. In addition, individual postings can have
internal structure. Posting 1, for example, structures its content into two paragraphs
and a bullet list with two items. Furthermore, the author of posting 1 uses hyperlinks to
connect certain segments of his posting with other Wikipedia pages (“Schwäbisch
Gmünd” and “Facebook”) and with Web resources external to Wikipedia
(“Gescheiterter Bud-Spencer-Tunnel/Focus.de” and “Artikel im Tages-Anzeiger”), plus
bold font weight to highlight the segment “Bud Spencer Tunnel” in the first paragraph.
27 In addition to the paragraph breaks between postings, the postings in example 1 are
also separated from each other by different levels of indentation. The indentations
were deliberately added by the authors in an attempt to create thread structures,
similar to those in discussion groups. Thus, the level of indentation is a feature of the
posting itself and not something that has been automatically assigned by the server.
28 The example given in figure 3 shows an excerpt from a chat logfile. In this case, the
postings are linearly placed one after another in the order of their arrival on the chat
server. In the user chat interface, each individual posting is rendered as a block, and
the server automatically adds information about the authors―the user’s nickname,
which is inserted in front of every posting.
105 Dill die rosi ihr englisch ist nihct vom feinsten
rosi’s english is not the best
106 Rosenstaub1979 Nö
Nope
107 Rosenstaub1979 is schon zuuulang her
it’s been toooooo long
108 Dill aber rosi ist prächtig
but rosi is magnificent
109 Dill prachtvoll
grand
110 Rosenstaub1979 Ich glaube, so 9 Jahre
I think, about 9 years
111 Rosenstaub1979 *lol* @Dill
*lol* @Dill
112 Dill 9 jahre?
9 years?
113 Rosenstaub1979 Ja, kommt fast hin
Journal of the Text Encoding Initiative, Issue 3 | November 2012
123

Yes, that’s about right
Figure 3: Sequence of postings in a chat room
29 A posting represents a category in its own right which is different from text or speech.
Below, we examine the TEI elements for divisions and paragraphs (components of texts)
and for utterances (components of spoken discourse) to check whether they would
suffice to encode postings.
30 According to the TEI Guidelines, the paragraph element <p> is used to mark “the
fundamental organizational unit for all prose texts, being the smallest regular unit into
which prose can be divided” (TEI P5: 3.1) while the element <div> identifies
subdivisions of a text, such as chapters or sections (TEI P5: 4.1). Being defined as an
“organizational unit” (of a text), the notion of the paragraph implies that there is an
author or at least an author-like authority (editor or publisher) who makes certain
structuring decisions while composing his text and, thus, divides it into a series of units
(for example, according to subtopics and information units). In CMC, on the other hand,
one author’s reach ends with the beginning and end of his current posting while the
structure of the sequence of postings is either due to a server routine (as in chat
logfiles) or a joint achievement of the group of users (as in Wikipedia talk pages and in
certain forums). Thus, the resulting structure is not based on any sort of authorial
structuring of the text. Modeling a user posting as a paragraph would therefore reduce
the original concept of the paragraph to absurdity: a paragraph is a holistic unit
determined by (one author’s) global text coherence, whereas a posting in CMC is an
atomic constituent of a written dialogue determined by the ongoing dialogue’s local
coherence.
31 For example, in figure 3, the user Rosenstaub sends posting 106 (“Nope”) as a direct
reaction to the previous posting 105 from user Dill. This reaction of hers was not
previously determined by an author (as is the case, for example, with individual
characters’ utterances in dramatic dialogues), but she reacted in this way because the
previous posting created a context which made this type of response seem sensible for
her locally. Before reading posting 105, Rosenstaub could not even know herself that her
own next contribution would be “Nope”; the intention for her “Nope” response is
directly caused through the reception and processing of posting number 105. On the
other hand, user Dill, when he sends his posting number 105, does not know which type
of posting will follow in 106 (or if any reaction at all will come from Rosenstaub) because
there is no author who planned the entire dialogue in advance; instead, the dialogue is
developed by the users as they go along; at the same time, each posting creates a
context for the partners’ responses that follow. Both participants are acting according
to their own communication goals; but neither of the participants can precisely predict
in advance how the dialogue will really develop.
32 Postings also differ greatly from utterances in spoken conversation. Thus, the element
<u> (utterance) from the TEI’s spoken module (“transcribed speech”)―describing “a
stretch of speech usually preceded and followed by silence or by a change of speaker”
(TEI P5: 8.3.1)―is also an inadequate option for the conceptualization of postings. The
simultaneity of verbalization, perception, and mental processing as one very central
characteristic of spoken utterances is not present in postings: Due to the “pre-
transmission composition” protocol discussed above, the turn-taking apparatus does
Journal of the Text Encoding Initiative, Issue 3 | November 2012
124

not function in the same way as in spoken conversation. Postings―like texts―are first
produced in their entirety; the composition process can accordingly not be tracked by
the other participants, its result (after having been submitted to and transmitted by the
server) can only be read retrospectively. In spoken conversation, on the other hand, the
listeners can give immediate feedback and, thus, directly react to (and affect) the
ongoing verbalization; they can anticipate the completion of turn-constructional units
and negotiate turns simultaneously with the linear unfolding of the current speaker’s
utterance (see, for example, Sacks, Schegloff and Jefferson 1974; Schegloff 2007).
33 Therefore, in our schema, the element <posting> is the basic structural element of a
CMC document. We consider it a macrostructural element, but it is the pivot between the
higher level macrostructural components thread and logfile (see section 3.3.2) and the
microstructure of the content which it encloses (see section 3.5). The structure of
<posting> is based on that of the existing <div> element.
34 The <div> and <posting> elements have the following similarities:
<div> and <posting> are high-level elements, belonging to the same class
(model.divLike);
<div> and <posting> contain the major divisions of text;
<div> and <posting> have similar internal content.
35 It is important to note that <posting>, like <div>, does not belong to the class of
pLike elements. One <posting> may consist of one or more paragraphs, similar to a
<div>. While a division may represent, for example, a chapter of a book, <posting>represents one user contribution to some computer-mediated communication event
(forum, blog, web-discussion, or chat). Such a contribution can contain multiple
paragraphs, just like <div>. In the chat example given in figure 3, all postings consist
of exactly one paragraph and the portion of text exhibits no special markup, but on the
Wikipedia talk page given in figure 2, some of the postings contain divisions and
markup that the authors inserted into the content of their postings in order to
structure their content. Therefore, <posting> cannot be a model.pLike element.
36 The <div> and <posting> elements have the following differences:
<div> is a self-nesting element, while <posting> is not;
<posting>s can only appear inside of a division which encloses one complete CMC
document (such as an entire forum thread, an entire blog with user comments, or a chat
logfile).
37 In other words, <posting> is a child element of <div> and shares its content model
except that it does not contain divisions and does not embed itself. Normally,
<posting> consists of one or more paragraphs. In some cases a posting contains a
head, typically with a title.
38 Attributes in the following classes can be used with the posting element:
att.ascribed, att.datable, att.global, att.typed. The most commonly
used attributes for posting are @synch and @who. @synch is used to signify the time
when a posting arrives at the server. Such sequential points in time are ordered on a
timeline encoded separately from the postings in the same XML document (in the
<front> section, as shown in the code snippet in fig. 4 and section 3.4). The @whoattribute refers to the profile of the person who submitted the posting. Profiles of all
users who contributed to the conversation recorded in one CMC document are listed in
the header of the XML document. The <person> element is used for this purpose.
•
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
125

39 In addition, we introduce new attributes in the TEI customization specifically for use
with the <posting> element: @revisedWhen, @revisedBy, and @indentLevel.
The first two attributes are similar to @synch and @who but differ from them in the
following aspect: they mark the time when a posting was revised and the person who
revised it (which, in some cases, appears in Wiki and in forum discussions). These
attributes take into account the fluidity of the CMC medium. Both the @who and the
@revisedBy attributes are added to the att.ascribed class; @synch and
@revisedWhen are added to the att.datable class. The values of @synch, @who,
@revisedWhen, and @revisedBy are URIs which point to a profile and to a point of
a timeline. The @indentLevel attribute is added to the att.global class. Its
function is to mark the (relative) level of indentation of the text in a posting (as defined
by its author). The value of this attribute must be an integer from 1 to ∞ depending on
the level of the indentation of the posting (see the encoding example given in fig. 5).
Figure 4: This example contains an encoding of a user profile, a part of the timeline, and one posting.For the complete encoding of this XML document, see http://www.empirikom.net/bin/view/Themen/CmcTEI.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
126

Figure 5: Encoding of postings 1 and 2 from the example given in figure 2
3.3.2. Threads and logfiles
40 As stated earlier, we use the term macrostructure to describe how series of postings are
arranged in CMC documents: CMC macrostructures do not emerge from the actions of
just one user but from all posting activities of all users involved in a CMC conversation,
plus server routines for ordering incoming user postings. Thus, the structuring on the
macrostructure level of a CMC document has a different status from the structuring
inserted by one and the same author into the content of his postings. In order to
differentiate between divisions on the macro- and the microstructural levels of CMC,
we therefore reserve the <p> element exclusively for divisions in the content of
individual postings, while we use the <div> element exclusively for the representation
of divisions on the macrolevel. In addition, we differentiate between two major types of
macrostructures in CMC:
logfiles, which arrange the sequence of postings in chronological order based on when they
reached the server (see the examples given in fig. 7)
threads, which structure the sequence of postings in two dimensions:
the above/below dimension, which usually stands for a temporal “before/after” relation;
the left/right dimension, in which one can use indentation to emphasize the topical
affiliation of one message to a previous message (see the example given in fig. 6).
41 To differentiate these two CMC-specific macrostructure types, we use the values thread
and logfile on the @type attribute of <div>.
1.
2.
1.
2.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
127

Figure 6: Differentiation between CMC macro- and microstructures in a CMC “thread” macrostructure
Figure 7: CMC “logfile” macrostructure
3.4. Metadata and Anonymization
3.4.1. Metadata
42 The TEI customization needs to account for metadata specific to CMC. In our context, it
is convenient to add metadata to each individual document, and the TEI header is
sufficient to record data relevant to the description of a CMC document. However, we
want to draw the attention of the reader to the following features which are particular
to the CMC document type:
Documents are quite difficult to identify on the Web. Mechanisms of persistent identifiers
are just now gaining ground and are far from being well established. We therefore follow a
double strategy: in cases where we are able to refer to a persistent identifier (as is the case
with versions of Wikipedia talk pages), we include that information as a part of the source
1.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
128

description. In cases where we cannot refer to a persistent identifier, we download the web
page and store it as a digital copy and refer to it in the source description.
As a part of the metadata, we store the profiles of the participants in the computer-mediated
interactions included in our corpus. We construct these profiles from those data recoverable
from the interaction. The reasons for doing so are explained below.
In addition, we store a timeline on which the individual users’ contributions (postings) are
situated via the @synch attribute of the element <posting> (see section 3.3.1). We are
aware that in most cases, we can only capture the point in time when a contribution is
received and processed by the server, but the interesting point for purposes of
documentation and analysis is the relative chronological order of contributions and not the
absolute point in time.
3.4.2. Anonymization
43 In order to be able to distribute the collected CMC data as widely as possible, we need to
anonymize the data. Our anonymization strategy shall support the following goals:
Every user of the data shall be able to associate a certain set of postings in a CMC document
to a user. This user, however, shall not be identifiable as an individual of the “real world”.
Despite that, some privileged (“authorized”) users shall be able to see and maintain the data
which could be used to identify an individual person as the author of certain postings. It
might be useful to automatically or individually recover only certain features of a (set of)
user(s), such as their gender, if such data are available.
44 To achieve these particular goals, we perform the following steps:
All of the recoverable personal data of a CMC participant are collected into a person profile
in a <person> element. This profile is provided with a value of @xml:id which is unique
within the particular TEI document. All person profiles are stored in the header of the
document; thus, they can easily be separated from the body of the document and therefore
be hidden from the less privileged users of the data.
Each <posting> is linked to a person profile via the @who attribute, which points to the
value of an @xml:id of a <person> element.
Instances of user names in segments of a given posting are also linked to a <person> (see
section 3.5.1.5 below).
45 We are aware that the procedure of identifying names and maintaining person
portfolios can be a time-consuming task. However, this effort is in some cases
unavoidable and a necessary prerequisite for the publication and distribution of
valuable data. We therefore want to ensure that a reliable anonymization strategy
exists and can be used in such cases.
46 For an example of this strategy in use, see the example in figure 4 (section 3.3.1).
3.5. Elements of the Document Microstructure
3.5.1. CMC-specific Types of Interaction Signs
47 Up to now, many assumptions about the Internet’s impact on language change have
been based upon small datasets and the linguistic intuition and experience of the
researchers. An annotation standard for typical elements of Internet
jargon―emoticons and acronyms, to name just two―would help to investigate their
usage and dissemination across (sub)languages and digital genres on a broader
2.
3.
•
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
129

empirical basis. However, there is no common terminology to classify the elements of
Internet jargon, nor consensus about the status of these elements in a natural language
grammar framework. To fill this gap, we have developed an annotation schema for
these phenomena on the microstructure level of CMC documents. The basic linguistic
description category of our approach is termed an interaction sign; in the schema,
instances of interaction signs such as emoticons, acronyms, etc. are represented using
the element <interactionTerm>. Below we briefly introduce the category of an
interaction sign and embed it into a broader grammatical framework. By means of
examples, we describe how the category and its subcategories are used for the
annotation of our German reference corpus.
48 First and foremost, our schema serves the annotation needs of the DeRiK project. Some
of the subcategories may be specific to German CMC, so it is clear that the annotation
schema suggested below has to be developed further and discussed within the CMC
community. For example, the set of subcategories of interaction sign may have to be
extended and adapted for other languages. In principle, we consider our proposal as a
first step towards the development of an annotation standard that will facilitate cross-
language, cross-genre, and micro-diachronic investigations of elements of Internet
jargon in CMC corpora. The schema favors a grammatical perspective, but it is open for
extensions motivated by other fields of research such as cultural studies or sentiment
analysis.
3.5.1.1. Interaction Signs: Definition and Subclasses
49 Spoken discourse typically contains elements like “hm”, “well”, “oh my god”, “oops”,
and “wow”. Grammar frameworks usually categorize them as interjections (see, for
example, Greenbaum 1996; McArthur et al. 1998; Blake 2008) or Interjektionen (DUDEN
2005), inserts (Biber et al. 1999; Biber et al. 2002), discourse markers (Schiffrin 1986),
discourse particles, or Gesprächspartikeln (DUDEN 1995). These interjections are different
from responsives like “yes” and “no”, which can occur in both spoken and written
dialogues.
50 In the system of syntactic categories of the three-volume German grammar of the
Mannheim Institut für Deutsche Sprache, Grammatik der deutschen Sprache (Zifonun,
Hoffmann, and Strecker 1997, henceforth GDS),10 both interjections and responsives are
categorized as Interaktive Einheiten (henceforth IE). In spoken discourse, IEs serve as
devices for conversation management: they can be used to express reactions to a
partner’s utterances or to display the speaker’s emotions.11 One important syntactic
feature of IE is that they are not integrated in the sentence’s syntactic structure (Ehlich
1986; Trabant 1998). Instead, they are often either used as sentence-equivalent
utterances (like “nö” in posting 106 of the example given in fig. 3 above) or used in
front of or after the sentence boundaries (like “ja, sollte eigentlich” in posting 2 of the
example given in fig. 2).
51 Many CMC-specific elements like emoticons and acronyms occur in the same positions
and have similar functions as IEs in spoken discourse. It is, thus, not surprising that
grammars―if they describe them at all―classify these elements as interjections.12 In
the STTS tagset, a standard for German part-of-speech classification,13 most IEs would
best be annotated using the POS-Tag ITJs (Interjektio) or PTKANT (Antwortpartikel); in the
CLAWS2 tagset for English,14 they would fit into the category UH (interjection).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
130

52 But this simple solution is not sufficient for corpus-based research on CMC jargon
across languages, cultures, and genres. On the one hand, elements like emoticons are
language-independent iconic signs that cannot be classified as syntactic units of
natural languages in a strong, narrow sense. On the other hand, iconic signs like the
emoticon “:-)” and symbolic signs like the abbreviation “*s*” (derived from the English
“smile”) are often used as synonyms. All these elements share topological and
functional features with natural language interjections in spoken discourse. By
subsuming all of these elements of Internet jargon under one category, “interaction
sign”, we want to account for their functional and semantic similarities (see fig. 8).
Figure 8: Typology of interaction signs (with examples)
53 In our schema, we introduce an element <interactionTerm> as a phrase-level
element (in the model.phrase class) which encloses one or more instances of
subclasses of interaction signs. The <interactionTerm> element can have
members of att.global as attributes. In addition, we introduce elements for the
following subclasses of interaction signs: the two subclasses of “Interaktive Einheiten”
as described by the GDS (interjection and responsive) and the four subclasses for elements
which are typically—but not exclusively—used in written CMC discourse
(<emoticon>, <interactionWord>, <interactionTemplate>, and
<addressingTerm>). Each of the elements is assigned a set of attributes by which
their occurrence in the corpus documents can be sub-classified according to formal,
positional, semiotic, semantic, and functional criteria. In the following, we outline the
underlying basic ideas of choosing these categories and describe the properties of the
elements introduced in our schema for their representation in our corpus data.
3.5.1.2. Emoticons
54 Emoticons are iconic units created using the keyboard. They are often used to portray
facial expressions, and they typically serve as emotion, illocution, or irony markers.
Due to their iconic character, the use of emoticons is not restricted to CMC in one
particular language; instead, the same emoticons can be found in CMC data in different
languages. There are several systems of emoticons: besides the Western-style
emoticons, there are, for example, Japanese and Korean style variants. Postings 3 and 5
in the example given in figure 2 include Japanese-style emoticons (“Kawaiicons”);
Western-style emoticons can be found in the example given in figure 9.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
131

Figure 9: Postings on a Wikipedia talk page displaying instances of the Western-style emoticons :o)and ;o) and instances of the interaction words *freu* (“happy”) and *g* (< “grin”). The combination of:o) and *freu* in posting 5 is an example of an interaction term that consists of two types ofinteraction signs.
55 In our schema, instances of emoticons are represented using the <emoticon>
element, which is assigned to the gLike element class. Conventionally, elements of
this class contain non-Unicode characters and glyphs. Although most emoticons are
produced as a sequence of keyboard characters (dot, comma, colon, and the like), the
resulting figure is comparable in its semiotic status to graphic characters. While some
smiley faces have been included in Unicode, the variety of emoticons is still larger than
can be captured by Unicode characters alone. That is why we place the <emoticon>element in the class of gLike elements.
56 The <emoticon> element includes attributes from the att.global class and a
number of new attributes from other classes, such as @style,
@systemicFunction, @contextFunction, and @topology, the first three of
which are members of the att.typed class. The @style attribute describes the
native region of an emoticon. The value list of @style is currently set to Western,
Japanese, Korean, and Other. The attributes @systemicFunction and
@contextFunction (explained below) share the following list of values:
emotionMarker:positive, emotionMarker:negative, emotionMarker:neutral,
emotionMarker:unspec, responsive, ironyMarker, illocutionMarker, virtualEvent.
57 The distinction between a systemic and a context function reflects the semantic
differentiation between the expression meaning and the utterance meaning of lexicalized
linguistic units (cf. Löbner 2002). The idea is that, comparable to other lexemes, these
types of emoticons (and other interaction words; see section 3.5.2.2) commonly used in
CMC can be assigned a general, context-independent meaning. On the Web, there are
many lists displaying the “most common emoticons” with descriptions of their
Journal of the Text Encoding Initiative, Issue 3 | November 2012
132

meaning (systemic function). Figure 10 shows an excerpt from Wikipedia’s list of
Western emoticons; the left column renders types of emoticons, the right column gives
short paraphrases of their (context-independent and, thus, systemic) function, as
assigned by the authors.
58 In a given context of use, the function of an instance of a given type of emoticon may
vary from its systemic function. Figure 11 shows an example (b) in which the smiley :-))
and its variant :), which are usually assigned the systemic function of a positive
emotion marker (“happy face”, see entry in fig. 10), are used for marking irony. The
context function of these elements in (b), thus, differs from their systemic function. On
the other hand, in (a) in figure 11, the context function of “:)” is identical with the
systemic function; here, the emoticon is used for displaying a positive emotion of
happiness.
59 The @topology attribute (which is a member of att.placement) captures the
position of the emoticon relative to the text to which it belongs. Consequently, the
range of values is set to front_position, back_position, intermediate_position, standalone.
Icon Meaning
>:] :-) :) :o) :] :3 :c) :> =] 8) =) :} :^) Smiley or happy face […]
>:D :-D :D 8-D 8D x-D xD X-D XD =-D =D =-3 =3 8-) Laughing, big grin, laugh with spectacles
:-)) Very happy
>:[ :-( :( :-c :c :-< :< :-[ :[ :{ >.> <.< >.< Frown, sad
:-|| Angry
>;] ;-) ;) *-) *) ;-] ;] ;D ;^) Wink, smirk
>:P :-P :P X-P x-p xp XP :-p :p =p :-Þ :Þ :-b :b Tongue sticking out, cheeky/playful […]
Figure 10: Excerpt from the list of Western emoticons as given in the English Wikipedia, page “List ofemoticons” (as of 2012-02-01)
11a: 178 system Shadok kommt aus dem Raum Alshain herein.
Shadok comes in from the room Alshain.
185 marc30 Holla Shaddy :)
Hey Shaddy :)
189 Shadok heya marc30 ;o)
hey marc30 ;o)
11b: 536 ThorThor... ärgert sich immer noch, daß die franzosen den pott nicht behalten
haben *gg*
Thor… is still upset that the french didn’t hold on to the pott *gg*
544 Erdbeere$Erdbeere$ ärgert sich mit .... der pott geht an frankreich und wir bekommen
die küste
Erdbeere$ feels your pain …. the pott goes to france and we get the coast
554 Bochum Bochum tritt erdbeere in den arsch :-))
Journal of the Text Encoding Initiative, Issue 3 | November 2012
133

Bochum kicks erdbeere in the butt :-))
564 Erdbeere$ ohh wie nett :)
ohh how nice :)
Figure 11: Convergence (11a) and divergence (11b) of systemic function and context function (excerptfrom document no. 2221006 in the Dortmund Chat Corpus).
3.5.1.3. Interaction Words
60 Interaction words are symbolic linguistic units. Their morphologic construction is based
on a word or a phrase of a given language which describes expressions, gestures, bodily
actions, or virtual events―for example, the units sing, g (< grins, “grin”), fg (< fat grin), s
(< smile), wildsei (“being wild”) in figure 12 are used as emotion or illocution markers
(postings 865, 876, 880), irony markers (postings 878, 879, 886) or to playfully mimic
simulated bodily activity (posting 864):
858 Turnschuh OHNE DEUTSCHLAND FAHRN WIR ZUR EM!
WE ARE GOING TO THE EUROPEAN CUP WITHOUT GERMANY
859 system Ryo hat die Farbe gewechselt
Ryo changed colors
860 Gangrulez jo schade
yep too bad
861 system Windy123 geht in einen anderen Raum: Forum
Windy123 is going to another room: Forum
862 juliana alle leute müssen ihre fernseher bei media markt bezahlen
all the people have to pay for their TV at media markt
863 juliana haha
haha
864 Turnschuh Es gab mal ein Rudi Völler.......es gab mal ein Rudi Völler.....♫sing♫
There once was a Rudi Völler.......there once was a Rudi Völler.....♫sing♫
865 Ryo *g*
*g*
866 Gangrulez hehe..das wurd eh gerichtlich gestoppt juliana
hehe..that was stopped by the courts anyway juliana
867 juliana echt?
really?
868 oz gang: echt ??
gang: really ??
869 Gangrulez ja
Journal of the Text Encoding Initiative, Issue 3 | November 2012
134

yeah
870 juliana wieso?
why?
871 Gangrulez wettbewerbsverzerrung
distortion of competition
872 Naturkonstantler Fussball ist sooo unendlich unwichtig...
Soccer is sooo incredibly unimportant…
873 juliana versteh ich nicht. ich fand es war ein cooler trick
I don’t understand. I thought it was a cool trick
874 Gangrulez aber es war eine Art Glücksspiel
but it was a kind of gamble
875 Turnschuhmag auch keinen Fussball......nur wollte ich das letzte Deutschlandspiel
sehen *fg*
Turnschuh also doesn’t like soccer......but I would have liked to have seen the last
Germany game *fg*
876 Chris-Redfield *s* aber net erlaubt @ juli
*s* but not allowed @ juli
877 julianafußball ist nen dreck wichtig. es ist ein spiel. hauptsache, die jungen
männer haben sich fitgehalten und ihrer gesundheit was getan :)
soccer isn’t worth it. it’s a game. Main thing, the young men have kept fit and
done something for their health :)
878 Gangrulez und das entspircht nicht dem Handel *g
and that wasn’t the deal *g
879 juliana chris, du weißt doch, daß ich ein gesetzesbrecher bin *g*
chris, you do know that i am a law breaker *g*
880 Chris-Redfield ja ich weiß *s*
yes i know *s*
881 juliana *wildsei*
*being wild*
882 juliana naja... äh.
oh well… um.
883 Gangrulez ach ich muss ja noch ne mail schreiben..
oh i have to write an e-mail..
884 juliana ich geh zu meinem buch und...
I’m going to go to my book and…
885 system Gangrulez geht in einen anderen Raum: sphere
Gangrulez goes to another room: sphere
Journal of the Text Encoding Initiative, Issue 3 | November 2012
135

886 Naturkonstantler
vielleicht können wir ja mal eine Greencard für potentielle Fussballspieler
einführen... ich werde eine Petition bein B-tag einreichen... Ja, so bin ich,
ich sorge mich um das Wohl der Allgemeinheit! *g*
maybe we can introduce a green card one day for potential soccer players… I will
submit a petition to congress… Yes, that’s how I am, I care for society’s well-being!
*g*
887 juliana mal schaun
we’ll see
888 system juliana verlässt den Raum
juliana leaves the room
Figure 12: Excerpt of a social chat displaying instances of interaction words (postings 864, 865, 875,876, 878, 879, 880, 881, 886) and of addressing terms (868, 876)
61 The element <interactionWord> in our schema is a member of
model.global.spoken. It shares properties of the <kinesic>, <incident>,
and <vocal> elements in TEI. The element <interactionWord> is provided with
attributes from the class att.global and several new attributes: @formType,
@systemicFunction, @contextFunction, @topology, and
@semioticSource. The attributes @systemicFunction, @contextFunction,
and @topology are used for the <emoticon> element. @formType is in the
att.typed class of attributes and is used to describe morphological properties of the
<interactionWord>. The list of values is currently set to simple, complex, and
abbreviated. The attribute @semioticSource is in the att.typed class of attributes
and is used to describe the semiotic mode that forms the basis for an interaction word;
its current list of values is set to mimic (such as for grins “grin” and stirnrunzel “frown”),
gesture (such as for kopfschüttel “shake head” and wink “wave”), bodilyReaction (such as
for schluck “gulp”, seufz “sigh”, and hüstel “little cough”), sound (such as for plätscher
“splash” and blubb ”plop”), action (such as for tanz “dancing”, knuddle “cuddling”, erklär
“explaining”, and mampf “munching”), sentiment (such as for freu “happy”), process
(such as for träum “dreaming”), and emotion (such as for schäm “ashamed”).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
136

Figure 13: Encoding snippet for example 11b from figure 11
3.5.1.4. Interaction Templates
62 Interaction templates are units that the user does not generate with the keyboard but by
activating a template which automatically inserts a previously prepared text or
graphical element into a space of the user’s choice.
63 The category of interaction templates includes graphic smileys, chosen by the user of a
CMC environment from a finite list of elements. These often portray facial expressions
but can depict almost anything; in the case of animated GIFs, they can even portray
entire scenes as moving pictures. This clearly goes beyond what can be expressed using
only keyboard-generated emoticons. On the other hand, users can invent new
emoticons by combining keyboard characters, while template-generated units are
always bound to predefined templates.
64 The element <interactionTemplate> in our schema belongs to the
model.global class of elements. It is provided with the att.global class of
attributes and a few new attributes which belong to different classes. The most
important attributes for this element are @type, @motion, @systemicFunction,
and @contextFunction.
65 As the attribute @type is used to characterize the surface of the figure, the list of
values is currently set to: iconic, verbal, and iconic-verbal.
66 The @motion attribute belongs to the att.typed class and has two possible values:
static and animated.
67 The attributes @systemicFunction and @contextFunction have already been
introduced in section 3.5.1.2, but one additional value of attribute
Journal of the Text Encoding Initiative, Issue 3 | November 2012
137

@systemicFunction should be mentioned: “evaluation” is used to express whether
the enclosed graphic element expresses appreciation or disapproval.
3.5.1.5. Addressing Terms
68 Addressing terms address an utterance to a particular interlocutor (see the examples in
the postings 868 and 876 in fig. 12). The most widely used form here is the one made
out of the “@” character together with a specification of the addressee’s name.
69 The element <addressingTerm> in our schema belongs to the model.nameLike
class of elements. While this element usually uses no attributes, our customization
includes the att.global attributes. The content of <addressingTerm> is
restricted to two elements: <addressMarker> and <addressee>.
70 The <addressMarker> element belongs to the class model.labelLike (used to
gloss or explain parts of a document) and is provided with the att.global class of
attributes. The purpose of <addressMarker> is to identify or to highlight the
addressee in a posting. This is typically achieved by using the “at” sign (“@”) or one of
a set of fixed phrases (English: “to”; German: “an” or “für”).
71 The element <addressee> is placed in the model.nameLike.agent class. It
includes the @who, @scope, and @formType attributes, plus those from the
att.global class. Names of addressees are often addressed using abbreviated or
nickname forms of their usernames, so the name of the addressee given in the
addressing term might not be identical with the username of the interlocutor. We
would like to enable the users of our corpus to retrieve the alternative form from the
data even after the corpus data have been anonymized (as explained in section 3.4). We
use the @formType attribute for this purpose and assign it the following set of values:
persNameFull, persNameAbbreviation, and persNameNickname. Thus, the attribute
@formType allows us to describe cases like the ones illustrated through the examples
in figure 14:
14a:
306 Lantonie Lantonie heiratet Thor....
Lantonie is marrying Thor….
308 Lantonie :))
:))
323 zora wos? *eifersüchtel*@lanto
what? *jealous*@lanto
14b:
104Chris-
Redfieldtom ram ist doch nicht alles im leben *g*
tom ram is not all there is in life *g*
108 TomcatMJ nö, aber hilft dem server weiter@c-r :-)
no, but helps the server@c-r :-)
14c:
Journal of the Text Encoding Initiative, Issue 3 | November 2012
138

117 RaebchenRaebchen rät allen Pärchen, nicht auf Deck zu knutschen (sowas hat die Titanic
sinken lassen! habe ich im Film gesehen)
Raebchen advises all couples not to make out on deck (that’s what made the Titanis
sink! i saw it in the movie)
123 McMike *lol*@Raeby
*lol*@Raeby
14d:
89 McMike könntet Ihr mich bitte zum Käpten ernennen?
could you all please appoint me captain?
94 ineli26 ineli26 ernennt McMike zum Kapitaen
Ineli26 appoints McMike captain
[…]
160 McMike Monk, kannst Du das steuer übernehmen?
Monk, can you take over the wheel?
164 Monk klar wohin solls gehen?
of course where to?
169 McMike Monk immer dem Fön nach
Monk keep following the Foen
172 ineli26 lol @ kapitaen
lol @ kapitaen
Figure 14: Types of addressees’ names in addressing terms: abbreviated form (14a and 14b) andnickname form (14c and 14d) (excerpts from documents no. 2221006, 2221007, and 2221001 in theDortmund Chat Corpus)
72 The @scope attribute is added to the att.scoping class. This attribute is used to
specify whether one or more persons or groups are addressed; the values of this
attribute are all, group, individual, and unspec.
73 The @who attribute is supposed to mark the name of the addressee (the recipient of the
posting). Its value points to the value of @xml:id of the <person> element for the
addressee.15
74 Figure 15 gives an encoding example for addressing terms in chat postings.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
139

Figure 15: Encoding snippet for postings 868 and 876 from the example in figure 12
3.5.2. User Signatures
75 An important element of the microstructure in postings in forums, bulletin boards, and
wiki discussions is the signature text predefined by a user and inserted into a posting
automatically (usually at its end). It often includes the name of the user plus additional
text (such as sayings, proverbs, quotes, or personal information about the user) or
graphics. In our schema, we do not represent signatures as a part of every single
posting; instead, we mark the position in the posting where the user signature is placed
and describe its content only once in the <person> element.
76 For the representation of the signature text’s position in the postings and for the
description of the signature content, we introduce two special elements: The element
<autoSignature> is an empty element contained in the model.pPart.editclass. It replaces the signature text in the posting. The user’s signature is kept in the
element <signatureContent> in the <person> element; it is placed in the
model.persStateLike class and referenced by the @target attribute on
<autoSignature>.
3.5.3. Postscripts, Openers, and Closers
77 Some elements in CMC discourse are similar to elements used in epistolary
correspondence. However, their use is less restricted than with their functional
equivalents in written letters.
78 One element of this type is the <postscript>. In CMC, a complete posting can be
marked by a user as a postscript (for example by introducing it with “p.s.”); in other
cases, a postscript can be a part of a paragraph (see the examples given in fig. 16). The
Journal of the Text Encoding Initiative, Issue 3 | November 2012
140

current TEI definition of the <postscript> element does not offer any opportunity
to encode such cases. In our schema, we therefore introduced a <segtype=“postscript”> for their annotation.
16a:
p.s.: ich hasse einfache antworten deshalb würde ich die antwort von <<user2>> kritisieren wollen:
warum ist der “normal-christliche” lebensstil in so feste bahnen zementiert? warum läuft es
trotzdem so schief. […]
p.s.: i hate simple answers which is why I would like to criticize the answer given by <<user2>>: why is the
“normal Christian” lifestyle so strictly regulated? Why despite this does is still go wrong. […]
(Follow-up message of user1 to his own prior posting in a blog discussion; anonymized)
16b:
Die genannten Quellen sind für die Fragestellung in keinster Weise reputabel, d.h. auch danach läge
Theoriefindung vor. In Volkach heisst die Mainbrücke auch nur Mainbrücke, weil es für
Einheimischen nur diese eine gibt. Aber der Eigentümer, das Land Bayern, hat natürlich mehrere
Mainbrücken, daher ist es nun einmal die Mainbrücke Volkach. Also Fahrradbrücke wird das
Bauwerk sicher nicht heissen, man müsste halt mal bei der Bauverwaltung der Stadt Konstanz
nachfragen. Anderenfalls dann doch gemäß reputabler Literatur auf Geh- und Radwegbrücke über den
Seerhein bei Konstanz verschieben. --Störfix 21:55, 13. Jul. 2011 (CEST) P.S. oder die Brücke endlich
z.B. nach einem verdienten OB benennen ;-)
The mentioned sources are in no way trustworthy for this question, i.e. it would be conspiracy theory. In
Volkach the Main Bridge is only called the Main Bridge because there is only the one for the locals. But the
owner, the state of Bavaria, of course, has several Main bridges, making this one the Main Bridge Volkach.
Thus, this construction will definitely not be called Bike Bridge, you would have to ask at the City of
Constance’s planning department. Otherwise, stick with the sme terminology as in the more respectable
literature, Geh- und Radwegbrücke über den Seerhein bei Konstanz. --Störfix 21:55, 13. Jul. 2011 (CEST) P.S. or
finally name the bridge after a deserving mayor ;-)
(Wikipedia talk page for the article “Geh- und Radwegbrücke über den Seerhein bei Konstanz”)
Figure 16: Types of postscripts in CMC: postscript posting (16a), postscript as part of a paragraphwithin a posting (16b)
79 CMC communication is characterized by a less conventional style of writing than in
epistolary correspondence, which affects the form of a posting. We assume that, similar
to conventional discourse types such as letters, some kinds of postings (especially in
asynchronous CMC genres such as forums, bulletin boards, and Wikipedia talk pages)
have a structure which consists of an opening part, the main part of a message, and a
closing part. However, the opening and closing parts are in many cases neither cleanly
separated from the body of the message nor necessarily the first or last part of the
message (see example below). Additionally, an opener or closer element can appear
more than once in a posting.
80 Unfortunately, the elements of the current TEI P5 framework which come closest to
these structures (the <opener> and <closer> elements) are too restricted in their
distribution. For example, the element <opener> may appear exclusively at the top of
a division, while <closer> is permitted at the bottom of a document only. For us to
use these elements, the content model for <div>s would have to be loosened to allow
these elements to appear in other places. Specifically, it would be useful if the
Journal of the Text Encoding Initiative, Issue 3 | November 2012
141

<opener> and <closer> elements could join the inter-level elements so that they
would be able to appear within as well as in between chunks of text. In the current
version of our schema, we use <seg> elements for the annotation of openers and
closers in CMC postings and use a @type attribute with a value of “opener” or “closer”
(see the example given in fig. 17).
Figure 17: Opener and closer inside one posting, encoded using the <seg> element
4. Conclusions and Outlook
81 We have shown in this paper that the TEI Guidelines offer an appropriate way of
structurally encoding documents of various CMC genres. We demonstrated this by
focusing on some of these genres—chats, forum, and wiki discussions, in particular—
and on some features of dialogic CMC which have figured prominently in the linguistic
literature about this text type.
82 Customization of the TEI Guidelines is one way of adapting the TEI encoding framework
to new genres and document types. However, considering the relevance of CMC in
today’s everyday communication, it could be an important extension to future versions
of the TEI Guidelines to include a standard for the representation of the features and
peculiarities of CMC genres and document types. Such a standard should include a
model for the representation of those structural and linguistic features of CMC
discourse which are not yet covered by the modules and elements in the P5 version of
the TEI Guidelines (among others, a <posting> element for representing the main
constituting units of the CMC document structure and elements for the annotation of
typical Internet jargon units such as the interaction signs described in section 3.5.1). A
standard for the representation of CMC discourse should take into account that the
distribution and content model of certain elements from existing modules in TEI P5
would have to be modified in order to use them for the annotation of their functional
equivalents in CMC postings. As shown in the example of postscript-, opener-, and
closer-like elements in CMC (see section 3.5.2), the position of the equivalent TEI
elements in the structure of the postings is less restricted than in epistolary
correspondence. In cases like these, a modification of existing TEI elements (the
elements <postscript>, <opener>, and <closer>) would ideally account for
both CMC’s orientation toward traditional text types and text elements as well as CMC’s
free and creative use and modification.
83 CMC is constantly gaining popularity, both as a medium of communication and as an
object of study. We therefore want to suggest with this paper that the TEI offers users a
Journal of the Text Encoding Initiative, Issue 3 | November 2012
142

framework for annotating resources of this type. We hope that the schema presented
here might pave the ground for such a development.
84 Much still has to be done to achieve a fuller understanding of CMC genres and their
peculiarities. This is not due to a lack of studies of this kind of communication, but to a
constant change both in the ways in which the medium is used and in its technological
frameworks. CMC is a fluid mode of communication, and we probably will have to
constantly adapt our modeling and schema to new forms and media of CMC which will
emerge in the future. We are confident that the TEI Guidelines will provide an
appropriate framework for this. We hope that further discussion of the schema
presented in this paper will help uncover the extent to which its core features can be
appropriate for the representation of CMC discourse in languages other than German
(and especially those with writing systems not using the Latin alphabet).
85 For DeRiK in particular, we are facing the following challenges in the near future:
Acquiring texts in larger proportions: Up to now we have been working with a small sample of
texts of various genres. In the future we will acquire a larger set of documents for our
reference corpus—ideally 10 million tokens per year. We have to clear the rights of many of
the text sources unless they have not already been cleared by the providers, as is the case
with Wikipedia talk pages, for example. We hope that we can acquire substantial portions of
data from projects focused on empirical research in the field of CMC (including the projects
from partners in the Empirikom network). Ideally, this would be a win-win situation: the
partners would get their texts curated and distributed in a way that the empirical basis of
their research could be used to replicate their work or to perform comparable research on
the same data, and more users and researchers could find and use this data easily.
Analyzing CMC texts linguistically: Software for automatic analysis and annotation of texts is
optimized for well-formed written clauses and sentences. CMC texts will therefore pose
challenges to these tools on different levels, from tokenization and sentence boundary
detection to part-of-speech tagging and syntactic parsing. We hope to have shown with the
examples in this paper that, seen from the perspective of a normative grammar for written
text, many productions of CMC are not “well-formed”. It will be a major challenge to find
and describe the regularities in text production which seem to be irregular at first sight. NLP
tools have to be adjusted accordingly. Of course there is a continuum ranging from well-
thought-out—and well-formulated—texts and dialogues (such as on Wikipedia talk pages or
scientific blogs) to very informal and highly speech-like contributions in some chat sessions.
Tools for the linguistic analysis of CMC should be able to cover the whole range.
Annotating the collected data using our TEI schema: Last but not least, the data collected for
integration in our corpus will be annotated using the schema presented in this paper. We
assume that some of its structure can be generated automatically on the basis of filters that
transform structural patterns of the raw data format (such as HTML) into the target format;
other components of the schema (especially the functional subclassification of types of
interaction signs using attributes) will, at least in the beginning, require manual or, at best,
semi-automatic encoding. Further analyses of CMC-specific units on the microlevel of
postings may help to develop strategies for a partial automatization of this task; we hope
that further discussions in the context of the Empirikom network will contribute to this.
Providing a framework for managing a corpus of CMC data: Scripts will be needed to transform
CMC data from various sources to the TEI target format; ideally this will be a framework
which can be parameterized for each individual source. In addition, scripts will be needed to
transform the TEI/XML-encoded data into something which can be displayed nicely; XSLT
•
•
•
•
Journal of the Text Encoding Initiative, Issue 3 | November 2012
143

scripts will be an appropriate means. We will provide such scripts and tools alongside the
schema and documentation on our website. Additional facilities will be provided by the
DWDS framework (see section 2.2).
BIBLIOGRAPHY
References
Beißwenger, Michael. 2002. “Getippte ‘Gespräche’ und ihre trägermediale Bedingtheit: Zum
Einfluß technischer und prozeduraler Faktoren auf die kommunikative Grundhaltung beim
Chatten.” In Moderne Oralität, edited by Ingo W. Schröder and Stéphane Voell, 265–299. Marburg:
Reihe Curupira.
———. 2003. “Sprachhandlungskoordination im Chat.” Zeitschrift für germanistische Linguistik 31
(2): 198–231.
———. 2007. Sprachhandlungskoordination in der Chat-Kommunikation. Linguistik, Impulse, &
Tendenzen 26. Berlin: de Gruyter.
———. 2010. “Chattern unter die Finger geschaut: Formulieren und Revidieren bei der
schriftlichen Verbalisierung in synchroner internetbasierter Kommunikation.” In Nähe und
Distanz, edited by Vilmos Àgel and Mathilde Hennig, 247–294. Linguistik, Impulse, & Tendenzen 35.
Berlin: de Gruyter.
Beißwenger, Michael and Angelika Storrer. 2011. “Digitale Sprachressourcen in
Lehramtsstudiengängen: Kompetenzen – Erfahrungen – Desiderate.” In Language Resources and
Technologies in E-Learning and Teaching, edited by Frank Binder, Henning Lobin, and Harald
Lüngen. Special issue, Journal for Language Technology and Computational Linguistics 26 (1): 119–139.
http://media.dwds.de/jlcl/2011_Heft1/9.pdf.
———. 2008. “Corpora of Computer-Mediated Communication.” In Corpus Linguistics. An
International Handbook. Volume 1, edited by Anke Lüdeling and Merja Kytö, 292–208. Handbooks of
Linguistics and Communication Science 29.1. Berlin: de Gruyter.
Beißwenger, Michael, Maria Ermakova, Alexander Geyken, Lothar Lemnitzer, and Angelika
Storrer. 2012. “DeRiK: A German Reference Corpus of Computer-Mediated Communication.”
Digital Humanities 2012. http://www.dh2012.uni-hamburg.de/conference/programme/abstracts/
derik-a-german-reference-corpus-of-computer-mediated-communication/.
Biber, Douglas et al. 1999. Longman Grammar of Spoken and Written English. Edinburgh: Pearson
Education Limited.
Biber, Douglas, Susan Conrad and Geoffrey Leech. 2002. Longman Student Grammar of Spoken and
Written English. Edinburgh: Pearson Education Limited.
Blake, Barry J. 2008. All About Language. New York: Oxford University Press.
Crystal, David. 2001. Language and the Internet. Cambridge: Cambridge University Press.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
144

Danet, Brenda, and Susan C. Herring, eds. 2007. The Multilingual Internet. Language, Culture, and
Communication Online. New York: Oxford University Press.
December, John. 1996. “Units of Analysis for Internet Communication,” Journal of Computer-
Mediated Communication 1 (4). Accessed February 03, 2012, http://jcmc.indiana.edu/vol1/issue4/
december.html.
DUDEN. 1995. Die Grammatik. 5th ed. Mannheim: Bibliographisches Institut.
DUDEN. 2005. Die Grammatik. 7th ed. Mannheim: Bibliographisches Institut.
Ehlich, Konrad. 1986. Interjektionen. Tübingen: Niemeyer.
Ferrara, Kathleen, Hans Brunner, and Greg Whittemore. 1991. “Interactive written discourse as
an emergent register.” Written Communication 8 (1): 8–34.
Garcia, Angela Cora, and Jennifer Baker Jacobs. 1998. “The Interactional Organization of
Computer Mediated Communication in the College Classroom.” Qualitative Sociology 21 (3): 299–
317.
———. 1999. “The Eyes of the Beholder: Understanding the Turn-Taking System in Quasi-
Synchronous Computer-Mediated Communication.” Research on Language and Social Interaction 32
(4): 337–367.
Geyken, Alexander. 2007. “The DWDS corpus: A reference corpus for the German language of the
20th century”. In Collocations and Idioms, edited by Christiane Fellbaum, 23–40. London:
Continuum Press.
Greenbaum, Sidney. 1996. The Oxford English Grammar. New York: Oxford University Press.
Herring, Susan C. 1996. “Introduction.” In Computer-Mediated Communication: Linguistic, Social and
Cross-Cultural Perspectives, edited by Susan C. Herring, 1–10. Pragmatics & Beyond n.s. 39.
Amsterdam: John Benjamins.
———. 1999. “Interactional Coherence in CMC.” Journal of Computer-Mediated Communication 4 (4).
http://jcmc.indiana.edu/vol4/issue4/herring.html.
Herring, Susan C., ed. 1996. Computer-Mediated Communication: Linguistic, Social and Cross-Cultural
Perspectives. Pragmatics & Beyond n.s. 39. Amsterdam: John Benjamins.
Herring, Susan, ed. 2010/2011. Computer-Mediated Conversation. Special issue, Language@Internet
7/8. http://www.languageatinternet.org/.
Hoffmann, Ludger. 2004. “Chat und Thema.” In Internetbasierte Kommunikation, edited by Michael
Beißwenger, Ludger Hoffmann, and Angelika Storrer, 103–122. Osnabrücker Beiträge zur
Sprachtheorie 50.
Klappenbach, Ruth, and Wolfgang Steinitz, eds. 1962–1977. Wörterbuch der deutschen
Gegenwartssprache. 6 vols. Berlin: Akademie-Verlag.
Löbner, Sebastian. 2002. Understanding Semantics. London: Edward Arnold Publishers.
McArthur, Tom, ed. 1998. Concise Oxford Companion to the English Language. Oxford: Oxford
University Press.
Ogura, Kanayo, and Kazushi Nishimoto. 2004. “Is a Face-to-Face Conversation Model Applicable to
Chat Conversations?” Paper presented at the Eighth Pacific Rim International Conference on
Artificial Intelligence, 2004. http://ultimavi.arc.net.my/banana/Workshop/PRICAI2004/Final/
ogura.pdf.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
145

Reynaert, Martin, Nelleke Oostdijk, Orphée De Clercq, Henk van den Heuvel, and Franciska de
Jong. 2010. “Balancing SoNaR: IPR versus Processing Issues in a 500-Million-Word Written Dutch
Reference Corpus,” Proceedings of the Seventh Conference on International Language Resources and
Evaluation (LREC'10): 2693–2698. Accessed February 03, 2012 http://eprints.eemcs.utwente.nl/
18001/01/LREC2010_549_Paper_SoNaR.pdf
Runkehl, Jens, Peter Schlobinski, und Torsten Siever. 1998. Sprache und Kommunikation im Internet:
Überblick und Analysen. Opladen: Westdeutscher Verlag.
Sacks, Harvey, Emanuel A. Schegloff, and Gail Jefferson. 1974. “A Simplest Systematics for the
Organization of Turn-Taking for Conversation,” Language 50 (4): 696–735.
Schegloff, Emanuel A. 2007. Sequence Organization in Interaction. Vol. 1 of A Primer in Conversation
Analysis. Cambridge: Cambridge University Press.
Schiffrin, Deborah. 1986. Discourse markers. Vol. 5 of Studies in Interactional Sociolinguistics.
Cambridge: Cambridge University Press.
Schönfeldt, Juliane, and Andrea Golato. 2003. “Repair in Chats: A Conversation Analytic
Approach.” Research on Language and Social Interaction 36 (3): 241–284.
Storrer, Angelika. 2001. “Getippte Gespräche oder dialogische Texte? Zur
kommunikationstheoretischen Einordnung der Chat-Kommunikation.” In Sprache im Alltag:
Beiträge zu neuen Perspektiven in der Linguistik; Herbert Ernst Wiegand zum 65. Geburtstag gewidmet,
edited by Andrea Lehr, Matthias Kammerer, Klaus-Peter Konerding, Angelika Storrer, Caja
Thimm, and Werner Wolski, 439–465. Berlin: de Gruyter.
———. 2009. “Rhetorisch-stilistische Eigenschaften der Sprache des Internets.” In Rhetorik und
Stilistik – Rhetorics and Stylistics: Ein internationales Handbuch historischer und systematischer
Forschung, edited by Ulla Fix, Andreas Gardt, and Joachim Knape, 2211–2226. Berlin: de Gruyter.
TEI Consortium. 2012. TEI P5: Guidelines for Electronic Text Encoding and Interchange. http://www.tei-
c.org/Guidelines/P5/.
Trabant, Jürgen. 1998. Artikulationen: Historische Anthropologie der Sprache. Frankfurt: Suhrkamp.
Werry, Christopher C. 1996. “Linguistic and interactional features of Internet Relay Chat.” In
Computer-Mediated Communication: Linguistic, Social and Cross-Cultural Perspectives, edited by Susan
C. Herring, 47–63. Pragmatics & Beyond n.s. 39. Amsterdam: John Benjamins.
Zifonun, Gisela, Ludger Hoffmann, and Bruno Strecker. 1997. Grammatik der deutschen Sprache. 3
vols. Schriften des Instituts für deutsche Sprache 7.1–7.3. Berlin: de Gruyter.
Zitzen, Michaela, and Dieter Stein. 2005. “Chat and conversation: a case of transmedial stability?”
Linguistics 42 (5): 983–1021.
WWW Resources
ARD/ZDF Onlinestudie (1997–2011). http://www.ard-zdf-onlinestudie.de/.
Digitales Wörterbuch der deutschen Sprache (DWDS). http://www.dwds.de/.
Dortmunder Chat-Korpus. http://www.chatkorpus.tu-dortmund.de/.
Grammis 2.0: das grammatische Informationssystem des Instituts für deutsche Sprache (IDS).
http://hypermedia.ids-mannheim.de/.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
146

“Online documentation of the DeRiK TEI schema for the representation of computer-mediated
communication.” http://www.empirikom.net/bin/view/Themen/CmcTEI.
“Projekt: Deutsches Referenzkorpus zur internetbasierten Kommunikation (DeRiK).” http://
www.empirikom.net/bin/view/Themen/DeRiK.
Scientific network (DFG). “Empirische Erforschung internetbasierter Kommunikation“
(“Empirical Research on Internet-based Communication“). http://www.empirikom.net.
“STTS Tag Table.” Institute for Natural Language Processing. http://www.ims.uni-stuttgart.de/
projekte/corplex/TagSets/stts-table.html.
Text Encoding Initiative (TEI). http://www.tei-c.org/index.xml.
“UCREL CLAWS2 Tagset.” University Centre for Computer Corpus Research on Language. http://
ucrel.lancs.ac.uk/claws2tags.html.
NOTES
1. http://www. ard-zdf-onlinestudie.de
2. For a brief description of the project, see also http://www.empirikom.net/bin/view/
Themen/DeRiK.
3. http://www.dwds.de/
4. We would like to thank the members of the scientific network Empirikom as well as
Laurent Romary and the participants of the Annual Conference and Members’ Meeting
of the TEI Consortium 2011 in Würzburg for valuable discussions on the subject and for
their comments on previous versions of the schema.
5. http://www.empirikom.net/bin/view/Themen/CmcTEI
6. http://www.chatkorpus.tu-dortmund.de
7. http://www.empirikom.net/bin/view/Themen/DeRiK
8. This dictionary is based on a six-volume printed dictionary, the Wörterbuch der
deutschen Gegenwartssprache (WDG, en.: Dictionary of Contemporay German) published
between 1962 and 1977 and compiled at the Deutsche Akademie der Wissenschaften.
9. Recent overviews are given in Storrer 2009 and Herring 2010/2011.
10. An online version of the GDS is available at http://hypermedia.ids-mannheim.de/; a
brief description of the category interaction sign ( Interaktive Einheit) can be found in
module http://hypermedia.ids-mannheim.de/call/public/sysgram.ansicht?
v_typ=d&v_id=370.
11. See GDS (362): “Ihre Funktion besteht in der unmittelbaren (oft automatisiert
ablaufenden) Lenkung von Gesprächspartnern, die sich elementar auf die laufende
Handlungskooperation, Wissensverarbeitung und den Ausdruck emotionaler
Befindlichkeit erstrecken kann”.
12. See, for example, DUDEN (2005, sec. 892) and Ehlich (1986).
13. See the STTS tag table: http://www.ims.uni-stuttgart.de/projekte/corplex/
TagSets/stts-table.html.
14. See the CLAWS2 tagset: http://ucrel.lancs.ac.uk/claws2tags.html.
15. This is part of the anonymization strategy discussed in section 3.4.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
147

ABSTRACTS
The paper presents an XML schema for the representation of genres of computer-mediated
communication (CMC) that is compliant with the encoding framework defined by the TEI. It was
designed for the annotation of CMC documents in the project Deutsches Referenzkorpus zur
internetbasierten Kommunikation (DeRiK), which aims at building a corpus on language use in the
most popular CMC genres on the German-speaking Internet. The focus of the schema is on those
CMC genres which are written and dialogic―such as forums, bulletin boards, chats, instant
messaging, wiki and weblog discussions, microblogging on Twitter, and conversation on “social
network” sites.
The schema provides a representation format for the main structural features of CMC discourse
as well as elements for the annotation of those units regarded as “typical” for language use on
the Internet. The schema introduces an element <posting>, which describes stretches of text
that are sent to the server by a user at a certain point in time. Postings are the main constituting
elements of threads and logfiles, which, in our schema, are the two main types of CMC
macrostructures. For the microlevel of CMC documents (that is, the structure of the <posting>
content), the schema introduces elements for selected features of Internet jargon such as
emoticons, interaction words and addressing terms. It allows for easy anonymization of CMC data
for purposes in which the annotated data are made publicly available and includes metadata
which are necessary for referencing random excerpts from the data as references in dictionary
entries or as results of corpus queries.
Documentation of the schema as well as encoding examples can be retrieved from the web at
http://www.empirikom.net/bin/view/Themen/CmcTEI. The schema is meant to be a core model
for representing CMC that can be modified and extended by others according to their own
specific perspectives on CMC data. It could be a first step towards an integration of features for
the representation of CMC genres into a future new version of the TEI Guidelines.
INDEX
Keywords: computer-mediated communication, CMC, web genres, thread, logfile, forum, chat
AUTHORS
MICHAEL BEISSWENGER
Michael Beißwenger is a researcher and lecturer for German Linguistics at TU Dortmund
University. He graduated from the University of Heidelberg with an M.A. in German Philology
and History (2000) and finished his Ph.D. (“Dr.phil.”) in German Linguistics at TU Dortmund
University with a monograph on interactional management in chats
(“Sprachhandlungskoordination in der Chat-Kommunikation,” Berlin/New York: de Gruyter,
2007). Since 2010, he is the coordinator of the scientific network “Empirical Research on
Internet-based Communication” (http://www.empirikom.net/) funded by the German Research
Foundation (DFG).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
148

MARIA ERMAKOVA
Maria Ermakova is studying Historical Linguistics (M.A.) at Humboldt University Berlin. Since
2010 she has been working as research assistant for the Digital Dictionary of the German
Language project (DWDS) at the Berlin-Brandenburg Academy of Sciences (BBAW).
ALEXANDER GEYKEN
Alexander Geyken is a researcher at the Berlin-Brandenburg Academy of Sciences (BBAW) where
he is Head of the Digital Dictionary of German language (DWDS), a long-term project of the
BBAW.
LOTHAR LEMNITZER
Lothar Lemnitzer is a lexicographer and researcher at the Berlin-Brandenburg Academy of
Sciences (BBAW). He has written introductory books in German about corpus linguistics and
lexicography. He graduated from the University of Heidelberg and finished his Ph.D. (“Dr. phil.”)
in English Linguistics at the University of Münster. He currently uses large corpora of
contemporary German as a basis for the compilation of articles for the Digital Dictionary of
German language (DWDS).
ANGELIKA STORRER
Angelika Storrer is professor for German linguistics at TU Dortmund University since 2002. Her
research interests include computational lexicography, corpus-based methods in linguistics, and
language on the Internet. As a member of the Berlin-Brandenburg Academy of Sciences (BBAW)
she is involved in the work on the Digital Dictionary of German language (DWDS).
Journal of the Text Encoding Initiative, Issue 3 | November 2012
149

Building and Maintaining the TEILingSIG BibliographyUsing Open Source Tools for an Open Content Initiative
Piotr Bański, Stefan Majewski, Maik Stührenberg and AntoninaWerthmann
1. Introduction
1 While the TEI has been successful in becoming a de facto standard for numerous
applications in Digital Humanities, its status in the area of linguistic annotation is not
as clear. After the initial success of the TEI-encoded British National Corpus (Dunlop
1995), the TEI has given way to simpler and more specialized formats for corpus
annotation, such as (X)CES (Ide et al. 1996; Ide 2000), TigerXML (Mengel and Lezius
2000; Lezius 2002), and, more recently, PAULA (Dipper and Götze 2005; Dipper et al.
2007). Currently, the ISO TC37 SC4 committee is working on the so-called LAF
(Linguistic Annotation Framework) family of standards: see (Stührenberg 2012) for
more details.
2 The LingSIG (the “TEI for Linguists” special interest group of the TEI)1 has been created
to examine the actual and potential relationship between TEI markup and the needs
and requirements of linguists. This goal may require adapting (or re-adapting) TEI
markup to the common tasks faced in everyday linguistic practice. In order to achieve
that, a serious review of existing resources is needed, as well as access to people who
are experts in the relevant areas. Both these infrastructural subtasks can be supported
by creating a comprehensive bibliography of works dealing with linguistic markup that
is TEI-inspired or that may inspire new TEI solutions. This bibliography can serve both
as a repository of knowledge and as a resource that can attract non-TEI markup
specialists by providing them with a useful service.
3 This paper addresses an infrastructural issue of universal relevance—the collective
creation of a shared bibliography—congenial with the TEI’s overall aims and
methodology and presented here in the context of the LingSIG. Below, we describe a
Journal of the Text Encoding Initiative, Issue 3 | November 2012
150

combination of open-source general tools and an open-access approach to creating
knowledge repositories. We believe that, for an initiative such as the TEI, it is important
to choose non-proprietary, freely available solutions. If these solutions have the
advantage of attracting new users and promoting the initiative itself, so much the
better, especially if it is done in a non-committal way: no one using the LingSIG
bibliographic repository has to be a user of the TEI. On the other hand, the solution
described here may enhance the culture of sharing that the TEI has grown within.
4 In what follows, we first mention the roots of the idea to establish a repository of
bibliographic references in the context of the TEI LingSIG, then briefly describe Zotero
—the tool that has been chosen to create, store and access the repository—and finally
present the TEI-Zotero Translator—initially a separate Firefox add-on and now part of
the Zotero package that further connects the communities involved by creating a
bridge between the bibliographic recommendations of the TEI Guidelines and the
activities of the LingSIG.
2. LingSIG Reference Library
5 The reference library discussed here is the product of activities connected with the
“TEI for Linguists” special interest group of the TEI (LingSIG). The LingSIG’s roots reach
back to the Digital Humanities conference in London in 2010, where its future
conveners met and decided to prepare a formal application to the TEI Council outlining
the SIG’s aims. What soon followed was the informal “LLiZ” (Linguistic Lunch in Zadar),
organized by Piotr Bański, and the first official SIG meeting during the 2010 Annual
Meeting of the TEI Consortium in Zadar. During that meeting, the participants agreed
that one of the aims that the SIG should address is the creation of a common repository
of references to works that should be taken into account in the process of building a
consistent set of TEI encoding proposals targeting the needs of linguists.
6 The first version of the reference library was created as a TEI Wiki resource and
announced on the SIG mailing list, but, despite an initially positive reaction, the low
number of responses indicated that the barrier to active contribution was too high. It
became obvious that, although using a wiki opened the resource for collective building, it
was only a partially successful move: the results could only be pasted straight from the
wiki page and each time had to be reformatted to conform to a given style sheet.
Furthermore, only a simple web-page search was available to locate references and a
lot of work would have to be devoted to maintaining the entries in a uniform shape. A
more flexible resource was needed that combined the Web 2.0 idea of collective
building and maintenance with greater flexibility of the result format, easier access to
bibliographic data and better search facilities. At this point, the decision was made to
transfer the development to the Zotero platform.2
7 These days, a researcher’s life is punctuated with deadlines. With the date of the next
TEI meeting approaching fast, Zotero-based development manifested one more
advantage over wiki-based creation: it was rapid. It took only a moment to import the
BibTeX of Maik Stührenberg’s extensive linguistic-markup-oriented bibliography and
only several days of Antonina Werthmann’s post-editing to create a sizeable and usable
resource.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
151
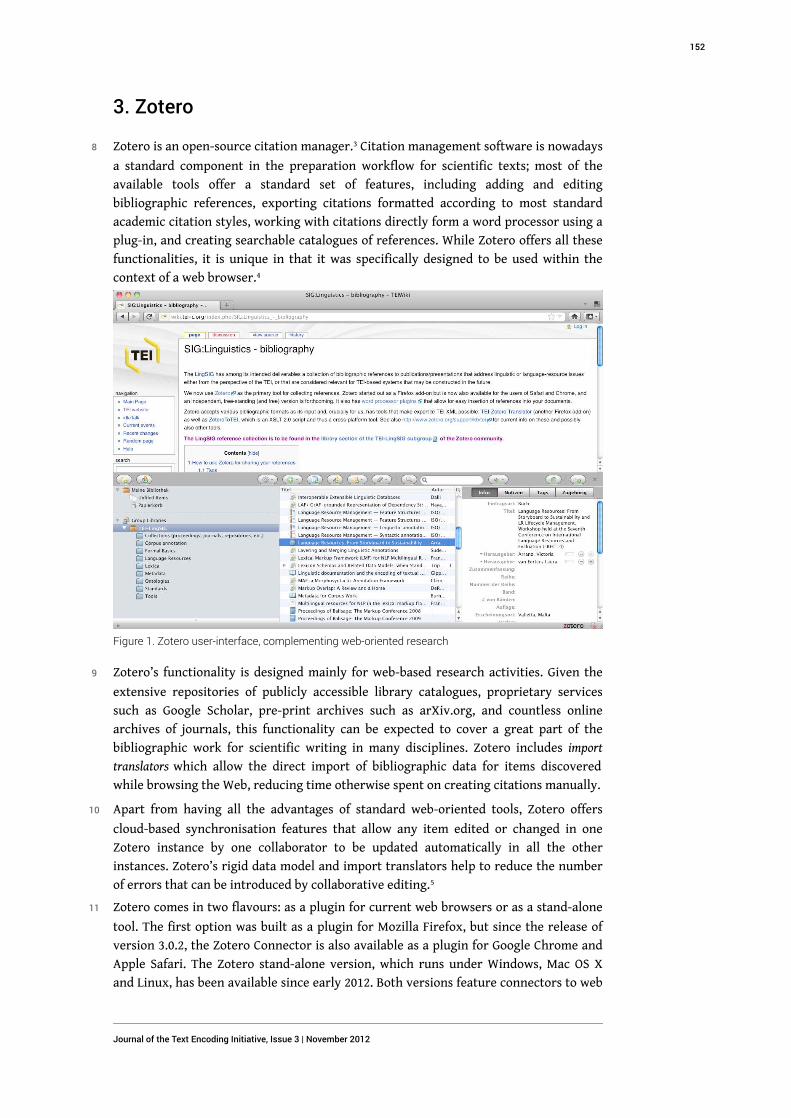
3. Zotero
8 Zotero is an open-source citation manager.3 Citation management software is nowadays
a standard component in the preparation workflow for scientific texts; most of the
available tools offer a standard set of features, including adding and editing
bibliographic references, exporting citations formatted according to most standard
academic citation styles, working with citations directly form a word processor using a
plug-in, and creating searchable catalogues of references. While Zotero offers all these
functionalities, it is unique in that it was specifically designed to be used within the
context of a web browser.4
Figure 1. Zotero user-interface, complementing web-oriented research
9 Zotero’s functionality is designed mainly for web-based research activities. Given the
extensive repositories of publicly accessible library catalogues, proprietary services
such as Google Scholar, pre-print archives such as arXiv.org, and countless online
archives of journals, this functionality can be expected to cover a great part of the
bibliographic work for scientific writing in many disciplines. Zotero includes import
translators which allow the direct import of bibliographic data for items discovered
while browsing the Web, reducing time otherwise spent on creating citations manually.
10 Apart from having all the advantages of standard web-oriented tools, Zotero offers
cloud-based synchronisation features that allow any item edited or changed in one
Zotero instance by one collaborator to be updated automatically in all the other
instances. Zotero’s rigid data model and import translators help to reduce the number
of errors that can be introduced by collaborative editing.5
11 Zotero comes in two flavours: as a plugin for current web browsers or as a stand-alone
tool. The first option was built as a plugin for Mozilla Firefox, but since the release of
version 3.0.2, the Zotero Connector is also available as a plugin for Google Chrome and
Apple Safari. The Zotero stand-alone version, which runs under Windows, Mac OS X
and Linux, has been available since early 2012. Both versions feature connectors to web
Journal of the Text Encoding Initiative, Issue 3 | November 2012
152

browsers and plugins for popular word processors, such as Microsoft Word or
OpenOffice/LibreOffice/NeoOffice.
3.1. Creating Bibliographies
12 New bibliographic items can be edited manually or created automatically from the
content of a particular site that the user is visiting (using an import translator). In the
first case, the information is entered into a form with predefined fields corresponding
to particular types of items (book, book section, journal article, etc.; see the lower right
part of fig. 1). In the case of automatic generation of bibliographic items, the required
metadata is copied automatically from web pages, though accuracy and completeness
depends on whether an import translator is available for the cited content. This
includes homepages of publishers, library catalogues, databases of journals and books,
but also sites such as scholar.google.com, amazon.com or popular blogging platforms.
The availability and quality of the assisted automatic creation of bibliographic items
within the Zotero database is dependent on whether the site provides such information
and on whether Zotero provides a suitable import plugin, whose presence is indicated
by an icon in the browser’s address bar. This icon generally corresponds to the
available item types and supplies a one-click-solution, that is, by clicking the icon, the
user saves all the corresponding metadata in the Zotero database. If a PDF file is
available as well, it will be automatically attached to the newly created item. After
creating a Zotero item, one may modify it by correcting or adding metadata entries.
Finally, the item can be tagged with categories, keywords and additional information.
13 In addition to importing data from individual Web pages, Zotero also supports import
of bibliographic metadata in the following bibliographic file formats: MODS (Metadata
Object Description Schema),6 BibTeX, RIS (Research Information System Format),
Refer/BibIX,7 and Unqualified Dublin Core RDF. Recent discussions on TEI-L and
between developers indicated that there is some interest in creating import facilities
for TEI bibliographies as well. The LingSIG plans to implement an import feature via a
student project or when a particular project that uses the exporter could immediately
benefit from reversing the flow of information.
3.2. Working with Reference Libraries
14 Once a Zotero library has been created, it is not only possible to use the information
stored in the metadata of the respective bibliographic items but also to add notes and
attachments (such as electronic versions of articles). In addition, the ability to define
tags allows for a very flexible categorization scheme (in addition to the use of folders to
organize library items). For the LingSIG library, we have chosen tags such as ”XCES”,
”TEI”, ”EXMARaLDA”, and ”BNC”; since these tags can be used for both searching and
organizing items, they constitute a facility that is powerful and easy to use.
15 Libraries created with Zotero can then be shared among the members of the respective
Zotero groups. By joining the LingSIG group,8 new members are allowed to use the
collection and to add to it in a manner much more straightforward than that offered by
wiki-based solutions. All members of the group are allowed to modify the library.9
Changes made by group members can be synchronized with the online library either on
demand or automatically. Apart from accessing the library via Zotero front-ends, one
Journal of the Text Encoding Initiative, Issue 3 | November 2012
153

can also use APIs for read- and write-access to the library using other tools. File
attachments can be synchronized via Zotero File Storage or WebDAV.
3.3. Exporting Bibliographies
16 Storing bibliographic items in a Zotero database opens up several export possibilities.
Citations and reference lists can be generated by Zotero in a great variety of
bibliographic styles as defined by the Citation Style Language (CSL).10 Some styles,
including Chicago, MLA, APA, and Vancouver, are already predefined in Zotero. Others
can be installed via the Zotero Style Repository.11
17 Apart from exporting single or multiple library items, Zotero can create reports,
interactive timelines, and reference lists (the last in a variety of formats, such as HTML
or RTF, and according to different styles). It thus promises to be a nearly universal
writing aid for the members of the LingSIG, and by extension, the entire TEI
community. This is made even more obvious by the fact that, thanks to work by Stefan
Majewski and feedback from the TEI community, Zotero is now able to export TEI XML
<biblStruct> elements directly. This is the topic of the following section.
4. TEI and Zotero
18 As we have shown above, there are numerous reasons for choosing Zotero for citation
management. While Zotero’s integration with major word processors is sufficient for
many purposes, text-encoding scholars often have more advanced needs. For this
reason, some members of the TEI community have begun developing tools capable of
transforming bibliographic items from Zotero to structures that may be used with TEI-
encoded documents. The resulting prototypes addressed particular requirements of
specific tasks and were not meant to be general-purpose tools, but the creation of the
TEI Zotero translator—once a separate Firefox plugin but now integrated into the
Zotero code itself—opens the way towards potential standardization in this area.
4.1. Possible Translation Workflows
19 Two approaches have been used for exporting bibliographic items from Zotero to TEI.
Firstly, it is possible to take one of the standardized output formats that are supported
by default (such as MODS12 and Zotero RDF13) and translate that into TEI XML by means
of an XSL transformation. Another option is to extend Zotero to provide facilities to
directly export its library to TEI XML. From the conceptual perspective, both
approaches are similar: the main challenge is to find the appropriate mapping between
Zotero fields and their closest matches in the TEI. Nevertheless, they differ in the
workflow required to generate the TEI encoding. The first approach requires an
additional transformational step after the initial export into an intermediate format.14
The other approach implements the transformation as a built-in Zotero feature that
might be selected as an option on export. Clearly, the latter requires one fewer step by
the user, offers greater stability (due to its lesser dependence on an intermediate
format controlled by a third party), and makes the task of maintenance simpler: only
the initial and the target data structures have to be considered, not how these map to
the intermediate format. The downside of this approach is that it requires the export
Journal of the Text Encoding Initiative, Issue 3 | November 2012
154

translator to be written in non-XML technology (in the case at hand, ECMAScript). In
what follows, we concentrate on the built-in exporter and, hence, on the direct
mapping from Zotero fields to TEI XML structures.
4.2. Data-mapping Decisions
20 Given an object that represents the items that should be exported, the translator has to
construct the most appropriate output representation. It is therefore essential to know
all possible data structures in the source format and their equivalents in the target
format. The documentation for Zotero plug-in developers is not explicit about the
available data fields in the source database. Nevertheless, as an open source project,
Zotero offers information on the data structures in its source code and in the ample
selection of available export translators, especially the translators to Zotero RDF and to
MODS, which provide good guidance on the availability and handling of the data fields.
21 In TEI encoding, it is often possible to represent information in multiple ways. That is
because the TEI offers a toolkit which has to be customized, with the particular
modeling decisions dependent on the particular use cases. While numerous out-of-the-
box TEI customizations exist, in the area addressed here no ready-made solutions are
available and each project tends to make its own choices. For the TEI Zotero export
translator, encoding decisions have been made at three levels, discussed in the sections
that follow: base encoding (section 4.2.1), item-type-specific encoding (section 4.2.2),
and item-specific encoding (4.2.3). By fleshing those decisions out for scrutiny, and by
offering the translator as a solution employed by the LingSIG bibliography, we hope to
take a step toward standardizing the resulting format.
4.2.1. Base Encoding
22 The fundamental modeling decision concerning the translator was made at the level of
what we call the “base encoding”: the choice among the three possible top-level
elements for bibliographic references (<bibl>, <biblStruct>, and <biblFull>).
For the purpose of Zotero’s export to TEI, the top-level element <biblStruct> is
used. In what follows, we justify this choice.
23 The element <bibl> is a container for any kind of bibliographic reference that
features a mixed content model: it may contain a mixture of plain text and elements in
any order. Therefore, <bibl> is specifically suited for the representation of existing
bibliographies (that is, the transcription of physical source documents), but it is not the
optimal choice for born-digital bibliographies designed for further processing. For the
latter, it is crucial to have unified, predictable encoding. For this purpose, the element
<biblStruct> was devised. It requires a specific structure and ensures that
particular types of information—especially the core information about the author, the
place of publication, and the title—are stored at the same location in the structure. The
core set of information is structured by bibliographic level: using the element
<monogr> for the monographic level, <analytic> for the analytic level, and
<series> for the series level. This distinction is particularly useful when it comes to
making formatting decisions in XSLT.
24 <biblFull> is similar to <biblStruct> in that it is highly structured, but it
follows a different approach: it uses the same content model as <fileDesc>, and is
Journal of the Text Encoding Initiative, Issue 3 | November 2012
155

thus less rigid with respect to ordering the relevant information. The more predictable
structure of <biblStruct> and its advantages for processing were the factors that
determined the choice for the base target encoding for the export from Zotero to TEI.
25 Bibliographic items are typically arranged in a list-like structure. Consequently, some
kind of a structuring device or a container has to be used to hold the individual items.
As suggested by the Guidelines, the <listBibl> element is used for this purpose in
the output of the translator. The base encoding for the Zotero export is therefore a
<listBibl> containing multiple <biblStruct>s.
4.2.2. Item-type-specific Encoding
26 The second level concerns the item-type-specific encoding—that is, the way in which
the item type for a Zotero item (“journal article”, ”book section”, etc.) affects the
mapping to the corresponding elements within the <biblStruct>. While every item
type within the Zotero database features a unique set of properties, many of these
properties are shared and the mapping to TEI is the same irrespective of the type. For
example, the place of publication will always be mapped to the element <pubPlace>within the <imprint> part of <biblStruct>. Nevertheless, some mappings are
affected by the item type: for example, the property item.title15 maps to <title>within <analytic> for analytic item types such as ‘journal article’ or ‘book section’,
and to <title> within <monogr> for types that do not have an analytic level.
27 The first fundamental question at this level of encoding is whether the given item
features an analytic level. The TEI Zotero translator defines the item types journal
article, book section, magazine article, newspaper article, and conference paper as
analytic. While Zotero has a schema that determines which fields may be used for a
bibliographic item of a specific type, it does not require the user to enter a minimal
amount of data for any item type. In practice, this can lead to situations where it is not
possible to meet the minimal requirements for <biblStruct>. For the rare cases
where no title is given for a bibliographic resource, an empty <title> element is
generated in <monogr> or respectively in <analytic>—in other words, the
translator remains neutral with respect to apparent omissions in the content of Zotero
items and translates them into corresponding empty elements in the TEI markup, thus
making them easier to spot in the process of validation.
4.2.3. Item-specific Encoding
28 Decisions made at the level of the individual bibliographic items are determined by the
values of the Zotero fields for these items. Firstly, as has been mentioned, the TEI
Zotero translator depends on which of the available fields are actually filled in by the
user. Secondly, for fields that may hold an arbitrary number of individual values, the
exporter will handle items differently depending on how many values they have. In
particular, the area where Zotero provides great flexibility is the assignment of
responsibilities for the creation of the work referenced, and these need to be carefully
mapped to TEI.
29 In Zotero, any bibliographic item can have an arbitrary number of creators of a
particular type. The available creator types are determined by the item type (for
example, in Zotero books may have editors while websites do not have editors but
rather contributors). Many of the Zotero creator types have direct equivalents in the
Journal of the Text Encoding Initiative, Issue 3 | November 2012
156

TEI (for example, creator.type with the value “editor” or the value “seriesEditor”
can both be mapped to the element <editor>). Nevertheless, this does not apply to
all available types (for example, creator.type with the value “contributor”). For
those creator types that do not map directly to TEI elements, a <respStmt> is used
with an element <resp> that contains the name of the Zotero creator type. Consider
the following example:
<respStmt>
<resp>contributor</resp>
<persName>
<forename>Kevin</forename>
<surname>Hawkins</surname>
</persName>
</respStmt>
30 The above fragment is the typical choice for the encoding of information about a
contributor to a wiki, while the following fragment would be the encoding of
information concerning the authorship of the present paper:
<author>
<forename>Piotr</forename>
<surname>Bański</surname></author>
<author>
<forename>Stefan</forename>
<surname>Majewski</surname>
</author>
<author>
<forename>Maik</forename>
<surname>Stührenberg</surname>
</author>
<author>
<forename>Antonina</forename>
<surname>Werthmann</surname>
</author>
31 This is an example of how the structure of the exported item is determined by the
content available within the given data field.
4.3. Output Options
32 Apart from the direct representation of the item data, the TEI Zotero translator offers a
set of output options. First of all, it optionally generates @xml:id attributes for each
exported <biblStruct>. These IDs are generated from the name of the author, the
Journal of the Text Encoding Initiative, Issue 3 | November 2012
157

year of publication, and if necessary a character for the disambiguation of publications
if there is more than one reference per author per year (e.g. “Dipper2005b”). Secondly,
the translator can optionally put a simple minimal TEI document around the
<listBibl> for use cases where a complete TEI file is needed for processing or
validation. Finally, since Zotero organizes bibliographic items in collections, it is
possible to represent Zotero’s collection structure within the generated TEI. Collections
in Zotero can, first of all, nest. Secondly, individual bibliographic items may be put into
multiple collections. As <listBibl> can nest as well, it is ideally suited to
representing Zotero collections. The title of the collection is put in a <head> element
at the beginning of the <listBibl> corresponding to the exported collection.
<listBibl>
<head>Recent Papers</head>
<listBibl>
<head>to be read</head>
<biblStruct>
…
</listBibl>
…
<listBibl>
33 While the TEI Zotero translator is now a mature piece of software, as evidenced by its
recent inclusion into the mainstream Zotero distribution, some important
functionality, such as import facilities for existing TEI-encoded bibliographies, is still
missing. It should be stressed, however, that the translator has been released under an
open-source license and is thus open to contributions in the form of code patches,
feedback, and general discussion.16
5. Summary and Conclusions
34 The present paper highlights the needs relevant for modern collaborative research
practice and, using the example of the TEI LingSIG, shows how Zotero answers many of
the demands that such practice creates. The existence of Zotero-to-TEI translation tools
further confirms that this is not a random choice, and the fact that the tool described
here, the TEI Zotero translator, has been integrated into Zotero testifies to the
reception of the ideas presented here by a broader community of developers and users.
35 The findings reported here go beyond the confines of the LingSIG for two reasons: its
Zotero repository is meant to be usable beyond the SIG and even the TEI community,
and the co-operative resource-building strategy recommended here constitutes a
feasible blueprint for other open-content and open-source initiatives. Also, the
mapping solution used by the translator follows a set of choices that are subject to
community acceptance as the potential de facto way of creating bibliographies.
36 Apart from the matter of acceptance of the Zotero-to-TEI mapping choices, which is an
issue to be decided by the TEI community, we have identified some features that Zotero
Journal of the Text Encoding Initiative, Issue 3 | November 2012
158

users would benefit from. One is the need to ensure preservation of Zotero databases
via automatic backups, versioning, or the like. It would also be beneficial in some
contexts to be able to require a value for some fields, such as the “title” field, possibly
by having incomplete citations appear in a shared “waiting room” before they are
added to the store as complete references. Being able to restrict and directly
manipulate the inventory of tags defined for a particular bibliography store would also
help ensure the overall consistency of the database.
37 The final issue concerns the definition and implementation of a TEI-to-Zotero mapping
(in the other direction). At first glance, it seems reasonable to expect to be able to
import <biblStruct> objects into Zotero, but more concrete solutions will require
needs analysis and further funding.
BIBLIOGRAPHY
Dipper, S. and M. Götze. 2005. “Accessing Heterogeneous Linguistic Data – Generic XML-based
Representation and Flexible Visualization”. In Human Language Technologies as a Challenge for
Computer Science and Linguistics: 2nd Language & Technology Conference, April 21–23, 2005: Proceedings,
206–210, Poznań, Poland: Wydawnictwo Poznańskie.
Dipper, S., M. Götze, U. Küssner, and M. Stede. 2007. “Representing and Querying Standoff XML”.
In Datenstrukturen für linguistische Ressourcen und ihre Anwendungen. Data Structures for Linguistic
Resources and Applications. Proceedings of the Biennial GLDV Conference 2007, edited by G. Rehm, A.
Witt, and L. Lemnitzer, 337–346, Tübingen, Germany: Gunter Narr Verlag.
Dunlop, D. 1995. “Practical considerations in the use of TEI headers in a large corpus.” Computers
and the Humanities 29: 85–98.
Ide, N., G. Priest-Dorman, and J. Véronis. 1996. Corpus Encoding Standard (CES). Technical report,
Expert Advisory Group on Language Engineering Standards (EAGLES).
Ide, N., P. Bonhomme, and L. Romary. 2000. “XCES: An XML-based Encoding Standard for
Linguistic Corpora”. In Proceedings of the Second International Language Resources and Evaluation
(LREC 2000), 825–830. Athens: European Language Resources Association (ELRA).
Lezius, W. 2002. Ein Suchwerkzeug für syntaktisch annotierte Textkorpora. Ph.D. Thesis, Institut für
Maschinelle Sprachverarbeitung der Universität Stuttgart.
Mengel, A. and W. Lezius. 2000. “An XML-based encoding format for syntactically annotated
corpora”. In Proceedings of the Second International Conference on Language Resources and Engineering
(LREC 2000), 21–126. Athens: European Language Resources Association (ELRA).
Stührenberg, M. 2012. “The TEI and Current Standards for Structuring Linguistic Data: An
Overview.” Journal of the Text Encoding Initiative, 3.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
159

NOTES
1. http://wiki.tei-c.org/index.php/SIG:TEI_for_Linguists
2. We are grateful to Stuart Yeates for the initial suggestion to use Zotero, made on the
LingSIG mailing list. We also wish to acknowledge the pioneer role that the SIG on
Education has played by setting up a Zotero repository of TEI-related works at http://
www.zotero.org/groups/tei. At the time when the LingSIG repository was created, the
general TEI repository had barely started, and the two were developed in parallel. Our
repository differs in scope, as its primary focus is linguistic markup, be it TEI or not.
Thus, the two repositories merely overlap to some extent. However, it is worth noting
that users who belong to both groups have all the resources at their disposal and can
combine them (and automatically detect and merge duplicates) in the user’s private
Zotero space. It is also worth noting that, unlike the Education SIG’s library, which is a
unitary resource that can only be searched by string-matching, the LingSIG library
features catalog-based and tag-based categories.
3. For a comparison of citation managers, see http://en.wikipedia.org/wiki/
Comparison_of_reference_management_software. What played a decisive role in our
case is that Zotero is open-source, cross-platform, web-oriented, and extremely
flexible.
4. In the presence of a running stand-alone instance, browser add-ons become merely
interfaces, or “connectors”, between the web content accessed by the browser and the
database controlled by the stand-alone Zotero.
5. One shortcoming of Zotero’s features for collaboration is the lack of version history
and the ease of propagation of errors introduced into the content. That is, if a major
maintenance error occurs, as, for example, when one participant accidentally deletes a
set of bibliographic items, there is no version history available that could be used to
revert the changes. Therefore, frequent manual backups by the project participants are
advisable pending an enhancement that targets this issue. On the other hand, Zotero
provides the functionality for duplicate detection and merging that is not present in
wiki-like resources.
6. MODS is developed by the Library of Congress. See http://www.loc.gov/standards/
mods/mods-schemas.html for schema files.
7. The import format of the EndNote citation manager is based on the Refer/BibIX
format.
8. The LingSIG group at Zotero is accessible at https://www.zotero.org/groups/tei-
lingsig.
9. This is not the only possible administrative choice in Zotero groups, but any attempt
to limit the write access would run counter to the aims of the entire project, which is to
involve as many contributors as we can.
10. See http://citationstyles.org/citation-style-language/schema/ for the current
version of the CSL schema in the RELAX NG notation. Since CSL 1.0, the schema is not
only supported by Zotero but by the Mendeley reference manager as well.
11. The Zotero Style Repository is located at http://www.zotero.org/styles/. The styles
can be used with any client software that supports CSL 1.0.
12. For more information on the Metadata Object Description Schema, see http://
www.loc.gov/standards/mods/.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
160

13. Zotero RDF is the custom export format of Zotero that can also export attached files
and notes.
14. Laura Mandell’s XSL Transformation from Zotero RDF to TEI follows this approach
(see http://wiki.tei-c.org/index.php/ZoteroToTEI).
15. Properties of the items as provided by Zotero are used in dot-notation (i.e.
item.property).
16. Contributions are welcome via E-Mail to Stefan Majewski or via https://
github.com/smjwsk/translators or http://code.google.com/p/tei-zotero-translator/.
The author follows discussions on TEI-L.
ABSTRACTS
The present contribution addresses an infrastructural issue of universal relevance, addressed in
the specific context of the TEI. We describe a combination of open-source tools and an open-
access approach to creating knowledge repositories that have been employed in building a
bibliographic reference library for the “TEI for Linguists” special interest group (LingSIG). The
authors argue that, for an initiative such as the TEI, it is important to choose open, freely
available solutions. If these solutions have the advantage of attracting new users and promoting
the initiative itself, so much the better, especially if it is done in a non-committal way: no one
using the LingSIG bibliographic repository has to be a member of the LingSIG or a “TEI-er” in
general.
INDEX
Keywords: LingSIG, Zotero, structured bibliography, reference management, collaborative
workflow
AUTHORS
PIOTR BAŃSKI
Piotr Bański is an assistant professor of Linguistics at the Institute of English Studies of the
University of Warsaw, and a senior researcher at the Institut für Deutsche Sprache in Mannheim,
where he is the coordinator of the project “Corpus Analysis Platform of the Next Generation”. He
is also an elected member of the TEI Technical Council for term 2011–2012 and an expert of the
ISO TC37 SC4 committee for Language Resources Management. His current interests focus mostly
on text encoding as well as the creation and use of robust language resources.
STEFAN MAJEWSKI
Stefan Majewski studied English Language and Literature as well as Sociology at the University of
Vienna, in addition to Electronics at the Vienna University of Technology. He graduated in
English Linguistics with a focus on research infrastructures for corpus linguistics. Currently, he is
Journal of the Text Encoding Initiative, Issue 3 | November 2012
161

working at the Austrian Academy of Sciences, where he is coordinating and working for the
“Data Service Infrastructure for the Social Sciences and Humanities” (DASISH) project. He is also
employed by the Göttingen State and University Library, where he works for the “TextGrid”
project in research and development. His current interests focus on research infrastructures and
annotation systems.
MAIK STÜHRENBERG
Maik Stührenberg received his Ph. D. in Computational Linguistics and Text Technology from
Bielefeld University in 2012. After graduating in 2001, he worked on various projects at the
Justus-Liebig-Universität Gießen and Bielefeld University. He is currently employed as a research
assistant at the Institut für Deutsche Sprache (IDS, Institute for the German Language) in
Mannheim as a member of the CLARIN-D project and is involved in the NA 105-00-06 AA, the
German mirror committee of ISO TC37 SC4. His main research interests include specifications for
structuring multiply annotated data (especially linguistic corpora), query languages, and query
processing.
ANTONINA WERTHMANN
Antonina Werthmann studied computational linguistics at Heidelberg University and has been
working since 2011 as a research assistant at the Institut für Deutsche Sprache in Mannheim (IDS,
Institute for the German Language) as a member of the CLARIN-D project. Her main research
tasks consist in the collection, description and extension of the information systems on standards
in the field annotation of linguistics resources.
Journal of the Text Encoding Initiative, Issue 3 | November 2012
162




















