
Supporting Information - Wiley-VCH
24
Supporting Information © Wiley-VCH 2006 69451 Weinheim, Germany
-
Upload
khangminh22 -
Category
Documents
-
view
3 -
download
0
Transcript of Supporting Information - Wiley-VCH

Supporting Information © Wiley-VCH 2006
69451 Weinheim, Germany

SEberle
The Core and The Most Useful Molecules of Organic Chemistry** Kyle J. M. Bishop, Rafal Klajn, and Bartosz A. Grzybowski* * Prof. Dr. Bartosz A. Grzybowski Department of Chemical and Biological Engineering and Northwestern Institute of Complexity Northwestern University 2145 Sheridan Rd. Evanston, IL 60208, USA Fax: (+1) 847-491-3728 Email: [email protected]

1
Graph Definitions and Algorithms
Directed Graph (or digraph) – “consists of a set of vertices V and a set of arcs E. The vertices
are also called nodes or points; the arcs could be called directed edges or directed lines. An arc is
an ordered pair of vertices (v,w). The arc (v,w) is often expressed by v w. We say that arc v
w is from v to w, and that w is adjacent to v.” [5]
Connected Component (CC) – “A connected component of a undirected graph G is a maximal
connected induced subgraph, that is, a connected induced subgraph that is not itself a proper
subgraph of any other connected subgraph of G.” To find connected components in a directed
graph, one examines the undirected graph constructed by neglecting the directed nature of arcs
(v,w), such that (v,w) is equivalent to (w,v).[5]
Strongly Connected Component (SCC) – “A strongly connected component of a directed graph is
a maximal set of vertices in which there is a path from any one vertex in the set to any other
vertex in the set.” [5]
Breadth-First Search (BFS) – Consider a directed graph G in which all vertices are initially
marked unvisited. BFS begins by selecting one vertex v of G as a start vertex; v is marked as
visited. Then each unvisited vertex adjacent to v is visited in turn. Note that we search as broadly
as possible – hence “breadth-first” – before moving to those unvisited vertices adjacent to v’s
neighbors. Once all vertices that can be reached from v have been visited, the search of v is
complete. If some vertices remain unvisited, we select an unvisited vertex as a new start vertex.
We repeat this process until all vertices of G have been visited.[5]
Depth-First Search (DFS) – “Suppose we have a directed graph G in which all vertices are
initially marked unvisited. DFS works by selecting one vertex v of G as a start vertex; v is
marked as visited. Then each unvisited vertex adjacent to v is searched in turn, using DFS
recursively. Once all vertices that can be reached from v have been visited, the search of v is

2
complete. If some vertices remain unvisited, we select an unvisited vertex as a new start vertex.
We repeat this process until all vertices of G have been visited.” [5]
Depth-First Spanning Forest – “During a depth-first traversal of a directed graph, certain arcs,
when traversed, lead to unvisited vertices. The arcs leading to new vertices are called tree arcs,
and the form a depth-first spanning forest for the given digraph.” [5]
Algorithm for Identifying SCCs [5]
1. Perform a depth-first search of G and number the vertices in order of completion of the
recursive calls.
2. Construct a new directed graph Gr by reversing the direction of every arc in G.
3. Perform a depth-first search of Gr starting the search from the highest-numbered vertex
according to the numbering assigned at step (1). If the depth-first search does not reach
all vertices, start the next depth-first search from the highest-numbered remaining
vertex.
4. Each tree in the resulting spanning forest is a strongly connected component of G.
Details of the MC Algorithm
Following the heuristic “formula” for combinatorial optimization by simulated annealing
given in Ref. [19].
1) System Configuration – Here, the system consists of a set of M nodes found in the core (i.e.,
the GSCC). From these nodes, sequential DFSs are performed to determine the total number of
nodes in the periphery, N, “reachable” from this set. Importantly, these searches do not allow the
traversal of arcs leading back into the core; instead, they start at each node in the set and proceed
selectively into the periphery. Note that if searches were allowed to traverse arcs leading to other
nodes within the core, every search from the core would reach every node in the periphery (by
the very definition of the periphery). Initially, the set consists of the top M core nodes as ranked
by a local topological measure, such as a node’s out degree.

3
2) Random “Move” Generation – In one MC “move” a single node A is selected from the set at
random and exchanged with another core node B that is not in the set, also chosen at random.
Specifically, node A is chosen from a uniform probability distribution such that the selection of
any node in the set is equally likely. In contrast, node B is selected with probability proportional
to its out degree, such that more highly connected nodes (of which there are few) are selected
just as often as poorly connected nodes (of which there are many). This is done to improve the
efficiency of the algorithm, leading to optimal solutions in fewer MC moves. The effectiveness
of this approach indicates that local topological measures (e.g., out degree) provide an educated
guess that can guide further optimized via stochastic methods. Once the exchange is made, N is
calculated for the modified set.
3) Quantitative Objective Function – This function is analogous to the “energy” of the system
and, here, is related to the number of molecules in the periphery that can be reached from the
target set found in the core. Mathematically, the “usefulness” function is given by
MAXMAX NMNNU /))(( −= , where N is the number of compounds reached from the target set,
and NMAX is the total number of substances in the periphery. This formulation was chosen such
that U ranges from zero to one and is a minimum for the optimal set of core substances. After
each MC “move,” U is calculated and compared to its value at the previous configuration. If U is
favorable (i.e., ΔU = Us – Us+1 < 0), it is accepted unconditionally. If, on the other hand, ΔU > 0,
it is accepted with conditional Boltzmann probability, )/exp( TUΔ− , where T is a control
parameter analogous to the “temperature” of the system. If T is large, the system “melts” into a
random configuration by accepting all moves both favorable and unfavorable. If T is small, the
system “freezes,” accepting only favorable moves, and is eventually trapped in a local (not
global) minimum of the usefulness function U. Therefore, to find the optimal solution, the
system must be annealed or cooled slowly from high T to low T such that it can overcome local
traps to approach the optimal set, characterized by a global minimum in U.
4) Annealing Schedule – Finally, in order to anneal the system into its optimal configuration, the
T parameter is decreased exponentially according to ( ))/)(/log(exp SsTTTT FII −= , where TI
and TF are the initial and final “temperatures,” respectively, s is the number of moves taken thus

4
far, and S is the total number of moves in the MC run (typically, millions to tens of millions).
Typically, TI = 10-4, TF = 10-6, and S/M = 10,000 moves per node in the set.
Optimal Set of 300 Core Substrates
In this section, we discuss the examples of similar compounds included in the top-300 list
generated by usefulness optimization:
Set 1. Sodioethyl malonate (177), Methyl malonate (186), Ethyl malonate (187)
(a) Although compounds #186 and #187 are certainly similar, they are nevertheless
chemically distinct, and the immediate products derived from them are different (albeit in an
often trivial manner). The inclusion of such similar compounds in an actual commercial offer
should depend on the scope of the Company’s catalog – in this particular example, the major
suppliers (Aldrich, TCI America, Fluka, Alfa Aesar, Merck, Lancaster) offer both #186 and
#187.
(b) The pair of compounds #177 and #188 is an instructive example of the scheme
according to which reactions are reported in Beilstein. First, we note that the majority of
reactions of malonates (and acetomalonates) involve substitution of acidic hydrogen(s) with an
alkyl group. This is a two-step process, in which ethyl malonate is deprotonated to sodioethyl
malonate, and only then the actual substitution occurs. Therefore, it is common in Beilstein to
find both ethyl malonate and sodioethyl malonate as reactants in very similar chemical processes.
Nevertheless, it is rare to find a product for which there is a reported reaction starting from both
ethyl malonate and sodioethyl malonate (see the “overlap” example in Set 3); hence, each makes
significant contributions to the overall usefulness of the set and are therefore included. Of course,
in the context of industrial importance, only one of the two compounds (here, ethyl malonate)
should be included in the “optimal” set. This example illustrates well that the results of network
analysis should always be confronted with a “common” chemical knowledge to avoid artifacts
stemming from the structure of the database underlying the analysis.
Set 2. Methyl (179) and Ethyl (180) acetoacetate
Again, as in the case of methyl and ethyl malonates, the optimization procedure has
selected both methyl and ethyl acetoacetates since their immediate products are not identical

5
(although there may be some overlap two steps from the core). For example, alkylation of 179 or
180 is often followed by hydrolysis, resulting in identical products after two synthetic steps;
however, the products of the first reaction (leaving the core) are not the same (methyl vs. ethyl
ester). Interestingly, despite chemical similarity, both compounds are sold by Aldrich, TCI
America, Fluka, Alfa Aesar, Merck, and Lancaster
Set 3. Phosphonium salts (209, 210) and ylide (204)
Again, despite obvious similarities, these compounds are chemically distinct and for the
most part do lead to different products. In a detailed analysis, we investigated all such products
within one synthetic step from compounds 204, 209 and 210, and we quantified the degree of
product “overlap” (i.e., how many products can be made from more than one of the substrates
204, 209, 210). We found that compound 204 gives 2,611 unique products and 759 (22 %)
products that overlap with those of 209/210. Likewise, compound 209 contributes 3,917 unique
products and the overlap with products of 204/210 is only 8% (317). Finally, compound 210
contributes 787 unique products and 377 (32%) products overlapping with those of 204/209.
This limited overlap suggests that companies might indeed consider inclusion of both 209 and
210 in their catalogs – in fact, Aldrich, TCI America, Fluka, Alfa Aesar, Merck, Lancaster do so.
The ylide 204, on the other hand, is probably not a good commercial candidate, since it is very
easily obtained from Methyltriphenylphosphonium iodide or bromide by deprotonation (although
one company, Ugarit Chemie, sells it).

6
Figure S1. Examples of elegant tandem reactions used in the total syntheses of natural products
demonstrating a vast structural change that may occur as a result of a single synthetic step: (a)
tandem hydrogenation-conrotatory 8π electrocyclization-disrotatory 6π electrocyclization-
intermolecular DA reaction sequence applied in the total synthesis of endriandric acid A,[22] (b)
acid-catalyzed cationic rearrangement generates the core scaffold of zaragozic acid A.[23]

7
Supplemental References
[22] K. C. Nicolaou, N. A. Petasis, J. Uenishi, R. E. Zipkin, J. Am. Chem. Soc. 1982, 104,
5557.
[23] K. C. Nicolaou, A. Nadin, J. E. Leresche, S. Lagreca, T. Tsuri, E. W. Yue, Z. Yang,
Angew. Chem. Int. Edit. 1994, 33, 2187.

#1 471223 C7H6O
#2 385877 C7H5OCl #3 636132 C7H5OBr #4 606301 C8H8O2
#5 742624 C7H5O3N
#6 386795 C7H5O3N #7 385772 C8H8O #8 385857 C7H5OF
#9 385858 C7H5OCl
#10 507100 C7H5OBr #11 471382 C8H8O2 #12 386796 C7H5O3N
#13 606802 C9H11ON
#14 473899 C9H10O3 #15 131691 C8H6O3 #16 396163 C10H12O4
#17 105755 C5H4O2
#18 105819 C5H4OS #19 605631 C6H7N #20 606074 C6H8N2
Optimal Set of 300 Core Substrates

#21 2204899 C6H6NI
#22 386210 C7H9ON
#23 605969 C6H6NCl
#24 636962 C6H6O2N2
#25 387672 C7H6NF3
#26 471281 C7H9N #27 471359 C6H6NCl
#28 742031 C6H6NBr
#29 508690 C6H6O2N2
#30 471556 C7H9ON #31 471389 C7H5OCl
#32 777991 C7H4O3NCl
#33 471492 C8H7OCl
#34 471606 C7H4OCl2 #35 636641 C7H4OClBr
#36 471918 C8H7O3Cl
#37 473192 C7H4O3NCl
#38 990249 C7H3O5N2Cl #39 907340 C7H5O2Cl
#40 1868192 C7H4O2Cl2

#41 516726 C14H10O3
#42 118515 C8H4O3
#43 153190 C12H6O3
#44 1073987 C9H9O3N3
#45 606716 C8H5ONS
#46 969616 C6H6O
#47 386123 C8H8O2
#48 906905 C6H6O2
#49 1305151 C7H8O
#50 1680024 C6H5OBr
#51 1817334 C10H14O
#52 606474 C8H7OBr
#53 607041 C9H9OBr
#54 607603 C8H6OClBr #55 607604 C8H6OBr2
#56 393567 C8H6O3NBr
#57 743112 C9H9O3Br
#58 471308 C7H7Cl
#59 385801 C7H7Br
#60 606667 C8H9OCl

#61 606498 C7H6Br2
#62 742796 C7H6O2NBr
#63 606926 C6H5O2SCl
#64 607898 C7H7O2SCl
#65 743518 C6H4O2SClBr
#66 746543 C6H4O4NSCl #67 746676 C8H8O3NSCl
#68 969212 C6H6
#69 1905429 C14H10
#70 103223 C5H5N
#71 107693 C8H7N
#72 509273 C6H4O2NCl
#73 508691 C6H4O2NCl
#74 613161 C6H3O4N2Cl #75 1588666 C6H2O6N3Cl
#76 605842 C8H8O
#77 386013 C8H7OCl
#78 386015 C8H7OBr #79 742313 C9H10O2
#80 471388 C7H6O2

#81 471352 C7H6O2
#82 472792 C8H8O3 #83 471803 C7H7O2N
#84 605461 C8H6
#85 471392 C7H5NS
#86 606080 C6H8N2 #87 3598088 C6H5N2Cl
#88 471391 C5H5ON
#89 506523 C6H6S
#90 774156 C6H5SCl #91 1237091 C6H5SeCl
#92 2039772 C6H5SeBr
#93 1236661 C5H5Br
#94 1446140 C6H5I
#95 639794 C12H10S2
#96 2047179 C12H10Se2
#97 605439 C3H5OCl
#98 878139 C2H5OCl
#99 605439 C2H2OCl2
#100 605440 C2H2OBr2

#101 774120 C2OCl3
#102 878139 CO3NSCl #103 506034 C2SCl4
#104 878169 C3H4Br2
#105 605278 C3H6ClBr
#106 635754 C6H13O2Br #107 1760158 C5H7O3Br
#108 1749700 C6H11O2Br
#109 157547 C11H10O2NBr
#110 1696892 CH2I2
#111 102378 C2H4O
#112 102415 CH2N2
#113 1209228 CH2O
#114 1098367 COCl2
#115 506297 CH3OSCl
#116 1732799 CBr4
#117 1361988 C2O2Cl2
#118 635994 C2H6O4S #119 3596974 C3H5OSK
#120 610776 C18H15P
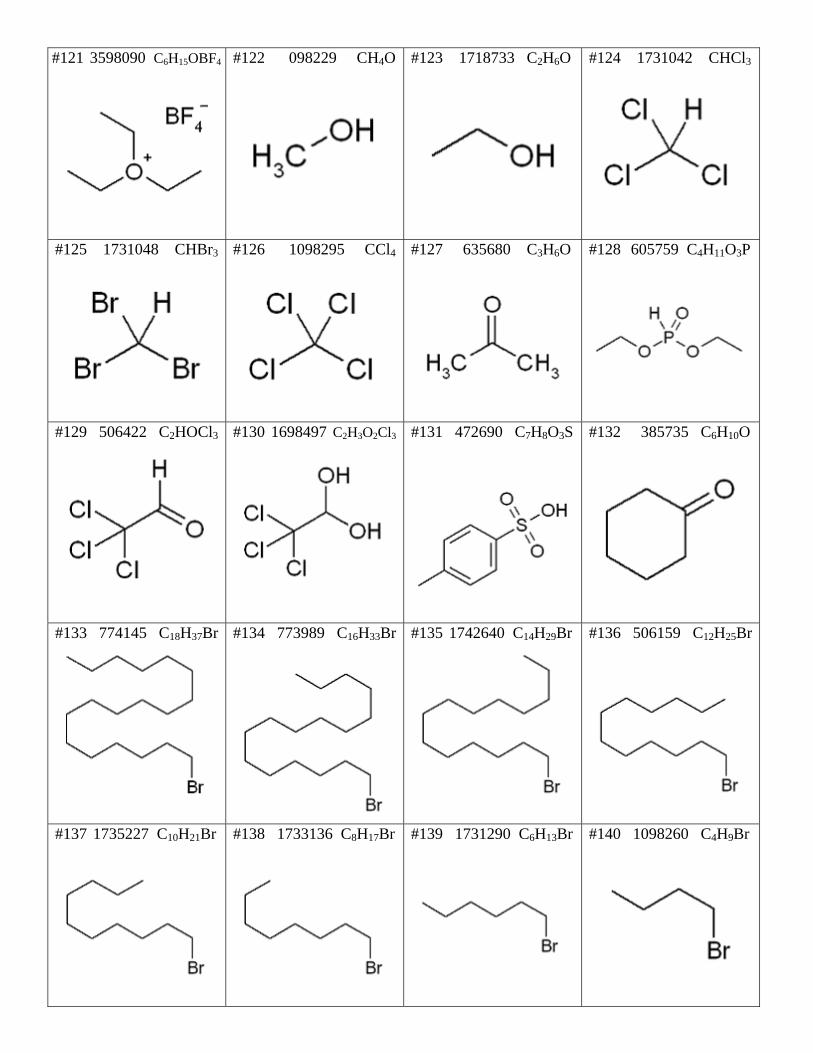
#121 3598090 C6H15OBF4
#122 098229 CH4O
#123 1718733 C2H6O
#124 1731042 CHCl3
#125 1731048 CHBr3
#126 1098295 CCl4
#127 635680 C3H6O
#128 605759 C4H11O3P
#129 506422 C2HOCl3
#130 1698497 C2H3O2Cl3 #131 472690 C7H8O3S
#132 385735 C6H10O
#133 774145 C18H37Br
#134 773989 C16H33Br
#135 1742640 C14H29Br
#136 506159 C12H25Br
#137 1735227 C10H21Br
#138 1733136 C8H17Br #139 1731290 C6H13Br
#140 1098260 C4H9Br

#141 1209224 C2H5Br
#142 741851 CH5N #143 605257 C2H7N
#144 605268 C4H11N
#145 102438 C5H11N
#146 102548 C5H9NO
#147 741984 C7H9N
#148 909664 C14H15N
#149 506156 C10H20Br2
#150 1236322 C6H12Br2 #151 1209245 C5H10Br2
#152 1071199 C4H8Br2
#153 635662 C3H6Br2
#154 605266 C2H4Br2
#155 605303 C2H3OCl
#156 385668 C5H9OCl
#157 639784 C18H35OCl
#158 972409 C16H31OCl #159 742254 C8H7OCl
#160 606265 C9H7OCl

#161 385737 C4H6O3
#162 746197 C4O3F6 #163 1787583 C4O3Cl6
#164 1911173 C10H18O5
#165 639784 C4H2O3
#166 1813600 C2O5S2F6 #167 969135 CH3I
#168 505934 C2H5I
#169 505937 C3H7I
#170 1098244 C3H7I
#171 1420755 C4H9I
#172 605308 C3H5Br
#173 605309 C3H3Br
#174 507487 C8H9Br #175 605384 C7H16O3
#176 506201 C8H18O3
#177 3574513 C7H11O4Na
#178 741937 C5H8O2 #179 506727 C5H8O3
#180 385838 C6H10O3

#181 742413 C10H10O2
#182 389944 C11H12O3 #183 387787 C8H12O3
#184 608356 C9H14O3
#185 471489 C8H12O2
#186 774261 C5H8O4 #187 774687 C7H12O4
#188 1366042 C7H10O5
#189 640146 C9H14O5
#190 605871 C5H7O2N #191 1343714 C8H17O5P
#192 783883 C9H15O5N
#193 1209232 C3H9ClSi
#194 1737446 C9H21ClSi #195 505999 C6H15ClSi
#196 644023 C16H19ClSi
#197 3591541C10H21O3SF3Si
#198 635752 C4H9O3SF3Si #199 2370068 C7H15O3SF3Si
#200 635752 C6H19NSi2

#201 397363 C19H15Cl
#202 798425 C20H17OCl #203 2471942 C21H19O2Cl
#204 745058 C19H17P
#205 750077 C21H19OP
#206 618430 C20H17O2P #207 757112 C23H23O2P
#208 754639 C22H21O2P
#209 3599467 C19H18PBr
#210 3599430 C19H18PI #211 3599630 C20H20PBr
#212 3599844 C19H18OPCl
#213 3586477 C23H24O2PBr
#214 1209226 C4H9IMg
#215 3587203 C2H5BrMg
#216 1098267 C4H9BrMg
#217 969335 C3H5BrMg
#218 4720968 C6H5BrMg
#219 636491 C7H7BrMg
#220 506256 C4H9BrO2

#221 506456 C4H7O2Br
#222 506455 C4H7O2Cl #223 1753010 C6H11O2Br
#224 773920 C5H9O2Br
#225 107654 C4H6O2N2
#226 385653 C3H5O2Cl #227 970619 C2O2Cl4
#228 970619 C3H2O2Cl4
#229 606778 C7H5O2Cl
#230 509751 C8H7O2Cl #231 605396 C4H6O2
#232 1071571 C9H8O
#233 509985 C15H12O
#234 607063 C6H6O4 #235 508189 C6H5PCl2
#236 512032 C12H10PCl
#237 471433 C4H10O3PCl
#238 654130 C12H10O3PCl #239 773967 C6H4O2
#240 878524 C10H6O2
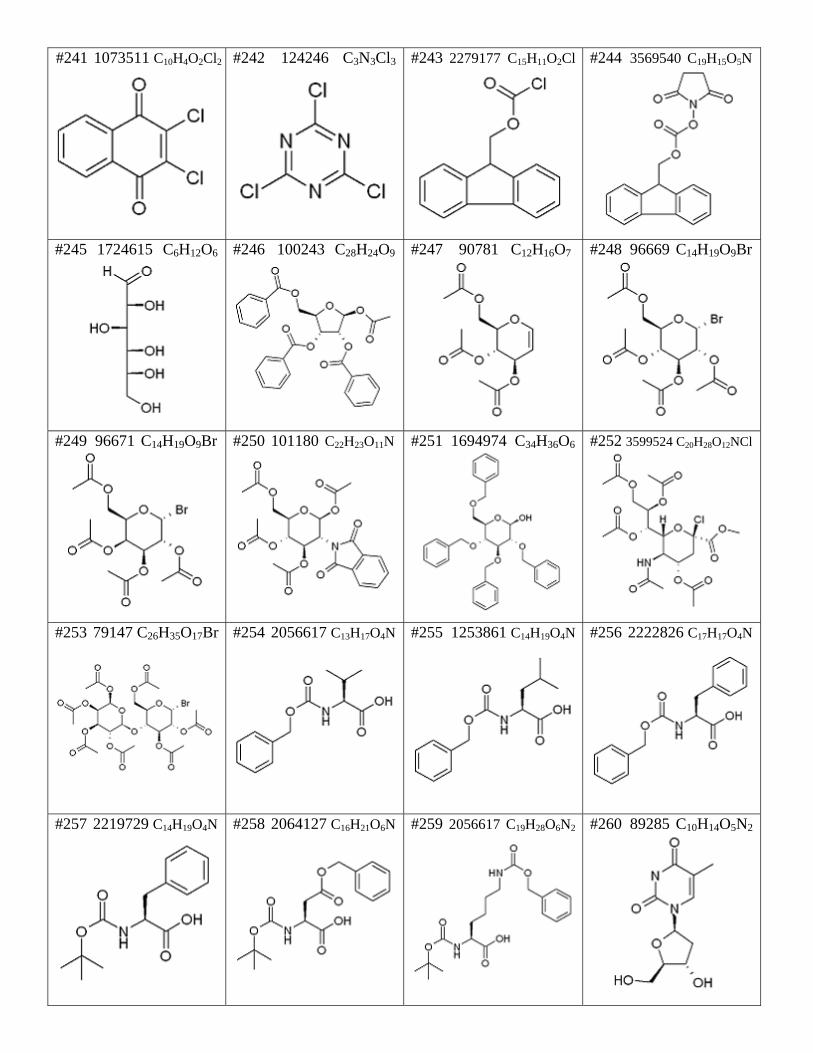
#241 1073511 C10H4O2Cl2
#242 124246 C3N3Cl3 #243 2279177 C15H11O2Cl
#244 3569540 C19H15O5N
#245 1724615 C6H12O6
#246 100243 C28H24O9
#247 90781 C12H16O7
#248 96669 C14H19O9Br
#249 96671 C14H19O9Br
#250 101180 C22H23O11N
#251 1694974 C34H36O6
#252 3599524 C20H28O12NCl
#253 79147 C26H35O17Br
#254 2056617 C13H17O4N #255 1253861 C14H19O4N
#256 2222826 C17H17O4N
#257 2219729 C14H19O4N
#258 2064127 C16H21O6N #259 2056617 C19H28O6N2
#260 89285 C10H14O5N2

#261 48813 C21H21O5Cl
#262 15080 C8H12O3N2S #263 48337 C19H21O3N
#264 2058647 C19H24O2
#265 474393 C10H21O2N
#266 3587194 I2
#267 4652394 CNK
#268 3594799 CNSK
#269 3563831 C2H6O4Hg
#270 3596540 C4H12O8Pb #271 605287 C2H6Cl2Si
#272 125513 C10H12N2
#273 128556 C12H15ON
#274 143237 C12H9NS #275 383659 C8H5O2N
#276 385941 C8H7N
#277 391839 C14H12O2
#278 606350 C6H10O4 #279 607236 C3OF6
#280 607374 C10H10O

#281 956578 C8H5O4NS2F6
#282 610130 C7H10O2N2S #283 615586 C6H6O4N4
#284 638434 C10H11O2
#285 742134 C10H8O
#286 779235 C13H10N2 #287 956578 C6H15O3P
#288 1701528 C9H21O3P
#289 880058 C10H16O5
#290 1524687 C7H7OBr #291 1237590 C7H7OBr
#292 608047 C14H10O2
#293 1238185 C13H10O
#294 1636531 C13H8O #295 1071910 C9H10O
#296 976722 C5Cl6
#297 1802118 C6F13I
#298 1904543 C6H4Br2 #299 1934216 C12H28OCl2Si2
#300 3588340 C15H32Sn




















