
Schweinberger 2014 WIREs
11
Advanced Review Speaker perception Stefan R. Schweinberger, 1,2∗ Hideki Kawahara, 3 Adrian P. Simpson, 2,4 Verena G. Skuk 1,2 and Romi Z ¨ aske 1,2 While humans use their voice mainly for communicating information about the world, paralinguistic cues in the voice signal convey rich dynamic information about a speaker´ s arousal and emotional state, and extralinguistic cues reflect more stable speaker characteristics including identity, biological sex and social gender, socioeconomic or regional background, and age. Here we review the anatomical and physiological bases for individual differences in the human voice, before discussing how recent methodological progress in voice morphing and voice synthesis has promoted research on current theoretical issues, such as how voices are mentally represented in the human brain. Special attention is dedicated to the distinction between the recognition of familiar and unfamiliar speakers, in everyday situations or in the forensic context, and on the processes and representational changes that accompany the learning of new voices. We describe how specific impairments and individual differences in voice perception could relate to specific brain correlates. Finally, we consider that voices are produced by speakers who are often visible during communication, and review recent evidence that shows how speaker perception involves dynamic face–voice integration. The representation of para- and extralinguistic vocal information plays a major role in person perception and social communication, could be neuronally encoded in a prototype-referenced manner, and is subject to flexible adaptive recalibration as a result of specific perceptual experience. © 2013 John Wiley & Sons, Ltd. How to cite this article: WIREs Cogn Sci 2014, 5:15–25. doi: 10.1002/wcs.1261 INTRODUCTION W hen listening to an unfamiliar person speaking over the telephone or in a radio broadcast, many people report forming a spontaneous impression about the speaker. While sex is usually perceived easily in adult voices, other impressions relate ∗ Correspondence to: [email protected] 1 Department of General Psychology and Cognitive Neuroscience, Institute of Psychology, Friedrich Schiller University, Jena, Germany 2 DFG Research Unit Person Perception, Friedrich Schiller University, Jena, Germany 3 Faculty of Systems Engineering, Wakayama University, Wakayama, Japan 4 Department of Speech, Institute of German Linguistics, Friedrich Schiller University, Jena, Germany Conflict of interest: The authors have declared no conflicts of interest for this article. Additional supporting information and example sound files are found in the online version of this article. Please refer to the resources tab at http://wires.wiley.com/WileyCDA/WiresArticle/wisId-WCS 1261.html to emotional state, 1 approximate speaker age, 2 health, attractiveness, 3 regional or social origin and competence, 4 trustworthiness and other aspects of personality. 5 Such voice-based impressions show a less than perfect correspondence with visual impressions: many people report occasional surprise when meeting in person someone who has been previously known over the telephone only. Nevertheless, the human voice is the primary auditory signal for person perception. Because of the variable use of terms in the scientific literature, it may be useful to state that here we take the domain of speaker perception to exclude speech comprehension, and to consider only the perception of all kinds of para- and extralinguistic information in the voice signal that provide information about a speaker. While a full discussion of interactions between speech and speaker perception is beyond the scope of this review, it should be noted that there is now evidence for such interactions. 6 For instance, systematic benefits to comprehension have been shown to occur when Volume 5, January/February 2014 © 2013 John Wiley & Sons, Ltd. 15
Transcript of Schweinberger 2014 WIREs

Advanced Review
Speaker perceptionStefan R. Schweinberger,1,2∗ Hideki Kawahara,3
Adrian P. Simpson,2,4 Verena G. Skuk1,2 and Romi Zaske1,2
While humans use their voice mainly for communicating information about theworld, paralinguistic cues in the voice signal convey rich dynamic informationabout a speaker´s arousal and emotional state, and extralinguistic cues reflectmore stable speaker characteristics including identity, biological sex and socialgender, socioeconomic or regional background, and age. Here we review theanatomical and physiological bases for individual differences in the human voice,before discussing how recent methodological progress in voice morphing andvoice synthesis has promoted research on current theoretical issues, such ashow voices are mentally represented in the human brain. Special attention isdedicated to the distinction between the recognition of familiar and unfamiliarspeakers, in everyday situations or in the forensic context, and on the processes andrepresentational changes that accompany the learning of new voices. We describehow specific impairments and individual differences in voice perception couldrelate to specific brain correlates. Finally, we consider that voices are produced byspeakers who are often visible during communication, and review recent evidencethat shows how speaker perception involves dynamic face–voice integration. Therepresentation of para- and extralinguistic vocal information plays a major role inperson perception and social communication, could be neuronally encoded in aprototype-referenced manner, and is subject to flexible adaptive recalibration as aresult of specific perceptual experience. © 2013 John Wiley & Sons, Ltd.
How to cite this article:WIREs Cogn Sci 2014, 5:15–25. doi: 10.1002/wcs.1261
INTRODUCTION
When listening to an unfamiliar person speakingover the telephone or in a radio broadcast,
many people report forming a spontaneous impressionabout the speaker. While sex is usually perceivedeasily in adult voices, other impressions relate
∗Correspondence to: [email protected] of General Psychology and Cognitive Neuroscience,Institute of Psychology, Friedrich Schiller University, Jena, Germany2DFG Research Unit Person Perception, Friedrich SchillerUniversity, Jena, Germany3Faculty of Systems Engineering, Wakayama University,Wakayama, Japan4Department of Speech, Institute of German Linguistics, FriedrichSchiller University, Jena, Germany
Conflict of interest: The authors have declared no conflicts ofinterest for this article.
Additional supporting information and example sound files arefound in the online version of this article. Please refer to the resourcestab at http://wires.wiley.com/WileyCDA/WiresArticle/wisId-WCS1261.html
to emotional state,1 approximate speaker age,2
health, attractiveness,3 regional or social origin andcompetence,4 trustworthiness and other aspects ofpersonality.5 Such voice-based impressions show a lessthan perfect correspondence with visual impressions:many people report occasional surprise when meetingin person someone who has been previously knownover the telephone only. Nevertheless, the humanvoice is the primary auditory signal for personperception. Because of the variable use of termsin the scientific literature, it may be useful tostate that here we take the domain of speakerperception to exclude speech comprehension, and toconsider only the perception of all kinds of para-and extralinguistic information in the voice signalthat provide information about a speaker. While afull discussion of interactions between speech andspeaker perception is beyond the scope of this review,it should be noted that there is now evidence forsuch interactions.6 For instance, systematic benefitsto comprehension have been shown to occur when
Volume 5, January/February 2014 © 2013 John Wiley & Sons, Ltd. 15

Advanced Review wires.wiley.com/cogsci
a listener is familiar with the speaker´s voice,suggesting a degree of speaker contingency in speechcomprehension.7 In turn, voice recognition tends to beeasier for speech when spoken in the listener´s nativelanguage.8
Despite a few early studies, the importancefor social communication of paralinguistic andextralinguistic information in spoken language hasonly recently prompted more systematic scientificinvestigation.9 It is important to emphasize thatspeaker perception involves an interaction betweenthe physical voice signal that is created by the vocalapparatus of a speaker, and characteristics of alistener. In that sense, speaker perception is subjective.Examples below will show how the specific nature ofa listener´s prior exposure to voices can modify, in ahighly systematic manner, the perception of the samevoice stimulus. One of the most salient cues in adulthuman voices relates to sexual dimorphism, whichbecomes apparent during puberty, and promotes theperception of biological sex. It has been arguedthat voice quality, and voice fundamental frequency(henceforth f0) in particular, is related to intersexualattraction and mate choice. Females prefer malevoices with lower f0, and this preference varies withhormonal status across the menstrual cycle.10,11 Moregenerally, the vocal apparatus differs as a functionof a speaker´s age or sex, and a speaker´s mood,learning history, or momentary intentions will havean influence on how the vocal apparatus is used.Thus, basic information of how the voice signal isproduced will promote a better understanding of thespeaker–listener interaction.
THE SPEECH SIGNAL
Tightly coordinated movements of approximately halfa speaker’s body create and modify an airstreamthat leaves the lungs on a controlled outbreath toproduce complex patterns of small high frequencychanges in air pressure—the acoustic speech signal.The airstream leaving the lungs is modified bymovements of the vocal folds, pharynx, tongue, lowerjaw and lips. By lowering the soft palate (velum) aircan also pass through the nasal cavity. Specifically,the high frequency fluctuations in air pressure havetwo chief sources. The first, most efficient soundproducing mechanism, is vocal fold vibration: airflowing between appropriately adducted vocal foldscauses them to open and close in a quasiperiodicfashion. Perceptually, the resulting signal is perceivedas a tone with a particular pitch. The secondimportant source of acoustic energy is turbulence: airforced through an opening too narrow for a laminar
flow to be maintained becomes turbulent causingchaotic changes in sound pressure, i.e. noise. Differentconfigurations of the pharynx, tongue, lips and velumcreate cavities with particular resonance frequencieswhich enhance different frequency components inthe turbulent noise or in the signal created bythe vibrating glottis, giving consonants and vowelstheir distinctive acoustic qualities. However, thesound pressure wave leaving a speaker’s body isa multiplex signal encoding both linguistic andnonlinguistic information at a number of differentlevels. Besides the linguistic information about theindividual sounds or temporal and melodic patternsthat structure utterances the speech signal containsa wealth of paralinguistic information, such asemotion, as well as extralinguistic information abouta speaker, such as group identity (e.g. gender) speechpathologies (e.g. lisp, stutter, etc.), but ultimately,and most particularly, also encoding their individualidentity.
Although every speaker uses the same body partsto speak, small differences in the dimensions andhistology of the individual parts, as well as differencesin muscular tension, the timing and the size ofmuscular contractions give us a system with numerousdegrees of freedom producing individual acousticpatterns for every speaker. The relevant acousticparameters can be divided into those originatingin the way the vocal folds vibrate during voicingand those originating from patterns of resonanceabove the glottis in the pharynx, nose and mouth.During voiced stretches of speech, the vocal foldsare opening and closing rapidly. The frequency ofvibration is dependent upon their length, mass andtension. Average male vocal folds are longer andthicker than female vocal folds causing them to vibrateat approximately half the frequency (100–120 Hz)than average female vocal folds (200–240 Hz).12
Interindividual differences in the dimensions of thevocal folds, as well as overall tension and the amountthe vocal folds are adducted during vibration causevariation in mean f0 and voice quality. Likewise,differences in the dimensions of the vocal tract,including the complex nasal passage with its paranasalsinuses, produce differences in the absolute andrelative positions of the resonance frequencies ofthe vocal tract. While some of these differencesare the product of anatomical and physiologicalinevitabilities, other aspects of the variation arethe product of learned behaviors, e.g. indexicalizinggender (see Box 1) and sexual orientation.13 Speakersalso vary in how they organize the voice source andthe resonance properties of the vocal tract over time,as manifested, for instance, in speech tempo.
16 © 2013 John Wiley & Sons, Ltd. Volume 5, January/February 2014

WIREs Cognitive Science Speaker perception
BOX 1
CLASSIFYING SEX IN ADULTSAND CHILDREN
Despite expected differences in formants arisingfrom vocal tract dimensional differences, aswith judgments of speaker similarity, f0 playsa more significant role in influencing listeners’judgments of a speaker’s sex. So, for instance,Lass et al.14 found listeners correctly classifiedspeaker sex for whispered (removing f0) vowels75% of the time, but were 91% correct forvowel stimuli low-passed filtered at 255 Hz(removing resonance information). However,there is some evidence that listeners judgespeaker sex from male better than they do fromfemale vowel stimuli,15 suggesting perhaps thatthe disproportionate changes to male laryngealand vocal tract morphology during puberty makemale f0 and formants perceptually more marked.
Sex classification of prepubertal childrenfrom voice is much worse than for adults,but better than one might expect given thatchildren only exhibit negligible differencesin the dimensions of laryngeal and vocaltract structures.16 By contrast to adults, sexclassification of single-vowel stimuli is generallyat chance level,17 confirming the lack ofdifferences in the sound producing apparatusitself. However, listeners attending to longerstimuli, such as whole sentences performmuch better than chance, suggesting sex-specific behavioral differences in a range ofother parameters, such as segment durations,intonation patterns, or tempo.
Although we can identify and measureparameters in the speech signal that differentiatespeakers, which ones are perceptually relevant? Forinstance, which parameters does a listener exploit toidentify a familiar voice, or what is it that makestwo unfamiliar speakers sound more or less similar?One way of analyzing the perceptually relevantacoustic aspects of speaker identity has been tocorrelate speaker similarity judgments with a range ofmeasured acoustic parameters in the stimuli. Based onthese similarity judgments, multidimensional scalingis used to produce a solution based on a numberof dimensions. These dimensions are then correlatedwith a restricted set of typical acoustic parameterscharacterizing the speech signal, such as f0 and the firstthree to five formants (F1–F5). For instance, Baumannand Belin18 had 32 (16 female) Canadian Frenchspeakers produce three vowels. F0 was found to be the
main parameter accounting for similarity judgmentsbetween both male and female voices. Using morecomplex stimuli and examining speaker similarity,Nolan, McDougall, and Hudson19 had listeners judgesimilarity between two short (∼3 seconds) excerptsof spontaneous speech with 15 young male speakersof Standard Southern British English. Again, f0 wasfound to correlate most strongly with similarityjudgments.
The results of these two recent studies largelyreplicate the findings of earlier research whichidentified f0 as an important correlate of speakersimilarity. However, the importance of f0 mayhave been overemphasized in these studies, preciselybecause it was found to be the most important of thoseparameters that happened to have been measured. Ina more elaborate study, Kreiman, Gerratt, Precoda,and Berke20 present a more complex picture takingseveral acoustic parameters into account that directlyrelate to voice quality (see Figure 1). Listeners (expertsand naive) judged speaker similarity of vowel stimuliproduced by 18 normal male speakers and 18 malespeakers with a range of voice disorders. Whereas f0again emerged as one of the most important correlatesof similarity overall, individual listeners relied ondifferent acoustic parameters such as jitter (localvariations in period length), shimmer (local variationin period amplitude), as well as harmonics-to-noiseratio and the difference in the amplitude of the firstand second harmonics. Moreover, different acousticparameters may be used for the identification ofdifferent speakers,21 perhaps depending on individualparameter salience.
Overall, our ability to recognize a familiar voicewould seem to rely on a combination of a whole rangeof acoustic parameters, from which none arises asbeing more prominent. Kreiman and Sidtis9 (p. 179)present an extensive list of individual voice signalparameters which listeners may use singly or in anycombination to identify a familiar voice.
IDENTIFYING SPEAKERSAND LEARNING NEW VOICES
Successfully identifying familiar speakers by voiceis a remarkable ability, and one that is bothbasic and well developed in humans. For instance,newborn babies have already learned their mothers´voices prenatally,22 and even fetuses recognize theirmothers´ voices when played from tape.23 Oneproblem for voice recognition is that the same speakeralmost never produces the same utterance twice.Moreover, a speaker´s voice can vary substantiallyas a function of mood, health, or other situational
Volume 5, January/February 2014 © 2013 John Wiley & Sons, Ltd. 17
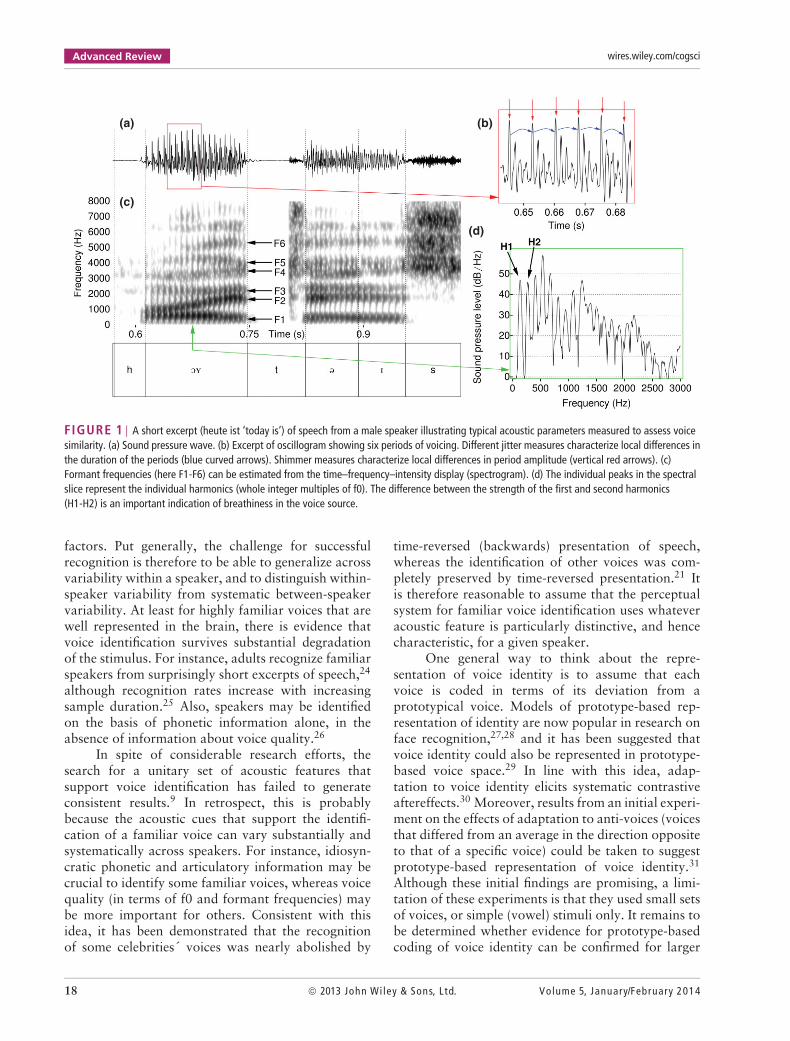
Advanced Review wires.wiley.com/cogsci
(a)
(c)
(b)
(d)
FIGURE 1 | A short excerpt (heute ist ‘today is’) of speech from a male speaker illustrating typical acoustic parameters measured to assess voicesimilarity. (a) Sound pressure wave. (b) Excerpt of oscillogram showing six periods of voicing. Different jitter measures characterize local differences inthe duration of the periods (blue curved arrows). Shimmer measures characterize local differences in period amplitude (vertical red arrows). (c)Formant frequencies (here F1-F6) can be estimated from the time–frequency–intensity display (spectrogram). (d) The individual peaks in the spectralslice represent the individual harmonics (whole integer multiples of f0). The difference between the strength of the first and second harmonics(H1-H2) is an important indication of breathiness in the voice source.
factors. Put generally, the challenge for successfulrecognition is therefore to be able to generalize acrossvariability within a speaker, and to distinguish within-speaker variability from systematic between-speakervariability. At least for highly familiar voices that arewell represented in the brain, there is evidence thatvoice identification survives substantial degradationof the stimulus. For instance, adults recognize familiarspeakers from surprisingly short excerpts of speech,24
although recognition rates increase with increasingsample duration.25 Also, speakers may be identifiedon the basis of phonetic information alone, in theabsence of information about voice quality.26
In spite of considerable research efforts, thesearch for a unitary set of acoustic features thatsupport voice identification has failed to generateconsistent results.9 In retrospect, this is probablybecause the acoustic cues that support the identifi-cation of a familiar voice can vary substantially andsystematically across speakers. For instance, idiosyn-cratic phonetic and articulatory information may becrucial to identify some familiar voices, whereas voicequality (in terms of f0 and formant frequencies) maybe more important for others. Consistent with thisidea, it has been demonstrated that the recognitionof some celebrities´ voices was nearly abolished by
time-reversed (backwards) presentation of speech,whereas the identification of other voices was com-pletely preserved by time-reversed presentation.21 Itis therefore reasonable to assume that the perceptualsystem for familiar voice identification uses whateveracoustic feature is particularly distinctive, and hencecharacteristic, for a given speaker.
One general way to think about the repre-sentation of voice identity is to assume that eachvoice is coded in terms of its deviation from aprototypical voice. Models of prototype-based rep-resentation of identity are now popular in research onface recognition,27,28 and it has been suggested thatvoice identity could also be represented in prototype-based voice space.29 In line with this idea, adap-tation to voice identity elicits systematic contrastiveaftereffects.30 Moreover, results from an initial experi-ment on the effects of adaptation to anti-voices (voicesthat differed from an average in the direction oppositeto that of a specific voice) could be taken to suggestprototype-based representation of voice identity.31
Although these initial findings are promising, a limi-tation of these experiments is that they used small setsof voices, or simple (vowel) stimuli only. It remains tobe determined whether evidence for prototype-basedcoding of voice identity can be confirmed for larger
18 © 2013 John Wiley & Sons, Ltd. Volume 5, January/February 2014

WIREs Cognitive Science Speaker perception
sets of familiar speakers, and for more naturalisticspeech samples.
It is crucial to distinguish between the processesthat enable listeners to recognize familiar voices, andthose that mediate the recognition or matching ofonce-heard unfamiliar speakers. In fact, impairmentsin familiar voice recognition and unfamiliar voicematching can occur independently of one another.32,33
Recent neuroimaging findings were also interpretedto support this distinction.34 It has been argued thatfamiliar voices are identified by analyzing the auditorypattern as a whole, and by aligning the auditorypercept to a pattern or long-term memory trace of thevoice - whereas the perception of unfamiliar voicesmay be characterized by a more feature-based typeof analysis.9 Regardless of how the representationaldifferences between unfamiliar and familiar voices arecharacterized, these findings raise the question of hownew voices are learned, and how the brain supportsthe acquisition of voices during familiarization. Onthe one hand, we know that learning new voicesis rather difficult, although performance can berelatively robust across retention intervals of severaldays.35 On the other hand, learning new voices canbe improved by reducing the number of identities tobe learned, and also by providing faces as contextinformation.35 Audiovisual information, particularlywhen it is dynamic, clearly supports voice learning36
and recognition37 because it may help to establishmultisensory representations of a speaker duringfamiliarization.
An important applied aspect of voice recognitionresearch concerns earwitness testimony in forensiccases. Even when earwitness evidence is admittedat court, such evidence needs to be regarded witha high degree of caution. Apart from the factthat unfamiliar voice identification is highly fallible,the relationship between recognition performanceand subjective confidence of identification has alsobeen repeatedly found to be disappointingly poor.38
Philippon, Cherryman, Bull, and Vrij (2007)39 useda questionnaire to assess the knowledge of factorsaffecting earwitness reliability and voice memory,and noted that both members of the general publicand police officers did not know about the lackingrelationship between identification performance andconfidence that has been observed in many studies.
THE BRAIN AND SPEAKERPERCEPTION: DISORDERSAND INDIVIDUAL DIFFERENCES
In the early 1980s, Van Lancker and Canter40 coinedthe term ‘phonagnosia’ to refer to an inability to
recognize voices—an impairment they reported ina few brain-injured patients with lesions to theright hemisphere, in the context of preserved speechperception. While more precise information aboutlesion location was largely unavailable at the time,the same group later demonstrated that deficits infamiliar voice recognition can be independent from apreserved ability to discriminate between unfamiliarvoices.32 Subsequent research with more extensivetest batteries and larger groups of patients showedthat the inability to recognize familiar voices afterbrain damage can occur in the context of completelypreserved memory for faces or personal names, aswell as preserved environmental sound recognitionand unfamiliar voice matching.33
In spite of these intriguing clinical observations,the starting point of more systematic neuroscientificresearch into speaker perception was probably markedby the first demonstration of regions in the humansuperior temporal cortex that responded selectively tovoices,41 using functional magnetic resonance imaging(fMRI). Those areas, which are often referred to as the‘temporal voice areas’ (TVA), are located bilaterally inthe middle and anterior superior temporal gyrus, andshow larger activation in response to vocal sounds, ascompared to various categories of non-vocal sounds.42
While the response of these areas has now beenstudied in various speaker recognition tasks,43,44 theperception of vocal emotional expressions appears toinvolve yet another network of bilateral brain areas.45
Based on findings that repeated exposure to thesame speaker´s voice leads to reduced activation inthat region,46 the right anterior superior temporalcortex is one important candidate region for voiceidentity processing. But there is also some initial fMRIresearch into how distributed patterns of brain activitycan be used to discriminate between a small set ofdifferent voices.47 Moreover, a recent fMRI studysuggests that voice identity processing is subserved bya whole network of brain areas, including superiortemporal areas that mediate acoustic representationof unfamiliar voices, and inferior frontal areas for theperceptual identification of familiar voices.34
However, the time resolution of fMRI isinsufficient to inform us about the neuronal timingof voice recognition. Electroencephalography (EEG)and magnetoencephalography (MEG) are thereforemethods of choice in order to determine the timecourse of various aspects of voice perception. Recentrelevant research from event-related potentials (ERPs)of the EEG suggests that the first voice-selectiveresponse (compared to non-vocal control sounds) canbe observed around 200 milliseconds after soundonset,48 whereas the initial computation of voice
Volume 5, January/February 2014 © 2013 John Wiley & Sons, Ltd. 19

Advanced Review wires.wiley.com/cogsci
identity (independent of speech content) appears totake about 100 milliseconds longer.49
Individual differences in the ability to perceiveand identify speakers have long been neglected byresearchers. In the field of face recognition, thereis now increasing interest in both the condition ofdevelopmental prosopagnosia (inability to recognizefaces in the absence of brain injury) and the oppositeextreme, represented by ‘super-recognizers’.50 Atthe same time, metacognitive abilities in terms ofthe correlation between recognition performanceand confidence have been found to be generallysurprisingly poor or fragile,51 and large individualdifferences and poor metacognitive abilities werealso described in the case of voice recognition.38,52
In the forensic context, this suggests that evidencefrom eye- or earwitnesses in criminal cases should beinterpreted with great caution, even when confidenceis reported to be high. Perhaps because personrecognition abilities are not formally assessed inour educational systems, it is possible that manyimpairments go undetected even by affected people,who may be able to compensate for their deficit byusing other ‘cues’. How else can we explain the factthat the number of reports of ‘face-blind’ people withdevelopmental prosopagnosia has literally exploded inthe past decade, whereas it took until 1976 before sucha striking and disabling condition (in the absence ofbrain injury) was first reported even in a single case.53
For voices and developmental phonagnosia, the firstwell-documented case was published as recently asin 200954! KH, a 60-year old active woman with anacademic profession, was tested with a large batteryof tasks including voice and face recognition, speechperception, vocal emotion recognition, perceptionof environmental sounds, and music. While shewas impaired on tasks that required famous voicerecognition and learning of new voices, she wasunimpaired on nearly all other tasks. We expectthat the scientific interest in individual differencesin various abilities of person perception (and theirinterrelationships as well as their neural correlates)will continue to increase.
CROSSMODAL FACE–VOICEINTEGRATION
Audiovisual face–voice integration is well-known tooccur during speech perception. Once a listenerlooks at a face, it is impossible to ignore visualinformation from the articulating face for speechperception. In fact, discrepancies between visual andauditory phonetic information, created by redubbingvideos, can lead to striking and systematic perceptual
illusions.55 When you try to understand someonespeaking in a noisy environment, such as in a busypub, you may have experienced that watching thespeaking face makes it much easier to understandthe speaker—and this facilitation of auditory speechcomprehension by vision is broadly equivalentto improving the signal-to-noise ratio by a veryconsiderable 10–15 dB56! More recently, findingshave emerged that suggest that face–voice integrationnot only occurs during speech perception, but alsowhen people perceive emotional expression or identityfrom a speaker.57 This may be understandable whenyou think of a typical communication situation. Thespeaker is a dynamic and multimodal stimulus, inwhich the auditory voice signal is systematically linkedin space and time to the dynamic visual signal from thearticulating face. Regular face–voice correspondencenot only exists in speech (e.g. which dynamic mouthshapes, or ‘visemes,’ correspond with which acousticphonemes), but also in person identification (whichfacial identity corresponds to which voice quality).But can the brain make use of this multisensorycorrespondence to process speaker identity?
A traditional view of the sensory brain holds thatmultimodal integration occurs only after extensiveunimodal processing in unisensory brain areas.Similarly, traditional models of person recognitionhold that face-voice integration is limited to latepostperceptual processing stages. An influentialmodel58 assumes that information from the faceand the voice first converges at a postperceptualstage of the so-called person identity node (PIN),at which the access to a person’s identity andsemantic information becomes available. But theview that face-voice integration does not occur atearly stages of perceptual processing has recentlybecome controversial. Generally, many researchersnow believe that multisensory integration occursquite early, and at multiple cortical areas, includingthose traditionally thought of as unisensory visualor auditory areas.59 More specifically, there isnow converging evidence for perceptual face-voiceintegration in speaker recognition before the PIN level.
First, experiments showed that when personallyfamiliar voices are recognized, combination of thevoice with a corresponding (same speaker identity)face facilitates recognition, whereas a simultaneousnoncorresponding face (of a different identity tothe voice) interfered with voice recognition onlywhen the face was presented dynamically andin precise time synchronization. Thus, whereasperceivers seem to be able to ignore noncorrespondingstatic faces, they are unable to voluntarily ignoresynchronously articulating faces when recognizing a
20 © 2013 John Wiley & Sons, Ltd. Volume 5, January/February 2014

WIREs Cognitive Science Speaker perception
familiar voice. In several experiments, this patternwas strong for personally familiar speakers, but wasreduced or eliminated in the case of unfamiliarspeakers. Accordingly, face-voice integration inspeaker identification appears to depend on familiaritywith a speaker, enabling the brain to ‘know’which facial identity corresponds to which voicequality.37,60 Importantly, multimodal integration infamiliar person recognition was observed for facesand voices, but not for faces and personal names (thelatter of which can be conceived as abstract labels,rather than biological stimuli that naturally co-occurwith faces).61
Second, there is evidence from fMRI thatfamiliar voices on their own can activate the fusiformface area (FFA), a region that is normally selectivelyactivated by faces.62 More recently, using probabilistictractography (a method to visualize fiber tracts in thebrain), it was shown that the FFA is structurallyconnected with voice-sensitive areas in the superiortemporal sulcus (STS), and to its middle and anteriorparts in particular63 (see Figure 2). The authorssuggested that this specific connectivity pattern ofdirect links between face- and voice-recognition areascould be used to optimize speaker recognition.Another brain region in posterior cingulate cortex,including retrosplenial cortex has been implicated as aneural site for the postperceptual processing of speakerfamiliarity independent of modality.64 There is alsosome ongoing discussion about the existence of brainregions that perceptually integrate faces and voicesinto a unique percept, as opposed to the hypothesisthat perceptual integration is based on direct linksbetween face- and voice processing areas.42,63,65,66
Third, considering that fMRI data providelittle information about the time course of neuralactivation, it is important that EEG and event-relatedpotential (ERP) studies have also revealed evidence forearly face–voice integration in speaker recognition.67
A recent study68 suggests that face–voice integrationinvolves several mechanisms at different points intime: Very early, at 50–80 ms after stimulus onset,face-voice presentation elicited an earlier frontocentralnegativity (compared to the sum of responses from thesame stimuli when presented unimodally as separatestimuli)—suggesting that audiovisual presentationspeeded up neural responses. Nevertheless, the earliestpoint in time at which ERPs picked up whether or notfamiliar speaker identity of a face and a voice were incorrespondence was around 250 ms (see Figure 3).
Fourth, research on contrastive aftereffects fromhigh-level perceptual adaptation in voice perceptionhas been boosted by methodological progress, and theavailability of auditory morphing software69 (see also
(a) (c)
(d)(b)
FIGURE 2 | Voice-sensitive (anterior, middle, and posterior STSregions depicted as blue, red, and green spheres) and face-sensitivebrain areas (FFA, yellow sphere) and direct connections between them,as found with probabilistic fiber tracking. Panels A to D show differentviews. Data are from one representative participant of a larger study.Results of that study suggested particularly prominent connectionsbetween the FFA and more anterior voice-sensitive areas in superiortemporal cortex. (Reprinted with permission from Ref 63. Copyright2011 Society for Neuroscience)
Box 2). Using this technique, the perception of voiceidentity in an identity-ambiguous voice was observedto be shifted away from a given speaker when the testvoice followed adaptation to that speaker´s voice.30,31
Intriguingly, adaptation to silent videos of a familiarspeakers’ articulating face also caused a similarcrossmodal aftereffect on voice perception.70 It can beargued that this effect depends on speaker familiarity,since no crossmodal aftereffects on voice perceptionwere observed in the case of unfamiliar speakers.71
BOX 2
METHODOLOGICAL ADVANCES IN VOICEPERCEPTION RESEARCH
Speech is an instantiation of linguistic, paralin-guistic, and extralinguistic information. It is nottrivial to decode all such information directlyfrom the speech waveform. Decomposition ofspeech signals into source information and fil-ter information provides a conceptually simpleand flexible framework to decode such aspects.A speech analysis, modification and resynthe-sis framework STRAIGHT72,73and its morphingextension74 were developed to promote anexploratory approach for investigating speechperception.
Volume 5, January/February 2014 © 2013 John Wiley & Sons, Ltd. 21

Advanced Review wires.wiley.com/cogsci
STRAIGHT decomposes speech signals intothree mutually independent parameters, f0,aperiodicity spectrogram (noise distribution),and spectral envelope. The first two repre-sent source information; the third parameterrepresents filter information. Interference-freerepresentations of instantaneous frequenciesand power spectra with a spectral enveloperecovery procedure that was reformulated bya new sampling theory (consistent sampling)enable virtually perfect suppression of interfer-ences between parameters. More importantly,STRAIGHT provides perceptually identical re-synthesized speech from only three parameterswhen no parameter modification is introduced.It allows physically precise control of parame-ters of naturally sounding speech and providesquantitative evaluation of perceptual effectsof manipulated parameters. Recent extensionof the morphing procedure made interpola-tion and extrapolation of individual parameterspossible.74 These techniques allow researchersto manipulate (e.g., to morph, caricature, oraverage) natural voices according to a spe-cific social signals of interest (e.g., identity,sex, or age). Please also refer to the soundexamples provided in the supporting infor-mation. This approach does not require priorknowledge on the physical correlates of the per-ceptual attribute. It only requires representativeexamples. Further information is available at theSTRAIGHT homepage, http://www.wakayama-u.ac.jp/∼kawahara/STRAIGHTadv/index_e.html.
OUTLOOK AND OPEN QUESTIONS
While substantial progress has been made in the lastdecade towards understanding both the perceptualand cognitive systems underlying speaker perceptionand their brain correlates, we expect that importantquestions for future research include the following:
How does the brain combine linguistic and non-linguistic information in voices? Although variousintriguing interactions have been reported betweenspeaker and speech perception, the conditions andlimits for these interactions and their underlyingmechanisms require further specification.
How exactly is information about age, sex,emotions, attractiveness, distinctiveness, and identityof a speaker´s voice represented in the brain? Forinstance, although initial evidence has been presentedto suggest norm-based representation of voice identity
0 200
Face only + voice only (sum)AV corrAV noncorr
Difference noncorr minus corr
50–80 100–140 164–204 250–600 600–1200 ms2.001.601.200.800.40−0.00−0.40−0.80−1.20−1.60−2.00
0 200 ms
C4C3
(a)
(b)
μV
FIGURE 3 | (a) Independent of speaker identity correspondence, afrontocentral ERP negativity to dynamic and time-synchronizedaudiovisual face-voice stimuli emerges around 50–80 milliseconds(arrow), substantially earlier than to algebraically summed ERPs to thesame individual unimodal stimuli. Note: Electrodes C3 and C4 arelocated 20% to the left and right of the vertex (top of the head,percentage is relative to the distance between the two pre-auricularpoints when measured across the vertex), and thus approximately overthe left and right hemispheric central sulci, respectively. (b) Scalpvoltage maps of the speaker correspondence effect (difference betweenaudiovisual—AV noncorresponding minus AV corresponding condition).Reliable correspondence effects first emerge around 250 milliseconds,when a central negativity is seen for noncorresponding pairs. Thisnegativity then increases and shifts to a rightfrontotemporal maximumbetween 600 and 1200 milliseconds. (Reprinted with permission fromRef 68. Copyright 2011 Elsevier)
for short vowels, the nature of representations of voiceidentity for more complex natural speech remains tobe determined.
What are the neurocognitive processes thataccompany the learning of new voices as humansbecome familiar with a speaker?
How many different voices can humans identify?Related to this, are there large individual differencesin voice perception? And if so, what do individualdifferences in voice and person perception tell us aboutthe set of social cognition abilities? What are the rolesof genetic and environmental variables?
Can we identify (both in the speaker and in thelistener) determinants of voice misidentification? Somespeakers have developed considerable proficiencyto disguise their own voice, including both groupidentity features such as dialect, and individualfeatures such as f0 and voice quality. This isperfectly exemplified by the actor Hugh Laurieplaying the aristocratic British buffoon (Black Adder,Jeeves and Wooster) or, more recently, the American
22 © 2013 John Wiley & Sons, Ltd. Volume 5, January/February 2014

WIREs Cognitive Science Speaker perception
doctor (House). Identifying factors that promote poorvoice identification can have considerable practicalimportance. For instance, do listeners identify voicesof their own age-group more easily than voices of
other age-groups? While considerable research existson own-group biases (e.g. for age or ethnicity) in facerecognition,75 there is little analogous research onvoices.
REFERENCES1. Banse R, Scherer KR. Acoustic profiles in vocal emotion
expression. J Pers Soc Psychol 1996, 70:614–636.
2. Mulac A, Giles H. ’’You’re only as old as yousound’’: Perceived vocal age and social meanings.Health Commun 1996, 8:199–215.
3. Bruckert L, Bestelmeyer P, Latinus M, Rouger J,Charest I, Rousselet GA, Kawahara H, Belin P. Vocalattractiveness increases by averaging. Curr Biol 2010,20:116–120.
4. Rakic T, Steffens MC, Mummendey A. When itmatters how you pronounce it: the influence of regionalaccents on job interview outcome. Br J Psychol 2011,102:868–883.
5. Vukovic J, Jones BC, Feinberg DR, DeBruine LM, SmithFG, Welling L, Little AC. Variation in perceptionsof physical dominance and trustworthiness predictsindividual differences in the effect of relationshipcontext on women’s preferences for masculine pitchin men’s voices. Br J Psychol 2011, 102:37–48.
6. Casserly ED, Pisoni DB. Speech perception andproduction. WIREs Cogn Sci 2010, 1:629–647.
7. Nygaard LC, Sommers MS, Pisoni DB. Speech-Perception As A Talker-Contingent Process. PsycholSci 1994, 5:42–46.
8. Perrachione TK, Wong PCM. Learning to recognizespeakers of a non-native language: implications forthe functional organization of human auditory cortex.Neuropsychologia 2007, 45:1899–1910.
9. Kreiman J, Sidtis D. Foundations of Voice Studies: AnInterdisciplinary Approach to Voice Production andPerception. Chichester: Wiley-Blackwell; 2011.
10. Feinberg DR, Jones BC, Law-Smith MJ, Moore FR,DeBruine LM, Cornwell RE, Hillier SG, Perrett DI.Menstrual cycle, trait estrogen level, and masculinitypreferences in the human voice. Horm Behav 2006,49:215–222.
11. Puts DA. Mating context and menstrual phase affectwomen’s preferences for male voice pitch. Evol HumBehav 2005, 26:388–397.
12. Stevens KN. Acoustic Phonetics. Cambridge, MA: MITPress; 1998.
13. Munson B, Babel M. Loose Lips and Silver Tongues,or Projecting Sexual Orientation Through Speech. LangLinguist Compass 2007, 1:416–449.
14. Lass NJ, Hughes KR, Bowyer MD, Waters LT, BourneVT. Speaker sex identification from voiced, whispered,
and filtered isolated vowels. J Acoust Soc Am 1976,59:675–678.
15. Owren MJ, Berkowitz M, Bachorowski JA. Listenersjudge talker sex more efficiently from male than fromfemale vowels. Percept Psychophys 2007, 69:930–941.
16. Fitch WT, Giedd J. Morphology and development ofthe human vocal tract: a study using magnetic resonanceimaging. J Acoust Soc Am 1999, 106:1511–1522.
17. Gunzburger D, Bresser A, Terkeurs M. Voiceidentification of prepubertal boys and girls by normallysighted and visually handicapped subjects. Lang Speech1987, 30:47–58.
18. Baumann O, Belin P. Perceptual scaling of voiceidentity: common dimensions for different vowels andspeakers. Psychol Res Psychologische Forschung 2010,74:110–120.
19. Nolan F, McDougall K, Hudson T. Some acousticcorrelates of perceived (dis)similarity between same-accent voices. Proceedings of XVIIth ICPhS, HongKong, 2011, 1506–1509.
20. Kreiman J, Gerratt BR, Precoda K, Berke GS. Individualdifferences in voice quality perception. J Speech HearRes 1992, 35:512–520.
21. VanLancker D, Kreiman J, Emmorey K. Familiarvoice recognition: patterns and parameters. Part I:Recognition of backward voices. J Phonet 1985,13:19–38.
22. DeCasper AJ, Fifer WP. Of human bonding:Newborns prefer their mothers’ voices. Science 1980,208:1174–1176.
23. Kisilevsky BS, Hains SMJ, Lee K, Xie X, Huang HF, YeHH, Zhang K, Wang ZP. Effects of experience on fetalvoice recognition. Psychol Sci 2003, 14:220–224.
24. Pollack I, Pickett JM, Sumby WH. On the identificationof speakers by voice. J Acoust Soc Am 1954,26:403–406.
25. Schweinberger SR, Herholz A, Sommer W. Recognizingfamous voices: influence of stimulus duration anddifferent types of retrieval cues. J Speech Lang HearRes 1997, 40:453–463.
26. Remez RE, Fellowes JM, Rubin PE. Talker identificationbased on phonetic information. J Exp Psychol HumPercept Perform 1997, 23:651–666.
27. Valentine T. A unified account of the effects ofdistinctiveness, inversion, and race in face recognition.Q J Exp Psychol 1991, 43A:161–204.
Volume 5, January/February 2014 © 2013 John Wiley & Sons, Ltd. 23

Advanced Review wires.wiley.com/cogsci
28. Leopold DA, O’Toole AJ, Vetter T, Blanz V. Prototype-referenced shape encoding revealed by high-levelaftereffects. Nat Neurosci 2001, 4:89–94.
29. Papcun G, Kreiman J, Davis A. Long-term memory forunfamiliar voices. J Acoust Soc Am 1989, 85:913–925.
30. Zaske R, Schweinberger SR, Kawahara H. Voiceaftereffects of adaptation to speaker identity. Hear Res2010, 268:38–45.
31. Latinus M, Belin P. Anti-voice adaptation suggestsprototype-based coding of voice identity. Front Psychol2011, 2:Article 175.
32. VanLancker D, Kreiman J. Voice discrimination andrecognition are separate abilities. Neuropsychologia1987, 25:829–834.
33. Neuner F, Schweinberger SR. Neuropsychologicalimpairments in the recognition of faces, voices, andpersonal names. Brain Cogn 2000, 44:342–366.
34. Latinus M, Crabbe F, Belin P. Learning-induced changesin the cerebral processing of voice identity. Cereb Cortex2011, 21:2820–2828.
35. Legge GE, Grossmann C, Pieper CM. Learningunfamiliar voices. J Exp Psychol Learn Mem Cogn1984, 10:298–303.
36. Sheffert SM, Olson E. Audiovisual speech facilitatesvoice learning. Percept Psychophys 2004, 66:352–362.
37. Schweinberger SR, Robertson D, Kaufmann JM.Hearing facial identities. Q J Exp Psychol 2007,60:1446–1456.
38. Saslove H, Yarmey AD. Long-term auditory memory:speaker identification. J Appl Psychol 1980, 65:111–116.
39. Philippon AC, Cherryman J, Bull R, Vrij A. Lay people’sand police officers’ attitudes towards the usefulnessof perpetrator voice identification. Appl Cogn Psychol2007, 21:103–115.
40. VanLancker DR, Canter GJ. Impairment of voice andface recognition in patients with hemispheric damage.Brain Cogn 1982, 1:185–195.
41. Belin P, Zatorre RJ, Lafaille P, Ahad P, Pike B. Voice-selective areas in human auditory cortex. Nature 2000,403:309–312.
42. Belin P, Bestelmeyer PEG, Latinus M, Watson R.Understanding voice perception. Br J Psychol 2011,102:711–725.
43. Andics A, McQueen JM, Petersson KM, Gal V, RudasG, Vidnyanszky Z. Neural mechanisms for voicerecognition. Neuroimage 2010, 52:1528–1540.
44. von Kriegstein K, Eger E, Kleinschmidt A, Giraud AL.Modulation of neural responses to speech by directingattention to voices or verbal content. Cogn Brain Res2003, 17:48–55.
45. Schirmer A, Kotz SA. Beyond the right hemisphere:brain mechanisms mediating vocal emotional process-ing. Trends Cogn Sci 2006, 10:24–30.
46. Belin P, Zatorre RJ. Adaptation to speaker’s voicein right anterior temporal lobe. NeuroReport 2003,14:2105–2109.
47. Formisano E, De Martino F, Bonte M, Goebel R.”Who” is saying ”What”? Brain-based decoding ofhuman voice and speech. Science 2008, 322:970–973.
48. Charest I, Pernet CR, Rousselet GA, Quinones I,Latinus M, Fillion-Bilodeau S, Chartrand JP, Belin P.Electrophysiological evidence for an early processing ofhuman voices. BMC Neurosci 2009, 10:1–11.
49. Schweinberger SR, Walther C, Zaske R, Kovacs G.Neural correlates of adaptation to voice identity. Br JPsychol 2011, 102:748–764.
50. Russell R, Duchaine B, Nakayama K. Super-recognizers:people with extraordinary face recognition ability.Psychon Bull Rev 2009, 16:252–257.
51. Luus CAE, Wells GL. The malleability of eyewitnessconfidence—co-witness and perseverance effects. J ApplPsychol 1994, 79:714–723.
52. Skuk VG, Schweinberger SR. Gender differences infamiliar voice identification. Hear Res 2013, 296:131–140.
53. McConachie HR. Developmental prosopagnosia—single case-report. Cortex 1976, 12:76–82.
54. Garrido L, Eisner F, McGettigan C, Stewart L, SauterD, Hanley JR, Schweinberger SR, Warren JD, DuchaineB. Developmental phonagnosia: a selective deficit ofvocal identity recognition. Neuropsychologia 2009,47:123–131.
55. McGurk H, MacDonald J. Hearing lips and seeingvoices. Nature 1976, 264:746–748.
56. Summerfield Q, MacLeod A, McGrath M, Brooke M.Handbook of research on face processing. In: YoungAW, Ellis HD, eds. Amsterdam: North-Holland; 1989,223–233.
57. Campanella S, Belin P. Integrating face and voice inperson perception. Trends Cogn Sci 2007, 11:535–543.
58. Burton AM, Bruce V, Johnston RA. Understanding facerecognition with an interactive activation model. Br JPsychol 1990, 81:361–380.
59. Ghazanfar AA, Schroeder CE. Is neocortex essentiallymultisensory? Trends Cogn Sci 2006, 10:278–285.
60. Robertson DMC, Schweinberger SR. The role ofaudiovisual asynchrony in person recognition. Q J ExpPsychol 2010, 63:23–30.
61. O’Mahony C, Newell FN. Integration of faces andvoices, but not faces and names, in person recognition.Br J Psychol 2012, 103:73–82.
62. von Kriegstein K, Kleinschmidt A, Sterzer P, GiraudAL. Interaction of face and voice areas during speakerrecognition. J Cogn Neurosci 2005, 17:367–376.
63. Blank H, Anwander A, von Kriegstein K. Directstructural connections between voice- and face-recognition areas. J Neurosci 2011, 31:12906–12915.
24 © 2013 John Wiley & Sons, Ltd. Volume 5, January/February 2014

WIREs Cognitive Science Speaker perception
64. Shah NJ, Marshall JC, Zafiris O, Schwab A, ZillesK, Markowitsch HJ, Fink GR. The neural correlatesof person familiarity. A functional magnetic resonanceimaging study with clinical implications. Brain 2001,124:804–815.
65. Joassin F, Pesenti M, Maurage P, Verreckt E, BruyerR, Campanella S. Cross-modal interactions betweenhuman faces and voices involved in person recognition.Cortex 2011, 47:367–376.
66. Joassin F, Maurage P, Campanella S. The neuralnetwork sustaining the crossmodal processing ofhuman gender from faces and voices: an fMRI study.Neuroimage 2011, 54:1654–1661.
67. Joassin F, Maurage P, Bruyer R, Crommelinck M,Campanella S. When audition alters vision: an event-related potential study of the cross-modal interactionsbetween faces and voices. Neurosci Lett 2004,369:132–137.
68. Schweinberger SR, Kloth N, Robertson DMC.Hearing facial identities: brain correlates of face-voice integration in person identification. Cortex 2011,47:1026–1037.
69. Kawahara H, Matsui H. Auditory morphing based onan elastic perceptual distance metric in an interference-free time-frequency representation. Proceedings ofICASSP, 2003, 256–259.
70. Zaske R, Schweinberger SR, Kawahara H. Voiceaftereffects of adaptation to speaker identity. Hear Res2010, 268:38–45.
71. Schweinberger SR, Casper C, Hauthal N, KaufmannJM, Kawahara H, Kloth N, Robertson DMC, SimpsonAP, Zaske R. Auditory adaptation in voice perception.Curr Biol 2008, 18:684–688.
72. Kawahara H, Masuda-Katsuse I, de CheveigneA. Restructuring speech representations using apitch-adaptive time-frequency smoothing and aninstantaneous-frequency-based F0 extraction: possiblerole of a repetitive structure in sounds. Speech Commun1999, 27:187–207.
73. Kawahara H, Morise M, Takahashi T, Nisimura R,Irino T, Banno H. Tandem-STRAIGHT: a temporallystable power spectral representation for periodic signalsand applications to interference-free spectrum, F0, andaperiodicity estimation. Proceedings of ICASSP, 2008,3933–3936 (2008).
74. Kawahara H, Nisimura R, Irino T, Morise M, Taka-hashi T, Banno H. Temporally variable multi-aspectauditory morphing enabling extrapolation withoutobjective and perceptual breakdown. Proceedings ofICASSP, 2009, 19–24.
75. Wiese H. The role of age and ethnic group in facerecognition memory: ERP evidence from a combinedown-age and own-race bias study. Biol Psychol 2012,89:137–147.
FURTHER READINGhttp://wires.wiley.com/WileyCDA/WiresArticle/wisId-WCS1261.html
Belin P, Campanella S, Ethofer T, eds. Integrating Face and Voice in Person Perception. New York, Heidelberg: Springer;2013.
Kreiman J, Sidtis D. Foundations of Voice Studies: An Interdisciplinary Approach to Voice Production and Perception.Chichester: Wiley-Blackwell; 2011.
Volume 5, January/February 2014 © 2013 John Wiley & Sons, Ltd. 25















![ESCC 3902/003 (Wires and Cables), [ARCHIVED] - ESCIES](https://static.fdokumen.com/doc/165x107/63281d0c6d480576770d9bd9/escc-3902003-wires-and-cables-archived-escies.jpg)




