
Projeto de banco de dados para pesquisas musicológicas em periódicos: um estudo de caso para os...
17
Projeto de banco de dados para pesquisas musicológicas em periódicos: um estudo de caso para os jornais da cidade de Rio Grande Pablo Palácios Universidade Federal de Pelotas [email protected] Resumo: A pesquisa “A música nos jornais de Rio Grande” utiliza periódicos como principal fonte de pesquisa. O acervo possui notícias relacionadas a música encontradas em três jornais da década de 1920, e, ao todo, somam-se mais de 1800 notícias. Neste trabalho, tratamos de apresentar o método empregado para a organização do banco de dados do nosso acervo, descrevendo os problemas que tivemos no início e a solução desenvolvida através do uso do framework Django. Essa solução constitui-se em um banco de dados centralizado, onde todos os pesquisadores envolvidos no projeto possuem acesso através da internet, e, além disso, nossa solução é dotada de mecanismos de busca, classificação e ordenação de dados, facilitando futuras pesquisas em nosso acervo. Palavras-Chave: história da música no Rio Grande do Sul, pesquisa em periódicos, projeto de banco de dados, python, django. Database design for musicological research with journals: a study case for the Rio Grande city newspapers. Abstract: The research “A música nos jornais de Rio Grande” uses journals as the main source of research. The collection has music related news found in three newspapers of the 1920s, and counting all the material, we have more than 1800 news. In this work, we present the method used to organize our news database, describing the problems we had at the beginning and the solution developed by using the Django framework. This solution is made up in a centralized database, which all the researches have access through the internet, and, more than this, our solution has interesting features such as data research engine and assortment and classification of data, which will help the researches that will come in the future. Keywords: music history of Rio Grande do Sul, journals research, database design, python, django. A pesquisa “A música na visão dos jornais de Rio Grande”, iniciada em 2010, tem como um de seus objetivos levantar as dinâmicas musicais presentes na cidade de Rio Grande – em Rio Grande do Sul, Brasil – na década de 1920 por meio da análise de periódicos publicados nesse mesmo período: A Lucta, O Tempo e Rio Grande. Além disso, a pesquisa também tem como objetivo formar e disponibilizar um banco de dados para futuras pesquisas. O método utilizado pode ser divido em três etapas principais: rastreio de notícias sobre música, organização e sistematização das notícias encontradas e, por fim, a análise delas. Dessas etapas, devido à grande quantidade de notícias encontradas na primeira parte do trabalho e à dificuldade no processo de classificação das notícias levantada por Ruthe Pocebon (2011), encontramo-nos agora em um processo de reorganização e reclassificação dos dados. No entanto,
Transcript of Projeto de banco de dados para pesquisas musicológicas em periódicos: um estudo de caso para os...

Projeto de banco de dados para pesquisas musicológicas emperiódicos: um estudo de caso para os jornais da cidade de Rio
Grande
Pablo PaláciosUniversidade Federal de Pelotas
Resumo: A pesquisa “A música nos jornais de Rio Grande” utiliza periódicos como principal fonte depesquisa. O acervo possui notícias relacionadas a música encontradas em três jornais da década de1920, e, ao todo, somam-se mais de 1800 notícias. Neste trabalho, tratamos de apresentar o métodoempregado para a organização do banco de dados do nosso acervo, descrevendo os problemas quetivemos no início e a solução desenvolvida através do uso do framework Django. Essa soluçãoconstitui-se em um banco de dados centralizado, onde todos os pesquisadores envolvidos no projetopossuem acesso através da internet, e, além disso, nossa solução é dotada de mecanismos debusca, classificação e ordenação de dados, facilitando futuras pesquisas em nosso acervo.
Palavras-Chave: história da música no Rio Grande do Sul, pesquisa em periódicos, projeto de bancode dados, python, django.
Database design for musicological research with journals: a study case for the Rio Grande citynewspapers.
Abstract: The research “A música nos jornais de Rio Grande” uses journals as the main source ofresearch. The collection has music related news found in three newspapers of the 1920s, and counting all thematerial, we have more than 1800 news. In this work, we present the method used to organize ournews database, describing the problems we had at the beginning and the solution developed by usingthe Django framework. This solution is made up in a centralized database, which all the researcheshave access through the internet, and, more than this, our solution has interesting features such asdata research engine and assortment and classification of data, which will help the researches that willcome in the future.
Keywords: music history of Rio Grande do Sul, journals research, database design, python, django.
A pesquisa “A música na visão dos jornais de Rio Grande”, iniciada em 2010,
tem como um de seus objetivos levantar as dinâmicas musicais presentes na cidade
de Rio Grande – em Rio Grande do Sul, Brasil – na década de 1920 por meio da
análise de periódicos publicados nesse mesmo período: A Lucta, O Tempo e Rio
Grande. Além disso, a pesquisa também tem como objetivo formar e disponibilizar
um banco de dados para futuras pesquisas.
O método utilizado pode ser divido em três etapas principais: rastreio de
notícias sobre música, organização e sistematização das notícias encontradas e, por
fim, a análise delas. Dessas etapas, devido à grande quantidade de notícias
encontradas na primeira parte do trabalho e à dificuldade no processo de
classificação das notícias levantada por Ruthe Pocebon (2011), encontramo-nos
agora em um processo de reorganização e reclassificação dos dados. No entanto,

durante esse processo, alguns problemas de ordem prática e técnica apareceram, o
que acabou por dificultar o processo de revisão. Por exemplo, questões mais
simples, como erros em nomes de arquivos (que acabaram gerando problemas
complexos) até a dificuldade no compartilhamento de dados atualizados entre
pesquisadores.
Sendo assim, apresentamos com este trabalho um projeto de modelo de
banco de dados, bem como um sistema para análise dos dados e sua divulgação,
para um acervo de notícias de jornais. Para tanto, utilizamos o processo de
mapeamento de planilhas de dados em objetos por meio de scripts em Python para
o framework Django, com o objetivo de resolver os problemas encontrados e facilitar
o processo de revisão. A partir desse mapeamento, o framework Django nos
possibilita fazer listas de notícias utilizando consultas por termos de interesse em
cima de qualquer atributo dos nossos modelos de dados, facilitando a extração de
informações para atender aos objetivos de nossas pesquisas.
Por fim, este trabalho tem como por objetivo apresentar as tecnologias
empregadas nesse processo de reorganização, discutir o projeto de banco de dados
para pesquisas em periódicos e apresentar os resultados obtidos até o momento
com os jornais da cidade Rio Grande.
1. O ANTES
1.1. ESTRUTURA DOS DIRETÓRIOS
O banco de dados de notícias utilizado anteriormente consistia em um
simples diretório de arquivos que se organizava da seguinte maneira: o diretório raiz
armazenava 3 subdiretórios, um para cada jornal; cada diretório de jornal possuía
um subdiretório para cada ano, e esse, por sua vez, possuía um subdiretório para
cada mês. Para cada diretório de mês, maioritariamente, encontrava-se uma lista de
documentos de texto do Microsoft Office (arquivos com extensão .doc) com as
transcrições das notícias extraídas dos jornais. Esses arquivos estavam nomeados,
de uma forma geral, com a data da notícia, precedida pelo seu título.
Vale notar que, embora cada diretório ou subdiretório possuísse um certo
nível de organização, se os analisássemos como um todo, as estruturas não
seguiam uma forma padrão. Por exemplo, ora os arquivos eram nomeados com a
data completa, ora com apenas o dia e o mês, ora só o dia.

Figura 1 – Estrutura dos diretórios.
No fim disso, um arquivo poderia possuir um endereço tão longo e confuso quanto
essa descrição (e esse endereço poderia ser ainda maior dependendo de onde o
diretório raiz se encontrasse no computador do pesquisador).
Figura 2 – Listagem de arquivos: longo e confuso.
Além disso, o diretório do periódico O Tempo diferenciava-se dos outros dois
por possuir um subdiretório extra, com fotografias das notícias. Quanto às notícias
desse periódico, devemos relatar que algumas delas ainda não haviam sido
transcritas, encontrando-se apenas no formato de imagem nesse diretório extra ou
com a imagem inserida em um documento .doc. Por fim, vale dizer que algumas
notícias possuíam apenas uma foto (geralmente referentes a pequenos anúncios de
lojas ou instrumentos), e outras possuíam até 9 fotos (como é o caso da notícia da
inauguração do Conservatório de Música de Rio Grande, que ocupou o espaço de
uma página inteira no jornal), mas todas com resoluções altíssimas, fazendo com
que essas imagens ocupassem bastante espaço no disco rígido.

1.2. Interface
Para possibilitar a análise das notícias, foram criados arquivos de planilhas
(arquivo do tipo .xsl) para servirem de interface com a estrutura de diretórios. Para
cada jornal havia um arquivo de planilha e para cada arquivo de planilha, havia uma
planilha para cada ano de notícias.
Figura 3 – Modelo de notícia antigo.
Como descreve Ruthe Pocebon (2011), o modelo de dados para descrever
uma notícia consistia nos seguintes atributos: ano, mês, dia, nome do periódico,
título da notícia em formato de hipertexto (apontando para o endereço do arquivo
que continha a notícia, seja sua transcrição em formato .doc, seja a fotografia da
notícia), página do periódico onde se encontrava a notícia, resumo, autor e tipologias
para classificações das notícias (figura 3). Cada um desses atributos correspondia a
uma coluna na planilha e cada linha na planilha correspondia a uma notícia.
Diferentemente do caso dos diretórios, as planilhas se apresentavam
consistentes entre elas, pois todas apresentavam o mesmo modelo de dados
apresentado acima. No entanto, entre os valores dos atributos das notícias, o nível
de não formalização era grande. Notícias que se repetiam em um mesmo mês
possuíam uma lista dos dias nas quais elas se repetiam. Em alguns casos, os
delimitadores de dias variavam entre vírgulas, pontos, ponto e vírgula ou mesmo
textos, como “até”. O problema é que, se quiséssemos fazer uma consulta atrás de
todas as notícias de um específico dia, provavelmente omissões ocorreriam, tendo
em vista que quando há um intervalo de dias números podem ser omitidos.

Figura 4 – Problema com delimitadores: o número 17 não aparece no texto “16 até 23”.
Para o campo das tipologias, o problema era semelhante ao do campo dos
dias, pois, como descreve Pocebon, algumas notícias possuem mais de uma
possibilidade de classificação tipológica:
[a tipologia de um] anúncio de um concerto, no qual se lê o histórico doconcertista e o programa a ser executado (…) é composta por umainformação principal e outras secundárias, registrando-seConcertos/Concertistas/Repertórios. (POCEBON, 2011)
Sendo assim, esse atributo também recebia múltiplos valores e a sua
formatação na planilha também recebia delimitadores variados, como barras,
vírgulas e a palavra “e”, o que acaba por dificultar uma ordenação ou filtragem das
notícias por tipologias. Outro problema encontrado para esse atributo é que ainda
havia muitas notícias necessitando de revisão quanto à classificação tipológica, visto
que muitas ainda apresentavam tipologias já em desuso na pesquisa.
Outro atributo que apresentava problemas de consistência em seus valores
era o de título e endereço, pois muitas notícias não possuíam o hipertexto com o
endereço da transcrição ou da imagem no diretório de arquivos. Isso acontecia
principalmente nos casos em que a notícia ainda não havia sido transcrita para .doc
ou por existir mais de uma fotografia por notícia, impossibilitando a criação do
hipertexto, pois esse só permite o endereço de um arquivo por texto.

De acordo com o conceito de normalização de banco de dados relacionais,
todos os atributos de um modelo de dados devem possuir dados atômicos
(BEIGHLEY, 2010), ou seja, cada atributo da nossa planilha não deve receber mais
que um valor, pois, assim, além de criarmos uma tabela consistente, também nos
facilitará fazermos consultas aos nossos dados posteriormente. Os atributos dias,
tipologias, título e endereço não possuíam dados atômicos, pois todos recebiam
mais de um valor. Uma consideração deve ser feita quanto ao atributo página, pois
embora esse campo também recebesse múltiplos valores (mais de um número de
página quando a notícia era longa) muito dificilmente serão feitas consultas
envolvendo número de páginas, caracterizando esse campo não como um dado a
ser pesquisado, mas sim como uma referência para o endereço da notícia no jornal.
1.3. PESQUISADORES
Certamente, o maior problema encontrado no antigo banco de notícias era a
sua descentralização. Desde o início da pesquisa, em 2009, um número razoável de
colaboradores chegou a trabalhar na organização e sistematização das notícias.
Obviamente, a organização de um banco com milhares de notícias não poderia ser
trabalho para apenas um único pesquisador. Para viabilizar esse processo, a
estrutura de diretórios e as interfaces eram copiadas (duplicadas) no computador de
cada pesquisador, possibilitando que todos tivessem acesso ao banco de notícias.
No entanto, foi devido a isso que os maiores problemas surgiram. Provavelmente, a
origem de uma não padronização completa entre os diretórios e as planilhas de
interface tenham sua origem aqui, pois, em determinados momentos, cada
pesquisador era responsável por um jornal e cada um possuía um método de
análise e maneira diferente de lidar com essas duas estruturas.
Como Pocebon (2011) diz, na interpretação de uma notícia de difícil
compreensão, pode ser necessário recorrer a outro periódico para obter uma
classificação tipológica mais apurada. O problema gerado é: como manter todos os
integrantes da pesquisa com informações atualizadas sobre as notícias? Também é
importante dizer que, para complicar a nossa situação, houve momentos em que
havia mais de uma planilha por jornal – com informações divergentes, ou com
classificações tipológicas já em desuso – proveniente de pesquisadores que já não
trabalhavam mais no projeto. Nasceu outro problema: como saber qual planilha
continha a classificação mais adequada? Sendo assim, inseriu-se mais uma etapa

no processo de revisão das planilhas, a comparação e revisão do trabalho feito por
antigos pesquisadores.
Mas o fato de termos um número grande de pesquisadores e a consequente
replicação dos dados não gerou apenas um problema de ordem prática, mas
também problemas de ordem técnica. Muitos pesquisadores significam muitos
computadores e muitos computadores significam softwares e versões de softwares
diferentes, bem como sistemas operacionais diferentes com sistemas de formatação
de discos diferentes.
Cada software utilizado para a edição das planilhas possuía uma maneira
diferente de tratar os hipertextos com os endereços dos arquivos das notícias.
Alguns softwares utilizavam o endereço absoluto do arquivo com a transcrição (ou
da imagem), enquanto outros usavam endereços relativos estáticos em relação ao
endereço da planilha. Isso significa que alguns hipertextos levavam para arquivos
que estavam no computador de outro pesquisador ou para arquivos que se
encontravam em estrutura de diretórios utilizada por esse mesmo outro pesquisador.
Ou seja, havia hipertextos com endereços que não levavam aos arquivos das
notícias, embora esses tivessem sido copiados para o computador do pesquisador.
Somente os softwares mais recentes faziam uma análise da estrutura de diretórios e
corrigia os endereços dos hipertextos automaticamente. Mas, se por acaso
houvesse uma vírgula a mais ou a menos no nome de um arquivo ou no nome de
um diretório, o software não seria capaz de atualizar os endereços. E isso nos leva a
um segundo problema que tivemos: embora a estrutura de diretórios e os nomes dos
arquivos não fossem mais alterados, o endereço dos hipertextos podia ainda estar
errado, mesmo se apontando para o lugar certo, parecendo-nos como alguma falha
no arquivo de planilhas (um bug na planilha). A justificativa para esse evento é o fato
de cada sistema operacional e cada sistema de formatação de arquivos tratar de
forma diferente nomes de arquivos longos e caracteres não ASCII (por exemplo ç, é,
ã e letras que não estão presentes no alfabeto inglês). Como visto anteriormente,
alguns endereços de arquivos poderiam ser bem compridos em função da estrutura
de diretórios, fazendo com que alguns sistemas truncassem o nome do arquivo.
Também vimos que os arquivos eram nomeados com os títulos das notícias, e em
todas as vezes que havia um caractere não ASCII no título da notícia, esse era
convertido para números hexadecimais. Por exemplo, o par de chaves “[texto
qualquer]” presente no título de algumas notícias (e, portanto, no nome do arquivo)

era alterado para “5Btexto qualquer5D”. Na planilha, o endereço do hipertexto
estava certo, mas no sistema de arquivos o nome aparecia errado, quebrando o
hipertexto. Enfim, mais uma etapa era adicionada ao processo de revisão, verificar
os endereços dos hipertextos; e cada vez mais o pesquisador se distanciava de
“apenas” revisar as classificações tipológicas.
2. TRANSIÇÃO
Para poder resolver os problemas levantados anteriormente e possibilitar um
fluxo de pesquisa livre de detalhes que se afastam da prática musicológica, propus,
com este trabalho, um novo modelo de banco de dados e uma nova interface para
interação com ele. Esse novo sistema deveria facilitar a manipulação das notícias. O
modelo de banco de dados e o método para conversão do banco antigo para o novo
são os mesmos utilizados em trabalhos anteriores e consistem no uso do framework
Django para o mapeamento dos dados e a criação de scripts em Python para a
conversão, pois, como visto em outros trabalhos:
O uso do framework Django […] nos possibilita tratar os dados como sefossem objetos e não apenas como linhas em uma tabela, dando-nospraticidade na extração dos dados relevantes à pesquisa, evitando quebuscas manuais em tabelas gigantes sejam feitas. (PALÁCIOS, 2013)
A primeira etapa consiste em redefinir o nosso modelo de dados, ou seja,
redefinir quais são os atributos do nosso objeto de pesquisa, no nosso caso, uma
notícia. Começamos por desmembrar o modelo antigo em três novas classes –
Notícia, Jornal e Tipologia – pois julgamos ser a melhor representação do nosso
objeto de estudo na vida real.
Para a classe Notícia, unimos os atributos dia, mês e ano do modelo antigo
em um único atributo chamado data. Pelo fato do atributo data somente permitir um
dia por data, criamos mais dois atributos para Notícia: repete? e notícia base. Dessa
maneira, possibilitaremos a criação de notícias repetidas baseadas em uma única
notícia e, caso haja necessidade de alteração em uma delas, todas as notícias que
possuam a mesma notícia-base serão alteradas. O atributo Título e Endereço foi
desmembrado em três novos atributos, Título, Endereço de Imagem e Transcrição
da Notícia.
É importante salientar que cada instância de nossas novas classes deverão

ter um identificador único: um número inteiro que não se repetirá em instâncias da
mesma classe, o que nos permite uma melhor comunicação entre as instâncias.
Sendo assim, o atributo tipologias da classe Notícia se transformou em uma lista de
identificadores de instâncias da classe Tipologia. Isso nos possibilita que, caso
encontremos uma melhor nomenclatura para uma determinada tipologia e
resolvamos alterá-la, todas as notícias que possuam essa tipologia em sua lista de
tipologias serão atualizadas automaticamente, sem perder o vínculo com a tipologia,
pois apenas o nome foi alterado e não o seu identificador.
As classes Tipologia e Jornal possuem os mesmos atributos, que são nome
e descrição. No caso da tipologia, podemos colocar na descrição o que define
aquela tipologia, quais são seus limites de classificação e adicionar exemplos de
notícias que foram classificadas com ela.
Figura 5 – Transformação do modelo antigo no modelo novo.
Dessa maneira, caso o pesquisador encontre alguma dificuldade no
processo de revisão das classificações tipológicas, poderá recorrer ao banco de
tipologias para sanar suas dúvidas. Já para a classe jornal, o campo descrição pode
servir para delinear qual é o perfil daquele veículo, também para ajudar o
pesquisador no processo de revisão citado anteriormente. No fim, a transformação
do modelo de dados pode ser representado conforme a figura 5.
Definido o novo modelo, criamos as classes (Notícia, Jornal e Tipologia) em
linguagem Python na sintaxe do framework Django, e por meio do comando syncdb

nosso novo sistema para manipulação de dados está pronto, no entanto, sem
nenhuma notícia ainda. O Django possibilita que insiramos várias instâncias de
nossas classes de uma só vez com o comando loaddata. Para tanto, nossas
instâncias devem possuir uma representação em texto no formato JSON. Para
sabermos qual é a formatação em JSON, criamos uma notícia dentro do sistema
gerado pelo framework e exportamos o banco de dados para JSON com o comando
dumpdata, obtendo um resultado semelhante à figura 6.
Figura 6 – Formato JSON das nossas classes.
A tarefa agora é transformar cada notícia do nosso antigo banco de dados
em sua representação em formato JSON e colocarmos todas em um único arquivo,
possibilitando a inserção desses dados no sistema gerado anteriormente e
permitindo que o Django transforme as nossas planilhas antigas em tabelas
dinâmicas que atendam às necessidades de nossos pesquisadores e facilitem
futuras pesquisas. Poderíamos fazer isso manualmente, escrevendo notícia por
notícia no seu formato JSON, mas devido à grande quantidade de material, criamos
scripts em Python para automatizar esse processo.
Tendo em vista a quantidade de problemas na estrutura do nosso banco de
dados antigo, a criação do algoritmo de conversão tomou um certo trabalho.
Primeiramente, antes de escrever qualquer código, precisávamos chegar a um

mínimo de padronização entre os dados de nossas planilhas. Para isso, unimos
todas as planilhas em um único arquivo, criando uma lista gigante de notícias.
Reparamos aqui que não é prático analisar uma tabela muito comprida, pois o
arquivo demorava muito para carregar todas as notícias, tornando lenta a navegação
e classificação dos dados por meio de editor de planilhas. Após a união das
planilhas, padronizamos todos os delimitadores utilizados nos atributos dia e
tipologias, assim, nosso script seria capaz de entender em quais dias determinada
notícia se repete e quais tipologias foram utilizadas para classificar cada notícia.
Além disso, corrigimos todos os hipertextos que não possuíam o endereço da
notícia. Aqui, nos deparamos com o problema de haver mais de uma imagem por
uma notícia, impossibilitando que o hipertexto levasse a todos os arquivos que
compunham a notícia. Por se tratar de poucas notícias nesse caso, utilizamos o
editor de imagens GIMP para realizar uma montagem de fotos, unindo todas as
imagens em um único arquivo, permitindo assim, a criação do hipertexto. Por fim,
todos os campos que estavam vazios receberam um texto informando que aquela
informação não existia.
Nesse estágio, já possuíamos uma planilha com todos os campos
completos, no entanto, ainda com dois grandes problemas: ainda havia a presença
de tipologias já em desuso e endereços que não levavam a nenhum arquivo. Para
ambos os casos, a metodologia foi a mesma, criamos scripts em Python para
analisar o conteúdo desses campos e gerar listas com as notícias que possuíam
algum valor problemático. A começar pelas tipologias, nosso script nos informou que
havia mais de sessenta tipologias cadastradas, embora hoje somente trinta e uma
estejam em uso. Revisamos cada notícia que recebia uma tipologia em desuso e as
classificamos de acordo com as novas tipologias. A cada reclassificação, rodávamos
mais uma vez o nosso script para saber quantas notícias ainda precisavam ser
revistas. O interessante, aqui, é ter um controle sobre o processo de revisão,
permitindo-nos programar para realizar as revisões (por exemplo, a cada dia,
revíamos uma tipologia em desuso, assim poderíamos manter o foco sempre em um
determinado conceito de classificação, além de matar a ansiedade para saber
quando o processo de revisão terminaria).
Já para a correção dos endereços, criamos um script para corrigir os nomes
de arquivos que apresentavam algum caractere em formato hexadecimal. Depois,
criamos outro script que gerava uma lista de notícias as quais, mesmo com os

nomes corrigidos, não levavam a nenhum arquivo. Para essas notícias, tentamos
por meio dos programas find e locale, presentes em sistemas operacionais com
base UNIX, localizar os arquivos em nossos diretórios. A surpresa foi saber que
havia hipertextos que apontavam para um mesmo arquivo, não por erro de quem
catalogou a notícia, mas sim por, em todas as vezes, a notícia ser uma duplicação
de outra notícia já existente. Por fim, criamos um script que criava um identificador
para cada notícia (um número inteiro que não se repete) e movia todos os arquivos
para um único diretório, nomeando-os com o identificador da notícia e atualizando o
hipertexto para apontar para esse novo arquivo. Caso a notícia estivesse em um
documento .doc, o script convertia-a para o formato HTML. Esse último passo foi
necessário pois, como dito anteriormente, havia notícias que não haviam sido
transcritas, mas que suas fotografias se encontravam em um documento .doc.
Dessa maneira, poderíamos utilizar o analisador de HTML para Python
BeautifulSoup para extrairmos as imagens e, caso houvesse mais de uma imagem
dentro do documento, utilizaríamos o programa ImageMagick para realizar a união
das imagens em uma única, sem que precisássemos fazer isso manualmente. Além
disso, o ImageMagick nos permitiu diminuir o tamanho das imagens, reduzindo o
tamanho do espaço em disco utilizado para armazená-las.
Finalmente, com todos os campos revistos, com a remoção das tipologias
antigas, a revisão dos hipertextos e a revisão dos delimitadores, foi possível criar o
último script que convertia nossa interface em um documento no formato JSON. A
única característica especial aqui é que o script analisava se a notícia se repetia ou
não e, em caso afirmativo, criava novas instâncias de notícias com base nela
mesma, apenas alterando a data.
Outra característica interessante de nossos scripts é que tivemos o cuidado
de criar testes para eles utilizando o framework de testes unittest para Python, com
objetivo de garantir que todos os dados de entrada se convertiam em um valor
adequado e coerente. Isso significa que, antes de fazer a conversão completa dos
nossos dados, criamos notícias fictícias com dados problemáticos e testávamos os
nossos scripts nelas, permitindo-nos ver se as conversões estavam ocorrendo de
forma adequada ou não. Com os nossos scripts aprovados nos testes, convertemos
nossas notícias em um arquivo no formato JSON e o entregamos para o Django
fazer o resto do trabalho, isto é, transformar esse arquivo em um banco de dados
relacionais com nível máximo de padronização e nos entregar uma interface para
análise das notícias.
3. HOJE
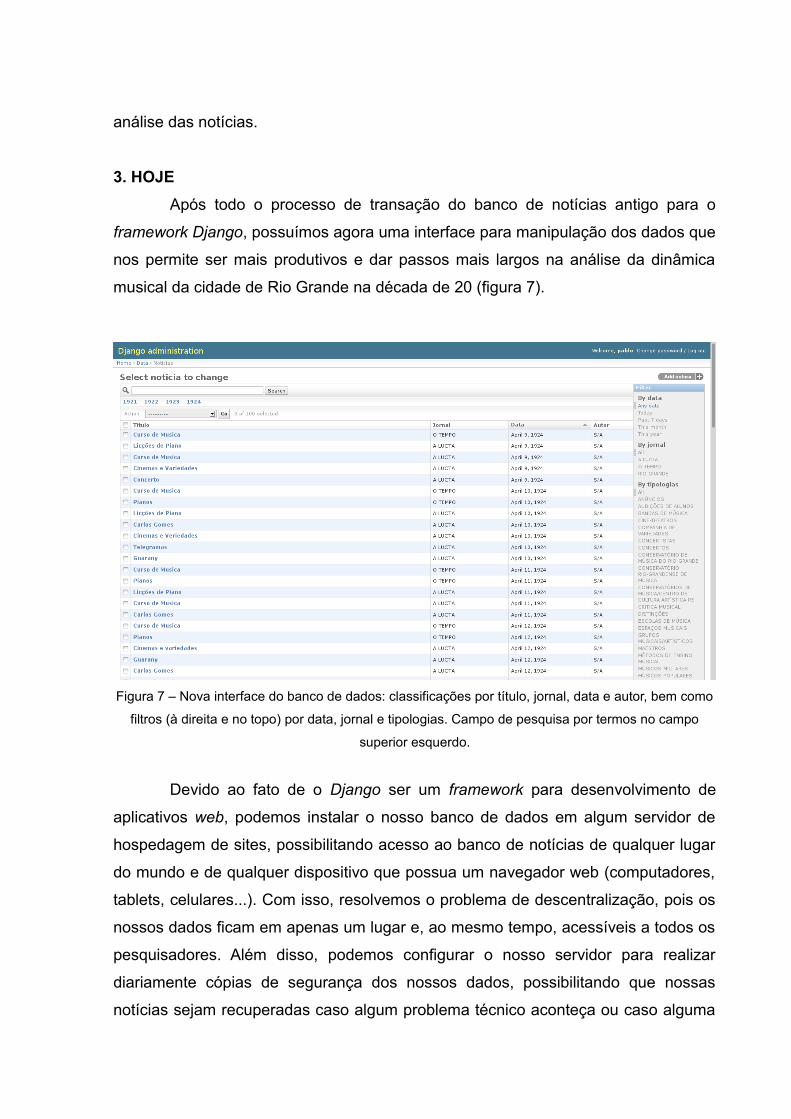
Após todo o processo de transação do banco de notícias antigo para o
framework Django, possuímos agora uma interface para manipulação dos dados que
nos permite ser mais produtivos e dar passos mais largos na análise da dinâmica
musical da cidade de Rio Grande na década de 20 (figura 7).
Figura 7 – Nova interface do banco de dados: classificações por título, jornal, data e autor, bem como
filtros (à direita e no topo) por data, jornal e tipologias. Campo de pesquisa por termos no campo
superior esquerdo.
Devido ao fato de o Django ser um framework para desenvolvimento de
aplicativos web, podemos instalar o nosso banco de dados em algum servidor de
hospedagem de sites, possibilitando acesso ao banco de notícias de qualquer lugar
do mundo e de qualquer dispositivo que possua um navegador web (computadores,
tablets, celulares...). Com isso, resolvemos o problema de descentralização, pois os
nossos dados ficam em apenas um lugar e, ao mesmo tempo, acessíveis a todos os
pesquisadores. Além disso, podemos configurar o nosso servidor para realizar
diariamente cópias de segurança dos nossos dados, possibilitando que nossas
notícias sejam recuperadas caso algum problema técnico aconteça ou caso alguma

notícia seja excluída equivocadamente. É válido dizer que o framework também nos
dá um sistema de autenticação, ou seja, somente pesquisadores cadastrados no
nosso banco poderão modificá-lo. Ainda em relação à segurança, contamos com o
sistema automático de validação de entrada de dados do Django, isto é, nunca será
possível atribuir um valor não válido a um determinado atributo (por exemplo, o
Django não permitirá inserir uma letra no campo data), o que garante a consistência
dos nossos dados.
Mas, além de resolver problemas de ordem técnica e prática de nossa
pesquisa, o ponto mais interessante da nossa nova interface é podermos criar novas
listas de notícias, com ordenações ou filtros baseados nas tipologias, nos nomes dos
autores ou por datas de publicação. Não somente, o framework Django possibilita
também que busquemos por palavras dentro dos valores de cada notícia. Um
exemplo prático disso é que, por termos convertido os arquivos .doc para texto puro,
podemos criar uma lista de notícias que contenham em sua transcrição o nome de
uma determinada pessoa. Se somarmos isso com o uso de filtros, podemos ter uma
lista de todos os programas de concertos nos quais um determinado compositor
aparece, o que nos facilita se quisermos fazer um estudo de repertório
posteriormente.
CONSIDERAÇÕES
A criação de scripts em Python e o uso do framework Django nos auxiliou a
resolver vários problemas que tínhamos com o nosso antigo banco de notícias,
como, por exemplo, o de descentralização e a inconsistência dos dados. Além disso,
nos possibilitou novos recursos para utilizarmos em nossa pesquisa, por exemplo, a
capacidade de ordenação e filtragem das notícias, bem como a capacidade de
pesquisa nos valores dos atributos da notícia. No entanto, para que o nosso banco
funcione de forma eficiente, ainda precisamos terminar de transpor todas as notícias
que apenas se encontram no formato de imagem. Vale dizer também que, pelo fato
das notícias terem sido transpostas fielmente como foram publicadas (com
português de época e erros gráficos), poderá haver omissões em listas de notícias
provenientes de pesquisas por termos. Quanto a isso, pensamos que um modelo
ideal de notícia também deva incluir um atributo para a transcrição em português
atual e com os erros devidamente corrigidos.
Quanto às imagens, ainda pensamos que poderíamos diminuir o espaço de

disco utilizado, tendo em vista que uma única foto em alta resolução seria suficiente
para uma página inteira de jornal. Dessa maneira, além de também nos facilitar a
leitura das notícias, isso também nos possibilitaria utilizarmos futuramente um
software de busca de texto em imagens, semelhante ao sistema utilizado pelo
acervo do jornal “O Estado de São Paulo”.1
Também é importante ressaltar que a migração de um banco de dados
utilizando o método apresentado nesse trabalho exige um conhecimento específico
quanto à programação e administração de sistemas, o que em alguns casos exigirá
um profissional qualificado na área para o desenvolvimento de recursos específicos.
Pelo mesmo motivo, também é difícil encontrar serviços de hospedagem que
ofereçam suporte às tecnologias empregadas, exigindo um investimento um pouco
maior se comparado com servidores que suportam outras tecnologias.
Por fim, esperamos que com este trabalho tenhamos conseguido mostrar
novas possibilidades para pesquisas com periódicos. É possível que alguns ajustes
ainda sejam feitos em função da demanda dos pesquisadores, mas, devido ao grau
de organização que possuímos agora, isso não deverá ser um problema. A próxima
etapa consiste na finalização do processo de revisão das classificações tipológicas e
na criação de uma interface pública para que outros pesquisadores não cadastrados
no nosso banco também tenham a possibilidade de consultá-lo.
REFERÊNCIAS
BEIGHLEY, Lynn. Use a cabeça: SQL. Rio de Janeiro: AltaBooks, 2010.
GOLDBERG, Luiz Guilherme. A música pelos jornais de Rio Grande: daproclamação da república ao conservatório de música. Anais do XX congresso daANPPOM, 2010.
PALÁCIOS, Pablo. A música brasileira no repertório da OSESP entre 2000 e 2009 .Anais do XXIII congresso da ANPPOM, 2013.
POCEBON, Ruthe. A música na visão dos jornais de Rio Grande: o problema nadefinição das tipologias. Anais do XX congresso de iniciação científica UFPEL, 2010.
1 Disponível em: http://acervo.estadao.com.br/. Acessado em 18/11/2013.


Pablo Palácios é aluno do curso de Bacharelado em Música com Habilitação em Ciências Musicais pelaUniversidade Federal de Pelotas (Brasil). Também é aluno do curso de Programação em Python pela O'ReillySchool of Technology (EUA). Sua principal frente de trabalho envolve o uso de tecnologias como ferramentasassistivas em pesquisas musicológicas.




















