
Proceedings of the XVIII Latin-Iberoamerican Conference on ...
976
Proceedings of the XVIII Latin-Iberoamerican Conference on Operations Research, CLAIO 2016 Sergio Maturana, Editor Pontificia Universidad Cat´ olica de Chile [email protected] c 2016 Instituto Chileno de Investigaci´ on Operativa (ICHIO) Santiago, Chile www.ichio.cl ISBN:978-956-9892-00-4
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Proceedings of the XVIII Latin-Iberoamerican Conference on ...

Proceedings of the XVIIILatin-Iberoamerican Conference onOperations Research, CLAIO 2016
Sergio Maturana, Editor
Pontificia Universidad Católica de [email protected]
c©2016Instituto Chileno de Investigación Operativa (ICHIO)Santiago, Chilewww.ichio.clISBN:978-956-9892-00-4

CLAIO-2016
Preface
The first CLAIO Conference at Rio de Janeiro in November 1982, marked the beginning of theLatin-Ibero-American Operations Research Society (ALIO). These conferences have continuedto be held every two years, congregating a large number of the best researchers in the field fromall over the world. The XVIII CLAIO, organized by the Industrial and Systems EngineeringDepartment of the Pontificia Universidad Católica de Chile, together with the Chilean Instituteof Operations Research (ICHIO) and the Latin Ibero-American Association of Operations Re-search Societies (ALIO), took place in Santiago, Chile, between October 2nd and October 6th,2016. This volume contains a selection of the papers presented at this conference. More than480 abstracts and papers were received from over 40 countries and 390 of these were presentedin the conference. This volume contains 123 selected papers that were presented in the con-ference. Many of these papers present relevant methodological advances while others describeinteresting applications in the many fields that Operations Research encompasses. We hopethat they become a valuable resource for the OR community.I wish to thank all the authors, referees, and track chairs for their hard work preparing andreviewing these papers. Special thanks to Ana Batista who did much of the hard work to puttogether the program and the proceedings.
October 2, 2016Santiago
Sergio MaturanaScientific Committee Chair
CLAIO 2016.
2

CLAIO-2016
Program Committee
Renzo Akkerman Technische Universität MünchenPaula Amaral FCT/CMA Universidad Nova de LisboaJohn Bartholdi Georgia Institute of TechnologyLuciana Buriol Federal University of Rio Grande do SulJaime Bustos Universidad de La FronteraJaime Camelio Virginia Institute of TechnologyHector Cancela Universidad de la República (Uruguay)Susan Cholette San Francisco State UniversityJose Correa Universidad de ChileGonzalo Cortazar Pontificia Universidad Católica de ChileGuillermo Duran Universidad de Buenos AiresRodrigo Garrido Universidad Diego Portales
Michel Gendreau École Polytechnique de MontréalMarcela Gonzalez Universidad de TalcaMarcos Goycoolea Universidad Adolfo IbañezIrene Loiseau Universidad de Buenos AiresNelson Maculan Universidade Federal do Rio de JaneiroVladimir Marianov Pontificia Universidad Catolica de ChileSergio Maturana Pontificia Universidad Católica de ChileDavid Mauricio Universidad Nacional Mayor de San MarcosJuan Carlos Munoz Pontificia Universidad Católica de ChileFernando Paredes Universidad Diego PortalesJavier Pereira Instituto Tecnológico y de Estudios Superiores de MonterreyLluis Pla University of LleidaCelso Ribeiro Universidade Federal FluminenseRoger Rios Universidad Autónoma de Nuevo LeonErnesto Santibañez Universidade Federal de Ouro PretoEnzo Sauma Pontificia Universidad Catolica de ChileLuis Torres Escuela Politécnica Nacional, EcuadorMaria Urquhart Universidad de la República, UruguayJorge Vera Pontificia Universidad Católica de ChileRene Villalobos Arizona State UniversityRichard Weber Universidad de ChileAndres Weintraub Universidad de Chile
3

CLAIO-2016
Table of Contents
Estimación de ocupación de carreras universitarias para una universidad privada en Chile 13
Luis Aburto and Luis Meza
Planificación de cosechas en entornos ”Just-in-time”. Un enfoque bicriterio . . . . . . . . . . . 21
Belarmino Adenso-Diaz, Placido Moreno, Sebastian Lozano and Raul Villar
Elementary shortest paths avoiding negative circuits . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Rafael Andrade and Rommel Saraiva
Detecting separation in logistic regression via linear programming . . . . . . . . . . . . . . . . . 38
Inácio Andruski-Guimarães
A multivariate approach for associating products to points of sale in the indirectdistribution channel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
Michel Anzanello, Guilherme Tortorella, Giuliano Marodin and Carlos Ernani Fries
Algoritmos de Branch-and-cut com Branch Combinatório para o Problema do ConjuntoDominante Mı́nimo Conexo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Paulo Henrique Macedo De Araujo and Rafael Castro De Andrade
Diseño Territorial para el Área de Ventas de una Empresa de Televisión por Cable . . . . . 61
César A. Arguello-Rosales, Elias Olivares-Benitez, Francisco Javier Méndez-Ramı́rezand Beatriz Pico-Gónzalez
The Longest Link Node Deployment Problem in Cloud Computing: a Heuristic Approach 69
Matheus Atáıde, Cid de Souza, Pedro J. de Rezende and Marcos Salles
Un enfoque multiobjetivo multinivel para resolver el problema de inversion de carriles detráfico y sincronización de semáforos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
Enrique Gabriel Baquela and Ana Carolina Olivera
Análisis de los factores asociados a la calidad en la producción de frutas: Un caso deestudio en Colombia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
Helga Bermeo Andrade, Javier Tovar Perilla, Claudia Valenzuela and Janeth Bohorquez
Some forbidden subgraphs for LS+-perfection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
Silvia Maria Bianchi, Mariana Escalante and Graciela Leonor Nasini
El problema de coloreo de aristas por etiquetado total bajo un enfoque de programaciónlineal entera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
Fabrizio Borghini, Zabala Paula and Isabel Méndez-Dı́az
PR-GRASP- Path Relinking GRASP Aplicado a Seleção de Caracteŕısticas . . . . . . . . . . 107
Raphael Broetto and Flávio Varejão
Water Networks: A Multi-Objective approach to Design an Eco-Industrial Park inValdivia, Chile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
Mariana Bruning, Fernando Arenas, Carlos Méndez and Felipe Dı́az-Alvarado
Optimización del diseño de una cadena de suministro sustentable mediante un modelomulti-objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
Linda Canales B, Alfredo Candia Vejar, Ernesto Dr Santibanez-Gonzalez and BrunoSantos Pimentel
Uma abordagem cont́ınua para o TSP e um método de descida para geração de soluçãoaproximada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
Luiz Carlos
4

CLAIO-2016
Sobre o número de Helly geodético em grafos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
Moisés Carvalho, Mitre Dourado and Jayme Szwarcfiter
Machine Learning aplicado à predição de interesse em filmes . . . . . . . . . . . . . . . . . . . . . 143
Juliana Christina Carvalho de Araújo, Marco Antônio Da Cunha Ferreira, Danilo DoCarmo, Reinaldo Castro Souza and Ricardo Tanscheit
Uma nova abordagem para o cálculo do precondicionador separador aplicado aosmétodos de pontos interiores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
Luciana Casacio, Aurelio R. L. Oliveira and Christiano Lyra
Simulación basada en agentes para identificar y cuantificar los asentamientos informalespor comuna de las personas desplazadas hacia el Municipio de Medelĺın, Colombia . . . . . 157
Julian Castillo, Fernando Ceballos and Elena Valentina Gutierrez
Acercamiento a la selección de estrategias de mitigación en la Gestión de Riesgos de laCadena de Suministro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
Tatiana Andrea Castillo Jaimes and Carlos Eduardo Dı́az Bohórquez
Análisis espectral del precondicionador Separador con base dispersa . . . . . . . . . . . . . . . . 172
C.O. Castro and A. R. L. Oliveira
Generación de columnas para un problema de ruteo e inventarios para la gestión de unared de cajeros automáticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
Alejandro Cataldo, Leandro Coelho, Cristián Cortés, Carlos Lagos and Pablo A Rey
Pricing and Composition of Multiple Bundles of Products and Services and MultipleMarket Segments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
Alejandro Cataldo and Juan-Carlos Ferrer
Propuesta de mejora a los altos tiempos de espera en puntos de atención al usuario enuna entidad promotora de salud empleando simulación discreta. . . . . . . . . . . . . . . . . . . . 206
Yony Fernando Ceballos, Natalia Uribe Mejia, Nestor Nestor Ivan Vasquez Marin andDiego Usuga Rico
Agricultural planning in sugarcane planting areas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
Adriana Cherri, Andréa Vianna, Rômulo Ramos and Helenice Florentino
Splitting versus setup trade-offs for scheduling to minimize weighted completion time . . . 221
José Correa, José Verschae and Victor Verdugo
Redes espacio-tiempo para itinerario de fiscalización de la evasión en buses deTransantiago. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
Cristián Cortés, Pablo A Rey, Diego Muñoz and Luis Trujillo
The Block-interchange and the Breakpoint Closest Permutation problems areNP-Complete . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239
Luis Cunha, Vińıcius Fernandes Dos Santos, Luis Kowada and Celina Figueiredo
A polyhedral approach to the adjacent vertex distinguishable proper edge coloringproblem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 247
Brian Curcio, Isabel Mendez-Diaz and Paula Zabala
Ranking do Desempenho Econômico-Financeiro e a relação com Atributos deGovernança Corporativa: Um estudo com Cooperativas Agropecuárias . . . . . . . . . . . . . . 255
Cristian Baú Dal Magro, Marcello Christiano Gorla, Adriana Kroenke and Nelson Hein
5

CLAIO-2016
Aprimoramento de previsões de seguros do Mercado Brasileiro utilizando novametodologia baseada em combinação de previsões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263
Juliana Christina Carvalho de Araújo, Bruno Quaresma Bastos and Reinaldo CastroSouza
Uma associação dos métodos de barreira e de barreira modificada . . . . . . . . . . . . . . . . . . 271
Jessica Antonio Delgado, Edméa Cássia Baptista and Edilaine Martins Soler
Uma heuŕıstica baseada em Programação Matemática para o Problema deEscalonamento de Médicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279
Valdemar Abrao P. A Devesse, Maristela Santos and Rafael Soares Ribeiro
Recommendation System for Social Networks based on the Influence of Actors throughGraph Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287
Julio Cesar Duarte, Claudia Marcela Justel and Geraldo de Souza Júnior
Aplicación de la metodoloǵıa de las decisiones robustas en la elección de una cartera deinversiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295
Mat́ıas Eiletz, Silvia Ramos, Horacio Rojo and Maŕıa Alejandra Castellini
The minimum chromatic violation problem: a polyhedral approach . . . . . . . . . . . . . . . . . 303
Mariana Escalante, Maria Elisa Ugarte and Maŕıa Del Carmen Varaldo
Dimensionamento de lotes e roteamento de véıculos em indústrias moveleiras depequeno porte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 311
Deisemara Ferreira, Pedro Miranda Lugo and Reinaldo Morabito
The socio-technical team formation problem: computational complexity, formulation,facets and experimental analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319
Tatiane Figueiredo, Manoel Campêlo and Ana Silva
A metaheuŕıstica Iterated Local Search e a técnica de busca Very Large-scaleNeighborhood Search aplicada ao Problema de Programação de Máquinas Paralelas . . . . 327
Rodrigo Ribeiro Franco and Gustavo Peixoto Silva
Proposta de modelo multicriteŕıo para selecÇão de pessoal no projeto dedesenvolvimento de aeromodelos de carga . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335
Patŕıcia Freire, Joana Karolyni Peixoto and Thomas Gonçalo
Sparse pseudoinverses via LP and SDP relaxations of Moore-Penrose . . . . . . . . . . . . . . . 343
Victor Fuentes, Marcia Fampa and Jon Lee
The Game Chromatic Number of Caterpillars . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 351
Ana Lúısa Furtado, Simone Dantas, Celina Figueiredo, Sylvain Gravier and SimonSchmidt
Measuring in weighted environments: Moving from Metric to Order Topology (Knowingwhen close really means close) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 359
Claudio Garuti
Modelo de simulación de un sistema de fabricación de cerveza. Aplicación didáctica encurŕıculos de Ingenieŕıa Qúımica en el área de Gestión de Producción y Operaciones(GPO) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 366
Jaime Giraldo and Jhonathan Vargas
Mathematical job-shop scheduling models for energy management in manufacturingsystems – A summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 371
Ernesto D.R. Santibanez Gonzalez and Nelson Maculan
6

CLAIO-2016
Proposta de Modelo multicritério para priorização de munićıpios da região semiáridapara direcionamento de recursos de combate à seca . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374
Thomas Gonçalo and Danielle Morais
Enfoque de justo a tiempo en un diseño multiobjetivo de cadena de suministro. . . . . . . . . 382
Aaron Guerrero Campanur, Elias Olivares-Benitez, Pablo A. Miranda, Rodolfo E.Pérez Loaiza and Salvador Hernández González
A utilização da Pesquisa Operacional para alocação de recursos na gestão acadêmica . . . . 390
Mariana Guimaraes and Joaquim Cunha Jr.
Otimização do Roteiro de Distribuição de Materiais no Sistema Público de Saúde naCidade de Joinville . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 398
Flavia Haweroth, Ana Paula Nunes Duarte and Vanina Macowski Durski Silva
Polifuncionalidad con Cadenas Cerradas en el Sector Servicios: Un Enfoque deOptimización Robusta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 406
César A. Henao, Juan C. Ferrer, Juan C. Muñoz and Jorge Vera
Beneficios de la Polifuncionalidad con Cadenas Cerradas en Sistemas Desbalanceados:Caso de Estudio en la Industria del Retail . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414
César A. Henao, Juan C. Muñoz and Juan C. Ferrer
iterações Iniciais Eficientes no Método de Pontos Interiores . . . . . . . . . . . . . . . . . . . . . . 422
M. R. Heredia and A.R.L. Oliveira
Technical Efficiency of Mexican Higher Education Institutions: A Data EnvelopmentAnalysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 430
Maria G. Hernández-Balderrama, Luis A. Moncayo-Martinez and AdrianRamirez-Nafarrate
Production Planning and Scheduling Optimization Model for glass industry . . . . . . . . . . 438
Laura Hervert-Escobar, Jesús Fabián López-Pérez, Neale R. Smith and JonnatanAvilés-González
Optimality of the exhaustible resource extraction in terms of a martingale fixed pointcharacterization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 446
Juri Hinz
Impact Of Household Renewable Energy And Other Retailers On Optimal Energy Storage454
Juri Hinz and Jeremy Yee
Análisis de la formación de precios y asignación de suministro de gas natural enColombia por medio de la simulación de subastas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462
Antonio Hoyos and Yris Olaya
The Influence of the Support Factor and Different Grids on the Static Stability ofPacking Problems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 470
Leonardo Junqueira and Thiago Queiroz
Line balancing with heterogeneous products: a two-step formulation to minimizenumber of stages in the whole system of lines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 478
Felipe Kesrouani Lemos, Juliano Augusto Nunes Paixão, Adriana Cristina Cherri,Silvio Alexandre de Araujo and Aline Marques
Jogos Vetoriais na Avaliação do Posicionamento Contábil de Empresas Brasileiras . . . . . . 485
Adriana Kroenke, Nelson Hein, Bianca Cecon and Volmir Eugênio Wilhelm
New research focus is needed in sport scheduling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 492
Leonardo Lamorgese and Tomas Nordlander
7

CLAIO-2016
An algorithm in dynamic programming for the Closest String Problem . . . . . . . . . . . . . . 499
Omar Latorre and Rosiane de Freitas
Aplicação do método Analytic Hierarchy Process - AHP para a análise da transposiçãodo rio São Francisco . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 507
Anna Flavia Lima, Rodolfo Sabiá, Francisco Sobreira Junior, Valério Salomon andMonica Liborio
Proposta de um modelo multicritério de apoio a decisão para priorização de regiõesatingidas pelo Aedes Aegypti no munićıpio de Mossoró-rn . . . . . . . . . . . . . . . . . . . . . . . 514
João Lopes, Ester Teixeira, Plácido Queiroz and Thomas Gonçalo
Zero-inflated Cure Rate Weibull Regression Model: An Application to Financial Dataon Time-to-default . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 521
Francisco Louzada, Mauro Oliveira and Fernando Moreira
Enfoque biobjetivo para planificar los flujos en una cadena de suministro con pérdidasde material . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 527
Sebastián Lozano and Belarmino Adenso-Diaz
Gestión de residuos peligrosos: Selección de oferentes con un método de soporte a ladecisión multicriterio grupal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 535
Nadia Ayelen Luczywo, José Francisco Zanazzi, Daniel Alberto Pontelli, José LuisZanazzi and José Maŕıa Conforte
Modelo para la planificación óptima de la producción y deshidratación de hierbasmedicinales y aromáticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 543
Maŕıa M. López, Jorge L. Recalde-Ramı́rez and Julio Canales
Seleção de Portfólio de Projetos com Restrição de Recursos e Escalonamento no Tempo . . 551
Guilherme Marcondes, Mateus Alves and Vanessa Rennó
Modelo para la asignación de terrenos, en el marco de la Reforma Rural Integral . . . . . . . 559
Karen Rocio Mart́ınez Lancheros, Natalia Quintero Avellaneda and Yony FernandoCeballos
Heuristica de agrupamiento de productos hortofrut́ıcolas para garantizar condiciones demaduración en almacenamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 567
Pedro Daniel Medina Varela, Paulo Machado Bados and Hugo Fernando GonzalezHurtado
A reactionary operational model for the air cargo schedule recovery under demanductuations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 581
Julio Mora and Felipe Delgado
Efficiency assessment of dota 2 competitive teams using network data envelopmentanalysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585
Mateus Nascimento, Rachel Magalhães and Lidia Angulo-Meza
Optimización de los niveles de glucosa en un paciente con diabetes mellitus tipo 1mediante de un modelo de programación lineal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593
Maximino Navarro Mentado and Esther Segura
Traffic light optimization for Bus Rapid Transit using a parallel evolutionary algorithm:the case of Garzon Avenue in Montevideo, Uruguay . . . . . . . . . . . . . . . . . . . . . . . . . . . . 601
Sergio Nesmachnow, Efrain Arreche, Renzo Massobrio, Christine Mumford, CarolinaOlivera and Pablo Vidal
8

CLAIO-2016
Optimización de operaciones loǵıstico-humanitarias para la planificación ante desastresen la ciudad de Talcahuano, Chile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 609
Francisco Núñez, Rodrigo Linfati and Pablo Ortiz
MCDA applied to project and project managers classification: an integrated method toallocate pro jects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 617
Elaine Oliveira, Luciana Alencar and Ana Paula Costa
Planificación jerárquica de la producción con demanda estacional y distribución uniforme 625
Virna Ortiz-Araya and Vı́ctor M. Albornoz
A multistage stochastic programming model for air cargo assignment under capacityuncertainty . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633
Bernardo Pagnoncelli, Felipe Delgado and Ricardo Trincado
Multicriteria decision-making under uncertainty: a behavioural experiment withexperienced participants in supply chain management . . . . . . . . . . . . . . . . . . . . . . . . . . 640
Fernando Paredes, Javier Pereira, Claudio Lavin, Luis Sebastián Contreras-Huertaand Claudio Fuentes
Optimizing a pinball computer player using evolutionary algorithms . . . . . . . . . . . . . . . . 649
Facundo Parodi Moraes, Sebastián Rodŕıguez Leopold, Santiago Iturriaga and SergioNesmachnow
Uma Heuŕıstica Hı́brida para Problemas de Roteamento de Véıculos comDimensionamento de Frota Heterogênea e Múltiplos Depósitos . . . . . . . . . . . . . . . . . . . . 657
Puca Huachi Penna, Luiz Satoru Ochi and Anand Subramanian
Using TODIM under imprecision and uncertainty conditions: application to thesuppliers development problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 665
Javier Pereira, Luiz Flavio Autran Monteiro Gomes, Elaine C.B. de Oliveira andPilar Arroyo
Towards a robustness metrics in ranking multicriteria problems, based on a flexibilityframework . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 672
Javier Pereira, Luiz Flavio Autran Monteiro Gomes, Fernando Paredes and GabrielSalinas
Aplicação de um modelo DEA para determinar onde instalar escolas profissionalizantes . . 680
Fabio Da Costa Pinto, Armando Zeferino Milioni and Mischel Belderrain
Inventory policies for the economic lot-sizing problem with remanufacturing andheterogeneous returns . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 688
Pedro Piñeyro
Designing robust supply chain: a methodological approach by using binary programming . 696
Andrés Polo, Dairo Muñoz and Rafael Tordecilla
Improving the Flow of Patients at a Projected Emergency Room Using Simulation . . . . . 704
Francisco Ramis, Liliana Neriz, Danilo Parada and Pablo Concha
Gerenciamento de recursos para programação da produção de produtos perećıveis emum ambiente de múltiplas linhas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 710
Rafael Ribeiro, Willy Soler and Maristela Santos
FITradeoff multicriteria method for a flexible and interactive preference elicitation insmall company decision problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 718
Sinndy Dayana Rico Lugo and Adiel Teixeira De Almeida
9

CLAIO-2016
Optimizing the production / logistic planning in the tomato processing industry . . . . . . . 726
Cleber Rocco and Reinaldo Morabito
Autoregresion Wavelet para Pronostico Multi-horizonte de Accidente de Transito . . . . . . 733
Nibaldo Rodriguez and Cecilia Montt
Modelo Hostil de Redes con Fallas en Aristas y Nodos . . . . . . . . . . . . . . . . . . . . . . . . . . 741
Pablo Romero, Franco Robledo and Daniel Lena
Improving Visual Attractiveness in Capacitated Vehicle Routing Problems: a HeuristicAlgorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 749
Diego Gabriel Rossit, Daniele Vigo, Fernando Tohmé and Mariano Frutos
The use of the multiple knapsack problem in strategic management of universities - casestudy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 757
Radoslaw Rynca, Dorota Kuchta, Dariusz Skorupka and Artur Duchaczek
Problema do Caixeiro Viajante Alugador com Passageiros: Uma Abordagem Algoŕıtmica 765
Gustavo Sabry, Marco Goldbarg and Elizabeth Goldbarg
Las prioridades competitivas de las PYMES en Quito-Ecuador, analizadas conforme a laAdministración de Operaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 773
Hernan Samaniego
Un modelo de inventario con roturas, asumiendo que la demanda dependeexponencialmente del precio y potencialmente del tiempo . . . . . . . . . . . . . . . . . . . . . . . . 779
Luis Augusto San José Nieto, Joaqúın Sicilia Rodŕıguez, Manuel González de La Rosaand Jaime Febles Acosta
Un modelo de inventarios EOQ con demanda dependiente del tiempo, coste no lineal dealmacenamiento y roturas parcialmente recuperables . . . . . . . . . . . . . . . . . . . . . . . . . . . 787
Luis Augusto San-José Nieto, Joaqúın Sicilia Rodŕıguez and Leopoldo EduardoCárdenas-Barrón
Uma Heuŕıstica Hı́brida baseada em Iterated Local Search para o Problema de Estoquee Roteamento de Múltiplos Véıculos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 795
Edcarllos Santos, Luiz Satoru Ochi, Luidi Simonetti and Pedro Henrique González
Vehicle Routing Problem with Fuel Consumption Minimization: a Case Study . . . . . . . . 803
Gregory T. Santos, Luiza Amalia P. Cantão and Renato F. Cantão
Análise da demanda de peças sobressalentes para navios de guerra: estudo de caso deuma fragata da Marinha do Brasil . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 811
Marcos Santos, Beatriz Magno, Jonathan Ramos, Ernesto Martins, Sérgio Baltar,Juliana Silva and Carlos Gomes
Uma ferramenta para construção de Cenários Florestais . . . . . . . . . . . . . . . . . . . . . . . . . 819
Paulo Amaro V. H. Dos Santos, Arinei Carlos Lindbeck Da Silva and Julio EduardoArce
Mental model comparison: recognized feedback loops versus shortest independent loop set 827
Martin Schaffernicht
Optimización del abastecimiento de combustible al norte de la Ciudad de México . . . . . . 835
Esther Segura and Daniel Alexander Tello
The problem of scheduling offshore supply port operations . . . . . . . . . . . . . . . . . . . . . . . 843
Rennan Danilo Seimetz Chagas and Virgilio Jose Martins Ferreira Filho
10

CLAIO-2016
Utilização de Metodologia Multicritério para Escolha de Cálculo mais Adequado deIBNR para uma Operadora de Plano de Saúde . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 851
José Fabiano Serra Costa and Larissa Mitie Yui
Uma nova formulação matemática eficiente para o Problema de Inundação em Grafos . . . 859
André Silva and Luiz Satoru Ochi
Um Ambiente Georreferenciado para Otimizar Rotas na Distribuição de Produtos ouServiços . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 867
Bruno Castro H. Silva, Gerardo Vald́ısio R. Viana and José Lassance C. Silva
Um Algoritmo Genético para o Problema de Roteirização de Véıculos com FrotaHeterogênea e Coleta e Entrega Separada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 875
José Lassance C. Silva, Cesar Augusto C. Sousa Filho and Bruno Castro H. Silva
Optimal Inventory in Bike Sharing Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 883
Fernanda Sottil de Aguinaga, Adrian Ramirez Nafarrate and Luis Moncayo Mart́ınez
Territorial Partitioning Problem applied to Brazil Healthcare System using aMulti-objective Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 891
Maria Steiner, Pedro Steiner Neto, Datta Dilip, José Figueira and Cassius Scarpin
An Optimized Approach for Location of Grain Silos in Brazil through a Multi-objectiveGenetic Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 898
Pedro Steiner Neto, Datta Dilip, Maria Steiner, Ośıris Canciglieri Júnior, JoséFigueira, Silvana Detro and Cassius Scarpin
Modelo timetabling multiobjetivo al servicio de estudiantes en pro de minimizar eltiempo de culminación de su pregrado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906
José Sánchez and Jainet Bernal
Métodos de Preenchimento de Matrizes de Posto Reduzido para o Tratamento de DadosFaltantes na Análise Envoltória de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 914
Leonardo Tomazeli Duarte and Cristiano Torezzan
The multiperiod cutting stock problem with usable leftover . . . . . . . . . . . . . . . . . . . . . . 922
Gabriela Torres Agostinho, Adriana Cristina Cherri, Silvio Alexandre de Araujo andDouglas Nogueira Do Nascimento
Modelos matemáticos para o problema de dimensionamento e sequenciamento de lotesem dois estágios com limpezas periódicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 930
Alyne Toscano, Deisemara Ferreira and Reinaldo Morabito
Modeling symmetry cuts for batch scheduling with realease times and non-identical jobsizes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 938
Renan Trindade, Olinto de Araújo, Marcia Fampa and Felipe Müller
Algoritmos exactos para subconjuntos de instancias para el problema de programaciónde tareas flexibles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 945
Daniel Vega-Araya and Victor Parada
Decisión conjunta para la delineación de terreno y selección de cultivos mediante el usode modelos de optimización . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 953
Marcelo Veliz Alcáıno and Vı́ctor M. Albornoz
El problema de asignación de recursos a un sistema de distribución de enerǵıa eléctrica . . 961
Jairo Villegas, Carlos Zapata and Gustavo Gatica
11

CLAIO-2016
Partição de conjuntos e metaheuŕısticas para o problema de roteamento de véıculos comjanelas de tempo e múltiplos entregadores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 969
Aldair Álvarez and Pedro Munari
12

Estimación de ocupación de carreras universitarias para una
universidad privada en Chile
Luis Aburto
Departamento de Ingeniería Industrial, Universidad de Chile
Luis Meza
Departamento de Ingeniería Industrial, Universidad de Chile
Abstract
El sistema de educación superior chileno se encuentra enmarcado en un modelo competitivo, donde todas
las instituciones están generando acciones para captar un mayor número de postulantes, y también atraer
una mayor cantidad de alumnos con buenos puntajes para así completar la mayor cantidad de las vacantes
que ofrecen en al mercado. Se generaron tres modelos con variables explicativas, dos de ellos Logit, uno
base y otro en el cual se incluía interacción entre las variables de entrada introducidas al modelo y un Árbol
de Decisión, que contenía el mismo set de variables que el modelo Logit base.
Los resultados principales que entregaron los modelos son que las ayudas económicas sí son importantes
en los alumnos y que afectan en distintos grados según el tipo de postulante. La demanda pasada de la
carrera también es un factor importante, siendo el que más impacta en la decisión, como también lo son las
actividades que realiza la universidad para generar conciencia de marca en sus postulantes. El modelo que
tuvo mejores resultados en cuanto a la predicción de matrícula fue el Logit base, con un error promedio en
la conversión de 5,7%.
Keywords: educación superior; modelos logit; árbol de decisión; data mining.
1 Introducción
El sistema de educación superior chileno se encuentra enmarcado en un modelo competitivo, donde todas
las instituciones están generando acciones para captar un mayor número de postulantes, y también atraer
una mayor cantidad de alumnos con buenos puntajes para así completar la mayor cantidad de las vacantes
que ofrecen en al mercado.
Es por este motivo que el presente trabajo tiene como objetivo identificar aquellas variables que tienen
una mayor influencia en la decisión de los postulantes en el momento de matricularse en una determinada
universidad, para luego estimar la probabilidad de matrícula de cada uno de ellos en una universidad
privada adscrita al sistema único de admisión universitaria.
Para cumplir el objetivo se desarrollarán tres modelos. Dos de los cuales serán Logit Binarios, uno base y
otro en el cual se generará interacción entre algunas de las variables ingresadas en el modelo base, y el
otro será un Árbol de Decisión. Lo que se busca es determinar cuál es el que tiene un mejor ajuste a los
datos y cuál tiene una mejor predicción. Esto se determinará en base a la matriz de confusión y a los
estadísticos de clasificación [1], como Tasa de aciertos, Recall, Precisión, etc.
CLAIO-2016
13

La información necesaria para la creación de las variables que serán utilizadas en los modelos es obtenida
de diversas fuentes de información, entre ellas se encuentra el Departamento de Evaluación, Medición y
Registro Educacional (DEMRE), de donde se obtiene la información de los postulantes tanto
socioeconómica, demográfica, académica y los puntajes que obtuvo cada persona que rindió la Prueba de
Selección Universitaria (PSU). Otra fuente importante de información es la universidad en la que se
realizó este estudio, de donde se obtiene información relativa a la interacción que tuvo el postulante con la
casa de estudio en cuestión, a través de las actividades de marketing y difusión que esta realiza.
Finalmente se obtiene información del simulador de becas que tiene la universidad, para que los
postulantes conozcan cuales podrían ser sus beneficios en caso de matricularse en la institución.
2 Revisión Bibliográfica
Trabajos similares donde se busca determinar cuáles factores influyen en la decisión de los postulantes
para matricularse en una institución de educación superior ya han sido realizados, tanto en Chile como en
el extranjero.
Partiendo por los estudios realizados en Chile se tiene el trabajo realizado por Mizala [2], donde identifica
las variables más influyentes en que un alumno que termina la educación media escoja la carrera de
pedagogía. Dentro de estos encuentra que a medida que el puntaje PSU del postulante aumenta con
respecto al nivel de referencia la probabilidad de que este elija una carrera de pedagogía disminuye
drásticamente. También se encontró evidencia de que el colegio de procedencia influye en la elección de
la persona, ya que un alumno que proviene de un colegio que pertenece al quintil de más bajos ingresos
tiene una probabilidad a elegir una carrera de pedagogía, y esta probabilidad va disminuyendo a medida
que el colegio va subiendo en su posición de acuerdo al quintil de ingreso que pertenece. Otras variables
que también afectan la decisión en la elección de este tipo de carreras son factores socioeconómicos del
hogar de procedencia, como el ingreso y el nivel de estudio de los padres. En el trabajo también se
encontró evidencia que el salario futuro era un factor importante en la decisión, ya que los alumnos ven la
educación superior como una inversión.
Otro trabajo realizado en Chile, esta vez por Munita [3], también para analizar los factores que influyen
en la probabilidad de que un alumno escoja una carrera de pedagogía. En él se encontró evidencia de que
variables como el género de la persona influye, es más, la probabilidad de escoger este tipo de carreras
disminuye un 3,3% si la persona es de género masculino, además este tendrá mayor probabilidad de
escoger carreras como ingeniería o ciencias. También se encontró evidencia de que el tipo de colegio
influye en la decisión, ya que si el alumno proviene de un colegio con un ingreso socioeconómico alto
tiende a optar por carreas del área de economía y leyes en desmedro de carreras del área de la educación.
En cuanto a trabajos realizados en el extranjero se encuentra el desarrollado por Chapman [4], en el cual
identifica que esta decisión se encuentra afectada por características propias de la persona y por factores
externos, que divide en tres grupos: I) influencia de personas importantes, II) características de la
institución, y III) publicidad realizada por la universidad. Dentro de las características individuales se
encuentra el aspecto socioeconómico como ingreso familiar, nivel educacional de los padres, también
influye su desempeño académico, ya que estudiantes con buenos antecedentes académicos son alentados a
seguir estudiando.
En otro estudio realizado por Jiménez y Salas [5], también plantean que el ingreso futuro es un factor que
influye en la elección de una determinada carrera, y que esto va acompañado de la proyección del
mercado laboral de esta, medida en la empleabilidad que tiene, ya que las personas ven la educación
CLAIO-2016
14

superior como una inversión. En este trabajo, realizado en España, se ven las diferencias entre escoger
una carrera de tres versus cuatro años de duración, donde se encuentra que los costos en los que se incurre
al estudiar, tanto directos como indirectos, son una variable relevante para los postulantes en el momento
de optar por una carrera.
Este último efecto también es medido con el efecto que las becas tienen sobre los postulantes, Barrientos
[5], encuentra que la conversión de los postulantes a una casa de estudio aumenta entre un 20 y un 30%
cuando se le otorga una beca, por lo que este factor también se torna relevante en la decisión del alumno.
3 Metodología y Resultados
Para llevar a cabo el modelo, se utilizaron los pasos explicados a continuación:
Paso Actividades
Revisión
Bibliográfica
• Investigación sobre trabajos similares donde se
estudie factores que influyen en la decisión de los
alumnos en ingresar al sistema de educación
superior.
Análisis
Descriptivo
• Investigar variables que pueden ser relevantes en la
conversión de los postulantes.
• Investigar todo tipo de información que posea la
empresa.
• Levantamiento de hipótesis
Procesamiento de
Datos
• Seleccionar datos relevantes para un modelo.
• Limpiar los datos seleccionados previamente.
• Transformación y normalización de variables.
Generación de los
Modelos
• Determinar variables explicativas que serán
utilizadas en esta ocasión.
• Generar los modelos elegidos con las variables que
son relevantes (significativas según el mismo
modelo).
Evaluación de
Resultados
• Revisar la calibración y validación de los modelos
con los datos.
• Comparación de los tres modelos desarrollados.
• Comparar los resultados obtenidos con lo sucedido
para el último proceso de admisión.
Los principales resultados obtenidos del modelo Logit Base muestran que hay cuatro variables que tienen
una mayor influencia en la probabilidad de matrícula del postulante, estas son: La conversión anterior de la
carrera, quiere decir que la información histórica sobre la demanda de la carrera tiene una alta influencia
en la predicción de la propensión de matrícula, a mayor conversión pasada se espera una alta conversión
para el actual proceso. La variable que le sigue es la que mide el desempeño del alumno en la prueba PSU,
esta variable mide el puntaje que obtuvo el postulante por 1sobre el puntaje promedio de la carrera a la que
postula, esto indica que a mayor puntaje obtenido por el postulante este tiene una mayor probabilidad de
1 Variables significativas al 99%.
CLAIO-2016
15

matrícula, esto puede deberse a que a mayor puntaje en la PSU tiene mayor probabilidad de elegir la carrera
que realmente quiere y por lo tanto que este haya postulado por gusto y no porque le alcanzó. La siguiente
variable que afecta positivamente la probabilidad de matrícula es si este postula en la primera preferencia
a la universidad. Finalmente, la última variable de este grupo es la que mide la variación entre la beca
simulada y la beca real otorgada, esta variable es positiva e indica que a mayor variación positiva entre la
beca que el postulante simuló en el portal web y la beca que realmente le corresponde la probabilidad de
matrícula aumenta, esto puede deberse a que al alumno se le otorga un beneficio mayor al esperado por lo
que tiene un mayor incentivo para matricularse. En la tabla N°1 se pueden ver los principales factores que
influyen positivamente en la probabilidad de matrícula.
Tabla 1: Variables principales y coeficientes.
Fuente: Elaboración propia.
En el gráfico N°1 se puede ver la curva ROC del modelo logit Base, en el cual el área bajo la curva es de
un 78%.
Variable Coeficiente Variable Coeficiente
Conversión anterior 2,14 Nivel estudios padre universitario 0,19
Ptje sobre ptje promedio de la carrera 1,43 Colegio Subvencionado 0,19
Postula 1ra preferencia 1,32 Postula a una sede de su misma comuna 0,19
Variación entre beca simulada y beca real 1,28 Nivel estudios padre CFT-IP 0,17
Colegio Particular 0,77 Nivel estudios padre ed. Media 0,12
Variación promedio beca simulada 0,62 Carreras del área salud 0,12
Egresó un año antes del proceso 0,60 Difusión 0,11
Log # de simulaciones 0,59 Sede República -0,08
Postula 2da preferencia 0,55 Sede Casona -0,22
Emité certificado 0,50 Sede Bellavista -0,24
Variación carrera en el mercado 0,49 Quintil 4 -0,30
Egresó dos años antes del proceso 0,48 Año 2015 -0,41
Beca externa 0,45 Sede Los Leones -0,41
CAE 0,41 Quintil 3 -0,52
Egresó tres años antes del proceso 0,38 Quintil 2 -0,74
Simula misma carrera que postula 0,33 Quintil 1 -0,85
Postula 3ra preferencia 0,31Carrera con baja conversión y valor
matrícula promedio IP-1,26
Egresó mismo año del proceso 0,24 Constante -4,59
Log beca interna simulada 0,23
CLAIO-2016
16
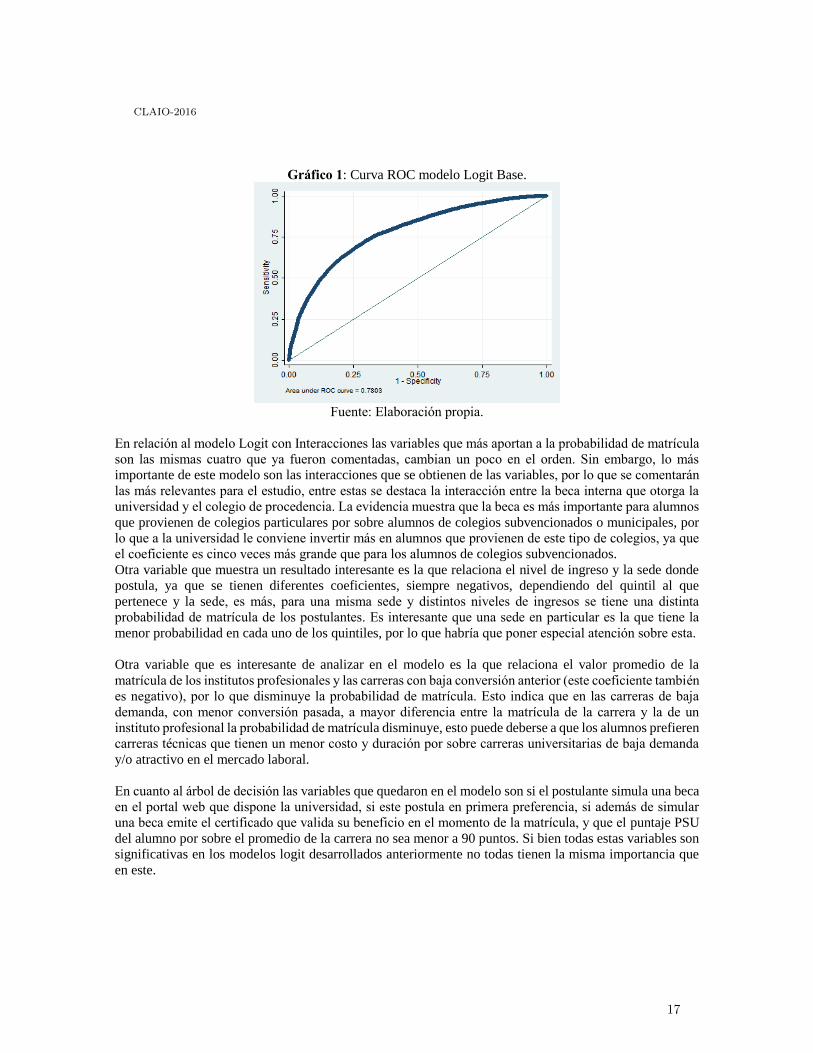
Gráfico 1: Curva ROC modelo Logit Base.
Fuente: Elaboración propia.
En relación al modelo Logit con Interacciones las variables que más aportan a la probabilidad de matrícula
son las mismas cuatro que ya fueron comentadas, cambian un poco en el orden. Sin embargo, lo más
importante de este modelo son las interacciones que se obtienen de las variables, por lo que se comentarán
las más relevantes para el estudio, entre estas se destaca la interacción entre la beca interna que otorga la
universidad y el colegio de procedencia. La evidencia muestra que la beca es más importante para alumnos
que provienen de colegios particulares por sobre alumnos de colegios subvencionados o municipales, por
lo que a la universidad le conviene invertir más en alumnos que provienen de este tipo de colegios, ya que
el coeficiente es cinco veces más grande que para los alumnos de colegios subvencionados.
Otra variable que muestra un resultado interesante es la que relaciona el nivel de ingreso y la sede donde
postula, ya que se tienen diferentes coeficientes, siempre negativos, dependiendo del quintil al que
pertenece y la sede, es más, para una misma sede y distintos niveles de ingresos se tiene una distinta
probabilidad de matrícula de los postulantes. Es interesante que una sede en particular es la que tiene la
menor probabilidad en cada uno de los quintiles, por lo que habría que poner especial atención sobre esta.
Otra variable que es interesante de analizar en el modelo es la que relaciona el valor promedio de la
matrícula de los institutos profesionales y las carreras con baja conversión anterior (este coeficiente también
es negativo), por lo que disminuye la probabilidad de matrícula. Esto indica que en las carreras de baja
demanda, con menor conversión pasada, a mayor diferencia entre la matrícula de la carrera y la de un
instituto profesional la probabilidad de matrícula disminuye, esto puede deberse a que los alumnos prefieren
carreras técnicas que tienen un menor costo y duración por sobre carreras universitarias de baja demanda
y/o atractivo en el mercado laboral.
En cuanto al árbol de decisión las variables que quedaron en el modelo son si el postulante simula una beca
en el portal web que dispone la universidad, si este postula en primera preferencia, si además de simular
una beca emite el certificado que valida su beneficio en el momento de la matrícula, y que el puntaje PSU
del alumno por sobre el promedio de la carrera no sea menor a 90 puntos. Si bien todas estas variables son
significativas en los modelos logit desarrollados anteriormente no todas tienen la misma importancia que
en este.
CLAIO-2016
17
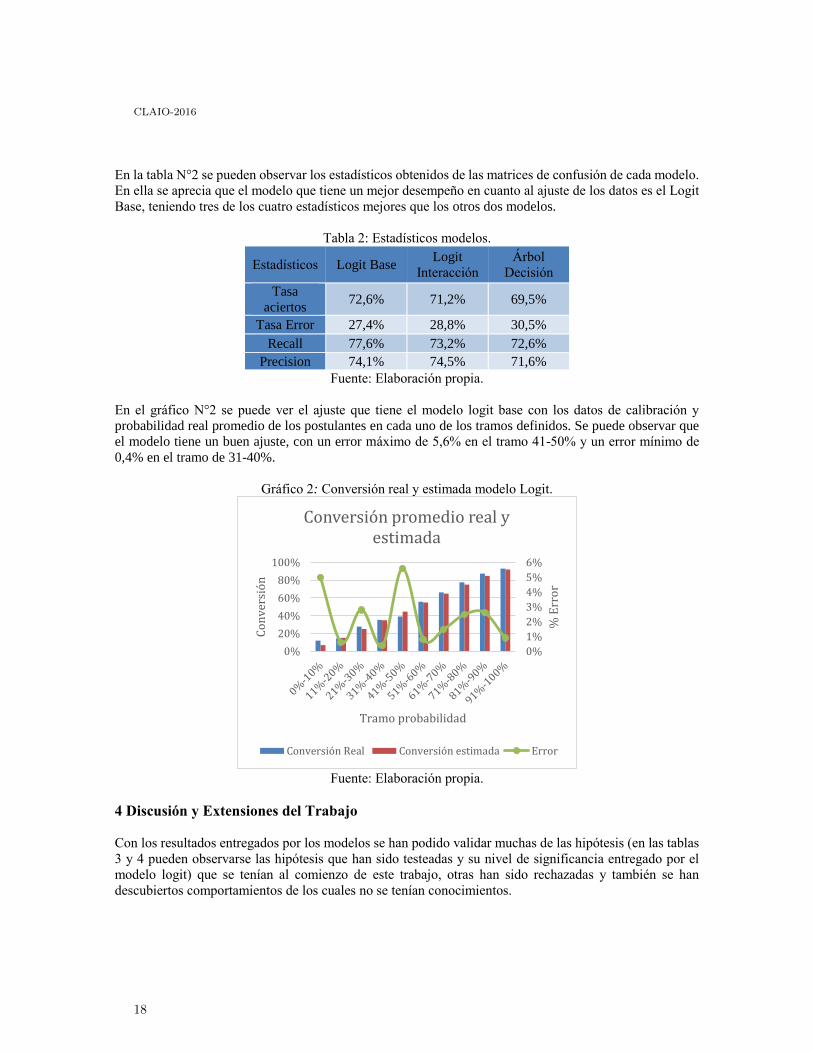
En la tabla N°2 se pueden observar los estadísticos obtenidos de las matrices de confusión de cada modelo.
En ella se aprecia que el modelo que tiene un mejor desempeño en cuanto al ajuste de los datos es el Logit
Base, teniendo tres de los cuatro estadísticos mejores que los otros dos modelos.
Tabla 2: Estadísticos modelos.
Estadísticos Logit Base Logit
Interacción
Árbol
Decisión
Tasa
aciertos 72,6% 71,2% 69,5%
Tasa Error 27,4% 28,8% 30,5%
Recall 77,6% 73,2% 72,6%
Precision 74,1% 74,5% 71,6%
Fuente: Elaboración propia.
En el gráfico N°2 se puede ver el ajuste que tiene el modelo logit base con los datos de calibración y
probabilidad real promedio de los postulantes en cada uno de los tramos definidos. Se puede observar que
el modelo tiene un buen ajuste, con un error máximo de 5,6% en el tramo 41-50% y un error mínimo de
0,4% en el tramo de 31-40%.
Gráfico 2: Conversión real y estimada modelo Logit.
Fuente: Elaboración propia.
4 Discusión y Extensiones del Trabajo
Con los resultados entregados por los modelos se han podido validar muchas de las hipótesis (en las tablas
3 y 4 pueden observarse las hipótesis que han sido testeadas y su nivel de significancia entregado por el
modelo logit) que se tenían al comienzo de este trabajo, otras han sido rechazadas y también se han
descubiertos comportamientos de los cuales no se tenían conocimientos.
0%
1%
2%
3%
4%
5%
6%
0%
20%
40%
60%
80%
100%%
Err
or
Co
nv
ersi
ón
Tramo probabilidad
Conversión promedio real y estimada
Conversión Real Conversión estimada Error
CLAIO-2016
18

Dentro de las principales hipótesis que fueron validadas por los modelos es que los beneficios económicos
que reciben los postulantes sí son importantes y afectan la decisión de ellos al momento de matricularse, ya
que el nivel de ingreso familiar es un factor que afecta negativamente, a menor ingreso menor probabilidad
de matrícula. Por otra parte, la interacción que se genera entre los postulantes y la universidad también tiene
un efecto positivo en la propensión de matrícula de los postulantes, por lo que es importante que la
universidad logre generar un reconocimiento de marca en los postulantes, para que cuando estos piensen
en estudios superiores tengan a la universidad como una alternativa válida.
Estos aspectos son importantes para la universidad, ya que estas variables, tanto los beneficios internos
como la interacción con los postulantes, pueden ser manejadas y administradas por ellos, en el presupuesto
que destinen para cada uno de estos ítems, y el saber cuánto afecta cada una les permite tener un mejor
conocimiento de sus postulantes y les permite una mejor planificación.
Otro aspecto importante y que se debe tener en cuenta es que este estudio no contempla el efecto que podría
tener la política de gratuidad en la educación superior en esta universidad en particular (política a la cual la
universidad en estudio no pertenecía), al ser una política que comenzó su implementación en este proceso
de admisión su efecto no pudo ser medido, por lo que no se puede decir que el comportamiento de los
postulantes acá encontrado se vaya a repetir en el futuro. De todas formas se puede observar que un efecto
que tuvo la gratuidad en la universidad. Este fue que desplazó las preferencias de los postulantes en, al
menos, una opción, esto quiere decir, que si sin gratuidad una persona postulaba a la universidad en la
primera preferencia con gratuidad lo hizo en segunda o tercera, esto debido a que en sus preferencias
anteriores colocó universidades que si estuvieran adscritas a gratuidad esperando lograr un cupo en estas
instituciones.
5 Conclusiones
Para el desarrollo del presente trabajo se realizaron tres modelos, dos de ellos Logit, uno base y uno con
interacción entre las variables, y un Árbol de Decisión. De los tres, el que tuvo un mejor desempeño
ajustándose a la data disponible, según los estadísticos de clasificación, fue el modelo Logit Base, teniendo
un Recall, Tasa de Aciertos y el F-Measure más altos que los otros modelos. Además, permitió validar
hipótesis que se tenían sobre el comportamiento de los postulantes a esta casa de estudios.
Las principales conclusiones obtenidas de los modelos son:
Si un alumno postula en primera preferencia su probabilidad de matrícula aumenta en promedio un 15,6%
por sobre alguien que postula en segunda. Esta diferencia aumenta a un 21% si en vez de postular en tercera
lo hace en primera opción.
Si un alumno simula un beneficio interno en el portal web de la universidad su probabilidad de matrícula
aumenta un 6,6%. Si este genera un certificado para validar su beneficio la probabilidad aumenta un 10%
por sobre alguien que simuló, pero no validó su beca.
Si un postulante posee un beneficio económico por parte del Estado, la probabilidad de que se matricule
aumenta en un 8% por sobre alguien que postula a la universidad, pero no cuenta con ayudas estudiantiles
por parte del Estado.
A la universidad le es más rentable otorgar una beca a alumnos de colegios particulares, pues la probabilidad
de matrícula aumenta en un 10% por sobre alumnos de colegios subvencionados. Se encontró una diferencia
del 14,3% en la propensión de matrícula entre alumnos de colegios particulares que no cuentan con beca y
CLAIO-2016
19

quienes sí, por lo que becar este segmento es más rentable, pues la diferencia en la probabilidad de matrícula
entre alumnos de colegios subvencionados que tienen beca interna y aquellos que no la tienen es de un 5%,
tres veces menor aproximadamente que para el otro grupo de alumnos.
De igual forma, la difusión es más efectiva en alumnos de establecimientos particulares, ya que la diferencia
en la probabilidad de matrícula entre quienes estuvieron presentes en actividades de difusión y quienes no
son del 11%.
También se encontró evidencia de que el nivel de ingreso juega un papel importante en la decisión de
matrícula, es más, dentro de una misma sede la probabilidad de matrícula es distinta para distintos niveles
de ingreso, habiendo diferencias de hasta un 13% en ella entre quienes pertenecen al primer quintil y quienes
pertenecen al cuarto para una sede en particular.
Finalmente, el trabajo cumple su objetivo y apoya a la universidad para tomar mejores decisiones en el
período de matrícula, le permite asignar mejor su presupuesto y planificar mejor sus actividades para el
próximo proceso.
Agradecimientos
Los autores quieren agradecer el financiamiento de esta investigación a CONICYT por su programa de
doctorado nacional y al Instituto Sistemas Complejos de Ingeniería.
Referencias
[1] T. Fawcett, “ROC graphs: Notes and practical considerations for researchers.” Machine learning 2004,
31:1-38
[2] A. Mizala, “Determinantes de la elección y deserción en la carrera de pedagogía.” FONIDE,
Departamento de estudios y desarrollo, Santiago, 2011.
[3] J. Munita, “Contexto social y la elección de ser profesor en Chile.”, M.S. Tesis, Pontificia Universidad
Católica de Chile, Santiago, Chile, 2011.
[4] D. Chapman, “A Model of Student Collegue Choice.”, Journal of Higher Education, 1981; 52(5):490-
505.
[5] J. De Dios, M. Salas, “Modeling educational choice. A binomial logit model applied to the demand
for Higher Education.” Journal of Higher Education, 2000; 40(3): 293-311.
CLAIO-2016
20

1
Planificación de cosechas en entornos “Just-in-time”. Un enfoque
bicriterio
Belarmino Adenso-Díaz
Universidad de Oviedo, España
Plácido Moreno
ESPOCH, Ecuador
Sebastián Lozano
Universidad de Sevilla, España
Raúl Villar López
Grupo Alimenario Citrus, Ribarroja, Valencia, España
Resumen El problema de planificación de cosechas se ha estudiado desde muy diversos puntos de vista
(maximización del beneficio, máximo rendimiento del agua disponible, sostenibilidad del plan de
cosecha…) En este trabajo se aborda un nuevo enfoque considerando las nuevas formas de relación
proveedor-cliente, en las que priman los acuerdos de colaboración a largo plazo, y donde las demandas
vienen establecidas con antelación. Esto da lugar a que las restricciones deban garantizar unos
determinados niveles de producción en ciertas fechas. Se presenta aquí un modelo biobjetivo, de tipo
lexicográfico, en el que además de minimizar costes, se pretende minimizar el riesgo de no atender las
demandas, usando dispersión geográfica. Se presentan unos resultados ilustrativos para mostrar la
efectividad del modelo.
Palabras clave: planificación de las cosechas; optimización lexicográfica; optimización biobjetivo;
1 Introducción
La producción de alimentos agrícolas es una actividad especialmente importante al satisfacer necesidades
básicas del ser humano. Sin embargo, su cadena logística presenta una especial complejidad
(principalmente al hablar de productos perecederos), dado que se debe garantizar la llegada de los
productos a su destino en tiempo y calidad adecuada para evitar problemas sanitarios, en entornos con
largos tiempos de suministro y con grandes incertidumbres (mercados, riesgos climatológicos, etc), todo
ello con escasos márgenes comerciales (Lowe, Preckel, 2004).
Las decisiones en esta cadena abarcan cuatro áreas funcionales (Ahumada, Villalobos, 2009): producción
(selección de productos, parcelas, fecha de siembra, volumen de producción, recursos usados, riego);
CLAIO-2016
21

2
cosecha (fecha, secuencia de actividades, recursos usados); almacenamiento (niveles de stock y venta en
cada período); y distribución (modo de transporte, rutas, secuencia de reparto).
La planificación de cosechas (“crop planning”) busca seleccionar los productos a plantar y la asignación
de un área donde hacerlo (tanto su localización como su tamaño). Tradicionalmente el objetivo ha sido el
de maximizar los beneficios obtenidos con esas decisiones (Nevo et al, 1994). El problema presenta una
especial dificultad dado el gran número de factores que intervienen (variedad de productos y sus
interacciones al ser plantados, localizaciones, aspectos socioculturales, disponibilidad de los inputs,
aspectos biológicos, de mercado…), además de la incertidumbre característica de esta industria (clima,
plagas…)
La programación lineal ha sido la herramienta tradicionalmente usada para abordar este problema desde
hace muchos años (Lowe, Preckel, 2004, mencionan en su review trabajos desde 1954). Sin embargo, en
ocasiones la propia dificultad del problema (incertidumbre, asunciones de linealidad, gran cantidad de
datos necesarios) ha dado lugar a que su implementación no haya sido todo lo exitosa que se esperaba
(Nevo et al, 1994). El rendimiento y los costes son función de ciertos factores determinísticos
(características del suelo –es decir, fertilidad-, riego, calidad de las semillas) además de aspectos
asociados al riesgo climático (Sarker et al, 1997).
Como se ha mencionado, la mayoría de los problemas reales abordando esta problemática considera
generalmente el beneficio como uno de los objetivos, siendo los recursos a gestionar el terreno disponible,
mano de obra y maquinaria, así como el agua disponible. Sin embargo, si se habla de agricultura
sostenible la problemática en general es de carácter multiobjetivo (Radulescu et al, 2014). Aquí se
incluyen objetivos tales como la rotación de los terrenos, el consumo de la menor cantidad de inputs, la
minimización del tiempo de trabajo pensando en la calidad de vida de los agricultores, o el riesgo de
pérdidas de cosechas.
1.1. Diversificación del riesgo en planificación de cosechas
Se suele considerar (Tadesse, Blank, 2003) que son tres los tipo de diversificación de riesgo usados en
agricultura. En primer lugar está la diversificación de productos, es decir, plantar diferentes productos en
las fincas disponibles, con lo que la varianza de los ingresos se reduce al participar en diversos mercados.
Es una estrategia fácil de implementar por cualquier agricultor, simplemente teniendo conocimiento de
cómo plantar diferentes semillas.
La segunda alternativa (la contemplada aquí) es la diversificación geográfica, consistente en plantar un
producto en fincas lo suficientemente separadas geográficamente como para evitar los riesgos generados
por las tormentas localizadas u otros fenómenos atmosféricos. Aquí el objetivo es reducir la varianza de la
cantidad recolectada, y requiere que el agricultor posea varias fincas en diversas zonas, por lo que resulta
más difícil de implementar. Nartea & Barry (1994) apuntan que además de las ventajas de esta estrategia
antes mencionadas, hay que tener en cuenta que se incrementan los costes de producción (transporte,
mano de obra, monitorización, supervisión y en definitiva la coordinación de la recolección). Concluyen
que esta estrategia es sobre todo interesante para grandes agricultores que no necesitan transportar muchas
máquinas.
Finalmente, la diversificación cultivar tiene en cuenta el factor tiempo, mezclando las dos anteriores y
obteniendo los dos tipos de ventajas mencionados. Para ello, planta un producto en diversas zonas de
CLAIO-2016
22

3
modo que su recolección se consiga en épocas del año diferente, minimizando riesgos tanto de pérdida de
cosecha como de precio de venta de los productos.
2 Problema de planificación de cosechas en entornos colaborativos
Tradicionalmente los agricultores tomaban sus decisiones de un modo aislado, adivinando cómo
evolucionarían los mercados y valorando los recursos disponibles. Una vez recolectados los frutos, los
ponían en el mercado y buscaban compradores que pagarían por ellos en función de la oferta disponible.
Esta visión de mundos diferentes en los que se mueven el cliente y el proveedor, hace ya tiempo que en
determinadas industrias (sobre todo en el ámbito del retail) se comenzó a cuestionar (Hamer, Champy,
1993), ya que al final perjudicaba tanto a quien oferta como a quien demanda: quien oferta asume riesgos
de encontrar comprador y obtener precios que rentabilicen su esfuerzo; el proveedor asume el riesgo de
encontrar en el momento que lo necesita el producto que busca, y de obtenerlo a un precio razonable. Por
tanto han surgido diversos movimientos (Collaborative Planning Forecasting and Replenishment, CPFR;
Vendor Managed Inventory, VMI; etc.) que buscan aumentar la relación a largo plazo con los
proveedores, y así hacer más transparente la cadena de suministro de modo que las decisiones de
planificación puedan ser realizadas con la mayor información posible.
También en el ámbito de la producción agrícola se puede apreciar en algunos casos este tipo de relaciones
a largo plazo. Algunas grandes cadenas de retailers (es bien conocido el caso por ejemplo en España de la
cadena Mercadona, The Economist, 2011) tienen acuerdos a largo plazo con proveedores, quienes a
cambio de garantizar un adecuado suministro en cantidad, calidad y tiempo, gozan de acuerdos a largo
plazo que les garantizan niveles de producción e ingresos.
En el ámbito que nos ocupa, grandes cadenas de retail contratan la producción de sus productos agrícolas
a grandes empresas agrícolas con las que tienen especiales acuerdos de colaboración a largo plazo, que de
este modo ven garantizados grandes niveles de producción, a cambio de ofrecer una determinada calidad
del servicio en calidad, cantidad y tiempo de entrega, además de exclusividad.
Por tanto, el problema de planificación de cosechas en estos casos no comprende la selección de
productos o los niveles de producción, sino cómo conseguir recoger los volúmenes de productos
comprometidos en las fechas prefijadas (es decir, la satisfacción de la demanda solicitada por el retailer).
La decisión es pues cuándo plantar cada producto, en qué finca, y en qué momento debe recolectarse ese
producto. Nótese que al tratarse en muchas ocasiones de productos perecederos (lechugas, tomates,…) no
conviene plantar de modo que recolecte más de lo que realmente ha demandado la cadena, ya que eso
daría lugar a productos de desecho. Se supone que estas empresas agrícolas disponen de información
suficiente como para saber el comportamiento de las fincas que poseen y la capacidad de producción que
cabe esperar.
3 Formulación del modelo de planificación de cosechas con demanda fijada
Se tienen N fincas Ff cada una dividida en parcelas, UP, como se indica en la Figura 1. Se observa que no
todas las UP tienen el mismo tamaño (las de los bordes pueden ser menores al tamaño estándar). Se sabe
la distancia dij entre las fincas para poder estimar luego los costes de transporte. La finca Ff tiene Kf
unidades UP.
CLAIO-2016
23

4
Se dispone asimismo de una lista de P productos hortofrutícolas p, cada uno perteneciente a modo de
ejemplo, a dos categorías (A –diferentes tipos de lechugas por ejemplo - y B –espinacas y otros productos
de hoja-). Llamemos Q(p) la función que nos da la categoría de un producto.
Se trata de hacer una planificación de qué plantar y en qué UP en cada semana, de modo que cuando se
vaya a recolectar (siempre antes de 15 semanas tras su plantación) no haya un excedente de productos que
sobrepasen la demanda en ese momento y así no se generen desperdicios. Además, se pretende que el
plan haga que se incurra en los menores costes (de transporte y de riego) y que a la vez se diversifique la
plantación de cada producto cada semana de modo que se reduzca el riesgo de que un problema en una
zona (heladas, inundaciones) ponga el riesgo toda la producción de esa semana. Restricciones adicionales
incluyen la imposibilidad de plantar ciertos productos en ciertas parcelas; en cada instante una parcela
sólo puede cultivar un producto y cuando dos parcelas adjuntas cultivan productos de diferente tipo hay
que dejar una porción de terreno sin plantar para separarlas; finalmente las horas de maquinaria son
limitadas,
Se conoce la demanda esperada de cada producto Dps en las próximas T semanas, además de diversa
información sobre fincas y UPs (rendimientos, superficies, costes riego, etc). Dado que el tiempo de
crecimiento de los productos es menor a ese tiempo (y que se supone conocido con exactitud en función
de la finca), se supone posible planificar totalmente la producción que satisfaga la demanda en las
semanas siguientes
Figura 1. Distribución geográfica de fincas y Unidades Productivas
Los datos necesarios en el modelo son las siguientes:
T Número de semanas para las que se hace la planificación (T=20)
Q(p) Función que para cada producto p indica a qué tipo de producto A o B pertenece
Dps Demanda del producto p en la semana s∈{1,…,T}
T(f,p,s,σ) Producción, en kg, obtenida en la finca f del producto p plantado en una UP
estándar completa, en la semana s={0..T-1}, y recogido σ={1,…,15} semanas
después
Afk % (en tanto por uno) de una superficie estándar que ocupa la UPfk
CRfk Coste en euros de regar cada semana la UPfk
Bfkp Binaria que indica si en la UPfk es posible plantar el producto p por razones de riego
ADYfkk’ Constantes binarias que indican si la UPfk y la UPfk’ son adyacentes o no
Ff
Ff’
100m
Dff’
UPfk
Ff
Ff’
100m
Dff’
UPfk
CLAIO-2016
24

5
KMm Horas totales disponibles de la máquina m en una semana cualesquiera
Mpm Horas de máquina m que requiere plantar el producto p en una UP estándar
MBpm Binaria que indica si la máquina m se requiere plantar el producto p (=1 si Mpm>0)
α % (en tanto por uno) de una UP que hay que dejar sin sembrar cuando está
adyacente con otra plantada con un producto incompatible (α=0.20).
CTf Coste (estimado) de recogida de un kg de cualquier producto en la finca f
CMfm Coste (estimado) semanal de envío a la finca f de la maquina m para trabajar allí en
la plantación de productos
Dff’ Distancia entre las fincas Ff y Ff ’
Respecto a las variables de decisión:
xpfkss’ Variables reales en [0,1] que indican el porcentaje de superficie UPfk a plantar con el
producto p en la semana s∈{0,..,T-1}, para recogerlo s’∈{1..15} semanas después.
Nótese que el s’ está acotado y debe ser tal que s+s’≤T (no se puede plantar nada
para recoger después del periodo cubierto por la demanda Dps), y por tanto es
s’∈{1..min{15,T-s}}
ypfks Variables binarias que valen 1 si en la semana s∈{0,..,T-1} está plantado el producto
p en la UPfk.
zfms Variables binarias que valen 1 si en la semana s∈{0,..,T-1} la maquinaria m será
necesaria para las plantaciones a realizar en la finca f
φpfs Variables binarias que valen 1 si en la semana s= {0…T-1} está plantado el producto
p en alguna UP de la finca Ff.
Θpff’s Variables binaria que vale 1 cuando en la semana s={0..T-1} está plantado el
producto p a la vez en alguna UP de las fincas Ff y Ff’, con f≠f’.
La primera función objetivo minimizará la suma de los costes derivados de la planificación (costes de
riego, costes de recogida y de movimiento de maquinaria).
Coste de riego:
[1]
Coste de recogida: Se supondrá (como aproximación) que los costes de recogida son proporcionales a un
valor asociado a la distancia de la finca f y a lo recogido en cada finca (hay un almacén central de
recogida del que parte un vehículo a cada finca a recoger el producto).
[2]
∑ ∑
−=fk Tsp
pfksfk yCR1..0,
∑ ∑
⋅⋅
−=−=f
sT
Tskpspfkfkf xAspfTCT
};15min{..1
1..0,,,,),,,(
σ
σσ
CLAIO-2016
25

6
Coste de plantación (maquinaria): Se supone de nuevo que hay un coste fijo semanal de llevar la
maquinaria a la finca (el coste variable de plantación se supone constante por finca por lo que no se
considera).
[3]
La segunda función objetivo minimizará los riesgos de tener toda la cosecha geográficamente cercana
usando unas variables asociadas al producto-finca-semana, al maximizar las distancias entre las fincas que
tienen plantados a la vez los mismos productos:
[4]
Para el cálculo correcto de las variables Θ, se añaden dos restricciones que fuerzan que Θpff ’s=1 sea el
producto de las variables φpfs y φpf’s, y por otra parte que φpfs, =1 ↔ Σk ypfks≥1:
[5] Θpff’s ≤ φpfs ∀p,f,f’≠f,s={0..T-1}
[6] Θpff’s ≤ φpf’s ∀p,f,f’≠f,s={0..T-1}
[7] φpfs ≤ Σk ypfks ∀p,f,s={0..T-1}
Finalmente, para completar el método lexicográfico necesitamos forzar que la nueva solución sea tan
buena como la obtenida con el primero objetivo; por tanto, si la solución óptima del primer objetivo fue
[1]+[2]+[3]=B, la nueva restricción será
[8] [1]+[2]+[3]≤Bχ
donde χ≥1.0 representa la holgura de hasta qué punto podríamos aceptar un aumento de coste para
obtener una mayor diversificación geográfica.
Respecto a las restricciones generales, tenemos:
• Demanda satisfecha
[9]
• No se planta más de un producto simultáneamente en una UPfk.
[10]
[11]
∑ ∑
−=fm Ts
fmsfm zCM1..0
},..,1{',)',,,( '',,
0},1'...14',15'{,
TspDxAssspfT psssspfk
sconsssskf
fk =∀∀=⋅⋅− −
≥−−−∈
∑
}1..0{,,1 −=∀≤∑ Tskfyp
pfks}1,...,{''
}};15min{..1{};1..0{;,,''
−+=∀
−=∀−=∀∀≤
σσσ
sss
sTTskfpyx pfkspfks
≥Ω
∀Θ≤Ω
Ω
∑≠
0
max
';
'' psDfff
spffff
CLAIO-2016
26

7
• En cualquier semana, no está plantado de un producto más de lo que cabe en una parcela .
[12]
• Asignación posible en función de riego.
[13]
• Asignación posible en función de adyacencia
[14]
• Hay máquinas disponibles para la plantación
[15]
• Cálculo de variables zfms (necesarias para la función objetivo)
[16]
• Asignación inicial
Para garantizar la factibilidad del modelo, dado que inicialmente hay determinados productos ya
plantados con distintas fechas de recolección, se añade esa producción esperada a la demanda
pendiente de asignar de modo que las restricciones de adyacencia de cultivos y de satisfacción de
demandas estén actualizadas.
3 Ilustración
Con la finalidad de ilustrar el modelo propuesto, se ha diseñado un ejemplo que consta de 4 fincas (N=4),
divididas en un total de 20 parcelas, con un tamaño variable entre 0.5 y 1 veces el tamaño estándar. La
distancia entre fincas, con vistas a diversificar la plantación, varía entre 20 y 200 kilómetros, con α=0.2 .
Se supone la existencia de 4 productos (P=4), 2 de la categoría A y 2 de la B. La demanda de cada
producto durante cada semana sigue una distribución de probabilidad uniforme desde el valor de 20 al
}1..0{,,, −=∀≤ TskfpBy fkppfks
}1,..,1{,,1
}}';15min{,...,1'{}},...,15)1(;0{max{'
,', −=∀∀∀≤∑−+−∈
−+∈
Tskfx
sTsssss
p
spfk
σ
σ
}}.'';15min{,...,1{''
};1'',...,1','{''
}}';15min{..1{'};1..0{'
;1:',);'()(:',;2 '''''''''
sT
ssss
sTTs
ADYkkpQpQppfxx fkksfkppfks
−∈∀−++=∀
−=∀−=∀
=∀≠∀∀−≤+
σσ
σασσ
}1..0{;
};15min{..1,,
−=∀∀≤⋅⋅∑−=
TsmKMMAx mpmfk
sTkfp
pfks
σ
σ
}1..0{;;
};15min{..1,
−=∀∀∀⋅∞≤⋅∑−=
TsmfzxMB fms
sTkp
pfkspm
σ
σ
CLAIO-2016
27

8
límite superior de 40 ton. A su vez, la adyacencia entre parcelas y la posibilidad de plantar cada producto
en cada parcela, constantes binarias ADYfkk’ y Bfkp respectivamente, se han obtenido de forma aleatoria.
Respecto a la maquinaria, se dispone de 6 tipos de máquinas (M=6), con una disponibilidad total de cada
máquina superior a las 200 horas, con tiempo requerido para plantación tomado valor aleatorio en torno a
5 horas. Los costes siguen distribuciones normales (riego con media 300 y d.t. 200; recogida con media
200 y d.t. 50; envío de la maquinaria con media 20 y d.t. 10.
Se resolvió la ilustración usando CPLEX, variando el parámetro χ entre 1.0 y 1.3 con el fin de observar la
relación entre un sacrificio en costes hasta de un 30%, frente a una mayor diversificación de las
plantaciones. Las soluciones se obtuvieron en un tiempo medio de XXX segundos (máximo= XX
segundos). Un resumen de los resultados se presentan en el la Figura 2.
Figura 2. Diferentes costes y diversificación (Ω) en función en los valores de χ
En la figura se observa que a partir de un determinado incremento de coste (20% en este caso) no se
obtiene una mayor diversificación geográfica de las cosecha, y hasta que no se produce un incremento
mínimo de coste (5% en el ejemplo) tampoco se produce ventaja ninguna. Asimismo, porcentualmente el
coste que más se incrementa al aumentar los costes totales son los de riego.
5 Conclusiones
En este trabajo se ha estudiado cómo planificar la plantación de productos agrícolas en entornos con
demanda prefijada, buscando una minimización de costes, con una segunda función objetivo consistente
en buscar una mayor diversificación geográfica de las plantaciones. Para instancias pequeñas es posible
resolver óptimamente este problema en tiempos menos de 30 minutos. Se observa que las ventajas dadas
por la diversificación aparecen acotadas incurriendo en ciertos incrementos de coste, no observándose
ventajas adicionales fuera de esos rangos. Es necesario presentar una batería de experimentos más grande
para confirmar estadísticamente estos resultados.
-145
-130
-115
-100
-85
-70
-55
-40
-25
-10
0
50000
100000
150000
200000
250000
300000
350000
400000
450000
1 1,025 1,05 1,075 1,1 1,125 1,15 1,175 1,2 1,225 1,25 1,275 1,3
Valores de costes y diversificación
CosteRiego CosteRecogida CosteMaq TotCoste - Omega
CLAIO-2016
28

9
Referencias
1. O. Ahumada, J. Rene Villalobos. Application of planning models in the agri-food supply chain: A review.
European Journal of Operational Research, 195:1-20, 2009.
2. M. Hammer & J. Champy. Reengineering the corporation: A manifesto for business revolution. Harper Collins,
New York, 1993.
3. T.J. Lowe & P.V. Preckel. Decision technologies for agribusiness problems: A brief review of selected
literature and a call for research. Manufacturing & Service Operations Management, 6(3):201-208, 2004.
4. G.V. Nartea & P.J. Barry. Risk efficiency and cost effects of geographic diversification, Review of Agricultural
Economics, 16:341-351, 1994.
5. A. Nevo, R. Oad, & T.H. Podmore. An integrated expert system for optimal crop planning. Agricultural
Systems, 45: 73-92, 1994
6. M. Radulescu, C.Z. Radulescu % G. Zbaganu. A portfolio theory approach to crop planning under
environmental constraints. Annals of Operations Research, 219:243-264, 2014.
7. R.A. Sarker, S. Talukdar, & A.F.M. Anwarul Haque. Determination of optimum crop mix for crop cultivation
in Bangladesh. Applied Mathematical Modelling, 21:621-632, 1997.
8. D. Tadesse & S.C. Blank. Cultivar diversity: A neglected risk management strategy. Journal of Agricultural
and Resource Economics, 28 (2):217-232, 2003.
9. The Economist, June 2nd
2011, http://www.economist.com/node/18775460
CLAIO-2016
29

Elementary shortest paths avoiding negative circuits
Rafael AndradeDepartment of Statistics and Applied Mathematics
Federal University of Ceará, Campus do Pici, BL 910, CEP 60.455-760Fortaleza, Ceará, Brazil
Rommel SaraivaDepartment of Computer Science
Federal University of Ceará, Campus do Pici, BL 910, CEP 60.455-760Fortaleza, Ceará, Brazil
Abstract
Let D = (V,A) be a digraph with a set of vertices V and a set of arcs A, with cij ∈ R rep-resenting the cost of an arc (i, j) ∈ A. The problem of finding the shortest elementary path inthe presence of negative cycles (SEPPNC) is NP-hard and consists in determining, if it exists,the path of minimum cost between two distinguished vertices s ∈ V and t ∈ V . We proposethree solution approaches for the SEPPNC, which are a compact primal-dual formulation, abranch-and-bound algorithm, and a cutting-plane method. An extensive computational studyperformed on both benchmark and randomly generated instances shows that our approachesoutperform state-of-the-art solution techniques for this problem, while providing optimal solu-tions for benchmark instances in very small execution times.
Keywords: Shortest elementary path in the presence of negative cycles; Compact formulation;Combinatorial Branch-and-Bound; Cutting-plane.
1 Introduction
Let D = (V,A) be a digraph with a set V of vertices and a set A of arcs. An arc from vertexi ∈ V to vertex j ∈ V is represented as (i, j) ∈ A with cij ∈ R being its cost. Given two distinctvertices s ∈ V and t ∈ V , a path from s to t (labeled here as s, t-path) is a sequence of verticesv1, v2, . . . , vn−1, vn, where v1 = s, vn = t and (vk, vk+1) ∈ A, for k = 1, . . . n − 1. An implicitassumption is that such path must be elementary, i.e., each vertex vk (k = 1, . . . , n) is visitedat most once, thus avoiding the presence of cycles. In this context, the problem of finding theshortest elementary path in the presence of negative cycles (SEPPNC) [6, 4, 7, 9, 8, 5, 11] consistsin determining, if it exists, an s, t-path of minimum cost when D contains negative (directed) cycles.This latter fact implies that the problem is NP-hard and therefore cannot be solved to optimalityusing exact optimization techniques for large scale problem instances.
CLAIO-2016
30

This work proposes mathematical programming based exact approaches and compare theirperformances with recent state-of-the-art solution strategies for this problem. More precisely, wederive an efficient compact primal-dual formulation (i.e., with a polynomial number of variablesand constraints), as well as a specialized combinatorial branch-and-bound algorithm and a newcutting-plane strategy for the SEPPNC. Extensive computational experiments conducted on bothbenchmark and new randomly generated instances show that our proposed approaches outperformexisting mathematical programming techniques reported in the literature so far.
The remainder of this work is organized as follows. Section 2 presents existing mixed-integerprogramming (MIP) formulations for the SEPPNC. Sections 3, 4 and 5 describe the new solutionapproaches. Section 6 reports computational experiments. Finally, Section 7 concludes the paperwith directions for future work.
2 Mixed-integer programming formulations
This section reports well established MIP formulations for the SEPPNC available in the literature.The following convention is adopted throughout the text. Given a digraph D = (V,A), let δ+j(resp. δ−j ) denote the set of arcs leaving (resp. entering) node j ∈ V . Further details concerningthe following models can be found in the corresponding references.
2.1 A linear flow based formulation
Ibrahim et al. [6] propose a compact linear MIP formulation based on a non-simultaneous networkflow model. Let xij (resp. yj) be a binary variable that takes the value 1 if arc (i, j) ∈ A (resp.vertex j ∈ V ) belongs to the solution, and 0 otherwise; and zkij > 0 be a continuous variable thatrepresents the flow through arc (i, j) ∈ A in the path from vertex s to vertex k ∈ V \{s}. Themodel in [6] is as follows.
(IMM ) min∑
(i,j)∈Acijxij (1)
s.t.∑
j∈δ+s
xsj = 1 (2)
∑
j∈δ−t
xjt = 1 (3)
∑
j∈δ+i
xij = yi, ∀i ∈ V \{s, t} (4)
∑
j∈δ−i
xji = yi, ∀i ∈ V \{s, t} (5)
∑
j∈δ+s
zksj −∑
j∈δ−s
zkjs = yk, ∀k ∈ V \{s} (6)
∑
j∈δ+i
zkij −∑
j∈δ−i
zkji = 0, ∀k ∈ V \{s}, i ∈ V \{s, k} (7)
CLAIO-2016
31

∑
j∈δ+k
zkkj −∑
j∈δ−k
zkjk = −yk, ∀k ∈ V \{s} (8)
zkij ≤ xij , ∀k ∈ V \{s}, (i, j) ∈ A (9)
xij ∈ {0, 1}, ∀(i, j) ∈ A (10)
yj ∈ {0, 1}, ∀j ∈ V (11)
zkij ≥ 0, ∀(i, j) ∈ A, k ∈ V \{s} (12)
The objective function (1) minimizes the total cost of the s, t-path. Constraints (2)–(5), (10)and (11) define an s, t-path, whereas the constraints (6)–(9) and (12) ensure that such path iselementary. Formulation (IMM) contains O(|V |2) binary variables, O(|V |3) continuous variables,and O(|V |3) constraints.
2.2 A non-linear formulation
Haouari et al. [4] conceive a compact non-linear MIP formulation that uses binary variable xij ,which designates whether arc (i, j) ∈ A is included (value 1) or not (value 0) in the solution; andcontinuous variable uj , which indicates the number of arcs in the s, t-path that connects vertex sto vertex j ∈ V \{s}. In the following formulation [4], assume that |δ−s | = |δ+t | = 0 and (s, t) 6∈ A.
(HMM ) min∑
(i,j)∈Acijxij (13)
s.t.∑
j∈δ+s
xsj = 1 (14)
∑
j∈δ−t
xjt = 1 (15)
∑
i∈δ−j
xij −∑
i∈δ+j
xji = 0, ∀j ∈ V \{s, t} (16)
∑
i∈δ−j
xij ≤ 1, ∀j ∈ V \{s, t} (17)
ujxij = (ui + 1)xij , ∀j ∈ V \{s, t}, i ∈ δ−j \{s} (18)
ujxsj = xsj , ∀j ∈ δ+s (19)
1 ≤ uj ≤ |V | − 1, ∀j ∈ V \{s} (20)
xij ∈ {0, 1}, ∀(i, j) ∈ A (21)
Constraints (14)–(16) in association with (21) enforce that x defines an s, t-path. Constraint (17)requires that each vertex j ∈ V \{s, t} has at most one incident arc. It is redundant but strengthensthe linear relaxation of this formulation. Finally, constraints (18)–(20) are subtour-eliminationconstraints. To linearize constraints (18) and (19), the authors use the reformulation-linearizationtechnique (RLT) of [12]. This is accomplished by the following substitutions of variables αij = ujxijand βij = uixij , for all j ∈ V \{s} and i ∈ δ−j \{s} (the reader is referred to [4] for further details).Thus, the non-linear MIP formulation (HMM) is equivalent to the following linear MIP formulation.
CLAIO-2016
32

(HMM-RLT ) min∑
(i,j)∈Acijxij (22)
s.t. (14), (15), (16), (17), (21)
αij = βij + xij , ∀j ∈ V \{s}, i ∈ δ−j \{s} (23)
xsj +∑
i∈δ−j
αij −∑
i∈δ+j
βji = 0, ∀j ∈ δ+s (24)
∑
i∈δ−j
αij −∑
i∈δ+j
βji = 0, ∀j ∈ V \{δ+s ∪ {s, t}} (25)
xij ≤ αij ≤ (|V | − 1)xij , ∀j ∈ V \{s}, i ∈ δ−j \{s} (26)
xij ≤ βij ≤ (|V | − 1)xij , ∀j ∈ V \{s}, i ∈ δ−j \{s} (27)
Constraints (23)–(27) are linear subtour-elimination constraints, whereas the remaining con-straints, as cited above, produce an s, t-path. Formulation (HMM-RLT) contains O(|V |2) binaryvariables, O(|V |) continuous variables, and O(|V |2) constraints.
3 A new MTZ based compact primal-dual formulation
In this section, we present a compact primal-dual formulation for the SEPPNC. For the sake ofsimplicity, let xij ((i, j) ∈ A) and uj (j ∈ V ) be decision variables similar to those employed informulation (HMM). Initially, consider the following observation.
Observation 1 Let v1, v2, v3, . . . , vn−1, vn be an elementary s, t-path in G = (V,A), where v1 = sand vn = t; and uv be the number of arcs from s to v in such path, for all v ∈ {v1, v2, v3, . . . , vn−1, vn}.Thus, uv1 = 0 and uvk = uvk−1
+ 1, for k = 2, 3, . . . , n.
One strategy is to capture the idea of Observation 1 with the aim of introducing a MIP formu-lation that connects primal variables x and dual variables u in a unique model, focusing solely onthose variables directly involved in the s, t-path. The formulation is as follows.
(CPD) min∑
(i,j)∈Acijxij (28)
s.t.∑
i∈δ−j
xij −∑
i∈δ+j
xji =
−1, if j = s,
+1, if j = t,
0, otherwise.
, ∀j ∈ V (29)
∑
i∈δ−j
xij ≤ 1, ∀j ∈ V \{s, t} (30)
uj − ui ≥ 1− |V |(1− xij), ∀(i, j) ∈ A (31)
uj − ui + (|V | − 1)xji + (|V | − 3)xij ≤ |V | − 2, ∀(i, j) ∈ A, i 6= s (32)
CLAIO-2016
33

us = 0, uj ≥ 0, ∀j ∈ V (33)
xij ∈ {0, 1}, ∀(i, j) ∈ A (34)
Constraints (29) and (34) define the existence of an s, t-path. Constraint (30) is redundantbut strengthens the linear relaxation of this formulation. Constraints (31)–(32) are the well knownMiller-Tucker-Zemlin [10] (MTZ) constraints which, in association with constraints (33), avoidcycles in any feasible solution. In particular, as shown in [3], constraints (32) correspond to a liftingof the inequalities uj − ui ≤ 1 + |V |(1 − xij), for all (i, j) ∈ A, that jointly with constraints (31)ensure that if an arc (i, j) ∈ A belongs to the solution, then uj − ui = 1. Formulation (CPD)contains O(|V |2) binary variables, O(|V |) continuous variables, and O(|V |2) constraints.
4 A combinatorial branch-and-bound algorithm
In this section, we describe the main operations of a specialized branch-and-bound (B&B) algorithmfor SEPPNC. These operations are at the core of our B&B approach and they show how subproblemsare evaluated and how branching is done.
4.1 Evaluation of subproblems
A convenient alternative to obtain a relaxation of the SEPPNC is to simply remove the subtour-elimination constraints (31)–(33) in model (CPD), as well as the integrality requirement on thevariables xij ((i, j) ∈ A). Thus, in each node of the B&B search tree we solve the following linearprogramming (LP) model, which is a combinatorial relaxation of the original problem.
(CPD-CR) min∑
(i,j)∈Acijxij (35)
s.t.∑
i∈δ−j
xij −∑
i∈δ+j
xji =
−1, if j = s,
+1, if j = t,
0, otherwise.
, ∀j ∈ V (36)
∑
i∈δ−j
xij ≤ 1, ∀j ∈ V \{s, t} (37)
xij ∈ [0, 1], ∀(i, j) ∈ A (38)
It can be checked that the matrix defining model (CPD-CR) is totally unimodular. It is com-posed of a classical network flow matrix (constraints (36)) and its non null coefficients appearingin the rows corresponding to constraints (37) (used only to avoid the intersection of two or morecycles or of a cycle with an s, t-path) are exactly the ones of the rows corresponding to the firstcolumns of the flow matrix referred to the incoming flows in each vertex j ∈ V of (36). Thus, thesolution of the above formulation is integer, i.e., an s, t-path possibly containing disjoint cycles.Note that B&B acyclic node solutions are feasible for the original problem, thus providing validupper bounds on the optimal solution value.
CLAIO-2016
34

4.2 Branching rule
In the B&B algorithm, when a relaxed node solution contains disjoint cycles, we represent all ofthem by C1, C2, . . . , Cm. The idea is to choose one cycle to be broken. In particular, our algorithmselects the cycle C∗ = Cj (1 ≤ j ≤ m) with the minimum cardinality (number) of arcs. Thisis intended to reduce the number of new partitions during the branching process of the B&Balgorithm, as explained below. Priority is given to the cycle with the largest cost in case of ties.Once determined the cycle C∗, let a1, a2, a3, . . . , a|C∗| be its arcs. The corresponding node will giveorigin to the following |C∗| branches: a1, a1a2, a1a2a3, . . . , a1a2a3 . . . a|C∗|. This strategy is calleddisjunctive combinatorial branch and has been explored in B&B schemes whose node formulationis a combinatorial optimization problem (see, e.g., [1, 2]).
We illustrate the branching process in Fig. 4.2. Solid (resp. dotted) lines show that an arcis included in (resp. removed from) the corresponding node solution. All possible new partitions(subproblems) are represented by the leaves in that tree. Fixing an arc in (resp. out of) the nodesolution can be done by setting the corresponding variable lower and upper bounds to one (resp. tozero). In this figure, for every new subproblem, F0 and F1 are the sets of arcs whose both boundsare fixed at zero and at one, respectively. Each new subproblem is solved before its inclusion in theB&B tree of open nodes. We use the best-first strategy to choose the open node to be evaluated,which explores the nodes in increasing order of solution value.
Figure 1: Disjunctive combinatorial branch: new partitions n1, n2, . . . , n|C∗| are leaves in this tree.
5 Cutting-plane method
We devote this section to conceive an exact cutting-plane (CP) method for the SEPPNC. Forsuch purpose, formulation (CPD-CR) is adopted to solve an initial LP relaxation of the originalproblem. Recall that this formulation returns an integer solution, but not necessarily feasible for theunderlying problem. While the relaxed solution contains cycles, we iteratively add valid inequalitiesto cut off them. If the relaxed solution is acyclic, then the optimal solution is reached.
Algorithm 1 gives the main steps of our CP method, as well as the inequality implemented tobreak cycles. In this algorithm, let containCycle be a boolean procedure that checks whether agiven relaxed solution passed as its argument contains cycles.
CLAIO-2016
35

Algorithm 1 Cutting-plane method for the SEPPNC1: sol← solve(CPD-CR)2: while containCycle(sol) do3: Let C1, C2, . . . , Cm represent the cycles of sol4: for i← 1,m do5: Let xj represent an arc j ∈ Ci
6: Add inequality∑
j∈Cixj ≤ |Ci| − 1 to (CPD-CR)
7: end for8: sol← solve(CPD-CR)9: end while10: return sol
6 Summary of numerical results
We compare our three solution approaches with the ones here reproduced from [6, 4]. We reporta short summary of numerical results for 105 problem instances categorized as follows: 38 generaldigraphs of [4], 50 randomly generated digraphs, and 17 grids of [9]. The complete analysis of theseexperiments will be reported in a full version of this work. They were performed on a PC IntelPentium i7 / 8 x 3.60 GHz / 16 GB DDR3 RAM under Linux Ubuntu 14.05 LTS. We use ILOGCPLEX 12.6 and Java concert. The CPU time limit for each instance is 3600 seconds.
For the benchmark instances [4], model (CPD) obtained optimal solutions in smaller CPU timefor about 58% (22) of them, while the CP algorithm presented better CPU times for 32% (12)of these instances and the B&B algorithm got better CPU times for 10% (4) of the remaininginstances. Nevertheless, the average CPU time of the CP algorithm was 1.296 seconds, while forthe B&B algorithm it was 1.819 seconds. Model (IMM) was not able to solve 17 of these instancesand model (HMM-RLT) found all optimal solutions in average CPU time equal to 13.454 seconds.
Concerning the new randomly generated instances, the B&B algorithm presented better CPUtimes for 56% (28) of these instances and the CP algorithm got better CPU times for 40% (20)of the remaining instances. For this set of instances, model (CPD) got better CPU times foronly 2 instances. The average CPU time of the CP algorithm was 2.327 seconds, while for theB&B algorithm it was 2.769 seconds. Model (IMM) solved only 11 of these instances, while model(HMM-RLT) found all optimal solutions in 106.621 seconds of average CPU time.
Finally, for the grid instances [9], model (CPD) provided optimal solutions in smaller CPUtime for about 88% (15) of them, while model (HMM-RLT) got better CPU time for the remaininginstances (2). These models found all optimal solution in 3.852 and 4.020 seconds, respectively.The total time spent by model (IMM) to solve these instances was 19.454 seconds. The B&B andCP algorithms did not find the optimal solution for one instance within 3600 seconds of CPU time.
7 Final remarks
We proposed new solutions approaches for the SEPPNC, including a compact primal-dual formula-tion, a branch-and-bound algorithm, and a cutting-plane method. Extensive numerical experimentsshowed that all of them outperform existing [6, 4] solutions techniques for this problem while ob-taining optimal solutions for all instances in only few seconds. For all benchmark [4] and randomlygenerated instances, the primal-dual formulation alternates better results with both branch-and-bound and cutting-plane algorithms. Regarding the grid instances [9], globally the primal-dual
CLAIO-2016
36

formulation showed to be more attractive than the remaining solution strategies.
References
[1] R. C. Andrade and A. T. Freitas. Disjunctive combinatorial branch in a subgradient treealgorithm for the dcmst problem with vns-lagrangian bounds. Electronic Notes in DiscreteMathematics, 41:5–12, 2013.
[2] M. Batsyn, B. Goldengorin, A. Kocheturov, and P. M. Pardalos. Tolerance-based vs. cost-basedbranching for the asymmetric capacitated vehicle routing problem. In Models, Algorithms, andTechnologies for Network Analysis, pages 1–10. Springer, 2013.
[3] M. Desrochers and G. Laporte. Improvements and extensions to the Miller-Tucker-Zemlinsubtour elimination constraints. Operations Research Letters, 10(1):27–36, 1991.
[4] M. Haouari, N. Maculan, and M. Mrad. Enhanced compact models for the connected subgraphproblem and for the shortest path problem in digraphs with negative cycles. Computers &Operations Research, 40(10):2485–2492, 2013.
[5] M. S. Ibrahim. A strong class of lifted valid inequalities for the shortest path problem indigraphs with negative cost cycles. Journal of Mathematics Research, 7(4):162–166, 2015.
[6] M. S. Ibrahim, N. Maculan, and M. Minoux. A strong flow-based formulation for the shortestpath problem in digraphs with negative cycles. International Transactions in OperationalResearch, 16(3):361–369, 2009.
[7] M. S. Ibrahim, N. Maculan, and M. Minoux. A note on the NP-hardness of the separationproblem on some valid inequalities for the elementary shortest path problem. Pesquisa Opera-cional, 34:117–124, 2014.
[8] M. S. Ibrahim, N. Maculan, and M. Minoux. Le Problème Du Plus Court Chemin Avec DesLongueurs Negatives. Editions universitaires européennes, Saarbrucken (Allemagne), 2015.
[9] M. S. Ibrahim, N. Maculan, and M. Minoux. Valid inequalities and lifting procedures for theshortest path problem in digraphs with negative cycles. Optimization Letters, 9(2):345–357,2015.
[10] C. E. Miller, A. W. Tucker, and R. A. Zemlin. Integer programming formulation of travelingsalesman problems. Journal of the ACM (JACM), 7(4):326–329, 1960.
[11] L. P. Pugliese and F. Guerriero. On the shortest path problem with negative cost cycles.Computational Optimization and Applications, 63(2):559–583, 2016.
[12] H. D. Sherali and W. P. Adams. A hierarchy of relaxations between the continuous andconvex hull representations for zero-one programming problems. SIAM Journal on DiscreteMathematics, 3(3):411–430, 1990.
CLAIO-2016
37

Detecting separation in logistic regression via linear
programming
Inácio Andruski-GuimarãesUTFPR - Universidade Tecnológica Federal do Paraná, Curitiba, Brasil
Abstract
The parameter estimation in logistic regression model is known to be dependent on the dataconfiguration. While the logistic model work well for many situations, may not work when thegroups of observations are completely separated. Separation is a common problem in the logisticregression. Mathematical Programming approaches have been used for detecting separated datain logistic regression, but most of these researches have focused on the two group problem. In thispaper we propose a linear programming formulation to detect separation in polytomous logisticregression. The proposed approach classifies data as completely separated, quasi-separated oroverlapped, and can be used as part of the parameter estimation. Comparison with othermethods, using different data sets taken from the literature, shows that our formulation maysuggest an efficient alternative to mathematical programming approaches for the multiple-groupproblem.
Keywords: Polytomous Logistic Regression; Complete Separation; Linear Programming.
1 Introduction
The logistic regression model is known as a powerful method widely applied to model the rela-tionship between a categorical - or ordinal - dependent variable and a set of explanatory variables,or covariates, that may be either continuous or discrete. The accuracy of the Logistic RegressionModel has been reported in many studies involving bankruptcy prediction, marketing applicationsand cancer classification, among others applications. However, the parameter estimation in logisticregression model is known to be dependent on the data configuration. While the logistic regressionmodel work well for many situations, may not work when the data set has no overlapping. Inorder to way out the problem that arises when the data set has no overlapping, Rousseeuw andChristmann (2003) proposes the Hidden Logistic Regression Model (HLR). Another approachesto deal with separation can be found in Heinze and Schemper (2002), for binary response, andAndruski-Guimarães and Chaves-Neto (2009), for polytomous response, to name just a few.
Mathematical Programming approaches have been used for detecting separated data in dis-criminant analysis, but almost all researches have focused on the two group problem. An algebraicapproach, suggested by Albert and Anderson (1984), uses ideas of linear programming and specifiesthe necessary constraints, but not an objective function. A mixed integer linear program, presentedby Santner and Duffy (1986), determines whether data is separated or overlapped. Silvapulle and
CLAIO-2016
38

Burridge (1986) uses linear programming to check the necessary conditions for the existence of a fi-nite maximum likelihood estimate for the logistic model. A single linear programming formulation,proposed by Bennett and Mangasarian (1992), generates a plan that minimizes an average sum ofmisclassified points belonging of two disjoint point sets in n-dimensional real space. An algorithmproposed by Konis (2007) is based on a linear program with a nonnegative objective function thathas a positive optimal value when separation is detected.
In this paper we propose a linear programming formulation to detect separation in polytomouslogistic regression. The proposed approach classifies data as completely separated, quasi-separatedor overlapped, and can be used as part of the parameter estimation. A comparative analysis withother conventional LP methods shows that our approach may suggest an efficient alternative totraditional statistical methods and LP formulations for the multiple-group classification problem.
This paper is organized as follows. Section 2 consists of a brief review of the Polytomous LogisticRegression Model. Section 3 presents an overview on linear programming for detecting separation.In section 4 we propose a linear programming formulation to detecting separated data. In Section 5we apply the proposed model on data sets taken from the literature and compare their performancewith those that were obtained from another methods. Section 6 gives a brief conclusion and makessuggestions for future studies.
2 Problem Description
Let us consider a sample of n independent observations, available from the groups G1, ..., Gs, anda vector of explanatory variables, xT = (x0, x1, ..., xp), where x0 ≡ 1, for convenience. Let Ydenote the polytomous dependent variable with s possible outcomes. We will summarize the nobservations in a matrix form given by:
X =
1 x11 ... xp11 x12 ... xp2... ... ... ...1 x1n ... xpn
The Classical Logistic Regression (CLR) Model assumes that the posterior probabilities havethe form:
P (Gk | x) =exp (B k)s∑
i=1
exp (B i)
,
where B k = βk0 +p∑
j=1
βkjxj , k = 1 , 2 , ... , s − 1 and B s = 0. In this paper the group s is
called reference group. The model involves (s− 1) (p+ 1) unknown parameters and the conditionallikelihood function is:
L (B | Y,x) =n∏
i=1
s∏
k=1
[P (Gk | x i)]Yki ,
CLAIO-2016
39

where Y = (Y1 , ... ,Yn)T and Yi = (Y1i, ..., Ysi), with Yki = 1 if Y = k , and Yki = 0 otherwise.Taking the logarithm, the log-likelihood function is given by:
` (B | Y,x) =n∑
i=1
s∑
k=1
Ykiln [P (Gk | x i)] .
Thus:
∂
∂βkj` (B | Y,x) =
n∑
i=1
xij (Yki − P (Gk | x i)) .
The Maximum Likelihood Estimator (MLE) B̂ is obtained by setting the derivatives to zeroand solving for B. The solution is found using an iterative procedure, such as Newton-Raphsonmethod.
In practice, the estimation of unknown parameters should be considering the possible config-urations of the sample points. Albert and Anderson (1984) suggested a sample classification intothree categories: Overlapped, completely separated and quasi-completely separated, when perfectprediction occurs only for a group of observations. They also proved that the MLE do not exists ifthere is complete separation among the groups. If there is complete, or quasi-complete separation,existing iterative methods fail to converge, or give a wrong answer.
3 Solution Method
The use of linear programming for detecting separation among the sample points was proposed byAlbert and Anderson (1984). We say that two groups are completely separated if there exists avector B ∈ Rm, where m = (s− 1)(p+ 1), such that for all i ∈ Gj , and j, t = 1, ..., s (j 6= t):
(B j −B t)Tx i > 0 .
We say there is quasi-complete separation if, for all i ∈ Gj , and j, t = 1, ..., s (j 6= t):
(B j −B t)Tx i ≥ 0 ,
with equality for at least one (i, j, t) triplet. The points for which the equality holds are said to bequasi-separated.
In binary logistic regression, if there is complete separation, the MLE do not exist. But, inpolytomous logistic regression, complete separation does not make the same sense, although theparameter estimation is not necessarily affected. We say that two groups Gi and Gj are linearlyseparable if there exists a vector Ω = (ω1, ..., ωp) and a real number δ such that Ω xk > δ if x k ∈ Gi
and Ω xk < δ if x k ∈ Gj , where i, j = 1, ..., s, i 6= j and k = 1, ..., n. When there are more thantwo groups, the difference between linear separability and separation becomes more important. Inthis case linear separability means the existence of a set of vectors Ω 1, ...,Ω s satisfying s(s − 1)inequalities given by:
CLAIO-2016
40

(Ω j −Ω t)Tx i ≥ δ ,
for all i = 1, ..., n, and j, t = 1, ..., s (j 6= t).For s > 2 groups, Bennett and Mangasarian (1992), defined the piecewise linear separability of
data from s groups as: The data from s groups are piecewise-linear-separable if there exist a vector(β0
k, β1k, ..., βp
k) ∈ Rp+1, k = 1, ..., s, such that, ∀i ∈ Gh:
β0h +
p∑
j=1
xijβjh ≥ β0k +
p∑
j=1
xijβjk + 1
where k 6= h.Let Xj be the matrix with rows xT
i such that i ∈ Gj . We can define the (s− 1)× s matrix X̃j
to have blocks Xj in each element of column j, blocks −Xj in row k and column k, for k < j, andin row k − 1 and column k, for j < k, and to be zero otherwise. For example, if the problem hasfour groups, the matrix X̃3, is given by:
X̃3 =
−X3 0 X3 0
0 −X3 X3 00 0 X3 −X3
.
As stated in Konis (2007), if we let
X̃ =
X̃1...
X̃s
,
then X̃B ≥ 0 implies that B satisfies the conditions for quasi-complete separation. If X̃jB ≥ 0, fora given j, then
(B j −B t)Tx i ≥ 0 ,
Let us consider s groups G1, ..., Gs, and a vector of explanatory variables, xT = (x1, ..., xp).Suppose there is complete separation among two groups, Gi and Gj , i = 1, ..., s− 1, j = 2, ..., s (i <j). Then there is a hyperplane Hij such that all of the sample points in Gi lie on one side of Hij andall of the sample points in Gj lie on the other side of the hyperplane. The distance of the x k pointfrom the hyperplane is given by dkij = x T
k U ij , where U ij is a unit vector normal to Hij . If thereis complete separation among Gi and Gj , then there is a vector U ij such that dkij < 0, if x k ∈ Gi,and dkij > 0, if x k ∈ Gj . If there is quasi-complete separation among the groups Gi and Gj , thendkij ≤ 0, if x k ∈ Gi, and dkij ≥ 0, if x k ∈ Gj , with equality for at least one value k = 1, ..., n. LetS(U ij) =
∑nk=1 dkij and a hyperplane Pij with normal vector U ∗
ij such that S(U ∗ij) is maximum.
In this case, finding U ∗ij can be posed as:
CLAIO-2016
41

Max S(U ij) =∑n
k=1 dkij
s.t dkij = x Tk U ij ≥ 0
dkij = x Tk U ij ≤ 0
If there is no vector U ij satisfying the constraints, then there is overlap among Gi and Gj . Ifthe model above is feasible, its solution provides a vector U ∗
ij such that S(U ∗ij) is maximum. An
additional constraint, given by U TijU ij = 1 is not considered because our purpose is to determine
if the sample point is completely separated, or quasi-completely separated, by U ij . Hence thelength of U ij is not relevant. Furthermore, the referred constraint gives a non linearly constrainedoptimization problem, which is not appropriated for our purpose. The proposed model can besolved using techniques of linear programming, such as Simplex Method or Interior Points Method.
4 Applications
In this section we consider two benchmark data sets, taken from the literature. Iris Data, taken fromFisher (1936), and Fatty Acid Composition Data, taken from Brodnjak−Vončina et al. (2005).We have applied the proposed model to both data sets. The results achieved are given in thesequence.Example 1: Iris Data. There are three groups of Iris flowers: Iris Setosa (G1), Iris Versicolor(G2) and Iris Virginica (G3). For each group there are 50 observations and four independentvariables: Sepal Length (x1), Sepal Width (x2), Petal Length (x3) and Petal Width (x4). In thispaper, the reference group is Iris Virginica.
Table 1: Vectors for Iris Data.
U 12 U 13 U 23
0,156579 0,115581 -x-
0,359894 0,306824 -x-
0,491712 0,434272 -x-
0,777289 0,838992 -x-
Our results showed that two groups, G2 (Iris Versicolor) and G3 (Iris Virginica), overlap andform a cluster completely separated from G1 (Iris Setosa).Example 2: Fatty Acid Data. There are 120 observations, five groups and seven variables,representing the percentage levels of seven fatty acids, namely palmitic (x1), stearic (x2), oleic (x3),linoleic (x4), linolenic (x5), eicosanoic (x6) and eicosenoic (x7) acids. In this paper we considerfive groups: rapeseed (G1), sunflower (G2), peanut (G3), corn (G4) and pumpkin (G5) oils. In this
CLAIO-2016
42

Table 2: Vectors for Fatty Acid Data.
U 12 U 13 U 14 U 15 U 23 U 24 U 25 U 34 U 35 U 45
-x- -x- 0,1377 -x- -x- 0,4265 -x- 0,1658 0,5642 -x-
-x- -x- 0,1239 -x- -x- 0,0477 -x- 0,6155 0,1678 -x-
-x- -x- 0,0310 -x- -x- 0,3265 -x- 0,2545 0,2409 -x-
-x- -x- 0,0422 -x- -x- 0,8396 -x- 0,8255 0,1247 -x-
-x- -x- 0,1550 -x- -x- 0,5246 -x- 0,3205 0,2104 -x-
-x- -x- 0,2023 -x- -x- 0,3522 -x- 0,2455 0,7823 -x-
-x- -x- 0,1002 -x- -x- 0,1155 -x- 0,1855 0,3401 -x-
paper the reference group is G5 (pumpkin oil). The original data set have eight groups, and thecomplete table of the original data can be found in Brodnjak−Vončina et al. (2005).
Our results showed that the group G3 (pumpkin oil) is completely separated from G1 (rapeseedoil). Furthermore, the group G4 (corn oil) is completely separated from G5) (pumpkin oil).
5 Conclusions
The purpose with this job is simply to develop and implement a simple and direct model basedon Linear Programming which allows the detection of separation among sample points, in order toestimate the parameters for the Polytomous Logistic Regression Model, and to explore the perfor-mance of the model. This paper is not intended to give a detailed explanation about theoreticalaspects which involves neither linear programming techniques nor the existence of the referred pa-rameters. The results achieved suggest that the proposed approach is a promising alternative todetecting separation, even when a large number of dimensions have to be considered. The proposedapproach does not need any particular ordering arrangement of data, which is an advantage forpractical purposes. Furthermore, there are not computational difficulties to implement the referredapproach.
References
[1] A. Albert, J. A. Anderson, On the existence of maximum likelihood estimates in logisticregression models, Biometrika, 71, 1–10 (1984).
[2] D.Brodnjak−Vončina Z.C.Kodba, e C.Novič, Multivariate data analysis in classification ofvegetable oils characterized by the content of fatty acids. Chemometrics and Intelligent Labo-ratory Systems 75, 31–43 (2005).
[3] R.A. Fisher, The use of multiple measurements in taxonomic problems. Annals of Eugenics 3,179–188 (1936).
[4] N. Freed, F. Glover, Simple but powerful goal programming models for discriminant problems.European Journal of Operational Research 7, 44-60 (1981).
CLAIO-2016
43

[5] K. Konis, Linear programming algorithms for detecting separated data in binary logistic re-gression models. DPhill in Computational Statistics, Worcester College, University of Oxford,Department of Statistics, 1 South Parks Road, Oxford OX1 3TG, United Kingdom, (2007).
[6] K. F. Lam, J. W. Moy, A piecewise linear programming approach to the two group discriminantproblem - an adaptation to Fishers linear discriminant function model. European Journal ofOperational Research 145, 471 - 481 (2003).
[7] T. J. Santner, D. E. Duffy, A note on A. Albert and J. A. Anderson’s conditions for theexistence of maximum likelihood estimates in logistic regression models. Biometrika, 73 , 1–10(1986).
CLAIO-2016
44

A multivariate approach for associating products to points of sale in
the indirect distribution channel
Michel Anzanello Department of Production Engineering and Transportation,
Federal University of Rio Grande do Sul, Brazil [email protected]
Guilherme Tortorella
Department of Production Engineering and Systems, Federal University of Santa Catarina, Brazil [email protected]
Giuliano Marodin Business Management, University of South Carolina, Columbia – USA
Carlos Ernani Fries Department of Production Engineering and Systems, Federal University of Santa Catarina, Brazil
Abstract Structured methods aimed at selecting the appropriate product mix to be offered to each point of sales are of utmost importance for firms that work in the indirect channel. This paper proposes a quantitative-based approach for selecting the recommended product mix to be directed to the POS based on products and customers’ patterns. For that matter, products and customers are grouped based on their features and their levels of relationship are identified. The proposed method relies on Multivariate Analysis techniques that allow the reduction of the number of variables describing product and customers’ features, and clustering techniques to group products and customers according to their similar behavior. When applied to an indirect distribution channel of a multinational company from the food and agricultural commodities sector, the method effectively clustered products and customers with similar patterns; such results were validated by company’s historical data and experts’ assessment. Keywords: Supply Chain Management (SCM); Indirect distribution channel; Product mix; POS (point of sale); Principal Component Analysis (PCA).
1 Introduction There is a continuous search for the efficient balance between low inventory and high availability of key products to customers at the point of sales (POS) (Kurata et al., 2007). Supply chain management plays an important role in providing greater value to the consumer, at a minimum cost (Christopher, 2011). In particular, decisions involving distribution channels (e.g. product mix and inventory levels at the POS) are strategic, and they substantially impact on revenue, availability and cost at the POS (Yao and Liu,
CLAIO-2016
45

2005). Efficiency and effectiveness of a supply chain come mostly from a coherent distribution strategy (Ballou, 2006). The food industry is a typical example where companies are challenged to deal with massive amounts of data for defining mix and inventory levels at the POS. In general, these companies choose the indirect sales channel, characterized by the existence of intermediaries - in this case, distributors and POS - between the company and the consumer. The main reasons for adopting this strategy are agility, coverage and capillarity that it provides to meet consumers (Lim and Hall, 2008). Since distributors act as the link between manufacturers and the market, it is essential their goals, rules and action plans to be well defined, especially those related to sales force. However, these settings between the industry and its partners usually rely on unstructured techniques and limited basis (Seifert et al., 2006; Rosenbloom, 2011). Relevant settings, such as the mix of products to be offered to each POS, are improperly carried out due to the lack of information or large volume of data involved (Hessels and Terjesen, 2010). As a result, there is an absence of explicit action plans to distributor’s sales, which entails losses of selling opportunities and facilitates the entry and expansion of competitors (Wallace et al., 2004). In light of that, this paper proposes a multivariate-based method for associating families of products with groups of POS based on quantitative data. It aims to generate results that assist companies in the planning, execution and control of the indirect distribution channel activities by facilitating the definition of the product mix that should be assigned to each POS. For this purpose, it applies multivariate techniques (more specifically, Clustering and Principal Component Analysis) to assess the relationship between products and customers profiles described by multiple variables. Such variables are typically related to number of orders and selling rates, among others, and may present elevated levels of correlation that reduce the effectiveness of multivariate techniques. To address that point, our propositions first convert the original variables into PCA scores; such uncorrelated new variables are then inserted into the clustering technique. A suggested index for measuring the proximity between clusters enables assessing the similarity between groups of products and customers. The proposed method also demonstrates an important contribution to practice: companies with portfolios comprised of thousand of products sold in thousands of different locations face a complex task in order to manage the POS product mix without structured quantitative methods. The proposed method tackles that problem by integrating straightforward, yet efficient multivariate techniques aimed at improving sales at the POS.
2 Theoretical background
2.1 Multivariate Data Analysis (MVA) Methodologies to extract database information described by several variables using statistical methods comprise the set of knowledge related to MVA (Johnson and Wichern, 2007), in which clustering tools and Principal Component Analysis (PCA) are widely applicable. Clustering tools are designed to analyze the relationships within a database to determine if it is possible or not describing such data in a summarized form, by a small number of observations of similar classes (Everitt, 1980; Gordon, 1999). According to Rencher (2002), the objects within a cluster must be similar to the others inserted into the same cluster (homogeneity), and different from objects allocated to other clusters (denoting separation). The main approaches to group observations described by quantitative variables comprise hierarchical and non-hierarchical methods. Hierarchical algorithms are a sequential process: at each step of an agglomerative process, an observation or a cluster is fused to another cluster. At the divisive process, the process starts with a cluster containing all observations, and with each iteration, a group is divided into two. Both processes try to find the optimum division (according to pre-defined criteria) at each stage of the grouping or the separation of clusters (Everitt et al., 2011).
CLAIO-2016
46

The second multivariate technique addressed in this study Principal Component Analysis (PCA), which enables to extract information from observations described by correlated quantitative variables through the reduction of the number of dimensions which characterize them. This is done by means of linear combinations, in which the original variables are transformed into a new set of orthogonal variables – called principal component (PC); PCs are uncorrelated and retain most of the variability present in the original data (Abdi and Williams, 2010; Jolliffe, 2002). The linear combination with maximum variation will be the first PC; the second component is a linear combination orthogonal to the first one, and so on (Rencher, 2002).
2.2 Methods for grouping products and customers Several studies have tackled the problem of grouping products and customers, especially in scenarios where there is a range of these elements. In most cases, the goal is to simplify management of such entities based on the consideration of groups rather than individual items, reducing the complexity of the scene (Serapião et al., 2016). In that sense, Wallstrom and Hogan (2007) present a non-supervised clustering method for free medical products according to their monitoring for predicting outbreaks of various diseases. The proposed approach relied on Bayesian clustering models which agglomerates medicines according to their demand profiles, forming categories of products with similar behavior over time. Jie et al. (2011) highlight the importance of grouping products with similar characteristics into clusters for facing competitive markets. In order to operationalize this approach, they propose a Genetic Algorithm (GA) technique based on fuzzy clustering to establish the optimal number of categories and the best classification of a specific set of products, according to pre-defined variables and criteria quantitatively translated into an objective function. As for customers’ grouping, Ho et al. (2012) combine the k-means with GA to insert consumers to groups. The GA finds an initial partition of the observations near the optimal allocation, solving the problem of starting the k-means method. Further, Mo et al. (2010) use k-means and self-organizing map (based on neural networks) to propose an algorithm in two stages: in the first stage, cities with similar characteristics are grouped based on consumer behavior variables; in the second, customers placed on each cluster of cities are categorized. According to the authors, the approach reduces the time required to segment customers and improves the final result of the algorithm. Wang et al. (2014) address the issue of grouping customers with similar characteristics in the context of logistics networks aimed at reducing operating costs and improving service level. The suggested approach relies on a fuzzy clustering algorithm applied to variables with different levels of importance for the determination of customer profiles, which are defined by a hierarchical analysis. When compared to three other techniques for fuzzy clustering, the method captures more accurately the similarity between customers according to the chosen validation index. To associate the result of clusters resulting from two different sets of items, Lingras et al. (2014) developed an iterative approach in which results of the grouping of a set of observations influence the description of the other set. The method is tested in a retail store: customers and products are represented by static variables - historical data of transactions - and by dynamic variables - number of products contained in each cluster that are purchased by each customer, and the number of customers of each cluster that acquires each product. The iterations stop when the dynamic set of variables is stabilized. The results show that it is possible to obtain significant conclusions regarding the association of customer and product profiles. 3 Methodological Procedures
The proposed method relies on four operational steps: (i) collect data describing products and customers’ profiles; (ii) apply PCA to data from step (i); (iii) group products and costumers based on the PCA scores
CLAIO-2016
47

generated in step (ii); and (iv) define an index assessing the distance between clusters of products and customers. Such steps are now detailed. In the data collection step two matrices are generated. The first matrix, Z, comprises the data regarding products and their selling behavior, which can be expressed by variables that include number of orders, selling days and average monthly sell out, among others. Each product is represented by pi (i = 1, 2,..., I), where I is the number of products in the matrix; variables xa (a = 1, 2,..., A) describe the selling behavior. The second matrix, W, is related to customers and their purchasing patterns (note that the POS are the direct customers that acquire from distributors). Each customer is represented by observation cj (j = 1, 2,..., J), where J is the number of customers in W, and described by yb (b = 1, 2, ..., B) where B is the number of variables in W. Matrices Z and W are not required to have the same dimensions, i.e., the number of variables describing products and customers patterns can be different in number and magnitude. In the second step, PCA is applied to matrices Z and W. The purpose of this step is to reduce the dimensions that describe the observations of each matrix, in order to increase the performance of the clustering step. Several previous studies have suggested that grouping observations based on uncorrelated variables (i.e. PCA scores) instead of on original variables tends to better capture the underlying structure of data (Anzanello et al., 2014). The number of PCA components to be retained is defined using the Screen Graph, which graphically assists in the identification of the PCs that retain most variability from the original data (Rencher, 2002). Once PCA is applied, original observations from matrix Z are described by PCA scores tr (r = 1, 2, ..., R), where R is the number of retained PCs; this new matrix, F, consists of I observations and R columns. Similarly, observations in matrix W are now described by ts (s = 1, 2,..., S), where S is the number of retained PCs and give rise to matrix G, with dimensions J × S. The next step of the suggested framework performs the clustering of observations belonging to matrices F and G using variables tr and ts. In matrix F, the idea is to group products presenting similar demand patterns; as for matrix G, we aim at clustering customers according to similarities on their purchasing profiles. We recommend using k-means as clustering technique due to its conceptual simplicity, stability and large availability in statistical packages (Rencher, 2002). Such technique requires the definition of the number of clusters to be formed; in that sense, consider l as the number of clusters emerging from data describing products patterns, and m as the number of clusters derived from data describing customers’ profile. We use the Silhouette Index (Equation 1) to define the number of clusters to be generated for each matrix; once each clustered observation yields an Silhouette Index value, we proposed using the average
silhouette index (�̅) for measuring the quality of the whole clustering procedure (Rousseeuw, 1987;
Kaufman and Rousseeuw, 2005). The number of clusters responsible for the highest �̅ in each matrix indicates the number of groups to be formed; in case � is similar for a large number of candidate clusters, we suggest taking into account the interpretability of groups to decide on the number of clusters to be generated. Note that l and m are not required to be equal; i.e., one could find that three clusters are proper for characterizing products, while five groups are recommended for customers’ description.
}a,max{b
a-b =SI
ii
iii (1)
Where ai is the average distance of the ith observation to all others in its cluster, and bi is the average distance of the ith observation to all others contained in nearest neighbor cluster. Finally, we calculate the Euclidean distances between the centroids of clusters derived from matrices F and G in order to determine the proximity index between these groups; results can be stored as in Table 1. The suggested proximity index, PI, is calculated by dividing the inverse of the distance between each cluster from F (denoted by f) to each cluster from G (denoted by g) by the sum of the inverse of the
CLAIO-2016
48

distances of the respective cluster in G for all clusters of matrix F (see Equation 2). This criterion ensures that PI is comprised in the range 0 to 1. The higher the index, the more suitable a family of products is to be allocated to a specific group of customers. In practical terms, this index can be used to guide families
of products to groups of customers (POS) that are more promising concerning commercialization aspects.
Table 1 – Distances between clusters Clusters G1 ... Gm
F1 distance F1-G1 - distance F1-Gm
...
- - -
Fl distance Fl-G1 - distance Fl-Gm
( )
∑=
−
−
− =l
1i
if
gfgf
d1
d1PI (2)
4 Results
The proposed method was applied to data from a multinational company that produces and commercializes food and agricultural products in 27 Brazilian states. The corporate division selected for analysis is responsible for selling products to the final consumer (POS) through an indirect distribution channel. This division has approximately 130 products and 37 distributors in the country; distribution companies are responsible for ensuring product availability not only in large retail chains, but also in small and medium size POS. To track the performance of distributors, the assessed company uses a data exchange solution, namely Data Sharing Intelligence (DSI). With this solution, retailers report their daily transactions of company’s products, and all involved companies have access to that data on a single online platform. However, even with such data availability, defining the best product mix to be offered to a specific POS is a hard task faced by the company and its distributors, mainly due to the lack of structured methods to analyze this information. In first step of the proposed method - data collection - variables xa and yb, respectively characterizing products and POS, were defined based on DSI analysis and interviews with process experts in the company. Eight variables describing products and five referring to customers were selected, as depicted in Tables 2 and 3, respectively. We collected data comprising all recorded transactions of 2013, which led to a matrix Z (relative to products) containing I = 135 products and A = 8 variables; data from customers yielded matrix W, which consisted of J = 11,467 customers and B = 5 variables. We then applied PCA to both matrices. The two retained PCs (R = 2) for matrix Z explained 99.01% of the variance, whereas the first two PCs (S = 2) for the matrix W explained 99.46% of the total variance. From now on, we consider a matrix F of dimensions 135 × 2 to describe products features and a matrix G with dimensions 11,467 × 2 to express customers’ patterns.
Table 2 - Variables describing products pattern
Index Metric Description
x1
Average monthly sell out (US$)
Average monthly balance for the entrance of distributor products to the POS (Sell out = sale + bonus – cancelling – refund)
x2 Average monthly sell out (units)
Average monthly balance for the entrance of distributor products to the POS (Sell out = sale + bonus – cancelling – refund)
x3 Average price Average selling price of a unit of product. x4 Selling days Number of days in the year in which the product had any unit sold.
CLAIO-2016
49
x5 Number of orders Number of orders placed at points of sale where the product has been contained. x6 Active Buyers Number of POS that bought the product.
x7 Conquered customers Number of POS that bought the first time an item from the supplier under analysis when purchased the product.
x8 Active Sellers Number of sellers that actually sold the product.
Table 3 - Variables describing customers (POS) profile Index Metric Description
y1
Average monthly sell out (US$)
Average monthly balance for the entrance of distributor products to the POS (Sell out = sale + bonus – cancelling – refund)
y2 Average monthly sell out (units)
Average monthly balance for the entrance of distributor products to the POS (Sell out = sale + bonus – cancelling – refund)
y3 Number of orders Number of requests made by POS to its distributor y4 Active products Number of different products purchased by the POS y5 Average ticket (US$) Average value of the orders performed by the POS to its distributor
Then, observations belonging to matrices F and G were clustered using the k-means method, varying the number of cluster from 2 to 15; an upper bound of 15 clusters per matrix was suggested by process experts, who judged that additional clusters would make data interpretation harder. For each clustering
iteration in the interval 2 to 15, the quality of the generated grouping was assessed by �̅; the group with
the highest �̅ indicates the recommended number of clusters to be generated (Rousseeuw, 2005) for further qualitative analysis.
The �̅ profile derived from clustering F suggests that two, three, four and thirteen clusters lead to
consistent clusters, as their �̅’s are higher than 0.7 (0.8503; 0.7775; 0.7479 and 0.7007 respectively).
Similarly, the analysis of �̅ for G suggests the formation of two, three, four, five and six clusters, all of them with an index above 0.85 (indicating good separation between the groups). In the propositions of this paper, the decision on the number of clusters to be formed also takes into account the possibility of analysis and qualitative interpretation of the generated clusters. Based on the aforementioned, process experts decided to generate four groups for both matrices F (products) and G (customers). After inserting products and customers into their clusters of destination through the k-means technique, experts judged that the generated clusters adequately represent the different characteristics and features of products and customers, satisfactorily grouping products with recognized similar behavior. In addition, experts corroborated that the number of generated clusters facilitate product mix definition and management of sales. Finally, we estimated the distances between the pairs of clusters emerging from F and G, and calculated PI. The resulting PIs are presented in Table 4.
Table 4 – Proximity index (PI) between pairs of clusters from F and G Costumer Cluster Product cluster
F1 F2 F3 F4
G1 0.0668 0.1681 0.1950 0.5700 G2 0.0065 0.0269 0.0158 0.9507 G3 0.0297 0.1467 0.0686 0.7551 G4 0.4028 0.1119 0.3355 0.1497
The suggested PIs assess the relationship between clusters of products and customers; the higher the PI, the stronger the similarity between products and customers from a specific pair of clusters. Further, as the PI from a group of customers sums up to 1, this index can be interpreted as the percentage of the product mix composition to be sent to each customer (POS). For example, indices in Table 4 indicate that the product mix offered to customers belonging to cluster G2 should consist of approximately 95% of products from cluster F4. In a similar analysis, the product mix for customers in cluster G4 should prioritize items from clusters F1 and F3 (with a share of approximately 40% and 34%, respectively); products from clusters F2 and F4 contribute with 11% and 15%, respectively. In our understanding, such
CLAIO-2016
50

results reduce the complexity of allocating products to POS, serving as a valuable tool for decision-making. Additionally, summing up the scaled distances inside each cluster of products may provide information on how such products are preferably offered to customers. Table 4 indicates that cluster F4 presents the highest PI summation (2.42), which corresponds to 60.64% of the overall mix of the company's products. This information can be useful for managing product delivery to distributors and their inventories, and also offers relevant information on previous levels of the distribution channel, as production planning. In order to validate results derived from the proposed method, we assessed the actual purchasing behavior of POS inserted into some of the clusters; data for such comparison were collected from company’s database. Historical data shows that customers inserted in cluster G2 purchased 83% of products belonging to cluster F4; our propositions estimated that number to be 0.9507. Similarly, real data indicated that products inserted into clusters F4 and F2 represented approximately 68% and 18% of sales for customers inserted into cluster G3; the estimated PI estimated these relations as 0.7551 and 0.1467, respectively. Such imprecision reinforces that outputs derived from the proposed framework are not definitive, but they represent a valuable support for decision-making and should be refined based on knowledge of market, customers, products and other relevant issues that impact on the business.
5 Conclusions This paper presented a multivariate-based framework aimed at allocating families of products to groups of customers (POS) in the indirect distribution and sales channel. For that matter, quantitative information on products and customers’ behavior (described by multiple variables of different natures) were initially remapped through PCA, and resulting variables were grouped using the k-means clustering technique. A proximity index (PI), ranging from 0 to 1, was then proposed to indicate the family of products recommended to a specific POS. To test and validate the proposed framework, it was been applied to real data from a company that processes and commercializes food and agricultural commodities. Results were deemed satisfactory when compared to the allocation performed by the company, as the method directed families of products to more suitable POS. Such results corroborate the framework as an appropriate technique to be used in companies with portfolios comprised of thousand of products sold in thousands of different locations. Our analysis also emphasized that the outcomes of the proposed method should be used as drivers for decision-making process, and refined with quantitative and qualitative knowledge of the specific market, cultural and demographic aspects of customers, economic issues and marketing activities, among other relevant factors. With regards to opportunities for future studies, we suggest: (i) the inclusion of demographic and economic variables to describe the customer profile in order to increase the accuracy of their clustering, which might improve the accuracy of the method results; (ii) the adaptation of the method for the direct sales channel, identifying the variables that best fit and describe the behavior of this channel; and (iii) the incorporation of qualitative analysis of experts in the method.
References
1. Abdi, H. and L. Williams. Principal Component Analysis. Wiley Interdisciplinary Reviews: Computational Statistics 2: 433-459, 2010.
2. Anzanello, M., R. Ortiz, K. Mariotti and R. Limberger. Performance of some supervised and unsupervised multivariate techniques for grouping authentic and unauthentic Viagra and Cialis. Egyptian Journal of Forensic
Sciences 4: 83-89, 2014. 3. Ballou, R. H. Gerenciamento da cadeia de suprimentos/logística empresarial. Porto Alegre: Bookman, 2006.
CLAIO-2016
51

4. Christopher, M. Logística e gerenciamento na cadeia de suprimentos. São Paulo: Cengage Learning, 2011. 5. Everitt, B. Cluster Analysis (2nd Edition). New York: Halsted Press, 1980. 6. Everitt, B., S. Landau, M. Leese and D. Stahl. Cluster Analysis (5th Edition). Chichester: John Wiley & Sons,
2011. 7. Gordon, A. Classification (2nd Edition). London: Chapman and Hall-CRC, 1999. 8. Hessels, J. and S. Terjesen. Resource dependency and institutional theory perspectives on direct and indirect
export choices. Small Business Economics 34 (2): 203-220, 2010. 9. Ho, G. T. S., W. Ip, C. Lee and W. Mou. Customer grouping for better resources allocatin using GA based
clustering technique. Expert Systems with Applications 39: 1979-1987, 2012. 10. Jie, L., G. Ailing and Y. Lianyong. Application of Product Cluster Method based on Fuzzy Cluster and Genetic
Algorithm. Procedia Engineering 15: 4930-4935, 2011. 11. Johnson, R. A. and D. Wichern. Applied Multivariate Statistical Analysis. New Jersey: Pearson Prentice Hall,
2007. 12. Jolliffe, I. T. Principal Component Analysis. New York: Springer, 2002. 13. Kaufman, L. and P. Rousseeuw. Finding Groups in Data: An Introduction to Cluster Analysis. New
York:Wiley, 2005. 14. Kurata, H., D. Yao and J. Liu. Pricing policies under direct vs. indirect channel competition and national vs.
store brand competition. European Journal of Operational Research 180 (1): 262-281, 2007. 15. Lim, W. M. and M. Hall. Pricing consistency across direct and indirect distribution channels in South West UK
hotels. Journal of Vacation Marketing 14 (4): 331-344, 2008. 16. Lingras, P., A. Elagamy, A. Ammar and Z. Elouedi. Iterative meta-clustering through granular hierarchy of
supermarket customers and products. Information Sciences 257: 14-31, 2014. 17. Mo, J., M. Kiang, P. Zou and Y. Li. A two-stage clustering approach for multi-region segmentation. Expert
Systems with Applications 37: 7120-7131, 2010. 18. Rencher, A. C. Methods of multivariate analysis. New Jersey: Wiley-Interscience, 2002. 19. Rosenbloom, B. Marketing channels. Cengage Learning, 2011. 20. Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of
Computational and Applied Mathematics 20: 53-65, 1987. 21. Seifert, R. W., U. Thonemann and M. Sieke. Integrating direct and indirect sales channels under decentralized
decision-making. International Journal of Production Economics 103 (1): 209-229, 2006. 22. Serapião, A., G. Corrêa, F. Gonçalves and V. Carvalho. Combining K-Means and K-Harmonic with Fish
School Search Algorithm for data clustering task on graphics processing units. Applied Soft Computing 41: 290-304, 2016.
23. Wallace, D. W., J. Giese, J. Johnson. Customer retailer loyalty in the context of multiple channel strategies. Journal of Retailing 80 (4): 249-263, 2004.
24. Wallstrom, G. L. and W. Hogan. Unsupervised clustering of over-the-counter healthcare products into product categories. Journal of Biomedical Informatics 40: 642-648, 2007.
25. Wang, Y., X. Ma, Y. Lao and Y. Wang. A fuzzy-based customer clustering approach with hierarchical structure for logistics network optimization. Expert Systems with Applications 41: 521-534, 2014.
26. Yao, D. Q. and J. Liu. Competitive pricing of mixed retail and e-tail distribution channels. Omega 33 (3): 235-247, 2005.
CLAIO-2016
52

Algoritmos de Branch-and-cut com Branch
Combinatório para o Problema do Conjunto
Dominante Mı́nimo Conexo
Paulo Henrique Macêdo de Araújo
Universidade Federal do Ceará, Campus de Quixadá, Avenida José de Freitas Queiroz,Cedro, 63902580 - Quixadá, CE - Brasil
E-mail: [email protected]
Rafael Castro de Andrade
Universidade Federal do Ceará, campus do Pici, Centro de Ciências, Departamento deEstat́ıstica e Matemática Aplicada, Bloco 910, 60440900 - Fortaleza, CE - Brasil
E-mail: [email protected]
Resumo
Neste trabalho, propomos dois algoritmos exatos para resolver o problema do ConjuntoDominante Mı́nimo Conexo, ou Minimum Connected Dominating Set Problem (MCDSP), ba-seados em uma abordagem de branch-and-cut com uma estratégia de ramificação denominada debranch combinatório. Esses algoritmos são adaptações de um método existente de decomposiçãode Benders que será usado para comparação com os aqui propostos. Resultados computacionaispara um grande conjunto de instâncias da literatura são apresentados e mostram que o algoritmode branch-and-cut que propomos gera melhores resultados, em termos de tempo de execução,para grande parte das instâncias.
Keywords: Branch-and-cut, Conjunto Dominante Mı́nimo Conexo, Conjunto Dominante
1 Introdução
Dado um grafo conexo não direcionado G = (V,E), onde V é o conjunto de vértices e E é oconjunto de arestas, um conjunto dominante de G é um conjunto D ⊆ V tal que Γ(D) = V , ondeΓ(D) = D ∪ {j ∈ V | (i, j) ∈ E, i ∈ D}. Um conjunto dominante conexo é um conjunto dominanteD tal que o subgrafo G(D) = (D,E(D)) seja conexo, onde E(D) = {(i, j) ∈ E | i ∈ D, j ∈ D}. Oproblema do conjunto dominante mı́nimo conexo, ou Minimum Connected Dominating Set Problem(MCDSP), consiste em determinar um conjunto dominante conexo de cardinalidade mı́nima. Em[5], prova-se que MCDSP é NP-Dif́ıcil.
O problema MCDSP possui diversas aplicações, tais como: desenho de redes ad-hoc de sensoressem fio, onde topologias de rede podem mudar dinamicamente [3], estratégias de defesa contra o
CLAIO-2016
53

ataque de worms em redes peer-to peer [11] e estudo das interações protéına-protéına [10]. Ele estádiretamente relacionado ao problema de Árvore Geradora com o Máximo Número de Folhas (ver[8] e [4] para mais detalhes).
Algoritmos aproximativos para o problema MCDSP foram desenvolvidos em [7] e [9]. Emrelação aos algoritmos exatos, um algoritmo com bons resultados é baseado em uma estratégia dedecomposição de Benders para um modelo de programação inteira que inicialmente possui apenasa restrição de dominância para cada vértice [6]. Neste trabalho, apresentamos um novo algoritmoexato para o problema MCDSP usando uma estratégia de branch-and-cut com a relaxação linear domodelo de programação inteira de [6]. Também mostramos uma variante do algoritmo branch-and-cut que inclui uma estratégia de ramificação denominada branch combinatório. Em [6] também éapresentado um modelo para o problema MCDSP baseado em uma formulação de árvore geradoraque é resolvido através de um algoritmo de branch-and-cut. Propomos também uma variação destealgoritmo usando a estratégia de branch combinatório para fins de comparação.
Resultados computacionais para um grande conjunto de instâncias da literatura são apresenta-dos e mostram que o algoritmo de branch-and-cut gera melhores resultados, em termos de tempode execução, para grande parte das instâncias.
O artigo está organizado da seguinte forma: Na seção 2, descrevemos modelos de programaçãointeira para o problema MCDSP. Na seção 3, apresentamos métodos de resolução para esses mo-delos matemáticos e comparamos resultados computacionais na seção 4. Uma breve conclusão éapresentada na seção 5.
2 Modelos Matemáticos
Em [6] foram propostas duas formulações de programação inteira para o problema MCDSP, ondese deseja encontrar um conjunto dominante de cardinalidade mı́nima que seja conexo. Dado umgrafo conexo não direcionado G = (V,E), a primeira formulação é dada por:
(M1) min∑
i∈V yi (1)
s.a.∑
j∈Γ({i}) yj −∑
e∈E(Γ({i})) xe ≥ 1, i ∈ V (2)∑e∈E xe =
∑i∈V yi − 1 (3)
yi ≤∑
e∈Eixe, i ∈ V (4)
xe ≤ yi, xe ≤ yj , e = (i, j) ∈ E (5)∑e∈E(S) xe ≤ |S| − 1, S ⊆ V, |S| > 2 (6)
yi ∈ {0, 1}, i ∈ V xe ∈ {0, 1}, e = (i, j) ∈ E,
onde Ei = {e = (i, j) | j ∈ V, (i, j) ∈ E}. Nesse modelo, as variáveis binárias y se referem aosvértices e x às arestas de G. Essas variáveis indicam para cada vértice i (cada aresta e) se pertencemao conjunto dominante, yi = 1 (xe = 1), ou não, yi = 0 (xe = 0). A função objetivo (1) minimizaa cardinalidade do conjunto dominante conexo. A restrição (2) garante, para todo vértice, queele está ou possui algum vértice adjacente no conjunto dominante mı́nimo. A restrição (3) induzum conjunto dominante com quantidade de arestas igual à quantidade de vértices menos umaunidade. Se um vértice está no conjunto dominante em uma solução ótima, então existe algumaaresta conectada a ele (restrição (4)). E se uma aresta está no conjunto dominante em uma
CLAIO-2016
54

solução ótima, então seus dois extremos também estão (restrição (5)). A restrição (6) (tambémchamada de SEC ) é utilizada para que o conjunto dominante ótimo seja aćıclico. Essa restriçãojunto à restrição (3) garantem a conectividade do conjunto dominante ótimo pois forma uma árvoregeradora do subgrafo induzido por y. Por (6) possuir uma quantidade exponencial de restrições,em [6] elas são relaxadas e o modelo resolvido por um algoritmo de branch-and-cut.
A segunda formulação possui apenas as variáveis de vértices, y, e é definida da seguinte forma:
(M2) miny∈{0,1}|V |
∑i∈V yi
s.a.∑
j∈Γ({i})\{i} yj ≥ 1, i ∈ V
conexo(y). (7)
Para a resolução deste modelo, as restrições de conectividade (7) são relaxadas em [6] e o modeloresolvido por uma estratégia de Decomposição de Benders.
3 Estratégias de Resolução
Propomos um algoritmo de branch-and-cut com branch combinatório (subseção 3.4) para o modelo(M1), denominado BB1CB, e também um algoritmo de branch-and-cut para o modelo (M2), refe-renciado por BB2, junto a uma versão com branch combinatório, BB2CB. Inclúımos e adaptamosestratégias de fixação de variáveis que são realizadas como pré-processamento do branch-and-cut.
Para o modelo (M1), as restrições (6) são relaxadas e para o modelo (M2) as restrições (7) deconectividade são relaxadas. Sendo assim, uma solução inteira encontrada durante a execução dosalgoritmos pode não ser viável. É o caso quando o conjunto dominante associado não é conexo.Para a verificação da conectividade de um conjunto dominante, basta a execução de um simplesalgoritmo de busca em largura no subgrafo definido pelo conjunto dominante referente à solução.
3.1 Heuŕıstica para Obtenção de uma Solução Inicial
A heuŕıstica usada em nossos algoritmos foi proposta em [6] e funciona da seguinte forma: SejaD ⊆ V o conjunto dominante conexo a ser formado e L ⊆ V \D o conjunto de vértices que possuempelo menos um vizinho em D. Inicialmente, D contém um único vértice de G, digamos v, e,consequentemente, L = {u ∈ V | (v, u) ∈ E}. A ideia é mover vértices de L para D, um porvez, mantendo a conectividade em D e atualizando o conjunto L, até que todos os vértices sejamdominados, ou seja, D ∪ L = V . A prioridade de escolha do vértice a ser movido de L para D épara o vértice que possui mais vizinhos em V \(D ∪ L). A melhor solução é escolhida dentre todasas possibilidades de vértices iniciais v ∈ V .
3.2 Cortes Válidos para o MCDSP
3.2.1 Corte de Otimalidade [6]∑
i∈Vyi ≤ z − 1, (8)
CLAIO-2016
55

onde z é o valor da melhor solução encontrada durante o algoritmo. Por isso, essa restrição deveser sempre atualizada. Essa restrição é usada em todos os algoritmos com o valor inicial de z sendoo valor da solução retornada pela heuŕıstica.
3.2.2 Corte de Viabilidade [6]∑
i∈S̄yi ≥ mS S ∈ C̄, (9)
onde C̄ é o conjunto de todos os subconjuntos S ⊆ V em que o subgrafo induzido por S, G(S), não éconexo. O parâmetro mS representa o mı́nimo número de vértices a ser adicionado a S que o tornaconexo. Esse corte elimina a solução dada por yi = 1 se, e somente se, i ∈ S (para mais detalhes,veja [6]). Em nossa implementação, calculamos mS a partir de um modelo de programação linearcom fluxo. O corte é incluido sempre que um conjunto dominante (solução inteira) não conexo éencontrado durante a execução dos algoritmos.
3.3 Fixação de Variáveis
Os procedimentos de fixação de variáveis são executados na ordem em que aqui se apresentam.Sejam N(v) o conjunto dos vizinhos de v em G e N [v] = N(v) ∪ {v}.
• Regras de Redução:
1. Para cada v ∈ V , particionamos N(v) em três subconjuntos: N1(v) = {u ∈ N(v) :N(u)\N [v] 6= ∅}, N2(v) = {u ∈ N(v)\N1(v) : N(u)∩N1(v) 6= ∅}, N3(v) = N(v)\(N1(v)∪N2(v)). Se N3(v) 6= ∅, então fixamos yv = 1 e yu = 0, ∀u ∈ (N2(v) ∪N3(v)).
2. Para cada par de vértices v, w ∈ V , v 6= w, definimos N(v, w) = N(v) ∪N(w)\{v, w} (eN [v, w] = N [v] ∪N [w]). Particionamos esse conjunto em três subconjuntos:N1(v, w) = {u ∈ N(v, w) : N(u)\N [v, w] 6= ∅}N2(v, w) = {u ∈ N(v, w)\N1(v, w) : N(u) ∩N1(v, w) 6= ∅}N3(v, w) = N(v, w)\(N1(v, w) ∪N2(v, w))
Se |N3(v, w)| > 1 e N3(v, w) não pode ser dominado por um único vértice em N2(v, w)∪N3(v, w), temos três casos:
(a) Se N3(v, w) não pode ser dominado por um único vértice de {v, w}, então fixamosyi = 0, ∀i ∈ N2(v, w) ∪N3(v, w) e yv = yw = 1.
(b) Se N3(v, w) ⊆ N(v), mas N3(v, w) 6⊆ N(w), então fixamos yv = 1 e yi = 0, ∀i ∈N3(v, w) ∪ (N2(v, w) ∩N(v))
(c) Se N3(v, w) ⊆ N(w), mas N3(v, w) 6⊆ N(v), então fixamos yw = 1 e yi = 0,∀i ∈ N3(v, w) ∪ (N2(v, w) ∩N(w))
A prova dessas regras estão descritas em [2], sendo válidas também para o problema MCDSPonde o conjunto dominante desejado necessita ser conexo.
• Vértice folha: Se v é um vértice de grau 1, fixamos yv = 0 e yu = 1, u ∈ V | (v, u) ∈ E.Pois v claramente não está em um conjunto dominante mı́nimo conexo.
CLAIO-2016
56

(a) Branch combinatório para o modelo (M1). (b) Branch combinatório para o modelo (M2).
Figura 1: Branch combinatório em arestas 1(a) e em vértices 1(b) para o ciclo {1,3,7}.
• Vértice de articulação: Se v é um vértice de articulação (vértice que quando removidodesconexa o grafo inicialmente conexo), fixamos yv = 1. Observe que v não pode estar fora deum conjunto dominante mı́nimo conexo D pois, pela caracteŕıstica de v, D não seria conexo.
• Vértice de grau 2: Adaptado do que foi proposto em [1], se v é um vértice de grau 2 eseus vizinhos são adjacentes, onde pelo menos um deles não está fixado em 0, então fixamosyv = 0. Isso é válido pela restrição de conectividade do conjunto dominante.
• Vértice de grau 3: Também adaptado da ideia sugerida em [1], se v é um vértice de grau3 e existe apenas um vizinho de v, digamos u, adjacente aos outros dois vizinhos de v, entãofixamos yv = 0 e yu = 1.
Se os vizinhos de v são todos adjacentes e existe pelo menos um deles não fixado em 0, entãofixamos yv = 0. Além disso, é posśıvel fixar em 1 um vizinho u de v, caso u seja o únicovizinho de v não fixado e os demais vizinhos de v estejam todos fixados em 0.
Observe que quando fixamos uma variável yv em 0 no modelo (M1), podemos também fixarxe = 0, ∀e = (v, w) | e ∈ E.
3.4 Branch Combinatório
A estratégia de ramificação que denominamos de branch combinatório é usada para ramificação nosalgoritmos de branch-and-cut quando a solução encontrada em um nó é inteira mas não satisfaz umarestrição que fora relaxada (no nosso caso, a restrição de conectividade). Esse tipo de ramificaçãoé bem ilustrado nas Figuras 1(a) e 1(b).
A Figura 1(a) mostra esse tipo de ramificação aplicada ao algoritmo de branch-and-cut domodelo (M1). Neste caso, encontrada uma solução inteira do modelo que não seja conexa (con-sequentemente um conjunto dominante, digamos S) durante o algoritmo, o branch combinatório érealizado nas arestas de um ciclo de S (pois a partir da restrição 3 é posśıvel afirmar a existênciade um ciclo em uma solução inteira não conexa). Esse mesmo ciclo, determinado a partir de umalgoritmo combinatório simples de uma variação de busca em profundidade, serve também paraadicionarmos um corte do tipo SEC (restrição (6)) associado a esse ciclo ao modelo (M1).
Na Figura 1(b) é ilustrado o branch combinatório aplicado ao algoritmo de branch-and-cut domodelo (M2). Nesse caso, encontrada uma solução inteira do modelo que não seja conexa durante
CLAIO-2016
57

o algoritmo, o branch combinatório é realizado nos vértices escolhidos para o conjunto dominanteda solução, representado por S na figura em questão.
3.5 Descrição dos Algoritmos
Lembramos que a heuŕıstica é executada no ińıcio de cada algoritmo. Portanto, já existe umasolução viável inicial para a restrição (8).
3.5.1 Algoritmos BB1 e BB1CB
Para o modelo (M1), o algoritmo de branch-and-cut funciona da seguinte forma:
1. Resolve-se a relaxação linear do modelo, inicialmente sem nenhuma restrição do tipo (6) naráız.
2. Se a solução de um nó não é inteira, uma variável fracionária é escolhida para a ramificaçãobinária, setando seu valor em 0 para um nó filho e em 1 para o outro nó filho. A variávelescolhida para ramificação é preferencialmente do tipo y.
(a) Caso a solução seja inteira, associado a um conjunto dominante S não conexo, então éadicionado um corte de viabilidade (9) e um corte SEC (6) ao subproblema do nó e eleé reposto na lista de nós a serem resolvidos.
(b) Se S é conexo, então o nó foi resolvido e verifica-se a posśıvel atualização da restrição (8).
O algoritmo BB1CB é o mesmo algoritmo BB1 diferenciando apenas no item (a), onde em vezde repor o nó após a adição dos cortes, é realizado um branch combinatório (subseção (3.4)).
3.5.2 Algoritmo Benders
O algoritmo de decomposição de Benders em [6] consiste em resolver alternadamente o modelo(M2) (com a restrição de conectividade (7) relaxada e mantendo a restrição de integralidade dasvariáveis) e um subproblema polinomial que determina um corte a ser incluido no modelo. Casoo conjunto dominante definido pela solução inteira y do modelo (M2) não seja conexo, inclui-seo corte de viabilidade (9) onde o parâmetro mS é determinado resolvendo-se um problema defluxo através de uma modelagem de programação linear. Esse procedimento é realizado até queum conjunto dominante conexo seja encontrado, pois neste caso ele é ótimo, devido à solução domodelo relaxado ser uma solução viável do modelo completo.
Esse algoritmo gera resultados melhores com o uso da abordagem denominada iterative probing.Nessa abordagem, o modelo resolvido (M2) é mais restrito por substituir a restrição (8) por umaigualdade. Por isso, uma solução ótima com essa modificação pode não representar uma soluçãoótima para o problema MCDSP. Ao resolver esse modelo restrito, quando uma solução viável éencontrada, existem duas alternativas: a primeira é quando a solução é conexa, então atualiza-se olado direito da restrição (8)(em igualdade) por ter sido encontrada uma solução com menor valor.A segunda é quando a solução não é conexa, então adiciona-se um corte de viabilidade (9) paraeliminar essa solução inviável. Esse procedimento é executado iterativamente até que o modelorestrito se torne inviável, pois nesse caso a melhor solução encontrada até então é a solução ótima.A prova de que se obtém a solução ótima para o MCDSP ao final do procedimento é baseada noseguinte lema:
CLAIO-2016
58

Lema 1. [6] Se não existe um conjunto dominante conexo com cardinalidade d+ 1 > 1, entãonão existe um conjunto dominante conexo com cardinalidade d.
3.5.3 Algoritmos BB2 e BB2CB
O algoritmo de branch-and-cut BB2 segue o mesmo procedimento do algoritmo BB1. Porém, omodelo resolvido é o modelo (M2) e por não possuir variáveis de arestas x, no item (a) não háadição do corte SEC (6). Já o algoritmo BB2CB é a versão com branch combinatório, seguindoa analogia dos algoritmos BB1 e BB1CB. Portanto, os algoritmos BB2 e BB2CB diferem doalgoritmo Benders para o modelo (M2), principalmente, por relaxarem linearmente as variáveis eutilizarem técnicas de ramificação em subproblemas menores.
4 Experimentos Computacionais
Comparamos os resultados computacionais entre os cinco algoritmos: BB1 (algoritmo de branch-and-cut em [6]), BB1CB, BB2, BB2CB e Benders (algoritmo de decomposição de Benders em [6])para instâncias que foram apresentadas inicialmente em [8].
A linguagem de programação usada foi C++ junto ao pacote CPLEX versão 12.4 para resoluçãodos modelos de programação linear inteira. A máquina utilizada, pertencente ao cluster CENAPADda UFC, possui a seguinte configuração: processador Intel Xeon E5640 2.67GHz, memória de 20GB RAM e SO Linux de 64 bits.
Quatro do total de 41 instâncias foram resolvidas dentro do tempo limite apenas pelos algoritmosBB1 e BB1CB por conta da densidade muito baixa desses grafos, onde o problema MCDSP setorna mais dif́ıcil.
Os experimentos mostram uma média de redução de tempo negativa de 2% com o uso daestratégia de branch combinatório. Porém, para algumas instâncias particulares, é obtida umaredução de até 15%. Em relação à pré-fixação de variáveis, observamos a fixação de quase 20%das variáveis em algumas instâncias, o que contribui para a redução do tempo de execução dosalgoritmos de branch-and-cut.
Apesar de mais nós avaliados no branch-and-cut do modelo (M2), os algoritmos BB2 e BB2CB
geram melhores resultados que os algoritmos BB1 e BB1CB em quase todas as instâncias.O algoritmo de decomposição de Benders possui globalmente os melhores resultados. Porém,
os algoritmos de branch-and-cut BB2 e BB2CB geram os melhores resultados em quase todas asinstâncias com |V | < 100 e em quase todas as instâncias densas (densidade > 50%), obtendo osmelhores resultados conhecidos na literatura para esses tipos de instância, que correspondem a 19do total de 41 instâncias aleatórias usadas nos experimentos.
5 Conclusão
Dois tipos de algoritmos exatos para o problema MCDSP foram propostos juntamente com suasvariantes de branch combinatório.
Comparando os algoritmos de branch-and-cut com suas versões de branch combinatório, obser-vamos que essa estratégia de branch reduz o tempo de execução para uma quantidade significativa
CLAIO-2016
59

de instâncias, principalmente para o algoritmo do modelo (M1). Por isso, acreditamos que a es-tratégia de branch combinatório possa também servir para algoritmos de branch-and-bound emoutros problemas de otimização.
Como trabalhos futuros, sugerimos o uso de heap para armazenamento dos nós dos algoritmos debranch-and-cut (com prioridade para o nó com melhor limite inferior) citados nesta pesquisa. Alémdisso, os algoritmos também podem ser melhorados adaptando-os a um modelo de programaçãoparalela com memória compartilhada onde os subproblemas podem ser resolvidos paralelamente.
Referências
[1] Jochen Alber, Hongbing Fan, Michael R. Fellows, Henning Fernau, Rolf Niedermeier, FranRosamond, and Ulrike Stege. A refined search tree technique for dominating set on planargraphs. J. Comput. Syst. Sci., 71(4):385–405, November 2005.
[2] Jochen Alber, Michael R. Fellows, and Rolf Niedermeier. Polynomial-time data reduction fordominating set. J. ACM, 51(3):363–384, May 2004.
[3] Balabhaskar Balasundaram and Sergiy Butenko. Handbook of Optimization in Telecommu-nications, chapter Graph Domination, Coloring and Cliques in Telecommunications, pages865–890. Springer US, Boston, MA, 2006.
[4] Tetsuya Fujie. An exact algorithm for the maximum leaf spanning tree problem. Computers& OR, 30(13):1931–1944, 2003.
[5] Michael R. Garey and David .S. Johnson. Computers and Intractability: A Guide to the Theoryof NP-Completeness. W. H. Freeman, 1979.
[6] Bernard Gendron, Abilio Lucena, Alexandre Salles Cunha, and Luidi Simonetti. Bendersdecomposition, branch-and-cut, and hybrid algorithms for the minimum connected dominatingset problem. INFORMS J. on Computing, 26(4):645–657, November 2014.
[7] Sudipto Guha and Samir Khuller. Approximation algorithms for connected dominating sets.Algorithmica, 20(4):374–387, April 1998.
[8] Abilio Lucena, Nelson Maculan, and Luidi Simonetti. Reformulations and solution algorithmsfor the maximum leaf spanning tree problem. Computational Management Science, 7(3):289–311, 2010.
[9] Madhav V. Marathe, H. Breu, Harry B. Hunt III, S. S. Ravi, and Daniel J. Rosenkrantz.Simple heuristics for unit disk graphs. NETWORKS, 25(2):59–68, 1995.
[10] Tijana Milenkovic, Vesna Memisevic, Anthony Bonato, and Natasa Przulj. Dominating biolo-gical networks. PLoS ONE, 6(8):1–12, 08 2011.
[11] Liang Xie and Sencun Zhu. A feasibility study on defending against ultra-fast topologicalworms. Peer-to-Peer Computing, 2007. P2P 2007. Seventh IEEE International Conferenceon, pages 61–70, 2007.
CLAIO-2016
60

DISEÑO TERRITORIAL PARA EL ÁREA DE VENTAS DE UNA EMPRESA DE TELEVISIÓN POR CABLE
César Antonio Argüello Rosales
Centro Interdisciplinario de Posgrados e Investigación, Universidad Popular Autónoma del Estado de Puebla, Puebla, México
Elías Olivares-Benítez Centro Interdisciplinario de Posgrados e Investigación, Universidad Popular
Autónoma del Estado de Puebla, Puebla, México [email protected]
Francisco Javier Méndez Ramírez
Facultad de Ingeniería, Benemérita Universidad Autónoma de Puebla, Puebla México.
Beatriz Pico González Centro Interdisciplinario de Posgrados e Investigación, Universidad Popular
Autónoma del Estado de Puebla, Puebla, México [email protected]
Abstract
Palabras clave: diseño territorial; ventas; p-mediana; Puebla.
El particionamiento territorial consiste en agrupar unidades básicas en un número
dado de grupos geográficos más grandes, denominados territorios. El problema de
particionamiento territorial en este trabajo se modela como un problema de la p-
mediana, en donde se analiza una zona determinada de una empresa de televisión por
cable en México compuesta de 79 unidades básicas definiendo 12 territorios para la
mejora del servicio de ventas. Tomando en cuenta los resultados obtenidos en este
primer análisis se espera que en trabajos posteriores se profundice en el diseño
territorial para balancear las cargas de trabajo así como los ingresos captados por
cada territorio.
CLAIO-2016
61

1 Introducción
El hablar del diseño territorial como parte de la fuerza de ventas se vuelve una actividad de importancia estratégica que sin duda pretende incrementar el nivel de servicio de los clientes por medio de la cobertura de los mercados. El problema del diseño territorial también es considerado como de distritación, circunscripciones políticas, distritos escolares, regiones de compra o entrega. (Bozcaya, Erkut, & Laporte, 2003) Los territorios que se diseñan en pequeñas áreas geográficas se definen según Correa, Ruvalcaba, Olivares & Zanella como Unidades de Cobertura de Ventas ó Sales Coverage Units (SCUs), en unidades geográficas más grandes que son conocidas como territorios según . (Correa Medina, Ruvalcaba Sánchez, Olivares Benitez, & Zanella, 2012). Estos territorios deben de satisfacer ciertas características determinadas por la empresa que lo defina en donde se deben de considerar los clientes que se atenderán, los tipos de productos, el área geográfica, el volumen de ventas, la fuerza de ventas, las dimensiones del territorio entre otras. Algunos de los beneficios del diseño territorial de ventas son: 1. Una mejor cobertura e incremento de la productividad en ventas, 2. Incremento de ventas priorizando cuentas de mayor potencial, 3. Reducción de los costos de ventas a través de tiempos de entrega más cortos y baratos, 4. Incremento en la moral, desempeño y permanencia de los vendedores al contar con una distribución equitativa de cuentas y contar con un sistema imparcial de beneficios de ventas, 5. Ventajas competitivas a través de la habilidad de llegar más rápidamente a nuevos mercados que la competencia, (Correa Medina, Ruvalcaba Sánchez, Olivares Benitez, & Zanella, 2012). Dentro de las aplicaciones que pueden existir en el desarrollo del problema del diseño territorial se mencionan las siguientes (Kalcsics, Nickel, & Schröder, 2005) partiendo de tres líneas claras que son: la distritación política, diseño territorial para ventas y servicio, y otras aplicaciones. Hay que considerar que tanto para la parte comercial como la parte del área de servicios las empresas invierten una cantidad considerable en la operación y la fuerza de ventas pues no solo se debe cumplir con lo que se espera de ambos departamentos sino que se debe cumplir con las expectativas del mercado (Kalcsics, Nickel, & Schröder, 2005). La función principal del diseño territorial es incrementar o disminuir el número de ventas o personal de servicio requerido dentro del ajuste del territorio. Otra razón es garantizar una mayor cobertura con el personal existente para eventualmente balancear la fuerza de trabajo entre ellos.
CLAIO-2016
62

En el diseño territorial de ventas y servicios se deben considerar criterios organizacionales, que hace referencia a el número de territorios que van directamente relacionados con las ventas obtenidas por la fuerza de ventas; áreas básicas en donde los clientes son agregados en áreas pequeñas que sirven como base del diseño del territorio (Kalcsics, Nickel, & Schröder, 2005). Debe haber una asignación exclusiva en áreas básicas que resulten en responsabilidades transparentes del representante de ventas que no le permitan contenerse entre ellas y que sean éstas las que le permitan relaciones a largo plazo con los clientes. La ubicación de los representantes de ventas es un factor importante para tomar en cuenta en los procesos del diseño territorial pues se deben hacer visitas regulares a los clientes tomando como base su ubicación; es decir oficina, matriz, etc. Hay otros criterios que deben tomarse en cuenta en el diseño territorial de ventas y servicios como lo son los criterios geográficos determinados por: contigüidad, accesibilidad, compactación, actividades de criterios relacionados, balanceo, y maximización de ingresos. Tomando en cuenta lo que comenta Mantrala et al. (2010) la compañía promedio gasta el 10%, y algunas industrias gastan tanto como el 40% de sus ventas totales en los costos de ventas lo cual se vuelve un instrumento de marketing en muchas industrias. Con esto podemos considerar que las ventas son un factor importante dentro de las empresas en donde se debe tomar en cuenta tanto los indicadores como al personal. Una revisión de literatura más amplia sobre aplicaciones y métodos para el diseño territorial las hacen Kalcsics, Nickel, & Schröder (2005) y Salazar-Aguilar, González-Velarde, & Rios-Mercado (2012). Una forma de abordar los problemas de diseño territorial es por medio del problema de la p-mediana en donde se requiere particionar (Díaz García, Bernabé Loranca, Luna Reyes, Olivarez Benítez, & Martínez Flores, 2012) un conjunto de territorios en exactamente p grupos de los cuales cada uno de los grupos estará caracterizado por uno de los objetos que es seleccionado como la mediana del grupo, y el subconjunto de objetos asignados a dicha mediana. Para cada par de objetos se especifica una distancia y se requiere minimizar la suma de distancias entre los objetos y las medianas a las que están asignados. A continuación se considera el siguiente modelo de programación matemática para el problema. Se definen las siguientes variables de decisión: p numero de grupos a localizar.
CLAIO-2016
63

𝑦𝑖 = 1, 𝑠𝑖𝑒𝑙𝑜𝑏𝑗𝑒𝑡𝑜𝑖𝑒𝑠𝑠𝑒𝑙𝑒𝑐𝑐𝑖𝑜𝑛𝑎𝑑𝑜𝑐𝑜𝑚𝑜𝑚𝑒𝑑𝑖𝑎𝑛𝑎0, 𝑒𝑛𝑜𝑡𝑟𝑜𝑐𝑎𝑠𝑜.
y
𝑥𝑖𝑗 = 1, 𝑠𝑖𝑒𝑙𝑜𝑏𝑗𝑒𝑡𝑜𝑗𝑠𝑒𝑎𝑠𝑖𝑔𝑛𝑎𝑎𝑙𝑎𝑚𝑒𝑑𝑖𝑎𝑛𝑎, 𝑖,0, 𝑒𝑛𝑜𝑡𝑟𝑜𝑐𝑎𝑠𝑜.
xij la facción de la demanda del cliente j que es suministrado por la mediana i. El problema se puede modelar de la siguiente manera:
𝑀𝑖𝑛𝑖𝑚𝑖𝑧𝑎𝑟𝑍 = 𝑑𝑗𝑐𝑖𝑗𝑥𝑖𝑗;<=><=
sujeto a 𝑥𝑖𝑗 = 1∀𝑗 ∈ 𝑁
>∈=
𝑦𝑖 = 𝑝>∈=
𝑥𝑖𝑗 − 𝑦𝑖 ≤ 0∀𝑖 ∈ 𝑁, 𝑗 ∈ 𝑁
𝑦𝑖 ∈ 0,1 ∀𝑖 ∈ 𝑁 𝑥𝑖𝑗 > 0∀𝑖 ∈ 𝑁; 𝑗 ∈ 𝑁.
La función objetivo (1) minimiza la sumatoria total ponderada de las distancias de acuerdo a las asignaciones. Las restricciones (2) aseguran quemedianas j deben ser satisfechas. La restricción (3) asegura pmedianas para ser asignadas. Finalmente, las restricciones (4)–(6) aseguran que los objetos solo puedan ser asignados a las medianas seleccionadas. 2 Descripción del Problema El problema del diseño territorial de ventas de una empresa de telecomunicaciones ha sido desarrollado a partir de una recopilación de datos en donde se obtuvieron las colonias en donde se tiene presencia por parte de la misma, considerando a todos los potenciales que se incluían en esa zona contando con los suscriptores activos y su nivel socioeconómico. De esta información se pudo identificar a las colonias en el programa arcGIS por medio del cual y con apoyo de un shade se identificaron los centroides de las
(1)
(2)
(3)
(4) (5) (6)
CLAIO-2016
64
colonias con las cuales se cuenta. Una vez que se contaba con las coordenadas geográficas se convirtieron a radianes para poder aplicar la fórmula de la distancia del circulo mayor que involucra la curvatura de la tierra. Contando con la matriz de distancias entre los barrios analizados, se calculó también la información de la demanda potencial para cada barrio tomando en cuenta los clientes potenciales y el porcentaje de penetración estimando un promedio de los montos contratados por parte de cada segmento de mercado. Para considerar un primer acercamiento de solución se plantearon los datos como un problema de la p-mediana en donde la asignación de los barrios se desarrolla por medio de una ponderación de ventas. Se toman las 12 cuadrillas de ventas que atienden la zona. Estos resultados se reflejaran en un mapa en arcGIS donde se identificaran aquellos territorios que son atendidos por cada una de las cuadrillas de ventas lo cual potenciará las ventas en un futuro. La solución del problema propuesto se obtuvo por medio de LINGO 15 en donde se propuso el modelo matemático de la p-mediana identificando los 79 barrios que forman parte de las unidades que son cubiertas en la zona por medio de las 12 cuadrillas de ventas. 3 Resultados El resultado principal que se obtiene por medio de la aplicación de la p-mediana con respecto de los 79 barrios de la empresa de televisión por cable es la ubicación con respecto de la atención que de forma óptima puede ser atendida por las cuadrillas y se muestra en el mapa. Se interpreta al identificar los centros que deben ser abiertos. Como se muestra en la tabla 1, se identifica a los barrios que deben ser atendidos por cada cuadrilla:
MEDIANA BARRIOS O UNIDADES
ASIGNADAS
TOTAL DE BARRIOS
VENTAS ASIGNADAS
HORAS DE TRABAJO
CD7 C3,C4,C5,C6,C7,C8,C9,C10,C11,
C31 10 $1,312,522.06 54592
CD14 C14,C62,C67,C69 4 $1,164,786.07 49919
CD32 C19,C20,C32,C68 4 $1,455,595.12 62383
CD33 C33 1 $734,302.80 31470 CD34 C34 1 $877,775.85 37619
CLAIO-2016
65
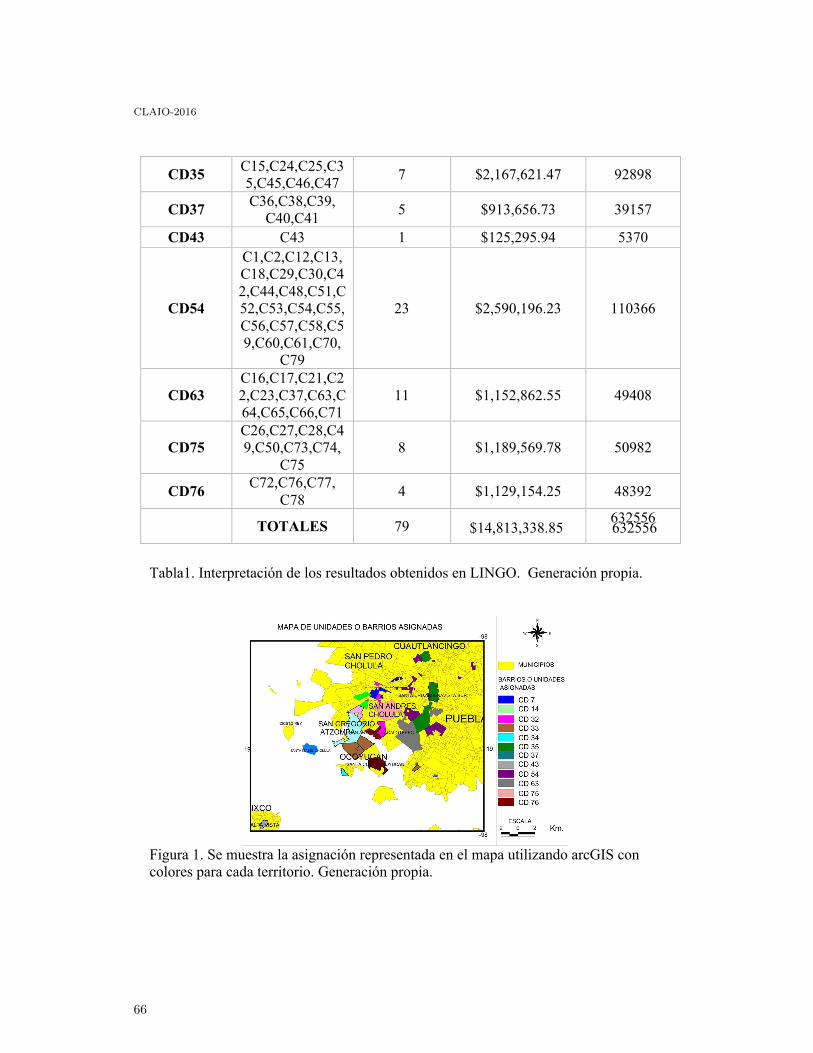
CD35 C15,C24,C25,C35,C45,C46,C47 7 $2,167,621.47 92898
CD37 C36,C38,C39, C40,C41 5 $913,656.73 39157
CD43 C43 1 $125,295.94 5370
CD54
C1,C2,C12,C13,C18,C29,C30,C42,C44,C48,C51,C52,C53,C54,C55,C56,C57,C58,C59,C60,C61,C70,
C79
23 $2,590,196.23 110366
CD63 C16,C17,C21,C22,C23,C37,C63,C64,C65,C66,C71
11 $1,152,862.55 49408
CD75 C26,C27,C28,C49,C50,C73,C74,
C75 8 $1,189,569.78 50982
CD76 C72,C76,C77, C78 4 $1,129,154.25 48392
TOTALES 79 $14,813,338.85 632556
632556
Tabla1. Interpretación de los resultados obtenidos en LINGO. Generación propia.
Figura 1. Se muestra la asignación representada en el mapa utilizando arcGIS con colores para cada territorio. Generación propia.
CLAIO-2016
66

Figura 2. En la figura 2 se muestra la asignación con líneas que parten de cada mediana para cada territorio. Generación propia. 4 Conclusiones El modelo de la p-mediana nos sirvió con respecto a las asignaciones como parte del acondicionamiento geográfico Como parte de trabajos futuros se recomienda balancear las ventas del problema pues como se puede ver en la tabla 1 no se consideró en este primer análisis el balancear las cargas de trabajo así como las horas que se dedican al total de los barrios asignados. Referencias
Correa Medina, J. G., Ruvalcaba Sánchez, L. G., Olivares Benitez, E., & Zanella, V.
(Febrero de 2012). Biobjetive model for redesigning sales territories. International Journal of Industrial Engineering, 19(9), 350-358.
Bozcaya, B., Erkut, E., & Laporte, G. (2003). A tabu search heuristic and adaptive memory procedure for political districting. European Journal of Operational Research, 144(1), 12-26.
Díaz García, J. A., Bernabé Loranca, M. B., Luna Reyes, D. E., Olivarez Benítez, E., & Martínez Flores, J. L. (2012). Lagrangean Relaxation for the Geographical Partitioning Problem. Revista de Matemática: Teoría y Aplicaciones , 169-181.
CLAIO-2016
67

Kalcsics, J., Nickel, S., & Schröder, M. (2005). Towards a Unified Territorial Design Approach - Applications, Algorithms and GIS Integration . Sociedad de Estadística e Investigación Operativa, 13(1), 1-74.
Mantrala, M., Albers, S., Caldieraro, F., Jensen, O., Joshep, K., Krafft, M., . . . Lodish, L. (10 de Marzo de 2010). Sales force modeling: State of the field and research agenda. Springer.
Olivares-Benitez, E., Bernabe Loranca, M. B., Ablanedo Rosas, J. H., & Wang, H. (s.f.). Designing Balanced Distribution Territories with Multiple Objetives using Weighted Tabu Search.
Olivarez-Benitez, E., Garcia-Bañuelos, S., Bernabe Loranca, M. B., Ablanedo Rosas, J. H., & Martínez Flores, J. L. (s.f.). Sales force deployment and territory partitioning with multiple objetives.
Salazar- Aguilar, M. A., Ríos-Mercado, R. Z., González-Velarde, J. L., & Molina, J. (4 de Enero de 2012). Multiobjective scatter search for a commercial territory design problem. Springer Science+Business Media, 343-360.
Salazar-Aguilar, M. A., Ríos-Mercado, R. Z., & Cabrera-Ríos, M. (7 de Enero de 2011). New Models for Commercial Territory Design. Springer Science+Businesss Media(11), 487-507.
Salazar-Aguilar, M. A., Ríos-Mercado, R. Z., & Gonzalez-Velarde, J. L. (Agosto de 2011). A bi-objetive programming model for redesigning compact and balanced territories in commercial districting. Transportation Research: Part C., 19(5), 885-895.
Salazar-Aguilar, M., González-Velarde, J., & Rios-Mercado, R. (2012). A Divide-and-Conquer Aproach to Comercial Territory Design. Computación y Sistemas, 16(3).
CLAIO-2016
68

The Longest Link Node Deployment Problem in
Cloud Computing: a Heuristic Approach∗
Matheus S. Atáıde, Cid C. de Souza, Pedro J. de RezendeInstitute of Computing – University of Campinas (unicamp){matheus.ataide@students.,cid@,rezende@}ic.unicamp.br
Marcos A. Vaz SallesDepartment of Computer Science – University of Copenhagen (diku)
Abstract
In this paper, we propose a grasp metaheuristic for the longest link node deployment problem(llndp). The llndp is NP-hard and models a machine assignment problem related to theoptimal usage of resources in a cloud computing environment. In a previous work [10], greedy andrandomized heuristics were proposed for the llndp. Computational tests carried out here on 450instances of various sizes and from three different classes revealed that our grasp outperformedthose heuristics with an average gain of 14.2% in the solution cost. An in-depth discussion ofthe results is presented.
Keywords: cloud computing; machine assignment optimization; grasp metaheuristic.
1 Introduction
The cloud has emerged as a new paradigm for deployment of computing applications [2]. Withcloud computing, application developers and users can rent computational resources flexibly, payingper hour of allocated resources or per usage of services offered by the cloud provider. A popularmodel of cloud computing is the one of infrastructure-as-a-service, in which users commonly allocatevirtual machines – denoted here VMs – as resources for their computing needs.
When allocating a number of VMs in the cloud, users are given the illusion of a virtual cluster,in which any of the VMs can communicate with any other through standard networking protocols.Unlike with a physical cluster, however, it has been observed that virtual clusters in the cloud sufferfrom a much higher degree of network latency heterogeneity [9]. In other words, mean latenciesfor message passing between any pair of VMs in a physical cluster are expected to be very similar;however, these mean latencies in virtual clusters allocated in popular cloud computing platforms,such as Amazon Web Services (AWS), Rackspace, or Google Compute Engine, are different in manycases by a factor of two or more [10]. In addition, the observed differences in mean latencies persistover long periods of time, ranging from days to weeks.
∗This research was supported by grants from Conselho Nacional de Desenvolvimento Cient́ıfico e Tecnológico(CNPq) #311140/2014-9, #477692/2012-5; #304727/2014-8; Fundação de Amparo à Pesquisa do Estado de SãoPaulo (Fapesp) #2015/08438-0, #2015/23270-9; Faepex/Unicamp; and an AWS in Education research grant award.
CLAIO-2016
69

High-performance computing applications are particularly vulnerable to latency heterogeneityin the cloud [4, 11]. The communication pattern in a number of these applications can be ab-stracted by the bulk-synchronous processes model [8], characterized by supersteps of computationby independent processes, referred to in this paper as application nodes, interspersed with barriersynchronization events where data exchange between processes may occur. As the degree of paral-lelism increases, the efficiency of applications following such a communication pattern relies on lowcost communication during barriers. However, since a barrier implies synchronization across all ap-plication nodes, either directly or transitively across supersteps, the longest delay in communicationbetween any two application nodes is a prime determinant of performance.
Suppose we model the communication resources between any two VMs in the cloud as a linkwith an associated cost. Now, the problem we are faced with is to deploy the application nodesto corresponding VMs in the cloud in a way that the cost of communication between applicationnodes arranged in a given topology is minimized. Since this communication cost is determinedby the cost of the longest link used, this problem is called the Longest Link Node DeploymentProblem (llndp) [9]. Previous work has shown that llndp is NP-hard, and that solutions based onenumeration of random deployments can achieve quality competitive with both mixed-integer andconstraint programming algorithms [10]. Besides, the quality achieved by randomization surpassesthat of greedy heuristics, though the latter spend much less wall-clock time to produce solutions.
Our contribution In this paper, we observe that the search of a randomized approach can beinformed by the greedy heuristics proposed for llndp via an instantiation of the Greedy RandomizedAdaptive Search Procedure (grasp) metaheuristic [6, 7]. We make the following contributions:
1. We propose a solution method based on grasp that randomizes the best previous greedyheuristic for the problem, complemented by novel local search schemes.
2. In a set of experiments, we show that our grasp-based solution method achieves deploymentswith gains in cost of 14.2% on average compared with the randomized approach over a setof benchmark instances generated based on latency measurements provided by the authorsof the previous work proposing the llndp [9, 10]. The gains are particularly expressive forapplication nodes organized in mesh topologies, a pattern very common in high-performancecomputing applications.
Organization of the text Section 2 formalizes the llndp and introduces relevant notation forthe paper. In Section 3, we present our grasp-based solution method, moving on to evaluate itexperimentally in Section 4. Finally, Section 5 concludes by outlining avenues for future work.
2 Problem Formulation and Modeling
To formalize the description of the Longest Link Node Deployment Problem (llndp), we regardthe application nodes as vertices of a graph – the Application Graph – whose directed edges arethe expected communication links of the desired topology. On the other hand, allocated VMsin the cloud may similarly be viewed as the vertices of a complete graph – the Cloud Graph –whose directed edges are arcs connecting each pair of these vertices, and whose weights are thepredetermined latencies for message passing between the particular (ordered) pair of VMs thatthose two vertices represent.
CLAIO-2016
70

In this framework, we can regard the llndp as a special case of the minimum weight subgraphisomorphism problem (mwsip) [5] that may be posed as follows. Given a graph H with k verticesand a graph G = (VG, EG, w) with weight function w : EG → R, an H-subgraph of G is a subgraphof G isomorphic to H. The mwsip seeks to determine a minimally weighted H-subgraph of G (or toestablish that one does not exist). To model the llndp as an mwsip, the weight of an H-subgraphH ′ of G is defined as the weight of the heaviest edge of H ′. Besides, notice that a solution alwaysexists as long as |VG| ≥ k, since, in our context, G is always a complete graph. Also, it is often thecase that an instance of the llndp involves a Cloud Graph with excess vertices when compared tothe Application Graph. As discussed in Section 4, for the experiments described therein, we setthis overload at 10% to provide room for a broader search for a good deployment of the ApplicationGraph within the Cloud Graph.
Problem Formulation The llndp may be stated as: given a (weighted) Cloud Graph G =(VG, EG, w) and an Application Graph H, we wish to determine an H-subgraph H ′ = (VH′ , EH′)of G whose heaviest edge e ∈ E′H has the least weight amongst all H-subgraphs of G.
3 A grasp for llndp
Greedy Randomized Adaptive Search Procedure (grasp) [7] is a metaheuristic extensively em-ployed to solve combinatorial optimization problems as it generates high quality solutions veryefficiently [6]. The nature of llndp makes it a prime candidate for applying this strategy whenseeking high grade solutions in a short computing time.
Due to space constraints, we refer the reader unfamiliar with the workings of a basic grasp(see Algorithm 1) to [6, 7]. In a nutshell, in the construction phase (see Algorithm 2), a restrictedcandidate list (RCL) of quasi-greedy choices is built from which a suboptimal solution is generated.One such viable solution needs not be optimal even within simple local neighborhoods. This iswhere the local search phase (see Algorithm 3) comes in: by successively superseding the currentsolution with a better one from within a small neighborhood, a local minimum is obtained.
We now describe the specifics of the use of grasp in the context of the llndp, but we limitourselves to outlining only the construction and the local search phases.
Construction Phase Our choice for a greedy strategy in which the construction phase is basedwas the one that generated, in practice, the best solutions for the llndp among those comparedin [10] (see Algorithm 4). For a detailed description of this algorithm, the reader is referred to Zouet al.’s algorithm G2 in [10]. Now, the essence of the Greedy Randomized Construction lies on howthe Restricted Candidate List (RCL) is built and what is the role of its α parameter. Considerthat the greedy choice encapsulated in lines 7 to 15 of Algorithm 4 leads to a single option forextending the mapping D one additional vertex at a time. By broadening this choice to withina more diverse set of vertices selected in a nearly greedy fashion, controlled by the α parameter,we expect to lower the ultimate cost of the mapping being composed. While this outcome is notguaranteed, the iterated nature of the grasp algorithm makes this prediction all the more likely.
Of course, the most encompassing candidate set to be considered when forming the RCL isthe set of all vertices yet unmapped. If we limit the choices among these to the α% that add theleast cost to the mapping, we are able to introduce flexibility within reasonable bounds. However,too broad a spectrum (α = 100%) leads to a completely random behavior, while in the oppositedirection we end up with an entirely greedy method. To assess the impact of various values for α,
CLAIO-2016
71

Algorithm 1: Generic grasp
1 while termination conditions not met do2 D ← GreedyRandomizedConstruction;3 LocalSearch(D);4 MemorizeBestSolutionSoFar(D);
5 return best solution found .
Algorithm 2: GreedyRandomizedConstruction
Output: Viable Solution1 D = ∅;2 Initialize the candidate set C and w(e) ∀e ∈ C;3 while C 6= ∅ do4 Build restricted candidate list: RCLα;5 D = D ∪ PickRandomCandidate(RCLα);6 Update set C and w(e) ∀e ∈ C;
7 return D.
Algorithm 3: LocalSearch
Input: Viable Solution DOutput: Improved Viable Solution
1 while D is not locally optimal do2 Find D′ ∈ N(D) with lower cost than D;3 D = D′;4 return D.
Algorithm 4: Greedy for llndp
Input: Cloud Graph G = (VG, EG, w),Application Graph H = (VH , EH)
Output: Mapping D : VH → VG
1 Find (u0, v0) ∈ EG of least w((u0, v0));2 Choose an arbitrary edge (x, y) ∈ EH ;3 D(x) = u0, D(y) = v0;4 for i = 1 to |VH | − 2 do5 cmin =∞;6 for (u, v) ∈ EG do7 for t s.t. (D−1(u), t) ∈ EH do8 cuv = w((u, v));9 for (t, x) ∈ EH do
10 if D(x) is defined and11 w((v,D(x))) > cuv then12 cuv = w((v,D(x)));
13 if cuv < cmin then14 cmin = cuv;15 vmin = v, tmin = t;
16 D(tmin) = vmin;17 return D.
Figure 1: grasp, grasp’s Construction Phase, grasp’s Local Search, llndp Greedy Algorithms
we developed five versions of the grasp algorithm for α ∈ {1, 2, 5, 10, 20}.Local Search At the core of the local search phase lies the concept of neighborhood of a viablesolution. Firstly, notice that interchanging the images of any two mapped vertices of a viablesolution leads to a new mapping that is equally feasible. Moreover, since the Cloud Graph is acomplete graph, our choices for remapping are as large as the allocation overload. These are, inessence, the two schemes we contrived to establish neighborhoods within which the local searchnavigates while seeking a local minimum.
While a thorough search can lead to a best-improvement type scrutiny and a lazier first-improvement analysis strategy is certainly much more efficient, our experiments showed that thequality gain of the former is immaterial compared to that of the latter. Therefore, we saw it bestto lean towards higher efficiency in all further experiments, as reported in the next section.
4 Computational Experiments
In this section, we describe the computational experiments that were carried out, reporting andanalyzing the results obtained for a collection of 450 instances of various sizes belonging to thethree different classes discussed in [10].
CLAIO-2016
72

Environment All experiments were run on a desktop PC equipped with an Intel R© CoreTM
i7-2600 processor at 3.40 GHz, 8 GB of RAM and running Ubuntu 12.04.5 LTS (GNU/Linux
3.2.0-31-generic x86 64). The coding was done in C++ and the programs compiled using g++.Furthermore, all tests were performed without other processes running concurrently on the machine.Each algorithm was allowed to run for 4 minutes on each instance.
Instances Recall that an instance of the llndp is comprised of two graphs: the Cloud Graphand the Application Graph (cf. Section 2). The former is a weighted complete graph in which edgeweights are the latencies between pairs of virtual machines in the cloud. Actual latency values weremeasured between 110 virtual machines on the EC2 service of AWS [1] by Dr. Tao Zou, one of thedevelopers of ClouDiA, and kindly made available to us in the form of a 110×110 matrix L. Togenerate the edge weights of a cloud graph on n < 110 vertices, we selected, at random, n rowand n column indices and assembled the corresponding n×n square submatrix of L. On the otherhand, the Application Graphs were generated within the three graph classes reported in [10] asbeing amongst the most common in practice, namely, complete bipartite graphs, trees and meshes(see Figure 2a).
y = 3
x = 2
y = 3
x=4
(a) A complete bipartite graphfor n = 5 (top) and a mesh graphfor n = 12.
Procedure GenerateTreeInstance(n)1 E ← ∅, V ← {1, . . . , n}2 For j from 2 to n3 i← Random Integer[1, j − 1]4 E ← E ∪ {(i, j)}5 Return (V,E)
Parameters for Generating Complete Bipartite Graphs(n = x+ y, x = (n/2)− j)
n group index (j) # instances per group
= 20 j = 0, . . . , 5 5
> 20 j = 0, . . . , 9 3
Parameters for Generating Mesh Graphs
n # instances per group (x× y) groups
20 30 (4× 5)
40 15, 15 (4× 10), (5× 8)
60 10, 10, 10 (4× 15), (5× 12), (6× 10)
80 10, 10, 10 (4× 20), (5× 16), (8× 10)
96 10, 10, 10 (4× 24), (6× 16), (8× 12)
(b) Algorithms and parameters to generate random instances.
Figure 2: Instance generation.
In each of theses classes, 30 instances with 20, 40, 60, 80 and 96 vertices were created. Theoverload we used was fixed at 10%, meaning that the size of the Cloud Graphs for these instanceswere 22, 44, 66, 88 and 106, respectively. The procedure to create random trees as well as theparameters used in the generation of meshes and complete bipartite random graphs are shownin Figure 2b. For mesh graphs, the parameters x and y in the table denote the number of rows
CLAIO-2016
73
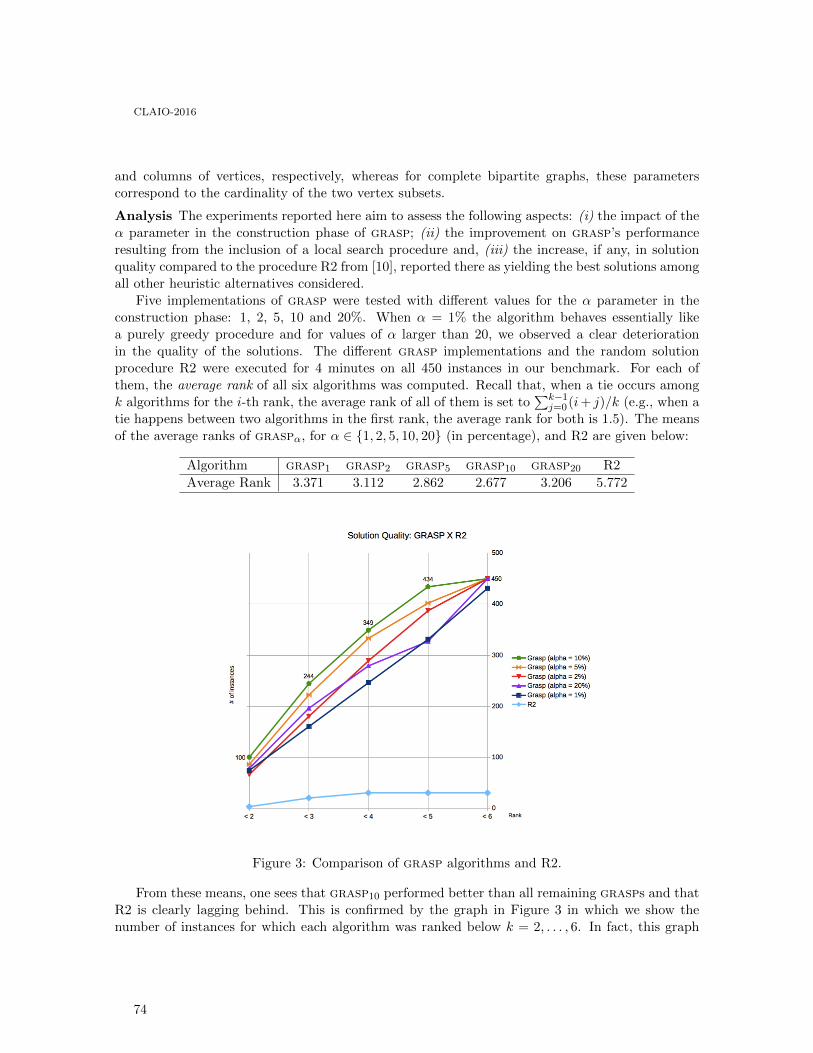
and columns of vertices, respectively, whereas for complete bipartite graphs, these parameterscorrespond to the cardinality of the two vertex subsets.
Analysis The experiments reported here aim to assess the following aspects: (i) the impact of theα parameter in the construction phase of grasp; (ii) the improvement on grasp’s performanceresulting from the inclusion of a local search procedure and, (iii) the increase, if any, in solutionquality compared to the procedure R2 from [10], reported there as yielding the best solutions amongall other heuristic alternatives considered.
Five implementations of grasp were tested with different values for the α parameter in theconstruction phase: 1, 2, 5, 10 and 20%. When α = 1% the algorithm behaves essentially likea purely greedy procedure and for values of α larger than 20, we observed a clear deteriorationin the quality of the solutions. The different grasp implementations and the random solutionprocedure R2 were executed for 4 minutes on all 450 instances in our benchmark. For each ofthem, the average rank of all six algorithms was computed. Recall that, when a tie occurs amongk algorithms for the i-th rank, the average rank of all of them is set to
∑k−1j=0(i+ j)/k (e.g., when a
tie happens between two algorithms in the first rank, the average rank for both is 1.5). The meansof the average ranks of graspα, for α ∈ {1, 2, 5, 10, 20} (in percentage), and R2 are given below:
Algorithm grasp1 grasp2 grasp5 grasp10 grasp20 R2
Average Rank 3.371 3.112 2.862 2.677 3.206 5.772
Figure 3: Comparison of grasp algorithms and R2.
From these means, one sees that grasp10 performed better than all remaining grasps and thatR2 is clearly lagging behind. This is confirmed by the graph in Figure 3 in which we show thenumber of instances for which each algorithm was ranked below k = 2, . . . , 6. In fact, this graph
CLAIO-2016
74

reveals that, except for grasp10 and grasp5, the algorithms had quite distinct performances andcould be ordered, from best to worst, in the following order: grasp10, grasp5, grasp2, grasp20,grasp1 and R2. To further investigate this issue, we ran statistical tests to compare the algorithmsaccording to the methodology suggested in [3]. Since we have more than two algorithms, the (non-parametric) Friedman test was used. As one would expect from the results, the null hypothesis(stating that all algorithms perform equally well) was rejected, for a confidence level of 95%. Thepost-hoc Nemenyi test was then executed and, for the same confidence level, resulted in a criticaldifference of 0.355. If the absolute values of the differences between the mean rank averages oftwo algorithms is below the critical difference, their performances are considered similar. TheNemenyi test left R2 in an isolated group confirming its poor performance when compared tothe grasp algorithms. Also, according to the test, only grasp5 could be grouped with grasp10,since their average rank difference was 0.19. However, statistically, grasp2 and grasp20 were notidentified by the test as being significantly different from grasp5, with the observed differencesrelative to the latter of 0.25 and 0.34, respectively. The analysis of the Nemenyi test, together withthat of Figure 3, led us to run the statistically stronger Wilcoxon Signed-Rank test to evaluatethe performances of grasp5 and grasp10, once again at 95% confidence level. The conclusionof the test was that none of the two algorithms outperforms the other in statistical terms. Wethen decided to continue our tests using grasp10, since Figure 3 suggests that it produces bettersolutions in general.
%Gain R2 %LS Gain %Iter2Best
≤ 0 29 (29 / 0 / 0) 30 (11 / 0 / 19) 0 (0 / 0 / 0)
Average 14.2 (5.3 / 19.7 / 17.5) 3.1 (1.9 / 5.0 / 2.3) 37.9 (31.8 / 46.5 / 35.5)
Max 27.0 (12.3 / 26.6 / 27.0) 12.3 (5.9 / 12.3 / 6.0) 99.9 (98.3 / 99.9 / 99.3)
Stdev 8.5 (3.0 / 6.4 / 6.8) 2.3 (1.2 / 2.6 / 1.3) 31.0 (31.0 / 28.6 / 31.6)
Min -0.8 (-0.8 / 2.4 / 2.3) 0.0 (0.0 / 1.1 / 0.0) 0.0 (0.0 / 0.2 / 0.0)
Table 1: grasp10: summary of results.
Table 1 summarizes the results for grasp10. All values are given as percentages. The cells incolumn “%Gain R2” refer to improvements yielded by grasp10 relative to R2. Those in column“%LS Gain” represent the portion of the previous improvement that was obtained exclusively bythe local search phase. Finally, the third column displays the percentage of the total number ofiterations that had been executed when the best solution was found by grasp10. The triplet ofvalues in parentheses denote the same statistics computed individually for each class of ApplicationGraphs, namely, bipartite graphs, mesh graphs and trees, in this order.
Consider the column %Gain R2 in Table 1. In only 29 instances R2 produced a solution noworse than that of grasp10. All of these instances correspond to graphs of 20 vertices (the smallestones), and belong to the bipartite class. This suggests that the bipartite graphs are harder tooptimize. That claim is supported by the fact that the average (max and min) improvements arealways smaller for that class than for the others. Let us examine the third column (%LS Gain).There, we see that only 30 instances the best solution found by grasp10 did not benefit from thelocal search phase. Roughly one fourth (3.1%) of the overall average improvement (14.2%) wasobtained by the local search (relative to the construction phase). However, the local search wasmore important for meshes than for bipartite graphs or trees. Finally, considering the last columnof Table 1, we see that, on average, only 37.9% of the total number of iterations executed withinthe 4 minutes allotted for computation were needed to reach the best solution. As each iteration
CLAIO-2016
75

takes about the same running time, if normal distribution is assumed, about 83% of the instanceswould have their best solution found after 68.9% (37.9 + 31.0) of the 4 minutes (≈ 2.75 minutes)had passed. The results revealed that this actually happened for 79% (357) of the instances, whichis not too far from the above rough estimation. This shows that the time limit we imposed for thetests was appropriate, at least for the classes of graphs and sizes in our benchmark. On the otherhand, the average gain relative to R2 obtained for bipartite instances on 96 vertices is 6.8%, lessthan the average (14.2%). In this case, grasp10 executed no more than 245 iterations. Nonetheless,in many successful grasp implementations reported in the literature, the total number of iterationsis at least three times larger than that.
5 Conclusions
We developed here a grasp heuristic for the llndp. Our tests showed that significant gains can beachieved when compared to the random procedure R2, pointed out in [10] as a very good alternativeto generate high quality solutions for the problem. Despite these encouraging results, further de-velopments are expected to improve the performance of grasp. Among those, the implementationof a reactive grasp and of a path relinking procedure are planned. Moreover, we envision tacklingin the near future the longest path node deployment problem, also discussed in [10], using grasp.
References
[1] Amazon web services. Elastic compute cloud (EC2). https://aws.amazon.com/ec2/.
[2] M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. H. Katz, A. Konwinski, G. Lee, D. A. Patterson,A. Rabkin, and M. Zaharia. Above the clouds: A Berkeley view of cloud computing. Technical ReportUCB/EECS-2009-28, Electrical Eng. and Comp. Sciences, University of California at Berkeley, 2009.
[3] J. Demšar. Statistical comparisons of classifiers over multiple data sets. The Journal of MachineLearning Research, 7:1–30, Dec. 2006.
[4] C. Evangelinos and C. N. Hill. Cloud computing for parallel scientific HPC applications. In Proc. FirstWorkshop on Cloud Computing and its Applications (CCA), Chicago, IL, October 2008.
[5] J. Plehn and B. Voigt. Finding minimally weighted subgraphs. In Graph-Theoretic Concepts in Com-puter Science: Proceedings of the 16th International Workshop WG, pages 18–29. Springer Berlin, 1991.
[6] M. G. Resende and C. C. Ribeiro. Greedy randomized adaptive search procedures: Advances, hybridiza-tions, and applications. In M. Gendreau and J.-Y. Potvin, editors, Handbook of Metaheuristics, volume146 of Int. Series in Operations Research & Management Science, pages 283–319. Springer US, 2010.
[7] M. G. Resende and C. C. Ribeiro. GRASP: Greedy Randomized Adaptive Search Procedures. In E. K.Burke and G. Kendall, editors, Search Methodologies, pages 287–312. Springer US, 2014.
[8] L. G. Valiant. A bridging model for parallel computation. Commun. ACM, 33(8):103–111, 1990.
[9] T. Zou, R. L. Bras, M. A. V. Salles, A. J. Demers, and J. Gehrke. ClouDiA: A deployment advisor forpublic clouds. PVLDB, 6(2):109–120, 2012.
[10] T. Zou, R. Le Bras, M. Salles, A. Demers, and J. Gehrke. ClouDiA: A deployment advisor for publicclouds. The VLDB Journal, 24(5):633–653, 2015.
[11] T. Zou, G. Wang, M. V. Salles, D. Bindel, A. Demers, J. Gehrke, and W. White. Making time-steppedapplications tick in the cloud. In Proc. SOCC, pages 20:1–20:14, 2011.
CLAIO-2016
76

Un enfoque multiobjetivo multinivel para resolver el
problema de inversión de carriles de tráfico y
sincronización de semáforos
Enrique Gabriel Baquela∗
Universidad Tecnológica Nacional - Facultad Regional San NicolásUniversidad Nacional de Rosario - Facultad de Ciencias Exactas, Ingenieŕıa y Agrimensura
Ana Carolina Olivera†
CONICET - Universidad Nacional de la Patagonia AustralCaleta Olivia, Argentina. [email protected]
Resumen
La inversión de carriles de tráfico es una herramienta útil para reducir el congestionamientoen sistemas de tráfico urbano cuando el mismo es causado por cambios temporales en la demandade tráfico. Sin embargo, su potencial no se expresa totalmente si no es combinado con otrastécnicas de gestión de tráfico. La sincronización de semáforos es una herramienta que permitebalancear el flujo de tráfico en situaciones de demanda estacionaria que puede amplificar elefecto de una inversión de carriles. En este trabajo presentamos un algoritmo binivel basadoen Optimización v́ıa Simulación (OvS) con el objetivo de resolver una versión multiobjetivo delproblema de inversión de carriles de tráfico en combinación con la sincronización de semáforos.Presentamos el enfoque general y utilizamos Optimización por Cúmulo de Part́ıculas combinadacon Recocido Simulado. La evaluación de cada solución se produce a través de una simulaciónmicroscópica del tráfico.
Palabras Clave: Lane Reversal; Traffic; Simulation; Optimization; Optimization via Simulation;Particle Swamp Optimization; Simulated Annealing.
1 Introducción
La inversión temporal del sentido de circulación en carriles de calles o avenidas ha probado ser unmétodo útil para resolver problemas de congestionamientos puntuales en sistemas de tráfico. Seha aplicado con mucha efectividad a los congestionamientos causados por lo que se conoce comoOlas de Tráfico [12]. Estas olas suelen ser generadas por la dinámica del tráfico durante las horaspico o punta, durante algún evento masivo (como un recital) o bien por alguna emergencia (unaevacuación, por ejemplo) [6].
∗Baquela E.G. se financió con fondos del proyecto PID TVUTNSN0003605 UTN-FRSN†Olivera A.C. participa de los proyectos PI 29/B168, PIP 2015-2017, PICT2014-0430 y PCB-I CONICET-ANII.
CLAIO-2016
77

Existen una gran cantidad de investigaciones que tratan este problema. [2] analiza las posiblesaplicaciones de la inversión de carriles. [6] analiza el status de 53 implementaciones de inversión decarriles distribuidas alrededor de todo el mundo. [9] estudia las caracteŕısticas de los sistemas detráfico sujetos a una inversión de carriles. [3] analiza el impacto de la inversión de carriles respectode las caracteŕısticas del flujo de vehicular en la red de tráfico objetivo.
Respecto de su implementación práctica, la inversión de carriles es un problema multiobjetivopara el cual es necesario analizar el impacto en toda la red de tráfico. No solamente interesa reducirlos tiempos de viaje, sinó también realizar la menor cantidad posible de cambios al sistema, ya queen la práctica son dif́ıciles de gestionar con rápidez. Con el fin de tomar en cuenta el comportamientodinámico del sistema de tráfico estudiado, [7] usa un enfoque basado en Optimización via Simulación(OvS), en el cual la optimización se realiza mediante un Algoritmo Genético y la evaluación decada solución en un simulador microscópico de tráfico. Sin embargo, restringe el problema al áreaafectada por la ola de tráfico sin contemplar un análisis global del impacto.
[12] analiza la bibliograf́ıa existente y propone un modelo de programación lineal multiobjetivoque integra la selección de carriles a invertir con la programación de los semáforos en el mismopaso, a fin de optimizar el sistema en una forma mas integral. En dicho modelo, la función objetivoconsiste en la suma ponderada de sus objetivos y la formulación es totalmente determińıstica yestática. El autor evalúa los resultados a posteriori en un simulador de tráfico.
En este trabajo proponemos un modelo de optimización multiobjetivo binivel basado en opti-mización v́ıa simulación (OvS) que utiliza un simulador microscópico (SUMO, [8]) a fin de evaluarel impacto de las soluciones sobre el flujo de tráfico. El bucle principal de optimización consisteen dos bucles anidados, el exterior encargado de decidir que carriles invertir y el interior responsa-ble de redefinir la poĺıtica de sincronización de semáforos. Para el bucle de optimización interior(el responsable de programar los semáforos) utilizamos Recocido Simulado (Simulated Annealing,SA), mientras que para el bucle exterior (la selección de carriles a invertir) aplicamos OptimizaciónMultiobjetivo por Cúmulo de Part́ıculas (SMPSO, por sus siglas en inglés). A fin de validar elmodelo, comparamos los resultados generados con una adaptación del método presentado en [12].
2 Descripción del problema
Un sistema de tráfico está representado por: Un grafo dirigido T (N,E), la red de tráfico, dondeE es el conjunto de arcos asociados a las v́ıas de circulación y N el conjunto de nodos asociados aintersecciones; un conjunto de semáforos S, en el cual cada elemento tiene un nodo asociado en Njunto con un programa P que regula su funcionamiento; y una demanda de tráfico D(I, F ), siendoI el conjunto de los veh́ıculos que circulan por el sistema y F la distribución del flujo de tráfico.Este sistema lleva asociado un tiempo de viaje promedio t que representa la capacidad del sistemapara permitir el traslado de todos los veh́ıculos en I desde sus oŕıgenes a sus destinos. El grafo Tpresenta la particularidad que, en caso de que una v́ıa de circulación consista en más de un carrily que dichos carriles puedan ser tratados independientemente en cuanto a la decisión de revertirloso no (por ejemplo, el caso de una avenida), los dos nodos que representan el inicio y fin de la v́ıaestarán conectados por más de un arco.
El problema de la inversión de carriles de tráfico y sincronización de semáforos consiste en hallarun nuevo conjunto de orientaciones para los elementos de E y un nuevo programa P para cadaconjunto de semáforos, de manera tal que se minimizen los siguientes dos objetivos: a) el tiempopromedio de circulación y b) la cantidad de cambios en los sentidos de circulación.
CLAIO-2016
78

3 Metodoloǵıa propuesta: (SMPSO*SA*SUMO)
El algoritmo de optimización que presentamos en este trabajo está basado en [1]. En forma general,consiste en dos fases, una de generación de soluciones y una de evaluación de las mismas. La fasede generación de soluciones consiste en un modelo de optimización binivel en el cual se seleccio-nan, en una primera etapa, un conjunto de carriles a invertir y, en una segunda etapa, se generanconfiguraciones de secuencia de semáforos para cada una de las inversiones de carriles previamenteobtenidas. Un esquema general del mismo se puede observar en la figura 1. El SMPSO se encargade generar un conjunto de alternativas de inversión de carriles. Cada una de ellas ingresa a unproceso regido por el SA, el cual genera para cada alternativa de inversión un conjunto de posiblesconfiguraciones de semáforos. Cada configuración de semáforos, con su inversión de carriles aso-ciada, ingresa entonces al módulo de simulación, el cual se encarga de reconstruir la red de tráfico,determinar los nuevos patrones de circulación de cada veh́ıculo, correr la simulación y resumir losresultados. Los tiempos medios de viaje aśı obtenidos son utilizados junto a la cantidad de carrilesinvertidos a efectos de seleccionar de entre todas las alternativas aquellas no dominadas, generaruna nueva población de alternativas de inversión y continuar con el algoritmo hasta alcanzar elnúmero de iteraciones máximo.
Figura 1: Especificación de la metodoloǵıa propuesta.
3.1 Inversión de carriles y caracterización de la Frontera de Pareto
La selección de carriles a invertir, la primer etapa del algoritmo, es realizada mediante una versióndel algoritmo de optimización por cúmulo de part́ıculas adaptado a problemas multiobjetivo (Speed-constrained Multi-objective PSO SMPSO, [5]).
Optimización por cúmulo de part́ıculas. El PSO canónico es un algoritmo de optimizaciónpoblacional en el cual en cada iteración tenemos un conjunto de soluciones potenciales (part́ıculas).Todas las part́ıculas quedan definidas en base a su posición p y velocidad v en un espacio n −
CLAIO-2016
79

dimensional. Iteración tras iteración, cada una evoluciona en base a la información históricaindividual que recolectó y en base a la información histórica global de toda la bandada, actualizandosu posición y velocidad. Esta evolución se regula según las ecuaciones 1 y 2:
vi,j(t+ 1) = w × vi,j(t) + c1 × r1 × (pi,j(t)− xi,j(t)) + c2 × r2 × (pg,j(t)− xi,j(t)) (1)
xi,j(t+ 1) = xi,j(t) + vi,j(t+ 1) (2)
Donde w es el factor de inercia, vi,j es la componente de la velocidad de la part́ıcula i en ladimensión j, c1 y c2 es la ponderación de la información individual y global en cada actualización,r1 y r2 ∼ U(0, 1) representan la aceleración diferencial de cada part́ıcula, pi es el mejor valorencontrado por la part́ıcula i (pbest) y pg es la mejor solución encontrada en toda la bandada(gbest). En cada iteración se actualiza el valor de la velocidad y luego el valor de la posición paracada part́ıcula.
En este trabajo, nos hemos decidido por el uso del Speed-constrained Multi-objective PSO (SM-PSO) [5]. En este algoritmo se seleccionan ĺıderes de la lista de soluciones no dominadas. El cálculode la no-dominancia sigue un criterio de dominancia no estricta o ε− dominancia. Los parámetrosc1 y c2 se seleccionan aleatoriamente, al igual que r1 y r2. Por último, se incorpora un procesode mutación en las soluciones. SMPSO agrega una restricción al cálculo de velocidades, con el finde impedir que la posición de las part́ıculas oscile entre sus extremos factibles sin evaluar puntosintermedios.
Codificación de la inversión de carriles. Dado el conjunto de arcos E, podemos asociarcada elemento del mismo a la componente de un n − vector booleano, donde n es el cardinal delconjunto E. Conociendo las direcciones iniciales de cada carril, podemos usar la convención devalor 1 para el caso que se decida invertir el carril en cuestión, y 0 para el caso contrario (figura 2).Este formalismo presenta una forma muy simple de evaluar la cantidad de cambios en el sistema,basta con calcular la suma de sus componentes.
Figura 2: Codificación de la inversión de carriles.
La creación de una nueva red de tráfico a partir de este formalismo, de manera tal que seasimulable por SUMO, también es relativamente sencilla. SUMO dispone de una herramienta de-nominada NETGENERATE que, a partir de la definición de los nodos de un grafo y los arcos
CLAIO-2016
80

del mismo, construye automáticamente el archivo de red de tráfico asociado. En caso que una v́ıatenga más de un carril, cada uno de ellos se especifica en otro archivo. Por cada v́ıa a invertir, esnecesario buscarla en el archivo de arcos e intercambiar las referencias a nodos de origin y destino,para luego volver a ejecutar NETGENERATE.
3.2 Sincronización de semáforos
La sincronización de los semáforos, en nuestro algoritmo, es un problema de optimización derivadode la inversión de carriles realizada previamente en la sección 3.1. Debido a que la única decisióna tomar es el tiempo que dura cada estado en cada semáforo, y que a efectos de la evaluación de lacalidad de las soluciones la estructura de la red es fija, se utilizó un algoritmo de Recocido Simulado[4] para diseñar la secuencia, evaluando solamente el tiempo medio de viaje resultante. Se fijó eltamaño de vecindario en 5 vecinos, la temperatura máxima 500 y el número máximo de iteracionesen 250.
Dado un cruce de v́ıas de tránsito, todos los semáforos del cruce mantienen su estado coordi-nado, es decir, sus luces se activan complementariamente (cuando uno esta en rojo el otro está enverde, por ejemplo). Por lo tanto, el estado de una intersección se puede definir mediante un vectoren el cual cada componente es el estado de cada semáforo. En una intersección con semáforos, porejemplo, un conjunto de cuatro estados factibles podŕıa ser: {rrrv, rrvr, rvrr, vrrr}. La sincroni-zación consiste en definir a cada uno de los estados de cada intersección un tiempo de duración.Un conjunto de semáforos permanece en el mismo estado la duración indicada y luego cambianal siguiente estado en forma secuencial, volviendo a comenzar el ciclo una vez alcanzado el últimoestado. La codificación de este secuenciamiento consiste entonces en la definición de un vector decomponente enteras en la cual cada una representa la duración de un estado en un conjunto desemáforos dado. A fin de poder evaluar cada combinación de inversión de carriles y sincronizaciónde semáforos generada en la etapa de optimización, es necesario actualizar la red de tráfico a lasituación propuesta y recalcular los patrones de flujo. Respecto de los patrones de tráfico, SUMOdispone de una herramienta denominada DUAROUTER que, a partir de una lista de oŕıgenes ydestinos de tráfico reconstruye las rutas de cada veh́ıculo según la nueva estructura de la red.
4 Experimentos
Con el fin de evaluar nuestra metodologia, se realizaron dos tipos de experimentos. En primerainstancia, se compararon los resultados del algoritmo contra los resultados obtenidos empleandola metodoloǵıa propuesta por [12] (Figura 3). Luego, se recreo la Frontera de Pareto de un nuevomodelo (mediante instancias sucesivas de nuestro algoritmo) y se obtuvieron indicadores de con-vergencia y uniformidad de las instancias individuales respecto de la misma. El procedimiento deOvS fué implementado en el software R [10, 11] utilizando nuestra biblioteca RSUMO (http:www.modelizandosistemas.com.ar/p/rsumo).
4.1 Comparación de OvS respecto de un modelo anaĺıtico
De los seis carriles de la avenida, los dos centrales son los únicos que se pueden invertir. Laduración de cada fase de semáforos está comprendida entre los 60 y 120 segundos. El flujo de
CLAIO-2016
81

Figura 3: Izq: Red de tráfico propuesta por [12] para evaluar el algoritmo. Der: Zoom sobreintersección central.
Tabla 1: Comparativa de OvS vs Modelo Anaĺıtico
Esce. 01 Esce. 2 Esce. 03 Esce. 04 Esce. 05 Esce. 06
Carriles Invertidos 0 0 0 2 2 2
Anaĺıtico - Saturación Intersección 1 0.683 0.553 0.523 0.602 0.596 0.802Anaĺıtico - Saturación Intersección 2 0.784 0.791 0.827 0.774 0.753 0.709Anaĺıtico - Saturación Intersección 3 0.523 0.647 0.691 0.689 0.654 0.741
OvS - Saturación Intersección 1 0.714 0.569 0.520 0.631 0.621 0.839OvS - Saturación Intersección 2 0.818 0.832 0.833 0.806 0.781 0.756OvS - Saturación Intersección 3 0.575 0.656 0.689 0.707 0.693 0.789
veh́ıculos máximo en cada carril es de 1900 vehiculos/hora y se desea que el flujo efectivo se ubiquecomo máximo al 0.85 de dicho valor. Siguiendo la metodoloǵıa de [12], se probaron 6 escenariossobre este modelo, cada uno con diferentes patrones de circulación. El algoritmo basado en OvS seejecutó 30 veces por escenario.
En la tabla 1 se pueden observar los resultados. Para cada uno de los 6 escenarios podemosobservar el nivel de saturación de cada intersección y el número de carriles invertidos que se utilizóen la comparación. Hay que notar que este modelo es muy simple, con poco impacto neto delos efectos dinámicos del flujo de tráfico, la no localidad y la aleatoriedad en la velocidad de losveh́ıculos. Sin embargo, se observa que la utilización del enfoque basado en OvS alcanza resultadosen promedio similares pero superando en algunos casos la versión anaĺıtica por una diferencia del0.05.
4.2 Análisis de la calidad de aproximación de la Frontera de Pareto
La segunda tanda de experimentos consistió en evaluar la calidad de la Frontera de Pareto halladaen una ejecución del algoritmo contra la Frontera de Pareto Real. Debido a que el problemaestudiado en 4.1 presenta una Frontera de Pareto muy pequeña (se pueden invertir 0, 1 o 2 carrilessolamente), se testeó el algoritmo con una red de tráfico del tipo grilla cuadrada de 20 calles delado. El origen de la ola de tráfico se situó en uno de los vertices de la grilla, fluyendo la mismahacia los lados opuestos del trazado. Para la demanda de tráfico, se crearon 10 escenarios distintos
CLAIO-2016
82

Tabla 2: Convergencia y uniformidad
Escenario Núm. de Veh́ıculos Totales Convergencia Uniformidad
1 1.500 0.27 [0.21-0.30] 0.30 [0.25-0.37]2 1.500 0.21 [0.18-0.23] 0.39 [0.34-0.42]3 1.500 0.30 [0.24-0.32] 0.35 [0.31-0.38]4 1.500 0.47 [0.32-0.53] 0.51 [0.42-0.63]5 2.500 0.18 [0.15-0.20] 0.25 [0.18-0.29]6 2.500 0.30 [0.27-0.36] 0.23 [0.17-0.31]7 2.500 0.17 [0.12-0.21] 0.22 [0.18-0.28]8 4.000 0.08 [0.06-0.09] 0.15 [0.12-0.19]9 4.000 0.27 [0.24-0.29] 0.21 [0.18-0.27]10 4.000 0.33 [0.28-0.35] 0.20 [0.16-0.23]
de flujo de veh́ıculos sobre esta misma red.A fin de evaluar la bondad del algoritmo, se mensuraron los coeficientes de convergencia y
uniformidad de la Frontera generada. El método que se utilizó para calcular convergencia fue el deDistancia Generacional, que promedia la distancia euclidea entre las curvas, según la ecuación 3.
Distancia Generacional =
√∑Ni=1 d
2i
N(3)
Donde N es el número total de soluciones que componen la Frontera de Pareto calculada porel algoritmo y di es la distancia eucĺıdea mı́nima desde la solución i a la Frontera de Pareto Real.
La uniformidad mide la cobertura de la Frontera estimada respecto la Real. Se calcula mediantela ecuación 4, donde df y dl son la distancia eucĺıdea mı́nima entre los extremos de las fronterasestimada y real, di es la distancia euclidea mı́nima desde la solución i a la solución i + 1, N es elnúmero de puntos en la frontera estimada y d̄ es el promedio de las N − 1 distancias di.
uniformidad =df + dl +
∑N−1i=1 |di − d̄|
df + dl + d̄(N − 1)(4)
En ambos indicadores, mientras menores son los valores, mas parecida es la Frontera de Paretoestimada a la real. Se ejecutaron 50 instancias del algoritmo, aproximándose la Frontera de Paretoreal del sistema mediante la unión de las 50 Fronteras de Pareto generadas y su posterior recálculosegún el criterio de dominancia. Esto nos permite obtener un conjunto más reducido de puntos queno son dominados por ninguna de las 50 Fronteras de Pareto generadas. Luego, se calcularon loscoeficientes de convergencia y uniformidad de las 50 fronteras iniciales contra este último conjuntode puntos. En la tabla 2 se pueden observar los resultados (se muestran los valores medios y losmı́nimos y máximos de cada experimento).
CLAIO-2016
83

5 Conclusiones
En este trabajo presentamos un modelo de optimización multiobjetivo del problema de inversiónde carriles de tráfico combinado con la sincronización de semáforos. Nuestro enfoque es novedosoy se encuentra inexplorado en la literatura sobre el tema. Los resultados respecto de la versiónutilizando optimización anaĺıtica son satisfactorios, logrando igualar o superar el desempeño delmismo en un caso en el cual la potencial ganancia por utilizar simulación aparentaŕıa ser escasadebido a que, por su tamaño, no aparecen tantos efectos dinámicos. En un caso de estudio de20× 20 el algoritmo tiene éxito a la hora de aproximar la Frontera de Pareto para diferentes flujosvehiculares, ya sea tanto en proximidad como en cobertura. Como trabajo futuro, queda reducirsu costo computacional. El espacio de soluciones es grande para el problema, por lo cual se esperaincorporar algún método para estimar -a priori- el resultado de simulaciones, descartando realizargran cantidad de las mismas. Esto significaŕıa una mejora de velocidad de ejecución.
Referencias
[1] Enrique Gabriel Baquela and Ana Carolina Olivera. An ovs-multiobjective algorithm approach for lanereversal problem. In VIII ALIO/EURO Workshop on Applied Combinatorial Optimization, Montevideo,Uruguay, 8-10/12/2014.
[2] Z. Bede, G. Szabó, and T. Peter. Optimization of road traffic with the applied of reversible directionslanes. Transportation Engineering, 38(1):3–8, 2010.
[3] W. Cheng, X. Li, and S. Liu. Research on the traffic control and organization coordinate applicationsof reversible lanes. In 3rd International Conference on Awareness Science and Technology (iCAST),pages 72–75, September 2011.
[4] J. Dréo, P. Siarry, A. Pétrowski, and E. Taillard. Metaheuristics for Hard Optimization - SimulatedAnnealing, Tabu Search, Evolutionary and Genetic Algorithms, Ant Colonies,. . . - Methods and CaseStudies. Springer, 2003.
[5] Juan J. Durillo, José Garcia-Nieto, Antonio J. Nebro, Carlos A. Coello Coello, Francisco Luna, andEnrique Alba. Multi-objective particle swarm optimizers: An experimental comparison. In EMO 2009.
[6] R. Kishore Kamalanathsharma. Reversible lanes: State of implementation on a global level. In AnnualATES Student Paper Competition, March 2011.
[7] Ampol Karoonsoontawong. Genetic algorithms for dynamic contraflow problem vol.1-2, pp. 1-17, june2010. Journal of Society for Transportation and Traffic Studies, 1(2):1–17, June 2010.
[8] Daniel Krajzewicz, Jakob Erdmann, Michael Behrisch, and Laura Bieker. Recent development andapplications of SUMO - Simulation of Urban MObility. International Journal On Advances in Systemsand Measurements, 5(3&4):128–138, December 2012.
[9] L. Lambert and B. Wolshon. Characterization and comparison of traffic flows on reversible roadroad.journal of Advanced Transportation, 44(2):113–122, April 2010.
[10] Duncan Temple Lang. XML: Tools for parsing and generating XML within R and S-Plus., 2012. Rpackage version 3.95-0.1.
[11] R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for StatisticalComputing, Vienna, Austria, 2012. ISBN 3-900051-07-0.
[12] J. Zhao, W. Ma, Y. Liu, and X. Yang. Integrated design and operation of urban arterials with reversiblelanes. Transpormetrica B: Transport Dynamics, 0:1–21, May 2014.
CLAIO-2016
84

Análisis de los factores asociados a la calidad en la producción de frutas: Un caso de estudio en Colombia
Helga Patricia Bermeo Andrade
Grupo GINNOVA, Facultad de Ingeniería, Universidad de Ibagué [email protected]
Nelson Javier Tovar Perilla Facultad de Ingeniería, Grupo PYLO, Universidad de los Andes
[email protected] Yanneth Bohórquez Pérez
Facultad de Ingeniería, Grupo CEDAGRITOL, Universidad del Tolima [email protected]
Claudia Valenzuela Real Facultad de Ingeniería, Grupo CEDAGRITOL, Universidad del Tolima
Resumen La calidad de los alimentos de origen agrícola como las frutas debe asegurarse con el uso de buenas prácticas agrícolas, de producción y de manejo logístico, desde los mismos sitios de cultivo hasta su comercialización final. En este artículo se explora, a través de la técnica de minería de datos, las razones asociadas al logro de un alto nivel de calidad en 613 productores de frutas -aguacate, mango, limón, papaya, mora, granadilla, tomate- consultados en una de las zonas de mayor tradición frutícola del centro de Colombia. Los resultados muestran que la calidad está asociada en mayor grado con el tipo de cultivo, el nivel de uso de buenas prácticas agrícolas, el nivel de uso de buenas prácticas en postcosecha y a la zona de cultivo; por otro lado, la calidad se evidencia asociada en menor grado, con el nivel de uso de buenas prácticas al momento de cosecha o con el tamaño de la unidad productiva. Keywords: Frutas; Calidad; Minería de Datos; Colombia 1. Introducción El concepto de “calidad” constituye un aspecto de vital importancia para cualquier producto, cuando de posicionamiento, comercialización efectiva y aceptación en el mercado se trata. En este sentido, los productos provenientes del sector agropecuario como las frutas no son la excepción, lo que exige el monitoreo y control continuo en cada una de las etapas y procesos que integran sus cadenas de suministro, en especial del producto en fresco, con el fin de garantizar el mantenimiento y conservación de sus estándares de calidad y su valor nutracéutico, desde el cultivo hasta la mesa del consumidor final [1], [2]. Este aspecto representa un verdadero reto para países como Colombia, que se potencia gracias a su biodiversidad como una despensa importante de frutas en el mercado internacional [3], pero cuya calidad y cantidad de producción se ven afectadas por la alta tasa de pérdidas poscosecha a lo largo de las cadenas de suministro. Según estadísticas de la FAO y el Ministerio de Salud Nacional, para el año 2012 se estima que las pérdidas poscosecha alcanzaron la cifra de 1.4 millones de toneladas entre frutas y vegetales, cifra que puede abarcar hasta el 50% de la producción total anual [4].
CLAIO-2016
85

Factores que inciden en la calidad de las frutas. De acuerdo a lo reportado en la literatura, son varios los factores que inciden directamente sobre la calidad de las frutas, en sus etapas de cultivo como de cosecha y poscosecha. A nivel de cultivo, factores como: variedad, condiciones edafoclimáticas (principalmente la temperatura y la intensidad solar), tipo de suelo, irrigación, fertilización, uso de agroquímicos, presencia de plagas y enfermedades, que pueden afectar la fisiología, la composición bioquímica, la inocuidad y atributos sensoriales del fruto (apariencia, textura, sabor y aroma) [5], [6]. Frutos como el aguacate “Hass”, presentan cambios en atributos relevantes como su perfil lipídico en dependencia a condiciones climáticas (temperatura) y nutricionales durante su crecimiento vegetativo, tal como lo reportan Ferreyra et al. [7]. Un caso similar se da para el mango, cuyas condiciones ambientales de cultivo (suelo, temperatura, luz solar, etc.) influyen sobre sus cualidades intrínsecas (textura, dulzura, acidez, aroma, vida útil y valor nutricional) y extrínsecas (color y tamaño) [8], igualmente factores de tipo genético y prácticas agronómicas tradicionales repercuten en la calidad y vida útil poscosecha de esta fruta [9].
Un óptimo manejo en cultivo, mediante buenas prácticas agrícolas (BPA), puede ser estropeado por inadecuados procedimientos al momento de la cosecha, perjudicando la calidad del fruto y acelerando su deterioro poscosecha. Para maximizar la vida útil de la fruta fresca hasta su comercialización, esta debe ser recolectada en óptimo estado de madurez, y debe estar libre de heridas o contusiones por daño mecánico o manipulación. Así mismo, debe contar debe contar con apropiadas condiciones logísticas de manejo desde el momento de separación de la planta, con el fin de minimizar su tasa respiratoria, intensidad de transpiración, producción de etileno, proliferación de microorganismos y por ende, el deterioro de la calidad fisicoquímica, bromatológica, funcional y sensorial [10]. Dentro de los factores de cosecha que pueden afectar la calidad de las frutas se encuentran: i) El estado de madurez o índice de cosecha, que para frutos climatéricos está dado por aspectos externos tales como color, forma, tamaño, facilidad de desprendimiento o por aspectos internos como la concentración de sólidos (°Brix), pH, % de acidez, textura e índice de madurez; mientras que para no climatéricos se evidencia cuando el fruto alcanza la madurez de consumo; ii) El método de cosecha, que puede variar entre manual y mecanizado en dependencia de la vulnerabilidad y fenología del fruto; iii) utensilios y herramientas de cosecha, los cuales deben ajustarse a las características físicas del fruto y topografía de la zona [11].
Por su parte, en la etapa poscosecha se consideran aspectos cruciales y decisivos para la conservación de los atributos de calidad en las frutas, los siguientes factores [10], [11]: i) Pre-enfriamiento y mantenimiento en la cadena de frío, para preservar las cualidades y prolongar la vida útil del producto [12], y evitar su maduración anormal, pérdida de agua y valor nutricional, pardeamiento enzimático, entre otros [13]; ii) Limpieza, selección y clasificación, operaciones realizadas ya sea manual o mecánicamente para mantener los estándares de calidad mediante la separación del material enfermo y defectuoso, así como para definir el uso y mercado destino de los frutos; iii) Empacado, materiales de empaque y paletización, actividad clave para mantener la integridad del fruto y obtener la máxima vida en anaquel; por regla general los empaques necesitan ventilación, ser lo suficientemente fuertes para evitar compresiones y tener un tamaño tal que se ajuste a la presión que puede soportar cada producto [14]; iv) Almacenamiento, tarea temporal implícita en el tránsito de los frutos a lo largo de las cadenas de suministro, que requiere control adecuado de la temperatura, ventilación y humedad relativa de las instalaciones físicas que los alojan; y v) Transporte, el cuál debe contar con unidades de refrigeración para mantener la cadena de
CLAIO-2016
86

frío, evitar la mezcla de frutos incompatibles para su almacenamiento conjunto, y requerir los tiempos de desplazamiento lo más cortos posibles, hasta su distribución final y comercialización.
Técnicas para la medición y análisis de factores incidentes. Lo anterior deja en manifiesto que son variados los factores que pueden ser causa de pérdidas de calidad en la producción de frutas y que su reconocimiento es necesario para el establecimiento de medidas correctivas y de control, que faciliten el logro de los estándares de calidad demandados por el mercado. En la literatura se evidencia el uso de las técnicas estadísticas para el análisis de incidencia de los factores pre y poscosecha en los atributos de calidad de las especies hortofrutícolas. Por ejemplo, Moreno et al. [15] utilizaron el análisis de varianza univariado (ANOVA) y multivariado (MANOVA) para evaluar las variables de calidad en el jugo de tomate, a partir de diversos tratamientos en cultivo; Akdeniz et al. [16] emplearon un diseño factorial (ANOVA) para evaluar el efecto de las condiciones de almacenamiento sobre el color de tomate secado al sol; Anwar et al. [17] analizaron mediante el ANOVA la influencia del material de empaque, temperatura y método de maduración sobre la calidad poscosecha de mango fresco; Akhatou y Fernández [18] evaluaron el efecto de la variedad y el sistema agronómico de cultivo sobre las propiedades nutricionales y organolépticas de la fresa, aplicando métodos estadísticos multivariados como al análisis de componentes principales y el análisis discriminante - regresión de mínimos cuadrados parciales, en tanto que Kasso y Bekele [19] recurrieron al análisis estadístico descriptivo para evaluar la influencia de diversos factores presentes a lo largo de la cadena de suministros sobre los porcentajes de pérdidas postcosecha y deterioro de la calidad en los frutos.
La ‘minería de datos’ o MD (también conocida como Datamining por su escritura en inglés) es una técnica alternativa para el análisis de datos, que ofrece versatilidad y transversalidad de uso [20] desde que permite análisis desde cuatro perspectivas a saber: ¿qué pasó? ‘analítica descriptiva’, ¿por qué paso? ‘analítica diagnóstica’, ¿qué podría pasar? ‘analítica predictiva’ y ¿cómo hacer que pase? ‘analítica prescriptiva’ [21]. Con la técnica MD se pueden abordar problemas de aprendizaje de máquina (machine learning problems, MLP) que requieren de un modelo para predecir una variable respuesta a partir de un conjunto de variables de entrada; de forma que los problemas pueden ser de clasificación, si la variable respuesta es categórica y se desea poder predecir la categoría de nuevos sujetos; o de regresión, si la variable respuesta es numérica y se desea predecir un valor continuo; así mismo, es de amplia aplicación por su utilidad en el análisis y control de calidad de procesos y productos [21]. Por otro lado, la MD ha sido empleada para analizar problemáticas propias de la agricultura, por ejemplo, para evaluar trazas de elementos y compuestos en muestras de café [22], para analizar y predecir la composición de los jugos de la uva [23], para predecir la efectividad de diversos tratamientos para el control de plagas en kiwi [24], así como para determinar los estados de madurez en la lechuga [25]. Considerando su aplicabilidad, el presente estudio recurrió a la MD para identificar los factores influyentes en la calidad de un conjunto de frutas representativas del Tolima, una de las regiones de mayor importancia hortofrutícola para Colombi por su diversidad y cantidad de la oferta de frutas y su proximidad a los tres grandes centros urbanos del país. 2. Metodología Este estudio se recurre a la técnica de Minería de Datos, para el análisis de los factores asociados a la producción de frutas con calidad. Para tal fin, se procede en dos fases: i)
CLAIO-2016
87
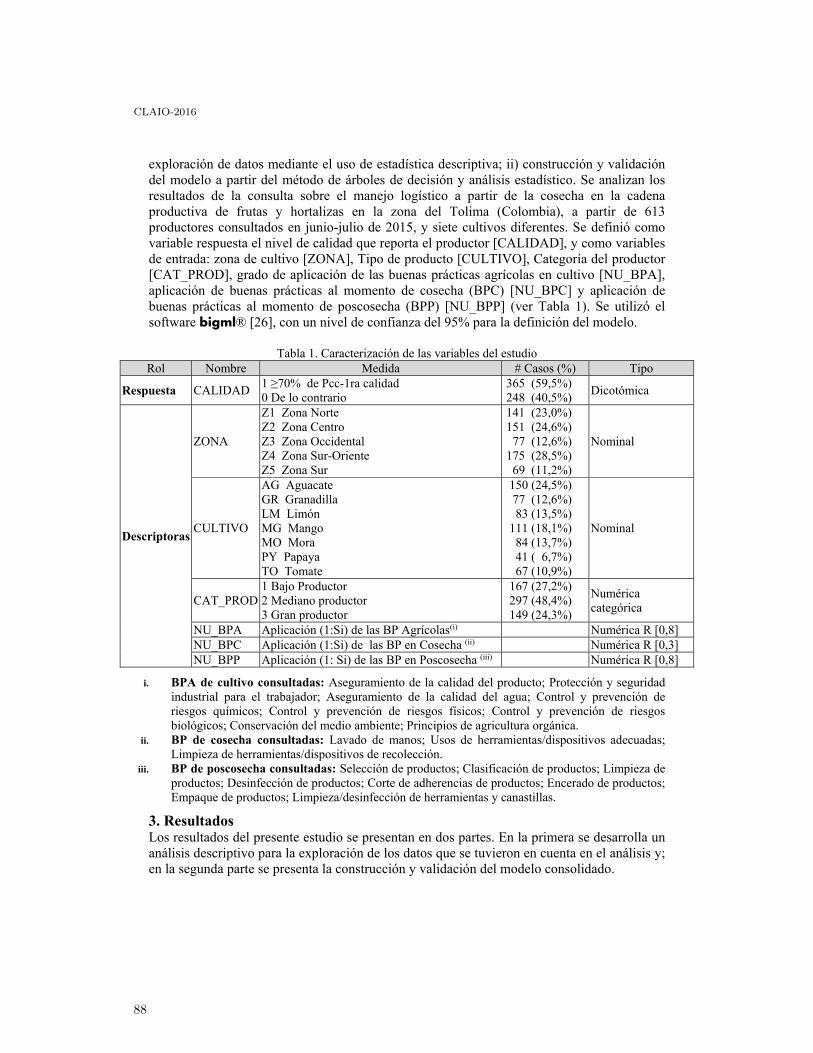
exploración de datos mediante el uso de estadística descriptiva; ii) construcción y validación del modelo a partir del método de árboles de decisión y análisis estadístico. Se analizan los resultados de la consulta sobre el manejo logístico a partir de la cosecha en la cadena productiva de frutas y hortalizas en la zona del Tolima (Colombia), a partir de 613 productores consultados en junio-julio de 2015, y siete cultivos diferentes. Se definió como variable respuesta el nivel de calidad que reporta el productor [CALIDAD], y como variables de entrada: zona de cultivo [ZONA], Tipo de producto [CULTIVO], Categoría del productor [CAT_PROD], grado de aplicación de las buenas prácticas agrícolas en cultivo [NU_BPA], aplicación de buenas prácticas al momento de cosecha (BPC) [NU_BPC] y aplicación de buenas prácticas al momento de poscosecha (BPP) [NU_BPP] (ver Tabla 1). Se utilizó el software bigml® [26], con un nivel de confianza del 95% para la definición del modelo.
Tabla 1. Caracterización de las variables del estudio Rol Nombre Medida # Casos (%) Tipo
Respuesta CALIDAD 1 ≥70% de Pcc-1ra calidad 0 De lo contrario
365 (59,5%) 248 (40,5%)
Dicotómica
Descriptoras
ZONA
Z1 Zona Norte Z2 Zona Centro Z3 Zona Occidental Z4 Zona Sur-Oriente Z5 Zona Sur
141 (23,0%) 151 (24,6%)
77 (12,6%) 175 (28,5%)
69 (11,2%)
Nominal
CULTIVO
AG Aguacate GR Granadilla LM Limón MG Mango MO Mora PY Papaya TO Tomate
150 (24,5%) 77 (12,6%) 83 (13,5%)
111 (18,1%) 84 (13,7%) 41 ( 6,7%) 67 (10,9%)
Nominal
CAT_PROD 1 Bajo Productor 2 Mediano productor 3 Gran productor
167 (27,2%) 297 (48,4%) 149 (24,3%)
Numérica categórica
NU_BPA Aplicación (1:Si) de las BP Agrícolas(i) Numérica R [0,8] NU_BPC Aplicación (1:Si) de las BP en Cosecha (ii) Numérica R [0,3] NU_BPP Aplicación (1: Si) de las BP en Poscosecha (iii) Numérica R [0,8]
i. BPA de cultivo consultadas: Aseguramiento de la calidad del producto; Protección y seguridad industrial para el trabajador; Aseguramiento de la calidad del agua; Control y prevención de riesgos químicos; Control y prevención de riesgos físicos; Control y prevención de riesgos biológicos; Conservación del medio ambiente; Principios de agricultura orgánica.
ii. BP de cosecha consultadas: Lavado de manos; Usos de herramientas/dispositivos adecuadas; Limpieza de herramientas/dispositivos de recolección.
iii. BP de poscosecha consultadas: Selección de productos; Clasificación de productos; Limpieza de productos; Desinfección de productos; Corte de adherencias de productos; Encerado de productos; Empaque de productos; Limpieza/desinfección de herramientas y canastillas.
3. Resultados Los resultados del presente estudio se presentan en dos partes. En la primera se desarrolla un análisis descriptivo para la exploración de los datos que se tuvieron en cuenta en el análisis y; en la segunda parte se presenta la construcción y validación del modelo consolidado.
CLAIO-2016
88

Exploración de los datos. En la Tabla 2 se muestra el resumen del análisis descriptivo para cada una de las variables tenidas en cuenta en el análisis. Como puede verse a partir de los histogramas generados en el software bigml®, la zona con mayor participación en el análisis fue la Z4 con el 28,5% y la de menor participación la Z3 con el 12,6% de los casos; por su parte, el cultivo con mayor representación en la consulta fue el Aguacate con el 24,5% y el lado opuesto está la Papaya con el 6,7%; del mismo modo la categoría de productor mediano fue la dominante en la consulta con el 48,4% de los casos.
En cuanto a la aplicación de las buenas prácticas agrícolas [NU_BPA], las BPA más aplicadas son: Conservación del medio ambiente (59,2%), Aseguramiento de la calidad del producto (57,4%) y Protección y seguridad industrial para el trabajador (49,8%), mientras que las BPA menos aplicadas por el gremio son el Control y prevención de riesgos químicos (23,5%) y de riesgos físicos (29,2%). Por su parte, entre las buenas prácticas al momento de cosecha [UN_BPC], se destaca el Lavado de manos con un grado de aplicación en el 76,2% de los casos consultados, mientras que la Limpieza de herramientas/dispositivos de recolección solo es una práctica regular en poco más de uno de cada tres productores analizados (36,1%). Finalmente, en la consulta de las buenas prácticas poscosecha [UN_BPP] se evidencia un notable rezago en el Tolima, pues 45 de los productores no aplica ninguna de las ocho BPP consultadas, y suman 229 los que solo aplican uno o dos BPP. Las BPP más aplicadas por los productores son: Empaque de productos (72,3%), Selección de productos (65,4%) y la Clasificación de productos (60,2%), y en menor medida se aplica: Encerado de productos (11,1%), Limpieza de productos (20,1%) y Limpieza/desinfección de herramientas y canastillas (24,8%).
En lo que respecta a la calidad lograda en la producción de frutas [CALIDAD], el 59,9% de los consultados indicaron obtener una producción anual clasificada como de primera calidad, en una proporción igual o superior al 70% de lo producido en las zonas de cultivo. Los productores con mayores tasas de calidad, en peso relativo a su participación en la muestra del estudio (n=613 casos), fueron los productores de papaya (90,2%), limón (83,1%) y mango (82,8%), mientas que las mayores tasas de no calidad están presentes en los productores de tomate (1,3%), aguacate (10,1%) y granadilla (22,0%).
Tabla 2. Resumen descriptivo de las variables incluidas en el modelo
Fuente: Este estudio a partir de los datos del proyecto Convenio 1032-2013
CLAIO-2016
89

Construcción y validación del modelo general. El software bigml® facilitó el
análisis de los datos, de tal forma que haciendo múltiples particiones de los datos a través de un modelo de clasificación, maximizara la ganancia de información para clasificar mejor. Para correr el modelo, el sistema se configuró con muestreo aleatorio, arrastramiento aleatorio y ordenamiento linear de los datos; de otro lado, se habilitó la opción de balance automático de las clases presentes en la variable objetivo [CALIDAD], en proporción a su frecuencia. Para determinar las principales variables asociadas con niveles altos de calidad en los productos hortofrutícolas se utilizó la técnica de árboles de decisión y los gráficos radiales de variables dominantes. Como se muestra en la Figura No.1, la variable raíz a partir de la cual se inicia la división de los datos, es la variable relativa a la zona de producción, seguida del tipo de cultivo y el nivel de aplicación de las BPA. Como lo siguiere la Figura No.1, se logra un nivel de predicción del 39% de los casos, con un 81,24% de confianza, si el productor se ubica en una zona diferente a la Z1 (zona norte del Tolima), si no es productor de Granadilla, y si al menos aplica una buena práctica agrícola en el proceso de producción.
Figura 1. Diagrama de árbol para predecir la ruta de la calidad
El modelo resultante del análisis de MD se resume en la Figura No.2. La predicción del
logro de un alto nivel de calidad en la producción anual de frutas en las fincas de esta región, está mayoritariamente asociado por nivel de importancia, a las variables: tipo de cultivo (25.02%), seguido del grado de aplicación de las BPA (20,51%), el grado de aplicación de las BPP (17,58%) y la zona del cultivo (16.79%). Por otro lado, las variables cuya incidencia es mínima para predecir la calidad en la producción, son el grado de aplicación de las BPC (10.54%) y la categoría del productor (9.56%). De los resultados obtenidos se extrae que dadas las condiciones específicas de cada cultivo, tales como el nivel de perecibilidad y la susceptibilidad a condiciones climáticas, el tipo de cultivo y la aplicación de buenas prácticas agrícolas al momento de cultivo, sean las principales variables que afectan el nivel de calidad de la producción de frutas.
CLAIO-2016
90

Figura 2. Modelo resumen propuesto para el diagnóstico
4. Conclusión El modelo propuesto a través del uso de la MD sirve de base para predecir el nivel de calidad de un productor a partir de sus características de operación, y a su vez, ofrece apoyo para la identificación de las actividades sobre las que se deben concentrar para asegurar un producto de mejor calidad y por ende, un mayor nivel de aceptación y mejores precios en el mercado. Agradecimientos Los autores agradecen la financiación del Convenio 1032-2013 "Diseño e implementación de un modelo logístico como base para la integración de valor en la cadena de la horticultura en Tolima ", a través del fondo de C&T del SGR en Tolima - Colombia. De igual forma, agradecen al equipo técnico por su apoyo en el trabajo de campo y preparación de los datos. Referencias [1] K. Kirezieva, J. Nanyunja, and L. Jacxsens, “Context factors affecting design and operation of food safety management systems in the fresh produce chain,” Trends in Food Science & Technology, vol. 32, pp. 108-127, 2013. [2] N. Babbar, H. S. Oberoi, and S. K. Sandhu, “Therapeutic and nutraceutical potential of bioactive compounds extracted from fruit residues,” Critical Reviews in Food Science and Nutrition, vol. 55, no. 3, pp. 319-337, 2015. [3] Finagro, “El agro colombiano se abre mercado en Expo Milán 2015,” 2015. [Online]. Available: https://www.finagro.com.co/noticias/el-agro-colombiano-se-abre-mercado-en-expo-mil%C3%A1n-2015. [Accessed: Jun-2016]. [4] Procolombia, “Logística de perecederos y cadena de frío en Colombia,” 2014. [Online]. Available: http://www.procolombia.co/sites/all/modules/custom/mccann/mccann_ruta_exportadora/files/06-cartilla-cadena-frio.pdf. [Accessed: Jun-2016]. [5] A. A. Kader, “Pre and postharvest factors affecting fresh produce quality, nutritional value, and implications for human health,” Proceedings of the International Congress Food Production and the Quality of Life, 2000, pp. 109-119, 2002. [6] M. S. Ladaniya, Citrus fruit: biology, technology and evaluation, 1st ed. Oxford: Elsevier Inc., 2008. [7] R. Ferreyra et al., “Identification of pre-harvest factors that affect fatty acid profiles of avocado fruit (Persea Americana Mill) cv. ‘Hass’ at harvest,” South African Journal of Botany, vol. 104, pp. 15-20, 2016.
CLAIO-2016
91

[8] M. Léchaudel and J. Joas, “An overview of preharvest factors influencing mango fruit growth , quality and postharvest behaviour,” Brazilian Journal of Plant Physiology, vol. 19, no. 4, pp. 287-298, 2007. [9] A. Rehman, A. U. Malik, H. Ali, M. W. Alam, and B. Sarfraz, “Preharvest Factors Influencing the Postharvest Disease Development and Fruit Quality of Mango,” Journal of Environmental and Agricultural Sciences, vol. 3, pp. 42-47, 2015. [10] M. J. Dumont, V. Orsat, and V. Raghavan, “Reducing Postharvest Losses,” Emerging Technologies for Promoting Food Security, C. Madramootoo, Ed. Cambridge: Elsevier Ltd, 2016, pp. 135-153. [11] M. S. Ahmad and M. W. Siddiqui, Postharvest Quality Assurance of Fruits. London: Springer, 2015. [12] J. Dehghannya, M. Ngadi, and C. Vigneault, “Mathematical Modeling Procedures for Airflow, Heat and Mass Transfer During Forced Convection Cooling of Produce: A Review,” Food Engineering Reviews, vol. 2, pp. 227-243, 2010. [13] M. Serrano, F. Riquelme, M. T. Pretel, and F. Romojaro, “Review: Role of polyamines in chilling injury of fruit and vegetables,” Food Science and Technology International, vol. 2, pp. 195–199, 1996. [14] L. Kitinoja and A. A. Kader, Small-Scale Postharvest Handling Practices: A Manual for Horticultural Crops, 4th ed., no. 8. Davis: University of California, 2003. [15] C. Moreno, I. Mancebo, A. M. Tarquis, and M. M. Moreno, “Univariate and multivariate analysis on processing tomato quality under different mulches,” Scientia Agricola, vol. 71, no. 2, pp. 114-119, 2014. [16] B. Akdeniz, D. D. Kavak, and N. Bağdatlioğlu, “Use of factorial experimental design for analyzing the effect of storage conditions on color quality of sun- dried tomatoes,” Scientific Research and Essays, vol. 7, no. 4, pp. 477-489, 2012. [17] R. Anwar, A. U. Malik, M. Amin, A. Jabbar, and B. A. Saleem, “Packaging Material and Ripening Methods Affect Mango Fruit Quality,” International Journal of Agriculture & Biology, vol. 10, pp. 35-41, 2008. [18] I. Akhatou and Á. Fernández-recamales, “Influence of cultivar and culture system on nutritional and organoleptic quality of strawberry,” Journal of the Science of Food and Agriculture, vol. 94, no. 5, pp. 866-875, 2014. [19] M. Kasso and A. Bekele, “Post-harvest loss and quality deterioration of horticultural crops in Dire Dawa Region, Ethiopia,” Journal of the Saudi Society of Agricultural Sciences, 2016. [20] D. Hand, H. Mannila, and P. Smyth, Principles of Data Mining, vol. 2001. Cambridge: MIT Press, 2001. [21] T. W. Liao, “Enterprise Data Mining: A Review and Research Directions,” Recent Advances in Data Mining of Enterprise Data: Algorithms and Applications, T. W. Liao, Ed. London: World Scientific Publishing Co. Pte. Ltd, 2007. [22] R. Melgaço, B. Lemos, R. M. Varrique, V. A. Coelho, A. D. Campiglia, and F. Barbosa, “The use of advanced chemometric techniques and trace element levels for controlling the authenticity of organic coffee,” Food Research International, vol. 61, pp. 246-251, 2014. [23] C. Maione et al., “Comparative study of data mining techniques for the authentication of organic grape juice based on ICP-MS analysis,” Expert Systems With Applications, vol. 49, pp. 60-73, 2016. [24] M. G. Hill, P. G. Connolly, P. Reutemann, and D. Fletcher, “The use of data mining to assist crop protection decisions on kiwifruit in New Zealand,” Computers and Electronics in Agriculture, vol. 108, pp. 250-257, 2014. [25] X. E. Pantazi, D. Moshou, D. Kasampalis, P. Tsouvaltzis, and D. Kateris, “Automatic Detection of Different Harvesting Stages in Lettuce Plants by Using Chlorophyll Fluorescence Kinetics and Supervised Self Organizing Maps ( SOMs ),” Engineering Applications of Neural Networks, L. Iliadis, H. Papadopoulos, and C. Jayne, Eds. Berlin: Springer, 2013, pp. 360-369. [26] BigMl Team, “Supervised Learning Guide, Version 2.0,” 2016. [Online]. Available: http://bigml.com. [Accessed: May-2016].
CLAIO-2016
92

Some forbidden subgraphs for LS+-perfection∗
S. BianchiFCEIA, Universidad Nacional de Rosario, Argentina
M. EscalanteFCEIA, Universidad Nacional de Rosario, Argentina - CONICET, Argentina
G. NasiniFCEIA, Universidad Nacional de Rosario, Argentina - CONICET, Argentina
Abstract
The Maximum Weighted Stable Set Problem is polynomial for LS+-perfect graphs, a familyof graphs which is known to contain many rich and interesting classes such as perfect and near-bipartite graphs, among others. However, no combinatorial or polyhedral characterization ofLS+-perfect graphs is known.
In the current contribution, we make some progress on this line by presenting an infinitefamily of forbidden subgraphs for LS+-perfection.
Keywords: stable set problem; lift-and-project methods; semidefinite programming; forbiddensubgraphs.
1 Introduction
In the early nineties, Lovász and Schrijver ([7]) introduced a semidefinite relaxation of STAB(G), thestable set polytope of the graph G, obtained by applying the semidefinite lift-and-project procedureLS+ (originally called N+ in [7]) to the edge relaxation. Following the same line of reasoning usedfor perfect graphs in [6], they proved that the Maximum Weighted Stable Set Problem can besolved in polynomial time for graphs G for which this relaxation coincides with STAB(G). Thesegraphs have been recently called LS+-perfect graphs ([2]) and constitute a super-class of perfectgraphs containing some rich and interesting other classes of graphs as h-perfect, near-bipartite andall those ones obtained by complete join or clique sum operations of them. Although the MaximumWeighted Stable Set Problem is polynomial on LS+-perfect graphs, no polyhedral nor combinatorialcharacterization has been obtained so far.
Concerning the polyhedral characterization, a conjecture on the stable set polytope of LS+-perfect graphs was stated in [1]:
∗This work is partially supported by grants PIP-CONICET 0277, PID-UNR 390, PICT-ANPCyT 0586, Math-AmSud 15Math06
CLAIO-2016
93

Conjecture 1.1. The stable set polytope of every LS+-perfect graph can be described by facetdefining inequalities with near-bipartite support.
Its validity has been proved on a super class of near-perfect graphs (fs-perfect graphs), webgraphs ([4]) and line graphs ([5]).
As in the case of perfection, the LS+-perfection is inherited by node induced subgraphs. There-fore, the identification of minimal forbidden subgraphs becomes a natural line of work in the attemptof finding a combinatorial characterization. A graph is LS+-imperfect if it is not LS+-perfect andit is minimally LS+-imperfect if it is LS+-imperfect but every proper node induced subgraph isLS+-perfect.
Since perfect graphs, odd holes (denoted by C2k+1) and odd anti-holes (C2k+1) are LS+-perfect,the simplest structure where we can find minimally LS+-imperfect graphs are those graphs whosenode set can be partitioned into a singleton and a set inducing a minimally imperfect graph.Formally, for k ≥ 2, we say that a graph G ∈ Fk if its node set is {0, 1, . . . , 2k + 1}, G − 0 isminimally imperfect and node 0 is not isolated nor universal (otherwise G is LS+-perfect).
In what follows, given G ∈ Fk, we consider nodes in V (G − 0) as the algebraic group on theset {1, . . . , 2k + 1} with the addition modulo 2k + 1. Let Gk = {G ∈ Fk : G − 0 = C2k+1} andJ k = {G ∈ Fk : G− 0 = C2k+1}.
We denote by N the set of nodes adjacent to 0 in G and B the nodes not adjacent to 0, i.e.,B = V (G − 0) − N . Clearly, V (G − 0) can be partitioned into 2r (r ≥ 1) integral interval setsN1, B1, . . . , Nr, Br such that, for all ` ∈ {1, . . . , r}, N` = [i`, f`] ⊆ N and B` = [f` + 1, i`+1−1] ⊆ B(the addition in the indices is modulo r). Observe that, once it is known that a graph G belongs Gkor Fk, this partition completely identifies G. So, by abuse of notation, we write G = N1B1 . . . NrBr.
In [2], Corollary 29 characterizes all LS+-imperfect graphs in Gk as well as the LS+-imperfectgraphs in J k having stability number 2. With the current notation, it can be restated in thefollowing form:
Lema 1.2 ([2]). Let G = N1B1 . . . NrBr ∈ Fk with k ≥ 2.
1. If G ∈ Gk, G is LS+-imperfect if and only if either there is j ∈ {1, . . . , r} such that |Nj | ≥ 3or one of the following conditions holds:
a) |Nj | = |Nt| = 2 for some j, t ∈ {1, . . . , r}, j 6= t,
b) |Nj | = 2, |B`| is even for some j, ` ∈ {1, . . . , r} and |Ni| = 1 for all i 6= j,
c) |Nj | = 1 for all j ∈ {1, . . . , r}, |B`| and |Bt| are even for some `, t ∈ {1, . . . , r}, ` 6= t.
2. If G ∈ J k and α(G) = 2 then G is LS+-imperfect.
In this work we characterize minimally LS+-imperfect graphs in Gk, we complete the character-ization of LS+-imperfect graphs in J k and identify those ones which are minimally LS+-imperfect.
2 Full-support facets of the stable set polytope of graphs in J k
A necessary condition for a graph G to be minimally LS+-imperfect is to have a full-support facetdefining inequality describing STAB(G). This condition is useful in the study of LS+-imperfectionof graphs in J k.
CLAIO-2016
94

Given a graph G, a root of a valid inequality of STAB(G) is the characteristic vector of a stableset of G satisfying it at equality. For simplicity we also say that the corresponding stable set is aroot of the inequality. It is straightforward that every root of a full-support facet defining inequalityof STAB(G) is a maximal stable set of G. If G = N1B1 . . . NrBr ∈ J k, its maximal stable sets areof two types:
• A maximal stable set is of type S if it contains the nodes i and i+ 1 for some i ∈ V (G− 0).Such a stable set is {i, i+ 1, 0} if {i, i+ 1} ⊂ B and {i, i+ 1} otherwise.
• A maximal stable set is of type R if it is of the form {i, 0} for some i ∈ V (G − 0). In thiscase, B` = {i} for some ` ∈ {1, . . . , r}.
We refer to a root of a full support valid inequality of STAB(G) as an S-root or as an R-root.
Theorem 2.1. Let G = N1B1 . . . NrBr ∈ J k with r ≥ 2 such that, |Ni| is odd for all i ∈ {1, . . . , r},Bj = {fj +1} and B` = {f`+1} for some 1 ≤ j ≤ ` ≤ r. Let ax ≤ b be a facet defining inequality ofSTAB(G). If R is a set of 2k+ 2 roots that contains the R-roots defined by Bj , B` and the S-rootscontaining the nodes in {i, i+ 1} for all i ∈ [fj + 1, f`], then ax ≤ b is not full-support.
Proof. W.l.o.g. suppose that j = 1 and B1 = {1}.Assume that the sets {1, 0}, {f`+1, 0}, as well as all the maximal stable sets containing {i, i+1}
for i ∈ [1, f`], belong to R.Let us first prove that there exists h ∈ {2, . . . , `− 1} such that |Bh| ≥ 2.Assume that |Bs| = 1 for every s ∈ {1, . . . , `}. Observe that, since |Ni| is odd for every
i ∈ {1, . . . , r}, f` is even and then, ` ≥ 2. Consider the matrix whose rows are the roots in Rcorresponing to the maximal the stable sets {0, 1}, {i, i+ 1} for i ∈ {1, . . . , f`} and {0, f` + 1}, inthis order. It is not hard to check that in this matrix the sum of the even rows equals the sum ofthe odd rows. This contradicts the fact that the roots in R are linearly independent.
Now, let h ∈ {2, . . . , `− 1} such that |Bs| = 1 for all s ∈ {1, . . . , h− 1} and |Bh| ≥ 2. By parityarguments, fh is even.
Observe that {fh + 1, fh + 2} ⊂ Bh and then, by hipothesis {fh + 1, fh + 2, 0} is a root of ax ≤ bin R. Therefore, afh+1 + afh+2 + a0 = b.
Moreover, {0, 1} and {i, i + 1} for all i ∈ [1, fh] belong to R. Then, we have that a0 + a1 = b,ai + ai+1 = b for all i ∈ {1, . . . , fh} implying that, for i ∈ {1, . . . , fh + 1},
ai =
{a0 if i is even,
b− a0 if i is odd.
Since fh is even, afh+1 = b− a0. Since afh+1 + afh+2 + a0 = b, afh+2 = 0 contradicting the factthat ax ≤ b is a full-support inequality.
Since in every graph in J k there are exactly 2k+1 maximal stable sets of type S, any full-supportfacet defining inequality of STAB(G) must have at least one R-root. Then,
Theorem 2.2. Let G = N1B1 . . . NrBr ∈ J k. If STAB(G) has a full-support facet defininginequality then there exist p, ` ∈ {1, . . . , r} such that |Np| is even and |B`| = 1.
CLAIO-2016
95

Proof. Suppose that ax ≤ b is a full-support facet defining inequality of STAB(G) and R is a setof 2k + 2 linearly independent roots. Since the maximal stable sets of type S are at most 2k + 1,there must be an R-root in R implying that |B`| = 1 for some ` ∈ {1, . . . , r}.
Remind that, for j ∈ {1, . . . , r}, we write Nj = [ij , fj ] and Bj = [fj + 1, ij+1 − 1]. If h is thenumber R-roots in R, let {j1, j2, . . . , jh} be the set of indices in {1, . . . , r} for which |Bjt | = 1, i.e.,Bjt = {fjt + 1} for t ∈ {1, . . . , h}.
It is clear that the sets It = [fjt + 1, fjt+1 ] for t ∈ {1, . . . , h} induce an h-partition of V (G− 0).Since we have h R-roots in R the number of S-roots in R is 2k+ 2−h = 2k+ 1− (h− 1), meaningthat at most h−1 maximal stable sets of type S do not belong to R. After the pigeonhole principle,there is a set Is with s ∈ {1, . . . , h} for which all the maximal stable sets of type S, containing{i, i+ 1} with i ∈ Is belong to R.
Suppose that |Ni| is odd for all i ∈ {1, . . . , r}. Clearly, we can apply Theorem 2.1 consideringBj = {fjs + 1} and B` = {fjs+1 + 1}. This leads us to a contradiction of the fact that ax ≤ b is afull-support inequality. Therefore, |Np| is even for some p ∈ {js + 1, . . . , js+1}.
3 The LS+-imperfection of graphs in J k
According to Lemma 1.2, in order to complete the study of LS+-imperfection of graphs in J k itonly remains to consider those graphs with stability number equal to three.
For k ≥ 2, let us consider the graph in J k with δ(0) = 2k. This graph is called Hk in [2] andfrom Lemma 1.2, it is LS+-imperfect for every k ≥ 2. Moreover, it plays an important role in theproof of the next results.
In fact, observe that if G = N1B1 . . . NrBr ∈ J k and Nj = [ij , fj ] has even cardinality for somej ∈ {1, . . . , r}, then the nodes in Nj ∪ {0, ij − 1, fj + 1} define an antihole G′ in G. Therefore, if
we find an extra node connected to all the nodes of G′ except one, G has Hp (p = |N1|2 + 1) as a
node induced subgraph and then it is not LS+-perfect.In the next result we analyze some particular graphs in J k that we also need for proving
Theorem 3.2. In fact, we show that these special cases correspond to near-bipartite graphs andthen, to LS+-perfect graphs. A graph is near-bipartite if after deleting any node and the nodesadjacent to it, the resulting graph is bipartite. We write G v the graph obtained by deletion ofnode v and all its neighbors.
Lema 3.1. Let G = N1B1 . . . NrBr ∈ J k. If
1. r = 1 and 2 ≤ |B| ≤ 4, or
2. r = 2 and |B1| = |B2| = 2
then G is near-bipartite.
Proof. It is easy to check that, for every G ∈ J k,
• if i ∈ N then V (G i) = {i− 1, i+ 1},
• if i ∈ B then V (G i) = {i− 1, i+ 1, 0} and
• if i = 0 then V (G i) = B.
CLAIO-2016
96

Then, G i is bipartite for every i ∈ N . Consider i ∈ B, since {i− 1, i+ 1} defines an edge of G,G i is bipartite if and only if {i − 1, i + 1} ∩ B 6= ∅. It is not hard to see that under the givenhypothesis this condition holds, as well as the fact that the subgraph induced by B is bipartite.
Now we can prove the following:
Theorem 3.2. Let G = N1B1 . . . NrBr ∈ J k with α(G) = 3. Then G is LS+-imperfect if and onlyif |Nj | is even for some j ∈ {1, . . . , r} and either r ≥ 3 or one of the following conditions holds:
1. r = 2 and |Bi| 6= 2 for some i ∈ {1, 2},
2. r = 1 and |B| ≥ 5.
Proof. Assume that for some j ∈ {1, . . . , r}, Nj = [ij , fj ] has even cardinality. W.l.o.g we setj = 1 and i1 = 1. Then N1 ∪ {0, 2k + 1, f1 + 1} induces an odd antihole in G. The proof of the“only if” part consists in finding an extra node v ∈ V (G − 0) for which the graph induced by
N1 ∪ {0, 2k + 1, f1 + 1, v} is the graph Hp for p = |N1|+22 .
If r ≥ 3 then v = f2 + 1 ∈ B satisfies the above condition.Let r = 2 and assume that |B1| 6= 2. If |B1| ≥ 3 then we choose v = f1 + 3. If |B1| = 1 then we
consider v = i2. Finally if r = 1 and |B| ≥ 5, then v = f1 + 3 ∈ B.In order to prove the converse, assume that |Ni| is odd for every i. Then, Theorem 2.2 shows
that there is no full-support facet defining inequality of STAB(G). Moreover, the only minimallyimperfect subgraph of G is G− 0 and then G− v is LS+-perfect for every v. This shows that G isLS+-perfect.
Now, if r ≤ 2 and conditions (i) and (ii) do not hold, Lemma 3.1 shows that the graph isLS+-perfect and the proof is complete.
4 Minimally LS+-imperfect graphs in Fk
Given G1 and G2 such that V (G1)∩V (G2) is a clique, the graph induced by the nodes in V (G1)∪V (G2) is the clique sum of G1 and G2. From results in [3] it follows that clique sum operationpreserves LS+-perfection.
Let G ∈ Gk and v ∈ V (G). It is clear that G− v is a clique sum of cycles and paths and, sincecycles and paths are LS+-perfect, G− v is LS+-perfect. This proves the following:
Lema 4.1. Let G ∈ Gk with k ≥ 2. Then G is minimally LS+-imperfect if and only if G isLS+-imperfect.
Hence, Lemma 1.2 characterizes all the minimally LS+-imperfect graphs in Gk. Unlike whathappens with graphs in Gk we will see that there are only two types of minimally LS+-imperfectgraphs in J k. For k ≥ 2, we define Lk the graph in J k such that Lk = N1B1N2B2 with |B1| =|B2| = |N1| = 1.
Lema 4.2. Hk and Lk are minimally LS+-imperfect, for any k ≥ 2.
Proof. Let k ≥ 2. From Lemma 1.2 we know that Hk and Lk are LS+-imperfect. Moreover, it iseasy to check that Hk− v is either perfect when v 6= 0 or minimally imperfect if v = 0. ConcerningLk, since |N2| is even, Lk − v is minimally imperfect if v ∈ N1 ∪ {0} and Lk − v is perfect in anyother case.
CLAIO-2016
97

In fact, we can state the following:
Theorem 4.3. Let G ∈ J k with k ≥ 2. Then G is minimally LS+-imperfect if and only if eitherG = Hk or G = Lk.
Proof. From Lemma 4.2 we only need to consider an LS+-imperfect graph G ∈ J k different fromHk and Lk. We prove that G has an LS+-imperfect proper subgraph.
If α(G) = 3 the proof of Theorem 3.2 shows the existence of Hs for s < k as a node inducedsubgraph of G.
If α(G) = 2 then G = N1B1, . . . , NrBr with |Bi| = 1 for every i ∈ {1, . . . , r} and r ≥ 2. Byparity arguments, there must be j ∈ {1, . . . , r} such that |Nj | is even and we can assume that j = 1.
Let r = 2. Since |N2| is odd and G 6= Lk, |N2| ≥ 3. Then, the set B2 ∪N1 ∪B1 ∪{0, i2} induces
a subgraph Hp in G for p = |N1|2 + 1 < k. If r ≥ 3, the nodes in the set Br ∪N1 ∪ B1 ∪ B2 ∪ {0}
induces again the graph Hp in G. Therefore, G is not minimally LS+-imperfect.
5 Conclusions
In this contribution all minimally LS+-imperfect graphs with the simplest possible structure arecharacterized, i.e., minimally imperfect graphs with only one extra node outside. However, theresults in [4] show that there are other minimally LS+-imperfect graphs, such as the web graphW 2
10, which is minimally LS+-imperfect and it is the only web graph with this property. Therefore,the existence of new families of minimally LS+-imperfect graphs is an interesting and promisingline of further research.
References
[1] S. Bianchi, M. Escalante, G. Nasini, L. Tunçel, Lovász-Schrijver SDP-operator and a superclassof near-perfect graphs. Electronic Notes in Discrete Mathematics 44 (2013). 339–344.
[2] S. Bianchi, M. Escalante, G. Nasini, L. Tunçel, Lóvasz-Schrijver SDP-operator, near-perfectgraphs and near-bipartite graphs. Submitted manuscript. Available in arXiv:1411.2069v1[cs.DM] (2014).
[3] V. Chvátal, On certain polytopes associated with graphs. Journal of Combinatorial Theory B18-2 (1975). 138–154.
[4] M. Escalante, G. Nasini, Lovász and Schrijver N+-relaxation on web graphs. Lecture Notes inComputer Science 8596 (2014). 221–230.
[5] M. Escalante, G. Nasini, A. Wagler, Characterizing N+-perfect line graphs. InternationalTransactions in Combinatorial Optimization. In press. (2016)
[6] M. Grötschel, L. Lovász, A. Schrijver, The ellipsoid method and its consequences in combina-torial optimization. Combinatorica 1 (1981). 169–197.
[7] L. Lovász, A. Schrijver, Cones of matrices and set-functions and 0-1 optimization, SIAMJournal on Optimization 1 (1991). 166–190.
CLAIO-2016
98

El problema de coloreo de aristas por etiquetado total
bajo un enfoque de programación lineal entera
Fabrizio [email protected]
Paula Zabala, Isabel Meńdez-Dı́azFCEN-Universidad de Buenos Aires - CONICET
{pzabala}{imendez}@dc.uba.ar
Abstract
En este trabajo se aborda bajo un enfoque de programación lineal entera el problema decoloreo de aristas por etiquetado total. Se propone una formulación para este problema y familiasde desigualdades válidas a partir de las cuales desarrollamos un algoritmo Branch-and-Cut. Conel objetivo de mejorar la eficiencia del algoritmo, desarrollamos heuŕısticas iniciales y primales.Finalmente, presentamos experiencia computacional que evidencia la buena performance delalgoritmo.
Keywords: Etiquetado total; Coloreo de aristas; Branch-and-Cut.
1 Introducción
El problema de coloreo de aristas por etiquetado total (PCAET ) es un problema de grafos intro-ducido en el año 2007 [1]. Consiste en etiquetar los vértices y las aristas de un grafo con etiquetas1, . . . , k de manera tal que los colores de las aristas formen un coloreo de aristas, donde el colorde una arista es determinado como la suma de su etiqueta y de las de sus vértices extremos. Estaasignación de etiquetas define un k-etiquetado total. Formalmente, sea G = (V,E) un grafo con Vel conjunto de vértices y E el conjunto de aristas. Se denomina coloreo de aristas por etiquetadototal a la función f : V ∪ E → {1, ..., k} tal que los colores de las aristas definidos como:
w(uv) = f(u) + f(uv) + f(v)
producen un coloreo de aristas, donde (u, v) ∈ E. Se define χ′t(G) como el menor entero k tal queG tiene un coloreo de aristas por un k-etiquetado total. Encontrar este valor es el objetivo delPCAET.
El PCAET se puede considerar una relajación del problema edge-irregular total labellings [2]donde la definición del color de una arista es la misma, pero se requiere que todos los colores de lasaristas sean diferentes.
En el mismo trabajo donde se introduce el problema [1], se presentan cotas inferior y superiorde χ′t(G) en términos del grado máximo ∆ de G:
CLAIO-2016
99

⌈∆ + 1
2
⌉≤ χ′t(G) ≤ ∆
χ′t(G) ≤ ∆/2 +O(√
∆ log ∆).
El problema se analizó bajo un enfoque de teoŕıa de grafos para diferentes clases especiales degrafos. En [1], se demostró que para un grafo cúbico G vale que χ′t(G) = 2 si y sólo si el conjuntode vértices de G puede ser particionado en dos subconjuntos A y B tal que induzcan matchingsperfectos. Además, si F es un bosque con grado máximo ∆, se cumple que χ′t(F ) =
⌈∆+1
2
⌉. Para
grafos completos Kn, si n 6≡ 2 (mod 4), entonces χ′t(Kn) =⌈n2
⌉y si n ≡ 2 (mod 4), entonces
χ′t(Kn) ≤ n2 + 1. En [3] se caracterizó χ′t(G) para grafos generalizados de Petersen y en [4] se
estudiaron los grafos circulantes 4-regulares.
Si bien el problema tiene cierto tratamiento en la literatura desde el punto de vista de teoŕıade grafos, no hemos encontrado propuestas de algoritmos exactos ni heuŕısticos que lo resuelvan.El objetivo de este trabajo es presentar un algoritmo exacto tipo Branch-and-Cut para el PCAETmediante programación lineal entera además de proponer dos heuŕısticas. En la Sección 2 sepresenta un modelo de programación entera y en la Sección 3 varias familias de desigualdadesválidas del poliedro asociado. En Seccion 4, se propone heuŕısticas iniciales y primales. Finalmenteen Sección 5 se presenta experimentación computacional que evidencia la buena performance deun algoritmo Branch-and-Cut que incluye las heuŕısticas primal e inicial y las desigualdes válidascomo planos de corte.
2 Modelo de programación lineal entera
Sean xv ∈ {1, . . . ,∆}, xuv ∈ {1, . . . ,∆} variables entera general que representan la etiqueta que lefue asignada al vértice v ∈ V y arista (u, v) ∈ E respectivamente y z ∈ {1, . . . ,∆} variable enterageneral que representa la mayor etiqueta utilizada. El objetivo es minimizar el valor de z quecaracteriza el valor del cromático χ′t(G). Además, para todo par de aristas (u, j), (j, v) definimosuna variable binaria δujv (definidas según orden lexicográfico) que toma valor 1 si w(uj) < w(jv)y 0 si w(uj) > w(jv). Esta variable expresa que w(uj) 6= w(jv), de tal manera que los coloresque reciben las aristas definan un coloreo. Basado en la definición de estas variables, se presenta elsiguiente modelo de programación lineal entera para el PCAET :
minimizar z
sujeto a
(1) xu ≤ z ∀u ∈ V (1)
(2) xuv ≤ z ∀(u, v) ∈ E (2)
(3) xu + xuj − xjv − xv ≥ 1− δujv(2∆− 1) ∀(u, j), (j, v) ∈ E y u < v (3)
(4) xu + xuj − xjv − xv ≤ −1 + (1− δujv)(2∆− 1) ∀(u, j), (j, v) ∈ E y u < v (4)
(5) 1 ≤ xw, xuv, z ≤ ∆, con xw, xuv, z ∈ Z ∀w ∈ V y (u, v) ∈ E (5)
(6) δujv ∈ {0, 1} ∀(u, j), (j, v) ∈ E y u < v (6)
CLAIO-2016
100

Las restricciones (1) y (2) indican que z tiene que ser mayor o igual que cada etiqueta que fueasignada a los vértices y aristas. De esta forma, ya que el objetivo es minimizar z, en el óptimo elvalor de la variable será igual al valor de la máxima etiqueta que fue asignada. Las restricciones(3) y (4) son las que definen el coloreo de aristas exigiendo que dos aristas que inciden en elmismo vértice reciben colores diferentes, es decir, w(uj) 6= w(jv) si (u, j), (j, v) ∈ E. El objetivode estas restricciones es representar esta ecuación como una disyunción: tiene que suceder quew(uj) < w(jv) o bien w(uj) > w(jv). Por último, las restricciones (5) y (6) definen los dominiosde las variables.
Al analizar las caracteŕısticas del oṕtimo de la relajación lineal se identificó que, independien-temente de la instancia, x∗v = 1 para todo vértice v y x∗uv = 1 para toda arista (u, v). Las variablesδ∗ toman valores 1
2∆−1 ≤ δ∗ujv ≤ 2∆−22∆−1 y z∗ = 1. Esto muestra que el valor objetivo de la relajación
lineal es muy bajo, lo que repercute en una mala performance de un algoritmo tipo Branch-and-Cut. En la siguiente sección, se presentan varias familias de desigualdades válidas que tienen elpróposito de ajustar la relajación lineal.
3 Desigualdades válidas
A continuación se enuncian familias de desigualdades válidas para el poliedro asociado a la for-mulación. El objetivo es desarrollar un algoritmo Branch-and-Cut que utilice estas desigualdadescomo planos de corte y mejore sustancialmente la performance de un algoritmo Branch-and-Cut depropósito general como lo es CPLEX [8].
Cotas máximas y mı́nimas
Dado un vértice se pueden acotar los valores de los colores de las aristas incidentes a él, tantoinferior como superiormente, sabiendo que se tiene que cumplir con la condición de coloreo dearistas y que el modelo restringe el valor máximo y mı́nimo del color de una arista (mı́nimo 3 ymáximo 3∆). Eso hace que existan configuraciones máximas y mı́nimas de los colores de las aristasincidentes a un mismo vértice, pudiéndose refinar estas cotas sabiendo cuáles aristas adyacentestienen un color mayor y cuáles tienen color menor. Esta información la codifica las variables δ.
Basado en este razonamiento, las siguientes son desigualdades válidas:
xvwi + xwi ≥ 2 +i−1∑
j=1
δwjvwi +
|N(v)|∑
j=i+1
(1− δwivwj ) ∀v ∈ V , i = 1, . . . , |N(v)|,∀wi ∈ N(v)
xvwi + xwi ≤ 2∆−i−1∑
j=1
(1− δwjvwi)−|N(v)|∑
j=i+1
δwivwj ∀v ∈ V , i = 1, . . . , |N(v)|, ∀wi ∈ N(v)
Donde N(v) es el conjunto de vértices adyacentes a v. Existen a lo sumo 2|E| desigualdadespara cada tipo de esta familia. Por este motivo, se decidió incluirlas expĺıcitamente en el modelo.
CLAIO-2016
101

Ciclos
Sea un ciclo C = {(v1, v2), (v2, v3), . . . , (vl−1, vl), (vl, v1)}, el objetivo es brindar una cota inferiorde los colores que pueden recibir las aristas de un ciclo. Si la longitud del ciclo es par, la mı́nimaasignación de colores que se puede hacer es alternar el color 3 y 4 a lo largo de las aristas ciclo.De esta manera, la mitad de las aristas recibirán el color 3 y la otra mitad el color 4. En el casode que la longitud del ciclo sea impar, el procedimiento para alternar los colores 3 y 4 es similarcon la excepción de que la última arista que se debe colorear tiene aristas adyacentes que recibenuna color 3 y la otra color 4. Por lo tanto, debemos emplear un nuevo color para dicha arista y elmenor posible es el color 5. Basado en este razonamiento, las siguientes son desigualdades validas:
∑
(u,r)∈Cxur + 2
l∑
i=1
xvi ≥ (3 + 4)l
2cuando l es par
∑
(u,r)∈Cxur + 2
l∑
i=1
xvi ≥ (3 + 4)l − 1
2+ 5 cuando l es impar
Teniendo en cuenta le experimentación computacional, el algoritmo de separación se restringea ciclos de tamaño 3 y la búsqueda se realiza en forma exhaustiva.
Ordenamiento lineal
Se puede notar que los colores de las aristas incidentes sobre un vértice configuran un ordenamientolineal dado por los valores que toman las variables δ. Por lo tanto se pueden extraer y reformularalgunas desigualdades propuestas para el problema de ordenamiento lineal [6]. Las primeras dosfamilias que se presentan están orientadas a prevenir ciclos en el orden de los colores. Sean v, u, r, z ∈V tales que u, r, z son adyacentes a v (u < r < z), las siguientes desigualdades son válidas:
δuvr + δrvz ≤ 1 + δuvz
δuvr + δrvz ≥ δuvzLas próximas desigualdades, denominadas k-fence, fueron estudiadas por Grötschel [6] [7] como
facetas del problema de ordenamiento lineal. Sean los conjuntos de vértices disjuntos U = {u1, . . . , uk},L = {l1, . . . , lk} ⊆ V de cardinalidad 3 ≤ k ≤ |V |2 . Se denomina k-fence al conjunto de aristas
A =k⋃
i=1({(ui, li)} ∪ {(li, uj) : j ∈ {1, . . . , k}, j 6= i})
Para adaptar este tipo de desigualdades a nuestro problema, se necesita que cada vértice de losconjuntos U y L estén unidos con un vértice en común v. Luego, la desigualdad k-fence para elPCAET se define como:
∑
(ui,li)∈Aδuivli +
∑
(li,uj)∈Aδlivuj
≤ k2 − k + 1
En base a la experiencia computacional reportada en [6], el problema de separación trabaja condesigualdades 3-fence. La búsqueda de ambas desigualdades es realizada en forma exhaustiva.
CLAIO-2016
102

4 Heuŕısticas
4.1 Heuŕısticas iniciales
Incorporar una heuŕıstica inicial previo a empezar con el Branch-and-Cut puede ser un factorimportante para mejorar el rendimiento del algoritmo. En este caso, dado un grafo G, el objetivoes producir de manera rápida un etiquetado total que forme un coloreo de aristas. Esta solucióninicial permite contar con una cota superior para χ′t(G) que sirve para reducir la cantidad devariables y restricciones del modelo.
A continuación se desarrollan dos heuŕısticas cuyo objetivo es intentar disminuir la cota conocidapara el valor de la etiqueta máxima (∆).
Heuŕıstica por Coloreo de Vértices (HCV)
Para tratar de obtener un etiquetado cuya máxima etiqueta sea menor que ∆, se propone primerorealizar un coloreo de los vértices (etiquetas de vértices adyacentes son diferentes). Luego, usandoeste etiquetado de vértices como punto de partida, se procede a etiquetar las aristas teniendocuidado que los colores (recordar que el color de una arista se define como la suma de la etiquetapropia de la arista y las etiquetas de sus vértices extremo) que reciban las aristas que inciden enun mismo vértice sean diferentes para generar un coloreo de aristas. La idea detrás de la heuŕısticaes tratar de generar una buena distribución de las etiquetas de los vértices para después no tenerque usar valores altos para las etiquetas de las aristas.
El coloreo de vértices se realiza mediante un algoritmo goloso secuencial que utiliza como eti-queta máxima a lo sumo el valor ∆−1. Notar que el proceso podŕıa fallar, en cuyo caso no encuentraningún etiquetado. Comienza etiquetando el vértice v1 con 1. Luego recorre los siguientes vérticesvj , asignándole la mı́nima etiqueta que no es usada por sus vértices adyacentes.
El algoritmo para etiquetar las aristas tiene una lógica similar al algoritmo anterior. Comienzaetiquetando la arista e1 con 1. Luego, prosigue con las siguientes aristas ej , haciendo lo siguiente:en primer lugar se calcula la suma p de las etiquetas de los vértices extremos de ej . A continuaciónse calculan los colores de las aristas que inciden en ej y ya fueron etiquetadas. La diferencia entrecada uno de estos colores y p determinan las etiquetas que no se pueden asignar a ej . Entonces, seelige la menor etiqueta que puede ser usada por la arista.
Heuŕıstica por Grafo Auxiliar (HGA)
Similarmente al procecimiento HCV, esta heuŕıstica tiene dos fases. En la primera se etiquetanvértices y en la segunda aristas. A diferencia de la anterior, el proceso de etiquetado de vértices noresponde a un coloreo de los vértices de G. Se considera X = (V,E(X)) un grafo auxiliar con losmismos vértices de G y tal que (v, u), (u,w) ∈ E ⇐⇒ (v, w) ∈ E(X). Se etiquetan los vertices de Xcon el algoritmo goloso de HCV, pero usando valores de etiquetas menores o iguales a
⌈∆+1
2
⌉+K,
donde K es un parámetro a variar. La intención es etiquetar los vértices del grafo X de tal maneraque los vértices en G que posean un vértice adyacente en común reciban distinto valor de etiqueta.Notar que al restringir el valor máximo de las etiquetas a asignar puede no generarse un coloreode vértices de X. Se etiqueta usando valores menores o iguales a
⌈∆+1
2
⌉+ K porque se sabe que⌈
∆+12
⌉es una cota inferior del problema (es decir, no se puede generar un coloreo de aristas por
un k-etiquetado total con k <⌈
∆+12
⌉). En los experimentos, se vaŕıa el K de tal manera que
CLAIO-2016
103

⌈∆+1
2
⌉+ K < ∆ ya que el propósito de la heuŕıstica es generar un etiquetado total con valor de
etiqueta máxima menor que ∆.Se comienza etiquetando el vértice v1 con 1 y luego, se etiqueta el resto de los vértices. Para
cada vértice vj se obtiene la mı́nima etiqueta que no es usada por los vértices adyacentes en X.Si el valor obtenido es menor o igual que la máxima etiqueta permitida, se le asigna ese valor avj . De lo contrario, se le asigna una etiqueta dentro del rango permitido de la siguiente forma: secuenta con una etiqueta next que comienza en 1, y cada vez que se supera el valor de la máximaetiqueta permitida, se asigna la etiqueta next y se incrementa en uno este valor. Si la etiqueta nextllega al máximo valor permitido, se vuelve a comenzar en 1. Una vez etiquetado los vértices de Gcon el procedimiento descrito anteriormente, se utiliza el mismo algoritmo secuencial explicado enla heuŕıstica anterior para etiquetar las aristas.
Para analizar el comportamiento de las heuŕısticas, se realizaron pruebas con grafos de 100vértices con distintas densidades de aristas generadas en forma aleatoria variando entre 10% y90%. Se considera que un grafo tiene densidad baja cuando es menor o igual al 30%, media cuandose encuentra entre 40% y 60% y alta para mayor de 70%. Por cada tipo de densidad generamos 15grafos. Una heuŕıstica es considerada satisfactoria cuando logra encontrar una solución con valormenor a ∆.
De acuerdo a la experimentación preliminar, se observó que HGA puede tener costo computa-cional un poco elevado debido a que recorre valores de K entre 0 y ∆ −
⌈∆+1
2
⌉para generar un
buen etiquetado. Esto motivó un análisis detallado del algoritmo, a partir del cual se pudo concluirque valores pequeños y altos de K no suelen generar buenas soluciones. En base a esto, se decidióvariar el valor de K entre d∆/8e y d3∆/8e para los experimentos computacionales dado que seobtienen soluciones de igual calidad en menor tiempo.
HCV HGA
densidad tiempo cantidad de soluciones tiempo cantidad de soluciones
(seg) satisfactorias (seg) satisfactorias
baja 0.09 13 0.24 15
media 0.43 8 2.11 15
alta 1.02 0 7.51 15
Table 1: Comparación entre la HCV y HGA.
En la tabla 1 se reporta por cada tipo de densidad, la cantidad de casos en los cuales elprocedimiento fue satisfactorio y el tiempo promedio de ejecución. Se puede notar que en generalHCV no funciona bien para grafos de media a alta densidad y que en la mayoŕıa de los grafosde densidad baja es satisfactoria. Intuitivamente esto era esperable, ya que en las soluciones delPCAET no es necesario que vértices adyacentes reciban etiquetas distintas (como sucede al colorearlos vértices del grafo) y esta situación es una restricción fuerte impuesta por esta heuŕıstica quepuede resultar contraproducente. Por otro lado, HGA logra encontrar etiquetados satisfactoriospara todos los grafos en poco tiempo. Basada en esta experimentación, HGA es la heuŕıstica elegidapara la implementación del algoritmo Branch-and-Cut.
CLAIO-2016
104
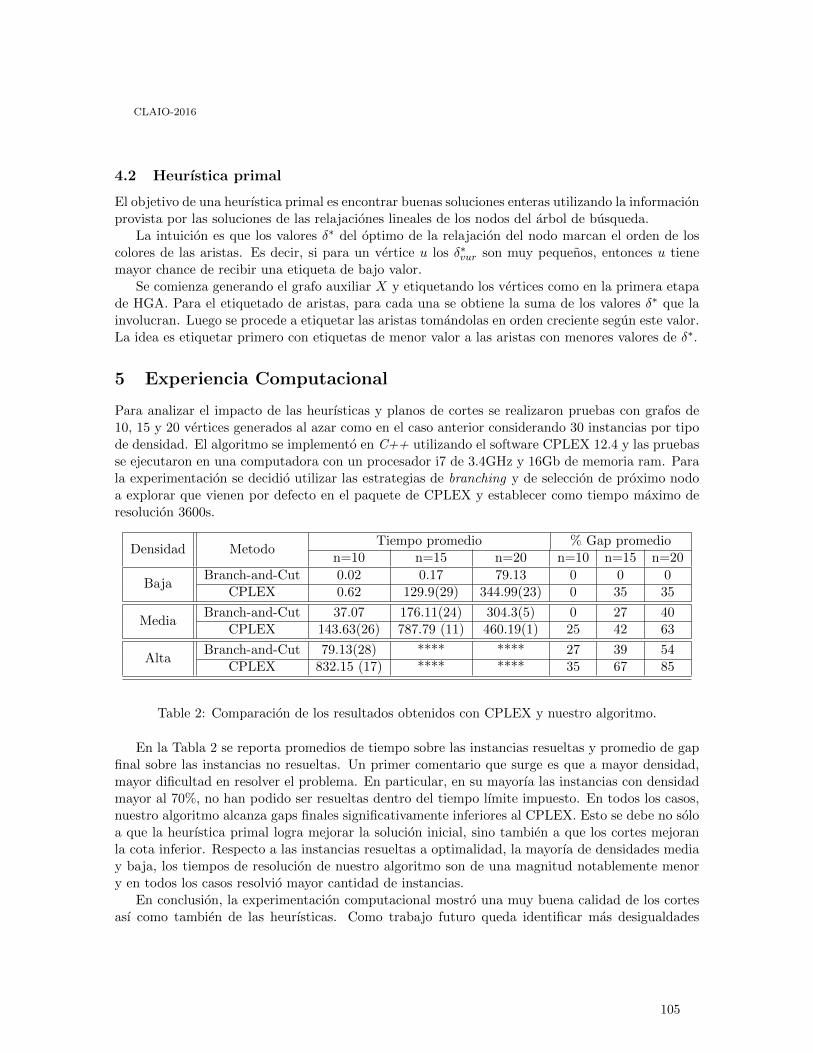
4.2 Heuŕıstica primal
El objetivo de una heuŕıstica primal es encontrar buenas soluciones enteras utilizando la informaciónprovista por las soluciones de las relajaciónes lineales de los nodos del árbol de búsqueda.
La intuición es que los valores δ∗ del óptimo de la relajación del nodo marcan el orden de loscolores de las aristas. Es decir, si para un vértice u los δ∗vur son muy pequeños, entonces u tienemayor chance de recibir una etiqueta de bajo valor.
Se comienza generando el grafo auxiliar X y etiquetando los vértices como en la primera etapade HGA. Para el etiquetado de aristas, para cada una se obtiene la suma de los valores δ∗ que lainvolucran. Luego se procede a etiquetar las aristas tomándolas en orden creciente según este valor.La idea es etiquetar primero con etiquetas de menor valor a las aristas con menores valores de δ∗.
5 Experiencia Computacional
Para analizar el impacto de las heuŕısticas y planos de cortes se realizaron pruebas con grafos de10, 15 y 20 vértices generados al azar como en el caso anterior considerando 30 instancias por tipode densidad. El algoritmo se implementó en C++ utilizando el software CPLEX 12.4 y las pruebasse ejecutaron en una computadora con un procesador i7 de 3.4GHz y 16Gb de memoria ram. Parala experimentación se decidió utilizar las estrategias de branching y de selección de próximo nodoa explorar que vienen por defecto en el paquete de CPLEX y establecer como tiempo máximo deresolución 3600s.
Densidad MetodoTiempo promedio % Gap promedio
n=10 n=15 n=20 n=10 n=15 n=20
BajaBranch-and-Cut 0.02 0.17 79.13 0 0 0
CPLEX 0.62 129.9(29) 344.99(23) 0 35 35
MediaBranch-and-Cut 37.07 176.11(24) 304.3(5) 0 27 40
CPLEX 143.63(26) 787.79 (11) 460.19(1) 25 42 63
AltaBranch-and-Cut 79.13(28) **** **** 27 39 54
CPLEX 832.15 (17) **** **** 35 67 85
Table 2: Comparación de los resultados obtenidos con CPLEX y nuestro algoritmo.
En la Tabla 2 se reporta promedios de tiempo sobre las instancias resueltas y promedio de gapfinal sobre las instancias no resueltas. Un primer comentario que surge es que a mayor densidad,mayor dificultad en resolver el problema. En particular, en su mayoŕıa las instancias con densidadmayor al 70%, no han podido ser resueltas dentro del tiempo ĺımite impuesto. En todos los casos,nuestro algoritmo alcanza gaps finales significativamente inferiores al CPLEX. Esto se debe no sóloa que la heuŕıstica primal logra mejorar la solución inicial, sino también a que los cortes mejoranla cota inferior. Respecto a las instancias resueltas a optimalidad, la mayoŕıa de densidades mediay baja, los tiempos de resolución de nuestro algoritmo son de una magnitud notablemente menory en todos los casos resolvió mayor cantidad de instancias.
En conclusión, la experimentación computacional mostró una muy buena calidad de los cortesaśı como también de las heuŕısticas. Como trabajo futuro queda identificar más desigualdades
CLAIO-2016
105

válidas y evaluar estrategias de branching.Cabe señalar que el tamaño de las instancias consideradas es chico si se compara con el de las
instancias utilizadas en otras versiones de problemas de etiquetado de grafos. Por ejemplo, parael problema clásico de coloreo de grafos se logra resolver de forma exacta instancias de más de100 vértices. Esto demuestra que el PCAET resulta un problema desafiante para el cual aún hayespacio para su estudio algoŕıtmico.
References
[1] Stephan Brandt, Kristna Budajov, Dieter Rautenbach, and Michael Stiebitz. Edge colouring by totallabellings. Discrete Mathematics, 310(2):199 – 205, 2010.
[2] Martin Bača, Mirka Miller, Joseph Ryan, et al. On irregular total labellings. Discrete Mathematics,307(11):1378–1388, 2007.
[3] Riadh Khennoufa, Hamida Seba, and Hamamache Kheddouci. Edge coloring total k-labeling of gener-alized petersen graphs. Information Processing Letters, 113(13):489–494, 2013.
[4] Hamida Seba and Riadh Khennoufa. Edge coloring by total labelings of 4-regular circulant graphs.Electronic Notes in Discrete Mathematics, 41:141–148, 2013.
[5] Jayadev Misra and David Gries. A constructive proof of vizing’s theorem. Information ProcessingLetters, 41(3):131–133, 1992.
[6] Martin Grötschel, Michael Jünger, and Gerhard Reinelt. A cutting plane algorithm for the linearordering problem. Operations research, 32(6):1195–1220, 1984.
[7] Martin Grötschel, Michael Jünger, and Gerhard Reinelt. Facets of the linear ordering polytope. Math-ematical Programming, 33(1):43–60, 1985.
[8] IBM. CPLEX Optimizer for z/OS. http://pic.dhe.ibm.com/infocenter/cplexzos/v12r4/index.jsp.
CLAIO-2016
106

PR-GRASP- Path Relinking GRASP Aplicado a Seleção deCaracterísticas
Raphael S. BroettoUniversidade Federal do Espírito Santo
Departamento de InformáticaVitória, Espírito Santo 29075-910
Flávio M. VarejãoUniversidade Federal do Espírito Santo
Departamento de InformáticaVitória, Espírito Santo 29075-910
Resumo
O método GRASP vem sendo largamente utilizado no ramo de otimização e aplicado ainúmeros problemas de busca, por sua robustez e simplicidade de implementação. Uma vez queo problema de seleção de características, um dos principais e mais estudados problemas do ramode Machine learning, é tipicamente modelado como um problema de busca, o método GRASPé naturalmente aplicável à este tipo de domínio. Este artigo apresenta um estudo avaliativo dameta-heuristica GRASP e da estratégia de convergência path relinking aplicados ao problemade seleção de características, realizando um comparativo entre estes métodos e o método debusca genética, além de realizar uma análise de sensibilidade sobre o parâmetro α do algoritmoGRASP.
Keywords: Seleção de características; GRASP; Path-Relinking.
1 Introdução
O Problema de Seleção de Características (PSC) consiste na atividade de selecionar um conjuntode características que forneça uma representação adequada para a classificação de uma base deexemplos. A qualidade deste conjunto é medida por meio de uma etapa de teste, que visa rotularexemplos de uma base utilizando uma base de exemplos previamente rotulados. Desta forma, épossível representar PSC como um problema de busca, onde o espaço de busca é composto portodos os subconjuntos de características possíveis, a função objetivo sendo o método classificadorque recebe como parâmetro uma base de exemplos e um subconjunto de características e o valor dafunção objetivo sendo o valor da taxa de acerto do método classificador utilizado, isto é, a razãoentre exemplos corretamente classificados e o número total de exemplos. Assumir PSC como sendoum problema de busca, possibilita a aplicação dos métodos bem conhecidos da literatura. E por
CLAIO-2016
107

este ser um problema de alta complexidade (categoria NP-hard), motiva-se a aplicação de meta-heurísticas ao invés de métodos exatos, pois estes seriam inviáveis para buscas em espaços geradospor grandes bases de exemplos. O trabalho base que demonstrou a integração do método GRASP[3]com PR[5] foi apresentado em [10] e desde então, diversos autores utilizaram o algoritmo PathRelinking GRASP (PR-GRASP). Em [1] foi proposto um método que deriva da heurística GRASPe aplica a estratégia PR, para abordar um problema bi-objetivo. Como parte dos resultados, ométodo PR-GRASP foi, de uma forma geral, recomendado para a solução de problemas multi-objetivos. Em [11] foi proposto a utilização do modelo GRASP para a solução do problema deseleção de características e foi realizado um estudo comparativo entre vários métodos. Este estudoinspirou um trabalho que propôs uma nova meta-heuristica baseada no método GRASP aplicada aoproblema de seleção de características, como uma forma de verificar se estrutura do GRASP obtemboa performance neste tipo de domínio. Em [2] foi proposto um método de seleção de característicashíbrido inspirado no algoritmo GRASP para selecionar conjunto de características em bases de altadimensionalidades. Para PSC não foram encontrados trabalhos que utilizaram PR-GRASP parasolucionar o problema.
A contribuição deste trabalho é a aplicação o método GRASP e a estratégia Path Relinkingem PSC, realizando um estudo de sensibilidade do parâmetro α e uma análise comparativa entre3 métodos de busca (GRASP, PR-GRASP e GS) para este tipo de problema. A Seção 2 introduzo método GRASP, a Seção 3 introduz o método PR-GRASP, a Seção 4 apresenta a preparaçãodos experimentos e os resultados obtidos e a Seção 5 apresenta as conclusões do trabalho e umadiscussão acerca de trabalhos futuros.
2 GRASP
GRASP (Greedy Randomized Adaptive Search Procedures) é uma metaheurística para aplicaçãode um método de busca local em diversas soluções iniciais diferentes. As soluções iniciais sãopreviamente geradas por algum tipo de construção aleatória/gulosa. O algoritmo possui um únicoparâmetro chamado α que varia no intervalo [0, 1] e representa o equilíbrio entre os aspectos gulosoe aleatório do processo de construção. Um valor baixo para α fornece uma etapa de construção maisaleatória, com maior potencial de exploração pelo espaço, enquanto um valor alto para α forneceuma etapa de construção mas gulosa. O Algoritmo 1 apresenta o método GRASP. A definiçãodo método recebe como parâmetros maxIter que denota o número máximo de iterações que serãorealizadas e α que guia o método durante a fase construtiva. Cada iteração do método é compostode três fases fundamentais: A fase construtiva, a fase de busca local onde alguma operação de buscalocal é aplicada sobre a solução construída na fase anterior e a fase de atualização da solução, onde éverificado se a solução obtida é superior à melhor solução obtida até o momento. Caso seja, atualiza.Neste trabalho, o algoritmo Hill-climbing[8] foi utilizado como método de busca local.
CLAIO-2016
108

Algorithm 1: GRASPinput : maxIter, αoutput: bestSolution
1 for k = 1, ..., maxIter do2 solution ← constructivePhase(α);3 solution ← localSearch(solution);4 updateSolution(solution, bestSolution);5 end
Algorithm 2: constructivePhaseinput : αoutput: solution
1 solution ← ∅;2 while True do3 Fcandidates ← {(fi, qi)|qi = eval(solution, fi) ∧ fi 6∈ solution ∧ qi > 0};4 if size(Fcandidates) = 0 then5 return solution;6 end7 minq ← minQuality(Fcandidates);8 maxq ← maxQuality(Fcandidates);9 ts← minq + α× (maxq −minq);
10 Rcl← {fi|(fi, qi) ∈ Fcandidates ∧ qi ≥ ts};11 solution← solution ∪ {selectRandomFeature(Rcl)};12 end
A fase construtiva do método GRASP é apresentada no Algoritmo 2. A função recebe comoparâmetro o valor de α e fornece como saída a solução gerada (solution). Primeiramente, a soluçãoé inicializada com conjunto vazio. O algoritmo realiza então duas tarefas.
A primeira consiste em criar uma lista de tuplas (fi,qi) onde fi denota cada característica nãopertencente a solution e qi denota o valor de qualidade da característica fi, definida a partir dafunção eval como sendo a diferença no valor da taxa de acerto (função objetiva) entre as soluçõessolution ∪ {fi} e solution. Qualidade negativa significa que a característica fi resultou em umadegradação da solução, portanto, estas características são eliminadas nesta iteração. Quando otamanho da lista gerada Fcandidates for igual a zero, indica que não há características com valor dequalidade positiva à ser adicionada. Neste caso, a iteração é interrompida e o valor da solução éretornado. Caso contrário, a segunda etapa do algoritmo é executada. Nela, é calculado um limiarts (Thresholding) que leva em consideração as qualidades máxima e mínima da lista e o valor de α.O objetivo é selecionar as melhores características em função de α, criando uma lista Rcl (RestrictedCandidate List). Uma característica é então selecionada aleatoriamente desta lista e inserida emsolution. O laço é então repetido até que a condição de parada seja atingida.
3 PR-GRASP
Path relinking é uma técnica de pós-otimização e aceleração de convergência utilizada em problemasde busca e otimização, para geração combinações lineares entre duas soluções. A abordagem PR
CLAIO-2016
109

tradicional consiste gerar um caminho entre duas soluções (solução inicial e de referência) por meiode operações de adição e remoção de características. O Algoritmo 3 apresenta o método. Nainicialização do algoritmo (linhas 1 à 4) é realizado a computação da diferença simétrica entre xs exr, isto é, o conjunto de todos os elementos que pertencem a uma das duas soluções, mas não àsduas simultaneamente, assim como a inicialização das variáveis de controle f∗ (mínimo da funçãoobjetiva), x∗ (x tal que f(x) = f∗) e x (posição atual no caminho entre xs e xr). A linha 5 iniciaum laço de repetição que visa diminuir a cada passo a diferença simétrica entre x e xr. A cadaiteração é selecionado o item m∗ do conjunto ∆(x, xt), tal que x ⊕ m∗ produza o maior valor defunção objetiva (linha 6). Esta tarefa reduz a diferença simétrica e produz uma reavaliação dosvalores de f∗ e x∗. O método termina quando ∆(x, xr) = ∅, representando que o caminho iniciadoem xs terminou em xr. Observa-se que esta definição do método utiliza uma heurística gulosa paragerar o caminho entre duas soluções, uma vez que a cada passo ele opta pelo atributo que representeo maior incremento para a função objetiva. O algoritmo PR-GRASP é apresentado no algoritmo4, onde a função TruncatePool filtra a lista mantendo apenas as poolMaxSize melhores soluções,impedindo assim que a lista cresça exponencialmente (poolMaxSize = 50 na experimentação destetrabalho).
Algorithm 3: PathRelinkinginput : Solução inicial xs e solução
referência xroutput: melhor solução x∗ encontrado no
caminho entre xs e xr1 calcule a diferença simetrica ∆(xs, xr);2 f∗ ← max{f(xs), f(xr)};3 x∗ ← argmax{f(xs), f(xr)};4 x← xs;5 while ∆(x, xr) 6= ∅ do6 m∗ ← argmax{f(x⊕m) : m ∈
∆(x, xr)};7 ∆(x⊕m∗, xr)← ∆(x, xr) \ {m∗};8 x← x⊕m∗;9 if f(x) > f∗ then
10 f∗ ← f(x);11 x∗ ← x;12 end13 end
Algorithm 4: PR-GRASPinput : maxIter, α, npaths,poolMaxSizeoutput: bestSolution
1 solutionPool ← ∅;2 for k = 1, ..., maxIter do3 solution ← constructivePhase(α);4 solution ← localSearch(solution);5 solutionPool ← solutionPool ⊕ solution;6 if size(poolSolution) > 2 then7 for i = 0...npaths do8 xs ← getRandom(poolSolution);9 xr ← getRandom(poolSolution);
10 x∗ ← pathRelinking(xs, xr);11 solutionPool ← solutionPool
⊕x∗;12 end13 end14 bestSolution ← getBest(solutionPool);15 TruncatePool(solutionPool,
poolMaxSize);16 end
O método para a escolha das soluções inicial e de referência, pode variar de acordo com o estudoconduzido. Neste presente trabalho, o algoritmo aleatório foi utilizado onde o par é selecionadoaleatoriamente de o dado conjunto de soluções.
CLAIO-2016
110

4 Experimentação
A Tabela 1 apresenta as descrições das bases de exemplos utilizadas na realização dos experimentos.Estas bases foram obtidas no repositório UCI[7]. Pela natureza do PSC, o número de característicasconstitui o aspecto mais importante para os experimentos deste trabalho. Portanto, foram selecio-nadas bases de dados com uma boa variabilidade de número de características, uma vez que basescom um número baixo de características (< 10), seriam triviais e não representariam desafio parao método de busca. O classificador utilizado em todos os experimentos foi o KNN (K=3). Esteclassificador foi escolhido por possuir desempenho reconhecido e sem necessidade de uma etapa detreinamento, fato este que acelera a realização dos experimentos. A codificação de solução adotadafoi a binária, onde cada solução é representada como um vetor binário de tamanho N (N=número decaracterísticas) e cada posição do vetor é preenchida com 0 ou 1 (ausência ou presença da caracterís-tica na solução, respectivamente). Para o método GRASP e PR-GRASP foi adotado maxIter=10em todas as ocasiões. O primeiro experimento realizado, consiste em observar como o parâmetro αdo método GRASP se comporta em espaços de buscas gerados por PSC. Um experimento foi con-duzido utilizando o método GRASP aplicado a duas bases de exemplos (ionosphere e hill-valley). Ométodo foi aplicado dez vezes para cada base e a cada execução o parâmetro α foi alterado dentrodo intervalo [0.1, 1.0] com passo incremental de 0.1. Os resultados atingidos são apresentados naSeção 4.1. Estas duas bases foram removidas dos demais experimentos, para eliminar um possívelbias. A partir do experimento descrito acima, um valor para α foi obtido e utilizado para compararo desempenho de três algoritmos distintos (Genetic Search (GS)[6], GRASP e Path Relink GRASP(PR-GRASP)). Para avaliar o desempenho do classificador e obter o valor da função objetivo, foiutilizado a técnica de validação cruzada[4], que consiste em subdividir uma base de exemplos em Npartições (folds) e, alternadamente, utilizar N−1 folds para treino (bases de conhecimento) e 1 foldpara teste. O resultado são as taxas de acerto médias e máximas obtidas a cada etapa. e o algo-ritmo genético foi ajustado com os parâmetros probabilidade de crossover=0.6, número máximo degerações=20, probabilidade de mutação=0.033 e tamanho da população=20. Os resultados obtidosneste estudo comparativo, são apresentados na seção 4.2.
Tabela 1: Descrição das bases de exemplos utilizadas
Base audiolog
y
autos
glass
h-statlog
hepa
titis
hill-valley
iono
sphe
re
sona
r
soyb
ean
vehicle
vowel
zoo
Características 70 26 10 14 20 101 35 61 36 19 14 18Exemplos 226 205 214 270 155 1212 351 208 683 846 990 101Classes 24 7 7 2 2 2 2 2 19 4 11 7
4.1 Ajuste do parâmetro α
A etapa de busca local do GRASP representa o gargalo do processo, uma vez que seu tempo deexecução é dependente da qualidade da solução inicial. O tempo gasto na busca local foi computadoe o tempo médio utilizado para análise. A Figura 1 apresenta o relacionamento entre o valor de α eo tempo gasto em busca local, para duas bases de dados: ionosphere e hill-valley. Para cada valorde α, o método GRASP foi aplicado dez vezes. Observa-se que o tempo gasto com a busca local
CLAIO-2016
111
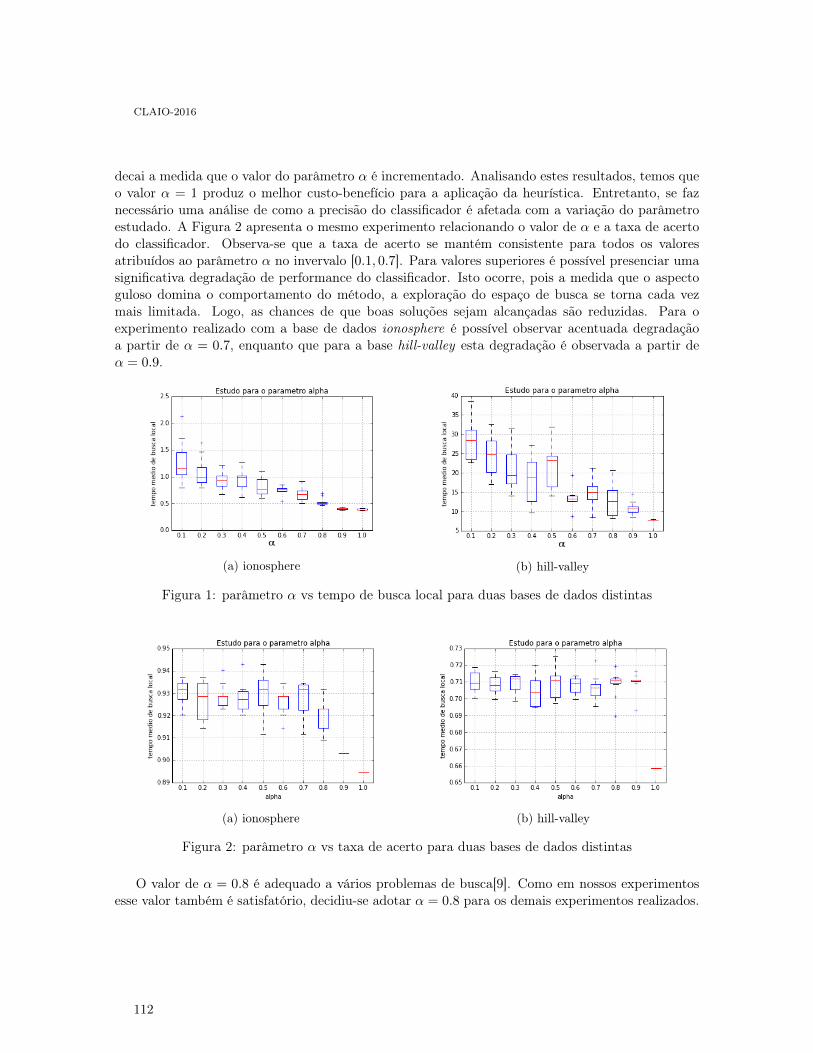
decai a medida que o valor do parâmetro α é incrementado. Analisando estes resultados, temos queo valor α = 1 produz o melhor custo-benefício para a aplicação da heurística. Entretanto, se faznecessário uma análise de como a precisão do classificador é afetada com a variação do parâmetroestudado. A Figura 2 apresenta o mesmo experimento relacionando o valor de α e a taxa de acertodo classificador. Observa-se que a taxa de acerto se mantém consistente para todos os valoresatribuídos ao parâmetro α no invervalo [0.1, 0.7]. Para valores superiores é possível presenciar umasignificativa degradação de performance do classificador. Isto ocorre, pois a medida que o aspectoguloso domina o comportamento do método, a exploração do espaço de busca se torna cada vezmais limitada. Logo, as chances de que boas soluções sejam alcançadas são reduzidas. Para oexperimento realizado com a base de dados ionosphere é possível observar acentuada degradaçãoa partir de α = 0.7, enquanto que para a base hill-valley esta degradação é observada a partir deα = 0.9.
(a) ionosphere (b) hill-valley
Figura 1: parâmetro α vs tempo de busca local para duas bases de dados distintas
(a) ionosphere (b) hill-valley
Figura 2: parâmetro α vs taxa de acerto para duas bases de dados distintas
O valor de α = 0.8 é adequado a vários problemas de busca[9]. Como em nossos experimentosesse valor também é satisfatório, decidiu-se adotar α = 0.8 para os demais experimentos realizados.
CLAIO-2016
112

4.2 Comparação de desempenho
O resultado da comparação experimental entre os métodos GS, GRASP e PR-GRASP é apresentadona Tabela 2. O GS foi escolhido como um método de referência por ser amplamente utilizado emPSC. Cada método foi executado 10 vezes.
Tabela 2: Resultados obtidos
Dataset GS GRASP PR-GRASPmax avg max avg max avg
audiology 0.761 0.744 0.770 0.762 0.779 0.769h-statlog 0.848 0.840 0.841 0.837 0.841 0.841autos 0.780 0.761 0.776 0.760 0.780 0.773vehicle 0.761 0.748 0.759 0.756 0.765 0.764hepatitis 0.890 0.881 0.877 0.877 0.877 0.877sonar 0.942 0.910 0.938 0.917 0.952 0.939zoo 0.960 0.950 0.960 0.956 0.960 0.960soybean 0.939 0.929 0.943 0.938 0.944 0.943vowel 0.961 0.958 0.960 0.959 0.961 0.961glass 0.738 0.732 0.734 0.731 0.734 0.734
Na Tabela 2 são apresentadas a taxa de acerto máxima e a média obtidas nas 10 execuções decada método Os melhores resultados obtidos nos experimentos são destacados em negrito. Pode-seobservar que o método PR-GRASP tem o melhor desempenho de todos. Ele atinge a melhor taxade acerto máxima em 7 das 10 bases utilizadas e a melhor taxa de acerto média em 9 das 10 basesutilizadas. Enquanto o algoritmo genético tem desempenho bem próximo na taxa de acerto máxima(vence em 6 das 10 bases), na taxa de acerto média ele só vence em 1 das 10 bases. Isto indica queo método PR-GRASP é superior e efetivamente mais robusto que o GS.
5 Conclusão
PSC contextualizado como um problema de busca possui aspectos que devem ser considerados, paraa escolha de um método de busca apropriado. A função objetiva é definida a partir de um métodoclassificador que, por sua vez, representa uma variável do problema. Sendo assim, torna-se inviávela definição de uma função objetiva universal para o PSC, pois esta depende do método classificadorescolhido e parametrização adotada. Da mesma forma, o espaço de busca pode apresentar um altograu de descontinuidade, pois a remoção ou adição de uma única característica pode alterar imprevi-sivelmente o valor da função objetiva dependendo da qualidade discriminativa desta característica.Um método de busca precisa ser robusto a estas dificuldades.
Para o método GRASP, foi realizado um estudo sobre o parâmetro de ajuste α, onde foi possívelconstatar que os estudos até então realizados na literatura são consistentes no escopo de PSC, umavez que os valores atingidos são similares.t Além disso, os experimentos deste trabalho revelaramque a meta heurística GRASP consegue alcançar soluções desejáveis, a despeito da complexidade dafunção objetiva e imprevisibilidade da movimentação dentro do espaço de busca. Da mesma forma,a aplicação da heurística de convergência PR culminou em resultados promissores com a aceleração
CLAIO-2016
113

da convergência, uma exploração do espaço de busca muito mais eficiente e, como consequência,melhores soluções encontradas.
Como trabalhos futuros, um número maior de bases de dados será considerado, visando aumentara variabilidade dos experimentos e o modelo classificador adotado será variável dentro dos experi-mentos. Além disso, será realizado um estudo estatístico para fortalecer a confiança nos resultadosobtidos.
Referências
[1] J.E.C. Arroyo, M. dos Santos Soares, and P.M. dos Santos. A grasp heuristic with path-relinking for a bi-objective p-median problem. In Hybrid Intelligent Systems (HIS), 2010 10thInternational Conference on, pages 97–102, Aug 2010.
[2] Pablo Bermejo, Jose A. Gámez, and Jose M. Puerta. A {GRASP} algorithm for fast hy-brid (filter-wrapper) feature subset selection in high-dimensional datasets. Pattern RecognitionLetters, 32(5):701 – 711, 2011.
[3] Thomas A Feo and Mauricio G.C Resende. A probabilistic heuristic for a computationallydifficult set covering problem. Operations Research Letters, 8(2):67 – 71, 1989.
[4] Seymour Geisser. Predictive inference: an introduction. Chapman & Hall, New York, 1993.
[5] Fred Glover. Tabu search and adaptive memory programming — advances, applications andchallenges. In RichardS. Barr, RichardV. Helgason, and JefferyL. Kennington, editors, Interfa-ces in Computer Science and Operations Research, volume 7 of Operations Research/ComputerScience Interfaces Series, pages 1–75. Springer US, 1997.
[6] David E. Goldberg. Genetic Algorithms in Search, Optimization and Machine Learning.Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1st edition, 1989.
[7] M. Lichman. UCI machine learning repository, 2013.
[8] C.M. Nunes, Jr. Britto, Ad.S., C.A.A. Kaestner, and R. Sabourin. An optimized hill climbingalgorithm for feature subset selection: evaluation on handwritten character recognition. InFrontiers in Handwriting Recognition, 2004. IWFHR-9 2004. Ninth International Workshopon, pages 365–370, Oct 2004.
[9] M. Prais and C.C. Ribeiro. Variação de parâmetros em procedimentos GRASP. InvestigaciónOperativa, 9:1–20, 2000.
[10] MauricioG.C. Resendel and CelsoC. Ribeiro. Grasp with path-relinking: Recent advances andapplications. In Toshihide Ibaraki, Koji Nonobe, and Mutsunori Yagiura, editors, Metaheuris-tics: Progress as Real Problem Solvers, volume 32 of Operations Research/Computer ScienceInterfaces Series, pages 29–63. Springer US, 2005.
[11] Silvia Casado Yusta. Different metaheuristic strategies to solve the feature selection problem.Pattern Recognition Letters, 30(5):525 – 534, 2009.
CLAIO-2016
114

Water Networks: A Multi-Objective approach to Design an Eco-
Industrial Park in Valdivia, Chile
Mariana Brüning González a
Fernando Arenas Araya a [email protected]
Felipe Díaz-Alvarado a,* [email protected]
* Corresponding author
a Departamento de Ingeniería Química y Biotecnología, Facultad de Ciencias Físicas y Matemáticas,
Universidad de Chile, Av. Beauchef 851, Piso 6-poniente, Grupo de Ingeniería Sistémica de Procesos y
Sustentabilidad, 8370456 Santiago, Chile.
Abstract Industrialization is one of the causes of climate change, species extinction, and other environmental impacts
all over the world. As the development of mankind cannot be stopped, production in Eco-Industrial Parks
(EIP) is an improvement. Several companies are connected in an EIP with the goal of reducing the global
impact (e.g. use of water or energy, waste generation) through material sharing.
How to configure the most sustainable EIP? How to quantify environmental, social, and economic
dimensions of sustainability? Thus, this work presents a methodology to design an EIP in Valdivia, Chile,
where companies use water from Calle Calle river. The design is modeled as a multi-objective optimization
problem taking into account two aspects of sustainability (economic and environmental) at once. The
problem is solved using the Goal Programming method. An alternative to determine the relative importance
of the objective functions is to use MACBETH, a theoretical tool oriented to multi-criteria decision-making.
Therefore, further work could include the social dimension of sustainability with a similar strategy.
Keywords: Eco-Industrial Park, Multi-objective optimization, Water networks.
1 Introduction The use of water increases with the development of cities and companies. Accordingly, the lack of water is
progressing all over the world. The Climate Change and the aforementioned water stress due to human
development impose a growing interest in water use technologies [1]. In this context, different authors have
been developing studies about water reuse through connection networks with the goal of minimizing the
use of freshwater [2].
Until now, the lack of water is not a problem in the southern region of Chile. However, the company
development is contributing to superficial and groundwater contamination by way of the discharge of liquid
industrial waste. Also, important water flows are used in company processes (about 20% of water [3]), with
CLAIO-2016
115

an impact in ecosystems and communities living in surrounding areas. Climate change may also contribute
to the lack of water in South of Chile, as it causes precipitation decrease [4].
Industrial symbiosis belongs to the emerging field of industrial ecology. It is focused on the material and
energy flows through local and regional economies. “Industrial symbiosis engages traditionally separate
companies in a collective approach to create competitive advantage involving physical exchange of
materials, energy, water, and/or by-products. The keys to industrial symbiosis are collaboration and the
synergistic possibilities offered by geographic proximity” [5].
A solution proposed by Industrial Ecology, is the development of Eco-Industrial Parks (EIP), where
companies are connected with the goal of minimizing environmental and other impacts, such as use of
water.
Multi-objective optimization is a useful technique in sustainability analysis because it can make it easier to
obtain optimal trade-off solutions that balance several criteria [6].
In this sense, the present challenge is how to configure an EIP including the three aspects of sustainability:
economy, environment, and society [7]. Therefore, this work has developed a multi-objective optimization
problem for the design of a sustainable EIP in Valdivia, Chile.
The focus of the problem is the use of water from Calle Calle river, in order to propose a formal
methodology to plan water integration networks. This methodology considers, environmental and economic
dimensions of sustainability.
2 Problem description We present the following instance to optimize the use of water in an industrial network in Valdivia. This
instance is proposed as a base for further developments.
The model includes four companies and their interaction with the Calle Calle river. The possible
interactions among these companies and the water treatment system are also represented. The model
includes water flows, maximum concentrations of contaminants, demands of water, capacities, costs of
treated water and pumping, all of them linked with the actors in the park. Then, the instance is formulated
as a Multi-objective optimization problem.
Methodology
The problem has two main groups of actors: the sources and the receptors of water. Sources are composed
by the river and the system of drinking water. Among receptors, there is a sink and four companies.
The notation of actors, their characteristics and parameters is proposed in this section. We also include a
list of variables, constraints, and objective function. It is important to remark the multi-objective
optimization technique: a Goal programming framework. Accordingly, the real objectives are combined in
a vector, minimizing the distance to an ideal solution (infeasible) [8]. The new objective function is
composed by auxiliary variables, linked with the aforementioned distance. These variables are related with
real objectives through respective equality constraints.
The present work is based in a uniform relevance of each objective function. These objectives were
normalized before composing a Goal Programming vector. The relative relevance of the objective functions
will be modified in the sensitivity analysis.
CLAIO-2016
116

To promote a better understanding of the problem, we divide the river in ten sections. Figure 1 shows the
proposed structure where the sets and the possible connections are presented.
Figure 1: Problem structure
Sets
𝑆𝑁: Set of companies {𝐸1 … 𝐸4}
𝑆𝑅: Set of sections of the river {𝑅0 … 𝑅9}. There are two extreme sections (𝑅0 and 𝑅9) and eight
intermediate parts, where 𝑅1, 𝑅3, 𝑅5 and 𝑅7 can give water to the companies, while 𝑅2, 𝑅4, 𝑅6 and 𝑅8 can
receive it.
𝑆𝐶: Set of contaminants, which can be Biological Oxygen Demand (𝐵𝑂𝐷), Total Suspended Solids (𝑇𝑆𝑆)
and Manganese (𝑀𝑛).
𝑆𝐵: Set for the rain. In this work, this set has one element, 𝐵, representing the rain that gives water flows
on the river sections.
𝑆𝐹: Set of contaminants sources {𝐹1. . . 𝐹4}
𝑆𝐻: Set for the drinking water system. This set has one element, 𝐻, representing the single source of
drinking water for the companies (a monopoly).
𝑆𝐾: Set for the water sink. This set has one element, 𝐾, that receives water from companies.
𝐹: Set of flows involved in the problem, which associate two elements of the previous sets listed herein
with the form (𝑥_𝑦), where 𝑥 is the initial point of the flow and 𝑦 is the receptor.
𝐵(𝐹): Subset of set 𝐹, which includes flows from rain to the river.
𝐺(𝐹): Subset of set 𝐹 that represent flows between the river sections 𝑆𝑅.
𝑆(𝐹): Subset of set 𝐹, which includes all flows from river sections to companies.
𝐸(𝐹): Subset of set 𝐹, which includes all flows from companies to river sections.
𝐸𝐸(𝐹): Subset of set 𝐹, which includes all flows that enter at each company.
𝐸𝐵(𝐹): Subset of set 𝐹, which represents all flows that need a pump to exist.
𝐾(𝐹): Subset of set 𝐹, which represents flows from companies to the sink.
𝐻(𝐹): Subset of set 𝐹, which represents flows from the source to each company.
𝐸𝑅𝐼𝑂(𝑆𝑅, 𝐹): Set of flows that arrive to the sections of the river
𝑆𝑅𝐼𝑂(𝑆𝑅, 𝐹): Set of flows which leave each section of the river.
𝐸𝐴𝐸𝑀𝑃(𝑆𝑁, 𝐹): Set of water flows that go to each company.
𝐸𝐶𝐸𝑀𝑃(𝑆𝑁, 𝐹): Set of contaminants which go to the companies.
CLAIO-2016
117

Parameters
𝐶𝑀𝐴𝑋𝐸(𝐸𝐸, 𝑆𝐶) : It represents the maximum concentration of contaminant of the set SC that accept a
company.
𝑄𝑀𝐼𝑁𝐸(𝑆𝑁): Minimum water flow that is required in a company.
𝑄𝑀𝐴𝑋𝐸(𝑆𝑁): Maximum water flow that is supported in a company.
𝐶𝐿𝐿(𝑆𝐶): Concentration of contaminant in the rain.
𝐶𝐻(𝑆𝐶): Concentration of contaminant in the drinking water system.
𝐶𝐹 (𝑇, 𝑆𝐶): Mass flow of contaminants generated by the companies, with 𝑇 ⊆ 𝐹.
𝐶0𝐶𝑂𝑁𝑇(𝑆𝐶): Initial concentration of contaminants in the river.
𝐶𝑀𝐴𝑋𝑅(𝑆𝐶): Maximum concentration of each contaminant allowed in the river.
𝑄𝑀𝐼𝑁𝐾 (𝐾): Minimum water flow at the sink inlet (physical feasibility).
𝑄𝑀𝐴𝑋𝐾 (𝐾): Maximum water flow at the sink inlet (physical feasibility).
𝑄𝑀𝐼𝑁𝑅: Minimum water flow in the river.
𝑄𝐵: Water flow from rain.
𝑄0: Initial water flow in the river.
𝑄𝑀𝐴𝑋𝑅𝐼𝑂: Maximum flow allowed in the river.
𝐶𝑂𝑆𝑇𝐴𝑃: Drinking water cost.
𝐶𝑂𝑆𝑇𝐸𝐵: Pumping cost.
Also, we defined the parameters necessaries for the kind of optimization used:
𝐹𝑂1𝐸 = 0: Expected values for the first objective function.
𝐹𝑂2𝐸 = 0: Expected values for the second objective function.
𝑊1 = 0.5: Relative relevance of the first objetive function respect to both objective function.
𝑊2 = 0.5: Relative relevance of the second objective function respect to both objective function.
Variables
Positive variables:
𝑄(𝐹): Water flow
𝐶(𝐹, 𝑆𝐶): Concentration of contaminant in the flow F
𝐹𝑂1: Water flow used from the river
𝐹𝑂2: Used water cost by the companies
𝛾: Minimized variable in the problem.
Free variable:
𝑂𝐵𝐽𝑇: Objetive function.
Constraints
Water mass balance in the river:
∑ 𝑄(𝐹)
𝐹∈𝐸𝑅𝐼𝑂
= ∑ 𝑄(𝐹)
𝐹∈𝑆𝑅𝐼𝑂
Contaminant mass balance in the river:
∑ 𝐶(𝐹, 𝑖) ⋅ 𝑄(𝐹)
𝐹∈𝐸𝑅𝐼𝑂
= ∑ 𝐶(𝐹, 𝑖) ⋅ 𝑄(𝐹)
𝐹∈𝑆𝑅𝐼𝑂
∀𝑖 ∈ 𝑆𝐶
Water mass balance in the companies:
∑ 𝑄(𝐹)
𝐹∈𝐸𝐴𝐸𝑀𝑃
= ∑ 𝑄(𝐹)
𝐹∈𝑆𝐸𝑀𝑃
CLAIO-2016
118

Contaminant mass balance in the companies:
∑ 𝐶(𝐹, 𝑖) ⋅ 𝑄(𝐹)
𝐹∈𝐸𝐴𝑀𝑃
= ∑ 𝐶(𝐹, 𝑖) ⋅ 𝑄(𝐹)
𝐹∈𝑆𝐸𝑀𝑃
∀𝑖 ∈ 𝑆𝐶
Maximum concentration of contaminants in the river by regulation:
𝐶(𝐺, 𝑆𝐶) ≤ 𝐶𝑀𝐴𝑋𝑅(𝑆𝐶) ∀𝐶 ∈ 𝑆𝐶 Concentration of contaminants in the first section of the river:
𝐶(𝑅0_𝑅1, 𝑖) = 𝐶0𝐶𝑂𝑁𝑇(𝑖) ∀𝑖 ∈ 𝑆𝐶 Maximum concentration of contaminants allowed in the companies:
𝐶(𝐸𝐸, 𝑖) ≤ 𝐶𝑀𝐴𝑋𝐸(𝐸𝐸, 𝑖) ∀𝑖 ∈ 𝑆𝐶
Maximum concentration of contaminants in the source:
𝐶(𝐻, 𝑖) ≤ 𝐶𝐻(𝑖) ∀𝑖 ∈ 𝑆𝐶
Water demand of the companies:
∑ 𝑄(𝑗, 𝑘)
𝑗∈𝐸𝐸
≥ 𝑄𝑀𝐼𝑁𝐸(𝑘) ∀𝑘 ∈ 𝑆𝑁
Maximum water flow allowed in the companies:
∑ 𝑄(𝑗, 𝑘)
𝑗∈𝐸𝐸
≤ 𝑄𝑀𝐴𝑋𝐸(𝑘) ∀𝑘 ∈ 𝑆𝑁
Minimum water flow required in the river:
𝑄(𝐺) ≥ 𝑄𝑀𝐼𝑁𝑅 Water flow from rain:
𝑄(𝐵) = 𝑄𝐵 Contaminants concentration in the rain:
𝐶(𝐵, 𝑖) = 𝐶𝐿𝐿(𝑖) ∀𝑖 ∈ 𝑆𝐶 Water mass flow in the source:
𝐶(𝑇, 𝑖) = 𝐶𝐹(𝑇, 𝑖) ∀𝑖 ∈ 𝑆𝐶 𝑄(𝑇) = 𝑄𝐹(𝑇)
Maximum and minimum water flow in the sink:
𝑄(𝐾) ≥ 𝑄𝑀𝐼𝑁𝐾(𝐾) 𝑄(𝐾) ≤ 𝑄𝑀𝐴𝑋𝐾(𝐾)
Relation between flows and concentrations:
𝐶(𝑗, 𝑖) ≤ 𝑄(𝑗) ∙ 𝑀 ∀𝑖 ∈ 𝑆𝐶, 𝑗 ∈ 𝐹 First objective function, associated to minimize the water use from the river:
𝐹𝑂1 =∑ 𝑄(𝑗)𝑗∈𝑆𝑁
∑ 𝑄𝑀𝐴𝑋𝐸(𝑗)𝑗∈𝑆𝑁
Second objective function, associated to minimize water use costs:
𝐹𝑂2 =∑ 𝑄(𝑗) ∙ 𝐶𝑂𝑆𝑇𝐸𝐵𝑗∈𝐸𝐵 + ∑ 𝑄(𝑗) ∙ 𝐶𝑂𝑆𝑇𝐴𝑃𝑗∈𝐴𝑃
∑ 𝑄𝑀𝐴𝑋𝐸(𝑗)𝑗∈𝑆𝑁 ∙ 𝐶𝑂𝑆𝑇𝐴𝑃
Constraints associated to objective function and the resolution method used:
𝐹𝑂1 − 𝑊1 ∙ 𝛾 ≤ 𝐹𝑂1𝐸 𝐹𝑂2 − 𝑊2 ⋅ 𝛾 ≤ 𝐹𝑂2𝐸
Objective function
𝑂𝐵𝐽𝑇 = 𝛾
The problem is non-linear (NLP) due to contaminant mass balance, shown on constraints. The solution of
the problem is obtained using the software GAMS, minimizing the objective function.
CLAIO-2016
119

3 Results and Discussion Using the goal programming to solve the multi-objective optimization problem presented above, we
obtained the connections displayed on Table 1. The graphical solution is shown in Figure 2.
Table 1: Flows of connections of the solution
Connection Flow [L/s] Connection Flow [L/s]
R1_E1 17.02 E1_E2 9.08
R3_E2 ~0 E1_E3 0.28
R5_E3 ~0 E1_E4 28.98
R7_E4 ~0 E2_E1 8.25
E1_R2 29.79 E2_E3 ~0
E2_R4 ~0 E2_E4 ~0
E3_R6 ~0 E3_E1 0.26
E4_R8 ~0 E3_E2 ~0
H_E1 16.041 E3_E4 ~0
H_E2 NE E4_E1 28.42
H_E3 NE E4_E2 ~0
H_E4 NE E4_E3 ~0
NE: Not existing connection.
Figure 2: Solution Diagram
As can be seen, just one of the companies needs water from the drinking water source, while companies
E2, E3 and E4 mainly use water from discharge of E1.
It is important to highlight that in spite of the cost involved in the use of pumps in connections, all the
companies are connected to each other.
Sensitivity Analysis
The aforementioned result considers 50% relative relevance between economic and environmental
objective functions.
CLAIO-2016
120
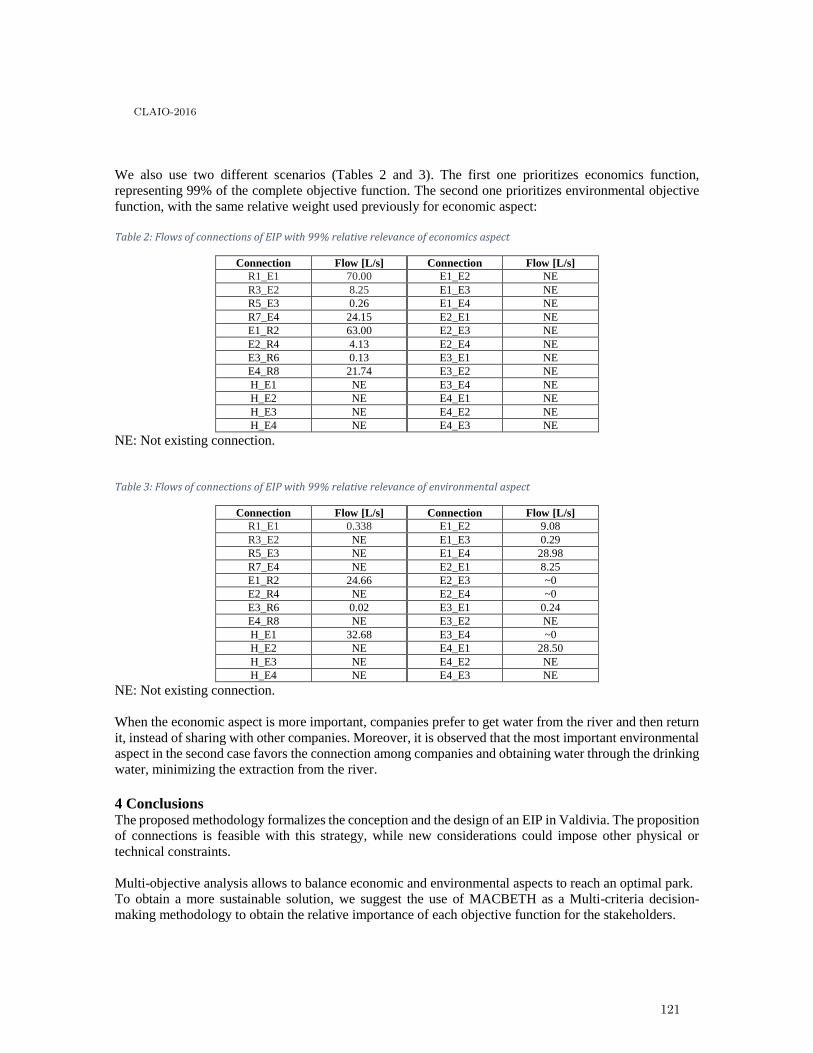
We also use two different scenarios (Tables 2 and 3). The first one prioritizes economics function,
representing 99% of the complete objective function. The second one prioritizes environmental objective
function, with the same relative weight used previously for economic aspect:
Table 2: Flows of connections of EIP with 99% relative relevance of economics aspect
Connection Flow [L/s] Connection Flow [L/s]
R1_E1 70.00 E1_E2 NE
R3_E2 8.25 E1_E3 NE
R5_E3 0.26 E1_E4 NE
R7_E4 24.15 E2_E1 NE
E1_R2 63.00 E2_E3 NE
E2_R4 4.13 E2_E4 NE
E3_R6 0.13 E3_E1 NE
E4_R8 21.74 E3_E2 NE
H_E1 NE E3_E4 NE
H_E2 NE E4_E1 NE
H_E3 NE E4_E2 NE
H_E4 NE E4_E3 NE
NE: Not existing connection.
Table 3: Flows of connections of EIP with 99% relative relevance of environmental aspect
Connection Flow [L/s] Connection Flow [L/s]
R1_E1 0.338 E1_E2 9.08
R3_E2 NE E1_E3 0.29
R5_E3 NE E1_E4 28.98
R7_E4 NE E2_E1 8.25
E1_R2 24.66 E2_E3 ~0
E2_R4 NE E2_E4 ~0
E3_R6 0.02 E3_E1 0.24
E4_R8 NE E3_E2 NE
H_E1 32.68 E3_E4 ~0
H_E2 NE E4_E1 28.50
H_E3 NE E4_E2 NE
H_E4 NE E4_E3 NE
NE: Not existing connection.
When the economic aspect is more important, companies prefer to get water from the river and then return
it, instead of sharing with other companies. Moreover, it is observed that the most important environmental
aspect in the second case favors the connection among companies and obtaining water through the drinking
water, minimizing the extraction from the river.
4 Conclusions The proposed methodology formalizes the conception and the design of an EIP in Valdivia. The proposition
of connections is feasible with this strategy, while new considerations could impose other physical or
technical constraints.
Multi-objective analysis allows to balance economic and environmental aspects to reach an optimal park.
To obtain a more sustainable solution, we suggest the use of MACBETH as a Multi-criteria decision-
making methodology to obtain the relative importance of each objective function for the stakeholders.
CLAIO-2016
121

References
[1] CHEW, I.M.L., TAN, R., NG, D.K.S., FOO, D.C.Y.,MAJOZI, T., GOUWS, J. Synthesis of Direct and
Indirect Interplant Water Network. Industrial & Engineering
Chemistry Research, 47(23): 9485–9496, Dec. 2008.
[2] BAGAJEWICZ, M. A review to recent design procedures for water networks in refineries and process
plants. Computers & Chemical Engineering, 24 (9-10): 2093-2113, Oct. 2000.
[3] UNITED NATIONS. (2005b). Agua y Desarrollo Sostenible (Inf. Téc.). ONU.
<http://www.un.org/spanish/waterforlifedecade/waterandsustainabledevelopment2015/pdf/
03{_}sustainable{_}development{_}esp.pdf>
[4] GARREAUD, R. Cambio Climático: Bases Físicas e Impactos en Chile. Tech. rep., Departamento de
Geofísica, Universidad de Chile, 2011.
[5] CHERTOW, M. Industrial Symbiosis: Literature and Taxonomy. Annual Review of Energy and the
Environment,25(1),313–337,Nov.2000.
<http://www.annualreviews.org/doi/full/10.1146/annurev.energy.25.1.313doi:10.1146/annurev.energy.25.
1.313.>
[6] GUILLÉN-GOSÁLBEZ, G. A novel MILP-based objective reduction method for multi-objective
optimization: Application to environmental problems. Computers & Chemical Engineering, 35(8): 1469–
1477, Aug. 2011.
[7] UNITED NATIONS ENVIRONMENT PROGRAMME. The Three Dimensions of Sustainable
Development. <http://web.unep.org/ourplanet/march-2015/unep-work/three-dimensions-sustainable-
development>
[8] Multiobjective Optimization. Standard Algorithms. University of Florida. Department of Mechanical &
Aerospace Engineering. <http://web.mae.ufl.edu/nkim/eas6939/multiobjMATLAB.pdf>
CLAIO-2016
122

Optimización del diseño de una cadena de suministro
sustentable mediante un modelo multi-objetivo
Linda Canales BUniversidad de Talca, Camino a Los Niches km. 1, Curicó, Chile.
Alfredo Candia-VéjarUniversidad de Talca, Camino a Los Niches km. 1, Curicó, Chile.
Ernesto Santibañez-GonzálezUniversidad de Talca, Camino a Los Niches km. 1, Curicó, Chile.
Bruno Santos PimentelVale do Rio Doce, [email protected]
Resumen
La definición de varias dimensiones de la sustentabilidad en la cadena de suministro, incluyen-do objetivos espećıficos de la industria minera, conduce a diseñar modelos y métodos capaces degestionar los compromisos entre varios objetivos. Proponemos un modelo de optimización multi-objetivo para el diseño de una cadena de suministro teniendo en cuenta la dimensión económicay ambiental de la sustentabilidad y el rendimiento de las plantas de procesamiento. El diseñoincluye las decisiones sobre la ubicación de las instalaciones y asignación de flujo para una cade-na compuesta de varios escalones, instalaciones, productos y flujos de reproceso. El modelo deoptimización multi-objetivo es resuelto mediante la aplicación de un algoritmo de Optimizaciónde Enjambre de Part́ıculas h́ıbrido multi-objetivo, el cual incorpora el concepto de dominanciade Pareto, PSO continuo y PSO binario. Se realizan experimentos computacionales para variasinstancias donde se compara el desempeño con el método eficiente AUGMECON a través de laaplicación de distintas métricas de desempeño. Basado en dichas métricas el enfoque propuestoes, en general, competitivo con AUGMECON, y, además, es mejor con respecto a las métricasrelacionadas con la diversidad y la distribución de las soluciones en la frontera.
Keywords: Diseño de la red de la cadena de suministro; Optimización multi-objetivo; Mineŕıasustentable; Algoritmo de optimización de enjambre de part́ıculas.
CLAIO-2016
123

1. Introducción
Uno de los mayores desaf́ıos enfrentados por el mundo actual es lograr un desarrollo susten-table, cuyo propósito es la integración de la actividad económica, la preservación ambiental y laspreocupaciones sociales. Muchas empresas se dirigen hacia la sustentabilidad de la cadena de su-ministro con el fin de asegurar el cumplimiento de leyes y reglamentos, y para adherirse y apoyarlos principios internacionales de conducta empresarial sustentable [20].
Una de las inquietudes ambientales actuales es el elevado y creciente consumo de recursosescasos y la contaminación que esto genera. Las emisiones de gases de efecto invernadero (GEI)son reconocidas como los elementos más nocivos para el medio ambiente y responsables del cambioclimático [4]. Del total de emisiones de GEI en el mundo hasta el año 2010 el sector industrial esel que emite mayor cantidad, con emisiones del 29 % del total. La industria de los minerales esla que genera más emisiones, donde la industria de hierro y acero emite un 4,8 % del total global[1]. De modo que el sector de los minerales se enfrenta a desaf́ıos reales de impulsar prácticas mássustentables.
Si bien ya se ha definido y analizado los desaf́ıos del sector minero, actualmente existen pocosart́ıculos que modelen el diseño de la red de su cadena de suministro a nivel estratégico [16] y muchosmenos que consideren la sustentabilidad [3], por lo que es fundamental desarrollar modelos en estaárea que permitan diseñar cadenas de suministro sustentables para cumplir con las regulaciones ylos requerimientos de los diferentes interesados.
Incorporar dimensiones de la sustentabilidad en el diseño de una cadena de suministro con-siderando objetivos espećıficos de la industria define un problema de varios objetivos, entoncesse requiere desarrollar modelos y metodoloǵıas que permitan analizar los compromisos entre losdistintos objetivos.Contribución y estructura del trabajoHemos desarrollado un modelo multi-objetivo que permite diseñar una cadena de suministro con-siderando objetivos relacionados a la sustentabilidad y a la industria minera. El diseño consideradecisiones de localización de instalaciones y asignación de flujos, para una cadena de cuatro es-labones, varias instalaciones, productos y flujo de reproceso. Dentro de los objetivos se considerala dimensión económica y ambiental de la sustentabilidad, y el rendimiento de las plantas de pro-cesamiento. Dentro de la planificación estratégica incluimos un problema que ha sido modeladosolamente para planificaciones operacionales y tácticas en la mineŕıa, relacionado con el rendimien-to de las operaciones en las plantas. El objetivo ambiental y económico se considera a lo largo detoda la cadena de suministro, a través de las emisiones por proceso y transporte. Para resolver elproblema y analizar los compromisos entre los distintos objetivos, diseñamos e implementamos unalgoritmo de Optimización de Enjambre de Part́ıculas h́ıbrido multi-objetivo modificado (MOHP-SO), que permite encontrar soluciones factibles e incorpora el concepto de dominancia de Pareto,PSO discreto y continuo, distancia crowding y control del archivo de soluciones no-dominadas.
El resto del documento está organizado de la siguiente manera. La Sección 2 presenta una revi-sión de las investigaciones anteriores relevantes. En la Sección 3 se describe el problema y el modelode optimización. En la Sección 4 se explican las caracteŕısticas del algoritmo y se presenta evalua-ciones experimentales para comparar el desempeño del algoritmo con otro método multiobjetivo entérminos de diferentes criterios. La Sección 5 está dedicada al análisis de soluciones. Finalmente,en la Sección 6 se presentan las principales conclusiones y futuras ĺıneas de investigación.
CLAIO-2016
124

2. Revisión de Literatura
En los últimos años ha habido un gran interés en la gestión de la cadena de suministro sustenta-ble (SSCM), principalmente por la presión ejercida sobre las empresas por los diferentes interesados[20]. Debido al interés en el tópico SSCM, se han realizado varias revisiones de literatura [11, 19, 3],donde se menciona que los modelos de diseño de redes parecen ser la nueva tendencia en SSCM.Eskandarpour et al. [8] presentan una revisión de los trabajos en SSCND (diseño de red de SCsustentable).
A pesar de que el tópico de SSC está teniendo cada vez más interés tanto por las empresascomo por los investigadores, existe poca literatura para el sector minero, donde hasta el año 2010exist́ıan solo 4 art́ıculos dentro de la categoŕıa de “Materiales, mineŕıa y enerǵıa” [11]. En generalen la literatura se presentan modelos que tratan problemas tácticos y operativos de la mineŕıa,como los modelos de secuenciación de bloques y asignación de equipos [16]. El diseño de redes SCes un problema estratégico relevante para la industria minera y que ha sido poco tratado hastaahora. Pimentel et al. [18] realizan un análisis de la literatura dedicada al desarrollo y aplicaciónde métodos cuantitativos de soporte de decisiones con las consideraciones de la sustentabilidad enla industria minera, donde enfatizan que aun hay poco desarrollo.
Eskandarpour et al. [8] menciona que las decisiones estratégicas como el diseño de la red tienenuna influencia significativa sobre las limitaciones y las decisiones tácticas y operativas. Sin embargo,la coordinación de los diferentes niveles ha sido casi ignorado en la literatura SCND sustentable.
En general, hay art́ıculos en que se diseña la red de una SC [4, 12, 21, 7], dentro de los cualesalgunos consideran una SC sustentable [7, 4, 10], donde se consideran decisiones estratégicas y seincorporan las dimensiones ambiental y económica principalmente. El impacto ambiental en generales medido como emisiones por transporte.
Los problemas de SCND sustentables son de naturaleza multi-objetivo, por lo que son necesariasmetodoloǵıas que permitan encontrar soluciones que consideren todos los objetivos, y donde ademásel impacto ambiental debe medirse en todos los pasos de la cadena de suministro [8].
Varios investigadores han desarrollado enfoques multi-objetivo para el diseño de una cadena desuministro, principalmente con el uso de metaheuŕısticas [2, 21, 7, 10] y el método epsilon-restricción[15, 22].
3. Descripción del Problema y del Modelo de Optimización
A continuación se describen las principales caracteŕısticas del problema estudiado y del modeloMILP propuesto.
3.1. Caracteŕısticas del problema estudiado
La exploración de mineral bruto (run of mine, ROM) se produce en los frentes de extracción delas minas, donde el mineral es removido. Cada frente de extracción explorado presenta una seriede caracteŕısticas f́ısicas y qúımicas conocidas previamente. Luego de ser extraido, el mineral estransportado hasta las instalaciones de cribado y trituración, donde el tamaño del mineral ROMes reducido de acuerdo a las necesidades.
Posteriormente el mineral es enviado a las plantas de procesamiento, donde se mejora la calidaddel producto por medio de procesos de clasificación y concentración (flotación, separación magnéti-
CLAIO-2016
125

ca) generando distintas familias de productos: fino y superfino. Básicamente estos productos sediferencian por rango granulométrico y porque serán aplicados más adelante en diferentes procesosde aglomeración. Finalmente, los productos son transportados hacia los puertos desde donde seránenviados hasta los clientes. Un ejemplo de esto se muestra en la Figura 1.
Los diferentes productos que se pueden generar por cada planta de procesamiento tienen, paracada parámetro de calidad, rangos de calidad que se deben cumplir. El procesamiento busca reducirlas diferencias entre los parámetros originales de calidad del mineral ROM y los parámetros decalidad de los productos finales. Por lo tanto, mientras mayores son las diferencias de calidad entrela entrada y la salida, menor será el rendimiento de la planta. La Tabla 1 muestra un ejemplo delas metas de calidad para cada parámetro de cada producto demandado por el cliente.
1
2
1 1
2
1
2
Mina (J) Planta (K) Puerto (L) Cliente (M)
X11
X21
Y11
Y12
Z11
Z22
Z21
rs Reproceso (K)
Z12
Desecho (K)
1
1u
Figura 1: Ejemplo de la cadena de suministro
Productos Fe SiO2 Al2O3 Mn P
P1 (fino) 64 4,0 1 0,80 0,06P2 (fino) 50 2,0 5 0,13 0,05
P3 (superfino) 64 1,0 5 1,50 0,01P4 (superfino) 69 0,9 10 3,00 0,06
Tabla 1: Ejemplo de metas ( %) de los parámetros de calidad de cada producto
3.2. Descripción del modelo
Presentamos un modelo de Programación Lineal Entera Mixta (MILP) multiobjetivo, que con-sidera tanto un objetivo económico como otro ambiental, donde para el primer caso se pretendeminimizar los costos totales por concepto de inversión y de transporte de los productos, y para elsegundo objetivo minimizar el nivel de emisiones de CO2eq. equivalente dadas por el transporte yel procesamiento de producto. Se incluye un tercer objetivo que permite optimizar el rendimientode las plantas de procesamiento a través de la minimización de las desviaciones de las metas de
CLAIO-2016
126

los parámetros de calidad de los productos. El modelo es de localización y asignación capacitado,para varios productos, eslabones e instalaciones. La Figura 1 ilustra un ejemplo de la cadena desuministro considerada con las variables de flujo involucradas para un producto. La cadena desuministro considera los eslabones: Minas, Plantas, Puertos y Clientes. Se incluye el reproceso demineral entre las plantas y los puertos, donde una cantidad del mineral (r) ingresado en la plantaes re-procesado para luego obtener una cantidad de cada producto (s) que se dirigirá a los puertosy una cantidad de mineral (u) que será considerado como desecho. Por lo que se incluye los balan-ces de flujo referentes al reproceso y al producto demandado en términos de las metas de calidaddemandadas de cada parámetro.
4. Algoritmo y Evaluación Experimental
Para resolver el problema propuesto existen varios métodos, dento de los cuales se encuen-tran las metaheuŕısticas que permiten optimizar todos los objetivos de manera simultánea. Losmetaheuŕısticas más utilizados en la literatura reciente para diseño de SC multiobjetivo son: elalgoritmo genético de clasificación no dominada II (NSGAII) [2], el optimizador de enjambre depart́ıculas multi-objetivo (MOPSO) [9] y el algoritmo de búsqueda de vecindario variable multi-objetivo (MOVNS) [7]. El algoritmo MOPSO, perteneciente a la inteligencia de enjambre [17], hademostrado tener un buen desempeño para resolver estructuras SC complicadas y de gran escala [5].El primer optimizador de enjambre de part́ıculas multi-objetivo (MOPSO) fue propuesto por Moorey Chapman [14], pero el interés real en el desarrollo de algoritmos MOPSOs comenzó en el 2002.Coello [6] presenta buenas definiciones del algortimo. En este trabajo utilizaremos un algoritmoMOPSO que combina el algoritmo PSO original y el PSO binario.
El algoritmo MOHPSO es comparado con el método AUGMECON propuesto por Mavrotas[13]. Este método consiste en la aplicación del método ε-constraint y se caracteriza por encon-trar soluciones de Pareto eficientes, pero tiene un alto costo computacional, dado que requiere laejecución del optimizador con cada objetivo para obtener cada punto del frente de Pareto.
Para poder evaluar el desempeño del algoritmo y compararlo con el método multiobjetivo, selleva a cabo un experimento a través de distintas instancias generadas. Teniendo en cuenta el númerode unidades posibles en cada eslabón, los problemas se clasifican en tres escalas (pequeña, mediana ygrande). En cada escala, se generan diez instancias aleatoriamente (es decir, un total de 30 instanciasde prueba). MOHPSO fue implementado en el lenguaje de programación Java y AUGMECON enGAMS 24.4.6 usando CPLEX como optimizador. Ambos métodos fueron ejecutados para cadainstancia en un computador personal con un procesador Intel Pentium N3510 de 1.99 GHz y 8GBde memoria RAM.
Con el fin de comparar ambos métodos, utilizamos métricas de evaluación de desempeño quepermiten medir la calidad de las soluciones. Donde se obtiene que para las instancias de tamañopequeño MOHPSO es capaz de encontrar soluciones eficientes de Pareto encontradas por AUGME-CON y algunas soluciones distintas. Para las demás instancias MOHPSO no encuentra solucionesóptimas de Pareto. Sin embargo, MOHPSO tiene una mejor distribución de las soluciones no-dominadas en la frontera obtenida para el 77 % de las instancias. Además presenta una mayordiversidad de las soluciones para más el 90 % de las instancias. Finalmente, para un 53 % de lasinstancias MOHPSO tiene una mayor tasa de éxito en relación a las tres funciones objetivos demanera simultánea, lo que indica que el algoritmo es competente.
CLAIO-2016
127

5. Resultados optimización multi-objetivo: Fronteras de Pareto
Para analizar las soluciones obtenidas hemos seleccionado una instancia de tamaño mediano,I.15. La frontera obtenida con ambos métodos se presenta en las Figuras 2a y 2b, cuyo espacioviene dado por las tres funciones objetivos evaluadas. Las soluciones obtenidas se pueden observaren relación a dos de sus ejes, donde se observa la variación de los valores para cada función objetivo.MOHPSO presenta una mejor dispersión de las soluciones para todos los objetivos. En MOHPSOtodos los valores de las funciones objetivo vaŕıan dentro de un amplio rango, en cambio para el Costoen AUGMECON, a pesar de tener un amplio rango, la mayoŕıa de las soluciones se concentran enun rango menor, por lo que es menos variable.
2 7 0 0 0 03 0 0 0 0 0
3 3 0 0 0 0
3 6 0 0 0 0
3 0 0 0
3 5 0 0
4 0 0 0
4 5 0 0
5 0 0 0
5 5 0 0
6 0 0 0
6 0 09 0 0
1 2 0 01 5 0 0
1 8 0 02 1 0 0
Emisio
nes (
MTCO
2)
R e n d i m i e n t o ( M T )
C o s t o ( M $ )
1 5 0 0 0 01 8 0 0 0 0
2 1 0 0 0 02 4 0 0 0 0
1 0 0 02 0 0 03 0 0 0
4 0 0 0
5 0 0 0
6 0 0 0
7 0 0 0
8 0 0 0
9 0 0 0
4 0 0
8 0 01 2 0 0
Emisio
nes (
MTCO
2)
R e n d i m i e n t o ( M T )
C o s t o ( M $ )
Figura 2: Fronteras de Pareto
6. Conclusiones y Trabajos Futuros
En este trabajo se presenta por primera vez, dentro de nuestra revisión bibliográfica, un modelomulti-objetivo que permite diseñar una cadena de suministro considerando objetivos relacionadosa la sustentabilidad y a la industria minera. Dentro de los objetivos se consideró la dimensióneconómica y ambiental de la sustentabilidad, y el rendimiento de las plantas de procesamiento.
Para resolver el modelo considerando todos los objetivos simultáneamente se utiliza el algoritmode Optimización de Enjambre de Part́ıculas h́ıbrido multi-objetivo MOHPSO, que une al algoritmoPSO continuo KPSO y el binario BPSO, utilizando la dominancia de Pareto y el control del archivoa través de la distancia crowding para obtener soluciones no-dominadas.
Con el fin de evaluar el desempeño del algoritmo MOHPSO en este tipo de problema, se com-paró con el método AUGMECON que es una mejora del método ε-constraint. Para esto se utilizaron5 métricas de evaluación distintas. En promedio, las soluciones obtenidas por el método AUGME-CON dominan las soluciones del algoritmo MOHPSO, debido a su alta eficiencia. Pero basado enlas demás métricas, MOHPSO tiene una mejor propagación de las soluciones, con una mejor distri-bución y además supera a AUGMECON en relación al éxito del alcance hacia todos los objetivossimultáneamente, demostrando ser competitivo. Aun cuando AUGMECON obtiene soluciones efi-cientes, utiliza un alto tiempo computacional para instancias de mayor tamaño. En general, dentrode la frontera se obtiene gran variabilidad de las soluciones para cada función objetivo evaluada,
CLAIO-2016
128

donde el método AUGMECON presenta una menor diversidad para el objetivo relacionado con elcosto total.
Para futuras investigaciones, proponemos comparar el desempeño del algoritmo MOHPSO conotras metaheuŕısticas multi-objetivo para el problema propuesto, con el objetivo de complementarel estudio.
Referencias
[1] ASN Bank and Ecofys. World ghg emissions flow chart 2010. Technical report, 2013.
[2] Susmita Bandyopadhyay and Ranjan Bhattacharya. Solving a tri-objective supply chain pro-blem with modified NSGA-II algorithm. Journal of Manufacturing Systems, 33(1):41–50, 2014.
[3] Marcus Brandenburg, Kannan Govindan, Joseph Sarkis, and Stefan Seuring. Quantitativemodels for sustainable supply chain management: Developments and directions. EuropeanJournal of Operational Research, 233(2):299–312, 2014.
[4] A. Chaabane, A. Ramudhin, and M. Paquet. Design of sustainable supply chains under theemission trading scheme. International Journal of Production Economics, 135(1):37 – 49, 2012.
[5] Yi-Wen Chen, Li-Chih Wang, Allen Wang, and Tzu-Li Chen. A particle swarm approach foroptimizing a multi-stage closed loop supply chain for the solar cell industry. Robotics andComputer-Integrated Manufacturing, 2015.
[6] Carlos A Coello Coello. An introduction to multi-objective particle swarm optimizers. In SoftComputing in Industrial Applications, pages 3–12. Springer, 2011.
[7] K. Devika, A. Jafarian, and V. Nourbakhsh. Designing a sustainable closed-loop supply chainnetwork based on triple bottom line approach: A comparison of metaheuristics hybridizationtechniques. European Journal of Operational Research, 235(3):594 – 615, 2014.
[8] Majid Eskandarpour, Pierre Dejax, Joe Miemczyk, and Olivier Péton. Sustainable supplychain network design: An optimization-oriented review. Omega, 54:11–32, 2015.
[9] Kannan Govindan, A Jafarian, R Khodaverdi, and K Devika. Two-echelon multiple-vehiclelocation–routing problem with time windows for optimization of sustainable supply chain net-work of perishable food. International Journal of Production Economics, 152:9–28, 2014.
[10] Kannan Govindan, Ahmad Jafarian, and Vahid Nourbakhsh. Bi-objective integrating sustai-nable order allocation and sustainable supply chain network strategic design with stochasticdemand using a novel robust hybrid multi-objective metaheuristic. Computers & OperationsResearch, 62:112–130, 2015.
[11] Elkafi Hassini, Chirag Surti, and Cory Searcy. A literature review and a case study of sustai-nable supply chains with a focus on metrics. International Journal of Production Economics,140(1):69–82, 2012.
CLAIO-2016
129

[12] Rajeshwar S Kadadevaramath, Jason CH Chen, B Latha Shankar, and K Rameshkumar.Application of particle swarm intelligence algorithms in supply chain network architectureoptimization. Expert Systems with Applications, 39(11):10160–10176, 2012.
[13] George Mavrotas. Effective implementation of the ε-constraint method in multi-objectivemathematical programming problems. Applied Mathematics and Computation, 213(2):455–465, 2009.
[14] Jacqueline Moore and Richard Chapman. Application of particle swarm to multiobjectiveoptimization. Department of Computer Science and Software Engineering, Auburn University,1999.
[15] Bruna Mota, Maria Isabel Gomes, Ana Carvalho, and Ana Paula Barbosa-Povoa. Towardssupply chain sustainability: economic, environmental and social design and planning. Journalof Cleaner Production, 105:14–27, 2015.
[16] Alexandra M Newman, Enrique Rubio, Rodrigo Caro, Andrés Weintraub, and Kelly Eurek. Areview of operations research in mine planning. Interfaces, 40(3):222–245, 2010.
[17] Konstantinos E Parsopoulos, Michael N Vrahatis, and IGI Global. Particle swarm optimizationand intelligence: advances and applications. Information Science Reference Hershey, 2010.
[18] Bruno Santos Pimentel, Ernesto Santibañez Gonzales, and Geraldo Oliveira Barbosa. Decision-support models for Sustainable Mining Networks: fundamentals and challenges. Journal ofCleaner Production, pages In Press, Accepted Manuscript, 2015.
[19] Stefan Seuring. A review of modeling approaches for sustainable supply chain management.Decision Support Systems, 54(4):1513–1520, 2013.
[20] Stefan Seuring and Martin Müller. From a literature review to a conceptual framework forsustainable supply chain management. Journal of Cleaner Production, 16(15):1699–1710, 2008.
[21] B Latha Shankar, S Basavarajappa, Jason CH Chen, and Rajeshwar S Kadadevaramath. Lo-cation and allocation decisions for multi-echelon supply chain network–a multi-objective evo-lutionary approach. Expert Systems with Applications, 40(2):551–562, 2013.
[22] Qi Zhang, Nilay Shah, John Wassick, Rich Helling, and Peter van Egerschot. Sustainablesupply chain optimisation: An industrial case study. Computers & Industrial Engineering,74:68–83, 2014.
CLAIO-2016
130

Uma abordagem contínua para o TSP e um método de descida para
geração de solução aproximada.
Luiz A. Carlos
Universidade Federal do Rio G. do Norte – UFRN - DIMAp
Resumo
Uma abordagem contínua ao TSP é apresentada e, baseado nela, um método de direção de descida é
descrito a gerar uma solução aproximada. Sendo 𝑛 o número de nós, define-se um hiperplano, de
dimensão 𝑛 − 1 e gerado por um conjunto de 𝑛 − 1 direções, sobre o qual se encontram as soluções
viáveis. As 𝑛 − 1 direções são escolhidas a fim de levarem a pontos viáveis, em virtude do tamanho do
passo dado, e, por isso, chamadas de direções básicas viáveis. O algoritmo tem início numa solução viável
e evolui gerando novas soluções, com as tais direções básicas viáveis, e reiniciando naquela de menor
valor, quando essa existir. Quando não existir melhora, busca-se no cone negativo, ou complementar, ao
cone gerado por estas direções básicas viáveis, outra direção de descida. Este processo termina com o
retorno ao ponto de partida, com a constatação de ótimo local, se o mesmo tiver sido gerado.
Palavras chave: Algoritmo Problema do caixeiro viajante Análise convexa Método de descida
1 Introdução
O Problema do Caixeiro viajante - PCV ou Travelling Salesman Problem - TSP tem exigido de
pesquisadores um grande esforço na busca de um algoritmo capaz de encontrar uma solução, dentre tantas
possíveis, de boa qualidade. Este esforço justifica-se não apenas pelo fato do problema servir de modelo
para muitos problemas reais, mas, principalmente, porque não se tem conhecimento de um algoritmo
polinomial a resolvê-lo. Este desconhecimento pode ser pela inexistência ou pela possibilidade do mesmo
ainda não ter sido encontrado. Por isso, como pode ser visto em [1], este problema pertence à chamada
classe dos problemas NP-Completos.
2 Descrição do problema
A teoria dos grafos tem se mostrado uma ferramenta bastante adequada à modelagem de problemas
discretos, como é o caso do TSP. Entretanto, a abordagem dada, aqui, a este problema é contínua,
partindo de seu modelo discreto define-se uma extensão do mesmo ao contínuo através da envoltória
convexa de soluções viáveis. Esta abordagem permite o uso de técnicas próprias para algoritmos
destinados a problemas contínuos, ainda que linear por partes, como é o caso, e, por isso, sem a garantia
de diferenciabilidade.
Esta abordagem foi escolhida não apenas pelo simples desejo do uso de técnicas de otimização no
contínuo, mas pela facilidade que a mesma pode propiciar, haja vista que a derivada pode orientar na
busca, ainda que sem derivadas em alguns pontos.
CLAIO-2016
131

Na representação inteira de 𝑛 nós, usada aqui, cada solução viável será um arranjo, 𝑥𝑖 = (𝑥𝑖1, … , 𝑥𝑖𝑛
) de
inteiros, sem repetição, a menos do primeiro, sendo repetido ao final para gerar o ciclo hamiltoniano
𝑐𝑙𝑖 = 𝑥𝑖1… 𝑥𝑖𝑛
𝑥𝑖1 de custo 𝑐(𝑥𝑖) = ∑ 𝑎𝑖𝑗
𝑛−1𝑗=1 + 𝑎𝑖1
, onde 𝑎𝑖𝑗 é o valor associado à aresta que liga o nó
𝑥𝑖𝑗 ao nó 𝑥𝑖𝑗+1
.
Observe que os caminhos 𝑥𝑖1𝑥𝑖2
𝑥𝑖3… 𝑥𝑖𝑛
, 𝑥𝑖2𝑥𝑖3
… 𝑥𝑖𝑛𝑥𝑖1
𝑥𝑖3… 𝑥𝑖𝑛
𝑥𝑖1𝑥𝑖2
e todos os outros decorrentes
do simples rearranjos por avanços da componentes inicial, mas preservadas as disposições originais dos
nós, têm o mesmo custo associado, quando se diz que todos esses caminhos pertencem ao mesmo anel.
Sendo assim, todos os pontos viáveis pertencem ao hipercubo dado por {1, … , 𝑛}𝑛 , para garantir que
todos os nós estejam presentes e, para garantir que não haja repetição, pertencem também ao hiperplano
𝐻: 𝑥𝑖1+ ⋯ + 𝑥𝑖𝑛
=𝑛(𝑛 + 1)
2
Portanto, deslocamentos que preservem viabilidade, a partir de pontos viáveis, deverão ser dados em
direções que pertencem ao espaço 𝑛𝑢𝑙𝑜(𝐻) e que respeite a integralidade. Para garantir a primeira
condição escolhem-se direções com as qualificações pedidas e para garantir a segunda condição escolhe-
se o passo adequado.
3 Construção da função objetivo
Uma função 𝑓: [1, 𝑘] → 𝑅 linear por partes e unimodal, será construída nas etapas 𝑖 = 1, … , 𝑘 , como
segue. Para tal, toma-se o ponto viável 𝑥𝑖−1 e admite-se que se tenha gerado, a partir dele, uma solução de
menor valor, 𝑥𝑖 , para as quais se obtém os correspondentes valores 𝑐(𝑥𝑖−1) 𝑒 𝑐(𝑥𝑖) satisfazendo a
𝑐(𝑥𝑖−1) > 𝑐(𝑥𝑖) , Ao mesmo tempo, toma-se a combinação linear convexa
𝑥𝑖(𝑡) = 𝑥𝑖−1 + (𝑡 − 𝑖 + 1)𝑥𝑖 𝑝𝑎𝑟𝑎 𝑡 ∈ [𝑖 − 1, 𝑖), 𝑖 = 1, … , 𝑘
e define-se para 𝑖 = 1, … , 𝑘 e 𝑡 ∈ [𝑖 − 1, 𝑖) a função linear
𝑙𝑖(𝑡) = {𝑐(𝑥𝑖−1) + (𝑡 − 𝑖 + 1)[𝑐(𝑥𝑖) − 𝑐(𝑥𝑖−1)
0 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟á𝑟𝑖𝑜
Observe que 𝑙𝑖 também pode ser definida por 𝑙𝑖(𝑡) = 𝐿𝑖(𝑥𝑖(𝑡), onde 𝐿𝑖: 𝑅𝑛 → 𝑅 é uma função linear, ou
seja, 𝑙𝑖 é uma restrição de 𝐿𝑖 cuja normal é qualquer direção 𝜇 tal que 𝜇𝑇(𝑥𝑖 − 𝑥𝑖−1) < 0. Logo para
𝑡 ∈ (𝑖 − 1, 𝑖) existe 𝑙𝑖′(𝑡) = 𝜇𝑇(𝑥𝑖 − 𝑥𝑖−1) < 0, onde ′ representa a derivada.
As direções básicas escolhidas são (±1, ±1,0, … ,0), (0, ±1, ±1,0, … ,0), … , (0,0, … ,0, ±1, ±1) , onde ±
indica se a componente aumenta ou diminui, mas sempre tomadas com sinais trocados, para ficar no nulo
de H.
A geração de uma nova solução a partir da solução viável 𝑥𝑖 e usando uma direção básica 𝑑𝑗 ∈ 𝑛𝑢𝑙𝑜(𝐻)
se faz por 𝑥𝑖+1 = 𝑥𝑖 + 𝛼𝑑𝑗 , onde 𝛼 = |𝑥𝑗𝑖− 𝑥𝑗𝑖±1
|, ou seja, uma simples troca de componentes. Esta nova
solução pode ser aceita ou não, mas sempre aceita quando for melhor.
CLAIO-2016
132

O uso de uma direção básica viável corresponde à troca de valores de componentes consecutivas, sendo
considerada etapa, para fins da construção da função, quando essa troca tem sucesso.
Por fim, sendo cada etapa obtida pela aplicação de uma direção básica viável de descida, define-se
𝑓(𝑡) = {𝑙𝑖(𝑡) 𝑝𝑎𝑟𝑎 𝑡 ∈ [𝑖 − 1, 𝑖)
0 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟á𝑟𝑖𝑜
Esta função é linear por parte, unimodal e não-diferenciável nos pontos 𝑡 = 0,1, … , 𝑘. Além disso, a
mesma depende da escolha das direções, constituintes de uma base para o 𝑛𝑢𝑙𝑜(𝐻), sendo este processo
de construção finito, pois, acaba com o retorno à solução de partida, depois de 𝑛(𝑛 − 1) ciclos de uso das
direções básicas viáveis ou prematuramente num ótimo local.
4 Caracterização de ótimo local
A referida parada prematura do processo se dá com a chegada em um ótimo local. Portanto, admitindo-se
que se alcançou o fim da construção de 𝑓 e sabendo que em cada etapa de sua construção se tem a
garantia de que 𝜇𝑖𝑇(𝑥𝑖 − 𝑥𝑖−1) < 0, 𝑖 = 1, … , 𝑘 e 𝜇𝑘
𝑇(𝑥𝑘+1 − 𝑥𝑘) > 0 , logo 𝜇𝑘𝑇(𝑥𝑘 − 𝑥𝑘+1) < 0 e
conclui-se que
𝑓(𝑡) ≥ 𝑓(𝑘) + 𝜇𝑘𝑇(𝑥𝑘 − 𝑥𝑘+1)(𝑘 − 𝑡), 𝑡 ∈ [1, 𝑘]
quando se diz que 𝜇𝑘𝑇(𝑥𝑘 − 𝑥𝑘+1) é um subgradiente para 𝑓 em 𝑡 = 𝑘.
O conjunto dado pela envoltória convexa ou combinação linear convexa de todos os possíveis
subgradientes de uma função convexa, 𝑓 , no ponto 𝑥 , é chamado de subdiferencial de 𝑓 , em 𝑥 , e
representado por 𝜕𝑓(𝑥). Além disso, um ponto 𝑥 é um ótimo local para 𝑓 quando 0 ∈ 𝜕𝑓(𝑥). Maiores
detalhes sobre o tema podem ser encontrados em [2,3,4].
Caracterização de ótimo local:
Se o processo de construção de 𝑓 acaba na etapa k com a geração de 𝑥𝑘 e todas as soluções geradas com
as direções básicas viáveis e mais as geradas com as direções do cone negativo, a partir de 𝑥𝑘, resultarem
em subida, então o ponto 𝑥𝑘 é um ótimo local.
A razão para esta afirmação está no fato das direções básicas viáveis constituírem uma base para o
𝑛𝑢𝑙𝑜(𝐻) adicionado ao fato do cone negativo ser de subida, pois, sendo assim, basta tomar o simétrico de
uma dessas direções de subida do cone negativo, para juntamente com as direções básicas viáveis gerarem
uma combinação linear nula com coeficientes não nulos, já que são 𝑛 e portanto um conjunto linearmente
independente, o que faz ser possível gerar um subgradiente nulo, ou seja, 0 ∈ 𝜕𝑓(𝑥𝑘), a condição de
otimalidade local.
5 Conclusões
Diferente das metaeurísticas nas quais a cada execução o algoritmo traça, provavelmente, um caminho
diferente, a proposta apresentada neste sugere um algoritmo determinístico. Este determinismo é, em
parte, pela prévia definição das direções viáveis entretanto outra possibilidades para a definição das
mesmas existem, para tal basta que sejam capazes gerar o 𝑛𝑢𝑙𝑜(𝐻).
CLAIO-2016
133

As direções escolhidas surgiram naturalmente, porém observa-se que elas têm uma baixa capacidade de
diversificação, obrigando a que se replique o seu uso, o que poderia ser evitado com outro conjunto de
direções com uma maior capacidade de diversificação.
Alguns algoritmos que contemplem esta abordagem estão sendo gerados com o fim de se comparar o
desempenho dos mesmos, tendo por base a TSP-Lib. Os resultados alcançados ainda são insipientes,
entretanto nos animam pela busca de uma versão que demonstre um bom desempenho.
References
1. Garey R. Michael and David S. Johanson (1979). COMPUTERS AND INTRACTABILITY A Guide to
the Theory of NP-Completeness, W. H. Freeman and Company, New York.
2. Hendrix, Eligious M. T. and Bogláka G. Tóth (2010) Introduction to Nonlinear and Global Optimization,
Springer, New York.
3. Minoux, Michel (1986) Mathematical Programming Theory and Algorithms, John Wiley and Sons Ltd. 4. Rockafellar, R. Tyrrell (1970) Convex Analysis, Princeton University Press, New Jersey.
CLAIO-2016
134

Sobre o Número de Helly Geodético em Grafos
Moisés Teles Carvalho JuniorPrograma de Engenharia de Sistemas e Computação, COPPE, UFRJ
Mitre Costa DouradoInstituto de Matemática, UFRJ
Jayme Luiz SzwarcfiterPrograma de Engenharia de Sistemas e Computação, COPPE, UFRJ
Resumo
Um conjunto de vértices S de um grafo G é geodeticamente convexo se todos os vértices dequalquer caminho mı́nimo entre dois vértices de S pertencem a S. O número de Helly de umgrafo G na convexidade geodética é o menor inteiro k para o qual toda famı́lia C de conjuntosgeodeticamente convexos k-intersectante de G, possui um vértice comum a todos os conjuntosde C. Apresentamos limitantes inferior e superior e teoremas que auxiliam no cálculo em gra-fos contendo um vértice simplicial espećıfico ou um subgrafo prisma generalizado. Mostramostambém uma decomposição por conjuntos separadores de gêmeos que permite calcular o númerode Helly nas componentes resultantes.
Palavras-chave: Convexidade; convexidade geodética; número de Helly
Abstract
A subset of vertices S ⊆ V (G) of a graph G is geodesically convex if all vertices belongingto any shortest path between two vertices of S lie on S. The Helly number of G is the leastinteger k, such that any subfamily of k-intersecting geodesically convex sets of G contains acommon vertex. We present lower and upper bounds and theorems that help calculating theHelly number for graphs containing a specific simplicial vertex or a generalized prism subgraph.We also show a decomposition by separators sets of twins that allows the calculation of theHelly number in the resulting components.
Keywords: Convexity; geodetic convexity; Helly number
CLAIO-2016
135

1 Introdução
Dado um conjunto finito V , uma famı́lia de subconjuntos C de V é uma convexidade em V :(1) O conjunto vazio e V pertencem a C.(2) C é fechado para interseção.Os subconjuntos de V em C são chamados conjuntos convexos e o menor conjunto convexo con-
tendo X ⊆ V é chamado envoltória convexa de X [8]. Neste trabalho vamos estudar a convexidadedos caminhos mı́nimos em grafos, também conhecida como convexidade geodética.
Dado um grafo G, uma geodésica entre dois vértices de G é um caminho mı́nimo entre eles eS ⊆ V (G) é convexo se para quaisquer dois vértices em S, todos os vértices numa geodésica entreeles estão em S. O intervalo fechado entre u e v é o conjunto I[u, v] de todos os vértices numageodésica entre eles, onde I[u, v] ⊇ {u, v}. Definimos o intervalo aberto I(u, v) = I[u, v]\{u, v}. SeS ⊆ V (G), então I[S] =
⋃u,v∈S
I[u, v]. O menor conjunto convexo de G contendo S, denotado por
〈S〉, é dito fecho convexo. O fecho convexo de um subconjunto sempre existe e é único. Denotamospor MG o conjunto de todos os conjuntos convexos de G.
Uma famı́lia de conjuntos C é um par ordenado (V (C), E(C)), onde V (C) = {v1, . . . , vn}, comn < ∞ e E(C) = {E1, . . . , Em}, onde Ei ⊆ V (C) e V (C) =
⋃Ei∈E(C)
Ei. O núcleo de C é definido
como núcleo(C) = E1 ∩ E2 ∩ . . . ∩ Em.Uma famı́lia C dita é k-intersectante se quaisquer k conjuntos de C tem núcleo não vazio. Uma
famı́lia C é k-Helly quando toda subfamı́lia k-intersectante de E(C) tem o núcleo não vazio. Onúmero de Helly de C é o menor k′ para o qual C é k′-Helly. Se k′ = 2, diz-se que C satisfaz apropriedade de Helly [7]. O número de Helly na convexidade geodética será denotado por h(G) [5].
Os resultados mostrados a seguir serão úteis em nossas demonstrações.
Teorema 1.1 (Berge e Duchet [2]). Uma famı́lia de conjuntos C é k-Helly se e somente se paratodo conjunto A ⊆ V (C) com |A| = k + 1, a interseção dos conjuntos Ej, com |Ej ∩A| ≥ k, é nãovazio.
Lema 1.2 (Berge, Duchet e Calder [6]). O número de Helly é o menor inteiro k tal que todoconjunto S, S ⊆ V , com |S| = k + 1, tem a propriedade
⋂a∈S〈S \ {a}〉 6= ∅.
Conjuntos convexos possuem aplicações em marketing em redes sociais, ao necessitar do menorconjunto de pessoas para divulgar satisfatoriamente um produto. A propriedade de Helly possuiaplicações em diversas áreas, por exemplo, em otimização em programação linear [1].
Em todas as demonstrações, só consideramos grafos simples, conexos e grafos não triviais.
2 Limite inferior e superior para o número de Helly
Se S é um conjunto convexo de um grafo G, h(G[S]) é um limitante inferior de h(G).
Proposição 2.1. Seja G um grafo. Se S é um conjunto convexo de G, então h(G[S]) ≤ h(G).
Demonstração. Como S é um convexo em G, então MG[S] ⊆MG.
A clique máxima é um subgrafo induzido e um conjunto convexo de G, então h(G) ≤ ω(G).
CLAIO-2016
136

Proposição 2.2. Seja G um grafo. Então h(G) ≤ |V (G)| = n.
Demonstração. Supondo h(G) > n. Pelo Lema 1.2, existe uma famı́lia C de n+1 conjuntos convexoscom pelo menos n vértices, n-intersectante, e núcleo vazio. Então |V (G)| ≥ n+1, uma contradição.
Em [3] é mostrado que h(G) = n se e somente se G = Kn.
3 Eliminando vértices simpliciais restritos
Um vértice a é dito simplicial restrito se N(a) induz uma clique não maximal em G \ {a}. NaFigura 1, a é simplicial restrito, pois N(a) = {b, f}, já o vértice d é simplicial não restrito.
a
b c
d
ef
Figura 1: Exemplo de um vértice simplicial restrito
Os lemas a seguir relacionam conjuntos convexos de G e de G \ {a}, onde a é simplicial.
Lema 3.1. Seja G um grafo, a um vértice simplicial em G e G′ = G \ {a}. Todo conjunto convexoS em G′ é também convexo em G.
Demonstração. Suponhamos S ⊆ V (G) não convexo em G. Para algum u e v em S, existe umageodésica P em G, entre u e v, que contém um vértice de V (G) \ S. Logo a ∈ P , caso contrário Pestaria em G′. Então ao menos dois vizinhos de a em P não são adjacentes, logo a não é simplicial.
Lema 3.2. Se S é um conjunto convexo em um grafo G, a um vértice simplicial em G e G′ =G \ {a}, então S \ {a} é convexo em G′.
Demonstração. Como a é simplicial, a não pertence a uma geodésica entre quaisquer dois vértices.
Teorema 3.3. Se a é um vértice simplicial restrito em um grafo G, então h(G) = h(G \ {a}).Demonstração. Seja G′ = G \ {a}, h(G) = k, e supondo, por contradição, que h(G′) 6= k.
Pelo Lema 3.1 temosMG′ ⊆MG, assim, pelo Teorema 2.1, h(G′) ≤ h(G), então h(G′) < h(G).Como G não é (k − 1)-Helly, pelo Lema 1.2, existe uma famı́lia CG de k conjuntos convexos,(k − 1)-intersectante, com núcleo vazio, ou seja, pelo Teorema 1.1, CG = {S1, . . . , Sk}:
S1 ⊇ {v2, v3, . . . , vk} + {v1}, S2 ⊇ {v1, v3, . . . , vk} + {v2}, . . . , Sk−1 ⊇ {v1, . . . , vk−2, vk} +
{vk−1}, Sk ⊇ {v1, . . . , vk−2, vk−1} + {vk} ek⋂i=1
Si = ∅.Para algum i, a = vi, caso contrário CG ⊆ MG′ . Sem perda de generalidade, tomemos a = v1.
Temos que I(a, vi) ∩ I(a, vj) = ∅, para todo 2 ≤ i < j ≤ k. Supondo o contrário, que existaw ∈ I(a, vi) ∩ I(a, vj), para algum i, j. Assim, a e w pertenceriam a todo convexo St, para t 6= 1.
CLAIO-2016
137

Tomando C′G′ = {S′1, . . . , S′k}, com S′i = Si \ {a}, pelo Lema 3.2, S′t são convexos em G′.Como CG é (k − 1)-intersectante, C′G′ = {S1, S2 \ {a}, . . . , Sk \ {a}} também será, pois w ∈ St,para t 6= 1, e como S′i ⊆ Si, CG possuir o núcleo vazio implica que C′G′ também possuirá, o queacarretaria em G′ não ser (k − 1)-Helly, uma contradição.
Como I(a, vi) ∩ I(a, vj) = ∅, para todo 2 ≤ i < j ≤ k, existe na clique um vértice exclusivonuma geodésica entre vi e a, então existem k − 1 vizinhos de a. Como a é simplicial restrito, aclique tem tamanho maior ou igual a k. Então G′ não é (k − 1)-Helly, uma contradição.
Um grafo G é dito de partição, ou split, quando V (G) pode ser totalmente particionado emuma clique e um conjunto independente. O Teorema 3.3 fornece resultado para grafos de partição.
Corolário 3.4. Seja G um grafo de partição. Então h(G) = ω(G).
Demonstração. Como G é split, admite uma partição de V (G) numa clique máxima e um conjuntoindependente I, onde I é composto somente por vértices simpliciais restritos.
Um grafo G é dito cordal quando todo ciclo de G de tamanho maior que três possui uma corda.Como grafos cordais possuem uma ordem de eliminação perfeita de vértices simpliciais, quandoexiste uma ordem de eliminação perfeita onde os vértices são simpliciais restritos, exceto os daclique máxima, temos h(G) = ω(G).
4 Grafos prisma generalizados
O produto cartesiano dos grafos G e H é o grafo G2H tal que V (G2H) é o produto cartesianoV (G) × V (H); e quaisquer dois vértices (v1, v2) e (w1, w2) são adjacentes em G2H se e somentese, ou v1 = w1 e v2 é adjacente a w2 em H, ou v2 = w2 e v1 é adjacente a w1 no grafo G. Umgrafo G é dito prisma generalizado quando é o produto cartesiano entre um grafo G′ qualquer e umcaminho Pm. Cada uma das m cópias de G′, G1, . . . , Gm, chamamos de base de G, assim G possuim bases isomorfas. Um subgrafo caminho Pm de G é dito pilar, denotado por π, se para todo parde vértices distintos de Pm, estes pertencem a bases distintas de G.
Para calcular o número de Helly de um grafo prisma generalizado, basta saber calcular o valordo parâmetro para uma de suas m bases.
Teorema 4.1 ([4]). Seja G um grafo prisma generalizado e Gp uma das bases de G. Entãoh(G) = h(Gp).
4.1 Eliminando subgrafos prisma generalizados
É posśıvel eliminar de um grafo G um subgrafo induzido prisma generalizado Pr, e calcularh(G) no grafo resultante. Denotaremos grafos prisma generalizados também como a união das mbases, ou seja, Pr = G1 ∪ ... ∪Gm.
Teorema 4.2. Seja G um grafo tal que G = G′ ∪ Pr, onde G′ e Pr são subgrafos induzidos de G,e Pr um grafo prisma generalizado. Se V (Gp) = V (G′ ∩ Pr), 1 ≤ p ≤ m, é um convexo em G,então h(G) = h(G′).
CLAIO-2016
138

Demonstração. Seja h(G) = k e, supondo por contradição, que h(G′) 6= k. Como G′ é um subgrafoinduzido e V (G′) convexo em G, pelo Teorema 2.1, h(G′) < h(G). Como G não é (k − 1)-Helly,pelo Lema 1.2, existe uma famı́lia CG = {S1, . . . , Sk} de k conjuntos convexos, (k−1)-intersectante,com núcleo vazio. Pelo Teorema, 1.1, CG é tal que:
S1 ⊇ {v2, v3, . . . , vk} + {v1}, S2 ⊇ {v1, v3, . . . , vk} + {v2}, . . . , Sk−1 ⊇ {v1, v2 . . . , vk−2, vk} +
{vk−1}, Sk ⊇ {v1, v2, . . . , vk−1} + {vk} ek⋂i=1
Si = ∅. Seja Vk = {v1, . . . , vk}.Ao menos um Si possui interseção não vazia com Pr \ Gp, caso contrário CG estaria em G′,
analogamente ao menos um Si possui interseção não vazia com G′ \Gp, caso contrário implicaria,pelo Teorema 4.1, existir numa base Gp (e em G′), uma famı́lia (k − 1)-intersectante com núcleovazio. Logo, ao menos um vértice de Vk está em Pr \Gp e ao menos um vértice em G′ \Gp. Semperda de generalidade, tomemos v1 em G′ \Gp e existirá vt em Pr \Gp, onde 2 ≤ t ≤ k.
Num grafo prisma generalizado, não ocorre dois vértices de Vk no mesmo π. Sem perda degeneralidade, tomemos v1 e v2 em π.
Caso 1: Vk ∩ π = {v1, v2}. Assim, temos os subcasos:Caso 1.1: Existe um vértice de Vk que não está numa base intermediária entre v1 e v2.Sem perda de generalidade, tomemos v1 ∈ Ga, v2 ∈ Gb e v3 ∈ Gc, onde a < b < c. Assim,
v2 ∈ S2, pois v2 ∈ I(v1, v3). Se v3 ∈ Ga, v1 ∈ Gb e v2 ∈ Gc, v1 ∈ I(v2, v3), uma contradição.Caso 1.2: Todo vértice de Vk \ {v1, v2} está numa base intermediária às de v1 e de v2.Sem perda de generalidade, tomemos v1 ∈ V (Ga), v2 ∈ V (Gb) e vq ∈ V (Gc), para q = 3, . . . , k;
onde a ≤ c ≤ b. Assim, existe vj ∈ π ∩Gc, então vj pertence ao núcleo.Caso 2: π ∩ (Vk \ {v1, v2}) 6= ∅.Sem perda de generalidade, tomemos v3 em π entre v1 e v2. Então v3 ∈ I(v1, v2), uma con-
tradição.Como v1 ∈ G′ \Gp e S1 + {v1}, então S1 pode ter ou não interseção não vazia com G′.Caso A: S1 ∩G′ 6= ∅.Assim, para vj ∈ Vk em Pr, existe wj em Gp (projeção de vj) no mesmo πj . Tomemos CG′ =
{S1, . . . , Sk} em G′, onde Si = Si ∩G′ e wl = vl, se vl ∈ (G′ \ Pr). Assim, cada Si é um convexo.Como Si∩Pr é um subprisma, então wj ∈ Si, para i 6= j, ou seja, Si ⊇ {w1, . . . , wi−1, wi+1, . . . , wk},assim, CG′ é (k− 1)-intersectante, e como Si ⊆ Si, então CG′ possui núcleo vazio, uma contradição.
Caso B: S1 ∩G′ = ∅.Temos então S1 ⊆ Gq∪Gq+1∪...∪Gq+l, sem perda de generalidade, de modo que p < q ≤ q+l ≤
m. Assim, Gq é a base de Pr de menor ı́ndice com Gq ∩ S1 6= ∅, isso implica que existe um vérticevj de Vk em Gq. Assim, existe um pilar π1 exclusivo para v1, tal que Si′ ∩π1 6= ∅, para i′ = 2, . . . , k;caso contrário, existiria um vj′ ∈ (Vk ∩π1) e wj′ ∈ Gq, tal que wj′ ∈ I(v1, vj′)∩ I(vj′ , vj)∩ I(v1, vj),o que implicaria wj′ pertencer ao núcleo.
Tomemos em G a famı́lia C′Gq = {S′1, . . . , S′k} onde S′i = Si ∩ Gq. Seja w1 = Gq ∩ π1, o queimplica que w1 /∈ S1, e wj a projeção de vj ∈ Vk em Gq por πj , para j = 2, . . . , k. Assim, cadaS′i é um convexo em Gq (interseção de conjuntos convexos) e C′Gq é (k − 1)-intersectante, poisS′i ⊇ {w1, . . . , wi−1, wi+1, . . . , wk}, e como S′i ⊆ Si, então C′G possui o núcleo vazio.
Como a base Gp é isomorfa a Gq e V (Gp) é um convexo em G′, existe em Gp (e em G′), umafamı́lia em C′Gp de convexos, (k− 1)-intersectante com núcleo vazio. Então G′ não é (k− 1)-Helly,uma contradição. Logo h(G) = h(G′).
CLAIO-2016
139

Na Figura 2, aplicamos o Teorema 4.2 em G[{e, f, g, h}], em G[{a, b, c, d, o, p, r, s, t, u, v}], edepois em G[{c, d, e, f, k, l,m, n}], e no grafo resultante, o Teorema 3.3, em sequência, nos vérticessimpliciais restritos l, j, k e i, obtendo um K4, logo h(G) = 4.
a b
c d
G
a b
cdG'
e f
g h
i j
k l
m n
p
s t
rq
o
uv
Figura 2: Grafo resolvido pela aplicação dos Teoremas 3.3 e 4.2
5 Decomposição por separadores de gêmeos
Um conjunto separador de gêmeos é um conjunto separador C de um grafo G onde para quaisqueru e v em C, N [u] = N [v]. Um bloco geminiano é o subgrafo maximal H de G tal que H não possuium conjunto separador de gêmeos. Dois ou mais vértices em G são ditos gemininanos entre siquando pertencem ao mesmo conjunto separador de gêmeos.
Lema 5.1. Sejam C1 e C2 conjuntos separadores de gêmeos de um grafo G. Então C1 ∩ C2 = ∅.Demonstração. Supondo, por contradição, que C1 ∩ C2 6= ∅.
Assim, existe um vértice v, tal que v ∈ C1 ∩ C2. Como C1 e C2 são distintos, existe u em(C1 \ C2) ∪ (C2 \ C1). Sem perda de generalidade, tomemos u ∈ C1 \ C2. Como N [u] = N [v] emG \ C1, N [u] = N [v] em G \ (C1 ∪ C2). Com efeito, para todo w, tal que w ∈ C2, N [v] = N [w] emG \ (C1 ∪ C2). Assim, w ∈ C2, N [u] = N [w] em G \ (C1 ∪ C2). Como u possui vértices adjacentesem ambas as componentes separadas por C2 (os mesmos adjacentes a v) mas u /∈ C2, então C2 nãoé um conjunto separador de G, uma contradição.
Lema 5.2. Seja CG uma famı́lia (k − 1)-intersectante de um grafo G com núcleo vazio, S umconjunto convexo de G e h(G) = k. Se CG ⊆MG[S] então h(G[S]) = h(G).
Demonstração. Como CG ⊆MG[S], h(G[S]) ≥ k, e pelo Teorema 2.1, h(G[S]) ≤ h(G) = k.
Se um grafo G contém conjuntos separadores de gêmeos, decompomos G por esses conjuntos eo número de Helly de G será o maior valor encontrado entre os seus blocos geminianos.
Teorema 5.3. Seja G um grafo e G1, G2, . . . , Gα os blocos geminianos de G. Então h(G) =max{h(G1), . . . , h(Gα)}.Demonstração. Seja h(G) = k e h(Gp) ≥ h(Gj), para j = 1, . . . , α. Supondo, por contradição,h(G) 6= h(Gp). Cada V (Gj) é um convexo em G, pois, dados dois vértices num bloco, todageodésica entre eles estará no bloco. Como MGp ⊆MG, pelo Lema 2.1, h(Gp) < h(G).
CLAIO-2016
140

Como G não é (k − 1)-Helly, pelo Lema 1.2, existe em G uma famı́lia CG com k conjuntosconvexos, (k − 1)-intersectante, com núcleo vazio, ou seja, pelo Teorema 1.1, CG = {S1, . . . , Sk}:
S1 ⊇ {v2, v3 . . . , vk} + {v1}, S2 ⊇ {v1, v3, . . . , vk} + {v2}, . . . , Sk−1 ⊇ {v1, . . . , vk−2, vk} +
{vk−1}, Sk ⊇ {v1, . . . , vk−1} + {vk} ek⋂i=1
Si = ∅. Seja Vk = {v1 . . . , vk}.Seja G′ o subgrafo induzido de G assim constrúıdo: todo bloco geminiano folha Gβ, 1 ≤ β ≤ α,
será removido se Gβ \ Cf , 1 ≤ f ≤ l; não possui vértices de Vk, onde Cf é o conjunto separadorque conecta Gβ a G. Então, cada bloco geminiano folha terá ao menos um vi de Vk. Como G′ éum subgrafo induzido e V (G′) um convexo de G, e CG ⊆MG′ , pelo Lema 5.2 que h(G) = h(G′).
Caso 1: ao menos um dos vértices de Vk pertence a algum conjunto separador de gêmeos.Sem perda de generalidade, tomemos v1 em Cf de G. Como todo bloco geminiano folha contém
ao menos um vértice de Vk que não pertence a Cf , então existem vr e vs em Vk, tal que V (Cf ) ⊆I(vr, vs). Assim, v1 ∈ I(vr, vs), uma contradição.
Caso 2: Vk ∩ Cf = ∅ para f = 1, . . . , l. Assim, temos os subcasos:Caso 2.1: dois ou mais vértices de Vk pertencem ao mesmo bloco geminiano folha.Seja Gt um bloco tal que |Gt ∩ Vk| ≥ 2 e Cf o conjunto que conecta Gt a G′. Sem perda
de generalidade, tomemos v1 e v2 em Gt. Assim, V (Cf ) está nas geodésicas entre v1 e os demaisvértices de Vk que não estão Gt, ou seja, V (Cf ) ⊆ S2. Analogamente, V (Cf ) ⊆ S1. Como V (Cf )também está contido nos demais conjuntos de CG, então estão no núcleo.
Caso 2.2: O conjunto Cf conecta dois ou mais blocos geminianos folha à G′.Sejam Gm′ , . . . , Gr′ tais blocos. Como cada bloco contém somente um vértice de Vk, tomemos
em Vk, vp′ ∈ Gp′ e vq′ ∈ Gq′ . Assim, V (Cf ) ⊆ Sp′ , pois estes estão nas geodésicas entre vq′ e osdemais vértices de Vk que não estão em Gq′ . Analogamente, V (Cf ) ⊆ Sm′ , e como estão nos demaisconjuntos de CG, então V (Cf ) está contido no núcleo, uma contradição.
Caso 2.3: Para todo Cf que conecta um bloco geminiano folha ao grafo G′, este bloco é único.Excluiremos de G′ os vértices dos blocos folha que não estão em conjuntos separadores. Como
a quantidade de conjuntos separadores que conectam blocos folha ao grafo é igual a quantidadede blocos folha, tomaremos, sem perda de generalidade, o ı́ndice para os conjuntos separadores
correspondente a dos respectivos blocos. Seja D =α⋃
j′=1
V (Gj′ \Cj′), para algum α ≤ α, onde cada
Gj′ é um bloco folha de G′ e Cj′ o conjunto que o conecta a G′, construindo assim o grafo G′′.Tomemos Si = Si \D. Cada Si é convexo em G′′. Formam uma famı́lia (k − 1)-intersectante,
pois em cada parte do bloco exclúıda havia apenas um vértice de Vk e todo w no conjunto separadorpertencente a Si pertence a Si. Pelo Lema 5.1, tal famı́lia tem o núcleo vazio (também porqueSi ⊆ Si). Então h(G′′) = h(G′) = h(G).
Como G é finito, repetindo o processo, ou ocorrerá um dos casos analisados, ou reduziremos G aum bloco Gz, com CGz , (k−1)-intersectante, com o núcleo vazio, então h(Gz) ≥ k, uma contradição.Logo existe um bloco Gl em G tal que h(Gl) ≥ h(G). Como k = h(G) ≥ h(Gp) ≥ h(Gj), paraj = 1, . . . , α; então ao menos para um bloco Gj , h(Gj) = h(G), ou seja, h(G) = h(Gp).
5.1 Grafos não biconexos
Quando o conjunto separador de gêmeos é um único vértice, tal conjunto é dito articulação e osblocos geminianos são ditos componentes biconexas ou blocos.
CLAIO-2016
141

Corolário 5.4. Dado um grafo G não biconexo e B1, B2, . . . , Bp suas componentes biconexas.Então h(G) = max{h(B1), h(B2), . . . , h(Bp)}.
Um grafo G é dito bloco quando toda componente biconexa de G é uma clique.
Corolário 5.5. Seja G um grafo bloco. Então h(G) = ω(G).
As demonstrações dos Corolários 5.4 e 5.5 são análogas a do Teorema 5.3.Na Figura 3, o grafo é decomposto em dois blocos através do conjunto separador de gêmeos
{c, g}, onde cada bloco resultantes possui um vértice simplicial restrito, o vértice a em um bloco eo vértice e no outro bloco, aplicando o Teorema 3.3 para eliminarmos esses vértices, restará duascliques de tamanho quatro, o que nos fornece o número de Helly do grafo original igual a quatro.
a
b c
e
d
gh
a
b c
e
c
g
b c
h
c
g
f
f fh g g
d d
Figura 3: Grafo resolvido pela aplicação dos Teoremas 5.3 e 3.3
Referências
[1] N. Amenta. Helly Theorems and generalized linear programming. In Symposium on ComputacionalGeometry, pp. 63-72, 1993.
[2] C. Berge, P. Duchet. A generalization of Gilmore’s Theorem. Recent Advances in Graph Theory (Fielder,M., ed.), Acad. Praha, Prague, 1975, 49–55.
[3] M. T. Carvalho Jr., M. C. Dourado, J. L. Szwarcfiter. O número de Helly geodético em convexidades.Matemática Contemporânea, aceito para publicação, 2015.
[4] M. T. Carvalho Jr., M. C. Dourado, J. L. Szwarcfiter. Reduction theorems for the goedetic Hellynumber of a graph. Discrete Mathematics, manuscrito submetido para publicação, 2016.
[5] M. C. Dourado, D. Rautenbach, V. G. Sá, J. L. Szwarcfiter. Polynomial time algorithm for the Radonnumber of grids in the geodetic convexity. Electronic Notes in Discrete Mathematics, Playa del Carmen,v.44, 2013, 371–376.
[6] P. Duchet. Convex set in graphs II. Minimal path convexity. Journal of Combinatorial Theory, sériesB 44, 1988, 307–316.
[7] E. Helly. Ueber Mengen konvexer Koerper mit gemeinschaftlichen Punkter, Jahresber. Math Verein.v.32, 1923, 175–176.
[8] M. L. J. Van de Vel. Theory of convex structures. North-Holland Mathematical Library, Elsevier,Amsterdan, London, New York, Tokyo, 1993.
CLAIO-2016
142

Machine Learning aplicado à predição de interesse em filmes
Juliana Christina Carvalho de Araújo, Marco Antônio Ferreira, Danilo do Carmo, Reinaldo
Castro Souza e Ricardo Tanscheit
Pontifícia Universidade Católica do Rio de Janeiro
Resumo
Desde a sua criação, a indústria cinematográfica tem produzido uma grande variedade de filmes e a cada
lançamento várias informações são disponibilizadas à população em geral. Sem muito tratamento, essas
informações não chegam de forma acessível e personalizada. Com o desenvolvimento dos sistemas de
recomendação, a maneira com que as pessoas compram pela internet mudou consideravelmente. Em meio
a uma gama de opções disponíveis, o usuário passou a ter um auxílio, capaz de guiá-lo até um produto
que possa interessá-lo. Assim, o objetivo deste trabalho é calibrar um modelo capaz de prover um sistema
colaborativo que vai sugerir um determinado filme para um usuário do serviço baseado na avaliação
efetuada por usuários de interesses similares.
Palavras-Chave: Movielens; sistema de recomendação; boosted decision tree.
1 Introdução
Desde a sua criação, a indústria cinematográfica tem produzido uma grande variedade de filmes e a cada
lançamento várias informações referentes ao filme são disponibilizadas à população em geral. Essas
mesmas informações são repassadas aos consumidores sem muito tratamento, não chegando de forma
acessível e personalizada. Tratar esse problema tem sido um dos desafios dos Sistemas de Recomendação
(SR) [1][2].
Sistemas de recomendação são oriundos de diferentes áreas, tais como a teoria da aproximação, sistemas
cognitivos, recuperação de informação, métodos de previsão e ciências gerenciais. Um sistema combina
várias técnicas computacionais para selecionar itens personalizados com base nos interesses dos usuários
e conforme o contexto no qual estão inseridos [1]. Tais itens podem assumir formas bem variadas como,
por exemplo, livros, filmes, notícias, música, vídeos, anúncios, links patrocinados, páginas de internet,
produtos de uma loja virtual, etc. Empresas como Amazon, Netflix, MovieFinder, eBay, Reel.com, e
CDNOW são reconhecidas pelo uso intensivo de sistemas de recomendação com os quais obtêm grande
vantagem competitiva [2].
Em um SR típico, as pessoas fornecem recomendações como entradas que o sistema agrega e direciona
para os indivíduos considerados potenciais interessados neste tipo de recomendação. Um dos grandes
desafios deste tipo de sistema é realizar a combinação adequada entre as expectativas dos usuários e os
produtos, serviços e pessoas a serem recomendados aos mesmos, ou seja, definir e descobrir este
relacionamento de interesses é o grande problema [1].
A predição de avaliações de itens ainda não avaliados pode ser feita de diferentes formas utilizando
métodos de aprendizado de máquinas, teorias de aproximação e vários tipos de heurísticas. Os sistemas de
recomendação são classificados de acordo com o método de predição utilizado, o que auxilia na pesquisa
da área. Esta classificação é feita usualmente em três categorias propostas inicialmente por Shoham e
CLAIO-2016
143

Balabanovic [3]. Contudo, a explicação de cada uma delas vem sendo complementada pelos diversos
trabalhos conduzidos desde então:
Recomendações Baseadas em Conteúdo: O usuário receberá recomendações de itens similares
a itens preferidos no passado [3];
Recomendações Colaborativas: O usuário receberá recomendações de itens que pessoas com
gostos similares aos dele preferiram no passado. Este método é subdividido em duas catergorias:
a primeira chamada de memory-based, e a segunda chamada de model-based;
Métodos Híbridos: Estes métodos combinam tanto estratégias de recomendação baseadas em
conteúdo quanto estratégias baseadas em colaboração.
Uma taxonomia detalhada destas técnicas pode ser encontrada em [4] e [5].
Neste sentido, o objetivo deste trabalho é calibrar um modelo capaz de prover um sistema colaborativo
que vai sugerir um determinado filme para um usuário do serviço baseado na avaliação efetuada por
usuários de interesses similares. (Enfatiza-se que o filme é tratado como um produto podendo assim ser
adaptado para qualquer informação, produto ou serviço a ser recomendado).
Assim, o artigo está estruturado da seguinte maneira. A seção 2 apresenta uma análise do conjunto de
dados. Na seção 3 uma explicação sobre a metodologia aplicada ao problema é fornecida, assim como a
métrica de erro utilizada para comparar a aplicação com outros métodos já propostos. Os principais
resultados obtidos com a aplicação da metodologia são organizados e apresentados na seção 4, enquanto a
seção 5 oferece observações conclusivas.
2 Base de dados
A base de dados do MovieLens (ML) tornou-se pública em 1988, descrevendo as preferências das pessoas
a respeito de filmes. Essas preferências são captadas por meio de avaliações efetuadas por usuários no
𝑤𝑒𝑏𝑠𝑖𝑡𝑒1, com notas que variam de um até cinco estrelas, além da nota zero que representa filmes ainda
não avaliados.
A base é composta por 943 usuários e 1682 filmes, sendo que cada usuário avaliou pelo menos 20 destes
para que haja um histórico a ser estudado.
O esquema de dados segue:
Usuário (ID de usuário , idade, gênero e profissão) ,
Filme (FilmeID , ano de lançamento e gênero),
Rates (userID , FilmeID)
Assim, o conjunto de dados possui 100,000 avaliações, sendo que a Figura 1 apresenta a distribuição das
notas dadas por cada usuário no dataset.
CLAIO-2016
144
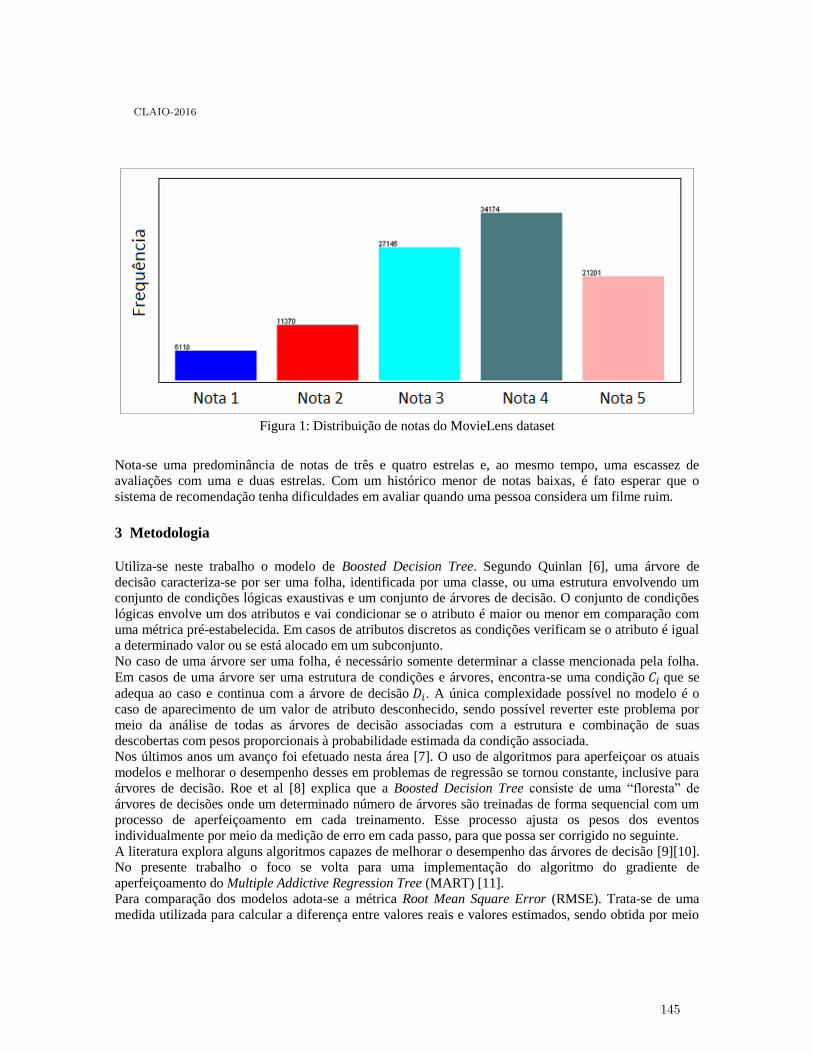
Figura 1: Distribuição de notas do MovieLens dataset
Nota-se uma predominância de notas de três e quatro estrelas e, ao mesmo tempo, uma escassez de
avaliações com uma e duas estrelas. Com um histórico menor de notas baixas, é fato esperar que o
sistema de recomendação tenha dificuldades em avaliar quando uma pessoa considera um filme ruim.
3 Metodologia
Utiliza-se neste trabalho o modelo de Boosted Decision Tree. Segundo Quinlan [6], uma árvore de
decisão caracteriza-se por ser uma folha, identificada por uma classe, ou uma estrutura envolvendo um
conjunto de condições lógicas exaustivas e um conjunto de árvores de decisão. O conjunto de condições
lógicas envolve um dos atributos e vai condicionar se o atributo é maior ou menor em comparação com
uma métrica pré-estabelecida. Em casos de atributos discretos as condições verificam se o atributo é igual
a determinado valor ou se está alocado em um subconjunto.
No caso de uma árvore ser uma folha, é necessário somente determinar a classe mencionada pela folha.
Em casos de uma árvore ser uma estrutura de condições e árvores, encontra-se uma condição 𝐶𝑖 que se
adequa ao caso e continua com a árvore de decisão 𝐷𝑖. A única complexidade possível no modelo é o
caso de aparecimento de um valor de atributo desconhecido, sendo possível reverter este problema por
meio da análise de todas as árvores de decisão associadas com a estrutura e combinação de suas
descobertas com pesos proporcionais à probabilidade estimada da condição associada.
Nos últimos anos um avanço foi efetuado nesta área [7]. O uso de algoritmos para aperfeiçoar os atuais
modelos e melhorar o desempenho desses em problemas de regressão se tornou constante, inclusive para
árvores de decisão. Roe et al [8] explica que a Boosted Decision Tree consiste de uma “floresta” de
árvores de decisões onde um determinado número de árvores são treinadas de forma sequencial com um
processo de aperfeiçoamento em cada treinamento. Esse processo ajusta os pesos dos eventos
individualmente por meio da medição de erro em cada passo, para que possa ser corrigido no seguinte.
A literatura explora alguns algoritmos capazes de melhorar o desempenho das árvores de decisão [9][10].
No presente trabalho o foco se volta para uma implementação do algoritmo do gradiente de
aperfeiçoamento do Multiple Addictive Regression Tree (MART) [11].
Para comparação dos modelos adota-se a métrica Root Mean Square Error (RMSE). Trata-se de uma
medida utilizada para calcular a diferença entre valores reais e valores estimados, sendo obtida por meio
CLAIO-2016
145

do somatório do quadrado dos erros, dividindo pelo número de pontos e, por fim, tirando a raiz quadrada
do resultado obtido (Equação 1) [12].
𝑅𝑀𝑆𝐸 = √1
𝑛∑ 𝑒𝑖
2𝑛𝑖=1 (1)
4 Aplicação e resultados
Inicialmente, divide-se a base em conjunto de treinamento, que representa 70% dos dados, conjunto de
validação, que representa 15% da base, e conjunto de teste, representando também, 15% dos dados. Os
modelos são treinados utilizando o conjunto de treinamento e depois aplicados no conjunto de validação
para que seja escolhido o mais apropriado para o problema proposto.
Os modelos foram avaliados utilizando-se a plataforma Azure Machine Learning Studio (Figura 2),
sendo escolhido o método de regressão por Boosted Decision Tree pelo melhor desempenho apresentado
nos resultados no conjunto de validação.
Figura 2: Fluxo do modelo proposto na plataforma Azure.
CLAIO-2016
146

Diferentes configurações para o modelo foram testadas a fim de aperfeiçoar os resultados. No fim,
para obtenção nas melhores métricas limitou-se o número de arestas durante a construção das árvores em
50, restringiu-se a o número mínimo de atributos nas árvores em 10 e ajustou-se a taxa de aprendizado
para 0,5. Com isso, o modelo melhorou consideravelmente, chegando a um RMSE de 1,001315 na fase de
validação. Com tal resultado em mãos, utiliza-se o modelo no conjunto de teste e obtém-se um RMSE de
1,007773, ou seja, o modelo está errando em média 1 ponto de nota para cada um dos casos.
5 Conclusão
Foram usados como baseline para este trabalho os modelos propostos por Bokde et al [13] e, como
estado-da-arte, o melhor sistema proposto por Jiang et al [14]. Apesar de ter ficado com resultado inferior
ao Boosted Item-based Collaborative Filtering de Jiang et al, que obteve um RMSE de 0,82, a Boosted
Decision Tree, proposta pelo presente trabalho, obteve resultados melhores em comparação com os
modelos de Pearson Correlation Similarity, Euclidean Distance Similarity e Log Likelihood Similarity,
propostos por Bokde et al, que obtiveram RMSE de 1,08, 1,026 e 1,025, respectivamente. Os resultados
são apresentados na Tabela 1, a seguir.
Tabela 1: Comparação da Performance dos Modelos
Modelo RMSE
Pearson Correlation Similarity 1,08
Euclidean Distance Similarity 1,026
Log Likelihood Similarity 1,025
Boosted Item-based Collaborative Filtering 0,82
Boosted Decision Treeª 1,0078
ªModelo Aplicado neste trabalho
Referências
1. P. Resnick and H. R. Varian, “Recommender systems,” Commun. ACM, vol. 40, no. 3, pp. 56–58, 1997.
2. J. Ben Schafer, J. Konstan, and J. Riedi, “Recommender Systems in E-Commerce,” Proc. 1st ACM Conf.
Electron. Commer. EC 99, vol. 2001, pp. 158–166, 1999.
3. M. Balabanović and Y. Shoham, “Fab: content-based, collaborative recommendation,” Commun. ACM,
vol. 40, no. 3, pp. 66–72, 1997.
4. G. Adomavicius and A. Tuzhilin, “Toward the next generation of recommender systems: A survey of the
state-of-the-art and possible extensions,” IEEE Trans. Knowl. Data Eng., vol. 17, no. 6, pp. 734–749, 2005.
5. S. C. Cazella, M. Nunes, and E. Reategui, “A Ciência da Opinião: Estado da arte em Sistemas de
Recomendação,” CSBC XXX Congr. da SBC Jorn. Atualização InformáticaJAI, pp. 161–216, 2010.
6. J. R. Quinlan, “Simplifying decision trees,” International journal of man-machine studies. 1987.
7. R. E. Schapire, P. Avenue, and A. Room, “The Boosting Approach to Machine Learning An Overview,” in
MSRI Workshop on Nonlinear Estimation and Classification, 2002, pp. 1–23.
8. B. P. Roe, H.-J. Yang, J. Zhu, Y. Liu, I. Stancu, and G. McGregor, “Boosted decision trees as an alternative
to artificial neural networks for particle identification,” Nucl. Instruments Methods Phys. Res. Sect. A Accel.
Spectrometers, Detect. Assoc. Equip., vol. 543, no. 2–3, pp. 577–584, 2005.
CLAIO-2016
147

9. Y. Freund and R. R. E. Schapire, “Experiments with a New Boosting Algorithm,” in International
Conference on Machine Learning, 1996, pp. 148–156.
10. J. H. Friedman, “Greedy Function Approximation: a Gradient Boosting Machine,” Ann. Stat., vol. 29, no.
5, pp. 1189–1232, 2001.
11. T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning: Data Mining, Inference,
and Prediction, no. 2. 2009.
12. T. Chai and R. R. Draxler, “Root mean square error (RMSE) or mean absolute error (MAE)? – Arguments
against avoiding RMSE in the literature,” Geosci. Model Dev., vol. 7, no. 3, pp. 1247–1250, 2014.
13. D. Bokde, S. Girase, and D. Mukhopadhyay, “An Item-Based Collaborative Filtering using Dimensionality
Reduction Techniques on Mahout Framework,” 2015.
14. X. Jiang, Z. Niu, J. Guo, G. Mustafa, and Z. Lin, “Novel Boosting Frameworks to Improve the
Performance of Collaborative Filtering,” in JMLR: Workshop and Conference Proceedings, 2013, pp. 87–99.
CLAIO-2016
148

Uma nova abordagem para o cálculo do precondicionadorseparador aplicado aos métodos de pontos interiores
Luciana CasacioFEEC - Universidade Estadual de Campinas (UNICAMP)
Aurelio Ribeiro Leite de OliveiraIMECC - Universidade Estadual de Campinas (UNICAMP)
Christiano Lyra FilhoFEEC - Universidade Estadual de Campinas (UNICAMP)
RESUMO
Neste trabalho métodos iterativos precondicionados são utilizados para solução dos sistemas linearesdos métodos de pontos interiores com o objetivo final de resolver problemas de otimização linear de grandeporte. Durante as iterações dos métodos de pontos interiores, a matriz de coeficientes se torna mal condicio-nada, ocasionando instabilidade numérica e dificuldades em encontrar a solução, mesmo utilizando métodositerativos. Assim, a escolha de um precondicionador eficiente é essencial para o sucesso da abordagem. Otrabalho propõe um novo critério de ordenamento das colunas para construção do precondicionador separa-dor que preserva a estrutura esparsa da matriz de coeficientes original. Os resultados teóricos desenvolvidosmostram que quando o ordenamento proposto é adotado, a matriz precondicionada tem o número de con-dição limitado. Estudos de caso mostram que a ideia é competitiva com métodos diretos pois o número decondição do sistema precondicionado é muito melhor do que o número de condição do sistema original.
Palavras-chave: Precondicionadores; Métodos de Pontos Interiores; Número de Condição.
ABSTRACT
The paper deals with preconditioners for solving linear systems arising from interior point methods,using iterative methods. The objective is to solve large scale linear programming problems. During theinterior point methods iterations, the coefficient matrix becomes ill conditioned, leading to numerical diffi-culties to find the solution, even with iterative methods. Therefore, the choice of an effective preconditioneris essential for the success of the approach. The paper proposes a new ordering for a splitting preconditionerapproach, taking advantage of the sparse structure of the original matrix. A formal demonstration shows that
CLAIO-2016
149

performing this new ordering the condition number of the preconditioned matrix is limited. Case studiesshow that the proposed idea is competitive with direct methods because the condition number of the systemis much better than the original.
Keywords: Preconditioners; Interior Point Methods; Condition Number.
1 Introdução
Os métodos de pontos interiores (MPI) têm sido amplamente utilizados para a solução de problemas deotimização linear. Suas propriedades teóricas e bons desempenhos computacionais têm motivado o interesseda comunidade científica, principalmente para a solução de problemas de grande porte.
Cada iteração dos MPI envolve a solução de um ou mais sistemas lineares, que em aplicações reais,quase sempre possuem dimensões elevadas e alto grau de esparsidade. Resolver esses sistemas é a parte demaior esforço computacional de cada iteração dos MPI.
Existem várias abordagens para resolver esses sistemas lineares. A maioria das implementações utilizama fatoração de Cholesky [7]. No entanto, durante as iterações dos MPI, a matriz de coeficientes se tornapior condicionada e densa. Isso tem motivado o estudo de métodos que contornem o problema do maucondicionamento. As abordagens iterativas são escolhas atrativas para solução desses sistemas e o uso debons precondicionadores é essencial para o sucesso dos métodos.
Oliveira e Sorensen [11] mostraram que todo precondicionador para o sistema de equações normaispode gerar um precondicionador para o sistema aumentado, mas o contrário não é verdadeiro. Depois disso,precondicionadores para o sistema de equações normais ganharam espaço, especialmente para solução deproblemas de programação linear por MPI [3, 1].
O precondicionador separador proposto por Oliveira e Sorensen [11] apresenta bons resultados nas ite-rações finais dos MPI, quando o sistema está muito mal condicionado. Este trabalho apresenta uma novaabordagem para a construção do precondicionador separador que melhora as características de esparsidadedos sistemas de equações através de um novo critério de ordenamento das colunas. Para isso, as colunas doprecondicionador são separadas em grupos e reordenadas após a separação. Resultados teóricos mostram ocomportamento do número de condição após a divisão dos grupos.
2 Sistemas lineares dos métodos de pontos interiores
Durante os métodos de pontos interiores, é necessário resolver o sistema linear
A 0 00 AT IZ 0 X
∆x∆y∆z
=
rp
rdrc
, (1)
onde rp = b−Ax, rd = c−AT y− z e rc = µe−XZe.Eliminando ∆z = X−1(rc−Z∆x) da segunda equação de (1), temos o sistema aumentado:
[−D−1 AT
A 0
]
︸ ︷︷ ︸A
[∆x∆y
]=
[grp
], (2)
onde D−1 = X−1Z and g = rd−X−1rc.
CLAIO-2016
150

Frequentemente, (2) é conhecido como sistema aumentado e A é uma matriz simétrica indefinida, dedimensões m+n×m+n e mal condicionado.
Eliminando ∆x de (2), o sistema é reduzido ao sistema de equações normais:
ADAT︸ ︷︷ ︸
S
∆y = ADg+ rp. (3)
A matriz S = ADAT em (3) é chamada de complemento de Schur. É uma matriz simétrica e definidapositiva de dimensões m× n, ainda mais mal condicionada que a matriz A . Normalmente a fatoração deCholesky é aplicada para resolver o sistema. No entanto, durante o processo de pivoteamento, a matriz decoeficientes perde sua estrutura esparsa e frequentemente ocorrem restrições de tempo de processamento elimitação de memória. Devido à isso, os métodos iterativos se tornam uma escolha natural e a escolha deum precondicionador eficiente contribui para o sucesso da abordagem.
Note que somente a matriz diagonal D se altera a cada iteração dos MPI. Além disso, D é altamentemal condicionada, em especial quando os MPI se aproximam da solução ótima. O objetivo deste estudoé melhorar o condicionamento do sistema. Especificamente, o trabalho estende os resultados apresentadosem [5] para o precondicionador separador [11]. O objetivo final do trabalho é obter uma implementaçãosimples, robusta e com tempo computacional aceitável.
3 Precondicionadores
Precondicionamento é um processo que deve ser aplicado aos métodos iterativos para melhorar as caracte-rísticas de convergência de sistemas que possuam a matriz de coeficientes com autovalores muito dispersos.Precondicionar um sistema linear é fazer com que a matriz dos coeficientes apresente condições desejadaspara que o método que está sendo aplicado para resolver o sistema seja eficiente. Para obter um bom pre-condicionador, suas operações devem ser de baixo custo, a matriz precondicionadora deve ser facilmenteconstruída, ter esparsidade próxima da matriz original, os autovalores da matriz precondicionada estarempróximos a unidade ou agrupados e, acima de tudo, reduzir o tempo total de processamento dos métodos.
É possível aplicar precondicionadores no sistema aumentado (2) e no sistema de equações normais(3). Lembrando que em [11], os autores mostraram que todo precondicionador para o sistema de equaçõesnormais pode gerar um precondicionador para o sistema aumentado, mas o contrário não é verdadeiro.Assim, o sistema de equações normais se mostra mais vantajoso.
O precondicionador separador, proposto por Oliveira e Sorensen, 2005 [11] foi originalmente criadopara o sistema aumentado dos MPI. No entanto, pode ser facilmente estendido para o sistema de equaçõesnormais. Seu bom desempenho nas iterações finais dos MPI, onde a maioria dos precondicionadores perdema eficiência é uma característica desejável.
Seja A = [B N]P onde P é a matriz de permutação e B é não singular. Considere também PDPT =[DB 00 DN
]. Sem perda de generalidade assuma P = I. Assim, ADAT = BDBBT +NDNNT .
Agora, multiplicando por D−12
B B−1 e pós-multiplicando pela sua transposta T =D−12
B B−1(ADAT )B−T D−12
B =
I +WW T , onde W = D−12
B B−1ND12N .
A matriz precondicionada é definida positiva e seus autovalores são maiores ou iguais a um, não pos-suindo nenhum autovalor na vizinhança de zero. Próximo da solução, pelo menos n−m entradas de Dsão pequenas. Assim, com uma escolha adequada das colunas de B, as diagonais de D−1
B e DN passam ater elementos muito pequenos próximo à solução. Nessa situação, W aproxima-se da matriz nula, a matriz
CLAIO-2016
151

precondicionada aproxima-se da matriz identidade, os maiores autovalores de T e o número de condição damatriz se aproximam de um.
O preço pago para evitar o cálculo do sistema de equações normais é encontrar B [6]. Uma opção é autilização da fatoração QB = LU , onde Q é uma permutação.
Em [11], os autores propuseram formar B minimizando ‖W‖, já que próximo da solução a matriz pre-condicionadora se aproxima da matriz identidade. Esse é um problema difícil de ser solucionado, mas umasolução aproximada pode ser obtida selecionando-se as m primeiras colunas linearmente independentescom a menor norma-1 de AD. Em [9], essa heurística foi aprimorada e resultados melhores foram obtidosutilizando-se a norma-2, o número de iterações do método de pontos interiores foi reduzido.
Uma propriedade interessante desse precondicionador é que pode-se manter o mesmo conjunto de colu-nas selecionadas (matriz B) por algumas iterações. Como consequência, o precondicionador não acrescentacusto computacional por iteração. No entanto, é importante notar que mesmo mantendo a matriz B por maisde uma iteração não significa que o precondicionador será o mesmo, pois D é alterada a cada iteração e,consequentemente, o precondicionador também.
A maneira mais simples de calcular B é através da fatoração LU , trabalhando com atualização atrasadapois quando uma coluna linearmente dependente aparece, ela é eliminada da fatoração e o método prosseguecom as próximas colunas, ordenadas conforme a heurística.
Uma desvantagem desse precondicionador é o excesso de preenchimento na fatoração LU . Isso se dádevido ao critério de reordenamento das colunas linearmente independentes, que não leva em consideraçãoo padrão de esparsidade de A. Uma boa estratégia para evitá-los consiste em interromper a fatoração quandopreenchimento permitido for ultrapassado. Nesse caso, as colunas são reordenadas e a fatoração é reiniciada.
Em resumo, o precondicionador separador foi desenvolvido para ser utilizado nas últimas iteraçõesdos MPI, uma vez que o sistema está altamente mal condicionado. Apesar de serem necessárias técnicassofisticadas de implementação na escolha das colunas linearmente independentes, com as estratégias de-senvolvidas pelos autores, esse precondicionador aplicado ao método dos gradientes conjugados apresentamelhores resultados na solução de problemas de grande porte, quando comparado à solução dos mesmosproblemas via métodos diretos.
3.1 Novo critério de ordenamento
Baseados em [10] e [5], este trabalho propõe reordenar as colunas da matriz A em ordem decrescente h j =
d1/2j j ‖a j‖ e dividir as colunas ordenadas em grupos de acordo com um critério de reordenamento.
O processo se inicia ordenando hδ (1) ≥ hδ (2) ≥ . . . ≥ hδ (n), onde δ é a permutação de {1, . . .n}. Parasimplificar a notação vamos considerar δ a matriz identidade. Então, particiona-se os escalares h j em kgrupos G1, . . . ,Gk, contendo n1, . . . ,nk elementos em cada grupo, tal que
minh j∈Gp
h j > maxh j∈Gp+1
h j, for p = 1, . . . ,k−1.
Seja Ji = { j : h j ∈ Gi} o conjunto dos índices dentro de cada grupo. Então, as a j colunas de A sãodivididas em k grupos {a j : j ∈ Ji}. A ordem das colunas dentro de cada grupo é arbitrária e pode seguiralgum critério escolhido. Neste trabalho, o critério adotado foi a esparsidade. Se σi é a permutação de Ji
depois da permutação dentro de cada grupo {a j : j ∈ Ji}, então, σ = (σ1, . . . ,σk) é a permutação de {1, . . .n}.A seleção das colunas da base B é determinada pelo Algoritmo 1 [5].O Teorema apresentado em [5] pode ser estendido para o Teorema 1 abaixo.
CLAIO-2016
152

Algoritmo 11: Seja B = /0, i = 1, k = 0.2: Enquanto |B|< m3: Se a coluna aσ(i) é L.I. no conjunto {a j : j ∈B}, então4: B = B∪{σ(i)}, k = k+1, bk = σ(i);5: Fim6: i =i+17: Fim8: B = {b1, . . . ,bm}, N = {1, . . . ,n}\B, B = AB, N = AN .
Teorema 1 Suponha que B seja a base encontrada no Algoritmo 1 e R = D−12
B B−1 o precondicionadorseparador. Então
cond(RADAT RT )≤ mnC2‖B−1‖2, onde C = max{c1, . . . ,ck}, ci =max{h j : j ∈ Ji}min{h j : j ∈ Ji}
, i = 1, . . . ,k.
A demonstração do Teorema pode ser encontrada em [2].O Teorema 1 mostra que o número de condição da matriz precondicionada considerando a separação
das colunas em grupos é limitado. Além disso, esse valor não é influenciado nem pelo número de iteraçõesdo método iterativo, nem pelo critério de ordenamento dentro de cada grupo.
4 Estudos de casos
Todos os experimentos foram realizados utilizando o código PCx [4] em linguagem de programação C. Arotina para solução do sistema linear (3) que originalmente era resolvida pela fatoração de Cholesky, foialterada para o método do gradiente conjugado precondicionado pelo precondicionador separador, adotandoo novo critério de ordenamento das colunas de B, proposto na Seção 3.1.
Testes computacionais sobre a quantidade de grupos indicaram que√
m/4 é um bom número, ondem é o número de linhas do problema. Essa escolha pode ser explicada pelo fato que se houver muitosgrupos, eles serão compostos de poucas colunas e o critério de esparsidade será perdido. Por outro lado, sehouver um número pequeno de grupos, o método dos gradientes conjugados requererá muitas iterações paraconvergir, fazendo a convergência dos métodos de pontos interiores lenta. Para divisão dos grupos utiliza-seos resultados do Teorema 1. Após o cálculo de todos os ci =
h jh j+1
, os maiores ci definem os limites de cadagrupo, de acordo com o Teorema 1. Dentro de cada grupo, as colunas são ordenadas pela mais esparsa até amenos esparsa. Depois disso, B é encontrado usando o Algoritmo 1.
O critério de parada para o método dos gradientes conjugados é o resíduo da norma Euclidiana ||rk||<10−8, ou quando um número máximo de iterações for atingido.
4.1 Número de Condição
Higham [8] apresentou um algoritmo para estimar a norma-1 de matrizes reais A e A−1. Usando essas ideias,é possível estimar o número de condição κ1(A) = ||A||1||A−1||1, utilizando o Algoritmo 2.
A matriz precondicionada A, usando o precondicionador é dada por A = D−12
B B−1ADAT B−T D−12
B .Essa rotina foi adicionada ao código PCx a fim de avaliar o número de condição da matriz de coeficientes
original ADAT e a matriz precondicionada RADAT RT , onde R = D−12
B B−1.
CLAIO-2016
153

Algoritmo 2: Dado A ∈ Rn×n, esse algoritmo calcula uma estimativa para γ ≤ ||A−1||11: Escolha x tal que ||x||1 = 12: Repita3: Calcule Ay = x4: ξ := sign(y)5: Calcule AT z = ξ6: Se ||z||∞ ≤ zT x então pare com γ = ||y||17: x: = e j, onde |z j|= ||z||∞.
4.2 Resultados Computacionais
Note que o Algoritmo 2 demanda um alto custo computacional. A fim de testar os resultados teóricos, osproblemas da coleção NETLIB1 foram selecionados.
O problema DEGEN2, da coleção NETLIB foi adotado para ilustrar o comportamento do número decondição da matriz de coeficientes ADAT e da matriz precondicionada RADAT RT a cada iteração dos MPI.Esse problema possui 445 linhas, 534 colunas e 4449 elementos não nulos (densidade de 0,18%).
Iterações MPI Núm condição de ADAT Núm condição de RADAT RT
1 1.40e03 1.42e042 4.12e03 3.56e043 3.57e04 2.86e034 2.85e05 4.02e035 2.27e06 2.55e046 1.55e07 2.32e047 8.78e07 1.39e048 8.13e08 5.31e039 8.81e09 1.39e0310 2.83e11 9.52e0211 1.40e15 4.35e02
Tabela 1: Análise do número de condição do problema DEGEN2.
Observando a Tabela 1, note que o número de condição da matriz original se torna mal condicionado nodecorrer das iterações dos MPI. Por outro lado, o número de condição da matriz precondicionada melhoradurante o processo, conforme desejado.
A Tabela 2 apresenta os resultados dos demais problemas. As primeiras colunas representam o nomedo problema, o número de linhas, colunas e elementos não nulos, respectivamente. As próximas duascolunas apresentam o número de condição da matriz original ADAT e o número de condição da matrizprecondicionada RADAT RT , referentes à última iteração dos MPI. As duas últimas colunas das tabelas são,respectivamente, o número total de iterações dos MPI e o tempo total de processamento, em segundos. Odemais problemas da NETLIB foram eliminados da tabela pois não atingiram convergência no Algoritmo 2.
Note que o número de condição melhorou em 66 dos 70 problemas que atingiram convergência. Observetambém que o tempo de processamento é adequado para todos esse problemas.
5 Conclusões
Este trabalho retomou a linha das contribuições de [11], que propuseram uma nova classe de precondicio-nadores para solução de sistemas de equações normais por métodos iterativos.
1http://www.netlib.org/
CLAIO-2016
154
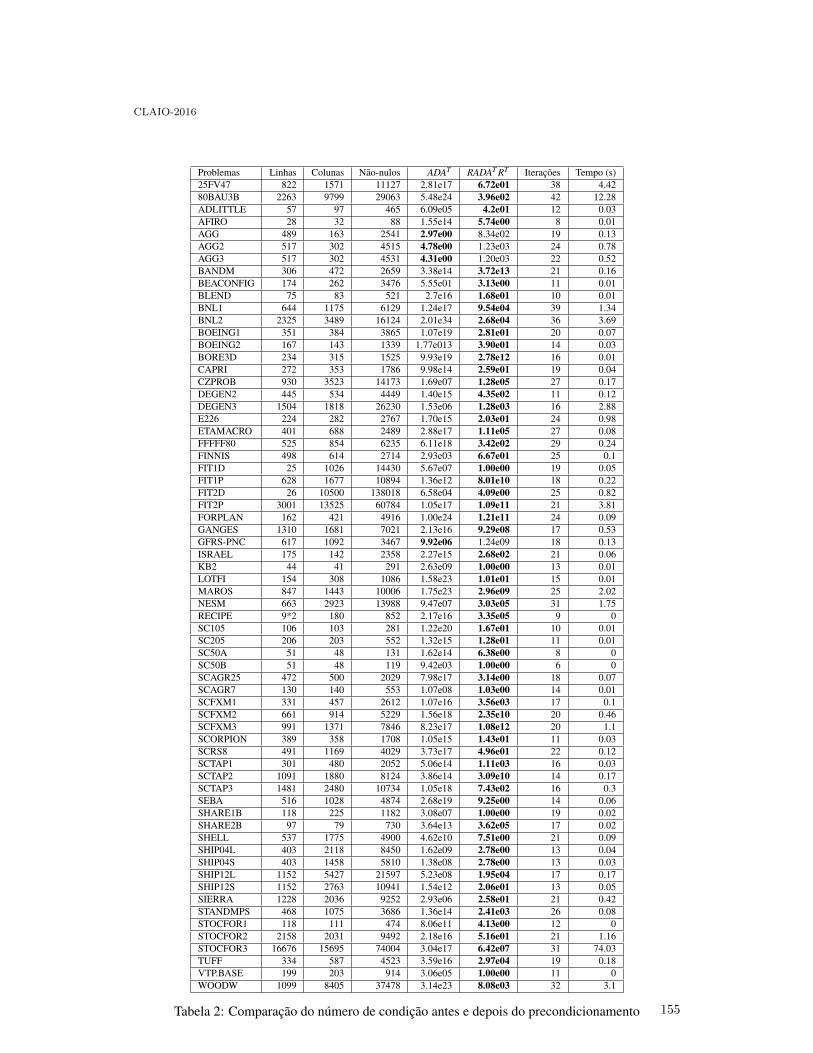
Problemas Linhas Colunas Não-nulos ADAT RADAT RT Iterações Tempo (s)25FV47 822 1571 11127 2.81e17 6.72e01 38 4.4280BAU3B 2263 9799 29063 5.48e24 3.96e02 42 12.28ADLITTLE 57 97 465 6.09e05 4.2e01 12 0.03AFIRO 28 32 88 1.55e14 5.74e00 8 0.01AGG 489 163 2541 2.97e00 8.34e02 19 0.13AGG2 517 302 4515 4.78e00 1.23e03 24 0.78AGG3 517 302 4531 4.31e00 1.20e03 22 0.52BANDM 306 472 2659 3.38e14 3.72e13 21 0.16BEACONFIG 174 262 3476 5.55e01 3.13e00 11 0.01BLEND 75 83 521 2.7e16 1.68e01 10 0.01BNL1 644 1175 6129 1.24e17 9.54e04 39 1.34BNL2 2325 3489 16124 2.01e34 2.68e04 36 3.69BOEING1 351 384 3865 1.07e19 2.81e01 20 0.07BOEING2 167 143 1339 1.77e013 3.90e01 14 0.03BORE3D 234 315 1525 9.93e19 2.78e12 16 0.01CAPRI 272 353 1786 9.98e14 2.59e01 19 0.04CZPROB 930 3523 14173 1.69e07 1.28e05 27 0.17DEGEN2 445 534 4449 1.40e15 4.35e02 11 0.12DEGEN3 1504 1818 26230 1.53e06 1.28e03 16 2.88E226 224 282 2767 1.70e15 2.03e01 24 0.98ETAMACRO 401 688 2489 2.88e17 1.11e05 27 0.08FFFFF80 525 854 6235 6.11e18 3.42e02 29 0.24FINNIS 498 614 2714 2.93e03 6.67e01 25 0.1FIT1D 25 1026 14430 5.67e07 1.00e00 19 0.05FIT1P 628 1677 10894 1.36e12 8.01e10 18 0.22FIT2D 26 10500 138018 6.58e04 4.09e00 25 0.82FIT2P 3001 13525 60784 1.05e17 1.09e11 21 3.81FORPLAN 162 421 4916 1.00e24 1.21e11 24 0.09GANGES 1310 1681 7021 2.13e16 9.29e08 17 0.53GFRS-PNC 617 1092 3467 9.92e06 1.24e09 18 0.13ISRAEL 175 142 2358 2.27e15 2.68e02 21 0.06KB2 44 41 291 2.63e09 1.00e00 13 0.01LOTFI 154 308 1086 1.58e23 1.01e01 15 0.01MAROS 847 1443 10006 1.75e23 2.96e09 25 2.02NESM 663 2923 13988 9.47e07 3.03e05 31 1.75RECIPE 9*2 180 852 2.17e16 3.35e05 9 0SC105 106 103 281 1.22e20 1.67e01 10 0.01SC205 206 203 552 1.32e15 1.28e01 11 0.01SC50A 51 48 131 1.62e14 6.38e00 8 0SC50B 51 48 119 9.42e03 1.00e00 6 0SCAGR25 472 500 2029 7.98e17 3.14e00 18 0.07SCAGR7 130 140 553 1.07e08 1.03e00 14 0.01SCFXM1 331 457 2612 1.07e16 3.56e03 17 0.1SCFXM2 661 914 5229 1.56e18 2.35e10 20 0.46SCFXM3 991 1371 7846 8.23e17 1.08e12 20 1.1SCORPION 389 358 1708 1.05e15 1.43e01 11 0.03SCRS8 491 1169 4029 3.73e17 4.96e01 22 0.12SCTAP1 301 480 2052 5.06e14 1.11e03 16 0.03SCTAP2 1091 1880 8124 3.86e14 3.09e10 14 0.17SCTAP3 1481 2480 10734 1.05e18 7.43e02 16 0.3SEBA 516 1028 4874 2.68e19 9.25e00 14 0.06SHARE1B 118 225 1182 3.08e07 1.00e00 19 0.02SHARE2B 97 79 730 3.64e13 3.62e05 17 0.02SHELL 537 1775 4900 4.62e10 7.51e00 21 0.09SHIP04L 403 2118 8450 1.62e09 2.78e00 13 0.04SHIP04S 403 1458 5810 1.38e08 2.78e00 13 0.03SHIP12L 1152 5427 21597 5.23e08 1.95e04 17 0.17SHIP12S 1152 2763 10941 1.54e12 2.06e01 13 0.05SIERRA 1228 2036 9252 2.93e06 2.58e01 21 0.42STANDMPS 468 1075 3686 1.36e14 2.41e03 26 0.08STOCFOR1 118 111 474 8.06e11 4.13e00 12 0STOCFOR2 2158 2031 9492 2.18e16 5.16e01 21 1.16STOCFOR3 16676 15695 74004 3.04e17 6.42e07 31 74.03TUFF 334 587 4523 3.59e16 2.97e04 19 0.18VTP.BASE 199 203 914 3.06e05 1.00e00 11 0WOODW 1099 8405 37478 3.14e23 8.08e03 32 3.1
Tabela 2: Comparação do número de condição antes e depois do precondicionamento
CLAIO-2016
155

A nova abordagem propõe a separação das colunas da matriz precondicionadora em grupos e adotandoa esparsidade como critério de reordenamento das colunas, obtém-se o precondicionador separador o maisesparso possível.
Resultados teóricos formais mostram que, utilizando a partição em grupos, o número de condição damatriz precondicionada é limitado, independente do critério de reordenamento adotado. Esse resultadomostra que a abordagem é especialmente atraente para solução de problemas de grande porte.
Referências
[1] S. Bocanegra, F. F. Campos, and A. R. L. Oliveira. Using a hybrid preconditioner for solving large-scale linear systems arising from interior point methods. Computational Optimization and Appli-cations, 36(1–2):149–164, 2007. Special issue on “Linear Algebra Issues arising in Interior PointMethods”.
[2] Luciana Casacio. Aperfeimento de precondicionadores para solu de sistemas lineares dosmdos de pontos interiores. PhD thesis, FEEC – UNICAMP, Campinas SP, Fevereiro, 2015.http://www.bibliotecadigital.unicamp.br/document/?code=000946504fd=y.
[3] Jordi Castro. An interior-point approach for primal block-angular problems. Special issue of Compu-tational Optimization and Applications, 36(2/3):195–219, 2007.
[4] Joseph Czyzyk, S. Mehrotra, Michael Wagner, and Stephen J. Wright. PCx an interior point code forlinear programming. Optimization Methods & Software, 11-2(1-4):397–430, 1999.
[5] Milan D. Drazic, Rade P. Lazovic, and Vera V. Kovacevic-Vujcic. Sparsity preserving preconditio-ners for linear systems in interior-point methods. Computational Optimization and Applications, 61(3):557–570, 2015. DOI: 10.1007/s10589-015-9735-7.
[6] C.T.L.S. Ghidini, A.R.L. Oliveira, and D.C. Sorensen. Computing a hybrid preconditioner approach tosolve the linear systems arising from interior point methods for linear programming using the gradientconjugate method. Annals of Management Science, 3:43–64, 2014.
[7] Gene H. Golub and Charles F. Van Loan. Matrix Computations Third Edition. The Johns HopkinsUniversity Press, Baltimore, Maryland, 1996.
[8] Nicholas J. Higham. Fortran codes for estimating the one-norm of a real or complex matrix, withapplications to condition estimation. ACM Transaction on Mathematical Software, 14:381–396, 1988.
[9] A. R. L. Oliveira M. I. V. Fontova and F. F. Campos. Heuristics for implementation of ahybrid precondicioner for interior-point methods. Pesquisa Operacional, 31(3):579–591, 2011.http://dx.doi.org/10.1590/S0101-74382011000300010.
[10] Renato D.C. Monteiro, Jerome W. O’Neil, and Takashi Tsuchiya. Uniform boundedness of a precon-ditioned normal matrix used in interior point methods. SIAM Journal of Optimization, 15(1):96–100,2005. http://dx.doi.org/10.1137/S1052623403426398.
[11] Aurelio R. L. Oliveira and D. C. Sorensen. A new class of preconditioners for large-scale linear systemsfrom interior point methods for linear programming. Linear Algebra and Its Applications, 394:1–24,2005.
CLAIO-2016
156

Simulación basada en agentes para identificar y cuantificar los
asentamientos informales por comuna de las personas desplazadas
hacia el Municipio de Medellín, Colombia
Julián Andrés Castillo Grisales
Universidad de Antioquia – Departamento de Ingeniería Industrial
Yony Fernando Ceballos
Universidad de Antioquia – Departamento de Ingeniería Industrial
Elena Valentina Gutiérrez
Universidad de Antioquia – Departamento de Ingeniería Industrial
Resumen
De acuerdo con el Alto Comisionado de las Naciones Unidas para los Refugiados el número de desplazados
por la fuerza a 2014 fue de 59.5 millones a nivel mundial; en Colombia se reportaron más de 6 millones de
desplazados por la fuerza a finales de 2014. La sociedad colombiana ha sido severamente afectadas por el
conflicto armado que ha existido en el país durante las últimas décadas, este ha originado diversas
problemáticas como el desplazamiento forzado hacia las ciudades capitales lo cual ha demandado la
intervención del Estado para mitigar el sufrimiento de las víctimas. Para el Municipio de Medellín existe la
norma regulatoria y clasificatoria para este tipo de asentamientos la cual es el Acuerdo 48 de 2014(POT)
aprobado por el Concejo Municipal. Utilizando la simulación se pretende establecer las posibilidades de
nuevos asentamiento de desplazados en las diferentes comunas de Medellín, utilizando información del
POT e información catastral para determinar resultados de como las personas se establecen en sitios
específicos de la ciudad y proponer políticas para mitigar el impacto en la sociedad de dichos asentamientos.
Palabras clave: OR in Development, Simulation, Behavioral OR, Multi-agent systems.
Introducción
La sociedad colombiana y sus estructuras sociales han sido severamente afectadas por el conflicto
armado que ha existido en el país durante las últimas décadas, el cual ha originado diversos fenómenos y
problemáticas sociales que han demandado la intervención del Estado para mitigar el sufrimiento de las
víctimas. Dentro de dichos fenómenos, el desplazamiento forzado es uno de los más representativos y
complejo, debido al gran número de personas que han enfrentado dicha situación. De acuerdo con el Alto
Comisionado de las Naciones Unidas para los Refugiados [1], el número de desplazados internos (IDP, por
sus siglas en inglés) entre 1996 y 2011 fue cercano a los 4 millones [2]. En particular, entre el 2011 y 2012,
el número de IDP fue de 133.592 y 143.116, respectivamente.
La situación de desplazamiento presenta casos donde las poblaciones rurales migran a zonas de alto
riesgo en las periferias de las áreas metropolitanas, o incluso a pequeñas zonas urbanas [3]. Dicha situación
genera problemáticas sociales, donde la población se ve afectada por la pobreza y la miseria, por la falta de
cobertura en los servicios públicos, la reducción del acceso a las escuelas, la falta de establecimiento de
viviendas dignas, e incluso el incremento de enfermedades sin un correcto tratamiento. Estos asentamientos
CLAIO-2016
157

son producto de políticas fallidas, corrupción, escasa regulación, precaria comunicación, urbanizadores
piratas y falta de voluntad política [4]. Por consiguiente, se genera una restricción en el potencial de
desarrollo humano que normalmente la vida urbana ofrece a dichas poblaciones [5].
Según la Organización para el Desarrollo y la Cooperación Económica de sus siglas en inglés OECD,
los asentamientos informales son áreas en las que se han construido grupos de viviendas en un terreno en
el cual los ocupantes no tienen derecho legal o lo ocupan ilegalmente, también se entiende como
asentamientos no planificados y zonas donde la vivienda no está de acuerdo con el planeamiento vigente y
las normas de construcción (vivienda no autorizada). Así mismo los asentamientos informales se ubican en
las zonas de las ciudades donde carecen condiciones dignas de vida y vivienda. Los barrios marginales
pueden ser reconocidos como Favelas, Kampungs, Tugurios, los cuales comprenden condiciones de vida
miserable. En estudios previos, la aparición de asentamientos urbanos informales ha sido analizada desde
un enfoque social y urbano[3], [6]. Sin embargo, la cantidad de personas que se ubican en estas zonas, generalmente representan la mayor parte de las viviendas urbanas [7].
La llegada de las personas desplazadas a Medellín para el modelo actual se plantea utilizando la jerarquía
vial definida en el Plan de Ordenamiento Territorial vigente para Medellín en el cual se identifican 8 rutas de ingreso a la ciudad, las cuales se detallan a continuación con su respectiva numeración:
1. Autopista Regional. Entrada norte. Conecta con el caribe colombiano (vía al mar).
2. Autopista Medellín – Bogotá. Conecta con la capital del país y el oriente cercano.
3. Santa Elena. Conecta con oriente cercano y el suroriente antioqueño.
4. Avenida las Palmas. Conecta con oriente cercano y el sureste antioqueño.
5. Autopista Regional. Entrada sur. Conecta con el sur del país.
6. Vía Suroccidente. Conecta con San Antonio de Prado y el occidente antioqueño.
7. Vía Noroccidente. Conecta con el noroccidente antioqueño y con Urabá.
8. Vía al Norte antioqueño. Conecta con el norte antioqueño y se conecta con la Vía al mar.
Este proyecto se enfoca en estudiar la dinámica de los asentamientos humanos informales en zonas de
límites urbanos de la ciudad de Medellín, con el fin de identificar puntos críticos en los cuales el uso de
conceptos y herramientas de la Investigación de Operaciones, puedan contribuir a analizar el impacto de
políticas públicas en esta población, con el ánimo de mejorar la calidad de vida y proponer acciones
contingentes que no atenten con los derechos de las personas que se ubican de manera informal en estas zonas.
Utilizando la simulación como herramienta conceptual que permita realizar una representación apropiada
de la realidad; la simulación basada en agentes ha demostrado ser una técnica útil para modelar sistemas
complejos, y particularmente sistemas sociales [8]. Mediante la simulación basada en agentes, el modelador
reconoce explícitamente que los sistemas complejos, y en particular los sociales, son producto de
comportamientos individuales y de sus interacciones. La simulación basada en agentes se diferencia de otras
técnicas de modelamiento en la forma en que se construye la primera abstracción del sistema real y,
consecuentemente, el modelo formal. En los modelos formales construidos mediante simulación basada en
agentes, los componentes básicos del sistema real están explícita e individualmente representados en el modelo.
Obtención de datos
La información de los predios informales del Municipio de Medellín fue obtenida mediante contacto
directo con la entidad con la cual se establece un protocolo de intercambio de información para la
realización del presente estudio. La información proporcionada por la Subsecretaría de Catastro
corresponde a la cantidad de predios informales y su respectiva comuna, dicha información se clasifica de
la siguiente forma: Rojo: Más de 5.000 predios, Amarillo: Entre 3.000 y 5.000 predios, Azul: Entre 2.000
CLAIO-2016
158

y 3.000 predios, Morado: Entre 1.000 y 2.000 predios, Verde: Entre 500 y 1.000 predios y Gris: Menos de 500 predios.
Modelo ODD
La descripción del modelo presentado sigue el protocolo ODD (Overview, Design concepts, Details) [9], [10].
1. Propósito
Para lograr una mayor comprensión de cómo surgen los asentamientos informales en el Municipio de
Medellín, se utiliza la información básica de su origen en Colombia [11], se realiza una extrapolación de
las condiciones de llegada de las personas desplazadas a Medellín por medio de las 8 rutas de ingreso arriba
mencionadas, con el fin de establecer información práctica y eficaz de cuántas personas desplazadas se
asientan en las comunas del Municipio de Medellín. Mediante la información catastral se pretende
identificar posibles sectores de asentamientos humanos ilegales, la forma en la cual se crean estos
asentamientos y el efecto de las políticas actuales de desarrollo urbano del municipio de Medellín, a través
del uso de principios de la investigación de operaciones que permita proponer políticas de mitigación de impactos adversos en la población.
2. Entidades, variables de estado y escalas
Las entidades utilizadas para esta simulación son las personas y el territorio, se establece una relación
directa entre como las personas se desplazan en dicho territorio y como toman decisiones para definir si se
asientan o no en determinado sitio; primero se define el terreno, este se puede visualizar en la figura 1 como
la división política del Municipio de Medellín, para este proceso se realiza una configuración de colores de acuerdo a la distribución de posesiones sin derecho real en Medellín, según lo reglamentado por la ley [12].
Figura 1. División Política del Municipio de Medellín y colores aplicados para la simulación [13]
Para este caso particular, se definen colores para las comunas de acuerdo a la capacidad del software
[14], utilizando información obtenida de Catastro Municipal [15], en la cual se clasifican los datos según lo visualizado en la figura 1.
La información catastral es utilizada en muchos modelos, ya que dicha información es la más apropiada
para definir la estructura del territorio [16].La clasificación de colores se hace de acuerdo a las capacidades
de Netlogo en manejo de imágenes RGB (Red, Green and Blue) y los colores antes descritos comparten
independencia entre ellos, por lo cual se simplifica la tarea de la manipulación del territorio por parte de
Netlogo en cuestiones RGB [17].
CLAIO-2016
159

Esta caracterización de colores se realiza sobre el mapa de Medellín y se genera un estimado, de acuerdo a la clasificación realizada previamente para los colores.
Se definen las siguientes variables para las personas:
• Energía: corresponde a la cantidad de energía que poseen las personas desplazadas, debido a que cada
movimiento resta energía se define para todos un estado inicial de 100.
• Ruta: se define aleatoriamente en el programa, asignando un valor entre 1 y 8 de acuerdo las rutas establecidas para el modelo.
• Movimiento: variable booleana que define el estado de movimiento de la persona, verdadero si se encuentra en movimiento y falso para lo contrario.
• Detenido: cuando la energía llega a cero la persona se detiene y se lleva un conteo del número de veces
que se ésta se queda inmóvil.
• Establecido: variable booleana que define si una persona se establece (asienta) o no de acuerdo a
criterios de la simulación.
Con respecto a la escala del protocolo ODD, no se define un límite de tiempo, por lo tanto cuando todas las personas se han establecido termina la simulación.
3. Introducción al proceso y programación
Para la simulación se carga el mapa de Medellín en el modelo con las zonas previamente categorizadas
por color según las disposiciones previamente explicadas, se definen sitios de emergencia para las personas
según las rutas de ingreso a la ciudad de Medellín. Posteriormente, se define la movilidad de las personas,
las cuales se mueven con un destino aleatorio y sin poderse salir del límite del Municipio de Medellín,
según la categorización propuesta se clasifican las comunas de mayor a menor, obteniendo mayor puntaje
las comunas con mayor cantidad de predios informales[18], con el fin de que las personas tomen decisiones
basándose en la cantidad de pasos (cansancio), la cantidad de veces que se detiene (cada persona se detiene
cuando se queda sin energía, cada paso quita una unidad de energía) y el puntaje de la comuna para
establecerse, de acuerdo a la decisión tomada por la persona esta se detiene y se establece en donde más le
conviene, al final la simulación se detiene cuando todas las personas están asentadas.
4. Conceptos de Diseño
Adaptación, Aptitud, Predicción e Interacción no se tienen en cuenta en el presente modelo.
Emergencia: La emergencia se representa en las personas, donde estas emergen en su totalidad en el
inicio de la simulación en cada una de las rutas de acceso al municipio de Medellín definidas previamente
[19]. Detección: Las personas toman decisiones con base en su movimiento y posición en el territorio, esta
interacción se define en la tabla 2, teniendo en cuenta que si una persona cumple con las condiciones
establecidas en dicha tabla la persona se establece en la primera ubicación, sino continúa su movimiento
hasta que cumpla con las respectivas condiciones[20]. Estocasticidad: Las personas representan la
estocasticidad del modelo, en cuanto a que su emergencia está definida por un procedimiento aleatorio, el
cual las envía a una de las 8 rutas de ingreso a Medellín. El movimiento y la recuperación de energía
contemplan valores aleatorios que determinan tanto la trayectoria como el establecimiento de las personas,
los cuales son establecidos mediante las funciones Random de Netlogo. Agrupaciones: Las agrupaciones
se obtienen una vez las personas se han establecido y son reportadas en los resultados. Observación: Al
momento de terminar la simulación (todas las personas se encuentran establecidas, es decir sin movimiento)
los resultados cuantifican las personas establecidas por comuna, y se establece un límite de 90 corridas,
para la presentación de los resultados del modelo.
5. Inicialización
CLAIO-2016
160
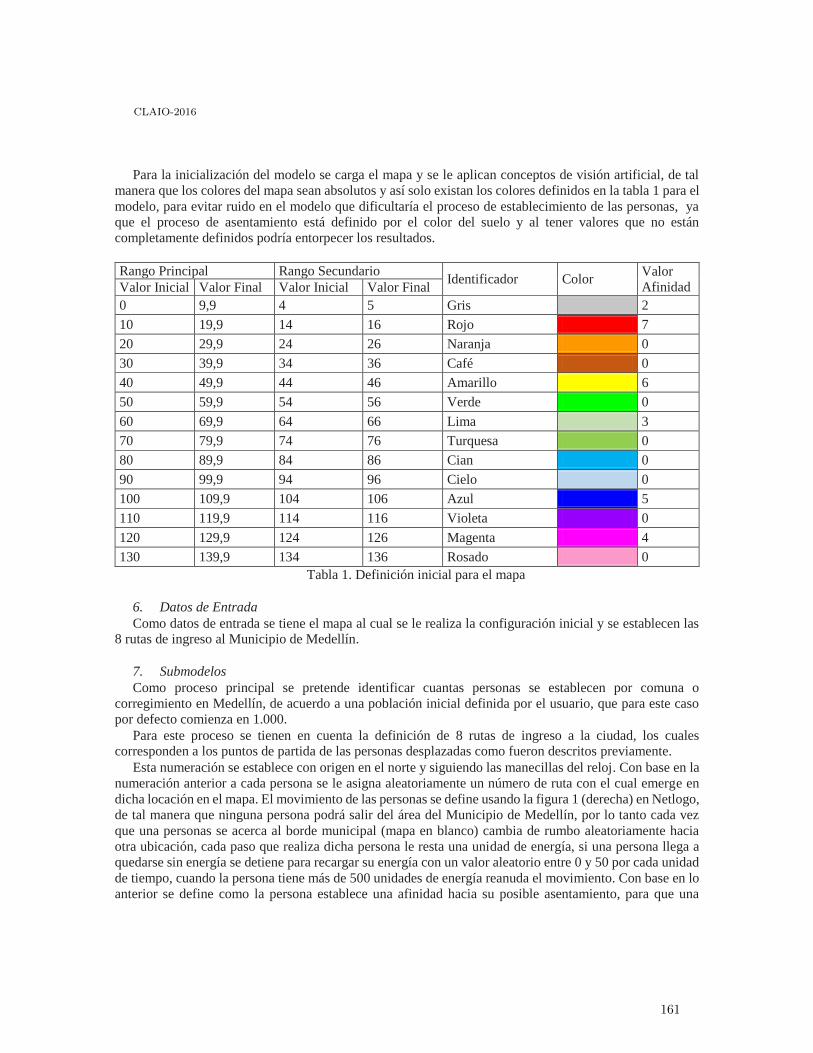
Para la inicialización del modelo se carga el mapa y se le aplican conceptos de visión artificial, de tal
manera que los colores del mapa sean absolutos y así solo existan los colores definidos en la tabla 1 para el
modelo, para evitar ruido en el modelo que dificultaría el proceso de establecimiento de las personas, ya
que el proceso de asentamiento está definido por el color del suelo y al tener valores que no están
completamente definidos podría entorpecer los resultados.
Rango Principal Rango Secundario Identificador Color
Valor
Afinidad Valor Inicial Valor Final Valor Inicial Valor Final
0 9,9 4 5 Gris 2
10 19,9 14 16 Rojo 7
20 29,9 24 26 Naranja 0
30 39,9 34 36 Café 0
40 49,9 44 46 Amarillo 6
50 59,9 54 56 Verde 0
60 69,9 64 66 Lima 3
70 79,9 74 76 Turquesa 0
80 89,9 84 86 Cian 0
90 99,9 94 96 Cielo 0
100 109,9 104 106 Azul 5
110 119,9 114 116 Violeta 0
120 129,9 124 126 Magenta 4
130 139,9 134 136 Rosado 0
Tabla 1. Definición inicial para el mapa
6. Datos de Entrada
Como datos de entrada se tiene el mapa al cual se le realiza la configuración inicial y se establecen las 8 rutas de ingreso al Municipio de Medellín.
7. Submodelos
Como proceso principal se pretende identificar cuantas personas se establecen por comuna o
corregimiento en Medellín, de acuerdo a una población inicial definida por el usuario, que para este caso
por defecto comienza en 1.000.
Para este proceso se tienen en cuenta la definición de 8 rutas de ingreso a la ciudad, los cuales corresponden a los puntos de partida de las personas desplazadas como fueron descritos previamente.
Esta numeración se establece con origen en el norte y siguiendo las manecillas del reloj. Con base en la
numeración anterior a cada persona se le asigna aleatoriamente un número de ruta con el cual emerge en
dicha locación en el mapa. El movimiento de las personas se define usando la figura 1 (derecha) en Netlogo,
de tal manera que ninguna persona podrá salir del área del Municipio de Medellín, por lo tanto cada vez
que una personas se acerca al borde municipal (mapa en blanco) cambia de rumbo aleatoriamente hacia
otra ubicación, cada paso que realiza dicha persona le resta una unidad de energía, si una persona llega a
quedarse sin energía se detiene para recargar su energía con un valor aleatorio entre 0 y 50 por cada unidad
de tiempo, cuando la persona tiene más de 500 unidades de energía reanuda el movimiento. Con base en lo
anterior se define como la persona establece una afinidad hacia su posible asentamiento, para que una
CLAIO-2016
161

persona pueda establecerse debe tener como mínimo dos detenimientos y se define su asentamiento de acuerdo a la tabla 2.
Identificador Color Detenciones Mínimas Detenciones Máximas
Rojo 2 4
Amarillo 4 6
Azul 6 8
Morado 8 10
Verde 10 12
Gris 12 14
Cualquier Color 14 Sin Limite
Tabla 2. Definición de la interacción de las personas con su respecto a su ubicación.
Con base en la tabla 2, cada vez que una persona se establezca en una comuna cambiará su apariencia, con el fin de facilitar su identificación visual en el aspecto gráfico del modelo.
Resultados
Para el presente informe de resultados, se utilizó un escenario de 90 corridas con una población inicial de 1.000 personas desplazadas.
Los resultados son expresados en color, por lo tanto se establecen los colores con su respectiva comuna
para la comprensión de los resultados: Rojo: Comunas 1, 3, 8 y 13; Amarillo: Comunas 2, 4 y 7; Azul:
Comunas 6, 9 y 16; Morado: Comunas 5 y 15, Corregimiento 60; Verde: Comuna 10, Corregimientos 50, 70, 80 y 90 y Gris: Comunas 11, 12 y 14 Colombia.
Se monitorea cuantas personas se encuentran quietas y en movimiento, reflejando que antes de que las
personas comiencen a establecerse existe una relación de movimiento y quietud de periodos, pero cuando
las personas comienzan a establecerse este gráfico cambia, reflejando un intercambio de valores
relacionados entre sí, es decir, a medida que uno se incrementa el otro se disminuye. En la figura 2 se
muestra la representación gráfica en líneas de los valores para las 90 corridas, mostrando una clara tendencia
en las comunas con mayor cantidad de predios informales. Y también se puede visualizar el resultado de personas poblando el territorio para una corrida.
Figura 2. Gráfico de resultados y ubicación final de personas en la simulación
CLAIO-2016
162

La tabla 3 representa por identificador (color) los valores promedio de cantidad de personas establecidas
por comuna y su respectivo porcentaje de participación en el total de la población desplazada para este
ejercicio. También se representa los valores máximos y mínimos obtenidos de las 90 corridas como punto de referencia para definir situaciones de asentamiento.
Identificador Color Valor
Promedio
Porcentaje
Promedio Máximo Mínimo
Rojo 901,12 89,75% 930 873
Amarillo 82,36 8,20% 106 63
Azul 14,04 1,40% 28 5
Morado 5,42 0,54% 12 1
Verde 1,06 0,11% 2 1
Gris 0,00 0,00% 0 0
Tabla 3. Resultados promedio por color y valores máximos y mínimos para cada identificador.
Conclusiones
Utilizando como referencia los resultados de la sección IV se muestra una clara tendencia de las personas
por seleccionar las comunas de color rojo, que comprenden las comunas 1-Popular, 3-Manrique, 8-Villa
Hermosa y 13-San Javier, con un valor promedio de 901 personas que seleccionan estas ubicaciones como
futuro sector de vivienda y consolidación, como segunda opción con un valor promedio muy inferior en
referencia con la primera elección se establecen las comunas 2-Santa Cruz, 4-Aranjuez y 7-Robledo con
valor promedio de 82 personas optando por estas comunas, con respecto a las demás comunas se concluye
que ninguna persona se establece en estos sectores, debido a que son las comunas donde existe menor
número de predios informales, además dichas comunas comprenden los sectores según POT [13] con un
valor promedio de estratificación superior a los de las demás comunas de la ciudad de Medellín.
Este estudio establece un punto de partida para la municipalidad, ya que permite identificar los sectores hacia los cuales se debe orientar el desarrollo de políticas de protección a desplazados.
Trabajo futuro
Para trabajo futuro se tiene planeado el definir un modelo adaptado a la llegada de desplazados al
Municipio de Medellín, mejorando el modelo donde la población desplazada en su totalidad no comience
en el tiempo 0 en la simulación sino que comiencen a llegar de manera aleatoria en cada una de las 8
entradas a la ciudad. Junto con lo anterior, definir la llegada de las personas por prioridades, de acuerdo a
cada una de las 8 rutas de llegadas asignando una jerarquía, la cual se implementaría con modelos aleatorios
obteniendo mayores probabilidades hacia las de más alta escala y finalmente debe procesarse y definirse la
información, con el fin de poder identificar los factores determinantes que influencian el crecimiento de los asentamientos, mediante una correcta caracterización de los criterios para evaluar los modelos.
Agradecimientos
Al Municipio de Medellín y en especial a la Subsecretaría de Catastro en cabeza del Dr. Iván Darío
Cardona, por facilitar la información necesaria para este proceso que tanto puede aportar a la ciudad de Medellín.
Referencias 1. ACNUR, “Mundo en Guerra - ACNUR Tendencias Globales, Desplazamiento Forzado en 2014,” 2014.
2. M. E. Urdiales Viedma, “Alto Comisionado de las Naciones Unidas para los Refugiados,” in Enciclopedia de Paz
CLAIO-2016
163

y Conflictos, vol. 1, 2004, pp. 20–21.
3. F. De Beer and H. Swanepoel, “Energy and the community of the poor: urban settlements, household needs and
participatory development in South Africa,” Energy Policy, vol. 22, no. 2, pp. 145–150, 1994.
4. N. Clichevsky, “Pobreza y acceso al suelo urbano. Algunas interrogantes sobre las políticas de regularización en
América Latina,” CEPAL, vol. Serie Medi, no. 75, p. 82, 2003.
5. G. Naranjo Giraldo, “El desplazamiento forzado en Colombia. Reinvenci{ó}n de la identidad e implicaciones en
las culturas locales y nacional,” Scr. Nov. - Rev. Electr{ó}nica Geogr. y Ciencas Soc., vol. Migraci{ó}, no. 94, p.
15, 2001.
6. J. Abbott, “The use of GIS in informal settlement upgrading: Its role and impact on the community and on local
government,” Habitat Int., vol. 27, no. 4, pp. 575–593, 2003.
7. A. El Menshawy, S. S. Aly, and A. M. Salman, “Sustainable upgrading of informal settlements in the developing
world, case study: Ezzbet Abd El Meniem Riyadh, Alexandria, Egypt,” Procedia Eng., vol. 21, pp. 168–177,
2011.
8. R. Conte and N. Gilbert, “Computer simulation for social theory,” Artif. Soc. Comput. Simul. Soc. life, pp. 1–18,
1995.
9. V. Grimm, U. Berger, F. Bastiansen, S. Eliassen, V. Ginot, J. Giske, J. Goss-Custard, T. Grand, S. K. S. Heinz,
G. Huse, and others, “A standard protocol for describing individual-based and agent-based models,” Ecol.
Modell., vol. 198, no. 1–2, pp. 115–126, Sep. 2006.
10. V. Grimm, U. Berger, D. L. DeAngelis, J. G. Polhill, J. Giske, and S. F. Railsback, “The ODD protocol: A review
and first update,” Ecol. Modell., vol. 221, no. 23, pp. 2760–2768, 2010.
11. L. M. Sánchez Steiner, “Migración forzada y urbanización en Colombia, perspectiva histórica y aproximaciones
teóricas,” Semin. Int. “Procesos Urbanos Informarles,” pp. 1–26, 2007.
12. Congreso de Colombia, Ley 57 de 1887 - Codigo Civil, vol. 1. Bogotá, Colombia: Congreso de Colombia, 1987.
13. D. A. de P. DAP, “Acuerdo 48: Plan de ordenamiento territorial de Medellín POT - 2014,” Gaceta Oficial del
Municipio de Medellín, 2014. .
14. K. Bajracharya and R. Duboz, “Comparison of three agent-based platforms on the basis of a simple
epidemiological model (WIP),” Proc. Symp. Theory Model. Simul. - DEVS Integr. M&S Symp., p. 6, 2013.
15. Subsecretaria de Catastro - Municipio de Medellín, “Predios Informales Vigentes en el Municipio de Medellín,”
Medellin, Colombia, 2015.
16. D. Valbuena, P. Verburg, A. Bregt, and A. Ligtenberg, “An agent-based approach to model land-use change at a
regional scale,” Landsc. Ecol., vol. 25, pp. 185–199, 2009.
17. E. Sklar, “NetLogo, a multi-agent simulation environment.,” Artif. Life, vol. 13, no. 3, pp. 303–11, Jan. 2007.
18. L. Panahikazemi and A. Rossi, “Spatializing the Social: Computational Strategies for Intervention in Informal
Settlements,” Int. J. Hous. Sci., vol. 38, no. 2, pp. 95–104, 2014.
19. N. Gilbert and R. Conte, “Emergence in social simulation,” in Societies: The computer simulation of social life,
1995, pp. 144–156.
20. A. G. Aguilar, “Peri-urbanization, illegal settlements and environmental impact in Mexico City,” Cities, vol. 25,
pp. 133–145, 2008.
CLAIO-2016
164

Acercamiento a la selección de estrategias de mitigación
en la Gestión de Riesgos de la Cadena de Suministro
Tatiana Andrea Castillo Jaimes
Estudiante de Maestría en Ingeniería Industrial – Universidad Industrial de
Santander
Carlos Eduardo Díaz Bohórquez
Docente planta Universidad Industrial de Santander
Resumen
Dado el aumento de la globalización en los últimos años, a los diversos eventos que han
ocurrido recientemente (ataques terroristas, catástrofes naturales, crisis económicas,
incendios, etc.) y acciones tendientes a aumentar la productividad en las organizaciones,
y por ende en las cadenas de suministro, han causado que su vulnerabilidad a imprevistos
aumente considerablemente. Para tratar de contrarrestar y reducir dicha situación ha
surgido la Gestión de Riesgos en la Cadena de Suministro (SCRM – Supply Chain Risk
Management) como un proceso que permita evaluar la situación actual del negocio e
implementar actividades y/o estrategias para disminuir su vulnerabilidad. Sin embargo,
dada la misma incertidumbre que gobierna las actividades entorno a la Cadena de
Suministro, evaluar el resultado que conllevaría la implementación de dichas estrategias y
del mismo proceso SCRM es difícil y en gran cantidad de ocasiones recae sobre los
gerentes o un grupo de expertos (lo que puede estar sujeto a la subjetividad que estos
tengan sobre el proceso en sí y sobre los mismos riesgos). Por tal motivo, se ha analizado
la creación de una herramienta que permita evaluar de forma a priori la selección de las
mejores estrategias.
Palabras clave: Gestión de Riesgos en la Cadena de Suministro; SCRM; Optimización;
Redes Bayesianas.
1 Introducción
En los últimos años, terremotos, huelgas, atentados terroristas, crisis económicas,
devaluación de la moneda, entre otros, han interrumpido o afectado las operaciones de la
cadena de suministro en varias ocasiones. Dichas interrupciones pueden tener un impacto
significativo en el rendimiento de la empresa a corto plazo. Por otro lado, la
subcontratación, la creciente variedad de productos y la globalización han hecho que las
cadenas de suministro se vuelvan más complejas y por lo tanto más vulnerables a sucesos
CLAIO-2016
165

que puedan llegar a causar interrupciones. Algunos ejemplos de estos eventos que se han
presentado en los últimos años son:
El caso de Ericsson, donde debido a un incendio en una planta de semiconductores
Phillips en 2000, la producción fue interrumpida, lo que finalmente condujo a $ 400
millones de pérdida de Ericsson (Chopra y Sodhi, 2004).
El terremoto, el tsunami y la posterior crisis nuclear que tuvo lugar en Japón en 2011
causaron que la producción de Toyota cayera en 40.000 vehículos, con un costo $ 72
millones en ganancias por día (Pettit y otros, 2013).
La catastrófica inundación de Tailandia en octubre 2011 afectó a las cadenas de
suministro de los fabricantes de ordenadores que dependen de los discos duros
fabricados allí, y también interrumpió las cadenas de suministro de las empresas
automotrices japonesas con plantas en Tailandia (Chopra y Sodhi, 2004).
El exceso de inventario y la caída de los precios hizo que Compac Computer Corp
redujera enormemente su rendimiento financiero a finales del 2000 (Liu y otros,
2014)
En estos casos se observa que las empresas que sufren de riesgos de la cadena de
suministro experimentaron entre un 33 y un 40% de rendimientos más bajos en sus
acciones con respecto a otras marcas de la misma industria (Liu y otros, 2014).
Con el fin de controlar y mitigar los efectos negativos causados por estos y otros riesgos,
se ha encontrado que una cantidad significativa de trabajos en el área SCRM que se lleva
a cabo en los círculos académicos (Fahimnia y otros, 2015). De forma que se han venido
desarrollando una serie de métodos y herramientas cualitativas y cuantitativas para
gestionar los riesgos de la cadena de suministro. Sin embargo, de acuerdo con Black y
Ray (2011) sólo el 10 por ciento de las empresas tienen planes detallados para hacer
frente a los riesgos en la cadena de suministro. Por otra parte, un análisis de la literatura,
realizado anteriormente por los autores, revela que la mayoría de las obras en las
estrategias de gestión de riesgos cadena de suministro y de mitigación de riesgos son más
bien de naturaleza cualitativa.
Lo que busca el presente documento es definir claramente en qué consiste SCRM,
explicar sus fases como proceso (identificación, evaluación y mitigación), cómo se ha
tratado hasta la fase de mitigación y a partir de esto proponer un modelo que permita
optimizar la última fase.
2 Riesgo en la Cadena de Suministro
En la actualidad no existe una definición formal y unánime del Riesgo en la Cadena de
Suministro, encontrando múltiples definiciones de diferentes autores. Sin embargo, en
dichas definiciones es visible la presencia de un evento, peligro o fenómeno que reduce el
rendimiento de la cadena.
CLAIO-2016
166

Por otro lado, algunos autores utilizan los términos riesgo e incertidumbre de forma
indistinta, incluso siendo conceptos diferentes. Knight (1921) hace una distinción entre el
riesgo y la incertidumbre, afirmando que el riesgo es algo medible mientras que la
incertidumbre no es cuantificable ya que las probabilidades de los posibles resultados no
se conocen. Es decir, la incertidumbre se refiere a la situación en la que hay una ausencia
total de información o conocimiento de la potencial ocurrencia de un evento.
Pese a lo anterior, en el contexto de SCRM, Heckmann y otros (2015) determinaron que,
los riesgos son eventos que se ocupan tanto de decisiones en condiciones de riesgo y de
decisiones bajo incertidumbre y que dichos eventos se caracterizan por su probabilidad de
ocurrencia y sus consecuencias relacionadas dentro de la cadena de suministro. Esta
definición pone de manifiesto las dos dimensiones que caracterizan el riesgo: impacto y
probabilidad de ocurrencia (también encontradas por Faisal y otros, 2007).
En conclusión, el riesgo en sí puede ser llamado como la interrupción, la vulnerabilidad,
la incertidumbre, el desastre, el peligro y/o el obstáculo cuando se habla de SCRM y que
su ocurrencia afecta a la gestión eficiente de la Cadena de Suministro y por ende tiene
consecuencias cuantificables en alguna medida.
3 Gestión de Riesgos en la Cadena de Suministro
En la literatura académica no existe una definición unánime, universal y ampliamente
aceptada de SCRM. La mayoría de los trabajos proponen definiciones que no se utilizan
en otros artículos. Sin embargo, se observa que cada definición propuesta enmarca
SCRM como un conjunto de enfoques y prácticas para la identificación, evaluación,
análisis y tratamiento de los riesgos en las cadenas de suministro para reducir su
vulnerabilidad. Otro hecho importante que aparece en la mayoría de las definiciones es la
participación colaborativa y coordinada entre los miembros de las cadenas, haciendo
hincapié en la idea de que la competencia se produce entre cadenas, y no a nivel de
empresas individuales, es decir, la gestión de riesgos a lo largo de la cadena depende de
la relación y la integración entre sus miembros. Finalmente, se entrevé que SCRM puede
ser concebido como un proceso (cíclico) de gestión del riesgo que identifica de riesgos,
los evalúa y genera e implementa planes de mitigación y/o control de los mismos.
De acuerdo a lo descrito por varios autores (Ghadge y Dani, 2012; Colicchia y Strozzi,
2012; y Monroe y otros, 2014) la gestión de riesgos dentro de las organizaciones no es un
fenómeno nuevo y su desarrollo en la construcción de teorías (al igual que en todas las
ramas científicas) ha sido influenciado por la evolución que caracteriza el ambiente de
negocios. Por tal razón se cree que SCRM se enfocó e impulsó sólo después de los
ataques del 11 de septiembre en los EE.UU, y que tuvo un crecimiento significativo
debido al brote de SARS en Asia en 2003 y al Huracán Katrina en 2005 (Wagner y Bode,
2006). En síntesis, a medida que el mundo se vuelve más y más desordenado y
turbulento, la gestión de riesgos desempeñará un papel más importante, que según
Fawcett y otros (2011) apoya tanto el diseño de la red de la cadena de suministro global y
CLAIO-2016
167

operativa como la toma de decisiones diaria. Adicionalmente, un análisis bibliométrico
realizado con anterioridad (Fahimnia y otros, 2015) demuestra que el interés en el tema
es cada vez mayor, pues el número de trabajos publicados recientemente en diferentes
aspectos de SCRM ha alcanzado un pico en 2011 (hallazgo también visto por Ghadge y
Dani, 2012).
Pese a todo el empeño dado por el entorno científico, son muchas las empresas que
tienden a subestimar la importancia de un enfoque proactivo en la gestión de riesgo y,
según lo afirman Colicchia y Strozzi (2012), sólo algunas de ellas toman acciones para
mitigar los riesgos de manera proactiva.
Identificación
La identificación de riesgos es el primer paso del SCRM. Como su nombre lo indica, se
trata de identificar los tipos de riesgo, los factores que los desencadenan o ambos.
Se ha encontrado que algunos métodos utilizados para identificar potenciales riesgos en
la SC han sido: Proceso Análisis Jerárquico (AHP), Mapa de vulnerabilidad de la cadena
de suministro, Modelo conceptual y Análisis Funcional de Peligros y Operatividad
(HAZOP).
Evaluación
La evaluación de riesgos es una fase intermedia antes de la escogencia e implantación de
una estrategia. De acuerdo con Heckmann y otros (2015), esta etapa está estrechamente
relacionada con los objetivos que se propone la cadena de suministro. Harland y otros
(2003) afirman que la evaluación del riesgo está asociada con la probabilidad de que
ocurra un evento y la importancia de las consecuencias (dado a partir de la definición de
riesgo), siendo este un elemento común encontrado en los artículos revisados.
Mitigación
La mitigación es la última etapa de SCRM. En esta fase lo que se pretende es definir un
conjunto de estrategias que encaminen a la reducción de los riesgos hallados y evaluados
en las secciones anteriores, y de acuerdo a los criterios establecidos por la cadena de
suministro seleccionar aquellas estrategias que más se adecuen a sus objetivos.
Kleindorfer y Saad (2005) definen las estrategias de mitigación como aquellas en las que
la empresa realiza alguna acción con antelación a la ocurrencia del evento; por lo tanto, la
empresa incurre en el costo de la acción atenuante. Chang y otros (2015) clasifican las
estrategias en dos grandes grupos: de redundancia y de flexibilidad. Las estrategias de
redundancia se centran en limitar o mitigar los efectos negativos de un riesgo mediante el
aumento de la disponibilidad de producto (o recursos) para ser utilizados en caso de una
eventualidad (Sheffi y Rice Jr., 2005). Por su parte, las estrategias de flexibilidad
consisten en la construcción de capacidades en la organización y entre organizaciones
para detectar amenazas a la continuidad de la oferta y poder responder a ellas de forma
rápida (Zsidisin y Wagner, 2010). Por otra parte, Qazi y otros (2015a) hablan de
CLAIO-2016
168

estrategias preventivas y reactivas; las estrategias preventivas buscan eliminar la
probabilidad de ocurrencia del riesgo mientras que las reactivas disminuyen el impacto.
Craighead y otros (2007) encontraron que la estructura de la cadena de suministro influye
en la selección de las estrategias óptimas que mitiguen los riesgos de la cadena de
suministro. Además, las múltiples fuentes potenciales de riesgos producen diversos
efectos en una cadena de suministro y complican la selección de las estrategias (Talluri y
otros, 2013). Por otro lado, debido a los pocos datos y la escasa presencia de buenas
estimaciones de la probabilidad y el impacto de los riesgos los análisis costo/beneficio o
de rentabilidad que insten a las organizaciones a implementar un plan SCRM no se han
llevado a cabo en las investigaciones encontradas. Adicionalmente, la investigación
empírica es limitada debido a que es difícil evaluar cómo un evento que tiene lugar en un
proveedor afecta al rendimiento de la empresa y la cadena de abastecimiento, ya que se
tiene que identificar y dar cuenta de los efectos las acciones tomadas por el proveedor.
Investigaciones realizadas en torno a la selección de estrategias con miras a la mitigación
del riesgo en la cadena de suministro incluyen el uso de metodologías ya conocidas
como: el modelo ISM (Interpretive Structural Modelling) y análisis MICMAC (Matriced
'Impacts Croisés Multiplication Appliquée à un Classement) por Aqlan y Lam (2015); la
metodología DEMATEL (DEcision MAking Trial and Evaluation Laboratory) junto con
la Teoría Gris y calificación de expertos por Rajesh y Ravi (2015); el análisis teórico y
conceptual por Chang y otros (2015); el análisis DOFA, las 5 estrategias de Porter y la
Casa del Riesgo (HOR - House of Risk) por Kasemset y otros (2014); el FMECA
(Failure mode, effects and criticality analysis), DOE (Design of Experiments), DES
(Discrete event simulation), AHP (Analytic Hierarchy Process) y DFA (Desirability
function approach) por Elleuch y otros (2013); el DEA (Data Envelopment Analysis), la
teoría de contingencia (CT - Contingency Theory) y la simulación de escenarios por
Talluri y otros (2013).
Los modelos de optimización también han sido usados en la selección de estrategias: Liu
y otros (2014) desarrollan un modelo de programación con restricciones estocásticas que
permiten la selección de estrategias de mitigación de riesgos maximizando el porcentaje
de reducción del riesgo que tiene cada estrategia sobre los mismos, teniendo como
limitantes un presupuesto y una reducción de riesgo esperada a partir de una distribución
normal; Micheli y otros (2014) idean un DSS (Decisión support system - Sistema de
soporte de decisiones) basado en un modelo de optimización matemática donde se busca
disminuir el perfil del riesgo total de una combinación de estrategias a partir de un
presupuesto dado usando números difusos triangulares en los parámetros de
incertidumbre; y, Qazi y otros (2015a) proponen un modelo de optimización para la
evaluación de las diferentes combinaciones de estrategias preventivas y reactivas por
medio de la utilización de redes bayesianas de modo que se determine la solución óptima
sobre la base de la máxima mejora en la red de la pérdida esperada, validando el modelo
a través de un estudio de simulación que tiene en cuenta 12 riesgos (o desencadenadores
de riesgo) en una cadena de suministro de 4 niveles.
CLAIO-2016
169

4 Modelo propuesto
Teniendo en cuenta las consideraciones expuestas en las secciones anteriores, se propone
un modelo de optimización que permita a las organizaciones tomar decisiones sobre la
implementación de un conjunto de estrategias para hacer frente a los riesgos a los que se
ve expuesta su cadena de suministro es decir, cuáles estrategias se recomiendan
implementar de acuerdo a los objetivos propuestos por la organización. Este modelo está
basado en el propuesto por Micheli y otros (2014) y considera las investigaciones
realizadas por Garvey y otros (2015), Qazi y otros (2015a, 2015b) y Badurdeen y otros
(2014), sobre redes Bayesianas en la cadena de suministro para el cálculo del perfil del
riesgo (probabilidad e impacto) como parámetro de entrada.
Referencias
1. S. Chopra y M.M.S. Sodhi. Managing risk to avoid supply-chain breakdown. MIT Sloan
Management Review, 46(1): 53-61, 2004.
2. T.J. Pettit, K.L. Croxton y J. Fiksel. Ensuring supply chain resilience: Development and
implementation of an assessment tool. Journal of Business Logistics, 34: 46-76, 2013.
3. L. Liu, S. Li y Y. Wu. Supply chain risk management in chinese chemical industry based on
stochastic chance-constrained programming model. Applied Mathematics and Information
Sciences, 8(3): 1201-1206, 2014.
4. B. Fahimnia, C.S. Tang, H. Davarzani y J. Sarkis. Quantitative models for managing supply
chain risks: A review. European Journal of Operational Research. 247(1): 1-15, 2015.
5. T. Black y S. Ray. Downside of just-in-time inventory. Business week. 24: 17-18, 2011.
6. F.H. Knight. Risk, Uncertainty and Profit. 1921. En: C. Colicchia y F. Strozzi. Supply chain
risk management: a new methodology for a systematic literature review. Supply Chain
Management: An International Journal. 17(4): 403-418, 2012.
7. I. Heckmann, T. Comes y S. Nickel. A critical review on supply chain risk - Definition,
measure and modeling. OMEGA-International Journal ff Management Science. 52: 119-132,
2015.
8. M.N. Faisal, D.K. Banwety R. Shankar. Quantification of risk mitigation environment of
supply chains using graph theory and matrix methods. European Journal of Industrial
Engineering. 1(1): 22-39, 2007.
9. A. Ghadge y S. Dani. Supply chain risk management: present and future scope. The
International Journal of Logistics Management. 23(3): 313-339, 2012.
10. R. W. Monroe, J. M. Teetsy P. R. Martin. Supply chain risk management: an analysis of
sources of risk and mitigation strategies. International Journal Applied Management Science.
6(1): 4-21, 2014.
11. S.M. Wagner y C. Bode. An empirical investigation into supply chain vulnerability. Journal
of purchasing and supply management. 12(6): 301-312, 2006.
12. S.E. Fawcett, C. Wallin, C. Allred, A.M. Fawcett y G. M. Magnan. Information technology as
an enabler of supply chain collaboration: A dynamic capabilities perspective. Journal of
Supply Chain Management. 47(1): 38-56, 2011.
13. C. Harland, R. Brenchley y H. Walker. Risk in supply networks. Journal of Purchasing &
Supply Management. 9: 51-62, 2003.
CLAIO-2016
170

14. P.R. Kleindorfer y G.H. Saad. Managing Disruption Risks in Supply Chains. Production and
Operations Management. 14(1):53-68, 2005.
15. W. Chang, A. E. Ellinger y J. Blackhurst. A contextual approach to supply chain risk
mitigation. The International Journal of Logistics Management. 26(3): 642-656, 2015.
16. Y. Sheffi y J.B. Jr. Rice. A supply chain view of the resilient enterprise. MIT Sloan
Management Review. 47(1): 41-48, 2005.
17. G.A. Zsidisin y S.M. Wagner. Do perceptions become reality? The moderating role of supply
chain resiliency on disruption occurrence. Journal of Business Logistics. 31(2): 1-20, 2010.
18. A. Qazi, J. Quigley, A. Dickson, B. Gaudenzi. A new modelling approach of evaluating
preventive and reactive strategies for mitigating supply chain risks. 6th International
Conference on Computational Logistics. 2015a.
19. C.W. Craighead, J. Blackhurst, M.J. Rungtusanatham y R.B. Handfield. The severity of
supply chain disruptions: design characteristics and mitigation capabilities. Decision Sciences.
38(1): 131-156, 2007.
20. S. Talluri, T.J. Kull, H. Yildiz y J. Yoon. Assessing the efficiency of risk mitigation strategies
in supply chains. Journal of Business Logistics. 34(4): 253-269, 2013.
21. Faisal Aqlan y Sarah S. Lam. Supply chain risk modelling and mitigation. International
Journal of Production Research. 53(18): 5640-5656, 2015.
22. R. Rajesh y V. Ravi. Modeling enablers of supply chain risk mitigation in electronic supply
chains: A Grey-DEMATEL approach. Computers and Industrial Engineering. 87:126-139,
2015.
23. W. Chang, A.E. Ellinger y J. Blackhurst. A contextual approach to supply chain risk
mitigation. International Journal of Logistics Management. 26(3): 642 – 656, 2015.
24. C. Kasemset, J. Wannagoat, W. Wattanutchariya y K.Y. Tippayawong. A risk management
framework for new product development: A case study. Industrial Engineering and
Management Systems. 13(2): 203-209, 2014.
25. Hatem Elleuch, Wafik Hachicha y Habib Chabchoub. A combined approach for supply chain
risk management: description and application to a real hospital pharmaceutical case study.
Journal of Risk Research. 16(5): 641-663, 2013.
26. Liping Liu, Shuxia Li y Yifan Wu. Supply chain risk management in chinese chemical
industry based on stochastic chance-constrained programming model. Applied Mathematics &
Information Sciences. 8(3): 1201-1206, 2014.
27. G.J.L. Micheli, R. Mogre y A. Perego. How to choose mitigation measures for supply chain
risks. International Journal of Production Research. 52(1): 117-129, 2014.
28. M.D. Garvey, S. Carnovale y S. Yeniyurt. An analytical framework for supply network risk
propagation: A Bayesian network approach. European Journal of Operational Research. 243
(2): 618-627, 2015.
29. A. Qazi, J. Quigley y A. Dickson. Supply Chain Risk Management: Systematic literature
review and a conceptual framework for capturing interdependencies between risks. 5th
International Conference on Industrial Engineering and Operations Management. 2015b.
30. F. Badurdeen, M. Shuaib, K. Wijekoon, A. Brown, W. Faulkner, J. Amundson, I.S. Jawahir,
T. J. Goldsby, De. Iyengar y B. Boden. Quantitative modeling and analysis of supply chain
risks using Bayesian theory. Journal of Manufacturing Technology Management. 25(5): 631-
654, 2014.
CLAIO-2016
171

Análisis espectral del precondicionador Separador con base dispersa
Cecilia Orellana CastroIMECC-UNICAMP
Aurelio Ribeiro L. OliveiraDMA, [email protected]
Resumen
Con el objetivo de mejorar el desempeño del precondicionador Separador aplicado alsistema de Ecuaciones Normales en el método primal-dual de Puntos Interiores se proponeuna nueva ordenación de las columnas de la matriz de restricciones de un problema deprogramación lineal. Esta propuesta dá énfasis al cálculo de una base dispersa para elprecondicionador Separador, adicionalmente se demuestra que con la ordenación propuestael número de condición de la matriz precondicionada es limitada uniformemente por unacantidad que únicamente depende de los datos del problema y no de la iteración del método dePuntos Interiores. Los experimentos numéricos se realizaron usando un precondicionamientohı́brido de dos fases, en la primera fase se usó el precondicionador Factorización Controladade Cholesky y en la segunda fase el precondicionador Separador. La implementación de estapropuesta en problemas de gran tamaño corroboró su robustez y eficiencia computacional.
Keywords: Método primal-dual de Puntos Interiores; Precondicionador Separador; BaseDispersa.
1. Introducción
El estudio de las propiedades teóricas y computacionales del Método primal-dual de Puntos Interiores(MPI), destacando entre estas su complejidad polinomial y la ventaja de no requerir un punto inicialfactible, consolidó este método como una herramienta competitiva para resolver problemas de ProgramaciónLineal (PL) de gran tamaño, vea [8]. En cada iteración del MPI, el cálculo de la dirección de búsquedarequiere el mayor esfuerzo computacional pues esta dirección es obtenida de sistemas lineales que puedentornarse densos y mal condicionados apesar de que la matriz de restricciones del problema de PL seadispersa. Actualmente, la dirección de búsqueda es obtenida de dos sistemas: el Sistema Aumentadoy el Sistema de Ecuaciones Normales (SEN). En este trabajo se resuelve el SEN usando el métodode los Gradientes Conjugados Precondicionado (GCP), por tanto, la construcción de precondicionadoreseficientes es indispensable. Las iteraciones iniciales usan el precondicionador Factorización Controladade Cholesky (FCC) con éxito, no obstante, su desempeño disminuye a medida que el algoritmo del MPIse aproxima a la solución óptima, esto se debe a que el número de condición de la matriz del SEN
CLAIO-2016
172

sin precondicionamento crece considerablemente, más precisamente en [4] se prueba que este número eslimitado por una cantidad de orden O(µ−2), donde µ denota el gap de dualidad de un problema de PL. Porotro lado, Oliveira y Sorensen [6] usan el comportamiento de la matriz diagonal D que aparece en el SEN yla condición de complementariedad del problema de PL para construir el Precondicionador Separador (PS),este precondicionador presenta un buen desempeño en las últimas iteraciones del MPI. La combinación deestos dos precondicionadores es conocida como el Abordaje Hı́brido propuesto en [1].
Los autores del PS y posteriormente sus colaboradores [7] hicieron ordenaciones basadas en heurı́sticas,algunas fueron exitosas, no obstante, aún existen problemas no resueltos y otros cuya solución demandamucho tiempo, esto acontece principalmente por dos motivos: primero, la elección de columnas linealmenteindependientes para conformar la base del PS depende de una factorización LU costosa y segundo, porquela base escogida no proporciona un precondicionador que disminuya considerablemente el número decondición. Ası́, el objetivo de este trabajo es el estudio del número de condición del SEN precondicionadopor el PS y a partir de esta información ordenar las columnas de la matriz de restricciones del problema dePL para construir una base dispersa que proporcione un número de condición limitado por una cantidad queno dependa de la iteración del MPI. Adicionalmente, la condición de mudanza de fase propuesta en [7] fueligeramente modificada añadiendo una condición basada en la ordenación propuesta, esta condición es unindicador de que el PS está preparado para presentar un buen desempeño.
Fue realizada una implementación de este nuevo abordaje para ser comparado con la versión actualmenteutilizada, vea [7]. Los experimentos computacionales mostraron que la nueva propuesta fue más eficiente yrobusta.
2. Dirección de búsqueda en el Método de Puntos Interiores
En este trabajo se considera el par primal-dual del problema de PL canalizado dado por:(P)
{min cTx s. a Ax = b, x+ s = u x, s ≥ 0
}e
(D){max bT y − uTw s. a AT y − w + z = c w, z ≥ 0 y ∈ Rm
},
donde x, s, w ∈ Rn y A es una matriz de tamaño m × n que será considerada de rango completo.Aplicando la penalidad barrera logarı́tmica en las restricciones de no negatividad de (P ) se obtiene elproblema: (P′)
{min cTx− µ∑n
i=1 log xi − µ∑n
i=1 log si s. a Ax = b, x+ s = u x, s > 0}. Dado
que (P′) es un problema convexo las condiciones KKT son suficientes y necesarias para encontrar lasolución óptima, para esto, considere su lagrangiano ` y las derivadas parciales,
`(x, s, y, w) = cTx− µn∑
i=1
log xi − µn∑
i=1
log si + yT (b−Ax) + wT (u− x− s),
∇x` = c − µX−1e − AT y − w, ∇s` = −µS−1e − w, ∇y` = b − Ax y ∇w` = u − x − s, dondeX−1 = diag(x−1
1 , . . . , x−1n ), S−1 = diag(s−1
1 , . . . , s−1n ) y eT = (1, . . . , 1) ∈ Rn. Si z ∈ Rn es definida
como z = µX−1e, las condiciones de optimalidad de (P′) son:
Ax = b;
x+ s = u x, s > 0;
AT y + z − w = c z, w > 0;
SWe = µe;
CLAIO-2016
173

XZe = µe.
Estas cinco ecuaciones son conocidas como las Ecuaciones de la Curva Central. Considere la funciónF (x, s, y, w, z) =
(Ax− b, x+ s− u, AT y + z − w − c, XZe− µe, SWe− µe
), la dirección de
búsqueda ∆X = (∆x,∆s,∆y,∆z,∆w)T en una iteración del MPI es encontrada aplicando el métodode Newton a la función F , o sea, resolviendo el siguiente sistema:
A 0 0 0 0In In 0 0 00 0 AT −In InZ 0 0 X 00 W 0 0 S
∆x∆s∆y∆z∆w
=
rbrurcr1
r2
, (1)
donde rb = b − Ax, ru = u − x − s, rc = c + w − z − AT y, r1 = µe − XZe, r2 = µe − SWe,eT = (1, . . . , 1) ∈ Rn, X = diag(x1, . . . , xn), Z = diag(z1, . . . , zn), S = diag(s1, . . . , sn),W = diag(w1, . . . , wn). Para evitar la pérdida de positividad en las variables x, s, z y w, el sistema (1)es modificado haciendo r1 = σµe − XZe, r2 = σµe − SWe, donde σ ∈ [0, 1] es llamado parámetrode centralización. Despejando de la segunda, cuarta y quinta ecuación del sistema (1) se obtienen:∆s = ru − ∆x, ∆z = X−1(r1 − Z∆x) y ∆w = S−1(r2 − W∆s), sustituyendo estas variables enla tercera ecuación de (1):
AT∆y − (X−1Z + S−1W )∆x = rc −X−1r1 + Sr2 − S−1Wru, (2)
usando la primera ecuación del sistema (1) y la ecuación (2) se obtiene el sistema Aumentado, dado en (3)(−D−1 AT
A 0
)(∆x∆y
)=
(rh
), (3)
donde D−1 = X−1Z + S−1W , r = rc − X−1r1 + S−1r2 − S−1Wru y h = rb. Despejando ∆x =DAT∆y−Dr de la primera ecuación del sistema (3) y sustituyendo enA∆x = h se obtiene la formulaciónconocida como SEN (4) cuya matriz es simétrica, definida positiva y de tamaño m :
ADAT∆y = h+ADr. (4)
Una vez obtenido ∆y, se obtienen ∆x = DAT∆y − Dr, ∆s = ru − ∆x, ∆z = X−1(r1 − Z∆x) y∆w = S−1(r2−W∆s). El sistema (4) precondicionado será usado para encontrar la dirección de búsqueda.
3. Precondicionador Separador aplicado a la matriz del Sistema de Ecuaciones Normales
La construcción del PS está basada en la condición de complementariedad de un problema de PL, en estecaso: xizi = 0 y siwi = 0 para todo i = 1, . . . , n. Observe que la matrizD que aparece en (4) tiene entradasdi =
(zix−1i + wis
−1i
)−1, es decir, en cada iteración del MPI la matriz D es modificada, particularmentecerca a la solución óptima, debido a la no negatividad de las variables, existirán ı́ndices j ∈ {1, . . . n} talesque dj → 0 o dj → ∞. Esta caracterı́stica es la justificación del éxito del PS en las últimas iteraciones delMPI y la motivación de la condición de mudanza de fase presentada en este trabajo.
En cada iteración del MPI considere una ordenación dσ(1) ≥ . . . ≥ dσ(m) ≥ . . . ≥ dσ(n) donde σ esuna permutación de {1, . . . n}, note que este orden es alterado en cada iteración. Considere los conjuntos de
CLAIO-2016
174

ı́ndices B = {σ(1), . . . , σ(m)} y N = {σ(m + 1), . . . , σ(n)}, si las columnas de las matrices A y D sonordenadas de acuerdo con σ, entonces la matriz de (4) es dada por:
ADAT = ABDBATB +ANDNATN . (5)
Si la submatrizAB fuese no singular el PS para el SEN es dado por la matriz P = D−1/2B A−1
B y la matriz(5) precondicionada por P es P (ADAT )P T = Im + WW T con W = D
−1/2B A−1
B AND1/2N . La situación
ideal sucede cuando D−1/2B → 0 y D1/2
N → 0 implicando que W → 0 y, por tanto, P (ADAT )P T ≈ Im.No obstante nada garantiza que AB sea no singular y aunque lo fuera, no todo dj con j ∈ B es un valorgrande. En efecto, cerca a la solución óptima existen por lo menos n−m valores próximos a cero.
Para realizar un análisis espectral de la matriz precondicionada suponga que (λ, v) sea un autoparde I + WW T , esto es, v + WW T v = λv. Multiplicando por vT se observa que |λ| ≥ 1, por tanto,κ(P (ADAT )P T ) = λmax
λmin≤ λmax. Observe que,
λmáx
(PADATP T
)= ‖PAD1/2‖22 ≤ ‖PAD1/2‖2F =
n∑
i=1
dj‖PAj‖22, (6)
ası́, usaremos (6) para estudiar un limitante superior del número de condición κ(P (ADAT )P T ). Porotro lado, encontrar columnas linealmente independientes de A para conformar la base AB del PS puededemandar mucho uso de memoria pues este trabajo es realizado usando una fatorización LU de la matrizA, un pivot nulo o próximo a cero indicará que la columna correspondiente a este pivot es linealmentedependiente. Cuando el llenado es excesivo, la factorización LU es reiniciada rescatando las columnaslinealmente independientes encontradas.
4. Nueva propuesta
A partir de las observaciones presentadas en la sección anterior, surge la idea de crear una ordenaciónque considere simultaneamente buen condicionamiento para el SEN y dispersidad para la base AB. Para talobjetivo, denote por nnz(Aj)= número de elementos no nulos en la columnaAj , j = 1, . . . , n, observe que:1 ≤ nnz(Aj) ≤ m para toda columna Aj de A, note que en problemas dispersos nnz(Aj) << m. Definakj = d
1/2j /nnz(Aj) y realize una ordenación decreciente de kj con j = 1, . . . n. Con esta ordenación se
propone el siguiente algoritmo para calcular los ı́ndices básicos B en una iteración del MPI.Algoritmo 1: Algoritmo para encontrar el conjunto de ı́ndices básicos B y no básicos N
Require: La matriz de restricciones A ∈ Rm×n de rango m y la matriz diagonal D.Ensure: Los conjuntos de ı́ndices básicos B = {b1, . . . bm} y no básicos N = {1, . . . , n}\B.
Obtener la permutación σ del conjunto {1, . . . , n} tal que: kσ(1) ≥ kσ(2) ≥ . . . ≥ kσ(n);Defina B = ∅, i = 1, k = 0;while |B| < m do
if Aσ(i) es linealmente independiente a {Aj : j ∈ B} thenB = B ∪ {σ(i)} ; k = k + 1; bk = σ(i);
end ifi = i+ 1.
end while
La ordenación decreciente de los valores k′js es motivada por la siguiente razón: si dos columnas Aj1 yAj2 son tales que nnz(Aj1) ≤ nnz(Aj2), es decir, Aj1 es más dispersa que Aj2 , entonces, 1/nnz(Aj1) ≥
CLAIO-2016
175

1/nnz(Aj2), luego la columna Aj1 tendrá prioridad sobre Aj2 si dj1 ≈ dj2 . Ası́, mientras los valores d1/2j
serán usados en el Teorema 4.1 para cuidar del buen condicionamiento, las cantidades nnz(Aj) procurandar prioridad a las columnas mas dispersas. La prueba del Teorema 4.1 está basada en [5] aumentando unacondición que considere la dispersidad de la matrizA. Para simplificar notación se considera σ como siendola permutación identidad, adicionalmente, se denota AB por B, y ‖.‖ denota a norma euclidiana.
Teorema 4.1. Si los ı́ndices básicos B y no básicos N del PS son obtenidos por el Algoritmo 1. Entonces:
1. d1/2j ‖D
−1/2B B−1Aj‖ = 1 para j ∈ B,
2. d1/2j ‖D
−1/2B B−1Aj‖ ≤ nnz(Aj)‖B−1Aj‖ para j ∈ {1, . . . , n}\B.
Adicionalmente, si K = máx{nnz(Aj) : j = 1, . . . n}, entonces: κ(PADATP T ) ≤ nK2‖B−1A‖2.
Demostración Se consideran dos casos:Caso 1. Si j ∈ B, entonces B−1Aj = ej donde ej es el j−ésimo vector canónico de Rm; luego,
d1/2j ‖D
−1/2B B−1Aj‖ = d
1/2j ‖D
−1/2B ej‖ = d
1/2j ‖d
−1/2j ej‖ = 1.
Caso 2. Si j /∈ B, son estudiadas dos situaciones:Caso 2.1 La columna Aj no fue considerada para entrar en la base de acuerdo con el Algoritmo 1,
esto es, para todo bi ∈ B, se cumple que j > bi, luego kbi ≥ kj . Si d1/20 = min{d1/2
bi: bi ∈ B} y
k0 = d1/20 /nnz(A0) entonces k0 ≥ kbm ≥ kj , luego,
d1/2j ‖D
−1/2B B−1Aj‖ ≤
d1/2j ‖B−1Aj‖
min{d1/2bi: bi ∈ B}
=kj nnz(Aj)
k0 nnz(A0)‖B−1Aj‖ ≤ nnz(Aj)‖B−1Aj‖. (7)
Caso 2.2 La columna Aj fue candidata para ser la r-ésima columna de B, pero Aj resultó serlinealmente dependiente a las columnas Ab1 , Ab2 , . . . , Abr−1 , esto es, Aj = B[u, 0]T , para u ∈ Rr−1.Observe que kbi ≥ kj para i = 1, . . . , r − 1, adicionalmente ‖u‖ = ‖B−1Aj‖.
Si d1/20 = min{d1/2
b1, . . . , d
12br−1} y k0 = d
1/20 /nnz(A0) entonces k0 ≥ kbr−1 ≥ kj , luego:
d1/2j ‖D
−1/2B B−1Aj‖ = d
1/2j
(r−1∑
i=1
d−1biu2i
)1/2
≤ kj nnz(Aj)
k0 nnz(A0)‖B−1Aj‖ ≤ nnz(Aj)‖B−1Aj‖. (8)
A partir de (6), λmáx = ‖D−1/2B B−1AD1/2‖2 ≤ ∑n
j=1 dj‖D−1/2B B−1Aj‖2, adicionalmente, usando
las desigualdades obtenidas en (7) y (8) se obtiene:λmáx
(PADATP T
)≤ K2
∑nj=1 ‖B−1Aj‖2 = K2‖B−1A‖2F ≤ mK2‖B−1A‖2.
Por otro lado, λmin(PADATP T
)≥ 1, por tanto, κ(PADATP T ) ≤ mK2‖B−1A‖2. �
Observe que el limitante del número de condición de la matriz precondicionada depende solamente delos datos del problema y no de la iteración del MPI. Adicionalmente, destacamos que computacionalmenteno usamos B mal condicionada pues las columnas de A com pivot pequeño son despreciadas, luego de larelación κ(B) = ‖B−1‖‖B‖, observamos que ‖B−1‖ no será una cantidad muy grande.
5. Nuevo criterio de Mudanza de Fase
La mudanza de fase propuesta en [7] para el precondicionamiento hı́brido tiene por objetivo aprovecharel precondicionador FCC en la mayor cantidad de iteraciones del MPI como sea posible. El llenado en cada
CLAIO-2016
176

columna del precondicionador FCC es controlado por un parámetro η, donde η es el número de entradasextras permitidas por columna, vea [2]. La mudanza de fase es realizada cuando el valor de η supera un lı́mitepermitido dado por un valor ηmax. Se observó que en varios problemas el PS está preparado para presentarun buen desempeño antes de alcanzar ηmax = 10, por tanto, fue establecida una condición adicional enla mudanza de fase que mejoró considerablemente el tiempo computacional en muchos de los problemasque fueron usados para los experimentos numéricos. La condición adicionada considera una ordenacióndecreciente de los elementos de la diagonal: d1 ≥ d2 ≥ . . . ≥ dm ≥ . . . ≥ dn, y define δ = s1 − s2, dondes1 =
∑mi=1 di y s2 =
∑ni=m+1 di. La mudanza de fase proposta es la siguiente:
Si el número de iteraciones del método GCP en una iteración del MPI es mayor que m/5 entonces sedebe verificar si η ≤ ηmáx y δ < 1,5 × 106, es decir, se debe verificar si el precondicionador FCC aún norequiere mucha memoria y si el PS aún no está preparado para presentar un buen desempeño pues la matrizD no presenta diferencias abruptas en los elementos de la diagonal. Si la condición fuese verdadera, η esaumentado en 10. En otro caso, esto es, si η > ηmáx o δ ≥ 1,5× 106, la mudanza de fase es realizada.
6. Resultados Numéricos
Cuadro 1: Número de iteraciones , Tiempo y tamañoIteraciones del MPI Tiempo Tamaño
Prob PSM PSC PSM PSC Fila Columna
cre-a 27 27 7,36 6,34 2989 6692cre-b 43 43 49,50 37,65 5328 36382cre-c 27 27 5,78 5,44 2370 5412cre-d 42 42 33,36 31,27 4094 28601ex05 39 39 6,49 6,52 832 7805ex09 45 50 58,23 64,91 1821 18184ken11 23 22 10,31 10,08 9964 16740ken13 29 29 103,22 59,13 22365 36561ken18 41 40 1246,82 844,12 78538 128434chr22b 29 29 19,84 21,75 5587 10417chr25a 29 29 45,68 48,01 8149 15325scr15 24 24 8,12 7,45 2234 6210scr20 21 21 66,54 66,62 5079 15980rou20 24 24 915,36 703,08 7359 37640nug12 – 20 – 71,56 3192 8856qap8 10 10 0,78 0,75 742 1632qap12 – 20 – 82,94 2794 8856ste36a 37 37 10178,34 9443,21 27683 13107625fv47 29 28 1,90 2,10 788 1843maros 40 20 2,44 0,79 655 1437nesm 31 31 1,69 0,80 654 2922BL 38 38 19,11 15,72 5729 12462NL 41 41 35,87 32,09 6665 14680stocfor2 21 21 1.21 0,89 1980 2868stocfor3 32 32 91,56 84,12 15362 22228
Los experimentos numéricos fueron realizados utilizando PCx, vea [3], no obstante, el método directousado para la solución de los sistemas lineales fue sustituido por el método de los GCP con el abordajehı́brido propuesto en [1]. Se comparan los resultados de los abordajes PSM y PSC , siendo PSM el abordajecon ordenación de la base B propuesta en [7], y PSC el abordaje con base B obtenida por el algoritmo dela sección 4. En el abordaje PSM se usó la mudanza de fase propuesta en [7] y en el abordaje PSC se usó
CLAIO-2016
177

la mudanza de fase presentada en la sección 5. La base B del PS puede ser usada por más de una iteracióndel MPI, el cálculo de la base es realizado cuando 8 ∗ ng ≥ m, donde ng denota el número de iteracionesdel método GCP en una iteración del MPI correspondiente a la segunda fase. Los problemas utilizados sonde dominio público extraidos de las bibliotecas NETLIB, QAP y KENNINGTON. Las últimas columnasdel cuadro indican el número de filas y columnas de los problemas pre-procesados por el PCx. Para evaluarnuestra propuesta comparamos el número total de iteraciones del MPI y el tiempo para resolver el problema.
Fueron seleccionados 25 problemas de gran tamaño. Las diferencias más notables fueron marcadas. Elsı́mbolo − indica que el problema no fue resuelto. Se observa que en 5 problemas el número de iteracionesdel MPI fue disminuido, los problemas nug12 y qap12 no fueron resueltos por el abordaje PSM . Noobstante, el problema ex-09 aumentó el número de iteraciones con el abordaje PSC . Respecto al tiempousado para resolver los problemas, el abordaje PSC ganó en 14 problemas y perdió solamente en 3.
7. Conclusiones
Los resultados numéricos muestran que la nueva propuesta es más eficiente y robusta debido a que elabordaje PSC acelera el cálculo de la base. Se observó que dar prioridad a columnas dispersas en el cálculode la base hizo que el número de columnas linealmente independientes encontradas antes del primer reiniciode la factorización LU sea superior al número de columnas linealmente independientes encontradas con elabordaje PSM . Adicionalmente, la nueva mudanza de fase favoreció a la nueva propuesta porque en algunosproblemas anticipó la mudanza de fase en una iteración del MPI.
Agradecimientos
Este trabajo contó con el apoyo financiero de la Fundação de Amparo à Pesquisa do Estado de SãoPaulo FAPESP y del Conselho Nacional de Desenvolvimento Cientı́fico e Tecnológico CNPq.
Referencias
[1] S. Bocanegra, F. F. Campos, and A. R. L. Oliveira. Using a hybrid preconditioner for solving large-scalelinear systems arising from interior point methods. computational optimization and applications. ComputationalOptimization and Applications, pages 149–164, 2007.
[2] F. F. Campos. Analysis of conjugate gradients-type methods for solving linear equations. PhD thesis, Universityof Oxford, 1995.
[3] J. Czyzyk, S. Mehrotra, M. Wagner, and S. J. Wright. Pcx user guide. Technical Report OTC 96/01, 1996.
[4] J. Gondzio. Matrix-free interior point method. Computacional Optimization and Applications, 51:457–480, 2012.
[5] R. D. C. Monteiro, J. W. O’Neal, and T. Tsuchiya. Uniform boundedness of a preconditioned normal matrix usedin interior-point methods. SIAM Journal on Optimization, 15(1):96–100, 2004.
[6] A. R. L. Oliveira and D. C. Sorensen. A new class of preconditioners for large-scale linear systems from interiorpoint methods for linear programming. Linear Algebra and its applications, 394:1–24, 2005.
[7] M. I. Velazco, A. R. L. Oliveira, and F. F. Campos. A note on hybrid preconditioners for large-scale normalequations arising from interior-point methods. Optimization Methods and Software, 25(2):321–332, 2010.
[8] S.J. Wright. Primal-dual Interior-Point Methods:. SIAM e-books. Society for Industrial and Applied Mathematics(SIAM, 3600 Market Street, Floor 6, Philadelphia, PA 19104), 1997.
CLAIO-2016
178

Generación de columnas para un problema de ruteo e
inventarios para la gestión de una red de cajeros
automáticos
Alejandro CataldoPontificia Universidad Católica de Chile
Leandro C. CoelhoUniversité Laval
Cristián E. CortésUniversidad de [email protected]
Carlos LagosPontificia Universidad Católica de Chile
Pablo A. ReyUniversidad de [email protected]
Resumen
En este trabajo se presenta un enfoque de programación entera mixta para resolver un prob-lema clasificado como inventory-routing en el contexto de una aplicación real relacionada con laplanificación de reposición de dinero en una red de cajeros automáticos. El problema estudiadoes distinto de otros trabajos en la literatura, ya que considera la posibilidad de que haya faltantede efectivo en los cajeros (quiebres de inventario), los cuales son penalizados. Bajo supuestos dedemanda determinista y consumo homogéneo del dinero a lo largo de los periodos, se proponeun esquema de generación de columnas. Se formula el problema maestro restringido que incluyevariables estáticas relativas a los niveles de dinero en los cajeros y a los faltantes, mientras quelas variables correspondientes a la selección de rutas y sus instantes de inicio, son generadas demanera dinámica. Los subproblemas de generación de columnas correspondientes son resueltoscon un modelo de programación entera mixta. Resultados preliminares muestran que el enfoquees factible, pero que la calidad de la relajación lineal no es muy buena, obteniendo gaps, entre lasolución entera y la relajación lineal, mayores al 30% en todos los casos resueltos. El siguientepaso es implementar un esquema branch & price para resolver el problema a optimalidad.
Keywords: problemas de ruteo e inventarios; generación de columnas; quiebres de inventario.
CLAIO-2016
179

1 Introducción
El presente trabajo describe un enfoque de programación entera mixta basado en generación decolumnas para un problema de inventario y ruteo que surge de la planificación de la reposición dedinero en una red de cajeros automáticos.
El problema estudiado se basa en el problema de administración de fondos disponibles en losdistintos cajeros de una red de cajeros automáticos y el ruteo de los camiones que realizan lareposición y retiro en los cajeros de la red. Este problema puede ser abordado como una variantedel problema de ruteo e inventarios.
Los problemas de ruteo e inventarios (inventory-routing problems, en ingles) integran dos prob-lemas bien estudiados: la administración de inventarios y el ruteo de veh́ıculos. Dado un conjuntode clientes a ser servidos en un horizonte de tiempo de varios periodos, el problema de ruteo einventarios, en terminos generales, consiste en determinar cuándo visitar cada cliente, qué cantidadentregar en la visita y cómo combinar estas entregas en rutas factibles, de manera que el costo totalobtenido como la suma de los costos de ruteo y los costos de inventario sea mı́nima [1]. De acuerdocon [4] en la literatura especializada han sido estudiadas varias variantes y no es posible indicarcuál es el problema clásico sino más bien referirse a las versiones básicas o a sus extensiones.
Coelho et al. [4] presentan una clasificación de las versiones básicas del problema siguiendo sietecriterios. Respecto del horizonte de tiempo y la estructura de la red de distribución, separan losproblemas que tienen un horizonte finito o infinito de planificación y si los despachos son realizadosen esquemas uno-a-uno, uno-a-varios o varios-a-varios. Respecto de la manera en que se realiza elruteo de los veh́ıculos, dividen los problemas en aquellos en que los veh́ıculos salen de una bodegay se dirigen a los clientes, si es un cliente por ruta, lo llaman de ruteo simple, mientras que sise visitan varios clientes en cada ruta el ruteo es múltiple. Por otro lado, en los casos que nohay una bodega involucrada, como por ejemplo en algunas aplicaciones de transporte maŕıtimo, serefieren al caso como ruteo continuo. De acuerdo a como se manejan los inventarios, los autoresconsideran dos criterios, la poĺıtica de inventarios (reponer a nivel máximo o hasta nivel) y lo quellaman decisiones de inventario, que consideran condiciones en que no puede haber quiebres deinventario (inventarios no negativos), o en caso de observar los quiebres, estos son consideradosventas perdidas o se permiten back-orders. Finalmente, respecto de la flota empleada, clasificanlos problemas de acuerdo a si la flota consiste en un unico veh́ıculo o múltiples veh́ıculos y en esteultimo caso, si los veh́ıculos son idénticos (flota homogénea) o se cuenta con veh́ıculos con diferentescaracteŕısticas (flota heterogénea).
En la literatura se encuentran aplicaciones de problemas de inventory-routing en un amplioabanico de áreas, como por ejemplo transporte y loǵıstica maŕıtima [3, 7] y terrestre [2], pormencionar algunas.
Para mayores detalles respecto a la literatura existente sobre inventory-routing, se recomiendaal lector los surveys recientes de Andersson et al. [1] y Coelho et al. [4]. El trabajo de Andersson etal. se enfoca en las aplicaciones industriales, mientras que el de Coelho et al. pone mayor énfasisen las contribuciones metodológicas.
Respecto de aplicaciones en el contexto de redes de cajeros automáticos, Van Anholt et al. [8]proponen un enfoque de programación entera para un problema de ruteo e inventarios. En esetrabajo, no son permitidas las faltas de efectivo que son una caracteŕıstica importante del problemapráctico que motiva el presente estudio. Recientemente, Larrain et al. [6] proponen un modelobasado en arcos para un problema similar al considerado en este estudio, pero con la simplificación
CLAIO-2016
180

que no es considerado el momento, dentro de la jornada, en que son visitados los cajeros.
2 Descripción del problema
A diferencia de la mayoŕıa de los problemas de ruteo con inventario estudiados previamente enla literatura [4], el problema que motiva esta investigación considera la posibilidad de faltantede dinero para satisfacer extracciones de los clientes (out-of-stocks). En este caso de estudio,los clientes corresponden a los cajeros automáticos. El dinero es almacenado y reemplazado engavetas. Ademas, las entregas consisten en un cambio de gaveta: la gaveta que estaba en el cajeroes retirada (con el dinero que contiene) y es reemplazada por una nueva gaveta llena. Hay unacantidad finita de opciones de gavetas (que corresponden a la cantidad de dinero que contiene).Espećıficamente: se cuenta con una red con I cajeros automáticos (i = 1, . . . , I) y para un horizontede tiempo predefinido compuesto por T periodos (t = 1, . . . , T ), se desea determinar rutas paralos camiones que retiran y reponen las gavetas con dinero. La demanda por cajero y por periodoes determińıstica y conocida de antemano. Se cuenta con una flota fija y homogenea de veh́ıculosque pueden realizar un viaje por periodo. La carga total que pueden transportar los camiones, pormotivos de seguridad, esta limitada a un valor máximo. De la misma manera, la duración de lasrutas puede estar limitada a un tiempo posiblemente menor a la duración total del turno. Puedehaber limitaciones en los turnos en que un cajero puede ser visitado, pero no se definen ventanasde tiempo de duración menor a un turno en esta version del problema. Los faltantes de dineroson permitidos, pero penalizados. Se busca minimizar el costo total que esta compuesto por laspenalidades (multas) por falta de efectivo en los cajeros más el costo de las operaciones de loscamiones que realizan la reposición.
2.1 Supuestos
Para especificar el problema y permitir su modelación, hacemos los siguientes supuestos:
• Las penalidades que incurre la empresa administradora son funciones lineales de la duracióntotal de los periodos de out-of-stock en los cajeros. El costo total que enfrenta la empresa esla suma de estas penalidades.• Ningún cajero es visitado más de una vez por periodo.• Cuando se realiza una visita a un cajero, la gaveta que está en ese cajero es retirada y
reemplazada por una gaveta nueva.• Existe un número finito de posibles montos de dinero con los que puede cargarse una gaveta.
Cualquiera de estos montos puede ser utilizado para cualquier cajero. Estos montos definenlos tipos de gavetas.• El contenido de la gaveta con menor valor posible es siempre suficiente para satisfacer la
demanda de dinero de un periodo.• El consumo de dinero se realiza de manera continua y a una tasa constante. A esta tasa la
llamaremos la demanda de dinero en ese cajero en el periodo.
CLAIO-2016
181

3 Modelamiento
Para construir el problema maestro se incluyen variables estáticas relativas a los niveles de stock dedinero en los cajeros y a los out-of-stocks, mientras que las variables correspondientes a la seleccionde rutas y sus horarios son generadas de manera dinámica. Por variables estáticas nos referimosa variables que son consideradas permanentemente. Las variables dinámicas, por su parte, noson todas inclúıdas en el modelo sino que van siendo generadas y agregadas al modelo durante laejecución del algoritmo de solución. Los subproblemas de generación de columnas correspondientesson resueltos con un modelo de modelo de programación entera mixta.
Antes de presentar el modelo de programación lineal entera correspondiente al problema mae-stro, discutimos brevemente la idea en que se basa la representación de las dinámicas con queevolucionan los inventarios de efectivo en los cajeros y su interaccion con las visitas de los camionesy los quiebres de inventario. Fijemos la siguiente notacion. Sean λit la demanda por efectivo en elcajero automático i en el periodo t y λ+it , la demanda por efectivo en el cajero automático i desde elmomento que se realiza la visita hasta el final del periodo t. Si un cajero no es visitado, este valores 0. Llamemos qit al monto de efectivo dejado en el cajero automático i en el periodo t si el cajeroes visitado, 0 en caso contrario. Finalmente, sit es el nivel de inventario en el cajero automático ial comienzo del periodo t y oit, el nivel de quiebre de inventario en el cajero automático i duranteel periodo t.
La evolucion de los inventarios y los montos faltantes de dinero por periodo cumplen con lasrelaciones:
si,t+1 =
{max{sit − λit, 0} si el cajero i no es visitado en el periodo t,
qit − λ+it si el cajero i es visitado en el periodo t;(1)
oit =
{max{λit − sit, 0} si el cajero i no es visitado en el periodo t,
max{(λit − λ+it)− sit, 0} si el cajero i es visitado en el periodo t.(2)
Estos niveles de inventarios y quiebres de inventario serán variables en el modelo que se presentaa continuación. Para representar los casos en que hay o no quiebre de inventario, se incluirá unconjunto de variables binarias. Las visitas corresponden a rutas seleccionadas que incluyen a cadacajero. Estas serán representadas por las variables que se generan dinámicamente.
A continuación se presenta el modelo correspondiente al problema maestro en el enfoque prop-uesto.
3.1 Problema maestro
Observemos que la demanda por dinero en cada cajero, λit no depende de la ruta que realiza lavisita, mientras que tanto la demanda desde el momento de la visita hasta el final del periodo λ+it ,como la carga entregada qit, śı lo hacen: λ+it depende del momento de la visita y qit es una decisionque esta incluida en la definición de ruta. Para formular el problema maestro, la carga entregaday la demanda hasta el final del periodo son parametros asociados a la ruta que visita al cajeroautomático. En particular, para la demanda hasta el final del periodo vamos a considerar que laruta se ejecuta lo más tarde posible, es decir, con el camión retornando a la base al final del periodo.
CLAIO-2016
182

El instante en que la ruta parte, se incorporará como variable de decisión.
Parámetros
Mi: cantidad de efectivo máxima que puede cargar una gaveta para el cajero automático i;Qirt: cantidad de efectivo entregado al cajero automático i en el periodo t por la ruta r;Λ̄irt: demanda por efectivo en el cajero automático i en el periodo t despues que llega elcamion que ejecuta la ruta r, si esta se ejecuta lo más trade posible;Rit: conjunto de rutas que visitan al cajero automático i en el periodo t;crt: costo de la ruta r del periodo t;drt: duración de la ruta r del periodo t, como fracción del periodo;gi: costo unitario por faltante de dinero en cajero i;hit: costo unitario de inventario en cajero i al inicio del periodo t (costo de oportunidad deldinero).
Variables estáticas
yit: variable binaria que vale 1 si hay quiebre de inventario en el cajero automático i en elperiodo t;sit: variable continua no negativa que registra el nivel de inventario en el cajero automáticoi al comienzo del periodo t;oit: variable continua no negativa que registra el nivel de quiebre de inventario en el cajeroautomático i durante el periodo t.
Variables dinámicas
xrt: variable binaria que vale 1 si la ruta r es seleccionada en el periodo t;frt: variable continua no negativa que indica el instante de inicio de la ruta r en el periodo t.Vale 0 si la ruta no se ejecuta, es decir, si xrt = 0.
El problema maestro restringido (observar que el conjunto de columnas para el periodo t esRt = ∪iRit) se muestra en la página siguiente.
La función objetivo minimiza el costo total asociado a las decisiones tomadas. Este costo esla suma de los costos de ejecutar las rutas seleccionadas, el costo asociado a enfrentar quiebres deinventario y el costo de oportunidad del dinero almacenado en los cajeros. Las restricciones (3)-(7)son para describir la dinámica de la evolución del inventario en cada cajero automático descritapor las ecuaciones (1) y (2). Las restricciones (8) y (9) se construyen para determinar el nivel delquiebre de inventario, si se produce, en cada cajero automático. La restriccion (10) asegura quepara cada cajero automático, y en cada periodo, no se seleccionará más de una ruta que lo visite.La restricción (11) limita el máximo tiempo que se puede anticipar una ruta e impone la condiciónque frt = 0 si xrt = 0.
CLAIO-2016
183

min∑
i,t
gioit +∑
r,t
crtxrt +∑
i,t
hitsit
−sit + si,t+1 −Mi
∑
r∈Rit
xrt − λityit ≤ −λit ∀i, t (3)
sit − si,t+1 −Mi
∑
r∈Rit
xrt ≤ λit ∀i, t (4)
−si,t+1 +∑
r∈Rit
(Qirt − Λ̄irt
)xrt + λit
∑
r∈Rit
frt ≤ 0 ∀i, t (5)
si,t+1 +∑
r∈Rit
(−Mi +Qirt − Λ̄irt
)xrt + λit
∑
r∈Rit
frt ≤Mi ∀i, t (6)
si,t+1 −∑
r∈Rit
(Qirt − Λ̄irt
)xrt +Miyit − λit
∑
r∈Rit
frt ≤Mi ∀i, t (7)
−sit +∑
r∈Rit
Λ̄irtxrt − λit∑
r∈Rit
frt − oit ≤ −λit ∀i, t (8)
−λityit + oit ≤ 0 ∀i, t (9)∑
r∈Rit
xrt ≤ 1 ∀i, t (10)
−(1− drt)xrt + frt ≤ 0 ∀r, t (11)
3.2 Subproblema
El subproblema de generación de columnas, corresponde a obtener rutas que pueden ser realizadaspor los camiones. Una vez resuelta la relajación lineal del problema maestro restrigindo, se utilizala información de las variables duales para determinar si existen rutas no consideradas que tengan,en las condiciones actuales, costo reducido negativo. Para esto se minimiza el costo reducido entrelas rutas factibles no incluidas en el problema maestro.
Para construir una ruta, se debe determinar la secuencia de cajeros y el monto que llevará lagaveta que se dejará en cada cajero. Además, se determina mejor momento para iniciar la ruta.Para los fines del problema maestro, la información que se obtiene corresponde a los parámetrosQirt, Λ̄irt, crt y drt.
Denotemos las variables duales asociadas a las restricciones (3)-(10) del problema maestro re-stringido aśı: αit son las duales de las restricciones (3), βit son las duales de las restricciones (4), γitson las duales de las restricciones (5), φit son las duales de las restricciones (6), ζit son las duales delas restricciones (7), δit son las duales de las restricciones (8) y µt son las duales de las restricciones(10).
El subproblema puede ser formulado con un modelo de programación entera mixta. Lo que sedesea es determinar una ruta factible visitando un conjunto de cajeros, lo que corresponde a unaruta en un problema cásico de ruteo de veh́ıculos. En esta primera versión del enfoque, utilizamosun modelo simple por arcos y con variables de tiempo de visita similar a la formulación MTZ parael TSP [5].
Para formular el modelo, definimos dos conjuntos de variables. Las variables binarias xipjq
CLAIO-2016
184

toman el valor 1 si la ruta visita el cajero i con una gaveta de tipo p y, a continuación, el cajeroj con una gaveta tipo q. Abusando un poco la notación, la bodega es considerada el “cajero 0”y definimos las variables binarias x0jq que toman el valor 1 si el primer cajero visitado luego desalir de la bodega es el cajero j y se le entrega una gaveta de tipo q y las variables binarias xip0que toman el valor 1 si el último cajero visitado antes del retorno a la bodega es el cajero i y sele entrega una gaveta de tipo p. Las variables enteras no negativas wi corresponden al instantede visita del cajero i si es visitado, y toman el valor 0, si no. La variable w0 correspondiente a labodega, registra el tiempo de retorno al final de la ruta.
Los nuevos parámetros necesarios son: tij , el tiempo de viaje del cajero i al cajero j; Q̄, la cargamáxima que puede transportar un camión; Lq, la cantidad de dinero en una gaveta de tipo q y T ,la duración del periodo.
Las restricciones siguientes modelan las condiciones para el subproblema de determinar unaruta para el periodo t es:
∑
j,q
xipjq −∑
j,q
xjqip = 0 ∀i, p; i 6= 0 (12)
∑
j,q
x0jq = 1 (13)
∑
i,p
xip0 = 1 (14)
−wj + wi + 2T∑
p,q
xipjq ≤ 2T − tij ∀i, j; i 6= 0 (15)
−wj + tij∑
q
x0jq ≤ ∀j 6= 0 (16)
wj − T∑
i,p,q
xipjq ≤ 0 ∀j 6= 0 (17)
∑
i,j,p,q
Lqxipjq ≤ Q̄ (18)
Las restricciones (12) son las conservaciones de flujo en las visitas a los cajeros. Las restricciones(13) y (14) garantizan que la ruta sale y termina en la bodega. Las restricciones (15) corresponden alas relaciones temporales entre las visitas a dos cajeros consecutivos mientras que las (16) garantizanque el primer cajero no sea visitado antes del tiempo de viaje requerido desde la bodega. Lasrestricciones (17) garantizan que la ruta se puede ejecutar dentro del periodo y fija en cero las wi
de los cajeros no visitados. La restricción (18) impone la condición sobre el máximo dinero que sepuede transportar en el camión.
Con las variables definidas, la función objetivo del subproblema queda:
min−µt +∑
i,j,p,q
[Mi(αit + βit + φit)− Lp(γit + φit − ζit)]xijpq
+∑
i
λit(−γit + φit − ζit − δit)(1− wi) (19)
CLAIO-2016
185

4 Comentarios finales e investigación futura
En este trabajo se ha presentado un enfoque de programación entera mixta basado en generaciónde columnas para un problema de inventario y ruteo en el contexto de la reposición de dinero enuna red de cajeros automáticos. El problema considerado difiere de los tratados anteriormente enla literatura ya que considera la posibilidad de que haya faltante de efectivo en los cajeros (quiebresde inventario, para el problema general de ruteo e inventarios), los cuales son penalizados.
En este punto del desarrollo se ha trabajado con algunos supuestos simplificadores, como porejemplo, que la demanda es determińıstica y más aun, que el dinero se consume de manera ho-mogénea a lo largo de un periodo. Los resultados con una implementacion preliminar muestran queel enfoque es factible, pero que la calidad de la relajacion lineal no es muy buena: se obtuvierongaps de integralidad mayores al 30% en todos los casos resueltos. En terminos de la metodoloǵıapropuesta, el siguiente paso, actualmente en desarrollo, es implementar un esquema de Branch &Price. En este esquema, la solución del subproblema de generación de columnas se puede resolvercon el modelo de programación entera aqui presentado o con un algoritmo combinatorial basadoen programación dinámica.
Agradecimientos
Esta investigación fue apoyada por CONICYT/FONDECYT/REGULAR/ No. 1141313 y el Insti-tuto de Sistemas Complejos de Ingenieŕıa (financiamiento ICM: P-05-004-F y CONICYT: FBO16).
Referencias
[1] H. Andersson, A. Hoff, M. Christiansen, G. Hasle, and A. Løkketangen. Industrial aspects and literatesurvey: Combined inventory management and routing. Computers and Operations Research, 37:1515–1536, 2010.
[2] A. Campbell and M. Savelsbergh. A decomposition approach for the inventory-routing problem. Trans-portation Science, 38:488–502, 2004.
[3] M. Christiansen. A decomposition of a combined inventory and time constrained ship routing problem.Transportation Science, 33:3–16, 1999.
[4] L. C. Coelho, J.-F. Cordeau, and G. Laporte. Thirty years of inventory-routing. Transportation Science,48:1–19, 2014.
[5] S. Irnich, P. Toth, and D. Vigo. The family of vehicle routing problems. In P. Toth and D. Vigo, editors,Vehicle routing problems: Problems, methods and applications, chapter 1, pages 1–33. SIAM, secondedition, 2014.
[6] H. Larrain, L. C. Coelho, and A. Cataldo. Managing the inventory and distribution of cash in auto-mated teller machines using a variable MIP neighborhood search algorithm. Technical Report 2016-01,CIRRELT, 2016.
[7] J. Song and K. Furman. A maritime inventory routing problem: Practical approach. Computers andOperations Research, 40:657–665, 2013.
[8] R. Van Anholt, L. C. Coelho, G. Laporte, and I. Vis. An inventory-routing problem with pickupsand deliveries arising in the replenishment of automated teller machines. Technical Report 2013-71,CIRRELT, 2013.
CLAIO-2016
186

Pricing and Composition of Multiple Bundles ofProducts and Services and Multiple Market Segments
Alejandro Cataldo - Juan–Carlos FerrerSchool of Engineering, Pontificia Universidad Católica de Chile,
Casilla 306, Correo 22 Santiago, Chile
[email protected] - [email protected]
Resumen
Este paper analiza el problema que enfrenta una empresa que debe determinar el
precio y la composición óptima de un grupo de paquetes de productos/servicios que
desea ofrecer en múltiples segmentos de mercado. El problema es descrito de manera
de asumir que los consumidores son tomadores de decisión que maximizan su utilidad
y que los competidores no reaccionan en el corto plazo a estas decisiones de la empresa.
El problema es enfrentado modelándolo como un problema de programación no
lineal en variables mixtas, el que no resolveremos de manera exacta sino que enfrenta-
mos mediante el uso de Metaheuŕısticas. En este sentido, diseñamos un método de dos
etapas. En la primera etapa encontramos una solución de partida, la que es obtenida
determinando la composición de los paquetes a través del uso del método propuesto
por Bitran y Ferrer (2007), y fijando el precio de estos paquetes mediante una optimi-
zación por gradiente conjugado. Esta solución inicial la mejoramos a través del uso de
diversas Metaheuŕısticas: Tabu Search, Simulating Annealing y Genetic Algorithm.
Los resultados obtenidos muestran que se pueden obtener beneficios económicos al
enfrentar el problema de fijación de precio y composición óptima de manera simultanea,
considerando que todos los paquetes pueden ser comprados en todos los segmentos de
mercado. En nuestro ejemplo de trabajo, vemos que el aumento de la utilidad es de
cerca de un 18 %.
Keywords: Pricing, Bundling, Revenue Management, Multiple Segments, Metaheu-
ristics.
1. Introducción
La estrategia de bundling es una herramienta muy importancia para las empresas que
sirven a clientes con preferencias heterogéneas. Cuando la discriminación de precios no es
1
CLAIO-2016
187

posible, las empresas deben buscar maneras alternativas para maximizar su beneficio, siendo
el diseño de sus productos/servicios y la determinación de un precio óptimo una forma de
hacerlo (Voss et al., 2008). En su forma más simple, bundling consiste en agrupar bienes o
servicios en un paquete y venderlos a un precio global que por lo general es más favorable
que si son vendidos de manera individual (Guiltinan and Gordon, 1988).
La estrategia de bundling juega un papel cada vez más importante en muchas industrias,
incluso algunas empresas del sector de servicios basan sus estrategias de negocio en estrategias
de bundling (Simon y Wuebker en Fuerderer et al. (1999)).
Algunos ejemplos sobre bundling consideran: un paquete de vacaciones que considera:
pasaje de avión ida y vuelta; alojamiento en un hotel y alquiler de un veh́ıculo. Otros ejemplos
se encuentran en: paquetes de seguros (vida y cesant́ıa), cartas de restaurantes (entrada, plato
principal, postre), paquetes de telecomunicaciones (local, larga distancia, acceso a internet,
teléfono celular) y en centros de relajación (piscina, masaje, jacuzzi, sauna).
Los trabajos de Dukart (2000) y Swartz (2000) sugieren que a las empresas les acomoda
más el concepto de agrupación de servicios que a clientes particulares. Ellos argumentan esto
en base a que las empresas requieren un número más grande de servicios y prefieren pagar
una sola cuenta. Altinkemer (2001) señala que desde la Ley de desregulación de Telecomuni-
caciones del año 1996 en Estados Unidos, las empresas de telecomunicaciones, tales como las
compañ́ıas telefónicas locales y de larga distancia, proveedores de servicios Internet (ISP),
compañ́ıas de cable y empresas de entretenimiento han estado luchando para ser la ventani-
lla única de mayor información. Por lo tanto, muchas compañ́ıas han unido sus fuerzas con
otras para completar su oferta. Como se evidencia mediante la fusión de MCI WorldCom y
Sprint, SBC, y Ameritech, AT&T y TCI, y Time Warner.
En lo que sigue el art́ıculo se organiza de la siguiente manera. En la Sección 2 se realiza
una revisión del estado del arte en el tema de bundling. En la Sección 3 se define el problema
que se aborda en este trabajo, considerando que se desea determinar la composición y precio
óptimo para múltiples bundles, que existe un único segmento de clientes heterogéneos entre
śı, y que se busca la maximización de la utilidad de la empresa. En la Sección 4 presentamos
un modelo de elección de los clientes basado en la maximización de su utilidad de éstos, y se
construye un modelo que permite dar respuesta al problema antes planteado. En la Sección
5 se resuelven los problemas de fijación de precios y determinación de la composición óptima
para los múltiples bundles, y en la Sección 7 se realiza un análisis de sensibilidad frente a
los parámetros más importantes del problema. Finalmente, en la Sección 7, se expresan las
conclusiones obtenidas en esta investigación y se proponen posibles extensiones y temas para
futuras investigaciones.
2
CLAIO-2016
188

2. Revisión Bibliográfica
El bundling ha sido ampliamente estudiado desde la perspectiva del comportamiento de
los consumidores, desde un punto de vista económico y desde las perspectivas del mercado.
En el área del comportamiento del consumidor, algunos estudios como los realizados por
Yadav and Monroe (1993) y Yadav (1994) se han centrado en el proceso por el cual los con-
sumidores evalúan diferentes paquetes de productos. Suri and Monroe (2000) examinaron
los efectos de factores contextuales, tales como las intenciones de los consumidores antes de
realizar la compra en su evaluación de los paquetes de productos. También se ha examinado
el grado en que el bundling puede estimular la demanda en condiciones de promoción es-
pećıfica. Sus resultados han mostrado que realizar promociones en los elementos individuales
que conforman un bundle puede reducir significativamente la evaluación que hacen los con-
sumidores de los paquetes de ofertas. Un estudio realizado por Herrmann, Huber, y Coulter
(Fuerderer et al., 1999) constató que el precio de descuento y la complementariedad de los
componentes del paquete parecen ser factores clave en la intención de compra.
En aquellos mercados donde los clientes poseen diferentes niveles de conocimiento de
los componentes del bundle, y por lo tanto, los clientes con un mayor conocimiento tienen
una mayor variabilidad en su precio de reserva por un componente, tal como lo exponen
Basu and Vitharana (2009). En su trabajo estos autores utilizan un modelo anaĺıtico para
determinar las condiciones que permiten obtener el máximo beneficio para cada una de las
estrategias analizadas: de venta de componentes individuales; de venta solo de bundles; y
mixta. Por otra parte, Gourville and Soman (2001) y Soman and Gourville (2000) muestran
que la agrupación de servicios puede dañar el consumo, y concluyen que ante la existencia
de costos hundidos es inducido el consumo de productos pues los consumidores están más
consciente de estos costos. Por lo tanto, si se emplea una estrategia de bundling los costos
hundidos tienden a ocultarse, con lo cual deja de existir el efecto antes descrito, y entonces,
se disminuye el consumo.
En otros estudios, se han presentado criterios numéricos para determinar la estrategia de
bundling que resulta ser más rentable. Esta ĺınea de investigación se basa en el estudio de
los bundles que contienen componentes no deseados (que reducen valor) y de los que proveen
un valor más alto al valor agregado de los elementos individuales que lo componen (Scha-
malensee, 1982; Dansby and Conrad, 1984; Schamalensee, 1984). Posteriormente, Salinger
(1995) extiende el resultado de Adam and Yellen (1976) y Schamalensee (1984), sugiriendo
que en presencia de funciones de demanda lineal y de costos relativamente altos y precios de
reserva correlacionados positivamente, se puede aumentar el incentivo para hacer bundling
si las economı́as de alcance prevalecen.
3
CLAIO-2016
189

Desde la perspectiva del consumidor, Hitt and Chen (2005) describen el concepto de bund-
ling personalizado, concepto bajo el cual los clientes tienen el derecho a escoger un bundle
compuesto por M productos de un total de N a cambio de un precio fijo, mostrando que su
estrategia supera a las estrategias de bundling puro y de no hacer bundling cuando existen
costos marginales positivos, y cuando la valoración de los consumidores es heterogénea. En
un trabajo más reciente, se indica que la estrategia de bundling personalizado mejora los
beneficios de la compañ́ıa cuando los consumidores no dan una valoración positiva a todos
los bienes, en comparación a estrategias de bundling puro o de no hacer bundling (Wu et al.,
2008; Yang and Ng, 2010).
Se han presentado modelos para encontrar segmentos de mercado para bundles de pro-
ductos heterogéneos en múltiples categoŕıas de productos, estimar los precios de reservas
individuales por un bundle, y determinar su precio óptimo para diferentes segmentos de
mercado (Chung and Rao, 2003; Mookherjee and Friesz, 2008). En diversos trabajos se ha
concluido que una modelación incorrecta de los precios de reserva puede llevar a grandes
pérdidas a la compañ́ıa, y ofrecer paquetes a mitad de temporada puede ser más efectivo que
realizar una reducción de precios para cada producto de manera individual (Gülder et al.,
2009; Bulut et al., 2009).
En otros estudios se proporcionan un enfoque de optimización que considera simultánea-
mente el diseño y fijación de precios de bundles. En Hanson and Martin (1990) se entrega
una formulación de programación matemática para determinar la configuración y el precio
de los bundles de manera de obtener el máximo beneficio, pero sin considerar expĺıcitamente
la variedad completa de soluciones factibles. Posteriormente, Venkatesh and Mahajan (1993)
consideraron dos dimensiones en el proceso de toma de decisiones de los consumidores (tiem-
po y dinero) y determinan el precio óptimo para un bundle dado, bajo diferentes estrategias
de bundling. En los trabajos desarrollados por Green et al (Green et al., 1991, 1992) se
presenta un algoritmo que permite resolver un modelo estocástico de programación entero
mixto para determinar los precios y las configuraciones de un bundle de productos. También
se ha utilizado un enfoque de programación no lineal entero mixto para estudiar bundling
personalizados para bienes de información. Considerados diferentes supuestos sobre la es-
tructura de costos de la compañ́ıa y la valoración de los consumidores (Wu et al., 2008).
En un trabajo más reciente, Proano et al. (2011) construyen un modelo de programación no
lineal entero-mixto para determinar el rango de precios factibles y el número de vacunas de
bundles de anticuerpos, de manera de maximizar la suma del beneficio total de los produc-
tores y del excedente total de los consumidores. Para resolver este problema, proponen una
heuŕıstica constructiva que les permita aproximarse a la solución óptima.
Finalmente, el problema de cómo determinar la composición y precio de un único bundle a
4
CLAIO-2016
190

fin de maximizar el beneficio total esperado por una compañ́ıa, considerando que este bundle
será ofrecido en un mercado donde competirá con bundles de otras compañ́ıas es estudiado
por Bitran and Ferrer (2007), y su extensión a múltiples bundles para un único segmento de
mercado fue presentado y resuelto por Cataldo et al. (2014).
Este trabajo de investigación se relaciona con la literatura anteriormente presentada.
Espećıficamente, se busca determinar la composición y el precio óptimo para un conjunto
de b bundles que se desea introducir al mercado. En consecuencia, este problema es una
extensión natural al trabajo desarrollado por Bitran and Ferrer (2007), y se entrega una
contribución al estado del arte proponiendo un modelo y un enfoque de solución para el
problema de determinación de la composición y el precio óptimo para múltiples bundles.
3. Definición del Problema
En este trabajo se aborda el problema que enfrenta una compañ́ıa que debe determinar
la composición y fijación del precio para múltiples bundles que serán ofrecidos a múltiples
segmentos de consumidores. La compañ́ıa tiene por objetivo maximizar su propio beneficio
formando estos bundles y determinando para éstos su precio óptimo (Urban and Hauser,
1993). Una versión de este problema que considera la introducción de un único bundle a un
único segmento de mercado fue propuesta y resuelta por Bitran and Ferrer (2007), posterior-
mente Cataldo et al. (2014) resuelven el problema cuando se debe determinar la composición
de múltiples bundles para ser ingresados a un único segmento de mercado. En este paper
se muestra cómo extender el alcance de estos dos trabajos, buscando determinar precio y
composición óptima de múltiples bundles que serán ofrecidos en múltiples segmentos de
mercado.
4. Formulación del Modelo
Antes de presentar el modelo que propondremos, se introducirá la siguiente notación para
los conjuntos, ı́ndices, parámetros y variables que serán utilizados en su formulación. Los
conjuntos corresponden a:
5
CLAIO-2016
191

W : conjunto de segmentos de mercados considerados. Abusando de la notación diremos
que Card(W) =W .
M : conjunto de componentes del bundle. Abusando de la notación diremos que
Card(M) =M.
K : conjunto de bundles que deben ser diseñados. Abusando de la notación diremos
que Card(K) = K.
Sj : conjunto de alternativas para la componente j de un bundle.
Los ı́ndices a emplear son:
i : ı́ndice asociado a los segmentos de mercado considerados.
k, k̂ : ı́ndice asociado a los bundles ofrecidos por la compañ́ıa.
n : ı́ndice asociado a los bundles ofrecidos por la competencia.
j : ı́ndice asociado al conjunto de componentes de un bundle.
u : ı́ndice asociado a las alternativas de selección posibles para una componente.
Los parámetros son:
p̂n : precio al que es ofrecido el bundle n por la competencia.
cju : costo de la alternativa u del conjunto de componentes j.
I iju : atractividad de la alternativa u del conjunto de componentes j para el segmento
i.
aij : peso que tiene en atractividad para el segmento i la componente j de la composición
del bundle.
H i : proporción de mercado que le corresponde el segmento i.
γi : utilidad de los bundles de mercado y de la no-compra ofrecidos en el segmento de
mercado i.
g : número de bundles ofrecidos por la competencia.
βi : sensibilidad de la utilidad frente al precio que presenta el segmento de mercado i
por un bundle (no depende del bundle que observa un individuo del segmento).
Las variables utilizadas para la construcción del modelo son:
6
CLAIO-2016
192

xjuk : variable binaria que indica si la alternativa u del conjunto de componentes j es
elegida en la composición del bundle k.
Xk : matriz binaria de h×m que representa la conformación del bundle k.
pk : precio del bundle k (el precio de un bundle es el mismo para todos los segmentos
de mercado).
qik : probabilidad de que un consumidor del segmento de mercado i escoja el bundle
k.
cXk: matriz binaria de h×m que representa el costo de la conformación del bundle k.
I iXk: matriz binaria de h × m que representa la atractividad de la conformación del
bundle k en el segmento de mercado i.
Los bundles que no están bajo el control de la compañ́ıa son considerados como infor-
mación dada en este modelo. Esta información está caracterizada por el atractivo de los
bundles de estas compañ́ıas en cada uno de los segmentos de mercado, IXin
con n ∈ N e
i ∈ W , y por su precio, p̂n con n ∈ N (mismo precio en todos los segmentos de mercado).
Las decisiones que están bajo el control de la compañ́ıa son la composición de los k bundles
que ésta ofrecerá a losW segmentos de mercado y el precio al que serán ofrecidos, de manera
de maximizar el beneficio que la empresa obtiene. Por lo tanto, la caracterización de estas
decisiones será a través de la atractividad de estos bundles en cada uno de los segmentos
de mercado I iXk, de su costo de composición cXk
, y de su precio pk. Asumiremos que los
competidores no reaccionan en el corto plazo a las decisiones de la compañ́ıa, y por lo tanto,
el modelo descrito será estático.
Desde el punto de vista de los consumidores, ellos pueden no comprar ninguno o escoger
solo uno de los bundles ofrecidos en el mercado. Para este efecto se considera que los consu-
midores son maximizadores de utilidad estocástica, supuesto que es compartido por muchos
otros modelos de elección de consumidores. Esto implica que la opción preferida por un con-
sumidor será aquella que le entregue la máxima utilidad percibida. Según expone McFadden
(1974), los consumidores observan cada elección sobre un conjunto de atributos. Entonces,
los consumidores realizan una elección basada en la evaluación total de cada posible selección
a través de funciones de utilidad, escogiendo aquella que les otorga el mayor valor.
En consecuencia, modelamos la utilidad que cada bundle entrega a un consumidor cual-
quiera para un segmento de consumidores cualquiera, como la suma de una componente
determińıstica y una componente estocástica. La parte determińıstica se denota por V (·) y
depende del precio y composición del bundle evaluado. La parte estocástica es una perturba-
ción independiente llamada εi, que considera todos los factores que hacen que el consumidor
no pueda determinar de manera exacta la utilidad de un producto. El siguiente modelo de
7
CLAIO-2016
193

utilidad aleatoria representa la utilidad percibida por los consumidores:
Ui = V i(pk, Xk) + εi ∀i = 1, ...,W , k = 1, ...,K,
donde la utilidad determińıstica está dada por V i(pk, Xk) = I iXk+ βipk, y la atractividad
del bundle conformado es I iXk=∑
j∈M aij∑
u∈Sj Iijuxjuk, donde se debe tener en cuenta que
el parámetro aij > 0 para todo j ∈ M e i ∈ W , y que el parámetro βi < 0 es un escalar
que entrega la sensibilidad de la utilidad frente al precio para el segmento de consumidores
i ∈ W .
Ben-Akiva and Lerman (1985) y McFadden (1974) muestran que la probabilidad de esco-
ger un bundle de entre un conjunto de alternativas tiene una forma cerrada de solución que
está dada por:
qi(pk, Xk) =eV (p,X)
ξ + eV (p,X)
donde ξ representa la utilidad de todos los bundles ofrecidos al segmento de consumidores en
el mercado más la utilidad de no compra. Si se considera que la compañ́ıa ofrece k bundles,
se tiene que la probabilidad de que sea escogido uno de estos k bundles en el segmento de
mercado i está dado por:
qik(pk, Xk) =eV
i(pk,Xk)
γi +∑k̂∈K
eVi(pk̂,Xk̂)
(1)
donde, considerando que V i0 es la utilidad determińıstica de no comprar para el segmento de
mercado i, se tiene que:
γi = eVi0 +
∑
n∈NeV
i(pn,Xn)
Considerando todo lo anteriormente expuesto, se presenta el siguiente modelo para deter-
minar la composición y fijación del precio de los K bundles que serán ofrecidos en un estos
W segmentos de mercado. Este problema lo denominamos A bundle and multiple segments
problem (MBMSP).
(MBMSP) máx Π(p1, . . . , pK , X1, . . . , XK) =K∑
k=1
W∑
i=1
H iqik(pk, Xk)(pk − cXk) (2)
8
CLAIO-2016
194

sujeto a:
qik(pk, Xk) =eIiXk
+βipk
γi +K∑k̂=1
eIiX
k̂+βipk̂
∀ i = 1, . . . ,W, k = 1, . . . , K. (3)
γi = eVi0 +
∑
n∈NeI
iXn
+βip̂n ∀ i = 1, . . . ,W. (4)
cXk=∑
j∈M
∑
u∈Sjcjuxjuk ∀k = 1, . . . , K. (5)
I iXk=∑
j∈Maij∑
u∈SjIjuxjuk ∀ i = 1, . . . ,W, k = 1, . . . , K. (6)
∑
u∈Sj
xjuk = 1 ∀ j ∈M, k = 1, . . . , K. (7)
∑
j∈M
∑
u∈Sj
xujkxujk̂ ≤M− 1 ∀ k = 1, . . . , K, k̂ = k + 1, . . . , K. (8)
xjuk ∈ {0, 1} ∀ j ∈M, u ∈ Sj, k = 1, . . . , K. (9)
pk ≥ 0 ∀k = 1, . . . , K. (10)
En la siguiente sección se entrega un enfoque de solución para MBMSP.
5. Resolviendo el Problema de Multiples Bundling y
Multiples Segmentos
La estructura del MBMSP permite separar el proceso de resolución en dos fases. En la
primera fase se determina el precio óptimo de los bundles (pk) considerando conocida la
composición del bundle (X). En la segunda fase se utiliza este precio óptimo para obtener
la composición que logra maximizar el beneficio.
5.1. Problema de optimización del precio del Bundle
Para determinar el precio óptimo de estos bundles consideraremos conocida la composición
de cada uno de ellos. Dado esto, las decisiones y restricciones asociadas a la composición se
eliminan, y reemplazando la restricción (3) en la función objetivo (2) se define el siguiente
9
CLAIO-2016
195

problema de optimización sin restricciones, que depende del precio de los bundles:
Π = máxp1,...,pK
K∑
k=1
W∑
i=1
H i eIiXk
+βipk
γi +K∑l=1
eIiXl
+βipl
(pk − cXk) (11)
del cual se desprende la siguiente proposición.
Proposición 1 El precio óptimo del k-ésimo bundle no se puede obtener de forma cerrada,
y queda determinado por la siguiente expresión:
p∗k = cXk+
(W∑i=1
K∑t=1:t6=k
H iβiqitqik (pt − cXt)
)−(W∑i=1
H iqik
)
W∑i=1
H iβiqik (1− qik)(12)
donde en todas las expresiones qik se encuentra pk. Se observa que el precio óptimo de cada
bundle depende del precio y de la composición de ese bundle, luego la expresión no es cerrada.
El precio óptimo pk es siempre mayor o igual a su costo de composición (cXk) siempre que se
asegure que pt − cXt ≥ 0 para todo bundle. Esto ya que H i, qit, qik ≥ 0, βi < 0, y (1− qik) ≥ 0
para todo segmento.
Demostración: Ver apéndice ??. �Esta función, que es del tipo p = f(p), no es contractante (demostración pendiente), luego,
no es una función de punto fijo. Ahora bien, es interesante destacar, y tal como se aprecia
en la expresión 12, el precio óptimo de un bundle que se ofrecerá en W segmentos, depende
del tamaño de cada uno de los mercado H i, de la intensidad de la competencia en cada uno
de los mercados γi y la sensibilidad al precio βi. Para verificar existencia y unicidad en la
búsqueda se estudia la forma de la función objetivo (11). Se postula la Proposición 2.
Proposición 2 La función objetivo (11) es cuasicóncava para precios tales que p ≥ cx.
Demostración: Ver apéndice ??. �Luego, es posible determinar el precio óptimo para los K bundles, dada la composición de
cada uno de ellos, utilizando cualquiera de los métodos existentes para búsqueda numérica
del máximo de una función no lineal. Particularmente, se utiliza el método del gradiente
conjugado en las pruebas numéricas que se realizaron, y cuyos resultados se muestran más
adelante.
10
CLAIO-2016
196

5.2. Problema de determinación de la composición optimización
del Bundle
La expresión obtenida en la sección anterior para determinar el precio óptimo de un
bundle, en este caso, no es una expresión cerrada. Esto impide su uso como preoptimización
para enfrentar el problema de composición tal como se realizó en Bitran and Ferrer (2007)
o en Cataldo et al. (2014).
Luego, para enfrentar el problema evaluaremos tres métodos heuŕısticos que permiten
trabajar sobre problema de optimización no lineales en variables enteras: Greedy Randomize
Adaptative (GRASP), Tabu Search (TS) y Algoritmos Genéticos (AG).
El procedimiento que empleamos es el mismo para todas las heuŕısticas, y se enumera a
continuación:
Paso 1: determinación de una composición inicial para los K bundles. Para esto, los
pasos son:
(1) Se componen los bundles óptimos de cada segmento según Bitran and Ferrer
(2007) y se determina la suma de sus ı́ndices BF para todos los segmentos de
mercado, multiplicando el resultado por H i, resultado que llamaremos SBF .
(2) Estos bundles se enlistan en orden descendente según el valor SFB que tienen.
Llamaremos L a esta lista y se construye el indicador s(h) que corresponde al
segmento desde el que fue confeccionado el bundle de la posición h en esta lista.
(3) Se construye el indicador n(i) que indica el número de bundles que han “sido
compuestos” desde el segmento i. Este indicador se inicializa en 1 para todo
i = 1, . . . ,W .
(4) La composición del bundle que tiene mayor SFB (y que es el primero en L) es
la composición inicial del bundle 1. Para el bundle seleccionado se conoce s(1), y
por lo tanto, su n(s(1)) = 2.
(5) Se compone el segundo mejor bundle del segmento s(1), determinado su SBF .
Se incorpora a L en la primera posición reemplazando al bundle seleccionado
anteriormente y se vuelve a ordenar L en orden descendente según SBF .
(6) La composición del bundle que tiene mayor SFB (y que es el primero en la nueva
L) es la composición inicial del bundle 2. Para el bundle seleccionado se conoce
s(1), y por lo tanto, su n(s(1)).
(7) Para determinar la composición inicial del tercer bundle se repiten los pasos (5)
y (6), y aśı sucesivamente.
11
CLAIO-2016
197

(8) Se repiten los pasos (5) y (6) hasta determinar la composición del bundle K
(último bundle a componer).
Paso 2: Teniendo determinada una composición para cada uno de los K bundles, se
determina un precio para cada uno de ellos. Para esto, se utiliza el método del gradiente
conjugado. Entonces, se obtiene p1 (X1, . . . , Xk), p2 (X1, . . . , Xk), . . ., pK (X1, . . . , Xk).
Paso 3: Se utiliza la heuŕıstica para determinar si la solución actual en la iteración n,
Xn1 , X
n2 , . . . , X
nK , p
n1 , pn2 , . . . , p
nK , cumple con las condiciones de detención de la heuŕısti-
ca (criterios de mejoramiento del valor de la función objetivo). De ser aśı, se detiene el
procedimiento y la solución actual se presenta como solución del problema. Si no es aśı,
a través de la heuŕıstica se determina una nueva composición Xn+11 , Xn+1
2 , . . . , Xn+1K ,
y se regresa al Paso 2.
En la siguiente sección se muestran los resultados sobre el desempeño de cada una de las
heuŕısticas.
6. Resolución de ejemplos
6.1. Caso de ejemplificación
Consideremos el caso espećıfico para dos segmentos de mercado, a los que les serán oferta-
dos dos bundles. La composición de cada bundle implica la selección de cuatro componentes.
En la Tabla 1 se entrega la información sobre el costo y el atractivo en cada segmento para
cada una de las alternativas de cada componente. También se muestra en la tabla el ı́ndi-
ca BF (definido en Bitran and Ferrer (2007)) para cada componente en cada segmento de
mercado. Los valores de los parámetros utilizados en este ejemplo son: K = 2, H1 = 0.07,
H2 = 0.93, γ1 = γ2 = 420,000 y β1 = β2 = −0.007.
Las celdas ennegrecidas y en gris indican cuál es la selección óptima para cada componente
si se estuviera diseñando un bundle espećıfico para cada uno de los dos mercados, y entonces,
considerando que no existe el otro mercado.
Al resolver esta instancia con el método propuesto en la sección 5.2, se pueden obtener
los siguientes resultados:
Estos resultados permiten concluir:
Composición óptima para segmento 1 - BO1: 15-24-35-44 a un precio óptimo de 2.801
y costo del bundle de 2.300.
12
CLAIO-2016
198
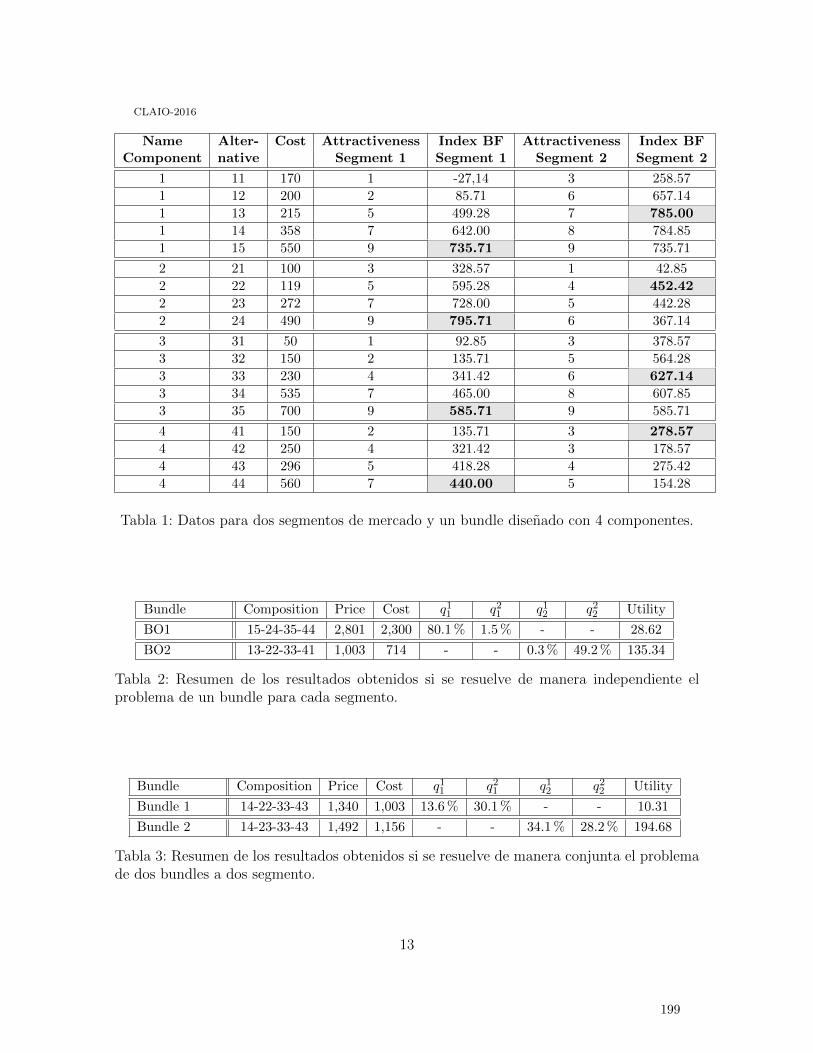
Name Alter- Cost Attractiveness Index BF Attractiveness Index BFComponent native Segment 1 Segment 1 Segment 2 Segment 2
1 11 170 1 -27,14 3 258.57
1 12 200 2 85.71 6 657.14
1 13 215 5 499.28 7 785.00
1 14 358 7 642.00 8 784.85
1 15 550 9 735.71 9 735.71
2 21 100 3 328.57 1 42.85
2 22 119 5 595.28 4 452.42
2 23 272 7 728.00 5 442.28
2 24 490 9 795.71 6 367.14
3 31 50 1 92.85 3 378.57
3 32 150 2 135.71 5 564.28
3 33 230 4 341.42 6 627.14
3 34 535 7 465.00 8 607.85
3 35 700 9 585.71 9 585.71
4 41 150 2 135.71 3 278.57
4 42 250 4 321.42 3 178.57
4 43 296 5 418.28 4 275.42
4 44 560 7 440.00 5 154.28
Tabla 1: Datos para dos segmentos de mercado y un bundle diseñado con 4 componentes.
Bundle Composition Price Cost q11 q21 q12 q22 Utility
BO1 15-24-35-44 2,801 2,300 80.1 % 1.5 % - - 28.62
BO2 13-22-33-41 1,003 714 - - 0.3 % 49.2 % 135.34
Tabla 2: Resumen de los resultados obtenidos si se resuelve de manera independiente elproblema de un bundle para cada segmento.
Bundle Composition Price Cost q11 q21 q12 q22 Utility
Bundle 1 14-22-33-43 1,340 1,003 13.6 % 30.1 % - - 10.31
Bundle 2 14-23-33-43 1,492 1,156 - - 34.1 % 28.2 % 194.68
Tabla 3: Resumen de los resultados obtenidos si se resuelve de manera conjunta el problemade dos bundles a dos segmento.
13
CLAIO-2016
199

Composición óptima para segmento 2 - BO2: 13-22-33-41 a un precio óptimo de 1.003
y costo del bundle de 714.
Como se aprecia, la probabilidad de compra es de 80,1 % para BO1 en el segmento
1 y de 49,2 % para BO2 en el segmento 2. Esto permite que BO1 tenga 1,5 % de
probabilidad de ser escogido en el segmento 2 y BO2 de 0,3 % de ser escogido en el
segmento 1. La utilidad es esta decisión es 163.96.
La composición óptima considerando ambos segmentos: 14-22-33-43 a un precio óptimo
de 1.340, que tiene una atractividad de 21 y 22 para el segmento 1 y 2 respectivamente.
Su costo es de 1.003. La probabilidad de que sea adquirido en el segmento 1 es 13,6 %
y 30,1 % en el segmento 2.
El segundo bundle es el 14-23-33-43 a un precio de 1.492, que tiene una atractividad de
23 y 23 para el segmento 1 y 2 respectivamente. Su costo es de 1.156. La probabilidad
de que sea adquirido en el segmento 1 es 34,1 % y 28,2 % en el segmento 2.
La utilidad total que se obtiene es de 193,41 (29,45 más).
Lo interesante de este resultado es que la composición óptima no es la composición óptima
que se tendŕıa si se pensará en un único segmento de mercado.
6.2. Resolución Masiva
Con el fin de determinar que tan bien funciona el procedimiento heuŕıstico diseñado
para determinar precio y composición óptima, se resolvieron 1.000 problemas experimentales
considerando dos segmentos de mercado y dos bundles a diseñar. Para realizar la comparación
entre la solución entregada por nuestro enfoque y la solución óptima, se resolvieron los 1.000
problemas por enumeración exhaustiva.
Todos los experimentos poseen al menos 4 y a lo más 5 componentes, cada componente
cuenta con al menos 3 y a lo más 6 alternativas, con lo que el problema dimensionalmente
más grande es uno en que se pueden diseñar 7.776 bundles, que da una enumeración de más
de 30 millones de parejas de bundles. Para evitar esto, los problemas se diseñaron de manera
que no se superarán las 100.000 parejas de bundles distintos.
En la Tabla 4 se entrega un resumen de los resultados obtenidos. Cabe destacar que cada
problema se corŕıa por a lo más 5 minutos sino cumpĺıa antes con los criterios de detención
de las heuŕısticas respectivas.
Los resultados muestran que de las tres heuŕısticas TS es la que tiene mejor desempeño
en todos los indicadores. Con esta heuŕıstica se alcanza el óptimo un 96.1 % de las veces,
14
CLAIO-2016
200

Indicator GRASP TS GA
Percentage cases with optimal solution found 88.5 96.1 93.5Average GAP 0.70 0.19 0.76Average GAP without cases with optimal solution found 3.25 1.71 4.61Maximum GAP 10.70 5.35 18.22Standard Deviation GAP 1.8 0.7 2.5
Tabla 4: Resumen de los resultados de 1.000 experimentos realizados.
obteniéndose un GAP promedio de 1.71 % en los casos en los que no se alcanza el óptimo
(con un máximo de 5.35 %).
7. Conclusiones y Comentarios Finales
El problema enfrentado difiere significativamente del problema de determinación de precio
y composición óptima para un bundle que será ofertado en un único segmento de mercado
y para múltiples bundles que son ofertas en un único segmento de mercado. Entre otras
caracteŕısticas que los diferencian, la atractividad con que cada segmento de mercado valora
las diferentes opciones para cada componente resulta la más evidente y la que da sentido
inicial a este trabajo. Alternativas muy bien valoradas en uno de los segmentos de mercado
podŕıan no serlo en otros, por lo que no resulta ser necesariamente cierto que la composición
óptima de alguno de los segmentos resulte ser la composición óptima de este problema.
Al enfrentar el problema apreciamos que la estructura del mismo impide obtener una
expresión cerrada para el precio en función de una composición dada, obteniéndose una
función del tipo punto fijo que puede tener más de una solución. Sin embargo, mediante
técnicas numéricas es posible encontrar el precio óptimo para una composición de bundle
dada. Es interesante destacar que el precio óptimo depende directamente de las caracteŕısticas
de cada uno de los segmentos de mercado. La forma de determinar la composición óptima
se basa en el uso de métodos heuŕısticos tradicionales para búsqueda poblacional. Es posible
realizar esto debido a que contamos con técnicas para determinar el precio óptimo dada
una composición –método del gradiente conjugado–, y que por lo tanto podemos valorizar
fácilmente el valor de la función objetivo para la composición que estemos considerando.
La extensión natural de esta problemática toma dos caminos: (1) incorporar una restric-
ción sobre la forma en la que los consumidores escogen –que hasta el momento es únicamente
maximizar su utilidad– una restricción presupuestaria, y (2) levar entonces el supuesto de
que un modelo Logit de elección discreta representa adecuadamente la forma en la que los
consumidores escogen.
15
CLAIO-2016
201

Referencias
Adam, W. and Yellen, J. (1976). Commodity bundling and the burden of monopoly. The
Quarterly Journal of Economics, 90(3):475–498.
Altinkemer, K. (2001). Bundling e-banking services. Communications of the ACM, 44(6):45–
47.
Bakos, Y. and Brynjolfsson, E. (1999). Bundling information goods: Pricing, profits, and
efficiency. Management Science, 45(12):1613–1630.
Bakos, Y. and Brynjolfsson, E. (2000). Bundling and competition on the internet. Marketing
Science, 19(1):63–82.
Basu, A. and Vitharana, P. (2009). Impact of customer knowledge heterogeneity on bundling
strategy. Marketing Science, 28(4):792–801.
Beasley, J. and Christofides, N. (1989). An algorithm for the resource constrained shortest
path problem. Networks, 19(4):379–394.
Bellman, R. (1957). Dynamic Programming. Princeton University Press.
Ben-Akiva, M. and Lerman, S. (1985). Discrete Choice Analysis. MIT Press, Cambridge,
Massachusetts.
Bitran, G. and Ferrer, J. (2007). On pricing and composition of bundle. Production and
Operation Management, 16(1):93–108.
Bulut, Z., Gürler, U., and Sen, A. (2009). Bundle pricing of inventories with stochastic
demand. European Journal of Operational Research, pages 897–911.
Cataldo, A., Ferrer, J., and Bitran, G. (2014). On pricing and composition of multiple
bundles. Working Paper.
Chang, S. and Tayi, G. (2009). An analytical approach to bundling in the presence of
customer transition effects. Decision Support Systems, 48:122–132.
Chung, J. and Rao, V. (2003). A general choice model for bundles with multiple-category
products: Application to market segmentation and optimal pricing for bundles. Journal
of Marketing Research, 40(2):115–130.
16
CLAIO-2016
202

Corless, R., Gonnet, D., Hare, D., Jeffrey, D., and Knuth, D. (1995). On the lambert w fun-
ction. Technical Report, Department of Applied Mathematics. University of Western Onta-
rio, London, Ontario, Canada. Available via anonymous ftp from cs-archive.uwaterloo.ca.
Cready, W. (1991). Premium bundling. Economic Inquiry, Huntington Beach, 29(1):173–181.
Dansby, R. and Conrad, C. (1984). Commodity bundling. The American Economic Review,
74(2):377–381.
Dobson, G. and Kalish, S. (1993). Heuristics for pricing and positioning a product-line using
conjoint and cost data. Management Science, 39(2):160–175.
Dukart, J. (2000). Bundling services on the fiber-optic network. Utility Business, 3(12):61–
73.
Ferrer, J., Mora, H., and Olivares, F. (2010). On pricing of multiple bundles of products and
services. European Journal of Operational Research, 206:197–208.
Fuerderer, R., Huchzermeier, A., and Schrage, L. (1999). Stochastic Option Bundling and
Bundle Pricing. Optimal Bundling. Springer.
Garey, M. and Johnson, D. (1979). Computers and intractability. A guide to the theory of
NP-completeness. Freeman, San Francisco, California.
Geng, X., Stinchcombe, M., and Whinston, A. (2005). Bundling information goods of de-
creasing value. Management Science, 51(4):662–667.
Gülder, U., Öztop, S., and Sen, A. (2009). Optimal bundle formation and pricing of two
products with limited stock. International Journal Productions Economics, 118:442–462.
Gourville, J. and Soman, D. (2001). The potential downside of bundling: How packaging
services can hurt consumption. Cornell Hotel and Restaurant Administration Quarterly,
42(3):29–37.
Green, P., Krieger, A., and Agarwal, M. (1991). Adaptive conjoint analysis: Some caveats
and suggestions. Journal of Marketing Research, 28(2):215–222.
Green, P., Krieger, A., and Agarwal, M. (1992)). An application of a product positioning
model to pharmaceutical products. Marketing Science, 11(12):117–132.
Grigoriev, A., Van Loon, J., Sviridenko, M., Uetz, M., and Vredeveld, T. (2008). Optimal
bundle pricing with monotonicity constraint. Operations Research Letters, 36:609–614.
17
CLAIO-2016
203

Guiltinan, J. and Gordon, P. (1988). Marketing Management: Strategies and Programs.
Third edition, McGraw-Hill.
Hanson, W. and Martin, R. (1990). Optimal bundle pricing. Management Science,
36(2):155–174.
Hitt, L. and Chen, P. (2005). Bundling with customer self-selection: A simple approach to
bundling low-marginal-costgoods. Management Science, 51(10):1481–1493.
McCardle, K., Rajaram, K., and Tang, C. (2007). Bundling retail products: Models and
analysis. European Journal of Operational Research, 177:1197–1217.
McFadden, D. (1974). Conditional logit analysis of qualitative choice behavior in Frontier in
Econometrics. P. Zarembka (ed.), Academic Press, New York, New York, pg. 105-142.
Mookherjee, R. and Friesz, T. (2008). Pricing, allocation, and overbooking in dynamic service
network competition when demand is uncertain. Production and Operations Management,
17:455–474.
Nalebuff, B. (2004). Bundling as an entry barrier. The Quarterly Journal of Economics,
119(1):159–187.
Proano, R., Jacobson, S., and Zhang, W. (2011). Making combination vaccines more acces-
sible to low-income countries: The antigen bundle pricing problem. Omega, doi:10.1016
j.omega.2011.03.006.
Salinger, M. (1995). A graphical analysis of bundling. Journal of Business, 68(1):85–98.
Schamalensee, R. (1982). Commodity bundling by single-product monopolies. Journal of
Law and Economics, 25(1):67–71.
Schamalensee, R. (1984). Gaussian demand and commodity bundling. The Journal of
Business, 57(1):211–230.
Shugan, S. and Radas, S. (1998). Managing service demand: Shifting and bundling. Journal
of Service Research, 1(1):47–64.
Soman, D. and Gourville, J. (2000). Transaction decoupling: How price bundling affects the
decision to consume. Journal of Marketing Research, 38(1):30–44.
Suri, R. and Monroe, K. (2000). The effects of need for cognition and trait anxiety on price
acceptability. Wireless Review, 17(2):62–64.
18
CLAIO-2016
204

Swartz, N. (2000). Bundling up. Wireless Review, 17(2):62–64.
Urban, G. and Hauser, J. (1993). Design and Marketing of New Products.
Venkatesh, R. and Mahajan, R. (1993). A probabilistic approach to pricing a bundle of
products or services. Journal of Marketing Research, 30(4):494–508.
Voss, C., Roth, A., and Chase, R. (2008). Experience, service operations strategy, and services
as destinations: Foundations and exploratory investigation. Production and Operations
Management, 17(3):247–266.
Warburton, A. (1987). Approximation of pareto optima in multiple-objetive, shortest-path
problems. Operations Research, 35(1):70–79.
Wu, S., Hitt, L. M., Chen, P. Y., and Anandalingam, G. (2008). Customized bundle pricing
for information goods: A nonlinear mixed-integer programming approach. Management
Science, 54(3):608–622.
Xia, C. and Dube, P. (2007). Dynamic pricing in e-services under demand uncertainty.
Production and Operations Management, 16(6):701–712.
Yadav, M. (1994). How buyers evaluate product bundles: A model of anchoring and adjust-
ment. Journal of Consumer Research, 21(2):342–353.
Yadav, M. and Monroe, K. (1993). How buyers perceive savings in a bundle price: An exa-
mination of a bundle’s transaction value. Journal of Marketing Research, 30(3):350–358.
Yang, B. and Ng, C. (2010). Pricing problem in wireless telecommunication product and
service bundling. European Journal of Operational Research, 207:473–480.
19
CLAIO-2016
205

PROPUESTA DE MEJORA A LOS ALTOS TIEMPOS
DE ESPERA EN PUNTOS DE ATENCIÓN AL
USUARIO EN UNA ENTIDAD PROMOTORA DE
SALUD EMPLEANDO SIMULACIÓN DISCRETA.
Natalia Uribe Mejía
Estudiante Ingenieria de sistemas, Instituto Tecnológico Metropolitano ITM.
Néstor Vásquez
Estudiante Ingenieria de sistemas, Instituto Tecnológico Metropolitano ITM. . [email protected]
Diego Usuga
Estudiante Ingenieria de sistemas, Instituto Tecnológico Metropolitano ITM.
Yony Fernando Ceballos PhD
Docente, Departamento Ingenieria Industrial, Universidad de Antioquia.
Resumen
Los servicios de salud en cualquier parte del mundo deben asegurar una atención oportuna,
segura y de alta calidad (Quality of Care). Por lo tanto, las entidades promotoras de salud
en Colombia (EPS) deben garantizar procesos fáciles y ágiles en los servicios ofrecidos,
evitando riesgos que pueden afectar la vida de los pacientes. Junto con lo anterior, en
Colombia se definió la ley anti-tramites, siendo el cumplimiento de esta ley una
problemática para las EPS ya que prestan servicios a más de 250.000 usuarios en ciudades
como Medellín (Colombia). Esta aglomeración de pacientes ocasiona quejas e
inconformidades de parte de los afiliados por las largas filas y demoras en los trámites que
se presentan en el punto de atención al usuario. Para tal fin, la entidad desea disminuir los
tiempos de atención, para evitar una sanción por parte de la superintendencia de salud
colombiana, empleando como herramienta la simulación y realizar una propuesta eficiente
que disminuya los costos y posibilidades de sanción.
Palabras claves: simulación, usuarios, EPS, ARENA SOFTWARE.
Abstract
Health services anywhere in the world must ensure a timely, safe and high quality of care.
Therefore, health promotion entities in Colombia (EPS) must ensure easy and streamlined
processes in the services offered, avoiding risks that can affect the lives of patients. Along
with the above, in Colombia law anti-procedures is defined, with the implementation of
CLAIO-2016
206

this law is created an issue for the EPS because they are serving more than 250,000 users
in cities like Medellin (Colombia). This causes agglomeration of patients, complaints and
objections from members by the long lines and delays in the procedures that are presented
at the point of customer service. To this end, the entity wishes to reduce service times to
avoid a penalty by the superintendent of Colombian health using simulation as a tool and
perform an efficient proposal to decrease the costs and possible penalties.
Keywords: simulation, users, EPS, ARENA SOFTWARE.
1 Introducción
Los tiempos de espera en cualquier proceso productivo y en situaciones de atención a
usuarios han sido ampliamente discutidos en la literatura (Caro, Möller, & Getsios, 2010;
Sharma, 2015; Werker, Sauré, French, & Shechter, 2009). No obstante, una solución
sostenible y que satisfaga las necesidades de los usuarios generalmente son costosas y
afecta significativamente los ingresos de las entidades que prestan sus servicios. En casos
del sistema de salud en cualquier país, es necesario asegurar una atención oportuna, segura
y de alta calidad.
El sector salud es cambiante, ya que no hay estrategias definidas para afrontar los cambios
repentinos. Los errores en administración por parte del estado ha generado dichos cambios
y algunos estudios, en cuanto a en que forma la salud de los colombianos puede mejorar la
calidad en la prestación de servicios y de atención por parte de las entidades prestadoras de
salud (EPS). Sin embargo, son muy pocos los estudios para esta área que emplean técnicas
de simulación y es una problemática a nivel mundial como se refleja en México (Ramírez-
Sánchez, Nájera-Aguilar, & Nigenda-López, 1998). Además, la forma en la cual se debe
abordar la dificultad involucra un conjunto de puntos de vista, que es necesario aclarar para
tener un modelo que represente la situación problemática en cuestión y permita reducir
tiempos y costos en la toma de decisiones (Ramírez-Sánchez et al., 1998). El análisis de
situaciones que conlleven al mejoramiento de la calidad en la atención de los usuarios y a
la disminución en los tiempos de espera por parte de los usuarios no ha sido una
problemática estudiada (García, 2013), por lo tanto, se pretende analizar y simular si una
aproximación que involucre una posible visión universal del problema, pero que a su vez,
sea sencilla y permita elaborar una aproximación simple de modelado a cualquier grupo
humano.
Como herramienta para resolver este problema se ha empleado la Simulación, e
”identificación de las variables de influencia en los tiempos de espera” (Cano, Medina,
Custardoy, Orozco, & Quince, 2003) no obstante, la calidad de servicio de las EPS se mide
por los tiempos de espera y posteriormente evaluando su impacto en miras de cambiar el
entorno en lo posible para mejoras. Esta opción no tiene en cuenta el impacto en la
comunidad a largo plazo, ya que la estimación del comportamiento futuro no hace parte de
los resultados de la Simulación. Por lo antes descrito, es necesario realizar un proceso de
creación de un modelado en evaluación, que sea apropiada para mejorar las situaciones que
CLAIO-2016
207

se le presentan a los usuarios a causa de largas esperas para ser atendidos y que además,
emplee algún tipo de herramienta de simulación, para hacer un estudio aproximado de la
pre-factibilidad de la mejora en tiempos de espera, desde un enfoque social y orientado al
desarrollo de la empresa y el mejoramiento del servicio.
En general, se han encontrado aplicaciones al análisis de la situación problemática antes
descrita que permita que se puedan tomar decisiones, aunque es necesario realizar una
depuración de la información, permitiendo justificar de manera contundente la necesidad
de este estudio (Gutierrez et al., 2009). Sin embargo, en la EPS no existe un análisis de
tiempos como el descrito para manejar mejor la atención y tomar decisiones oportunas
cuando los tiempos de atención a los usuarios sean muy largos. Por lo tanto, la forma como
se debe afrontar el problema debe ser con la creación de un modelo de simulación, que
represente la situación permitiendo su análisis y comprensión realizando determinados
cambios bajo determinadas condiciones (Gutierrez et al., 2009), que dé como resultado un
mejoramiento en la atención de la creciente demanda de usuarios.
2 Descripción del problema
Actualmente los tiempos de espera para servicio son superiores a una hora, por lo tanto, se
busca en esta investigación proponer una solución rápida y efectiva que acorte los tiempos
de espera por parte de los usuarios y que la EPS como entidad cumpla con su promesa de
servicio. Para ello se realiza una investigación en la sala de espera, identificando el proceso
de atención a usuarios, recolectando así los datos necesarios para modelar una simulación
de la problemática actual y lograr demostrar por medio de ella el comportamiento de los
tiempos de espera en sala, a su vez también brindarle a la EPS una propuesta solución
eficiente para que la empresa pueda intervenir los procesos y mejorar los tiempos de
espera de máximo 15 minutos en sala, con un costo mínimo en la operación.
El problema a resolver se concentra en la sucursal de Medellín exactamente en el área de
servicio al cliente llamado PAU (Punto de atención al usuario), el cual tiene un horario de
atención de 7am a 5pm de lunes a viernes, en este lugar se atiende todos los 250.000
afiliados, se atiende un promedio de 1000 usuarios diarios, a raíz de que el 1 de marzo de
2014 fueron asignados por la superintendencia de salud 50.000 usuarios de la EPS
Comfenalco Antioquia que fue liquidada y en julio de 2014; otros 2000 usuarios de
Aliansalud EPS. Esta alta cantidad de usuarios ocasiona insatisfacción en los usuarios por
el tiempo de espera, por incremento de afiliados que se acercan hacer sus trámites
ocasionando congestión, quejas y demoras en el servicio. La empresa desea cumplir con la
promesa de servicio es de 15 minutos ya que se encuentra en proceso de acreditación, y
poder dar fin a las largas filas que se presentan día a día en el PAU que está conformado
por, 23 analistas Integrales de servicio al cliente, de los cuales se rotan los siguientes
usuarios, roles y servicios:
Tipos de Usuarios: Afiliado, Nuevo, Gestante, Tercera Edad, Discapacitados,
Usuarios con niños en Brazos, Radicación de Tutelas Entes Judiciales, Alianzas
Grupo analistas: Informador, Multiservicios, Caja Rápida, Preferencial
CLAIO-2016
208

El Informador es el encargado de generar Certificaciones, Autorizaciones, Información al
usuario, Usuario devuelto, Solicitud o entrega de historia clínica, entrega de orden,
condonaciones, paz y salvo y estado de cuenta, Actualización de datos y/o anexos.
El empleado de Multiservicios está encargado de generar certificaciones, Pagos,
Autorizaciones, Cirugías, Carne, Multiafiliados y traslados, Novedades de contributivo,
Prestaciones, Comité Técnico Científico, Independiente Nuevo, Independiente Antiguo,
Afiliaciones Madre-Comunitaria, Afiliaciones Servicio-Doméstico, Afiliaciones
Pensionados, Radicación de tutelas Entes Judiciales, Quejas y derechos de petición,
Información al usuario, tutela, carta de negación, Procedimiento alto Costo, PILA, Carta
de Direccionamiento, Solicitud o entrega de hc, Autorizaciones de oncología, cita
interciudad, entrega de orden, Entrega carta de derechos y deberes, condonaciones,
afiliaciones dependientes, Aes y registro, paz y salvo y estado de cuenta, Actualización de
datos y/o anexos.
Los analistas, quienes atienden el gran volumen de personas, manifiestan un sobrecargo
laboral debido a los largos turnos que se extienden más de lo debido, lo cual ha causado
múltiples quejas y reclamos ante la superintendencia nacional de salud. De parte de los
usuarios también han existido quejas, ya que no se cumple con los 15 minutos en atención
como está pactado en la promesa de servicio de dicha entidad.
En la Caja Rápida se generan Certificaciones, autorizaciones, Comité Técnico Científico,
información Al usuario, Solicitud o entrega de historia clínica, entrega orden,
condonaciones, paz y salvo y estado de cuenta, Actualización de datos y/o anexos.
El proceso de atención a usuarios (ver Figura1), comienza con una llegada de tipo
probabilística, quienes se dirigen a la Taquilla Informador, desde este módulo son
clasificados por medio de un número de turno, ellos se dirigen a la sala de espera para ser
llamados por parte de la taquilla correspondiente, ya sea preferencial, caja rápida o
multiservicios. Luego de ser atendidos probabilísticamente se direccionan a la salida.
Por lo tanto, es necesario mejorar el ingreso de usuarios con el informador y proceso de
clasificación de trámites podría ayudar a reducir el problema. Se pretendió simular el
tiempo cuando un usuario entra a la EPS en el punto de atención hasta que sale, es decir,
todos los procesos eficientes o no, contribuyen a identificar el servicio del punto de
atención y poder utilizar el software de simulación Arena, el cual es una herramienta
necesaria para modelar estas interacciones y comportamientos. Un modelo de simulación
mostraría cómo cambios propuestos afectarían la EPS y permitir mejor toma de decisiones.
CLAIO-2016
209

Figura1. Diagrama de flujo
Este modelo de simulación permite a la EPS probar un flujo de usuarios más rápido y
eficiente, para garantizar el análisis completo y determinar el camino correcto a seguir. Se
decidió emplear el software de simulación, utilizado para simulación discreta ya que
grandes empresas y universidades en el mundo lo utilizan, existen varios casos de estudio
exitosos. Ejecutivos reconocieron el valor que un estudio de simulación podría
proporcionar en la organización y que el desarrollo de un modelo de simulación de la EPS
actual permite evaluar diferentes escenarios de cambio.
3 Resultados
De la base de datos suministrada por la EPS, se ordenaron los datos y se obtiene como
resultado la Tabla1.
Tabla 1. Datos de entrada
Llegada
usuarios
7-8
am
8-9
am
9-10
am
10-
11
am
11-
12
am
12-1
pm
1-2
pm
2-3
pm
3-4
pm
4-5
pm
Total
Cantidad 149 167 129 134 140 139 118 125 132 197 1430
Se puede observar el número de personas que llegan cada hora a la EPS, e identificar varios
aspectos importantes como la hora de menor afluencia de personas, la hora pico, la cual
sería de 4pm a 5pm, de la misma base de datos se tomaron los tiempos de llegada, se
consolidaron por tipo de entidad y se generó un archivo plano por cada entidad para poder
CLAIO-2016
210
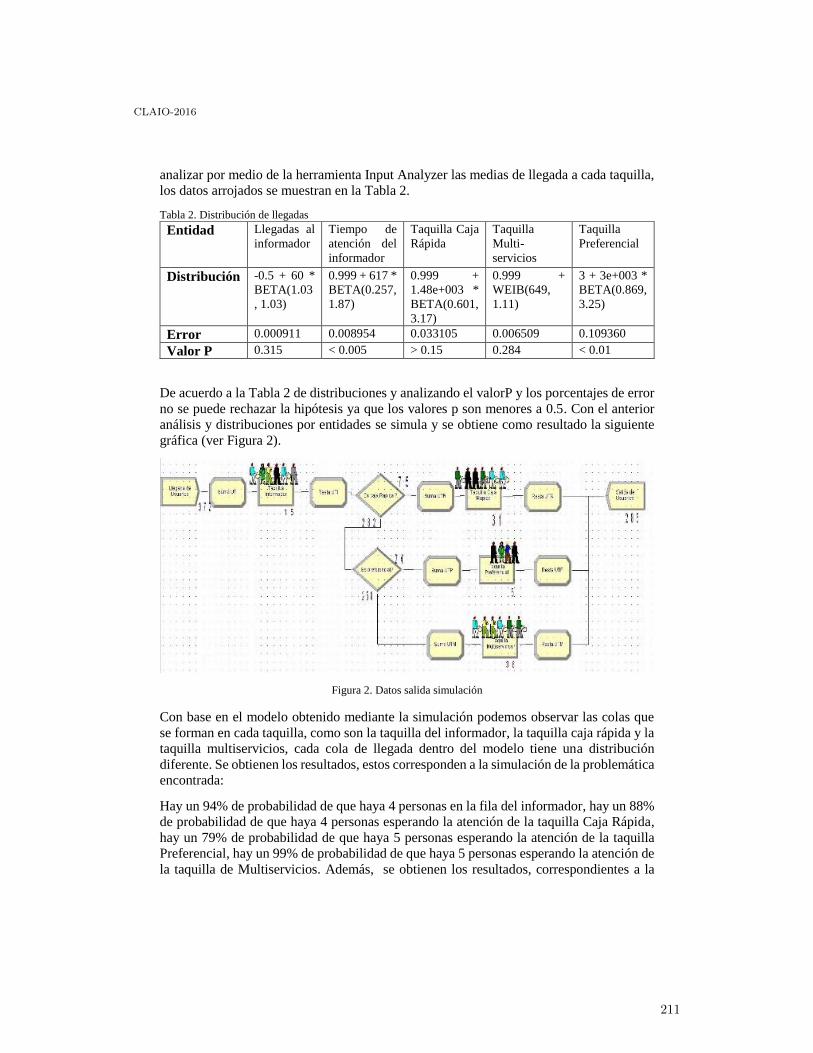
analizar por medio de la herramienta Input Analyzer las medias de llegada a cada taquilla,
los datos arrojados se muestran en la Tabla 2.
Tabla 2. Distribución de llegadas
Entidad Llegadas al
informador
Tiempo de
atención del
informador
Taquilla Caja
Rápida
Taquilla
Multi-
servicios
Taquilla
Preferencial
Distribución -0.5 + 60 *
BETA(1.03
, 1.03)
0.999 + 617 *
BETA(0.257,
1.87)
0.999 +
1.48e+003 *
BETA(0.601,
3.17)
0.999 +
WEIB(649,
1.11)
3 + 3e+003 *
BETA(0.869,
3.25)
Error 0.000911 0.008954 0.033105 0.006509 0.109360
Valor P 0.315 < 0.005 > 0.15 0.284 < 0.01
De acuerdo a la Tabla 2 de distribuciones y analizando el valorP y los porcentajes de error
no se puede rechazar la hipótesis ya que los valores p son menores a 0.5. Con el anterior
análisis y distribuciones por entidades se simula y se obtiene como resultado la siguiente
gráfica (ver Figura 2).
Figura 2. Datos salida simulación
Con base en el modelo obtenido mediante la simulación podemos observar las colas que
se forman en cada taquilla, como son la taquilla del informador, la taquilla caja rápida y la
taquilla multiservicios, cada cola de llegada dentro del modelo tiene una distribución
diferente. Se obtienen los resultados, estos corresponden a la simulación de la problemática
encontrada:
Hay un 94% de probabilidad de que haya 4 personas en la fila del informador, hay un 88%
de probabilidad de que haya 4 personas esperando la atención de la taquilla Caja Rápida,
hay un 79% de probabilidad de que haya 5 personas esperando la atención de la taquilla
Preferencial, hay un 99% de probabilidad de que haya 5 personas esperando la atención de
la taquilla de Multiservicios. Además, se obtienen los resultados, correspondientes a la
CLAIO-2016
211

propuesta presentada para dar solución al problema en donde se evidencia que se cumple
con la promesa de servicio ya que todas las probabilidades superan el 95%. Hay un 99%
de probabilidad de que haya 3 personas en la fila del informador.
Hay un 98% de probabilidad de que haya 3 personas esperando la atención de la taquilla
Caja Rápida, hay un 99% de probabilidad de que haya 4 personas esperando la atención de
la Preferencial y hay un 97% de probabilidad de que haya 3 personas esperando la atención
de la taquilla de Multiservicios (Ver Figura 3).
Validación y verificación: La validación de la simulación se realizó mediante la forma de
intuición de expertos, con el supervisor del punto de atención al usuario quien tiene doce
años de experiencia en la empresa, confirmo que la simulación se asemeja a la realidad o
al ambiente real que se presenta en la sala de atención al usuario.
Figura 9. Taquilla Preferencial y Taquilla Multiservicios Propuesta Solución
A través de la prueba de consistencia se ejecutó la verificación de la simulación, según los
datos de entrada y la cantidad de personas que llegan cada hora concuerda con la cantidad
simulada durante las primeras 3 horas, ya que el software utilizado en este artículo es una
versión estudiantil que solo permite simular 150 entidades, intentar simular más tiempo,
desborda la simulación.
4 Conclusiones y trabajo futuro
Haciendo los ajustes necesarios según el resultado obtenido en el Output Analyzer
podemos llegar a la simulación solución y asegurarle a la empresa con una certeza del 95%,
de que los usuarios no tengan que esperar y sean atendidos, con esta simulación llegamos
al análisis y discusión con la cual le podemos recomendar a la EPS que para garantizar la
atención manejando costos mínimos en nómina, se debe contar como mínimo 2
Informadores, 5 Cajas rápidas, 2 cajas preferenciales y 19 analistas multiservicios. En total
28 analistas distribuidos con los roles anteriormente mencionados. En el anterior análisis
no se tuvieron en cuenta los diferentes ausentismos o incapacidades que se pueden
presentar por parte de los analistas, por lo tanto la empresa debe tener por su parte
disposición de personal supernumerario que llene las vacantes no programadas. El costo
requerido para cumplir con la propuesta solución son 10 salarios mínimos legales vigentes
CLAIO-2016
212

ya que se propone contratar 5 analistas adicionales que cubran las 10 horas diarias, y
adicional el pago de los parafiscales como son salud, pensión y riesgos laborales.
5 Bibliografía
Cano, J., Medina, E., Custardoy, J., Orozco, D., & Quince, F. (2003). Identificación de las
variables de influencia en los tiempos de espera en atención especializada. Gaceta
Sanitaria. http://doi.org/10.1157/13053649
Caro, J. J., Möller, J., & Getsios, D. (2010). Discrete Event Simulation : The Preferred
Technique for Health Economic Evaluations ? Value in Health, 13(8), 1056–1060.
http://doi.org/10.1111/j.1524-4733.2010.00775.x
García, M. M. (2013). Estudio del triaje en un servicio de urgencias hospitalario.
RevistaEnfermeríaCyL. Retrieved from
http://www.revistaenfermeriacyl.com/index.php/revistaenfermeriacyl/article/view/9
1
Gutierrez, E., Ramos, W., Uribe, M., Ortega-Loayza, A. G., Torres, C., Montesinos, D., …
Galarza, C. (2009). Tiempo de espera y su relación con la satisfacción de los usuarios
en la farmacia central de un hospital general de Lima. Rev Peru Med Exp Salud
Publica, 26(1), 61–65.
RAMÍREZ-SÁNCHEZ, T. D. J., NÁJERA-AGUILAR, P., & NIGENDA-LÓPEZ, G.
(1998). Percepción de la calidad de la atención de los servicios de salud en México:
perspectiva de los usuarios. Salud Pública de México. http://doi.org/10.1590/S0036-
36341998000100002
Sharma, P. (2015). Discrete-event simulation. INTERNATIONAL JOURNAL OF
SCIENTIFIC & TECHNOLOGY RESEARCH, 4(04), 136–140.
Werker, G., Sauré, A., French, J., & Shechter, S. (2009). The use of discrete-event
simulation modelling to improve radiation therapy planning processes. Radiotherapy
and Oncology : Journal of the European Society for Therapeutic Radiology and
Oncology, 92(1), 76–82. http://doi.org/10.1016/j.radonc.2009.03.012
CLAIO-2016
213

Agricultural planning in sugarcane planting areas
Adriana Cristina Cherri
Departamento de Matemática, FC, UNESP, Bauru SP, Brasil.
Andrea Carla Goncalves Vianna
Departamento de Computação, FC, UNESP, Bauru SP, Brasil.
Rômulo Pimentel Ramos
PG Energia na Agricultura, FCA, UNESP, Botucatu SP, Brasil.
Helenice de Oliveira Florentino
Departamento de Bioestatística, IB, UNESP, Botucatu SP, Brasil.
Abstract
The sugarcane harvesting process uses extensively mechanization that promotes rational and economical
resources, increases operational efficiency and reduces environmental impact. On the other hand, the
mechanized harvesting must be properly planned, starting with the preparation of the area intended for
planting. In this paper, we propose a methodology for planning the division of the plantation area into
rectangular plots and for their allocation in order to perform mechanized harvesting. The problem is
represented as a two-dimensional cutting stock problem and it is solved by the AND/OR graph method.
Experimental results based on real data are showed and discussed.
Keywords: sugarcane; planting planning; AND/OR graph approach; OR in Agriculture.
1 Introduction
Sugarcane has important highlight in the economy of some countries, mainly in Brazil. Currently,
Brazil is the largest producer of sugarcane and the largest exporter of sugar and ethanol in the world. Due
to the growth in the consumption of ethanol and sugar, the production process has undergone important
changes, mainly in harvesting methods that must became all mechanized (UNICA, 2007).
To obtain a good performance of the sugarcane harvesting machine, the planting area must be
planned. This planning begins with soil preparation, determination of the most appropriate row spacing to
avoid stump trampling and to adopt suitable sugarcane varieties for mechanical harvesting (Benedini and
Donzelli, 2007). For maximum efficiency of the harvesting machine and minimal costs it is necessary to
plan the plot design, that must be rectangular, and sugarcane rows, in such a way to perform the fewest
possible maneuvers (Anselmi, 2008). According to Benedini and Conde (2008), the plots should have
furrow length of 500-800 meters and width of 150-400 meters. For Rossetto and Santiago (2012), the
spacing between rows should be 1.5 meters. The plots are generally subdivided based on topography and
soil homogeneity and should present an average area of 10 and 20 hectares.
CLAIO-2016
214

Zhou et al. (2014) developed a planning method that generates a feasible area coverage plan for
agricultural machines executing non-capacitated operations in fields containing multiple obstacle areas.
The problem was formulated as a traveling salesman problem and it was solved using ant colony
algorithmic heuristic.
To guarantee the efficiency of the mechanized harvesting, we propose a methodology for
planning the division of the planting area in plots and their allocation in the area. Rectangular plots are
generated and allocated in planting areas minimizing the number of harvesting machine maneuvers. The
methodology proposes approximating the real problem in a two-dimensional cutting stock problem
(2DCSP). To solve the problem of selecting and allocating the plots the AND/OR graph proposed by
Morabito et. al (1992) was used. Since some planted areas have regions where it is not possible or
permitted to plant sugarcane, some peculiarities of the 2DCSP were considered, so that no plot is
allocated in these regions. Computational experiments were performed with real cases and are discussed.
The remainder of the paper is organized as follow: in Section 2, the generation of the plots is
described. In Section 3, we present the briefly description of the AND/OR graph approach, which is the
strategy used to select and allocate plots in the planting areas. Section 4 shows how the interpretation of
the solutions presented by the AND/OR graph approach is carried out. In Section 5, solutions for some
real cases are presented. Conclusions are presented in Section 6.
2 Problem description
Consider an available area for planting sugarcane of H hectares and let J be the set of all possible
plots that can be allocated to this area. The plot generation problem is defined as:
A planting area must be divided into rectangular plots with dimensions (lj, wj), where lj is the
length and wj is the width of the plot j J, in order to increase yield, reduce traffic and minimize the
maneuvers of the sugarcane harvesting machine.
According to the literature, an acceptable space between sugarcane rows is 1.5 meters. Thus, the
calculation of the number of harvesting machine maneuvers in the plot j is given by ⌊𝑤𝑗
1.5⌋ − 1, where⌊𝑥⌋
indicates the largest integer not greater than the corresponding element x. Our objective is minimize the
number of harvest machine maneuvers in the plot j and, simultaneously, taking advantage of the
plantation area with constraints on the dimensions and in the area of the plots. For this, we impose lower
(llow and wlow) and upper (lupp and wupp) bounds on the lengths and widths of the plots and also, on the areas
of the plots (Arealow ≤ ljwj ≤ Areaupp). To ensure that the plots have the form of a long rectangle, we
consider the width (wj), j J, of the plot smaller than or equal to a percentage (p) of the length (lj), j J,
that is, wj ≤ plj.
According to the recommendations of the mills (Cervi, 2013), the area of the plot (ljwj), j J,
must be smaller than or equal to 15% of the total area to be planted (ljwj ≤ 0,15H104 ) and the sum of the
plot areas be less than or equal to the total area.
Using all the recommendations cited in this section, the length and width of the plots were
generated and combined, originating rectangles (plots). With the suitable plots generated, the AND/OR
graph approach was used to select and allocate the plots in order to minimize the maneuvers of the
sugarcane harvesting machine.
3 Plot Allocation Using the AND/OR Graph Approach
To solve the rectangular plot allocation problem in a sugarcane plantation area, this problem will
be related to the 2DCSP (Gilmore and Gomory, 1965). This problem consists of allocating small
CLAIO-2016
215

rectangular pieces in larger rectangular plates. For this, the irregular plantation area is manually
approximated to the two-dimensional plate, and the plots are considered as the rectangular pieces. The
allocation of plots in the plantation area is similar to the generation of a cutting pattern in the cutting stock
problem. Figure 3.1 illustrates the representation of one irregular area and the approximation made with a
rectangular plate.
(a) (b)
Figure 3.1: (a) Example of an irregular region; (b) Approximation with one rectangular plate.
Besides the irregular form, some areas used to planting sugarcane can contain preservation areas,
constructions projects, lakes or other areas where the plot allocation is not allowed. Due to this restriction
in some areas, a particularity of the 2DCSP was considered, including the possibility of a defect in the
plate (Vianna and Arenales, 2006). Figure 3.2 shows the same region presented in Figure 3.1 with some
areas considered as defects in the plate (hatched rectangles). Plots are not allocated in these areas.
(a) (b) Figure 3.2: (a) Identification of the defect; (b) Possible plot allocation on the plate/region.
To solve the 2DCSP with a defective plate, Vianna and Arenales (2006) proposed a modification
of the AND/OR graph presented by Morabito et al. (1992). In the AND/OR graph, the cutting patterns are
represented as a complete path in a special graph.
An AND/OR graph is a directed tree with a set of nodes (rectangles) and a set of directed arcs
(cuts). In our problem, the cuts will be consider guillotine type, that is, when the plate is cut, two new
rectangles/plates are generated. An OR-arc chooses between several arcs that emerge from a node and an
AND-arc establishes a relationship between both branches of the chosen arc.
The cutting patterns are generated using the AND/OR graph verifying in each node all the cut
possibilities until the same rectangle is reproduced (0-cut). At this point, no further cut is made. The cuts
on a plate (vertical or horizontal) can be restricted, without loss of generality, to a finite set, called the
"discretization set", which is formed by non-negative linear combinations of the item sizes. Details about
the discretization set can be found in Herz (1972). Using the AND/OR graph, it is possible to represent a
cutting pattern as a complete path in a graph and enumerate the sizes implicitly with the objective of
finding the optimal solution.
Cutting patterns in a defective plate are solved using an AND/OR graph similarly to the case
without defects, with minor modifications (Vianna and Arenales, 2006). The most important modification
in the AND/OR graph is realized during the construction of the discretization set. The defects are
represented by one or more rectangles with a fixed position (Figure 3.2). The discretization set provides
position of the cuts for the plate and it is applied until a defect is found. From the localization of the
CLAIO-2016
216

defect, the discretization set beginnings again following sequentially until a new defect is found or the
discretization set is exhausted. Details on the implementation of the AND/OR graph with defective plate
can be found in Vianna and Arenales (2006).
After approximating the planting area using a plate and defining the allocation of all possible
plots using the AND/OR graph approach, the next step consists of approximating the solution to the real
area of sugarcane planting. The treatment of this solution is presented in Section 4.
4 Treatment of the Solution
After the plot allocation in sugar planting areas, a post-optimization process is manually realized
to approximate the solution generated by the AND/OR graph approach to the real area. From Figure
3.2(b), the planting area with defined plots is presented in Figure 4.1.
Figure 4.1: Solution adapted to planting area.
Comparing the solutions presented in Figure (4.1) and (3.2b), it is possible to see that the plots in
the edge of the defined region are not rectangular. This is natural since the planting area is not a regular
region.
During the post-optimization process, some generated waste (large hatch in Figure (3.2b)) are
incorporated into the nearest allocated rectangle. However, the limits on the dimensions of the plots are
respected within an acceptable level of tolerance.
Considering agricultural management practices, the cane rows should be aligned with terrain
contour lines to minimize soil erosion. Although our strategy provides straight cuts, it can give a good
idea to the manager during the division of the plantation area and, from the proposed approximating the
plots in rectangles, it is possible make the better adjustment considering the terrain contour lines.
5 Computational Experiments
To analyze the performance of the proposed methodology, we considered two real regions (slope
less than 12%) on a farm located in the interior of the São Paulo state, Brazil. Currently, this farm is
administered by a mill and will reformulate the planting area for mechanized harvesting. The first region
has an area of 178.84 hectares (map1) and the second region with 101.69 hectares (map2). For these
maps, defects were defined.
To obtain the solution, first we generate the set J of the plots using the strategy presented in
Section 2. Next, plots from J are selected by the AND/OR graph, and the plot allocation is performed,
allowing 90° rotation of the plots to be allocated. Finally, the solution is adjusted (post-optimization).
The plot generation was performed using the values proposed by Benedini and Conde (2008) and
that were acceptable by the mill manager: llow = 500 meters, lupp = 800 meters, wlow = 150 meters, wupp =
400 meters, Arealow = 80,000 meters and Areaupp = 190,000 meters. We also define p = 50 to guarantee
that the generated rectangles are elongated and the machine harvesting reaches its full potential.
The algorithm used to generate and allocate the plots in the planting area was created in Pascal-
language and and executed on a PC equipped with an Intel Core 2 Duo processor.
CLAIO-2016
217

Figure 5.1(a) shows map 1 with the regions currently used for sugarcane planting and the plots
divided for manual harvesting. According to this map, there is a farmhouse and an access path to the farm
in this region. To avoid plot allocation in these areas, we define defects in these places (Figure 5.1(b)).
Certainly, other defects could have been defined. Still in the Figure 5.1(b), observe that there is a large
region covered by the rectangle that does not belong to map 1, and there is a large region in the map that
is not covered by the rectangle. This region has a shape that is similar to the rectangle and dimensions that
satisfy the imposed limits, thus, it will be treated during the post-optimization process. The planting area
can be rotated or be covered by a different rectangle if it is attractive or necessary. Figure 5.1(c) shows
the final solution to the real planting area, after adjust the solution generated by the AND/OR graph.
(a) (b) (c)
Figure 5.1: (a) Map 1 with plots currently allocated; (b) Rectangle adjustment and definition of the defect in map 1;
(c) Final solution in map 1.
To analyze the solution, we compare the number of maneuvers that the harvesting machine
performs using solution illustrated in Figure 5.1(c) with the current plot division presented in Figure
5.1(a). With the plots defined in Figure 5.1(a), the number of maneuvers was 3,694, and after applying
our methodology (Figure 5.1(c)) the number of maneuvers was 2,193. This solution represents a reduction
of 40.63% in the number of maneuvers realized by the harvesting machine and, consequently, reductions
in the time that the machine is used, the hours worked by the machine operator and an increase in fuel
economy that also reflected in environmental benefits.
Figure 5.2(a) shows map 2 of the farm with the plots currently used. Figure 5.2(b) illustrates the
rectangle approximation for the region. In this planting area, there are no nature preservation areas,
construction areas, rivers, lakes or other areas that do not allow the allocation of plots. The defects were
allocated only outside of the region. Figure 5.2(c) presents the final solution.
(a) (b) (c)
Figure 5.2: (a) Map 2 with plots currently allocated; (b) Rectangle adjustment and definition of the defect in map 2;
(c) Final solution in map 2.
With the defined defects in the map 2, The number of maneuvers of the harvesting machine using
the solution presented in Figure 5.2(c) is 1,011, representing a reduction of 63.91% compared with the
current allocation (Figure 5.2(a)).
CLAIO-2016
218

During the harvest of sugar cane, take optimally the necessary resources can generate higher
profits. Planning plots for planting, help to reduce the number of maneuvers of the harvesting machine,
reduces the time that the harvesting machine is used, reduce the hours worked by the machine operator,
the consumption of fuel, among others. Furthermore, the planning of the harvest procedure has as
consequence an important reduction of the environment impacts.
The results obtained were presented for the mill manager that stayed very satisfied. Thus, we
consider the performance of the proposed strategy very good and well suited to assist mill managers in the
planning of the sugarcane planting areas. For the allocations presented in this section, the computational
time was acceptable in practice (about 10 seconds for the definition of each region).
6 Conclusions
In this paper, we proposed a strategy for dividing the planting areas into rectangular plots for
mechanized sugarcane harvesting. In the proposed methodology, first the plots are generated with realistic
dimensions, next the planting area is approximated by a rectangle and defects are defined. Thus, the
AND/OR graph is used to select and allocate plots to this rectangle. A post-optimization process is carried
out to approximate the solution obtained by the AND/OR graph to the real sugarcane planting area.
To verify the performance of the strategy, we use two real regions of one farm located in the
interior of the São Paulo state, Brazil. Currently, this farm has a sugarcane plantation and will reformulate
all area for mechanized harvesting. With our strategy, was possible a reduction of over 40% in the
number of maneuvers of the sugarcane harvesting machines, compared with currently division of the
plots. This reduction implies many economic and environmental advantages. When presented to the mill
manager, the solutions met the expectations. We are sure that the proposed methodology can assist the
mills managers in the planning of sugarcane planting areas or, due the flexibility of the strategy, it can be
adapted and used to various planting areas.
Acknowledgements
The authors would like to thank the Fundação de Amparo à Pesquisa do Estado de São Paulo
(FAPESP - Proc. nº 2015/03066-8) for the financial support.
References 1. R. Anselmi. Sistematização correta reduz custo das operações no campo. Jornal da cana 171.
http://www.jornalcana.com.br/, accessed December 2015, 2008.
2. M. S. Benedini and J. L. Donzelli. Colheita mecanizada de cana crua: caminho sem volta. Revista Coplana 40:
22-25, 2007.
3. M. S. Benedini, and A. J. Conde. Sistematização de área para colheita mecanizada da cana-de-açúcar. Revista
Coplana 53: 23-25, 2008.
4. R. G. Cervi. Modelagem matemática para maximização da produção da cana-de-açúcar (saccharum spp.) e
impactos sobre o custo de operações mecanizadas de corte e carregamento. PhD Thesis, Faculdade de
Ciências Agronômicas, UNESP, 2013.
5. P. Gilmore and R. Gomory. Multi-stage cutting stock problems of two and more dimensions. Operations
Research 14:1045-1074, 1965.
6. J. Herz. Recursive computational procedure for two-dimensional stock cutting. IBM Journal of Research and
Development, 16:462-469, 1972.
7. R. Morabito, M. Arenales and V. Arcaro. An AND/OR-graph approach for two-dimensional cutting problems.
European Journal of Operational Research. 58: 263-271, 1992.
8. R. Rossetto and A. D. Santiago. Plantio da cana-de-açúcar. http://www.agencia.cnptia.embrapa.br/gestor/ cana-
de-acucar/arvore/CONTAG01_33_711200516717.html, accessed in December 2015, 2012.
CLAIO-2016
219

9. UNICA - União da Indústria de Cana-de-Açúcar. http://www.unica.com.br/protocolo-agroambiental, accessed
december 2015, 2007.
10. A. C. G. Vianna, and M. N. Arenales. O problema de corte de placas defeituosas. Pesquisa Operacional,
26:185-202, 2006.
11. K.Zhou, A. Leck Jensen, C.G. Sørensen, P. Busato and D. D. Bothtis. Agricultural operations planning in
fields with multiple obstacle areas. Computers and Electronics in Agriculture, 109:12-22, 2014.
CLAIO-2016
220

Splitting versus setup trade-offs for scheduling
to minimize weighted completion time
José CorreaDepartamento de Ingenieŕıa Industrial, Universidad de Chile.
Victor VerdugoDepartamento de Ingenieŕıa Industrial, Universidad de Chile
Departement d’Informatique, École normale supé[email protected]
José VerschaeFacultad de Matemáticas & Escuela de Ingenieŕıa,
Pontificia Universidad Católica de [email protected]
Abstract
We study scheduling problems when jobs can be split and a setup is required before processingeach part, to minimize the weighted sum of completion times. Using a simple splitting strategyand a reduction to an orders scheduling problem we derive a 2-approximation algorithm for thecase with uniform weights and setups, improving upon previous work. We extend this idea tothe general identical machine case and conclude by designing a constant factor approximationalgorithm when machines are unrelated.
Keywords: Scheduling; job splitting; weighted completion time.
1 Introduction
Scheduling problems in which jobs are allowed to be split into many parts and be processed inde-pendently and concurrently on different machines naturally model situations in which jobs consistof a large number of small identical operations. When processing a job (or its small operations)the setup cost is negligible, while when switching to a different job a setup time is required, duringwhich the machine cannot process or setup any other job (see Figure 1). This family of schedul-ing problems was introduced by Potts and Van Wassenhove [9] to study batching and lot-sizingintegrated with scheduling decisions in manufacturing.
CLAIO-2016
221

· · · · · ·· · · · · ·sj (1− α)pj
sj αpj
Figure 1: Example where a job is split in two pieces.
In this paper we consider a stylized version of the model in which jobs can be arbitrarilysplit, introduced by Serafini [11] as a scheduling model for the textile industry. More specifically,our model considers a set M of m machines and a set J of n jobs under two different machineenvironments: unrelated and identical machines. In the unrelated machine setting, each job j ∈ Jhas a machine dependent setup time sij and processing time pij , while for identical machines theprocessing and setup times are machine independent, so pij = pj and sij = sj for all j ∈ J andi ∈ M . On the other hand, each job j ∈ J is associated with a nonnegative weight wj and theobjective is to minimize the weighted sum of job completion times. Thus, the problems studied aredenoted by R|split|∑wjCj (unrelated machines) and P |split|∑wjCj (identical parallel machines).
A number of scheduling problems with split jobs are polynomially solvable in the absenceof setup times [11, 13], however when setup times are present these problems become NP-hard.Indeed, Schalekamp et al. [10] show that P |split|∑wjCj is NP-hard even with uniform setuptimes (sj = s). They also design a 2.781-approximation algorithm for the uniform setup timeversion of P |split|∑Cj and an exact polynomial time algorithm for the case m = 2, though thecomplexity is open for m ≥ 3. Xing and Zhang [13] consider the problem of minimizing makespanon identical machines with splitting jobs and setup times, P |split|Cmax, obtaining a (1.75− 1/m)-approximation algorithm. This was later improved to an algorithm with a worst-case factor of 5/3by Chen et al. [2]. Recently, Correa et al. [3] obtain a (2.618 + ε)-approximation algorithm for thecase of unrelated machines, R|split|Cmax. We refer to the survey by Allahverdi et al. [1] for furtherrelated results.
In this paper, an outgrowth of [12], we first improve upon the results of Schalekamp et al. [10],who design a greedy strategy for P |split|∑Cj and uniform setups. In their algorithm jobs aresorted by their size and split among an appropriate number of machines such that the job finishesthe earliest. The algorithm and its analysis combine the decision of how to split and how toschedule simultaneously. This provokes extra technical difficulties in the analysis. In contrast, wepropose a simple but new scheme that separates the decision of splitting and scheduling. Thisprovides a robust strategy that extends naturally to different specifications and yields clean andsimple arguments. Specifically we split jobs into uniform pieces of size essentially equal to thesetup. We then interpret the problem we are left with as a problem of scheduling orders, whereorders correspond to jobs and jobs correspond to pieces, and by applying existing machinery [7, 8]we obtain a factor 4 approximation algorithm for P |split|∑wjCj , which improves to (2 + ε) ifthe setups are uniform, and further to 2 if also the objective is unweighted. In the latter case theanalysis becomes remarkably simple.
To wrap-up we consider the most general version of the problem for which we can designa constant factor approximation algorithm. This turns out to be the unrelated machine problemR|split, rij |
∑wjCj in which additionally jobs have machine-dependent release dates. In this setting
the splitting concept is that of Correa et al. [3] where if a fraction xij of job j is assigned to machinei it requires time xijpij + sij to be processed.
CLAIO-2016
222

2 Identical Machines
Clearly in the identical machine case we can consider that pj , wj , sj ∈ Z+. Recall that a job maybe split into several parts, which can be processed simultaneously on different machines and beforeprocessing any part of a job a setup time is required, during which the machine cannot process orsetup any other job. These setup times affect Cj , the completion time of job j ∈ J , and thereforealso
∑j∈J wjCj , the objective to be minimized.
2.1 Splitting jobs into orders
Key to our algorithms is a rule that pre-specifies the splitting pattern of every job j. If a job j hasa positive setup time, the rule splits the job into parts of size sj , which together with their setupsneed a total processing time of 2sj each. If the setup time is zero, the rule splits the job into mparts of size pj/m. The variant obtained, where jobs are split and each part is not splittable, canbe interpreted as the following scheduling problem with orders. Consider a set of jobs J that ispartitioned into sets L1 ∪ . . . ∪ Lk with Ls ∩ Ls′ = ∅ for all s 6= s′. Each set Ls corresponds to anorder, that is completed when the last of its jobs is completed. Thus, the completion time of orderL is CL := max{Cj : j ∈ L}. Given weights wL ∈ Z+ for each order L, we aim to find a scheduleon m machines that minimizes
∑LwLCL. We denote this problem as P |part|∑wLCL [4].
Given an instance I of P |split|∑wjCj , we transform it to an instance I ′ of P |part|∑wLCLas follows: each job with sj > 0 is split into dpj/sje parts, each of size 2sj . A job j with sj = 0is split into m parts of size pj/m. Together, the parts of a given job j are interpreted as an orderLj where the parts corresponds to jobs and the weight of Lj is wLj := wj . We remark that thenumber of jobs in I ′ might be pseudo-polynomial. In Section 2.2 we discuss how we deal with thistechnical issue. The next two lemmas show how to transform feasible schedules for an instance Iof P |split|∑wjCj into schedules for the transformed instance I ′ of P |part|∑wLCL and back.
Lemma 1. A feasible schedule for I ′ with completion times CLj can be transformed into a feasibleschedule to I with completion times Cj ≤ CLj for each j ∈ J .
Lemma 2. A feasible schedule for I with completion times Cj can be transformed into a feasibleschedule for I ′ with completion times CLj ≤ 2Cj for each j ∈ J .
Corollary 3. For any α ≥ 1, an α-approximation algorithm for P |part|∑wLCL implies a pseudo-polynomial 2α-approximation algorithm for P |split|∑wjCj .
The last result is an immediate consequence of Lemmas 1 and 2 and it naturally raises thequestion of whether the proposed way of splitting can be done more effectively. We show thatif each job is split into several parts independently to the rest of the instance, then our splittingprocedure is best possible regarding the worst-case loss in the objective function. More precisely,we say that F (·, ·) is a splitting function if F (p, s) is a vector (f1(p, s), . . . , fr(p,s)(p, s)) such that∑r(p,s)
`=1 f`(p, s) = p. Then, any splitting function defines a feasible way of splitting job j in r(pj , sj)many pieces, of sizes sj + f`(pj , sj) for ` ∈ {1, . . . , r(pj , sj)}. The proof of the lemma can be foundin the Appendix.
Lemma 4. Consider an instance of P |split|∑wjCj and a splitting function F . If each job is splitaccording to F , then there exists an instance for which the transformation increases the optimalvalue by a factor of at least 2.
CLAIO-2016
223

2.2 A 4-approximation for P |split|∑wjCj
Now we obtain a 4-approximation algorithm for the general P |split|∑wjCj problem using Corol-lary 3 and a result of Leung et al [7] for P |part|∑wLCL. Leung et al. [7] design a list-schedulingalgorithm for R|part|∑wjCj which specialized to the identical parallel machine setting leads toa 2-approximation algorithm. The algorithm works as follows. First relabel the orders such thatp(L1)/wL1 ≤ . . . ≤ p(Ln)/wLn , where p(L) :=
∑j∈L pj . For each k = 1, . . . , n, take all jobs in
Lk in arbitrary order and schedule them iteratively in the machine with the smallest load. In theinstance of P |part|∑wLCL constructed in Corollary 3 the number of jobs is pseudopolynomial andall jobs within an order have the same processing time. We now argue how we can use this fact inorder to implement this algorithm in polynomial time. In this setting, a schedule is described byspecifying the number of jobs nik of each order Lk assigned to machine i.
Lemma 5. The list-scheduling algorithm by Leung et al. [7] can be implemented in polynomialtime if all jobs in an order have the same processing times and the number of jobs per order ispseudopolynomial.
We conclude the following result.
Theorem 6. The problem P |split|∑wjCj admits a 4-approximation algorithm.
2.3 Uniform setup times
We now turn to the special case in which the setup times are independent of the jobs. For thecorresponding problem with orders, this translates into the case in which all jobs have the sameprocessing times, P |pj = p,part|∑wLCL. In what follows we argue that this problem admits aPTAS. To this end we first prove that for P |pj = p,part|∑wLCL we can focus on solutions givenby a list-scheduling algorithm. However, unlike the list-scheduling algorithm studied in Section 2.2,the sequence of orders is not necessarily given by Smith’s rule. Without loss of generality we assumethat p = 1.
Lemma 7. For each instance of P |pj = 1, part|∑wLCL there exists a list-scheduling optimalsolution.
Lemma 7 teaches us an important lesson. Optimal solutions to P |pj = p,part|∑wLCL arecharacterized by the sequence of orders. We next show that we can further reduce the problem toa single machine problem with a non-linear objective, namely
∑wjdCj/me.
Lemma 8. The instances of P |pj = p, part|∑wLCL are in a cost-preserving one-to-one corre-spondence to instances of 1||∑wjdCj/me.
With Lemma 8 we can design approximation algorithms for the single machine problem, whichis strongly NP-hard [6], and then transfer them to the problem with orders. To this end we use thePTAS for 1||∑j wjf(Cj) [8], where f is any computable non-negative non-decreasing function, anddirectly obtain a PTAS for P |pj = p,part|∑wLCL, and a (2 + ε)-approximation for uniform setuptimes. We remark that the fact that the transformation in Corollary 3 creates a pseudopolynomialnumber of jobs per order does not affect the polynomiality of the algorithm just described. Indeed,the number of jobs in the instance of P |pj = p,part|∑wLCL corresponds to the processing timeof jobs of the instance of 1||∑wjf(Cj), which can be described with polynomially many bits.
CLAIO-2016
224

Theorem 9. There exists a (2 + ε)-approximation for the problem with splittable jobs and equalsetup times.
Finally, when all setup times are equal and all weights are unit, i.e., P |sj = s, split|∑Cj .The same reasoning allows us to reduce the problem to 1||∑dCj/me by losing a factor of 2 in theapproximation guarantee. For the latter problem a simple swapping argument amounts to concludethat the SPT rule yields an optimal schedule, and therefore we obtain a 2-approximation algorithm.
Theorem 10. The split scheduling problem admits a 2-approximation in the case of uniform setuptimes and uniform weights.
3 Unrelated Machines
We now focus on the unrelated machine case, R|split|∑wjCj . A fraction y of job j on machine iuses sij+y ·pij time units in total. We consider the problem under machine-dependent release datesrij for each machine-job pair i, j. For technical reasons we scale the processing and setup timessuch that pij ≥ m for all nonzero pij ’s. Additionally, we can assume that if pij = 0 then sij ≥ 1.Thus, any feasible solution satisfies Cj ≥ 1 for all j. Our algorithm is based on an time-indexed LPintroduced by Hall et al. [5] and the extension in [4]. Let T be an upper bound on the makespan ofthe optimal schedule, e. g., T =
∑i,j rij + sij + pij . Given α ∈ (1, 2], let q be such that αq−1 ≥ T .
We partition the time axis in intervals [τ0, τ1], . . . , (τq−1, τq], where τ0 = 1 and τk = αk−1. Our LPconsiders variables yijk ∈ [0, 1] that represent the fraction of j that finishes at interval (τk−1, τk] foreach k ≥ 2, and yij1 represents the fraction of j finishing in [0, 1]. When it is not specified k rangesin {1, . . . , q}, i ranges in M and j ∈ J .
min∑
j
wjCj
s.t.∑
i,k
yijk = 1 for all j, (1)
∑
j
∑
`≤kyij`(pij + sij) ≤ τk for all k, i, (2)
∑
i,k
yijkτk−1 ≤ Cj for all j, (3)
yijk = 0 for all i, j, k : rij > τk or sij > τk, (4)
yijk ≥ 0 for all i, j, k.
It is easy to see that (1), (2), and (4) are valid inequalities for our problem. To see also that(3) is valid notice that for all k we have that τk−1 ≤ Cj if yijk > 0: this holds by definition of yijkfor k ≥ 2 and because Cj ≥ 1 for k = 1. Thus (3) follows by (1). Hence, the previous LP is arelaxation to our problem.
Consider an optimal solution (yijk)ijk and (CLPj )j of this LP. Our rounding technique consists
of two steps. First, since the LP solution can process a fraction of job j at a time much larger thanCLPj , we truncate the solution so that no job finishes later than γ · CLP
j /(γ − 1), for some γ > 1that will be chosen appropriately. Unfortunately, the resulting fractional solution it is still not afeasible schedule since the LP only reserved a fraction of the needed setup for each piece of a job.
CLAIO-2016
225

To overcome this difficulty, we interpret each interval-machine pair (i, k) as a machine and roundusing the technique of [3] that studies the split job problem in the minimum makespan setting. Itis worth mentioning that both transformations maintain variables yijk = 0 untouched, and thus (4)is always satisfied. Finally we construct the final schedule with a greedy algorithm based on therounded LP solution. The next lemma specifies how to truncate the solution given by the LP.
Lemma 11. Let γ > 1 and Yj =∑
i,k:τk−1≤γCLPjyijk for each job j. Then,
y′ijk =
{0 if τk−1 > γ · CLP
j ,
yijk/Yj if τk−1 ≤ γ · CLPj ,
satisfies (1) and (4). Also, (2) is satisfied if the right-hand-side is multiplied by γ/(γ − 1).
We further round the solution by using the following recent result for R|split|Cmax, implicitlyproven in [3]. The theorem gives a way of rounding a fractional solution into a fractional solutionin which the setups are fully considered, while the total load of the machine is at most twice theoriginal fractional load plus one setup.
Theorem 12 ([3]). Consider an instance of R|split|Cmax. For any non-negative assignment vectorx such that
∑i xij = 1 for all j, there exists a non-negative solution x̃ such that:
∑i x̃ij = 1 for
each j, if xij = 0 then x̃ij = 0, and for each machine i
∑
j:x̃ij>0
(x̃ijpij + sij) ≤ 2∑
j
xij(pij + sij) + maxj:xij>0
sij .
The next step of our algorithm consists in interpreting a machine-interval pair as a machine inthe previous theorem and applying it to solution y′ given by Lemma 11. This leads to a solution ỹsatisfying for all i, k:
∑
j:ỹijk>0
(ỹijk · pij + sij) ≤ 2∑
j
y′ijk(pij + sij) + maxij:y′ijk>0
sij
≤ 2∑
j
y′ijk(pij + sij) + τk, (5)
where the last inequality follows from (4) since y′ijk > 0 implies that yijk > 0. Let Jik = {j : ỹijk >0}. The final step of the algorithm is the following. For every k = 1, . . . , q and every machine i,our algorithm takes each job j (in arbitrary order) in Jik and processes its setup time sij and afraction of ỹijk as early as possible while obeying the release dates.
Theorem 13. The problem R|rij , split|∑j wjCj admits a 19.7864-approximation algorithm.
Acknowledgements
This work was supported by Nucleo Milenio Información y Coordinación en Redes ICM/FIC P10-024F, by EU-IRSES grant EUSACOU, and by FONDECYT project No. 11140579.
CLAIO-2016
226

References
[1] A. Allahverdi, C.T. Ng, T.C.E. Cheng, and M. Kovalyov. A survey of scheduling problemswith setup times or costs. European Journal of Operational Research, 187:985–1032, 2008.
[2] B. Chen, Y. Ye, and J. Zhang. Lot-sizing scheduling with batch setup times. Journal ofScheduling, 9:299–310, 2006.
[3] J. R. Correa, A. Marchetti-Spaccamela, J. Matuschke, O. Svensson, L. Stougie, V. Verdugo,and J. Verschae. Strong LP formulations for scheduling splittable jobs on unrelated machines.Mathematical Programming - Series B, 154:305–328, 2015.
[4] J. R. Correa, M. Skutella, and J. Verschae. The power of preemption on unrelated machinesand applications to scheduling orders. Mathematics of Operations Research, 37:379–398, 2012.
[5] L. A. Hall, A. S. Schulz, D. B. Shmoys, and J. Wein. Scheduling to minimize average completiontime: off-line and on-line approximation algorithms. Mathematics of Operations Research,22:513–544, 1997.
[6] W. Höhn and T. Jacobs. On the performance of Smith’s rule in single-machine schedulingwith nonlinear cost. ACM Transactions on Algorithms, 11:25, 2015.
[7] J. Y. T. Leung, H. Li, M. Pinedo, and J. Zhang. Minimizing total weighted completiontime when scheduling orders in a flexible environment with uniform machines. InformationProcessing Letters, 103:119–129, 2007.
[8] N. Megow and J. Verschae. Dual techniques for scheduling on a machine with varying speed.In Automata, Languages, and Programming (ICALP 2012), volume 7965 of LNCS, pages 745–756. 2013.
[9] C. N. Potts and L. N. Van Wassenhove. Integrating scheduling with batching and lot sizing: Areview of algorithms and complexity. The Journal of Operational Research Society, 43:395–406,1992.
[10] F. Schalekamp, R. Sitters, S. van der Ster, L. Stougie, V. Verdugo, and A. van Zuylen. Splitscheduling with uniform setup times. Journal of Scheduling, 18:119–129, 2014.
[11] P. Serafini. Scheduling jobs on several machines with the job splitting property. OperationsResearch, 44:617–628, 1996.
[12] V. Verdugo. Algoritmos de aproximación para la programación de trabajos divisibles contiempos de instalación en máquinas paralelas. Master’s thesis, Department of Industrial En-gineering and Department of Mathematical Engineering, University of Chile, 2014.
[13] W. Xing and J. Zhang. Parallel machine scheduling with splitting jobs. Discrete AppliedMathematics, 103:259–269, 2000.
CLAIO-2016
227

4 Appendix
Identical Machines
Proof of Lemma 1. Consider a feasible schedule for I ′. Since each job in Lj has processing time2sj , we can use the time slots occupied by jobs in Lj to process job j. In this slot we can schedulethe setup time sj plus sj processing time units of job j. The chosen number of dpj/sje parts forjob j guarantees that job j can be processed for sj · dpj/sje ≥ pj units of time, and thus fullycompleted before CLj .
Proof of Lemma 2. By a simple swapping argument, we can restrict ourselves to consider a schedulefor I that processes each job contiguously on each machine. Let tij be the amount of time used toschedule job j on machine i (without considering the setup). We will see that duplicating the totaltime spent to process job j on each machine i, that is sij + tij , is enough to process the completeorder Lj .
If the job j has a positive setup time, doing this gives a total of 2(sj + tij) = 2sj (1 + tij/sj) ≥2sjdtij/sje units of time available for order Lj on machine i. Hence, we can process at least dtij/sjejobs of Lj on machine i. For this case, the lemma follows by noticing that the total number of jobsof Lj that we can process is
∑
i∈M
⌈tijsj
⌉≥⌈∑
i∈M
tijsj
⌉≥⌈pjsj
⌉= |Lj |.
When the job has a setup time equal to zero, by duplicating the time we obtain a total of 2tij ≥(pj/m) ·d2m ·tij/pj−1e units of time available for order Lj on machine i. Therefore, we can processd2m · tij/pj − 1e jobs of order Lj on machine i and thus in total we can process at least m jobs ofLj :
∑
i∈M
⌈2m · tijpj
− 1
⌉≥⌈∑
i∈M
(2m · tijpj
− 1
)⌉= m.
Proof of Lemma 4. Consider a single job with processing time p ∈ Z+ and setup time s = 1.Suppose there exists an entry in F (p, s) with value f ≥ 1 and there are m = p2 machines. Anysolution with this splitting has a cost of at least 1 + f ≥ 2. In an optimal schedule the job is splituniformly over the p2 machines achieving a cost of 1+1/p. Therefore, the splitting scheme inducedby F increases the cost by at least a factor of 2/(1 + 1/p), which converges to 2 when p→∞.
Now suppose that every entry in the vector F (p, s) is at most α < 1, which implies thatr(p, s) ≥ p/α. If the instance contains a single machine, then the cost of scheduling the pieces onthe machine is at least p/α+ p. In an optimal schedule the job is not split, yielding a cost of 1 + p.We obtain that cost increases by a factor of at least
p/α+ p
1 + p>
2p
1 + p
p→∞−→ 2.
Proof of Lemma 5. Let us assume that we have scheduled orders L1, . . . , Lk−1, and let Ti be thecompletion time (load) of machine i in that schedule. We denote by Ck the completion time oforder Lk in the list-scheduling algorithm and by pk the processing time of a job in Lk. We notice
CLAIO-2016
228

the following property: after scheduling order Lk each machine that processes a job in Lk has loadin [Ck − pk, Ck]. Thus, we have that
nik ∈{⌈
Ck − pk − Tipk
⌉,
⌈Ck − pk − Ti
pk
⌉+ 1
}.
Consider the function h(C) =∑
i∈Md(C − pk − Ti)/pke, which is an estimate of the number ofjobs of size pk that can be used to greedily schedule jobs having a completion time at most C.In particular it holds that 0 ≤ |Lk| − h(Ck) ≤ m. Moreover, we know that mini∈M Ti ≤ Ck ≤mini∈M Ti + |Lk|pk. Since h is non-decreasing, by running a binary search procedure we can findC∗ such that |Lk| −m ≤ h(C∗) ≤ |Lk|. Then we assign d(C∗ − pk − Ti)/pke many jobs of Lk toeach machine i. The at most m missing jobs in Lk can be assigned greedily.
Proof of Lemma 7. Consider an optimal schedule S with completion times CL and relabel theorders such that CL1 ≤ CL2 ≤ · · · ≤ CLn . We feed the list-scheduling algorithm with the sequenceof orders L1, . . . , Ln. The completion time of order Lj in this schedule is C ′Lj
= d 1m∑
k≤j |Lk|e.On the other hand, in the original schedule S all the orders L1, . . . , Lj have been completed up totime CLj , and then we have that mCLj ≥
∑k≤j |Lk|. Because of the integrality of CLj it holds
that CLj ≥⌈
1m
∑k≤j |Lk|
⌉= C ′Lj
.
Proof of Lemma 8. We map each instance Io of the problem with orders to an instance Is forthe single machine problem as follows. Each order L of Io corresponds to a job j(L) in Is withprocessing time |L| and weight wL. Clearly this mapping is bijective. By Lemma 7 we know thatthere exists an optimal schedule for Io given by a list-scheduling algorithm. Let L1, . . . , Ln be anysequence of orders. If we schedule the jobs in Is according to this sequence, the total cost is
n∑
j=1
wLj
⌈CLj
m
⌉=
n∑
j=1
wLj
1
m
∑
k≤j|Lk|
,
which coincides with the cost of the solution for Io following the corresponding list-schedulingsolution. Thus, any solution for Is is in one-to-one correspondence to a list-scheduling solution Ioof equal cost.
Unrelated Machines
Proof of Lemma 11. The vector y′ satisfies (1) and (4) by definition. We will show that for all i, j, kit holds that y′ijk ≤ yijk · γ/(γ − 1). This is enough to conclude the lemma since y satisfies (2).Notice that Yj ≥ (γ − 1)/γ,
∑
i,k
yijkτk−1 ≥∑
i,k:τk−1≥γCLPj
yijk · γ · CLPj = γCLP
j (1− Yj) > CLPj ,
contradicting (3). We conclude that y′ijk ≤ yijk/Yj ≤ yijk · γ/(γ − 1) for all i, j, k, which impliesthe lemma.
CLAIO-2016
229

Proof of Theorem 13. Let τ̄k = 1/(α−1)+∑k
`=1(2∑
j y′ijk(pij +sij)+τ`). We prove that all pieces
of jobs corresponding to Jik can be completely processed (including setup) within [τ̄k−1, τ̄k]. Indeed,for all j ∈ Jik we have that ỹijk > 0 and thus yijk > 0, which in turn implies that rij ≤ τk by (4).Thus, since 1 < α ≤ 2, we have that
rij ≤ τk ≤1
α− 1+τk − 1
α− 1=
1
α− 1+k−1∑
`=1
τ` ≤ τ̄k−1.
Therefore all jobs in Jik are available at time τ̄k−1. Moreover, since τ̄k − τ̄k−1 = 2∑
j y′ijk(pij +
sij)+τk, Equation (5) implies that all the pieces in Jik, together with their setups, can be processedwithin [τ̄k−1, τ̄k]. Hence, all pieces of Jik are finished by time
τ̄k =1
α− 1+
k∑
`=1
2
∑
j
y′ijk(pij + sij) + τ`
≤ 1
α− 1+ 2
γ
γ − 1τk +
k∑
`=1
τ`
≤ α(
2γ
γ − 1+
α
α− 1
)τk−1.
Here, the first inequality follows since by Lemma 11 y′ satisfies (2) with the right-hand-side amplifiedby a factor γ/(γ − 1), and the second by the definition of τk. We conclude that all pieces of a job
j ∈ Jik finish by time α(
2 γγ−1 + α
α−1
)τk−1. Moreover, if j ∈ Jik then ỹijk > 0, and thus by
Theorem 12 y′ijk > 0. By the definition of y′ in Lemma 11 this implies that τk−1 ≤ γ · CLPj .
Therefore job j is completely finished by time γα(2 γγ−1 + α
α−1)CLPj . Choosing1 α = 1.39775 and
γ = 1.60225 we obtain that each job j finishes by times 19.7864 · CLPj and thus the overall cost is
at most 19.7864∑
j wjCLPj .
1The values of α and γ are computed numerically in order to approximately minimize the approximation factor.The exact optimal values cannot be determined analytically since they correspond to the solutions of higher orderpolynomial equations.
CLAIO-2016
230

Redes espacio-tiempo para itinerario de fiscalización de
la evasión en buses de Transantiago.
Cristián E. Cortés C.Departamento de Ingenieŕıa Civil, Universidad de Chile
Pablo A. ReyDepartamento de Ingenieŕıa Industrial, Universidad de Chile
Diego Muñoz C.Gerencia Planificación, Desarrollo y Control, STP Santiago S.A.
Luis Trujillo J.Departamento de Ingenieŕıa Industrial, Universidad de Chile
8 de abril de 2016
Resumen
Desde sus inicios, la evasión del pago ha sido un problema relevante para Transantiago. Eneste art́ıculo se reporta un trabajo conjunto con un operador de buses del sistema, en base a dosĺıneas de acción: (i) atacar la evasión en la totalidad de servicios que maneja la compañ́ıa y susparaderos, con inspectores fiscalizando en paraderos durante turnos definidos, (ii) controlar laevasión en un sólo servicio y sus paraderos asociados, con inspectores que pueden controlar tantoen paradas como en buses. En ambos casos, el objetivo es rutear eficientemente a los inspectores,buscando maximizar el ingreso proveniente del pago recuperado de potenciales evasores. Seutilizan enfoques de programación entera mixta basados en redes expandidas en espacio-tiempo,para obtener el itinerario de los inspectores. Se proponen dos formulaciones alternativas: unamediante modelos de flujo en redes, y otra usando una heuŕıstica basada en generación decolumnas.
Keywords: Evasión en transporte público; Programación entera mixta; Redes espacio-tiempo.
1. Introducción
Transantiago, el sistema de transporte público de la ciudad de Santiago, Chile, comenzó a operaren Febrero, 2007. Posee una estructura troncal alimentadora e integra servicios de buses operadospor 7 compañ́ıas. Todos los d́ıas existen transferencias entre servicios de buses y el tren subterráneo.
CLAIO-2016
231

Los usuarios hacen efectivo el pago usando una tarjeta personal, llamada Bip!, al pasarla porsensores electrónicos ubicados en los buses, en algunos paraderos y en estaciones de Metro. Estacaracteŕıstica, hace que sea más fácil evadir el pago del pasaje para un porcentaje importante de lapoblación, afectando aśı las finanzas de la compañ́ıa por una parte, y la percepción sobre el nivelde servicio por otra.
Este trabajo fue desarrollado con datos y requerimientos presentados por la empresa operadorade buses STP Santiago S.A. Entre los requerimientos acordados en conjunto con la compañ́ıa,existen dos formas de enfrentar el problema de evasión por medio de inspectores, para escenariosdiferentes de operación: (i) asignar eficientemete el equipo de inspectores para controlar lo mejorposible la evasión existente en todos los paraderos de la compañ́ıa, considerando el total de recorridosalimentadores; y (ii) controlar evasión sólo en paraderos correspondientes a un servicio espećıfico,pero con inspectores que además de fiscalizar en las paradas, lo hacen arriba de los buses; esteúltimo esquema tiene sentido en el caso de un recorrido troncal a cargo de la empresa .
Para modelar las modalidades expuestas, se consideran diversos tipos de turnos de trabajo paralos inspectores. Los turnos pueden ser de jornada completa o parcial más una hora de descanso enperiodos cercanos a la mitad de su jornada.
El problema a resolver se puede sintetizar en realizar el ruteo de una flota de inspectores duranteel d́ıa laboral, maximizando el control de evasión en los paraderos que presentan altos niveles deevasión en diferentes instantes de la jornada, recuperando aśı la mayor cantidad posible de pagosprovenientes de los evasores potenciales.
De esta manera, el trabajo se estructura como sigue. En la sección 2 se plantean los modelosy enfoques de solución para la primera forma de operar explicada anteriormente. Estos enfoquesde solución también son válidos para el tratamiento de un servicio con fiscalización bajo y sobrelos buses. En la sección 3 se presenta sólo el modelamiento utilizado en la segunda modalidad delproblema. Finalmente, en la sección 4 se presenta una śıntesis con las conclusiones más relevantes.
2. Modelos y enfoques de solución para abordar la totalidad deparaderos y servicios
Para esta modelación, se añadieron 2 aspectos que conectan el problema con la realidad y quevale la pena mencionar. Primero, poder encontrar itinerarios de inspección que no fueran predeciblespor los evasores. En la literautra, la predictabilidad puede relacionarse con problemas de ruteode veh́ıculos de seguridad y transporte de dinero, etc., donde este aspecto es clave. Buscandosobre predictabilidad se puede mencionar por ejemplo el art́ıculo de Duchenne et al. [4], dondese resuelve un m-peripatetic tsp para encontrar un conjunto de m rutas disjuntas en arcos comoposibles elecciones de alguna entidad. En este caso, no es necesario aplicar un modelo como elanterior. Con otra metodoloǵıa los modelos pueden encontrar paquetes de itinerarios de inspecciónintercambiables entre jornadas laborales. El segundo aspecto a considerar es que dentro de un d́ıade trabajo, existen paraderos que son muy atractivos para fiscalizar dado el alto nivel de evasiónpresente. Por esto, los modelos también pueden forzar sistemáticamente a estos paraderos a sercontrolados en la jornada, dentro de todos los paquetes de itinerarios.
CLAIO-2016
232
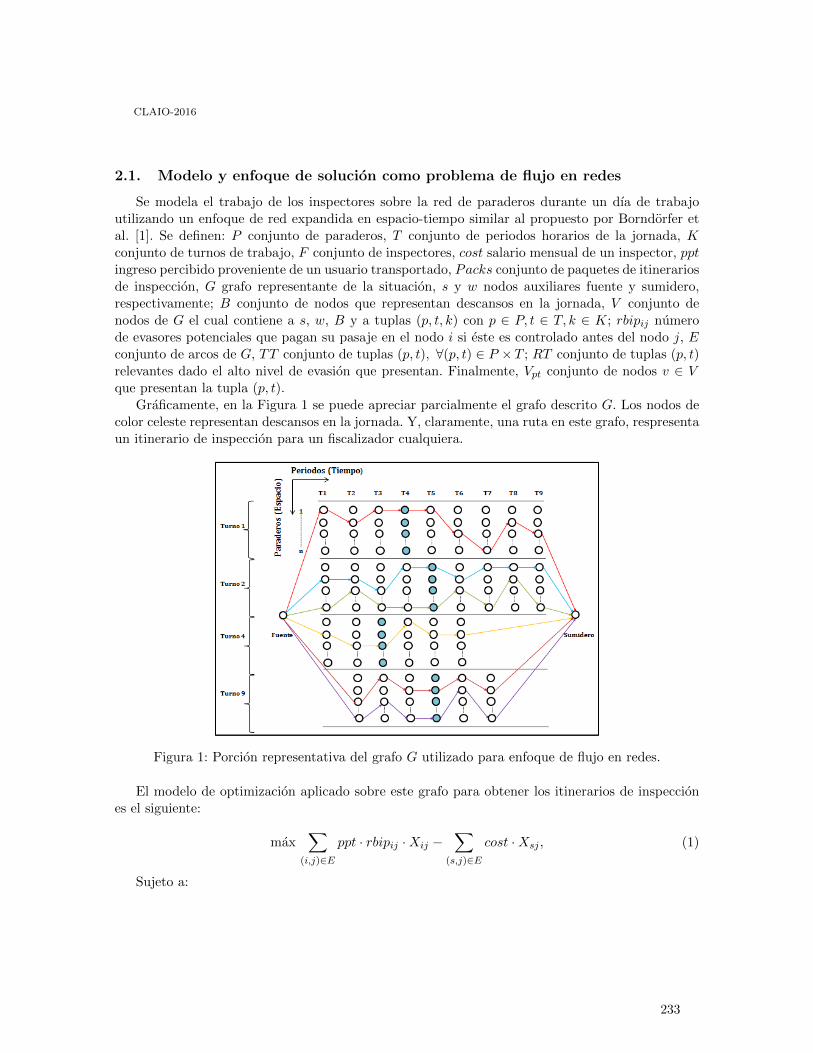
2.1. Modelo y enfoque de solución como problema de flujo en redes
Se modela el trabajo de los inspectores sobre la red de paraderos durante un d́ıa de trabajoutilizando un enfoque de red expandida en espacio-tiempo similar al propuesto por Borndörfer etal. [1]. Se definen: P conjunto de paraderos, T conjunto de periodos horarios de la jornada, Kconjunto de turnos de trabajo, F conjunto de inspectores, cost salario mensual de un inspector, pptingreso percibido proveniente de un usuario transportado, Packs conjunto de paquetes de itinerariosde inspección, G grafo representante de la situación, s y w nodos auxiliares fuente y sumidero,respectivamente; B conjunto de nodos que representan descansos en la jornada, V conjunto denodos de G el cual contiene a s, w, B y a tuplas (p, t, k) con p ∈ P, t ∈ T, k ∈ K; rbipij númerode evasores potenciales que pagan su pasaje en el nodo i si éste es controlado antes del nodo j, Econjunto de arcos de G, TT conjunto de tuplas (p, t), ∀(p, t) ∈ P ×T ; RT conjunto de tuplas (p, t)relevantes dado el alto nivel de evasión que presentan. Finalmente, Vpt conjunto de nodos v ∈ Vque presentan la tupla (p, t).
Gráficamente, en la Figura 1 se puede apreciar parcialmente el grafo descrito G. Los nodos decolor celeste representan descansos en la jornada. Y, claramente, una ruta en este grafo, respresentaun itinerario de inspección para un fiscalizador cualquiera.
Figura 1: Porción representativa del grafo G utilizado para enfoque de flujo en redes.
El modelo de optimización aplicado sobre este grafo para obtener los itinerarios de inspecciónes el siguiente:
máx∑
(i,j)∈Eppt · rbipij ·Xij −
∑
(s,j)∈Ecost ·Xsj , (1)
Sujeto a:
CLAIO-2016
233

∑
(s,j)∈EXsj =
∑
(i,w)∈EXiw, (2)
∑
(i,j)∈EXij =
∑
(j,i)∈EXji, ∀ j ∈ V − {s, w}, (3)
∑
(s,j)∈EXsj ≤ |F | · |Packs| , (4)
∑
j∈Vpt
∑
i∈V :(i,j)∈EXij ≤ 1, ∀(p, t) ∈ TT −RT, (5)
∑
j∈Vpt
∑
i∈V :(i,j)∈EXij = |Packs| , ∀(p, t) ∈ RT, (6)
0 ≤ Xij ≤ |Packs| , ∀(i, j) ∈ E, (7)
Xij ∈ N ∪ {0}, ∀(i, j) ∈ E, (8)
La función objetivo (1) maximiza el ingreso proveniente del pago de potenciales evasores, consi-derando el salario de los inspectores. Las restricciones en (2) y (3) son de conservación de flujo. Larestricción (4) indica el número de rutas a generarse en la red. Las familias de restricciones (5) y (6)indican que sólo las tuplas relevantes en términos de evasión estarán presentes en todos los paquetesde itinerarios, mientras que el resto sólo estará máximo una vez. Finalmente, las restricciones (7)y (8) caracterizan a las variables de decisión de flujo en arcos.
2.2. Modelo y enfoque de solución basado en generación de columnas
En este enfoque, para solucionar el problema, se modifica la red definida en la sección anterior.Aśı, cada turno de trabajo posee su propio grafo, como se aprecia en la Figura 2. Esto es debido aque en este caso cada una de estas redes, establece un subproblema para el esquema de generaciónde columnas, los cuales producirán rutas o itinerarios de inspección, cuales serán las variables delproblema maestro a resolver.
Continuando con la formulación del modelo, se definen: r una ruta cualquiera en los grafos
anteriores, Rk : conjunto de rutas posibles correspondientes al subproblema k,⋃n=|K|
n=1 Rn conjuntode todas las rutas posibles, R ⊆ R subconjunto de rutas usadas en el problema maestro restringido,Vk : conjunto de nodos del grafo relacionado al subproblema k el cual contiene a sk y wk (nodosauxiliares fuente y sumidero, respectivamente), a Bk (conjunto de nodos que representan descansosen la jornada) y a tuplas (p, t), ∀(p, t) ∈ TT . Ek conjunto de arcos relacionados con el grafovinculado al subrpoblema k, Cij beneficio percibido por usar el arco (i, j) ∈ Ek, ∀k ∈ K; brbeneficio por usar la ruta r ∈ R, vjr parámetro binario que vale 1 si la ruta r pasa por el nodo j y0 si no. Finalmente, Yr variable de decisión del problema, la cual vale 1 si se ocupa la ruta r y 0 sino.
Formulando el esquema de generación de columnas como se indica en la literatura (Desrosiersy Lübbecke [3]), a continuación se establecen el problema maestro y los subproblemas. Se exponeprimero la relajación del problema maestro restringido:
máx∑
r∈Rbr · Yr, (9)
CLAIO-2016
234

Figura 2: Porción de los grafos utilizados para enfoque de generación de columnas.
sujeto a:∑
r∈Rvjr · Yr ≤ 1, ∀ j ∈ TT −RT, (10)
∑
r∈Rvjr · Yr = |Packs| , ∀ j ∈ RT, (11)
∑
r∈RYr ≤ |F | · |Packs| , (12)
Yr ≥ 0, ∀ r ∈ R, (13)
La función objetivo (9) y las restricciones (10), (11) y (12) son equivalentes, respectivamente,con las expresiones (1), (5), (6) y (4) del modelo de la subsección anterior. La restricción (13)corresponde a la relajación lineal de la variable de decisión.
Subproblema relacionado al turno de trabajo k:
(SPk) máxr∈Rk
br −∑
j∈TT−RT
αj · vjr −∑
j∈RT
βj · vjr − γ, (14)
Lo anterior es equivalente a:
(SPk) máx∑
(i,w)∈Ek
Ciw ·Xiw +∑
i∈Vk−{s},j∈TT−RT :(i,j)∈Ek
(Cij − αj) ·Xij +∑
i∈Vk−{s},j∈RT :(i,j)∈Ek
(Cij − βj) ·Xij
+∑
i∈Vk,j∈Bk:
(i,j)∈Ek
Cij ·Xij − γ,(15)
CLAIO-2016
235

sujeto a:
∑
(s,j)∈Ek
Xsj =∑
(i,w)∈Ek
Xiw, (16)
∑
(i,j)∈Ek
Xij =∑
(j,i)∈Ek
Xji, ∀ j ∈ Vk − {s, w}, (17)
∑
(s,j)∈Ek
Xsj ≤ 1, (18)
Xij ∈ {0, 1}, ∀ (i, j) ∈ Ek, (19)
Afortunadamente, se visualiza que cada subproblema corresponde a encontrar la ruta más largaen un grafo dirigido aćıclico. Los cuales pueden resolverse eficientemente con el algoritmo propuestopor, Dasgupta et al. [2] , con complejidad O(|Vk|+ |Ek|).
3. Modelo para servicio troncal con paraderos de un único servicio
Para este caso de estudio, se modela el trabajo de los inspectores sobre los paraderos de unsólo servicio de la compañ́ıa, ubicados en un corredor importante de la ciudad de Santiago. En estaocasión, los inspectores pueden moverse libremente entre los paraderos, en vez de cumplir periodoshorarios en ellos. Para esto, se formula una nueva red, y se definen: P conjunto de paraderos en laruta del servicio, el cual está compuesto por paraderos del sentido de Ida del servicio: {1, ..., 24},aśı como también por los del sentido de Retorno: {25, ..., 47}. C es el conjunto de paraderos ca-bezales iniciales o terminales del servicio en ambos sentidos de la ruta, ubicados en Plaza Italiay Plaza Puente Alto ({PIini, P Ifin, PAini, PAfin}). A continuación, en la Figura 3, se aprecia ladistribución espacial de los paraderos y el sentido de avance del servicio.
Figura 3: Distribución de paraderos del servicio estudiado y sentido de avance del mismo.
Siguiendo con la definición de parámetros, se tiene: B conjunto de nodos bPIfin y bPAfinque
representan descansos luego de alcanzar los paraderos terminales PIfin y PAfin, respectivamente.T conjunto de instantes de tiempo donde ocurren hitos del timetable del servicio, p′ paraderocorrespondiente al paradero p, ubicado cruzando la calle, ∀ p ∈ P−{1}; p paradero inmediatamentesiguiente al paradero p en relación al sentido de avance del servicio. Tp conjunto de instantes detiempo donde ocurren hitos del time table en paradero el p, tp,p′ tiempo promedio de caminataentre el paradero p y el paradero p′, ∀ p ∈ P − {1}. G(V,E) grafo en el cual se modela el trabajode los inspectores sobre la red de paraderos del servicio. V y E son los conjuntos de nodos y arcosdel grafo G, respectivamente. V , al igual que los modelos anteriores, presenta los nodos auxiliaresfuente s y sumidero w. Λp
t instante de tiempo donde ocurre un hito en el paradero p inmediatamentedespués de un instante de tiempo dado t. En otras palabras: Λp
t := min {Λ ∈ Tp : Λ > t}. Además,
CLAIO-2016
236

∆pt instante de tiempo donde ocurre un hito en el paradero p inmediatamente después o justo
en un instante de tiempo dado t. En otras palabras: ∆pt := min {∆ ∈ Tp : ∆ ≥ t}. Cada nodo
v ∈ V representa una acción o tarea a ser realizada por un inspector, pudiendo ser de dos tipos,caracterizados por las tuplas siguientes:
a) (p, t) : controlar paradero p en el instante t ∈ Tp. Arcos salientes poseen beneficio asociado.
b) (bus, p, t) : estar dentro del bus que pasó por el paradero p en el instante t ∈ Tp justo antes deque siga su recorrido.
En cuanto a los arcos de G, se presenta un esquema de los posibles movimientos que puedehacer un inspector, dado el paradero en que se encuentre:
� Si p ∈ P :
(p, t)→{
(p,Λpt ) , controlar bus siguiente que pase por p.
(bus, p, t), subirse al bus justo después de controlar p.(20)
� Si p ∈ P − {1}:
(p, t)→{
(p′,∆p′t+tp,p′
) , ir a controlar paradero correspondiente a p.
(bus, p′,∆p′t+tp,p′
), subirse al bus que pase por pardero correspondiente a p.(21)
� Si p ∈ P ∪ {PIini, PAini}:
(bus, p, t)→{
(p,Λpt ), controlar paradero siguiente a p. (22)
� Si p ∈ P − {24, 47} ∪ {PAini}:
(bus, p, t)→{
(p′,∆p′t+tp,p′
) , controlar paradero correspondiente del siguiente a p.
(bus, p′,∆p′t+tp,p′
), subirse a bus en paradero corresp. del siguiente de p.(23)
� Si p ∈ P − {24, 47} ∪ {PIini, PAini}:
(bus, p, t)→{
(bus, p,Λpt ), quedarse arriba del bus en el paradero siguiente a p. (24)
� Si p ∈ {PIfin, PAfin}:
(p, t)→{
(bus, p,∆pt ), terminar un recorrido y comenzar otro en sentido opuesto.
(bp, t) , llegar a una terminal y comenzar el descanso.(25)
�(bPIfin , t)→{
(bus, PIini,∆PIinit+1hr.), subirse después de descanso de 1 hr. en terminal Plaza Italia.
(26)
CLAIO-2016
237

�(bPAfin, t)→
{(bus, PAini,∆
PAinit+1hr.), subirse después de descanso de 1 hr. en terminal Puente Alto.
(27)Para finalizar, al igual que en la primera modalidad, este modelo también admite aspectos como
paquetes de itinerarios y fijar visitas sitemáticas en determinados paraderos relevantes. Asimismo,notar que se pueden emplear los mismos enfoques de solución, debido a que sólo vaŕıan algunosparámetros. Por ejemplo, en este caso el conjunto RT de tuplas (p, t) relevantes a visitar sistemáti-camente, p seŕıa un paradero relacionado al servicio estudiado y t seŕıa un instante del timetablerelacionado a p.
4. Conclusiones
Como primera conclusión importante, debe notarse que el problema de la evasión en Transan-tiago puede abordarse efectivamente modelando el trabajo de los inspectores con redes expandidasen espacio-tiempo, combinado con enfoques de programación entera mixta para resolverlo. En par-ticular, se rescata el hecho de que distintas modalidades del problema puedan resolverse con losmismos esquemas de solución.
De los resultados obtenidos, se concluye que el enfoque basado en un programa de flujo enredes es más útil en instancias pequeñas con pocos paraderos, otorgando la posibilidad de tomardecisiones casi inmediatamente. Sin embargo, el esquema basado en generación de columnas esidóneo si se aborda el problema para la totalidad de paraderos de la compañ́ıa.
Finalmente, la solución obtenida genera un impacto tangible para la compañ́ıa al poder aumen-tar el ingreso percibido proveniente del pago de potenciales evasores en el sistema.
Agradecimientos
Esta investigación fue apoyada por CONICYT/FONDECYT/REGULAR/ No. 1141313 y elInstituto de Sistemas Complejos de Ingenieŕıa (financiamiento ICM: P-05-004-F y CONICYT:FBO16).
Referencias
[1] Ralf Borndörfer, Guillaume Sagnol, and Elmar Swarat. An ip approach to toll enforcementoptimization on german motorways. In Operations Research Proceedings 2011, pages 317–322.Springer, 2012.
[2] Sanjoy Dasgupta, Christos H Papadimitriou, and Umesh Vazirani. Algorithms. McGraw-Hill,Inc., 2006.
[3] Jacques Desrosiers and Marco E Lübbecke. A primer in column generation. Springer, 2005.
[4] Éric Duchenne, Gilbert Laporte, and Frédéric Semet. Branch-and-cut algorithms for the undirec-ted m-peripatetic salesman problem. European journal of operational research, 162(3):700–712,2005.
CLAIO-2016
238

The Block-interchange and the Breakpoint Closest
Permutation problems are NP-Complete∗
Lúıs Felipe Ignácio CunhaUniversidade Federal do Rio de Janeiro
Vińıcius Fernandes dos SantosUniversidade Federal de Minas Gerais
Luis Antonio Brasil KowadaUniversidade Federal Fluminense
Celina Miraglia Herrera de FigueiredoUniversidade Federal do Rio de Janeiro
Abstract
The Closest Problem aims to find one object in the center of all others. It was studiedfor strings with respect to the Hamming distance to be the metric to compute distances. TheHamming Closest String Problem (Hamming–CSP) was settled to be NP-Complete inthe case of binary strings. The Closest Permutation Problem was also studied, sincepermutations are the natural restrictions of general strings. A permutation is a string with aunique occurrence of each letter of the alphabet, and by considering the Cayley distance, theCayley Closest Permutation Problem (Cayley–CPP) was settled to be NP-Complete. Inthis paper, we consider well-known metrics to compute distances of permutations in the contextof genome rearrangements, and we prove two NP-Completeness, the Block-interchange–CPPand the Breakpoint–CPP.
Keywords: Closest Permutation; NP-Completeness; Hamming distance; Block-interchange dis-tance; Breakpoint distance.
1 Introduction
The Closest Permutation Problem (CPP) is a combinatorial challenge with applications incomputational biology [11], where an input permutation set models a set of genomes, and we wantto find a solution genome that is closely related to all others, i.e. a permutation minimizing the
∗This research is partially supported by CAPES/MathAmSud 021/14 and CNPq.
CLAIO-2016
239

radius of the input permutation set. Several metrics corresponding to genome rearrangementssuch as Cayley, Transposition, Block-interchange, Breakpoint, and Reversal have been studied [7].Popov [12] studied the CPP regarding the Cayley metric, and proved that the Cayley–CPPis NP-Complete. The CPP has not been studied regarding other metrics to compute distances,for instance with respect to the Block-interchange, for which the distance problem is polynomialsolvable [6] and is a generalization of the Cayley metric.
A more general problem, asking for a closest string regarding the Hamming distance, was provedto be NP-Complete by Lanctot et al. [9]. Gramm et al. [8] proposed a fixed-parameter algorithmwith respect to the radius parameter, and they also considered another variation, by asking for theclosest substring of a given set of strings, where they proved to be W [1]-hard with respect to theparameter number of input strings, which corroborates the hypothesis that the Hamming ClosestString Problem is easier than the more general Hamming Closest Substring Problem.
A related problem is the Median Problem, where we ask for the solution string/permutationthat minimizes the sum of the distances between the solution and the input string/permutation set.The Hamming Median String Problem is a polynomial problem [8], but regarding permutationsthe Breakpoint [10], Transposition [1], and Reversal [5] Median Permutation Problems are NP-Complete.
In this paper, we consider the Closest Permutation Problem with respect to two well-known metrics, by proving that the Block-interchange and the Breakpoint Closest PermutationProblems are NP-Complete.
This paper is organized as follows: in Section 2 we define the Hamming Closest String Prob-lem, the Closest Permutation Problem, and the metrics we deal with in this paper; in the sub-sequent sections we prove NP-Completenesses, where in Section 3 we prove Block-interchange–CPP is NP-Complete, and in Section 4 we prove Breakpoint–CPP is NP-Complete; and finallyin Section 5 we discuss some open questions for further work about complexity and approximationalgorithms on the closest and the related median problems.
2 Preliminaries
An alphabet Σ is a non empty set of letters, and a string over Σ is a sequence of letters of Σ.The Hamming distance between two strings si and σ denoted dH(si, σ) is defined as the number ofmismatched positions between si and σ. We call the Hamming distance of a string the number ofmismatched positions between si and ι = 0m, such that si has length m. The Hamming ClosestString Problem is defined as follows:
Hamming Closest String Problem (H–CSP)INPUT: Set of strings {s1, s2, . . . , s`} over alphabet Σ of length m each, and a non-negative integer f .QUESTION: Is there a string σ of length m such that max
i=1,...,`dH(si, σ) ≤ f?
In case of positive answer for H–CSP, we call a solution of H–CSP any string σ that satisfiesmaxi=1,...,`
dH(si, σ) ≤ f , and Lanctot et al. [9] proved the surprising result.
Theorem 1. [9] H–CSP is NP-Complete for a binary alphabet.
CLAIO-2016
240

A permutation of length n is a particular string with a unique occurrence of each letter, since itis a bijection from the set {1, 2, . . . , n} onto itself π = [π(0)π(1)π(2) · · · π(n)π(n+1)], such thatπ(0) = 0 and π(n+1) = n+ 1. The operations we consider will never act on π(0) nor π(n+1).
Given a metric M and dM (pi, π) the minimum number of operations regarding the metric Mto transform pi into π, the Closest Permutation Problem is defined as follows:
Metric M Closest Permutation Problem (M–CPP)INPUT: Set of permutations {p1, p2, . . . , pk} of length n and a non-negative integer d.QUESTION: Is there a permutation π of length n such that max
i=1,...,kdM (pi, π) ≤ d?
In case of positive answer for M–CPP, we call a solution of M–CPP any permutation π thatsatisfies max
i=1,...,kdM (pi, π) ≤ d.
Given a set of permutations, the Closest Permutation Problem aims to find a solutionpermutation that minimizes the maximum distance between the solution and all other input per-mutations. The metric to compute distances depends on the context of the problem.
We call the distance between two permutations the minimum number of the correspondingoperations to transform one permutation into another one, and we call the distance of a permutationthe minimum number of operations to transform the permutation into the identity permutationι = [0 1 2 · · · n n+ 1].
In this work, we consider two metrics: the Block-interchange distance, and the Breakpointdistance.
The Block-interchange operation transforms one permutation into another one by exchangingtwo blocks, and generalizes the Transposition operation where the blocks are consecutive and theCayley operation where the blocks are unitary. The Block-interchange distance is the minimumnumber of block exchanges in a permutation to transform one permutation into another one.
Note that regarding the distance problem general operations do not imply the same complexitywith respect to the complexity of more particular operations, for instance the Block-interchangeand the Cayley distances can be computed in polynomial time [6, 7], whereas the Transpositiondistance is an NP-Complete problem [4]. On the other hand, If a distance problem is NP-Complete,then the Closest problem for the same operation is also NP-Complete.
The Breakpoint distance is the number of consecutive elements in one permutation that are notconsecutive in the other one. Note that on the Breakpoint distance we do not apply any operationto transform a permutation into another.
Now, we review how to obtain in polynomial time the distances between permutations, basedon the reality and desire diagram, or on the breakpoints.
The Block-interchange distance A useful graph proposed by Bafna and Pevzner [2], namedreality and desire diagram, allowed non-trivial bounds on the Transposition distance, and the exactBlock-interchange distance developed by Christie [6].
Given a permutation π of length n, the reality and desire diagram G(π) of π, is a multigraphG(π) = (V,R ∪ D), where V = {0,−1,+1,−2,+2, · · · ,−n,+n,−(n + 1)}, each element of πcorresponds to two vertices and we also include the vertices labeled by 0 and −(n + 1), and theedges are partitioned into two sets: the reality edges R and the desire edges D. The realityedges represent the adjacency between the elements on π, that is R = {(+π(i), −π(i + 1)) |i =
CLAIO-2016
241

1, · · · , n − 1} ∪ {(0, −π(1)), (+π(n), −(n + 1))}; and the desire edges represent the adjacencybetween the elements on ι, that is D = {(+i, −(i+ 1)) |i = 0, · · · , n}. Please refer to Fig. 1.
0 -2 +2 -1 +1 -11-4 +4 -3 +3 -5 +5 -6 +6 -7 +7 -8 +8 -9 +9 -10+10-12+12 +11 -13
Figure 1: The reality and desire diagram of the permutation [0 2 1 4 3 5 6 7 8 9 10 12 1113].
As a direct consequence of the construction of the reality and desire diagram, every vertex inG(π) has degree 2, so G(π) can be partitioned into disjoint cycles. We say that a cycle in π haslength k, or that it is a k-cycle, if it has exactly k reality edges (or, equivalently, k desire edges).Hence, the identity permutation of length n has n+ 1 cycles of length 1. We denote C(G(π)) thenumber of cycles in G(π).
After applying to permutation π a block-interchange b`, the number of cycles C(G(π)) changesin such a way that C(G(πb`)) = C(G(π))+x, where x ∈ {−2, 0, 2}; the block-interchange b` is thusclassified as an x-move for π. Christie [6] proved that in any optimal sorting sequence, a 2-movecan always be applied, therefore we have the block-interchange distance.
Theorem 2. [6] The Block-interchange distance of a permutation π of length n is dBI(π) =(n+1)−C(G(π))
2 .
On the other hand, by considering the transposition distance, a 2-move is not always possibleto be applied. Bafna and Pevzner [2] showed conditions with respect to the reality edges of atransposition to be x-move, where x ∈ {−2, 0, 2}. If a transposition t is a −2-move, then t affectsthree distinct cycles. On the other hand, if a transposition t is a 0-move or a 2-move, then t affectselements of the same cycle [2].
The reduced permutation of π, denoted gl(π), is the permutation whose reality and desirediagram G(gl(π)) is equal to G(π) without the cycles of length 1, and has its vertices relabeledaccordingly, for instance the reduced permutation corresponding to the permutation in Fig. 1 is[0 2 1 4 3 5 7 6 8]. Christie [6] proved an important equality.
Theorem 3. [6] The Block-interchange distances of a permutation π and its reduced permutationgl(π) satisfy dBI(π) = dBI(gl(π)).
The Breakpoint distance An adjacency (resp. a reverse adjacency) in a permutation π withrespect to another permutation δ is a pair (a, b) of consecutive elements in π such that (a, b)(resp. the pair (b, a)) is also consecutive in δ. If a pair of consecutive elements is neither anadjacency nor a reverse adjacency, then (a, b) is called a breakpoint, and we denote b(π, δ) thenumber of breakpoints of π with respect to δ. Hence, the breakpoint distance between π and δ isdBP (π, δ) = b(π, δ).
Next, we apply transformations from a generic instance of the H–CSP to particular instancesof the M–CPP with respect to the Block-interchange, and the Breakpoint metrics. In each one
CLAIO-2016
242

we establish a relationship between the Hamming distance of binary strings and the permutationdistance on the corresponding metric.
3 Block-interchange–CPP is NP-Complete
Firstly, we apply Algorithm 1 that transforms an arbitrary binary string s of length m into aparticular permutation λs of length 2m.
Algorithm 1: PermutBI(s)
input : Binary string s of length moutput: Permutation λs
1 each occurrence of 0 in position i corresponds to the elements 2i− 1 and 2i in positions2i− 1 and 2i, respectively.
2 each occurrence of 1 in position i corresponds to the elements 2i− 1 and 2i in positions 2iand 2i− 1, respectively.
Fig. 2 illustrates the construction of a permutation for a given string with respect to Algorithm 1.
0 13
Figure 2: Permutation λs = [0 2 1 4 3 5 6 7 8 9 10 12 1113] obtained from Algorithm 1 — with itsreality and desire diagram in Fig. 1 — where s = 110001, with reduced permutation gl(λs) =[0 2 1 4 3 5 7 6 8], and number of cycles of its reality and desired diagram C(G(gl(λs))) = 2. TheHamming distance of s is equal to the Block-interchange distance of λs.
Lemma 4. Given a string s 6= 0m of length m and a permutation λs of length 2m obtained inAlgorithm 1, then the reduced permutation gl(λs) has length n′, where 2dH(s) ≤ n′ ≤ 3dH(s)− 1.
Proof. If the string s of length m is s = 1dH(s)0m−dH(s) (or s = 0m−dH(s)1dH(s)) then the reducedpermutation has less 2(m− dH(s)) elements, therefore the associated permutation has length n′ =2m−2(m−dH(s)) = 2dH(s). If s of length m is s = (01)
m2 (or s = (10)
m2 ) then each adjacency 2i−
1, 2i is removed in the reduced permutation, excepted the first adjacency 1, 2 (or the last adjacency2m − 1, 2m) for which both elements are removed. So, the length of the reduced permutation isn′ = 2dH(s) + dH(s)− 1.
Lemma 5. If λs is a permutation obtained in Algorithm 1 and gl(λs) its reduced of length 2dH(s)+x, for 0 ≤ x ≤ dH(s)− 1, then C(G(gl(λs))) = x+ 1.
Proof. There exist x contiguous sequences of bits 0 in s between two contiguous sequences of bits 1,implying in a cycle in the reality and desire diagram for each contiguous sequence of bits 1.
Next, we establish the key equality between the Hamming distance of an input string and theBlock-interchange distance of its output permutation obtained from Algorithm 1.
CLAIO-2016
243

Lemma 6. Given λs the permutation obtained from a binary string s by Algorithm 1, the Block-interchange distance of the permutation πs is equal to the Hamming distance of the string s,dBI(λs) = dH(s).
Proof. Since dBI(λs) = dBI(gl(λs)), we have from Lemma 5 that dBI(gl(λs)) = 2dH(s)+x+1−(x+1)2 ,
which implies dBI(λs) = dH(s).
Now, we show how a solution for the H–CSP implies in a solution for the Block-interchange–CPP, and vice versa.
Lemma 7. Given a set of k permutations obtained by Algorithm 1, there is a Block-interchangeclosest permutation with max distance at most d if and only if there is a Hamming closest stringwith max distance equal to d.
Proof Sketch. (⇒) “from permutation to string”. If λ′ can be built by Algorithm 1 for some inputstring s′, then, by Lemma 6, s′ is a closest string.
Otherwise, we search from the left to the right the permutation to find the first position wherethe corresponding element is different from the one intended to be by the algorithm, which can bea position 2i− 1 or a position 2i. Then, we do a case analysis on the positions we have found thedifference, and we transform to a new permutation with a longer prefix agreeing with the algorithmoutput, without increasing the distance to any input permutation.
In order to guarantee that the distance is not increasing, we apply transpositions and show theworst operation is a 0-move with respect to any input permutation, since such transposition affectselements of same cycle in the reality and desire diagram.
By repeating this process, a string agreeing with the algorithm output can be found and, byLemma 6, a string with maximum distance equal to d can be constructed.
(⇐) “from string to permutation”. Given a solution string s, we obtain the associated per-mutation λs given by Algorithm 1. By Lemma 6 we have the solution s regarding the H–CSPcorresponding to the permutation λs with the same value of max distance d.
Theorem 8. The Block-interchange–CPP is NP-Complete.
4 Breakpoint–CPP is NP-Complete
Firstly, we apply Algorithm 2 that transforms an arbitrary binary string s of length m into aparticular permutation βs of length 4m.
Algorithm 2: PermutBP (s)
input : Binary string s of length m.output: Permutation βs
1 each occurrence of 0 in position i corresponds to the elements 4i− 3, 4i− 2, 4i− 1 and 4i inpositions 4i− 3, 4i− 2, 4i− 1, 4i, respectively.
2 each occurrence of 1 in position i corresponds to the elements 4i− 3, 4i− 2, 4i− 1 and 4i inpositions 4i− 2, 4i− 3, 4i− 1, 4i, respectively.
Fig. 3 illustrates the construction of a permutation for a given string with respect to Algorithm 2.
CLAIO-2016
244

0 13
Figure 3: Permutation βs = [0 1 2 3 4 6 5 7 8 10 9 11 12 13] where s = 011, obtained fromAlgorithm 2, with the breakpoint distance dBP (βs) = 4, since the breakpoints are (4, 6), (5, 7),
(8, 10) and (9, 11). The Hamming distance of s is dH(s) = dBP (βs)2 = 2.
Next, we establish the following relationship between the Hamming distance of an input stringand the Breakpoint distance of its output permutation obtained from Algorithm 2.
Lemma 9. Given βs the permutation obtained from a binary string s by Algorithm 2, the Breakpointdistance of βs is dBP (βs) = 2dH(s).
Proof. Each element 1 of the binary string yields an exchange between two consecutive elements,hence we are creating exactly two breakpoints.
Now, we show how a solution for the H–CSP implies in a solution for the Breakpoint–CPP, andvice versa.
Lemma 10. Given a set of k permutations obtained by Algorithm 2, there is a Breakpoint closestpermutation with max distance equal to 2d if and only if there is a Hamming closest string withmax distance equal to d.
Proof Sketch. (⇒) “from permutation to string”. If β′ can be built by Algorithm 2 for some inputstring s′, then, by Lemma 9, s′ is a closest string.
Otherwise, we search from the left to the right the permutation to find the first position wherethe corresponding element is different from the one intended to be by the algorithm. Then, we do acase analysis on the positions we have found the difference, and we transform to a new permutationwith a longer prefix agreeing with the algorithm output, without increasing the distance to anyinput permutation. By repeating this process, a string agreeing with the algorithm output can befound and, by Lemma 9, a string with maximum distance equal to d can be constructed.
(⇐) “from string to permutation”. Given a solution string s, we obtain the associated per-mutation βs given by Algorithm 2. By Lemma 9 we have the solution s regarding the H–CSPcorresponding to the permutation βs with the value of max distance equal to 2d.
Theorem 11. The Breakpoint–CPP is NP-Complete.
5 Further work
This paper describes the complexity of the Closest Permutation Problem with respect to twowell-known metrics. Despite the hardness to decide the center permutation with respect to thesemetrics, some interesting questions arise.
CLAIO-2016
245

How to improve the 2-approximation algorithm that computes all pairwise distances?By the triangular inequality, a necessary condition for a permutation to be the center with radiusat most d is that the distance of any pair in the input permutation set must be at most 2d. Hence,if such condition is true for a given input permutation set, then any permutation of the input is asolution with approximation ratio 2 of an optimal solution. Since the two considered metrics admitpolynomial algorithms to compute the distances, one question would be to lower the approximationratio.
What can we say about the Kendall-τ Median problem? The Kendall-τ operation, alsoknown as the bubble sort, is an exchange between two consecutive elements in a permutation. Hence,the Block-interchange, as well as the Transposition and the Cayley, is also a generalization of theKendall-τ operation. The Kendall-τ Median problem is known to be NP-Complete, but itscomplexity is open when the input set has three permutations [3].
References
[1] Bader, M.: The transposition median problem is NP-complete. Theor. Comput. Sci., 412, 1099–1110(2011)
[2] Bafna, V., Pevzner, P. A.: Sorting by transpositions. SIAM J. Disc. Math, 11, 224–240 (1988)
[3] Blin, G., Crochemore, M., Hamel, S., Vialette, S.: Medians of an odd number of permutations. PureMath. Appl., 21(2), 161–175 (2010)
[4] Bulteau, L., Fertin, G., Rusu, I. Sorting by transpositions is difficult. SIAM J. Disc. Math, 26(3),1148–1180 (2012)
[5] Caprara, A.: The reversal median problem. INFORMS J. Comput., 15, 93–113 (2003)
[6] Christie, D. A.: Sorting permutations by block-interchange. Inf. Process. Lett., 60, 165–169 (1996)
[7] Fertin, G., Labarre, A., Rusu, I., Tannier, E., Vialette, S.: Combinatorics of Genome Rearrangements.The MIT Press (2009)
[8] Gramm, J., Niedermeier, R., Rossmanith, P.: Fixed-Parameter Algorithms for CLOSEST STRINGand Related Problems. Algorithmica, 37, 25–42 (2003)
[9] Lanctot, J. K., Li, M., Ma, B., Wang, S., Zhang, L.: Distinguishing string selection problems. Inform.and Comput., 185(1), 41–55 (2003)
[10] Pe’er, I., Shamir, R.: The median problems for breakpoints are NP-complete. Technical report TR98-071. The Electronic Colloquium on Computational Complexity (1998)
[11] Pevzner, P. A.: Computational Molecular Biology: An Algorithmic Approach. The MIT Press (2000)
[12] Popov, V. Y.: Multiple genome rearrangement by swaps and by element duplications. Theor. Comput.Sci., 385, 115–126 (2007)
CLAIO-2016
246

A polyhedral approach to the adjacent vertex
distinguishable proper edge coloring problem
Brian CurcioUniversidad de Buenos Aires and CONICET, Argentina
Isabel Méndez-Dı́azUniversidad de Buenos Aires, Argentina
Paula ZabalaUniversidad de Buenos Aires and CONICET, Argentina
Abstract
The adjacent vertex distinguishable proper edge coloring problem is the problem of findingthe minimum number of colors required for a proper edge coloring such that every pair ofadjacent vertices is distinguishable.
In this paper we propose an integer linear programming approach to solve the problem. Westudy the underlying polyhedron, develop a Branch and Cut algorithm and present computa-tional results that show a very good performance of the algorithm on random graphs.
Keywords: Adjacent Vertex Distinguishable Edge Coloring; Polyhedral study; Branch and Cut.
1 Introduction
An edge coloring of a simple graph G = (V,E) is an assignment of colors to the edges of G. Aproper edge coloring is an edge coloring such that no two adjacent edges are assigned the samecolor. A proper edge coloring is vertex distinguishing if for every pair of vertices u and v, the setof colors assigned to the edges incident to u is different from the set of colors assigned to the edgesincident to v. If we limit the restriction to vertices u and v which are adjacent we have an adjacentvertex distinguishing proper edge coloring (avdec). If a graph has an avdec with k colors it is calledk−avdec. In this paper we focus on the adjacent vertex distinguishing proper edge coloring problemwhich is defined as the problem of finding the minimum number of colors χ′a(G), known as avdecchromatic index of G, such that G has an avdec.
Zhang et al. [16] studied these colorings and determined the chromatic indices for several classesof graphs and proposed the following conjecture:
Conjecture 1 If G is a connected graph with at least 6 vertices, then χ′a(G) ≤ ∆ + 2 where∆ = max{d(u) : u ∈ V } with d(u) = |{v ∈ V such that (u, v) ∈ E}|
CLAIO-2016
247

Balister et al.[1] confirmed Conjecture 1 for all bipartite graphs and graphs with ∆ = 3.Hatami[8] showed that every normal graph G with ∆ > 1020 has χ′a(G) ≤ ∆ + 300. Bu et al.[4]verified Conjecture 1 for planar graphs of girth at least 6. Chen and Guo[5] determined completelythe adjacent vertex distinguishing chromatic indices for hypercubes. Wang and Wang[14] studiedthe adjacent vertex distinguishing of graphs with small maximum average degree. It is shown in [6]that if G is a planar bipartite graph with ∆ ≥ 12 then χ′a(G) ≤ ∆ + 1. Wang and Wang[15] gavea complete characterization for χ′a(G) of K4-minor free graphs with ∆ ≥ 5. Tian and Wang[12]characterized the adjacent vertex distinguishing edge coloring of lexicographic product of graphs.Bazgan et al.[2] proved that for graphs with n vertices there exists a vertex distinguishing properedge coloring with at most n + 1 colors. Since a vertex distinguishing proper edge coloring is anavdec, then we have an upper bound on χ′a(G). They also proved [3] that if d(v) > n/3 ∀v ∈ V ,then χ′a(G) ≤ ∆ + 5 .
Given that there has been a wide theoretical study of adjacent vertex distinguishing edge color-ings and that many layout problems have been successfully solved by integer linear programming([11],[10]), in this paper we propose a Branch and Cut algorithm to find the avdec-chromatic indexof a graph. We study the structure of the problem and characterize some valid inequalities whichproved to be very useful as cutting planes. Computational results show a very good performanceof the algorithm on random graphs. In the following sections we present details of our proposal.
2 ILP-Model
Consider C the set of colors, k ∈ C, u ∈ V , (u, v) ∈ E and the binary variables: xuk equal to 1 iffcolor k is used by an edge incident to u; wuvk for d(u) = d(v) equal to 1 iff color k is used by u or v(exclusive); auvk equal to 1 iff color k is assigned to edge (u, v) and rk equal to 1 iff color k is used.
The following ILP formulation solves the avdec problem:
min∑
k∈Crk
s.t∑
k∈Cwuvk ≥ 1 ∀(u, v) ∈ E ∧ d(u) = d(v) (1)
xuk − xvk ≤ wuvk ∀(u, v) ∈ E ∧ d(u) = d(v) ∧ k ∈ C (2)
xvk − xuk ≤ wuvk ∀(u, v) ∈ E ∧ d(u) = d(v) ∧ k ∈ C (3)
wuvk ≤ xuk + xvk ∀(u, v) ∈ E ∧ d(u) = d(v) ∧ k ∈ C (4)
wuvk ≤ 2− (xuk + xvk) ∀(u, v) ∈ E ∧ d(u) = d(v) ∧ k ∈ C (5)
xuk =∑
v∈N (u)
auvk ∀u ∈ V ∧ k ∈ C (6)
∑
k∈Cauvk = 1 ∀(u, v) ∈ E (7)
xuk ≤ rk ∀u ∈ V ∧ k ∈ C (8)
rk ≤∑
u∈V (G)
xuk ∀k ∈ C (9)
CLAIO-2016
248

Inequality (1) imposes the restriction of having at least one different colored edge between allconflicting vertices. Inequalities (2) and (3) prevent variables w taking a value of 0 if two adjacentvertices have a distinguishing color. We set an upper bound for variables w with equations (4) and(5): if two vertices u and v have an incident edge of color k, or if neither of them do, then wuvk willbe 0. Equation (6) sets the value of variables xuk if there is an incident edge of vertex u with colork. Inequality (7) allows exactly one color assigned to each edge. The cost function is minimizingthe number of colors. We set the variables rk with inequalities (8) and (9). The last inequality isnot necessary for the model but it is added to improve the computational performance.
3 Polyhedral results
Let G be a graph with n vertices, m edges and m′ conflicting edges (edges between vertices of samedegree). Consider P = {(x, a, w) ∈ Rn × Rm × Rm′} : A(x, a, w) ≤ b} the linear relaxation of ourmodel ignoring variables r and S = P ∩ {(x, a, w) ∈ Bn ×Bm ×Bm′} are all those points satisfyingintegrality constraints.
In this section we study the convex hull of S since analyzing the structure of the linear pro-gramming formulation can help us to characterize valid inequalities.
3.1 Minimal Equation system
In addition to the equations (6) and (7) we have the following result:
Proposition 1 The following equalities are valid in our model:
wuvk = auu′k + avv′k ∀(u, v) such that d(u) = d(v) = 2
(u, u′), (v, v′) ∈ E
Furthermore, we found that there is no other valid equation in all graphs up to order 8. Ourconjecture is that these equations, (6) and (7) form the minimal equation system.
3.2 Valid inequalities
We found 4 families of valid inequalities. These inequalities can not be deduced from the inequalitiesin the model and can be used to cut solutions from the linear relaxation.
The next inequality is a reinforced version of restriction (4). It forces variables wuvk to 0 if theedge between vertices u and v is colored with k.
wuvk + 2auvk ≤ xuk + xvk ∀k ∈ C, (u, v) ∈ E ∧ d(u) = d(v)
Let us consider a complete subgraph K3 = {u1, u2, u3} (three vertices, adjacent to each other)such that d(u1) = d(u2) = d(u3). If an edge between vertex u1 and u2 has color k, then the wu1u2kvariable of the corresponding edge is 0 and wu1u3k = wu2u3k. The next inequality is based on thisproperty:
au1u2k + wu1u3k ≤ 1 + wu2u3k ∀k ∈ C, (u1, u2), (u1, u3), (u2, u3) ∈ Ed(u1) = d(u2) = d(u3)
CLAIO-2016
249

Similar to previous case, if u1 and u2 differ on color k, then u3 differs on color k with u1 or u2.This is set by the following inequality:
wu1u2k ≤ wu1u3k + wu2u3k ∀k ∈ C, (u1, u2), (u1, u3), (u2, u3) ∈ Ed(u1) = d(u2) = d(u3)
Finally, consider a vertex t such that {u, v} ⊆ N(t) and d(u) = d(v). If no other incident edgeto u or v has color k, and one of the edges (u, t) or (v, t) does, then wuvk = 1. The next is a validinequality:
autk + avtk ≤ wuvk +∑
z∈N(u)∪N(v)z 6=u,v,t
xzk ∀k ∈ C, t ∈ V,N(t) = {u, v} ∧ d(u) = d(v)
3.3 Elimination of symmetric solutions
Since colors are indistinguishable, there exist many assignments of colors for a same given numberof colors. This symmetry drawback can make a Branch and Cut algorithm behaves poorly. Beingcognizant of it, we look for different valid inequalities that allow to reduce the number of solutionsof the problem by eliminating some possible symmetric solutions.
Let φ be a function that maps each edge to a number between 1 and m. We consider thefollowing symmetry breaking constraints:
rk ≥ rk+1 ∀k ∈ C (10)∑
v∈Vxvk ≥
∑
v∈Vxvk+1 ∀k ∈ C (11)
aijk ≤∑
(u,v)∈Ek−1≤φ(u,v)≤φ(i,j)−1
auvk−1 ∀k ∈ C ∧ (i, j) ∈ E (12)
The first one (10) establishes an order in the used colors, the k + 1-th color can be assignedto an edge provided color k has already been assigned. Constraint (11) imposes that the numberof vertices that an incident edge is assigned color k must be greater or equal than the number ofvertices which have an incident edge colored by k+ 1. Finally, a third option (12) orders the colorsby the least numbered edge that is colored by each one.
It is worth mentioning that the first and the third one allows us to do a preprocessing of thegraph by coloring the largest star in the graph. This is not possible with the second alternativebecause the color of each edge depends on how many edges are colored in the solution.
4 Heuristic
A heuristic is used to construct a first feasible solution. This gives us an upper bound on thenumber of colors, allowing us to reduce the number of variables in the problem.
We define the color set of a vertex as the set of colors of its incident edges, and the adjacentcolors of an edge as the union of the color sets of its endpoints.
CLAIO-2016
250

The general outline of the sequential algorithm is to color each edge in turn until there are nomore left, choosing the edge with the largest number of adjacent colors. In case of tie, an edge israndomly selected from the set of vertices tied. The selected edge (u, v) is colored by the smallestpossible used color. If none is feasible, an already colored edge incident to u changes its color to anew one making possible to select a color to (u, v).
Algorithm 1 Greedy Heuristic for avdec
Coloredge is the color of edge edgeMaxColor is the value of the maximum colorMaxColor ← 1while there are uncolored edges do
edge← a random uncolored edge with maximum adjacent colorsu, v ← endpoints of edgeif d(u) = d(v) ∧ colorset(u) = colorset(v) ∧ |colorset(u)| = d(u)− 1 then
ColoredEdge← a colored edge incident to uColorColoredEdge ←MaxColor + 1MaxColor ←MaxColor + 1
end ifMinColor ← minimum color that can be assigned to edge that satisfies the constraintsColoredge ←MinColorUpdate MaxColor, colorset(u) and colorset(v)
end while
Because the edge to be colored is randomly selected, we can use the algorithm multiple timesand use the best solution, allowing us to reduce a greater number of variables.
5 Computational Results
In this section we present an overview with some experiments we made with the Branch and CutAlgorithm. We used CPLEX 12.4 to implement the algorithm in C++ and did the tests on a 3.4GHz i7 computer in single thread mode. CPU times are reported in seconds. Some default settingson how the branch and bound tree is explored where changed. About branching strategies, wefound that branching first on the x variables by pseudo cost rule reduces the number of openednodes. Node selection follows the best bound rule.
To evaluate performance we generated random instances for different values of number of verticesand densities. Number of vertices varies from 10 to 59, for each one we used 10%, 50% and 90% ofdensity. For each combination, we consider 6 instances.
5.1 Heuristic
We tested the initial heuristic with a time limit of 10 seconds. Since all solutions will have at least∆ + k colors, we measured the average k for each different density. This tells us how far is thenumber of colors from the lower bound. For each density we report the average number of colorsused in the heuristic solution for each range of sizes.
CLAIO-2016
251

n 10-11 12-15 16-19 20-23 24-27 28-31 32-35 36-39 40-43 44-47 48-51 52-55 56-59
10% 0.79 1.00 1.00 1.00 1.00 1.00 1.08 1.00 1.04 1.17 1.21 1.12 1.2950% 0.75 1.00 1.00 1.04 1.04 1.04 1.08 1.29 1.25 1.46 1.29 1.46 1.5490% 0.75 1.17 1.04 1.25 1.17 1.08 1.50 1.46 1.71 2.42 2.29 2.71 3.17
Table 1: Heuristic results
We can see from table 1 that the heuristic produced very good results for low and mediumdensity instances. For these instances, we were able to make a significant reduction on the numberof variables, obtaining in many cases more than 75% of size reduction. The heuristic on high densityinstances could not improve the upper bound in almost any case. This was an expected behaviorbecause for dense graphs there is not a significant difference between the lower (∆) and the upperbound (n+ 1).
5.2 Symmetry breaking
We tested the alternative symmetry breaking restrictions on a CPLEX default Branch and Cutalgorithm. We considered three versions of the algorithm by adding:
AVDEC-OC: Restriction (10) ordered the colors used in the solution.
AVDEC-OS: Restriction (11) has an ordering on the size of the solutions.
AVDEC-ON: Restriction (12) orders the colors by a number assigned to each edge.
In the first part of table 2 we display for each variant the percentage of solved instances andthe average used time to solve them within a 5 minute time limit. For low density graphs, thereare not remarkable differences, but on medium and high density instances we can see that it isworth breaking symmetry. For example, only 28% of the bigger high density instances could besolved without any breaking restrictions. Moreover, we can see that the best results are producedby using AVDEC-OC, achieving a good trade off on used time and percentage of solved instances.
As we mentioned before, both AVDEC-OC and AVDEC-ON allow us to fix the coloring of a starand to make an extra preprocessing procedure of the instance by having an initial partial coloring.In the last part of table 2 we report the results for these variants. It shows that by eliminatingfurther the symmetric solutions the algorithm has better overall performance.
5.3 Valid inequalities
The purpose of the following experiment is to compare the standard Branch and Cut built in CPLEXwith a Branch and Cut algorithm (AVDEC-BC ) adding the valid inequalities as cutting planesusing an exhaustive search procedure on violated inequalities. AVDEC-BCH uses the respectiveapproach but also with an initial heuristic. Both algorithms consider restriction (10) as breakingsymmetry rule. Table 3 shows for each variant the percentage of instances solved and the averagetime to solve them. It shows that the valid inequalities significantly increase the performance ofthe algorithm. Moreover, by adding an initial heuristic, the algorithm’s performance is increasedfurther being able to solve the larger instances.
CLAIO-2016
252
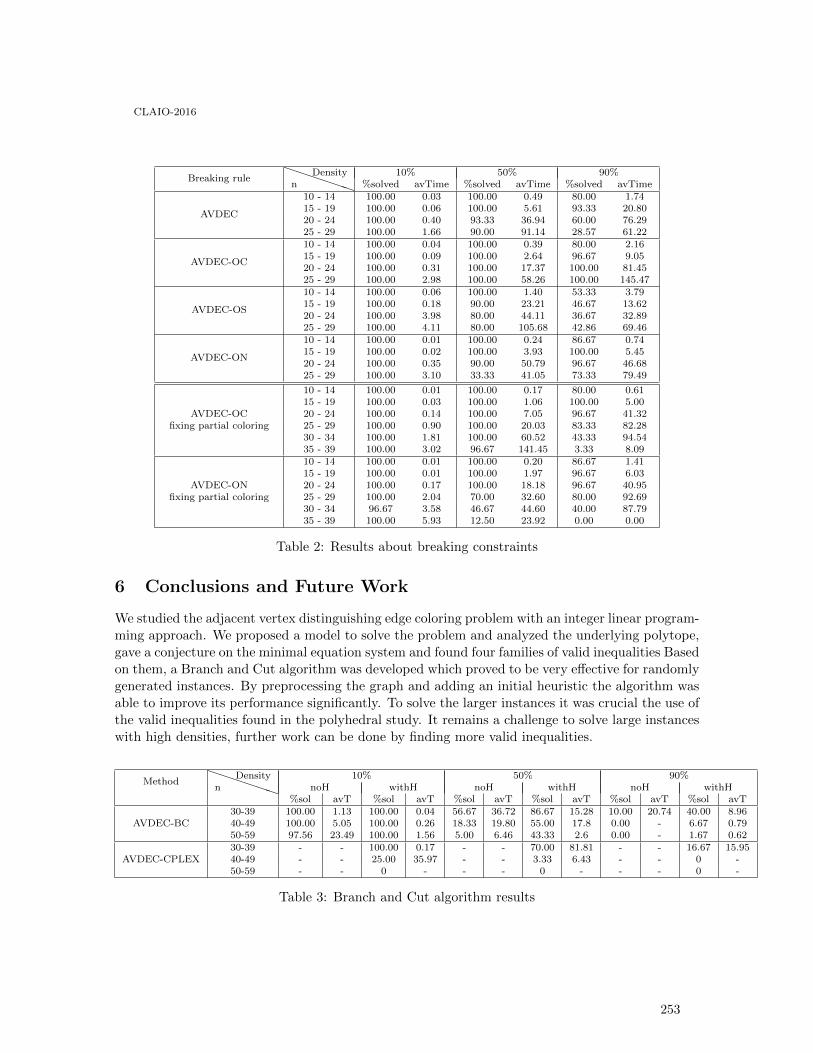
Breaking rulePPPPPPn
Density 10% 50% 90%%solved avTime %solved avTime %solved avTime
AVDEC
10 - 14 100.00 0.03 100.00 0.49 80.00 1.7415 - 19 100.00 0.06 100.00 5.61 93.33 20.8020 - 24 100.00 0.40 93.33 36.94 60.00 76.2925 - 29 100.00 1.66 90.00 91.14 28.57 61.22
AVDEC-OC
10 - 14 100.00 0.04 100.00 0.39 80.00 2.1615 - 19 100.00 0.09 100.00 2.64 96.67 9.0520 - 24 100.00 0.31 100.00 17.37 100.00 81.4525 - 29 100.00 2.98 100.00 58.26 100.00 145.47
AVDEC-OS
10 - 14 100.00 0.06 100.00 1.40 53.33 3.7915 - 19 100.00 0.18 90.00 23.21 46.67 13.6220 - 24 100.00 3.98 80.00 44.11 36.67 32.8925 - 29 100.00 4.11 80.00 105.68 42.86 69.46
AVDEC-ON
10 - 14 100.00 0.01 100.00 0.24 86.67 0.7415 - 19 100.00 0.02 100.00 3.93 100.00 5.4520 - 24 100.00 0.35 90.00 50.79 96.67 46.6825 - 29 100.00 3.10 33.33 41.05 73.33 79.49
AVDEC-OCfixing partial coloring
10 - 14 100.00 0.01 100.00 0.17 80.00 0.6115 - 19 100.00 0.03 100.00 1.06 100.00 5.0020 - 24 100.00 0.14 100.00 7.05 96.67 41.3225 - 29 100.00 0.90 100.00 20.03 83.33 82.2830 - 34 100.00 1.81 100.00 60.52 43.33 94.5435 - 39 100.00 3.02 96.67 141.45 3.33 8.09
AVDEC-ONfixing partial coloring
10 - 14 100.00 0.01 100.00 0.20 86.67 1.4115 - 19 100.00 0.01 100.00 1.97 96.67 6.0320 - 24 100.00 0.17 100.00 18.18 96.67 40.9525 - 29 100.00 2.04 70.00 32.60 80.00 92.6930 - 34 96.67 3.58 46.67 44.60 40.00 87.7935 - 39 100.00 5.93 12.50 23.92 0.00 0.00
Table 2: Results about breaking constraints
6 Conclusions and Future Work
We studied the adjacent vertex distinguishing edge coloring problem with an integer linear program-ming approach. We proposed a model to solve the problem and analyzed the underlying polytope,gave a conjecture on the minimal equation system and found four families of valid inequalities Basedon them, a Branch and Cut algorithm was developed which proved to be very effective for randomlygenerated instances. By preprocessing the graph and adding an initial heuristic the algorithm wasable to improve its performance significantly. To solve the larger instances it was crucial the use ofthe valid inequalities found in the polyhedral study. It remains a challenge to solve large instanceswith high densities, further work can be done by finding more valid inequalities.
MethodPPPPPPn
Density 10% 50% 90%noH withH noH withH noH withH
%sol avT %sol avT %sol avT %sol avT %sol avT %sol avT
AVDEC-BC30-39 100.00 1.13 100.00 0.04 56.67 36.72 86.67 15.28 10.00 20.74 40.00 8.9640-49 100.00 5.05 100.00 0.26 18.33 19.80 55.00 17.8 0.00 - 6.67 0.7950-59 97.56 23.49 100.00 1.56 5.00 6.46 43.33 2.6 0.00 - 1.67 0.62
AVDEC-CPLEX30-39 - - 100.00 0.17 - - 70.00 81.81 - - 16.67 15.9540-49 - - 25.00 35.97 - - 3.33 6.43 - - 0 -50-59 - - 0 - - - 0 - - - 0 -
Table 3: Branch and Cut algorithm results
CLAIO-2016
253

References
[1] Paul N Balister, E Gyo ri, Jenö Lehel, and Richard H Schelp. Adjacent vertex distinguishing edge-colorings. SIAM Journal on Discrete Mathematics, 21(1):237–250, 2007.
[2] Cristina Bazgan, Amel Harkat-Benhamdine, Hao Li, and Mariusz Woźniak. On the vertex-distinguishing proper edge-colorings of graphs. Journal of Combinatorial Theory, Series B, 75(2):288–301, 1999.
[3] Cristina Bazgan, Amel Harkat-Benhamdine, Hao Li, and Mariusz Woźniak. A note on the vertex-distinguishing proper coloring of graphs with large minimum degree. Discrete Mathematics, 236(1):37–42, 2001.
[4] Yuehua Bu, Ko-Wei Lih, and Weifan Wang. Adjacent vertex distinguishing edge-colorings of planargraphs with girth at least six. Discussiones Mathematicae: Graph Theory, 31(3), 2011.
[5] Meirun Chen and Xiaofeng Guo. Adjacent vertex-distinguishing edge and total chromatic numbers ofhypercubes. Information Processing Letters, 109(12):599–602, 2009.
[6] Keith Edwards, Mirko Horňák, and Mariusz Woźniak. On the neighbour-distinguishing index of agraph. Graphs and Combinatorics, 22(3):341–350, 2006.
[7] Frank Harary. Conditional colorability in graphs. Graphs and Applications, Proc. First Colo. Symp.graph theory (F. Harary and J. Maybee eds), Wiley intersci., Publ. NY, 1985.
[8] Hamed Hatami. δ+ 300 is a bound on the adjacent vertex distinguishing edge chromatic number.Journal of Combinatorial Theory, Series B, 95(2):246–256, 2005.
[9] Jon Lee and Janny Leung. A comparison of two edge-coloring formulations. Operations research letters,13(4):215–223, 1993.
[10] Isabel Méndez-Dı́az and Paula Zabala. A branch-and-cut algorithm for graph coloring. Discrete AppliedMathematics, 154(5):826–847, 2006.
[11] George L Nemhauser and Sungsoo Park. A polyhedral approach to edge coloring. Operations ResearchLetters, 10(6):315–322, 1991.
[12] Shuangliang Tian and Qian Wang. Adjacent vertex distinguishing edge-colorings and total-colorings ofthe lexicographic product of graphs. Discrete Applied Mathematics, 185:220–226, 2015.
[13] Vadim G Vizing. On an estimate of the chromatic class of a p-graph. Diskret. Analiz, 3(7):25–30, 1964.
[14] Weifan Wang and Yiqiao Wang. Adjacent vertex distinguishing edge-colorings of graphs with smallermaximum average degree. Journal of combinatorial optimization, 19(4):471–485, 2010.
[15] Weifan Wang and Yiqiao Wang. Adjacent vertex-distinguishing edge colorings of k4-minor free graphs.Applied Mathematics Letters, 24(12):2034–2037, 2011.
[16] Zhongfu Zhang, Linzhong Liu, and Jianfang Wang. Adjacent strong edge coloring of graphs. AppliedMathematics Letters, 15(5):623–626, 2002.
CLAIO-2016
254

Ranking do Desempenho Econômico-Financeiro e a relação com
Atributos de Governança Corporativa: Um estudo com
Cooperativas Agropecuárias
Cristian Baú Dal Magro
Universidade Regional de Blumenau - FURB
E-mail: [email protected]
Marcello Christiano Gorla
Universidade Regional de Blumenau - FURB
E-mail: [email protected]
Adriana Kroenke
Universidade Regional de Blumenau - FURB
E-mail: [email protected]
Nelson Hein
Universidade Regional de Blumenau - FURB
E-mail: [email protected]
Resumo O objetivo do estudo consiste em estabelecer um ranking das cooperativas agropecuárias com base nos
indicadores econômico financeiros e a relação com atributos de governança corporativa. A amostra é
composta de 25 cooperativas agropecuárias. A coleta dos dados foi realizada por meio dos relatórios de
gestão e das demonstrações contábeis divulgadas em 2013. Os resultados indicaram o rol de
cooperativas que apresentaram melhores posicionamentos com base nos indicadores estudados.
Concluiu-se que a separação de propriedade e controle está relacionada com desempenhos econômico
financeiros mais satisfatórios e que não existe uma relação entre o tamanho do conselho de
administração e o número de cooperados com o ranking dos indicadores de desempenho econômico
financeiro. Além disso, a participação de capital de terceiros, liquidez geral e retorno sobre o patrimônio
líquido foram os indicadores que se mostraram preponderantes à separação de propriedade e controle
das cooperativas estudadas.
Palavras-Chave: Ranking; Desempenho Econômico-Financeiro; Governança Corporativa;
Cooperativas Agropecuárias.
1 Introdução Na atualidade, torna-se pertinente utilizar-se da Teoria dos Jogos aplicada em estudos sobre
sociedades cooperativas. Este fato, tem se concretizado, pois estas sociedades começam a tratar com
maior cuidado, das questões que há algum tempo preocupam as sociedades anônimas, quais sejam: o
conflito derivado da separação entre propriedade e gestão, o que, por sua vez, cria um problema de
monitoramento das relações entre os associados e os administradores [1]. A competição e a ênfase por
resultados satisfatórios e eficientes têm feito com que os diretores de cooperativas questionem a
adequação da estrutura de governança corporativa [2].
Além disso, o modelo de gestão das cooperativas vem recebendo críticas, pelas deficiências que
comprometem a competividade, principalmente, devida a ineficiência da administração que coloca em
risco a sobrevivência e a eficiência organizacional. Dentre os problemas apontados, tem-se a falta de
competência dos dirigentes do conselho de administração, ou seja, falta de profissionalização [3]. Os
fatos fazem emergir a utilidade da teoria dos jogos para definição de um ranking das cooperativas, que
apresentam melhor desempenho com base em seus indicadores econômico financeiro.
Diante do exposto, emergiu a seguinte questão de pesquisa: qual o ranking das cooperativas
agropecuárias com base nos indicadores econômico financeiros e sua relação com os atributos de
governança corporativa? O estudo objetiva estabelecer um ranking das cooperativas agropecuárias com
base nos indicadores econômico financeiros e a relação com os atributos de governança corporativa.
CLAIO-2016
255

2 Fundamentação Teórica
2.1 Teoria dos Jogos Um jogo é considerado, quando há situações em que os jogadores tomam decisões estratégicas
que são utilizadas para definir o payoffs dos jogadores, que são valores associados a possibilidade dos
resultados, ou seja, uma empresa estabelece preço e como consequência os payoffs serão os lucros [4].
Considerando os elementos e as regras para a realização de um jogo, a teoria presume que um
jogo seja jogado uma única vez. Contudo, [5] define que isso não elimina a possibilidade de repetição
do jogo por um número finito ou infinito de vezes. Surge a importância de definir o conceito de jogos
cooperativos e não cooperativos. Nos jogos cooperativos a diferença de um mesmo jogo ser repetido n
vezes e de que há jogos com n repetições independentes do mesmo jogo não é relevante, mas é essencial
nos jogos não cooperativos [5]. Nos jogos não cooperativos de soma variável, os jogadores possuem a
possibilidade de sinalização de um desejo, e os demais jogadores devem fazer o mesmo [5].
A busca pela maximização conjunta dos resultados pelos jogadores é caracterizada de jogo
cooperado [6]. Para [7] nos jogos cooperativos os benefícios são repartidos para incentivar a cooperação
entre os jogadores. Por outro lado, no jogo não cooperativo cada jogador busca maximizar seu próprio
resultado, não havendo cooperação [6].
[5] comenta que nos jogos de soma zero o ganho de um jogador implica na perda do outro
jogador. Nos jogos de duas pessoas e soma zero, admite-se que o resultado positivo para um jogador
implica em um resultado negativo para o seu adversário [8]. Por fim, tem-se que os jogos são
estabelecidos de estratégias adotadas pelos jogadores, denominada também de plano completo do jogo.
Para cada jogo, os jogadores possuem um conjunto de opções que são denominadas de
estratégias puras [8]. Por outro lado, quando o ponto de sela não é encontrado, adotam-se estratégias
mistas, onde o jogador, ao invés de escolher sua estratégia, transfere essa decisão a um dispositivo
lotérico, com probabilidade associada a cada estratégia pura [5].
2.2 Desempenho Econômico Financeiro A análise de índices envolve métodos, cálculos e interpretações que auxiliam na compreensão,
análise e monitoramento do desempenho da organização. A demonstração do resultado do exercício e
o balanço patrimonial são as demonstrações fundamentais para a elaboração dos indicadores [10]. Neste
estudo, será mensurado o desempenho das sociedades cooperativas agropecuárias em relação a três
grupos de indicadores: estrutura de capital, liquidez e rentabilidade.
A estrutura de capital expõe as grandes linhas de decisões financeiras, em termos de obtenção
e aplicação dos recursos. Este grupo é formado pelos seguintes indicadores: participação de capital de
terceiros; composição do endividamento; imobilização do patrimônio líquido; imobilização dos
recursos não correntes [11]. Quanto aos indicadores de liquidez, [12] cita a capacidade de serem
utilizados na avaliação da capacidade de pagamento levando em conta o longo prazo, curto prazo ou
prazo imediato. Por fim, [13] comenta que os indicadores de rentabilidade são utilizados para
mensuração da capacidade das empresas em produzir lucro a partir do capital investido.
2.3 Atributos de Governança Corporativa em Sociedades Cooperativas A governança corporativa tem sua ênfase no equilíbrio e na força que regula o poder entre os
grupos de interesse, proprietários, gerentes, empregados, governo e público em geral [14]. Nos países
da Europa e em economias desenvolvidas como Estados Unidos e Holanda, as práticas de governança
corporativa de cooperativas promovem a desvinculação dos cooperados da gestão, em que na maioria
dos casos existe um conselho profissional de gestão [2].
No Brasil a maioria das cooperativas concentram a propriedade e a decisão da gestão, ou seja,
não promovem a separação entre propriedade, controle e decisão [15]. A configuração que estabelece a
separação de propriedade e controle nas cooperativas é a existência de um conselho de administração
eleito para executar as decisões de controle, e a diretoria executiva para exercer a gestão [16].
O cooperado exercer, enquanto membro eleito para o conselho de administração, as decisões
de controle e gestão simultaneamente, sem que haja uma Diretoria Executiva contratada, pode
CLAIO-2016
256

prejudicar o desempenho da cooperativa [15]. [17] complementa que os incentivos ao esforço dos
executivos serão maiores se forem contratados pela cooperativa, pois os incentivos internos são baixos.
Para [18] o conselho de administração exerce importante influência sobre o desempenho da
cooperativa, por meio do monitoramento das ações das diretorias de administração e executiva. Assim,
um conselho de administração distribuído de forma abrangente e com número de membros que seja
condizente ao tamanho da cooperativa, pode ser um importante atributo de governança corporativa [2].
[19] comenta que os membros detentores do capital das cooperativas tendem a estar sob enfoque
nas pesquisas sobre governança. Deste modo, a participação de um maior número de associados pode
influenciar os membros da diretoria a exercerem as atividades de gestão e controle de forma mais
eficiente [19]. O número maior de associados proporciona poder nas assembleias gerais e maior
comprometimento dos membros eleitos com a apresentação de melhores resultados [20]. [21] utilizam
o número de cooperados como proxy para representar a separação entre propriedade e controle.
2.4 Estudos Correlatos É possível encontrar diversos trabalhos que abordaram em diferentes dimensões a governança
corporativa e o desempenho de sociedades cooperativas. [22] abordaram as práticas de governança
corporativa em uma cooperativa catarinense. Os resultados indicam que a transparência da gestão
administrativa é compartilhada em assembleia geral anual. Os achados mostram que de 50 aspectos
investigados intrínsecos em 5 temas (profissionalização, associados, conselho de administração, gestão
e conselho fiscal) a Cooper Alfa cumpre com 34 ações relacionadas com governança corporativa.
[23] discutiu aspectos relacionados à estrutura interna e comportamento estratégico das
cooperativas de lácteos em relação a globalização. Os resultados sugeriram que a consolidação mediante
fusões e incorporações, formação de alianças estratégicas, adoção de sistema profissional e governança
corporativa são condições necessárias para o fortalecimento do sistema cooperativista neste mercado.
[15] identificaram a necessidade de mensuração da separação entre propriedade e decisão de gestão em
cooperativas agropecuárias brasileiras. Os resultados demonstraram que há um grupo delas que adota
modelos com separação parcial entre propriedade e gestão.
3 Procedimentos Metodológicos
A população da pesquisa é composta de 90 cooperativas agropecuárias da região Sul,
registradas nas Organizações das Cooperativas. A população foi delineada considerando as cooperativas
que dispuseram no website os relatórios de gestão do ano de 2013 para download. A amostra ficou
composta pelas cooperativas que dispunham de todas informações para operacionalização das 6
cooperativas registradas na OCESC, 14 na OCEPAR e 5 na OCERGS. Para a análise dos dados e
elaboração do ranking foi utilizado um conjunto de indicadores econômico financeiros, conforme
consta no Quadro 1.
Quadro 1 – Indicadores econômico financeiros
Indicadores econômico financeiros
Indicador Fórmula
Estrutura de Capital
Participação de Capital de Terceiros
(PARTCTERC) =
𝑃𝑎𝑠𝑠𝑖𝑣𝑜 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒 + 𝑃𝑎𝑠𝑠𝑖𝑣𝑜 𝑁ã𝑜 − 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒
𝑃𝑎𝑡𝑟𝑖𝑚ô𝑛𝑖𝑜 𝐿í𝑞𝑢𝑖𝑑𝑜
Imobilização do Patrimônio
Líquido (IMOBPL) =
𝐼𝑚𝑜𝑏𝑖𝑙𝑖𝑧𝑎𝑑𝑜 + 𝐷𝑖𝑓𝑒𝑟𝑖𝑑𝑜
𝑃𝑎𝑡𝑟𝑖𝑚ô𝑛𝑖𝑜 𝐿í𝑞𝑢𝑖𝑑𝑜
Liquidez
Liquidez Geral (LIQGER) =𝐴𝑡𝑖𝑣𝑜 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒 + 𝐴𝑡𝑖𝑣𝑜 𝑁ã𝑜 − 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒
𝑃𝑎𝑠𝑠𝑖𝑣𝑜 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒 + 𝑃𝑎𝑠𝑠𝑖𝑣𝑜 𝑁ã𝑜 − 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒
Liquidez Corrente (LIQCOR) =𝐴𝑡𝑖𝑣𝑜 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒
𝑃𝑎𝑠𝑠𝑖𝑣𝑜 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒
Liquidez Seca (LIQSEC) =𝐴𝑡𝑖𝑣𝑜 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒 − 𝐸𝑠𝑡𝑜𝑞𝑢𝑒𝑠 − 𝐷𝑒𝑠𝑝𝑒𝑠𝑎𝑠 𝐴𝑛𝑡𝑒𝑐𝑖𝑝𝑎𝑑𝑎𝑠
𝑃𝑎𝑠𝑠𝑖𝑣𝑜 𝐶𝑖𝑟𝑐𝑢𝑙𝑎𝑛𝑡𝑒
Rentabilidade
CLAIO-2016
257

Margem Bruta (MRGBRU) =𝐿𝑢𝑐𝑟𝑜 𝐵𝑟𝑢𝑡𝑜
𝑉𝑒𝑛𝑑𝑎𝑠 𝐿í𝑞𝑢𝑖𝑑𝑎𝑠
Rentabilidade do Ativo (ROA) =𝐿𝑢𝑐𝑟𝑜 𝐿í𝑞𝑢𝑖𝑑𝑜
𝐴𝑡𝑖𝑣𝑜 𝑇𝑜𝑡𝑎𝑙
Rentabilidade do Patrimônio
líquido (ROE) =
𝐿𝑢𝑐𝑟𝑜 𝐿í𝑞𝑢𝑖𝑑𝑜
𝑃𝑎𝑡𝑟𝑖𝑚ô𝑛𝑖𝑜 𝐿í𝑞𝑢𝑖𝑑𝑜
Fonte: [24].
Este conjunto de indicadores foi utilizado para a instrumentalização da pesquisa e construção
de ranking evidenciando o desempenho das cooperativas. [9] organizou o ranqueamento de um conjunto
de empresas, em que as estratégias mistas foram utilizadas para posicionamento contábil. Esta versão
lidou com jogos escalares. Assim, uma estratégia mista para um jogador é uma distribuição de
probabilidade no conjunto de suas estratégias puras. Tipicamente um jogador possui n estratégias puras.
Uma estratégia mista para ele é uma n-upla 𝑥 = (𝑥1, 𝑥2, … , 𝑥𝑛) tal que ∑ 𝑥𝑖 = 1𝑛𝑖=1 , 0 ≤ 𝑥𝑖 ≤ 1, onde
𝑥𝑖 indica a probabilidade com que o jogador selecionará sua i-ésima estratégia pura.
Seja 𝐴 = (𝑎𝑖𝑗), 1 ≤ 𝑖 ≤ 𝑛; 1 ≤ 𝑗 ≤ 𝑚 a matriz de pagamentos do jogo. Sejam X e Y os
conjuntos de estratégias mistas dos jogadores I e II, respectivamente:
𝑋 = {𝑥 ∈ ℝ𝑚 / ∑ 𝑥𝑖
𝑛
𝑖=1
= 1; 𝑥𝑖 ≥ 0, 𝑖 = 1,2, … , 𝑛}
𝑌 = {𝑦 ∈ ℝ𝑛/ ∑ 𝑦𝑖 = 1
𝑚
𝑗=1
; 𝑦𝑖 ≥ 0, 𝑗 = 1,2, … , 𝑚}
Na análise do resultado de um jogo onde um (ou ambos) jogador (es) utilizam estratégias mistas,
é possível a utilização do conceito de valor esperado, neste caso a função de pagamentos do jogo é:
𝑣(𝑥, 𝑦) = ∑ ∑ 𝑥𝑖
𝑚
𝑗=1
𝑛
𝑖=1
𝑎𝑖𝑗𝑦𝑗; 𝑥 ∈ 𝑋, 𝑦 ∈ 𝑌
Onde, 𝑣(𝑥, 𝑦) é o valor esperado em conseguir os pagamentos do jogo com a combinação das
estratégias mistas 𝑥 ∈ 𝑋 𝑒 𝑦 ∈ 𝑌. Para cada estratégia mista 𝑥 ∈ 𝑋, o nível de segurança do jogador I é
o valor esperado que possa ser assegurado com essa estratégia, independente das ações do jogador II.
𝑣𝐼(𝑥) = min𝑦∈𝑌
𝑣(𝑥, 𝑦)
De similar modo, para cada estratégia mista 𝑦 ∈ 𝑌, o nível de segurança do jogador II é o valor
esperado que possa assegurar essa estratégia, independente das ações do jogador I.
𝑣𝐼𝐼(𝑦) = max𝑥∈𝑋
𝑣(𝑥, 𝑦)
O valor maximin dado pelas estratégias mistas do jogador I é:
𝑣𝐼𝑀 = max
𝑥∈𝑋min𝑦∈𝑌
𝑣(𝑥, 𝑦)
Uma estratégia de segurança ou estratégia maximin é a que proporciona ao jogador seu valor
maximin. O valor minimax dado pelas estratégias mistas do jogador II é:
𝑣𝐼𝐼𝑀 = min
𝑦∈𝑌max𝑥∈𝑋
𝑣(𝑥, 𝑦)
Para tanto, uma estratégia de segurança ou estratégia minimax é a que proporciona ao jogador
seu valor minimax. As estratégias mistas 𝑥∗ ∈ 𝑋 e 𝑦∗ ∈ 𝑌 são ótimas para os jogadores I e II
respectivamente, se:
𝑣𝐼𝑀 = min
𝑦∈𝑌𝑣(𝑥∗, 𝑦) = min
𝑦∈𝑌𝑥∗𝑡𝐴𝑦 e 𝑣𝐼𝐼
𝑀 = max𝑥∈𝑋
𝑣(𝑥, 𝑦∗) = max𝑥∈𝑋
𝑥𝑡𝐴𝑦∗
O nível de segurança para uma estratégia mista 𝑥 ∈ 𝑋 vem dado por 𝑣𝐼(𝑥) = min𝑦∈𝑌
𝑥𝑡𝐴𝑦, cuja
valoração pode ser obtida por meio do problema dual anterior:
𝑀𝑎𝑥𝜆(𝑥)
Sujeito a: 𝑒𝜆(𝑥) ≤ 𝑥𝑡𝐴
𝑥 ∈ 𝑋, 𝜆(𝑥) ∈ ℝ
CLAIO-2016
258

Sendo 𝑒 = (1, … , 1)𝑡 . As estratégias que proporcionam os melhores níveis de segurança são as
que verificam 𝑣𝐼𝑀 = max
𝑥∈𝑋𝑣𝐼(𝑥). Estas estratégias, assim como o valor do jogo podem ser obtidas por
meio do problema de programação linear:
𝑀𝑎𝑥𝑣𝐼
Sujeito a:𝑒𝑣𝐼 ≤ 𝑥𝑡𝐴
𝑥 ∈ 𝑋 Pode-se assumir o mesmo raciocínio para o jogador II.
Neste artigo, as cooperativas compõem as opções do jogador I e seus indicadores as do jogador
II. O ranqueamento de empresas por jogos escalares foi desenvolvido por [9]. A análise desenvolvida
está inserida nos jogos matriciais escalares, nos quais representa-se os pagamentos que os jogadores
recebem por números reais.O modelo apresenta-se na forma:
Max 𝑍 = 𝑣 Sujeito a:
𝑎11𝑥1 + 𝑎12𝑥2 + 𝑎13𝑥3 + ⋯ + 𝑎1𝑛𝑥𝑛 ≥ 𝑣
𝑎21𝑥1 + 𝑎22𝑥2 + 𝑎23𝑥3 + ⋯ + 𝑎2𝑛𝑥𝑛 ≥ 𝑣
⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 𝑎𝑚1𝑥1 + 𝑎𝑚2𝑥2 + 𝑎𝑚3𝑥3 + ⋯ + 𝑎𝑚𝑛𝑥𝑛 ≥ 𝑣
𝑥1 + 𝑥2 + 𝑥3 + ⋯ + 𝑥𝑛 = 1
𝑥1 , 𝑥2, 𝑥3, … , 𝑥𝑛 ≥ 0
Os resultados do modelo aplicado na forma de problemas de programação linear (PPLs) são
apresentados na seção descrição e análise dos dados. O ranking gerado é comparado com os atributos
de governança corporativa observados nas cooperativas investigadas. O Quadro 2 mostra a
categorização dos atributos de governança corporativa para cooperativas utilizados no presente estudo.
Quadro 2– Categorização dos atributos de governança corporativa em sociedades cooperativas
Atributos
Governança
Corporativa
Variáveis Categoria Base
teórica
Separação de
propriedade e
controle
Não existe separação de propriedade e controle
(Presidente da diretoria de administração eleito em
assembleia exerce as atividades de gestão).
0 [17]; [18];
[1]; [15];
[2]
Existe separação de propriedade e controle (Uma diretoria
executiva é contratada para exercer a atividade de gestão).
1
Tamanho do conselho
de administração
Composição dos membros efetivos do conselho de
administração
Número de
membros
[2]
Número de
Cooperados
Composição do quadro de cooperados que fazem parte da
cooperativa.
Número de
cooperados
[19]; [20]
Fonte: Dados da pesquisa.
Observa-se no Quadro 2 que para as cooperativas que apresentaram separação de propriedade
e controle foi atribuído o número 1 e 0 para as que não apresentaram. O tamanho do conselho foi
categorizado pelo número de conselheiros efetivos e o número de cooperados pelo número de
cooperados que fazem parte da cooperativa. Como teste adicional utilizou-se a regressão logística para
verificar quais indicadores de desempenho econômico-financeiro, usados para estabelecer o ranking de
desempenho das cooperativas, podem ter tido fatores explicativos dos atributos de governança. O
modelo uado foi o Logit, devido ao pequeno tamanho da amostra (25 casos).
4 Análises dos Resultados A Tabela 1 apresenta o ranking de posicionamento contábil gerado com base nos indicadores
econômico financeiros mediante a aplicação do modelo na forma de problemas de programação linear
(PPL’s) e a possível associação com os atributos de governança corporativa.
CLAIO-2016
259
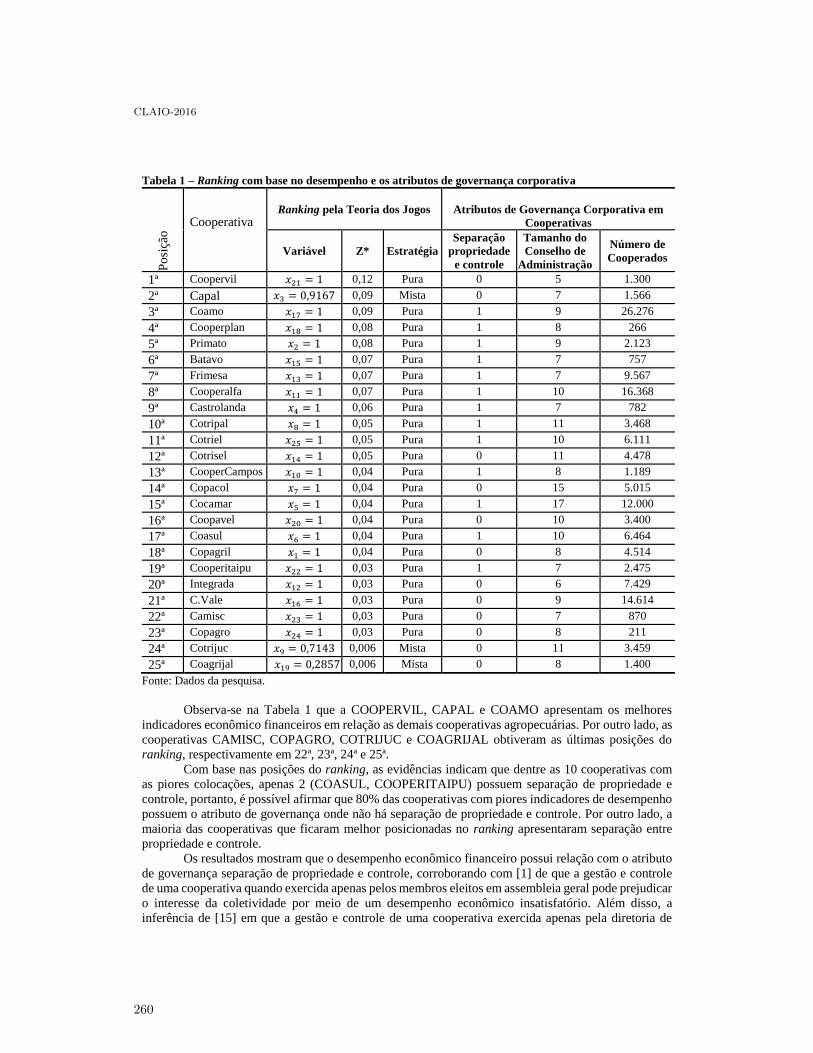
Tabela 1 – Ranking com base no desempenho e os atributos de governança corporativa
Po
siçã
o Cooperativa
Ranking pela Teoria dos Jogos
Atributos de Governança Corporativa em
Cooperativas
Variável Z* Estratégia
Separação
propriedade
e controle
Tamanho do
Conselho de
Administração
Número de
Cooperados
1ª Coopervil 𝑥21 = 1 0,12 Pura 0 5 1.300
2ª Capal 𝑥3 = 0,9167 0,09 Mista 0 7 1.566
3ª Coamo 𝑥17 = 1 0,09 Pura 1 9 26.276
4ª Cooperplan 𝑥18 = 1 0,08 Pura 1 8 266
5ª Primato 𝑥2 = 1 0,08 Pura 1 9 2.123
6ª Batavo 𝑥15 = 1 0,07 Pura 1 7 757
7ª Frimesa 𝑥13 = 1 0,07 Pura 1 7 9.567
8ª Cooperalfa 𝑥11 = 1 0,07 Pura 1 10 16.368
9ª Castrolanda 𝑥4 = 1 0,06 Pura 1 7 782
10ª Cotripal 𝑥8 = 1 0,05 Pura 1 11 3.468
11ª Cotriel 𝑥25 = 1 0,05 Pura 1 10 6.111
12ª Cotrisel 𝑥14 = 1 0,05 Pura 0 11 4.478
13ª CooperCampos 𝑥10 = 1 0,04 Pura 1 8 1.189
14ª Copacol 𝑥7 = 1 0,04 Pura 0 15 5.015
15ª Cocamar 𝑥5 = 1 0,04 Pura 1 17 12.000
16ª Coopavel 𝑥20 = 1 0,04 Pura 0 10 3.400
17ª Coasul 𝑥6 = 1 0,04 Pura 1 10 6.464
18ª Copagril 𝑥1 = 1 0,04 Pura 0 8 4.514
19ª Cooperitaipu 𝑥22 = 1 0,03 Pura 1 7 2.475
20ª Integrada 𝑥12 = 1 0,03 Pura 0 6 7.429
21ª C.Vale 𝑥16 = 1 0,03 Pura 0 9 14.614
22ª Camisc 𝑥23 = 1 0,03 Pura 0 7 870
23ª Copagro 𝑥24 = 1 0,03 Pura 0 8 211
24ª Cotrijuc 𝑥9 = 0,7143 0,006 Mista 0 11 3.459
25ª Coagrijal 𝑥19 = 0,2857 0,006 Mista 0 8 1.400
Fonte: Dados da pesquisa.
Observa-se na Tabela 1 que a COOPERVIL, CAPAL e COAMO apresentam os melhores
indicadores econômico financeiros em relação as demais cooperativas agropecuárias. Por outro lado, as
cooperativas CAMISC, COPAGRO, COTRIJUC e COAGRIJAL obtiveram as últimas posições do
ranking, respectivamente em 22ª, 23ª, 24ª e 25ª.
Com base nas posições do ranking, as evidências indicam que dentre as 10 cooperativas com
as piores colocações, apenas 2 (COASUL, COOPERITAIPU) possuem separação de propriedade e
controle, portanto, é possível afirmar que 80% das cooperativas com piores indicadores de desempenho
possuem o atributo de governança onde não há separação de propriedade e controle. Por outro lado, a
maioria das cooperativas que ficaram melhor posicionadas no ranking apresentaram separação entre
propriedade e controle.
Os resultados mostram que o desempenho econômico financeiro possui relação com o atributo
de governança separação de propriedade e controle, corroborando com [1] de que a gestão e controle
de uma cooperativa quando exercida apenas pelos membros eleitos em assembleia geral pode prejudicar
o interesse da coletividade por meio de um desempenho econômico insatisfatório. Além disso, a
inferência de [15] em que a gestão e controle de uma cooperativa exercida apenas pela diretoria de
CLAIO-2016
260
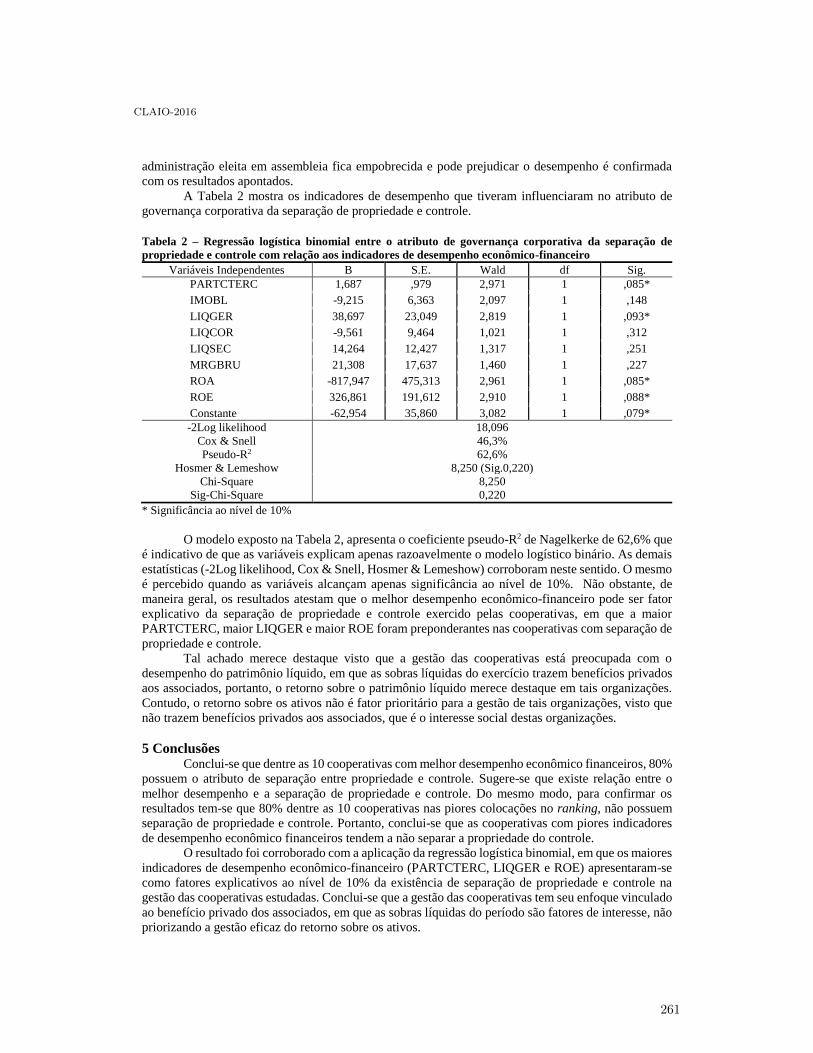
administração eleita em assembleia fica empobrecida e pode prejudicar o desempenho é confirmada
com os resultados apontados.
A Tabela 2 mostra os indicadores de desempenho que tiveram influenciaram no atributo de
governança corporativa da separação de propriedade e controle.
Tabela 2 – Regressão logística binomial entre o atributo de governança corporativa da separação de
propriedade e controle com relação aos indicadores de desempenho econômico-financeiro
Variáveis Independentes B S.E. Wald df Sig.
PARTCTERC 1,687 ,979 2,971 1 ,085*
IMOBL -9,215 6,363 2,097 1 ,148
LIQGER 38,697 23,049 2,819 1 ,093*
LIQCOR -9,561 9,464 1,021 1 ,312
LIQSEC 14,264 12,427 1,317 1 ,251
MRGBRU 21,308 17,637 1,460 1 ,227
ROA -817,947 475,313 2,961 1 ,085*
ROE 326,861 191,612 2,910 1 ,088*
Constante -62,954 35,860 3,082 1 ,079*
-2Log likelihood
Cox & Snell
Pseudo-R2
Hosmer & Lemeshow
18,096
46,3%
62,6%
8,250 (Sig.0,220)
Chi-Square 8,250
Sig-Chi-Square 0,220
* Significância ao nível de 10%
O modelo exposto na Tabela 2, apresenta o coeficiente pseudo-R2 de Nagelkerke de 62,6% que
é indicativo de que as variáveis explicam apenas razoavelmente o modelo logístico binário. As demais
estatísticas (-2Log likelihood, Cox & Snell, Hosmer & Lemeshow) corroboram neste sentido. O mesmo
é percebido quando as variáveis alcançam apenas significância ao nível de 10%. Não obstante, de
maneira geral, os resultados atestam que o melhor desempenho econômico-financeiro pode ser fator
explicativo da separação de propriedade e controle exercido pelas cooperativas, em que a maior
PARTCTERC, maior LIQGER e maior ROE foram preponderantes nas cooperativas com separação de
propriedade e controle.
Tal achado merece destaque visto que a gestão das cooperativas está preocupada com o
desempenho do patrimônio líquido, em que as sobras líquidas do exercício trazem benefícios privados
aos associados, portanto, o retorno sobre o patrimônio líquido merece destaque em tais organizações.
Contudo, o retorno sobre os ativos não é fator prioritário para a gestão de tais organizações, visto que
não trazem benefícios privados aos associados, que é o interesse social destas organizações.
5 Conclusões Conclui-se que dentre as 10 cooperativas com melhor desempenho econômico financeiros, 80%
possuem o atributo de separação entre propriedade e controle. Sugere-se que existe relação entre o
melhor desempenho e a separação de propriedade e controle. Do mesmo modo, para confirmar os
resultados tem-se que 80% dentre as 10 cooperativas nas piores colocações no ranking, não possuem
separação de propriedade e controle. Portanto, conclui-se que as cooperativas com piores indicadores
de desempenho econômico financeiros tendem a não separar a propriedade do controle.
O resultado foi corroborado com a aplicação da regressão logística binomial, em que os maiores
indicadores de desempenho econômico-financeiro (PARTCTERC, LIQGER e ROE) apresentaram-se
como fatores explicativos ao nível de 10% da existência de separação de propriedade e controle na
gestão das cooperativas estudadas. Conclui-se que a gestão das cooperativas tem seu enfoque vinculado
ao benefício privado dos associados, em que as sobras líquidas do período são fatores de interesse, não
priorizando a gestão eficaz do retorno sobre os ativos.
CLAIO-2016
261

Agradecimento: Os autores agradecem ao Conselho Nacional de Desenvolvimento Científico e Tecnológico
(CNPq) pelo apoio nesta pesquisa.
Referências 1. J. Treter and M. L. Kelm. A questão da governança corporativa nas organizações cooperativas. XXIV
Encontro Nacional de Engenharia de Produção–ENEGEP, Florianópolis, p. 3270-3277, 2004.
2. J. Bijman; G. Hendrikse and A. Oijen. Accommodating two worlds in one organization: changing board
models in agricultural cooperatives. Managerial and Decision Economics, v. 34, n. 3-5, p. 204-217, 2013.
3. L. M. Antonialli and A. A. Fischmann. Sucessão de Dirigentes e Continuidade das Estratégias
Administrativas em uma Cooperativa Agropecuária. Organizações Rurais & Agroindustriais, v. 4, n. 2,
2011.
4. R. S. Pindyck and D. L. Rubinfeld. Econometric Models & Economic Forecast, 3ª Edition, McGraw-Hill
International, 1991.
5. M. H. Simonsen. Ensaios analíticos. Rio de Janeiro: Editora da Fundação Getúlio Vargas, 1994.
6. A. C. A. Sauaia and D. Kallás. O dilema cooperação-competição em mercados concorrenciais: o conflito do
oligopólio tratado em um jogo de empresas. RAC – Revista de Administração Contemporânea, Ed.
Especial, 2007.
7. M. R. Junqueira. Aplicação da teoria dos jogos cooperativos para a alocação de custos de transmissão
em mercados elétricos.2005. 116 f. Dissertação (Mestrado em Ciências em Planejamento energético). Rio
de Janeiro, Universidade Federal do Rio de Janeiro, 2005.
8. M. P. E. Lins and G. M. Calôba. Programação linear: com aplicações em teoria dos jogos e avaliação de
desempenho (data envelopment analysis). Rio de Janeiro: Interciência, 2006.
9. F. Kreuzberg. Indicadores econômicos versus indicadores sociais: uma análise de empresas listadas na
BM&F Bovespa por meio da Teoria dos Jogos. 2013. Dissertação do Programa de Pós-Graduação em
Ciências Contábeis do Centro de Ciências Sociais Aplicadas da Universidade Regional de Blumenau, Santa
Catarina, Brasil, 2013.
10. L. J. Gitman. Princípios de administração financeira. 12. ed. São Paulo: Pearson Prentice Hall, 2010.
11. D. C. Matarazzo. Análise financeira de balanços. 6. ed. São Paulo: Atlas, 2003
12. J. C. Marion. Contabilidade Empresarial. 13. ed. São Paulo: Atlas, 2007.
13. A. C. R. Reis. Demonstrações Contábeis: estrutura e análise. Saraiva, 2009.
14. H. Macmillan and M. Tampoe. Strategic Management: process, content and implementation. Oxford:
Oxford University Press, 2000.
15. D. R. M. Costa; F. R. Chaddad and P. F. Azevedo. Separação entre propriedade e decisão de gestão nas
cooperativas agropecuárias brasileiras. Revista de Economia e Sociologia Rural, v. 50, n. 2, p. 285-300,
2012.
16. G. W. J. Hendrikse. Contingent Control Rights in Agricultural Cooperatives. In: T. Theurl and E. C. Meijer.
(eds). Strategies for Cooperation. Aachen: ShakerVerlag, p. 385-394, 2005.
17. M. Ricketts. The economics of business enterprise: new approaches to the firm. New York: Harvester
Wheat sheaf, 1987.
18. T. Fronzaglia. Análise de fatores que determinam a não separação entre propriedade e controle em uma
cooperativa agroindustrial. 2004. 234 fls. Dissertação (Mestrado em Contabilidade) – Universidade de São
Paulo, São Paulo: FEA/USP, 2004.
19. P. G. Spear. Herpes simplex virus: receptor sand ligands for cell entry. Cell. Microbiol. n. 6, p. 401–410,
2004.
20. P. Singer and A. R. Souza. (Org.). A economia solidária no Brasil. São Paulo: Contexto, 2000.
21. G. Gorton and F. Schmid. Corporate governance, ownership dispersion and efficiency: Empirical evidence
from Austrian cooperative banking. Journal of Corporate Finance, v. 5, n. 2, p. 119-140, 1999.
22. I. M. Oro; J. Frozza and J. Eidt. Práticas de Governança Corporativa em Cooperativa Agropecuária: o caso
da Cooperalfa. Anais... In: II Congresso UFSC de Controladoria e Finanças, Florianópolis, 2008.
23. F. R. Chaddad. Cooperativas no agronegócio do leite: mudanças organizacionais e estratégicas em resposta à
globalização. Organizações Rurais & Agroindustriais, v. 9, n. 1, 2011.
24. J. H. Perez Junior and G. A. Begalli. Elaboração e análise das demonstrações contábeis.4 ed. São Paulo:
Atlas, 2009.
CLAIO-2016
262

Aprimoramento de previsões de seguros do Mercado Brasileiro
utilizando nova metodologia baseada em combinação de previsões
Juliana Christina Carvalho de Araújo, Bruno Quaresma Bastos, Reinaldo Castro Souza
Pontifícia Universidade Católica do Rio de Janeiro (PUC-Rio)
Abstract
A previsão do prêmio dos seguros é de grande importância para seguradoras e resseguradoras. Ela fornece
subsídios para que as seguradoras planejem suas estratégias. Apesar da importância para esse mercado, o tema da previsão de seguros é pouco difundido na literatura acadêmica. Como consequência, não há
referências suficientes que indiquem o melhor tipo de modelagem para a previsão dos diversos tipos de
seguro. Neste contexto, este trabalho propõe uma metodologia prática, composta por quatro etapas, que utiliza diferentes técnicas de combinação para combinar previsões de modelos individuais. As
combinações são feitas de modo a obter a maior quantidade possível de informações para prever as séries
de seguros com mais acurácia. São estudadas as séries de seguros de automóveis, vida, acidentes pessoais,
viagem grupal, empresarial e habitacional. Os tipos de modelagem utilizados no trabalho foram: Box & Jenkins, Amortecimento Exponencial, Redes Neurais Artificiais, BATS, STL, e Naïve. Os resultados da
metodologia proposta são satisfatórios, quando comparados aos resultados de modelos individuais.
Keywords: combinação de previsões; mercado de seguros.
1 Introdução
Previsões acuradas são essenciais para diversos segmentos da economia. Elas podem servir de base para o
planejamento de negócios, planejamento econômico, controle de estoque e de produção, previsão de
vendas, avaliação de estratégias alternativas de economias, entre outros [1, 2]. A previsão do prêmio dos seguros, em específico, é de grande importância para seguradoras e resseguradoras. Ela fornece subsídios
para estratégias de negócios, e fornece diretrizes para que as seguradoras planejem sua carteira de
produtos. Apesar da importância para esse mercado, o tema da previsão de seguros é pouco difundido na literatura
acadêmica. Uma rápida pesquisa em bases bibliográficas, utilizando palavras-chave como “seguro”,
“previsão”, “modelos”, “prêmio”, “risco” e “demanda de seguros”, nos mostra que são poucos os artigos
que tratam da previsão de seguros, e que são raros os artigos que tratam do uso de modelos estatísticos ou computacionais para previsão de séries de prêmio de seguros. Como consequência, não há referências
suficientes que indiquem o melhor tipo de modelagem para a previsão dos diversos tipos de seguro; não
há indicativo de modelos que melhor descrevam o processo gerador das diferentes séries de seguro. Uma solução para este problema consiste em prever as séries com diferentes modelos, e combinar as previsões
individuais. Esta solução é justificada, pois a combinação de previsões é conhecida por aprimorar a
acurácia de previsões individuais [3, 4].
A ideia de se combinar previsões provindas de diferentes fontes, para se obter melhor acurácia e confiabilidade, não é nova [5], já tendo sido bastante estudada na literatura. As técnicas existentes mais
básicas são as de média estatística, como a média e a média truncada [6]. Estas muitas vezes fornecem
resultados melhores que técnicas mais avançadas de combinação. Outras técnicas existentes conferem pesos às previsões das diferentes fontes (problema de combinação linear), onde os pesos seriam obtidos a
partir dos erros de previsão in-sample. As técnicas tradicionais, que conferem peso às previsões, são
constrained least squares, simple Bates & Granger, entre outros [7]. Ultimamente, técnicas de
CLAIO-2016
263
inteligência computacional têm sido propostas para determinar os pesos das previsões, e.g. redes neurais
[7, 8]. Os artigos das Refs. [3, 9] revisam algumas das técnicas mais tradicionais de combinação de previsão.
O objetivo do trabalho é aprimorar a previsão de séries do Mercado Brasileiro de seguros. Para tanto, este
trabalho propõe uma metodologia prática, que utiliza diferentes técnicas de combinação para obter a
maior quantidade possível de informações para prever as séries temporais estudadas. Modelos individuais de previsão são estimados para as séries. Para cada modelo estimado, prevê-se a série p-passos à frente.
As previsões p-passos à frente dos modelos individuais são combinadas (todas as combinações possíveis
são feitas). Deste modo, fica-se com previsões p-passos à frente para todas as combinações possíveis de previsões de modelos individuais. Avalia-se qual a melhor previsão (combinação ou individual) p-passos
à frente utilizando-se uma métrica de acurácia. Seleciona-se o modelo de melhor desempenho para prever
as séries de seguro p+k passos à frente. Os modelos individuais aplicados neste estudo compreendem: Box & Jenkins (B&J), Amortecimento
Exponencial (AE), Redes Neurais Artificiais (ANN), modelo BATS, modelo STL, e Naïve. As técnicas
de combinação utilizadas foram a média e a mediana.
O artigo está estruturado da seguinte maneira: após a presente seção de introdução, a segunda seção do artigo apresenta as séries estudadas neste trabalho. Na terceira seção é descrita a metodologia de
combinação e previsão adotada. A quarta seção apresenta os resultados obtidos, e a quinta seção apresenta
os comentários finais e conclusões dos autores.
2 Base de dados
As séries de prêmios de seguros utilizadas nesse trabalho são disponibilizadas pela Superintendência de Seguros Privados (SUSEP) do Brasil. Elas se concentram em três sub-ramos do mercado: seguro
automotivo, seguros de pessoas e seguro patrimonial. São elas: automóveis, vida, acidentes pessoais,
viagem grupal, empresarial e habitacional. Estas séries foram escolhidas devido à sua complexidade estrutural e à sua importância representativa no mercado brasileiro de seguros (os seguros ora citados,
juntamente com a previdência privada, foram responsáveis por mais de 84% da receita do mercado de
seguros Brasileiro em 2013). Todas apresentam periodicidade mensal, e totalizam 166 observações cada (histórico de outubro de 2000 a Junho de 2014). As séries apresentam tendência e sazonalidade, conforme
pode ser observado na Figura 1.
Automóveis Empresarial Habitacional
Acidentes Pessoais Vida Viagem Grupal
Figura 1 – Gráficos das séries de seguro
CLAIO-2016
264

3 Metodologia
A metodologia de previsão de seguros, proposta neste trabalho, e que pretende aprimorar a acurácia da
previsão de modelos individuais, é composta por basicamente quatro etapas. As etapas compreendem (i)
estimação dos modelos individuais e previsão da série para p+k passos à frente, (ii) combinação das
previsões p-passos à frente dos modelos individuais (todas as possíveis combinações) com as técnicas de combinação ‘média’ e ‘mediana’, (iii) seleção do modelo (combinado ou individual) de melhor
desempenho para a série estudada, e (iv) previsão mais k-passos à frente com a combinação selecionada.
A Figura 2 apresenta um resumo da metodologia.
Figura 2 – Ilustração da metodologia proposta no trabalho
As séries temporais de seguros são separadas em três partes para este trabalho. A primeira parte (i.e.
observações de t = 1 a t = 148) é utilizada para treinamento (estimação) dos modelos. A segunda parte (i.e. observações de t = 149 a t = 154) é utilizada para auxílio na seleção do melhor modelo (combinado
ou individual) para a série. A terceira parte (t = 155 a t = 166), por sua vez, serve para testar a
metodologia, frente aos modelos individuais. A Figura 3 ilustra a divisão da série de automóveis. Cada modelo individual estimado é utilizado para prever a série k+p passos à frente (i.e. para prever de t = 149
a t = 166). Nas subseções a seguir, as etapas da metodologia são apresentadas.
Figura 3 – Divisão da série de prêmio de seguro de automóveis em treinamento, seleção e teste
3.1 Estimação e Previsão com Modelos Individuais
Existe na literatura um grande número de modelos utilizados na previsão de séries temporais. Estes
podem ser divididos em basicamente três categorias [10]: modelos estatísticos (e.g. regressão múltipla, Box&Jenkins, Amortecimento Exponencial), modelos de inteligência computacional (e.g. redes neurais,
lógica fuzzy), e modelos híbridos (e.g. neuro-fuzzy). A escolha entre os diferentes modelos depende de
diversos fatores, tais como (i) comportamento do processo gerador de dados, (ii) conhecimento a priori da natureza do processo (ou dos dados) e (iii) objetivo da análise que se deseja empreender. Para este
trabalho, foram escolhidos cinco métodos baseados em estatística clássica (modelo ingênuo,
Box&Jenkins, Amortecimento Exponencial, BATS e STL) e um método de inteligência Computacional
(Redes Neurais Artificiais). Esta primeira etapa da metodologia consiste em estimar estes modelos e em aplica-los para prever a série. A seguir uma breve descrição desses modelos é apresentada.
CLAIO-2016
265

3.1.1 Modelo Ingênuo
O modelo Ingênuo, também conhecido como Naïve, é comumente utilizado como baseline para
comparação com outros métodos de previsão mais sofisticados. É um modelo simples, que consiste em assumir o último valor observado como previsão:
�̂�𝑇(𝜏) = 𝑍𝑇
Onde, ẐT(τ) é o valor esperado da previsão τ-passos à frente, realizada no instante T; e ZT é o valor
observado da série no instante T.
3.1.2 Box & Jenkins
A metodologia Box&Jenkins [1], que compreende um classe específica de modelos estocásticos lineares [11], consiste em ajustar modelos autorregressivos integrados de média móveis a um conjunto de dados. É
representado por ARIMA (p, d, q), onde p é o número de defasagens da série, d é a ordem de integração
para tornar a série estacionária e q o número de defasagens dos erros aleatórios (at). A modelagem Box&Jenkins pode ainda ser estendida para captar efeitos sazonais (SARIMA). O modelo
SARIMA(p, d, q) × (P, D, Q)S pode ser descrito como:
𝛻𝑆𝐷𝛻𝑑𝜙(𝐵)𝛷(𝐵𝑆)𝑍𝑡 = 𝜃(𝐵)𝛩(𝐵𝑆)𝑎𝑡
Onde, B é o operador de atraso; 𝛻𝑑 = (1 − 𝐵)𝑑;𝛻𝑆𝐷 = (1 − 𝐵𝑆)𝐷;𝜙(𝐵) = 1 − 𝜙1𝐵 − ⋯ − 𝜙𝑝𝐵𝑝; 𝛷(𝐵𝑆) = 1 −
𝛷1𝐵𝑆 − ⋯ 𝛷𝑃𝐵𝑃𝑆; 𝜃(𝐵) = 1 − 𝜃1𝐵 − ⋯ − 𝜃𝑞𝐵𝑞;𝛩(𝐵𝑆) = 1 − 𝛩1𝐵𝑆 − ⋯ − 𝛩𝑄𝐵𝑄𝑆.
Os dados que compõem a série devem ter distribuição normal e variância constante. Para construir o
modelo seguimos um algoritmo composto por quatro etapas: Identificação – A estrutura do modelo é identificada analisando-se a função de autocorrelação (FAC
1)
e a função de autocorrelação parcial (FACP2); busca-se identificar os valores de p, q, e d;
Estimação – Após a identificação da estrutura do modelo, os parâmetros φ𝑖’s e θ𝑗’s são estimados de
forma a minimizar a soma dos quadrados dos resíduos;
Verificação – As estruturas identificadas são validadas através de testes de sobrefixação. Verifica-se,
ainda, se o modelo ajustado é adequado aos dados através de uma análise de resíduos (e.g. teste de Ljung&Box). Se os resíduos são autocorrelacionados, então, a dinâmica da série não é completamente
explicada pelos coeficientes do modelo ajustado, devendo-se voltar à fase de identificação;
Previsão – Após a verificação, aplica-se a equação do modelo estimado para prever valores futuros da variável em estudo.
3.1.3 Amortecimento Exponencial
O método de Amortecimento Exponencial (AE) compreende uma classe de modelos que descreve
previsões como combinações ponderadas de observações passadas e presentes. Neste método, o valor dos
pesos das observações decresce exponencialmente à medida que as observações se tornam mais antigas.
Existe uma variedade de modelos que se inserem na família de AE. Hyndman et al. [12] identificam 24
variações desse método. No entanto, existem três variações básicas de AE mais comumente usadas:
suavização exponencial simples [13], suavização exponencial com correção de tendência [14], e método
de Holt-Winter [15] com correção de tendência e sazonalidade.
1 Medida padronizada da dependência linear de lag k: 𝜌𝑘 =
𝛾𝑘
𝛾0=
𝐶𝑜𝑣[𝑧𝑡 ,𝑧𝑡+𝑘]
√𝑣𝑎𝑟(𝑧𝑡).𝑣𝑎𝑟(𝑧𝑡+𝑘)
2 Medida de dependência linear ou correlação linear entre Zt e Zt+k eliminando a dependência dos termos intermediários Zt+1, Zt+2 . . . Zt+k-1
CLAIO-2016
266

3.1.4 Modelo BATS
O BATS é um modelo criado por De Livera, Hyndman e Snyder [16]. O nome BATS refere-se às
principais características do modelo: transformação de Box-Cox, erros Autoregressivos e de Médias
Móveis (ARMA), Tendência e Componentes Sazonais [16]. É complementada com argumento (ω, φ, p, q, m1, m2,..., mT) para indicar o parâmetro de Box-Cox (ω), o parâmetro de amortecimento (φ), os
parâmetros ARMA ( p e q ) , e os períodos sazonais (m1, ... , mT).
O modelo BATS é uma generalização dos modelos tradicionais de Amortecimento Exponencial. Ele permite considerar vários períodos sazonais. O modelo não acomoda, no entanto, sazonalidade não
inteira.
3.1.6 Rede Neural Artificial
As redes neurais artificiais (ANN) são modelos paramétricos não-lineares inspirados nas conexões neurológicas do cérebro humano. As ANNs caracterizam-se por um processador maciçamente e
paralelamente distribuído de unidades de processamento simples, capaz de armazenar conhecimento
experimental e torná-lo disponível para o uso [17]. Uma das principais aplicações das redes neurais
artificiais está relacionada com o reconhecimento de padrões temporais e com sua previsão. Neste trabalho, utilizou-se uma ANN recorrente com uma camada oculta. As entradas da rede são
defasagens (de lag 1 a p) da variável de estudo. A camada oculta possui 𝑘 nós. O número de defasagens
(𝑝 e P, onde P é a defasagem sazonal) foi escolhido a partir da análise da FAC e da FACP de cada série.
O número de nós da rede foi definido como 𝑘 = (𝑝 + 𝑃 + 1) 2⁄ , arredondando k para o número inteiro
mais próximo. Vinte e cinco redes neurais com estruturas similares e pesos iniciais aleatórios são
treinadas e a média das previsões é obtida como resposta para cada série de seguro O modelo ajustado se
equivale a um ARIMA(p,0,0)(P,0,0) com funções não-lineares [18].
3.1.7 Modelo STL
O modelo STL decompõe a série temporal de estudo e a ajusta considerando sazonalidade. A previsão da
série é feita considerando-se a série ajustada, e utiliza modelos convencionais de séries temporais para
tanto.
3.2 Combinação das previsões
Após a primeira etapa, ter-se-á obtido, para cada modelo individual, previsões p+k passos à frente para a
série. No caso deste trabalho, p foi definido como sendo seis (t = 149,..., 154), e k foi definido como
sendo doze (t = 155,..., 166). Na segunda etapa, o intuito é combinar as previsões de modelos individuais de modo a produzir previsões
combinadas para as séries. As previsões combinadas são criadas para todas as combinações possíveis de
modelos disponíveis, de modo a se obter a maior quantidade possível de informações sobre o futuro das séries.
O total de previsões combinadas ou individuais, considerando-se n modelos disponíveis, é (2𝑛 − 1) .
Levando-se em conta que se utiliza w técnicas de combinação para se combinar as previsões de modelos
individuais, o número total de previsões possíveis será [((2𝑛 − 1) ∙ 𝑤) − (𝑛 ∙ (𝑤 − 1))]. No caso deste
trabalho, que utilizou seis modelos (n = 6) e duas técnicas de combinação3 (w = 2), o total de previsões
possíveis foi 120. Neste contexto, cria-se uma matriz de zeros e uns, que indica quais modelos terão suas previsões
combinadas (ou não), de modo a auxiliar na produção de combinações. Na Tabela I, a matriz criada para
este trabalho, é apresentada. Cada linha apresenta uma possibilidade de combinação, levando-se em conta
3 A média e a mediana.
CLAIO-2016
267

os modelos disponíveis e as técnicas de combinação disponíveis.
A previsão combinada para o passo à frente i, é obtida combinando os valores dos modelos individuais em questão no passo i. Por exemplo, na terceira linha, a previsão combinada para o passo i será a média
de �̂�𝑖𝑁𝑎ï𝑣𝑒 e �̂�𝑖
𝑆𝑇𝐿 . Adotando-se i = 1,...,p+k, é possível obter a previsão combinada para os p+k-passos à
frente.
Tabela I – Matriz auxiliar da produção de combinações
Deste modo, para cada série temporal de prêmio de seguros estudada, serão produzidas 120 previsões
p+k-passos à frente. De posse destas, se avaliará, com métricas de acurácia, qual tem o melhor desempenho nos p primeiros passos à frente da série estudada. A previsão com melhor desempenho será
selecionada como a previsão dos próximos k passos seguintes.
3.3 Seleção da melhor combinação
Na terceira etapa da metodologia, após produzir as previsões combinadas – para todas as combinações possíveis – utiliza-se a segunda parte da série (ver Figura 3), que havia sido escondida do treinamento,
para se avaliar e selecionar qual o melhor modelo (combinado ou individual) para a série em questão.
Neste estudo, utilizou-se a métrica Mean Absolute Percentage Error (MAPE), que calcula o erro médio absoluto percentual da previsão. A expressão da métrica MAPE é a seguinte:
𝑀𝐴𝑃𝐸 (%) = 1
𝑁∑
|𝑃𝑖 − 𝑅𝑖|
𝑅𝑖
𝑁
𝑖=1
Onde, 𝑃𝑖 é o valor previsto para o passo i; 𝑅𝑖 é o valor real do passo i; e N é a quantidade de passos utilizados na avaliação com a métrica.
Todas as previsões produzidas (seja combinada ou individual) são avaliadas em termos da métrica
MAPE. A que obtiver melhor desempenho delas é selecionada. Ao final, se terá selecionado o melhor
modelo (combinado ou individual) para cada série.
3.4 Previsão com a melhor combinação
Nesta última etapa da metodologia, a melhor combinação de modelos, selecionada para a série na etapa
anterior, é utilizada para prever seus valores futuros. Na seção a seguir, são apresentados e avaliados os
resultados da metodologia para as séries de prêmio de seguros do mercado Brasileiro, em comparação com os resultados dos modelos individuais.
CLAIO-2016
268

4 Resultados
Os modelos individuais descritos na seção anterior foram implementados no software R. O treinamento
destes modelos foi realizado com 148 observações consecutivas das séries de prêmio de seguros
estudadas. Foram realizadas previsões para 18 passos à frente, sendo que os primeiros 6 passos foram
utilizados para seleção do melhor modelo (combinado ou individual), e os outros 12 foram utilizados para testar a metodologia em face dos resultados individuais. A combinação das previsões foi implementada
no software MATLAB, e a avaliação das previsões via MAPE foi realizada no Excel. A seguir, são
apresentados os resultados para as seis séries estudadas.
4.1 Seleção de modelos
Após combinar as previsões individuais, estas são avaliadas para os 6 primeiros passos à frente via
métrica MAPE. Na Tabela II, são apresentados os modelos de menor MAPE para cada série, que foram,
portanto, selecionados para a previsão dos 12 passos seguintes. A referida tabela apresenta os resultados da seleção do modelo para cada série, juntamente com o MAPE da seleção. Os MAPEs de seleção foram
os menores para o trecho (da série) guardado para avaliação (de t = 149 a t = 154).
Tabela II – Resultados da seleção dos modelos (combinados e individuais)
Série Modelo selecionado pela metodologia MAPE seleção
Acidentes Pessoais mediana(B&J, BATS, STL) 4,76%
Automóveis mediana(Naïve, AE, BATS) 3,02%
Empresarial mediana(Naïve, AE, BATS) 3,48%
Habitacional mediana(B&J, BATS) 2,12%
Viagem Grupal B&J 22,47%
Vida B&J 8,17%
4.2 Previsão com o modelo selecionado
Para cada série, se utilizou o modelo selecionado da Tabela II para previsão dos 12 passos seguintes. A
avaliação desta previsão consta na Tabela III. É possível ver que, apesar de terem tido os melhores
MAPEs para a seleção, os modelos propostos não foram unanimidade na previsão.
Tabela III – Resultados da previsão para as séries estudadas
Séries \ Modelos B&J AE ANN BATS STL Naïve Proposto
Acidentes Pessoais 3,24% 3,90% 13,19% 3,07% 3,06% 15,85% 2,84%
Automóveis 3,66% 4,47% 15,04% 6,40% 4,52% 6,87% 4,48%
Empresarial 6,32% 6,18% 8,92% 10,20% 10,47% 6,48% 5,63%
Habitacional 5,01% 4,26% 21,79% 2,73% 15,90% 19,90% 3,87%
Viagem Grupal 30,38% 22,20% 42,85% 39,40% 26,27% 39,93% 30,38%
Vida 5,85% 13,09% 10,36% 6,27% 6,59% 11,01% 5,85%
5 Conclusões
Este trabalho apresentou previsões de séries do Mercado Brasileiro de Seguros utilizando uma nova
metodologia de previsão combinada. A metodologia, composta por quatro etapas, seleciona o melhor
modelo (combinado ou individual), em uma janela de avaliação, para prever a série de seguro. A metodologia proposta apresenta resultados satisfatórios, quando comparados aos modelos individuais.
Observou-se, no decorrer do trabalho, que uma questão importante da metodologia concernia ao método
CLAIO-2016
269

de seleção do melhor modelo. O método utilizado no trabalho (i.e. que utiliza de parte da previsão da
série para calcular acurácia e selecionar o modelo) tinha seus resultados alterados sobremaneira para diferentes valores de p e de k. Frente a esta questão, os autores testaram outro método de seleção de
modelos, que consistia em selecionar o modelo (combinado ou individual) que apresentava melhor ajuste
(fit) para a série histórica estudada (utilizada para treinamento). Este método se mostrou falho, pois o
modelo de melhor ajuste para a série histórica não apresentava (na grande maioria das vezes) os melhores valores de previsão. Deste modo, propõe-se como trabalho futuro o aprimoramento da metodologia
apresentada, tendo-se em vista técnicas mais robustas e avançadas de seleção de modelos.
References
[1] G. Box e G. Jenkins, Time Series Analysis: Forecasting and Control, San Francisco, California: Holden-Day
Inc., 1976.
[2] C. Chatfield, Time-series Forecasting, Boca Raton, Florida: Chapman & Hall / CRC, 2000.
[3] R. Clemen, “Combining forecasts: A review and annotated bibliography,” International Journal of Forecasting, vol. 5, n. 4, pp. 559-583, 1989.
[4] S. Makridakis e M. Hibon, “The M3-competition: Results, conclusions and implications,” International
Journal of Forecasting, vol. 16, n. 4, pp. 451-476, October 2000.
[5] C. Conflitti, C. De Mol e D. Giannone, “Optimal combination of survey forecasts,” International Journal of
Forecasting, vol. 31, n. 4, pp. 1096-1103, October 2015.
[6] V. Jose e R. Winkler, “Simple robust averages of forecasts: Some empirical results,” International Journal of Forecasting, vol. 24, n. 1, pp. 163-169, January 2008.
[7] R. Valle dos Santos e M. Vellasco, “Neural Expert Weighting: A NEW framework for dynamic forecast
combination,” Expert Systems with Applications, vol. 42, n. 22, pp. 8625-8636, December 2015.
[8] R. Adhikari, “A neural network based linear ensemble framework for time series forecasting,”
Neurocomputing, vol. 157, pp. 231-242, June 2015.
[9] L. De Menezes, D. Bunn e J. Taylor, “Review of guidelines for the use of combined forecasts,” European Journal of Operational Research, vol. 120, n. 1, pp. 190-204, January 2000.
[10] G. Sudheer e A. Suseelatha, “Short term load forecasting using wavelet transform combined with Holt–Winters
and weighted nearest neighbor models,” Journal of Electrical Power and Energy Systems, vol. 64, pp. 340-346,
2015.
[11] C. Chatfield, The analysis of time series: Theory and practice, London: Chapman and Hall, 1975.
[12] R. J. Hyndman, A. B. Koehler, R. D. Snyder e S. Grose, “A Stade Space Framework for Automatic Forecasting
Using Exponential Smoothing Methods,” International Journal of Forecasting, vol. 18, pp. 439-454, 2002.
[13] R. G. Brown, Statistical Forecasting for Inventory Control, New York: McGraw-Hill, 1959.
[14] C. C. Holt, “Forecasting Trend Seasonal by Exponentially Wheighted Averages,” International Journal of
Forecasting, vol. 20, pp. 5-13, 2004.
[15] P. Winters, “Forecasting Sales by Exponentially Weighted Moving Averages,” Management Science, vol. 6, n. 3, pp. 324-342, 1960.
[16] A. M. De Livera, R. J. Hyndman e R. D. Snyder, “Forecasting Times Series with Complex Seasonal Patterns
Using Exponential Smoothing,” Journal of the American Statistical Association, vol. 106, n. 496, pp. 1513-
1527, 2011.
[17] S. Haykin, Neural Networks: A Comprehensive Foundation, Prentice Hall, 1999.
[18] R. Hyndman, Dezembro 2012. [Online]. Available: http://robjhyndman.com/hyndsight/forecast4/. [Acesso em Abril 2016].
CLAIO-2016
270

Uma associação dos métodos de barreira e de barreira modificada
Jéssica Antonio Delgado
Pós-Graduação em Engenharia Elétrica- FEB- Unesp- Bauru-SP
Edméa Cássia Baptista
Departamento de matemática-FC-Unesp-Bauru-SP
Edilaine Martins Soler
Departamento de matemática-FC-Unesp-Bauru-SP
Resumo
Neste trabalho propõe-se uma abordagem que utiliza uma associação de dois métodos: primal-dual
barreira logarítmica e o da função Lagrangiana barreira logarítmica modificada para a resolução do
problema de Fluxo de Potência Ótimo Reativo. Na abordagem proposta, as restrições de desigualdade
são transformadas em igualdade ao introduzir variáveis de folga e excesso, as quais são tratadas pela
função barreira logarítmica ou pela função barreira logarítmica modificada, e as demais restrições são
tratadas pelos multiplicadores de Lagrange. Testes numéricos, utilizando os sistemas elétricos IEEE 14,
30 e 57 barras indicam que o método é eficiente e robusto.
Palavras-chave: método primal-dual barreira logarítmica; método da função Lagrangiana barreira
logarítmica modificada; problema de Fluxo de Potência Ótimo Reativo.
1 Introdução
Dentre os diversos problemas de otimização encontrados na engenharia elétrica, destaque-se o problema
de Fluxo de Potência Ótimo (FPO), estudado na área de sistemas elétricos de potência. O objetivo de um
problema FPO é determinar o estado de um sistema de transmissão de energia elétrica que otimize um
dado desempenho deste sistema e satisfaça suas restrições físicas e operacionais. Neste trabalho é
investigado o FPO reativo (FPOR), o qual é um caso particular do FPO, no qual os controles associados
à potência ativa estão fixos e somente são consideradas as variáveis associadas à potência reativa.
Em geral, no problema de FPO, os modelos matemáticos utilizados possuem características como não
linearidade, não convexidade, restrições de igualdade e desigualdade e variáveis contínuas ou discretas, o
que o torna um desafio para os pesquisadores desta área. Desde apresentado por [2], a busca por métodos
eficientes e robustos, para sua resolução, continua até o momento.
O objetivo deste trabalho é associar dois métodos: o método primal-dual barreira logarítmica (PDBL) e o
método da função Lagrangiana barreira logarítmica (FLBLM) em uma única abordagem. A ideia surgiu
com o trabalho de [5], que propôs a associação de dois métodos: o de barreira e de barreira modificada
para resolver problemas de otimização não linear. Seus resultados foram promissores e o autor conclui
CLAIO-2016
271

que sua proposta é mais eficiente que a aplicação dos métodos separadamente. Outra motivação em
aplicar esta associação no FPOR é que ambos os métodos já foram investigados separadamente, por
alguns autores tais como [4], [13], [1] [9], [7], para a sua resolução e mostraram-se eficiente.
Na associação dos métodos, abordada neste trabalho, as restrições de desigualdade do problema são
transformadas em igualdade através da utilização de variáveis de folga e excesso positivas. As variáveis
de folga e excesso são tratadas pelas funções barreira logarítmica ou barreira logarítmica modificada,
respectivamente, e as demais restrições através de multiplicadores de Lagrange. Estes métodos serão
utilizados em duas etapas. Inicialmente aplica-se o método PDBL até que uma condição de parada seja
satisfeita, em seguida aplica-se o método da FLBLM até que uma condição de convergência seja
satisfeita.
Este trabalho encontra-se dividido da seguinte maneira: na seção 2 é apresentado o problema de Fluxo de
Potência Ótimo Reativo; na seção 3 são apresentados os métodos PDBL e da FLBLM respectivamente;
na seção 4 é apresentada a associação dos métodos; finalmente os testes e considerações finais são
apresentados nas seções 5 e 6, respectivamente.
2 O Problema de Fluxo de Potência Ótimo Reativo
O modelo geral do FPOR pode ser representado, segundo [10] como:
i
j
min max
k k k
min max
p p p
Minimizar f ( t ,v, )
sujeitoa : P( t ,v, ) 0 i=1,2,...,NBCCR
Q ( t,v, ) 0 j=1,2,...,NBC
Q Q ( t,v, ) Q , k=1,2,...,NBCR
v v v p=1,2,.
min max
q q q
..,NB
t t t q=1,2,...,NT
(1)
em que:
NB é o número de barras do sistema elétrico;
NBC é o número de barras de carga;
NBCR é o número de barras de controle de reativo;
NBCCR é o número de barras de carga e de controle de reativo;
NT é o número de transformadores com tap variável; min max
k kQ e Q são os limites mínimos e máximos de geração de potência reativa, respectivamente; min max
p pv e v são os limites mínimos e máximos das magnitudes da tensão, respectivamente;
min max
p pt e t são os limites mínimos e máximos dos taps dos transformadores, respectivamente.
As variáveis do problema são: T
1 2 NTt ( t ,t ,...,t ) é o vetor dos taps dos transformadores; T
1 2 NBv ( v ,v ,...,v ) é o vetor das magnitudes de tensão nas barras e T
1 2 NB( , ,..., ) é o vetor dos
ângulos de tensão nas barras .
As funções de (1) são descritas a seguir:
CLAIO-2016
272

2 2
km k m k m kmkm
G C
i i i imm i
2
im im i im im i m im im im im
G sh 2 C
j j j j j jmm j
jm jm j
f ( t ,v, ) g ( v v 2v v cos );
P( t ,v, ) P P P ( t ,v, ),com
P ( t ,v, ) ( t v ) g ( t v )v ( g cos b sen );
Q ( t ,v, ) Q b v Q Q ( t,v, ),com
Q ( t v
2 sh
jm jm jm j m jm jm jm jm
C sh 2 2 sh
k k k k km k km km km k m km km km km
) ( b b ) ( t v )v ( b cos g sen );
Q ( t ,v, ) Q b v ( t v ) ( b b ) ( t v )v ( b cos g sen ),
em que: é o conjunto de todas as linhas de transmissão; k é o conjunto de todas as barras vizinhas
á barra k; sh
km km kmg ,b e b são a condutância e as susceptâncias da linha km; G C
k kP e P são as potências
ativas geradas e consumidas, respectivamente; G C
k kQ e Q são as potências reativas geradas e consumidas,
respectivamente.
3 Métodos de Solução.
Seja o problema de otimização não linear com restrições de igualdade e desigualdade de acordo com (2):
(2)
em que: T
1 mg( x ) ( g ( x ),...,g ( x )) é o vetor das restrições de igualdade,
T
1 rh( x ) ( h ( x ),...,h ( x )) é o
vetor restrições de desigualdade e f(x) é a função objetivo. Considere que nx ,
f: n m r
i j, g : ,i 1,...,m e h : , j 1,...,r são funções contínuas e diferenciáveis.
3.1 O método primal-dual barreira logarítmica
Dentre os métodos de pontos interiores, pode-se dizer que o PDBL é um método robusto e eficiente.
Neste método, as restrições de igualdade são tratadas através dos multiplicadores de Lagrange, o método
de barreira [3] é utilizado para tratar as restrições de desigualdade e o método de Newton é utilizado para
resolver o sistema das equações não lineares, gerado pelas condições necessárias de 1ª ordem. No
problema (2), o método PDBL exige que as restrições de desigualdade sejam transformadas em igualdade
utilizando variáveis de folga positivas. Na sequência adiciona-se uma função barreira logarítmica na
função objetivo afim de garantir a não negatividade das variáveis de folga. Desta forma, obtêm-se a
seguinte função Lagrangiana barreira logarítmica:
( )
: g( ) 0,
h( ) 0,
Minimizar f x
sujeito a x
x
CLAIO-2016
273

(3)
Sendo:m re os vetores dos multiplicadores de Lagrange, isto é, as variáveis duais do
problema, µ o parâmetro de barreira e 1s o vetor das variáveis de folga.
A condição de otimalidade é aplicada sobre (3), gerando um sistema de equações não lineares. As raízes
do sistema de equações não lineares são determinadas através do método de Newton. O método de
Newton gera as direções de busca T
1( x, s , , ) , as quais serão utilizadas para a atualização das
variáveis do sistema.
Os vetores das variáveis 1
x,s , e são atualizados da seguinte forma:
k 1 k k
p
k 1 k k
1 1 p 1
k 1 k k
d
k 1 k k
d
x x x
s s s
(4)
em que: p de são os passos utilizados na atualização das variáveis primais e duais, respectivamente.
Para a determinação dos passos primais e duais adotou-se uma adaptação da estratégia utilizada por [4],
[11], entre outros. O passo primal é determinado de modo a garantir que as variáveis de folga sejam
positivas e é dado por:
(5)
Já o passo dual é calculado de forma que cada componente dos vetores duais permaneçam com seus
respectivos sinais, isto é:
(6)
em que = 0,9995. A atualização do parâmetro de Barreira µ, é dada por:
(7)
em que 1 . Neste trabalho adota-se 10 .
1 1 11 1 1
( , , ,s )= ( ) ( ) ( ) ( ( ) )r m r
i i j jj jj i j
FLBL x f x s g x h x s
1k
k
1
0 e S 01 11
min{( min ,1)}.j
pS
j jj
s
s
1 1
1
0 e 01
min{( min ,1)},j
j jj
d
CLAIO-2016
274

3.2 O método da função Lagrangiana barreira logarítmica modificada
O método da FLBLM foi apresentado por [9]. Neste método, as restrições de igualdade são tratadas
através dos multiplicadores de Lagrange, o método de barreira modificada [8] é utilizado para tratar as
restrições de desigualdade e o método de Newton é utilizado para resolver o sistema das equações não
lineares, gerado pelas condições necessárias de 1ª ordem.
Dado o problema (2) acrescentam-se as variáveis de folga positivas com objetivo de transformar as
restrições de desigualdade em restrições de igualdade. Na sequência aplica-se uma relaxação, nas
condições de não negatividade do problema, utilizando o parâmetro de barreira. Associado ao problema
(2) têm-se a seguinte função Lagrangiana barreira logarítmica modificada:
(8)
em que: 1
1 1 1j j j( s ) ln( s 1), se s , j 1,...,r ,
j1( s ) é a função barreira modificada
logarítmica, m re são os vetores dos multiplicadores de Lagrange, 1u é o vetor dos
estimadores dos multiplicadores de Lagrange, µ é o parâmetro de barreira e 1s é o vetor das variáveis de
folga.
A condição de otimalidade é aplicada sobre a função Lagrangiana barreira logarítmica modificada (8),
gerando um sistema de equações não-lineares. As raízes do sistema de equações não lineares são
determinadas através do método de Newton. O método de Newton gera as direções de busca T
1( x, s , , ) , as quais serão utilizadas para a atualização das variáveis.
A atualização dos vetores das variáveis 1
x,s , e é dado por (4), como no método PDBL
O parâmetro de Barreira µ é atualizado, Segundo [6] e é dado por:
(9)
em que r é o número de restrições de desigualdade do problema e
11
1
1max( ), 1,..., para s 0.
1 j
j
j rs
(10)
O vetor dos estimadores dos multiplicadores de Lagrange u é atualizado pela regra de [8]:
1
11
1 1
1
k k
jk
k k
j
uu
s
(11)
Os passos primais e duais são calculados como no método PDBL, isto é, dados em (5) e (6).
1 1 1 11 1 1
( , , ,s )= ( ) ( ) ( ) ( ( ) )r m r
i i j ji j jj i j
FLBLM x f x u s g x h x s
1 (1 ),k k
r
CLAIO-2016
275

4. A associação dos métodos
Propõe-se utilizar o método PDBL e o método da FLBLM de maneira mista. A ideia consiste em: aplicar
o método PDBL até que um critério de parada seja satisfeito e em seguida aplicar o método FLBML até
que um critério de convergência seja satisfeito. Neste trabalho adotou-se como critério de parada (13)
com 2
2 10 para o método PDBL.
O critério de parada para o método da FLBLM, é a condição de convergência do algoritmo, ou seja,
adotou-se o critério apresentado por [12], da seguinte forma:
(12)
(13)
(14)
em que: 1 2 3, e são denominados de tolerância e assumem um valor pequeno. Se os
critérios 1 1 2 2 3 3
, ,k k kv v v estão satisfeitos, então a factibilidade primal e dual escalar estão
garantidas, o que significa que na iteração k têm-se uma solução que satisfaz as condições de Karush-
Kuhn-Tucker (KKT). Os valores utilizados para as tolerâncias neste trabalho são 2 5 2
1 2 310 , 10 , 10 .
A abordagem proposta foi aplicada no problema de FPOR associado aos sistemas do Institute of Eletrical
and Eletronics Engineers (IEEE) 14, 30 e 57 barras (http://www.ee.washington.edu/research/pstca/). Para
verificar a eficiência do método proposto, seus resultados foram comparados aos resultados obtidos pelos
métodos PDBL e FLBLM, separadamente. Os métodos PDBL e FLBLM foram implementados em
MATLAB R.2010b, em um computador Intel Core i5- 2GHz, com 4 Gbytes de memória RAM.
5. Testes e Resultados
5.1 Teste com o sistema IEEE 14 barras
O sistema IEEE 14 barras possui as seguintes características: 1 barra de geração (slack), 4 barras de
controle reativo, 9 barras de carga, 17 linhas de transmissão e 3 transformadores tap variável. O problema
de FPO associado ao sistema IEEE 14 barras é composto por 22 equações de igualdade, 4 equações
canalizadas de potência reativa, 14 restrições canalizadas de magnitudes de tensão , 125 variáveis
associado ao método PDBL e 163 variáveis associado ao método da FLBLM.
1 1 1
1
2 2 2
3 3 3
|| ( ) ||
| ( ) ( ) |
1 | ( ) |
= || ( ) ||
k k
k kk
k
k k
v v g x
f x f xv v
f x
v v h x
CLAIO-2016
276
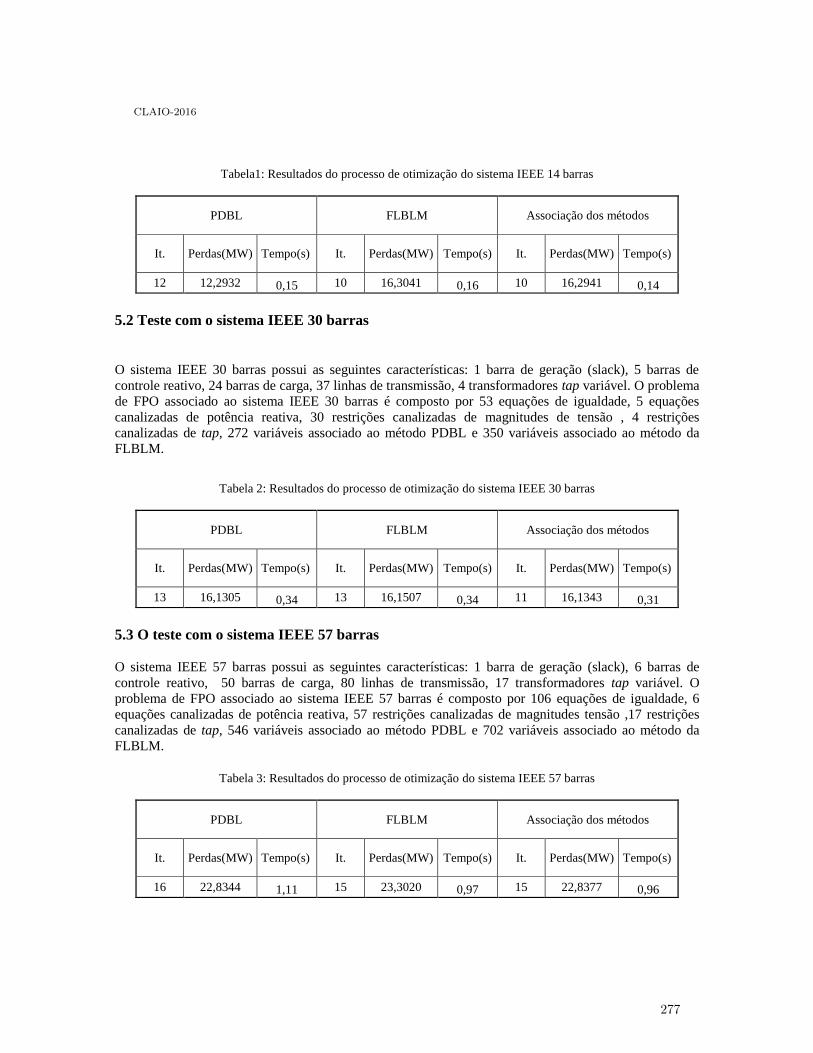
Tabela1: Resultados do processo de otimização do sistema IEEE 14 barras
PDBL FLBLM Associação dos métodos
It. Perdas(MW) Tempo(s) It. Perdas(MW) Tempo(s) It. Perdas(MW) Tempo(s)
12 12,2932 0,15 10 16,3041 0,16 10 16,2941 0,14
5.2 Teste com o sistema IEEE 30 barras
O sistema IEEE 30 barras possui as seguintes características: 1 barra de geração (slack), 5 barras de
controle reativo, 24 barras de carga, 37 linhas de transmissão, 4 transformadores tap variável. O problema
de FPO associado ao sistema IEEE 30 barras é composto por 53 equações de igualdade, 5 equações
canalizadas de potência reativa, 30 restrições canalizadas de magnitudes de tensão , 4 restrições
canalizadas de tap, 272 variáveis associado ao método PDBL e 350 variáveis associado ao método da
FLBLM.
Tabela 2: Resultados do processo de otimização do sistema IEEE 30 barras
PDBL FLBLM Associação dos métodos
It. Perdas(MW) Tempo(s) It. Perdas(MW) Tempo(s) It. Perdas(MW) Tempo(s)
13 16,1305 0,34 13 16,1507 0,34 11 16,1343 0,31
5.3 O teste com o sistema IEEE 57 barras
O sistema IEEE 57 barras possui as seguintes características: 1 barra de geração (slack), 6 barras de
controle reativo, 50 barras de carga, 80 linhas de transmissão, 17 transformadores tap variável. O
problema de FPO associado ao sistema IEEE 57 barras é composto por 106 equações de igualdade, 6
equações canalizadas de potência reativa, 57 restrições canalizadas de magnitudes tensão ,17 restrições
canalizadas de tap, 546 variáveis associado ao método PDBL e 702 variáveis associado ao método da
FLBLM.
Tabela 3: Resultados do processo de otimização do sistema IEEE 57 barras
PDBL FLBLM Associação dos métodos
It. Perdas(MW) Tempo(s) It. Perdas(MW) Tempo(s) It. Perdas(MW) Tempo(s)
16 22,8344 1,11 15 23,3020 0,97 15 22,8377 0,96
CLAIO-2016
277

Observa-se nas tabelas 1, 2 e 3, respectivamente, que a proposta de associar os dois métodos é tão
eficiente quanto os métodos aplicados separadamente. Quando compara-se com o método PDBL o
número de iterações é sempre inferior e quando compara-se com o método da FLBLM tem o mesmo
número de iterações, no entanto no sistema IEEE 57 barras as perdas de potência ativa foram menores.
6 Considerações finais
O problema de FPOR pode ser modelado como um problema de programação não linear com variáveis
discretas e contínuas, com restrições de igualdade e desigualdade. Neste trabalho resolveu-se o FPOR
com um novo método que associa os métodos PDBL e FLBLM. Testes numéricos utilizando os sistemas
elétricos IEEE 14, 30 e 57 barras demonstram o potencial do método para resolução do problema.
Futuramente, serão realizados testes numéricos para os sistemas elétricos IEEE 118 e 300 barras.
Agradecimentos
Os autores agradecem o apoio financeiro do CNPq (Bolsista-CNPq e processo nº 448645/2014-9) e da
CAPES.
Referências
1. F. Capitanescu., M. Glavic., D. Ernst. e L. Wehenkel. Interior- point based algorithms for the solution of
optimal power flow problems. Electric Power systems research, 77(5), 508-517, 2007.
2. J. Carpentier. Contribution to the economic dispatch problem. Bulletin de la Societe Francoise des
Electriciens, 3(8): 431-447, 1962.
3. K. R. Frisch. The logarithmic potential method of convex programming. Memorandum,University.
Institute of Economics, 5(6). Oslo,1955.
4. S. Granville. Optimal reactive dispatch through interior point methods. IEEE Transactions on Power
Systems, 9(1): 136-146, 1994.
5. I. Griva. Numerical experiments with an interior-exterior point method for nonlinear programming.
Computational Optimization and Applications, 29(2): 173-195, 2004.
6. A. Melman e R. Polyak. The Newton modied barrier method for QP problems. Annals of Operation
Research, 62(1): pp.465-519, Springer, 1996.
7. R. B. N. Pinheiro, A. R. Balbo, E.C. Baptista e L. Nepomuceno. Interior-exterior point method with global
convergence strategy for solving the reactive optimal power flow problem. International Journal of
Electrical Power & Energy Systems, 66:235-246, 2015.
8. R. Polyak. Modified barrier functions (theory and methods). Mathematical programming, 54(1-3): pp.177-
222, Springer, 1992.
9. V. A. Sousa, E. C. Baptista, e G. R. M. Costa. Fluxo de potência ótimo reativo via método da função
lagrangiana barreira modificada. Sba: Controle & Automação Sociedade Brasileira de Automatica,
19(1):89- 92, SciELO Brasil, 2008.
10. E. M. Soler, E. N. Asada e G. R. da Costa. Penalty-based nonlinear solver for optimal reactive power
dispatch with discrete controls. Power Systems, IEEE Transactions on, 28(3):2174-2182, 2013.
11. G. L. Torres e V. H Quintana. On a nonlinear multiple-centrality-corrections interior-point method for
optimal power flow, Power Systems, IEEE Transactions on, 16 (2):222-228, 2001.
12. G. L. Torres e V.H Quintana. An interior-point method for nonlinear optimal power using voltage
rectangular coordinates, Power Systems, IEEE Transactions on, 13 (4):1211-1218, 1998.
13. Y. C. Wu, A. S. Debs, R. E. Marsten. A direct nonlinear predictor-corrector primal-dual interior point
algorithm for optimal power flows. Power Systems, IEEE transactions on, 9(2), 876-883, 1994.
CLAIO-2016
278

Uma heuŕıstica baseada em Programação Matemática
para o Problema de Escalonamento de Médicos
Valdemar Abrão P. A. DevesseInstituto de Ciências Matemáticas e de Computação – Universidade de São Paulo (USP)
Rafael Soares RibeiroInstituto de Ciências Matemáticas e de Computação – Universidade de São Paulo (USP)
Maristela Oliveira SantosInstituto de Ciências Matemáticas e de Computação – Universidade de São Paulo (USP)
Julho, 2016
Resumo
O Problema de Escalonamento de Médicos (PEM) pode ser definido como a alocação detarefas a grupo de médicos durante um horizonte de planejamento, considerando um conjuntode regulamentações de trabalho, preferências individuais e regras de organização, regras estasque são muitas vezes conflitantes. O problema lida majoritariamente com objetivos qualitativos,sendo neste caso, produzir escalas de modo a maximizar o atendimento das restrições de pre-ferência pessoal, respeitando as restrições laborais e organizacionais. Neste artigo apresenta-seum modelo de Programação Inteira Mista fundamentado em obras da literatura e propõe-se umaheuŕıstica derivadas da formulação matemática para resolução eficiente de instâncias baseadasem dados reais do PEM.
Keywords: Problema de Escalonamento de Médicos; Programação Inteira Mista; MIP-Heuŕısticas.
1 Introdução
O Problema de Escalonamento de Médicos (PEM ) é uma variante do Problema de Escalonamentode Pessoal (PEP) e consiste em atribuir tarefas a médicos durante um horizonte de planejamentorespeitando regras laborais, contratuais e de preferências pessoais de modo a satisfazer a demandade serviços do hospital. O problema lida majoritariamente com objetivos qualitativos, sendo nestecaso, produzir escalas de modo a maximizar o atendimento das restrições de preferência pessoal,respeitando as restrições laborais e organizacionais. O PEM pertence a grande área de PEP,cujos os estudos iniciais foram feitos por [1] e [2]. Revisões exaustivas e aprofundadas podem serencontradas em [3], [4] e [5].
CLAIO-2016
279

Na saúde, setor em que se aplica esta classe de problemas, tem se dado maior foco ao Problemade Escalonamento de Enfermeiros em detrimento do PEM e essa é uma forte motivação para odesenvolvimento de pesquisas sobre o PEM.
Para a resolução das variantes do PEM, entre os métodos mais usados estão a programaçãomatemática e meta-heuŕısticas, segundo [3]. [6] propõem um modelo de programação inteira eo aplicam para alocação de médicos em serviços de pronto socorro. [8] também faz estudo dealocação de médicos em serviços de pronto socorro com o diferencial de considerar somente médicosresidentes e como abordagem de resolução propõe um modelo de programação por metas. [9]fazem o estudo do PEM em um Hospital Universitário e propõem a aplicação do método Branch-and-Bound. [10] aplicando em serviço de pronto socorro propõem resolução do PEM por meio deAlgoritmos Genéticos . Sobre este tipo de problema, acredita-se que para instâncias pequenas ossolvers de otimização possam ser usados, enquanto que para instâncias maiores e mais complexospodem ser utilizadas meta-heuŕısticas.
O objetivo deste trabalho é reformular um modelo matemático para o PEM e desenvolvermétodos de resolução baseados na formulação matemática proposta. Este artigo apresenta naSeção 2 a descrição do problema em estudo e respectiva modelagem. O método de resolução éapresentado na Seção 3 e os resultados dos experimentos encontram-se na Seção 4. Consideraçõesfinais e perspectivas são apresentadas na Seção 5.
2 Descrição do Problema
2.1 Modelagem proposta
Para modelar este problema, consideramos um conjunto de médicos I que no horizonte de pla-nejamento J , dado em dias que podem ser alocados a cada um dos turnos diários de um dia j,sendo |J | múltiplo de 28. O conjunto de turnos de um dia j é definido por K(j) e é constitúıdo deturnos matutinos KM, vespertinos KA, noturnos KN e extraordinários KD e KE (plantões de manhãe de noite), respectivamente. Para simplificação da notação, utilizaremos K no lugar de K(j) nasrestrições do modelo associadas a um determinado dia. Os médicos podem ter contrato a tempointegral IFT ou parcial IPT. Um médico pode ser do subconjunto de médicos sênior IS, se tiver maisque 5 anos de experiência ou residente IR, caso contrário. Existem subconjuntos de turnos K̃ eJ̃ dias que cada médico pode solicitar para trabalhar ou folga. Aos subconjuntos de números desemanas e meses designam-se JW e JM respectivamente, onde JW = {1, . . . , |J |/7} e JM = {1, . . . ,|J |/28}. Assumimos que as semanas iniciam-se sempre na segunda-feira. Em cada turno é exigidauma quantidade mı́nima (djk) e máxima (Djk) de médicos. Um médico pode cumprir até c diasconsecutivos de trabalho. Cada turno k tem uma duração de hk horas. Espera-se que o médico icumpra Hi horas semanais, mas tolera-se vwi horas extra na semana l, somente para o conjunto demédicos com contrato a tempo integral e uwil horas em falta para todos os médicos. Espera-se queum médico i cumpra Sim turnos no mês m, contudo tolera-se desvio por excesso vkim e ukim porfalta. Deseja-se que um médico i cumpra a quantidade Fim de turnos requisitados em um mês m,considerando um excesso uxim e falta vxim. Além desta, existem também as quantidades máximasde horas mensais a cumprir nos plantões do mês m, UD
im e da noite UNim. Para tatar as violações
assumimos que as preferências podem não ser atendidas por meio de um custo a ser minimizado afim de obter um cronograma de trabalho flex́ıvel e vantajoso para o hospital.
Parâmetros
CLAIO-2016
280

αi , βi taxa de violações das restrições de cumprimento de turnos extraordinários enoturno requisitados pelo i-ésimo médico, por falta e por excesso,respectivamente;
γi, δi taxa de violações das restrições de cumprimento de horas pelo i-ésimomédico, por falta e por excesso, respectivamente;
πi, ωi taxa de violações das restrições de distribuição de turnos requisitidos peloi-ésimo médico, por falta e por excesso, respectivamente;
Variáveisxijk Variável de alocação do i-ésimo médico no k-ésimo turno do j-ésimo dia;
(xijk = 1 , se i-ésimo médico for alocado no k-ésimo turno do j-ésimo diaxijk = 0, caso contrário.);
Neste problema deseja-se minimizar a soma ponderada dos desvios ás restrições de turnos ex-traordinários, cumprimento de horas e de distribuição, ou seja:
min∑
i∈I
( |JM|∑
m=1
αiuxim +
|JM|∑
m=1
βivxim +
|JW|∑
l=1
γiuwil +
|JW|∑
l=1
δivwil +
|JM|∑
m=1
πiukim +
|JM|∑
m=1
ωivkim
)(1)
sujeito a:∑i∈I
xijk ≥ djk j ∈ J, k ∈ K (2)
∑i∈I
xijk ≤ Djk j ∈ J, k ∈ K (3)
∑i∈IS
xijk ≥ 1 j ∈ J, k ∈ KM ∪KT ∪KN (4)
∑k∈K
xijk ≤ 1 i ∈ I, j ∈ J (5)
∑k∈KA
xi(j−1)k +∑
k∈KM
xijk ≤ 1 i ∈ I, j ∈ J (6)
∑k∈KA
xi(j−1)k +∑
k∈KD
xijk ≤ 1 i ∈ I, j ∈ J (7)
∑k∈KN
xi(j−1)k +∑
k/∈KN
xijk ≤ 1 i ∈ I, j ∈ J (8)
∑k∈KE
xi(j−1)k +∑
k∈KM
xijk ≤ 1 i ∈ I, j ∈ J (9)
∑k∈KE
xi(j−1)k +∑
k∈KA
xijk ≤ 1 i ∈ I, j ∈ J (10)
∑k∈KE
xi(j−1)k +∑
k∈KN
xijk ≤ 1 i ∈ I, j ∈ J (11)
∑k∈KE
xi(j−1)k +∑
k∈KD
xijk ≤ 1 i ∈ I, j ∈ J (12)
xijk = 0 ∀i ∈ I, j ∈ J̃ , k ∈ K̃ (13)
CLAIO-2016
281

j∑f=j−c
∑k∈K
xifk ≤ c i ∈ I, j ∈ J (14)
∑j∈JM
∑k∈KD
hkxijk ≤ UDim i ∈ I,m ∈ {1, ..., |JM|} (15)
∑j∈JM
∑k∈KE
hkxijk ≤ UNim i ∈ I,m ∈ {1, ..., |JM|} (16)
∑k∈K
(xi(j−1)k + xijk) ≤ 1 i ∈ I, j ∈ {1, 8 . . . , |J | − 6} (17)
∑j∈JM
∑k∈K
xijk − vxim + uxim = Fim i ∈ IFT,m ∈ {1, ..., |JM|} (18)
∑j∈JW
∑k∈K
hkxijk − vwil + uwil = Hi i ∈ IFT, l ∈ {1, ..., |JW|} (19)
∑j∈JW
∑k∈K
hkxijk + uwil = Hi i ∈ IPT, l ∈ {1, ..., |JW|} (20)
∑j∈JM
∑k∈K
xijk − vkim + ukim = Sim i ∈ I,m ∈ {1, ..., |JM|} (21)
xijk ∈ {0, 1} i ∈ I, j ∈ J, k ∈ K (22)
vxim, uxim ∈ R+ i ∈ I,m ∈ {1, ..., |JM|} (23)
vwil, uwil ∈ R+ i ∈ I, l ∈ {1, ..., |JW|} (24)
ukim, vkim ∈ R+ i ∈ I,m ∈ {1, ..., |JM|} (25)
O atendimento da demanda mı́nima e máxima é garantida pelas restrições (2) e (3). Demanda-setambém que no mı́nimo 1 médico sênior atenda durante a semana em cada um dos turnos: manhã,tarde e noite por meio das restrições em (4). As restrições (5) implicam que um médico podecumprir somente um turno no dia. O tratamento de não alocação em turnos conflitantes em diasconsecutivos é feito pelas restrições (6) a (12). Por exemplo, na restrição (6) se o médico i for alocadoa um turno da tarde no dia seguinte ele não podera trabalhar no turno da manhã. Agora no caso darestrição (8) se o médico i for alocado a um turno noturno no próximo dia ele não pode ser alocadoa um turno que não seja noturno. Note que essas restrições levam em conta condições iniciais dotérmino do último cronograma. As restrições no conjunto (13) controlam folgas e dias de férias. Omáximo de c dias consecutivos de trabalho é tratado pelas restrições em (14). O limite máximo dehoras trabalhadas em turnos extraordinários é tratado pelas restrições (15) e (16). As restriçõesem (17) visam que um médico alocado ao domingo não cumpra a segunda-feira seguinte. Médicoscom contrato a tempo integral cumprem os turnos requisitados com desvio por excesso e por faltamediante as restrições em (18). De modo análogo, cada médico deve cumprir horas trabalhadas,considerando excesso e falta. O tratamento para médicos com contrato a tempo integral é feito nasrestrições em (19) e para os médicos com contrato a tempo parcial nas restrições em (20). Umadistribuição semanal justa de médicos, considerando os turnos requisitados é desejável para todosos médicos e essas restrições são tratadas em (21). O domı́nio das variáveis é apresentado nasrestrições (22) a (25).
CLAIO-2016
282

3 Abordagem heuŕıstica baseadas na formulação Matemática
Para obtenção de soluções de qualidade razoável para o problema foi adotada a aplicação deheuŕısticas baseadas na formulação matemática do tipo relax-and-fix e fix-and-optimize.
A heuŕıstica relax-and-fix aplicada, inicialmente proposta por [7] funciona do seguinte modo:do problema principal (Q), o conjunto de variáveis inteiras é dividido em subconjuntos disjuntos R,podendo se representar cada conjunto como Qr com r = 1, . . . , R. Desta forma Q = Q1 ∪ . . . ∪QR
e Q1 ∩ . . . ∩ QR = ∅. A cada iteração um subproblema MIP r é resolvido com r = 1, . . . , R.Tomando o primeiro subproblema MIP 1 as variáveis do subconjunto (Q1) são definidas comobinárias, enquanto que as dos demais subconjuntos, (Q2 . . . QR) são mantidas linearmente relaxadase o subproblema é resolvido em função desta estrutura, tomando em consideração a estratégia departicionamento eleita. Após a resolução do MIP 1, o subconjunto de variáveis inteiras, Q1, doproblema é fixado com os valores obtidos, caso a solução seja fact́ıvel e o processo é repetido para osdemais conjuntos Q2 . . . QR. A solução da MIPR é a solução da heuŕıstica para o problema original.E caso em alguma iteração não se obtenha solução fact́ıvel, o processo é abortado e desse modonão se encontrando solução para o problema original usando a estratégia de particionamento eleita.A relax-and-fix aplicada usa estratégia de decomposição em turnos, sendo que a cada iteração sãofixados 5 turnos e denominamo-la RFSP (relax-and-fix with shift partitioning).
Por sua vez, a heuŕıstica fix-and-optimize, também proposta por [7] com a designação exchange,é uma estratégia de melhoria. Tomando determinada estratégia de particionamento de variáveisinteiras nos conjuntos Qr, com r = 1, . . . , R, todas as variáveis são fixadas com os valores da melhorsolução obtida pela heuŕıstica construtiva, com exceção das variáveis que do conjunto Qr restritasao domı́nio inteiro. Se uma solução melhor é obtida, então este procedimento é repetido. Sutilmentepode se constatar que se se tomar a partição das variáveis que são liberadas, esta heuŕıstica podeser considerada um algoritmo de busca local. Para a heuŕıstica de melhoria deste tipo aplicou-se a estratégia de decomposição em peŕıodo, sendo que a solução inicial é obtida da heuŕısticarelax-and-fix. A cada iteração são liberadas 2 semanas. Denominamos a esta heuŕıstica FOSWP(fix-and-optimize with shift and weekend partitioning).
4 Resutados Computacionais
As implementações dos métodos foram em C++, usando bibliotecas do solver IBM ILOG CPLEX12.6 e compilados com o g++ versão 4.8.4 ubuntu1 14.04. Os testes foram feitos num computador In-tel Xeon E5-2680v2 de 2.8 GHz com dez núcleos e 128 GB de memória, do projeto CEPID/FAPESP(processo 2013/073750).
4.1 Estabelecimento dos custos
A definição dos pesos da função objetivo é feita mediante a prioridade de cada um dos objetivos.Em vista disso, os pesos das restrições são os apresentados na Tabela 1.
4.2 Definição de Parâmetros usados
Nesta secção apresentam-se os parâmetros do solver de otimização CPLEX usados para o suportena execução dos métodos aplicados. Os parâmetros aplicados foram para cada método os seguintes:
CLAIO-2016
283
Tabela 1: Pesos por restrição
RESTRIÇÃO VARIÁVEL PRIORIDADE PESO
(18) vxim 3 0,05
(18) uxim 3 0,05
(19) vwil 1 0,5
(19) - (20) uwil 2 0,45
(21) ukim 4 0,015
(21) vkim 4 0,015
tempo limite de execução (Tmax) definido em 3600s, limite de memória (Mem) definido em 128GB,parâmetro de ênfase do CPLEX balanceada e tamanho e tipo de partições consideradas pelasheuŕısticas.
4.3 Instâncias de Teste
Foi usado grupo de instâncias fict́ıcias dividido em 5 classes com 4 instâncias cada. Para gerá-las,combinou-se as caracteŕısticas do problema às instâncias de um benchmark, em [12], a fim detorná-las mais realÃsticas. Das instâncias em benchmark foram extráıdas os dados relativos a diasde folga/férias e preferências de trabalho. As caracteŕısticas das instâncias teste são quantidade demédicos, quantidade de turnos, 5 para todas as classes, tamanho do peŕıodo, demanda, duraçãodos turnos, horas de trabalho, quantidade de turnos, número máximo de dias consecutivos, dias deFolga e férias. Temos instâncias cuja nomenclatura é InstanceND NW , onde ND indica númerode médicos e NW indica número de semanas.
A Tabela 2 apresenta os resultados obtidos aplicando o modelo ponderado e a heuŕısticaFOSWP. Além das colunas Classe e Instância, têm-se as colunas Obj, em que figura o melhorvalor da função objetivo no tempo de execução e limite de memória estabelecidos. Em seguida,apresenta-se a coluna LB, que é o limitante inferior. Foi apurada a qualidade da solução através
do GAP expresso em percentagem, dado pela relação GAP =(Obj − LB)
Obj× 100.
Dentre as classes, a que melhores resultados obteve foi a dummyPSP1 em que se registam 3instâncias com soluções ótimas, enquanto que nas demais, embora não se tenham obtido soluçõesótimas, foram obtidas soluções de boa qualidade. Nas outras classes, observa-se que as instânciasde 10 médicos são as mais dif́ıceis de resolver, pois destas obtêm-se as soluções de menor qualidadeno Tmax.
Durante os testes computacionais, constata-se que da heuŕıstica baseada na formulação ma-temática algumas soluções são obtidas em tempo computacional inferior ao do modelo, todavia suaqualidade não é superior. Em relação ao modelo, um comportamento comum a todas as instânciasé o limitante inferior que não evolui com o tempo, vide a Figuras 1 em que tomamos a instânciaInstance10 4 como exemplo.
A fim de se melhorar as soluções, estima-se que a criação de novas estratẽgias de construção emelhoria sejam interessantes para amenizar os impasses observados. Em relação á construção desoluções iniciais, já têm sido estudados sobre o problema a heuŕıstica de construção por turnos.Esta heuŕıstica de construção permitirá maior tempo ás estratégias de melhoria e possibilidade dese obter melhores soluções.
CLAIO-2016
284

Figura 1: Limitantes da Instância Instance10 4
Tabela 2: Resultados Computacionais para o Modelo e para as heuŕısticas Fix-and-OptimizeCLASSE INSTÂNCIA
CPLEX FOSWPObj LB GAP (%) Tempo Exec. [s] Obj GAP (%) Tempo Exec. [s]
dummyPSP1
Instance10 4 19,26 17,13 11,06 3600 19,26 11,06 1808,62Instance20 4 54,03 54,03 0,00 44,02 54,03 0 44,36Instance30 4 201,07 201,07 0,00 3,7 201,07 0 3,97Instance40 4 108,48 108,48 0,00 245,16 108,48 0 247,24
dummyPSP2
Instance10 8 40,12 33,50 16,49 3600 40,12 33,50 1805,11Instance20 8 109,62 109,62 0,00 3268,77 109,62 0 1664,92Instance30 8 402,41 402,37 0,0099 6,2 402,41 0,0099 7,48Instance40 8 408,58 408,58 0,00 5,19 408,58 0 6,17
dummyPSP3
Instance10 12 69,76 44,11 36,77 3600 69,76 36,77 1810,05Instance20 12 171,87 171,87 0,00 241,37 171,87 0 241,90Instance30 12 618,03 618,03 0,00 10,25 618,03 0 13,50Instance40 12 340,02 333,32 1,97 3600 340,02 1,97 1849,4
dummyPSP4
Instance10 24 147,35 113,29 23,12 3600 147,46 23,17 3600Instance20 24 300,52 282,37 6,04 3600 306,57 7,89 3600Instance30 24 1169,11 1169,11 0,00 61,59 1169,11 0 76,02Instance40 24 711,23 604,83 14,96 3600 711,23 14,96 1816,49
dummyPSP5
Instance10 36 235,54 182,64 22,46 3600 262,45 30,41 3600Instance20 36 508,23 478,63 5,82 3600 508,23 5,82 1841,2Instance30 36 1909,49 1909,49 0,00 77,97 1909,49 0 121,257Instance40 36 1318,67 1074,38 18,53 3600 1349,07 20,36 3600
5 Conclusões
Com os resultados computacionais, pode se inferir que os resultados da heuŕıstica fix-and-optimizenão foram melhores que o modelo matemático, de todo, porém foram competitivas para maior partedas instâncias apresentando resultados iguais ou muito próximos em tempo computacional reduzido.Embora as instâncias tinham sido geradas de forma mais reaĺıstica posśıvel, a concatenação de dadosde outras instâncias pode ter influenciado na sua qualidade. De tal sorte que a geração de instânciasmais reaĺısticas que esta torna-se uma medida pertinente. As soluções obtidas são de modo geralde limitantes inferiores fracos. Este fato se deve a relaxação linear fraca obtida em virtude dogrande número de restrições de factibilidade. Sendo que a heuŕıstica proposta deriva da relaxaçãolinear do problema e sendo que a relaxação linear do problema é fraca, as heuŕıstica tiveram umdesempenho igual ou pior que o modelo, em termos de qualidade das soluções. Uma solução paratratar este problema em particular é a inclusão de desigualdades válidas no modelo ou o uso denovas estratégias de particionamento para melhoria das soluções.
CLAIO-2016
285

6 Agradecimentos
Ao CNPq no âmbito do PEC-PG, Processo 190728/2013-2 e ao CEPID/FAPESP.
Referências
[1] Leslie C. Edie. Traffic Delays at Toll Booths. Journal of the Operations Research Society of America,2:107–138, 1954.
[2] George B. Dantzig A Comment on Edie’s ”Traffic Delays at Toll Booths” Journal of the OperationsResearch Society of America, 2:339–341, 1954.
[3] A.T. Ernst and Houyuan Jiang and Mohan Krishnamoorthy and David Sier, scheduling and rostering:A review of applications, methods and models European Journal of Operational Research, 2(153):3–27,2004.
[4] A.T. Ernst and H. Jiang and M. Krishnamoorthy and B. Owens and D. Sier An Annotated Bibliographyof Personnel Scheduling and Rostering Annals of Operations Research, 1-4(127):21-144, 2004.
[5] Peter Brucker and Rong Qu and Edmund Burke. Personnel scheduling: Models and complexity Euro-pean Journal of Operational Research, 2(210):467–473, 2011.
[6] Huguette Beaulieu and Jacques A. Ferland and Bernard Gendron and Philippe Michelon. A mathema-tical programming approach for scheduling physicians in the emergency room Health Care ManagementScience, 3(2):193–200, 2000.
[7] Yves Pochet and Laurence A. Wolsey Springer Series in Operations Research and Financial Enginee-ring. Springer Series in Operations Research and Financial Engineering, Berlin, Germany, 2006.
[8] Seyda Topaloglu. A multi-objective programming model for scheduling emergency medicine residentsComputers and Industrial Engineering, 4(51):375–388, 2006.
[9] Jeroen Belien and Erik Demeulemeester Scheduling trainees at a hospital department using a branch-and-price approach European Journal of Operational Research, 1(175):258 – 278, 2006.
[10] Javier Puente and Alberto Gomez and Isabel Fernandez and Priore Paolo Medical doctor rosteringproblem in a hospital emergency department by means of genetic algorithms European Journal ofOperational Research, 2(56):1232–1242, 2009.
[11] José Eduardo Pécora Esquematização de médicos em salas de emergências: Uma abordagem Hı́bridaInstituto de Matemática, Estat́ıstica e Computação Cient́ıfica, UNICAMP,thesis, 2002.
[12] www.cs.nott.ac.uk/ psztc/NRP/ Benchmark NRP Instances, University of Nottingham, site.
CLAIO-2016
286

Recommendation System for Social Networks based on
the Influence of Actors through Graph Analysis
Geraldo de Souza [email protected]
Claudia Marcela [email protected]
Julio Cesar [email protected]
Military Institute of Engineering, Rio de Janeiro, Brazil
Abstract
Nowadays, social interaction plays an important role in life, allowing people to achieve theirdesires, like a product you want to buy, a new professional contact or the resumption of a friend-ship. In this context, it is possible to receive recommendations that will help fulfill social goals,improving not only our experience as users but also the experience of others. We present a rec-ommendation technique between items based on a mixed approach of collaborative and contentfiltering, and social network analysis. From a root item, a relationship’s graph is generated andused to extract network metrics. The similarity of the root item with other items present inthe graph is evaluated and combined with the obtained metrics. We test these contributionsin a usecase, a co-authorship network. The combination of the similarity with metrics for so-cial network analysis of the relationship’s subgraph allows the configuration of recommendationalgorithms according to different semantics of use.
Keywords: Social Network Analysis; Recommendation Systems; Computer Science; ArtificialIntelligence.
1 Introduction
The emergence of social networks sparked a huge reform on the internet and how the information isspread. Social collaborative networks such as Linkedin or Facebook allow the integration betweenactors to help them achieve their goals: a new job indicated by someone, a new music shared by afriend or an old friend of the school that just added you. Sociologically speaking, people tend toadd to their “friends’ list” people that they already know in real life [11], which is the case of socialnetworks like Facebook. In a different context, like corporates or academic, it is more interestingto be in contact with people you don’t necessarily know yet [2] and that have a good influence inthe network or stay in touch with these people close contacts. In both cases, it is possible to buildrecommendation systems that help people to achieve these social objectives, representing a qualityimprovement in the user experience [10].
CLAIO-2016
287

In this article, we propose a recommendation technique that considers the influence of the userin the network. Our goal is to use the social power of actors, represented by centrality measures,in order to recommend other actors that are not only similar, but also influential. We instantiatethis approach in an affiliation network (AN), in which actors are connected via co-membership ofgroups of some kind [9]. In our research, we focus on a specific example of ANs, called co-authorshipnetwork of academics, where an actor is an academic author and has connection with other authorsthrough co-authored articles [8]. We create graphs by extracting data from a public search enginefor academic articles and literature to calculate the influence. The experiments were conductedby combining similarity and centrality measures to obtain a recommendation of a new possible co-author. The empirical results demonstrate that the centrality measures can help achieve differentsemantics in terms of recommendation.
The rest of this article is organized as follows. In the second section, we give a brief back-ground of social networks analysis. In Section 3, we review works similar to our approach. Therecommendation method and the data set construction, including the way that we collected datafrom Microsoft Academic Search under study, the network used and the methodology adopted forrecommendation are discussed in Sections 4, 5 and 6, respectively. In Section 7, we analyze the re-sults of the experiments conducted. Finally, we show our conclusions in the last section, discussionpossible future works.
2 Social Power and Influence in Social Networks
Social network analysis has produced many results concerning social influence, social groupings,inequality, disease propagation, communication of information and so on. An affiliation network ofscientists consists in links (edges) between two scientists (nodes) established by their co-authorshipof one or more scientific papers [8]. The term centrality refers to a property of a whole graphor network. Besides the idea of a central actor on the network, measures of graph centrality canreflect the dominance of this actor. There are two well known centrality measures in social networkanalysis: Betweenness and Closeness [9].
The Betweenness centrality measures the extent to which a vertex lies on paths between othernodes. The nodes with high betweenness coefficients are the ones that have more influence inthe network, because they control the flow of information passing between others. Formally, thebetweenness centrality of a vertex i in a network can be defined as follows: Cb(i) =
∑∀s 6=t6=i n
is,t/gs,t,
where nis,t is the number of shortest paths between s and t that pass through vertex i, and gs,t
is the total number of shortest paths between s and t. High betweenness nodes are often criticalto collaboration across clusters and to keep the spread of information through an entire network.Because of their locations between network communities, they are natural brokers of informationand collaboration.
The Closeness centrality measures the distance from a node to all other nodes. The higherthe coefficient of a node is, the lower is the distance of it to the rest of the graph. The closenesscentrality can be classified as a measure of fastness, computing the speed that information will taketo spread to other nodes sequentially. Formally, the closeness centrality of a vertex i in a networkcan be defined in as Cc(i) =
∑∀s 6=i 1/dist(i, s), where dist(i, s) is the length of the shortest path
between nodes i and s. Nodes with high closeness values have a lot of influence within their localnetwork cluster. They may often not be known figures to the entire network of a corporation orprofession, but they are often respected locally and they also occupy short paths for information
CLAIO-2016
288

spread within their network community.
3 Related Work
In this section, we survey several methods in the literature related with our work. In [7], the authorpresents a thorough survey of data mining in social networks using graph structure representations.The basis and recent developments in Social Networks and Graph Mining, each one with its appli-cations, are reported. The work developed by [5], focuses in experimenting and analyzing differentproximity metrics for the nodes in a network. The Adamic/Adar coefficient outperformed, showingbest results in several datasets. In [6] a model based on node centrality and weak-tie theory isgiven. In this model, the significance of each common neighbor of two nodes is different accordingto their centralities. Experiments on five real-world networks were conducted and compared withother four link prediction algorithms. The experimental results show that the proposed algorithmcan outperform or gives competitively good predictions comparing to others.
The research developed by [12] proposes an approach that takes into account the social powerin the network. They developed a system called COCOON (Coalitions in Cooperation Networks)based on betweenness centrality and interest similarity. A dataset was created by collecting infor-mation from a local university database, called Dspace. Authors and other relevant informationare extracted from documents in the database and a co-authorship network is created. The corerecommendation of COCCON is based on two types of computations: betweenness centrality forevery author in the co-authorship network and the similarity among keywords from the publicationsof the authors. Then, a final score is determined. Two sets of recommendations were provided tothe participants: one focused on all candidate authors, including co-authors of a target user. Andthe other one focused on new co-authors of a target user to foster creativity, excluding currentco-authors. In our approach, we propose a recommendation technique based on the structure andthe content of a social network. Besides the similarity among keywords, two centrality measures(betweenness and closeness) are considered to compute the final score for a user, with the objectiveof predicting new relationships.
4 Recommendation Process
A recommendation system naturally computes similarity between items or users, whatever therecommendation methodology adopted. But if similarity is not enough to make a prediction, whatother techniques besides looking for similar users can be considered? We propose an answer to thisquestion by considering the user’s influence in the network. The influence of a node is obtained bycomputing betweenness and closeness centrality measures from the user’s sub-graph.
Our implementation focuses on the use of an affiliation network of co-authors. Each actor isan academic author and there is a relation between two actors when there is at least one coau-thored publication between them. A network is built and some information about the authorsand publications are evaluated. The similarity between nodes is calculated by using the keywordspresent in the authors’ papers. The centrality measures betweenness and closeness are determined,for convenient nodes, indicating the influence of the authors in the network. Individuals with highcentrality scores are often more likely to be the leaders, good conduits of information and probablythe early adopters of anything that spreads in a network [3]. Authors with high betweenness, for
CLAIO-2016
289

instance, are important to the collaboration between departments or research’s lines. On the otherhand, authors with high closeness can transmit information more quickly. These assumptions arenot restricted to this kind of collaboration network, making it possible to be extended to othertypes of social networks, with different purposes.
5 Co-Authorship Data
In order to build the co-authorship graphs, we use the official web service provided by MicrosoftAcademic Search - MAS (http://academic.research.microsoft.com/). After determining a root au-thor, a depth-first search is started, which extracts all publications. All co-authors of the rootauthor are then extracted. The data is stored in a local database (off-line), for quick retrieval inlater purposes (graph visualization, measure evaluation, consulting paper or author data, etc.). Inaddition to publications and authors, keywords are also extracted and used to compute similaritybetween two authors. In this case, if one paper has three co-authors, all keywords of this paper willbe related to each one of the three authors. After that, data from 9 root authors were extracted,resulting in a total of 44,700 authors, 1,647,347 publications and 41,926 keywords.
To improve the similarity and centrality measures of authors, the misspelled authors detectedwere processed by merging in one profile all the articles and keywords related to one misspelledauthor’s name.
Finally, a graph is generated for each selected root author and saved in GEXF format(GraphExchange XML Format), a xml-based format used for describing complex networks structures,their associated data and dynamics. This format is used by the Gephi Project [1], an open sourceplatform for visualization and exploration of networks of all kind and complex systems, includingdynamic and hierarchical graph. Gephi has an API available in Java language that allows us tocompute several measures from a graph written in a GEXF file, which was used in this project.
6 Method
After the data retrieval, data filtering and construction of the graph, a recommendation of thebest classified authors for some user can be generated. As described in Algorithm 1, the processbegins by loading all the nodes in the graph (N) and their betweenness and closeness centralitymeasures. In the following step, all authors publications are considered to obtain the frequency ofnodes keywords. With the keywords frequency evaluated, the cosine similarities between the rootnode and all other nodes in the graph are determined.
The final score is, then, evaluated by computing a convex combination of the three variables:similarity (Sim(n)), betweenness (Cb(n)) and closeness (Cc(n)), each one with its own respectiveweight: S, B and C. Finally, the top-k authors, that do not have scored less than a defined thresholdth, are recommended.
7 Results
In this section, we discuss the results of our experiments. Nine root authors extracted from MASwere used to evaluate the performance of our recommendation system. The selected authors areresearchers from our university department, over multiple areas of research. We conducted the
CLAIO-2016
290

Algorithm 1 Recommendation Algorithm based in influence and similarity
1: function recommend(N,Sim,Cb, Cc, S, C,B, th)2: for all node n ∈ N do3: Score[n]← (Sim[n] ∗ S) + (Cb[n] ∗B) + (Cc[n] ∗ C)4: end for5: Ord←Sorting(Score)6: for j = 1→ N do7: if Score[Ord[j]] < th then8: break9: end if
10: end for11: return Ord[1:min(j,k)]12: end function
experiments by creating two different scenarios. The first scenario has no restriction, resulting ina normal recommendation. The second scenario consists in the elimination of all publications foreach root author, implying that each root author has no publication with his coauthors. In thiscase, the coauthors that only have publications with the root authors were not considered.
The classifier built has a simple heuristic: the final list is composed by authors that had aminimum score in relation to a threshold of the best score. Three thresholds considered were0.5, 0.6 and 0.7. The first scenario is executed considering only the similarity variable. Thesecond scenario is executed with four combinations of the weights similarity (S), Betweenness (B)and Closeness(C), previously presented in Algorithm 1. These combinations are: similarity only(S = 1, B = C = 0), similarity and betweenness (S = B = 0.5, C = 0), similarity and closeness(S = C = 0.5, B = 0) and the three variables combined (S = 0.5, B = 0.25, C = 0.25).
The most popular indexes in the evaluation of a recommendation system are precision, recall andthe F1 metric [4] [10]. The precision stands for the ratio of recommended items that are relevant,for example, a set of movies precision is the number of correct recommended movies divided bythe number of all returned movies. Formally, the precision is defined as follows: precision =|{relevantItens} ∩ {recommendedItens}| / |{recommendedItens}|.
The recall metric stands for the ratio of relevant items that are recommended. In the moviesset example, is the number of correct recommended movies divided by the number of movies thatshould have been recommended. The recall is formally defined as: recall = |{relevantItens} ∩{recommendedItens}| / |{relevantItens}|.
In general, if we increase the size of the recommendation list, there is more possibility ofbeing correct about the user’s interests. Therefore, recall increases but precision decreases. Inorder to average recall and precision, it is used the F1 metric, described as 2 ∗ precision ∗recall / (precision + recall). To evaluate the recommendation’s results, we use these met-rics. Table 1 shows the results with the three different thresholds using similarity only. The authorcolumn shows the respective root author’s id in MAS.
Author 6157727 obtained null results in the tests, since no authors present in the recommen-dation list has reached the threshold of 0.5. Much of the academic publications of this author isnot present at the base of the MAS. For threshold 0.5, many authors have precision values closeor equal to 1, with the exception of the authors 3510228, 23566420 and 9236120. By increasing
CLAIO-2016
291
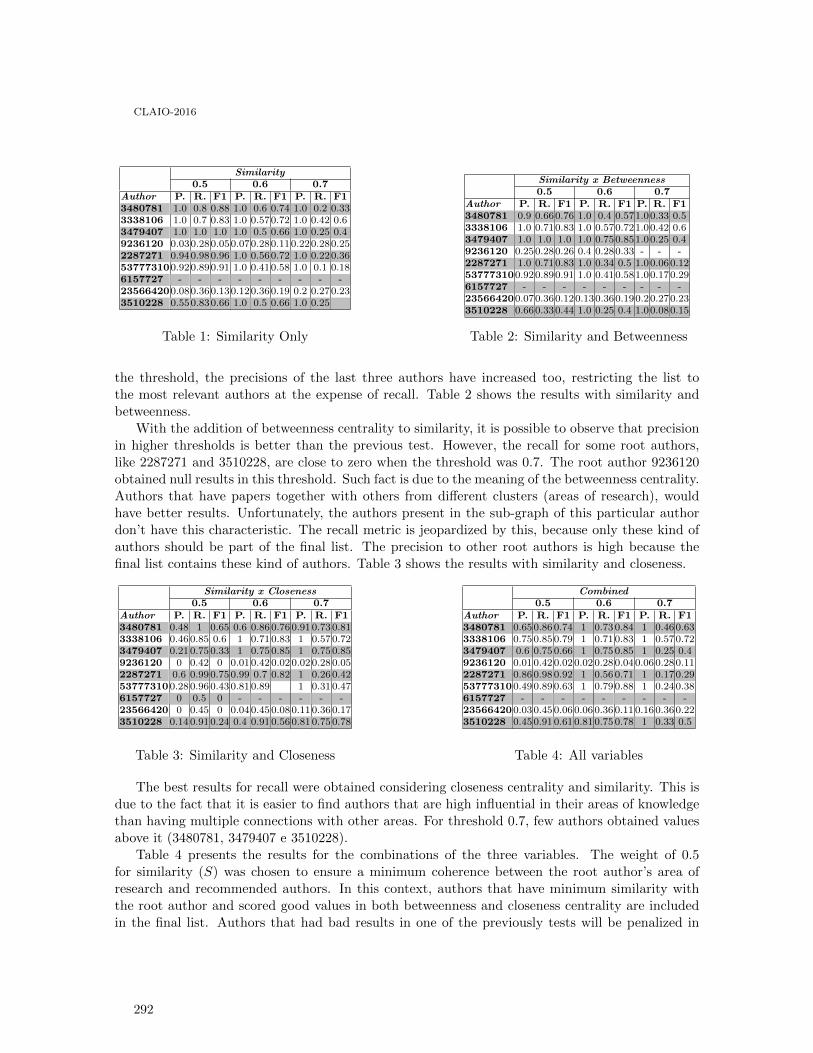
Similarity0.5 0.6 0.7
Author P. R. F1 P. R. F1 P. R. F13480781 1.0 0.8 0.88 1.0 0.6 0.74 1.0 0.2 0.333338106 1.0 0.7 0.83 1.0 0.570.72 1.0 0.42 0.63479407 1.0 1.0 1.0 1.0 0.5 0.66 1.0 0.25 0.49236120 0.030.280.050.070.280.110.220.280.252287271 0.940.980.96 1.0 0.560.72 1.0 0.220.36537773100.920.890.91 1.0 0.410.58 1.0 0.1 0.186157727 - - - - - - - - -235664200.080.360.130.120.360.19 0.2 0.270.233510228 0.550.830.66 1.0 0.5 0.66 1.0 0.25
Table 1: Similarity Only
Similarity x Betweenness0.5 0.6 0.7
Author P. R. F1 P. R. F1 P. R. F13480781 0.9 0.660.76 1.0 0.4 0.571.00.33 0.53338106 1.0 0.710.83 1.0 0.570.721.00.42 0.63479407 1.0 1.0 1.0 1.0 0.750.851.00.25 0.49236120 0.250.280.26 0.4 0.280.33 - - -2287271 1.0 0.710.83 1.0 0.34 0.5 1.00.060.12537773100.920.890.91 1.0 0.410.581.00.170.296157727 - - - - - - - - -235664200.070.360.120.130.360.190.20.270.233510228 0.660.330.44 1.0 0.25 0.4 1.00.080.15
Table 2: Similarity and Betweenness
the threshold, the precisions of the last three authors have increased too, restricting the list tothe most relevant authors at the expense of recall. Table 2 shows the results with similarity andbetweenness.
With the addition of betweenness centrality to similarity, it is possible to observe that precisionin higher thresholds is better than the previous test. However, the recall for some root authors,like 2287271 and 3510228, are close to zero when the threshold was 0.7. The root author 9236120obtained null results in this threshold. Such fact is due to the meaning of the betweenness centrality.Authors that have papers together with others from different clusters (areas of research), wouldhave better results. Unfortunately, the authors present in the sub-graph of this particular authordon’t have this characteristic. The recall metric is jeopardized by this, because only these kind ofauthors should be part of the final list. The precision to other root authors is high because thefinal list contains these kind of authors. Table 3 shows the results with similarity and closeness.
Similarity x Closeness0.5 0.6 0.7
Author P. R. F1 P. R. F1 P. R. F13480781 0.48 1 0.65 0.6 0.860.760.910.730.813338106 0.460.85 0.6 1 0.710.83 1 0.570.723479407 0.210.750.33 1 0.750.85 1 0.750.859236120 0 0.42 0 0.010.420.020.020.280.052287271 0.6 0.990.750.99 0.7 0.82 1 0.260.42537773100.280.960.430.810.89 1 0.310.476157727 0 0.5 0 - - - - - -23566420 0 0.45 0 0.040.450.080.110.360.173510228 0.140.910.24 0.4 0.910.560.810.750.78
Table 3: Similarity and Closeness
Combined0.5 0.6 0.7
Author P. R. F1 P. R. F1 P. R. F13480781 0.650.860.74 1 0.730.84 1 0.460.633338106 0.750.850.79 1 0.710.83 1 0.570.723479407 0.6 0.750.66 1 0.750.85 1 0.25 0.49236120 0.010.420.020.020.280.040.060.280.112287271 0.860.980.92 1 0.560.71 1 0.170.29537773100.490.890.63 1 0.790.88 1 0.240.386157727 - - - - - - - - -235664200.030.450.060.060.360.110.160.360.223510228 0.450.910.610.810.750.78 1 0.33 0.5
Table 4: All variables
The best results for recall were obtained considering closeness centrality and similarity. This isdue to the fact that it is easier to find authors that are high influential in their areas of knowledgethan having multiple connections with other areas. For threshold 0.7, few authors obtained valuesabove it (3480781, 3479407 e 3510228).
Table 4 presents the results for the combinations of the three variables. The weight of 0.5for similarity (S) was chosen to ensure a minimum coherence between the root author’s area ofresearch and recommended authors. In this context, authors that have minimum similarity withthe root author and scored good values in both betweenness and closeness centrality are includedin the final list. Authors that had bad results in one of the previously tests will be penalized in
CLAIO-2016
292

this combination.
8 Conclusion
Social networks are an important part of people’s life, that enables us to communicate and cooperatewith other people sharing the same interests. With the aid of recommendation systems, users mayhave new contacts, discover new interests based on their network connections and also indirectly,can help other people spreading knowledge or experience. The aspect of recommendation systemsin a social network is an important combination to keep the network alive and running.
We presented a hybrid technique for recommendation systems in social networks based onsimilarity and centrality measures. We also presented experiments with a co-authorship networkin order to evaluate the performance of the recommendation system, under different scenarios, byusing the user’s network topology and its content.
By extracting data from the MAS API, we created a database of authors, publications andkeywords, exploring the relationship between co-authors. For each root author, all of his publica-tions are extracted and, from those publications, all of their co-authors, establishing a relationshipbetween them. From this extracted data, a graph of authors’ relationship is generated, in orderto compute the betweenness and closeness centrality measures. The recommended authors are notnecessarily those which have high similarity with the root author. The proposed technique increasesflexibility in data analysis. In order to produce a recommendation, this technique allows to choosea combination of similarity between the actors (based on content) with two types of parameters(betweenness and closeness) that measure the influence of the same actors on the network.
The achieved results were consistent with reality of each one of the root authors. There is nogood or bad results since it is hard to achieve a homogeneous solution starting from a heterogeneouspremise, like the connections of each author. By combining similarity and centrality measures, theusers have the possibility to adjust with more or less intensity, the interests that they are searchingfor.
Future works should focus on the balance between the similarity and the centrality measures,based in each individual coefficient combined with the author specific interest in the recommenda-tion. A machine learning approach could be used in order to define a better weighting factor for aparticular author and general. Also, we should consider the decay through the years of the level ofimportance of the the keywords. The keywords of a publication produced ten years ago can havea different weight from on produced in the last year (the author might have changed his line ofresearch, for instance). All these new questions should be studied and then incorporated to therecommendation process in order to improve our methodology.
References
[1] Mathieu Bastian, Sebastien Heymann, and Mathieu Jacomy. Gephi: An open source softwarefor exploring and manipulating networks. In International AAAI Conference on Weblogs andSocial Media, 2009.
[2] Joan DiMicco, David R. Millen, Werner Geyer, Casey Dugan, Beth Brownholtz, and MichaelMuller. Motivations for social networking at work. In Proceedings of the 2008 ACM Conferenceon Computer Supported Cooperative Work, CSCW ’08, pages 711–720, 2008.
CLAIO-2016
293

[3] Robert A. Hanneman and Mark Riddle. Introduction to social network methods. University ofCalifornia, Riverside, Riverside, CA, 2005.
[4] Dietmar Jannach, Markus Zanker, Alexander Felfernig, and Gerhard Friedrich. RecommenderSystems: An Introduction. Cambridge University Press, New York, NY, USA, 1st edition,2010.
[5] David Liben-Nowell and Jon Kleinberg. The link-prediction problem for social networks. J.Am. Soc. Inf. Sci. Technol., 58(7):1019–1031, May 2007.
[6] Haifeng Liu, Zheng Hu, Hamed Haddadi, and Hui Tian. Hidden link prediction based on nodecentrality and weak ties. EPL, 101(1), 1 2013.
[7] David F. Nettleton. Data mining of social networks represented as graphs. Computer ScienceReview, 7:1 – 34, 2013.
[8] M. E. J. Newman. Scientific collaboration networks. i. network construction and fundamentalresults. Phys. Rev. E, 64:2001, 2001.
[9] Mark Newman. Networks: An Introduction. Oxford University Press, Inc., New York, NY,USA, 2010.
[10] Francesco Ricci, Lior Rokach, and Bracha Shapira. Recommender systems handbook. InRecommender Systems Handbook. Springer, 2011.
[11] John P. Scott and Peter J. Carrington. The SAGE Handbook of Social Network Analysis. SagePublications Ltd., 2011.
[12] Rory Sie. COCOON CORE: CO-author REcommendations Based on Betweenness Centralityand Interest Similarity. PhD thesis, Open Universiteit, 2012.
CLAIO-2016
294

Aplicación de la metodología de las decisiones robustas en la
elección de una cartera de inversiones
Matías Eiletz Grupo GIDESA, Facultad de Ingeniería, Universidad de Buenos Aires
Silvia Adriana Ramos
Grupo GIDESA, Facultad de Ingeniería, Universidad de Buenos Aires [email protected]
Horacio Rojo
Grupo GIDESA, Facultad de Ingeniería, Universidad de Buenos Aires [email protected]
María Alejandra Castellini
Grupo GIDESA, Facultad de Ingeniería, Universidad de Buenos Aires [email protected]
Abstract
En el presente trabajo se busca modelar el proceso de toma de decisiones de un inversor que debe elegir como componer su cartera de inversiones, entre un conjunto de acciones de once empresas, que son las que constituyen el índice MERVAL. Considerando que el objetivo del inversor es maximizar su rentabilidad, esta decisión se encuentra sometida a la incertidumbre del precio futuro de las acciones. Por ello se utiliza la metodología de las decisiones robustas, que busca obtener decisiones que, en lugar de maximizar u optimizar un valor esperado, se comporten lo mejor posible a lo largo de un espectro amplio de futuros probables. Keywords: Decisiones robustas; cartera de inversiones; escenarios. 1 Introducción Una cartera de acciones (o portafolio) es una determinada combinación de acciones en las cuales se invierte. El objetivo de la diversificación es minimizar la exposición al riesgo, lo cual conlleva, generalmente, a una disminución de la rentabilidad. Diversificando la inversión se logra una compensación de pérdidas de determinadas acciones, mediante la ganancia obtenida con otras acciones. De esta forma, se elimina el riesgo de depender de únicamente una empresa. Se busca generalmente combinar las acciones de manera que, cuando una variable macroeconómica afecta negativamente a una compañía, esa misma variable afecte positivamente a la otra compañía de la cual también se poseen acciones. De esta manera, haciendo buenas combinaciones entre varias empresas, se podría disminuir considerablemente el riesgo aumentando lo máximo posible la rentabilidad. Dentro de las teorías de la optimización y balance de portafolios, Harry Markowitz (1952) fue quien llevó a cabo las primeras investigaciones importantes. En su modelo, propone que el inversor aborde la cartera
CLAIO-2016
295

como un todo, estudiando las características de riesgo y retorno global, en lugar de escoger valores individuales en virtud del retorno esperado de cada valor en particular. La teoría de selección de cartera toma en consideración el retorno esperado a largo plazo y la volatilidad esperada en el corto plazo. Según Markowitz, los inversionistas tienen una conducta racional a la hora de seleccionar su cartera de inversión y por lo tanto siempre buscan obtener la máxima rentabilidad sin tener que asumir un alto nivel de riesgo. Su trabajo también expone cómo hacer una cartera óptima disminuyendo el riesgo, de manera que el rendimiento no se vea afectado. Para poder integrar una cartera de inversión equilibrada lo más importante es la diversificación, ya que de esta forma se reduce la el impacto de la variación de los precios. La idea de la cartera según este modelo es, entonces, diversificar las inversiones en diferentes mercados y plazos, para así disminuir las fluctuaciones en la rentabilidad total de la cartera y por lo tanto también el riesgo. Para encontrar el mejor conjunto de inversiones, lo que considera el modelo de Markowitz es por ello tanto la minimización de la varianza del portafolio. Éste y otros enfoques similares, tienen falencias al no considerar la volatilidad de la varianza de los datos tomados en el tiempo. Se toma esa varianza como constante en el tiempo, y eso no es correcto. Otros enfoques más modernos, hacen pronósticos sobre escenarios futuros. Se hacen curvas de predicción, y se busca el resultado que maximiza la renta futura. Un enfoque robusto brinda la posibilidad de tomar decisiones sin hacer predicciones sobre el futuro, sino basándose en información pasada de causa – efecto. Así como en el ámbito agrícola y en otras actividades, malas condiciones externas pueden llevar a grandes pérdidas económicas (aunque en principio haya sido una solución óptima), también sucede en la decisión de elección de una cartera de inversiones. Con un enfoque robusto no se busca por tanto hallar la solución que maximice la ganancia sin importar las condiciones que se puedan dar a futuro, sino que se busca encontrar una solución que brinde ganancias y que sea lo más independiente posible a sucesos externos y no controlables. En otras palabras, resulta necesario el diseño de una metodología de decisión que brinde alternativas robustas, es decir un procedimiento que seleccione estrategias que tengan un resultado aceptable y sean poco vulnerables a la incertidumbre de los escenarios futuros. En la actualidad, con los sistemas informáticos que pueden manejar enormes cantidades de datos, es posible aplicar un enfoque robusto, utilizando conceptos de data mining bajo la metodología de las decisiones robustas, la cual se describirá en el próximo capítulo. 2 Descripción del problema y de la metodología 2.1 Descripción del problema Los mercados de valores son un tipo de mercado de capitales en el que se negocia la renta variable y la renta fija de una forma estructurada, a través de la compraventa de valores negociables. Permite la canalización de capital a medio y largo plazo de los inversores a las empresas. El funcionamiento del mercado de valores actúa en un espacio de negociación entre compradores y vendedores que, en términos financieros, se traduce en empresas e inversionistas. El presente estudio se hizo sobre las acciones que componen el índice Merval del Mercado de Valores de Buenos Aires. Las empresas que participan son: Petrobras (APBR), YPF (YPFD), Grupo Financiero Galicia (GGAL), Tenaris (TS), Siderar (ERAR), Pampa Energía (PAMP), Soc. Comercial del Plata (COME), Aluar (ALUA), Banco Macro (BMA), EDENOR (EDN) y BBVA Banco Francés (FRAN). 2.2 Descripción de la metodología En los problemas de toma de decisiones respecto a un futuro donde los sucesos son difíciles de predecir con exactitud, existe un riesgo asociado a la decisión tomada. Actualmente, dado el avance de la
CLAIO-2016
296

tecnología y la capacidad creciente de procesar gran cantidad de información, ha surgido en el ámbito académico un método alternativo para la toma de decisiones en un contexto de incertidumbre. Ese método se denomina “Metodología de Decisiones Robustas” (MDR) y busca tomar buenas decisiones sin hacer predicciones sobre el futuro. En efecto, la MDR asume el desconocimiento de probabilidades de ocurrencias futuras, y a partir de datos históricos, desarrolla estrategias cuyo mejor resultado sea aceptable para la mayor parte de los escenarios posibles. Es decir, en lugar de utilizar modelos computacionales y datos para estimar el futuro y luego tomar la mejor decisión, el MDR ejecuta modelos de muchos escenarios posibles (de cientos a miles) para describir cómo actúan las estrategias en un vasto número de futuros plausibles. Con la información obtenida, se identifica, se evalúa y se eligen estrategias robustas, esto es, las estrategias que mejor se desempeñan en un amplio espectro de futuros posibles o las estrategias más insensibles a diversos cambios que puedan surgir. Según Lempert (2007) (uno de los “padres” de esta metodología), “la MDR es un procedimiento de decisión analítico e iterativo que ayuda a identificar estrategias robustas candidatas, caracterizar sus vulnerabilidades y evaluar otras alternativas que sean más sólidas cuando las candidatas sean vulnerables”.
Lempert divide la metodología en una serie de etapas:
1) Generación y definición de estrategias: Siendo el portafolio una unidad, esta puede ser fragmentada en tantas partes como el inversor quiera. Las diferentes estrategias consisten en elegir qué porcentaje de cada acción habrá en el portafolio. Al aplicar la MDR, se debe definir con anterioridad a empezar el estudio, de cuánto será la fragmentación y cuántas acciones distintas hay para adquirir. Sabiendo estos dos factores, se puede saber exactamente cuántas estrategias habrá mediante cálculos de combinatoria. Un término empleado al hablar de la fragmentación del portafolio, es el de “granularidad”. Cuanto mayor sea la granularidad, en mayores partes podrá estar dividido el portafolio y este tendrá mayores posibilidades de combinación. 2) Generación y definición de escenarios:
Cada escenario está definido por un momento determinado de un período de tiempo. Cada escenario, además de estar caracterizado por el valor de cotización de determinadas acciones en ese momento, está descripto por una serie de factores o variables macroeconómicas, las cuales se sospecha que pueden llegar a influir en la cotización de las mismas acciones. 3) Evaluación de las estrategias en los escenarios:
Una vez definidos las estrategias y los escenarios, se procede a observar el comportamiento de cada estrategia en cada uno de los escenarios. En este punto, es importante destacar que para hacer posible la evaluación, no se tomarán los valores absolutos de las variables en cada uno de los escenarios. Por el contrario, se tendrán en cuenta las variaciones respecto a sus valores en el período inmediatamente anterior. Por lo tanto, el escenario “i” va a estar finalmente representado por la tasa de cambio respecto al escenario “i-1”. Se utiliza este método para poder relacionar el aumento o disminución del rendimiento de la estrategia, con la tasa de cambio de cada una de las variables. Si se tomaran valores absolutos, esto no sería posible. A partir del análisis de estas variaciones, es que se construirá luego el árbol de decisiones y se identificarán “escenarios vulnerables”. Al evaluarse entonces cada estrategia en cada escenario, se podrá obtener un histograma de rendimiento por cada estrategia. 4) Evaluación de los rendimientos y elección de estrategia candidata:
Una vez obtenidos los histogramas de todas las estrategias, se pueden elegir muchos criterios para elegir a priori la mejor estrategia. Uno de ellos podría ser, por ejemplo, escoger la estrategia cuya distribución tenga la mayor media. Otro criterio podría ser elegir la estrategia de mayor mediana, o aún otro, elegir la estrategia que haya obtenido el mayor valor de rendimiento. Una propuesta interesante es obtener
CLAIO-2016
297

valores de percentiles bajos de la distribución, lo cual conlleva a ganar en robustez. Por ejemplo, el valor del percentil 30. Si este valor es mayor a cero, permite asegurar que el 70% de las veces, la estrategia tiene rendimiento positivo, y que solamente el 30%, el rendimiento es menor. Por lo tanto este es un criterio robusto; sabemos que la estrategia tiene falencias en un pequeño número de ocasiones. Otra métrica de análisis es la de Expected Shortfall (CVaR). En este criterio, el CVaR, es un valor en el cual se refleja cuánta es la perdida una vez que se supera el percentil 5. Es decir, suponiendo que tenemos un valor a la izquierda de la distribución (5% del área total), cuál es el valor más probable allí. 5) Identificación de escenarios vulnerables:
A partir de la estrategia candidata inicialmente elegida, se obtienen los escenarios vulnerables. Se le da ese nombre a aquellos escenarios en los que el rendimiento de la estrategia candidata fue menor al valor del criterio elegido como métrica robusta. 6) Búsqueda de estrategias que se comporten mejor que la candidata en los escenarios vulnerables:
Una vez divididos los escenarios entre buenos y malos, se procede a formular un gráfico en el cual saldrá como resultado una frontera de preferencias. 7) Evaluar la conveniencia de otra estrategia:
En este último paso se evalúa la conveniencia de otras estrategias, más allá de la elegida inicialmente como candidata. Es aquí donde se evalúan algunas o todas las preguntas planteadas en el paso anterior, y finalmente, se termina optando por una u otra estrategia. El proceso puede ser iterativo. Sin embargo, habrá patrones observables que harán que el inversor pueda sacar conclusiones en un número no muy grande de iteraciones.
3 Aplicación de la metodología de las decisiones robustas al armado de una cartera de
acciones en el Merval 3.1 Estrategias, escenarios y sus combinaciones Las estrategias estarán compuestas por las 11 (once) acciones que componen el índice Merval que, como se ha nombrado en 2.1., son: Petrobras (APBR), YPF (YPFD), Grupo Financiero Galicia (GGAL), Tenaris (TS), Siderar (ERAR), Pampa Energía (PAMP), Soc. Comercial del Plata (COME), Aluar (ALUA), Banco Macro (BMA), EDENOR (EDN) y BBVA Banco Francés (FRAN). En el armado del portafolio robusto, buscando la diversificación del mismo, habrá primero que decidir cuál será la granularidad. En este trabajo se optó por una granularidad del 25%. Siendo 11 acciones para elegir y además estando la posibilidad de no invertir en las porciones de la cartera, las combinaciones arrojan un total de 1365 estrategias. En el caso de elegir una granularidad mayor, la cantidad de combinaciones haría prácticamente inmanejable al estudio. El periodo de tiempo tenido en cuenta en este estudio es de un poco más de 5 (cinco) años. Más exactamente, el estudio toma desde el mes de enero de 2010 hasta marzo de 2015. La cantidad de escenarios, luego, queda definida por los horizontes de tiempo que se tomen (diarios, semanales, mensuales, trimestrales, etc.) En este estudio se decidió tomar escenarios mensuales, por lo que cinco años y dos meses dan como resultado 62 escenarios. El horizonte de tiempo mensual es adecuado para medir las variaciones de rendimientos mes a mes, y también medir en ese período de tiempo la variación de los factores que caracterizan los escenarios. Mediante esos factores será como se describirán los escenarios vulnerables y los favorables. Los factores que se miden y analizan en este estudio, caracterizando a los escenarios, son: el valor del dólar, del real, el índice de precios al consumidor (“IPC”, representa la inflación) y el precio de las siguientes commodities: petróleo, soja, aceite de girasol, cebada, maíz, sorgo, trigo, naranja, carne vacuna, carne de pollo, azúcar, algodón, aluminio, hierro, cobre, plomo, estaño, níquel, zinc, oro, platino y plata.
CLAIO-2016
298

Luego de definir las estrategias y los escenarios, estos deberán combinarse de manera de generar los histogramas a partir de los cuales se obtendrá el parámetro robusto de cada uno de ellos. Con 1365 estrategias y 62 escenarios, cuando estos se multiplican (ya que se analiza cada estrategia en cada uno de los escenarios), se obtienen 83265 rendimientos distintos. En un principio, la métrica elegida para el análisis fue el de percentil 30 (p30). Fue elegido este criterio puesto que es un valor bajo de percentil, lo cual lo hace robusto, pero no lo suficientemente bajo para tener solo resultados negativos de percentiles (lo cual entorpecería el estudio). A partir del p33, ya hay un margen de suficientes resultados de percentiles positivos para luego trabajar con mayor comodidad eligiendo distintos valores en el análisis final de la frontera de preferencias. Esto se muestra mejor en la tabla No 1, en la cual se indica la posición del valor de percentil nulo para cada percentil:
p30 p31 p32 p33 p34 p35 3 4 6 15 34 72
Podría decirse que a menor valor de percentil, salen estrategias más robustas, puesto que tienen un mejor comportamiento en una mayor cantidad de escenarios. Sin embargo, entre buen comportamiento en el 70% de los escenarios y en el 65% de escenarios, no hay una gran diferencia. Por eso el análisis luego se seguirá con la frontera de preferencias y no solo con este criterio, que se usa en principio para elegir la estrategia con la cual se iniciará luego el análisis en la frontera de preferencias. Se optó en este caso, hacer el análisis con el criterio de p34 puesto que en sus primeros valores, incluye estrategias que están presentes en casi todos los otros percentiles. Por ejemplo, incluye la estrategia 900, la 901 y la 1010. Y, además, tiene un margen suficiente de estrategias por encima de la estrategia nula (1365), que es la que consiste en no invertir. 3.2 Primeras estrategias robustas Una vez elegida la métrica, empieza a hacerse el análisis centrado en ese criterio. Esto significa que el árbol de decisiones se hará en torno a la “mejor estrategia elegida (a priori) por el criterio elegido (p34)”. Lo mismo se hace con la frontera de preferencias. Como se muestra en la tabla No 2, la mejor estrategia es, a priori, la n° 678.
Estr. 678 901 971 77 888 977 889 900 694 1010 Valor p 0,00934 0,0089 0,00874 0,00858 0,00838 0,00825 0,00658 0,00585 0,00534 0,00529
Por lo tanto, en principio se toma como que la estrategia con más robustez es la número 678, y los análisis de árboles de decisión y de frontera de preferencias, se harán en un principio alrededor de esta estrategia, como vemos en el Gráfico N° 1.
Tabla N°1
Tabla N°2
CLAIO-2016
299
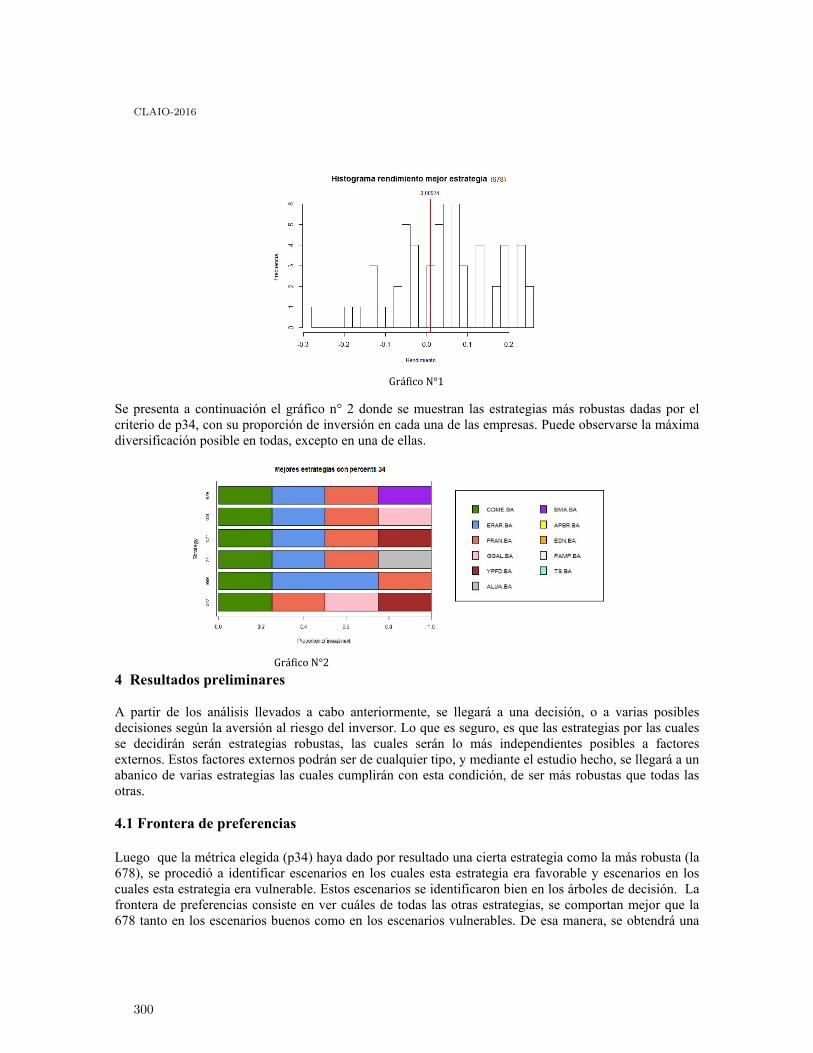
Se presenta a continuación el gráfico n° 2 donde se muestran las estrategias más robustas dadas por el criterio de p34, con su proporción de inversión en cada una de las empresas. Puede observarse la máxima diversificación posible en todas, excepto en una de ellas.
4 Resultados preliminares A partir de los análisis llevados a cabo anteriormente, se llegará a una decisión, o a varias posibles decisiones según la aversión al riesgo del inversor. Lo que es seguro, es que las estrategias por las cuales se decidirán serán estrategias robustas, las cuales serán lo más independientes posibles a factores externos. Estos factores externos podrán ser de cualquier tipo, y mediante el estudio hecho, se llegará a un abanico de varias estrategias las cuales cumplirán con esta condición, de ser más robustas que todas las otras.
4.1 Frontera de preferencias
Luego que la métrica elegida (p34) haya dado por resultado una cierta estrategia como la más robusta (la 678), se procedió a identificar escenarios en los cuales esta estrategia era favorable y escenarios en los cuales esta estrategia era vulnerable. Estos escenarios se identificaron bien en los árboles de decisión. La frontera de preferencias consiste en ver cuáles de todas las otras estrategias, se comportan mejor que la 678 tanto en los escenarios buenos como en los escenarios vulnerables. De esa manera, se obtendrá una
Gráfico N°1
Gráfico N°2
CLAIO-2016
300
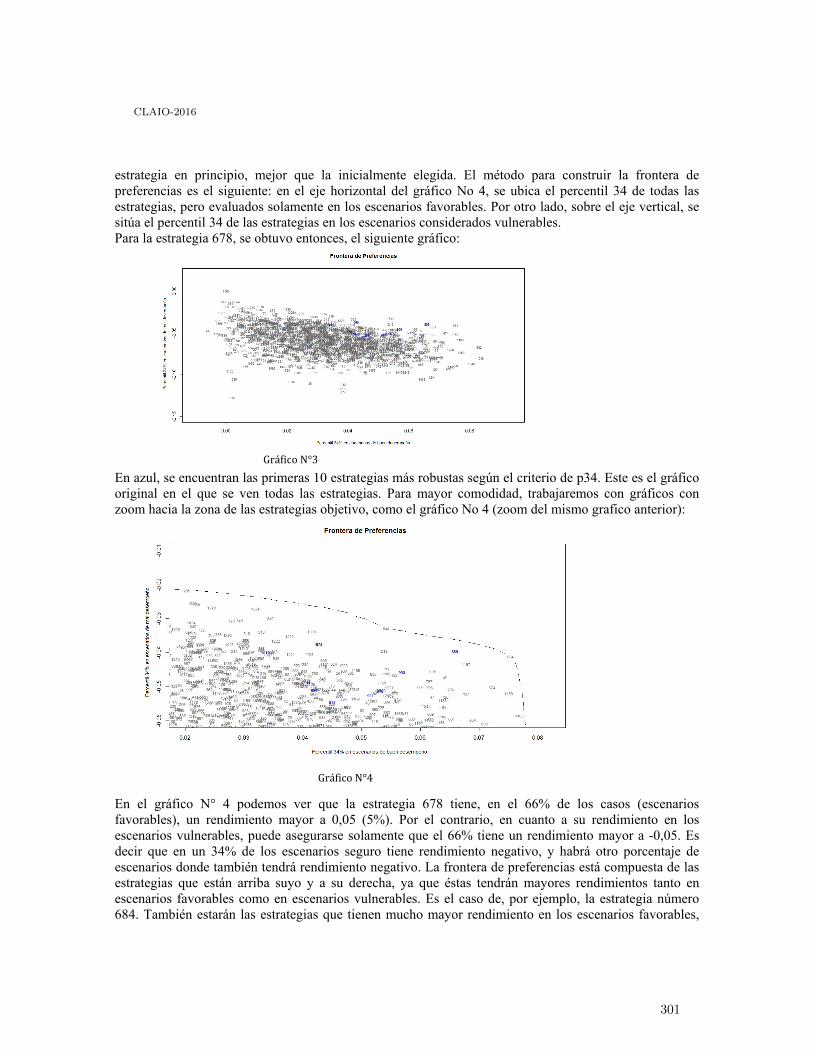
estrategia en principio, mejor que la inicialmente elegida. El método para construir la frontera de preferencias es el siguiente: en el eje horizontal del gráfico No 4, se ubica el percentil 34 de todas las estrategias, pero evaluados solamente en los escenarios favorables. Por otro lado, sobre el eje vertical, se sitúa el percentil 34 de las estrategias en los escenarios considerados vulnerables. Para la estrategia 678, se obtuvo entonces, el siguiente gráfico:
En azul, se encuentran las primeras 10 estrategias más robustas según el criterio de p34. Este es el gráfico original en el que se ven todas las estrategias. Para mayor comodidad, trabajaremos con gráficos con zoom hacia la zona de las estrategias objetivo, como el gráfico No 4 (zoom del mismo grafico anterior):
En el gráfico N° 4 podemos ver que la estrategia 678 tiene, en el 66% de los casos (escenarios favorables), un rendimiento mayor a 0,05 (5%). Por el contrario, en cuanto a su rendimiento en los escenarios vulnerables, puede asegurarse solamente que el 66% tiene un rendimiento mayor a -0,05. Es decir que en un 34% de los escenarios seguro tiene rendimiento negativo, y habrá otro porcentaje de escenarios donde también tendrá rendimiento negativo. La frontera de preferencias está compuesta de las estrategias que están arriba suyo y a su derecha, ya que éstas tendrán mayores rendimientos tanto en escenarios favorables como en escenarios vulnerables. Es el caso de, por ejemplo, la estrategia número 684. También estarán las estrategias que tienen mucho mayor rendimiento en los escenarios favorables,
Gráfico N°3
Gráfico N°4
CLAIO-2016
301

resignando un poco de rendimiento en los escenarios malos, como la estrategia 1163. Y por último también formarán parte las estrategias que tienen un menor rendimiento en los escenarios buenos, pero tienen un mucho mejor rendimiento en los escenarios desfavorables. Este es el caso de la estrategia 1295. Observando la frontera de preferencias, entonces, el inversor puede decidir por una estrategia u otra. Un inversor conservador, por ejemplo, podrá elegir la nª 1295, donde hay poco rendimiento en los escenarios favorables, pero no hay muy mal rendimiento en los escenarios malos. Un inversor más arriesgado, podrá optar por la 1163 y uno intermedio, la 684. 4.2 Conclusiones obtenidas A partir de diversos métodos de análisis, finalmente se llega a un estadío en donde no hay una sola estrategia o decisión correcta a tomar, sino que se forma un abanico de posibilidades. En éste, se encuentran diferentes posibilidades, y se puede llegar a un conocimiento profundo de cada una de ellas según cada uno de los métodos utilizados. Gracias a esto, el inversor puede decidir con cual quedarse. Inicialmente, según la métrica utilizada, surgen unas primeras estrategias candidatas, las cuales ya pueden considerarse robustas debido precisamente a la métrica. Luego, se escoge la primera de ellas y se identifican escenarios buenos y malos, construyéndose a partir de ellos, los árboles de decisiones y luego la frontera de preferencias. A la vez de esto, también puede analizarse cómo está correlacionada la estrategia con las variables extrernas elegidas para la caracterización de los escenarios. Existirán variables que poco habrán influido en el comportamiento de la estrategia a lo largo del tiempo evaluado, y variables que sí lo han hecho. De éstas, se espera que en periodos siguientes también lo hagan. Mirando luego la frontera de preferencias, se observa cuáles son las estrategias que se comportan mejor tanto en sus escenarios buenos como en escenarios malos. Si estas estrategias han resultado anteriormente robustas según la métrica utilizada, mucho mejor. En este período, se puede elegir una estrategia y construir a partir de ella una nueva frontera de preferencias, haciendo este paso infinitas veces. Aquí es cuando se pasan a considerar nuevamente los percentiles y, para un mejor análisis, las distribuciones de percentiles. Aquí, podrían evaluarse las estrategias según otras métricas mencionadas, como el Omega Ratio o el Valor en Riesgo (CVar). Teniendo todos estos factores en consideración, es que el inversor elige la estrategia más acorde a sus preferencias.
Referencias 1. H. Markowitz Portfolio Selection. The Journal of Finance 7 (1): 77–91., 1952
2. R. J. Lempert, and M. T. Collins. Managing the Risk of Uncertain Threshold Responses: Comparison of
Robust, Optimum, and Precautionary Approaches. Risk Anal, 2007.
3. J.W. Hall, R.J. Lempert, K. Keller, A. Hackbartg, C. Mijere and D.J. McInerney. Robust Climate Policies
Under Uncertainty: A Comparison of Robust Decision Making and Info‐Gap Methods. Risk Analysis, 32(10),
1657-1672. (2012).
CLAIO-2016
302

The minimum chromatic violation problem: a
polyhedral approach ∗
M. S. EscalanteFCEIA, Universidad Nacional de Rosario, Argentina - CONICET, Argentina
M. E. UgarteFCEIA, Universidad Nacional de Rosario, Argentina
M.C. VaraldoFCEIA, Universidad Nacional de Rosario, Argentina
Abstract
In this contribution we analyze the problem of finding a vertex coloring of a graph with theadditional property that there are a fixed set of edges whose endpoint can have the same color.We say that these edges can be violated with respect to the usual property of coloring in a graph.We present an integer programming formulation of this problem and begin with the study ofthe convex hull of integer solutions in it. These formulation involves the standard constraintsfor coloring in a graph and therefore we are forced to study this polytope for the families ofgraphs herein considered. We obtain the dimension, the minimum inequality system and someexponentially sized group of valid inequalities that we strongly believe suffice to describe thechromatic violation polytope for small instances of complete graphs with one violable edge.
Keywords: graph coloring; violation; valid inequalities.
1 Introduction
In this contribution we consider a coloring problem. Let G = (V,E) be a graph, F ⊂ E a fixedsubset of edges and C be a finite set of colors. We say that a function defined on V is a semi-coloringif it is a coloring of G \ F (in fact, it can assign the same color to the extreme points of the edgesof F ). Due to the fact that the usual restriction for coloring is not imposed to the edges in Fthey are called violable edges. Given a semi-coloring φ, ν(G,F, C, φ) is the chromatic violation ofφ, i.e., the number of edges in F whose endpoints share the same color. The minimum chromaticviolation problem (MCVP) on a graph G and a set of violable edges F consists then, on finding asemi-coloring φ with minimum ν(G,F, C, φ). This problem is clearly NP-hard since it generalizesthe standard vertex coloring problem in a graph (Karp [6]). For a survey on coloring, see [7].
∗Partially supported by grant PID UNR 390
CLAIO-2016
303

As far as we know there is no previous study of this problem and therefore our main purposeis to initiate it by means of linear programming and polyhedral tools. We first present a formu-lation based on the standard vertex coloring problem, introducing as many extra binary variablesas violable edges in the graph. In [4, 5] and [1, 2], the authors analyze two different 0 − 1 in-teger programming models for the vertex coloring problem, the standard and the representativeformulations, respectively.
We consider the feasible region of this linear program and we begin the usual polyhedral analysisof it. In order to better understand this polytope we pursue families of valid inequalities involvingthe new variables introduced in this model. Then, we focus on a particular family of graphs whichare present in most of the exponentially sized families of valid inequalities found herein. For thisfamily of graphs we distinguish between two different types of constraints: those associated withthe coloring polytope and those where the new variables appear.
Given i ∈ V and c ∈ C let xic be a binary variable such that xic = 1 if i is assigned color c andxic = 0 otherwise. We also consider the binary variable z{i,j} for each {i, j} ∈ F where z{i,j} = 1 ifthe nodes i and j have the same color, and z{i,j} = 0 otherwise. In this setting the MCVP can beformulated as minimizing
∑{i,j}∈F z{i,j} subject to the following constraints:
∑
c∈Cxic = 1 i ∈ V, (1.1)
xic + xjc ≤ 1 {i, j} ∈ E \ F, c ∈ C, (1.2)
xic + xjc − z{i,j} ≤ 1 {i, j} ∈ F, c ∈ C, (1.3)
xic ∈ {0, 1} i ∈ V, c ∈ C, (1.4)
z{i,j} ∈ {0, 1} {i, j} ∈ F. (1.5)
The first two constraints assert that every node must be colored by exactly one color and thatadjacent nodes must have different colors, the usual constraints corresponding to vertex coloringbut in G \ F for (1.2).
Constraints (1.3) connect the two sets of binary variables and force z{i,j} = 1 when the nodes iand j have the same color. We refer to the constraints (1.4)-(1.5) as boolean constraints.
Since our purpose is the polyhedral study of this problem, for a given graph G = (V,E),a set F ⊂ E and a finite number of colors C, we define the chromatic violation polytope of G,PCV (G,F, C) ⊂ R|V ||C|+|F |, as the convex hull of feasible solutions of points (x, z) satisfying (1.1)-(1.5).
Let us first determine its dimension and a minimal equation system. Due to space requirements,we omit some of the proofs of our results.
Lema 1.1. If |C| > χ (G \ F ) then the dimension of PCV (G,F, C) is
|V | (|C| − 1) + |F | .
In the sequel, we consider the graph G = (V,E), F ⊂ E the set of violable edges and C the setof available colors. Also, we simply write PCV (G) instead of PCV (G,F, C) or PCV (G,F ) when thesets F and/or C are clear from the context.
Let us recall that a clique is a set of nodes inducing a complete graph and we denote by Kr thecomplete graph of r nodes.
CLAIO-2016
304

Proposition 1.2. If |C| > χ (G \ F ) then:
1. For {i, j} ∈ E \F and c ∈ C, the constraints (1.2) define facets of PCV (G) if and only if {i, j}is a maximal clique in G.
2. For i ∈ V and c ∈ C, xic ≥ 0 defines a facet of PCV (G), whereas xic ≤ 1 does not induce afacet of PCV (G) in general.
3. For {i, j} ∈ F , the constraint z{i,j} ≤ 1 induces a facet of PCV (G), whereas z{i,j} ≥ 0 doesnot induce a facet of PCV (G) in general.
Let us now begin our study of some new inequalities valid for PCV (G). For simplicity wewrite λx + µz ≤ λ0 for the constraint
∑i∈V,c∈C λicxic +
∑{i,j}∈F µijz{i,j} ≤ λ0, valid for PCV (G).
Moreover, we can also refer to it as (λ, µ, λ0). Given a valid inequality (λ, µ, λ0) for PCV (G), itssupport graph GS(λ) is the subgraph of G induced by the nodes in {i ∈ V : λic 6= 0 for some c ∈ C}.Under this notation we can easily observe that:
Remark 1.3. If (λ, µ, λ0) is a valid inequality for PCV (GS(λ)) then it is also valid for PCV (G).
Let PC(G, C) be the coloring polytope associated with the graph G = (V,E) and the set ofcolors C, i.e., the convex hull of 0− 1 solutions satisfying
∑
c∈Cxic = 1 i ∈ V, (1.6)
xic + xjc ≤ 1 {i, j} ∈ E, c ∈ C, (1.7)
Let us point out that, as far as we know, there is no complete characterization of PC(G, C) evenfor simple and small graphs, except for trees and block graphs (see [4] and [5]). Clearly, there is astrong relationship between the chromatic violation polytope and the coloring polytope.
Remark 1.4. Every valid inequality for PC(G \F ) is also valid for PCV (G,F ). In particular, thisholds for the clique inequality,
∑i∈Q xic ≤ 1, where Q is a clique in G \ F and c ∈ C.
In order to simplify the notation, if G′ is a node induced subgraph of G and T a subset of edgesof G, we write G′ ∩ T to indicate the set of edges of G′ that also belong to T .
If Q is a maximal clique in G of size r inducing Kr such that Kr ∩ F = {{j, k}}, then∑
i∈Qxic − z{j,k} ≤ 1 (1.8)
is called a semiclique inequality associated with c ∈ C.Theorem 1.5. The semiclique inequality (1.8) is valid for PCV (G). Moreover, if |C| > χ (G \ F )+1it also defines a facet of PCV (G).
Note that the semiclique inequality (1.8) is stronger than (1.3) when {j, k} ( Q.If Q is a maximal clique in G of size r inducing Kr such that Kr ∩F = {{j, k}} and ∅ 6= M ⊂ C
then ∑
i∈Q
∑
c∈Mxic − z{j,k} ≤ |M | (1.9)
is called an M -semiclique inequality.
CLAIO-2016
305

Theorem 1.6. The M -semiclique inequality (1.9) is valid for PCV (G).
Proof. Let M be a subset of colors, (x, z) be an integer extreme point of PCV (G) and e = {j, k}.We consider the following possible situations:
Case 1 : If (x, z) is such that j and k are colored with different colors, then∑i∈Q
xic ≤ 1 for every
c. Therefore, ∑
c∈M
∑
i∈Qxic ≤ |M |,
and then, the inequality holds either if ze = 0 or ze = 1.Case 2: Let (x, z) be such that j and k are colored with the same color d ∈ C.If d ∈M then ∑
c∈M
∑
i∈Qxic ≤ |M |+ 1 = |M |+ ze.
On the other hand, if d /∈M∑
c∈M
∑
i∈Qxic ≤ |M | ≤ |M |+ ze.
Moreover, the following family of inequalities generalizes the one introduced in (1.8).Let Q be a maximal clique in G of size r inducing Kr such that Kr∩F = {{j, k}}, U ⊂ Q\{j, k},
A ⊂ C and M ⊂ C \A then
∑
i∈Q\U
(∑
c∈Axic −
∑
d∈Mxid
)+ 2
∑
i∈U
∑
c∈Axic − z{j,k} ≤ 2|A| − 1 (1.10)
is called a (U,A,M)-semiclique inequality.
Theorem 1.7. The (U,A,M)-semiclique inequality (1.10) is valid for PCV (G) if |M | ≥ |Q|− |C|+|U | − |A|+ 1.
Proof. For fixed sets U , A and M , let us rewrite the inequality as follows:
∑
i∈Q
∑
c∈Axic +
∑
i∈U
∑
c∈Axic −
∑
i∈Q\U
∑
d∈Mxid − z{j,k} ≤ 2|A| − 1. (1.11)
In order to prove its validity we can restrict ourselves to the integer extreme points (x, z) ofPCV (G). We consider the following cases:
Case 1 : If (x, z) is such that all the colors in A are used in U (i.e., for every c ∈ A there isi ∈ U such that xic = 1) then
∑
i∈Q
∑
c∈Axic =
∑
i∈U
∑
c∈Axic = |A|
Furthermore, as |Q| − |U | ≥ |C| − |A| − |M |+ 1, either at least one color of M must be used inQ \ U , or j and k must be assigned the same color. Then
CLAIO-2016
306

∑
i∈Q\U
∑
d∈Mxid + z{j,k} ≥ 1
and therefore, (1.11) is satisfied.Case 2 : If (x, z) is a solution such that there is a proper subset of colors in A assigned to nodes
in U , say A1, and A2 = A \ A1 is the set of colors of A assigned elsewhere, we consider differentsituations. For instance, if j and k have the same color in A2, then
(LHS) ≤ |A|+ 1 + |A1| −∑
i∈Q\U
∑
d∈Mxid − 1 = 2 |A| −
∑
i∈Q\U
∑
d∈Mxid + |A2|
where (LHS) is the left-hand-side of (1.11). Since A2 6= ∅, the inequality (1.11) holds.A similar analysis can be done when j and k have the same color but not in A2, or when j and
k do not have the same color. In this last case, it is enough to consider z{j,k} = 0.
Note that the strongest (U,A,M)-semiclique inequalities are those satisfying |M | = |Q| − |C|+|U | − |A| + 1. Since this is an exponentially sized family of valid inequalities it makes sense toanalyze the separation problem associated with it. In fact, even for the extreme cases of U = ∅ orU = Q \ {j, k}, the inequalities happen to cut fractional extreme points. In this line, we have thefollowing.
Lema 1.8. Let |C| = |V |. Then the (U,A,M)-semiclique inequalities can be separated in polynomialtime for U = Q \ {j, k} and every A ⊂ C, M ⊂ C \A such that |M | = |Q| − |C|+ |U | − |A|+ 1.
Proof. Given a point (x, z) satisfying the restrictions (1.1)-(1.3), the clique constraints and therelaxed integrality constraints to the interval [0, 1] we have to check, in polynomial time, if itviolates a (U,A,M)-semiclique inequality satisfying the the hypothesis.
Clearly, it is enough to consider |Q| = |C| and since Q \ {j, k} we have that |M |+ |A| = |C| − 1.Using these facts, we rewrite the constraint (1.10) as follows:
2∑
c∈A
∑
i∈Qxic − ze ≤ 2|A| − 1 +
∑
c∈(A∪M)
(xjc + xkc) (1.12)
Let {c̃} = C\(A∪M) and using (1.1) we have that∑
c∈(A∪M)(xjc+xkc) = 2−(xjc̃+xkc̃). Replacingthis equality in (1.12) we have that the constraint (1.10) is equivalent to
∑
c∈A
∑
i∈Q(xic − 1) ≤ 1
2(1− (xjc̃ + xkc̃ − xe)) (1.13)
Clearly, we can separate this inequality in polynomial time as follows. For every c̃ ∈ C we orderthe positive terms
∑i∈Q(xic − 1) increasingly for c 6= c̃. We define the set A accordingly summing
up those positive terms until the constraint is violated.
The next result relates the facet defining inequalities of the vertex coloring polytope with theones defining the chromatic violation polytope when |F | = 1 in a general graph G.
CLAIO-2016
307

Theorem 1.9. Let F be the set of violable edges satisfying |F | = 1 and λx ≤ λ0 be a valid inequalityfor PCV (G,F ) different from the boolean constraints. Then, λx ≤ λ0 defines a facet of PCV (G,F )if and only if it defines a facet of PC(G \ F ).
Proof. Since |F | = 1, we can write (x, z) ∈ R|C||V | × R to indicate the points in PCV (G,F ).Let us first assume that λx ≤ λ0 defines a facet of PCV (G,F ). If x ∈ PC(G \ F ) it satisfies the
constraints (1.1)-(1.2) and then (x, 1) ∈ PCV (G,F ). Then, λx ≤ λ0 is valid for PC(G \ F ).Let m = |V |(|C| − 1) + 1 be the dimension of PCV (G,F ). Since the constraint is facet defining
there are m + 1 affinely independent points (x, z) ∈ PCV (G,F ) satisfying it at equality. Since|F | = 1 it is clear that at most two of them can have the same projection onto the x-variables.Moreover, all these projections belong to PC(G \ F ) thus having m affinely independent points inPC(G \ F ) satisfying the constraint at equality. This proves that it defines a facet of PC(G \ F ).
To see the converse, assume that λx ≤ λ0 defines a facet of PC(G\F ). Since (x, z) ∈ PCV (G,F )implies that x ∈ PC(G \ F ), the inequality is valid for PCV (G,F ).
As before, if m = |V |(|C| − 1) + 1, there are m affinely independent roots in PC(G \ F ), sayx1, . . . , xm. Since the inequality is a facet there must be at least one of them, say x̂, having differentcolor in j and k (otherwise the polyhedron would be contained in xjc = xkc = 1 for some c). Then,(x1, 1), . . . , (xm, 1), (x̂, 0) are affinely independent points, they belong to PCV (G,F ) and satisfy theconstraint at equality.
According to the previous results, the complete graphs having only one violable edge play animportant role in the description of the chromatic violation polytope. In this line, when |F | = 1,we consider Gn = Kn \ F that is, the complete graph of n nodes where a single edge is removed.We refer to this graph as the n-semiclique graph Gn (cf. Remark 1.4).
2 The chromatic violation polytope for complete graphs
Taking Theorem 1.9 into account, we have that the facet defining inequalities for PCV (Kn, F ) with|F | = 1, can be partitioned into those having nonzero z-coefficient and the facet defining inequalitiesdescribing PC(Gn). In the previous section we found some of the former valid inequalities forPCV (Kn, F ) (taking Q = V in theorems 1.5, 1.6 and 1.7). However, PC(Gn) is not completelydescribed in the literature.
In this line, we present two families of valid inequalities for the coloring polytope of Gn. In thesequel, consider Q = V = {1, . . . , n} and F = {{n− 1, n}}.
Let H be a proper subset of Q \ {n− 1, n} inducing the complete graph Kh (i.e. h = |H|). LetQ1 = H ∪ {n− 1} and Q2 = H ∪ {n}. If C1, C2 and C3 are pairwise disjoint nonempty color setssatisfying |C1 ∪ C2| = h+ 1 and |C1 ∪ C2 ∪ C3| ≤ n− 1. Then
∑
i∈Q1
∑
d∈C1
xid +∑
i∈Q2
∑
d∈C2
xid +∑
i∈Q
∑
d∈C3
xid ≤ |C1 ∪ C2 ∪ C3| (2.1)
is called a (H,C1, C2, C3)-inequality.
Theorem 2.1. The (H,C1, C2, C3)-inequality is valid for the coloring polytope PC(Gn) for n ≥ 4.
CLAIO-2016
308

Let H be a proper subset of Q\{n−1, n} inducing the complete graph Kh. Let Q1 = H∪{n−1}and Q2 = H ∪ {n}. Let H ′ be a proper subset of H and Q′1 = H ′ ∪ {n− 1} and Q′2 = H ′ ∪ {n}. IfD = (d1, . . . , d4) is a 4-tupla of different colors of C, then
∑
i∈Q1
xid1 +∑
i∈Q2
xid2 +∑
i∈Q′1
xid1 +∑
i∈Q′2
xid2 +∑
i∈(Q1∪Q2)
xid3 + 2∑
i∈Qxid4 ≤ 7
(2.2)
is called a (H,H ′, D)-inequality.
Theorem 2.2. The (H,H ′, D)-inequality is valid for the coloring polytope PC(Gn) for n ≥ 5.
3 Example
The main purpose of this section is to identify some of the inequalities introduced in this contribu-tion for PCV (K5, F ) and |F | = 1. All the facets were obtained by using PORTA [3] and the numberof them is up to 1816. Let us also point out that this number grows dramatically for bigger valuesof n.
Let G = K5, F = {4, 5} y C = {1, 2, 3, 4, 5}. The following inequalities appear in PCV (G,F, C):
(B-1) x15+x25+x35+x45+x55 -z <= 1
(B-2) x12+x13+x22+x23+x32+x33+x42+x43+x52+x53 +z >= 2
(B-3) x31+x41+x51-x33-x34}-x43-x44-x53-x54+2x11+2x21+z <= 1
(B-4) x41+x42+x43+x51+x52+x53-x44-x54+2x11+2x12+2x13
+2x21+2x22+2x23+2x31+2x32+2x33 +z >= 5
(B-5) x11+x21+x41+x12+x13+x22+x23+x52+x53+x14+x24
+x34+x44+x54 <= 4
(B-6) x11+x21+x41+x12+x22+x52+x11+x41+x12+x52+x13+x23
+x43+x53+2x14+2x24+2x34+2x44+2x54 <= 7
The inequality (B-1) is a semiclique inequality associated with c = 5.The constraint (B-2) is an M -semiclique inequality, for M = {2, 3}.In (B-3) we have a (U,A,M)-semiclique inequality taking U = {1, 2}, A = {1} and M = {3, 4}.The inequality in (B-4) is a (U,A,M)-semiclique inequality, for U = {3, 4, 5}, A = {1, 2, 3} and
M = {4}.In (B-5) we have an (H,C1, C2, C3)-inequality, for H = {1, 2}, C1 = {1}, C2 = {2, 3} and
C3 = {4}.The constraint (B-6) is an (H,H ′, D)-inequality, for H = {1, 2}, H ′ = {1} and D = (1, 2, 3, 4).
4 Conclusions
In this paper we have done the first polyhedral study of the minimum chromatic violation problemin graphs. First, we have presented an integer programming formulation for this problem using twosets of binary variables and based on the standard formulation of the vertex coloring problem. Wehave next analyzed the feasible region of this problem, denoted by PV C(G,F ) for a graph G and a
CLAIO-2016
309

set of violable edges F . We have determined its dimension and identified the original restrictionsthat define facets of it.
In addition, we have found three types of new valid inequalities, two of them exponentiallysized. All of them are related to the maximal cliques in the graph having one violable edge inthe complete graph induced by them. This led us to focus on the chromatic violation polytope ofcomplete graphs with exactly one violable edge (G = Kn and |F | = 1). In this polytope the facetdefining inequalities can be partitioned into two sets: those having nonzero coefficient in the newvariable associated with F and those corresponding to the standard coloring polytope in the graphwhere the violable edge is removed (Kn \ F ). Then, since the coloring polytope (PC(G)) is notknown for general graphs, we found necessary to look for valid inequalities for it when G = Kn \Fand |F | = 1. In this case, we could identify two new exponentially sized valid inequalities forPC(Kn \ F ).
Due to the huge number of inequalities arising in the description of the chromatic violationpolytope even for graphs with at most five nodes and strong symmetry, we could only handle smallexamples. However, for G = Kn and |F | = 1 we found that the families herein identified completelydescribe the chromatic polytope when the graph has at most n = 5 nodes. In fact, we stronglybelieve that this situation holds for all values of n.
These results show a prominent line of future research, including to look for conditions underwhich the valid inequalities define facets of the chromatic violation polytope, the study of thecomplexity of the separation problem associated with them and a deep analysis of the standardcoloring polytope in new families of graphs.
References
[1] M. Campêlo, R. Corrêa and Y. Frota. Cliques, holes and the vertex coloring polytope. Infor-mation Processing Letters, 89:159–164, 2004.
[2] V. Campos, R. Corrêa, D. Delle Donne, J. Marenco and A. Wagler. Polyhedral studies ofvertex coloring problems: The asymmetric representatives formulation. arXiv:1509.02485v1[math.CO], 2015.
[3] T. Christof and A. Löbel. PORTA - POlyhedron Representation Transformation Algorithm.http://www.zib.de/Optimization/Software/Porta/.
[4] P. Coll, J. Marenco, I. Mendez Diaz and P. Zabala. Facets of the Graph Coloring Polytope.Annals of Operations Research, 116:79–90, 2002.
[5] D. Delle Donne and J. Marenco. Polyhedral studies of vertex coloring polytope: The stan-dard formulation. Technical Report, National University of General Sarmiento. Available atOptimization Online, 2015.
[6] R. Karp Reducibility Among Combinatorial Problems. In Complexity of Computer Compu-tations. New York: Plenum, 85-103, 1972.
[7] Z. Tuza. Graph colorings with local constraints - A survey. Discussiones Mathematicae -Graph Theory, 17:161–228, 1997.
CLAIO-2016
310

Dimensionamento de lotes e roteamento de véıculos em
indústrias moveleiras de pequeno porte
Pedro Luis Miranda Lugo, Reinaldo MorabitoUniversidade Federal de São Carlos
[email protected]; [email protected]
Deisemara FerreiraUniversidade Federal de São Carlos - campus Sorocaba
Resumo
Para resolver um problema integrado de dimensionamento de lotes e rotamento de véıculost́ıpico de empresas moveleiras de pequeno porte é proposto um modelo de programação inteiramista. O modelo inclui caracteŕısticas próprias do setor, como produção e estocagem de itens,rotas de distribuição estendendo-se por vários peŕıodos, múltiplas janelas de tempo e prazosde entrega. Testes computacionais mostraram que o modelo representa de forma apropriada asituação real. Além disto, testes realizados com base em um conjunto de exemplares gerados ale-atoriamente, mostram que o CPLEX 12.6 encontra soluções ótimas ou fact́ıveis para exemplaresde até n = 10 clientes em tempos computacionais razoáveis.
Keywords: Dimensionamento de lotes; Roteamento de véıculos; Indústria moveleira.
1 Introdução
Neste artigo é estudado o problema integrado de dimensionamento de lotes e roteamento devéıculos em indústrias moveleiras de pequeno porte. O problema de dimensionamento de lotes(PDL) consiste em tomar decisões sobre as quantidades de produção e os ńıveis de estoque ao longode um horizonte de planejamento dado com o objetivo de minimizar custos de produção, preparaçãoe estocagem. Por outro lado, o problema de roteamento de véıculos (PRV) visa projetar as rotaspara atender a demanda de um conjunto de clientes espalhados geograficamente ao menor custoposśıvel.
Na prática é comum que esses problemas sejam resolvidos de forma isolada. As decisões tomadasno PDL servem de base para resolver o PRV [2]. Entretanto, integrar essas decisões pode levar àredução de custos operacionais e ao atendimento da demanda dos clientes de forma mais efetiva[13, 12].
Esse novo problema, que visa reduzir conjuntamente os custos de estocagem, produção e ro-teamento, tem recebido muita atenção nos últimos anos, tanto no desenvolvimento de modelosde otimização quanto de métodos de solução efetivos. Os trabalhos seminais na área foram apre-sentados por [10] e [11], e reportaram o valor econômico de integrar as decisões de produção edistribuição. Métodos de solução, como GRASP [8], algoritmos genéticos [9], ALNS [1], heuŕısticas
CLAIO-2016
311

baseadas em Branch-and-price [6, 7] e heuŕısticas de programação matemática [4], tem sido propos-tos para abordar o problema integrado de uma planta de produção que produz um único produtofinal e possui uma frota homogênea de véıculos.
O cenário com múltiplos produtos tem sido abordado com menor frequência e, como no casoanterior, o foco tem sido o desenvolvimento de métodos de solução, como abordagens de decom-posição [11], heuŕısticas lagrangianas [14] e busca tabu com religação de caminhos [5]. Em termosda modelagem matemática, o trabalho proposto por [3] é o único nesta categoria que inclui decisõesde sequenciamento no contexto da produção e distribuição de produtos perećıveis.
O trabalho apresentado por [15] considera um problema com múltiplas plantas de produção, umúnico produto e frota heterogênea de véıculos. Até onde observou-se na revisão bibliográfica, este éo único trabalho que incorpora tais caracteŕısticas na modelagem matemática. Os autores tambémapresentam uma heuŕıstica de decomposição de dois estágios que obtêm melhores resultados que osolver CPLEX.
Neste estudo, propõe-se um modelo de programação inteira mista para representar e resolverum problema em que o produtor possui uma linha de pintura, considerada o gargalo de produçãonesta indústria, e um único de véıculo de entrega que realiza múltiplas rotas ao longo do horizontede planejamento. Algumas particularidades próprias de empresas moveleiras, como (i) produção eestocagem de itens, (ii) rotas estendendo-se ao longo de vários peŕıodos, (iii) múltiplas janelas detempo e (iv) prazos de entrega, também são consideradas na modelagem. Este cenário representaadequadamente o contexto de empresas moveleiras de pequeno porte.
O restante do artigo está organizado como segue: A Seção 2 apresenta a descrição do problemae o modelo matemático proposto. A Seção 3 descreve a avaliação computacional e os resultadosobtidos. Finalmente, a Seção 4 apresenta as conclusões e perspectivas de pesquisa futura.
2 Descrição do problema
Considera-se uma micro-empresa de móveis que possui uma linha de produção e um únicovéıculo de entrega. A planta produz um conjunto de itens, c ∈ C, que são utilizados na montagemde um conjunto de produtos finais, p ∈ P. A fabricação de uma unidade do produto p requer ηcpunidades do item c, e assume-se que ηcp = 0 se c /∈ Fp, em que Fp ⊆ C representa o subconjunto deitens requeridos para a montagem do produto p. Um custo fixo de preparação, fc, é incorrido emcada peŕıodo t ∈ T que houver produção do item c, e cada unidade produzida do item c consome ρcunidades de capacidade da linha, Kt. A produção é para estocagem e atrasos não são permitidos.O custo de estocagem unitário, o ńıvel de estoque inicial e o ńıvel de estoque mı́nimo do item c sãodados por hc, Ic0 e Imin
c , respectivamente.O véıculo pode realizar múltiplas rotas ao longo do horizonte de planejamento. Cada rota
r = 1, . . . , R começa e finaliza no depósito, {0, n + 1}, respectivamente, e pode se estender porvários peŕıodos. Para cada peŕıodo, o cliente i ∈ C̄ = {1, . . . , n} possui uma janela de tempo,[δit, δ̄it], que indica quando pode ser visitado. A demanda do produto p no cliente i, Dpi, deveser atendida em uma única visita (i.e., entregas fracionadas não são permitidas) e antes do prazode entrega ∆i, que indica o tempo máximo para o ińıcio do serviço do cliente i. A capacidade decada rota é dada por θ, e cada unidade do produto p a bordo do véıculo consome ϕp unidades decapacidade. A taxa de carga e descarga no depósito e nos clientes é dada por λ, e o tempo (custo)de viagem entre localizações é denotado por τij(cij), i, j ∈ C̄ ∪ {0, n + 1}, respectivamente. SejamM0j e Mij dois número suficientemente grandes, definidos como:
CLAIO-2016
312

M0j = δ̄0|T | + λmin{θ,∑
i∈C̄
∑
p∈PϕpDpi}+ τ0j , j ∈ C̄
Mij = ∆i + λ∑
p∈PϕpDpi + τij , i ∈ C̄, j ∈ {C̄, n+ 1}
O problema consiste em determinar a quantidade a ser produzida de cada item em cada peŕıodo,as rotas de entrega do véıculo e o tempo em que cada cliente deveria ser servido ao longo do horizontede planejamento, com o objetivo de minimizar os custos de preparação, estocagem e roteamento.
2.1 Modelagem Matemática
Antes de apresentar o modelo integrado de dimensionamento de lotes e roteamento de véıculo,LSVRP, considere a seguinte conjunto de variáveis:
xct : Quantidade produzida do item c no peŕıodo t;
Ict : Estoque do item c no final do peŕıodo t;
yct : 1 se o item c é produzido no peŕıodo t;
Qirt : 1 se a demanda do nó i é atendida pela rota r que inicia no peŕıodo t;
wijr : 1 se a rota r viaja diretamente do nó i para o nó j;
φirt : 1 se o nó i é atendido pela rota r no peŕıodo t;
µir : Instante em que a rota r começa a servir o nó i;
min∑
c∈C
∑
t∈Tfcyct +
∑
c∈C
∑
t∈ThcIct +
∑
i∈{0,C̄}
∑
j∈{C̄,n+1}
R∑
r=1
cijwijr (1)
Sujeito a:
Ic,t−1 + xct =R∑
r=1
∑
i∈C̄
∑
p∈PηcpDpiQirt + Ict, c ∈ C, t ∈ T (2)
Ic,t−1 ≥R∑
r=1
∑
i∈C̄
∑
p∈PηcpDpiQirt, c ∈ C, t ∈ T (3)
Ict ≥ Iminc , c ∈ C, t ∈ T (4)
∑
c∈Cρcxct ≤ Kt, t ∈ T (5)
xct ≤Mctyct, c ∈ C, t ∈ T (6)∑
j∈{C̄,n+1}w0jr = 1, r = 1, . . . , R (7)
∑
i∈{0,C̄}wi(n+1)r = 1, r = 1, . . . , R (8)
∑
j∈{C̄,n+1}j 6=i
wijr =∑
j∈{0,C̄}j 6=i
wjir, i ∈ C̄, r = 1, . . . , R (9)
CLAIO-2016
313

∑
i∈{0,C̄}i 6=j
R∑
r=1
wijr = 1, j ∈ C̄ (10)
∑
i∈C̄wi(n+1)r ≥
∑
i∈C̄w0i(r+1), r = 1, . . . , R− 1 (11)
∑
i∈C̄Qirt ≤ |N |φ0rt, t ∈ T , r = 1, . . . , R (12)
∑
t∈TQirt =
∑
j∈{C̄,n+1}j 6=i
wijr, i ∈ C̄, r = 1, . . . , R (13)
∑
t∈Tφirt =
∑
j∈{C̄,n+1}j 6=i
wijr, i ∈ C̄, r = 1, . . . , R (14)
∑
t∈Tφ0rt = 1− w0(n+1)r, r = 1, . . . , R (15)
∑
t∈Tφ0rt =
∑
t∈Tφ(n+1)rt, r = 1, . . . , R (16)
δit − δit(1− φirt) ≤ µir ≤ δ̄it + (Mi − δ̄it)(1− φirt), i ∈ N , t ∈ T , r = 1, . . . , R (17)
µjr ≥ µ0r + λ
(∑
i∈C̄
∑
t∈T
∑
p∈PϕpDpiQirt
)+ τ0j −M0j (1− w0jr) , j ∈ C̄, r = 1, . . . , R (18)
µjr ≥ µir + λ
(∑
p∈PϕpDpi
)+ τij −Mij (1− wijr) , i ∈ C̄, j ∈ {C̄, n+ 1},
r = 1, . . . , R : i 6= j(19)
µir ≤ ∆i
∑
j∈{C̄,n+1}j 6=i
wijr, i ∈ C̄, r = 1, . . . , R (20)
µ0(r+1) ≥ µ(n+1)r, r = 1, . . . , R− 1 (21)∑
p∈Pϕp∑
i∈C̄
∑
t∈TDpiQirt ≤ θ, r = 1, . . . , R (22)
xct, Ict ≥ 0, c ∈ C, t ∈ T (23)
yct ∈ {0, 1}, c ∈ C, t ∈ T (24)
Qirt ∈ {0, 1}, i ∈ C̄, r = 1, . . . , R, t ∈ T (25)
φirt ∈ {0, 1}, i ∈ N , r = 1, . . . , R, t ∈ T (26)
wijr ∈ {0, 1}, i, j ∈ N , r = 1, . . . , R (27)
µir ≥ 0, i ∈ N , r = 1, . . . , R (28)
A função objetivo (1) minimiza a soma dos custos fixos de preparação, estocagem de itens eroteamento. O conjunto de restrições (2) descreve o balanceamento de estoque do item c no peŕıodot. O conjunto de restrições (3) limita o fluxo de sáıda do item c ao estoque remanescente do peŕıodoanterior, Ic,t−1.
As restrições (4) impõem um ńıvel de estoque mı́nimo no final de cada peŕıodo. A seguir, arestrição de capacidade é dada por (5). As restrições (6) garantem que o custo fixo de preparação
CLAIO-2016
314

do item c só seja inclúıdo na função objetivo quando houver produção desse item. O parâmetro
Mct é definido pela expressão Mct = min(bKtρc c,
∑i∈C̄∑
p∈P̄ ηcpDpi
).
As restrições (7)-(8) indicam que toda rota inicia e finaliza no depósito, respectivamente. Aconservação do fluxo nos clientes é garantida pelas restrições (9).
Cada cliente deve ser visitado exatamente uma vez ao longo do horizonte de planejamento,como estabelecido pela restrição (10). O conjunto de restrições (11) estabelece precedências entreas rotas a fim de reduzir simetrias no espaço de soluções. Estas desigualdades indicam que a rotar + 1 somente pode ser utilizada se a rota r for utilizada. Observe que quando uma rota viajadiretamente do nó 0 para o nó n+ 1, tem-se que
∑i∈C̄ wi(n+1)r = 0.
As restrições (12) estabelecem que se a expressão∑
i∈C̄ Qirt for positiva para a rota r no peŕıodot, então φ0rt deve ser igual a 1, i.e., a rota r deve iniciar no peŕıodo t. Similarmente, se φ0rt for zero,então
∑i∈C̄ Qirt = 0. Observe que Qirt = 0 para todo i não significa que a rota r não é utilizada,
mas que ela não inicia no peŕıodo t. Assim, a rota r ainda pode iniciar em algum outro peŕıodot′ ∈ T .
As restrições (13) garantem que a demanda do cliente i seja atendida pela rota r, somente se ocliente i fizer parte da rota r. As restrições (14), estabelecem que a rota r deve visitar o cliente inum único peŕıodo t, se i pertencer a rota r. As restrições (15)-(16) garantem que todas as rotasutilizadas devem iniciar e finalizar num único peŕıodo, respectivamente.
As inequações (17) representam as restrições de janela de tempo. O valor do parâmetro Mi
depende do fato do nó i ser um cliente ou o depósito. No primeiro caso, Mi = ∆i, enquanto nosegundo caso Mi = δ̄i|T |. As restrições (18)-(19) estabelecem limitantes inferiores no tempo em quea rota r começa a servir o nó j, j ∈ N .
As restrições (20) garantem que a demanda do cliente i seja atendida antes do prazo de entrega,enquanto as restrições (21) estabelecem que a rota r + 1 somente pode começar após a finalizaçãoda rota r. O limite de capacidade do véıculo é imposto pelas restrições (22) e, finalmente, o domı́niodas variáveis de decisão é dado por (23)-(28).
3 Avaliação Computacional
Um conjunto de exemplares foi gerado aleatoriamente com base em algumas informações for-necidas por uma empresa moveleira de pequeno porte. O número de produtos (|P|), itens (|C|),peŕıodos (|T |) e clientes (n) são {2,3}, {3,5}, {3,5} e {5,10}, respectivamente. Cinco exemplaresforam gerados para cada combinação de |P|, |C|, |T | e n, totalizando 80 exemplares. A Tabela 1mostra como foram gerados os demais parâmetros do modelo LSVRP.
O modelo LSVRP foi implementado na linguagem de modelagem algébrica AMPL e resolvidocom a configuração default do solver CPLEX 12.6, utilizando um computador com processadorIntel Core i7 3.40 GHz e 12 Gigabytes de RAM. Um tempo computacional limite de 3.600 segundosfoi imposto para cada exemplar.
A Tabela 2 apresenta os resultados médios para cada combinação de parâmetros (colunas 1-4).Para cada combinação, o número de exemplares resolvidos até otimalidade é apresentado na coluna5. Como observado, os 40 exemplares com n = 5 são resolvidos até otimalidade em menos de 14segundos cada um. Entretanto, para o subconjunto de problemas com n = 10 o CPLEX somenteprovou a otimalidade de 16 dos 40 exemplares. Tal dificuldade deve-se ao aumento do númerode restrições e variáveis do problema, em decorrência do aumento do número de nós. Observe,nas colunas 9-11, que duplicar o número de nós resulta em um aumento de, em média, 4 vezes o
CLAIO-2016
315

Unidades do item c por unidade do produto p ηcp ∈ U [0, 5]Largura (Wc) and comprimento (Lc) do item c Wc, Lc ∈ U [20, 50]
Custo de estocagem unitário do item c hc = 0.001 ·Wc · LcCusto fixo de preparação do item c fc = 1000 · hc
Tempo de processamento unitário do item c ρc = Wc·Lc2500
Demanda do produto p no cliente i Dpi ∈ U [10, 100]
Capacidade de produção no peŕıodo t Kt = 3.5
⌈∑c∈C ρc(
∑p∈P
∑i∈N Dpiηcp)
|T |
⌉
Estoque inicial (mı́nimo) do item c Ic0 = Iminc =
⌈(∑
p∈P∑
i∈N Dpiηcp)|T |
⌉
Coordenadas do nó i (Xi, Yi) ∈ [0, 500]
Tempo de viagem do nó i para o nó j τij =
⌈60100
(√(Xi −Xj)2 + (Yi − Yj)2
)⌉
Custo de viagem do nó i para o nó j cij =
⌊√(Xi −Xj)2 + (Yi − Yj)2
⌋
Peso unitário do produto p ϕp =⌈0.001 ·∑c∈CWc · Lc · ηcp
⌉
Capacidade do véıculo θ =∑p∈P
∑i∈N Dpi · ϕp
Janela de tempo do nó i ∈{
0, C̄}
no peŕıodo t[δit, δ̄it
]= [480 + 1440 (t− 1) , 1080 + 1440 (t− 1)]
Janela de tempo do nó n+ 1 no peŕıodo t[δ(n+1)t, δ̄(n+1)t
]= [1440 (t− 1) , 1440t]
Taxa de carregamento/descarregamento λ = 1/50Prazo de entrega do cliente i ∈ C̄ ∆i = δ̄i|T |
Máximo número de rotas no horizonte de planejamento R = n
Tabela 1: Geração de exemplares
número de restrições e variáveis do problema. Para os outros 24 exemplares com n = 10, o CPLEXencontrou soluções fact́ıveis de boa qualidade para 20 deles, enquanto que, para os 4 exemplaresrestantes nenhuma solução fact́ıvel foi encontrada no tempo computacional permitido.
A fim de ilustrar algumas caracteŕısticas do modelo LSVRP, a Figura 1 apresenta a soluçãode um exemplar ilustrativo com n = 10, |P| = 2, |C| = 3 e |T | = 3. Os demais parâmetros doexemplar foram gerados com base nas informações da Tabela 1.
O plano de produção (Figura 1a) apresenta, para cada item, o ńıvel de estoque, a quantidadeproduzida e a quantidade enviada em cada peŕıodo do horizonte de planejamento. Por exemplo,para o item 1, o estoque ao ińıcio do primeiro peŕıodo é de 356 unidades e a quantidade produzidanesse peŕıodo foi de 3.459 unidades. Dado que não houve nenhum envio no primeiro peŕıodo, o
356
3815
18761423
239
3815
1272 954
109
1742
568 436
3459
1876
3576
1633
-3815
-453
-2543
-318 -1174 -132
-4000
-3000
-2000
-1000
0
1000
2000
3000
4000
5000
6000
Periodo
1
Periodo
2
Periodo
3
Periodo
4
Periodo
1
Periodo
2
Periodo
3
Periodo
4
Periodo
1
Periodo
2
Periodo
3
Periodo
4
Item 1 Item 2 Item 3
Estoque Produção Entrega
(a) Plano de produção
17
50
20
00
22
50
25
00
27
50
30
00
32
50
35
00
37
50
40
00
42
50
Depósito (0)
Cliente 1
Cliente 2
Cliente 4
Cliente 10
Depósito (n+1)
Depósito (0)
Cliente 5
Cliente 9
Cliente 8
Cliente 6
Cliente 3
Depósito (n+1)
Depósito (0)
Cliente 7
Depósito (n+1)
Ro
ta 1
Ro
ta 2
Ro
ta 3
Serviço Viagem Espera Janelas de tempo
(b) Plano de distribuição
Figura 1: Solução do exemplar ilustrativo
CLAIO-2016
316
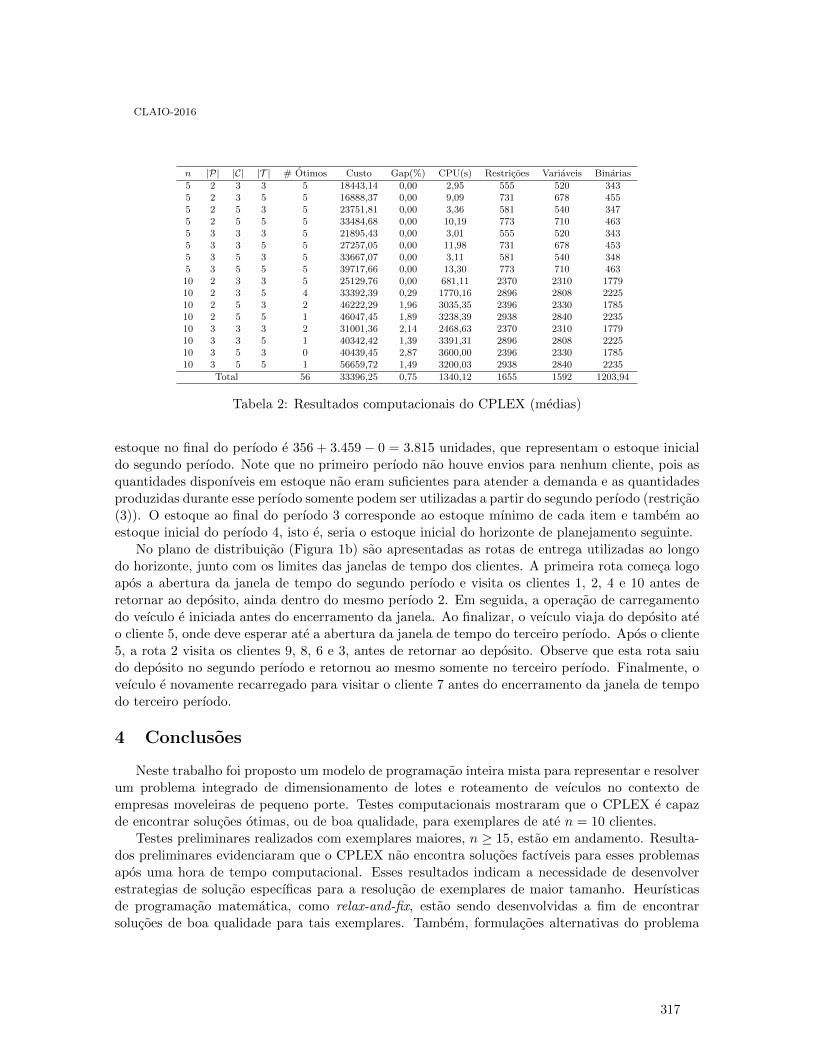
n |P| |C| |T | # Ótimos Custo Gap(%) CPU(s) Restrições Variáveis Binárias
5 2 3 3 5 18443,14 0,00 2,95 555 520 3435 2 3 5 5 16888,37 0,00 9,09 731 678 4555 2 5 3 5 23751,81 0,00 3,36 581 540 3475 2 5 5 5 33484,68 0,00 10,19 773 710 4635 3 3 3 5 21895,43 0,00 3,01 555 520 3435 3 3 5 5 27257,05 0,00 11,98 731 678 4535 3 5 3 5 33667,07 0,00 3,11 581 540 3485 3 5 5 5 39717,66 0,00 13,30 773 710 46310 2 3 3 5 25129,76 0,00 681,11 2370 2310 177910 2 3 5 4 33392,39 0,29 1770,16 2896 2808 222510 2 5 3 2 46222,29 1,96 3035,35 2396 2330 178510 2 5 5 1 46047,45 1,89 3238,39 2938 2840 223510 3 3 3 2 31001,36 2,14 2468,63 2370 2310 177910 3 3 5 1 40342,42 1,39 3391,31 2896 2808 222510 3 5 3 0 40439,45 2,87 3600,00 2396 2330 178510 3 5 5 1 56659,72 1,49 3200,03 2938 2840 2235
Total 56 33396,25 0,75 1340,12 1655 1592 1203,94
Tabela 2: Resultados computacionais do CPLEX (médias)
estoque no final do peŕıodo é 356 + 3.459− 0 = 3.815 unidades, que representam o estoque inicialdo segundo peŕıodo. Note que no primeiro peŕıodo não houve envios para nenhum cliente, pois asquantidades dispońıveis em estoque não eram suficientes para atender a demanda e as quantidadesproduzidas durante esse peŕıodo somente podem ser utilizadas a partir do segundo peŕıodo (restrição(3)). O estoque ao final do peŕıodo 3 corresponde ao estoque mı́nimo de cada item e também aoestoque inicial do peŕıodo 4, isto é, seria o estoque inicial do horizonte de planejamento seguinte.
No plano de distribuição (Figura 1b) são apresentadas as rotas de entrega utilizadas ao longodo horizonte, junto com os limites das janelas de tempo dos clientes. A primeira rota começa logoapós a abertura da janela de tempo do segundo peŕıodo e visita os clientes 1, 2, 4 e 10 antes deretornar ao depósito, ainda dentro do mesmo peŕıodo 2. Em seguida, a operação de carregamentodo véıculo é iniciada antes do encerramento da janela. Ao finalizar, o véıculo viaja do depósito atéo cliente 5, onde deve esperar até a abertura da janela de tempo do terceiro peŕıodo. Após o cliente5, a rota 2 visita os clientes 9, 8, 6 e 3, antes de retornar ao depósito. Observe que esta rota saiudo depósito no segundo peŕıodo e retornou ao mesmo somente no terceiro peŕıodo. Finalmente, ovéıculo é novamente recarregado para visitar o cliente 7 antes do encerramento da janela de tempodo terceiro peŕıodo.
4 Conclusões
Neste trabalho foi proposto um modelo de programação inteira mista para representar e resolverum problema integrado de dimensionamento de lotes e roteamento de véıculos no contexto deempresas moveleiras de pequeno porte. Testes computacionais mostraram que o CPLEX é capazde encontrar soluções ótimas, ou de boa qualidade, para exemplares de até n = 10 clientes.
Testes preliminares realizados com exemplares maiores, n ≥ 15, estão em andamento. Resulta-dos preliminares evidenciaram que o CPLEX não encontra soluções fact́ıveis para esses problemasapós uma hora de tempo computacional. Esses resultados indicam a necessidade de desenvolverestrategias de solução espećıficas para a resolução de exemplares de maior tamanho. Heuŕısticasde programação matemática, como relax-and-fix, estão sendo desenvolvidas a fim de encontrarsoluções de boa qualidade para tais exemplares. Também, formulações alternativas do problema
CLAIO-2016
317

estão sendo exploradas no intuito de resolver exemplares de maior tamanho em tempos computa-cionais razoáveis.
Agradecimentos
Os autores agradecem à Fapesp (processo 2014/10565-8) e ao CNPq (processos 140179/2014-3e 312569/2013-0) pelo suporte financeiro para o desenvolvimento desta pesquisa.
Referências
[1] Yossiri Adulyasak, Jean-françois Cordeau, and Raf Jans. Optimization-Based Adaptive Large Neigh-borhood Search for the Production Routing Problem. Transportation Science, 48(1):20–45, August2014.
[2] Yossiri Adulyasak, Jean-François Cordeau, and Raf Jans. The production routing problem: A reviewof formulations and solution algorithms. Computers & Operations Research, 55:141–152, March 2015.
[3] P. Amorim, M.a.F. Belo-Filho, F.M.B. Toledo, C. Almeder, and B. Almada-Lobo. Lot sizing versusbatching in the production and distribution planning of perishable goods. International Journal ofProduction Economics, 146(1):208–218, November 2013.
[4] Claudia Archetti, Luca Bertazzi, Giuseppe Paletta, and M. Grazia Speranza. Analysis of the maximumlevel policy in a production-distribution system. Computers & Operations Research, 38(12):1731–1746,December 2011.
[5] V.A. Armentano, A.L. Shiguemoto, and A. Løkketangen. Tabu search with path relinking for an inte-grated production–distribution problem. Computers & Operations Research, 38(8):1199–1209, August2011.
[6] Jonathan F. Bard and Narameth Nananukul. Heuristics for a multiperiod inventory routing problemwith production decisions. Computers & Industrial Engineering, 57(3):713–723, October 2009.
[7] Jonathan F. Bard and Narameth Nananukul. A branch-and-price algorithm for an integrated productionand inventory routing problem. Computers & Operations Research, 37(12):2202–2217, December 2010.
[8] M. Boudia, M.a.O. Louly, and C. Prins. A reactive GRASP and path relinking for a combinedproduction–distribution problem. Computers & Operations Research, 34(11):3402–3419, November2007.
[9] M. Boudia and C. Prins. A memetic algorithm with dynamic population management for an integratedproduction–distribution problem. European Journal of Operational Research, 195(3):703–715, June2009.
[10] Pankaj Chandra. A Dynamic Distribution Model with Warehouse and Customer Replenishment Re-quirements. Journal of the Operational Research Society, 44(7):681–692, 1993.
[11] Pankaj Chandra and Marshall L Fisher. Coordination of production and distribution planning. EuropeanJournal of Operational Research, 72:503–517, 1994.
[12] Zhi-Long Chen. Integrated Production and Distribution Operations: Taxonomy, Models, and Review.In D Simchi-Levi, S.D. Wu, and Z.-J. Shen, editors, Handbook of Quantitative Supply Chain Analysis:Modeling in the E-Business Era, chapter 17, pages 1–32. Kluwer Academic Publishers, 2004.
[13] M. Dı́az-Madroñero, D. Peidro, and J. Mula. A review of tactical optimization models for integratedproduction and transport routing planning decisions. Computers & Industrial Engineering, 88:518–535,2015.
[14] Francesca Fumero and Carlo Vercellis. Synchronized Development of Production, Inventory, and Dis-tribution Schedules. Transportation Science, 33(July 2014):330–340, 1999.
[15] Lei Lei, Shuguang Liu, Andrzej Ruszczynski, and Sunju Park. On the integrated production, inventory,and distribution routing problem. IIE Transactions, 38(11):955–970, November 2006.
CLAIO-2016
318

The socio-technical team formation problem:
computational complexity, formulation, facets and
experimental analysis
Tatiane Fernandes∗, Manoel Campêlo∗, Ana Silva∗
ParGO Research GroupUniversidade Federal do Ceará, Campus do Pici, BL 910, 60.455-760 Fortaleza, CE, Brazil
{tatiane,mcampelo}@lia.ufc.br, [email protected]
Abstract
We introduce a new combinatorial optimization problem referred to as socio-technical teamformation problem (STFP), which arises from the formation of cooperatives teams by consideringsocial and technical constraints between individuals. We initially prove the NP-hardness ofSTFP. Then, we present a binary integer linear programming formulation for the underlyingproblem and conduct a polyhedral study by deriving some facet-inducing inequalities relatedto its polytope. Three exact approaches based on the proposed formulation are tested on a setof 120 randomly generated instances with known optimal value. The experiments attest theefficiency of our implementations.
Keywords: Combinatorial optimization; Facets of polyhedra; Integer linear programming; Socio-technical team formation problem.
1 Introduction
The notion of socio-technical system was created in the context of labor studies by the TavistockInstitute in London in the late fifties [1]. It concerns teams’relations at all levels in a single orga-nization. More precisely, socio-technical systems focus on the reciprocal interrelationship betweenhumans - and on their knowledge - in workplaces with the aim of structuring an organization so asto meet efficiency and job satisfaction.
In this scenario, we introduce a novel combinatorial optimization problem referred to as socio-technical team formation problem (STFP, for short). It aims at forming a certain number of workteams as harmonious as possible, each team having the desired skills. Formally, the problem inputis a 5-tuple (K,S, T, s, t) defined by: an edge-weighted complete graph K = (V,E,w), where Vis the set of vertices (representing the individuals), and E is the set of edges such that an edgebetween vertex u ∈ V (K) and vertex v ∈ V (K) (to be denoted uv ∈ E(K)) is associated with a
∗Partially supported by CNPq, CAPES and FUNCAP.
CLAIO-2016
319

weight wuv ∈ N - the lower the value of wuv, the higher the degree of the mutual affinity betweenu and v; a set S, describing the considered skills; a set T , indexing the teams to be formed; afunction s : V (K) → 2S that assigns to each individual u ∈ V (K) a subset s(u) ⊆ S of skills;and a function t : T × S →∈ N, where t(j, s) ∈ N is the minimum number of individuals havingskill s required in team j. STFP asks for determining disjoint subsets Vj ⊂ V , j ∈ T , and a skillf(u) ∈ s(u), for each u ∈ ⋃j∈T Vj such that |{u ∈ Vj : f(u) = s}| ≥ t(j, s), for all j ∈ T , s ∈ Sand
∑j∈T
∑u,v∈Vj wuv minimized. In other words, the problem is to form |T | teams such that: (i)
each individual u ∈ V (K) is allocated in at most one team j ∈ T with a specific skill s ∈ s(u);(ii) in each team j, skill s ∈ S is associated with at least t(j, s) of its participants; and (iii) thedisharmony of the teams is minimized.
This work considers relevant aspects of STFP. First, we show that it is NP-hard (Sect. 2) andhence unlikely to be solvable in polynomial time, unless P = NP. Then, we conceive an integerlinear programming (ILP) formulation (Sect. 3) that afterwards allows us to present a partial studyof the facial structure of its polytope (Sect. 4). Numerical experiments (Sect. 5) performed on a setof 120 randomly generated instances – with known optimum – attest the efficiency of three exactapproaches based on the ILP formulation. They comprise (i) the standard ILP model, (ii) theILP model implemented with some complementary constraints (e.g., facets), and (iii) a customizedsimulated annealing algorithm that achieves promising feasible solutions for STFP, which are used,in turn, as pruning criterion in a branch-and-bound scheme to reduce the number of evaluatedsubproblems. General conclusions (Sect. 6) come at the end of the paper.
2 Computational complexity
Given an unweighted graph G = (V,E) and a fixed constant k ∈ N, the problem of checking whetherG contains an independent set of size at least k is known to be NP-complete [2]. It may be viewedas a decision version of the STFP. More specifically, let K ′ = (V (G), E) be a weighted completegraph where wuv = 1 if uv ∈ E(G), and wuv = 0 otherwise. Moreover, let S = s(u) = {1}, forall u ∈ V (K ′), T = {1} and t(1, 1) = k. One can state that G contains an independent set of sizeat least k if and only if (K ′, S, T, s, t) has a solution of value zero. By this observation, we canestablish the following proposition.
Proposition 1. STFP is NP-hard even if |S| = 1 and |T | = 1.
Nevertheless, a feasible solution of STFP can be found in polynomial-time. Actually, we cantranslate the feasiblity problem into a maximum flow problem (see Fig. 1(a)). Given an instanceISTFP = (K,S, T, s, t) of STFP , we construct a network IMF as follows. Create a node vu for eachu ∈ V (K); a node vjs for each pair (j, s) ∈ T × S such that t(j, s) > 0; and two nodes a and b;then, add an arc from a to vu with capacity 1, for all u ∈ V (G), an arc from vjs to b with capacityt(j, s), for all node vjs, and an arc from vu to vj,s with capacity 1, whenever s ∈ s(u, j).
Lemma 1. Let f∗ be an integer maximum flow in IMF . ISTFP is feasible if and only if |f∗| =∑j∈T
∑s∈S
t(j, s). Moreover, if f∗vuvjs = 1, then u should be allocated in team j with skill s.
Another approach for the feasibility problem is to look at the bipartite graph obtained fromIMF by removing a, b, ignoring the direction of the arcs, and making t(j, s) copies of each nodevj,s. Let G∗ be the obtained graph, and W be the subset of nodes related to vj,s. See Figure 1(b).
CLAIO-2016
320

Finding a feasible solution consists in finding a matching in G∗ that covers W . By Hall’s Theorem,we get the following proposition.
Proposition 2. ISTFP is feasible if and only if |V (S′)| ≥ n(T, S′) ∀S′ ⊆ S, where n(T, S′) =∑j∈T
∑s∈S′ t(j, s) and V (S′) = {u ∈ V (K) : s(u) ∩ S′ 6= ∅}.
team 1
team 2
a
v1
v2
v3
v4
v11
v12
v22
b
1
1
1
1
11
11
1
1
1 1
112
(a) Feasibility via max-flow
team 1
team 2
U W
v1
v2
v3
v4
v111
v112
v122
v222
(b) Feasibility via matching
Figure 1: Instance of the STFP where V (K) = {1, 2, 3, 4}, T = {1, 2}, S = {1, 2}, s(v1) = {1, 2},s(v2) = {1}, s(v3) = s(v4) = {2}, t(1, 1) = t(1, 2) = 1, t(2, 1) = 0 and t(2, 2) = 2.
3 ILP formulation
In this section, we describe an ILP formulation for STFP. For let s(u, j) = {s ∈ S : s ∈ s(u), t(j, s) >0} be the subset of skills of individual u ∈ V (K) that are required by team j ∈ T . Such a formulationis described by two sets of 0-1 decision variables. On the one hand, variables X correlate teams,individuals and skills so that Xujs = 1 if and only if individual u is allocated to team j to useskill s, for all u ∈ V (K), j ∈ T , and s ∈ s(u, j). On the other hand, variables Z group pairs ofindividuals, i.e. Zuv = 1 if individuals u ∈ V (K) and v ∈ V (K) belong to the same team. Bearingthese definitions in mind, the STFP may be formulated by the binary ILP formulation given below.
min w(X,Z) =∑
uv∈E(K)
wuvZuv (1)
s.t.∑
s∈s(u,j)
Xujs +∑
s∈s(v,j)
Xvjs − Zuv ≤ 1, ∀j ∈ T, ∀u, v ∈ V (K) : s(u, j) 6= ∅, s(v, j) 6= ∅ (2)
∑
j∈T
∑
s∈s(u,j)
Xujs ≤ 1, ∀u ∈ V (K), (3)
∑
u∈V (K):s∈s(u)
Xujs ≥ t(j, s), ∀j ∈ T, s ∈ S, (4)
Xujs ∈ {0, 1}, ∀u ∈ V (K), ∀j ∈ T, ∀s ∈ s(u, j) (5)
Zuv ∈ {0, 1}, ∀uv ∈ E(K). (6)
CLAIO-2016
321

Observe that, in a feasible solution (X,Z), we may have Zuv = 1 even if individuals u and vare in the same team. This is not an issue due to the objective function. A feasible solution (X,Z)where Z only marks the pairs in the same team, as allocated by X, will be called pure and denotedby (X, ·) (this means that Z can be derived from X). Associated with this formulation, we definethe polytope P (STFP ) = conv{(X,Z) : (X,Z) satisfies (2)–(6)}. The existence of points in suchpolytope is intrinsically related to Proposition 2, which leads us to consider the following family ofassumptions (Ak), for k ∈ N.
Assumption (Ak): |V (S′)| ≥ n(T, S′) + k, for every S′ ⊆ S.
It is worth observing that the above assumptions are not restrictive when each team mustcontain at least two individuals (n(j, S) ≥ 2 for all j ∈ T ). Indeed, in this case we can alwayssatisfy Assumption (Ak), for any k ≥ 0, by including in V (K) a set D of k dummy individuals suchthat s(u) = S and wuv = +∞, for all u ∈ D and v ∈ V (K) ∪D. Note that the modified instanceis equivalent to the original one since dummy individuals can only take part in an optimal solutionif the original problem is infeasible.
On the other hand, these assumptions play an important role in the polyhedral study ofP (STFP ). If (Ak) holds and U ⊆ V (K) is a subset of size k, then there exists a feasible so-
lution where no vertex of U is in any team. Such a solution is denoted by (XU , ·) in what follows.Moreover, consider euv ∈ {0, 1}|E| and eujs ∈ {0, 1}|V |×|T |×|S| as unit vectors with 1 in the entriesindexed by uv and ujs, respectively.
Proposition 3. P (STFP ) is non-empty if and only if A0 holds. Also, P (STFP ) is full-dimensionalif and only if A1 holds.
Proof. For emptiness, the equivalence comes from Proposition 2. To prove that P (STFP ) is full-dimensional, first assume that A1 does not hold. Then, either P (STFP ) = ∅ or there exists S′ ⊆ Ssuch that |V (S′)| = n(T, S′), in which case each u ∈ V (S′) must be associated to some skill inS′, i.e.,
∑j∈T
∑s∈S′∩s(u,j)Xujs = 1 is valid for P (STFP ). Now, assume that A1 holds. Suppose
that P (STFP ) ⊆ {(X,Z) : λX + πZ = θ} and let u, v ∈ V (K). Then, the solutions (Xu, ·) and(Xu, ·) + (0, euv) show that πuv = 0. Therefore, π = 0. Finally, let j ∈ T and s ∈ s(u, j). Then,the solutions (Xu + eujs, ·) and (Xu, ·) imply that λujs = 0. Hence, λ = 0.
4 Facet-inducing inequalities
In this section, we present some facet-inducing inequalities for P (STFP ). In order to prove thata face F ′ = {(X,Z) ∈ P (STFP ) : λ′X + π′Z = θ′} defines a facet of P (STFP ), we show that ifa facet F = {(X,Z) ∈ P (STFP ) : λX + πZ = θ} contains F ′, then there exists a ∈ R such thatλ = aλ′ and π = aπ′ [3].
Proposition 4. Suppose A2. Then, for all j ∈ T and u, v ∈ V (K) such that s(u, j) 6= ∅ ands(v, j) 6= ∅, Inequality (2) induces a facet of P (STFP ).
Proof. Note that F contains solutions (X, ·) where u (or v) is in team j. Thus, let w ∈ V (K)\{u, v},and (X,Z) be a solution equal to (X{u,w} + eujs, ·), for any s ∈ s(u, j). Also, let z ∈ V (K) \ {w},
CLAIO-2016
322

j′ ∈ T \ {j} and s′ ∈ s(w, j′). Then, (X,Z), (X,Z) + (0, ewz) and (X ′, Z ′) = (X + ewj′s′ , ·)
belong to F . Moreover, note that Zuv = Z ′uv. Hence, πwz = 0 and therefore λwj′s′ = 0. Now, letw ∈ U = {u, v}, j′ ∈ T , and s′ ∈ s(w, j′). Let also w′ ∈ U \ {w}, s ∈ s(w′, j), and (X,Z) be a
solution equal to (XU + ew′js, ·). Clearly, (X,Z) belongs to F . If j′ 6= j, then (X + ewj
′s′ , ·) ∈ F ,and hence λwj′s′ = 0. Otherwise, (X ′, Z ′) = (X + ewjs
′, ·) belongs to F . Thus, Zuv = 0 and
Z ′uv = 1. Therefore, λwjs′ = −πuv.
Proposition 5. Suppose A1. Then, for all u ∈ V (K), Inequality (3) induces a facet of P (STFP ).
Proof. Let w ∈ V (K) \ {u} and consider a feasible solution (Xw, ·), which exists since (A1) holds.Without loss of generality, we can suppose that u belongs to any team in (Xw, ·), i.e., (Xw, ·) ∈ F .Also, for any v ∈ V (K)\{w} and (j, s) ∈ T×S such that s ∈ s(w, j), the solutions (Xw, ·)+(0, ewv)and (Xw + ewjs, ·) belong to F . Then, πwv = 0, which also implies λwjs = 0. Finally, for any twopairs (j, s), (j′, s′) ∈ T × S such that s ∈ s(u, j) and s′ ∈ s(u, j′), the solutions (Xu + eujs, ·) and(Xu + euj
′s′ , ·) belong to F . Thus, λujs = λuj′s′ , which concludes the proof.
Proposition 6. Suppose A2. Then, for all j ∈ T and s ∈ S with t(j, s) > 0, Inequality (4) inducesa facet of P (STFP ).
Proof. Let w ∈ V (K) and consider a feasible solution (Xw, ·), which exists since A2 holds. Withoutloss of generality, we can suppose that (Xw, ·) belongs to F . For any v ∈ V (K) \ {w}, (Xw, ·) +(0, ewv) also belongs to F . Hence, πwv = 0. Moreover, for any pair (j′, s′) ∈ T × S 6= (j, s), withs′ ∈ s(w, j′), a feasible solution in F is found by adding w to team j′ with skill s′ in (Xw, ·), i.e.,(Xw + ewj
′s′ , ·). Thus, λwj′s′ = 0. Finally, suppose that s ∈ s(w, j) ∩ s(v, j) and let U = {w, v}.Again, there exists a feasible solution (XU , ·) belonging to F . Let u ∈ V (K)\U such that XU
ujs = 1.
The solutions (XU−eujs+ewjs, ·) and (XU−eujs+evjs, ·) both belong to F and then λwjs = λvjs.
Now, we generalize Inequality (2) as follows.
Proposition 7. Let j ∈ T , V ′ ⊆ {v ∈ V : s(v, j) 6= ∅}, and α ∈ Z. The inequality below is validfor P (STFP ). Moreover, if |V ′| ≥ 3, α ∈ {1, 2, . . . , |V ′| − 2} and (A|V ′|) hold, then such inequalityalso induces a facet of P (STFP ).
∑
u,v∈V ′:u6=vZuv ≥
∑
u∈V ′
∑
s∈s(u,j)αXujs − α(α+ 1)/2 (7)
Proof. Let (X,Z) be feasible for (2)–(6) and define x =∑
u∈V ′∑
s∈s(u,j)Xujs as the number of
individuals of V ′ in team j. Then, the clique induced by V ′ is given by∑
u,v∈V ′:u6=v Zuv ≥x(x−1)
2 .
Therefore, it suffices to show that x(x−1)2 ≥ αx−α(α+1)
2 or, equivalently, x2−(2α+1)x+α(α+1) ≥ 0.This holds whenever x ≤ α or x ≥ α + 1, which means that it always holds since x and α areintegers. The second part of the proof is similar to that for Propositon 4. Details are omitted forspace limitation and will be given in a full version of this work.
CLAIO-2016
323

5 Numerical experiments
We report computational results for a set of 120 randomly generated instances (see [4] for furtherdetails). Two different implementations based on the formulation presented in Sect. 3 were codedin C language using CPLEX 12.4 callable library. The experiments were carried out on a desktopmachine equipped with Intel Pentium i5, 8 × 3.60 GHz, 8 GB of RAM under Linux Ubuntu 14.05.
For both implementations, a preprocessing phase is carried out in order to fix the values ofsome variables. Since there is always an optimal solution that is pure and satisfies (4) at equality,we can generate an equivalent model if we shift the weights by a constant. So, first we replace wuvby wuv −min{wrs : rs ∈ E(K)} ≥ 0, for all uv ∈ E(K). Then, we set Zuv = 1 whenever wuv = 0,for all uv ∈ E(K). This is because at least one optimal solution satisfying the aforementionedrequirement exists. As a consequence, Constraints (2) related to the fixed Z variables are removedfrom the model. This allows us to obtain significant computational gains. In what follows, werefer to as AB the proposed (basic) formulation (1)-(6), while AF corresponds to AB includingInequality (7) for α ∈ {3, 4}, V ′ = {v ∈ V : s(v, j) 6= ∅ and j ∈ T .
In Figs. 2(a)–2(d), we present graphically the results for a set of 96 instances where bothversions AB and AF reached the optimal solution within a CPU time limit of 5000 seconds. Theseinstances are grouped in four domains, namely, groups 1, 2, 3 and 4. These groups are composedof instances whose average CPU time (in seconds) is in the real interval [0, 1], [1, 10], [5, 100], and[100, 3000], respectively. All graphics uses a logarithmic scale. By analysing such figures, note thatAF consistently got better CPU times than AB.
For another set of instances consisting of 10 test cases AF again outperforms AB. Actually, thislatter version did not find any optimal solution within the CPU time limit.
Globally, AF solved – within the CPU time limit of 5000 seconds for each run – 106 instancesto optimality. For the remaining instances (14), AF did not find the optimal solution in the timelimit. This drawback encouraged us to implement a non-monotonic simulated annealing (SA) [5]algorithm whose main goal is to obtain a good upper bound (i.e., a feasible solution) for STFP.Thus, the number of evaluated nodes of the CPLEX branch-and-bound search tree may be severelyreduced since we prune nodes whose values of the linear relaxations are greater than or equal tothat bound. This insight allowed us to solved the remaining 14 instances where the time limit wasan important concern.
Algorithm 1 presents a general description of the SA algorithm. A step-by-step explanation isgiven below.
The method setInitialSolution builds a feasible solution Q to STFP in polynomial time, usinga maximum flow algorithm, shown in 1. Solution Q is represented by sets U(j) for each j ∈ T ,containing the individuals of the team j. Each set U(j) is coded as a |V (G)|-dimensional vectorwhere the entry corresponding to u ∈ V (G) equals s ∈ s(u) if u participates on team j with skill s,or receive 0 to register that u does not participate on that team.
The method neighborSolution searches for neighboring solutions through two operators basedon the swap operator defined in [6]. Given two teams (j1 e j2) and two individuals u1 ∈ U(j1) eu2 ∈ U(j2) performing the same skill s1 in their respective teams, the first operator, called swap1does an interchange such that, in the end of the operation, u2 ∈ U(j1) and u1 ∈ U(J2).
Given two distinct teams j1 e j2 and two distinct individuals u1 ∈ U(j1), performing skill s1
and having skill s2, and u2 ∈ U(j2), performing skill s2 and having skill s1, with s1 6= s2, thesecond operator, called swap2, does a change such that, in the end of the operation, u2 ∈ U(j1)
CLAIO-2016
324
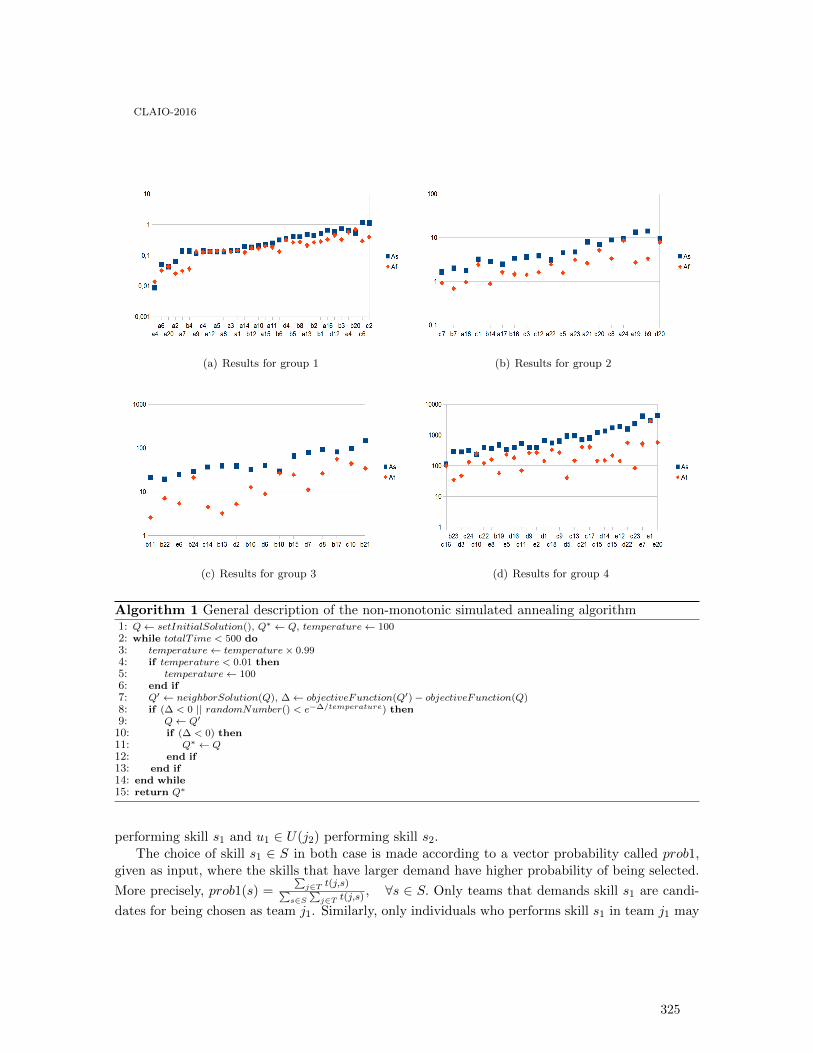
(a) Results for group 1 (b) Results for group 2
(c) Results for group 3 (d) Results for group 4
Algorithm 1 General description of the non-monotonic simulated annealing algorithm1: Q← setInitialSolution(), Q∗ ← Q, temperature← 1002: while totalT ime < 500 do3: temperature← temperature× 0.994: if temperature < 0.01 then5: temperature← 1006: end if7: Q′ ← neighborSolution(Q), ∆← objectiveFunction(Q′)− objectiveFunction(Q)8: if (∆ < 0 || randomNumber() < e−∆/temperature) then9: Q← Q′
10: if (∆ < 0) then11: Q∗ ← Q12: end if13: end if14: end while15: return Q∗
performing skill s1 and u1 ∈ U(j2) performing skill s2.The choice of skill s1 ∈ S in both case is made according to a vector probability called prob1,
given as input, where the skills that have larger demand have higher probability of being selected.
More precisely, prob1(s) =∑
j∈T t(j,s)∑s∈S
∑j∈T t(j,s)
, ∀s ∈ S. Only teams that demands skill s1 are candi-
dates for being chosen as team j1. Similarly, only individuals who performs skill s1 in team j1 may
CLAIO-2016
325

be an option for being u1 ∈ U(j1). Both choices are made randomly.If the individual u1 selected has only the skill that he performs, the operator swap1 is used.
Otherwise, we consider the two possibilities of swap. The choice of swap is made with probabilityprob2, given as input, which is proportional to
∑u∈V |s(u)|. Precisely, the choice probability
of swap2 is prob2 = (∑
u∈V |s(u)|)/(|V | × |S|). If operator swap2 is selected, skill s2 is chosenrandomly among the skills that individual u1 has. Again, only teams that demands skills s1 ands2 are candidates for being team j2. Similarly, only individuals who perform skill s2 and have skills1 in team j2 may be part of the options for being u2 ∈ U(j2). Both choices are made randomly.
The algorithm stops when the time limit is reached (500 seconds). Note also that the temper-ature of SANM is initialized with a value of 100 units. Each iteration this temperature decreasesto 99, 9% of its current value. When the temperature assumes a value less than 0.01, the systemis reheated to 100 units. With reheating, the system returns to have new chances to search otherregions of the solution space during the optimization process.
6 Final remarks
We introduced in this work a novel combinatorial optimization problem referred to as socio-technicalteam formation problem (STFP). The problem is shown to beNP-hard and hence instances of prac-tical interest may not be solved to optimality in reasonable time. Nevertheless, we conceived aninteger linear programming formulation for STFP and enumerated some facet-defining inequalitiesassociated with its corresponding polytope. Two exact approaches based on the proposed formu-lation are tested on a set of randomly generated instances. In particular, for instances where thetime limitation was a drawback, we used promising upper bounds – achieved by a non-monotonicsimulated annealing algorithm – to prune subproblems of the branch-and-bound search tree. In theend, we could solve all test instances to optimality within 5000s.
References
[1] E. Trist. The evolution of socio-technical systems. Occasional paper, 2:1981, 1981.
[2] I. M. Bomze, M. Budinich, P. M. Pardalos, and M. Pelillo. The maximum clique problem. InHandbook of combinatorial optimization, pages 1–74. Springer, 1999.
[3] L. A. Wolsey and G. L. Nemhauser. Integer and combinatorial optimization. John Wiley &Sons, 2014.
[4] T. F. Figueiredo. Problema de formação de equipes sociotécnicas: Complexidade, formulaçõesmatemáticas e resultados computacionais. Master’s thesis, Universidade Federal do Ceará, 2014.
[5] S. Kirkpatrick. Optimization by simulated annealing: Quantitative studies. Journal of statisticalphysics, 34(5-6):975–986, 1984.
[6] A. E. Eiben and Z. Ruttkay. Self-adaptivity for constraint satisfaction: learning penalty func-tions. In Proceedings of IEEE International Conference on Evolutionary Computation, pages258–261, 1996.
CLAIO-2016
326

A metaheurística Iterated Local Search e a técnica de busca Very
Large-scale Neighborhood Search aplicada ao Problema de Programação de Máquinas Paralelas
Rodrigo Ribeiro Franco
Universidade Federal de Ouro Preto, MG, Brasil [email protected]
Gustavo Peixoto Silva
Universidade Federal de Ouro Preto, MG, Brasil [email protected]
Abstract Neste trabalho são apresentadas duas versões da metaheurística ILS para o problema de programação de máquinas paralelas com minimização do atraso ponderado. Para cada tarefa é conhecido o tempo de processo, a data de entrega e o peso por dias de atraso. O objetivo é alocar as tarefas às máquinas minimizando a soma dos atrasos ponderados. Para otimizar cada máquina, foram usadas buscas locais do tipo swap - a troca da posição de duas tarefas, e twist - a inversão da ordem de um conjunto de tarefas. Na versão ILS-Clássica, a otimização entre máquinas se dá por movimentos de realocação e troca de tarefas. Na segunda versão, foi utilizada a técnica Very Large-scale Neighborhood Search-VLNS. Foram realizados testes computacionais com problemas benchmak, cujas soluções ótimas são conhecidas e com problemas maiores, para os quais não são conhecidas as soluções ótimas. Assim, foi possível verificar que a versão ILS-VLNS foi mais eficiente na resolução do problema do que a versão ILS-Clássica. Keywords: parallel machines total weighted tardiness problem; Iterated Local Search; Very Large-scale
Neighborhood Search. 1 Introdução
O problema de programação de máquinas paralelas com minimização da soma do atraso ponderado consiste em atribuir um conjunto de n tarefas a um conjunto de m maquinas de tal forma que cada tarefa seja executada por uma única máquina. Em determinados casos, as tarefas exigem um determinado tempo de preparação da máquina para a sua execução. Este tempo de preparação pode ser constante como também pode depender da sequência em que as tarefas são realizadas. Na verdade, existe uma grande variedade de problemas de sequenciamento de tarefas. Este trabalho trata do problema de sequenciamento de tarefas em maquinas paralelas e idênticas sem tempo de preparação, ou seja, o parallel-machines total
tardeness problem denotado na literatura por Pm||∑wjTj.
Nos problemas do tipo Pm||∑wjTj é dado um conjunto de tarefas N = {1, 2, ...., n}, com o tempo de processamento pj, pesos wj e as datas de entrega dj para cada tarefa j∈N. As tarefas são processadas em uma sequencia S em um conjunto M = {1, 2, ...., m} de máquinas identificas e paralelas de modo que as completudes Cj das tarefas minimizem a função objetivo T(S) dada por (1).
∑∑==
−==n
j
jjj
n
j
jj dCwTwST11
}0,{max)( (1)
CLAIO-2016
327

Para m = 1 temos o problema de atraso total de uma única máquina, bem estudado e resolvido tanto com métodos exatos quanto com métodos heurísticos (Pan & Shi, 2007; Congram et al., 2002; Grosso et al., 2004). A literatura parece ser limitada para o problema de máquinas paralelas. Para conhecer outras abordagens, consultar os trabalhos de Anghinolfi & Paolucci (2007), Bilge et al. (2004), Koulamas (1997) e Rodrigues et al. (2008).
No Pm||∑wiTi procura-se obter uma sequência de tarefas a ser realizada por cada máquina de tal forma que cada tarefa seja executada por uma única máquina, cada máquina realize uma tarefa por vez, de forma não preemptiva, e a função objetivo seja minimizada. De acordo com Lenstra et al. (1977), este problema é do tipo NP-hard, por esta razão, são utilizadas metaheurísticas para se obter boas soluções em um tempo de processamento razoável (Du & Leung, 1990).
A busca VLNS é um método de busca local que explora vizinhanças complexas de problemas de otimização combinatória. Tais vizinhanças são caracterizadas por ter um número exponencial de soluções de vizinhos, mas que podem ser exploradas em tempo polinomial por métodos exatos ou heurísticos (Ahuja 2002). O ILS pode ser acoplado ao VLNS com sucesso, movendo a complexidade do algoritmo para a exploração da vizinhança. Os trabalhos de Congram et al. (2002) e Ergun & Orlin (2006) são exemplos da aplicação da técnica VLNS, chamada dynasearch, para o problema 1||∑wjTj.
Rodrigues et al. (2008) propôs um algoritmo Iterated Local Search-ILS (Lourenço et al. 2001) simples e eficiente para o problema de máquinas paralelas usando uma busca local baseada em operadores de troca entre pares. Baseado neste trabalho, foi implementada a metaheurística ILS que utiliza como busca local a técnica VLNS. Mas diferentemente de Rodrigues et. al. (2008), a VLNS foi empregada, no presente trabalho, para realizar a otimização entre máquinas e não intra-máquina como fizeram os autores. Na etapa de otimização de cada maquina, foram implementadas as mesmas heurísticas de busca local utilizados por Rodrigues et al. (2008).
Neste trabalho serão apresentadas duas versões da metaheurística ILS. Na versão ILS-Clássica são empregadas buscas locais baseadas nas estruturas de vizinhança comumente descritas na literatura, como o swap: a troca da posição de duas tarefas em uma máquina e o twist: a inversão da ordem de operação de um conjunto de tarefas em uma máquina. Considerando várias máquinas, foram implementadas buscas locais baseadas nos movimentos de realocação e troca de tarefas entre duas máquinas. Na segunda versão, denominada ILS-VLNS, foi utilizada a técnica Very Large-scale Neighborhood Search –VLNS (Ahuja et
al. 2002) como busca local entre máquinas. As metaheurísticas foram testadas com dados de problemas
benchmark disponíveis na internet para os quais são conhecidos os melhores resultados. Também foram realizados testes com um conjunto de problemas de maior porte, para os quais não são conhecidas as soluções ótimas. Desta forma, foi possível verificar a eficiência da versão ILS-VLNS para o problema.
O artigo está dividido da seguinte forma: na seção 2 é apresentada a implementação da metaheurística ILS proposta para o problema. Na seção 3 são apresentados e discutidos os resultados obtidos. Na seção 4 são apresentadas as conclusões do trabalho.
2 A Implementação do ILS para a resolução do problema
A metaheurística ILS é um arcabouço de busca local que pode ser visto como um tradeoff entre a metaheurística Mult-Start- MS e uma metaheurística mais complexa como a Busca Tabu ou Algoritmos Genéticos. Na MS, uma busca local é iniciada a partir de diferentes soluções geradas aleatoriamente. Este processo se repete normalmente um grande número de vezes a fim de escapar de ótimos locais e explorar um grande conjunto de soluções. Em metaheurística mais complexas, um número sofisticado de dispositivos como memória de curto e longo prazo, cruzamentos genéricos, entre outros, são aplicados a fim de fugir de ótimos locais pobres. Na ILS a pesquisa é recomeçada a partir de uma perturbação
CLAIO-2016
328

realizada nas melhores soluções conhecidas. Com este tipo de recomeço, a solução de partida de cada busca local não é completamente aleatória e a perturbação, no caso chamada de kick, tenta projetar a busca “não muito longe” do ótimo local anteriormente explorado, ou seja, sem perder completamente suas estruturas parcialmente otimizadas (Lourenço et al. 2001). A seguir são descritos os procedimentos que compõem a metaheurística ILS implementada neste trabaho.
2.1 Geração da Solução Inicial Este procedimento gera uma solução factível, de boa qualidade, para dar início ao processo de otimização. No caso foi empregada a estratégia do Early Due Date – EDD (Baker, 1984), que consiste em ordenar as tarefas priorizando aquelas com menor data de entrega. Após a ordenação crescente da data de entrega das tarefas, deve ser verifico no final de qual máquina a tarefa de menor data de entrega deve ser alocada de tal forma que incorra no menor custo possível. A tarefa é alocada no final desta máquina e o processo se repete até que todas as tarefas tenham sido alocadas.
2.2 Estruturas de Vizinhança para uma Única Máquina Considerando uma única máquina, foram implementados os operadores Generalized Pairwise
Interchanges - GPI que atuam em uma sequência de tarefas σ produzindo uma nova sequência σ’. Seja a sequência de tarefas em uma máquina dada por σ = αiπjω, onde as tarefas i e j estão nas posições k e l, respectivamente e α, π e ω são subsequências de tarefas. Os operadores GPI mais comuns são: i) Swap: αiπjω → αjπiω, sendo que π pode ser uma sequencia vazia; ii) Forward insertion: αiπjω → απjiω; iii) Backward insertion: αiπjω → αjiπω; e iv) Twist: αiπjω → αjπ’iω, sendo que π’ = π revertido
Foram implementados os operadores swap e twist, pois com eles é possível produzir resultados semelhantes aos produzidos pelo forward e backward insertions. Tais operações se aplicam a uma única máquina não vazias e com função de custo linear.
2.3 Estruturas de Vizinhança para Máquinas Paralelas Para máquinas paralelas, os movimentos que definem as vizinhanças de uma solução são modificações que envolvem pares de máquinas. Estes movimentos, denominados 2-optimal, são muito utilizados para diferentes problemas, e podem ser resumido em movimentos de realocação e a troca de elementos entre componentes de uma solução. Neste trabalho foram implementadas as vizinhanças baseadas nos movimentos descritos a seguir. Considerando um par de máquinas m1 e m2, com os respectivos sequenciamentos de tarefas σ1 e σ2 temos os movimentos: i) extrai uma tarefa i de σ1 e a insere em σ2, ou seja, faz a realocação da tarefa i da máquina m1 para a máquina m2; e ii) extrai uma tarefa i pertencente σ1 e uma tarefa j pertencente σ2. Insere i em σ2 - {j}, e insere j em σ1 - {i}. Este é um movimento de troca das tarefas i e j entre as máquinas m1 e m2. Nestas vizinhanças, uma tarefa j deve ser inserida na melhor posição da sequencia σk para onde ela for designada. Estes movimentos definem suas respectivas estruturas de vizinhança que foram utilizadas nas heurísticas de busca local. A vizinhança associada à busca VLNS também foi utilizada no ambiente de máquinas paralelas, cujo detalhamento é apresentado a seguir.
2.4 Heurísticas de Busca Local Foram implementadas as três heurísticas clássicas de busca local: Best Improvement Search-BIS, First
Improvement Search-FIS e o Random Descent Search-RDS, considerando os dois cenários. A busca Very
Large-scale Neighborhood Search-VLNS foi empregada apenas para máquinas paralelas.
Very Large Local Search - VLNS
As buscas do tipo 2-optimal são muito utilizadas para resolver problema combinatoriais. Entretanto, existem vizinhanças mais amplas que permitem uma busca em um espaço muito maior de soluções. A técnica de busca VLNS é uma generalização da vizinhança de realocação e troca aos pares, onde um vizinho é obtido através da realização de uma troca cíclica ou de uma troca em cadeia. A vizinhança de
CLAIO-2016
329

troca cíclica envolve a troca aos pares, mas também permite que tarefas de três ou mais máquinas estejam envolvidas na troca. Considerando o caso de três máquinas e de troca cíclica, uma tarefa da maquina 1 é realocada para a maquina 2, que por sua vez tem uma tarefa realocada para a máquina 3, que finalmente tem uma tarefa realocada para a maquina 1. No caso da troca em cadeia, a maquina 3 não realoca qualquer tarefa para a maquina 1 e após o movimento a maquina 1 terá uma tarefa a menos, assim como a maquina 3 contará com uma tarefa além do que havia anteriormente.
Para que seja possível realizar uma busca na vizinhança de troca cíclica ou em cadeia, de forma eficiente, é necessário construir um grafo direcionado que represente a vizinhança de uma dada solução S. Tal grafo, denominado grafo de melhoria G(S), é definido para cada solução factível S do problema. Considerando n tarefas e m máquinas, seja S[j] a máquina que contém a tarefa j, então, G(S) = (N, E) é uma grafo direcionado com o conjunto de nós N contendo um nós para cada tarefa i = 1, .., n, um nó para cada máquina j = n+1, ..., n+m, e um super-nó t = n+m+1. O conjunto E contém os seguintes arcos: 1. (i, j) de uma tarefa i para outra j que representa a substituição da tarefa j pela tarefa i na máquina S[j]
que contém a tarefa j. O custo deste tipo de arco é dado por c({i}∪S[j]\{j}) – c(S[j]); 2. (i, mj) de uma tarefa i para uma máquina mj, sendo mj ≠ S[i], que representa a realocação da tarefa i
para a máquina mj. Neste caso, o custo do arco é calculado pela expressão c({i}∪mj) – c(mj); 3. (t, j) do super-nó t para cada tarefa j, que considera a retirada da tarefa j da máquina em que se
encontra. O custo deste arco é dado por c(S[j]\{j}) – c(S[j]); 4. (mj, t) de cada máquina mj para o super-nó t, que permitir a formação de ciclos. Estes arcos tem custo
zero. Um ciclo negativo no grafo G(S) corresponde a uma troca cíclica que melhora o valor da função objetivo referente à solução S. Esta é uma maneira eficiente de buscar por soluções vizinhas de S que melhoram a função objetivo. Portanto, basta encontrar um ciclo negativo no grafo direcionado G(S) para se obter um vizinho melhor. Neste trabalho foi implementado o algoritmo de Walk to the root (Cherkassky & Goldberg, 1999) que tem complexidade O(n2
m), ou seja, apresenta complexidade polinomial.
Uma vez encontrado um ciclo negativo, as trocas referentes ao ciclo são realizadas, e o grafo de melhoria é atualizado. O processo é repetido até nenhum ciclo negativo seja encontrado no grafo de melhoria. Quando o grafo não apresentar qualquer ciclo negativo, então a solução corrente é uma solução ótima local segundo esta vizinhança.
2.5 Perturbação de uma Solução A perturbação de uma solução é a etapa da ILS que tem como objetivo escapar da uma solução ótima local e explorar outras regiões do espaço de soluções. Ela deve ser calibrada para não ser muito fraca, impossibilitando a saída do “vale” do ótimo local corrente, e nem muito forte que perca boas características da solução corrente. Na implementação desenvolvida, a perturbação consistiu em aplicar um número limitado de movimentos aleatórios do tipo swap para uma única máquina e de movimento de troca de tarefas entre máquinas escolhidas aleatoriamente.
2.6 Critério de Aceitação e de Parada Este procedimento determina qual deve ser a nova solução corrente para a próxima iteração. O critério de aceitação foi determinístico, ou seja, uma nova solução só é aceita se ela for melhor do que a melhor solução conhecida. Foi considerado como critério de parada o tempo de processamento limitado a 15 minutos.
2.7 A Metaheurística ILS para o Problema Pm||∑WjTj
CLAIO-2016
330

A metaheurística ILS, implementada conta com duas buscas locais: a busca em N1, realizada pela função descida1(), na linha 4 do Algoritmo 1, tenta melhorar o sequenciamento das tarefas de cada máquina isoladamente. A busca em N2, feita pela função descida2() na linha 6 do Algoritmo 1, faz a otimização considerando movimentos entre máquinas. Na primeira versão do ILS, a busca entre máquinas foi realizada por meio de movimentos do tipo 2-optimal. Na segunda versão foram feitas buscas do tipo n-
optimal, ou seja, foi utilizada a busca VLNS considerando movimentos entre máquinas. Assim, dependendo do método empregado para realizar a busca local entre máquinas, temos uma versão diferente do ILS. Utilizando realocação de troca de tarefas entre máquinas, temos a versão ILS-Clássica. Por outro lado, ao empregar o VLNS, temos a versão ILS-VLNS. Nas linhas 19 e 22 ocorre a perturbação intra-máquinas aplicando a função kick1( ), ou seja, são modificadas as posições das tarefas em máquinas escolhidas aleatoriamente. Posteriormente, na linha 22, é realizada a perturbação via kick2( ), que consiste em aplicar movimentos de troca de tarefas escolhidas de pares de máquinas tomadas aleatoriamente. Iterated Local Search (N1, N2, T(), EDD(), Tempo, MaxSemMelhora)
1. S* = S = EDD();
2. IterCont = 0;
3. enquanto tempo de processamento < Tempo faça 4. S1 = decida1(S, N1);
5. Repita 6. S2 = decida2(S1, N2);
7. se(T(S2) < T(S1) então 8. S1 = S2;
9. fim_se; 10. até que N2 não melhore S1 11. se T(S1) < T(S*) então 12. S* = S1;
13. interCont = 0;
14. senão 15. interCont = interCont + 1;
16. fim_se; 17. se N2 falhar em melhorar S1 então 18. se iterCont > MaxSemMelhora então 19. S = kick1(S*);
20. interCont = 0;
21. senão 22. S = kick2(S2);
23. fim_se; 24. fim_se; 25. fim_enquanto; 26. retorna S*;
Algoritmo 1. Pseudocódigo da implementação do ILS.
3 Testes Computacionais e Análise dos Resultados
Inicialmente foram realizados testes para determinar quais são os métodos mais eficientes de busca local, assim como as estruturas de vizinhança que produzem os melhores resultados. Posteriormente, foram realizados testes com as duas versões do ILS com diferentes conjuntos de problemas benchmark. Testes preliminares mostraram que, entre as heurísticas clássicas de busca local, a BIS foi mais eficiente do que as demais. No caso de máquinas paralelas, foi observado que o método de busca local BIS associado com a vizinhança de troca de tarefas foi a combinação mais eficiente e, portanto, foi adotada no ILS-Clássico.
3.1 Teste da Metaheurística ILS
CLAIO-2016
331
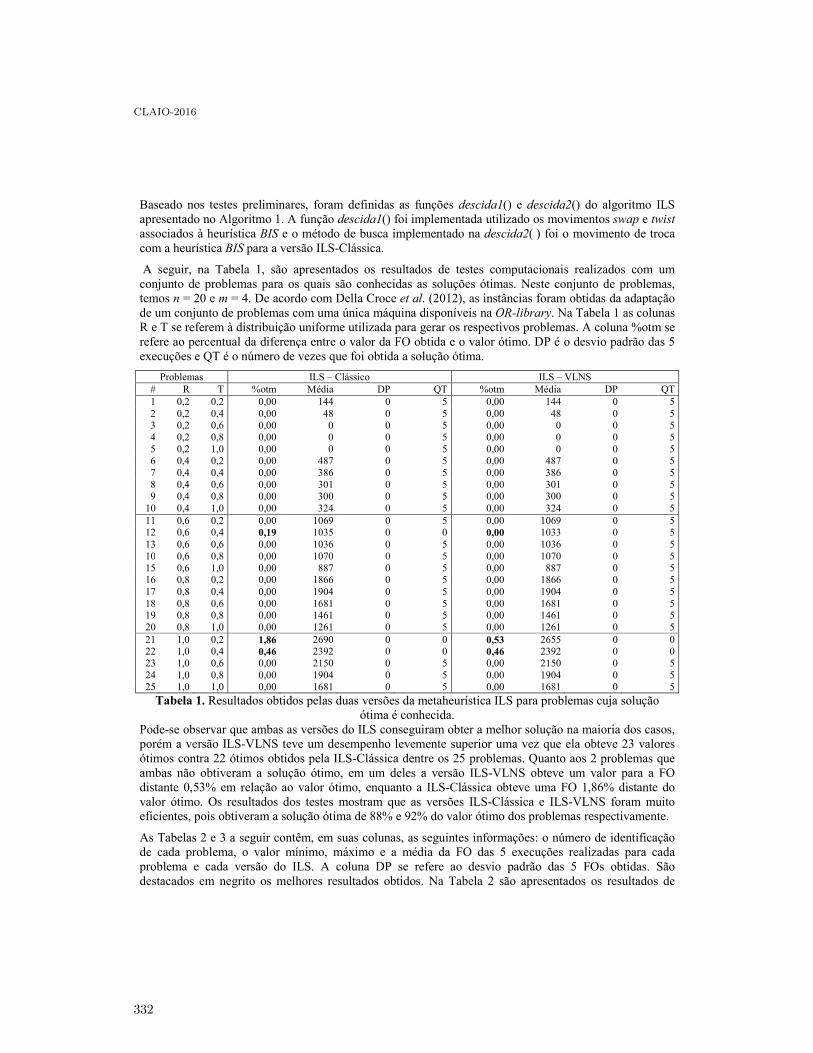
Baseado nos testes preliminares, foram definidas as funções descida1() e descida2() do algoritmo ILS apresentado no Algoritmo 1. A função descida1() foi implementada utilizado os movimentos swap e twist associados à heurística BIS e o método de busca implementado na descida2( ) foi o movimento de troca com a heurística BIS para a versão ILS-Clássica.
A seguir, na Tabela 1, são apresentados os resultados de testes computacionais realizados com um conjunto de problemas para os quais são conhecidas as soluções ótimas. Neste conjunto de problemas, temos n = 20 e m = 4. De acordo com Della Croce et al. (2012), as instâncias foram obtidas da adaptação de um conjunto de problemas com uma única máquina disponíveis na OR-library. Na Tabela 1 as colunas R e T se referem à distribuição uniforme utilizada para gerar os respectivos problemas. A coluna %otm se refere ao percentual da diferença entre o valor da FO obtida e o valor ótimo. DP é o desvio padrão das 5 execuções e QT é o número de vezes que foi obtida a solução ótima.
Problemas ILS – Clássico ILS – VLNS # R T %otm Média DP QT %otm Média DP QT 1 0,2 0,2 0,00 144 0 5 0,00 144 0 5 2 0,2 0,4 0,00 48 0 5 0,00 48 0 5 3 0,2 0,6 0,00 0 0 5 0,00 0 0 5 4 0,2 0,8 0,00 0 0 5 0,00 0 0 5 5 0,2 1,0 0,00 0 0 5 0,00 0 0 5 6 0,4 0,2 0,00 487 0 5 0,00 487 0 5 7 0,4 0,4 0,00 386 0 5 0,00 386 0 5 8 0,4 0,6 0,00 301 0 5 0,00 301 0 5 9 0,4 0,8 0,00 300 0 5 0,00 300 0 5
10 0,4 1,0 0,00 324 0 5 0,00 324 0 5 11 0,6 0,2 0,00 1069 0 5 0,00 1069 0 5 12 0,6 0,4 0,19 1035 0 0 0,00 1033 0 5 13 0,6 0,6 0,00 1036 0 5 0,00 1036 0 5 10 0,6 0,8 0,00 1070 0 5 0,00 1070 0 5 15 0,6 1,0 0,00 887 0 5 0,00 887 0 5 16 0,8 0,2 0,00 1866 0 5 0,00 1866 0 5 17 0,8 0,4 0,00 1904 0 5 0,00 1904 0 5 18 0,8 0,6 0,00 1681 0 5 0,00 1681 0 5 19 0,8 0,8 0,00 1461 0 5 0,00 1461 0 5 20 0,8 1,0 0,00 1261 0 5 0,00 1261 0 5 21 1,0 0,2 1,86 2690 0 0 0,53 2655 0 0 22 1,0 0,4 0,46 2392 0 0 0,46 2392 0 0 23 1,0 0,6 0,00 2150 0 5 0,00 2150 0 5 24 1,0 0,8 0,00 1904 0 5 0,00 1904 0 5 25 1,0 1,0 0,00 1681 0 5 0,00 1681 0 5
Tabela 1. Resultados obtidos pelas duas versões da metaheurística ILS para problemas cuja solução ótima é conhecida.
Pode-se observar que ambas as versões do ILS conseguiram obter a melhor solução na maioria dos casos, porém a versão ILS-VLNS teve um desempenho levemente superior uma vez que ela obteve 23 valores ótimos contra 22 ótimos obtidos pela ILS-Clássica dentre os 25 problemas. Quanto aos 2 problemas que ambas não obtiveram a solução ótimo, em um deles a versão ILS-VLNS obteve um valor para a FO distante 0,53% em relação ao valor ótimo, enquanto a ILS-Clássica obteve uma FO 1,86% distante do valor ótimo. Os resultados dos testes mostram que as versões ILS-Clássica e ILS-VLNS foram muito eficientes, pois obtiveram a solução ótima de 88% e 92% do valor ótimo dos problemas respectivamente.
As Tabelas 2 e 3 a seguir contêm, em suas colunas, as seguintes informações: o número de identificação de cada problema, o valor mínimo, máximo e a média da FO das 5 execuções realizadas para cada problema e cada versão do ILS. A coluna DP se refere ao desvio padrão das 5 FOs obtidas. São destacados em negrito os melhores resultados obtidos. Na Tabela 2 são apresentados os resultados de
CLAIO-2016
332
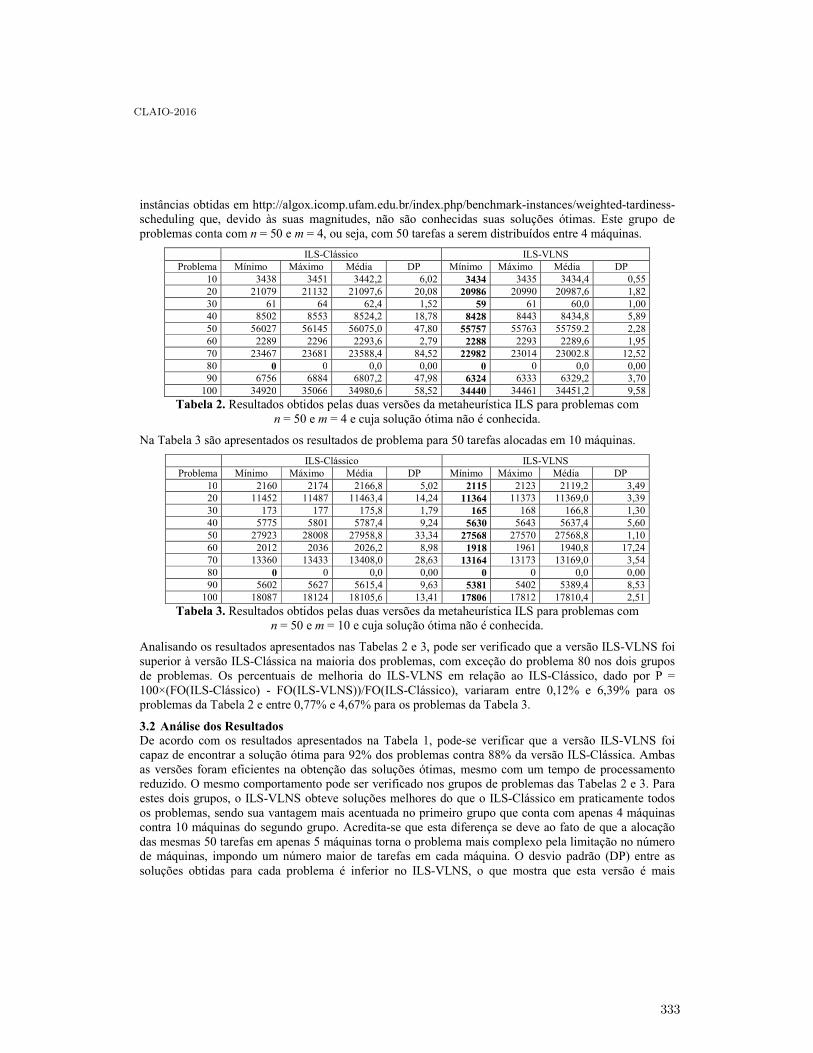
instâncias obtidas em http://algox.icomp.ufam.edu.br/index.php/benchmark-instances/weighted-tardiness-scheduling que, devido às suas magnitudes, não são conhecidas suas soluções ótimas. Este grupo de problemas conta com n = 50 e m = 4, ou seja, com 50 tarefas a serem distribuídos entre 4 máquinas.
ILS-Clássico ILS-VLNS
Problema Mínimo Máximo Média DP Mínimo Máximo Média DP 10 3438 3451 3442,2 6,02 3434 3435 3434,4 0,55 20 21079 21132 21097,6 20,08 20986 20990 20987,6 1,82 30 61 64 62,4 1,52 59 61 60,0 1,00 40 8502 8553 8524,2 18,78 8428 8443 8434,8 5,89 50 56027 56145 56075,0 47,80 55757 55763 55759.2 2,28 60 2289 2296 2293,6 2,79 2288 2293 2289,6 1,95 70 23467 23681 23588,4 84,52 22982 23014 23002.8 12,52 80 0 0 0,0 0,00 0 0 0,0 0,00 90 6756 6884 6807,2 47,98 6324 6333 6329,2 3,70
100 34920 35066 34980,6 58,52 34440 34461 34451,2 9,58
Tabela 2. Resultados obtidos pelas duas versões da metaheurística ILS para problemas com n = 50 e m = 4 e cuja solução ótima não é conhecida.
Na Tabela 3 são apresentados os resultados de problema para 50 tarefas alocadas em 10 máquinas.
ILS-Clássico ILS-VLNS Problema Mínimo Máximo Média DP Mínimo Máximo Média DP
10 2160 2174 2166,8 5,02 2115 2123 2119,2 3,49 20 11452 11487 11463,4 14,24 11364 11373 11369,0 3,39 30 173 177 175,8 1,79 165 168 166,8 1,30 40 5775 5801 5787,4 9,24 5630 5643 5637,4 5,60 50 27923 28008 27958,8 33,34 27568 27570 27568,8 1,10 60 2012 2036 2026,2 8,98 1918 1961 1940,8 17,24 70 13360 13433 13408,0 28,63 13164 13173 13169,0 3,54 80 0 0 0,0 0,00 0 0 0,0 0,00 90 5602 5627 5615,4 9,63 5381 5402 5389,4 8,53
100 18087 18124 18105,6 13,41 17806 17812 17810,4 2,51
Tabela 3. Resultados obtidos pelas duas versões da metaheurística ILS para problemas com n = 50 e m = 10 e cuja solução ótima não é conhecida.
Analisando os resultados apresentados nas Tabelas 2 e 3, pode ser verificado que a versão ILS-VLNS foi superior à versão ILS-Clássica na maioria dos problemas, com exceção do problema 80 nos dois grupos de problemas. Os percentuais de melhoria do ILS-VLNS em relação ao ILS-Clássico, dado por P = 100×(FO(ILS-Clássico) - FO(ILS-VLNS))/FO(ILS-Clássico), variaram entre 0,12% e 6,39% para os problemas da Tabela 2 e entre 0,77% e 4,67% para os problemas da Tabela 3.
3.2 Análise dos Resultados De acordo com os resultados apresentados na Tabela 1, pode-se verificar que a versão ILS-VLNS foi capaz de encontrar a solução ótima para 92% dos problemas contra 88% da versão ILS-Clássica. Ambas as versões foram eficientes na obtenção das soluções ótimas, mesmo com um tempo de processamento reduzido. O mesmo comportamento pode ser verificado nos grupos de problemas das Tabelas 2 e 3. Para estes dois grupos, o ILS-VLNS obteve soluções melhores do que o ILS-Clássico em praticamente todos os problemas, sendo sua vantagem mais acentuada no primeiro grupo que conta com apenas 4 máquinas contra 10 máquinas do segundo grupo. Acredita-se que esta diferença se deve ao fato de que a alocação das mesmas 50 tarefas em apenas 5 máquinas torna o problema mais complexo pela limitação no número de máquinas, impondo um número maior de tarefas em cada máquina. O desvio padrão (DP) entre as soluções obtidas para cada problema é inferior no ILS-VLNS, o que mostra que esta versão é mais
CLAIO-2016
333

robusta do que a versão Clássica da metaheurística. Os testes realizados permitem inferir que a versão ILS-VLNS é mais eficiente do que a versão ILS-Clássica na resolução do problema.
4 Conclusões
Este trabalho apresenta a implementação da metaheurística ILS para resolver o problema de sequenciamento de máquinas paralelas e uniformes considerando duas versões: uma que utiliza métodos clássicos de busca local, o ILS-Clássico, e outra versão que emprega a busca em vizinhança de grande porte VLNS para realizar a otimização entre máquinas, denominada ILS-VLNS.
No primeiro grupo de problemas foi verificada a capacidade das duas versões de atingir a solução ótima dos problemas, sendo que ambas foram eficientes, com uma vantagem para a versão ILS-VLNS que obteve maior número de soluções ótimas assim como soluções mais próximas da ótima nos casos em que não a solução ótima não foi encontrada. Nos dois últimos grupos de problemas, foi confirmada a superioridade da versão ILS-VLNS sobre a versão ILS-Clássica em praticamente todos os problemas, com melhorias variando entre 0,12% e 6,39% de diferença entre a FO das duas versões. Desta forma, este trabalho contribuiu testando uma combinação ainda inédita que mostra ser promissora.
Agradecimentos Os autores agradecem à FAPEMIG, ao CNPq e à UFOP pelo apoio recebido para este trabalho.
Referências Bibliográficas
1. Ahuja, R. K., Ergun, Ö., Orlin, J. B. & Punnen, A. P. (2002). A survey of very large-scale neighborhood search techniques. Discrete Applied Mathematics, 123(1-3), 75–102.
2. Anghinolfi, D. & Paolucci, M. (2007). Parallel machine total tardiness scheduling with a new hybrid metaheuristic approach. Computers & Operations Research, 34(11), 3471-3490.
3. Baker, K. R. (1984). Sequencing rules and due-date assignments in a job shop. Management Science, 30(9), 1093–1104.
4. Bilge, Ü., Kıraç, F., Kurtulan, M. & Pekgün, P. (2004). A tabu search algorithm for parallel machine total tardiness problem. Computers & Operations Research, 31(3), 397-414.
5. Cherkassky, B. V & Goldberg, A. V. (1999). Negative-cycle detection algorithms. Mathematical Programming, 85(2), 277–311.
6. Congram, R. K., Potts, C. N. & van de Velde, S. L. (2002). An iterated dynasearch algorithm for the single-machine total weighted tardiness scheduling problem. INFORMS Journal on Computing, 14(1), 52-67.
7. Della Croce, F., Garaix, T. & Grosso, A. (2012). Iterated local search and very large neighborhoods for the parallel-machines total tardiness problem. Computers & Operations Research, 39(6), 1213–1217.
8. Du, J. & Leung, J. Y. T. (1990). Minimizing total tardiness on one machine is NP-hard. Mathematics of
Operations Research, 15(3), 483-0,495. 9. Ergun, Ö. & Orlin, J. B. (2006). Fast neighborhood search for the single machine total weighted tardiness
problem. Operations Research Letters,34(1), 41-45. 10. Grosso, A., Della Croce, F. & Tadei, R. (2004). An enhanced dynasearch neighborhood for the single-machine
total weighted tardiness scheduling problem. Operations Research Letters, 32(1), 68-72. 11. Koulamas C. (1997) Decomposition and hybrid simulated annealing heuristics for the parallel-machine total
tardiness problem. Naval Research Logistics, 44, 109–25. 12. Lenstra, J. K., Rinnooy Kan, A. H. G. & Brucker, P. (1977). Complexity of machine scheduling problems.
Annals of Discrete Mathematics, 1, 343–362. 13. Lourenco, H. R., Martin, O. C. & Stutzle, T. (2001). Iterated Local Search. In R. Glover & G. Kochenberger
(Eds.), Handbook of Metaheuristics, 253–321. ISORMS. 14. Pan, Y. & Shi, L. (2007). On the equivalence of the max-min transportation lower bound and the time-indexed
lower bound for single-machine scheduling problems. Mathematical Programming, 110(3), 543-559. 15. Rodrigues, R., Pessoa, A., Uchoa, E. & Poggi de Aragão, M. (2008). Heuristic algorithm for the parallel
machine total weighted tardiness scheduling problem. Relatório de Pesquisa em Engenharia de Produção, 8(10).
CLAIO-2016
334

PROPOSTA DE MODELO MULTICRITÉRIO PARA
SELEÇÃO DE PESSOAL NO PROJETO DE
DESENVOLVIMENTO DE AEROMODELOS DE CARGA
Patrícia Rafaela Leite Freire
Universidade Federal Rural do Semi-Árido (UFERSA)
Joana Karolyni Cabral Peixoto
Universidade Federal Rural do Semi-Árido (UFERSA) [email protected]
Thomas Edson Espíndola Gonçalo
Universidade Federal Rural do Semi-Árido (UFERSA) [email protected]
Resumo
Dentre as diversas ações realizadas na formação dos engenheiros, destacam-se as competições
relacionadas à construção de aeromodelos de carga. O processo de construção de uma aeronave
enquadra-se como um Projeto de Desenvolvimento de Produtos (PDP). Uma importante decisão na
área envolve a seleção de pessoal, fator gerencial que afeta o desempenho do projeto. O presente
trabalho tem a finalidade de propor um modelo de apoio à decisão multicritério para tomada de
decisão em grupo quanto à seleção de pessoal para equipes de desenvolvimento de aeronaves para
competição. O modelo é composto por duas etapas, onde a primeira envolve as avaliações
individuais dos tomadores de decisão e a segunda agrega as opiniões dos envolvidos em uma
opinião do grupo. O modelo proposto é aplicado para o caso da equipe Pegazuls Aerodesign, da
Universidade Federal Rural do Semiárido, resultando na seleção adequada dos participantes que
irão compor a equipe do projeto.
Palavras-chave: Seleção de pessoal. Tomada de decisão em grupo. Projeto de desenvolvimento de
produtos.
1. Introdução
De acordo com Rozenfeld et al. (2006), o desenvolvimento de produtos consiste
basicamente de um conjunto de tarefas cujo objetivo é chegar às especificações de projeto de um
produto bem como do seu processo de produção. O processo de desenvolvimento de produto
também envolve o acompanhamento do produto logo após o seu lançamento para que possam ser
realizadas eventuais mudanças necessárias que possam surgir no processo ou até mesmo ao longo
do ciclo de vida do produto.
A construção de uma aeronave é considerada como sendo um projeto de desenvolvimento
de produtos, cujo processo é amplo em quantidade e variedade de atividades, e que deve envolver
toda a equipe, pois as decisões tomadas por um membro influenciam e são influenciadas pelas
decisões dos demais. Observa-se, com isso, o que é destacado por Romeiro Filho (2010), Rozenfeld
et al. (2006), Baxter (2011) e Rotondaro (2010) ao apresentarem os aspectos que devem ser
considerados em um projeto de produto, por meio dos quais se constata a importância da seleção de
uma boa equipe para o projeto. O sucesso do desenvolvimento das atividades do PDP dependerá das
decisões tomadas pelas pessoas escolhidas para fazerem parte do projeto.
De acordo com Rozenfeld et al. (2006), as atividades do PDP influenciam e são
influenciadas pelo trabalho da equipe, já que o produto será desenvolvido, produzido e controlado
CLAIO-2016
335

tanto envolvendo quanto sendo envolvido por todos os setores do projeto. Ainda segundo os
autores, a determinação das responsabilidades e do nível de dedicação de cada participante da
equipe de projeto também precisa estar incluída no modelo de referência e servirá de parâmetro
para definição das competências esperadas nas pessoas selecionadas para compor a equipe. Pitchai,
Reddy e Savarimuthu (2016) complementam ao afirmar que a formação de uma equipe de projeto
efetiva possui um importante papel na obtenção dos resultados de um projeto e constitui-se como
um problema desafiador de decisão multicritério na maioria das organizações.
O processo de seleção de uma equipe configura-se geralmente como uma análise
multicritério, uma vez que há a consideração de mais de um critério ou atributo para se selecionar a
melhor equipe para o projeto. Neste contexto, Alencar e Almeida (2010) apontam que a seleção da
equipe de projeto é, na prática, um problema de tomada de decisão multicritério no qual múltiplos
tomadores de decisão avaliam atributos requeridos aos candidatos. Segundo Jannuzzi, Miranda e
Silva (2009), os Métodos Multicritério de Apoio à Decisão (MCDA) são considerados ferramentas
de apoio à decisão, cujo caráter pode ser tanto qualitativo quanto quantitativo, de modo que sua
capacidade permite que a tomada de decisão seja realizada com base nos critérios do problema, por
meio dos decisores, através de um processo interativo com outros atores. Para Gonçalo e Alencar
(2014), as abordagens multicritério vêm ganhando atenção devido à sua robustez e facilidade para
tratar problemas complexos de maneira bastante efetiva. Campos (2011) complementa afirmando
que, no processo de decisão, é relevante levantar quais seriam os quesitos importantes e
imprescindíveis para alcançar a satisfação do resultado final. Em um processo decisório nas
organizações a decisão escolhida pelos membros terá repercussão coletiva.
Conforme explicitado por Almeida (2013), o processo decisório pode envolver, de modo
geral, apenas um decisor ou um grupo de decisores, responsáveis pelas consequências da decisão
tomada. No contexto de seleção de equipes, principalmente em projetos, é bastante comum que a
tomada de decisão seja realizada por mais de um decisor, podendo incorporar, também, os diversos
stakeholders envolvidos. Maximiliano (200) aponta que a decisão ocorre cada vez mais
descentralizada e coletiva, sendo importante o conhecimento sobre a tomada de decisão em grupo.
Existem várias formas para apoiar a tomada de decisão em grupo, sendo a mais conhecida
delas denominada de sistemas de votação. Segundo Almeida et al. (2012), um sistema de votação
tem como finalidade apoiar um processo de decisão multicritério de um grupo de decisores, pois
está associado a um dos tipos de procedimentos para agregação de decisão em grupo, que é a
agregação a partir dos resultados e escolhas finais dos decisores. Existem diversos tipos de
procedimentos que são utilizados para solucionar problemas referentes à votação.
Desta forma, pretende-se propor um modelo multicritério para seleção de pessoal
participante na equipe de desenvolvimento de aeronaves para competições universitárias. Para
tanto, na seção 2 buscou-se investigar como ocorre a seleção de novos participantes para a equipe
Pegazuls Aerodesign. Na seção 3, é proposto um modelo multicritério de decisão em grupo para
apoiar nesse processo. Em seguida, na seção 4, é realizada a aplicação do modelo para selecionar a
equipe, com base em avaliações da equipe de recrutamento do projeto. Por fim, são expostas as
considerações finais acerca do estudo realizado.
2.Processo atual de seleção da equipe Pegazuls Aerodesign
A equipe Pegazuls Aerodesign da Universidade Federal Rural do Semi-Árido– UFERSA é
formada por estudantes, a partir do segundo ao sexto semestre, de graduação dos cursos de
Engenharia e Ciência e Tecnologia. A equipe é composta por dezessete participantes, de acordo
com o regulamento da SAE Brasil, sendo três alocados a área de Aerodinâmica, três a Desempenho,
dois a Desenho e Fabricação, dois a Cargas e Estrutura, dois a Projeto Elétrico, dois a Estabilidade e
Controle e três a Planejamento, Marketing e Financeiro. Tais integrantes possuem responsabilidades
específicas quanto ao desenvolvimento do produto. A seleção de pessoal realizada pela equipe
Pegazuls segue conforme exposto na Figura 1 e descrito a seguir.
CLAIO-2016
336

Figura 1 – Processo atual para a seleção de novos participantes
A primeira etapa do modelo proposto envolve a definição de como deve ocorrer o processo
seletivo para seleção de membros do projeto naquele período. A partir do momento em que tal
decisão é determinada, a próxima fase inclui a elaboração do edital, o qual deverá conter a
finalidade do projeto com as principais áreas do mesmo e a quantidade de vagas distribuídas pelos
respectivos campos do projeto; bem como as etapas da seleção como inscrição online, envio do
histórico, currículo e uma planilha com os horários livres; o conteúdo da prova com os assuntos e a
bibliografia; o período de inscrições; e divulgação dos resultados.
Inicia-se então o período de inscrições e o envio dos currículos, históricos e das planilhas de
horários livres dos candidatos que deseja participar da seleção. Após o encerramento das inscrições
é então divulgada a lista com os nomes dos inscritos que irão participar da próxima fase, que é a
prova escrita.
Em seguida é realizada a aplicação das provas baseadas na bibliografia sugerida no edital,
de modo que o candidato deverá ter uma pontuação mínima de 50%, para que assim possa seguir
para a etapa seguinte do processo seletivo, que é a entrevista individual. Ao final da aplicação das
provas é realizada a divulgação dos participantes que estarão aptos à entrevista individual. Após a
divulgação dos aprovados na fase anterior, dá-se início a análise minuciosa de todos os documentos
dos mesmos. A seguir é realizada a entrevista com os candidatos aprovados até aquele momento.
Por fim, é divulgada a lista final dos participantes selecionados para fazer parte da equipe Pegazuls.
Observa-se que a seleção ocorre de maneira relativamente estruturada, mas carece de
suporte quanto à tomada de decisão em grupo. Nesse caso, a decisão em grupo é realizada a partir
da avaliação inicial de cada decisor, sendo necessário se chegar ao consenso acerca dos parâmetros
que serão utilizados para se fazer a escolha da equipe. Tal fato pode criar situações de conflito entre
os agentes envolvidos no processo de selecionar os participantes. Além disso, seguindo o
procedimento atual, não é considerada a hesitação dos decisores na avaliação das alternativas.
3. Proposta de modelo de decisão em grupo para formação de equipe de projetos de
desenvolvimento de aeromodelos de carga
O modelo multicritério para apoiar a tomada de decisão em grupo para formação de equipe
de projetos de aerodesign é apresentado na Figura 2.
Figura 2 – Modelo para seleção de pessoal para a equipe Pegazuls Aerodesign
Inicialmente deve ser realizado o cadastro dos participantes no processo seletivo, onde os
mesmos devem apresentar as informações necessárias para a avaliação, bem como suas respectivas
CLAIO-2016
337

comprovações. Em seguida, deve ser realizada a pré-seleção dos candidatos, na qual são avaliados
as habilidades e conhecimentos por meio da realização de prova, análise de currículo e histórico e
desempenho na entrevista. Neste contexto, cada participante apresentará seu respectivo desempenho
nos aspectos avaliados durante a pré-seleção. Caso o participante não alcance os requisitos mínimo
para algum dos testes, o mesmo é eliminado do processo. A partir daí o processo restante de seleção
ocorre em duas etapas distintas.
Na primeira etapa são realizadas as avaliações individuais junto aos decisores envolvidos na
decisão de montar a equipe de projeto. De acordo com a situação avaliada e o perfil dos tomadores
de decisão deve ser selecionado o método mais adequado para a tomada de decisão multicritério.
Neste sentido, diversos métodos podem ser selecionados para apoiar a tomada de decisão.
Vincke (1992) aponta a existência de três famílias de métodos de apoio multicritério à decisão. A
primeira família, de inspiração americana, consiste na agregação de diferentes pontos de vista em
uma única função, que é consequentemente otimizada. A segunda família, de inspiração francesa,
tem por objetivo inicial construir uma relação chamada sobreclassificação, que representa a
preferência do tomador de decisão, e explorar estas relações para auxiliar o tomador de decisão. A
terceira família, e mais recente, alterna passos de cálculo (estabelecendo sucessivas soluções de
compromisso) e passos de diálogo (fontes de informações extras acerca da preferência do tomador
de decisão).
Dentre os métodos de sobreclassificação, destaca-se a família PROMETHEE. Para tanto, de
acordo com Almeida (2013), é necessário que o decisor estabeleça um peso para cada critério. A
partir desses pesos é obtido , bem como o grau de sobreclassificação de a sobre b, que é
obtido conforme segue:
Onde é a função de diferença entre o desempenho das
alternativas, de modo que quando , , e quando . Existem seis formas básicas para a função , onde o tomador
de decisão estabelece suas preferências usando a forma mais adequada para cada critério, sendo
eles:
Critério usual, quando não há parâmetro a ser definido;
Quase-critério, para a qual define-se o parâmetro q;
Limite de preferência, definindo o parâmetro p;
Pseudo-critério, considerando os parâmetros q e p;
Área de indiferença, considerando, também, os parâmetros q e p;
Critério Gaussiano, no qual o desvio padrão deve ser fixado. Conforme Almeida (2013), cada um dos critérios gerais, formas das funções e os
respectivos parâmetros são utilizados com a finalidade de identificar a intensidade da preferência do
decisor. Em seguida, dois indicadores de pré-ordens completas são utilizados, sendo o primeiro
representando o fluxo de sobreclassificação de saída , conforme definido abaixo
(ALMEIDA, 2013):
E o segundo o fluxo de sobreclassificação de entrada :
Segundo Almeida (2013), o método PROMETHEE II é baseado na utilização do fluxo
, levando em consideração os dois fluxos e . Dessa forma, é possível obter uma
ordenação das alternativas.
CLAIO-2016
338

Na segunda fase do modelo deve ser realizada a agregação das opiniões dos decisores
envolvidos em uma opinião do grupo. Neste contexto, é proposta a utilização de votação. Segundo
Almeida et al. (2012), os sistemas de votação podem ser utilizados com outras finalidades, além de
uma eleição. Estes podem, portanto, ser utilizados como apoio a um processo multicritério de
decisão envolvendo um grupo de decisores. Destacam-se diversos procedimentos que são
reconhecidamente utilizados para solucionar problemas que demandem uma votação, conforme
mostra a Tabela 1.
Tabela 1 – Tipos de sistemas de votação
Tipos de procedimentos de votação Descrição
Sistema de votação paulista É um dos métodos mais simples, onde a opção que receber o maior
número de votos vence.
Teoria de escolha social
É a base para os procedimentos de votação, de modo que o perfil de
preferências juntamente com o método de votação determina a seleção
de alternativas.
Procedimento de Borda É responsável por agregar o julgamento de vários membros de um júri.
Procedimento de Condorcet É o método que consiste numa avaliação baseada em comparação par a
par.
Procedimento de votação com agenda Esse método refere-se à ordem em que as alternativas são colocadas em
votação.
Procedimento de votação de aprovados
(Approval Voting)
É um método no qual cada decisor pode indicar quantas alternativas
quiser para ganhar a primeira posição.
Procedimento de Copeland
É o método que se baseia em comparação par a par para se determinar
o valor de cada alternativa, selecionando então a alternativa de maior
valor.
Votação ponderada por quartil
Procedimento que considera três regiões (superior, mediana e inferior)
para poder ser efetuada a ponderação das alternativas.
Procedimento de Hare
Método que consiste na eliminação sucessiva dos candidatos menos
votados, com a transferência de votos destes para os mais votados.
Adaptado de Almeida et al. (2012)
No que se refere à aplicação do modelo, o método PROMETHEE II foi selecionado para a
1ª fase do modelo devido ao fato do mesmo ser bastante útil em estabelecer uma pré-ordem
completa entre as alternativas. O método definido apresenta a modelagem das preferências
(quantitativas/qualitativas) dos decisores, por se tratar de um método não compensatório simples e
de fácil entendimento, além de ser capaz de incluir a hesitação da decisão. Além disso, conforme
explicado por Gonçalo e Alencar (2014), o método PROMETHEE traz liberdade para os tomadores
de decisão, no que se refere ao estabelecimento dos pesos. Para a agregação das preferências do
grupo, foi selecionado o sistema de votação de Copeland. O mesmo apresenta fácil entendimento e,
por ser um procedimento que utiliza os rankings individuais obtidos na aplicação do método
PROMETHEE II, o mesmo se adéqua aos dados de entrada obtidos a partir da 1ª fase do modelo.
A seguir é apresentada a aplicação do modelo para o caso de seleção de pessoal para a
equipe Pegazuls Aerodesign.
3.1 Aplicação e validação do modelo Para o caso específico da Pegazuls Aerodesign, são considerados os pontos de vista de três
decisores (D1, D2 e D3), sendo: D1 é o capitão da equipe; D2 representa o vice-capitão; e D3,
representante administrativo da equipe. Todas as funções são delegadas pelo responsável pelo
projeto, geralmente professor da área de Engenharia Mecânica.
Para a aplicação proposta neste estudo, já se considera que a pré-seleção foi realizada.
Desta forma, são pré-selecionados quinze candidatos (A1, A2, A3, A4, A5, A6, A7, A8, A9, A10,
A11, A12, A13, A14, A15). São levantados doze critérios importantes para a tomada de decisão,
apresentados na Tabela 2 a seguir:
CLAIO-2016
339
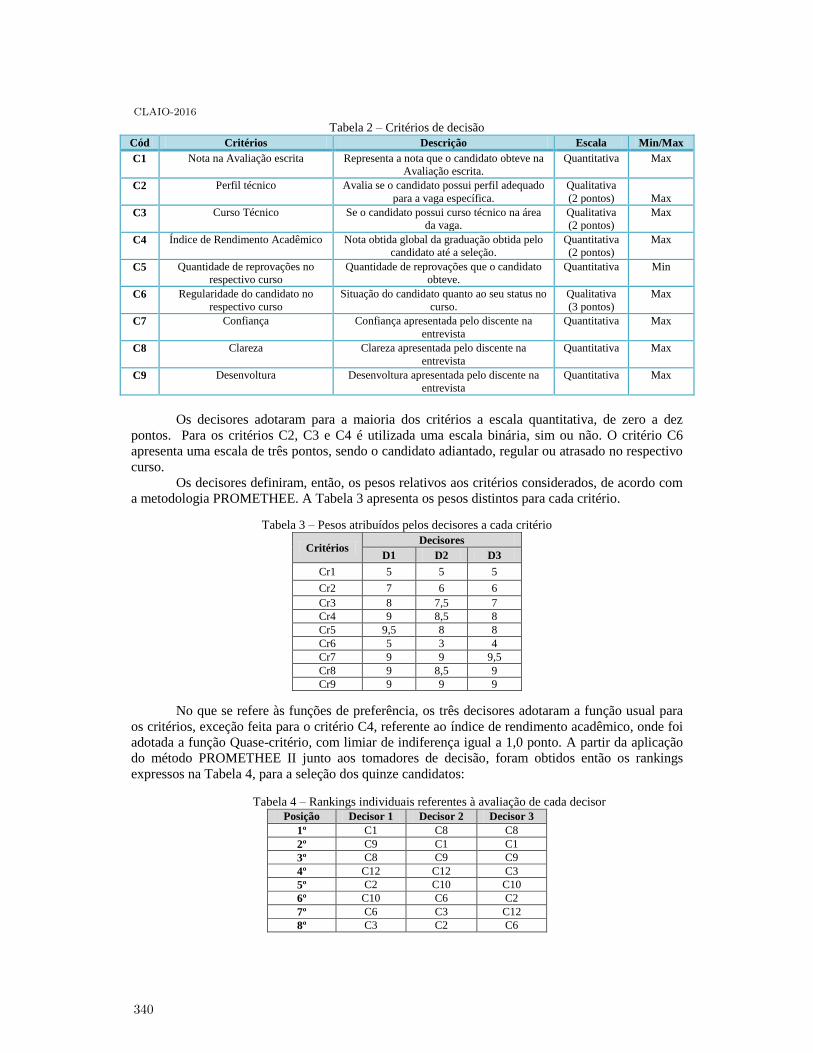
Tabela 2 – Critérios de decisão
Cód Critérios Descrição Escala Min/Max
C1 Nota na Avaliação escrita Representa a nota que o candidato obteve na
Avaliação escrita.
Quantitativa
Max
C2 Perfil técnico Avalia se o candidato possui perfil adequado
para a vaga específica.
Qualitativa
(2 pontos)
Max
C3 Curso Técnico Se o candidato possui curso técnico na área
da vaga.
Qualitativa
(2 pontos)
Max
C4 Índice de Rendimento Acadêmico Nota obtida global da graduação obtida pelo
candidato até a seleção.
Quantitativa
(2 pontos)
Max
C5 Quantidade de reprovações no
respectivo curso
Quantidade de reprovações que o candidato
obteve.
Quantitativa
Min
C6 Regularidade do candidato no
respectivo curso
Situação do candidato quanto ao seu status no
curso.
Qualitativa
(3 pontos)
Max
C7 Confiança Confiança apresentada pelo discente na
entrevista
Quantitativa
Max
C8 Clareza Clareza apresentada pelo discente na
entrevista
Quantitativa
Max
C9 Desenvoltura Desenvoltura apresentada pelo discente na
entrevista
Quantitativa
Max
Os decisores adotaram para a maioria dos critérios a escala quantitativa, de zero a dez
pontos. Para os critérios C2, C3 e C4 é utilizada uma escala binária, sim ou não. O critério C6
apresenta uma escala de três pontos, sendo o candidato adiantado, regular ou atrasado no respectivo
curso.
Os decisores definiram, então, os pesos relativos aos critérios considerados, de acordo com
a metodologia PROMETHEE. A Tabela 3 apresenta os pesos distintos para cada critério.
Tabela 3 – Pesos atribuídos pelos decisores a cada critério
Critérios Decisores
D1 D2 D3
Cr1 5 5 5
Cr2 7 6 6
Cr3 8 7,5 7
Cr4 9 8,5 8
Cr5 9,5 8 8
Cr6 5 3 4
Cr7 9 9 9,5
Cr8 9 8,5 9
Cr9 9 9 9
No que se refere às funções de preferência, os três decisores adotaram a função usual para
os critérios, exceção feita para o critério C4, referente ao índice de rendimento acadêmico, onde foi
adotada a função Quase-critério, com limiar de indiferença igual a 1,0 ponto. A partir da aplicação
do método PROMETHEE II junto aos tomadores de decisão, foram obtidos então os rankings
expressos na Tabela 4, para a seleção dos quinze candidatos:
Tabela 4 – Rankings individuais referentes à avaliação de cada decisor
Posição Decisor 1 Decisor 2 Decisor 3
1º C1 C8 C8
2º C9 C1 C1
3º C8 C9 C9
4º C12 C12 C3
5º C2 C10 C10
6º C10 C6 C2
7º C6 C3 C12
8º C3 C2 C6
CLAIO-2016
340
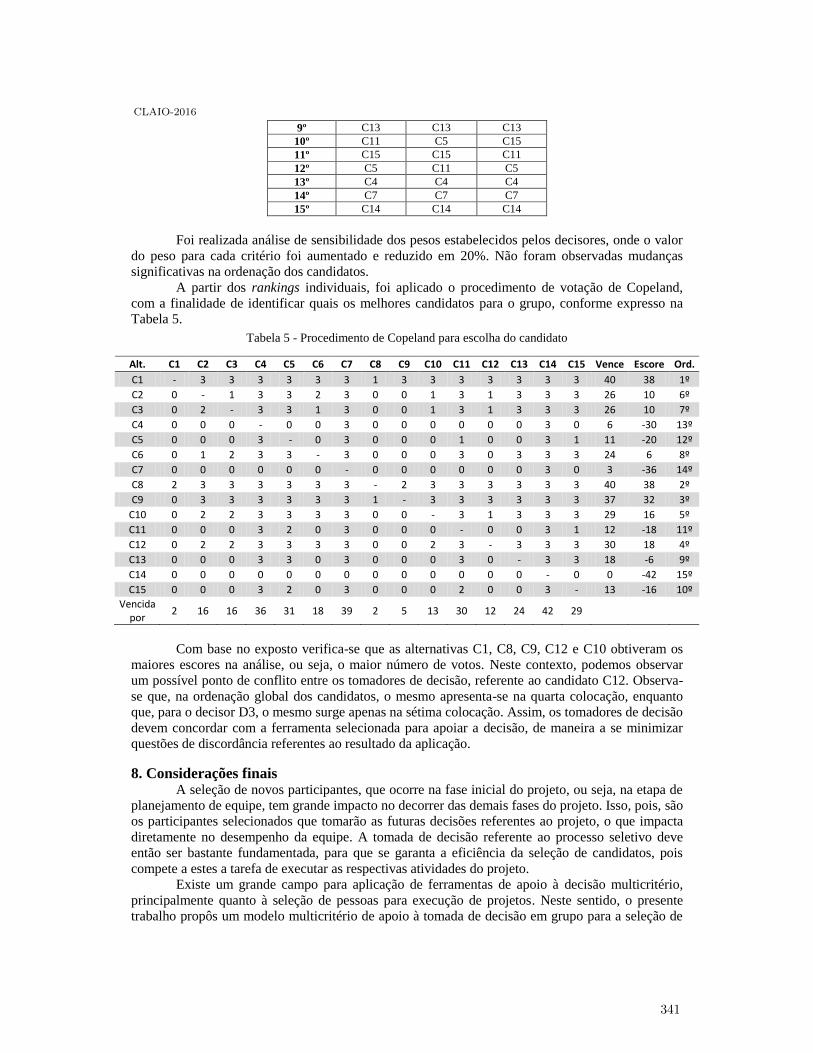
9º C13 C13 C13
10º C11 C5 C15
11º C15 C15 C11
12º C5 C11 C5
13º C4 C4 C4
14º C7 C7 C7
15º C14 C14 C14
Foi realizada análise de sensibilidade dos pesos estabelecidos pelos decisores, onde o valor
do peso para cada critério foi aumentado e reduzido em 20%. Não foram observadas mudanças
significativas na ordenação dos candidatos.
A partir dos rankings individuais, foi aplicado o procedimento de votação de Copeland,
com a finalidade de identificar quais os melhores candidatos para o grupo, conforme expresso na
Tabela 5.
Tabela 5 - Procedimento de Copeland para escolha do candidato
Alt. C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 C15 Vence Escore Ord.
C1 - 3 3 3 3 3 3 1 3 3 3 3 3 3 3 40 38 1º
C2 0 - 1 3 3 2 3 0 0 1 3 1 3 3 3 26 10 6º
C3 0 2 - 3 3 1 3 0 0 1 3 1 3 3 3 26 10 7º
C4 0 0 0 - 0 0 3 0 0 0 0 0 0 3 0 6 -30 13º
C5 0 0 0 3 - 0 3 0 0 0 1 0 0 3 1 11 -20 12º
C6 0 1 2 3 3 - 3 0 0 0 3 0 3 3 3 24 6 8º
C7 0 0 0 0 0 0 - 0 0 0 0 0 0 3 0 3 -36 14º
C8 2 3 3 3 3 3 3 - 2 3 3 3 3 3 3 40 38 2º
C9 0 3 3 3 3 3 3 1 - 3 3 3 3 3 3 37 32 3º
C10 0 2 2 3 3 3 3 0 0 - 3 1 3 3 3 29 16 5º
C11 0 0 0 3 2 0 3 0 0 0 - 0 0 3 1 12 -18 11º
C12 0 2 2 3 3 3 3 0 0 2 3 - 3 3 3 30 18 4º
C13 0 0 0 3 3 0 3 0 0 0 3 0 - 3 3 18 -6 9º
C14 0 0 0 0 0 0 0 0 0 0 0 0 0 - 0 0 -42 15º
C15 0 0 0 3 2 0 3 0 0 0 2 0 0 3 - 13 -16 10º
Vencida por
2 16 16 36 31 18 39 2 5 13 30 12 24 42 29
Com base no exposto verifica-se que as alternativas C1, C8, C9, C12 e C10 obtiveram os
maiores escores na análise, ou seja, o maior número de votos. Neste contexto, podemos observar
um possível ponto de conflito entre os tomadores de decisão, referente ao candidato C12. Observa-
se que, na ordenação global dos candidatos, o mesmo apresenta-se na quarta colocação, enquanto
que, para o decisor D3, o mesmo surge apenas na sétima colocação. Assim, os tomadores de decisão
devem concordar com a ferramenta selecionada para apoiar a decisão, de maneira a se minimizar
questões de discordância referentes ao resultado da aplicação.
8. Considerações finais A seleção de novos participantes, que ocorre na fase inicial do projeto, ou seja, na etapa de
planejamento de equipe, tem grande impacto no decorrer das demais fases do projeto. Isso, pois, são
os participantes selecionados que tomarão as futuras decisões referentes ao projeto, o que impacta
diretamente no desempenho da equipe. A tomada de decisão referente ao processo seletivo deve
então ser bastante fundamentada, para que se garanta a eficiência da seleção de candidatos, pois
compete a estes a tarefa de executar as respectivas atividades do projeto.
Existe um grande campo para aplicação de ferramentas de apoio à decisão multicritério,
principalmente quanto à seleção de pessoas para execução de projetos. Neste sentido, o presente
trabalho propôs um modelo multicritério de apoio à tomada de decisão em grupo para a seleção de
CLAIO-2016
341

pessoal, levando em consideração as preferências de cada decisor da equipe. O modelo foi aplicado
para o caso da formação da equipe Pegazuls Aerodesign da Universidade Federal Rural do Semi-
Árido. O modelo mostrou-se adequado a ser utilizado no projeto e permitiu, através da aplicação do
método PROMETHEE II, a obtenção das ordenações dos candidatos pré-selecionados, para cada
decisor, com base nas suas respectivas estruturas de preferência. E, por meio da aplicação do
procedimento de votação de Copeland, obteve-se então um ranking geral dos candidatos para a
equipe. O modelo pode servir de facilitador para tomada de decisões futuras no que se refere à
seleção de pessoal para a equipe Pegazuls e projetos semelhantes.
Para trabalhos futuros sugere-se a aplicação de modelos similares, adequados a outros tipos
de projetos, no âmbito das Universidades. Sugere-se ainda, a aplicação da ferramenta de apoio à
decisão multicritério e à tomada de decisão em grupo em outras etapas do PDP da Pegazuls
Aerodesign. Neste sentido, existem várias oportunidades de aplicação da ferramenta no suporte à
decisão no processo de desenvolvimento de produtos.
Referências:
1. ALENCAR, L. H. and ALMEIDA, A. T. A model for selecting project team members using multicriteria
group decision making. Pesquisa Operacional: 30(1):221-236, 2010.
2. ALMEIDA, A. T. et al. Decisão em grupo e negociação:Métodos e Aplicações. São Paulo: Atlas, 2012.
3. ALMEIDA, A. T. Processo de decisão nas organizações: construindo modelos de decisão multicritério. São
Paulo: Atlas, 2013.
4. BAXTER, Mike. Projeto de Produto: guia prático para o design de novos produtos. Trad. Itiro lida. São
Paulo: Blucher, 2011.
5. CAMPOS, M. B. A. Métodos multicritérios que envolvem a tomada de decisão. Universidade Federal de
Minas Gerais Instituto de Ciências Exatas, Departamento de Matemática, Belo Horizonte, 14 de fevereiro de
2011.
6. GONÇALO, T. E.; ALENCAR, L. H. A supplier selection model based on classifying its strategic impact
for a company’s business results. Pesquisa Operacional:34(2), 1-23, 2014.
7. JANNUZZI, P. M.; MIRANDA, W. L.; SILVA, D. S. G. Análise Multicritério e Tomada de Decisão em
Políticas Públicas: Aspectos Metodológicos, Aplicativo Operacional e Aplicações. Informática Pública: 11(1)
69–87, 2009.
8. MAXIMIANO, A. C. Introdução à administração. São Paulo: Atlas, 2000.
9. PITCHAI, A., REDDY, A. V., SAVARIMUTHU, N. Fuzzy based Quantum Genetic Algorithm for Project
Team Formation. International Journal of Intelligent Information Technologies: 10(1), 31-46, 2016.
10. ROMEIRO FILHO, E. (coord.). Projeto do produto. Rio de Janeiro: Elsevier, 2010. 11. ROTONDARO, R. G.; MIGUEL, P. A. C.; GOMES, L. A. de V. G. Projeto do Produto e do Processo.
São paulo: Atlas, 2010
12. ROZENFELD, H. et al. Gestão de Desenvolvimento de Produtos: Uma referência para a melhoria do
processo. São Paulo: Saraiva, 2006.
13. P. Vincke. Multicriteria decision aid. Wiley, New York, 1992.
CLAIO-2016
342

Sparse pseudoinverses via LP and SDP
relaxations of Moore-Penrose∗
Victor K. FuentesUniversity of [email protected]
Marcia FampaUniversidade Federal do Rio de Janeiro
Jon LeeUniversity of [email protected]
June 15, 2016
Abstract
Pseudoinverses are ubiquitous tools for handling over- and under-determined systems ofequations. For computational efficiency, sparse pseudoinverses are desirable. Recently, sparseleft and right pseudoinverses were introduced, using 1-norm minimization and linear program-ming. We introduce several new sparse pseudoinverses by developing linear and semi-definiteprogramming relaxations of the well-known Moore-Penrose properties.
Keywords: sparse; pseudoinverse; semi-definite programming; linear programming.
Introduction
Pseudoinverses are a central tool in matrix algebra and its applications. Sparse optimization is con-cerned with finding sparse solutions of optimization problems, often for computational efficiency inthe use of the output of the optimization. There is usually a tradeoff between an ideal dense solutionand a less-ideal sparse solution, and sparse optimization is often focused on tractable methods forstriking a good balance. Recently, sparse optimization has been used to calculate tractable sparseleft and right pseudoinverses, via linear programming. We extend this theme to derive several othertractable sparse pseudoinverses, employing linear and semi-definite programming.
In §1, we give a very brief overview of pseudoinverses, and in §2, we describe some prior work onsparse left and right pseudoinverses. In §3, we present new sparse pseudoinverses based on tractable
∗Partial support from NSF grant CMMI–1160915 and ONR grant N00014-14-1-0315.
CLAIO-2016
343

convex relaxations of the Moore-Penrose properties. In §4, we present preliminary computationalresults. Finally, in §5, we make brief conclusions and describe our ongoing work.
In what follows, In/0n/~0n/~1n denotes an order-n identity matrix/zero matrix/zero vector/all-ones vector.
1 Pseudoinverses
When a real matrix A ∈ Rm×n is not square or not invertible, we consider pseudoinverses of A (see[11] for a wealth of information on this topic). For example, there is the well-known Drazin inversefor square and even non-square matrices (see [3]) and the generalized Bott-Duffin inverse (see [2]).
The most well-known pseudoinverse of all is the M-P (Moore-Penrose) pseudoinverse, inde-pendently discovered by E.H. Moore and R. Penrose. If A = UΣV ′ is the real singular valuedecomposition of A (see [5], for example), then the M-P pseudoinverse of A can be defined asA+ := V Σ+U ′, where Σ+ has the shape of the transpose of the diagonal matrix Σ, and is derivedfrom Σ by taking reciprocals of the non-zero (diagonal) elements of Σ (i.e., the non-zero singularvalues of A). The M-P pseudoinverse, a central object in matrix theory, has many concrete uses.For example, we can use it to solve least-squares problems, and we can use it, together with a norm,to define condition numbers of matrices. The M-P pseudoinverse is calculated, via its connectionwith the real singular value decomposition, by the Matlab function pinv.
2 Sparse left and right pseudoinverses
It is well known that in the context of seeking a sparse solution in a convex set, a surrogate forminimizing the sparsity is to minimize the 1-norm. In fact, if the components of the solution haveabsolute value no more than unity, a minimum 1-norm solution has 1-norm no greater than thenumber of nonzeros in the sparsest solution. With this in mind, [4] defines sparse left and rightpseudoinverses in a natural and tractable manner. Below, ‖ · ‖1 denotes entry-wise 1-norm.
For an “overdetermined case”, [4] defines a sparse left pseudoinverse via the convex formulation
min {‖H‖1 : HA = In} . (O)
For an “underdetermined case”, [4] defines a sparse right pseudoinverse via the convex formulation
min {‖H‖1 : AH = Im} . (U)
These definitions emphasize sparsity, while in some sense putting a rather mild emphasis on theaspect of being a pseudoinverse. We do note that if the columns of A are linearly independent, thenthe M-P pseudoinverse is precisely (A′A)−1A′, which is a left inverse of A. Therefore, if A has fullcolumn rank, then the M-P pseudoinverse is a feasible H for (O). Conversely, if A does not havefull column rank, then (O) has no feasible solution, and so there is no sparse left inverse in such acase. On the other hand, if the rows of A are linearly independent, then the M-P pseudoinverse isprecisely A′(AA′)−1, which is a right inverse of A. Therefore, if A has full row rank, then the M-Ppseudoinverse is a feasible H for (U). Conversely, if A does not have full row rank, then (U) hasno feasible solution, and so there is no sparse right inverse in such a case.
CLAIO-2016
344

These sparse pseudoinverses are easy to calculate, by linear programming:
min{∑
ij∈m×n tij : tij ≥ hij , tij ≥ −hij , ∀ij ∈ m× n; HA = In
}(LPO)
for the sparse left pseudoinverse, and
min{∑
ij∈m×n tij : tij ≥ hij , tij ≥ −hij , ∀ij ∈ m× n; AH = Im
}(LPU )
for the sparse right pseudoinverse. In fact, the (LPO) decomposes row-wise for H, and (LPU )decomposes column-wise for H, so calculating these sparse pseudoinverses can be made very efficientat large scale. Also, these sparse pseudoinverses do have nice mathematical properties (see [4]).
3 New sparse relaxed Moore-Penrose pseudoinverses
We seek to define different tractable sparse pseudoinverses, based on the the following nice charac-terization of the M-P pseudoinverse.
Theorem 3.1. For A ∈ Rm×n, the M-P pseudoinverse A+ is the unique H ∈ Rn×m satisfying:
AHA = A (P1)
HAH = H (P2)
(AH)′ = AH (P3)
(HA)′ = HA (P4)
If we consider properties (P1) - (P4) which characterize the M-P pseudoinverse, we can observethat properties (P1), (P3) and (P4) are all linear in H, and the only non-linearity is property (P2),which is quadratic. Another important point to observe is that without property (P1), H couldbe the all-zero matrix and satisfy properties (P2), (P3) and (P4). Whenever property (P1) holds,H is called a generalized inverse. So, in the simplest approach, we can consider minimizing ‖H‖1subject to property (P1) and any subset of the properties (P3) and (P4). In this manner, we getseveral (four) new sparse pseudoinverses which can all be calculated by linear programming.
To go further, we can also consider convex relaxations of property (P2). To pursue that direc-tion, we enter the realm of semi-definite programming (see [1],[16],[17], for example).
We can see property (P2) ashi·Ah·j = hij ,
for all ij ∈ m× n. So, we have mn quadratic equations to enforce, which we can see as
1
2
(hi·, h′·j
) [ 0m AA′ 0n
](h′i·h·j
)= hij , (3.1)
for all ij ∈ m× n. We can view these quadratic equations (3.1) as
1
2
⟨Q,
(h′i·h·j
)(hi·, h′·j
)⟩= hij ,
CLAIO-2016
345

for all ij ∈ m× n, where
Q :=
[0m AA′ 0n
]∈ R(m+n)×(m+n),
and 〈·, ·〉 denotes element-wise dot-product.Now, we lift the variables to matrix space, defining matrix variables
Hij :=
(h′i·h·j
)(hi·, h′·j
)∈ R(m+n)×(m+n),
for all ij ∈ m× n. So, we can see (3.1) as the linear equations
1
2〈Q,Hij〉 = hij , (3.2)
for all ij ∈ m× n, together with the non-convex equations
Hij −(
h′i·h·j
)(hi·, h′·j
)= 0m+n, (3.3)
for all ij ∈ m×n. Next, we relax the equations (3.3) via the convex semi-definiteness constraints:
Hij −(
h′i·h·j
)(hi·, h′·j
)� 0m+n, (3.4)
for all ij ∈ m× n. So we can relax the M-P property (P2) as (3.2) and (3.4), for all ij ∈ m× n.To put (3.4) into a standard form for semi-definite programming, we create variables vectors
xij ∈ Rm+n, and we have linear equations
xij =
(h′i·h·j
). (3.5)
Next, for all ij ∈ m × n, we introduce symmetric positive semi-definite matrix variables Zij ∈R(m+n+1)×(m+n+1), interpreting the entries as follows:
Zij =
[x(0)ij x′ijxij Hij
]. (3.6)
Then the linear equation
x(0)ij = 1 (3.7)
and Zij � 0(m+n+1)×(m+n+1) precisely enforce (3.4).Finally, we re-cast (3.2) as
1
2
⟨Q̄, Zij
⟩= hij , (3.8)
where
Q̄ :=
[0 ~0′m+n
~0m+n Q
]∈ R(m+n+1)×(m+n+1). (3.9)
In summary, we can consider minimizing ‖H‖1 subject to property (P1) and any subset of (P3),(P4), and (3.2)+(3.4) for all ij ∈ m× n (though we reformulate (3.2)+(3.4) as above, so it is in a
CLAIO-2016
346

convenient form for semi-definite programming solvers like CVX). In doing so, we get many (eight)new sparse pseudoinverses which are all tractable (via linear or semi-definite programming).
Of course all of these optimization problems have feasible solutions, because the M-P pseudoin-verse A+ always gives a feasible solution. For the cases in which we have semi-definite programs,an important issue is whether there is a strictly feasible solution — the Slater condition(/constraintqualification) — as that is sufficient for strong duality to hold and affects the convergence of algo-rithms (e.g., see [1]). Even if the Slater condition does not hold, there is a facial-reduction algorithmthat can induce the Slater condition to hold on an appropriate face of the feasible region (see [10]).
4 Preliminary computational experiments
We made some preliminary tests of our ideas, using CVX/Matlab (see [7], [6]). Before describingour experimental setup, we observe the following results.
Proposition 4.1. If A has full column rank n and H satisfies (P1), then H is a left inverse of A,and H satisfies (P2) and (P4). If A has full row rank m and H satisfies (P1), then H is a rightinverse of A, and H satisfies (P2) and (P3),
Corollary 4.2. If A has full column rank n and H satisfies (P1) and (P3), then H = A+. If Ahas full row rank m and H satisfies (P1) and (P4), then H = A+.
Because of these results, we decided to focus our experiments on matrices A with rank lessthan min{m,n}. We generated random dense n×n rank-r matrices A of the form A = UV , whereeach U and V ′ are n × r, with n = 40, and five instance for each r = 4, 8, 16, . . . , 36. The entriesin U and V were iid uniform (−1, 1). We then scaled each A by a multiplicative factor of 0.01,which had the effect of making A+ fully dense to an entry-wise zero-tolerance of 0.1. In computingvarious sparse pseudoinverses, we used a zero-tolerance of 10−5. We measured sparsity of a sparsepseudoinverse as the number of its nonzero components divided by n2. We measured quality of asparse pseudoinverse H, relative to the M-P pseudoinverse A+ in two ways:
• least-squares ratio (‘lsr’): ‖AHb − b‖2/‖AA+b − b‖2, with arbitrarily b := ~1m. (Note thatx := A+b always minimizes ‖Ax− b‖2.)
• 2-norm ratio (‘2nr’): ‖HA~1n‖2/‖A+A~1n‖2. (Note that x := HA~1n is always a solution toAx = A~1n, whenever H satisfies (P1), and one that minimizes ‖x‖2 is given by x := A+A~1n.)
Proposition 4.3. If H satisfies (P1) and (P3), then AH = AA+.
Proof.
AHA = AA+A (by (P1))
H ′A′A = (A+)′A′A (by (P3))
A′AH = A′AA+
(A+)′A′AH = (A+)′A′AA+
AH = AA+,
the last equation following directly from a well-known property of A+.
CLAIO-2016
347

Corollary 4.4. If H satisfies (P1) and (P3), then x := Hb (and of course A+b) solves min{‖Ax−b‖2 : x ∈ Rn}.
Similarly, we have the following two results:
Proposition 4.5. If H satisfies (P1) and (P4), then HA = A+A.
Corollary 4.6. If H satisfies (P1) and (P4), and b is in the column space of A, then Hb (and ofcourse A+b) solves min{‖x‖2 : Ax = b, x ∈ Rn}.So in the situations covered by Corollaries 4.4 and 4.6, we can seek and use sparser pseudoinversesthan A+. Our computational results are summarized in Table 1. ‘1nr’ (1-norm ratio) is simply‖H‖1/‖A+‖1. ‘sr’ (sparsity ratio) is simply ‖H‖0/‖A+‖0. Note that the entries of 1 reflect theresults above. We observe that sparsity can be gained versus the M-P pseudoinverse, often with amodest decrease in quality of the pseudoinverse, and we can observe some trends as the rank varies.
5 Conclusions and ongoing work
We have introduced eight tractable pseudoinverses based on using 1-norm minimization to inducesparsity and making convex relaxations of the M-P properties. It remains to be seen if any of thesenew pseudoinverses will be found to be valuable in practice. There is a natural tradeoff betweensparsity and closeness to the M-P properties, and where one wants to be on this spectrum may wellbe application dependent. We are in the process of carrying out more thorough experiments.
In particular, we are testing our sparse pseudoinverses that need semi-definite programming. Inthe manner of [13] and [14], we may go further and enforce more of (3.3) using “disjunctive cuts”,producing a better convex relaxation of (3.3) than (3.4). But this would come at some significantcosts: (i) greater computational effort, (ii) decreased sparsity as we work our way toward enforcingmore of the M-P properties, (iii) lack of specificity.
Another idea that we are exploring is to develop update algorithms for sparse pseudoinverses.Of course the Sherman-Morrison-Woodbury formula gives us a convenient way to update a matrixinverse of A after a low-rank modification. Extending that formula, A+ can be updated efficiently(see [8] and [12]). It is an interesting challenge to see if we can take advantage of a sparse pseu-doinverse of A in calculating a sparse pseudoinverse of a low-rank modification of A.
In related work, we are in the process of investigating techniques for decomposing an inputmatrix C̄ into A + B, where B has low rank and A has a sparse (pseudo)inverse. In that context,A is a matrix variable, so even the left- and right-inverse constraints (HA = In and AH = Im)are non-convex quadratic equations. So, already in that context, we are applying similar ideas tothe ones we presented here for relaxing these equations. When we instead consider our new sparsepseudoinverses (based on the M-P properties), again in the context where A is a matrix variable,already the M-P properties (P3) and (P4) are quadratic and properties (P1) and (P2) are cubic(in A and H). We can still apply our basic approach for handling quadratic equations, now to(P3) and (P4). As for (P1) and (P2), we can take a variety of approaches. One possibility is tointroduce auxiliary scalar variables to get back to quadratic equations; though even then there areissues to consider in choosing the best way to carry this out (see [15]). Another possibility is tointroduce auxiliary matrix variables, to get back to quadratic matrix equations — some fascinatingquestions then arise if we consider how to extend the results in [15]. Another possibility is to employsemi-definite programming relaxations for polynomial systems (e.g., see [9]).
CLAIO-2016
348
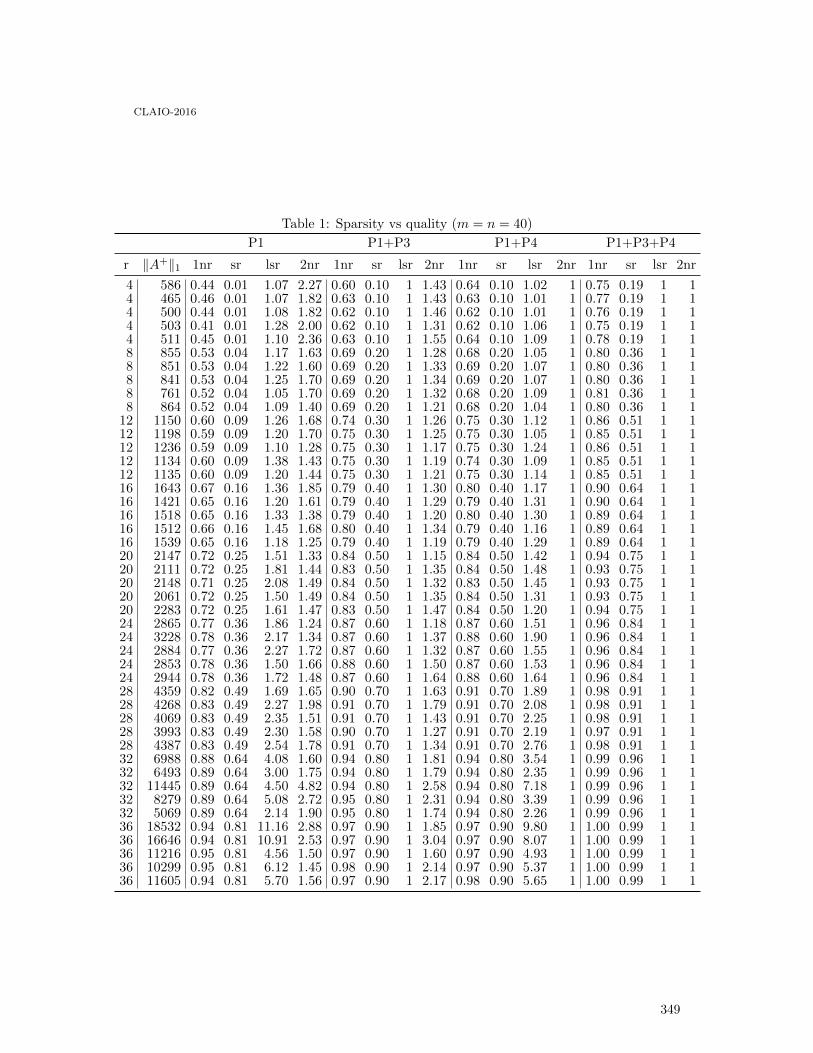
Table 1: Sparsity vs quality (m = n = 40)
P1 P1+P3 P1+P4 P1+P3+P4
r ‖A+‖1 1nr sr lsr 2nr 1nr sr lsr 2nr 1nr sr lsr 2nr 1nr sr lsr 2nr
4 586 0.44 0.01 1.07 2.27 0.60 0.10 1 1.43 0.64 0.10 1.02 1 0.75 0.19 1 14 465 0.46 0.01 1.07 1.82 0.63 0.10 1 1.43 0.63 0.10 1.01 1 0.77 0.19 1 14 500 0.44 0.01 1.08 1.82 0.62 0.10 1 1.46 0.62 0.10 1.01 1 0.76 0.19 1 14 503 0.41 0.01 1.28 2.00 0.62 0.10 1 1.31 0.62 0.10 1.06 1 0.75 0.19 1 14 511 0.45 0.01 1.10 2.36 0.63 0.10 1 1.55 0.64 0.10 1.09 1 0.78 0.19 1 18 855 0.53 0.04 1.17 1.63 0.69 0.20 1 1.28 0.68 0.20 1.05 1 0.80 0.36 1 18 851 0.53 0.04 1.22 1.60 0.69 0.20 1 1.33 0.69 0.20 1.07 1 0.80 0.36 1 18 841 0.53 0.04 1.25 1.70 0.69 0.20 1 1.34 0.69 0.20 1.07 1 0.80 0.36 1 18 761 0.52 0.04 1.05 1.70 0.69 0.20 1 1.32 0.68 0.20 1.09 1 0.81 0.36 1 18 864 0.52 0.04 1.09 1.40 0.69 0.20 1 1.21 0.68 0.20 1.04 1 0.80 0.36 1 1
12 1150 0.60 0.09 1.26 1.68 0.74 0.30 1 1.26 0.75 0.30 1.12 1 0.86 0.51 1 112 1198 0.59 0.09 1.20 1.70 0.75 0.30 1 1.25 0.75 0.30 1.05 1 0.85 0.51 1 112 1236 0.59 0.09 1.10 1.28 0.75 0.30 1 1.17 0.75 0.30 1.24 1 0.86 0.51 1 112 1134 0.60 0.09 1.38 1.43 0.75 0.30 1 1.19 0.74 0.30 1.09 1 0.85 0.51 1 112 1135 0.60 0.09 1.20 1.44 0.75 0.30 1 1.21 0.75 0.30 1.14 1 0.85 0.51 1 116 1643 0.67 0.16 1.36 1.85 0.79 0.40 1 1.30 0.80 0.40 1.17 1 0.90 0.64 1 116 1421 0.65 0.16 1.20 1.61 0.79 0.40 1 1.29 0.79 0.40 1.31 1 0.90 0.64 1 116 1518 0.65 0.16 1.33 1.38 0.79 0.40 1 1.20 0.80 0.40 1.30 1 0.89 0.64 1 116 1512 0.66 0.16 1.45 1.68 0.80 0.40 1 1.34 0.79 0.40 1.16 1 0.89 0.64 1 116 1539 0.65 0.16 1.18 1.25 0.79 0.40 1 1.19 0.79 0.40 1.29 1 0.89 0.64 1 120 2147 0.72 0.25 1.51 1.33 0.84 0.50 1 1.15 0.84 0.50 1.42 1 0.94 0.75 1 120 2111 0.72 0.25 1.81 1.44 0.83 0.50 1 1.35 0.84 0.50 1.48 1 0.93 0.75 1 120 2148 0.71 0.25 2.08 1.49 0.84 0.50 1 1.32 0.83 0.50 1.45 1 0.93 0.75 1 120 2061 0.72 0.25 1.50 1.49 0.84 0.50 1 1.35 0.84 0.50 1.31 1 0.93 0.75 1 120 2283 0.72 0.25 1.61 1.47 0.83 0.50 1 1.47 0.84 0.50 1.20 1 0.94 0.75 1 124 2865 0.77 0.36 1.86 1.24 0.87 0.60 1 1.18 0.87 0.60 1.51 1 0.96 0.84 1 124 3228 0.78 0.36 2.17 1.34 0.87 0.60 1 1.37 0.88 0.60 1.90 1 0.96 0.84 1 124 2884 0.77 0.36 2.27 1.72 0.87 0.60 1 1.32 0.87 0.60 1.55 1 0.96 0.84 1 124 2853 0.78 0.36 1.50 1.66 0.88 0.60 1 1.50 0.87 0.60 1.53 1 0.96 0.84 1 124 2944 0.78 0.36 1.72 1.48 0.87 0.60 1 1.64 0.88 0.60 1.64 1 0.96 0.84 1 128 4359 0.82 0.49 1.69 1.65 0.90 0.70 1 1.63 0.91 0.70 1.89 1 0.98 0.91 1 128 4268 0.83 0.49 2.27 1.98 0.91 0.70 1 1.79 0.91 0.70 2.08 1 0.98 0.91 1 128 4069 0.83 0.49 2.35 1.51 0.91 0.70 1 1.43 0.91 0.70 2.25 1 0.98 0.91 1 128 3993 0.83 0.49 2.30 1.58 0.90 0.70 1 1.27 0.91 0.70 2.19 1 0.97 0.91 1 128 4387 0.83 0.49 2.54 1.78 0.91 0.70 1 1.34 0.91 0.70 2.76 1 0.98 0.91 1 132 6988 0.88 0.64 4.08 1.60 0.94 0.80 1 1.81 0.94 0.80 3.54 1 0.99 0.96 1 132 6493 0.89 0.64 3.00 1.75 0.94 0.80 1 1.79 0.94 0.80 2.35 1 0.99 0.96 1 132 11445 0.89 0.64 4.50 4.82 0.94 0.80 1 2.58 0.94 0.80 7.18 1 0.99 0.96 1 132 8279 0.89 0.64 5.08 2.72 0.95 0.80 1 2.31 0.94 0.80 3.39 1 0.99 0.96 1 132 5069 0.89 0.64 2.14 1.90 0.95 0.80 1 1.74 0.94 0.80 2.26 1 0.99 0.96 1 136 18532 0.94 0.81 11.16 2.88 0.97 0.90 1 1.85 0.97 0.90 9.80 1 1.00 0.99 1 136 16646 0.94 0.81 10.91 2.53 0.97 0.90 1 3.04 0.97 0.90 8.07 1 1.00 0.99 1 136 11216 0.95 0.81 4.56 1.50 0.97 0.90 1 1.60 0.97 0.90 4.93 1 1.00 0.99 1 136 10299 0.95 0.81 6.12 1.45 0.98 0.90 1 2.14 0.97 0.90 5.37 1 1.00 0.99 1 136 11605 0.94 0.81 5.70 1.56 0.97 0.90 1 2.17 0.98 0.90 5.65 1 1.00 0.99 1 1
CLAIO-2016
349

References
[1] S. Boyd and L. Vandenberghe. Convex Optimization. Cambridge University Press, 2004.
[2] Y. Chen. The generalized Bott-Duffin inverse and its applications. Linear Algebra and itsApplications, 134:71–91, 1990.
[3] R.E. Cline and T.N.E. Greville. A Drazin inverse for rectangular matrices. Linear Algebra andits Applications, 29:53–62, 1980.
[4] I. Dokmanić, M. Kolundžija, and M. Vetterli. Beyond Moore-Penrose: Sparse pseudoinverse.In ICASSP 2013, pp. 6526–6530. 2013.
[5] G.H. Golub and C.F. Van Loan. Matrix Computations (3rd Ed.). Johns Hopkins UniversityPress, Baltimore, MD, USA, 1996.
[6] M. Grant and S. Boyd. Graph implementations for nonsmooth convex programs. In RecentAdvances in Learning and Control. pp. 95–110. Springer, 2008.
[7] M. Grant and S. Boyd. CVX, version 2.1, 2015.
[8] C.D. Meyer. Generalized inversion of modified matrices. SIAM J. App. Math, 24:315–323, 1973.
[9] P.A. Parrilo. Semidefinite programming relaxations for semialgebraic problems. Math. Prog.,96(2):293–320, 2003.
[10] G. Pataki. Strong duality in conic linear programming: Facial reduction and extended duals.In Computational and Analytical Mathematics. pp. 613–634. Springer, 2013.
[11] C.R. Rao and S.K. Mitra. Generalized Inverse of Matrices and Its Applications. Probabilityand Statistics Series. Wiley, 1971.
[12] K.S. Riedel. A Sherman-Morrison-Woodbury identity for rank augmenting matrices withapplication to centering. SIAM J. Matrix Anal. Appl., 13(2):659–662, 1992.
[13] A. Saxena, P. Bonami, and J. Lee. Convex relaxations of non-convex mixed integer quadrati-cally constrained programs: Extended formulations. Math. Prog., Ser. B, 124:383–411, 2010.
[14] A. Saxena, P. Bonami, and J. Lee. Convex relaxations of non-convex mixed integer quadrati-cally constrained programs: Projected formulations. Math. Prog., Ser. A, 130:359–413, 2010.
[15] E. Speakman and J. Lee. Quantifying double McCormick. arXiv:1508.02966v2, 2015.
[16] L. Vandenberghe and S. Boyd. Semidefinite programming. SIAM Review, 38(1):49–95, 1996.
[17] H. Wolkowicz, R. Saigal, and L. Vandenberghe. Handbook of semidefinite programming: theory,algorithms, and applications. Kluwer, Boston, 2000.
CLAIO-2016
350

The Game Chromatic Number of Caterpillars∗
Ana FurtadoCOPPE, Universidade Federal do Rio de Janeiro, Brasil / CEFET-RJ.
Simone DantasIME, Universidade Federal Fluminense, Brasil.
Celina M. H. de FigueiredoCOPPE, Universidade Federal do Rio de Janeiro, Brasil.
Sylvain GravierCNRS, Université Joseph Fourier, France.
Simon SchmidtUniversité Joseph Fourier, France.
Abstract
The coloring game is played by Alice and Bob on a finite graph G. They take turns properlycoloring the vertices with t colors. If at any point there is an uncolored vertex without availablecolor, then Bob wins. The game chromatic number of G is the smallest number t such thatAlice has a winning strategy. It is known that for forests this number is at most 4. We findexact values for the game chromatic number of two infinite subclasses of forests (composed bycaterpillars), in order to contribute to the open problem of characterizing differences betweenforests with game chromatic number 3 and 4.
Keywords: Coloring game; Combinatorial games; Game chromatic number; Caterpillar.
1 Introduction
The coloring game is a two player non-cooperative game conceived by Steven Brams, firstly pub-lished in 1981 by Martin Gardner [5], as a map-coloring game, and reinvented in 1991 by Bodlaen-der [1], who studied the game in the context of graphs. The first application of a variation of thisgame to a non-game graph packing problem was presented in 2009 by Kierstead and Kostochka [7].
∗Partially supported by CAPES/MathAmSud 021/14, CNPq and FAPERJ.
CLAIO-2016
351

Given t colors, Alice and Bob take turns properly coloring an uncolored vertex. The goal ofAlice is to color the input graph with t colors, and Bob does his best to prevent it. Alice winswhen the graph is completely colored with t colors; otherwise, Bob wins. The game chromaticnumber χg(G) of G is the smallest number t of colors that ensures that Alice wins. Usually, inthe literature, Alice starts the game, but Bob can start the game as well. We denote by χa
g(G) (or
simply χg(G)) the game chromatic number of G when Alice starts the game, and χbg(G) when Bob
does it.Clearly, for a graph G, χ(G) ≤ χg(G) ≤ ∆(G) + 1, where χ(G) denotes the chromatic number
and ∆(G) the maximum degree. So, we have that a complete graph Kn has χg(Kn) = n, becauseχ(Kn) = ∆(Kn) + 1 = n, and, analogously, an independent set Sn has χg(Sn) = 1. Analyzing thegame chromatic number of paths Pn, with n vertices, we can quickly check that χg(P1) = 1 andχg(P2) = χg(P3) = 2. For n ≥ 4, we have that χg(Pn) = 3 because, regardless of where Alice colorsat her first turn, Bob can always give a different color to a vertex at distance 2 of the vertex thatAlice colored, forcing the third color. Using the same idea, we have that a cycle Cn has χg(Cn) = 3,and that the stars K1,p with p ≥ 1 are the only connected graphs satisfying χg(G) = 2.
The game has been much studied for different graph classes in order to obtain better upperand lower bounds to χg(G): forests [3], planar graphs [9], outerplanar graphs [6], toroidal grids [8],partial k-trees [10], and the cartesian products of some classes of graphs [2].
Bodlaender [1] showed an example of a tree with game chromatic number at least 4 and provedthat every tree has game chromatic number at most 5. In 1993, Faigle et al. [4] improved this boundby proving that every forest has game chromatic number at most 4. Despite the vast literaturein this area, only in 2015, Dunn et al. [3] considered the distinction between forests with differentgame chromatic numbers, and investigated special cases where χg(F ) is 3 or 4, getting a criteriafor determining χg(F ), for a forest without vertex with degree 3, in polynomial time. Due to thedifficulty concerning this subject, the problem of characterizing forests with χg(F ) = 3 remainsopen. In our work, we contribute to this study by analyzing a special tree called the caterpillar.
A caterpillar cat(k1, k2, . . . , ks) is a tree obtained from a central path v1, v2, v3, ..., vs (calledspine) by joining ki leaf vertices to vi, for each i = 1, . . . , s; and with number of vertices n =s+
∑si=1 ki. If ki ≥ 1, then we say that the vertex vi has ki adjacent leg leaves.
The motivation to focus on caterpillars relies on the fact that the example presented by Bodlaen-der [1] to prove the existence of a tree H with χg(H) ≥ 4 is a caterpillar (see Figure 1). Actually,Dunn et al. [3] proved that caterpillar H is the smallest tree T such that χg(T ) = 4.
Figure 1: The smallest tree H with χg(H) = 4.
As Faigle et al. [4] and Dunn et al. [3] worked with forests, the first question that we canask is: in a forest F with connected components Ti, for i = 1, ..., r, is it true that χg(F ) =max {χg(Ti)| i = 1, ..., r}? The answer is no, and we have an example in Figure 2 such that Alicewins the coloring game with 2 colors by coloring the vertex of (a), forcing Bob to start coloring avertex in (b). Regardless of where Bob colors at his first turn, Alice can always give the same colorto a vertex at distance 2 of the vertex that Bob colored. So, χg(F ) = 2, although χg(P4) = 3.
CLAIO-2016
352

Figure 2: Forest F with χg(F ) = 2, but (a) χg(P1) = 1 (b) χg(P4) = 3.
In fact, we cannot say that χg(F ) ≤ max {χg(Ti)| i = 1, ..., j} either. In Figure 3, we give anexample of a forest F composed by two copies of H1 such that χg(H1) = 3, but χg(H1 ∪H1) = 4.Faigle et al. [4] proved for trees that χg(T ) ≤ 4 and stated that there is no loss of generality whenwe think of forests, that is, the proof that χg(T ) ≤ 4 can be extended to obtain χg(F ) ≤ 4. Inthe same spirit of [3] and [4], we analyze forests (composed of caterpillars), studying first the gamechromatic number in the connected case.
Figure 3: Forest F = H1 ∪H1, χg(H1) = 3, but χg(F ) = 4.
In Section 2, we study two infinite subclasses of caterpillars and we obtain exactly the gamechromatic number of each one, showing strategies for Alice or Bob to win the coloring game with3 colors. In Theorems 2.1 and 2.7, we characterize caterpillars with maximum degree 3 and thosewithout vertex with degree 2, respectively, and these results are extended to forests. In Section 3,we present our conclusion and further questions.
2 Caterpillar
We know that every caterpillar G that is not a star has χg(G) ≥ 3. We shall define two infinitesubclasses of caterpillars for which we are able to establish the exact value of the game chromaticnumber:
• a caterpillar G with maximum degree 3 that is not a star satisfies χg(G) = 3;
• a caterpillar G without vertex with degree 2 satisfies χg(G) = 4 if, and only if, G has at leastfour vertices with degree at least 4.
In order to analyze these two subclasses, we present two definitions. Let Z be a set of verticesof V (G) such that for all v ∈ Z, c(v) 6= ∅. We denote by χg(G,Z) the smallest number t of colorsthat ensures that Alice wins in the partially colored graph G. Let l(F ) be the number of edges ofthe longest path in the forest F .
2.1 Caterpillar with maximum degree 3
Next Theorem 2.1 has the goal of studying the game chromatic number of caterpillars G with∆(G) = 3, and its consequence when we extend to forests.
Theorem 2.1. Let G be the caterpillar cat(k1, ..., ks) with ∆(G) = 3. We have that G hasχag(G), χb
g(G) ≤ 3. Moreover, let F be the forest where each connected component is a caterpillarand ∆(F ) = 3. We have that F has χa
g(F ) ≤ 3.
CLAIO-2016
353

Proof. We divide the proof into three claims:Claim 1) Let G be the caterpillar cat(k1, ..., ks), s ≥ 3, k1 = ks = 0 and ∆(G) = 3. If
Z = {v1, vs}, then χag(G,Z), χb
g(G,Z) ≤ 3, except for the caterpillars with s odd, which has
χbg(G,Z) ≤ 4.
Proof. Proof by induction in s. In the caterpillar G = cat(0, 1, 0), χag(G,Z), χb
g(G,Z) ≤ 3, if
c(v3) = c(v1); and χbg(G,Z) = 4, if c(v3) 6= c(v1). This case is the unique exception: when s (for
s ≥ 5 they can have the same color and Bob still can force that four colors are needed).Assume that the result is true for any caterpillar G with s ≤ j.Now, we analyze the caterpillar G′ with s = j + 1. Since v1 and vj+1 are colored, Alice colors
v3 with the same color of v1, for j + 1 even, or Alice colors v4, for i odd. If Bob starts playing andj + 1 is even, then he can color a vertex vi of the spine of the caterpillar (and Alice colors a vertexin the subcaterpillar with odd number of vertex in the spine), or he colors a leaf leg adjacent tovi. In the last case, if i is even, Alice colors vi+1 with the same color that Bob has used, or, ifi is odd, she colors vi−1 with the same color that Bob has used. The result follows by inductionhypothesis.
Claim 2) Let G be the caterpillar cat(k1, ..., ks), s ≥ 3, k1 = ks = 0 and ∆(G) = 3. If Z = {v1},then χa
g(G,Z), χbg(G,Z) ≤ 3.
Proof. Similarly to Case 1, we prove by induction in s. In the caterpillar G = cat(0, 1, 0), χag(G,Z),
χbg(G,Z) ≤ 3. Assume that the result is true for any caterpillar G with s ≤ j.
Now, we analyze the caterpillar G′ with s = j + 1. Alice color v2 with color 2, and the resultfollows by induction hypothesis. If Bob colors a vertex vi of the spine of the caterpillar, withi = 3, ..., j + 1 and i odd, then Alice colors a vertex vk the between v1 and vi, with k odd, inorder to avoid the case when the subcaterpillars cat(k1, ..., ki) or cat(ki, ..., kj) have both extremescolored, i or j − i + 1 is odd, and Bob is the next to play. If Bob colors vi, with i even, then theresult follows by induction hypothesis and Claim 1. If Bob colors a leaf leg adjacent to vi, then,if i is even, Alice colors vi; else, Alice colors vi+1. The result follows by induction hypothesis andand Claim 1.
Claim 3) Let G be the caterpillar cat(k1, ..., ks), s ≥ 3, k1 = ks = 0 and ∆(G) = 3. We havethat χa
g(G), χbg(G) ≤ 3.
Proof. Similarly to previous cases, we prove by induction in s. In the caterpillar G = cat(0, 1, 0),χag(G), χb
g(G) ≤ 3. Assume that the result is true for any caterpillar G with s ≤ j.Now, we analyze the caterpillar G′ with s = j + 1. Alice can color vertex v2, and, by Claim 2,
χag(G′) ≤ 3. If Bob starts the game, he can color a vertex of the spine of the caterpillar (and again,
by Claim 2, χbg(G′) ≤ 3), or he can colors a leaf leg. In the last case, Alice colors the vertex of the
spine adjacent of it, and the result follows by Claim 2.
So, χag(G) = χb
g(G) ≤ 3, for G caterpillar cat(k1, ..., ks) with ∆(G) = 3.In a forest F where each connected component G1, ..., Gr is a caterpillar and ∆(F ) = 3, there is
at least one caterpillar Gi, for i = 1, ..., r, that has ∆(Gi) = 3, and we have that χag(Gi), χ
bg(Gi) ≤ 3.
Moreover, the caterpillars such that the maximum degree is 2 are paths and they have gamechromatic number at most 3, independently of who starts the game. Thus, the game chromaticnumber in each connected component of F is at most 3, independently of who starts the game ineach one. Therefore, χg(F ) ≤ 3, and this ends the proof of Theorem.
CLAIO-2016
354

Corollary 2.2. Let F be a forest where each connected component is a caterpillar and ∆(F ) = 3.We have that χg(F ) = 3 if, and only if,:
• l(F ) ≥ 4 or
• l(F ) = 3, |V (F )| is odd, and none component with diameter 3 is a path.
Proof. The result follows by Theorem 11 [3], which characterizes forests of χg(F ) = 2, and Theo-rem 2.1.
2.2 Caterpillar without vertex with degree 2
Theorem 2.7 has the goal of studying the game chromatic number of caterpillars G without vertexwith degree 2, and its consequence when we extend to forests. First, we need four lemmas.
Lemma 2.3. Let G be the caterpillar cat(0, 2, 0), G′ be the caterpillar cat(0, 2, 1, 0). We have thatχbg(G,Z), χb
g(G′, Z ′) = 4, where Z = {v1, v3| c(v1) 6= c(v3)} and Z ′ = {v1, v4}. See Figure 4.
Figure 4: The partially colored caterpillars (a) G; (b) G′.
Proof. Bob colors with color 3 a leg leaf adjacent to v2 in G or he colors with color 2 a leg leafadjacent to v2 in G′, making impossible to Alice to color the caterpillars with 3 colors.
Lemma 2.4. Let G be the caterpillar cat(0, 2, 2, 0). We have that χag(G,Z) = 4, where Z =
{v1, v4| c(v1) = c(v4)}, and χbg(G,Z ′) = 4, where Z ′ = {v1, v4}.
Proof. Assume that c(v1) = c(v4) = 1. When Alice starts, she can color a vertex in the spine ofthe partially colored caterpillar, suppose v2 with the color 2, and, by Lemma 2.3, χa
g(G,Z) = 4. Ifshe colors a leaf leg adjacent to v2 with color 1 or 2, then Bob colors a leaf leg adjacent to v2 withcolor 1 or 2, forcing Alice to color v3 with color 3. So, Bob can color the other leaf leg adjacent tov2 with color 2, and χa
g(G,Z) = 4.When Bob starts (independent if c(v1) = c(v4) or c(v1) 6= c(v4)), he colors a leaf leg adjacent to
v2 with color 2, forcing Alice to color v2 with color 3, and he colors a leaf leg adjacent to v3 withcolor 2, and χb
g(G,Z ′) = 4.
Lemma 2.5. Let G be the caterpillar cat(k1, ..., ks), s ≥ 3, k1 = ks = 0, kj ≥ 2 for some uniquej ∈ {2, ..., s− 1}, and ki = 1 for all i ∈ {1, ..., j − 1, j + 1, ..., s}. We have that χb
g(G,Z) = 4, whereZ = {v1, vs| c(v1) 6= c(vs)}.
Proof. For s = 3 and s = 4, is exactly the graphs of Lemma 2.3 and they have χbg(G,Z) = 4.
When s = 5, we have two possible caterpillars, as in Figure 5. In both cases, if Bob colors v3 withcolor 3, then it is impossible to color all the graph with 3 colors, and χb
g(G,Z) = 4.
CLAIO-2016
355

Figure 5: cat(0, 1, k3, 1, 0) and cat(0, k2, 1, 1, 0), where k3, k2 ≥ 2.
For s ≥ 6, Bob color the vertices of the spine of the caterpillar in the order: v3, vs−2, v5, vs−4,..., until he obtains a subcaterpillar as shown previously in the cases where s = 3, s = 4 or s = 5.
Thus, χbg(G,Z) = 4.
Lemma 2.6. Let G be the caterpillar cat(k1, ..., ks), s ≥ 5, k1 = ks = 0, kp, kq ≥ 2 for just twop, q ∈ {2, ..., s− 1}, q − p > 1, and ki = 1 for all i ∈ {1, ..., p− 1, p+ 1, ..., q − i, q + 1, ..., s}. Wehave that χa
g(G,Z) = χbg(G,Z) = 4, where Z = {v1, vs| c(v1) 6= c(vs)}.
Proof. If Alice colors a vertex vi with p ≤ i ≤ q, then, by Lemma 2.5, χag(G,Z) = 4. If Alice colors
a leaf leg adjacent to a vertex vi with i < p and i > q, then Bob colors its adjacent vertex and wehave a subcaterpillar with the same properties as the input partially colored caterpillar. All thefollowing situations end with χa
g(G,Z) = 4 by Lemma 2.5: if Alice colors a leaf leg adjacent to avertex vi with p < i < q, then Bob colors its adjacent vertex; if Alice colors a a vertex vi with i < por i > q, then Bob colors a vertex vi with p < i < q; and, if Alice colors a leaf leg adjacent to avertex vp or vq, then Bob colors the other leaf leg forcing Alice to color vp or vq, respectively.
If Bob starts the game, he colors vi with p < i < q, and, by Lemma 2.5, χbg(G,Z) = 4.
Theorem 2.7. Let G be the caterpillar without vertex with degree 2. We have that χag(G) =
χbg(G) = 4 if, and only if, G is caterpillar cat(k1, ..., ks), such that k1 = ks = 0, ki 6= 0, ∀i ∈{2, ..., s− 1}, and there are at least four vertices with degree at least 4.
Moreover, let F be the forest without vertex with degree 2 where each connected component is acaterpillar. We have that χa
g(F ) = 4 if, and only if, there is a component G in F that has at leastfour vertices with degree at least 4.
Proof. Let vp, vq, vr and vt be four vertices with degree at least 4 in G′ subcaterpillar of G.Case 1) G′ has no two consecutive vertices in the spine with degree at least 4.If Alice colors a vertex vi in the spine of G′, then Bob colors another vertex vj in the spine of
G′ in a way that between vi and vj there are exactly two vertex with degree at least 4 and, byLemma 2.6, χa
g(G) = 4.If Alice colors a leg leaf, then Bob colors with a different color a vertex in the spine of G with
distance 2 of the leg leaf that Alice have colored. In this way, Bob forces Alice to color a vertex inthe spine, and he can uses the previous strategy. There is a exception: if r = q+ 2 and Alice colorsthe leaf leg adjacent to vq+1, then Bob colors vq+1, and in future he can color vp−1 or vt+1 and, byLemma 2.6, χa
g(G) = 4.If Bob starts, then he colors vertex vq+1.Case 2) vp, vq and vr are adjacent, and t− r > 1If Alice colors vp−1, vp, vr or vr+1, then, by Lemma 2.4, χa
g(G) = 4. If she colors vq or vi, withi > t, or a leaf leg, then we use the strategy of Case 1. If she colors vi, r < i ≤ t, with color 1, thenBob colors vp−1 with color 2. So, to avoid the situation of Lemma 2.4, Alice color vq with color 2,and, by Lemma 2.5, χa
g(G) = 4. Using the same idea, if Alice colors vi, i < p, with color 1, thenBob colors vr+1 with color 2.
CLAIO-2016
356

If Bob starts, then he colors vp−1 with color 1. So, to avoid the situation of Lemma 2.4, Alicecolor vq with color 1, and Bob can use the strategy of Case 1 coloring vt+1 with color 2.
Case 3) vq and vr are adjacent, q − p > 1 and t− r > 1If Alice colors vq−1 or vr+1, then, by Lemma 2.4, χa
g(G) = 4. If she colors vi, i < p, vq or leafleg, then Bob uses the strategy of Case 1.
If Alice color vi, p ≤ i < q, with color 1, then Bob colors vi+2, vi+4, vi+6... with color 2 and1 alternately forcing Alice to color vi+1, vi+3, vi+5... with color 3. He keeps doing this until hecolors vertex vq−1 or vq. So, he uses Lemma 2.4 or the strategy of Case 1. The other cases areisomorphic.
If Bob starts, then he colors vp−1 with color 1, and independently of where Alice plays, Bobuses the previous strategy.
Case 4) vp and vq are adjacent, r − q > 1 and t− r > 1If Alice colors vp−1 or vq+1, then, by Lemma 2.4, χa
g(G) = 4. If she colors vi, i ≥ p, or leaf leg,then Bob uses the strategy of Case 1.
If she colors vi, i < p, then Bob colors vi+2, vi+4, vi+6... with color 2 and 1 alternately forcingAlice to color vi+1, vi+3, vi+5... with color 3. He does this until he colors vertex vp−1 or vp. So, heuses Lemma 2.4 or the strategy of Case 1.
If Bob starts, then he colors vp−1 as in Case 2.Case 5) vp and vq are adjacent, vr and vt are adjacent and r − q > 1If Alice colors vp−1, vq+1, vr−1 or vt+1, then, by Lemma 2.4, χa
g(G) = 4. If she colors vp or leafleg, then Bob uses the strategy of Case 1.
If she colors vi, i < p, with color 1, and p − i is odd, then Bob colors vi+2, vi+4, vi+6... withcolor 2 and 1 alternately, forcing Alice to color vi+1, vi+3, vi+5... with color 3. He keeps doing thisuntil he colors vertex vp−1. So, he uses Lemma 2.4.
If she colors vi, i < p, with color 1, and p− i = 2, then Bob colors vq+1 with color 2.If she colors vi, i < p, with color 1, and p − i ≥ 4 is even, then Bob colors vq+1 with color 1.
To avoid Lemmas 2.3 and 2.4, Alice colors vq with color 2 (and the result follows by Lemma 2.5),or she colors vp with color 2, and then Bob colors vp−2, vp−4, vp−6... with color 3 and 2 alternatelyforcing Alice to color vp−1, vp−3, vp−5... with color 1 and 3, respectively. He keeps doing this untileither he colors vertex vi+2, and so he colors the leaf leg adjacent to vi+1 with a different color ofvi+2, and the result follows by Lemma 2.3.
If Alice colors vi, q ≤ i < r with color 1, then Bob uses the same strategy as in case that Alicecolors vi, i < p.
If Bob starts, then he colors vp−1 with color 1.Thus, if G has G′ a subcaterpillar cat(k1, ..., ks), such that ki 6= 0, ∀i ∈ {1, ..., s}, and there are
four vertices with degree at least 4, then χag(G) = χb
g(G) = 4.We omit in this extended abstract the proof that if G has just one, two or three vertices with
degree at least 4, then χag(G) = χb
g(G) ≤ 3.If F is a forest without vertex with degree 2 where each connected component G1, ..., Gr is a
caterpillar and there is a component Gi, for i = 1, ..., r, in F that has at least four vertices withdegree at least 4, then χa
g(Gi) = χbg(Gi) = 4. So, χa
g(F ) ≥ 4, but we know by [4] that χag(F ) ≤ 4.
Else, the χag(Gj), χ
bg(Gj) ≤ 3. Therefore, χg(F ) = 4.
CLAIO-2016
357

3 Further Questions
We determine the game chromatic number of a forest where each connected component is a cater-pillars with maximum degree 3 or caterpillars without vertices with degree 2. But the problem ofdetermining the game chromatic number of an arbitrary forest is still open.
We can now answer, for caterpillars, Question 32 of Dunn et al. [3] that says: does there exista polynomial time algorithm to determine if a forest with maximum degree 3 has game chromaticnumber 4? For a forest composed by caterpillars, there is no forest with maximum degree 3 andgame chromatic number 4, by Theorem 2.1. So, we answer “no” in constant time (O(1)).
Similar to Dunn et at. [3], we never distinguish between vertices with degree exactly 4 andvertices with degree at least 4. We propose a conjecture to address this point in caterpillars.
Conjecture 1: Let G be a caterpillar cat(k1, ..., ks) and G′ be a caterpillar cat(l1, ..., ls), suchthat li = ki, if ki ≤ 2, and li = 2, if ki > 2. We have that χg(G) = χg(G′).
Another fact that could help us to study the game chromatic number in any forest is:Conjecture 2: χa
g(G) ≤ χbg(G), for a tree G.
We know that Conjecture 2 is false for an arbitrary graph G. In Figure 6, we present an exampleof graph G that has χa
g(G) = 5 and χbg(G) = 3.
Figure 6: Graph G with χag(G) = 5 and χb
g(G) = 3.
References
[1] H. Bodlaender. On the complexity of some coloring games. In R. H. Mohring. Graph-Theoretic Conceptsin Computer Science, vol. 484 of Lecture Notes in Computer Science, pp. 30–40. Springer, London, 1991.
[2] S. Charmaine. The game chromatic number of some families of cartesian product graphs, AKCEInternational Journal of Graphs and Combinatorics 6 (2), pp. 315–327, 2009.
[3] C. Dunn and V. Larsen and K. Lindke and T. Retter and D. Toci. The game chromatic number of treesand forests, Discrete Mathematics and Theoretical Computer Science 2(17):31–48, 2015.
[4] U. Faigle and W. Kern and H. Kierstead A. and W. Trotter. On the game chromatic number of someclasses of graphs Ars Combinatoria (35), pp. 143–150, 1993.
[5] M. Gardner. Mathematical Games. Scientific American. Vol. 23, 1981.
[6] D. Guan and X. Zhu. Game chromatic number of outerplanar graphs, Journal of Graph Theory (30),pp. 67–70, 1999.
[7] H. A. Kierstead and A. V. Kostochka. Efficient graph packing via game colouring, Combinatorics,Probability and Computing (18), pp. 765–774, 2009.
[8] A. Raspaud and W. Jiaojiao. Game chromatic number of toroidal grids, Information Processing Letters109 (21-22), pp. 1183–1186, 2009.
[9] X. Zhu. Game coloring of planar graphs, Journal of Combinatorial Theory, Series B, (75), pp. 245–258,1999.
[10] X. Zhu. The game coloring number of pseudo partial k-trees, Discrete Mathematics 215 (1-3), pp.245–262, 2000.
CLAIO-2016
358

MEASURING IN WEIGHTED ENVIRONMENTS Moving from Metric to Order Topology (Knowing when close really means close)
Claudio Garuti
Fulcrum Ingenieria Ltda. [email protected]
Abstract
This article addresses the problem of measuring closeness in weighted environments(decision-making environments), using the concept of compatibility of priority vectors and value systems. When using the concept of closeness come in mind immediately what means to be close (when close really means close). Thus when measuring closeness or proximity we should add a point of comparison (a threshold) that make possible to compare or decide if our positions, system values or priorities are really close. Keywords: Weighted environments, Measurement, Compatibility, Order Topology. 1. Introduction
We will show a proposition for a compatibility index able to measure closeness in a weighted environment, thus, able to assess: pattern recognition; medical diagnosis support measuring the degree of closeness between disease-diagnosis profiles, Buyer-Seller matching profiles; measuring the degree of closeness between house buyer and seller projects or employment degree of matching; measuring the degree of closeness between a person’s profile with the desired position profile; in curricula network design, Conflict Resolution; measuring closeness of two different value systems (ways of thinking) by identify and measuring the discrepancies, and in general measuring the degree of compatibility between any priority vectors in cardinal measure bases (order topology). For our purposes, compatibility is defined as the proximity or closeness between vectors within a weighted space. 2.- Hypotheses/Objectives
In order topology, measurement deals with dominance between preferences (intensity of preference), for instance: D(a,b)=3, means that dominance or intensity of preference of “a” over “b” is equal to 3, or that, a is 3 times more preferred than b. When talking about preferences a relative absolute ratio scale is applied. Relative; because priority is a number created as a proportion of a total (percent or relative to the total) and has no needs for an origin or predefined zero in the scale. Absolute; because it has no dimension since it is a relationship between two numbers of the same scale leaving the final number with no unit. Ratio; because it is built in a proportional type of scale (6kg/3kg=2). Thus, making a general analogy between the two topologies, one might say that: “Metric Topology is to Distance as Order Topology is to Intensity”. An equivalent concept of distance is presented in order to make a parallel between the three properties of distance of metric topology. This is applied in the order topology domain, considering a compatibility function (Eq.1) similar to distance function, but over vectors instead of real numbers. Consideration: A, B, C are priority vectors of positive coordinates and Σiai= Σibi = Σici =1. Next, is presented the compatibility function expressed as:
G(A,B) = ½Σi(ai+bi)Mini(ai,bi)/Maxi(ai,bi) (Eq.1)
This function presents the following conditions: 1.- 0 ≤ G(A,B) ≤ 1 (Non negative real number) The compatibility function G, returns a non negative real number that lays in the 0 - 1 range. With G(A,B)=0, iif A and B are perpendicular vectors (A┴B), and represent the definition of total incompatibility between priority vectors A, B. (AºB=0). Also, G(A,B)=1, iif A and B are parallel vectors, (A=B for normalized vectors), and represent the definition of total compatibility between priority vectors A and B. (AºB=1) 2.- G(A,B) = G(B,A) (Symmetry) Symmetry condition, the compatibility measured from A to B is equal to the compatibility measured from B to A. Easy to proof, just interchanging A for B and B for A in the compatibility function G. 3.- G(A,B) + G(B,C) ≥ G(A,C) (Triangular inequality)
CLAIO-2016
359

4.- ACB and BCC =><= ACC (Non transitivity of compatibility): If A is compatible with B, and B compatible with C, do not implies that A is necessarily compatible with C. This situation can be geometrically viewed in the next figure:
Figure A: Maximum circle of compatibility for position A, related to B and C
Figure A, is showing the compatibility neighborhood for A, in relation with B and C, with its minimum compatibility value of 0.9 represented by the radius of the circle. (In the center the compatibility reaches its maximum value of 1.0). Thus, G(A,B)=G(A,C)=0.9 is representing the minimum compatibility point, or the maximum distance for positions B and C to still be compatible with position A. Of course, G(B,C)<0.9 that represents a non-compatible position for points B and C. Notice that property 3, G(A,B) + G(B,C) ≥ G(A,C) is still valid, indeed any combination that one can be made will keep the inequality satisfied since if C gets closer to A (increasing the right side of the equation), then G(B,C) will also grow. The extreme case when C is over A, (G(A,C)=1.0) then G(B,A)+G(B,C)=0.9+0.9=1.8>1.0 keeping the inequality satisfied. We may also define incompatibility function as the arithmetic complement of the compatibility: Incompatibility = 1 – Compatibility. Thus: Incompatibility is equivalent to 1 - G. By the way, the incompatibility concept is more close to the idea of distance, since the greater the distance the greater the incompatibility. Two simple examples of this parallel between D(x,y) and G(X,Y) are given. But first, to make D and G functions comparable, absolute distance D must be transformed into relative terms as a percent value since the priority vectors are normalized vectors for the G function. Thus, the maximum possible value for D1 (Norm1) is 2 and for D2 (Norm2) is , while performing the ratios with respect to the maximum possible value and obtaining D in relative terms as percent of the maximum value. For the first example, two different and very different vectors A and B with coordinate: {0.3, 0.7} with {0.7, 0.3} and {0.1, 0.9} with {0.9, 0.1} are considered. Considering also Incompatibility= 1– Compatibility or 1 – G(A,B). Then: Compatibility between A and B is shown by G(A,B) (Real positive value laying in 0-1 range). Incompatibility between A and B is shown by 1– G(A,B) (Real positive value laying in 0-1 range). Table 1a shows the results of applying D1, D2 and (1-G) functions.
Table 1a: Evaluating distance and incompatibility for non-similar set of coordinates
A,B Coordinates
D1(a.b) Distance A-B in
Norm1 (normalized)
D2(a,b) Distance A-B in
Norm2 (normalized)
Incompatibility= 1 - G(A,B)
A={0.3, 0.7} B={0.7, 0.3} 0.8/2= 0.4 (40%) 0.4√2/√2= 40% 1-(0.3/0.7)= 57%
A={0.1, 0.9} B={0.9, 0.1} 1.6/2= 0.8 (80%) 0.8√2/√2= 80% 1-(0.1/0.9)= 89%
Figure B shows in 2D Cartesian axes how far (incompatible) is A from B in both cases. Notice that for the case represented in brown (for D=80% and G=89%), vectors A and B are (geometrically) almost in a perpendicular position (A relative to B).
0.9 0.9 C
A B
CLAIO-2016
360
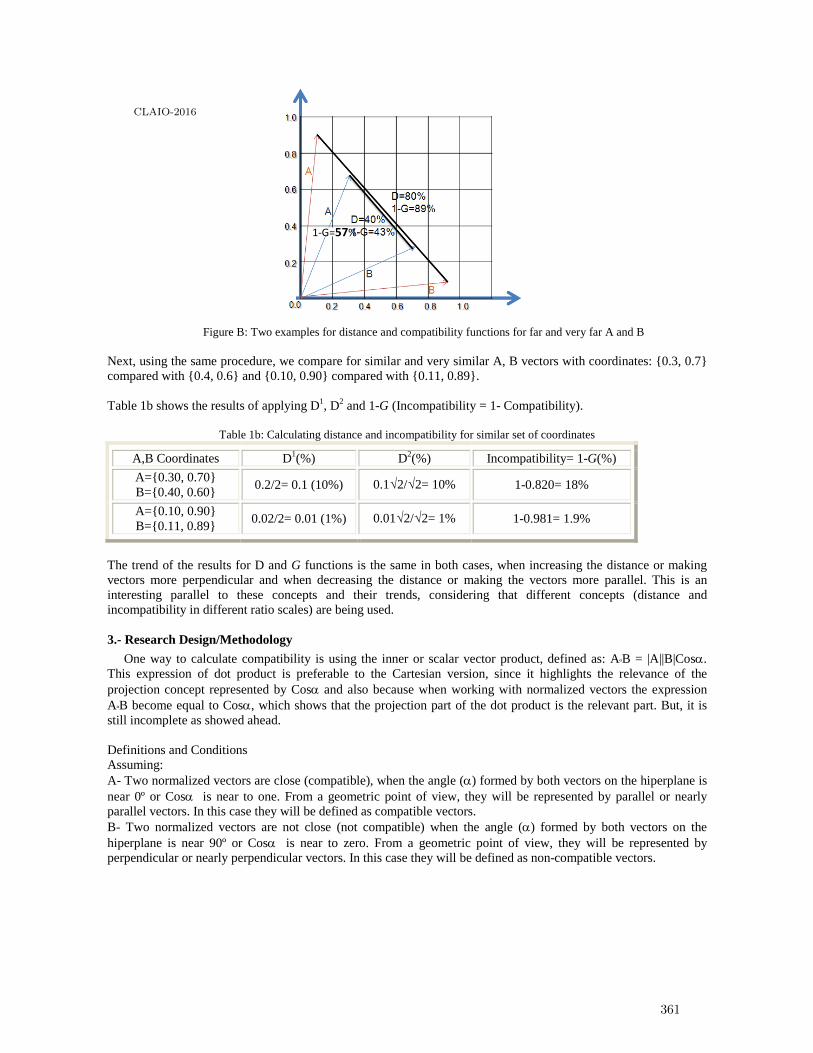
Figure B: Two examples for distance and compatibility functions for far and very far A and B
Next, using the same procedure, we compare for similar and very similar A, B vectors with coordinates: {0.3, 0.7} compared with {0.4, 0.6} and {0.10, 0.90} compared with {0.11, 0.89}. Table 1b shows the results of applying D1, D2 and 1-G (Incompatibility = 1- Compatibility).
Table 1b: Calculating distance and incompatibility for similar set of coordinates
A,B Coordinates D1(%) D2(%) Incompatibility= 1-G(%) A={0.30, 0.70} B={0.40, 0.60} 0.2/2= 0.1 (10%) 0.1√2/√2= 10% 1-0.820= 18%
A={0.10, 0.90} B={0.11, 0.89} 0.02/2= 0.01 (1%) 0.01√2/√2= 1% 1-0.981= 1.9%
The trend of the results for D and G functions is the same in both cases, when increasing the distance or making vectors more perpendicular and when decreasing the distance or making the vectors more parallel. This is an interesting parallel to these concepts and their trends, considering that different concepts (distance and incompatibility in different ratio scales) are being used.
3.- Research Design/Methodology
One way to calculate compatibility is using the inner or scalar vector product, defined as: AºB = |A||B|Cosα. This expression of dot product is preferable to the Cartesian version, since it highlights the relevance of the projection concept represented by Cosα and also because when working with normalized vectors the expression AºB become equal to Cosα, which shows that the projection part of the dot product is the relevant part. But, it is still incomplete as showed ahead. Definitions and Conditions Assuming: A- Two normalized vectors are close (compatible), when the angle (α) formed by both vectors on the hiperplane is near 0º or Cosα is near to one. From a geometric point of view, they will be represented by parallel or nearly parallel vectors. In this case they will be defined as compatible vectors. B- Two normalized vectors are not close (not compatible) when the angle (α) formed by both vectors on the hiperplane is near 90º or Cosα is near to zero. From a geometric point of view, they will be represented by perpendicular or nearly perpendicular vectors. In this case they will be defined as non-compatible vectors.
1-G=57%
CLAIO-2016
361
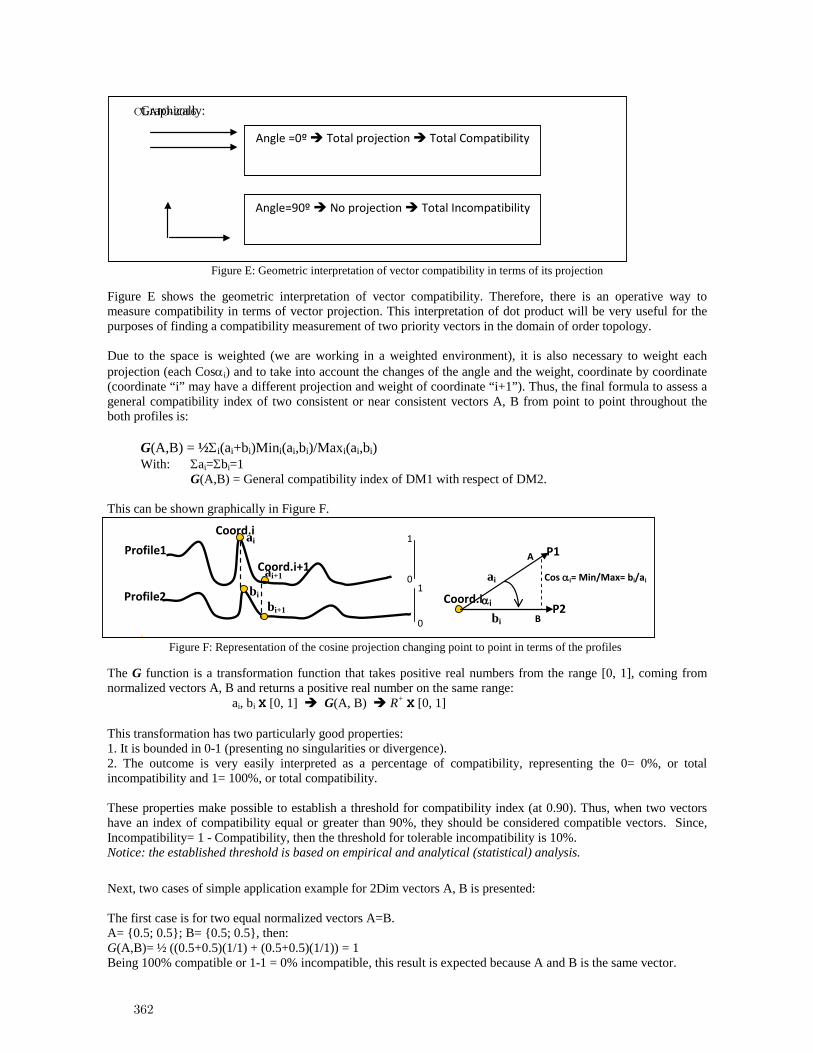
Graphically:
Figure E: Geometric interpretation of vector compatibility in terms of its projection
Figure E shows the geometric interpretation of vector compatibility. Therefore, there is an operative way to measure compatibility in terms of vector projection. This interpretation of dot product will be very useful for the purposes of finding a compatibility measurement of two priority vectors in the domain of order topology. Due to the space is weighted (we are working in a weighted environment), it is also necessary to weight each projection (each Cosαi) and to take into account the changes of the angle and the weight, coordinate by coordinate (coordinate “i” may have a different projection and weight of coordinate “i+1”). Thus, the final formula to assess a general compatibility index of two consistent or near consistent vectors A, B from point to point throughout the both profiles is:
G(A,B) = ½Σi(ai+bi)Mini(ai,bi)/Maxi(ai,bi) With: Σai=Σbi=1
G(A,B) = General compatibility index of DM1 with respect of DM2.
This can be shown graphically in Figure F.
. Figure F: Representation of the cosine projection changing point to point in terms of the profiles
The G function is a transformation function that takes positive real numbers from the range [0, 1], coming from normalized vectors A, B and returns a positive real number on the same range: ai, bi X [0, 1] G(A, B) R+ X [0, 1] This transformation has two particularly good properties: 1. It is bounded in 0-1 (presenting no singularities or divergence). 2. The outcome is very easily interpreted as a percentage of compatibility, representing the 0= 0%, or total incompatibility and 1= 100%, or total compatibility. These properties make possible to establish a threshold for compatibility index (at 0.90). Thus, when two vectors have an index of compatibility equal or greater than 90%, they should be considered compatible vectors. Since, Incompatibility= 1 - Compatibility, then the threshold for tolerable incompatibility is 10%. Notice: the established threshold is based on empirical and analytical (statistical) analysis. Next, two cases of simple application example for 2Dim vectors A, B is presented: The first case is for two equal normalized vectors A=B. A= {0.5; 0.5}; B= {0.5; 0.5}, then: G(A,B)= ½ ((0.5+0.5)(1/1) + (0.5+0.5)(1/1)) = 1 Being 100% compatible or 1-1 = 0% incompatible, this result is expected because A and B is the same vector.
ai
B
αi
A
bi Coord.i bi
bi+1 1
0
Angle =0º Total projection Total Compatibility
Angle=90º No projection Total Incompatibility
ai+1
Coord.i Profile1
Profile2
ai
Cos αi= Min/Max= bi/ai
P1
P2
Coord.i+1
1
0
CLAIO-2016
362
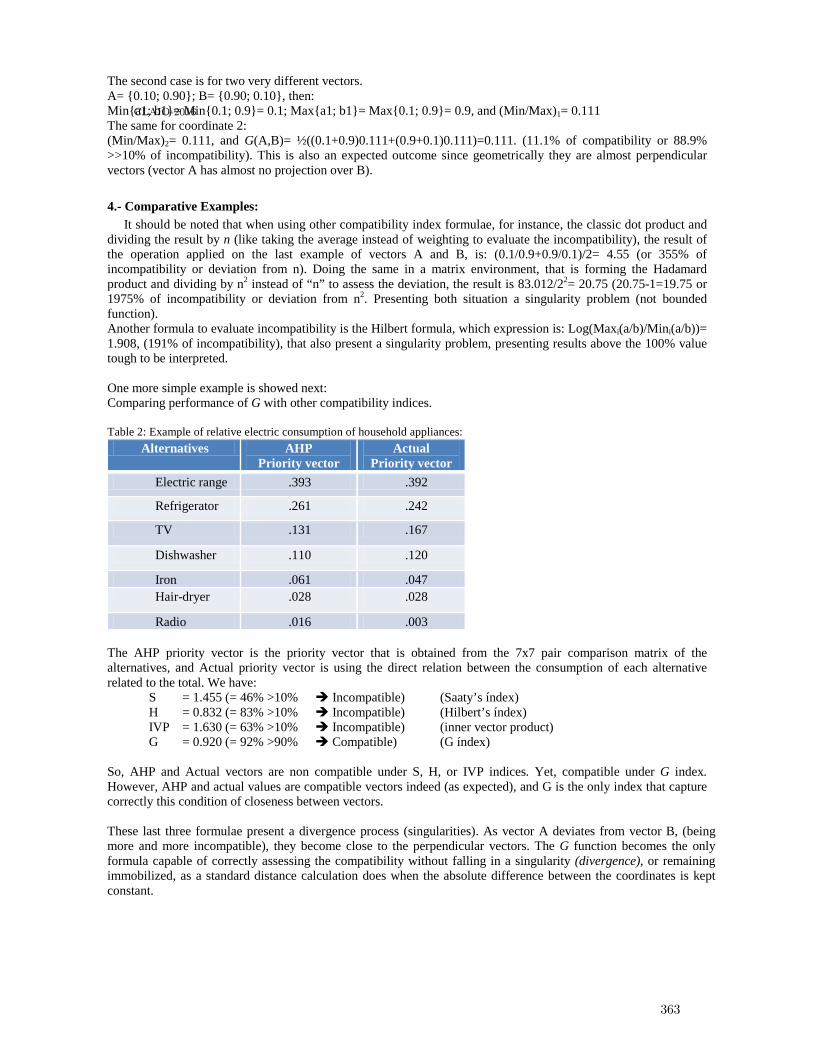
The second case is for two very different vectors. A= {0.10; 0.90}; B= {0.90; 0.10}, then: Min{a1; b1}= Min{0.1; 0.9}= 0.1; Max{a1; b1}= Max{0.1; 0.9}= 0.9, and (Min/Max)1= 0.111 The same for coordinate 2: (Min/Max)2= 0.111, and G(A,B)= ½((0.1+0.9)0.111+(0.9+0.1)0.111)=0.111. (11.1% of compatibility or 88.9% >>10% of incompatibility). This is also an expected outcome since geometrically they are almost perpendicular vectors (vector A has almost no projection over B). 4.- Comparative Examples:
It should be noted that when using other compatibility index formulae, for instance, the classic dot product and dividing the result by n (like taking the average instead of weighting to evaluate the incompatibility), the result of the operation applied on the last example of vectors A and B, is: (0.1/0.9+0.9/0.1)/2= 4.55 (or 355% of incompatibility or deviation from n). Doing the same in a matrix environment, that is forming the Hadamard product and dividing by n2 instead of “n” to assess the deviation, the result is 83.012/22= 20.75 (20.75-1=19.75 or 1975% of incompatibility or deviation from n2. Presenting both situation a singularity problem (not bounded function). Another formula to evaluate incompatibility is the Hilbert formula, which expression is: Log(Maxi(a/b)/Mini(a/b))= 1.908, (191% of incompatibility), that also present a singularity problem, presenting results above the 100% value tough to be interpreted. One more simple example is showed next: Comparing performance of G with other compatibility indices.
Table 2: Example of relative electric consumption of household appliances:
Alternatives AHP Priority vector
Actual Priority vector
Electric range .393 .392
Refrigerator .261 .242
TV .131 .167
Dishwasher .110 .120
Iron .061 .047 Hair-dryer .028 .028
Radio .016 .003 The AHP priority vector is the priority vector that is obtained from the 7x7 pair comparison matrix of the alternatives, and Actual priority vector is using the direct relation between the consumption of each alternative related to the total. We have:
S = 1.455 (= 46% >10% Incompatible) (Saaty’s índex) H = 0.832 (= 83% >10% Incompatible) (Hilbert’s índex) IVP = 1.630 (= 63% >10% Incompatible) (inner vector product) G = 0.920 (= 92% >90% Compatible) (G índex)
So, AHP and Actual vectors are non compatible under S, H, or IVP indices. Yet, compatible under G index. However, AHP and actual values are compatible vectors indeed (as expected), and G is the only index that capture correctly this condition of closeness between vectors.
These last three formulae present a divergence process (singularities). As vector A deviates from vector B, (being more and more incompatible), they become close to the perpendicular vectors. The G function becomes the only formula capable of correctly assessing the compatibility without falling in a singularity (divergence), or remaining immobilized, as a standard distance calculation does when the absolute difference between the coordinates is kept constant.
CLAIO-2016
363

5.- Conclusions There are two global conclusions of this study:
First: we need some kind of index for distance/alignment measurement in weighted environments (order topology domain), in order to mathematically define if two profiles (or behaviours) are really close. This index (compatibility index) should make possible a matching analysis process, analysis of quality of the results or have one more tool for conflict resolution on group decision making to achieve a possible agreement. Considering that those profiles may represent: system values, a pattern recognition process, benchmarking, or even a membership analysis (closeness analysis). Second: this analysis shows that the only compatibility index that performs correctly for every case is G index, keeping the outcome always in the 0-100% range (like Euclidean formula), and this is an important condition, since any value out of the 0-100% range would be difficult to interpret (and the beginning of a possible divergence). It is interesting to note also that function G depends on two different dimensional factors, on one side is the intensity of preference (related with the weight of the element), and on the other side is the angle of projection between the vectors (the profiles). This means that G is a function of the intensity of preference (I) and the angle of projection (α) between the priority vectors, that is: G= f(I,α). Thus, the G function is not the simple dot product (as normally defined), but something more complex and rich of information. It is also important to note that both data (intensity and angle) are normally implicit in the coordinates of the priority vectors and have to be correctly extracted (depending if the priorities are presented in relative or absolute measurement format). The possible applications of this index are huge and for different fields, as an example, for Social & Management Sciences the possibilities are: Table 3: Possible application for compatibility index G in decision making environment
On Medicine Measuring the degree of matching (proximity) between patient and disease diagnose profiles.
On Buyers-Seller profiles Measuring the degree of matching between house buyers and sales project.
On Group Decision Making (Conflict Resolution)
Measuring how close are two (or more) different value systems (where they differ and for how much).
On Quality Tests Measuring what MCDM decision method can builds a better metric.
On Agricultural Production & Supplier Selection
Measuring the proximity between the cultivate plants against a healthy plant (based on its micro & macro nutrients) and selecting the best nutrient seller.
On Shiftwork Prioritization Measuring how close are the different views among the different stakeholders (Workers view, Company view, Community view).
On Company Social Responsibility (CSR) Measuring how close are the different views among the different stakeholders (Economic, Environmental and Social view).
Notice: all the examples mentioned above are coming from real cases application. 6.- Key References: • Garuti, C. 2014. Measuring In Weighted Environments. International Journal of AHP (IJAHP) 2014. (Article). • Garuti, C Compatibility of AHP/ANP vectors with known results. Presentation of a suggested new index of compatibility
in weighted environments. ISAHP2014 International Symposium of the Analytic Hierarchy Process. 2014. • Garuti, C. 2012. Measuring in Weighted Environments: Moving from Metric to Order Topology. Santiago, Chile:
Universidad Federico Santa Maria.(Book, 72pp). • Garuti, C. A. 2007. Measuring Compatibility in Weighted Environments: When close really means close? International
Symposium on AHP, 9, Viña del Mar, Chile. 2007. (Paper) • Hilbert, D. 1895 "Ueber die gerade Linie als kürzeste Verbindung zweier Punkte", Mathematische Annalen (Springer
Berlin / Heidelberg) 46: 91–96,doi:10.1007/BF02096204, ISSN 0025-5831, JFM 26.0540.02 • Mahalanobis, P.C. ''On the generalised distance in statistics'', Proceedings of the National Institute of Science of India 12
(1936) 49-55. • Papadopoulos, A.; Troyanov, M. (2014), Handbook of Hilbert Geometry, European Mathematical Society
CLAIO-2016
364

• Saaty, L. T. 2010. GROUP DECISION MAKING: Drawing out and Reconciling Differences. Pittsburgh: RWS. (Book, 385pp).
• Saaty, L.T. 2001. The Analytic Network Process: Decision Making with Dependence and Feedback. (Book, 376pp). • Whitaker, R. 2007. Validation Examples of the Analytic Hierarchy Process and Analytic Network Process. Mathematical
and Computer Modeling. Vol. 46, pp. 840-859. (Paper).
CLAIO-2016
365

Modelo de simulación de un sistema de fabricación de cerveza.
Aplicación didáctica en currículos de Ingeniería Química en el
área de Gestión de Producción y Operaciones (GPO) Jaime Alberto Giraldo (Universidad Nacional de Colombia, [email protected]), Jhonathan Mauricio
Vargas
El modelo de decisión desarrollado permite a estudiantes de Ingeniería Química entrenarse para la toma de decisiones en temas relacionados con la GPO (Vargas Barbosa, 2016) dado que la simulación permite experimentar con una abstracción de un proceso sin afectarlo ni correr con los riesgos y costos que conlleva experimentar con el sistema real (Vargas Barbosa y Giraldo García, 2015). Adicionalmente se tiene que la GPO busca la construcción y sostenibilidad de las capacidades competitivas de la unidad empresarial, lo que implica el entendimiento del papel de todas las funciones organizacionales y especialmente la producción como función clave de la misión empresarial (Cárdenas Aguirre, y otros, 2008). La simulación al propiciar un ambiente virtual puede ser una herramienta muy útil al momento de situar a los estudiantes en escenarios prácticos, que para el caso lo constituye la toma de decisiones en GPO, ya que pueden acceder a modelos de sistemas productivos reales y modificar algunas condiciones de operación, las cuales en el mundo real no lo pueden hacer, por razones que van desde el costo hasta el riesgo de ser sancionados ante pobres decisiones (Fredes y otros, 2012). El modelo desarrollado representa un sistema de producción de cerveza mediante el cual los discentes tienen la posibilidad de establecer los niveles de diferentes variables de decisión (causas) del proceso de producción: gestión de inventarios, control y programación de producción, tiempos de operación de equipos, capacidades y costos de producción para comprobar el cambio en diferentes medidas de desempeño (efectos) del sistema: producción por tipo de producto, costos de producción, niveles de WIP (Work In Process) y utilización de equipos según se muestra en la figura 1.
Figura 1. Representación gráfica del modelo de simulación De manera muy general el proceso desarrollado a través del sistema modelado consiste en que al sistema ingresa el agua y el lúpulo. Esta materia prima pasa por un proceso de filtrado- maceración para luego ser fermentados (proceso que dura entre 8 y 20 días según el tipo de cerveza a producir); seguidamente pasan a la maduración (etapa que puede durar 15 días o más) para finalmente ser filtrada y empacada en botellas. En la simulación del sistema de producción, el usuario final establece cual es la producción requerida para satisfacer la demanda y cuál es el tiempo pactado de entrega y según la configuración escogida de los niveles de las variables de decisión comprueba si se puede o no cumplir a los clientes satisfaciendo cierto desempeño del sistema en términos de niveles de producción, costos de operación y gestión de inventarios (trade-offs). Como marco metodológico en lo didáctico se ha empleado el paradigma ABP (Aprendizaje Basado en Problemas). Para Vizcarro y Juárez (2008) el ABP implica una recopilación de problemas cuidadosamente construidos, los cuales se presentan en un lenguaje sencillo, poco técnico y planteando un reto, mediante el cual la tarea de los estudiantes es discutir estos problemas y producir explicaciones tentativas a los fenómenos. En tal sentido, un docente puede formular una instancia de problema que los discentes deben
CLAIO-2016
366
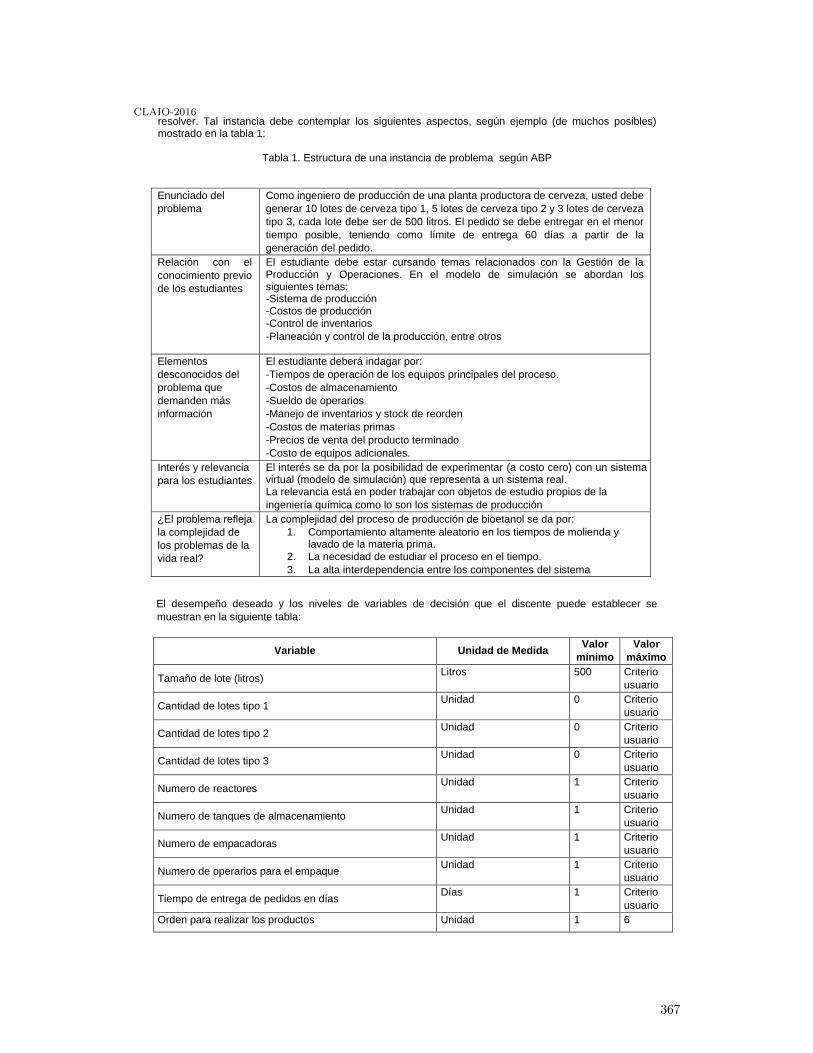
resolver. Tal instancia debe contemplar los siguientes aspectos, según ejemplo (de muchos posibles) mostrado en la tabla 1:
Tabla 1. Estructura de una instancia de problema según ABP
Enunciado del
problema
Como ingeniero de producción de una planta productora de cerveza, usted debe
generar 10 lotes de cerveza tipo 1, 5 lotes de cerveza tipo 2 y 3 lotes de cerveza
tipo 3, cada lote debe ser de 500 litros. El pedido se debe entregar en el menor
tiempo posible, teniendo como límite de entrega 60 días a partir de la
generación del pedido.
Relación con el
conocimiento previo
de los estudiantes
El estudiante debe estar cursando temas relacionados con la Gestión de la Producción y Operaciones. En el modelo de simulación se abordan los siguientes temas: -Sistema de producción -Costos de producción
-Control de inventarios
-Planeación y control de la producción, entre otros
Elementos
desconocidos del
problema que
demanden más
información
El estudiante deberá indagar por:
-Tiempos de operación de los equipos principales del proceso.
-Costos de almacenamiento
-Sueldo de operarios
-Manejo de inventarios y stock de reorden
-Costos de materias primas
-Precios de venta del producto terminado
-Costo de equipos adicionales.
Interés y relevancia
para los estudiantes
El interés se da por la posibilidad de experimentar (a costo cero) con un sistema virtual (modelo de simulación) que representa a un sistema real. La relevancia está en poder trabajar con objetos de estudio propios de la
ingeniería química como lo son los sistemas de producción
¿El problema refleja
la complejidad de
los problemas de la
vida real?
La complejidad del proceso de producción de bioetanol se da por:
1. Comportamiento altamente aleatorio en los tiempos de molienda y lavado de la materia prima.
2. La necesidad de estudiar el proceso en el tiempo.
3. La alta interdependencia entre los componentes del sistema
El desempeño deseado y los niveles de variables de decisión que el discente puede establecer se
muestran en la siguiente tabla:
Variable Unidad de Medida Valor
mínimo
Valor
máximo
Tamaño de lote (litros) Litros 500 Criterio
usuario
Cantidad de lotes tipo 1 Unidad 0 Criterio
usuario
Cantidad de lotes tipo 2 Unidad 0 Criterio
usuario
Cantidad de lotes tipo 3 Unidad 0 Criterio
usuario
Numero de reactores Unidad 1 Criterio
usuario
Numero de tanques de almacenamiento Unidad 1 Criterio
usuario
Numero de empacadoras Unidad 1 Criterio
usuario
Numero de operarios para el empaque Unidad 1 Criterio
usuario
Tiempo de entrega de pedidos en días Días 1 Criterio
usuario
Orden para realizar los productos Unidad 1 6
CLAIO-2016
367
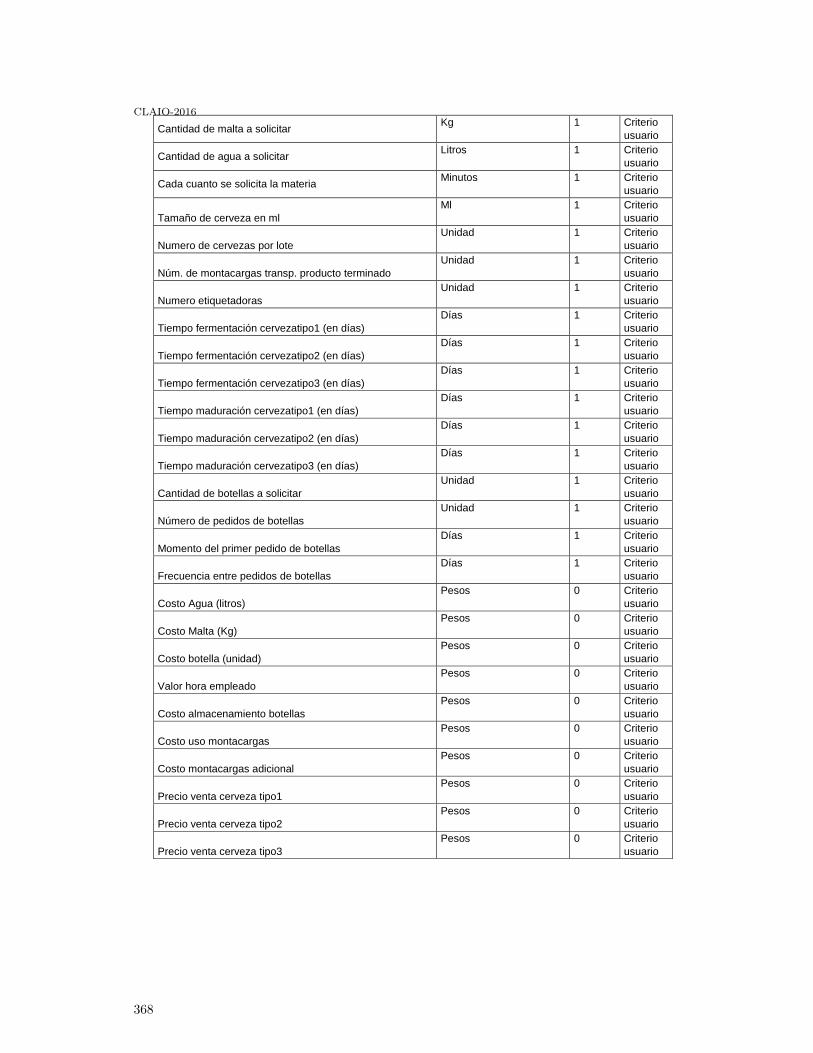
Cantidad de malta a solicitar Kg 1 Criterio
usuario
Cantidad de agua a solicitar Litros 1 Criterio
usuario
Cada cuanto se solicita la materia Minutos 1 Criterio
usuario
Tamaño de cerveza en ml
Ml 1 Criterio
usuario
Numero de cervezas por lote
Unidad 1 Criterio
usuario
Núm. de montacargas transp. producto terminado
Unidad 1 Criterio
usuario
Numero etiquetadoras
Unidad 1 Criterio
usuario
Tiempo fermentación cervezatipo1 (en días)
Días 1 Criterio
usuario
Tiempo fermentación cervezatipo2 (en días)
Días 1 Criterio
usuario
Tiempo fermentación cervezatipo3 (en días)
Días 1 Criterio
usuario
Tiempo maduración cervezatipo1 (en días)
Días 1 Criterio
usuario
Tiempo maduración cervezatipo2 (en días)
Días 1 Criterio
usuario
Tiempo maduración cervezatipo3 (en días)
Días 1 Criterio
usuario
Cantidad de botellas a solicitar
Unidad 1 Criterio
usuario
Número de pedidos de botellas
Unidad 1 Criterio
usuario
Momento del primer pedido de botellas
Días 1 Criterio
usuario
Frecuencia entre pedidos de botellas
Días 1 Criterio
usuario
Costo Agua (litros)
Pesos 0 Criterio
usuario
Costo Malta (Kg)
Pesos 0 Criterio
usuario
Costo botella (unidad)
Pesos 0 Criterio
usuario
Valor hora empleado
Pesos 0 Criterio
usuario
Costo almacenamiento botellas
Pesos 0 Criterio
usuario
Costo uso montacargas
Pesos 0 Criterio
usuario
Costo montacargas adicional
Pesos 0 Criterio
usuario
Precio venta cerveza tipo1
Pesos 0 Criterio
usuario
Precio venta cerveza tipo2
Pesos 0 Criterio
usuario
Precio venta cerveza tipo3
Pesos 0 Criterio
usuario
CLAIO-2016
368

A partir del desempeño deseado (objetivos) y configuración (niveles de las variables de decisión
establecidas) del sistema de producción, el modelo se simula según los pasos mostrados en la figura 2:
Figura 2. Procedimiento de solución del problema mediante simulación
Finalmente, la simulación muestra on-line el desempeño del sistema representado. La figura 3 ilustra el
tipo de resultados arrojados en términos de las medidas de desempeño:
Figura 3. Resultados del desempeño de una instancia del problema
Se espera que con dichos resultados el discente se retroalimente para que en la siguiente simulación varié
los niveles de las variables de decisión que lo conlleven a mejorar el desempeño del sistema representado,
y por consiguiente se entrene virtualmente en toma de decisiones en DPO.
Referencias
Cárdenas Aguirre, D. M., Castrillón Gómez, Ó. D., Becerra Rodríguez, F., Giraldo García, J. A., Ibarra
Mirón, S., y Zapata Gómez, A., Gestión De La Producción: Una Aproximación Conceptual. Bogotá:
Universidad Nacional de Colombia, Unibiblos (2008).
Fredes C. A., Hernández J. P., y Díaz D. A., "Potencial y problemas de la simulación en ambientes
virtuales para el aprendizaje", Formación Universitaria, pp. 45-56. (2012).
Vargas Barbosa, J. M. Tesis de Maestría: Modelo De Soporte Al Proceso Enseñanza/Aprendizaje De La
Gestión De La Producción Y Operaciones Basado En TIC. Aplicación Al Programa De Ingeniería Química.
Universidad Nacional de Colombia Sede Manizales. (2015).
CLAIO-2016
369

Vargas Barbosa, J. M., y Giraldo García, J. A. Modelo de entrenamiento en toma de decisiones
relacionadas con gestión de producción y operaciones de un sistema de fabricación de bioetanol. Iteckne,
7-16. (2015).
Vizcarro C, y Juárez E., «¿Qué es y cómo funciona el aprendizaje basado en problemas?,» de La
Metodología del Aprendizaje Basado en Problemas, Murcia, Editum, Ediciones de la Universidad de
Murcia. (2008).
CLAIO-2016
370

Mathematical job-shop scheduling models for energy management in manufacturing
systems – A summary
Ernesto DR Santibanez Gonzalez1* and Nelson Maculan2
1*Departamento Ingeniería Industrial, Universidad de Talca, Talca, Chile 2COPPE, Federal University of Rio de Janeiro, Rio de Janeiro, Brazil
Abstract
The classical job shop scheduling problem has existed for over 60 years. In this paper is summarized the recent mathematical models developed for addressing the job-shop scheduling problem under environmental constraints. It analyzes the mathematical models that capture the main environmental characteristics of the related processes and the solution methods developed so far. In this paper, the investigated problems are defined and classified, modeling gaps are highlighted and future research developments are proposed
Introduction
Manufacturing industry accounts 31% of primary energy consumption and is responsible
for about 36% of global CO2 emissions. With the increasing concern about climate change
and the rigorous regulations that have been put forward to mitigate its negative impacts,
manufacturing industry is looking for sustainable practices that help to reduce greenhouse
gas emissions. One of these practices is the efficiency management of the energy
consumption in the manufacturing processes. Recently, the European Commission has
estimated in about 25% the technical energy saving potentials in the manufacturing sectors;
this is a very promising area of research with great potential impact. In particular, job-shop
scheduling could play an important role in energy efficiency and the mitigation of climate
change. Researchers are increasing interested in developing mathematical models that help
decision-makers to understand and solve those problems. A great body of research has
recently been published on this arena, but the authors are not aware of any attempt to
summarize the potential contributions of energy-conscious job-shop scheduling models to
mitigating climate change. Therefore, this paper summarizes the current literature on the
modeling of energy-conscious job-shop scheduling systems that are based on the classical
scheduling problems, and it analyzes the mathematical models that capture the main
environmental characteristics of the related processes and the solution methods developed
so far. In this paper, the investigated problems are defined and classified, modeling gaps are
highlighted and future research developments are proposed. Throughout this paper special
attention is given to sustainable issues.
This is the first attempt to systematically study energy- conscious job-shop scheduling
mathematical modeling in the context of sustainability and energy management. Some of
CLAIO-2016
371

the questions addressed in this paper area the following: How energy consumption
parameters are incorporated in classical production/manufacturing planning problems, in
particular the job-shop scheduling problem; how modeling approaches handle the intrinsic
complexities that environmental issues convey; and what are the gaps between the current
research and the practice. (Ku & Beck, 2016) highlighted that in the Journal of Scheduling
2014 more than 30% of the published papers apply a Mixed Integer Programming (MIP) to
solve scheduling problems, more than any other approach. It is intended to analyze how this
approach has been used in solving job-shop scheduling problems with environmental
considerations.
It is surprising that classical literature on energy management focuses on the
implementation of energy efficient technologies, the replacing of inefficient equipment and
the care and maintenance of technology to preserve an efficient operation (Gordic, D.,
Babic, M., Jovicic, N., Sustersic, V., Koncalovic, D., Jelic, 2010). In addition, energy
management is devoted to cover the energy efficiency gap, i.e., the discrepancy between
optimal and actual implementation as explained by Jaffe and Stavins (1994). According to
Abdelaziz et al. (2011) a “successful energy management consists of three parts: energy
auditing to gain knowledge about energy flows, courses and training to increase and
maintain awareness and house-keeping that includes keeping up the operations.” John
(2004) and Swords, et al. (2007) describes strategic energy management practices in terms
of capture data, set efficiency goals, communicate on-going energy performance to
stakeholders in an organization and action. None of them identify job-shop scheduling as a
suitable energy management practice. However Backlund et al. (2012) define an extended
energy efficiency gap and highlight that including non-technical improvements could help
to also improve energy efficiency. In this context, energy-conscious job-shop scheduling is
one of the management practices that aim at improving energy efficiency, i.e., it could
reduce the energy efficiency gap in the manufacturing sector.
References
Abdelaziz, E.A., Saidur, R., Mekhilef, S. (2011). A review on energy saving strategies in industrial sector. Renewable and Sustainable Energy Reviews, 15, 150–168.
Backlund, S., Thollander, P., Palm, J., & Ottosson, M. (2012). Extending the energy efficiency gap. Energy Policy, 51, 392–396. http://doi.org/10.1016/j.enpol.2012.08.042
Bunse, K., Vodicka, M., Schönsleben, P., Brülhart, M., & Ernst, F. O. (2011). Integrating energy efficiency performance in production management – gap analysis between industrial needs and scientific literature. Journal of Cleaner Production, 19(6–7), 667–679. http://doi.org/http://dx.doi.org/10.1016/j.jclepro.2010.11.011
Chen, J. (2011). The impact of sharing customer returns information in a supply chain with and without a buyback policy. European Journal of Operational Research, 213(3), 478–488. http://doi.org/10.1016/j.ejor.2011.03.027
Gordic, D., Babic, M., Jovicic, N., Sustersic, V., Koncalovic, D., Jelic, D. (2010). Development of an energy management system—case study of a Serbian car manufacturer. Energy Conversion and Management, 51, 2783–2790.
Jaffe, A.B., Stavins, R. N. (1994). The energy efficiency gap: what does it mean? Energy Policy,
CLAIO-2016
372

22(10), 60–71. John, C. (2004). Maximizing energy savings with enterprise energy management systems. In IEEE
power & energy magazine. Ku, W.-Y., & Beck, J. C. (2016). Mixed Integer Programming models for job shop scheduling: A
computational analysis. Computers & Operations Research, 73, 165–173. http://doi.org/10.1016/j.cor.2016.04.006
Schulze, M., Nehler, H., Ottosson, M., & Thollander, P. (2015). Energy management in industry – a systematic review of previous findings and an integrative conceptual framework. Journal of Cleaner Production. http://doi.org/10.1016/j.jclepro.2015.06.060
Swords, B., Coyle, E., Norton, B. (2007). An enterprise energy-information system. Applied Energy, 85, 61–69.
Zhou, L., Li, J., Li, F., Meng, Q., Li, J., & Xu, X. (2016). Energy consumption model and energy ef fi ciency of machine tools : a comprehensive literature review. Journal of Cleaner Production, 112, 3721–3734. http://doi.org/10.1016/j.jclepro.2015.05.093
CLAIO-2016
373

Proposta de Modelo multicritério para priorização de
municípios da região semiárida para direcionamento de
recursos de combate à seca
Thomas Edson Espíndola Gonçalo
Universidade Federal Rural do Semiárido (UFERSA) e Universidade Federal de
Pernambuco (UFPE)
Danielle Costa Morais
Universidade Federal de Pernambuco (UFPE)
Resumo
A região Semiárida brasileira enfrenta o seu maior período de estiagem dos últimos 100 anos, com
chuvas abaixo da média histórica. A situação não é diferente no Estado do Rio Grande do Norte
(RN), que possui grande parte de seu território situado em área de semiárido. Diante de tal contexto,
a gestão de recursos hídricos e o combate aos efeitos da seca ganham ainda mais importância
quanto à minimização dos impactos sofridos pela população. As decisões tomadas nesse âmbito
podem considerar múltiplos critérios avaliados por mais de um tomador de decisão. Este estudo tem
como objetivo propor um modelo multicritério para tomada de decisão em grupo quanto à
priorização de municípios da atingidos pela estiagem. O modelo foi aplicado para o caso dos
municípios situados no RN e, a partir de tal aplicação, os gestores públicos podem direcionar seus
esforços quanto às ações de combate à seca.
Palavras-chave: Decisão em grupo; Decisão multicritério; Combate à seca.
1. Introdução De acordo com ANA (2011), os conflitos pelo uso da água não surgiram hoje e são
recorrentes em toda a história da humanidade; o que se modifica é a forma como as sociedades se
organizam para enfrentá-los. Dong et al (2015) e Choi, Kim e Lee (2012) complementam
destacando que a rápida urbanização e o crescimento populacional resultaram um grave problema
mundial de escassez de água e deterioração do ambiente, sendo essencial a gestão eficiente da
alocação de recursos hídricos escassos e recursos ambientais. Segundo Sadr et al. (2015), a escassez
de água fresca está relacionada a diversos fatores e tornou-se uma crescente preocupação em
diferentes partes do mundo.
A região semiárida brasileira, que abriga aproximadamente 12% da população, possui
características naturais que lhe conferem relações desfavoráveis quanto ao balanço hídrico. Altas
temperaturas, baixas amplitudes térmicas, forte insolação e altas taxas de evapotranspiração, além
de baixos índices pluviométricos e regime de chuvas irregular resultam em rios com baixa ou
nenhuma disponibilidade hídrica. Após de quatro anos seguidos de baixas precipitações, a região
permanece em situação crítica em termos de disponibilidade hídrica, já que os índices de chuvas de
2015 não foram suficientes sequer para a manutenção dos estoques de água. (ANA, 2016)
De acordo com Silva e Morais (2010), a tomada de decisão acerca da gestão de recursos
hídricos é geralmente complexa devido à necessidade de se considerar vários objetivos e por
envolver conseqüências de impactos ambientais, sociais e econômicos. De acordo com Vincke
(1992), o apoio multicritério à decisão tem por objetivo dar ao tomador de decisão ferramentas para
possibilitar-lhe avanços na solução de problemas de decisão onde diversos, muitas vezes
contraditórios, pontos de vista devem ser levados em consideração.
CLAIO-2016
374

Para Kalbar, Karmakar e Asolekar (2013), decisões ambientais requerem a participação de
múltiplos stakeholders e possuem implicações de larga escala, que afetam tanto o ambiente local
quanto o ambiente global. Hatami-Marbini e Tavana (2011) complementam ao afirmar que um
problema de decisão em grupo requer a redução de diferentes preferências individuais em um
conjunto de preferências coletivas. Segundo destacado por Wu (2009), um dos pontos-chave do
apoio à decisão em grupo envolve a escolha da função e os operadores de agregação para combinar
os diferentes pontos de vista dos agentes em um único valor numérico. Zhang et al (2009) expõe
que o número de tomadores de decisão envolvidos é um dos fatores que deve ser levado em
consideração, juntamente com grau de incerteza envolvido e a natureza dos critérios, quando se
busca a solução de problema desse tipo. Silva, Morais e Almeida (2010) apontam que o
envolvimento de múltiplos decisores na gestão de recursos hídricos pode ser bastante complexo,
envolvendo possibilidade de conflitos entre os stakeholders. Além disso, decisores com mais
poderes podem influenciar a preferência dos demais participantes.
Assim, de modo a lidar com o problema apresentado, este estudo pretende propor um
modelo multicritério para criação de uma ordenação dos municípios do semiárido como
direcionador para ações de combate à seca e mitigação dos seus efeitos.
Na seção 2 é apontada a conjuntura da situação de recursos hídricos na região Semiárida do
Rio Grande do Norte. Na seção 3 é apresentado o modelo multicritério para priorização de
municípios quanto às ações de combate à seca. A seguir, na seção 4, é apresentada aplicação
numérica do modelo utilizando a ferramenta PROMETHEE GDSS. Na seção 5 os resultados
apresentados na seção 4 são discutidos. Por fim, são apresentadas as considerações finais.
2. Conjuntura da situação dos recursos hídricos na Região Semiárida brasileira
O Estado do Rio Grande do Norte possui cerca de 92% de seu espaço territorial situado na
região Semiárida, passando por períodos de estiagem frequentemente. Por esse motivo, o Governo
do Estado, através do Decreto Nº 25931 de 21/03/2016, reiterou a situação de emergência em 153
dos 167 municípios do estado, o equivalente a 91,6% do total. Destes, 21 municípios encontram-se
em colapso total, só recebendo água através de carros pipa ou poços artesianos. A estimativa do
Governo do Estado é que, caso se confirme a previsão das chuvas, até Fevereiro de 2017 serão 80
municípios em colapso no abastecimento.
Segundo a SEMARH (2016), o Estado possui 16 bacias hidrográficas, destas, as maiores
são as bacias Apodi/Mossoró e Piranhas/Açu, que se encontravam com 21,85% e 17,25% de sua
capacidade, no mês de Março de 2016. Segundo dados da ANA (2016), o nível de volume de água
em reservatórios no Estado chegou a preocupante marca de 19,9% de ocupação. Dada a previsão de
chuvas abaixo da média para este ano, a tendência é que a região caminhe para o desabastecimento
em larga escala já no ano de 2017.
De acordo com dados da ANA (2015), a demanda de consumo total estimada para o Brasil
em 2010 foi de 2.373 m³/s. O setor da irrigação é o responsável pela maior parcela de retirada (54%
do total ou 1.270 m³/s), seguido das vazões de retiradas para fins de abastecimento humano urbano,
industrial, animal e humano rural. Em regiões com déficit hídrico, a irrigação assume papel
primordial no desenvolvimento dos arranjos produtivos.
Um importante agente na gestão de Recursos Hídricos são os Comitês de Bacia
Hidrográfica (CBH) que, segundo ANA (2016), têm como objetivo a gestão participativa e
descentralizada dos recursos hídricos, por meio da implementação dos instrumentos técnicos de
gestão, da negociação de conflitos e da promoção dos usos múltiplos da água, na bacia hidrográfica.
No Estado do Rio Grande do Norte, desde 1996 a atribuição de planejar, coordenar e executar as
ações públicas estaduais que contemplem a oferta e a gestão de recursos hídricos e do meio
ambiente compete à Secretaria do Meio Ambiente e Recursos Hídricos (SEMARH). A seguir é
proposto um modelo multcritério para priorização dos municípios quanto às ações de combate à
seca.
CLAIO-2016
375

3. Modelo multicritério para priorização de municípios quanto às ações de combate à seca
O modelo proposto, apresentado na Figura 1, suporta a metodologia proposta por Macharis,
Brans e Mareschal (1998) para o PROMETHEE GDSS.
Figura 1 – Modelo multicritério para priorização de regiões semiáridas quanto ao abastecimento de
água
Inicialmente o problema a ser tratado deve ser definido, o que inclui o primeiro contato do
facilitador com os tomadores de decisão. Nesse sentido, são definidos o problema e quais os
envolvidos que serão consultados para a decisão. Em seguida prossegue a avaliação individual, que
inicia com a geração das alternativas de priorização e a concepção do conjunto estável de
alternativas para o grupo. Em seguida os critérios são definidos, podendo ser considerados critérios
comuns e/ou individuais. Cada decisor, então, determina pesos e demais parâmetros necessários ao
método selecionado para avaliação, constituindo sua matriz de avaliação. A avaliação individual é,
então, realizada obtendo-se o ranking das alternativas para cada decisor, bem como seus escores
relativos. Deve ser realizada análise de sensibilidade quanto aos resultados obtidos nesta fase.
Em seguida devem ser definidos os pesos de cada decisor, de acordo com o seu poder para
aquela decisão. É, então, montada a matriz de avaliação global das alternativas. Uma vez realizada
obtida a avaliação global das alternativas, deve ser realizada análise de sensibilidade para avaliar os
resultados obtidos e conflitos quanto à solução devem ser discutidos.
Existem diversas ferramentas de apoio à tomada de decisão em grupo que podem ser
utilizadas para converter as decisões individuais em decisões para o grupo. Para este estudo foi
selecionado o método PROMETHEE GDSS, proposto por Macharis, Brans e Mareschal (1998),
devido ao fato do mesmo possuir caráter não compensatório, por facilitar a avaliação subjetiva de
critérios e por possibilitar a consideração da hesitação dos tomadores de decisão. Além disso,
através do PROMETHEE GDSS é possível utilizar estrutura metodológica semelhante tanto na
realização das avaliações individuais, quanto na avaliação do grupo.
CLAIO-2016
376

No que se refere à etapa de avaliação individual, os autores propõem a utilização da
metodologia PROMETHEE para cada tomador de decisão envolvido. O método, segundo Brans et
al (1998) destaca-se ao envolver conceitos e parâmetros que possuem alguma interpretação física ou
econômica, de fácil entendimento para o tomador de decisão. Brans e Vincke (1985) apontam que,
designados pesos representando grau de importância para cada critério, o grau de
sobreclassificação é computado de acordo com a equação abaixo:
Onde é um número entre 0 e 1 que aumenta quando aumenta e é
igual a zero se . Para que se encontre o valor da função , o tomador de decisão
pode escolher, para cada critério, uma das seis funções, de acordo com valores dos limiares de
preferência (p) e de indiferença (q): (1) Critério usual, quando não há parâmetro a ser definido; (2)
Quase-critério, para a qual se define o parâmetro q; (3) Limite de preferência, definindo o
parâmetro p; (4) Pseudo-critério, considerando os parâmetros q e p; (5) Área de indiferença,
considerando, também, os parâmetros q e p; (6) Critério Gaussiano, no qual o desvio padrão deve
ser fixado.
Uma vez obtidos os valores de , duas preordens completas podem ser obtidas, sendo
a primeira representando uma ordenação de ações seguindo ordem decrescente dos números
E outro seguindo a ordem crescente dos números
A intersecção destes dois fluxos gera a preordem parcial resultado da aplicação do método PROMETHEE I. O método PROMETHEE II, por sua vez, consiste em ordenar as ações seguindo o fluxo tal qual . Dessa forma, obtêm-se uma única
preordem completa.
Procede-se, então, a avaliação das opiniões do grupo de decisores considerados, tal qual
proposto por Macharis, Brans e Mareschal (1998). É montada a matriz de avaliação utilizando os
fluxos líquidos gerados a partir da aplicação do PROMETHEE II como desempenho das
alternativas para cada critério, neste caso, cada decisor. Nesse sentido, a cada tomador de decisão
pode ser atribuído um peso fixando o poder de cada um. A metodologia PROMETHEE II é aplicada
para gerar a ordenação das alternativas com base nas posições expressas por cada decisor.
Macharis, Brans e Mareschal (1998) destacam, ainda, a necessidade de lidar com conflitos
quanto determinados tomadores de decisão não concordam com a solução de compromisso obtida
através da aplicação do método. Destaca-se que não há uma regra geral para lidar com os conflitos
gerados, sendo recomendado retornar a avaliação a passos anteriores para tratar dos conflitos.
De modo a lidar com o problema de priorização das cidades do Rio Grande do Norte como
direcionador para as ações do poder público, o modelo foi aplicado para uma situação hipotética.
4. Aplicação numérica do modelo
A partir da proposta do modelo expresso na seção 3, foi realizada uma aplicação numérica
do método, de maneira a se verificar a aplicabilidade do modelo para direcionar os esforços dos
órgãos gestores quanto à atenção à gestão de recursos hídricos e combate à seca. Para tanto, são
considerados como tomadores de decisão gestores das áreas de Recursos Hídricos (D1), Economia
(D2) e do CBH (D3), representando a população da região da referida bacia hidrográfica.
A seguir são levantados os critérios de interesse para cada tomador de decisão, resultando
na lista de critérios na Tabela 1:
Tabela 1 – Critérios levantados para priorização de municípios
CLAIO-2016
377
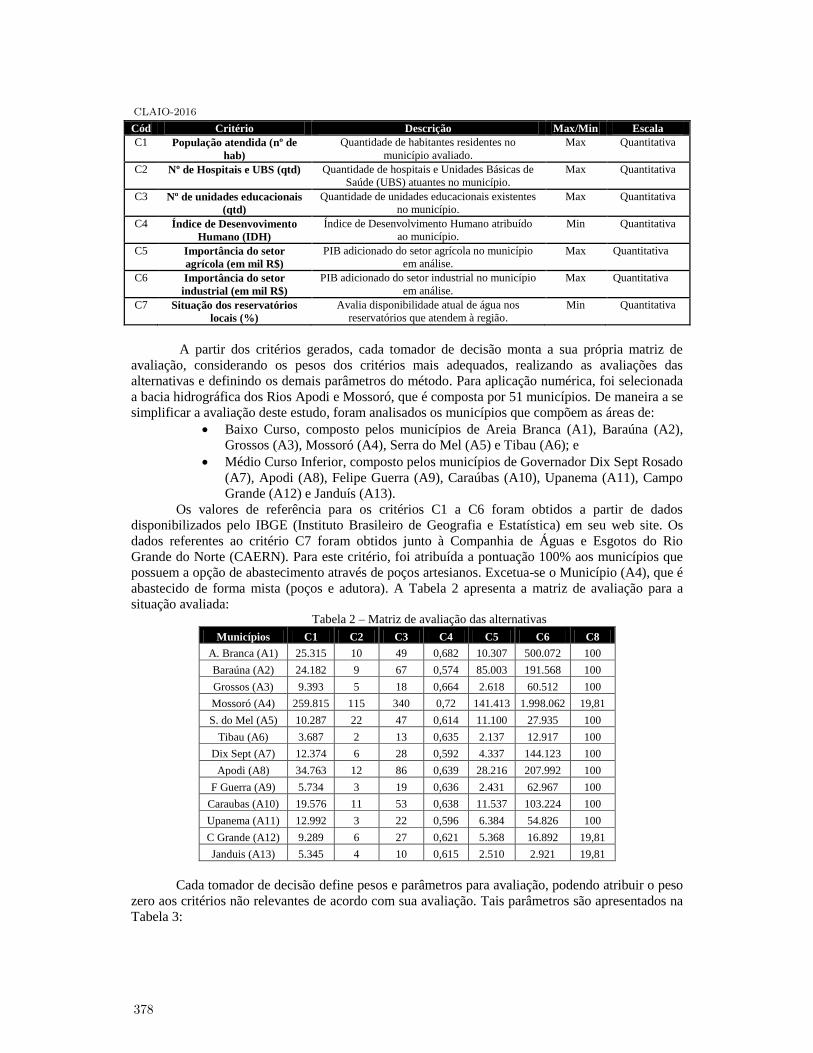
Cód Critério Descrição Max/Min Escala
C1 População atendida (nº de
hab)
Quantidade de habitantes residentes no
município avaliado.
Max Quantitativa
C2 Nº de Hospitais e UBS (qtd) Quantidade de hospitais e Unidades Básicas de
Saúde (UBS) atuantes no município.
Max Quantitativa
C3 Nº de unidades educacionais
(qtd)
Quantidade de unidades educacionais existentes
no município.
Max Quantitativa
C4 Índice de Desenvovimento
Humano (IDH)
Índice de Desenvolvimento Humano atribuído
ao município.
Min Quantitativa
C5 Importância do setor
agrícola (em mil R$)
PIB adicionado do setor agrícola no município
em análise.
Max Quantitativa
C6 Importância do setor
industrial (em mil R$)
PIB adicionado do setor industrial no município
em análise.
Max Quantitativa
C7 Situação dos reservatórios
locais (%)
Avalia disponibilidade atual de água nos
reservatórios que atendem à região.
Min Quantitativa
A partir dos critérios gerados, cada tomador de decisão monta a sua própria matriz de
avaliação, considerando os pesos dos critérios mais adequados, realizando as avaliações das
alternativas e definindo os demais parâmetros do método. Para aplicação numérica, foi selecionada
a bacia hidrográfica dos Rios Apodi e Mossoró, que é composta por 51 municípios. De maneira a se
simplificar a avaliação deste estudo, foram analisados os municípios que compõem as áreas de:
Baixo Curso, composto pelos municípios de Areia Branca (A1), Baraúna (A2),
Grossos (A3), Mossoró (A4), Serra do Mel (A5) e Tibau (A6); e
Médio Curso Inferior, composto pelos municípios de Governador Dix Sept Rosado
(A7), Apodi (A8), Felipe Guerra (A9), Caraúbas (A10), Upanema (A11), Campo
Grande (A12) e Janduís (A13).
Os valores de referência para os critérios C1 a C6 foram obtidos a partir de dados
disponibilizados pelo IBGE (Instituto Brasileiro de Geografia e Estatística) em seu web site. Os
dados referentes ao critério C7 foram obtidos junto à Companhia de Águas e Esgotos do Rio
Grande do Norte (CAERN). Para este critério, foi atribuída a pontuação 100% aos municípios que
possuem a opção de abastecimento através de poços artesianos. Excetua-se o Município (A4), que é
abastecido de forma mista (poços e adutora). A Tabela 2 apresenta a matriz de avaliação para a
situação avaliada: Tabela 2 – Matriz de avaliação das alternativas
Municípios C1 C2 C3 C4 C5 C6 C8
A. Branca (A1) 25.315 10 49 0,682 10.307 500.072 100
Baraúna (A2) 24.182 9 67 0,574 85.003 191.568 100
Grossos (A3) 9.393 5 18 0,664 2.618 60.512 100
Mossoró (A4) 259.815 115 340 0,72 141.413 1.998.062 19,81
S. do Mel (A5) 10.287 22 47 0,614 11.100 27.935 100
Tibau (A6) 3.687 2 13 0,635 2.137 12.917 100
Dix Sept (A7) 12.374 6 28 0,592 4.337 144.123 100
Apodi (A8) 34.763 12 86 0,639 28.216 207.992 100
F Guerra (A9) 5.734 3 19 0,636 2.431 62.967 100
Caraubas (A10) 19.576 11 53 0,638 11.537 103.224 100
Upanema (A11) 12.992 3 22 0,596 6.384 54.826 100
C Grande (A12) 9.289 6 27 0,621 5.368 16.892 19,81
Janduis (A13) 5.345 4 10 0,615 2.510 2.921 19,81
Cada tomador de decisão define pesos e parâmetros para avaliação, podendo atribuir o peso
zero aos critérios não relevantes de acordo com sua avaliação. Tais parâmetros são apresentados na
Tabela 3:
CLAIO-2016
378
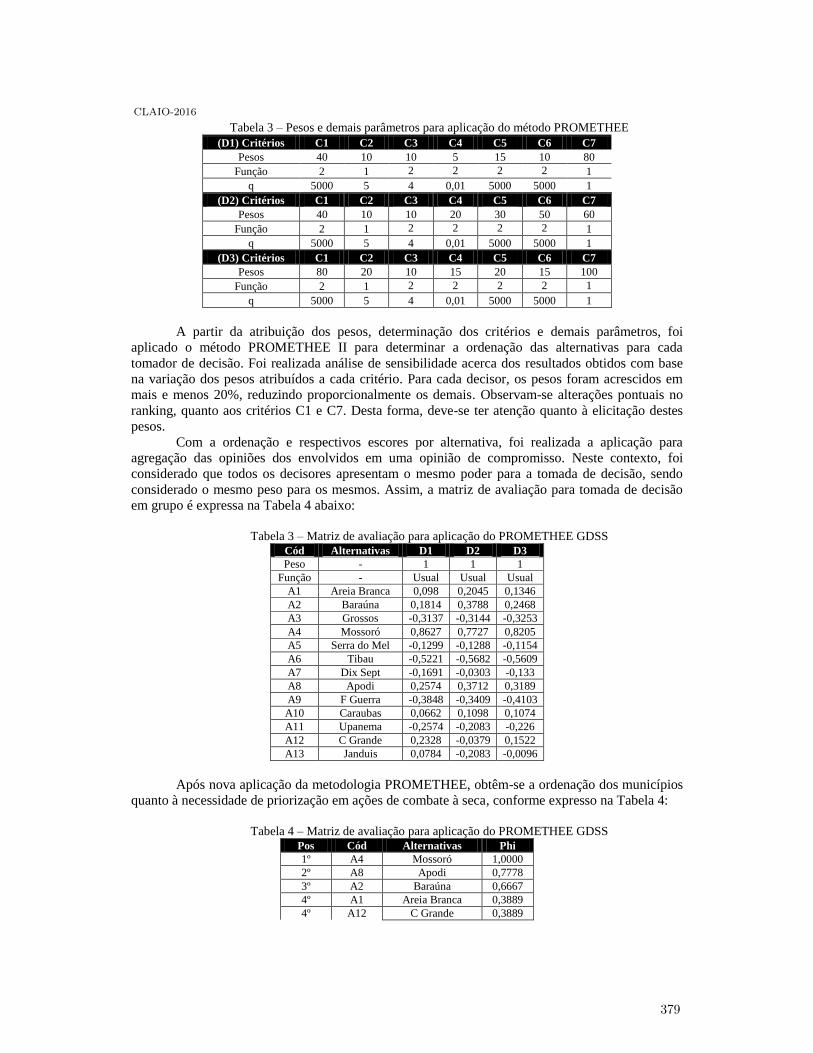
Tabela 3 – Pesos e demais parâmetros para aplicação do método PROMETHEE
(D1) Critérios C1 C2 C3 C4 C5 C6 C7
Pesos 40 10 10 5 15 10 80
Função 2 1 2 2 2 2 1
q 5000 5 4 0,01 5000 5000 1
(D2) Critérios C1 C2 C3 C4 C5 C6 C7
Pesos 40 10 10 20 30 50 60
Função 2 1 2 2 2 2 1
q 5000 5 4 0,01 5000 5000 1
(D3) Critérios C1 C2 C3 C4 C5 C6 C7
Pesos 80 20 10 15 20 15 100
Função 2 1 2 2 2 2 1
q 5000 5 4 0,01 5000 5000 1
A partir da atribuição dos pesos, determinação dos critérios e demais parâmetros, foi
aplicado o método PROMETHEE II para determinar a ordenação das alternativas para cada
tomador de decisão. Foi realizada análise de sensibilidade acerca dos resultados obtidos com base
na variação dos pesos atribuídos a cada critério. Para cada decisor, os pesos foram acrescidos em
mais e menos 20%, reduzindo proporcionalmente os demais. Observam-se alterações pontuais no
ranking, quanto aos critérios C1 e C7. Desta forma, deve-se ter atenção quanto à elicitação destes
pesos.
Com a ordenação e respectivos escores por alternativa, foi realizada a aplicação para
agregação das opiniões dos envolvidos em uma opinião de compromisso. Neste contexto, foi
considerado que todos os decisores apresentam o mesmo poder para a tomada de decisão, sendo
considerado o mesmo peso para os mesmos. Assim, a matriz de avaliação para tomada de decisão
em grupo é expressa na Tabela 4 abaixo:
Tabela 3 – Matriz de avaliação para aplicação do PROMETHEE GDSS
Cód Alternativas D1 D2 D3
Peso - 1 1 1
Função - Usual Usual Usual
A1 Areia Branca 0,098 0,2045 0,1346
A2 Baraúna 0,1814 0,3788 0,2468
A3 Grossos -0,3137 -0,3144 -0,3253
A4 Mossoró 0,8627 0,7727 0,8205
A5 Serra do Mel -0,1299 -0,1288 -0,1154
A6 Tibau -0,5221 -0,5682 -0,5609
A7 Dix Sept -0,1691 -0,0303 -0,133
A8 Apodi 0,2574 0,3712 0,3189
A9 F Guerra -0,3848 -0,3409 -0,4103
A10 Caraubas 0,0662 0,1098 0,1074
A11 Upanema -0,2574 -0,2083 -0,226
A12 C Grande 0,2328 -0,0379 0,1522
A13 Janduis 0,0784 -0,2083 -0,0096
Após nova aplicação da metodologia PROMETHEE, obtêm-se a ordenação dos municípios
quanto à necessidade de priorização em ações de combate à seca, conforme expresso na Tabela 4:
Tabela 4 – Matriz de avaliação para aplicação do PROMETHEE GDSS
Pos Cód Alternativas Phi
1º A4 Mossoró 1,0000
2º A8 Apodi 0,7778
3º A2 Baraúna 0,6667
4º A1 Areia Branca 0,3889
4º A12 C Grande 0,3889
CLAIO-2016
379

6º A10 Caraubas 0,1667
7º A13 Janduis -0,0833
8º A5 Serra do Mel -0,1667
8º A7 Dix Sept -0,1667
10º A8 Upanema -0,4722
11º A3 Grossos -0,6667
12º A9 F Guerra -0,8333
13º A6 Tibau -1,000
Foi realizada análise de sensibilidade nos resultados obtidos de maneira semelhante à
avaliação realizada para o caso individual. Aumentando-se o peso de importância dos decisores em
20% não se observam mudanças significativas no ranking, mas apenas desempates entre as
alternativas que estavam com mesma posição na ordenação.
5. Discussão dos resultados
Analisando os resultados obtidos, expressos na Tabela 4, podem ser realizadas algumas
análises. Em primeiro lugar na ordenação ficou a cidade de Mossoró (A4). A mesma teve este
posicionamento devido ao fato de ser a cidade de maior porte da região delimitada. Devido a sua
maior população e fatores econômicos, a mesma descolou-se das demais. Salienta-se que parte do
abastecimento da cidade é realizado através de poços, o que acaba não sendo uma solução viável no
longo prazo. Apodi (A8) apresenta-se na segunda colocação principalmente devido a fatores
econômicos e sociais. Destaca-se, ainda, o município de Areia Branca (A1), que mesmo sendo de
pequeno porte aparece na quarta colocação na ordenação obtida. Tal município apresenta grande
destaque no setor industrial, sendo responsável por importante parcela da produção de sal nacional.
Os municípios de Campo Grande (A12) e Janduís (A13), por sua vez, surgem em colocação
elevada na ordenação principalmente devido ao fato do abastecimento destes ser realizado através
do uso de barragens, não sendo utilizados poços para extração da água.
Comparando-se a ordenação obtida globalmente com os resultados para cada decisor,
observa-se certo grau de coerência quanto aos três primeiros colocados no ranking. A4 destaca-se
como primeiro colocado para todos os decisores. D2 apresenta uma inversão referente à A2 e A8,
mas os mesmos apresentam desempenho próximo. As alternativas A1, A2, A12, A13 e A10
apresentam configuração semelhante quanto aos decisores, com a alternativa A12 destacando-se
dentre todas. O mesmo é observado quanto às últimas alternativas avaliadas para o grupo. A partir
de tais avaliações podem surgir conflitos quanto ao posicionamento de determinadas alternativas na
ordenação. Nesse contexto, pode-se retornar às fases anteriores para refinar as avaliações e tratar as
discrepâncias encontradas. De forma geral, o ranking global representa de maneira bastante próxima
às avaliações individuais dos tomadores de decisão.
A seguir são apresentadas as considerações finais acerca do estudo realizado.
Considerações finais
O mundo enfrenta o problema da escassez cada vez maior de água nas mais diversas
regiões. Enquanto muitas localidades enfrentam problemas devido à qualidade das águas obtidas,
outros convivem com a mais elevada escassez de água. Neste contexto, destaca-se a região do
Semiárido nordestino brasileiro, que enfrenta duradouro período de estiagem. No estado do RN, já
existem municípios que estão em colapso total no abastecimento de água, que só é realizada através
de caminhões-pipa. Tal situação tende a se deteriorar, caso confirmadas as previsões de que as
chuvas do ano de 2016 serão abaixo da media histórica.
Neste contexto, foi proposto um modelo multicritério para ordenação dos municípios da
região para direcionar os esforços do poder público no combate à seca e mitigação de seus efeitos.
O modelo inclui a possibilidade da tomada de decisão em grupo, que leva em consideração o ponto
de vista dos diversos envolvidos na área. A partir da aplicação do modelo é possível obter uma
CLAIO-2016
380

ordenação de compromisso dos municípios, apoiando a tomada de decisão no âmbito do Governo
Estadual. O modelo foi aplicado para um caso hipotético, com o objetivo de se verificar a
funcionalidade da metodologia proposta. Para tanto, foi selecionada a metodologia PROMETHEE
GDSS. A aplicação foi realizada para municípios de duas regiões da Bacia Hidrográfica dos Rios
Apodi e Mossoró e foi gerado um ranking dos municípios quanto à atenção no combate à seca.
Como trabalhos futuros, o modelo proposto será aplicado para o caso real, sendo definidos
os decisores com base no contato com a Secretaria de Recursos Hídricos do Estado do Rio Grande
do Norte, a Companhia de águas e esgotos do estado, bem como o Comitê da Bacia Hidrográfica
considerada. A partir desta aplicação, será possível apoiar a tomada de decisão dos gestores do
setor, com base nesta análise de dados.
Agradecimentos: Este trabalho é parte de um projeto de pesquisa apoiado pelo Conselho Nacional
de Pesquisa (CNPq).
Referencias:
1. Agência Nacional de Águas (ANA). Cadernos de capacitação em recursos hídricos. ANA, Brasília,
2011.
2. Agência Nacional de Águas (ANA). Conjuntura dos recursos hídricos no Brasil: Informe 2014. ANA,
Brasília, 2015.
3. Agência Nacional de Águas (ANA). Açudes do Semiárido. Disponível em:
http://www2.ana.gov.br/Paginas/servicos/saladesituacao/v2/acudesdosemiarido.aspx. Acesso em 2 de
Abril de 2016.
4. S. Choi, J. H. Kim, and D. Lee. Decision of the Water Shortage Mitigation Policy Using Multi-criteria
Decision Analysis. KSCE Journal of Civil Engineering. 16(2):247-253, 2012.
5. F. Dong et al. Uncertainty-Based Multi-Objective Decision Making with Hierarchical Reliability
Analysis Under Water Resources and Environmental Constraints. Water Resources Management. 30:805-
822, 2016.
6. A. Hatami-Marbini, and M. Tavana. An extension of the Electre I method for group decision-making
under a fuzzy environment. Omega, 39:373–386, 2011.
7. P. P. Kalbar, S. Karmakar, and S. R. Asolekar. The influence of expert opinions on the selection of
wastewater treatment alternatives: A group decision-making approach. Journal of Environmental
Management. 128: 844-851, 2013.
8. C. Macharis, J. P. Brans, and B. Mareschal. The GDSS PROMETHEE procedure. Journal of Decision
Systems. 7:283-307, 1998.
9. S. M. K. Sadr et al. A group decision-making tool for the application of membrane technologies in
different water reuse scenarios. Journal of Environmental Management. 156: 97-108, 2015.
10. Secretaria do Meio Ambiente e dos Recursos Hídricos do Estado do Rio Grande do Norte (SEMARH).
Sistema de informações – Bacias Hidrográficas. Disponível em:
http://servicos.searh.rn.gov.br/semarh/sistemadeinformacoes/consulta/cBacia.asp. Acesso em 2 de Abril
de 2016.
11. V. B. S. Silva, D. C. Morais, e A. T. Almeida. A Multicriteria Group Decision Model to Support
Watershed Committees in Brazil. Water Resources Management, 24: 4075-4091, 2010.
12. V. B. S. Silva, and D. C. Morais. Supporting water resource management committees by using
multicriteria analysis. In IEEE International Conference on Systems, Man and Cybernetics (SMC), 2010.
13. P. Vincke. Multicriteria decision aid. Wiley, New York, 1992.
14. D. Wu. Supplier selection in a fuzzy group setting: A method using grey related analysis and Dempster–
Shafer theory. Expert Systems with Applications, 36:8892–8899, 2009.
15. D. Zhang et al. An novel approach to supplier selection based on vague sets group decision. Expert
Systems with Applications, 36:9557–9563, 2009.
CLAIO-2016
381

Enfoque de justo a tiempo en un diseño multiobjetivo de cadena
de suministro.
Guerrero-Campanur A.
Tecnológico Nacional de México / Instituto Tecnológico Superior de Uruapan
E. Olivares-Benítez
Universidad Popular Autónoma del Estado de Puebla
Pablo A. Miranda
Pontificia Universidad Católica de Valparaíso
Rodolfo E. Pérez Loaiza
Tecnológico Nacional de México / Instituto Tecnológico Apizaco
Salvador Hernández González
Tecnológico Nacional de México / Instituto Tecnológico de Celaya
Abstract
En esta investigación se presenta un problema multiobjetivo de diseño de cadena de suministro de
tres escalones, incorporando de manera simultánea decisiones tácticas y estratégicas considerando
múltiples minoristas y grupos de potenciales localizaciones de plantas y almacenes. La principal
contribución del estudio es extender la literatura actual incorporando el análisis de la técnica justo a
tiempo en un problema de localización-inventario considerando una demanda estocástica,
integración de riesgo y política de inventarios en conjunto con decisiones de localización y
asignación entre los escalones. Proporcionando un diseño de cadena de suministro que satisface la
minimización de costos de operación de la cadena de suministro y la minimización de la cantidad de
la orden bajo el enfoque de justo a tiempo. La política de inventarios en los costos de operación y
cantidad de la orden bajo el enfoque de justo a tiempo genera una formulación no lineal en ambas
funciones objetivo del problema. Para esto se propone una doble linealización de la formulación
utilizando una aproximación lineal basada en una función lineal a tramos, generando un modelo
lineal entero mixto que puede ser resuelto utilizando un solver comercial. El método de epsilon-
restricción es utilizado como enfoque de optimización multiobjetivo e interpretado mediante una
frontera eficiente de Pareto.
Keywords: Inventory-location; multiobjective supply chain design; economic order quantity, just-
in-time; piecewise linear function.
CLAIO-2016
382

1. Introducción y contexto del problema.
La cadena de suministro se compone de todas las partes involucradas, directa e indirectamente, en
satisfacer las necesidades de los clientes. La literatura estándar sobre la gestión de la cadena de
suministro clasifica los problemas en tres niveles jerárquicos: estratégicos (largo plazo), tácticos
(mediano plazo) y operacionales (corto plazo). Tradicionalmente se enfrentan estos problemas de
manera aislada, es decir decisiones estratégicas se toman a nivel gerencial, tácticas a nivel de
jefatura, y operacionales a nivel de piso (Miranda & Garrido 2004). Los diseños de cadena de
suministro tradicional tienen como único objetivo
el minimizar los costos ó maximizar sus
ganancias. Sin embargo, actualmente la gestión de
la cadena de suministro involucra el enfoque de
nuevas estrategias y técnicas para responder a los
desafíos y demanda de los clientes. Una de estas
nuevas técnicas es justo a tiempo JIT (por sus
siglas en ingles Just in time), JIT es una de las
modernas técnicas de fabricación más populares y
su uso ha ayudado a muchas empresas a ser más
productivo y competitivo. JIT está diseñado para
eliminar virtualmente la necesidad de mantener
los artículos en inventario (Wu, 2011). Así mismo
un número considerable de investigaciones de
diseño de la cadena de suministro discuten sobre el problema de localización-inventario
considerando comúnmente el modelo de cantidad económica de pedido EOQ. Este modelo de
control de inventarios tiene como objetivo la reducción de los costos de mantener en inventario, y
el costo por ordenar un pedido, obteniendo la cantidad óptima de la orden Q para minimizar costos
por orden de pedido y mantenimiento en inventario del producto generando pedidos con menor
frecuencia, sin embargo, esto se contrapone a la técnica JIT. En JIT se apoya la estrategia de cero
inventarios, donde, el costo de ordenar y el tiempo de entrega se reducen, lo que permite tamaños de
los lotes más pequeños generando pedidos con más frecuencia, reduciendo la cantidad de la orden
Q. En esta investigación se presenta un modelo no lineal entero mixto NL-DCS del diseño de una
cadena de suministro de tres escalones (Fig. 1) analizado bajo el enfoque de optimización
multiobjetivo. La modelación se basa en el problema de localización-inventario considerado una
extensión del problema de localización de instalaciones con capacidad (capacitated facility location
problem CFLP), catalogado NP-Hard. Los objetivos a tratar son la minimización de los costos de
transporte, costos de localización e inventario EOQ en las distintos escalones de la cadena de
suministro (Z1) y la minimización de la cantidad de la orden Q bajo el enfoque de JIT (Z2). El NL-
DCS es reformulado mediante una doble aproximación lineal (función lineal a tramos) en Z1 y Z2,
obteniendo un modelo lineal entero mixto PWL-DCS. El método de epsilon-restricción es utilizado
como enfoque de optimización multiobjetivo, e interpretado mediante una frontera eficiente u
óptimo de Pareto.
2. Revisión bibliográfica
En la literatura de diseño de cadenas de suministro podemos encontrar varios trabajos que han
enfocado en el análisis multiobjetivo y de justo a tiempo. Olhager (2002) presenta un estudio del
gestión de la cadena de suministro desde una perspectiva justo a tiempo, el cual se centra en los
mecanismos de vinculación entre empresas y la eficiencia colectiva en la cadena de suministro.
Shen y Daskin (2005) extendió el modelo de localización bajo risk pooling incluyendo el
componente de servicio al cliente basado en una fracción de la demanda en relación a una distancia
especifica del centro de distribución proponiendo un modelo no lineal bi-objetivo. Utilizando
Algoritmos Genéticos como enfoque de solución. Gaur y Ravindran (2006) estudiaron un modelo
P-J W-K R-L
PLANTAS ALMACENES MINORISTAS
Fig.1. Cadena de suministro tres escalones.
CLAIO-2016
383

estocástico de optimización bi-criterio para representar el problema de agregación de inventario
bajo un ambiente de risk pooling con el objetivo de determinar el tradeoff entre los costos y la
capacidad de respuesta. Farahani & Elahipanah (2008) presentan un modelo de distribución de justo
a tiempo en el contexto de la gestión de la cadena de suministro de tres escalones, con los objetivos
de reducir al mínimo los costos y minimizando la suma de los pedidos pendientes y los excedentes
de productos en todos los períodos. El enfoque de solución propuesto consiste en un mediante un
algoritmo genético de clasificación no dominada híbrida. Venkatesan et al. (2009) desarrollan un
modelo matemático para una red de cadena de suministro con los objetivos de minimizar el costo
total y el tiempo de entrega de las órdenes y proponen el uso de la técnica de computación evolutiva
NSGA-II. Shu-Hsien Liao et al. (2011) proponen un modelo integrado donde incorporan decisiones
de control de inventario, tales como orden económica, stock de seguridad y decisiones de reposición
de inventario, dentro de los modelos típicos de localización de instalaciones, el modelo se resuelve
mediante la técnica NSGA-II.
3. Descripción de la formulación del modelo.
En esta sección se presenta la formulación del modelo matemático del problema a tratar en la
presente investigación. En la Sección 3.1 se presenta la formulación de un modelo no lineal
entero mixto del diseño de una cadena de suministro NL-DCS. En la Sección 3.2 se muestra el
proceso de linealización de los costos de inventario de seguridad e inventario en proceso en Z1,
así mismo, la cantidad económica de pedido en Z2. En el proceso de linealización es formulada
una aproximación basada en una función lineal a tramos en Z1 y Z2, obteniendo un modelo
lineal entero mixto PWL-DCS.
3.1. Modelo no lineal entero mixto.
3.1.1. Notación y definiciones
Conjuntos
J: Conjunto de localización de plantas j=1,2,…,J.
K: Conjunto de localización de almacenes, k=1,2,…,K.
L: Conjunto de minoristas, l=1,2,..,L
Variables de decision
xk: 1 si un almacén es localizado en k; 0 en otro caso.
yj: 1 si una planta si es localizada j; 0 en otro caso.
wjk: 1 si la planta j sirve al almacén k; 0 en otro caso.
zkl: 1 si el almacén k sirve minorista l; 0 en otro caso.
sjkl: 1 si el wjk = 1 y zkl: 1; 0 en otro caso.
Variables auxiliares
: Demanda promedio asignada a la planta j
: Varianza de la demanda asignada a la planta j
: Demanda promedio asignado al almacén k
: Varianza de la demanda asignada al almacén k
Simplificación de expresiones
Parámetros
cwk: Capacidad máxima del almacén k
cpj: Capacidad máxima de la planta j
dl: Demanda promedio del minorista l
FCpj: Costo fijo de apertura de la planta en la
localización j
FCwk: Costo fijo de apertura del almacén en la
localización k
HCwk: Costo de inventario por unidad en almacén k
LTwk: Tiempo de entrega deterministico en almacén
k
OCwk: Costo de ordenar en almacén k
TCbjk: Costo de transporte por unidad de planta j a
almacén k
TCckl: Costo de transporte por unidad de almacén k a
minorista l
ul: Varianza de la demanda del minorista l
: Valores de ZT para un nivel de servicio dado
asumiendo una distribución normal.
: Costo de inventario en almacén k
: Inventario de seguridad en almacén k
Formulando el modelo matemático para el problema de la siguiente manera.
j
j
k
k
2 w w
k k k kOC HC
w
k k kLT
1Z
k
k
CLAIO-2016
384

Min Z1 =
1 1 1 1 1
1 1
J J K L K
j j jk jk l jkl k k k k k
j j k l k
K L
kl l kl
k l
FC y UC B d s FC z
C d w
(1)
Min Z2 = 2 k k
k
OCMax
HC
(2)
Sujeto a:
1
1
1 1,... (3)
K
kl
k
J
jk k
j
w l L
v z
1,... (4)
+ w - 1 1,... 1,... 1,... (5)
1
jkl jk kl
jkl jk
k K
s v j J k K l L
s v j
1 1
,... 1,... 1,... (6)
w 1,... 1,... 1,... (7)
= 1
jkl kl
J K
jkl
j k
J k K l L
s j J k K l L
s
1
1 1
1,... (8)
1,... (9)
L
l kl k
l
J L
k l jkl k
j l
l L
d w k K
LT u s
1 1
1,... (10)
1,... (11)
J L
l jkl j
j l
k k k
k K
d s j J
cw z
1,... (12)
j j j
i I
cp y
1,... (13)
, , , , 0,1 1,... , 1,... , 1,... (14)j k jk kl jkl
i I
y z v w s j J k K l L
Donde la función objetivo Z1 busca minimizar los costos operación de la cadena de suministro
relacionados en Eq.(1), incluyendo el costo económico de pedido EOC, costo de inventario en
proceso en cada almacén WIC, costos fijos de localización de un almacén k o planta j, así como el
costo de compra y transporte de las unidades enviadas de planta j hacia almacén k y de almacén k al
minorista l. Mientras que el objetivo de Z2, presentado en Eq. (2), busca minimizar la máxima
cantidad económica de pedido EOQ basado en la política de compras JIT para el conjunto de
almacenes k. Las desigualdades (3) y (4) son restricciones de asignación. La restricción (3) asegura
que un minorista l es asignado a un solo almacén k, mientras que Eq. (4) garantiza que cada
almacén k localizado es atendido por una sola planta j. En las desigualdades (5), (6), (7), y (8) se
integra la variable binaria sjkl, la función de esta variable es evitar la generación de términos no
lineales en (10) y (11) formando un camino que parte con un minorista l, a través de un almacén k y
concluyendo en una planta j. En Eq. (5) la variable sjkl = 1, si wjk = 1 y zkl = 1, en otro caso sjkl = 0.
Las desigualdades (6) y (7) aseguran que el camino sjkl se forma con arcos abiertos en (3) y (4), así
mismo la Eq.(8) garantiza que a cada minorista l es integrado exactamente a un solo camino abierto
sjkl. En Eq. (9) y (10) se calcula la demanda y la varianza promedio transferida del conjunto de
minoristas l a cada almacén k. Así mismo Eq. (11) se calcula la demanda promedio transferida de
los almacenes a cada planta j. En las desigualdades (12) y (13) se garantizan que la capacidad del
CLAIO-2016
385

conjunto de plantas j y almacenes k no es excedida. Finalmente, Eq. (14) describe las variables
binarias utilizadas.
3.2. Aproximación lineal de NL-DCS.
En esta sección se presenta un enfoque de aproximación lineal del NL-DCS basado en una función
lineal a tramos o segmentos (piecewise linear PWL) para EOC, y WIC en Z1, así mismo para EOQ
en Z2. La aproximación está definida por dos o más líneas rectas que se presentan en diferentes
secciones del dominio de la función. Por ejemplo en Eq. (15) EOC en el almacén k se presenta una
función no lineal.
2k k k kEOC OC HC
(15)
EOC es reformulado como una aproximación de función lineal a tramos presentada en Eq. (16).
1
M
m m PWL
k k k k
m
Min q
(16)
Sujeto a:
1
Mm m
k k k
m
q
1,...k K (17)
1
1M
m
k
m
q
1,...k K (18)
1,..., Nm
kq SOS2 1,...k K (19)
En las restricciones (17), (18), y (19) se emplea un conjunto de variables no negativas del tipo
SOS2 o S2 (Special Ordered Sets of type 2). Las variables SOS2 se garantizan que solo dos
variables adyacentes, qkm y qk
m+1 pueden tener un valor diferente a cero y además en un orden
consecutivo. Eq. (17) se asegura que la suma del producto de las variables SOS2 con el valor de
del almacén k en la sección m es igual a k . En la Eq. (18) la suma de las variables SOS2 es igual
a 1. Mediante esta aproximación basada en una función lineal a tramos en Z1 y Z2, es obtenido un
modelo lineal entero mixto PWL-DCS.
4. Enfoque de optimización multiobjetivo.
El método de epsilon-restricción es considerado como el enfoque de optimización multiobjetivo a
usar en PWL-DCS. De acuerdo a este método se optimiza uno de los objetivos, y el resto se
incorporan al modelo en forma de restricción paramétrica (epsilon) . En este caso se toma Z2 para
ser incorporada como restricción paramétrica como se muestra en Eq. (20). El método de epsilon-
restricción es interpretado mediante una frontera eficiente (óptimo de Pareto). En este caso el valor
de epsilon es representado por Qmax.
2max 1,... (20) k k
k
OCMax Q k K
HC
5. Resultados y discusión.
En esta sección se presenta un diseño de una cadena de suministro configurado por 3 potenciales
plantas, 5 potenciales almacenes y 25 minoristas. La resolución el caso fue resuelto utilizando el
PWL-DCS con una licencia comercial de LINGO 14. Un nivel de servicio del 95% fue considerado
para todas las instancias. En las Tablas 1-3 se muestran los valores de los parámetros base, con los
cuales se trabajaron las diferentes instancias.
CLAIO-2016
386
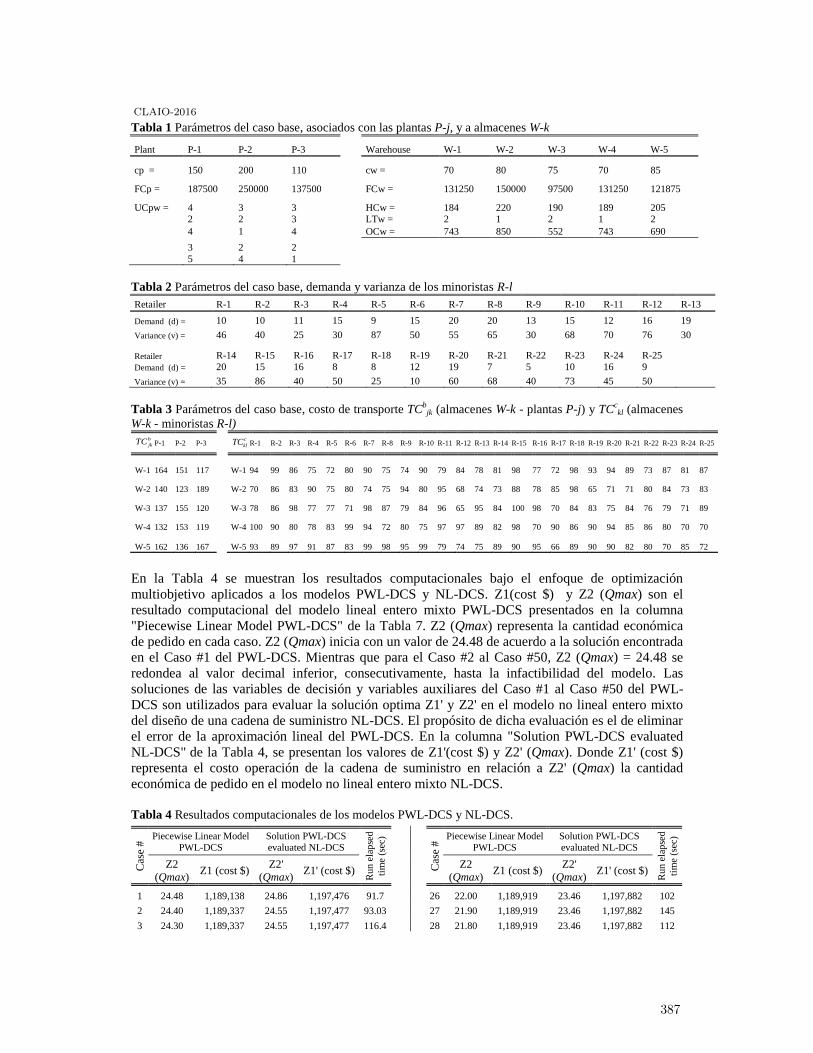
Tabla 1 Parámetros del caso base, asociados con las plantas P-j, y a almacenes W-k
Plant P-1 P-2 P-3
Warehouse W-1 W-2 W-3 W-4 W-5
cp = 150 200 110
cw = 70 80 75 70 85
FCp = 187500 250000 137500
FCw = 131250 150000 97500 131250 121875
UCpw = 4 3 3
HCw = 184 220 190 189 205
2 2 3 LTw = 2 1 2 1 2
4 1 4 OCw = 743 850 552 743 690
3 2 2
5 4 1
Tabla 2 Parámetros del caso base, demanda y varianza de los minoristas R-l
Retailer R-1 R-2 R-3 R-4 R-5 R-6 R-7 R-8 R-9 R-10 R-11 R-12 R-13
Demand (d) = 10 10 11 15 9 15 20 20 13 15 12 16 19
Variance (v) = 46 40 25 30 87 50 55 65 30 68 70 76 30
Retailer R-14 R-15 R-16 R-17 R-18 R-19 R-20 R-21 R-22 R-23 R-24 R-25
Demand (d) = 20 15 16 8 8 12 19 7 5 10 16 9
Variance (v) = 35 86 40 50 25 10 60 68 40 73 45 50
Tabla 3 Parámetros del caso base, costo de transporte TCbjk (almacenes W-k - plantas P-j) y TC
ckl (almacenes
W-k - minoristas R-l)
P-1 P-2 P-3
R-1 R-2 R-3 R-4 R-5 R-6 R-7 R-8 R-9 R-10 R-11 R-12 R-13 R-14 R-15 R-16 R-17 R-18 R-19 R-20 R-21 R-22 R-23 R-24 R-25
W-1 164 151 117
W-1 94 99 86 75 72 80 90 75 74 90 79 84 78 81 98 77 72 98 93 94 89 73 87 81 87
W-2 140 123 189
W-2 70 86 83 90 75 80 74 75 94 80 95 68 74 73 88 78 85 98 65 71 71 80 84 73 83
W-3 137 155 120
W-3 78 86 98 77 77 71 98 87 79 84 96 65 95 84 100 98 70 84 83 75 84 76 79 71 89
W-4 132 153 119
W-4 100 90 80 78 83 99 94 72 80 75 97 97 89 82 98 70 90 86 90 94 85 86 80 70 70
W-5 162 136 167
W-5 93 89 97 91 87 83 99 98 95 99 79 74 75 89 90 95 66 89 90 90 82 80 70 85 72
En la Tabla 4 se muestran los resultados computacionales bajo el enfoque de optimización
multiobjetivo aplicados a los modelos PWL-DCS y NL-DCS. Z1(cost $) y Z2 (Qmax) son el
resultado computacional del modelo lineal entero mixto PWL-DCS presentados en la columna
"Piecewise Linear Model PWL-DCS" de la Tabla 7. Z2 (Qmax) representa la cantidad económica
de pedido en cada caso. Z2 (Qmax) inicia con un valor de 24.48 de acuerdo a la solución encontrada
en el Caso #1 del PWL-DCS. Mientras que para el Caso #2 al Caso #50, Z2 (Qmax) = 24.48 se
redondea al valor decimal inferior, consecutivamente, hasta la infactibilidad del modelo. Las
soluciones de las variables de decisión y variables auxiliares del Caso #1 al Caso #50 del PWL-
DCS son utilizados para evaluar la solución optima Z1' y Z2' en el modelo no lineal entero mixto
del diseño de una cadena de suministro NL-DCS. El propósito de dicha evaluación es el de eliminar
el error de la aproximación lineal del PWL-DCS. En la columna "Solution PWL-DCS evaluated
NL-DCS" de la Tabla 4, se presentan los valores de Z1'(cost $) y Z2' (Qmax). Donde Z1' (cost $)
representa el costo operación de la cadena de suministro en relación a Z2' (Qmax) la cantidad
económica de pedido en el modelo no lineal entero mixto NL-DCS.
Tabla 4 Resultados computacionales de los modelos PWL-DCS y NL-DCS.
Cas
e #
Piecewise Linear Model PWL-DCS
Solution PWL-DCS evaluated NL-DCS
Run
ela
pse
d
tim
e (s
ec)
Cas
e #
Piecewise Linear Model PWL-DCS
Solution PWL-DCS evaluated NL-DCS
Run
ela
pse
d
tim
e (s
ec)
Z2
(Qmax) Z1 (cost $)
Z2'
(Qmax) Z1' (cost $)
Z2
(Qmax) Z1 (cost $)
Z2'
(Qmax) Z1' (cost $)
1 24.48 1,189,138 24.86 1,197,476 91.7
26 22.00 1,189,919 23.46 1,197,882 102
2 24.40 1,189,337 24.55 1,197,477 93.03
27 21.90 1,189,919 23.46 1,197,882 145
3 24.30 1,189,337 24.55 1,197,477 116.4
28 21.80 1,189,919 23.46 1,197,882 112
b
jkTC c
klTC
CLAIO-2016
387
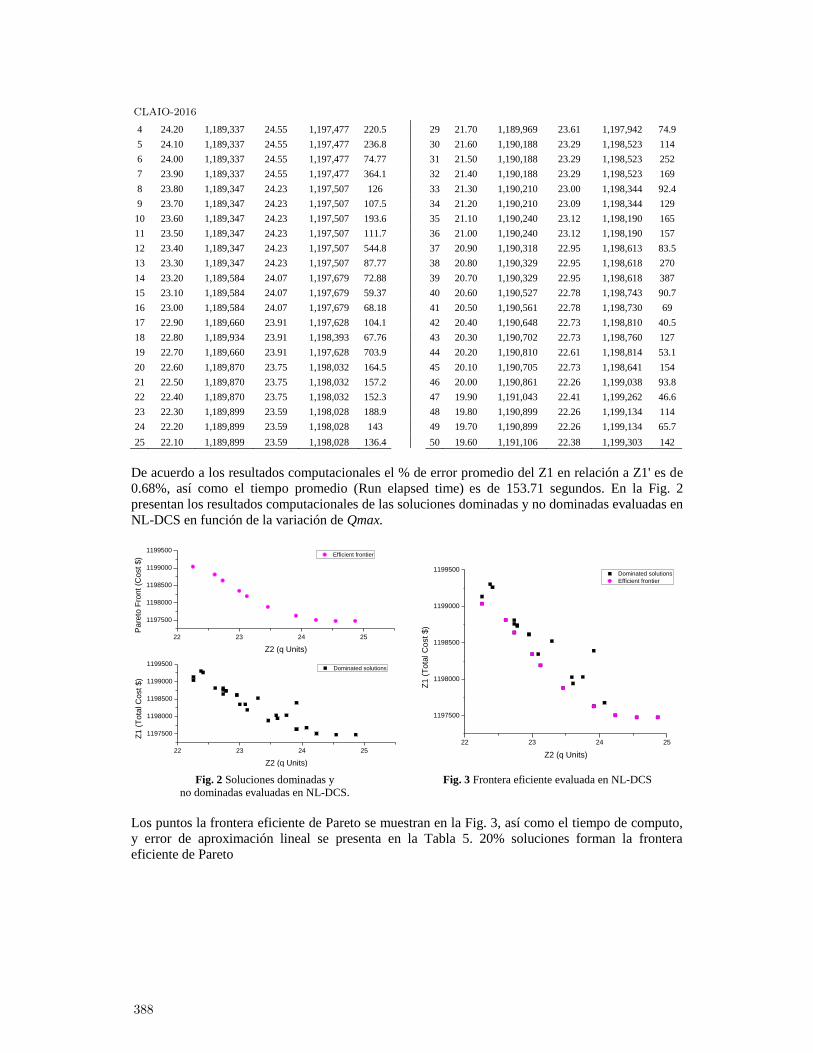
4 24.20 1,189,337 24.55 1,197,477 220.5
29 21.70 1,189,969 23.61 1,197,942 74.9
5 24.10 1,189,337 24.55 1,197,477 236.8
30 21.60 1,190,188 23.29 1,198,523 114
6 24.00 1,189,337 24.55 1,197,477 74.77
31 21.50 1,190,188 23.29 1,198,523 252
7 23.90 1,189,337 24.55 1,197,477 364.1
32 21.40 1,190,188 23.29 1,198,523 169
8 23.80 1,189,347 24.23 1,197,507 126
33 21.30 1,190,210 23.00 1,198,344 92.4
9 23.70 1,189,347 24.23 1,197,507 107.5
34 21.20 1,190,210 23.09 1,198,344 129
10 23.60 1,189,347 24.23 1,197,507 193.6
35 21.10 1,190,240 23.12 1,198,190 165
11 23.50 1,189,347 24.23 1,197,507 111.7
36 21.00 1,190,240 23.12 1,198,190 157
12 23.40 1,189,347 24.23 1,197,507 544.8
37 20.90 1,190,318 22.95 1,198,613 83.5
13 23.30 1,189,347 24.23 1,197,507 87.77
38 20.80 1,190,329 22.95 1,198,618 270
14 23.20 1,189,584 24.07 1,197,679 72.88
39 20.70 1,190,329 22.95 1,198,618 387
15 23.10 1,189,584 24.07 1,197,679 59.37
40 20.60 1,190,527 22.78 1,198,743 90.7
16 23.00 1,189,584 24.07 1,197,679 68.18
41 20.50 1,190,561 22.78 1,198,730 69
17 22.90 1,189,660 23.91 1,197,628 104.1
42 20.40 1,190,648 22.73 1,198,810 40.5
18 22.80 1,189,934 23.91 1,198,393 67.76
43 20.30 1,190,702 22.73 1,198,760 127
19 22.70 1,189,660 23.91 1,197,628 703.9
44 20.20 1,190,810 22.61 1,198,814 53.1
20 22.60 1,189,870 23.75 1,198,032 164.5
45 20.10 1,190,705 22.73 1,198,641 154
21 22.50 1,189,870 23.75 1,198,032 157.2
46 20.00 1,190,861 22.26 1,199,038 93.8
22 22.40 1,189,870 23.75 1,198,032 152.3
47 19.90 1,191,043 22.41 1,199,262 46.6
23 22.30 1,189,899 23.59 1,198,028 188.9
48 19.80 1,190,899 22.26 1,199,134 114
24 22.20 1,189,899 23.59 1,198,028 143
49 19.70 1,190,899 22.26 1,199,134 65.7
25 22.10 1,189,899 23.59 1,198,028 136.4
50 19.60 1,191,106 22.38 1,199,303 142
De acuerdo a los resultados computacionales el % de error promedio del Z1 en relación a Z1' es de
0.68%, así como el tiempo promedio (Run elapsed time) es de 153.71 segundos. En la Fig. 2
presentan los resultados computacionales de las soluciones dominadas y no dominadas evaluadas en
NL-DCS en función de la variación de Qmax.
Fig. 2 Soluciones dominadas y
no dominadas evaluadas en NL-DCS.
Fig. 3 Frontera eficiente evaluada en NL-DCS
Los puntos la frontera eficiente de Pareto se muestran en la Fig. 3, así como el tiempo de computo,
y error de aproximación lineal se presenta en la Tabla 5. 20% soluciones forman la frontera
eficiente de Pareto
22 23 24 25
1197500
1198000
1198500
1199000
1199500
22 23 24 25
1197500
1198000
1198500
1199000
1199500
Dominated solutions
Z1 (
Tota
l C
ost $)
Z2 (q Units)
Efficient frontier
Pare
to F
ront (C
ost $)
Z2 (q Units)
22 23 24 25
1197500
1198000
1198500
1199000
1199500 Dominated solutions
Efficient frontier
Z1 (
Tota
l C
ost $)
Z2 (q Units)
CLAIO-2016
388
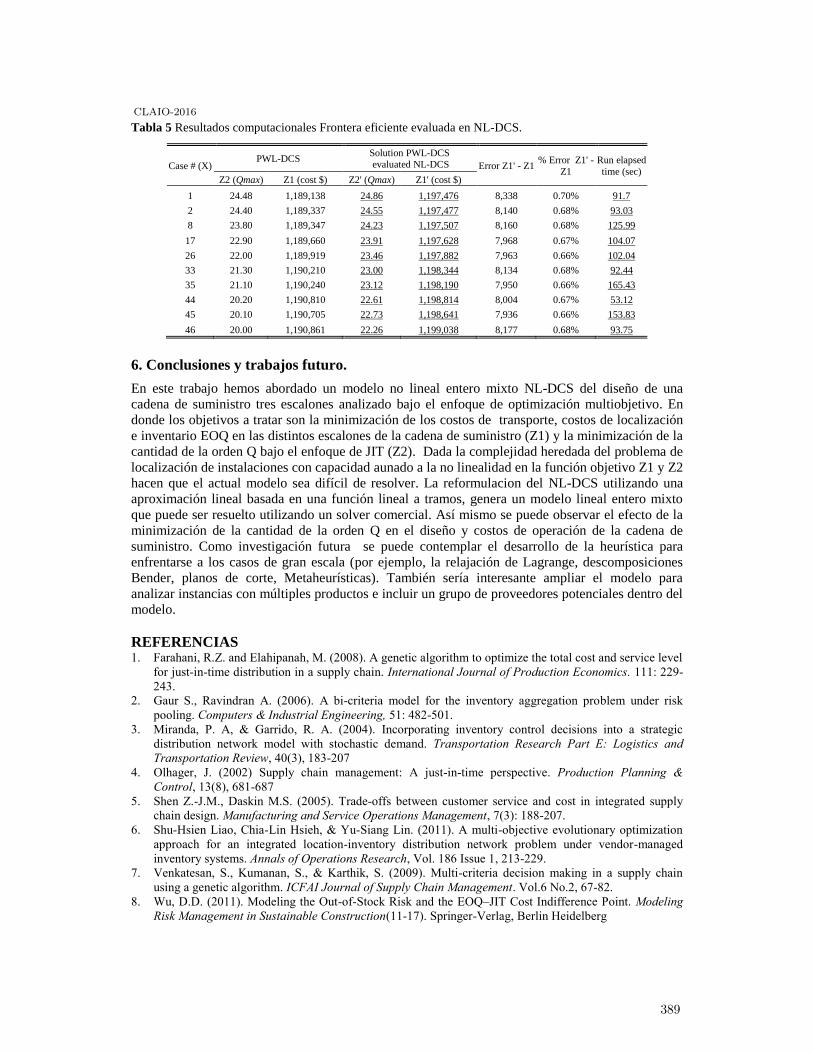
Tabla 5 Resultados computacionales Frontera eficiente evaluada en NL-DCS.
Case # (X) PWL-DCS
Solution PWL-DCS evaluated NL-DCS Error Z1' - Z1
% Error Z1' -
Z1
Run elapsed
time (sec) Z2 (Qmax) Z1 (cost $) Z2' (Qmax) Z1' (cost $)
1 24.48 1,189,138 24.86 1,197,476 8,338 0.70% 91.7
2 24.40 1,189,337 24.55 1,197,477 8,140 0.68% 93.03
8 23.80 1,189,347 24.23 1,197,507 8,160 0.68% 125.99
17 22.90 1,189,660 23.91 1,197,628 7,968 0.67% 104.07
26 22.00 1,189,919 23.46 1,197,882 7,963 0.66% 102.04
33 21.30 1,190,210 23.00 1,198,344 8,134 0.68% 92.44
35 21.10 1,190,240 23.12 1,198,190 7,950 0.66% 165.43
44 20.20 1,190,810 22.61 1,198,814 8,004 0.67% 53.12
45 20.10 1,190,705 22.73 1,198,641 7,936 0.66% 153.83
46 20.00 1,190,861 22.26 1,199,038 8,177 0.68% 93.75
6. Conclusiones y trabajos futuro.
En este trabajo hemos abordado un modelo no lineal entero mixto NL-DCS del diseño de una
cadena de suministro tres escalones analizado bajo el enfoque de optimización multiobjetivo. En
donde los objetivos a tratar son la minimización de los costos de transporte, costos de localización
e inventario EOQ en las distintos escalones de la cadena de suministro (Z1) y la minimización de la
cantidad de la orden Q bajo el enfoque de JIT (Z2). Dada la complejidad heredada del problema de
localización de instalaciones con capacidad aunado a la no linealidad en la función objetivo Z1 y Z2
hacen que el actual modelo sea difícil de resolver. La reformulacion del NL-DCS utilizando una
aproximación lineal basada en una función lineal a tramos, genera un modelo lineal entero mixto
que puede ser resuelto utilizando un solver comercial. Así mismo se puede observar el efecto de la
minimización de la cantidad de la orden Q en el diseño y costos de operación de la cadena de
suministro. Como investigación futura se puede contemplar el desarrollo de la heurística para
enfrentarse a los casos de gran escala (por ejemplo, la relajación de Lagrange, descomposiciones
Bender, planos de corte, Metaheurísticas). También sería interesante ampliar el modelo para
analizar instancias con múltiples productos e incluir un grupo de proveedores potenciales dentro del
modelo.
REFERENCIAS 1. Farahani, R.Z. and Elahipanah, M. (2008). A genetic algorithm to optimize the total cost and service level
for just-in-time distribution in a supply chain. International Journal of Production Economics. 111: 229-
243.
2. Gaur S., Ravindran A. (2006). A bi-criteria model for the inventory aggregation problem under risk
pooling. Computers & Industrial Engineering, 51: 482-501.
3. Miranda, P. A, & Garrido, R. A. (2004). Incorporating inventory control decisions into a strategic
distribution network model with stochastic demand. Transportation Research Part E: Logistics and
Transportation Review, 40(3), 183-207
4. Olhager, J. (2002) Supply chain management: A just-in-time perspective. Production Planning &
Control, 13(8), 681-687
5. Shen Z.-J.M., Daskin M.S. (2005). Trade-offs between customer service and cost in integrated supply
chain design. Manufacturing and Service Operations Management, 7(3): 188-207.
6. Shu-Hsien Liao, Chia-Lin Hsieh, & Yu-Siang Lin. (2011). A multi-objective evolutionary optimization
approach for an integrated location-inventory distribution network problem under vendor-managed
inventory systems. Annals of Operations Research, Vol. 186 Issue 1, 213-229.
7. Venkatesan, S., Kumanan, S., & Karthik, S. (2009). Multi-criteria decision making in a supply chain
using a genetic algorithm. ICFAI Journal of Supply Chain Management. Vol.6 No.2, 67-82.
8. Wu, D.D. (2011). Modeling the Out-of-Stock Risk and the EOQ–JIT Cost Indifference Point. Modeling
Risk Management in Sustainable Construction(11-17). Springer-Verlag, Berlin Heidelberg
CLAIO-2016
389

A utilização da Pesquisa Operacional para alocação de
recursos na gestão acadêmica
Mariana Mendes GuimarãesInstituto de Engenharia e Tecnologia - Centro Universitário de Belo Horizonte - UniBH
Joaquim José da Cunha JúniorPrograma de Pós-Graduação em Engenharia de Produção - Universidade Federal de Minas Gerais
Instituto de Engenharia e Tecnologia - Centro Universitário de Belo Horizonte - [email protected]
Resumo
A gestão acadêmica tem se tornado um dos grandes temas discutidos nas Instituições deEnsino Superior - IES, em especial entre as privadas. Em um mercado concorrido, em que onúmero de IES cresce a cada ano, ser estratégico e se preocupar com uma efetiva gestão daqualidade e dos custos pode garantir não só a sobrevivência da instituição mas também a suarenovação como negócio e sua sustentabilidade a longo prazo. Para isso, é importante que osprocessos para tomada de decisão utilizem técnicas e ferramentas capazes de oferecer soluçõesque gerem vantagens competitivas. Neste trabalho, foi desenvolvido um modelo matemáticopara alocação de recursos em um evento acadêmico de grande porte, com foco na otimização dautilização dos espaços dispońıveis e consequente redução de custo. Foram utilizados os dadosde uma IES privada e os resultados comprovam a eficácia da técnica, com redução de 63,5% dasjanelas de tempo com uma estrutura pelo menos 32% menor do que a utilizada sem o modelo.
Keywords: Pesquisa Operacional; Pesquisa Operacional na Educação; Gestão Acadêmica; OtimizaçãoCombinatória;
1 Introdução
Nas últimas décadas, o Brasil passou por uma profunda expansão do ensino superior com acriação de poĺıticas públicas que visam democratizar o seu acesso e atender a uma demanda pormão de obra mais qualificada. Segundo o Instituto Nacional de Estudos e Pesquisas EducacionaisAńısio Teixeira ([5]), o número de matŕıculas nos cursos de graduação aumentou 110,1% de 2001para 2010 e tende a continuar crescendo nesta década. Dados do Censo da Educação Superiorindicam que, no ano de 2013, foram contabilizadas 7.305.977 matŕıculas na graduação em todo opáıs, sendo 5.373.450 feitas em instituições privadas. De acordo com o Portal Brasil ([10]), nesse anoo Brasil já contava com 32.000 cursos e 2.391 instituições de ensino superior, sendo 2.090, ou seja,87,4%, privadas. Outro dado que merece destaque é a evolução no número de IES - Instituições deEnsino Superior, um aumento de 71,7% entre os anos de 2001 e 2010 ([6]).
CLAIO-2016
390

Frente a esse cenário, é importante que as IES, especialmente as privadas, desenvolvam posiçõesmais estratégicas e se preocupem com o ganho de vantagem competitiva em um mercado cada vezmais concorrido. Em instituições de ensino, sua qualidade precisa ser percebida pelos alunos epelo mercado e, paralelamente, é de extrema importância a efetiva gestão dos sistemas de custos,como deve acontecer em qualquer organização. Os métodos utilizados para tomada de decisões queenvolvam custos para a instituição precisam ser tratados cada vez mais como uma ciência e nãoapenas através de intuição gerencial.
Uma das formas para a melhoria da gestão acadêmica é o aprimoramento das suas ferramentaspara tomadas de decisão, visando atrair (e reter) os alunos, professores e colaboradores, aumentara rentabilidade da instituição e a qualidade do ensino recebida pelos estudantes e percebida pelosórgãos competentes. Ser mais produtivo significa um melhor aproveitamento dos recursos na ofertade serviços, o que pode proporcionar um custo menor para a empresa e, consequentemente, elevá-lano patamar de competitividade ([3]).
Alguns trabalhos já publicados dão a dimensão da grande contribuição da Pesquisa Operacionalpara a gestão acadêmica, como na construção de quadro de horários/timetabling, estudo realizadopor diversos autores, entre eles [2], [4] e [11], no problema de alocação de professores com foco emganho de desempenho tratado por [7] e na alocação de turmas em salas de aula, produzido por [1].O presente artigo tem como objetivo dar continuidade aos estudos iniciados em [8] e mostrar maisuma aplicação da Pesquisa Operacional na gestão acadêmica, através do desenvolvimento de ummodelo matemático que auxilie o processo de tomada de decisão ao otimizar a alocação de recursosem um evento realizado por uma instituição de ensino superior privada.
2 Timetabling e o problema de alocação de recursos
O problema de timetabling pode ser definido, na área de pesquisa operacional, como a alocaçãohorária de recursos ([4]). Apesar desse objetivo geral em comum a todos que se utilizam do conceito,cada situação onde ele se aplica será composto por particularidades do próprio ambiente, que serãoa base para a criação das restrições do modelo.
O timetabling pode ser aplicado a diversos contextos de alocação de recursos, como no escalona-mento de funcionários em turnos, no remanejamento de máquinas em fábricas e, também, na tabelade horários de turmas, exames, salas de aula etc. ([11]). Isso o torna uma ferramenta importantena gestão acadêmica, com variadas aplicações no ambiente educacional, onde encontram-se diversosrecursos (professores, alunos, espaços, equipamentos) com suas respectivas demandas, preferênciase limitações (horário de trabalho dos professores, perfil de matŕıcula dos alunos, quantidade deequipamentos dispońıveis, número de salas de aula etc.) que precisam ser executados em umdeterminado espaço de tempo.
Portando, três conjuntos básicos de elementos finitos definem um timetable genérico, são eles:atividades (eventos, exames, seminários, projetos etc.), horários para realização das atividades eos agentes, que são pessoas que irão monitorar/instruir/acompanhar tais atividades. Em suma,o evento e, acontecendo no horário h com a participação do agente a ([9]). Esses conceitos irãonortear a construção do modelo de alocação de recursos para o evento acadêmico proposto nestetrabalho.
A realização de eventos acadêmicos, além de proporcionar a troca de conhecimento e a inter-disciplinaridade entre os docentes, é uma oportunidade de evidenciar todo o potencial cient́ıfico
CLAIO-2016
391

e tecnológico de uma instituição e atrair não só alunos, como empresas parceiras, fornecedores einvestidores. Este estudo de caso é um exemplo de aplicação da Pesquisa Operacional na realidadede uma IES privada, como ferramenta de apoio à tomada de decisões. Ao final de cada semestre, ainstituição promove um circuito, onde alunos de áreas e peŕıodos distintos apresentam os projetosinterdisciplinares desenvolvidos ao longo do ciclo para uma banca de professores. Uma estrutura éespecialmente montada para a sua realização e comporta programações diversas ao longo dos dias,sendo um dos eventos com o maior aporte de investimento da instituição. Para cada trabalho apre-sentado, cerca de 1.500 por edição, é necessária a alocação de recursos diversos, tais como estandes,equipamentos e professores avaliadores em dias e horários predeterminados pela organização, alémde toda a estrutura existente por trás de qualquer evento desse porte, que conta com uma equiperesponsável por seu planejamento ao longo do ano.
A modelagem matemática desenvolvida visa facilitar a alocação dos recursos e reduzir o temponecessário nessa etapa que ainda é feita, em parte, manualmente, e otimizar a distribuição dosespaços, diminuindo a amplitude de ocupação dos estandes e, com isso, minimizar os custos comlocação de estrutura.
2.1 O modelo para alocação de recursos na gestão acadêmica
Com base nos objetivos já citados anteriormente e após o mapeamento das caracteŕısticas doevento acadêmico, foram definidos os parâmetros e as variáveis do modelo, além da função objetivoe das restrições. Como parâmetros estão a quantidade de grupos que apresentarão seus trabalhosno circuito (G), os tipos de estande que estarão dispońıveis (I), os horários existentes dentro daprogramação (H), a quantidade de turmas que farão apresentações no circuito (T), considerandoque cada turma possui vários grupos, e a capacidade de cada estande, seja total (C) ou por horário(φ). As informações referentes a cada grupo também são parâmetros, como o tipo de estandesolicitado para cada apresentação (σ), quais grupos correspondem a qual turma de graduação (λ)e, por fim, qual é o horário preferencial para as apresentações de determinada turma, de acordocom o horário de aula da disciplina de desenvolvimento do trabalho (θ).
A função objetivo visa minimizar as penalidades que serão contabilizadas caso um ou mais doscritérios abaixo não sejam atendidos:- O grupo g deverá, preferencialmente, apresentar o trabalho no tipo de estande i selecionado peloprofessor como o mais adequado;- O grupo g deverá, preferencialmente, fazer sua apresentação no horário h, conforme o horárioprogramado para a disciplina de desenvolvimento do trabalho;- Cada estande deverá ser utilizado em sua capacidade máxima, evitando as janelas de horário.
Para cada penalidade foi atribúıdo um peso através dos parâmetros α, β e γ, respectivamente.
Minimizar FO =∑
i∈I
∑
g∈G
∑
h∈Hygih ·σgi ·α+
∑
i∈I
∑
g∈G
∑
h∈H
∑
t∈Tygih ·λgt ·θth ·β+
∑
i∈I
∑
h∈Hxih+
∑
i∈Iki ·γ
(1)São variáveis:
xih: variável inteira que informa quantos estandes do tipo i serão necessários no horário h;
CLAIO-2016
392

ygih: variável binária que informa se o grupo g apresentará seu trabalho no tipo de estande i eno horário h;
ztih: variável binária que informa se a turma t apresentará seu trabalho no tipo de estande i eno horário h;
si: variável inteira que informa quantos estantes do tipo i serão necessários com base na alocaçãofeita;
ki: variável inteira que informa quantos espaços dispońıveis existirão no estante tipo i apósserem realizadas todas as alocações.
Sujeito a:
∑
i∈I
∑
h∈Hygih = 1 ∀ g ∈ G (2)
∑
g∈Gygih ≤ xih · φih ∀ i ∈ I, ∀ h ∈ H (3)
∑
i∈Iygih · λgt =
∑
i∈Iztih · λgt ∀ t ∈ T, ∀ g ∈ G, ∀ h ∈ H (4)
∑
h∈Hygih · λgt =
∑
h∈Hztih · λgt ∀ t ∈ T, ∀ g ∈ G, ∀ i ∈ I (5)
si ≥ xih ∀ i ∈ I, ∀ h ∈ H (6)
si ≥∑
g∈G∑
h∈H ygih∑h∈H φih
∀ i ∈ I (7)
C · si −∑
g∈G
∑
h∈Hygih ≤ ki ∀ i ∈ I (8)
xih ∈ Z ∀ i ∈ I, ∀ h ∈ H (9)
ygih ∈ {0, 1} ∀ g ∈ G, ∀ i ∈ I, ∀ h ∈ H (10)
ztih ∈ {0, 1} ∀ t ∈ T, ∀ i ∈ I, ∀ h ∈ H (11)
si ∈ Z ∀ i ∈ I (12)
ki ∈ Z ∀ i ∈ I (13)
As restrições classificadas como Hard são aquelas que limitam o número de soluções posśıveis edevem obrigatoriamente ser atendidas, conforme as descritas abaixo:
CLAIO-2016
393

- Cada grupo deverá apresentar seu trabalho uma única vez durante o circuito, conforme (2);- Cada estande comporta no máximo 03 apresentações (de 30min cada) por horário, ou seja, acapacidade dos estandes é limitada, conforme (3);- Os grupos de uma mesma turma deverão apresentar seus trabalhos no mesmo horário, conforme(4);- Os grupos de uma mesma turma deverão apresentar seus trabalhos no mesmo tipo de estande,conforme (5);- A quantidade de estandes que deverá ser contratada precisa atender à demanda de todos oshorários de apresentação, conforme (6);- A quantidade de estandes que deverá ser contratada é definida pela razão entre o total de apre-sentações e a capacidade de cada tipo de estande, conforme (7);- A quantidade de espaços ainda dispońıveis é definida pela diferença entre a capacidade total dosestandes contratados e o total de apresentações que ocorrerá em cada tipo de estande, conforme (8).
As restrições denominadas Soft são aquelas que devem, preferencialmente, ser atendidas, e, casonão sejam, irão contribuir com penalizações na função objetivo, conforme apresentado em (1). Asdemais, definidas em (9), (10), (11), (12), (13) definem os domı́nios das variáveis xih, ygih, ztih, sie ki.
3 Resultados e Análises
O modelo foi implementado em AMPL e resolvido em CPLEX 12.6.0 em um Intel Xeon X5690@ 3,47 gigahertz com 24-CPU e memória RAM de 132 gigabytes e sistema operacional Linux.
Os dados utilizados referem-se à distribuição de apresentações do peŕıodo de 2015-2 (segundosemestre de 2015) e foram utilizados para que fosse posśıvel comparar o planejamento real, ou seja,a programação que, de fato, aconteceu com o resultado do modelo proposto. O circuito acadêmicoacontece em dois turnos distintos, manhã e noite, e, por isso, os turnos serão avaliados separada-mente, no primeiro momento e, após essa análise, as conclusões apresentadas irão considerar oevento como um todo, uma vez que o investimento em estrutura é único. Portanto, a quantidadede estandes dispońıveis para a turma da noite será a mesma para a turma da manhã, mesmo quea demanda na parte da manhã seja menor, conforme informações na Tabela 1. Por esse motivo,será realizada uma análise mais detalhada dos resultados obtidos ao aplicar o modelo no turno danoite, pois ele será a referência para o cálculo da disponibilidade de estandes do turno da manhã.
Tabela 1: Dados referentes às apresentações e caracteŕısticas do evento nos dois turnos em que eleaconteceu, no peŕıodo 2015-2
Turno T G Dias Horários/dia Cap. estande (φ) Tipo de estante
Manhã 86 403 03 02 03 02Noite 211 1108 05 02 03 02
As tabelas abaixo mostram a otimização na utilização dos recursos (estandes) necessários para arealização do circuito acadêmico nos turnos manhã e noite. Os modelos ‘Otimizado A’ e ‘OtimizadoB’ se diferem pelo valor do peso atribúıdo ao parâmetro γ, referente à penalidade absorvida pela
CLAIO-2016
394
função objetivo para cada janela de horário encontrada na solução. No modelo A esse parâmetrocorresponde a 10% do peso dado aos outros parâmetros de penalidade, α e β, sendo esse o modeloconsiderado conservador, pois prioriza mais o cumprimento do horário e do tipo de estande emdetrimento da redução de janelas de tempo. Já no modelo B, o valor de γ é 50% do valor de α e β.
Tabela 2: Comparativo entre a alocação de recursos ocorrida no circuito acadêmico em 2015-2 eos resultados obtidos através do modelo matemático para otimização da utilização dos estandes -turno: Manhã
Tipo 1 Tipo 2
Cenário Apresentações Estandes Redução Apresentações Estandes Redução
Real* 143 13 260 20Otimizado A 139 13 0% 270 17 15%Otimizado B 139 08 38,5% 270 15 25%
Para que a otimização fosse posśıvel de acordo com a função objetivo proposta e ao consideraros critérios descritos quanto ao tipo de estande solicitado e ao horário de apresentação do trabalhocomo sendo restrições Soft, alguns rearranjos na programação das apresentações foram realizados.Nos resultados de ‘Otimizado A’ todos os grupos apresentarão o trabalho nos horários preferenciaise, em ‘Otimizado B’, 18 grupos não o farão, o que corresponde a 4,4%. Em ambos os casos apenas0,01% dos grupos foram alocados no tipo de estande diferente do solicitado.
Tabela 3: Comparativo entre a alocação de recursos ocorrida no circuito acadêmico em 2015-2 eos resultados obtidos através do modelo matemático para otimização da utilização dos estandes -turno: Noite
Tipo 1 Tipo 2
Cenário Apresentações Estandes Redução Apresentações Estandes Redução
Real* 287 31 821 44Otimizado A 280 16 48,3% 822 35 20,5%Otimizado B 298 11 64,5% 804 27 38,6%
* No cenário Real, seis grupos do turno da manhã apresentaram seus trabalhos no turno danoite. Essas exceções não foram consideradas no modelo e poderão ser alocadas, manualmente, nasjanelas de horário existentes.
A maior redução do número de estandes no turno da noite levou a um maior rearranjo de tipose horários em comparação ao ocorrido no turno da manhã. Para o resultado A todos os gruposapresentarão o trabalho nos horários preferenciais e 1,4% (15 grupos) foram alocados no tipo deestande diferente do solicitado. Já para o resultado B, 23 grupos (2,1%) apresentariam o trabalhoem outro estande e 96 (8,7%) em horário diferente do solicitado.
Uma análise mais detalhada foi realizada com os resultados obtidos no turno da noite. Aavaliação dos percentuais de janelas de horários foi feita com base na capacidade total de cadaestande e do número de apresentações programadas, conforme (14):
CLAIO-2016
395
capacidadeociosa = capacidadetotal − capacidadeutilizada (14)
Tabela 4: Comparativo entre a quantidade de janelas de horários existentes no estante tipo 01 antese após a otimização da alocação dos recursos através do modelo matemático proposto, no peŕıodode 2015-2 - turno: Noite
Cenário Qde estandes Captotal No de apresentações Capociosa
Real 31 930 287 643Otimizado A 16 480 280 200Otimizado B 11 330 298 32
Tabela 5: Comparativo entre a quantidade de janelas de horários existentes no estante tipo 02 antese após a otimização da alocação dos recursos através do modelo matemático, proposto no peŕıodode 2015-2 - turno: Noite
Cenário Qde estandes Captotal No de apresentações Capociosa
Real 44 1320 821 499Otimizado A 35 1050 822 228Otimizado B 27 810 804 06
4 Conclusão
O modelo proposto mostrou-se eficiente para o objetivo do trabalho, a otimização dos recursos(estandes) utilizados na realização de um evento acadêmico de uma instituição de ensino superiorprivada. A solução apresentada diminuiu a amplitude de ocupação dos estandes durante todo opeŕıodo do circuito e a quantidade de estrutura necessária em cada horário da programação ficoumais nivelada. Com isso, houve redução das janelas de horários que passaram de 69% para 10%no modelo mais otimizado, para o tipo de estande 1, e de 38% para 1% para o estande tipo 2,também considerando o modelo B. Foi posśıvel alocar o mesmo evento realizado no 2o semestre de2015 com um número de estandes 32% menor se considerado o modelo otimizado mais conservador(onde as restrições consideradas Soft foram obedecidas quase em sua totalidade) e 49% menor nosegundo modelo, em que foram necessários maiores rearranjos nos horários e tipos de estande decada apresentação. Os tempos de resposta foram considerados satisfatórios para todos os modelossendo que o de maior demanda computacional levou 213 segundos para encontrar a solução.
Para trabalhos futuros são sugeridas novas análises dos pesos atribúıdos às restrições quecompõem a função objetivo e avaliação junto aos gestores acadêmicos dos impactos posśıveis comas mudanças nos horários das apresentações bem como no tipo de estande em que o trabalhoserá alocado, uma vez que percebe-se, através dos resultados deste estudo, que maiores rearranjosnesses parâmetros impactam diretamente no tamanho da estrutura necessária e, consequentemente,no custo de realização do evento. Além disso, após a definição de um modelo único, adequado àrealidade e aos objetivos institucionais, recomenda-se sua aplicação em anos anteriores para com-
CLAIO-2016
396

parações e análises em peŕıodos de tempo maiores. Por fim, propõem-se que ele seja utilizadoefetivamente como ferramenta de gestão acadêmica para a alocação de recursos em eventos futuros.
O trabalho apresentado é o ińıcio de um estudo mais profundo para o desenvolvimento de ferra-mentas para tomada de decisão na gestão acadêmica através da utilização da Pesquisa Operacionale pode ser considerado um estudo de importante colaboração para desdobramentos diversos não sóno ambiente acadêmico como para alocação de recursos em outros cenários empresariais.
Referências
[1] A. F. B. Andrade. Modelo de alocação de turmas com foco na minimização do número de salas utilizadaspor turma. Trabalho de Conclusão de Curso (Engenharia de Produção) – Instituto de Engenharia eTecnologia, Centro Universitário de Belo Horizonte - UNIBH. Belo Horizonte, Brasil, 2015.
[2] B. Lara. Quadro de horários acadêmico: uma abordagem com foco na avaliação institucional e na gestãode custos de instituições de ensino superior privadas brasileiras. Dissertação de Mestrado (Ciência daComputação) – Instituto de Ciências Exatas, Universidade Federal de Minas Gerais. Belo Horizonte,Brasil, 2006.
[3] D. Moreira. Medida da Produtividade na empresa moderna. Pioneira, São Paulo, Brasil, 1991. 152 p
[4] E. S. Sales and F. M. Muller and E. O. Simonetto. Solução do problema de alocação de salas utilizandoum modelo matemático multi-́ındice. Anais do Simpósio Brasileiro de Pesquisa Operacional, 2015.
[5] INEP. Censo da Educação Superior 2011: principais resultados Dispońıvel em:http://download.inep.gov.br. Acesso em 02 mar. 2016.
[6] INEP. Censo da Educação Superior 2013: resultados Dispońıvel em: http://download.inep.gov.br.Acesso em 27 out. 2015.
[7] J. J. da Cunha Jr. and B. R. G. M. Couto and A. F. B. Andrade and M. C. Souza. Alocação de profes-sores, com foco em ganhos de desempenho, conforme critérios avaliativos do Ministério da Educação.Anais do Simpósio Brasileiro de Pesquisa Operacional, 2015.
[8] M. M. Guimarães and J. J. da Cunha Jr. Otimização na alocação de recursos em uma instituiçãode ensino superior com a utilização da Pesquisa Operacional. Anais do XII Encontro Mineiro deEngenharia de Produção, 2016.
[9] P. Ross and H. Fang and D. Corne. Genetic Algorithms for Timetabling e scheduling. Universidadede Edinburgh, 80 South Brige, Edinburgh EH 11HN, Scotland. 1999. apud S. K. Borges. Resoluçãode timetabling utilizando algoritmos genéticos e evolução cooperativa. Dissertação de Mestrado (In-formática) - Departamento de Informática, Universidade Federal do Paraná. Curitiba, Brasil, 2003.
[10] Portal Brasil. Ensino superior registra mais 7,3 milhões de estudantes. Dispońıvel emhttp://www.brasil.gov.br. Acesso em 01 out. 2015.
[11] S. K. Borges. Resolução de timetabling utilizando algoritmos genéticos e evolução cooperativa. Dis-sertação de Mestrado (Informática) - Departamento de Informática, Universidade Federal do Paraná.Curitiba, Brasil, 2003.
CLAIO-2016
397

Otimização do Roteiro de Distribuição de Materiais no
Sistema Público de Saúde na Cidade de Joinville
Flavia Haweroth Universidade Federal de Santa Catarina
Ana Paula Nunes Duarte Universidade Federal de Santa Catarina
Vanina Macowski Durski Silva Universidade Federal de Santa Catarina
Resumo
O conceito de Gerenciamento da Cadeia de Suprimentos, que já é amplamente conhecido
e aplicado por empresas do setor privado, também pode ser adaptado ao setor público, no
entanto a sistemática de contratação e os entraves do sistema licitatório são barreiras para
seu efetivo uso. As atividades de transporte e administração de estoques representam um
alto custo para qualquer empresa, inclusive para um almoxarifado público, e as
ferramentas de roteirização de veículos são fundamentais na redução destes custos. Este
artigo se propõe a aplicar uma heurística de resolução do Problema de Roteirização de
Veículos em um almoxarifado do sistema público de saúde na cidade de Joinville, no
Brasil, propondo assim uma rota alternativa de distribuição física. As rotas atuais e
propostas pela heurística são comparadas a fim de encontrar melhora. O resultado foi
satisfatório, e mostrou uma redução de 18,3% da distância percorrida no mês.
Palavras-chave: cadeia de suprimentos; problema de roteirização de veículos;
distribuição física; administração pública.
1 Introdução
O Gerenciamento da Cadeia de Suprimentos (GCS) para Ballou (2006) trata do conjunto
de atividades logísticas, que se repetem inúmeras vezes ao longo do canal pelo qual
matérias-primas vão sendo convertidas em produtos acabados. Esse conceito também é
aplicável na Administração Pública, onde o cliente final seria a população através do uso
dos serviços públicos fornecidos, atendendo os princípios de economicidade e qualidade
exigidas desses serviços (TRIDAPALLI, 2008). Dentre as atividades logísticas que
compõem o GCS, a administração de estoque e o transporte são as que se destacam como
mais custosas a qualquer empresa, pública ou privada, por isso para a redução de custos
CLAIO-2016
398

deve-se estudar os procedimentos dessas duas atividades, que numa visão mais ampla
tem reflexos em todos os outros departamentos (ASSINI et al., 2012). Segundo Tridapalli
(2008, p. 42):
“Trabalhar com o conceito de ‘chão de fábrica’ no setor
público, lidando com redução de custos e aumento de
eficiência, é a bandeira de vários segmentos sociais para
combater a falência do Estado. O poder público brasileiro
precisa de qualidade na gestão e a tecnologia de
racionalização de custos usada pelo setor privado, para
aumentar a eficiência.”
Entre as decisões a serem tomadas no transporte de mercadorias destaca-se a escolha do
modal e o roteirização de veículos ao longo da rede de transporte a fim de minimizar os
tempos ou distâncias (BALLOU, 2006). Diante desse contexto o objetivo deste trabalho é
propor uma alternativa para a rota de distribuição de materiais ambulatoriais no setor da
saúde do município de Joinville. Para isso será aplicado um método heurístico de
resolução do Problema de Roteirização de Veículos (PRV) implementado em linguagem
de programação. A rota obtida será posteriormente comparada com a atual levando em
considerando as limitações da modelagem e dos dados.
O trabalho está estruturado como segue: o presente capítulo que contém a parte
introdutória, em seguida no capítulo 2 apresenta-se o referencial teórico dos temas
pertinentes ao trabalho, o capítulo 3 contempla a definição do problema a ser estudado.O
quarto capítulo apresenta a metodologia aplicada, o quinto capítulo apresenta a análise
dos resultados seguido do capítulo final de conclusão.
2 Referencial teórico
2.1 Distribuição física de produtos
A logística é definida pelo Conselho de Gerenciamento da Cadeia de Suprimentos citado
por Tadeu (2008, p. 17) como “processo de planejamento, implementação e controle
eficiente e eficaz do fluxo e armazenagem de mercadorias, serviços e informações
relacionadas desde o ponto de origem até o ponto de consumo, com objetivo de atender
às necessidades do cliente”. A logística de distribuição compõe o elo final da Cadeia de
Suprimentos fazendo a interface entre empresa e consumidor. Esse elo envolve
transferência de produtos entre fábrica e os armazéns próprios ou de terceiros seus
estoques, os subsistemas de entrega urbana e interurbana (ALVARENGA e NOVAES,
2000).
De acordo com Coêlho (2010), na área da saúde pública os processos logísticos, devido
às suas características muito específicas, precisam ser encarados com uma abordagem
orientada não só para a racionalização de custos, mas também como elemento
fundamental de apoio à prestação de cuidados de saúde aos pacientes. Para tanto, deve-se
CLAIO-2016
399

haver um eficiente esquema de planejamento das atividades de compras, armazenagem e
gerenciamento de materiais em estoque, bem como na distribuição desses materiais
destinados ao uso em atividades hospitalares, uma vez que a falta de um mecanismo
eficiente de controle impede a apuração das reais necessidades de abastecimento.
2.2 Problema de roteirização de veículos
O PRV é um problema de roteirização em nós onde o objetivo é a definição de rotas de
entrega (sequência de nós) a serem percorridas por uma frota de veículos com um custo
mínimo, originando e terminando em uma garagem ou depósito central. A frota deve
servir um conjunto de clientes, cada qual caracterizado por sua localização no espaço
bidimensional, demanda e tempo de serviço. Cada cliente tem sua demanda suprida por
exatamente um veículo e a demanda total dos clientes não deve exceder a capacidade
total do veículo. O tempo total de qualquer rota não pode exceder um limite previamente
estabelecido, incluindo os tempos de viagem entre clientes e tempos de serviço em cada
cliente (BARBOSA, 2005). Uma formulação de programação matemática para o PRV foi
dada por Fisher e Jaikumar (1981), apresentada pelas Equações (1) à (8).
𝑀𝑖𝑛 𝑍 = ∑(𝑐𝑖𝑗 ∑ 𝑥𝑖𝑗𝑘
𝑘
)
𝑖,𝑗
(1)
Sujeito a:
∑ 𝑦𝑖𝑘
𝑘
= 1 𝑖 = 2, … , 𝑛 (2)
∑ 𝑦𝑖𝑘
𝑘
= 𝑚 𝑖 = 1 (3)
∑ 𝑞𝑖𝑦𝑖𝑘
𝑖
≤ 𝑄𝑘 𝑘 = 1, … , 𝑚 (4)
∑ 𝑥𝑖𝑗𝑘
𝑗
= ∑ 𝑥𝑗𝑖𝑘
𝑖
= 𝑦𝑖𝑘 𝑖 = 1, … , 𝑛 𝑘 = 1, … , 𝑚 (5)
∑ 𝑥𝑖𝑗𝑘
𝑖,𝑗 ∈ 𝑆
≤ |𝑆| − 1 ∀𝑆 ⊆ {2, … , 𝑛}, 𝑘 = 1, … , 𝑚 (6)
𝑦𝑖𝑘 ∈ {0,1} 𝑖 = 1, … , 𝑛 𝑘 = 1, … , 𝑚 (7)
𝑥𝑖𝑗𝑘 ∈ {0,1} 𝑖, 𝑗 = 1, … , 𝑛 𝑘 = 1, … , 𝑚 (8)
Em que:
xijk é uma variável binária que assume o valor 1 quando o veículo k visita o
cliente j imediatamente após o cliente i, o em caso contrário;
yik é uma variável binária que assume valor 1 se o cliente i é visitado pelo veículo
k, o em caso contrário;
qi é a demanda do cliente i;
Qk é a capacidade do veículo k;
CLAIO-2016
400

cij é o custo de percorrer o trecho que vai do cliente i ao cliente j.
As restrições (2) asseguram que um veículo não visite mais de uma vez um cliente. As
restrições (3) garantem que o depósito recebe uma visita de todos os veículos. As
restrições (4) obrigam que a capacidade dos veículos não seja ultrapassada. As restrições
(5) garantem que os veículos não interrompam suas rotas em um cliente e as restrições
(6) são as tradicionais restrições de eliminação de subrotas.
2.3 Método de Clarke e Wright
O PRV pertence à categoria de problemas NP - difíceis, cuja dificuldade de encontrar a
solução aumenta rapidamente à medida que o número de nós cresce (OLIVEIRA, 2007).
Laporte (1992) cita e exemplifica uma série de algoritmos exatos, mas reconhece a
limitação que estes apresentam ao lidar com problemas maiores e mais complexos,
indicando as meta-heurísticas como um campo de estudos mais promissor. Apesar dos
métodos heurísticos não garantirem que uma solução ótima seja encontrada, os
benefícios, tanto em termos computacionais como por apresentar boa representação da
realidade, obtendo soluções satisfatórias, são suficientes para adotar a abordagem
heurística em problemas de otimização.
O algoritmo de Clarke e Wright ou método das economias foi proposto pela primeira vez
em 1964 por Clarke e Wright para resolver o PRV em que o número de veículos é livre. O método inicia com n roteiros contendo o depósito e um cliente, onde n é o número de
clientes a serem atendidos, e a cada etapa um par de rotas é mesclado de acordo com a
maior economia que pode ser gerada (LAPORTE, 1992). A economia sij gerada na união
de dois roteiros é calculada através da Equação (9), onde doi, doj e dij são as distâncias
entre os pontos. A partir disso, lista-se em ordem decrescente as economias de todos os
pares de vértices e a cada iteração avalia-se o topo da lista para fazer a união das rotas.
Um par de rotas não será mesclado se as restrições de capacidade do veículo e tempo
total de percurso forem ultrapassadas. A Figura 2 exemplifica uma união de duas rotas.
𝑠𝑖𝑗 = 𝑑𝑜𝑖 + 𝑑𝑜𝑗 − 𝑑𝑖𝑗 (9)
Figura 2: Combinação de rotas na heurística de Clarke e Wright. Fonte: Autor.
CLAIO-2016
401

Segundo Ballou (2006), este método é relativamente rápido, em termos computacionais,
para problemas com um número moderado de paradas, e capaz de gerar soluções que são
quase ótimas. Através da avaliação dos métodos existentes para resolução do PRV, este
se mostrou mais apropriado para este artigo.
3 Metodologia
Neste artigo, o local em estudo é o almoxarifado da Secretaria da Saúde do município de
Joinville, chamado de Serviço de Administração de Materiais Ambulatoriais (SAMA) e
todas as informações necessárias foram obtidas por entrevista e visita ao local. A SAMA
recebe dos fornecedores e armazena até a distribuição, que é terceirizada através de um
contrato de quilometragem fixa de 3000 km por mês. O contrato inclui um veículo
(modelo Ducato Cargo da Fiat) e um motorista que trabalha 8 horas diárias. Nesse tipo de
contrato o valor é pago integralmente mesmo que a quilometragem real não atinja o
limite e esses 3000 km são usados nas atividades de distribuição e também em outras que
serão desconsideradas por este artigo. A distribuição segue um cronograma mensal
organizado em 4 semanas que serão tratadas separadamente na resolução do problema. A
Tabela 1 mostra o cronograma das duas primeiras semanas do mês de agosto de 2015.
Com essas questões levantadas, surgiu o interesse em analisar se há um melhor a
caminho a ser realizado pelo motorista a fim de minimizar a quilometragem gasta
mensalmente e, assim possibilitar uma redução da quilometragem do contrato.
O método de resolução a ser aplicado é a heurística de Clarke e Wright (versão paralela)
implementada em linguagem C++ pelas autoras. Para aplicar o método foram necessárias
a matriz de distâncias, as demandas dos clientes e os tempos de percurso e parada. A
matriz de distâncias foi obtida através do Software ArcGIS 10 usando a ferramenta
network analysis. As distâncias são assimétricas e relativas as rotas mais curtas entre um
ponto e outro. A demanda de cada unidade de saúde é variável e os materiais entregues
não são unitizados, sendo assim difícil definir demanda e capacidade do veículo. Para
tratar desse problema foi solicitada a ajuda a uma funcionária na unidade que é
responsável pela separação dos pedidos. A mesma classificou as unidades em quatro
categorias qualitativas de tamanho, onde a maior seria a que ocuparia toda a capacidade
do veículo. Essa classificação qualitativa foi quantificada através de pesos ponderados
com base em roteiros do cronograma com vários pontos, conforme mostra a Tabela 2.
O tempo de percurso foi obtido assumindo a velocidade de 30 km/h e o máximo percurso
foi de 4 horas que corresponde a jornada cumprida pelo motorista em cada período. Os
tempos de parada nas unidades para descarregar foram considerados constantes com
valor de 30 minutos, sugerido pelo motorista. Tendo sido definido todos os valores e
limites necessários no programa, o mesmo foi executado em computador com
processador Intel Core I5 de 3,10 GHz, 4 GB de memória RAM e sistema operacional
Windows 7 Ultimate.
CLAIO-2016
402
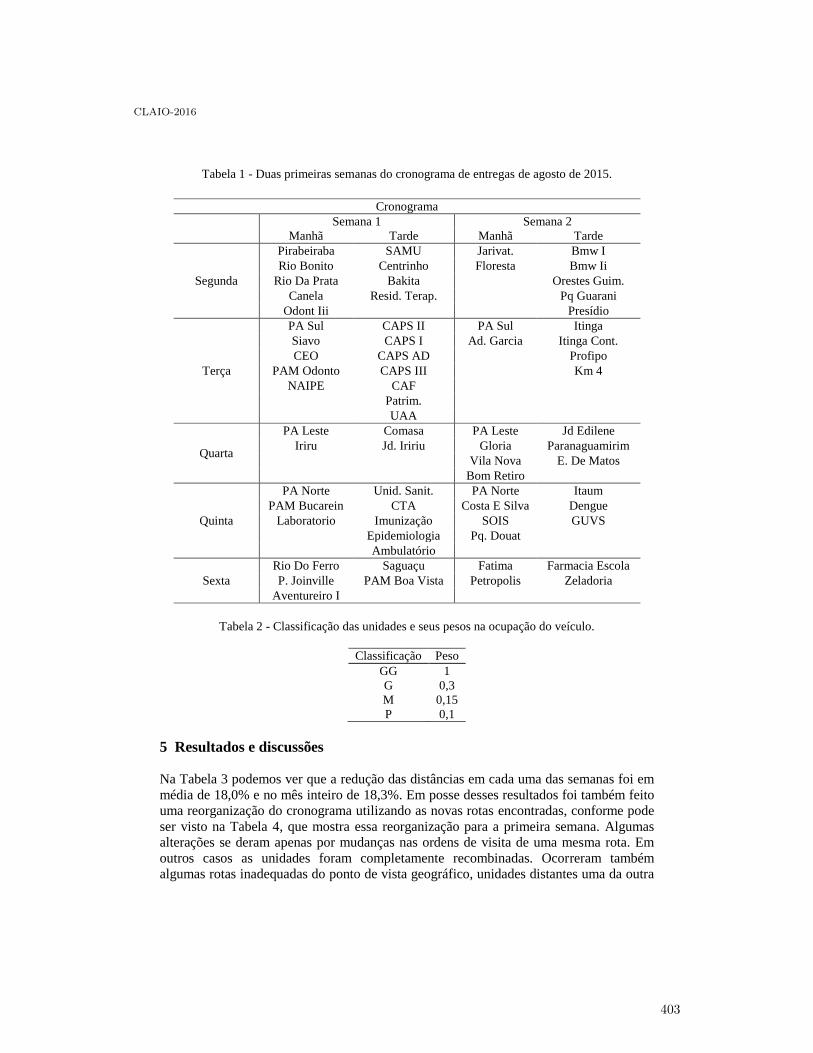
Tabela 1 - Duas primeiras semanas do cronograma de entregas de agosto de 2015.
Cronograma
Semana 1 Semana 2
Manhã Tarde Manhã Tarde
Segunda
Pirabeiraba SAMU Jarivat. Bmw I
Rio Bonito Centrinho Floresta Bmw Ii
Rio Da Prata Bakita Orestes Guim.
Canela Resid. Terap. Pq Guarani
Odont Iii Presídio
Terça
PA Sul CAPS II PA Sul Itinga
Siavo CAPS I Ad. Garcia Itinga Cont.
CEO CAPS AD Profipo
PAM Odonto CAPS III Km 4
NAIPE CAF
Patrim.
UAA
Quarta
PA Leste Comasa PA Leste Jd Edilene
Iriru Jd. Iririu Gloria Paranaguamirim
Vila Nova E. De Matos
Bom Retiro
Quinta
PA Norte Unid. Sanit. PA Norte Itaum
PAM Bucarein CTA Costa E Silva Dengue
Laboratorio Imunização SOIS GUVS
Epidemiologia Pq. Douat
Ambulatório
Sexta
Rio Do Ferro Saguaçu Fatima Farmacia Escola
P. Joinville PAM Boa Vista Petropolis Zeladoria
Aventureiro I
Tabela 2 - Classificação das unidades e seus pesos na ocupação do veículo.
Classificação Peso
GG 1
G 0,3
M 0,15
P 0,1
5 Resultados e discussões
Na Tabela 3 podemos ver que a redução das distâncias em cada uma das semanas foi em
média de 18,0% e no mês inteiro de 18,3%. Em posse desses resultados foi também feito
uma reorganização do cronograma utilizando as novas rotas encontradas, conforme pode
ser visto na Tabela 4, que mostra essa reorganização para a primeira semana. Algumas
alterações se deram apenas por mudanças nas ordens de visita de uma mesma rota. Em
outros casos as unidades foram completamente recombinadas. Ocorreram também
algumas rotas inadequadas do ponto de vista geográfico, unidades distantes uma da outra
CLAIO-2016
403
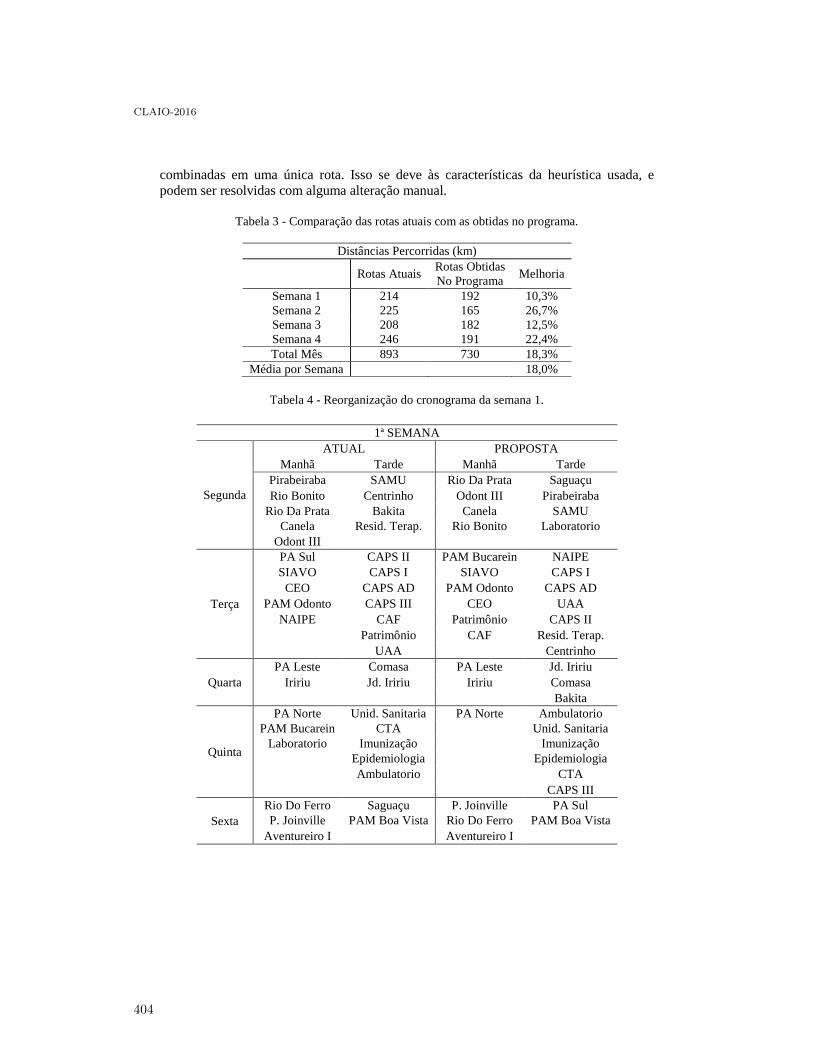
combinadas em uma única rota. Isso se deve às características da heurística usada, e
podem ser resolvidas com alguma alteração manual.
Tabela 3 - Comparação das rotas atuais com as obtidas no programa.
Distâncias Percorridas (km)
Rotas Atuais
Rotas Obtidas
No Programa Melhoria
Semana 1 214 192 10,3%
Semana 2 225 165 26,7%
Semana 3 208 182 12,5%
Semana 4 246 191 22,4%
Total Mês 893 730 18,3%
Média por Semana 18,0%
Tabela 4 - Reorganização do cronograma da semana 1.
1ª SEMANA
Segunda
ATUAL PROPOSTA
Manhã Tarde Manhã Tarde
Pirabeiraba SAMU Rio Da Prata Saguaçu
Rio Bonito Centrinho Odont III Pirabeiraba
Rio Da Prata Bakita Canela SAMU
Canela Resid. Terap. Rio Bonito Laboratorio
Odont III
Terça
PA Sul CAPS II PAM Bucarein NAIPE
SIAVO CAPS I SIAVO CAPS I
CEO CAPS AD PAM Odonto CAPS AD
PAM Odonto CAPS III CEO UAA
NAIPE CAF Patrimônio CAPS II
Patrimônio CAF Resid. Terap.
UAA
Centrinho
Quarta
PA Leste Comasa PA Leste Jd. Iririu
Iririu Jd. Iririu Iririu Comasa
Bakita
Quinta
PA Norte Unid. Sanitaria PA Norte Ambulatorio
PAM Bucarein CTA
Unid. Sanitaria
Laboratorio Imunização
Imunização
Epidemiologia
Epidemiologia
Ambulatorio
CTA
CAPS III
Sexta
Rio Do Ferro Saguaçu P. Joinville PA Sul
P. Joinville PAM Boa Vista Rio Do Ferro PAM Boa Vista
Aventureiro I
Aventureiro I
CLAIO-2016
404

6 Conclusão Os resultados obtidos neste artigo mostraram a possibilidade de melhoria no desempenho
logístico do setor público através de investimento em tecnologia e uso de sistemas de
gerenciamento e otimização dos processos, como a roteirização de veículos. O setor
público tem dificuldades de implementar as mesmas soluções da iniciativa privada,
devido à dependência do sistema licitatório. A proposta de um novo cronograma de
entregas baseado no resultado desse artigo poderia ser implementada na prática, mas não
necessariamente implicaria na alteração do contrato ao término de sua vigência.
Como sugestão para trabalhos futuros seria necessário um acompanhamento das entregas
para se obter dados reais de tempo dos percursos e o tempo de parada nas unidades.
Assim como estudar a possibilidade de trabalhar com o cronograma mensal como um
todo, utilizando restrições de janela de tempo. Referências
1. A.C. Alvarenga e A.G. Novaes. Logística Aplicada. 3ª Edição. São Paulo, 2000.
2. D.J. Assini, F.O. Vaz, J.R. Tiossi Jr., J.C.B. Alves, e L.F. Otero. Logística no Setor Público.
Maringá, 2012.
3. R.H. Ballou. Gerenciamento da Cadeia de Suprimentos/Logística Empresarial. 5ª Edição.
Porto Alegre, 2006.
4. M.R. Barbosa. Aplicação de uma Abordagem Adaptativa de Busca Tabu a Problemas de
Roteirização e Programação de Veículos. São Carlos, 2005.
5. E.P.F. Coêlho. Logística de Dispensação na Rede de Saúde Pública, In: III CONGRESSO
CONSAD DE GESTÃO PÚBLICA. Brasília, 2010.
6. M.L. Fisher e R. Jaikumar. A Generalized Assignment Heuristic for Vehicle Routing.
Networks, v.11, n.2, p. 109-124, 1981.
7. G. Laporte. The Vihicle Routing Problem: na Overview of Exact and Approximate
Algorithms. European Journal Of Operational Research, nº 59: 345-358, 1992.
8. H.C.B. Oliveira. Um Modelo Hibrido Estocástico para Tratamento de um Pproblema de
Roteamento de Veículos com Janela de Tempo. Tese de Mestrado. UFPE, Recife, 2007.
9. H.F.B. Tadeu. Logística Empresarial. Fundac-BH. 17p. Belo Horizonte, 2008.
10. J.P. Tripadalli. Comércio Eletrônico: uma Perspectiva no Setor Público para Melhoria da
Logística. Rio de Janeiro, 2008.
CLAIO-2016
405

Polifuncionalidad con Cadenas Cerradas en el Sector Servicios: Un
Enfoque de Optimización Robusta
César Augusto Henao
Departamento de Ingeniería Industrial, Universidad del Norte
Departamento de Ingeniería de Transporte y Logística, Pontificia Universidad Católica de Chile
Juan Carlos Ferrer
Departamento de Ingeniería Industrial y de Sistemas, Pontificia Universidad Católica de Chile
Juan Carlos Muñoz
Departamento de Ingeniería de Transporte y Logística, Pontificia Universidad Católica de Chile
Jorge Vera
Departamento de Ingeniería Industrial y de Sistemas, Pontificia Universidad Católica de Chile
Resumen
La inherente variabilidad y estacionalidad de la demanda genera un descalce natural entre la oferta
planificada y la demanda observada en las empresas del sector servicios. El uso de personal polifuncional
es una fuente de flexibilidad atractiva para minimizar tal descalce. Este trabajo presenta un modelo de
programación lineal entera mixta y una heurística constructiva para estructurar las habilidades
polifuncionales de un conjunto de empleados. Para incorporar explícitamente la incertidumbre de la
demanda en el modelo de optimización, se utiliza un enfoque de optimización robusta. Posteriormente,
mediante simulación Montecarlo se analiza el desempeño de las soluciones robustas para distintos niveles
de variabilidad en la demanda y distintos niveles de aversión al riesgo en las soluciones. La metodología
entrega estructuras de polifuncionalidad tipo cadenas cerradas, con distintos largos, que proveen un
excelente desempeño a nivel costo-efectivo. También se brindan algunos lineamientos para elegir un nivel
apropiado de aversión al riesgo y generar un plan de capacitación que requiera una inversión en
polifuncionalidad mucho menor a la exigida por la solución robusta más conservadora (i.e., peor caso).
Palabras claves: Encadenamiento, Optimización Robusta; Polifuncionalidad.
1 Introducción
El sector servicios, y en particular la industria de retail, enfrentan fenómenos predecibles como la
estacionalidad de la demanda, y no predecibles como su incertidumbre y el ausentismo no programado de
personal. Como resultado, se presenta un descalce entre la oferta y la demanda de personal que genera
problemas de sobredotación y subdotación en varios momentos durante el curso de una semana. La
literatura reporta que muchos sectores han enfrentado este descalce con personal polifuncional, en el cual
empleados son entrenados para trabajar en diferentes actividades (e.g., Simchi-Levi y Wei, 2012). Sin
embargo, aunque la polifuncionalidad puede ser muy beneficiosa, también conlleva un costo. Entrenar
empleados para que trabajen en múltiples actividades puede ser muy costoso. Así, las empresas evitan la
polifuncionalidad total, donde todos los empleados son entrenados para trabajar en todas las actividades.
CLAIO-2016
406

En consecuencia, es relevante identificar diseños eficientes de polifuncionalidad, que aseguren la mayor
proporción de los beneficios potenciales a un costo razonable. Muchos autores han concluido que los
empleados con dos habilidades aparecen como la fuerza laboral polifuncional más costo-efectiva (e.g.,
Henao et al., 2015). Este tipo de política de flexibilidad parcial es conocida como diseño 2-flexibilidad.
El problema de asignación de personal a diferentes actividades puede ser modelado como un problema
de asignación sobre un grafo bipartito donde los nodos de oferta son empleados y los nodos de demanda
son actividades. Si el número de recursos siendo asignados es igual al número de recursos siendo
requeridos, entonces el sistema es catalogado como balanceado. En un grafo como este, un diseño 2-
flexibilidad es conocido como una Cadena Larga Cerrada (CLC) si sus arcos forman exactamente un ciclo
no dirigido conteniendo todos los nodos de oferta y demanda (Simchi-Levi y Wei, 2012). Una Cadena
Corta Cerrada (CCC) es definida como un sub-grafo bipartito inducido que forma un ciclo no dirigido.
Simchi-Levi y Wei (2012), en un estudio sobre la producción de automóviles en un sistema balanceado
con múltiples plantas, demostraron que las CLC son óptimas entre todas las configuraciones 2-
flexibilidad en sistemas balanceados. Las CLC son preferidas sobre las CCC, ya que ellas pueden
adaptarse mejor a una mayor cantidad de escenarios inciertos y su desempeño es tan bueno como el
proporcionado por la polifuncionalidad total, pero a un costo considerablemente menor. Por otra parte, el
problema de asignación del personal en empresas del sector servicios es inherentemente desbalanceado,
ya que el número de empleados excede significativamente el número de actividades.
Este trabajo propone una metodología novedosa para evaluar los beneficios del encadenamiento en
sistemas desbalanceados con demanda incierta. Primero, el problema se formula como un Modelo de
Programación Lineal Entera Mixta (MPLEM) determinístico. Nuestra formulación se diferencia del resto
de los trabajos en la literatura, porque las restricciones del MPLEM garantizan un plan de capacitación
que entrega la cantidad óptima de empleados polifuncionales por actividad, y simultáneamente garantiza
la formación de un conjunto de cadenas cerradas (CLC y/o CCC) que requiere el mínimo número de
entrenamientos. Sin embargo, este MPLEM no prioriza la construcción de CLC sobre la construcción de
CCC. Segundo, el MPLEM es reformulado mediante optimización robusta para incorporar explícitamente
la incertidumbre de la demanda. Tercero, a partir de la dotación óptima de empleados polifuncionales
entregada por el MPLEM robusto y mediante el uso de una heurística constructiva se genera una solución
factible que prioriza la construcción de CLC sobre CCC. Finalmente, este trabajo aplica esta metodología
a un caso de estudio en una firma de retail chilena. A partir de los resultados obtenidos se definen
políticas que responden dos preguntas fundamentales sobre polifuncionalidad: ¿Cuánta y cómo agregarla?
2 Descripción del problema
Para aplicar estructuras de polifuncionalidad tipo cadenas cerradas en sistemas desbalanceados nosotros
proponemos el siguiente enfoque para modelar el problema. Primero, la fuerza laboral podría dividirse en
dos grupos; un grupo se mantendrá especializado (i.e., tienen una sola habilidad), mientras el otro grupo
será polifuncional (i.e., entrenado en una segunda habilidad). Segundo, los empleados polifuncionales son
vinculados a estructuras tipo cadenas cerradas. Por lo tanto, en el análisis de sistemas desbalanceados en
la industria de servicios surgen dos preguntas: (i) ¿Cuántos empleados en cada actividad deben ser
polifuncionales? (ii) ¿Cómo deben ser organizados los empleados polifuncionales dentro las cadenas
cerradas? La Figura 1(a-c) ilustra tres ejemplos de estructuras de polifuncionalidad tipo cadenas cerradas
en sistemas desbalanceados: (a) una cadena larga cerrada (1CL), un empleado polifuncional por actividad formando una CLC; (b) doble cadena larga cerrada (2CL), dos empleados polifuncionales por
actividad formando dos CLC (en este caso son idénticas); y (c) cadenas cerradas mixtas (CCM), en la que
hay una combinación de una CLC y una CCC. Una línea sólida en la figura representa el entrenamiento
primario de empleados mientras que una línea punteada representa una habilidad adicional.
CLAIO-2016
407

Figura 1: Ejemplos de estructuras de encadenamiento en sistemas desbalanceados: (a) 1CL, (b) 2CL, (c) CCM.
En un horizonte de planificación semanal, el problema propuesto consiste en asignar horas de trabajo a
cada empleado y diseñar un plan de capacitación a una fuerza laboral conocida e inicialmente especialista.
Sin pérdida de generalidad, la modelación asumirá el contexto de una tienda de retail donde los
empleados podrían ser entrenados para trabajar en un segundo departamento (actividad) convirtiéndose en
polifuncionales. La formulación del problema considera los siguientes supuestos: (1) La demanda
semanal por horas para cada departamento es incierta y se asume independencia entre ellas. (2) El costo
de subdotación se incluye en la función de costos y corresponde al costo esperado por ventas perdidas. (3)
Se incorpora también el costo de sobredotación de personal, el cual permite cuantificar el costo de
oportunidad incurrido al pagar por personal ocioso que podría estar realizando tareas productivas. (4) El
costo de capacitación también es incluido en la función de costos. Se asume que los costos de
subdotación, sobredotación, y capacitación son iguales por departamento. (5) El problema de asignación
de personal es totalmente equilibrado, i.e., las horas disponibles para ser asignadas en cada departamento
son exactamente igual al valor en horas de la demanda media de cada departamento. (6) No hay
ausentismo de personal. (7) Todos los empleados tienen igual tipo de contrato, por lo que deben trabajar
semanalmente la misma cantidad de horas. (8) Inicialmente todos los empleados son especialistas. (9) La
mano de obra es homogénea, es decir, la productividad individual de los empleados es la misma.
Finalmente, (10) los empleados polifuncionales sólo pueden trabajar en un total de dos departamentos.
3 Metodología
3.1 Modelo de optimización determinístico
Esta subsección presenta el MPLEM determinístico para resolver el problema de asignación de
personal con encadenamiento. A continuación se presenta la notación matemática del problema.
Conjuntos y parámetros del modelo:
I Empleados actuales, indexado en i
L Departamentos de la tienda, indexado en l
lI Dotación de empleados contratados para el departamento ,l lI I
c Costo de capacitar a un empleado para trabajar en algún departamento; [$-sem /Empleado]
u , s Costo de subdotación y sobredotación por hora; [$/Hora]
lr Número de horas semanales demandadas en el departamento ,l , l L
h Cantidad de horas semanales que debe trabajar un empleado de acuerdo a su contrato
im Departamento en el cual el empleado i está entrenado inicialmente, i I
Variables de decisión del modelo:
ilx Igual a 1 si el empleado i es entrenado para trabajar en el departamento ,l ,i I l L
CLAIO-2016
408

iv Igual a 1 si el empleado i es polifuncional, de otra forma igual a 0, i I
l Cantidad de empleados polifuncionales pertenecientes al departamento ,l l L
il Horas semanales asignadas a trabajar al empleado i en el departamento ,l ,i I l L
l , l Subdotación y sobredotación en horas semanales en el departamento ,l l L
El modelo determinístico de programación lineal entera mixta es formulado a continuación:
: i
l l ill L l L i I l L l mMin u s cx
(1)
s.a.
il l l li Ir
l L (2)
ill Lh
i I (3)
il ilhx ,i I l L (4)
1ilx , : ii I l L l m (5)
: ii ill L l m
v x
i I (6)
1iv i I (7)
{ }l ll i ili I i I I
v x
l L (8)
{0,1}ilx ,i I l L (9)
, , , , 0i l il l lv ,i I l L (10)
La función objetivo (FO) (1) minimiza los siguientes costos semanales: (a) subdotación; (b)
sobredotación; y (c) capacitación de empleados en habilidades adicionales. Las restricciones (2) entregan
el nivel de sub/sobredotación (no negativo) asociado a cada departamento. Las restricciones (3)
garantizan que los empleados trabajen exactamente la cantidad de horas semanales exigidas por su
contrato. Las restricciones (4) aseguran que cada empleado sea asignado a trabajar en un departamento, si
y sólo si es entrenado para ese departamento. Las restricciones (5) establecen el departamento en el cual
está entrenado inicialmente cada empleado. Las restricciones (6) indican para cada empleado si este es
polifuncional o si continúa siendo especializado. Las restricciones (7) aseguran que cada empleado
polifuncional esté entrenado en una sola habilidad adicional. Esto garantiza la construcción de un diseño
2-flexibilidad. Las restricciones (8) aseguran para cada departamento ,l que exista igualdad entre la
cantidad de empleados propios del departamento l que son entrenados para trabajar en otros
departamentos de la tienda l
l ii Iv
y la cantidad de empleados pertenecientes a otros
departamentos que recíprocamente son entrenados para trabajar en el departamento l { }lili I I
x . Las
restricciones (7) y (8) garantizan la formación de cadenas cerradas tipo CLC o CCC. La formación de
cualquier cadena cerrada exige que el grado de entrada de cada nodo de oferta que pertenezca a ella, sea
igual al grado de salida de su respectivo nodo de demanda. Las restricciones (9) y (10) son de dominio.
3.2 Modelo de optimización robusto
Para tratar la incertidumbre de la demanda este estudio usó el enfoque de optimización robusta (OR)
desarrollado originalmente por Bertsimas y Sim (2004). Sin embargo, también se usaron modificaciones
introducidas por los estudios de Bertsimas y Thiele (2006) y Bohle et al. (2010). El objetivo fue ajustar la
CLAIO-2016
409

restricción de la demanda del MPLEM a la estructura general del paradigma de robustez presentado en
Bertsimas y Sim (2004). Inicialmente, basándonos en el trabajo de Bertsimas y Thiele (2006) planteamos
una formulación equivalente para (1) y (2), veamos:
: il ill L i I l L l m
Min cx
(11)
l il li Is r
l L (12)
l il li Iu r
l L (13)
La variable l representa el costo total de sobre/subdotación en el departamento .l Bajo el enfoque de
Bohle et al., el parámetro de presupuesto de incertidumbre ( ) para las restricciones (12)-(13) se
expresará como una fracción, 0 1, del número total de parámetros inciertos, esto es . Si 0,
nosotros estamos en el caso determinístico, donde no se considera la incertidumbre. Por otro lado, 1
es el mayor nivel de protección para las restricciones y representa el escenario del peor caso. Es decir, el
escenario que considera la máxima incertidumbre posible en el problema. Luego, siguiendo los enfoques
de Bertsimas y Sim y Bohle et al., el conjunto de incertidumbre para el parámetro lr es expresada como:
ˆ, : , ; , ; 1l l l l l l l
l J
U r l J r r z r l z l z l
(14)
La metodología de OR asume que el parámetro incierto tiene un valor nominal ,lr y una variación
máxima permitida, ˆ ,lr expresada como una fracción del valor nominal. Adicionalmente, J define el
conjunto de departamentos que están sujetos a incertidumbre simultáneamente. En este trabajo nosotros
asumimos que J = L. Finalmente, apoyados en el trabajo de Bohle et al. (2010) realizamos la
reformulación robusta de las restricciones determinísticas (12) y (13), veamos:
l il l ll J l J i Is r z q
(15)
l il l ll J l J i Iu r z q
(16)
l il l li Is r z q
l J (17)
l il l li Iu r z q
l J (18)
ˆl lz q r l J (19)
, 0lz q l J (20)
Las restricciones robustas (17)-(18) pueden ser interpretadas como “desagregadas” de las restricciones
robustas “agregadas” (15) y (16) respectivamente. Esta acción generará una protección sobre las
restricciones (12)-(13), protección que está correlacionada con la protección determinada por las
restricciones agregadas (15)-(16), y para las cuales sólo una fracción del presupuesto de incertidumbre es
aplicada. Las variables iz y ijq son las variables duales resultantes de la aplicación del enfoque de OR.
3.3 Heurística constructiva
Esta subsección propone una heurística constructiva que prioriza la construcción de CLC sobre CCC en
un sistema desbalanceado y también evita resolver un subproblema de vendedor viajero en nuestro
CLAIO-2016
410

MPLEM, que sería necesario resolver si al MPLEM se le exigiera entregar soluciones del tipo CLC. La
heurística propuesta usa reglas de decisión intuitivas para determinar en qué departamento adicional va a
ser entrenado cada empleado polifuncional identificado por la solución del MPLEM robusto (ver
algoritmo 1 (A-CLC)). Bajo nuestro enfoque, en lugar de usar una sola CLC, una combinación de CLC y
CCC es explorada. La notación matemática usada en el algoritmo es presentada a continuación. (1)
Entradas: Sean R el conjunto de empleados polifuncionales y *
l la cantidad óptima de empleados
polifuncionales del departamento l (ambos resultados del MPLEM). Sea lCV el coeficiente de variación
de la demanda del departamento l, tal que /l l lCV . Donde l y
l son la media y la desviación
respectivamente. (2) Salidas: Sea ilkf igual a 1 si el empleado polifuncional i del departamento l es
entrenado para trabajar en el departamento k, de otra forma igual a 0; i R y , :l k L l k .
4 Resultados y discusión
Esta sección describe los experimentos realizados para evaluar el beneficio del encadenamiento en
diferentes escenarios de variabilidad en la demanda. La metodología propuesta fue aplicada sobre un caso
de estudio en una tienda de Mejoramiento del Hogar en Santiago de Chile. Todas las pruebas comparten
las siguientes dos características: (1) Bajo el enfoque de OR, es el nivel de variabilidad de la demanda,
tal que 0 1. Luego, la máxima variación permitida es expresada como ˆ 2 ,l lr tal que ,l lr
.l L (2) Se consideran solo empleados full-time que trabajan 45 horas semanales.
Se consideran 6 niveles de variabilidad, tal que 5%, 10%, 20%, 30%, 40%, y 50%. Por otra
parte, el valor de fue normalizado para variar de 0 a 1 en pasos de 0.1, lo cual genera 11 instancias del
problema. Cada una de estas instancias fue resuelta para los 6 niveles de variabilidad de la demanda,
resultando en 66 soluciones robustas. Adicionalmente, el caso de estudio considera una tienda que cuenta
con 6 departamentos y 30 empleados. Sea ln la dotación semanal en horas del departamento ,l .l L
Para el departamento 1 (D1), los parámetros son 1 1 315n r (i.e., siete empleados), mientras que para el
Algoritmo 1: Rutina que prioriza la construcción de cadenas largas cerradas (A-CLC)
Fase 1: Inicialización: Ingresar información del algoritmo: *, , ,l l lCV l L
Fase 2: Generación de cadenas cerradas Paso 1: Tomar los empleados polifuncionales de cada departamento de la tienda y formar una colección
S de subconjuntos. Cada conjunto s S debe satisfacer las siguientes reglas:
a. Contener la mayor cantidad posible de empleados polifuncionales. Pero no puede contener
más de un empleado polifuncional del mismo departamento.
b. *.ls S l LS
Garantiza que el conjunto de CLC construidas usen todo el
personal polifuncional requerido por la solución del MPLEM robusto.
Paso 2: Construir una CLC con cada conjunto .s S Se deben satisfacer las siguientes políticas simples.
a. Para cada CLC crear arcos de entrenamiento ( )ilkf entre los departamentos con mayor
.CV Si se asume que l kCV CV , : ,l k L l k en la CLC crear arcos de
entrenamiento ( )ilkf entre los departamentos con mayor .
b. En la medida de lo posible evitar entrenar más de un empleado de un departamento dado en
el mismo departamento adicional, i.e., evitar ilk jlhf f , , :i j R i j y , , : .l k h L k h
Fase 3: Término
Paso 3: Retornar cantidad de cadenas generadas y ,ilkf i R y , : .l k L l k
CLAIO-2016
411
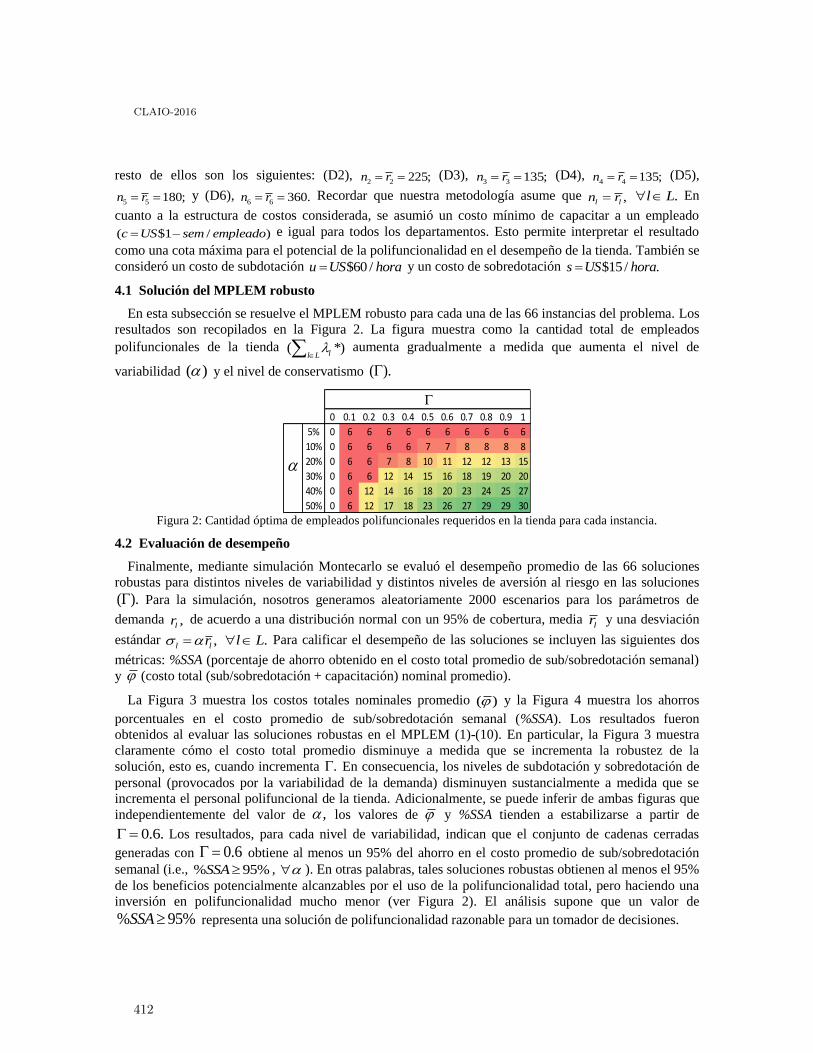
resto de ellos son los siguientes: (D2), 2 2 225;n r (D3),
3 3 135;n r (D4), 4 4 135;n r (D5),
5 5 180;n r y (D6), 6 6 360.n r Recordar que nuestra metodología asume que ,l ln r .l L En
cuanto a la estructura de costos considerada, se asumió un costo mínimo de capacitar a un empleado
( $1 / )c US sem empleado e igual para todos los departamentos. Esto permite interpretar el resultado
como una cota máxima para el potencial de la polifuncionalidad en el desempeño de la tienda. También se
consideró un costo de subdotación $60 /u US hora y un costo de sobredotación $15 / .s US hora
4.1 Solución del MPLEM robusto
En esta subsección se resuelve el MPLEM robusto para cada una de las 66 instancias del problema. Los
resultados son recopilados en la Figura 2. La figura muestra como la cantidad total de empleados
polifuncionales de la tienda ( *)ll L
aumenta gradualmente a medida que aumenta el nivel de
variabilidad ( ) y el nivel de conservatismo ( ).
Figura 2: Cantidad óptima de empleados polifuncionales requeridos en la tienda para cada instancia.
4.2 Evaluación de desempeño
Finalmente, mediante simulación Montecarlo se evaluó el desempeño promedio de las 66 soluciones
robustas para distintos niveles de variabilidad y distintos niveles de aversión al riesgo en las soluciones
( ). Para la simulación, nosotros generamos aleatoriamente 2000 escenarios para los parámetros de
demanda ,lr de acuerdo a una distribución normal con un 95% de cobertura, media lr y una desviación
estándar ,l lr .l L Para calificar el desempeño de las soluciones se incluyen las siguientes dos
métricas: %SSA (porcentaje de ahorro obtenido en el costo total promedio de sub/sobredotación semanal)
y (costo total (sub/sobredotación + capacitación) nominal promedio).
La Figura 3 muestra los costos totales nominales promedio ( ) y la Figura 4 muestra los ahorros
porcentuales en el costo promedio de sub/sobredotación semanal (%SSA). Los resultados fueron
obtenidos al evaluar las soluciones robustas en el MPLEM (1)-(10). En particular, la Figura 3 muestra
claramente cómo el costo total promedio disminuye a medida que se incrementa la robustez de la
solución, esto es, cuando incrementa . En consecuencia, los niveles de subdotación y sobredotación de
personal (provocados por la variabilidad de la demanda) disminuyen sustancialmente a medida que se
incrementa el personal polifuncional de la tienda. Adicionalmente, se puede inferir de ambas figuras que
independientemente del valor de , los valores de y %SSA tienden a estabilizarse a partir de
0.6. Los resultados, para cada nivel de variabilidad, indican que el conjunto de cadenas cerradas
generadas con 0.6 obtiene al menos un 95% del ahorro en el costo promedio de sub/sobredotación
semanal (i.e., % 95%SSA , ). En otras palabras, tales soluciones robustas obtienen al menos el 95%
de los beneficios potencialmente alcanzables por el uso de la polifuncionalidad total, pero haciendo una
inversión en polifuncionalidad mucho menor (ver Figura 2). El análisis supone que un valor de
% 95%SSA representa una solución de polifuncionalidad razonable para un tomador de decisiones.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
5% 0 6 6 6 6 6 6 6 6 6 6
10% 0 6 6 6 6 7 7 8 8 8 8
20% 0 6 6 7 8 10 11 12 12 13 15
30% 0 6 6 12 14 15 16 18 19 20 20
40% 0 6 12 14 16 18 20 23 24 25 27
50% 0 6 12 17 18 23 26 27 29 29 30
CLAIO-2016
412
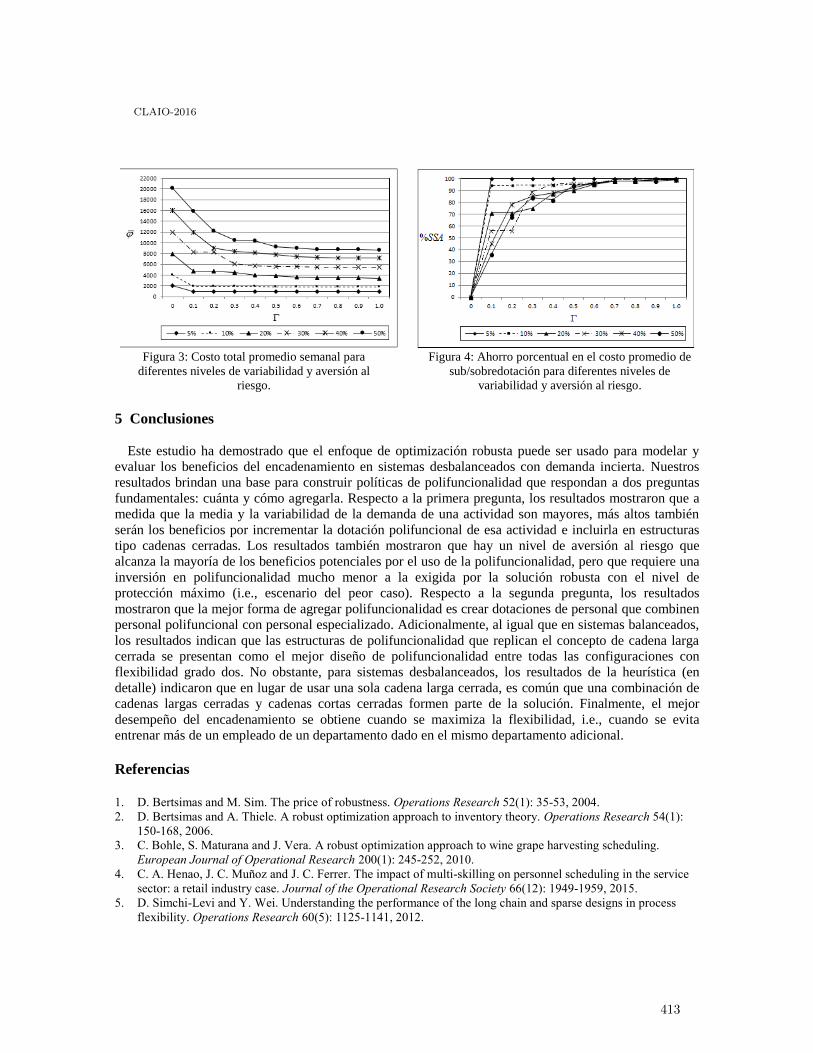
Figura 3: Costo total promedio semanal para
diferentes niveles de variabilidad y aversión al
riesgo.
Figura 4: Ahorro porcentual en el costo promedio de
sub/sobredotación para diferentes niveles de
variabilidad y aversión al riesgo.
5 Conclusiones
Este estudio ha demostrado que el enfoque de optimización robusta puede ser usado para modelar y
evaluar los beneficios del encadenamiento en sistemas desbalanceados con demanda incierta. Nuestros
resultados brindan una base para construir políticas de polifuncionalidad que respondan a dos preguntas
fundamentales: cuánta y cómo agregarla. Respecto a la primera pregunta, los resultados mostraron que a
medida que la media y la variabilidad de la demanda de una actividad son mayores, más altos también
serán los beneficios por incrementar la dotación polifuncional de esa actividad e incluirla en estructuras
tipo cadenas cerradas. Los resultados también mostraron que hay un nivel de aversión al riesgo que
alcanza la mayoría de los beneficios potenciales por el uso de la polifuncionalidad, pero que requiere una
inversión en polifuncionalidad mucho menor a la exigida por la solución robusta con el nivel de
protección máximo (i.e., escenario del peor caso). Respecto a la segunda pregunta, los resultados
mostraron que la mejor forma de agregar polifuncionalidad es crear dotaciones de personal que combinen
personal polifuncional con personal especializado. Adicionalmente, al igual que en sistemas balanceados,
los resultados indican que las estructuras de polifuncionalidad que replican el concepto de cadena larga
cerrada se presentan como el mejor diseño de polifuncionalidad entre todas las configuraciones con
flexibilidad grado dos. No obstante, para sistemas desbalanceados, los resultados de la heurística (en
detalle) indicaron que en lugar de usar una sola cadena larga cerrada, es común que una combinación de
cadenas largas cerradas y cadenas cortas cerradas formen parte de la solución. Finalmente, el mejor
desempeño del encadenamiento se obtiene cuando se maximiza la flexibilidad, i.e., cuando se evita
entrenar más de un empleado de un departamento dado en el mismo departamento adicional.
Referencias
1. D. Bertsimas and M. Sim. The price of robustness. Operations Research 52(1): 35-53, 2004.
2. D. Bertsimas and A. Thiele. A robust optimization approach to inventory theory. Operations Research 54(1):
150-168, 2006.
3. C. Bohle, S. Maturana and J. Vera. A robust optimization approach to wine grape harvesting scheduling.
European Journal of Operational Research 200(1): 245-252, 2010.
4. C. A. Henao, J. C. Muñoz and J. C. Ferrer. The impact of multi-skilling on personnel scheduling in the service
sector: a retail industry case. Journal of the Operational Research Society 66(12): 1949-1959, 2015.
5. D. Simchi-Levi and Y. Wei. Understanding the performance of the long chain and sparse designs in process
flexibility. Operations Research 60(5): 1125-1141, 2012.
CLAIO-2016
413

Beneficios de la Polifuncionalidad con Cadenas Cerradas en
Sistemas Desbalanceados: Caso de Estudio en la Industria del Retail
César Augusto Henao
Departamento de Ingeniería Industrial, Universidad del Norte
Departamento de Ingeniería de Transporte y Logística, Pontificia Universidad Católica de Chile
Juan Carlos Muñoz
Departamento de Ingeniería de Transporte y Logística, Pontificia Universidad Católica de Chile
Juan Carlos Ferrer
Departamento de Ingeniería Industrial y de Sistemas, Pontificia Universidad Católica de Chile
Resumen
Este trabajo presenta una nueva metodología para estructurar las habilidades polifuncionales de un
conjunto de empleados que inicialmente sólo cuentan con una función especialista. Asumiendo una
demanda estocástica y una modelación continua de la fuerza laboral, la metodología descompone el
problema de polifuncionalidad en tres etapas y lo resuelve de forma secuencial. La primera etapa entrega
una expresión analítica simple para estimar la dotación de empleados polifuncionales requerida en cada
actividad del sistema. La segunda etapa aplica una heurística constructiva a estas estimaciones para
generar un conjunto factible de cadenas cerradas para el sistema. La tercera etapa usa simulación
Montecarlo y un modelo de programación lineal para evaluar el desempeño de las cadenas cerradas
generadas. Como resultado se obtienen estructuras de polifuncionalidad tipo cadenas cerradas que son
robustas ante la variabilidad de la demanda, minimizan el costo total esperado de subdotación, y exhiben
el mejor desempeño a nivel costo-efectivo. La metodología también entrega a los tomadores de decisiones
políticas de polifuncionalidad que responden a tres preguntas fundamentales sobre la polifuncionalidad en
sistemas desbalanceados: dónde, cuánta, y cómo agregarla.
Palabras claves: Planificación de Recursos Humanos; Polifuncionalidad; Encadenamiento.
1 Introducción
El sector servicios es reconocido por su rápido crecimiento, ser una industria altamente competitiva, y
el uso intensivo de personal. El sector incluye industrias tales como el retail, salud, transporte, y centros
de llamadas. En un contexto dinámico, el sector servicios, y en particular la industria de retail, enfrentan
problemas de sobredotación y subdotación de personal en varios momentos durante el curso de una
semana, y en el último caso el descalce generado puede propagarse a periodos sucesivos (Henao et al.,
2015). Muchos autores en diferentes sectores han encontrado que el personal polifuncional tiende a
mejorar la flexibilidad, ya que brinda la capacidad de minimizar tal descalce (e.g., Deng, 2013). Sin
embargo, la polifuncionalidad viene con un costo, pues contratar y entrenar empleados en múltiples
actividades puede ser muy costoso. Por lo tanto, llega a ser importante establecer políticas claras que
permitan identificar diseños eficientes de polifuncionalidad a un costo reducido.
CLAIO-2016
414

Tales políticas deben responder tres preguntas fundamentales: dónde agregar la polifuncionalidad,
cuánta agregar, y cómo agregarla. Muchos autores en distintos sectores han coincidido en concluir que los
empleados con dos habilidades aparecen como la fuerza laboral más costo-efectiva (e.g., Henao et al.,
2015). Esta política de flexibilidad es conocida como flexibilidad grado 2. Apoyados en esta política,
varios investigadores han estudiado una estrategia de polifuncionalidad conocida como encadenamiento
(e.g., Jordan y Graves, 1995; Simchi-Levi y Wei, 2012, Deng, 2013). El encadenamiento, concepto
introducido por Jordan y Graves (1995), propone que algunos empleados sean entrenados para trabajar en
una segunda actividad, tal que el conjunto de entrenamientos adicionales requeridos por estos empleados
polifuncionales formarán cadenas en un grafo bipartito.
En un contexto de manufactura, Simchi-Levi y Wei (2012) muestran analíticamente para un sistema
balanceado (i.e., donde el número de nodos de oferta (plantas) es igual al número de nodos de demanda
(productos)) y con demandas estocásticas e independientes, que una Cadena Larga Cerrada (CLC) que
conecte todos los nodos de oferta y demanda del sistema, son el diseño óptimo entre todas las
configuraciones con flexibilidad grado 2. También muestran que varias Cadenas Cortas Cerradas (CCC),
donde cada CCC conecta un número sustancial de nodos de oferta y demanda, se desempeñan tan bien
como la CLC. Adaptando este análisis a un contexto de polifuncionalidad laboral, las plantas
corresponden a empleados y los productos corresponden a actividades. Sin embargo, el problema de
asignación de empleados en el sector servicios es inherentemente desbalanceado. Ya que el número de
empleados excede significativamente el número de actividades, el desbalance surge.
Para aplicar estructuras de polifuncionalidad tipo cadenas cerradas en sistemas desbalanceados nosotros
proponemos el siguiente enfoque. Primero, la mano de obra debe ser dividida en dos grupos; un grupo se
mantendrá especializado (i.e., tienen una sola habilidad), mientras el otro grupo será entrenado para ser
polifuncional (i.e., entrenados en una segunda habilidad). Segundo, los empleados polifuncionales son
vinculados a estructuras tipo cadenas cerradas. Por lo tanto, en el análisis de sistemas desbalanceados en
la industria de servicios surgen dos preguntas: (i) ¿Cuántos empleados en cada actividad deben ser
polifuncionales? (ii) ¿Cómo deben ser organizados los empleados polifuncionales dentro las cadenas
cerradas? La Figura 1(a-c) ilustra tres ejemplos de estructuras de polifuncionalidad tipo cadenas cerradas
en sistemas desbalanceados: (a) una cadena larga cerrada (1CL), un empleado polifuncional por actividad formando una CLC; (b) doble cadena larga cerrada (2CL), dos empleados polifuncionales por
actividad formando dos CLC (en este caso son idénticas); y (c) cadenas cerradas mixtas (CCM), en la que
hay una combinación de una CLC y una CCC. Una línea sólida en la figura representa el entrenamiento
primario de empleados mientras que una línea punteada representa una habilidad adicional.
Figura 1: Ejemplos de estructuras de encadenamiento en sistemas desbalanceados: (a) 1CL, (b) 2CL, (c) CCM.
Este trabajo propone una simple y novedosa metodología para modelar los beneficios del
encadenamiento en sistemas desbalanceados y definir políticas de polifuncionalidad. Finalmente, este
trabajo aplica esta metodología a un caso de estudio en una firma de retail chilena.
CLAIO-2016
415

2 Descripción del problema
El problema que nosotros proponemos estudiar consiste en desarrollar una solución secuencial, rápida,
y eficiente para un problema ampliamente estudiado en la literatura: capacitación y asignación de
personal polifuncional. Para un horizonte de planificación semanal, el problema consiste en asignar horas
de trabajo a cada empleado y diseñar un plan de capacitación asociado a una fuerza laboral conocida y
que inicialmente está capacitada para trabajar en una sola actividad. Sin pérdida de generalidad, la
modelación asumirá el contexto de una tienda de retail en el cual los empleados pueden ser entrenados
para trabajar en un segundo departamento (actividad) convirtiéndose en polifuncionales. Nuestra
formulación del problema refleja los siguientes supuestos: (1) La demanda semanal por departamento
tiene una distribución de probabilidad conocida y se asume correlación cero entre las demandas por
departamento. (2) Los costos de subdotación y de capacitación son iguales por departamento. (3) El
problema de asignación de personal es totalmente equilibrado, es decir, las horas disponibles para ser
asignadas en cada departamento son exactamente igual al valor en horas de la demanda media de cada
departamento. (4) No hay ausentismo de personal. (5) Todos los empleados tienen igual contrato y por lo
tanto trabajan igual cantidad de horas semanales. (6) Inicialmente todos los empleados son especialistas.
(7) La mano de obra es homogénea, es decir, la productividad individual de los empleados es la misma.
Finalmente, (8) Empleados polifuncionales sólo pueden trabajar en un total de dos departamentos.
3 Metodología
3.1 Etapa 1: Expresión analítica para el uso de la polifuncionalidad
Esta primera etapa responde a las primeras dos preguntas fundamentales sobre la polifuncionalidad:
¿Dónde? y ¿Cuánto? Aquí se propone realizar un análisis aislado por departamento para estimar la
dotación óptima de empleados polifuncionales. Este análisis asume que todos los departamentos de la
tienda son exactamente iguales al departamento bajo análisis. Es decir, todos los departamentos tienen la
misma dotación, idéntica f.d.p de la demanda, e iguales costos de capacitación y subdotación. Aún más,
se asume que la tienda cuenta con sólo dos departamentos idénticos. De esta forma, la modelación
considera una estructura de polifuncionalidad simple tipo cadena recíproca. Es decir, en una cadena
conformada por sólo dos departamentos, el departamento bajo análisis tiene asociado un departamento
espejo idéntico. El departamento espejo es el único que puede transferirle empleados polifuncionales en
escenarios de subdotación al departamento bajo análisis, y viceversa. Luego, mediante un análisis
continuo, se desarrolla una ecuación cerrada para hallar el valor óptimo en horas hombre polifuncionales
que minimice una función de costo total esperado. A continuación se presenta la notación matemática
usada en la modelación del problema.
Variables aleatorias:
,l eD D Demanda semanal en el departamento l y en el departamento espejo e; [Horas-sem]
ls Subdotación semanal en el departamento l; [Horas-sem]
Parámetros:
,l en n Dotación total semanal en el departamento l y en el departamento espejo e; [Horas-sem]
,d cc c Costo de subdotación y costo de entrenamiento por hora respectivamente; [$/Hora]
h Cantidad de horas semanales que debe trabajar un empleado; [Horas-sem / Empleado]
Resultados:
CLAIO-2016
416

:n Horas polifuncionales del departamento espejo capacitadas para trabajar en el departamento
bajo análisis; [Horas-sem]
( )lDf d , ( )
lDF d Función de densidad y función acumulada de la demanda del departamento l
( ) ( )ls nf x Función de densidad de la subdotación del departamento l, dado que el departamento espejo
tiene n horas-sem polifuncionales, 0, 0n x
( )lE s n Subdotación esperada en el departamento l, dado que el departamento espejo tiene n horas-sem
polifuncionales, 0;n [Horas-sem]
Dado 0,n el costo total esperado semanal del departamento l, que representa la suma del costo de
subdotación esperado y el costo de capacitación incurrido, se expresa de la siguiente forma:
( )0
( ) ( ) ( )l
d c d c
l l s nx
CTP n c E s n c n c f x xdx c n
(1)
De la ecuación (1) podemos ver que para calcular el valor óptimo de ,n necesitamos modelar primero
( ) ( ).ls nf x Paul y MacDonald (2014) explican que para una estructura de polifuncionalidad tipo cadena
recíproca, denotando dos departamentos como l y e, la probabilidad de que ocurra una subdotación
alrededor de x en el departamento l puede ser calculada como la suma de dos efectos: un efecto base (i.e.,
cuando el departamento espejo no puede prestar empleados polifuncionales) y un efecto directo (i.e.,
cuando el departamento espejo puede prestar empleados polifuncionales). Por lo tanto, dado que ambos
departamentos son idénticos (i.e., l en n n y l eD D D ), se puede calcular ( ) ( )s nf x como:
( )0
( ) ( )[1 ( )] ( ) ( ) ( ) ( )n
s n D D D D D Dy
Efecto baseEfecto directo
f x f n x F n f n y x f n y dy f n n x F n n
(2)
La expresión (2) es válida independiente de la f.d.p que se asuma para las demandas. Reemplazando (2)
en (1) se obtiene finalmente la expresión del costo total esperado semanal. Además, al resolver ( )
0CTP n
n
se puede encontrar el valor óptimo de n que minimiza la función de costo total esperado.
Luego, el modelo se resume en hallar una cantidad *n que satisfaga:
( *)c
D d
cF n n
c
1*c
dcn n
c
; . ; 0c d dt q c c c (3)
La ecuación (3) se obtiene al suponer que las f.d.p de las demandas por departamento distribuyen 2( , )N y que la media de la demanda es exactamente igual a la dotación del departamento (i.e.,
n ). Donde 1() representa la función de distribución acumulada inversa. Finalmente, dado que
asumimos que todos los empleados tienen el mismo tipo de contrato, la cantidad óptima de empleados
polifuncionales requeridos por departamento ( *)m puede ser calculado de forma aproximada por la razón
*/ .n h Sin embargo, */n h será la mayoría de las veces un valor continuo, pues *n es obtenido bajo
un análisis continuo. Luego, dado que la función del costo total esperado es cóncava hacia arriba, *m
será igual a uno de estos dos valores enteros *n
h
ó *n
h
. Se selecciona el de menor costo esperado.
CLAIO-2016
417

3.2 Etapa 2: Generación del conjunto atractivo de cadenas cerradas
Esta segunda etapa usa como input la dotación óptima de empleados polifuncionales hallada en la etapa
uno y responde la tercera pregunta fundamental sobre la polifuncionalidad: ¿Cómo agregarla? El enfoque
de solución en esta etapa propone realizar un análisis conjunto de la tienda para determinar el conjunto
atractivo de cadenas cerradas que lograría el mejor desempeño del sistema. A diferencia de la etapa uno,
acá se considera que la tienda está conformada por distintos departamentos, cada uno de los cuales puede
tener una dotación de personal diferente y una f.d.p de la demanda distinta.
Bajo nuestro enfoque, en lugar de usar una sola CLC, una combinación de CLC y CCC es explorada.
Usando reglas de decisión intuitivas, proponemos una heurística para generar la mínima cantidad de
cadenas cerradas en un sistema desbalanceado (ver algoritmo 1 (A-CLC)). La notación matemática usada
en el algoritmo es presentada a continuación. (1) Entradas: Sea L el conjunto de departamentos de la
tienda. Sean R el conjunto de empleados polifuncionales y *
lm la cantidad óptima de empleados
polifuncionales del departamento l (ambos resultados de la Etapa 1). Sea lCV el coeficiente de variación
de la demanda del departamento l, tal que /l l lCV . Donde l y l son la media y la desviación
respectivamente. (2) Salidas: Sea ilkf igual a 1 si el empleado polifuncional i del departamento l es
entrenado para trabajar en el departamento k, de otra forma igual a 0; i R y , :l k L l k .
Finalmente, el desempeño de las cadenas generadas a través del Algoritmo 1 es comparado con dos
estructuras de polifuncionalidad que representan soluciones extremas: (a) Cero polifuncionalidad (CP), es
decir, todos los empleados de la tienda son especializados; y (b) Polifuncionalidad total (PT), es decir,
cada empleado de la tienda está capacitado para trabajar en cualquier departamento de la tienda.
3.3 Etapa 3: Evaluación del desempeño y selección de las mejores estructuras de polifuncionalidad
Esta etapa de la metodología usa como input las estructuras de polifuncionalidad generadas en la etapa
dos, y posteriormente, mediante el uso de simulación Montecarlo y un Modelo de Programación Lineal
Algoritmo 1: Rutina que prioriza la construcción de cadenas largas cerradas (A-CLC)
Fase 1: Inicialización: Ingresar información del algoritmo: *, , ,l l lm CV l L
Fase 2: Generación de cadenas cerradas Paso 1: Tomar los empleados polifuncionales de cada departamento de la tienda y formar una colección
S de subconjuntos. Cada conjunto s S debe satisfacer las siguientes reglas:
a. Contener la mayor cantidad posible de empleados polifuncionales. Pero no puede contener
más de un empleado polifuncional del mismo departamento.
b. *.ls S l LS m
Garantiza que el conjunto de CLC construidas usen todo el
personal polifuncional requerido por la Etapa 1.
Paso 2: Construir una CLC con cada conjunto .s S Se deben satisfacer las siguientes políticas simples.
a. Para cada CLC crear arcos de entrenamiento ( )ilkf entre los departamentos con mayor
.CV Si se asume que l kCV CV , : ,l k L l k en la CLC crear arcos de
entrenamiento ( )ilkf entre los departamentos con mayor .
b. En la medida de lo posible evitar entrenar más de un empleado de un departamento dado en
el mismo departamento adicional, i.e., evitar ilk jlhf f , , :i j R i j y , , : .l k h L k h
Fase 3: Término
Paso 3: Retornar cantidad de cadenas generadas y ,ilkf i R y , : .l k L l k
CLAIO-2016
418

(MPL) compara sus desempeños para identificar las mejores entre ellas. Sea P el conjunto de estructuras
de polifuncionalidad conformado por las siguientes tres estructuras: A-CLC, CP, y PT. Sea K el conjunto
de escenarios de la demanda, tal que k K es un arreglo que contiene exactamente una realización de la
demanda estocástica de cada departamento de la tienda, tal que .k L Sea ilkp una variable que
representa la cantidad de horas semanales asignadas a trabajar al empleado i en el departamento l , bajo el
escenario de la demanda ,k y estructura .p Sea lkp una variable que representa la subdotación en horas
semanales en el departamento ,l escenario de la demanda k , y estructura .p Sea kp una variable que
representa el costo total semanal de subdotación en el escenario de la demanda k y estructura .p El
MPL para un escenario k y estructura de polifuncionalidad p es formulado a continuación:
i
c
kp ilpi L l LMin c f
(4)
s.a.
ilkp lkp lk
i I
r
, ,l L k K p P (5)
ilkp
l L
h
, ,i I k K p P (6)
ilkp ilphf , , ,i I l L k K p P (7)
d
lkp kp
l L
c
,k K p P (8)
, , 0ilkp lkp kp , , ,i I l L k K p P (9)
La función objetivo (FO) (4) minimiza los costos semanales de subdotación y de capacitación de
empleados en habilidades adicionales. Notar que dado que la polifuncionalidad es un input en este
modelo, los costos de capacitación corresponden a un costo fijo.
4 Resultados y discusión
Esta sección describe los experimentos realizados para evaluar el beneficio del encadenamiento en
diferentes escenarios de prueba. La metodología propuesta fue aplicada sobre un caso de estudio en una
tienda de Mejoramiento del Hogar en la ciudad de Santiago de Chile. Todas las pruebas comparten las
siguientes dos características: (1) Se asume que las demandas distribuyen de acuerdo a una función 2( , ),l l lN .l L (2) Se consideran solo empleados full-time que trabajan 45 horas semanales.
4.1 ¿Dónde y cuánta polifuncionalidad agregar?
Se considera una tienda de retail que cuenta con 6 departamentos y 30 empleados. Para el departamento
1 (D1), los parámetros son 1 1 315n r (i.e., siete empleados), mientras que para el resto de ellos son los
siguientes: (D2), 2 2 225;n r (D3),
3 3 135;n r (D4), 4 4 135;n r (D5),
5 5 180;n r y (D6),
6 6 360.n r El caso de estudio evalúa 12 escenarios de prueba. Cada escenario corresponde a una
combinación distinta entre el coeficiente de variación de la demanda ( / ),l l lCV y el costo de
capacitación ( ).cc Fueron elegidos 6 valores representativos para el primero (5%, 10%, 20%, 30%, 40%,
50%) y 2 valores para el último (1, 30 $ /US sem Empleado ). También se asume que el costo de
subdotación es el mismo a través de todos los escenarios de prueba ( $60 / ).dc US hora La Figura 2(a-b)
muestra para cada cc y cada %CV la cantidad óptima de empleados polifuncionales requerida en cada
departamento de la tienda *( ).lm La figura indica que *m aumenta gradualmente a medida que aumenta
el %CV de la demanda y la dotación ( ),n pero disminuye ante aumentos en el costo de capacitación.
CLAIO-2016
419
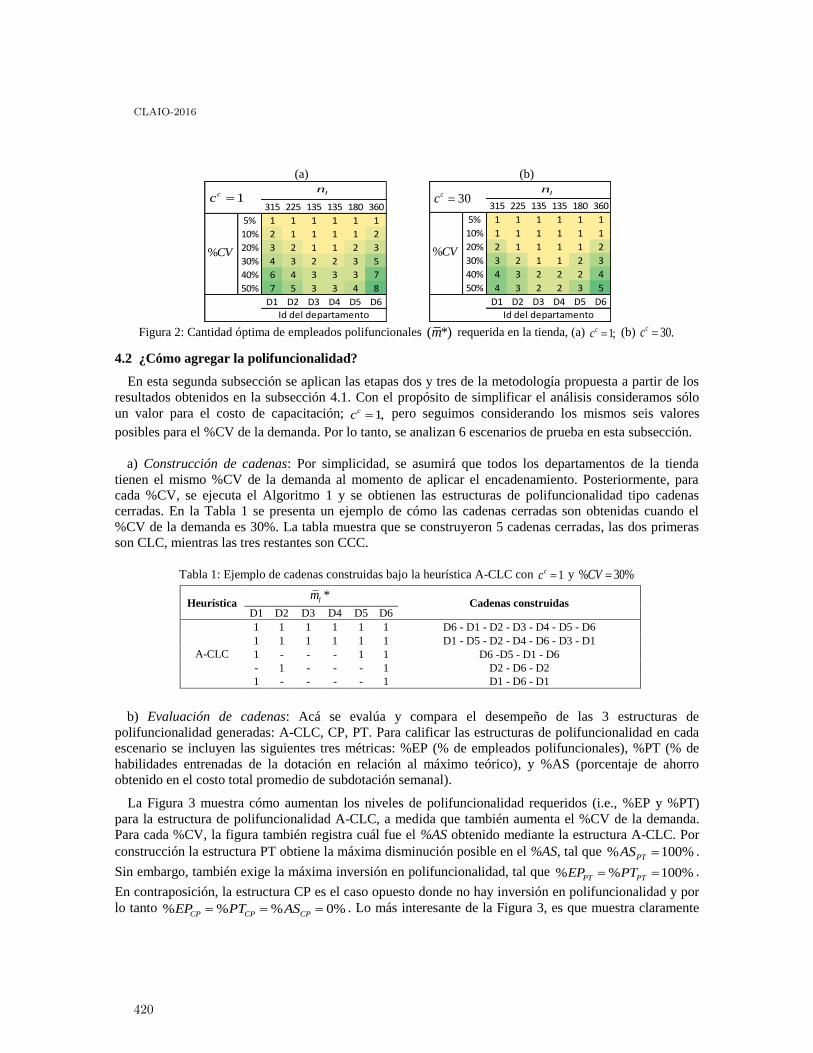
(a) (b)
Figura 2: Cantidad óptima de empleados polifuncionales ( *)m requerida en la tienda, (a) 1;cc (b) 30.cc
4.2 ¿Cómo agregar la polifuncionalidad?
En esta segunda subsección se aplican las etapas dos y tres de la metodología propuesta a partir de los
resultados obtenidos en la subsección 4.1. Con el propósito de simplificar el análisis consideramos sólo
un valor para el costo de capacitación; 1,cc pero seguimos considerando los mismos seis valores
posibles para el %CV de la demanda. Por lo tanto, se analizan 6 escenarios de prueba en esta subsección.
a) Construcción de cadenas: Por simplicidad, se asumirá que todos los departamentos de la tienda
tienen el mismo %CV de la demanda al momento de aplicar el encadenamiento. Posteriormente, para
cada %CV, se ejecuta el Algoritmo 1 y se obtienen las estructuras de polifuncionalidad tipo cadenas
cerradas. En la Tabla 1 se presenta un ejemplo de cómo las cadenas cerradas son obtenidas cuando el
%CV de la demanda es 30%. La tabla muestra que se construyeron 5 cadenas cerradas, las dos primeras
son CLC, mientras las tres restantes son CCC.
Tabla 1: Ejemplo de cadenas construidas bajo la heurística A-CLC con 1cc y % 30%CV
b) Evaluación de cadenas: Acá se evalúa y compara el desempeño de las 3 estructuras de
polifuncionalidad generadas: A-CLC, CP, PT. Para calificar las estructuras de polifuncionalidad en cada
escenario se incluyen las siguientes tres métricas: %EP (% de empleados polifuncionales), %PT (% de
habilidades entrenadas de la dotación en relación al máximo teórico), y %AS (porcentaje de ahorro
obtenido en el costo total promedio de subdotación semanal).
La Figura 3 muestra cómo aumentan los niveles de polifuncionalidad requeridos (i.e., %EP y %PT)
para la estructura de polifuncionalidad A-CLC, a medida que también aumenta el %CV de la demanda.
Para cada %CV, la figura también registra cuál fue el %AS obtenido mediante la estructura A-CLC. Por
construcción la estructura PT obtiene la máxima disminución posible en el %AS, tal que % 100%PTAS .
Sin embargo, también exige la máxima inversión en polifuncionalidad, tal que % % 100%PT PTEP PT .
En contraposición, la estructura CP es el caso opuesto donde no hay inversión en polifuncionalidad y por
lo tanto % % % 0%CP CP CPEP PT AS . Lo más interesante de la Figura 3, es que muestra claramente
315 225 135 135 180 360
5% 1 1 1 1 1 1
10% 2 1 1 1 1 2
20% 3 2 1 1 2 3
30% 4 3 2 2 3 5
40% 6 4 3 3 3 7
50% 7 5 3 3 4 8
D1 D2 D3 D4 D5 D6
Id del departamento
%CV
ln1cc
315 225 135 135 180 360
5% 1 1 1 1 1 1
10% 1 1 1 1 1 1
20% 2 1 1 1 1 2
30% 3 2 1 1 2 3
40% 4 3 2 2 2 4
50% 4 3 2 2 3 5
D1 D2 D3 D4 D5 D6
Id del departamento
%CV
ln30cc
Heurística *lm
Cadenas construidas D1 D2 D3 D4 D5 D6
A-CLC
1 1 1 1 1 1 D6 - D1 - D2 - D3 - D4 - D5 - D6
1 1 1 1 1 1 D1 - D5 - D2 - D4 - D6 - D3 - D1
1 - - - 1 1 D6 -D5 - D1 - D6
- 1 - - - 1 D2 - D6 - D2
1 - - - - 1 D1 - D6 - D1
CLAIO-2016
420

que aun cuando el costo de capacitación se asume mínimo, la estructura de polifuncionalidad A-CLC
obtiene casi el 100% de los beneficios pero haciendo una inversión en polifuncionalidad mucho menor.
Figura 3: Métricas de desempeño alcanzadas con la estructura A-CLC para cada %CV de la demanda. Caso 1cc
5 Conclusiones
Nuestros resultados brindan una base para el diseño de políticas de polifuncionalidad que sean
atractivas para las industrias del sector servicios. Dichas políticas van dirigidas a responder tres preguntas
fundamentales: Dónde, Cuánta, y Cómo agregar la polifuncionalidad. Respecto a la primera pregunta, los
resultados mostraron que a medida que la media y el coeficiente de variación de la demanda de una
actividad son mayores, más altos también serán los beneficios por incrementar la dotación polifuncional
de esa actividad e incluirla en estructuras de polifuncionalidad tipo cadenas cerradas. Para la segunda
pregunta, este trabajo entrega una expresión analítica para estimar la cantidad óptima de empleados
polifuncionales y especializados por actividad que minimice el costo total esperado. Los resultados
mostraron que aun cuando el costo de capacitación se asuma a un nivel mínimo, no es necesario tener una
configuración con polifuncionalidad total para alcanzar el máximo beneficio posible. Respecto a la tercera
y última pregunta, los resultados mostraron que la mejor forma de agregar polifuncionalidad es generando
estructuras de dotación de personal que combinen personal polifuncional con personal especializado.
Adicionalmente, al igual que en sistemas balanceados, los resultados indican que las estructuras de
polifuncionalidad que replican el concepto de cadena larga cerrada se presentan como el mejor diseño de
polifuncionalidad entre todas las configuraciones con flexibilidad grado dos. No obstante, para sistemas
desbalanceados, en lugar de usar una sola cadena larga cerrada, es común que una combinación de
cadenas largas cerradas y cadenas cortas cerradas formen parte de la solución. Finalmente, los mejores
rendimientos del encadenamiento se obtienen cuando se maximiza la flexibilidad.
Referencias
1. T. Deng. Process flexibility design in unbalanced and asymmetric networks. Doctoral dissertation, University of
California, Berkeley, 2013.
2. C. A. Henao, J. C. Muñoz and J. C. Ferrer. The impact of multi-skilling on personnel scheduling in the service
sector: a retail industry case. Journal of the Operational Research Society 66(12): 1949-1959, 2015.
3. W. C. Jordan and S. C. Graves. Principles on the benefits of manufacturing process flexibility. Management
Science 41(4): 577-594, 1995.
4. J. A. Paul and L. MacDonald. Modeling the benefits of cross-training to address the nursing shortage.
International Journal of Production Economics 150(1): 83-95, 2014.
5. D. Simchi-Levi and Y. Wei. Understanding the performance of the long chain and sparse designs in process
flexibility. Operations Research 60(5):1125-1141, 2012.
CLAIO-2016
421

Iterações Iniciais Eficientes no Método de Pontos Interiores
Manolo Rodriguez HerediaIMECC-UNICAMP
Aurelio Ribeiro L. OliveiraDMA, [email protected]
Resumo
A Abordagem Hı́brida (AH) consiste no cálculo da direção de busca do Método primal-dualde Pontos Interiores (MPI) via o Método dos Gradientes Conjugados Precondicionado (MGCP)em duas fases, nas iterações iniciais usa o precondicionador Fatoração Controlada de Cholesky(FCC) e depois de um critério de troca de fase o precondicionador Separador (PS) é usado. NoFCC os parâmetros que controlam o preenchimento e a correção das falhas que ocorrem nadiagonal são modificados para reduzir o número de reinı́cios da fatoração durante a construçãodeste precondicionador. Propõe-se uma modificação nos parâmetros do precondicionador FCCcom o objetivo de aprimorar a eficiência e robustez da AH. O cálculo dos novos parâmetros éfeito considerando a relação que existe entre as componentes da FCC obtida antes e depois dafalha na diagonal. Experimentos numéricos que resolveram problemas de programação linear degrande porte corroboraram que esta abordagem é competitiva.
Keywords: Métodos primal-dual de Pontos Interiores; Precondicionador; Fatoração Controladade Cholesky.
1 Introdução
As propriedades teóricas e computacionais do MPI, destacando entre estas a complexidade polinomial e o fatode não precisar um ponto inicial factı́vel consolidaram este método como uma ferramenta competitiva pararesolver problemas de Programação Linear (PL) de grande porte, veja [10]. O maior esforço computacionalconsiste no cálculo da direção de busca que é obtida de sistemas lineares. Estes sistemas, tornam-se malcondicionados nas últimas iterações do MPI pois a condição de complementariedade do PL é satisfeitaprogressivamente. Atualmente a direção de busca é obtida de dois sistemas: o sistema Aumentado e o Sistemade Equações Normais (SEN). Neste trabalho o SEN é resolvido usando a AH. As iterações iniciais usamo FCC proposto em [3] com sucesso, porém seu desempenho reduz à medida que o algoritmo do MPI seaproxima da solução ótima. Isto pode ser justificado pelo fato de que o número de condição do SEN semprecondicionamento é da ordem O(µ−2), onde µ denota o gap de dualidade do PL, veja [5]. Por outro lado,
CLAIO-2016
422

os autores do PS usam a condição de complemetariedade do problema de PL e o comportamento da matrizdiagonal no SEN para construir um precondicionador usado nas últimas iterações do MPI, veja [7].
O FCC está construı́do com base na Fatoração Incompleta de Cholesky (FIC). O preenchimento da matriz doFCC segue uma heurı́stica apresentada em [3], a qual permite que o precondicionador varie desde uma matrizdiagonal até uma matriz com igual ou maior número de elementos não nulos que a matriz contruı́da pelaFIC. Por outro lado, na FIC é possı́vel encontrar falhas na diagonal e em [6] foi provado que se uma matrizV é simétrica e definida positiva, existe uma constante α > 0 tal que uma FIC de V + αdiag(V ) existe. Adesvantagem é que não existe em [6] uma fórmula que permita calcular o valor de α. Na construção do FCCas falhas que ocorrem durante a fatoração são corrigidas com um incremento exponencial e o cálculo doselementos do precondicionador é reiniciado. Isto é uma desvantagem, pois aumenta o tempo do cálculo doprecondicionador, quer seja devido a reconstrução da FCC, quer seja a perda de qualidade dele, veja [2].
Baseado no trabalho de [1], existe o precondicionador FCCβ que evita reinı́cios, este é apresentado em [8].Os resultados obtidos pela FCCβ não são competitivos quando comparados com o FCC pois o tempo compu-tacional em alguns problemas é incrementado. De um modo geral, o uso das técnicas atuais para correção defalhas na diagonal tem a desvantagem de aumentar o tempo de precondicionamento e, consequentemente, otempo de resolução dos problemas.
Propõe-se uma modificação destes parâmetros com o objetivo de reduzir o número de reinı́cios da fatoraçãodurante a construção do FCC e, portanto, reduzir o tempo na primeira fase da AH. Usa-se a variação entrea quantidade de elementos não nulos da matriz do SEN e o número de elementos não nulos da matriz derestrições do problema de PL para calcular o parâmetro de preenchimento da FCC. Além disso, usa-seferramentas algébricas e geométricas para obter uma relação entre os elementos que ocasionaram a falha e asnovas componentes da matriz que evita a falha na diagonal. Logo, calcula-se um valor adequado de α parausá-lo no próximo reinı́cio.
2 Direção de busca no método de Pontos Interiores
Neste trabalho considera-se o par primal-dual do problema de PL canalizado,
(P){
min cTx s. a Ax = b, x+ s = u x, s ≥ 0}
e
(D){
max bT y − uTw s. a AT y − w + z = c w, z ≥ 0 y ∈ Rm} (1)
onde x, s, w ∈ Rn e A ∈ Rm×n que é considerada de posto completo. Nas condições de otimalidade de(P′)
{min cTx− µ∑n
i=1 log xi − µ∑n
i=1 log si s. a Ax = b, x+ s = u x, s > 0}
, aplica-se o métodode Newton para achar a direção de busca ∆X = (∆x,∆s,∆y,∆z,∆w)T numa iteração do MPI é. Oproblema (P′) é obtido aplicando a penalidade barreira logarı́tmica nas restrições de não negatividade de (P ).Assim, se rb = b− Ax, ru = u− x− s, rc = c+ w − z − AT y, r1 = µe−XZe, r2 = µe− SWe comeT = (1, . . . , 1) ∈ Rn, a direção de busca obtem-se de (2)
AΘAT∆y = h+ADr, (2)
onde Θ−1 = X−1Z + S−1W , r = rc − X−1(µe − XZe) + S−1(µe − SWe) − S−1Wru, h = rbe X = diag(x1, . . . , xn), Z = diag(z1, . . . , zn), S = diag(s1, . . . , sn), W = diag(w1, . . . , wn) sãomatrizes diagonais. O sistema (2) é conhecido como SEN, a matriz deste sistema é simétrica e positiva
CLAIO-2016
423

definida de tamanho m. As outras componentes do vetor da direção de busca são obtidas recursivamente apartir de ∆y. O sistema (2) será resolvido usando a AH.
3 O precondicionador Fatoração Controlada de Cholesky
Considere a matrizAΘAT de (2), suponha que L e L̃ sejam as matrizes triangulares da fatoração de Choleskye FCI de AΘAT respectivamente, isto é, LLT = AΘAT = L̃L̃T +R, onde R é a matriz resı́duo. Define-sea matriz E = L− L̃; logo, L̃−1
(AΘAT
)L̃−T = (I + L̃−1E)(I + L̃−1E)T , observe que se L̃ ≈ L então
E ≈ 0 e, portanto L̃−1(AΘAT
)L̃−T ≈ Im. O FCC é baseado nesta ideia, na minimização da norma de
Frobenius da matrizE, para isto é considerado o problema de minimizar∑m
j=1 cj , onde cj =∑m
i=1 |lij− l̃ij |2,reescrevendo este problema, tem-se:
minm∑
j=1
mj+η∑
k=1
|likj − l̃ikj |2 +m∑
k=mj+η+1
|likj |2 , (3)
onde mj é o número de componentes não nulas abaixo da diagonal da j-ésima coluna da matriz AΘAT e ηrepresenta o número de componentes extras permitidas por coluna. Na iteração inicial, o número de entradasnão nulas permitidas é fixado da seguinte maneira: (a) η0 = nnz(AΘAT )/m, se nnz(AΘAT ) < 10m;(b) η0 = −nnz(AΘAT )/m, caso contrário. À medida que o número de iterações do MGCP é incrementado,o valor de η é aumentado. Se o número de iterações supera m/5, o valor de η é acrescido de 10. Quandoη > ηmax = 10 é feita a mudança na Abordagem Hı́brida, veja [9]. Por outro lado, na construção da matrizdo FCC é possı́vel encontrar falhas na diagonal, estas falhas são corrigidas com um incremento exponencial.O valor do incremento é αt = 5 ·10−4 ·2t−1, onde t = 1, . . . , 15 representa o número de reinı́cios permitidosno FCC, veja [2].
4 O Precondicionador Separador
A construção do PS está baseada na condição de complementariedade de um problema de PL, neste caso:xizi = 0 e siwi = 0 para todo i = 1, . . . , n. Observe que as componentes da matriz diagonal Θ que apareceem (2) são dadas por θi =
(zix−1i + wis
−1i
)−1, isto implica que em cada iteração do MPI a matriz Θ sealtera, particularmente, próximo à solução ótima, pela não negatividade das variáveis, existirão ı́ndicesj ∈ {1, . . . n} tais que θj → 0 ou θj → ∞. Esta caracterı́stica é justificativa do sucesso dele nas últimasiterações do MPI.
5 Novas Propostas
Encontra-se o parâmetro de correção de falhas, denotado por α, por meio de outro problema cuja soluçã éuma aproximação de α. Este novo problema surge da idea geométrica que envolve uma falha na diagonal,veja Figura 5.1. Assim, procura-se evitar reinı́cios na mesma coluna e atingir o valor de α tal que a FIC deAΘAT exista, veja 5.1.
CLAIO-2016
424

Por outro lado, dado que é possı́vel modificar o preenchimento no FCC, procura-se não trabalhar com umamatriz diagonal nas primeiras iterações como faz o atual FCC. Para tanto, calcula-se a variação do número deelementos da matriz A do problema do PL e a matriz AΘAT do SEN. Este cociente permite estabelecer se amatriz se a matriz AΘAT é densa comparada com a matriz A, veja 5.2
5.1 Parâmetro de correção de falhas
Doravante, denota-se por A à matriz AΘAT , isto é, A é simétrica, definida positiva de ordem m e escalada;isto é, aij = 1, se i = j e aij ≤ 1, quando i 6= j, onde j = 1, . . . ,m. Na construção do FCC, diz-se queexiste uma falha na diagonal quando dj < tol para algum j = 1, . . . ,m e tol = 10−8. A proposta para ocálculo do novo incremento está baseada na fatoração LDLT , neste caso, se A = A + αI , procuram-seas matrizes L, D, L e D tal que A = LDLT e A = L D L
T . Usando as componetes destas matrizestriangulares e diagonais obtem-se:
dj = dj + α+
j−1∑
k=1
(dk`
2jk − dk`
2jk
);
`ij = `ijdj
dj+
1
dj
j−1∑
k=1
(`ikdk`jk − `ikdk`jk
),
(4)
para j = 1, . . .m e i = j + 1, . . . ,m. Se existe uma falha na coluna j; isto é, dj < tol, baseados nasequações em (4) propõe-se um resultado dado na Proposição 5.1 e a partir dele é feita a construção dos novosparâmetros para a correção de falhas.Proposição 5.1. Quando dj < tol, a função Ft : R −→ R, dada por α 7−→ ∑t−1
k=1 dk`2tk é decrescente,
onde t = 2, . . . , j e Ft(0) =∑t−1
k=1 dk`2tk. Além disso, para cada α ≥ tol − dj se satisfaz dj > tol e se
0 < dj < tol, para cada α ≥ tol se satisfaz dj > tol.
Como consequência de proposição acima, um incremento αt = tol − dj poderia ser usado para construiro FCC. No entanto, procura-se que o incremento αt seja próximo de zero para que A ≈ A, observeque nada garante que tol − dj seja um número pequeno. Por outro lado, quando dj < tol, deve-seresolver: (Pα){minα s. a
∑j−1k=1 dk`
2jk ≤ ajj + α − tol ; α > 0}, pois é procurado que A ≈ A.
Esta idea é consequênça da equação (4) e de que para cada α > 0 se satisfaz dj > tol se, e somente se,∑j−1k=1 dk`
2jk ≤ ajj + α − tol. Observe que neste caso, os valores dk nem `jk não são conhecidos, para
k = 1, . . . , j−1. Em vez de resolver (Pα), procura-se uma função que seja equivalente a∑j−1
k=1 dk`2jk quando
α se aproxima de zero1. Para tanto, consideram-se as funções f, g : R→ R dadas por α 7→∑j−1k=1
(dk`jk)2
dk+αe
α 7→∑j−1k=1
αdk+α
dk`2jk, respectivamente. Usa-se f e g, pois (f + g)(α) =
∑j−1k=1 dk`
2tk e pela Proposição
5.1, tem-se∑j−1
k=1 dk`2jk ≤ (f + g)(α). Dado que f(α) ∼ ∑j−1
k=1 dk`2jk quando α se aproxima de zero,
procura-se a solução de (Pα) {minα s. a f(α) ≤ ajj − tol ; α > 0}, para obter uma aproximação dasolução de (Pα). Apresenta-se uma interpretação geométrica quando j = 3 na Figura 5.1. Como f é uma
1As funções f(x) e g(x) são equivalentes, isto é denotado por f ∼ g, quando x se aproxima de a se
limx−→a
f(x)
g(x)= 1 .
CLAIO-2016
425

função decrescente α é solução de (Pα) se, e somente se, f(α) = ajj − tol. Usa-se o método de Newtonpara calcular numericamente este valor.
x1
x2
y
Q
Pb
b
b
b
P
Q
Figura 1: Hiperparaboloide y = a33 + α − (x21 + x22).Denota-se por P , Q, P e Q os pontos (d1/21 `31, d
1/22 `32, 0),
(d1/21 `31, d
1/22 `32, d3), (d
1/2
1 `31, d1/2
2 `32, 0) e (d1/2
1 `31, d1/2
2 `32, d3), respectivamente. Procura-se que o ponto Ppertença ao conjunto
{x ∈ R2 × {0} | x21 + x22 < a33 − tol
}para que d3 > tol. Para tanto, resolve-se Pα.
5.2 Modificação no Preenchimento do Precondicionador Fatoração Controlada de Cholesky
Nesta proposta procura-se que o preenchimento da matriz do FCC dada por L̃ seja no máximo nnz(A) +musando a igualdade nnz(L̃) = nnz(A) +mη, onde η é obtida da definição do FCC no problema (3). Paradeterminar o η inicial, denotado por η0, calcula-se o valor da constante c tal que cnnz(A) ≤ nnz(A) paraobter os seguintes casos: (i) η0 = 1, se 1 ≤ c < 2; (ii) η0 = −nnz(A)/(2m) + 1, caso contrário. Acondição dada no item [i] implica que nnz(A) ≈ nnz(A), mais ainda, as colunas de A e de A são esparsas,pois se uma coluna de A fosse cheia isto implicaria que nnz(A) >> nnz(A). Já no item [ii], tem-se que opreenchimento de nnz(A) aumentou, nesse caso deve-se reduzir o preenchimento permitido para L̃ com umvalor de η negativo.
Se o número de iterações do MGCP é maior quem/5, outra heurı́stica para determinar o incremento do η será:(i) ηk = 1, quando η0 = 1; (ii) ηk = ηk−1/2, caso contrário. Também o valor de ηk será incrementado,ηk = ηk−1/2, se ηk−1 < 0 quando para cada j = 1, . . . ,m e i = j + 1, . . . ,m, |l̃ij | < 1/1 + α na iteraçãok − 1. Por outro lado, o η final, denotado por ηf é dado por: (i) ηf = 1, quando η0 = 1; (ii) ηf = 0,caso contrário. Assim, o maoir peenchimento da matriz L̃ será nnz(A) +m e pela definição de c, tem-se:m ≤ nnz(L̃) ≤ nnz(A) +m.
6 Resultados Numéricos
O código original do PCx, veja [4], e da FCC foram modificados para incorporar a FCC1 e FCC2. A FCC1utiliza o parâmetro de correção apresentado na subseção 5.1 e a FCC2 usa ambos os parâmetros apresentadosna seção 5. A modificação proposta por [8] é chamada de FCCβ. Os testes computacionais foram realizadosem ambiente Linux, em uma máquina equipada com processador core i7 de 2.0 GHz e 8Gb de memória RAM.Os problemas utilizados para avaliar o desempenho das novas abordagens foram extraı́dos das bibliotecas:NETLIB, QAP e KENNINGTON. Foram testados problemas de grande porte onde o número de linhas o
CLAIO-2016
426
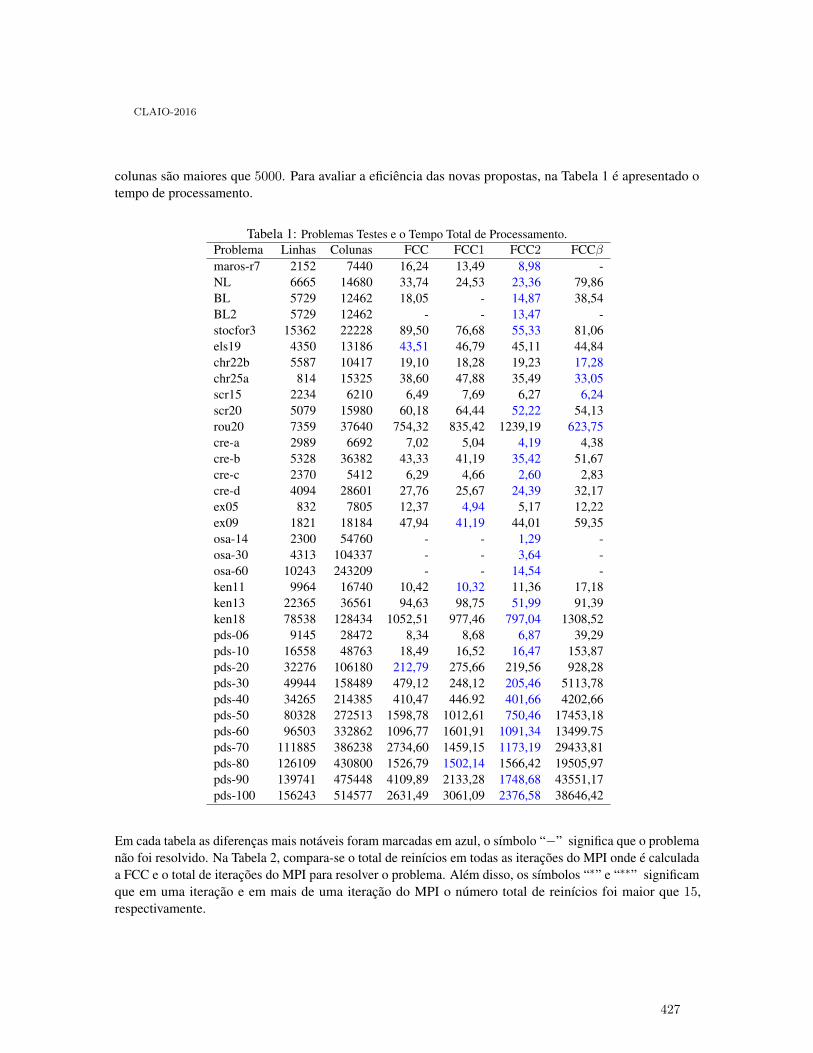
colunas são maiores que 5000. Para avaliar a eficiência das novas propostas, na Tabela 1 é apresentado otempo de processamento.
Tabela 1: Problemas Testes e o Tempo Total de Processamento.Problema Linhas Colunas FCC FCC1 FCC2 FCCβmaros-r7 2152 7440 16,24 13,49 8,98 -NL 6665 14680 33,74 24,53 23,36 79,86BL 5729 12462 18,05 - 14,87 38,54BL2 5729 12462 - - 13,47 -stocfor3 15362 22228 89,50 76,68 55,33 81,06els19 4350 13186 43,51 46,79 45,11 44,84chr22b 5587 10417 19,10 18,28 19,23 17,28chr25a 814 15325 38,60 47,88 35,49 33,05scr15 2234 6210 6,49 7,69 6,27 6,24scr20 5079 15980 60,18 64,44 52,22 54,13rou20 7359 37640 754,32 835,42 1239,19 623,75cre-a 2989 6692 7,02 5,04 4,19 4,38cre-b 5328 36382 43,33 41,19 35,42 51,67cre-c 2370 5412 6,29 4,66 2,60 2,83cre-d 4094 28601 27,76 25,67 24,39 32,17ex05 832 7805 12,37 4,94 5,17 12,22ex09 1821 18184 47,94 41,19 44,01 59,35osa-14 2300 54760 - - 1,29 -osa-30 4313 104337 - - 3,64 -osa-60 10243 243209 - - 14,54 -ken11 9964 16740 10,42 10,32 11,36 17,18ken13 22365 36561 94,63 98,75 51,99 91,39ken18 78538 128434 1052,51 977,46 797,04 1308,52pds-06 9145 28472 8,34 8,68 6,87 39,29pds-10 16558 48763 18,49 16,52 16,47 153,87pds-20 32276 106180 212,79 275,66 219,56 928,28pds-30 49944 158489 479,12 248,12 205,46 5113,78pds-40 34265 214385 410,47 446.92 401,66 4202,66pds-50 80328 272513 1598,78 1012,61 750,46 17453,18pds-60 96503 332862 1096,77 1601,91 1091,34 13499.75pds-70 111885 386238 2734,60 1459,15 1173,19 29433,81pds-80 126109 430800 1526,79 1502,14 1566,42 19505,97pds-90 139741 475448 4109,89 2133,28 1748,68 43551,17pds-100 156243 514577 2631,49 3061,09 2376,58 38646,42
Em cada tabela as diferenças mais notáveis foram marcadas em azul, o sı́mbolo “−” significa que o problemanão foi resolvido. Na Tabela 2, compara-se o total de reinı́cios em todas as iterações do MPI onde é calculadaa FCC e o total de iterações do MPI para resolver o problema. Além disso, os sı́mbolos “∗” e “∗∗” significamque em uma iteração e em mais de uma iteração do MPI o número total de reinı́cios foi maior que 15,respectivamente.
CLAIO-2016
427
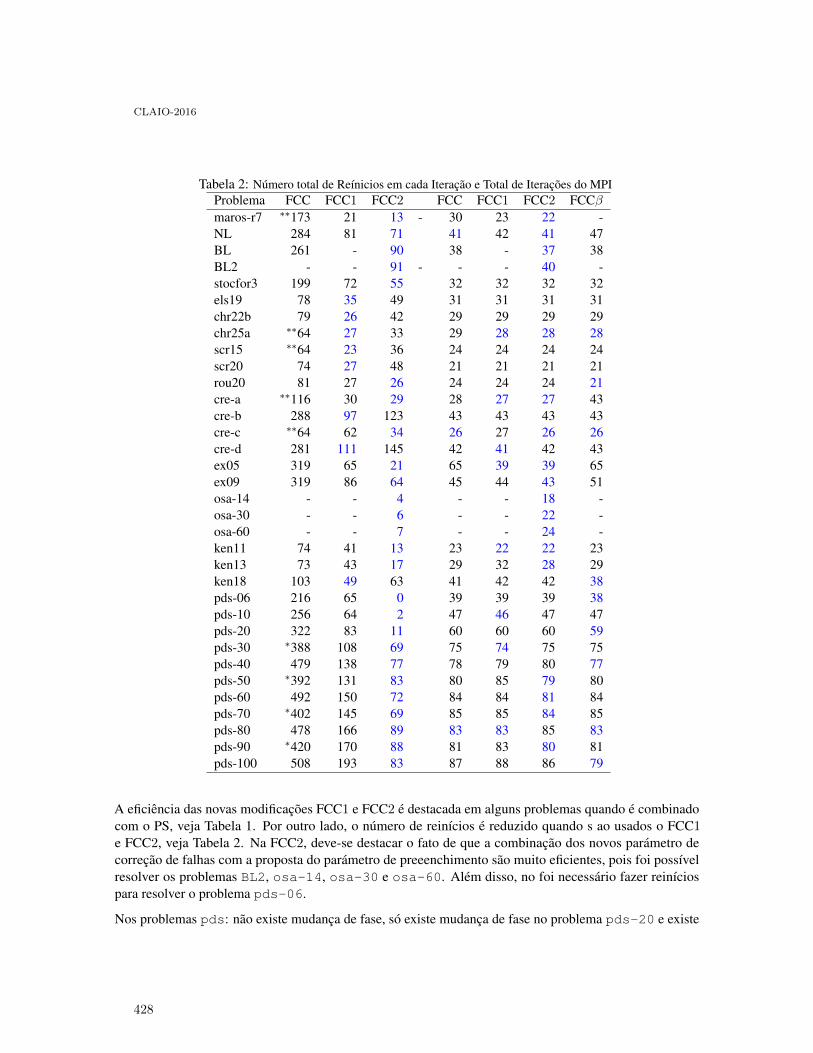
Tabela 2: Número total de Reı́nicios em cada Iteração e Total de Iterações do MPIProblema FCC FCC1 FCC2 FCC FCC1 FCC2 FCCβmaros-r7 ∗∗173 21 13 - 30 23 22 -NL 284 81 71 41 42 41 47BL 261 - 90 38 - 37 38BL2 - - 91 - - - 40 -stocfor3 199 72 55 32 32 32 32els19 78 35 49 31 31 31 31chr22b 79 26 42 29 29 29 29chr25a ∗∗64 27 33 29 28 28 28scr15 ∗∗64 23 36 24 24 24 24scr20 74 27 48 21 21 21 21rou20 81 27 26 24 24 24 21cre-a ∗∗116 30 29 28 27 27 43cre-b 288 97 123 43 43 43 43cre-c ∗∗64 62 34 26 27 26 26cre-d 281 111 145 42 41 42 43ex05 319 65 21 65 39 39 65ex09 319 86 64 45 44 43 51osa-14 - - 4 - - 18 -osa-30 - - 6 - - 22 -osa-60 - - 7 - - 24 -ken11 74 41 13 23 22 22 23ken13 73 43 17 29 32 28 29ken18 103 49 63 41 42 42 38pds-06 216 65 0 39 39 39 38pds-10 256 64 2 47 46 47 47pds-20 322 83 11 60 60 60 59pds-30 ∗388 108 69 75 74 75 75pds-40 479 138 77 78 79 80 77pds-50 ∗392 131 83 80 85 79 80pds-60 492 150 72 84 84 81 84pds-70 ∗402 145 69 85 85 84 85pds-80 478 166 89 83 83 85 83pds-90 ∗420 170 88 81 83 80 81pds-100 508 193 83 87 88 86 79
A eficiência das novas modificações FCC1 e FCC2 é destacada em alguns problemas quando é combinadocom o PS, veja Tabela 1. Por outro lado, o número de reinı́cios é reduzido quando s ao usados o FCC1e FCC2, veja Tabela 2. Na FCC2, deve-se destacar o fato de que a combinação dos novos parámetro decorreção de falhas com a proposta do parámetro de preeenchimento são muito eficientes, pois foi possı́velresolver os problemas BL2, osa-14, osa-30 e osa-60. Além disso, no foi necessário fazer reinı́ciospara resolver o problema pds-06.
Nos problemas pds: não existe mudança de fase, só existe mudança de fase no problema pds-20 e existe
CLAIO-2016
428

mudança de fase em todos os problemas pds quando é usado o FCC, FCC1 e FCC2, e FCCβ, respectivamente.Observa-se que o desempenho do precondicionador FFCβ foi discrepante em relação a estes problemas, poisa mudança de fase implicou que o PS incrementasse o tempo computacional.
7 Conclusões
As modificações no FCC tanto no parâmetro de correção de falhas na diagonal α quanto no parâmetro depreenchimento η reduziram o número de reinı́cios no cálculo deste precondicionador. O número máximode reinı́cios permitidos não foi atingido em nenhum problema, isto implicou que o número de iterações doMGCP seja diminuı́do e, portanto, a primeira fase da AH é eficiente.
Embora os reinicios na fatoração foram feitos nas novas propostas, o tempo total para resolvê-los é menordo que o tempo utilizando a modificação FCCβ, a qual não realiza reinı́cios. Novas formas de calcular aatualização desta modificação para evitar reinicios na Fatoração Controlada de Cholesky serão investigadas.
Agradecimentos
Este trabalho contou com o apoio financeiro da FAPESP e do CNPq.
Referências
[1] S. Bellavia, V. D. Simone, D. Di Serafino, and B. Morini. A preconditioning framework for sequences of diagonallymodified linear systems arising in optimization. SIAM Journal on Numerical Analysis, 50(6):3280–3302, 2012.
[2] S. Bocanegra, F. F. Campos, and A. R. L. Oliveira. Using a hybrid preconditioner for solving large-scale linearsystems arising from interior point methods. Computational Optimization and Applications, 36(2-3):149–164,2007.
[3] F. F. Campos. Analysis of conjugate gradients-type methods for solving linear equations. PhD thesis, Universityof Oxford, 1995.
[4] J. Czyzyk, S. Mehrotra, M. Wagner, and S. J. Wright. Pcx user guide. Technical Report OTC 96/01, 1996.
[5] J. Gondzio. Matrix-free interior point method. Computacional Optimization and Applications, 51:457–480, 2012.
[6] T. A. Maunteuffel. An incomplete factorization technique for positive definite linear systems. Mathematics ofcomputation, 34(150):473–497, 1980.
[7] A. R. L. Oliveira and D. C. Sorensen. A new class of preconditioners for large-scale linear systems from interiorpoint methods for linear programming. Linear Algebra and its applications, 394:1–24, 2005.
[8] L. M. Silva. Modificações na Fatoração Controlada de Cholesky para Acelerar o Precondicionamento de SistemasLineares no Contexto Pontos Interiores. Tese de Doutorado, Universidade Estadual de Campinas, 2014.
[9] M. I. F. Velazco, A. R. L. Oliveira, and F. F. Campos. Heuristics for implementation of a hybrid preconditioner forinterior-point methods. Pesquisa Operacional, 31(3):579–591, 2011.
[10] S. J. Wrigth. Primal-dual Interior-Point Methods:. SIAM e-books. Society for Industrial and Applied Mathematics(SIAM), 1997.
CLAIO-2016
429

Technical Efficiency of Mexican Higher Education
Institutions: A Data Envelopment Analysis
Maŕıa G. Hernández–Balderrama†
Luis A. Moncayo–Mart́ınez∗
Adrián Ramı́rez–Nafarrate‡
Instituto Tecnológico Autónomo de México (ITAM)Department of Industrial & Operations Engineering
[email protected]†, [email protected] ∗, [email protected] ‡
Abstract
Higher Education Institutions (HEI) face the need to manage effectively and efficiently theirresources because the demand for quality educational services from the private sector, govern-ment, and society. So as to measure the technical efficiency of 40 Mexicans HEI, we applied thedata envelopment analysis (DEA) which is a methodology to empirically measure the productiveefficiency of decision–making units (DMU).
In this paper, we measure three core functions of every HEI: teaching, research, and knowledgedissemination. We particularly applied the output–oriented BCC-Primal model given that theCCR model does not accommodate returns to scales.
As a result, the HEI are classified as either technical efficiency or technical inefficiency;thus, we identified potential improvements for the technical inefficient HEI. These results couldsupport the decision–making process to improve the performance of the HEI.
Keywords: Technical Efficiency; Higher Education Institutions; Data Envelopment Analysis.
1 Introduction
Multiple studies are showing that high levels of education allow higher rates of employment andhigher income levels (see [1, 2]); thus, more people are keen to achieve a university degrees. Gov-ernments obtained benefits from it, given that people’s higher income levels could results in aneconomical growth.
According to the Organisation for Economic Co-operation and Development (OECD), govern-ments need to spend their resources efficiently and need to develop and implement educationalpolicies that maximise the social benefits, e.g. maximise the number of people with a graduatedegree [2].
Therefore, HEI are under pressure to achieve objectives such as: (a) to graduate people withhigher degrees; (b) to create new knowledge through research; and (c) to disseminate the knowl-edge. So as to know the level of achievements, governments (and society in general) must evaluatethe performance of HEI, especially when they are financed with public funds
CLAIO-2016
430

In this research, we analyse the Tertiary-type A programmes, defined by the OECD as “largelytheory-based programmes, designed to provide sufficient qualifications for entry to advanced re-search programmes and professions with high skill requirements. American Masters are includedin this category.”
One objective of this work is to apply data envelopment analysis (DEA) to identify the vari-ables that directly affect the HEI performance in relation to teaching, research, and knowledgedissemination. We develop three models with different inputs and outputs to measure each of theobjectives. We use the inputs of a database called ExECUM developed by the Universidad Na-cional Autónoma de México (UNAM), see [3] for a detailed description. Another objective is torecommend potential improvements to those HEI with some degree of technical inefficiency, so theycan focus their efforts on those variables that impact directly on the management of their resourcesefficiently.
Technical efficiency is the capacity of a decision–making units (DMU) can get the maximumoutput given some inputs. It is computed comparing the value of the DMU technical efficiencywith the optimum value represented by an estimated production frontier [4]. Mathematically, Ef-ficiency = Outputs/Inputs. Concerning HEI, technical efficiency indicates the degree of technicalexploitation of resources used to meet the objectives of educational production.
DEA has been used widely in very different industries. The top–five industries are banking,health care, agriculture and farm, transportation, and education. The highest growth nowadays isin energy and environment as well as finance [5]. In education, a similar analysis has been carriedout in universities from Spain, UK, Philippines, Australia, and Portugal. Even though the inputsand outputs are different in each case because the aim of the analysis had different purposes, e.g.the output of the analysis of UK universities measures the income for consultancy and research [6].Our analysis is different since we develop three models to asset each of the outputs to be evaluated(teaching, research, and knowledge dissemination).
2 Problem Description
In this section, we briefly present the basic concepts in DEA. Firstly, there are n DMUj (j =1, . . . , n) each one with m inputs xij (i = 1, . . . ,m) and s outputs yrj (r = 1, . . . , s).
Secondly, the virtual inputs and outputs of each DMUj are weighted by vi and ur, respec-tively. Finally, the objective is to find the value of vi and ur, that maximise the relation (virtualoutput)/(virtual input) (Eq. 1) for a given DMUj=o (for simplicity DMUo).
maxu,v
u1y1o + u2y2o + . . .+ usysov1x1o + v2x2o + . . .+ vmxmo
=
s∑
r=1
uryro
m∑
i=1
vixio
=uyovxo
(1)
Subject to∑s
r=1 uryrj −∑m
i=1 vrxij ≤ 0 ∀ j and u ≥ 0,v ≥ 0 where u = {u1, . . . , us} and v ={v1, . . . , vm}. This is called the fractional programming formulation with a matrix of inputs Xm×nand outputs Ys×n. The most basic model called CCR can be formulated as a Linear Programming
CLAIO-2016
431

Model (LPM) in which the objetive could be minimised inputs while satisfying at least the givenoutput levels (i.e. input–oriented model) or to maximise outputs without requiring more of any ofthe observed values (i.e. output–oriented model). Following, the primal and dual of the output–oriented CCR model are presented [4]:
Primal
minu,v
vxo
subject to
uyo = 1
−vX + uY ≤ 0
v,u ≥ 0
⇐⇒
Dual
maxη,λ
η
subject to
xo −Xλ ≥ 0
ηyo − Y λ ≤ 0
λ ≥ 0
(2)
The solution of the CCR model (Eq. 2) is a reference set (E′o) which has the efficient DMUj ,see Eq. 3.
E′o =
{j ∈ (1, . . . , n) |
s∑
r=1
u∗ryrj =m∑
i=1
v∗i xij
}(3)
2.1 Output–oriented BCC Model
One drawback in CCR model (Eq. 2) is the assumption about the constant return of scale. The BCCmodel relaxes this assumption (that is restrictive and unreal) by adding the condition
∑nj=1 λi = 1
to the Dual output–oriented problem (Eq. 2). The additional constraint can be rewritten such as eλwhere e is a row vector with all elements unity and λ ≥ 0 is a column vector. The output-orientedBCC model employed in this study is formulated as (Eq. 4):
BCC Primal
minu,v
vxo − v0subject to
uyo = 1
vX − uY − v0e ≥ 0
v,u ≥ 0
v0 free in sign
⇐⇒
BCC Dual
maxη,λ
η
subject to
xo −Xλ ≥ 0
ηyo − Y λ ≤ 0
eλ = 1
λ ≥ 0
(4)
2.2 Problem of HEI to Carry out the DEA
There are n = 40 DMU’s (j = 1, . . . , 40) which represent each of the HEI. In this paper, everyDMUj is a public or state university. All the DMUj are financed entirely or partially by theMexican federal government, the local government finances them as well. There are m = 3 inputs(i = 1, 2, 3); thus, the input matrix is X3×40. The output matrix is Y7×40; therefore, there ares = 7 outputs (r = 1, . . . , 7).
CLAIO-2016
432

Figure 1: Box–plot of the inputs and outputs
The inputs i are: 1) number of full/partial–time teachers; 2) amount of money received by thefederal or local government; and 3) number of researchers in the Researchers’ National System (SNIin Spanish). In i = 1, the people who their main task is to do research are not included.
The outputs r are: 1) alumni (i.e. graduate students from all schools/departments/centres);2) number of accredited undergraduate programs; 3) number of journal papers indexed e.g. ISI–Thomson, SCOPUS–Elsevier; 4) number of patents granted by the Mexican institute of the int-electual property; 5) number of accredited postgraduate programs; 6) number of edited journalsindexed in the Latindex and/or in the index of the Mexican Council of Science and Technology;and 7) number of cites of a journal papers with an affiliation related to j.
Remember that the value of the inputs and outputs are retrieved from the data base ExECUM[3].
Fig. 1 shows that there are important differences in HEI’s size. While there is an HEI withonly 116 teachers (input i = 1), there is another with 10,868 teachers. We note that most of thedata (75%) are below the average. Additionally, the median value is much lower than the mean inall DMUj ; thus, we confirm that there are “big” HIE’s in the data base.
3 Solution Method
Considering the particular characteristics of the HEI, we concluded that it is more appropriate forefficiency analysis to use a BCC returns to scale.
In relation to the scale of production, due to differences in the number of teachers and regis-tration number in the institutions we can see that they are in different scales of production; Then,the model BCC it will assess the efficiency of institutions comparing them only with the efficientof similar size. As for the orientation of the model, it was decided to work with an output-orientedmodel, it gives us the chance to explore an increase in outputs, while the inputs are fixed. That is,
CLAIO-2016
433

Figure 2: Set reference E′o (Eq. 3) for each model
HEI teaching can increase their production, research and dissemination, from available resources itwill be analysed by what percentage.
Our aim is to compute a relatively efficiency in three areas: teaching, research, and knowledgedissemination. Nevertheless, some of the outputs are not related to each area, e.g. the number ofpatents (r = 4) and the number of edited journals by a HEI (r = 6) are not results of teaching.Therefore, we solve three BCC models (Eq. 4) with the same inputs X3×40. The teaching efficiencyproblem A is the BCC model defined in Eq. 4 with the following inputs r = 1, 2 (Y2×40). The re-search efficiency problem B has the inputs r = 3, 4, 5 (Y3×40). Finally, the knowledge disseminationproblem C has the inputs r = 6, 7 (Y2×40).
The results were generated using the standard software Efficiency Measurement System (EMS)v. 3.1.
The set reference E′o (Eq. 3) for each problem – E′o(A), E′o(B), and E′o(C) – is shown in Fig.2. For example, the following HEI’s E′o(C)= {2, 4, 6, 10, 26, 31, 34, 39, 3, 20, 29, 30} are technicalefficient in relation to the objective of knowledge dissemination, i.e. the j ∈ E′o(C) are referencesfor the other HEI’s in relation to the objective C.
The HIE’s that are not efficient in A, B, and C are j = {1, 7, 9, 12, . . . , 37, 38, 40}, i.e. the onesoutside the Fig. 1. On the other hand, the HIE’s efficient in all models are j = {6, 10, 26, 31, 34, 39}.
Table 1 summarises the results, e.g. the mean efficiency of the HIE is about 80.58% in relationto the objective of teaching. Moreover, 24 out of 40 HIE’s rate 100% in any of the 3 models, theseHIE’s determine the efficient frontier in each case. The other institutions have technical inefficiencysince it could increase outputs and continue to consume the same amount of resources.
CLAIO-2016
434
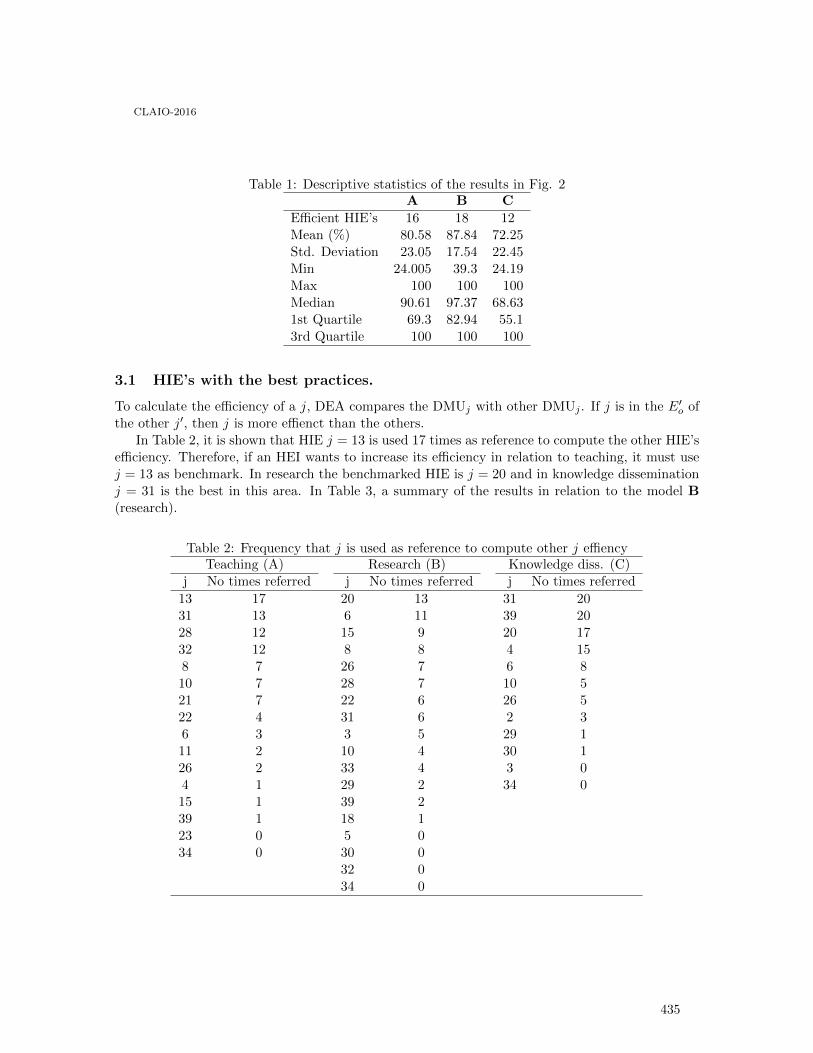
Table 1: Descriptive statistics of the results in Fig. 2A B C
Efficient HIE’s 16 18 12Mean (%) 80.58 87.84 72.25Std. Deviation 23.05 17.54 22.45Min 24.005 39.3 24.19Max 100 100 100Median 90.61 97.37 68.631st Quartile 69.3 82.94 55.13rd Quartile 100 100 100
3.1 HIE’s with the best practices.
To calculate the efficiency of a j, DEA compares the DMUj with other DMUj . If j is in the E′o ofthe other j′, then j is more effienct than the others.
In Table 2, it is shown that HIE j = 13 is used 17 times as reference to compute the other HIE’sefficiency. Therefore, if an HEI wants to increase its efficiency in relation to teaching, it must usej = 13 as benchmark. In research the benchmarked HIE is j = 20 and in knowledge disseminationj = 31 is the best in this area. In Table 3, a summary of the results in relation to the model B(research).
Table 2: Frequency that j is used as reference to compute other j effiencyTeaching (A) Research (B) Knowledge diss. (C)
j No times referred j No times referred j No times referred
13 17 20 13 31 2031 13 6 11 39 2028 12 15 9 20 1732 12 8 8 4 158 7 26 7 6 810 7 28 7 10 521 7 22 6 26 522 4 31 6 2 36 3 3 5 29 111 2 10 4 30 126 2 33 4 3 04 1 29 2 34 015 1 39 239 1 18 123 0 5 034 0 30 0
32 034 0
CLAIO-2016
435
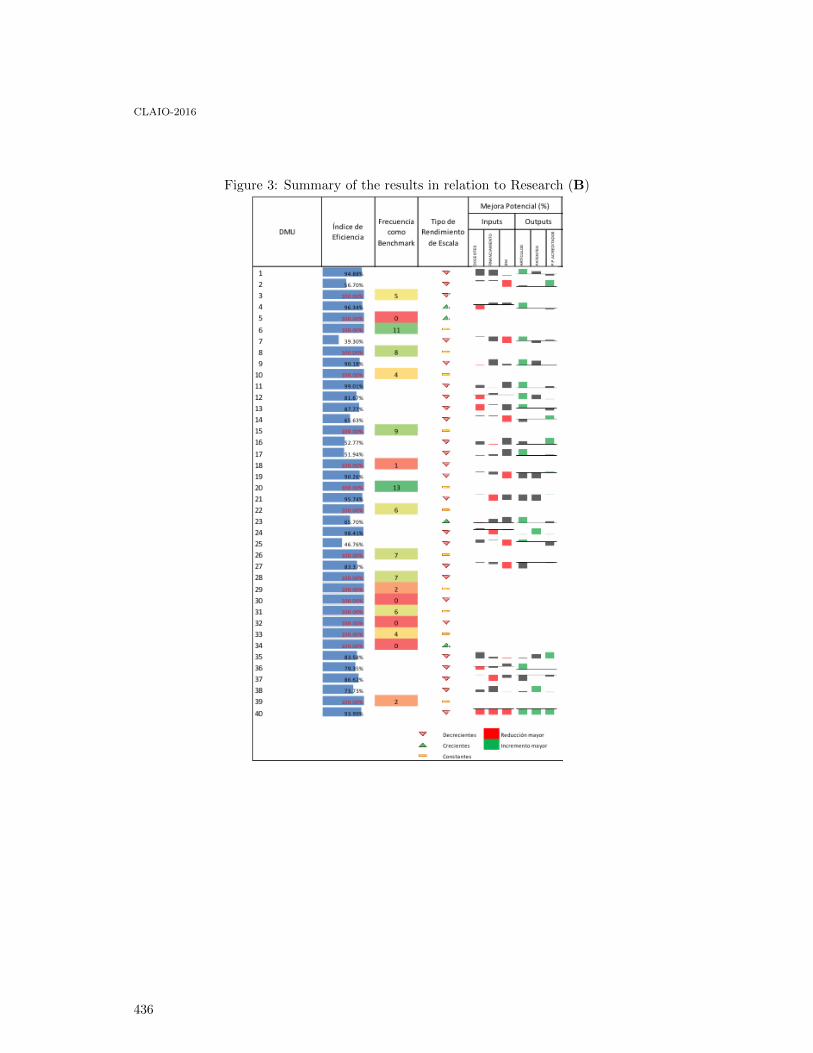
Figure 3: Summary of the results in relation to Research (B)
CLAIO-2016
436

4 Conclusions
The purpose of this empirical work is to apply the methodology called DEA. It is important to clarifythat the DEA is not an appropriate methodology to generate rankings on the quality of institutions.However, the methodology has many advantages that make it a suitable tool for evaluating publiceducation institutions characterised by the presence of multiple inputs and outputs.
Three models that compute the relatively efficient of HIE in relation to teaching, research, andknowledge dissemination. The results shown the HIE that are efficient in every models, moreover,the HIEs that are efficient in the three models are identified, and the HIE that are not efficient inany model.
In this work we identify the HIE’s with the relative highest efficiency; thus, the other HIE’scould use them as benchmark to obtain better results.
Regarding the results, it should be mentioned that reducing inputs, as suggested by the thevalues obtained in the public education system is not easy. The difficulty is that these inputs arenot controllable by the administrations of the institutions, at least not directly, as for the inputLectures should be considered factors such as the budget that is counted, the demand for teachersaccording to the number of students and type of program to teach as well as agreements withunions. With respect to input Financing, this distribution is determined from consideration ofcriteria of quality control and efficiency of institutions.
5 Acknowledgements
This research is supported by Asociación Mexicana de Cultura A.C. and the Mexican NationalCouncil of Science and Technology (CONACyT)
References
[1] S. Levy and N . Schady. Latin America’s Social Policy Challenge: Education, Social Insurance, Redis-tribution. The Journal of Economic Perspectives, 27(2):193–218, 2013.
[2] OECD. OECD Factbook 2014: Economic, Environmental and Social Statistics. OECD Publishing.http://dx.doi.org/10.1787/factbook-2014-en.
[3] A. Márquez Jiménez Estudio comparativo de universidades mexicanas (ECUM): otra mirada a larealidad universitaria. Revista Iberoamericana de Educacion Superior , 1(1):148–156, 2010.
[4] W.W. Cooper, L.W. Seiford and K. Tone. Introduction to Data Envelopment Analysis and Its Uses .Springer, 2nd Ed., London, UK, 2007.
[5] J.S. Liu, L.Y.Y. Lu, W.M. Lu and B.J.Y. Lin. A survey of DEA applications. Omega, 41(5):893–902,2013.
[6] M.G. Hernandez–Balderrama. Análisis de le Eficiencia de Instituciones Públicas de Educación Superioren México utilizando Análisis Envolvente de Datos. MS Thesis, Instituto Tecnológico Autónomo deMéxico (ITAM), 2015.
[7] H. Lee and C. Kim Benchmarking of service quality with data envelopment analysis. Expert Systemswith Applications, 41(8):3761–3768, 2014.
CLAIO-2016
437

Production Planning and Scheduling Optimization
Model for glass industry
Laura Hervert-EscobarInstituto Tecnológico de Estudios Superiores de Monterrey - SINTEC
Jesus Fabián López-PérezSINTEC
Neale R SmithInstituto Tecnológico de Estudios Superiores de Monterrey
Jonnatan Avilés-GonzálezInstituto Tecnológico de Estudios Superiores de Monterrey
Abstract
Based on a case study, this paper deals with the production planning and scheduling problemof the glass container industry. This is a facility production system that has a set of furnaceswhere the glass is produced in order to meet the demand, being afterwards distributed to a setof parallel molding machines. Due to huge setup times involved in a color changeover, manu-facturers adopt their own mix of furnaces and machines to meet the needs of their customers asflexibly and efficiently as possible. In this paper we proposed an optimization model that maxi-mizes the fulfillment of the demand considering typical constraints from the planning productionformulation as well as real case production constraints such as the limited product changeoversand the minimum run length in a machine. The complexity of the proposed model is assessedby means of an industrial real instance.
Keywords: Production: Scheduling; Glass industry; Inventory.
1 Introduction
Currently, the activities of the planning and control of companies are becoming increasingly com-plex. The managers of this area are constantly pressured to reduce operating costs, maintaininventories at adequate levels, to fulfill the demand of customers, and to respond effectively tochanges. There are plenty tools that help to meet these goals, however, they do not consider realfactors that have and impact in the result, consequently, additional decisions should be make tocomplete the process.
CLAIO-2016
438

This research is focused on the planing production and scheduling. Typically, the main goal inthis problem is to align the supply of a manufacturing company with the demand for its products,while maximizing its performance within the framework of the company competitive status in termsof quality, cost and delivery [1].
Research community tended to be divided between researchers investigating planning problemsand researchers interested in scheduling problems. Pure planning models only determine the lot sizeper period, and are not concerned with the sequence of lots in a period. Furthermore, schedulingdecisions are taken afterwards for each period separately [2].
The high degree of interrelation between planning and scheduling decisions enhances the im-portance of an integrated decision making. Recently, due to good opportunities of research on theinterface between scheduling and inventory theory, some effort has been made to bridge the gapbetween the two research communities. Several approaches have been introduced in the literatureto enable and resolve problems encountered in integrating process planning and scheduling in or-der to achieve optimal manufacturing performance. Some of the mostly known approaches are asfollows:
• Nonlinear process planning (NLPP): NLLP makes all possible alternative process plansfor each part before it enters the shop floor [3]. NLPP is based on static shop floor situation.All possible process plans are ranked based on some criteria and stored in a data base.Scheduling selects one of those plans; if the first plan is not suitable the second one is selectedand so on. FLEXPLAN is a typical example of NLPP that is developed in the University ofHanover
• Closed loop process planning (CLPP): It overcomes the shortcomings of NLPP by gen-erating process plans by means of dynamic feedback from production scheduling. Schedulingtells process planning which machines are available for the coming job, based on this infor-mation suitable process plan is generated. Real time information is crucial in CLPP [4].
• Distributed process planning (DiPP):DiPP performs process planning and schedulingsimultaneously. There are two phases in the process planning. The first phase is pre-planningwhich analyses features and their interrelationships, and determines corresponding manufac-turing processes. In the second phase, required job operations are matched with operationcapabilities of the available manufacturing resources to reach final process plans. The integra-tion occurs at the point when resources are available and the job is required. This approachrequires high capacity and capability from hardware and software [5]
Several other approaches also proposed in the literature to integrate process planning andscheduling, objectives and constraints are defined according to the application. Driven by a realindustrial case, this research is focused on the glass container production planning and schedulingproblem. Due to the size and operation of the company, the planning production and schedulingfunctions are centralized and performed by a single scheduler. Therefore, this research provides asolution tool to define an optimal plan for scheduling production in order to obtain higher servicelevel performance with a better resource utilization. This paper is organized as follows. Thedescription of the problem and general mixed integer linear programming (MILP) formulation ispresented in section 2. Results of a set of real case tested scenarios is presented in section 3. Finally,conclusions are presented in section 4.
CLAIO-2016
439

2 Problem Description
Consider a manufacturing system that produces glass containers. The process begins with themixtures of raw materials which determines the color of the glass (typically amber, flint or green),this mixture includes the recycling glass (’cullet’). The mixture is transported into a furnace whereit is melted. The glass paste is fed to a set of parallels glass moulding machines that shape theproduct. The formed containers are then passed through a strict quality inspection. Containersfound to be defective are discarded and melted down in the furnace as ’cullet’. Once they havebeen quality approved, the containers are packed on pallets at the end of the product lines. If itis required, the product pass through a decoration process, otherwise the product is stored in thewarehouse or shipped for sale. Figure 1 illustrates the flow of the production process.
Decoration
Packaging
Calcium carbonate
The raw ingredients
of glass are fed into the furnace
Waste glass
Sand
Sodium carbonate
A gob is dropped into the
mold Compressed air forces the glass into the shape of
the mold The finished glass bottle is removed
from its mold
The furnace is heated up to 2550 ºF (1400 ºC) to melt the raw materials
Inspection
Figure 1: Production process of glass container
Sales of glass containers have two main characteristics: a high seasonality and a high variability[6].Since production capacity remains almost constant, the high seasonality leads to occasional pro-duction incapacities to face demand. Additionally, the number of furnaces and the color campaignschedules reduce the production flexibility. Only one color of glass can be produced at any time ineach furnace. Machines served by the same furnace produce only one color of glass. Also, a colorchangeover in this study case can reach a week setup time which leads to a color long runs and,therefore, furnace color’s specialization. Due to this research is based in a case study, a calendarcolor campaign is always predefined in a tactical level. It includes maintenances strategies as wella cost planning decisions. Furnaces are operated continuously and machine lines operate on a 24hour basis for seven days a week. Therefore, there is a little freedom for varying output to matchfluctuations in demand. Each machine can only run one product at a time. The production rateis given by the combination of product and machine, however, a product changeover on a machinedecreases the rate in 25%. Mainly for the setup and stabilizing process times required to startproduction. The product changeovers are undertook by a team of highly skilled workers, therefore,they are limited to happen only one per week and during weekdays. Additional assumptions inthis research includes the availability of raw material, the capacity of machines does not exceedthe capacity of the furnace, and the decoration and packing processes are unlimited. Notation for
CLAIO-2016
440

mathematical formulation is given in Table 1.
Sets Parameters
S Final products or SKU’s D Demand of SKU’s
J Shapes or subproduct to obtained SKU’s(J ⊂ S)
Ds Demand of shapes given by∑
i∈J(j)Di
T Days in the planning horizon A Warehouse daily capacity
M Glass moulding machines r Daily production rate
W Week days for the whole planning horizon(W ∪Wn = T )
a Normalized cost associated with acombination of product-machine
Wn Weekend days for the whole planninghorizon (W ∪Wn = T )
TB Timetable that indicates if machinej is able to produce shape j in day t
Variables
Xj,m,tBinary variable to assign shape j to amachine m the day t
I Continuos variable to define theinventory level
Cj,m,tBinary variable to define if shape j startproduction in machine m the day t
V ,V u
Continuos variable to define the salesvolume
Pj,m,tContinuos variable to define the productionvolume of shape j in machine m the day t
F ,Fu
Unsatisfied demand
Table 1: Notation of the mathematical model
Mathematical formulation of the model is defined in the following equations
Maximize(z) =∑
j
∑
t
Vj,t −∑
j
∑
m
∑
t
aj,mXj,m,t −∑
j
∑
t
4 ∗ Fj,t (1)
Subject to:
Xj,m,t ≤ 1 ∀j ∈ J,m ∈M, t ∈ T (2)
Xj,m,t ≤ TBj,m,t ∀j ∈ J,m ∈M, t ∈ T (3)
Xj,m,t−1 + Xj,m,t+1 ≥ Xj,m,t ∀j ∈ J,m ∈M, t = 2, ..., T − 1 (4)
Xj,m,t−2 + Xj,m,t+1 ≥ Xj,m,t−1 ∀j ∈ J,m ∈M, t = 3, ..., T − 1 (5)
Xj,m,t−2 + Xj,m,t ≥ Xj,m,t−1 ∀j ∈ J,m ∈M, t = 3, ..., T (6)
Xj,m,t −Xj,m,t−1 ≤ Cj,m,t ∀j ∈ J,m ∈M, t = 2, ..., T (7)
Xj,m,t −Xj,m,t−1 ≤ −1 + 2 ∗ Cj,m,t ∀j ∈ J,m ∈M, t = 2, ..., T (8)∑
j
∑
m
Cj,m,t ≤ 1 ∀j ∈ J,m ∈M, t ∈W (9)
∑
j
∑
m
Cj,m,t = 0 ∀j ∈ J,m ∈M, t ∈Wnd (10)
rj,m,t ∗Xj,m,t − 0.25 ∗ rj,m,t ∗ Cj,m,t = Pj,m,t ∀j ∈ J,m ∈M, t ∈ T (11)∑
m
Pj,m,t + Ij,t−1 = Ij,t + Vj,t ∀j ∈ J, t ∈ T (12)
CLAIO-2016
441

Dsj,t = Vj,t + Fj,t ∀j ∈ J, t ∈ T (13)∑
j
Ij,t ≤ A ∀j ∈ J, t ∈ T (14)
∑
i∈JIi,t = Ij,t ∀j ∈ J, t ∈ T (15)
∑
i∈JFui,t = Fj,t ∀j ∈ J, t ∈ T (16)
Di,t = V ui,t + Fui,t ∀i ∈ S, t ∈ T (17)
Di,t ≥ V ui,t ∀i ∈ S, t ∈ T (18)
Objective function given in Equation (1) maximizes the fulfillment of demand by penalizing thelack of inventory. Thus, the cost of not being able to satisfied the demand is four times greater thanthe benefit. Additionally, a normalized cost of production is considered. This cost is associated withthe performance of the combination of product-machine. Constraints for this model are as follows:A machine m can produce only one type of shape j during period t, this condition is checked inEquation (2). The availability of a machine for a certain product in period t is checked in Equation(3). Due to availability of staff for changeovers as well as stability of the process, the minimum runlength per machine allowed is three days, this condition is given in Equations (4) to (6). Equations(7) and (8) allow to identify the day of changeover a product in a machine. Equations (9) and(10) limits to one changeover product in the whole plant during the weekdays, and prevent changesduring the weekend. The production is given by the rate of the selected machine, however, whena change of product happen, the rate decreases 25%, this condition is given in Equation (11).Inventory balance equation is given in Equation (12). The balance of satisfied (V ) and unsatisfieddemand(F ) is given in Equation (13). Capacity of the warehouse is given in Equation (14). In thisresearch, it is assumed that capacity of decoration and packing are unlimited, therefore, Equations(15) to (18) turns shapes into SKU’s according to the demand.
3 Solution Method
To test de performance of the proposed model, a set of scenarios were designed. First, the productsare classified into three categories: A, B, C regarding the variability and the volume of the demand.In this way, products under A classification represent 75% of the total demand with low variability.Classification B represents 20% of the total demand and medium variability. Finally, classification Crepresents 5% of the total demand with high variability. There are three furnaces in the productionplant. Furnaces handle only one color at the time. The color and availability of the furnaces andmachines is given in a predefined calendar. This calendar was designed considering decisions suchas holidays for human resources, maintenance planning cost and raw material availability. The firstfurnace (FA) has a capacity of 260 ton and has two parallel molding machines (A1, A2) to shape theproduct. Second furnace (FB) has a capacity of 360 ton and has three parallel molding machines(B1,B2,B3) to shape the product/ Finally, the third furnace also has a capacity of 360 ton but has4 molding parallel machines to shape the product (C1,C2,C3,C4). The molding machines are ableto produce 55 types of shapes or sub-products that are later turn into 135 types of final products
CLAIO-2016
442

(SKU’s). This transformation takes place in the decoration process, which has unlimited capacity.The configuration of the process is showed in figure 2.
PHASE 4 FINISHED PROCESS
PHASE 3 SHAPED PROCESS
PHASE 2 MELTING PROCESS
PHASE 1 MIXING PROCESS
FURNACE A
FURNACE B
FURNACE C
A1
A2
B1
B3
C1
C3
B2
C2
C4
Amber
Green
Flint
DECORATION
PACKING
Figure 2: Production process configuration
The set of scenarios were designed according to the needs of the company and are resume intable 2. Since products classified as type C represent only 5% of the total demand, there is no needto define a safety stock to fulfill the demand. However, it is necessary to define a upper bound inthe model. Consequently, the maximum inventory level for these products is given by the capacityof the warehouse. The horizon planning is for 550 days with a bucket of one day.
ID Description
Max%Use of
InventoryDays
WarehouseA B
E0 Same condition as the last year 30 80 100%
E1 Increase 5% of the demand 30 80 100%
E2 Increase inventory levels 35 90 100%
E3 Unlimited warehouse capacity 30 80 –
E4 Decrease warehouse capacity 12.5% 30 80 87.5%
E5 Decrease warehouse capacity 25% 30 80 75%
E6 Reduce inventory levels for products A and B 25 70 100%
E7 Build enough inventory to stop operations at the end of the year 30 80 –
Table 2: Scenarios tested
The proposed model was implemented using AMPL to call the optimizer GUROBI 5.6. Theresults of the proposed methodology are given in terms of business metrics and the execution time.The results for business metrics are showed in table 3. Where rows are used to identify the scenarioand columns denote the business metric of interest. The table provides the result for each couple ofscenario and business metric, such as the satisfied and unsatisfied demand, the average inventory
CLAIO-2016
443
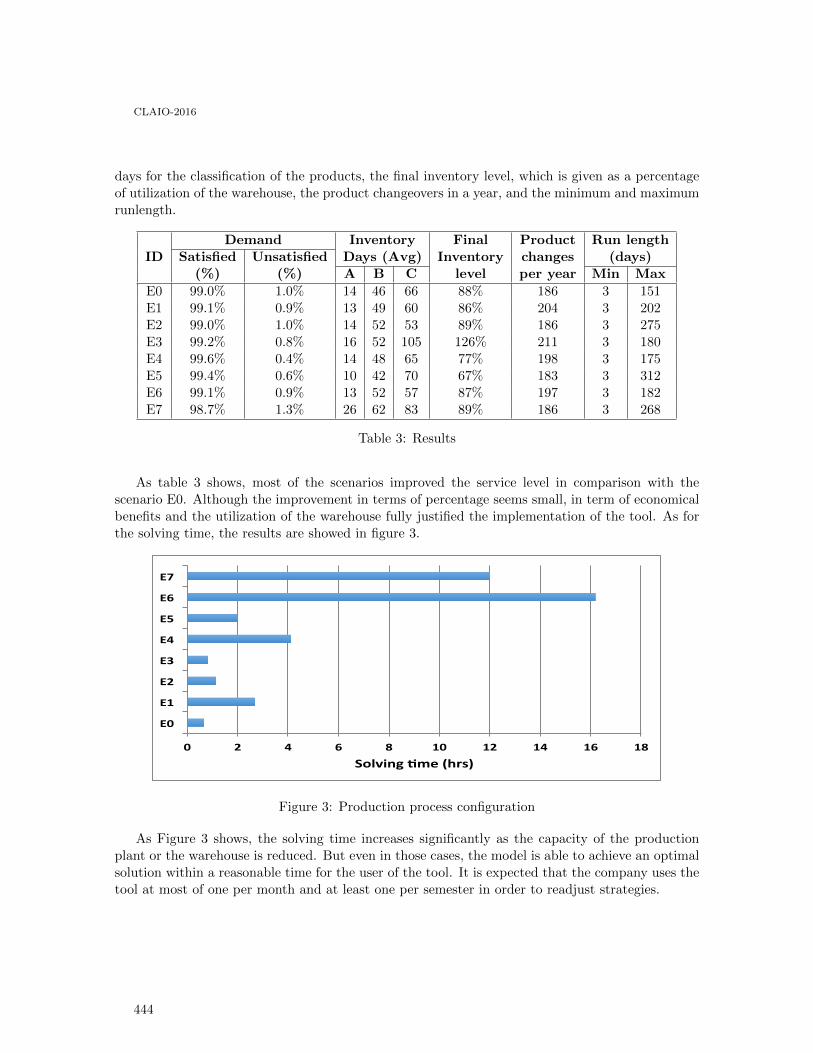
days for the classification of the products, the final inventory level, which is given as a percentageof utilization of the warehouse, the product changeovers in a year, and the minimum and maximumrunlength.
IDDemand Inventory Final Product Run length
Satisfied Unsatisfied Days (Avg) Inventory changes (days)(%) (%) A B C level per year Min Max
E0 99.0% 1.0% 14 46 66 88% 186 3 151E1 99.1% 0.9% 13 49 60 86% 204 3 202E2 99.0% 1.0% 14 52 53 89% 186 3 275E3 99.2% 0.8% 16 52 105 126% 211 3 180E4 99.6% 0.4% 14 48 65 77% 198 3 175E5 99.4% 0.6% 10 42 70 67% 183 3 312E6 99.1% 0.9% 13 52 57 87% 197 3 182E7 98.7% 1.3% 26 62 83 89% 186 3 268
Table 3: Results
As table 3 shows, most of the scenarios improved the service level in comparison with thescenario E0. Although the improvement in terms of percentage seems small, in term of economicalbenefits and the utilization of the warehouse fully justified the implementation of the tool. As forthe solving time, the results are showed in figure 3.
0 2 4 6 8 10 12 14 16 18
E0
E1
E2
E3
E4
E5
E6
E7
Solving 3me (hrs)
Figure 3: Production process configuration
As Figure 3 shows, the solving time increases significantly as the capacity of the productionplant or the warehouse is reduced. But even in those cases, the model is able to achieve an optimalsolution within a reasonable time for the user of the tool. It is expected that the company uses thetool at most of one per month and at least one per semester in order to readjust strategies.
CLAIO-2016
444

4 Conclusions
This paper presents an approach to solve a real life production planning and scheduling problem.The model represents as well as possible the operation of a glass container industry. Due tohuge impact of production plans in management (and industrial) key performance indicators, glasscontainer production planning has received some attention in recent years. However, researchershave assumed the standard hierarchical procedure, and analyzed mainly the scheduling of short-term level. In this research, we provide a tool that provides an strategy for the planning productionas well as detailed information (scheduling plan) to apply the strategy. The tool is flexible enoughto test different scenarios under a reasonable time according to the availability of the final user.Next step in this research is to include the scheduling of the color campaign in the furnaces andthe load of product machines simultaneously. This will lead to analyze different approaches for thesolution since the size and complexity of the problem will increase significantly.
5 Acknowledgments
The authors are grateful to SINTEC for financial and technical support during the development ofthis research.
References
[1] Mukhopadhyay, S.K.; Dwivedy, J,; Kumar, A. Design and implementation of an integrated produc-tion planning system for a pharmaceutical manufacturing concern in India Production Planning &Control,9(4):391-402, 1998.
[2] Almada-Lobo,B.; Oliveira, J. F.; & Caravilla M. A. Production planning and scheduling in the glasscontainer industry: A VNS approach. International Journal of Production Economics,114(1): 363-375,2008.
[3] Tonshoff, H. K.,Beckendorff,U.,&Andress, N. FLEXPLANÑA concept for intelligent process planningand scheduling. Proceedings of the CIRP International Workshop on Computer Aided Process Planning,pages 21-22. Hanover University, Germany, 1989.
[4] Kempenaers, J., Pinte, J., Detand, J., & Kruth, J.-P. A collaborative process planning and schedulingsystem. Advances in Engineering Software,25(1):3-8, 1996.
[5] Zhang, H. C. Production scheduling problem in the glass-container industry. OperationReasearch,27(2):290-302, 1997.
[6] J. Paul. Production scheduling problem in the glass-container industry. Operation Reasearch,27(2):290-302, 1997.
CLAIO-2016
445

Optimality of the exhaustible resour e extra tion in terms of a
martingale �xed point hara terization.
Juri Hinz, University of Te hnology, Sydney
S hool of Mathemati al and Physi al S ien es,
PO Box 123, Broadway NSW 2007, SYDNEY, Australia
E-mail: juri.hinz�uts.edu.au
April 3, 2016
Abstra t
Diverse problems in the area of optimal resour e management, exploration of natural
reserves, pension fund management, and environmental prote tion an naturally be for-
mulated under a uni�ed framework, as sto hasti ontrol problems of a spe i� type. We
show that solutions to these problems are hara terized in terms of �xed-point equations
for martingales, where the martingale �xed-point pro ess represents a marginal pri e of
the resour e remaining in the reserve. We address the existen e of the martingale �xed
point and elaborate on e� ient solution of our ontrol problems.
1 Introdu tion
Let us point out that some typi al ontrol problems arising in the are of mining and natural
resour e exploration, pension fund management, ele tri ity generation, and emission trading
are naturally formulated under the following uni�ed framework. Assume that an e onomi
agent is onfronted with a sequential de ision problem, where within a sto hasti environment,
at the beginning of ea h de ision epo h t = 0, 1 . . . , T − 1 , the optimal level ξt of an a tivity
is sele ted. Thereby, both the osts Ct(ξt) of the a tivity ξt and its resour e onsumption
Et(ξt) must be optimally balan ed against ea h other. While the ost Ct(ξt) has an immediate
e�e t, the impa t of the resour e onsumption Et(ξt) is un ertain sin e it be omes relevant at
a future date. On this a ount, a hoi e of the optimal a tivity level ξt represents a trade-o�
between the value of the extra ted resour es and the osts asso iated with the s ar ity of these
resour es in the future.
1
CLAIO-2016
446

Let us present some examples where su h problems naturally arise. In the mining operation
optimization, the ommodity extra tion an be e�e ted through di�erent te hnologies using
diverse operation modes. Thereby, the osts in lude the in ome from the extra ted ommodity
subje t to the extra tion osts, whereas the resour e onsumption is dire tly asso iated with
the environmental impa t of mining whi h diminishes the future ommodity availability. In
the ele tri ity generation from hydro-storages, the a tivity is determined by the volume of pro-
du ed energy through diverse generators, supplied from a ommon system of hydro-storages.
Here the osts are determined by the revenue from generated ele tri ity whereas the resour e is
represented by the water level in the reservoir. In the area of emission abatement, the a tivity
is related to the produ tion of goods whi h auses environmental pollution. On this a ount,
the optimal produ tion intensity naturally represents a trade-o� between the in ome from
the urrent produ tion and the osts aused by the future environmental e�e ts. In the area
of ele troni trading, the order liquidation problem is related to the optimal order pla ement
whi h in ludes the hoi e of order type and size with impa ts on revenues from asset liquida-
tion. Usually, a faster liquidation auses losses whi h are to be balan ed against the risk from
asset positions, potentially remaining at the end of liquidation phase. Finally, some pension
fund management problems, for instan e, related to the so- alled variable annuity ontra ts
fall under the same framework. Here, the funds are invested in risky se urities and an be
withdrawn on regular basis subje t to several restri tions and fees whi h depend on to the
withdrawn volume. The size of the withdrawn funds is to be optimized against the fund value
remaining at maturity of the ontra t.
A typi al di� ulty with su h ontrol problems is originated from a omplex stru ture of the
the spa e Ξ of all feasible a tivities. For instan e, the optimal management of hydro-ele tri
plants would require de�ning Ξ as the olle tion of all feasible one-period produ tion plans,
for ea h generator. Similarly, for environmental prote tion, the set Ξ must omprise all
admissible one-period s hedules for the entire range of polluting units. Let us highlight how to
pass over the omplexity of the set Ξ by an equivalent problem re-formulation to obtain ontrol
problems with one-dimensional a tion spa e. The idea is simple: If at any time t = 0, . . . T
there was a (forward) pri e At for a right to re eive one unit of resour es at the end of the
planing horizon, then an optimal a tivity ξ∗t at any time t would be a minimizer to
Ξ → R, ξt 7→ Ct(ξt) + AtEt(ξt).
Indeed, having in mind that the agent an possess (or an buy) the resour es remaining at the
end of extra tion period, it seems optimal to hose an a tivity level whose resour e onsumption
represents the best possible hoi e given today's pri e of resour es available at the �nal date.
Following a detailed study of this intuitive idea, we observe that it is possible to introdu e a
2
CLAIO-2016
447

(virtual) resour e pri e whi h starts driving the optimal extra tion a tivity and be omes the
true de ision variable, whose optimal hoi e is hara terized by a ertain martingale property.
2 Exhaustible resour e extra tion
Let us state our problem more pre isely. The targeted strategy (ξt)T−1t=0 is supposed to attain
an optimal balan e between the total a tivity osts
∑T−1t=0 Ct(ξt) and the resour e level Γ −
∑T−1t=0 Et(ξt) remaining at time T . Here,
∑T−1t=0 Et(ξt) des ribes the umulated resour e
onsumption and Γ stands for the initial resour e level whi h is not known in advan e and is
represented by a random variable. We assume that the total resour e onsumption is expressed
in monetary units as H(∑T−1
t=0 Et(ξt) − Γ) with a given real-valued fun tion H on R . That
is, the umulative expe ted burden of the poli y ξ = (ξt)T−1t=0 is given by the expe ted value
B(ξ) = E(
T−1∑
t=0
Ct(ξt) + H(
T−1∑
t=0
Et(ξt) − Γ)).
of the total �nal revenue
∑T−1t=0 Ct(ξt) + H(
∑T−1t=0 Et(ξt) − Γ) . To deal with su h sto hasti
ontrol problems, we introdu e a �ltered probability spa e (Ω,F , P, (Ft)Tt=0) and write Et(·)
and Pt to denote, respe tively, the onditional expe tation and the onditional distribution
with respe t to Ft . Further, we agree that all sto hasti pro esses onsidered in what follows
are adapted to the �ltration (Ft)Tt=0 . We suppose that at ea h time t = 0, 1 . . . , T the agent
hooses a strategy x ∈ Ξ from the set Ξ of all possible a tivities, whi h is des ribed by
a omplete and separable metri spa e equipped with the Borel sigma algebra B(Ξ) . Any
Ξ -valued sto hasti pro ess (ξt)T−1t=0 is referred to as poli y in what follows. The goal of the
ontroller is to determine a poli y ξ∗ = (ξ∗t )T−1
t=0 whi h minimizes the total expe ted burden.
Given x ∈ Ξ , in the situation ω ∈ Ω , at de ision time t = 0, . . . , T − 1 , the agent realizes
the a tivity osts Ct(x)(ω) ∈ R and the resour e onsumption Et(x)(ω) whi h are given in
terms of B(Ξ) ⊗ Ft �measurable real-valued fun tions Ct, Et : Ξ × Ω → R . Furthermore, let
us introdu e the following Legendre-type transform, assuming that
for a ∈ R, the minimization problem
infx∈Ξ (Ct(x) + aEt(x))
possesses a unique solution Xt(a).
(1)
Let us agree to write for ea h a ∈ R and t = 0, . . . , T − 1
ct(a) := Ct(Xt(a)) + aEt(Xt(a)), (2)
et(a) := Et(Xt(a)). (3)
3
CLAIO-2016
448

Now, let us introdu e our optimal ontrol problem
determine a poli y ξ∗ = (ξ∗t )
T−1t=0 whi h
minimizes the burden B(ξ∗) ≤ B(ξ)
over all poli ies ξ = (ξt)T−1t=0 .
(4)
Suppose that the
the fun tion H is onvex whose derivative ∇H(y) = h(y)
exists and is ontinuous at (Lebesgue) almost ea h point
and is bounded ∞ < h = inf h(y), ∞ > h = suph(y).
(5)
Consider a related martingale �xed-point problem:
determine a martingale A∗ = (A∗t )
Tt=0 whose
terminal value satis�es A∗T = h(
∑T−1t=0 et(A
∗t ) − Γ).
}(6)
In what follows, we elaborate on the relation between (4) and (6) under the following standing
model assumption:
the onditioned distribution PT−1(Γ ∈ dy)
possess no point masses almost surely.
}(7)
3 Optimal extra tion and martingale �xed point
In the next proposition, we show that the solution of the martingale �xed point problem (6)
determines the solution to our optimal ontrol problem (4). The reminder of this se tion is
devoted to the dis ussion of the existen e of a solution to (6).
Proposition 1. Given a solution (A∗t )
Tt=0 to (6), de�ne
ξ∗t = Xt(A
∗t ), t = 0, . . . , T − 1. (8)
Then the poli y (ξ∗t )T−1
t=0 is a solution to (4).
Proof. Using Bellman prin iple, we later prove that if the optimality ondition
Ct(ξt) + Et(H(∑T−1
s=0,s 6=t Es(ξ∗s ) + Et(ξt) − Γ)) ≤
≤ Ct(ξ∗t ) + Et(H(
∑T−1s=0,s 6=t Es(ξ
∗s) + Et(ξ
∗t ) − Γ))
for t = 0, . . . , T − 1 for ea h Ft-measurable Ξ-valued ξt
(9)
4
CLAIO-2016
449

is satis�ed, then the poli y (ξ∗t )T−1
t=0 is in fa t a solution to (4). Now, let us show with the hoi e
of (ξ∗t )
T−1t=0 and in (8) the assertion (9) holds. First, observe that be ause of the onvexity of
H we obtain for ea h t = 0, . . . , T − 1 the estimate
H(
T−1∑
s=0,s 6=t
Es(ξ∗s ) + Et(ξt) − Γ) ≥ H(
T−1∑
s=0,s 6=t
Es(ξ∗s) + Et(ξ
∗t ) − Γ)+
+h(T−1∑
s=0,s 6=t
Es(ξ∗s) + Et(ξ
∗t ) − Γ) · (Et(ξt) − Et(ξ
∗t )). (10)
On the other hand, using the assumption (8) whi h ensures Et(ξ∗t ) = et(A
∗t ) for t = 0, . . . , T −
1 , we obtain
A∗T = h(
T−1∑
s=0,s 6=t
Es(ξ∗s ) + Et(ξ
∗t ) − Γ). (11)
Given this terminal value, the martingale property of (A∗t )
Tt=0 implies that
Et(h(
T−1∑
s=0,s 6=t
Es(ξ∗s ) + Et(ξ
∗t ) − Γ) · (Et(ξt) − Et(ξ
∗t ))) = A∗
t (Et(ξt) − Et(ξ∗t )) (12)
for t = 0, . . . , T −1 . Applying the onditional expe tation Et on both sides of (10) and using
(12), we obtain
Et(H(
T−1∑
s=0,s 6=t
Es(ξ∗s ) + Et(ξt) − Γ)) ≥ Et(H(
T−1∑
s=0,s 6=t
Es(ξ∗s ) + Et(ξ
∗t ) − Γ)) +
+A∗t · (Et(ξt) − Et(ξ
∗t ))
whi h is equivalent to
A∗t · (Et(ξt) − Et(ξ
∗t )) ≤
≤ Et(H(
T−1∑
s=0,s 6=t
Es(ξ∗s ) + Et(ξ
∗t ) − Γ)) − Et(H(
T−1∑
s=0,s 6=t
Es(ξ∗s ) + Et(ξt) − Γ)). (13)
On the other hand, the assumption (8) yields
Ct(ξ∗t ) + A∗
t Et(ξ∗t ) ≤ Ct(ξt) + A∗
t Et(ξt), t = 0, . . . , T − 1.
from whi h we on lude
Ct(ξ∗t ) − Ct(ξt) ≤ A∗
t (Et(ξt) − Et(ξ∗t )), t = 0, . . . , T − 1.
whi h we ombine with (13) to estimate for t = 0, . . . , T − 1
Ct(ξ∗t ) − Ct(ξt) ≤
≤ Et(H(
T−1∑
s=0,s 6=t
Es(ξ∗s ) + Et(ξ
∗t ) − Γ)) − Et(H(
T−1∑
s=0,s 6=t
Es(ξ∗s ) + Et(ξt) − Γ))
5
CLAIO-2016
450

whi h is the desired optimality equation (9).
To verify that (9) in fa t ensures the optimality, we follow a standard argumentation. Given
a poli y ξ = (ξt)T−1t=0 , the poli y value
V ξt : R × Ω → R, (e, ω) 7→ Et(
T−1∑
s=t
Cs(ξs) + H(e +T−1∑
s=t
Es(ξs) − Γ))(ω)
is de�ned as the revenue resulting from following the ontinuation (ξs)T−1s=t of the poli y
ξ = (ξs)T−1s=0 starting with the amount e ∈ R of onsumed resour es. These poli y values
(V ξt )T−1
t=0 satisfy the ba kward re ursion
V ξt−1(e) = Et−1(V
ξt (e + ξt)), t = T − 1, . . . , 1, e ∈ R. (14)
If a poli y ξ∗ = (ξ∗t )
T−1t=0 satis�es the optimality ondition (9), then from (14) it follows by
indu tion that for arbitrary poli y ξ = (ξt)T−1t=0 it holds that
V ξ∗t (e) ≤ V ξ(e) for t = T, . . . , 0 , and e ∈ R ,
thus we obtain the desired optimality B(ξ∗) = V ξ∗0 (0) ≤ V ξ
0 (0) = B(ξ) .
In what follows, we address the existen e of a solution to (6) utilizing an approa h suggested
in [4℄. It turns that the assumptions of the previous se tion are su� ient for the existen e of
the martingale �xed point (A∗t )
Tt=0 . Thereby, the martingale (Γt = Et(Γ))Tt=0 losed by Γ
plays a ru ial role. For later use, let us introdu e its in rements
εt = Γt − Γt−1 t = 1, . . . , T.
The urrent state is determined at time time t , in the s enario ω by
Gt =
t−1∑
s=0
et(A∗s) − Γt, t = 0, . . . , T. (15)
Following the intuition that martingale �xed point at time t shall be determined by the
urrent situation, we assume that
A∗t (ω) = ht(Gt(ω))(ω), ω ∈ Ω, t = 0, . . . , T, (16)
and address the hypotheti fun tionals
ht : R × Ω → [h, h], B(R) ⊗ Ft -measurable, for t = 0, . . . T . (17)
Note that at the last time point T , hT given by the derivative h of H :
hT (g)(ω) = h(g), ω ∈ Ω, g ∈ R. (18)
6
CLAIO-2016
451

Note that, if (16) is true and the fun tionals (17) are known, then the pri e pro ess (A∗t )
Tt=0
is indeed well-de�ned by the re ursive appli ation of (15) and (16):
A∗t := ht(Gt), (19)
Gt+1 := Gt + et(A∗t ) − εt+1, (20)
started at G0 := Γ0. (21)
Generated by this re ursion, the pro ess (A∗t )
Tt=0 follows a martingale if, for all t = 0, . . . T −1
ht(g) = EQt (ht+1(g + et(ht(g)) − εt+1)), for all g ∈ R .
In other words, it is su� ient to ensure that
for ea h g ∈ R, ht(g)(ω) solves
a = EQt (ht+1(g + et(a) − εt+1))(ω)
for almost all ω ∈ Ω.
(22)
Indeed, it an be shown that the fun tionals (17) are re ursively obtained as the unique
solution to (22), starting with hT from (18). We address a solution to (6) in the last point of
the following proposition, whose detailed proof is given in [2℄
Proposition 2. Suppose that for t ∈ {0, . . . , T − 1}
et : R × Ω → R, B(R) ⊗ Ft-measurable su h that (23)
a 7→ et(a)(ω) is non-in reasing, ontinuous (24)
ht+1 : R × Ω → [h, h], B(R) ⊗ Ft+1-measurable su h that (25)
g 7→ ht+1(g)(ω) is non-de reasing for all ω ∈ Ω. (26)
Under the above assumptions it hold that
i) There exist fun tionals
ht : R × Ω → [h, h], B(R) ⊗ Ft -measurable, t = 0, . . . T (27)
whi h ful�ll for all g ∈ R
hT (g) = h(g), (28)
ht(g) = Et(ht+1(g + et(ht(g)) − εt+1)), t = 0, . . . , T − 1. (29)
ii) There exists a martingale (A∗t )
Tt=0 whi h satis�es
A∗T = h(
T−1∑
t=0
et(A∗t ) − Γ). (30)
7
CLAIO-2016
452

4 Con lusion and Outlook
This paper presents an optimality hara terization for a ertain sto hasti ontrol problem
in terms of martingale property for a Legendre-type transform of the de ision variable. An
interesting aspe t of this approa h is that the optimality is obtained without any Markovian-
type assumption on the underlying dynami s. This remarkable generality omes at the osts
of solutions expressed in terms of path-dependent fun tionals ht , t = 0, 1, . . . , T and allows
a natural interpretation: In the ase of emission trading, the transformed ontrol variable
(At)Tt=0 stands for the market pri es of emission erti� ates and their martingale property
is dire tly related to the no-arbitrage property whi h is an immediate onsequen e of the
market equilibrium. Following this line, on lusions about so ial optimality with respe t to
the so- alled risk-neutral measure an be dedu ed [1℄, and onstru tions of relevant sto hasti
equilibrium-like models of emission markets are suggested.
Furthermore, under additional assumption that there exists a Markov state pro ess (Zt)Tt=0
su h that for ea h t = 0, . . . T − 1 the Ft - onditioned distribution of (εs)Ts=t depends on
Zt only and the randomness in Ct(·), Et(·) enters through the variable Zt , the resour e
optimization problem an be formulated in the standard ontext of Markov De ision theory.
In this ase, with the te hniques provided by [3℄ a detailed numeri al analysis of exhaustible
resour e extra tion an be performed in [5℄.
Referen es
[1℄ P. Falbo and J. Hinz. Sto hasti s of Environmental and Finan ial E onomi s: Centre of
Advan ed Study, Oslo, Norway, 2014-2015, hapter Risk Aversion in Modeling of Cap-
and-Trade Me hanism and Optimal Design of Emission Markets, pages 265�284. Springer
International Publishing, Cham, 2016.
[2℄ J. Hinz. A martingale �xed point hara terization in optimal extra tion of exhaustible
reserves. Work in progress.
[3℄ J. Hinz. Optimal sto hasti swit hing under onvexity assumptions. SIAM Journal on
Control and Optimization, 52(1):164�188, 2014.
[4℄ J. Hinz and A. Novikov. On fair pri ing of emission-related derivatives. Bernoulli,
16(4):1240�1261, 2010.
[5℄ J. Hinz and J. Yee. Commodity resour e valuation and extra tion: A pathwise program-
ming approa h. Workiong paper, pages 1�17, 2016.
8
CLAIO-2016
453

Impact Of Household Renewable Energy And Other
Retailers On Optimal Energy Storage
Juri HinzUniversity of Technology Syndey
Jeremy YeeCSIRO and University of Technology Sydney
April 3, 2016
Abstract
This short paper considers the optimal management of a battery storage device for an elec-tricty retailer exposed to household renewable energy generation and other retailers who alsotrade in the wholesale electricity market. This paper provides a numerical solution for theresulting stochastic control problem.
1 Motivation
Rapid improvements in battery technology has opened the possibility of storing electricity invast quantities. This coupled with the proliferation of renewable energy systems in householdssuch rooftop solar panels has very significant implications for the modern day energy grid. Thispaper will examine this issue from the perspective of a Retailer i in the energy system representedby Figure 1. This model comprises of three distinct types of participants: 1) households, 2)retailers and 3) energy suppliers. The households consume but also generate energy from theirrenewable energy systems and the net difference is taken/supplied to the electricity retailers.A typically retailer will purchase electricity in advance to satisy their customers’ net energydemand by trading forward contracts in the so-called day-ahead market. Any imbalance betweentheir forward position and the net customer demand will need to be rectified immediately bypurchasing electricity from the energy suppliers at the real time grid price determined by theforces of demand and supply. With the introduction of efficient battery storage devices for theretailers, the net customer demand can also be taken/supplied to these storage devices. Similarly,these storage devices can also be recharged to a chosen level by purchasing electricity from thesuppliers in the day-ahead market. In this sense, the battery act as a valuable buffer for theretailer. However, these batteries have a finite capacity and so any electricity shortage/excesspast capacity will still need to be rectified in real time. Unlike in the traditional energy market,the retailer here will need to simultaneously set the optimal forward position and the optimalenergy storage levels. This optimal control problem is challenging due to the high dimensionalityof the state spaces often involved and so efficient numerical schemes will have great practicalsignificance.
1
CLAIO-2016
454

Households Retailers Suppliers
Consumer
RenewableEnergy
Retailer i
Battery
Retailer -i(Other Retailers)
WholesaleMarket
orGrid
Figure 1: Electricity system. The blue lines represent the flow of energy.
2 Problem Setting
Supppose that in our model, there are two energy retailers: Retailer i and Retailer −i. Thesedealers essentially act as intermediaries between their household customers and the energy sup-pliers/grid. Let us consider the control problem faced by Retailer i. Within a given time horizont = 0, . . . , T −1, the daily net energy demand Qt is the difference between the consumer demandand the household renewable energy output. Given an existing forward position Ft, the energyimbalance Ft−Qt will be compensated using the energy from the battery storage followed by apossible offset through real-time energy from the power grid if required. That is, in the case ofthe energy surplus Ft −Qt ≥ 0, the electricity is first used to charge Retailer i’s battery up toa maximally possible amount and the remaining energy is then supplied to the grid. Similarly,if there is an energy shortage Ft −Qt < 0, the required electricity is supplied from the batteryup to a maximally possible amount before the remaining electricity is taken from the grid.
Let us assume that the net demand realization is given by Qt = qt + εt with zero-meanrandom variable εt describing the deviation of the net demand Qt from its predicted level qt.The process (qt)
T−1t=0 will be assumed to be known at t = 0. Suppose that the forward position
is given in terms of Ft = qt + a where the quantity a describes energy retailer’s decision tobuy/sell in the forward market an energy amount qt + a which deviates from the predicted netdemand by a pre-determined safety margin a. We model the decision of the retailer in the choiceFt = Ft(a) of forward positions in terms of the action a ∈ A from a finite set A of all possibleactions. Given action a ∈ A, the realized net household energy surplus faced by Retailer i attime t is given by
Ft(a)−Qt = qt + a− (qt + εt) = a− εt, a ∈ A.
That is, the action a ∈ A determines a certain distribution νt(a) of the net household energysurplus faced by Retailer i determined by νt(a) ∼ a− εt for all a ∈ A.
For simplicty, we will assume that the evolution of the forward price (Πt)Tt=0 is uncontrolled
by the energy retailers. Let Zt ∈ Z ⊆ Rd be a vector representing the relevant uncontrolledmarket forces which is assumed to follow the following linear dynamics
[Z̃t+1 Γt+1 Πt+1]> =: Zt+1 = Wt+1Zt, t = 0, 1, . . . , T − 1,
where Γt+1 is the revenue from each unit of energy sold to the household, Wt+1 is d× d matrixcontaining random but integrable entries and Z̃t+1 is a vector of size (d−2) used to capture all theother relevent uncontrolled market conditions. Denote the real time prices at which the dealerscan take and supply energy to the grid by Πt and Πt, respectively. These prices are governed bythe economic forces of demand and supply. Let us represent the buy price Πt : R+ × Z → R+
by the pricing schedule/supply curve Πt(x, Zt), where x is the aggregate unplanned purchase of
CLAIO-2016
455

energy by all the retailers and Zt is the vector containing the uncontrolled market conditions.In practice, a tiered system is often used in the generation of electricity where cheap sourcesare used first before moving on to more expensive generators. Therefore, realistically, Πt(x, Zt)should be non-decreasing in x. Since Πt represents the price of the planned supply of energy attime t, Πt(x, Zt) should also be non-decreasing in Πt using the same logic. Similarly, let the realtime sell grid price Πt : R+×Z→ R+ be given by the pricing schedule/demand curve Πt(y, Zt)where y is the aggregate unplanned supply of energy to the energy grid. Both these functionsare assumed to be convex functions in Zt.
Now suppose that the random variable ε−it represents Retailer −i’s unplanned net purchaseof electricity from the energy grid. The random variables ε−it and εt are correlated but areindependent across time. In order to describe the battery control problem, we discretized thestorage levels by a finite set P. Having chosen the action a ∈ A, Retailer i’s net energy changeFt(a)−Qt follows a distribution νt(a) which determines for each battery storage level p ∈ P aprobability αap,p′ that the storage reaches the next-day level p′ ∈ P. Now, after applying actiona ∈ A to position p ∈ P, the expected market value of Retailer i’s unplanned energy purchasefrom the grid e : P×Z×A→ R+ and unplanned energy supply to the grid e : P×Z×A→ R+
are uniquely determined and defined as
et(p, Zt, a) = E[ε̄t,p,aΠ(ε̄t,p,a, Zt)|ε̄t,p,a > 0, ε−it ≤ 0
]P(ε̄t,p,a > 0 ∩ ε−it ≤ 0)
+ E[ε̄t,p,aΠ(ε̄t,p,a + ε−it , Zt)|ε̄t,p,a > 0, ε−it > 0
]P(ε̄t,p,a > 0 ∩ ε−it > 0)
and
et(p, Zt, a) = E[εt,p,aΠ(εt,p,a, Zt)|εt,p,a > 0, ε−it ≥ 0
]P(εt,p,a > 0 ∩ ε−it ≥ 0)
+ E[εt,p,aΠ(εt,p,a − ε−it , Zt)|εt,p,a > 0, ε−it < 0
]P(εt,p,a > 0 ∩ ε−it < 0)
where ε̄t,p,a := εt − p − a + min P gives the net battery deficit after absorbing the householddemand and εt,p,a := p+ a− εt −max P gives the net battery surplus.
Let us now turn to the specification of the rewards/costs. At t = T , Retailer i sells allhis/her stored energy at the forward price Πt and this determines the scrap value. The revenueassociated with the action a ∈ A depends on the current forward price Πt, and the battery levelp ∈ P through
rT (p, ZT ) = pZ(d)T
rt(p, Zt, a) = qtZ(d−1)T − (qt + a)Z
(d)t − et(p, Zt, a) + et(p, Zt, a), t = 0, 1, . . . , T − 1,
where Z(d)t = Πt, Z
(d−1)t = Γt and qtZ
(d−1)t is the expected revenue from the households.
Retailer i’s objective is to maximise the expected total sum of the rewards.
3 Markov Decision Processes
Problems of this type can formulated as Markov decision processes where the state space isgiven by E = P×Z. For each a ∈ A, we assume that Ka
t (x, dx′) is a stochastic transition kernelon E. A mapping πt : E 7→ A which describes the action that the controller takes at time tis called a decision rule. A sequence of decision rules π = (πt)
T−1t=0 is called a policy. For each
initial point x0 ∈ E and each policy π = (πt)T−1t=0 , there exists a probability measure Px0,π and
a stochastic process (Xt)Tt=0 such that Px0,π(X0 = x0) = 1 and
Px0,π(Xt+1 ∈ B |X0, . . . , Xt) = Kπt(Xt)t (Xt,B) (1)
CLAIO-2016
456

holds for each B ⊂ E at all times t = 0, . . . , T − 1. That is, given that system is in state Xt at
time t, the action a = πt(Xt) is used to pick the transition probability Ka=πt(Xt)t (Xt, ·) which
randomly drives the system from Xt to Xt+1 with the distribution Kπt(Xt)t (Xt, · ). Given an
initial point x0, the goal is to maximize the expected finite-horizon total reward, in other wordsto find the argument π∗ = (π∗t )T−1t=0 such that
π∗ = arg maxπ∈D
Ex0,π
(T−1∑
t=0
rt(Xt, πt(Xt)) + rT (XT )
), (2)
where D is the set of all policies, and Ex0,π denotes the expectation over the controlled Markovchain defined by (1). The maximization (2) is well-defined under diverse additional assumptions(see Bauerle and Rieder (2011), p. 199). The following subsection describes our numericalapproach.
3.1 Numerical Approach
Let us introduce the so-called sub-gradient envelope SGmf of a convex function f : Rd → Ron a grid Gm ⊂ Rd with m points i.e. Gm = {g1, . . . , gm} by SGmf = ∨g∈Gm(Ogf) which isa maximum of the sub-gradients Ogf of f on all grid points g ∈ Gm. Using the sub-gradientenvelope operator, define the double-modified Bellman operator as
T m,nt v(p, z) = SGmmaxa∈A
rt(p, z, a)+
∑
p′∈P
αap,p′
n∑
k=1
νnt+1(k)v(p′,Wt+1(k)z)
where the probability weights (νnt+1(k))nk=1 corresponds to the distribution sampling (Wt+1(k))nk=1
of each disturbance Wt+1. The corresponding backward induction
vm,nT (p, z) = SGmrT (p, z), p ∈ P, z ∈ Rd (3)
vm,nt (p, z) = T m,nt vm,nt+1 (p, z), t = T − 1, . . . 0. (4)
yields the so-called double-modified value functions (vn,mt )Tt=0. Under appropriate assumptionsthat are met in this paper (see Hinz (2014)), the double-modified value functions convergeuniformly to the true value functions on compact sets. Note that any piecewise linear functionf can be described by a matrix where each linear functional is represented by a row in thematrix. Given a function f and a matrix F , we write f ∼ F whenever f(z) = max(Fz) holdsfor all z ∈ Rd. Let us emphasize that the sub-gradient envelope operation SGm is reflected interms of a specific row-rearrangement operator
f ∼ F ⇔ SGmf ∼ ΥGm [F ]
where the row-rearrangement operator ΥGm acts on matrix F by:
(ΥGmF )i,· = Fargmax(Fgi),· for all i = 1, . . . ,m. (5)
If f1 ∼ F1 and f2 ∼ F2 holds, then it follows that
SGm(f1 + f2) ∼ ΥGm(F1) + ΥGm(F2)
SGm(f1 ∨ f2) ∼ ΥGm(F1 t F2)
SGm(f1(W ·) ∼ ΥGm(F1W )
where W is an arbitrary d × d matrix and the operator t stands for binding matrices byrows. Therefore, the backward induction (3) and (4) can be expressed in terms of the matrix
CLAIO-2016
457

representatives V m,nt (p) of the value functions v(m,n)t (p, z) for p ∈ P, z ∈ Rd and t = 0, . . . T
and which is given by the following algorithm.
Algorithm 3.1: Value Function Approximation
1 for p ∈ P do2 V m,nT (p)← SGmrT (p, .)3 end4 for t ∈ {T − 1, . . . , 0} do5 for p ∈ P do
6 Ṽ m,nt+1 (p)←∑nk=1 ν
nt+1(k)ΥGm [V m,nt+1 (p)Wt+1(k)]
7 end8 for p ∈ P do
9 V m,nt (p)← ΥGm
[ta∈A
(SGmrt(p, ., a) +
∑p′∈P α
ap,p′ Ṽ
m,nt+1 (p′)
)]
10 end
11 end
A candidate for a nearly optimal policy is given by
πm,nt (p, z) = arg maxa∈A
rt(p, z, a) + max
∑
p′∈P
αap,p′ Ṽm,nt+1 (p′)z
. (6)
To gauge the quality of the approximations returned by Algorithm 3.1, let us first introducethe zero mean random variable
ϕ(p, z, a) =∑
p∈P
αap,p′1
I
I∑
i=1
maxV m,nt+1 (p′)W (1)t+1(i)z −maxV m,nt+1 (Pt+1)W
(2)t+1z (7)
for some number I. The random variables W(1)t+1,W
(2)t+1 ∼Wt+1 are independent and identically
distributed and we denote W(1)t+1(i) to be a particular realization of the random variable W
(1)t+1 in
the nested simulation. Now for a set of interested sample paths (ωi)Ni=1 with Z0 = z0 a.s. and
using Equation 6 and Equation 7, Algorithm 3.2 acts as a diagnostic tool for Algorithm 3.1.
Algorithm 3.2: Solution Diagnostics
1 for ωi ∈ {ω1, . . . , ωN} do2 for p ∈ P do3 υT (p, ZT (ωi))← υT (p, ZT (ωi))← rT (p, ZT (ωi))4 end5 for t ∈ {T − 1, . . . , 0} do6 for p ∈ P do7 zt ← Zt(ωi)8 â← πm,nt (p, zt)
9 υ(i)t (p, zt)← rt(p, zt, â) + ϕt(p, zt, â)(ωi) +
∑p′∈P α
ap,p′υ
(i)t+1(p′, zt+1)
10 υ(i)t (p, zt)←
maxa∈A
{rt(p, zt, a) + ϕt(p, zt, a)(ωi) +
∑p′∈P α
ap,p′υ
(i)t+1(p′, zt+1)
}
11 end
12 end
13 end
14 υ0(p, z0)← 1N
∑Ni υ
(i)0 (p, z0) and υ0(p, z0)← 1
N
∑Ni υ
(i)0 (p, z0), ∀p ∈ P
CLAIO-2016
458

It holds thatE(υ0(p, z0)) ≤ v0(p, z0) ≤ E(υ0(p, z0)) (8)
where v0(p, z0) is the true value function and equality holds on both sides when πm,nt (p, zt) =π∗t (p, zt) and
φ(p, z, a) =∑
p′∈P
αp,p′(a)E (vt+1(p′,Wt+1z))− vt+1(Pt+1,Wt+1z).
We refer any interested readers to Hinz and Yap (pear) for the proofs. The tighter the boundsin Equation 8 and the lower the standard errors of the bounds, the closer the value functionapproximations and candidate policy is to optimality.
4 Numerical Example
In the following numerical example, suppose the unexpected net household energy demand forboth retailers follows a bivariate Normal distribution i.e.
[εtε−it
]∼ N
(0,Σ =
[σ2i ρi,−iσiσ−i
ρ−i,iσ−iσi σ2−i
])
where Σ denotes the covariance matrix and the correlation satisfies 0 < ρ < 1. To describe theevolution of the battery storage levels, let us assume that the finite set P describes the storagelevels of the battery which are equidistantly spaced with step size ∆ > 0 between the minimalp = min P and the maximal p = max P. Suppose that having chosen the action a ∈ A at thecurrent battery level Pt+1, the next level battery level Pt+1 is governed by
Pt+1 = arg minp∈P|p− (Pt + a− εt)|,
from which the transition probabilities in the storage level induced by the action a are given by
αap,p′ =
Np+a,σ2i([p′ −∆/2, p′ + ∆/2]) if p < p′ < p,
Np+a,σ2i(]−∞, p+ ∆/2]) if p′ = p,
Np+a,σ2i([p−∆/2,+∞[) if p′ = p
where Np+ a, σ2i is the probability measure associated with the normal distribution with mean
p + a and variance σ2i . The forward price Πt is assumed to be uncontrolled and follows an
auto-regression of order one i.e
Zt+1 :=
[1
Πt+1
]=
[1 0
µ+ ςNt+1 φ
] [1
Πt
],
with constants µ ∈ R, ς ∈ R+, φ ∈ [0, 1] and independent standard normally distributedrandom variables (Nt)
T−1t=0 . For simplicty, assume that the household price of electricity Γt is
deterministic and that the real time grid sell price is given by Πt(x,Πt) = 0 and the real timebuy price follows Πt(x,Πt) = x+ Πt. Therefore, the expected market value of the excess energyis et(p,Πt, a) = 0 and the shortage et(p,Πt, a) is given by
et(p,Πt, a) =
∫ p
−∞(p− x)(x+ Πt)Np+a,σ2
i(dx) +
∫ p
−∞
∫ ∞
0
(p− x)yNp+a,Σ(dydx)
where Np+a,Σ is the probability measure associated with the bivariate normal distribution withmean [x, y]> = [p + a, 0]> and covariance matrix Σ. Recall that the second component of Ztrepresents the forward price and so the resulting reward functions can be written as
rt(p, (z(1), z(2)), a) = qtΓt − (qt + a)z(2) − et(p,Πt, a), t = 0, . . . , T,
CLAIO-2016
459

for all a ∈ A, p ∈ P and (z(1), z(2)) ∈ R2 and the scrap value by
rT (p, (z(1), z(2))) = pz(2), p ∈ P, (z(1), z(2)) ∈ R2.
The following numerical results were generated using a grid containing 201 equally spacedpoints on the line from zT = [1, 0] to zT = [1, 20] and the disturbance sampling was constructedusing the 10, 000 quantiles from the standard normal distribution. The battery storage specifi-cations are given by p = 0 MWh, p = 100 MWh, and ∆ = 5 MWh. The energy retailer choosesaction a ∈ {0MWh, 2.5MWh, 5MWh, . . . , 30MWh}. A time horizon of a year at daily frequencyis considered i.e t = 0, 1, . . . , 364 and the auto-regressive process for the forward price is deter-mined by µ = 1, ς = 1 and φ = 0.9, which has stationary value 10. We set the the standarddeviations for the random deviations εt and ε−it at σi = 5 and σ−i = 50, respectively, with nocorrelation i.e. ρi,−i = 0. The price of electricity sold to the households is set at Γt = $10/MWhand the predicted demand ast qt = 1 MWh for t = 1, ..., 364. The solution diagnostics in Table1 were generated by running Algorithm 3.2 with 500 sample paths for the price and 500 subsim-ulations for each path at each non-terminal decision epoch. The tight bounds and low standarderrors indicate that the output in Figure 2 are close to optimality. These results were generatedusing the authors’ R package.
Table 1: Optimal Expected Total Rewards for Π0 = 10Battery Level (MWh) Lower Bound ($) Upper Bound ($)
0 -252.16964(.03842519) -252.14909(.03850193)5 -202.16964(.03842519) -202.14909(.03850193)10 -152.16964(.03842519) -152.14909(.03850193)15 -104.45198(.03808954) -104.43162(.03816470)20 -60.36955(.03756374) -60.34951(.03763699)25 -19.42662(.03690795) -19.40699(.03697874)30 18.55026(.03617239) 18.56943(.03623981)35 53.71191(.03539339) 53.73058(.03545697)40 86.17286(.03460176) 86.19101(.03466170)45 116.01856(.03382550) 116.03619(.03388241)50 143.31156(.03308792) 143.32870(.03314244)55 168.09673(.03240556) 168.11340(.03245818)60 190.40556(.03178834) 190.42180(.03183939)65 210.25964(.03124133) 210.27549(.03129102)70 227.67337(.03076663) 227.68888(.03081513)75 242.65614(.03036451) 242.67133(.03041200)80 255.21381(.03003384) 255.22875(.03008051)85 265.35000(.02977243) 265.36473(.02981846)90 273.06682(.02957740) 273.08139(.02962296)95 278.36149(.02944587) 278.37595(.02949113)100 281.29609(.02937384) 281.31048(.02941894)
Table 1 gives the lower and upper bounds for the maximum possible expected total rewardsunder different starting battery levels at Π0 = 10 MWh. The standard errors are given in theparanthesis. The lines shown on the right plot in Figure 2 contains the graphically illustrationof the candidate optimal policies while the left plot contains the value function approximations.
CLAIO-2016
460
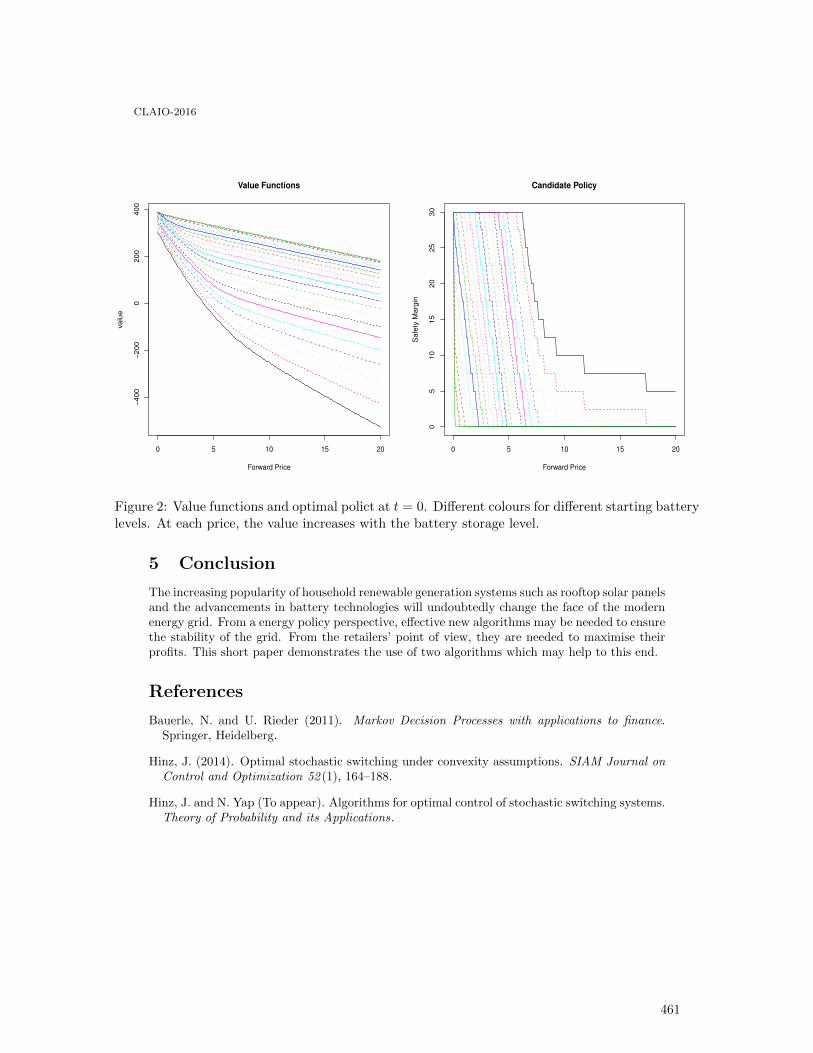
0 5 10 15 20
−400
−200
0200
400
Value Functions
Forward Price
valu
e
0 5 10 15 20
05
10
15
20
25
30
Candidate Policy
Forward Price
Safe
ty M
arg
in
Figure 2: Value functions and optimal polict at t = 0. Different colours for different starting batterylevels. At each price, the value increases with the battery storage level.
5 Conclusion
The increasing popularity of household renewable generation systems such as rooftop solar panelsand the advancements in battery technologies will undoubtedly change the face of the modernenergy grid. From a energy policy perspective, effective new algorithms may be needed to ensurethe stability of the grid. From the retailers’ point of view, they are needed to maximise theirprofits. This short paper demonstrates the use of two algorithms which may help to this end.
References
Bauerle, N. and U. Rieder (2011). Markov Decision Processes with applications to finance.Springer, Heidelberg.
Hinz, J. (2014). Optimal stochastic switching under convexity assumptions. SIAM Journal onControl and Optimization 52 (1), 164–188.
Hinz, J. and N. Yap (To appear). Algorithms for optimal control of stochastic switching systems.Theory of Probability and its Applications.
CLAIO-2016
461

Análisis de la formación de precios y asignación de suministro de
gas natural en Colombia por medio de la simulación de subastas
Antonio Hoyos Chaverra
Universidad Nacional de Colombia - Sede Medellín
Yris Olaya Morales
Universidad Nacional de Colombia - Sede Medellín
Abstract
We present an agent-based simulation model to investigate price formation and gas allocation in
Colombia’s primary natural gas market. Specifically, we model the simultaneously ascending clock auction
(SACA) defined in annex 5 of order RES CREG 089 – 2013. Three types of agents: sellers, buyers, and
auctioneer interact within the rules defined in RES CREG 089 – 2013. The simulation explores how
competitive and strategic behaviors from agents affect final prices and allocations in the auction.
Keywords: Gas market, simultaneous ascending-clock auction, bidding strategy, agent-based simulation,
modeling strategic behavior.
1 Introducción
La asignación de recursos naturales escasos es uno de los temas de mayor interés en la teoría económica y
es una decisión estratégica para muchas naciones. Particularmente, en el ámbito de los recursos energéticos,
las decisiones de localización y propiedad son de interés prioritario por su alto impacto sobre la estabilidad
de la industria y el desarrollo nacional.
En Colombia, desde 1970 se ha impulsado el desarrollo del mercado del gas, a través de planes y regulación
que han propiciado mayor madurez del mercado. El plan de masificación del consumo de gas iniciado en
1990 (CONPES 2571 1991, CONPES 2646 1993) permitió el desarrollo de infraestructura de transporte y
de distribución en las regiones más pobladas. Junto con las reformas del sector eléctrico de 1994 (LEY 142
143 1994), el plan de masificación impulsó el desarrollo de nuevos mercados para el gas natural y permitió
en 2013, la liberación de precios de gas en boca de pozo. Como resultado de la liberación de los precios de
gas natural, y con el fin de aumentar la transparencia en la asignación, en el año 2013, el gobierno de
Colombia a través de la resolución CREG 089 definió nuevas reglas para el mercado mayorista de gas.
Estas reglas incluyen la realización de una subasta simultánea de reloj ascendente en los periodos en los
que la demanda supere a la oferta.
A la fecha esta subasta no se realizado y existe incertidumbre respecto a los efectos y las implicaciones del
proceso de subasta, por tal motivo se propone un modelo para estudiar el impacto del diseño de la subasta
en la formación de precios y la asignación de suministro de gas natural.
2 Subasta simultánea de reloj ascendente
La subasta simultánea de reloj ascendente (SACA) es un mecanismo diseñado para la asignación de
múltiples bienes la cual permite asignar “m” conjuntos de bienes entre “n” compradores de manera
individual, realizando una subasta inglesa para cada uno de los bienes en venta. En cada ronda el subastador
CLAIO-2016
462

anuncia un precio para cada producto y cada comprador indica las cantidades que desea de cada producto
a los precios actuales. El proceso se repite hasta que no exista exceso de demanda para cada uno de los
productos (Cramton, Shoham, & Steinberg, 2006).
Los formatos de subasta simultánea se usan con frecuencia en la asignaciones de recursos naturales, donde
existen múltiples bienes divisibles con relaciones de complementariedad, sustitución o ambas (Wellman,
Osepayshvili, Mackie-mason, Arbor, & Reeves, 2007). No obstante, a pesar de las ventajas de la subasta
simultánea, existe el riesgo por exposición, el cual se define como la posibilidad de que un comprador no
pueda adquirir el conjunto de bienes al que le asigna la mayor valoración. Esto se debe a que no es posible
pujar por combinaciones de paquetes sino por bienes individuales a la vez (Cramton et al., 2006). En el
caso colombiano, los contratos negociados en la subasta tienen la misma fecha de inicio y pueden ser
tratados como sustitutos desde el punto de vista de los compradores, lo cual reduce el riesgo de exposición
para el comprador (Harbord, Pagnozzi, & Von der Fehr, 2011).
La existencia de comportamiento estratégico, específicamente de colusión, es una preocupación de carácter
práctico en las subastas. En el pasado se han identificado formas de colusión relacionas con la información
disponible en la subasta, tal fue el caso de la subasta de espectro de E.E.U.U., en donde los compradores
utilizaron los precios para repartir el mercado de usuarios (Cramton & Schwarts, 2000). Otras formas de
colusión más sofisticadas incluyen el uso por parte de los vendedores de compradores marionetas que se
encargan de presionar el mercado para que los precios aumenten. También se han reportado casos de
colusión en los que se ve involucrado el subastador. Una de las ventajas de la subasta SACA es que la
colusión tácita a través de señales de precio es reducida ya que la puja se manifiesta en cantidades de bienes
y no en precios (Cramton et al., 2006).
3 Modelación de subastas
Desde el inicio de la teoría de subastas se han desarrollado modelos analíticos con el fin de conocer los
posibles resultados de la aplicación de las subastas en la formación de precios, de estudiar el contexto
estratégico entre vendedores y compradores, específicamente, los ingresos de los vendedores, las estrategias
de oferta de los compradores y los modelos de valoración en la subasta Vickrey (1961) Myerson (1981)
(Kemplerer, 1999; Lucking-reiley, 1994 ).
La mayoría de estos análisis fueron realizados con fuertes supuestos como la racionalidad perfecta de los
agentes y la imposibilidad de colusión en la subasta. Para superar esta limitación se han propuesto estudios
desde la economía experimental. Principalmente, se estudió la relación entre las predicciones de la teoría
económica y el comportamiento real de los agentes en las subastas (Cox, Roberson, & Smith, 1982) y los
usos prácticos de las subasta como mecanismos de fijación de precios. En este campo se han demostrado
relaciones entre el diseño de las subastas y sus resultados (Pickl & Wirl, 2011) y la importancia del diseño
de las mismas para alcanzar los objetivos del subastador o regulador (Cramton, 2009). También se ha
observado que algunos tipos de subastas son altamente vulnerables a la aparición de la colusión y/o los
comportamientos predatorios (Rego & Parente, 2013).
En la actualidad la simulación se utiliza con frecuencia para analizar subastas, ya que permite mayor grado
de representación de los procesos reales y, en concreto, del comportamiento de los agentes del mercado
(Macal & North, 2010). En especial, se ha notado que los modelos de la teoría económica cuando se
enfrentan a situaciones reales se encuentran limitados frente a la complejidad de las relaciones entre los
agentes y el tipo de comportamiento que emerge de su interacción (Smith, 1994).
Desde la simulación, la principal técnica utilizada para el análisis de subastas ha sido la modelación basada
en agentes (MBA), por su capacidad de representar a los individuos que conforman el mercado y la
CLAIO-2016
463

complejidad de sus relaciones de una manera realista. (Azadeh, Skandari, & Maleki-Shoja, 2010). Con esta
técnica, por ejemplo, se han definido los agentes de la subasta asignándoles reglas de decisión y
comportamiento para explorar la relación de la especulación y la coordinación (Ziogos & Tellidou, 2011),
el desarrollo de estrategias de aprendizaje (Rahimiyan & Mashhadi, 2008) y adaptabilidad (Weidlich &
Veit, 2008). El MBA permite incluir tantas características como sean necesarias al modelo para realizar el
análisis, en consonancia con el principio de parsimonia que guía el desarrollo de modelos de simulación
(Pidd, 1999). En este trabajo se eligió el enfoque de simulación con MBA por las características del
problema, la capacidad de representación de la técnica y la posibilidad de realizar análisis sobre sistemas
complejos y de probar distintos escenarios de subastas en un ambiente que representará el mercado de gas
natural en Colombia.
4 Metodología
Para la conceptualización de modelo se optó por la aplicación del protocolo ODD (Overview, Design
concepts and Details), que permite realizar de manera estructurada una descripción de los elementos
principales presentes en el modelo y además se constituye en una guía de un proceso riguroso de
formulación (Grimm et al., 2010). El modelo fue implementado en la versión 5.1.0 de NetLogo (Wilens|ky,
1999), utilizando la librería LPsolver como método de solución del problema de optimización de cada uno
de los compradores para conformar su puja. El enfoque de programación utilizado fue el de programación
orientada a objetos en coherencia con la esencia de NetLogo; para la realización de los experimentos se
utilizó la herramienta Analizador de comportamiento de NetLogo.
El propósito del modelo es explorar, mediante la realización de experimentos, la formación de precios y la
asignación de suministro en el desarrollo de la subasta simultánea de reloj ascendente definida en la
resolución CREG 089 de 2013 para la comercialización de gas en el mercado mayorista de gas en Colombia,
bajo el supuesto que se desarrollará en el año 2018. Los tipos de agentes modelados son:
Subastador: encargado de desarrollar la subasta mediante la aplicación de las reglas establecidas
en el formato SACA adoptado por el regulador. Realiza: incremento de precio y publicación de
precios y oferta disponible en cada ronda.
Vendedores: son los productores – comercializadores de gas en el contexto colombiano. Su rol
consiste en declarar antes de la ronda 0 su oferta disponible y precio de reserva para cada tipo de
producto. Durante el desarrollo de la subasta los vendedores no realizarán ninguna acción.
Compradores: en el contexto colombiano es posible identificar tres tipos de compradores
(usuarios no regulados) que están habilitados para participar en la subasta: generadores térmicos,
grandes industrias y comercializadores, que son de dos tipos: tipo A, compradores de contratos
firmes y contratos de firmeza condicionada, pero no de contratos de opción de compra de gas y
tipo B, compradores de contratos firmes y contratos de opción de compra de gas, pero no de
contratos de firmeza condicionada.
Los agentes compradores poseen una función de valoración máxima como atributo, la cual, junto con sus
funciones de utilidad y presupuesto, determinan las cantidades a demandar en cada ronda de la subasta. En
cuanto a la oferta, en la subasta participan productores de dos campos con gas en todas las modalidades
contractuales: contratos de energía firme, de firmeza condicionada y de opción de compra de gas, con
duraciones de 1 y 5 años, por lo que en total existen 12 productos en la simulación. Todas las cantidades de
energía en el modelo están dadas en MBTUD y los precios en USD/MBTUD.
La simulación de la subasta simultánea de reloj ascendente tiene tres etapas:
Preparación de la subasta: se genera el número de vendedores que participarán en la subasta y se le
asigna a cada vendedor la cantidad a ofrecer y el precio de reserva para cada uno de los productos. De
CLAIO-2016
464

igual forma, se genera el número de compradores del tipo generador térmico, industrial y
comercializador; asignando a cada uno un tipo (A o B) y una demanda máxima para toda la subasta.
Luego, cada vendedor indica la cantidad de producto de cada tipo que pondrá a la venta en la subasta.
La ronda 0 se ejecuta comparando la oferta y demanda de cada producto a los precios de reserva. De
no encontrase exceso de demanda para ningún producto, no se realiza la subasta; en caso contrario, se
incrementa el precio a los productos con exceso de demanda y se anuncia a los compradores para iniciar
la subasta.
Desarrollo de la subasta: si después de la ejecución de la ronda 0 se encuentra exceso de demanda en
algún producto, y mientras esa condición se mantenga, en cada ronda los compradores realizarán su
puja, indicando las cantidades que desean a los precios actuales. Luego, el subastador controlará que la
demanda de un producto no se reduzca de una ronda a otra, de tal forma que se genere un exceso de
oferta y verificará el exceso de demanda de cada producto en la ronda, incrementando el precio de los
productos en el este que exista. Para la siguiente ronda, se genera la oferta al nuevo precio. Por último,
se verifica si se cumple la regla de convergencia para finalizar la subasta; en caso de que no, se pública
la información de la ronda y se inicia un nuevo ciclo.
Cierre de la subasta: una vez se alcanza el criterio de parada o se cumpla la regla de convergencia, se
debe terminar la subasta. Esto implica adjudicar a cada comprador su última puja más una penalidad si
por su comportamiento hubo exceso de oferta en algún producto, y reportar los precios finales y las
asignaciones de cada uno de los productos para cada comprador.
Por último, para representar el contexto específico de la subasta simultánea de reloj ascendente (SACA)
diseñada pare el caso colombiano, se incorporaron los siguientes principios e hipótesis de manera
consistente con los diseños propuestos por consultorías contratadas por la CREG disponibles en Cramton
(2008) y Harbord & Pagnozzi (2011): racionalidad en la conformación de pujas, reducción monótona de la
demanda agregada y la inexistencia de riesgo de contraparte en la contratación y del riesgo de exposición.
5 Experimentación y análisis de resultados
Para analizar el impacto de tipo de comportamiento se definió un conjunto de estrategias para compradores,
vendedores y el subastador. A partir de dichas estrategias, se realizaron análisis de sensibilidad y escenarios.
Comportamiento de los agentes
Los compradores pueden conformar su puja de tres formas: de forma sincera, eligiendo las cantidades de
productos que maximizan su utilidad a los precios de la ronda en ejecución y sus restricciones; conformando
su puja basado en el precio pronosticado de 5 rondas en el futuro o aplicando una reducción estratégica de
la demanda, con el objetivo evitar el aumento de precios entre rondas, lo cual se logra conformando la puja
con un precio artificialmente inflado. Por otro lado, los vendedores pueden intervienen en determinando la
cantidad y precio de reserva de cada producto a ofrecer, por lo que su comportamiento se enmarca en cuanto
a la oferta en: sincero, es decir, ofrece las cantidades reales de energía en firme que tiene disponibles para
la venta y acaparador, cuando pone en venta una fracción menor a la que realmente tiene.
Por su parte, el subastador puede decidir el incremento de precios con los siguientes comportamientos:
experto, al considerar incrementos altos para los productos con mayor exceso de demanda; miope, cuando
no usa información de la subasta y realiza siempre el mismo incremento a lo largo de la subasta; codicioso,
cuando busca incrementos cada vez más grandes de los precios de los productos subastados y aleatorio
cuando toma sus decisiones de manera errática y en desconexión con lo que sucede en la subasta.
Análisis de sensibilidad
El análisis de sensibilidad busca identificar los principales factores a los cuales son sensibles las medidas
de desempeño de interés en una simulación; en este caso: número de rondas, ingreso de los vendedores y
CLAIO-2016
465

asignaciones por tipo de demanda. Se corrieron 150 réplicas por cada factor, observando la sensibilidad a
los precios de reserva de vendedor, las estrategias de puja de los compradores y a los tipos de incrementos
del subastador. A partir de los experimentos, se comprobó que la duración de la subasta se reduce frente a
aumentos en los precios de reserva de los vendedores, al uso de las estrategias de pronóstico y reducción
de la demanda por parte de los compradores y cuando se aplican las estrategias de incremento experto y
codicioso del subastador. Ver ilustración 1.
Ilustración 1. Sensibilidad de la duración de la subasta. Elaboración propia.
Así mismo, se estableció que los ingresos de los vendedores no se ven afectados por la fijación de los
precios de reserva, siempre y cuando estos se encuentren por debajo de los niveles de las valoraciones
máximas de los compradores. Por el contrario, los ingresos de los vendedores se reducen cuando los
compradores usan de manera coordinada las estrategias de pronóstico y demanda reducida y aumentan
cuando el subastador usa estrategias con incrementos altos de precio. En cuanto a las asignaciones finales
de la subasta, se observó que no se ven afectadas por la fijación de precios de reserva de los compradores,
por el uso coordinado de estrategias de pronóstico y reducción de la demanda cuando se usan de manera
coordinada, ni por el tipo de incremento de los precios.
Análisis de escenarios Para observar el impacto de las decisiones de los agentes en el desarrollo de la subasta se plantearon tres
escenarios que exploran la interacción entre comportamientos estratégicos de los compradores, vendedores
y el subastador. Los escenarios se detallan en la tabla 1. Escenario Condiciones Hipótesis
Reducción
estratégica de la
oferta en firme
1. Compradores sinceros
2. Precios de reserva sinceros
3. Subastador miope
4. Acaparamiento de la oferta
H1: una reducción estratégica de la oferta en firme aumenta los
precios de los contratos de gas en firme.
H2: una reducción estratégica de la oferta en firme aumenta los
ingresos del vendedor.
Reducción
estratégica de la
demanda y respuesta
del subastador
1. Compradores estratégico
2. Precios de reserva sinceros
3. Subastador miope, aleatorio,
experto y codicioso.
4. Oferta sincera
H3: los incrementos altos en los precios reducen el efecto de la
estrategia de reducción de demanda de los compradores sobre
el ingreso del vendedor.
Coordinación y
reducción
estratégica de la
demanda
1. Compradores estratégicos,
coordinados y no coordinados.
2. Precios de reserva sinceros
3. Subastador miope.
4. Oferta sincera
H4: el uso de una estrategia de reducción de la demanda solo
es racional para el comprador cuando existe coordinación.
Tabla 1. Escenarios de experimentación. Elaboración propia.
CLAIO-2016
466
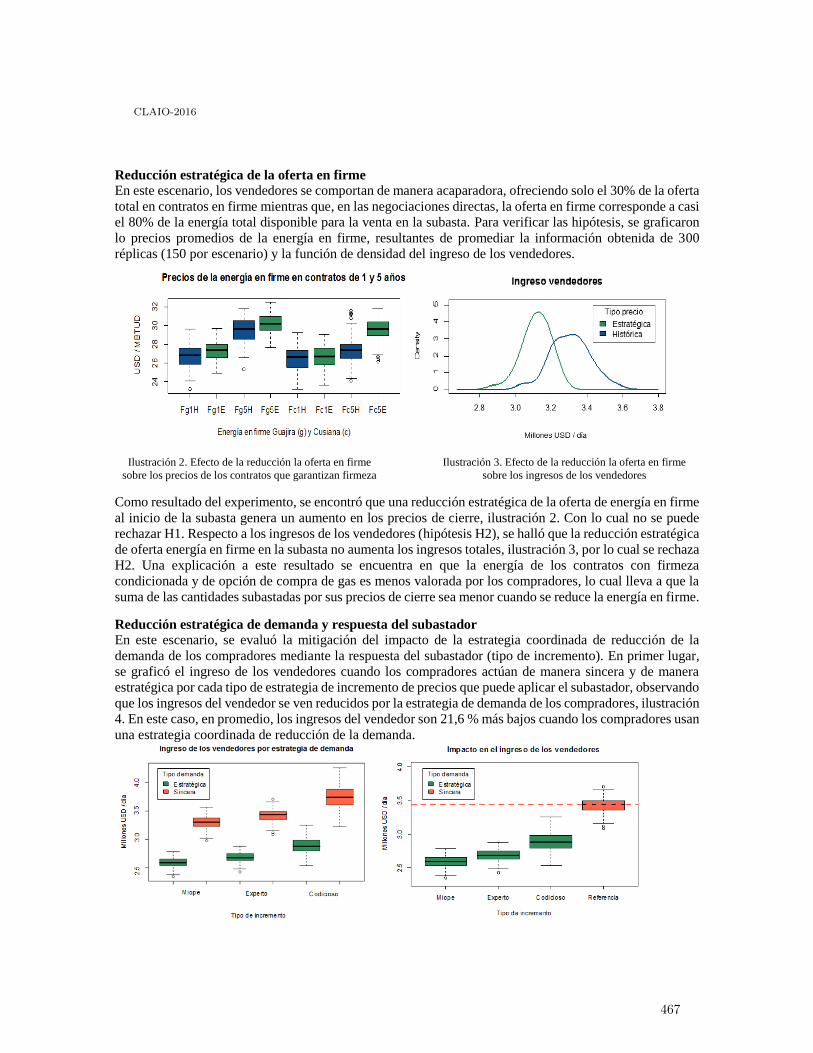
Reducción estratégica de la oferta en firme
En este escenario, los vendedores se comportan de manera acaparadora, ofreciendo solo el 30% de la oferta
total en contratos en firme mientras que, en las negociaciones directas, la oferta en firme corresponde a casi
el 80% de la energía total disponible para la venta en la subasta. Para verificar las hipótesis, se graficaron
lo precios promedios de la energía en firme, resultantes de promediar la información obtenida de 300
réplicas (150 por escenario) y la función de densidad del ingreso de los vendedores.
Ilustración 2. Efecto de la reducción la oferta en firme
sobre los precios de los contratos que garantizan firmeza
Ilustración 3. Efecto de la reducción la oferta en firme
sobre los ingresos de los vendedores
Como resultado del experimento, se encontró que una reducción estratégica de la oferta de energía en firme
al inicio de la subasta genera un aumento en los precios de cierre, ilustración 2. Con lo cual no se puede
rechazar H1. Respecto a los ingresos de los vendedores (hipótesis H2), se halló que la reducción estratégica
de oferta energía en firme en la subasta no aumenta los ingresos totales, ilustración 3, por lo cual se rechaza
H2. Una explicación a este resultado se encuentra en que la energía de los contratos con firmeza
condicionada y de opción de compra de gas es menos valorada por los compradores, lo cual lleva a que la
suma de las cantidades subastadas por sus precios de cierre sea menor cuando se reduce la energía en firme.
Reducción estratégica de demanda y respuesta del subastador
En este escenario, se evaluó la mitigación del impacto de la estrategia coordinada de reducción de la
demanda de los compradores mediante la respuesta del subastador (tipo de incremento). En primer lugar,
se graficó el ingreso de los vendedores cuando los compradores actúan de manera sincera y de manera
estratégica por cada tipo de estrategia de incremento de precios que puede aplicar el subastador, observando
que los ingresos del vendedor se ven reducidos por la estrategia de demanda de los compradores, ilustración
4. En este caso, en promedio, los ingresos del vendedor son 21,6 % más bajos cuando los compradores usan
una estrategia coordinada de reducción de la demanda.
CLAIO-2016
467

Ilustración 4. Efecto del incremento de precios y las
estrategias de demanda de los compradores sobre los
ingresos de los vendedores
Ilustración 5. Efecto de la estrategia de incremento de
precios del subastador en la mitigación del impacto de la
reducción de demanda de los compradores
Tomando como referencia el ingreso del vendedor cuando los compradores actúan de manera sincera y el
subastador realiza incrementos con la estrategia de experto (3.43 Millones USD/día), es posible observar,
en la ilustración 5, que el efecto de una estrategia coordinada de reducción de la demanda por parte de los
compradores se reduce a medida que se aplican estrategias con incrementos de precios altos. Por lo cual no
se puede rechazar H3.
Coordinación y reducción estratégica de la demanda
En el análisis de sensibilidad se demostró que las asignaciones totales de oferta para cada uno de los sectores
que componen la demanda en el mercado simulado no se ven afectadas cuando todos los agentes
compradores utilizan la estrategia de reducción de la demanda de manera coordinada. Para verificar la
hipótesis 4 se graficó el resultado de 150 réplicas de cada uno de tres experimentos, en los cuales se tomó
a cada grupo de agentes como un conglomerado de agentes no mayoritario coordinado para reducir la
demanda. Los experimentos arrojaron que el grupo de agentes que aplicó la reducción de la demanda obtuvo
asignaciones totales de la oferta de gas en la subasta entre el 1 y 4%, con lo cual se hace evidente que la
estrategia de reducción de la demanda solo es útil cuando todos los compradores la siguen de manera
coordinada. Ver ilustración 6.
Ilustración 6. Efecto del uso de manera minoritaria de la estrategia de reducción de la demanda sobre las asignaciones agregadas
de los productos
Con los resultados obtenidos es posible afirmar que en la subasta SACA existen incentivos para demandar
de acuerdo con las valoraciones reales, por lo cual una demanda sincera es una estrategia pura dominante
para los compradores que participan en un ambiente de competencia.
6 Conclusiones y trabajos futuros
Consistentemente con la literatura se encontró que el uso de una estrategia de reducción de la demanda por
parte de los compradores disminuye los precios finales de los bienes subastados. De igual forma, se halló
que las asignaciones finales de cada producto por grupo de agentes no sufren variaciones significativas
cuando todos los agentes usan la misma estrategia de demanda y que el uso de una estrategia de reducción
de la demanda solo es racional para un comprador individual si se tiene confianza en la posibilidad de
coordinación de todos los agentes compradores. En cuanto al rol de subastador, se observó que incrementos
de precios altos entre rondas generan un mayor valor esperado del ingreso de los vendedores y que el efecto
de la reducción estratégica de la demanda puede ser mitigado durante la subasta con incrementos altos de
precio por parte del subastador.
En lo que respecta al poder de mercado, una vez realizado el análisis de sensibilidad se pudo constatar que
el vendedor mayoritario en el caso colombiano tiene y puede ejercer poder de mercado mediante la
determinación de las cantidades a ofrecer de cada producto en la subasta, aumentado el costo de la energía
en firme y reservando su oferta para negociarla en condiciones más favorables, implementando estrategias
CLAIO-2016
468

para vender su suministro a corto plazo y en condiciones de firmeza condicionada u opción de compra de
gas. En este sentido y en un ambiente de escasez, el vendedor decide la cantidad y calidad de los contratos
en venta. Si bien el control del precio final de los productos queda fuera de su alcance, lo que vende y en
qué condiciones sigue siendo una decisión estratégica a su cargo.
Para trabajos futuros, se propone explorar modelos de valoración común y valoración privada más ajustados
a la realidad y adaptativos de forma que se puedan predecir los precios y las asignaciones. En cuanto al
modelo, se puede extender para considerar restricciones de transporte. Otra línea de investigación futura
está en la identificación de las mejores estrategias individuales y la influencia del aprendizaje en los
resultados de este tipo de subasta a través de experimentos de laboratorio.
Referencias 1. Azadeh, A., Skandari, M. R., & Maleki-Shoja, B. (2010). An integrated ant colony optimization approach to
compare strategies of clearing market in electricity markets: Agent-based simulaction. Energy Policy, 38, 6307–
6319.
2. Cox, J., Roberson, B., & Smith, V. (1982). Theory and behavior of single object auctions. Research in
Experimental Economics. Retrieved from http://www.excen.gsu.edu/jccox/research/SingleObjectAuctions.pdf
3. Cramton, P. (2008). Auctioning Long-term Gas Contracts in Colombia, (September), 15.
4. Cramton, P. (2009). How Best to Auction Natural Resources, 24.
5. Cramton, P., & Schwarts, J. A. (2000). Collusive Bidding : Lessons from the FCC Spectrum Auctions. Journal
of Regulatory Economics.
6. Cramton, P., Shoham, Y., & Steinberg, R. (2006). Combinatorial auctions. Boston: MIT Press.
7. Grimm, V., Berger, U., DeAngelis, D. L., Polhill, J. G., Giske, J., & Railsback, S. F. (2010). The ODD protocol:
A review and first update. Ecological Modelling, 221(23), 2760–2768.
8. Harbord, D., & Pagnozzi, M. (2011). Simultaneous Ascending Clock Auction for Gas Supply Contracts in
Colombia Final Report, 1–16.
9. Harbord, D., Pagnozzi, M., & Von der Fehr, N.-H. (2011). Designing and Structuring Auctions for Firm and
Interruptible Colombia Tasks 1 and 2 Report.
10. Kemplerer, P. (1999). Auction theory: a guide to the literature. Journal of Economic Surveys, 95.
11. Lucking-reiley, B. D. (1994). Using Field Experiments to Test Equivalence Between Auction Formats : Magic
on the Internet.
12. Macal, C., & North, M. (2010). Tutorial on agent-based modelling and simulation. Journal of Simulation, 4, 151–
162.
13. Myerson, R. B. (1981). Optimal auction design. Mathematics of Operations Research, 6(1), 58–73.
14. Pickl, M., & Wirl, F. (2011). Auction design for gas pipeline transportation capacity—The case of Nabucco and
its open season. Energy Policy, 39(4), 2143–2151. http://doi.org/10.1016/j.enpol.2011.01.059
15. Pidd, M. (1999). Just Modeling Through: A Rough Guide to Modeling. Interfaces, 29(2), 118–132.
16. Rahimiyan, M., & Mashhadi, H. R. (2008). Supplier’s optimal bidding strategy in electricity pay-as-bid auction:
Comparison of the Q-learning and a model-based approach. Electric Power Systems Research, 78, 165–175.
17. Rego, E. E., & Parente, V. (2013). Brazilian experience in electricity auctions: Comparing outcomes from new
and old energy auctions as well as the application of the hybrid Anglo-Dutch design. Energy Policy, 55, 511–520.
18. Smith, V. L. (1994). Economics in the Laboratory. The Journal of Economic Perspectives, 113–131.
19. Vickrey, W. (1961). Counterspeculation, Auctions, and Competitive Sealed Tenders. The Journal of Finance,
16(1), 8–37.
20. Weidlich, A., & Veit, D. (2008). A critical survey of agent-based wholesale electricity market models. Energy
Economics, 30(4), 1728–1759. http://doi.org/10.1016/j.eneco.2008.01.003
21. Wellman, M. P., Osepayshvili, A., Mackie-mason, J. K., Arbor, A., & Reeves, D. M. (2007). Bidding Strategies
for Simultaneous Ascending Auctions, 1–35.
22. Wilensky, U. (1999). Netlogo 5.1.0. Northwestern: Center for Connected Learning and Computer-Based
Modeling.
23. Ziogos, N. P., & Tellidou, A. C. (2011). An agent-based FTR auction simulator. Electric Power Systems Research
Journal, 81, 1239–1246.
CLAIO-2016
469

The Influence of the Support Factor and Different Grids on the
Static Stability of Packing Problems
Leonardo Junqueira
Postgraduate Program in Production Engineering, Nove de Julho University,
Av. Francisco Matarazzo, 612, 05001-100, Água Branca, São Paulo – SP, Brasil.
Thiago Alves de Queiroz
Institute of Mathematics and Technology, Federal University of Goiás/Catalão Sectional,
Av. Dr. Lamartine Pinto de Avelar, 1120, 75704-020, Setor Universitário, Catalão – GO, Brasil.
Abstract
In this paper, we investigate conditions for cargo static stability in packing problems. In particular, we
address the constrained two-dimensional knapsack problem, which consists in orthogonally packing
rectangular items in a single rectangular container, with the aim of maximizing the packed area. An
integer linear programming model that positions the items over a discrete grid of points is used to solve
the problem. The model has embedded constraints that ensure a minimum support for the base of each
item. The solutions obtained with the model for different support factors and grids of points are then
evaluated by a procedure that verifies the conditions for the static stability of the resultant packing.
Computational tests were performed with this approach and a large variety of randomly generated
instances, and the results show that some classes of instances are more likely to present static instability
than others.
Keywords: two-dimensional packing problems; cargo vertical stability; support factor; grid-based position
MIP formulation; static equilibrium of rigid bodies.
1 Introduction
Cargo vertical stability constraints arise when orthogonally packing rectangular items (e.g., boxes,
pallets, etc.) in containers (e.g., intermodal containers, trucks, ships, etc.), and they have large practical
importance to avoid damages to the goods transported (Bortfeldt and Wäscher, 2013). These constraints
impose that the items are organized is such a way that they do not move (i.e., rotate and fall) due to the
action of gravity. By assuming that only gravity acts on the items and that they lie in rest or at constant
speed, cargo vertical stability constraints are normally considered from the point of view of statics of
material bodies (Hibbeler, 2010).
Stability has been usually considered under packing problems by means of a support factor (e.g., a
percentage between 0 and 100) for the base of the items, i.e., each item must have a given minimum
fraction of its base supported by other items placed immediately below and in direct contact with it, or by
the container floor. Some studies that employ this approach include, e.g., Gehring and Bortfeldt (2002),
Junqueira et al. (2012) and Bortfeldt and Homberger (2013).
The use of a support factor allows the intuitive development of models and/or algorithms to tackle
the packing of items. However, its use is also a complicating element when defining the ideal value for
CLAIO-2016
470

the minimum percentage. In other words, unless it is considered a support factor of 100% (i.e., each item
must have its base totally supported by other items or by the container floor), it is not possible to ensure
that the conditions for static stability are met (Queiroz and Miyazawa, 2014). It occurs because the
conditions for static stability impose that the items must have a fraction of their base supported by other
items (in case they are not on the container floor), and additionally that the center of mass of each item
lies on a stable region. Because the objects lie on the Earth surface, assuming a uniform gravitational
field, and considering that the objects have negligible dimensions when compared to the Earth, the center
of gravity of each object matches its center of mass.
There are still few studies that address vertical stability from the point of view of the equilibrium of
material bodies, i.e., whose approaches are independent of a support factor. Silva et al. (2003) presented
an approach based on the solution of equilibrium equations of rigid bodies to verify the feasibility of
packing a given set of boxes in a set of identical three-dimensional containers. Queiroz and Miyazawa
(2014) followed the approach of Silva et al. (2003), however addressing the packing of rectangles, and
they presented an approach that computes the forces passed through the items, which allows the update of
the center of mass of the items and to verify which items fail to meet the static stability conditions. Ramos
et al. (2016) consider the same approach of Queiroz and Miyazawa (2014), however addressing the
packing of boxes in three-dimensional containers. All of these authors consider the static equilibrium of
rigid bodies in their approaches.
The approaches of Queiroz and Miyazawa (2014) and Ramos et al. (2016) require a complete
analysis of the packing as new items are inserted. These approaches are more effective than the approach
presented by Silva et al. (2003), since the conditions imposed to an item to be stable, as proposed by the
latter authors, are not easily testable.
In this paper, we consider the problem of orthogonally packing rectangles (i.e., two-dimensional
items) in a single rectangular container, known as the constrained two-dimensional knapsack problem
(2CKP). We aim at investigating the influence of the support factor in the solutions of an integer linear
programming model for the 2CKP, which considers the available space of the container as a grid of
discrete points, each of which associated with a decision variable. The influence of the support factor is
analyzed in what concerns the quality of the solutions found as well as its “ability” in providing statically
stable solutions. It is also verified the influence over these two aspects of the use of different grids of
points. We consider three types of grids: the unitary distance between coordinates, also known as full sets,
the discretization coordinates of Herz (1972), also known as normal patterns, and the discretization
coordinates of Scheithauer and Terno (1996), also known as reduced raster points. The static stability of
the resultant packing over different support factors and grids is then verified using the approach of
Queiroz and Miyazawa (2014).
This work is organized as follows. In Section 2, we present the model for the 2CKP and different
forms of obtaining a discrete grid. In Section 3, we present how vertical stability constraints are
embedded in the 2CKP model to consider the support factor. We also briefly describe the approach of
Queiroz and Miyazawa (2014), which is used to verify the static stability of the solutions obtained with
the model. In Section 4, we present the computational results obtained with a large variety of randomly
generated instances. Finally, in Section 5, we present concluding remarks and some perspectives for
future research.
2 Formulation for the 2CKP
The 2CKP is defined over a set of types of rectangular items in , such that each has length
, height , value and a maximum number of identical copies that can be packed in a single
rectangular container with length and height . The objective is to find an arrangement of maximum
value that considers a subset of items in , such that the items are placed without overlapping and
CLAIO-2016
471

completely inside container , and that the maximum number of identical copies of each type is not
exceeded. Without loss of generality, we assume that the dimensions of the items and container are
integer.
An integer linear programming model for the 2CKP can consider the container as discretized in a
grid of points, with sets and denoting the possible
coordinates along the length and height, respectively, where an item can be placed, such that the bottom
left corner of the items must be positioned in one of the grid points. Sets and are here called full sets.
Therefore, let be a binary variable that is equal to 1 if the bottom left corner of item is positioned at
coordinates , for , and , and equal to 0 otherwise. The model for the 2CKP can be
written as a particular case of the formulation presented in Junqueira et al. (2012) for the three-
dimensional case:
Maximize (1)
Subject to:
(2)
(3)
(4)
The objective function (1) aims at maximizing the value of the items packed in . Constraints (2)
impose that each point of the grid is covered by at most some item that is placed at point ,
constraints (3) impose that at most copies of each item can be packed, and constrains (4) impose the
domain of the variables.
According to Herz (1972), the container can be discretized in a grid of points containing only
points obtained from the conical combinations involving the dimensions of the items, i.e., a discretized
point along the length (respectively, the height) has a value (respectively, ) obtained by
means of a constrained non-negative integer linear combination of the length (respectively, the height)
dimensions of the items in . More precisely, sets and , denoting the possible coordinates along the
length and height, respectively, allow us to restrict the full sets and to:
(5)
(6)
According to Herz (1972), there is not loss of generality when considering sets and for the
2CKP (this also applies for other related problems). Sets and are usually called normal patterns (or
normal sets). Note that each packed item can always be moved down and/or to the left, until its bottom
and left-hand edge are adjacent to other items or to the container.
A further restricted discretization definition was presented in Scheithauer and Terno (1996). These
sets, usually called reduced raster points, allow the elimination of symmetries that are obtained with the
normal patterns. However, it is not yet conclusive if there is loss of generality when using these sets in
the more general case, i.e., the non-guillotine packing. Queiroz et al. (2012) comment about the validity
of these sets when generating guillotine patterns, while Queiroz et al. (2015) show that these sets are valid
CLAIO-2016
472

for non-guillotine patterns of L-type. More precisely, sets and , denoting the possible coordinates
along the length and height, respectively, allow us to restrict the normal patterns and to:
(7)
(8)
According to Queiroz et al. (2015), these sets of points are not closed to the subtraction operation,
such that the operator < > in expressions (7)-(8) is used to ensure that the subtraction of two coordinates
results in a coordinate in the respective set of points.
3 Cargo Vertical Stability
To Queiroz and Miyazawa (2014) and Ramos et al. (2016), the cargo vertical stability constraint is
related to the positioning of the items’ center of mass in a stable region. The center of mass if defined as
the point where all mass of a given object is concentrated. In uniform density objects, the center of mass
matches its centroid (in case the object is a rectangle, it matches its geometric center). In case the object is
made by a discrete set of point masses, the center of mass is computed as a weighted arithmetic mean of
masses and the respective distances, which involve an inertial frame of reference and the respective
position of the masses (Hibbeler, 2010).
When considering that only gravity acts on the packing, we have only the weight acting on the
items’ center of mass, which is defined as the product of the item’s mass and the gravitational
acceleration ( ). In the case of rectangles packing there are three stable regions for the position
of an items’ center of mass: (i) the items’ projection must lie between two other items placed immediately
below and in direct contact with it; (ii) the items’ projection must lie above another item immediately
below and in direct contact with it; and (iii) the item is in direct contact with the container floor (in this
case it is always stable).
Figure 1(a) shows an item whose center of mass matches its centroid and is projected over two
other items, which characterizes a stable region. Figure 1(b) shows an item that has another item above
it, thus its center of mass is displaced from its centroid to a position that does not lie on a stable region,
and the resultant packing is unstable.
(a) Item i whose center of mass matches its centroid.
(b) Item j whose center of mass is displaced due to another
item (mass) above it.
Figure 1: Relation of the center of mass with the stability of the items.
One way of dealing with the cargo vertical stability constraint is by imposing a support factor to
the support of the items base. This approach brings an approximation to dealing with real situations, since
only for a value of (i.e., full support) it is possible to ensure a statically stable packing.
However, as this approach is too conservative, it also hardly constraints the possible packing patterns. On
CLAIO-2016
473

the other hand, for any value of , it is not possible to ensure a statically stable packing. Note in
Figure 1(a) that item is stable for a value of , while in Figure 1(b) item is unstable for a value
of .
Junqueira et al. (2012) presented a formulation for the cargo vertical stability constraint that
follows the modeling paradigm of model (1)-(4). Its adaptation for the two-dimensional case is
straightforward and constraints (9) ensure that for any item placed at coordinates other than the
container floor, there must exist a non-empty subset of items placed below item and in direct contact
with it, such that of the base of item (i.e., of its length) is supported by items in : (9)
where refers to the length of the contact between the base of
item and the top of item . Yamashita and Morabito (2013) extended model (1)-(4) with constraints (9) of Junqueira et al.
(2012) for the three-dimensional case, in order to allow the decision maker to choose which points of the
base of the items (boxes, in this case) must be supported (e.g., the corner points or the edges of the
boxes). The authors performed experiments with the extended model to some few values of , besides the
two options for choosing the base points, however they do not verify if the resultant packing are statically
stable.
Junqueira et al. (2012) highlight that constraints (9) ensure the generality of the solution only for
when considering the normal patterns. In what concerns the use of the reduced raster points,
note that it is not possible to ensure the generality of the solution even for , since in the first
sum in (9) the value would be replaced by , which would result in eliminating items in
that could support item (note that these items are considered when using the normal patterns).
On the other hand, Queiroz and Miyazawa (2014) mention that considering a discretized container
does not favor the cargo stability, independently of the grid. As the center of mass is defined over
continuous positions, any infinitesimal displacement of some item can turn the final packing unstable.
The approach of these authors to deal with the cargo vertical stability constraint, when considering two-
dimensional packing problems, is related to the computation of the center of mass of the items. Therefore,
the authors use an iterative procedure to compute the center of mass of each item, taking into account the
influence of the items above and not necessarily in direct contact with it.
The way the mass of each item influences (directly or not) the other items impacts the computation
of the center of mass, because if an item depends on several masses, it is necessary to determine how
much weight it receives from other items. More precisely, it is necessary to determine how much force
(and where) each item transmits to its adjacent items, i.e., items placed immediately below and in direct
contact with item . The forces are only computed after verifying that a considered item is stable. Therefore, its weight
is transmitted to its adjacent items according to each case in Figure 2. In any case, assuming that the items
are rigid bodies, we can apply the static equilibrium equations of rigid bodies, which determine that a
given system is in equilibrium when the resultant of all forces and the resultant of all torques (moments of
force) acting on the system are both null.
Therefore, in Figure 2(a) the resultant force is fully transmitted to the adjacent item (at the red
dot), while in Figures 2(b) and 2(c) the resultant force of the considered item is transmitted to the adjacent
items according to the solution of the static equilibrium equations of rigid bodies (at the red dots).
Additional details can be found in Queiroz and Miyazawa (2014).
CLAIO-2016
474

(a) Only one adjacent item.
(b) Exactly two adjacent items.
(c) Three or more adjacent items.
Figure 2: Cases mentioned by Queiroz and Miyazawa (2014) for the transmission of forces.
Therefore, our objective is to verify the static stability of the solutions found with model (1)-(4)
with the support factor-based vertical stability constraints (9), when considering different values for the
support factor and different grid types. We consider three versions of the given model: (i) with the grid
defined by sets and , i.e., the full sets; (ii) with the grid defined by sets and , i.e., the normal
patterns; and (iii) with the grid defined by sets and , i.e., the reduced raster points. The influence of
the support factor and the grids is then verified with the stability approach of Queiroz and Miyazawa
(2014), which considers static equilibrium equations of rigid bodies.
4 Computational Experiments
Model (1)-(4) with constraints (9) and the approach of Queiroz and Miyazawa (2014) were
implemented in the programming language C with the use of libraries of the IBM ILOG CPLEX
Optimization Studio 12.6.1. All computer tests were performed in a Intel Core i7-4790k 4.0 GHz with 32
GB RAM, running Ubuntu 14.04 LTS. The approach was tested with randomly generated instances using
the following parameters:
Four different container dimensions: 25, 50, 75 and 100. For the sake of simplicity, in all instances
we considerer square containers, i.e., with dimensions .
Three different item types : 5, 10 and 20. In all cases, the items have fixed orientation.
Two different ways of generating the items dimensions: (i) with items dimensions varying between
50% and 90% of the container dimensions, i.e., and ; and (ii) with items dimensions varying between 25% and 75% of the container dimensions, i.e.,
and . In the first case larger items tend to be generated,
while in the second case medium-sized items tend to be generated.
The value was defined as the percentage of the container area used by an item of type , i.e.,
. The available amount of items of type that can be packed in the container was randomly
generated by a uniform distribution in the interval . Note that, with these
values for , the 2CKP becomes constrained with respect to the availability of item type . The value of the support factor , in the case of constraints (9), was varied one by one from 100%
(i.e., full support) to 0% (i.e., with no support requirement).
For each value of container dimension, for each amount of item types, and for each different way of
generating the items dimensions, there were generated 5 instances, totalizing 120 different instances. Each
instance was solved for each value of , therefore 101 times. Besides that, each instance was solved for
each of the three grids of points (full sets, normal patterns and reduced raster points), i.e., it was solved
CLAIO-2016
475
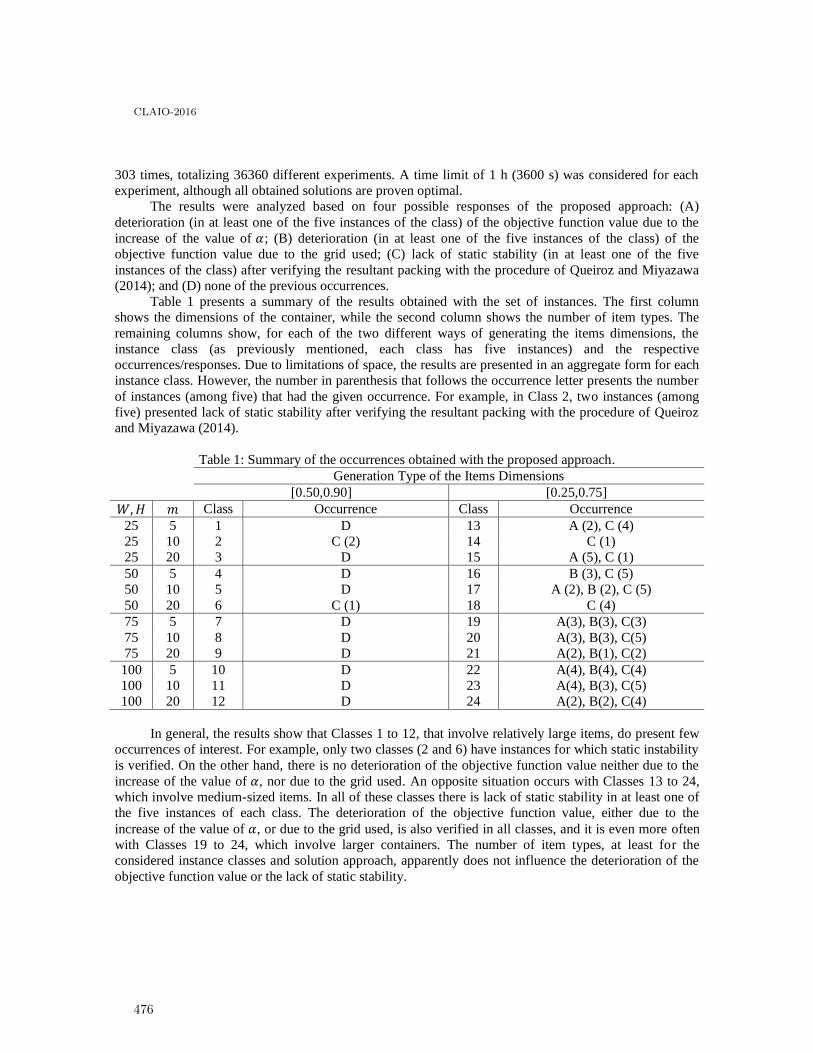
303 times, totalizing 36360 different experiments. A time limit of 1 h (3600 s) was considered for each
experiment, although all obtained solutions are proven optimal.
The results were analyzed based on four possible responses of the proposed approach: (A)
deterioration (in at least one of the five instances of the class) of the objective function value due to the
increase of the value of ; (B) deterioration (in at least one of the five instances of the class) of the
objective function value due to the grid used; (C) lack of static stability (in at least one of the five
instances of the class) after verifying the resultant packing with the procedure of Queiroz and Miyazawa
(2014); and (D) none of the previous occurrences.
Table 1 presents a summary of the results obtained with the set of instances. The first column
shows the dimensions of the container, while the second column shows the number of item types. The
remaining columns show, for each of the two different ways of generating the items dimensions, the
instance class (as previously mentioned, each class has five instances) and the respective
occurrences/responses. Due to limitations of space, the results are presented in an aggregate form for each
instance class. However, the number in parenthesis that follows the occurrence letter presents the number
of instances (among five) that had the given occurrence. For example, in Class 2, two instances (among
five) presented lack of static stability after verifying the resultant packing with the procedure of Queiroz
and Miyazawa (2014).
Table 1: Summary of the occurrences obtained with the proposed approach.
Generation Type of the Items Dimensions
[0.50,0.90] [0.25,0.75]
Class Occurrence Class Occurrence
25 5 1 D 13 A (2), C (4)
25 10 2 C (2) 14 C (1)
25 20 3 D 15 A (5), C (1)
50 5 4 D 16 B (3), C (5)
50 10 5 D 17 A (2), B (2), C (5)
50 20 6 C (1) 18 C (4)
75 5 7 D 19 A(3), B(3), C(3)
75 10 8 D 20 A(3), B(3), C(5)
75 20 9 D 21 A(2), B(1), C(2)
100 5 10 D 22 A(4), B(4), C(4)
100 10 11 D 23 A(4), B(3), C(5)
100 20 12 D 24 A(2), B(2), C(4)
In general, the results show that Classes 1 to 12, that involve relatively large items, do present few
occurrences of interest. For example, only two classes (2 and 6) have instances for which static instability
is verified. On the other hand, there is no deterioration of the objective function value neither due to the
increase of the value of , nor due to the grid used. An opposite situation occurs with Classes 13 to 24,
which involve medium-sized items. In all of these classes there is lack of static stability in at least one of
the five instances of each class. The deterioration of the objective function value, either due to the
increase of the value of , or due to the grid used, is also verified in all classes, and it is even more often
with Classes 19 to 24, which involve larger containers. The number of item types, at least for the
considered instance classes and solution approach, apparently does not influence the deterioration of the
objective function value or the lack of static stability.
CLAIO-2016
476

5 Conclusions
In this paper, we present an integer linear programming model to solve the constrained two-
dimensional knapsack problem (2CKP) considering support factor-based cargo vertical stability
constraints. The model considers the container as discretized in a grid of points. Computational tests were
performed with the model and a large variety of randomly generated instances, considering different
support factors and grids of points, with the aim of evaluating the influence of these parameters in what
concerns the quality of the solutions found as well as their “ability” in providing statically stable
solutions. The static stability of the solutions was verified with a procedure that considers static
equilibrium equations of rigid bodies. The results allow us to conclude that relatively large items tend to
generate statically stable solutions, which does not occur with medium-sized items. In the near future we
intend to further investigate the influence of the support factor and the grids when considering even
smaller items, the possibility of rotations and the unconstrained version of the problem.
Acknowledgements. This research was partially supported by CNPq, FAPEG and FAPESP.
References
1. A. Bortfeldt and J. Homberger. Packing first, routing second - a heuristic for the vehicle routing and
loading problem. Computers & Operations Research, 40(3): 873-885, 2013.
2. A. Bortfeldt and G. Wäscher. Constraints in container loading – a state-of-the-art review. European
Journal of Operational Research, 229(1): 1-20, 2013.
3. H. Gehring and A. Bortfeldt. A parallel genetic algorithm for solving the container loading problem.
International Transactions in Operational Research, 9(4): 497-511, 2002.
4. J. C. Herz. A recursive computational procedure for two-dimensional stock-cutting. IBM Journal of
Research Development, 16(5): 462-469, 1972.
5. R. C. Hibbeler. Statics & Mechanics of Materials. 3º ed. Prentice Hall, 2010.
6. L. Junqueira, R. Morabito and D. S. Yamashita. Three-dimensional container loading models with
cargo stability and load bearing constraints. Computers & Operations Research, 39(1): 74-85, 2012.
7. T. A. Queiroz, F. K. Miyazawa, Y. Wakabayashi and E. C. Xavier. Algorithms for 3D guillotine
cutting problems: Unbounded knapsack, cutting stock and strip packing. Computers & Operations
Research, 39(2): 200-212, 2012.
8. T. A. Queiroz and F. K. Miyazawa. Order and static stability into the strip packing problem. Annals of
Operations Research, 223(1): 137-154, 2014.
9. T. A. Queiroz, F. K. Miyazawa and Y. Wakabayashi. On the L-approach for generating unconstrained
two-dimensional non-guillotine cutting patterns. 4OR (Berlin), 13: 199-219, 2015.
10. A. G. Ramos, J. F. Oliveira and M. Lopes. A physical packing sequence algorithm for the container
loading problem with static mechanical equilibrium conditions. International Transactions in
Operational Research, 23(1-2): 215-238, 2016.
11. G. Scheithauer and J. Terno. The G4-heuristic for the pallet loading problem. Journal of the
Operational Research Society, 47: 511-522, 1996.
12. J. L. C. Silva, N. Y. Soma and N. Maculan. A greedy search for the three-dimensional bin packing
problem: the packing static stability case. International Transactions in Operational Research, 10(2):
141-153, 2003.
13. D. S. Yamashita and R. Morabito. Uma nota sobre modelagem matemática de carregamento de caixas
dentro de contêineres com considerações de estabilidade da carga. Produção, 25 (1): 113-124, 2015.
CLAIO-2016
477

Line balancing with heterogeneous products: a two-step formulation
to minimize number of stages in the whole system of lines
Felipe Kesrouani Lemos
Faculdade de Engenharia de Bauru, Universidade Estadual Paulista (UNESP)
Juliano Augusto Nunes Paixão
Faculdade de Engenharia, Universidade do Oeste Paulista (Unoeste)
Adriana Cristina Cherri
Faculdade de Ciências, Universidade Estadual Paulista (UNESP)
Silvio Alexandre de Araujo
Instituto de Biociência, Letras e Ciências Exatas, Universidade Estadual Paulista (UNESP)
Aline Marques
Faculdade de Engenharia, Universidade do Oeste Paulista (Unoeste)
Abstract
The paper addresses the Mixed-model Assembly Line Balancing Problem on an audio amplifier factory
with objective of minimizing total number of stages. Two characteristics make it different from classic
problems: several assembly lines are optimized as a whole; and products are heterogeneous, so converting
precedence diagrams in a joint one is unrealistic. A two-step formulation is proposed: first, cycle times
are minimized for each product and all possible number of stages; and a global optimization (with data
from first model), where configurations of the lines are chosen to minimize the total number of stages.
Data from 24 products, 4 lines and 337 tasks were collected on the factory. Results were obtained in 26.5
seconds and promoted a reduction of 44.8% of the stages. The paper impacts literature exploring
particularly the optimization of a whole sector, without necessity of joint precedence graphs; and also the
company, reducing meaningfully the number of stages used.
Keywords: Line balancing; Mixed-model assembly line; Two-step formulation; Mixed integer linear
problem.
1 Introduction The Assembly Line Balancing Problem (ALBP) consists of the assignment of tasks necessary to assemble
a certain product to a set of workstations of that line [1], aiming to optimize one or more objectives (such
as to minimize cycle time or number of workstations), subject to precedence constraints and other
CLAIO-2016
478

particular line restrictions [2]. It is a classical problem from operations research literature, since [3] when
it was first studied.
ALBP was reviewed in [4], where it is categorized according to the mix of products manufactured in
single-model lines (one model), mixed-model lines (several products mixed) and multi-model lines
(several products, one at a time, separated by setup times). More recently, [5] reviews the problem,
classifying in eight types, by the combination of numbers of models (single-model or multi-model);
nature of task times (deterministic or probabilistic); and type of assembly line (straight-type or U-type).
In this paper, we address a MALBP, on an audio amplifier factory. The company produces 24 products in
4 assembly lines, having a total of 29 stages before this study, with an 83% balancing efficiency, as
defined in [6]. The products are not homogeneous, so it is difficult or unrealistic to convert several
precedence diagrams in a joint diagram, as seen in [7]. Products vary from 4 to 27 tasks (average of 14).
The objective is to minimize the number of stages in the whole system of lines, since the company,
currently, has a scenario of demand scarcity. Using typology in [5], it’s a multi-model, deterministic task
times and straight-type assembly line (MM_D_S).
The objective of this paper is to propose a two-step formulation as an exact solution to MALBP with two
specific characteristics: (i) the sector is composed of more than one line to be optimized as a whole; and
(ii) the products are heterogeneous enough to be unrealistic to convert precedence diagrams in a joint one.
Classical MALBP problems were fully explored in literature, as it can be seen in [5], although it is
pointed out that much less work is done on multi-model than single-model lines. Several particular
conditions for the MALBP are studied by other papers. Heterogeneous workforce is addressed by [8],
considering a context of disabled workers. Multi-manned assembly lines, the ones where several tasks
are performed in each stage, are approached in [9] using simulated annealing to optimize cycle time. The
same problem is addressed in [10], where a mathematical formulation is proposed with a metaheuristic
and neighborhood search approach. Two-sided lines are seen in [11], where both sides of the line can be
used to produce high-volume large-sized standardized products.
A particular characteristic close to the problem addressed here is parallelism. It is defined by [12] when
two or more stages are set in parallel to allow better cycle times. In [13] it can be seen parallel lines; while
in [14] parallel workstations performing the same task set; and in [15] parallel two sided lines. Neither
cases reflect the situation considered here, where the focus is not the possibility of performing a task in
more than one stage; or using better resources sharing among lines. The focus of the paper is optimizing a
set of independent lines that must attend to production schedule.
2 Problem description and mathematical formulation This paper proposes an optimization method, for the minimization of the number of stages on a set of
parallel lines through a two-step formulation: firstly, it is optimized the cycle time (C) for each product
and a certain configuration (number of stages in the line), subject to its precedence network and
uniqueness constraints; secondly, with all optimum cycle times for each product and each possible
configuration, it is possible to optimize which configurations must be chosen in each line.
2.1. First step: optimizing cycle times
Let I be a set of tasks of a product (i = 1, …, n) to be performed on an assembly line; and K, a set of
stages (k = 1, …, m). Let aij be a binary parameter which denotes precedence between tasks i and j, being
1 when there is precedence and 0, otherwise. Let ui, also be a binary parameter, which assumes value 1 if
task i must be performed isolated on a stage (intermediate quality tests, in general) and 0, otherwise.
Finally, cycle time of each task is given by ti.
Decision variables considered are cycle time C, already mentioned, and also xik, a binary variable which
assumes value 1 when task i is assigned to stage k and 0, otherwise. The mathematical formulation that
minimizes C on assembly line is given by (1.1)-(1.8).
CLAIO-2016
479

Min 𝐶 (1.1)
s.a. ∑ 𝑥𝑖𝑘
𝑚
𝑘=1
= 1 𝑖 ∈ {1, … , 𝑛} (1.2)
∑ 𝑡𝑖𝑥𝑖𝑘
𝑛
𝑖=1
≤ 𝐶 𝑘 ∈ {1, … , 𝑚} (1.3)
𝑥𝑗𝑘 ≤ (1 − 𝑎𝑖𝑗) + ∑ 𝑎𝑖𝑗𝑥𝑖𝑙
𝑘
𝑙=1
𝑖 ∈ {1, … , 𝑛}, 𝑗 ∈ {1, … , 𝑛}, 𝑘 ∈ {1, … , 𝑚} (1.4)
∑ 𝑥𝑖𝑘
𝑛
𝑖=1
≥ 1 𝑘 ∈ {1, … , 𝑚} (1.5)
∑ 𝑢𝑖𝑥𝑖𝑘
𝑛
𝑖=1
≤ 1 𝑘 ∈ {1, … , 𝑚} (1.6)
∑ 𝑥𝑖𝑘
𝑛
𝑖=1
≤ 1 + 𝑛 × (1 − ∑ 𝑢𝑖𝑥𝑖𝑘
𝑛
𝑖=1
) 𝑘 ∈ {1, … , 𝑚} (1.7)
𝑥𝑖𝑘 ∈ {0,1}, 𝑖 ∈ {1, … , 𝑛}, 𝑘 ∈ {1, … , 𝑚}, 𝐶 ∈ ℝ+ (1.8)
The objective function (1.1) consists of minimizing cycle time of the line, considering m stages available.
Constraint (1.2) assures that each task is assigned to one, and only one, stage. Constraint (1.3) assures that
the total time assigned to a certain stage is inferior to cycle time. On (1.4) precedence constraints are
imposed. Constraint (1.5) imposes the use of all stages (important to second step formulation), requiring
at least one task on each stage. Constraints (1.6) and (1.7) assure tasks which require isolation to be alone
on a stage. Finally, on (1.8), it is expressed the decision variables domain.
2.2. Second step: optimizing the total number of stages
Running formulation (1.1)-(1.8) for each product and each possible line configuration (configuration
meaning number of stages on assembly line), it is possible to obtain a set of cycle times optimized for a
product and a configuration. With these data, it is proposed a model that aims to minimize the number of
stages on the set of lines available.
Let an assembly sector with M assembly lines, in which it is possible to produce each one of P products
of the portfolio of a factory. Each line can be configured in K different formats (k = 1, …, K), according
to the number of stages k. The demand of product p is given by Dp; the minimum and maximum number
of stages on line m; besides tpk, the optimized cycle time of a product k with a line configured with k
stages (obtained in the first step). The total time available to schedule all demands is given by T.
Decision variables are xpmk, the number of units of product p to be assembled in line m with configuration
k. Let Emk be a binary set that assumes value 1 if line m is configured with k stages and 0, otherwise.
Finally, Upm is a binary set with value 1 if the product p is scheduled to line m and 0, otherwise.
Mathematical model is exposed in (2.1)-(2.10).
CLAIO-2016
480

Min 𝐸𝑇 = ∑ ∑ 𝐸𝑚𝑘𝑘
𝑀
𝑚=1
𝐾
𝑘=1
(2.1)
s.a. ∑ ∑ 𝑥𝑝𝑚𝑘
𝐾
𝑘=1
𝑀
𝑚=1
= 𝐷𝑝 𝑝 ∈ {1, … , 𝑃} (2.2)
∑ 𝐸𝑚𝑘
𝐾
𝑘=1
= 1 𝑚 ∈ {1, … , 𝑀} (2.3)
∑ 𝑥𝑝𝑚𝑘
𝑃
𝑝=1
≤ 𝐸𝑚𝑘 ∑ 𝐷𝑝
𝑃
𝑝=1
𝑚 ∈ {1, … , 𝑀}, 𝑘 ∈ {1, … , 𝐾} (2.4)
∑ ∑ 𝑥𝑝𝑚𝑘𝑡𝑝𝑘
𝑃
𝑝=1
𝐾
𝑘=1
≤ 𝑇 𝑚 ∈ {1, … , 𝑀} (2.5)
∑ 𝐸𝑚𝑘𝑘
𝐾
𝑘=1
≤ 𝐾𝑀𝐴𝑋𝑚 𝑚 ∈ {1, … , 𝑀} (2.6)
∑ 𝐸𝑚𝑘𝑘
𝐾
𝑘=1
≥ 𝐾𝑀𝐼𝑁𝑚 𝑚 ∈ {1, … , 𝑀} (2.7)
∑ 𝑈𝑝𝑚
𝑀
𝑝=1
= 1 𝑝 ∈ {1, … , 𝑃} (2.8)
∑ 𝑥𝑝𝑚𝑘
𝐾
𝑘=1
≤ 𝑈𝑝𝑚𝐷𝑝 𝑝 ∈ {1, … , 𝑃}, 𝑚 ∈ {1, … , 𝑀} (2.9)
𝑥𝑝𝑚 ∈ ℤ+, 𝐸𝑚𝑘 ∈ {0,1}, 𝑝 ∈ {1, … , 𝑃}, 𝑘 ∈ {1, … , 𝐾}, 𝑚 ∈ {1, … , 𝑀} (2.10)
The objective function (2.1) consists of minimizing the total number of stages in the M lines with
different configurations to be chosen. Constraint (2.2) imposes that the demand of a product p (Dp) must
be manufactured in the sum of the productions of each line. Constraint (2.3) assures that only one
configuration must be chosen for each line. Coherence between xpmk and Emk is assured in (2.4), allowing
productions to be assigned only to configurations that are chosen. Total time available (T) limits the sum
of times assigned to each of the M lines in (2.5). The minimum and maximum number of stages of a line
is respected through (2.6) and (2.7). The limitation of manufacturing each product on a single line is
translated by (2.8). This last constraint is a requisite of the studied factory, but it is not necessarily
mandatory in any system. Constraint (2.9) assures coherence between xpmk and Upm. Finally, decision
variables domain is defined in (2.10).
3 Data collection and results The assembly sector of the company is composed of 4 assembly lines (M = 4), where 24 products are
assembled (P = 24). The set of tasks of each product was described and measured, totalizing 337 tasks.
A time study was performed during four months, from February to May (2015). Shooting techniques were
used, in order to measure times spent without pressure on workers. Data were analyzed with other
CLAIO-2016
481
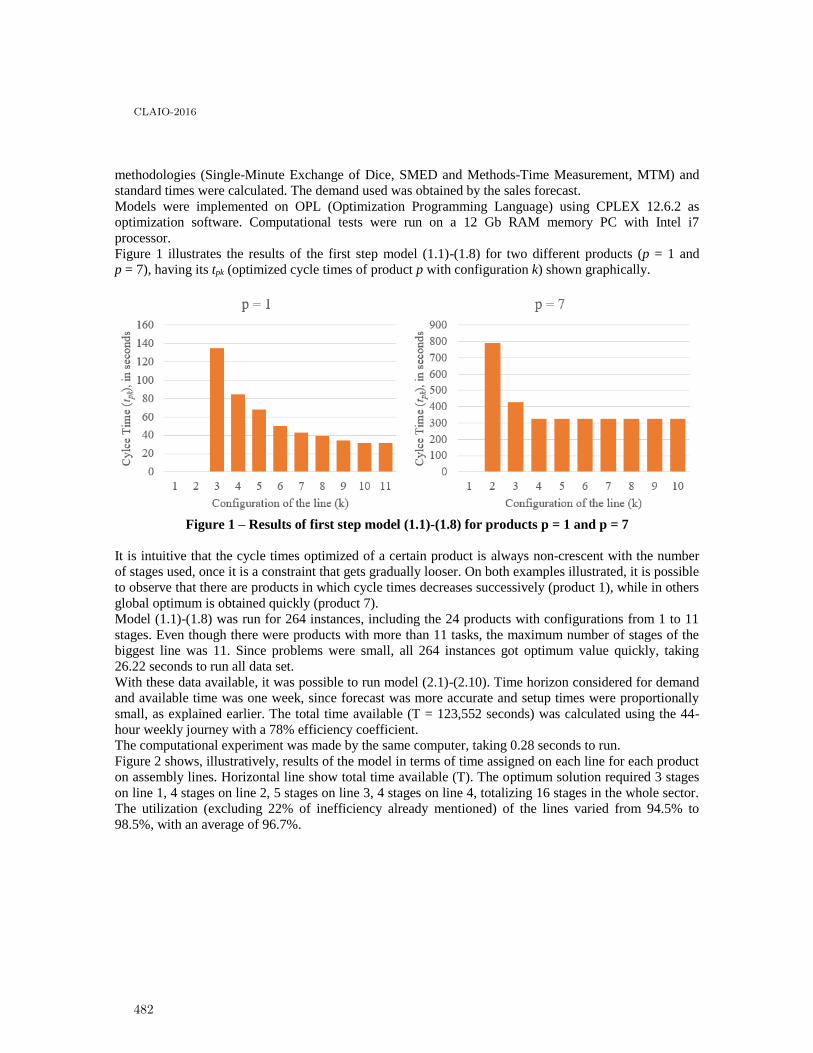
methodologies (Single-Minute Exchange of Dice, SMED and Methods-Time Measurement, MTM) and
standard times were calculated. The demand used was obtained by the sales forecast.
Models were implemented on OPL (Optimization Programming Language) using CPLEX 12.6.2 as
optimization software. Computational tests were run on a 12 Gb RAM memory PC with Intel i7
processor.
Figure 1 illustrates the results of the first step model (1.1)-(1.8) for two different products (p = 1 and
p = 7), having its tpk (optimized cycle times of product p with configuration k) shown graphically.
Figure 1 – Results of first step model (1.1)-(1.8) for products p = 1 and p = 7
It is intuitive that the cycle times optimized of a certain product is always non-crescent with the number
of stages used, once it is a constraint that gets gradually looser. On both examples illustrated, it is possible
to observe that there are products in which cycle times decreases successively (product 1), while in others
global optimum is obtained quickly (product 7).
Model (1.1)-(1.8) was run for 264 instances, including the 24 products with configurations from 1 to 11
stages. Even though there were products with more than 11 tasks, the maximum number of stages of the
biggest line was 11. Since problems were small, all 264 instances got optimum value quickly, taking
26.22 seconds to run all data set.
With these data available, it was possible to run model (2.1)-(2.10). Time horizon considered for demand
and available time was one week, since forecast was more accurate and setup times were proportionally
small, as explained earlier. The total time available (T = 123,552 seconds) was calculated using the 44-
hour weekly journey with a 78% efficiency coefficient.
The computational experiment was made by the same computer, taking 0.28 seconds to run.
Figure 2 shows, illustratively, results of the model in terms of time assigned on each line for each product
on assembly lines. Horizontal line show total time available (T). The optimum solution required 3 stages
on line 1, 4 stages on line 2, 5 stages on line 3, 4 stages on line 4, totalizing 16 stages in the whole sector.
The utilization (excluding 22% of inefficiency already mentioned) of the lines varied from 94.5% to
98.5%, with an average of 96.7%.
CLAIO-2016
482
Figure 2 – Assignment of products on each line (m) with configurations chosen (k) and total time
spent on each line
Results were compared to company’s reality. The previous configuration totalized 29 stages and
utilization was 29 with 83% utilization as shown on Table 1.
Table 1 – Final results of line balancing
4 Conclusions This paper presented a two-step mathematical formulation to minimize the total number of stages on a
system of mixed-model lines on an audio amplifier factory. Results were favorable, with a decrease of
more than 40% of the stages, compared to the actual configuration. So, the method impacts the factory
immediately, since it allows assembling the same demand with reduced costs.
It also impacts MALBP literature, once it considers two particular conditions: (i) heterogeneous products;
and (ii) a set of flexible lines that must be optimized as a whole. The first condition is relevant, once joint
precedence diagrams in this case could be unrealistic. With this method, this simplification is avoided.
The second condition, although very simple, is often seen in reality.
Data collected in the company presented configured a small instance, so the problem was solved on
reasonable computational time (26.4 second for both formulations). Bigger instances could face
computational limitations, so future extensions can study heuristic methods.
M Before study After line balancing
1 11 3
2 4 4
3 6 5
4 8 4
Total stages 29 16
Utilization 83% 96.7%
CLAIO-2016
483

References
1. J. Bautista; C. Batalla-García; R. Alfaro-Pozo. Models for assembly line balancing by temporal, spatial and
ergonomic risk attributes. European Journal of Operations Research, 251: 814-829, 2016.
2. L. Tiacci. J. Simultaneous balancing and buffer allocation decisions for the design of mixed-model assembly
lines with parallel workstations and stochastic task times. International Journal of Production Economics, 162:
201-215, 2015.
3. M. E. Salveson. The assembly line balancing problem. Journal of Industrial Engineering, 6: 18-25, 1955.
4. C. Becker; A. Scholl. A survey on problems and methods in generalized assembly line balancing. European
Journal of Operations Research, 168: 694-715, 2006.
5. P. Sivasankaran; P. Shahabudeen. Literature review of assembly line balancing problems. International Journal
of Manufacturing Technology, 73: 1665-1694, 2014.
6. R. Panneerselvam. Production and operations management, 2nd ed. PHI Learning, New Delhi, 2005.
7. B. Yagmahan. Mixed-model assembly line balancing using a multi-objective ant colony optimization approach.
Expert Systems with Applications, 38: 12453-12461, 2011.
8. P. M. C. Cortez; A. M. Costa. Sequencing mixed-model assembly lines operating with a heterogeneous
workforce. International Journal of Production Research, v. 53, n. 11, p. 3419-3432, 2015.
9. A. Roshani; D. Giglio. A simulated annealing approach for multi-manned assembly line balancing problem type
II. IFAC-PapersOnLine, 48-3: 2299-2304, 2015.
10. T. Kellegöz. Assembly line balancing problems with multi-manned stations: a new mathematical formulation
and Gantt based heuristic method. Annals of Operations Research, in press, 2016.
11. U. Özcan. Balancing stochastic two-sided assembly lines: A chance-constrained, piecewise-linear, mixed
integer program and a simulated annealing algorithm. European Journal of Operational Research, 205: 81–97,
2010.
12. C. Becker; A. Scholl. Balancing assembly lines with variable parallel workplaces: Problem definition and
effective solution procedure. European Journal of Operations Research, 199: 359-374, 2009.
13. H. Gokcen; K. Agpak; R. Benzer. Balancing of parallel assembly lines. International Journal of Production
Economics, 103: 600-609, 2006.
14. B. Cakir; F. Altiparmak; B. Dengiz. Multi-objective optimization of a stochastic assembly line balancing: a
hybrid simulated annealing algorithm. Computers and Industrial Engineering, 60:376-384, 2011.
15. A. Roshani; P. Fattahi; A. Roshani; M. Salehi; A. Roshani. Cost-oriented two-sided assembly line balancing
problem: a simulated annealing approach. International Journal of Computer Integrated Manufacturing, 25: 689-
715, 2012.
CLAIO-2016
484

Jogos Vetoriais na Avaliação do Posicionamento Contábil de
Empresas Brasileiras
Adriana Kroenke
Universidade Regional de Blumenau - FURB
Nelson Hein
Universidade Regional de Blumenau - FURB
Volmir Eugênio Wilhelm
Universidade Federal do Paraná - UFPR
Bianca Cecon
Universidade Regional de Blumenau - FURB
Resumo
O objetivo deste artigo é estabelecer o posicionamento contábil de empresas de metalurgia e siderurgia
listadas na BM&FBovespa utilizando a teoria dos jogos. São usados quatro lotes de indicadores econômico-
financeiros: liquidez, endividamento, rentabilidade e atividade. Para tal, as empresas representam as
estratégias do jogador I e os indicadores econômico-financeiros representam as estratégias do jogador II.
Para determinar os posicionamentos foram aplicados três modelos, os quais pertencem a família dos jogos
multicriteriais. Para o primeiro modelo foram gerados os rankings R1 e R2, para o segundo, os rankings R3
e R4 e para o terceiro modelo, o ranking R5, totalizando cinco rankings. Os resultados mostram que os
rankings obtidos refletem os dados coletados, ou seja, observa-se a adequação dos modelos aplicados.
Conclui-se que é possível aplicar os modelos de Teoria dos Jogos para estabelecer posicionamentos de
empresas.
Keywords: Teoria dos Jogos; Indicadores contábeis; Ranking.
1 Introdução
Os fundamentos da teoria dos jogos foram estabelecidos por John von Neumann em 1928 e
expostos no livro Theory of Games and Economic Behavior, que publicou junto a Oskar Morgenstern em
1944. Esta teoria põe de manifesto que os acontecimentos das ciências sociais podem ser descritos mediante
modelos de jogos de estratégia com uma maior riqueza de detalhes, pois os agentes atuam muitas vezes uns
contra os outros para a consecução de seus objetivos.
A teoria dos jogos é utilizada para obter a solução de problemas decisórios ou sistemas competitivos.
Exemplo dessa utilização encontra-se nos trabalhos de [1], [2], [3], [4] e [5]. Tradicionalmente as
ferramentas de tomada de decisão, assim como jogos contra a natureza ou jogos entre duas pessoas são
baseados no conceito de um único pagamento (ganho, perdas, utilidade, etc.). Os resultados da análise e
CLAIO-2016
485

resolução de problemas de tomada de decisão nem sempre são apropriadas e adequadas aos problemas da
vida real caso os parâmetros dos modelos matemáticos para a tomada de decisão são determinados sem
considerar a incerteza e a imprecisão presentes em sistemas competitivos. Quando dois oponentes elegem suas estratégias (alternativas), não só os resultados apresentam uma
soma não-nula, mas ela também possui uma forma de um vetor ao invés de um escalar. Jogos reais entre
dois personagens, devem ser entendidos como sequências de ganhos e perdas, em que não necessariamente
o ganho de um é a perda do outro em cada movimento. Os jogadores não são imediatamente ganhadores ou
perdedores. O uso de estratégias mistas ou randômicas nem sempre são adequadas e a cooperação muitas
vezes substitui a concorrência.
A leitura de cada empresa segundo seus vetores formados por indicadores econômico-financeiros
serão o escopo desta pesquisa. Estes vetores serão obtidos dos indicadores contábeis extraídos das
demonstrações contábeis. Serão utilizados indicadores de liquidez, endividamento, rentabilidade e
atividade de empresas de metalurgia e siderurgia listadas na BM&FBovespa. Desta forma, definiu-se a
questão de pesquisa: Qual o posicionamento contábil de empresas de metalurgia e siderurgia listadas na
BM&FBovespa?
Para responder a esta questão e atender o objetivo desta pesquisa serão aplicados três modelos. Por
meio da avaliação do posicionamento econômico-financeiro das empresas de metalurgia e siderurgia
usando jogos vetoriais, a pesquisa irá comparar os três modelos formados: um pela aplicação de jogos
vetoriais comuns, que utilizam múltiplos pagamentos; um segundo com a inclusão de metas (goals) na
elaboração do ranking; e um terceiro que mescla por meio dos conjuntos difusos os dois primeiros, tratando
os pagamentos por metas nebulosas.
A teoria dos jogos proporciona um marco unificado para a análise econômico-financeira em muitos
campos, o que contribui na estruturação de modelagem do comportamento econômico envolvido.
2 Jogos matriciais multicriteriais
Os jogos nos quais os pagamentos que os jogadores recebem vem representados por vetores em
lugar de números reais são denominados jogos vetoriais, jogos multicritério ou jogos com pagamentos
múltiplos [6]. Jogadores, ao avaliarem alternativas, optam por aquelas que lhe tragam maiores ou melhores
resultados. Maiores no caso do jogo ser não-cooperativo e melhor no caso cooperativo. Em ambos os casos
é feito um ranking das alternativas, ordenando as mesmas frente aos objetivos naturais, ou seja, maximizar
ganhos e minimizar perdas. Contabilmente seria, por exemplo, objetivar a melhor liquidez e um menor
endividamento. Contudo, os resultados podem ser múltiplos e podem ser medidos de várias formas:
unidades monetárias, índices, graus, números, etc., caracterizando múltiplos pagamentos.
Nestes jogos, se não há cooperação entre os jogadores como ocorre no caso de jogos de soma nula,
se acrescenta a dificuldade da não existência de uma ordem total entre os elementos da matriz de
pagamentos, no que a valoração das estratégias e a comparação entre as mesmas é um problema adicional
na teoria dos jogos, sendo o conceito de solução clássica difícil de ser desenvolvido. Por esta razão tem
aparecido novos conceitos de solução [7]. Neste sentido o conceito de estratégia de segurança Pareto-Ótima
é importante à solução de jogos com múltiplos pagamentos, utilizando conceitos de solução baseados nos
níveis de segurança dos jogadores.
[8] definem pontos de equilíbrio com níveis de segurança Pareto-Ótimas e pontos de sela de Pareto.
Para determinar o conjunto de estratégias de Pareto-Ótimas estabelecem dois jogos escalares, um para cada
jogador e provam que as estratégias maximin e minimax destes jogos são estratégias de segurança Pareto-
Ótimas para o jogador correspondente.
[9] obteve as estratégias de segurança Pareto-Ótimas de um jogo vetorial de soma zero
transformando o jogo original em um jogo escalar. [9] demonstrou, por meio de um longo processo que
uma extensão do conjunto formado pelos vetores de nível de segurança é um conjunto poliédrico. A partir
CLAIO-2016
486

deste resultado estabelece uma “escalarização” estritamente positiva em uma condição necessária e
suficiente para obter uma estratégia de segurança Pareto-Ótima, para tais jogos.
3 Modelos
Com efeito, para esta pesquisa pretende-se como resultado a formulação de estratégias para o
jogador I (empresas) frente as estratégias do jogador II (indicadores), o que se traduz na forma de um
problema de programação linear denominado de problema linear do jogo multicritério (PLJM). (Modelo
1).
max 𝑣1, … , 𝑣𝑘
𝑠. 𝑎: 𝑥𝑡𝐴(𝑠) ≥ (𝑣𝑘 , … , 𝑣𝑘) 𝑠 = 1,… , 𝑘; 𝑘 = 1,… ,4 (𝑔𝑟𝑢𝑝𝑜 𝑑𝑒 𝑖𝑛𝑑𝑖𝑐𝑎𝑑𝑜𝑟𝑒𝑠)
∑𝑥𝑖 = 1
𝑛
𝑖=1
𝑥 ≥ 0
O Modelo-2 é formulado como um problema de programação linear multiobjetivo, denominado
problema linear do jogo multicritério por objetivos (JMO)p:
max 𝑣1, … , 𝑣𝑘 𝑆𝑢𝑗𝑒𝑖𝑡𝑜 𝑎: 𝑥𝑡𝐴𝑝(𝑠) ≥ (𝑣𝑠, … , 𝑣𝑠); 𝑠 = 1,… , 𝑘
∑𝑥𝑖 = 1
𝑛
𝑖=1
𝑥 ≥ 0
A aplicação deste modelo necessita a determinação de um nível de segurança P e nesta pesquisa
foi definido como: 𝑃 = (0,5,… ,0,5).
O Modelo-3 formulado para jogos multiobjetivos bipessoais de soma-zero com funções de
pertinência de metas difusas dadas em sua forma linear, agregadas pela regra de decisão difusa (Bellman-
Zadeh), cuja solução maximin para o jogador I, com respeito ao grau de atendimento a meta difusa agregada
é dada pelo problema de programação linear:
𝑀𝑎𝑥 𝜆
𝑆𝑢𝑗𝑒𝑖𝑡𝑜 𝑎: �̂�1𝑗1 𝑥1 + ⋯+ �̂�𝑚𝑗𝑥𝑚 + 𝑐1 ≥ λ; j = 1,… , n
⋯
�̂�1𝑗𝑟 𝑥1 + ⋯+ �̂�𝑟
𝑚𝑗𝑥𝑚 + 𝑐1 ≥ λ; j = 1,… , n
𝑥1 + ⋯+ 𝑥𝑚 = 1
𝑥𝑖 ≥ 0, 𝑖 = 1,… ,𝑚
Este modelo de programação linear inclui metas difusas e por não se encontrar descrito na forma
padrão, passou por modificações antes de ser resolvido. Ao resolver um jogo vetorial por meio de
programação linear multiobjetivo o jogador depara-se com um conjunto de estratégias de segurança P
dentre os quais terá que escolher em qual irá jogar. Considerando o problema linear ponderado 𝑃(𝜆)
associado ao problema linear do jogo multicritério por objetivos o jogador I pode estabelecer valores para
os pesos deste problema de diferentes formas. Pode considerar as metas que estabeleceu em cada jogo
CLAIO-2016
487

escalar ou ainda a probabilidade em alcançá-las, ou inclusive os desvios em relação às metas. No caso em
que os objetivos não estejam mensurados nas mesmas unidades podem ser modificados multiplicando-se
por um fator de equiparação de escalas.
4 Aspectos metodológicos
A população é definida como o conjunto de elementos que apresentam os atributos necessários para
o desenvolvimento do estudo [10]. No caso desta pesquisa, foram selecionadas as empresas que
apresentaram os dados dos indicadores de liquidez, endividamento, rentabilidade e atividade. A população
foi definida intencionalmente, consistindo nas 12 empresas de siderurgia e metalurgia listadas na
BM&FBovespa. Todas as empresas apresentaram os dados necessários, logo, nenhuma empresa foi
excluída da análise.
Destaca-se o fácil acesso às informações contábeis e seu alto grau de confiabilidade por se tratarem
de empresas de capital aberto. As empresas do ramo de siderurgia e metalurgia utilizadas nesta investigação
são apresentadas no Quadro 1.
Quadro 1 – Empresas do setor de siderurgia e metalurgia listadas na BM&FBovespa
Empresa Nome do Pregão Atuação
Paranapanema PARANAPANEMA Artefatos de cobre
Fibam Companhia Industrial FIBAM Artefatos de Ferro e Aço
Mangels Industrial S.A. MANGELS INDL Artefatos de Ferro e Aço
Metalúrgica Duque S.A. MET DUQUE Artefatos de Ferro e Aço
Panatlantica S.A. PANATLANTICA Artefatos de Ferro e Aço
Siderurgica J. L. Aliperti S.A. ALIPERTI Artefatos de Ferro e Aço
Tekno S.A. – Indústria e Comércio TEKNO Artefatos de Ferro e Aço
CIA Ferro Ligas da Bahia - FERBASA FERBASA Siderurgia
CIA Siderurgia Nacional SID NACIONAL Siderurgia
GERDAU S.A. GERDAU Siderurgia
Metalurgica Gerdau S.A GERDAU MET Siderurgia
Usinas SID de Minas Gerais S.A. -
USIMINAS
USIMINAS Siderurgia
Fonte: Dados da pesquisa.
Os dados foram coletados por meio do ECONOMÁTICA©, obtidos das demonstrações contábeis
consolidadas, Balanço Patrimonial e Demonstração do Resultado do Exercício. Foram extraídos
indicadores econômico-financeiros de liquidez, endividamento, rentabilidade e atividade. De cada grupo
foram extraídos três, formando um grupo de 12 indicadores analisados: (a) liquidez: liquidez seca (LS),
liquidez corrente (LC), liquidez geral (LG), (b) endividamento: imobilização do patrimônio líquido (IPL),
participação de capital de terceiros (PCT), composição do endividamento (CE), (c) rentabilidade: margem
líquida (ML), retorno sobre o ativo (ROA), retorno sobre o patrimônio líquido (ROE), (d) atividade: prazo
médio de estoques (PME), prazo médio de fornecedores (PMF) e prazo médio de recebimento (PMR).
Os três modelos foram aplicados e obteve-se como resultado 5 rankings, pois, os modelos 1 e 2
foram aplicados sem e com valor da informação, gerando dois rankings para cada modelo. O modelo 3
gerou apenas um ranking. Para determinar o valor da informação necessário para os modelos 1 e 2 calculou-
se a entropia da informação.
CLAIO-2016
488

5 Análise de Dados
A análise de dados referentes aos indicadores de liquidez, endividamento, rentabilidade e atividade
acabam por formar a matriz de pagamentos do jogo multicriterial que pode ser observada abaixo. Em linha,
observa-se dados de cada uma das empresas, Paranapanema até Usiminas. Na coluna, os dados dos
indicadores de cada grupo LG, LC, até PMR.
P =
[ (1.02, 1.10, 0.53)(1.02, 1.12, 0.54)
(0.74, 1.16, 0.97)(0.41, 0.64, 0.58)(1.55, 2.20, 1.68)(0.76, 1.35, 0.93)(5.84, 7.91, 6.66)(5.59, 6.90, 4.39)(0.63, 3.30, 2.74)
(0.85, 2.10, 0.94)(0.78, 1.80, 0.81) (0.93, 1.99, 1.30)
(94.95, 186.42, 84.79)(94.64, 227.86, 57.28)
(657.10, 2388.88, 46.66)(143.29, 158.06, 61.41)(44.96, 98.41, 68.79)(114.15, 64.45, 46.20)(36.19, 13.13, 70.24)(42.98, 12.39, 63.28)
(226.57, 447.27, 15.91)
(68.37, 84.36, 32.20)(73.42, 99.01, 34.38)(89.95, 77.03, 37.88)
(−5.12,−4.93, 14.13)(−3.95,−5.64, 18.48)
(31.39, 21.99, 547.40)(0.17, 0.09, 0.24)(4.13, 4.48, 8.89)(16.58, 3.26, 5.36)(14.51, 8.45, 9.56)(12.09, 6.55, 7.36 )
(−2.84,−0.97,−5.33)
(3.94, 2.82, 5.20)(3.51, 2.50, 4.97)
(−4.18,−1.62,−2.87)
(124.64, 158.73, 40.23)(69.52, 17.59, 48.40)
(52.77, 70.64, 41.02)(18.29, 51.66, 20.10)(66.68, 39.33, 69.19)(240.57, 23.17, 29.85)(86.38, 21.37, 65.95)(149.13, 19.35, 60.31)(106.76, 58.38, 38.24)
(97.72, 33.14, 35.03)(97.72, 33.14, 35.03)(112.95, 68.23, 44.42) ]
Os valores são adimensionais, ou seja, não possuem uma unidade em especial. Contudo, cada
indicador será transformado por meio de uma contração de Lipschitz 𝑑(𝑓(𝑥), 𝑓(𝑦)) ≤ 𝑘𝑑(𝑥, 𝑦) .
Basicamente a contração é feita usando o teorema de Tales, ou seja, em cada um dos 12 indicadores há um
máximo 𝑖𝑗+; 𝑗 = 1,… ,12 e um mínimo 𝑖𝑗
−; 𝑗 = 1,… ,12. Fazendo 𝑓(𝑖𝑗−) = 0 e 𝑓(𝑖𝑗
+) = 1, assim 𝑓(𝑖𝑗) =𝑖𝑗−𝑖𝑗
_
𝑖𝑗+−𝑖𝑗
_. No caso dos indicadores de endividamento pretende-se quanto menor melhor, logo a formulação
passa a ser 𝑓(𝑖𝑗) = 1 −𝑖𝑗−𝑖𝑗
_
𝑖𝑗+−𝑖𝑗
_. Isto também é aplicado ao indicador PME (prazo médio de estoques) e PMR
(prazo médio de recebimento).
Para obter o peso da informação, utilizada nos dois primeiros modelos, aplicou-se a entropia da
informação e obteve-se a entropia associada a cada lote de indicadores dado por:
e(liquidez)=0,8681069
e(endividamento)=0,960037
e(rentabilidade)=0,969933
e(atividade)=0,916057
A soma da entropias é dada por E=3,656717. Aplicando a fórmula 𝜆𝑖 =[1−𝑒(𝑑𝑖)]
𝑛−𝐸 , tem-se o valor
dos pesos da informação:
𝜆1 = 0,55147 𝜆2 = 0,116415 𝜆3 = 0,087587 𝜆4 = 0,244529
A partir destes dados os três modelos foram aplicados e obtive-se os posicionamentos para cada
um. Cada modelo foi rodado 11 vezes, pois, a cada rodada retirava-se a melhor empresa até classificar
todas. Na ocorrência de empates, ou seja, estratégias iguais foi definido como critério que a empresa que
atendia ao maior número de níveis de segurança P seria a empresa classificada naquela posição.
A disposição final dos rankings é apresentada no Quadro 2.
CLAIO-2016
489
Quadro 2 – Posicionamentos referentes aos rankings gerados pelos 3 modelos aplicados
Posição R1 R2 R3 R4 R5
1ª Tekno Tekno Ferbasa Ferbasa Tekno
2ª Sid. Nacional Ferbasa Tekno Tekno Ferbasa
3ª Ferbasa Sid. Nacional Aliperti Paranapanema Panatlântica
4ª Usiminas Usiminas Sid. Nacional Sid. Nacional Usiminas
5ª Gerdau Paranapanema Gerdau Gerdau Fibam
6ª Gerdau Met Panatlântica Gerdau Met Gerdau Met Paranapanema
7ª Paranapanema Gerdau Paranapanema Usiminas Gerdau
8ª Aliperti Gerdau Met Usiminas Duque Gerdau Met
9ª Panatlântica Aliperti Duque Aliperti Aliperti
10ª Duque Mangels Fibam Mangels Sid. Nacional
11ª Fibam Duque Panatlântica Fibam Duque
12ª Mangels Fibam Mangels Panatlântica Mangels
Fonte: Dados da pesquisa.
Observa-se, mediante aplicação dos três modelos que a Tekno se mantém nas primeiras posições e
observou-se que possui melhores indicadores dentre os 12 possíveis. São eles: LG, LC, LS, IPL, ROA e
ROE. Considerando os dados coletados ela apresenta os melhores indicadores. Isto atesta a aplicabilidade
dos modelos propostos.
6 Conclusão
A classificação das empresas por meio de indicadores econômico-financeiros pode sem dúvida ser
elaborada por estudiosos da contabilidade, que por meio de seus métodos e técnicas levam a rankings
semelhantes aos obtidos pela presente pesquisa. Entretanto, o incremento da cesta de indicadores, da
aplicação do horizonte temporal e inclusão de mais empresas no conjunto em investigação fará com que o
nível de dificuldade aumente em forma diretamente proporcional, inviabilizando a análise frente as
limitações do raciocínio humano dada a complexidade do cenário em estudo.
Com base no exposto observa-se a importância da elaboração de uma metodologia (conjunto de
métodos) de auxílio à decisão. Usando os cinco rankings, foi possível atingir o objetivo geral: estabelecer
o posicionamento contábil das empresas de metalurgia e siderurgia listadas na BM&FBovespa utilizando a
teoria dos jogos.
Os rankings mostram-se justos, pois a empresa Tekno, possui melhores indicadores dentre os 12
possíveis. São eles: LG, LC, LS, IPL, ROA e ROE. De similar modo, a empresa Mangels ocupar as últimas
posições, advém da constatação da mesma possuir 5 piores indicadores da cesta. São eles: IPL, PCT, ML,
ROA e ROE.
Em exame sumário, a Teoria dos Jogos fornece sustentação matemática, instrumental e formal a
várias e distintas escolhas estratégicas por parte de jogadores em situações de impasse ou conflitos. Esses
agentes podem focar a convergência de interesses, na tentativa de melhorar seu payoff. Além disso, com
essa atitude, esses jogadores também podem primar por uma cooperação mútua.
Referências
1. J. Neumann and O. Morgenstern. Theory of games and economic behavior. New York: Wiley, 1944.
2. J. C. Harsany. Rational behavior and bargaining equilibrium in games and social situations. New York:
Cambridge University Press, 1977.
CLAIO-2016
490

3. J. C. Harsany and R. Selten. A general theory of equilibrium selection in games. Massachusetts: The MIT Press,
1988.
4. D. Fundenberg and J. Tirole. Game theory. Massachusetts: The MIT Press, 1991.
5. G. Owen. Game theory. San Diego: Academic Press, Third Edition, 1995.
6. M. Zeleny. Multiple criteria decision making. New Yor: McGraw-Hill, 1982.
7. F. R. Fernández and L. Monroy. Multi-criteria simple games. In: V. Barichard et. al. Multiobjective programming
and goal programming: theoretical results and practical applications. Berlin Heidelberg: Spring-Verlag, 2009.
8. D. B. Ghose and U. R. Prasad. Solution concepts in two-person multicriteria games. Journal of Optimization
Theory and Applications, n. 63, p. 167-189, 1989.
9. D. B. Ghose. A necessary and sufficient condition for Pareto-optimal security strategies in multicriteria matrix
games. Journal of Optimization Theory and Applications, n. 68, p. 463-480, 1991.
10. A. Silveira. (Coord.). Roteiro básico para apresentação e editoração de teses, dissertações e monografias. 2. ed.
rev., atual e ampl. Blumenau: Edifurb, 2004.
CLAIO-2016
491

New research focus is needed in sport scheduling Leonardo Lamorgese, Tomas Eric Nordlander
SINTEF ICT, Department of Applied Mathematics, Oslo, Norway [email protected], [email protected]
Abstract
Sport directly or indirectly affects the lives of millions of people around the world. For professional federations, the quality of the schedules strongly affects their financial turnover (media revenue, sales at stadiums, ticket sales etc.). For non-professional tournaments, it affects the distribution of games, tournament length, travelling distances, associated costs etc. Scheduling sport competitions is a hard combinatorial optimisation problem, studied at length by researchers, at least for some problem variants. In this position paper, we argue that there are still several challenges in this field that are worthy of attention. On one side, ‘traditional’ sport scheduling problems (SSPs) still present open research questions that should be investigated. On the other, we argue that there has been a skewed focus towards the SSPs of interest for professional sport federations, while other SSPs have received less attention despite their theoretical and practical interest.
Keywords: sport, sports, scheduling, optimisation
Introduction Sport leagues and tournaments around the world are scheduled on a daily basis by thousands of professional and non-professional sport federations, associations, clubs and organisers. Events such as the Football World Cup or the Olympics have high resonance and are broadcasted across the world to millions of fans, with different countries fighting over the rights to organise them. Many professional federations and leagues (across sport disciplines) also have a high following, significantly contributing to the economy and social fabric of nations. In addition, millions of people engage in amateur/non-professional sport competitions, which directly or indirectly affect their lives and those of the people around them. In such a setting, it is not hard to make a case for the importance of sport scheduling and its impact on society.
For professional sport federations, schedules affect a variety of stakeholders (teams, fans, communities). The quality of such schedules affects the revenue of the teams (and federations themselves), as television networks are willing to pay higher broadcasting rights depending on whether the schedule meets certain requirements (e.g. games that draw larger audiences are scheduled on ‘attractive’ dates). Fans often also decide whether to buy tickets based on similar reasons. Improved scheduling boosts attendance and generates a positive effect on the local economy. Additionally, more attendance rates and viewers increase the chances of attracting greater sponsoring or advertising income from national and international firms.
Non-professional tournaments are scheduled in the hundreds of thousands each year, each involving many participants, families, businesses and communities. Unevenly distributed games, unnecessarily long tournaments and long travelling distances are only some of the many problems that participants typically
CLAIO-2016
492

face. Bad scheduling can be simply inconvenient but also result in teams resigning from tournaments, reducing income for clubs and organisers, which, in turn, reduces the number of tournaments. A particular case must be made for youth tournaments, which are a large share of the total. The surging trend of ‘marginalising’ physical activities in school makes the role of such tournaments ever more central from a societal point of view, and efficient scheduling should foster participation and increase convenience for families.
From a research perspective, scheduling sport leagues or tournaments is a hard combinatorial optimisation problem which, at least for the problem variants regarding scheduling professional leagues, has been extensively studied in the scientific literature. However, the research field still presents several interesting challenges. The Constrained Minimum Break Problem is among the most studied sport scheduling problems in the literature (see the background section). A number of methodologies have been devised to tackle this problem, with perhaps the most successful being the use of decomposition to partition the overall problem into sub-problems, then solved by means of different solution methods. Despite the many papers that describe some variant of this scheme and/or address related theoretical issues, there are still some open, interesting research questions to be investigated that could significantly impact the state of the art and practice (see the section on challenges).
‘Sport scheduling’ generally brings to mind professional leagues, where world-class teams and athletes compete with media coverage and the constant attention of fans. Not surprisingly, the resulting scheduling (optimisation) problems have been studied at length and, in some countries, researchers help leagues and federations first-hand in delivering schedules year after year. This is undeniably an important achievement for the research community – one to be proud of. However, figures at hand, professional leagues and tournaments together only make up a fraction of all the competitions taking place around the world. Indeed, the vast majority of these are non-professional leagues and tournaments. Scheduling these competitions (particularly the large-scale ones) is often an equally challenging (combinatorial optimisation) problem, one that, despite being by far more common, has received little attention from the research community. We argue that there has been a skewed proportion of research focus between professional and amateur leagues and federations, something that should be adjusted.
This position paper is organised as follows: In the next section, we give an overview of different sport scheduling problems. In section 3, we argue our case. In the last section, we present our conclusions.
Background Sport scheduling problems (SSPs) are combinatorial optimisation problems that have attracted a lot of interest from the research community over the years due to very hard theoretical problems with obvious practical applications [13]. SSPs share similar features, in some cases, but vary in structure, rules and size. Sport scheduling terminology in the literature has traditionally been far from consistent, so in this paper, we refer to the definitions used in [13]. When scheduling a league or a tournament, games must be allocated to time slots in such a way that each team plays at most one game at each slot. The sequence of home (H) or away (A) games of a given team is called a pattern and is a crucial aspect of some SSPs. A pattern is said to have a break in each slot where the sequence is not alternating (e.g. HAHHA). Perhaps the most common structure is the so-called round robin tournament, where all teams must play each other a fixed number of times (usually twice). Although each league may have its own specific requirements, most commonly, a feasible schedule must comply with the following, including:
● Pattern constraints. Limit on the number of consecutive games a team may play at home or away.
CLAIO-2016
493

● Geographical constraints. Avoiding teams from the same region to play at home in the same slot (e.g. for safety reasons).
● Complementary constraints. Teams sharing the same venue cannot play at home in the same slot. ● Place constraints. Ensuring a team plays at home or away in a specific slot.
For further insight on other typical constraints, we refer to [1] and [13]. As noted in [13], these many requirements are ‘what makes scheduling a league extremely hard’.
Perhaps the most well-studied SSPs are the Constrained Minimum Break Problem (CMBP) [13] and the Travelling Tournament Problem (TTP) [5]. In this paper, we will focus on the former.
The first methods to appear in the SSP literature were constructive, graph-based methods for generating round-robin leagues (e.g. [4, 19]), but mainly in a theoretical setting. In the 1990s, the focus moved from theory to practice. The importance of minimising the number of breaks in practice and the increasing number of additional constraints led to the formulation of the CMBP, which applies to many sport leagues across disciplines. Different authors have attempted to tackle this problem over the years using a number of different methods, ranging from and often combining combinatorics, graph theory, heuristics, integer programming and constraint programming. Among methodologies, perhaps the most common (and successful) choice among authors has been resorting to decomposition. The CMBP is decomposed into smaller sub-problems to be solved independently using one (or more) of the above solution methods, e.g., in chronological order, [17, 12, 18, 7, 14, 4, 15, 16]. Typically, this involves generating a set of patterns and assigning teams to patterns and lastly teams to matches. When carried out in this order, it is commonly referred to as the so-called first-break-then-schedule approach. In some papers, e.g. [20], these steps are carried out in the opposite order (first-schedule-then-break). For a full overview of the literature, we refer to the many excellent surveys (e.g. [9, 13]).
The SSPs studied in the above papers belong to the class of temporally constrained problems, when there is a one to one correspondence between available slots and rounds. The complementary class of problems is that of time relaxed problems, where the number of time periods is larger than the minimum number of rounds to play all the games (thus not all teams play at all rounds or slots). Examples can be found in [24, 26, 27]. A common (although less studied) SSP variant arises when scheduling tournaments that take place on one or more venues not associated with any specific participants. We refer to this problem (and more broadly to its variants) as the (Multiple) Venue Sports Scheduling problem (MVSSP)1. Tournament organisers face the challenge of scheduling one (or more) round robin tournaments on available fields at (one or more) venues, within a certain timeframe (most tournaments with such structure are time relaxed). This often requires scheduling thousands of games and multiple tournaments in a few days on a limited amount of fields (e.g. Norway Cup and Gothia Cup2). Size (many teams and, often, tournaments), time (tournament duration) and space (available fields) constraints make this problem hard.
As mentioned in the introduction, few research papers have looked into the venue problem. Among these are [21, 22, 23, 25]. Urban and Russell [21] note its affinity with the (classroom) Timetabling problem [10]. Timetabling problem has been extensively studied by the research community and shown to be NP-complete by [6]. The MVSSP (even in the standard form described above) can be shown to be at least as hard as the Timetabling problem. The problems are equivalent in the standard case, where each venue is a classroom, each team is a student and each referee is a teacher. In practice, due to the variety of sport types, rules, and tournament structures around the world, the MVSSP rarely arises in its standard version. 1 Definition inspired by (Urban & Russell, 2003) which assumes that the venues are more than one. 2 Largest youth tournaments in the world http://www.norwaycup.no/en/ and http://www.gothiacup.se/
CLAIO-2016
494

Thus, the MVSSP generally has many more constraints. In addition, while the Timetabling problem is a feasibility problem, the MVSSP may require optimising over an objective function (or, more often, many). Despite the above, the MVSSP has received still relatively little research focus so far, and in turn there are (to our knowledge) even less real-life applications.
Challenges Professional leagues (‘classic’ CMBP): In the previous section, we gave a brief overview of the sport scheduling literature and the methodologies that have been applied. The approach that has arguably been the most successful (or at least applied) for CMBP is decomposition, also briefly introduced in the previous section (sequentially generating patterns, assigning them to teams and then scheduling to games, in some order). However, there are still interesting research questions to be tackled:
First, the identification of a sufficient condition for a pattern set to have a feasible team assignment (in first-break-then-schedule). Miyashiro et al. identified a necessary condition for pattern sets to have a feasible game schedule [11], an important result for the sport scheduling scientific community. The authors showed how this condition can be checked in polynomial time for a minimum break schedule (i.e. a schedule that has the minimum possible number of breaks, NN-2). Briskorn identified a tighter necessary condition [3], conjectured to be also sufficient but later disproved by [8]. This condition requires solving the linear relaxation of the game assignment problem (formulated as an integer program).3 To this day, identifying a sufficient condition for a pattern set to have a feasible team assignment has, to our knowledge, defied the research community. Finding it would be a very important scientific result and could have a strong impact on the practice of sport scheduling. Thus, in our opinion, the sport scheduling research community should turn its focus to this challenge once again. Another interesting research question is whether an exact scheme for generating schedules can be successfully applied to real-life (or at least realistic) CMBPs. Regarding the decomposition approach, while some works solve (some of) the different sub-problems (pattern set generation, pattern assignment and schedule generation) to optimality (using Integer Programming or Constraint Programming), to our knowledge, all related papers present an overall heuristic scheme. This is due to different reasons: patterns being chosen among a predefined set, the ‘communication’ between sub-problems taking place via constraints that are not necessarily valid (in the sense that they potentially cut away feasible solutions) or indeed one of the sub-problems also being solved heuristically. In other words, there is a gap in the literature with respect to a methodology that allows the solving of the CMBP to optimality. One (reasonable) objection is that the problem is multi-criteria by nature, which implies that the objective function is very hard to define in practice and always ends up being an approximation of what is actually desired. Moreover, it can be very challenging for the tournament or league owners themselves (even at a professional level) to fully express their (often many and conflicting) requirements or wishes in a systematic way. Nevertheless, we believe this is a matter of specifications (which may be improved using appropriate techniques like, for instance, weight elicitation). Therefore, under the assumption that the objective function is correctly modelled (often unrealistic, but not outrageous), the practical advantage of finding optimal solutions over good ones is evident. Moreover, even from a theoretical point of view, developing an exact (and effective!) mathematical methodology for sport scheduling leagues would be a major achievement. In our opinion, the idea of using a decomposition scheme to exploit the structure of
3 More formally, the problem addressed is referred to as the maximum round-robin tournament in [7]
CLAIO-2016
495

the original problem is the most promising approach. Cracking the previous research question would clearly be a significant step in this direction. Amateur or non-professional tournaments: As mentioned in the introduction, many non-professional tournaments require scheduling SSP variants that present fundamental differences from the canonical professional tournaments (e.g. MVSSP). In fact, these types of tournaments actually constitute the vast majority of tournaments scheduled around the world, in terms of sheer numbers, people involved and practical impact on people’s lives. For example, just for football, in Norway and Sweden alone, there are around 4,000 tournaments yearly that each involve hundreds to thousands of teams. In Europe, there are estimated to be at least 40 times the amount of tournaments of this scale (again, only for football). Bringing in other popular sports such as ice hockey, volleyball, basketball, paddle tennis, table tennis, floorball, tennis, darts, chess and more, the figures soar. Due to their (often very large) size and numerous constraints and objectives to be taken into account simultaneously, scheduling these tournaments can be challenging and time consuming for tournament organisers. Indeed, these require scheduling up to thousands of games on a limited number of fields, taking into account time windows and preferences, preferences, travelling costs and more. Despite the interesting challenges, these applications have so far failed to attract extensive interest from academics. Moreover, from a commercial perspective, one would expect a market of this size to present a significant and attractive business opportunity. Instead, perhaps even more surprisingly, there are still relatively few software tools that help tournament organisers schedule their tournaments.4 No vendor has emerged with a flexible, sufficiently advanced optimisation-based scheduling tool to become a clear market leader. The few existing systems have several limitations in that they: consider a single type of tournament structure, produce poor schedules, need exceedingly long computation times, scale badly with problem size and/or cannot be easily adjusted to handle new constraints. This may, at least partially, be attributed to the lower appeal these types of tournaments have. Nevertheless, the figures for these types of tournaments alone make a case for this change. Moreover, we believe that focus from the research community could also jumpstart interest from software vendors, as the main obstacle for these companies is to deliver an optimisation engine that is efficient, robust and flexible enough to be sold to tournament organisers. Norway is one of the (still relatively few) countries with a history of using mathematical optimisation techniques to assist sport scheduling. SINTEF's optimisation group developed an optimisation engine CupCom for Profixio (then called Spectare) in 2005, which just in 2014 scheduled around 150,000 matches of handball, football and volleyball for customers in Norway and Sweden.
Conclusion Sport affects directly or indirectly the lives of millions of people across the world. Aside from their obvious attractiveness, sports have also become a large business in the global economy. This goes for mass events such as the Olympics and football’s World Cup for professional leagues, but also for the countless non-professional tournaments organised each day around the word. For these reasons, it is not hard to see the considerable socio-economic impact of sport scheduling. In this position paper, we give a short overview of different sport scheduling problems and present some differences and similarities in SSPs that arise in professional and non-professional sport competitions. Tackling these SSPs is a hard combinatorial optimisation problem that has received significant interest for the case of scheduling professional leagues, while little attention has been given to SSPs arising for non-professional tournaments. In this position paper, we argue that there has been, somewhat understandably, a skewed proportion of research focus towards SSPs of interest for professional federations, but this is something 4 At least embedding optimisation engines of proven quality
CLAIO-2016
496

that should be adjusted. On one hand, there are undeniably some interesting research questions related to well-studied SSPs such as the Constrained Minimum Break Problem (see the background) that deserve to be further addressed. On the other hand, scheduling non-professional tournaments presents interesting challenges, theoretically and computationally, scarcely addressed so far by researchers. Interest from the research community may also open the road for businesses5 to enter this market. Given the sheer number (and often size) of these tournaments, this should present a very interesting commercial opportunity and lead to a concrete impact on the lives of the millions involved in these tournaments. For these reasons mainly we advocate and hope for a new surge in sport scheduling research, with the challenges highlighted in the previous section as a good starting point.
Acknowledgement This work is supported by the Research Council of Norway (grant no. 245682/O30). We would like to thank Ole Kristian Engvoll at PROFIXIO AS and Nils Fisketkjønn at the Norwegian Football Federation (Norges Fotballforbund) for their discussion and opinion on this topic.
References 1. Bartsch, T., Drexl, A., & Kroger, S. (2006). Scheduling the professional leagues of Austria and Germany.
Computers & Operations Research 33, 1907-1937. 2. Briskorn, D. (2008). Feasibility of home-away pattern sets for round robin tournaments. Operations Research
Letters 3. de Werra, D. (1981). Scheduling in sports. In P. Hansen, editor, Studies on Graphs and Discrete Programming,
pages 381-395. 4. Duran, G., Guajardo, M., Miranda, J., Saure', D., Souyris S., Weintraub, A., Wolf R. (2007). Scheduling the
Chilean Soccer League by Integer Programming. Interfaces 5. Easton, K., Nemhauser, G., & Trick, M. (2003). Solving the travelling tournament problem: a combined integer
programming and constraint programming approach. Lecture Notes in Computer Science. 6. Even, S., Itai, A., Shamir, A., (1976). On the complexity of timetable and multicommodity flow problems. SIAM
Journal on Computing 5 (4), 691–703. 7. Henz, M. (2001). Scheduling a major league basketball conference - revisited. Operations Research, 49:163-168. 8. Horbach, A. (2010). A combinatorial property of the maximum round-robin tournament problem. Operations
Research Letters. 9. Kendall, G., Knust, S., Ribeiro, C., & Urrutia, S. (2010). Scheduling in sports: An annotated bibliography.
Computers & Operations Research. 10. Kingston, J.H., (1995). Bibliography on practice and theory of automated timetabling. Available at:
http://liinwww.ira.uka.de/bibliography/Misc/timetabling.html 11. Miyashiro R., Iwasaki H., Matsui T. (2002). Characterizing feasible patterns sets with a minimum number of
breaks. Lecture notes in Computer Science. 12. Nemhauser, G., & Trick, M. (1998). Scheduling a major college basketball conference. Operations Research
46(1), 1-8. 13. Rasmussen, R. V., & Trick, M. (2006). Round robin scheduling - a survey. European Journal of Operational
Research. 14. Rasmussen, R., & Trick, M. (2007). A Benders approach for the constrained minimum break problem. European
Journal of Operational Research, 177(1):198-213. 15. Recalde, D., Torres, R., Vaca, P. (2013). Scheduling the professional Ecuadorian football league by Integer
Programming. Computers & Operations Research, 40 (10): 2478-2484.
5Software companies developing optimization-based solutions for sport scheduling
CLAIO-2016
497

16. Ribeiro, C.C., Urrutia, S. (2009). Scheduling the Brazilian Soccer Tournament: Solution Approach and Practice. Interfaces.
17. Russell R., Leung G. (1994). Devising a cost effective schedule for a Baseball league. Operations Research, 42(4):614-625
18. Schaerf, A. (1999). Scheduling sports tournaments using constraint logic programming. Constraints, 4:43-65 19. Schreuder J. (1980). Constructing timetables for sport competitions. Mathematical Programming Study. 35:301–
12. 20. Trick, M. (2001). A schedule-then-break approach to sports timetabling. Lecture notes in computer science, vol.
2079. Berlin: Springer; 2001. p. 242–52. 21. Urban, T., Russell R., (2003). Scheduling sports competitions on multiple venues. European Journal of
Operational Research. 22. Della Croce, F., Tadei, R., Asioli, P.S. (1999) Scheduling a round robin tennis tournament under courts and
players availability constraints, Annals of Operations Research 92, 349-361. 23. Ikebe, Y.T., Tamura, A. (2008) On the existence of sports schedules with multiple venues, Discrete Applied
Mathematics 156, 1694-1710. 24. Knust, S., (2010). Scheduling non-professional table-tennis leagues, European Journal of Operational Research,
200: 358-367. 25. Russell, R.A., Urban, T.L. (2006) A constraint programming approach to the multiple-venue sport-scheduling
problem, Computers and Operations Research 33, 1895-1906. 26. Schönberger, J., Mattfeld, D.C., Kopfer, H. (2004) Memetic algorithm timetabling for non-commercial sport
leagues, European Journal of Operational Research, 153: 102-116. 27. Suksompong, W. (2016) Scheduling asynchronous round-robin tournaments, Operations Research Letters, 44:
96-100.
CLAIO-2016
498

An algorithm in dynamic programming for the Closest
String Problem
Omar Latorre Vilca, Rosiane de FreitasInstitute of Computing PPGI/IComp, UFAM
Manaus-AM Brazil{omarlatorre, rosiane}@icomp.ufam.edu.br
Abstract
The Closest String Problem (CSP) that arises in computational molecular biology, codingtheory and web searching is to find a string that minimizes the maximum Hamming distancefrom a given set of strings, the CSP is NP-hard problem. Several approximation and exactalgorithms have been proposed for the problem to achieve optimal solutions using Mixed IntegerLinear Programming. This paper proposes a new algorithm for the problem, based on dynamicprogramming. The algorithm is compared with an integer programming formulation for CSP.Furthermore, computational experiments in comparison tables will show the effectiveness of theproposed algorithm.
Keywords: Dynamic Programming; Integer Programming; Combinatorial Optimization.
1 Introduction
The Closest String Problem (CSP) is known to be NP-hard because its decision problem versionover a binary alphabet is NP-complete [3]. In computational biology problems related with stringsoften arise: Given strings are compared with each other and their common part is searched for.Among such problems, the closest string problem, is to find a string that minimizes the maximumHamming distance from a given set of strings. That is, let a finite set of strings S = {s1, s2, ...., sn}with n strings, with the same size m, over an alphabet A, we want find a string x, of length m,over A and minimizes the value of d such that for all string x and s is computing the number ofpositions that both string are different. For instance, if x = ATT and s = GCT , then dH(x, s) = 2,where x and s are different in the first and second position.
One of the challenges of web searching is multiple occurrences of the same data, whether inexact duplicates or with minor changes. In other application domains, in cryptography for dataencryption, for those reasons there is a greater practical interest in finding methods to solve it. Ingeneral there are different methods such as approximation, exact algorithm and heuristics [10, 11,12].
In the literature, it is possible to find different names for the CSP, each of them highlights maincharacteristics of the problem, such as Center String Problem [7, 6, 2], Motif Finding Problem [5],Consensus String Problem [1, 7, 2], Hamming Center Problem [4], and Minimum Radius Problem[3].
CLAIO-2016
499

In the following, the article is divided in sections, the Section 2 presents an integer programmingformulation, the Section 3 poses a naive algorithm, the Section 4 claims an algorithm in dynamicprogramming, in the Section 5 are reported computational results and at last, the conclusion sectionconcludes the paper.
2 Integer-Programming Formulation
In [9] are presented three formulations in IP 0-1 for the CSP. The third formulation was established,from the following definition for binary variables xj,k
xj,k =
{1 If the character j is used in the position k in the solution0 otherwise
The authors in [9] proposed the formulation:
min d (1)
s.a.:∑
j∈Vkxj,k = 1 k = 1, . . . ,m (2)
d ≥ m−m∑
k=1
xsik,ki = 1, . . . , n (3)
xj,k ∈ {0, 1} j ∈ Vk; k = 1, . . . ,m (4)
d ≥ 0 and integer (5)
Look at this formulation has m + n inequalities and 1 +∑m
k=1 |Vk| decision variables. theconstrain (2) makes that for each vector solution x has in the position k one of the charactersfrom Vk. the constrain (3) calculates the Hamming distance between the vector solution x andthe strings in S. Constraints (4) are binary inequalities, meantime the constraint (5) forces d toassume a nonnegative integer value. The main sense is minimizing the value d.
3 A naive algorithm by Implicit Enumeration
A first simple tentative to solve the CSP, it is using implicit enumeration.
Figure 1: A directed graph m-partite from a CSP instance.
T
C
A
T
G
C
A
T
G
C
A
T
G
A
T
G
T
G
C
T
G
T
G
C
A
T
G
C
T
G
A
Let S an instance for the CSP, that is, S = {ACGAGCGCGA, CACGGGTACG, TGATTTG-GTT, ATTAGCGTGA, TGTGTGTACT}. The Figure 1 shows a directed graph given from in-stance S, we have, S = {s1, . . . , s5}, n = 5, with lenght m = 10 and alphabet |Σ| = 4, let Vk ∈ Σ
CLAIO-2016
500

a set of k characters, represents the k-th column, with 1 ≤ k ≤ m, so we have V1 = {A,C, T},V2 = {A,C,G, T}, V3 = {A,C,G, T}, V4 = {A,G, T}, V5 = {G,T}, V6 = {C,G, T} V7 = {G,T},V8 = {A,C,G, T}, V9 = {C,G, T}, V10 = {A,G, T}.
Let t a path, the characters from the path t forming a current solution for the instance S. Thesearch space (enumerating all the possible paths in the graph) grows in the order 4m, where m isthe length of the strings in S. So the computational complexity will be O(|Σ|mn).
4 Dynamic Programming
An exact algorithm to solve the Closest String Problem is, let X ⊂ S, where X is a subset of S,S = {s1, s2, · · · , sn} and let p, with 1 ≤ p ≤ m, so we define:
W (X, p)
as optimal value for the instance X, restricted to the subset of strings in X, where each string inX are the first characters p (prefixes) of the original sequences in S. In truth with this notationwe are interested in W (S,m).
Let σ ∈ Σ, a character where X ⊂ S, let r a position with 1 ≤ r ≤ m we define Xσr as subset
of strings from X that have a character σ in the position r, then
Xσr := {s ∈ X : s[r] = σ}
The intuition of dynamic programming is, suppose that the value v, until the position p−1, for thesequences that have σ until position p, is greater than the value w for sequences that have othercharacter in the position p. So the optimal solution will be σ in the position p. Therefore, σ in theposition r is finding in the string solution.
In truth the value from this set ended in σ did not change it, and for others will increase in1, that is, v > w, then v ≥ w. However, if more of one σ′s will find a greater value than (v), sothere is no conflict, if the character σ is putting in the position p, even so, the value will increasein 1, therefore one of the maximums will be for the sequences ended with a conflict, that is, thecharacter σ that we are analyzed.
The following recurrence does it, more formally:
W (X, p) = maxσW (Xσp , p− 1) + ∆ (6)
Where ∆ = 0 if and only if σ is under the maximum, and ∆ = 1 in other case. The optimal solutioncan be restructured to take one of the σ that is under the maximum and inserted in the position p.
Note that an eventual recurrence will find the base case, because, in the X we have a minimumvalue and / or p decrease.
As complexity of the algorithm, we have a table of O(2nm) entrance. Computing the inputstrings of (S) we have O(|Σ|). If the length of the alphabet is fixed, that is, a constant time. Inother words, the length of the alphabet is always polynomial as presented n number of strings andm the length of strings, so that’s holds. �
Theorem 1 The Closest String Problem can be solved in complexity time O(2nm|Σ|) for the dy-namic programming.
CLAIO-2016
501

Also we have the following parameter of complexity with parameter fixed
Theorem 2 The Closest String Problem can be solved in polynomial time, when n (the number ofstrings) is fixed.
Example 1 Let S an instance for the CSP, that is, S = {AGCTG, GATGC, CTTTG, ACAGT,CTTCG} with s1 = AGCTG, s2 = GATGC, s3 = CTTTG, s4 = ACAGT , and s5 = CTTCG wehave the sets Vk for k ∈ {1, . . . ,m}. We have V1 = {A,C,G}, V2 = {A,C,G, T}, V3 = {A,C, T},V4 = {C,G, T}, V5 = {C,G, T}. The Table 1 presents the Hamming distance between each pair ofstrings si for all si ∈ S with 1 ≤ i ≤ m.
Table 1: Hamming distances between each pair of strings from S.
dH(., .) s1 s2 s3 s4 s5
s1 0 5 3 4 4s2 5 0 4 4 4s3 3 4 0 5 1s4 4 4 5 0 5s5 4 4 1 5 0
The algorithm searches for a solution s ∈ S that is closest to all other strings in S. In this casethere is not a special choice, that is, maxi∈{1,...,5}dH(s, si) = 5, may be s3 because it is closest tos5 but farthest to s4. Now, we built modified strings from s3 based on his positions. For instance,we get s3k,σ∈Vk in this case we modify the position k with the character σ ∈ Vk. Let M be a matrix
of Hamming distances between si and s3k,σ∈Vk for k ∈ {1, . . . ,m} with dimensions |Σ|m× n. So wehave the Table 2
Table 2: Hamming distances between s3k,σ∈Vk and all strings in S.
dH(., .) s31A s31C s31G s32A s32C s32G s32T s33A s33C s33T s34C s34G s34T s35C s35G s35Ts1 2 3 3 3 3 2 3 3 2 3 4 4 3 4 3 4s2 4 4 3 3 4 4 4 5 5 4 4 3 4 3 4 4s3 1 0 1 1 1 1 0 1 1 0 1 1 0 1 0 1s4 4 5 5 5 4 5 5 4 4 5 5 4 5 5 5 4s5 2 1 2 2 2 2 1 2 2 1 0 1 1 2 1 2
max 4 5 5 5 4 5 5 5 5 5 5 4 5 5 5 4
After that, we choice the minimum value of Hamming distances, that is, {x1A, x2C , x4G, x5T },in this case we take x1A, we change the character σ in the first position of s, that is, s = ATTTGnow we have the Table 3.
Therefore, the minimum value is 3, so in this case we take x4G, we change the character σ inthe fourth position of s, that is, s = ATTGG. Hence dH(s, S) ≤ 3 is an optimal solution.
CLAIO-2016
502

Table 3: Hamming distances between sk,σ∈Vk and all strings in S.
dH(., .) s1A s1C s1G s2A s2C s2G s2T s3A s3C s3T s4C s4G s4T s5C s5G s5Ts1 2 3 3 2 2 1 2 2 1 2 3 3 2 3 2 3s2 4 4 3 3 4 4 4 5 5 4 4 3 4 3 4 4s3 1 0 1 2 2 2 1 2 2 1 2 2 1 2 1 2s4 4 5 5 4 3 4 4 3 4 4 4 3 4 4 4 3s5 2 1 2 3 3 3 2 3 3 2 1 1 2 3 2 3
max 4 5 5 4 4 4 4 5 5 4 4 3 4 4 4 4
5 Computational Experiments
We now present the computational experiments carried out with the algorithms described in Sec-tions 4 and 2. Initially, we describe the set of instances used in the tests. Then, in Section 5.2 theresults obtained by the IP and by the proposed algorithm are discussed.
5.1 Test environment
All the programs were developed in C++ and used the compiler Gnu C++ without optimizations.All tests were executed on a desktop computer with the following configuration: Dell processorIntel Core I7 with speed of 3.4 Ghz and 7.7 GB of RAM under Linux Ubuntu 14.04 LTS work on64 bits. The solver IBM ILOG CPLEX version 12.5 was used to solve IP formulation, also we usedthe user manual CPLEX version 12 [8].
5.2 Instances and experimental results
400 instances for the CSP were used, they were created with the instances generator describe inthe reference [9]. These instances consider alphabets with two and four characters.
In the following will be presented the computational results for instances of the CSP of typeBinary, that is, Σ = {0, 1}, and type DNA that is, Σ = {A,C,G, T}, which obtain optimal solutionsused the proposed algorithm using dynamic programming described in the Section 4.
The headers on tables 4 and 5 have the following means: The first block indicates the testedinstance, with parameters indicating, (n) number of strings, and (m) length of strings; the blocksDynamic Programming (DP) and Integer programming formulation (IP) claim their optimal values,the parameters (Min, Avg, and Max) presents the minimum, average, and maximum optimalsolutions obtained from five different instances with the same parameters (n and m), (Time) timeof execution in milliseconds.
Notice the IP formulation uses CPLEX in multi-thread mode under the default settings whereCPLEX uses a number of threads equal to the number of cores – in this case eight – while asingle-thread implementation of DP is used for the tests.
CLAIO-2016
503
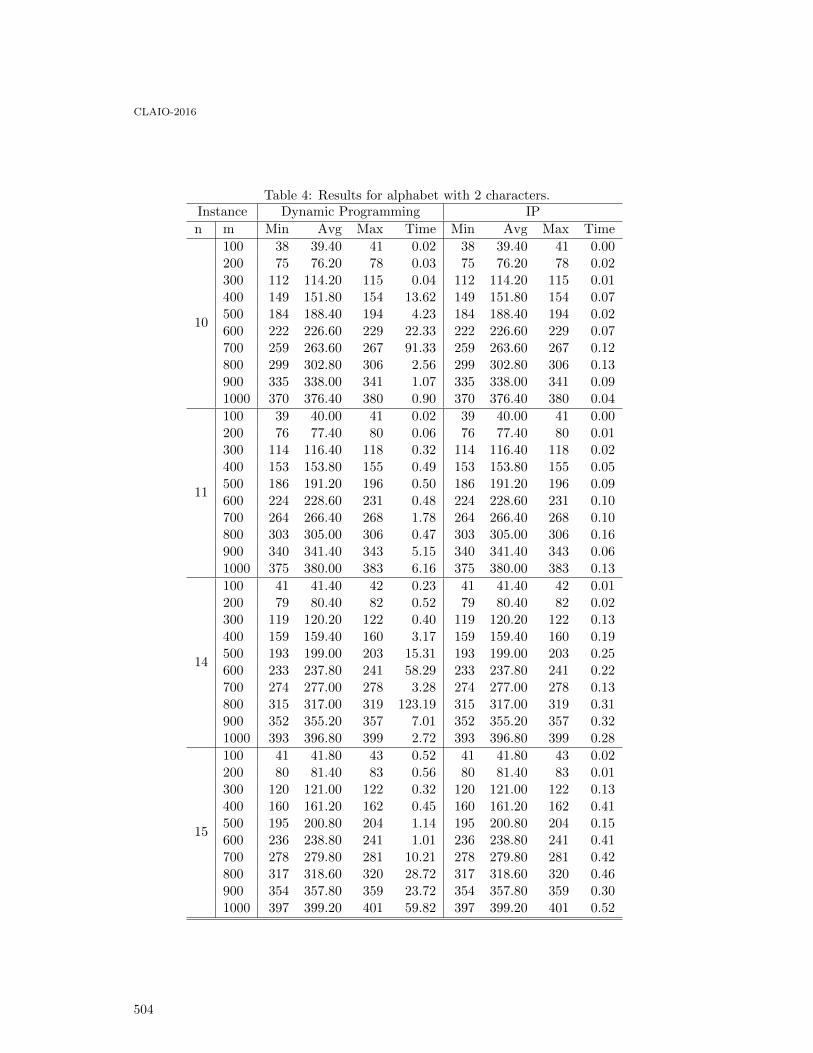
Table 4: Results for alphabet with 2 characters.Instance Dynamic Programming IP
n m Min Avg Max Time Min Avg Max Time
10
100 38 39.40 41 0.02 38 39.40 41 0.00200 75 76.20 78 0.03 75 76.20 78 0.02300 112 114.20 115 0.04 112 114.20 115 0.01400 149 151.80 154 13.62 149 151.80 154 0.07500 184 188.40 194 4.23 184 188.40 194 0.02600 222 226.60 229 22.33 222 226.60 229 0.07700 259 263.60 267 91.33 259 263.60 267 0.12800 299 302.80 306 2.56 299 302.80 306 0.13900 335 338.00 341 1.07 335 338.00 341 0.091000 370 376.40 380 0.90 370 376.40 380 0.04
11
100 39 40.00 41 0.02 39 40.00 41 0.00200 76 77.40 80 0.06 76 77.40 80 0.01300 114 116.40 118 0.32 114 116.40 118 0.02400 153 153.80 155 0.49 153 153.80 155 0.05500 186 191.20 196 0.50 186 191.20 196 0.09600 224 228.60 231 0.48 224 228.60 231 0.10700 264 266.40 268 1.78 264 266.40 268 0.10800 303 305.00 306 0.47 303 305.00 306 0.16900 340 341.40 343 5.15 340 341.40 343 0.061000 375 380.00 383 6.16 375 380.00 383 0.13
14
100 41 41.40 42 0.23 41 41.40 42 0.01200 79 80.40 82 0.52 79 80.40 82 0.02300 119 120.20 122 0.40 119 120.20 122 0.13400 159 159.40 160 3.17 159 159.40 160 0.19500 193 199.00 203 15.31 193 199.00 203 0.25600 233 237.80 241 58.29 233 237.80 241 0.22700 274 277.00 278 3.28 274 277.00 278 0.13800 315 317.00 319 123.19 315 317.00 319 0.31900 352 355.20 357 7.01 352 355.20 357 0.321000 393 396.80 399 2.72 393 396.80 399 0.28
15
100 41 41.80 43 0.52 41 41.80 43 0.02200 80 81.40 83 0.56 80 81.40 83 0.01300 120 121.00 122 0.32 120 121.00 122 0.13400 160 161.20 162 0.45 160 161.20 162 0.41500 195 200.80 204 1.14 195 200.80 204 0.15600 236 238.80 241 1.01 236 238.80 241 0.41700 278 279.80 281 10.21 278 279.80 281 0.42800 317 318.60 320 28.72 317 318.60 320 0.46900 354 357.80 359 23.72 354 357.80 359 0.301000 397 399.20 401 59.82 397 399.20 401 0.52
CLAIO-2016
504
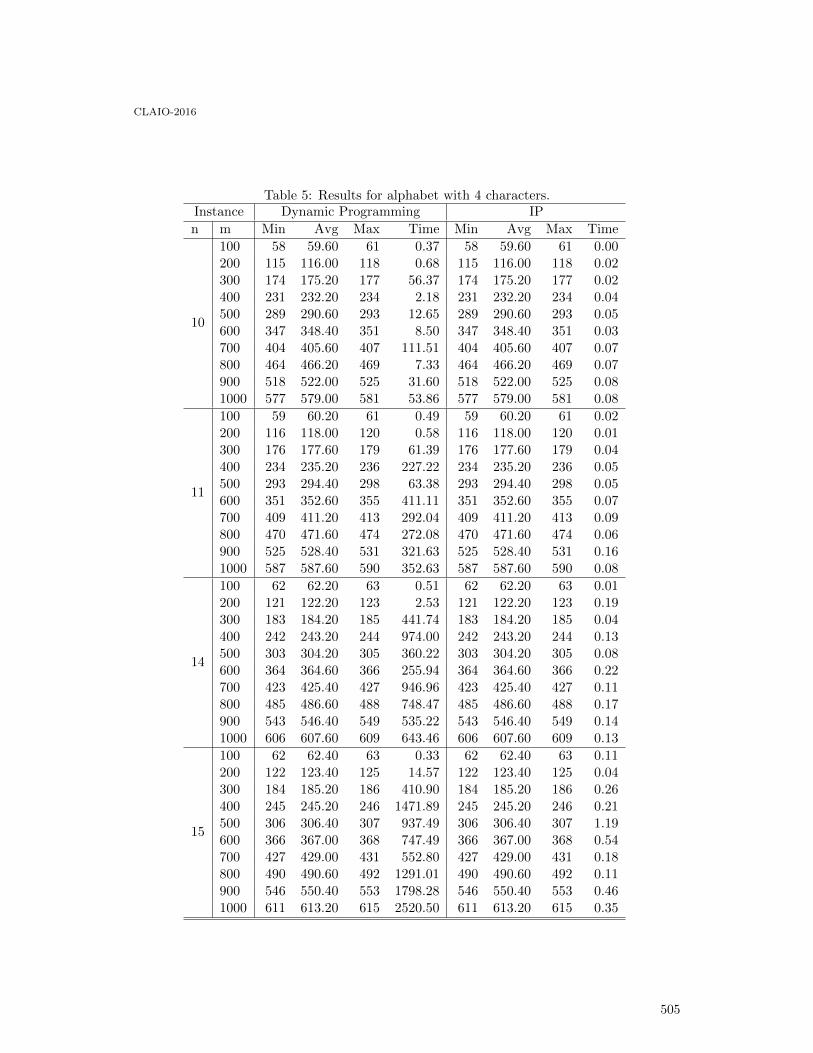
Table 5: Results for alphabet with 4 characters.Instance Dynamic Programming IP
n m Min Avg Max Time Min Avg Max Time
10
100 58 59.60 61 0.37 58 59.60 61 0.00200 115 116.00 118 0.68 115 116.00 118 0.02300 174 175.20 177 56.37 174 175.20 177 0.02400 231 232.20 234 2.18 231 232.20 234 0.04500 289 290.60 293 12.65 289 290.60 293 0.05600 347 348.40 351 8.50 347 348.40 351 0.03700 404 405.60 407 111.51 404 405.60 407 0.07800 464 466.20 469 7.33 464 466.20 469 0.07900 518 522.00 525 31.60 518 522.00 525 0.081000 577 579.00 581 53.86 577 579.00 581 0.08
11
100 59 60.20 61 0.49 59 60.20 61 0.02200 116 118.00 120 0.58 116 118.00 120 0.01300 176 177.60 179 61.39 176 177.60 179 0.04400 234 235.20 236 227.22 234 235.20 236 0.05500 293 294.40 298 63.38 293 294.40 298 0.05600 351 352.60 355 411.11 351 352.60 355 0.07700 409 411.20 413 292.04 409 411.20 413 0.09800 470 471.60 474 272.08 470 471.60 474 0.06900 525 528.40 531 321.63 525 528.40 531 0.161000 587 587.60 590 352.63 587 587.60 590 0.08
14
100 62 62.20 63 0.51 62 62.20 63 0.01200 121 122.20 123 2.53 121 122.20 123 0.19300 183 184.20 185 441.74 183 184.20 185 0.04400 242 243.20 244 974.00 242 243.20 244 0.13500 303 304.20 305 360.22 303 304.20 305 0.08600 364 364.60 366 255.94 364 364.60 366 0.22700 423 425.40 427 946.96 423 425.40 427 0.11800 485 486.60 488 748.47 485 486.60 488 0.17900 543 546.40 549 535.22 543 546.40 549 0.141000 606 607.60 609 643.46 606 607.60 609 0.13
15
100 62 62.40 63 0.33 62 62.40 63 0.11200 122 123.40 125 14.57 122 123.40 125 0.04300 184 185.20 186 410.90 184 185.20 186 0.26400 245 245.20 246 1471.89 245 245.20 246 0.21500 306 306.40 307 937.49 306 306.40 307 1.19600 366 367.00 368 747.49 366 367.00 368 0.54700 427 429.00 431 552.80 427 429.00 431 0.18800 490 490.60 492 1291.01 490 490.60 492 0.11900 546 550.40 553 1798.28 546 550.40 553 0.461000 611 613.20 615 2520.50 611 613.20 615 0.35
CLAIO-2016
505

6 Concluding remark
This article proposes a new algorithm based on dynamic programming applied to CSP. It waspossible to obtain optimal values compared to the IP formulation found in the literature. Theexperimental results demonstrate the efficiency of the method, both convergence and capacity toobtain the optimal solution for the CSP.
7 Acknowledgments
The results presented in this article are part of a collaboration with professor Cláudio Nogueira deMeneses, who works in the Center of Mathematic, Computation and Cognition at Federal Universityof ABC. Also with professor Giuseppe Lancia, who works in the Department of Mathematical andComputer Science at University of Udine in Italy. This work was supported by the Brazilian FederalAgency for Post-Graduate Education (CAPES), Grant No. 00.889.834/0001-08.
References
[1] A. Amir, G. M. Landau, J. C. Na, H. Park, K. Park, and J. S. Sim. Consensus Optimizing Both DistanceSum and Radius, pages 234–242. Springer Berlin Heidelberg, Berlin, Heidelberg, 2009.
[2] L. Bulteau, F. Hüffner, C. Komusiewicz, R. Niedermeier, et al. Multivariate algorithmics for np-hardstring problems. Bulletin of EATCS, 3(114), 2014.
[3] M. Frances and A. Litman. On covering problems of codes. Theory of Computing Systems, 30(2):113–119, 1997.
[4] L. Gasieniec, J. Jansson, and A. Lingas. Efficient approximation algorithms for the hamming centerproblem. pages 905–906, 1999.
[5] F. C. Gomes, C. N. Meneses, P. M. Pardalos, and G. V. R. Viana. A parallel multistart algorithm forthe closest string problem. Computers & Operations Research, 35(11):3636–3643, 2008.
[6] J. Gramm, R. Niedermeier, and P. Rossmanith. Exact solutions for closest string and related problems.In Algorithms and Computation, pages 441–453. Springer, 2001.
[7] J. Gramm, R. Niedermeier, P. Rossmanith, et al. Fixed-parameter algorithms for closest string andrelated problems. Algorithmica, 37(1):25–42, 2003.
[8] ILOG Inc. CPLEX 12.6.1 User’s Manual, 2014.
[9] C. Meneses, Z. Lu, C. Oliveira, and P. Pardalos. Optimal solutions for the closest string problem viainteger programming. INFORMS Journal on Computing, 16(4):419–429, 2004.
[10] C. Meneses, C. Oliveira, and P. Pardalos. Optimization techniques for string selection and comparisonproblems in genomics. Engineering in Medicine and Biology Magazine, IEEE, 24(3):81–87, May 2005.
[11] O. L. Vilca. Métodos para problemas de seleção de cadeias de caracteres. Master’s thesis, UniversidadeFederal do ABC, Santo André, São Paulo, 2013.
[12] O. L. Vilca and C. N. Meneses. Planos de corte e heuŕısticas para o closest string problem. CLAIO -SBPO 2012, 1(1):3306–3314, 2012.
CLAIO-2016
506

APLICAÇÃO DO MÉTODO ANALYTIC HIERARCHY PROCESS – AHP PARA A ANÁLISE DA TRANSPOSIÇÃO DO
RIO SÃO FRANCISCO
Rodolfo José Sabiá Universidade Regional do Cariri
Francisco de Assis Vilar Sobreira Júnior
Universidade Regional do Cariri [email protected]
Anna Flávia de Oliveira Lima Universidade Regional do Cariri
Valério Antonio Pamplona Salomon Universidade Estadual Paulista
Itayna Mônica Cardoso Libório Universidade Regional do Cariri [email protected]
Resumo As variáveis utilizadas para os problemas ambientais decorrem de fenômenos tangíveis, intangíveis e goodwill. A fim de estudar o comportamento desses critérios, utilizando ferramentas do MCDM, o Processo de Análise Hierárquica (AHP) apresenta-se como ferramenta prática para os tomadores de decisão que enfrentam tais problemas de priorização. Este trabalho é direcionado a um estudo de decisões relacionadas à Transposição do Rio São Francisco, onde as aplicações dos dados foram feitas no programa Expert Choice. Esse método mostrou ser eficiente para o processo de tomada de decisão, determinando a influência que os critérios tiveram sobre o resultado final. Portanto, a aplicação mais eficaz para esses problemas é aquela que separa os subcritérios, de acordo com o seu respectivo critério estratégico, para obter uma melhor visualização da tomada de decisão. Palavras-chave: Analytic Hierarchy Process; Transposição do Rio São Francisco; Variáveis Tangíveis e Intangíveis. 1 Introdução Em muitos momentos da vida, se deparar com escolhas e ter, de alguma forma que decidir qual é a melhor opção para determinadas ocasiões, é algo diário. Portanto é preciso tomar-se uma decisão, que
CLAIO-2016
507

seja mais adequada para que não haja equívoco em seu resultado. Assim, surge a tomada de decisão com múltiplos critérios, Multiple Criteria Decision Making – MCDM, que é uma ferramenta que auxilia na sua escolha. Dentre os métodos existentes para análise de multicritério o método Analytic Hierarchy
Process – AHP, equilibra as interações entre o critério de decisão e sintetiza as informações em um vetor de preferências entre as alternativas, como um método de tomada de decisão MCDM (SAATY, 2008). Toledo Hernández (2011) diz que o processo de tomada de decisão começou uma nova fase nas organizações, pois a partir de 1970 o crescente custo dos recursos financeiros e humanos e a escassez dos mesmos fizeram com se voltassem às tomadas de decisões com os múltiplos critérios. Segundo Shimizu apud Toledo Hernández (2011), para tratar variáveis qualitativas, ou não vai existir uma solução ou os métodos de programação matemática podem ser inadequados, já para todos os outros critérios essas seriam soluções viáveis. Com o intuito de auxiliar o processo de tomada de decisão em problemas ambientais, utiliza-se o método Analytic Hierarchy Process – AHP, visto que as variáveis utilizadas para problemas ambientais decorrem de fenômenos tangíveis que são mensuráveis, físicos e rígidos que diferem dos fenômenos intangíveis que é igualmente mensurável, mas são comportamentais e possuem flexibilidade, ou seja, diferentes óticas para um mesmo elemento usadas para o seu julgamento. Há também o goodwill que é mais complexo, carecendo de muitas das distinções associadas aos fenômenos como identificabilidade e separabilidade sendo motivo de discussão devido sua dificuldade em ser mensurado, fazendo com que a mensuração e o cálculo sejam feitos pelo método holístico. Para Aguiar e Salomon (2007), o AHP é o mais popular método de decisão com múltiplos critérios, e permite a medição da coerência dos julgamentos das decisões, citando ainda que o AHP, para problemas decisórios, representa uma das aproximações mais promissoras, levando também em consideração a questão da transitividade que deve ser feito com teste através do decisor, pois se, como exemplo, A é preferível a B e B é preferível a C então A é preferível a C, logo não sendo respeitada haverá uma inconsistência que deve ser mostrada ao tomador de decisão. O Processo de Análise Hierárquica (AHP) oferece uma ferramenta prática para os tomadores de decisão que enfrentam tais problemas de priorização (SAATY & SHANG, 2011). Segundo Barbieri (2007), o crescimento da consciência ambiental, ao modificar os padrões de consumo, constitui umas das mais importantes estratégias em defesa do meio ambiente. Assim, o AHP surge como uma ferramenta que ajuda na tomada de decisão. Saaty e Shang (2011), afirmam que a solução de um problema com a medição relativa requer maior esforço para estabelecer a estrutura e realizar comparações de medida relativa para esse problema, pois os aspectos de atividades humanas, tendo base de multicritério, têm sido difíceis de quantificar objetivamente. Em contra partida, nos fenômenos tangíveis os atributos numéricos serão adaptados a partir de características inerentes do mesmo. Portanto, a pesquisa estudará um modelo que se separou os seus respectivos subcritérios em seus critérios, que foram tangíveis, intangíveis e goodwill, utilizando o AHP como ferramenta de gestão ambiental em organizações sustentáveis. 2 Material e Métodos Este trabalho é direcionado a um estudo de decisões relacionadas à Transposição do Rio São Francisco. O método de pesquisa utilizado foi um estudo de uma análise aprofundada do objeto de estudo e coleta de dados. Foram utilizadas pesquisas bibliográficas em livros, artigos, anais, revistas, sites, entre outros. Assim, a técnica de pesquisa é de caráter exploratório. Utilizando ferramentas do MCDM, a fim de estudar o comportamento dos critérios intangíveis e tangíveis no caso da Transposição do Rio São Francisco, o método escolhido foi o AHP como o mais adequado. Todas as aplicações dos dados, sejam elas reais ou simuladas, foram feitas no programa Expert Choice, que é usado para a aplicação do método AHP, para simular os dados obtidos. Foi realizada uma hierarquia e avaliada a sua consistência perante os dados dispostos. Logo, a pesquisa foi desenvolvida separando os subcritérios de acordo com o seu
CLAIO-2016
508

respectivo critério estratégico, usando uma matriz de comparações pairwise, ou seja, dois a dois para obter um resultado que julgará qual a mais adequada ou não para um determinado objetivo, sendo este, “Avaliar a viabilidade da Transposição das águas do Rio são Francisco”, onde os critérios estratégicos escolhidos foram: tangíveis, intangíveis e goodwill. 3 Resultados e Discussão A pesquisa foi desenvolvida com a aplicação do método AHP, utilizando tanto ativos tangíveis quanto intangíveis, onde a aplicação foi uma análise do estudo da transposição do Rio São Francisco, no qual se utilizou os aspectos tangíveis, intangíveis e goodwill como critérios estratégicos. Os subcritérios foram separados de acordo com o seu respectivo critério estratégico para ter uma melhor visualização do peso que mais influenciou na tomada de decisão. Sendo seus dados fornecidos pelo Estudo do Impacto Ambiental e Relatório de Impacto Ambiental – EIA/RIMA (2004) do projeto de transposição das águas do Rio São Francisco conforme Ministério do Meio Ambiente – MMA (2004). A Figura 1 mostra a hierarquia da transposição do Rio São Francisco.
Figura 1: Hierarquia da transposição do Rio São Francisco Para o critério tangível os subcritérios escolhidos foram: a Extensão do Rio (ER), Área da Bacia Hidrográfica (AH), Vazão firme na foz (VF), Vazão média na foz (VM), Vazão disponibilizada para
Objetivo
Tangível Intangível Goodwill
GE
DF
C
AC
PBR
ER
AH
VF
VM
VC
VS
VI
Viável Inviável
EX
DE
CT
A
PA
CLAIO-2016
509

consumos variados (VC), Vazão mínima fixada após Sobradinho (VS) e Vazão firme para a integração das bacias (VI). Esses elementos foram escolhidos, pois eles detêm de dados objetivos para a sua quantificação. Já para o critério intangível, os subcritérios usados foram: a Geração de Empregos (GE), Diminuição da fome no Semiárido (DF), Clima (C), Aumento da disponibilidade de água para consumo no Semiárido (AC) e a Perenização das bacias dos rios Jaguaribe – CE, Apodi – RN, Piranhas-Açu – PB e RN, Paraíba – PB, Moxotó e Brígida – PE (PBR). Por não serem elementos palpáveis tornam-se, então, adequados para esse critério, pois os intangíveis são incorpóreos representados por bens e direitos associados a uma organização. Os subcritérios escolhidos para o goodwill foram: o Êxodo Rural (EX), Desenvolvimento agrícola irrigada (DE), Concentração de terras (CT), Assoreamento (A) e Poluição do ar e das águas (PA), pois além de serem subjetivos, eles tem uma característica única que é a não separabilidade no processo, estes elementos que vão acontecer e o todo tem que trabalhar para que minimize os efeitos causados holisticamente. As alternativas escolhidas são: transposição viável ou inviável. Analisando a Figura 2 que correspondente ao subcritério tangível para o caso da transposição do Rio São Francisco, nota-se que o subcritério AH teve um peso em relação à alternativa “Transposição Inviável” valendo- se ainda do subcritério VC, que tendeu para a mesma alternativa, porém com um peso menor. Considerando os subcritérios ER, VF, VM e VI, que tenderam à alternativa “Transposição Viável”, por serem em maior quantidade, acabaram influenciando o resultado final mesmo com o subcritério AH com maior peso. O subcritério VS teve uma participação nula, ou seja, não influenciou nem na alternativa “Transposição Viável” e nem na “Transposição Inviável”.
Figura 2: Subcritérios do critério tangível gerado pelo programa Expert Choice
Analisando a Figura 3, dados do critério intangível, percebe-se que o subcritério DF tem grande peso na alternativa “Transposição Viável” em relação aos demais subcritérios, que tenderam para esse mesmo lado que foram GE, AC e PBR. Deixando nítido que o resultado do critério intangível é a alternativa “Transposição Viável”, pois o único subcritério que está contra é o C, que não possui peso suficiente para inverter o resultado, mas tende à alternativa “Transposição Inviável”.
CLAIO-2016
510
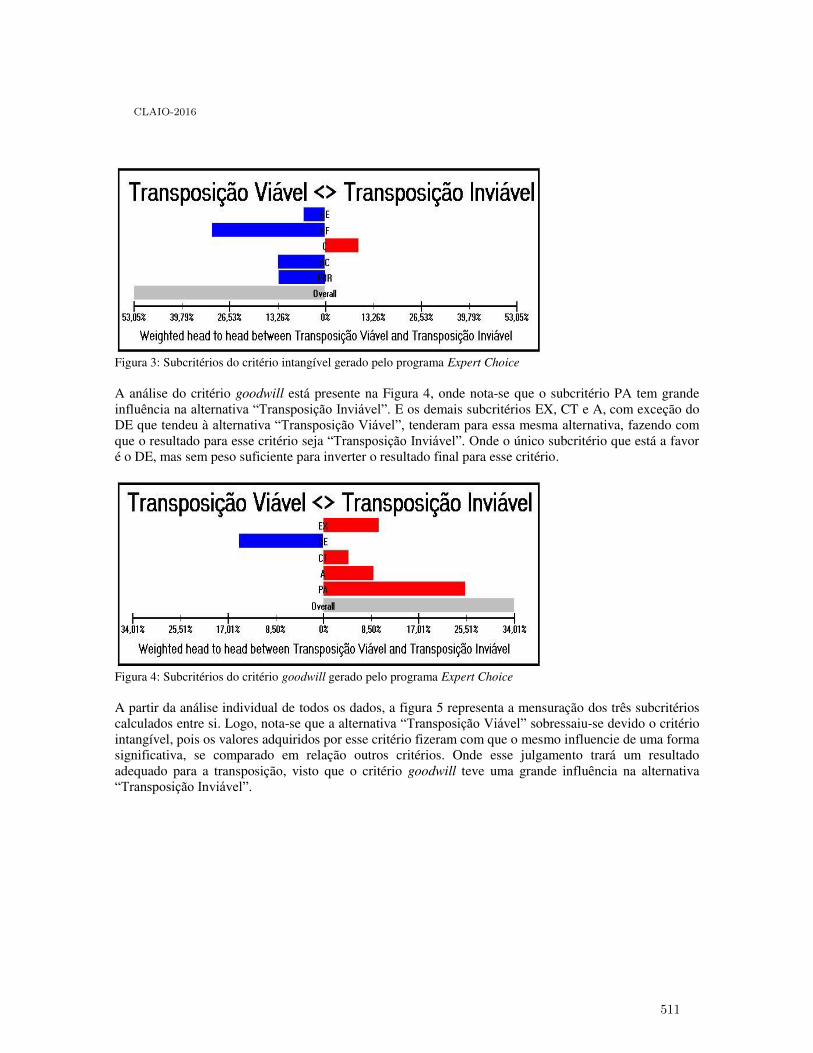
Figura 3: Subcritérios do critério intangível gerado pelo programa Expert Choice A análise do critério goodwill está presente na Figura 4, onde nota-se que o subcritério PA tem grande influência na alternativa “Transposição Inviável”. E os demais subcritérios EX, CT e A, com exceção do DE que tendeu à alternativa “Transposição Viável”, tenderam para essa mesma alternativa, fazendo com que o resultado para esse critério seja “Transposição Inviável”. Onde o único subcritério que está a favor é o DE, mas sem peso suficiente para inverter o resultado final para esse critério.
Figura 4: Subcritérios do critério goodwill gerado pelo programa Expert Choice A partir da análise individual de todos os dados, a figura 5 representa a mensuração dos três subcritérios calculados entre si. Logo, nota-se que a alternativa “Transposição Viável” sobressaiu-se devido o critério intangível, pois os valores adquiridos por esse critério fizeram com que o mesmo influencie de uma forma significativa, se comparado em relação outros critérios. Onde esse julgamento trará um resultado adequado para a transposição, visto que o critério goodwill teve uma grande influência na alternativa “Transposição Inviável”.
CLAIO-2016
511

Figura 5: Resultado da análise dos critérios pelo programa Expert Choice Dessa forma, os resultados demonstram que o critério estratégico intangível define o resultado favorável a transposição, ao tempo em que o goodwill tendência o resultado para a inviabilidade da transposição. Contudo o critério estratégico tangível pouco influenciou positivamente. A Figura 6 mostra a porcentagem da influência que cada critério estratégico e as alternativas obtiveram no resultado final.
Figura 6: Porcentagem dos critérios estratégicos e das alternativas Percebe-se que o critério Tangível, teve um peso maior, mas ao observar a Figura 5 nota-se que o critério Intangível foi o que mais influenciou à tomada de decisão. Vale à pena salientar, que desta forma, observa-se a importância da mensuração correta dos aspectos intangíveis e goodwill, sendo necessária uma aplicação criteriosa e exploratória para a obtenção dos dados e a geração dos resultados. 4 Conclusões O método AHP mostrou ser eficiente para a compreensão do processo de tomada de decisão utilizando critérios estratégicos tangíveis, intangíveis e goodwill. Pois o mesmo calculou e demonstrou, a partir de gráficos, o peso que cada critério teve sobre a tomada de decisão, determinando a influência que eles tiveram sobre o resultado final. Garantindo desta forma, a eficiência na tomada de decisão. Uma aplicação de forma convencional do AHP é muito útil para a gestão de empresas, porém para problemas ambientais fica difícil compreender o impacto de um fenômeno intangível ou goodwill, pois todos esses elementos estão integrados no mesmo critério. Sendo o resultado, o produto da interação entre os mesmos, sem distinção do peso do concreto ou abstrato. Portanto, fica evidente que a aplicação mais reveladora para os problemas ambientais é aquela que separa os subcritérios de acordo com o seu respectivo critério estratégico para ter uma melhor visualização da tomada de decisão, onde os critérios foram: tangíveis, intangíveis e goodwill. Onde é nítida a contribuição
CLAIO-2016
512

dos critérios em relação à tomada de decisão e os pesos que indicam a influência que o concreto e o abstrato terão na definição do resultado final. Referências
1. C. TOLEDO HERNÁNDEZ. Gerenciamento da Logística Reversa: Um modelo conceitual. São Paulo: Blucher Acadêmico, 2011.
2. D. C. de AGUIAR and V. A. P. SALOMON. Avaliação da prevenção de falhas em processos utilizando
métodos de tomada de decisão. Produção, Guaratinguetá, v. 17, n. 3, p.502-519, dez. 2007. 3. J. C. BARBIERI. Gestão ambiental empresarial: conceitos, modelos e instrumentos. 2. ed. São Paulo. 2007. 4. T. L. SAATY and J. S. SHANG. An innovative orders-of-magnitude approach to AHP-based mutli-criteria
decision making: Prioritizing divergent intangible humane acts. European Journal Of Operational Research. Pittsburgh, p. 703-715. 2011.
5. T. L. SAATY. Decision making with the analytic hierarchy process. International Journal of Services Sciences; 1(1): 83 – 98, 2008.
CLAIO-2016
513

PROPOSTA DE UM MODELO MULTICRITÉRIO DE
APOIO A DECISÃO PARA PRIORIZAÇÃO DE REGIÕES
ATINGIDAS PELO AEDES AEGYPTI NO MUNICÍPIO DE
MOSSORÓ-RN
João Victor Nunes Lopes
Universidade Federal Rural do Semi-Árido (UFERSA)
Ester Medley Bezerra Teixeira
Universidade Federal Rural do Semi-Árido (UFERSA)
Plácido Carlos Fernandes de Queiroz
Universidade Federal Rural do Semi-Árido (UFERSA)
Thomas Edson Espindola Gonçalo
Universidade Federal Rural do Semi-Árido (UFERSA)
Resumo
A saúde pública está vivenciando um grande problema atualmente, a proliferação do mosquito
Aedes Aegypti, transmissor da dengue, além de ter sido associado a outras doenças, entre elas a
febre Chikungunya e a febre pelo vírus Zika. Este estudo propor um modelo multicritério para
priorização dos bairros de uma cidade quanto à atenção no combate à proliferação do vetor. Para a
aplicação, foi utilizada a metodologia PROMETHEE GDDS para obter uma ordenação final para os
bairros que represente o ponto de vista dos diversos decisores envolvidos. Portanto, ao diagnosticar
quais os níveis de prioridades existentes, é possível destinar de maneira mais eficaz os recursos
públicos.
Palavras-chaves: Apoio Multicritério à Decisão, Aedes aegypti, PROMETHEE GDSS, Tomada de
decisão em Grupo.
1 Introdução
O mosquito Aedes Aegypti, responsável pela transmissão de várias doenças, tem atraído
atenção e trazido sérias preocupações para a população brasileira, entidades governamentais e
especialistas da área da saúde. De acordo com os dados do Ministério da Saúde (2016a, 2016b), no
ano de 2015, foram registrados 1.649.008 casos prováveis de dengue no país e, até fevereiro de
2016, já eram 396.582 casos prováveis de dengue e 3.748 casos suspeitos de febre Chikungunya. Já
em relação ao vírus Zika, os números não são conclusivos, porém sabe-se que foram notificados
2.975 casos suspeitos de microcefalia relacionada à infecção por esse vírus no mesmo período.
Segundo Barreto e Teixeira (2008), esse aumento de ocorrências relacionadas às doenças
transmitidas pelo Ae. Aegypti tem posto a sociedade em estado de alerta e se tornado constante
objeto de preocupação e mobilização das autoridades competentes. Considerando o caráter
emergencial da situação, bem como a limitação de recursos e de tempo, faz-se necessária uma
tomada de decisão acertada e eficiente em relação às medidas adotadas pelas entidades competentes
para combater a proliferação do mosquito e, consequentemente, das doenças por ele transmitidas.
CLAIO-2016
514

As ferramentas de apoio à decisão multicritério podem ser utilizadas para apoiar a tomada
de decisão referente ao combate à propagação das referidas doenças. Segundo Lima et al (2012), a
metodologia de apoio multicritério à decisão consiste em uma ferramenta de auxílio ao decisor
durante a análise e tomada de decisão, recomendando ações que devem ser realizadas para tornar
claro o processo decisório, de acordo com as preferências das partes envolvidas no processo. Poleto
et al (2012) complementam ao afirmar que as decisões precisam ser tomadas considerando a
preferência de vários decisores, que, por possuírem visões diferentes, podem ser tendenciados a
decidir com base em objetivos divergentes, o que pode prejudicar a eficácia da decisão.
Neste contexto, este trabalho se propõe a apresentar um modelo de apoio à decisão
multicritério para apoiar a tomada de decisão em grupo quanto à priorização dos bairros de uma
cidade em relação à necessidade de intervenção no combate à propagação do vetor. O modelo
proposto é aplicado para o caso da cidade de Mossoró/RN, que vem enfrentando um surto de
doenças transmitidas pelo mosquito. Para tanto, são considerados vários fatores que tornariam os
bairros mais ou menos suscetíveis à proliferação desse vetor. A seguir, na seção 2 são apresentadas
informações referentes ao Aedes Aegypti e doenças a ele associadas. A seção 3 fala da maneira
como se dão as ações de combate ao mosquito. Na seção 4 é introduzido o modelo multicritério
para priorização de bairros para o combate ao mosquito e na seção 5, tem-se a aplicação desse
modelo na cidade Mossoró/RN. Posteriormente, são discutidos os resultados na seção 6 e feitas as
considerações finais a respeito da contribuição e relevância do trabalho.
2 O mosquito Aedes aegypti
Confome exposto por Braga e Valle (2007) e Câmara et al. (2007), o Aedes Aegypti
adaptou-se facilmente ao ambiente urbano e comumente se reproduz nos ambientes domésticos e
nos seus entornos. É antropofílico e possui hábitos diurnos, dando preferência a se alimentar e
depositar seus ovos no início da manhã e final da tarde.
Entre outras doenças, o mosquito é responsável pela transmissão da dengue, da febre
Chikungunya e da febre causada pelo vírus Zika, além de ser indiretamente responsável pelas outras
complicações a essas associadas.
Conforme Câmara et al (2007) e De Araújo, Ferreira e Nogueira (2008) apontam, a dengue
é uma doença considerada como um grave problema de saúde pública nos países em
desenvolvimento. De acordo com Chaves et al (2015), a chikungunya possui formas graves que
podem acontecer principalmente em recém-nascidos idosos e pacientes com doenças crônicas. De
acordo com Luz, Santos e Vieira (2015), a circulação do vírus Zika (ZIKV) no Brasil foi
confirmada em Maio de 2015, após o registro e investigação de casos surgidos na região Nordeste.
È, em geral, uma doença mais branda do que as anteriormente citadas, porém há possíveis
complicações neurológicas que podem advir dela, como a síndrome de Guillain-Barré e a
microcefalia nos recém-nascidos, cuja relação foi confirmada pelo Ministério da Saúde em
Novembro de 2015
3 Combate ao aedes aegypti
Como ainda não se dispõe de vacinas eficazes para prevenir cada uma das doenças, a
melhor forma que se tem hoje de combate às doenças é atacando o próprio mosquito. De acordo
com Braga e Valle (2007), o controle de vetores tem como principais objetivos: administrar os
problemas existentes, como surtos e epidemias; prevenir epidemias ou a reintrodução das doenças e
reduzir os fatores de risco ambiental da transmissão. Para isso, deve-se dispor de várias alternativas,
adequadas à realidade local, que permitam sua execução de forma integrada e seletiva, levando em
consideração as condições ambientais e a dinâmica populacional do vetor. O processo compreende
a definição de local, o levantamento das informações necessárias e a decisão sobre o momento e
forma de implementação.
Atualmente, as medidas de controle atuam de forma a tentar eliminar o mosquito em suas
diferentes fases, mas com baixa efetividade, não conseguindo conter a disseminação do vírus. Além
CLAIO-2016
515

disso, as mesmas são bastante dispendiosas e possuir outras implicações desfavoráveis, como o uso
de inseticidas. As diversas condições envolvidas, entre as quais a capacidade de adaptação do Ae.
Aegypti e as características ambientais dos centros urbanos modernos que variam dinamicamente e
formam um cenário complexo, limitam as tentativas de estuda-los e usá-los de forma consistente.
(BARRETO; TEIXEIRA, 2008)
É nesse contexto que ferramentas gerenciais podem ser inseridas com a finalidade de
auxiliar as entidades competentes no processo decisório, consistindo em um fundamento sólido em
que apoiar decisões de impacto elevado como estas.
4 Modelo Multicritério para priorização de bairros para combate à propagação do Aedes
Aegypti
O modelo proposto para priorização dos bairros é apresentado na Figura 1 abaixo:
Figura 1 – Modelo Multicritério para priorização dos bairros da cidade quanto ao combate da
propagação do Aedes Aegypti
O modelo inicia na caracterização do problema na qual deve ser definido o escopo do
problema. Devem ser identificados os responsáveis pelo processo de decisão, entendidos como os
decisores. Em seguida deve-se selecionar as alternativas e os critérios que irão compor a matriz de
avaliação, após isso deve-se coletar as avaliações de cada decisor e aplicar o PROMETHEE II
individualmente. São obtidos, então, os fluxos líquidos que serão utilizados para a aplicação do
PROMETHEE GDSS e por fim, será apresentado o ranking final e definidas as ações para mitigar o
problema.
Para operacionalizar o modelo foi escolhido o método PROMETHEE GDSS que, segundo
Gonçalves e Belderrain (2011), faz parte da família de métodos de sobreclassificação. O princípio
básico desses métodos é que se uma alternativa possui um desempenho maior que outra na maioria
dos critérios, e não apresenta desempenho fortemente menor em outro, então ela será a alternativa
preferida. O método foi desenvolvido por Macharis, Brans e Mareschal (1998) e tem o intuito de
agregar as preferências individuais dos decisores mitigando ao máximo os conflitos de ideias. Inicia
a partir das tomadas de decisões individuais e, utilizando os valores obtidos nos rankings (fluxo
líquido), gera-se um novo ordenamento contemplando as preferências dos decisores envolvidos.
5 Aplicação do modelo para o caso da cidade de Mossoró-RN
Em visitas realizadas aos diversos agentes, foram observados alguns problemas
relacionados o atual sistema de tomada de decisão, um dos mais notórios foi o empirismo ao
selecionar ações para um determinado bairro. Alguns recursos (agentes de endemia, carros de Ultra
Baixo Volume (UBV), ações educacionais etc) concentravam esforços em bairros onde o
Levantamento Rápido do Índice de Infestação por Aedes aegypti (LIRAa) foi destacado como
crítico. Vale ressaltar que o LIRAa é um índice estatístico proposto pelo Ministério da Saúde, para
estimar o potencial de focos do mosquito aedes aegypti por bairros. Tem caráter apenas paliativo
não sendo tão preciso, podendo assim não retratar a realidade daquele bairro de forma correta. Além
disso, é observada forte limitação orçamentária, o que demanda uma tomada de decisão eficiente.
Diversos atores estão envolvidos com este processo, entretanto, o papel do Centro de
Controle de Zoonoses (CCZ) é bastante destacado, por atuar diretamente com o combate ao
mosquito, desde ações preventivas até ações corretivas por meio de agentes de endemias e carros
CLAIO-2016
516
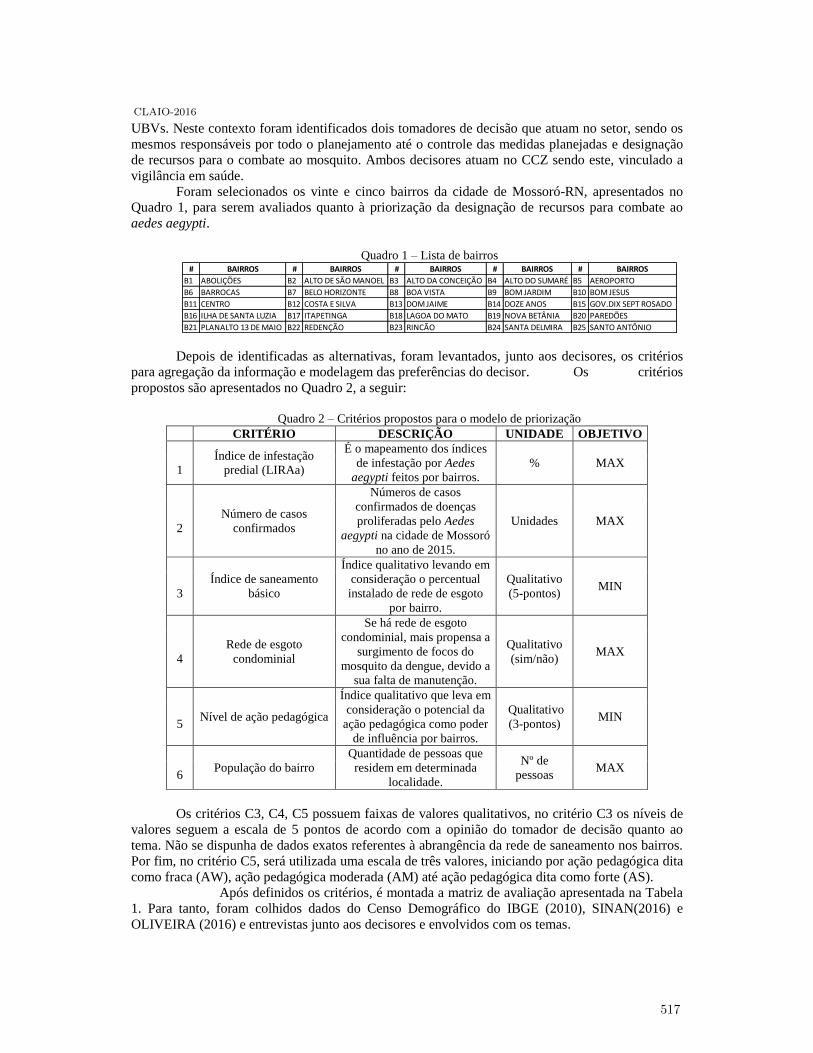
UBVs. Neste contexto foram identificados dois tomadores de decisão que atuam no setor, sendo os
mesmos responsáveis por todo o planejamento até o controle das medidas planejadas e designação
de recursos para o combate ao mosquito. Ambos decisores atuam no CCZ sendo este, vinculado a
vigilância em saúde.
Foram selecionados os vinte e cinco bairros da cidade de Mossoró-RN, apresentados no
Quadro 1, para serem avaliados quanto à priorização da designação de recursos para combate ao
aedes aegypti.
Quadro 1 – Lista de bairros
Depois de identificadas as alternativas, foram levantados, junto aos decisores, os critérios
para agregação da informação e modelagem das preferências do decisor. Os critérios
propostos são apresentados no Quadro 2, a seguir:
Quadro 2 – Critérios propostos para o modelo de priorização
# CRITÉRIO DESCRIÇÃO UNIDADE OBJETIVO
C
1
Índice de infestação
predial (LIRAa)
É o mapeamento dos índices
de infestação por Aedes
aegypti feitos por bairros.
% MAX
C
2
Número de casos
confirmados
Números de casos
confirmados de doenças
proliferadas pelo Aedes
aegypti na cidade de Mossoró
no ano de 2015.
Unidades MAX
C
3
Índice de saneamento
básico
Índice qualitativo levando em
consideração o percentual
instalado de rede de esgoto
por bairro.
Qualitativo
(5-pontos) MIN
C
4
Rede de esgoto
condominial
Se há rede de esgoto
condominial, mais propensa a
surgimento de focos do
mosquito da dengue, devido a
sua falta de manutenção.
Qualitativo
(sim/não) MAX
C
5 Nível de ação pedagógica
Índice qualitativo que leva em
consideração o potencial da
ação pedagógica como poder
de influência por bairros.
Qualitativo
(3-pontos) MIN
C
6 População do bairro
Quantidade de pessoas que
residem em determinada
localidade.
Nº de
pessoas MAX
Os critérios C3, C4, C5 possuem faixas de valores qualitativos, no critério C3 os níveis de
valores seguem a escala de 5 pontos de acordo com a opinião do tomador de decisão quanto ao
tema. Não se dispunha de dados exatos referentes à abrangência da rede de saneamento nos bairros.
Por fim, no critério C5, será utilizada uma escala de três valores, iniciando por ação pedagógica dita
como fraca (AW), ação pedagógica moderada (AM) até ação pedagógica dita como forte (AS).
Após definidos os critérios, é montada a matriz de avaliação apresentada na Tabela
1. Para tanto, foram colhidos dados do Censo Demográfico do IBGE (2010), SINAN(2016) e
OLIVEIRA (2016) e entrevistas junto aos decisores e envolvidos com os temas.
# BAIRROS # BAIRROS # BAIRROS # BAIRROS # BAIRROS
B1 ABOLIÇÕES B2 ALTO DE SÃO MANOEL B3 ALTO DA CONCEIÇÃO B4 ALTO DO SUMARÉ B5 AEROPORTO
B6 BARROCAS B7 BELO HORIZONTE B8 BOA VISTA B9 BOM JARDIM B10 BOM JESUS
B11 CENTRO B12 COSTA E SILVA B13 DOM JAIME B14 DOZE ANOS B15 GOV.DIX SEPT ROSADO
B16 ILHA DE SANTA LUZIA B17 ITAPETINGA B18 LAGOA DO MATO B19 NOVA BETÂNIA B20 PAREDÕES
B21 PLANALTO 13 DE MAIO B22 REDENÇÃO B23 RINCÃO B24 SANTA DELMIRA B25 SANTO ANTÔNIO
CLAIO-2016
517
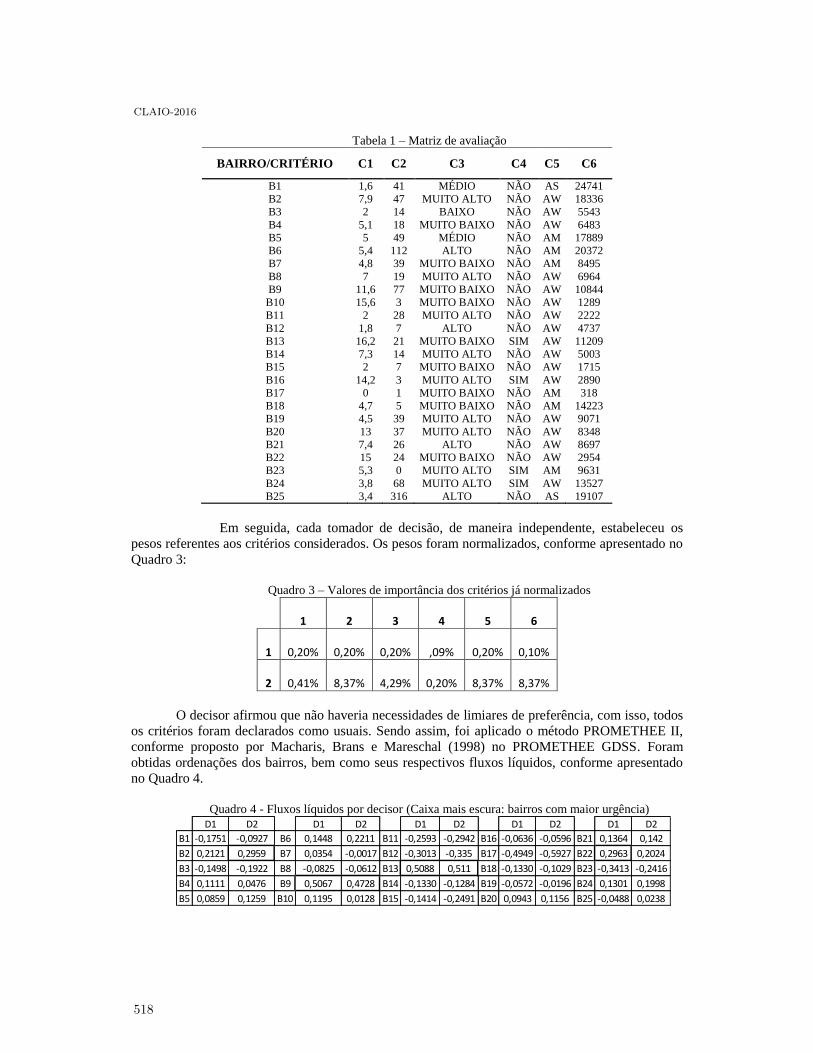
Tabela 1 – Matriz de avaliação
BAIRRO/CRITÉRIO C1 C2 C3 C4 C5 C6
B1 1,6 41 MÉDIO NÃO AS 24741
B2 7,9 47 MUITO ALTO NÃO AW 18336
B3 2 14 BAIXO NÃO AW 5543
B4 5,1 18 MUITO BAIXO NÃO AW 6483
B5 5 49 MÉDIO NÃO AM 17889
B6 5,4 112 ALTO NÃO AM 20372
B7 4,8 39 MUITO BAIXO NÃO AM 8495
B8 7 19 MUITO ALTO NÃO AW 6964
B9 11,6 77 MUITO BAIXO NÃO AW 10844
B10 15,6 3 MUITO BAIXO NÃO AW 1289
B11 2 28 MUITO ALTO NÃO AW 2222
B12 1,8 7 ALTO NÃO AW 4737
B13 16,2 21 MUITO BAIXO SIM AW 11209
B14 7,3 14 MUITO ALTO NÃO AW 5003
B15 2 7 MUITO BAIXO NÃO AW 1715
B16 14,2 3 MUITO ALTO SIM AW 2890
B17 0 1 MUITO BAIXO NÃO AM 318
B18 4,7 5 MUITO BAIXO NÃO AM 14223
B19 4,5 39 MUITO ALTO NÃO AW 9071
B20 13 37 MUITO ALTO NÃO AW 8348
B21 7,4 26 ALTO NÃO AW 8697
B22 15 24 MUITO BAIXO NÃO AW 2954
B23 5,3 0 MUITO ALTO SIM AM 9631
B24 3,8 68 MUITO ALTO SIM AW 13527
B25 3,4 316 ALTO NÃO AS 19107
Em seguida, cada tomador de decisão, de maneira independente, estabeleceu os
pesos referentes aos critérios considerados. Os pesos foram normalizados, conforme apresentado no
Quadro 3:
Quadro 3 – Valores de importância dos critérios já normalizados
C1
C2
C3
C4
C5
C6
D1
20,20%
20,20%
20,20%
9,09%
20,20%
10,10%
D2
20,41%
18,37%
14,29%
10,20%
18,37%
18,37%
O decisor afirmou que não haveria necessidades de limiares de preferência, com isso, todos
os critérios foram declarados como usuais. Sendo assim, foi aplicado o método PROMETHEE II,
conforme proposto por Macharis, Brans e Mareschal (1998) no PROMETHEE GDSS. Foram
obtidas ordenações dos bairros, bem como seus respectivos fluxos líquidos, conforme apresentado
no Quadro 4.
Quadro 4 - Fluxos líquidos por decisor (Caixa mais escura: bairros com maior urgência)
D1 D2 D1 D2 D1 D2 D1 D2 D1 D2
B1 -0,1751 -0,0927 B6 0,1448 0,2211 B11 -0,2593 -0,2942 B16 -0,0636 -0,0596 B21 0,1364 0,142
B2 0,2121 0,2959 B7 0,0354 -0,0017 B12 -0,3013 -0,335 B17 -0,4949 -0,5927 B22 0,2963 0,2024
B3 -0,1498 -0,1922 B8 -0,0825 -0,0612 B13 0,5088 0,511 B18 -0,1330 -0,1029 B23 -0,3413 -0,2416
B4 0,1111 0,0476 B9 0,5067 0,4728 B14 -0,1330 -0,1284 B19 -0,0572 -0,0196 B24 0,1301 0,1998
B5 0,0859 0,1259 B10 0,1195 0,0128 B15 -0,1414 -0,2491 B20 0,0943 0,1156 B25 -0,0488 0,0238
CLAIO-2016
518

Foi realizada análise de sensibilidade dos pesos de cada critério para cada decisor adotando
uma variação para mais e para menos de 15%. Foi observado que não houveram alterações pontuais
na ordenação no ranking assegurando a robustez do resultado obtido até aqui.
Para a segunda fase aplicação do PROMETHEE GDSS foram utilizados os valores obtidos
no Quadro 4. Foram definidos valores de importância de 65% para D1 e 35% para a D2. Foi
consenso entre os decisores que D1 possui maior responsabilidade na tomada de decisão e D2 atua
na área de suporte de combate a vetores. É obtido, então, a ordenação dos bairros da cidade de
Mossoró quanto à necessidade de atenção ao combate ao Aedes Aegypti, conforme exposto no
Quadro 5.
Quadro 5 – Ranking final dos bairros
Foi realizada uma análise de sensibilidade referente ao peso de cada decisor na decisão em
grupo. O procedimento adotou uma variação para mais e para menos 15% do valor do peso de cada
critério, reduzindo-se proporcionalmente os pesos dos demais. Não houve nenhuma alteração de
posições no ranking, assegurando a robustez do resultado.
6 Discussão dos resultados
No caso deste modelo, o decisor obteve um ranking de prioridades e priorizou ações aos
bairros mais bem ranqueados (B13, B9, B2, B22), pois estes possuem uma maior urgência de
recursos comparados aos outros bairros. Foi observado que o ranking final encontrado demonstra
bem que a unilateralidade da decisão pode prejudicar o processo decisório. Pode-se perceber que
dos três primeiros bairros apenas um seria contemplado caso a metodologia vigente de priorização
persistisse (aquela que privilegia apenas o LIRAa). Os resultados condizem bem com os
pensamentos individuais das decisores, havendo apenas alteração na terceira posição entre os
bairros B2 e B22 comparando com os rankings individuais de cada uma delas. Dessa forma,
observa-se uma coerência entre os resultados obtidos.
Considerações finais
E epidemia crescente de doenças relacionadas ao Aedes Aegypti vem preocupando os
brasileiros. Dengue, Chikungunya e, mais recentemente, o Zika Vírus vem trazendo uma série de
prejuízos para o dia a dia do brasileiro, o que impacta na economia do país. Soma-se a isso as
complicações decorrentes destas doenças, que podem causar fatalidades dentre os infectados. O
combate ao vetor, por sua vez, apresenta-se bastante complicado, demandando fortes investimentos
em recursos e em conscientização.
Tendo em vista que muitas das decisões são tomadas sem embasamento teórico, este artigo
propôs um modelo multicritério de apoio a decisão para fundamentar a tomada de decisão dos
gestores públicos na priorização da designação de recursos e ações emergenciais para os bairros em
estado crítico devido a proliferação do mosquito Aedes aegypti. Foi utilizada a metodologia
PROMETHEE GDSS, que permitiu, a partir dos critérios sugeridos, e respectivos graus de
RANK BAIRROS PHI
1 B13 1
2 B9 0,9167
3 B2 0,7792
4 B22 0,775
5 B6 0,6958
6 B21 0,5542
7 B24 0,5292
8 B4 0,3042
9 B10 0,3
10 B20 0,2792
CLAIO-2016
519

importância, estabelecidos em consonância com as preferências dos decisores, a elaboração do
ranking dos bairros com o maior índice de criticidade devido ao Aedes aegypti.
A utilização do apoio multicritério à decisão é de grande valia para os gestores públicos,
pois permite que estes decisores avaliem a melhor opção sob a ótica de vários fatores que
influenciam a priorização de ações emergenciais em um bairro. Dessa forma, espera-se que este
estudo ofereça uma ferramenta útil e de fácil aplicação, além de contribuir para a tomada de decisão
mais consistente e mais rápida por parte dos gestores públicos. Para estudos futuros pretende refinar
melhor os critérios, como também, propor um modelo que contemple municípios do Rio Grande do
Norte.
Referências
1. BRASIL, Ministério da Saúde. Boletim Epidemiológico – nº 03. Brasília, 2016a.
2. BRASIL, Ministério da Saúde. Boletim Epidemiológico – nº 14. Brasília, 2016a.
3. BARRETO, M. L.; TEIXEIRA, Maria Glória. Dengue no Brasil: situação epidemiológica e contribuições
para uma agenda de pesquisa. Estudos avançados: 22(64), 53-72, 2008.
4. LIMA, M. V. A. de et al. Apoio Multicritério na Gestão da Estrutura de Capital de Pequenas e Médias
Empresas. Revista Gestão & Tecnologia: 12(3), 146-173, 2012.
5. POLETO, T. et al. Uma abordagem de decisão em grupo para priorização de business process
management system-BPMS. Anais do XXXII Encontro Nacional de Engenharia de Produção. 2012.
6. BRAGA, I. A.; VALLE, D. Aedes aegypti: inseticidas, mecanismos de ação e resistência. Epidemiologia
e Serviços de Saúde: 16(4), 179-293, 2007.
7. CÂMARA, F. P. et al. Estudo retrospectivo (histórico) da dengue no Brasil: características regionais e
dinâmicas. Revista da Sociedade Brasileira de Medicina Tropical: 40(2), 192-196, 2007.
8. DE ARAÚJO, J. R.; FERREIRA, F. E.; NOGUEIRA, A. M. E. Revisão sistemática sobre estudos de
espacialização da dengue no Brasil. Revista Brasileira de Epidemiologia, 2008.
9. CHAVES, M. R. et al. Dengue, Chikungunya e Zika: a nova realidade brasileira. Newslab: 132, 2015.
10. LUZ, K. G.; SANTOS, G.; VIEIRA, R. M. Febre pelo vírus Zika. Epidemiologia e Serviços de Saúde:
24(4), 785-788, 2015.
11. BARRETO, M. L.; TEIXEIRA, M. G. Dengue no Brasil: situação epidemiológica e contribuições para
uma agenda de pesquisa. Estudos avançados: 22(64), 53-72, 2008.
12. GONÇALVES, T. J.; BELDERRAIN, M. C. N. Decisão em Grupo com PROMETHEE GDSS e GAIA:
Priorização de Subsistemas no Projeto do Satélite ITA-SAT. XLIII Simpósio Brasileiro de Pesquisa
Operacional (SOBRAPO) Ubatuba, 2011.
13. MACHARIS, C.; BRANS, J. P.; MARESCHAL, B. The GDSS PROMETHEE procedure – A
PROMETHEE-GAIA based procedure for group decision support. . Journal of Decision Systems: 7:283-
307, 1998.
14. GEOGRAFIA E ESTATÍSTICA, Instituto Brasileiro de. Censo demográfico 2010: População do RN.
Rio de Janeiro: IBGE, 2011. Acompanha 1 CD-ROM.
15. SINAN – Sistema de Informação de Agravos de Notificação. Casos confirmados de dengue 2015 –
residentes em Mossoró. Mossoró, 29 de fevereiro de 2016.
CLAIO-2016
520

Zero-inflated Cure Rate Weibull Regression Model:
An Application to Financial Data on Time-to-default
Francisco LouzadaInstitute of Mathematical Science and Computing, University of São Paulo, Brazil
Mauro Ribeiro de Oliveira JrCaixa Econômica Federal and Federal University of São Carlos, Brazil
Fernando MoreiraCredit Research Centre, University of Edinburgh Business School, Scotland, UK
Abstract
In this paper, we introduce a methodology based on zero-inflated long-term survival data inorder to deal with fraud rate estimation in bank loan portfolios. Our approach enables us toaccommodate three different types of loan borrowers, i.e., fraudsters, those who are susceptibleto default and finally, those who are not susceptible to default. Regarding to the survival analysisframework, an advantage of our approach is to accommodate zero-inflated times, which is notpossible in the standard cure rate model introduced by Berkson & Gage (1952). The parameterestimation is reached by maximum likelihood estimation procedure. To illustrate the proposedmethod, a real dataset of loan survival times is fitted by the zero-inflated Weibull cure ratemodel.
Keywords: bank loans; high-risk customers; zero-inflated.
1 Introduction
In some cases, financial institutions completely lose contact with clients as soon as their loans aregranted and, therefore, all amount lent is lost. These kind of borrowers are considered fraudsterswith, by definition, loan survival time equal to zero. On the other hand, there are customers whono longer honour their loan instalments, but unlike fraudsters, they honour their instalments for awhile. At some future moment, by private financial reasons, they no more meet their debts withthe bank and, so, become a defaulter. However now, the client has a positive loan survival time,represented by the elapsed time until the occurrence of the default, see for example Abad et al.(2009). To complete the picture, and ensure the survival of bankers, there are good customers,those who keep up to date with their obligations and, therefore, there will not be records of eventsof default. Interested readers can refer to Tong et al. (2012) for cure models in credit scoring(Lessmann et al., 2015).
CLAIO-2016
521

Such data analysis must be addressed to make a holistic risk management of the banking loanportfolio, that is, dealing with fraud prevention, control and mitigation of default and, finally,ensure the customer loyalty growth within the group of clients non-susceptible to default. Thus,for the survival of bankers and mainly the maximisation of profits, they must seek to maintain highrate of non-defaulting loans, while the rates of fraudsters and defaulters must be very low.
The dataset analysed in this work comprises customers who, in one way or another, have nothonoured their contractual obligations with the bank, either by fraud in the application process,or the loss of creditworthiness over time, along with good clients who honour their obligationsand have never experienced the event of default. Such data analysis must be addressed to makea holistic risk management of the banking loan portfolio, that is, dealing with fraud prevention,control and mitigation of default and, finally, ensure the customer loyalty growth within the groupof clients non-susceptible to default. As we see in Figure 1, these considerations delimit the datawe cover in this work: a set of zeros, positives and unrecorded banking loan times-to-default.
Figure 1: Loan survival time data.
2 Model formulation
Focusing on the portfolio credit risk context, we define the following proportions to be accom-modated in the new proposed model: γ0: the proportion of zero-inflated times, i.e., related tofraudsters, and γ1: the proportion of immune to failure, i.e., related to non-defaulters (cured).
Thus, we have the following expression for the improper survival function of a dataset comprisedby all possible loan survival times,
S(t) = γ1 + (1− γ0 − γ1)S∗(t), t ≥ 0, (1)
where S∗ is the survival function related to the (1− γ0 − γ1) proportion of subjects susceptible tofailure, γ1 is the proportion of subjects immune to failure (cured or non-defaulted) and finally, γ0is the proportion of individuals fraudsters (with survival time equal to zero).
The associated (improper) cumulative distribution function (CDF) and failure density function(PDF) are given by,
F (t) = γ0 + (1− γ0 − γ1)F ∗(t), t ≥ 0, (2)
CLAIO-2016
522

f(t) =
{γ0, if t = 0,(1− γ0 − γ1)f∗(t), if 0 < t.
(3)
F ∗ and f∗ are, respectively, the cumulative distribution function and probability density func-tion underpinning the (1 − γ0 − γ1) proportion of subject susceptible to default. Note that, theimproper CDF of the zero-inflated cure rate model, F (t), has the advantageous property of accom-modating the excess of zeros, γ0, since it satisfies: F (0) = γ0.
The likelihood contribution of each client i must take in consideration three different sources:it is equals to γ0, if i is a fraudster, (1 − γ0 − γ1)f
∗(ti), if i is not censored, and γ1 + (1 − γ0 −γ1)S
∗(ti), if i is censored.In order to keep the formulation of de model fully parametrical, let (α, λ) denotes the parameter
vector of a Weibull distribution and (γ0, γ1) be the parameters associated, respectively, with theproportion of fraudsters (inflation of zeros) and the proportion of long-term survivors (cure rate).The Weibull distribution is focused due to its historical importante as a survival distribution.
The likelihood function of the zero-inflated Weibull cure rate model, with a four-parametervector ϑ = (α, λ, γ0, γ1), based on a sample of n observations, D = {ti, δi}, under non-informativecensoring scheme is given by,
L(ϑ;D) ∝∏
ti=0
{γ0}∏
ti>0
{[(1− γ0 − γ1)f∗w(ti)]
δi [γ1 + (1− γ0 − γ1)S∗w(ti)]1−δi
}. (4)
We introduce a way to link covariates with the parameter set in the zero-inflated Weibull curerate model. This modelling allows us to determine the effect of covariates all at once on thezero-inflated times, on the cure rate and on the failure times. Then, the parameters are given by,
γ0i = ex>1iβ1
1+ex>1iβ1+e
x>2iβ2,
γ1i = ex>2iβ2
1+ex>1iβ1+e
x>2iβ2,
α = eα′,
λi = ex>3iβ3 ,
(5)
where βj ’s are three vectors of regression coefficients to be estimated.Note that, as required, the component link functions ensure that 0 < γ0i, γ1i < 1, 0 < 1− γ0i −
γ1i < 1 and λi > 0 are always satisfied.Parameter estimation is performed by straightforward use of maximum likelihood estimation
(MLE). Hence, the maximum likelihood estimator ϑ̂, regarding the parameter vector ϑ, bothconsidering the model with or without covariates, are obtained through direct maximisation of`(ϑ;D) = log{L(ϑ;D)} (Migon et al., 2014).
3 Application
The Table 1 presents the frequency and a briefly summary of 4, 138 lifetimes (in months) of aconsumer loan data. The loans were made in 2012 and followed until the end of 2015. A subdivisionconsidering one available covariate is considered. For reasons of confidentiality, we will refer to thecharacteristic of the client by a covariate with x label. In this particular case, we can see below
CLAIO-2016
523
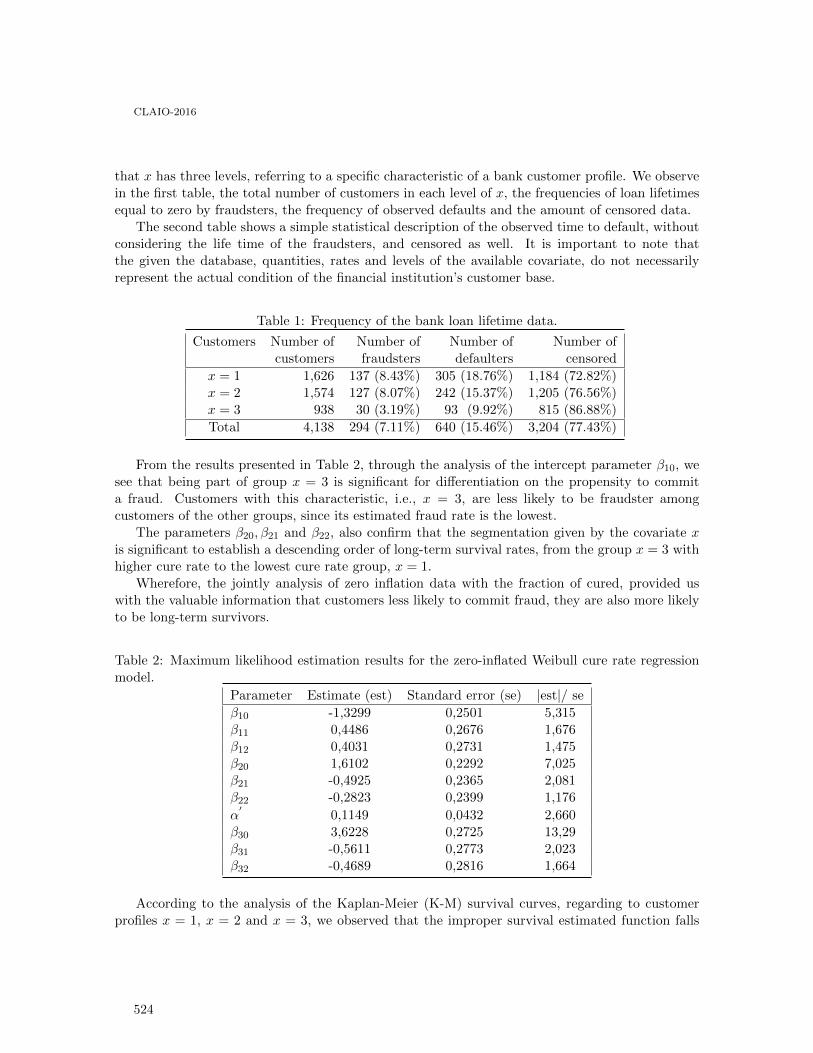
that x has three levels, referring to a specific characteristic of a bank customer profile. We observein the first table, the total number of customers in each level of x, the frequencies of loan lifetimesequal to zero by fraudsters, the frequency of observed defaults and the amount of censored data.
The second table shows a simple statistical description of the observed time to default, withoutconsidering the life time of the fraudsters, and censored as well. It is important to note thatthe given the database, quantities, rates and levels of the available covariate, do not necessarilyrepresent the actual condition of the financial institution’s customer base.
Table 1: Frequency of the bank loan lifetime data.
Customers Number of Number of Number of Number ofcustomers fraudsters defaulters censored
x = 1 1,626 137 (8.43%) 305 (18.76%) 1,184 (72.82%)x = 2 1,574 127 (8.07%) 242 (15.37%) 1,205 (76.56%)x = 3 938 30 (3.19%) 93 (9.92%) 815 (86.88%)
Total 4,138 294 (7.11%) 640 (15.46%) 3,204 (77.43%)
From the results presented in Table 2, through the analysis of the intercept parameter β10, wesee that being part of group x = 3 is significant for differentiation on the propensity to commita fraud. Customers with this characteristic, i.e., x = 3, are less likely to be fraudster amongcustomers of the other groups, since its estimated fraud rate is the lowest.
The parameters β20, β21 and β22, also confirm that the segmentation given by the covariate xis significant to establish a descending order of long-term survival rates, from the group x = 3 withhigher cure rate to the lowest cure rate group, x = 1.
Wherefore, the jointly analysis of zero inflation data with the fraction of cured, provided uswith the valuable information that customers less likely to commit fraud, they are also more likelyto be long-term survivors.
Table 2: Maximum likelihood estimation results for the zero-inflated Weibull cure rate regressionmodel.
Parameter Estimate (est) Standard error (se) |est|/ se
β10 -1,3299 0,2501 5,315β11 0,4486 0,2676 1,676β12 0,4031 0,2731 1,475β20 1,6102 0,2292 7,025β21 -0,4925 0,2365 2,081β22 -0,2823 0,2399 1,176
α′
0,1149 0,0432 2,660β30 3,6228 0,2725 13,29β31 -0,5611 0,2773 2,023β32 -0,4689 0,2816 1,664
According to the analysis of the Kaplan-Meier (K-M) survival curves, regarding to customerprofiles x = 1, x = 2 and x = 3, we observed that the improper survival estimated function falls
CLAIO-2016
524
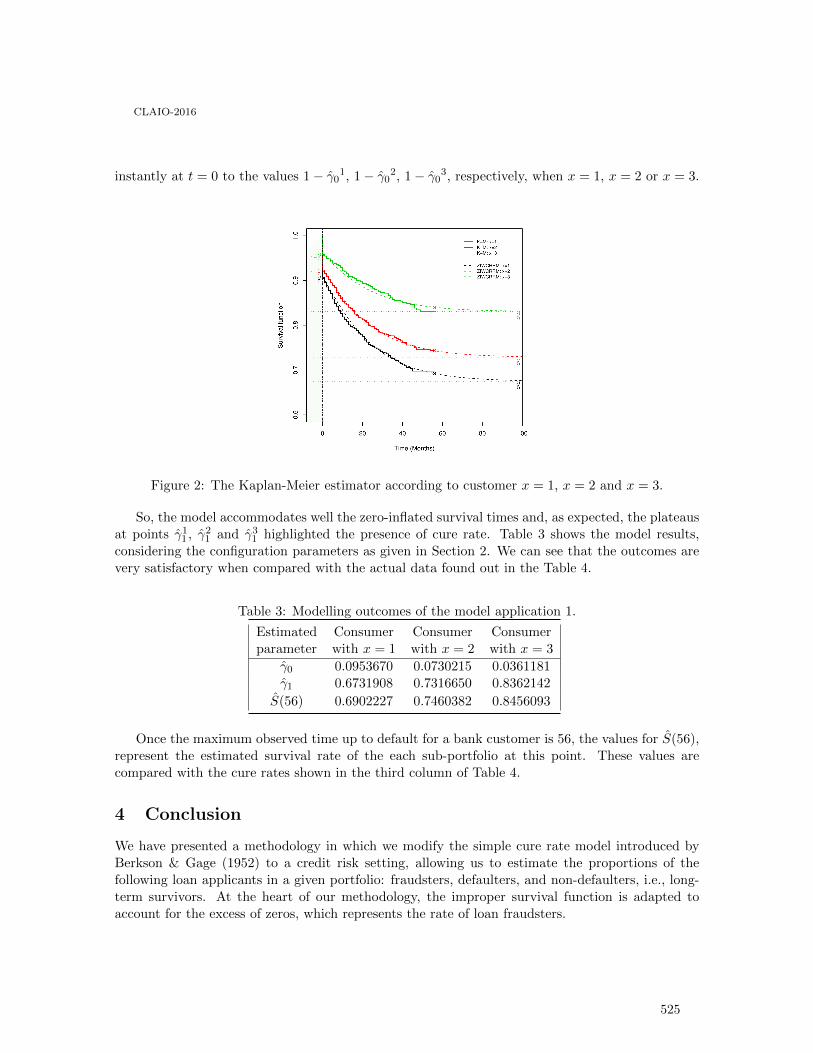
instantly at t = 0 to the values 1− γ̂01, 1− γ̂02, 1− γ̂03, respectively, when x = 1, x = 2 or x = 3.
Figure 2: The Kaplan-Meier estimator according to customer x = 1, x = 2 and x = 3.
So, the model accommodates well the zero-inflated survival times and, as expected, the plateausat points γ̂11 , γ̂21 and γ̂31 highlighted the presence of cure rate. Table 3 shows the model results,considering the configuration parameters as given in Section 2. We can see that the outcomes arevery satisfactory when compared with the actual data found out in the Table 4.
Table 3: Modelling outcomes of the model application 1.
Estimated Consumer Consumer Consumerparameter with x = 1 with x = 2 with x = 3
γ̂0 0.0953670 0.0730215 0.0361181γ̂1 0.6731908 0.7316650 0.8362142
Ŝ(56) 0.6902227 0.7460382 0.8456093
Once the maximum observed time up to default for a bank customer is 56, the values for Ŝ(56),represent the estimated survival rate of the each sub-portfolio at this point. These values arecompared with the cure rates shown in the third column of Table 4.
4 Conclusion
We have presented a methodology in which we modify the simple cure rate model introduced byBerkson & Gage (1952) to a credit risk setting, allowing us to estimate the proportions of thefollowing loan applicants in a given portfolio: fraudsters, defaulters, and non-defaulters, i.e., long-term survivors. At the heart of our methodology, the improper survival function is adapted toaccount for the excess of zeros, which represents the rate of loan fraudsters.
CLAIO-2016
525

Table 4: Summary of fraud and censored lifetime data.
Customers Number of Number offraudsters censored
x = 1 157 (9.538%) 1184 (71.940%)x = 2 114 (7.303%) 1205 (77.194%)x = 3 34 (3.609%) 815 (86.518%)
Total 305 (7.351%) 3204 (77.223)
To illustrate the proposed method, a loan survival times of a Brazilian bank loan portfolio ismodelled by the proposed zero-inflated Weibull cure rate model, and the results showed satisfactory.
An advantage of our approach is to accommodate zero-inflated times, which is not possible inthe standard cure rate model. In this scenario, information from fraudsters is exploited throughthe joint modelling of the survival time of fraudsters, who are equal to zero, along with the survivaltimes of the remaining portfolio.
In this way, the model fits a survival curve for the defaulter sub-population and simultaneouslyestimates the proportion of zero-inflated times, which are related to fraudsters, and the proportionof non-defaulters. The importance of the jointly analysis of zero inflation data with the fraction ofcured, is that it could provide us with the information that applicants less likely to commit fraudare also more likely to be long-term survivors.
References
[1] Abad, R. C., Fernández, J. M. V. & Rivera, A. D. Modelling consumer credit risk via survival analysis.SORT: Statistics and Operations Research Transactions, 33(1), 3 – 30, 2009.
[2] Berkson, J. & Gage, R. P. Survival curve for cancer patients following treatment. Journal of theAmerican Statistical Association, 47(259), 501 – 515, 1952.
[3] Lessmann, S., Baesens, B., Seow, H. & Thomas, L Benchmarking state-of-the-art classification algo-rithms for credit scoring: A ten-year update. European Journal of Operational Research, 247, 124 – 136,2015.
[4] Migon, H. S., Gamerman, D. & Louzada, F. Statistical inference: an integrated approach. CRC press:London, 2014.
[5] Louzada, F., Oliveira, M. R. & Moreira, F. F The zero-inflated cure rate regression model: Applicationsto fraud detection in bank loan portfolios. arXiv preprint arXiv:1509.05244, 2015.
[6] Tong, E. N., Mues, C. & Thomas, L. C Mixture cure models in credit scoring: If and when borrowersdefault. European Journal of Operational Research, 218(1), 132 – 139, 2012.
CLAIO-2016
526

Enfoque biobjetivo para planificar los flujos en una cadena de suministro con pérdidas de material
Sebastián Lozano Segura
Universidad de Sevilla, España [email protected]
Belarmino Adenso-Díaz Universidad de Oviedo
Resumen Este trabajo usa un enfoque biobjetivo para planificar los flujos en una red de suministro con pérdidas de material tratando de, simultáneamente, minimizar los costes y las pérdidas de material. Para ello se va a usar un enfoque de Análisis por Envoltura de Datos (DEA) considerando una red de procesos formada por los diferentes nodos y arcos de la cadena de suministro. Se supone que están disponibles observaciones de los flujos de material en una serie de periodos anteriores, lo cuales se van a usar para definir la tecnología DEA, esto es, los puntos de operación factibles. El modelo biobjetivo propuesto busca dentro de ese conjunto de puntos de operación factibles aquel que da lugar a menores costes y menores pérdidas de material. Palabras clave: cadena de suministro; pérdidas de material; Network DEA; optimización biobjetivo 1 Introducción La minimización del coste de los flujos en una red es un problema clásico de Investigación Operativa que se puede resolver de forma muy eficiente usando versiones específicas del algoritmo simplex de Programación Lineal (e.g. Bertsekas & Tseng 1988, Ahuja et al. 1993). Uno de las características de ese tipo de problemas es la conservación del flujo en los nodos. Hay ocasiones, sin embargo, en las que hay pérdidas en los nodos (además de en los arcos). En la medida en que las tasas de pérdidas no sean uniformes en la red sino que varían de unos nodos a otros y de unos arcos a otros resulta que las pérdidas globales en la red dependen de por dónde circule el flujo de material. Pero no sólo las pérdidas dependen del patrón de flujo. Los costes totales (incluyendo costes de procesamiento y costes de transporte) también dependen de los flujos. Tenemos, pues, un problema de optimización biobjetivo ya que queremos, simultáneamente, minimizar costes y pérdidas. Supongamos que las tasas de pérdidas en cada nodo o arco no son conocidas a priori. De hecho, en un mismo nodo o arco las pérdidas pueden haber sido diferentes de unos periodos a otros. Si tenemos datos de los flujos (y las pérdidas asociadas a los mismos) en diferentes periodos de tiempo podemos usar la metodología DEA (Data Envelopment Analysis) para identificar las mejores prácticas y calcular las menores pérdidas en cada nodo o arco y usar esa información para planificar los flujos de material a lo largo de la red. El modelo DEA que resulta es complejo porque es de tipo red de procesos y esto implica ma una tecnología específica para cada nodo y arco de la cadena de suministro (e.g. Tone and Tsutsui 2009, Lozano 2011). Es, además, una aplicación peculiar de DEA ya que en DEA los procesos
CLAIO-2016
527

normalmente hacen una transformación de entradas en salidas. En nuestro caso, los procesos sólo tienen una entrada y una salida y además el producto de salida es el mismo que el de entrada, sólo que en menor cantidad. Aumentar la eficiencia de un proceso corresponde a reducir la pérdida en el mismo. Nótese que la metodología DEA nos va a permitir planificar flujos que van a tener las mínimas pérdidas posibles (de acuerdo con las mejores prácticas observadas) pero eso no significa que las pérdidas vayan a desaparecer completamente. Aparte está el hecho de que, al tratarse de un problema de optimización biobjetivo, hay que encontrar los equilibrios de compensación (trade-offs) entre ambos objetivos de forma, que generalmente, (y en particular en los Óptimos de Pareto) se pueden reducir las pérdidas usando rutas de flujo de material que suponen un mayor coste. La estructura de este trabajo es la siguiente. En la sección 2 se presenta la notación utilizada y se formula el modelo Network DEA. En la sección 3 se usa una pequeña red de suministro (con datos generados aleatoriamente) para ilustrar el enfoque propuesto. Finalmente, se muestran las concusiones del estudio. 2 Formulación del modelo Network DEA Supongamos una cadena de suministro estándar con 4 niveles: Proveedores (S), Plantas de fabricación (P), Almacenes mayoristas (W) y Minoristas (R). Sin pérdida de generalidad supongamos que puede existir flujo entre cada par de nodos de dos capas contiguas, por ejemplo, entre cada planta y cada almacén mayorista. Cada arco tiene asociados unos costes unitarios de transporte. Igualmente, cada nodo de la cadena de suministro tiene asociado un coste unitario de procesamiento. Aparte de los costes, un elemento importante a tener en cuenta son las pérdidas de material (spoliage) que se pueden producir tanto en los nodos como en los arcos. Se supone que tenemos una serie de observaciones históricas de los flujos ocurridos en períodos anteriores. Sean
sjx cantidad de producto que entra en la red a través del proveedor s en el período j
spjz cantidad de producto enviado por el proveedor s a la planta p en el período j spiju cantidad de producto recibida en la planta p procedente del proveedor s en el período j pwijz cantidad de producto enviado por la planta p al mayorista w en el período j pwiju cantidad de producto recibida en el mayorista w procedente de la planta p en el período j wrijz cantidad de producto enviado por el mayorista p al minorista r en el período j wriju cantidad de producto recibida en el minorista r procedente del mayorista w en el período j rijy cantidad de producto vendida por el minorista r en el periodo j
Con estos datos se puede plantear un modelo Network DEA en el que los procesos son los nodos de la cadena de suministro así como los arcos entre dichos nodos. Estos procesos van a estar interconectados reproduciendo el patrón de conexiones de la cadena de suministro subyacente. Cada proceso tiene una entrada y una salida. Salvo los procesos asociados a los proveedores (cuyas entradas son exógenas) y los procesos que representan a los minoristas (cuyas salidas son finales) el resto de procesos reciben entradas de procesos aguas arriba y sus salidas van hacia otros procesos aguas abajo. Lo que sí es importante reconocer es que cada proceso va a tener su propia tecnología, esto es, su propio conjunto de puntos de operación factibles. Esas tecnologías de proceso se infieren, usando los axiomas clásicos de DEA (esto es, envoltura, libre desecho, convexidad y escalabilidad) e implican que cada proceso va a requerir, en el
CLAIO-2016
528

modelo de optimización, un juego de variables de intensidad λ (con los que formar las correspondientes combinaciones lineales de los puntos observados) propio. Como es usual en DEA, combinando linealmente las entradas y salidas observadas para cada proceso (e imponiendo los flujos intermedios entre procesos) se van a calcular unos valores objetivo (targets) para cada entra y salida de cada proceso. Esos valores objetivo son los flujos de material calculados por el modelo y serán tales que el valor objetivo de salida siempre es menor (o como mucho igual) al de entrada. De hecho, la diferencia entre ambos será la pérdida objetivo en ese proceso. El modelo propuesto tiene orientación de entrada en el sentido de que se supone que son conocidas las demandas en cada minorista y se desea planificar los flujos a través de la red empezando en los proveedores de forma que, descontando las pérdidas que se produzcan, los minoristas deben disponer de dichas cantidades con vistas a satisfacer la demanda. Por tanto, como el flujo total de salida de la red es dato, minimizar las pérdidas equivale a minimizar el flujo total de entrada en la red. Aparte está el coste del flujo que dependerá de por dónde circule éste. Matemáticamente, sean
rŷ Demanda a satisfacer en el minorista r
fc Coste unitario de procesamiento (respectivamente, coste unitario de transporte) en el nodo (respectivamente, arco) f de la cadena de suministro
sx̂ Cantidad objetivo a introducir en la red a través del proveedor s spẑ Cantidad objetivo a enviar desde el proveedor s a la planta p spû Cantidad objetivo a recibir en la planta p procedente del proveedor s pwẑ Cantidad objetivo a enviar desde la planta p al mayorista w pwû Cantidad objetivo a recibir en el mayorista w procedente de la planta p wrẑ Cantidad objetivo a enviar desde el mayorista w al minorista r wrû Cantidad objetivo a recibir en el minorista r procedente del mayorista w sĥ Objetivo de pérdida en el proveedor s spĥ Objetivo de pérdida en el arco (s,p) pĥ Objetivo de pérdida en la planta p pwĥ Objetivo de pérdida en el arco (p,w) wĥ Objetivo de pérdida en el mayorista w wrĥ Objetivo de pérdida en el arco (w,r) rĥ Objetivo de pérdida en el minorista r
ĥ− Objetivo de pérdida en el conjunto de la red sjλ Variables de intensidad para el proceso s
CLAIO-2016
529

spjλ Variables de intensidad para el proceso (s,p) pjλ Variables de intensidad para el proceso p pwjλ Variables de intensidad para el proceso (p,w) wjλ Variables de intensidad para el proceso w wrjλ Variables de intensidad para el proceso (w,r) rjλ Variables de intensidad para el proceso r
El modelo biobjetivo a resolver es
s,ps s,p p,ws s,p p p,w
s (s,p) p s (p,w)
p,w w,rw,rw w,r r
w p (w,r) r w
ˆ ˆ ˆ ˆMin c x c z c u c z
ˆ ˆ ˆc u c z c u
+ + + +
+ + +
∑ ∑ ∑ ∑ ∑
∑ ∑ ∑ ∑ ∑ (1.1)
s
s
r r
r r
x̂ĥMin 1
ˆ ˆy y
−= +
∑
∑ ∑ (1.2)
s.t.
s s sj j
jˆx x sλ = ∀∑ (2)
sp sp sp spsj j j j
j jˆz z z (s,p) SxPλ = = λ ∀ ∈∑ ∑ (3)
sp s s
p
ˆˆ ˆz x h s= − ∀∑ (4)
sp sp sp p spj j j j
j jˆu u u (s,p) SxPλ = = λ ∀ ∈∑ ∑ (5)
sp sp spˆˆ ˆu z h (s,p) SxP= − ∀ ∈ (6)
p pw pw pw pwj j j j
j jˆz z z (p,w) PxWλ = = λ ∀ ∈∑ ∑ (7)
pw sp p
w s
ˆˆ ˆz u h p= − ∀∑ ∑ (8)
pw pw pw pwwjj j j
j jˆu u u (p,w) PxWλ = = λ ∀ ∈∑ ∑ (9)
CLAIO-2016
530

pw pw pwˆˆ ˆu z h (p,w) PxW= − ∀ ∈ (10)
w wr wr wr wrj j j j
j jˆz z z (w,r) WxRλ = = λ ∀ ∈∑ ∑ (11)
pwwr w
r p
ˆˆ ˆz u h w= − ∀∑ ∑ (12)
wr wr wr r wrj j j j
j jˆu u u (w,r) WxRλ = = λ ∀ ∈∑ ∑ (13)
wr wr wrˆˆ ˆu z h (w,r) WxR= − ∀ ∈ (14)
r wr r
w
ˆˆ ˆy u h r= − ∀∑ (15)
r r rj j
jˆy y rλ = ∀∑ (16)
r s
r s
ˆˆ ˆy x h−= −∑ ∑ (17)
ps w rj j jj0, 0, 0, 0 j s p w rλ ≥ λ ≥ λ ≥ λ ≥ ∀ ∀ ∀ ∀ ∀ (18) sp pw wr
jj j0, 0, 0 (s,p) SxP (p,w) PxW (w,r) WxRλ ≥ λ ≥ λ ≥ ∀ ∈ ∀ ∈ ∀ ∈ (19) ps w rˆ ˆ ˆ ˆ ˆh 0, h 0, h 0, h 0, h 0 s p w r− ≥ ≥ ≥ ≥ ≥ ∀ ∀ ∀ ∀ (20)
El modelo anterior es un modelo de programación lineal biobjetivo. La función objetivo (1.1) corresponde a los costes totales y la (1.2) a la minimización del porcentaje de pérdidas. Las cantidades adquridas a los proveedores y enviadas por cada posible ruta hasta llegar a los minoristas son calculadas mediante combinaciones lineales de las observaciones y, por tanto, están dentro de los respectivos conjuntos de puntos de operación factibles de los diferentes procesos. Obsérvese cómo hay las variables de intensidad que se utilizan para calcular esas combinaciones lineales son específicas para cada proceso. Obsérvese también que, a través de las restricciones (16) se imponen las demandas a satisfacer en cada minorista. El modelo calcula tamién las pérdidas que se producen en cada proceso así como en el conjunto de la red.
3 Ilustración En este apartado se va a aplicar el enfoque propuesto a una red con datos aleatorios. Se ha supuesto una cadena de suministro compuesta de 4 proveedores, 1 planta, 3 mayoristas y 6 minoristas. Se han generado aleatoriamente 52 observaciones correspondientes a flujos en otros tantos períodos anteriores. Esos flujos se han generado suponiendo unos factores de pérdida extraidos de una distribución uniforme en cada nodo y arco de la red. La demanda a satisfacer en cada uno de los 6 minoristas se ha considerado igual a la media de las demandas en dichos minoristas para las 52 observaciones históricas. Concretamente, el vector de demanda es (2,101.8 2,041.1 1,982.5 2,055.2 2,039.6 1,963.5). Los coeficients de coste unitario de procesamiento y de transporte han sido generados aleatoriamente en el intervalo [0.8;1.2]. El punto ideal, formado por los valor óptimos de las dos funciones objetivo consideradas separadamente, es (Costemin, %Pérdidasmin)=(86,044.2 3.21%). La Figura 1 muestra el Frente de Pareto de este problema.
CLAIO-2016
531
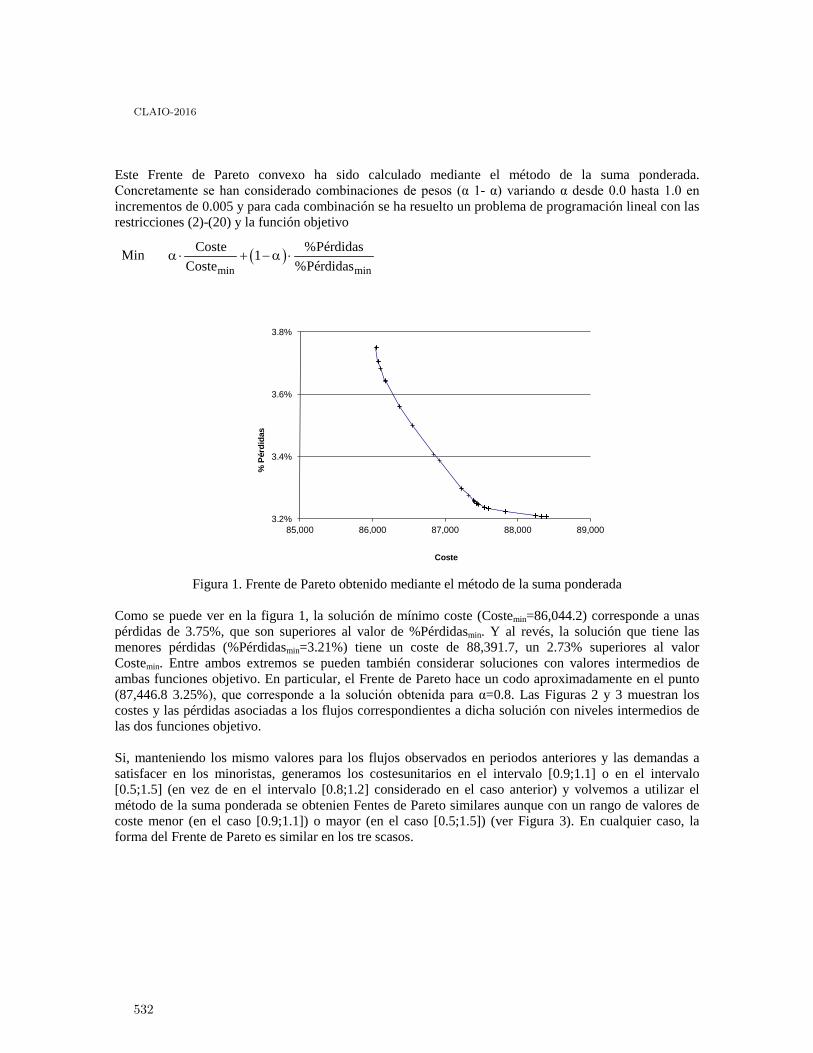
Este Frente de Pareto convexo ha sido calculado mediante el método de la suma ponderada. Concretamente se han considerado combinaciones de pesos (α 1- α) variando α desde 0.0 hasta 1.0 en incrementos de 0.005 y para cada combinación se ha resuelto un problema de programación lineal con las restricciones (2)-(20) y la función objetivo
Min ( )min min
Coste %Pérdidas1Coste %Pérdidas
α ⋅ + − α ⋅
Figura 1. Frente de Pareto obtenido mediante el método de la suma ponderada Como se puede ver en la figura 1, la solución de mínimo coste (Costemin=86,044.2) corresponde a unas pérdidas de 3.75%, que son superiores al valor de %Pérdidasmin. Y al revés, la solución que tiene las menores pérdidas (%Pérdidasmin=3.21%) tiene un coste de 88,391.7, un 2.73% superiores al valor Costemin. Entre ambos extremos se pueden también considerar soluciones con valores intermedios de ambas funciones objetivo. En particular, el Frente de Pareto hace un codo aproximadamente en el punto (87,446.8 3.25%), que corresponde a la solución obtenida para α=0.8. Las Figuras 2 y 3 muestran los costes y las pérdidas asociadas a los flujos correspondientes a dicha solución con niveles intermedios de las dos funciones objetivo. Si, manteniendo los mismo valores para los flujos observados en periodos anteriores y las demandas a satisfacer en los minoristas, generamos los costesunitarios en el intervalo [0.9;1.1] o en el intervalo [0.5;1.5] (en vez de en el intervalo [0.8;1.2] considerado en el caso anterior) y volvemos a utilizar el método de la suma ponderada se obtenien Fentes de Pareto similares aunque con un rango de valores de coste menor (en el caso [0.9;1.1]) o mayor (en el caso [0.5;1.5]) (ver Figura 3). En cualquier caso, la forma del Frente de Pareto es similar en los tre scasos.
3.2%
3.4%
3.6%
3.8%
85,000 86,000 87,000 88,000 89,000
% P
érdi
das
Coste
CLAIO-2016
532
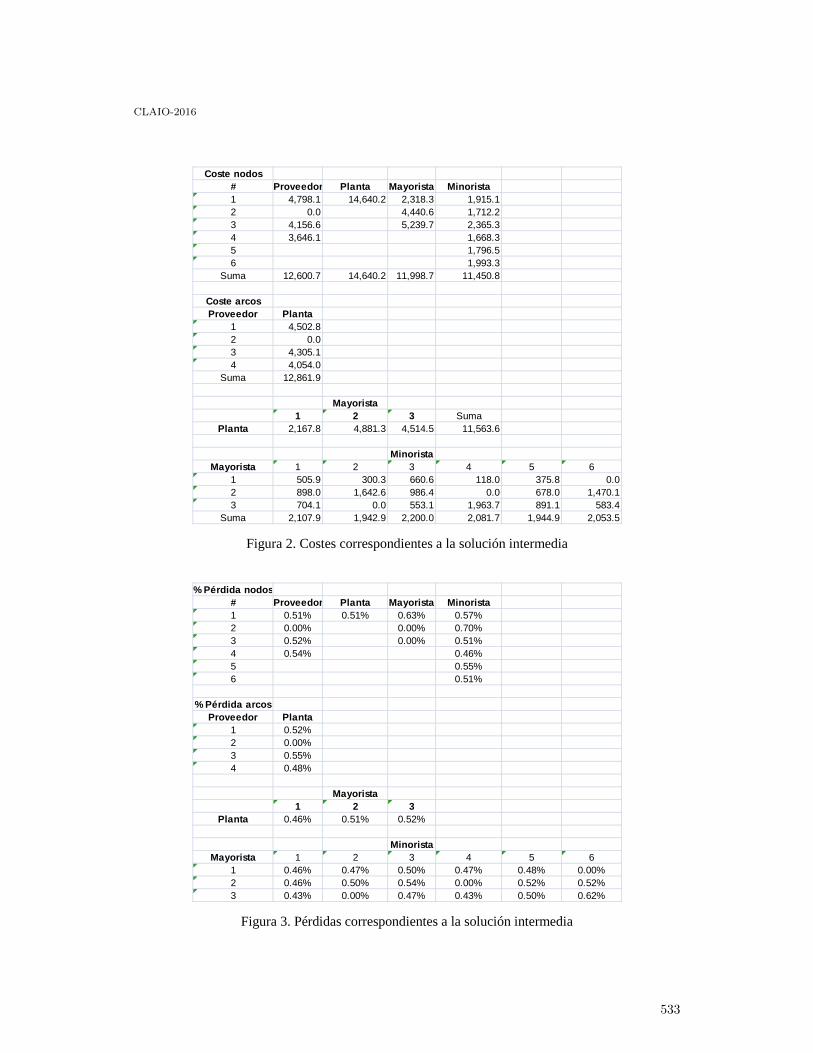
Figura 2. Costes correspondientes a la solución intermedia
Figura 3. Pérdidas correspondientes a la solución intermedia
% Pérdida nodos# Proveedor Planta Mayorista Minorista1 0.51% 0.51% 0.63% 0.57%2 0.00% 0.00% 0.70%3 0.52% 0.00% 0.51%4 0.54% 0.46%5 0.55%6 0.51%
% Pérdida arcosProveedor Planta
1 0.52%2 0.00%3 0.55%4 0.48%
Mayorista1 2 3
Planta 0.46% 0.51% 0.52%
MinoristaMayorista 1 2 3 4 5 6
1 0.46% 0.47% 0.50% 0.47% 0.48% 0.00%2 0.46% 0.50% 0.54% 0.00% 0.52% 0.52%3 0.43% 0.00% 0.47% 0.43% 0.50% 0.62%
Coste nodos# Proveedor Planta Mayorista Minorista1 4,798.1 14,640.2 2,318.3 1,915.12 0.0 4,440.6 1,712.23 4,156.6 5,239.7 2,365.34 3,646.1 1,668.35 1,796.56 1,993.3
Suma 12,600.7 14,640.2 11,998.7 11,450.8
Coste arcosProveedor Planta
1 4,502.82 0.03 4,305.14 4,054.0
Suma 12,861.9
Mayorista1 2 3 Suma
Planta 2,167.8 4,881.3 4,514.5 11,563.6
MinoristaMayorista 1 2 3 4 5 6
1 505.9 300.3 660.6 118.0 375.8 0.02 898.0 1,642.6 986.4 0.0 678.0 1,470.13 704.1 0.0 553.1 1,963.7 891.1 583.4
Suma 2,107.9 1,942.9 2,200.0 2,081.7 1,944.9 2,053.5
CLAIO-2016
533

Figura 4. Frente de Pareto para diferentes rangos de los costes unitarios
5 Conclusiones En este trabajo se ha estudiado la planificación los flujos de material a lo largo de una cadena de suministro en la que se producen pérdidas. El objetivo es doble: minimizar los costes de operación y minimizar las pérdidas. Para ello se ha propuesto un enfoque novedoso basado en Network DEA que, basándose en datos de flujos en periodos anteriores, es capaz de encontrar las mínimas pérdidas que se pueden producir en cada nodo y arco de la cadena. Para resolver el modelo de optimización lineal biobjetivo que resulta se ha usado, por su sencillez, el método de la suma ponderada, el cual permite obtener todo el Frente de Pareto de forma que el decisor puede elegir entre múltiples soluciones Óptimas de Pareto aquella que mejor se adecúa a sus preferencias. Agradecimientos Este trabajo ha sido financiado por el Ministerio de Economía y Competitividad, Gobierno de España (Proyecto de Investigación DPI2013-41469-P) y por el fondo FEDER. Referencias
1. R.K. Ahuja, T.L. Magnanti & J.B. Orlin. Network Flows: Theory, Algorithms, and Applications. Prentice Hall, 1993
2. D. Bertsekas & P. Tseng. Relaxation methods for minimum cost for ordinary and generalized network flow problems. Operations Research, 36: 93-114, 1988
3. S. Lozano. Scale and cost efficiency analysis of networks of processes. Expert Systems With Applications, 38 (6): 6612-6617, 2011
4. S. Lozano. Alternative SBM Model for Network DEA. Computers & Industrial Engineering, 82: 33-40, 2015 5. K. Tone, K. & M. Tsutsui. Network DEA: A slacks-based measure approach. European Journal of Operational
Research, 197: 243-252, 2009
3.2%
3.4%
3.6%
3.8%
84,000 85,000 86,000 87,000 88,000 89,000 90,000 91,000
% P
érdi
das
Coste
coste_unitario [0.9;1.1] coste_unitario [0.8;1.2] coste_unitario [0.5;1.5]
CLAIO-2016
534

Gestión de residuos peligrosos: Selección de oferentes
con un método de soporte a la decisión multicriterio
grupal.
Nadia Ayelen LuczywoUniversidad Nacional de Córdoba- FCEFyN- LIMI
Universidad Nacional de Córdoba- FCE- Instituto de Estad́ıstica y Demograf́ı[email protected]
José Francisco ZanazziUniversidad Nacional de Córdoba- FCEFyN- LIMI
Daniel PontelliUniversidad Nacional de Córdoba- FCEFyN- LIMI
José Luis ZanazziUniversidad Nacional de Córdoba- FCEFyN- LIMI
José Maŕıa ConforteUniversidad Nacional de Córdoba- FCEFyN- LIMI
Resumen
Este trabajo aborda el problema de seleccionar un proveedor externo para la gestión de residuospatógenos en una entidad universitaria. Se propone aqúı el uso de una método multicriteriogrupal (Procesos DRV), desarrollado para sustentar decisiones, estimular la generación de con-senso y reducir el efecto de la presión grupal, a la vez que considera las perturbaciones sobre lainformación disponible (incertidumbre, imprecisión, datos confusos o inexistentes). Se propiciade esta manera la construcción de conocimiento compartido y el compromiso posterior con lasacciones acordadas. El documento presenta y discute los resultados de una aplicación real. Enlas conclusiones se resalta el potencial de este enfoque metodológico para el estudio de problemascomplejos de toma de decisiones.
Keywords: Residuos Patógenos; Toma de decisiones en grupo; DRV (Decisión con reducción dela variabilidad); Construcción de conocimiento colectivo.
CLAIO-2016
535

1. Introducción
El presente documento aborda el problema de seleccionar un proveedor externo para la gestión deresiduos patógenos en una entidad universitaria. El asunto es complejo porque resulta necesarioconsiderar las posturas de diversas dependencias y personas. Por ese motivo, este trabajo proponela aplicación de un método multicriterio diseñado para sustentar decisiones grupales.La Universidad en cuestión, realizó un llamado a Licitación Pública para la adjudicación del ser-vicio de recolección, transporte, tratamiento y disposición final de residuos patógenos. Presentaronpliegos tres empresas, a las que se identifica como oferentes uno, dos y tres. Para ello, se designóuna comisión de seis técnicos, vinculados con distintas dependencias.Las actividades colectivas no son sencillas y están influenciadas por aspectos humanos que condi-cionan la captura y el uso del conocimiento[23]. De hecho, los ejercicios grupales deben enfrentarciertas dificultades. Entre estas se encuentran: por un lado, las perturbaciones sobre la informaciónutilizada en las aplicaciones de toma de decisiones en grupo que son incertidumbre o presencia devaloraciones y percepciones distintas por parte de cada miembro, imprecisión vinculada a erroresde medición y la falta de disponibilidad de algunos datos[15]; y por otro, los riesgos de resignarlas verdaderas posturas ante la presión del grupo[24][20]. Las consecuencias de estas distorsionespueden ser significativas, porque no se obtienen aportes reales de los participantes, el aprendizajegrupal se corrompe y no se logra el compromiso de los actores[12][13]. En consecuencia, resul-ta recomendable que en el análisis se consideren aspectos como la interacción y la comunicaciónentre los actores[1], aśı como el empoderamiento de las personas involucradas[4] lo que posibili-tará el aprendizaje, la elicitación y apalancamiento del capital intelectual y la administración delconocimiento[25]. Precisamente, la literatura considera a la toma de decisiones en grupo como esen-cial para la Gestión del conocimiento, porque permite a los tomadores de decisiones examinar losproblemas multidimensionales, identificar las prioridades para cada factor de decisión, y evaluar laclasificación de alternativas[16]. Igualmente, se acepta que las aplicaciones grupales multicriteriofavorecen el aprendizaje colectivo de los participantes[6].Sin embargo, las aproximaciones multicriterio realizadas sobre problemas similares, soslayan la im-portancia del grupo dado que adoptan un paradigma t́ıpico de decisor individual. Es posible men-cionar los trabajos de: Demesouka, Vavatsikos, y Anagnostopoulos [5]; Liu, Wu, y Li[18]; Özkan[21];Thampi y Rao[30]. Este enfoque puede no ser el mejor, de hecho, Georgiou[15] y Franco y Lord[10]alertan que la falta de consideración de los diferentes intereses, disminuye las posibilidades de éxitoposterior del plan de acciones acordado.Por ese motivo, este trabajo estudia y resuelve el problema con un método especialmente prepara-do para tomar decisiones en forma grupal, denominado Procesos DRV (Decisión con Reducción deVariabilidad)[31]. Esta aproximación estimula el aprendizaje conjunto entre participantes. De esemodo, además de la decisión propiamente dicha, se genera un espacio de construcción de conoci-mientos compartidos y se fortalece el consenso respecto a las acciones a seguir.
2. Antecedentes relevantes.
Las organizaciones se encuentran surcadas por procesos de toma de decisiones. La selección deproveedores para la gestión de residuos patógenos puede entenderse como un proceso de este tipo,
CLAIO-2016
536

sometido a diversas perturbaciones (incertidumbre, imprecisión, datos confusos o inexistentes), quecondicionan el éxito de cualquier proyecto.
2.1 Aproximaciones multicriterio a la decisión.
Dentro del ámbito del apoyo multicriterio a la decisión (MCDM), es posible distinguir a los méto-dos de estructuración de problemas (PSM) y a la Decisión Multicriterio Discreta (DMD). En elprimer conjunto es natural trabajar con la interacción del grupo, de forma que sea posible intercam-biar opiniones, contrastar experiencias, compartir conocimientos y evolucionar hacia una posturacomún. Las aplicaciones PSM proveen beneficios como el análisis participativo, el desarrollo delconocimiento compartido, el alcance de soluciones integrales y el compromiso posterior[27][11].La DMD se ha concentrado en dar un soporte matemático y técnico para el logro de la decisión.En general, las aproximaciones multicriterio grupales se caracterizan por modelar la variabilidaden la información básica. Para representar las preferencias y prioridades de los miembros del grupo,se utilizan distintas herramientas. Entre las más frecuentes se encuentran: la teoŕıa matemática dela evidencia[14], los conjuntos borrosos[19] y la Teoŕıa de la Utilidad Multiatributo - MAUT-[17].Dentro de esta última corriente, es posible encontrar diversos enfoques.Un primer conjunto de autores está centrado en encontrar soluciones razonables, aun cuando existeruido, mediante la propuesta de diferentes modalidades de agregación, por ejemplo a través demedias geométricas o aritméticas. (Forman y Peniwati[9]; Shih, Shyur y Lee[26]).Otra vertiente se orienta a modelar el ruido, pero sin su reducción. Un método inscripto en estacorriente es el Stochastic Multicriteria Acceptability Analysis (SMAA)[29].Ahora bien, Montibeller y Winterfeld[20] indican que si bien se ha prestado atención a la obtenciónde juicios (probabilidades, valores, pesos, etc.) para la toma de decisiones y el análisis de los riesgos,es sorprendente la escasa atención prestada a las posibles distorsiones en el análisis. Sin embargo, esconveniente trabajar con estas perturbaciones, a fin de reducirlas, para aumentar las posibilidadesde éxito de las propuestas de acción acordadas.Esta realidad es reconocida por un tercer grupo de investigadores cuyas contribuciones reconocen laexistencia de ruido y tratan de reducirlo con diversos enfoques metodológicos. Entre las aproxima-ciones que trabajan de esta manera puede mencionarse a: Dias y Climaco[6], Altuzarra y otros[2];Escobar y Moreno-Jiménez[8]; y Dong y Saaty[7].En particular, la metodoloǵıa aplicada en este documento: Procesos DRV[31], se inscribe en estaúltima vertiente. Este método se orienta a facilitar la identificación de soluciones, a la vez quereduce los efectos de la presión del grupo y minimiza las perturbaciones.
2.1 Presentación del método Procesos DRV.
El método Procesos DRV puede aplicarse con problemas que requieren elegir un objeto entre unacantidad finita de alternativas. Además se supone que los miembros del grupo comparten objetivosen cuanto al problema analizado, es decir que no se trata de situaciones de negociación o de conflic-to. El método se desarrolla en tres etapas: Estabilización; Agregación y Ordenamiento. La primerapermite que el grupo analice en plenario los diferentes sub problemas que integran el proceso deci-sional, estimula a los miembros del grupo para que intercambien conocimientos y experiencias y seestablezca consenso básico. La Agregación permite obtener valores globales para cada alternativade decisión. La última fase permite ordenar las alternativas, desde la mayor a la menor preferenciay establecer relaciones de preferencia estricta o equivalencia.Al iniciar la fase de Estabilización de un sub problema, las percepciones de cada uno de los integran-tes pueden ser completamente distintas, porque cada persona filtra la realidad de forma selectiva
CLAIO-2016
537

en función de su área de conocimiento y experiencias anteriores.El método DRV propone que dichas percepciones sean recolectadas a través de la asignación indi-vidual de utilidades de tipo subjetivo[17].En esas condiciones, la función de distribución de probabilidad más razonable, al iniciar la estabi-lización, parece ser la Uniforme o Rectangular.Ahora bien, el trabajo grupal debe contribuir a reducir las diferencias. Es decir, la dispersión obser-vada debe mantener una tendencia sostenida a la reducción. Cuando se ha arribado a un aceptablenivel de consenso, las asignaciones de utilidades deben ser similares, por lo que función de distri-bución de probabilidad esperada es la Distribución Normal.Si se consideran: equipo de trabajo con N individuos; K número de elementos de decisión a evaluar;y se denomina wkn al valor de la función de utilidad asignada por el integrante n (n = 1, 2, ...N)al elemento k (con k = 1, 2, 3, ... K), las utilidades estandarizadas se indican en la expresión (1).
wkn =ukn∑Kk=1 ukn
(1)
Los resultados se representan en términos de la suma de cuadrados de los wkn como refleja (2).
SCTotal =
K∑
k=1
(w̄k − ¯̄w)2 +
K∑
k=1
N∑
n=1
(wkn − w̄k)2 (2)
Donde ¯̄w es la media general y w̄k es el promedio para cada una de las ramas. A su vez, el primertérmino puede denominarse: suma de cuadrados entre elementos y el segundo: suma de cuadradosdentro de los elementos (SCD). La sumatoria dentro de los cuadrados es la que representa las di-ferencias entre las opiniones y la que debe disminuir a medida que avanza el análisis.La estabilidad se evalúa a partir del indicador IVR (́Indice de Variabilidad Remanente) y la verifi-cación de la compatibilidad de los datos con una distribución Normal de probabilidad. El alcancede estabilidad implica que las utilidades ya no pueden cambiar demasiado, aun cuando prosiga elanálisis. El IVR se obtiene según la expresión (3).
IV R =SCD
SCU∗ 100 % (3)
Siendo SCU = N−13k la suma de cuadrados correspondientes a la Distribución Uniforme la que
se considera referencia para calcular el IVR. En la práctica, los valores de IVR por debajo deveinticinco por ciento se consideran estables.Cuando todos los subproblemas se estabilizan, es momento para agregar las utilidades. Entonces esfactible determinar valores globales para cada alternativa. Para la obtención de coeficientes globalesse trabajó con la ponderación lineal. Aśı, Wj es la variable aleatoria que representa los pesos de loscriterios, y las Uij son variables aleatorias que simbolizan las utilidades asignadas a los candidatosal evaluar la alternativa genérica i bajo el criterio j. La contribución parcial a la prioridad asignadase obtiene como el producto de las dos variables aleatorias conforme a (4).
Zij = Wj ∗ Uij (4)
Las distribuciones de las variables Zij , son formuladas mediante la integral de la expresión (5).
P (Wj ∗ Uij < Z) =
∫∫
(w,u)∈[Wj∗Uij<Z]
1
2π
1
σWjσUije
12
wj−µWjσWj e
12
uij−µUijσUij du.dw (5)
CLAIO-2016
538

Si bien la integral (5) no tiene solución anaĺıtica, se pueden aproximar sus momentos, tanto alorigen como centrados. De este modo, es posible determinar que tanto la asimetŕıa como la curtosisde las distribuciones resultantes, son similares a las t́ıpicas de las distribuciones gaussianas.Asimismo, los valores globales de una alternativa genérica Vi, se obtienen como se indica en (6).
Vi =J∑
i=1
Wj ∗ Uij =J∑
i=1
Zij (6)
La comparación de los promedios de las valoraciones Vi permite establecer un ordenamiento de lamayor a la menor preferencia. Sin embargo, dado que los valores observados pueden estar afectadospor el error muestral, es posible que esta modalidad conduzca a identificar relaciones de preferenciaque no son reales. Para distinguir estas situaciones el método aplica pruebas repetidas de compa-ración de variables dependientes y controla la tendencia a cometer errores de tipo I, con la tasa dedescubrimiento falso propuesta por Benjamini y Yekutieli[3].
3. Metodoloǵıa.
La secuencia de operaciones es la siguiente: (1) Estructuración del problema: La recolección deinformación se realizó a través de entrevistas individuales y semi estructuradas con los integrantesde la comisión evaluadora y a través de la recopilación documental sobre el pliego de licitación. Lainformación de campo se sistematizó a partir de la grilla de repertorio de Kelly[28] y permitió elicitarlos criterios a emplear. (2) Estudio de un sub-problema: se recorrieron los sub problemas, uno poruno. (3) Análisis grupal del sub problema: se realizaron ejercicios que permiten definir los elementosa comparar en el sub problema e intercambiar conocimientos. El análisis conjunto contribuye a lareducción de las diferencias de posturas. (4) Asignación de utilidades a los elementos comparados:los participantes aportaron sus juicios con independencia al asignar utilidades de tipo subjetivo. (5)Análisis de las utilidades: para verificar la estabilidad y el consenso se operó con el Indicador IVR(́Indice de Variabilidad Remanente) y el análisis de normalidad de los datos. Este último, se realizócon la prueba de hipótesis de verificación de Normalidad de Shapiro-Wilks modificada por Rahmany Govindarajulu[22]. (6) Verificación de consenso: cuando todas las utilidades asignadas a cada unode los elementos comparados, pudieron ser representadas con una Distribución Normal, fue posiblepresumir consenso y pasar a un nuevo sub problema (paso 2). (7) Agregación: cuando todos lossub problemas estuvieron estabilizados, fue posible agregar las utilidades. (8) Ordenamiento de lasalternativas: se pudo ordenar desde la mayor a la menor preferencia.
4. Resultados y discusión.
Las actividades de estructuración permitieron adoptar los siguientes criterios: modalidad operativay loǵıstica, mejora del servicio, costo, tratamiento y disposición final de los residuos, experiencia,flota de veh́ıculos y condiciones de higiene y seguridad. El estudio del sub problema referido a loscriterios requirió dos ciclos de análisis. El primer ensayo indicó que exist́ıan diferencias significativas,aún después del trabajo grupal de estructuración (IVR= 43,85 %). En consecuencia, se trabajó en
CLAIO-2016
539

un segundo ciclo de análisis completo en el que se observó una mejora notable del indicador. Enel cuadro 1, se presenta la śıntesis de esta evolución. La suma de cuadrados refleja los niveles deincertidumbre e imprecisión que afectan al proceso de decisión, es decir las perturbaciones. En estecaso el nivel de ruido se reduce a menos de un 15 % del valor de referencia.
Cuadro 1: Análisis de subproblemas (criterios de evaluación)Iteración Suma de cuadrados IVR
Elemento de referencia 0, 2381) 100, 00 %Primera iteración 0, 1044 43, 85 %Segunda iteración 0, 0345 14, 49 %
En el segundo ciclo todas las pruebas de normalidad resultaron aceptables. Lograda la estabilidad,los pesos resultantes fueron los siguientes: modalidad operativa y loǵıstica, 0,302; costo, 0,224;experiencia, 0,136; flota, 0,117; mejora del servicio, 0,079; condiciones de higiene y seguridad, 0,076;y tratamiento, 0,066.Los valores promedio globales para cada alternativa, se reproducen en el cuadro 2 .
Cuadro 2: Utilidades globales.Oferente 1 Oferente 2 Oferente 3
Valor Global promedio 0, 44 0, 38 0, 18
El análisis de los valores del cuadro 2 hace evidente que los oferentes uno y dos, tienen valoressignificativamente mayores que el oferente tres. No obstante, las diferencias entre los oferentes unoy dos pueden originarse en el error muestral y no evidenciar una preferencia estricta.La aplicación de pruebas de comparación de medias, arroja los resultados que se presentan en elcuadro 3. Alĺı se obtienen diferencias significativas entre los oferentes.
Cuadro 3: Ordenamiento final.Oferentes comparado Valor t Valor p observado Valor p de contraste Decisión
1 con 2 4,68 0,00545 0,00909 Hay Diferencia1 con 3 19,4 0,00001 0,01819 Hay Diferencia2 con 3 16,07 0,00002 0,02728 Hay Diferencia
En el cuadro 3, el valor p de contraste se obtiene mediante la aplicación del algoritmo de Benjaminiy Yekutieli. Cuando el valor p observado en la prueba es menor que el valor de contraste la diferenciase considera significativa. En este caso hay preferencia estricta de la alternativa uno con las restantes
5. Conclusiones
La experiencia se considera positiva. La aplicación del método permitió la selección de un oferentedentro de los plazos formales de la licitación. Asimismo, se destaca que no se presentaron objecionesni observaciones al proceso decisorio.Los integrantes del grupo participaron activamente en todas las fases del método y no presentaron
CLAIO-2016
540

dificultades para utilizar las herramientas matemáticas necesarias. A su vez, se identificaron lassituaciones de aparente consenso, y se trabajó sobre la diferencia de posturas de manera que fueposible construir conocimiento conjunto.El método DRV posibilitó la reducción de los efectos negativos resultantes de la presión grupal através de la asignación de utilidades subjetivas en forma individual. Asimismo, fue posible trabajaren la minimización de las distorsiones sobre la información que se gestiona.Por ese motivo, ante problemas complejos, resulta recomendable la realización de análisis grupalescon el apoyo del método Procesos DRV. Es una forma de definir planes de acción consensuados, ala vez que se genera conocimiento compartido para sostener esos planes.
Referencias
[1] N. Aarts, and C. van Woerkum Dealing with uncertainty in solving complex problems. WheelbarrowsFull of Frogs: Social Learning in Rural Resource Management–International Research and Reflections,421–435, 2002
[2] A. Altuzarra, J.M. Moreno-Jiménez and M. Salvador Consensus building in AHP-group decision ma-king: a Bayesian approach. Operations Research, 58(6): 1755–1773, 2010
[3] Y. Benjamini and D. Yekutieli The control of the false discovery rate in multiple testing under depen-dency. Annals of statistics, 1165–1188, 2001
[4] R. Bodstein The complexity of the discussion on effectiveness and evidence in health promotion prac-tices. Promotion y Education, 14(1): 16–20, 2007
[5] O. E. Demesouka, A. P Vavatsikos,and K. P. Anagnostopoulos GIS-based multicriteria municipal solidwaste landfill suitability analysis: A review of the methodologies performed and criteria implemented.Waste Management y Research, 32(4): 270–296, 2014
[6] L. Dias, and J. Climaco Dealing with imprecise information in group multicriteria decisions: a metho-dology and a GDSS architecture. European Journal of Operational Research, 160(2): 291–307, 2005
[7] Q. Dong, and T. L. Saaty An analytic hierarchy process model of group consensus Journal of SystemsScience and Systems Engineering, 23(3): 362–374, 2014
[8] M. T. Escobar, J. M. Moreno-Jiménez and M. Salvador Aggregation of individual preference structuresin AHP-group decision making. Group Decision and Negotiation, 16(4): 287–301, 2007
[9] E. Forman, and K. Peniwati Aggregating individual judgments and priorities with the analytic hierarchyprocess. European Journal of Operational Research, 108(1): 165–169, 1998
[10] L. A. Franco, and E. Lord Understanding multi-methodology: evaluating the perceived impact of mixingmethods for group budgetary decisions Omega, 39(3): 362–372, 2011
[11] L. A. Franco, and G. Montibeller Facilitated modelling in operational research. European Journal ofOperational Research, 205(3): 489–500, 2010
[12] L.A Franco Rethinking soft OR interventions: models as boundary objects. European Journal ofOperational Research, 231(3): 720–733, 2013
[13] L.A Franco, E. Rouwette and H.Korzilius Different paths to consensus? The impact of need for closureon model-supported group conflict management. European Journal of Operational Research, 249(3):878–889, 2016
CLAIO-2016
541

[14] C. Fu y S. Yang An evidential reasoning based consensus model for multiple attribute group decisionanalysis problems with interval-valued group consensus requirements. European Journal of OperationalResearch, 223(1): 167–176, 2012
[15] I. Georgiou Making decisions in the absence of clear facts. European Journal of Operational Research,185(1): 299–321, 2008
[16] Y. H.Hung, S. C. T.Chou, and G. H.Tzeng Knowledge management adoption and assessment for SMEsby a novel MCDM approach. Decision Support Systems, 51(2): 270–291, 2011
[17] R. L. Keeney and H. Raiffa, Decisions with multiple objectives: preferences and value trade-offs..Cambridge university press, 1993.
[18] H. C. Liu, J. Wu, y P. Li, Assessment of health-care waste disposal methods using a VIKOR-basedfuzzy multi-criteria decision making method. Waste management, 33(12): 2744–2751, 2013
[19] J. M. Merigó and A. M. Gil-Lafuente Fuzzy induced generalized aggregation operators and its applica-tion in multi-person decision making. Expert Systems with Application, 38(8): 9761–9772, 2011
[20] G. Montibeller and D. Winterfeldt Cognitive and motivational biases in decision and risk analysis. RiskAnalysis, 35(7): 1230–1251, 2015
[21] A. Özkan Evaluation of healthcare waste treatment/disposal alternatives by using multi-criteriadecision-making techniques. Waste Management y Research, 31(2): 141–149, 2013
[22] M. M. Rahman and Z. Govindarajulu A modification of the test of Shapiro and Wilk for normality.Journal of Applied Statistics, 24(2): 219–236, 1997
[23] G. Richards and L. Duxbury Work-Group Knowledge Acquisition in Knowledge Intensive Public-SectorOrganizations: An Exploratory Study. Journal of Public Administration Research and Theory, 35(7):1230–1251, 2014
[24] S. Robbins and M. Coulter, Administración. Pearson, México DF México, 2005.
[25] B. Rubenstein-Montano, J. Liebowitz, J. Buchwalter, D. McCaw, B. Newman, K.Rebeck, and T. K. M.M. Team, A systems thinking framework for knowledge management. Decision support systems, 31(1):5–16, 2001
[26] H. S.Shih, H. J. Shyur, and E. S. Lee An extension of TOPSIS for group decision making. Mathematicaland Computer Modelling, 45(7): 801–813, 2007
[27] L. Sørensen, and R. V. V.Vidal The anatomy of soft approaches. Investigacao Operacional, 24(2):173–188, 2003
[28] M. T. Padilla-Carmona La rejilla de constructos personales: un instrumento para el diagnóstico y laorientación. Ágora digital, 2: 1–6, 2001
[29] T. Tervonen SMAA: open source software for SMAA computations. International Journal of SystemsScience, 45(1): 69–81, 2014
[30] A. Thampi y B. Rao Application of Multi-criteria Decision Making Tools for Technology Choice inTreatment and Disposal of Municipal Solid Waste for Local Self Government Bodies—A Case Study ofKerala, India. The Journal of Solid Waste Technology and Management, 41(1): 84–95, 2015
[31] J. L. Zanazzi Toma de decisiones en grupos de trabajo. El método Procesos DRV. Tesis doctoral. UNC,Córdoba., 2016
CLAIO-2016
542

Modelo para la planificación óptima de la producción y
deshidratación de hierbas medicinales y aromáticas
María M. López
Facultad Politécnica, Universidad Nacional de Asunción
Jorge L. Recalde-Ramírez
Facultad Politécnica, Universidad Nacional de Asunción
Julio Canales Fernández
Escuela de Ingeniería Industrial, Pontificia Universidad Católica de Valparaíso
Resumen
Se presenta el diseño de un modelo matemático de Programación Lineal (PL), para el apoyo de la gestión
de operaciones de deshidratado de tres hierbas aromáticas y medicinales, utilizando como fuente de
energía biogás. El modelo incluye variables relacionadas a la planificación de la producción y compra de
materia prima, la deshidratación y almacenamiento temporal del producto terminado, con el objetivo de
minimizar el costo total. Fue probado utilizando datos obtenidos de revisiones y proveídos por un
potencial cliente y un productor con una finca agrícola en Areguá, Paraguay. La planeación a corto plazo
permite la utilización de los recursos con mayor eficiencia al calcularse la cantidad de parcelas a destinar
a cada materia prima, las horas hombres, horas máquinas y recursos asociados que se requerirán por
periodo. El costo mínimo obtenido para la planificación de 72 meses es de USD 43.181, con la
satisfacción del 25% de la demanda, y utilizando 51% de la capacidad de deshidratado.
Palabras clave: planificación de la producción; Programación Lineal; hierbas aromáticas y medicinales.
1 Introducción
La deshidratación es un procedimiento utilizado para la preservación de alimentos como carnes, pescados,
hierbas, frutas y vegetales, de tal forma a conservarlos en diferentes temporadas, además permite reducir
los riesgos de contaminación, reducir el peso y el volumen del alimento en forma significativa. Según
análisis de organismos oficiales, en el Paraguay existe una debilidad en la etapa del deshidratado de las
hierbas medicinales y aromáticas por la utilización principalmente de la luz solar para realizar el secado,
lo que implica la contaminación del producto con agentes extraños y una buena calidad no asegurada.
El principal objetivo de este trabajo es diseñar un modelo matemático de Programación Lineal (PL), para
el apoyo de gestiones operativas, y que en particular represente de buena manera el proceso de
deshidratación de hierbas aromáticas y medicinales producidas y/o adquiridas por una finca agrícola, que
utilizará como fuente de energía el biogás, como alternativa a otras fuentes más comúnmente empleadas.
2 Descripción del problema
En el Paraguay para la deshidratación de hierbas aromáticas y medicinales son utilizados métodos
tradicionales como el secado al aire libre, y deshidratadores que funcionan a base de energía eléctrica,
solar, biomasa, gas licuado de petróleo, entre otros. Se considera la existencia de una debilidad en la
etapa del deshidratado de las hierbas por la utilización de los métodos mencionados, pues conllevan la
CLAIO-2016
543

contaminación de producto con agentes extraños, afectan su color y su calidad, principalmente para el
caso del secado solar. Para los deshidratadores que utilizan madera o carbón como fuente de energía, se
debe considerar el impacto ambiental y el uso sustentable de los mismos. En cuanto al uso general de
deshidratadores y energía alternativa, existen referencias de la promoción del empleo del biogás en el país
(MAG, 2011).
En el contexto de la utilización de biogás para el proceso de deshidratación de hierbas, la propuesta
responde a la necesidad de apoyar las decisiones relativas a la gestión de las operaciones de producción y
procesamiento de la materia prima, con bases cuantitativas, y con el objetivo de incurrir en los menores
costos posibles.
3 Revisión bibliográfica
3. 1 Marco conceptual
1) Deshidratación de alimentos: Consiste en la remoción de agua contenida en el alimento hasta un valor
en el cual microorganismos no se proliferen y la conservación se prolongue (Baeza, 2009). Con su
aplicación se logra la reducción del peso y el volumen del alimento en forma significativa, lo que
contribuye a la reducción de costos de envasado, manipulación, almacenamiento y distribución de los
productos (Valentas, 1997). El prototipo de deshidratador a ser considerado en el trabajo es de operación
discontinua, de convección y en forma de cabina con bandejas; fue desarrollado por la Facultad de
Ciencias Agrarias de la Universidad Nacional de Asunción (FCA, 2013). Algunas de las ventajas de uso
son: construcción y mantenimiento de bajo costo, la capacidad de control de parámetros como
temperatura y tiempo de secado, conservación de propiedades de las hierbas, no dependencia de
condiciones climáticas para su uso, mayor control de agentes contaminantes.
2) Fuentes de energía alternativa para la deshidratación: En Paraguay, de acuerdo al último balance
energético, la oferta bruta de energía fue principalmente renovable compuesta por 53 % de hidroenergía,
29 % de biomasa, y 18 % de combustibles derivados del petróleo importados (VMME, 2015). Algunos
motivos para el desarrollo de otros tipos de energías renovables son la posibilidad de disponer de mayores
excedentes eléctricos para la exportación, son alternativas de generación de energía para la zona rural, la
disminución o inclusive erradicación de la deforestación con la sustitución de la biomasa y la
descentralización de la generación de electricidad para asegurar el suministro (GIZ, 2011).
3) Hierbas aromáticas y medicinales: Las hierbas medicinales son aquellas que elaboran “principios
activos”, sustancias que ejercen una acción farmacológica beneficiosa o perjudicial sobre el ser humano.
Las hierbas aromáticas constituyen aproximadamente el 0,7 % del total de hierbas medicinales, se
caracterizan por la composición en forma total o parcial de esencias en sus principios activos, pueden ser
de cultivo anual o perenne. Se comercializan en el mercado nacional 108 especies empleadas como
medicinales. En cuanto al origen, el 66 % son plantas nativas, 9 % son importadas y 25 % aclimatadas
(Degen, 2004). La producción es mediante cultivos a pequeña escala o por extracción intensiva de su
hábitat natural (en un 66%), que conlleva una sobreexplotación (MAG, 2011).
3.2 Marco Referencial
La planificación implica la asignación de recursos escasos, es decir, la toma de decisiones complejas, que
a través de la aplicación de métodos de programación lineal es posible optimizar. Se hallaron evidencias
de la aplicación de modelos de PL a problemas de planificación agrícola a mediados del siglo XVIII,
siendo uno de los primeros problemas analizados en este ámbito la elección de un plan de rotación de
cultivos (Boussard, 1977). Entre los años 70 y 90 se plantearon modelos para la solución de problemas
como la selección de maquinarias para la producción, políticas de corte, calendarios de cosecha, uso y
CLAIO-2016
544

mezcla de fertilizantes, expansiones de finca, operación diaria de cosechas, calendario de riegos, etc.
(Glen, 1987).
También existen evidencias de trabajos relacionados con la producción de hierbas aromáticas y
medicinales, así como de los métodos y procesos de deshidratación, que en general aportan información
acerca de: planificación de producción y cultivo de hierbas, estudios de caso y factibilidad de la
producción, reglamentaciones y buenas prácticas, diseño, construcción y análisis de la efectividad de
maquinarias utilizadas para el proceso de deshidratación. El empleo de modelos matemáticos de PL, en
investigaciones acerca del proceso de deshidratación se evidencia con trabajos como “Linear
programming for formulation of vegetables paste and drying operation in spouted bed” (Quites, 2011), y
“Modelo de planeación de la producción para una empresa agroindustrial” (Peña y Santacruz, 2001).
4 Materiales y métodos
Se realizó la definición del problema, y posteriormente el diseño, solución y análisis de un modelo
matemático de PLEM que fue resuelto computacionalmente con el software IBM® ILOG CPLEX
Optimization Studio, versión 12.6 con licencia académica, en un computador portátil con procesador Intel
Core i3® de 2.20 GHz con 4 GbRAM, utilizando datos técnicos de revisiones y datos proveídos por el
potencial cliente y el productor, propietario de una finca de agrícola en la ciudad de Areguá, Paraguay. Se
realizaron corridas del modelo para escenarios, de acuerdo a la satisfacción del 50% o del 25% de la
demanda, considerando el uso de la fuente de energía biogás como alternativa a fuentes convencionales.
4. 1 Planteamiento del problema a modelar
A partir de la demanda de hierbas aromáticas y medicinales deshidratadas (productos) por parte de un
cliente potencial (fraccionadora), se requiere la elaboración de un plan de producción para la
deshidratación de hierbas frescas (materia prima), por parte de la finca agrícola que cuenta para la
plantación o cultivo con 50 parcelas de 200m2 cada una; pero que además puede realizar compras de
proveedores, debido a que las hierbas son de producción estacional y discontinua. Las materias primas
consideradas son Burrito (Aloysia polystachya), Cedrón Paraguay (Lippia citriodora) y Rosa Mosqueta
(Rosa moschatta), todas con diferentes rendimientos y con 5 años de vida útil luego de su cultivo.
La totalidad de parcelas debe ser utilizada para el cultivo de alguna hierba, pudiéndose cultivar el Burrito
en 6 meses del año, el Cedrón y la Rosa Mosqueta en 4 meses del año (mes de posible cultivo).
Para ejemplificar la disponibilidad de las materias primas en las parcelas, en la Tabla 1, se observa los
meses en que se recomienda el cultivo de Burrito, conforme a esto se determina que podría haber 6 meses
de posible cultivo (entre marzo y agosto).
En la tabla el valor 1 (uno), indica la realización de la cosecha o corte de las hierbas. Para el caso del
Burrito el primer corte se realizaría luego de cinco meses del cultivo y los cortes posteriores cada tres
meses. El Cedrón puede cultivarse entre agosto y noviembre, el primer corte se debe realizar 3 meses
luego del cultivo y los siguientes cada cuatro meses. La Rosa Mosqueta puede cultivarse entre setiembre
y diciembre, y realizarse todos los cortes cada cuatros meses.
Con la resolución del modelo se obtendrá el número de parcelas a cultivar en cada mes posible, y por
ende la cantidad de materia prima disponible para la cosecha y posterior deshidratación. La capacidad
diaria del deshidratador es de 60 kg de materia prima y luego del proceso se obtiene un lote de 18 kg de
producto terminado (el rendimiento es de 30 %), además no es posible deshidratar dos hierbas diferentes
al mismo tiempo.
CLAIO-2016
545

Tabla 1. Disponibilidad de la materia prima Burrito para el corte, de acuerdo a los posibles periodos de
cultivo o plantación.
4.2 Modelo matemático general a. Subíndices
𝑖: 𝑡𝑖𝑝𝑜 𝑑𝑒 𝑚𝑎𝑡𝑒𝑟𝑖𝑎 𝑝𝑟𝑖𝑚𝑎, 𝑖 = 1 … 3, donde i=1 es Burrito; i=2 es Cedrón; i=3 es Rosa Mosqueta
𝑡: 𝑝𝑒𝑟𝑖𝑜𝑑𝑜𝑠 𝑑𝑒 𝑝𝑙𝑎𝑛𝑖𝑓𝑖𝑐𝑎𝑐𝑖ó𝑛 𝑒𝑛 𝑚𝑒𝑠𝑒𝑠, 𝑡 = 1 … 72
𝑏: 𝑚𝑒𝑠 𝑑𝑒 𝑝𝑜𝑠𝑖𝑏𝑙𝑒 𝑐𝑢𝑙𝑡𝑖𝑣𝑜 𝑑𝑒 𝐵𝑢𝑟𝑟𝑖𝑡𝑜 𝑏 = 1 … 6 𝑐: 𝑚𝑒𝑠 𝑑𝑒 𝑝𝑜𝑠𝑖𝑏𝑙𝑒 𝑐𝑢𝑙𝑡𝑖𝑣𝑜 𝑑𝑒 𝐶𝑒𝑑𝑟ó𝑛 𝑃𝑎𝑟𝑎𝑔𝑢𝑎𝑦 𝑐 = 1 … 4
𝑟: 𝑚𝑒𝑠 𝑑𝑒 𝑝𝑜𝑠𝑖𝑏𝑙𝑒 𝑐𝑢𝑙𝑡𝑖𝑣𝑜 𝑑𝑒 𝑅𝑜𝑠𝑎 𝑀𝑜𝑠𝑞𝑢𝑒𝑡𝑎 𝑟 = 1 … 4
b. Variables de decisión 𝐵𝑈𝑏: Cantidad de parcelas de Burrito cultivadas en el mes 𝑏 (número de parcelas)
𝐶𝐸𝑐: Cantidad de parcelas de Cedrón Paraguay cultivadas en el mes 𝑐 (número de parcelas)
𝑅𝑀𝑟: Cantidad de parcelas de Rosa Mosqueta cultivadas en el mes 𝑟 (número de parcelas)
𝑋𝐶𝑀𝑖𝑡: Cantidad de materia prima i a comprar en el periodo t (kg)
𝐼𝐶𝑖𝑡: Cantidad de materia prima i cosechada y comprada a inventariar al final del periodo 𝑡 (kg)
𝑌𝐷𝑡 {1, si se deshidrata alguna materia prima en el periodo 𝑡
0, en otro caso
𝑋𝐷𝑖𝑡: Cantidad de lotes de materia prima i a deshidratar en el periodo 𝑡 (número de lotes de 18 kg)
𝐼𝐷𝑖𝑡: Cantidad de producto terminado i a inventariar al final del periodo 𝑡 (kg)
𝑀𝐴𝑄t: Cantidad de máquinas deshidratadoras a emplear en el periodo 𝑡 (número de máquinas)
c. Parámetros 𝑐𝑎𝑝𝑚𝑝𝑡: Capacidad total de almacenamiento de materias primas (mp) en el periodo t (bolsas o lotes)
𝑐𝑎𝑝𝑝𝑡𝑡: Capacidad total de almacenamiento de producto terminado en el periodo t (bolsas o lotes)
𝑐𝑐𝑜𝑚𝑖𝑡: Costo unitario de compra de la materia prima i en el periodo 𝑡 (USD/kg)
𝑐𝑐𝑜𝑟𝑖: Costo de cosechar/cortar una parcela de la materia prima i (USD/parcela)
𝑐𝑓𝑒𝑟𝑖 : Costo de cuidar una parcela de materia prima i luego de cada cosecha (USD/parcela)
𝑐𝑓𝑝𝑖 : Costo fijo de plantar una parcela de materia prima i (USD/parcela)
𝑐𝑓𝑑𝑒𝑠: Costo fijo de deshidratar por periodo (USD/periodo)
𝑐𝑖𝑛𝑣𝑐𝑖 : Costo de unitario de inventariar/almacenar la materia prima i al finalizar el periodo 𝑡 (USD/kg)
𝑐𝑖𝑛𝑣𝑑𝑖 : Costo unitario de inventariar/almacenar el producto terminado i al final del periodo t (USD/kg)
𝑐𝑚𝑖: Costo de mantener una parcela de materia prima i (USD/parcela)
𝑐𝑝𝑟𝑜𝑑: Costo de decidir deshidratar alguna materia prima en un periodo (USD/periodo)
𝑐𝑣𝑑𝑒𝑠𝑖 : Costo variable de deshidratar un lote de la mp i para obtener el producto terminado (USD/lote)
𝑑𝑏𝑏𝑡: Matriz binaria, 1 indica la disponibilidad para la cosecha en el periodo t de la parcela de Burrito
cultivada en el mes 𝑏
𝑑𝑐𝑐𝑡: Matriz binaria, 1 indica la disponibilidad para la cosecha en el periodo 𝑡 de la parcela de Cedrón
cultivada en el mes 𝑐
Mes de corte
Mes de cultivo Ene Feb Mar Abr May Jun Jul Ago Sep Oct Nov Dic
Burrito
Marzo 0 0 0 0 0 0 0 1 0 0 1 0
Abril 0 0 0 0 0 0 0 0 1 0 0 1
Mayo 0 0 0 0 0 0 0 0 0 1 0 0
Junio 0 0 0 0 0 0 0 0 0 0 1 0
Julio 0 0 0 0 0 0 0 0 0 0 0 1
Agosto 0 0 0 0 0 0 0 0 0 0 0 0
CLAIO-2016
546

𝑑𝑟𝑟𝑡: Matriz binaria, 1 indica disponibilidad para la cosecha en el periodo t de la parcela de Rosa M. cultivada
en el mes 𝑟
𝑑𝑒𝑚𝑖𝑡: Demanda del producto i en el periodo 𝑡 (kg)
ℎℎ𝑜𝑚𝑖: Horas hombre requeridas para cosechar una parcela del producto i (hs/parcela)
ℎ𝑚𝑎𝑞𝑖: Horas máquinas requeridas para deshidratar un lote del producto i (hs/lote)
𝑖𝑐𝑖𝑛𝑖𝑐𝑖𝑎𝑙: Inventario inicial de materias primas (kg)
𝑖𝑑𝑖𝑛𝑖𝑐𝑖𝑎𝑙: Inventario inicial de productos terminados (kg)
𝑞𝑐𝑜𝑟𝑡𝑒: Tamaño de cada lote introducido al deshidratador (kg)
𝑞𝑙𝑜𝑡𝑒: Tamaño de cada lote obtenido al final del proceso de deshidratación (kg)
𝑁: un número muy grande 𝑟𝑒𝑛𝑑𝑑𝑖 : Rendimiento de la materia prima i al realizarse el deshidratado (proporción)
𝑟𝑒𝑛𝑑𝑝𝑖𝑡: Rendimiento de la materia prima i al realizarse una cosecha en el periodo t (kg/parcela)
𝑡ℎℎ𝑜𝑚𝑡: Total horas hombre disponibles en el periodo 𝑡 para la cosecha (hs mensuales)
𝑡ℎ𝑚𝑎𝑞𝑡: Total horas máquina disponibles en el periodo 𝑡 para el deshidratado (hs mensuales)
𝑡𝑜𝑡𝑝𝑎𝑟: Total de parcelas disponibles para el cultivo de materias primas (número de parcelas)
𝑡𝑠𝑖: Horas máquinas requeridas para la limpieza del deshidratador al culminarse cada lote de mp i (hs)
d. Función objetivo: 𝑀𝑖𝑛𝑖𝑚𝑖𝑧𝑎𝑟 𝑍 = (1) Costo fijo de plantar cada parcela de materia prima
∑(𝐵𝑈𝑏 ∗ 𝑐𝑓𝑝1 + 𝐵𝑈𝑏 ∗ 0,2 ∗ 𝑐𝑓𝑝1) +
𝐵
𝑏=1
∑(𝐶𝐸𝑐 ∗ 𝑐𝑓𝑝2 + 𝐶𝐸𝑐 ∗ 0,2 ∗ 𝑐𝑓𝑝2)
𝐶
𝑐=1
+
∑(𝑅𝑀𝑟 ∗ 𝑐𝑓𝑝3 + 𝑅𝑀𝑟 ∗ 0,2 ∗ 𝑐𝑓𝑝3)
𝑅
𝑟=1
Suponiendo que las mismas parcelas son nuevamente plantadas, luego de los 5 años de vida útil de las
hierbas, se adiciona el costo de plantar nuevamente, asumiendo el pago de sólo el 20% de dichos costos
en el primer año, a fin de distribuir los costos de forma anual (0,2 ∗ 𝑐𝑓𝑝i).
(2) Costo de comprar cada unidad de la materia prima:
∑ ∑(𝑋𝐶𝑀𝑖𝑡 ∗ 𝑐𝑐𝑜𝑚𝑖𝑡) +
𝑇
𝑡=1
𝐼
𝑖=1
(3) Costo de cosechar, cuidar y mantener cada parcela de materia prima
∑ ∑(𝐵𝑈𝑏 ∗ 𝑑𝑏𝑏𝑡) ∗ (𝑐𝑐𝑜𝑟1 + 𝑐𝑓𝑒𝑟1 + 𝑐𝑚1) +
𝑇
𝑡=1
𝐵
𝑏=1
∑ ∑(𝐶𝐸𝑐 ∗ 𝑑𝑐𝑐𝑡) ∗ (𝑐𝑐𝑜𝑟2 + 𝑐𝑓𝑒𝑟2 + 𝑐𝑚2) +
𝑇
𝑡=1
𝐶
𝑐=1
∑ ∑(𝑅𝑀𝑟 ∗ 𝑑𝑟𝑟𝑡) ∗ (𝑐𝑐𝑜𝑟3 + 𝑐𝑓𝑒𝑟3 + 𝑐𝑚3) +
𝑇
𝑡=1
𝑅
𝑟=1
(4) Costo de almacenar al final de cada periodo c/ unidad de materia prima comprada o cosechada
∑ ∑(𝐼𝐶𝑖𝑡 ∗ 𝑐𝑖𝑛𝑣𝑐𝑖) +
𝑇
𝑡=1
𝐼
𝑖=1
(5) Costo fijo por periodo , (6) Costo fijo de deshidratar alguna materia prima y (7) Costo variable de
deshidratar cada lote de materia prima
(𝑐𝑓𝑑𝑒𝑠 ∗ 72) + ∑(𝑌𝐷𝑡 ∗ 𝑐𝑝𝑟𝑜𝑑)
𝑇
𝑡=1
+ ∑ ∑(𝑋𝐷𝑖𝑡 ∗ 𝑐𝑣𝑑𝑒𝑠𝑖) +
𝑇
𝑡=1
𝐼
𝑖=1
CLAIO-2016
547

(8) Costo de almacenar cada unidad del producto terminado en cada periodo:
∑ ∑(𝐼𝐷𝑖𝑡 ∗ 𝑐𝑖𝑛𝑣𝑑𝑖)
𝑇
𝑡=1
𝐼
𝑖=1
e. Restricciones: 1) Balance de unidades de cada tipo de materia prima en cada periodo
𝐼𝐶𝑖𝑡−1 + 𝑋𝐶𝑀𝑖𝑡 + ∑(𝐵𝑈𝑏 ∗ 𝑑𝑏𝑏𝑡 ∗ 𝑟𝑒𝑛𝑑𝑝𝑖𝑡)
𝐵
𝑏=1
= 𝑋𝐷𝑖𝑡 ∗ 𝑞𝑐𝑜𝑟𝑡𝑒 + 𝐼𝐶𝑖𝑡 ; 𝑖 = 1; ∀ 𝑡
𝐼𝐶𝑖𝑡−1 + 𝑋𝐶𝑀𝑖𝑡 + ∑(𝐶𝐸𝑐 ∗ 𝑑𝑐𝑐𝑡 ∗ 𝑟𝑒𝑛𝑑𝑝𝑖𝑡)
𝐶
𝑐=1
= 𝑋𝐷𝑖𝑡 ∗ 𝑞𝑐𝑜𝑟𝑡𝑒 + 𝐼𝐶𝑖𝑡; 𝑖 = 2; ∀ 𝑡
𝐼𝐶𝑖𝑡−1 + 𝑋𝐶𝑀𝑖𝑡 + ∑(𝑅𝑀𝑟 ∗ 𝑑𝑟𝑟𝑡 ∗ 𝑟𝑒𝑛𝑑𝑝𝑖𝑡)
𝑅
𝑟=1
= 𝑋𝐷𝑖𝑡 ∗ 𝑞𝑐𝑜𝑟𝑡𝑒 + 𝐼𝐶𝑖𝑡; 𝑖 = 3; ∀
2) Satisfacer la demanda de producto elaborado con la materia prima en cada periodo 𝐼𝐷𝑖𝑡−1 + (𝑋𝐷𝑖𝑡 ∗ 𝑟𝑒𝑛𝑑𝑑𝑖 ∗ 𝑞𝑐𝑜𝑟𝑡𝑒) = 𝑑𝑒𝑚𝑖𝑡 + 𝐼𝐷𝑖𝑡 ; ∀ 𝑖 = 1. . 𝐼; ∀ 𝑡
3) No sobrepasar la capacidad de cosecha de materia prima en cada periodo (Hs hombre para corte)
∑(𝐵𝑈𝑏 ∗ 𝑑𝑏𝑏𝑡 ∗ ℎℎ𝑜𝑚1) + ∑(𝐶𝐸𝑐 ∗ 𝑑𝑐𝑐𝑡 ∗ ℎℎ𝑜𝑚2)
𝐶
𝑐=1
+ + ∑(𝑅𝑀𝑟 ∗ 𝑑𝑟𝑟𝑡 ∗ ℎℎ𝑜𝑚3)
𝑅
𝑟=1
≤ 𝑡ℎℎ𝑜𝑚𝑡; ∀ 𝑡
𝐵
𝑏=1
4) No sobrepasar la capacidad de deshidratado en cada periodo (Hs máquina para deshidratado)
∑ 𝑋𝐷𝑖𝑡 ∗ (ℎ𝑚𝑎𝑞𝑖 + 𝑡𝑠𝑖) ≤ 𝑀𝐴𝑄𝑡 ∗ 𝑡ℎ𝑚𝑎𝑞𝑡
𝐼
𝑖=1
; ∀ 𝑡
5) No sobrepasar la cantidad de parcelas disponibles para el cultivo de materia prima
∑ 𝐵𝑈𝑏 + ∑ 𝐶𝐸𝑐 + ∑ 𝑅𝑀𝑟
𝑅
𝑟=1
= 𝑡𝑜𝑡𝑝𝑎𝑟
𝐶
𝑐=1
𝐵
𝑏=1
6) No sobrepasar la capacidad de almacenamiento de materia prima en cada periodo
∑(𝑋𝐶𝑀𝑖𝑡 + 𝐼𝐶𝑖𝑡) + ∑(𝐵𝑈𝑏 ∗ 𝑑𝑏𝑏𝑡 ∗ 𝑟𝑒𝑛𝑑𝑝1𝑡)
𝐵
𝑏=1
+ ∑(𝐶𝐸𝑐 ∗ 𝑑𝑐𝑐𝑡 ∗ 𝑟𝑒𝑛𝑑𝑝2𝑡)
𝐶
𝑐=1
𝐼
𝑖=1
+ ∑(𝑅𝑀𝑟 ∗ 𝑑𝑟𝑟𝑡 ∗ 𝑟𝑒𝑛𝑑𝑝3𝑡)
𝑅
𝑟=1
≤ 𝑐𝑎𝑝𝑚𝑝𝑡 ∗ 𝑞𝑐𝑜𝑟𝑡𝑒; ∀ 𝑡
7) No sobrepasar la capacidad de almacenamiento de producto terminado en cada periodo
∑ 𝐼𝐷𝑖𝑡 ≤ 𝑐𝑎𝑝𝑝𝑡𝑡 ∗ 𝑞𝑙𝑜𝑡𝑒; ∀ 𝑡
𝐼
𝑖=1
8) No sobrepasar la cantidad máxima de máquinas a utilizar para el deshidratado en cada periodo 𝑀𝐴𝑄𝑡 = 1; ∀ 𝑡
9) Deshidratar la materia prima sólo si se decide hacerlo en cada periodo
∑ 𝑋𝐷𝑖𝑡 ≤ 𝑁 ∗ 𝑌𝐷𝑖𝑡
𝐼
𝑖=1
; ∀ 𝑡
10) El inventario inicial de cada materia prima y el inventario inicial de cada producto terminado 𝐼𝐶𝑖0 = 𝑖𝑐𝑖𝑛𝑖𝑐𝑖𝑎𝑙; ∀ 𝑖 y 𝐼𝐷𝑖0 = 𝑖𝑑𝑖𝑛𝑖𝑐𝑖𝑎𝑙; ∀ 𝑖
CLAIO-2016
548

11) No negatividad de las variables; 12) Variables con valores enteros y 13) Variable binaria 𝐵𝑈𝑏; 𝐶𝐸𝑐; 𝑅𝑀𝑟; 𝑋𝐶𝑀𝑖𝑡; 𝐼𝐶𝑖𝑡; 𝑋𝐷𝑖𝑡; 𝐼𝐷𝑖𝑡; 𝑀𝐴𝑄𝑡 ≥ 0 ∀ 𝑏, 𝑐, 𝑟, 𝑖, 𝑡; 𝐵𝑈𝑏; 𝐶𝐸𝑐; 𝑅𝑀𝑟; 𝐼𝐶𝑖𝑡; 𝐼𝐷𝑖𝑡; 𝑀𝐴𝑄𝑡 ∈ ℤ ∀ 𝑏, 𝑐, 𝑟, 𝑖, 𝑡; YDit ∈ {1,0} ∀ 𝑖, 𝑡
5 Resultados
Conforme a las actividades analizadas y formuladas con un modelo matemático de PLEM, se presentan
los resultados obtenidos con el uso de biogás como fuente alternativa a las energías convencionales.
Debido a la baja capacidad productiva agrícola de la finca y el alto costo de compra de materia prima para
cubrir el 50% de la demanda potencial, para realizar la evaluación del modelo se decidió disminuir la
cobertura a un 25% en los seis años o 72 meses.
Con la resolución del modelo compuesto por 1.023 variables y 865 restricciones, en 9 segundos, se
obtuvo el costo mínimo de 43.181 USD para la cobertura del 25% de la demanda total, empleando en
promedio el 51 % de la capacidad de un deshidratador.
Se deberían destinar 11 parcelas para el cultivo de “Cedrón Paraguay” en el mes de agosto (𝑐 = 1) y 19
en el mes de setiembre (𝑐 = 2), así también se deben cultivar 10 parcelas de “Burrito” en marzo (𝑏 = 1),
y 10 parcelas en abril (𝑏 = 2); el total de parcelas es equivalente al máximo disponibles en la finca. Esta
solución conlleva a planificar la compra del 100 % de la Rosa Mosqueta necesaria, 31% el Cedrón y 58%
del Burrito para su posterior deshidratación.
La demanda es cubierta en los periodos requeridos con productos procesados en el mismo periodo o
inventariados de acuerdo al plan obtenido. Como ejemplo se presentan en la Figura 1 los resultados de
cantidades anuales a deshidratar en kg para el caso del Burrito. Por otro lado, en la Figura 2, se
ejemplifican los resultados del plan de producción de Burrito en el año 2015. Para este caso, el plan indica
que se debe deshidratar la materia prima en siete meses en cantidades iguales o superiores a la demanda.
La obtención de los planes de producción e inventario mensuales, permite determinar la programación a
corto plazo y distribuir los recursos con mayor eficiencia, incurriendo en menores costos por su
utilización, por ejemplo permite calcular con exactitud las horas hombres, horas máquinas y recursos
asociados a la producción que se requerirán en cada periodo.
6 Conclusiones
La gran proporción de hierbas medicinales y aromáticas obtenidas a través de su hábitat natural han
impulsado en los últimos años el análisis de proyectos que permitan su obtención sustentable a través de
la producción en fincas; además para el deshidratado son utilizados generalmente procesos al aire libre
con energía solar, lo que no garantiza la calidad e inocuidad del producto. Por lo mencionado, una
alternativa es la deshidratación utilizando deshidratadores con fuentes de energía renovables. Para la
planificación de las operaciones se propuso la utilización de un modelo matemático de PLEM,
realizándose el diseño, programación y posterior resolución del modelo, a través del cual se pudo obtener
un plan de producción, compra e inventario de materia prima, y un plan de deshidratación e inventario de
tres productos en periodos mensuales. De acuerdo a los resultados, los costos de producción, compra e
inventario de materia prima corresponden al 67% de los costos totales, y los costos de deshidratación al
33%, por tanto en trabajos posteriores se deberían analizar alternativas para la disminución de costos a
través de la prestación del servicio de deshidratado a otro productores o el trabajo conjunto de varias
fincas para la satisfacción de la demanda.
A partir de este trabajo, con el uso de biogás como alternativa, se puede plantear la comparación de la
productividad del uso de esta fuente con otras convencionales para la deshidratación de las materas
CLAIO-2016
549
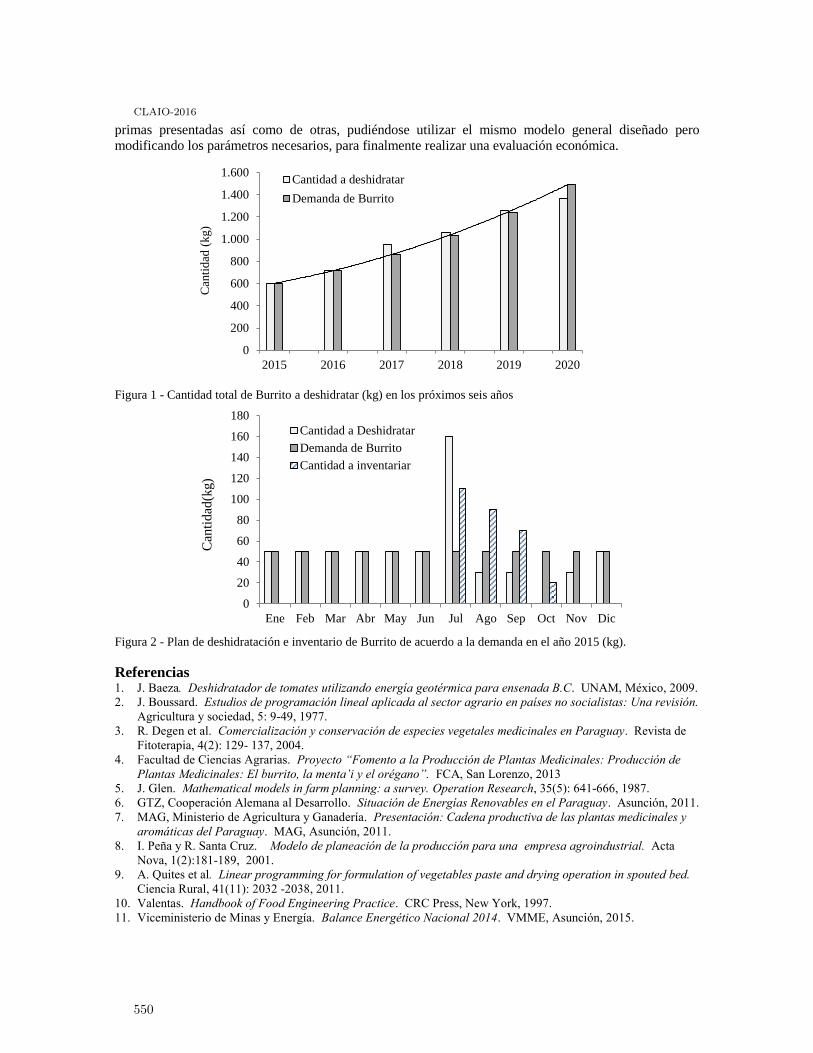
primas presentadas así como de otras, pudiéndose utilizar el mismo modelo general diseñado pero
modificando los parámetros necesarios, para finalmente realizar una evaluación económica.
Figura 1 - Cantidad total de Burrito a deshidratar (kg) en los próximos seis años
Figura 2 - Plan de deshidratación e inventario de Burrito de acuerdo a la demanda en el año 2015 (kg).
Referencias 1. J. Baeza. Deshidratador de tomates utilizando energía geotérmica para ensenada B.C. UNAM, México, 2009.
2. J. Boussard. Estudios de programación lineal aplicada al sector agrario en países no socialistas: Una revisión.
Agricultura y sociedad, 5: 9-49, 1977.
3. R. Degen et al. Comercialización y conservación de especies vegetales medicinales en Paraguay. Revista de
Fitoterapia, 4(2): 129- 137, 2004.
4. Facultad de Ciencias Agrarias. Proyecto “Fomento a la Producción de Plantas Medicinales: Producción de
Plantas Medicinales: El burrito, la menta’i y el orégano”. FCA, San Lorenzo, 2013
5. J. Glen. Mathematical models in farm planning: a survey. Operation Research, 35(5): 641-666, 1987.
6. GTZ, Cooperación Alemana al Desarrollo. Situación de Energías Renovables en el Paraguay. Asunción, 2011.
7. MAG, Ministerio de Agricultura y Ganadería. Presentación: Cadena productiva de las plantas medicinales y
aromáticas del Paraguay. MAG, Asunción, 2011.
8. I. Peña y R. Santa Cruz. Modelo de planeación de la producción para una empresa agroindustrial. Acta
Nova, 1(2):181-189, 2001.
9. A. Quites et al. Linear programming for formulation of vegetables paste and drying operation in spouted bed.
Ciencia Rural, 41(11): 2032 -2038, 2011.
10. Valentas. Handbook of Food Engineering Practice. CRC Press, New York, 1997.
11. Viceministerio de Minas y Energía. Balance Energético Nacional 2014. VMME, Asunción, 2015.
0
20
40
60
80
100
120
140
160
180
Ene Feb Mar Abr May Jun Jul Ago Sep Oct Nov Dic
Can
tidad
(kg)
Cantidad a Deshidratar
Demanda de Burrito
Cantidad a inventariar
0
200
400
600
800
1.000
1.200
1.400
1.600
2015 2016 2017 2018 2019 2020
Can
tid
ad (
kg)
Cantidad a deshidratar
Demanda de Burrito
CLAIO-2016
550

Seleção de Portfólio de Projetos com Restrição de Recursos e
Escalonamento no Tempo
Guilherme Augusto Barucke Marcondes
Instituto Nacional de Telecomunicações
Mateus de Oliveira Alves
Instituto Nacional de Telecomunicações
Vanessa Mendes Rennó
Instituto Nacional de Telecomunicações
Abstract
One of the companies’ main challenges is to improve the efficiency of their investments in R&D projects.
The objective evaluation of expected return and risk of their projects portfolio is an important support for
this decision. However, besides the economic criteria, it is important to consider the restrictions usually
imposed on projects execution. This paper presents an R&D projects portfolio selection model using as
selection criteria the mean-Gini and stochastic dominance. In addition, it employs triangular probability
distribution to characterize the projects expected return, as recommended by PMBOK®, the restriction of
human resources available for developing project activities and the analysis of projects on time in order to
optimize the use of these resources. The result is an objective selection model for projects portfolio, which
allows considering real restrictions.
Keywords: Portfolios, Mean-Gini, Stochastic Dominance.
1 Introdução
A necessidade de realizar a seleção entre projetos candidatos é usual, dado que a escassez de
recursos, em geral, não permite financiar todos [1, 4, 8, 21]. Este tem sido um dos problemas mais críticos
no gerenciamento de projetos [29]. Assim, com frequência, gestores enfrentam situações em que precisam
tomar decisões de seleção de projetos a serem executados, tendo que priorizá-los e excluindo as opções que
não estejam alinhadas às estratégias da empresa ou que possam levar a perdas, com o objetivo de executar
o melhor conjunto de projetos [21]. O conjunto de projetos selecionados pelos gestores é denominado de
portfólio de projetos.
A análise de portfólio permite gerenciar o risco em um grupo de ativos para determinar as
combinações que oferecem menor risco para um dado nível de retorno esperado ou o maior retorno esperado
para um dado nível de risco. Estes portfólios são chamados eficientes. Desta forma, pela estimativa do
retorno esperado e o risco associado a projetos, pode-se aplicar a análise de portfólio para fazer a seleção
das opções mais atrativas.
O trabalho de [19] foi pioneiro no estudo da seleção de portfólio, estabelecendo a estratégia ótima
para maximizar o retorno e minimizar a variância associada. O portfólio de média-variância (MV) de [19]
tem sido empregado de forma direta para seleção de projetos, como nos trabalhos de [5], [14] e [27].
Porém, [11] mostrou que o portfólio MV apresenta resultados confiáveis somente quando os
retornos são normalmente distribuídos ou quando a função utilidade é quadrática. Contudo, estas suposições
CLAIO-2016
551

são muito restritivas para os problemas de seleção de projetos no mundo real, em que, raramente, o retorno
esperado possui distribuição normal [3].
Uma abordagem interessante para a seleção de portfólio é apresentada por [24], denominada de
média-Gini (MG), que é empregada por [6] na seleção de portfólios de investimentos. [12] e [23]
empregaram a abordagem MG para seleção de portfólio de projetos. Sua aplicação não requer conhecimento
explícito da função de utilidade do tomador de decisão e permite a construção de portfólios que são
eficientes pelo critério da dominância estocástica (fornece as condições necessárias para a dominância
estocástica de segunda ordem) [23, 24, 25], que é a comparação de alternativas incertas, considerando toda
a distribuição de probabilidade do retorno esperado [16].
Porém, além dos aspectos financeiros a serem considerados na seleção de portfólios de projetos,
em muitos casos as empresas enfrentam restrições de recursos disponíveis para sua execução. Esta limitação
pode ser pela disponibilidade de recursos humanos, de ambiente físico e laboratórios para execução das
atividades, de equipamentos necessários, entre outros. Assim, torna-se importante a consideração desta
limitação na seleção.
Mesmo tendo a limitação de recursos, uma forma de minimizar o seu impacto é realizando um
escalonamento no tempo da execução dos projetos. Ou seja, em vez de se considerar a execução simultânea
dos projetos, se os limites de prazos de conclusão permitirem, um planejamento pode ser feito para melhor
ocupação dos recursos limitados.
Apesar da interessante abordagem de [23], nela os projetos têm seu retorno esperado modelado por
distribuição de probabilidade finita discreta. Isto permite algumas simplificações da avaliação. Entretanto,
uma distribuição de probabilidade comum aplicada na estimativa de projetos é a triangular (contínua), que
é recomendada pelo [22] e aplicada nos trabalhos de [2, 9, 20, 26]. Outro aspecto importante também não
abordado no trabalho de [23] é a consideração da limitação de recursos disponíveis para a execução dos
projetos incluídos no portfólio.
Assim, este trabalho propõe uma modificação na seleção de portfólios de projetos como proposto
por [23], considerando a limitação de recursos humanos disponíveis para a realização das atividades, seu
escalonamento no tempo e a caracterização do retorno dos projetos pela distribuição de probabilidade
triangular, levando à lista de portfólios de projetos viáveis. Estes portfólios são pré-selecionados pelo
critério de eficiência da média-Gini. Sobre os portfólios eficientes é aplicado o critério da dominância
estocástica para indicar a lista final de portfólios recomendados.
2 Retorno e Risco de Portfólio de Projetos
Na literatura, diversos trabalhos utilizam o retorno e o risco como critérios de comparação para a
definição de portfólios de projetos eficientes [12, 13, 14, 23, 27].
O retorno esperado de um projeto é medido pela média dos valores estimados, considerando a
distribuição de probabilidade aplicada. Já o retorno de um portfólio de projetos pode ser obtido pela soma
dos retornos esperados dos projetos que o compõem, como apresentado na equação a seguir [19].
𝑅𝑃 = ∑ 𝑥𝑖𝑅𝑖𝑁𝑖=1 (1)
em que 𝑥𝑖 ∈ {0,1} representa a inclusão ou não do projeto 𝑖 no portfólio, 𝑅𝑖 é o retorno esperado para o
projeto 𝑖 e 𝑁 é o total de projetos a serem considerados para o portfólio.
Existem diversas possibilidades de atribuição da probabilidade de ocorrência dos retornos
esperados para os projetos que compõem um portfólio. Este trabalho empregou a distribuição triangular do
retorno, como feito por [20] e que é recomendada pelo PMBOK® [22]. Ela é uma distribuição de
probabilidade contínua com limite inferior a, limite superior b e moda c, de forma que a < c < b.
Para o caso de aplicação desta distribuição na estimativa de retorno de projetos, o menor valor
esperado (estimativa pessimista) pode ser atribuído ao valor do parâmetro a, o maior valor esperado
(estimativa otimista) ao valor do parâmetro b e o valor esperado mais provável ao parâmetro c [9, 20, 26].
CLAIO-2016
552

Por ter maior facilidade de definição de seus parâmetros, a distribuição triangular é frequentemente mais
utilizada do que outras também empregadas (como a distribuição beta, por exemplo), sendo ainda uma
distribuição de aplicação mais direta no contexto de gerenciamento de projetos [9, 26].
Como nos trabalhos de [6], [12] e [23], no presente trabalho o risco é medido pelo coeficiente Gini.
O coeficiente de Gini é uma medida de dispersão estatística para representar a distribuição de renda de
pessoas que vivem em um país ou uma região. Apesar de seu objetivo original, este coeficiente tem sido
aplicado em diversas formas de medida de dispersão entre valores. [24] e [25], por exemplo, apresentaram
a aplicação dos valores do coeficiente de Gini para análise de risco de portfólio, em que tal abordagem
aparece como uma alternativa à abordagem tradicional da variância.
Trata-se de uma medida intuitiva e que é fácil de ser apresentada ao tomador de decisão, além de
não depender da necessidade de distribuição normal do retorno esperado e nem de se conhecer a função
utilidade aplicada [23]. O coeficiente de Gini é definido como a distância esperada entre duas realizações
da mesma variável aleatória, calculado, de forma prática, como duas vezes a covariância do retorno 𝑅𝑃 e
de sua função cumulativa de probabilidade 𝐹(𝑅𝑃), como apresentado na Equação (2) [24].
Γ𝑃 = 2 𝑐𝑜𝑣[𝑅𝑃 , 𝐹(𝑅𝑃)] (2)
3 Critérios de Seleção de Portfólio de Projetos e Restrições
Originalmente, a medida proposta por [19] foi por meio da variância do retorno esperado. Apesar
de ser esta a medida provavelmente mais utilizada na seleção de portfólios de investimentos segundo [28]
e [17], ela apresenta restrições para aplicação na seleção de portfólio de projetos. Seus resultados são
confiáveis nos casos em que a distribuição do retorno é normal ou quando a função utilidade é quadrática
[11]. Contudo, estas suposições são muito restritivas para os problemas de seleção de projetos no mundo
real, uma vez que raramente acontecem [3, 23].
Desta forma, os trabalhos de [13] e [23] indicam o coeficiente de Gini como medida de risco de
portfólios de projetos, que combinado com a medida de retorno esperado originam o método de seleção
denominado média-Gini. Por ele o Portfólio I domina o Portfólio II se, e somente se:
𝑅𝑃𝐼≥ 𝑅𝑃𝐼𝐼
(3.a)
Γ𝑃𝐼≤ Γ𝑃𝐼𝐼
(3.b)
de forma que pelo menos uma das duas condições (3.a) e (3.b) seja atendida por desigualdade. Um portfólio
que seja dominado por algum outro é excluído da fronteira eficiente.
Por sua vez, a dominância estocástica é uma técnica para comparação de alternativas incertas,
aplicada, entre outras áreas, para análise de decisão [16]. Esta técnica pode ser empregada para decidir entre
opções de portfólios de projetos [13], [18] e [23]. Ela pode ser de ordem n, sendo o critério de segunda
ordem empregado na maioria dos testes na prática, para definir aqueles que serão recomendados para
escolha [18].
O método da dominância estocástica de segunda ordem considera a premissa de que a função de
utilidade é crescente em relação ao retorno. Adicionalmente, ele considera que o tomador de decisão é
avesso ao risco [13, 18]. Por este critério, o portfólio I domina o portfólio II se, e somente se:
∫ [𝑭(𝑹𝑷𝑰𝑰) − 𝑭(𝑹𝑷𝑰
)] 𝒅𝑹 ≥ 𝟎𝒛
−∞ (4)
para todos os valores de (z) sobre o retorno R , desde que a condição de desigualdade ocorra em pelo menos
uma situação, na qual 𝑭(𝑹𝑷𝒊) é a distribuição de probabilidade cumulativa do retorno do portfólio i.
A aplicação deste método deve ser feita par a par, o que a torna muito trabalhosa com o aumento
do número de projetos [12]. Neste caso, pode ser conveniente a pré-seleção por meio de outro critério, antes
da aplicação do critério da dominância estocástica. O que pode ser feito pela seleção pela média-Gini, uma
CLAIO-2016
553

vez que os portfólios eficientes por este critério atendem à condição necessária para a seleção pelo critério
da dominância estocástica de segunda ordem [24].
A análise de eficiência por meio da média-Gini, como apresentada no trabalho de [23], leva em
conta, exclusivamente, critérios econômicos, não considerando eventuais restrições que podem existir para
a realização dos projetos. Porém, os recursos são escassos e não suficientes para atender a todos os projetos
[1, 4, 8, 21].
Com frequência, tomadores de decisão devem enfrentar as restrições impostas pela limitação de
recursos. Número máximo de pessoas que podem se envolver nas atividades, equipamentos necessários que
precisam ser compartilhados, horas de laboratórios necessárias à execução dos projetos são alguns
exemplos de recursos que podem impor limitações à execução dos projetos.
Desta forma, um método de seleção de portfólios deve levar em consideração eventuais limitações
que restrinjam a execução de seus projetos. Estas limitações devem estar integradas no processo de seleção,
em conjunto com os critérios econômicos, para evitar a possibilidade de portfólios inviáveis (que não
atendam à restrição) influenciarem na definição dos portfólios eficientes viáveis.
Como a avaliação de eficiência é relativa, ou seja, baseada na comparação entre os portfólios, se a
limitação não é tratada de forma integrada, um portfólio inviável pode ser considerado eficiente, excluindo
da fronteira eficiente um portfólio viável, que não seria excluído caso o primeiro não fosse considerado na
avaliação (por ser inviável). Esta abordagem poderia mascarar a definição dos portfólios viáveis mais
eficientes, levando o tomador de decisão a escolher entre opções que não sejam as melhores.
Entretanto, um aspecto importante na avaliação das restrições é considerar sua distribuição no
tempo. Um dado conjunto de projetos pode ser inviabilizado pelo total de recursos que demanda (acima do
limite) se todos iniciarem ao mesmo tempo, porém, pode ser viável se estes projetos forem escalonados no
tempo. Este escalonamento somente pode ocorrer, se puder ser determinado um prazo máximo para
conclusão dos projetos.
O escalonamento no tempo significa deslocar o início de alguns projetos, de forma que todos sejam
concluídos dentro do prazo máximo estipulado e visando à ocupação mais uniforme dos recursos. Desta
forma, a ocupação dos recursos disponíveis pode ser distribuída no tempo, podendo viabilizar alguns
portfólios. Esta ação pode diminuir a concentração da demanda pelos recursos no início do período de
execução dos projetos.
4 Modelo de Seleção Proposto
Este trabalho propõe a seleção dos portfólios de projetos considerando os critérios da média-Gini e
da dominância estocástica, além da limitação de recursos humanos para execução das atividades e do
escalonamento no tempo de execução. A Figura 1 apresenta a sequência empregada na seleção. Ela toma
como base o método de seleção apresentado por [23] e o altera com a modelagem do retorno dos projetos
considerando a distribuição de probabilidade triangular, integrando a limitação de recurso no procedimento
de seleção e considerando o escalonamento dos projetos no tempo para uma melhor utilização destes
recursos.
O primeiro e segundo passos da seleção visam avaliar a limitação considerada e listar somente os
portfólios viáveis, que atendam ao limite máximo de recursos humanos disponíveis para as atividades. No
primeiro passo, são identificadas todas as possíveis combinações de portfólio de projetos e todos os projetos
que compõem os portfólios são assumidos como iniciando na mesma data. Os portfólios que não atendem
a esta limitação são avaliados no segundo passo. Nele, uma ferramenta busca identificar se, considerado
um prazo máximo de execução dos projetos e a possibilidade de iniciá-los em momentos diferentes, é
possível que alguns dos portfólios avaliados possam ser executados, respeitando a limitação de recursos
humanos. Os portfólios identificados nestes passos são denominados viáveis.
CLAIO-2016
554

Figura 1 – Sequência de seleção de portfólios de projetos
No terceiro passo da seleção, são calculados o retorno esperado e o coeficiente de Gini de todos os
portfólios viáveis, usando as Equações (1) e (2), respectivamente, e a distribuição de probabilidade
triangular. No quarto passo, as condições apresentadas nas Equações (3a) e (3b) são utilizadas para a
comparação entre os portfólios, para identificar os portfólios que formam a fronteira eficiente, segundo o
critério da média-Gini.
No quinto passo, o critério da dominância estocástica é aplicado. Por meio da comparação
apresentada na Equação (4), cada par de portfólios eficientes é avaliado, resultando na lista final de
portfólios recomendados para a execução, que são aqueles não dominados por nenhum outro. Segundo [7],
a seleção de projetos por mais de um método tende a ter um desempenho melhor, o que ocorre com o
emprego da pré-seleção pela média-Gini e a posterior seleção final pela dominância estocástica.
De posse da lista final, o tomador de decisão pode escolher qual portfólio de projetos executar, por
exemplo, considerando aquele que apresente maior retorno esperado dentre os selecionados. Este modelo
permite, ainda, avaliar cenários diferentes, pela sua facilidade de aplicação. Avaliar cenários em que o
limite de recursos humanos é aumentado ou diminuído, ou cenários em que o prazo máximo de conclusão
dos projetos é alterado, são alguns exemplos. Ela dá maior segurança para a escolha, uma vez que,
considerando os critérios empregados e as limitações impostas, os portfólios selecionados são os mais
eficientes possíveis e viáveis.
5 Resultados Numéricos
Para exemplificar o modelo proposto no presente trabalho são utilizados dez projetos de uma
empresa prestadora de serviços em desenvolvimento de software, que é um dos segmentos de negócios que
mais investem em P&D no mundo [10, 29]. Esta escolha, porém, não leva a perda da generalidade da
aplicação da proposta, uma vez que ela pode ser empregada em projetos de qualquer natureza que permitam
a caracterização do retorno esperado por meio da distribuição triangular.
A Tabela 1 apresenta os dados dos dez projetos utilizados. Nela, da segunda à quarta linhas, as
estimativas de retorno dos projetos são apresentadas em milhares de Reais, o total de pessoas envolvidas
em cada projeto é apresentado na quinta linha e a sexta linha apresenta a duração estimada para os projetos
em meses.
Tabela 1 – Projetos.
Projeto A B C D E F G H I J
Retorno
Pessimista 4 8 3 6 4 5 9 2 7 3
Mais Provável 5 11 5 9 8 9 10 3 10 4
Otimista 6 13 8 11 12 11 12 4 11 6
Pessoas 5 7 3 4 6 5 6 2 6 2
Duração 4 10 3 6 6 7 7 2 4 2
CLAIO-2016
555

O modelo de seleção de portfólios foi simulado, considerando o limite de 16 pessoas disponíveis
para as atividades de projetos. Para o escalonamento no tempo, foi considerado um prazo máximo de 12
meses, de forma que todos os projetos do portfólio devem estar concluídos neste prazo.
Para permitir uma comparação, diferentes cenários foram simulados. No primeiro, os portfólios
foram selecionados considerando o modelo proposto por [23], sem considerar a limitação dos recursos
humanos e depois esta limitação foi avaliada, sem considerar o escalonamento dos projetos no tempo. No
segundo cenário, os portfólios foram selecionados considerando a limitação de recursos humanos, mas sem
aplicar o escalonamento. Por fim, o terceiro cenário considerou a limitação de recursos humanos e a
possibilidade de escalonamento dos projetos no tempo de forma integrada na seleção dos portfólios,
seguindo o modelo apresentado na Figura 1.
Como resultado da simulação do primeiro cenário, nove portfólios viáveis foram considerados
eficientes pelo critério da média-Gini. Destes, cinco foram selecionados pelo critério da dominância
estocástica. Dos cinco portfólios selecionados, aquele que apresentou maior possibilidade de retorno foi o
portfólio que inclui os projetos A, G e I (denominado Portfólio AGI), com retorno esperado de R$22.651.
Na simulação do segundo cenário, a pré-seleção indicou 18 portfólios viáveis eficientes pela média-Gini e
dez portfólios selecionados pela dominância estocástica. Destes, o que apresentou maior possibilidade de
retorno esperado foi o portfólio ADGHIJ, com valor de R$40.666.
No terceiro cenário, inicialmente foi definido o conjunto de portfólios viáveis de serem executados
considerando a limitação de recursos e o escalonamento dos projetos no tempo (primeiro e segundo passos
da Figura 1). Como resultado, foram identificados 604 portfólios viáveis (as simulações do primeiro e
segundo cenários consideraram os 1.023 portfólios inicialmente como possíveis). Para exemplificar o
escalonamento empregado dos projetos no tempo, pode-se tomar o portfólio ACDFGIJ. Na Tabela 2, pode-
se observar que foi possível atender a execução de todos os projetos considerando sua execução distribuída
no prazo de 12 meses. Pode-se observar, também, que se o início dos projetos fosse simultâneo no mês 1,
o limite de recursos humanos seria excedido nos meses de 1 a 4, inviabilizando o portfólio.
Tabela 2 – Ocupação de pessoas do portfólio ACDFGIJ – início escalonado.
Projeto Mês
1 2 3 4 5 6 7 8 9 10 11 12
A 5 5 5 5
C 3 3 3
D 4 4 4 4 4 4
F 5 5 5 5 5 5 5
G 6 6 6 6 6 6 6
I 6 6 6 6
J 2 2
Total 16 16 16 16 15 15 16 15 13 10 10 0
Aplicando o critério da média-Gini (quarto passo da Figura 1) aos 604 portfólios viáveis, são pré-
selecionados 26 portfólios eficientes. A estes portfólios foi aplicada a última etapa da seleção, que os avalia
pelo critério da dominância estocástica de segunda ordem. Assim, como resultado são recomendados 17
portfólios para a execução, que estão relacionados a seguir:
ACDFGIJ ACDFGHI ADFGHIJ ADFGIJ ADFGHI ADGHIJ
ADFGI ADGIJ ADGHI ADGI AGIJ AGHI
AGI AGH AG AH H
Para o terceiro cenário, o portfólio ACDFGIJ foi, dentre os selecionados, aquele que apresentou
maior retorno esperado (R$51.280). Neste caso, este foi o cenário que apresentou a possibilidade de maior
retorno esperado entre os portfólios selecionados. Isto acontece pelo critério utilizado no modelo proposto.
CLAIO-2016
556

Nas simulações dos dois primeiros cenários, o modelo proposto por [23] é aplicado sem uma avaliação
prévia de viabilidade, considerando a limitação de recursos humanos. Desta forma, o portfólio ACDFGIJ
(retorno R$51.280 e coeficiente de Gini 1.300) não é incluído na fronteira eficiente, pois ele é dominado
pelo portfólio ABCDGHI (retorno R$52.330 e coeficiente de Gini 1.210) pelo critério da média-Gini.
Assim, um portfólio inviável do ponto de vista da limitação de recursos humanos (ABCDGHI) não permitiu
a entrada na fronteira eficiente de um portfólio viável e eficiente, dada a restrição.
Comparando assim os cenários simulados e considerando que o tomador de decisão fará a opção
pelo portfólio da lista de selecionados que apresentar o maior retorno esperado, o terceiro cenário é o que
oferece o melhor resultado. Isto porque, pelo modelo proposto, a restrição é tratada de forma integrada com
os critérios econômicos de seleção, permitindo avaliar a eficiência entre os portfólios possíveis e viáveis.
6 Conclusão
Este trabalho apresenta um modelo de seleção projetos, baseado no retorno e risco do portfólio,
considerando limitações de recursos humanos e o escalonamento dos projetos no tempo. O emprego deste
modelo, no exemplo apresentado, permitiu reduzir os 1.023 portfólios de projetos possíveis para 17
indicados. Estes são portfólios eficientes e, ao mesmo tempo, atendem à restrição de recursos humanos
imposta. Sua aplicação, permitiu, também, identificar portfólios selecionados com retorno esperado maior,
se comparado com o outro modelo simulado.
O fato de considerar a possibilidade de escalonamento da execução dos projetos no tempo, permite
uma distribuição mais equilibrada dos recursos humanos necessários, facilitando o atendimento da restrição
imposta. Sem esta possibilidade, o número de portfólios indicados seria menor.
Por meio do emprego deste modelo, o tomador de decisão pode tanto optar por um dos portfólios
indicados, quanto buscar a ampliação dos recursos de forma a incluir mais portfólios na lista de indicados.
O ponto principal é oferecer um modelo que aplica critérios objetivos e diretos para a seleção de portfólio
de projetos.
O fato de utilizar mais de um critério na seleção, fazendo uma pré-seleção por meio da média-Gini
e a seleção final pela dominância estocástica, dá mais robustez à escolha. Ela também tende a ter um
desempenho melhor, se comparado com outros modelos que utilizem somente um critério.
O emprego da distribuição de probabilidade triangular para descrever o retorno estimado dos
projetos acrescenta um caráter mais prático ao modelo, uma vez que ela é uma das recomendações do
PMBOK®. Além disto, esta é uma distribuição comum de ser empregada em projetos, principalmente pelas
equipes que utilizam a estimativa de três pontos.
Outra característica deste modelo que aproxima sua aplicação da prática é a consideração da
restrição de recursos humanos e a possibilidade de escalonamento da execução dos projetos no tempo.
Ambas são realidade no dia-a-dia das equipes de projetos nas empresas. Adicionalmente, a aplicação do
escalonamento pode ser bastante útil na utilização mais equilibrada dos recursos disponíveis.
Apesar deste trabalho empregar os critérios de seleção pela média-Gini e pela dominância
estocástica, ele é facilmente adaptável ao emprego de outros critérios. Ele também pode ser adaptado de
maneira fácil para considerar outros tipos de restrições, mais restrições ou mesmo diferentes classificações
das restrições (por exemplo, em vez de utilizar somente recursos humanos de forma geral, usar recursos
humanos classificados por especialização).
Referências
1. Abbassi, M.; Ashrafi, M.; Tashnizi, E. S. Selecting balanced portfolios of R&D projects with interdependencies:
A cross-entropy based methodology. Technovation, v. 34, n. 1, p. 54–63, 2014.
2. Batselier, J.; Vanhoucke, M. Construction and evaluation framework for a real-life project database. International
Journal of Project Management, v. 33, n. 3, p. 697–710, 2015.
CLAIO-2016
557

3. Better, M.; Glover, F. Selecting project portfolios by optimizing simulations. The Engineering Economist, v. 51,
n. 2, p. 81–98, 2006.
4. Casault, S.; Groen, A. J.; Linton, J. D. Selection of a portfolio of R&D projects. In: LINK, A. N.; VONORTAS,
N. S. (Ed.). Handbook on the Theory and Practice of Program Evaluation: Edward Elgar, 2013. p. 89–111.
5. Cho, W.; Shaw, M. J. Portfolio selection model for enhancing information technology synergy. IEEE
Transactions on Engineering Management, v. 60, n. 4, p. 739–749, 2013.
6. Cillo, P. D. A. Mean-risk analysis with enhanced behavioral content. European Journal of Operational Research,
v. 239, n. 3, p. 764–775, 2014.
7. Cooper, R.; Edgett, S.; Kleinschmidt, E. Portfolio management for new product development: results of an
industry practices study. R&D Management, Blackwell Publishers Ltd, v. 31, n. 4, p. 361–380, 2001.
8. Cullmann, A.; Schmidt-Ehmckey, J.; Zloczysti, P. R&D efficiency and barriers to entry: a two stage semi-
parametric DEA approach. Oxford Economic Papers, v. 64, n. 1, p. 176–196, 2012.
9. Dorp, J. R. van; Kotz, S. A novel extension of the triangular distribution and its parameter estimation. Journal
of the Royal Statistical Society, v. 51, n. 1, p. 63–79, 2002.
10. Eur. Comission. The 2013 EU Industrial R&D Inv. Scoreboard. Eur. Union, 2013. EU R&D Scoreboard, 2013
11. Feldstein, M. S. Mean-variance analysis in the theory of liquidity preference and portfolio selection. The Review
of Economic Studies, v. 36, n. 1, p. 5–12, 1969.
12. Gemici-Ozkan, B.; Wu, S. D.; Linderoth, J. T.; Moore, J. E. R&D project portfolio analysis for the semiconductor
industry. Operations Research, v. 58, n. 6, p.1548–1563, 2010.
13. Graves, S. B.; Ringuest, J. L. Probabilistic dominance criteria for comparing uncertain alternatives: A tutorial.
Omega, v. 37, n. 2, p. 346–357, 2009.
14. Gutjahr, W. J.; Froeschl, K. A. Project portfolio selection under uncertainty with outsourcing opportunities.
Flexible Services and Manufacturing Journal, v. 25, n. 1-2, p. 255–281, 2013.
15. Jafarzadeh, M.; Tareghian, H. R.; Rahbarnia, F.; Ghanbari, R. Optimal selection of project portfolios using
reinvestment strategy within a flexible time horizon. European Journal of Operational Research, v. 243, n. 2, p.
658–664, 2015.
16. Levy, H. Stochastic dominance and expected utility: Survey and analysis. Management Science, v. 38, n. 4, p.
555–593, 1992.
17. Levy, H.; Levy, M. The benefits of differential variance-based constraints in portfolio optimization. European
Journal of Operational Research, v. 234, n. 2, p. 372–381, 2014.
18. Lizyayev, A. Stochastic dominance efficiency analysis of diversified portfolios: classification, comparison and
refinements. Annals of Operations Research, v. 196, n. 1, p.391–410, 2012.
19. Markowitz, H. Portfolio selection. Journal of Finance, v. 7, p. 77–91, 1952.
20. Mathews, S. Valuing risky projects with real options. Research Techn. Management, v. 52, n. 5, p. 32–41, 2009.
21. Perez, F.; Gomez, T. Multiobjective project portfolio selection with fuzzy constraints. Annals of Operations
Research, v. 236, p. 1–23, 2014.
22. PMI. A Guide to the Project Management Body of Knowledge. 5 ed.: Project Management Institute, 2013.
23. Ringuest, J. L.; GRAVES, S. B.; H., C. R. Mean-Gini analysis in R&D portfolio selection. European Journal of
Operational Research, v. 154, n. 1, p. 157–169, 2004.
24. Shalit, H.; Yitzhaki, S. Mean-Gini, portfolio theory, and the pricing of risky assets. The Journal of Finance, v.
39, n. 5, p. 1449–1468, 1984.
25. Shalit, H.; Yitzhaki, S. The mean-Gini efficient portfolio frontier. The Journal of Finance Research, XXVIII, n.
1, p. 59–75, 2005.
26. Yang, I.-T. Impact of budget uncertainty on project time-cost tradeoff. IEEE TRANSACTIONS ON
ENGINEERING MANAGEMENT, v. 52, n. 2, p. 167–174, 2005.
27. Yu, L. et al. Genetic algorithm-based multi-criteria project portfolio selection. Annals of Operations Research,
v. 197, n. 1, p. 71–86, 2012.
28. Zopounidis, C.; Doumpos, M.; Fabozzi, F. J. Preface to the special issue: 60 years following Harry Markowitz’s
contributions in portfolio theory and operations research. European Journal of Operational Research, v. 234, n.
2, p. 343–345, 2014.
29. Barry, J.; Staack, V.; Goehle, B. Proven Paths to Innovation Success: Ten years of research reveal the best R&D
strategies for the decade ahead. PWC, 2014. Global Innovation 1000, n. 77/Winter2014.
CLAIO-2016
558

MODELO PARA LA ASIGNACIÓN DE TERRENOS,
EN EL MARCO DE LA REFORMA RURAL
INTEGRAL
Karen Martínez Lancheros
Estudiante Ingenieria Industrial, Universidad de Antioquia.
Natalia Quintero Avellaneda
Estudiante Ingenieria Industrial, Universidad de Antioquia.
Yony Fernando Ceballos PhD
Docente, Departamento Ingenieria Industrial, Universidad de Antioquia.
Resumen
El conflicto interno en Colombia, tiene como posibles causas la tenencia de tierras y/o el
factor agrario, ya que se encuentra estrechamente relacionado con tres necesidades
básicas, vivienda, alimentación e ingresos. El surgimiento de movimientos armados como
las FARC, nace con un alto contenido de reivindicación por una reforma en la
distribución de las tierras, y es por ello que uno de los primeros temas tratados en las
mesas de negociación fue la creación de una Reforma Rural Integral. El objetivo
principal del proyecto se centró en desarrollar un modelo matemático que permitió
asignar segmentos de tierras, a los diferentes beneficiarios del programa de acceso
integral y uso de tierras en el marco de dicha reforma. El documento contiene, el
desarrollo de algunas etapas de la metodología de Checkland, pasando de una situación
problemática de carácter blando a una solución dura, mediante una adaptación del GAP.
Los resultados obtenidos después recrear un caso en el Oriente Antioqueño, demostraron
que el modelo desarrollado concuerda idóneamente con el modelo conceptual planteado.
Palabras claves: Checkland, GAP, Reforma Rural Integral, asignación, terrenos,
beneficiarios, conflicto armado.
Abstract
The internal conflict in Colombia, has as possible causes, the property of lands and the
agrarian issue, because they are strongly related to three basics needs, dwelling, food and
income. The emergence of the armed movements as the FARC is related to a strong
desire of people for a reform that guarantees a fair distribution of land, and because of
that, one of the first topics in the negotiation table was the creation of an Integral Rural
Reform. The main purpose of that project was focused in to develop a mathematic model
that allowed allocating pieces of land to the different beneficiaries of the Integral Access
CLAIO-2016
559

Program and the use of land in reference to that reform. The document contains a
development of some stages in the Checkland methodology, passing from a problematic
situation of lenient sort to a radical solution by an adaptation of the GAP. The results
gotten after recreating a case in the East of Antioquia department revealed that the
developed model agrees to the conceptual purposed model.
Keywords: Checkland, GAP, Integrated Rural Reform, assigning, land, beneficiaries,
armed conflict.
1 Introducción
El conflicto armado en Colombia es un problema que ha existido desde mediados de
1960, las razones que dieron su origen aún siguen siendo un tema de debate para los
principales actores del conflicto (Comisión Histórica del Conflicto y sus Víctimas, 2015),
no obstante, mediante las reuniones realizadas por este grupo en el marco del acuerdo de
paz adelantado en La Habana (Cuba), se logró determinar diversos factores que se
presumen marcaron el surgimiento del conflicto interno, según Darío Fajardo
comisionado de este grupo, la tenencia de tierras o el factor agrario es uno de estos, “ya
que esta, se encuentra estrechamente relacionada con tres necesidades básicas, vivienda,
alimentación e ingresos” (Cantillo Barrios, 2015), según explico el comisionado, en la
medida en que el Estado ha fallado garantizando estas tres necesidades, se legitima el
derecho a la rebelión, generando así el surgimiento de la insurgencia.
La importancia del sector agropecuario en Colombia radica en su contribución al
desarrollo económico y social del país, generando más del 20% del empleo nacional y
alrededor del 50% del empleo en las áreas rurales, además de su trascendencia frente
aspectos fundamentales como el abastecimiento de alimentos y de materias primas para la
agroindustria (Leibovich & Estrada, 2009).Sin embargo, ha venido perdiendo dinamismo
en su crecimiento como consecuencia del conflicto armado.
Dado lo anterior, el tema agrario es uno de los pilares sobre los cuales se desarrollan los
diálogos en La Habana (Cuba). La Reforma Rural Integral, expuesta a partir de estas
conversaciones, propone en materia de asignación de terrenos consideraciones sobre: la
productividad del campo, beneficiar e impactar al mayor número de ciudadanos, asegurar
la sostenibilidad socio ambiental, respetar la compatibilidad entre vocación y uso del
suelo rural, y dar prioridad a la producción de alimentos (Gobierno de la República de
Colombia y Fuerzas Armadas Revolucionarias de Colombia., 2014).
A partir de la problemática expuesta, se consideró pertinente desarrollar un modelo
matemático que permitió asignar segmentos de tierras, a los diferentes beneficiarios del
programa de acceso integral y uso de tierras en el marco de la Reforma Rural Integral. En
este documento, se presenta de manera general el desarrollo de la metodología de
Checkland, seleccionada para abarcar el problema, al igual, que el método de
delimitación del mismo. Se exhiben los resultados de las etapas iniciales como: la
definición de la situación problema no estructurada y la determinación de la situación
problema expresada, etapas en las cuales se caracterizó la problemática a abarcar.
Conjuntamente, se presenta el diseño del modelo desarrollado y la comparación de este
frente al modelo conceptual, en donde se analizan los resultados obtenidos para el caso
CLAIO-2016
560

recreado y se contrasta con los objetivos iniciales de la modelación. Finalmente se
describen las conclusiones de la elaboración del trabajo y se expone un aspecto de
interés, que podría ser pertinente en posible estudio futuro.
2 Marco teórico
El trabajo se desarrolló de manera general bajo la metodología SSM (Metodología de
Sistemas Blandos, por sus siglas en inglés) desarrollada por el inglés Peter Checkland con
el propósito de ocuparse de problemas de alto contenido social, político y humano
(Checkland, 1992). Dicha metodología propone siete etapas, donde se busca en primera
instancia, una identificación clara del contexto y el problema, al mismo tiempo se
identifican las variables o condiciones deseadas, para finalmente proponer las acciones
requeridas por el sistema. La adopción de este tipo de metodologías se debe a la estrecha
relación entre la problemática presentada, con asuntos de carácter político, económico y
social.
Por otro lado, la delimitación del problema sobre una región específica, se hizo necesaria
no solo en una de las etapas iniciales de la metodología de Checkland, sino también en la
recreación del caso aplicado, dicha delimitación se desarrolló bajo el Modelo Analítico
Jerárquico (AHP, siglas en ingles), el cual es una herramienta sistemática implementada
en problemas multicriterio, que busca ponderar el desempeño de las diferentes
alternativas en cada uno de los criterios establecidos, para así poder jerarquizar la
relevancia de las mismas; el resultado final es la valoración global de cada una de las
alternativas, en donde aquellas que obtengan mayor puntuación serán las mejores bajo los
criterios analizados.
La aplicación de AHP facilitó la selección de la región más impactada por la violencia,
pues se considera que esta será la más vulnerable a la transformación estructural del
campo que se adelantara en la Reforma Rural Integral, ya que a criterio del gobierno
según lo afirmado en el borrador conjunto, las bases de la transformación estructural del
campo buscan reversar los efectos del conflicto y cambiar las condiciones de persistencia
del mismo (Gobierno de la República de Colombia y Fuerzas Armadas Revolucionarias
de Colombia., 2014).
3 Resultados
A continuación se presentan los resultados encontrados en las principales etapas de la
metodología de Checkland:
Situación problema no estructurada
De manera general, se realizó un análisis sobre el desarrollo del conflicto interno en
Colombia, con el fin de identificar la relación existente entre las motivaciones que darán
inicio a la restructuración del campo y el conflicto. En la Ilustración 1, se presenta el
árbol de problemas, en este se observa que una de las principales causas de la existencia y
prolongación de la violencia ha sido el acceso inequitativo a la propiedad rural, generado
por factores como la presencia de corrupción e inadecuadas metodologías para la
sucesión de predios.
CLAIO-2016
561

Ilustración 1. Árbol de problemas. Fuente: Elaboración Propia.
Situación problema estructurada
Dado lo anterior, y en conformidad con el principal pilar planteado en la Reforma Rural
Integral, surge la necesidad de proponer un modelo matemático que permita asignar
porciones de terreno a los diferentes beneficiarios del programa de acceso integral y uso
de tierras. Conjuntamente, se propone la inclusión de principios fundamentales como:
garantizar la vocación del suelo, determinar dimensiones mínimas rentables de los
terrenos otorgados a los beneficiarios e impulsar el cultivo de productos promisorios,
pues al considerar estos factores se busca velar por la sostenibilidad de los beneficiarios y
del medio ambiente.
Por otra parte, dentro de la fase de definición del problema se realizó la delimitación de la
región de estudio, con el fin de recrear un caso aplicando el modelo a desarrollar, esta
selección se realizó bajo el Método Analítico Jerárquico, en el cual se evaluaron seis
regiones del departamento de Antioquia: Nordeste, Norte, Occidente, Suroeste, Oriente y
Valle de Aburrá, las cuales comprenden 96 municipios. De igual forma se identificaron
cuatro factores de evaluación correspondientes a: homicidios, desplazamiento forzoso,
accidentes por minas antipersonales y confrontaciones encabezadas por las FARC, en los
cuales sobresalen diversas regiones dado el impacto que estas tuvieron.
En la tabla 1, se muestra que el método de calificación implementado se deriva de la
clasificación de las regiones dentro de los rangos del Box-plot de los datos recolectados
para cada criterio, en el caso del factor homicidio, los datos corresponden a la tasa de
homicidios por cada cien mil habitantes durante el periodo (1990-2012).
CLAIO-2016
562
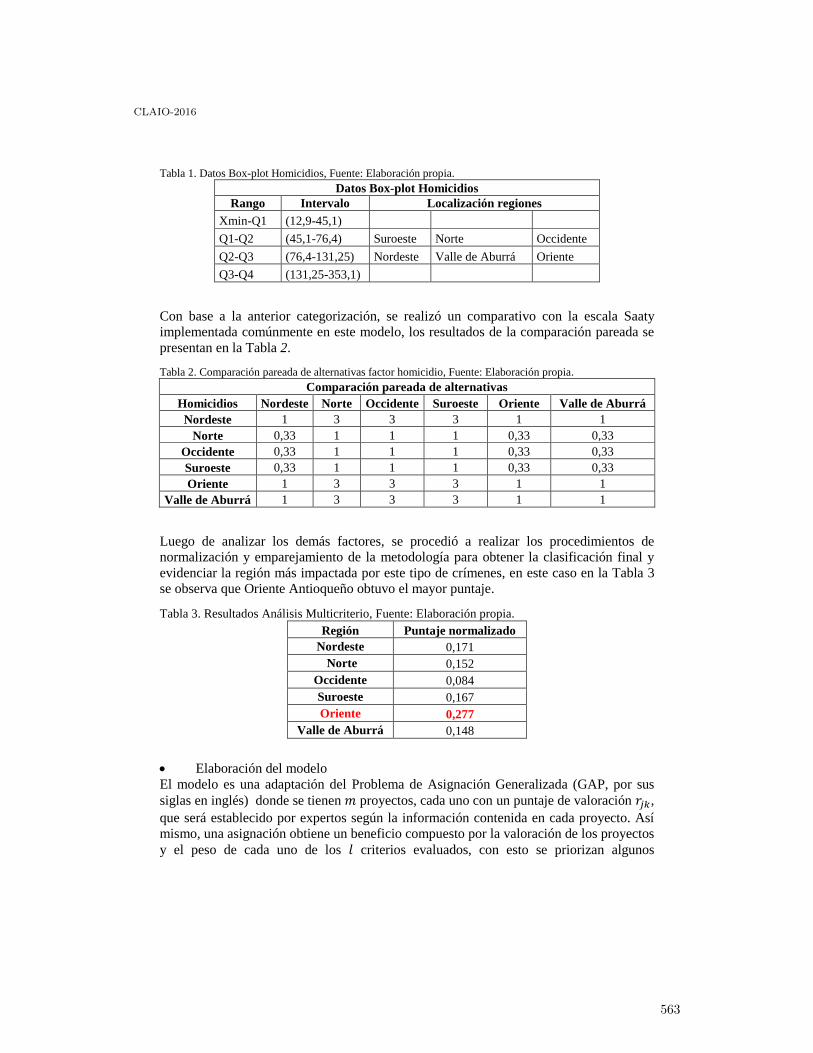
Tabla 1. Datos Box-plot Homicidios, Fuente: Elaboración propia.
Datos Box-plot Homicidios
Rango Intervalo Localización regiones
Xmin-Q1 (12,9-45,1)
Q1-Q2 (45,1-76,4) Suroeste Norte Occidente
Q2-Q3 (76,4-131,25) Nordeste Valle de Aburrá Oriente
Q3-Q4 (131,25-353,1)
Con base a la anterior categorización, se realizó un comparativo con la escala Saaty
implementada comúnmente en este modelo, los resultados de la comparación pareada se
presentan en la Tabla 2.
Tabla 2. Comparación pareada de alternativas factor homicidio, Fuente: Elaboración propia.
Comparación pareada de alternativas
Homicidios Nordeste Norte Occidente Suroeste Oriente Valle de Aburrá
Nordeste 1 3 3 3 1 1
Norte 0,33 1 1 1 0,33 0,33
Occidente 0,33 1 1 1 0,33 0,33
Suroeste 0,33 1 1 1 0,33 0,33
Oriente 1 3 3 3 1 1
Valle de Aburrá 1 3 3 3 1 1
Luego de analizar los demás factores, se procedió a realizar los procedimientos de
normalización y emparejamiento de la metodología para obtener la clasificación final y
evidenciar la región más impactada por este tipo de crímenes, en este caso en la Tabla 3
se observa que Oriente Antioqueño obtuvo el mayor puntaje.
Tabla 3. Resultados Análisis Multicriterio, Fuente: Elaboración propia.
Región Puntaje normalizado
Nordeste 0,171
Norte 0,152
Occidente 0,084
Suroeste 0,167
Oriente 0,277
Valle de Aburrá 0,148
Elaboración del modelo
El modelo es una adaptación del Problema de Asignación Generalizada (GAP, por sus
siglas en inglés) donde se tienen 𝑚 proyectos, cada uno con un puntaje de valoración 𝑟𝑗𝑘,
que será establecido por expertos según la información contenida en cada proyecto. Así
mismo, una asignación obtiene un beneficio compuesto por la valoración de los proyectos
y el peso de cada uno de los 𝑙 criterios evaluados, con esto se priorizan algunos
CLAIO-2016
563

proyectos, de modo que permita la creación de escenarios y la composición de
alternativas de asignación.
Por otra parte, se cuenta con 𝑛 terrenos, donde cada uno tiene una cantidad máxima de
hectáreas disponibles 𝑑𝑖, los cuales serán asignados según la cantidad requerida por cada
proyecto ℎ𝑗 y la vocación del suelo. Para esto último, se creó un parámetro 𝑞𝑖𝑗 con la
pertinencia de los terrenos asignables a cada proyecto, los cuales se clasificarán según
atributos considerados por los expertos. El objetivo del problema será entonces encontrar
una solución que maximice el beneficio del programa de asignación de terrenos,
manteniendo una priorización de los proyectos y la pertinencia de los terrenos. A
continuación se presenta el modelo.
𝑪𝒐𝒏𝒋𝒖𝒏𝒕𝒐𝒔
𝑇 = 𝑡𝑒𝑟𝑟𝑒𝑛𝑜𝑠 (𝑖 = 1,2, … , 𝑛)
𝑃 = 𝑝𝑟𝑜𝑦𝑒𝑐𝑡𝑜𝑠 (𝑗 = 1,2, … , 𝑚)
𝐶 = 𝑐𝑟𝑖𝑡𝑒𝑟𝑖𝑜𝑠 (𝑘 = 1,2, … , 𝑙)
𝑷𝒂𝒓𝒂𝒎𝒆𝒕𝒓𝒐𝒔
𝑑𝑖 = 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛𝑒𝑠 𝑑𝑒𝑙 𝑡𝑒𝑟𝑟𝑒𝑛𝑜 𝑖 ℎ𝑗 = 𝑛ú𝑚𝑒𝑟𝑜 𝑑𝑒 ℎ𝑒𝑐𝑡𝑎𝑟𝑒𝑎𝑠 𝑟𝑒𝑞𝑢𝑒𝑟𝑖𝑑𝑎𝑠 𝑝𝑎𝑟𝑎 𝑒𝑙 𝑝𝑟𝑜𝑦𝑒𝑐𝑡𝑜 𝑗
𝑝𝑘 = 𝑝𝑒𝑠𝑜 𝑑𝑒𝑙 𝑐𝑟𝑖𝑡𝑒𝑟𝑖𝑜 𝑘
𝑟𝑗𝑘 = 𝑝𝑢𝑛𝑡𝑎𝑗𝑒 𝑑𝑒𝑙 𝑝𝑟𝑜𝑦𝑒𝑐𝑡𝑜 𝑗 𝑑𝑒𝑙 𝑐𝑟𝑖𝑡𝑒𝑟𝑖𝑜 𝑘
𝑞𝑖𝑗 = 𝑝𝑒𝑟𝑡𝑖𝑛𝑒𝑛𝑐𝑖𝑎 𝑑𝑒 𝑡𝑒𝑟𝑟𝑒𝑛𝑜 𝑖 𝑝𝑎𝑟𝑎 𝑒𝑙 𝑝𝑟𝑜𝑦𝑒𝑐𝑡𝑜 𝑗.
𝑽𝒂𝒓𝒊𝒂𝒃𝒍𝒆 𝒅𝒆 𝒅𝒆𝒄𝒊𝒔𝒊𝒐𝒏
𝑥𝑗𝑖 = {1 𝑠𝑖 𝑎𝑠𝑖𝑔𝑛𝑜 𝑒𝑙 𝑝𝑟𝑜𝑦𝑒𝑐𝑡𝑜 𝑗 𝑎𝑙 𝑡𝑒𝑟𝑟𝑒𝑛𝑜 𝑖0 𝑑𝑒 𝑙𝑜 𝑐𝑜𝑛𝑡𝑟𝑎𝑟𝑖𝑜
𝑭𝒖𝒏𝒄𝒊ó𝒏 𝒐𝒃𝒋𝒆𝒕𝒊𝒗𝒐
𝑀𝑎𝑥𝑖𝑚𝑖𝑧𝑎𝑟 ∑ ∑ ∑ 𝑝𝑘
𝑙
𝑘 ∈ 𝐶
𝑛
𝑖 ∈ 𝑇
𝑚
𝑗 ∈ 𝑃
𝑟𝑗𝑘𝑥𝑗𝑖𝑞𝑖𝑗
𝑺𝒖𝒋𝒆𝒕𝒐 𝒂
El proyecto puede ser o no ser asignado a un terreno
∑ 𝑞𝑖𝑗𝑥𝑗𝑖
𝑛
𝑖 ∈ 𝑇
≤ 1 ∀ 𝑗 ∈ 𝑃
No sobrepasar la capacidad del terreno
∑ 𝑞𝑖𝑗ℎ𝑖𝑥𝑗𝑖
𝑚
𝑗 ∈ 𝑃
≤ 𝑑𝑖 ∀ 𝑖 ∈ 𝑇
Naturaleza de la variable
𝑥𝑗𝑖 ∈ {1,0} ∀𝑗 ∈ 𝑃, ∀𝑖 ∈ 𝑇
CLAIO-2016
564
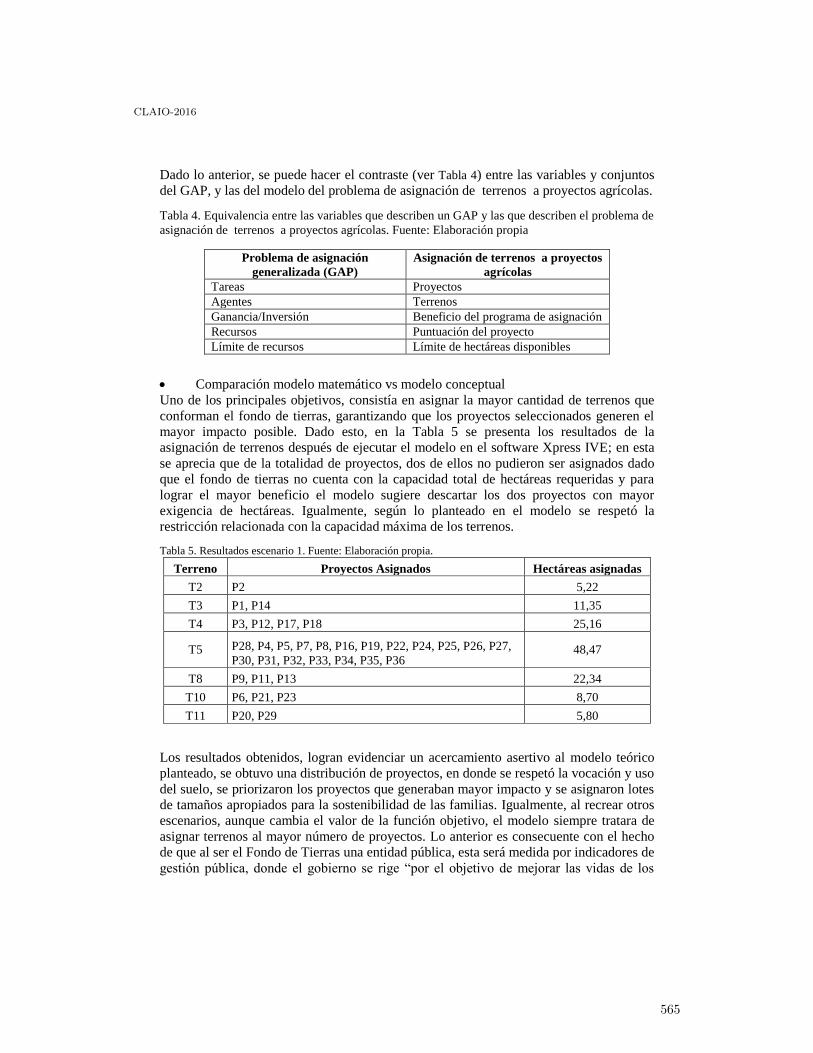
Dado lo anterior, se puede hacer el contraste (ver Tabla 4) entre las variables y conjuntos
del GAP, y las del modelo del problema de asignación de terrenos a proyectos agrícolas.
Tabla 4. Equivalencia entre las variables que describen un GAP y las que describen el problema de
asignación de terrenos a proyectos agrícolas. Fuente: Elaboración propia
Problema de asignación
generalizada (GAP)
Asignación de terrenos a proyectos
agrícolas
Tareas Proyectos
Agentes Terrenos
Ganancia/Inversión Beneficio del programa de asignación
Recursos Puntuación del proyecto
Límite de recursos Límite de hectáreas disponibles
Comparación modelo matemático vs modelo conceptual
Uno de los principales objetivos, consistía en asignar la mayor cantidad de terrenos que
conforman el fondo de tierras, garantizando que los proyectos seleccionados generen el
mayor impacto posible. Dado esto, en la Tabla 5 se presenta los resultados de la
asignación de terrenos después de ejecutar el modelo en el software Xpress IVE; en esta
se aprecia que de la totalidad de proyectos, dos de ellos no pudieron ser asignados dado
que el fondo de tierras no cuenta con la capacidad total de hectáreas requeridas y para
lograr el mayor beneficio el modelo sugiere descartar los dos proyectos con mayor
exigencia de hectáreas. Igualmente, según lo planteado en el modelo se respetó la
restricción relacionada con la capacidad máxima de los terrenos.
Tabla 5. Resultados escenario 1. Fuente: Elaboración propia.
Terreno Proyectos Asignados Hectáreas asignadas
T2 P2 5,22
T3 P1, P14 11,35
T4 P3, P12, P17, P18 25,16
T5 P28, P4, P5, P7, P8, P16, P19, P22, P24, P25, P26, P27,
P30, P31, P32, P33, P34, P35, P36 48,47
T8 P9, P11, P13 22,34
T10 P6, P21, P23 8,70
T11 P20, P29 5,80
Los resultados obtenidos, logran evidenciar un acercamiento asertivo al modelo teórico
planteado, se obtuvo una distribución de proyectos, en donde se respetó la vocación y uso
del suelo, se priorizaron los proyectos que generaban mayor impacto y se asignaron lotes
de tamaños apropiados para la sostenibilidad de las familias. Igualmente, al recrear otros
escenarios, aunque cambia el valor de la función objetivo, el modelo siempre tratara de
asignar terrenos al mayor número de proyectos. Lo anterior es consecuente con el hecho
de que al ser el Fondo de Tierras una entidad pública, esta será medida por indicadores de
gestión pública, donde el gobierno se rige “por el objetivo de mejorar las vidas de los
CLAIO-2016
565

ciudadanos en modos que no pueden ser fácilmente valorados en miles” (Guinar, 2003),
es por esto que una entidad pública debe buscar mayor cobertura de beneficiarios y es allí
donde la función objetivo del modelo los está optimizando pese a la limitada
disponibilidad de terrenos.
4 Conclusiones y trabajo futuro
La metodología de Checkland implementada para captar la esencia de problemas blandos
en ingeniería, fue una herramienta eficaz a la hora de enfrentarse a la problemática de
inequidad en la tenencia de tierras, puesto que permitió identificar importantes
particularidades del problema. Conjuntamente, el modelo construido como un hibrido del
GAP demostró ser muy asertivo frente a las expectativas planteadas inicialmente, pues
tuvo en cuenta los proyectos y sus requerimientos, los terrenos y sus características,
además de los criterios que actualmente se utilizan para evaluar los proyectos que
participan en programas de agro que fomenta el gobierno.
De manera general, con el modelo se trató de dar una solución dura a una problemática
que es muy subjetiva, con esto se pretende que la población acceda a terrenos sin
importar la influencia de aspectos políticos, sociales y/o económicos, sino que por el
contrario premie aquellas personas que tienen proyecciones en el agro y que se les
garantice una rentabilidad con el producto que decidan cultivar.
Finalmente, sería interesante vincular la cercanía del origen del proyecto con el terreno
asignado, mediante algoritmos de localización, con el fin de que los beneficiarios logren
establecerse en lugares cercanos a sus viviendas actuales.
5 Bibliografía
1. Cantillo Barrios, J. (18 de Febrero de 2015). Las teorías del origen del conflicto
armado en Colombia. El Heraldo.
2. Checkland, P. (1992). Pensamiento de Sistemas, práctica de sistemas. México:
LIMUSA.
3. Comisión Histórica del Conflicto y sus Víctimas. (2015). Contribución al
entendimiento del conflicto armado en Colombia. Habana.
4. Gobierno de la República de Colombia y Fuerzas Armadas Revolucionarias de
Colombia. (2014). Borrador conjunto: Hacia un Nuevo Campo Colombiano,
Reforma Rural Integral., (pág. 21). La Habana .
5. Guinar, J. M. (Octubre de 2003). Indicadores de gestión para las entidades
públicas. VIII Congreso Internacional del CLAD sobre la Reforma del Estado y
de la Administración Pública, (págs. 28-31). Panamá.
6. Leibovich, J., & Estrada, L. (2009). Diagnóstico y recomendaciones de política
para mejorar la competitividad del sector agropecuario colombiano.
CLAIO-2016
566

HEURISTICA DE AGRUPAMIENTO DE PRODUCTOS
HORTOFRUTÍCOLAS PARA GARANTIZAR CONDICIONES
DE MADURACIÓN EN ALMACENAMIENTO
Hugo Fernando González Hurtado
Escuela de Ingeniería Industrial, Universidad del Valle. Cali, Colombia.
Paulo Machado Bados
Escuela de Ingeniería Industrial, Universidad del Valle. Cali, Colombia. Código
Pedro Daniel Medina Varela
Facultad de Ingeniería Industrial, Universidad Tecnológica de Pereira. Pereira, Colombia.
RESUMEN.
Este artículo presenta el diseño de una heurística de formación de clusters para establecer grupos desde
una visión de la manufactura celular para una empresa hortofrutícola del Norte del Valle del Cauca. La
cual busca dar respuesta al problema de la correcta disposición del inventario en proceso y en tránsito,
como las dos formas recurrentes de stock manejado por las empresas que poseen el canal de producción
y comercialización de productos en fresco. La clasificación de los ítems resulta una tarea de apoyo en
la gestión de productos perecederos, ya que existen múltiples factores que afectan de manera positiva
y/o negativa en el aprovisionamiento, la gestión eficiente del inventario, el transporte y almacenamiento
adecuado del cliente. Cada grupo conformado se podrá enfocar en las necesidades de los productos
pertenecientes a éste, dado la condición de Maduración qué es el punto crítico de control para las
empresas de este sector.
Palabras Claves: Formación de Clusters; Manufactura Celular; Peso Ponderado; Condición de
Maduración; Sensibilidad al Etileno; Capacidad de Almacenamiento.
ABSTRACT.
This article present the design of a clusters formation heuristic for establish groups from a vision of the
cellular manufacturing for horticulture company of North Valle del Cauca. Which find get answer to
problem of the correct available of inventory in process and inventory in transit, as much the two
relapsing forms of management stock of enterprises that own the production canal and products fresh
commercialization. The classification of the resulting items a task support in the perishable product
management, since there multiple factors affecting the positive way and/o negative in the provisioning,
the management stock efficient, the transport and storage appropriate for each client. Each group
confirmed it might focus in the requirement of the perishable products to this; give the maturation
condition, which it is a critical point of control for the enterprises of this sector.
Key words: Clusters formation; Cellular Manufacturing; Weighted weight; maturation condition;
Ethylene Sensitivity, Storage Capacity.
CLAIO-2016
567

1. INTRODUCCIÓN
Al existir la necesidad de conservar ciertas características de los productos con el objetivo de satisfacer requerimientos
exigidos por los clientes, se llega a identificar la importancia de su preservación o almacenamiento, en especial los
productos tales como las frutas y hortalizas, siendo la venta de estos el negocio en el cuál se especializa la empresa caso
de estudio, perteneciente al sector agroindustrial; de esta manera se vuelve imprescindible contar con herramientas que
soporten los medios para responder a las necesidades de los clientes manteniendo los estándares aceptables para cada
target group (mercado objetivo). Por este hecho se debe conocer cuáles son los factores que afectan las condiciones del
producto dentro del tiempo en que es inventariado, haciendo uso de mecanismos que contrarresten los efectos producidos
por los tales factores, siempre teniendo en cuenta el estado físico del producto al ser manipulado.
Es así como los métodos de clasificación y agrupación toman el papel principal para abordar el problema de garantizar
en su totalidad producto en fresco a través de toda la cadena de abastecimiento, considerando que las Pymes (Pequeñas
y medianas empresas) no tienen un apalancamiento financiero con el cuál accedan a sistemas de atmosferas controladas
o refrigeración mecánica para asegurar ciertos atributos de los productos desde los procesos de cosecha, y postcosecha,
hasta la recepción del producto realizada por los clientes. La incorporación de recursos ingenieriles en el campo de la
manufactura celular logra la adaptación de estrategias con argumentos cuantitativos, como los heurísticos y modelos de
optimización, que plasman una solución inmediata al problema en cuestión; además de esto los heurísticos son
herramientas computacionales que producen resultados no tan exactos como los métodos de optimización, pero arrojan
soluciones aceptables para los problemas en los que se desea intervenir. Estos poseen ventajas tales como la baja cantidad
de recursos computacionales para obtener resultados, y un tiempo considerablemente menor para realizar los cálculos en
contraste con las herramientas de optimización, que demandan mayores recursos computacionales.
Para una mayor comprensión por parte del lector se explicará la aplicación de la metodología propuesta en las siguientes
fases: Primero se realizará una ampliación de la situación que generó la construcción y aplicación del heurístico,
mostrando a su vez el entorno en que se da la manipulación de inventario en proceso y en tránsito; como segundo punto
se clasifican los productos hortofrutícolas, en esta etapa se describirán los factores que afectan los inventarios
anteriormente mencionados y su apreciación dentro del heurístico; tercero, se presentará un algoritmo de formación de
clusters, aquí se muestra a través de un paso a paso el funcionamiento de la estrategia metodológica construida para la
solución del problema, además de denotar cada uno de los elementos que la componen; cuarto, se muestra un caso de
estudio, en el que se ilustra el desarrollo del algoritmo dentro del contexto de investigación atribuido a una empresa
comercializadora de productos hortofrutícolas de Colombia en la región norte del departamento del Valle del Cauca;
quinto, análisis de resultados obtenidos en el desarrollo del caso de estudio; sexto y último las conclusiones referentes al
desarrollo de la investigación.
1. Problemas dentro de la cadena de abastecimiento
En los países tropicales como Colombia, el almacenamiento de frutas y hortalizas se realiza como respuesta a las
condiciones coyunturales de oferta y demanda. Aunque algunas veces es resultado de un análisis estructural de la
situación internacional, buscando conservar el producto en función de las “ventanas de mercado” por algunas semanas,
el almacenamiento casi siempre se realiza para garantizar el suministro permanente de materia prima al área de proceso
de la empresa comercializadora. Las condiciones del clima, la concentración de la producción en épocas de cosecha, la
incidencia de plagas y enfermedades así como el hecho de que la producción de frutas y hortalizas, no se realiza de manera
programada en muchas Pymes del sector agroindustrial, considerándose estos factores como las causas de variabilidad
del volumen de producto producido; al mismo tiempo el producto es afectado por elementos físico-químicos que
intervienen en el estado de maduración de una fruta u hortaliza, esto quiere decir que la condición de maduración de los
ítems hortofrutícolas garantiza la venta total de los volúmenes producidos y al mismo tiempo diversifica la unidad de
negocio, dado a que hay un estado de maduración que cada cliente acepta según su contexto y criticidad del producto,
por esta razón la labor de mantenerlo en buenas condiciones es una tarea de supervisión compleja que requiere de un
monitoreo constante en los procesos de Postcosecha y despacho del producto al cliente. Según informes de la
Organización de las Naciones Unidas para la alimentación y la Agricultura (FAO) muestra las pérdidas post-cosecha en
una variación entre 25 a 50% de productos frescos [4], justificando la construcción y aplicación de un método
organizacional en el manejo de inventario, para la clasificación y agrupación de producto, especialmente en este sector
económico.
CLAIO-2016
568

2. Clasificación de productos hortofrutícolas y algoritmo de formación de clusters.
2.1 Clasificación de productos hortofrutícolas
Clasificar los ítems resulta una tarea de apoyo en la gestión de productos perecederos, ya que existen múltiples factores
que afectan de manera positiva y/o negativa en el aprovisionamiento, la gestión eficiente del inventario, el transporte y
almacenamiento adecuado del cliente. Cada grupo conformado se podrá enfocar en las necesidades de los productos
pertenecientes a él [1]. Es viable establecer una metodología para la integración de grupos (clusters) de productos
hortofrutícolas, desde una visión de la manufactura celular, extrapolada al sector de bienes primarios, como lo es el caso
de las frutas y hortalizas frescas. Esta metodología actúa de manera consecuente a la premisa en aplicación de la filosofía
de tecnología de grupos, la cual plantea que “cosas parecidas deberían de ser fabricadas de manera parecida”.
Para los almacenes de cadena se tienen valores estandarizados: Se exige un porcentaje de maduración mínimo del 30%
y que no exceda el 50%, con un peso bruto en canastilla de 12kg y en guacal de 10kg (unidades de comercialización). La
apariencia física debe tener un máximo de 10% de imperfecciones y de forma redonda, sin ninguna señal de agentes
externos.
Para las plazas de mercado se selecciona productos como la papaya con pesos alrededor de los 1100 gr en calidad
corriente, con una variedad de forma entre redonda y larga, y un porcentaje de maduración de máximo 63%, pues es
donde la papaya contiene mayor nivel de azucares y es apetecida en la plaza por estas características, ya que son para
consumo inmediatos. El peso máximo en canastilla está entre 12.5kg y 14 kg. La calidad jugosa requiere frutas de un
peso aproximado a los 900gr, las cuales son distribuidas en la canastilla hasta alcanzar la capacidad máxima de espacio,
no hay mucha exigencia en cuanto a las características físicas del fruto.
En general, los factores que pueden llegar a alterar los productos en comparación a los estándares del mercado se deben
a: El daño mecánico, la ventilación de la fruta, la Temperatura, enfermedades que pueda llegar a sufrir el producto,
Agentes de maduración, entre otros. Bajo una apreciación en el entorno de las Pymes, los factores de mayor impacto en
el cambio del estado físico de la fruta son: El daño mecánico y los agentes de maduración. Factores que pueden llegar a
ser controlados considerablemente en las organizaciones, si se posee un adecuado proceso de clasificación y agrupación.
Es por esto que el agrupamiento de frutas y hortalizas se enfatiza en la condición de maduración de estos productos,
siguiendo los fundamentos la manufactura celular, por lo tanto se debe identificar la dependencia de tal condición y el
efecto generado al juntar un producto con otro.
Agentes de maduración: El etileno es el principal agente inductor de la maduración de frutas y hortalizas, y puede causar
la maduración prematura de algunos productos o arruinar otros. Nunca se deben transportar o almacenar frutas y verduras
que producen bastante etileno con productos que son sensibles al mismo, algunos de ellos se encuentran en la tabla 1.
CLAIO-2016
569
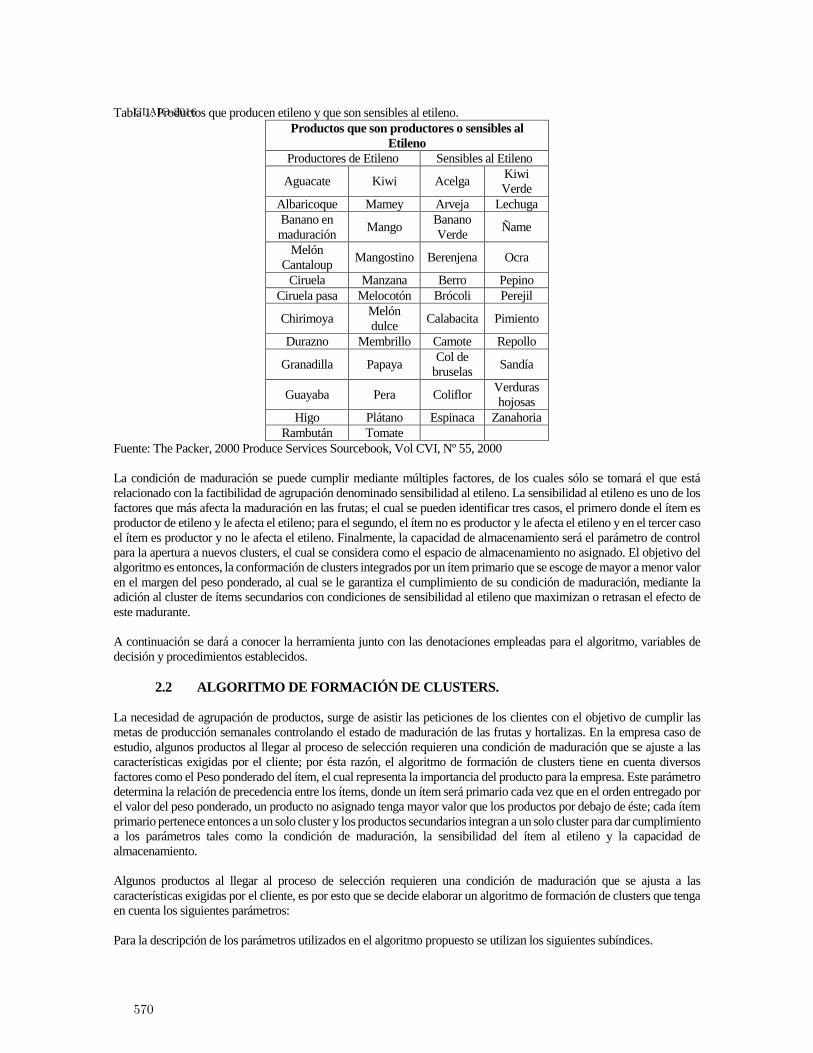
Tabla 1. Productos que producen etileno y que son sensibles al etileno.
Productos que son productores o sensibles al
Etileno
Productores de Etileno Sensibles al Etileno
Aguacate Kiwi Acelga Kiwi
Verde
Albaricoque Mamey Arveja Lechuga
Banano en
maduración Mango
Banano
Verde Ñame
Melón
Cantaloup Mangostino Berenjena Ocra
Ciruela Manzana Berro Pepino
Ciruela pasa Melocotón Brócoli Perejil
Chirimoya Melón
dulce Calabacita Pimiento
Durazno Membrillo Camote Repollo
Granadilla Papaya Col de
bruselas Sandía
Guayaba Pera Coliflor Verduras
hojosas
Higo Plátano Espinaca Zanahoria
Rambután Tomate
Fuente: The Packer, 2000 Produce Services Sourcebook, Vol CVI, Nº 55, 2000
La condición de maduración se puede cumplir mediante múltiples factores, de los cuales sólo se tomará el que está
relacionado con la factibilidad de agrupación denominado sensibilidad al etileno. La sensibilidad al etileno es uno de los
factores que más afecta la maduración en las frutas; el cual se pueden identificar tres casos, el primero donde el ítem es
productor de etileno y le afecta el etileno; para el segundo, el ítem no es productor y le afecta el etileno y en el tercer caso
el ítem es productor y no le afecta el etileno. Finalmente, la capacidad de almacenamiento será el parámetro de control
para la apertura a nuevos clusters, el cual se considera como el espacio de almacenamiento no asignado. El objetivo del
algoritmo es entonces, la conformación de clusters integrados por un ítem primario que se escoge de mayor a menor valor
en el margen del peso ponderado, al cual se le garantiza el cumplimiento de su condición de maduración, mediante la
adición al cluster de ítems secundarios con condiciones de sensibilidad al etileno que maximizan o retrasan el efecto de
este madurante.
A continuación se dará a conocer la herramienta junto con las denotaciones empleadas para el algoritmo, variables de
decisión y procedimientos establecidos.
2.2 ALGORITMO DE FORMACIÓN DE CLUSTERS.
La necesidad de agrupación de productos, surge de asistir las peticiones de los clientes con el objetivo de cumplir las
metas de producción semanales controlando el estado de maduración de las frutas y hortalizas. En la empresa caso de
estudio, algunos productos al llegar al proceso de selección requieren una condición de maduración que se ajuste a las
características exigidas por el cliente; por ésta razón, el algoritmo de formación de clusters tiene en cuenta diversos
factores como el Peso ponderado del ítem, el cual representa la importancia del producto para la empresa. Este parámetro
determina la relación de precedencia entre los ítems, donde un ítem será primario cada vez que en el orden entregado por
el valor del peso ponderado, un producto no asignado tenga mayor valor que los productos por debajo de éste; cada ítem
primario pertenece entonces a un solo cluster y los productos secundarios integran a un solo cluster para dar cumplimiento
a los parámetros tales como la condición de maduración, la sensibilidad del ítem al etileno y la capacidad de
almacenamiento.
Algunos productos al llegar al proceso de selección requieren una condición de maduración que se ajusta a las
características exigidas por el cliente, es por esto que se decide elaborar un algoritmo de formación de clusters que tenga
en cuenta los siguientes parámetros:
Para la descripción de los parámetros utilizados en el algoritmo propuesto se utilizan los siguientes subíndices.
CLAIO-2016
570

i: Este subíndice representa cada cluster creado.
j’: Existencia de un ítem primario.
j: Existencia de un ítem secundario.
Variables:
Qj’: Condición de maduración del ítem primario j’ del cluster Ci, es 1 si está activo para la iteración, 0 de lo contrario.
Qj: Condición de maduración del ítem secundario j del cluster Ci, es 1 si está activo para la iteración, 0 de lo contrario.
Condición de Maduración: Este es el punto crítico de control para las empresas que comercializan en este sector, es tenido
en cuenta durante todo el proceso desde la cosecha, postcosecha y recepción del producto por los clientes. El monitoreo
de este factor, conlleva dos tipos de necesidades, aumentar la maduración o por el contrario mantener la maduración,
logrando el objetivo de estabilizar los valores de maduración esperados. La condición de maduración se puede cumplir
mediante múltiples factores, de los cuales sólo se tomará el que está relacionado con la factibilidad de agrupación
denominado sensibilidad al etileno.
Sj’: Sensibilidad al etileno, 1 si garantiza que la condición Qj se cumpla, 0 de lo contrario.
Sensibilidad al etileno: El etileno es uno de los factores que más afecta la maduración en las frutas [2]; pueden existir
entonces tres casos, el primero donde el ítem es productor de etileno y le afecta el etileno, para el segundo el ítem no es
productor y le afecta el etileno, y en el tercer caso el ítem es productor y no le afecta el etileno. Esta característica es
seleccionada por tener componentes de estudio fuertemente desarrolladas, y una razón de peso adicional, es que en el
ámbito de las PyMES por condiciones de alta inversión no es posible acceder a almacenamientos con atmósferas
controladas y lo mínimo que se puede garantizar es una organización que permita la mínima afección por el madurante
etileno.
Ci: Cluster integrado por el ítem j’ que cumple con la condición Qj’ garantizada por el factor de sensibilidad al etileno Sj
y que cumple con el límite de almacenamiento:
Kij’: Espacio de almacenamiento asignable al cluster i para el ítem primario j’.
Kij: Espacio de almacenamiento asignable al cluster i, integrado por ítems secundarios j.
Una vez realizada la descripción de los subíndices, se detallan a continuación los parámetros y Condiciones que debe
cumplir la solución:
ε: Capacidad de la Bodega.
El valor inicial de la capacidad del a bodega ε(0) se determina considerando los valores estandarizados de peso de la
estantería fija-móvil (canastilla) y el área de almacenamiento que en la práctica es un volumen; al dividir el volumen del
almacenamiento disponible por el volumen ocupado por una canastilla, se obtiene el número de canastillas máximo a
disponer y como cada una de ellas posee un peso estandarizado, este valor se multiplica por dicho peso; esta restricción
de capacidad viene dada por las dos clases de inventario manejados por las empresas del tipo fruver fresco, los cuales son
inventarios en proceso y en tránsito.
τi: Carga total asignada en el cluster i.
α: Parámetro de control, espacio o capacidad no asignada en bodega.
Capacidad de almacenamiento: Este factor será el parámetro de control para la apertura a nuevos clusters [3], se
considera como el espacio de almacenamiento no asignado. El espacio de almacenamiento se verá reducido en un
valor
∝= 𝜀 − ∑ 𝜏𝑖𝑛𝑖 (1)
CLAIO-2016
571

Espacio de almacenamiento asignable al cluster i: Esta condición establece que la sumatoria de las cargas atribuidas
a los clusters deben ser menores o iguales a la capacidad de la bodega.
∑ τ𝑖 ≤
𝑛
𝑖=1
ε (2)
Límite de almacenamiento para clusters: compete lógica de poseer una sumatoria de los espacios de
almacenamientos asignables para los ítems primarios y secundarios menor o igual a la carga a la carga total asignada
a cada cluster
𝑲𝑖𝑗′ + ∑ k𝑖𝑗 ≤
𝑛
𝑗≠𝑗′
τ𝑖 (3)
Pj’: Ponderación obtenida del producto de la participación en fracción de los ingresos brutos multiplicado por el valor de
la escala que representa la fracción en volumen para el ítem j’.
Donde, Pj’ = 𝐴𝑗′ × 𝑉𝑗′ (4), donde Aj’ representa la calificación que mide la importancia del ítem respecto a su
participación porcentual en el peso total durante un horizonte de tiempo [7]. Vj’ es la fracción de participación de las
ventas del ítem respecto a las ventas totales durante el mismo horizonte de estudio.
Pj: Ponderación obtenida del producto de la participación en fracción de los ingresos brutos multiplicado por el valor de
la escala que representa la fracción en volumen para los ítems j.
Donde, Pj = 𝐴𝑗 × 𝑉𝑗 (5), donde Aj representa la calificación que mide la importancia del ítem respecto a su participación
porcentual en el peso total durante un horizonte de tiempo. Vj es la fracción de participación de las ventas del ítem respecto
a las ventas totales durante el mismo horizonte de estudio.
Peso ponderado del ítem: Esta variable se genera como resultado de la multiplicación del porcentaje de ingresos
brutos de cada ítem, por un valor dentro de una escala normalizada de 1 a 4, que representa la importancia del
producto para la organización, esta escala puede apreciarse en la tabla 2. La importancia del producto para la empresa
es determinante, ya que este tipo de empresas buscan impulsar y fortalecerse en ciertas líneas de productos y
reconocerse por ellos. Este parámetro es quien dictamina la relación de precedencia entre los ítems, un ítem será
primario (j’) cada vez que en el orden entregado por el valor del peso ponderado, un producto no asignado tenga
mayor valor que los productos por debajo de él, no asignados (j); cada ítem primario pertenece a un solo cluster por
vez y los productos secundarios integran a un solo cluster para dar cumplimiento a los parámetros definidos [10].
Tabla 2.
Escala de referencia importancia de productos
Fuente: Autores
El objetivo del algoritmo es la conformación de clusters integrados por un ítem primario que se escoge de mayor a menor
valor en el margen del peso ponderado Pj, al cual se le garantiza el cumplimiento de su condición de maduración Qj’,
mediante la adición al cluster de ítems secundarios con condiciones de sensibilidad al etileno Sj, que maximizan o retrasan
el efecto de este madurante, utilizando los siguientes pasos:
Paso 0: Ordenar los datos de acuerdo al peso ponderado de participación Pj de manera descendiente; este ejercicio puede
ser respaldado por el análisis en la clasificación ABC según la participación en ventas o volumen producido, como puede
apreciarse en la tabla 3.
CONCEPTO VALORES PARTICIPACIÓN
Muy Importante 4 50% - 100%
Por encima de la Media 3 4,5% - 49,9%
Por debajo de la Medio 2 1,2% - 4,4%
Importancia Baja 1 0% - 1,19%
CLAIO-2016
572

Tabla 3.
Aplicación del paso 0 para el peso ponderado Pm.
Fuente: Autores.
Paso 1: Seleccionar el ítem de la primera posición Pj de los ítems j no asignados y activar su condición de maduración
Qj’ y Qj con el valor de 1, de lo contrario el valor de 0. [11]
Paso 2: Si el espacio de almacenamiento requerido Kij’ por el ítem primario Pj no es superior a τ, inaugure un nuevo
cluster Ci.
Paso 3: Activar la condición de sensibilidad Sj con el valor de 1, para los ítems j que garantiza el cumplimiento de la
condición Qj’; 0 de lo contrario. A su vez activar las condiciones de maduración Qj de los ítems secundarios viables para
integrar al cluster Ci.
Paso 4: Si la condición Qj’ del primer ítem primario j’ (j’1) es 1, ingrese al cluster Ci el primer ítem secundario j (j1) con
el peso ponderado Pj menor con el valor de Sj igual a 1, cumpliendo la restricción (1). De no cumplirse alguna de las
condiciones pasar al paso 5.
Paso 5: Cerrar el cluster Ci cuando se agreguen todo los ítems que cumplen con Sj igual a 1, de peso ponderado Pj de
menor a mayor, siempre que se cumpla la restricción (2). Si aún existen productos sin asignar, continuar con el siguiente
paso, de lo contrario se da por concluida la asignación de los clusters.
Paso 6: Inaugurar un nuevo cluster Ci cada vez que no existan opciones de agrupación de acuerdo al Sj habilitado por la
condición Qj’, del peso ponderado Pj, del ítem no agrupado j y respetando las restricciones de capacidad (1) y (2), repetir
la sucesión de pasos, hasta asignar la totalidad de ítems.
3. CASO DE ESTUDIO
En este caso se aborda el problema de la correcta asignación de productos perecederos para una empresa del sector
agrícola, que tiene como objetivo mejorar las condiciones de almacenamiento dentro del área de producto en proceso
para evitar efectos no deseados en su punto crítico de control, estimado como maduración.
La empresa manipula en la actualidad 8 productos, de los cuales dos de ellos surgen debido a los procesos de selección
en Postcosecha bajo el mismo insumo, refiriéndose a los ítems papaya selecta y papaya corriente, el primero en mención
es considerado como el producto estrella, debido al estudio de clasificación ABC lo ubica como el producto más
representativo en ingresos brutos, y la estrategia del nicho manejada para este ítem, aporta una característica de
especialización dentro del mercado de producción y comercialización de este. Para los otros productos se obtiene una
menor importancia ya que están comenzando la penetración de mercado.
La organización apropiada para el transporte y almacenamiento de frutas y hortalizas frescas, no se puede definir desde
la concepción de almacenamiento como provisión para futuras ventas, puesto que, para el caso de estudio, esta figura
ocurre en momentos que para la cadena de abastecimiento se definen como:
Inventario en tránsito: Es aquel flujo de materia, producto semi-terminado, o producto terminado que deberá trasladarse
a través de un medio de transporte como entrega de un proveedor a un cliente o puede considerarse cuando ocurre un
Promedio
AnualValor Ponderado (Pm)
Papaya Selec 61,11% 4 2,444
Papaya Cte 27,91% 3 0,837
Pimentón Selec 4,81% 2 0,096
Pimentón Colores 2,31% 3 0,069
Melón Cantalup 1,27% 2 0,025
Melón Caribean 1,11% 1 0,011
Berenjena 0,74% 2 0,015
Maracuyá 0,74% 1 0,007
100% 3,506
ítemsCLASIFICACIÓN ABC
CLAIO-2016
573

desplazamiento de material entre estaciones de trabajo, este a su vez es una medida de efectividad con base en el tiempo
de transporte del stock. [6]
Inventario en proceso: Son existencias que se tienen a medida que se añade mano de obra, otros materiales y de más
costos indirectos a la materia prima bruta, la que se llegará a conformar ya sea un sub.-ensamble o componente de un
producto terminado; mientras no concluya su proceso de fabricación, ha de ser inventarios en procesos.
Estos dos sistemas resumen el valor que puede tomar la variable ε, con el valor máximo de almacenamiento ya que sea
del espacio de inventario en proceso, o del vehículo que transporta el producto terminado para su entrega. A continuación
se aplican los diferentes pasos definidos en el algoritmo para el caso estudiado.
Paso 1: Se activa la condición de maduración Qj’ con el valor de 1, del primer ítem (Papaya Selecta), obtenido de la
ponderación Pj, al resto de ítems se les desactiva su factor con el valor de 0. En la tabla 4 se muestra el paso iterativo.
Tabla 4.
Paso 1 – Iteración 1.
Fuente: Autores.
Paso 2: Se inaugura el nuevo cluster C1, integrado por el ítem Papaya selecta cuya capacidad requerida para almacenarse
Kij’ es igual a 8.120 kg, siendo un valor menor al espacio disponible ε de 19.600 kg; por lo tanto el parámetro de control
α es 11.480. En la tabla 5 se presenta el resumen de los parámetros y la asignación del primer cluster. Cabe mencionar
que para el caso τ = ε puesto que no se tendrá estimada un volumen por cluster en el inicio del estudio.
Tabla 5.
Paso 2 Iteración 1
Fuente: Autores.
Paso 3: Se activa la condición de sensibilidad Sj con el valor de 1, para los ítems j que garantiza el cumplimiento de la
condición Qj’, para la iteración 1 estos son Pimentón Selecto y Berenjena; el valor de cero desactiva los otros ítems. A su
Aumentar Mantener
Papaya Selec 0 1 1
Papaya Cte 0 0
Pimentón Selec 0 0
Pimentón Colores 0 0
Melón Cantalup 0 0
Melón Caribean 0 0
Maracuyá 0 0
Berenjena 0 0
CASOS DE MADURACIÓN (Qm)Iteraciónítems
Papaya Selec
Papaya Cte
Pimentón Selec
Pimentón Colores
Melón Cantalup
Melón Caribean
Maracuyá
Berenjena
ítems
CLAIO-2016
574
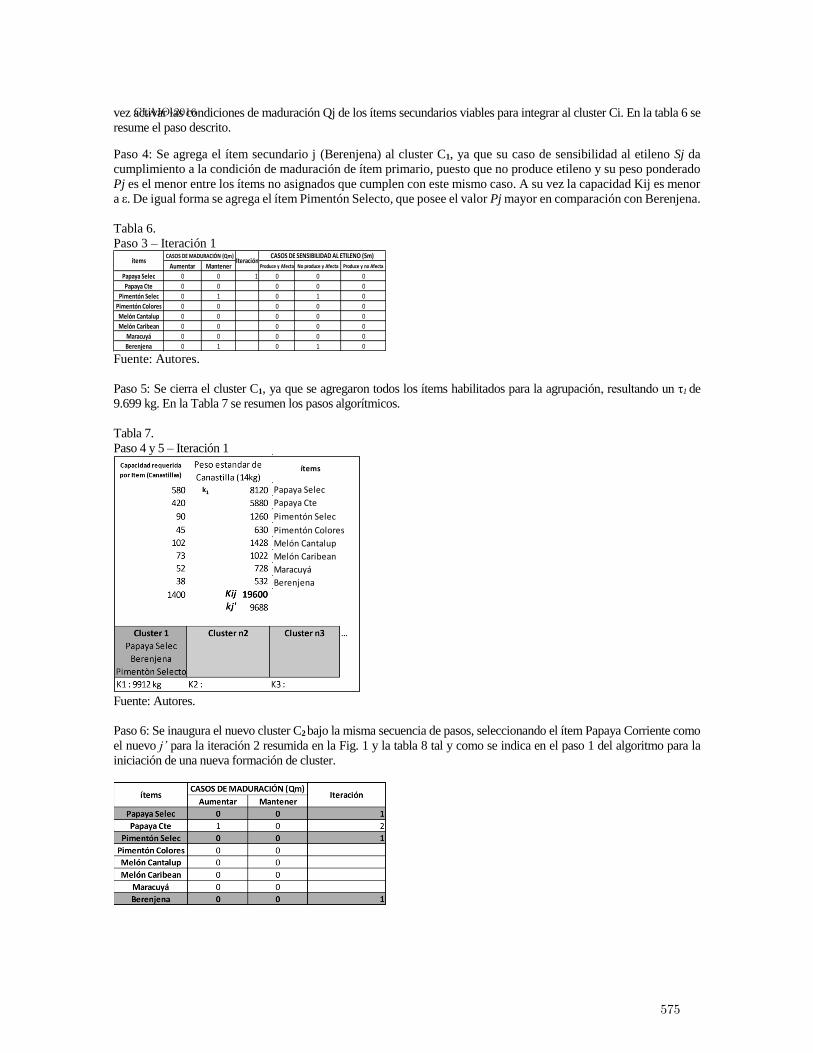
vez activar las condiciones de maduración Qj de los ítems secundarios viables para integrar al cluster Ci. En la tabla 6 se
resume el paso descrito.
Paso 4: Se agrega el ítem secundario j (Berenjena) al cluster C1, ya que su caso de sensibilidad al etileno Sj da
cumplimiento a la condición de maduración de ítem primario, puesto que no produce etileno y su peso ponderado
Pj es el menor entre los ítems no asignados que cumplen con este mismo caso. A su vez la capacidad Kij es menor
a ε. De igual forma se agrega el ítem Pimentón Selecto, que posee el valor Pj mayor en comparación con Berenjena.
Tabla 6.
Paso 3 – Iteración 1
Fuente: Autores.
Paso 5: Se cierra el cluster C1, ya que se agregaron todos los ítems habilitados para la agrupación, resultando un τ1 de
9.699 kg. En la Tabla 7 se resumen los pasos algorítmicos.
Tabla 7.
Paso 4 y 5 – Iteración 1
Fuente: Autores.
Paso 6: Se inaugura el nuevo cluster C2 bajo la misma secuencia de pasos, seleccionando el ítem Papaya Corriente como
el nuevo j’ para la iteración 2 resumida en la Fig. 1 y la tabla 8 tal y como se indica en el paso 1 del algoritmo para la
iniciación de una nueva formación de cluster.
Aumentar Mantener Produce y Afecta No produce y Afecta Produce y no Afecta
Papaya Selec 0 0 1 0 0 0
Papaya Cte 0 0 0 0 0
Pimentón Selec 0 1 0 1 0
Pimentón Colores 0 0 0 0 0
Melón Cantalup 0 0 0 0 0
Melón Caribean 0 0 0 0 0
Maracuyá 0 0 0 0 0
Berenjena 0 1 0 1 0
CASOS DE SENSIBILIDAD AL ETILENO (Sm)ítems
CASOS DE MADURACIÓN (Qm)Iteración
Papaya Selec
Papaya Cte
Pimentón Selec
Pimentón Colores
Melón Cantalup
Melón Caribean
Maracuyá
Berenjena
ítems
CLAIO-2016
575
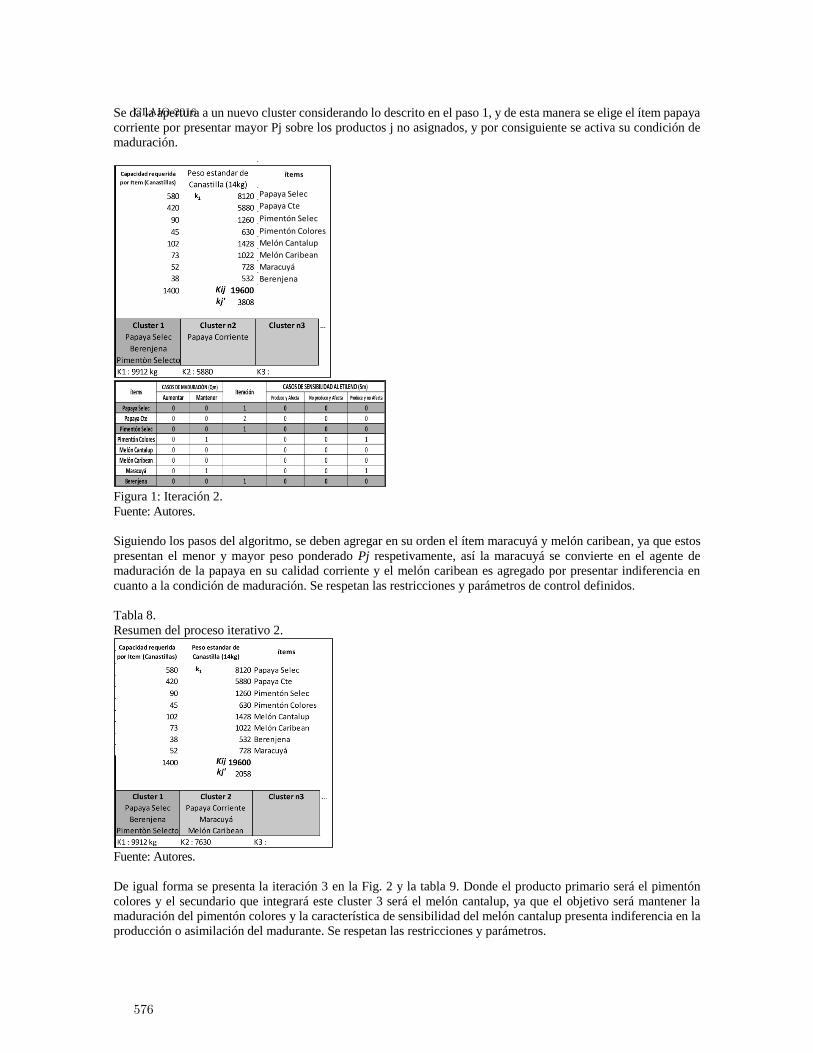
Se da la apertura a un nuevo cluster considerando lo descrito en el paso 1, y de esta manera se elige el ítem papaya
corriente por presentar mayor Pj sobre los productos j no asignados, y por consiguiente se activa su condición de
maduración.
Figura 1: Iteración 2.
Fuente: Autores.
Siguiendo los pasos del algoritmo, se deben agregar en su orden el ítem maracuyá y melón caribean, ya que estos
presentan el menor y mayor peso ponderado Pj respetivamente, así la maracuyá se convierte en el agente de
maduración de la papaya en su calidad corriente y el melón caribean es agregado por presentar indiferencia en
cuanto a la condición de maduración. Se respetan las restricciones y parámetros de control definidos.
Tabla 8.
Resumen del proceso iterativo 2.
Fuente: Autores.
De igual forma se presenta la iteración 3 en la Fig. 2 y la tabla 9. Donde el producto primario será el pimentón
colores y el secundario que integrará este cluster 3 será el melón cantalup, ya que el objetivo será mantener la
maduración del pimentón colores y la característica de sensibilidad del melón cantalup presenta indiferencia en la
producción o asimilación del madurante. Se respetan las restricciones y parámetros.
Papaya Selec
Papaya Cte
Pimentón Selec
Pimentón Colores
Melón Cantalup
Melón Caribean
Maracuyá
Berenjena
ítems
CLAIO-2016
576
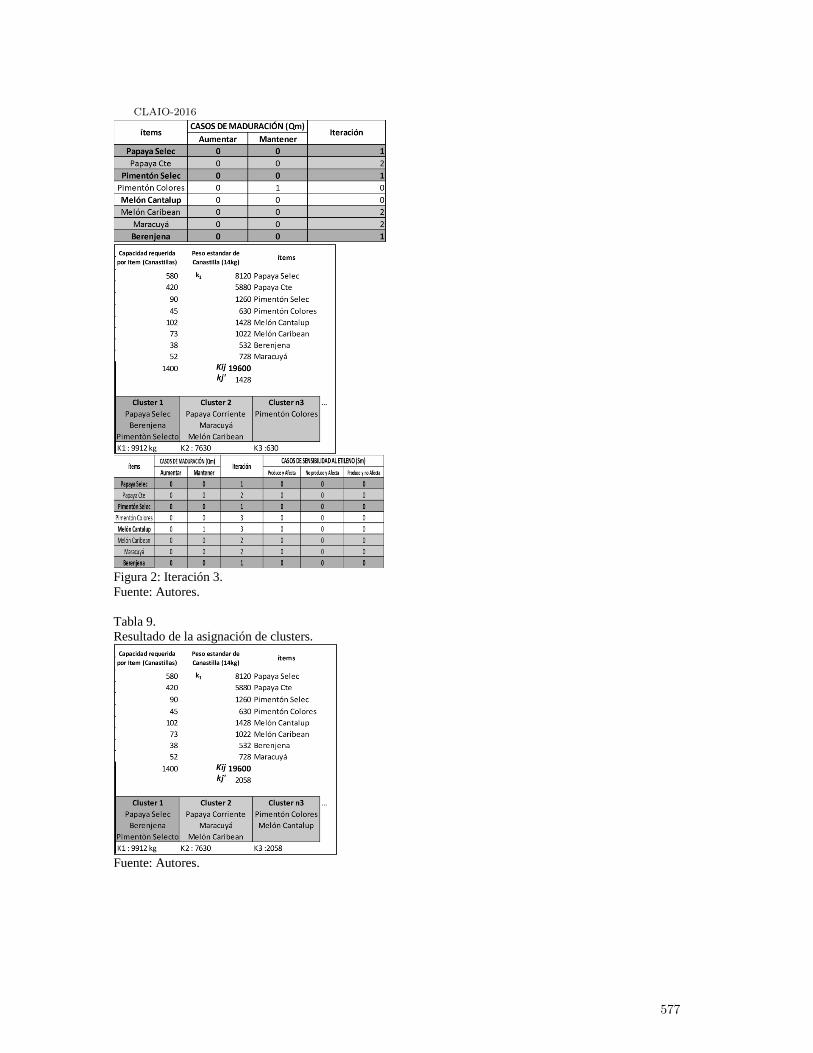
Figura 2: Iteración 3.
Fuente: Autores.
Tabla 9.
Resultado de la asignación de clusters.
Fuente: Autores.
CLAIO-2016
577

Como resultado de la aplicación del algoritmo se generan tres clusters, bajo el siguiente orden:
Cluster 1: Contiene los ítems Papaya Selecta, Berenjena y Pimentón Selecto.
Cluster 2: Formado por Papaya corriente, Maracuyá y Melón Caribean.
Cluster 3: Pimentón Colores y Melón Cantalup.
4. ANALISIS DE LOS RESULTADOS
Los grupos contienen varias características intrínsecas al proceso de su construcción, de las cuales se enuncian las
siguientes:
Son compatibles con el objetivo de preservación de las frutas y hortalizas en el manejo de inventario en proceso y
tránsito. Este factor de acopio de los productos ya procesados o en espera, brindan una ventaja comparativa frente al
negocio de las frutas y hortalizas frescas, ya que no será necesaria la aplicación de agentes madurantes, así como
preservantes o procesos de congelación que garanticen las condiciones en las que el cliente espera el producto.
Organización ideal de acuerdo a los grupos de compatibilidad establecidos en el manual de prácticas de manejo post-
cosecha de productos hortofrutícolas [5]
La flexibilidad en la estrategia de diferenciación aplicada: Sus unidades estratégicas de negocio se dividen según su
aporte en ingresos brutos, esto permite que a la vez que se le da un tratamiento adecuado a las frutas y hortalizas, su
propuesta de calidad natural se concreta.
A pesar de encontrar en este caso agrupaciones conformadas por dos o más ítems, existe la posibilidad de encontrar
la apertura y cierre de un cluster con un único ítem, según las condiciones que se puedan presentar al variar los
parámetros como numero de ítems, casos de sensibilidad al etileno y las condiciones de maduración exigidas por los
procesos, clientes o dinámica del mercado.
5. CONCLUSIONES
Se aplica el algoritmo para la conformación de unidades estratégicas flexibles, herramienta que contempla de
manera implícita los factores de almacenamiento y transporte, que responden a la pregunta: ¿Cómo ubicar de
manera correcta las materias primas o productos terminados para evitar su deterioro en el proceso de producción
y transporte? Los grupos de compatibilidad generados por el algoritmo, van más allá de sopesar al etileno como
factor de maduración, adicional a esta característica también plantea que debe existir una relación de precedencia
entre los productos que más incrementan los ingresos brutos, que de aquellos que poseen menor participación, esto
se da por la salvedad de que los productos ofrecidos pertenecen a los grupos de compatibilidad 5 y 6 (del análisis
de grupos de compatibilidad de la FAO), por esta razón, si el mix de producción es dividido en clusters que variarán
con la estrategia de mercadeo de la firma, esta adquirirá mayor flexibilidad, convirtiéndose en una ventaja
comparativa y cumpliendo en este orden con el segundo objetivo específico de clasificar las frutas y verduras
comercializadas para identificar las asociaciones entre las cadenas de cada producto.
Esta herramienta aumenta la posibilidad de contar con más ventajas competitivas en las Pymes del sector
agroindustrial o empresas que no posean un estado financiero que soporte la adquisición de sistemas de inventario
con refrigeración mecánica o atmosfera controlada para garantizar ciertos estados del producto sobre toda la cadena
de abastecimiento o parte de ella; esto se alcanza considerando variables críticas dentro de los procesos de
manipulación e inventariado de los productos hortofrutícolas.
Variables como la sensibilidad al etileno que permiten controlar cierto grado de maduración de estos productos.
Teniendo en cuenta que existen otros criterios que debe atender la empresa comercializadora del producto a la hora
de inventariar y manipular las frutas y hortalizas, condiciones como el daño físico, enfermedades y grados brix
fruta también deben tomarse encuentra para un análisis más complejo sobre la agrupación de los ítems para generar
mayor control sobre la maduración de los productos, y más sin embargo dado las capacidades de ajuste y
adherencia al caso de estudio puede decirse que este método puede llegar a emplearse como estrategia de negocios,
CLAIO-2016
578

debido a que cada grupo de ítems establecido denota cada condición de una posible unidad de negocio sustentable
según la participación en ventas de la organización, con la flexibilidad del conjunción de cada clusters a partir de
criterios como la sensibilidad al etileno.
El caso de estudio presentado, es un caso ideal, que tomo los valores de inventario en la rotación semanal de una
empresa comercializadora de frutas y hortalizas del norte del valle del cauca, Colombia. Estos valores se adecuaron
al espacio de almacenamiento manejado por la empresa para facilitar la ubicación ideal de los ítems, llenando todo
el espacio disponible. Asimismo los pesos estándares de canastilla fueron tomados de la empresa. Un estudio futuro
se puede proponer en torno a la agrupación ideal en los vehículos, allí se deberá estimar un control para cada εi que
corresponderá a los espacios de almacenamiento de cada automotor.
Al mostrar la ejecución del algoritmo dentro de la dimensión del inventario en proceso, se obtiene como resultado
una agrupación de ítems conforme a los objetivos del algoritmo, los cuales son preservar las condiciones de
maduración en los productos hortofrutícolas en los lugares donde se almacene y deposita, para su correcto manejo
y movilización consecuente para la venta a los clientes. Pero este es uno de los tantos escenarios que pueden
esquematizarse dentro del algoritmo, y las situaciones donde se requiere la asignación de espacios dentro de los
embarques o flotas de transporte del producto también es uno estos contextos, que puede llegar a ser extensión de
este trabajo con la finalidad de incluir otras restricciones referentes al espacio disponible para la agrupación y entre
otros elementos sustanciales para la ejecución y resultados del algoritmo.
REFERENCIAS
1. IRANI, S. Handbook of Cellular Manufacturing Systems. John Wiley & Sons, 1999.
2. CALVO et al., G. &. . Tendencias para la conservación de frutas de pepita. Redalyc, 2012.
3. MEDINA, P. e. Programming Problem of Operations and Tools in a Flexible Manufacturing System: Loading Heuristic Phase II. Scientia
Et Technica, 2008.
4. Manual para el mejoramiento del manejo poscosecha de frutas y hortalizas, OFICINA REGIONAL DE LA FAO PARA AMERICA LATINA
Y EL CARIBE, pag. 92, Chile, 1987.
5. KITINOJA LISA Y KADER ADELA. Manual de prácticas de manejo post-cosecha de productos hortofrutícolas a pequeña escala, de la
FAO (Organización de las naciones Unidas para la agricultura y la alimentación) [en línea] UNIVERSIDAD DE CALIFORNIA,
Departamento de Pomología SERIES DE HORTICULTURA POSTCOSECHA NO. 8S January, date of reference 1996 14th May 2015,
Cap. 4: http://www.fao.org/Wairdocs/X5403S/x5403s0a.htm
6. S.L. Narasimhan, D. M. Planeación de la producción y control de inventarios. 2da Edición, 1996.
7. SAATY, T. A scaling method for priorities in hierarchical structures. Journal of Mathematical Psychology, vol 15, pp. 234-281, 1977.
8. M. Bernasconi , C. Choirat and R. Seri, "The analytic hierarchy process and the theory of measurement", Manage Sci., vol. 56, pp. 699-
711, 2010.
9. Salas Bacalla, Julio; Leyva Caballero, Máximo; Calenzani Fiestas, Adolfo Modelo del proceso jerárquico análitico para optimizar la
localización de una planta industrial Industrial Data reference december 2014, Universidad Nacional Mayor de San Marcos, Perú, vol. 17,
núm. 2, pp. 112-119
10. Patrick T. Harker and L. G. Vargas, The theory of ratio scale estimation saaty’s analytic hierarchy process; - Management Science Vol.
33, pp. 2-6, 1987.
11. De la Fuente García, D. Pino Diez, R. Parreño Fernández, Formación de celdas trabajo-máquina en tecnología de grupos mediante redes
neuronales artificiales, Investigaciones Europeas, Vol. 1, N" 2, pp. 51-68, 1995.
12. MANUAL DE MANEJO POSTCOSECHA DE FRUTAS TROPICALES (Papaya, piña, plátano, cítricos), date reference 26th June
2007, cap. 2: http://www.fao.org/inpho/content/documents/vlibrary/ac304s/ac304s00.htm
13. Flórez O. Marín H. & Zapata J. Estudio de las practices de cosecha y poscosecha de la papaya (Carica papaya cv. Maradol), Revista de
investigación agraría y ambiental, pp. 29-36, 2009
14. A. Nouri Houshyar, Z. Leman, H. Pakzad Moghadam, R. Sulaiman, Review on cellular manufacturing system and its components,
International Journal of Engeering and Advanced Technology, pp. 52-55, 2014.
CLAIO-2016
579

15. A. GUNASEKARAN, S.K. GOYAL, I, VIRTANEN AND P. YLI-OLLI, An investigation into the application of group technology in
advance manufacturing systems, INT J. COMPUTER INTEGRATED MANUFACTURING, pp. 215-228, 1994
16. M. Murugan and V. Selladurai, Formation of Machine Cells/ Part Families in Cellular Manufacturing Systems Using an ART-Modified
Single Linkage Clustering Approach – A Comparative Study. Jordan Journal of Mechanical and Industrial Engineering, Volume 5, June
pp. 199 – 212, 2011.
17. Jainarine Bansee 1 , Boppana V. Chowdary 2, A New Concept of Cellular Manufacturing: A Case Study, Fifth LACCEI International
Latin American and Caribbean Conference for Engineering and Technology (LACCEI’2007) “Developing Entrepreneurial Engineers for
the Sustainable Growth of Latin America and the Caribbean: Education, Innovation, Technology and Practice” pp. 1-9, Tampico, México,
2007,
18. Dr V.Anbumalar* R.Mayandy K.Arun Prasath, Implementation and Selection of Optimum Layout Design in Cellular Manufacturing
for Process Industry –A Case Study, International Journal of Innovative Research in Advanced Engineering (IJIRAE) ISSN: 2349-2163
Volume 1 Issue 6 (July 2014)
19. Nomden, G., & Slomp, J., The applicability of cellular manufacturing techniques: an exploration in industry. In Proceedings of the third
international conference on group technology/cellular manufacturing, pp. 3-5, 2006.
20. Arauz, L. F., & Mora, D.. Evaluación preliminar de los problemas postcosecha en seis frutas tropicales de Costa Rica. Agronomía
Costarricense, 7(1/2), pp. 43-53, 1983.
CLAIO-2016
580

A reactionary operational model for the air cargo
schedule recovery under demand fluctuations
Julio MoraDepartment of Transport Engineering and Logistics
Pontificia Universidad Católica de Chile, [email protected]
Felipe Delgado BreinbauerDepartment of Transport Engineering and Logistics
Pontificia Universidad Católica de Chile, [email protected]
Abstract
In air cargo transportation, there is a high uncertainty in the demand to be carried indue to the following factors: i) There are a reduced number of clients who transport largevolumes of cargo; ii) Reservations are done in short time windows, which makes difficult tocorrectly estimate the supply of freighters to be provided; iii) Cargo booked to travel, in severaloccasions only arrives partially; iv) There are no economic penalties to clients for not showingup with the cargo or to the airline for leaving booked cargo behind. All these factors cause animbalance between the planned freighter supply and the demand. In this work, we formulatea mixed integer programming model that optimize the schedule adjustment by taking intoaccount the demand fluctuations at the moment of a flight departure and solved it using ahybrid metaheuristic. This formulation aims to maximize profits taking as starting point a pre-established schedule over which adjustment actions can be taken which affect crew assignmentand freighter maintenance the least possible. The results show that the proposed solutionalgorithm attained on average profits that are 10% higher and computational times that are86% faster than those obtained by traditional solver.
Keywords: Air Cargo Schedule recovery; Pickup and Delivery; Column Generation; GRASPmetaheuristic.
1 Introduction
In air cargo transportation, unlike passengers, there is a high uncertainty in the demand to becarried in each itinerary. This uncertainty is due to the following factors: i) There are a reducednumber of clients who transport large volumes of cargo. ii) Reservations are done in short timewindows, which makes it difficult to correctly estimate the supply of freighters to be provided. iii)Cargo booked to travel, in several occasions only arrives partially (NoShow), out of deadline or lastminute. iv) There are no economic penalties to clients for not showing up with the cargo or to theairline for leaving booked cargo behind.
CLAIO-2016
581

All these factors cause the demand, for which the freighter schedule is planned, to not take placein practice, causing an imbalance between the planned freighter supply and the demand. Thesedemand fluctuations which are difficult to anticipate, usually occur a few hours before closing aflight, causing a significant number of freighters traveling with low Load Factors (LF) generatingloses to the airline.
To tackle this problem, airlines make last minute manual adjustments to the schedule based onthe decision-makers experience. These changes are adjustment actions such as flight cancellation,re-routing and re-timing. These actions are corrective, reactionary and local in nature, not seekingto build a schedule again from scratch. The goal of making minor local corrections lies in tryingto affect the least possible the already assigned crew. However, these solutions are generally sub-optimal which directly affect the costs of the company.
In this work we formulate and solve a mixed integer programming model that optimize theschedule adjustment by taking into account the demand fluctuations at the moment of a flightdeparture. This formulation aims to maximize profits taking as starting point a pre-establishedschedule over which adjustment actions can be taken which affect crew assignment and freightermaintenance the least possible.
2 Literature Review
The problem of schedule design and planning in the airline industry has been mainly based onthe passenger market [1, 2, 3, 4, 5]. However, the literature regarding freighter schedule planningand operation is limited. Derigs et al [6] address the problem of incremental freighter scheduledesign, where the authors try to improve a base schedule by modifying certain flights. Derigs andFriederichs [7] extend the same problem by considering a set of mandatory flights and others thatare not. Yan et al [8] formulate a model that integrates the schedule design and fleet assignmentfor freighters. The underlying model is a multi commodity flow problem that integrates a flightnetwork with a cargo request network. Their results show that the model can be solved in a limitedamount of time, so the authors claim that it can be used for operational purpose. However, theydo not consider some important operational constraint such as crews and additional cost due tochanges to the planned schedule.
From the above, it can be observed that the problem of last minute adjustments to counteractdisruptions starting from a pre-established base schedule has not been addressed in the literature.This problem has some special features where decisions must be taken shortly before departurewhen crew members have already been assigned. The actions to be carried out must be such thatthey affect the least possible the process of crew scheduling and freighter maintenance.
3 Methodology
The problem is formulated as a Pickup and Delivery problem with time windows [9, 10, 11] withadditional constraints for air cargo transport. In our formulation, each node represents an eventthat has associated a specific airport and time window. These events are: departure or landing ofa flight and loading or unloading of cargo request. Thereby, a request is defined by a pickup nodewhere the cargo request is loaded and a delivery node where it is unloaded. The objective of themodel is to maximize profits while affecting the least possible the original schedule. The decision
CLAIO-2016
582

variables determine which freighter to assign to each link, the arrival time to each node and thefreighter load departing each node.
To solve the problem we use Dantzig-Wolfe decomposition [12], where each sub problem repre-sents a pick up and delivery problem for a single freighter. Then the relaxed master problem andthe sub problems are solved by mean of column generation [13].
Given that each sub problem is NP-Hard a GRASP metaheuristic [14, 15] is used.
4 Preliminary Results and Conclusions
The algorithm was coded in Python and Gurobi 5.6.0 is used to solve it. The numerical test wasconducted in a 4 core Intel(R) Core (TM) i5-3210M, 2.5 GHz with 8 GB of RAM.
An instance based on real data was constructed to test the model. We consider a planninghorizon of 3 days. The network has 4 freighters B777 each with a capacity of 100 ton. Eachfreighter has a starting and a destination airport where they have to be at the end of the planninghorizon.
The base schedule of this network consists of 32 flights visiting a total of 16 airports. The totaldemand carried is 995 tons. To perturb the initial schedule we consider 15 new cargo requests thatadds a new airport to be visited, roughly a 30% increase in the total demand to be carried.
To test our solution approach we have compared our results against those obtained by thetraditional branch and bound methodology applied by Gurobi solver. Since the model must beused for operational purposes where decisions must be taken in short periods of time, we set a timelimit for both GRASP and MIP of one hour. During this time the proposed GRASP metaheuristiccan execute several runs. We consider two different scenarios: i)All, where all legs in the baseschedule have the same cancellation costs and ii) Priority, where we distinguish two different setof legs with and without cancellation costs.
Our preliminary results show that the proposed solution algorithm attained profits that onaverage are 10% higher and computational times that are on average 86% faster than those obtainedby traditional solver.
The results show the potential that the proposed model has to be used in the daily operationwhere solutions must be obtained in short periods of time. In order to solve larger instances, theauthors are working in improving the heuristic used in the GRASP metaheuristic and parallelizingcomputational tasks.
Acknowledgements
We acknowledge the support of the Chilean Fund for Scientific and Technological Development(FONDECYT) through Project 11140436. The author Felipe Delgado would like to acknowledgethe University of New South Wales for allowing access to the various facilities during his stay as avisiting professor at the School of Aviation.
References
[1] J. Abara Applying integer linear programming to the fleet assignment problem Interfaces,19:20–28, 1989.
CLAIO-2016
583

[2] B. Rexing, C., Barnhart, T. Kniker, A. Jarrah and N. Krishnamurthy Airline Fleet Assignmentwith Time Windows, Transportation Science, 34: 1–20, 2000.
[3] C. Barnhart, P. Belobaba and A. Odoni. Applications of Operations Research in the AirTransport Industry. Transportation Science, 37(4): 307-324, 2003.
[4] M. Lohatepanont and C. Barnhart. Airline Schedule Planning: Integrated Models and Al-gorithms for Schedule Design and Fleet Assignment. Transportation Science, 38(1): 19-32,2004.
[5] G. Froyland, S. Maher and C.L. Wu. The recoverable robust tail assignment problem Therecoverable robust tail assignment problem, 48(3):351–372,2013.
[6] U. Derigs, S. Friederichs and S. Schfer. A New Approach for Air Cargo Network Planning.Transportation Science, 43(3): 370-380, 2009.
[7] U. Derigs and S. Friederichs. Air cargo scheduling: integrated models and solution procedures.OR Spectrum, 35(2): 325-362, 2012.
[8] S. Yan, S.-C. Chen and C.-H. Chen. Air cargo fleet routing and timetable setting with multipleon-time demands. Transportation Research Part E: Logistics and Transportation Review, 42(5):409-430, 2006.
[9] Y. Dumas, J. Desrosiers and F. Soumis. The pickup and delivery problem with time windowsEuropean Journal of Operational Research, 54: 7-22, 1991.
[10] JF. Cordeau, G. Desaulniers, J. Desrosiers, MM. Solomon, F. Soumis VRP with time windows.In: P. Toth and D. Vigo, editors The Vehicle Routing Problem. SIAM, Philadelphia, PA, SIAMMonographs on Discrete Mathematics and Applications, 9:175-193, 2002.
[11] S.N. Parragh, K.F. Doerner and R.F. Hartl. A survey on pickup and delivery problems. JournalFr Betriebswirtschaft,58(1): 21-51, 2008.
[12] G.B. Dantzig and P. Wolfe. Decomposition Principle for Linear Programs. Operations Re-search, 8(1): 101–111, 1960.
[13] C. Barnhart, E.L. Johnson, G.L. Nemhauser, M.W.P. Salvelsbergh and P.H. Vance. Branch-and-Price: Column generation for solving huge integer programs. Operations Research, 46:316–329, 1998.
[14] T. Feo and M. Resende. Greedy Randomized Adaptive Search Procedures. Journal of GlobalOptimization, 6(2):109-133,1995.
[15] M. Talebian and M. Salari. A GRASP algorithm for a humanitarian relief transportationproblem. Engineering Applications of Artificial Intelligence, 41: 259-269, 2015.
CLAIO-2016
584

Efficiency assessment of DotA 2 competitive teams using Network
Data Envelopment Analysis
Mateus de Paula Nascimento
Universidade Federal Fluminense, Brazil
Rachel Farias Magalhães
Universidade Federal Fluminense, Brazil
Lidia Angulo-Meza
Universidade Federal Fluminense, Brazil
Abstract
This paper proposes the use of a Network DEA (NDEA) model to evaluate the efficiency of 16
professional teams of Defense of the Ancients 2 (known as DotA 2). The data used in this paper is from
the World Championship organized by Valve in August 2015 at the city of Seattle. The NDEA approach
in opposition to the standard DEA is more suitable to the configuration of the teams since it performs
divisional interactions, the estimated efficiency produced is more representative of the process. Besides
the efficiency index, which is used to establish a ranking, both efficiency and inefficiency sources among
the teams separated are identified and analyzed. Subsequently, with the aims to reduce the benevolent
nature of DEA models, the inverted frontier is used and a composed efficiency index is calculated taking
into account both NDEA efficiency indexes and the inverted frontier.
Keywords: Network DEA, efficiency, inverted frontier, DotA 2.
1. Introduction
In an increasingly cyber and electronic world, the "real" life is being replaced by the "virtual" life
where people allocate large periods of their time in an imaginary world, on what they cease to be who
they are to become characters, or rather the heroes they have chosen.
Online games based on the Multiplayer Online Battle Arena (MOBA) system attract many
individuals of different age groups, especially young people between 18 and 25 years (Arantes; Gomes,
2013). In the United States of America several studies and analysis are being developed on this subject,
that indeed the DFC Intelligence (2012) - American Institute of Statistics - reported that in 2012 the
League of Legends (LOL) was the game the users most spent hours in front of monitors, exceeding one
billion and two hundred thousand hours of playing.
In the same path, tracks one of the main games of this style which has grown around the world
known as DotA 2 (Defense of the Ancients 2). DotA 2 has conquered so many young people players in
the world, that in 2011, Valve (DotA 2 production company) started a world championship that each year
takes place in a different city, and in 2015 the prize broke all records for the best team totalizing
CLAIO-2016
585

approximately in eighteen million dollars. As it is expected, teams take a lot of effort in improving their
performances every year, defining strategies and identifying sources of potential improvements and the
overall evaluation of their teams.
Data Envelopment Analysis – DEA (Charnes; Cooper; Rhodes, 1978) has been implemented in
different studies in a wide variety of subjects due to the ease of characterizing the production units, called
decision making units (DMUs), as efficient or inefficient based on a comparison. In addition, it identifies
the aspects or characteristics that can be improved at the process being analyzed. However, to the best of
our knowledge DEA has not been used to measure the efficiency of online games teams on MOBA.
Therefore, this study aims to assess the efficiency of 16 teams that competed at the last autumn
championship, organized by Valve in August 2015 in Seattle, using a Network DEA (NDEA) approach.
Later, as DEA models are benevolent in nature, an additional technique, the inverted frontier, is used in
order to take into account also the least satisfactory features of every team, this way getting a better
restriction of benchmarks for each player position.
This paper is structured in the following order: section 2 presents the base theory regarding DEA,
the models and a brief understanding of network DEA and inverted frontier. Section 3 presents a
description of DotA 2. Section 4 shows the development using the NDEA model, followed by the
application of the inverted frontier for better discrimination of the results. Finally, the results are
contained in section 5, followed by the conclusion in section 6.
2. Data Envelopment Analysis: Network DEA
Charnes, Cooper, and Rhodes (1978) were pioneers of DEA. This methodology is a non-parametric
approach in order to measure and compare the efficiencies of homogeneous DMUs which have similar
tasks, practices and characteristics, differing only in the quantities of inputs and outputs (Soares de Mello,
2005). Benchmarks and goals for improving efficiency are also identified.
There are two traditional models: the first model, which is known as CCR (Charnes; Cooper;
Rhodes, 1978) takes into account constant scale returns (CRS), assuming proportionality between inputs
and outputs; the second, known as BCC (Banker et al., 1984), replaces the proportionality by the
convexity supposition considering variables returns of scale (VRS). In any DEA model can be applied
two types of orientation to calculate DMUs efficiencies: input orientation which minimizes inputs
keeping a constant level of production and output orientation to maximize the products (Angulo-Meza et
al., 2015).
DEA models have been widely applied in several fields, also in sports such as the works by Haas et
al. (2004), Moreno and Lozano (2014), Chitnis and Vaidya (2014), among others.
The standard DEA approach considers DMUs as a black-box, ignoring its internal processes, just
transforming inputs into outputs , Thus, Färe and Grosskopf (2000) proposed to independently model and
formulate the inside of the black-box, which is the internal sub-processes of the DMUs. This
nonparametric and sophisticated new approach is known as Network Data Envelopment Analysis
(NDEA). By determining the efficiency corresponding to the different sub-processes, the general
efficiency is divided into specific sections. In this approach, the connection between stages are the
intermediate variables that can be defined as inputs for one stage and outputs for another (Moreno;
Lozano, 2014) and they are essential for achieving results. Hence, one of the method main advantages is
to perform an analysis and efficiencies calculation in a more refined level enabling better model
discrimination and consequently of DMUs (Lozano, 2015).
CLAIO-2016
586

2.1. Relational NDEA Model
In order to represent the different configurations of the internal process of a DMU, different NDEA
models can be found, being the multi-stage serial model the most common.
Kao and Hwang (2008) presented the relational multiplicative model. This model is based on the
CRS (constant return to scale) DEA, where E0 is the efficiency of the fractional programming problem
(1):
s.t
The efficiencies related to the stages 1 and 2 are calculated by the models (2) and (3):
s.t
s.t
Where ur, vi, and wd are the optimum weights calculated by (2) and (3). Thus, the global efficiency
(4) is the product of the individual efficiencies in each stage:
2.2. Inverted Frontier
Yamada et al. (1994) and Entani et al. (2002) proposed the inverted frontier with the objective to
identify a pessimistic frontier in DEA and determine an interval for the DMUs efficiency indexes.
Though, it can be used and interpreted in other ways different than the one intended, in this paper the
inverted frontier is used as a way to identify disadvantageous characteristics of a DMU, often disregard in
classic in DEA which highlights the DMUs best characteristics.
To calculate the efficiency of a DMU in the inverted frontier is necessary to switch the inputs of the
traditional model with outputs and vice-versa (Leta et al, 2005).
On the corporative point of view, the inverted frontier have an important role, since it shows the
company’s worst management practices allowing to know where they need to improve and be more
competitive and rental (Silveira et al., 2012). The composed efficiencies for each DMU are calculated by
(5) (Leta et al, 2005).
CLAIO-2016
587

3. Defense of the Ancients 2 (DotA 2)
The electronic game DotA 2 (Defense of the Ancients 2) was released by VALVE in 2013. It is a
MOBA game, therefore, it is based on the battle between two teams, consisting of five players on each
team. The main goal of each team is to destroy the enemy's crystal and in order to achieve it, the player
must face obstacles which are composed of units controlled by the computer itself, defense towers and
enemy “heroes” (Laranjeira et al., 2013). Each match lasts approximately 40-60 minutes long and takes
place on a squared map where each crystal’s team is located at opposite vertices (Arantes; Gomes, 2013).
Before starting the game each player chooses among a universe of available heroes which one he
will be. Once a hero is chosen no other player can pick the same one. Each hero has its own personality
and skills. The choice of heroes, balancing the strengths and weaknesses of each, is so important that a
wrong choice can provide the opposite team a great advantage at the start (Conley; Perry, 2013).
4. DEA Modeling
In the assessment of the efficiency of the DotA 2 competitive teams, we aim to evaluate the
capacity from each team to win games taking into account how much of the resources they have used for
it. Therefore, we will use a NDEA model and the configuration of teams will need to determine the
variables and the configuration. We will use two stages, as seen in Figure 1.
The first stage, called Team Work Performance, will assess how many products the team will
create with the limited amount of gold that they get during the game. Gold is the resource used in this
stage, i. e. the currency gained automatically every 0,6 seconds and used by the heroes to buy items and
map vision. The product (the intermediate variables) included in this stage are: Level: Amount of
experience that a hero can get. Its range goes from 1 up to a maximum of 25 for each player; Last Hit:
Periodically during the game, each base spawns creatures called creeps to protect the ancient. This
variable represents the amount of creatures killed by the team; Kills: Total amount of players killed by the
team during the whole game. This variable doesn’t have a minimum or a maximum, because each killed
hero will reborn in a short period of time; Inverse Death: Considering the mechanics explained above,
this product represents the inverse of times that the members of the team die during a game; Assists: Like
every other team sport, when a player helps other to get a kill, it also takes into account.
Figure 1 – Two-stage modeling representation.
In the second stage, called Objective Gaming Performance, we assess the capacity of each team to
use these intermediate products to win the game. Some teams get a lot of intermediate products, which are
considered resources in this stage, but they don’t use them properly to destroy the enemy ancient, giving
the opponent an opportunity to “comeback” and win the game.
The data used in this paper were collected at the Dotabuff (2015) website and were generated in the
DotA 2 world championship - group stage, which was organized by Valve in August 2015 at the city of
Seattle. 16 professional teams were qualified to play the tournament, and all of them will be evaluated
CLAIO-2016
588
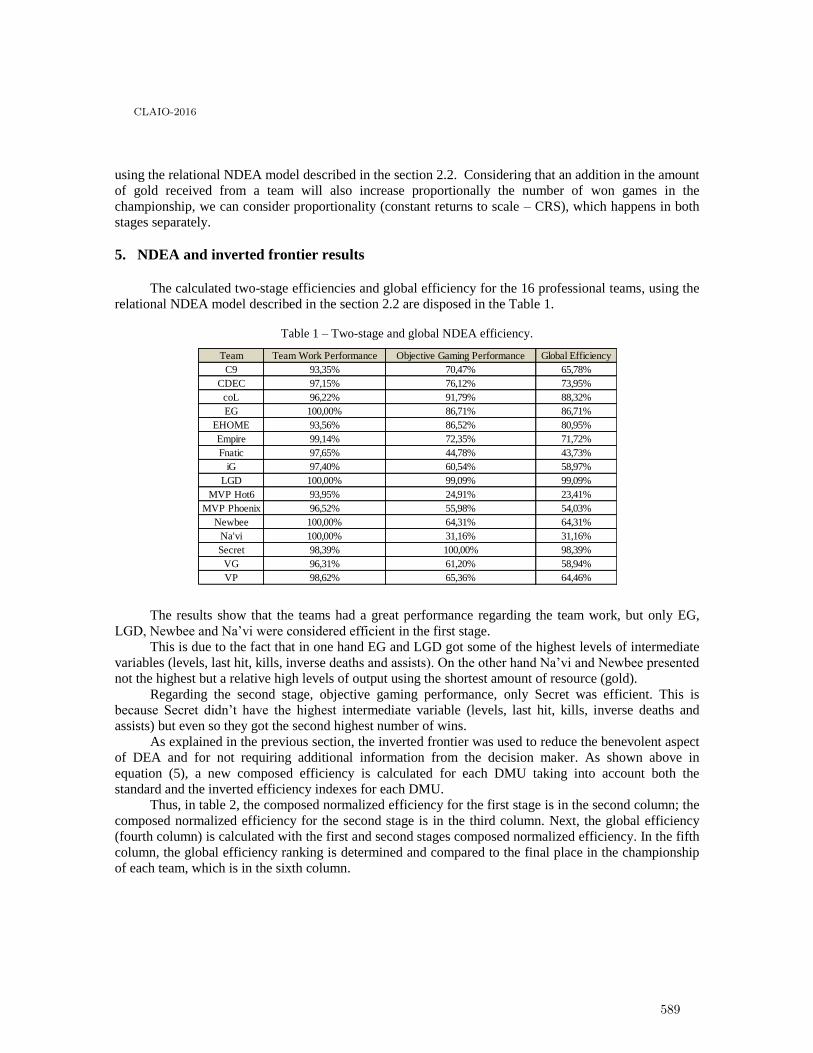
using the relational NDEA model described in the section 2.2. Considering that an addition in the amount
of gold received from a team will also increase proportionally the number of won games in the
championship, we can consider proportionality (constant returns to scale – CRS), which happens in both
stages separately.
5. NDEA and inverted frontier results
The calculated two-stage efficiencies and global efficiency for the 16 professional teams, using the
relational NDEA model described in the section 2.2 are disposed in the Table 1.
Table 1 – Two-stage and global NDEA efficiency.
The results show that the teams had a great performance regarding the team work, but only EG,
LGD, Newbee and Na’vi were considered efficient in the first stage.
This is due to the fact that in one hand EG and LGD got some of the highest levels of intermediate
variables (levels, last hit, kills, inverse deaths and assists). On the other hand Na’vi and Newbee presented
not the highest but a relative high levels of output using the shortest amount of resource (gold).
Regarding the second stage, objective gaming performance, only Secret was efficient. This is
because Secret didn’t have the highest intermediate variable (levels, last hit, kills, inverse deaths and
assists) but even so they got the second highest number of wins.
As explained in the previous section, the inverted frontier was used to reduce the benevolent aspect
of DEA and for not requiring additional information from the decision maker. As shown above in
equation (5), a new composed efficiency is calculated for each DMU taking into account both the
standard and the inverted efficiency indexes for each DMU.
Thus, in table 2, the composed normalized efficiency for the first stage is in the second column; the
composed normalized efficiency for the second stage is in the third column. Next, the global efficiency
(fourth column) is calculated with the first and second stages composed normalized efficiency. In the fifth
column, the global efficiency ranking is determined and compared to the final place in the championship
of each team, which is in the sixth column.
Team Team Work Performance Objective Gaming Performance Global Efficiency
C9 93,35% 70,47% 65,78%
CDEC 97,15% 76,12% 73,95%
coL 96,22% 91,79% 88,32%
EG 100,00% 86,71% 86,71%
EHOME 93,56% 86,52% 80,95%
Empire 99,14% 72,35% 71,72%
Fnatic 97,65% 44,78% 43,73%
iG 97,40% 60,54% 58,97%
LGD 100,00% 99,09% 99,09%
MVP Hot6 93,95% 24,91% 23,41%
MVP Phoenix 96,52% 55,98% 54,03%
Newbee 100,00% 64,31% 64,31%
Na'vi 100,00% 31,16% 31,16%
Secret 98,39% 100,00% 98,39%
VG 96,31% 61,20% 58,94%
VP 98,62% 65,36% 64,46%
CLAIO-2016
589
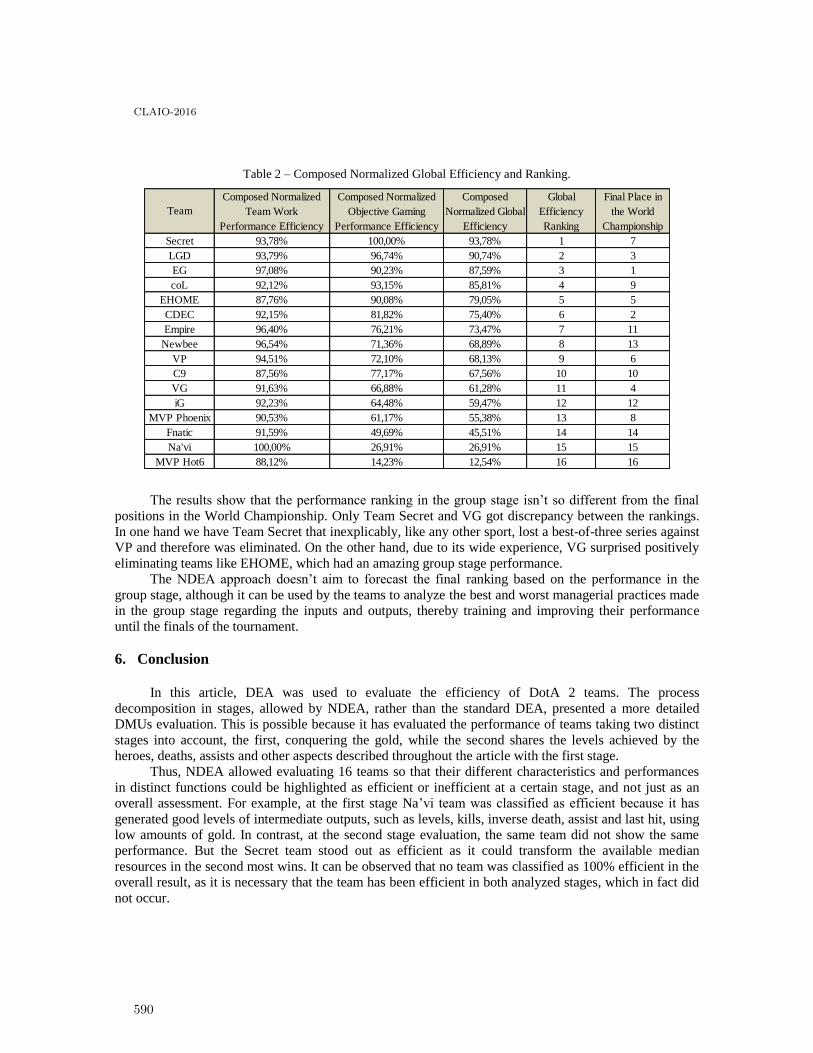
Table 2 – Composed Normalized Global Efficiency and Ranking.
The results show that the performance ranking in the group stage isn’t so different from the final
positions in the World Championship. Only Team Secret and VG got discrepancy between the rankings.
In one hand we have Team Secret that inexplicably, like any other sport, lost a best-of-three series against
VP and therefore was eliminated. On the other hand, due to its wide experience, VG surprised positively
eliminating teams like EHOME, which had an amazing group stage performance.
The NDEA approach doesn’t aim to forecast the final ranking based on the performance in the
group stage, although it can be used by the teams to analyze the best and worst managerial practices made
in the group stage regarding the inputs and outputs, thereby training and improving their performance
until the finals of the tournament.
6. Conclusion
In this article, DEA was used to evaluate the efficiency of DotA 2 teams. The process
decomposition in stages, allowed by NDEA, rather than the standard DEA, presented a more detailed
DMUs evaluation. This is possible because it has evaluated the performance of teams taking two distinct
stages into account, the first, conquering the gold, while the second shares the levels achieved by the
heroes, deaths, assists and other aspects described throughout the article with the first stage.
Thus, NDEA allowed evaluating 16 teams so that their different characteristics and performances
in distinct functions could be highlighted as efficient or inefficient at a certain stage, and not just as an
overall assessment. For example, at the first stage Na’vi team was classified as efficient because it has
generated good levels of intermediate outputs, such as levels, kills, inverse death, assist and last hit, using
low amounts of gold. In contrast, at the second stage evaluation, the same team did not show the same
performance. But the Secret team stood out as efficient as it could transform the available median
resources in the second most wins. It can be observed that no team was classified as 100% efficient in the
overall result, as it is necessary that the team has been efficient in both analyzed stages, which in fact did
not occur.
Secret 93,78% 100,00% 93,78% 1 7
LGD 93,79% 96,74% 90,74% 2 3
EG 97,08% 90,23% 87,59% 3 1
coL 92,12% 93,15% 85,81% 4 9
EHOME 87,76% 90,08% 79,05% 5 5
CDEC 92,15% 81,82% 75,40% 6 2
Empire 96,40% 76,21% 73,47% 7 11
Newbee 96,54% 71,36% 68,89% 8 13
VP 94,51% 72,10% 68,13% 9 6
C9 87,56% 77,17% 67,56% 10 10
VG 91,63% 66,88% 61,28% 11 4
iG 92,23% 64,48% 59,47% 12 12
MVP Phoenix 90,53% 61,17% 55,38% 13 8
Fnatic 91,59% 49,69% 45,51% 14 14
Na'vi 100,00% 26,91% 26,91% 15 15
MVP Hot6 88,12% 14,23% 12,54% 16 16
Final Place in
the World
Championship
Team
Composed Normalized
Team Work
Performance Efficiency
Composed Normalized
Objective Gaming
Performance Efficiency
Composed
Normalized Global
Efficiency
Global
Efficiency
Ranking
CLAIO-2016
590

After the results obtained by NDEA, the application of the inverted frontier, also provided
additional information to the model, adding the inefficiency calculation which allowed a better
discrimination of the proposed model. This approach highlighted the strengths without failing to take into
account the adverse characteristics, allowing making better choices of strategies in the game.
Faced with the values obtained from the modeling compared to the Seattle championship final
results, it was observed that the model can be applied before the tournament with the data from the
qualifiers, after the group stage, or even after the end of the tournament, and its results aim to guide the
inefficient teams to focus on improving their weaknesses benchmarking the best practices regarding both
the team work performance, which is the capability to take advantage during the game and the objective
gaming performance, which is the capability to turn this advantage into a victory, destroying the enemy’s
ancient.
Another possible future study is to treat each one of the five players as a DMU, being part of a
bigger network DEA. This modification can be useful, because each player has different and flexible
inputs and outputs. In this analysis, a DEA cross-efficiency evaluation could be used.
References
1. L. Angulo Meza; R. P. Valério; J. C. C. B. Soares De Mello. Assessing the Efficiency of Sports in Using
Financial Resources with DEA Models. Procedia Computer Science, v. 55, p. 1151-1159, 2015.
2. T. T. Arantes; N. S. Gomes. Uma Análise da Linguagem dos Jogadores do Dota. In: XVII Congresso Nacional
de Linguística e Filologia, 2013, Rio De Janeiro. Cadernos do CNLF, vol. XVII, nº 12 Sociolinguística,
Dialetologia. Rio de Janeiro: Cifefil, v. 17, p. 216-225, 2013.
3. R. D. Banker; A. Charnes; W. W. Cooper. Some Models for Estimating Technical Scale Inefficiencies in Data
Envelopment Analysis. Management Science, 30(9), 1078-1092, 1984.
4. A. Charnes; W. W. Cooper; E. Rhodes. Measuring the Efficiency of Decision Making Units, European Journal
of Operational Research, 2 (6), 429-444, 1978.
5. A. Chitnis; O. Vaidya. Performance Assessment of Tennis Players: Application of DEA. Procedia Social and
Behavioral Sciences, v. 133, p. 74-83, 2014.
6. K. Conley; D. Perry. How Does He Saw Me? A Recommendation Engine for Picking Heroes in DOTA 2. CS229
Previous Projects, 2013.
7. DFC. League Of Legends Most Played PC Game. DFC Intelligence (2012). Available At:
<http://www.dfcint.com/archive/wp/?p=343> Accessed on: 17/11/2015.
8. Dotabuff. Dota 2 Statistics (2015). Available at: <http://www.dotabuff.com>. Accessed on: 10/11/2015.
9. T. Entani; Y. Maeda; H. Tanaka. Dual Models of Interval DEA and its Extensions to Interval Data. European
Journal of Operational Research, v. 136, p. 32-45, 2002.
10. R. Fare; S. Grosskopf. Network DEA. Socio-Economic Planning Sciences, 34(1), 35-49, 2000.
11. D. Haas; M. G. Kocher; M. Sutter. Measuring Efficiency of German Football Teams by Data Envelopment
Analysis. Central European Journal of Operations Research 12.3, p. 251-268, 2004.
12. C. Kao; S. N. Hwang. Efficiency Decomposition in Two-Stage Data Envelopment Analysis: an application to
non-life Insurance companies in Taiwan, European Journal of Operational Research, 185 (1), 418-429, 2008.
13. P. C. P. Laranjeira; E. P. Bezerra; P. R. L. Pinheiro. Além da arena: análise das estruturas de organização e
comunicação surgidas em comunidades de jogadores de jogos tipo MOBA. In: XII Simpósio Brasileiro de Jogos
e entretenimento digital, 2013, São Paulo. Proceedings do XII Simpósio Brasileiro de Jogos e Entretenimento
Digital (SBGames 2013), 2013.
14. F. R. Leta; J. C. C. B. Soares De Mello. Métodos de melhoria de ordenação em DEA aplicados à avaliação
estática de tornos mecânicos. Investigação Operacional, Lisboa, v. 25, n. 2, 2005.
15. S. Lozano. Alternative SBM Model for Network DEA. Computers and Industrial Engineering. 32, p. 33–40,
2015.
16. P. Moreno; S. Lozano. A Network DEA Assessment of Team Efficiency in the NBA. Annals of Operations
Research 214: 99-124, 2014.
CLAIO-2016
591

17. J. Q. Silveira; L. Angulo-Meza; J. C. C. B. Soares De Mello. Identificação de benchmarks e anti-benchmarks
para companhias aéreas usando modelos DEA e fronteira invertida. Produção (São Paulo. Impresso), v. 22 (4),
p. 788-795, 2012.
18. J. C. C. B. Soares De Mello. Modelo Dea-Savage para Análise de Eficiência do Parque de Refino Brasileiro.
Relatórios de Pesquisa em Engenharia de Produção da UFF, v. 5, p. 5, 2005.
19. Y. Yamada; T. Matui; M. Sugiyama. New Analysis of Efficiency Based on DEA. Journal of the Operations
Research Society of Japan, v. 37, p. 158-67, 1994.
CLAIO-2016
592

Optimización de los niveles de glucosa en un paciente con diabetes
mellitus tipo 1 mediante de un modelo de programación lineal
Maximino Navarro Mentado
Facultad de Ingeniería, UNAM. México
Esther Segura Pérez
Facultad de Ingeniería, UNAM. México
Abstract
Muchos tratamientos se han enfocado solo a controlar los niveles de glucosa en la sangre de un paciente
con diabetes en ayunas, sin embargo, estudios recientes han relacionado los altos niveles de glucosa que se
generan después de comer al riesgo de complicaciones diabéticas, por lo que resulta ya insuficiente tratar a
una persona con este padecimiento teniendo en cuenta solo su estado en ayuno. En este proyecto se optimiza
el índice glucémico a través de la sugerencia de los alimentos a ingerir en una dieta de 1800 calorías, tras
la ingesta de los alimentos (posprandial), tomando en cuenta su aporte energético, así como su contenido
en grasas, proteínas y principalmente los carbohidratos. El modelo de optimización se basa en la
minimización del índice glucémico sin considerar los costos de los alimentos. A partir del índice glucémico
obtenido se calcula la carga glucémica para finalmente dar una propuesta de dieta.
Palabras clave: Diabetes mellitus, Programación lineal, Índice glucémico, Carga glucémica, optimización,
problema de la dieta, aporte calórico.
Introducción La diabetes es una afección crónica que se desencadena cuando el organismo pierde su capacidad de
producir suficiente insulina o de utilizarla con eficacia. La insulina es una hormona que se fabrica en el
páncreas y que permite que la glucosa de los alimentos pase a las células del organismo, en donde se
convierte en energía para que funcionen los músculos y los tejidos. Como resultado, una persona con
diabetes no absorbe la glucosa adecuadamente, de modo que ésta queda circulando en la sangre
(hiperglucemia) y dañando los tejidos con el paso del tiempo. Este deterioro causa complicaciones para la
salud potencialmente letales. Abordaremos los tipos 1 y 2 de diabetes por ser casos muy similares
(NORMA, 2016).
Diabetes Mellitus tipo 1
La diabetes tipo 1 es causada por una reacción autoinmune, en la que el sistema de defensas del organismo
ataca las células productoras de insulina del páncreas. Como resultado, el organismo deja de producir la
insulina que necesita. La razón por la que esto sucede no se acaba de entender. La enfermedad puede afectar
a personas de cualquier edad, pero suele aparecer en niños o jóvenes adultos. Las personas con este tipo de
diabetes necesitan inyecciones de insulina a diario con el fin de controlar sus niveles de glucosa en sangre.
Sin insulina, una persona con diabetes tipo 1 morirá. (NORMA, 2016).
CLAIO-2016
593

Las personas con diabetes tipo 1 pueden llevar una vida normal y saludable mediante una combinación de
terapia diaria de insulina, estrecha monitorización, dieta sana y ejercicio físico habitual.
El número de personas que desarrollan diabetes tipo 1 aumenta cada año. Las razones para que esto suceda
siguen sin estar claras, pero podría deberse a los cambios de los factores de riesgo medioambiental, a
circunstancias durante el desarrollo en el útero, a la alimentación durante las primeras etapas de la vida o a
infecciones virales.
Diabetes tipo 2
La diabetes tipo 2 es el tipo más común de diabetes. Suele aparecer en adultos, pero cada vez más hay más
casos de niños y adolescentes. En la diabetes tipo 2, el organismo puede producir insulina, pero no es
suficiente, o el organismo no responde a sus efectos, provocando una acumulación de glucosa en la sangre.
Las personas con diabetes tipo 2 podrían pasar mucho tiempo sin saber de su enfermedad debido a que los
síntomas podrían tardar años en aparecer o en reconocerse, tiempo durante el cual el organismo se va
deteriorando debido al exceso de glucosa en sangre.
En contraste con las personas con diabetes tipo 1, la mayoría de quienes tienen diabetes tipo 2 no suelen
necesitar dosis diarias de insulina para sobrevivir. Sin embargo, para controlar la afección se podría recetar
insulina unida a una medicación oral, una dieta sana y el aumento de la actividad física.
El número de personas con diabetes tipo 2 está en rápido aumento en todo el mundo. Este aumento va
asociado al desarrollo económico, al envejecimiento de la población, al incremento de la urbanización, a
los cambios de dieta, a la disminución de la actividad física y al cambio de otros patrones de estilo de vida.
(NORMA, 2016).
Índice Glucémico
Cuando tomamos cualquier alimento rico en glúcidos, los niveles de glucosa en sangre se incrementan
progresivamente según se digieren y asimilan los almidones y azúcares que contienen. La velocidad a la
que se digieren y asimilan los diferentes alimentos depende del tipo de nutrientes que los componen, de la
cantidad de fibra presente y de la composición del resto de alimentos presentes en el estómago e intestino
durante la digestión (WWW, 2016).
Estos aspectos se valoran a través del índice glucémico de un alimento. Dicho índice es la relación entre el
área de la curva de la absorción de la ingesta de 50 gr. de glucosa pura a lo largo del tiempo, con la obtenida
al ingerir la misma cantidad de ese alimento.
Se obtiene midiendo el nivel de glucosa en sangre generado por un alimento y comparándolo con un
alimento de referencia: la glucosa, a quien se le otorga el valor 100. A pesar de ser bastante complicado de
determinar, su interpretación es muy sencilla: los índices elevados implican una rápida absorción, mientras
que los índices bajos indican una absorción progresiva.
𝐼𝐺(%) =𝐴𝐵𝐶𝑎𝑙𝑖𝑚𝑒𝑛𝑡𝑜𝑠
𝐴𝐵𝐶𝑎𝑙𝑖𝑚𝑒𝑛𝑡𝑜_𝑒𝑠𝑡á𝑛𝑑𝑎𝑟× 100
Donde:
𝐼𝐺(%): Í𝑛𝑑𝑖𝑐𝑒 𝑔𝑙𝑢𝑐é𝑚𝑖𝑐𝑜 𝑑𝑒𝑙 𝑎𝑙𝑖𝑚𝑒𝑛𝑡𝑜 𝑒𝑛 𝑖𝑛𝑣𝑒𝑠𝑡𝑖𝑔𝑎𝑐𝑖ó𝑛.
𝐴𝐵𝐶𝑎𝑙𝑖𝑚𝑒𝑛𝑡𝑜: Á𝑟𝑒𝑎 𝑏𝑎𝑗𝑜 𝑙𝑎 𝑐𝑢𝑟𝑣𝑎 𝑑𝑒 𝑟𝑒𝑠𝑝𝑢𝑒𝑠𝑡𝑎 𝑔𝑙𝑖𝑐é𝑚𝑖𝑐𝑎 𝑑𝑒𝑙 𝑎𝑙𝑖𝑚𝑒𝑛𝑡𝑜 𝑒𝑛 𝑖𝑛𝑣𝑒𝑠𝑡𝑖𝑔𝑎𝑐𝑖ó𝑛.
CLAIO-2016
594

𝐴𝐵𝐶𝑎𝑙𝑖𝑚𝑒𝑛𝑡𝑜_𝑒𝑠𝑡á𝑛𝑑𝑎𝑟: Á𝑟𝑒𝑎 𝑏𝑎𝑗𝑜 𝑙𝑎 𝑐𝑢𝑟𝑣𝑎 𝑑𝑒 𝑟𝑒𝑠𝑝𝑢𝑒𝑠𝑡𝑎 𝑔𝑙𝑖𝑐é𝑚𝑖𝑐𝑎 𝑑𝑒𝑙 𝑎𝑙𝑖𝑚𝑒𝑛𝑡𝑜 𝑒𝑠𝑡á𝑛𝑑𝑎𝑟.
Por lo tanto, el índice glucémico es una forma sistemática de clasificar a los hidratos de carbono, en función
de su efecto sobre el incremento inmediato sobre los niveles de glucemia (glucosa en sangre).
Se considera índice glucémico alto al que está entre 70 y100; medio entre 50 y 70; y bajo, inferior
a 50.
Rangos de Referencia del Índice Glucémico
Índice glucémico alto 70-100
Índice glucémico medio 50-70
Índice glucémico bajo <50
Tabla 1.- Rangos de referencia del índice Glucémico. Fuente: www2.fammed.wisc.edu
Carga glucémica
La carga glucémica de calcula dividiendo el índice glucémico del alimento por 100 y multiplicándolo por
la cantidad de hidratos de carbono en gramos de esa ración. De esta forma, obtenemos un dato más real de
cuánto va influir esa ración de alimento que vayamos a consumir a nuestra glucemia (WWW2, 2016).
𝐶𝐺 =𝐼𝐺 × 𝐶𝑎𝑛𝑡𝑖𝑑𝑎𝑑 𝑑𝑒 𝑐𝑎𝑟𝑏𝑜ℎ𝑖𝑑𝑟𝑎𝑡𝑜𝑠
100
A partir de esto, se puede generar un valor para los niveles de carga glucémica de la forma siguiente:
Carga Glucémica
Carga Glucémica alta >20
Carga Glucémica media 11-19
Carga Glucémica baja ≤10
Tabla 2.- Carga glucémica. Fuente: www2.fammed.wisc.edu
Problemas ocasionados por los alimentos de elevado índice glucémico
En primer lugar, al aumentar rápidamente el nivel de glucosa en sangre se segrega insulina en grandes
cantidades, pero como las células no pueden quemar adecuadamente toda la glucosa, el metabolismo de las
grasas se activa y comienza a transformarla en grasas. Estas grasas se almacenan en las células del tejido
adiposo. Nuestro código genético está programado de esta manera para permitirnos sobrevivir mejor a los
CLAIO-2016
595

periodos de escasez de alimentos. En una sociedad como la nuestra, en la que nunca llega el periodo de
hambruna posterior al atracón, todas las reservas grasas se quedan sin utilizar y nos volvemos obesos.
Posteriormente, toda esa insulina que hemos segregado consigue que el azúcar abandone la corriente
sanguínea y, dos o tres horas después, el azúcar en sangre cae por debajo de lo normal y pasamos a un
estado de hipoglucemia. Cuando esto sucede, el funcionamiento de nuestro cuerpo y el de nuestra cabeza
no está a la par, y sentimos la necesidad de devorar más alimento. Si volvemos a comer más carbohidratos
para calmar la sensación de hambre ocasionada por la rápida bajada de la glucosa, volvemos a segregar otra
gran dosis de insulina, y así entramos en un círculo vicioso que se repetirá una y otra vez.
Tabla de niveles de glucosa
En la tabla 3 se observan los niveles de glucosa [mg/dl] dependiendo del estado de salud de la persona, por
ejemplo, las personas con diabetes muestran 200 [mg/dl], mientras que una persona sana muestra solo de
70 a 100 [mg/dl]. 6. (Foster-Powell, Holt y Brand-Miller, 2002).
Tabla 3.- Niveles de glucosa. Fuente:www3.diabetesbienestarysalud.com
Descripción del problema
Uno de los mayores problemas para los pacientes con diabetes es el control de las altas y bajas de glucosa
en la sangre, tomando en cuenta dos enfoques: una es cuando el paciente está en ayunas y la otra es después
de que éste consume un alimento. A partir de estos dos enfoques, se pueden asociar complicaciones que
muchas veces pueden ser discapacitadoras y potencialmente letales debido una diabetes mal controlada.
Aumenta el riesgo de padecer enfermedades renales, cardiovasculares, lesiones nerviosas e inclusive la
muerte. En este modelo centraremos nuestra atención en los alimentos que consumirá la persona ya que se
observan niveles más elevados de glucosa tipo posprandial que en ayunas (sin consumir alimentos), como
se observa en la tabla 3.
Lo que nosotros trataremos de obtener con este modelo será la reducción de los grandes picos en los niveles
de glucosa, es decir, estabilizarlos mediante el uso de alimentos con un índice glucémico medio y bajo,
CLAIO-2016
596
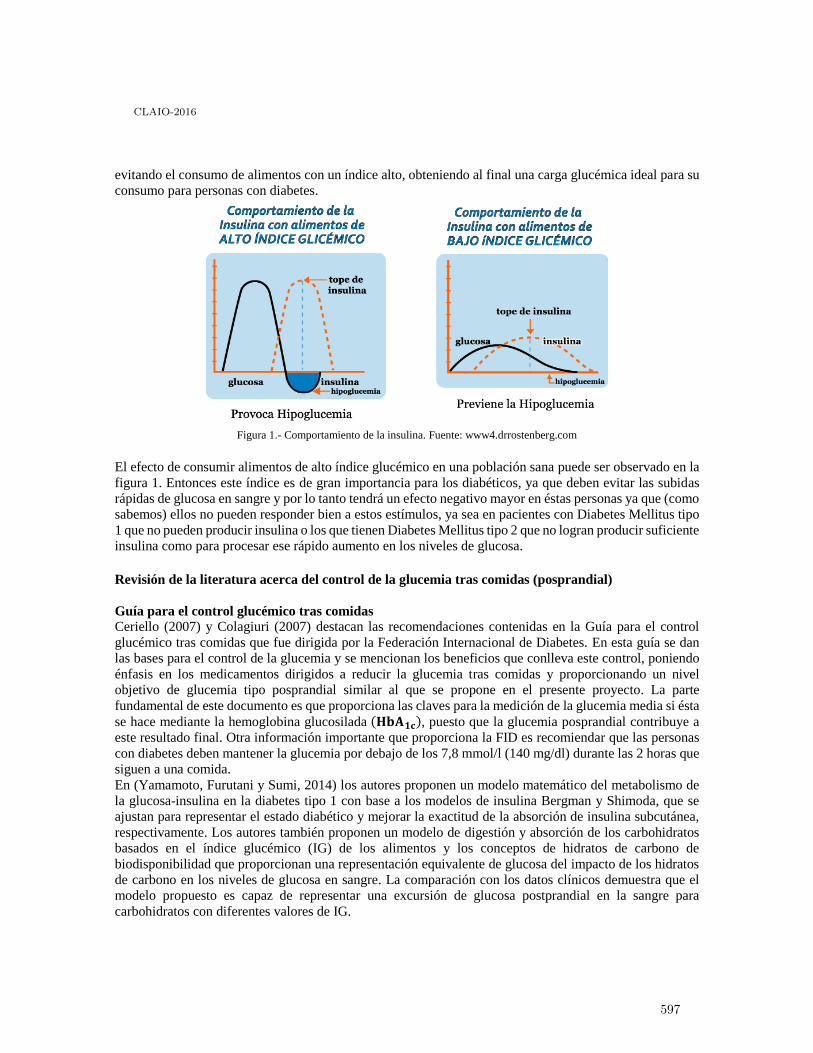
evitando el consumo de alimentos con un índice alto, obteniendo al final una carga glucémica ideal para su
consumo para personas con diabetes.
Figura 1.- Comportamiento de la insulina. Fuente: www4.drrostenberg.com
El efecto de consumir alimentos de alto índice glucémico en una población sana puede ser observado en la
figura 1. Entonces este índice es de gran importancia para los diabéticos, ya que deben evitar las subidas
rápidas de glucosa en sangre y por lo tanto tendrá un efecto negativo mayor en éstas personas ya que (como
sabemos) ellos no pueden responder bien a estos estímulos, ya sea en pacientes con Diabetes Mellitus tipo
1 que no pueden producir insulina o los que tienen Diabetes Mellitus tipo 2 que no logran producir suficiente
insulina como para procesar ese rápido aumento en los niveles de glucosa.
Revisión de la literatura acerca del control de la glucemia tras comidas (posprandial)
Guía para el control glucémico tras comidas
Ceriello (2007) y Colagiuri (2007) destacan las recomendaciones contenidas en la Guía para el control
glucémico tras comidas que fue dirigida por la Federación Internacional de Diabetes. En esta guía se dan
las bases para el control de la glucemia y se mencionan los beneficios que conlleva este control, poniendo
énfasis en los medicamentos dirigidos a reducir la glucemia tras comidas y proporcionando un nivel
objetivo de glucemia tipo posprandial similar al que se propone en el presente proyecto. La parte
fundamental de este documento es que proporciona las claves para la medición de la glucemia media si ésta
se hace mediante la hemoglobina glucosilada (𝐇𝐛𝐀𝟏𝐜), puesto que la glucemia posprandial contribuye a
este resultado final. Otra información importante que proporciona la FID es recomiendar que las personas
con diabetes deben mantener la glucemia por debajo de los 7,8 mmol/l (140 mg/dl) durante las 2 horas que
siguen a una comida.
En (Yamamoto, Furutani y Sumi, 2014) los autores proponen un modelo matemático del metabolismo de
la glucosa-insulina en la diabetes tipo 1 con base a los modelos de insulina Bergman y Shimoda, que se
ajustan para representar el estado diabético y mejorar la exactitud de la absorción de insulina subcutánea,
respectivamente. Los autores también proponen un modelo de digestión y absorción de los carbohidratos
basados en el índice glucémico (IG) de los alimentos y los conceptos de hidratos de carbono de
biodisponibilidad que proporcionan una representación equivalente de glucosa del impacto de los hidratos
de carbono en los niveles de glucosa en sangre. La comparación con los datos clínicos demuestra que el
modelo propuesto es capaz de representar una excursión de glucosa postprandial en la sangre para
carbohidratos con diferentes valores de IG.
CLAIO-2016
597

En (Bernard et al., 2006) el propósito del estudio fue evaluar la concordancia entre los valores CG obtenidos
mediante métodos directos e indirectos de medida en 20 voluntarios sanos. Una curva estándar en el que la
dosis de glucosa se representó frente a la glucosa en sangre área bajo la curva incremental (IAUC) se generó
usando bebidas que contienen 0, 12.5, 25, 50, y 75 g de glucosa. El contenido de carbohidratos IG y
disponible de 5 alimentos se midieron. Los alimentos (pan blanco, pan de frutas, barras de granola, papas
instantáneas, y garbanzos) se consumieron en 3 tamaños de las porciones, obteniéndose 15 combinaciones
de tamaño de comida / porciones. La CG se determinó directamente relacionando la IAUC de un alimento
de prueba con la curva estándar de glucosa. Para 12 de 15 combinaciones de dimensiones de los alimentos
/ de las porciones, la CG determinó a través de IG de 3 hidratos de carbono disponibles no difieren de la
CG medida a partir de la curva estándar.
Planteamiento del modelo Problema de la dieta con un enfoque a la disminución del nivel de glucosa en la sangre. En este modelo
previo utilizamos el índice glucémico promedio de cada grupo de alimentos y lo tomamos como nuestra
función objetivo, tomando como restricciones el aporte calórico, cantidad de proteínas, grasas y
principalmente su contenido de hidratos de carbono, posteriormente se utiliza el concepto de la carga
glucémica para calcular la cantidad final que representará esta dieta.
Obtención de datos
Los datos y valores que se presentan se obtuvieron de la Guía de alimentos de la población mexicana de la
Secretaría de Salud (WWW4, 2016) y se compararon igualmente con datos de la NORMA Oficial Mexicana
NOM-015-SSA2-2010, para la prevención, tratamiento y control de la diabetes mellitus y del Sistema
mexicano de alimentos equivalentes. Las variables que se presentan están basadas en la clasificación que
se hizo en dichos documentos y se excluyen así los azúcares por no ser un grupo de alimentos
recomendables para estas personas. Se optó por utilizar estos datos debido a que se hace una clasificación,
en el que cada grupo tiene el mismo contenido energético, gramos de carbohidratos, grasas y proteínas.
A partir de este modelo podremos encontrar una solución que minimice el índice glucémico de los alimentos
a consumir, reduciendo así los niveles de glucosa en la sangre de una persona con diabetes tipo 1.
Variables
X1 = Cereales y Tubérculos sin grasa
X2 = Cereales y Tubérculos con grasa
X3 = Verduras
X4 = Frutas
X5 = Alimentos de origen animal muy bajas en grasa
X6 = Alimentos de origen animal bajas en grasa
X7 = Leche descremada
X8 = Leche entera
X9 = leguminosas
X10 = Grasas monoinsaturadas
X11 = Grasas polinsaturadas
X12 = Grasas saturadas y transaturadas.
Función Objetivo: Minimizar el índice glucémico del grupo de alimentos disponibles. 𝑀𝑖𝑛𝑧 = 35𝑋1 + 45𝑋2 + 52𝑋3 + 46𝑋4 + 0𝑋5 + 0𝑋6 + 30𝑋7 + 30𝑋8 + 15𝑋9 + 15𝑋10 + 0𝑋11 + 35𝑋12
S.A 70𝑋1 + 115𝑋2 + 25𝑋3 + 60𝑋4 + 40𝑋5 + 55𝑋6 + 95𝑋7 + 150𝑋8 + 120𝑋9 + 70𝑋10 + 45𝑋11 + 45𝑋12 = 1800 … (1)
15𝑋1 + 15𝑋2 + 4𝑋3 + 15𝑋4 + 0𝑋5 + 0𝑋6 + 12𝑋7 + 12𝑋8 + 20𝑋9 + 3𝑋10 + 0𝑋11 + 0𝑋12 ≤ 220 … (2)
0𝑋1 + 5𝑋2 + 0𝑋3 + 0𝑋4 + 1𝑋5 + 3𝑋6 + 2𝑋7 + 8𝑋8 + 1𝑋9 + 5𝑋10 + 5𝑋11 + 5𝑋12 ≤ 65 … (3)
2𝑋1 + 2𝑋2 + 2𝑋3 + 0𝑋4 + 7𝑋5 + 7𝑋6 + 9𝑋7 + 9𝑋8 + 8𝑋9 + 3𝑋10 + 0𝑋11 + 0𝑋12 ≤ 85 … (4)
CLAIO-2016
598

𝑋𝑖 > 0, 𝑝𝑎𝑟𝑎 𝑖 = 1,2,3 … 12 … (5)
De donde se tiene que:
La ecuación (1) se refiere al aporte energético de cada grupo de alimentos, igualado a las 1800 calorías que
se requieren para dicha dieta. Se incluyen las restricciones en gramos de Hidratos de Carbono (2), grasas
(3), proteínas (4) y finalmente la condición de no negatividad aplicada a cada una de las variables.
Propuesta de solución y análisis de resultados
Se programó el modelo en el software LINGO (LINDO, 2016) y se obtuvieron los siguientes resultados.
Tabla 3. Resultados obtenidos por el software LINGO
Se observa en la tabla 3 que las cantidades a ingerir por grupo de alimento son: 1.632 X1 que corresponde
al grupo de cereales y tubérculos sin grasa, una porción del 0.504 de X5 (Alimentos de origen animal muy
bajas en grasa), 9.776 porciones de X9 (leguminosas) y un 10.944 de X11 (Grasas poliinsaturadas). Se logra
obtener a un índice glucémico igual a 203.76.
Para calcular la carga glucémica se tienen los siguientes datos:
1.632 de X1 que tiene un contenido de HC 15 g e IG igual a 35
0.504 de X5 que no contiene HC, por lo tanto, su IG es igual a 0
9.776 de X9 que tiene un contenido de 20g en carbohidratos y un IG igual a 15
10.944 de X11 que tampoco tiene un contenido en carbohidratos.
Tomando estos datos, tenemos que:
𝐶𝐺 = 1.632 (35 × 15
100) + 0.504 (
0 × 10
100) + 9.776 (
15 × 20
100) + 10.944 (
10 × 0
100)
𝐶𝐺 = 37.896
Tenemos que la carga glucémica total de los alimentos a consumir será de 37.9 y lo podríamos considerar
un valor muy alto si todo ese alimento se consumiera en una sola comida, pero debemos tomar en cuenta
que la cantidad de glucemia se debe dividir en las porciones a consumir de acuerdo a un plan de
alimentación completo: desayuno, comida y cena, e incluyendo pequeñas ingestas de alimento entre cada
comida (colaciones).
CLAIO-2016
599

El objetivo de incluir un grupo de alimentos en nuestro modelo, fue la de obtener una gran variedad de
opciones a consumir a lo largo del día, pues si se tomaba en cuenta cada alimento, los resultados serían muy
limitados y la dieta estaría muy lejos de ser una opción real (como sucedía con el modelo de la dieta original,
en donde se pretendía la reducción de costos). Aun a pesar de este resultado, se percibe una limitante, puesto
que el consumo alimentos como las leguminosas y grasas poliinsaturadas sería más alto que otros tipos de
alimentos como frutas y verduras que podrían enriquecer de cierta manera las necesidades vitamínicas de
una persona.
Conclusiones En este proyecto se optimiza el índice glucémico a través de la sugerencia de los alimentos a ingerir en una
dieta de 1800 calorías, tras la ingesta de los alimentos (posprandial), tomando en cuenta su aporte
energético, así como su contenido en grasas, proteínas y principalmente los carbohidratos. Se puede afirmar
que los resultados obtenidos no están lejos de ser una alternativa real en una dieta, si bien, el consumo de
grasas podría considerarse muy alto, pero por ser un tipo de grasas insaturadas no afectará a un paciente
con diabetes puesto que para ellos las grasas de este tipo no están restringidas en su dieta, sin embargo, las
grasas saturadas sí podrían afectar a su salud. El uso de alimentos con bajo índice glucémico en una dieta,
implica una diferencia sustancial respecto al consumo de cualquier otro tipo de carbohidratos (simples y
complejos) en una dieta tradicional de conteo de calorías, puesto que ahora se tiene una herramienta más
eficaz para conocer los efectos que tiene el consumo de ciertos tipos de alimentos que contengan una
cantidad importante de glúcidos. Ahora ya se saben los efectos negativos que los alimentos con un alto
índice glucémico provocan en el organismo y se tienen bases para evitar a toda costa su consumo. Algo que
se puede cambiar en estas dietas es la cantidad de calorías a consumir, será muy diferente una dieta para
una persona normal, que para alguien que tiene un sobrepeso u obesidad, de igual forma, esto variará
respecto a las necesidades de cada persona, por lo tanto, la validación del modelo queda puesto a prueba,
pues se necesitará medir la respuesta glucémica del paciente y además de que el número de equivalentes
varía de acuerdo a los requerimientos energéticos y estos se calculan de acuerdo al peso deseable, la
estatura, la edad, el sexo y la actividad física del individuo.
Referencias 1. NORMA, (2016). NORMA Oficial Mexicana NOM-015-SSA2-2010, Para la prevención, tratamiento y control de la
diabetes mellitus. Consultado el 20 junio del 2016 en sitio web:
http://dof.gob.mx/nota_detalle.php?codigo=5168074&fecha=23/11/2010
2. WWW4, (2016). Guía de alimentos para la población mexicana. Consultado el 10 de diciembre en sitio web:
http://www.imss.gob.mx/sites/all/statics/salud/guia-alimentos.pdf
3. Ceriello, A., y Colagiuri, S. (2007). Guía para el control glucémico tras las comidas. Diabetes Voice, 52(3), 9-11.
4. Foster-Powell, K., Holt HA., S., y Brand-Miller C., J. (2002). International table of glycemic index and glycemic load
values. The American Journal of Clinical Nutrition, 76(1), 5-56.
5. WWW3, (2016). Tabla de raciones de Hidratos de Carbono, Índice Glucémico y Carga Glucémica. Consultado el 20 de
marzo del 2016 en sitio web: https://www.diabalance.com/vivir-con-diabetes/control-de-la-glucemia/734-tabla-de-
equivalencias.
6. Yamamoto N, C. C., Furutani, E., y Sumi, S. (2014). Mathematical Model of Glucose-Insulin Metabolism in Type 1
Diabetes Including Digestion and Absorption of Carbohydrates. SICE Journal of Control, Measurement, and System
Integration, 7(6), 314–320.
7. Bernard, J. V., Wallace, A. J., Monro, A. J., Perry, T., Brown, P., Frampton, C., y Green, T. J. (2006). Methodology and
Mathematical Modeling. The Journal of nutrition, 136: 1377–1381.
8. WWW1, (2016). Índice Glucémico y Carga Glucémica. Consultado el 20 de marzo del 2016 en sitio web:
http://www.fammed.wisc.edu/files/webfm-uploads/documents/outreach/im/handout_glycemic_index_patient_sp.pdf
9. WWW2, (2016). www2.fammed.wisc.edu 10. WWW4, (2016). www.drrostenberg.com
CLAIO-2016
600

Traffic light optimization for Bus Rapid Transit
using a parallel evolutionary algorithm:
the case of Garzón Avenue in Montevideo, Uruguay
Efráın Arreche, Sergio Nesmachnow, Renzo MassobrioUniversidad de la República, Montevideo, Uruguay{efrain.arreche,sergion,renzom}@fing.edu.uy
Christine MumfordCardiff University, Wales, UK
Ana Carolina Olivera, Pablo VidalUniversidad de la Patagonia Austral, Argentina
[email protected], [email protected]
Abstract
This article proposes the design and implementation of a parallel evolutionary algorithm forpublic transport optimization on Garzón Avenue, Montevideo, Uruguay. This is an interestingcomplex urban scenario, due to the number of crossings, streets, and traffic lights in the zone.We introduce an evolutionary algorithm to efficiently synchronize traffic lights and improve theaverage speed of buses and other vehicles. The experimental analysis compares the numericalresults of the evolutionary algorithm against a baseline scenario that models the current reality.The results show that the proposed evolutionary algorithm achieves better quality of serviceimproving up to 15.3% average bus speed and 24.8% the average speed of other vehicles.
Keywords: traffic light synchronization; evolutionary algorithms; bus rapid transit.
1 Introduction
The number of vehicles has been growing steadily in the last twenty years worldwide. This growthseverely affects the development of cities and also the quality of life of people [4]. Traffic problemsprogressively decrease the average speed of vehicles, which in turn lowers the acceptance of publictransport. A number of intelligent solutions for transport systems have been proposed. Bus RapidTransit (BRT), for example, has gained popularity because it provides a good user experience andreduced implementation costs when compared against other solutions.
Montevideo has a growing problem of traffic congestion. The local authorities have implementeda Urban Mobility Plan to reduce the impact of this problem [8]. The transport system in theUrban Mobility Plan is inspired by BRTs: several streets and avenues with priority for buses havebeen proposed for the city. The first element of the Urban Mobility Plan was implemented inGarzón Avenue (north of Montevideo). This avenue includes 24 intersections with traffic lightsand exclusive lanes for buses. The BRT on Garzón Avenue has been much criticized for failing tostreamline public transport, which is one of the main objectives of the Urban Mobility Plan.
CLAIO-2016
601

Two main strategies are applied for traffic optimization: influencing drivers’ behavior (by settingtraffic lights, installing signs, etc.) and changing the infrastructure (adding new lanes, wideningstreets, etc.) [9]. Infrastructure modifications can significantly improve the traffic flow, but theyare expensive and need physical space that is not often available. Strategies to influence the drivers’behavior are usually a better (or even the only viable) option in many scenarios. Methods forsynchronizing traffic lights are among the most effective in speeding transit and avoiding congestion.The synchronization problem is complex when dealing with real-world scenarios, thus computationalintelligence techniques are applied to find good quality solutions efficiently [6, 13, 14].
This article presents a parallel evolutionary algorithm (EA) for traffic optimization by synchro-nizing traffic lights in Garzón Avenue. We aim to provide an efficient and innovative solution,improving the quality of service offered to the citizens. Garzón poses a complex challenge due toan extensive urban area, a large number of crossings and traffic lights, rules for exclusive lanes, anddifferent types of traffic on the roads. The experimental results show that the proposed parallelEA improves the average speed of buses and vehicles when compared with the current scenario.
The main contributions of the research reported in this article include: i) a study of the problemof traffic light synchronization to streamline public transport; ii) the design and implementation ofa parallel EA that is able to efficiently solve the problem; and iii) the experimental evaluation ofthe proposed EA over realistic instances of the problem, created using real data collected in-situ.
The article is organized as follows. Section 2 presents the problem description. The proposedEA is described in Section 3. Section 4 presents the experimental analysis over realistic case studiesin Garzón area. The conclusions and the lines of current and future work are discussed in Section 5.
2 Public transport optimization via traffic light optimization
This section presents the problem model and its mathematical formulation.
2.1 Problem model
The problem model simplifies the reality, considering only those feaures relevant for traffic lightsynchronization. We build a map of the area and instances including real data collected in-situ.Simulations are used to evaluate the solutions. The methodology and tools used are described next.
Traffic simulator. We use SUMO [3], a free open-source traffic simulator that allows modelingstreets, vehicles, public transport, and traffic lights. SUMO applies a microscopic model, explicitlysimulating each element in the scenario. Based in a set of configuration files that represent the roadnetwork, vehicles, traffic, and traffic lights, SUMO generates output files with useful informationfrom the simulated scenario: simulation time, number and speed of vehicles, travel durations, etc.
Map. We used the Open Street Map (OSM) service [7] to design a map of the Garzón area,compatible with the SUMO simulator. The Java OSM Editor was used to adapt the map, keep-ing only the relevant elements for the problem. We validated the map by comparing it withdata gathered in-situ and from other services (Google Maps/Bing Maps). All inconsistencies de-tected were corrected in the map used in the research. The studied area includes Garzón Avenueand two parallel paths on each side (there are no real parallel streets, so we included a set ofparallel and internal roads, see Figure 1). Each parallel path includes two-way streets or twoone-way streets to guarantee connectivity. We imported the map from OSM and used the Net-Convert application to include real data for traffic lights collected in situ (see next paragraph).
CLAIO-2016
602

Figure 1: OSM (left) and SUMO map (right).
Field research: gathering real data fromtraffic lights and vehicles. The real data avail-able from the local government is scarce, so fieldresearch was needed to get the real traffic dataon five representative intersections of the stud-ied area. We applied the recommendations forvehicle counting by Smith and McIntyre [15] toavoid bias: counting vehicles on a working day(Wednesday), with sunny weather, and in rep-resentative hours (15:00 to 17:00). Additionaldata from traffic light configurations and traveltimes were collected by traveling (in bus andin car) on the studied scenario and also fromvideos recorded in the zone.
2.2 Mathematical formulation
The mathematical model is based on combining two relevant problem goals regarding the qualityof service provided to the users: the average speed for buses (sB) and the average speed for othervehicles (sO) in the studied scenario. We optimize (i.e., maximize) both speeds simultaneously, byapplying a linear aggregation approach defined by the fitness function f = wB × sB +wO × sO, tobe used for solution evaluation in the proposed EA. This way, we can focus on assigning a higherpriority to public transport (buses), by choosing appropriate values for weight wB.
The traffic speed optimization is performed not only on Garzón Avenue, but over the entire roadnetwork. Applying this global optimization approach is crucial to achieve a traffic light configurationthat guarantees a sustainable mobility improvement. This cannot be assured if the problem modelonly considers some streets (e.g., only Garzón Avenue) or optimizes each intersection separately.
2.3 Related works
A number of recent articles have addressed the optimization of BRTs by traffic light synchronizationusing evolutionary computing techniques. The most closely related publications are described next.
Sánchez et al. [14] applied an EA for traffic light synchronization to improve the traffic flowin a city scenario with 42 traffic lights and 20 output roads in Santa Cruz de Tenerife, España.Nine hand-made solutions from the City Hall are used as the initial population, and a traditionaltwo-point crossover is applied. The fitness function evaluates the travel time for vehicles in thesimulated road network. The evolutionary approach was able to improve up to 26% the trip timesover the City Hall solutions, but no details about the benefits for public transportation are reported.
Rouphail et al. [13] studied a small traffic network (9 crossings) in Chicago, USA, including busstops and real traffic data. The authors proposed an EA to control traffic lights, using a fitnessfunction that takes into account the delays and the length of the queues in each crossing. The EAwas able to reduce the delays in up to 44% when comparing against the non-optimized scenario.
The previous works apply a similar approach to the one we apply in our research. However,our study is performed over a larger scenario (6.5 km in Garzón Avenue, more than 30 km2), asignificantly larger number of intersections, 28 bus stops included in the zone, and specific mobilitylogic due to the BRT regulations (exclusive lines, priorities, and allowed/forbidden turning corners).
CLAIO-2016
603

3 A parallel EA for traffic light synchronization
This section describes the methodology and the parallel EA for traffic light synchronization.
3.1 Metaheuristics and evolutionary algorithms
Metaheuristics are high-level strategies for designing computational methods to find approximatesolutions for complex problems [11]. EAs are non-deterministic metaheuristic methods that emulatethe evolution of species in nature to solve optimization, search, and learning problems [2]. In thepast thirty years, EAs have been applied to solve many highly complex optimization problems.
EAs are iterative methods that apply stochastic operators on a set of individuals (the population)that encode candidate solutions for a problem. The initial population is generated randomly orusing a specific heuristic. A fitness value is assigned to every individual, indicating how good it isat solving the problem. Iteratively, probabilistic variation operators (recombination of individualsor mutations in their contents) are applied for building new solutions during the search. The searchis guided by a probabilistic selection-of-the-best technique to tentative solutions of higher quality.
Parallel models for metaheuristics and EAs have been proposed to speed up the computing timeof the search when dealing with complex objective functions and hard search spaces [1]. In thiswork, we apply a master-slave model for parallelization, to reduce the execution time of performingthe traffic simulations for the studied scenario. This work applies a traditional EA, implementedin C++ within the Malva library for optimization [5]. We included specific modifications in theMalva code in order to implement the parallel model for fitness evaluation using threads.
3.2 The proposed implementation
Solution encoding. The proposed encoding includes the elements needed for traffic light planning:i) the duration for each of the multiple phases allowed in every intersection, and ii) the offset,indicating the time the light cycle starts. All values are expressed in seconds. Figure 2 presentsan example of the solution encoding: the information is logically grouped into crossings, storingthe time for each phase (amber lights are omitted, as they do not affect the times of passingvehicles). The length of a representation depends on the number of crossings and the number ofphases defined. This encoding allows the overall optimization of the scenario (all intersections areoptimized simultaneously).
Fitness function. We apply the fitness function defined in Section 2, which accounts for theoptimization of the average speed of buses and vehicles over the defined scenario. Several weightcombinations are used to explore different priorities between buses and vehicles.
Population initialization. A set of initial solutions is built by using the data collected from thecurrent (non-optimized) reality on Garzón Avenue. Small perturbations (i.e., phase time and offsetchanges) are applied to provide diversity to the initial population.
Recombination. We apply a modified one point crossover: after selecting the crossover point,offspring are built by combining phases and offsets, trying to keep nearby crossings synchronized.
Mutation. Two mutation operators are applied: i) a Gaussian mutation to modify the valuesof phases; and ii) a random modification (according to a uniform distribution) of the offset values.Both mutations are applied according to a given mutation probability.
Selection and replacement. We use tournament selection (three individuals participate, onesurvives). The (µ+λ) evolution model is applied, where parents and offspring compete for survival.
CLAIO-2016
604

Figure 2: Example of the solution encoding applied in the parallel EA.
Parallel model. A master-slave model is applied for fitness function evaluation: a master processhandles the population and a pool of threads. In each generation, the master assigns a set ofsolutions to slave processes, executing in those threads. Slaves perform the simulations to evaluateeach traffic light configuration and return the results to the master, to be used in the evolution.
4 Experimental analysis
This section reports the experimental evaluation of the proposed EA for traffic optimization inGarzón Avenue. The analysis was performed on an AMD Opteron 6272 at 2.09GHz (64 cores,48GB RAM, CentOS Linux 6.5), from Cluster FING, Universidad de la República, Uruguay [10].
4.1 Problem instances
We designed realistic problem instances using data from the field research and from the city author-ities. A baseline scenario is built using the actual configuration of traffic lights in Garzón Avenue,to be used as a reference to compare the results computed by the proposed parallel EA.
Three XML files are used in the SUMO simulation: i) traffic light configuration, defining thelocation, phases and offsets; ii) vehicle routes, built in Traffic Modeler [12] using real data and amobility model that provides good granularity for traffic density; and iii) public transport details,including paths, frequencies, stop locations, and delay times in each stop. We collected data from allurban lines in the zone (G, D5, 2, 148 and 409 ), analyzed one month of GPS data (position/speed)from buses to determine mobility patterns and average speed in Garzón Avenue (14.5 km/h), andstudied videos to compute the delays (between 20 and 35 seconds, depending on the stop).
Three traffic patterns are studied: i) normal traffic, with data from the field research, including2000 vehicles and 70 buses; ii) low traffic, using data from weekends and night hours, having 1000vehicles and 70 buses, and significantly shorter delays on the bus stops because fewer people use thepublic transport; and iii) high traffic using data from rush hours, including 3000 vehicles and 70buses. Bus frequencies are not affected by the traffic density. All data was contrasted and verifiedwith the information provided by the city administration.
CLAIO-2016
605

4.2 Parameters setting
We studied the simulation time for the proposed scenarios and the best values for population size,stopping criterion, and probabilities of recombination (pR) and mutation (pM ) in the parallel EA.
To avoid bias, a different set of instances was used for the parameter setting analysis: low traffic,(500 vehicles/30 buses); normal traffic (1000 vehicles/60 buses); and high traffic, (2000 vehicles/120buses). Ten independent executions of the proposed EA were performed for each problem instance.
Simulation time. The best results were obtained using 4000 simulation steps, which represent66 minutes in reality, allowing more than 85% of the vehicles in the scenario to reach destination.
Stopping criterion. We try to balance the solution quality and the execution time of the proposedEA. As the fitness values did not vary significantly after 400 generations, we decided to use a limitof 500 generations, which demands between 1 and 24 hours of execution time.
Population size. We consider the quality of results, the execution time, and the computingelements available to find an appropriate population size in the proposed EA. We analyzed using32, 48, and 64 individuals. No significant improvements in the fitness values were detected whenusing larger populations, so we decided to use 32 individuals, to have the shorter execution times.
Operators probabilities. We explored all combinations of the candidate values pR ∈ {0.5, 0.8, 1},and pM ∈ {0.01, 0.05, 0.1}. A statistical analysis applying the Student t-test concluded that thecombinations (pR=0.5, pM=0.1) and (pR=0.5, pM=0.01) computed the best results. We chose theparameter configuration (pR=0.5, pM=0.01), which provides faster execution times.
4.3 Numerical results for Garzón Avenue
We performed 30 independent executions of the proposed EA for each problem instance studied,and compared the results against those obtained for the baseline scenario. The baseline results forthe comparison were computed by simulating the baseline scenario. We verified that the results foraverage speed and travel times matched those computed when processing the GPS data from thecity authorities, thus validating the proposed approach using simulations.
Table 1 reports the results of the optimization using the proposed parallel EA. Speeds areexpressed in km/h and improvements are computed over the results of the baseline scenario. Theparallel EA allows improving the average speed over the baseline scenario (for the three trafficpatterns studied) up to 24.2% (fitness), up to 15.3% (average bus speed), and up to 24.8%(average vehicle speed). We applied the Kruskal-Wallis test to analyze the results distributions. Theproposed parallel EA outperformed the baseline results with statistical significance in all scenarios.
Table 1: Numerical results of the proposed parallel EA.
instance
baseline scenario parallel EA results
sB sO fitness sB sOfitness fitness improvement
average±σ best average best
low traffic 15.89 32.45 13.42 17.92±0.18 34.30±0.40 14.50±0.14 14.88 8.04 % 10.8 %medium traffic 14.59 28.81 12.0 16.95±0.32 33.29±0.29 13.95±0.15 14.19 15.7 %0 17.7 %high traffic 14.31 26.36 11.30 16.51±0.61 32.90±0.25 13.72±0.17 14.04 21.40 % 24.2 %
Table 2 shows the results when using different weights to prioritize the speed of buses or vehicles.The results indicate that an additional 2% of improvement in the speed of buses can be achieved,with a negligible reduction on the speed of other vehicles (results in bold font).
CLAIO-2016
606
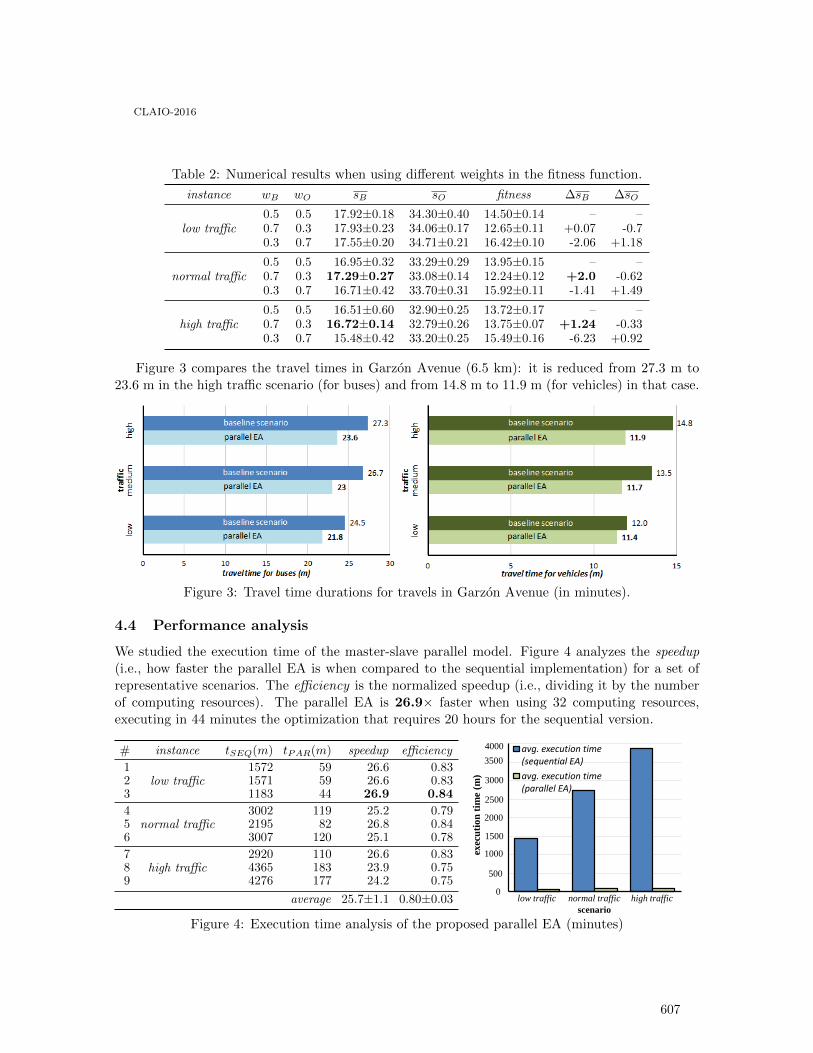
Table 2: Numerical results when using different weights in the fitness function.
instance wB wO sB sO fitness ∆sB ∆sO
low traffic0.5 0.5 17.92±0.18 34.30±0.40 14.50±0.14 – –0.7 0.3 17.93±0.23 34.06±0.17 12.65±0.11 +0.07 -0.70.3 0.7 17.55±0.20 34.71±0.21 16.42±0.10 -2.06 +1.18
normal traffic0.5 0.5 16.95±0.32 33.29±0.29 13.95±0.15 – –0.7 0.3 17.29±0.27 33.08±0.14 12.24±0.12 +2.0 -0.620.3 0.7 16.71±0.42 33.70±0.31 15.92±0.11 -1.41 +1.49
high traffic0.5 0.5 16.51±0.60 32.90±0.25 13.72±0.17 – –0.7 0.3 16.72±0.14 32.79±0.26 13.75±0.07 +1.24 -0.330.3 0.7 15.48±0.42 33.20±0.25 15.49±0.16 -6.23 +0.92
Figure 3 compares the travel times in Garzón Avenue (6.5 km): it is reduced from 27.3 m to23.6 m in the high traffic scenario (for buses) and from 14.8 m to 11.9 m (for vehicles) in that case.
Figure 3: Travel time durations for travels in Garzón Avenue (in minutes).
4.4 Performance analysis
We studied the execution time of the master-slave parallel model. Figure 4 analyzes the speedup(i.e., how faster the parallel EA is when compared to the sequential implementation) for a set ofrepresentative scenarios. The efficiency is the normalized speedup (i.e., dividing it by the numberof computing resources). The parallel EA is 26.9× faster when using 32 computing resources,executing in 44 minutes the optimization that requires 20 hours for the sequential version.
# instance tSEQ(m) tPAR(m) speedup efficiency
1low traffic
1572 59 26.6 0.832 1571 59 26.6 0.833 1183 44 26.9 0.84
4normal traffic
3002 119 25.2 0.795 2195 82 26.8 0.846 3007 120 25.1 0.78
7high traffic
2920 110 26.6 0.838 4365 183 23.9 0.759 4276 177 24.2 0.75
average 25.7±1.1 0.80±0.030
500
1000
1500
2000
2500
3000
3500
4000
low traffic normal traffic high traffic
exec
uti
on
tim
e (m
)
scenario
avg. execution time (sequential EA)
avg. execution time (parallel EA)
Figure 4: Execution time analysis of the proposed parallel EA (minutes)
CLAIO-2016
607

5 Conclusions and future work
This article presented a parallel EA to optimize public transport by synchronizing traffic lightsin Garzón Avenue, Montevideo, Uruguay. We considered several complex features of a real urbanzone to devise a methodology that apply real maps and data, analysis of GPS information, trafficmodeling and simulation, and computational intelligence for optimization. This is an innovativeapproach in our country, where intelligent transport systems have not been applied up to date.
The experimental analysis compared the parallel EA against the results from a baseline scenariothat models the current reality. The results indicate that the parallel EA is able to compute trafficlight configurations that accounts for a better quality of service, improving up to 15.3% the averagebus speed and 24.8% the average speed of vehicles. An additional improvement of 2% in the speedof buses is achieved when assigning a higher priority to this objective.
The master-slave parallel model was effective to reduce the execution times needed to solvethe problem, achieving speedup values of up to 26.9×, allowing to execute in 44 minutes theoptimization that would require 20 hours when using the sequential version.
The main lines for future work include studying infrastructure modifications in Garzón Avenue.The proposed methodology can also be applied for traffic optimization in other urban scenarios.
References
[1] E. Alba, G. Luque, and S. Nesmachnow. Parallel metaheuristics: Recent advances and new trends.Int. Trans. in Operational Research, 20(1):1–48, 2013.
[2] T. Bäck, D. Fogel, and Z. Michalewicz. Handbook of evolutionary computation. Oxford Univ., 1997.
[3] M. Behrisch, L. Bieker, J. Erdmann, and D. Krajzewicz. SUMO–Simulation of Urban MObility: AnOverview. In 3rd Int. Conf. on Advances in System Simulation, pages 63–68, 2011.
[4] A. Bull. Congestión de tránsito: el problema y cómo enfrentarlo. United Nations Publications, 2003.
[5] G. Fagúndez and R. Massobrio. The Malva Project: A framework for comutational intelligence in C++,2014. Online, http://themalvaproject.github.io, March 2016.
[6] J. Garcia-Nieto, A. Olivera, and E. Alba. Optimal cycle program of traffic lights with particle swarmoptimization. IEEE Transactions on Evolutionary Computation, 17(6):823–839, 2013.
[7] M. Haklay and P. Weber. OpenStreetMap: User-Generated Street Maps. IEEE Pervasive Computing,7(4):12–18, 2008.
[8] IMM. Plan de movilidad urbana, 2010. Online, http://www.montevideo.gub.uy, March 2016.
[9] D. McKenney and T. White. Distributed and adaptive traffic signal control within a realistic trafficsimulation. Engineering Applications of Artificial Intelligence, 26(1):574–583, 2013.
[10] S Nesmachnow. Computación cientıfica de alto desempeño en la Facultad de Ingenierıa, Universidad dela República. Revista de la Asociación de Ingenieros del Uruguay, 61:12–15, 2010.
[11] S. Nesmachnow. An overview of metaheuristics: accurate and efficient methods for optimisation.Int. Journal of Metaheuristics, 3(4):320–347, 2014.
[12] L. Papaleondiou and M. Dikaiakos. Trafficmodeler: A graphical tool for programming microscopictraffic simulators through high-level abstractions. In 69th Vehicular Technology Conf., pages 1–5, 2009.
[13] N. Rouphail, B. Park, and J. Sacks. Direct signal timing optimization: strategy development andresults. In XI Pan American Conf. in Traffic and Transportation Engineering, pages 195–206, 2000.
[14] J. Sánchez, M. Galán, and E. Rubio. Applying a traffic lights evolutionary optimization to a real case:“Las Ramblas” area in Santa Cruz de Tenerife. IEEE Trans. on Evolut. Comput., 12(1):25–40, 2008.
[15] D. Smith and J. McIntyre. Handbook of simplified practice for traffic studies. Technical Report 455,Iowa State University, 2002.
CLAIO-2016
608

Optimización de operaciones logístico-humanitarias para la
planificación ante desastres en la ciudad de Talcahuano, Chile
Francisco Núñez Cerda
Universidad del Bío-Bío
Rodrigo Linfati Medina
Universidad del Bío-Bío
Pablo Ortiz Núñez
Universidad del Bío-Bío
Resumen
La logística humanitaria se reconoce como un campo de estudio que aborda diversos aspectos logísticos y
operacionales que suceden en el contexto de la gestión del riesgo de desastres. Una de las actividades que
generan mayor atención en éste ámbito, corresponde a la asistencia hacia los posibles afectados desde un
punto de vista logístico. La presente investigación aplicada aborda la generación de rutas óptimas de
evacuación ante un tsunami, en conjunto con la posterior localización de albergues y centros de
abastecimiento en la ciudad de Talcahuano, Chile, mediante un algoritmo de programación matemática
basado en p-medianas capacitado y un sistema de información geográfico (SIG), cuyo objetivo
corresponde a la minimización de los tiempos totales de viaje. Finalmente, se efectuó el análisis de los
resultados obtenidos en virtud de instancias de aplicación con datos y escenarios reales en esta comuna.
Keywords: Logística humanitaria, rutas de evacuación, localización de albergues.
1 Introducción
En la actualidad, existen diversas conductas del ser humano que no contribuyen a la disminución del
riesgo de desastres, acrecentando la vulnerabilidad de numerosas localidades y exponiendo a sus
habitantes a amenazas propiciadas por la masiva urbanización carente de planificación urbana. En este
ámbito, convive el concepto de la gestión del riesgo de desastres, el cual se entiende como “un proceso
social complejo que conduce al diseño y aplicación de políticas, estrategias, instrumentos y medidas que
se orientan a impedir, reducir, prever y controlar los adversos efectos de fenómenos peligrosos sobre la
población, los bienes, servicios y el medioambiente” (Lavell, 2001).
En efecto, el problema planteado se origina debido a carencias de información referentes a la generación
de rutas de evacuación hacia zonas seguras, y a la localización de albergues de emergencia y posterior
asignación de personas afectadas hacia estos refugios, para dar respuesta a la necesidad de utilizar
herramientas, estrategias y metodologías adecuadas para el análisis de tales operaciones logístico-
humanitarias. Se considera capacidad en los conjuntos de albergues y almacenes de abastecimiento, así
como el tránsito a través de las redes viales en función de la rapidez de desplazamiento de las personas.
CLAIO-2016
609

Así pues, existen casos donde se utilizan diversas herramientas para buscar solución a las problemáticas
ocasionadas por los desastres a nivel mundial, considerando criterios de optimización en base a
localización (Ma, Li, He, Qi & Diao, 2012), ruteo (Hamedi, Haghani & Yang, 2012) o ambas (Chang,
Wu, Lee & Shen, 2014). En Saadatseresht, Mansourian y Taleai (2009) se aborda el uso de un modelo
multiobjetivo para planificar la evacuación de las personas afectadas por un desastre hacia una zona
segura, considerando por un lado el criterio de capacidad de éstas zonas, y por otro lado el criterio de la
distancia existente entre las personas y las zonas seguras, para así asignar la mayor cantidad de población
hacia estas zonas en el mínimo tiempo posible. En Guo, Lijun y Zhaohua (2014) se aborda la
optimización de las rutas de evacuación ante una emergencia, considerando el control del tráfico en
función de modelos de flujo y costo. En Wood, Jones, Schelling y Schmidtlein (2014), se expone una
propuesta de localización de refugios para desarrollar evacuación vertical ante tsunamis, en base a un
análisis geoespacial multicriterio con el apoyo de un sistema de información geográfico (En adelante,
SIG), considerando criterios demográficos, variables y atributos espaciales, tales como la infraestructura
territorial existente, la distancia recorrida y la pendiente del terreno, parámetros que configuran la rapidez
del desplazamiento de la población afectada. Por otra parte, en Forcael, González, Orozco, Vargas,
Pantoja y Moscoso (2014) se aborda el diseño de rutas de evacuación en modalidad caminata ante
tsunamis por medio de un algoritmo de optimización basado en colonias de hormigas, utilizando
estructura de redes. Este modelo es validado mediante el contraste con los tiempos de viaje obtenidos en
base a las rutas oficiales en la localidad evaluada, obteniendo diferencias favorables para el modelo.
En lo que respecta a este artículo, se evidencia en la literatura que la principal variable de decisión
estudiada corresponde al tiempo de viaje de la población, además de un uso mayoritario de algoritmos de
optimización y sistemas de información geográficos, con el objetivo de obtener resultados eficientes y
gráficos. El presente artículo tiene como propósito plantear herramientas para el apoyo a la toma de
decisiones, y exhibir sus ventajas para la planificación de contingencias ante desastres.
2 Materiales y métodos
En primer lugar se consideró un escenario de riesgo para la ciudad de Talcahuano, en base al Estudio de
Riesgos de Sismo y Maremoto para las comunas costeras de la región del Biobío (Laboratorio de Estudios
Urbanos, 2010). Específicamente, se consideró la ocurrencia de un tsunami que generaría un nivel de
inundación mayor a 2 metros para cierta porción de la población. Cabe destacar que en principio, gran
parte de la población acude a zonas seguras luego de un desastre, y solo las personas que resultan con sus
viviendas dañadas se refugian posteriormente en albergues. En virtud de lo anterior, se utilizó un SIG y
un modelo de programación matemática basado en optimización lineal.
Figura 1. Representación espacial de manzanas censales y sus centroides
En cuanto a la aplicación de localización de albergues y centros de abastecimiento (almacenes), se
considera un escenario de terremoto mayor a 8 Mw. Se define un conjunto de nodos que representa a la
CLAIO-2016
610

población afectada, los cuales corresponden a los centroides de las manzanas censales (Figura 1), nodos
que concentran la información de las viviendas afectadas por el evento en base a su materialidad (índice
irrecuperable), y necesariamente deben ser asignados a un albergue. Luego, se consideran otros dos
conjuntos adicionales, los cuales corresponden a los albergues potenciales y a los centros de
abastecimiento. Se consideró a los supermercados de la zona estudiada como centros de abastecimiento, y
a la red de colegios y escuelas de la localidad como albergues de emergencia. Una de las principales
características de esta aplicación se basa en la consideración de capacidad para todos sus conjuntos.
Con respecto a la identificación y generación de rutas de evacuación, éste procedimiento consta de la
selección de nodos orígenes (manzanas censales afectadas) y nodos destinos (puntos de acceso a las zonas
seguras), para luego evaluar la ruta más corta entre ellos (Dijkstra, 1959), en base a las redes viales de la
zona de estudio. Los nodos origen corresponden a la población afectada ante un desastre (centroides) los
cuales concentran en cada punto a la demanda agregada por refugio de cada manzana censal (Figura 1).
Los nodos destino para la generación de rutas se especifican mediante los puntos de acceso a las zonas
seguras ante tsunami, es decir, zonas con una altura mayor a 30 metros. Estos puntos de acceso han sido
definidos por el Departamento de Gestión del Riesgo de la Ilustre Municipalidad de Talcahuano, Chile.
La modalidad de evacuación es mediante caminata, por lo cual el objetivo es minimizar los tiempos de
traslado de las personas. Cabe destacar que en base a Laghi, Polo, Cavalleti y Gonella (2007), la
velocidad de desplazamiento que se utilizó corresponde a 1,2 m/s. Sin embargo, lo anterior se encuentra
afecto a las condiciones del terreno que dificultan el desplazamiento, dada por la naturaleza topográfica
de la zona de estudio, registrándose altas pendientes. En base a esta consideración, se generó un modelo
tridimensional para el cálculo de la pendiente promedio de cada segmento o arco de ruta. Así, se penalizó
la velocidad de desplazamiento de las personas en base a lo indicado en Laghi, et al. (2007).
2.1. Definición de la capacidad de un albergue de emergencia
Una propuesta de estimación de capacidad total por albergue se calcula en base al producto entre la
matrícula de alumnos de cada establecimiento y la superficie destinada para cada alumno en cada aula,
correspondiendo este último valor a 1,1m2 (MINVU, 1992). Este producto constituye el espacio total para
su uso como dormitorios. Luego, el valor resultante se divide por los 3,5m2 recomendados como el área
mínima por persona albergada (ESFERA, 2011). Lo anterior se explica mediante la siguiente ecuación:
𝑄 =𝑀 · 𝛼
𝛽
(1)
Donde:
Q: Capacidad de refugio (personas)
M: Matrícula total de alumnos del colegio o escuela (personas)
α: Superficie teórica utilizada por alumno en cada sala de clases (1,1m2 por persona)
β: Superficie teórica mínima por persona en un albergue (3,5m2 por persona)
Se establece que los albergues potenciales existentes en la comuna de Talcahuano ascienden a un total de
50, de los cuales solo 20 se encuentran en una zona sin riesgos. Según el parámetro definido, estos
albergues potenciales cuentan con una capacidad total de refugio que asciende a 3.510 personas.
2.2. Integración SIG y modelo matemático
En el desarrollo de la presente investigación se utilizó un SIG y un modelo de programación matemática
basado en optimización lineal, bajo un enfoque de articulación flexible (Malczewski, 2006). Los análisis
CLAIO-2016
611

resultantes del procesamiento de información por el SIG corresponden a la generación de rutas de
evacuación y a la generación de áreas de cobertura mediante el análisis de una red de proximidad.
Cabe destacar que éstos análisis se sustentan en rutinas de optimización internas, configuradas en base a
algoritmos exactos que tienen por objetivo la búsqueda de la ruta más corta entre orígenes y destinos
(Dijkstra, 1959). El modelo de programación matemática se formuló en base al algoritmo de las P-
medianas (Hakimi, 1964), sin embargo, se considera capacidad en todos sus conjuntos, tanto en las
manzanas afectadas, como en los albergues de emergencia y en los almacenes de abastecimiento. 3 Resultados
El primer escenario presentado fue resuelto utilizando el solver CPLEX 12.5.1.0, programado en lenguaje
AMPL Versión 20021031 (Win 32) e implementado en un equipo con procesador Intel ® Core™ i5-3337
CPU @ 1.80 Ghz y 6GB de memoria RAM. El segundo y tercer escenario se resolvieron mediante la
extensión Network Analyst de ArcGIS ® 10. Las cifras utilizadas provienen de bases de datos facilitadas
por el Laboratorio de Economía Espacial de la Universidad del Bío-Bío.
3.1. Escenario 1: Localización de albergues y centros de abastecimiento
Se realizó un pre procesamiento de información, eliminando los albergues y almacenes candidatos a ser
localizados que se encuentren en zonas de riesgos. En efecto, se tienen 20 albergues que constituyen una
oferta por refugio de 3.510 plazas para alojamiento, y 5 almacenes candidatos para el área de estudio, para
los cuales se definió un valor de capacidad estimativo de 2.000 kits de emergencia por almacén. La
demanda por albergues en esta instancia abarca un total de 56 manzanas censales, las cuales suman una
superficie total de 1,94 km2 y considera 2.058 habitantes a refugiar.
Figura 2. Localización de albergues y almacenes en instancia terremoto
Con respecto a los almacenes, se localizaron tres de cinco posibles. Se asignaron 53 de las 56 manzanas
censales originales a los albergues localizados, ya que 3 manzanas del conjunto no poseen habitantes. El
costo total de esta solución comprende un monto correspondiente a $491.996.096, lo que equivale a una
semana por refugio para los 2.058 habitantes estimados, por lo cual, el costo promedio de refugio por
persona al día asciende a $34.152. Cabe destacar que este costo se compone en un 59,1% de la
habilitación de albergues, costo que asciende a $290.706.096.
CLAIO-2016
612

3.2. Escenario 2: Representación de rutas de evacuación
En el segundo escenario analizado se considera la representación espacial de rutas de evacuación en base
a dos instancias: inundación por tsunami e inundación por desborde de cauces. Con respecto a la instancia
de inundación por tsunami, se tiene un total de 68 manzanas censales afectadas, lo cual impacta a 4.129
habitantes, mientras que en la instancia de inundación por desborde de cauces, se tiene un total de 19
manzanas censales afectadas, impactando a 2.282 habitantes. Se tiene un total de 33 accesos a zonas
seguras, distribuidos en distintos sectores del área de estudio.
Figura 3. Representación de las rutas de evacuación por tsunami
Los mayores tiempos de evacuación se registran en las zonas Base Naval (Zona norte Figura 3) y
Población San Marcos (Zona este Figura 3), ambos mayores a 30 minutos. Esta última posee un tiempo
de evacuación promedio de 44,03 minutos, y se reconoce como una zona crítica ya que fue afectada
severamente en el terremoto y tsunami del año 2010. Lo anterior debido a que se encuentra solo a 1 km de
distancia del mar, y es una de las zonas más lejanas a los puntos de encuentro. Las 65 rutas generadas
convergen en 10 puntos de encuentro seleccionados. Los tiempos de evacuación totalizan 1.647,8
minutos, y promedian 25,34 minutos desde las manzanas afectadas hacia los accesos.
Figura 4. Tiempos de evacuación por tsunami
0
20
40
60
80
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65
Tie
mp
o (
min
uto
s)
Rutas generadas (unidades)
Tiempo (min)
CLAIO-2016
613

3.3. Escenario 3: Análisis de tiempos de cobertura y proximidad
En el tercer escenario analizado se considera la representación espacial de los tiempos de cobertura de
evacuación ante tsunami, y un análisis de proximidad hacia los accesos a las zonas seguras mediante áreas
de influencia. Para la instancia de inundación por tsunami, se trabajó en base a la red vial bajo modalidad
caminata, y además se consideró como base el análisis realizado en el escenario previo, al igual que los
puntos de encuentro o accesos a zonas seguras.
La generación de áreas de cobertura se basó en la identificación de un conjunto de nodos a analizar. En
este caso este conjunto se definió como los centroides asociados a las manzanas censales afectadas ante
un desastre. Posteriormente se definieron los intervalos de tiempo que se representarían espacialmente,
los cuales corresponden a tiempos menores a 5, 10 y 15 minutos, asociados a los colores verde, amarillo y
rojo, respectivamente, emulando una evacuación desde los centroides señalados anteriormente. Cabe
destacar que son 15 minutos los definidos por la autoridad como tiempo máximo para alcanzar una zona
segura ante tsunami, desplazándose a pie (ONEMI, 2014). El objetivo de este análisis es dar cuenta del
alcance real que tiene la población al efectuar procedimientos de escape ante una emergencia o desastre,
ya que existen variables que influyen determinantemente en los tiempos de ejecución de esta tarea, tales
como la consideración de la red vial, o la consideración de la pendiente del terreno, ya que no es lo mismo
simular una evacuación en una emergencia con distancias lineales dejando de lado la accesibilidad de las
rutas, y mucho menos en condiciones ideales de planicie, especialmente en territorios con presencia de
considerables relieves como Talcahuano.
Figura 5. Representación de tiempos de cobertura de evacuación por tsunami
El último análisis de este escenario consiste en la exposición de las zonas críticas del área de estudio ante
un tsunami. Es así como en la Figura 7 se presenta la red de proximidad hacia éstas zonas seguras o
puntos de encuentro. La presente red de proximidad se creó en virtud de los tiempos de llegada desde
todos los posibles orígenes hasta los accesos a las zonas seguras definidas. Se presentan las coberturas
correspondientes a los tramos de tiempo de evacuación menores a 5, 10 y 15 minutos, y mayores a 15
minutos, todo lo anterior sobre la red vial de la comuna de Talcahuano.
CLAIO-2016
614

Figura 6. Red de proximidad a zonas seguras ante tsunami
Se identifican zonas que poseen proximidad a una zona segura en menos de 15 minutos casi en su
totalidad, tales como el sector Centro y el sector de Las Higueras, sin embargo se evidencia que una gran
porción de la red se encuentra dentro del intervalo de tiempo de acceso mayor a 15 minutos,
específicamente, un 55,3% del total. Es posible exponer que de los sectores con mayor criticidad, el sector
Salinas es nuevamente el más afectado. En virtud de lo anterior, se propone considerar la implementación
de medidas de mitigación y/o mayores alternativas de evacuación para esta área en particular, como por
ejemplo, el acondicionamiento necesario para la realización de evacuaciones verticales, presentándose
como una gran oportunidad de mejora dadas las altas condiciones de exposición evidenciadas.
4 Conclusiones
La implementación de herramientas de optimización aplicadas en el ámbito de la logística humanitaria
constituye un insumo relevante para la toma de decisiones y la planificación de las operaciones de
emergencia ante desastres. Se revelaron ciertas brechas en torno a los niveles de seguridad y exposición a
riesgos existentes en la zona de estudio, además de sus capacidades e infraestructura disponible. Se
establece que en la zona analizada existe un total de 50 albergues potenciales constituidos por colegios y
escuelas. De esta cantidad, 20 albergues se encuentran en zonas sin exposición a riesgos, y su oferta de
refugio totaliza 3.510 plazas de alojamiento. Se identifica que en el sector de Los Cerros de Talcahuano
existe una carencia de albergues potenciales ante el escenario de terremoto analizado, ya que la población
afectada de esta zona tardaría aproximadamente 140 minutos en llegar al refugio más cercano. Por otra
parte, un 55,3% del total de la población de Talcahuano no lograría llegar a una zona segura ante un
tsunami de proporciones, es decir, tardaría más de 15 minutos en lograrlo. Específicamente, una de las
zonas más vulnerables identificadas corresponde al sector Salinas, ya que este territorio posee un tiempo
promedio de llegada a los puntos de encuentro de 44,03 minutos, constituyéndose prácticamente en una
zona de sacrificio ante un tsunami.
Finalmente, la capacidad de escalar las metodologías utilizadas en esta investigación da pie para
fortalecer el sistema nacional de gestión del riesgo de desastres, previniendo y mitigando los futuros
daños que los desastres que se avecinan generarán.
Sector Salinas
Sector Higueras
Sector Centro
Sector Medio Camino
Sector Los Cerros
CLAIO-2016
615

Referencias 1. Chang, F., Wu, J., Lee, C., Shen, H. Greedy-search-based multi-objective genetic algorithm for emergency
logistics scheduling. Expert Systems with Applications, 41(6):2947–2956, 2014.
2. Dijkstra, E. A note on two problems in connexion with graphs. Numerische Mathematik, 1(1):269-271.
1959.
3. ESFERA. Carta humanitaria y normas mínimas para la respuesta humanitaria. 3ª ed. Reino Unido,
Practical Action Publishing. 450p, 2011.
4. Forcael, E., González, V., Orozco, F., Vargas, S., Pantoja, A., Moscoso, P. Ant colony optimización model
for tsunamis evacuation routes. Computer-Aided Civil and Infrastructure Engineering, 29:723-737, 2014.
5. Guo, L., Lijun, Z., Zhaohua, W. Optimization and planning of emergency evacuation routes considering
traffic control. The Scientific World Journal, Vol. 2014, 15p, 2014.
6. Hakimi, S. Optimal location of switching centers and the absolute centers and medians of a graph,
Operations Research, 12:450–459, 1964.
7. Hamedi, M., Haghani, A., Yang, S. Reliable transportation of humanitarian supplies in disaster response:
model and heuristic. Procedia – Social and Behavioral Sciences, 54:1205–1219, 2012.
8. Laghi, M., Polo, P., Cavalletti, A., Gonella, M. G.I.S. Applications for Evaluation and Management of
Evacuation Plans in Tsunami Risk Areas. European Geosciences Union General Assembly 2007. Vienna,
Austria, 2007.
9. Lavell, A. Sobre la gestión del riesgo: Apuntes hacia una definición. San José, Costa Rica, 2001.
10. Laboratorio de Estudios Urbanos. Estudio de riesgos de sismos y maremotos para comunas costeras de la
Región del Biobío. Universidad del Bío-Bío. Concepción, Chile, 2010.
11. Ma, C., Li, Y., He, R., Qi, B., Diao, A. Research on location problem of emergency service facilities based
on genetic-simulated annealing algorithm. International Journal of Wireless and Mobile Computing,
5(2):206–211, 2012.
12. Malczewski, J. GIS‐based multicriteria decision analysis: a survey of the literature. International Journal of
Geographical Information Science, 20(7):703-726, 2006.
13. MINVU. Ley General de Urbanismo y Construcción. Santiago, Chile, 1992. Recuperado en
http://www.leychile.cl/Navegar?idNorma=8201
14. MINVU. Plan de Reconstrucción MINVU. Santiago, Chile, 2010. Recuperado en
http://www.minvu.cl/opensite_20111122105648.aspx
15. ONEMI. Mesa técnica interinstitucional de recomendaciones para la preparación y respuesta ante
tsunamis. Recomendaciones para la preparación y respuesta ante tsunamis. Santiago, Chile, 2014.
Recuperado en http://www.shoa.cl/manual_de_tsunami/manual_de_tsunami.pdf
16. Saadatseresht, M., Mansourian, A., Taleai, M. Evacuation planning using multiobjective evolutionary
optimization approach. European Journal of Operational Research, 198(1):305-314, 2009.
17. Wood, N., Jones, J., Schelling, J., Schmidtlein, M. Tsunami vertical-evacuation planning in the U.S. Pacific
Northwest as a geospatial, multi-criteria decision problem. International Journal of Disaster Risk
Reduction, 9:68-83, 2014.
CLAIO-2016
616

MCDA applied to project and project managers
classification: an integrated method to allocate
projects
Elaine Cristina Batista de OliveiraIFPB - Campus João Pessoa, Brasil
Tecnologico de Monterrey, Campus Toluca, Mé[email protected]
Luciana Hazin AlencarUniversidade Federal de Pernambuco, Brasil
Ana Paula Cabral Seixas CostaUniversidade Federal de Pernambuco, Brasil
Abstract
This paper puts forward a framework to support the process of allocating projects in line withan organizations restrictions by using mathematical programming. The model was formulatedafter reviewing the literature and being guided by the findings of searches; an MCDA methodwas used to classify projects and PMs (first stage) and mathematical programming to allocateprojects (second stage) and subsequently information on the learning effect was added as avariable to the model. An application of the proposed model was implemented at a Brazilianelectric energy company. The results demonstrated that projects and project managers canbe classified into definable categories, thereby enabling the process of project allocation to beundertaken more effectively and doing so in a systematic and more efficient way. The proposedmodel can support an organization by allocating its most critical projects to its best qualifiedand experienced professionals whose performances have been successful.
Keywords: MCDA; Project Management; Allocation Problem.
1 Introduction
It is recognized that choosing and allocating resources affects an organization’s strategy for inducingthe good performance of innovations, especially in portfolio management [12]. In the context ofprojects, the importance that a project manager (PM) has in bringing about the success of aproject, is well known [14], which makes the decision on how best to allocate projects of criticalimportance. Because of the complexity of projects, assessing what activities they demand with aview to assigning an appropriate PM is a difficult task [16]. Evaluating PMs and matching them to
CLAIO-2016
617

projects requires the use of multiple criteria decision aid (MCDA) because after establishing the setof criteria, the preferences of the organization can be used to evaluate the alternatives [7]. Thus,selecting where best to allocate a PM in accordance with the needs of a project is also a multiplecriteria problem [9]. Methodologies to evaluate and choose a PM have been developed and somemodels can be found in [16, 17, 22, 9]. These models are summarized in the next section which isa Literature Review. Although past experience of using a given PM to manage projects has beenrecognized as an important factor when assigning him/her to new projects [10], the studies founddo not adopt this view as a variable in the assignment process. Therefore, in our proposal, thelearning curve (also called a learning effect) that a PM has undergone because of past experiencewhen managing similar projects, is incorporated as an efficiency factor that reduces the time asuccessful PM needs to manage similar projects in future. Due to the scarcity of experienced andsuccessful PMs, it is very common for the same PM to manage multiple projects at the same time.Therefore, they are engaged on multi-tasking. This results in a phenomenon called switchover timeloss, namely the time lost when switching attention from one activity to another [5, 17]. This isan important factor that should be considered when allocating projects, so it has been added toour model. Finally, a PM’s workload and time left available to undertake projects must also betaken into account, since it is very common for a PM to accumulate other roles or functions in acompany [13, 18]. This paper sets out to present a framework to allocate projects in accordancewith a multiple criteria analysis to match PM’s competences to the needs of a set of projects. Thefinal allocation uses mathematical programming to optimize the allocation of resources. The firstpart of the paper reviews studies on project allocation, PM selection and criteria to classify projectsand PMs. The second part describes the method proposed, the stages and the variables chosenfor allocating projects and an empirical application in an electric energy company. The final partof the paper discusses some limitations of this methodology, draws some conclusions and makessuggestions for further research.
2 Literature Review
To manage a set of projects and/or programs together more efficiently and to do so while meetingthe strategic business needs of a company, a project portfolio has, inter alia, to prioritize theresources available between its projects [21]. This gives rise to the need for a Project ManagementOffice - PMO, led by a Project Management Officer - PMOr, whose responsibilities can rangefrom providing support to PMs to actually being responsible for the management and results ofthe projects [20]. In the literature on project allocation, a few such studies can be found. [16]present a model that uses a set of project requirements and evaluates PMs as to their experience,managerial knowledge and leadership. To do so, they used Quantitative Matrix Strategic Planning,which calculates a score representing the degree of association between the characteristics of aproject and a set of PMs, thus generating a list of PMs with the most suitable profiles. [17]developed a model that considered the strategic importance of projects, the resource limitations,the interdependencies between projects and their interactions, and the availability of PMs. Todefine a set of criteria, a multi-case study was conducted using the Delphi method and the finalallocation was made by using a integer linear programming (ILP) model. The model developedby [11, 22] made use of fuzzy sets, artificial neural networks and genetic algorithms to evaluateprojects and PMs, according to attributes and scores; at the end of the process, it generates a listof managers who were later interviewed in order to make the final allocation. Finally, [24] developed
CLAIO-2016
618

a method that uses DEA - Data Envelopment Analysis to explore PM’s skills and experience so asto identify the best way to allocate projects after analyzing PMs previous performance in projectmanagement in past cycles. The objectives of the projects are modeled on mathematical functionsso as to achieve the maximum expected contribution per project. Thereafter, in accordance with theresults of their performance, PMs are allocated to projects. In these models, the learning effect wasnot considered as a variable to be included in the parameters. From our point of view, a PM’s pastexperience must be considered in the project assignment process, because such experience, is highlybeneficial both when reorganizing tasks that were poorly structured, and when conducting theseand other complex tasks [1]. The learning effect represents the process of acquiring experience as aconsequence of having performed similar tasks. As a result of the learning effect, the time requiredto perform subsequent tasks is decreased [4]. In the project management field, approaches thathave been widely used, for example are models: to evaluate productivity [23], to plan developmentprojects [6], for IT projects that seek to maximize an organization’s productivity gains [15], forprojects on implementing new technologies [19], for aircraft projects [8] and there is a large numberof other applications [2]. In the project allocation process, multi-tasking has been studied and canbe defined as and when it is necessary to shift attention to multiple tasks simultaneously, sincethis leads to a reduction in a PM’s performance when compared to his/her implementing activitysequentially [3]. Specifically, in project management the switchover time loss was measured [17]and can be inferred by Sn, which represents the switchover time-loss of PMn, as represented inEquation (1):
Sn =
{1.5Yn + 4.5 if Yn > 1
0 otherwise,(1)
where Yn is total number of projects allocated to PMn minus 1.
3 Proposed method for allocating projects
The proposed model was developed in two main processes; the first one focuses on classifying theprojects and PMs and the objective of the second is to allocate each project to a PM. So, theassumptions of the model are:i. The projects must be allocated according to a multiple criteria analysis that evaluates theproject’s characteristics and PMs’ competences;ii. PMs can be allocated to more than one project, or even to no projects;iii. The workload cannot be more than that for which the PM has available time.
The MCDA classification starts by defining the set of criteria that will be used to evaluate theprojects’ characteristics and the PMs’ competences. After having defined the MCDA method forclassification, the following must be chosen: the parameters, classes, decision-maker and weights tobe used in order to aggregate the organization’s preferences. Then the information about projectsand PMs should be collected for evaluation and application of an MCDA. This phase should receiveassistance from an analyst in multiple criteria decision-making. The result is a classification ofprojects and PMs into different classes. This paper suggests the creation of three classes for PMsand projects, where Class 1 is for the most critical projects, Class 2 for critical projects whileClass 3 consists of non-critical projects; in the same way, Class 1 is for senior PMs, Class 2 for
CLAIO-2016
619

PMs with average experience and Class 3 for junior PMs. For an example of this process see [5].After having defined the classification of projects and PMs, the linear programming can be applied.When making assumptions about the hours necessary to conduct a project, information about anyprior experience on previous similar projects i.e. the value of the learning effect should be addedwith a view to reducing the time needed to manage new projects.
The 2nd process now begins by entering data into the optimization model. The values of theEF for each PM should now be entered into the optimization model. The objective function isto minimize the number of hours (H) allocated to the projects. The model can be represented byEquation (2) :
MinH =M∑
m=1
N∑
n=1
tmnpmn, (2)
where n = 1, ..., N is the PM number; m = 1, ...,M is the project number; tmn represents thenumber of hours that PMn needs to manage the project m; pmn, the decision variable, equals 1 ifproject m is allocated to manager n, 0 otherwise. In Equation (3), thn represents the total hoursthat PMn has available to manage projects. Defining Yn = (
∑M(m=1) pmn − 1), Sn holds.
The objective function it has the following resource availability constraints:
M∑
m=1
tmnpmn ≤ thn − Sn, n = 1, . . . , N. (3)
The model was applied in a Electrical Energy Company and the results are presented bellow.The project criteria were considered according to Table 1.
Table 1: Project CriteriaCode Description
c1 Complexity: In terms of cost and number of departments involved.c2 Resources: Number of man-hours.c3 Rate of development (pace): How urgent is the project.c4 Contribution to organizational strategy: Degree to which the project contributes
to fulfilling organizational goals.c5 Technologies: If the project use well-established technologies.
The PMOr along with the analyst made an analysis of existing methods for classification, andthe possibilities and goals being set by the PROMSORT method.
The results of the project classification are presented on Table 2. As for projects, the PMs wereevaluated in accordance with a set of criteria, see Table 3.
The classification results after using PROMSORT, are presented in Table 4.Then, a matrix was formatted with time to manage the PMs’ information on projects considering
the Efficiency Factor and finally the linear program was applied. The results of the allocation arepresented in Table 5.
Projects P1, P13, P16, P17, P18, P19, P23, P24, P35 e P39 were not allocated because of theworkload restriction. The allocation results show that the company has a problem since the numberof PMs available is less than the projects need.
CLAIO-2016
620

Table 2: Project ClassificationClass Project Classification
Class 1 P44, P46, P47.Class 2 P1, P2, P3, P4, P5, P6, P7, P8, P9, P10, P11, P13, P14, P16, P17, P18, P19,
P21, P23, P24, P25, P27, P28, P29, P30, P32, P33, P35, P36, P37, P38, P39,P40, P41, P42, P43, P47, P48, P49.
Class 3 P12, P15, P20, P22, P26, P31, P34.
Table 3: Project Manager CriteriaCode Description
c1 Experience as a PM: years of experience in leading projects.c2 Training Level: bachelor’s, specialization diploma, master’s and/or a doctorate.c3 Knowledge and use of technical and project management tools: years in experience
in project management .c4 Focus on the customers’ needs: the percentage of projects that have been success-
fully managed.c5 Ability to solve problems: Number of problems solved/recorded number of system
problems.c6 Project manager Maturity: Number of managed projects in the last five years.c7 Commitment: Measured by an average grade according to the evaluation that the
PM must report to PMO.c8 Size of previous projects: project largest previously managed project in terms of
cost.c9 Project complexity experience: maximum number of departments involved in
projects previously managed by the PM.c10 Negotiation: this criterion took account of previous experience in managing
projects with a large team of experts from different backgrounds.
Table 4: Project Manager ClassificationClass PM Classification
Class 1 PM2, PM7, PM8.Class 2 PM1, PM 3, PM5, PM6, PM9, PM10, PM12, PM16.Class 3 PM4, PM11, PM13, PM14, PM15.
CLAIO-2016
621

Table 5: Project AllocationPM ID Project Allocation
PM1 P14, P27, P33, P37PM2 P5, P47PM3 P8,P10,P40,P48PM4 P22PM5 P6,P11,P29PM6 P3, P41,P43,P49PM7 P25,P44PM8 P38,P46PM9 P30PM10 P20,P26,P28,P42,P45PM11 P15PM12 P4,P9,P21,P32PM13 P12PM14 P31PM15 P34PM16 P2,P7,P36
4 Conclusions
In the project management context, how best to allocate human resources still remains a field to befurther explored in order to find methods or systems to help organizations to improve their efficiency.This study contributes a method developed with operational tools to process the allocation ofhuman resources, which provides the decision maker with an aid for this difficult task. A majoradvantage of this method is that in addition to helping in this process, it also serves as a diagnostictool of organizational needs. For example, the application showed that there is a shortage ofexperienced PMs in the company, resulting in a work overload for the more experienced PMs.Nevertheless, by using an optimization process, this problem is reduced. For future studies, it isrecommended that the MCDA application be undertaken when there are multiple decision makers.Similarly, another future study could investigate if this method produces more realistic, aggregate,probabilistic variables as this would also enhance the process described in this paper.
References
[1] M Abdolmohammadi and A Wright. An examination of the effects of experience and taskcomplexity on audit judgments. Accounting Review, 62(1):1–13, 1987.
[2] Michel Jose Anzanello and Flavio Sanson Fogliatto. Learning curve models and applications:Literature review and research directions. International Journal of Industrial Ergonomics,41(5):573–583, 2011.
[3] T Buser and N Peter. Multitasking. Experimental Economics, 15(4):641–655, 2012.
CLAIO-2016
622

[4] Albert Corominas, Jordi Olivella, and Rafael Pastor. A model for the assignment of a setof tasks when work performance depends on experience of all tasks involved. InternationalJournal of Production Economics, 126(2):335–340, 2010.
[5] Elaine Cristina Batista de Oliveira, Luciana Hazin Alencar, and Ana Paula CabralSeixas Costa. An integrated model for classifying projects and project managers and projectallocation: A portfolio management approach. International Journal of Industrial Engineering,22(3):330–342, 2015.
[6] Colin Eden, Terry Williams, and Fran Ackermann. Dismantling the learning curve: the roleof disruptions on the planning of development projects. International Journal of Project Man-agement, 16(3):131–138, 1998.
[7] H. Eilat, B. Golany, and A. Shtub. R&D project evaluation: An integrated DEA and balancedscorecard approach. Omega, 36(5):895–912, 2008.
[8] E Gholz. Eisenhower versus the spin-off story: Did the rise of the military-industrial complexhurt or help america’s commercial aircraft industry? Enterprise & Society, 12(1):46–95, 2011.
[9] Yossi Hadad, Baruch Keren, and Zohar Laslo. A decision-making support system module forproject manager selection according to past performance. International Journal of ProjectManagement, 31(4):532–541, 2013.
[10] Katharina Hölzle. Designing and implementing a career path for project managers. Interna-tional Journal of Project Management, 28(8):779–786, 2010.
[11] Fateme Jazebi and Abbas Rashidi. An automated procedure for selecting project managers inconstruction firms. Journal of Civil Engineering and Management, 19:97+, 2013.
[12] Ronald Klingebiel and Christian Rammer. Resource allocation strategy for innovation portfoliomanagement. Strategic Management Journal, 35(2):246–268, 2014.
[13] A. J. Kuprenas, C.L. Jung, S. A. Fakhouri, and G. W. Jreij. Project managerworkload-assessment of values and influences. Project Management Journal, 31(4):44–51, 2000.
[14] J. R. Meredith and Jr Mantel, S. J. Project management—A management approach. J Wiley,New York, 8rd edition, 2011.
[15] Ojelanki Ngwenyama, Aziz Guergachi, and Tim McLaren. Using the learning curve to max-imize it productivity: A decision analysis model for timing software upgrades. InternationalJournal of Production Economics, 105(2):524–535, 2007.
[16] Stephen Ogunlana, Zafaar Siddiqui, Silas Yisa, and Paul Olomolaiye. Factors and proceduresused in matching project managers to construction projects in bangkok. International Journalof Project Management, 20(5):385–400, 2002.
[17] P. Patanakul, D. Z. Milosevic, and T. R. Anderson. A decision support model for projectmanager assignments. Engineering Management, IEEE Transactions on, 54(3):548–564, 2007.
CLAIO-2016
623

[18] Peerasit Patanakul and Dragan Milosevic. The effectiveness in managing a group of multipleprojects: Factors of influence and measurement criteria. International Journal of ProjectManagement, 27(3):216–233, 2009.
[19] Malgorzata Plaza, Ojelanki K. Ngwenyama, and Katrin Rohlf. A comparative analysis of learn-ing curves: Implications for new technology implementation management. European Journalof Operational Research, 200(2):518–528, 2010.
[20] PMI. A guide to the project management body of knowledge PMBoK GUIDE: Project Man-agement Institute. 2008.
[21] Institute Project Management. The Standard for Portfolio Management. Project ManagementInstitute, 2013.
[22] A Rashidi, F Jazebi, and I Brilakis. Neurofuzzy genetic system for selection of constructionproject managers. Journal of Construction Engineering and Management-Asce, 137(1):17–29,2011.
[23] HR THOMAS, CT MATHEWS, and JG WARD. Learning-curve models of construction pro-ductivity. Journal of Construction Engineering and Management-Asce, 112(2):245–258, 1986.
[24] Yan Xu and Chung-Hsing Yeh. A performance-based approach to project assignment andperformance evaluation. International Journal of Project Management, (0), 2013.
CLAIO-2016
624

Planificación jerárquica de la producción
con demanda estacional y distribución uniforme
Virna Ortiz-Araya
Grupo de Investigación en Agronegocios. Departamento de Gestión Empresarial. Facultad de
Ciencias Empresariales.
Universidad del Bío-Bío. Chillán. Chile.
Víctor M. Albornoz
Departamento de Industrias, Campus Santiago Vitacura.
Universidad Técnica Federico Santa María. Santiago. Chile.
Resumen
La planificación jerárquica de la producción es una metodología empleada para sincronizar las decisiones
a nivel táctico con aquellas más detalladas a nivel operacional. En este artículo se presentan diferentes
modelos de optimización para una estructura jerárquica conformada por tres niveles, tomando en cuenta
aspectos del proceso productivo y de la cadena de suministro. El primer modelo trata un problema de
planificación agregada de producción con demanda estacional bajo incertidumbre utilizando la
programación estocástica con recurso multi-etapa, determinando el plan maestro de producción. Un
segundo modelo determinista desagrega las decisiones a nivel de detalle por familia de productos, que en
un tercer modelo determina los volúmenes a elaborar y distribuir por cada producto final y tipo de cliente.
Estos modelos son aplicados a un caso de estudio de artículos de escritorio obteniendo resultados que
muestran la pertinencia y validez de la metodología propuesta.
Palabras claves: planificación de la producción; planificación jerárquica de la producción; planificación
agregada de la producción; modelos con recurso de programación estocástica multi-etapa.
1 Introducción
El concepto de planificación jerarquizada de la producción (HPP: Hierarchical Production Planning) ha
sido tratado por numerosos autores. Es posible identificar publicaciones que tratan esta metodología,
analizando y explicando la manera en la cual puede ser implementada en un sistema de producción.
Diferentes trabajos toman como base la propuesta realizada por Bitran and Hax [4] probando la robustez,
coherencia y factibilidad en los procesos de desagregación [2][9][13][16][18][1]. Otros autores analizan
las ventajas y limitaciones que proporciona el uso de una estructura HPP aplicándola a casos industriales
como: agroalimentaria [8], fabricación de cajas metálicas [14], producción de calzado [6], múltiples
productos y múltiples máquinas [17], semiconductores [5], productos de librería [15], entre otros.
La demanda usualmente determina la complejidad de los modelos que utilizan una estructura HPP. En la
mayoría de los casos, a nivel agregado esta demanda es considerada como una demanda previsional sobre
un horizonte de planificación de mediano o largo plazo. En cambio, a nivel de detalle, puede ser conocida
para un periodo fijo. Estudios como [11][12][19] establecen que una de las principales causas en la
generación del efecto “bola de nieve” (Bullwhip effect) se debe a la incertidumbre presente en las
demandas. Con el propósito de poder controlar esta incertidumbre, se establece una metodología de
planificación jerarquizada que consta de un primer modelo de programación estocástica multi-etapa ante
CLAIO-2016
625

una demanda estacional bajo incertidumbre [3], representada por una distribución uniforme para cada tipo
de familia. Este modelo es resuelto mediante el algoritmo de Casey and Sen [7], que al cabo de las
iteraciones resultantes aproxima esta distribución uniforme mediante un árbol de escenarios que le
representa en términos discretos. El empleo de un modelo de esta naturaleza permite adoptar aquellas
decisiones más inmediatas del horizonte de planeación tomando en cuenta no solo el comportamiento
dinámico y estacional de las demandas futuras sino también ante posibles escenarios futuros para estas
mismas de acuerdo a la distribución asumida.
En lo que sigue, el artículo se estructura de la siguiente manera: en la Sección 2 se presenta los modelos
de planificación utilizados para cada nivel jerárquico, en la Sección 3 se muestra el caso de estudio con
los resultados y análisis obtenidos y, finalmente, en la Sección 4 se entregan las conclusiones del trabajo
así como las expectativas de estudio futuro.
2 Modelos de planificación jerarquizada
El plan agregado de planificación se aborda mediante un modelo lineal de programación estocástica
multi-etapa en variables entera-mixta, asumiendo una demanda con estacionalidad bajo condiciones de
incertidumbre más allá del horizonte que determinan las decisiones más inmediatas que habrán de ser
desagregadas a un nivel detallado. Este modelo provee un plan agregado para tipos de familias que busca
minimizar los costos esperados de producción, inventario, pendientes y mano de obra asociado a los
distintos turnos en cada máquina o taller. El caso de estudio, en particular, considera 10 tipos de familias
y un horizonte de planeación de 12 meses. La demanda presenta una gran estacionalidad, siendo el mes de
Julio el de menor demanda y teniendo el mayor incremento para los meses de Enero, Febrero y Marzo.
La incertidumbre se modela como un proceso estocástico en tiempo discreto que como resultado del
propio esquema de resolución del modelo queda representado finalmente por un número finito de
escenarios denotados por s ϵ S, donde S es el conjunto de todos los posibles escenarios. Así, los
escenarios especifican la demanda de cada tipo de familia en cada etapa y donde las decisiones dependen
igualmente de estos escenarios. El modelo propuesto considera la siguiente notación os parámetros
asociados a la demanda son denotados de la siguiente forma:
Conjuntos e índices
F: Conjunto de tipos de familias de productos finales.
i: Índice del tipo de familia de productos, iF.
T: Número de etapas del horizonte de planificación.
t: Etapas, t=1,2,….,T.
M: Total de máquinas disponibles para el proceso productivo.
m: Índice de máquina en uso, m=1,2,…,M.
P[m]: Conjunto de tipos de familias que utilizan la máquina m.
h: Índice del turno de trabajo, h=1,2,3.
Parámetros
dits: Demanda de la familia tipo i en la etapa t dado el escenario s.
ps: Probabilidad asociada al escenario s.
rmht: Costo de operar la máquina m en turno h durante la etapa t.
ntmt: Costo de iniciar un nuevo turno en la máquina m en la etapa t.
I0i: Inventario inicial del tipo de familia i.
ctmt: Costo de dejar de operar un turno en la máquina m en la etapa t.
fit: Costo por postergar la demanda del tipo de familia i en t.
phri: Unidades elaboradas del tipo de familia i por hora.
hrtmht: Horas disponibles en la máquina m para turno h en la etapa t.
dht: Días laborales para la etapa t.
Variables de decisión
Xits: Volumen elaborado de la familia tipo i en la etapa t, dado el escenario s.
Iits: Inventario de la familia tipo i al final del periodo t, dado el escenario s.
CLAIO-2016
626

Uits: Unidades pendientes de demanda para la familia tipo i en la etapa t, dado el escenario s.
NTmts: Variable que verifica si se abre un nuevo turno para m en la etapa t, asociada al escenario s.
CTmts: Variable que verifica si se cierra un turno de m en la etapa t, asociada al escenario s.
Rmhts: Variable binaria (1 si opera turno h en la máquina m del periodo t; 0 sino), asociada al escenario s.
A continuación, se presenta la reformulación determinista equivalente en su forma extendida del modelo
de programación estocástica multi-etapa:
)1()()()(111
Mm
T
t
s
mtmt
s
mtmt
Mm Hh
T
t
s
mhtmht
Fi
T
t
s
itit
s
itit
s
itit
Ss
s CTctNTntRrUfIinvXcpMin
s.a.
)2(},,...,1{,,)1()1( SsTtFiUdUIIX s
ti
s
it
s
it
s
it
s
ti
s
it
)3(},,...,1{,,, SsTtHhMmRprodxhora
X
Hh
smht
Fi i
sit
)4(},,...,1{,,,1 SsTtHhMmR
Hh
smht
)5(,,00 SsFiII i
si
)6(,,0 SsFiU siT
)7(},,...,1{,,,0,)1( SsTtHhMmRRMáxNTHh
stmh
smht
smt
)8(},,...,1{,,,0,)1( SsTtHhMmRRMáxCTHh
stmh
smht
smt
)9(},,,,,{ KRCTNTUIX
)10(},,...,1{,,},1,0{ SsTtHhMmRsmht
)11(},3,2,1{,,,0,0,0,0,0 SstMmFiCTNTUIX smt
smt
sit
sit
sit
La función objetivo en (1) es la minimización de los costos totales, esto incluye los costos de producción,
inventario, demanda pendiente y horas-hombre requeridas para el uso de maquinarias. Las decisiones se
restringen a su vez por la ecuación (2) que representa los requerimientos de demanda de la etapa sujeta al
escenario s. La restricción (3) corresponde a la capacidad disponible en la planta. La restricción (4) indica
que como mínimo debe operar un turno por cada máquina m. En (5) se define el inventario inicial de cada
tipo de familia i. En (6) se impone que no se dejen productos pendientes al final del horizonte de
planificación. Las restricciones (7) y (8) son relaciones que permiten dar cuenta de la apertura o cierre de
turnos que operarán en cada máquina.
Las políticas de producción deben poder implementarse, esto quiere decir que si dos escenarios s y s’ son
idénticos hasta una etapa determinada, las decisiones también deben ser idénticas hasta esa etapa. De esta
forma, el modelo no depende de la información que no está disponible todavía, independientemente de
qué escenario se pueda tomar o seguir. Es así como la información disponible de cada uno de los
escenarios al comienzo de cada etapa es idéntica. Luego, el punto clave en cualquier modelo de
optimización estocástica multi-etapa consiste en que las decisiones no se anticipen a los resultados
futuros. Por ello, se define en (9) un conjunto de restricciones, conocidas como restricciones no-
anticipativas [3], que para el caso de las decisiones de producción denotamos por:
}},...,1{,}',{,/{: TtSssxxXxK s
it
s
it
s
it (12)
donde X representa el vector para las decisiones de cantidad de producción que contiene los elementos Xits
y que por extensión se impone sobre todas las variables del modelo en (9). Cabe hacer notar que esta
restricción es la única que vincula los escenarios en las etapas donde son iguales. Si no fuese agregada, el
modelo se podría descomponer en un problema distinto para cada escenario, esto es que el modelo sería
equivalente a poseer tantos problemas deterministas independientes como escenarios se considere.
Finalmente, (10) y (11) representan la naturaleza de las variables de decisión.
CLAIO-2016
627

Modelo de desagregación por cada tipo de familia
Las decisiones óptimas de producción, inventario y demanda pendiente en el modelo (13)-(21) son
incorporadas en un segundo modelo, denominado plan intermedio de desagregación, que minimiza los
costes de set-up por cada familia de productos pertenecientes a un tipo de familia dado. Considerando los
patrones de demanda de la industria en la que se aplicará el modelo, se busca lotes de producción grandes,
evitando los costes de preparación por set-ups frecuentes. Este segundo modelo propuesto tiene como
restricciones los requerimientos de demanda y un conjunto adicional de restricciones que garantizan la
coherencia entre las decisiones por familia con lo propuesto por el plan agregado para el tipo de familia al
cual pertenecen. La notación empleada para el tipo de familia i es la siguiente:
Conjuntos e índices.
J[i]: Conjunto de familias de productos del tipo i.
j: Índice familia de productos, jJ[i].
Parámetros.
Djt: Demanda de la familia j en t.
X*it: Producción total del tipo de familia i en t.
I*it: Inventario total del tipo de familia i al final de t.
U*it: Unidades de demanda pendiente del tipo de familia i en t.
Id0j: Inventario inicial de j.
sjt: Costo de set-up de j en t.
Maxj: Tamaño máximo del lote de producción para cada j.
Variables de decisión.
Yjt: Producción de j en t.
Vjt: Unidades de demanda pendiente de j en t.
Idjt: Unidades de j almacenadas en inventario al final de t.
Sjt: variable binaria (1 si se produce j en t; 0 sino).
El modelo del plan intermedio de desagregación corresponde a:
iJj
T
tjtjt SsMin
'
1
(13)
s.a.
tjtj
VjtDjtVjtIdtj
IdjtY ,)1()1(
(14)
tjX itiJj
jtY ,*
(15)
tjI itiJj
jtId ,*
(16)
tjU it
iJjjtV ,*
(17)
tjjMaxjtSjtY , (18)
jjIdjId 00 (19)
tjjtVjtIdjtY ,0;0;0 (20)
tjjtS ,1,0 (21)
En este modelo, la función objetivo en (13) minimiza los costes de set-up incurridos al preparar los lotes de
producción de todas las familias pertenecientes a un tipo de familia dado. La restricción (14) define el
requerimiento de demanda de cada familia, que son satisfechos con la producción y las existencias en inventario, permitiendo una eventual postergación de la demanda gracias a la variable auxiliar de demanda
pendiente. Las restricciones (15), (16) y (17) representan una conexión entre el plan agregado de la producción
CLAIO-2016
628

y este nivel de desagregación. Lo que se logra a través de estas restricciones, es que el total resultante de
unidades elaboradas, de demanda pendiente e inventario, coincidan con la decisión óptima del modelo (1)-(12)
para el tipo de familia respectivo que las agrupa. En (18) se presenta una restricción lógica que da el valor 1 a
la respectiva variable de set-up cada vez que se elabora una familia de productos e impone a su vez una cota
superior que puede adoptar el lote de producción de la familia j. La restricción (19) define el inventario inicial
de cada familia y, por último, (20) y (21) imponen la naturaleza de las variables de decisión. El modelo
propuesto es un modelo lineal de programación entera-mixta que permite abordar adecuadamente la
desagregación de cada tipo de familia en el horizonte más inmediato cuyas decisiones definirán la
programación detallada de las operaciones.
Modelo de desagregación por cada familia de producto
Por último, las decisiones óptimas de producción, inventario y demanda pendiente del modelo (22)-(30) son
incorporadas en un tercer modelo de optimización denominado plan de desagregación por familia. Este último
desagrega dichas decisiones, separadamente para cada familia, en decisiones óptimas para cada producto de la
respectiva familia e integra un nuevo aspecto de la cadena de suministros, relacionado ahora con los clientes.
Este modelo emplea la siguiente notación:
Conjuntos e índices.
K[j]: Conjunto de productos pertenecientes a j.
k: Índice para definir cada producto k K[j].
C[j]: Conjunto de clientes que demandan j.
c: Índice para definir cada cliente cC[j]
Parámetros.
dckt: Demanda de c del producto k en t.
fckt: Costo de posponer la demanda de k para c en t.
sckt: Costo de transportar a c una unidad de k en t.
Y*jt: Unidades de j en t.
Id*jt: Unidades de inventario de j al final de t.
V*jt: Unidades de demanda insatisfecha de j en t.
osckt: Nivel máximo de inventario para c que se almacena de k en t.
Variables de decisión.
Zckt: Producción para c de k en t.
Wckt: Unidades de demanda pendiente de c para k en t.
Ipckt: Unidades de inventario para c de k almacenadas en t.
El nivel final de desagregación se modela como sigue:
ckttckcktcktcktcktjCc jKk t
WWdsWfMinT
)1(][ ][ 1
' (22)
s.a.
tkcWdWIpIpZ tckcktcktckttckckt ,,)1()1( (23)
tY jtcktZ
jCc jKk
][ ][
* (24)
tV jtcktW
jCc jKk
][ ][
* (25)
tId jtcktIp
jCc jKk
][ ][
* (26)
tkcckt
ostck
Iptck
Wckt
dcktZ ,,)1()1(
,0max
(27)
tkcckt
Wtck
Wckt
d ,,0)1(
(28)
CLAIO-2016
629

kcck
Ipck
Ip ,00
(29)
tkcckt
Wckt
Ipckt
Z ,,0;0;0 (30)
En (22) se busca minimizar los costes en que incurre la empresa por cada unidad transportada a sus clientes y
aquellos asociados a demanda pendiente (de acuerdo a la relevancia del cliente), que provea una solución de
compromiso ante estos dos aspectos clave de la cadena de suministro, uno en relación con la distribución de
productos por parte de la empresa y otro relacionado con el nivel de servicio otorgado a sus clientes. La
restricción (23) define el requerimiento de demanda de cada producto, considerando la producción, las
existencias en inventario y una eventual postergación de la demanda. Por su parte, las restricciones (24), (25) y
(26) representan una conexión entre el nivel intermedio de desagregación del modelo (13)-(21) y el presente
modelo para los productos de una familia dada, permitiendo que el total resultante de unidades elaboradas,
pendientes y de inventario, coincidan con la respectiva decisión óptima de la familia a la cual pertenecen. En
(27) se define el límite superior que puede adoptar la variable producción. En (28) se limita la cantidad de
demanda pendiente que se pueden asignar a cada cliente. En (29) se define el inventario inicial de cada
producto. Por último, en (28) se impone la no-negatividad de las variables de decisión.
3 Caso de estudio y resultados
Los modelos descritos anteriormente fueron aplicados a una instancia de datos de una compañía fabricante de
un amplio portafolio de productos de escritorio de consumo masivo orientados a la satisfacción de diversos
tipos de necesidades que se encuentran tanto en la oficina, el hogar, colegios e instituciones de educación
superior. El problema considera 10 tipos de familias (Archivadores, Cuadernos Universitarios, Blocks,
Profesional, Portátil, Grapado, Espiralado, Triple, Cosidos y Agendas), cada una de las cuales contiene entre
una y tres familias de productos, con un total de 284 productos finales.
El modelo multi-etapa de planificación agregada consideró 5 etapas, siendo las 3 primeras los meses de inicio
del horizonte de planeación anual. En base a un pronóstico de demanda se asumió una distribución uniforme
con un25% respecto del valor pronosticado para la cuarta y quinta etapa. Resuelto el modelo mediante el
algoritmo de Casey and Sen [7] se obtiene un árbol de escenarios para todos los tipos de familias que se puede
apreciar en la Figura 1.
Costo Total
RP $10.184.819.685
EV $10.159.344.854
EEV4 $10.205.304.932
VSS4 $ 20.485.247
Figura 1. Árbol de escenarios Tabla 1. Valores para RP y VVS
Para medir la importancia del modelo estocástico, cuyo valor óptimo corresponde a RP en la Tabla 1, se
calcula el valor de la solución estocástica (VSS), que en el caso de un modelo multi-etapa se define para cada
etapa t como: VSSt = EEVt – RP [10], donde EEVt corresponde al valor óptimo que alcanza el modelo
estocástico multi-etapa (1)-(11) fijando el valor de todas las decisiones hasta la etapa t-1 en aquellos valores
que resultan de resolver el modelo (1)-(11) para un único escenario: el escenario promedio (soslayando con
ello la incertidumbre presente en las demandas). Un valor nulo de VSSt indica que utilizar la solución del
modelo estocástico sería posiblemente innecesario respecto del modelo determinista para el escenario
promedio. En la Tabla 1, EV corresponde al valor óptimo de dicho modelo determinista y dado que el árbol de
escenarios tiene una demanda conocida para cada producto en las primeras etapas (meses) se muestra en
particular el valor de VSS4 que permite mostrar la magnitud de las diferencias entre ambos modelos. En la
Tabla 2, se puede apreciar las diferencias de costos entre el modelo determinista que resulta de considerar el
escenario promedio y el modelo multi-etapa propuesto en las 3 primeras etapas (meses) del horizonte de
planificación que da cuenta de las diferencias obtenidas.
CLAIO-2016
630
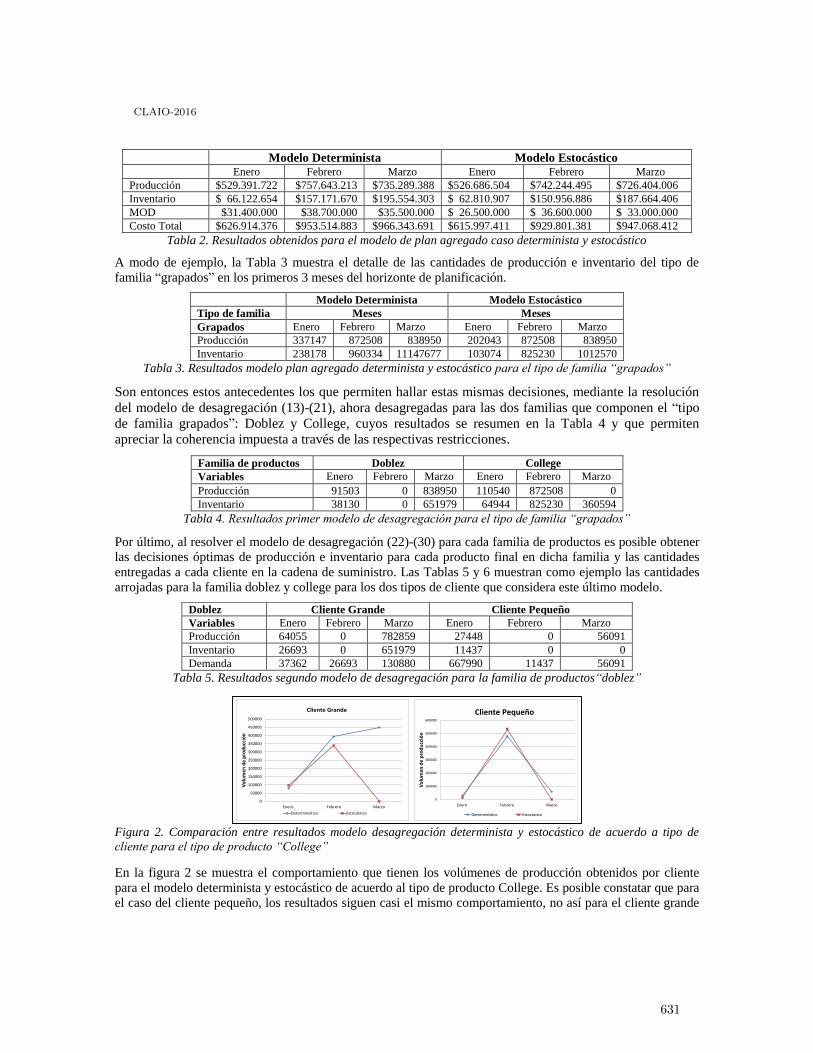
Modelo Determinista Modelo Estocástico Enero Febrero Marzo Enero Febrero Marzo
Producción $529.391.722 $757.643.213 $735.289.388 $526.686.504 $742.244.495 $726.404.006
Inventario $ 66.122.654 $157.171.670 $195.554.303 $ 62.810.907 $150.956.886 $187.664.406
MOD $31.400.000 $38.700.000 $35.500.000 $ 26.500.000 $ 36.600.000 $ 33.000.000
Costo Total $626.914.376 $953.514.883 $966.343.691 $615.997.411 $929.801.381 $947.068.412
Tabla 2. Resultados obtenidos para el modelo de plan agregado caso determinista y estocástico
A modo de ejemplo, la Tabla 3 muestra el detalle de las cantidades de producción e inventario del tipo de
familia “grapados” en los primeros 3 meses del horizonte de planificación.
Modelo Determinista Modelo Estocástico
Tipo de familia Meses Meses
Grapados Enero Febrero Marzo Enero Febrero Marzo
Producción 337147 872508 838950 202043 872508 838950
Inventario 238178 960334 11147677 103074 825230 1012570
Tabla 3. Resultados modelo plan agregado determinista y estocástico para el tipo de familia “grapados”
Son entonces estos antecedentes los que permiten hallar estas mismas decisiones, mediante la resolución
del modelo de desagregación (13)-(21), ahora desagregadas para las dos familias que componen el “tipo
de familia grapados”: Doblez y College, cuyos resultados se resumen en la Tabla 4 y que permiten
apreciar la coherencia impuesta a través de las respectivas restricciones.
Familia de productos Doblez College
Variables Enero Febrero Marzo Enero Febrero Marzo
Producción 91503 0 838950 110540 872508 0
Inventario 38130 0 651979 64944 825230 360594
Tabla 4. Resultados primer modelo de desagregación para el tipo de familia “grapados”
Por último, al resolver el modelo de desagregación (22)-(30) para cada familia de productos es posible obtener
las decisiones óptimas de producción e inventario para cada producto final en dicha familia y las cantidades
entregadas a cada cliente en la cadena de suministro. Las Tablas 5 y 6 muestran como ejemplo las cantidades
arrojadas para la familia doblez y college para los dos tipos de cliente que considera este último modelo.
Doblez Cliente Grande Cliente Pequeño
Variables Enero Febrero Marzo Enero Febrero Marzo
Producción 64055 0 782859 27448 0 56091
Inventario 26693 0 651979 11437 0 0
Demanda 37362 26693 130880 667990 11437 56091
Tabla 5. Resultados segundo modelo de desagregación para la familia de productos“doblez”
Figura 2. Comparación entre resultados modelo desagregación determinista y estocástico de acuerdo a tipo de
cliente para el tipo de producto “College”
En la figura 2 se muestra el comportamiento que tienen los volúmenes de producción obtenidos por cliente
para el modelo determinista y estocástico de acuerdo al tipo de producto College. Es posible constatar que para el caso del cliente pequeño, los resultados siguen casi el mismo comportamiento, no así para el cliente grande
0
50000
100000
150000
200000
250000
300000
350000
400000
450000
500000
Enero Febrero Marzo
Vo
lum
en d
e p
rod
ucc
ión
Determinístico Estocástico
Cliente Grande
0
100000
200000
300000
400000
500000
600000
Enero Febrero Marzo
Vo
lum
en
de
pro
du
cció
n
Determinístico Estocástico
Cliente Pequeño
CLAIO-2016
631

cuyo volumen de producción para el tercer mes es cero ya en el mes anterior genera volumen de inventario que
satisface la demanda.
4 Conclusiones y perspectivas
El empleo de modelos de optimización estocástica constituye una metodología adecuada en apoyo a la toma de
decisiones en un problema de planificación de la producción. Estos modelos no sólo permiten obtener una
decisión óptima a nivel desagregado considerando inicialmente un horizonte de planificación de mediano
plazo, sino que igualmente toman en cuenta la variabilidad que puede existir en las demandas de los diferentes
productos.
La utilización de una estructura jerarquizada en problemas de planificación de producción que abarca un gran
número de productos (cerca de 300 en el caso de estudio) resulta ser una buena metodología para determinar
volúmenes de producción tomando en cuenta decisiones que abarca la cadena de suministro.
La estabilidad y robustez en los modelos de optimización que permiten decidir a mediano plazo es un tema de
interés cuando se trata de dar solución a problemas aplicados a empresas.
Agradecimientos Este trabajo ha sido posible gracias al apoyo de financiamiento otorgado por la Dirección General de
Investigación y Postgrado (Proyecto DIUBB Nº161418 3/R) de la Universidad del Bío-Bío.
Referencias 1. El-H. Aghezzaf, C. Sitompul and M. Najid. Models for robust tactical planning in multi-stage production systems with
uncertain demands. Computers & Operations Research 37: 880 – 889, 2010.
2. S. Axsäter and H. Jönsson. Aggregation and disaggregation in herarchical production planning. European Journal of
Operational Research 17(3): 338-350, 1984.
3. J.R. Birge and F. Louveaux. Introduction to Stochastic Programming. Second Edition. New York: Springer, 2011.
4. G.R. Bitran and A.C. Hax. On design of hierarchical production planning systems. Decisions Sciences 8: 28-55, 1977.
5. J. Bang and Y. Kim, Hierarchical Production Planning for Semiconductor Wafer Fabrication Based on Linear Programming
and Discrete-Event Simulation, IEEE Transactions on Automation Science and Engineering 7(2): 326-336, 2010.
6. M.A. Caravilla and J.P. de Sousa. Hierarchical production planning in a Make-To-Order company: A case study. European
Journal of Operation Research 86: 43-56, 1995.
7. M. Casey and S. Sen. The Scenario Generation Algorithm for Multistage Stochastic Linear Programming. Mathematics of
Operations Research 30(3), 615-631, 2005.
8. R. Erromdhani, M. Eddaly and A. Rebai. Hierarchical production planning with flexibility in agroalimentary environment: a
case study. Journal of Intelligent Manufacturing 23: 811–819, 2012.
9. J. Erschler, G. Fontan and C. Mercé. Consistency of the disaggregation process in hierarchical planning. Operations
Research 34: 464-469, 1986.
10. L.F. Escudero, A. Garín, M. Merino, G. Pérez. The value of the stochastic solution in multistage problems. TOP 15: 48-64,
2007.
11. J.W. Forrester. Industrial Dynamics: A major breakthrough for decision makers, Harvard Business Review 36(4): 37-66,
1958.
12. H.L. Lee, K.C. So, C.S. Tang. Value of information sharing in a two-level supply chain. Management Science 46(5): 626-
643, 2000.
13. Mercé, C. Cohérence des décisions en planification hiérarchisée. Thèse de Doctorat d’Etat, Université Paul Sabatier.
Toulouse. 1987.
14. B. Neureuther, G. Polak and N. Sanders. A hierarchical production plan for a make-to-order steel fabrication plant.
Production Planning & Control: The Management of Operations 15(3): 324-335, 2004.
15. V. Ortiz-Araya, V.M. Albornoz and D.A. Bravo. A hierarchical production planning in a supply chain with seasonal demand
products. DYNA Management 3(1):1-15, 2015.
16. L. Özdamar, A. Ö. Atli and M.A. Bozyel. Heuristic family disaggregation techniques for hierarchical production planning
systems. International Journal of Production Research 34(9): 2613-2628, 1996.
17. M. Qui, L. Fredendall and Z. Zhu. Application of hierarchical production planning in a multiproduct, multimachine
environment, International. Journal of Production Research 39(13): 2803-2816, 2001.
18. E. Vicens, M.E. Alemany, C. Andres and J.J. Guarch. A design and application methodology for hierarchical production
planning decision support systems in an enterprise integration context. International Journal of Production Economics 74: 5-
20, 2001.
19. X. Wang, S.M. Disney. The bullwhip effect: Progress, trends and directions. European Journal of Operational Research
250: 691–701, 2016.
CLAIO-2016
632

A multistage stochastic programming model for air
cargo assignment under capacity uncertainty
Ricardo Trincado FehlandtDepartment of Transport Engineering and Logistics
Pontificia Universidad Católica de Chile, [email protected]
Bernardo PagnoncelliBusiness School
Universidad Adolfo Ibáñez, [email protected]
Felipe Delgado BreinbauerDepartment of Transport Engineering and Logistics
Pontificia Universidad Católica de Chile, [email protected]
Abstract
Air cargo transportation represents an important source of income for airlines. Cargo canbe transported via freight planes or in the belly aircrafts for passengers (“belly cargo”). One ofthe main difficulties faced by the belly cargo mode is the uncertainty on the available capacity:the actual availability for cargo is only known after the passengers have boarded and had theirluggage loaded. We propose a multistage stochastic programming model whose goal is to findthe optimal allocation of cargo to the passengers network in order to maximize profit. We solvethe resulting problem using decomposition techniques. In addition, we develop a policy to usethe solution in real instances using data from a major commercial airline. The policy achievedhigher expected profits, better level of service, and a decrease in the variability of the resultswhen compared against its deterministic counterpart.
Keywords: Air Cargo Transportation; Multi-Commodity Flow Problem; Multistage StochasticOptimization.
1 Motivation
In the air cargo industry, freight can be transported in two different ways: i) in freighter aircraftsor ii) in the belly of passenger flights, which is referred to as belly cargo. In the latter case, oneof the main difficulties is the uncertainty of the capacity left for cargo transportation. Given thatthe main business for airlines is to transport passengers, cargo capacity for a specific flight willstrongly depend on the number of passengers and their luggage inside that flight. Other factorssuch as weather conditions and state of the runaway also affect the maximum load a plane can
CLAIO-2016
633

carry. Unfortunately, the effective cargo capacity is only revealed shortly before a flight departs,immediately after passengers have boarded, and when cargo freight is ready to be loaded in therunaway. For such reasons, it is not uncommon that some flights depart not fully loaded (eventhough they have enough freight), while others have to leave some freight behind because maximumcapacity has been reached.
Cargo industry also presents flexibilities that are not present in passenger transportation. Oneexample is the presence of different types of requests, or cargo movements. While some requestshave priority and short delivery time, others can be left behind before they are shipped if thedemand exceeds the flight capacity. The main advantage in this case is that the cargo load can besent by different routes independently of the number of connections and travel time, as long as itarrives to their destination on time.
In this work we propose a multistage stochastic formulation for allocating cargo loads betweendifferent origin destination pairs in the passenger network, taking into account the uncertainty inflight capacity.
2 Literature Review
Our problem is formulated as a multicommodity flow problem (MCFP). The MCFP has been widelystudied in the literature, with different applications such as emergency evacuations [1], transport[2] and logistics [3]. Regarding the solution method to solve this type of problem, Ouorou et al. [4]give a complete review of the different algorithms, solution techniques, and real world applications.
However, in most studies the MCFP has been addressed as a pure deterministic problem, andonly few studies have incorporated the inherent uncertainty present in the demand and/or supplyside of this problem. Möller et al. [5] and DeMiguel and Mishra [6], in the context of air passengertransport, tackle the problem of determining which passengers to accept in order to maximizeprofits considering uncertainty in passenger demand. In this context, both the capacity and thepassenger routing are known in advance. Furthermore, both models were solved for small networks.Only Barbarosoǧlu and Arda [7] have explicitly introduce uncertainty in the supply in the contextof catastrophe response. The authors formulate a two stage stochastic programming model, wherethe first stage decision is to send resources (medicines, food) without knowledge of the state of theroutes and the demand of each resource, which are revealed in the second stage. In this work, thestate of the route is revealed in one stage only, which is a substantial difference with our proposedwork. In our approach, capacity is only revealed minutes before the flight departs, and capacityfor future flights in the network remain unknown. To the best of our knowledge, no previous workhas considered capacity uncertainty in the context of air cargo transportation, and has solved theproblem for realistic networks.
3 Problem description
The problem is formulated as a MCFP considering uncertainty in flight capacity. This uncertaintywill be represented for each flight as a discrete number of possible states. A stage is defined as theinstant during the time horizon when the capacity of a certain flight is revealed, and a decisionshould be taken. Finally, a scenario is a collection of sample realizations. The problem can bemodeled as a decision tree as shown in Figure 1, where each node represents a state, each arc a
CLAIO-2016
634

stage and a scenario is a path from the root to the leaf nodes.
Figure 1: Scenario tree
We will first present the notation used in our model, and then the explicit formulation of theproblem.
3.1 Notation
Sets
K: Set of potential demand requests.V : Set of all flights in the network.S: Set of scenarios.Vv: Set of all flights up to flight v.Sn: Set of scenarios that are equal up to node n.St: Set of scenarios that are equal up to time t (time when the demand request is accepted).
Parameters
pk: Tariff of request k [$/kg.]Lk: Penalty associated to request k [$/kg.]Dk: Total demand of request k [kg.]Ak: Allotment of request k [kg.]Prs: Probability of ocurrence of scenario s.cv: Cost of flight v [$/kg.]Qw(v, s): Weight capacity of flight v in scenario s [kg.]Qv(v, s): Capacity, in positions, of flight v in scenario s [pos.]ρk: Density of request k [kg./pos.]γvk : 1 if flight v has the same origin that request k, 0 otherwise.θvk: 1 if flight v has the same destination that request k, 0 otherwise.αgv: 1 if the destination of flight g is the same as the origin of flight v, -1 if flight g has the
same origin as flight v and 0 otherwise.
CLAIO-2016
635

µvk: 0 if the origin of flight v is the same as the destination of request k, 1 otherwise.
Decision Variables
x(k, v, s): Amount of demand request k sent in flight v, in scenario sY (k, s): Amount of demand request k accepted in scenario s.w(k, s): Amount of demand request k that was accepted but not delivered in scenario s.
3.2 Formulation
Max∑
s∈SPrs(
∑
k∈K(pk · Y (k, s) +
∑
v∈V−cv · x(k, v, s)− Lk · w(k, s))) (1)
s.t. Y (k, s) ≤ Dk ∀k ∈ K, s ∈ S (2)
Y (k, s) ≥ Ak ∀k ∈ K, s ∈ S (3)∑
k∈Kx(k, v, s) ≤ Qw(v, s) ∀v ∈ V, s ∈ S (4)
∑
k∈K
x(k, v, s)
ρk≤ Qv(v) ∀v ∈ V, s ∈ S (5)
x(k, v, s) ≤ γvk · Y (k, s) +∑
g∈Vv
αgv · x(k, g, s) ∀k ∈ K, v ∈ V, s ∈ S (6)
∑
v∈Vθvk · x(k, v, s) + w(k, s) = Y (k, s) ∀k ∈ K, s ∈ S (7)
x(k, v, si) = x(k, v, sj) ∀si, sj ∈ Sn, v ∈ V, k ∈ K (8)
Y (k, si) = Y (k, sj) ∀si, sj ∈ St, k ∈ K (9)
0 ≤ x(k, v, s) ≤ µvk ·Dk ∀k ∈ K, v ∈ V, s ∈ S (10)
The objective (1) is to maximize expected profits of the network, taking into account the incomesobtained by each request, the operational cost, and a penalty cost for those cargo that were acceptedbut not delivered. Constraints (2) and (3) are associated to the maximum and minimum amountof each request that the airline can accept in each scenario, satisfying flight capacities (4) and (5).Flow conservation constraints at each node are expressed in (6), and the determination of penaltycosts for not flying an accepted request is given by constraint (7). Nonanticipativity constraints aregiven by (8) and (9), and finally constraint (10) ensures that an accepted request must be positiveand cannot be moved when it arrives to its destination.
Our formulation allows the rerouting of cargo requests when they have already left their originairports. As a consequence, if the cargo request is assigned to a future flight and this flight has asmaller than predicted capacity, such cargo request may be left behind and sent to another route,or may even return to its origin airport to be loaded onto a later flight.
4 Solution Method
The number of decision variables V AR grows exponentially with the number of flights with randomcapacity, and is given by V AR = K · (V + 2) · EF , where K represents the number of requests, V
CLAIO-2016
636

the total number of flights, F the number of flights with variability, and E the number of capacityoutcomes per flight. If we consider the network of one day of a real world airline with 60 flightsand 100 demand requests, and assuming variability in all flights with three capacity outcomes perflight, the total number of decision variables will be 2.6 · 1031.
In order to solve the problem we first propose two different preprocessing heuristics to reducethe number of decision variables. The use of the preprocessing heuristics allows us to eliminate99,99% of the decisions variables. The resulting problem is solved to until a stopping criteria isreached. We used an external library specially built to solve stochastic problems called PySP [8] inPyomo [9], and solved the problem using Gurobi 5.6.0 in the computational cluster of the Schoolof Engineering at Pontificia Universidad Católica.
4.1 Policy implementation
Even if one considered a very large number of capacity scenarios, say 100, the actual observedcapacity would be different from all scenarios. Our model only gives solutions for the scenarioswe considered in the model. In this sense, after solving the problem a policy is not immediatelyavailable. However, the solution allows us to create an a posteriori policy that is useful in practice.
The policy can be summarized as follows. Let us consider three possible outcomes per flight(pessimistic Qw(f)−, average Qw(f) and optimistic Qw(f)+), and consider that weight and positioncapacity are correlated (an increase in weight capacity implies an increase in the position capacityin the same proportion). Lets define z(f) as the real capacity value of flight f , which can take anyvalue between a(f) (smaller than Qw(f)−) and b(f) (greater than Qw(f)+). Each stage has a setof decision variables x(k, v, s) associated with demand request k sent in flight v, in scenario s. Thefollowing policy is proposed:
• if z(f) ≤ Qw(f)− the allocation associated with the pessimistic outcome will be used.
• if Qw(f)− ≤ z(f) ≤ Qw(f) the allocation associated with the average outcome will be used.
• if Qw(f) ≤ z(f) the allocation associated with the optimistic outcome will be used.
Figure 2 shows an example for two flights of the proposed policy. The grey area represents thespectrum of all possible capacity outcomes. In this example, the real capacity for flight 1 (z(1))was higher than the pessimistic case, but smaller than the average, then the average allocation isselected as indicated by the white dot. A similar behavior is occurs with flight 2.
5 Results
The model is tested using real data of a high demand week of an important commercial airline. Weconsider a two-day network composed of 114 flights and 109 demand requests. From the data, 25out of 114 flights must deal with capacity uncertainty. However, at this point, we have been ableto solve the problem including the 6 flights showing greater capacity variability. For each flightwith capacity uncertainty three outcomes are considered: pessimistic, average and optimistic. Thecapacity in each stage was based on real data from the airline. From the data, the pessismistic(optimistic) outcome was defined as the average capacity minus (plus) one standard deviation.
CLAIO-2016
637

Figure 2: Implementation policy
The model was compared against the deterministic counterpart of the same problem undersimulation. For this purpose 10.000 runs where carried out assuming that flight capacity follows aNormal Distribution. The results show that the stochastic model exceeds the deterministic modelin almost every proposed index. The stochastic model obtained higher profits up to 1,22%, and areduction up to a 2,39% in the coefficient of variation, and therefore in the overall risk, allowing fora more stable cash flow. Such results imply in daily savings of thousands of dollars for the airline.
6 Conclusions
We proposed and solved the problem of allocating flight capacity to cargo demands taking intoaccount flight capacity uncertainty. The proposed model shows the following novel features: i) ittakes into account the uncertainty in flight capacity of the entire network, ii) it gives flexibility torespond to unforeseen events allowing cargo re-routing, and iii) proposes a more conservative policyof cargo allocation. This formulation heavily increases the problem complexity, but delivers higherexpected profits than its deterministic counterpart.
The proposed policy achieves better results than the deterministic model by obtaining higherprofits up to 1.22%, a more stable cash flow by reducing the coefficient of variation by 52%. It isimportant to point out that the stochastic model outperforms the deterministic one, even thoughonly 24% of the flights with capacity uncertainty could be included. The potential for greater gainsis significant and will be further investigated by the authors using specialized versions of the currentalgorithm.
Avenues for current and future research include the implementation of a Nested Decompositionmethodology to solve bigger instances of the problem, and the possibility of replacing the expectedvalue by some risk measure in the objective function.
References
[1] M. Lahmar, T. Assavapokee and S. Ardekani. A dynamic transportation planning support system forhurricane evacuation In Intelligent Transportation Systems Conference, 2006. ITSC’06. IEEE, pages612–617.
CLAIO-2016
638

[2] E. Köhler, R.H. Möhring and M. Skutella. Traffic networks and flows over time In J. Lerner, D.Wagner and K. Zweig, editors Algorithmics of Large and Complex Networks, volume 5515, pages166–196. Springer Berlin Heidelberg, 2009.
[3] S. Hernández, S. Peeta and G. Kalafatas A less-than-truckload carrier collaboration planning problemunder dynamic capacities Transportation Research Part E: Logistics and Transportation Review, 47(6):933–946, 2011.
[4] A. Ouorou and P. Mahey and J.-Ph. Vial A Survey of Algorithms for Convex Multicommodity FlowProblems Management Science, 46(1):126–147, 2000
[5] A. Möller, W. Römisch and K. Weber A new approach to O&D revenue management based on scenariotrees. Journal of Revenue and Pricing Management, 3(3):265–276,2004.
[6] DeMiguel, V. and N. Mishra What multistage stochastic programming can do for network revenuemanagement. Working paper, London Business School, Optimization Online URL: http://www. opti-mizationonline. org/DB HTML/2006/10/1508. html, London, 2006.
[7] G. Barbarosoǧlu and Y. Arda A two-stage stochastic programming framework for transportation plan-ning in disaster response Journal of the Operational Research Society, 55(1):43–53, 2004.
[8] J. P. Watson, D.L. Woodruff and W.E. Hart PySP: Modeling and solving stochastic programs inPython. Mathematical Programming Computation, 4(2): 109–149, 2012.
[9] W.E. Hart, J.P. Watson and D.L. Woodruff Pyomo: modeling and solving mathematical programs inPython. Mathematical Programming Computation, 3(3): 219–260, 2011.
CLAIO-2016
639

Multicriteria decision-making under uncertainty: a behaviouralexperiment with experienced participants in supply chain
management
F. ParedesEscuela de Ingenierı́a Industrial, Universidad Diego Portales, Chile
J. PereiraTecnologico de Monterrey, Campus Toluca, México
C. Lavin, S. Contreras-Huerta, C. FuentesCEAR, Universidad Diego Portales, Chile
[email protected],[email protected],[email protected]
Abstract
The bullwhip-effect is an undesired upstream increasing of production variability in a supply chain,related to demand variability at the retail stage. It has extensively studied in literature. However, mostof analysis use a single criterion framework. In this article, an exploratory study is developed to analyzebehaviour of participants in a fictitious three-stage supply chain. The aim is to detect if they use mono-criterion or multi-criterion strategies to define the order level to control the bullwhip effect. A multi-criterion strategy means that an individual makes decisions by using a criterion that aggregates more thanone preference dimension. In the experiment, only trained people is considered, but two treatments (pullmethod and unspecific strategy) are included in the experiment. Results show that, although feedbackinformation about demand, work-in-process and inventory should be used to make decisions, trainedpeople focus on inventory. They fail to identify a right strategy to damp down the bullwhip effect, beingoverconfidents to inventory-based rules and showing resilience to multi-criteria heuristics, which aremore effective in the proposed model.
Keywords: Multi-criteria; bullwhip effect; supply chain; pull policy.
1 Introduction
The “bullwhip-effect” is an undesired progressive upstream increasing of production variability, which man-ifests as amplification, phase lag and oscillation, caused by a supply chain’s demand variability at the retaillevel [16]. The main structural reasons of bullwhip effect mentioned in literature are frequently reportedout the origin of this phenomenon [8]: demand signal processing, leadtime, information flow time delays,strategic ordering behavior, ordering batching and price variations. In addition, a number of possible causescome from heuristics and biases that decision makers use in complex and uncertain supply chain contexts
CLAIO-2016
640

[6, 15]: illusory correlation, anchoring and adjustment heuristics, inconsistency, conservatism, mispercep-tion of feedback, fundamental attribution of error, illusion of control, hindsight bias. [9] provides experi-mental results to show that players in the beer-distribution-game ignore the supply chain line, under-react tobacklog and keep higher than necessary inventory levels.
It has been assumed that decision makers having correct information could take better decisions, damp-ing down the bullwhip effect [3]. Recently, [4] found that amplification is reduced when the best orderingstrategy is communicated to people. In a previous work, it has been shown that an optimal strategy in thecontext of a first-order auto-regressive demand process, AR(1), corresponds to the pull ordering method[11]. Only elementary information flows upstream in the supply chain, a strategy minimizing the inventorylevels, synchronizing the stages in the supply chain and, under certain circumstances, reducing the bullwhipeffect. It can be shown that the pull policy is based on a feedback structure involving three gap criteria: theforecasted demand level; the desired vs the actual work-in-process; the desired vs the actual inventory level[11]. One could affirm that experienced people will do fine when using a pull strategy, because the impli-cations of an optimal strategy should be understood. In this article, results of an exploratory experimentalstudy are presented which hypothesis is: “trained people use a multi-criteria approach aiming to control thebullwhip effect”. Two independent experiments are run to explore the emergence of multi-criteria heuristicsin the context of a first-order autoregressive, AR(1), demand process. Main results are reported and lessonsfor practice are also proposed.
The article is organized as follows. The section 2 presents a summary of previous results and relatedwork. The section 3 introduces the experimental setting. Results are reported in section 4. In section 5,behavioural explanations for results are discussed. Conclusions are presented in section 6.
2 Preliminary work
2.1 Supply chain model
Let us consider a multi-stage, single-item, supply chain structure composed by production stages Pi (i =1, . . . ,n), stock sites Bi (i = 0, . . . ,n), and a supplier stage “Supplier”, as shown in the model of Fig. 1.In this model, Lambda (λ ), Mu (µ), Sigma (σ ) and at (at) are parameters aiding to generate the demandvalues (see eq. 6 below).
Page -1-
B2 B1 B0
Wip 1
Wip 2
Wip 3
P3 P2 P1 D
O1Prod 1
O2Prod 2
O3Prod 3
Lambda at Mu Sigma
L
L
L
Figure 1: Supply chain model drawn in STELLATM
The i-th production stage periodically receives an order Oi, which defines how many units from Bi need
CLAIO-2016
641

to be processed and further stocked in Bi−1. The lead time is a parameter: Li = L (i = 1, . . . ,n). Weconsider a periodic ordering method managing the production levels on each stage of the supply chain.
Let us define Dt , the demand rate on stock site B0, in number of units per period; Oit , number of units
ordered to stage Pi, calculated at the end of t; Pit , production units produced on the stage Pi; during t, placed
on stock Bi−1 at the beginning of t + 1; Bi−1t , downstream stock level for stage i, calculated at the end of
t; WIPit , number of units in process on stage i (work-in-process), calculated at the end of t. Therefore, the
supply chain model remains defined by the production, stock and order equations:
Pit = Oi
t−L, (i = 1, . . . ,n), (1)
Bi−1t =
{Bi−1
t−1 +Pit−1−Dt if i = 1,
Bi−1t−1 +Pi
t−1−Pi−1t−1 otherwise.
(2)
WIPit =
L
∑j=1
Ot−L−1+ ji. (3)
The following equation defines the pull policy [11]:
Pull : Oit = Dt−(i−1)L. (4)
Essentially, the pull strategy is a no-brainer policy of type “placing the incoming orders as productionorders”, while other methods (e.g., the push method) enhance the use of forecasting as a way to adapt to thedemand process.
2.2 Amplification in pull ordering methods
Usually, the bulwhip effect is evaluated by an amplification measure, which is expressed as follows:
Amp(Oit) =
V (Oit)
V (D), ∀i, (5)
where V (.) is the variance of a magnitude. An acceptable ordering method should satisfy Amp(Oit) ≤ 1,∀i
[11]. Under an AR(1) demand process and no-backlog situations, the pull method is an optimal strategy andit can be shown that Amp(Oi
t) = 1,∀i [11]. If capacity constraints or backlog is allowed, a pull policy underperforms when compared to other policies [12].
3 A behavioural experiment
In this section, an exploratory study is described which aims to obtain insights about the following questions:Is amplification observed when trained people are instructed to use a pull ordering method? Do trainedpeople use a mono or multi criteria approach when making decisions? Therefore, two experiments havebeen developed. In the first experiment, six groups of students coming from Industrial Engineering, havingprevious formation on operations and production management. The experiment is coded as TNR (Trained,No-Rule) because they do not receive any instruction. In the second experiment, six groups of undergraduateof undergraduate Management Science students are asked to follow a pull strategy. This experiment is codedTR (Trained, Rule). All groups face the same AR(1) customer demand process.
CLAIO-2016
642

Each group is composed of three individuals emulating the distribution and production of beer in a threestage supply-chain: retailer, distributor and factory. Each player takes place in one stage of the supply chainand she/he must place orders with his upstream supplier and fill orders placed by his downstream customer.Both upstream and downstream actions are made repeatedly in periods of time representing weeks in thegame (one week equals one turn in the game). For each week, a stage (decision maker): 1) receives theshipment of materials (beers) from the upstream supplier, 2) receives the order made by the downstreamcustomer, 3) fulfills the order from its inventory and ship it, and 4) makes the decision and place the ordersrequired from its upstream supplier. In this last step, an individual has to make an actual decision, whichrepresents the main unit of analysis. For each experiment, the game is played by all participants in the sameday at the same time, and they are instructed not to discuss or talk with any other participant. Subjects arriveto a classroom and are randomly assigned to one of the four teams, and in turn, randomly assigned to onerole in the team (i.e. retailer, distributor or factory).
Participants play on a board version of a supply chain, similar to the procedure described in [14], fol-lowing the model of Figure 1. Each team plays on a long table, distributed as shown in Figure 2. At thebeginning of the game, every stage is set with an inventory of 1000 units of beers, outstanding orders of 100and incoming shipment of 100. Participants are told that in the first two weeks the customer demand wouldbe 100 units of beers in order to get familiarized with the game. After the third week, the customer demandvaries. The orders and shipment of materials have delays. In our setting, one week is required to processorders, and one week to ship orders. Thus, two weeks pass from when the player makes the order until theshipment of beers arrives at his stage, i.e., L = 1 (see Figure 2).
Retailer (I = 1000)
Distributor (I = 1000)
Factory (I = 1000)
100
100
100
100
100
100
ORDERS
Customer Demand
100
100
SHIPMENTS OF MATERIALS
Figure 2: Game table schema
Participants are told that the objective of the game is to make the supply-chain brewery as efficientas possible through the orders made by each stage of the chain. In the first experiment, no instruction orparticular ordering method is proposed to any role in a supply chain. In the second experiment, people aresaid to keep the inventory at a constant level, which could be achieved by ordering the consumption quantityobserved immediatly downstream in the supply chain. The weekly variation of the customer demand isgenerated using the following function:
Dt = λDt−1 +(1−λ )µ +at , (6)
where at ∼ N(0,σ2(1−λ 2) is a normal distributed perturbation variable, λ ∈ (0,1) is the autocorrelationparameter of the demand process and µ is the mean value of the demand process. In the experiments,λ = 0.9, µ = 100 and σ = 10. We set a high value of λ in order to compare the DMs’ behaviour with theworst possible case [13]. The initial conditions of the experiments would assure a permanent availabilityof beer units during the game, avoiding inventory ruptures. There is not any capacity constraint, and eachstage could order the number of units that it considers necessary. Participants are told that the game wouldlast 50 weeks, but the actual number of weeks played is set to 40, in order to avoid end-of-game behavior
CLAIO-2016
643

that may facilitate under-ordering. Participants only know information about their own stages and limitedinformation about adjacent stages. Except for the retailer, stages do not have direct information about thebehavior of the customer demand.
4 Results
4.1 Amplification levels
Results concerning the amplification of order for the Experiment TNR are presented in Table 1. The averagevalue evidences the upstream increasing of amplification, which is very bad when compared to the pullpolicy (under the ideal conditions).
Table 1: Amplification level of order in Experiment TNR
Group 1 Group 2 Group 3 Group 4 Group 5 Group 6 AverageRetailer 45 14 3 2 6 4 12Wholesaler 181 129 36 17 15 16 65Factory 272 582 38 31 78 210 201
The bullwhip effect for one group of the Experiment TR is observed in Figure 3: the retailer keeps theorder very close to the demand process, while the wholesaler and the factory stage amplifies the demandvariability.
0 10 20 30 400
200
400
600
Dt
t
Ord
erle
vel
0 10 20 30 400
500
1,000
1,500
t
Inve
ntor
yle
vel
Retailer Wholesaler Factory
Figure 3: Orders and inventory on Group 1, Experiment TR
In Table 2 the amplification level of order in the Experiment TR is presented. Amplification is observedfor some groups (e.g., groups 1 and 4), while the amplification level in groups 2 and 5 is very good. Re-garding the TNR experiment, a time-dependent data bootstrap has been applied for every stage and groupon both experiments, using a moving-block sampling method [7]. The Mann-Whitney U test has been runfor the retailer, wholesaler and factory stages. In the contest TNR and TR, significant differences (exactp-value p≤ 0.05) are observed at the retail and factory levels. This means that the pull strategy could havea positive effect on performance.
4.2 Analysis
[15] proposed that a feedback structure of the order level aids to control the bullwhip effect. Such structure
CLAIO-2016
644
Table 2: Amplification level of order for each stage and group in Experiment TR
Group 1 Group 2 Group 3 Group 4 Group5 Group6 AverageRetailer 2 2 23 90 1 3 20Wholesaler 25 2 26 39 2 7 17Factory 164 6 24 84 2 62 57
aims to reduce three gaps: the expected demand level; the desired vs the actual work-in-process; the desiredvs the actual inventory level. It can be expressed as follows:
Oit = µ + γ(Si−Bi−1
t )+δ (W i−WIPt), (7)
where γ,δ ∈ [0,1] and µ,Si,W i are the expected demand rate, the inventory and the work-in process expectedlevels, respectively. If Si and W i are constants and γ = 1,δ = 1 then (7) represents a the pull policy [10]:
Oit = µ +(Si−Bi−1
t )+(W i−WIPt). (8)
Notice that (8) aggregates information coming from three dimensions: demand, inventory and work-in-process levels. Moreover, it sums up three criteria, represented by the respective gaps. It is a multi-criteriaequation. In order to explore whether the structure of the decision-making processes of individuals is closeto the pull policy or not, multiple linear regression is performed for each experiment. In Table 3, Ot is thedependent variable and the independent variables are as follows: demand (D); downstream demand (DS),distinct from demand for wholesaler and factory stages; work-in-process (WIP); inventory (B); and theincoming order (IO) received in a stage from its upstream supplier, corresponding to Ot−L.
Table 3: Multiple Linear Regression In Experiment TNR (p≤ 0.05)
Group 1 Group 2 Group 3 Group 4 Group 5 Group 6
Retailer
F = 6.336 F = 17.417 F = 12.254 F = 41.371r2 = .448 r2 = .691 r2 = .611 r2 = .821
B : β =−.665 B : β =−.655 B : β =−.312 B : β =−.247
Wholesaler
F = 10.648 F = 10.336 F = 9.010 F = 13.073 F = 92.848 F = 45.846r2 = .577 r2 = .570 r2 = .536 r2 = .626 r2 = .923 r2 = .855
D : β = 1.180DS : β = 1.231 DS : β = .691 DS : β = 1.801
B : β =−.238 B : β =−.423 B : β =−.786 B : β =−.591 B : β =−.304 B : β =−.127IO : β =−.350
Factory
F = 7.396 F = 17.076 F = 11.476r2 = .493 r2 = .651 r2 = .602
DS : β = .383
B : β =−.212 B : β =−.439 B : β =−.568
It seems that in TNR individuals focus on information feedback provided by the inventory level (thir-teen from eighteen cases). The order equation for this experiment could be represented by the followingexpression:
CLAIO-2016
645
Oit = γ(Si
t −Bi−1t ), (9)
where Sit corresponds to the expected inventory level, possibly changing as a function of t. The scaling
parameter γ corresponds to the β value in the regression analysis, at the respective stage i. Then, µ = 0 andδ = 0 for most of participants in this experiment. In Table 4 analysis of experiment TR shows that B is agood predictor and DS a possible explaining variable. The equation has the following structure:
Oit = αDSt + γ(Si
t −Bi−1t ), (10)
which could mean that most of participants in this experiment partially follow the proposed rule. Thus,trained people mainly focus on the inventory level, even if the rule also suggests monitoring the downstreamdemand.
Table 4: Multiple Linear Regression In Experiment TR (p≤ 0.05)
Group 1 Group 2 Group 3 Group 4 Group 5 Group 6
Retailer
F = 46.295 F = 20.672 F = 12.025 F = 8.798 F = 22.412 F = 16.640r2 = .859 r2 = .731 r2 = .613 r2 = .620 r2 = .747 r2 = .686
B : β =−.401 B : β =−.545 B : β =−.469 B : β =−.446 B : β =−.332
Wholesaler
F = 129.264 F = 36424.547 F = 28.077 F = 31.751r2 = .943 r2 = 1,000 r2 = .783 r2 = .803
DS : β = .937 DS : β = 1.003 DS : β = .430 DS : β = .477WIP : β =−.190B : β =−.199 B : β =−.237 B : β =−.298
Factory
F = 27.420 F = 22.585 F = 37.387r2 = .779 r2 = .748 r2 = .827
DS : β = .554 DS : β = .782 DS : β = .177WIP : β = .425B : β =−.158 B : β =−.313 B : β =−.066
5 Discussion
In general, groups fail to keep the bullwhip effect under control because the expected feedback structure isnot identified. The TNR experiment shows that participants use mainly the inventory. In the TR experimentparticipants actually change their strategies, but the inventory is still the main ordering predictor, even thoughthe downstream demand predicts several ordering processes. Participants show a partially common strategyin both experiments: overconfidence on their knowledge [1]. They might judge the situation with theirintuition given by experience, having more difficulties to change their strategy based on external rules [2],and having poor insight into the limits of their knowledge.
Though it was expected that the pull instruction was properly followed in the TR case, both experimentsshow that participants are mainly guided by a mono-criterion strategy. Research on different domains showthat a simple decision-making rule can be very successful, but when people has few knowledge (not-trained)about the context where decisions are made [5]. In most situations, trained people is unable to use oridentify the simple rule. In our experiments, we argue that trained people changed one simple rule (the pull
CLAIO-2016
646

instruction) by another that was not successful. We are not able to affirm that not-trained people will succeedto find the multi-criteria structure of (8). Other experiments are necessary. However, in the case of trainedpeople, it has been proposed that better knowledge reduces the probability to use a wrong strategy [5]. Theobjective would be that decision makers understand the multi-criteria structure of the ordering policy: bylearning about the consequences of their decisions in the supply chain, and showing the actual benefits ofthe pull method, in the context of an AR(1) demand process.
6 Conclusion
In this article, an exploratory study has been presented which aims to detect whether decision makers in afictitious supply chain use mono-criterion or multi-criterion strategies to define the order level and controlthe bullwhip effect. Results show that trained people fail to identify a right strategy, they are overconfident toinventory-based rules and show resilience to multi-criteria heuristics. In general, it is found that participantsreplace a good simple decision-making rule by another that cannot reduce the bullwhip effect. In this sense,individuals in experiments apply a mono-criterion strategy. We suggest that this can be improved by learninga priori the consequences of decision-making and by best knowing the behaviour of proper rules. Futurework concerns behaviour of not trained people in similar conditions. Another research is needed to exploreother settings where people prefer to use a mono-criterion versus a multi-criteria decision-making strategy.
References
[1] S.P. Aukutsionek and A.V. Belianin. Quality of forecasts and business performance: A survey studyof russian managers. Journal of Economic Psychology, 22(5):661–692, 2001.
[2] J. D. Cohen, S. M. McClure, and A. J. Yu. Should i stay or should i go? how the human brain managesthe trade-off between exploitation and exploration. Philosophical Transactions of the Royal Society ofLondon, Series B, Biological Sciences(362):933–942, 2007.
[3] R. Croson and K. Donohue. Upstream versus downstream information and its impact on the bullwhipeffect. System Dynamics Review, 21(3):249–260, 2005.
[4] R. Croson, K. Donohue, E. Katok, and J. Sterman. Order stability in supply chains: Coordination riskand the role of coordination stock. Production and Operations Management, 23(2):176–196, 2013.
[5] G. Gigerenzer. Gut feelings: the intelligence of the unconscious. Penguin Books, 2007.
[6] Francesca Gino and Gary Pisano. Toward a theory of behavioral operations. Manufacturing & ServiceOperations Management, 10(4):676–691, 2008.
[7] H. Künsch. The jackknife and the bootstrap for general stationary observations. Annals of Statistics,(17):1217–1241, 1989.
[8] H. Lee, K. So, and C. Tang. The value of information sharing in a two-level supply chain. ManagementScience, 46(5):626–643, 2000.
[9] R. Oliva and P. Gonçalves. Behavioral causes of demand amplification in supply chains: “satisficing”policies with limited information cues. In Proceedings of International System Dynamics Conference,July 2005.
CLAIO-2016
647

[10] J. Pereira. Flexibility in manufacturing processes: a relational, dynamic and multidimensional ap-proach. In R. Cavana, J. Vennix, E. Rouwette, M. Stevenson-Wright, and J. Candlish, editors, 17thInternational Conference of the System Dynamics Society and the 5th Australian and New ZealandSystems Conference, pages 63–75, Wellington, New Zealand, 1999. System Dynamics Society.
[11] J. Pereira and B. Paulre. Flexibility in manufacturing systems: a relational and a dynamic approach.uropean Journal of Operational Research, 130(1):70–85, 2001.
[12] J. Pereira and M. Rivas. A multicriteria analysis of five ordering methods under high- variability andnormal demand processes. In Proceedings of EURO 2001, Roterdam, Netherlands, 2001.
[13] J. Pereira, K. Takahashi, L. Ahumada, and F. Paredes. Flexibility dimensions to control bullwhip-effectin a supply chain. International Journal of Production Research, 47(22):6357–6374, 2009.
[14] J. Sterman. Modeling managerial behavior: Misperceptions of feedback in a dynamic decision makingexperiment. Management Science, 35(3):321–339, 1989.
[15] J. Sterman. The Bullwhip Effect in supply chains: a review of methods, components and cases, chapterOperational and behavioral causes of supply chain instability. Palgrave McMillan, 2006.
[16] K. Takahashi, S. Hiraki, and M. Soshiroda. Flexibility of production ordering systems. InternationalJournal of Production Research, 32(7):1739–1752, 1994.
CLAIO-2016
648

Optimizing a pinball computer player
using evolutionary algorithms
Facundo Parodi, Sebastián Rodŕıguez Leopold, Santiago Iturriaga, Sergio NesmachnowFacultad de Ingenieŕıa, Universidad de la República, Uruguay
{facundo.parodi,sebastian.rodriguez.leopold,siturria,sergion}@fing.edu.uy
Abstract
This article presents an evolutionary approach for the optimization of a computer playerfor video games. We develop an artificial intelligence for playing the pinball game and thenoptimize it applying a parallel evolutionary algorithm. Our proposal is compared against an ap-proach which uses backtracking and local search, and against human players. This evolutionarycomputer player is able to improve between 43% and 541% over the results obtained by humanplayers and also improves over backtracking/local search results.Keywords: Artificial Intelligence; Evolutionary Algorithms; Pinball.
1 Introduction
Developing an artificial intelligence (AI) is a complex task that depends on the knowledge availableabout the target environment to produce a simple, efficient program, capable of making decisionsusing few information and resources. When only partial knowledge is available, an empirical processto optimize the quality of the final result through exploration of the environment is needed [11].Automation of AI optimization allows relieving from testing and refining different configurations.
AI has an important role in games, powering artificial characters that populate game worldsand enable vivid storytelling by providing realistic interactions to the players [13]. Furthermore, ithas been also applied to aid game testing [10]. This article proposes the optimization of an AI forplaying pinball using Evolutionary Algorithms (EA). To our knowledge, this is an original approachto automate games, as few proposals applying EAs are found in the related literature. We applya parallel island-based EA to optimize the gameplay of an AI module for playing pinball. Theexperimental results show that the proposed method improves over the results obtained by humanplayers, and over the backtracking/local search method proposed in [8].
The main contributions of this article are: i) a study of the problem of gameplay automationbased on game-state inspection; ii) the design and implementation of an AI module and a parallelEA capable of automating gameplay efficiently; and iii) the evaluation of the proposed AI againstrealistic opponents: human players of varying skill levels and a previous AI proposed for the game.
The article is organized as follows. Next section presents a description of the problem ofautomating gameplay for the pinball game and reviews the related work. Section 3 describes theproposed EA. The experimental analysis of the proposed computer player is reported in Section 4,including a comparison against a previously proposed AI player and several human players. Finally,the conclusions and the main lines for future work are presented in Section 5.
CLAIO-2016
649

2 Evolutionary optimization for computer AI in games
This section presents the problem model and a review of related works.
2.1 Problem model
We model a pinball game with two screens (stages): i) the upper half of the playfield (UP stage);and ii) the lower half (DOWN stage), see Figure 1). Each pinball match is simulated using theopen source NES emulator FCEUX [4]. We modified the FCUX implementation in order to includethe AI module and several tweaks to enable applying high performance computing techniques.
Figure 1: UP stage (left) and DOWN stage (right) of the pinball game.
The proposed AI player is modeled using 20 circular trigger zones, each one defined by the stageit is in (i.e. UP or DOWN), the position of its center in the screen, its radius, and an action to beperformed when the ball is inside a trigger zone. Valid actions for a trigger zone are either move theleft, right, or both flippers. Besides the 20 trigger zones, 3 additional parameters are included inthe model: the amount of frames to wait with the plunger compressed before releasing the ball intothe playfield, the number of frames the ball must stay in the same position before assuming it gotstuck, and the amount of frames to stay inactive waiting for the ball to get unstuck. The learningproblem consists in optimizing all these parameters, modeling the prior knowledge available tothe AI. The game state is the NES RAM emulated by FCEUX. The AI directly reads specificportions containing the current ball position and stage at each frame. All relevant RAM offsetswere identified by manual inspection during live gameplay (using the FCEUX integrated memoryinspector) and they are hard-coded into the AI module. The position of other static elements (e.g.,flippers, plungers, etc.) were determined using the same technique.
The AI module decides which action to perform on each frame based on the parameters andthe game state. This decision is taken as follows: i) the ball position is determined; ii) if the ballis stuck, no button is pressed for the specified time; iii) in case the ball is near the plunger, it getspulled the specified time before releasing it; iv) if the ball is on the playfield, the trigger zones areinspected to see if one of them contains the ball, executing the action of the first one that applies.
The mathematical model for optimization is based on combining two relevant problem goals: thescore (S) and the remaining balls count (b). We propose optimizing (i.e., maximizing) both valuessimultaneously by applying a linear aggregation approach defined by the function f = S + b × P ,where the weight P defines the worth in points assigned to each remaining ball.
CLAIO-2016
650

2.2 Related work
Some articles have proposed EAs in the optimization of computer players for games.Jørgensen and Sandberg [7] applied EA and reinforcement learning for optimizing the weights of
an Artificial Neural Network (ANN) that learns to play Super Mario. The fitness function combinesthe distance traveled, enemies killed, time left and life lost. The EA/ANN approach obtained mixedresults: it performed well in basic levels, but it was not able to generalize to more complex ones.
Simpson [12] analyzed the main advantages and roadblocks exhibited by ANNs—trained withEAs—, for playing video games. The article also includes examples of successful AIs implementedwith these techniques.
Hong and Cho [6] studied the problem of producing diverse behaviors for an AI that playsRobocode. The authors proposed an EA to combine simple, primitive behaviors into more sophis-ticated ones, using a fitness function that simulates three battles against specific enemies. The EAwas able to generate appropriate strategies for defeating all proposed enemies.
Hausknecht et al. [5] presented a survey of neuro-evolution algorithms for learning to play 61different Atari-2600 games. The proposed strategies outperformed several planning and temporal-difference algorithms in most games, as well as human players in three of them.
Murphy proposed Learnfun and Playfun [8], a general approach to optimize NES games, whichwe use as a comparison baseline for our EA. Learnfun infers the game objectives by analyzing ahuman player recording and Playfun plays the game applying a local search based on backtrackingand a set of possible moves inferred from the training recording. Learnfun/Playfun yielded mixedresults, performing remarkable well on multiple NES games while falling short in others.
All the previous works describe different strategies for implementing AI in video games formultiple platforms. The study we present in this article combines the advantages of the optimizationusing EAs with a computationally efficient resulting AI.
3 The proposed EA for optimizing the pinball AI
The proposed EA was developed over the Watchmaker framework [3]. Specific modifications wereincluded into Watchmaker to enable the parallel evaluation of each subpopulation by applying atwo-level parallel model using threads. The main implementation details are described next.
Solution encoding. The solution is encoded as an array of genes. Each gene represents onetrigger zone or one extra parameter required by the AI. The composition of each type of gene isthe same as explained in section 2.1. In total, the encoding includes 20 trigger zones and 3 extraparameters (plunger compress time, number of frames for detecting that a ball is stuck and forreleasing the ball). Figure 2 presents an example of a solution encoding.
(a) Solution encoding. (b) Trigger
Figure 2: Example of solution encoding.
CLAIO-2016
651

Fitness function. The fitness values are computed considering the linear aggregation functionf = S + b × P , defined in Section 2. The values of score and remaining balls are determined byperforming a simulation of the game using the FCEUX emulator and applying the AI module fordeciding the action to perform in each frame. We use P = 10000. Fitness values are cached inorder to skip unnecessary evaluations of identical individuals.
Population initialization. The initial population is generated by applying an ad-hoc randomizedmethod for building AI configurations. Twelve points are selected (three points for each flipper, ineach one of the two stages of the playfield), whose positions are randomly selected to fit in the areareachable by the corresponding flipper. The remaining eight points are located randomly anywhereon the playable area, four per each stage. This way, the 20 points that define the trigger zones areinitialized. The extra parameters are initialized with a random value chosen uniformly in the range[0, 150].
Selection and replacement. We apply the Stochastic Universal Sampling selection operator,which provides a balanced tradeoff between selection pressure and diversity [2]. For replacement,the proposed EA uses the traditional (µ, λ) evolution model. In each generation, elitism is used tokeep the best individual in every island.
Recombination. After evaluating several options for the crossover operator, we determined thata uniform crossover allows computing the best results. Crossover is performed by swapping genesin even positions between two parents to form two offspring.
Mutation. A special mutation operator was developed, taking into account the structure ofeach gen: i) with a probability of 0.5, selecting a trigger zone (X,Y,Radius) and modify each valueapplying a Gaussian mutation; ii) with a probability of 0.33, modifying the action to perform,using a uniform distribution to select between the other two options; and iii) with a probabilityof 0.167 the stage is switched, applying a bit flip mutation. For the extra parameters, a standardGaussian mutation is applied.
Parallel model. The proposed EA follows the distributed subpopulations parallel model [1].A two-level approach is applied: both the evolution process within every subpopulation and theevaluation of every individual are executed in parallel.
4 Experimental evaluation
This section reports the experimental evaluation of the proposed evolutionary AI. First, we de-scribe the problem instances used in the analysis. After that, the parameter setting experimentsare reported. For the evaluation of the proposed evolutionary AI, we analyze and report the fit-ness results obtained by the EA in the learning process, and compare the scores obtained by theoptimized AI against human players and the Playfun approach. Finally, we study the generality ofthe resulting AI to play a large number of different pinball matches.
4.1 Problem instances
The game employs a random number generator to define some of the ball bounces, modify theplunger strength, and other physical events. The number of frames the player waits before pressingthe start button is used as the seed. Given the same set of keystrokes the game outcome variesdepending on this seed only. We defined game instances by introducing a start delay parameter.
CLAIO-2016
652

We use three instances for the parametric configuration tests, defined using 0, 10 and 20 frames.The proposed EA is evaluated using six new instances, defined using 30, 40, 50, 60, 70, and 80frames. In both parametric setting and evaluation experiments, 20 independent executions of theproposed EA are performed for each problem instance. For the comparison against human playersand Playfun, a varied set of instances, randomly defined by the starting time, is defined. Finally,for the generality tests we use training instances with 10000, 30000, and 50000 frames and a largeset of 80 problem instances defined using from 0 to 79 frames for evaluation.
4.2 Parameters settings
Parallel model. An unidirectional ring topology is used to apply a synchronous migration thatexchanges two individuals with a migration frequency of 25 generations.
Simulation time. We decided to simulate 10000 frames, which provides an acceptable balancebetween the solution quality and the total execution time.
Stopping criterion. We use a fixed effort stopping criteria, limiting the evolution to 1000 gen-erations. This value allows keeping the required simulation time manageable for the optimization.
Population size. We performed initial experiments analyzing the trade-off between the qualityof solutions and the execution time. According to the results, we decided to use a population sizeof 40 individuals.
Operator probabilities. A parameter setting analysis was performed to determine the best valuesfor the crossover (pC) and mutation (pM ) probabilities. The candidate values were pM ∈ {0.05, 0.1},and pC ∈ {0.6, 0.9}. Table 1 reports the results obtained for the 20 executions of the EA usingeach parametric configuration for each of the three instances used.
Table 1: Results of the parameter setting analysis
(pC ,pM )f #gen T (minutes) p-value Friedman
min max avg σ max avg min max avg σ S-W rank
(0.9,0.1) 69670 159460 122510.5 23163.39 827 599.88 63.23 83.92 70.50 2.30 0.0237 2.22(0.6,0.05) 83940 161310 118243.2 21646.24 510 581.78 63.86 117.2 76.35 8.18 0.0135 2.42(0.6,0.1) 77940 166330 115846.5 23622.41 958 597.35 63.86 117.2 72.97 10.80 0.0014 2.53(0.9,0.05) 72260 146680 110536.8 20240.67 762 590.28 68.33 91.39 74.62 2.79 0.0340 2.83
The Shapiro-Wilk (S-W) test with significance level α = 0.05 indicate that the results are notnormally distributed. Thus, a Friedman test was performed to analyze the result distributions.The best parametric configuration according to the Friedman test, the average fitness values, andthe computing time required is pM = 0.9 and pC = 0.1. We use these parameter values for theexperimental evaluation.
4.3 Numerical results
Results of the optimization process. Table 2 reports the results obtained in the 20 executions per-formed by the proposed EA over the six problem instances studied. The evaluation was performedon an AMD Opteron 6272 at 2.09GHz with 64 cores, 48GB of RAM, and CentOS Linux 6.5, hostedat Cluster FING, Universidad de la República, Uruguay [9].
CLAIO-2016
653
Table 2: Results of the experimental analysis
instancef #gen T (minutes) p-value
min max avg σ avg avg S-W
30 72380 156450 117493.0 26393.85 494.35 72.38 0.174340 82050 153490 117794.0 24438.51 656.10 74.54 0.060150 77540 167650 118456.0 23873.86 546.75 68.04 0.896260 83550 154600 120297.0 19916.95 644.50 70.57 0.771970 86190 157430 119697.5 22954.17 627.95 68.31 0.105380 80950 167730 124374.5 27574.74 627.00 68.74 0.0221
The results in Table 2 indicate that the proposed evolutionary AI is able to compute good qualitysolutions as evidenced by the fitness values, which correspond to high scores in the game (accordingto the definition in Section 3. In addition, the standard deviation on the fitness values indicatethat the EA is still capable to evolve after playing 10000 frames. These facts suggest that theevolutionary process is able to compute high quality solutions while maintaining an appropriatediversity in the population. Next subsections compare and discuss the results computed by theevolutionary AI against those obtained by human players and the Playfun approach [8].
Comparison against human players. Table 3 shows the scores obtained by eight human playersthat played 10 pinball matches each. Players are ordered by descending skill level (from the bestat the top to the least skilled at the bottom).
Table 3: Results for the human players matches
playerS T (minutes) p− value
min max avg σ min σ S-W
#1 43890 115670 79484 25186.26 4.38 1.06 0.6219#2 10380 117370 51924 29573.94 4.57 2.17 0.1687#3 29720 74460 45790 14938.76 4.59 1.61 0.0056#4 19170 66570 38383 15003.87 2.13 0.09 0.2913#5 26470 42810 34410 4891.94 3.74 0.72 0.9728#6 15520 64740 33575 15184.57 4.38 1.51 0.2524#7 9580 47570 27383 11037.62 3.30 1.34 0.9986#8 10690 44620 24618 9763.58 1.65 0.38 0.9506
The results reported in Tables 2 and 3 indicate that the proposed evolutionary AI is able tocompute scores that are significantly better than those obtained by the human players. The bestscore achieved by player #2, the best human player in the tests performed is 117370, which is lowerthan the average fitness value obtained by the EA.
Moreover, the evolutionary AI is able to further improve the results, as the fitness values arecomputed in a simulation that is usually interrupted due to an exceeded frame count (fitness iscalculated by adding 10000 points to the score for each remaining ball). When the rest of the matchis simulated, the AI generally obtains more than the 10000 expected points per extra ball.
CLAIO-2016
654
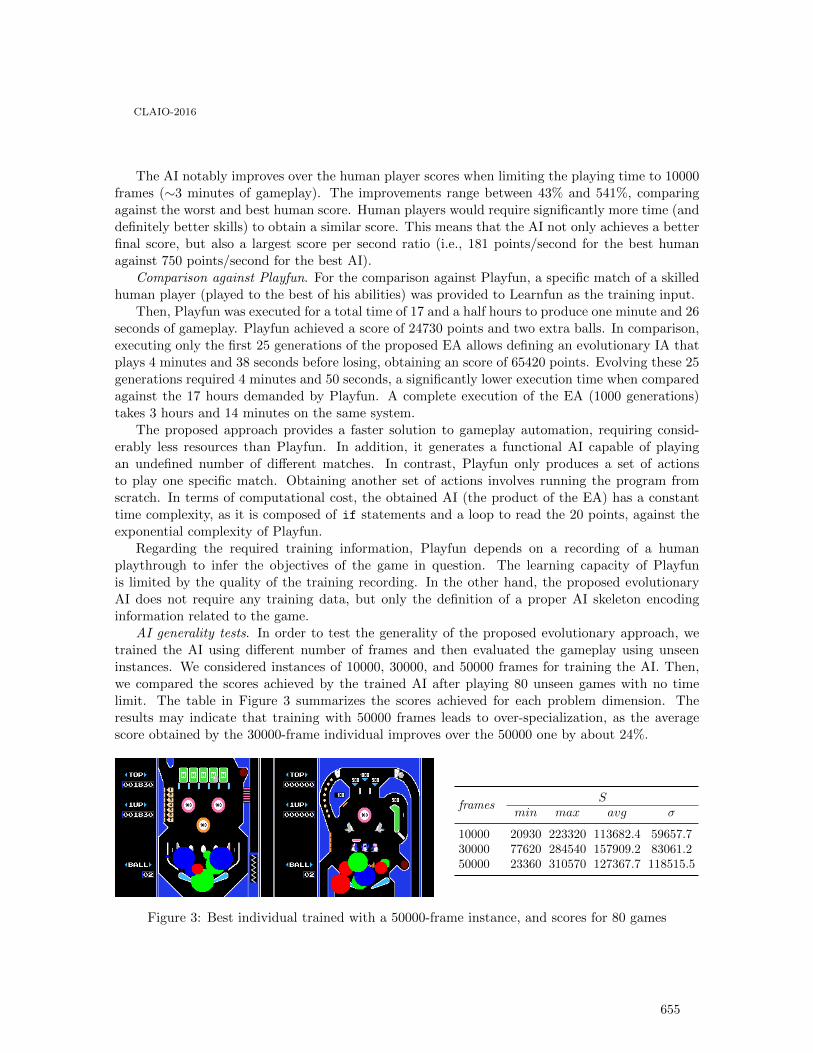
The AI notably improves over the human player scores when limiting the playing time to 10000frames (∼3 minutes of gameplay). The improvements range between 43% and 541%, comparingagainst the worst and best human score. Human players would require significantly more time (anddefinitely better skills) to obtain a similar score. This means that the AI not only achieves a betterfinal score, but also a largest score per second ratio (i.e., 181 points/second for the best humanagainst 750 points/second for the best AI).
Comparison against Playfun. For the comparison against Playfun, a specific match of a skilledhuman player (played to the best of his abilities) was provided to Learnfun as the training input.
Then, Playfun was executed for a total time of 17 and a half hours to produce one minute and 26seconds of gameplay. Playfun achieved a score of 24730 points and two extra balls. In comparison,executing only the first 25 generations of the proposed EA allows defining an evolutionary IA thatplays 4 minutes and 38 seconds before losing, obtaining an score of 65420 points. Evolving these 25generations required 4 minutes and 50 seconds, a significantly lower execution time when comparedagainst the 17 hours demanded by Playfun. A complete execution of the EA (1000 generations)takes 3 hours and 14 minutes on the same system.
The proposed approach provides a faster solution to gameplay automation, requiring consid-erably less resources than Playfun. In addition, it generates a functional AI capable of playingan undefined number of different matches. In contrast, Playfun only produces a set of actionsto play one specific match. Obtaining another set of actions involves running the program fromscratch. In terms of computational cost, the obtained AI (the product of the EA) has a constanttime complexity, as it is composed of if statements and a loop to read the 20 points, against theexponential complexity of Playfun.
Regarding the required training information, Playfun depends on a recording of a humanplaythrough to infer the objectives of the game in question. The learning capacity of Playfunis limited by the quality of the training recording. In the other hand, the proposed evolutionaryAI does not require any training data, but only the definition of a proper AI skeleton encodinginformation related to the game.
AI generality tests. In order to test the generality of the proposed evolutionary approach, wetrained the AI using different number of frames and then evaluated the gameplay using unseeninstances. We considered instances of 10000, 30000, and 50000 frames for training the AI. Then,we compared the scores achieved by the trained AI after playing 80 unseen games with no timelimit. The table in Figure 3 summarizes the scores achieved for each problem dimension. Theresults may indicate that training with 50000 frames leads to over-specialization, as the averagescore obtained by the 30000-frame individual improves over the 50000 one by about 24%.
framesS
min max avg σ
10000 20930 223320 113682.4 59657.730000 77620 284540 157909.2 83061.250000 23360 310570 127367.7 118515.5
Figure 3: Best individual trained with a 50000-frame instance, and scores for 80 games
CLAIO-2016
655

The best individual scored 310570 points. Figure 3 shows the trigger zones using colored circles:triggers in red activate the left flipper, triggers in green activate the right flipper, and those in blueactivate both. When analyzing these zones, we found that not all of the available trigger zones arebeing used by the AI (i.e., there are three trigger zones with negligible radius). Hence, even forthese larger instances, the maximum number of trigger zones in the proposed encoding is enoughfor modeling the AI behavior. Furthermore, most of the trigger zones are located near the flippers.This suggests that the efficiency of the evolutionary process could be further improved by reducingthe search space and considering only the location of trigger zones near the flippers.
5 Conclusions and future work
This article presents a parallel EA to optimize the gameplay of an AI for playing pinball.We introduce a model to represent the game knowledge and rules, and an EA to optimize the
proposed AI. The experimental analysis compares the evolutionary AI against human players andPlayfun, a previous backtracking/local search algorithm. The results indicate that the evolutionaryAI is able to improve human scores up to 541.4%, and it also improves the Playfun results up to264.5% in much shorter computation time (i.e., less than five minutes vs. 17 hours). Furthermore,when testing for generality, the evolutionary AI was accurate in both seen and unseen instances.
The presented approach set the groundwork for a general method that enables optimization ofany NES game with few modifications. The main lines for future work are focused on expanding theproposed approach in order to support other NES games, by means of automatic objective inference.
References
[1] E. Alba, G. Luque, S. Nesmachnow Parallel Metaheuristics: Recent Advances and New Trends. Int.Transactions in Operational Research, 20(1):1–48, 2013.
[2] T. Back, D. Fogel, and Z. Michalewicz. Handbook of evolutionary computation. Oxford Univ., 1997.
[3] D. Dyer. Watchmaker Framework for Evolutionary Computation. [Online]http://watchmaker.uncommons.org, March 2016.
[4] FCEUX. The all in one NES/Famicom Emulator. [Online] http://www.fceux.com, February, 2016.
[5] M. Hausknecht, J. Lehman, R. Miikkulainen, P. Stone. A Neuroevolution Approach to General AtariGame Playing. In IEEE Trans. on Computational Intelligence and AI in Games 6(4):355–366, 2014.
[6] J. Hong, S. Cho. Evolution of Emergent Behaviors for Shooting Game Characters in Robocod. In IEEECongress on Evolutionary Computation 2004, pp. 634–638, 2004.
[7] L. Jørgensen, T. Sandberg Playing Mario using advanced AI techniques. Advanced AI in Games, ITUniversity of Copenhagen, 2009.
[8] T. Murphy VII. The First Level of Super Mario Bros. is Easy with Lexicographic Orderings and TimeTravel. In Proc. 7 th Annual SIGBOVIK Conference, pp. 112–133, 2013.
[9] S. Nesmachnow Computación cient́ıfica de alto desempeño en la Facultad de Ingenieŕıa, Universidadde la República. Revista de la Asociación de Ingenieros del Uruguay, 61:12–15, 2010.
[10] H. Newman. The Talos Principle underwent 15,000 hours of playtesting—but not by humans. [Online]http://tinyurl.com/aitesting/, June 2016.
[11] S. Russell, P. Norvig. Artificial Intelligence: A Modern Approach. Prentice Hall, 3rd Ed, 2009.
[12] R. Simpson Evolutionary Artificial Intelligence in Video Games. University of Minnesota. 2012.
[13] J. Westra, F. Dignum Evolutionary Neural Networks for Non-Player Characters in Quake III. 2009IEEE Symposium on Computational Intelligence and Games, Milano, 2009, pp. 302-309.
CLAIO-2016
656

Uma Heuŕıstica Hı́brida para Problemas de
Roteamento de Véıculos com Dimensionamento de
Frota Heterogênea e Múltiplos Depósitos
Puca Huachi Vaz PennaDepartamento de Computação - Universidade Federal de Ouro Preto
Anand SubramanianDepartamento de Engenharia de Produção - Universidade Federal da Paráıba
Luiz Satoru OchiInstituto de Computação - Universidade Federal Fluminense
Resumo
Este trabalho trata o Problema de Roteamento de Véıculos com Dimensionamento de FrotaHeterogênea e Múltiplos Depósitos (PRVDFHMD). O PRVDFHMD é NP-dif́ıcil pois é umageneralização do Problema de Roteamento de Véıculos (PRV), onde os clientes são atendidospor uma frota heterogênea de véıculos com capacidades e custos distintos e mais de um depósitoestá dispońıvel. Para resolver o problema é usada uma abordagem h́ıbrida, baseado na meta-heuŕıstica Iterated Local Search, que faz uso de um método exato baseado no Problema deParticionamento de Conjuntos para incorporar memória ao algoritmo heuŕıstico. Para verificaresta eficiência, esta é testada em problemas-teste da literatura. O algoritmo desenvolvido obtivevalores melhores ou iguais aos melhores resultados conhecidos em diversos problemas. Estesresultados mostram que o algoritmo desenvolvido produz soluções finais de alta qualidade quandocomparados com os algoritmos da literatura.
Palavras-Chaves: Problema de Roteamento de Véıculos; Frota Heterogênea; Múltiplos Depósi-tos; Iterated Local Search; Meta-heuŕıstica.
1 Introdução
O Problema de Roteamento de Véıculos (PRV) é um dos problemas de otimização mais estuda-dos na área de Pesquisa Operacional (PO). Ele foi introduzido por [2] em seu trabalho denominadoThe Truck Dispatching Problem. Os autores definiram o problema como determinar um conjuntode rotas para um frota de véıculos de modo a atender um dado conjunto de clientes. O PRVé problema combinatorial computacionalmente dif́ıcil de resolver por isso tem sido intensamenteestudado no últimos cinquenta anos [8]. Inspirado em problemas reais e pelo benef́ıcio econômico
CLAIO-2016
657

prático associado a otimização das rotas, diversas variantes foram propostas ao longo dos anos. Es-tas variantes incluem caracteŕısticas como janelas de tempo, múltiplos depósitos, duração de rotas,frota heterogênea, etc.
A importância no desenvolvimento de Sistemas Automatizados para essas empresas se devetambém pelo fato de eles propiciarem economias médias entre 5% a 10% nos custos finais detransporte [17]. Em muitas empresas de médio e grande porte, esses percentuais representamvalores altamente significativos.
Neste trabalho, nosso interesse recai sobre o PRV com Dimensionamento de Frota Heterogêneae Múltiplos Depósitos (PRVDFHMD). O modelo básico desta classe problemas se diferencia doPRV por trabalhar com a possibilidade de utilização de mais de um depósito e com uma frotaheterogênea de véıculos, ao invés de uma frota com véıculos idênticos (homogêneos). Esta situaçãopode ser facilmente encontrada na prática e o PRVDFHMD modela este tipo de aplicação.
2 Descrição do Problema
A generalização do PRV, onde mais de um depósito é levado em consideração, é denominadaPRVMD e foi apresentado em [16]. Já sua generalização com dimensionamento de frota heterogê-nea, denominada PRVDFH, foi proposto por [5]. O O Problema de Roteamento de Véıculos comDimensionamento de Frota Heterogênea e Múltiplos Depósitos (PRVDFHMD) foi descrito pelaprimeira vez em [13] e possui caracteŕısticas dessas duas importantes variantes do PRV.
O PRVDFHMD pode ser definido da seguinte forma. Seja seja D = {1, . . . , d} o conjunto dedepósitos, V ′ = {1, . . . , n} o conjunto de clientes, G = (V,E) um grafo completo com V = D ∪ V ′representando o conjunto de n + d vértices, E = {(i, j) : i, j ∈ V, i 6= j} o conjunto de arestas,qi a demanda do cliente i ∈ V ′. A frota é composta por m diferentes tipos de véıculos, comM = {1, . . . ,m}. Para cada tipo u ∈ M , o número de véıculos dispońıveis é ilimitado, ou seja,mu = +∞, ∀u ∈ M , onde cada um possui uma capacidade Qu. A cada véıculo está associadoum custo fixo denotado por fu. Por fim, a cada aresta (i, j) ∈ A está associado custo cuij , sendocuij = lij × ru, onde lij é a distância entre os vértices (i, j) e ru um custo variável de viagem, porunidade de distância, associado ao véıculo do tipo u. Assume-se que a demanda dos depósitos énula, assim como a distância lij = ∞ ∀i, j ∈ D. O objetivo é determinar a melhor composiçãoda frota, bem como o conjunto de rotas que minimizam a soma dos custos fixos e os custos deviagem, de tal modo que: (i) toda rota começa e termina no mesmo depósito (i1 = i|R| = d, d ⊆ De {i2, . . . , i|R|−1} ⊆ V ′) e está associada a um tipo de véıculo; (ii) a demanda de todos os clientes
deve ser atendida; (iii) a capacidade do veiculo não pode ser violada (∑|R|−1
h=2 qih 6 Qu); (iv) cadacliente pertence a exatamente uma rota.
2.1 Trabalhos Relacionados
Na literatura é posśıvel encontrar diversos trabalhos relacionados ao PRV e suas variantes. Umarevisão bibliográfica detalhada do PRV, pode ser encontrada em [4, 17, 1, 3]. Para as variantesrelacionadas, pode-se encontrar uma revisão sobre o PRVMD em [10] e sobre o PRVDFH em [6, 7].
Apesar do grande número de trabalhos sobre o PRV e as variantes PRVMD e PRVDFH, oPRVDFHMD é pouco estudado. O PRVDFHMD foi proposto em [13], denominado pelos autoresde Multi-Depot Vehicle Fleet Mix Problem (MDVFMP). Uma diferença básica entre o PRVMD comfrota homogênea para a versão apresentada pelos autores possui como objetivo dimensionar a frota
CLAIO-2016
658

de véıculos, apesar de na literatura do PRVMD o número de véıculos ser conhecido. Os autoresdesenvolveram uma heuŕıstica de várias fases baseada no algoritmo proposto em [12], que utilizamecanismos de perturbação, realocação, combinação, troca e redução em suas fases. Os autoresadaptaram as instâncias do PRVMD para o PRVDFHMD. Recentemente, em [14], os autores apre-sentaram uma formulação que foi utilizada para gerar alguns limites inferiores para o problema,utilizando o resolvedor CPLEX. Além dessa formulação os autores também desenvolveram um heu-ŕıstica baseada na meta-heuŕıstica VNS para resolver o problema. Atualmente, o melhor trabalhoencontrado na literatura para o problema é um Algoritmo Genético (AG) h́ıbrido proposto em [18].
A Tabela 1 apresentam as caracteŕısticas dos trabalhos encontrados na literatura para resolvero PRVDFHMD.
Tabela 1: Caracteŕısticas dos trabalhos para o PRVDFHMD
Custo Custo
Trabalho Método Abordagem Frota Fixo. Var.
Salhi & Sari, 1997 [13] MLH heuŕıstica Ilimitada X X
Salhi et al., 2014 [14] VNS2 VNS Ilimitada X X
Vidal et al., 2014 [18] HGSADC+ AG Ilimitada X X
3 O Algoritmo Heuŕıstico Hı́brido
Nesta seção é descrito o algoritmo Heuŕıstico Hı́brido para resolver as variantes do PRVHF,denominado HILS-RVND-SP. Este algoritmo é uma extensão do algoritmo ILS-RVND-SP, descritoem um trabalho anterior de nossa autoria [15] e aplicado às variantes PRVDFH e PRVFHF. Oalgoritmo desenvolvido faz uso da heuŕıstica, ILS-RVND, apresentada em [11] e incorpora ummétodo exato baseado no Problema de Particionamento de Conjuntos (PPC) (Set Partitioning, emĺıngua inglesa). Este método é tratado por um resolvedor de Programação Inteira Mista (PIM).
O ILS-RVND é baseado na meta-heuŕıstica ILS e incorpora as principais caracteŕısticas dosalgoritmos mais bem sucedidos da literatura para resolução do PRV. No entanto, conforme jádescrito, o algoritmo ILS apresenta boa relação entre intensificação e diversificação, porém nãoutiliza uma estrutura de memória (memoryless). O ILS-RVND utiliza uma estratégia multi-start,porém as informações da solução de uma iteração não são utilizadas pelo algoritmo nas iteraçõesseguintes, ou seja, o ILS-RVND também não implementa nenhum mecanismo de memória. Segundo[9], os métodos multi-start podem obter melhores resultados quando utilizam algum mecanismo dememória. Para tirar proveito dos múltiplos reińıcios do algoritmo ILS-RVND, a sua versão h́ıbrida,o HILS-RVND-SP implementa um mecanismo de memória descrito na seção seguinte.
3.1 Implementando Memória com Particionamento de Conjuntos
Com a finalidade de obter melhores resultados e de melhorar o desempenho computacional doILS-RVND, o HILS-RVND-SP implementa um mecanismo de memória baseado na formulação doPPC. Este modelo é implementado como segue. Seja R o conjunto de todas as posśıveis rotas paratodos os tipos de véıculos, Ri ⊆ R o subconjunto de rotas contendo o cliente i ∈ V ′, e Ru ⊆ Ro conjunto de rotas associadas ao véıculo do tipo u ∈ M . Define-se yj como a variável binária
CLAIO-2016
659

associada à rota j ∈ R, onde yj = 1 se a rota j estiver na solução, e cj como o custo associada aesta rota. A formulação do PPC para os PRVFHs é apresentada a seguir:
Min∑
j∈Rcjyj (1)
sujeito a∑
j∈Ri
yj = 1 ∀i ∈ V ′ (2)
∑
j∈Ru
yj ≤ mu ∀u ∈M (3)
yj ∈ {0, 1}. (4)
A função objetivo (1) minimiza a soma dos custos escolhendo a melhor combinação das rotas.As restrições (2) garantem que uma única rota do subconjunto Ri irá visitar o cliente i ∈ V ′. Asrestrições (3) determinam a composição da frota. As restrições (4) definem o domı́nio das variáveisde decisão. Visto que esta formulação completa possui um número exponencial de variáveis, ela nãopode ser resolvida em um tempo computacional aceitável. Mesmo utilizando técnicas de branch-and-price ou métodos relacionados, como proposto na literatura, é computacionalmente caro e naprática sua resolução só é posśıvel até um determinado tamanho. No algoritmo HILS-RVND-SP,atualmente, resolve-se um PPC similar ao problema (1 – 4), porém com um conjunto R reduzidoe limitado a algumas poucas mil rotas geradas pela heuŕıstica ILS-RVND.
No caso das variantes que envolvem o dimensionamento de frota, ou seja, frota ilimitada, asrestrições (3) não são utilizadas, pois não existe nenhuma restrição ao número máximo de véıculosde cada tipo.
O Algoritmo 1 descreve o HILS-RVND-SP desenvolvido. É posśıvel observar que sua estruturaé bem semelhante a ILS-RVND, se diferenciando pela inclusão de um conjunto de rotas utilizadopara implementar o mecanismo de memória. Esta memória, ConjuntoRotas, é preenchida, na linha9, com as rotas da solução s∗ e no laço principal do ILS com as rotas da solução s′′ (linha 13). Ométodo AdicionaRotasTemporárias adiciona as rotas da solução fornecida, caso ainda não tenhamsido adicionadas e se o custo da solução for menor ou igual ao custo da melhor solução obtida até omomento vezes uma dada tolerancia. Essas rotas farão parte da memória temporária do algoritmo.Ao final da execução do ILS, se o número de clientes n, do problema, for maior que um dado valorMaxN o procedimento que resolve o modelo do PPC (Algoritmo 2) é executado utilizando-se asrotas armazenadas até o momento (linhas 18 – 19). Após o término do laço do multi-start, se o nfor menor que o MaxN o modelo do PPC é resolvido com o conjunto de rotas armazenado, dentrode uma margem de tolerância, ao longo de toda a execução do HILS-RVND-SP. O PPC pode serexecutado durante a fase multi-start do algoritmo ou após seu término, dependendo do númerode clientes do problema. Esta separação foi feita pois foi observado que para problemas com umgrande número de clientes o modelo do PPC fica muito grande e imposśıvel de ser resolvido emum tempo computacional razoável ao final no algoritmo, portanto se optou por executar o modelodiversas vezes com um conjunto de rotas menor. O método de gerenciamento desse conjunto derotas, para que HILS-RVND-SP tire proveito do uso de memória, é apresentado no Algoritmo 2.
CLAIO-2016
660

Algoritmo 1: HILS-RVND-SP(MaxIterMS, β, MaxTempo, Tolerancia, n, MaxN)
1 Ińıcio2 v ← Inicializa frota3 f(s∗)←∞4 para i← 1 até MaxIterMS hacer5 iterILS ← 06 MaxIterILS ← CalcularMaxIterILS(n, v, β)7 s← GeraSoluçãoInicial(v)8 s′∗ ← BuscaLocal(s)9 AdicionaRotasTemporárias(ConjuntoRotas, s∗′, f(s∗), Tolerancia)
10 enquanto (iterILS ≤MaxIterILS) faça11 s′ ← Perturbação(s∗′)12 s′′ ← BuscaLocal(s′)13 AdicionaRotasTemporárias(ConjuntoRotas, s′′, f(s∗), Tolerancia)14 se (f(s′′) < f(s∗′)) então15 s∗′ ← s′′
16 iterILS ← 0
17 iterILS ← iterILS + 1
18 se (n ≥MaxN) então19 s∗′ ← ResolvePPC(ConjuntoRotas, s∗′, MaxTempo, Tolerancia)
20 se (f(s∗′) < f(s∗)) então21 s∗ ← s∗′
22 se (n < MaxN) então23 s∗ ← ResolvePPC(ConjuntoRotas, s∗, MaxTempo, Tolerancia)
24 retorna s∗
25 Fim
O PPC é tratado pelo resolvedor PIM, descrito no Algoritmo 2. Na linha 2, as rotas das soluçãos∗ são adicionadas ao conjunto de rotas. As rotas da solução s∗ fazem parte da memória permanentedo algoritmo e não são apagadas quando a memória é reinicializada (linha 11). O algoritmo possuium laço que é executado enquanto houver uma melhora no custo da solução corrente (linhas 4 – 16).O modelo do PPC é criado na linha 5, conforme formulação dada pelas expressões (1) – (4). Após,o modeloPC e a solução s∗ são fornecidos ao resolvedor PIM que chama o ILS-RVND, por meio doprocedimento IncumbentCallback, sempre que uma nova solução é obtida (Procedimento 3). Se asolução s′ dada pelo resolvedor PIM melhorar o custo da melhor solução, então s∗ é atualizado e suasrotas são adicionadas a memória permanente (linhas 7 – 9). Caso contrário memória temporáriaé limpa (linha 11). Assume-se que o resolvedor PIM utiliza um método de Branch-and-bound ouBranch-and-cut e que seus critérios de parada são dados por: (i) a solução ótima do PPC é obtida;(ii) o tempo de execução do resolvedor para alcançar um dado valor máximo fornecido. Caso (i)ocorra e se o resolvedor PIM conseguir solucionar o problema no nó raiz, a tolerância é aumentadaem 2%, pois o modelo está leve e, assim pode-se adicionar mais rotas à memória (linhas 13 – 14).No entanto, se o resolvedor finalizar por tempo (caso (ii)), o valor da tolerância é reduzido em 2%,pois significa que o resolvedor PIM não consegue encontrar uma solução no tempo estabelecido;logo, o número de rotas a serem adicionadas na memória deve ser menor (linhas 15 – 16).
CLAIO-2016
661

Procedimento 2: ResolvePPC(ConjuntoRotas, s∗, MaxTempo, Tolerancia)
1 Ińıcio2 AdicionaRotasPermanentes(ConjuntoRotas, s∗)3 melhorouSolucao← verdadeiro4 enquanto (melhorouSolucao) faça5 modeloPC ← CriaModeloPPC(ConjuntoRotas, v)6 s′ ← ResolvedorPIM(modeloPC, s∗,MaxTempo, IncumbentCallback(s∗))7 se (f(s′) < f(s∗)) então8 s∗ ← s′
9 AdicionaRotasPermanentes(ConjuntoRotas, s∗)10 senão11 RemoveRotasTemporárias(ConjuntoRotas)12 melhorouSolucao← falso
13 se (Problema for resolvido na raiz) então14 Aumenta a Tolerancia em 2%
15 se (Tempo do PIM > MaxTempo) então16 Diminui a Tolerancia em 2%
17 retorna s∗
18 Fim
O método IncumbentCallback é mostrado no Procedimento 3. Este procedimento é executadosempre que o resolvedor PIM encontrar uma nova solução (Procedimento 2). Na linha 2, a soluçãoencontrada pelo resolvedor é carregada, e o método ILS-RVND1 é chamado, passando-se a soluçãoincumbente s e com o número de iterações MaxIterMS igual a um, ou seja, apenas uma iteraçãoda fase multi-start. Se a solução s′ tiver um custo inferior ao da solução s∗, está é atualizada. Asolução s obtida pelo resolvedor pode ser melhor ou pior da a melhor solução, mas é importantesalientar que mesmo ela seja pior o ILS-RVND1 é executado pois pode ser uma solução que eleainda não tenha visitado. O ILS-RVND1 é semelhante ao algoritmo ILS-RVND, diferenciando-seapenas por atualizar a memória ConjuntoRotas, conforme linha 13 do Algoritmo HILS-RVND-SP.
Procedimento 3: IncumbentCallback(s∗)
1 Ińıcio2 s← Solução Incumbente3 s′ ← ILS-RVND1(1, β, s, ConjuntoRotas)4 se f(s′) < f(s∗) então5 s∗ ← s′
6 Fim
4 Resultados do HILS-RVND-SP para o PRVFHMD
O PRVFHMD foi testado nas instâncias propostas em [13]. Essas instâncias foram adaptadasdo PRVMD, adicionando-se 5 tipos diferentes de véıculos. Para cada tipo k, sua capacidade Qk,
CLAIO-2016
662

seu custo fixo fk e variável rk foram gerados usando os dados dos véıculos originais, tal que:
Qk = (0, 4 + 0, 2k)Q k = 1, 2, 3, 4, 5 (5)
fk = (70 + 10k) k = 1, 2, 3, 4, 5 (6)
rk = (0, 7 + 0, 1k) k = 1, 2, 3, 4, 5 (7)
Os resultados obtidos pelo HILS-RVND-SP são comparados com o algoritmos encontrados naliteratura, mostrados na Tabela 1, e apresentados na Tabela 2 .
Tabela 2: Resultados do HILS-RVND-SP para o PRVFHMD.
Método Melhor Gap Tempo (s) # Sol. obtidas CPUgap médio médio (s) (Melhor/Igual/Total)
MLH [13] 2.8 – 269.74 00/01/23 VAX4000
VNS2 [14] 1.52 – 1036.36 00/01/23 Pentium 4MHGSADC+ [18] 0.05 0.11 700.74 00/21/23 Opt 2.4GHzILS-RVND 0.06 0.76 91.05 02/15/23 I7 2.93GHz
Comparando-se o Melhor Gap entre as soluções obtidas pelos algoritmos, é posśıvel observarque o HILS-RVND-SP conseguiu obter um resultado bem superior aos das heuŕıstica MLH e VNS2e resultados bem competitivos quando comparados ao HGSADC+. Além disso, o HILS-RVND-SP conseguiu encontrar duas novas melhores soluções. Em relação ao tempo computacional, oHILS-RVND-SP foi o que obteve o melhor desempenho quando comparado aos demais algoritmos.
5 Conclusão
Este trabalho trata o Problema de Roteamento de Véıculos com Dimensionamento de FrotaHeterogênea e Múltiplos Depósitos (PRVDFHMD). Este problema aparece na prática em sistemasde transporte e loǵıstica. O PRVDFHMD foi resolvido por uma heuŕıstica h́ıbrida baseada nameta-heuŕıstica Iterated Local Search (ILS) e que implementa um mecanismo de memória baseadona formulação do Problema de Partionamento de Conjuntos (PPC).
O algoritmo proposto se mostrou altamente competitivo quando comparados aos melhores re-sultados da literatura, obtendo um desvio médio em relação as melhores soluções da literatura deapenas 0,06%. Além disso, o algoritmo foi capaz de encontrar duas novas soluções com um excelentedesempenho computacional.
Agradecimentos Os autores agradecem à FAPEMIG por apoiar este trabalho de pesquisa.
Referências
[1] J.-F Cordeau, G. Laporte, M. W. P. Savelsbergh, and D. Vigo. Transportation, Handbooksin Operations Research and Management Science, volume 14, chapter Vehicle Routing, pages367–428. Elsevier, Amsterdam, 2007.
[2] G. B. Dantzig and J. H. Ramser. The truck dispatching problem. Management Science,6:80–91, 1959.
CLAIO-2016
663

[3] B. Golden, S. Raghavan, and E. Wasil. The Vehicle Routing Problem: Latest Advances andNew Challenges. Springer, New York, 2008.
[4] B. L. Golden and A. A. Assad. Vehicle Routing: Methods and Studies. North-Holland, 1988.
[5] B. L. Golden, A. A. Assad, L. Levy, and F. G. Gheysens. The fleet size and mix vehicle routingproblem. Computers & Operations Research, 11:49–66, 1984.
[6] A. Hoff, H. Andersson, M. Christiansen, G. Hasle, and A. Løkketangen. Industrial aspectsand literature survey: Fleet composition and routing. Computers & Operations Research,37:2041–2061, 2010.
[7] Çağri Koç, Tolga Bektaş, Ola Jabali, and Gilbert Laporte. Thirty years of heterogeneousvehicle routing. European Journal of Operational Research, 249(1):1 – 21, 2016.
[8] Gilbert Laporte. Fifty years of vehicle routing. Transportation Science, 43(4):408–416, 2009.
[9] R. Mart́ı, J.M. Moreno-Vega, and A. Duarte. Advanced multi-start methods. In Michel Gen-dreau and Jean-Yves Potvin, editors, Handbook of Metaheuristics, volume 146 of InternationalSeries in Operations Research & Management Science, pages 265 – 281. Springer, 2010.
[10] J. R. Montoya-Torres, J. L. Franco, S. N. Isaza, H. F. Jiménez, and N. Herazo-Padilla. Aliterature review on the vehicle routing problem with multiple depots. Computers & IndustrialEngineering, 79:115 – 129, 2015.
[11] P. H. V. Penna, A. Subramanian, and L. S. Ochi. An iterated local search heuristic for theheterogeneous fleet vehicle routing problem. Journal of Heuristics, 19(2):201–232, 2013.
[12] S. Salhi and G. K. Rand. Incorporating vehicle routing into the vehicle fleet compositionproblem. European Journal of Operational Research, 66:313–330, 1993.
[13] S. Salhi and M. Sari. A multi-level composite heuristic for the multi-depot vehicle fleet mixproblem. European Journal of Operational Research, 103(1):95 – 112, 1997.
[14] Said Salhi, Arif Imran, and Niaz A. Wassan. The multi-depot vehicle routing problem withheterogeneous vehicle fleet: Formulation and a variable neighborhood search implementation.Computers & Operations Research, 52:315 – 325, 2014.
[15] Anand Subramanian, Puca Huachi Vaz Penna, Eduardo Uchoa, and Luiz Satoru Ochi. Ahybrid algorithm for the heterogenous fleet vehicle routing problem. European Journal ofOperational Research, 221:285 – 295, 2012.
[16] F. A. Tillman. The multiple terminal delivery problem with probabilistic demands. Transpor-tation Science, 3(3):192–204, 1969.
[17] P. Toth and D. Vigo. The Vehicle Routing Problem. Monographs on Discrete Mathematicsand Applications. SIAM, Philadelphia, 2002.
[18] T. Vidal, T. G. Crainic, M. Gendreau, and C. Prins. Implicit depot assignments and rotationsin vehicle routing heuristics. European Journal of Operational Research, 237(1):15 – 28, 2014.
CLAIO-2016
664

Using TODIM under imprecision and uncertainty conditions:
application to the suppliers development problem
J. PereiraTecnologico de Monterrey, Campus Toluca, México
L.F.A.M GomesIBMEC, Rio de Janeiro, Brazil
E.C.B. de OliveiraIFPB, Campus João Pessoa, Brazil
Tecnologico de Monterrey, Campus Toluca, Mé[email protected]
P. ArroyoTecnologico de Monterrey, Campus Toluca, México
Abstract
In different industries where the demands of end customers for faster and more reliable deliveries,better quality and lower prices increases, success strongly relies on supplier development. In this article,the TODIM multicriteria method is used to propose a ranking of suppliers for development in a realcontext defined by the Mexican aerospace industry. Given that poor information on available inputdata is observed, an extension of the TODIM multicriteria method is used to solve the problem. Itutilizes preference thresholds to model imprecision and Monte Carlo simulation to deal with uncertainty.Outcomes of the standard TODIM and the extension are compared, which reveals the effect of bothimprecision and uncertainty.
Keywords: Supplier development; multicriteria; uncertainty; imprecision; TODIM.
1 IntroductionLead companies, for example, in the automotive and aerospace sectors, are investing a significant amountof resources in the design of systems and processes to develop supplier capabilities as a mean to guaranteethe competitiveness of their supplier base [1, 7]. Thus, the supplier development (SD) problem addressesthe following questions: What suppliers to develop? What development activities need to be implementedto guarantee an improvement in supplier’s performance? and How to allocate the development activities tosuppliers according to multiple criteria as cost, improvement and time? The objective of this work concernsthe first question introducing a problem formulation, based on multiple criteria decision analysis.
In a recent study applied in the Mexican aerospace industry [15] a survey was applied to evaluate suppliershaving potential for development. Data collected evaluated suppliers in terms of several conflicting criteria,
CLAIO-2016
665

but had two issues. First, mostly nominal and ordinal scales were used. Transformations and preparationfor model evaluation used instrumental and scaling procedures that introduced imprecision. Second, thesame supplier was evaluated by different buyers which implied uncertainty (in the form of non-punctualevaluations).
A MCDA method aiming to rank suppliers would adapt to situations where input data are impreciseand/or uncertain. In the present paper, an extension of TODIM multicriteria method, previously introduced[14], is applied to this Mexican case, by considering imprecision and uncertainty. Preference thresholds areproposed for modeling imprecision, while uncertainty is dealt with Monte Carlo Simulation. A final rankingof suppliers is provided, which can be further used by the decision makers to discriminate suppliers toimprovement. Results show that modeling imprecision and uncertainty has an effect on outcomes.
The article is organized as follows. In section 2 the TODIM method is described. Next, section 3 presentsthe extension of this method to deal with imprecision and uncertainty. Section 4 describes the applicationof this extension and the standard TODIM to the Mexican case. Conclusions are presented in section 5.
2 The TODIM method
TODIM first appeared in the literature in the early nineties [6] and applications have covered a wide spectrumof situations [5, 11]. Different extensions of this method are available for sorting problems, fuzzy set basedpreference modelling and a generalization to deal with intuitionistic fuzzy information [10].
Let us consider A = {a1, . . . , an} a set of alternatives and G = {g1, . . . , gm} a set of m quantitativeand qualitative criteria. For each criterion gc ∈ G and two alternatives ai and aj , TODIM relies on avalue function that computes the preferences of relative gains and losses of ai over aj . If gr is a referencecriterion defined as the one with the highest importance, then the relative weight of each criterion gc becomeswcr = wc/wr. In TODIM, a piecewise non-linear function modelling the DM’s preferences is defined asfollows:
φc(ai, aj) =
(wcr∑m
c=1 wcr(gic − gjc)
)αif (gic − gjc) > 0,
0 if (gic − gjc) = 0,
− 1θ
(∑mc=1 wcr
wcr(gjc − gic)
)αotherwise.
(1)
Positive values of (gic−gjc) could be interpreted as gains while negative values as losses, likewise in ProspectTheory1. The θ parameter is called the attenuation factor of losses, which shapes the prospect theoreticalvalue function in the negative part of (1).
TODIM could be procedurally separated into a “construction step” and an “exploitation step” [3]. In theconstruction step, preferences restricted to each criterion are aggregated into a dominance relation betweeneach pair of alternatives, which is expressed as follows:
δ(ai, aj) =
m∑
c=1
φc(ai, aj). (2)
In the explotation step, a recommendation in TODIM emerges from a ranking of the alternatives in A,obtained by defining the global dominance of the alternative ai with regards to the other alternatives asfollows:
∆(ai) =
n∑
j=1
δ(ai, aj). (3)
1A complete analysis of similarities between TODIM and the Cumulative Prospect Theory (CPT) is provided by (author?)[4].
CLAIO-2016
666

Normalization of (3) allows to calculate the global performance of the alternative ai with regards to all otheralternatives, which leads to a complete pre-order of alternatives in A:
ξi =∆(ai)−mini ∆(ai)
maxi ∆(ai)−mini ∆(ai). (4)
3 Dealing with poor information in TODIM
3.1 Imprecision thresholds
Let us consider the following value function φ+c , defined in the case gic ∈ [0, 1](∀i, c):
φ+c (ai, aj) =
{(gic − gjc)
αif (gic − gjc) > 0,
0 if (gic − gjc) ≤ 0,(5)
and define the following weight factors
w(T )c =
(wcr∑m
c=1 wcr
)αif (gic − gjc) > 0,
0 if (gic − gjc) = 0,
− 1θ
(∑mc=1 wcr
wcr
)αotherwise.
(6)
The TODIM’s global dominance function can now be expressed as follows:
∆(ai) =∑
j
∑
φ+c (ai,aj)≥0
w(T )c φ+
c (ai, aj)−
∑
j
∑
φ+c (aj ,ai)>0
w(T )c φ+
c (aj , ai). (7)
A main drawback of the standard TODIM is that it does not consider situations where input data areimprecise, but the decision analyst still wants to use it for providing a framework on which an analysiscan be based. In order to consider situations where input data on preferences are imprecise [14] proposeto introduce the indifference and preference thresholds qc and pc (pc > qc), respectively. The indifferencethreshold qc measures the maximum tolerance between evaluations of two alternatives on a criterion suchthat they are considered indifferent to each other, respect to c. The preference threshold pc represents theminimum difference between evaluations of two alternatives in order to have clear evidence in favor of oneof them. Let us define a modified version of (5) as follows:
φ+c (ai, aj , qc, pc) =
0 if (gic − gjc) ≤ qc,
(gic−gjc−qc
pc−qc)α if qc < (gic − gjc) ≤ pc,
1 if (gic − gjc) > pc.
(8)
In Figure 1 an example of φ+c (ai, aj , qc, pc) is depicted. The value function φ+
c (ai, aj), without thresholds, isalso represented by a dashed line.
3.2 Modeling uncertainty in TODIM
Let us consider situations where a decision maker (DM) has an unknown or partially known preference struc-ture, such that both evaluations and weights of criteria are random variables obeying a known probabilitydistribution on each case [9]. Uncertain evaluations gic can be represented by stochastic variables ξic with
CLAIO-2016
667

−1 −0.5 0 0.5 1−1
−0.5
0
0.5
1
φc(ai, aj)
gic − gjc
φ+ c(a
i,aj,q,p)
Figure 1: Value function φ+c (ai, aj , q, p) when qc = 0.1 and pc = 0.5
density functions fχ(ξ) in the space χ ⊆ <n×m. The weight space is represented by a weight distributionwith joint density function fW (w), where W = {w ∈ <m : 0 ≤ w ≤ 1 ∧∑m
c=1 wc = 1}.Let W r
i (ξ) be the set of favourable weights granting that ai ranks r. Therefore, the rank acceptabilityindex is defined as
bri =
∫
ξ∈χ
fχ(ξ)
∫
w∈W ri (ξ)
fW (w)dwdξ, (9)
where bri ∈ [0, 1]. If it equals 1 then ai is placed in rank r whatever the weights, but 0 indicates that itnever reaches this rank in the selected scenarios. SMAA provides TODIM with a procedure to compute briby Montecarlo Simulation through a large number of iterations, minimizing the error margins [18]. It allowsto consider problems where neither evaluations nor weights are precise or known in advance.
4 Application to the supplier development problem
The problem concerned with the suppliers improvement is called the supplier development problem [8].Supplier development (SD) involves all activities, practices and efforts undertaken by the buyer firms toimprove their suppliers’ capabilities and performance. These efforts include projects oriented to improve theproduct design, quality of products and process, delivery and cost [17, 12, 13].
Multi-criteria approaches have been extensively used to evaluate and identify suppliers to be developed.For instance, [12] proposes an approach to evaluate and rank supplier quality development programs usingTOPSIS. [17] introduce capabilities and willingness as dimensions for evaluating suppliers. Recently, [16] haveproposed a method using fuzzy AHP to supplier segmentation, defining classes that aid the decision makerto handle suppliers in different ways. [2] also propose a supplier segmentation process using PROMSORTfor identifying groups of suppliers where performance could be improved by development programs.
In a previous study applied in Mexico, data was collected from suppliers experience on the aerospaceindustry [15]. Multi-dimensional scaling was applied to rank and further identify suppliers for improvement.In this work, TODIM is applied to the same data set, but considering that these are imprecise and uncertain.Thus, let us consider a set of suppliers S = {s1, . . . , s15} to be evaluated. A family of criteria is defined:g1, product price; g2, product quality; g3, supplying fiability; g4, technological development; g5, post-saleservice; g6 , financial capability; and g7, risk management process.
In the original study, the criteria weights were determined by using the AHP technique [15]. Thoughthis method provided weights in form of punctual evaluations, we consider that these come from uniform
CLAIO-2016
668

distributions satisfying the induced preorder of criteria, as initially evaluated. Then the set of initial weightvalues is W = {0.164, 0.280, 0.207, 0.109, 0.109, 0.016, 0.11}.
The suppliers evaluations matrix is presented in Table 1. It is assumed that evaluations come fromuniform probability distributions. Three fictitious suppliers are used as control alternatives: the ideal s13,the anti-ideal s14, and s15, having the mean value in the scale of each criterion. According to the standardTODIM method, the evaluations are further normalized into the [0, 1] scale. We assume that imprecision ismainly due to scales used on each criterion, but define thresholds in order to observe the difference betweenthe standard TODIM and the version including imprecision. Therefore, qc = .03, pc = .3,∀c.
Table 1: Suppliers evaluations matrix
Supplier g1 g2 g3 g4 g5 g6 g7s1 8.0 8.8 4.0 9.7 0.0 9.4 3.8s2 8.0 10.0 8.5 9.8 8.8 8.6 8.0s3 8.0 10.0 10.0 9.8 8.8 7.3 7.5s4 4.0 6.9 8.5 8.4 5.2 10.0 6.0s5 8.0 9.2 10.0 9.0 10.0 10.0 8.0s6 7.5 8.3 9.1 9.5 9.2 10.0 8.0s7 7.0 9.4 10.0 10.0 10.0 10.0 10.0s8 7.5 9.4 10.0 9.8 10.0 10.0 10.0s9 8.0 9.4 5.4 9.7 9.2 8.0 9.8s10 8.0 8.0 9.0 8.5 6.4 8.6 6.0s11 8.0 10.0 10.0 10.0 8.8 8.0 8.0s12 6.0 8.0 8.8 7.8 7.2 8.6 6.0s13 10.0 10.0 10.0 10.0 10.0 10.0 10.0s14 0.0 0.0 0.0 0.0 0.0 0.0 0.0s15 5.0 5.0 5.0 5.0 5.0 5.0 5.0
The results are shown in Table 2. Monte Carlo Simulation is applied in both versions. To construct eachpre-order, the following rule is considered: if the acceptability index is greater or equal to the lower bound70% a single rank position is reported; if not, the most probable rank positions are obtained by adding therespective acceptability indexes up to overcome the lower bound. In those cases, two or more probable rankpositions are reported. For instance, with TODIM, the supplier s2 has probably the sixth or seventh rankposition. Instead, with TODIM-imprecision, this supplier has probably the seventh or eighth rank.
Table 2: Pre-orders obtained with TODIM and TODIM-imprecision
s1 s2 s3 s4 s5 s6 s7 s8 s9 s10 s11 s12 s13 s14 s15TODIM 13 6,7 8,9 11,12 4 5 2,3 2,3 8,9 10 6,7 11,12 1 15 14TODIM-imprecision 13 7,8 6 12 4 7,8 3 2 9 11 5,6 10 1 15 14
As expected, the pre-orders obtained with the two versions of TODIM differ. Thus, imprecision anduncertainty have an effect on this problem. An exhaustive analysis of possible outcomes with a series ofqc and pc values is beyond the scope of this contribution. However, some tests show that it is alwayspossible to choose thresholds for which the pre-orders can be very close each other, or even be equal (e.g.,qc = 0, pc = 1,∀c). It remains the same problem observed in outranking based methods, v.g., the correctelicitation of threshold values. Although more research is needed in this aspect, we think that this modelingtechnique is appealing and simple to understand.
5 ConclusionsIn this article, an extension of the TODIM multicriteria method is used to propose a ranking of suppliersfor development in a real context defined by the Mexican aerospace industry. Given that poor informationon available input data is observed, preference thresholds are defined to model imprecision, likewise theoutranking based methods. The TODIM extension incorporates the SMAA technique which allows to apply
CLAIO-2016
669

the Monte Carlo simulation to deal with uncertainty. The application shows the feasibility of the TODIMextension in the Mexican aerospace problem.
Future research is in progress to apply the TODIM extension in other real problems. A drawback thatneeds to be addressed is the definition of thresholds, a problem also observed in outranking methods.
References
[1] R. Abdullah, M. Keshavlall, and K. Tatsuo. Supplier development framework in the Malaysian automo-tive industry: Proton’s experience. International Journal of Economics and Management, 2(1):29–58,2008.
[2] C. Araz and I. Ozkarahan. Supplier evaluation and management system for strategic sourcing based ona new multicriteria sorting procedure. International Journal of Production Economics, (106):585–606,2007.
[3] D. Bouyssou. Outranking relations: Do they have special properties? Journal of Multi-Criteria DecisionAnalysis, 5(2):99–111, 1996.
[4] L. F. A. M. Gomes, M.A.S. Machado, X.I. González, and L.A.D Rangel. Behavioral multi-criteriadecision analysis: the TODIM method with criteria interactions. Annals of Operations Research,211(1531-548), 2013.
[5] L.F.A. M. Gomes, L.A.D. Rangel, and F.J.C. Maranhão. Multicriteria analysis of natural gas des-tination in brazil: An application of the TODIM method. Mathematical and Computer Modelling,50(1-2):92–100, 2009.
[6] L.F.A.M. Gomes and M.M.P.P. Lima. TODIM: Basics and application to multicriteria ranking ofprojects with environmental impacts. Foundations of Computing and Decision Sciences, 16(4):113–127,1991.
[7] J. Hartley and T. Choi. Supplier development: Customers as a catalyst of process change. BusinessHorizons, July-August:37–44, 1996.
[8] D. Krause, R. Handfield, and T. Scanell. An empirical investigation of supplier development: reactiveand strategic processes. Journal of Operations Management, (17):39–58, 1998.
[9] R. Lahdelmaa and P. Salminen. Prospect Theory and Stochastic Multicriteria Acceptability Analysis(SMAA). Omega, (37):961–971, 2009.
[10] R. Lourenzutti and R.A. Krohling. A study of TODIM in a intuitionistic fuzzy and random environment.Expert Systems with Applications, 40(16):6459–6468, 2013.
[11] H.M. Moshkovich, L.F.A.M. Gomes, A.I. Mechitov, and L.A.D. Rangel. Influence of models and scaleson the ranking of multiattribute alternatives. Pesquisa Operacional, 32(3):263–275, 2012.
[12] K. Noshad. A multi - criteria framework for Supplier Quality Development. PhD thesis, ConcordiaInstitute for Information Systems Engineering (CIISE), Concordia University, 2013.
[13] O.C.T. Onesime, X. Xu, and D. Zhan. A decision support system for supplier selection process. Inter-national Journal of Information Technology & Decision Making, 3(3):453–470, 2004.
[14] J. Pereira, L.F.A.M. Gomes, F. Paredes, and H. Paredes-Frigolett. Modelling imprecision and uncer-tainty in a MCDA method inspired on Prospect Theory. Submitted, 2016.
[15] J. A. Ramos-Rangel. Evaluation of strategic suppliers in Mexico. PhD Thesis, industrial EngineeringGraduate Program, Tecnologico de Monterrey, Campus Toluca, 2015.
CLAIO-2016
670

[16] J. Rezaei and R. Ortt. Multi-criteria supplier segmentation using a fuzzy preference relations basedahp. European Journal of Operational Research, (225):75–84, 2013.
[17] J. Rezaei, J. Wang, and L Tavasszy. Linking supplier development to supplier segmentation using BestWorst Method. Expert Systems With Applications, (42):9152–9164, 2015.
[18] T. Tervonen and J. Figueira. A survey on Stochastic Multicriteria Acceptability Analysis Methods.Journal of Multi-Criteria Decision Analysis, (15):1–14, 2008.
CLAIO-2016
671

A robustness index in a MCDA problem, based on a flexibility
framework
J. PereiraTecnologico de Monterrey, Campus Toluca, México
L.F.A.M GomesIBMEC, Rio de Janeiro, Brazil
F. ParedesEscuela de Ingenieŕıa Industrial, Universidad Diego Portales, Chile
Abstract
A robustness index is proposed for solutions in multiple criteria decision analysis problem,which involves different decision makers participating in the decision process. This index can beunderstood as a flexibility measure where robustness is defined as a fitness criterion, groundedon a distance between a solution (an ordinal ranking) and the expected solutions representingthe decision makers’ preferences. The usage of the proposed index is illustrated in a problemregarding the ranking of suppliers of photovoltaic power plants.
Keywords: Robustness index; Flexibility; Multiple Criteria Decision Aiding; Ranking problem.
1 Introduction
Robustness analysis has an important status in Operational Research and in Multiple CriteriaDecision Aiding (MCDA). A lot of research has been done to provide a clear definition and ac-ceptable metrics aiding to evaluate robustness of solutions provided by a multicriteria method[11, 12]. Actually, robustness is confused with concepts such as sensitivity, stability, adaptability,agility, flexibility, resilience and similar concepts [10, 5]. As a consequence, there are still multipledefinitions and evaluation schemes that make measurement elusive [14].
In MCDA, robustness may involve different things: decision processes, methods, solutions orconclusions [15]. It has been defined as the ability to cope with uncertainties interacting in a deci-sion making problem [9, 16], some reflecting more or less arbitrary choices of the decision analyst
CLAIO-2016
672

(method, modelling technique, qualitative and quantitative evaluation scales), and others con-cerning external uncertainties (parameters, evaluation of alternatives over the criteria, preferenceinstabilities and biases).
It has been proposed that a robustness concern needs to be explicit in a problem such thatthe robustness analysis is driven by a specific aim [1]. For instance, [6] has proposed a mixedRobust Ordinal Regression-SMAA approach, in which the outcomes of a decision analysis methodcould be classified as necessarily or possibly robust. This approach places the DM in the centerof the robustness analysis process. It proposes that a preference statement is robust whether itagrees (locally o globally) with the DM’s preferences or not. Given a pair of alternatives a, b froma set of alternatives, “a necessarily outranks b”, if a outranks b for all compatible sets of additivevalue functions. Otherwise, “a possibly outranks b” if there exists at least one compatible valuefunction agreeing with the argument. A compatible function is derived from the indirect preferenceinformation provided by a decision maker (DM) in the form of pairwise comparisons of the referencealternatives.
In this contribution, we introduce a robustness index computed as the best-worst-case distancebetween a ordinal ranking, a solution found by using a MCDM technique, and the ordinal rankingsproposed by several DMs. The robustness index globally measures how close is the inspectedsolution to the DMs’ preferences.
The article is organized as follows. In Section 2 we introduce the concepts of local and globalrobustness. These are used to propose a robustness index for ranking problems. After illustratingthe operational use of robustness, in Section 3 we propose a definition of robustness as based on aflexibility approach. Section 4 briefly describes a MCDA application and the use of the robustnessmetrics. The conclusions are presented in Section 5.
2 An index for evaluating robustness
2.1 Local robustness value
Let us assume a decision-aiding problem where the decision analyst has identified a set A of alter-natives, a family F of criteria and a MCDA method aiding to build a pre-order, an ordinal ranking,on A. Hence, let O be a solution, a complete pre-order from the application of the multi-criteriamethod. In addition, let us define Oe as a complete pre-order on A, reflecting a reference solution,called the expected pre-order. We suppose that the decision analyst has elicited Oe from the DMpreferences, using a proper technique [6].
The aim is to determine how close O is from Oe. Classical approaches to do it suggest theKendall’s tau and the Spearman ranking index [2]. While the former measures the total numberof pairwise inversions among rankings, the latter measures the total displacement of elements fromthe identity ranking. If the position of an alternative ai on the ranking O is denoted as O(i), usingthe Kendall’s tau metrics between Oe and O, the distance may be expressed as
K(Oe, O) =∑
Oe(i)>Oe(j)
[O(i) < O(j)], (1)
where [O(i) < O(j)] = 1 if O(i) < O(j), 0 otherwise. This is a metrics that measures how close is thesolution to the DM’s pre-order. Therefore, we will say that K(Oe, O) measures the local robustness
CLAIO-2016
673

of O regarding Oe. Although other kind of metrics could be used to measure the distance betweentwo pre-orders, we restrict here to the case of metrics applicable for ordinal rankings.
2.2 Global robustness value
Let us consider nE DMs in the decision aiding problem. A robustness analysis framework isproposed in this article where the robustness concern can be summarized as: “to what extent asolution represents the expectations of different DMs”. Thus, the more a solution is consistent withthose expectations, the more robust it is. A completely robust solution is an outcome fulfilling theexpectations of every single DM. In consequence, we propose an approach where the decision analystneeds to identify one or several expected states, each one proposed as an experiment allowing therobustness testing of a given solution. Thus, assessing the robustness of a solution will consist ofevaluating how close it is to the set of expected states.
Let E = {Oe|e = 1, . . . , nE} be a set of nE expected pre-orders. For simplicity, we assume thateach DM proposes just one expected state representing her preferences. In general, these pre-orderscan be different, but in some circumstances two or more could coincide, which could be interpretedas that the involved DMs evidence the same preferences, given the actual conditions of the decisionaiding process.
Let us consider Ω a set of n pre-orders produced by the MCDA method chosen by the decisionanalyst. For every pair Oi ∈ Ω and Oe ∈ E, the value K(Oe, Oi) can be calculated. A robustpre-order on Ω can be identified by defining a minimax-regret criterion (Kouvelis, Yu 1997), thatis, the pre-order minimizing the worst-case value among the pre-orders on Ω and the expectedstates on E:
Ommr = arg minOi∈Ω
((1 + log(|E|/|vi|))(1 + maxe∈E
K(Oe, Oi))− 1), (2)
where vi is the number of pre-orders in E where Oi maximizes maxe∈E K(Oe, Oi). In particular,when all the DMs propose the same expected pre-order Oc, it follows Ommr = arg minOi∈Ω K(Oc, Oi).Thus, the solution Oi having the minimum distance to the common expected pre-order should behave a better robustness value than the other solutions in Ω. Furthermore, for each Oi, the expres-sion maxe∈E K(Oe, Oi) says that the robustness value of a solution depends on highest distance tothe set of expected pre-orders. The less this distance is low, the more the robustness value of thissolution should be better regarding the DMs expectations.
2.3 A robustness index
Let us consider the solution Ommr, as presented in (2). A robustness index can be defined as follows
R(Ommr) = 1− minOi∈Ω ((1 + log(|E|/|vi|))(1 + maxe∈E K(Oe, Oi))− 1)
(1 + log(|E|))(1 + Km)− 1, (3)
where Km is the worst distance that can be obtained between two pre-orders of size |A|, and vi is thenumber of DMs agreeing with the solution Oi. In particular, if the DMs have a common expectedpre-order Oc and it happens that there exists one Oi = Oc, it follows R(Ommr) = R(Oi) = 1.
In Table 1 the values of R are shown for the case of |A| = 4, two up to five DMs participatingin the decision aiding process, and Km = 6. The K value on each row indicates the distance fromOmmr to the expected pre-orders, according to the Kendall tau; the v values indicate how many
CLAIO-2016
674

DMs agree with a solution having a K value. For instance, if K = 0 and there are two DMs in thedecision process and both agree with the solution Ommr, then R = 1. However, if just one of themagrees with the solution (v = 1), then R = .96.
Table 1: Robustness value R for a solution Ommr, when |A| = 4
v=5 v=4 v=3 v=2 v=1
2 DMsK=6 0.26 0.00K=5 0.38 0.16K=4 0.51 0.32K=3 0.63 0.48K=2 0.75 0.64K=1 0.88 0.80K=0 1.00 0.963 DMsK=6 0.36 0.23 0.00K=5 0.46 0.35 0.16K=4 0.57 0.48 0.32K=3 0.68 0.60 0.47K=2 0.79 0.73 0.63K=1 0.89 0.86 0.79K=0 1.00 0.98 0.954 DMsK=6 0.41 0.33 0.21 0.00K=5 0.46 0.38 0.27 0.16K=4 0.57 0.50 0.41 0.31K=3 0.68 0.63 0.55 0.47K=2 0.79 0.75 0.69 0.63K=1 0.89 0.87 0.83 0.78K=0 1.00 0.99 0.97 0.945 DMsK=6 0.45 0.39 0.31 0.19 0.00K=5 0.54 0.49 0.42 0.32 0.16K=4 0.63 0.59 0.53 0.45 0.31K=3 0.72 0.69 0.64 0.58 0.47K=2 0.82 0.79 0.76 0.71 0.62K=1 0.91 0.89 0.87 0.84 0.78K=0 1.00 0.99 0.98 0.96 0.94
Notice that, the more the solution Ommr is far from the expectations, the lower the robustnessvalue. For instance, in a decision aiding process with five DMs, where all of them agree with thesolution, but it is at distance K = 6 from the expected pre-order, R = .45. This is a little betterthan the case having four DMs (R = .41). Equally, the more DMs agree with the solution Ommr
the best the value of R. For example, with five DMs and K = 3, the robustness value increases.
3 The robustness index as a flexibility measure
It has been proposed that flexibility of a system is an adaptation capability to changes that occurin its environment [8]. A system may be any device or entity: a machine, a mechanism, a logic,a procedure, a process, a program, a technique, an apparatus, an organization, etc. An observermay assess the adaptation capability as the closeness between the system and its environment. In
CLAIO-2016
675

this way, the appraisal of the adaptation capability involves at least three aspects: the model ofthe system and the environment; the logic aiding to assess the closeness between the system andthe environment; and the observer.
Let us assume that an observer accepts that a system and its environment may be characterizedthrough the states they take in a set S. For simplicity, we may consider this as a numerable set.Equally, assume that rS , rE ⊂ S are the subset of realizable states of the system and the set ofthe states in which the environment moves, respectively. In addition, let st ∈ rS , et ∈ rE , s
∗t ∈ S
be the system’s observed current state, the environment’s observed current state and the system’sexpected current state, respectively. We will suppose that the observer recognizes a logic L in thesystem such that
L(et, st) = (s∗t , s∗t − st), (4)
i.e., L determines the expected state s∗t and the distance from the current system’s state to thatexpectation. Accordingly, using the logic, the observer may appreciate that the system is in partialequilibrium whether s∗t − st = 0. If s∗t − st 6= 0 then
Flexibility is the system’s local property which tends to realize the partial equilibriumbetween the system and the environment, adjusting the current system’s state to thecurrent expected state (as determined by the logic L).
Let D = s∗1, s∗2, . . . , s
∗n be a finite succession of n expected states, as determined by the logic L.
Additionally, let F = s1, s2, . . . , sn be the respective succession of states achieved by the systemwhen it seeks to adjust to D, as identified by the observer. The system’s global flexibility is amultidimensional property, which needs to be appreciated by three dimensions: the adjustmentdegree evaluating how close is F to D; the time of adjustment measuring how much time it takesthe adaptation process; and the effort of adjustment evaluating how much effort the system needsto that adjustment [8].
The adjustment degree evaluates the “fitness degree” between the system and its environment.It represents how robust is the system to adapt to the expected states defined by L. In systemsengineering, robustness has been defined as the feature persistence of a system under specified per-turbations [5], or the system’s capability to remain insensitive to change in parameters in spite ofexternal changes [10]. In production systems, robustness is the system’s stability against differentvarying conditions [14]. In an optimization problem, a solution is robust if it is the one having thebest performance under the worst case (min-max rule) [7]. In this article, more than a propertyinherent to the observed system, we understand robustness as the fitness property between the sys-tem and its environment. It represents the adjustment degree in the flexibility framework describedabove. According to this approach, the local robustness can be evaluated when local flexibility isobserved, while the global robustness is assessed by a fitness function computed with regards to aseries of expected states.
4 Application
Let us consider a medium size company studying the installation of a 10 KW/h photovoltaic powerplant [13]. The study aims to rank the supplying alternatives under given conditions, interests,preferences and business constraints. Three DMs participate in the decision analysis process: the
CLAIO-2016
676

company’s President (DM1), the CEO (DM2), and a technical analyst (DM3). A decision analystis involved who wants to develop the decision aiding process being respectful of company’s interests,concerns and constraints. During this study several conflicting criteria have been identified: c1,investment (1.00); c2, components quality (0.67); c3, guarantees (1.00); c4, supplier’s experience(0.78); c5, supplier’s specialization (0.67); c6, number of projects developed (0.67); c7, supplier’sprestige (0.56). The relative importances among criteria (value in parenthesis) have been obtainedin different sessions with the DMs. In Table 2 the evaluations of eight suppliers and the criteriaweights are shown.
Table 2: Evaluation of eight suppliers on the photovoltaic power plant problem
1 0.67 1 0.78 0.67 0.67 0.56
Supplier C1 C2 C3 C4 C5 C6 C7OP1 0.13 0.14 0.13 0.22 0.15 0.17 0.10OP2 0.11 0.14 0.14 0.20 0.12 0.14 0.10OP3 0.06 0.14 0.13 0.22 0.18 0.17 0.14OP4 0.11 0.14 0.12 0.12 0.14 0.17 0.13
The TODIM multicriteria decision aiding method has been applied in this case. TODIM is basedon Prospect Theory, which is reflected in the shape of its value function, the same as the CumulativeProspect Theory [3, 4]. A global additive function aggregates measures of gains and losses overall criteria in a problem, which summarizes arguments in favour and against an alternative whencompared to another. Such a function is supposed to account for dominance relations among allpairs of alternatives, through a pairwise comparison process. Finally, by normalizing the dominancefunction the method leads to a global ordering of the alternatives. In Table 3 the complete pre-orderfound by this method, OT , is shown.
Table 3: Solution found by the application of TODIM
Supplier Rank Score
OP1 1 1.00OP3 2 0.98OP4 3 0.79OP2 4 0.72
In order to know if this solution is interesting or not for the DMs, the decision analyst askthem to propose four different pre-orders by each one of them, based on their own preferences andthe available evaluations of suppliers. The K value of the worst case between each DM and theproposed solution found by TODIM is presented in Table 4.
Table 4: K-distance between the solution and the proposed pre-orders from DMs
worst-case K value
DM1 2DM2 2DM3 0
In this case, the robustness index of the solution can be computed by the following expression
CLAIO-2016
677

R(OT ) = 1− ((1 + log(3/2))(1 + maxdmK(Odm, OT ))− 1)
(1 + log(3))(1 + Km)− 1, (5)
where dm ∈ {DM1, DM2, DM3}. Inspecting the Table 1 for three decision makers, K = 2 andv = 2, the robustness value is R = 0.73. Let us suppose that DM1 agrees with the solution OT
such that the worst K value is obtained only with DM2. In such case, the robustness value fallsdown to 0.63. This means that if this solution was adopted, its robustness value would be lowerthan if two or more DM agreed with it.
The robustness index could be also computed in the case where only one DM is asked to proposedifferent pre-orders, representing her/his preferences. In the example above, let us consider a DMwhere the four proposed rankings give K-values equalling 0, 2, 2, 2. Despite that there is anexpected pre-order completely agreeing with the solution, three other pre-orders disagree. In thiscase, the robustness value of the solution equals R = 0.75, corresponding to the entry 4DMs,K = 2 and v = 3 in Table 4.
5 Conclusions
In this contribution, a robustness index is proposed for solutions expressed as ordinal rankingsbuilt by an MCDA method, which involves different decision makers participating in the decisionaiding process. The definition of robustness and the correspondant index are based on a flexibilityframework. The robustness value of a solution found by the MCDA method is calculated as adistance criterion between a solution and the expected solutions representing the decision makers’preferences. Therefore, the more the solution is compatible with the expected solutions, the morerobustness value is high.
This index is built to compute the robustness value of solutions in a problem regarding theranking of suppliers of photovoltaic power plants. In this example, four alternatives and 2 up to 5decision makers are considered. We show that the robustness value of a solution can be improvedwhen the number of DMs supporting it increases. It is proposed that the robustness index couldbe applied to the case of just one DM.
Future research is needed in order to evaluate pertinence and usability of the proposed index.In addition, more research is required to assess compatibility of our approch with other robustnessanalysis frameworks in MCDA.
References
[1] H. Aissi and B. Roy. Robustness in Multicriteria Decision Aiding. In M. Ehrgott, J.R. Figueira,and S. Greco, editors, Trends in Multiple Criteria Decision Analysis, pages 87–121. Springer,New York, 2010.
[2] P.Y. Chen and P.M. Popovich. Correlation: Parametric and nonparametric measures. Sage,Thousand Oaks, 2002.
[3] L.F.A.M. Gomes and M.M.P.P. Lima. TODIM: Basics and application to multicriteria rankingof projects with environmental impacts. Foundations of Computing and Decision Sciences,16(4):113–127, 1991.
CLAIO-2016
678

[4] J.A. Gómez-Limón and J. Berbel. Multicriteria analysis of derived water demand functions:a spanish case study. Agricultural Systems, (63):49–72, 2000.
[5] E. Jen. Stable or robust? what’s the difference? Complexity, 8(3):12–18, 2003.
[6] M. Kadziński, S. Grecco, and R. Slowinski. Selection of a representative set of parameters forrobust ordinal regression outranking methods. Computers and Operations Research, (39):2500–2519, 2012.
[7] P. Kouvelis and G. Yu. Robust discrete optimization and its applications, volume 14 of Non-convex optimization and its applications. Kluwer Academic Publishers, Dordrecht (Boston),1997.
[8] J. Pereira and B. Paulre. Flexibility in manufacturing systems: a relational and a dynamicapproach. uropean Journal of Operational Research, 130(1):70–85, 2001.
[9] J. Rosenhead, M. Elton, and S.K. Gupta. Robustness and optimality as criteria for strategicdecisions. Operational Research Quarterly, 23(4):413–431, 1972.
[10] A. Ross, D. Rhodes, and D. Hastings. Defining changeability: Reconciling flexibility, adapt-ability, scalability, modifiability, and robustness for maintaining system lifecycle value. SystemsEngineering, 11(3):246–262, 2008.
[11] B. Roy. To better respond to the robustness concern in decision aiding: four proposals based ona twofold observation. In C. Zopounidis and P.M. Pardalos, editors, Handbook of MulticriteriaAnalysis, pages 3–24. Springer, Heidelberg, 2010.
[12] B. Roy, A. Alloulou, and R. Kaläı. Robustness in OR-DA. Annales du LAMSADE No7,Université Paris Dauphine, 2007.
[13] G. Salinas. Métricas y protocolo de análisis de robustez en el método TODIM. Technicalreport, Industrial Engineering, Universidad Diego Portales, Chile, 2013.
[14] N. Stricker and G. Lanza. The concept of robustness in production systems and its correlationto disturbances. Procedia CIRP, (19):87–92, 2014.
[15] P. Vincke. About robustness analysis. Newsletter of the European Working Group - MCDANewsletter, Series 3(8), 2003.
[16] J. Wallenius, J.S. Dyer, P.C. Fishburn, R.E. Steuer, S. Zionts, and K. Deb. Multiple CriteriaDecision Making, Multiattribute Utility Theory: Recent accomplishments and what lies ahead.Management Science, (54):1336–1349, 2008.
CLAIO-2016
679

Aplicação de um modelo DEA para determinar onde instalar escolas profissionalizantes
Fabio da Costa Pinto
Instuituto Tecnológico de Aeronáutica - ITA [email protected]
Armando Zeferino Milioni
Instuituto Tecnológico de Aeronáutica - ITA [email protected]
Mischel Carmen Neyra Belderrain
Instuituto Tecnológico de Aeronáutica - ITA [email protected]
Resumo
O presente trabalho propõe um modelo que irá ajudar os tomadores de decisão a identificar os municípios mais eficientes que poderão ser candidatos a receber uma escola profissionalizante dentro de um determinado estado no Brasil. Será aplicada a Análise Envoltória de Dados (DEA - Data Envelopment Analysis) para ranquear os municípios através da avaliação de eficiência. Os indicadores que serão utilizados pela DEA foram definidos por um modelo utilizado pelo Instituto de Pesquisa e Estratégia Econômica do Ceará (IPECE). Os municípios do estado objeto do estudo serão classificados por regiões conforme os Arranjos Produtivos Locais (APL). Os resultados obtidos serão confrontados com os cenários de investimentos industriais previstos pelo Governo para cada região para validar a escolha do município-candidato. PALAVRAS-CHAVE. Análise Envoltória de Dados, Arranjos Produtivos Locais, Escola profissionalizante. 1 Introdução O decreto 7.566, de 23 de setembro de 1909, assinado pelo presidente Nilo Peçanha, é considerado o marco inicial do ensino profissional, científico e tecnológico de abrangência federal no Brasil. O ato criou 19 Escolas de Aprendizes Artífices, que tinham o objetivo de oferecer ensino profissional primário e gratuito para pessoas que o Governo chamava de “desafortunadas” à época (Portal Brasil, 2015). A Constituição Federal de 1988 inclui entre os direitos sociais a educação e o trabalho. É na educação profissional e tecnológica que se tornam ainda mais evidentes os vínculos entre educação, trabalho, território e desenvolvimento, elementos cuja articulação é indispensável (Portal do Ministério da Educação, 2015). O Programa Nacional de Acesso ao Ensino Técnico e Emprego (PRONATEC) foi criado pelo Governo Federal, em 2011, por meio da Lei 11.513/2011, com o objetivo de expandir, interiorizar e democratizar a oferta de cursos de educação profissional e tecnológica no país, além de contribuir para a melhoria da qualidade do ensino médio público (Portal do PRONATEC, 2015).
CLAIO-2016
680

O PRONATEC busca ampliar as oportunidades educacionais e de formação profissional qualificada aos jovens, trabalhadores e beneficiários de programas de transferência de renda. Um dos objetivos norteados pelo PRONATEC é o aumento da rede física de escolas profissionalizantes e isto vai necessitar de grandes investimentos. Mas, como definir um local para instalação de uma nova escola profissionalizante? O presente trabalho propõe uma modelo que pode ajudar os tomadores de decisão a identificar as localidades-candidatas a receber uma escola profissionalizante dentro de uma determinada região ou estado do Brasil. 2 Índice de Desenvolvimento Municipal (IDM-CEARÁ) e Arranjos
Produtivos Locais (APLs) O Índice de Desenvolvimento Municipal (IDM-CEARÁ), segundo o Portal do IPECE (2015), carrega em sua essência a ideia de uma análise multidimensional, que por meio de técnicas estatísticas traduz o nível de desenvolvimento relativo de cada um dos municípios cearenses em um indicador. Para o cálculo do IDM são empregados trinta indicadores relacionados a aspectos sociais, econômicos, fisiográficos e de infraestrutura. Esses indicadores são agregados em quatro grupos. Para o desenvolvimento desse trabalho foram escolhidos os indicadores do Grupo 2 por eles retratarem o nível de desenvolvimento econômico das localidades-candidatas. Os APLs são aglomerações de empresas, localizadas em um mesmo território, que apresentam especialização produtiva e mantêm vínculos de articulação, interação, cooperação e aprendizagem entre si e com outros atores locais, tais como: governo, associações empresariais, instituições de crédito, ensino e pesquisa. (Portal APL, 2015) 3 Análise Envoltória de Dados (Data Envelopment Analysis - DEA) A Análise Envoltória de Dados (DEA) é uma ferramenta da estatística não paramétrica que permite medir a eficiência realtiva de DMUs que operam em um mesmo processo de produção. Também, é capaz de fornecer um “benchmark” para as DMUs e indicar o caminho a seguir (Avellar, Milioni & Rabello, 2005). A eficiência é definida pela razão da soma ponderada dos outputs pela soma ponderada dos inputs, essa ponderação é feita através de pesos atribuídos conforme algoritmo de programação linear, segundo Isihzaka & Namery (2013, p.262). A DMU (Decision Making Unit) é uma unidade utilizada como tomadora de decisão e a DEA utiliza referenciando-a a um padrão de fato (Benchmark). A DMU assume valor máximo igual a um. Quando isso acontece dizemos que ela se encontra na fronteira de eficiência. A DMU que se encontra na fronteira pode ser associada a um exemplo de aplicação das melhores práticas (Charnes, Cooper & Rhodes, 1981).
Formulação dos modelos clássicos de DEA Na formulação dos modelos será adotada a nomenclatura de Johnes (2004):
= output = input
= é a quantidade de r de output produzido pelo DMU k
= é a quantidade de input i consumido pela DMU k = , … , = , … , = , … ,
CLAIO-2016
681

= é o peso de output r = é o peso do input i
n = quantidade de DMUs k = número da DMU estudada m = quantidade de inputs s = quantidade de outputs
Modelo DEA-CCR: CHARNES, COOPER e RHODES (1978) A formulação para calcular a eficiência de cada DMU, orientado ao input ou orientado ao output estabelecidos por Charnes, Cooper & Rhodes (1978) é mostrada a seguir. Orientado ao Input
∑ Sujeito a: ∑ − ∑ ≥ ,
= , . . , , ∑ = ,
, > 0 ∀ = , … , ; = , . . , .
Orientado ao Output ∑
Sujeito a: ∑ − ∑ ≥ ,
= , . . , , ∑ = , , > 0 ∀ = , … , ; = , . . , .
Modelo DEA-BCC: BANKER, CHARNES e COOPER (1984) A formulação para calcular a eficiência de cada DMU, orientado ao input ou orientado ao output estabelecidos por Banker, Charnes & Cooper (1984) e mostrada a seguir. Orientado ao Input
∑ + Sujeito a: ∑ − ∑ − ≥ ,
= , . . . , , ∑ = , , > 0 ∀ = , … , ; = , . . , .
Orientado ao Output ∑ −
Sujeito a: ∑ − ∑ − ≥ ,
= . . , , ∑ = ,
, > 0 ∀ = , … , ; = , . . , .
Fronteira Invertida É uma curva construída com base no modelo DEA padrão trocando somente os inputs pelos outputs conforme Yamada (1994). Essa curva mostra as DMUs mais ineficientes. Para ordenar é necessário calcular o índice de eficiência agregado. O processo de ordenação seguirá os seguintes passos segundo Leta, Mello, Gomes & Meza (2005): (1) calcular o índice de eficiência de cada DMU utilizando o Modelo DEA padrão, (2) inverter os inputs pelos outputs, (3) calcular o índice de eficiência da Fronteira Invertida, (4) calcular a média aritmética entre o índice de eficiência padrão e o índice de ineficiência (1 – eficiência da Fronteira Invertida) e (5) ajustar o resultado dividindo todos os valores pelo maior índice calculado anteriormente.
CLAIO-2016
682

Neste trabalho o modelo de Fronteira Invertida será utilizado para evitar os problemas da baixa discriminação, ou seja, reduzindo a possibilidade de empate entre as DMUs ranqueadas sem a necessidade de manusear os pesos. É pressuposto que o leitor esteja familiarizado com a metodologia DEA. Informações adicionais podem ser encontradas em Cooper, Tone & Seiford (2005). 4 Modelo proposto da DEA aplicado a decisões de escolha de localidades O modelo que tem como objetivo avaliar as localidades-candidatas para instalação de uma nova unidade operacional de uma escola profissionalizante. O modelo esta dividido em 3 fases: Fase 1: Ranqueamento das localidades-candidatas Nesta fase a Análise Envoltória de Dados (DEA - Data Envelopment Analysis) será aplicada para avaliar eficiência relativa das localidades-candidatas e ranqueá-las. Esta fase é composta por duas etapas que são responsáveis por fazer o ranqueamento final das localidades-candidatas. Etapa 1: Avaliação da eficiência utilizando DEA-CCR padrão. Nesta etapa será aplicado o modelo DEA-CCR orientado ao input. O motivo de se utilizar este modelo é o interesse é obter a eficiência total das localidades-candidatas, ou seja, aquela que compara uma DMU com todas as suas concorrentes independentes da escala de cada DMU. As definições das variáveis seguirão os mesmos indicadores utilizados pelo modelo que determina o Índice de Desenvolvimento Municipal (IDM) do Estado do Ceará, criada pelo Instituto de Pesquisa e Estatística Econômica do Ceará (IPECE). O grupo escolhido foi o de Demográficos e Econômicos que tem como objetivo estudar o nível de desenvolvimento econômico dos municípios. Para o emprego do modelo DEA-CCR, o grupo de indicadores será dividido em inputs e outputs. Inputs: Densidade demográfica: razão entre a população e a área do município. Mostra como
a população se distribui pelo território do Estado; Taxa de urbanização: proporção da população urbana em relação à população total. O conceito de população urbana utilizado é do IBGE, ou seja, considera-se como urbana a população residente em sedes de municípios, distritos e vilas; Receita orçamentária per capita: parcela da receita orçamentária municipal destinada a cada habitante. Percentual do consumo de energia elétrica da indústria e comércio: participação do consumo de energia industrial e comercial no consumo total de energia elétrica do município. Percentual de trabalhadores do emprego formal com rendimento superior a dois salários mínimos: proporção de trabalhadores com rendimento maior que dois salários mínimos em relação ao total de trabalhadores do emprego formal. Outputs: Produto interno bruto per capita: é o valor monetário dos bens e serviços finais produzidos por habitante. Percentual do produto interno bruto do setor industrial: participação do PIB do setor industrial no PIB total do município.
CLAIO-2016
683

Etapa 2: Ranqueamento do índice de eficiência agregado Aplicando um modelo definido por Leta et al (2005) será definido o ranqueamento final das localidades-candidatas calculando o índice de eficiência agregado: (1) calcular a média aritmética entre o índice de eficiência padrão e o índice de ineficiência (1 – eficiência da Fronteira Invertida) e (2) ajustar o resultado dividindo todos os valores pelo maior índice calculado anteriormente. Fase 2: Classificação de acordo com os APLs. A localidade-candidata melhor ranqueada dentro de cada APL será considerada indicada para a implantação de uma nova unidade operacional de uma escola profissionalizante. Fase 3: Confrontação com Investimentos previstos. Na última fase do modelo serão confrontados os cenários de investimentos industriais previstos pelo Governo para cada região com os resultados do ranqueamento e da classificação final do modelo para validar a escolha do município-candidato. Serão utilizadas informações com previsão de investimentos fornecidos por órgãos dos Governos: Municipal, Estadual e Federal. 5 Aplicação do modelo proposto: caso de escolas profissionalizantes do
setor industrial no Estado do Espírito Santo Será apresentada uma aplicação do modelo proposto para identificação de localidades-candidatas à instalação de uma nova unidade operacional de uma instituição de educacional profissional que trabalha com formação profissional no segmento indústria no Estado do Espírito Santo. O Estado do Espírito Santo é composto por 78 municípios e se localiza na região Sudeste do Brasil. Para o cálculo das eficiências e ineficiências que foram avaliadas do modelo DEA foi utilizado o software: MaxDea Basic V6.4, que é fornecido gratuitamente, e sem limitação na quantidade de DMUs (http://www.maxdea.cn/MaxDEA.htm). Para fazer a classificação das localidades-candidatas foi utilizado o critério de classificação por Arranjo Produtivo Local considerando o Estado do Espírito Santo e desenvolvido pelo Núcleo Estadual de APL-ES (NE-APL-ES). APL de Vestuário da Região Noroeste – 2007 (A); APL de Móveis de Linhares - 2010/2014 (B); APL de Rochas Ornamentais de Cachoeiro do Itapemirim - 2010/2014 (C); APL Metalmecânico da Grande Vitória – 2007 (D); APL de Agronegócios e Agroturismo da Região das Montanhas Capixabas – 2007
(E); APL de Agroturismo das Montanhas Capixabas - 2010/2014 (F); APL da Construção Civil do Espírito Santo - 2010/2014 (G). Tabela 1 – Resultado final da classificação por APL
Municípios DEA-CCR Score
Fronteira Invertida
Score Eficiência Agregada
Eficiência Ajustada
APL
Afonso Cláudio 0,44769 0,77518 0,67251 0,40312 E, F Água Doce do Norte 0,46853 1,00000 0,46853 0,28085 Águia Branca 0,81656 0,61766 1,19890 0,71865 Alegre 0,44789 0,93914 0,50875 0,30496 A Alfredo Chaves 0,40228 1,00000 0,40228 0,24114 Alto Rio Novo 1,00000 0,94048 1,05952 0,63510 Anchieta 1,00000 0,33174 1,66826 1,00000
CLAIO-2016
684
Apiacá 0,99334 0,97225 1,02109 0,61207 Aracruz 1,00000 0,44106 1,55894 0,93447 D Atílio Vivacqua 0,77273 0,91769 0,85504 0,51254 A Baixo Guandu 1,00000 0,81996 1,18005 0,70735 C Barra de São Francisco 0,78133 0,92587 0,85546 0,51279 Boa Esperança 0,35018 1,00000 0,35018 0,20991 B Bom Jesus do Norte 1,00000 1,00000 1,00000 0,59943 Brejetuba 0,50327 1,00000 0,50327 0,30167 F Cachoeiro de Itapemirim 0,92193 0,99011 0,93181 0,55855 G, A Cariacica 0,90294 1,00000 0,90294 0,54125 D, G Castelo 0,66632 0,90440 0,76192 0,45671 E, A Colatina 1,00000 0,57343 1,42658 0,85513 C Conceição da Barra 0,55451 0,71659 0,83793 0,50228 B Conceição do Castelo 0,32067 0,90956 0,41110 0,24643 F Divino de São Lourenço 0,32440 1,00000 0,32440 0,19445 Domingos Martins 0,50039 0,69023 0,81017 0,48564 E Dores do Rio Preto 0,40551 0,98294 0,42257 0,25330 Ecoporanga 1,00000 0,75056 1,24944 0,74895 Fundão 1,00000 0,58167 1,41833 0,85019 G Governador Lindenberg 0,84402 0,66759 1,17643 0,70519 Guaçuí 0,43483 0,96685 0,46798 0,28052 A Guarapari 0,53575 0,94905 0,58670 0,35168 G Ibatiba 1,00000 0,80629 1,19371 0,71554 Ibiraçu 1,00000 0,72846 1,27154 0,76220 Ibitirama 0,36463 1,00000 0,36463 0,21857 Iconha 0,38315 0,87827 0,50488 0,30264 A Irupi 0,44326 0,85459 0,58868 0,35287 Itaguaçu 0,36824 0,91081 0,45743 0,27420 F Itapemirim 1,00000 0,71780 1,28220 0,76859 A Itarana 0,45256 0,66473 0,78783 0,47225 F Iúna 0,41806 0,92841 0,48966 0,29351 A Jaguaré 0,76916 0,54013 1,22904 0,73672 B Jerônimo Monteiro 0,38371 1,00000 0,38371 0,23001 João Neiva 0,72199 0,73807 0,98392 0,58979 Laranja da Terra 1,00000 0,79753 1,20247 0,72079 F Linhares 0,84774 0,57945 1,26829 0,76025 D, G, B Mantenópolis 0,43673 0,99776 0,43897 0,26313 Marataízes 1,00000 0,79993 1,20007 0,71935 Marechal Floriano 0,76994 0,57210 1,19785 0,71802 E, F Marilândia 1,00000 0,50417 1,49583 0,89664 Mimoso do Sul 0,50573 0,89901 0,60672 0,36368 A Montanha 0,85358 0,81148 1,04210 0,62466 B Mucurici 1,00000 1,00000 1,00000 0,59943 B Muniz Freire 0,37605 0,86189 0,51416 0,30820 A Muqui 0,40494 0,93054 0,47440 0,28437 Nova Venécia 0,59443 0,70789 0,88655 0,53142 C Pancas 0,55562 1,00000 0,55562 0,33306 Pedro Canário 0,97886 0,96192 1,01694 0,60958 B Pinheiros 0,86636 1,00000 0,86636 0,51932 B Piúma 0,81279 0,92307 0,88973 0,53333 Ponto Belo 0,90811 0,84748 1,06063 0,63577 Presidente Kennedy 1,00000 0,67519 1,32481 0,79412 A Rio Bananal 0,43869 0,92683 0,51186 0,30682 B Rio Novo do Sul 0,47444 1,00000 0,47444 0,28439 A Santa Leopoldina 0,42093 0,88781 0,53313 0,31957 F Santa Maria de Jetibá 0,54793 0,87047 0,67746 0,40609 F Santa Teresa 0,79790 0,76678 1,03112 0,61808 F São Domingos do Norte 1,00000 0,61627 1,38373 0,82945 C São Gabriel da Palha 0,67039 0,78885 0,88155 0,52842 C São José do Calçado 0,65008 1,00000 0,65008 0,38968
CLAIO-2016
685
São Mateus 0,52455 0,85460 0,66996 0,40159 D, B São Roque do Canaã 0,67714 0,76190 0,91524 0,54862 Serra 1,00000 0,58445 1,41556 0,84852 D, G Sooretama 0,73718 0,62108 1,11609 0,66902 B Vargem Alta 0,59471 0,97805 0,61667 0,36965 E, A Venda Nova do Imigrante 0,53134 0,84277 0,68857 0,41274 E, F, A Viana 0,74775 0,82836 0,91938 0,55110 G Vila Pavão 0,78595 0,70579 1,08016 0,64748 Vila Valério 0,93946 1,00000 0,93946 0,56313 Vila Velha 0,83030 1,00000 0,83030 0,49770 D, G Vitória 1,00000 1,00000 1,00000 0,59943 D, G
A Tabela 1 mostra a localidade-candidata melhor ranqueada dentro de cada região escolhida à implantação de uma nova unidade operacional de uma escola profissionalizante. A Tabela 2 mostra os investimentos previstos que serão confontados.
Tabela 2 – Investimentos, maiores Projetos anunciados – Período 2013-2018.
Obs.: Informações atualizadas até fevereiro de 2014 Fonte: Renai (Rede Nacional de informações sobre investimentos), IJSN (Instituto Jones dos Santos Neves) e imprensa. 6 Conclusão O modelo DEA oferece uma contribuição significativa neste estudo de caso por permitir
a avaliação da eficiência relativa das localidades-candidatas com a mínima interferência dos decisores mostrando que o modelo é eficiente comparando com os resultados. O resultado do estudo de caso mostra que a comparação entre os investimentos previstos pelo Governo e a avaliação das localidades-candidatas valida o modelo como um todo. A utilização da classificação das localidades-candidatas de acordo com os APLs mostra quais áreas de atividades podem ser desenvolvidas dentro de cada unidade operacional de
Projeto Setor Descrição Municípios R$ Milhão Petrobras – Exploração e Desenvolvimento da produção dos campos do litoral sul do
Espírito Santo Energia Desenvolvimento e Produção dos campos
do Litoral Sul do Espírito Santo. Anchieta, Piúma,
Itapemirim, Marataízes e Presidente Kennedy. 14.829,70
Petrobras - Exploração na bacia do Espírito
Santo Energia Exploração na bacia do Espírito Santo.
Vila Velha, Vitória, Serra, Fundão, Aracruz, Linhares, São Mateus e
Conceição da Barra. 9.859,30
Petrobras, Shell e ONGC Parque das
Conchas – Desenvolvimento e
Produção dos campos do litoral sul.
Energia Desenvolvimento e Produção dos campos do Litoral Sul do Espírito Santo.
Anchieta, Piúma, Itapemirim, Marataízes e Presidente Kennedy.
7.856,80
Desenvolvimento dos campos de Baleia Azul,
Baleia Anã, Baleia Franca, Cachalote e
Jubarte - P-58. Energia
Desenvolvimento dos campos de Baleia Azul, Baleia Anã, Baleia Franca,
Cachalote e Jubarte. Com a construção e instalação de uma UEP do tipo FPSO (P-
58), com capacidade de tratamento de 180.000 bpd de óleo e 6 milhões m³/d de
gás.
Anchieta, Piúma, Itapemirim, Marataízes e Presidente Kennedy.
6.574,80
ANADARCO, DEVON - Desenvolvimento e Produção dos campos
do litoral sul. Energia Desenvolvimento e Produção dos campos
do Litoral Sul do Espírito Santo. Anchieta, Piúma,
Itapemirim, Marataízes e Presidente Kennedy.
5.892,60
CLAIO-2016
686

ensino profissionalizante instalada. As áreas mapeadas para cada APL foram: Metalmecânica, Construção Civil, Agronegócios, Agroturismo, Rochas Ornamentais, Moveleiro e Vestuário. É fundamental integrar a nova unidade operacional de uma escola profissionalizante com os APLs, para assim, oportunizar geração de emprego e aumento de renda. Para trabalho futuro fica a sugestão da inserção de outros APLs que tenham apoio de outras entidades como, por exemplo, a Federação das Indústrias do Estado do Espírito Santo (FINDES), para que mais municípios participem da etapa de classificação. 7 Referências 1. Avellar, J.V.G., Milioni, A.Z. & Rabello,T.N. (2005). Modelos DEA com variáveis limitadas
ou soma constante. Pesquisa Operacional (Impresso), Rio de Janeiro, RJ, 25(1): 135–150. 2. Banker, R. D., Charnes, A. & Cooper, W. W. (1984). Some models for estimating technical
scale inefficiencies in data envelopment analysis. Management Science Vol. 30, n. 9, p. 1078-1092.
3. Charnes, A., Cooper, W. W. & Rhodes, E. L. (1978). Measuring the efficiency of decision making units. European Journal of Operational Research, 2, 429–444.
4. Charnes, A., Cooper, W. W. & Rhodes, E. L. (1981). Evaluating program and managerial efficiency: An application of DEA to program follow through. Management Science, 27(6), 668–697.
5. Cooper, W.W., Tone, K. & Seiford, L.M. (2005). Introduction to Data Envelopment Analysis and its uses: with DEA-solver software and references. New York: Springer-Verlag.
6. Ishizaka, A. & Nemery, P. (2013). Multi-criteria decision analysis: methods and software. Hardcover: Wiley.
7. Johnes, J. (2004). Efficiency measurement. In G. Johnes, & J. Johnes (Eds.), International handbook on the economics of education (pp. 613-742). Cheltenham: Edward Elgar Publishing Ltd.
8. Leta, F.R., Mello, J.C.C.B.S., Gomes, E.G. & Meza, L.A. (2005). Métodos de melhora de ordenação em DEA aplicados à avaliação estática de tornos mecânicos. Investigação Operacional, Portugal, v. 25, n.2, p. 1.
9. Portal APL. O que são. (2015). Disponível em: < http://portalapl.ibict.br/menu/itens_menu/apls/apl_o_que_sao.html >. Acesso em: 09 de julho de 2015.
10. Portal Brasil. Surgimento das escolas técnicas. (2015). Disponível em: <http://www.brasil.gov.br/educacao/2011/10/surgimento-das-escolas-tecnicas>. Acesso em: 09 de julho de 2015.
11. Portal do IPECE. Indicadores Socioeconômicos. (2015). Disponível em: http://www.ipece.ce.gov.br/categoria4/indicadores-socioeconomicos.html Acesso em: 09 de julho de 2015.
12. Portal do Ministerio da Educação. Secretaria de Educação Profissional e Tecnológica. (2015). Disponível em: <http://portal.mec.gov.br/index.php?option=com_content&view=article&id=12496&Itemid=800>. Acesso em: 09 de julho de 2015.
13. Portal do PRONATEC. Objetivos e iniciativas. (2015). Disponível em: <http://pronatec.mec.gov.br/institucional-90037/objetivos-e-iniciativas>. Acesso em: 09 de julho de 2015.
14. Prata, B. A. & Arruda, J. B. F. (2007). Aplicação da análise envoltória de dados na avaliação de eficiência de municípios: o caso do Estado do Ceará. In: XXXIX Simpósio Brasileiro de Pesquisa Operacional, Fortaleza. 15. Yamada, Y. & Matui, T. & Sugiyama, M. (1994). New analysis of eficiency based on DEA. Journal of the Operations Research Society of Japan, v. 37, n. 2, p. 158-167.
CLAIO-2016
687

Inventory policies for the economic lot-sizing problem with remanufacturing and heterogeneous returns
Pedro Piñeyro
Instituto de Computación, Facultad de Ingeniería, Universidad de la República, Uruguay [email protected]
Abstract This paper addresses the economic lot-sizing problem with production and remanufacturing in which the returns are sorted into different levels of quality. We provide a mathematical formulation for the problem and show that it can be as hard as solve that the problem with ungraded returns. Different inventory policies are suggested and compared by means of adding specific constraints to the original formulation. Useful managerial insights are obtained from the numerical experiment carried out, such as it is suitable to either produce or remanufacture but not both in the same period and that it is profitable to remanufacture those returns of only one quality class which in turn may be not the higher one. Keywords: Lot-sizing problem; Remanufacturing; Returns quality; Inventory Policies. 1 Introduction We consider a lot-sizing problem in which the demand of a single item can be also satisfied by remanufacturing used items returned to origin, i.e. we assume that remanufactured products are as good as new. Input returns are classified into different quality levels according to the amount of work needed for obtaining a remanufactured product that looks like new. Costs are incurred for replenishment orders and for holding inventory. All demand, returns and costs values are known in advance for each of the periods over a finite planning horizon. The objective is to determine the quantities to produce and remanufacture at each period in order to meet the demand requirements on time and minimizing the sum of all the involved costs. The study of such lot-sizing problems have received a growing attention of academic researchers in the recent years, because governmental and social pressures as well as economic opportunities have motivated industrial practitioners to integrate used products into their production system (Guide, 2000; Mahapatra et al., 2012). Remanufacturing is an industrial option for recovery for which it is warranted that the recovered products offer the same quality and functionality that those newly manufactured (Ijomah, 2002). Products that are remanufactured include automotive parts, engines, tires, aviation equipment, cameras, medical instruments, furniture, toner cartridges, copiers, computers, and telecommunications equipment. For recent surveys about production planning with remanufacturing we direct the readers to Lage and Godinho-Filho (2012), Barquet et al. (2013) and Agrawal et al. (2015). In this paper we investigate the Economic Lot-Sizing Problem with Remanufacturing and Returns with Heterogeneous Quality (ELSR-HQ) under the assumptions of dynamic demand and returns values, time-invariant costs for set-up and holding inventory and no unit costs for the replenishment activities. The reasons for these assumptions on the costs are argued in Teunter et al. (2006). We provide a mathematical formulation for the problem and show that it is NP-hard since it can be considered a generalization of the ELSR, i.e. the problem with ungraded returns, which is a known NP-hard problem (Retel-Helmrich et al., 2014; Baki et al., 2014). We also show that the characterization of the optimal solutions can be more difficult to determine in the case of graded returns. Different inventory policies are suggested and compared by means of adding specific constraints to the original formulation. A numerical experiment is
CLAIO-2016
688

conducted in order to evaluate the inventory policies suggested with the aim to provide managerial insights under assumptions that often occur in practice such as insufficient returns for covering the demand requirements. The objective is to provide helpful information for practitioners as well as researchers in order to control an inventory system with different lines for production and remanufacturing returns with heterogeneous quality. The reminder of the paper is organized as follows. The literature review is presented in the next section. In Section 3 we provide the mathematical formulation for the problem along with certain remarks about its complexity. The suggested inventory policies are defined in Section 4 and compared in Section 5. Section 6 concludes the paper with some guidelines for future research. 2 Literature review We focus on the literature about the ELSR with graded returns. For recent surveys about the original ELSR we direct the reader to Retel-Helmrich et al. (2014), Sifaleras et al. (2015) and Piñeyro and Viera (2015). Ferguson et al. (2009) suggest a model for a lot-sizing problem in which the replenishment is only by remanufacturing used products. The model includes salvage values for returns, selling price for remanufacturable products, backlogging costs and capacity constraints. Under mild assumptions they establish that the optimal policy is to remanufacture the exact demand requirement at each period, remanufacturing the returns in descent order of quality, i.e. higher quality returns are remanufactured first. The benefits of grading returns are also investigated. Nenes and Nikolaidis (2012) address also a lot-sizing problem for only remanufactured products by means of a profit model considering multi-supplier for returns, salvage values, set-up costs, backlogging and capacity constraints. A Mixed Integer Linear Programing (MILP) is formulated and evaluated under several scenarios that the authors claim that could exist in real life applications. Mahapatra et al. (2012) develop a MILP for a hybrid production and remanufacturing multi-product lot-sizing problem that includes salvage returns, desired levels for (re)manufacturing and inventories quantities, raw material costs, fixed costs for capacity readjustment and final disposal of returns. A numerical experiment is applied on the MILP to analyze the impact for heterogeneous quality and other parameters. Dong et al. (2011) suggest a LP formulation for an ELSR with graded returns that includes disassembly and assembly. Mezghani and Loukil (2011) investigate an ELSR with graded returns by means of a Goal Programming approach for the case of replenishment only by remanufacturing. Dobos and Richter (2006), Galbreth and Blackburn (2010), Konstantaras et al. (2010) and Guo and Ya, (2015) consider the production planning problem with product recovery and heterogeneous returns quality, assuming constant demand. Denizel et al. (2010) and Nenes et al. (2010) consider the problem under stochastic assumptions. Regarding the literature, in this paper we tackle a production planning problem with recovery in which not only remanufacturing but also the production of new items is involved. Moreover, separate set-up costs for production and remanufacturing are assumed. 3 Problem formulation and complexity analysis The ELSR-HQ can be stated as follows. There are demand requirements for a single item over a finite planning horizon that can be either satisfied by producing new items or by remanufacturing used items returned to origin. Input returns at each period are inspected and sorted according to different levels of quality for remanufacturing. The number of quality levels is finite and known in advance. We assume that returns can be remanufactured regardless of their quality level. Thus, the final disposal of returns is not considered. There are separate set-up costs for production and remanufacturing and unit costs for carrying inventory of both used and serviceable (produced or remanufactured) items. The returns costs depend on its quality, i.e., different returns quality may lead to different set-up and holding inventory costs. Demand
CLAIO-2016
689

and returns quantities may be different at each period and cost values are assumed time-invariant. All values are assumed non-negative integers and known in advance. Backlogging demand is not allowed and capacities for replenishment as well as inventory are assumed infinite. Lead times and initial inventory levels of both serviceable and used products are assumed zero. Without loss of generality we can assume zero initial inventory levels and positive demand in the first period (Teunter et al., 2006). The objective is to determine the quantities to produce and remanufacture at each period in order to meet the demand requirements on time and minimizing the sum of all the costs involved. The ELSR-HQ can be formulated as the following MILP, which can be considered an extended version of the formulation for the original ELSR provided by Teunter et al. (2006), Schulz (2011), Li et al. (2014), Baki et al. (2014), Sifaleras et al. (2015) and Piñeyro and Viera (2015).
( ) ( ) ( )
:subject to
1min1 1
,,1
∑∑∑= =
++T
t
Q
q
utq
uq
rtq
rq
T
=t
st
spt
p yhδKyh+δK
( )21,2,...1
, T,=tDr+p+y=y t
Q
qtqt
s1t
st ∀−∑
=−
( )31,2,...,1,2,...,,)(,, T,=tQ,=qR+ry=y tqtqu
1tqu
tq ∀∀−−
( )41,2,...T,=tpMδ tp
t ∀≥
( )51,2,...,1,2,...,, T,=tQ,=qrMδ tqr
tq ∀∀≥
( )61,2,...00,0 Q,=q=y=y uq
s ∀
{ } ( )71,2,...,1,2,...00,1 ,,, T,=tQ,=qy,y,r,pδ,δu
tqsttqt
rtq
pt ∀∀≥∈
In model (1) – (7) the parameter T denotes the length of the planning horizon; Q the number of levels for grading returns with 1=q to represent the class of higher quality returns and Q=q for the worst
expected quality; tD is the demand requirement and tqR , the returns amount of quality Q,=q 1,... in
periods T,=t 1,... , respectively; pK is the set-up cost for production and rqK the set-up cost for
remanufacturing the returns of quality q; sh is the unit cost of holding inventory for serviceable items and u
qh the unit cost of holding inventory for used items of quality Q,=q 1,... (without loss of generality
we can assume that uj
ui hh ≥ with Qji ≤≤≤1 ); M is an integer number at least as large as the maximum
between the total demand and the total returns within the planning horizon. The decision variables tp and
tqr , denote the number of units produced and remanufactured of quality q in periods T,=t 1,... ,
respectively; ptδ ( r
tqδ , ) is a binary variable equal to 1 if production (remanufacturing of returns of quality
q) is carried out in periods T,=t 1,... , or 0 otherwise; sty and u
tqy , are the inventory level of serviceable
items and used items of quality q for periods T,=t 1,... , respectively. Objective function (1) takes into account the sum of all the involved costs for replenishment and holding inventory. Constraints (2) and (3) are the inventory balance equations for serviceable and used products, respectively. Constraints (4) and (5) establish that a set-up cost is incurred whenever a positive amount is produced or remanufactured, respectively. The zero initial inventory-level for both serviceable and used items is represented by constraints (6). Constraints (7) fix the domain for the different decision variables.
CLAIO-2016
690

We note that the ELSR-HQ as formulated above is a generalization of the original ELSR, i.e. the problem with ungraded returns. Indeed an ELSR instance is equivalent to an ELSR-HQ instance in which either the number of quality levels is equal to one (Q = 1) or the number of returns is zero except by only one quality. Thus, we can conclude that solving the ELSR-HQ is at least as hard as solving the ELSR. Unfortunately the ELSR is a known NP-hard problem in general and even under the assumptions of time-invariant costs and no unit costs for replenishment (Retel-Helmrich et al., 2014; Baki et al., 2014). Thus, it is unlikely that we can optimally solve ELSR-HQ instances with a large number of periods. We also note that the characterization of the optimal solutions may be more difficult as it is shown in the following numeric example. Consider an ELSR-HQ instance with T = 2 and Q = 2, demand vector )1,1(=D , returns
vectors of superior quality )1,1(1 =R and inferior quality )0,2(2 =R , and costs as follows: 20=pK ,
81 =rK , 102 =rK , 1=sh , 8.01 =uh and 5.02 =uh . The optimal solution is )0,0(=p , )0,0(1 =r and
)0,2(2 =r with an optimal value of 13.4. Thus, the total demand is satisfied by remanufacturing only in the first period and only by returns of inferior quality. This demonstrates that are no longer valid the results of Ferguson et al. (2009) for the problem with only remanufacturing for replenishment, in which it is shown to be optimal to remanufacture at each period only for the current demand and beginning with the highest quality returns. 4 Inventory policies We suggest below ten inventory policies for the ELSR-HQ. Each policy is implemented by means of adding specific linear constraints to the original formulation (1) – (7) of above. Full Remanufacturing (FullRem): Remanufacture all the available returns within the planning horizon. The following constraints are added to the original formulation:
( )81 1
,1 1
, ∑∑∑∑= == =
=T
t
Q
qtq
T
t
Q
qtq Rr
No Remanufacturing (NoRem): Remanufacturing quantity is zero for each period within the planning horizon. The following constraints are added to the original formulation:
( )901 1
, =∑∑= =
T
t
Q
q
rtqδ
Single Source per Period (SSP): Either manufacturing or remanufacturing but not both in the same period. The following constraints are added to the original formulation:
( )101,2,...,1,2,...,1, T,=tQ,=qδδr
tqp
t ∀∀≤+
Single Quality per Period (SQP): Only one class of returns quality can be remanufactured in a certain period. The following constraints are added to the original formulation:
( )111,2,...,11
, T,=tδ
Q
q
rtq ∀≤∑
=
CLAIO-2016
691

Zero Incoming Inventory Level of Serviceable Items (ZIS): Production or remanufacturing occurs in certain period if and only if the incoming inventory level of serviceable items is zero. The following constraints are added to the original formulation (Teunter et al., 2006):
( )121,2,...,1,2,...*}),max{1( ,)1( T,=tQ,=qMδδy rtq
pt
st ∀∀−≤−
Zero Outgoing Inventory Level of Used Items (ZOU): Remanufacturing in certain period involves all the available returns of the same quality. The following constraints are added to the original formulation:
( )131,2,...,1,2,...*)1( ,, T,=tQ,=qMδy rtq
utq ∀∀−≤
Bottom-Up Quality (BUQ): Remanufacturing begins with lower quality returns. The following constraints are added to the original formulation:
( )141,2,...),1(1,2,...,,1, T,=tQ,=qδδr
tqr
tq ∀−∀≤ +
Top-Down Quality (TDQ): Remanufacturing begins with higher quality returns. The following constraints are added to the original formulation:
( )151,2,...),1(1,2,...,,1, T,=tQ,=qδδr
tqr
tq ∀−∀≥ +
Remanufacturing First (RemFirst): Remanufacturing used items is always preferred than producing new items. The following constraints are added to the original formulation:
( )161,2,...,1,2,...,, T,=t,Q=qδδr
tqp
t ∀∀≤
Producing First (ProdFirst): Producing news items is always preferred than remanufacturing used items. The following constraints are added to the original formulation:
( )171,2,...,1,2,...,, T,=t,Q=qδδr
tqp
t ∀∀≥
5 Comparison of the suggested inventory policies In this section the inventory policies suggested in Section 4 are evaluated and compared by means of a numerical experiment based on that of Schulz (2011). As it is common in practice, it is assumed that returns are at most equal to the demand values and that holding inventory for used items is less expensive than for serviceable items. However, set-up costs for remanufacturing can be greater than the set-up costs for producing new items. A planning horizon of T = 12 periods is used for all instances. Input returns are graded into three different quality levels corresponding to superior (q = 1), medium (q = 2) and inferior (q = Q = 3) quality. Set-up cost values for production pK and remanufacturing returns of medium quality
rK2 can be 200, 500 and 2000. The set-up cost for returns of superior (inferior) quality rK1 ( rK3 ) are determined by subtracting (adding) 100 units to the set-up cost of medium quality because it is assumed that remanufacturing costs decrease as quality returns increases. The inventory holding cost for serviceable items sh is 1 and for the used items of medium quality rh2 can be 0.2, 0.5 and 0.8. The
CLAIO-2016
692
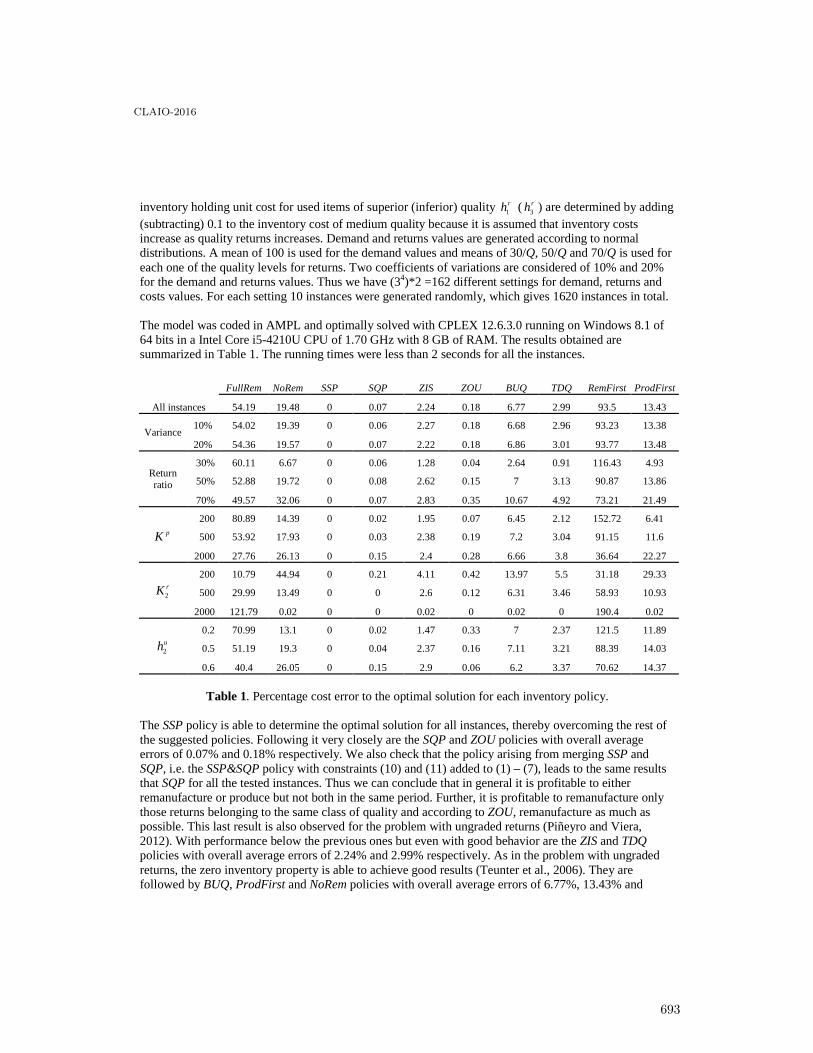
inventory holding unit cost for used items of superior (inferior) quality rh1 ( rh3 ) are determined by adding (subtracting) 0.1 to the inventory cost of medium quality because it is assumed that inventory costs increase as quality returns increases. Demand and returns values are generated according to normal distributions. A mean of 100 is used for the demand values and means of 30/Q, 50/Q and 70/Q is used for each one of the quality levels for returns. Two coefficients of variations are considered of 10% and 20% for the demand and returns values. Thus we have (34)*2 =162 different settings for demand, returns and costs values. For each setting 10 instances were generated randomly, which gives 1620 instances in total. The model was coded in AMPL and optimally solved with CPLEX 12.6.3.0 running on Windows 8.1 of 64 bits in a Intel Core i5-4210U CPU of 1.70 GHz with 8 GB of RAM. The results obtained are summarized in Table 1. The running times were less than 2 seconds for all the instances.
FullRem NoRem SSP SQP ZIS ZOU BUQ TDQ RemFirst ProdFirst
All instances 54.19 19.48 0 0.07 2.24 0.18 6.77 2.99 93.5 13.43
Variance 10% 54.02 19.39 0 0.06 2.27 0.18 6.68 2.96 93.23 13.38
20% 54.36 19.57 0 0.07 2.22 0.18 6.86 3.01 93.77 13.48
Return ratio
30% 60.11 6.67 0 0.06 1.28 0.04 2.64 0.91 116.43 4.93
50% 52.88 19.72 0 0.08 2.62 0.15 7 3.13 90.87 13.86
70% 49.57 32.06 0 0.07 2.83 0.35 10.67 4.92 73.21 21.49
pK
200 80.89 14.39 0 0.02 1.95 0.07 6.45 2.12 152.72 6.41
500 53.92 17.93 0 0.03 2.38 0.19 7.2 3.04 91.15 11.6
2000 27.76 26.13 0 0.15 2.4 0.28 6.66 3.8 36.64 22.27
rK2
200 10.79 44.94 0 0.21 4.11 0.42 13.97 5.5 31.18 29.33
500 29.99 13.49 0 0 2.6 0.12 6.31 3.46 58.93 10.93
2000 121.79 0.02 0 0 0.02 0 0.02 0 190.4 0.02
uh2
0.2 70.99 13.1 0 0.02 1.47 0.33 7 2.37 121.5 11.89
0.5 51.19 19.3 0 0.04 2.37 0.16 7.11 3.21 88.39 14.03
0.6 40.4 26.05 0 0.15 2.9 0.06 6.2 3.37 70.62 14.37
Table 1. Percentage cost error to the optimal solution for each inventory policy.
The SSP policy is able to determine the optimal solution for all instances, thereby overcoming the rest of the suggested policies. Following it very closely are the SQP and ZOU policies with overall average errors of 0.07% and 0.18% respectively. We also check that the policy arising from merging SSP and SQP, i.e. the SSP&SQP policy with constraints (10) and (11) added to (1) – (7), leads to the same results that SQP for all the tested instances. Thus we can conclude that in general it is profitable to either remanufacture or produce but not both in the same period. Further, it is profitable to remanufacture only those returns belonging to the same class of quality and according to ZOU, remanufacture as much as possible. This last result is also observed for the problem with ungraded returns (Piñeyro and Viera, 2012). With performance below the previous ones but even with good behavior are the ZIS and TDQ policies with overall average errors of 2.24% and 2.99% respectively. As in the problem with ungraded returns, the zero inventory property is able to achieve good results (Teunter et al., 2006). They are followed by BUQ, ProdFirst and NoRem policies with overall average errors of 6.77%, 13.43% and
CLAIO-2016
693

19.48% respectively. FullRem and RemFirst policies show the worst performance with overall average errors of 54.19% and 93.5% respectively. Considering the results obtained for BUQ and TDQ, we conclude that remanufacturing in either pure ascendant or pure descendant order of quality does not seem to be the best choice in general except in those cases where remanufacturing costs are high enough. In such case, both orders achieve very good results. However, in the case that we must choice an order of quality for remanufacturing the descendant order of quality, i.e. higher quality first, should be selected because we check that TDQ outperforms BUQ for all of the tested instances not only in average. We recall that this result is also observed by Fergurson et al. (2009) for the problem with graded returns and only remanufacturing for replenishment. In the case of ProdFirst and NoRem the results obtained are not surprising because under these policies the economic benefits of low-cost returns are completely neglected. On the other hand, considering the performance of the FullRem and RemFirst policies, an extreme preference for remanufacturing seems to be a bad choice in the case that the returns are insufficient for meeting the demand requirements. We also note that the minimum and maximum percentage errors for all the policies are in the same section of Table 1 corresponding to variations on the set-up costs for remanufacturing. This finding is not observed in the numerical experiments of Teunter et al. (2006) and Schulz (2011) for the problem with ungraded returns. Thus, for the problem with graded returns, variations on the remanufacturing costs seem to have a greater impact on the optimal solution than the other parameters. 6 Conclusions and future research In this paper we investigate the economic lot-sizing problem with remanufacturing and returns with heterogeneous quality. We provide a mathematical formulation for the problem and show that it is as hard as solve than the problem with ungraded returns, which is an NP-hard problem even under the assumptions considered here of time-invariant costs and no units costs for replenishment. We suggest and evaluate several inventory policies by means of adding specific constraints to the original formulation. From the results of the numerical experiment conducted we can conclude that it is desirable to either produce or remanufacture but not both in the same period. Further, in a certain period may be profitable to remanufacture those returns on a single level of quality, which in turn may be not the higher one. These findings can be used to develop new solving procedures for the problem or even adapt the existing ones (Schulz, 2011; Sifaleras et al., 2015; Piñeyro and Viera, 2015). Other possible direction for future research is to extend the problem tackled here by means of including more real-life characteristics such as dynamic costs, unit costs for replenishment, salvage returns or capacity constraints (Fergurson et al., 2009; Nenes and Nikolaidis, 2012). On the other hand, it would be also interesting to investigate more simple cases such as the case of joint set-up cost for production and remanufacturing with the hope to find efficient algorithms for solving the problem (Teunter et al., 2006). Acknowledgements Thanks to Luciano Álvarez, Gabriela Arriola and Matilde Macció for providing the data instances and the AMPL code for the original formulation, developed as part of their thesis degree for Computer Engineer. This work was supported in part by CSIC and PEDECIBA, Uruguay. References
1. A. Agrawal, R. J. Singh and Q. Murtaza. A literature review and perspectives in reverse logistics. Resources, Conservation and Recycling, 97(1):76–92, 2015.
CLAIO-2016
694

2. M. F. Baki, B. A. Chaouch and W. Abdul-Kader. A heuristic solution procedure for the dynamic lot sizing problem with remanufacturing and product recovery. Computers & Operations Research, 43(1):225-236, 2014.
3. A. P. Barquet, H. Rozenfeld and F. A. Forcellini. An integrated approach to remanufacturing: model of a remanufacturing system. Journal of Remanufacturing, 3:1, 2013.
4. M. Denizel, M. Ferguson, and G. C. Souza. Multiperiod remanufacturing planning with uncertain quality of inputs. IEEE Transactions on Engineering Management, 57(3):394-404, 2010.
5. I. Dobos and K. Richter. A production/recycling model with quality consideration. International Journal of Production Economics, 104(2):571-579, 2006.
6. M. Dong, S. Lu and S. Han. Production planning for hybrid remanufacturing and manufacturing system with component recovery. In Advances in Electrical Engineering & Electrical Machines, 511–518, D. Zeng (Ed.), Springer, Berlin, 2011.
7. M. Ferguson, V. D. Guide Jr., E. Koca and G. C. Souza. The Value of Quality Grading in Remanufacturing. Production and Operations Management, 18(3):300-314, 2009.
8. M. R. Galbreth and J. D. Blackburn. Optimal acquisition quantities in remanufacturing with condition uncertainty. Production and Operations Management, 19(1):61-69, 2010.
9. V.D.R. Guide Jr.. Production planning and control for remanufacturing: industry practice and research needs. Journal of Operations Management, 18:467-483, 2000.
10. J. Guo and G. Ya. Optimal strategies for manufacturing/remanufacturing system with the consideration of recycled products. Computers & Industrial Engineering, 89:226-234, 2015.
11. W. L. Ijomah. A model-based definition of the generic remanufacturing business process. PhD thesis, The University of Playmouth, United Kindom, 2002.
12. I. Konstantaras, K. Skouri, M.Y. Jaber. Lot sizing for a recoverable product with inspection and sorting. Computers & Industrial Engineering, 58:452–462, 2010.
13. M. Lage Jr. and M. Godinho-Filho. Production planning and control for remanufacturing: literature review and analysis. Production Planning & Control: The Management of Operations, 23(6):419-435, 2012.
14. X. Li, M. F. Baki, P. Tian and B. A. Chaouch. A robust block-chain based tabu search algorithm for the dynamic lot sizing problem with product returns and remanufacturing. Omega, 42(1):75–87: 2014.
15. S. Mahapatra, R. Pal and R. Narasimhan. Hybrid (re)manufacturing: manufacturing and operational implications. International Journal of Production Research, 50(14):3786-3808, 2012.
16. M. Mezghani and T. Loukil. Remanufacturing planning with imprecise quality inputs through the goal programming and the satisfaction functions. In Proceedings of 4th International Conference on Logistics (LOGISTIQUA), pp. 122-125. IEEE, 2011.
17. G. Nenes, S. Panagiotidou and R. Dekker. Inventory control policies for inspection and remanufacturing of returns: A case study. International Journal of Production Economics, 125:300–312, 2010.
18. G. Nenes and Y. Nikolaidis. A multi-period model for managing used product returns. International Journal of Production Research, 50(5):1360-1376, 2012.
19. P. Piñeyro and O. Viera, Analysis of the quantities of the remanufacturing plan of perfect cost. Journal of Remanufacturing 2(3):1-8, 2012.
20. P. Piñeyro and O. Viera, The economic lot-sizing problem with remanufacturing: analysis and an improved algorithm. Journal of Remanufacturing 5(12):1-13, 2015.
21. M. J. Retel-Helmrich, R. Jans, W. van den Heuvel and A. P. M. Wagelmans. Economic lot-sizing with remanufacturing: complexity and efficient formulations. IIE Transactions, 46(1):67–86, 2014.
22. T. Schulz. A new Silver–Meal based heuristic for the single-item dynamic lot sizing problem with returns and remanufacturing. International Journal of Production Research, 49(9):2519-2533, 2011.
23. A. Sifaleras, I. Konstantaras and N. Mladenović. Variable neighborhood search for the economic lot sizing problem with product returns and recovery. International Journal of Production Economics, 160(1):133-143, 2015.
24. R. Teunter, Z. Bayındır and W. van den Heuvel. Dynamic lot sizing with product returns and remanufacturing. International Journal of Production Research, 44(20): 4377-4400, 2006.
CLAIO-2016
695

Designing robust supply chain: a methodological approach by using
binary programming
Andrés Polo Roa
Fundación Universitaria Agraria de Colombia
Dairo Steven Muñoz
Fundación Universitaria Agraria de Colombia
Munoz.dairo@ uniagraria.edu.co
Rafael David Tordecilla Madera
Fundación Universitaria Agraria de Colombia
Abstract Supply Network Design (SND) is a strategic option to develop the supply network to get better performance
in terms of productivity, competitiveness and sustainability. The present study presents a robustness
paradigm on SND problems. This research is oriented to proposing a methodological approach for designing the supply network, considering perturbation parameters, robustness requirements, and
performance features were qualitatively and quantitatively identified and the impact of the perturbation
parameters on the robustness requirements and the performance features which have been determined. The methodology was validated on milk supply network, especially in storage and refrigeration process, where
the primary milk distribution network was made by SND and robustness parameters jointly. The SND
problem was attended the location of cooling tanks, assignment of producers for the tanks, and calculations
of system capacity. The goal of this research is to identify the most robust and cost efficient configuration.
Keywords: Robustness, Supply Network Design, facility location, milk supply network.
1 Introduction
In the process of Supply Network Design (SND), uncertainty is an important factor that may influence the configuration and coordination efficiency and significantly affect performance (Peidro, Mula & Poler,
2009). However, limited studies have considered this factor. The review by Melo, Nickel, & Saldanha-da-
Gama (2009) found that 20% of all publications consider stochastic variables, whereas the review by Mula, Peidro, Diaz-Madronero, & Vicens (2010) stated that 30% of the studies consider uncertainty.
This lack of research indicates that uncertainty is frequently ignored in studies that investigate problems
associated with supply chains. Blackhurst, Wu, & O'Grady (2004) considered the dynamical nature and
uncertain demand within supply chains as causes of the inherent complexity within such chains. Several authors have suggested that ignoring uncertainty may have negative effects on supply chains (Jung, Blau,
Pekny, Reklaitis & Eversdyk, 2004).
One method of managing such uncertainty is by considering the concept of robustness. A survey of the literature on the robustness of supply chains reveals that the organizational design of robust supply chains
CLAIO-2016
696

is not guided by an integral framework. These authors also indicate that robustness can be considered at
conceptual, qualitative and quantitative model levels. Vlajic, van der Vorst, & Haijema (2012) suggest that at the qualitative level, robustness is considered an important property of the supply chains that can be
utilized to improve resilience. Thus, robustness is mainly related to overcoming vulnerabilities in the chain
caused by a variety of general interruptions and uncertainties. At the quantitative level, robustness is
primarily considered in according to different problems in the supply chain, such as planning (Komoto, Tomiyama, Silvester, & Brezet, 2011), programming (Adhitya, Srinivasan, & Karimi, 2007), network
design (Peng, Snyder, Lim, & Liu, 2011), and inventory management (Kastsian, & Mönnigmann, 2011).
Ali et al. (2004) proposed a methodology referred to as the “FePIA procedure” (Features, Perturbation, Impact, Analysis) for use as a gauge for robustness that can quantitatively measure the robustness of a
system. The present article is essentially based on the application of the methodology proposed by
Tordecilla-Madera, & González-Rodríguez (2014), which is based on Ali et al. (2004). In the present work, the methodology is applied to place cooling tanks within a milk cooperative considering an uncertain supply
of raw milk. Thus, the achievement of this goal constitutes a contribution to the field because, to our
knowledge, the FePIA procedure has not been applied in this context.
2 Problem description In Colombia, most of the commercially available milk is produced by specialized companies, which is
beneficial to small- and medium-sized businesses primarily in cold regions of the country close to consumer
centers. The current government policies for consumer groups indicate that in-depth analyses are required
of milk production and distribution in certain regions of Boyacá and Cundinamarca. Cooperatives have been established in these regions and function as intermediaries between farmers and the dairy industry. In
certain instances, the operators of the supply chain provide the required resources to cooperatives, such as
goods, equipment and transportation. Small properties in these areas are typically in rural areas with low accessibility to vehicles and low availability of storage for raw milk; moreover, these cooperatives lack
production goals, good production practices, and performance records for milk production with their cows.
However, the greatest obstacle for the supply of raw milk is the lack of appropriate transportation of the product to the processing centers. To date, a cold chain to slow down or stop changes in the product,
including microbiological (growth of microorganisms), physiological (ripening), biochemical (browning,
lipid oxidization) and/or physical (e.g., loss of moisture) changes, is not available. The current collection
conditions prevent raw milk from being used in the production of pasteurized milk, and the milk may be rejected or used for the production of low–quality cheese, which constitutes an economic loss for the
cooperatives. The diversity of conditions is an obstacle for the operators of the supply chain because it
complicates adopting recommended techniques for farmers to meet their quality and volume requirements and avoid seasonal fluctuations.
To improve these conditions, seminars on good farming practices have been organized and contribute to
increases of daily milk production. Economic assistance has been provided so that farmers can invest in
cellars and equipment to manipulate raw milk and perform milking. To provide for quality preservation and safety of the milk, the government and private entities have offered raw milk cooling tanks to improve the
processes of milk collection and storage. An efficient cold chain is designed to provide the best possible
conditions to avoid or delay changes to the milk for a sufficiently long period of time (James, & James 2010), and the design must consider intrinsic variations of dairy production in mountainous regions,
including the daily production of milk per cow, distances to be traversed for milk delivery, and necessary
number and capacity of cooling tanks. These parameters are fundamental and must be carefully considered to adequately place the tanks in the network. The greatest challenge in the design of a raw milk distribution
network that maintains the cold chain is related to the seasonal and geographic fluctuations of milk
production as well as variability in its demand because of unstable economic conditions. The inability to
CLAIO-2016
697

manage these uncertainties may lead to either an unfeasible design or sub-optimal performance of the
supply chain. The goal of supply-chain design from a strategic perspective is to determine a configuration that optimizes
its long-term performance within the planning horizon. Because of the permanent nature of placement
choices, the planning horizon cannot be known with absolute certainty. In the present article, a raw-milk
supply chain will be configured to efficiently manage a variety of future scenarios belonging to the class of decision problems known as strategic planning under uncertainty. The supply chain will be configured
through a robust design and in general terms, the future uncertainty is modeled using scenarios.
3 Methodology
The SND robust of a logistic system for milk storage and cooling at the cooperative studied in this article is based in the methodology proposed by Tordecilla-Madera, & González-Rodríguez (2014). These authors
introduced a general methodology based on a theoretical model for characterizing the relationship between
robustness and cost in capacity planning and warehouse location problem in supply chains. This methodology was based on the work by Ali et al. (2004). In their methodology, Tordecilla-Madera, &
González-Rodríguez (2014) proposed 4 stages, which were applied meticulously in the present article to
the specific problem of the cooperative. However, because this is a real-world problem and presents the specific characteristics described above, a fifth stage was introduced to conclude the system design. The
tool used in the design of this system was binary programming. The mathematical model utilized as an
experimentation tool is shown next, followed by the methodology proposed in the present article, which is
summarized into five stages. The input for the model is based on real data provided by the cooperative.
3.1 Mathematical model
The mathematical model used here is based on the work of Sánchez, & Muñoz (2014), which was adapted
to the specific characteristics of the present study. This model contains only binary variables, and certain variables determine whether a cluster is open or closed, whereas other variables specify whether a producer
belongs to either of the open clusters, which fits into a location model that seeks to minimize costs and
optimize cooling tank positions, one for each open cluster. To ease handling and maintenance, tanks must be placed within the properties of the producers and not in uninhabited locations. Thus, the system network
is composed of nodes of only one type: producer nodes. The number assigned to each node corresponds to
the authors’ choice for labeling each producer, and the coordinates were collected in situ using a Global
Positioning System (GPS). Based on this distribution, the authors designed the following positioning model:
Subscripts 𝑖 = 𝑃𝑟𝑜𝑑𝑢𝑐𝑡𝑜𝑟 𝑙𝑎𝑏𝑒𝑙; 𝑖 = 1, 2, … , 𝐼
𝑗 = 𝐶𝑙𝑢𝑠𝑡𝑒𝑟 𝑙𝑎𝑏𝑒𝑙; 𝑗 = 1, 2, … , 𝐽
𝑘 = 𝐶𝑎𝑝𝑎𝑐𝑖𝑡𝑦 𝑜𝑓 𝑡ℎ𝑒 𝑐𝑜𝑜𝑙𝑖𝑛𝑔 𝑡𝑎𝑛𝑘𝑠; 𝑘 = 1, 2, … , 𝐾
Parameters
𝑆𝐷𝑎𝑖𝑙𝑦𝑖 = 𝐷𝑎𝑖𝑙𝑦 𝑚𝑖𝑙𝑘 𝑠𝑢𝑝𝑝𝑙𝑦 [𝑙𝑖𝑡𝑒𝑟𝑠] 𝑜𝑓 𝑝𝑟𝑜𝑑𝑢𝑐𝑒𝑟 𝑖 𝐴𝐻𝑖 = 𝐴𝑏𝑠𝑐𝑖𝑠𝑠𝑎 𝑜𝑓 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑜𝑟 𝑖 𝑂𝐻𝑖 = 𝑂𝑟𝑑𝑖𝑛𝑎𝑡𝑒 𝑜𝑓 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑜𝑟 𝑖 𝑋𝑗 = 𝐴𝑏𝑠𝑐𝑖𝑠𝑠𝑎 𝑜𝑓 𝑡ℎ𝑒 𝑙𝑜𝑐𝑎𝑡𝑖𝑜𝑛 𝑜𝑓 𝑡ℎ𝑒 𝑠𝑡𝑜𝑟𝑎𝑔𝑒 𝑐𝑒𝑛𝑡𝑒𝑟 𝑐𝑜𝑟𝑟𝑒𝑠𝑝𝑜𝑛𝑑𝑖𝑛𝑔 𝑡𝑜 𝑐𝑙𝑢𝑠𝑡𝑒𝑟 𝑗
𝑌𝑗 = 𝑂𝑟𝑑𝑖𝑛𝑎𝑡𝑒 𝑜𝑓 𝑡ℎ𝑒 𝑙𝑜𝑐𝑎𝑡𝑖𝑜𝑛 𝑜𝑓 𝑡ℎ𝑒 𝑠𝑡𝑜𝑟𝑎𝑔𝑒 𝑐𝑒𝑛𝑡𝑒𝑟 𝑐𝑜𝑟𝑟𝑒𝑠𝑝𝑜𝑛𝑑𝑖𝑛𝑔 𝑡𝑜 𝑐𝑙𝑢𝑠𝑡𝑒𝑟 𝑗
𝐷𝑖𝑗 = 𝑆ℎ𝑜𝑟𝑡𝑒𝑠𝑡 𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒 [𝑘𝑚] 𝑏𝑒𝑡𝑤𝑒𝑒𝑛 𝑝𝑟𝑜𝑑𝑢𝑐𝑒𝑟 𝑖 𝑎𝑛𝑑 𝑠𝑡𝑜𝑟𝑎𝑔𝑒 𝑐𝑒𝑛𝑡𝑒𝑟 𝑗:
𝐷𝑖𝑗 = 110.6 ∗ √(𝑋𝑗 − 𝐴𝐻𝑖)2
+ (𝑌𝑗 − 𝑂𝐻𝑖)2
𝐶𝑃𝐶𝑘 = 𝐶𝑎𝑝𝑎𝑐𝑖𝑡𝑦 [𝑙𝑖𝑡𝑒𝑟𝑠] 𝑜𝑓𝑎 𝑡𝑎𝑛𝑘 𝑜𝑓 𝑡𝑦𝑝𝑒 𝑘
CLAIO-2016
698

𝐶𝐴𝑘 = 𝐷𝑎𝑖𝑙𝑦 𝑑𝑒𝑝𝑟𝑒𝑐𝑖𝑎𝑡𝑖𝑜𝑛 𝑐𝑜𝑠𝑡 ($/𝑑𝑎𝑦) 𝑜𝑓 𝑎 𝑡𝑎𝑛𝑘 𝑜𝑓 𝑡𝑦𝑝𝑒 𝑘
𝐶𝐼𝑁𝑘 = 𝐷𝑒𝑝𝑟𝑒𝑐𝑖𝑎𝑡𝑖𝑜𝑛 𝑐𝑜𝑠𝑡 ($/𝑑𝑎𝑦) 𝑜𝑓 𝑡ℎ𝑒 𝑖𝑛𝑓𝑟𝑎𝑠𝑡𝑟𝑢𝑐𝑡𝑢𝑟𝑒 𝑜𝑓 𝑡𝑦𝑝𝑒 𝑘 𝑡𝑎𝑛𝑘𝑠
𝐶𝑅𝐹𝑘 = 𝑅𝑒𝑓𝑟𝑖𝑔𝑒𝑟𝑎𝑡𝑖𝑜𝑛 𝑐𝑜𝑠𝑡 ($/𝑙𝑖𝑡𝑒𝑟) 𝑜𝑓 𝑡𝑦𝑝𝑒 𝑘 𝑡𝑎𝑛𝑘𝑠
𝑆𝐷 = 𝑆𝑎𝑙𝑎𝑟𝑦 ($/𝑑𝑎𝑦) 𝑜𝑓 𝑎𝑛 𝑒𝑚𝑝𝑙𝑜𝑦𝑒𝑒 𝑚𝑎𝑖𝑛𝑡𝑎𝑖𝑛𝑖𝑛𝑔 𝑎 𝑐𝑜𝑜𝑙𝑖𝑛𝑔 𝑡𝑎𝑛𝑘 𝑎𝑛𝑑 𝑖𝑡𝑠 𝑖𝑛𝑓𝑟𝑎𝑠𝑡𝑟𝑢𝑐𝑡𝑢𝑟𝑒 𝐶𝑇𝑅 = 𝑇𝑟𝑎𝑛𝑠𝑝𝑜𝑟𝑡𝑎𝑡𝑖𝑜𝑛 𝑐𝑜𝑠𝑡 𝑜𝑓 𝑜𝑛𝑒 𝑙𝑖𝑡𝑒𝑟 𝑜𝑓 𝑚𝑖𝑙𝑘 ($/(𝑘𝑚. 𝑙𝑖𝑡𝑒𝑟))
𝑃𝑉 = 𝑠𝑒𝑙𝑙𝑖𝑛𝑔 𝑝𝑟𝑖𝑐𝑒 𝑝𝑒𝑟 𝑙𝑖𝑡𝑒𝑟 𝑜𝑓 𝑚𝑖𝑙𝑘 ($)
Variables 𝑈𝑇 = 𝑇𝑜𝑡𝑎𝑙 𝑈𝑡𝑖𝑙𝑖𝑡𝑦 (𝐶𝑜𝑙𝑜𝑚𝑏𝑖𝑎𝑛 𝑝𝑒𝑠𝑜 [$/𝑑𝑎𝑦])
𝑍𝑗𝑘 = 𝐵𝑖𝑛𝑎𝑟𝑦 𝑣𝑎𝑟𝑖𝑎𝑏𝑙𝑒 𝑠𝑝𝑒𝑐𝑖𝑓𝑦𝑖𝑛𝑔 𝑤ℎ𝑒𝑡ℎ𝑒𝑟 𝑐𝑙𝑢𝑠𝑡𝑒𝑟 𝑗 𝑜𝑓 𝑐𝑎𝑝𝑎𝑐𝑖𝑡𝑦 𝑘 𝑖𝑠 𝑜𝑝𝑒𝑛 (𝑍𝑗𝑘 = 1) 𝑜𝑟 𝑐𝑙𝑜𝑠𝑒𝑑 (𝑍𝑗𝑘 = 0)
𝑊𝑖𝑗𝑘 = 𝐵𝑖𝑛𝑎𝑟𝑦 𝑣𝑎𝑟𝑖𝑎𝑏𝑙𝑒 𝑠𝑝𝑒𝑐𝑖𝑓𝑦𝑖𝑛𝑔 𝑤ℎ𝑒𝑡ℎ𝑒𝑟 𝑝𝑟𝑜𝑑𝑢𝑐𝑒𝑟 𝑖 𝑏𝑒𝑙𝑜𝑛𝑔𝑠 (𝑊𝑖𝑗𝑘 = 1) 𝑜𝑟 𝑛𝑜𝑡 (𝑊𝑖𝑗𝑘
= 0) 𝑡𝑜 𝑐𝑙𝑢𝑠𝑡𝑒𝑟 𝑗 𝑜𝑓 𝑐𝑎𝑝𝑎𝑐𝑖𝑡𝑦 𝑘
Objective Functions
𝑀𝑎𝑥 𝑈𝑇 = ∑(𝑃𝑉 ∗ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖)
𝐼
𝑖=1
− ∑ ∑ ∑(𝐶𝑇𝑅 ∗ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖 ∗ 𝐷𝑖𝑗 ∗ 𝑊𝑖𝑗𝑘)
𝐾
𝑘=1
𝐽
𝑗=1
𝐼
𝑖=1
− ∑ ∑[(𝐶𝐴𝑘 + 𝐶𝐼𝑁𝑘 + 𝑆𝐷) ∗ 𝑍𝑗𝑘]
𝐾
𝑘=1
𝐽
𝑗=1
− ∑ ∑ ∑(𝐶𝑅𝐹𝑘 ∗ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖 ∗ 𝑊𝑖𝑗𝑘)
𝐾
𝑘=1
𝐽
𝑗=1
𝐼
𝑖=1
(1)
Constraints
∑ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖 ∗ 𝑊𝑖𝑗𝑘 ≤ 𝐶𝑃𝐶𝑘 ∗
𝐼
𝑖=1
𝑍𝑗𝑘 ∀ 𝑗, 𝑘 (2)
∑ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖 ∗ 𝑊𝑖𝑗𝑘 ≥ 0,7 ∗ 𝐶𝑃𝐶𝑘 ∗
𝐼
𝑖=1
𝑍𝑗𝑘 ∀ 𝑗, 𝑘 (3)
∑ ∑ 𝑊𝑖𝑗𝑘 = 1
𝐾
𝑘=1
𝐽
𝑗=1
∀ 𝑖 (4)
∑ 𝑍𝑗𝑘
𝐾
𝑘=1
≤ 1 ∀ 𝑗 (5)
∀ 𝑍𝑗𝑘 , 𝑊𝑖𝑗𝑘 ∈ {0,1} (6)
In this model, Eq. (1) indicates the objective function, which seeks to maximize total utility of the supply chain, discounting transportation, operation and refrigeration costs. Equation (2) establishes that the total
amount of milk transported to a cluster cannot exceed the capacity of the corresponding tank. Equation (3)
sets the minimum capacity required per cooling tank, which is a requirement of the cooperative directives, for which it is important to use at least 70% of the capacity of any tank that is placed. Equation (4) ensures
that each producer belongs to only one cluster. Equation (5) ensures that each cluster corresponds at most
one cooling tank. Equation (6) indicates that all of the variables in the model are binary.
3.2.1 Stage 1. Preliminary description of the supply chain. This stage consists of the qualitative and quantitative description of the robustness requirements, performance characteristics and perturbation
parameters. The robustness requirement is an interval associated with one or more indicators, and it
indicates whether the supply chain is operating correctly or not. Numerous performance measures can be found in the literature for generic supply chains (Chan, 2003) and agri-food supply chains (Aramyan, Oude
Lansink, van der Vorst & van Kooten, 2007). Once this interval has been established, two robustness
requirements associated with this indicator are defined: the average distance Γ1 (km) traversed by every producer for the transportation of milk from their property to the cooling tank and the distance weighted by
the volume of milk transported (Γ2 (km*liter)) by each producer from their property to the cooling tank. To
CLAIO-2016
699

simplify the handling of the variables, time will not be treated directly (as defined by Aramyan et al., 2007)
but rather distances will be applied. Because of the relation between time and distance, the system will be considered more robust for smaller distance values. Equations (7) and (8) illustrate the robustness
requirements mathematically:
𝛤1 =∑ ∑ ∑ 𝐷𝑖𝑗 ∗ 𝑊𝑖𝑗𝑘
𝐾𝑘=1
𝐽𝑗=1
𝐼𝑖=1
∑ ∑ ∑ 𝑊𝑖𝑗𝑘𝐾𝑘=1
𝐽𝑗=1
𝐼𝑖=1
(7) 𝛤2 =∑ ∑ ∑ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖 ∗ 𝐷𝑖𝑗 ∗ 𝑊𝑖𝑗𝑘
𝐾𝑘=1
𝐽𝑗=1
𝐼𝑖=1
∑ ∑ ∑ 𝑊𝑖𝑗𝑘𝐾𝑘=1
𝐽𝑗=1
𝐼𝑖=1
(8)
Regarding the performance characteristics, they must present a limited variation so that the described robustness requirement is met (Ali et al., 2004). Based on the model described above, the following
performance characteristics were considered:
Number of open clusters (𝝋𝟏): indicates the number of clusters that must be opened according to each supply scenario. The number of open clusters is defined as follows:
𝜑1 = ∑ ∑ 𝑍𝑗𝑘
𝐾
𝑘=1
𝐽
𝑗=1
(9)
Total installed capacity (𝝋𝟐): refers to the sum of the total capacities of all tanks in the system. The total installed capacity is defined as follows:
𝜑2 = ∑ ∑ 𝐶𝑃𝐶𝑘 ∗ 𝑍𝑗𝑘
𝐾
𝑘=1
𝐽
𝑗=1
(10)
Configuration of the supply chain (𝝋𝟑): indicates the number of clusters to be opened along with
the precise location of each cooling tank and information on whether a tank belongs to each cluster after the model algorithm has been run with the corresponding modifications in the input variables.
Note that this definition does not include the installed capacity. Compared with the previously defined
variables, the configuration of the supply chain is a qualitative variable.
The perturbation parameters refer to uncontrollable variables that are subject to uncertainty and affect the performance characteristics of the system and therefore, its robustness (Ali et al., 2004). According to
Peidro et al. (2009), there are three sources of uncertainty in a supply chain: supply, processing-
manufacturing, and demand. In the current work, the only source of uncertainty that was considered was associated with processing because of the great variability in cattle milk production. Thus, it was
established that the only perturbation parameter for the system would be the total daily milk supply,
which is shown in Eq. (11).
𝜋 = ∑ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖
𝐼
𝑖=1
(11)
3.2.2 Stage 2. Identification of perturbation parameter π impacts on the robustness requirements Γs
and performance characteristics φr. In this stage, the supply (π) is varied in a controlled manner to
identify the behavior of the robustness requirements Γs and performance characteristics φr. For such variation, the work of Sánchez & Muñoz (2014) was considered, in which the number of heads of cattle
owned by each producer of the cooperative (𝑁𝐶𝑖) was determined through polling. However, the work by
Fonseca Carreño et al. (2013) was also considered and used to establish that the daily production of one
head of cattle may oscillate between 6 and 25 liters depending on conditions such as climate, diet,
technological infrastructure and production system. Therefore, the supply (𝑆𝐷𝑎𝑖𝑙𝑦𝑖) implemented in the
mathematical model, which is used as the input for the mathematical model to calculate the perturbation
parameter, would oscillate according to Eq. (12), in which δ is a parameter that varies between zero (0) and
ten (10). The total input for the model consists of 11 values of 𝑆𝐷𝑎𝑖𝑙𝑦𝑖 (∀𝑖), which vary linearly and
proportionally through all the possible temperature values.
CLAIO-2016
700

𝑆𝐷𝑎𝑖𝑙𝑦𝑖 = [6 +𝛿 ∗ (25 − 6)
10] ∗ 𝑁𝐶𝑖 ∀𝑖 (12)
3.2.3 Stage 3. Determination of the behavior of each identified configuration. The results from Stage 4 specify a chain configuration for each considered value of the average supply π (11 values in total).
However, the same configurations were observed for certain values of π; thus, a total of eight distinct
configurations were obtained. By means of additional restrictions, the model was forced to adopt each configuration, and for each parameter, π is varied once more through the 11 values considered in the
previous stage. Furthermore, the installed capacities were not fixed, which is consistent with the definition
of “configuration” provided in Sec. 3.2.1. Thus, the following model modifications were implemented:
1) A new parameter 𝑎𝑗, which is a binary matrix indicating whether a tank is (𝑎𝑗 = 1) or is not (𝑎𝑗 = 0)
located on the property of producer j, was introduced.
2) Equation (5) was replaced by Eq. (13), which forces the model to adopt a specific configuration and allows for the behavioral analysis of each of the configurations in terms of Γs, φr and total utility (UT)
as the supply is varied [Eqs. (11) and (12)].
∑ 𝑍𝑗𝑘
𝐾
𝑘=1
= 𝑎𝑗 ∀ 𝑗 (13)
3.2.4 Stage 4. Characterization of the robustness–utility relation. Once Γs, φr and CT have been determined separately for each configuration according to the controlled variation of the total daily supply
(π), the relationships among the different parameters were graphically analyzed. The most relevant
parameters for the characterization of the robustness–utility relation are as follows:
Total daily supply (π) vs. average distance (Γ1)
Total daily supply (π) vs. average weighted distance (Γ2)
Total daily supply (π) vs. total utility (UT)
From those plots, the most robust configurations, or configurations with the greatest capability of
maintaining the average distance and the average weighted distance within acceptable limits, were
determined along with the utility of achieving these configurations, which indicates the utility of
guaranteeing the highest robustness for a given configuration. 3.2.5 Stage 5. Strategic plan for tank utilization. Once the best configuration in terms of the robustness–
utility relationship has been selected, the cooperative proceeds to install the infrastructure at each of the
selected properties and position the cooling tanks. In this stage, the methods by which the tanks will be used for the 11 scenarios corresponding to the different values of π are determined. Compared with Stage
3, the installed capacities were fixed. Thus, the following model modifications were implemented:
1) A new parameter 𝑏𝑗𝑘, which is a binary matrix indicating whether a tank of capacity k is (𝑏𝑗𝑘 = 1) or
is not (𝑏𝑗𝑘 = 0) located in the property of producer j, was introduced.
2) A new variable 𝐵𝐴𝑗 , which indicates whether the tank located in the property of producer j is utilized
(𝐵𝐴𝑗 = 1) or not (𝐵𝐴𝑗 = 0), was introduced.
3) Equation (1), which corresponds to the objective equation, was replaced as follows:
𝑀𝑎𝑥 𝑈𝑇 = ∑(𝑃𝑉 ∗ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖)
𝐼
𝑖=1
− ∑ ∑ ∑(𝐶𝑇𝑅 ∗ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖 ∗ 𝐷𝑖𝑗 ∗ 𝑊𝑖𝑗𝑘)
𝐾
𝑘=1
𝐽
𝑗=1
𝐼
𝑖=1
− ∑ ∑[(𝑆𝐷) ∗ 𝑍𝑗𝑘]
𝐾
𝑘=1
𝐽
𝑗=1
− ∑ ∑[(𝐶𝐴𝑘 + 𝐶𝐼𝑁𝑘)]
𝐾
𝑘=1
𝐽
𝑗=1
− ∑ ∑ ∑(𝐶𝑅𝐹𝑘 ∗ 𝑆𝐷𝑎𝑖𝑙𝑦𝑖 ∗ 𝑊𝑖𝑗𝑘)
𝐾
𝑘=1
𝐽
𝑗=1
𝐼
𝑖=1
(14)
Compared with Eq. (1), the utilities associated with the depreciation of the tank and infrastructure are
always incurred in Eq. (14) and do not depend on whether the tank is used or not. 4) Equation (5) was replaced by Eq. (15), which allows a tank to be utilized or not depending on the level
of supply on a given day.
CLAIO-2016
701

𝑍𝑗𝑘 = 𝑏𝑗𝑘 ∗ 𝐵𝐴𝑗 ∀ 𝑗, 𝑘 (15)
5) Equation (3) was suppressed because a minimum tank capacity utilization is no longer strategically
required because for low milk production periods, it is likely that certain tanks will not be utilized or filled at only a small fraction of their capacities.
4 Results and discussion
In this study we were considered 61 producers label, 20 clusters label and 10 different capacity of de cooling
tanks. At this point, each of the configurations was individually analyzed, and π was initially plotted against
the Γ1 traversed by each producer for each of the identified configurations. This plot, which shows that each configuration generally shows a slight decrease in the average distance because the tank locations are
fixed for each configuration; thus, significant variation was not observed for the distance traversed by the
producers. However, this slight change is not observed for the scenario with the lowest supply for configurations E, C and B, which has a high value of Γ1 because the minimum volume of 70% for each
tank cannot be met when there are many open clusters. Therefore, certain clusters are closed, and the
producers must travel greater distances.
Based on these results, it was suggested to the cooperative that the cooling tanks should be located according to configuration F, which show higher robustness, meaning that there are shorter average distances and
weighted distances from the producers’ properties to the cooling tanks, and increase management utility for
most of the supply scenarios. The improved robustness implies shorter transport times and improved milk quality through a prolonged shelf life. For configuration F, φ1= 8 refrigeration tanks located, φ2 = 17,500
liters per day, Γ1= 1.02 km and Γ2 = 246.874 km per liter milk.
4.1 Strategic plan for tank utilization
The last stage of this study consists of elaborating on a plan for the utilization of the installed tanks for the
different supply scenarios. After the 11 runs described in Sec. 3.2.5 were performed, the model produced
that the best alternative to utilize the refrigeration’s tanks, is keep open tanks during all periods of low, medium and high production. An additional result that must be considered is the assignment of producers
to each tank or cluster.
5 Conclusions In the present investigation the logistic milk storage and refrigeration system for a cooperative was designed using a binary programming model. This design included the location of refrigeration tanks that can store
milk from several producers. To maximize the total utility, decisions were made regarding the number of
tanks to be placed at each location, installed capacity for each tank, and which producer should be assigned to each tank. Thus, a set of clusters was formed, with one for each tank. Because the daily milk supply is
variable, a variety of scenarios were considered for the design. The supply was varied in a controlled manner
that spanned the various ranges found in the literature. As a result, seven distinct configurations were
obtained and individually evaluated for each of the supply scenarios considered to determine the robustness and utilities of each configuration. Robustness was associated with the parameters “average distance (km)
traveled by each producer for milk transportation from their property to the cooling tank," and “average
weighted distance (km*liter) traveled by each producer for milk transportation from their property to the cooling tank.” It was determined that the best configuration in terms of robustness and utility included eigth
tanks located in eight clusters with an average distance ranging from 1.132 km/producer (high-supply
scenario) to 1.27 km/producer (low-supply scenario). The utility associated with this configuration oscillates between a minimum of $ $2,862,354 Colombian pesos/day for the low-supply scenarios to a
maximum of $13,069,830 Colombian pesos/day for the high-supply scenarios. The total installed capacity
CLAIO-2016
702

for this configuration is 17,500 liters. A strategic plan was then developed for tank utilization in the low-,
medium- and high-supply scenarios, and it established that the all tanks need be open. From an academic perspective, this investigation proposed a novel methodology to solve a strategic
placement problem. The derived robust design, which can withstand variations in milk supply at a maximal
utility without disturbing normal operations, was offered to a milk cooperative. The most robust design did
not necessarily imply a higher utility; therefore, deeper studies on the robustness–utility relationship must be conducted.
Other uncertainty sources in addition to that of supply should be included in future investigations. For
example, rural roads can be affected by rain, which may prevent the efficient transportation of milk; thus, the effect of such parameters on robustness and cost should be further investigated.
References
1. A. Adhitya, R. Srinivasan and I. A. Karimi. A model-based rescheduling framework for managing abnormal supply chain events. Computers and Chemical Engineering, 31; 496–518, 2007.
2. S. Ali, A. A. Maciejewski, H. J. Siegel and J. K. Kim. Measuring the robustness of a resource allocation. IEEE
Transactions on Parallel and Distributed Systems, 15; 630-641, 2004.
3. L. H. Aramyan, A. G. J. M. Oude Lansink, J. G. A. J. van der Vorst and O. van Kooten. Performance
measurement in agri-food supply chains: a case study. Supply Chain Management: An International Journal,
12; 304-315, 2007.
4. J. Blackhurst, T. Wu and P. O'Grady. Network-based approach to modelling uncertainty in a supply
chain. International Journal of Production Research, 42: 1639-1658, 2004.
5. F. T. S. Chan. Performance measurement in a supply chain. International Journal of Advanced Manufacturing
Technology, 21; 534-548, 2003.
6. J. A. Fonseca Carreño, J. A. Cleves Leguízamo and M. Páez Barón. Integración de microempresas lácteas del
corredor central del departamento de Boyacá (Colombia). Revista De Investigación Agraria y Ambiental, 4;
117-133, 2013.
7. J. Y. Jung, G. Blau, J. F. Pekny, G. V. Reklaitis and D. Eversdyk. A simulation based optimization approach to
supply chain management under demand uncertainty. Computers & Chemical Engineering, 28: 2087-2106,
2004.
8. D. Kastsian, and M. Mönnigmann. Optimization of a vendor managed inventory supply chain with guaranteed
stability and robustness. International Journal of Production Economics, 131; 727-735, 2011.
9. H. Komoto, T. Tomiyama, S. Silvester and H. Brezet. Analyzing supply chain robustness for OEMs from a life
cycle perspective using life cycle simulation. International Journal of Production Economics, 134: 447-457, 2011.
10. M. T. Melo, S. Nickel and F. Saldanha-da-Gama. Facility location and supply chain management - A
review. European Journal of Operational Research, 196: 401-412, 2009.
11. J. Mula, D. Peidro, M. Diaz-Madronero and E. Vicens. Mathematical programming models for supply chain
production and transport planning. European Journal of Operational Research, 204: 377-390, 2010.
12. D. Peidro, J. Mula and R. Poler. Quantitative models for supply chain planning under uncertainty: a
review. International Journal of Advanced Manufacturing Technology, 43: 400-420, 2009.
13. P. Peng, L. V. Snyder, A. Lim and Z. Liu, Z. Reliable logistics networks design with facility disruptions. Transportation Research Part B. 45; 1190–1211, 2011.
14. D. L. Sánchez and D. S. Muñoz. Estudio de reconfiguración de la cadena de suministro para productores
lecheros en el municipio de Lenguazaque mediante el uso de modelación matemática. Undergraduate thesis,
Fundación Universitaria Agraria de Colombia, Bogotá, 2014.
15. Tordecilla-Madera, R. & González-Rodríguez, L. Characterization of the robustness-cost relation in capacity planning and warehouse location problem in supply chains through a methodology based on the FePIA procedure. Unpublished paper, Universidad de la Sabana, Chía, Colombia. 2014
16. J. V. Vlajic, J. G. A. J. van der Vorst and R. Haijema. A framework for designing robust food supply
chains. International Journal of Production Economics, 137: 176-189, 2012
CLAIO-2016
703

Improving the Flow of Patients at a Projected Emergency
Room Using Simulation
Francisco Ramis
Centro Avanzado de Simulación de Procesos, Universidad del Bío-Bío, Chile.
Liliana Neriz
Departamento Control de Gestión y SI, Universidad de Chile, Chile.
Danilo Parada
Centro Avanzado de Simulación de Procesos, Universidad del Bío-Bío, Chile.
Pablo Concha
Centro Avanzado de Simulación de Procesos, Universidad del Bío-Bío, Chile.
Abstract
The main objective of the paper is to show the power of Discrete Event Simulation (DES)
in the design of clinical facilities, which will enable to build or adapt these centers
achieving the expected Key Performance Indicators (KPI´s), such as standard waiting
times according to acuity, average stay times and others. A detailed example is presented
where in order to minimize the average time of patients at a projected Emergency Unit of
a public hospital in Chile, the operation of the adult care area is analyzed by using a
simulation model. To do this, the different areas involved in the process are identified:
admission, triage, medical evaluation, procedures and treatments, among others, which
are modeled based on the seven steps methodology [1]. The computational model is built
and validated using expert judgment and supporting statistical data. Then, three scenarios
are studied, resulting one of them in a 50% decrease in the average cycle time of patients
compared to the original model, by mainly modifying the patient´s attention model.
Keywords: Emergency Room Modeling; Healthcare Simulation; KPI.
1 Introduction
Emergency Rooms (ER) are critical in stabilizing the health of patients and for requiring
an efficient management of their scarce resources to achieve their services goals. For over
three decades, simulation has been an important tool for planning and innovation in
operations, and facility design as summarized [2].
CLAIO-2016
704

A recent and detailed literature review of simulation applications to ER is presented in
[3], which also covers different models of patient´s flows to minimize the time to medical
evaluation and the total length of stay of patients discharged. The use of object-oriented
simulation is shown in “Designing Emergency Rooms using Simulation” [4].
Improvements through interventions in the flow of patients to minimize waiting times
and reduce the abandonment rates are discussed in [5]; these interventions are important
because they often do not require physical changes to the ER. Tan, Lau and Lee [6]
discuss dynamic and comprehensive patient prioritization strategies to manage demand,
while with dynamic adjustment of resources to manage supply in ER. Optimal allocation
of ER resources while minimizing patient waiting time are discussed in [7].
The performance of an ER is given by integration of the physical design of the ER, the
staffing, the equipment and service model; inadequate design of any of these may result
in poor performance of the future facility. Because of the complexity among the different
processes and the variability present in ER, this situation can be studied by using a DES
model.
The main objective of the paper is to show the power of Discrete Event Simulation (DES)
in the design of clinical facilities, which will enable to build or adapt these centers
achieving the expected Key Performance Indicators (KPI´s), such as standard waiting
times according to acuity, average stay times and others.
2 Materials and Methods
The study is based on the use of DES tools, which are used to study KPI´s such as
average cycle time, time to first medical evaluation, utilization factor of the different
rooms and resources. The model was developed using the simulation software called
Flexsim Healthcare, which is an object oriented software, designed for the development
of healthcare simulation models. The methodology of the study is the proposed by Law
[1], which has the following 7 steps: problem formulation, construction and validation of
the conceptual model, simulation model construction and validation, design of
experiments, analysis of results and documentation and presentation.
The process of patient care contains several steps, depending on the complexity, these
activities are: admission, triage, medical assessment, treatments/procedures, diagnostic
support and discharge from the ER.
To estimate the demand to use in the model, the data were extracted from the database of
a nearby hospital, located in the metropolitan region of Chile. It was estimated that the
projected ER will have a 70% of the demand of this nearby hospital, which was
considered appropriate because the population have similar demographic characteristics.
In general, the model will receive an average of 1389 patients per week. In Figure 1 is
presented the hourly demand for the different days of the week. It can be seen that
between midnight and seven o´clock, there is very little demand. But, that there is a peak
demand around noon.
CLAIO-2016
705

Figure 1: Hourly demand for each week day.
Verification and validation of model
Verification is performed by analyzing the performance of the model, taking special
attention whether the model runs without programming errors and the use of resources is
correct. In figure 2 is presented a view of the simulation model built with FlexsimHC.
Figure 2: Simulation Model of the ER.
To validate the computational model, its performance was compared with real data from
the nearby hospital, however, as the original model is not yet operational, the validation
is performed in two ways: with the team responsible for the development and
implementation of the project, and based on the discharge of patients from the simulation
model and the actual production of the ER of the nearby hospital used as reference. It is
concluded that there is no significant difference between the performance of the model
and the actual production.
The KPI´s used to evaluate the performance of the ER are the following ones:
Average cycle time (primary measure for decision making).
CLAIO-2016
706
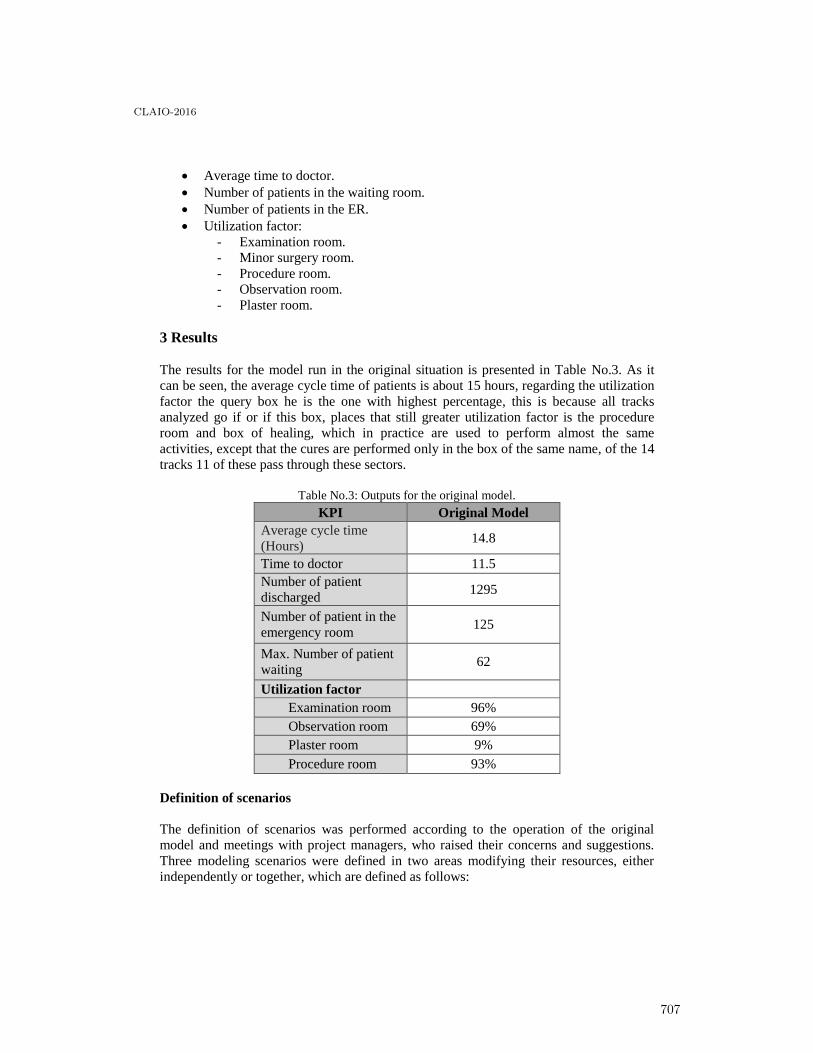
Average time to doctor.
Number of patients in the waiting room.
Number of patients in the ER.
Utilization factor:
- Examination room.
- Minor surgery room.
- Procedure room.
- Observation room.
- Plaster room.
3 Results
The results for the model run in the original situation is presented in Table No.3. As it
can be seen, the average cycle time of patients is about 15 hours, regarding the utilization
factor the query box he is the one with highest percentage, this is because all tracks
analyzed go if or if this box, places that still greater utilization factor is the procedure
room and box of healing, which in practice are used to perform almost the same
activities, except that the cures are performed only in the box of the same name, of the 14
tracks 11 of these pass through these sectors.
Table No.3: Outputs for the original model.
KPI Original Model
Average cycle time
(Hours) 14.8
Time to doctor 11.5
Number of patient
discharged 1295
Number of patient in the
emergency room 125
Max. Number of patient
waiting 62
Utilization factor
Examination room 96%
Observation room 69%
Plaster room 9%
Procedure room 93%
Definition of scenarios
The definition of scenarios was performed according to the operation of the original
model and meetings with project managers, who raised their concerns and suggestions.
Three modeling scenarios were defined in two areas modifying their resources, either
independently or together, which are defined as follows:
CLAIO-2016
707

First scenario: Add a stretcher in the procedure room.
Second scenario: Add ten stretchers in the observation room.
Third scenario: Add a stretcher in the procedure room and ten stretchers in the
observation room (scenarios 1 and 2 together).
Table No. 4 presents the cycle time and time to doctor. It can be seen that the scenarios
with the best performance according to the target are scenarios 1 and 3. It is interesting to
notice that both cycle time and time to doctor are significantly decreased, 75% and 90%
respectively
Table No.4: Sample KPI´s Original model and for scenarios.
KPI Original
Model
Scenario
1
Scenario
2
Scenario
3
Average
cycle
time
(Hours)
14.8 3.7 11.9 3.4
Time to
doctor
(Hours)
11.5 1.1 8.7 0.9
4 Conclusions
The simulation study conducted to future functioning of the ER under construction aid to
decision -making from the hospital, allowing modifications generate and analyze the
possible results before implementing them.
According to the scenarios previously defined, wherein the amount of stretchers in two
areas: the procedure room and the observation room, and were subsequently evaluated
according to the average cycle time for patients. With 95% confidence, the scenarios that
presented a significant difference in the cycle time of the patients are scenarios 1 and 3,
which have a confidence interval whose boundaries have the same sign, in this case
negative; indicating that the average cycle time for patients is lower in both scenarios
with respect to the original model. However, it should be mentioned that in practice,
scenario 3 may not be feasible for an issue of resources and physical space.
Finally, according to the analysis of the three scenarios, the best option based on the
reduction of cycle time of patients is the scenario 1, add a stretcher in the procedure room
and change the model of care, which leads the cycle time down from 14.8 hours (original
model) to 3.7 hours (scenario 1) and the time to doctor from 11.5 to 1.1 hours.
CLAIO-2016
708

References
1. A. Law. Simulation Modeling & Analysis. 5º ed, Tucson, McGraw-Hill, 2014.
2. E. Hamrock, K. Paige, J. Parks, J. Scheulen, and S. Levin. “Discrete Event Simulation for
Healthcare Organizations: A Tool for Decision Making”. Journal of Healthcare Management
58:110-124, 2013.
3. S. Chonde, C. Parra, and C. J. Chang. “Minimizing Flow-Time and Time-to-First-Treatment
in an Emergency Department through Simulation”. In Proceedings of the 2013 Winter
Simulation Conference, edited by R. Pasupathy, S.-H. Kim, A. Tolk, R. Hill, and M. E. Kuhl,
2374-2385. Piscataway, New Jersey: IEEE Press, 2013.
4. F. J. Ramis, L. Neriz, and J. A. Sepúlveda. “Designing Emergency Rooms using Simulation”.
Proceedings of the 2013 Industrial and Systems Engineering Research Conference, edited by
A. Krishnamurthy and W.K.V. Chan, 2013.
5. Y. He, T. Lei, and G. Kremer. “Resource-centric Patient Flow Performance Comparisons in
the Emergency Department”. In Proceedings of the 2013 Industrial and Systems
Engineering Research Conference, edited by A. Krishnamurthy and W.K.V. Chan, 2013.
6. K.-W. Tan, H.-C. Lau, and F. Lee. “Improving patient length-of-stay in emergency
department through dynamic queue management”. In Proceedings of the 2013 Winter
Simulation Conference, edited by R. Pasupathy, S.-H. Kim, A. Tolk, R. Hill, and M. E. Kuhl,
2374-2385. Piscataway, New Jersey: IEEE Press, 2013.
7. S.-J. Weng, B.-C. Cheng, S.-T. Kwong, L.-M. Wang, and C.-Y. Chang. “Simulation
optimization for emergency department resources allocation”. In Proceedings of the 2011
Winter Simulation Conference, edited by S. Jain, R.R. Creasey, J. Himmelspach, K.P. White,
and M. Fu, 1231-1238. Piscataway, New Jersey: IEEE Press, 2011.
CLAIO-2016
709

Gerenciamento de recursos para programação da
produção de produtos perećıveis em um ambiente de
múltiplas linhas
Rafael Soares RibeiroUniversidade de São Paulo - ICMC
Willy Alves de Oliveira SolerUniversidade Federal de Mato Grosso do Sul – INMA
Maristela Oliveira dos SantosUniversidade de São Paulo - ICMC
Resumo
Nesse artigo estudamos um problema de planejamento da produção motivado por umaindústria aliment́ıcia que produz carnes embaladas. A indústria é caracterizada pela pereci-bilidade dos produtos, sequenciamento dos lotes e pela necessidade da sincronização de recursosescassos para operação das linhas de produção. Em indústrias desse ramo existem altos custosassociados a estocagem a fim de evitar a deterioração dos itens, de modo que é essencial a oti-mização dos processos industriais visando a minimização dos custos. Formulamos o problemapor meio de um modelo de programação inteira mista e analisamos duas abordagens para trataro aspecto da perecibilidade por meio de testes computacionais.
Palavras-chave: Dimensionamento e sequenciamento de lotes; Linhas paralelas; Perecibilidade.
1 Introdução
O problema de planejamento considerado nesse artigo teve como motivação o caso de uma indústriaaliment́ıcia, que produz carnes embaladas. A maior parte de sua produção é destinada a restau-rantes, churrascarias, cozinhas industriais, hipermercados, açougues e lojas de conveniência.
Devido ao aspecto de perecibilidade considera-se que os produtos estão sujeitos a diferentesprazos de validade (shelf-life) em que podem ser comercializáveis sem prejúızo, isto é, os produtosapós sua fabricação possuem um limite de tempo para permanência em estoque e após este peŕıodoeles perdem seu valor de mercado.
Na indústria considerada o mix de produção é formado por famı́lias de produtos distintas comdiferentes custos e tempos de preparação entre os produtos (devido a trocas de maquinário, limpezada matéria-prima, etc), associadas biunivocamente às linhas de produção.
CLAIO-2016
710

Existem trabalhos na literatura que consideram problemas aplicados de dimensionamento e se-quenciamento de lotes com famı́lias de produtos: recepientes de vidro (Almada-Lobo et al. (2008)),rações (Toso et al. (2009)) e materiais (Araujo e Clark (2013)), por exemplo. Porém não conside-rando sequenciamento entre os produtos, somente entre as famı́lias.
Segundo a revisão de Amorim et al. (2013) existe pouco estudo sobre planejamento da produçãocom itens perećıveis. Dentre os trabalhos cita-se Kopanos et al. (2010), Amorim et al. (2011) ePahl et al. (2011).
Kopanos et al. (2010) realizaram um estudo de caso em uma indústria de iogurtes onde deve-setomar decisões de produção, estocagem e sequenciamento em diversas linhas de empacotamento.
Amorim et al. (2011) baseiam-se na produção de iogurtes para formular um problema multiob-jetivo com linhas paralelas, que devem ser configuradas para a produção de famı́lias de produtos.A perecibilidade é tratada na função objetivo, do seguinte modo, quanto mais tempo o produtopermanece em estoque, menos renda ele retorna.
Pahl et al. (2011) formulam dois modelos para o problema de dimensionamento e sequenci-amento de lotes. Os autores consideram que a deterioração do produto em estoque é permitidamediante a um custo.
Outra caracteŕıstica do problema abordado nesse artigo é que as linhas compartilham recur-sos limitados (trabalhadores e máquinas) o que torna imposśıvel a abertura de todas as linhassimultaneamente, podendo gerar atrasos no atendimento dos pedidos.
Para auxilar no planejamento da produção da indústria formulamos esse problema por meio deum modelo matemático de programação inteira mista com duas abordagens para modelagem daperecibilidade.
Esse artigo está organizado da seguinte forma. Na Seção 2 descreve-se as simplificações assu-midas para a modelagem e apresenta-se um modelo matemático para tratar o problema. Na Seção3 analisa-se os resultados de experimentos computacionais para a avaliação das abordagens. E porfim, as conclusões e perspectivas são apresentados na Seção 4.
2 Definição do problema e modelagem
No ambiente industrial considerado o gerente programa quais produtos devem ser produzidos se-gundo a demanda do mercado. Simultaneamente, deve-se decidir quais linhas de produção serãomontadas por meio da alocação dos funcionários nos setores da fábrica, respeitando-se os recursosdispońıveis (quantidades de trabalhadores e de máquinas).
Na Figura 1 apresenta-se uma descrição do problema considerando 21 produtos divididos em trêslinhas (ou famı́lias), com suas respectivas necessidades de funcionários e máquinas para operação.Supondo que só existe uma máquina de cada tipo, a abertura da linha 3 impossibilita a montagemdas demais linhas, pois ela utiliza as máquinas M1 e M2 o que impede o funcionamento das linhas1 e 2 respectivamente.
Figura 1: Representação do chão-de-fábrica
CLAIO-2016
711

2.1 Modelagem matemática
Para esse problema de dimensionamento e sequenciamento de lotes assumimos as seguintes premis-sas: cada linha está associada a apenas uma famı́lia de produtos perećıveis com diferentes prazosde validade; as linhas possuem um conjunto de máquinas e trabalhadores para sua operação; aslinhas não podem ser desativadas no peŕıodo em que foram abertas; a produtividade das linhasnão dependem do número de trabalhadores alocados, pois isso depende apenas da eficiência dasmáquinas; estrutura de tempo/custo de preparação dependente da sequência de produtos da linha;existe conservação do estado da linha durante os peŕıodos; as preparações nas linhas (trocas deprodutos) são completadas dentro do peŕıodo.
Uma formulação foi obtida através da adaptação do modelo GLSP (Fleischmann e Meyr (1997)).Nessa formulação cada peŕıodo é discretizado em S micropeŕıodos sem sobreposição, cuja a duraçãoé implicitamente uma variável de decisão definida pela restrição da capacidade da linha.
Notação
Índices e conjuntosj ∈ P = {1, ..., J} – Conjunto de produtos.t ∈ H = {1, ..., T} – Conjunto de peŕıodos.l ∈ F = {1, ..., L} – Conjunto de linhas.k ∈ Q = {1, ..., U} – Conjunto de máquinas.Slt = {init, ..., fimt} – Conjunto de micropeŕıodos da linha l associados ao peŕıodo t, iniciandoem init e terminando em fimt.Pl – Conjunto de produtos que são produzidos na linha l.Parâmetroshj – Custo unitário de estocagem do produto j.bj – Custo unitário de atraso da demanda j.csij – Custo de preparação da linha para produção do produto j após o produto i.djt – Demanda do produto j no peŕıodo t.Ij0 – Estoque inicial do produto j.aj – Tempo unitário de produção do produto j.tsij – Tempo de preparação da linha para produção do produto j após o produto i.M – Um número grande.pminj – Quantidade mı́nima para a produção do produto j em qualquer micropeŕıodo.nl – Número de funcionários para ativação da linha l.rh – Número total de funcionários na fábrica.mkl – Quantidade de máquinas do tipo k necessária para a operação da linha l.Nk – Quantidade de máquinas do tipo k dispońıvel na fábrica.θj – Número máximo de peŕıodos que o produto j pode permanecer em estoque.Variáveis de decisãoxjs – Quantidade produzida do produto j no micropeŕıodo s.Ijt – Quantidade do produto j em estoque no final do peŕıodo t.I−jt – Quantidade de itens em atraso do produto j no peŕıodo t.δlt – (Binária) indica se a linha l está em funcionamento no peŕıodo t.zijs – (Binária) indica se houve troca de produção (i para j) na linha no micropeŕıodo s.yjs – (Binária) indica se a linha está preparada para produção do produto j no micropeŕıodo s.
CLAIO-2016
712

Formulação matemática
Min∑j
∑t hjIjt +
∑j
∑t bjI
−jt +
∑l
∑i∈Pl
∑j∈Pl
∑s csijzijs (1)
s.aIjt + I−j,t−1 + djt = Ij,t−1 + I−jt +
∑s∈Slt
xjs ∀l,∀j ∈ Pl,∀t (2)
I−jT = 0 ∀j (3)∑s∈Slt
∑j∈Pl
ajxjs +∑i∈Pl
∑j∈Pl
∑s∈Slt
tsijzijs ≤ Klt ∀l,∀t (4)
xjs ≤Myjs ∀j,∀s (5)xjs ≥ pminj (yjs − yj,s−1) ∀j,∀s (6)∑
j∈Plyjs = δlt ∀l,∀t,∀s ∈ Slt (7)∑
l nlδlt ≤ rh ∀l,∀t (8)∑lmklδlt ≤ Nk ∀k, ∀t (9)
zijs ≥ yjs + yi,s−1 − 1 ∀l,∀i ∈ Pl, ∀j ∈ Pl, ∀s (10)x, I, I−, δ, z ≥ 0, y ∈ {1, 0} (11)
A função objetivo (1) a ser minimizada representa os custos de estocagem, atraso e preparações.As restrições (2) representam o balanceamento de estoque. As restrições (3) indicam que toda ademanda é atendida até o final do horizonte. As restrições (4) denotam o limite de capacidadedas linhas. As restrições (5) forçam a variável inteira assumir valor positivo para a produção. Asrestrições (6) indicam que um lote mı́nimo deve ser produzido sempre que a linha tiver troca deestado. As restrições (7) significam que quando a linha está aberta apenas um produto pode serproduzido em cada micropeŕıodo. As restrições (8) e (9) implicam que nas linhas abertas respeitam-se a quantidade de trabalhadores e máquinas, respectivamente. O sequenciamento nas linhas é dadopelas restrições (10). Por fim, o domı́nio das variáveis é definido pelas restrições (11).
2.1.1 Modelando a perecibilidade
Geralmente nos problemas de dimensionamento de lotes a quantidade de produtos que pode serarmazenada é limitada apenas pelo espaço f́ısico do depósito. Nesse artigo os produtos estão sujeitosao efeito de deterioração, isto é, a perda parcial ou completa de seus benef́ıcios ao longo do tempo.Assim para o tratamento da perecibilidade consideramos duas abordagens da literatura.
• Abordagem E não permite deterioração (Entrup et al. (2005)) - limita a quantidade emestoque de cada produto em cada peŕıodo pelas demandas dos peŕıodos futuros até atingir adata de validade. Dada pela seguinte restrição:
Ijt ≤∑t+θjk=t+1 djk ∀j,∀t (12)
• Abordagem D permite deterioração (Pahl et al. (2011)) - os produtos em estoque podemestragar mediante a uma penalidade de
∑j
∑t pjvjt, onde vjt é uma variável, que define a
quantidade do item j estragada no peŕıodo t com domı́nio dado por (13) e pj representa ocusto relacionado. Além disso, temos a alteração da equação de balanceamento de estoquedado por (14) e a quantidade de itens deteriorados é dada por (15).
vjt ≥ 0 ∀j,∀t (13)
Ijt + I−j,t−1 + djt + vjt = Ij,t−1 + I−jt +∑s∈Slt
xjs ∀l,∀j ∈ Pl, ∀t (14)
vjt ≥∑t−θjk=1
∑s∈Slk
xjs−∑tk=1 djk−
∑t−1k=1 vjk ∀l,∀j ∈ Pl,∀t ≥ θj (15)
CLAIO-2016
713

2.1.2 Desigualdades válidas da literatura
Para o modelo foram adotadas as inequações de fluxo (16) e (17) de Wolsey (2002) dadas a seguir:Para a produção do produto j no micropeŕıodo s existe a alteração do estado da linha do
produto i para o produto j no mesmo micropeŕıodo. Essa restrição é dada por (16).∑i∈Pl
zijs = yjs ∀j ∈ Pl, ∀s, ∀l (16)Se a linha está configurada para a produção do item i no micropeŕıodo s-1, então no ińıcio do
próximo micropeŕıodo a linha preserva a preparação. Essa restrição é dada por (17).∑j∈Pl
zijs = yi,s−1 ∀l,∀i ∈ Pl,∀s ∈ Slt\{init},∀t (17)Essa restrição não é válida para s = init ∀t, porquê teriamos a abertura da linha em todos os
peŕıodos podendo gerar um problema infact́ıvel devido a limitação dos recursos.De fato, suponha que yi,init−1 = 1. Então
∑j∈Pl
zij,init = 1⇒ yj,init = 1 ⇒ δlt = 1.Podemos evitar trocas desnecessárias na linha por meio das restrições (18). Esse grupo de
restrições não permite que a linha volte para um item preparado anteriormente no mesmo peŕıodo.∑i∈Pli 6=j
∑s∈Slt
zijs ≤ 1 ∀j ∈ Pl, ∀l,∀t (18)Em resumo, temos dois modelos: Modelo E (sem deterioração) dado pelas expressões (1) −
(12) ∪ (16)− (18); Modelo D (com deterioração) dado pelas expressões (1)− (11) ∪ (13)− (18).
3 Estudo computacional
Nessa seção apresentamos os resultados de testes computacionais para a avaliação das abordagenspara tratar a perecibilidade e sua influência no desempenho do CPLEX.
O modelos matemático foi implementado em linguagem C++ utilizando bibliotecas do pacotede otimização IBM ILOG CPLEX 12.6 na configuração padrão. Os experimentos foram realizadosem um computador com processador Intel Core(TM) i7-4790 CPU 3.6 GHz com memória RAM 16GB com o sistema operacional Windows 8.1.
Para realização desse estudo foram geradas instâncias com distribuição uniforme baseadas emAraujo e Clark (2013) com um horizonte de planejamento de 7 peŕıodos. Para os parâmetrosespećıficos deste problema assumimos: Perecibilidade (θj) [1,3] (Pahl et al. (2011)); Custo dedeterioração pj = θj (Pahl et al. (2011)); Estoque inicial de 60 unidades para todos os itens;Número de trabalhadores por linha (nl) [5,10]; Distribuição das máquinas (mkl) [0,1]; A quantidadede tipos de máquinas (U) é definida por (L − 3)/2, onde L representa a quantidade de linhas; Onúmero de trabalhadores na fábrica (rh) é dado por 0, 8.
∑l nl.
Na Tabela 1 temos a descrição de duas classes de instâncias geradas para os experimentoscomputacionais com suas respectivas quantidades de linhas, produtos, micropeŕıodos por peŕıodoe variáveis inteiras. Para cada conjunto de instâncias foram gerados 5 exemplares.
Tabela 1: Descrição das instânciasClasses Linhas Produtos Micropeŕıodos Variáveis inteiras
A 3 9 3 189
5 30 6 1260B 7 42 6 1764
9 54 6 2268
CLAIO-2016
714

3.1 Experimento da Classe A
Nos testes da Classe A consideramos dois cenários produtivos I e II definidos a seguir.O cenário I considera posśıvel o atraso no atendimento das demandas e que não existe estoque
inicial (Ij0 = 0 ∀j). Enquanto que o cenário II considera um estoque inicial positivo, mas sempermitir atraso dos pedidos (I−jt = 0 ∀j,∀t).
A motivação de considerar o cenário II se deve ao fato, de que, o atraso das demandas ocorresobretudo no ińıcio do horizonte de planejamento, isto é, os pedidos que não são atendidos noprazo correspondem as linhas que não são abertas nos primeiros peŕıodos do horizonte. Portanto aexistência de um estoque inicial poderia garantir o atendimento dos pedidos sem atraso. Outra jus-tificativa para assumir um estoque inicial de produtos perećıveis consiste em notar, que simulaçõesde problemas de dimensionamento de lotes mostram baixa utilização do depósito e da capacidadenos últimos peŕıodos. Logo, faz sentido a produção no término do horizonte a fim de antecipar asdemandas dos próximos peŕıodos de programação.
Na Tabela 2 apresenta-se uma comparação das soluções ótimas obtidas pelo CPLEX na resoluçãodas instâncias (in) da Classe A, considerando os dois modelos (E e D), sujeitos aos dois cenários (C)- a função objetivo dos modelos; o tempo de execução em segundos; o estoque é dado pela médiada quantidade armazenada durante todo o horizonte de planejamento; o atraso é definido pelototal de pedidos que não foram atendidos no prazo; a quantidade de trocas nas linhas; deterioradosrepresenta a quantidade de itens que foram perdidos devido a deterioração.
Tabela 2: Resultados do CPLEX na resolução da Classe AFunção Objetivo Tempo (s) Estoque Atraso Trocas Deteriorados
C in E D E D E D E D E D E D
1 30882 30882 48 18 195,44 195,44 9 9 22 22 – 02 19859 19859 30 276 228,43 228,43 3 3 19 19 – 0
I 3 24626 24626 49 239 203,57 203,57 3 3 22 22 – 04 22740 22740 215 314 179,43 179,43 4 4 22 22 – 05 23698 23698 30 131 220,71 220,71 3 3 21 21 – 0
1 16174 16050 4868 1180 212,14 207,71 0 0 24 24 – 312 11903 11895 813 2069 192,86 192,57 0 0 19 19 – 2
II 3 15129 15040 383 137 202,71 199,71 0 0 20 20 – 214 13651 13639 307 699 171,57 170,29 0 0 21 21 – 95 13679 13637 223 89 190,71 188,29 0 0 19 19 – 17
Pelos resultados da Tabela 2 nota-se que a abordagem D se mostra vantajosa tanto em relaçãoao custo (redução de 0,36% em média), quanto ao tempo de resolução (redução de 26,04% no total).
As soluções obtidas pelos modelos foram equivalentes no cenário I. No cenário II o modelo Dpromoveu uma maior economia, embora com pouca relevância, além disso, nota-se uma diferençadas quantidades em estoque nos dois modelos. Isto se deve a deterioração do estoque inicial, queé utilizado para atender a demanda do primeiro peŕıodo e o restante é eliminado, caso o custo deestocagem do produto seja suficientemente maior que o de deterioração. Assim como o atraso dospedidos, a deterioração dos itens ocorreu somente no ińıcio do horizonte.
Também foram realizados testes considerando o custo de deterioração superior ao de estocagem.Nesses testes os dois modelos fornecem a mesma solução nos dois cenários produtivos.
CLAIO-2016
715
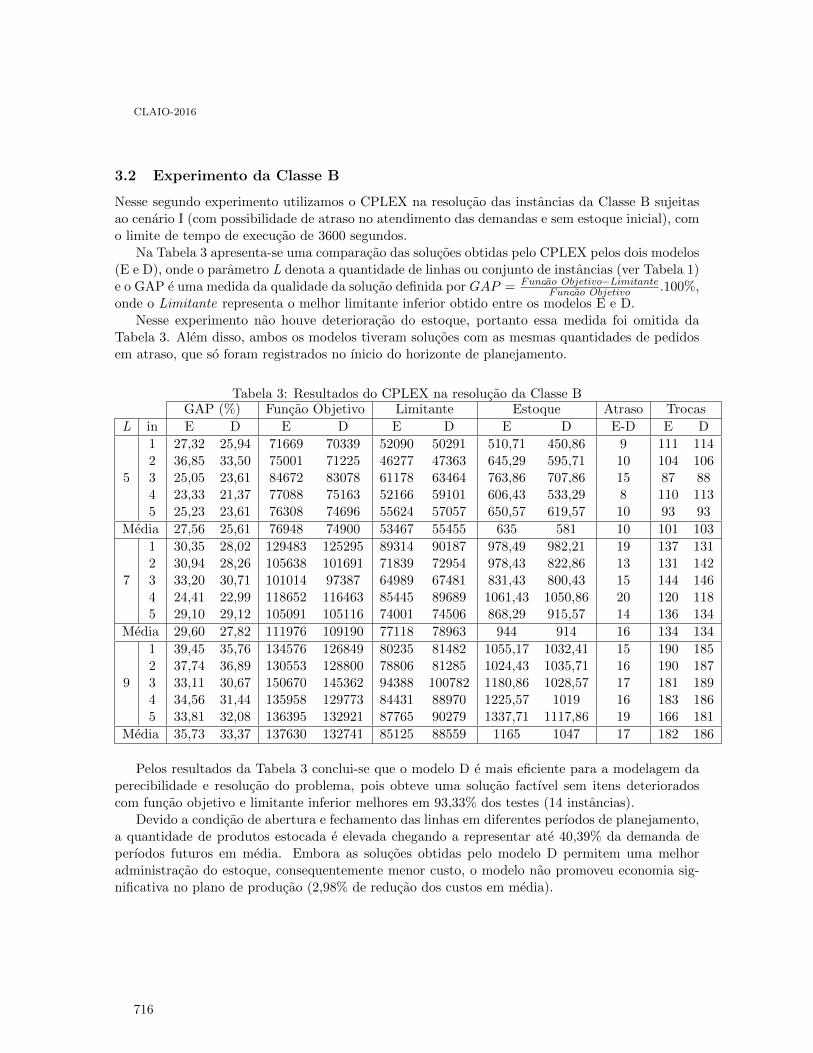
3.2 Experimento da Classe B
Nesse segundo experimento utilizamos o CPLEX na resolução das instâncias da Classe B sujeitasao cenário I (com possibilidade de atraso no atendimento das demandas e sem estoque inicial), como limite de tempo de execução de 3600 segundos.
Na Tabela 3 apresenta-se uma comparação das soluções obtidas pelo CPLEX pelos dois modelos(E e D), onde o parâmetro L denota a quantidade de linhas ou conjunto de instâncias (ver Tabela 1)e o GAP é uma medida da qualidade da solução definida por GAP = Função Objetivo−Limitante
Função Objetivo .100%,onde o Limitante representa o melhor limitante inferior obtido entre os modelos E e D.
Nesse experimento não houve deterioração do estoque, portanto essa medida foi omitida daTabela 3. Além disso, ambos os modelos tiveram soluções com as mesmas quantidades de pedidosem atraso, que só foram registrados no ı́nicio do horizonte de planejamento.
Tabela 3: Resultados do CPLEX na resolução da Classe BGAP (%) Função Objetivo Limitante Estoque Atraso Trocas
L in E D E D E D E D E-D E D
1 27,32 25,94 71669 70339 52090 50291 510,71 450,86 9 111 1142 36,85 33,50 75001 71225 46277 47363 645,29 595,71 10 104 106
5 3 25,05 23,61 84672 83078 61178 63464 763,86 707,86 15 87 884 23,33 21,37 77088 75163 52166 59101 606,43 533,29 8 110 1135 25,23 23,61 76308 74696 55624 57057 650,57 619,57 10 93 93
Média 27,56 25,61 76948 74900 53467 55455 635 581 10 101 103
1 30,35 28,02 129483 125295 89314 90187 978,49 982,21 19 137 1312 30,94 28,26 105638 101691 71839 72954 978,43 822,86 13 131 142
7 3 33,20 30,71 101014 97387 64989 67481 831,43 800,43 15 144 1464 24,41 22,99 118652 116463 85445 89689 1061,43 1050,86 20 120 1185 29,10 29,12 105091 105116 74001 74506 868,29 915,57 14 136 134
Média 29,60 27,82 111976 109190 77118 78963 944 914 16 134 134
1 39,45 35,76 134576 126849 80235 81482 1055,17 1032,41 15 190 1852 37,74 36,89 130553 128800 78806 81285 1024,43 1035,71 16 190 187
9 3 33,11 30,67 150670 145362 94388 100782 1180,86 1028,57 17 181 1894 34,56 31,44 135958 129773 84431 88970 1225,57 1019 16 183 1865 33,81 32,08 136395 132921 87765 90279 1337,71 1117,86 19 166 181
Média 35,73 33,37 137630 132741 85125 88559 1165 1047 17 182 186
Pelos resultados da Tabela 3 conclui-se que o modelo D é mais eficiente para a modelagem daperecibilidade e resolução do problema, pois obteve uma solução fact́ıvel sem itens deterioradoscom função objetivo e limitante inferior melhores em 93,33% dos testes (14 instâncias).
Devido a condição de abertura e fechamento das linhas em diferentes peŕıodos de planejamento,a quantidade de produtos estocada é elevada chegando a representar até 40,39% da demanda depeŕıodos futuros em média. Embora as soluções obtidas pelo modelo D permitem uma melhoradministração do estoque, consequentemente menor custo, o modelo não promoveu economia sig-nificativa no plano de produção (2,98% de redução dos custos em média).
CLAIO-2016
716

4 Conclusões e perspectivas futuras
Nesse artigo, estudamos um problema de programação da produção em linhas paralelas baseadoem uma indústria aliment́ıcia com decisões de produção, estocagem e sequenciamento restritas arecursos conflitantes (máquinas e trabalhadores).
Comparamos duas poĺıticas da litetura para o tratamento da perecibilidade do estoque. Os expe-rimentos computacionais realizados mostraram que a abordagem com possibilidade de deterioraçãodo estoque é promissora para obtenção de melhores resultados, porém as soluções encontradas aindaapresentam baixa qualidade quando comparadas com o GAP relacionado.
Portanto, devido a dificuldade computacional do problema futuramente investigaremos métodosheuŕısticos e reformulações matemáticas para a obtenção de boas soluções.
5 Agradecimentos
Os autores agradecem ao ICMC-USP, UFMS, CAPES, CNPq e a Fundação de Amparo à Pesquisado Estado de São Paulo (FAPESP) via CEPID No. 2013/07375-0 pelo apoio à esta pesquisa.
Referências
[1] B. Almada-Lobo, J. F. Oliveira e M. A. Carravilla. Production planning and scheduling in the glasscontainer industry: A VNS approach. International Journal of Production Economics, 114, 363–375,2008.
[2] P. Amorim, C. H. Antunes e B. Almada-Lobo. Multi-objective lot-sizing and scheduling dealing withperishability issues. Industrial Engineering Chemistry Research, 50(6):3371–3381, 2011.
[3] P. Amorim, C. Meyr, C. Almeder e B. Almada-Lobo. Managing perishability in production-distributionplanning: A discussion and review. Flexible Service and Manufacturing Journal, 25(3), 389-413, 2013.
[4] S. A. Araujo e A. Clark. A priori reformulations for joint rolling-horizon scheduling of materials pro-cessing and lot-sizing problem. Computers Industrial Engineering, 65 (4), 577-585, 2013.
[5] L. M. Entrup, H.-O. Gunther, P. Van Beek, M. Grunow, e T. Seiler. Mixed-Integer Linear Programmingapproaches to shelf-life-integrated planning and scheduling in yoghurt production. International Journalof Production Research 43 (23): 5071–5100, 2005.
[6] B. Fleischmann e H. Meyr. The general lotsizing and scheduling problem. OR Spektrum 19, 11-21,1997.
[7] G. M. Kopanos, L. Puigjaner e M. C. Georgiadis. Optimal production scheduling and lot-sizing in dairyplants: The yogurt production line. Ind. Eng. Chem. Res, 49, 701–718, 2010.
[8] J. Pahl, S. Voß, e D. L. Woodruff. Discrete Lot-Sizing and Scheduling with Sequence-Dependent SetupTimes and Costs including Deterioration and Perishability Constraints. In IEEE, HICSS-44, 2011.
[9] E. Toso, R. Morabito e A. Clark. Lot sizing and sequencing optimisation at an animalfeed plant.Computers and Industrial Engineering, 57(3): 813–821, 2009.
[10] L. A. Wolsey. Solving multi item lot sizing problems with an MIP solver using classification and refor-mulation. Management Science, 12(48), 1587–1602, 2002.
CLAIO-2016
717

FITradeoff multicriteria method for a flexible and interactive
preference elicitation in small company decision problem
Sinndy Dayana Rico Lugo
Universidade Federal de Pernambuco
Adiel Teixeira de Almeida
Universidade Federal de Pernambuco
Abstract
In this paper, an application of the Flexible and Interactive Tradeoff (FITradeoff) method in a Colombian
small company is presented. The specific decision problem is related of determining of raw materials
requirements in bakery production and the construction process of decision model is detailed. The main
characteristics of method and the validation of its assumptions in the problem are explained. The FITradeoff
uses partial information on preferences for solving a multicriteria decision problem. Additionally, some
features of a decision support system (DSS), in which the method is built in are described. The FITradeoff
provides same recommendation given by the traditional tradeoff elicitation procedure, requiring less
information from the decision maker and improving much more the consistence of results. Moreover, it is
observed that the elicitation process is completed in fewer cycles than in classical tradeoff procedure,
working with partial information.
Keywords: FITradeoff method; Flexible preference elicitation; Multiple criteria analysis; SME.
1 Introduction
Determining the requirements of materials in Small and Medium Enterprises (SMEs) has been categorized
in the literature as a problem caused by the complex underlying decision-making process, generated by the
large number of variables in the manufacturing system, the appropriation levels of information technology
and the characteristics of the models and tools that currently are available [2][1].
Usually, in this kind of company the decision making process is empirically done, taking into account only
the type of material and its quantity in a moment. This shows the lack of proper planning of requirements
and determination of production capacity [17]. Generally, the head of production is who makes the
decisions, without considering or integrate the information coming from other areas, such as the shopping
area, because sometimes are manufactured-products that customers have not requested, simply because
there are a lot of an specific raw material. In other cases, some of the products that have been ordered are
not made, what finally generates dissatisfaction of some customers [13].
On the other hand, there are various methods of multi-criteria decision that could be used to help the
enterprises inside this process. The use of multi-criteria approach techniques is common that covers all
areas of knowledge and seeks to support each part of a company or organization (i.e. financial,
environmental, purchase, etc.). Depending on the situation, traditional methods have been used (Electre,
MAUT AHP, etc.) [15][20], hybrid methods [3][12], and new methods have been established also [18][9].
CLAIO-2016
718

However, the number of publications decreases when the scope is limited to SME, especially in Latin
America. In addition, one sees the relative absence of studies on the determination of material requirements,
especially those that rely on applications, case studies and use of DSS (Decision Support Systems). Besides,
only some of them focus on the characteristics of SMEs, which are, for example, short time for the
elicitation process, low levels of understanding mathematical methods and unawareness of their own
problem of decision by DM (decision maker) [5]. Those characteristics leave to work with partial
information in many cases and give more possibilities to the DM, as stop the process before find an optimal
solution when the process is considerate too long or make adjustments becomes the process more flexible
[7].
Within this framework, this paper presents an application of a new method called “Flexible and Interactive
Tradeoff (FITradeoff)” [7] in one Colombian small company to determine the requirements of one row
material, including the characterization and construction of decision problem, the execution of the
elicitation process of DM's preferences, and the explanation of method steps using the respective software.
The FITradeoff uses partial information on preferences for solving a multicriteria decision problem. Since
the FITradeoff requires less information from the decision maker and uses cognitively easier information,
it improves much more the consistence of results [7].
2 Problem description
Around the world, SMEs usually are the most productive units and generate over half of employment and
these companies represents more than that part of the economy. However, the level of information and
communication technology ownership is still small compared with countries with developed economies,
and the quantity of problems into the decision making process is bigger at the same time that their DMs do
not have easy access to mathematical methods nowadays developed to help them.
In this sense, the requirement of raw materials is one of the problems in which small companies need
assistance, and then the multi-criteria methods appear as a solution. However, it is relevant to say a method
by self does not constitutes a real solution. The method only uses the information provided by the DM to
calculate and present a solution for the problem, but the DM is who really takes the decision and monitors
the process to really obtain a solution for the problem.
Thereby, a Colombian small company was selected to study the characteristics of the problem, decision
environment and to apply the multi-criteria new method. The company manufactures bakery products and
cakes in a production environment Job Shop, where there are products that can only be produced in certain
machines, there are machines that are used only for certain products, and there are products that can be
produced on different machines. This leads to the production schedule and the working groups are
continuously adjust depending on the flow and characteristics of orders.
Moreover, because it is an industry specifically dedicated to the production of perishable foods and it has a
very limited manufacturing process for the quality of raw materials and the processing time for each job,
one needs special care during production planning (which is usually done on a daily basis) [16]. That care
is important to comply properly with customer requirements and not get into unnecessary production costs,
which can usually take this kind of company to bankruptcy.
Therefore, considering that, the procedure for decision problem resolution includes choosing the most
appropriate method to address a decision problem in terms of its fundamental characteristics; the study
included the construction of decision model following the process of the three phases divided into twelve
steps proposed by [6].
These stages are the preliminary stage, the preferences modeling and choice of method, and finishing. The
first contains five stages where the basic elements of problem formulation are structured, like actors,
objectives, criteria, alternatives and consequences; the second contains three steps, which could be
considered as the most relevant to the choice of method MCDA, as preference elicitation and intra-criteria
CLAIO-2016
719

and inter-criteria evaluation; and the last includes four steps that aims at implementing the selected method
and the results of sensitivity analysis.
In the first stage, the DM supported by analyst established that the fundamental objective was determining
the quantity of raw material to be requested (quantity of box of eggs) and selected four criteria that he
considered as adequately representative of the problem. The criteria are the natural type and satisfy the
properties of no redundancy, completeness and consistency necessary to ensure that the criteria established
family is consistent, measurable and represents the problem. We also observed the characteristic of
preference independence between all criteria, by using Keeney & Raiffa procedure [11] to confirm that the
conditional preference within consequences of a criterion given a consequence the other criterion is not
dependent on that other criterion. Consequently, the use of an additive model in MAVT (Multi- Attribute
Value Theory) scope is possible.
Regarding the establishment of the structure of the consequences space, it is deterministic, because it is
usually known the behavior of each alternative amount of raw material over the defined criteria. The set of
alternatives is stable and globalized, implying that each alternative (quantity requirement of raw material)
excludes any alternative. In addition, the problematic presented corresponds to an issue of choice, because
the DM want to select one of the options of quantity of raw material in order to meet the objectives.
In the second stage is carried out the characterization of the DM's preference structure, finding that includes
strict preference (P) and indifference (I) relations between the alternatives, which led to define the most
appropriate structure to represent the preferences of the DM is the (P, I). This was determined from a small
initial evaluation process with the DM. Thus, for example, for each pair of a set of alternatives [A1, A2,
A3, A4, A5] corresponding to different quantities of raw materials, it was noted that the DM had a clear
preference for one or none at all criteria, being able to express it was a strict preference or indifference.
Moreover, the fact that a decider preferred A2 to A4 and A4 to A5 also implied that A2 is preferred to A5.
Thus, it was proven that the preference structure of the DM satisfies the properties of ordination and
transitivity necessary to use methods of single criterion synthesis. Moreover, the good performance of an
alternative compensates a criterion which has not a good performance in another; therefore the approach to
this problem is the compensatory type.
The other steps of second stage (intra-criteria and inter-criteria evaluation) and the first step of the third
stage (alternatives evaluation) were executed using the FITradeoff method and its respective software. This
steps are going to be dealt in section 4. The remaining steps of third stage corresponds to implementation
of the final decision by the DM or conform future work, such as sensitivity analysis, and it will not be
discuss in this paper.
3 FITradeoff method
The method used in this paper is a new method called “Flexible and Interactive Tradeoff (FITradeoff)”. It
proposes a flexible elicitation procedure, which collects information from the DM, and evaluates this
information. The main difference from previous studies, like traditional additive model with tradeoff
elicitation, is related to the elicitation process. In this case, the method uses flexible elicitation, in which
incomplete or imprecise information, a priori, is not assumed. Whether the DM is or is not able to give
complete information, this is evaluated in the elicitation process itself, in a flexible way. For this reason,
the flexible process seeks complete information, based on the tradeoff elicitation procedure. However, at
any point further on, it may consider incomplete information in either of the following two situations: when
a unique solution is found or when the DM is not able to give additional information [7].
The characteristic of flexibility means that the elicitation procedure can be adapted to diverse conditions at
the moment that they occur; thereby DM is expected to provide less information requiring less effort during
the elicitation process than in the tradeoff standard procedure. In order to reduce the subset of potentially
CLAIO-2016
720

optimal alternatives, a weights vector space is considered throughout the FITradeoff steps, which is
constructed with the DM answers [7].
In the classical tradeoff method, the aim is to obtain indifference relations applied to pairs of consequences.
The indifference value is denoted 𝑥𝑖𝐼, where 𝑥 is the outcome of criterion 𝑖 for which the indifference is
obtained. Instead, FITradeoff seeks to obtain 𝑥𝑖′ and 𝑥𝑖
′′ based on the preference relation judgments of the
DM, where 𝑥𝑖′ and 𝑥𝑖
′′ are the upper and lower limits for 𝑥𝑖𝐼.
According to the performance of alternatives in the weights space, these alternatives are classified into three
different groups: potentially optimal, dominated, or optimal. For that, the DSS developed to apply the
method seeks an alternative that has the maximum value (normalized) in the alternatives set and taking into
account the weight space. The software conducts the elicitation process in a flexible way in order to specify
𝑥𝑖′ and 𝑥𝑖
′′, in a range ( 𝑥𝑖′- 𝑥𝑖
′′) sufficient to obtain a unique solution.
On the other hand, the FITradeoff model is based on the same assumptions of the classical tradeoff
elicitation procedure ([4][10]): the weights are normalized; it is assumed that ranked weights are obtained;
it is assumed that the DM can specify 𝑥𝑖′ and 𝑥𝑖
′′ ; the model incorporates criteria with consequences
monotonically either increasing or decreasing; and the criteria may be either continuous or discrete.
In relation to the application explained in this paper, the decision problem satisfices all of assumptions
above, permitting the use of this method to help the decision process of raw materials requirements in the
SME.
The elicitation process of FITradeoff contains tree steps: intra-criteria evaluation, ranking criteria weights
and evaluation of criteria weights. The first consists in obtain the value functions 𝑣𝑖(𝑥𝑖), which can be linear
or nor linear. There are either of two possibilities for the DSS: it supports the elicitation of value function;
or it support the input process for parameters of standard functions (linear, exponential, s-shape or
logarithmic).
The second step is subdivided in two parts. One consists of eliciting the order of values for criteria weights;
whereas the second tries to solve the problem with the available weight space, but in which strict inequality
is replaced by a greater than or equal condition in the linear programming problem model. In this stage, if
a unique solution is found the procedure stops, otherwise the third step starts.
In the third step, the values for 𝑥𝑖′ and 𝑥𝑖
′′ are elicited through four sub-steps, which are run until either a
unique solution is found, or the DM chooses not to give additional information. The first part is a preparation
for collecting inputs from the DM, where a computation is conducted in order to prepare the next question
to the DM, so as to set a value for 𝑥𝑖, to evaluate the value for 𝑥𝑖′ or 𝑥𝑖
′′. At this point, it is important to say
that the procedure for choosing a value for 𝑥𝑖 is a heuristic, in which the objective is to minimize the number
of questions making the procedure easier. The second sub-step of this stage puts questions that ask the DM
to choose between two consequences, considering the new consequence 𝑥𝑖 obtained in the first sub-step,
for evaluation of 𝑥𝑖′ or 𝑥𝑖
′′.
Finally, the third sub-step consists of trying to solve the problem regarding the present weight space,
comparing the alternatives in order to classified as dominated, optimal or potentially optimal. If a unique
solution is found, then the finalization is conducted, called sub-step four. Otherwise, the dominated
alternatives are eliminated and the third step starts again until find a unique solution.
More details about FITradeoff can be found at www.fitradeoff.org, where a list of papers is available and
the software may be obtained by request.
4 Method application
As mentioned in the sections above, the analysis of the specific decision problem of a bakery production
small company was developed according to tree stage procedure by [6]. The next sub-sections are going to
show the specific input data and presents the more relevant details of the application and of DSS.
CLAIO-2016
721
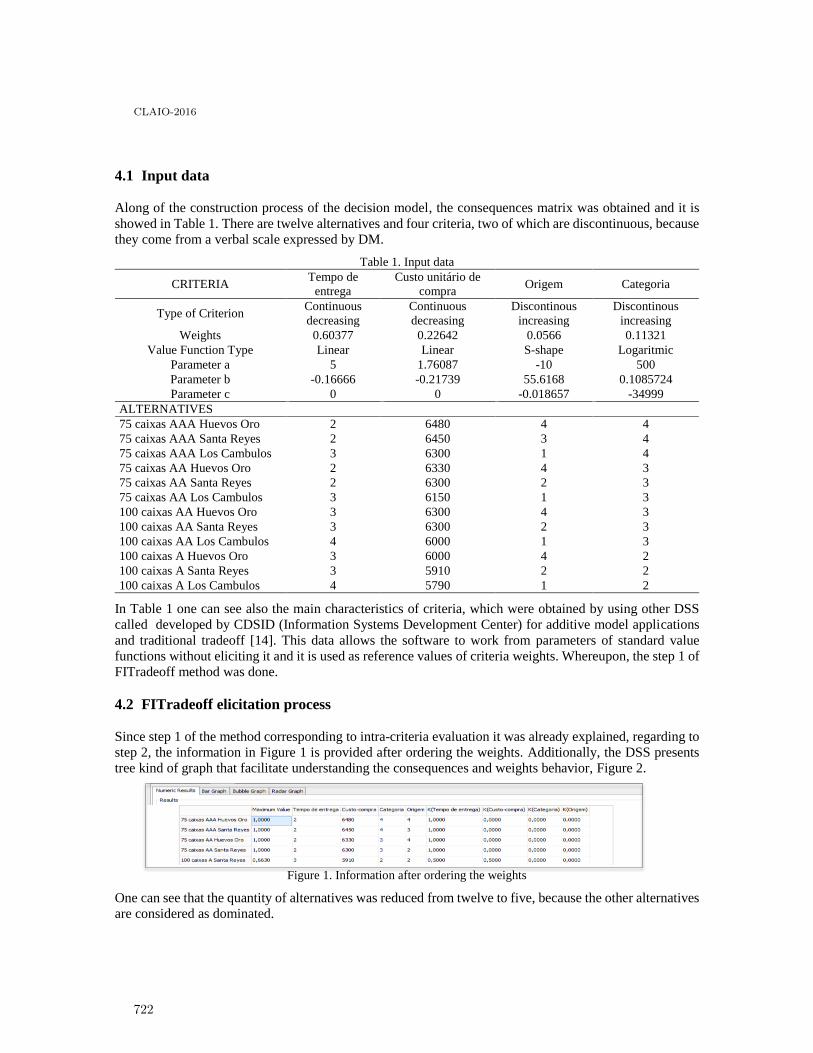
4.1 Input data
Along of the construction process of the decision model, the consequences matrix was obtained and it is
showed in Table 1. There are twelve alternatives and four criteria, two of which are discontinuous, because
they come from a verbal scale expressed by DM.
Table 1. Input data
CRITERIA Tempo de
entrega
Custo unitário de
compra Origem Categoria
Type of Criterion Continuous
decreasing
Continuous
decreasing
Discontinous
increasing
Discontinous
increasing
Weights 0.60377 0.22642 0.0566 0.11321
Value Function Type Linear Linear S-shape Logaritmic
Parameter a 5 1.76087 -10 500
Parameter b -0.16666 -0.21739 55.6168 0.1085724
Parameter c 0 0 -0.018657 -34999
ALTERNATIVES
75 caixas AAA Huevos Oro 2 6480 4 4
75 caixas AAA Santa Reyes 2 6450 3 4
75 caixas AAA Los Cambulos 3 6300 1 4
75 caixas AA Huevos Oro 2 6330 4 3
75 caixas AA Santa Reyes 2 6300 2 3
75 caixas AA Los Cambulos 3 6150 1 3
100 caixas AA Huevos Oro 3 6300 4 3
100 caixas AA Santa Reyes 3 6300 2 3
100 caixas AA Los Cambulos 4 6000 1 3
100 caixas A Huevos Oro 3 6000 4 2
100 caixas A Santa Reyes 3 5910 2 2
100 caixas A Los Cambulos 4 5790 1 2
In Table 1 one can see also the main characteristics of criteria, which were obtained by using other DSS
called developed by CDSID (Information Systems Development Center) for additive model applications
and traditional tradeoff [14]. This data allows the software to work from parameters of standard value
functions without eliciting it and it is used as reference values of criteria weights. Whereupon, the step 1 of
FITradeoff method was done.
4.2 FITradeoff elicitation process
Since step 1 of the method corresponding to intra-criteria evaluation it was already explained, regarding to
step 2, the information in Figure 1 is provided after ordering the weights. Additionally, the DSS presents
tree kind of graph that facilitate understanding the consequences and weights behavior, Figure 2.
Figure 1. Information after ordering the weights
One can see that the quantity of alternatives was reduced from twelve to five, because the other alternatives
are considered as dominated.
CLAIO-2016
722
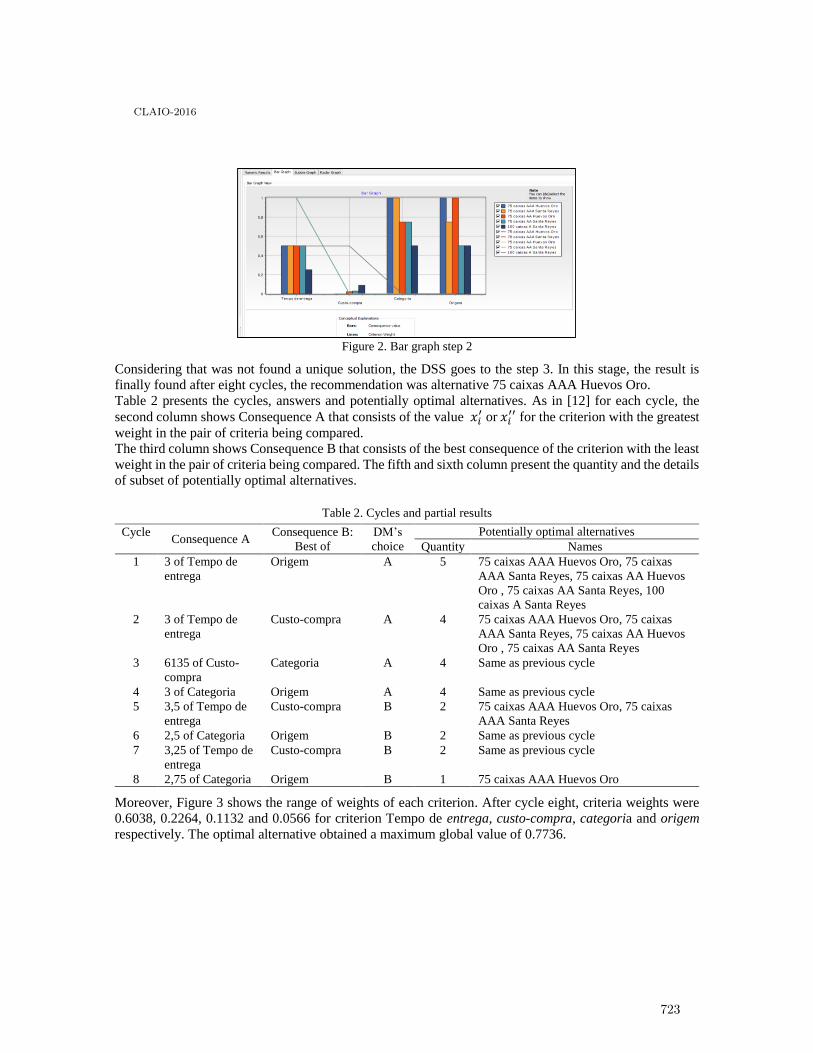
Figure 2. Bar graph step 2
Considering that was not found a unique solution, the DSS goes to the step 3. In this stage, the result is
finally found after eight cycles, the recommendation was alternative 75 caixas AAA Huevos Oro.
Table 2 presents the cycles, answers and potentially optimal alternatives. As in [12] for each cycle, the
second column shows Consequence A that consists of the value 𝑥𝑖′ or 𝑥𝑖
′′ for the criterion with the greatest
weight in the pair of criteria being compared.
The third column shows Consequence B that consists of the best consequence of the criterion with the least
weight in the pair of criteria being compared. The fifth and sixth column present the quantity and the details
of subset of potentially optimal alternatives.
Table 2. Cycles and partial results
Cycle
Consequence A
Consequence B:
Best of
DM’s
choice
Potentially optimal alternatives
Quantity Names
1 3 of Tempo de
entrega
Origem A 5 75 caixas AAA Huevos Oro, 75 caixas
AAA Santa Reyes, 75 caixas AA Huevos
Oro , 75 caixas AA Santa Reyes, 100
caixas A Santa Reyes
2 3 of Tempo de
entrega
Custo-compra A 4 75 caixas AAA Huevos Oro, 75 caixas
AAA Santa Reyes, 75 caixas AA Huevos
Oro , 75 caixas AA Santa Reyes
3 6135 of Custo-
compra
Categoria A 4 Same as previous cycle
4 3 of Categoria Origem A 4 Same as previous cycle
5 3,5 of Tempo de
entrega
Custo-compra B 2 75 caixas AAA Huevos Oro, 75 caixas
AAA Santa Reyes
6 2,5 of Categoria Origem B 2 Same as previous cycle
7 3,25 of Tempo de
entrega
Custo-compra B 2 Same as previous cycle
8 2,75 of Categoria Origem B 1 75 caixas AAA Huevos Oro
Moreover, Figure 3 shows the range of weights of each criterion. After cycle eight, criteria weights were
0.6038, 0.2264, 0.1132 and 0.0566 for criterion Tempo de entrega, custo-compra, categoria and origem
respectively. The optimal alternative obtained a maximum global value of 0.7736.
CLAIO-2016
723
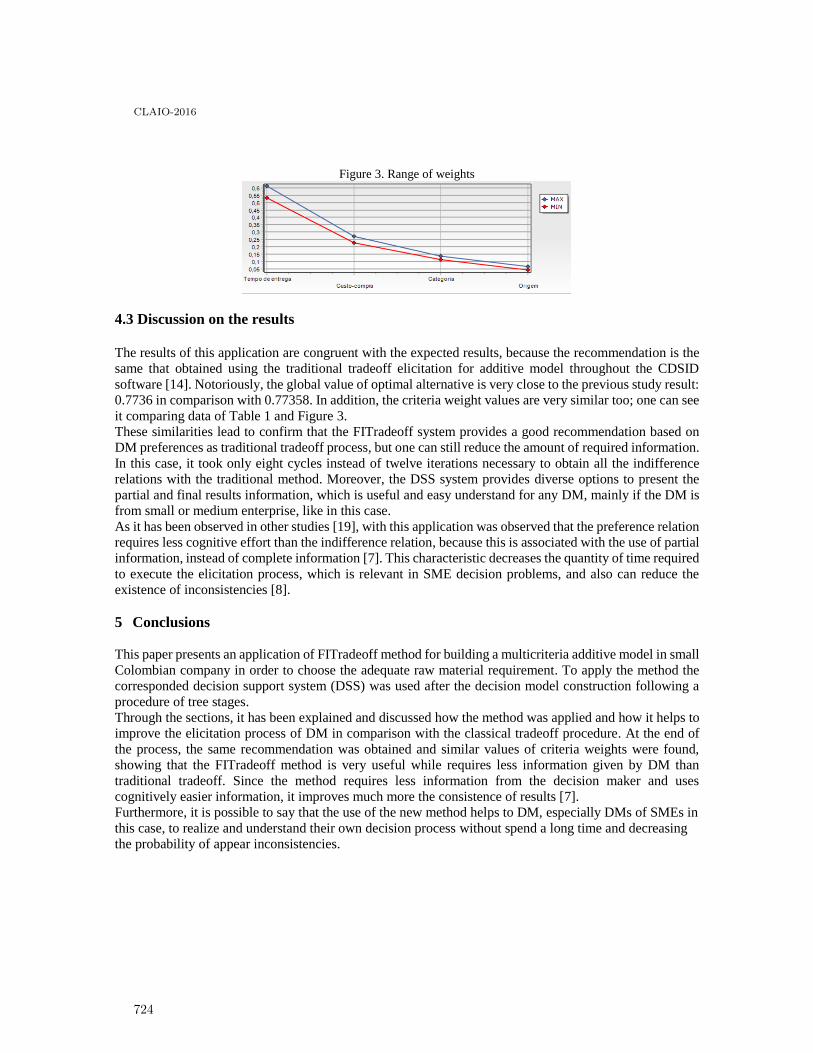
Figure 3. Range of weights
4.3 Discussion on the results
The results of this application are congruent with the expected results, because the recommendation is the
same that obtained using the traditional tradeoff elicitation for additive model throughout the CDSID
software [14]. Notoriously, the global value of optimal alternative is very close to the previous study result:
0.7736 in comparison with 0.77358. In addition, the criteria weight values are very similar too; one can see
it comparing data of Table 1 and Figure 3.
These similarities lead to confirm that the FITradeoff system provides a good recommendation based on
DM preferences as traditional tradeoff process, but one can still reduce the amount of required information.
In this case, it took only eight cycles instead of twelve iterations necessary to obtain all the indifference
relations with the traditional method. Moreover, the DSS system provides diverse options to present the
partial and final results information, which is useful and easy understand for any DM, mainly if the DM is
from small or medium enterprise, like in this case.
As it has been observed in other studies [19], with this application was observed that the preference relation
requires less cognitive effort than the indifference relation, because this is associated with the use of partial
information, instead of complete information [7]. This characteristic decreases the quantity of time required
to execute the elicitation process, which is relevant in SME decision problems, and also can reduce the
existence of inconsistencies [8].
5 Conclusions
This paper presents an application of FITradeoff method for building a multicriteria additive model in small
Colombian company in order to choose the adequate raw material requirement. To apply the method the
corresponded decision support system (DSS) was used after the decision model construction following a
procedure of tree stages.
Through the sections, it has been explained and discussed how the method was applied and how it helps to
improve the elicitation process of DM in comparison with the classical tradeoff procedure. At the end of
the process, the same recommendation was obtained and similar values of criteria weights were found,
showing that the FITradeoff method is very useful while requires less information given by DM than
traditional tradeoff. Since the method requires less information from the decision maker and uses
cognitively easier information, it improves much more the consistence of results [7].
Furthermore, it is possible to say that the use of the new method helps to DM, especially DMs of SMEs in
this case, to realize and understand their own decision process without spend a long time and decreasing
the probability of appear inconsistencies.
CLAIO-2016
724

Acknowledgment This work had partial support from CNPq (the Brazilian Research Council) through the PEC-PG
(Agreement Student Graduate Program). The CNPq was not involved in the study or in writing this paper,
but we would like to thank it.
References
[1] M. C. Arazi and G. Baralla. La situación de las pymes en América Latina. Inter-American Development Bank
(IADB), 2012.
[2] S.B.A ás Micro. Participação das micro e pequenas empresas na economia brasileira. Brasília: Unidade de Gestão
Estratégica{UGE. Disponível em:< http://www. sebrae. com.br/Sebrae/Portal% 20Sebrae/Estudos% 20e%
20Pesquisas/Participacao% 20das% 20micro%20e% 20pequenas% 20empresas. pdf> Acessado em, 26:2014,
2014.
[3] M. B. Ayhan and H. S. Kilic. A two stage approach for supplier selection problem in multiitem/multi-supplier
environment with quantity discounts. Computers & Industrial Engineering, 85:1-12, 2015.
[4] K. Borcherding, T. Eppel, and D. Von Winterfeldt. Comparison of weighting judgments in multiattribute utility
measurement. Management science, 37(12):1603-1619, 1991.
[5] V. Clivill_e, L. Berrah, and M. Gilles. Deploying the ELECTRE III and Macbeth multicriteria ranking methods
for smes tactical performance improvements. Journal of Modelling in Management, 8(3):348-370, 2013.
[6] A. T. De Almeida, C. A. V. Cavalcante, M. H. Alencar, R. J. P. Ferreira, A.T. Almeida-Filho, and T. V. Garcez.
Multicriteria and multiobjective models for risk, reliability and maintenance decision analysis. International Series
in Operations Research & Management Science, 231, 2015.
[7] A. T. De Almeida, J. A. De Almeida, A. P. C. S. Costa, and A. T. De Almeida-Filho. A new method for elicitation
of criteria weights in additive models: Flexible and interactive tradeoff. European Journal of Operational
Research, 250(1):179-191, 2016.
[8] W. Edwards and F. H. Barron. SMARTS and SMARTER: Improved simple methods for multiattribute utility
measurement. Organizational behavior and human decision processes, 60(3):306-325, 1994.
[9] D. Kannan, K. Govindan, and S. Rajendran. Fuzzy axiomatic design approach based green supplier selection: a
case study from singapore. Journal of Cleaner Production, 96:194-208, 2015.
[10] R. L. Keeney. Value-focused thinking: A path to creative decision making. Harvard University Press, 2009.
[11] R. L. Keeney and H. Raiffa. Decisions with multiple objectives: preferences and value trade-offs. Cambridge
university press, 1993.
[12] H. S. Kilic, S. Zaim, and D. Delen. Selecting the best ERP system for SMEs using a combination of ANP and
PROMETHEE methods. Expert Systems with Applications, 42(5):2343-2352, 2015.
[13] S. D. R. Lugo. Modelo multicritério para escolha de requerimentos de matéria prima em PME com ambientes
Job Shop e elicitação de preferências. Universidade Federal de Pernambuco, 2015.
[14] S. D. R. Lugo, V. A. P. A. Santos, A. T. De Almeida, B. D. Spenser, and T. R. N. Clemente. Elicitation for
tradeoff additive model with linear or non-linear value function and sensitivity analysis - web-based (tu-t2omo-
wt1). http://www.cdsid.org.br/, 2015.
[15] M. S. Memon, Y. H. Lee, and S. I. Mari. Group multi-criteria supplier selection using combined grey systems
theory and uncertainty theory. Expert Systems with Applications, 42(21):7951-7959, 2015.
[16] T. G. Motoa Garavito, J. C. Osorio Gómez, and J. P. Orejuela Cabrera. Planificación jerárquica de la producción
(Hierarchical Production Planning) el estado del arte y presentación de experiencias. 2013.
[17] R. J. Romero Reyes, S. D. Rico Lugo, and J. Barón Velándia. Impacto de un sistema ERP en la productividad de
las pyme. Tecnura, 16(34):94-102, 2012.
[18] A. Singh. Supplier evaluation and demand allocation among suppliers in a supply chain. Journal of Purchasing
and Supply Management, 20(3):167-176, 2014.
[19] M. Webwer and K. Borcherding. Behavioral influences on weight judgments in multiattribute decision making
European Journal of Operational Research, 67(1):1-12, 1993.
[20] I. B. Zafeirakopoulos and M. E. Genevois. An analytic network process approach for the environmental aspect
selection problem a case study for a hand blender. Environmental Impact Assessment Review, 54:101-109, 2015.
CLAIO-2016
725

Optimizing the production/logistic planning in the
tomato processing industry
Cleber Damião Rocco
Universidade Estadual de Campinas � Unicamp
Reinaldo Morabito
Universidade Federal de São Carlos � Ufscar
Abstract
The objective of this study was to address the problem of planning the production and logisticoperations of the agricultural and industrial activities in the tomato processing industry. Wehave developed a mathematical optimization model to support tactical decisions, which arethe sizing of areas cultivated with tomatoes, the transportation from the growing regions toprocessing plants, the production lot sizing of concentrated tomato pulps and �nal products toconsumers, as well as, the transport and inventories of these products in the supply chain. Themixed integer programming model presented here represents appropriately the main agriculturaland industrial decisions and proved to be useful to generate optimized production and logisticplans for the tomato processing industry.
Keywords: agriculture; production planning; mixed integer programming.
1 Introduction
Tomatoes for processing are subject to environmental restrictions, which impose production season-ality due to climate and land use conditions. The demand of manufactured tomato-based productsextends along the entire year and often experiences �uctuation due to market behaviors. In thetomato processing industry there are several decisions that should be taken every year to conductthe agricultural and industrial activities, such as the sizing of the cultivated areas and selection oftomato varieties, the allocation of the agricultural production to processing plants, the operationof manufacturing concentrated pulps (CP) and �nal products (FP) to consumers, the managementof inventories and transportation of CP and FP in the supply chain. The contribution of this paperis to present a mixed integer programming model that represents and optimizes the main tacticaldecisions in the tomato processing industry. To the best of our knowledge, we are not aware ofother studies in the literature in this line for the tomato processing industry.
CLAIO-2016
726

2 Problem description
The mathematical model developed in this study was inspired in two large and typical tomato pro-cessing industry in Brazil. The activities modeled were grouped in two stages based on the processand outputs. Despite this grouping all the production and logistic planning decisions are stronglylinked and a certain decision directly a�ects others no matter in which stage. Planting, harvestingand transporting tomatoes from regions to plants are grouped in the so-called �agricultural stage�,in which the output is the tomatoes. This stage is characterized by �pushing� the production, sincethe tomato is perishable and must be processed immediately after harvesting.
In the agricultural stage there are several regions with distinct soil and climate characteristics,as well as, technical levels of farming where tomatoes can be cultivated. There are also severaltomato varieties with distinct agronomic features (yield, maturation curve etc.) and also industrialones (pulp color, fruit �rmness etc.) Some varieties are more suitable to be planted early in thecrop season, while others are preferably late. There are still more aspects that in�uence the choiceof a particular tomato variety for a region, such as the plant resistance to pests and diseases and theability to withstand droughts. In the model presented here, only the crop yield and the maturationcurve, referring speci�cally to the content of soluble solids (brix) were considered.
In the practice of the companies followed for this study, �rstly decisions are taken as to whichtomato varieties should be allocated to which regions according to the experience of previouscultivations that indicate the best combination between varieties and regions. Agricultural teamknows that, in certain regions, it is not recommended to cultivate a particular variety due to theproblems or high susceptibility to pests, diseases or droughts. After planting the tomatoes, theharvest periods are estimated according to the variety cycle known by previous cultivation for eachcombination of variety-region.
The agricultural team allocates the tomato production from the regions to plants following thelogic of the least transportation cost. However, this logic may not apply in situations where there isan excess or shortage of tomatoes in the plants. For instance, when a plant does not receive enoughtomatoes for whatever reasons (e.g., a broken harvester or lack of trucks), the team dispatchestomatoes from other regions, sometimes further than the previous one, to overcome this temporarysupply shortage in the plant. The logistics of transporting tomatoes may involve managing hundredsof trucks on a daily basis to a single plant of large capacity. Currently, planning how many trucksare needed for each region is done based on estimating the agricultural productivity of the areas,as well as, the harvesting expected time. An issue faced by companies is managing truck arrivalsat the plants in order to avoid long waiting times for unloading tomatoes. It is well known thatthere are signi�cant losses of tomato juice as time passes to wait for unloading [1].
The second stage is called the �industrial stage�, which can be further subdivided into two morestages, also according to the processes and outputs. The �rst industrial stage is responsible forreceiving the tomatoes and to transform them into concentrated tomato pulps (paste or crush),which the key process is to evaporate water from the tomato juice. The second industrial stageproduces �nal products to consumers (ketchup, sauces etc.), which the key process is to mix andcook concentrated pulps with food ingredients. Basically, the production of the agricultural stageis �pushed� to the second industrial stage as the tomato harvested must be processed immediately.The production of the second industrial stage is triggered by consumers' demands and is linked tothe �rst industrial stage through the stocks of concentrated tomato pulps.
The scheme presented below (Figure 1) is based on visits in two typical companies in Brazil.
CLAIO-2016
727

There may be some variations of the activities described here, which most likely could be observedin other companies, but which obviously can also be considered. In Figure 1, from left to right,there is the agricultural stage where several regions are available to produce tomatoes, whichare represented by set R = {1, 2, ..., r}. Tomatoes of distinguished varieties represented by setI = {1, 2, ..., i} can be cultivated in these regions. Harvested tomatoes should be transported tothe plants referred by set K = {1, 2, ..., k}. The planning horizon is divided into equal time periodscorresponding to months, represented by set T = {1, 2, ..., t}. All processing plants in the supplychain should contribute by their productions to meet the aggregate demand for �nal products.
Tomatoes delivered to the plant are transformed into concentrated pulps in the �rst industrialstage by means of water evaporation from the tomato juice performed in concentrators. Theseproducts can be consumed to make �nal products, or they can be sent to stocks at the plant or can betransported to the stocks of other plants. The production of �nal products takes place at the secondindustrial stage by operations of mixing and cooking concentrated pulps with food ingredients.Some companies have more than one processing plant in operation, which may be located close tothe agricultural regions, whereas others are further away. However, the distant ones are typicallynear consumer markets. The spatial location of the plants and their characteristics imply in di�erentproduction strategies. Generally, plants near agricultural regions are particularly for producingconcentrated pulps. Others far from crops, but close to consumer markets, have strategies ofproducing �nal products. This strategy aims to minimize the transportation of tomatoes over longdistances, since the fruit has about 93% of water content. Tactical production and logistics planningof the tomato processing industry attempts to handle and settle con�icts between the agriculturaland industrial stages.
Figure 1: Modeling the supply chain of the processing tomato industry.
CLAIO-2016
728

The brix value of the tomato juice in the plant is a weighted average of the quantity of tomatoesreceived from various tomato �elds with distinguished brix level and yield. The brix of the tomatoharvested is represented by parameter εirt and the variable Qtomirkt represents the quantity of tomatovariety i harvested in region r and transported to plant k in period t. For each region, the harvestedarea, tomato yield and brix are speci�c and they may be distinct compared to others. Consideringthe brix value of the tomato juice in each plant k in period t represented by parameter φkt, whichis calculated by the Equation 1, and illustrated Figure 2. Thus, the calculation of the weightedaverage is a nonlinear operation, which involves the division of decision variables in the model. Toovercome the non-linearity, we de�ne hypothetical linear curves representing the brix of the tomatojuice in the plant for every period of the planning horizon.
φkt =
∑ir εirtQ
tomirkt∑
irQtomirkt
∀ k, t (1)
Area 1Harvest: 60 hectareTomato brix: 0.035Crop yield: 80 t/ha
Area 2Harvest: 20 hectareTomato brix: 0.045Crop yield: 70 t/ha
Brix of the tomato juice in plant in period :
Arithmetic average:
0.035 0.0452 0,04
Weighted average:60 ∙ 80 ∙ 0.035 20 ∙ 70 ∙ 0.045
60 ∙ 80 20 ∙ 70
0,03726
Figure 2: Example of calculating the value of the tomato juice in plant k in period t
Parameters and equations for building the hypothetical brix curves:
αmax: maximum value of the brix curves; αmin: minimum value of the brix curves; α∆: intervalsize of each step in the brix curves (step is one part of the discretized curve); φ−s : lower bound ofthe brix value at step s; φ+
s : upper bound of the brix value at step s; |S|: cardinality of the set S,which is the number of discretized steps in the brix curves.
Equation 2 de�nes the interval size of each step in the brix curves. Equation 3 de�nes the curveof lower bound values for the steps. Equation 4 de�nes the upper bound values for the steps.
α∆ =(αmax − αmin)
|S| (2)
φ−s = αmin + (s− 1)α∆ ∀ s (3)
φ+s = αmin + sα∆ ∀ s (4)
CLAIO-2016
729

3 Mathematical model
It consists of an objective function (OF) (Eq. 5) that minimizes the main production and logisticscosts in the supply chain, while providing an economic bene�t to produce stocks of concentratedpulps (CP) in the last period of the planning horizon. The components of the OF are: costof transporting tomatoes from the regions to the plants, inventory cost of CP, procurement costof CP in the market, transportation cost of CP among plants, energy cost to produce CP in theconcentrators, inventory cost of �nal products (FP), and the bene�t of making stocks of CP that willbe consumed in the period inter crops. The constraining equations are the limit of area to cultivatetomatoes (Eq. 6), reception capacity of each plant (Eq. 7), equation for converting tomatoes intosoluble solids to produce CP (Eq. 8), constraints to calculate the brix of the tomato juice in theplants (Eq. 9, 10 and 11), constraints to set the evaporation capacity of the concentrators (Eq.12 and 13); balance inventory equations for CP and FP (Eq. 14 and 17), inequalities in chargeof blending CP to produce FP (Eq. 15), constraints to set the production capacity of FP (Eq.16), and �nally, the constraints to meet the demand for PF (Eq. 18), besides, the non-negativityconstraints of the variables (Eq. 19) and the binary constraint (Eq. 20).
Model sets: t: time period; i: tomato variety; r: region; k: processing plant; l concentratedpulp; g: group of the concentrated pulp; p: �nal product; Lg: concentrated pulp in group g; Lp:concentrated pulp into �nal product p; Pk: �nal products set to be produced in plant p; s: stepsfor discretization of the brix curves.
Parameters: βkt: reception capacity of tomatoes; γr: available area; δirt: crop yield; εirt:tomato brix; ηrk: transportation cost; τl: storage cost of CP; θl: brix of the CP; µl: CP marketprice; ρkk̂: transportation cost between plants; υl: bene�t of storing CP; h: storage cost of FP; λgp:
FP recipe; dpt: demand of FP; πtimekt : available time for evaporation, πprodpkt : production capacity ofFP; ωklt: production time for CP; Ωkl: energy cost to produce CP; bigM : a large number.
Variables: Qtomirkt: quantity of tomato variety i harvested in region r to supply plant k in periodt; P rawlkt : production of CP type l in plant k in period t; M raw
lkt : procurements of CP type l for plant
k in period t; T rawlkk̂t
: transport of CP type l from plant k to plant k̂ in period t; Irawlkt inventory of
CP; Crawlpkt : consumption of CP type l to produce FP type p; P prodpkt : production of FP type p in
plant k; Iprodpkt : inventory of FP; Cprodpkt : consumption of FP from plant k to meet the demand inperiod t. TCklt: production time of CP type l in plant k in period t; Xskt: binary variable whichde�nes the brix of the tomato juice in plant k in period t, identi�ed by step s in the brix curves.
Equations:
(5)
Minimize:∑
irktδirt 6=0
ηrkQtomirkt +
∑
lkt
τlIrawlkt +
∑
lkt
µlMrawlkt
+∑
lkk̂t
ρkk̂Trawlkk̂t
+∑
klt
ΩklPrawklt +
∑
pkt
hIprodpkt −∑
Lk,k
υlIrawlk|T|
∑
iktδirt 6=0
Qtomirktδirt
≤ γr ∀ r (6)
CLAIO-2016
730

∑
irδirt 6=0
Qtomirkt ≤ βk ∀ k, t,∑
ir
δirt 6= 0 (7)
∑
irδirt 6=0
εirtQtomirkt ≥
∑
ll∈Lk
θlPrawklt ∀ k, t,
∑
ir
δirt 6= 0 (8)
∑
irδirt 6=0
εirtQtomirkt ≥ φ−s
∑
irδirt 6=0
Qtomirkt − bigM(1−Xskt) ∀ k, t, s,∑
ir
δirt 6= 0 (9)
∑
irδirt 6=0
εirtQtomirkt ≤ φ+
s
∑
irδirt 6=0
Qtomirkt − bigM(1−Xskt) ∀ k, t, s,∑
ir
δirt 6= 0 (10)
∑
s
Xskt = 1 ∀ k, t,∑
ir
δirt 6= 0 (11)
TCklt ≥ ωklsP rawklt − πtimekt (1−Xskt) ∀ Lk, t, s (12)
TCklt ≤ ωklsP rawklt + πtimekt (1−Xskt) ∀ Lk, t, s (13)
Irawklt = Irawklt−1 + P rawklt −∑
pp∈Lp
Crawklpt +M rawklt +
∑
k̂
T rawlk̂kt−∑
k̂
T rawlkk̂t
∀ k, l, t (14)
∑
ll∈(Lp∪Lg)
θlCrawklpt ≥ λpgP prodpkt ∀ Pk, g, t (15)
P prodpkt ≤ πprodpkt ∀ p, k, t (16)
Iprodkpt = Iprodkpt−1 − Cprodkpt + P prodkpt ∀ k, p, t (17)
∑
k
Cprodkpt ≥ dpt ∀ t, p (18)
Qirkt, Plkt,Mlkt, Tlkk̂t, Ilkt, Clpkt, Ipkt, Cpkt, TCklt ≥ 0 for all indexes. (19)
Xskt ∈ {0, 1} ∀ s, k, t (20)
4 Results
The mathematical model was implemented in the General Algebraic Modeling System (GAMS)version 24.0.2 and solved by the CPLEX 12.5 in its defaut settings and using three threads in aPentium I3 processor. Extensive computational experiments were carried out using data from aBrazilian tomato processing company that have agreed to collaborate with this study. The modelsolutions were compared to the company's achievements and plans. The overall outcomes haveindicated better economic results accounted in the components of the model's objective functioncompared to the company's accomplishments and plans. The magnitude of the economic savingsand gains depended on the data set used, for an instance composed of two processing plants, threetomato regions, �ve types of concentrated pulp, three families of �nal products and planning horizonof twelve months, using forty steps for the brix curves, the savings on the total costs ranged from5% to 30% and for the bene�ts of making more stocks of concentrated pulp ranged from 3% to30%, compared to the data of the company's accomplishment.
CLAIO-2016
731

5 Conclusions
The mixed integer programming model presented here appropriately represents and optimizes thesupply chain of the processing tomato industry.The model was able to support the key tacticalplanning decisions in the agricultural and industrial activities. The outcomes of this study arepromising and encourage further research for developing decision support tools for the tomatoprocessing industry. An obvious challenge for this kind of study is to obtain data and to outline�nal results because those depend on the data set used. All the model approach presented here isdeterministic and a straightforward extension is to build robust or stochastic models to deal withuncertainty in the data set, since agricultural systems are naturally subjected to uncertainty. Moredetail about this study can be found in [2].
References
[1] A. H. Gameiro, J. V. Caixeta-Filho, C. D. Rocco and R. Rangel. Modelagem e gestão das perdas nosuprimento de tomates para processamento industrial. Gestão e Produção, 15(1):101�115, 2008.
[2] Rocco, C.D. Modelagem do planejamento agrícola e industrial no setor de tomate para processamentoutilizando programação matemática e otimização robusta [Modeling of Agricultural and Industrial Plan-ning in the Tomato Processing Industry by Using Mathematical Programming and Robust Optimization].PhD diss., Universidade Federal de São Carlos, São Carlos, SP, Brasil, 2014.
CLAIO-2016
732

Autoregresión Wavelet para Pronóstico
Multi-horizonte de Accidente de Tránsito
Nibaldo RodriguezPontificia Universidad Católica de Valpráıso
Cecilia MonttPontificia Universidad Católica de Valpráıso
Abstract
Este art́ıculo presenta un modelo de pronóstico multi-horizonte para series de tiempo basadosobre la transformada wavelet estacionaria (SWT) combinada con un modelo autoregresivoMIMO (multi-estrada/multi-salida). El modelo propuesto es implementado usando dos etapas.En la primera etapa la series de tiempo es separada en una componente de alta frecuencia y unacomponente de baja frecuencia por el uso de SWT, mientras que en la segunda etapa un modeloautoregresivo MIMO (MIMO-AR) es calibrado y evaludo usando el método de los mı́nimoscuadrados lineales. El modelo de pronóstico propuesto es evaluado con una series de tiempode personas lesionadas semanalmente en accidente de tránsito en la región Metropolitana deSantiago de Chile para un peŕıodo desde el año 2000 al 2014. La calibración del modelo MIMO-AR fue realizada con el 80% de la serie de tiempo y la fase de testing fue evaluada con el resto delos datos. El modelo de pronóstico MIMO-AR propuesto para un horizonte futuro de 8 semanasdurante la etapa de testing obtuvo una varianza explicada del 95% con un error absoluto mediode 0.01.
Keywords: Pronóstico; Análisis Wavelet; Autoregresión.
1 Introduction
Durante las últimas décadas el método indirecto y directo han sido generalmente usado en laliteratura para implementar modelos de pronósticos multi-horizonte [1]-[5]. El método iterativoitera p veces el mismo modelo de pronóstico 1-step para obtener los p valores predichos, mientrasque el método directo estima un conjunto de p modelos de pronósticos, cada uno retorna unapredicción para el τ -ésimo valor, con τ ∈ {1, 2, ..., p}. En otras palabras, p modelos son calibradosdesde la serie de tiempo ( uno para cada horizonte). Algunos autores sugieren que el método directoes más exacto que el método indirecto, porque el método indirecto tiene algunas dificultades debidoa factores tales como acumulación de errores y baja exactidud [1]-[5]. Esta última caracteŕısticaha sido un criterio para evaluar sólo el método directo en este paper. Por otro lado, El modeloMIMO es un método de predicción directo, el cual utiliza sólo un modelo con múltiples entradas ymúltiples salida para pronosticar los p valores futuros.
CLAIO-2016
733

Para mejorar la exactitud de pronóstico de series de tiempo no-estacionarias algunos investi-gadores han utilizado la transformada wavelet [6, 7, 8]. La ventaja del análisis wavelet es suhabilidad para detectar y separar las componentes de alta frecuencia y baja frecuencia de una seriede tiempo no-estacionaria. Después de la separació cada componente es más regular que la seriede tiempo original, lo cual puede ayudar a mejorar el rendimiento de predicción. Además, análisiswavelet ha sido evaluado de modo exitoso en modelos de pronósticos de 1 − step en diversas áreastales como mercado eléctrico [9, 10], mercado financiero [11]-[13] y método de suavizado [14]-[17].
En este art́ıculo, es propusto un modelo de pronóstico multi-horizonte de accidente de tránsitoen el área Metropolitana de Santiago de Chile. El modelo de predicción es implementado usando dosetapas. En la primera etapa la series de tiempo es separada en una componente de alta frecuencia(AF)y una componente de baja frecuencia (BF) por el uso de la transformada wavelet estacionaria(SWT), mientras que en la segunda etapa las componentes de AF y BF son utilizadas para calibrary evaluar un modelo de predicción MIMO-AR.
La polica chilena (Carabineros de Chile) recolecta las caracteŕısticas de los accidentes de tránsito,y CONASET analiza los datos. La población de Santiago se estima en 6.061.185 habitantes, equiv-alente al 40% aproximadamente de la población nacional. Santiago muestra un alto ı́ndice desiniestros con lesiones severas desde 2000 al 2014, con 260.074 personas lesionadas. Durante di-cho peŕıodo una serie de tiempo fue recolectada con frecuencia de muestreo semanal, la cual fuecreada considerando las 20 causas con mayor número de personas lesionadas durente un accidentede tránsito. Las 20 causas cubren el 75% de los siniestros con personas lesionadas.
El art́ıculo es organizado de la siguiente manera. La sección 2 presenta una corta descripción dela descomposición wavelet y la sección 3 describe el modelo de pronóstico multi-horizonte propuesto,mientras que la sección 4 presenta la discusión de resultados logrado con el modelo MIMO-AR ylas conclusiones son presentada en la sección 5.
2 Stationary wavelet transform (SWT)
La SWT fue propuesta independientemente por varios autores y es conocida en la literatura bajovarios nombres, tales como non-decimated wavelet transform, invariant wavelet transform andredundant wavelet transform. La caracteŕıstica clave es que la SWT ofrece una mejor aproximaciónque la discrete wavelet transform (DWT) [6, 7] , puesto que la SWT es redundante, lineal einvariante a la traslación [14]-[17]. La SWT es similar a la DWT [6, 7] en que los filtros pasa-bajoy pasa-alto son aplicados a la señal de entrada en cada nivel, pero la señal de salida nunca esdecimada. En su lugar, los filtros son interpolados en cada nivel de descomposición [14].
Ahora, consideremos la siguiente serie de tiempo discreta a0 = xn con N = 2J para algún enteroJ . En el primer nivel de la SWT, la señal de entrada a0 es convolucionada con el filtro pasa-bajo h0
de longitud r para obtener el coeficiente de aproximación a1 y con el filtro pasa-alto g0 de lengitudr para obtener el coeficiente de detalle (escala) d1. Esto es dado como:
a1(n) =∑
k
h0(n − k)a0(k) (1a)
d1(n) =∑
k
g0(n − k)a0(k) (1b)
porque no es realizado el sub-muestreo, a1 y d1 son de longitud N en lugar de N/2 como es en elcaso de DWT. En el siguiente nivel de la SWT, el coeficiente de aproximación a1 es devidido en
CLAIO-2016
734

dos partes usando la misma estrategia previa, pero con un nuevo par de filtros h1 y g1, los cualesson obtenidos insertando un valor cero entre los elementos de los filtros usados en el paso previo(i.e., h0 and g0 ). El proceso general de la SWT es continuado iterativamente for j = 1, . . . , J − 1y es dado como
aj+1(n) =∑
k
hj(n − k)aj(k) (2a)
dj+1(n) =∑
k
gj(n − k)aj(k) (2b)
donde hj and gj son obtenidos por el operador de interpolación. El operador de interpolacióninserta 2j − 1 ceros entre los elementos de los filtros h0 and g0; respectivamente. La SWT escompletamente definida por la selección de un par de filtros (i.e., h0 and g0) y el número de nivelesJ de descomposición
3 Modelo de Pronóstico Propuesto
El modelo de pronóstico propuesto está basado en dos etapas. En la primera etapa es realizado unanálisis espectral de la serie de tiempo y luego la serie de tiempo es separada en una componente dealta y baja frecuencia por el uso de la SWT, mientras que en la segunda etapa un modelo MIMOAutoregresivo (MIMO-AR) es calibrado y evaluado usando el método de los mı́nimos cuadradoslineales. La estrategia de pronóstico calibra sólo un modelo MIMO-AR para predecir los p valoresfuturos. La siguiente ecuación es usada para representar el modelo de predicción:
[x̂(n + 1), x̂(n + 2) . . . , x̂(n + p)] = F [xB(n − i), xA(n − i)] + e(n) (3)
donde {xB, xA, i = 1, 2, . . . , m} representan las componentes de baja y alta frecuencias obtenidaspor el uso de la SWT, mientras que F (.) representa una función defina como F : R2m → Rp.La función F es estimada usando un modelo MIMO-AR lineal, cuya estructura es representadausando notación matricial. Para ello, consideremos un conjunto de T muestras de calibración con2m muestras de entradas y p muestras de salidas, entonces el modelo MIMO-AR es dado por lasiguiente ecuación matricial
X̂(T, P ) = XBA(T, 2m)Θ(2m,P ) (4)
Finalmente, la matriz de parámetros Θ es obtenida usando el método de los mı́nimos cuadradoslineales dado como [18]
Θ = X†BAX (5)
4 Discusión de Resultados
En esta sección es presentada la etapa de calibración y validación del modelo de pronóstico prop-uesto. La etapa de calibración fue implemtada usando el 80 de la serie de tiempo y el resto delos datos fue usado para la etapa de validación. La Figure 1(a) presenta la serie de tiempo deaccidente de tránsito con resultado de muerte para el peŕıodo desde 2000 al 2014 y la Figure 1(b)muestra el espectrum de Fourier de dicha serie de tiempo. Desde la Figure 1(b) pueden ser obser-vado dos peak espectrales con un nivel de significancia del 99%, donde el primer peak reprsenta
CLAIO-2016
735

un peŕıodo de alta frecuencia de periodicidad de 4 semanas y el segundo peak denota un peŕıdode baja frecuencia de aproximadamente 17 semanas. Por lo tanto, podemos separar la series detiempo en una compoente de AF y una componente BF usando la SWT. Las Figura 2 y la Figura3 muestran las componentes de alta y baja frecuencia obtenidas por el usdo de la SWT. Desde laFigura 2(b) puede ser observado un peak significativo de 17 semanas y desde la Figura 3(b) unpeak significativo de 4 semanas. Por lo tanto, el modelo de predicción MIMO-AR será calibradousando m = 17 semanas predictoras para predecir las p semanas futuras.
La Figura 4 presenta los resultados del proceso de testing del modelo MIMO-AR obtenidodurante la etapa de calibración. Desde la Figura 4 puede ser observado que las métricas residualescrecen significativamente cuando el horizonte es mayor a 7 semanas. Para un horizonte de 8 semanasfuturas el modelo MIMO-AR logra un Error Absoluto Medio (MAE) aproximado de 0.01, mientrasque la raz del error cuadrático medio (RMSE) es aproximadamente 0.02 y el ı́ndice de acuerdo esdel orden del 90%.
Finalmente, la Figura 5 presenta los resultados predichos versus los valores originales para unhorizonte de 8 semanas. Desde la Figura 5(a) es observo que los valores predichos y valores originalesprsentan una alta semilitud, mientras que la Figura 5(b) presenta el diagrama de dispersin, la cualrefleja una varianza explicada por el modelo MIMO-AR de aproximadamente un 95%.
5 Conclusiones
En este art́ıculo fue propuesta una estratega de pronóstico multi-horizonte basada sobre dos etapas.En la primera etapa es utilizada la transformada wavelet estacionaria para descomponer una seriede tiempo en componentes de alta y baja frecuencia, los cuales son usados en la segunda etapacomo variables de entradas/salidas para calibrar y evalaur un modelo de predicción MIMO-AR. Laserie de tiempo usada para evaluar el modelo de MIMO-AR fue el número de personas lesionadassemanalmente en accidentes de tránsito en la región metropolinada de Santiago de Chile duranteel pŕıodo 2000 al 2014. Los resultados obtenidos durante la fase de testing muestran que el modeloMIMO-AR propuesto permite predecir las ocho semanas futuras con MAE de 0.01 y una varianzaexplicada de 95%. En el futuro el modelo MIMO-AR lineal será comparado con un modelo MIMO-AR no-lineal para predicción multi-horizonte de series de tiempo no-estacionarias y no-lineales.
References
[1] Li Zhang,Wei-Da Zhou, Pei-Chang, Ji-Wen Yang, Fan-Zhang LI., ”Iterated time series prediction withmultiple support vector regression models”, Neurocomputing, vol. 99, p.411-422, 2013
[2] Coskun Hamzaebi, Diyar Akay, and Fevzi Kutay, ”Comparison of direct and iterative articial neuralnetwork forecast approaches in multi-periodic time series forecasting”, Expert Systems with Applications,vol. 36(2), p.3839-3844, 2009.
[3] Sorjamaa A., Hao J., Reyhani N.,, Ji Y., and Lendasse A., ”Methodology for long-term prediction oftime series”, Neurocomputing, vol. 70(16-18), p.2861-2869, October 2007.
[4] Cheng Haibin, Pang-Ning Tan, Jing Gao, and Jerry Scripps, ”Multistep-ahead time series prediction”,In Wee Keong Ng, Masaru Kitsuregawa, Jianzhong Li, and Kuiyu Chang, editors, PAKDD, vol. 918,Lecture Notes in Computer Science, p.765-774. Springer, 2006.
CLAIO-2016
736

[5] D. M. Kline, ”Methods for multi-step time series forecasting with neural networks”, In G. Peter Zhang,editor, Neural Networks in Business Forecasting, Information Science Publishing,p.226-250, 2004
[6] Daubechies, I., ”Ten lectures on wavelets”, SIAM monographs. Philadelphia, PA:SIAM,1992.
[7] Mallat, S., ”A wavelet tour of signal processing”, San Diego, CA: Academic Press, 1998.
[8] Torrence C, Compo GP, ”A practical guide to wavelet analysis”, Bull Am Meteorol Soc, vol. 79, p.61-78,1998.
[9] Nitin Anand Shrivastava and Bijaya Ketan Panigrahi, ”A hybrid wavelet-ELM based short term priceforecasting for electricity markets”, International Journal of Electrical Power Energy Systems, vol. 55,vol. p.41-50, February 2014.
[10] Nima A., Farshid K., ”Day ahead price forecasting of electricity markets by a mixed data model andhybrid forecast method”, International Journal of Electrical Power Energy Systems, vol. 30(9), p.533-546, 2008.
[11] Lahmiri, S., ”Forecasting direction of the S-P500 movement using wavelet transform and support vectormachines”, Int. J.Strateg. Decis. Sci. vol. 4, p.78-88, 2013
[12] Tsung-Jung Hsieh, Hsiao-Fen Hsiao, Wei-Chang Yeh., ”Forecasting stock markets using wavelet trans-forms and recurrent neural networks: An integrated system based on artificial bee colony algorithm”,Applied Soft Computing , vol. 11, Issue 2, p.2510-2525, March, 2011
[13] Bai-Ling Z., Richard C., Jabri, M.A., Dersch D., Flower B., ”Multiresolution forecasting for futurestrading using wavelet decompositions”, IEEE Transaction on neural networks, vol. 12, issues 4, p.765-775, 2001.
[14] Nason, G., Silverman, B., ”The stationary wavelet transform and some statistical applications”, LectureNotes in Statistics: Wavelets and Statistics, p.281-299, 1995.
[15] Coifman, R. R., Donoho, D. L., ”Translation-invariant de-noising”, Lecture Notes in Statistics: Waveletsand Statistics, Springer-Verlag, p.125-150, 1995.
[16] Pesquet, J.C., Krim, H., Carfantan, H., ”Time-invariant orthonormal wavelet representations”, IEEEtransactions on signal processing, vol. 44, issues 8, p.1964-1970, 1996.
[17] Percival, D. B., Walden, A. T., ”Wavelet Methods for Time Series Analysis”, Cambridge, England:Cambridge University Press, 2000
[18] Serre D., ”Matrices: theory and applications”, New York, Springer, 2002.
CLAIO-2016
737
00.10.20.30.40.50.60.70.80.9
11.1
(a)
Time (week)
Norm
alize
d Valu
e
1 25
49
73
97
121
145
169
193
217
241
265
289
313
337
361
385
409
433
457
481
505
529
553
577
601
625
649
673
697
721
745
769
793
2 4 6 8 10 12 14 16 18 20 22
5
10
15
20
25
30
35
40
45
50
(b)
Period (cycles/weeks)
Four
ier S
pectr
um
Conf. Level=99%4,4
17,6
Figure 1: Número de Lesionados
0.39
0.49
0.59
0.69
0.79
0.89
0.99
(a)
Time (week)
Nor
mal
ized
Val
ue
1 25
49
73
97
121
145
169
193
217
241
265
289
313
337
361
385
409
433
457
481
505
529
553
577
601
625
649
673
697
721
745
769
793
2 4 6 8 10 12 14 16 18 20 22
5
10
15
20
25
30
35
40
45
(b)
Period (cycles/weeks)
Four
ier S
pect
rum
Conf. Level=99%
17,66
Figure 2: Baja Frecuencia
CLAIO-2016
738
−0.68−0.58−0.48−0.38−0.28−0.18−0.08
0.020.120.22
(a)
Time (week)
Nor
mal
ized
Val
ue
1 25
49
73
97
121
145
169
193
217
241
265
289
313
337
361
385
409
433
457
481
505
529
553
577
601
625
649
673
697
721
745
769
793
2 4 6 8 10
50
100
150
200
250
300
(b)
Period (cycles/weeks)
Four
ier S
pect
rum
Conf. Level=99%4,4
Figure 3: Alta Frecuencia
1 2 3 4 5 6 7 8 90
0.01
0.02
0.03
0.04
0.05
0.06
0.07(a)
Horizonte(semana)
Rend
imie
nto
1 2 3 4 5 6 7 8 960
70
80
90
100
Horizonte(semana)
Id. A
cuer
do (%
)
RMSEMAE
Figure 4: Metric versus Horizonte
CLAIO-2016
739
10 20 30 40 50 60 70 80 90 100 110 120 130 140 1500
0.2
0.4
0.6
0.8(a)
Tiempo(semana))
Val
or N
orm
aliz
ado
ActualPredicho
0 0.1 0.2 0.3 0.4 0.5 0.6 0.70
0.1
0.2
0.3
0.4
0.5
0.6
0.7
(b) y=0.93948x+0.02789
Target X
Y: L
inea
r Fit
Data PointsBest Linear FitY=X
Figure 5: Pronóstico 8-Semanas Futuras con Datos de Testing
CLAIO-2016
740

Modelo Hostil de Redes con Fallas en Aristas y Nodos
Daniel [email protected]
Franco [email protected]
Pablo [email protected]
Facultad de Ingenieŕıa. Universidad de la República
Abstract
En confiabilidad de redes, se desea hallar la probabilidad de correcta operación de una redsujeta a fallas. En este art́ıculo se estudia un modelo hostil de red, donde pueden fallar tantolos enlaces como los nodos en forma independiente. Tomaremos como hipótesis de trabajo laindependencia de fallas de los componentes no terminales, y funcionamiento perfecto de susterminales. La red opera correctamente siempre que los terminales (nodos distinguidos de lamisma) permanezcan comunicados.
Este modelo generaliza el problema clásico de confiabilidad de redes, y pertenece comoconsecuencia a la clase de problemas NP-Dif́ıciles. Brindamos en este art́ıculo métodosestad́ısticos de estimación de la confiabilidad del modelo hostil. Se realiza una comparación delrendimiento de tres métodos estad́ısticos, tomando como referencia grafos utilizadospreviamente en la literatura especializada.
Palabras Clave: Confiabilidad de Redes; Modelo Hostil; Complejidad Computacional.
1 Introducción
Históricamente, la prioridad en el diseño de redes radicaba en la disponibilidad del servicio. Unsignificativo ejemplo es el servicio de telefońıa pública conmutada, donde el diseño se enfoca en laconectividad y alta disponibilidad. El proceso creciente de digitalización y la presencia de la Webimpactaron en el diseño de redes [2], donde además de disponibilidad es preciso garantizar calidady robustez ante fallas de componentes.
En la confiabilidad clásica, se desean comunicar ciertos puntos estratégicos de la red,denominados terminales, y se asume que los enlaces pueden fallar con probabilidadesindependientes. La confiabilidad clásica se estudia matemáticamente a partir de grafos aleatorios,y el modelo de Gilbert de fallas independientes captura toda su estructura [3]. Por otra parte,Arnie Rosenthal ha enmarcado su complejidad computacional, probando que el cálculo exacto dela confiabilidad clásica es al menos tan dif́ıcil como el Problema de Steiner en grafos [14]. Puestoque tal problema pertenece a la lista de Karp [11] de los primeros 21 problemas combinatorios
CLAIO-2016
741

NP-Completos, Rosenthal ha demostrado que el cálculo de la confiabilidad clásica pertenece a laclase NP-Dif́ıcil. Como consecuencia, la literatura clásica brinda métodos exponenciales decálculo exacto, y también métodos aproximados, en su mayoŕıa, basados en simulación por MonteCarlo [8]. Si bien el método de Monte Carlo crudo permite una aproximación estad́ıstica deparámetros fundamentales de un sistema, se muestra impreciso a efectos de estimar laconfiabilidad clásica de redes altamente robustas [15].
Cuestionamos dos de las hipótesis de trabajo del modelo clásico. La primera es que los nodospueden fallar. Casos concretos son las redes de fibra óptica para la transmisión digital, o loscentros de defensa militar en un sistema de defensa, que también presentan cierta vulnerabilidad.La segunda hipótesis es el uso de Monte Carlo para la aproximación numérica de la confiabilidadclásica.
En este art́ıculo, estudiamos la confiabilidad de un modelo hostil, donde los nodos no terminalestambién pueden fallar. Adicionalmente, estimaremos la confiabilidad del modelo hostil con tresmétodos estad́ısticos, cuando las redes son altamente robustas. Contrastaremos el método deMonte Carlo Crudo (MCC) con otros dos métodos estad́ısticos, a saber, el método de Reducciónde Varianza Recursiva (RVR) y el método de Muestreo por Importancia (MI).
El art́ıculo se organiza de la siguiente manera. En la Sección 2 presentamos al modelo hostilcomo caso particular de sistema binario estocástico. En la Sección 3 presentaremos MCC, y lamotivación para considerar métodos alternativos de aproximación. Como consecuencia, se detallanlos métodos RVR y MI para el modelo hostil en la Sección 4, en permanente analoǵıa con elestudio del modelo clásico. La Sección 5 presenta una fiel comparación de los tres métodos deestudio, considerando redes disponibles en la literatura. Finalmente, se brindan conclusiones en laSección 6.
2 Modelo Hostil
En esta sección se define el modelo hostil a partir de uno más abstracto y general, que es el desistema binario estocástico, o SBE por sus siglas. Adoptaremos la terminoloǵıa de Ball [1].
Un SBE es una terna (S, φ, p), siendo S = {s1, . . . , sr} un conjunto ordenado de r componentesdel sistema, φ : {0, 1}r → {0, 1} una función denominada regla o estructura, que asigna 1 acada subconjunto de S que responde al sistema en correcto funcionamiento, o bien 0 si el sistemano funciona correctamente, y p un vector que contiene las probabilidades de operación de cadacomponente del sistema.
Sea ahora X = (X1, . . . , Xr) un vector aleatorio a coordenadas independientes, donde cada Xi
responde a un modelo de Bernoulli con probabilidad de éxito P (Xi = 1) = pi. La confiabilidad Rde un SBE es la siguiente probabilidad:
R = P (φ(X) = 1) = E(φ(X)) (1)
Obsérvese que φ(X) es la variable aleatoria Bernoulli que indica si el sistema permanece operativoo no. Decimos que un SBE es monótono si φ(S1) ≤ φ(S2) siempre que S1 ⊆ S2. En otros términos,todo sistema en correcta operación va a seguir funcionando correctamente si se incoporan nuevoscomponentes a estado de operación. En un SBE monótono, un conjunto de corte es un subconjuntode componentes de S tales que cuando fallan aseguran que el sistema esté en estado de falla.
Presentamos a continuación diferentes SBE:
CLAIO-2016
742

1. Modelo Clásico: sea G = (V,E) un grafo simple, K ⊆ V el conjunto de terminales y p : E →[0, 1] la probabilidad de operación de las aristas. Se considera el grafo aleatorio G = (V, E),donde el conjunto aleatorio de aristas E responde a la ley de probabilidad p. La confiabilidadclásica R(K,G, p) es la probabilidad que todos los terminales permanezcan comunicados enel grafo G.
2. Modelo de Aristas y Nodos: al modelo anterior se agregan fallas en todos los nodos, por loque p : E ∪ V → [0, 1], y los nodos también pueden fallar en el grafo aleatorio G = (V, E).Cuando un nodo cae, también lo hacen todos sus enlaces incidentes.
3. Diámetro Confiabilidad de Redes: al modelo clásico se le considera además un entero positivod, denominado diámetro. La diámetro confiabilidad de redes es la probabilidad de que todopar de terminales permanezcan comunicados en el grafo aleatorio por caminos de largo d omenos.
4. Modelo Hostil: es un caso especial del modelo de aristas y nodos, pero se asume que p(v) = 1para todo nodo terminal v ∈ K.
El modelo clásico es monótono, pues el agregado de aristas nunca desconecta a los terminales.Un hecho similar ocurre en el modelo de diámetro confiabilidad de redes. No obstante, el modelode aristas y nodos no es monótono. Tómese por ejemplo un camino que une a dos terminales ensus extremos. La falla de un terminal (o de ambos) lleva a que la definición de correcta operaciónse cumpla trivialmente, puesto que toda pareja de terminales se comunica (de hecho, ya no hay dosterminales). Esta situación no es deseable. El lector puede comprobar que cuando los terminalesno fallan, el sistema se torna nuevamente monótono. Entonces, el modelo hostil es monótono. Eladjetivo hostil) proviene del hecho que es más adverso que el clásico.
Si bien existe más abundante literatura del modelo clásico, el modelo hostil también ha sidotratado con anterioridad.
Jacques Carlier et. al. desarrollan un método de cálculo exacto de confiabilidad en modelosclásico y hostil para grafos de tamaño reducido, utilizando la descomposición de Rosenthal [6].Otros autores estudian problema de maximización de la confiabilidad bajo el modelo de cáıda dearistas y nodos, sujeto a un presupuesto acotado [7]. El lector puede hallar una discusión de modelosde confiabilidad de redes en el libro [10].
3 Monte Carlo Crudo
A nivel macroscópico, el método de Monte Carlo Crudo o MCC permite la simulación de sistemascomplejos. Mediante el uso leyes fuertes, se posibilita la estimación de un parámetro fundamentaldel sistema [8]. Daremos aqúı una descripción de MCC para estimar la confiabilidad de cualquierSBE, y evidenciaremos su principal deficiencia, que es el problema central de la simulación deeventos raros [15].
Dado un SBE (S, φ, p), se dispone de una muestra independiente X1, . . . , XN , donde cadaXj = (X1
j , . . . , Xrj ) es un vector aleatorio que describe los componentes en operación, y respeta la
ley del vector p. La estimación de confiabilidad mediante MCC es la siguiente:
RMCC =1
N
N∑
j=1
φ(Xj) (2)
CLAIO-2016
743

Conviene notar que por la Ley Fuerte de Grandes Números, RMCC converge casi seguramente aE(φ(X)), es decir, a la confiabilidad del SBE. Por ser un promedio muestral, es en efecto insesgado,y su error cuadrático medio coincide con su varianza.
Asumamos ahora que las probabilidades de operación de los componentes del SBE son idénticas,es decir, p(si) = p para todo si ∈ S, para un valor alto de p. Sea γ = 1−R la anticonfiabilidad delSBE. Puesto que el sistema es monótono, tenemos que la anticonfiabilidad decae a cero cuando pse aproxima a la unidad. Existe un compromiso entre la proximidad de p a la unidad y el tamañode muestra N necesario para tener un error relativo controlado. Vamos a valernos del Teoremadel Ĺımite Central para conseguir una medida de rapidez de convergencia. Como preámbulo, esconveniente considerar los conceptos de error relativo (ER) y las propiedades de error relativoacotado (ERA) y error relativo desvaneciente (ERD):
Definición 1 (Error Relativo) Dado un nivel de confianza α, el error relativo del estimador esel radio del intervalo de confianza para γ, dividido entre el valor real γ. Denotaremos ER al errorrelativo.
Definición 2 (Error Relativo Acotado) Decimos que un estimador de la anticonfiabilidadverifica la propiedad de error relativo acotado (ERA) si su error relativo permanece acotadocuando p tiende a la unidad.
Definición 3 (Error Relativo Desvaneciente) Decimos que un estimador de laanticonfiabilidad verifica la propiedad de error relativo desvaneciente (ERD) si su error relativotiende a cero cuando p tiende a la unidad.
La propiedad ERD asegura ERA; el rećıproco no es cierto. Para comprender el problema centralde simulación de eventos raros calculemos el RE para estimar la anticonfiabilidad mediante MCC.Sea α un nivel de confianza (usualmente de 1% o inferior, según la aplicación). El promedio demuestras independientes con idéntica distribución se aproxima mediante el Teorema del ĹımiteCentral por una ley normal con esperanza γ y varianza σ̂2 = γ(1− γ)/N . El radio del intervalo deconfianza es σ̂zα/2, siendo zα/2 la abscisa que deja área α/2 en una campana de Gauss estándar.Sustituyendo tenemos que:
REMCC =
√γ√
(1− γ)√Nγ
zα/2 ≈zα/2√N√γ>> 1 (3)
Se observa que MCC no satisface ni siquiera la propiedad ERA. Ese es el principal problema desimulación de eventos raros. La siguiente sección invita al estudio de dos alternativas promisoriaspara abordar este problema.
4 Otros Métodos Estad́ısticos
4.1 Reducción de Varianza Recursiva
Este método ha sido propuesto originalmente por H. Cancela y Mohammed El Khadiri para elmodelo clásico [5]. La esencia consiste en reconocer un conjunto de corte C ⊆ S, y particionarlos posibles estados del sistema según la presencia o ausencia del corte. Decimos que el corte Cestá presente si todos los componentes de C fallan. En caso contrario, puesto que S está ordenado
CLAIO-2016
744

existe un primer elemento i de C que está en operación. Sea Yi la anticonfiabilidad del sistemacondicionada a este evento, V la variable que indica el primer componente en operación, y qC laprobabilidad de ocurrencia del corte C. Tenemos que la variable aleatoria Z:
Z = qC + (1− qC)
|C|∑
i=1
1{V=i}Yi. (4)
es un estimador insesgado para la anticonfiabilidad. La variable aleatoria Z da pautas para realizaruna recursión, donde cada vez se consideran sistemas más pequeños, tras fijar el estado de algunode sus componentes. Los autores señalan en su art́ıculo original que una manera de construir uncorte bajo el modelo clásico es seleccionando todos los enlaces incidentes a un terminal. Asimismo,demuestran que la varianza del método RVR nunca es superior que la de MCC. También es posiblehallar cortes eficientemente en cualquier SBE monótono. Invitamos al lector interesado a unademostración en [4]. Por lo tanto, el método RVR es aplicable al modelo hostil, y su varianza(luego su error cuadrático medio) es menor que en MCC.
4.2 Muestreo por Importancia
El método de Muestreo por Importancia (MI) propone un cambio de medida, de manera que elevento raro se torne más probable bajo la nueva medida de probabilidad. Luego, el muestreo damayor importancia al evento raro, y comprime la probabilidad del evento complementario. Esteconcepto es bien general, y el cambio de medida coincide con la derivada de Radon Nikodim conrespecto a una medida absolutamente continua [9]. SeaX el vector aleatorio que representa el estadode la red, y P (x) = P (X = x) la probabilidad de ocurrencia del estado x. Si φ es la estructura quedetermina si le red permanece o no operativa, tenemos que la nueva ley de probabilidad es P̂ :
P̂ (x) = (1− φ(x))P (x)/γ (5)
Nótese que la nueva probabilidad de los estados inoperantes es nula, por lo que el evento de correctaoperación ocurre con probabilidad uno bajo esta nueva medida. Se realiza el muestreo sobre la nuevaley, y se calcula un promedio muestral:
RIS = 1− 1
N
N∑
j=1
(1− φ(Xj))L(Xj), (6)
siendo L(xj) = P (x)/P̂ (x) cuando P̂ (x) > 0, y 0 en caso contrario. Puesto que la probabilidadde correcta operación es igual a uno, el nuevo estimador presenta varianza nula. Sin embargo,conocer la ley P̂ requiere determinar γ, que es nuestro objetivo. L’ Ecuyer et. al. han investigadoel método MI para la anticonfiabilidad del modelo clásico, y desarrollaron un método recursivode MI con varianza casi nula, denominado AZVIS por sus siglas inglesas [12]. Vale destacar queAZVIS cumple la propiedad ERA, y bajo condiciones de diseño especiales (selección de cortes demáxima probabilidad) también cumple ERD. Invitamos al lector a consultar el art́ıculo original pormayores detalles [12].
CLAIO-2016
745

1 2
867
16915
17201014
18191113
12
4
5 3
(a) Dodecahedro
1
2 3 4 5 6
7
8
91011121314
15 16 17 18
19
20
(b) Grafo ArpaNet
5 Resultados Experimentales
Una manera práctica de comparar los métodos MCC, RVR y AZVIS es considerando tanto eltiempo de ejecución (sobre un mismo ordenador) como la varianza es la ganancia de eficiencia:
ŴCMCM
=V̂CMC .tMCC
V̂M .tM(7)
donde aqúı M puede ser el método AZV IS o RV R. Para ilustrar el desempeño de cada métodose consideran Arpanet, Dodecahedro y la red de transporte de nuestra Administración Nacionalde Telecomunicaciones, ANTEL, cuya representación se encuentra disponible en la tesis [13]. Paratodos ellos fueron seleccionados los nodos terminales como los de mayor conectividad (nodos conconectividad mayor o igual que 3), de modo que la cantidad de nodos terminales no supere el 40%del total de nodos. Para estudiar redes confiables se toma p ∈ {0.95, 0.99} en todos sus enlaces,y u ∈ {0.95, 0.97, 0.99} en los nodos no terminales. Hay entonces 2 × 3 = 6 escenarios por grafo,con N = 104 ejecuciones para cada método. En las tablas de resultados se despliegan, para cadamétodo y par (p, u), el estimador de anticonfiabilidad γ̂ y de varianza V̂ , el tiempo de ejecuciónt y ganancia Ŵ respecto a MCC. Los tiempos de ejecución del método AZVIS son superiores queel método RVR. No obstante, su varianza resulta menor en la mayoŕıa de escenarios. Cuandola anticonfiabilidad es superior a 10−4 el método RVR muestra mejor rendimiento, mientras queAZVIS supera a RVR en casos con anticonfiabilidad inferior.
Dodecahedro
M p u N γ̂ V̂ t Ŵ
RVR 0.95 0.95 104 0.0090535 3.14E − 07 205.8 1.84AZVIS 0.95 0.95 104 0.0089496 1.22E − 07 2609 37.4RVR 0.95 0.97 104 0.004785 1.07E − 07 306 2.48
AZVIS 0.95 0.97 104 0.0047531 3.31E − 08 3550.1 0.69RVR 0.95 0.99 104 0.0019989 2.19E − 08 358 5.41
AZVIS 0.95 0.99 104 0.0020218 1.14E − 08 3854.2 0.96RVR 0.99 0.95 104 0.00087277 2.95E − 10 137.8 465
AZVIS 0.99 0.95 104 0.0009255 6.77E − 09 1556.8 1.78RVR 0.99 0.97 104 0.00025812 9.55E − 10 166.2 71.5
AZVIS 0.99 0.97 104 0.00026312 1.61E − 10 1851.9 38RVR 0.99 0.99 104 5.00E-05 4.22E − 11 296.4 147
AZVIS 0.99 0.99 104 3.49E-05 2.99E − 12 3049.9 201
Resultados Numéricos de MCC, RVR y AZVIS
CLAIO-2016
746

ArpaNet
M p u N γ̂ V̂ t Ŵ
RVR 0.95 0.95 104 0.051351 1.68E − 06 245 2.29AZVIS 0.95 0.95 104 0.036738 1.60E − 06 761.1 0.75RVR 0.95 0.97 104 0.044748 1.17E − 06 214.4 2.78
AZVIS 0.95 0.97 104 0.040738 9.32E − 07 865.9 0.86RVR 0.95 0.99 104 0.023175 3.67E − 07 197.1 6.47
AZVIS 0.95 0.99 104 0.023244 5.98E − 07 839 0.93RVR 0.99 0.95 104 0.0078039 6.60E − 08 244 9.55
AZVIS 0.99 0.95 104 0.0086097 7.71E − 08 794.9 2.51RVR 0.99 0.97 104 0.00349 2.37E − 08 210.5 16.3
AZVIS 0.99 0.97 104 0.0041413 5.82E − 08 811.2 1.73RVR 0.99 0.99 104 0.0011238 5.46E − 09 213.3 20.9
AZVIS 0.99 0.99 104 0.0013126 1.06E − 09 813.7 28.2
Resultados Numéricos de MCC, RVR y AZVIS
ANTEL
M p u N γ̂ V̂ t Ŵ
RVR 0.95 0.95 104 0.41953 1.32E − 06 369.8 6.52AZVIS 0.95 0.95 104 0.40769 1.02E − 06 5713.9 0.29RVR 0.95 0.97 104 0.31029 9.05E − 05 472 0.68
AZVIS 0.95 0.97 104 0.31433 2.66E − 05 6193.1 0.73RVR 0.95 0.99 104 0.22542 7.50E − 05 441 1.41
AZVIS 0.95 0.99 104 0.21542 8.74E − 05 6499.5 0.36RVR 0.99 0.95 104 0.14596 8.11E − 06 369.8 24
AZVIS 0.99 0.95 104 0.16962 1.21E − 06 5670 2.85RVR 0.99 0.97 104 0.07284 1.47E − 05 400.2 12.7
AZVIS 0.99 0.97 104 0.066295 5.47E − 06 5688.3 1.18RVR 0.99 0.99 104 0.022951 1.70E − 05 598.5 5.69
AZVIS 0.99 0.99 104 0.015605 2.75E − 06 6074.5 2.30
Resultados Numéricos de MCC, RVR y AZVIS
6 Conclusiones
En este art́ıculo se ha presentado el modelo hostil, donde pueden caer tanto los enlaces como nodosno terminales. El modelo hostil responde a un sistema binario estocástico monótono. Por lo tanto,se aplican los métodos de Muestreo por Importancia y el de Reducción de Varianza Recursiva.Ambos métodos son competitivos, y adaptan mejor que el método de Monte Carlo Crudo ante lapresencia de un evento raro. Como trabajo futuro se desea estudiar sistemas binarios estocásticosno monótonos (por ejemplo con cáıda de terminales), y diseñar métodos de aproximación generalescon mayor rendimiento que Monte Carlo Crudo.
Referencias
[1] Michael O. Ball. Computational complexity of network reliability analysis: An overview. IEEETransactions on Reliability, 35(3):230 –239, aug. 1986.
[2] Tim Berners-Lee, Robert Cailliau, Jean-François Groff, and Bernd Pollermann. World-wideweb: The information universe. Electronic Networking: Research, Applications and Policy,1(2):74–82, 1992.
[3] B. Bollobás. Random Graphs. Cambridge University Press, 2001.
CLAIO-2016
747

[4] E. Canale, H. Cancela, J. Piecini, F. Robledo, P. Romero, G. Rubino, and P. Sartor. Recursivevariance reduction method in stochastic monotone binary systems. In Reliable Networks Designand Modeling (RNDM), 2015 7th International Workshop on, pages 135–141, Oct 2015.
[5] H. Cancela and M. El Khadiri. A recursive variance-reduction algorithm for estimatingcommunication-network reliability. IEEE Transactions on Reliability, 44(4):595–602, 1995.
[6] Jacques Carlier and Corinne Lucet. A decomposition algorithm for network reliabilityevaluation. Discrete Applied Mathematics, 65(1?3):141 – 156, 1996. First InternationalColloquium on Graphs and Optimization.
[7] R.K. Dash, N.K. Barpanda, P.K. Tripathy, and C.R. Tripathy. Network reliability optimizationproblem of interconnection network under node-edge failure model. Applied Soft Computing,12(8):2322 – 2328, 2012.
[8] George S. Fishman. A Monte Carlo sampling plan for estimating network reliability. OperationsResearch, 34(4):581–594, 1986.
[9] G.B. Folland. Real analysis: modern techniques and their applications. Pure and appliedmathematics. Wiley, 1999.
[10] Ilya B. Gertsbakh and Yoseph Shpungin. Models of Network Reliability: Analysis,Combinatorics, and Monte Carlo. CRC Press, Inc., Boca Raton, FL, USA, 1st edition, 2009.
[11] R. M. Karp. Reducibility among combinatorial problems. In R. E. Miller and J. W. Thatcher,editors, Complexity of Computer Computations, pages 85–103. Plenum Press, 1972.
[12] Pierre L’Ecuyer, Gerardo Rubino, Samira Saggadi, and Bruno Tuffin. Approximate zero-variance importance sampling for static network reliability estimation. IEEE Transactions onReliability, 60(3):590–604, 2011.
[13] Claudio Risso. Using GRASP and GA to design resilient and cost-effective IP/MPLS networks.Theses, University of the Republic, Uruguay, May 2014.
[14] A. Rosenthal. Computing the reliability of complex networks. SIAM Journal on AppliedMathematics, 32(2):384–393, 1977.
[15] G. Rubino and B. Tuffin. Rare event simulation using Monte Carlo methods. Wiley, 2009.
CLAIO-2016
748

Improving Visual Attractiveness in Capacitated
Vehicle Routing Problems: a Heuristic Algorithm
Diego Gabriel RossitDI, Universidad Nacional del Sur and CONICET, Argentina
DEI, Università di Bologna, [email protected]
Daniele VigoDEI, Università di Bologna, Italy
Fernando TohméDE, Universidad Nacional del Sur and CONICET, Argentina
Mariano FrutosDI, Universidad Nacional del Sur and CONICET, Argentina
2016
Abstract
The widespread applicability of the Vehicle Routing Problem in different fields has lead toa variety of formulations involving different objectives and constraints. In opposition to themain interest in optimizing quantitative objectives (e.g. length), the literature is rather scarceon the analysis of more subjective aspects. We focus here on such a goal, namely optimizingvisual attractiveness. Generating “nice” routes is important since they are seen as being bothmore intuitive and efficient, simplifying not only the implementation of a routing plan butalso the positive collaboration between the planning and operational management levels inan organization. This paper presents preliminary results on the development of a heuristicalgorithm to enhance visual attractiveness in a Capacitated Vehicle Routing Problem. Tests onbenchmark instances show that the heuristic is able to find well-behaved solutions for differenttraditional visual beauty measures.
Keywords: vehicle routing problem; visual attractiveness; heuristic.
1 Introduction
Among the objectives that can be taken into account in a Vehicle Routing Problem (VRP) we canfind on the one hand, the traditional quantitative objectives that correspond to established cost
CLAIO-2016
749

or performance measures, such as the minimization of transportation costs, travel distances, traveltimes, necessary number of vehicles or number of weak constraints violations (e.g., time windows).On the other hand, we can consider subjective objectives such as routes visual attractiveness.An exact definition of the grade of visual attractiveness of a routing plan is not easy to state(see, e.g.,[2]). However many authors insisted on relating such subjective concept with a set ofcaracteristics that a routing plan may fulfil: compactness of the routes ([9]), [12] and [14]), minimaloverlapping between the convex hulls of the routes ([7]), reduced number of crossings between theroutes ([11], [12], [14] and [17]) or reduced number of customers that are nearer to the center ofanother route than to the center of the route to which they are assigned ([7], [12], [13] , [14] and[17]).
The paper is organized as follows: in Section 2 we present a literature review of the last researchin the field of visual attractiveness in routing problems; in Section 3 we describe a heuristic forsolving the Capacitated Vehicle Routing Problem enhancing visual beauty; in Section 4 we presentsome first results of the heuristic; and in Section 5 important conclusions from this paper arediscussed.
2 Literature review
Despite the difficulty to find a clear definition for visual attractiveness, the paramount importanceof considering this subjective aspect has been highlighted in the literature. According to Matis [12]if VRP solution presents overlapping routes, it is aimed to be criticized by the drivers who have tocarry out the trips as they may think it is an inefficient routing plan. A few years before, Poot et al.[14] have already set the importance of what they called ”region constraint” in real-life problems.They stated that visually attractive plans seem to be more logical and closer to the manual way ofworking, generating trust in the plan among the drivers and planners.
Lu and Dessousky [11] and Zhou et al. [19] presented insertion-based heuristics to solve aPDPTW that considers the reduction of crossings between routes as an objective. Tang andMiller-Hooks [17] presented a heuristic to solve a VRP that optimizes two visually attractivenessaspects. The first one is an inter-route measure: the number of customers that are closer to themedian of another route than to the median of the route they are assigned to. The second one is anintra-route measure: the average distance from the customers within a trip to the median of thatroute. They do not considered capacity or time windows constraints but they fixed a maximumallowed duration for a single trip.
Sahoo et al. [15] presented an algorithm that optimizes “visual beauty” along with conventionalobjectives for a waste management company using a GIS-based route-planning application. Theyenhanced visual attractiveness by using a combination of balanced clustering and greedy insertionto construct compact initial solutions. Kim et al. [9] developed a cluster-based algorithm to solve awaste collection VRP with time windows (VRPTW) with the aim of improving visual attractiveness.Another field where private companies show a strong interest in performing visually beauty routes isproduct distribution. Kant et al. [8] established the importance of maintaining customers-driversrelationship through assigning the same driver to geographically near clients and presented anheuristic algorithm that has performed a substantial saving to the Coca-Cola Enterprises throughthe consideration of compactness measures. According to Hollis and Green [7] if a customer cannotbe serviced at the preferred time, as long as the vehicle stays in the same geographical area, it willbe easier to return to service the customer at a later time; if there is some problem that prevents the
CLAIO-2016
750

driver from performing the scheduled route, as a traffic jam or road disruptions, it is easier to findalternative routes if the clients are distributed in a limited area. In their paper, a complex heuristicalgorithm was outlined to generate visually attractive solutions to fulfil the needs of SchweppesAustralia Pty. Ltd operational. This algorithm is composed by two different stages: first a novelvariation of the Solomon’s insertion algorithm [16] is applied for constructing the initial solution;then, a guided local search is implemented to improve the solution.
More recently Battarra et al. [1] enumerated some applications where route compactness isof major importance such as, for instance, the transportation of the elderly to recreation centers,where the customers prefer to be picked up together with their neighbors. Another example cited in[1] are “gated communities”, which are residential or productive areas enclosed in walled enclavesfor safety and protection reasons. Whenever more than one customer from a gated communityrequires to be serviced, these customers should be visited in the same trip considering that crossingthe gates can represent a time-consuming duty because, e.g., drivers must pass a check-point.Gretton and Kilby [5] introduced a novel way of penalizing unattractive plans by borrowing theconcept of “bending energy” from the computer vision field in a Large Neighbourhood Search(LNS) algorithm. Cosntantino et al. [2] proposed a variant to the traditional mixed capacitated arcrouting problem (MCARP): the bounded MCARP (BCARP). This problem adds to the traditionalMCARP a constraint that imposed an upper bound to the number of share nodes between differentroutes to produce “nicer” solutions.
3 Proposed heuristic
The idea of this paper is to present the preliminary results of an efficient heuristic to optimizevisual attractiveness for the Capacitated VRP (CVRP) while not deteriorating significantly theconventional quantitative objectives. The Capacitated VRP was first defined by Dantzig andRamser [3] in 1959 and is the special case of VRP in which a homogeneous fleet of vehicles mustserve a set of customers and only considers the capacity constraints of the vehicles. The heuristicstarts with the construction of a feasible solution. Then, it tries to improve the solution with a setof local search and a reconstruction operator. The heuristic stops either if the maximum number ofiterations (maxIt) is achieved or if no improvement is produced in p∗maxIt consecutive iterations.
3.1 Evaluation of visual attractiveness
In this paper, visual attractiveness is evaluated through four different measures which have alreadybeen implemented in the literature: number of crossings between different routes [11, 12, 14, 19],number of customers that are closer to another center of route than to the center of the route towhich they are assigned to [7, 12, 14, 17], compactness of the routes [9, 7] and number of nodesthat belongs to more than one convex hull [7, 9, 14].
1. Number of nodes that belongs to more than one convex hull (CH). The avoidance of overlap-ping between convex hulls will lead to inexistence of crossings between routes. Let K be theset of routes and CHI be the number of nodes that belong to route I ∈ K that are includedin the convex hull of a route U ∈ K and U 6= I. For constructing the convex hull of a routewe used the algorithm proposed by Graham [4]. Then we can calculate the measure CH as:
CH =∑
I∈KCHI (1)
CLAIO-2016
751

2. Number of crossings between different routes (NC).
3. Compactness of the routes. Routes that are compact have less chances of overlapping withother routes and also are beneficial for operational purposes as was described in Section 1.To measure this we define COMPI as the sum of distances from all the nodes in a routeto the center of the route [9]. Let cI be the center of the route I ∈ K and TI be the setof customers assigned in route I. Moreover, let dist(h, j) be the function that returns theeuclidean distance between any pair of points h and j.
COMP =∑
I∈KCOMPI =
∑
I∈K
∑
t∈TI
dist(t, cI) (2)
4. Number of customers that are nearer to another center of route than to the one of theroute where they are assigned. Let O′I be the number of customers from route I ∈ K thatare nearer to the center of another route than to the route where they have been assigned:dist(t ∈ I, cI) > dist(t ∈ I, cU ), U ∈ K,U 6= I. Then we calculate DGRB as:
DGRB =∑
I∈KDGRBI =
∑
I∈K
O′I|I| (3)
To apply equations (2) and (3) the concept of center of route must be defined. Despite from beingthe most intuitive approach, selecting the center of the route as the geometric centroid ([7], [12] and[14]) requires computing the distance to a point that may vary during the optimization process.Other authors have chosen to make the center of the route coincident with one of the customersthat are assigned to it, as Kant et al. [8] who chose the customer located in the intermediateposition of the trip. In this paper, taking advantage that the matrix of distances between nodes isan input for the CVRP [3], we will follow the rule used in [5], [9] and [17] selecting the customerthat minimizes the total distance with all the other customers assigned to the same route.
3.2 Initial solution
To construct a feasible initial solution we used an adaptation of the construction method proposedin [9] because it allows the heuristic to get a nice initial solution within a short period of time. Theprocess for constructing an initial feasible solution is the following: in the first step, the farthest nodefrom the depot is chosen, which will be the seed of a new route; in a second step, the surroundingnodes are added to the seed in order of increasing distance from the seed customer until thecapacity limit is reached; at the third step, the node farthest from the depot which still is unroutedis selected as the new seed customer; the process repeats second and third steps until all customersare assigned to one route. The order in which customers in a route are visited is determined throughthe application of the well-known Lin-Kernighan-Helsgaun (LKH) TSP heuristic [6, 10].
3.3 Local search operators
Once a initial solution has been obtained, the algorithm tries to improve the solution by twodifferent procedures: local search and reconstruction. The local search was performed by fourdifferent operators:
1. One-To-Zero. This operator selects a node which has a distance with the center of its routegrater than a threshold distance, say th1. Then, it tries to move this node to a new route
CLAIO-2016
752
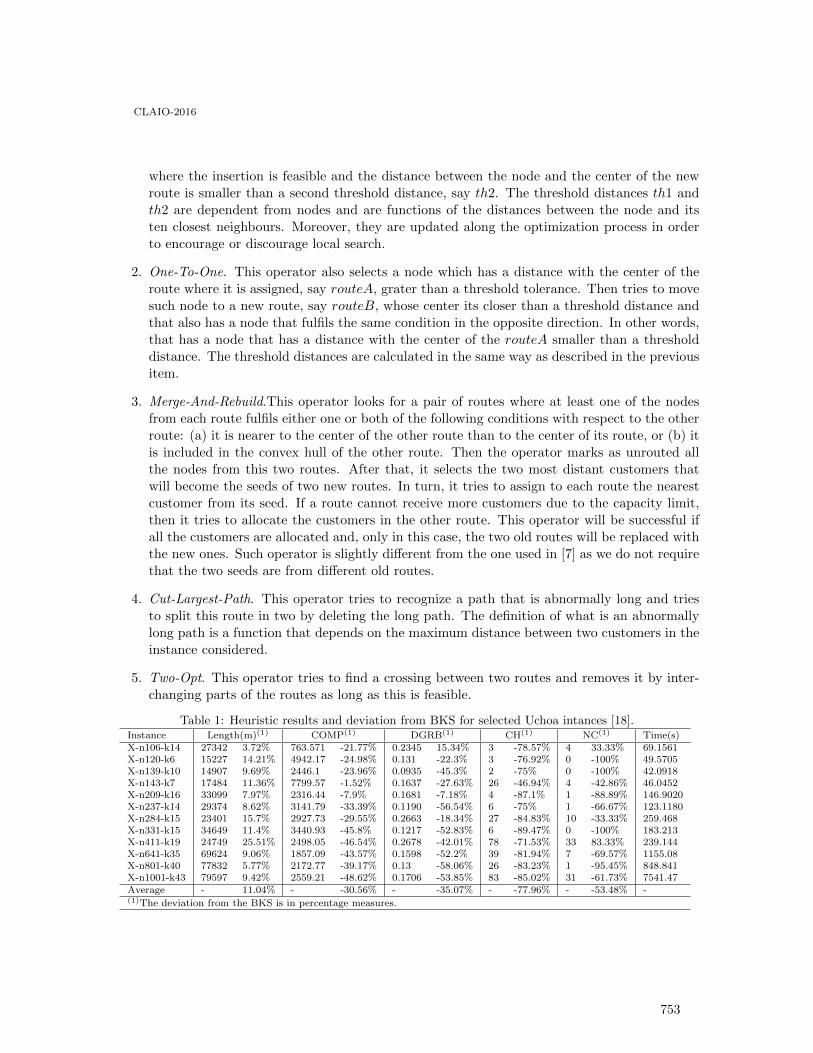
where the insertion is feasible and the distance between the node and the center of the newroute is smaller than a second threshold distance, say th2. The threshold distances th1 andth2 are dependent from nodes and are functions of the distances between the node and itsten closest neighbours. Moreover, they are updated along the optimization process in orderto encourage or discourage local search.
2. One-To-One. This operator also selects a node which has a distance with the center of theroute where it is assigned, say routeA, grater than a threshold tolerance. Then tries to movesuch node to a new route, say routeB, whose center its closer than a threshold distance andthat also has a node that fulfils the same condition in the opposite direction. In other words,that has a node that has a distance with the center of the routeA smaller than a thresholddistance. The threshold distances are calculated in the same way as described in the previousitem.
3. Merge-And-Rebuild.This operator looks for a pair of routes where at least one of the nodesfrom each route fulfils either one or both of the following conditions with respect to the otherroute: (a) it is nearer to the center of the other route than to the center of its route, or (b) itis included in the convex hull of the other route. Then the operator marks as unrouted allthe nodes from this two routes. After that, it selects the two most distant customers thatwill become the seeds of two new routes. In turn, it tries to assign to each route the nearestcustomer from its seed. If a route cannot receive more customers due to the capacity limit,then it tries to allocate the customers in the other route. This operator will be successful ifall the customers are allocated and, only in this case, the two old routes will be replaced withthe new ones. Such operator is slightly different from the one used in [7] as we do not requirethat the two seeds are from different old routes.
4. Cut-Largest-Path. This operator tries to recognize a path that is abnormally long and triesto split this route in two by deleting the long path. The definition of what is an abnormallylong path is a function that depends on the maximum distance between two customers in theinstance considered.
5. Two-Opt. This operator tries to find a crossing between two routes and removes it by inter-changing parts of the routes as long as this is feasible.
Table 1: Heuristic results and deviation from BKS for selected Uchoa intances [18].Instance Length(m)(1) COMP(1) DGRB(1) CH(1) NC(1) Time(s)X-n106-k14 27342 3.72% 763.571 -21.77% 0.2345 15.34% 3 -78.57% 4 33.33% 69.1561X-n120-k6 15227 14.21% 4942.17 -24.98% 0.131 -22.3% 3 -76.92% 0 -100% 49.5705X-n139-k10 14907 9.69% 2446.1 -23.96% 0.0935 -45.3% 2 -75% 0 -100% 42.0918X-n143-k7 17484 11.36% 7799.57 -1.52% 0.1637 -27.63% 26 -46.94% 4 -42.86% 46.0452X-n209-k16 33099 7.97% 2316.44 -7.9% 0.1681 -7.18% 4 -87.1% 1 -88.89% 146.9020X-n237-k14 29374 8.62% 3141.79 -33.39% 0.1190 -56.54% 6 -75% 1 -66.67% 123.1180X-n284-k15 23401 15.7% 2927.73 -29.55% 0.2663 -18.34% 27 -84.83% 10 -33.33% 259.468X-n331-k15 34649 11.4% 3440.93 -45.8% 0.1217 -52.83% 6 -89.47% 0 -100% 183.213X-n411-k19 24749 25.51% 2498.05 -46.54% 0.2678 -42.01% 78 -71.53% 33 83.33% 239.144X-n641-k35 69624 9.06% 1857.09 -43.57% 0.1598 -52.2% 39 -81.94% 7 -69.57% 1155.08X-n801-k40 77832 5.77% 2172.77 -39.17% 0.13 -58.06% 26 -83.23% 1 -95.45% 848.841X-n1001-k43 79597 9.42% 2559.21 -48.62% 0.1706 -53.85% 83 -85.02% 31 -61.73% 7541.47Average - 11.04% - -30.56% - -35.07% - -77.96% - -53.48% -(1)The deviation from the BKS is in percentage measures.
CLAIO-2016
753

3.4 Reconstruction
When for p2 ∗maxIt consecutive iterations no improvement is found, the reconstruction operatoris called. Such operator tries to reallocate the nodes of the route with the smallest demand, aslong as such demand is smaller than a certain value minDem, in other routes according to thefollowing hierarchical options: (a) if it is feasible the operator moves the customer to a route thatalready includes the node inside its convex hull; (b) otherwise if it is feasible it moves the customerto a route that minimizes the individual compactness of that route (COMPI); or (c) otherwise,because there is no feasible insertion in any other route, it creates a new route for that customers.In this last case the reconstruction operator creates a new route composed by only one node. Dueto its small demand, this route will have a high probability of been selected by the reconstructionoperator in the next iteration. To avoid this loop the reconstruction is prevented from selectingthe last two routes that were created for reallocation.
When a route has been transformed by an operator, either local search or reconstruction, wecan obtain a beneficial reduction of the length of the trip by reordering the customers tour. Thisis the reason why we apply the LKH heuristic every time a route has changed.
4 Implementation and experiments
The algorithm was implemented in C++. To test the algorithm a selection of the large CVRPinstances proposed by Uchoa et al. [18] are used. Within such benchmark the number of routes isnot fixed. The general naming for these instances is X-nA-kB where A represents the number ofnodes (including the depot) and B the minimum number of routes required to serve all customers.This set of instances can be downloaded either form the website suggested in [18] or, for the specificinstances used in this paper, from the website of the VRP-REP project http://www.vrp-rep.org/datasets/item/uchoa-et-al-2014.html.
For the results reported in Table 1 the values for the parameters presented in Sections 3.3 and3.4 are maxIt = 40, p = 0.4, p2 = 0.1 and minDem = Capacity
3 . The experiments were run ona personal computer with 16GB of RAM memory, a 3.60GHz processor and a 64 bits operatingsystem.
4.1 Results
In Table 1 we present for the selected instances the results obtained by our heuristic and therespective deviation from the BKS for length and visual attractiveness, this last in terms of themeasures described in Section 3.1. On average, as expected, the heuristic results presented in Table1 show better performance in terms of visual attractiveness objectives (30.56%, 35.075%, 77.96%and 53.49% better in terms of COMP , DGRB, CH and NC, respectively) but worst in terms oftotal length (11.04%) compared to the BKSs. The heuristic also presented large computing times.Usually the heuristic kept the same number of routes as the BKS, although this is not fix.
The worst relative deterioration in length occurred in (instance) X-n411-k19 with the heuristicsolution obtaining a length 25.51% higher than the BKS. The largest percentage reduction inCOMP was obtained in X-n1001-k13 (48.62%) with a length deterioration of 9.42%. In instanceX-n801-k40 the highest reduction in DGRB was obtained (58.06%) with a length deteriorationof 5.77%. For CH the best relative improvement occurred in X-n209-k16 (87.1%) with a length
CLAIO-2016
754

that is 7.97% higher than the BKS. And for NC the highest reduction was achieved in X-n120-k6(100%) with a length deterioration of 14.21%. As an example we present a layout of the routingplans for the instance X-n801-k40 in Figure 1. The left image is the BKS and the right is the oneobtained by the heuristic. For the sake of clarity, the initial and final links from and to the depotare not drawn.
0 200 400 600 800 1000
020
040
060
080
010
00
Best Known Solution
x[[1L]]
x[[2
L]]
0 200 400 600 800 1000
020
040
060
080
010
00
Heuristic solution
x[[1L]]
Figure 1: routing plans for instance X-n801-k40.
5 Conclusions
Visual attractiveness is of paramount importance when optimizing a Vehicle Routing Problem(VRP) model. Not only because a “nice” routing plan is seen as more intuitive and logical by theoperational levels of an organization, but also because visually attractive plans can achieve real sav-ings for the companies in relation to implementation costs. For these reasons, it is recommendableto included some indicators of visual attractiveness during the optimizing process of a VRP. Thepreliminary results obtained with the heuristic performed well in terms of visual attractiveness.However they need to be improved in order to be competitive in terms of computing times and thelength of solutions.
6 Acknowledgement
The first author was supported by the Academic Mobility for Inclusive Development in Latin Amer-ica (AMIDILA) program from the Erasmus Mundus Action 2 scheme of the European Commission.
References
[1] M. Battarra, G. Erdogan, and D. Vigo. Exact algorithms for the clustered vehicle routingproblem. Operations Research, 62(1):58–71, 2014.
[2] M. Constantino, L. Gouveia, M. C. Mourão, and A. C. Nunes. The mixed capacitated arcrouting problem with non-overlapping routes. European Journal of Operational Research,244(2):445–456, 2015.
[3] G. B. Dantzig and J. H. Ramser. The truck dispatching problem. Management science,6(1):80–91, 1959.
CLAIO-2016
755

[4] R. L. Graham. An efficient algorithm for determining the convex hull of a finite planar set.Information processing letters, 1(4):132–133, 1972.
[5] C. Gretton and P. Kilby. A study of shape penalties in vehicle routing. In Proceedings ofEighth Triennial Symposium on Transportation Analysis, San Pedro de Atacama, Chile, 2013.
[6] K. Helsgaun. An effective implementation of the lin–kernighan traveling salesman heuristic.European Journal of Operational Research, 126(1):106–130, 2000.
[7] B. L. Hollis and P. J. Green. Real-life vehicle routing with time windows for visual attractive-ness and operational robustness. Asia-Pacific Journal of Operational Research, 29(04):1250017,2012.
[8] G. Kant, M. Jacks, and C. Aantjes. Coca-cola enterprises optimizes vehicle routes for efficientproduct delivery. Interfaces, 38(1):40–50, 2008.
[9] B. I. Kim, S. Kim, and S. Sahoo. Waste collection vehicle routing problem with time windows.Computers & Operations Research, 33(12):3624–3642, 2006.
[10] S. Lin and B. W. Kernighan. An effective heuristic algorithm for the traveling-salesmanproblem. Operations research, 21(2):498–516, 1973.
[11] Q. Lu and M. M. Dessouky. A new insertion-based construction heuristic for solving thepickup and delivery problem with time windows. European Journal of Operational Research,175(2):672–687, 2006.
[12] P. Matis. Decision support system for solving the street routing problem. Transport, 23(3):230–235, 2008.
[13] P. Matis and M. Koháni. Very large street routing problem with mixed transportation mode.Central European Journal of Operations Research, 19(3):359–369, 2011.
[14] A. Poot, G. Kant, and A. P. M. Wagelmans. A savings based method for real-life vehiclerouting problems. Journal of the Operational Research Society, pages 57–68, 2002.
[15] S. Sahoo, S. Kim, B. I. Kim, B. Kraas, and A. Popov Jr. Routing optimization for wastemanagement. Interfaces, 35(1):24–36, 2005.
[16] M. M. Solomon. Algorithms for the vehicle routing and scheduling problems with time windowconstraints. Operations research, 35(2):254–265, 1987.
[17] H. Tang and E. Miller-Hooks. Interactive heuristic for practical vehicle routing problem withsolution shape constraints. Transportation Research Record: Journal of the TransportationResearch Board, (1964):9–18, 2006.
[18] E. Uchoa, D. Pecin, A. Pessoa, M. Poggi, A. Subramanian, and T. Vidal. New benchmarkinstances for the capacitated vehicle routing problem. Optimization Online, 2014.
[19] C. Zhou, Y. Tan, L. Liao, and Y. Liu. Solving the multi-vehicle pick-up and delivery problemwith time widows by new construction heuristic. In Intelligent Systems Design and Applica-tions, 2006. ISDA’06. Sixth International Conference on, volume 2, pages 1035–1042. IEEE,2006.
CLAIO-2016
756

The use of the multiple knapsack problem in strategic management of universities - case study
Radosław Ryńca
Wroclaw University of Technology
Wybrzeże Wyspiańskiego 27
50-370 Wrocław, Poland
Radosł[email protected]
Dorota Kuchta*
Wroclaw University of Technology
Wybrzeże Wyspiańskiego 27
50-370 Wrocław, Poland
Dariusz Skorupka
Wroclaw Military Academy of Land Forces,
ul. Czajkowskiego 109
51 -150 Wrocław, Poland
Artur Duchaczek
Wroclaw Military Academy of Land Forces,
ul. Czajkowskiego 109
51 -150 Wrocław, Poland
Abstract
In the literature there are many methods and tools that can be helpful in strategic management of
universities. Some of them are related to the aspect of sustainability, in terms of balancing the level of
fulfillment of different objectives, often conflicting, which must be considered when building strategies.
These tools include portfolio analysis methods. However, their use is often intuitive and detached from
the quantitative aspects of management, such as, for instance, cost. This article presents a proposal of the
modification of the portfolio methods application through the use of one of discrete optimization
problems, namely - the multiple knapsack problem. The proposal is applied to a selected university. The
case study is presented and discussed.
Keywords: portfolio planning methods, strategic management, generalized assignment problem, multiple
knapsack problem
1 Introduction
Universities today, both state-owned and private ones, have to use management methods like any other
company. Otherwise they risk disappearing from the market. They have to have a well thought of
CLAIO-2016
757

strategy, they have to analyze the current situation and current trends on the market, they have to try to
satisfy their customers (above all students) as well as other stakeholders. In the present paper it is shown
how portfolio methods, whose usage is normal in business, can be used in order to improve the strategic
position of a university. Also it is shown how the multiple knapsack problem can be applied in order to
make the portfolio methods more quantitatively justified.
The structure of the paper is as follows: first, the portfolio methods are shortly presented. Then, a
combination of the multiple knapsack problem (i.e. of the generalized assignment problem) with the
portfolio methods is proposed. Finally, a case study is described, where the proposed combination is
applied to a selected university.
2 Portfolio planning methods
In the literature many portfolio matrix planning methods and their application to strategic management
are proposed. Such methods help to assess and influence companies’ current and future market position.
They help to position e.g. companies’ products, technologies or strategic units. In the literature the
following portfolio matrix methods are known (Porth 2003): Boston Consulting Group (BCG), General
Electric (GE), Arthur D.Little (ADL), Hofer’s and Schendl’s matrix or Ansoff’s matrix. All of them have
the same underlying idea: the objects being evaluated (products, departments etc.) are placed in various
fields (areas) of a matrix. The areas are characterized by certain evaluation criteria and so are the objects
lying in the corresponding areas. Some matrix areas are more desirable, some less. If the decision maker
is satisfied with positions of the objects, nothing is done, but if he is not (which is the normal case), the
decision is taken to move some objects to another area, if it is possible, where their evaluation would be
better. Usually not all the desirable moves would be feasible, for various reasons (market barriers,
budgetary limits). In order to put desirable moves into action, corrective actions have to be undertaken
(e.g. publicity, a new customer service unit etc.).
An example of a matrix with four areas is presented if Fig.1. The most desirable area is the right hand -
upper one, the least desirable - the left hand lower one. The other two are desirable from the point of view
of one criterion and undesirable as far as the other criterion is taken into account. Six objects evaluated
from the point of view of the two criteria are shown in their present positions and both desirable and
feasible moves are shown. The details are described below.
3 Model using multiple knapsack (generalized assignment) problem in portfolio analysis
Generally each matrix used in the portfolio analysis consists of M areas 𝐴𝑗, 𝑗 = 1, … , 𝑀. Each area may
have a different value in the eyes of the decision-maker. There are N objects 𝐷𝑖, 𝑖 = 1, … , 𝑁 being
examined. If the object 𝐷𝑖 is in an area 𝐴𝑗, it has value 𝑣𝑖𝑗, whereas the value is determined by experts and
includes an assessment of the area 𝐴𝑗 in terms of the considered evaluation criteria.
Each area may be thought of as a knapsack and thus we can make use of the generalized assignment
problem, also called the multiple knapsack problem (Haddadi and Ouzia 2004). Some knapsacks and the
objects placed in them will be more desirable in the eyes of the decision maker, some less, which is
measured by the values 𝑣𝑖𝑗. We have thus the following objective function:
∑ ∑ 𝑣𝑖𝑗𝑥𝑖𝑗𝑁𝑖=1
𝑀𝑗=1 → 𝑚𝑎𝑥 (1)
CLAIO-2016
758

where:
ijv - is the value of the i-th object in the j-th area
ijx - binary variable that takes value 1 if the i-th element will be placed in the j-th area in the consequence
of corrective actions, 0-otherwise
The constraints are designed in collaboration with the decision-maker. They may represent for example
the maximum /minimum number of elements that can be placed in each area (the limit may be a
consequence of the market barriers), or a budgetary constraints may be imposed. An example of a general
budgetary constraint (one budget for all the corrective actions) is as follows:
∑ ∑ 𝑐𝑖𝑗𝑥𝑖𝑗𝑛𝑁𝑖=1
𝑀𝑗=1 ≤ 𝐵 (2)
where:
𝑐𝑖𝑗 denotes the cost of placing the i-th element in j-th area as a consequence of a corrective action (it may
mean the transfer from the area in which it is placed currently), if the i-th object is already in the j-th area
then 𝑐𝑖𝑗 = 0, if the respective transfer is not possible, 𝑐𝑖𝑗 is a big number.
In the next section we show a combination of the portfolio planning methods with the multiple knapsack
problem. This combination will allow to make the usage of portfolio planning methods more
quantitatively justified. We will present the approach in the university context.
4 Portfolio planning methods based on the generalised assignment method for universities
Let us assume a university with N objects 𝐷 𝑖, 𝑖 = 1, … 𝑁, representing its departments. The departments
are evaluated using two criteria: the attractiveness in the eyes of potential students and the profitability.
In the literature the problem of attractiveness measure of a university departments - from the point of
view of different stakeholders - is widely known and often articulated (e.g. (Aldrige and Rowley 1998),
(Álvarez and Rodríguez 1997), (Crumbley et al 2001), (Langbein 2008)). As it can be concluded from the
literature, the assessment of the university departments attractiveness covers different areas and is made
on the basis of different criteria.
Evaluation of attractiveness iE of department iD would be therefore expressed by formula (3) where K
criteria are assumed, the criteria being taken from the literature and selected and completed together with
the decision makers:
𝐸𝑖 = ∑ 𝑤𝑖𝑘𝑒𝑖𝑘𝐾𝑖=1 (3)
where ikw is the weight of the k-th criterion for the i-th department and ike denotes the value of the k-th
criterion for the i-th department.
Profitability iR of department iD is determined by the formula:
iii KPR (4)
where, for a selected accounting period, iP denotes the revenues generated by the department iD and
iK the cost linked to the functioning of department iD .
CLAIO-2016
759

The authors of the present paper propose a simplified formula for determining the revenue of the
department iD :
𝑃𝑖 = 𝑇𝑖𝑆𝑖 + 𝐺𝑖 (5)
where iT denotes the tuition height per student for a year, iS the number of students and iG the amount
of state subvention for department iD for a year.
The lack of appropriate management information in the departments can cause problems with the determining of cost iK of department iD . In this respect the use of Activity Based Costing method may
turn out to be useful. In the literature, there are many publications on this problem, for instance
(Gooddard and Ooi 1998). Activity Based Costing helps to determine the cost referring to department iD :
both its direct cost as well as the appropriate share of university common cost. Especially the latter is a
problem and the Activity Based Costing can be here of a considerable help.
5 Case study
Here we will give concrete values for the case study and the results of the application of the model at a
selected university.
At the examined university there were 6 departments. The values ijv were given by the decision maker.
Here they depend only on the area in the matrix - departments sharing the same matrices have thus the same
value.
Matrix area in which iD is placed ijv
1 0
2 4
3 5
4 8
Table 1. Assessment of ijv for individual areas and iD (own elaboration)
The factors of department attractiveness were identified on the basis of the literature and a pilot study
conducted on a group of 250 students from various departments. The criteria weights were assigned by the
university management based on the preferences of the students. In a further step the different criteria were
assessed by the students. Each parameter was scored on a scale of 1 to 5, where 1 means low rate and 5 the
highest possible evaluation. Departments attractiveness survey was conducted on a group of 300 students
from various departments. The results for one of the departments are given in Table 2.
CLAIO-2016
760
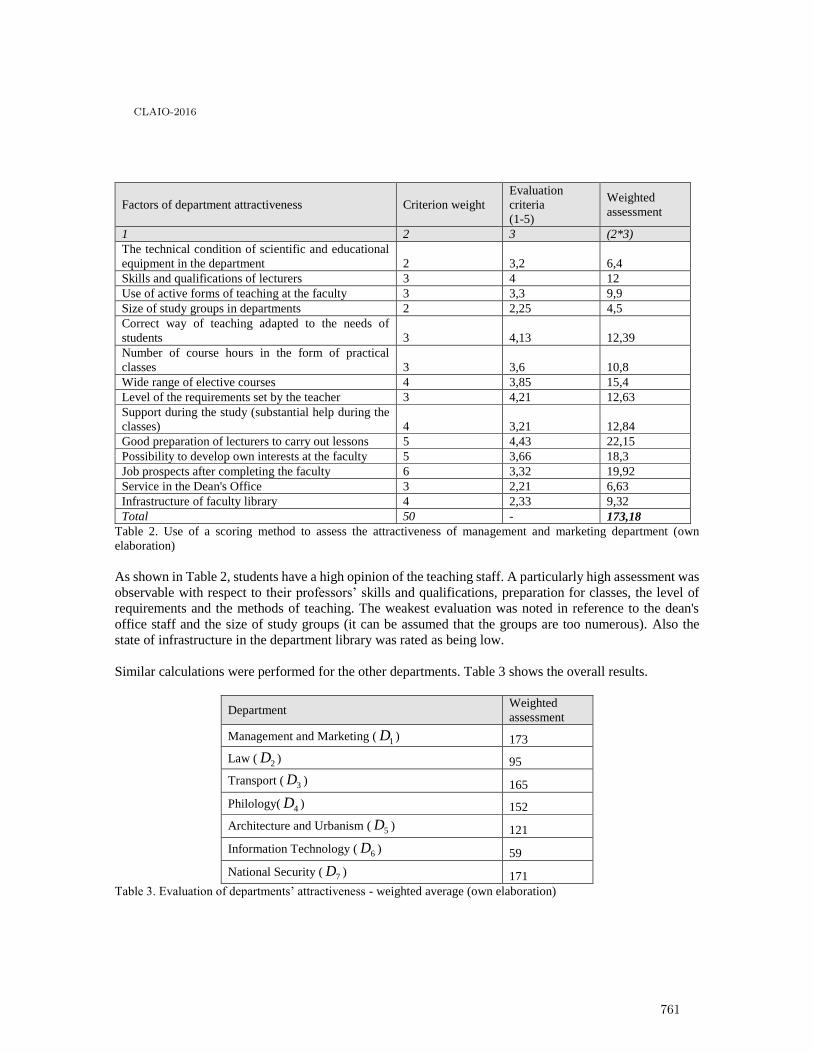
Factors of department attractiveness Criterion weight
Evaluation
criteria
(1-5)
Weighted
assessment
1 2 3 (2*3)
The technical condition of scientific and educational
equipment in the department 2 3,2 6,4
Skills and qualifications of lecturers 3 4 12
Use of active forms of teaching at the faculty 3 3,3 9,9
Size of study groups in departments 2 2,25 4,5
Correct way of teaching adapted to the needs of
students 3 4,13 12,39
Number of course hours in the form of practical
classes 3 3,6 10,8
Wide range of elective courses 4 3,85 15,4
Level of the requirements set by the teacher 3 4,21 12,63
Support during the study (substantial help during the
classes) 4 3,21 12,84
Good preparation of lecturers to carry out lessons 5 4,43 22,15
Possibility to develop own interests at the faculty 5 3,66 18,3
Job prospects after completing the faculty 6 3,32 19,92
Service in the Dean's Office 3 2,21 6,63
Infrastructure of faculty library 4 2,33 9,32
Total 50 - 173,18
Table 2. Use of a scoring method to assess the attractiveness of management and marketing department (own
elaboration)
As shown in Table 2, students have a high opinion of the teaching staff. A particularly high assessment was
observable with respect to their professors’ skills and qualifications, preparation for classes, the level of
requirements and the methods of teaching. The weakest evaluation was noted in reference to the dean's
office staff and the size of study groups (it can be assumed that the groups are too numerous). Also the
state of infrastructure in the department library was rated as being low.
Similar calculations were performed for the other departments. Table 3 shows the overall results.
Department Weighted
assessment
Management and Marketing ( 1D ) 173
Law ( 2D ) 95
Transport ( 3D ) 165
Philology( 4D ) 152
Architecture and Urbanism ( 5D ) 121
Information Technology ( 6D ) 59
National Security ( 7D ) 171
Table 3. Evaluation of departments’ attractiveness - weighted average (own elaboration)
CLAIO-2016
761
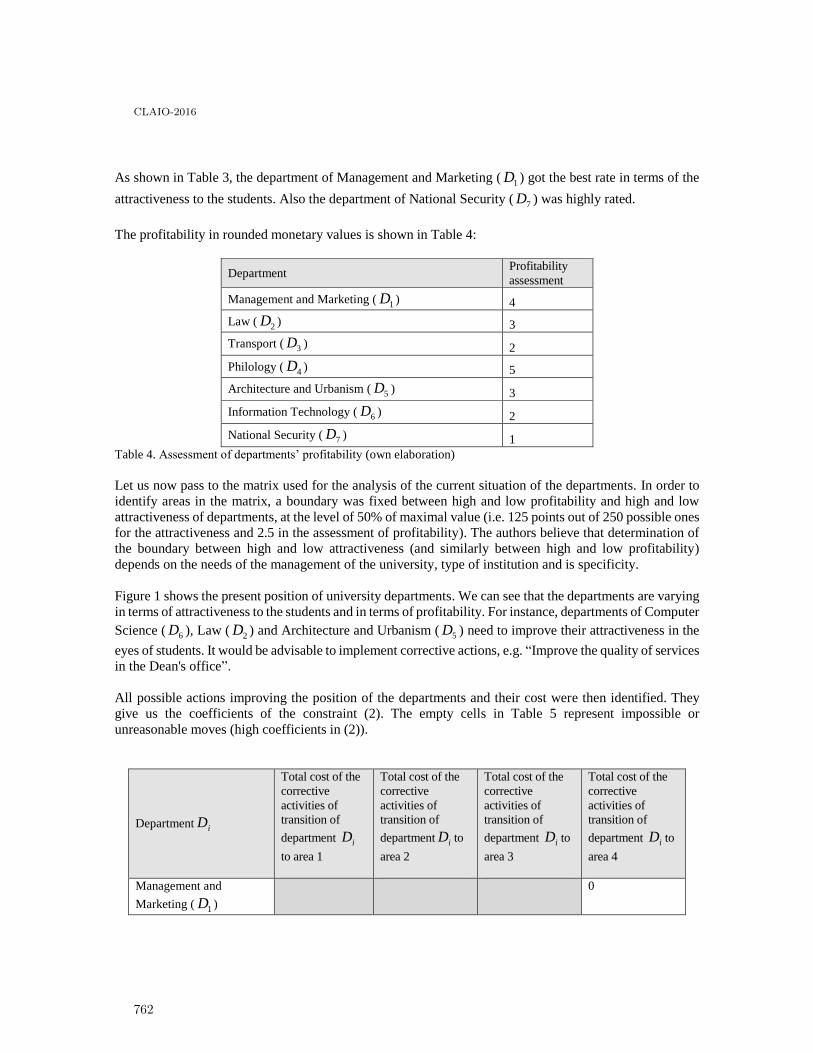
As shown in Table 3, the department of Management and Marketing ( 1D ) got the best rate in terms of the
attractiveness to the students. Also the department of National Security ( 7D ) was highly rated.
The profitability in rounded monetary values is shown in Table 4:
Department Profitability
assessment
Management and Marketing ( 1D ) 4
Law ( 2D ) 3
Transport ( 3D ) 2
Philology ( 4D ) 5
Architecture and Urbanism ( 5D ) 3
Information Technology ( 6D ) 2
National Security ( 7D ) 1
Table 4. Assessment of departments’ profitability (own elaboration)
Let us now pass to the matrix used for the analysis of the current situation of the departments. In order to
identify areas in the matrix, a boundary was fixed between high and low profitability and high and low
attractiveness of departments, at the level of 50% of maximal value (i.e. 125 points out of 250 possible ones
for the attractiveness and 2.5 in the assessment of profitability). The authors believe that determination of
the boundary between high and low attractiveness (and similarly between high and low profitability)
depends on the needs of the management of the university, type of institution and is specificity.
Figure 1 shows the present position of university departments. We can see that the departments are varying
in terms of attractiveness to the students and in terms of profitability. For instance, departments of Computer
Science ( 6D ), Law ( 2D ) and Architecture and Urbanism ( 5D ) need to improve their attractiveness in the
eyes of students. It would be advisable to implement corrective actions, e.g. “Improve the quality of services
in the Dean's office”.
All possible actions improving the position of the departments and their cost were then identified. They
give us the coefficients of the constraint (2). The empty cells in Table 5 represent impossible or
unreasonable moves (high coefficients in (2)).
Department iD
Total cost of the
corrective
activities of
transition of
department iD
to area 1
Total cost of the
corrective
activities of
transition of
department iD to
area 2
Total cost of the
corrective
activities of
transition of
department iD to
area 3
Total cost of the
corrective
activities of
transition of
department iD to
area 4
Management and
Marketing ( 1D )
0
CLAIO-2016
762
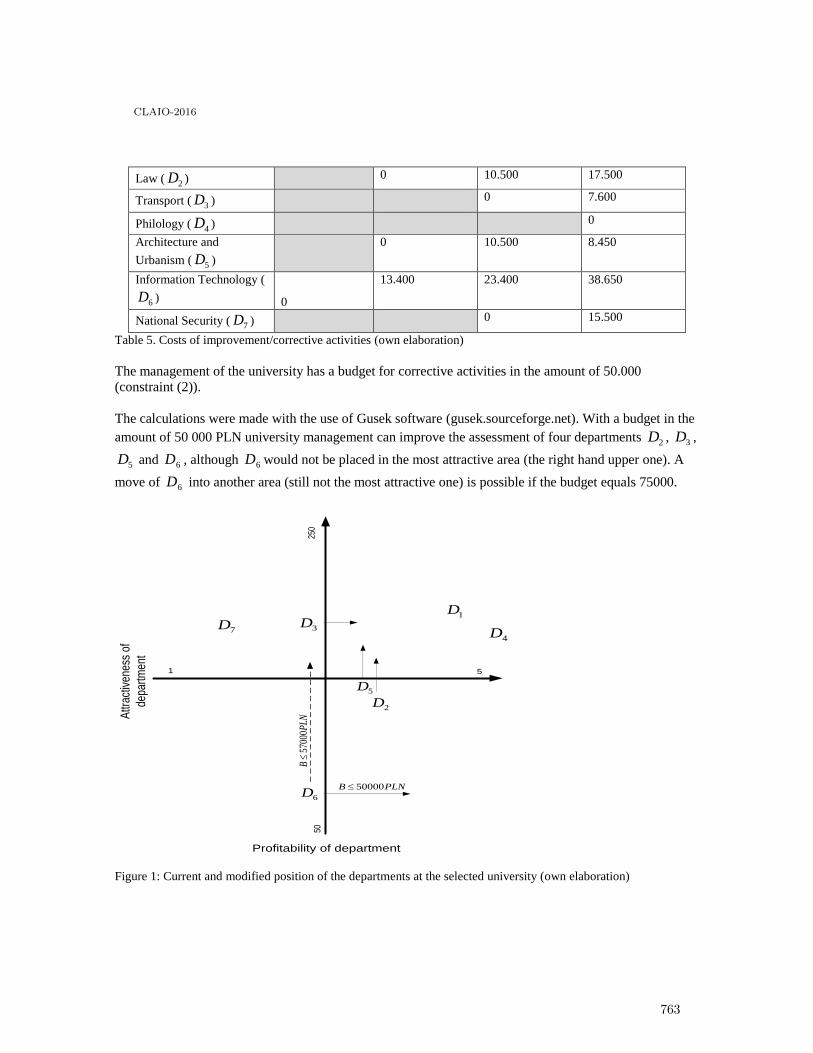
Law ( 2D ) 0 10.500 17.500
Transport ( 3D ) 0 7.600
Philology ( 4D ) 0
Architecture and
Urbanism ( 5D )
0 10.500 8.450
Information Technology (
6D ) 0
13.400 23.400 38.650
National Security ( 7D ) 0 15.500
Table 5. Costs of improvement/corrective activities (own elaboration)
The management of the university has a budget for corrective activities in the amount of 50.000
(constraint (2)).
The calculations were made with the use of Gusek software (gusek.sourceforge.net). With a budget in the
amount of 50 000 PLN university management can improve the assessment of four departments 2D , 3D ,
5D and 6D , although 6D would not be placed in the most attractive area (the right hand upper one). A
move of 6D into another area (still not the most attractive one) is possible if the budget equals 75000.
Profitability of department
Attr
activ
enes
s of
depa
rtm
ent
250
50
51
1D
2D
3D4D
5D
6D
7D
PLNB 50000
PLN
B57
000
Figure 1: Current and modified position of the departments at the selected university (own elaboration)
CLAIO-2016
763

With budget for corrective actions equal to 50 000 PLN, it is possible to attain the overall attractiveness equal to 87.5% of highest possible attractiveness. Increasing the budget to 75 000 PLN allows to increase
the overall profitability. The model can be modified and developed in cooperation with students, university
management and other stakeholders.
5 Conclusions
In the paper the application of portfolio strategic position analysis methods combined with the multiple
knapsack problem to the analysis of the current strategic position and its improvement possibilities of a
university is proposed. The university aspect is present here in the case study, but the idea proposed in
this paper can be easily extended to other organizations.
Whatever the organization type, further case studies are needed in order to find indications as far as the
collection of the model entry data and the dialog with stakeholders are concerned. Especially, it may be
difficult to determine the department cost and revenues, but also for example the overall opinion of
students. The students and their motivations are so diverse that aggregating them into one opinion may be
close to impossible. Thus, there is still much to be done as far the proposed approach is concerned, but it
seems that the further research and application work is worth doing.
References
1. S. Aldridge and J., Rowley. Measuring customer satisfaction in higher education. Quality Assurance in
Education, 6(4):197-204,1998.
2. M. Álvarez and S. Rodríguez. La calidad total en la universidad: ¿Podemos
hablar de clientes? Boletín de Estudios Económicos ,52(161):207–226, 1997.
3. L. Crumbley, B. Henry, S. Kratchman. Students’ perceptions of evaluation of college teaching. Quality
Assurance in Education, 9(4):197-207,2001;
4. A. Goddard, K. Ooi. Activity-Based Costing and Central Overhead Cost Allocation in Universities: A case
study. Public Money & Management, 18(3): 31-38,1998.
5. S. Haddadi, H. Ouzia. Effective Algorithm and Heuristic for the Generalized Assignment Problem. European
Journal of Operational Research, 153(1):184–190,2004.
6. L. Langbein. Management by results: Student evaluation of faculty teaching and the mis-measurement of
performance. Economics of Education Review, 27(4):417-2 2008.
7. S.J. Porth. Strategic Management: A Cross-Functional Approach, Pearson Education, Inc., Upper Saddle River,
New Jersey, 2003.
CLAIO-2016
764

Problema do Caixeiro Viajante Alugador com Passageiros: Uma
Abordagem Algorítmica
Gustavo de Araujo Sabry
Universidade Federal do Rio Grande do Norte
Campus Universitário, Lagoa Nova, Natal, RN
Marco Cesar Goldbarg
Universidade Federal do Rio Grande do Norte
Campus Universitário, Lagoa Nova, Natal, RN
Elizabeth Ferreira Gouvêa Goldbarg
Universidade Federal do Rio Grande do Norte
Campus Universitário, Lagoa Nova, Natal, RN
Resumo
O trabalho apresenta uma nova variante do Caixeiro Viajante denominada de Caixeiro Viajante
Alugador com Passageiros (PCV-AlPa) e descreve um algoritmo Memético e um algoritmo GRASP
(Greedy Randomized Adaptive Search Procedure) para sua solução. Os algoritmos desenvolvidos são
validados através de um experimento computacional e submetidos a uma análise estatística. Ao final são
tecidas conclusões sobre os resultados alcançados tanto em relação ao problema abordado e seu grau de
complexidade, quanto em relação ao desempenho dos algoritmos propostos.
Palavras-chave: Problema do Caixeiro Viajante Alugador com Passageiros; Algoritmo Memético;
GRASP.
1 Introdução
O Problema do Caixeiro Viajante (PCV) é um dos mais tradicionais e conhecidos na área de
programação matemática (APPLEGATE et al., 2006). É considerado um problema clássico na área de
Otimização Combinatória, consiste na procura de uma rota para um vendedor onde seja percorrida a
menor distância possível, começando em uma cidade qualquer, entre várias, visitando cada uma das
cidades uma única vez e regressando à cidade inicial.
CLAIO-2016
765

O PCV possui diversas variantes (ILAVARASI; JOSEPH, 2014). Duas variantes recentemente
relatadas na literatura são o Caixeiro Viajante Alugador (GOLDBARG et al., 2013; GOLDBARG;
ASCONAVIETA; GOLDBARG, 2011) e o Caixeiro Viajante com Caronas (CALHEIROS, 2015).
O Caixeiro Viajante Alugador é uma generalização do Caixeiro Viajante onde o caixeiro pode
alugar diferentes carros para percorrer a rota. Diferentes carros com diferentes características estão
disponíveis para alugar em cada cidade visitada pelo caixeiro. O caixeiro pode trocar um carro alugado
por outro sempre que julgar interessante. Cada diferente carro pode possuir um diferente custo de
operação em cada aresta do grafo de ligações do problema. Se o caixeiro optar por trocar o carro em uma
cidade diferente da cidade onde o carro foi alugado deverá pagar uma taxa de retorno do carro até a sua
cidade de origem. A taxa depende do carro e das cidades onde o carro foi alugado e retornado. O objetivo
do problema é minimizar os custos do caixeiro. Essa variante possui aplicação ao turismo.
O Caixeiro Viajante com Passageiros (ou caronas) é uma versão do PCV em que o caixeiro
cumpre sua rota tendo a possibilidade de dividir despesas com eventuais passageiros que embarquem
oportunisticamente. O carro do caixeiro possui uma capacidade máxima para o transporte de passageiros.
Se um passageiro é embarcado, deve ser obrigatoriamente desembarcado em seu destino. O valor máximo
que o passageiro está disposto a pagar pela viagem é limitado em função de algum critério associado ao
trajeto realizado pelo passageiro. O valor pago por qualquer participante da rota é obtido pela soma do
rateio das despesas nos arcos que o participante percorra embarcado. As despesas são divididas de modo
equitativo pelos ocupantes do carro em cada arco e o caixeiro é considerado um ocupante e participa da
divisão como se um passageiro fosse. O objetivo do problema é minimizar os custos do caixeiro. Essa
variante possui aplicação na otimização de sistemas de ridersharing, atualmente em ampla expansão no
mundo (AGATZ et al. 2012).
O PCV-AlPa une as características do Caixeiro Viajante Alugador com as descritas no Caixeiro
Viajante com Passageiros. Pode ser entendido como uma variação do Caixeiro Alugador onde o caixeiro
vai reduzir suas despesas tanto pelo uso combinado de diferentes carros alugados quanto pela otimização
da ocupação dos assentos no carro alugado. O objetivo do caixeiro continua sendo realizar sua viagem
gastando o mínimo possível. Como herança dos problemas que compõem o caso, a capacidade do veículo
alugado, a taxa de retorno de cada carro trocado e as restrições de custos e de embarque e desembarque
dos passageiros devem ser atendidas.
O item 2 do presente trabalho descreve o problema do Caixeiro Alugador com Passageiros. O
item 03 descreve um algoritmo evolucionário de solução. O item 04 descreve um algoritmo GRASP de
solução. O item 05 relata um experimento computacional para a análise de desempenho dos algoritmos. O
item 06 relata as conclusões e trabalhos futuros.
2 Descrição do Problema
O objetivo do PCV-AlPa é encontrar, em um grafo G=(N, M) onde N={1,...,n} modela o conjunto
de vértices do grafo, ou localidades e M = {1,...,m} o conjunto de arestas ou ligações rodoviárias, o ciclo
Hamiltoniano que resulte na menor despesa para o caixeiro. O caixeiro paga para percorrer uma dada
aresta de seu ciclo, o valor necessário para que o carro alugado percorra tal aresta (custos que envolvem o
combustível, o aluguel do carro, eventual pedágio e outros) dividido pelo número de pessoas que estão no
carro por ocasião do tráfego pela mesma. O caixeiro paga, adicionalmente e sem rateio com os
CLAIO-2016
766

passageiros, uma taxa de retorno de cada carro alugado em uma cidade i e eventualmente entregue em
uma cidade j, com j≠i, i,jN. O número de passageiros transportados no carro não pode exceder, em cada
aresta, a capacidade do carro que percorre a aresta. Nenhum passageiro k pode ter uma despesa total de
deslocamento obtida no rateio entre a cidade de embarque i e a cidade de desembarque j maior que lijk, um
valor conhecido para k, e para o par i-j. Um passageiro embarcado somente pode ser desembarcado em
sua cidade de destino. Todos os passageiros embarcados devem ser desembarcados em alguma cidade da
rota do caixeiro. Em todas as cidades do grafo G existe um passageiro que pode ser embarcado. Em todas
as cidades de G existem s diferentes tipos de carros que podem ser alugados. Em todas as cidades de G
qualquer carro alugado pode ser devolvido. Não é possível alugar mais de uma vez um mesmo tipo de
carro.
3 Algoritmo Memético para o PCV-AlPa
Os algoritmos evolucionários são eficientes ferramentas para a solução de problemas da classe
NP-Difícil. Dentre os mais tradicionais algoritmos evolucionários destacam-se os Algoritmos Genéticos
(AGs) (WHITLEY; SUTTON, 2012) e os Algoritmos Genéticos Híbridos / Meméticos (NERI; COTTA,
2012). Na classe dos AGs híbridos, os denominados Algoritmos Meméticos (AM) são uma variante já
reconhecida como promissora pelo estado da arte (ONG; KEANE, 2004). Para a classe do Caixeiro
Alugador, o desempenho promissor dos algoritmos evolucionários é confirmado (GOLDBARG;
ASCONAVIETA; GOLDBARG, 2011). Em razão disso, o presente tópico relata um algoritmo
evolucionário para o PCV-AlPa. O Algoritmo Memético implementado (MCARs) segue a arquitetura
geral do quadro 01.
Algoritmo MCARs Início 01 Gerar uma população inicial 02 Avaliar a fitness dos indivíduos da população 03 Para i = 1, ..., NUM_ITERACOES faça 04 Selecionar um conjunto de pais na população 05 Cruzar os pais de modo que se reproduzam 06 Avaliar a fitness dos filhos gerados 07 Substituir os filhos julgados inadequados 08 Realizar mutação 09 Realizar busca local 10 Fim_para
Fim
Algoritmo da Definição dos Automóveis Início
01 Sol.carro[1] ← sorteioCarro (nCar)
02 qCar ← sorteiaQuantidadeDeCarros (nCar)
03 iCid ← sorteiaProximaTroca (nCid) 04 Para j = 2, ..., NUM_CIDADES faça
05 Sol.carro[j] ← Sol.carro[j-1] 06 Se j = iCid
07 Sol.carro[j] ← sorteioCarro (nCar)
08 iCid ← sorteiaProximaTroca (nCid) 09 Fim_se 10 Fim_para
Fim
Quadro 01 - Algoritmo Memético para o PCV-AlPa Quadro 02 - Algoritmo da Definição dos Automóveis
O passo 01 do quadro 01 é construtivo. A construção da rota inicia-se na cidade 1. A sequência
das cidades na rota é obtida com o método da roleta selecionado a próxima aresta e, consequentemente,
próxima cidade. Sorteiam-se aleatoriamente quantas trocas de carro serão realizadas e as cidades de troca.
Sorteiam-se aleatoriamente quais os tipos de carros que ocuparão os diferentes trechos da rota. O quadro
02 resume o processo. O embarque de passageiros ocorre segundo a sequência das cidades sorteando-se,
CLAIO-2016
767

aleatoriamente, se o passageiro embarca ou não. Verifica-se, na ocasião do embarque, a capacidade do
carro, se o destino do viajante ainda não foi visitado no percurso e a exigência da tarifa máxima. O passo
04 executa o número de reproduções induzidas pela taxa de reprodução. Os pais são selecionados de
forma aleatória na população. O passo 05 emprega um operador de recombinação com 1 ponto de quebra,
com a posição de quebra sorteada aleatoriamente no intervalo das posições 2 e n-1 do cromossomo. O
filhoA herda a primeira metade dos genes do paiA e segunda metade do paiB. Já o filhoB, herda a
primeira metade dos genes do paiB e a segunda metade do paiA. Os genes permutados referem-se às rotas
de visita. O procedimento de alocação de automóveis nas rotas formadas e de embarque de passageiros
segue o mesmo método construtivo da formação da população inicial. O passo 07 é realizado de forma
elitista, preservando os mais aptos da população. O passo 08 é um procedimento que pode antecipar ou
postergar aleatoriamente a troca dos automóveis na rota. Por exemplo, sendo as cidades 3, 4, 2 e 1 de uma
rota que é percorrida pelos carros A, A ,B e C. considerando que a taxa de mutação para seja igual a 1
cidade, a aplicação da mutação resultaria no estabelecimento das seguintes configurações viáveis de
antecipação: do carro B - ABBC, do carro C- AACC; E as seguintes configuração de adiamento: do carro
A - AAAC, do carro B - AABB. Após a reparação de embarque dos passageiros, o procedimento
seleciona a configuração que resulta no cromossomo de melhor fitness. O passo 09 é realizado com uma
busca local 2-Swap (APPLEGATE et al., 2006), trocando sistematicamente as cidades da rota, duas a
duas e preservando a melhor rota encontrada. Com a rota otimizada pela busca local, aplica-se um
procedimento para melhoria da configuração de carros na solução. O procedimento insere um novo
veículo na solução em substituição a um existente. Todos os carros fora da solução são considerados. O
novo carro é inserido em cada possível posição de forma iterativa. Por exemplo, em uma instância onde
os carros A, B, C, e D podem ser alugados. Considere-se uma solução com cinco cidades representadas
pelo tour (1,2,3,4,5) e uma distribuição inicial de carros na solução (B,B,C,C,D), onde o carro B é
alugado na cidade 1 e entregue na cidade 2 e assim por diante. O procedimento vai examinar a
possibilidade de inserção do carro A. A é inserido na cidade 1 resultando em (A,B,C,C,D), depois em
continuidade na posição 2, resultando em (A,A,C,C,D) e em (A,A,A,C,D) e assim por diante. Depois o
carro A substitui o segundo carro na solução, resultando em (B,B,A,C,D), (B,B,A,A,D) e assim por diante
até as demais possibilidades serem examinadas.
4 Algoritmo GRASP para o PCV-AlPa
A denominada meta-heurística GRASP (Greedy Randomized Adaptive Search Procedure) possui
várias aplicações na solução de problemas de otimização combinatória e, recentemente, conta com relatos
promissores para aplicação em roteamento de veículos enriquecidos (VILLEGAS et al., 2010). O
Algoritmo GRASP implementado seguiu o modelo exibido no Quadro 03.
O passo 1 algoritmo GRASP-AlPa cria um conjunto de 100 soluções através de um procedimento
de construção semelhante ao empregado pelo algoritmo MCARs para construção da população. O
conjunto será atualizado com as melhores soluções encontradas pelo GRASP. A diferença do
procedimento construtivo do GRASP-AlPa em relação ao procedimento do MCARs é que a escolha da
nova aresta a ser incluída na solução não considera todas as arestas possíveis incidentes na cidade.
Somente as p melhores arestas são relacionadas em uma Lista Restrita de Candidatos (LRC). O tamanho
da lista é reativo e controlado pela seguinte fórmula: p = 1 + α (λ - 1). Em que p é o número de
elementos, λ é o número total de arestas candidatas e α é um parâmetro que tem valores definidos no
intervalo [0, 1]. A nova aresta é selecionada pela roleta em LRC. O procedimento construtivo de MCARs
empregou α = 1. A etapa de busca local dessa construção está descrita no Quadro 04. No passo 04 do
quadro 03, o procedimento construtivo é diferente daquele usado para a população. Esse passo usa um
CLAIO-2016
768

valor de α adaptativo, onde para cada solução construtiva o valor de α é sorteado em uma roleta dentre os
valores de 0,2, 0,4, 0,6 ou 0,8. Caso a solução obtida venha a integrar o conjunto de elite, o valor de α
associado recebe mais um ponto para ponderar o sorteio da roleta. Cada iteração pode empregar,
consequentemente, um valor de α diferente. O passo 07 atualiza o conjunto de elite.
Algoritmo GRASP-AlPA Início 01 Gerar um conjunto de soluções 02 Avaliar a aptidão das soluções 03 Para i = 1, ..., NUM_ITERACOES faça 04 Gerar uma nova solução 05 Avaliar a aptidão da solução gerada 06 Realizar busca local 07 Remove a pior solução existente 08 Fim_para Fim
Algoritmo Busca Local Início
01 alvo ← selecionaMelhorSolucao() 02 Para i = 1, ..., NUM_SOLUCOES faça
03 base ← sol[i]
04 intermed1 ← herdaCidades (alvo, base)
05 intermed2 ← herdaCidades (base, alvo)
06 intermed1 ← reparaCidades (intermed1)
07 intermed2 ← reparaCidades (intermed2) 08 Definir carros para intermed1e intermed2 09 Embarcar passageiros em intermed1e intermed2 10 Realocar carros de em intermed1e intermed2 11 Realizar busca local 2-Swap em intermed1 e intermed2 12 Avaliar a qualidade das soluções geradas 13 Fim_para
Fim
Quadro 03 - Algoritmo GRASP para o PCV-AlPA Quadro 04 - Algoritmo de Busca Local
A busca local (ver Quadro 04) realiza as operações que se seguem: Passo 01: seleciona a melhor solução
do conjunto de elite denominada solução alvo. Passo 03: escolhe no conjunto uma solução denominada
base. Passo 04: intermed1 herda a primeira metade das cidades de alvo e a segunda metade das cidades de
base. Passo 05: intermed2 herda a primeira metade das cidades de base e a segunda metade de alvo. Passo
06 e 07: elimina possíveis rotas geradas com cidades repetidas, substituindo a mesma pela primeira cidade
da sequência que não tiver sido visitada. Passos 08, 09 e 11 como em MCARs. Passo 10 identifica todos
os pontos onde pode existir troca de automóveis e os automóveis que são utilizados no percurso. Realiza
as possíveis combinações (sequência de automóveis) dos veículos que são utilizadas no percurso e
possíveis alteração dos pontos de troca dos veículos de forma semelhante ao procedimento para melhoria
da configuração de carros do algoritmo MCARs, todavia apenas considerando os carros que participam da
solução. Preserva-se a solução de menor custo encontrada. Essa solução passa a ser a alvo e aplica-se a
busca local 2-Swap nas duas soluções geradas.
5 Experimento Computacional
Os experimentos computacionais utilizaram máquinas com processador i5 Core 3ª geração (2.60
GHz), com 8 GB de memória, as implementações foram feitas em C++, o compilador foi o Dev-C++ e o
sistema operacional foi o Windows 7 (64 bits).
CLAIO-2016
769

5.1 Instâncias
O experimento computacional utilizou as instâncias da biblioteca do PCV Alugador descrita em
(ASCONAVIETA, 2011) e disponibilizada no link http://www.dimap.ufrn.br/lae/projetos/CaRS.php. As
instâncias foram acrescidas da capacidade de cada automóvel, da origem e destino de cada passageiro
disponível na instância e do valor máximo de tarifa admissível para o passageiro. As instâncias foram
nomeadas da seguinte forma: Nome da Instância: BrasilRJ; Número de cidades: 14; Tipo da matriz de
distância (E- euclidiana, N – não euclidiana, Nb – não euclidiana b); Veículos e Capacidade (2,3,3 – total
de três veículos, um com capacidade 2 e dois com capacidade 3); Tarifa (t07 – tarifa máxima de 7% da
solução ótima do tour caixeiro alugador) representando a restrição financeira de cada passageiro e ao
destino de cada viajante.
5.2 Ajuste de Parâmetros
Os algoritmos Memético e GRASP tiveram o comportamento de seus parâmetros analisados em
um conjunto de 12 instâncias BrasilRJ com 14 cidades e 12 instâncias BrasilRN com 16 cidades. As
instâncias possuíam 2 diferentes carros com capacidade variando entre 3 e 4 passageiros. A taxa de tarifa
variou entre 7% e15% do valor da solução ótima do caixeiro alugador para a instância. Para o Algoritmo
Memético, foram examinadas 28 configurações variando os parâmetros da seguinte forma: Número de
Indivíduos (100 ou 200); Número de Iterações (50 ou 100); Taxa de Reprodução (0,1 ou 0,2); Taxa de
Mutação (0,1 ou 0,2) e Taxa de Busca Local (0,1 ou 0,2). Cada uma dessas configurações foi executada 5
vezes em um total de 3360 execuções. A configuração com a melhor média de resultados foi adotada:
População: 200; Número de Iterações: 50; Taxa de Reprodução: 0,2; Taxa de Mutação: 0,1e Taxa de
Busca Local: 0,1.
Para o GRASP, foram examinadas 10 configurações variando os parâmetros da seguinte forma:
Número de Iterações (50 ou 100) e Alfa (0,2, 0,4, 0,6, 0,8 ou Adaptativo). No procedimento adaptativo
para cada solução que irá compor a população inicial são geradas 4 soluções com alfas diferentes (0,2,
0,4, 0,6 e 0,8) e selecionado apenas o melhor. Cada configuração foi executada 5 vezes em um total de
1200 execuções. A configuração que obteve uma média melhor de resultados obtidos foi a seguinte:
Número de Iterações: 50 e Alfa: Adaptativo.
5.3 Resultados
Os algoritmos propostos foram executados 10 vezes para cada instância, anotando-se os tempos e
os resultados quantitativos alcançados em cada execução. A condição de parada foi 10% das iterações
sem melhorias da melhor solução da população ou do grupo de elite.
A tabela 01 exibe os resultados médios calculados nas 10 execuções. A análise das médias sugere
que o algoritmo GRASP, nesse conjunto de instâncias examinadas, obtém um notório e superior
desempenho em tempo de processamento, alcançando massivamente diferenças favoráveis, algumas da
ordem de 200 % a 300%.
Sob o aspecto qualitativo os resultados não são tão evidentes. Um teste estatístico
tradicionalmente utilizado para analisar o desempenho de dois conjuntos de resultados cuja distribuição
possui características desconhecidas é o teste de Mann-Whitney (1947), também conhecido como U-Teste
(CONOVER, 1999).
CLAIO-2016
770
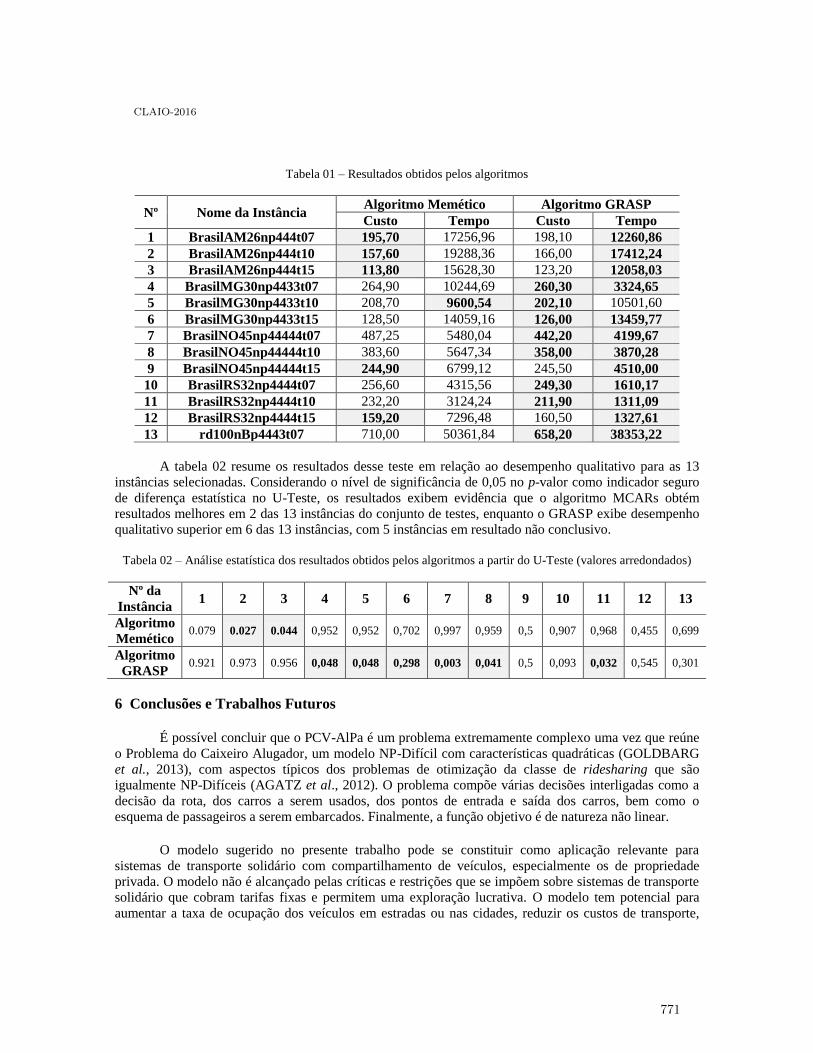
Tabela 01 – Resultados obtidos pelos algoritmos
Nº Nome da Instância Algoritmo Memético Algoritmo GRASP
Custo Tempo Custo Tempo
1 BrasilAM26np444t07 195,70 17256,96 198,10 12260,86
2 BrasilAM26np444t10 157,60 19288,36 166,00 17412,24
3 BrasilAM26np444t15 113,80 15628,30 123,20 12058,03
4 BrasilMG30np4433t07 264,90 10244,69 260,30 3324,65
5 BrasilMG30np4433t10 208,70 9600,54 202,10 10501,60
6 BrasilMG30np4433t15 128,50 14059,16 126,00 13459,77
7 BrasilNO45np44444t07 487,25 5480,04 442,20 4199,67
8 BrasilNO45np44444t10 383,60 5647,34 358,00 3870,28
9 BrasilNO45np44444t15 244,90 6799,12 245,50 4510,00
10 BrasilRS32np4444t07 256,60 4315,56 249,30 1610,17
11 BrasilRS32np4444t10 232,20 3124,24 211,90 1311,09
12 BrasilRS32np4444t15 159,20 7296,48 160,50 1327,61
13 rd100nBp4443t07 710,00 50361,84 658,20 38353,22
A tabela 02 resume os resultados desse teste em relação ao desempenho qualitativo para as 13
instâncias selecionadas. Considerando o nível de significância de 0,05 no p-valor como indicador seguro
de diferença estatística no U-Teste, os resultados exibem evidência que o algoritmo MCARs obtém
resultados melhores em 2 das 13 instâncias do conjunto de testes, enquanto o GRASP exibe desempenho
qualitativo superior em 6 das 13 instâncias, com 5 instâncias em resultado não conclusivo.
Tabela 02 – Análise estatística dos resultados obtidos pelos algoritmos a partir do U-Teste (valores arredondados)
Nº da
Instância 1 2 3 4 5 6 7 8 9 10 11 12 13
Algoritmo
Memético 0.079 0.027 0.044 0,952 0,952 0,702 0,997 0,959 0,5 0,907 0,968 0,455 0,699
Algoritmo
GRASP 0.921 0.973 0.956 0,048 0,048 0,298 0,003 0,041 0,5 0,093 0,032 0,545 0,301
6 Conclusões e Trabalhos Futuros
É possível concluir que o PCV-AlPa é um problema extremamente complexo uma vez que reúne
o Problema do Caixeiro Alugador, um modelo NP-Difícil com características quadráticas (GOLDBARG
et al., 2013), com aspectos típicos dos problemas de otimização da classe de ridesharing que são
igualmente NP-Difíceis (AGATZ et al., 2012). O problema compõe várias decisões interligadas como a
decisão da rota, dos carros a serem usados, dos pontos de entrada e saída dos carros, bem como o
esquema de passageiros a serem embarcados. Finalmente, a função objetivo é de natureza não linear.
O modelo sugerido no presente trabalho pode se constituir como aplicação relevante para
sistemas de transporte solidário com compartilhamento de veículos, especialmente os de propriedade
privada. O modelo não é alcançado pelas críticas e restrições que se impõem sobre sistemas de transporte
solidário que cobram tarifas fixas e permitem uma exploração lucrativa. O modelo tem potencial para
aumentar a taxa de ocupação dos veículos em estradas ou nas cidades, reduzir os custos de transporte,
CLAIO-2016
771

minimizar impactos ambientais devidos à poluição introduzida pelos carros, melhorar o conforto dos
passageiros, bem como diminuir engarrafamentos e áreas ocupadas por estacionamento de carros.
Os resultados do experimento computacional realizado sobre um banco de instâncias de 13 casos
teste sugere que o algoritmo GRASP descrito no trabalho possui um potencial promissor para ser
considerado como uma fonte de inspiração para futuros e mais eficientes algoritmos de solução do
problema. A eficiência em tempo de processamento destaca-se. Observe-se que o algoritmo de
comparação emprega boas técnicas da computação evolucionária, usa estruturas de busca local
semelhante às empregadas no próprio GRASP e foi parametrizado em um experimento que usou
significativos recursos computacionais. A alteração do parâmetro α ao longo das iterações do GRASP,
realizado em função dos resultados obtidos na busca, revelou-se igualmente promissora no sentido de
tornar mais eficiente a emergência de solução de boa qualidade.
Sugere-se como trabalhos futuros o desenvolvimento de algoritmos com base em swarm
intelligence no sentido de explorar a possibilidade de descentralização das diversas decisões que são
exigidas no modelo. Ainda se sugere que sejam solucionadas instâncias de maior porte que 100 cidades,
mesmo diante da notável explosão combinatória que se verifica.
Referências Bibliográficas
1. AGATZ, N.A.H.; ERERA, A.; SAVELSBERGH, M.W.P.; WANG, X. Optimization for dynamic
ridesharing: A review. European Journal of Operational Research 223(2):29-303.2012.
2. APPLEGATE, D. L.; BIXBY, R. M.; CHVÁTAL, V.; & COOK, W. J. (2006), The Traveling Salesman
Problem. Princeton University Press. 2006.
3. CALHEIROS, Z. S. A. Algoritmos Evolucionários na Solução do Caixeiro Viajante com Caronas. Trabalho
de Conclusão do Curso de Bacharelado em Ciência da Computação - Universidade Federal do Rio Grande do
Norte, 2015.
4. CONOVER, W. J. Practical nonparametric statistics. John Wiley & Sons. 2001.
5. GOLDBARG, M. C.; GOLDBARG, E. F. G.; MENEZES, M. S.; LUNA, H. P. L. A transgenetic algorithm
applied to the Traveling Car Renter Problem. Expert Systems with Applications, 40:6298-6310. 2013.
6. GOLDBARG, M. C.; ASCONAVIETA, P. H. S.; GOLDBARG, E. F. G. Memetic algorithm for the
Traveling Car Renter Problem: an experimental investigation. Memetic Computing, X3:X1-X21. 2011.
7. ILAVARASI; K.; JOSEPH, K. S. Variants of travelling salesman problem: A survey, In: International
Conference on Information Communication and Embedded Systems (ICICES), 1-7. 2014
8. MANN, H.B. WHITNEY, D.R. On a test of Whether one of two random variable is stochastically larger
than the other. Annals of Mathematical Statistics 18:50-60. 1947
9. NERI, F.; COTTA, C. Memetic algorithms and memetic computing optimization: A literature review,
Swarm and Evolutionary Computation 2:1-14.2012.
10. ONG, Y-S.; KEANE, A.J. Meta-lamarckian learning in memetic algorithms. IEEE Transactions on
Evolutionary Computation, 8(2):99–110. 2004.
11. VILLEGAS, J. G.; PRINS, C.; PRODHON, C.; MEDAGLIA, A. L.; & VELASCO, N. GRASP/VND and
multi-start evolutionary local search for the single truck and trailer routing problem with satellite depots,
Engineering Applications of Artificial Intelligence 23(5):780-794, 2010.
12. WHITLEY, D.; & SUTTON, A. M. Genetic Algorithms – A Survey of Models and Methods, Handbook of
Natural Computing, 637-671. 2012.
CLAIO-2016
772

Las prioridades competitivas de las PYMES en Quito-
Ecuador, analizadas conforme a la Administración de
Operaciones
Hernán W. Samaniego Guevara
particular
Resumen
La Innovación Empresarial, como todo ciclo de Gestión, requiere de una fase de
evaluación que permita conocer el estado de cualquier Empresa y posibilite efectuar cambios para mejorar su administración y gestión. Dichas empresas por más pequeñas
que sean, como por ejemplo una pequeña y mediana empresa (PYMES) busca la manera
de permanecer en el tiempo, lo cual pueden lograrlo si optimizan sus recursos e incluso
pueden obtener un incremento en sus utilidades.
El trabajo que se plantea a consideración es la determinación de las prioridades
competitivas de las PYMES en Quito-Ecuador; acorde a uno de los modelos establecidos por la administración de operaciones, el mismo que busca analizar qué aspectos de estas
empresas pueden ser considerados como prioridades para competir con empresas de
similares características o superiores en aspectos como producción, personal, etc.
Estas prioridades son especificadas con base en un estudio efectuado en las PYMES de la
zona geográfica indicada, en el que se pretende determinar cuáles son los factores
principales competitivos que este tipo de empresas utilizan para la ejecución de sus
actividades normales de trabajo.
Palabras Claves: PYMES, prioridades competitivas, administración de operaciones
Abstract
Business Innovation, as all cycle management requires an evaluation phase that allows
knowing the status of any company and making it possible to make changes to improve
its administration and management. Those for smaller companies that are, such as a small and medium enterprises (SMEs) seeking ways to stay in time, which can achieve it by
optimizing their resources and thus can even get an increase in profits.
The work that arises for consideration is the determination of competitive priorities of
SMEs in Quito-Ecuador; according to one of the models set by the administration of
operations, the same that seeks to analyze what aspects of these companies can be considered as priorities for companies compete with similar characteristics or higher in
areas such as production, personnel, etc.
CLAIO-2016
773

These priorities are specified based on a study in SMEs in the geographical area
indicated, in which it is intended to determine the main competitive factors such
companies used to execute their normal work activities.
Keywords: SMEs, competing priorities, operations management
1 Introducción
Cuando se desea especificar el campo de acción de la Administración de Operaciones, se
visualiza que el mismo es amplio y puede ser estudiado tanto en empresas dedicadas a la prestación de servicios como a la elaboración de productos; existen varios caminos para
obtener una aplicabilidad de la administración de operaciones; ante esto surge la pregunta
¿Cómo la administración de operaciones puede ayudar en la administración de las PYMES?
Para responder esta duda, se desea conocer o investigar la forma que dichas PYMES aplican esta ciencia en sus campos de servicio o producción; pero analizadas desde un
modelo establecido por Heizer, J., Render, B. (2009), quienes señalan que toda empresa
sea de bienes o servicios dispone de procesos internos establecidos conforme a la
existencia de: marketing, producción y/u operaciones; finanzas-contabilidad.
Dicho modelo en la ciudad de Quito-Ecuador puede ser aplicado a todo tipo de empresas,
en este caso a las PYMES, y constituye un camino para determinar las prioridades competitivas que les afecta directamente en la producción de bienes o generación de
servicios.
2 Descripción del problema
La administración de operaciones según Krajewski, L., Ritzman, L., Malhotra, M., (2013) es una ciencia que se refiere “al diseño, dirección y control sistemático de los procesos
que transforman insumos en servicios y productos para los clientes”, en otras palabras la
administración de operaciones busca que los procesos de una empresa se encuentren
relacionados entre sí, permitiendo obtener los mayores ingresos con la utilización de la menor cantidad de recursos.
La aplicación de la administración de operaciones puede lograr resultados satisfactorios si la misma es utilizada de manera correcta a las necesidades que puede requerir cualquier
empresa; esta ciencia puede ser replicada en empresas de cualquier tamaño, por ende
también en PYMES de Quito-Ecuador.
Las PYMES en el Ecuador se originaron conforme a las necesidades de la sociedad, para
estructurar pequeñas organizaciones en busca de lograr objetivos comunes. Criterio que
es apoyado por Zamora y Villamar (2010, pág. 25) “En los años cincuenta y sesenta del
CLAIO-2016
774
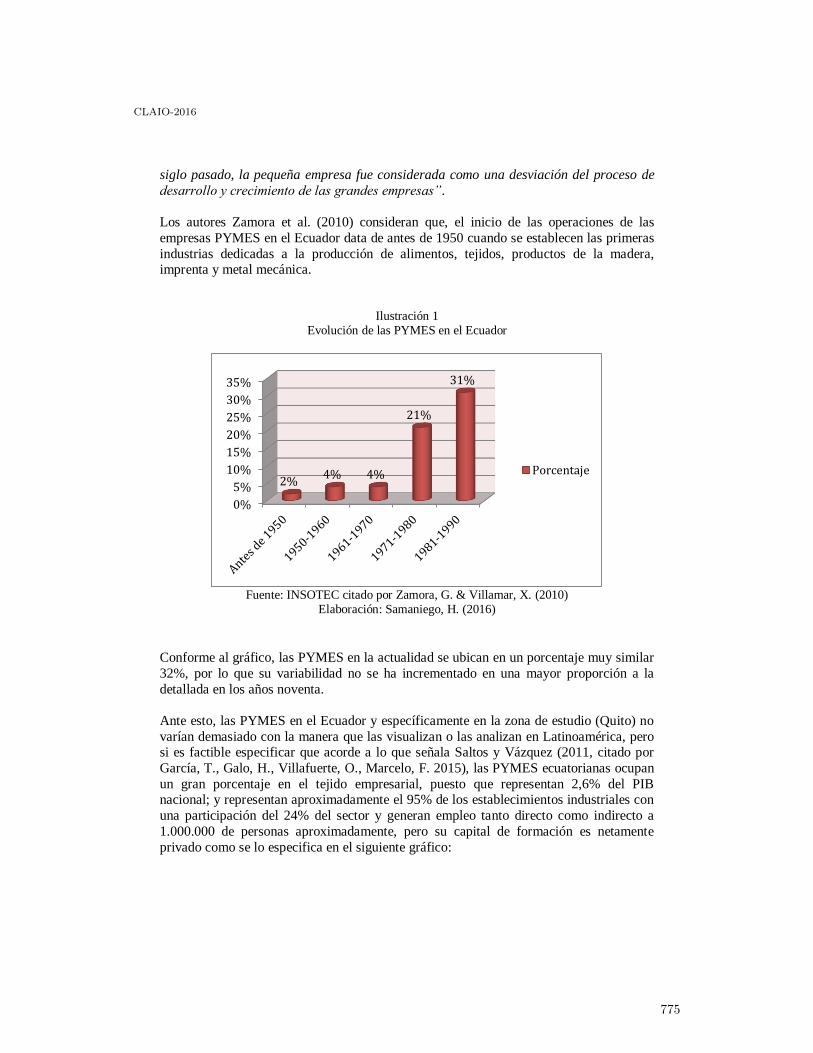
siglo pasado, la pequeña empresa fue considerada como una desviación del proceso de
desarrollo y crecimiento de las grandes empresas”.
Los autores Zamora et al. (2010) consideran que, el inicio de las operaciones de las
empresas PYMES en el Ecuador data de antes de 1950 cuando se establecen las primeras
industrias dedicadas a la producción de alimentos, tejidos, productos de la madera, imprenta y metal mecánica.
Ilustración 1
Evolución de las PYMES en el Ecuador
Fuente: INSOTEC citado por Zamora, G. & Villamar, X. (2010)
Elaboración: Samaniego, H. (2016)
Conforme al gráfico, las PYMES en la actualidad se ubican en un porcentaje muy similar
32%, por lo que su variabilidad no se ha incrementado en una mayor proporción a la
detallada en los años noventa.
Ante esto, las PYMES en el Ecuador y específicamente en la zona de estudio (Quito) no
varían demasiado con la manera que las visualizan o las analizan en Latinoamérica, pero si es factible especificar que acorde a lo que señala Saltos y Vázquez (2011, citado por
García, T., Galo, H., Villafuerte, O., Marcelo, F. 2015), las PYMES ecuatorianas ocupan
un gran porcentaje en el tejido empresarial, puesto que representan 2,6% del PIB nacional; y representan aproximadamente el 95% de los establecimientos industriales con
una participación del 24% del sector y generan empleo tanto directo como indirecto a
1.000.000 de personas aproximadamente, pero su capital de formación es netamente
privado como se lo especifica en el siguiente gráfico:
0%
5%
10%
15%
20%
25%
30%
35%
2% 4% 4%
21%
31%
Porcentaje
CLAIO-2016
775
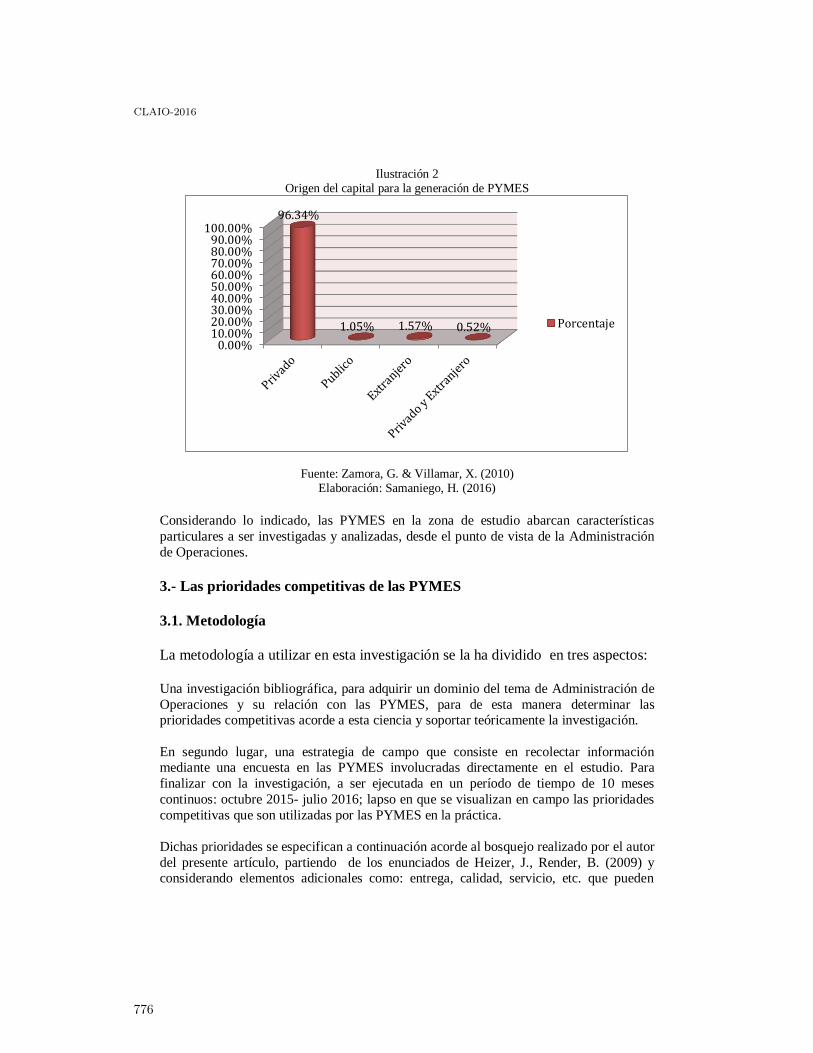
Ilustración 2
Origen del capital para la generación de PYMES
Fuente: Zamora, G. & Villamar, X. (2010) Elaboración: Samaniego, H. (2016)
Considerando lo indicado, las PYMES en la zona de estudio abarcan características
particulares a ser investigadas y analizadas, desde el punto de vista de la Administración
de Operaciones.
3.- Las prioridades competitivas de las PYMES
3.1. Metodología
La metodología a utilizar en esta investigación se la ha dividido en tres aspectos:
Una investigación bibliográfica, para adquirir un dominio del tema de Administración de
Operaciones y su relación con las PYMES, para de esta manera determinar las prioridades competitivas acorde a esta ciencia y soportar teóricamente la investigación.
En segundo lugar, una estrategia de campo que consiste en recolectar información mediante una encuesta en las PYMES involucradas directamente en el estudio. Para
finalizar con la investigación, a ser ejecutada en un período de tiempo de 10 meses
continuos: octubre 2015- julio 2016; lapso en que se visualizan en campo las prioridades
competitivas que son utilizadas por las PYMES en la práctica.
Dichas prioridades se especifican a continuación acorde al bosquejo realizado por el autor
del presente artículo, partiendo de los enunciados de Heizer, J., Render, B. (2009) y considerando elementos adicionales como: entrega, calidad, servicio, etc. que pueden
0.00%10.00%20.00%30.00%40.00%50.00%60.00%70.00%80.00%90.00%
100.00%96.34%
1.05% 1.57% 0.52% Porcentaje
CLAIO-2016
776

formar parte de esta relación; y ser factores que toda empresa sea grande o pequeña debe
considerar:
Ilustración 3
Relación de factores acorde a la Administración de Operaciones
Producción y Operaciones
Entrega Calidad Servicio Procesos Internos
Marketing Publicidad Comunicación
tradicional Estrategias Comunicación
WEB
Finanzas Precio Costos Estados
financieros Rendimientos
financieros
Fuente: Heizer, J., Render, B. (2009)
Elaboración: Samaniego, H. (2016)
Se conoce por estudios efectuados por la Cámara de Pequeños y Medianos Industriales de Pichincha (CAPEIPI, 2013) que el número de PYMES, es de 388, ante esto, se determina
un número específico de muestra a ser utilizado sobre el cual se aplica la encuesta
diseñada. Esta encuesta es validada acorde a la metodología alfa de Cron Bach para determinar su fiabilidad y consistencia.
Esta encuesta es aplicada a personas con las características determinadas en la tabla
siguiente:
Tabla 1
Características de la Población a ser encuestada
Cargo Empresa Perfil
Accionistas,
Gerentes,
Administradores
y Jefes de
PYMES
PYMES de servicios
conforme a los sectores
especificados por la CAPEIPI
(alimenticio, construcción,
gráfico, maderero,
metalmecánico, químico y
textil)
Ingenieros, licenciados, tecnólogos,
bachilleres con una experiencia de
dos (02) años en la administración
de PYMES ubicadas en Quito-
Ecuador
Fuente: Linares, J. & Geizzelez, M. (2007)
Elaboración: Samaniego, H. (2016)
CLAIO-2016
777

Esta investigación se sujeta a dar respuesta a los siguientes objetivos:
Especificar las prioridades competitivas de las PYMES en el Ecuador
Determinar si estas prioridades competitivas pueden permanecer en el tiempo
4 Resultados
El principal resultado a ser alcanzado a través de esta investigación, es la determinación de las prioridades competitivas acorde a la Administración de Operaciones, que las
PYMES consideran como primordiales para su posicionamiento en el mercado de la
ciudad de Quito-Ecuador. Estas prioridades, están en función de lo que actualmente utilizan dichas empresas para ejecutar sus actividades o tareas.
De la misma manera, utilizando los datos encontrados en esta investigación es factible determinar cómo estas prioridades podrán variar o modificarse en el tiempo, mediante la
generación de un modelo de simulación basado en dinámica de sistemas y con la
utilización del sistema informático Vensim.
Esta simulación estará en concordancia a los principios establecidos en la Administración
de Operaciones y será ejecutada conforme a los resultados alcanzados en una empresa
considerada como PYMES, con lo cual se podrá determinar si las prioridades competitivas identificadas, en un futuro seguirán siendo las mismas o cambiarán
conforme les afecte en su posicionamiento o desarrollo empresarial.
5. Referencias
1. Cámara de la Pequeña y Mediana Empresa de Pichincha (2015). Análisis información Censo CAPEIPI 2013. Recuperado el 19, 20 y 21 de junio 2015 del sitio Web www.capeipi.org.ec
2. García, T., Galo, H., Villafuerte, O., Marcelo, F. (2015). Las restricciones al financiamiento
de las PYMES en el Ecuador y su incidencia en la política de inversiones. Actualidad
contable FACES Año 18 número 30 págs. 49-73 [Fecha de consulta: 22 de marzo de 2016]
Disponible en: http://www.saber.ula.ve/bitstream/123456789/40593/1/articulo3
3. Heizer, J., Render, B. (2009). Principios de administración de operaciones. México: Pearson Educación
4. Krajewski, L., Ritzman, L., Malhotra, M., (2013). Administración de operaciones. Procesos y
cadena de suministros. México: Pearson Educación
5. Linares, A., y Geizzelez, L. (2007). Administración de proyectos en ingeniería del software.
Telos, Sin mes, 26-41. (Sin mes): [Fecha de consulta: 3 de julio de 2015] Disponible
en:<http://www.redalyc.org/articulo.oa?id=99314566002>
6. Pérez, A. (2006). Estudio de las prioridades competitivas de la estrategia de operaciones de
las PYMI en Venezuela Volumen 6, No 1 (Nueva serie) páginas 107-126. [Fecha de consulta:
21 de marzo de 2016] Disponible https://dialnet.unirioja.es/servlet/articulo?codigo=4000855
7. Zamora, G. y Villamar, X. (2010). Caracterización de la PYME en la industria
manufacturera del distrito metropolitano de Quito. Quito: Centro de Publicaciones PUCE
CLAIO-2016
778

Un modelo de inventario con roturas, asumiendo que
la demanda depende exponencialmente del precio y
potencialmente del tiempo
Luis Augusto San-José NietoIMUVA, Departamento de Matemática Aplicada, Universidad de Valladolid, España
Joaqúın Sicilia RodŕıguezDpto. de Mat., Estad. e Investigación Operativa, Universidad de La Laguna, España
Manuel González de la RosaDpto. de Dirección de Empresas e Hist. Económica, Universidad de La Laguna, España
Jaime Febles AcostaDpto. de Dirección de Empresas e Hist. Económica, Universidad de La Laguna, España
Resumen
En este trabajo se analiza un modelo EOQ de inventario para art́ıculos con patrón de de-manda dependiente tanto del precio de venta como del tiempo. Más concretamente, se consideraque la tasa de demanda combina multiplicativamente los efectos de una función exponencial delprecio unitario de venta y el patrón de demanda potencial. Además, se admite la posibilidadde escasez o rotura del stock. El objetivo es determinar el tamaño óptimo del lote, la longitudóptima del ciclo y el precio óptimo de venta que maximizan los beneficios por unidad de tiempo.Se desarrolla un procedimiento para determinar la solución óptima del problema en función delas diferentes combinaciones de valores de los parámetros del modelo.
Palabras clave: Modelos EOQ; Patrón de demanda dependiente del precio y del tiempo; Roturadel stock.
1. Introducción
En cualquier empresa u organización que se dedique a distribuir art́ıculos a otras empresas o biensuministrarlos directamente a los clientes, uno de los principales objetivos consiste en establecerla cantidad suficiente de productos en stock, para atender la demanda de los clientes a un precioaceptable y dentro de un periodo de tiempo razonable.
En general, esta demanda de art́ıculos no es constante sino que fluctúa con el tiempo por causasexternas debidas a las incidencias en los mercados. Por ello, el control del stock de productos es
CLAIO-2016
779

una actividad dinámica que requiere la revisión continua de los métodos operacionales para reflejarlos posibles cambios. Como consecuencia, los sistemas de inventarios deben adecuarse a nuevassituaciones aplicando en todo momento las poĺıticas de inventarios más eficientes.
La administración y gestión de los inventarios busca controlar el nivel de stock disponible delos productos, de forma que se cubra la demanda de los clientes invirtiendo para ello el menorcoste posible. En dicho control, se trabaja con modelos matemáticos que permiten representar laspropiedades de los sistemas de inventarios y determinar las mejores poĺıticas que deben aplicarsepara la correcta gestión de los inventarios.
En el presente trabajo se estudia un modelo de inventario donde se busca determinar la cantidadeconómica de pedido para productos con demanda dependiente del tiempo y del precio de venta delart́ıculo. La tasa de demanda es una función potencial del tiempo y recoge también una dependenciaexponencial del precio del art́ıculo. Se permite la existencia de roturas o falta de existencias. Sepretende determinar la poĺıtica óptima de gestión de inventarios de forma que se maximice elbeneficio por unidad de tiempo, representado éste como la diferencia entre los ingresos derivadosde la venta del producto y los costes de compra, mantenimiento, rotura y reposición del art́ıculo.Teniendo en cuenta lo anterior se desarrolla un procedimiento para la determinación del tamañodel lote óptimo, el periodo de gestión y el precio óptimo del producto.
El resto del trabajo se organiza de la forma siguiente. En la segunda sección se establecen laspropiedades del sistema de inventario a estudiar y se presenta la notación que seguiremos a lolargo del trabajo. Posteriormente, se determina el nivel de inventario como función del tiempo ydel precio del producto y se formula el problema de optimización a resolver relativo a la gestióndel inventario. En la cuarta sección se presentan algunos resultados que permiten determinar unprocedimiento algoŕıtmico para obtener la poĺıtica óptima de inventario. Luego, se introducenalgunos ejemplos numéricos que permiten visualizar la aplicación del procedimiento de optimizacióndescrito previamente. Finalmente, en las conclusiones, se sintetizan las principales aportaciones deeste trabajo y se presentan posibles trabajos futuros dentro del área de la gestión de los inventarios.
2. Hipótesis y notación
El modelo matemático asociado al sistema de inventario que se estudia en este trabajo se basaen las siguientes hipótesis:
1. El inventario es de un solo art́ıculo y no se consideran órdenes conjuntas con otros productos.
2. El horizonte de planificación es infinito y el plazo de reabastecimiento es cero.
3. El control del inventario se realiza mediante un sistema de revisión continua.
4. La demanda por unidad de tiempo λ(s, t) es una función dependiente del tiempo y del preciounitario de venta. Se supone que λ(s, t) = λ1(s)λ2(t), siendo λ1(s) una función exponencialdel precio y λ2(t) una función potencial del tiempo. Es decir, la tasa de demanda combinamultiplicativamente los efectos del precio de venta y un patrón potencial de demanda. Elpatrón potencial de demanda fue introducido por Naddor [4] y ha sido utilizado por diversosautores en los últimos años (ver, por ejemplo, Mishra et al. [3], Rajeswari e Indrani [5], Siciliaet al. [6, 7], Singh y Kumar [8] y Tripathi [10]). La suposición de demanda exponencialmentedependiente del precio ha sido ya utilizada anteriormente en la literatura (ver, por ejemplo,Hanssens y Parsons [1], Jeuland y Shugan [2] y Song et al. [9]).
CLAIO-2016
780

Tabla 1. Notación
q Tamaño del lote o cantidad a pedir (> 0)T Longitud del ciclo de inventario (> 0, variable de decisión)τ Longitud del intervalo de cada ciclo de inventario con existencias (≥ 0)Ψ Longitud del intervalo de cada ciclo con escasez, es decir, Ψ = T − τ (≥ 0)M Nivel máximo de inventario (≥ 0, variable de decisión)b Nivel máximo de escasez por ciclo (≥ 0)K Coste de realizar un pedido (> 0)p Coste unitario de compra (> 0)h Coste unitario de almacenamiento por unidad de tiempo (> 0)ω Coste de escasez por unidad servida con retraso y por unidad de tiempo (> 0)s Precio unitario de venta (s ≥ p, variable de decisión)λ(s, t) Demanda en el tiempo t cuando el precio de venta es s, para 0 < t < TI(s, t) Nivel de inventario en el tiempo t cuando el precio de venta es s, para 0 ≤ t < T
n Índice del patrón potencial de demanda (> 0)B(s,M, T ) Beneficio total por unidad de tiempo
5. Se acepta la situación de escasez o rotura del stock. La demanda no atendida en el periodode escasez se cubre con la llegada de la siguiente reposición.
6. Los pedidos de reabastecimiento se realizan cuando la escasez acumulada alcanza un deter-minado nivel b y la cantidad pedida q es siempre la misma.
7. El coste unitario de compra es conocido y constante.
8. El coste de realizar un pedido es constante e independiente del tamaño del pedido.
9. El coste de almacenamiento es una función lineal basada en el inventario medio.
La notación que utilizaremos a lo largo del trabajo se muestra en la Tabla 1.
3. Modelo matemático
En este trabajo se considera un sistema de inventario con revisión continua sobre un horizontede planificación infinito en el que toda la demanda durante el periodo de escasez se sirve con retraso.En consecuencia, el nivel de inventario I(s, t) es una función periódica de periodo T continua en elintervalo (0, T ). En ese intervalo, el nivel de inventario decrece debido a la demanda y, por tanto,viene dado por
I(s, t) = M −∫ t
0λ(s, u)du =
∫ τ
tλ(s, u)du = λ1(s)
∫ τ
tλ2(u)du. (1)
Supondremos que λ1(s) es la función exponencial dada por
λ1(s) = αe−βs, con α > 0 y β > 0, (2)
donde α puede interpretarse como el máximo nivel posible de demanda y β es un coeficiente desensibilidad al precio, y λ2(t) es la función potencial dada por
CLAIO-2016
781

λ2(t) =1
n
(t
T
)(1−n)/n
, con n > 0. (3)
Por tanto,
I(s, t) = αe−βsT
[(τ
T
)1/n
−(t
T
)1/n]
= M − αe−βsT(t
T
)1/n
, (4)
donde el nivel máximo de inventario es
M = αe−βsT(τ
T
)1/n
. (5)
Luego el nivel máximo de escasez por ciclo es
b =
∫ T
τλ(s, u)du = αe−βsT −M (6)
y la cantidad a pedir o tamaño del lote es
q = M + b = αe−βsT. (7)
Teniendo en cuenta las hipótesis anteriores, el beneficio por ciclo P (s,M, T ) se obtiene comola diferencia entre los ingresos (por ciclo) y la suma de los costes de reabastecimiento, compra,almacenamiento y escasez. Los ingresos por ciclo son sq, el coste de reabastecimiento es K, loscostes de compra son pq, el coste de almacenamiento es
h
∫ τ
0I(s, t)dt =
αe−βs
n+ 1hT 2
(τ
T
)1+1/n
=h
n+ 1TM
(eβsM
αT
)n(8)
y el coste de escasez está dado por
ω
∫ T
τ[−I(s, t)] dt = ω
[n
n+ 1αe−βsT 2 −MT +
1
n+ 1TM
(eβsM
αT
)n]. (9)
En consecuencia, el beneficio por unidad de tiempo es
B(s,M, T ) =P (s,M, T )
T=
1
T
[(s− p)q −K − h
∫ τ
0I(s, t)dt+ ω
∫ T
τI(s, t)dt
]
= (s− p)αe−βs − K
T− h+ ω
n+ 1M
(eβsM
αT
)n− n
n+ 1ωαe−βsT + ωM
Aśı, el problema de optimización que debe resolverse está dado por
máx(s,M,T )∈Ω
B(s,M, T ), (10)
donde Ω ={
(s,M, T ) : T > 0, 0 ≤M ≤ αe−βsT y p ≤ s}
.
CLAIO-2016
782

4. Análisis del problema
Para un valor fijo de s, la función bivariante Bs(M,T ) = B(s,M, T ) es estrictamente cóncavay alcanza su valor máximo en el punto (M∗(s), T ∗(s)) que se obtiene resiolviendo las ecuaciones∂∂MBs(M,T ) = 0 y ∂
∂TBs(M,T ) = 0. Es decir,
T ∗(s) =
√√√√√(n+ 1)Keβs
nωα
(1−
(ω
h+ω
)1/n) (11)
M∗(s) = αe−βs(
ω
h+ ω
)1/n
T ∗(s) (12)
Evaluando la función Bs(M,T ) en ese punto, obtenemos la función de la variable s
G(s) = Bs(M∗(s), T ∗(s)) = (s− p)αe−βs − 2
√αe−βsδ, (13)
donde, por simplicidad, definimos
δ =
√√√√ n
n+ 1Kω
(1−
(ω
h+ ω
)1/n). (14)
De esta forma, hemos reducido el problema de optimización trivariante (10) al problema deoptimización univariante
máxs≥p
G(s). (15)
A continuación, exponemos algunas propiedades interesantes de la función G(s).
Lema 1 Sea G(s) dada por (13).
1. Se tiene G(p) < 0 y ĺıms→∞G(s) = 0.
2. La función G(s) es de clase C1 en el intervalo (p,∞) y signo(G′(s)) =signo(g(s)), donde g(s)es la función estrictamente convexa dada por
g(s) = 1 + β(p− s) + βδ
√eβs
α. (16)
Por conveniencia, consideraremos que la función g(s) está definida en el conjunto de todoslos números reales.
3. La función G(s) es estrictamente creciente en el intervalo (p,∞) en los casos (i) g(s0) ≥ 0,o (ii) p ≥ s0, siendo
s0 =2
βln
(2√α
βδ
). (17)
CLAIO-2016
783

4. La función G(s) posee un máximo local en el punto
s1 = args∈(p,s0){g(s) = 0} (18)
cuando p < s0 y g(s0) < 0.
Utilizando los resultados anteriores, podemos dar el siguiente criterio para determinar el precioóptimo.
Teorema 1 Sean G(s), g(s), s0 y s1 dados, respectivamente, por (13), (16), (17) y (18).
1. Si p ≥ s0, entonces s∗ =∞ y B∗ = G(s∗) = 0.
2. Si p < s0 y g(s0) ≥ 0, entonces s∗ =∞ y B∗ = G(s∗) = 0.
3. Si p < s0 y g(s0) < 0, entonces:
a) s∗ =∞ y B∗ = 0, cuando G(s1) < 0.
b) s∗ = s1 y B∗ = G(s1), en otro caso.
Nota 1 Obsérvese que el sistema de inventario es rentable solamente en el caso (3.b) del teoremaanterior.
A continuación, se expresan algunas de las condiciones establecidas en el teorema previo sinutilizar las funciones g(s) y G(s).
Lema 2 Sean δ, s0 y s1 dados, respectivamente, por (14), (17) y (18).
1. Se incurre en el caso (2) del Teorema 1 si s0 ≤ p+ 3β .
2. Se está en el caso (3.a) del Teorema 1 si s0 > p+ 3β y s1 > p+ 2
β .
Teniendo en cuenta todos los resultados anteriores, proponemos en siguiente algoritmo eficientepara determinar la poĺıtica óptima del sistema de inventario estudiado en este trabajo.
Algoritmo 1 Cálculo del precio y la poĺıtica óptima
Paso 1 Calcular s0 utilizando (17).
Paso 2 Si s0 ≤ p+ 3/β, entonces ir al Paso 6.
Paso 3 Calcular s1 = args∈[p,s0]{g(s) = 0}.
Paso 4 Si s1 > p+ 2β , entonces ir al Paso 6.
Paso 5 Tomar s∗ = s1.
Calcular T ∗ = T ∗(s1) utilizando (11).
Calcular M∗ = M∗(s1) usando (12).
Calcular q∗ = αe−βs1T ∗ usando (7).
Calcular B∗ = G(s1) usando (13).
Paso 6 Tomar s∗ =∞ y B∗ = 0.
CLAIO-2016
784

5. Ejemplos numéricos
En esta sección presentamos varios ejemplos numéricos para ilustrar los resultados obtenidosen la sección anterior.
Ejemplo 1 Consideremos un sistema de inventario con las hipótesis asumidas en este trabajo enel que los valores de los parámetros son los siguientes: p = 8, K = 500, h = 2, ω = 3.2, α = 1250,β = 0.2 y n = 2.5. Utilizando la notación introducida en la sección anterior, se tiene δ = 14.2030y s0 = 32.1458. Como p + 3/β = 23 < s0, calculamos s1 = 14.7572. Teniendo en cuenta quep+2/β = 18, deducimos que s∗ = s1. Utilizando (11), se obtiene T ∗ = T ∗(s1) = 4.35544 y, usando,(12), el nivel máximo de inventario es M∗ = 234.319. En consecuencia, el beneficio máximo porunidad de tiempo es B∗ =211.853 y el tamaño del lote es q∗ = 284.543.
Ejemplo 2 Supongamos los mismos parámetros como en el ejemplo anterior, pero cambiando aho-ra el valor del parámetro β por β = 0.4. Ahora s0 = 12.6072 y p+3/β = 15.5 ≥ s0. Aśı, nos situamosen el caso descrito en el Paso 2 del Algoritmo 1. Por tanto, el sistema de inventario es no rentablepara cualquier precio unitario de venta.
Ejemplo 3 Consideremos los mismos parámetros como en ele Ejemplo 1, pero modifiquemos elvalor del parámetro β por β = 0.3. Ahora s0 = 18.7274 y p + 3/β = 18 < s0. En consecuencia,calculamos s1 = 15.3505. Como p + 2/β = 14.6667, estamos en el caso descrito en el Paso 4 delAlgoritmo 1. Al igual que en el ejemplo anterior, el sistema de inventario es no rentable, aunqueahora la función G(s) tenga un máximo local en el punto s1.
6. Conclusiones
En este trabajo se estudia un sistema de inventario para art́ıculos cuya demanda combinamultiplicativamente una función potencial del tiempo y una función exponencial del precio deventa. Se permite la rotura del stock, en cuyo caso toda la demanda pendiente se sirve con lallegada del nuevo pedido. El objetivo es maximizar el beneficio por unidad de tiempo, suponiendoque el coste del inventario es la suma de los costes de almacenamiento, escasez y compra. Se presentaun algoritmo eficiente para determinar el precio óptimo de venta, el tamaño óptimo del lote y lalongitud óptima del ciclo de inventario.
Como futuras ĺıneas de investigación relacionadas con este trabajo tenemos: (i) extensión alcaso de art́ıculos perecederos; (ii) extensión al caso en el que la demanda sea estocástica y (iii)extensión al caso de rotura parcialmente recuperable.
Agradecimientos
Este trabajo está parcialmente subvencionado por el Ministerio de Ciencia e Innovación deEspaña mediante el proyecto MTM2013-43396-P cofinanciado con fondos FEDER.
CLAIO-2016
785

Referencias
[1] D. M. Hanssens y L. Parsons. Econometric and time-series: Market response models. In J. Eliashberg
y G. L. Lilien, editors, Handbooks in Operations Research and Management Science: Marketing, pages
409–464. Elsevier Science Publishers, Amsterdam, The Netherlands, 1993.
[2] A. P. Jeuland y S. M. Shugan. Channel of distribution profits when channel members form conjectures.
Marketing Science, 7(2):202–210, 1988.
[3] S. Mishra, L. K. Raju, U. K. Misra y G. Misra. A study of EOQ model with power demand of
deteriorating items under the influence of inflation. General Mathematics Notes, 10(1):41–50, 2012.
[4] E. Naddor. Inventory Systems. Wiley, New York, USA, 1966.
[5] N. Rajeswari y K. Indrani. EOQ policies for linearly time dependent deteriorating items with power
demand and partial backlogging. International Journal of Mathematical Archive, 6(2):122–130, 2015.
[6] J. Sicilia, J. Febles-Acosta y M. González-de la Rosa. Deterministic inventory systems with power
demand pattern. Asia-Pacific Journal of Operational Research, 29(5):1250025 (28 pages), 2012.
[7] J. Sicilia, J. Febles-Acosta y M. González-de la Rosa. Economic order quantity for a power demand
pattern system with deteriorating items. European Journal of Industrial Engineering, 7(5):577–593,
2013.
[8] D. P. Singh, S. Kumar. A study of order level inventory system using power demand pattern for
deteriorate items. International Journal of Engineering and Mathematical Sciences, 1:178–184, 2012.
[9] Y. Y. Song, S. Ray y S. L. Li. Structural properties of buyback contracts for price-setting newsvendors.
Manufacturing and Service Operations Management, 10(1):1–18, 2008.
[10] R. P. Tripathi. Optimal pricing and ordering policy for inflation dependent demand rate under permissi-
ble delay in payments. International Journal of Business, Management and Social Sciences, 2(4):35–43,
2011.
CLAIO-2016
786

Un modelo de inventarios EOQ con demanda
dependiente del tiempo, coste no lineal de
almacenamiento y roturas parcialmente recuperables
Luis Augusto San-José NietoIMUVA, Departamento de Matemática Aplicada, Universidad de Valladolid, España
Joaqúın Sicilia RodŕıguezDpto. de Mat., Estad. e Investigación Operativa, Universidad de La Laguna, España
Leopoldo Eduardo Cárdenas BarrónEscuela de Ingenieŕıa y Ciencias, Tecnológico de Monterrey, México
Resumen
En este trabajo se estudia un modelo del tamaño del lote para art́ıculos cuya demanda vaŕıacon el tiempo y es sensible al precio de venta. Se considera que el coste unitario de almacenamien-to es una función no lineal dependiente del tiempo que el art́ıculo permanece en el inventario.Se admite la posibilidad de escasez en el inventario. En ese caso, solamente una fracción vari-able de la demanda se sirve con retraso. Se formula el problema de inventario y se presenta unprocedimiento algoŕıtmico para determinar la poĺıtica óptima del inventario. El sistema aqúı de-sarrollado incluye como casos particulares varios modelos de inventarios EOQ estudiados porotros autores. Finalmente, los resultados se ilustran con varios ejemplos numéricos.
Palabras clave: Modelos EOQ; Demanda dependiente del tiempo; Roturas parcialmente recu-perables; Coste no lineal de almacenamiento.
1. Introducción
La administración y control de inventarios estudia y desarrolla la metodoloǵıa necesaria parala planificación del número de art́ıculos y las cantidades en stock de los mismos, de forma quese permita satisfacer la demanda de los clientes. Ello conlleva la coordinación de las funciones decompra, manufactura y distribución que se realizan en la actividad comercial y en el funcionamientode las organizaciones empresariales, con el objetivo de lograr el máximo beneficio cumpliendo conlos requerimientos de los clientes.
En la estructura organizacional de las empresas son varios los departamentos implicados enla gestión de los inventarios, desde los departamentos de planificación y marketing, hasta el de-partamento comercial o ventas, pasando por los departamentos de finanzas, compras, producción,
CLAIO-2016
787

distribución, calidad y atención al cliente. De ah́ı la importancia de una gestión adecuada de losinventarios y su alta incidencia en los resultados económicos de la actividad empresarial.
La gestión de inventarios estudia cada cuánto tiempo deben reponerse los inventarios y el tamañode las cantidades que deben solicitarse para reponer los stocks de los productos, de forma que seminimice el coste total relacionado con el mantenimiento, la rotura y la reposición de los productos.
En este trabajo se analiza un sistema de inventario de un producto cuyo precio es establecidopor el mercado y por tanto es exógeno a la organización. La demanda depende del tiempo, y estambién sensible a ese precio de venta. Más concretamente, el sistema tiene un patrón escalonado dedemanda (enfoque utilizado ya por otros autores como Kumar y Rajput [3]). Se permite la escasezde productos, y solo una fracción variable de la demanda no servida está dispuesta a esperar a lasiguiente reposición de productos para cubrir su petición. Además, se permite que el coste unitariode almacenamiento sea dependiente del tiempo.
El trabajo se estructura en varios apartados. Primero, se describe la notación empleada y lashipótesis en que se fundamenta el sistema de inventario que queremos analizar. A continuación, sedescribe el modelo de inventario, determinando las funciones de los diferentes costes que intervienenen el sistema y se formula el problema de inventario que debemos resolver. En el cuarto apartadose presentan varios resultados que nos permitan caracterizar la poĺıtica óptima de inventario de-pendiendo de los parámetros de entrada del sistema. Posteriormente, se analizan algunos modelosde inventarios que son casos particulares del sistema aqúı presentado. Aśı, se puede comprobar queel modelo introducido en este trabajo generaliza a algunos sistemas previamente estudiados en laliteratura. En el sexto apartado se incluyen algunos ejemplos numéricos que ayudan a entender losresultados teóricos previamente propuestos. Finalmente, en las conclusiones, se resume las aporta-ciones del nuevo modelo de inventario y se presentan nuevas ĺıneas de investigación que permitiŕıanextender y continuar el análisis desarrollado en este trabajo.
2. Hipótesis y notación
El sistema de inventario que se analiza en este trabajo admite las siguientes hipótesis. Se con-sidera un solo producto con demanda independiente. El horizonte de planificación es infinito. Lareposición es instantánea, es decir, el periodo de reposición es cero. El coste unitario de compraes conocido y constante. El coste de realizar un pedido es constante e independiente del tamañodel pedido. El coste unitario de almacenamiento es una función potencial del tiempo que el pro-ducto está en stock. El control del inventario se realiza mediante un sistema de revisión continua.Se acepta la situación de escasez o rotura del stock. En ese caso, se considera que hay clientesque no desean esperar hasta la llegada del siguiente pedido para satisfacer su demanda, mientrasque otros clientes śı que están dispuestos a esperar. La fracción de demanda que se satisface conretraso se describe por medio de una función (tipo racional) del tiempo de espera. El coste porcada unidad que se sirve con retraso incluye un coste fijo y un coste proporcional al tiempo quese espera hasta que se recibe el art́ıculo. El coste de una venta perdida sin incluir la pérdida debeneficios es constante. El sistema de inventario tiene un patrón escalonado de demanda. Aśı, enel periodo con inventario positivo, la demanda por unidad de tiempo es una función potencial deltiempo (es decir, sigue un patrón potencial de demanda como en Naddor [5]), mientras que enel periodo de escasez, la demanda es constante e independiente del tiempo. Además, se consideraque la demanda es sensible a cambios en el precio de venta. Dicho precio es exógeno al sistemay viene determinado por las condiciones del mercado. Otros trabajos en los que se considera un
CLAIO-2016
788

Tabla 1. Lista de notaciones
K Coste de realizar un pedido (> 0)p Coste unitario de compra (> 0)s Precio unitario de venta (s > p)H(t) Coste unitario de almacenamiento durante t unidades de tiempo (> 0)ω0 Coste fijo de escasez por unidad que se sirve con retraso, indep. del tiempo (≥ 0)ω Coste de escasez por unidad servida con retraso y por unidad de tiempo (≥ 0)η0 Coste de pérdida de confianza por cada venta perdida (≥ 0)D(t) Demanda en el tiempo t
n Índice del patrón potencial de demanda (> 0)I(t) Nivel neto de inventario en el tiempo tM Nivel máximo del inventario (≥ 0)τ Longitud del intervalo de cada ciclo de inventario con existencias (≥ 0)Ψ Longitud del intervalo de cada ciclo con escasez (≥ 0)T Longitud del ciclo de inventario; es decir, T = τ + Ψ (> 0)Q Tamaño del lote (> 0)b Demanda total pendiente de servir (≥ 0)L Cantidad total de ventas perdidas en cada ciclo (≥ 0)B(τ,Ψ) Beneficio total por unidad de tiempo
patrón potencial de demanda son, por ejemplo, los de Datta y Pal [1], Krishnaraj y Ramasamy [2],Kumar y Singh [4], y Palanivel y Uthayakumar [6].
A lo largo de este trabajo, utilizaremos la notación que se muestra en la Tabla 1.
3. Desarrollo del modelo
Teniendo en cuenta las hipótesis dadas anteriormente sobre la demanda, la demanda por unidadde tiempo podemos expresarla como
D(t) =
{α(s) + γ1d(t) si 0 ≤ t < τα(s) + γ2 si τ ≤ t < T = τ + Ψ
, (1)
donde α(s) representa la parte de la demanda sensible al precio de venta, d(t) = (1/n)(t/τ)(1−n)/n
y γ1 ≥ γ2 > 0. Suponemos que α(s) es una función positiva, como en Soni [9] y Wu et al. [10].Aśı, para 0 < t < τ , el nivel neto de inventario viene definido por la ecuación diferencial
dI1(t)
dt= − (α(s) + γ1d(t)) (2)
con la condición I1(τ) = 0. Resolviendo (2), se obtiene
I1(t) = α(s)(τ − t) + γ1τ
[1−
(t
τ
)1/n]. (3)
En el periodo de escasez suponemos que solamente se satisface con retraso una fracción β(y) dela demanda, siendo y el tiempo que falta hasta la llegada del siguiente pedido. Consideraremos que
β(y) =ρ
1 + θy, para y ≥ 0, (4)
CLAIO-2016
789

donde 0 ≤ ρ ≤ 1 y θ > 0. Por tanto, para τ < t < τ + Ψ, el nivel neto de inventario viene definidopor la ecuación diferencial
dI2(t)
dt= − (α(s) + γ2)
ρ
1 + θ(τ + Ψ− t) (5)
con la condición I2(τ) = 0. Resolviendo (5), se obtiene
I2(t) =ρ (α(s) + γ2)
θln
(1− θ(t− τ)
1 + θΨ
). (6)
De (3) se sigue que el nivel máximo de inventario es M = I1(0) = (α(s)+γ1)τ . De (6), la deman-
da total pendiente de servir al final del ciclo de inventario es b = −I2(τ+Ψ) = ρ(α(s)+γ2)θ ln (1 + θΨ).
Por tanto, el tamaño del lote viene dado por Q = M + b = I1(0)− I2(τ +Ψ) que, tras unas sencillasmanipulaciones algebráicas, podemos expresarlo como
Q = (α(s) + γ1) (τ + Ψ)− (α(s) + γ2)
(Ψ− ρ
θln (1 + θΨ)
)− (γ1 − γ2)Ψ. (7)
Los ingresos por ciclo se obtienen por la venta del lote Q y, por tanto, dichos ingresos son sQ.Análogamente, los costes de compra por ciclo son pQ. Consideraremos que el coste unitario dealmacenamiento durante t unidades de tiempo es H(t) = htδ, con h > 0 y δ ≥ 1. Por tanto, el costede almacenamiento por ciclo es
HC(τ) =
∫ τ
0H(t)
[−I ′1(t)]dt =
ξ(s)
δ + 1τ δ+1, (8)
donde
ξ(s) = h
(α(s) +
δ + 1
nδ + 1γ1
)> 0. (9)
El coste de escasez por demanda pendiente de servir es
BC(Ψ) = ω0b+ ω
∫ τ+Ψ
τ[−I2(t)] dt =
(α(s) + γ2) ρ
θ
[(ω0 −
ω
θ
)ln (1 + θΨ) + ωΨ
]. (10)
Las ventas perdidas son L = (α(s) + γ2)Ψ− b. Aśı, el coste de escasez por pérdida de confianza es
LC(Ψ) = η0L = (α(s) + γ2) η0
(Ψ− ρ
θln (1 + θΨ)
). (11)
En consecuencia, el beneficio por ciclo es
P (τ,Ψ) = (s− p)Q−K −HC(τ)−BC(Ψ)− LC(Ψ) (12)
y, de (7), se sigue que
P (τ,Ψ) = (s− p) (α(s) + γ1) (τ + Ψ)− [K +HC(τ) + SC(Ψ)] , (13)
donde
SC(Ψ) = (α(s) + γ2)
[µ0Ψ + µ1
(Ψ
θ− ln (1 + θΨ)
θ2
)]+ (γ1 − γ2)(s− p)Ψ, (14)
CLAIO-2016
790

siendoµ0 = ρω0 + (1− ρ)(η0 + s− p) ≥ 0 (15)
yµ1 = ρ (ω + θ(η0 + s− p− ω0)) . (16)
Luego el beneficio por unidad de tiempo es
B(τ,Ψ) =P (τ,Ψ)
τ + Ψ= (s− p) (α(s) + γ1)− C(τ,Ψ), (17)
donde
C(τ,Ψ) =K +HC(τ) + SC(Ψ)
τ + Ψ(18)
En consecuencia, nuestro problema consiste en determinar las variables de decisión τ y Ψ, conτ ≥ 0, Ψ ≥ 0 y τ + Ψ > 0 que minimizan la función C(τ,Ψ) definida en (18).
4. Análisis y solución
En primer lugar, vamos a considerar un valor fijo de la variable Ψ y definimos CΨ(τ) = C(τ,Ψ).Se verifica el siguiente resultado.
Teorema 1 La función CΨ(τ) es estrictamente convexa y, además, alcanza su valor mı́nimo enun punto τ∗Ψ ∈ (0,∞), que es un cero de la función continua L1Ψ(τ) definida por
L1Ψ(τ) =ξ(s)τ δ+1 + (δ + 1)
{K + (α(s) + γ2)
[µ0Ψ + µ1
(Ψθ −
ln(1+θΨ)θ2
)]+ (γ1 − γ2)(s− p)Ψ
}
τ + Ψ
−(δ + 1)ξ(s)τ δ
De acuerdo con este resultado, el problema inicial lo hemos reducido ahora al problema dedeterminar la variable no negativa Ψ que minimiza la función
C(τ∗Ψ,Ψ) = ξ(s)(τ∗Ψ)δ. (19)
Por este motivo, vamos a estudiar algunas propiedades de esta función, como nos indica el siguienteteorema.
Teorema 2 La función C(τ∗Ψ,Ψ) es de clase C1 y verifica signo(dC(τ∗Ψ,Ψ)
dΨ
)= signo(L2(Ψ)), donde
L2(Ψ) = δ
[(α(s) + γ2)
(µ0 +
µ1Ψ
1 + θΨ
)+ (γ1 − γ2)(s− p)
]1+1/δ
+[(α(s) + γ2) (δ + 1) ξ(s)1/δµ1
] ( ln (1 + θΨ)
θ2− Ψ
θ(1 + θΨ)
)− (δ + 1) ξ(s)1/δK
Además, signo(L′2(Ψ)) = signo(µ1), donde µ1 está dado por (16).
Basándonos en los dos teoremas anteriores, podemos proporcionar un algoritmo eficiente paradeterminar la poĺıtica óptima del problema de inventario objeto de este trabajo.
CLAIO-2016
791

Tabla 2. Valor óptimo de (τ,Ψ)
∆ > 0 ∆ = 0 ∆ < 0
µ1 > 0 (τ∗0 , 0) (τ∗0 , 0)(τ∗
Ψ̃, Ψ̃)
µ1 = 0 (τ∗0 , 0) todo punto (τ∗Ψ,Ψ) (τ∗∞,∞)
µ1 < 0
{C0 ≤ C∞C0 > C∞
(τ∗0 , 0)(τ∗∞,∞)
(τ∗∞,∞) (τ∗∞,∞)
donde τ∗0 =(K(δ+1)δξ(s)
) 1δ+1 , τ∗∞ =
((α(s)+γ2)(µ0+µ1/θ)+(γ1−γ2)(s−p)
ξ(s)
) 1δ
Ψ̃ = argΨ>0{L2(Ψ)}, τ∗Ψ = argτ>0{L1Ψ(τ)}C0 = ξ(s) (τ∗0 )δ, C∞ = (α(s) + γ2) (µ0 + µ1/θ) + (γ1 − γ2)(s− p)
Algoritmo 1 Obtención de la poĺıtica óptima
1. Calcular los siguientes valores: µ0 = ρω0 +(1−ρ)(η0 +s−p), µ1 = ρ (ω + θ(ηo + s− p− ωo))y ∆ = δ[(α(s) + γ2)µ0 + (γ1 − γ2)(s− p)] δ+1
δ − (δ + 1) ξ(s)1/δK.
2. Utilizar la Tabla 2 para calcular los valores óptimos Ψ∗ y τ∗.
3. Calcular el beneficio óptimo B(τ∗,Ψ∗) = (s− p) (α(s) + γ1)− ξ(s)(τ∗)δ.
5. Algunos casos particulares
El sistema de inventario que se estudia en este trabajo incluye como casos particulares diver-sos modelos de inventario estudiados por otros autores. Como situaciones especiales del sistemapropuesto tenemos, entre otros, los siguientes:
1. Modelo con fracción fija de roturas recuperables.
Si tomamos ĺımite cuando θ → 0+ en (4), se obtiene β(y) = ρ, para y ≥ 0. Es decir, laproporción de clientes que esperan la llegada del siguiente pedido es constante y no dependedel tiempo de espera. El Algoritmo 1 puede ser adaptado a esta situación de forma inmediata,como se indica a continuación.
Algoritmo 2 Obtención de la poĺıtica óptima, caso constante
a) Calcular µ0 = ρω0 +(1−ρ)(η0 +s−p) y ∆ = δ [(α(s) + γ2)µ0 + (γ1 − γ2)(s− p)]1+1/δ−(δ + 1) ξ(s)1/δK.
b) Utilizar la Tabla 3 para calcular los valores Ψ∗ y τ∗.
c) Calcular B(τ∗,Ψ∗) = (s− p) (α(s) + γ1)− ξ(s)(τ∗)δ.
2. Modelo con patrón de demanda constante y coste de almacenamiento lineal.
Si tomamos n = 1, δ = 1, α(s)→ 0+ y γ1 = γ2, se obtiene el modelo con demanda constantey función de impaciencia racional estudiado por San-José et al. [7] con la notación D = γ1 ya = θ.
CLAIO-2016
792

Tabla 3. Valor óptimo de (τ,Ψ) cuando β(y) = ρ
∆ > 0 ∆ = 0 ∆ < 0
ρω > 0 (τ∗0 , 0) (τ∗0 , 0)(τ∗
Ψ̃, Ψ̃)
ρω = 0 (τ∗0 , 0) todo punto (τ∗Ψ,Ψ) (τ∗∞,∞)
3. Modelo con patrón de demanda potencial y sin escasez.
Si consideramos µ0 →∞, entonces es claro que ∆ > 0 y C∞ →∞, luego del Algoritmo 1 se
sigue que Ψ∗ = 0 y τ∗ = τ∗0 =(K(δ+1)δξ(s)
)1/(δ+1), que es la solución del modelo con patrón de
demanda potencial en el que no se permite escasez.
Si además de µ0 → ∞, suponemos que δ = 1 y α(s) → 0+, se obtiene el modelo con patrónde demanda potencial y sin escasez estudiado por Sicilia et al. [8], con la notación r = γ1 yA = K.
Evidentemente, todos los modelos de inventarios EOQ obtenidos como casos particulares de lostres sistemas anteriores son también casos particulares del modelo aqúı estudiado.
6. Ejemplos numéricos
En esta sección presentamos varios ejemplos numéricos para mostrar cómo podemos aplicar elAlgoritmo 1 para obtener las poĺıticas óptimas.
Ejemplo 1 Consideremos un sistema de inventario con las hipótesis dadas en este trabajo en elque los valores de los parámetros son los siguientes: α(s) = 70 − 5s, γ1 = γ2 = 15, n = 1,K = 50, h = 0.53, δ = 1, ω0 = 0.2, ω = 2, η0 = 10, p = 8, s = 12, ρ = 0.95 y θ = 0.1.Como µ0 = 0.89, µ1 = 3.211 y ∆ = −829.938, el valor óptimo de Ψ se obtiene resolviendo laecuación L2(Ψ) = 850915
4 ln(1 + Ψ/10) − 80275(554Ψ + 2329)/(4(Ψ + 10)2) + 1866285/4 = 0. Esdecir, Ψ∗ = 0.173839. Por tanto τ∗ = 2.71445, el tamaño del lote es Q∗ = 71.9545, el coste esC(τ∗,Ψ∗) = 35.9665 y el beneficio es B(τ∗,Ψ∗) = 64.0335.
Ejemplo 2 Cambiemos ahora el valor de ρ por ρ = 0.9. Se obtiene µ0 = 1.58, µ1 = 3.042 y∆ = 235.25. Aplicando el Algoritmo 1 se tiene Ψ∗ = 0 y τ∗ = τ∗0 = 2.74721. Además, el tamañodel lote es Q∗ = 68.6803, el coste es C(τ∗,Ψ∗) = 36.4005 y el beneficio es B(τ∗,Ψ∗) = 63.5995.
7. Conclusiones
En este trabajo se presenta un modelo de inventario en el que se permite la rotura del stock ydonde la demanda vaŕıa potencialmente con el tiempo y es sensible al precio de venta. Se suponeque solamente una fracción de la demanda en el periodo de rotura se sirve con retraso y, además,es una función racional del tiempo de espera hasta la llegada del siguiente pedido. Se considera queel coste unitario de almacenamiento es una función no lineal dependente del tiempo. Se realiza unanálisis del sistema y se proporciona un algoritmo para determinar la poĺıtica óptima. Finalmente,este trabajo generaliza varios modelos de inventarios EOQ estudiados por otros autores.
Como futuras extensiones de la ĺınea de investigación reflejada en este trabajo, podemos señalarlas siguientes: (i) considerar en el sistema otras posibles funciones de rotura parcial; (ii) asumir
CLAIO-2016
793

descuentos en el precio de compra; (iii) trabajar con art́ıculos perecederos y (iv) suponer reposiciónno instantánea y considerar una tasa finita de reabastecimiento.
Agradecimientos
Este trabajo está parcialmente subvencionado por el Ministerio de Ciencia e Innovación deEspaña mediante el proyecto MTM2013-43396-P cofinanciado con fondos FEDER.
Referencias
[1] T. K. Datta y A. K. Pal. Order level inventory system with power demand pattern for items with
variable rate of deterioration. Indian Journal of Pure and Applied Mathematics, 19(11):1043–1053,
1988.
[2] R. B. Krishnaraj y K. Ramasamy. An inventory model with power demand pattern, Weibull distribution
deterioration and without shortages. The Bulletin of Society for Mathematical Services and Standards,
2:33–37, 2012.
[3] S. Kumar y U. S. Rajput. A partially backlogging inventory model for deteriorating items with ramp
type demand rate. American Journal of Operational Research, 5(2):39–46, 2015.
[4] V. Kumar y S. R. Singh. A finite horizon inventory model with life time, power demand pattern and
los sales. International Journal of Mathematical Sciences, 10(3-4):435-446, 2011.
[5] E. Naddor. Inventory Systems. Wiley, New York, USA, 1966.
[6] M. Palanivel y R. Uthayakumar. An EOQ model for non-instantaneous deteriorating items with power
demand, time dependent holding cost, partial backlogging and permissible delay in payments. In-
ternational Journal of Mathematical, Computational, Physical, Electrical and Computer Engineering,
8(8):1127–1137, 2014.
[7] L. A. San-Jose, J. Sicilia y J. Garćıa-Laguna. The lot size-reorder level inventory system with cuspomers
impatience functions. Computers & Industrial Engineering, 49:349–362, 2005.
[8] J. Sicilia, J. Febles-Acosta y M. González-de la Rosa. Deterministic inventory systems with power
demand pattern. Asia-Pacific Journal of Operational Research, 29(5):1250025 (28 pages), 2012.
[9] H. N. Soni. Optimal replenishment policies for non-instantaneous deteriorating items with price and
stock sensitive demand under permissible delay in payment. Int. J. Production Economics, 146:259–268,
2013.
[10] J. Wu, K. Skouri, J. T. Teng y L. Y. Ouyang. A note on “optimal replenishment policies for non-
instantaneous deteriorating items with price and stock sensitive demand under permissible delay in
payment”. Int. J. Production Economics, 155:324–329, 2014.
CLAIO-2016
794

Uma Heurística Híbrida baseada em Iterated LocalSearch para o Problema de Estoque e Roteamento de
Múltiplos Veículos
Edcarllos SantosUniversidade Federal Fluminense, Brasil
Luiz Satoru OchiUniversidade Federal Fluminense, Brasil
Luidi SimonettiUniversidade Federal do Rio de Janeiro, Brasil
Pedro Henrique GonzálezUniversidade Federal do Rio de Janeiro, Brasil
Resumo
Este trabalho aborda o Problema de Estoque e Roteamento de Múltiplos Veículos onde ofornecedor distribui, usando uma frota homogênea de veículos, um único tipo de produto aolongo de um horizonte de planejamento finito. O principal objetivo é a minimização dos custosoperacionais de transporte e armazenamento dos produtos. Para resolver o problema é propostoum algoritmo baseado na metaheurística Iterated Local Search (ILS), do qual incorpora umaheurística Variable Neighborhood Descent com ordenação randômica de vizinhanças (RVND)durante a etapa de busca local. Além disso, um procedimento exato baseado em programaçãomatemática é combinado ao algoritmo desenvolvido com a finalidade de resolver, de forma ótima,o subproblema de gerenciamento de estoque. Para avaliar a abordagem desenvolvida, testescomputacionais são realizados em 560 problemas-teste, alcançando resultados competitivos emcomparação aos melhores algoritmos da literatura.
Palavras-chave: PERMV; Metaheurísticas Híbridas; ILS.
1 Introdução
Ao longo dos últimos anos, a logística se tornou uma importante tendência de mercado proporcio-nando eficiência e controle sobre todas as etapas da cadeia de suprimentos. Neste contexto surge oProblema de Estoque e Roteamento de Veículos (PERV), onde decisões atuam na minimização de
CLAIO-2016
795

custos operacionais sobre distribuição e armazenamento de produtos. Neste trabalho é abordadouma extensão do PERV denominada Problema de Estoque e Roteamento de Múltiplos Veículos(PERMV), do qual considera uma frota homogênea de veículos para distribuir, a partir de umfornecedor, um único tipo de produto em um horizonte de planejamento finito.
Para resolver este problema, diferentes abordagens têm sido propostas. Em [2] o problemafoi modelado e uma heurística híbrida baseada em Adaptive Large Neighborhood Search (ALNS)combinando a solução de dois subproblemas foi desenvolvida. Para aprimorar a qualidade de serviço,os autores adotaram as políticas estruturais de maximum level e order-up-to. Em [1] foram propostasformulações e algoritmos de branch-and-cut para duas versões do PERV, usando restrições de quebrade simetria para melhorar as formulações e uma heurística ALNS para determinar limites superiores.Em [3] foi apresentado um algoritmo branch-and-cut para tratar diferentes classes de PERMV. Alémdisso, algumas desigualdades foram adaptadas para suportar múltiplos veículos e uma heurística foidesenvolvida para aprimorar a qualidade de soluções encontradas na árvore de busca. Por fim, em[4] uma nova formulação foi elaborada e um algoritmo branch-and-price-and-cut com heurística demarcação ad-hoc para resolução dos subproblemas da geração de colunas foi desenvolvido.
Este trabalho propõe um algoritmo híbrido multi-start baseado em ILS, usando um procedimentoRVND na etapa de busca local. Além disso, um procedimento exato é usado para resolver osubproblema de gerenciamento de estoque e uma nova heurística construtiva é apresentada. Esteartigo está organizado da seguinte forma: na Seção 2, a definição formal do PERMV é apresentada.Na Seção 3, são descritas abordagens de resolução para o problema. Experimentos computacionaissão reportados na Seção 4. Por fim, a Seção 5 apresenta as considerações finais deste trabalho.
2 Definição do Problema
Denote por G = (V,A) um grafo completo com conjunto de vértices V e conjunto de arcos A.O vértice 0 representa o fornecedor e V ′ = V \{0} os clientes. Demandas de clientes v ∈ V ′ noperíodo t ∈ T é representado por dtv. O fornecedor produz pt unidades do produto no período t,de tal maneira que seu estoque é capaz de suprir todas as demandas do horizonte de planejamento.Cada cliente v ∈ V ′ mantém um estoque com capacidade máxima Cv. Para atender as demandas, ofornecedor conta com uma frota homogênea composta porK veículos de capacidadeQ que percorremno máximo uma rota por período.
A quantidade de produto entregue pelo fornecedor para o cliente v no período t é denotado pelavariável qtv. O nível de estoque ao fim do período t para o fornecedor ou cliente v é representadopela variável Itv, onde para cada unidade de produto armazenada em estoque, existe um custo deestocagem hv associado (v ∈ V, t ∈ T ). O custo de transporte associado a cada arco (i, j) ∈ A édefinido por cij . Desta maneira, o objetivo principal do problema é minimizar os custos operacionaisrelativos ao transporte e estocagem de produtos. No PERMV as seguintes decisões devem sertomadas: quando um cliente deve ser atendido; quantas unidades de produtos devem ser entreguesem cada atendimento; quais são as melhores rotas para distribuição dos produtos. Tais decisõesestão sujeitas as seguintes restrições: cada rota inicia e termina no fornecedor; nenhuma rota deveexceder a capacidade do veículo; nenhuma falta de estoque é permitida; a capacidade máxima deestocagem para cada cliente deve ser respeitada. Mais detalhes sobre a formulação matemática parao PERMV pode ser encontrada em [2].
CLAIO-2016
796

3 Algoritmo HILS-RVND
Iterated local search (ILS) é um método de otimização global que explora o espaço de soluçãomediante sucessivas perturbações em ótimos locais. Essas soluções são obtidas durante a etapa debusca local, que por sua vez utiliza como ponto de partida uma solução provida por um procedimentoconstrutivo ou por um mecanismo de perturbação. Então ao invés de considerar todo o espaço desolução, o ILS foca sua procura somente em um espaço reduzido composto por ótimos locais. Todosos componentes necessários ao desenvolvimento do algoritmo ILS são descritos na próxima subseção.
3.1 Heurística de construção Forward Delivery
A heurística construtiva denominada Forward Delivery é capaz de gerar soluções de boa qualidadeatravés da dissociação das decisões de transporte e estocagem de produtos. Uma análise em duasfases é realizada em cada período. A primeira fase, descrita pelo Procedimento 1, consiste de suprir,se necessário, a demanda de um período mediante um novo atendimento. Dado um período t, onível de estocagem é verificado para cada cliente v ∈ V ′. Caso uma falta de estoque seja identificada(linha 2), um novo atendimento é realizado para suprir a demanda mínima requerida para evitar ainviabilidade no período t (linha 3) e o cliente v é inserido à lista de candidatos LC (linha 4). Porfim, todos os clientes presentes na lista LC são adicionados à rotas no período t (linha 6).
Dois critérios são utilizados para determinar o custo de inserção de um cliente k ∈ LC para umadada rota r no período t. O primeiro critério, denotado por g(k, t) = crik, computa a distância entreo cliente k e cada cliente i já inserido na solução parcial do período t. O segundo critério, denotadopor g(k, t) = (crik + crkj − crij)− γ(cr0k + crk0), determina o custo de inserção entre o cliente k e cadapar de clientes adjacentes i e j já incluídos na solução parcial. Para este último critério de inserção,o segundo termo corresponde a uma penalidade para evitar inserção tardia de clientes localizadosdistantes do fornecedor. Em ambos os critérios, a inserção associada com o custo mínimo é realizadae o cliente inserido na rota é então removido da lista LC.
A segunda fase é descrita pelo Procedimento 2 e tem como finalidade expandir a quantidade deperíodos servidos por um atendimento criado na primeira fase, através do aumento da quantidadede produtos entregues aos clientes no período t. Um período tf maior ou igual a t é aleatoriamenteselecionado com o intuito de diversificar a solução inicial (linha 3). Caso o estoque seja capaz dearmazenar a quantidade mínima necessária para suprir as demandas do intervalo [t, tf ] (linha 13),a quantidade de produtos entregue no atendimento da primeira fase é incrementada e o nível deestoque do cliente v é atualizado do período t em diante (linha 16). Caso contrário, o intervalo deatendimento é reduzido (linha 11) e a análise é então reiniciada. Por fim, a capacidade residual darota associada ao cliente v naquele período é atualizada (linha 17). Ambas as fases são executadassequencialmente para cada período do horizonte de planejamento.
3.2 Busca Local
Quatro estruturas de vizinhança inter-período foram desenvolvidas com o intuito de executar umaanálise integrada e simultânea das decisões de transporte e estocagem de produtos. São elas:
Service Insertion: Um novo atendimento é criado no período ti para o cliente v, através darealocação de produtos vinculados a um atendimento do período tr. Desta maneira, o custo detransporte é incrementado e, em contrapartida, o custo de estocagem é reduzido. Esse movimento
CLAIO-2016
797

é sujeito as seguintes pré-condições: tr < ti; qtrv > 0; qtiv = 0; alguma rota com capacidade residualpositiva deve existir no período ti.
Procedimento 1: Fase 1Entrada: Solução s, Período t, LC ← ∅
1 para cada Cliente v ∈ V faça2 se Itv < 0 então3 AtualizarEstoque(v, t, −Itv)4 LC ← LC + {v}
5 LC ←Misturar(LC)6 s← ConstruirRotas(LC, t)7 retorna s, t, LC
Algoritmo 1: HILS-RVND1 f(s∗)←∞2 para iterMS ← 0 ate MaxIterMS faça3 iterILS ← 04 s← ConstruirSolucaoInicial()5 para iterILS ← 0 ate MaxIterILS faça6 s← BuscaLocal(s)7 se f(s) < f(s∗) então8 s∗ ← s9 iterILS ← −1
10 s← Perturbacao(s∗)11 iterILS ← iterILS + 1
12 iterMS ← iterMS + 1
13 s← GerenciamentoEstoque(s∗)14 retorna s
Procedimento 2: Fase 2Entrada: Solução s, Período t, Lista LC
1 LC ←Misturar(LC)2 para cada Cliente v ∈ LC faça3 tf ← Aleatorio(t, T )4 se tf = t então5 v ← v + 1
6 enquanto tf > t faça7 del← 0
8 se Itfv < 0 então
9 del← del − Itfv
10 se operação é inviável então11 tf ← tf − 1
12 senão13 fim enquanto
14 se operação é viável então15 se I
tfv < 0 então
16 AtualizarEstoque(v, t, −Itfv )
17 s←AtualizaRota(del)
18 retorna s
Service Removal : Um atendimento é removido do período tr para o cliente v e os produtosentregues são transferidos para um atendimento existente no período ti. A operação reduz o custode transporte e aumenta o custo de estocagem. Esse movimento possui os seguintes pré-requisitos:qtrv > 0; qtiv > 0; a rota associada ao cliente v no período ti deve possuir capacidade residualsuficiente para armazenar todos os produtos do atendimento removido no período tr.
Shift Delivery : Parte dos produtos entregues para um cliente v de um atendimento no períodotr é transferido para um atendimento existente no período ti. Desta forma, apenas o custo deestocagem é reduzido. Essa operação está sujeita as seguintes pré-condições: tr < ti; qtrv > 0;alguma rota com capacidade residual positiva deve existir no período ti.
Swap Route: Transfere uma rota rt do período tr para o período ti, reduzindo o custo deestocagem e mantendo inalterado o custo de transporte. Essa operação é sujeita as seguintes pré-condições: tr < ti;
∑v∈rt q
tiv = 0; algum veículo não utilizado esteja disponível no período ti.
Com o objetivo de reduzir os custos entre rotas de um mesmo período, cinco estruturas de vizi-nhança inter-rota foram implementadas: Swap(1,1), Swap(2,1), Swap(2,2), Shift(1,0) e Shift(2,0).Além disso, outras cinco estruturas de vizinhança intrarrota foram implementadas com a finalidadede reduzir os custos de transporte em cada rota: Exchange, 2-opt, Reinsertion, Or-opt2 e Or-opt3.Maiores detalhes sobre essas estruturas de vizinhança clássicas podem ser encontradas em [5].
3.3 Gerenciamento de estoque
De maneira a reduzir os custos de estocagem de produtos, é proposto um modelo de programaçãolinear capaz de determinar a solução exata para o subproblema de gerenciamento de estoque, dadorotas como solução de entrada do modelo matemático. A contante binária ztv assume o valor um,se e somente se, existe um atendimento para o cliente v no período t. Esse problema pode ser
CLAIO-2016
798

formulado da seguinte forma:
Minimizar∑
v∈V
∑
t∈ThvI
tv (1)
Sujeito a:
It0 = It−10 + pt −∑
v∈V ′qtv t ∈ T (2)
Itv = It−1v + qtv − dtv v ∈ V ′ t ∈ T (3)Itv ≥ 0 v ∈ V t ∈ T (4)
Itv ≤ Cv v ∈ V ′ t ∈ T (5)
qtv ≤ Cv − It−1v v ∈ V ′ t ∈ T (6)∑
v∈rtqtv ≤ Q t ∈ T (7)
qtv ≥ ztv v ∈ V ′ t ∈ T (8)qtv = 0 v ∈ V ′ t ∈ T, ∀ ztv = 0 (9)
A função objetivo (1) é o somatório dos custos de estocagem para fornecedor e clientes. Asrestrições (2) e (3) determinam, respectivamente, o nível de estoque para fornecedor e clientes.As restrições (4) e (5) estipulam, na devida ordem, um nível mínimo e máximo de estoque a serconsiderado. As restrições (6) asseguram que o nível de estoque de um cliente após um atendimentonão possa exceder a capacidade máxima de estocagem. Já as restrições (7) garantem que o somatóriodos produtos entregues por todos os clientes atendidos pela rota rt não exceda a capacidade física doveículo. Por fim, as restrições (8) asseguram, para cada período, que um atendimento seja realizadopara os clientes atendidos pelas rotas disponibilizadas como entrada do modelo.
3.4 Mecanismos de Perturbação
Três mecanismos de perturbação baseados em estruturas de vizinhanças inter-período foram de-senvolvidos. Durante a etapa de perturbação, uma das seguintes estruturas é aleatoriamente se-lecionada: Supply Insertion; Supply Removal ; Shift Delivery. Em seguida, múltiplos movimentossão arbitrariamente executados para a vizinhança escolhida. O número de movimentos a seremexecutados é escolhido de forma aleatória dentro do intervalo [1, 4], que por sua vez foi delimitadoatravés de testes empíricos. É importante destacar que apenas movimentos viáveis são consideradosdurante essa etapa.
3.5 Incorporando as componentes
Todas as componentes descritas nesta seção são incorporadas ao HILS-RVND por meio do Algoritmo1. Em cada uma das MaxIterMS iterações (linhas 2 - 12), uma solução é gerada utilizando aheurística construtiva Forward Delivery (linha 4). Em seguida, uma busca local é realizada pararefinar a solução corrente (linha 6). Durante esta etapa, um RVND contendo apenas vizinhançasinter-período é executado e logo em seguida um RVND composto somente por vizinhanças inter-rotae intrarrota é aplicado. É importante ressaltar que, durante a busca local, todas as vizinhanças sãoexecutadas de forma exaustiva, considerando apenas soluções viáveis utilizando a estratégia Best
CLAIO-2016
799

Improvement. Por fim, a melhor solução corrente é perturbada (linha 10) e o nível de estoque paracada cliente é atualizado por intermédio do modelo de gerenciamento de estoque (linha 13).
4 Resultados computacionais
Os algoritmos apresentados neste trabalho foram codificados em C++ e a biblioteca IBM CplexConcert Technology 12.2 foi utilizada como resolvedor matemático para o subproblema de geren-ciamento de estoque. Testes computacionais foram executados em um computador Intel®Core™2Quad 2.83 GHz com 8 GB de RAM rodando Ubuntu 12.04 OS e usando somente uma única thread.
Para avaliar a performance, o algoritmo proposto foi testado em um conjunto introduzido em [2],composto por 560 problemas-teste. O conjunto-teste disponibilizado é dividido em dois subgrupos: oprimeiro apresenta um horizonte de planejamento |T | ∈ {3} e |V | ∈ {10, 15, 20, 25, 30, 35, 40, 45, 50}clientes; já o segundo subgrupo consiste em um horizonte de planejamento |T | ∈ {6} e |V | ∈{10, 15, 20, 25, 30} clientes. Ambos subgrupos possuem uma frota homogênea composta por |K| ∈{2, 3, 4, 5} veículos e cada combinação conta com custos de estocagem baixo e alto e cinco diferentesconfigurações. Mediante testes de calibração, os parâmetros MaxIterMS e MaxIterILS foramrespectivamente fixados em (10000 × T × K) e 10. Para cada problema-teste, o HILS-RVND foiexecutado 10 vezes com um limite máximo de tempo de 300 segundos.
Nas tabelas seguintes, indicadores de qualidade foram usados para classificar as soluções doHILS-RVND sobre outras abordagens da literatura. As colunas Ind, Quantity e Optimal são, nadevida ordem, os indicadores de qualidade, a média da quantidade de soluções e o número desoluções ótimas obtidas. A coluna Avg Gap é o gap médio entre soluções HILS-RVND e as melhoressoluções conhecidas. Por fim, a coluna Avg Time é o tempo médio de execução em segundos.
A Tabela 1 apresenta os resultados do HILS-RVND comparados com as melhores soluções dosalgoritmos branch-and-cut [3] e branch-price-and-cut [4]. Os resultados mostram que o HILS-RVNDfoi capaz de igualar em 127 casos as melhores soluções conhecidas, dentre esses, 124 com otimalidadeprovada. Além disso, 125 outras soluções foram melhoradas. O gap médio foi de -0.76% e em relaçãoa esforço computacional, o tempo médio foi 34 vezes menor quando comparado às abordagens exatas.
Haja visto que uma estratégia pode se comportar de maneira distinta conforme as característicasdo conjunto-teste, com o intuito de observar a versatilidade do HILS-RVND, os resultados foramanalisados em separado de acordo com seus respectivos enfoques. Nesse contexto, as Tabelas 2e 3, representam, respectivamente, os resultados para problemas-teste com baixo e alto custo deestocagem. Em ambos os casos, o gap médio entre as soluções obtidas pelo HILS-RVND e osmelhores limites superiores conhecidos foi de aproximadamente -0.7%. Além do mais, o tempopermaneceu balanceado bem como a quantidade de soluções que igualaram ou empataram em relaçãoas melhores soluções conhecidas. Desta maneira, pode-se verificar que o algoritmo apresentou umcomportamento satisfatório em ambos os casos, demonstrando a flexibilidade da abordagem.
A Tabela 4 apresenta os resultados do HILS-RVND comparados ao ALNS híbrido apresentadoem [2]. Os valores apresentados em [2] consistem em valores médios dos resultados obtidos paraas cinco diferentes configurações de cada combinação de parâmetros, sendo assim a comparação foiexecutada em separado em relação às abordagens exatas. Neste caso, o HILS-RVND melhorou 32soluções, o que corresponde a 66% dos problemas-teste. Além disso, o gap médio foi de -0.33% e otempo médio de execução foi 64 vezes inferior ao apresentado pelo algoritmo ALNS.
CLAIO-2016
800
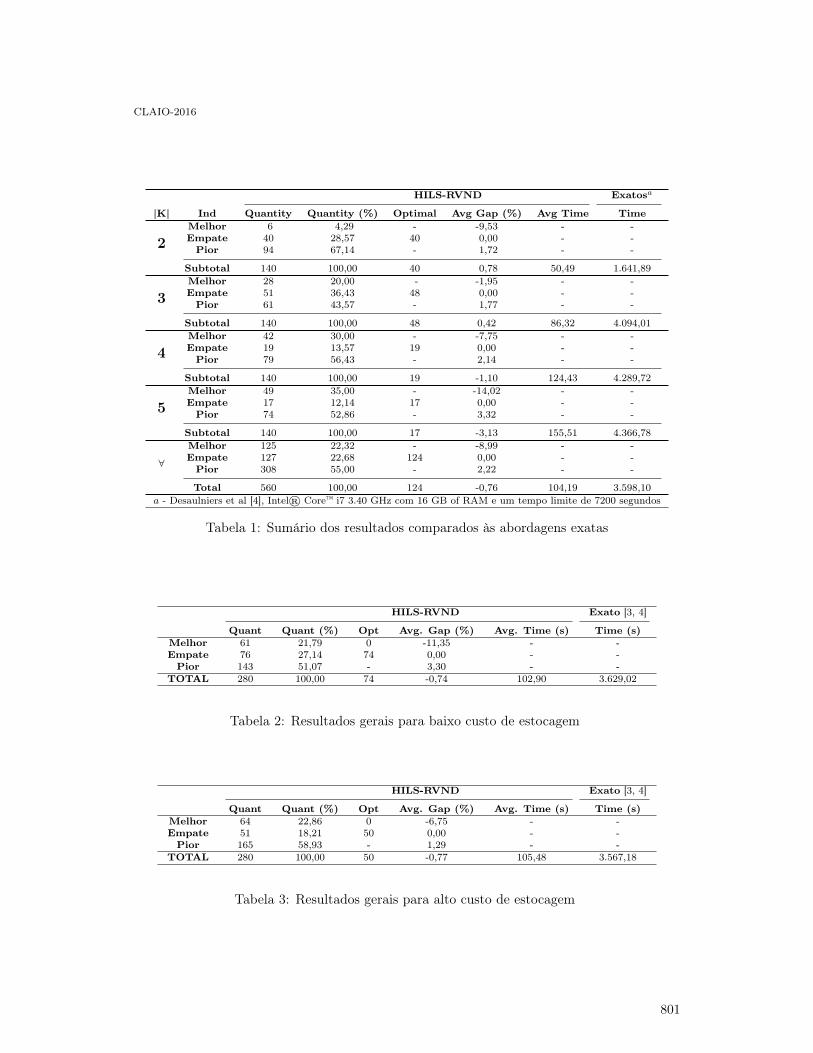
HILS-RVND Exatosa
|K| Ind Quantity Quantity (%) Optimal Avg Gap (%) Avg Time Time
2Melhor 6 4,29 - -9,53 - -Empate 40 28,57 40 0,00 - -Pior 94 67,14 - 1,72 - -
Subtotal 140 100,00 40 0,78 50,49 1.641,89
3Melhor 28 20,00 - -1,95 - -Empate 51 36,43 48 0,00 - -Pior 61 43,57 - 1,77 - -
Subtotal 140 100,00 48 0,42 86,32 4.094,01
4Melhor 42 30,00 - -7,75 - -Empate 19 13,57 19 0,00 - -Pior 79 56,43 - 2,14 - -
Subtotal 140 100,00 19 -1,10 124,43 4.289,72
5Melhor 49 35,00 - -14,02 - -Empate 17 12,14 17 0,00 - -Pior 74 52,86 - 3,32 - -
Subtotal 140 100,00 17 -3,13 155,51 4.366,78
∀Melhor 125 22,32 - -8,99 - -Empate 127 22,68 124 0,00 - -Pior 308 55,00 - 2,22 - -
Total 560 100,00 124 -0,76 104,19 3.598,10a - Desaulniers et al [4], Intel® Core™ i7 3.40 GHz com 16 GB of RAM e um tempo limite de 7200 segundos
Tabela 1: Sumário dos resultados comparados às abordagens exatas
HILS-RVND Exato [3, 4]
Quant Quant (%) Opt Avg. Gap (%) Avg. Time (s) Time (s)Melhor 61 21,79 0 -11,35 - -Empate 76 27,14 74 0,00 - -Pior 143 51,07 - 3,30 - -
TOTAL 280 100,00 74 -0,74 102,90 3.629,02
Tabela 2: Resultados gerais para baixo custo de estocagem
HILS-RVND Exato [3, 4]
Quant Quant (%) Opt Avg. Gap (%) Avg. Time (s) Time (s)Melhor 64 22,86 0 -6,75 - -Empate 51 18,21 50 0,00 - -Pior 165 58,93 - 1,29 - -
TOTAL 280 100,00 50 -0,77 105,48 3.567,18
Tabela 3: Resultados gerais para alto custo de estocagem
CLAIO-2016
801

HILS-RVND ALNSa
Ind Quantity Quantity (%) Avg Gap (%) Avg Time (s) Avg Time (s)Melhor 32 66,66 -0,76 - -Empate 0 0,00 0,00 - -Pior 16 33,33 0,51 - -Total 48 100,00 -0,33 77,40 4.934,69
a - Coelho et al. [2], AMD Dual Core Opteron 2.20 GHz
Tabela 4: Sumário dos resultados comparados ao ALNS Híbrido
5 Conclusão e trabalhos futuros
Um novo método para resolver o problema de estoque e roteamento de múltiplos veículos foi pro-posto. O método consiste de uma heurística híbrida baseada na metaheurística iterated local search,usando, durante a etapa de busca local, uma heurística variable neighborhood descent com ordenaçãorandômica de vizinhanças. Para gerar soluções iniciais, uma nova heurística construtiva foi desen-volvida do qual desassocia a análise das decisões referentes à distribuição e estocagem de produtos.Além disso, um procedimento exato foi usado para solucionar de maneira ótima o subproblema degerenciamento de estoque. Nossos experimentos mostraram que o método proposto foi capaz deencontrar soluções de boa qualidade quando comparadas a outras abordagens da literatura. Outroponto de interesse se refere ao tempo de execução do algoritmo proposto que, na maioria dos casos,foi bastante inferior que outros algoritmos presentes na literatura. Pesquisas futuras consistirão naadaptação do algoritmo para operar com a variante de múltiplos produtos e na adoção de novaspolíticas estruturais com o intuito de melhorar a qualidade de serviço para o problema.
Referências
[1] Yossiri Adulyasak, Jean-François Cordeau, and Raf Jans. Formulations and Branch-and-CutAlgorithms for Multivehicle Production and Inventory Routing Problems. INFORMS Journalon Computing, 26(1):103–120, February 2014.
[2] Leandro C. Coelho, Jean-François Cordeau, and Gilbert Laporte. Consistency in multi-vehicleinventory-routing. Transportation Research Part C: Emerging Technologies, 24:270–287, October2012.
[3] Leandro C Coelho and Gilbert Laporte. The exact solution of several classes of inventory-routingproblems. Computers & Operations Research, 40(2):558–565, February 2013.
[4] Guy Desaulniers, Jørgen Glomvik Rakke, and Leandro C. Coelho. A branch-price-and-cut al-gorithm for the inventory-routing problem. Technical report, GERAD - Department of Mathe-matics and Industrial Engineering Polytechnique Montréal, Montreal, 2014.
[5] Puca Huachi Vaz Penna, Anand Subramanian, and Luiz Satoru Ochi. An Iterated Local Searchheuristic for the Heterogeneous Fleet Vehicle Routing Problem. Journal of Heuristics, 19(2):201–232, September 2011.
CLAIO-2016
802

Vehicle Routing Problem with Fuel Consumption
Minimization: a Case Study
Gregory Tonin SantosUniversidade Estadual Paulista Júlio de Mesquita Filho, UNESP
Luiza Amalia Pinto CantãoUniversidade Estadual Paulista Júlio de Mesquita Filho, UNESP
Renato Fernandes CantãoUniversidade Federal de São Carlos, UFSCar
Abstract
In this paper we present the development of a Vehicle Routing Problem model geared towardsfuel consumption reduction. We also present an application of the model on the daily schedulingof the collecting trucks from CORESO, a cooperative for recycling based on the city of Sorocaba,SP. Results show that routes obtained with the model can bring a significant reduction on fuelcomsuption, with a neglegible impact in journey time, when compared with models focused onjourney time reduction.
Keywords: Vehicle Routing Problem; Fuel Consumption; Optimization.
1 Introduction
According to [12], the Vehicle Routing Problem (VRP) is one of the most important and studiedproblems among the combinatorial optimization ones. It was introduced by Dantzig and Ramser in1959, when they sought a mathematical and algorithmic formulation for the fuel delivery problemto a network of gas stations. Later, in 1964, Clarke and Wright had an effective heuristic methodwhich improved the approach of Dantzig and Ramser.
The conventional VRP aims to study the economical impact of different routing models incompanies or organizations that perform transportation work. The addition of environmental goalsto VRP increases its complexity with the introduction of new scenarios where a balance betweenenvironmental and economic costs must be achieved.
Every transportation process generates a series of environmental impacts, either direct ones (gasemissions) or indirect ones (extraction of raw materials for fuel production, for instance). In thesecases, finding routes that minimize fuel consumption is instrumental on reducing these impacts.This association between VRP and environmental concerns became known as Green Vehicle RoutingProblem [7].
CLAIO-2016
803

To [13] one of the possibilities to implement the green PRV is considering the cost of travelingalong a route directly dependent on factors such as distance, load, speed, road conditions, fuel com-suption rate (FCR), fuel prices and so on. On the other hand, indirect factors such as depreciationof vehicles, drivers’ wages, maintenance costs, taxes and tolls, appear to have no direct influenceon this calculation. Thus, factors directly related to fuel consumption are considered as a problemvariable.
As pointed by [13], fuel consumption depends on a number of factors. As for [4], the determinantfactors are the unloaded and gross vehicle weight as well as vehicle plus load weight. For [7], thesefactors are indeed critical because they define the function for the FCR. Both [4] and [13] used alinear function that relates the fuel consumption per unit distance to the total weight of the vehicleplus load.
Fuel consumption costs can reach 60% of the total transportation cost of a product [4]. Itsreduction, in addition to economic benefits, also brings an environmental gain: the reduction ofgreenhouse gases (GHS) like CO2, a component of the gases emitted during the fuel burning.
In [10] the authors present a model aiming the reduction of emissions by making the decisionvariable, the vehicle speed, time-dependent. Their approach showed best results on minimizinggreenhouse gas emissions than the models with time reducing constraints. They also pointedthat traffic jammed zones have higher emissions, and avoiding traffic peak times does not reduceemissions significantly; in this case models that reduce routes can be an effective way to decreaseemissions.
In this context, many VRP models include on their formulations the minimization of fuelconsumption — adding it to the objective function — in addition to minimizing the route. Examplesof this approach are presented in [1, 2, 3, 4, 6, 9, 7, 13].
In Section 2 we introduce the mathematical model covered in this study, in Section 3 we showthe application of the model on a test case for assessment and calibration, as well as the real casestudy. also being applied. Section 4 is dedicated to present the materials and methods needed toimplement the model, while Section 5 brings the results obtained from both the assessment caseand the case study with data from CORESO cooperative. Section 6 is used for the conclusions,followed by the references.
2 Mathematical modelling
2.1 Vehicle routing problem with fuel consumption minimization
The mathematical model used here is based on the very detailed one presented in [13]. It will beapplied in the case of the recycling cooperative of Sorocaba – SP (CORESO). The benchmark casefor the model is taken from [11].
The model presented in [11] minimizes collection time and it will be used as a benchmark forcomparison with the model proposed here. We raise the hypothesis that the route requiring lesstime to perform is not necessarily the most economic one.
Its main variables are the weights of the empty and loaded vehicles, the key factors for a modelthat reduces fuel consumption and the emission of greenhouse gases, as pointed out by [13, 4].
In order to start describing the model, we pinpoint the collection points – the nodes – theirrespective demands and the distances among them. We then proceed to create the FCR fuelconsumption rate function. The FCR function models the amount of fuel (in liters) needed for
CLAIO-2016
804

the vehicle to travel one kilometer. We have used a linear function on the load weight, as seen onEquation (1)
ρij = ρ(Qij) = ρ0 + αQij , α =ρ? − ρ0Q
. (1)
with α being the angular coefficient.Here ρ0, ρ
? and Q are, respectively, the FCR for the unloaded and fully loaded vehicle and itstotal load capacity. The variable Qij corresponds to the load weight being carried from node i tonode j. According to [13], better estimatives for the FCR can be obtained through statistics ordirectly with the truck manufacturer.
To simplify the explanation, we define c0 as fuel price, dij as distance from node i to node j,Di as demand of node i, F as fixed transportation cost, yij as cargo weight from node i to nodej and xij as a binary decision variable. If xij = 1 the vehicle travels from node i to node j; xij iszero otherwise.
In order to keep the problem consistent, we have to add a few extra restrictions: (i) the cargoweight cannot exceed the total capacity of the vehicle; (ii) each node is visited only once and (iii)the routes must start and end at node 0 (depot).
With these restrictions the formulation of the VRP with fuel consumption minimization is givenby the equations in (2):
min
n∑
j=1
Fx0j +
n∑
i=0
n∑
j=0
c0dij(ρijxij + αyij) (2a)
s.t.n∑
j=0
xij = 1 ∀j = 1, . . . , n (2b)
n∑
j=0
xij −n∑
j=0
xji = 0 ∀j = 1, . . . , n (2c)
n∑
j=0j 6=i
yij −n∑
j=0j 6=i
yji = Di ∀j = 1, . . . , n (2d)
yij ≤ Qxij ∀i, j = 1, . . . , n (2e)
xij ∈ {0, 1} ∀i, j = 1, . . . , n (2f)
Each restriction from (2) has a purpose: (2a) is the objective function (minimize fuel cost);(2b) means that a customer can only be visited once; (2c) states that a vehicle must enter andleave a node; (2d) represents the load increase after visitation of any node. The increase is equalto demand; (2e) means that the loaded cargo cannot exceed vehicles’ limit and finally (2f) is thebinary decision variable.
Although based on the work of [13], there are some differences in our present model that mustbe pointed out. Equation (2d) has the summations inverted because the vehicle leaves with fullcargo and returns empty (for example, a water delivery truck). Here the collection truck leaves thedepot empty and returns loaded to the recycling center, thus reversing the summations. Also, wesimplify the objective function by ignoring the fixed cost component, given that we are insterested
CLAIO-2016
805

only in the costs associated to fuel comsuption. We can simplify (2a) even further if we considerthat ρij already encompasses the slope α (1), allowing us to minimize only the cost between nodes.
With these simplifications the objective function in Equation (2a) becomes
n∑
i=1
n∑
j=1
c0ρijdijxij (3)
3 Case study
Model (2) was applied to the transportation of recyclables from the CORESO cooperative – Soro-caba, SP – in order to develop a daily schedule with the biggest reduction of greenhouse gasesemissions. The test model was applied to the REVIVER cooperative of Sorocaba, SP.
3.1 Test model
Data for the test model was fully obtained from [11]. It consists of the collection spots, distancesamong them and their respective demands, all amounting to a grand total of 401 streets and 6404collection points. To make the problem treatable the points were grouped into 67 nodes, includingthe depot.
It is very important to mention that, despite our use of the data as a benchmark, it is en-tirely from a real problem, meaning that the results here obtained can also be used by REVIVERcooperative.
3.2 CORESO model application
For the case study data was kindly provided by CORESO, a recycling cooperative in the east-ern region of Sorocaba, SP. Data comprises 318 streets with an estimated 5000 collection points(both domestic and collective), as well as details on the cooperative internal procedures (basicallycollection days and weight of the collected materials).
Data were essential to the study: streets were used for the establishment of collection nodes,collected weight for demands evaluation and collection days were needed to draft a new dailyschedule for the trucks.
4 Materials and methods
Test models and case studies have been solved with GAMS 24.3 and CPLEX 12.3.0.0, on a 2nd
generation Intel i7 processor clocked 3.4 GHz and with 8 Gb of RAM.In both cases we consider a truck with a capacity of 1500 kg. Its characteristics in relation to
emissions of the main greenhouse gases as CO2 (carbon dioxide), CO (carbon oxide), NOx (nitrogenoxides) and NMHC (Hydrocarbons) were obtained from [5]. The vehicle used in the cooperativedoes not appear in this table, so we consider one with similar characteristics, namely a Jinbei VanCargo, motor 2.0 16V version L.
We have adopted an average efficiency of 5 km/L, with 6 km/L and 4 km/L for the empty andfully loaded cenarios. That gives us ρ0 = 1/6L/km = 0.16667L/km and ρ? = 1/4L/km = 0.25L/km.
CLAIO-2016
806

Following (1), we can obtain α ≈ 6×10−5 resulting in the FCR function ρ = 0.16667 + 6×10−5Q.Fuel price is assumed R$ 3.10 per liter.
5 Results and Discussion
5.1 Test model
In Tables 1 to 6 the cost of each route is obtained through (3), while the collected weight wasevaluated according to the demand of each node. For comparison purposes we present the routesfrom [11] on Tables 2, 4 and 6; the results for the model considering fuel consumption are onTables 1, 3 and 5.
Table 1: Route cost considering fuel consumption – Region 1.route col. weight (kg) cost (R$)0 - 7 - 22 - 23 - 18 - 17 - 16 - 11 – 0 1332,54 20,840 - 13 - 14 - 15 - 12 - 10 – 0 888,37 18,090 - 20 - 21 - 19 - 24 - 25 - 26 - 9 - 8 – 0 1406,93 20,40
Table 2: Route cost considering time windows [11] – Region 1.route col. weight (kg) cost (R$)0 - 9 - 26 - 16 - 11 – 0 807,4 17,740 - 22 - 23 - 19 - 21 - 20 - 18 - 24 - 8 – 0 1439,75 21,230 - 7 - 25 - 17 - 14 - 15 - 12 - 13 - 10 – 0 1380,69 20,75
Table 3: Route cost considering fuel consumption – Region 2.route col. weight (kg) cost (R$)0 - 29 - 43 - 44 - 45 - 46 – 0 1090,62 11,000 - 30 - 41 - 27 - 28 - 40 - 42 – 0 1425,69 26,450 - 34 - 35 - 33 - 32 - 31 – 0 1123,47 10,270 - 39 - 38 - 37 - 36 – 0 1408,17 11,14
Table 4: Route cost considering time windows [11] – Region 2.route col. weight (kg) cost (R$)0 - 44 - 43 – 0 308,79 6,660 - 27 - 28 - 40 - 41 - 42 – 0 1403,79 24,630 - 45 - 46 – 0 759,93 6,780 - 32 - 33 - 34 - 35 – 0 895,71 10,360 - 39 - 38 - 30 – 0 777,45 14,930 - 29 - 31 - 37 - 36 – 0 902,28 12,93
Table 7 summarizes the costs for all 3 regions in consideration. Its columns are, in order, theregion number, the total cost obtained with our model, the total cost obtained with the benchmarkmodel [11] and the difference between the last two. As it can be seen, all three regions can be
CLAIO-2016
807
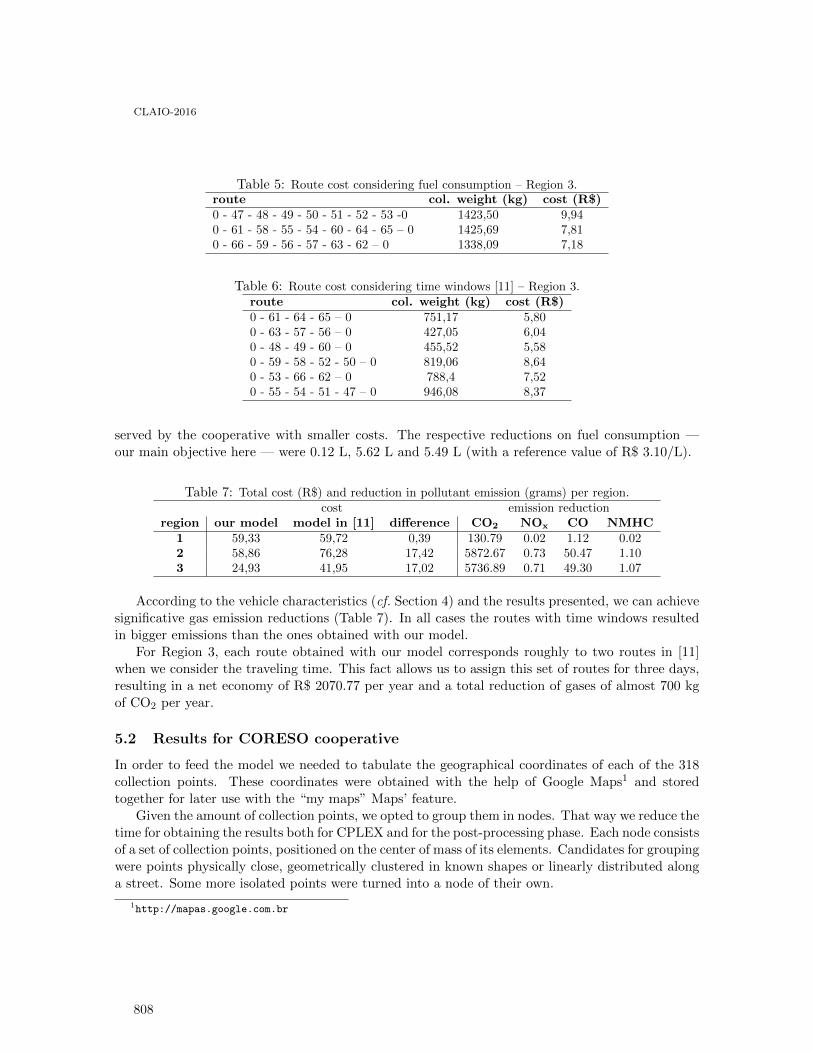
Table 5: Route cost considering fuel consumption – Region 3.route col. weight (kg) cost (R$)0 - 47 - 48 - 49 - 50 - 51 - 52 - 53 -0 1423,50 9,940 - 61 - 58 - 55 - 54 - 60 - 64 - 65 – 0 1425,69 7,810 - 66 - 59 - 56 - 57 - 63 - 62 – 0 1338,09 7,18
Table 6: Route cost considering time windows [11] – Region 3.route col. weight (kg) cost (R$)0 - 61 - 64 - 65 – 0 751,17 5,800 - 63 - 57 - 56 – 0 427,05 6,040 - 48 - 49 - 60 – 0 455,52 5,580 - 59 - 58 - 52 - 50 – 0 819,06 8,640 - 53 - 66 - 62 – 0 788,4 7,520 - 55 - 54 - 51 - 47 – 0 946,08 8,37
served by the cooperative with smaller costs. The respective reductions on fuel consumption —our main objective here — were 0.12 L, 5.62 L and 5.49 L (with a reference value of R$ 3.10/L).
Table 7: Total cost (R$) and reduction in pollutant emission (grams) per region.cost emission reduction
region our model model in [11] difference CO2 NOx CO NMHC1 59,33 59,72 0,39 130.79 0.02 1.12 0.022 58,86 76,28 17,42 5872.67 0.73 50.47 1.103 24,93 41,95 17,02 5736.89 0.71 49.30 1.07
According to the vehicle characteristics (cf. Section 4) and the results presented, we can achievesignificative gas emission reductions (Table 7). In all cases the routes with time windows resultedin bigger emissions than the ones obtained with our model.
For Region 3, each route obtained with our model corresponds roughly to two routes in [11]when we consider the traveling time. This fact allows us to assign this set of routes for three days,resulting in a net economy of R$ 2070.77 per year and a total reduction of gases of almost 700 kgof CO2 per year.
5.2 Results for CORESO cooperative
In order to feed the model we needed to tabulate the geographical coordinates of each of the 318collection points. These coordinates were obtained with the help of Google Maps1 and storedtogether for later use with the “my maps” Maps’ feature.
Given the amount of collection points, we opted to group them in nodes. That way we reduce thetime for obtaining the results both for CPLEX and for the post-processing phase. Each node consistsof a set of collection points, positioned on the center of mass of its elements. Candidates for groupingwere points physically close, geometrically clustered in known shapes or linearly distributed alonga street. Some more isolated points were turned into a node of their own.
1http://mapas.google.com.br
CLAIO-2016
808

The whole grouping process resulted in 92 clustered nodes. It should be noted that due to theincreased capacity of hardware the whole problem could be processed at once, making the divisionin regions as in the test model unnecessary.
The data provided by CORESO showed that some streets have a high demand, resulting inmore than one visit a week. These streets were assigned to more than one geographical coordinatesuch that each coordinate ended up as part of a different cluster. With that arrangement we couldgarantee multiple visits to the same street on different days.
Gross demands were obtained from the collected weight recorded by the cooperative at the endof the day. These weights were averaged weekly during a month and further divided by the numberof streets, resulting in a per-node collection demand.
Distances among nodes and among nodes and the cooperative were approximated using a simpleEuclidean distance (length of the straight line connecting two points).
Table 8 shows the optimal routes and associated costs for the case study. The weight of thecollected load is in correspondence with the demand of each node. We have considered the samevehicle used for the test case.
Table 8: Routes for the case study, along with collected weights and costs.
# routecollectedweight (kg)
cost (R$)
1 0 - 11 - 9 - 10 - 5 - 1 - 2 - 3 - 4 - 6 - 7 - 8 - 37 - 28 – 0 1390,12 9,422 0 - 25 - 45 - 46 - 38 - 39 - 41 - 43 - 44 - 27 – 0 876,38 7,473 0 - 29 - 33 - 30 - 34 - 70 - 64 - 67 - 66 - 91 - 31 – 0 1420,34 7,984 0 - 71 - 62 - 61 - 58 - 53 - 57 - 55 - 59 - 60 - 63 - 88 – 0 1450,56 9,385 0 - 73 - 22 - 23 - 24 - 85 - 82 - 83 - 84 - 86 - 80 - 77 – 0 1208,80 12,436 0 - 78 - 81 - 79 - 92 - 76 - 69 - 68 - 72 - 74 - 75 - 87 – 0 1420,34 9,297 0 - 89 - 32 - 65 - 51 - 52 - 47 - 49 - 54 - 56 - 48 - 36 - 35 - 40 - 50 - 0 1450,56 9,778 0 - 90 - 21 - 19 - 12 - 16 - 15 - 14 - 13 - 17 - 18 - 20 - 42 - 26 – 0 1148,36 8,75
The total cost of all routes amounts to R$ 74.49. Considering an average of 5 km/L for the fuelconsumption with a fuel price of R$ 3.10 per liter, the total fuel consumption for all routes is 24.03L. All routes sum up to 120.13 Km with emissions of 25108.11 g of CO2, 3.12 g of NOx, 215.76 gof CO and 4.69 g of NMHC
It is interesting to point out that the biggest variation on fuel cost is naturally related to weight;in other words, street sections where the truck is closer to be fully loaded demands more fuel. Thesesections correspond exactly to the connections among the collection points and the cooperative:they are further apart and usually the truck returns to the cooperative fully loaded.
After the determination of the routes we applied a route designation model (cf. Reference [8])in order to schedule them along the week. We considered eight periods distributed in five days(Monday to Friday) thus guaranteing that no period stood with a larger number of streets thanwhat is routinely made by the cooperative. Another important point is that with this schedulingSaturdays are a day off.
6 Concluding remarks
According to what has been proposed the presented model seeks to minimize fuel consumption.Comparison with the model of time window developed in [11] we have obtained cheaper and greener
CLAIO-2016
809

routes.In some cases for the test model the routes did not respect the working hours (7 hours/day).
This fact can be reverted in benefits for the workers as compensatory times off or overtime monetarycompensantion.
The model was them implemented and applied to the real case of CORESO cooperative resultingnot only in the routes, but also in the scheduling along the week. The solution not only have thelowest cost in fuel and lowest gases emissions, but also respects working hours.
References
[1] Tolga Bektaş and Gilbert Laporte. The pollution-routing problem. Transportation Research Part B:Methodological, 45(8):1232 – 1250, 2011. Supply chain disruption and risk management.
[2] Emrah Demir, Tolga Bektaş, and Gilbert Laporte. A review of recent research on green road freighttransportation. European Journal of Operational Research, 237(3):775 – 793, 2014.
[3] Sevgi Erdoǧan and Elise Miller-Hooks. A green vehicle routing problem. Transportation Research PartE: Logistics and Transportation Review, 48(1):100 – 114, 2012. Select Papers from the 19th InternationalSymposium on Transportation and Traffic Theory.
[4] Daya Ram Gaur, Apurva Mudgal, and Rishi Ranjan Singh. Routing vehicles to minimize fuel consump-tion. Operations Research Letters, 41(6):576 – 580, 2013.
[5] INMETRO – Instituto Nacional de Metrologia, Qualidade e Tecnologia. Pro-grama brasileiro de etiquetagem – PBE, 2015 (accessed April 4, 2015).http://www.inmetro.gov.br/consumidor/pbe/veiculos leves 2015.pdf.
[6] Yong-Ju Kwon, Young-Jae Choi, and Dong-Ho Lee. Heterogeneous fixed fleet vehicle routing consideringcarbon emission. Transportation Research Part D: Transport and Environment, 23:81 – 89, 2013.
[7] Canhong Lin, K.L. Choy, G.T.S. Ho, S.H. Chung, and H.Y. Lam. Survey of green vehicle routingproblem: Past and future trends. Expert Systems with Applications, 41(4, Part 1):1118 – 1138, 2014.
[8] Fernando Augusto Silva Marins. Introdução à pesquisa operacional. Cultura Acadêmica, São Paulo,2011.
[9] Lorena Pradenas, Boris Oportus, and Vctor Parada. Mitigation of greenhouse gas emissions in vehiclerouting problems with backhauling. Expert Systems with Applications, 40(8):2985 – 2991, 2013.
[10] Jiani Qian and Richard Eglese. Fuel emissions optimization in vehicle routing problems with time-varying speeds. European Journal of Operational Research, 248(3):840 – 848, 2016.
[11] Felipe Sanches Stark, Luiza Amalia Pinto Cantão, and Renato Fernandes Cantão. Problema de rotea-mento na coleta seletiva: estudo na cooperativa reviver, sorocaba sp. In Anais do SBPO 2013. XLVSBPO Simpósio Brasileiro de Pesquisa Operacional, October 2013.
[12] P. Toth and D. Vigo. The Vehicle Routing Problem. Society for Industrial and Applied Mathematics,2002.
[13] Yiyong Xiao, Qiuhong Zhao, Ikou Kaku, and Yuchun Xu. Development of a fuel consumption optimiza-tion model for the capacitated vehicle routing problem. Computers and Operations Research, 39(7):1419– 1431, 2012.
CLAIO-2016
810

Análise da demanda de peças sobressalentes para navios de guerra:
estudo de caso de uma fragata da Marinha do Brasil
Marcos dos Santos
Marinha do Brasil – Centro de Análises de Sistemas Navais (CASNAV)
Juliana Bonfim Neves da Silva
Marinha do Brasil – Centro de Análises de Sistemas Navais (CASNAV)
Luciangela Galletti da Costa
Serviço Nacional de Aprendizagem Industrial – SENAI CETIQT
Sergio Baltar Fandino
Universidade Estadual da Zona Oeste (UEZO)
Ernesto Rademaker Martins
Marinha do Brasil – Centro de Análises de Sistemas Navais (CASNAV)
Beatriz Duarte Magno
Serviço Nacional de Aprendizagem Industrial – SENAI CETIQT
Jonathan Cosme Ramos
Serviço Nacional de Aprendizagem Industrial – SENAI CETIQT
Resumo
No ano de 2011, a Fragata União, navio de guerra da Marinha do Brasil (MB), foi incorporada à
Força Interina das Nações Unidas no Líbano (UNIFIL). Durante a missão, observou-se a necessidade de
um modelo de previsão de demanda de peças sobressalentes para manutenção dos equipamentos de bordo
mais adequado à nova realidade operacional do navio. Analisadas as demandas a partir de uma série
histórica dos anos de 2012, 2013 e 2014, identificou-se que a demanda da maioria das peças apresentava
um comportamento de acordo com a Curva Normal. Todavia, outras passavam longos períodos sem
demanda, apresentando um comportamento severamente estocástico. O presente estudo utilizou os
métodos de Croston e Syntetos-Boylan Approximation (SBA) comparando-os com o modelo utilizado
atualmente pela MB. O estudo mostra-se relevante por ser totalmente inédito na MB e possuir um caráter
dual, podendo ser adaptado em outros setores produtivos que necessitem de itens sobressalentes de
elevado valor agregado.
Palavras-chave: análise da demanada; demanda esporádica; peças sobressalentes; navio de guerra.
CLAIO-2016
811

1 Introdução Em novembro de 2011, a Fragata União, navio de guerra da Marinha do Brasil, foi incorporada a
referida missão UNIFIL. O navio, mostrado na figura 1, ampliou a capacidade operacional da Força-
Tarefa, por ser um navio de maior porte e, consequentemente, com maiores recursos em termos de
permanência, sensores e sistemas de armas. Além disso, o navio é equipado com uma aeronave Super
Linx, com um Grupo de Mergulhadores de Combate e com um destacamento de Fuzileiros Navais.
Figura 1 – Fragata União em missão de paz no Líbano
Fonte: www.defesaaereanaval.com.br
Durante a missão, observou-se a necessidade de um modelo de previsão de demanda de peças
sobressalentes para manutenção dos equipamentos de bordo mais adequado à nova realidade operacional
do navio. Algumas peças sobressalentes apresentaram demanda de acordo com a curva normal, enquanto
outras apresentaram comportamento severamente estocástico, evidenciando que a média aritmética
simples, modelo adotado até então, passou a apresentar graves distorções para ser utilizado no novo
cenário. A necessidade de um modelo de maior acurácia é reforçada pelo elevado custo de algumas peças
de reposição para manutenção, aliado aos recursos limitados da instituição.
2 Problema
O artigo possui como foco a avaliação da demanda de peças sobressalentes de um motor de um dos
seus navios. Os itens sobressalentes para este equipamento apresentam uma grande variedade. Foi
verificado que o tipo de motor em estudo poder ser dividido em oito subsistemas, são eles: subsistema de
combustível; subsistema de ar de alimentação; subsistema dos cilindros; subsistema do pistão; subsistema
dos cabeçotes; subsistema do eixo de manivelas; subsistema de óleo lubrificante; e subsistema de
resfriamento.
2.1 Atendimento dos pedidos – fluxo de atividades
Os itens podem são armazenados em dois depósitos: deposito local e depósito central. De acordo com
a determinação de necessidades levantadas pelo setor de manutenção, o solicitante faz o pedido do item
por meio de um sistema informatizado. Se houver em estoque, localizado no depósito local, o produto é
encaminhado para setor de manutenção, senão o sistema verifica a existência do pedido no depósito
central. Se o item estiver em estoque no depósito central, o material é encaminhado ao depósito local, e
em seguida para o solicitante. Entretanto, se o depósito central não tiver o item, o setor de compras faz o
pedido ao fornecedor.
2.2 Modelo atual de previsão da demanda
O modelo utilizado atualmente pelo setor de planejamento da MB para o gerenciamento de seus itens
reposição é função de alguns parâmetros, que são comuns a todos os tipos de itens que a empresa possui.
Não há tratamento diferenciado para as peças reposição com demanda esporádica, todos os itens são
tratados da mesma maneira. A política atual adotada na previsão da demanda para manter o estoque dos
seus itens é baseada no modelo de média simples dos 24 últimos meses da demanda real. De posse destes
CLAIO-2016
812

dados, o analista utiliza estas informações como ponto de partida para novas compras com horizonte nos
próximos 2 anos. Além disso, como a 95% dos itens sobressalentes são importados, o lead time varia
entre 40 e 60 dias. Por segurança, a empresa adotada 80 dias.
3 Modelo proposto
A proposta deste artigo é encontrar o método de previsão de demanda que forneça uma melhor
acurácia. Como o foco do repousa sobre os itens com demanda esporádica, dois métodos de previsão
foram analisados, são eles: o método de previsão de Croston e SBA. Há um interesse particular nos
métodos selecionados pela capacidade de se ajustarem aos dados com comportamento esporádico. Os dois
métodos serão comparados com o modelo atual utilizado pela Marinha. Também será dado um enfoque
sobre os erros entre o previsto e o observado. A medida de precisão utilizada foi o Erro Médio Absoluto
(EMA). Quanto menores os valores dessa medida, melhor será a previsão.
3.1 Modelo de Croston
O método de Croston (1972) foi desenvolvido para aplicação específica nos casos em que a demanda
tem como característica uma série temporal de valores zero no consumo de alguns períodos. No seu
trabalho, Croston propôs um método de ajuste exponencial para previsão de demanda que separa a
estimação dos intervalos entre demandas da estimação dos volumes demandados em cada ocorrência.
Esse método executa separadamente, dois ajustes exponenciais: sobre a demanda (z) e sobre o
intervalo entre as demandas (p). Primeiro, utiliza o ajuste exponencial simples sobre a demanda,
estimando a demanda média futura. Depois, aplica-se o ajuste exponencial simples sobre o intervalo entre
as demandas, estimando o intervalo médio futuro. Se não houver ocorrência de demanda no espaço entre
uma revisão do período e outra (período t), o método somente incrementa a contagem dos períodos desde
a última demanda. Esta contagem dos períodos entre as demandas é representada pela variável q. Em
seguida, divide-se z por p, obtendo assim a previsão da demanda y*, onde y*=z/p. O autor afirma que tal
procedimento elimina o viés causado pelo ajuste exponencial aplicado sobre a série temporal. A previsão
pelo método de Croston é dada pelas equações a seguir:
Se não houver demanda no período, yt = 0, então:
Se houver demanda no período, yt ≠ 0, então:
Combinando a estimativa do tamanho da demanda com a estimativa do intervalo entre demandas,
obtém-se:
CLAIO-2016
813

Onde:
zt - Estimativa de Croston do tamanho médio da demanda;
pt - Estimativa de Croston no intervalo médio entre as transações;
q - Intervalo de tempo desde a última demanda;
α - Parâmetro de suavização entre 0 e 1;
yt - Demanda de um item no tempo t;
y* - Previsão da demanda.
As previsões somente são atualizadas quando ocorre uma demanda. Pode-se notar que a variável q,
conforme equações (3) e (6): se a cada período de revisão, ao final de cada mês, não foi verificado
demanda, a variável q vai crescendo (3), até que uma demanda se confirme no período. No entanto,
quando houver demanda, naturalmente a variável q assume o valor 1(um), conforme mostrado na equação
(6). Esta foi a maneira que Croston encontrou para administrar os períodos sem demanda e permitir o uso
do ajuste exponencial.
3.2 Modelo de Croston Modificado (SBA)
Syntetos e Boylan (2001) demonstram que a formulação proposta por Croston em 1972 apresenta
viés para cima, ou seja, a previsão tende a carregar o estoque. Diante disto, os autores propuseram
modificação na equação de Croston, que ficou conhecido como SBA – Syntetos Boylan Approximation.
Essa nova versão, também atualiza o tamanho e o intervalo da demanda, tal como efetuado no modelo de
Croston, porém corrige a equação (7) para previsão da demanda da seguinte forma:
3.3 Erro de previsão
A precisão da previsão consiste no quão próximo às previsões se aproximam dos dados reais.
Previsões muito próximas dos dados reais significam erros baixos, e logo são mais aceitas. Todavia, se os
erros de precisão são muito maiores é sinal que o modelo de previsão deve ser alterado ou ajustado.
3.3.1 Erro médio absoluto (EMA)
Segundo Slack, Chambers e Johnston (2009), o erro médio absoluto (EMA) é a média do módulo das
diferenças entre a demanda prevista e a demanda real. É representada pela fórmula:
4 Análise da demanda
A primeira parte da análise da demanda consiste na coleta dos dados históricos dos itens utilizados
no motor no período de 2009 a 2013. Foi levantado o volume total dos itens utilizados pelo setor de
CLAIO-2016
814
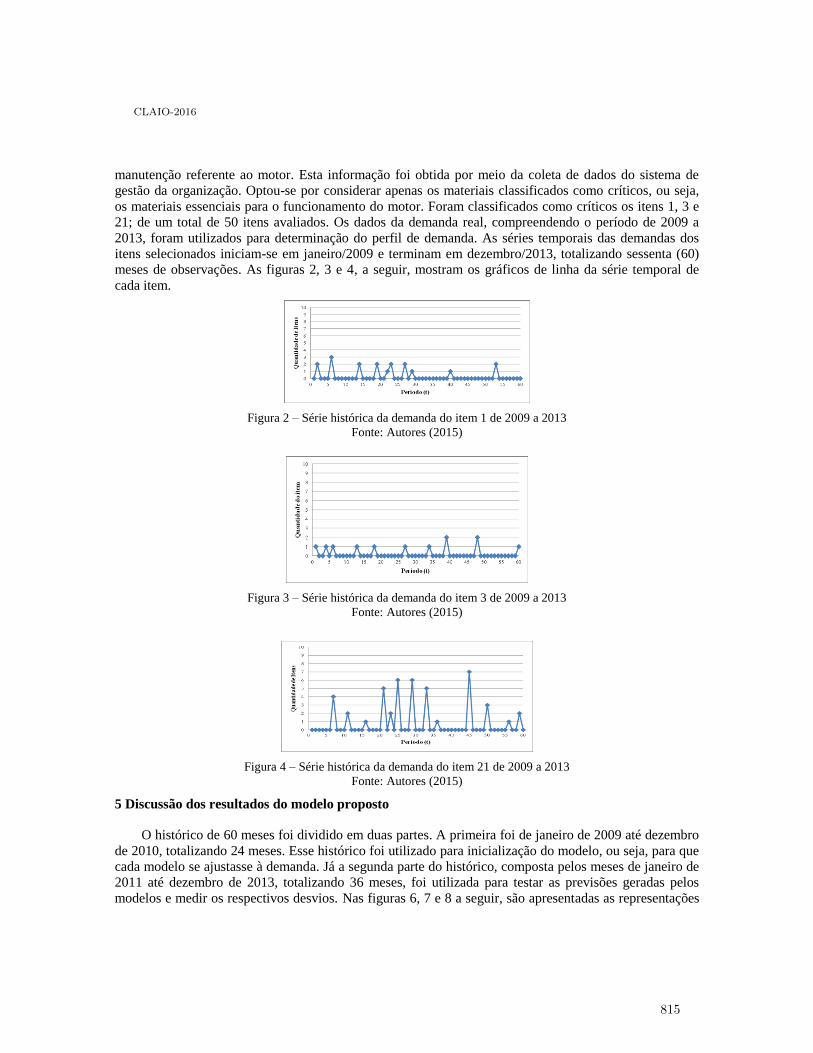
manutenção referente ao motor. Esta informação foi obtida por meio da coleta de dados do sistema de
gestão da organização. Optou-se por considerar apenas os materiais classificados como críticos, ou seja,
os materiais essenciais para o funcionamento do motor. Foram classificados como críticos os itens 1, 3 e
21; de um total de 50 itens avaliados. Os dados da demanda real, compreendendo o período de 2009 a
2013, foram utilizados para determinação do perfil de demanda. As séries temporais das demandas dos
itens selecionados iniciam-se em janeiro/2009 e terminam em dezembro/2013, totalizando sessenta (60)
meses de observações. As figuras 2, 3 e 4, a seguir, mostram os gráficos de linha da série temporal de
cada item.
Figura 2 – Série histórica da demanda do item 1 de 2009 a 2013
Fonte: Autores (2015)
Figura 3 – Série histórica da demanda do item 3 de 2009 a 2013
Fonte: Autores (2015)
Figura 4 – Série histórica da demanda do item 21 de 2009 a 2013
Fonte: Autores (2015)
5 Discussão dos resultados do modelo proposto
O histórico de 60 meses foi dividido em duas partes. A primeira foi de janeiro de 2009 até dezembro
de 2010, totalizando 24 meses. Esse histórico foi utilizado para inicialização do modelo, ou seja, para que
cada modelo se ajustasse à demanda. Já a segunda parte do histórico, composta pelos meses de janeiro de
2011 até dezembro de 2013, totalizando 36 meses, foi utilizada para testar as previsões geradas pelos
modelos e medir os respectivos desvios. Nas figuras 6, 7 e 8 a seguir, são apresentadas as representações
CLAIO-2016
815
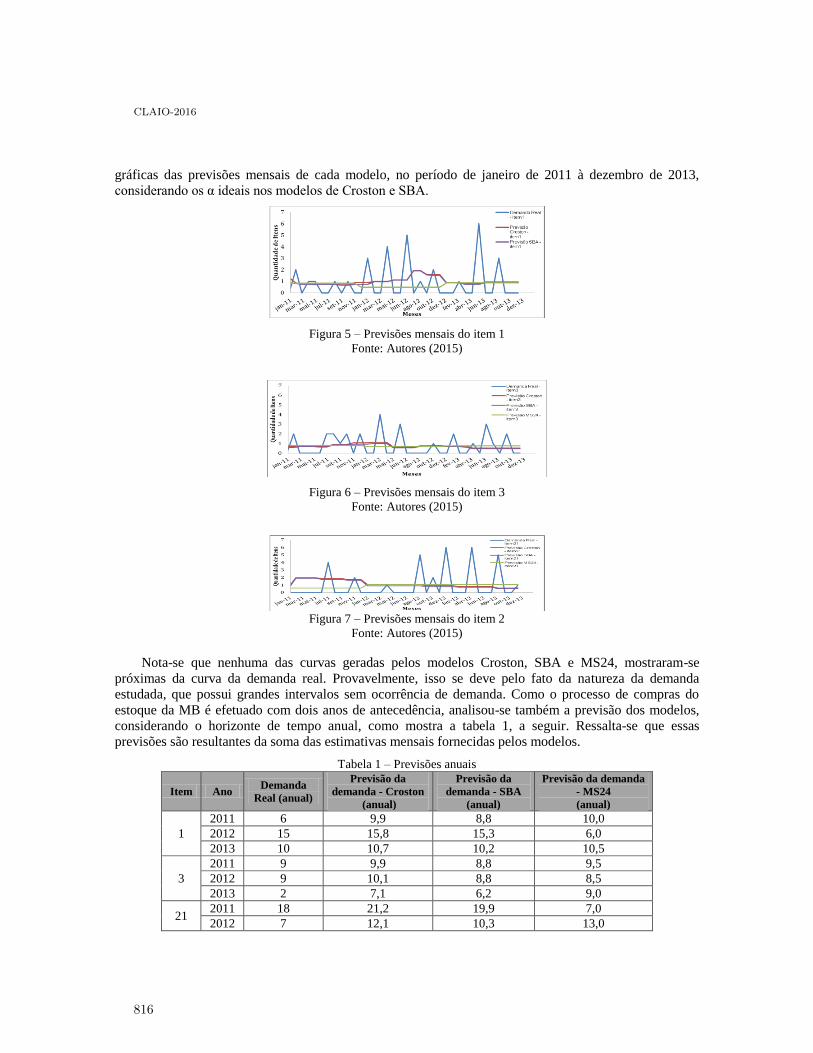
gráficas das previsões mensais de cada modelo, no período de janeiro de 2011 à dezembro de 2013,
considerando os α ideais nos modelos de Croston e SBA.
Figura 5 – Previsões mensais do item 1
Fonte: Autores (2015)
Figura 6 – Previsões mensais do item 3
Fonte: Autores (2015)
Figura 7 – Previsões mensais do item 2
Fonte: Autores (2015)
Nota-se que nenhuma das curvas geradas pelos modelos Croston, SBA e MS24, mostraram-se
próximas da curva da demanda real. Provavelmente, isso se deve pelo fato da natureza da demanda
estudada, que possui grandes intervalos sem ocorrência de demanda. Como o processo de compras do
estoque da MB é efetuado com dois anos de antecedência, analisou-se também a previsão dos modelos,
considerando o horizonte de tempo anual, como mostra a tabela 1, a seguir. Ressalta-se que essas
previsões são resultantes da soma das estimativas mensais fornecidas pelos modelos.
Tabela 1 – Previsões anuais
Item Ano Demanda
Real (anual)
Previsão da
demanda - Croston
(anual)
Previsão da
demanda - SBA
(anual)
Previsão da demanda
- MS24
(anual)
1
2011 6 9,9 8,8 10,0
2012 15 15,8 15,3 6,0
2013 10 10,7 10,2 10,5
3
2011 9 9,9 8,8 9,5
2012 9 10,1 8,8 8,5
2013 2 7,1 6,2 9,0
21 2011 18 21,2 19,9 7,0
2012 7 12,1 10,3 13,0
CLAIO-2016
816

2013 6 9,0 7,7 12,5
Fonte: Autores (2015)
Para melhor visualização das previsões são apresentadas nas figuras 8, 9 e 10 a seguir, as
representações gráficas das previsões anuais de cada modelo, no período de janeiro de 2011 à dezembro
de 2013.
Figura 8 – Demanda anual do item 1
Fonte: Autores (2015)
Figura 9 – Demanda anual do item 3
Fonte: Autores (2015)
Figura 10 – Demanda anual do item 21
Fonte: Autores (2015)
Pode-se verificar, que diferente da representação das demandas mensais, as curvas das previsões
anuais apresentadas mostraram-se mais próximas da curva da demanda real.
5.1 Erro de previsão
Após determinadas às previsões anuais das demandas dos seis (6) itens selecionados, foi mensurado
o desempenho de cada modelo, por meio dos: Erro médio absoluto (EMA). Esse erro foi escolhido porque
consegue tratar dados de demanda nula e ser de fácil comparação entre os modelos de previsão. Na tabela
2 são mostrados os comparativos entre os três métodos empregados. Em negrito destacam-se os melhores
resultados.
CLAIO-2016
817
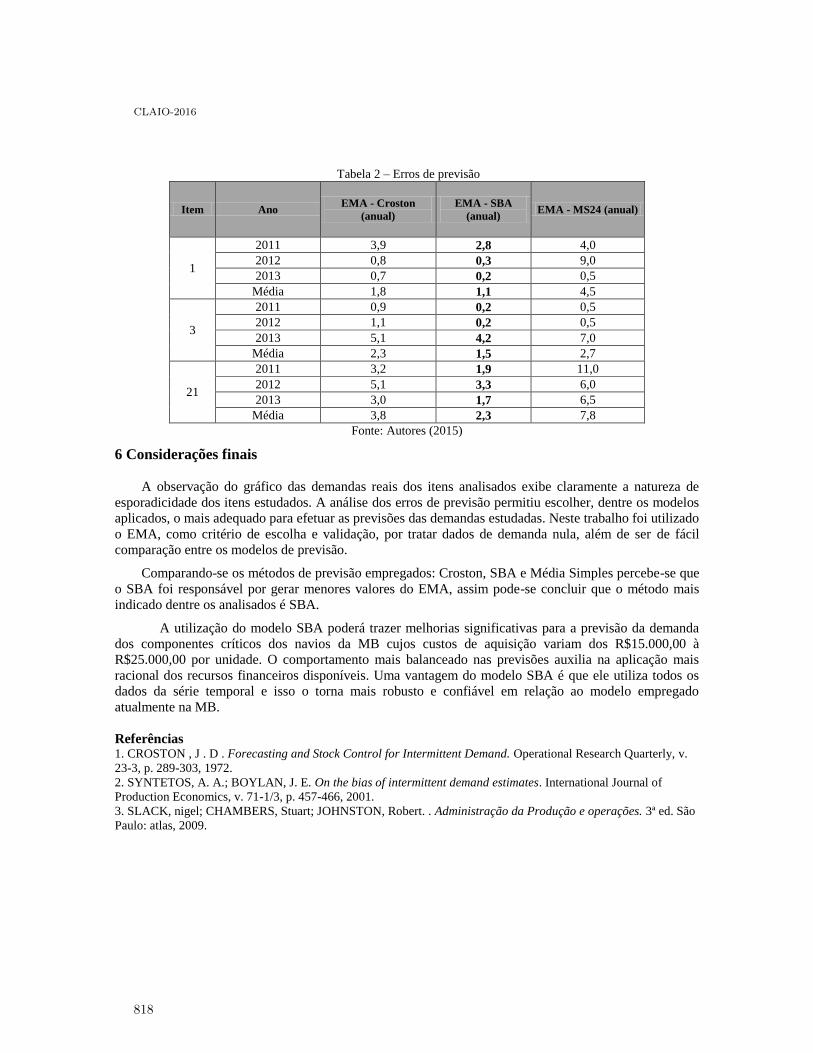
Tabela 2 – Erros de previsão
Item Ano EMA - Croston
(anual)
EMA - SBA
(anual) EMA - MS24 (anual)
1
2011 3,9 2,8 4,0
2012 0,8 0,3 9,0
2013 0,7 0,2 0,5
Média 1,8 1,1 4,5
3
2011 0,9 0,2 0,5
2012 1,1 0,2 0,5
2013 5,1 4,2 7,0
Média 2,3 1,5 2,7
21
2011 3,2 1,9 11,0
2012 5,1 3,3 6,0
2013 3,0 1,7 6,5
Média 3,8 2,3 7,8
Fonte: Autores (2015)
6 Considerações finais
A observação do gráfico das demandas reais dos itens analisados exibe claramente a natureza de
esporadicidade dos itens estudados. A análise dos erros de previsão permitiu escolher, dentre os modelos
aplicados, o mais adequado para efetuar as previsões das demandas estudadas. Neste trabalho foi utilizado
o EMA, como critério de escolha e validação, por tratar dados de demanda nula, além de ser de fácil
comparação entre os modelos de previsão.
Comparando-se os métodos de previsão empregados: Croston, SBA e Média Simples percebe-se que
o SBA foi responsável por gerar menores valores do EMA, assim pode-se concluir que o método mais
indicado dentre os analisados é SBA.
A utilização do modelo SBA poderá trazer melhorias significativas para a previsão da demanda
dos componentes críticos dos navios da MB cujos custos de aquisição variam dos R$15.000,00 à
R$25.000,00 por unidade. O comportamento mais balanceado nas previsões auxilia na aplicação mais
racional dos recursos financeiros disponíveis. Uma vantagem do modelo SBA é que ele utiliza todos os
dados da série temporal e isso o torna mais robusto e confiável em relação ao modelo empregado
atualmente na MB.
Referências 1. CROSTON , J . D . Forecasting and Stock Control for Intermittent Demand. Operational Research Quarterly, v.
23-3, p. 289-303, 1972.
2. SYNTETOS, A. A.; BOYLAN, J. E. On the bias of intermittent demand estimates. International Journal of
Production Economics, v. 71-1/3, p. 457-466, 2001.
3. SLACK, nigel; CHAMBERS, Stuart; JOHNSTON, Robert. . Administração da Produção e operações. 3ª ed. São
Paulo: atlas, 2009.
CLAIO-2016
818

Uma ferramenta para construção de Cenários Florestais
Paulo Amaro Velloso Henriques dos Santos
Instituto Federal de Santa Catarina – Campus Joinville
Arinei Carlos Lindbeck da Silva
Universidade Federal do Paraná – Centro Politécnico – Curitiba
Julio Eduardo Arce
Universidade Federal do Paraná – Campus Jardim Botânico – Curitiba
Resumo
Uma das áreas de aplicação da Pesquisa Operacional que, nas últimas cinco décadas,
apresentou um crescente número de publicações é o Planejamento Florestal. Começando
na década de 60, com 4 artigos precursores, e tendo um importante marco no trabalho de
Johnson e Scheurman em 1977. Porém, foi apenas no final da década de 80 que o
Planejamento Florestal passou a ser tratado em seus diferentes níveis hierárquicos:
Estratégico, Tático e Operacional. Destes três, o nível Operacional é o que apresenta maior
complexidade e menor prazo para planejamento, necessitando de ferramentas robustas e
ágeis para otimizá-lo. Uma das etapas que pode consumir muito tempo no desenvolvimento
de ferramentas de otimização é a coleta dos dados do cenário florestal, devido à escassez
destes dados na rede. Assim, o presente trabalho pretende apresentar uma ferramenta que
crie cenários florestais virtuais, com base em dados e conhecimentos de cenários reais, com
agilidade e, assim, auxiliar no desenvolvimento e comparação de diferentes métodos de
otimização para o Planejamento Florestal em seu nível Operacional.
Palavras-Chave: Planejamento Florestal; Planejamento Operacional; Cenário Florestal.
1 Introdução
Nas últimas 5 décadas o Planejamento Florestal passou a ser estudado e otimizado.
Os trabalhos precursores de Curtis (1962), Loucks (1964), Leak (1964) e Nautiyal e Pearse
(1967), deram início a uma linha de pesquisa que envolve técnicas de Pesquisa Operacional
na otimização de problemas de Planejamento Florestal. Na década seguinte, Johnson e
Scheurman (1977) publicaram um trabalho importantíssimo onde os autores classificaram
os problemas de Planejamento Florestal em dois modelos: o modelo Tipo I, que inclui o
formato apresentado por Loucks (1964), trabalha com um controle geográfico da floresta
e com um número maior de variáveis; o modelo Tipo II, que inclui o formato apresentado
por Nautiyal e Pearse (1967), não trabalha com controle geográfico da floresta, porém
CLAIO-2016
819

apresenta um número reduzido de variáveis. Esta publicação se tornou uma das maiores
referências no assunto.
Os estudos publicados até o final da década de 80 apresentavam a otimização do
Planejamento Florestal como a otimização do plantio visando maximizar a colheita. Porém
entre o final da década de 80 e o início da década de 90, os trabalhos publicados começaram
a separar o Planejamento Florestal em seus três níveis hierárquicos: Estratégico, Tático e
Operacional. O trabalho de Weintraub e Cholaky (1991) é um dos primeiros a apresentar
esta distinção de níveis em seu desenvolvimento.
Desde então, a quantidade de trabalhos publicados sobre o tema do Planejamento
Florestal cresceu, especialmente nos níveis Estratégico e Tático. O nível Operacional é o
que apresenta uma menor quantidade de publicações até então. Isto pode ser atribuído à
complexidade de se otimizar o nível Operacional do Planejamento Florestal. Neste nível o
número de variáveis tende a crescer exponencialmente e, por se tratar de um planejamento
de curto prazo, é fundamental que o tempo de processamento não seja elevado.
2 Descrição do Problema
Observando a quantidade de trabalhos publicados nas últimas décadas, é inegável
que a otimização do Planejamento Florestal é uma necessidade já que este ramo de mercado
movimenta valores elevados (por exemplo o custo de aquisição de um harvester, na ordem
de US$ 500.000,00) e atende a diversos clientes como: indústrias de papel, indústrias
moveleiras, setores de produção de energia, entre outras. Em 2008, o professor Julio
Eduardo Arce, escreveu um artigo de opinião para o site www.colheitademadeira.com.br
onde ele cita que “a tomada de decisões na cadeia produtiva florestal é um desafio cada
vez mais complexo. Sem ferramentas ágeis e ao mesmo tempo robustas para o
processamento e a análise das informações, a tomada de decisões pode-se tornar
simplesmente um labirinto sem saída” (ARCE, 2008).
Além de toda a complexidade computacional para se desenvolver um sistema de
otimização para o nível Operacional do Planejamento Florestal, soma-se a isso a escassez
de dados florestais para que se possa testar e melhorar os sistemas desenvolvidos.
Atualmente, o método mais comum para tal desenvolvimento é realizar convênios com
empresas privadas para poder utilizar os dados florestais desta empresa e trabalhar sobre
estes dados para buscar otimizar a colheita da empresa em questão. Porém, este processo
de coleta de informações é dispendioso e depende de um conhecimento florestal que, na
maioria das vezes, os pesquisadores da área de Pesquisa Operacional não possuem. Pode
se dizer que falta para este tipo de problema uma biblioteca de dados de teste, como existem
para problemas de transporte ou de carregamento de contêineres por exemplo.
É neste ínterim que o presente trabalho propõe uma ferramenta para construção de
Cenários Florestais. A ideia central deste trabalho é construir cenários de maneira a auxiliar
no desenvolvimento e teste de métodos de otimização para o Planejamento Florestal em
seu nível Operacional. Esta construção de cenários proposta poderá auxiliar docentes da
área florestal no desenvolvimento de problemas para trabalhar em sala de aula, bem como
pesquisadores, especialmente em nível de pós-graduação, que tenham por objetivo otimizar
o Planejamento Florestal.
CLAIO-2016
820

Basicamente, pretende-se criar um cenário que contenha talhões que difiram na
espécie florestal plantada, na área ocupada, na produtividade, no relevo do terreno e na
acessibilidade (especialmente em épocas de chuva). O operador da ferramenta tem certo
controle sobre alguns itens específicos, mas a criação também apresentará aleatoriedade na
localização, tamanho e produtividade dos talhões.
Assim, os autores de trabalhos sobre o Planejamento Florestal em seu nível
Operacional poderiam desenvolver métodos de otimização e testá-los em cenários padrões
que podem ser disponibilizados em uma biblioteca virtual. Desta forma, os resultados de
um autor podem ser comparados com os dos demais autores e também métodos podem ser
desenvolvidos para cenários mais abrangentes do que os métodos que são desenvolvidos
especificamente para os cenários de empresas privadas.
Com base nos dados destes cenários e definindo alguns critérios como número de
frentes de corte, produtividade das frentes de corte, tamanho da frota de transporte de
madeira, demanda dos produtos florestais diversos, entre outros, poderiam ser otimizados
problemas que visem, por exemplo:
a) Minimizar os deslocamentos das Frentes de Corte;
b) Atender às demandas requeridas dos diversos produtos que podem ser
colhidos;
c) Manter uma distância média de deslocamento para transporte dos
produtos;
d) Manter um estoque médio de madeira nos clientes dentro de um nível
desejável.
3 Ferramenta de Criação de Cenários Florestais
Ao se deparar com a dificuldade de obter dados florestais, já citada, afim de
desenvolver e testar uma heurística para a otimização do nível Operacional do
Planejamento Florestal, os autores decidiram então desenvolver uma ferramenta que
fornecesse os dados necessários para tal desenvolvimento. Para isso foram realizados
estudos para compreender as características inerentes a floresta que podem interferir na
produtividade da colheita dos produtos florestais.
A ferramenta de criação dos Cenários Florestais foi implementada em linguagem
Visual Basic© e deu origem a um aplicativo desenvolvido para dar ao operador condições
de determinar algumas das características do problema.
A seguir, apresentam-se os passos que devem ser seguidos pelo operador (pessoa
responsável pela utilização da ferramenta) afim de criar um Cenário Florestal. É
interessante observar que o operador possui a autonomia de indicar algumas das
características enquanto outras características são definidas dentro de certa aleatoriedade,
evitando que o operador crie cenários tendenciosos. Juntamente com a sequência de passos
do programa são apresentadas algumas imagens da ferramenta elaborada que auxiliam a
visualização destes passos.
1º passo. Inicialmente, o operador informa o tamanho da planta do terreno onde serão
alocados os talhões. De forma padronizada, adotou-se um formato quadrado
para a planta do terreno onde o operador informa o tamanho do lado do
CLAIO-2016
821

quadrado, conforme apresenta a FIGURA 1a. A ferramenta não estabelece
uma unidade de medida padrão, ficando o operador livre para utilizar o
sistema de medidas que for mais interessante no seu caso específico. Porém,
a mesma unidade utilizada pelo operador para determinar o tamanho será
utilizada para estabelecer as unidades de área dos talhões (por exemplo: num
terreno com 50 km de lado, as áreas dos talhões serão apresentadas em km2).
(a) (b) (c) (d)
FIGURA 1 – COMANDOS DA FERRAMENTA DE CRIAÇÃO DE CENÁRIOS
(a) – Inserção da informação do tamanho do terreno
(b) – Inserção das informações sobre topologia, sementes e núcleos dos talhões
(c) – Inserção das informações sobre os talhões (quantidade, tamanhos, espécies,
produtos e distâncias)
(d) – Inserção da quantidade de centros
2º passo. Nesta etapa, com o tamanho do terreno apresentado, o operador informa três
características essenciais para a ferramenta: a quantidade de topografias
diferentes (‘Tipos’); a quantidade de posições para cada topografia diferente
(‘Sementes’); a quantidade de núcleos para concentrar talhões (‘Núcleos’),
como apresenta a FIGURA 1b. A característica da topografia será essencial
para determinar a produção de cada frente de corte no talhão, visto que o
relevo do talhão pode dificultar ou até inviabilizar o deslocamento de frentes
de corte altamente mecanizadas. A quantidade de posições de cada topografia
que serão dispostas na planta do terreno, inicialmente é definida em
quantidades iguais de posições por topografia. Com esta informação, a
tendência é que os talhões se distribuam formando esta quantidade de
agrupamentos por tipo de topografia na planta do terreno. Os núcleos são
criados em posições aleatórias da planta e sua finalidade é concentrar maior
densidade de talhões em relação às regiões sem núcleos. Ou seja, quando o
aplicativo for gerar os talhões aleatoriamente, estes serão gerados com maior
probabilidade próximo aos núcleos da planta do terreno.
CLAIO-2016
822
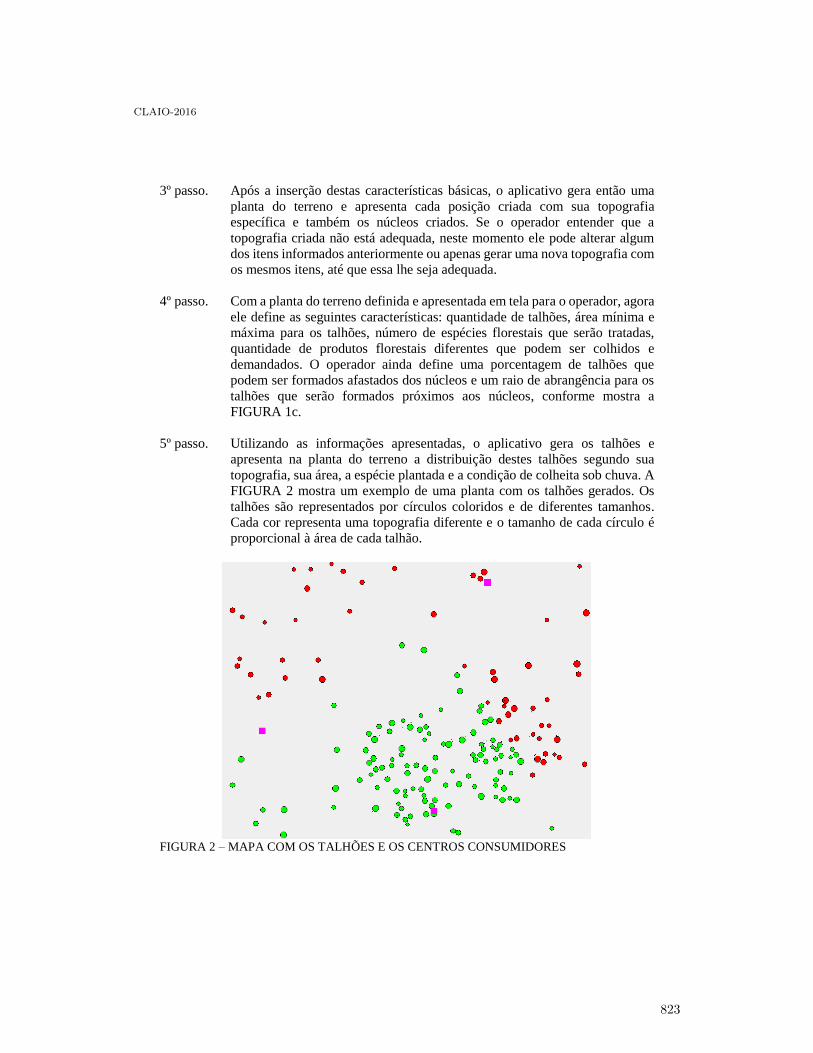
3º passo. Após a inserção destas características básicas, o aplicativo gera então uma
planta do terreno e apresenta cada posição criada com sua topografia
específica e também os núcleos criados. Se o operador entender que a
topografia criada não está adequada, neste momento ele pode alterar algum
dos itens informados anteriormente ou apenas gerar uma nova topografia com
os mesmos itens, até que essa lhe seja adequada.
4º passo. Com a planta do terreno definida e apresentada em tela para o operador, agora
ele define as seguintes características: quantidade de talhões, área mínima e
máxima para os talhões, número de espécies florestais que serão tratadas,
quantidade de produtos florestais diferentes que podem ser colhidos e
demandados. O operador ainda define uma porcentagem de talhões que
podem ser formados afastados dos núcleos e um raio de abrangência para os
talhões que serão formados próximos aos núcleos, conforme mostra a
FIGURA 1c.
5º passo. Utilizando as informações apresentadas, o aplicativo gera os talhões e
apresenta na planta do terreno a distribuição destes talhões segundo sua
topografia, sua área, a espécie plantada e a condição de colheita sob chuva. A
FIGURA 2 mostra um exemplo de uma planta com os talhões gerados. Os
talhões são representados por círculos coloridos e de diferentes tamanhos.
Cada cor representa uma topografia diferente e o tamanho de cada círculo é
proporcional à área de cada talhão.
FIGURA 2 – MAPA COM OS TALHÕES E OS CENTROS CONSUMIDORES
CLAIO-2016
823
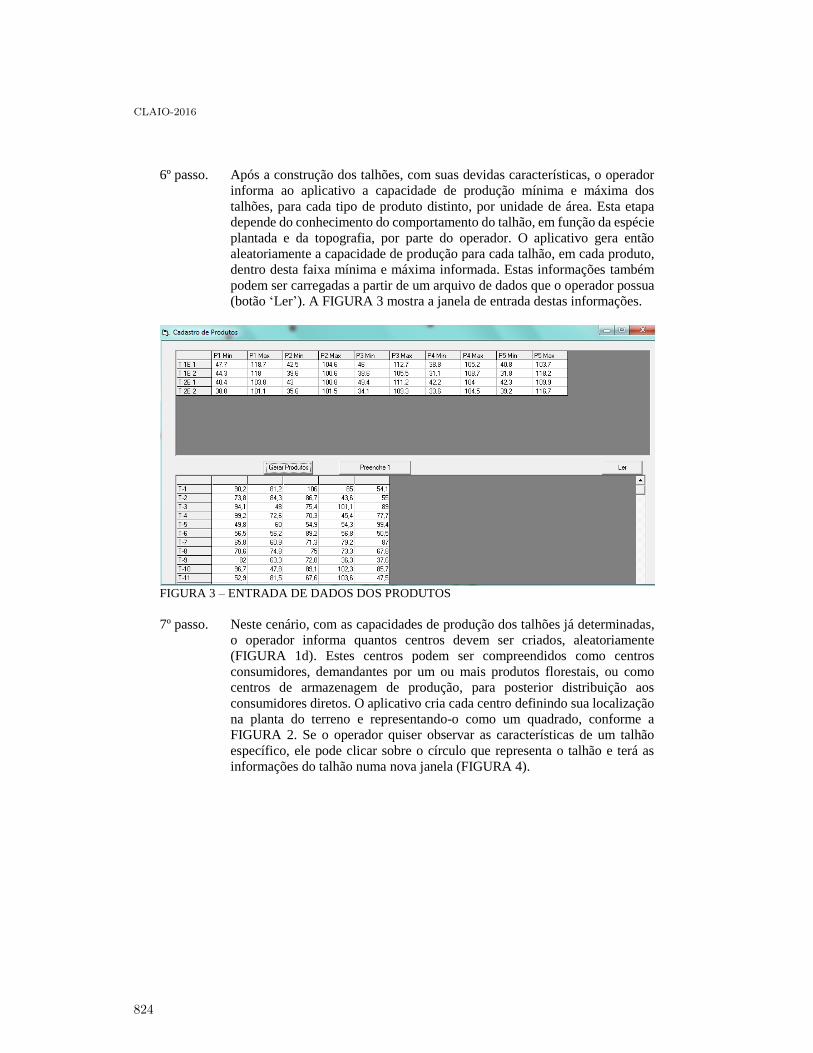
6º passo. Após a construção dos talhões, com suas devidas características, o operador
informa ao aplicativo a capacidade de produção mínima e máxima dos
talhões, para cada tipo de produto distinto, por unidade de área. Esta etapa
depende do conhecimento do comportamento do talhão, em função da espécie
plantada e da topografia, por parte do operador. O aplicativo gera então
aleatoriamente a capacidade de produção para cada talhão, em cada produto,
dentro desta faixa mínima e máxima informada. Estas informações também
podem ser carregadas a partir de um arquivo de dados que o operador possua
(botão ‘Ler’). A FIGURA 3 mostra a janela de entrada destas informações.
FIGURA 3 – ENTRADA DE DADOS DOS PRODUTOS
7º passo. Neste cenário, com as capacidades de produção dos talhões já determinadas,
o operador informa quantos centros devem ser criados, aleatoriamente
(FIGURA 1d). Estes centros podem ser compreendidos como centros
consumidores, demandantes por um ou mais produtos florestais, ou como
centros de armazenagem de produção, para posterior distribuição aos
consumidores diretos. O aplicativo cria cada centro definindo sua localização
na planta do terreno e representando-o como um quadrado, conforme a
FIGURA 2. Se o operador quiser observar as características de um talhão
específico, ele pode clicar sobre o círculo que representa o talhão e terá as
informações do talhão numa nova janela (FIGURA 4).
CLAIO-2016
824
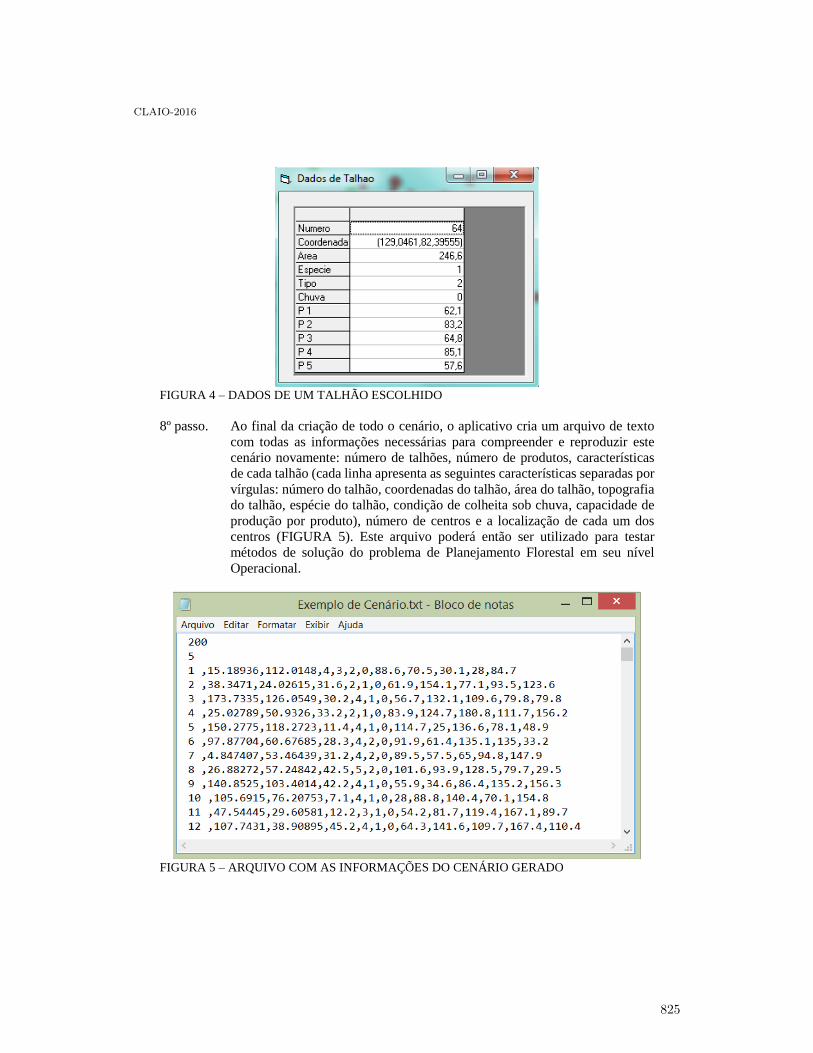
FIGURA 4 – DADOS DE UM TALHÃO ESCOLHIDO
8º passo. Ao final da criação de todo o cenário, o aplicativo cria um arquivo de texto
com todas as informações necessárias para compreender e reproduzir este
cenário novamente: número de talhões, número de produtos, características
de cada talhão (cada linha apresenta as seguintes características separadas por
vírgulas: número do talhão, coordenadas do talhão, área do talhão, topografia
do talhão, espécie do talhão, condição de colheita sob chuva, capacidade de
produção por produto), número de centros e a localização de cada um dos
centros (FIGURA 5). Este arquivo poderá então ser utilizado para testar
métodos de solução do problema de Planejamento Florestal em seu nível
Operacional.
FIGURA 5 – ARQUIVO COM AS INFORMAÇÕES DO CENÁRIO GERADO
CLAIO-2016
825

4 Conclusão
Com a Ferramenta de Criação de Cenários apresentada é possível gerar cenários
com agilidade e, assim, auxiliar no desenvolvimento de métodos de solução para o
problema do Planejamento Florestal em seu nível Operacional. Desta forma também, os
cenários utilizados por um pesquisador para testar seu método podem ser disponibilizados
para outros pesquisadores testarem métodos diferentes, comprando os resultados obtidos.
Espera-se, em breve, criar uma base de dados com cenários gerados a partir desta
ferramenta e disponibilizá-la na internet para que outros pesquisadores possam utilizá-la e
até melhorar os resultados já obtidos. Estuda-se também viabilizar que a ferramenta
também tenha possibilidade de importar características de cenários reais já mapeados,
através de arquivos shape (.SHP).
Agradecemos ao GTAO (Grupo de Tecnologia Aplicada à Otimização – UFPR)
por disponibilizar meios e materiais para a realização desta pesquisa.
Referências
1. ARCE, J. E. Planejamento Florestal Otimizado. Colheita de Madeira – Mídia especializada
em Operações Florestais (Artigo de Opinião), disponível em:
http://colheitademadeira.com.br/noticias/planejamento_florestal_otimizado, 20/03/2015 às
10:06.
2. CURTIS, F.H. Linear programming in the management of a forestry property. Journal of
Forestry, Bethesda, v. 60, p. 611-616. 1962.
3. JOHNSON, K.N.; SCHEURMAN, H.L. Techniques for prescribing optimal timber harvest
and investment under different objectives: discussion and synthesis. Forest Science, Bethesda,
v. 31, Monograph 18, 1977.
4. LEAK, W.B. Estimating maximum allowable timber yields by linear programming – a case
study. Journal of Forestry, Bethesda, v. 65, p. 644-646, 1964.
5. LOUCKS, D.P. The development of an optimal program for sustained-yield management.
Journal of Forestry, Bethesda, v. 62 p. 485-490, 1964.
6. NAUTIYAL, J.C.; PEARSE, P.H. Optimizing the conversion to sustained-yield – a
programming solution. Forest Science, Bethesda, v. 13, p. 131-139, 1967.
7. WEINTRAUB, A.; CHOLAKY, A. A Hierarchical Approach to Forest Planning. Forest
Science, Bethesda, v. 37, n. 2, p. 439-460, jun. 1991.
CLAIO-2016
826

Mental model comparison: recognized feedback loops versus
shortest independent loop set
Martin FG Schaffernicht
Facultad de Economía y Negocios – Universidad de Talca
Abstract
This paper deals with one aspect of feedback loops in mental models of dynamic systems. Advances in
recent years have led to the recognition that when using mental models to research the understanding of
dynamic systems, feedback loops should be taken into account. The current method does so focusing on
those feedback loops which have been explicitly recognized by the mental model owner. However,
untrained individuals usually fail to recognize most of the feedback loops implied by the causal structure
they articulate. This paper takes the example of two mental models articulated the context of the current
research project and renders the feedback loops into alternative ways: the loops recognized the loops
implied by the structure. Relevant differences and the interpretation of the mental models and the
comparisons between the mental models are shown and discussed in a preliminary way. It is shown that
the existing method to analyze mental models of dynamic system would benefit from incorporating the
possibility to include also those feedback loops which have not been recognized by an individual.
Keywords: Mental model of dynamic systems, feedback loops, shortest independent loop set
1 Introduction
Strategic challenges – like leading a firm in a competitive market to an economically sustainable path -
are dynamic situations. They can be represented as sets of interacting feedback loops emerging from
accumulating and draining resources. Feedback loops emerge when the change of one resource depends
on the stock of another resource. The dynamics of such situations are driven by the feedback loops and
their interaction, leading to dynamic complexity [1]. The way managers perceive and deal with strategic
challenges is framed by their mental models. Since the complexity of a situation can only be absorbed by
a mental model of equivalent complexity, these mental models should comprise a representation of the
feedback loops. Standard mental model elicitation leads to maps of attributed causal structures which can
be represented and processed as directed graphs [2]. However: whereas standard mental models only
represent variables and causal links, a mental model of a dynamic system (MMDS) has three different
levels of description: the elements (variables and causal links), the individual feedback loops and the
entire model [3]. The elicitation and analysis method has been extended to deal with the three levels [4],
calculating an “Element Distance Ratio” for variables and causal links, a “Loop Distance Ratio” for every
pair of comparable loops and a “Model Distance Ratio” for the entire set of loops conforming the model.
Analysis tools have been developed for the current version of this method [5].
The level of analysis dealt with in this paper is feedback loops. Data from a current research project about
the mental models of winemakers in the Maule region of Chile (Fondecyt 1140638) suggests that a
model’s structure can contain many more loops than are recognized by the managers [6].
CLAIO-2016
827

There are two problems: for once, loops are important drivers of a system’s behavior [7], and by failing to
recognize them, managers are in danger of not perceiving important drivers in their decisions [8]. This so-
called misperception of feedback has been the focus of attention in the literature so far [9]. Second, the
current analysis and comparison of models based upon the extended “distance ratio method” includes
only recognized loops [4] – and two given models may be much more or much less different from one
another in their underlying structure than when only the loops recognized by the decision maker are taken
into account.
This paper shows the differences between the underlying versus the recognized loops. It uses to ask him
theory mental models taken from the current project and establishes to different sets of feedback loops for
each of them. One such loop set consists of the feedback loops recognized by the owner of the mental
model; the other loop set is the so-called shortest independent loop set (SILS) [10]. The differences and
similarities which appear when comparing the recognized loops with the SILS show how little of the
causal structure driving the situations dynamics has been recognized by the owners of these mental
models. Comparison between both models based on the SILS shows aspects that are invisible when
comparing them using only the recognized loops.
This report presents only partial results, while the project and the analysis are still progressing. Therefore,
the conclusions mention the steps to be carried out in the chose future.
2 Methods
Elicitation and coding
The MMDS were elicited by in-depth interviews with 10 owners or general managers of wine yards in the
Maule region (central Chile). Interviews were recorded and then transcribed. The ensuing coding allowed
to generate a set of variables, causal links and feedback loops.
For this purpose, a variable is represented by its name. A causal link has a direction and a polarity, which
can be either positive or negative. Additionally, a causal link can have a delay mark, when it is
significantly slower than the other links to transmit an effect. A feedback loop is a closed sequence of
causal links connecting a serious of variables; it has a polarity, which is the consequence of constituting
links’ polarity can be either positive or negative. To avoid confusion between loops and links, positive
loops are called reinforcing loops and negative loops balancing loops. Feedback loops are an essential
component of dynamic systems [3]. They drive the mode of behavior of the variables. A reinforcing loop
generates exponential behavior, whereas a balancing loop creates goal seeking behavior; failure to
recognize feedback loops usually leads to flawed expectations concerning a system’s behavior [7].
Shortest independent loop set
In models of dynamic systems, most of the variables are contained in one or several feedback loops.
However, the data in the current project is in accord with the generally established finding that individuals
who have not undergone specific training two reason with feedback loops do not recognized loops, but
tends to think in linear sequences of input-output. This leads to the fact that in such mental models, the
actual number of feedback loops implied by the articulated causal structure exceeds the number of
feedback loops which have been explicitly recognized by the interviewee. Since by definition, the
interviewee did not indicate the feedback loops he or she did not recognize, a replicable way to identify
these unrecognized feedback loops is needed.
We can not simply boric with the complete set of feedback loops. Usually, there is a hierarchy of
feedback loops, and several relatively short loops combine into larger ones. The total number of feedback
CLAIO-2016
828

loops quickly rises to words unmanageable quantities, but if one can determine a loop set such as to
assure that each variable a causal link which belongs to any positive number of loops is taken into account
at least once, then none of the possible behavioral implications of any of the feedback loops is eliminated
by the fact of not taking into account the combined loops. Such a set is called an independent loop set
[11].
Of specific interest is the so-called shortest independent loop set (SILS), which assures that unnecessary
complexity would be avoided [10]. Such a loop set is elaborated starting with one variable and searching
the shortest possible path to come back to this variable; along the path, each causal link used is marked.
Upon returning to the initial variable, if there are any other feedback loops with links on marked so far,
the steps are repeated. If there are no more possible feedback loops, another variable selected and the
procedure repeated.
The two mental models used in this paper have been taken from the sample of models of the project. Any
variables which do not belong to any feedback loop (inputs or outputs) have been eliminated to keep the
models as simple as possible for the purpose of analyzing the loop sets.
3 Data
The stripped-down versions of the MMDS used for this paper have 25 and 26 variables each, but only
five of them belong to both models; fact, both models are very different when looked upon at the level of
the elements (see Table 1):
Table 1: Variables in the two MMDS
Only in MMDS 1 In both Only in MMDS 2
business climate, energy
efficiency, fair trade prime,
global supply, incentives to
grow grapes, labor efficiency,
labor supply, mechanization,
overstock, production cost of
field, production costs,
production per hectare,
revenues, revenues from wine
sales, salary costs, sales
costs access to media for associated vineyards, attractiveness for
opinion leaders, category in the market, differentiation,
feasibility of price increase, focus on volume in business
model of majority, frauds, incentive to decrease costs,
incentives to enter market, interest of reference consumers,
maximum planted area, price of grapes, production
volume, profits, publications, quality of grapes, rooting in
terroir
planted area
price of wine
profitability
quality of wine
A MMDS is best looked upon when represented as a causal loop diagram. In the case of the first model,
Figure 1 shows a tightly interconnected set of variables, in which to feedback loops are specifically
labeled because they have been recognized by the interviewee. The first such loop has to do with the price
of wine and represents the way in which attractive prices lead to increased supply which, in turn, puts
pressure on the price; this is a balancing loop. The second loop is reinforcing, and shows how a decrease
of price puts pressure on the wineries revenues and how the reaction to increase production diminishes the
quality of wine and further increases the pressure on the price. In the causal loop diagram, these loops are
easy to see because the constituting causal links are printed fat and there are “B” and “R” loop labels.
CLAIO-2016
829
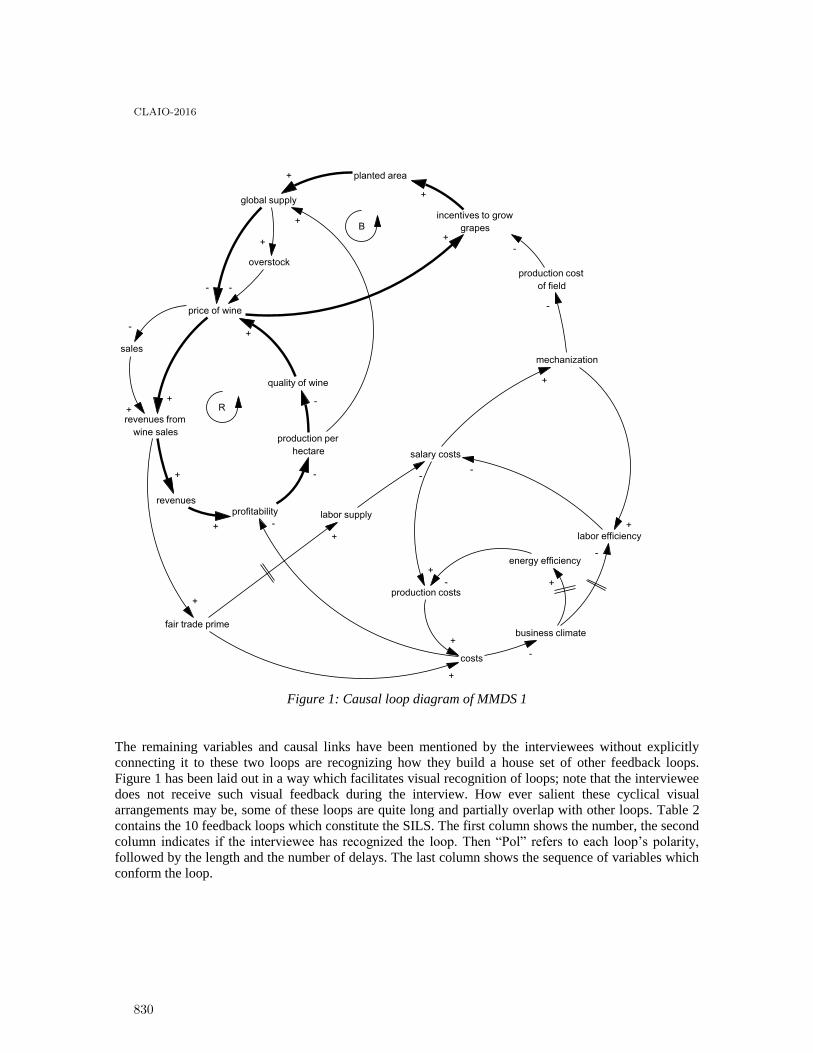
Figure 1: Causal loop diagram of MMDS 1
The remaining variables and causal links have been mentioned by the interviewees without explicitly
connecting it to these two loops are recognizing how they build a house set of other feedback loops.
Figure 1 has been laid out in a way which facilitates visual recognition of loops; note that the interviewee
does not receive such visual feedback during the interview. How ever salient these cyclical visual
arrangements may be, some of these loops are quite long and partially overlap with other loops. Table 2
contains the 10 feedback loops which constitute the SILS. The first column shows the number, the second
column indicates if the interviewee has recognized the loop. Then “Pol” refers to each loop’s polarity,
followed by the length and the number of delays. The last column shows the sequence of variables which
conform the loop.
global supply
overstock
+
price of wine
production costs
salary costs
+
production per
hectare
quality of wine
+
-
+
labor supply
mechanization
+
energy efficiency
production cost
of field
incentives to grow
grapes
planted area
-+
+
revenues
costs
+
+
revenues from
wine sales
+
+
fair trade prime
+
+
sales
+
profitability
-
-
business climate
-
labor efficiency
-
+
+
- -
-
-
+
-
-
+
-
B
R
CLAIO-2016
830
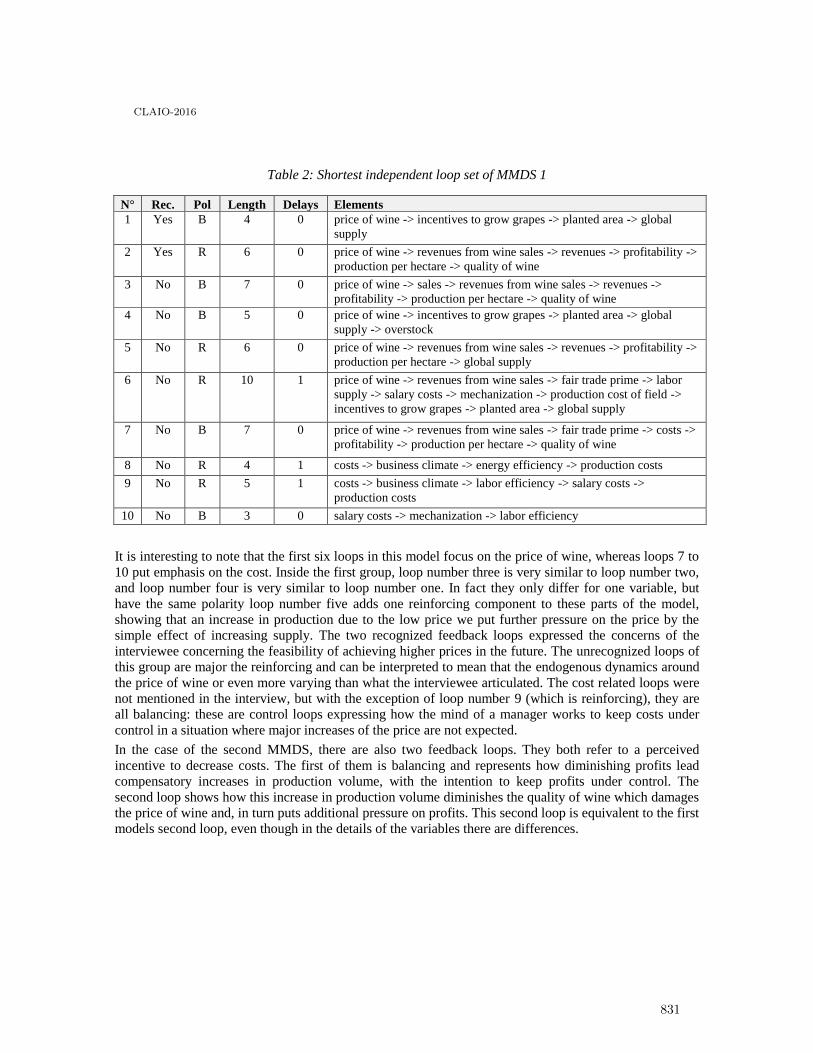
Table 2: Shortest independent loop set of MMDS 1
N° Rec. Pol Length Delays Elements
1 Yes B 4 0 price of wine -> incentives to grow grapes -> planted area -> global
supply
2 Yes R 6 0 price of wine -> revenues from wine sales -> revenues -> profitability ->
production per hectare -> quality of wine
3 No B 7 0 price of wine -> sales -> revenues from wine sales -> revenues ->
profitability -> production per hectare -> quality of wine
4 No B 5 0 price of wine -> incentives to grow grapes -> planted area -> global
supply -> overstock
5 No R 6 0 price of wine -> revenues from wine sales -> revenues -> profitability ->
production per hectare -> global supply
6 No R 10 1 price of wine -> revenues from wine sales -> fair trade prime -> labor
supply -> salary costs -> mechanization -> production cost of field ->
incentives to grow grapes -> planted area -> global supply
7 No B 7 0 price of wine -> revenues from wine sales -> fair trade prime -> costs ->
profitability -> production per hectare -> quality of wine
8 No R 4 1 costs -> business climate -> energy efficiency -> production costs
9 No R 5 1 costs -> business climate -> labor efficiency -> salary costs ->
production costs
10 No B 3 0 salary costs -> mechanization -> labor efficiency
It is interesting to note that the first six loops in this model focus on the price of wine, whereas loops 7 to
10 put emphasis on the cost. Inside the first group, loop number three is very similar to loop number two,
and loop number four is very similar to loop number one. In fact they only differ for one variable, but
have the same polarity loop number five adds one reinforcing component to these parts of the model,
showing that an increase in production due to the low price we put further pressure on the price by the
simple effect of increasing supply. The two recognized feedback loops expressed the concerns of the
interviewee concerning the feasibility of achieving higher prices in the future. The unrecognized loops of
this group are major the reinforcing and can be interpreted to mean that the endogenous dynamics around
the price of wine or even more varying than what the interviewee articulated. The cost related loops were
not mentioned in the interview, but with the exception of loop number 9 (which is reinforcing), they are
all balancing: these are control loops expressing how the mind of a manager works to keep costs under
control in a situation where major increases of the price are not expected.
In the case of the second MMDS, there are also two feedback loops. They both refer to a perceived
incentive to decrease costs. The first of them is balancing and represents how diminishing profits lead
compensatory increases in production volume, with the intention to keep profits under control. The
second loop shows how this increase in production volume diminishes the quality of wine which damages
the price of wine and, in turn puts additional pressure on profits. This second loop is equivalent to the first
models second loop, even though in the details of the variables there are differences.
CLAIO-2016
831

Figure 2: Causal Loop Diagram of MMDS 2
As becomes clear in Figure 2, this model has many more loops. Around the two recognized feedback
loops there are six more feedback loops which all have to do with costs. Loops number 3 and 7 (refer to
Table 3 for the loop numbers) pass through the incentive to decrease costs and the production volume.
Loop number 6 goes through the frauds but otherwise is very similar to loop number 2. Loops number
four and five both passed through the planted area, the production volume and profits as well as
profitability and incentives to enter the market. Why one shows how this generates a self reinforcing
importers, the second one is balancing because the territory available for the planted area is limited. For
out of the several loops are balancing, revealing a control logic expressed by the interviewee. However
the only loop which is equivalent to one of the first model is a reinforcing one.
Loops 9 to 11 shed light on an aspect which has not been mentioned in the first model: the focus on
volume in the business model of the majority of Chilean wine yards. All three loops have an effect on the
category in the market and the ensuing feasibility of price increases. Loop number 10 indicates how the
resulting pressure on the price of grapes affects the quality of wine negatively, and loop 11 represents
how the increased pressure to decrease costs increases frauds, which diminishes the quality of wine, and
after a delay impact negatively the category in the market.
The last four feedback loops are reinforcing, and they all left to do with the price of wine. The
interviewee holds the view that the role of the terroir is essential for differentiation and for the
attractiveness for opinion leaders, which have much effect on the price of wine.
planted area
profitability
incentives to
enter market+
maximum
planted area-
++
+
quality of
wine
production
volumeprice of
wine
+
-
incentive to
decrease costs
+
Costs-
+
-
profits
+
attractiveness for
opinion leaders
publications
interest ofreference
consumers
+
+
+
price of
grapes
-
frauds+
+
quality of grapes
+
category in the
market+
+
access to media for
associated vineyards
differentiation
+
+
rooting in
terroir
+
focus on volume inbusiness model of
majority
-
+
+
-
feasibility of
price increase
+
-
-
+
-
+
+ -
+
B
R
CLAIO-2016
832
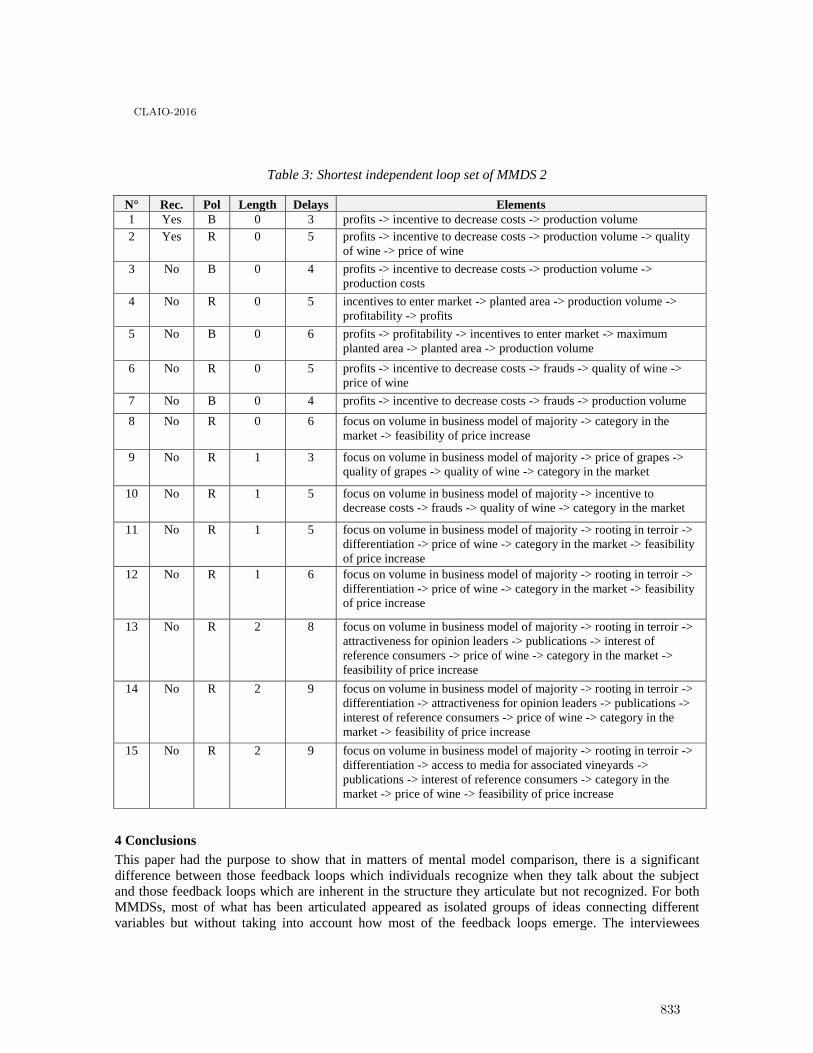
Table 3: Shortest independent loop set of MMDS 2
N° Rec. Pol Length Delays Elements
1 Yes B 0 3 profits -> incentive to decrease costs -> production volume
2 Yes R 0 5 profits -> incentive to decrease costs -> production volume -> quality
of wine -> price of wine
3 No B 0 4 profits -> incentive to decrease costs -> production volume ->
production costs
4 No R 0 5 incentives to enter market -> planted area -> production volume ->
profitability -> profits
5 No B 0 6 profits -> profitability -> incentives to enter market -> maximum
planted area -> planted area -> production volume
6 No R 0 5 profits -> incentive to decrease costs -> frauds -> quality of wine ->
price of wine
7 No B 0 4 profits -> incentive to decrease costs -> frauds -> production volume
8 No R 0 6 focus on volume in business model of majority -> category in the
market -> feasibility of price increase
9 No R 1 3 focus on volume in business model of majority -> price of grapes ->
quality of grapes -> quality of wine -> category in the market
10 No R 1 5 focus on volume in business model of majority -> incentive to
decrease costs -> frauds -> quality of wine -> category in the market
11 No R 1 5 focus on volume in business model of majority -> rooting in terroir ->
differentiation -> price of wine -> category in the market -> feasibility
of price increase
12 No R 1 6 focus on volume in business model of majority -> rooting in terroir ->
differentiation -> price of wine -> category in the market -> feasibility
of price increase
13 No R 2 8 focus on volume in business model of majority -> rooting in terroir ->
attractiveness for opinion leaders -> publications -> interest of
reference consumers -> price of wine -> category in the market ->
feasibility of price increase
14 No R 2 9 focus on volume in business model of majority -> rooting in terroir ->
differentiation -> attractiveness for opinion leaders -> publications ->
interest of reference consumers -> price of wine -> category in the
market -> feasibility of price increase
15 No R 2 9 focus on volume in business model of majority -> rooting in terroir ->
differentiation -> access to media for associated vineyards ->
publications -> interest of reference consumers -> category in the
market -> price of wine -> feasibility of price increase
4 Conclusions
This paper had the purpose to show that in matters of mental model comparison, there is a significant
difference between those feedback loops which individuals recognize when they talk about the subject
and those feedback loops which are inherent in the structure they articulate but not recognized. For both
MMDSs, most of what has been articulated appeared as isolated groups of ideas connecting different
variables but without taking into account how most of the feedback loops emerge. The interviewees
CLAIO-2016
833

recognized the circular logic of what is happening in the market and identified the danger of a downwards
pointing price spiral. However, the ways in which their own decisions build interdependent pieces of
causal structure were not recognized. Therefore if one applied the logic of the “loop distance ratio” [4] to
the same MMDS, once taking the recognized loop and once the SILS, the resulting ratios would indicate a
huge distance. Also, when comparing two different MMDS and computing the “loop distance ratio” based
on the feedback loops contained in the SILS, their resulting ratios would arguably show aspects of the
distance between the compared models which remain invisible as long as only recognized feedback loops
are taking into account.
Instead of attempting a conclusive statement, the consequence of the preceding appears to be that the
method and the tools for MMDS analysis and comparison [5] ought to be enhanced by incorporating the
possibility to detect and utilize the SILS, make intra-model comparisons based on the different loop set
and calculate two sets of “loop distance ratios” based on the recognized feedback loops and the SILS.
This will allow to quantify the distance between the mental model articulated by the decision maker and
the mental model which an analyst with experience in system dynamics hordes of the decision-makers
mental model. To the extent that the failure to recognize feedback loops is a blind spot hindering
decision-makers to realize dynamic aspects of the challenges they are resolving, this will opens new
possibilities of research in differences between mental models held by individuals with different
background knowledge.
References
1. Özgün, O. and Y. Barlas, Effects of systemic complexity factors on task difficulty in a stock
management game. System Dynamics Review, 2015. 31(3): p. 115-146.
2. Markóczy, L. and J. Goldberg, A Method for Eliciting and Comparing Causal Maps. Journal of
Management, 1995. 21(2): p. 28.
3. Groesser, S. and M. Schaffernicht, Mental Models of Dynamic Systems: Taking Stock and
Looking Ahead. System Dynamics Review, 2012. 28(1): p. 22.
4. Schaffernicht, M. and S. Groesser, A Comprehensive Method for Comparing Mental Models of
Dynamic Systems. European Jornal of Operational Research, 2011. 210(1): p. 10.
5. Schaffernicht, M. and S. Groesser, The SEXTANT software: A tool for automating the
comparative analysis of mental models of dynamic systems. European Jornal of Operational
Research, 2014. 238(2): p. 12.
6. Schaffernicht, M. and S. Groesser. Capturing Managerial Cognition in Chilean Wineries:
Hardening a New Method to Elicit and Code Mental Models of Dynamic Systems. in 33rd
International Conference of the System Dynamics Society. 2015. Cambridge, MA: System
Dynamics Society.
7. Sterman, J.D., Business dynamics: systems thinking and modeling for a complex world. 2000,
Boston, USA: McGraw-Hill.
8. Sterman, J.D., Modeling managerial behavior - misperceptions of feedback in a dynamic
decision-making experiment. Management Science, 1989. 35: p. 321–339.
9. Sterman, J.D., Does formal system dynamics training improve people's understanding of
accumulation? System Dynamics Review, 2010. 26: p. 316–334.
10. Oliva, R., Model Structure Analysis Through Graph Theory: Partition Heuristics and Feedback
Structure Decomposition. System Dynamics Review, 2004. 20(4): p. 313-336.
11. Kampman, C. Feedback loops gains and system behavior. in International System Dynamics
Conference,. 1996. Cambridge, Mass: System Dynamics Society.
CLAIO-2016
834

Optimización del abastecimiento de combustible al norte de la
Ciudad de México
Daniel Tello Gaete
Universidad Austral de Chile / Universidad Nacional Autónoma de México
Esther Segura Pérez
Facultad de Ingeniería Universidad Nacional Autónoma de México
Abstract
En este trabajo se optimiza la red de distribución de combustible desde una Terminal de Distribución a un
conjunto de Estaciones de Servicio ubicadas al norte de la Ciudad de México. La empresa actualmente
distribuye el combustible con una flota homogénea y desea saber si la inclusión de una flota heterogénea
minimiza los costos de distribución e inventario, respetando las restricciones de almacenamiento y
capacidad de oferta. Para la optimización de la red se propone realizar recopilación de datos, análisis del
comportamiento de la demanda, cálculo de costos de transporte e inventario y proponiendo un modelo
matemático utilizando el método heurístico Greedy Randomized Adaptive Search Procedure (GRASP)
para su solución, combinando elementos propios de la programación lineal. Finalmente se analizan los
resultados donde se logra un ahorro total de un 84.4% en relación a la situación actual, ya que disminuyen
cantidades de combustible a ordenar y en la periodicidad de la distribución, por lo que se rechaza la
hipótesis de que la flota heterogénea minimizaría los costos de distribución.
Keywords: Modelamiento matemático; métodos heurísticos; GRASP; inventarios, transporte, logística,
cadena de abastecimiento.
1 Introducción
El combustible a base de petróleo se ha vuelto indispensable para el desarrollo de la vida humana en cada
una de las comunidades del planeta. La Ciudad de México es una de las grandes metrópolis de América
Latina y del Mundo, el abastecimiento del combustible a cada una de las delegaciones de la ciudad no es
una tarea fácil.
El objetivo de este trabajo es realizar una optimización matemática que indique la cantidad óptima a pedir
en cada una de las estaciones de servicio que permita minimizar los costos de distribución y de inventario.
2 Descripción del Problema
En la Ciudad de México, hay cuatro Terminales de Distribución de combustible (TD 1 Ciudad de México,
TD 2 Ciudad de México, TD 3 Ciudad de México y TD 4 Estado de México), a partir de las que se
distribuyen tres tipos de combustibles: Gasolina A (GA), Gasolina B (GB) y Diésel (D) a 371 estaciones
de servicio (ES) distribuidas en 16 delegaciones y algunos de los municipios del Área Metropolitana. Las
TD tienen una flota homogénea que abastecen con combustible diariamente a cada una de las ES.
CLAIO-2016
835

Cada ES ha implementado un sistema de revisión y control de inventarios de manera periódica, con el fin
de mantener un buen nivel de servicio para los consumidores, así como un método de pronóstico de
demanda y calendarización semanal.
Actualmente la compañía distribuye el combustible desde la TD hasta la ES empleando una flota
homogénea de camiones que transportan 20,000 m3. Por lo que la empresa desea conocer si es
conveniente utilizar una flota heterogénea de camiones y la frecuencia de abastecimiento de combustible
a cada una de las ES ubicadas en la Delegación Azcapotzalco al norte de la ciudad de México de tal
manera de minimizar los costos de inventario y transporte. En la Figura 1 se aprecia la región del estudio.
Figura 1: Región de estudio y ubicación de ES.
Fuente: http://www.ubicalas.com
A continuación se presentara una propuesta de abastecimiento y administración de inventario donde se
espera reducir los costos de transporte de la flota de camiones, así como determinar el tipo de camiones
que se deben utilizar. Para validar esta situación se utilizaron como referencia la investigación
desarrollada por otros autores como Coelho, Cordeau y Laporte (2012), donde realizan un modelo
matemático que minimiza los costos de inventario y transporte de una flota de vehículos; Kasthuri y
Seshaiah (2013) que realizan un modelo de inventario orientado a varios productos con demanda
dependiente; y Genedi y Zaki (2011) que formulan un modelo orientado al control de calidad de
inventarios.
3 Materiales y Métodos
3.1 Recopilación de datos
Como sólo se cuentan con datos de las demandas mensuales (entre enero 2014 y octubre 2015) de las ES1
y ES6. Para calcular las 16 ES faltantes se empleó una estructura geométrica denominada Diagramas de
Voronoi (Gult & Klingel, 2012) para delimitar las áreas a ser suministradas (Okabe, Boots & Sugihara
1992) por cada ES y así obtener una estimación de la demanda en relación a la población con el área que
tienen que abastecer cada una de ellas, datos que se obtuvieron utilizando herramientas de AutoCAD y
bases de datos extraídas del INEGI (http://www.inegi.org.mx/).
3.2 Comportamiento de la demanda
El análisis de comportamiento de la demanda del combustible se realizó con el coeficiente de variabilidad
(CV) desarrollado por Peterson & Silver (1987), el cual sirve para comprobar si la demanda es
CLAIO-2016
836
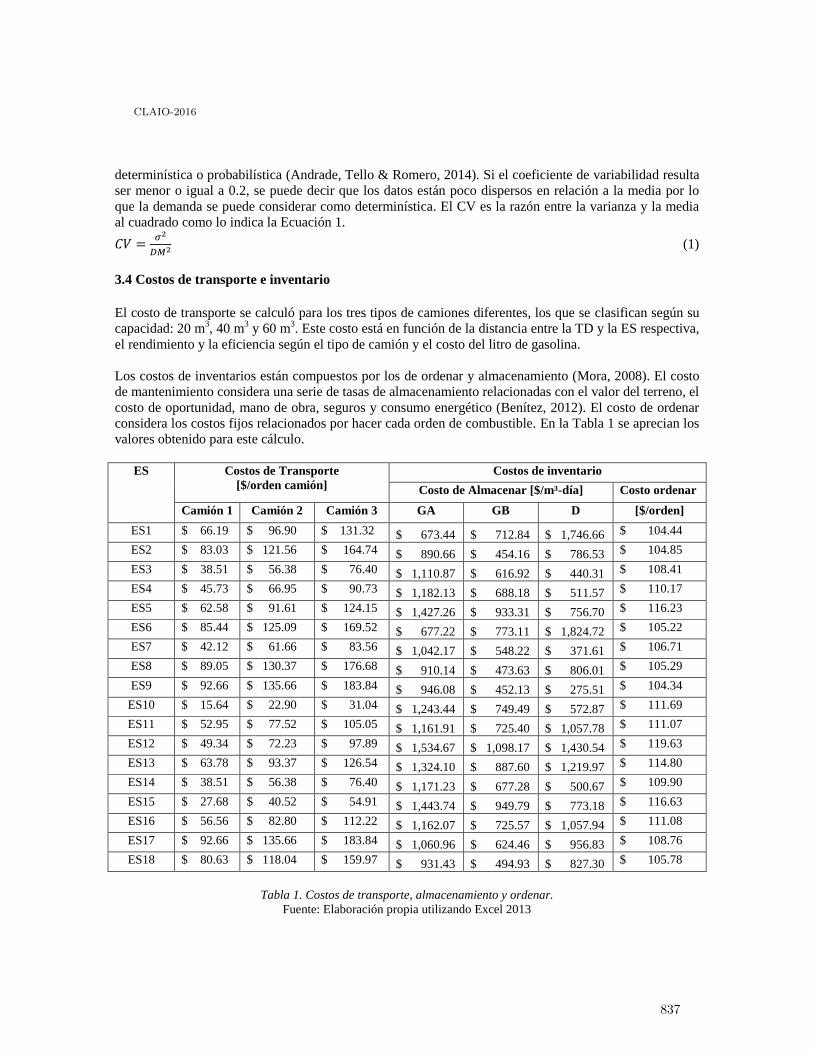
determinística o probabilística (Andrade, Tello & Romero, 2014). Si el coeficiente de variabilidad resulta
ser menor o igual a 0.2, se puede decir que los datos están poco dispersos en relación a la media por lo
que la demanda se puede considerar como determinística. El CV es la razón entre la varianza y la media
al cuadrado como lo indica la Ecuación 1.
(1)
3.4 Costos de transporte e inventario
El costo de transporte se calculó para los tres tipos de camiones diferentes, los que se clasifican según su
capacidad: 20 m3, 40 m
3 y 60 m
3. Este costo está en función de la distancia entre la TD y la ES respectiva,
el rendimiento y la eficiencia según el tipo de camión y el costo del litro de gasolina.
Los costos de inventarios están compuestos por los de ordenar y almacenamiento (Mora, 2008). El costo
de mantenimiento considera una serie de tasas de almacenamiento relacionadas con el valor del terreno, el
costo de oportunidad, mano de obra, seguros y consumo energético (Benítez, 2012). El costo de ordenar
considera los costos fijos relacionados por hacer cada orden de combustible. En la Tabla 1 se aprecian los
valores obtenido para este cálculo.
ES Costos de Transporte
[$/orden camión]
Costos de inventario
Costo de Almacenar [$/m³-día] Costo ordenar
Camión 1 Camión 2 Camión 3 GA GB D [$/orden]
ES1 $ 66.19 $ 96.90 $ 131.32 $ 673.44 $ 712.84 $ 1,746.66 $ 104.44
ES2 $ 83.03 $ 121.56 $ 164.74 $ 890.66 $ 454.16 $ 786.53 $ 104.85
ES3 $ 38.51 $ 56.38 $ 76.40 $ 1,110.87 $ 616.92 $ 440.31 $ 108.41
ES4 $ 45.73 $ 66.95 $ 90.73 $ 1,182.13 $ 688.18 $ 511.57 $ 110.17
ES5 $ 62.58 $ 91.61 $ 124.15 $ 1,427.26 $ 933.31 $ 756.70 $ 116.23
ES6 $ 85.44 $ 125.09 $ 169.52 $ 677.22 $ 773.11 $ 1,824.72 $ 105.22
ES7 $ 42.12 $ 61.66 $ 83.56 $ 1,042.17 $ 548.22 $ 371.61 $ 106.71
ES8 $ 89.05 $ 130.37 $ 176.68 $ 910.14 $ 473.63 $ 806.01 $ 105.29
ES9 $ 92.66 $ 135.66 $ 183.84 $ 946.08 $ 452.13 $ 275.51 $ 104.34
ES10 $ 15.64 $ 22.90 $ 31.04 $ 1,243.44 $ 749.49 $ 572.87 $ 111.69
ES11 $ 52.95 $ 77.52 $ 105.05 $ 1,161.91 $ 725.40 $ 1,057.78 $ 111.07
ES12 $ 49.34 $ 72.23 $ 97.89 $ 1,534.67 $ 1,098.17 $ 1,430.54 $ 119.63
ES13 $ 63.78 $ 93.37 $ 126.54 $ 1,324.10 $ 887.60 $ 1,219.97 $ 114.80
ES14 $ 38.51 $ 56.38 $ 76.40 $ 1,171.23 $ 677.28 $ 500.67 $ 109.90
ES15 $ 27.68 $ 40.52 $ 54.91 $ 1,443.74 $ 949.79 $ 773.18 $ 116.63
ES16 $ 56.56 $ 82.80 $ 112.22 $ 1,162.07 $ 725.57 $ 1,057.94 $ 111.08
ES17 $ 92.66 $ 135.66 $ 183.84 $ 1,060.96 $ 624.46 $ 956.83 $ 108.76
ES18 $ 80.63 $ 118.04 $ 159.97 $ 931.43 $ 494.93 $ 827.30 $ 105.78
Tabla 1. Costos de transporte, almacenamiento y ordenar.
Fuente: Elaboración propia utilizando Excel 2013
CLAIO-2016
837

3.5 Modelamiento algoritmo GRASP
A partir de los datos obtenidos se desarrolló un modelo de optimización del problema de distribución
planteado que nos indique la cantidad óptima a ordenar en la estación respectiva además del tipo de flota
por la que se distribuirá.
A partir de los datos obtenidos se desarrolló un modelo matemático que nos indique la cantidad óptima a
ordenar en la estación respectiva, además del tipo de flota por el que se distribuirá. La naturaleza del
modelo se desarrolla con programación no lineal, donde la función objetivo es no lineal y las restricciones
son lineales.
Índices
Variables decisión
αijk : v. a. continua que indica factor de m3 de combustible tipo i a transportar con el camión j a la a ES k.
Naturaleza variables decisión
,
Parámetros
.
.
.
Ecuaciones
(2)
(3)
CLAIO-2016
838

Propuesta de solución: Algoritmo GRASP
Este algoritmo se realiza mediante la construcción aleatoria que busca producir un conjunto de soluciones
hasta ir encontrando la mejor (Martí, 2011). El modelo de optimización se programó en el software
LINGO versión 11, sin embargo no arrojó ninguna solución factible, debido a la alta complejidad del
problema.
1. Asignación de valor alto a Cijk.
2. while iteraciones ≤ iteraciones totales {
if (Cijk* ≤ Cijk){ Xijk = Cijk*} else{ Xijk = Cijk
{
3. End
Paso 1: Consiste en asignar un valor inicial a la variable Xijk = Cijk
*.
Paso 2: En función del número de iteraciones deseadas se van asignando variables aleatorias a nijk y a αijk
para construir la ecuación 3, en el caso de que el valor Cijk, sea menor al Cijk*, se mantiene la variable Cijk
para Xijk, en caso contrario se asigna el nuevo valor Cijk a Xijk llegando a ser una variable Cijk*. Cuando se
obtiene un nuevo valor Cijk*
se aplica un modelo de programación lineal binaria que se explica a
continuación: la función objetivo consiste en minimizar los costos de inventario y distribución en
trasladar combustible tipo i con un camión tipo j a la ES k; la primera restricción indica que cada ES k es
abastecida, la última restricción indica la naturaleza binaria de la variable decisión.
4 Resultados
El desarrollo del modelo se efectuó en el Microsoft Excel 2013 con herramientas de Visual Basic donde
se obtuvieron los siguientes resultados de las cantidades a ordenar Tabla 2, realizando 32,767 iteraciones
que fue lo que soportó el software. Todos los resultados arrojaron que con el Camión 1 de 20 m3 deben
realizarse las entregas. A partir de estos datos fueron calculados los costos de almacenamiento, ordenar y
transporte, y la cantidad de órdenes a la semana, los que están presentados en la Tabla 3.
CLAIO-2016
839

ES GA [m3] GB [m
3] D [m
3]
ES1 18.04 18.54 18.39
ES2 18.56 18.11 18.76
ES3 18.96 18.42 18.05
ES4 18.85 18.09 18.90
ES5 18.79 18.43 18.57
ES6 18.97 18.62 18.24
ES7 18.29 18.93 18.18
ES8 18.34 18.02 18.17
ES9 18.71 18.80 18.36
ES10 18.11 18.17 18.99
ES11 18.18 18.79 18.28
ES12 18.07 18.35 18.87
ES13 18.58 18.56 18.13
ES14 18.33 18.72 18.90
ES15 18.53 18.10 18.56
ES16 18.44 18.41 18.36
ES17 18.69 18.25 18.33
ES18 18.92 18.51 18.14
Tabla 2. Cantidad a ordenar en las ES.
Fuente: Elaboración propia utilizando Excel 2013
De la Tabla 3 se observa que los ahorros de los costos de almacenamiento se redujeron en su mayoría
sobre el 32%, mientras que los costos de ordenar y distribución, algunos disminuyeron hasta el 67%, sin
embargo la mayoría aumentó entre 0.2 y 17%. Un aspecto importante a considerar que pese a los costos
de ordenar y transporte aumenten, no es una diferencia relevante en cuanto a los costos de almacenar ya
que estos son más significativos, debido a que el costo de almacenar 1 m3 de combustible es mucho más
elevado al costo de transportarlo. Lo que en términos generales en los ahorros de la red de distribución se
observan entre un 3.4 y 1,322% en la operación, logrando un ahorro semanal de un 83.4% en total,
equivalente a $2.35 millones a la semana.
CLAIO-2016
840
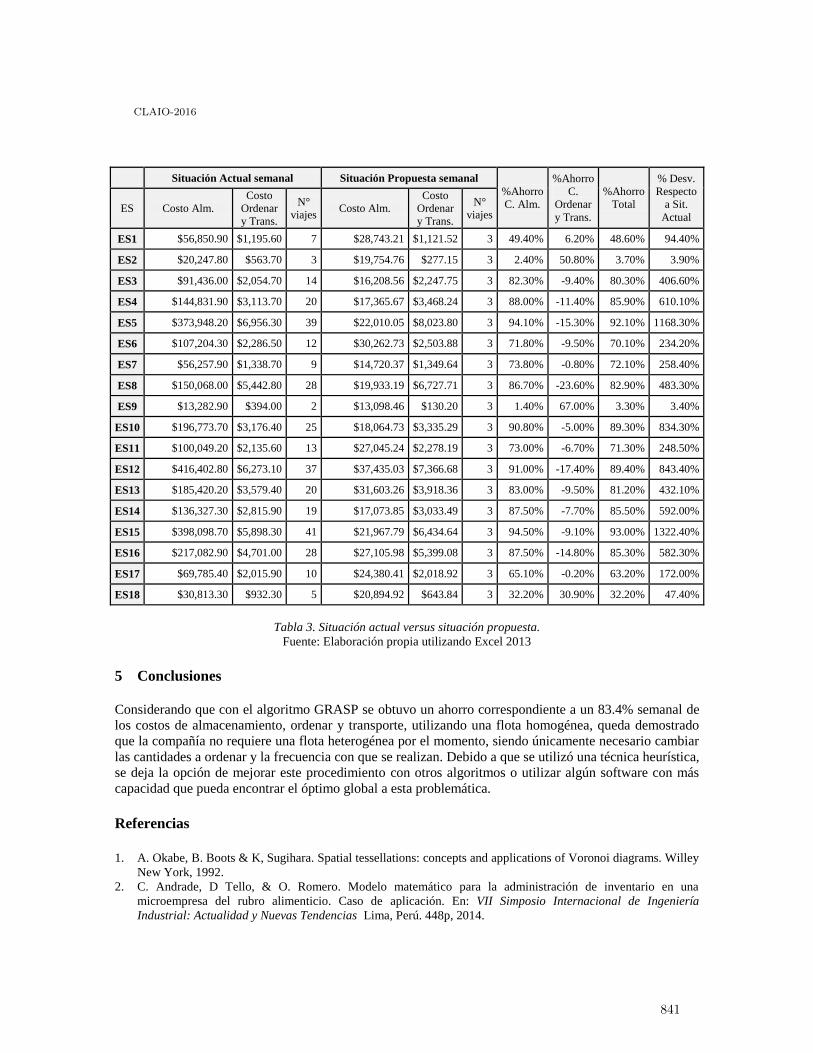
Situación Actual semanal Situación Propuesta semanal
%Ahorro
C. Alm.
%Ahorro
C.
Ordenar
y Trans.
%Ahorro
Total
% Desv.
Respecto
a Sit.
Actual ES Costo Alm.
Costo
Ordenar
y Trans.
N°
viajes Costo Alm.
Costo
Ordenar
y Trans.
N°
viajes
ES1 $56,850.90 $1,195.60 7 $28,743.21 $1,121.52 3 49.40% 6.20% 48.60% 94.40%
ES2 $20,247.80 $563.70 3 $19,754.76 $277.15 3 2.40% 50.80% 3.70% 3.90%
ES3 $91,436.00 $2,054.70 14 $16,208.56 $2,247.75 3 82.30% -9.40% 80.30% 406.60%
ES4 $144,831.90 $3,113.70 20 $17,365.67 $3,468.24 3 88.00% -11.40% 85.90% 610.10%
ES5 $373,948.20 $6,956.30 39 $22,010.05 $8,023.80 3 94.10% -15.30% 92.10% 1168.30%
ES6 $107,204.30 $2,286.50 12 $30,262.73 $2,503.88 3 71.80% -9.50% 70.10% 234.20%
ES7 $56,257.90 $1,338.70 9 $14,720.37 $1,349.64 3 73.80% -0.80% 72.10% 258.40%
ES8 $150,068.00 $5,442.80 28 $19,933.19 $6,727.71 3 86.70% -23.60% 82.90% 483.30%
ES9 $13,282.90 $394.00 2 $13,098.46 $130.20 3 1.40% 67.00% 3.30% 3.40%
ES10 $196,773.70 $3,176.40 25 $18,064.73 $3,335.29 3 90.80% -5.00% 89.30% 834.30%
ES11 $100,049.20 $2,135.60 13 $27,045.24 $2,278.19 3 73.00% -6.70% 71.30% 248.50%
ES12 $416,402.80 $6,273.10 37 $37,435.03 $7,366.68 3 91.00% -17.40% 89.40% 843.40%
ES13 $185,420.20 $3,579.40 20 $31,603.26 $3,918.36 3 83.00% -9.50% 81.20% 432.10%
ES14 $136,327.30 $2,815.90 19 $17,073.85 $3,033.49 3 87.50% -7.70% 85.50% 592.00%
ES15 $398,098.70 $5,898.30 41 $21,967.79 $6,434.64 3 94.50% -9.10% 93.00% 1322.40%
ES16 $217,082.90 $4,701.00 28 $27,105.98 $5,399.08 3 87.50% -14.80% 85.30% 582.30%
ES17 $69,785.40 $2,015.90 10 $24,380.41 $2,018.92 3 65.10% -0.20% 63.20% 172.00%
ES18 $30,813.30 $932.30 5 $20,894.92 $643.84 3 32.20% 30.90% 32.20% 47.40%
Tabla 3. Situación actual versus situación propuesta.
Fuente: Elaboración propia utilizando Excel 2013
5 Conclusiones
Considerando que con el algoritmo GRASP se obtuvo un ahorro correspondiente a un 83.4% semanal de
los costos de almacenamiento, ordenar y transporte, utilizando una flota homogénea, queda demostrado
que la compañía no requiere una flota heterogénea por el momento, siendo únicamente necesario cambiar
las cantidades a ordenar y la frecuencia con que se realizan. Debido a que se utilizó una técnica heurística,
se deja la opción de mejorar este procedimiento con otros algoritmos o utilizar algún software con más
capacidad que pueda encontrar el óptimo global a esta problemática.
Referencias
1. A. Okabe, B. Boots & K, Sugihara. Spatial tessellations: concepts and applications of Voronoi diagrams. Willey
New York, 1992.
2. C. Andrade, D Tello, & O. Romero. Modelo matemático para la administración de inventario en una
microempresa del rubro alimenticio. Caso de aplicación. En: VII Simposio Internacional de Ingeniería
Industrial: Actualidad y Nuevas Tendencias Lima, Perú. 448p, 2014.
CLAIO-2016
841

3. INEGI: Instituto Nacional de Estadística y Geografía (INEGI). Web site: www.inegi.org.mx.
4. K. Kotb, H.Genedi & S. Zaki. Quality Control for Probabilistic Single-Item EOQ Model with Zero Lead Time
under Two Restriction: A Geometric Programming Approach. International Journal of Mathematical Archive,
Mar -2011, pp. 335-338
5. L. Coelho, J. Cordeau & G. Laporte. The inventory-routing problem with transshipment. Computers &
Operation Research. 39 (2012) 2537-2548, 2012.
6. LINGO 11.0. Web site: http://www.lindo.com/.
7. L. Mora. Gestión Logística Integral. Ecoe Ediciones. Bogotá, 2008.
8. Microsoft Excel 2013. Web site: https://www.office.com/.
9. N. Guth & P. Klingel. Demand Allocation in Water Distribution Network Modelling – A GIS-Based Approach
Using Voronoi Diagrams with Constraints. Application of Geographic Information Systems, Dr. Bhuiyan
Monwar Alam (Ed.), ISBN: 978-953-51-0824-5, InTech, DOI: 10.5772/50014, 2012.
10. R. Benítez. Influencia de los costos de mantenimiento en la toma de decisiones. La Habana: Centro de
Inmunología Molecular, 2012.
11. R. Kasthuri. & C. Seshaiah. Multi-item EOQ model with demand dependent on unit price. Applied and
Computational Mathematics. Vol. 2, No. 6, pp. 149-151, 2013.
12. R. Martí, V. Campos, M. Resende & A. Duarte. Multi-objetctive grasp with path-relinking. AT&T Labs
Research Technical Report. 2011.
13. R. Peterson & E. Silver. Decision systems for inventory management and production planning. Willey New
York, 1985.
14. Ubicalas.com. Web site. http://www.ubicalas.com/.
15. Visual Basic. Web site: https://msdn.microsoft.com/es-es/vstudio/default.aspx.
16. W. Winston. Investigación de operaciones: Aplicaciones y algoritmos (4ª ed.). Thompson. México D. F., 2004.
CLAIO-2016
842

The problem of scheduling offshore supply port operations
Rennan Danilo Seimetz Chagas
Federal University of Rio de Janeiro
Virgílio José Martins Ferreira Filho
Federal University of Rio de Janeiro
Abstract
The oil industry has grown considerably in recent years, particularly in the offshore environment (in Brazil,
for example) and technological developments are essential to improve their processes. This work is focused
on the transportation of cargo to offshore units. The units are supported by a logistics system that is critical
to ensure the mobility of products efficiently and on time, reducing the total logistics cost. The objective of
this work is improve the operations involving the transportation of defining the departure times of supply
vessels by modeling and solving it as a mixed integer programming problem. This problem is known as
Berth Allocation Problem (BAP) and consists in choosing the best schedule to the offshore supply port
operations. Two formulations paradigms were developed for the problem. The models proved to be very
useful for realistic applications, reducing the planning time from day to a few hours reaching seconds in
some cases.
Keywords: Berth Allocation Problem; Integer Programming; Offshore logistics.
1 Introduction
Oil companies intent to explore and find oil, no matter where it is, restricted to its economic and
technical viability. In Brazil, many oil fields were discovered subsea, especially in Campus Basin and more
recently in pre-salt fields. The distance in relation to Brazil’s coast, as well the depth of the oil reservoirs
location, impose a huge logistical effort for the supply operations.
The offshore units demand food, tools, pipes and many other products. Those goods contracted
from suppliers are concentrated in supply ports, for load on Platform Supply Vessels (PSV). One key point
of this logistical network is the port. Both load and backload cargo of the maritime units must be handled
in the port. This large warehouse needs a scarce resource, which is time. The delivery liability of products
for the units is influenced by the way the port is managed. In addition to that, an efficient planning of the
port activities allows the same terminal to be used for more docking operations without the need to build
or hire a new one.
The objective of this work is to investigate and improve the operations involving the
transportation of deck cargo to the offshore units defining the departure times of supply vessels by modeling
and solving it as a mixed integer programming problem. This problem is known in the literature as Berth
Allocation Problem (BAP) and consists in choosing the best schedule to the offshore supply port operations.
This means defining the best berthing times for the respective supply routes, taking into account the
following restrictions.
In addition to the inherent constraints of a classic parallel machines scheduling problem, some
others need to be added for the studied case. The several units served by one vessel are grouped according
CLAIO-2016
843

to their demand profile and proximity. Each cluster has a frequency of weekly visits according to its
demand. This frequency can be from one up to seven visits per week. It is important for the travels belonging
to the same group to be spaced throughout the week. It would not make sense that a new supply vessel
leaves the port, in direction of the same units, a few hours after the previous trip. Thus, clusters with two
weekly visits should have a spacing of approximately 84 hours, clusters with 3 visits, about 56 hours and
so forth. This uniform allocation of trips throughout the week provides greater stability to the units
operations and a safer control of inventories. There are types of demand that are not compatible with certain
berths. For security reasons, transactions involving diesel loading or other fluids should not occur near the
beach, some berths do not support the weight of the load, or simply do not have the most appropriate
equipment. In addition, vessels handling times and slack security for mooring should be considered.
2 Literature review
The Berth Allocation Problem (BAP) refers to the assignment of a pool of vessels to a physical
location in the port terminal for cargo handling, given the quay layout, planning horizon, and an objective
function to optimize. Some additional data may be considered such as vessel length and depth, arrival times
of vessels and handling time [1]. The BAP was proven to be a 𝒩𝒫-hard problem related to set partitioning
problem [11] and to bi-dimensional cut problem [9].
Imai et al. [7] consider the dynamic berth allocation problem with ships service priorities. The
proposed model is solved with subgradient method just like it was proposed by Nishimura et al. [13]. The
relaxed model results in a quadratic assignment problem, leading the authors to implement a solution
method based on genetic algorithms. Robenek et al. [16] solve the problem for bulk cargo through a banch-
and-price algorithm. Umang et al. [16] use a set partitioning formulation with squeaky wheel heuristic for
construction and improvement of feasible solutions. Cordeau et al. [3] compare the performance of
formulations and Tabu Search heuristics to minimize waiting time of vessels for a discrete and continuous
berth layout. An hybrid heuristic based on a clustering method search with solutions generation by
Simulated Annealing was implemented by Oliveira et al. [14]. Genetic Algorithms were used to solve BAP
by Nishimura et al. [13], Imai et al. [7] and Imai et al. [8]. Cheong et al. [2] apply genetic algorithms to
solve a multibojective variation of the problem. Another BAP variation is presented by Xu et a. [17] who
considers berth assignment constrained by vessel draft and tide time windows. Also a formulation of space-
time network may be used to work with BAP [18].
The literature over stochastic berth allocation problem is scarce. Several randomness are present
when dealing with port operations. Among them, we highlight: suppliers deliveries at right time;
unavailability of operational resources; and handling times. Karafa et al. [10] deal with BAP with stochastic
handling times. Their method is based on a bi-objective model which minimizes expected total vessel
waiting time and the risk of delay in relation to what has been programmed. Zhou et al. [15] consider
random arrival times and random handling times with the introduction of chance constraints. This same
group of random variables was considered by Golias et al. [6] on a robust programming method.
A common point between the studies reviewed and this publication is to deal with a discrete layout
of quay with integer programming [2, 7, 13, 17]. Other publications resemble ours for dealing with
scheduling problems, such as oil rigs maintenance scheduling [4, 5, 12]. Although some studies attempt to
solve the BAP with exact optimization methods, none of them worked an issue with the level of generality
that this paper will present. None of the listed works presented more flexible models to ensure moorings at
fixed times, or precedence relations between moorings.
Furthermore, no one of the publications considers periodical planning of the moorings. They must
finish, in general, before the planning horizon. If we deal with a planning time of one week, which starts at
Monday midnight and finishes Sunday, it is not possible, with the presented works, to produce a schedule
where a mooring may start at Sunday and finish after Monday begins.
CLAIO-2016
844

3 Problem Definition
The several maritime units served by a port have supply demands that may vary between bulk
cargo, fluids, diesel, food and others. In a simply way they may be separated between production units and
oil Rigs due to the large difference of their demands. These units are then clustered according to its
proximity (Figure 1). Each cluster has its frequency of service. For example, a cluster of production units
(CPP) has frequency of 2 visits per week and a cluster of oil rigs (CSS) has frequency of 3 visits per week.
It is important that vessel trips for a same cluster have a balanced time interval. It is bad for the
operations if the platforms or rigs have an intermittent supply. This way, assuming that the planning horizon
is a week (168 hours), clusters with frequency 2 should have a time interval of 84 hours, with frequency 3
a 56 hours interval and so on. This uniform allocation of vessel trips allows predictability and stability for
the offshore units operations. Some of those units need more services per week. However, they are not
numerous enough, or they are far from each other. To deal with this problem some clusters are associated
as conjugated clusters (Figure 2). Conjugated clusters share at least one unit. If both clusters have frequency
of two trips per week, then the conjugated unit will have 4 trips per week. For this event the ideal time
space between trips is equal to 42 hours.
Figure 1: Cluster representation
Figure 2: Conjugate cluster representation
Another important aspect concerning time between trips is the tolerance slack. It may be possible
to find feasible optimal solutions where time interval are exactly those listed on the previous paragraph.
However, consider this as a hard constraint may lead to infeasibility. Assuming this, is acceptable to tolerate
a deviation at this measure. The last premise is berth compatibility. Some demands are not compatible with
all berths. For safety and environmental reasons diesel and other fluids loads should not occur on the berth
which is the nearest to the beach. Also, a slack time due to safety and ships maneuvers should be respected
between moorings.
4 Mathematical Formulations
In this section the proposed formulations for the BAP are presented and descripted. There are
two types of formulations. Models with sorting variables and scheduling variables. Each type shows
characteristics that influence implementation and computational efficiency. For both formulations the
parameters are the same
4.1 Sorting variables formulation
Set and indices:
𝐵, 𝑖 Berths;
𝑅, 𝑗, 𝑟 Moorings;
𝑂, 𝑘, 𝑡 Orders;
𝐶 ⊂ 𝑅 × 𝑅 Conjugates;
Cluster 1 Cluster 2
Conjugate
CLAIO-2016
845

Parameters:
dj Time to handle mooring j at port;
Lprec Ideal time interval between trips of same mooring;
Lconjj,r Ideal time interval between conjugated moorings;
Bincompi,j Binary parameter. Indicates if berth i is compatible with mooring j;
precj,r Binary parameter. Indicates if mooring j precedes mooring r;
Tmax Planning horizon;
Decision variables:
𝑦𝑖,𝑗𝑘 Binary. equals 1 if mooring j is the k- th handled at berth i;
𝑥𝑗 Time which mooring j starts;
𝑑𝑝𝑗,𝑟+ , 𝑑𝑝𝑗,𝑟
− Positive and negative slack times in relation to ideal time interval between trips;
𝑑𝑐𝑗,𝑟+ , 𝑑𝑐𝑗,𝑟
− Positive and negative slack times in relation to ideal time interval between conjugated clusters;
𝑴𝒊𝒏 ( ∑ 𝑑𝑝𝑗,𝑟+ + 𝑑𝑝𝑗,𝑟
−
(𝑗,𝑟)|prec𝑗,𝑟
) + ( ∑ 𝑑𝑐𝑗,𝑟+ + 𝑑𝑐𝑗,𝑟
−
(𝑗,𝑟)∈𝐶
) (1)
s.t.
∑ ∑ 𝑦𝑖,𝑗𝑘
𝑘∈𝑂𝑖∈𝐵
= 1 ∀ 𝑗 ∈ 𝑅 (2)
∑ 𝑦𝑖,𝑗𝑘
𝑗∈𝑅
≤ 1 ∀ 𝑖 ∈ 𝐵, 𝑘 ∈ 𝑂 (3)
∑ 𝑦𝑖,𝑗𝑘+1
𝑗∈𝑅
≤ ∑ 𝑦𝑖,𝑗𝑘
𝑗∈𝑅
∀ 𝑖 ∈ 𝐵, 𝑘 ∈ 𝑂 (4)
𝑥𝑟 ≥ 𝑥𝑗 + 𝑑𝑗 − 𝑇𝑚𝑎𝑥 ∙ (2 − ∑ 𝑦𝑖,𝑗𝑘
𝑘∈𝑂|1≤𝑘≤𝑡
− ∑ 𝑦𝑖,𝑟𝑘
𝑘∈𝑂|𝑡+11≤𝑘≤#𝑂
) ∀ 𝑖 ∈ 𝐵, 𝑗, 𝑟 ∈ 𝑅, 𝑡 ∈ 𝑂 (5)
∑ ∑ ∑ 𝐵𝑖𝑛𝑐𝑜𝑚𝑝𝑖,𝑗 ∙ 𝑦𝑖,𝑗𝑘
𝑘∈𝑂𝑗∈𝑅𝑖∈𝐵
= 0 (6)
𝑥𝑟 = 𝑥𝑗 + 𝐿𝑝𝑟𝑒𝑐 + 𝑑𝑝𝑗,𝑟+ − 𝑑𝑝𝑗,𝑟
− ∀ 𝑗, 𝑟 ∈ 𝑅 | prec𝑗,𝑟 (7)
𝑥𝑟 = 𝑥𝑗 + 𝐿𝑐𝑜𝑛𝑗𝑗,𝑟+ 𝑑𝑐𝑗,𝑟
+ − 𝑑𝑐𝑗,𝑟− ∀ (𝑗, 𝑟) ∈ 𝐶 (8)
𝑥𝑗 ≤ 𝑇𝑚𝑎𝑥 − 𝑑𝑗 ∀ 𝑗 ∈ 𝑅 (9)
𝑦𝑖,𝑗𝑘 ∈ {0,1} ∀ 𝑖 ∈ 𝐵, 𝑗 ∈ 𝑅, 𝑘 ∈ 𝑂 (10)
𝑑𝑝𝑗,𝑟+ , 𝑑𝑝𝑗,𝑟
− ∈ ℝ+ ∀ 𝑗, 𝑟 ∈ 𝑅 | prec𝑗,𝑟 (11)
𝑑𝑐𝑗,𝑟+ , 𝑑𝑐𝑗,𝑟
− ∈ ℝ+ ∀ (𝑗, 𝑟) ∈ 𝐶 (12)
The objective function (1) minimizes the sum of deviation in relation to ideal trip intervals.
Constraint (2) guarantees that each mooring will assigned to one berth. Equation (2) assures that each berth
will process just one mooring for each position in the schedule. Inequalities (4) indicate that moorings are
allocated consecutively. Constraints (5) determine start time of s service at berth, which depends on the
allocated previously. Constraint (6) prohibits moorings to be assigned to incompatible berths. Constraints
(7) - (9) determine: the max value of 𝑥𝑗, 𝑦𝑖,𝑗𝑘 as binaries, and 𝑑𝑝𝑗,𝑟
+ , 𝑑𝑝𝑗,𝑟− , 𝑑𝑐𝑗,𝑟
+ and 𝑑𝑐𝑗,𝑟− as non negatives.
4.2 Scheduling variables formulation New decision variables:
𝑙𝑖,𝑗𝑟 Binary. Equals 1 if mooring j is assigned before r at berth i;
𝑥𝑖,𝑗 Binary. Equals 1 if mooring j is assigned at berth i;
𝑆𝑗 Start time of j;
CLAIO-2016
846

𝑴𝒊𝒏 ( ∑ 𝑑𝑝𝑗,𝑟+ + 𝑑𝑝𝑗,𝑟
−
(𝑗,𝑟)|prec𝑗,𝑟
) + ( ∑ 𝑑𝑐𝑗,𝑟+ + 𝑑𝑐𝑗,𝑟
−
(𝑗,𝑟)∈𝐶
) (13)
s.t.
∑ ∑ 𝑥𝑖,𝑗
𝑘∈𝑂𝑖∈𝐵
= 1 ∀ 𝑖 ∈ 𝐵, ∀ 𝑗 ∈ 𝑅 (14)
𝑆𝑟 ≥ 𝑆𝑗 + 𝑑𝑗 − 𝑇𝑚𝑎𝑥 ∙ (1 − 𝑙𝑖,𝑗𝑟 ) ∀ 𝑖 ∈ 𝐵, ∀ 𝑗, 𝑟 ∈ 𝑅 | 𝑗 ≠ 𝑟 (15)
𝑙𝑖,𝑗𝑟 + 𝑙𝑖,𝑟
𝑗≤
1
2∙ (𝑥𝑖,𝑗 + 𝑥𝑖,𝑟) ∀ 𝑖 ∈ 𝐵, ∀ 𝑗, 𝑟 ∈ 𝑅 | 𝑗 < 𝑟 (16)
𝑙𝑖,𝑗𝑟 + 𝑙𝑖,𝑟
𝑗≥ 𝑥𝑖,𝑗 + 𝑥𝑖,𝑟 − 1 ∀ 𝑖 ∈ 𝐵, ∀ 𝑗, 𝑟 ∈ 𝑅 | 𝑗 < 𝑟 (17)
∑ ∑ 𝐵𝑖𝑛𝑐𝑜𝑚𝑝𝑖,𝑗 ∙ 𝑥𝑖,𝑗
𝑗∈𝑅𝑖∈𝐵
= 0 (18)
𝑆𝑟 = 𝑆𝑗 + 𝐿𝑝𝑟𝑒𝑐 + 𝑑𝑝𝑗,𝑟+ − 𝑑𝑝𝑗,𝑟
− ∀ 𝑗, 𝑟 ∈ 𝑅 | prec𝑗,𝑟 (19)
𝑆𝑟 = 𝑆𝑗 + 𝐿𝑐𝑜𝑛𝑗𝑗,𝑟+ 𝑑𝑐𝑗,𝑟
+ − 𝑑𝑐𝑗,𝑟− ∀ (𝑗, 𝑟) ∈ 𝐶 (20)
𝑥𝑖,𝑗 ∈ {0,1} ∀ 𝑖 ∈ 𝐵, 𝑗 ∈ 𝑅 (21)
𝑙𝑖,𝑗𝑟 ∈ {0,1} ∀ 𝑖 ∈ 𝐵, ∀ 𝑗, 𝑟 ∈ 𝑅 (22)
𝑑𝑝𝑗,𝑟+ , 𝑑𝑝𝑗,𝑟
− ∈ ℝ ∀ 𝑗, 𝑟 ∈ 𝑅 | prec𝑗,𝑟 (23)
𝑑𝑐𝑗,𝑟+ , 𝑑𝑐𝑗,𝑟
− ∈ ℝ ∀ (𝑗, 𝑟) ∈ 𝐶 (24)
𝑆𝑗 ≤ 𝑇𝑚𝑎𝑥 − 𝑑𝑗 ∀ 𝑗 ∈ 𝑅 (25)
New objective function (13) is the same as (1). Constraint (14) guarantees that one mooring will be
assigned to just one vessel. Constraint (15) assures that, if mooring j and r are allocated to berth i, and j is
processed before r, then the start time of j plus its duration is less than r start time. Equations (16) and (17)
impose that j is before r or r is before j if, and only if, they are both assigned to the same berth. Constraint
(18) prohibits moorings to be assigned to incompatible berths. (19) and (20) measure the slack variables.
4.3 Revised scheduling variables formulation
The formulations presented previously do not include all possible operational constraints. The
problem of the case study in section 6. They were designed to present general porpoise formulations and
choose which one is better for a realistic problem after the computational experiments. As it will be
discussed in section 5, scheduling formulation is faster and provides solution with better quality. For these
reasons another formulation based is proposed to validate the model with a realistic instance.
New parameters:
ℎ𝑓𝑗 Fixed time for mooring j;
𝑓𝑖𝑗 Time upper bound for mooring j;
𝑓𝑓𝑗 Time lower bound for mooring j;
𝑓𝑜𝑙𝑔𝑎𝑗 Security slack time between moorings;
𝑚𝑎𝑛𝑏𝑟𝑗 Maneuver time for vessel at mooring j;
𝑴𝒊𝒏 𝑀𝑎𝑥{𝑑𝑝𝑗,𝑟+ , 𝑑𝑝𝑗,𝑟
− , 𝑑𝑐𝑗,𝑟+ , 𝑑𝑐𝑗,𝑟
− } (26)
s.a.
(14) - (24)
𝑆𝑗 ≤ 167 ∀ 𝑗 ∈ 𝑅 (27)
𝑆𝑗 = ℎ𝑓𝑗 ∀ 𝑗 ∈ 𝑅|ℎ𝑓𝑗 ≥ 0 (28)
𝑆𝑗 ≥ 𝑓𝑖𝑗 ∀ 𝑗 ∈ 𝑅|𝑓𝑖𝑗 ≥ 0 (29)
𝑆𝑗 + 𝑑𝑗 ≤ 𝑓𝑓𝑗 ∀ 𝑗 ∈ 𝑅|𝑓𝑓𝑗 ≥ 0 (30)
𝑆𝑗 + 𝑇𝑚𝑎𝑥 ∙ (1 − 𝑙𝑖,𝑗𝑟 ) ≥ (𝑆𝑟 + 𝑑𝑟 − 168 + 𝑓𝑜𝑙𝑔𝑎𝑟 + 𝑚𝑎𝑛𝑏𝑟𝑟) ∀ 𝑖 ∈ 𝐵, ∀ 𝑗, 𝑟 ∈ 𝑅 | 𝑗 ≠ 𝑟 (31)
CLAIO-2016
847
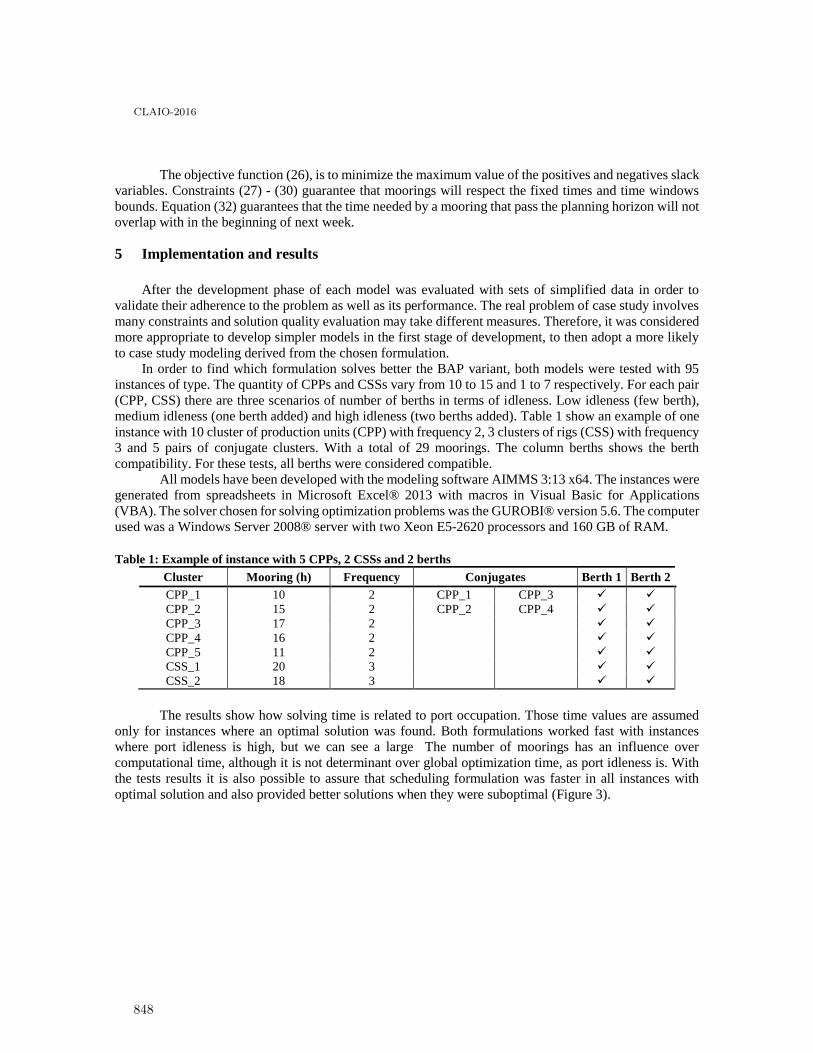
The objective function (26), is to minimize the maximum value of the positives and negatives slack
variables. Constraints (27) - (30) guarantee that moorings will respect the fixed times and time windows
bounds. Equation (32) guarantees that the time needed by a mooring that pass the planning horizon will not
overlap with in the beginning of next week.
5 Implementation and results
After the development phase of each model was evaluated with sets of simplified data in order to
validate their adherence to the problem as well as its performance. The real problem of case study involves
many constraints and solution quality evaluation may take different measures. Therefore, it was considered
more appropriate to develop simpler models in the first stage of development, to then adopt a more likely
to case study modeling derived from the chosen formulation.
In order to find which formulation solves better the BAP variant, both models were tested with 95
instances of type. The quantity of CPPs and CSSs vary from 10 to 15 and 1 to 7 respectively. For each pair
(CPP, CSS) there are three scenarios of number of berths in terms of idleness. Low idleness (few berth),
medium idleness (one berth added) and high idleness (two berths added). Table 1 show an example of one
instance with 10 cluster of production units (CPP) with frequency 2, 3 clusters of rigs (CSS) with frequency
3 and 5 pairs of conjugate clusters. With a total of 29 moorings. The column berths shows the berth
compatibility. For these tests, all berths were considered compatible.
All models have been developed with the modeling software AIMMS 3:13 x64. The instances were
generated from spreadsheets in Microsoft Excel® 2013 with macros in Visual Basic for Applications
(VBA). The solver chosen for solving optimization problems was the GUROBI® version 5.6. The computer
used was a Windows Server 2008® server with two Xeon E5-2620 processors and 160 GB of RAM.
Table 1: Example of instance with 5 CPPs, 2 CSSs and 2 berths
Cluster Mooring (h) Frequency Conjugates Berth 1 Berth 2
CPP_1 10 2 CPP_1 CPP_3
CPP_2 15 2 CPP_2 CPP_4
CPP_3 17 2
CPP_4 16 2
CPP_5 11 2
CSS_1 20 3
CSS_2 18 3
The results show how solving time is related to port occupation. Those time values are assumed
only for instances where an optimal solution was found. Both formulations worked fast with instances
where port idleness is high, but we can see a large The number of moorings has an influence over
computational time, although it is not determinant over global optimization time, as port idleness is. With
the tests results it is also possible to assure that scheduling formulation was faster in all instances with
optimal solution and also provided better solutions when they were suboptimal (Figure 3).
CLAIO-2016
848

Figure 3: Scheduling and Sorting formulations performance by port occupancy rate
6 Case Study
As presented on previous sections, the scheduling model was chosen to implement a full version
of the general problem. In this section, we present the results of implementation of the revised scheduling
variables formulation with realistic instances. Each instance includes: i) Unavailability of berths 1 and 2
due to maintenance Wednesday at 9h; ii) 13 clusters of type CPP; iii) 3 clusters of type CSS; iv) 7 moorings
for “extra service” ships; v) 4 moorings for crew transfer (Monday, Tuesday, Wednesday and thurday)
during mooring (7h – 18h) and; vi) berth 3 exclusive for fluids and pump operations.
Tree types of instances were evaluated: a) Without conjugates (SC); b) with conjugates (CC); c) with capacity grow with and without conjugates (ECC and ESC) - Fluid and Pump operations removed and berth 3 free to any operations. Each instance were processed with a time limit of 5 hours.
We can see by Table 2 that the instances with capacity grow were solved really fast, on the other hand, the
cases with high berth utilization the problem stopped with suboptimal solutions.
Table 2: Summary of results for realistic constraints
Instance Upper bound Lower bound cpu (s) Variables Constraints
SC 4 0 18.000 22.874 45.261
CC 4,75 0 18.000 22.890 45.285
ECC 0 0 30,95 28.222 55.848
ESC 0 0 5,24 28.206 55.824
7 Conclusion
In this paper we presented three formulations for the berth allocation problem and some variations of
these models. These formulations are divided into two groups that model the problem with different logics.
In the first group the main decision variable chooses the position that each mooring will occupy in a given
berth which leads to a model based on sorting variables. In the second group, what will be decided is the
relative position of a mooring to another, creating a model based on scheduling variables.
It became clear after experimentation that the model with scheduling variables can be efficient in
processing time. The final formulation proposed has proved to be a powerful alternative to practical use
being able to reduce many hours or even days of manual work to some hours, obeying all constraints and
providing good quality solutions. The results of the experiments indicate that two variables can impact the
processing time. As expected, increasing the number of moorings will increase also the processing time for
solving the assignment problem. However, idleness level has a much bigger impact over solver efficiency
including also the capacity of the formulation to generate feasible solutions. Any of the publications revised
0,1
1
10
100
1000
10000
0,45 0,5 0,55 0,6 0,65 0,7 0,75 0,8 0,85 0,9
Log(
tim
e)(
s)
Occupancy rate
Sequenciamento OrdenaçãoScheduling Sorting
CLAIO-2016
849

made such kind of analysis about how data and model interacts. The literature despite having good and
varied works concerning the more classic variant of the BAP has few studies on more general cases where
several operating restrictions may be necessary and also dedicate terminal, where arrival times do not
matter.
As future work, more advanced methods can be used such as using lagrangian relaxation in conjunction
with the columns and rows generation. Furthermore, metaheuristics can be used to achieve initial solutions
of good quality, also reducing the processing time. Concerning the stochasticity nature of the problem,
studying the distribution of loading times and add this information to the optimization model can give
information how much this security time slack may be undersized and even propose different schedules
that minimize the delay of deliveries in long term.
References
1. Bierwirth C, Meisel F (2010) A survey of berth allocation and quay crane scheduling problems in container
terminals. Eur J Oper Res 202:615–627. doi: 10.1016/j.ejor.2009.05.031
2. Cheong CY, Tan KC, Liu DK, Lin CJ (2008) Multi-objective and prioritized berth allocation in container
ports. Ann Oper Res 180:63–103. doi: 10.1007/s10479-008-0493-0
3. Cordeau J-F, Laporte G, Legato P, Moccia L (2005) Models and Tabu Search Heuristics for the Berth-
Allocation Problem. Transp Sci 39:526–538. doi: 10.1287/trsc.1050.0120
4. Costa L (2005) Soluções para o problema de otimização de itinerário de sondas. UFRJ
5. Duhamel C, Cynthia Santos A, Moreira Guedes L (2012) Models and hybrid methods for the onshore wells
maintenance problem. Comput Oper Res 39:2944–2953. doi: 10.1016/j.cor.2012.02.026
6. Golias M, Portal I, Konur D, Kaisar E, Kolomvos G (2014) Robust berth scheduling at marine container
terminals via hierarchical optimization. Comput Oper Res 41:412–422. doi: 10.1016/j.cor.2013.07.018
7. Imai A, Nishimura E, Papadimitriou S (2003) Berth allocation with service priority. Transp Res Part B
Methodol 37:437–457. doi: 10.1016/S0191-2615(02)00023-1
8. Imai A, Nishimura E, Papadimitriou S (2013) Marine container terminal configurations for efficient
handling of mega-containerships. Transp Res Part E Logist Transp Rev 49:141–158. doi:
10.1016/j.tre.2012.07.006
9. Imai A, Sun X, Nishimura E, Papadimitriou S (2005) Berth allocation in a container port: using a continuous
location space approach. Transp Res Part B Methodol 39:199–221. doi: 10.1016/j.trb.2004.04.004
10. Karafa J, Golias MM, Ivey S, Saharidis GKD, Leonardos N (2012) The berth allocation problem with
stochastic vessel handling times. Int J Adv Manuf Technol 65:473–484. doi: 10.1007/s00170-012-4186-0
11. Lim A (1998) The berth planning problem. Oper Res Lett 22:105–110.
12. Mattos Ribeiro G, Desaulniers G, Desrosiers J (2012) A branch-price-and-cut algorithm for the workover rig
routing problem. Comput Oper Res 39:3305–3315. doi: 10.1016/j.cor.2012.04.010
13. Nishimura E, Imai A, Papadimitriou S (2001) Berth allocation planning in the public berth system by
genetic algorithms. Eur J Oper Res 131:282–292. doi: 10.1016/S0377-2217(00)00128-4
14. de Oliveira RM, Mauri GR, Nogueira Lorena LA (2012) Clustering Search for the Berth Allocation
Problem. Expert Syst Appl 39:5499–5505. doi: 10.1016/j.eswa.2011.11.072
15. Pengfei Z, Haigui K, Li L (2006) A dynamic berth allocation model based on stochastic consideration. In:
World Congr. Intell. Control Autom. IEEE, Dalian, pp 7297–7301
16. Robenek T, Umang N, Bierlaire M, Ropke S (2014) A branch-and-price algorithm to solve the integrated
berth allocation and yard assignment problem in bulk ports. Eur J Oper Res 235:399–411. doi:
10.1016/j.ejor.2013.08.015
17. Xu D, Li C-L, Leung JY-T (2012) Berth allocation with time-dependent physical limitations on vessels. Eur
J Oper Res 216:47–56. doi: 10.1016/j.ejor.2011.07.012
18. Yan S, Lu C-C, Hsieh J-H, Lin H-C (2015) A network flow model for the dynamic and flexible berth
allocation problem. Comput Ind Eng 81:65–77. doi: 10.1016/j.cie.2014.12.028
CLAIO-2016
850

Utilização de Metodologia Multicritério para Escolha de Cálculo mais Adequado de IBNR para uma Operadora de Plano de Saúde
José Fabiano da Serra Costa
Universidade do Estado do Rio de Janeiro [email protected]
Larissa Mitie Yui
Universidade do Estado do Rio de Janeiro [email protected]
Abstract
Resumo: O objetivo deste artigo é encontrar o método mais adequado de cálculo para a Provisão de Sinistros Ocorridos mas Não Avisados (IBNR - Incurred But Not Reported), para um Operadora de Plano de Saúde já estabelecida no mercado brasileiro, através da análise multicritério. Para este estudo, foi aplicado o método AHP (Analytic Hierarchy Process) e, as alternativas consideradas foram baseadas na bibliografia específica: Método proposto pela Agencia Nacional de Saúde, Método Chain Ladder, Método Bornhuetter-Ferguson, Método Benktander-Hovinen, Método Bootstrap e Método Log-Normal. Os critérios da análise foram: Cenário Passado Próprio, Sinistralidade do Mercado, Possibilidade de Simulação e Complexidade dos Cálculos. Os especialistas foram Atuários com experiência na área de Provisões Técnicas e Solvência. Os resultados encontrados apontaram para o método Log-Normal, seguido do método Bootstrap (métodos estocásticos). Palavras-chave: Ciências Atuariais; Decisão Multicritério; IBNR. 1 Introdução Segundo Veiga et al. (2014), se no início dos anos de 1960, o setor hospitalar brasileiro era custeado quase totalmente pela iniciativa pública, hoje é o segundo maior sistema privado de saúde do mundo. Em setembro de 2015, mais de 50 milhões de brasileiros eram beneficiários (possuíam vínculos) aos planos de saúde privados no Brasil, ou seja, mais de 1/4 da população do país. Em 2014, o mercado de saúde suplementar movimentou um montante de aproximadamente 125 bilhões de reais referentes às receitas, de acordo com os dados consolidados da Agencia Nacional de Saúde (ANS, 2016). Provisões Técnicas são montantes que têm por finalidade garantir o pagamento de ocorrências futuras, não permitindo que as parcelas destinadas a cobrir os riscos assumidos (prêmio puro) seja consumida pela companhia seguradora antes do prazo de vigência do negócio (Castiglione, 2007). Dentre as provisões técnicas existentes, as operadoras de planos de saúde utilizam a IBNR (Incurred But Not Reported). A ideia da IBNR é constituir um montante para que a companhia possa arcar com seus compromissos futuros, especificamente sobre as datas de ocorrência e aviso do sinistro. O IBNR é uma das provisões técnicas listadas pela Agência Nacional de Saúde (ANS) que devem ser obrigatoriamente provisionadas pelas operadoras de planos privados de assistência à saúde. No Brasil a constituição da reserva IBNR é obrigatória desde 1998. Embora a ANS sugira uma metodologia básica,
CLAIO-2016
851

cada operadora pode utilizar a metodologia que julgar mais adequada a seu perfil. Nesse sentido, destacam-se as metodologias: Chain Ladder, Bornhuetter-Ferguson, Benktander-Hovinen, Bootstrap e Log-Normal. Esse artigo utiliza uma metodologia multicritério (AHP – Analitic Hierarch Process) para escolha do método mais adequado a uma operadora de saúde para o cálculo do IBNR, segundo os critérios pré-definidos pela própria operadora: Cenário Passado Próprio, Sinistralidade do Mercado, Possibilidade de Simulação e Complexidade dos Cálculos. 2 Descrição do Problema O IBNR identifica uma importante reserva que deve ser constituída pelas companhias de seguro em geral em todos os seguimentos. Esta reserva, em um determinado instante de tempo, deve corresponder ao montante necessário para o pagamento de indenizações de todos os sinistros já ocorridos, porém ainda não informados à Seguradora. A SUSEP (Superintendência de Seguros Privados) estabelece critérios para cálculo desta reserva e efetua o acompanhamento das reservas estabelecidas pelas seguradoras. No ramo da saúde, um evento ocorrido e não avisado pode ser definido pelos serviços de saúde que foram prestados e não foram faturados ou registrados pelo médico, clínica, hospital ou organização. Um exemplo pode ser ilustrado por uma cirurgia realizada em um hospital. Além dos gastos com o cirurgião, serviços de reabilitação e medicamentos, também podem ser incluídos nestes custos, eventuais despesas adicionais relacionados a complicações pós-operatórias, acompanhadas de tratamento extensivo. Nesse sentido, a Seguradora será cobrada integralmente em semanas, meses ou trimestres após o paciente ser devidamente liberado. Portanto, ao longo do período compreendido entre a data de ocorrência e a data de aviso, o sinistro é considerado como um evento ocorrido e não avisado (IBNR), pois em qualquer data-base selecionada dentro daquele intervalo, o sinistro já ocorreu e ainda não foi registrado. A escolha da metodologia para o cálculo do IBNR, varia de operadora para operadora de acordo com suas características. Entretanto as metodologias mais comumente utilizadas são (Mano & Pereira, 2009; Corazza & Pizzi, 2011; Veiga et al., 2014): • ANS – Nos primeiros doze meses de operação ou até que ocorra a aprovação de metodologia específica,
as operadoras deverão constituir valores mínimos de IBNR, observando o maior entre os seguintes valores: 9,5% do total de contraprestações líquidas nos últimos 12 meses, na modalidade de preço preestabelecido ou 12% do total de eventos indenizáveis conhecidos na modalidade de preço preestabelecido, nos últimos 12 meses (ANS, 2015).
• Chain Ladder - Parte do pressuposto que as evoluções passadas, observadas no triângulo run-off (onde linhas representam a ocorrência do sinistro e colunas representam o tempo de atraso), continuarão a verificar-se no futuro (Taylor, 2000). Todos os métodos de triângulo run-off assumem que o desenvolvimento das reclamações de sinistros ao longo dos anos de desenvolvimento segue um padrão idêntico para cada ano de ocorrência de sinistros.
• Bornhuetter-Ferguson - Utiliza não somente informações contidas no triângulo de run-off, como também informações externas. Através dessas informações externas, pode-se obter uma estimativa da quantidade total de sinistros ou o montante a ser indenizado para cada período de ocorrência associado a elas (Bornhuetter & Ferguson, 1972).
• Benktander-Hovinen - Tem como objetivo permutar os dois métodos apresentados anteriormente. Enquanto o método Chain Ladder ignora as informações a priori sobre os sinistros finais, o método Bornhuetter-Ferguson não leva em consideração as últimas observações da diagonal. A solução
CLAIO-2016
852

encontrada foi realizar uma mistura da credibilidade desses dois métodos (Benktander, 1976). Este método obtém resultados intermediários se comparados com o Chain Ladder e o Bornhuetter-Ferguson.
• Bootstrap - Técnica de reamostragem, que permite aproximar a distribuição de uma função das observações pela distribuição empírica dos dados baseada em uma amostra de tamanho finita. Produz uma distribuição de probabilidade em torno da melhor estimativa da provisão que está sendo calculada. Assim esse método simula a distribuição da provisão projetando triângulos alternativos baseados no triângulo de desenvolvimento original (England & Verrall, 1999).
• Log-Normal – É baseado em Modelos Lineares Generalizados, foi proposto (em seu modelo básico) por Christofides (1990) e muito bem utilizado para estimativas de previsões de sinistros. É considerado que cada uma das entradas do triângulo representa uma observação de uma variável aleatória e a ideia é modelar esse valor tendo como variáveis explicativas o mês de aviso e o período de desenvolvimento.
Importante notar que, caso seja superdimensionado, o IBNR compromete a distribuição de lucros da empresa e gera um custo indireto chamado custo de capital. Esse montante que fica parado na empresa é investido em ativos cuja remuneração é inferior à taxa de retorno esperada considerando o risco envolvido na operação. Uma vez subdimensionado, ela pode conduzir à insolvência da operadora. Isso afeta diretamente os clientes, empregados, fornecedores e indiretamente as concorrentes, pois abala a credibilidade do mercado onde o produto é o risco (Veiga et al., 2014). 3 Metodologia Multicitério Segundo Bana e Costa (1992) uma Metodologia Multicritério de Apoio à Decisão consiste em um conjunto de métodos e técnicas para auxiliar ou apoiar pessoas e organizações a tomarem decisões, sob a influência da multiplicidade de critérios. A aplicação de qualquer método de análise multicritério pressupõe a necessidade de especificação anterior, dos objetivos pretendidos pelo decisor, quando da comparação de alternativas. A principal distinção entre as metodologias multicritérios e as metodologias tradicionais de avaliação é o grau de incorporação dos valores subjetivos nos modelos, permitindo que uma mesma alternativa seja analisada de forma diversa de acordo com os critérios de valor individual (muitas das vezes conflitantes) de cada especialista (Gershon & Grandzol, 1994). Uma das principais e das mais atraentes características das metodologias multicritério de apoio à decisão é a capacidade de reconhecer a subjetividade como fator inerente aos problemas e utilizar julgamento de valor como forma de trata-la cientificamente. Entre as Metodologias Multicritério mais utilizadas (Vaidya & Kumar, 2006) destaca-se o método AHP (Analytic Hierarchy Process) proposto por Saaty (1980), que objetiva a seleção, escolha ou priorização de alternativas, em um processo que considera diferentes critérios de avaliação, por vezes incorporando atributos subjetivos. O método se fundamenta na construção de hierarquias, nos julgamentos paritários e na consistência lógica. A construção da hierarquia representa a estruturação do problema. Os elementos-chave de uma hierarquia são: foco principal - objetivo global em estudo; conjunto de alternativas viáveis - definição das opções que serão analisadas à luz dos critérios definidos; critérios e subcritérios - universo de atributos que serão avaliados em pares de alternativas. Os avaliadores (ou especialistas) são os indivíduos responsáveis pela análise de desempenho dos elementos de uma camada ou nível da hierarquia em relação àqueles aos quais estão conectados na camada superior da mesma com base na escala de Saaty (1980). A coleta dos julgamentos paritários é uma das etapas fundamentais do AHP. A partir das opiniões emitidas pelos especialistas são geradas as matrizes de julgamentos, quadradas, positivas e recíprocas, com valores
CLAIO-2016
853

unitários na diagonal principal. Dessa forma, a priorização é feita em quatro etapas: Obtenção das Matrizes de Julgamento; Normalização das Matrizes de Julgamento; Cálculo de Prioridades Médias Locais; Cálculo de Prioridades Globais. A figura 1 ilustra a hierarquia do AHP.
Figura 1: Hierarquia do AHP
Fonte: Saaty (1980)
As Prioridades Médias Locais (PML) são obtidas para cada um dos nós de julgamentos, pelas médias das colunas dos quadros normalizados. Após a conclusão dos cálculos das Prioridades Médias Locais, será possível verificar quais alternativas obtiveram as maiores prioridades em relação ao critério julgado. Para calcular as Prioridades Globais (PG) é necessário combinar as Prioridades Médias Locais relativas a alternativas e critérios (e subcritérios, quando existirem). Os elementos de PG armazenam os desempenhos (prioridades) das alternativas à luz do Foco Principal. Mesmo quando os julgamentos são oriundos de especialistas pequenas inconsistências podem ocorrer. No caso do AHP, segundo Saaty (1980), uma forma de se mensurar o grau da inconsistência em uma matriz paritária é avaliar o quanto o maior autovalor desta matriz (λmáx) se afasta da ordem da matriz (n). Assim o Índice de Consistência (IC) pode ser calculado como mostra a equação 1.
IC = |λmáx – n| / (n-1) (1)
Ainda segundo Saaty (1980), a gravidade da ocorrência de inconsistência é reduzida com o aumento da ordem da matriz de julgamentos. O valor da Razão de Consistência (RC) serve como um parâmetro para avaliar a inconsistência em função da ordem da matriz de julgamentos e é descrito na equação 2.
RC = IC/IR (2)
onde: IC = índice de consistência; IR = índice de consistência obtido para uma matriz recíproca, com elementos não negativos, gerada de forma randômica (Tabela 1). Caso a Razão de Consistência seja inferior a 0,10, a matriz é considerada consistente (Vargas, 1982).
Tabela 1 Tabela com Índices de Consistência Randômica.
Ordem da matriz 2 3 4 5 6 7 8 9 10
Valor de IR 0,00 0,58 0,90 1,12 1,24 1,32 1,41 1,45 1,49
Fonte: Saaty (1980) 4 Resultados
Objetivo
Critério 1 Critério 2 ... Critério n
Alternativa 1 Alternativa 2 ... Alternativa m
CLAIO-2016
854

Definidas as seis alternativas (ANS, Chain Ladder, Bornhuetter-Ferguson, Benktander-Hovinen, Bootstrap e Log-Normal), o passo seguinte é definir os critérios, incluindo todos os interesses dos tomadores de decisão. A estruturação de tais critérios de modo hierárquico é característica do método e estruturação deve se dar de forma cuidadosa, para que os critérios aplicados em cada nível hierárquico sejam homogêneos, não redundantes, complementares e operacionais. O quadro 1 mostra os critérios e suas definições.
Quadro 1: Critérios x Definições
Critério Definição
C1: Cenário Próprio Passado O quanto o método considera o cenário passado da operadora de saúde, ou seja, a evolução dos pagamentos de sinistros passados.
C2: Sinestralidade do Mercado O quanto o método considera a sinistralidade do mercado. C3: Possibilidade de Simulação O quanto o método é capaz de realizar simulações no cálculo. C4: Complexidade de Cálculos O quão complexo são os cálculos envolvidos no método.
Fonte: Autores
A escolha dos critérios, neste trabalho, foi uma prerrogativa dos especialistas envolvidos no processo. Segundo Azevedo e Costa (2001), a eficácia dos resultados está associada à competência dos avaliadores em emitir os julgamentos de valor. Assim, devem-se utilizar, em cada etapa de julgamento do AHP, avaliadores que tenham um alto conhecimento sobre o tópico em julgamento. O grupo de especialistas foi formado por Atuários com experiência de pelo menos dez anos na área de cálculo de provisões e IBNR. Forman e Peniwati (1998) afirmam que quando indivíduos de um grupo decisor desejam acima de tudo o bem da organização que representam, a despeito de suas próprias preferências, valores e objetivos, eles agem em sintonia e realizam seus julgamentos de modo que o grupo se comporta como um novo indivíduo (Agregação Individual de Julgamentos – AIJ). Dessa forma, a partir dos julgamentos individuais realizados pelos especialistas, devem ser obtidas as matrizes conjuntas de comparação das alternativas em relação aos critérios (figura 2) bem como dos critérios em relação ao foco principal (figura 3).
Figura 2: Matrizes conjuntas de alternativas em relação a critérios
C1 ANS CL BF BH BS LN C2 ANS CL BF BH BS LN ANS 1 0,17 0,22 0,18 0,18 0,16 ANS 1 0,93 0,28 0,34 0,65 0,71 CL 5,97 1 1,83 1,32 0,78 0,84 CL 1,08 1 0,39 0,54 0,54 0,68 BF 4,63 0,55 1 0,62 0,44 0,39 BF 3,52 2,57 1 1,51 1,04 1,32 BH 5,67 0,76 1,62 1 0,49 0,37 BH 2,94 1,85 0,66 1 1,00 0,90 BS 5,60 1,27 2,28 1,79 1 0,94 BS 1,54 1,85 0,96 1,00 1 0,76 LN 6,36 1,19 2,53 2,35 1,07 1 LN 1,40 1,48 0,76 1,11 1,32 1
C3 ANS CL BF BH BS LN C4 ANS CL BF BH BS LN
ANS 1 0,62 0,46 0,46 0,12 0,13 ANS 1 0,30 0,25 0,30 0,20 0,19 CL 1,61 1 0,58 0,71 0,14 0,20 CL 3,30 1 0,93 0,54 0,41 0,36 BH 2,19 1,73 1 1,11 0,25 0,30 BF 4,04 1,08 1 0,54 0,50 0,34 BF 2,19 1,40 0,90 1 0,19 0,25 BH 3,34 1,85 1,16 1 0,40 0,33 BS 8,19 7,07 4,08 5,20 1 0,70 BS 5,04 2,17 2,12 2,49 1 0,61 LN 7,61 4,88 3,34 4,08 1,29 1 LN 5,20 2,70 2,97 3,00 1,65 1
Fonte: Autores
Figura 3: Matrizes conjuntas de critérios em relação ao foco principal
Foco C1 C2 C3 C4 C1 1 4,99 1,91 3,99
CLAIO-2016
855

C2 0,20 1 0,47 1,32 C3 0,52 2,12 1 2,53 C4 0,25 0,44 0,39 1
Fonte: Autores Para calcular a Prioridade Global, que expressa a prioridade de cada produto no modelo, é necessário combinar as Prioridades Médias Locais no vetor de prioridades global (PG). Os elementos de PG armazenam os desempenhos (prioridades) das alternativas à luz do Foco Principal. A tabela 2 mostra as Prioridade Globais.
Tabela 2: Prioridade Global
Alternativas Prioridade Global ANS
0,044
Chain Ladder 0,143
Bornhuetter-Ferguson 0,127
Benktander-Hovinen 0,135
Bootstrap 0,267
Log-Normal 0,284
Fonte: Autores Em relação a Prioridade Global (tabela 2), o método Log-Normal obteve a maior prioridade (0,284), seguido do método Bootstrap (0,267) e em último lugar ficou o método da ANS (0,044). Para verificar a consistência do modelo e dos julgamentos emitidos pelos especialistas é realizada a análise de consistência. A tabela 3, mostra análise de consistência dos julgamentos do modelo, onde verifica-se que o modelo é consistente (todos RCs são menores que 0,10).
Tabela 3: Análise de Consistência
Critério/Foco λmax IC Razão de Consistência
C1: Cenário Próprio Passado 6,048 0,009 0,007
C2: Sinestralidade do Mercado 6,108 0,021 0,017
C3: Possibilidade de Simulação 6,050 0,010 0,008
C4: Complexidade de Cálculos 6,069 0,014 0,011
Foco Principal 3,942 0,019 0,021
Fonte: Autores Na utilização do AHP, o processo decisório é tipicamente iterativo, permitindo o uso de análise de sensibilidade em qualquer parte do modelo. Esse procedimento deve ser realizado sempre que o grupo de avaliadores se mostrar inseguro sobre os juízos de valor emitidos, Nestas circunstancias é importante examinar quão sensível é a alternativa selecionada quanto às mudanças nos juízos emitidos pelo grupo de avaliadores (Menezes e Belderrain, 2008). Na análise de sensibilidade em processos decisórios, os dados de entrada de um modelo podem ser ligeiramente modificados a fim de observar o impacto sobre os resultados encontrados. Se a classificação não mudar, o resultado pode ser considerado robusto. Assim considera-se os dados de entrada como os critérios e variam-se um ou mais critérios, verificando se o resultado encontrado apresenta variações
CLAIO-2016
856
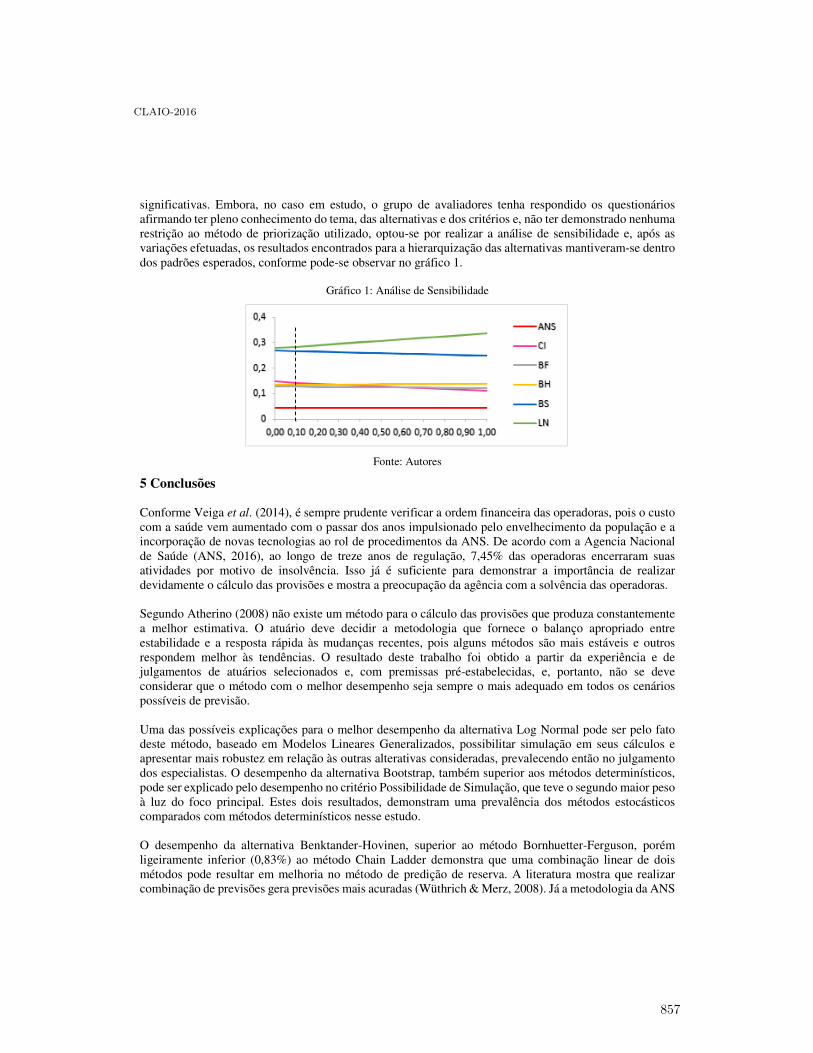
significativas. Embora, no caso em estudo, o grupo de avaliadores tenha respondido os questionários afirmando ter pleno conhecimento do tema, das alternativas e dos critérios e, não ter demonstrado nenhuma restrição ao método de priorização utilizado, optou-se por realizar a análise de sensibilidade e, após as variações efetuadas, os resultados encontrados para a hierarquização das alternativas mantiveram-se dentro dos padrões esperados, conforme pode-se observar no gráfico 1.
Gráfico 1: Análise de Sensibilidade
Fonte: Autores
5 Conclusões Conforme Veiga et al. (2014), é sempre prudente verificar a ordem financeira das operadoras, pois o custo com a saúde vem aumentado com o passar dos anos impulsionado pelo envelhecimento da população e a incorporação de novas tecnologias ao rol de procedimentos da ANS. De acordo com a Agencia Nacional de Saúde (ANS, 2016), ao longo de treze anos de regulação, 7,45% das operadoras encerraram suas atividades por motivo de insolvência. Isso já é suficiente para demonstrar a importância de realizar devidamente o cálculo das provisões e mostra a preocupação da agência com a solvência das operadoras. Segundo Atherino (2008) não existe um método para o cálculo das provisões que produza constantemente a melhor estimativa. O atuário deve decidir a metodologia que fornece o balanço apropriado entre estabilidade e a resposta rápida às mudanças recentes, pois alguns métodos são mais estáveis e outros respondem melhor às tendências. O resultado deste trabalho foi obtido a partir da experiência e de julgamentos de atuários selecionados e, com premissas pré-estabelecidas, e, portanto, não se deve considerar que o método com o melhor desempenho seja sempre o mais adequado em todos os cenários possíveis de previsão. Uma das possíveis explicações para o melhor desempenho da alternativa Log Normal pode ser pelo fato deste método, baseado em Modelos Lineares Generalizados, possibilitar simulação em seus cálculos e apresentar mais robustez em relação às outras alterativas consideradas, prevalecendo então no julgamento dos especialistas. O desempenho da alternativa Bootstrap, também superior aos métodos determinísticos, pode ser explicado pelo desempenho no critério Possibilidade de Simulação, que teve o segundo maior peso à luz do foco principal. Estes dois resultados, demonstram uma prevalência dos métodos estocásticos comparados com métodos determinísticos nesse estudo. O desempenho da alternativa Benktander-Hovinen, superior ao método Bornhuetter-Ferguson, porém ligeiramente inferior (0,83%) ao método Chain Ladder demonstra que uma combinação linear de dois métodos pode resultar em melhoria no método de predição de reserva. A literatura mostra que realizar combinação de previsões gera previsões mais acuradas (Wüthrich & Merz, 2008). Já a metodologia da ANS
CLAIO-2016
857

apresentou o pior resultado, como era esperado, visto que somente dever ser usada por operadoras em início de funcionamento, até que se encontre um método mais adequado as suas características. A metodologia multicritério adotada (AHP) se mostrou bastante eficaz e eficiente, além de simples no manuseio, segundo os especialistas consultados, tanto que os valores encontrados na análise de consistência para os julgamentos envolvidos no modelo foram muito abaixo dos limites aceitáveis. Além disso, os resultados encontrados tanto para Prioridades Globais, quanto para Prioridades Médias Locais, foram apresentados aos especialistas envolvidos no modelo, que em consenso referenciaram as conclusões. Referências
1. R. S. Atherino. Estimação de Reservas IBNR por Modelos em Espaço de Estado: Empilhamento por Linhas do Triângulo Runoff. Tese de Doutorado, PUC-Rio, 57p. 2008.
2. ANS - Agência Nacional de Saúde. Caderno de Informação da Saúde Suplementar. Disponível em: <http://www.ans.gov.br/perfil-do-setor/dados-e-indicadores-do-setor>. Acesso em: Fevereiro, 2016.
3. ANS - Agência Nacional de Saúde. Resolução Normativa, n. 209, abril de 2009. Disponível em: < <http://www.ans.gov.br/index2.php?option=com_legislacao&view=legislacao&task=TextoLei&forma t=raw&id=1571> Acesso em: novembro, 2015.
4. M. C Azevedo e H. G. Costa. Elecomp: metodologia multicritério para avaliação de competitividade. In: Anais XXV Enanpad. Campinas, SP, 2001.
5. C. A. Bana e Costa. Structuration, Construction et Exploitation dún Modèle Multicritère dAide à la Decision, Tese de Doutorado, Universidade Téc. Lisboa, Portugal, 1992.
6. G. Benktander. An Approach to Credibility in calculating IBNR for Excess Reinsurance. The Actuarial Review 7, 1976.
7. R. L. Bornhuetter and R. R. Ferguson. The Actuary and IBNR. Proceedings of the Casualty Actuarial Society, n. 59, 1972.
8. L. R. Castiglione. Seguros: Conceitos e Critérios de Avaliação de Resultados. Editora Manuais Técnicos de Seguros, SP, 1997.
9. S. Christofides. Regression Models Based on Logincremental Payments. Claims Reserving Manual, 2, Institute of Actuaries, London. 1990.
10. M. Corazza and C. Pizzi. Mathematical and Statistical Methods for Actuarial Sciences and Finance. Springer - Business & Economics, 329 p. 2011.
11. P. D. England and R. J. Verrall. Analytic and Bootsrap Estimates of Prediction Erros in Claim Reserving. Insurance. Mathematics and Economics, v.25, p. 281-293. 1999.
12. E. Forman and K. Peniwati. Aggregating Individual Judgments and Priorities with the Analytic Hierarchy Process. European Journal of Operacional Research, n.108, pp. 165-169, 1998.
13. M. Gershon and J. Grandzol. Multiple Criteria Decision Making, Quality Progress, pp. 69-73, 1994. 14. C. C. A. Mano e P. P. Ferreira. Aspectos Atuariais e Contábeis das Provisões Técnicas. Funenseg, 1a edição, 432
p. 2009. 15. A. B. Menezes e M. C. N. Belderrain. Método de Análise Hierárquica (AHP) em Priorização de Investimentos.
In: Anais 14o ENCITA, São José dos Campos, SP, 2008. 16. T. L. Saaty. The Analytic Hierarchy Process. EUA, Nova Iorque, McGraw-Hill, 287 p. 1980. 17. G. Taylor. Loss Reserving: an actuarial perspective. Kluwer, Boston, 2000. 18. O. S. Vaidya and S. Kumar. Analytic Hierarchy Process: An Overview of Applications. European Journal of
Operational Research, 169, 1, pp. 1-29, 2006. 19. L. G. Vargas. Reciprocal Matrices with Random Coefficients. Mathematical Modelling, 3, 69-81, 1982. 20. F. A. A. Veiga; B. P. Souza; J. F. S. Costa; M. F. Carvalho. Análise atuarial da provisão de eventos ocorridos e
não avisados da saúde suplementar de uma operadora de planos de saúde. Revista PO e Desenvolvimento, v.6, n.2, p.279-298, 2014.
21. M. V. Wüthrich and M. Merz. Stochastic Claims Reserving Methods in Insurance. Wiley- Business & Economics - 438 p. 2008.
CLAIO-2016
858

Uma nova formulação matemática eficiente para o
Problema de Inundação em Grafos
André Renato Villela da SilvaInstituto de Ciência e Tecnologia - Universidade Federal Fluminense
Luiz Satoru OchiInstituto de Computação - Universidade Federal Fluminense
Resumo
Este trabalho aborda o Problema de Inundação em Grafos, cujo objetivo é tornar mono-cromático um grafo colorido em vértices com o menor número posśıvel de inundações. Porinundação, entende-se a mudança da cor de um vértice pivô para uma cor c, o que faz com queesse vértice seja agregado a todos os vértices vizinhos que tenham a mesma cor c. A literaturado problema apresenta uma formulação matemática na forma de um Programa Inteiro Misto.Uma nova formulação matemática é proposta e experimentos computacionais mostraram queesta formulação tem desempenho muito superior à da literatura.
Keywords: Problema de Inundação em Grafos; Otimização Combinatória; Programa InteiroMisto
1 Introdução
No popular jogo chamado Flood-It [5] existe uma matriz de tamanho N×M , na qual cada elementoé representado por uma cor. Elementos adjacentes (apenas na vertical e/ou horizontal) que sejamda mesma cor são considerados unidos, formando assim uma região monocromática. O objetivo dojogo é tornar toda a matriz monocromática através da mudança de cor de uma região de cada vez,com o menor número posśıvel de etapas. Sempre que ocorre uma mudança de cor de uma regiãopara uma cor c, a região se une a todas as demais regiões monocromáticas adjacentes que tenhama mesma cor c. Esse processo chama-se inundação. A Figura 1 mostra a sequência de inundaçõesque tornam monocromática a matriz em questão.
São conhecidas duas versões do jogo Flood-It. Na versão fixa, apenas uma das regiões mono-cromáticas pode mudar de cor inicialmente. As demais só poderão mudar quando forem inundadaspela região inicial. Na versão livre, qualquer uma das regiões pode ser recolorida a qualquer mo-mento. O objetivo, porém, permanece o mesmo: tornar a matriz monocromática com o menornúmero posśıvel de etapas (inundações). Algumas implementações do jogo definem um númeromáximo Q de etapas para se cumprir o objetivo, criando assim um problema de decisão. O pro-blema pode ser formulado da seguinte maneira: “é posśıvel tornar a matriz monocromática em no
CLAIO-2016
859

Figura 1: Sequência de colorações que tornam a matriz monocromática: (a) inicialmente a matrizapresenta 6 regiões monocromáticas, sendo a região 1 fixa; (b) escolhida a cor vermelha, o queinunda a região 5; (c) escolhida a cor preta, inundando também as regiões 2 e 3; (d) escolhida a corazul; (e) escolhida a cor verde, tornando toda a matriz monocromática em 4 etapas.
máximo Q inundações?”. O problema em sua forma de minimização é NP-dif́ıcil. Portanto, nãosão conhecidos algoritmos eficientes para encontrar a solução ótima em tempo aceitável.
O jogo em questão pode ser utilizado como modelo para algumas aplicações reais, como pro-pagação de doenças descritas em [1], que podem ocorrer de forma similar ao jogo.
O restante deste trabalho se divide da seguinte forma: na Seção 2 são apresentados algunsresultados de trabalhos anteriores da literatura. Na Seção 3, uma nova formulação matemática parao problema, na versão fixa, é proposta. Os resultados computacionais das formulações matemáticasestudadas são mostrados na Seção 4. A Seção apresenta as conclusões deste trabalho.
2 Revisão da literatura
Em [2], os autores mostraram que as duas versões (fixa e livre) para matrizes N ×N coloridas commais de três cores são NP-dif́ıceis. Em [7], foi mostrado que a versão livre pode ser resolvida emtempo polinomial para matrizes 1 × N . As duas versões permanecem NP-dif́ıceis para matrizes3 × N coloridas com pelo menos quatro cores. Entretanto, nestas mesmas matrizes o problemapermanece em aberto se forem utilizadas apenas três cores.
Para matrizes 2 × N , na versão fixa do problema, foi apresentado um algoritmo de tempopolinomial em [4]. Para estas matrizes, a versão livre permanece NP-dif́ıcil, podendo ser resolvidaem tempo polinomial em grafos 2-coloridos, de acordo com [8]. Em [6], mostrou-se que a versãolivre é polinomialmente solucionável em ciclos e que as duas versões são NP-dif́ıceis em árvores.
Também existem algoritmos de tempo polinomial para os seguintes casos, como mostrado em[11]: grades circulares 2 × N , a segunda potência de um ciclo com n vértices, d-tabuleiros 2 × N(grades 2 ×N onde a d-ésima coluna é monocromática). Nestes dois últimos casos, a versão livreé NP-dif́ıcil.
Em [3], foi apresentada uma primeira formulação para a versão fixa do problema. A matrizfoi transformada em um grafo colorido em vértices, de forma que cada região monocromática damatriz seja representada por um vértice de mesma cor no grafo. As arestas representam a relaçãode adjacência das regiões monocromáticas da matriz. Na formulação apresentada, as variáveisbinárias yb,t valem 1 se a componente monocromática (vértice) b é inundada no tempo t; ou valem0, caso contrário. As variáveis binárias xc,t valem 1 se a cor c é escolhida no tempo t; ou valem0, caso contrário. A variável inteira positiva z representa o número de inundações, enquanto Be C representam os conjuntos de todos os vértices do problema e de todas as cores dispońıveis,respectivamente. A formulação completa pode ser vista a seguir.
CLAIO-2016
860

min z (1)
s.a. yp,0 = 1 (2)
|B|∑
t=0
yb,t = 1 ∀b∈B (3)
∑
c∈Cxc,t = 1 ∀t=1,..,|B| (4)
yb,t ≤ xc(b),t ∀b∈B ∀t=1,..,|B| (5)
yb,t ≤∑
u∈N(b)
t−1∑
i=0
yu,i ∀b∈B ∀t=1,..,|B| (6)
z ≥ t ∗ yb,t ∀b∈B ∀t=1,..,|B| (7)
yb,t ∈ {0, 1} ∀b∈B ∀t=0,..,|B| (8)
xc,t ∈ {0, 1} ∀c∈C ∀t=1,..,|B| (9)
A Eq. (1) visa minimizar o número de inundações (z). A restrição (2) indica que inicialmenteapenas o vértice pivô (p) está inundado. As equações (3) forçam com que cada vértice seja inundadoexatamente uma vez. Em (4) é exigido que apenas uma cor seja escolhida a cada instante de tempo.As restrições (5) permitem que um vértice b só seja inundado no tempo t se a cor escolhida naqueletempo for a mesma cor de b. Um vértice b também só poderá ser inundado no tempo t se pelomenos um de seus vizinhos u ∈ N(b) já estiver inundado antes de t, conforme (6). Nas restrições(7), o valor de z é limitado pelo tempo t no qual um vértice qualquer é inundado. Desta forma, emconjunto com (1), quanto mais cedo for posśıvel inundar todos os vértices melhor. O domı́nio dasvariáveis binárias é definido em (8) e (9).
Ainda em [3] a formulação foi testada em instâncias com matrizes de tamanho 14× 14 e 6 coresdistintas. A formulação foi comparada a resultados obtidos por critérios heuŕısticos, encontrandoa solução ótima entre 150 e 6500 segundos, de acordo com o sistema computacional utilizado.
3 Formulação matemática proposta
A formulação apresentada em [3] será chamada de F1, em contraposição à formulação proposta nestetrabalho que será chamada de F2. A principal diferença entre as formulações está no significado dasvariáveis yb,t. Em F2, essas variáveis são denotadas por yti e valem 1 se o vértice i já foi inundadoaté o instante de tempo t. Na formulação F1, o valor 1 só existiria unicamente no instante t, valendo0 em todos os outros. Em F2, a partir do instante no qual o vértice i é inundado até o final dohorizonte de tempo, todas as variáveis relativas ao vértice i passam a valer 1.
Esse relacionamento entre as variáveis do mesmo vértice é mais forte do que aquele em F1, poisolhando qualquer variável yti é posśıvel saber se esse vértice já sofreu alguma inundação ou não,enquanto na formulação F1 é preciso olhar todas as variáveis y ao longo do horizonte de tempopara se obter a mesma informação. As variáveis y em ambas as formulações modelam o problemade inundação como se fosse um problema de escalonamento. Tal abordagem de F2, modificando osignificado das variáveis, também foi utilizada com muito sucesso em [10].
CLAIO-2016
861

A formulação F2 completa pode ser vista a seguir. A entrada do problema deve ser um grafoG = (V,A), onde V é o conjunto de vértices e A o conjunto de arestas. O conjunto de coresdispońıveis é denotado por C, enquanto T determina o último instante do horizonte de tempoconsiderado.
min z (10)
s.a. y0p = 1 (11)
y0i = 0 ∀i 6=p ∈V (12)
yTi = 1 ∀i 6=p ∈V (13)
yti ≥ yt−1i ∀i∈V ∀t=1,..,T (14)
yti ≤∑
(i,j)∈Ayt−1j ∀i∈V ∀t=1,..,T (15)
yti ≤ yt−1i + xtc(i) ∀i∈V ∀t=1,..,T (16)∑
c∈Cxtc ≤ 1 ∀t=1,..,T (17)
z ≥ t ∗ xc,t ∀c∈C ∀t=1,..,|B| (18)
yb,t ∈ {0, 1} ∀b∈B ∀t=0,..,|B| (19)
xc,t ∈ {0, 1} ∀c∈C ∀t=1,..,|B| (20)
A função-objetivo (10) continua sendo minimizar o número de etapas necessárias para tornarmonocromático o grafo de entrada. As equações (11) e (12) fazem com que apenas o vértice pivôesteja inundado antes do primeiro instante de tempo. Por meio das equações (13), cada vérticeé obrigado a ser inundado até o final do horizonte de tempo. As restrições (14) fazem com queum vértice, após sua inundação, seja considerado inundado até o final do horizonte de tempo. Umvértice i só pode ser considerado inundado no tempo t se: (i) houver pelo menos um vizinho j jáinundado no tempo t − 1 (15); e (ii) se ele já tiver sido inundado antes ou se a cor escolhida parao tempo t for a mesma cor de i (16).
As restrições (17) garantem que no máximo uma cor será escolhida por instante de tempo. Seuma cor for escolhida no instante de tempo t, a solução ótima terá obrigatoriamente valor maiorou igual a t (18). O domı́nio das variáveis da formulação é dado pelas restrições (19) e (20).
É importante notar que o horizonte de tempo utilizado pela formulação F2 é um parâmetro T ,que não é o mesmo da F1 (|B|). O valor de |B| é o maior horizonte posśıvel, considerando que ografo em questão seja na verdade uma sequência linear de vértices e que cada inundação incorporeapenas um vértice de cada vez. Com exceção desse único caso, o limite superior proposto porF1 é muito maior do que a solução ótima, já que uma só mudança de cor pode inundar diversosvértices, como se espera. Utilizar um valor T mais próximo posśıvel do valor da solução ótima podefazer com a que formulação tenha um número muito menor de colunas e, portanto, seja executadamais rapidamente e consuma muito menos memória. A formulação F1 também pode se valer destamesma estratégia, bastando desconsiderar o valor fixo de |B| e utilizar um parâmetro variável Tda mesma forma. No entanto, em [3] essa possibilidade sequer foi levada em consideração.
A formulação F2 tende a produzir uma matriz de coeficientes mais esparsa do que a F1. Istoé muito interessante do ponto de vista prático, pois muitos dos otimizadores comerciais que estão
CLAIO-2016
862

dispońıveis atualmente fazem bom uso da esparsidade da matriz, tanto na questão do consumo dememória quanto na aplicação de algoritmos espećıficos para essas matrizes, conforme [9].
Dois conjuntos extras de restrições também são propostos neste trabalho para melhorar aexecução da formulação. As restrições (17) permitem que em qualquer etapa nenhuma cor seja es-colhida, o que chama-se inundação nula. Depois do grafo totalmente inundado, faz sentido que nãohaja mais escolhas de cor. No entanto, obviamente não há benef́ıcio algum em realizar inundaçõesnulas antes da completa inundação do grafo. Sem possuir uma boa solução incumbente, o algoritmode branch-and-bound pode começar a explorar nós que tenham essa caracteŕıstica indesejável depossuir uma etapa de inundação nula. As restrições (21) são úteis para evitar que isto aconteça,pois elas só permitem etapas nulas ao final do horizonte de tempo, depois de todas as etapas deinundação efetivas já terem ocorrido.
∑
c∈Cxtc ≥
∑
c∈Cxt−1c ∀t = 2, .., T (21)
z ≥∑
c∈C
T∑
t=1
xtc (22)
As restrições (22) visam melhorar os valores de relaxação linear da formulação. De acordo comas restrições (18), é posśıvel diminuir o valor de z por meio de valores fracionários baixos para asvariáveis xtc. Ao impor que z não seja menor que o número de cores escolhidas, o que é situaçãológica, mesmo que as variáveis xtc tenham valores fracionários baixos, seu somatório tende a forçaro valor de z para cima. Portanto, a principal contribuição deste trabalho consiste na proposta daformulação F2, que compreende as restrições (10)-(22). As restrições adicionais não fazem sentidose aplicadas à formulação F1, pois nela sempre haverá escolha de cor a cada instante de tempo.
4 Resultados computacionais
Os experimentos foram realizados utilizando um notebook com as seguintes configurações: proces-sador Intel I7-3630QM, 8GB de memória RAM, sistema operacional Windows 8.0, Cplex 12.6.1.As instâncias estão dispońıveis em www.professores.uff.br/asilva/flooding_problems.html.Em [3], foram utilizadas instâncias compostas por matrizes quadradas N × N , sendo N=14 e 6cores dispońıveis. Infelizmente, essas instâncias não foram disponibilizadas. Para os experimentosdeste trabalho, foram geradas 5 instâncias com N = 12, 15, 20 e 6 cores. As cores foram geradascom probabilidade uniforme. Também foram geradas mais 3 instâncias adicionais com N = 20 e7 ou 8 cores, respectivamente. Quanto maior o número de cores, menores tendem a ser as regiõesmonocromáticas da matriz e, consequentemente, as grafos tendem a possuir uma ordem maior.
O primeiro experimento visa comparar o desempenho das duas formulações F1 e F2, de formadireta (tempo computacional e limites primais e duais) e de forma indireta (densidade e valorda relaxação linear). Estes últimos aspectos, por si só, não garantem que uma formulação serámelhor executada do que outra, mas são indicativos de quão mais forte pode ser uma formulaçãoteoricamente. Os resultados obtidos são mostrados na Tabela 1, N indica o tamanho do ladoda matriz quadrada, C indica o número de cores da instância, # é um identificador próprio dainstância, T indica o valor do horizonte de tempo utilizado tanto para F2 quanto para F1. Essevalor foi escolhido arbitrariamente. A coluna Sol. mostra o valor da solução incumbente. O tempo
CLAIO-2016
863
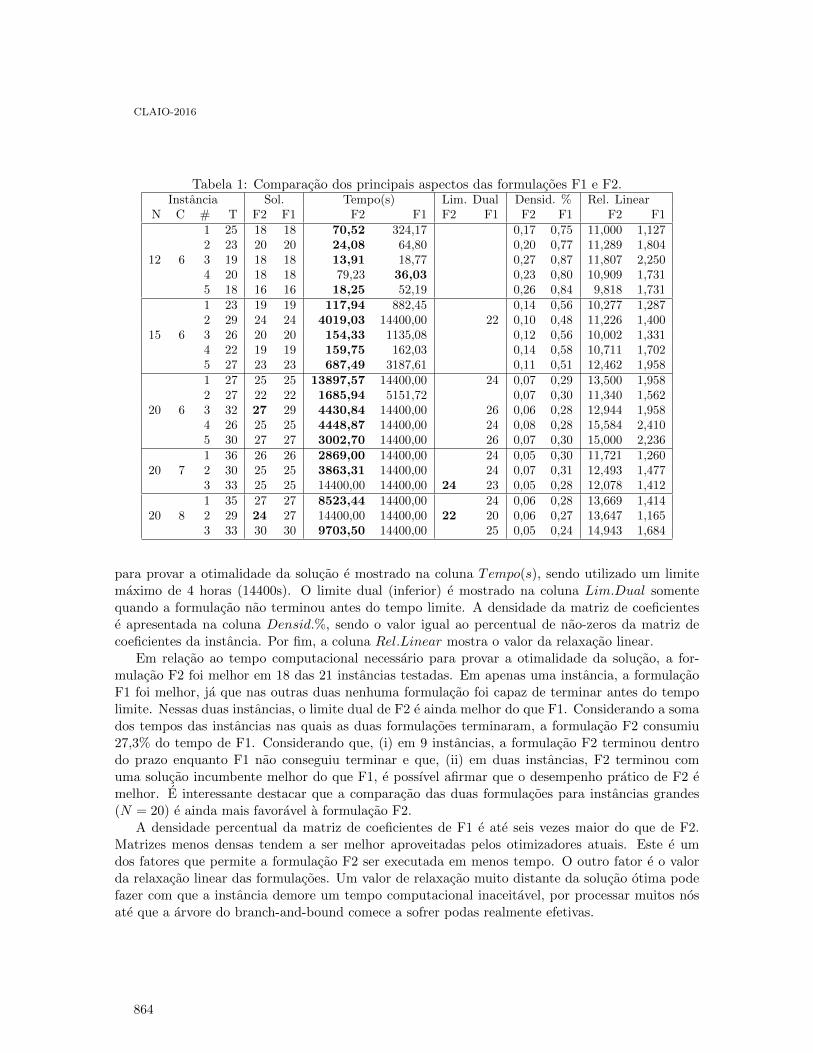
Tabela 1: Comparação dos principais aspectos das formulações F1 e F2.Instância Sol. Tempo(s) Lim. Dual Densid. % Rel. Linear
N C # T F2 F1 F2 F1 F2 F1 F2 F1 F2 F1
12 6
1 25 18 18 70,52 324,17 0,17 0,75 11,000 1,1272 23 20 20 24,08 64,80 0,20 0,77 11,289 1,8043 19 18 18 13,91 18,77 0,27 0,87 11,807 2,2504 20 18 18 79,23 36,03 0,23 0,80 10,909 1,7315 18 16 16 18,25 52,19 0,26 0,84 9,818 1,731
15 6
1 23 19 19 117,94 882,45 0,14 0,56 10,277 1,2872 29 24 24 4019,03 14400,00 22 0,10 0,48 11,226 1,4003 26 20 20 154,33 1135,08 0,12 0,56 10,002 1,3314 22 19 19 159,75 162,03 0,14 0,58 10,711 1,7025 27 23 23 687,49 3187,61 0,11 0,51 12,462 1,958
20 6
1 27 25 25 13897,57 14400,00 24 0,07 0,29 13,500 1,9582 27 22 22 1685,94 5151,72 0,07 0,30 11,340 1,5623 32 27 29 4430,84 14400,00 26 0,06 0,28 12,944 1,9584 26 25 25 4448,87 14400,00 24 0,08 0,28 15,584 2,4105 30 27 27 3002,70 14400,00 26 0,07 0,30 15,000 2,236
20 71 36 26 26 2869,00 14400,00 24 0,05 0,30 11,721 1,2602 30 25 25 3863,31 14400,00 24 0,07 0,31 12,493 1,4773 33 25 25 14400,00 14400,00 24 23 0,05 0,28 12,078 1,412
20 81 35 27 27 8523,44 14400,00 24 0,06 0,28 13,669 1,4142 29 24 27 14400,00 14400,00 22 20 0,06 0,27 13,647 1,1653 33 30 30 9703,50 14400,00 25 0,05 0,24 14,943 1,684
para provar a otimalidade da solução é mostrado na coluna Tempo(s), sendo utilizado um limitemáximo de 4 horas (14400s). O limite dual (inferior) é mostrado na coluna Lim.Dual somentequando a formulação não terminou antes do tempo limite. A densidade da matriz de coeficientesé apresentada na coluna Densid.%, sendo o valor igual ao percentual de não-zeros da matriz decoeficientes da instância. Por fim, a coluna Rel.Linear mostra o valor da relaxação linear.
Em relação ao tempo computacional necessário para provar a otimalidade da solução, a for-mulação F2 foi melhor em 18 das 21 instâncias testadas. Em apenas uma instância, a formulaçãoF1 foi melhor, já que nas outras duas nenhuma formulação foi capaz de terminar antes do tempolimite. Nessas duas instâncias, o limite dual de F2 é ainda melhor do que F1. Considerando a somados tempos das instâncias nas quais as duas formulações terminaram, a formulação F2 consumiu27,3% do tempo de F1. Considerando que, (i) em 9 instâncias, a formulação F2 terminou dentrodo prazo enquanto F1 não conseguiu terminar e que, (ii) em duas instâncias, F2 terminou comuma solução incumbente melhor do que F1, é posśıvel afirmar que o desempenho prático de F2 émelhor. É interessante destacar que a comparação das duas formulações para instâncias grandes(N = 20) é ainda mais favorável à formulação F2.
A densidade percentual da matriz de coeficientes de F1 é até seis vezes maior do que de F2.Matrizes menos densas tendem a ser melhor aproveitadas pelos otimizadores atuais. Este é umdos fatores que permite a formulação F2 ser executada em menos tempo. O outro fator é o valorda relaxação linear das formulações. Um valor de relaxação muito distante da solução ótima podefazer com que a instância demore um tempo computacional inaceitável, por processar muitos nósaté que a árvore do branch-and-bound comece a sofrer podas realmente efetivas.
CLAIO-2016
864
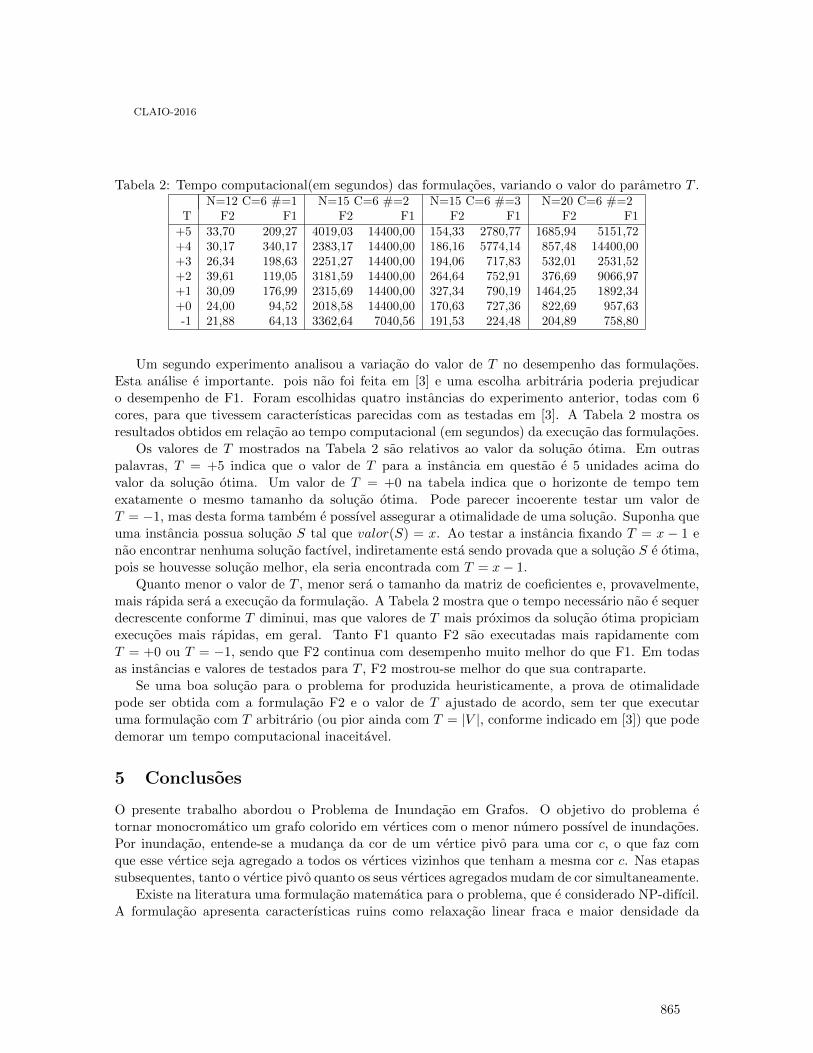
Tabela 2: Tempo computacional(em segundos) das formulações, variando o valor do parâmetro T .N=12 C=6 #=1 N=15 C=6 #=2 N=15 C=6 #=3 N=20 C=6 #=2
T F2 F1 F2 F1 F2 F1 F2 F1+5 33,70 209,27 4019,03 14400,00 154,33 2780,77 1685,94 5151,72+4 30,17 340,17 2383,17 14400,00 186,16 5774,14 857,48 14400,00+3 26,34 198,63 2251,27 14400,00 194,06 717,83 532,01 2531,52+2 39,61 119,05 3181,59 14400,00 264,64 752,91 376,69 9066,97+1 30,09 176,99 2315,69 14400,00 327,34 790,19 1464,25 1892,34+0 24,00 94,52 2018,58 14400,00 170,63 727,36 822,69 957,63-1 21,88 64,13 3362,64 7040,56 191,53 224,48 204,89 758,80
Um segundo experimento analisou a variação do valor de T no desempenho das formulações.Esta análise é importante. pois não foi feita em [3] e uma escolha arbitrária poderia prejudicaro desempenho de F1. Foram escolhidas quatro instâncias do experimento anterior, todas com 6cores, para que tivessem caracteŕısticas parecidas com as testadas em [3]. A Tabela 2 mostra osresultados obtidos em relação ao tempo computacional (em segundos) da execução das formulações.
Os valores de T mostrados na Tabela 2 são relativos ao valor da solução ótima. Em outraspalavras, T = +5 indica que o valor de T para a instância em questão é 5 unidades acima dovalor da solução ótima. Um valor de T = +0 na tabela indica que o horizonte de tempo temexatamente o mesmo tamanho da solução ótima. Pode parecer incoerente testar um valor deT = −1, mas desta forma também é posśıvel assegurar a otimalidade de uma solução. Suponha queuma instância possua solução S tal que valor(S) = x. Ao testar a instância fixando T = x − 1 enão encontrar nenhuma solução fact́ıvel, indiretamente está sendo provada que a solução S é ótima,pois se houvesse solução melhor, ela seria encontrada com T = x− 1.
Quanto menor o valor de T , menor será o tamanho da matriz de coeficientes e, provavelmente,mais rápida será a execução da formulação. A Tabela 2 mostra que o tempo necessário não é sequerdecrescente conforme T diminui, mas que valores de T mais próximos da solução ótima propiciamexecuções mais rápidas, em geral. Tanto F1 quanto F2 são executadas mais rapidamente comT = +0 ou T = −1, sendo que F2 continua com desempenho muito melhor do que F1. Em todasas instâncias e valores de testados para T , F2 mostrou-se melhor do que sua contraparte.
Se uma boa solução para o problema for produzida heuristicamente, a prova de otimalidadepode ser obtida com a formulação F2 e o valor de T ajustado de acordo, sem ter que executaruma formulação com T arbitrário (ou pior ainda com T = |V |, conforme indicado em [3]) que podedemorar um tempo computacional inaceitável.
5 Conclusões
O presente trabalho abordou o Problema de Inundação em Grafos. O objetivo do problema étornar monocromático um grafo colorido em vértices com o menor número posśıvel de inundações.Por inundação, entende-se a mudança da cor de um vértice pivô para uma cor c, o que faz comque esse vértice seja agregado a todos os vértices vizinhos que tenham a mesma cor c. Nas etapassubsequentes, tanto o vértice pivô quanto os seus vértices agregados mudam de cor simultaneamente.
Existe na literatura uma formulação matemática para o problema, que é considerado NP-dif́ıcil.A formulação apresenta caracteŕısticas ruins como relaxação linear fraca e maior densidade da
CLAIO-2016
865

matriz de coeficientes. Como alternativa a essa formulação, chamada de F1, foi proposta nestetrabalho uma nova formulação F2.
Os testes com um conjunto de 21 instâncias mostrou que F2 obteve desempenho muito superiorem praticamente todos os casos e aspectos analisados. O desempenho de F2 é comparativamentemelhor nas instâncias de maior porte e com maior número de cores, o que implica em grafosmaiores. A variação do horizonte de tempo dado ao problema (representado pelo parâmetro T )também mostrou que F2 continua obtendo melhores resultados do que F1, podendo ser consideradaa melhor formulação conhecida para o problema.
6 Agradecimentos
Agradecemos à FAPERJ pelo suporte na realização desta pesquisa.
Referências
[1] M. Adriaen, P. De Causmaecker, P. Demeester, and G. Vanden Berghe. Spatial simulation model forinfectious viral disease with focus on sars and the common flu. In 37th Annual Hawaii InternationalConference on System Sciences, IEEE Computer Society, ISBN: 0-7695-2056-1, 2004.
[2] D. Arthur, R. Clifford, M. Jalsenius, and A. Montanaro ans B. Sach. The complexity of flood fillinggames. In FUN, volume 6099 of Lecture Notes in Computer Science, Springer, ISBN 978-3-642-13121-9, pages 307–318. 2010.
[3] B.J.S. Barros, R.G.S. Pinheiro and U.S. Souza. Métodos heuŕısticos e exatos para o Problema deInundação em Grafos. In: Anais do XLVII Simpósio Brasileiro de Pesquisa Operacional (SBPO2015),Salvador/Brasil, 2015.
[4] R. Clifford, M. Jalsenius, A. Montanaro, and B. Sach. The complexity of flood filling game. TheoryComput Syst, 50:72–92, 2012. DOI: 10.1007/s00224-011-9339-2.
[5] LabPixies. Labpixies - the coolest games! Dispońıvel em: http://www.labpixies.com, 2015. Acessadoem 27/04/2015.
[6] A. Lagoutte. Jeux d’inondation dans les graphes. Technical report, ENS Lyon, HAL: hal-00509488,2010.
[7] K. Meeks and A. Scott. The complexity of free-flood-it on 2n boards. Theoretical Computer Science,500:25–43, 2013. DOI: 10.1016/j.tcs.2013.06.010.
[8] K. Meeks and A. Scott. The complexity of flood-filling games on graphs. Discrete Applied Mathematics,160:959–969, 2011. DOI:10.1016/j.dam.2011.09.001.
[9] C.T.L. da Silva, M.N. Arenales and R. Silveira. Métodos tipo dual simplex para problemas de oti-mização linear canalizados e esparsos Pesquisa Operacional, 27:457–486,2007. DOI:10.1590/S0101-74382007000300004.
[10] A.R.V. Silva and L.S. Ochi, Heuŕısticas evolutivas h́ıbridas para o problema de escalonamento de proje-tos com restrição de recursos dinâmicos. In: Computação Evolucionária em Problemas de Engenharia.Eds. H. S. Lopes and R. H. C. Takahashi. Omnipax, 273–300,2011.
[11] U.S. Souza, F. Protti, and M. Dantas da Silva. An algorithmic analysis of flood-it and free-flood-it ongraph powers. Discrete Mathematics and Theoretical Computer Science, 16:279–290, 2014.
CLAIO-2016
866

Um Ambiente Georreferenciado para Otimizar Rotas na Distribuição de Produtos ou Serviços
Bruno de Castro Honorato Silva
Universidade Federal do Ceará, Campus de Crateús [email protected]
Gerardo Valdisio Rodrigues Viana
Universidade Estadual do Ceará, Departamento de computação [email protected]
José Lassance de Castro Silva
Universidade Federal do Ceará, DEMA/Centro de Ciências [email protected]
Abstract This article presents a computational tool that can be applied to minimize costs in the distribution of products or services with transport. An application of the Vehicle Routing Problem was used to optimize the routing process of deliveries of products or services. In the literature, this problem has an association with the Traveling Salesman Problem (TSP). Also in this study, the TSP is approached through a Georeferenced Routing Environment (GRE) designed by the development, implementation and testing of hybrid heuristics, built specifically for the problem. Computational experiments were performed with instances of the literature. It was possible to measure the good performance of these techniques. Heuristics are also attached and executed within the GRE, modeled with road networks maps, where it is possible create and analyze the solutions of the problem with graphic monitoring. Keywords: Combinatorial Optimization; Heuristics; Traveling Salesman Problem. 1 Introdução No Brasil, as exportações e importações respondem por 15% e 12%, respectivamente, do seu Produto Interno Bruto (PIB), com isso a relevância do sistema logístico é de alta prioridade. O transporte representa o elemento logístico mais custoso e consequentemente, o candidato preponderante para otimização. Segundo o Instituto de Logística e Supply Chain (ILOS), os custos com transporte por parte das empresas correspondem a 6,9% do PIB. Este fato, associado ao número considerável de congestionamentos de veículos observados nas malhas viárias das grandes cidades, além do aumento no consumo de combustíveis e do intervalo de tempo para se percorrer um determinado trajeto, tem despertado o interesse, tanto no meio profissional como no acadêmico, por estudos que venham a otimizar o processo de roteirização, afim de minimizar os custos decorrentes deste processo e melhorar o gerenciamento do mesmo.
O termo roteirização, ou routing do idioma inglês, pode ser descrito como um processo de sequências de paradas determinadas que um veículo deva percorrer, com o objetivo de atender pontos dispersos geograficamente, conforme [1]. Na literatura, o problema relacionado com roteirização mais conhecido é
CLAIO-2016
867

o clássico Problema do Caixeiro Viajante (PCV), que busca encontrar um roteiro, ou rota, entre “n” pontos de passagem, de forma a realizar todo o percurso e minimizar a distância total percorrida.
Nos trabalhos [2], [3] e [4] são tratadas várias instâncias de problemas práticos do PCV nas empresas Correios-Fortaleza (distribuição de encomendas – SEDEX 10), Thyssenkrupp-Ceará (distribuição de equipes para conserto e manutenção de elevadores e escadas rolantes) e RB Distribuidora (distribuição de sorvetes Kibon), respectivamente. Em todos estes trabalhos, os autores descrevem a dificuldade de operacionalizar e monitorar as instâncias do PCV e visualizar suas soluções gráficas em um único ambiente computacional integrado.
Com base neste contexto, propomos o desenvolvimento de um Ambiente de Roteirização Georreferenciado (ARG), com o intuito de avaliar e verificar o processo de resolução do problema por meio das técnicas criadas e implementadas, assim como ambientar o problema sobre uma perspectiva espacial. O ARG é composto por um Sistema de Informação Georreferenciado (SIG) robusto suficiente que permite a modelagem de mapas de malhas viárias baseada na Teoria dos Grafos (determinando e visualizando um caminho mínimo entre dois pontos quaisquer da rota), a criação de instâncias georreferenciadas do PCV, a resolução destas instâncias e o acompanhamento gráfico do processo de resolução em tempo real.
O processo de resolução é operado por heurística híbridas, criadas e implementadas neste trabalho com base nas técnicas tradicionais e rápidas de resolução para o PCV. Para mensurar a eficiência destes métodos heurísticos foram realizadas várias aplicações em instâncias da literatura (TSP-Library) [5], como as que foram usadas no artigo [6].
O presente trabalho organiza-se da seguinte maneira: Na Seção 2, é apresentado o ARG bem como suas funcionalidades, propriedades e arquitetura. Na Seção 3, são descritos os métodos heurísticos e técnicas computacionais propostos para a resolução de instâncias do PCV. Na Seção 4, constam os resultados dos experimentos computacionais. As conclusões são descritas na Seção 5 e o trabalho é finalizado com a descrição das referências bibliográficas consultadas. 2 Ambiente de Roteirização Georreferenciado O ARG proposto segue uma premissa acadêmica, servir como ferramenta de facilitação, para o estudo a cerca da aplicação prática do PCV, no segmento de roteamento. Ele pode funcionar dentro de uma rede interna ou externa de computadores (internet/intranet) com a arquitetura Cliente-Servidor. Neste trabalho, no lado do Servidor, constam as Heurísticas Híbridas propostas e as rotinas do SIG de acesso a banco de dados e de geração de grafos, programadas em linguagem Java seguindo o paradigma da Programação Orientada a Objetos. O lado Cliente consiste na interface gráfica do SIG que conta com rotinas para visualizar e interagir com mapas e realizar as requisições ao Servidor.
O SIG é assistido por um SGBD (Sistema de Gerenciamento de Banco de Dados) e um Servidor WMS (Web Map Service). Neste SGBD, foi criado um banco de dados denominado GRAPH, para persistir todos os dados do ARG, que permite a visualização dos objetos geoespaciais, geração do grafo sobre o mapa de uma malha viária e a criação de instâncias a partir do cadastro de pontos. O processo de geração do grafo baseia-se na topologia arco-nó, onde os nós (vértices) do grafo são desenhados a partir das interseções entre as ruas, e os arcos (arestas) são representados pelos trechos das ruas delimitados pelos nós. Técnicas semelhantes sobre a representação de malhas viárias em grafos podem ser encontradas em [7] e [8]. Neste trabalho, os dados da malha viária são da cidade de Fortaleza-CE.
Na Figura 1, dada a seguir, uma parte do mapa da cidade é ilustrada, onde cada rua é formada pela união de segmentos, cada um com duas extremidades georreferenciadas denominadas início e fim. Dois atributos do segmento determinam como um veículo pode se movimentar nele através do sentido (Único ou Duplo) e da direção (Norte-Sul, Sul-Norte, Leste-Oeste ou Oeste-Leste). A geração do grafo proposto
CLAIO-2016
868

é feita baseada numa lista de pontos de interseção entre as ruas dispostas no mapa, inserida na tabela NODE do banco de dados. Dessa forma, conclui-se o processo de geração dos nós do grafo.
Figura 1– Amostras do grafo da malha viária de Fortaleza e rota gerada pelas rotinas do ARG.
Nesta arquitetura, os segmentos representam as arestas do grafo, armazenados na tabela EDGE do
banco de dados, com a descrição georreferenciada do nó inicial e final deste segmento, levando em consideração os dois nós associados cadastrado na tabela NODE com as mesmas coordenadas geográficas. Se o mapa da malha viária informar o sentido das ruas, o grafo gerado é orientado, caso contrário, o grafo produzido é não orientado. A criação das instâncias do PCV no ARG ocorre a partir do cadastramento de pontos georreferenciados de localização dos clientes no banco de dados, através de uma interface gráfica que permite plotar um ponto no mapa clicando sobre o mesmo na posição específica, armazenando posteriormente as coordenadas do ponto específico e outras informações do cliente, criando um objeto tipo Point (ponto) na tabela INSTANCE do banco de dados.
Um formulário foi criado no ARG para acionar a(s) Heurística(s) usada(s) especificamente para a resolução do PCV. Depois de acionada uma dessas Heurísticas, a primeira operação é criar uma matriz de custo D dos pontos ativos da tabela INSTANCE que servirá como uma instância do problema. No banco de dados foi criada a tabela HISTORY que armazena informações sobre a execução dos métodos heurísticos. Assim, têm-se os dados armazenados das soluções e tempo de execuções propostos pela heurísticas, onde é possível fazer uma análise acurada.
A Figura 1.(a) mostra uma solução dada por uma heurística selecionada baseada em distância euclidiana, onde é possível ver a ordem das visitar para cada um dos pontos ativos. O Algoritmo de Dijkstra foi implementado e adicionado a este ambiente para construir uma rota real a partir da solução dada pela heurística, considerando a estrutura do grafo modelado. Em [9] há exemplos e detalhes sobre o Algoritmo de Dijkstra. Nesta versão, o algoritmo calcula o melhor trajeto para ser percorrido no mapa indo de ponto de cliente a outro cliente. A Figura 1.(b) mostra a rota real gerada para o exemplo ilustrado da rota da Figura 1.(a) usando este procedimento.
CLAIO-2016
869

3 Heurísticas Híbridas Uma Heurística Híbrida concebida para a resolução de problemas de otimização é uma abordagem que incorpora características de mais de uma heurística. Neste trabalho, foram desenvolvidas e implementadas Heurísticas Híbridas capazes de apresentar soluções satisfatórias para o PCV, com um tempo de execução muito baixo, mesmo para instâncias de grande porte. Elas possuem uma fase de construção de roteiros e uma fase de melhoria de roteiros. A fase de construção de cada uma destas abordagens híbridas é realizada por uma variação da Heurística do Vizinho mais Próximo (HVP) ou da Inserção Mais Barata (HIMB). Já a fase de melhoria de roteiros de todas as heurísticas híbridas desenvolvidas, é feita pela Heurística 4-Opt [10].
A primeira Heurística desenvolvida foi denominada Heurística Híbrida do Vizinho mais Próximo (HHVP), onde o processo de construção da rota seleciona uma cidade inicial e segue adicionando cidades à rota em formação. A cidade i mais próxima de um dos extremos da rota, ainda não visitada, é colocada na rota a cada iteração. Para diversificar a fase de construção, o processo de escolha da cidade inicial é repetido para todas as cidades que constituem o itinerário almejado. Desta forma, uma rota é constituída iniciando por cada cidade do problema, sendo a melhor delas selecionada para a fase de melhoria de roteiros, por meio da heurística 4-Opt.
A segunda Heurística Híbrida desenvolvida por nós e denominada de Heurística do Vizinho mais Próximo com 2 Caminhos Paralelos (HVP2) é realizada por uma variação da HHVP cujo processo de construção de rotas é feito a partir da conexão de 2 caminhos configurados paralelamente. O processo de seleção de cidades a serem inseridas em um dos dois caminhos em formação utiliza o mesmo critério de avaliação da HHVP, onde é selecionada a cidade mais próxima de um dos extremos dos dois caminhos paralelos. A fase de melhoria de roteiros por meio do algoritmo 4-Opt também se repetiu aqui para a HVP2.
Implementou-se uma modificação no critério de seleção para uma cidade ser inserida em um dos dois caminhos paralelos, dando origem a uma nova metodologia de tentar solucionar o problema específico, denominada de Heurística do Vizinho mais Próximo com 2 caminhos paralelos e a inserção de uma cidade por iteração (HVP2B). Este critério insere uma cidade por iteração, sendo selecionada aquela cidade que estiver mais próxima de um dos dois caminhos paralelos. Antes eram inseridas duas cidades em cada iteração, uma para cada caminho paralelo. Neste novo procedimento isto não mais ocorre.
Considerando ainda a metodologia empregada para HVP2, foi desenvolvida a Heurística do Vizinho mais Próximo com 4 Caminhos Paralelos (HVP4). A diferença deste método para HVP2 é que aqui são utilizados 4 caminhos paralelos. Este procedimento irá formar mais de uma rota viável para o problema, em cada iteração, devido as várias formas de unir estes caminhos paralelos na geração de uma rota.
A última Heurística desenvolvida foi a Heurística Híbrida da Inserção Mais Barata Modificada (HIMBM). A estratégia deste método é aplicar o método 4-Opt no processo de construção de rotas da Heurística da Inserção Mais Barata (HIMB). Desta forma, quando uma sub-rota (ciclo com menos de n cidades) é formada pelo princípio da HIMB com 8 ou mais cidades, aplica-se o método 4-Opt para cada nova cidade inserida nesta sub-rota. Este processo termina quando tiver sido inserido na sub-rota todas as n cidades. Em HIMBM, o processo de escolha da cidade inicial é selecionado para cada uma das n cidades, gerando n soluções distintas e tomando-se a melhor delas como a solução do problema.
Após a realização de vários testes, com as instâncias da literatura, adotou-se um novo critério aplicado na heurística 4-Opt, denominado de Salto, com o intuito de evitar um gasto excessivo de tempo sem melhoria na busca pela solução ótima. Este critério diminui bastante o número de soluções geradas e avaliadas. Maiores detalhes e os pseudocódigos das heurísticas podem ser encontrados em [11]. 4 Experimentos Computacionais
CLAIO-2016
870
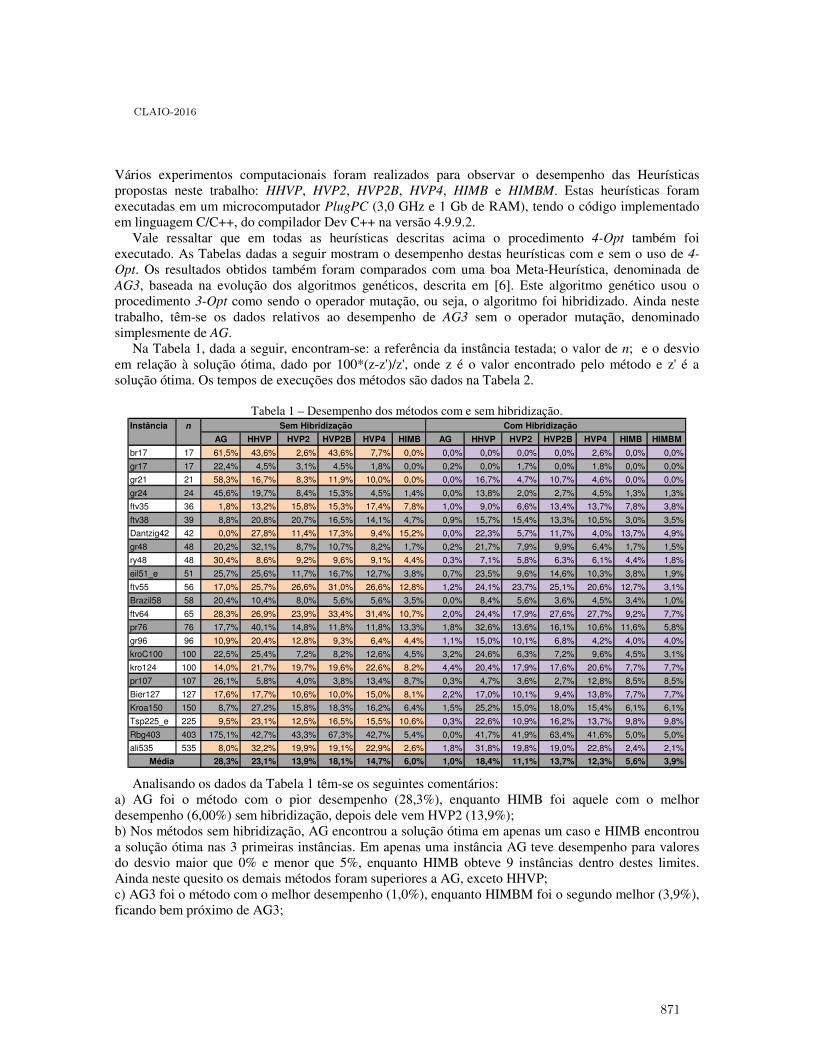
Vários experimentos computacionais foram realizados para observar o desempenho das Heurísticas propostas neste trabalho: HHVP, HVP2, HVP2B, HVP4, HIMB e HIMBM. Estas heurísticas foram executadas em um microcomputador PlugPC (3,0 GHz e 1 Gb de RAM), tendo o código implementado em linguagem C/C++, do compilador Dev C++ na versão 4.9.9.2.
Vale ressaltar que em todas as heurísticas descritas acima o procedimento 4-Opt também foi executado. As Tabelas dadas a seguir mostram o desempenho destas heurísticas com e sem o uso de 4-
Opt. Os resultados obtidos também foram comparados com uma boa Meta-Heurística, denominada de AG3, baseada na evolução dos algoritmos genéticos, descrita em [6]. Este algoritmo genético usou o procedimento 3-Opt como sendo o operador mutação, ou seja, o algoritmo foi hibridizado. Ainda neste trabalho, têm-se os dados relativos ao desempenho de AG3 sem o operador mutação, denominado simplesmente de AG.
Na Tabela 1, dada a seguir, encontram-se: a referência da instância testada; o valor de n; e o desvio em relação à solução ótima, dado por 100*(z-z')/z', onde z é o valor encontrado pelo método e z' é a solução ótima. Os tempos de execuções dos métodos são dados na Tabela 2.
Tabela 1 – Desempenho dos métodos com e sem hibridização.
Instância n Sem Hibridização Com Hibridização
AG HHVP HVP2 HVP2B HVP4 HIMB AG HHVP HVP2 HVP2B HVP4 HIMB HIMBM
br17 17 61,5% 43,6% 2,6% 43,6% 7,7% 0,0% 0,0% 0,0% 0,0% 0,0% 2,6% 0,0% 0,0%
gr17 17 22,4% 4,5% 3,1% 4,5% 1,8% 0,0% 0,2% 0,0% 1,7% 0,0% 1,8% 0,0% 0,0%
gr21 21 58,3% 16,7% 8,3% 11,9% 10,0% 0,0% 0,0% 16,7% 4,7% 10,7% 4,6% 0,0% 0,0%
gr24 24 45,6% 19,7% 8,4% 15,3% 4,5% 1,4% 0,0% 13,8% 2,0% 2,7% 4,5% 1,3% 1,3%
ftv35 36 1,8% 13,2% 15,8% 15,3% 17,4% 7,8% 1,0% 9,0% 6,6% 13,4% 13,7% 7,8% 3,8%
ftv38 39 8,8% 20,8% 20,7% 16,5% 14,1% 4,7% 0,9% 15,7% 15,4% 13,3% 10,5% 3,0% 3,5%
Dantzig42 42 0,0% 27,8% 11,4% 17,3% 9,4% 15,2% 0,0% 22,3% 5,7% 11,7% 4,0% 13,7% 4,9%
gr48 48 20,2% 32,1% 8,7% 10,7% 8,2% 1,7% 0,2% 21,7% 7,9% 9,9% 6,4% 1,7% 1,5%
ry48 48 30,4% 8,6% 9,2% 9,6% 9,1% 4,4% 0,3% 7,1% 5,8% 6,3% 6,1% 4,4% 1,8%
eil51_e 51 25,7% 25,6% 11,7% 16,7% 12,7% 3,8% 0,7% 23,5% 9,6% 14,6% 10,3% 3,8% 1,9%
ftv55 56 17,0% 25,7% 26,6% 31,0% 26,6% 12,8% 1,2% 24,1% 23,7% 25,1% 20,6% 12,7% 3,1%
Brazil58 58 20,4% 10,4% 8,0% 5,6% 5,6% 3,5% 0,0% 8,4% 5,6% 3,6% 4,5% 3,4% 1,0%
ftv64 65 28,3% 26,9% 23,9% 33,4% 31,4% 10,7% 2,0% 24,4% 17,9% 27,6% 27,7% 9,2% 7,7%
pr76 76 17,7% 40,1% 14,8% 11,8% 11,8% 13,3% 1,8% 32,6% 13,6% 16,1% 10,6% 11,6% 5,8%
gr96 96 10,9% 20,4% 12,8% 9,3% 6,4% 4,4% 1,1% 15,0% 10,1% 6,8% 4,2% 4,0% 4,0%
kroC100 100 22,5% 25,4% 7,2% 8,2% 12,6% 4,5% 3,2% 24,6% 6,3% 7,2% 9,6% 4,5% 3,1%
kro124 100 14,0% 21,7% 19,7% 19,6% 22,6% 8,2% 4,4% 20,4% 17,9% 17,6% 20,6% 7,7% 7,7%
pr107 107 26,1% 5,8% 4,0% 3,8% 13,4% 8,7% 0,3% 4,7% 3,6% 2,7% 12,8% 8,5% 8,5%
Bier127 127 17,6% 17,7% 10,6% 10,0% 15,0% 8,1% 2,2% 17,0% 10,1% 9,4% 13,8% 7,7% 7,7%
Kroa150 150 8,7% 27,2% 15,8% 18,3% 16,2% 6,4% 1,5% 25,2% 15,0% 18,0% 15,4% 6,1% 6,1%
Tsp225_e 225 9,5% 23,1% 12,5% 16,5% 15,5% 10,6% 0,3% 22,6% 10,9% 16,2% 13,7% 9,8% 9,8%
Rbg403 403 175,1% 42,7% 43,3% 67,3% 42,7% 5,4% 0,0% 41,7% 41,9% 63,4% 41,6% 5,0% 5,0%
ali535 535 8,0% 32,2% 19,9% 19,1% 22,9% 2,6% 1,8% 31,8% 19,8% 19,0% 22,8% 2,4% 2,1%
Média 28,3% 23,1% 13,9% 18,1% 14,7% 6,0% 1,0% 18,4% 11,1% 13,7% 12,3% 5,6% 3,9%
Analisando os dados da Tabela 1 têm-se os seguintes comentários: a) AG foi o método com o pior desempenho (28,3%), enquanto HIMB foi aquele com o melhor desempenho (6,00%) sem hibridização, depois dele vem HVP2 (13,9%); b) Nos métodos sem hibridização, AG encontrou a solução ótima em apenas um caso e HIMB encontrou a solução ótima nas 3 primeiras instâncias. Em apenas uma instância AG teve desempenho para valores do desvio maior que 0% e menor que 5%, enquanto HIMB obteve 9 instâncias dentro destes limites. Ainda neste quesito os demais métodos foram superiores a AG, exceto HHVP; c) AG3 foi o método com o melhor desempenho (1,0%), enquanto HIMBM foi o segundo melhor (3,9%), ficando bem próximo de AG3;
CLAIO-2016
871
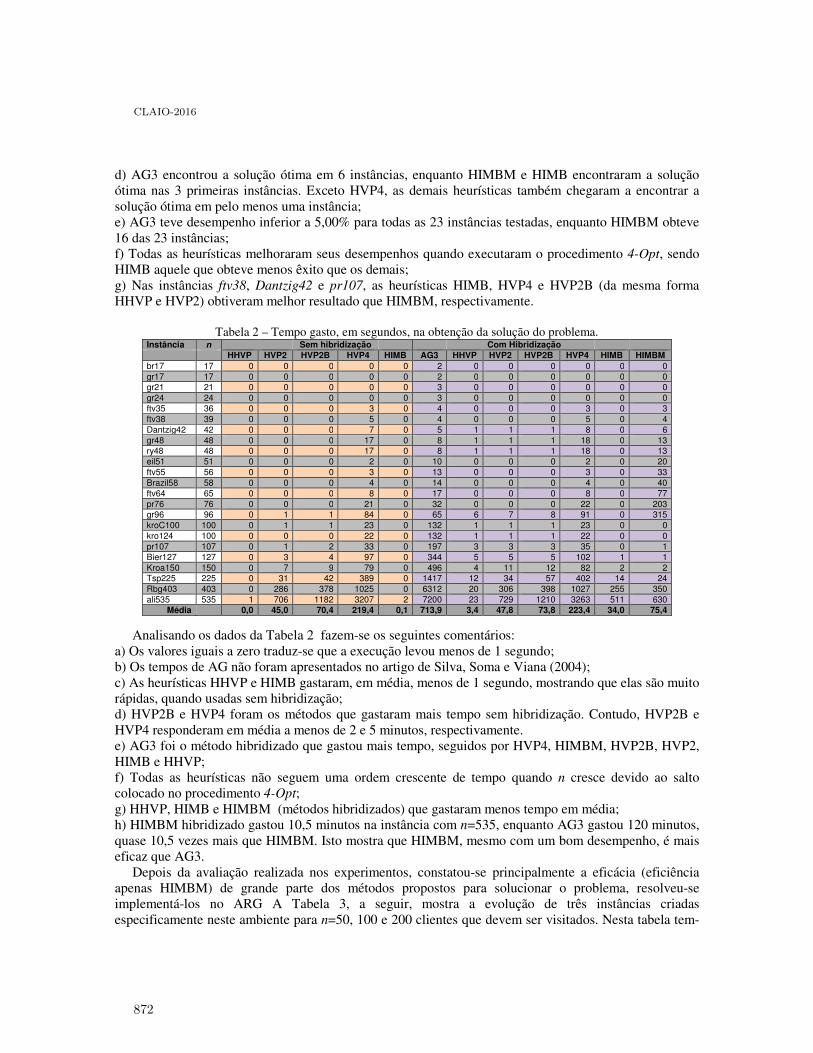
d) AG3 encontrou a solução ótima em 6 instâncias, enquanto HIMBM e HIMB encontraram a solução ótima nas 3 primeiras instâncias. Exceto HVP4, as demais heurísticas também chegaram a encontrar a solução ótima em pelo menos uma instância; e) AG3 teve desempenho inferior a 5,00% para todas as 23 instâncias testadas, enquanto HIMBM obteve 16 das 23 instâncias; f) Todas as heurísticas melhoraram seus desempenhos quando executaram o procedimento 4-Opt, sendo HIMB aquele que obteve menos êxito que os demais; g) Nas instâncias ftv38, Dantzig42 e pr107, as heurísticas HIMB, HVP4 e HVP2B (da mesma forma HHVP e HVP2) obtiveram melhor resultado que HIMBM, respectivamente.
Tabela 2 – Tempo gasto, em segundos, na obtenção da solução do problema.
Instância n Sem hibridização Com Hibridização
HHVP HVP2 HVP2B HVP4 HIMB AG3 HHVP HVP2 HVP2B HVP4 HIMB HIMBM
br17 17 0 0 0 0 0 2 0 0 0 0 0 0
gr17 17 0 0 0 0 0 2 0 0 0 0 0 0
gr21 21 0 0 0 0 0 3 0 0 0 0 0 0
gr24 24 0 0 0 0 0 3 0 0 0 0 0 0
ftv35 36 0 0 0 3 0 4 0 0 0 3 0 3
ftv38 39 0 0 0 5 0 4 0 0 0 5 0 4
Dantzig42 42 0 0 0 7 0 5 1 1 1 8 0 6
gr48 48 0 0 0 17 0 8 1 1 1 18 0 13
ry48 48 0 0 0 17 0 8 1 1 1 18 0 13
eil51 51 0 0 0 2 0 10 0 0 0 2 0 20
ftv55 56 0 0 0 3 0 13 0 0 0 3 0 33
Brazil58 58 0 0 0 4 0 14 0 0 0 4 0 40
ftv64 65 0 0 0 8 0 17 0 0 0 8 0 77
pr76 76 0 0 0 21 0 32 0 0 0 22 0 203
gr96 96 0 1 1 84 0 65 6 7 8 91 0 315
kroC100 100 0 1 1 23 0 132 1 1 1 23 0 0
kro124 100 0 0 0 22 0 132 1 1 1 22 0 0
pr107 107 0 1 2 33 0 197 3 3 3 35 0 1
Bier127 127 0 3 4 97 0 344 5 5 5 102 1 1
Kroa150 150 0 7 9 79 0 496 4 11 12 82 2 2
Tsp225 225 0 31 42 389 0 1417 12 34 57 402 14 24
Rbg403 403 0 286 378 1025 0 6312 20 306 398 1027 255 350
ali535 535 1 706 1182 3207 2 7200 23 729 1210 3263 511 630
Média 0,0 45,0 70,4 219,4 0,1 713,9 3,4 47,8 73,8 223,4 34,0 75,4
Analisando os dados da Tabela 2 fazem-se os seguintes comentários: a) Os valores iguais a zero traduz-se que a execução levou menos de 1 segundo; b) Os tempos de AG não foram apresentados no artigo de Silva, Soma e Viana (2004); c) As heurísticas HHVP e HIMB gastaram, em média, menos de 1 segundo, mostrando que elas são muito rápidas, quando usadas sem hibridização; d) HVP2B e HVP4 foram os métodos que gastaram mais tempo sem hibridização. Contudo, HVP2B e HVP4 responderam em média a menos de 2 e 5 minutos, respectivamente. e) AG3 foi o método hibridizado que gastou mais tempo, seguidos por HVP4, HIMBM, HVP2B, HVP2, HIMB e HHVP; f) Todas as heurísticas não seguem uma ordem crescente de tempo quando n cresce devido ao salto colocado no procedimento 4-Opt; g) HHVP, HIMB e HIMBM (métodos hibridizados) que gastaram menos tempo em média; h) HIMBM hibridizado gastou 10,5 minutos na instância com n=535, enquanto AG3 gastou 120 minutos, quase 10,5 vezes mais que HIMBM. Isto mostra que HIMBM, mesmo com um bom desempenho, é mais eficaz que AG3.
Depois da avaliação realizada nos experimentos, constatou-se principalmente a eficácia (eficiência apenas HIMBM) de grande parte dos métodos propostos para solucionar o problema, resolveu-se implementá-los no ARG A Tabela 3, a seguir, mostra a evolução de três instâncias criadas especificamente neste ambiente para n=50, 100 e 200 clientes que devem ser visitados. Nesta tabela tem-
CLAIO-2016
872
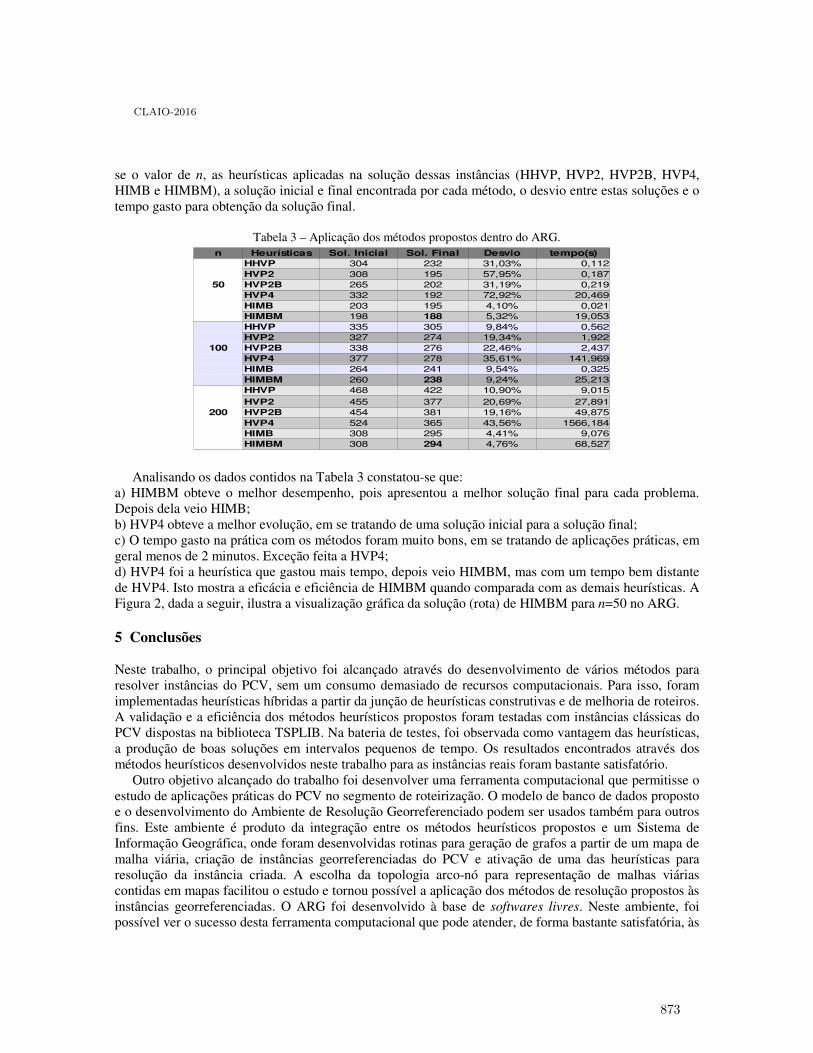
se o valor de n, as heurísticas aplicadas na solução dessas instâncias (HHVP, HVP2, HVP2B, HVP4, HIMB e HIMBM), a solução inicial e final encontrada por cada método, o desvio entre estas soluções e o tempo gasto para obtenção da solução final.
Tabela 3 – Aplicação dos métodos propostos dentro do ARG.
Analisando os dados contidos na Tabela 3 constatou-se que:
a) HIMBM obteve o melhor desempenho, pois apresentou a melhor solução final para cada problema. Depois dela veio HIMB; b) HVP4 obteve a melhor evolução, em se tratando de uma solução inicial para a solução final; c) O tempo gasto na prática com os métodos foram muito bons, em se tratando de aplicações práticas, em geral menos de 2 minutos. Exceção feita a HVP4; d) HVP4 foi a heurística que gastou mais tempo, depois veio HIMBM, mas com um tempo bem distante de HVP4. Isto mostra a eficácia e eficiência de HIMBM quando comparada com as demais heurísticas. A Figura 2, dada a seguir, ilustra a visualização gráfica da solução (rota) de HIMBM para n=50 no ARG. 5 Conclusões Neste trabalho, o principal objetivo foi alcançado através do desenvolvimento de vários métodos para resolver instâncias do PCV, sem um consumo demasiado de recursos computacionais. Para isso, foram implementadas heurísticas híbridas a partir da junção de heurísticas construtivas e de melhoria de roteiros. A validação e a eficiência dos métodos heurísticos propostos foram testadas com instâncias clássicas do PCV dispostas na biblioteca TSPLIB. Na bateria de testes, foi observada como vantagem das heurísticas, a produção de boas soluções em intervalos pequenos de tempo. Os resultados encontrados através dos métodos heurísticos desenvolvidos neste trabalho para as instâncias reais foram bastante satisfatório.
Outro objetivo alcançado do trabalho foi desenvolver uma ferramenta computacional que permitisse o estudo de aplicações práticas do PCV no segmento de roteirização. O modelo de banco de dados proposto e o desenvolvimento do Ambiente de Resolução Georreferenciado podem ser usados também para outros fins. Este ambiente é produto da integração entre os métodos heurísticos propostos e um Sistema de Informação Geográfica, onde foram desenvolvidas rotinas para geração de grafos a partir de um mapa de malha viária, criação de instâncias georreferenciadas do PCV e ativação de uma das heurísticas para resolução da instância criada. A escolha da topologia arco-nó para representação de malhas viárias contidas em mapas facilitou o estudo e tornou possível a aplicação dos métodos de resolução propostos às instâncias georreferenciadas. O ARG foi desenvolvido à base de softwares livres. Neste ambiente, foi possível ver o sucesso desta ferramenta computacional que pode atender, de forma bastante satisfatória, às
n Heurísticas Sol. Inicial Sol. Final Desvio tempo(s)
HHVP 304 232 31,03% 0,112
HVP2 308 195 57,95% 0,187
50 HVP2B 265 202 31,19% 0,219
HVP4 332 192 72,92% 20,469
HIMB 203 195 4,10% 0,021
HIMBM 198 188 5,32% 19,053
HHVP 335 305 9,84% 0,562
HVP2 327 274 19,34% 1,922
100 HVP2B 338 276 22,46% 2,437
HVP4 377 278 35,61% 141,969
HIMB 264 241 9,54% 0,325
HIMBM 260 238 9,24% 25,213
HHVP 468 422 10,90% 9,015
HVP2 455 377 20,69% 27,891
200 HVP2B 454 381 19,16% 49,875
HVP4 524 365 43,56% 1566,184
HIMB 308 295 4,41% 9,076
HIMBM 308 294 4,76% 68,527
CLAIO-2016
873

empresas que usam a roteirização com racionalidade na distribuição dos seus produtos ou serviços aos seus clientes. Ainda nesta ferramenta, o controle e o acompanhamento desta distribuição podem ser vistos em tempo real.
Figura 2 - Ilustração da solução de HIMBM noARG para n=50.
Para trabalhos futuros podemos sugerir o desenvolvimento e a implementação de algoritmos para
realizar a clusterização dos clientes no ARG, tornando-o um ambiente robusto com a aplicação do PRV e suas variações: frota heterogênea; janela de tempo; coleta e entrega; etc. Referências Bibliográficas
1. C. B. Cunha. Aspectos práticos da aplicação de modelos de roteirização de veículos a problemas reais, Revista
Transportes da Associação Nacional de Pesquisa e Ensino em Transportes, 8(2):51-74, 2000. 2. J. U. Campelo Júnior. Proposta de otimização da roteirização dos distritos dos carteiros: Um estudo de caso no
centro de entrega de encomendas de Fortaleza. Universidade Federal do Ceará, Dissertação Mestrado em Logística e Pesquisa Operacional, 2010.
3. R. F. S. Gomes. Aplicação da Meta-Heurística Tabu Search na otimização de rotas de manutenção preventiva
em campo. Universidade Federal do Ceará, Dissertação Mestrado em Logística e Pesquisa Operacional, 2011. 4. F. P. Bezerra. Um algoritmo genético aplicado no problema da roteirização periódica de veículos com caso
prático. Universidade Federal do Ceará, Dissertação Mestrado em Logística e Pesquisa Operacional, 2012. 5. TSPLIB. Disponível em: http://elib.zib.de/pub/mp-testdata/tsp/tsplib/tsplib.html. Acesso em: 29/05/2015. 6. J. L. C. Silva, N. Y. Soma e G. V. R. Viana. Um algoritmo genético híbrido construtivo para problemas de
otimização combinatór ia permutacional. Anales del CLAIO, Havana-Cuba, 2004. 7. E. D. Assad e E. E. Sano. Sistema de informações geográficas: aplicações na agricultura. EMBRAPA,
Brasília-DF, 1998. 8. J. Lisboa, C. Iochpe e K. A. V. Borges. Reutilização de Esquema de Banco de Dados em Aplicações de Gestão
Urbana. Annals of I Latin American Conference on Pattern Languages of Programming, Rio de Janeiro, 2001. 9. T. H. Cormen, C. E. Leiserson, R. L. Rivest and C. Stein. Introduction to Algorithms. The MIT Press,
Cambridge, 2001. 10. S. Lin and B. W. Kernighan. An Effective Heuristic Algorithm for the Traveling Salesman Problem.
Operations Research, 21:498-516, 1973. 11. B. C. H. Silva. Otimização de Rotas Utilizando Abordagens Heurísticas em um Ambiente Georreferenciado.
Universidade Estadual do Ceará, Dissertação Mestrado em Ciências da Computação, 2013.
CLAIO-2016
874

Um Algoritmo Genético para o Problema de Roteirização de Veículos com Frota Heterogênea e Coleta e Entrega Separada
José Lassance de Castro Silva
Universidade Federal do Ceará, DEMA/Centro de Ciências
Cesar Augusto Chaves e Sousa Filho
Universidade Federal do Ceará, GESLOG
Bruno de Castro Honorato Silva
Universidade Federal do Ceará, Campus de Crateús
Abstract This work presents a Genetic Algorithm (AG) for solving the Vehicle Routing Problem (VRP) with a
heterogeneous fleet and pickup and delivery separated. The problem tries to generate the most economical
route to efficient use of the available fleet. The case study shows a particular situation of VRP, where
pickup and delivery of passengers are carried at separate times. In the AG, three different crossover
operators are tested in the search for better results. In the case study, the algorithm was capable of solving
the problem in a short time space, using efficiently the fleet and fulfilling all requests of visit. The
instances of the problem belong the Social Development and Employment Department of Ceará State.
Keywords: Combinatorial Optimization, Genetic algorithm, Vehicle Routing Problem.
1 Introdução
No Brasil, as exportações e importações respondem por 15% e 12%, respectivamente, do seu Produto
Interno Bruto (PIB), com isso a relevância do sistema logístico é de alta prioridade. O transporte
representa o elemento logístico mais custoso e consequentemente, o candidato preponderante para
otimização. Segundo o Instituto de Logística e Supply Chain (ILOS), os custos com transporte por parte
das empresas correspondem a 6,9% do PIB. Este fato, associado ao número considerável de
congestionamentos de veículos observados nas malhas viárias das grandes cidades, além do aumento no
consumo de combustíveis e do intervalo de tempo para se percorrer um determinado trajeto, tem
despertado o interesse, tanto no meio profissional como no acadêmico, por estudos que venham a otimizar
o processo de roteirização, afim de minimizar os custos decorrentes deste processo, melhorar o
gerenciamento do mesmo e evitar o uso demasiado de CO2 na atmosfera terrestre.
O termo roteirização, ou routing do idioma inglês, pode ser descrito como um processo de sequências
de paradas determinadas que um veículo deva percorrer, com o objetivo de atender pontos dispersos
geograficamente [1]. Na literatura, o clássico Problema de Roteirização de Veículos (PRV), busca
encontrar um ou mais roteiro, ou rota, para os veículos disponíveis entre n pontos de visitas a serem
realizadas, com o menor custo possível para visitar todos os pontos previstos.
CLAIO-2016
875

Nos trabalhos [2], [3] e [4] são tratadas várias instâncias de problemas práticos do PRV nas empresas
Correios-Fortaleza (distribuição de encomendas – SEDEX 10), Thyssenkrupp-Ceará (distribuição de
equipes para conserto e manutenção de elevadores) e RB Distribuidora (distribuição de sorvetes Kibon).
Nestes trabalhos, os autores descrevem a dificuldade de operacionalizar e monitorar as instâncias do PRV,
controlando suas soluções em um único ambiente.
O PRV surge como uma boa opção para dar um suporte às empresas no tocante a distribuição dos seus
produtos ou serviços. Ele apresenta uma enorme dinamicidade, a fim de se estudar de maneira específica
algumas destas situações presentes em instâncias reais. Uma delas é a consideração da capacidade de
carga de cada veículo e o tempo em que os clientes podem ser atendidos (janela de tempo), tendo apenas
um depósito central de onde partem os veículos, ficando conhecido como Problema de Roteirização de
Veículos com Janela de Tempo e Frota Heterogênea (PRVJTFH) que pode ser formulado da seguinte
maneira: Um conjunto de veículos não idênticos, representado pelo conjunto V={1, ..., M}i, necessita
realizar entregas em uma região. Os n clientes dentro desta região estão representados pelo conjunto C,
que são vértices de um grafo G = (C, A), com A sendo o conjunto de arestas. Adicionalmente, incluem-se
dois outros vértices, os vértices 0 e n+1 que representam o depósito central de onde partirão e chegarão
todos os veículos, respectivamente. São dados os tsi, ki, tij e cij que representam respectivamente o tempo
de serviço usado para descarregar a carga no cliente i, a capacidade do veículo i, o tempo e a distância
necessários para ir do cliente i ao cliente j. Cada cliente i tem uma demanda, ou seja, uma quantidade de
carga qi. Além disso, cada cliente deverá ser atendido por um único veículo, não sendo permitida a
divisão de uma carga por dois ou mais veículos. Quanto à janela de tempo, dada pelo intervalo [ai, bi],
indica que a partir do instante inicial ai é permitido o início da entrega ou coleta no cliente i. Caso a
chegada do veículo no cliente i se dê antes do instante ai, o veículo deverá esperar. O veículo nunca
poderá chegar depois do instante bi, pois viola a restrição de tempo do problema. Este tipo de restrição de
tempo é conhecido na literatura como janela de tempo rígida ou hard time window. O PRVJTFH tem
como objetivo fazer a entrega da demanda de todos os clientes minimizando a distância total percorrida.
Em [5] pode ser encontrado maiores detalhes sobre os métodos de resolução e variações do PRVJTFH.
Neste trabalho, uma nova variação do PRVJTFH é abordada, onde a coleta e entrega de passageiros
em determinados locais e em momentos distintos são requisitados (PRVJTFHCE). Encontramos na
literatura vários artigos sobre o PRVJTFH com coleta e entrega, no mesmo instante, de produtos ou
serviços ([6], [7], [8], [9] e [10]), denominado na literatura de Fleet Size and Mix Vehicle Routing
Problem with Time Windows, Pickup and Delivery.
Com base neste contexto, um Algoritmo Genético (AG) foi desenvolvido com o intuito de avaliar e
verificar o processo de resolução do problema. O operador mutação diversifica e intensifica bastante a
busca, sendo ele o operador genético que mais gasta tempo de execução do algoritmo. Para mensurar a
eficiência deste método, várias aplicações em 17 instâncias reais foram concebidas, haja vista que não
encontramos na literatura instâncias que abordem o problema específico aqui descrito. As instâncias são
solicitações de visitas a serem realizadas em diversos horários, datas e locais da cidade de Fortaleza-CE
pelos funcionários da Secretaria do Trabalho e Desenvolvimento Social do Estado do Ceará (STDS), entre
01 e 31/03/2010.
O presente trabalho organiza-se da seguinte maneira: Na Seção 2, o estudo de caso prático da STDS é
apresentado. Na Seção 3, o AG aplicado ao problema é descrito com todos os seus passos. Na Seção 4,
constam os resultados dos experimentos computacionais. As conclusões são descritas na Seção 5 e o
trabalho é finalizado com a descrição das referências bibliográficas consultadas.
2 O Estudo de Caso da STDS
CLAIO-2016
876

O presente trabalho abordará um estudo de caso da STDS, órgão público do Estado do Ceará localizada
na rua Soriano Albuquerque, no. 230, no bairro Joaquim Távora, Fortaleza – CE. A STDS tem por missão
“Coordenar e executar as políticas do Trabalho, Assistência Social e Segurança Alimentar, voltadas para a
elevação da qualidade de vida da população, sobretudo dos grupos socialmente vulnerabilizados
auxiliando direta e indiretamente o Governador nas suas Políticas de Governo”.
O sistema para transportar funcionários deve acontecer por meio de um sistema web da STDS e
funciona pelo cadastramento de solicitações de visitas, que devem ser realizadas até o final do expediente
do dia anterior, somente sendo possível a solicitação no mesmo dia caso seja comprovada a urgência da
solicitação e esta seja aprovada pelo gerente administrativo. As visitas devem ocorrer em dias úteis de
serviço, no horário compreendido entre 06h e 17h, devendo ser recolhidos até às 18h. A frota da STDS
dispõe de 9 automóveis, 5 caminhões, 1 ônibus e 7 motocicletas. Os veículos da frota devem ser
conduzidos preferencialmente por servidores designados para esta função.
Ao solicitar um veículo para realizar uma visita, o solicitante deve informar: data; hora de chegada no
destino; hora de retorno; latitude e longitude do destino; quantidade de passageiros; e motivo da visita.
Um relatório de todas as solicitações é gerado pelo sistema para que estas possam ser gerenciadas e
atendidas. No final do dia, o sistema é atualizado com as solicitações atendidas ou não. Desta forma, as
instâncias do problema são configuradas baseadas nos dados do sistema web e dados da frota disponível
diariamente da STDS.
O problema da STDS visa designar racionalmente os veículos de sua frota, bastante limitada, para
atender todas as solicitações diárias. Dado o número grande de solicitações não atendidas mensalmente, o
problema tem como objetivo utilizar a frota disponível de forma mais eficiente para que o não
atendimento de solicitações possa ser sanado e que as rotas utilizadas percorram a menor quantidade de
quilômetros. Uma vez que a instância tenha sido elaborada, a resolução do problema deve buscar a
melhor forma de alocar as solicitações aos veículos disponíveis e traçar rotas otimizadas para eles.
A estrutura de dados para representar as solicitações de coletas e entregas quando da alocação das
solicitações nos veículos usa dois vetores ordenados, onde o primeiro vetor colocará em ordem crescente
de horário de retorno todas as solicitações, ou seja, da coleta que deverá acontecer mais cedo até a coleta
que deverá acontecer mais tarde. Da mesma forma, o segundo vetor ordenado colocará as solicitações em
ordem crescente de horário de chegada no destino. Desse modo, cada solicitação irá gerar duas posições
de viagens nesta estrutura, uma viagem de ida (entrega) e outra de retorno (coleta). Um procedimento foi
criado para distinguir quando aquela solicitação alocada em uma viatura é coleta ou entrega. As
solicitações são numeradas de tal forma que, numa instância com n solicitações, as solicitações de 1 a n
são viagens de coleta e as solicitações de entrega são numeradas de n+1 a 2n. Assim, se n=5 e os vetores
coleta=[5 2 1 3 4] e entrega=[7 9 10 6 8], significa que a ordem crescente dos horários das entregas são
das solicitações 2, 4, 5, 1 e 3. Isto foi feito para otimizar o tempo gasto no processo de alocação das
solicitações de entregas e coletas nos veículos, pois quando se tem uma coleta, o veículo será preenchido
com um ou mais passageiro, enquanto entrega o veículo vai liberar vaga(s) com passageiro(s) saindo dele.
A estrutura usada para representar uma solução do problema foi uma matriz m×3n, onde a linha i da
matriz informa a(s) rota(s) que o veículo i fará naquele dia. Por exemplo, se n=6 e a linha 3 da matriz é
igual a [5 3 7 0 8 2 0 10], então o veículo 3 fará três rotas das seguintes solicitações: 1ª rota, vai atender as
coletas das solicitações 5, 3 e 7, nesta ordem, e volta a STDS; depois a 2ª rota tem início na STDS e vai
atender a entrega da solicitação 3, a coleta da solicitação 2 e retorna a STDS, nesta ordem; a 3ª e última
rota tem início na STDS, atende a entrega da solicitação 5 e retorna a STDS.
Outro requisito importante na hora de alocar funcionários nos veículos é que o tempo de permanência
de um passageiro dentro do veículo não ultrapasse 3 horas. Esse parâmetro garante que um passageiro não
desperdice tempo desnecessariamente dentro do veículo enquanto ausente da sede da STDS e respeitando
seu horário de trabalho diário na instituição. Outro parâmetro usado foi a velocidade média dos veículos
CLAIO-2016
877

em 20 Km/k, definido com base nas possíveis variações do trânsito, como congestionamentos, semáforos
e vias com tráfego mais intenso.
3 Algoritmo Genético
O Algoritmo Genético foi criado por Holland, para simular computacionalmente o comportamento da
seleção natural [11]. O AG é formado por uma população de indivíduos que representam as soluções do
problema. Os indivíduos são avaliados por uma função que atribui um valor chamado aptidão a cada
indivíduo da população, segundo sua qualidade em relação à função objetivo do problema. Os indivíduos
são escolhidos por um procedimento inspirado na seleção natural para passarem por operações genéticas
que resultam em descendentes que comporão a nova população. Este processo de gerar novas populações
é chamado de geração. O melhor indivíduo é a solução a ser apresentada para o problema. Nos AGs, as
soluções potenciais de um problema específico são codificadas em uma estrutura de dados semelhante a
um cromossomo, sobre a qual são aplicados operadores de recombinação com o objetivo de preservar
informações críticas. Em [12], os passos na preparação de um AG são a determinação da representação do
cromossomo, da função de aptidão, das regras de geração da população inicial, do método de seleção, dos
operadores genéticos cruzamento e mutação, da estratégia geracional, dos parâmetros e variáveis para
controlar o algoritmo, do modo de reconhecimento do resultado e do critério de parada. A seguir definem-
se as componentes usadas na construção do nosso algoritmo genético, seguindo a estrutura dessas oito
componentes:
a) O cromossomo representa uma permutação dos m veículos disponíveis da frota, definindo
uma sequência de prioridade na alocação das entregas e coletas para cada um dos veículos.
b) A função custo (The fitness function) do problema é feita com base na soma das distâncias
que cada veículo vai percorrer, onde duas funções são usadas. A primeira função, denominada função
distância, calcula a distância percorrida entre todos os pontos visitados por cada veículo. Ela retorna a
distância total percorrida, em quilômetros, pelos veículos para atender todas as solicitações de entregas e
coletas. Esta distância é calculada utilizando as informações de latitude e longitude dos pontos de coletas
e entregas que o veículo vai visitar mais aqueles de saída e chegada na STDS, em cada rota. A segunda
função, denominada de função tempo, faz uso do resultado retornado pela função distância em cada
trecho de rota e do valor da velocidade média do veículo. Com estas funções e informações, o AG é capaz
de calcular o tempo médio de viagem em cada rota para cada veículo, assim também como controlar os
horários de chegada e retorno nas entregas e coletas das solicitações, respectivamente, verificando a
viabilidade para não ultrapassar os horários da janela de tempo. A função distância calcula a distância
entre dois pontos A=(x1, y1) e B=(x2, y2) para cada trecho da rota dado por Dist(A,B)=acos(p1 .p2 + p3.p4
.p5).6371, onde p1=cos((90-x1).(π /180º)), p2=cos((90-x2).(π /180º)), p3=sen((90-x1).(π /180º)), p4=sen(
(90-x2).(π /180º)), p5=cos((y1-y2).(π /180º) e o valor 6.371 é o raio do planeta terra em quilômetros. Na
função tempo, o AG aloca cada entrega à primeira rota do primeiro veículo disponível, verificando
durante este processo, se a capacidade do veículo comporta a quantidade de passageiros a serem
transportados, se a alocação realizada obedece à regra do tempo máximo de permanência dentro do
veículo e se a janela de tempo da solicitação é viável para atender aquela solicitação. Isto acontece sempre
observando a ordem que os veículos se encontram na permutação. Ainda se tratando de entregas, o AG
verifica se é possível um veículo realizar uma nova rota com as entregas que ainda não foram atendidas.
Quando não for mais possível adicionar nenhuma entrega aos veículos dispostos na permutação, o AG
passa a atuar nas coletas da mesma forma que foi feita nas entregas. Uma vez que todas as coletas e
entregas de todas as solicitações sejam alocadas, o AG avança à fase de calcular o custo daquela solução.
O AG penaliza o custo total da solução em 10.000 Km, quando se tem uma entrega ou coleta não atendida
por ela. Esta penalidade tem como objetivo informar que uma solução com valor inferior a 10.000 é
viável para o problema.
CLAIO-2016
878

c) O AG proposto tem uma população inicial com 10 (NPop) indivíduos, cujas permutações do
conjunto M de veículos são construídas da seguinte forma: 1ª permutação – Os veículos são ordenados
de forma decrescente baseados em suas capacidades de passageiros; 2ª permutação – Inverte a ordem da
primeira permutação, ou seja, os veículos são ordenados de forma crescente de suas capacidades; 3ª permutação – Altera a ordem dos elementos da primeira permutação 1 a 1, simetricamente, começando
pelo veículo de maior capacidade; 4ª permutação – Altera a ordem dos elementos da primeira
permutação 1 a 1, simetricamente, começando pelo veículo de menor capacidade; 5ª permutação –
Altera a ordem dos elementos da primeira permutação 1 a 1, simetricamente, começando pelo elemento
central da primeira permutação, com o segundo elemento sendo aquele adjacente a direita do elemento
central; 6ª permutação – Altera a ordem dos elementos da primeira permutação 1 a 1, simetricamente,
começando pelo elemento central da primeira permutação, com o segundo elemento sendo aquele
adjacente a esquerda do elemento central; 7ª permutação – Altera a ordem dos elementos da sexta
permutação 1 a 1, simetricamente, começando pelo primeiro elemento dela; 8ª permutação – Altera a
ordem dos elementos da sexta permutação 1 a 1, simetricamente, começando pelo último elemento dela;
9ª permutação – Altera a ordem dos elementos da sexta permutação 1 a 1, simetricamente, começando
pelo elemento central, com o segundo elemento sendo aquele adjacente a direita do elemento central; e
10ª permutação – Altera a ordem dos elementos da sexta permutação 1 a 1, simetricamente, começando
pelo elemento central, com o segundo elemento sendo aquele adjacente a esquerda do elemento central.
Exemplificando, se m=10 e a 1ª permutação é [1 2 3 4 5 6 7 8 9 10], então a 3ª, 6ª e 9ª permutações são [1
10 2 9 3 8 4 7 5 6], [5 6 4 7 3 8 2 9 1 10] e [3 8 7 2 4 9 6 1 5 10], respectivamente..
d) A Seleção para cruzamento e mutação será feita com todos os indivíduos da população.
e) O cruzamento será feito entre todos os indivíduos da população, dando 45 cruzamentos (combinação de
10 dois a dois). Quatro operadores de cruzamento foram usados no nosso AG: order crossover com um
ponto de corte (1P), order crossover com dois pontos de corte (2P) e partially mapped crossover (PM).
Os operadores 1P, 2P e PM são bastante conhecidos e usados na computação evolucionária e podem ser
encontrados detalhadamente em [13] e [14]. Os dois pontos de corte usados em 2P e PM são dados por
c1=m/3+1 e c2=2×m/3 + 1. O ponto de corte usado em 1P é dado por c1=m/2. O Operador Mutação
a ser utilizado neste AG é um procedimento que permutará todas as trocas possíveis de quatro posições do
cromossomo. Seja R o número de subconjuntos distintos de M={1, 2, 3, ..., m} com quatro elementos
distintos. Assim, o operador mutação vai gerar 10×23×R soluções, pois para cada cromossomo da
população tem-se a geração de 23 (4!-1) novas permutações geradas para um subconjunto de M com
quatro elementos distintos.
f) A estratégia geracional proposta para o nosso AG é substituir integralmente todos os
indivíduos da população pelos melhores indivíduos encontrados no operador mutação e cruzamento, com
isso pretende-se diversificar e intensificar mais ainda a busca pela solução ótima do problema.
g) Inicialmente o critério de parada usava o limite de valores propostos para três variáveis:
número de iterações do algoritmo, tempo máximo de execução e a média dos fitness das soluções da
população. Depois das análises feitas com os testes de execução do algoritmo com vários problemas da
literatura, verificou-se que nunca o algoritmo parou para os valores das duas primeiras variáveis: número
de iterações do algoritmo no máximo igual a m e tempo máximo de execução limitado a uma hora. Para a
terceira variável foi usado o valor médio na função objetivo das 10 soluções da população atual e
comparado com o valor médio da população imediatamente anterior, quando estes valores forem iguais,
em pelo menos 2 iterações seguidas o algoritmo pára e apresenta a melhor solução encontrada como
solução do problema. Com isto evitamos avaliações de soluções que podem ser distintas, mas que tiveram
o mesmo desempenho de soluções similares, muitas vezes estas soluções são repetidas, foi o que se
constatou nos experimentos. Isso evitou o desgaste no tempo de execução.
h) A última etapa de um AG é a calibração dos valores dos seus parâmetros, como tamanho da
população, taxa de crossover, entre outras. Os parâmetros de um AG interagem entre si de forma não-
CLAIO-2016
879
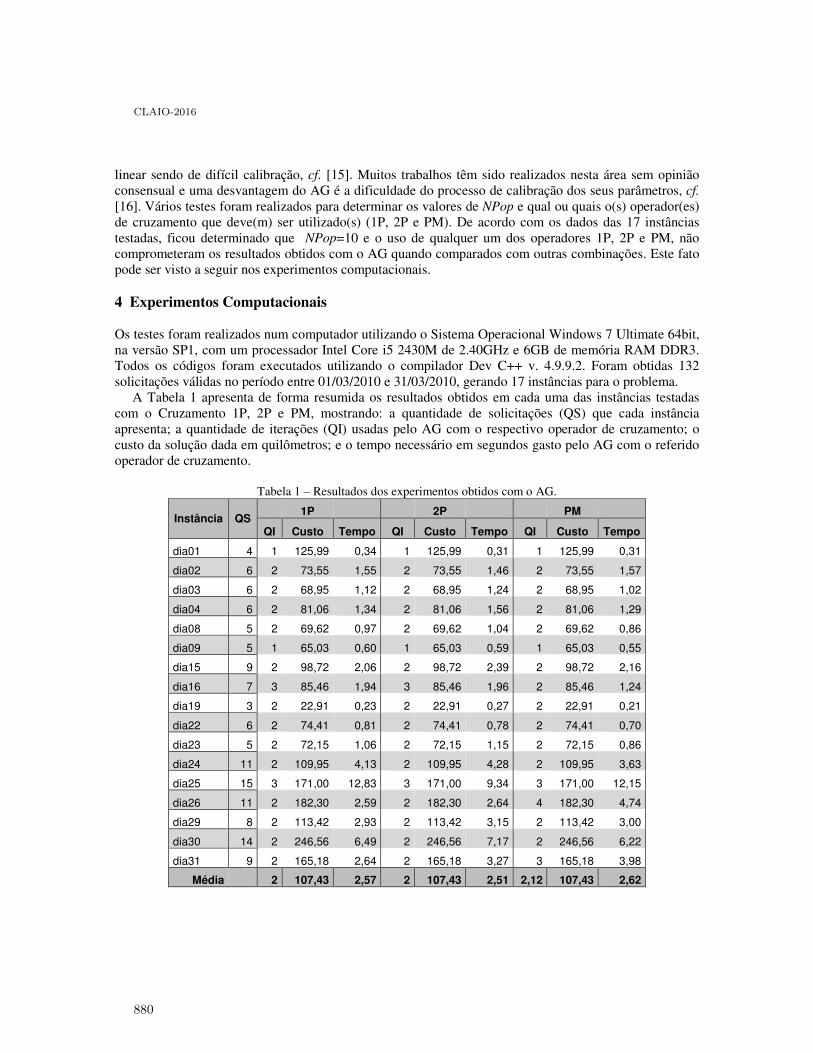
linear sendo de difícil calibração, cf. [15]. Muitos trabalhos têm sido realizados nesta área sem opinião
consensual e uma desvantagem do AG é a dificuldade do processo de calibração dos seus parâmetros, cf.
[16]. Vários testes foram realizados para determinar os valores de NPop e qual ou quais o(s) operador(es)
de cruzamento que deve(m) ser utilizado(s) (1P, 2P e PM). De acordo com os dados das 17 instâncias
testadas, ficou determinado que NPop=10 e o uso de qualquer um dos operadores 1P, 2P e PM, não
comprometeram os resultados obtidos com o AG quando comparados com outras combinações. Este fato
pode ser visto a seguir nos experimentos computacionais.
4 Experimentos Computacionais
Os testes foram realizados num computador utilizando o Sistema Operacional Windows 7 Ultimate 64bit,
na versão SP1, com um processador Intel Core i5 2430M de 2.40GHz e 6GB de memória RAM DDR3.
Todos os códigos foram executados utilizando o compilador Dev C++ v. 4.9.9.2. Foram obtidas 132
solicitações válidas no período entre 01/03/2010 e 31/03/2010, gerando 17 instâncias para o problema.
A Tabela 1 apresenta de forma resumida os resultados obtidos em cada uma das instâncias testadas
com o Cruzamento 1P, 2P e PM, mostrando: a quantidade de solicitações (QS) que cada instância
apresenta; a quantidade de iterações (QI) usadas pelo AG com o respectivo operador de cruzamento; o
custo da solução dada em quilômetros; e o tempo necessário em segundos gasto pelo AG com o referido
operador de cruzamento.
Tabela 1 – Resultados dos experimentos obtidos com o AG.
Instância QS 1P 2P PM
QI Custo Tempo QI Custo Tempo QI Custo Tempo
dia01 4 1 125,99 0,34 1 125,99 0,31 1 125,99 0,31
dia02 6 2 73,55 1,55 2 73,55 1,46 2 73,55 1,57
dia03 6 2 68,95 1,12 2 68,95 1,24 2 68,95 1,02
dia04 6 2 81,06 1,34 2 81,06 1,56 2 81,06 1,29
dia08 5 2 69,62 0,97 2 69,62 1,04 2 69,62 0,86
dia09 5 1 65,03 0,60 1 65,03 0,59 1 65,03 0,55
dia15 9 2 98,72 2,06 2 98,72 2,39 2 98,72 2,16
dia16 7 3 85,46 1,94 3 85,46 1,96 2 85,46 1,24
dia19 3 2 22,91 0,23 2 22,91 0,27 2 22,91 0,21
dia22 6 2 74,41 0,81 2 74,41 0,78 2 74,41 0,70
dia23 5 2 72,15 1,06 2 72,15 1,15 2 72,15 0,86
dia24 11 2 109,95 4,13 2 109,95 4,28 2 109,95 3,63
dia25 15 3 171,00 12,83 3 171,00 9,34 3 171,00 12,15
dia26 11 2 182,30 2,59 2 182,30 2,64 4 182,30 4,74
dia29 8 2 113,42 2,93 2 113,42 3,15 2 113,42 3,00
dia30 14 2 246,56 6,49 2 246,56 7,17 2 246,56 6,22
dia31 9 2 165,18 2,64 2 165,18 3,27 3 165,18 3,98
Média 2 107,43 2,57 2 107,43 2,51 2,12 107,43 2,62
CLAIO-2016
880

De maneira geral, diferenças significativas não houveram entre os resultados obtidos com o AG
quando aplicado a cada operador de cruzamento individualmente, praticamente quase todos os resultados
foram idênticos. Há, no entanto, pequenas diferenças nos tempos de execuções. Percebe-se que, em
média, o AG gastou menos de 3 segundos com qualquer operador de cruzamento. O AG com 1P e 2P
usou 2 iterações em média, enquanto PM usou 2,12. Na quantidade de iterações, 1P e 2P tiveram
resultados iguais, enquanto comparando-se 1P e 2P com PM, houveram pequenas diferenças nas mesmas
instâncias nos dias 16, 23 e 31/03/2010.
Analisando os resultados obtidos para o estudo de caso, vê-se que foram atendidas as 132 solicitações
de visitas com uma quantidade total de 188 passageiros transportados para entregas e coletas em horários
distintos. Para todas as instâncias a mesma frota foi disponibilizada, composta de 7 veículos: sendo cinco
deles com capacidade para quatro passageiros; e dois com capacidade para oito passageiros. No relatório
de solicitações de visitas praticadas pela STDS constatou-se que 25 das 132 solicitações não foram
atendidas e 23 solicitações não tem indicação se foram ou não atendidas.
A frota de sete veículos utilizada para os cálculos do AG, apesar de menor que a frota real da STDS,
foi suficiente para suprir todas as solicitações de visitas apresentadas. Isto significa dizer que pelo menos
18,94% das visitas deixaram de ser realizadas neste período (considerando somente as que têm a
marcação “não atendida”), e estas poderiam ter sido realizadas caso fosse utilizado o procedimento AG,
como uma ferramenta automatizada para tratar este assunto.
Vale ressaltar que das 17 instâncias concebidas, apenas a instância relativa ao dia 26/03/2010 fez uso
de todos os sete veículos disponibilizados. Todas as demais instâncias conseguiram atender a todas as
solicitações utilizando-se de seis ou menos veículos, mais um resultado importante obtido com o AG.
5 Conclusões
O principal objetivo deste trabalho foi alcançado através da utilização de um Algoritmo Genético para a
resolução de um problema logístico de roteirização de veículos. O AG utilizado neste trabalho mostrou
ser capaz de fornecer em tempo hábil e com poucos recursos computacionais, uma solução viável para o
problema, apresentando soluções de baixo custo e que foram capazes de atender na totalidade as
solicitações de visitas, mostrando assim ser uma alternativa mais eficiente que o método manual utilizado
pela instituição estudada (STDS).
Este trabalho conseguiu também apresentar os conceitos relativos ao PRV, mostrando suas
características, restrições, formulação matemática, aplicações, métodos de abordagens e como este
problema da Pesquisa Operacional pode ser utilizado enquanto ferramenta para a resolução de problemas
logísticos. Por ser um campo de grande relevância tanto acadêmica como comercial, o estudo do PRV
está em evidência e mostra-se ser um campo de estudo em expansão, com novos problemas surgindo para
suprir as necessidades da logística atual, a exemplo do problema estudado neste trabalho.
O Algoritmo Genético utilizado durante este trabalho foi elaborado especificamente para a
resolução do problema abordado. O algoritmo foi desenvolvido, implementado, testado e validado em
várias instâncias, com diferentes operadores de cruzamento obtendo resultados satisfatórios de baixo
custo e em tempo hábil, sendo capaz de indicar um modo mais eficiente para a utilização da frota da
instituição que serviu de base para o estudo.
5.1 – Recomendações para Trabalhos Futuros O presente trabalho teve seu foco na elaboração de um Algoritmo Genético que buscou
solucionar um problema logístico de utilização eficiente de frota. Considerando a grande relevância deste
problema tanto no âmbito acadêmico como no comercial, seguem abaixo algumas recomendações para os
futuros trabalhos sobre roteirização de veículos:
a) Utilização de outros operadores de mutação e cruzamento para o AG proposto;
CLAIO-2016
881

b) Utilização de outras meta-heurísticas na resolução do problema específico.
Referências Bibliográficas
1. C. B. Cunha. Aspectos práticos da aplicação de modelos de roteirização de veículos a problemas reais, Revista
Transportes da ANPET, 8(2):51-74, 2000.
2. J. U. Campelo Júnior. Proposta de otimização da roteirização dos distritos dos carteiros: Um estudo de caso no
centro de entrega de encomendas de Fortaleza. Universidade Federal do Ceará, Dissertação Mestrado em
Logística e Pesquisa Operacional, 2010.
3. R. F. S. Gomes. Aplicação da Meta-Heurística Tabu Search na otimização de rotas de manutenção preventiva
em campo. Universidade Federal do Ceará, Dissertação Mestrado em Logística e Pesquisa Operacional, 2011.
4. F. P. Bezerra. Um algoritmo genético aplicado no problema da roteirização periódica de veículos com caso
prático. Universidade Federal do Ceará, Dissertação Mestrado em Logística e Pesquisa Operacional, 2012.
5. A. Hoff , H. Andersson, M. Christiansen, G. Hasle and A. Lokketagen. Industrial aspects and literature survey:
fleet composition and routing. Computers and Operations Research, 37:2041-2061, 2010.
6. F. H. Liu and S. Y. Shen. The fleet size and mix vehicle routing problem with time windows. Journal of
Operational Research Society, 50, 721–732, 1999.
7. M. Dell’Amico, M. Monaci, C. Pagani and D. Vigo. Heuristic Approaches for the Fleet Size and Mix Vehicle
Routing Problem with Time Windows. Transportation Science, 41:516–526, 2007.
8. W. Dullaert, G. K. Janssens, K.Söerensen and B. Vernimmen. New heuristics for the fleet size and mix vehicle
routing problem with time windows. Jornal of the Operational Research Society, 53:1232–1238, 2002.
9. S. Bassi. Pesquisa operacional aplicada à área de logística de transportes rodoviários em projetos de grande
porte. Trabalho de Formatura - Escola Politécnica, USP, São Paulo, 2009.
10. J. L. V. Manguino e D. P. Ronconi. Problema de Roteamento de Veículos com Frota Mista, Janela de Tempo e
custos escalonados. Anais do CLAIO, pp. 1718-1729, 2012.
11. J. H. Holland. Adaptation in natural artificial systems. University of Michigan, Michigan, 1975.
12. J. R. Koza. Genetic Programming: On the Programming of Computers by Means of Natural Selection.
Cambrige, MIT Press, 1992.
13. D. E. Goldberg. Genetic Algorithms in Search, Optimization, and Machine Learning. Addison Wesley,
Reading, MA, 1989.
14. C. R. Reeves, C. R. Modern heuristic techniques for combinatorial problems. Berkshire: McGrawHill Book
Company, 1993.
15. M. Mitchell. An introduction to genetic algorithms. Cambridge, MIT Press, 1998.
16. R. Ruiz, C. Maroto and J. Alcaraz. Two newrobust genetic algorithms for the flowshop scheduling problem.
The International Journal the Management Science (Omega), 34:461-476, 2006.
CLAIO-2016
882

Optimal Inventory in Bike Sharing Systems
Fernanda Sottil de Aguinaga†
Adrián Ramírez Nafarrate*
Luis A. Moncayo Martínez‡
Instituto Tecnológico Autónomo de México
Department of Industrial & Operations Engineering
Mexico City. MEXICO. 01080 †
[email protected], * [email protected],
Abstract
Bike sharing systems allow people to take and later return a bicycle at one of many stations scattered
around the city. Users naturally imbalance the system by creating demands in a highly asymmetric
pattern. In order for bike sharing systems to meet the fluctuating demand for bicycles and parking docks,
inventory optimization among stations is crucial. In this paper, we model a subset of stations of the bike
sharing system in Mexico City (ECOBICI) using discrete-event simulation and we evaluate different
heuristics for the initial allocation of bicycles. In addition, we compare those heuristics with a simulation-
optimization method to assess the optimal number of bicycles that should be placed at each station during
the rush-hour period to enable the system to comply with ECOBICI’s operational requirement. The
results show that simulation-optimization method outperforms other heuristics.
Keywords: Bike-Sharing Systems (BSS); inventory optimization; discrete-event simulation.
1 Introduction In recent years, bicycles have dramatically increased their popularity because they provide an affordable,
efficient, sustainable and healthy means for urban transportation. In the past five years, more than 500
cities around the world have implemented Bike-Sharing Systems (BSS) as a key urban mobility system,
including Mexico City, Sao Paulo, Buenos Aires and Santiago [Larsen, 2013]. Those are cities with
favorable geospatial conditions where short cycling trips usually complement longer ones taken through
other transportation modes. The advantages provided by BSS makes it a very attractive alternative for
large cities in developing countries, where public transportation is usually insufficient and inefficient.
Regardless the multiple benefits of BSS, resource unavailability (bicycles or parking docks) across
stations and throughout the day can be an important cause of user insatisfaction and an incentive to cease
its use. In this paper, we present a simulation-based methodology and preliminary results to optimize the
inventory of bicycles across stations for achieving a desired service level. The content of this paper is part
of an ongoing project to model and optimize re-balancing operations in BSS. In particular, this paper
focuses on the study of Mexico City´s BSS, called ECOBICI.
ECOBICI started operations in 2010 with only 85 stations. In five years, ECOBICI has increased its
capacity to 446 stations, 6000 bicycles and 12000 parking docks that provide service to more than 100000
users [ECOBICI, 2016]. It is the third largest BSS in the world (after Paris and London) in terms of size
(numbers of bicycles and stations) and it has one of the best services worldwide. However, some users
still complain about the lack of resources. For instance, 21% of users complain about bicycle or locker
shortage during rush hours [Encuesta ECOBICI, 2014].
CLAIO-2016
883

Few papers have been published analyzing BSS. For instance, O´Mahony and Shmoys [2015] proposed a
methodology to analyze bicycle demand and optimize the rebalancing operations in New York´s BSS
(CitiBike). The rebalancing problem consists on determining the number of bicycles to move from one
station to another throughout the day. In the proposed methodology, the authors first analyze the demand
to classify each station into one out of three categories based on the net flow of bicycles: consumers
(show a high demand of bicycles), producers (accumulate bicycles) or self-balancing (net flow near to
zero). Then, they formulate an integer programming model to rebalance the stations during the rush hours
and design an operational strategy to ensure that each user is able to find an available bicycle or dock
within a reasonable distance from the final destination. In addition, the authors proposed another mixed
integer programming model and a vehicle routing heuristic to rebalance the stations overnight.
Schuijbroek et al. [2013] propose a two-stage heuristic to define clusters of stations and determine the
balancing route of the vehicle that transports bicycles to minimize transportation cost and satisfy pre-
defined service levels. The authors test the heuristic with data of the BSS from Boston (Hubway) and
Washington, D.C. (Capital Bikeshare). Similarly, Chemla et al. [2013] model the rebalancing problem
using a mixed integer program that combines constraints of the traveling salesman problem with
operational constraints (vehicle capacity). Given that the problem is NP-hard, the authors propose some
heuristics and constraint relaxations to find effective solutions.
In this paper, we do not solve the rebalancing problem yet, but we tackle the precedent problem of
determining the optimal number of bicycles across stations to satisfy a pre-defined service level. In
Section 2 we present the problem definition and the framework to model a BSS. Section 3 analyzes the
demand of ECOBICI system and classifies the stations into three profiles depending on the net flow of
bicycles. Section 4 presents the results of the simulation-optimization methodology to optimize bicycle
inventory. Finally, Section 5 presents the concluding remarks and discusses extensions to this work.
2 Problem Definition In a BSS, each station is a demand point where customers arrive searching for one of two products:
bicycles or parking docks. The demand of one product reduces its availability (decrease of inventory) but
it also increases the availability of the other product. Thus, if users demand bicycles from one particular
station, the number of bicycles in that station may decrease up to zero (no bicycles in inventory) and the
number of parking docks will increase up to its maximum level.
Let station i have a capacity of Ci docks to store bicycles. Then, the dynamic of demand for bicycles and
parking docks can be represented by the transition diagram shown in Figure 1.
Figure 1. Transition diagram showing demand of bicycles and parking docks in a station.
where the state of the station Si = {0, 1, 2, …, Ci} represents the number of available docks to return a
bicycle, i(t) is the arrival rate of users searching for a bicycle in station i at time t and i(t) is the arrival
rate of users searching for a parking dock to return a bicycle in station i at time t. Then, one way to
CLAIO-2016
884

evaluate the service level in station i is to compute the probability (or fraction of the time) that station i is
completely full of bicycles or empty, P(Si=0) and P(Si=Ci), respectively. The arrival rate of users
searching for a parking dock in station i depends on the probability that a user takes a bicycle on any
station of the system (including station i) and travels to station i to return it. Figure 2 shows this
probability in a BSS with N stations. In this figure, pij is the probability of taking a bicycle in station i and
returning it in station j. Therefore, for all i, ∑ .
Figure 2. Probability of taking and returning a bicycle in any given pair of stations of the BSS.
Solving the inventory optimization problem analytically is not trivial since 1) a BSS can comprise dozens
of stations, each of them with a different capacity Ci, 2) the arrival rates i(t) and i(t) are not stationary
since there are rush hours on the demand of bicycles and 3) the system is not steady-state since it operates
only a fraction of hours of the day (19.5 hours for ECOBICI). Therefore, we propose a simulation-based
methodology to optimize inventory in each station. Simulation models are able to capture complex
behavior of systems, including non-stationarity of arrivals.
The performance measure used in the simulation-optimization methodology proposed in this paper is the
fraction of users that find a bicycle (parking dock) in station i before T time units (tolerance), which is
defined as:
m
j
ki
j
ki TWImTQ1
,1, (1)
where i is the index of the station that belongs to the BSS, therefore i = {1,2,…N}; k = {bicycle, parking
dock}, T is the allowed tolerance to find a bicycle (parking dock), m is the total number of users that
arrive to station i searching for a bicycle (parking dock) during the simulation experiment, and I is an
indicator function that equals 1 if the waiting time of the jth user that arrives to station i searching for the
kth product is smaller than or equal to the allowed tolerance. Thus:
otherwise
TWifTWI
ki
jki
j0
1 ,
, (2)
Therefore, a single service level of the overall BSS, according to this performance measure, can be
determined by:
k i
kiBSS TQkiTQ ,1 (3)
CLAIO-2016
885

In particular, we select Maximize QBSS
(0) as the main objective of the BSS. In fact, ECOBICI has
established, as an operational parameter, that a user should be able to take (return) a bicycle without
waiting 94% of the times that he attempts to do so (i.e., shortage events must occur in less than 6% of the
cases). Furthermore, we focus on finding the optimal inventory level at the beginning of the day (t = 6am)
and analyze its effect on the service level during the morning rush hours (6am < t < 10am).
In order to analyze and optimize inventory levels in multiple stations of a BSS, we developed a discrete-
event simulation model of a subset of stations of ECOBICI system where users arrive to station i
searching for a bicycle according to a non-stationary Poisson process. When the user is able to get the
bicycle (immediately or after a waiting period) he travels to station j with probability pij. The travel time
(length of bicycle usage) is a random variable. When the user arrives to the destination, he returns the
bicycle (immediately or after a waiting period). Then, the user leaves the system.
Given that the problem is very large even using simulation, we focus on a proof-of-concept model that
includes a small subset of stations (e.g. 22 stations). However, due to usage patterns in the whole system
and how they affect the BSS performance, it is not possible to analyze these stations as a closed system.
Therefore, we consolidated the remaining stations (e.g. 424) in a single station.
The simulation model is developed in Simio Simulation Software [Simio, 2016] which includes an
optimization tool called OptQuest [OptQuest, 2016]. OptQuest is based on optimization algorithms that
include Tabu Search, Neural Networks, Scatter Search and Linear/Integer Programming to generate and
evaluate scenarios in search for optimal system configurations. The optimal values of Bi(t) obtained
through OptQuest were compared with the following bicycle allocation heuristics:
1) 50%: At the beginning of the day, the number of bicycles in each station is half of its installed
capacity.
2) 90%-10%-50%: This heuristic is based on the findings of O´Mahony and Shmoys [2015]. At the
beginning of the day, the fill level for each station depends on its usage profile as follows: consumer
stations are filled up to 90% of its installed capacity; producer stations are filled up to 10% of its
installed capacity; self-balancing stations are filled up to 50% of its installed capacity.
3) 0%. At the beginning of the day, all stations of the analyzed subset are empty. The station that
consolidates all the remaining stations in the system has all the bicycles. Therefore, during the
simulation, the bicycles move from the stations out of the analysis to the stations within the scope of
the analysis.
4) 100%. At the beginning of the day, all stations of the analyzed subset are full of bicycles.
3 Analysis of Demand and Classification of Stations The analysis of bicycle demand of ECOBICI is based on 26 million hourly data entries covering the years
between 2010 and 2015 [Laboratorio de Datos, 2016]. We test for several parameters in the analysis, such
as intra-weekday variations and seasonality. We identify those stations that are the most congested at both
morning and evening rush hours (the main candidates for rebalancing operations), from which we select a
sample of 22 stations with unique characteristics as the focus of our rebalancing approach.
Given that 70% of ECOBICI trips are related with daily work routines, we tested for difference in usage
patterns during weekdays (Monday-Friday). The analysis of usage patterns across weekdays and
throughout a day is based on the net flow of bicycles for each station, defined as:
tsAtsDtsF iii (4)
CLAIO-2016
886
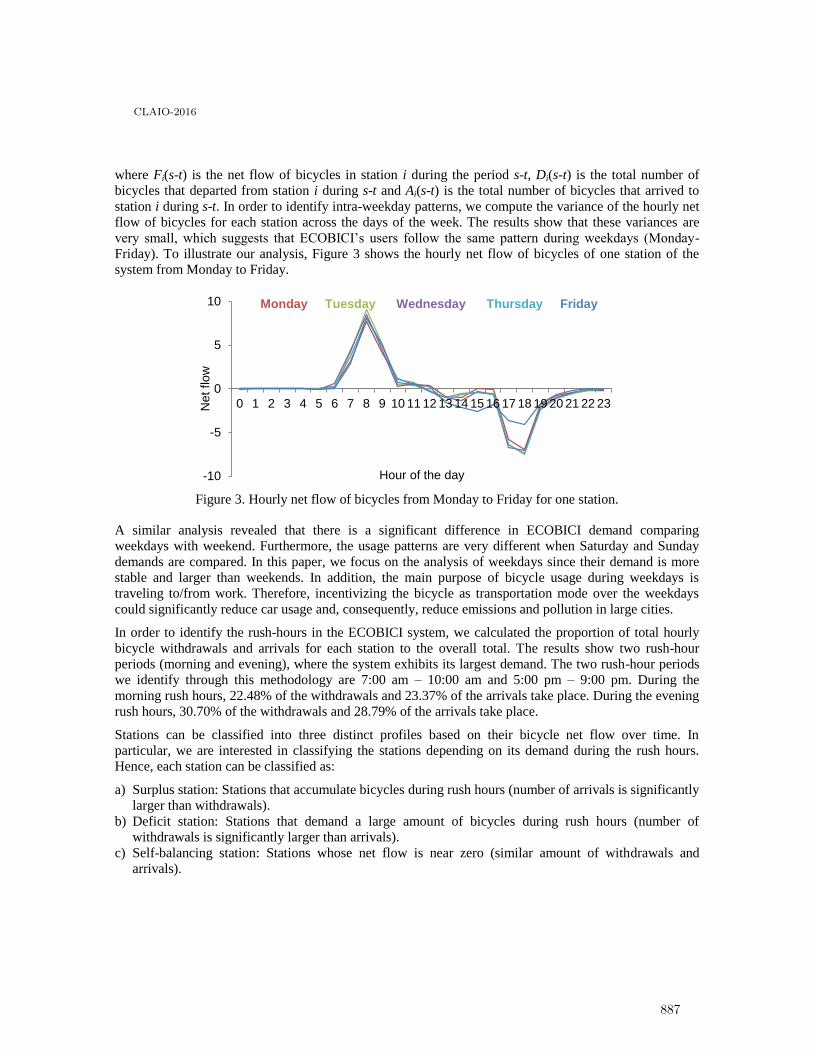
where Fi(s-t) is the net flow of bicycles in station i during the period s-t, Di(s-t) is the total number of
bicycles that departed from station i during s-t and Ai(s-t) is the total number of bicycles that arrived to
station i during s-t. In order to identify intra-weekday patterns, we compute the variance of the hourly net
flow of bicycles for each station across the days of the week. The results show that these variances are
very small, which suggests that ECOBICI’s users follow the same pattern during weekdays (Monday-
Friday). To illustrate our analysis, Figure 3 shows the hourly net flow of bicycles of one station of the
system from Monday to Friday.
Figure 3. Hourly net flow of bicycles from Monday to Friday for one station.
A similar analysis revealed that there is a significant difference in ECOBICI demand comparing
weekdays with weekend. Furthermore, the usage patterns are very different when Saturday and Sunday
demands are compared. In this paper, we focus on the analysis of weekdays since their demand is more
stable and larger than weekends. In addition, the main purpose of bicycle usage during weekdays is
traveling to/from work. Therefore, incentivizing the bicycle as transportation mode over the weekdays
could significantly reduce car usage and, consequently, reduce emissions and pollution in large cities.
In order to identify the rush-hours in the ECOBICI system, we calculated the proportion of total hourly
bicycle withdrawals and arrivals for each station to the overall total. The results show two rush-hour
periods (morning and evening), where the system exhibits its largest demand. The two rush-hour periods
we identify through this methodology are 7:00 am – 10:00 am and 5:00 pm – 9:00 pm. During the
morning rush hours, 22.48% of the withdrawals and 23.37% of the arrivals take place. During the evening
rush hours, 30.70% of the withdrawals and 28.79% of the arrivals take place.
Stations can be classified into three distinct profiles based on their bicycle net flow over time. In
particular, we are interested in classifying the stations depending on its demand during the rush hours.
Hence, each station can be classified as:
a) Surplus station: Stations that accumulate bicycles during rush hours (number of arrivals is significantly
larger than withdrawals).
b) Deficit station: Stations that demand a large amount of bicycles during rush hours (number of
withdrawals is significantly larger than arrivals).
c) Self-balancing station: Stations whose net flow is near zero (similar amount of withdrawals and
arrivals).
-10
-5
0
5
10
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23Ne
t flo
w
Hour of the day
Monday Tuesday Wednesday Thursday Friday
CLAIO-2016
887

The results of the classification provide a preliminary approach to determining where bicycles need to be
placed to anticipate user demand. In the business districts, the results suggest that there exists a mirror
behavior among the stations during the two rush hour periods within the day. This means that if a station
has a surplus of bicycles during the mornings, it will present a deficit of bicycles during the evenings and
vice versa. In this case, users finish their morning journey to their workplace using ECOBICI and thus
rapidly fill the stations that collect bicycles. To head home, they withdraw a bicycle and therefore leave
deficit stations without available bicycles. This pattern is also detected in Figure 3.
In order to build a proof-of-concept model of the system, we selected a subset of 22 neighbor stations
from the pre-identified group of stations with the largest demand. The demand within the selected stations
accounts for 11.83% of total usage in ECOBICI system and include all three types of stations among
them (surplus 41%, deficit 23% and self-balancing 36%).
4 Results As discussed in Section 2, the objective of the simulation-optimization model is to optimize the initial
inventory in each of the 22 selected stations for analysis (e.g., finding the optimal value of Bi(6am)) in
order to Maximize QBSS
(0) and determine if this value is larger than 94% (specified by ECOBICI) during
the morning rush hour.
Given that the initial inventory for each station of the subset can take any integer value between 0 and its
maximum capacity, the size of the search space of Bi(6am) for i = {1, 2,…, 22} is 4.42 x1030
. In order to
search for the optimal values in the most efficient way using OptQuest, we define the problem as a single-
objective problem (Maximize QBSS
(0)) and define a search range between zero and the maximum capacity
of each station. Each simulation experiment using Simio and OptQuest is executed for a period of four
hours (6am to 10am). Once the best scenarios are identified, additional iterations are performed using the
best values obtained for Bi(6am) in the previous step. In the next step, we create and evaluate 200
different scenarios, each with 6 replications, 95% confidence level for estimating QBSS
(0) and a relative
error of 0.1. Once the variance for the results is sufficiently small, we identify the best scenario using a
sequential procedure developed by Kim and Nelson (Simio KN).
The results of the simulation-optimization model and the initial bicycle allocation heuristics are shown in
Table 1. The results show the main objective function of the model which consists of maximizing the
fraction of overall users that are able to find an available bicycle/parking dock immediately upon arrival
(QBSS
(0)). In addition, the results show, separately, the fractions of users that are able to find an available
bicycle/parking dock and the average waiting time to take or return a bicycle. Table 1 suggests that none
of the initial allocation heuristics or the simulation-optimization method is able to reach the desired
performance level of 94%. However, the simulation-optimization method outperforms all the heuristics.
With the initial inventory determined by the simulation-optimization method, users are able to return a
bicycle immediately 100% of the times. However, only 88.4% of users can take a bicycle immediately
and the average waiting time to take a bicycle is 13.6 min. Among the heuristics, the rule based on 50%
of the capacity produces the best results. The heuristics based on full/zero capacity are the worst
evaluated. The 0% heuristic produces a relatively good performance on the time to return a bicycle, but a
poor result on the time to take a bicycle. Meanwhile, the 100% heuristic has an inverse effect on these
objectives. The performance of the heuristic proposed in O´Mahony and Shmoys [2015] is not close to
the desired performance. In the analysis of the best scenarios found by the simulation-optimization
method, the average initial inventory is set to 87.5% for deficit stations, 16.3% for surplus stations and
32.51% for self-balancing stations.
CLAIO-2016
888
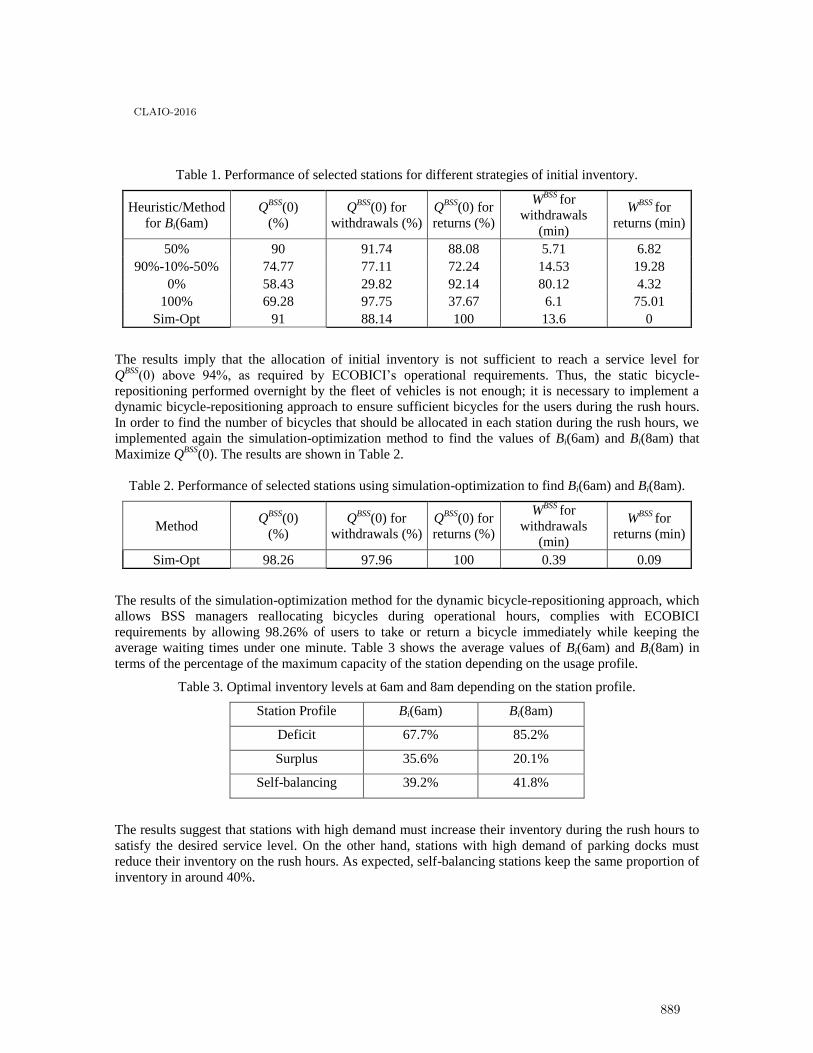
Table 1. Performance of selected stations for different strategies of initial inventory.
Heuristic/Method
for Bi(6am)
QBSS
(0)
(%)
QBSS
(0) for
withdrawals (%)
QBSS
(0) for
returns (%)
WBSS
for
withdrawals
(min)
WBSS
for
returns (min)
50% 90 91.74 88.08 5.71 6.82
90%-10%-50% 74.77 77.11 72.24 14.53 19.28
0% 58.43 29.82 92.14 80.12 4.32
100% 69.28 97.75 37.67 6.1 75.01
Sim-Opt 91 88.14 100 13.6 0
The results imply that the allocation of initial inventory is not sufficient to reach a service level for
QBSS
(0) above 94%, as required by ECOBICI’s operational requirements. Thus, the static bicycle-
repositioning performed overnight by the fleet of vehicles is not enough; it is necessary to implement a
dynamic bicycle-repositioning approach to ensure sufficient bicycles for the users during the rush hours.
In order to find the number of bicycles that should be allocated in each station during the rush hours, we
implemented again the simulation-optimization method to find the values of Bi(6am) and Bi(8am) that
Maximize QBSS
(0). The results are shown in Table 2.
Table 2. Performance of selected stations using simulation-optimization to find Bi(6am) and Bi(8am).
Method Q
BSS(0)
(%)
QBSS
(0) for
withdrawals (%)
QBSS
(0) for
returns (%)
WBSS
for
withdrawals
(min)
WBSS
for
returns (min)
Sim-Opt 98.26 97.96 100 0.39 0.09
The results of the simulation-optimization method for the dynamic bicycle-repositioning approach, which
allows BSS managers reallocating bicycles during operational hours, complies with ECOBICI
requirements by allowing 98.26% of users to take or return a bicycle immediately while keeping the
average waiting times under one minute. Table 3 shows the average values of Bi(6am) and Bi(8am) in
terms of the percentage of the maximum capacity of the station depending on the usage profile.
Table 3. Optimal inventory levels at 6am and 8am depending on the station profile.
Station Profile Bi(6am) Bi(8am)
Deficit 67.7% 85.2%
Surplus 35.6% 20.1%
Self-balancing 39.2% 41.8%
The results suggest that stations with high demand must increase their inventory during the rush hours to
satisfy the desired service level. On the other hand, stations with high demand of parking docks must
reduce their inventory on the rush hours. As expected, self-balancing stations keep the same proportion of
inventory in around 40%.
CLAIO-2016
889

5 Conclusions BSS have increased their presence around the world, including the largest cities in Latin America since
they represent an efficient alternative of public transportation. However, the willingness to make use of
them and user satisfaction depend on the availability of their resources: bicycle and parking docks.
In this paper, we evaluate several heuristics for the initial allocation of bicycles in congested stations and
compare them with the values obtained through a simulation-optimization method in order to satisfy,
immediately, at least 94% of the demand during the morning rush hour of the BSS in Mexico City. The
results show that the simulation-optimization method outperforms the other heuristics, some of them
suggested in current literature. Nevertheless, the optimization of initial inventory is not sufficient to
satisfy the desired performance during the morning rush hour. Therefore, rebalancing operations must be
carried on during operational hours. When the simulation-optimization method is applied to optimize
inventory not only at the beginning of the day, but also during the middle of the rush hour, the results
show that a large fraction of the demand is satisfied, complying with the objectives of Mexico City BSS.
Given that this paper shows the first set of experiments of a project that aims to optimize rebalancing
operations in BSS, there are multiple extensions that can be addressed, including: a) take into account
rebalancing costs into the optimization framework; b) expand the analysis to the complete BSS; c) expand
the analysis to the whole day, which experiences two rush periods and low demand hours; d) include the
capacitated vehicle routing problem in the rebalancing operations; d) analyse the rebalancing problem in
stations with macrodemand (demand significantly larger than the other stations in the BSS).
Acknowledgements We thank the support and collaboration provided by ECOBICI. This research is supported by Asociación
Mexicana de Cultura A.C. This research is supported by CONACYT through grant 2015-01-1234.
References 1. D. Chemla, F. Meunier and R.W. Calvo. Bike Sharing Systems: Solving the Static Rebalancing
Problem. Discrete Optimization 10(2):120-146, 2013.
2. ECOBICI: Sistema de Transporte Individual. 2016. Available at: https://www.ecobici.df.gob.mx/ Last
access: February 15, 2016.
3. Encuesta ECOBICI 2014. Available at:
https://www.ecobici.df.gob.mx/sites/default/files/pdf/ecobici_2014_encuesta.pdf Last Access:
February 15, 2016.
4. Laboratorio de Datos. 2016. Available at: http://datos.labplc.mx/ Last Access: February 15, 2016.
5. Larsen, J. 2013. Bike-Sharing Programs Hit the Streets in Over 500 Cities Worldwide. Earth Policy
Institute. Available at: http://www.earth-policy.org/plan_b_updates/2013/update112 Last access:
February 15, 2016.
6. E. O'Mahony and D.B. Shmoys. Data Analysis and Optimization for (Citi) Bike Sharing. In Twenty-
Ninth AAAI Conference on Artificial Intelligence. Pp: 687-694, 2015.
7. OptQuest Engine. 2016. Available at: http://www.opttek.com/OptQuest Last access: February 15,
2016.
8. Simio Simulation Software. 2016. Available at: http://www.simio.com/index.php Last access:
February 15, 2016.
9. J. Schuijbroek, R. Hampshire and W.J. Van Hoeve. Inventory Rebalancing and Vehicle Routing in
Bike Sharing Systems. Tepper School of Business. Paper 1491. Pp: 1-27, 2013.
CLAIO-2016
890

Territorial Partitioning Problem applied to Brazil Healthcare System using a Multi-objective Approach
Maria Teresinha Arns Steiner
PPGEPS-PUCPR, Curitiba, Paraná, Brasil [email protected]
Pedro José Steiner Neto
PPGAD-UP, Curitiba, Paraná, Brasil [email protected]
Datta Dilip
Tezpur University, Tezpur, Indial [email protected]
José Rui Figueira
IST de Lisboa, Portugal [email protected]
Cassius Tadeu Scarpin
PPGMNE-UFPR, Curitiba, Paraná, Brasil [email protected]
Abstract Under the broad name of a territorial or network districting or partitioning problem, this article proposes aggregating the health services of the municipalities of Parana State in Brazil into partitions called microregions to form a map and facilitate the inter-microregion flow of patients for procedures not offered in their own microregions. The problem is formulated as a multi-objective partitioning of the nodes of an undirected graph/network with the districts and towns as the nodes and the roads connecting them as the edges of this graph. Three objective functions are considered: maximizing the homogeneity of population size, maximizing the variety of the medical procedures offered, and minimizing the distances to be traveled between microregions. A binary-coded multi-objective genetic algorithm is taken as the optimization tool, which yields a significant improvement to the existing healthcare system map of Parana. The results obtained may have a strong impact on healthcare system management in Parana. The model proposed in this paper can be considered a useful tool to aid health management decision-making, and can be implemented for better organization of any healthcare system, including those of other Brazilian states. Keywords: Health service; Healthcare system; graph/network partitioning; multi-objective optimization; genetic algorithm.
CLAIO-2016
891

1 Introduction
One of the challenges of logistics is to provide products/services where and when they are needed. A bottom line task in logistic handling is to structure systems or distribution configurations so that markets away from production sources can be served in an optimized way or services can be provided in as short time as possible (Ballou, 2004). In this light, the healthcare system of Parana State in Southern Brazil is studied here.
Parana has a population close to 11 million inhabitants, and is divided into 399 municipalities. In the
case of health services in Parana State, funds are transferred from the Federal and State authorities to local units based on population size and variety as well as the number of health procedures expected to be performed. There is a proposal for decentralization of the healthcare services of Parana by combining its municipalities into smaller groups, known as microregions, where the majority of health procedures should be offered so as to reduce the number of inter-microregion trips and the distances that patients have to travel (Brasil, 2004).
For this purpose, Parana State is first transformed into an undirected graph/network with its
municipalities as the nodes and connecting roads of the municipalities as the edges of the network. The network is then partitioned into some non-empty zones, each zone representing a microregion, so as to “optimize” three objectives subject to five constraints. The first objective is population homogeneity in the microregions, which would ease the distribution of facilities and funds. The second is the maximization of the variety of medical procedures offered within a microregion so that precious time and money can be saved by reducing the need to send patients from one microregion to another. The third objective is the minimization of the distances that patients have to travel between microregions.
During the partitioning optimization process, care is taken to maintain the integrity of the
municipalities by avoiding the inclusion of the same municipality in multiple microregions and to maintain the contiguity of a microregion by forming it with inter-connected municipalities only. Care is also taken to avoid the complete embedding (avoiding the presence of “holes”) of a microregion by another and to maintain the number of municipalities in a microregion within a given range. Finally, every effort is made to maintain the number of microregions within another given range. These five requirements are treated as the five hard constraints of the problem. A binary-coded multi-objective genetic algorithm (Datta et al., 2013) is adapted and employed as the optimization tool for the problem. In the experimental part, a potential best compromise scenario is presented by comparing the results of the genetic algorithm with the existing healthcare system map, partitioning the 399 municipalities into 83 microregions.
The rest of the paper is organized as follows. Section 2 presents problem formulation and describing
the methodology used in this work. Section 3 presents the results and managerial implications. The paper is concluded in Section 4. 2 Problem Formulation In this section we present some basic and introductory concepts, the problem formulation, and a method for its solution. It is assumed that the desired number of microregions within the territory of interest (Parana State) is 83, for the purpose of comparison with the current partitioning. Therefore, the task is to divide the state by separately grouping its 399 municipalities (nodes) into 83 nonempty and disjointed microregions forming thus a territory partition. We are interested in the set of feasible partitions
CLAIO-2016
892

of the network to satisfy several constraints regarding integrity, contiguity, embedding (also called absence of holes), the size of a microregion and number of microregions, as mentioned in Section 1. Next we define our network model with three-objective functions and five constraints for the problem. Parameters:
399=V : is the number of municipalities;
83=K : is the number of microregions;
hi: is the number of inhabitants in vi, i = 1, 2, …, V ;
ai: is the number of medical procedures in vi, i = 1, 2, …, V ;
d(vi, vj): is the distance between the municipalities vi and vj, i, j = 1, 2, …, V .
Variables:
==
=otherwise 0,
K ..., 2, 1, ;V; ..., 2, 1, ,n microregio the tobelongs ty municipali if ,1 liVvx
lil
i
Objective Functions: 1. Homogenize the number of inhabitants in each one of 83 microregions. We can achieve this by minimizing the microregion deviation of the inhabitants from their microregion average value, as shown in equation (1).
Minimize ∑∑= =
−=K
l
lii Hxh
Kxz
1
V
1i1
1)( (1)
where ∑=
=V
iih
KH
1
1is the average number of inhabitants per microregion. There is a need to divide the
equation (1) by “K” in order to minimize the per microregion average deviations. 2. Maximize the number of medical procedures per microregion. We can achieve this objective by maximizing the number of different medical procedures per microregion, assigning to each micro-region the maximum number among the municipalities belonging to it, as shown in equation (2).
Maximize }{max1
)(1
V ..., ,12
lii
K
li
xaK
xz ∑= =
≡ (2)
At this point it is very important to stress that we should consider the variety of different medical procedures and not the amount performed. As there are around 6,000 different medical procedures, many of them considered low complexity, it should be very important to offer a wide range of services in each microregion. When a procedure is not offered in a microregion, the patient has to be transported to another microregion, which affects time and cost. We have to emphasize that we do not have the information of which procedures are been offered by each municipality, just the number of different procedures. As a proxy, we used the number of procedures by the municipality with the highest number within a microregion as the number of procedures for the microregion. The reason for that is that basic procedures are offered on every health unit, and as the complexity of a procedure increases, the fewer health units will offer it. Therefore, every procedure offered within a microregion should at least be
CLAIO-2016
893

offered in the unit with the highest number of procedures. 3. Minimize the distance within each of the 83 microregions. This can be done as shown in Equation (3).
{ }∑ ∑= =
=====
K
l
V
i
lj
lijii KlVjxxvvdhxz
1 13 ,...,1;,...,1;1;0);,(min)( Minimize
(3)
where, if li
li Vvx ∉⇒= 0 and if l
jlj Vvx ∈⇒= 1 . In a very simple way, we can say that Equation (3)
models the minimum weighted sum from all vertices vi )( li Vv ∉ to all the vertices vj )( l
j Vv ∈ . This
objective function is adapted from Teitz & Bart (1968), who presented a formulation for the p-medians problem.
The method for solving this problem was based on the one used in Datta et al. (2012), which is a binary-coded multi-objective GA for partitioning a geographical territory into a given number of zones, requiring adaptations and reprogramming for handling the concerning problem. The main adjustment was the adaptation for the three objective functions (1)-(3) as presented above. 3 Results As there was a need to define several GA parameters in the computer software, close to 50 trial runs were performed in order to calibrate the algorithm parameters. After the results were scrutinized, the following parameters were set: random seed = 0.03; crossover probability = 0.9; mutation probability = 0.05 and distribution index = 20 (Datta & Figueira, 2013). With these values, there was a final run, this time with a population of 1,000 solutions and 10,000 generations. This run time was 75h15min. The variation of the number of non-dominated solutions on each generation, after the first 20, varied within the range [88,100], and at the final generation, there were 92 non-dominated solutions. In Table 1, objective function values for five solutions are presented, showing the minimum values obtained for objective functions 1 and 3 and the maximum value for objective function 2 (bold characters), a compromise solution and the current solution.
At this point additional input was provided by heath authorities, helping to reduce the set of feasible solutions and establishing a method for obtaining a compromise solution. It is important to mention that any non-dominant solution presented could be used. The solution presented as the compromise solution was chosen based on the input about preference information received form the managers.
The compromise solution secures good values for every objective, whilst none of them is the best
possible for a given objective, as they are conflicting. As any objective is important, the compromise solution should balance every one and bring the best overall result based on an ad hoc analysis. We have to say that we didn’t use a systematic interactive procedure, since in this case it was not necessary given the preference information by the managers only a simple, called ad hoc, procedure was necessary.
All the solutions presented in Table 1 are better than the current solution. By comparing the current and compromise solutions, the following improvements can be seen for each objective function: z1 23.54% reduction, z2 7.83% increase; z3 7.12% reduction.
CLAIO-2016
894
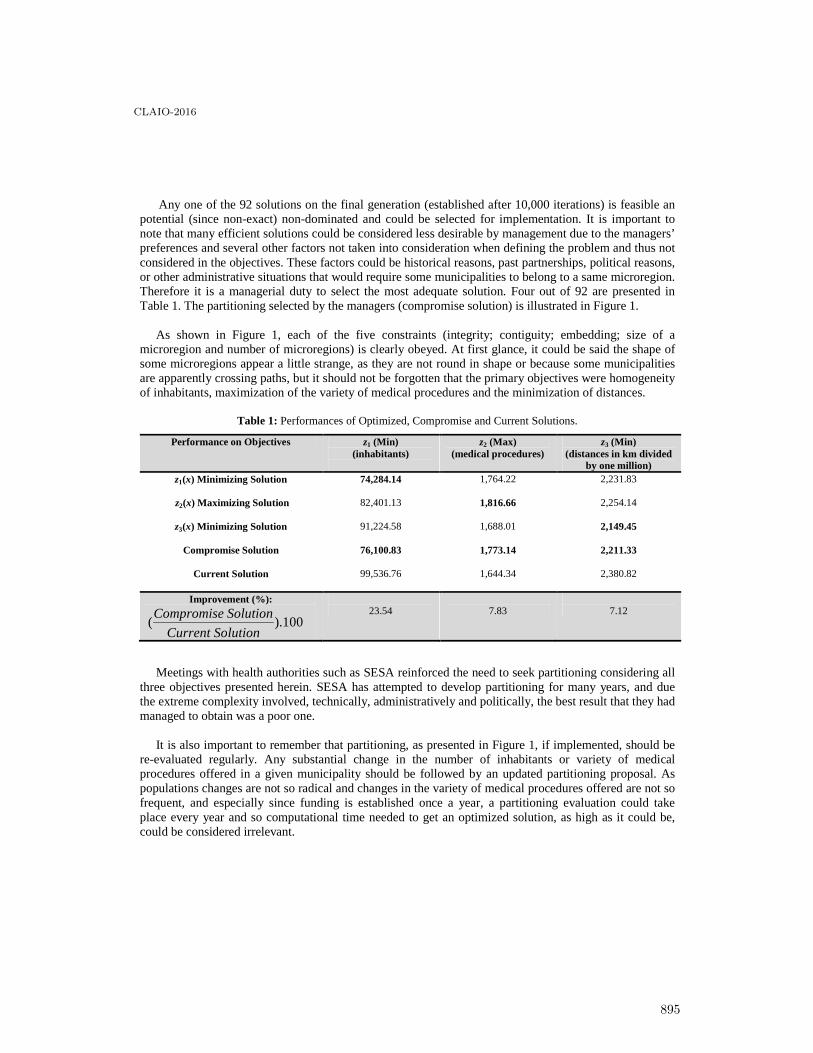
Any one of the 92 solutions on the final generation (established after 10,000 iterations) is feasible an potential (since non-exact) non-dominated and could be selected for implementation. It is important to note that many efficient solutions could be considered less desirable by management due to the managers’ preferences and several other factors not taken into consideration when defining the problem and thus not considered in the objectives. These factors could be historical reasons, past partnerships, political reasons, or other administrative situations that would require some municipalities to belong to a same microregion. Therefore it is a managerial duty to select the most adequate solution. Four out of 92 are presented in Table 1. The partitioning selected by the managers (compromise solution) is illustrated in Figure 1.
As shown in Figure 1, each of the five constraints (integrity; contiguity; embedding; size of a microregion and number of microregions) is clearly obeyed. At first glance, it could be said the shape of some microregions appear a little strange, as they are not round in shape or because some municipalities are apparently crossing paths, but it should not be forgotten that the primary objectives were homogeneity of inhabitants, maximization of the variety of medical procedures and the minimization of distances.
Table 1: Performances of Optimized, Compromise and Current Solutions.
Performance on Objectives z1 (Min) (inhabitants)
z2 (Max) (medical procedures)
z3 (Min) (distances in km divided
by one million) z1(x) Minimizing Solution
74,284.14 1,764.22 2,231.83
z2(x) Maximizing Solution
82,401.13 1,816.66 2,254.14
z3(x) Minimizing Solution
91,224.58 1,688.01 2,149.45
Compromise Solution
76,100.83 1,773.14 2,211.33
Current Solution
99,536.76 1,644.34 2,380.82
Improvement (%):
100).
(lutionCurrent So
SolutionCompromise
23.54
7.83
7.12
Meetings with health authorities such as SESA reinforced the need to seek partitioning considering all three objectives presented herein. SESA has attempted to develop partitioning for many years, and due the extreme complexity involved, technically, administratively and politically, the best result that they had managed to obtain was a poor one.
It is also important to remember that partitioning, as presented in Figure 1, if implemented, should be
re-evaluated regularly. Any substantial change in the number of inhabitants or variety of medical procedures offered in a given municipality should be followed by an updated partitioning proposal. As populations changes are not so radical and changes in the variety of medical procedures offered are not so frequent, and especially since funding is established once a year, a partitioning evaluation could take place every year and so computational time needed to get an optimized solution, as high as it could be, could be considered irrelevant.
CLAIO-2016
895

4 Conclusions
In this paper an application has been presented for a multi-objective optimization approach dealing with a real-world spatial problem of aggregating municipalities in order to form microregions in Parana State, Brazil. Partitioning is needed for better management and for better health services, especially since most SUS patients cannot pay for alternative providers. This paper proposes partitioning Parana State, with its 11 million inhabitants and 399 municipalities 83 microregions to improve the public health system.
As there are currently 83 microregions, in order to compare results better, this number of microregions
was maintained. The proposed approach involved the formulation of three different objective functions in relation to each microregion (homogenizing its population size; maximizing the variety of medical procedures on offer and minimizing the distances between its municipalities. Five constraints for the problem were also considered (integrity; contiguity; embedding; size of a microregion and number of microregions). The solution was obtained through the use of a binary-coded three-objective GA. Four of the 92 solutions are presented in Table 1 and are compared with the one that is currently in place. Any of the four solutions would present better values for every single objective. The complexity of the task explains the importance of the use of the presented optimization. Additional objectives could be considered: age of inhabitants, homogeneity and birth rate rates (older people and babies require more services). Homogeneity of low income population could be another one, and there could be others.
Figure 1: Optimized partitioning of Parana State into 83 microregions (compromise solution).
The solution presented reflects the status quo at the time of the data collection, and the beliefs of the health system management. Should there be environmental, administrative or political changes, a new
CLAIO-2016
896

solution could be obtained by adapting constraints (e.g., number of microregions, minimum and maximum number of municipalities in a given microregion, minimum population size, new facilities, etc.). According to an evaluation by health specialists, the results presented could be very helpful in providing better and more homogeneous health services for the population as a whole, acting as a powerful managerial tool that could be extended to other states in Brazil which, like Parana State, are in need of improvements to their healthcare systems. References 1. R. Ballou. Business Logistics/Supply Chain Management. Pearson Education, 2004. 2. BRASIL. Conselho Nacional de Secretários da Saúde. Regionalização solidária: proposta para a Oficina
Agenda para um novo pacto de gestão do SUS. Brasília: CONASEMS, 2004. 3. S.J. D'Amico; S-J Wang; R. Batta and C.M. Rump. A simulated annealing approach to police district design. 4. D. Datta; J. Malczewski; J.R. Figueira. Spatial aggregation and compactness of census areas with a
multiobjective genetic algorithm: a case study in Canada. Environment and Planning B: Planning and Design, 39:376-392, 2012.
5. D. Datta; J.R. Figueira; A.M. Gourtani; A. Morton. Optimal administrative geographies: An Algorithmic approach. Socio-Economic Planning Sciences, 47(3):247-257, 2013.
6. D. Datta; J.R. Figueira (2013). A real-integer-discrete-coded differential evolution. Applied Soft Computing, 13:3884-3893, 2013.
7. M.B. Teitz; P. Bart. Heuristics methods for estimating the generalized vertex median of a weighted graph. Operations Research, 16:955-961, 1968.
CLAIO-2016
897

An Optimized Approach for Location of Grain Silos in Brazil through a Multi-objective Genetic Algorithm
Pedro José Steiner Neto
PPGAD-UP, Curitiba, Paraná, Brasil [email protected]
Datta Dilip
Tezpur University, Tezpur, India [email protected]
Maria Teresinha Arns Steiner
PPGEPS-PUCPR, Curitiba, Paraná, Brasil [email protected]
Osíris Canciglieri Júnior
PPGEPS-PUCPR, Curitiba, Paraná, Brasil [email protected]
José Rui Figueira
IST de Lisboa, Portugal [email protected]
Silvana Detro
PPGEPS-PUCPR, Curitiba, Paraná, Brasil [email protected]
Cassius Tadeu Scarpin
PPGMNE-UFPR, Curitiba, Paraná, Brasil [email protected]
Abstract
Soybean and corn production has increased steadily in Brazil and Paraná State is the second largest producer of these grains in the country. The increased production has now necessitated to increase the storing facility also. Accordingly, partitioning the storage is a proposal to aggregate the municipalities of Paraná into regions as a way of facilitating production and transportation of the grains. Motivated by the requirement, this paper aims to organize the storage regions of Paraná by modeling its municipalities as a multi-objective graph (territory) partitioning problem with the municipalities being the nodes and roads linking them as the edges of the graph. In order to find the effective number of new silos to be constructed and region-wise their locations, maximization of the homogeneity of storage deficit and minimization of the distances from production sources to storage points are considered as two objective functions of the problem. A multi-objective genetic algorithm based results, presented here, should have a strong impact on the grain storage system management in Paraná. Keywords: Multi-objective optimization, genetic algorithm, grain storage system, territory partitioning problems.
CLAIO-2016
898

1 Introduction
With the growth of the world economy and the demand for agricultural products, grain production (particularly soybeans and corn) has increased in Brazil in last 20 years with an improvement from 45 million tons in 1994 to around 200 million tons in 2013 (an increase of over 300%). In order to achieve this record change, Brazil had to expand its farmland as well as to invest heavily in technology. On technical reasons, the crop rotation system has been employed in a considerable part of the planted land with cycles of three harvests, two for soybean and one for corn. Soybean and corn production altogether is significantly larger than any other type of grain produced in Brazil.
In the 2013 calendar year, total grain production was 195,906.8 tons with soybeans amounting to 90,025.1 tons (45.95% of total production) and corn amounting to 78,783.5 tons (40.21% of total production). Thus, all other types of Brazilian grains (cotton, rice, oats, canola, rye, barley, beans, sunflower seeds, castor beans, wheat and others) were only 13.84% of total production (CONAB, 2013).
Brazil is the world’s second largest soybean producer and the third largest corn producer. Soybeans are the most preferred oil seed in the world and may be used in various ways, including meeting the worldwide demand for vegetable oils, production of animal feed, food for human consumption and industrial applications. Corn is the dominant grain on international markets. Its main use in Brazil is for animal feed and human foodstuff. The grain is used for producing oil, flour, starch, margarine and other products. Together with soybeans, corn is the main raw material in livestock production.
In spite of having the opportunity for further growth by incorporating new technologies, Brazil suffers heavy competition from other exporting countries, especially from the Mercosur region, because of their advantages in terms of productivity and production costs. One of the major difficulties in exporting grains is the need to transport the product for processing or storage immediately after the harvest. Brazilian storage capacity is less than that recommended for most of the bulk cultures, such as soybeans and corn. Hence, in order to avoid the damage of the grains in intermediate adverse seasons, the farmers are compelled to dispose their grains at a compromise price immediately after harvesting, instead of waiting to sell in favorable seasons. Moreover, almost all the grains are transported by road involving a higher transportation cost, which impacts directly on the farmers’ profit. Studies have shown that freight and toll charges increase the cost of soybeans up to 35% (USDA, 2012). The Port of Paranaguá, located in the South-East part of Paraná State, has become the second largest exporter of the grains being having access to the Atlantic Ocean. This has, however, enabled Paraná to partly reduce the transportation cost of grains, making the State an advantageous one over other Brazilian States.
The aim of the present work is to identify the effective locations for new storage facilities (silos) to be built across the State in order to overcome the existing storage deficit for around 6.6 million tons of grains. This is performed as a multi-objective territory partitioning problem by addressing the homogeneity in storage deficits and minimizing the distances to be traveled from production sources to locations having storage facilities. The transformed problem is investigated with a multi-objective genetic algorithm in such a way that new silos are to be constructed in each region (partition). The scenarios of varying number of silos are also analyzed in order to find the best number of regions. A number of factors influence the decision on the location for installation of a facility, including proximity of suppliers and consumers, local infrastructure, location of competitors, government restrictions, economic impact, environmental effect, etc. On the other hand, determining the number of installations requires to ensure an advisable level of services. Accordingly, two different mathematical models are then used to decide the municipalities in which new silos are to be installed as well as the total number of new silos in each region.
The rest of the paper is organized as follows. Section 2 presents the two-phase methodology – the investigated multi-objective genetic algorithm and the mathematical models used to solve the problem.
CLAIO-2016
899

The numerical results are presented in Section 3 along with their detail discussion and, finally, the paper is concluded in Section 4.
2 Methodology
The method for resolving the problem presented here is divided into two phases – the first phase partitions the municipalities of Paraná into regions (partitions) by simultaneously optimizing multiple objective functions (the TPP part), and the second phase decides the number of silos to be built in each region along with their locations (the FLP part). These are described in detail in Sections 2.1 and 2.2.
2.1. TPP Model: Multi-Objective Approach
The partitioning of the municipalities of Paraná is first formulated as a multi-objective territory partitioning problem (TPP) for simultaneously (i) homogenizing the production and storage facilities in the regions and (ii) minimizing the overall distances to be travelled in accessing the storing facilities located in other regions, subject to five number of general constraints, namely the integrity of a municipality, contiguity of a region, embedding of regions, size of a region, and number of total regions. Then the integer-coded multi-objective GA, proposed by Datta et al., 2012, is customized for solving the TPP formulation.
2.1.1. TPP Formulation The following are the notations used in the formulation of the TPP: Parameters: W : Number of municipalities; Z : Number of regions;
iv : .thi municipality; Wi ,...,2 ,1= ;
kz : .thk region; Zk ,...,2 ,1= ;
ip : Production in iv ; Wi ,...,2 ,1= ;
ic : Storage capacity in iv ; Wi ,...,2 ,1= ;
ijd : Distance between iv and jv ; Wji ,...,2 ,1, = .
Variables:
ijX : ≠
otherwise ,0
; , . . . 2, 1, = , connected; are and if ,1 jiWjivv ji
ikY : ==∈
otherwise ,0
,...,2 ,1 and ,...,2 ,1 ; f ,1 ZkWizvi ki
1f : Objective function on deviation in production and storage facility
2f : Objective function on inter-region traveling distance. In terms of the above notations, the TPP is formulated as follows: Objective functions:
CLAIO-2016
900

1. Minimize the deviation in the difference between the storage capacity and production in each region from its mean value (in other words, maximize the homogeneity between production and storage capacity), i.e.,
Minimize ∑∑= =
−−=W
i
Z
kikii AYpc
Zf
1 11 ] )[(
1 (1)
where ∑=
−=W
iii pc
ZA
1
)(1
is the average of differences between storing capacity and production
considering all the municipalities. 2. Minimize the inter-region traveling distance, which can be achieved by evaluating the distance of
each municipality of a region to the nearest municipality of every other region, i.e.,
Minimize ∑ ∑= = =
−=Z
k
W
ijkikiji
WjYYdpf
1 1,...,1
2 })1({min (2)
Eq. (2) estimates the minimum distance from iv to jv , where 0=ikY (i.e., ki zv ∉ ) and 1=jkY
(i.e., kj zv ∈ ), and k = 1, 2, …, Z and i, j = 1, 2, …, W.
2.1.2. Genetic algorithm to handle the TPP
The integer-coded multi-objective genetic algorithm (GA), originally proposed by Datta et al., 2012 and Datta et al., 2013, based on NSGA-II (Deb et al., 2002), is customized here for solving the TPP formulation. This variant of GA was also applied by Datta et al., 2013, and Steiner et al., 2015, in the healthcare system partitioning problem. Since GA is now a well-established metaheuristic, without going through its basic concepts, directly the customized variant of the GA applied to the present problem. 2.2. FLP Models
In order to determine the number of silos in a region of a given scenario, a simple non-linear programming (NLP) model is used. It is to be mentioned that for operational reasons, only a pre-decided type of silos will be installed in a location, i.e., silos having only one type of capacity will be installed in a region. Accordingly, the NLP model for determining the number of required new silos in a region can be expressed as (3)–(5).
In the formulation given by Eqs. (3)–(5), Rk is the total installation cost of all new silos of region
k ; m is the number of types of available silos; 'ic is the capacity of a silo of type i ; ir is the cost
associated with a silo of type i ; ks is the shortage (deficit) in storing capacity in region k ; kix is an
integer-valued variable giving the number of silos of type i to be installed in region k ; and 'kiY is a {0,1}
binary-valued decision variable with 1' =kiY if a silo of type i is installed in region k and 0' =kiY
otherwise. The constraint of Eq. (4) ensures the meeting of the capacity deficit in region k , while that of Eq. (5) guarantees the installation of a single type of silos in that region.
Minimize ∑=
=m
ikikiik YxrR
1
' (3)
CLAIO-2016
901

Subject to ∑=
≥m
ikkikii sYxc
1
'' (4)
∑=
=m
ikiY
1
' 1 (5)
integer kix }1 ,0{' ∈kiY
Zk ,...,2 ,1= After obtaining the number of required new silos in a region by solving Eqs. (3)–(5), the next step
is to find their municipality-wise distribution. This can be achieved by solving a binary integer linear programming (BILP) model as expressed below (Lorena and Senne, 2004), (6)–(9), known as p-median problem adapted for the storage problem approached here.
Minimize ∑∑= =
=k kz
i
z
jijijk YaD
1 1
'' (6)
Subject to ∑=
==kz
ikij zjY
1
'' ,...,2 ,1 ;1 (7)
∑=
=
kz
i
kii p
pY
1 max
'' (8)
kiiij zjiYY ,...,2 ,1 , ;'''' =≤ (9)
}1 ,0{ '' ∈ijY
In the formulation given by Eqs. (6)–(9), kD is the total distance to be travelled in region k for
accessing the new silos from the production centers of its municipalities, kz is the size of region k (i.e.,
the number of municipalities in the region), ija are the weighted distances, i.e., the distances multiplied
by the amount of storage deficiency of municipality j that has to be transported to silos in municipality i . The constraint in Eq. (7) assures that the product of a municipality j will be stored in one and only
one municipality i which has silos. The constraint in Eq. (8) fixes the number of municipalities to be identified for installing the silos of region kz , where maxp is the maximum number of silos permitted to
install in a municipality, and kp is the total number of new silos to be installed in region kz as given by
kix in the FLP model of Eqs. (3)–(5). Finally, the constraint in Eq. (9) assures that the transport of the
municipalities j (with no silos) has to be done to municipality(ies) i which has silos. The decision
variable 1'' =ijY if municipality j is to transport its product to municipality i and 0'' =ijY otherwise.
Also, 1'' =iiY if municipality i will receive a new silo and 0'' =iiY otherwise.
3 Results
The results for the two phases (TPP and FLP) of the methodology, are presented here, which involve the determination best partitioning in terms of differences and distances objectives given by Eqs.
CLAIO-2016
902
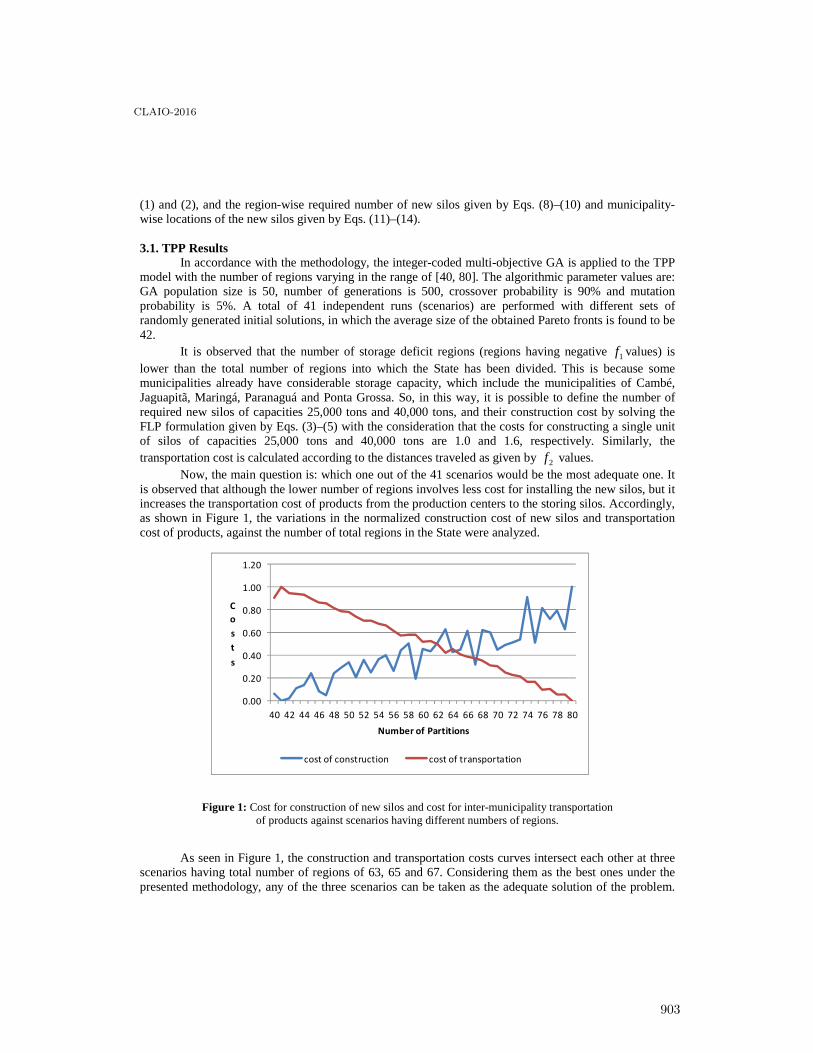
(1) and (2), and the region-wise required number of new silos given by Eqs. (8)–(10) and municipality-wise locations of the new silos given by Eqs. (11)–(14).
3.1. TPP Results
In accordance with the methodology, the integer-coded multi-objective GA is applied to the TPP model with the number of regions varying in the range of [40, 80]. The algorithmic parameter values are: GA population size is 50, number of generations is 500, crossover probability is 90% and mutation probability is 5%. A total of 41 independent runs (scenarios) are performed with different sets of randomly generated initial solutions, in which the average size of the obtained Pareto fronts is found to be 42.
It is observed that the number of storage deficit regions (regions having negative 1f values) is lower than the total number of regions into which the State has been divided. This is because some municipalities already have considerable storage capacity, which include the municipalities of Cambé, Jaguapitã, Maringá, Paranaguá and Ponta Grossa. So, in this way, it is possible to define the number of required new silos of capacities 25,000 tons and 40,000 tons, and their construction cost by solving the FLP formulation given by Eqs. (3)–(5) with the consideration that the costs for constructing a single unit of silos of capacities 25,000 tons and 40,000 tons are 1.0 and 1.6, respectively. Similarly, the transportation cost is calculated according to the distances traveled as given by 2f values.
Now, the main question is: which one out of the 41 scenarios would be the most adequate one. It is observed that although the lower number of regions involves less cost for installing the new silos, but it increases the transportation cost of products from the production centers to the storing silos. Accordingly, as shown in Figure 1, the variations in the normalized construction cost of new silos and transportation cost of products, against the number of total regions in the State were analyzed.
Figure 1: Cost for construction of new silos and cost for inter-municipality transportation
of products against scenarios having different numbers of regions.
As seen in Figure 1, the construction and transportation costs curves intersect each other at three scenarios having total number of regions of 63, 65 and 67. Considering them as the best ones under the presented methodology, any of the three scenarios can be taken as the adequate solution of the problem.
0.00
0.20
0.40
0.60
0.80
1.00
1.20
40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80
C
o
s
t
s
Number of Partitions
cost of construction cost of transportation
CLAIO-2016
903

The scenario partitioning the State into 63 regions is selected here randomly for analysis. This scenario has 59 regions with storage deficit and only 4 regions with self-sufficient storage capacity.
3.2. FLP Results
Selecting the scenario of 63 regions in Section 3.1, it is further analyzed here. In this scenario, regions 2, 9, 15 and 51 are already self-sufficient being bearing positive storage capacities. The optimum number of new silos required in each of the remaining storage deficit 59 regions is then obtained by feeding its storage deficiency in the NLP model of Eqs. (3)–(5).
Finally, the best municipalities for installing the new silos in each of the storage deficit 59 regions are identified by solving the BILP model of Eqs. (6)–(9) using the region-wise required number of new silos. These municipalities (total 59), along with newly obtained surplus in storage capabilities of the corresponding regions, can be defined. It is to be mentioned that, due to the operational restrictions, the installation of a maximum of 12 silos is permitted in a municipality, i.e., pmax in Eq. (13) is 12. Because of this restriction, two municipalities are identified in each of the regions 7 and 54 for installing their new silos, which in number (i.e., the values of pk in Eq. (8)) are 13 and 14, respectively.
The corresponding map of Paraná State, partitioning it into 63 regions, is shown in Figure 2, where the municipalities, in which the new silos are supposed to be installed, are marked with small circles. Further, the names of the five municipalities, having high surplus storage capacities, Paranaguá, Ponta Grossa, Cambé, Jaguapitã and Maringá, are also shown in the figure, from right to left.
Figure 2: Optimized Partitioning of Paraná State into 63 regions, with the municipalities to receive new silos
marked by small circles.
CLAIO-2016
904

4 Conclusions
Due to the acute storage of proper storage space in Paraná State in Brazil, farmers are bound to export the majority of their grains immediately after harvesting without waiting for favorable seasons. This not only increases transportation costs in exporting in a short interval of time, but also reduces commercial opportunities. This paper attempts to come out with a suggestion for constructing more storage facilities (new silos) in an optimized way, so as to overcome the above mentioned drawback of the State. A multi-objective genetic algorithm (MOGA) based methodology is proposed for partitioning the municipalities of the State into a number of regions, and then to find the region-wise optimum requirement of new silos along with identifying the best municipalities for installing the silos.
Upon applying the methodology to the real-case of the State, the MOGA yields that one of the best solutions is to divide the State into 63 regions by achieving both the considered objectives – maximization of the homogeneity of the lack of storage capacity among the regions, and minimization of the distances to be traveled from the production centers to the storing silos. Then two mathematical models are applied to the MOGA-based partitions, one for finding the region-wise optimum requirement of new silos and another for identifying the region-wise municipalities for installing its new silos.
According to an evaluation by agricultural specialists, the results presented here could be very helpful in providing better and more homogeneous grain storage partitions. Being a powerful managerial tool, it could also be extended to other similar cases for the improvement in their agricultural systems. References [1] CONAB, August 2013. Companhia Nacional de Abastecimento. http://www.conab.gov.br. [2] D. Datta; J.R. Figueira; C.M. Fonseca and F. Tavares-Pereira. Graph partitioning through a multi-objective
evolutionary algorithm: A preliminary study. In: Genetic and Evolutionary Computation Conference (GECCO-2008). Atlanta, Georgia, USA, pp. 625–632, 2008.
[3] D. Datta; J.R. Figueira; A. Gourtani and A. Morton. Optimal administrative geographies: an algorithmic approach. Socio-Economic Planning Sciences, 47(3):247–257, 2013.
[4] D. Datta; J. Malczewski and J.R. Figueira. Spatial aggregation and compactness of census areas with a multi-objective genetic algorithm: a case study in Canada. Environment & Planning B: Planning and Design, 39:376–392, 2012.
[5] K. Deb; S. Agarwal; A. Prata and T. Meyarivan. A fast and elitist multi-objective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation, 6(2):182–197, 2002.
[6] L.A.N. Lorena and E.L.F. Senne. A column generation approach to capacitated p-median problems. Computers & Operations Research, 31:863-876, 2004.
[7] M.T.A. Steiner; D. Datta; P.J. Steiner Neto; C.T. Scarpin and J.R. Figueira Multi-objective optimization in partitioning the healthcare system of Paraná State in Brazil. Omega, 52:53–64, 2015.
[8] USDA. United States Department of Agriculture. http://www.usda.gov, 2012.
CLAIO-2016
905

Modelo timetabling multiobjetivo al servicio de estudiantes, en pro
de minimizar el tiempo de culminación de su pregrado
Sánchez José Universidad Central
Bernal Jainet Universidad Central
Resumen
Al observar la necesidad estudiantil de determinar las materias a inscribir de una oferta dada para el
siguiente semestre, este documento ofrece una alternativa automatizada basada en la investigación de
operaciones para la operación de un modelo binario multi-objetivo, el cual propende minimizar el tiempo
de terminación del pregrado universitario buscando una solución óptima al tratar de determinar, de
acuerdo al gusto del estudiante (dificultad o importancia), las materias que debe inscribir en el siguiente
periodo estudiantil. Adicional, el apoyo de un segundo modelo inmerso en la interfaz permite visualizar
específicamente cuál de los diferentes grupos de cada materia debe inscribir respetando los cruces de
horarios. En este artículo se presenta una aplicación puntual del modelo desarrollado, para estudiantes del
Plan de Estudios 4035 de Ingeniería Industrial de la Universidad Central, teniendo en cuenta las diferentes
restricciones en cuanto a las políticas de la Universidad, presupuesto del estudiante y respetando la ruta
crítica encontrada para el plan de estudiados. La finalidad, es identificar los cursos a matricular cada
semestre y una opción de horario del mismo, buscando terminar su pregrado lo antes posible y respetando
las condiciones propias del pregrado y las limitaciones de tiempo y presupuesto del estudiante, siendo este
un aplicativo que ´puede ser adaptado y replicado a las necesidades y condiciones de otros programas de
pregrado de la Universidad y de otras instituciones para ampliar el número de estudiantes beneficiados.
Palabras Claves:Problemas Multiobjetivo, Problemas Timetabling, Plan de Estudios Universitario
1 Introducción
Al iniciar cada periodo académico, algunas universidades permiten a sus estudiantes escoger de una oferta
de cursos las materias a inscribir en el semestre entrante, lo cual puede representar un problema para
aquellos estudiantes que no cuentan con el conocimiento del plan de estudios o con el tiempo de revisar
exhaustivamente la mejor opción para optimizar su tiempo y sus recursos, convirtiéndose en un dilema
profundo y, en la mayoría de casos, en una mala decisión, puesto que si no se eligen algunas materias que
son prerrequisitos futuros, podrían atrasar el tiempo de terminación del pregrado. Para ayudar a este tipo
de estudiantes en el proceso descrito anteriormente, el presente documento está orientado, en su primera
fase, a describir un modelo matemático desarrollado que sugiere al estudiante los cursos a inscribir para el
periodo académico a comenzar, de tal forma que se minimice el tiempo de terminación de todo el plan de
estudios, pero teniendo en cuenta las restricciones de presupuesto y prerrequisitos que puedan existir. Así
mismo, se espera que el modelo incorpore información histórica del plan de estudios, como el conjunto de
cursos que más prerrequisitos anidados tienen, es decir, “cursos que forman la ruta crítica del plan de
estudios” que puedan incidir en el tiempo de culminación del plan de estudios, por ejemplo, una
ponderación que prevalezca en la selección a aquellos cursos que históricamente han requerido un mayor
CLAIO-2016
906

tiempo promedio para ser aprobados. En su segunda fase, se describe otro modelo con el cual el
estudiante podrá contemplar los grupos específicos de cada materia que debe matricular con el fin de
identificar, según el criterio del estudiante, el grupo en particular que él debe matricular de acuerdo a sus
preferencias y restricciones de horario. Es necesario aclarar, que el trabajo aquí descrito tiene como
referente un documento desarrollado por [1], quien realizó un estudio orientado a definir como
universidad, cuál sería la oferta de materias a inscribir de los estudiantes de todo el pregrado, pero sin
tener en cuenta más de un objetivo ni las necesidades particulares y preferencias de horario de cada uno
de ellos. Es por esto, que este trabajo resulta una mirada distinta y un complemento a dicho estudio, y útil
para otras instituciones, incluyendo los aspectos mencionados y desarrollando un aplicativo de escritorio,
que permite al estudiante seleccionar de manera fácil y rápida los parámetros necesarios para operar el
modelo teniendo en cuenta su presupuesto y preferencias.
Por último, para que el modelo desarrollado tenga una funcionalidad más cercana al estudiante se diseña
una interfaz en Excel, el cual permite obtener una apariencia amigable en términos de comprensión y
recursos, además de ofrecer una herramienta que responda a las necesidades y parámetros puntuales de
cada estudiante.
2 Marco Referencial
El desarrollo de modelos matemáticos de investigación de operaciones, emerge dentro de las diferentes
industrias como la solución a una necesidad específica, que para el caso de algunas universidades
trasciende en diferentes tipos de problemas, como el mencionado en este documento, el cual se basa en la
asignación de horarios como lo afirma [1]. Los modelos para la asignación de horarios, según la literatura,
tienen diferentes campos de aplicación: En primer lugar, están los modelos de Programación de horarios
de evaluaciones y exámenes (ExaminationTimetabling), (SchoolCourseTimetabling),
(UniversityCourseTimetabling), [2]. Dos tipos de modelos Timetabling recientes utilizados
académicamente y en la industria son el Modelo de Transporte (TransportTimetabling) y el Modelo de
Deportes (SportsTimetabling), [3] ambos modelos son catalogados como modelos NP.La determinación
de este tipo de problemas de asignación de horarios (UniversityCourseTimetabling), corresponde a unas
políticas dadas por cada universidad, entre las cuales está, dar un libre albedrío a los estudiantes para
escoger las materias que quieren matricular el próximo semestre [2]. Distintas variaciones según el
enfoque se pueden observar, sin embargo pocos contemplan la variación de la decisión estudiantil, por
ejemplo, una perspectiva de la satisfacción de los profesores es mostrado en el modelo realizado por [4],
dando unas ponderaciones específicas de asignación para contemplar las sugerencias de horarios y
condiciones de movilidad terrestre.
Varios autores como [5], [6] y [7] han abordado el problema desde la perspectiva de las instituciones y
universidades, pero no desde la perspectiva de los estudiantes. Cada uno de estos documentos basa su
foco en optimizar las funciones de desempeño estudiantiles, nivelar cargas académicas o la maximización
de las funciones objetivos por medio de heurísticas robustas. Un ejemplo es el trabajo realizado en Chile
por [8], quien modeló y resolvió un problema de Programación de Horarios en Universidades a través de
Programación Lineal Entera, ofreciendo una solución satisfactoria desde cualquier punto de vista a
problemas “duros computacionalmente”. Otro de gran interés, es el modelo desarrollado por [9], en
Barranquilla (Universidad del norte) en donde se usan algoritmos evolutivos. Estos modelos pueden ser
resueltos por medio de heurísticas, que llegan a una solución en tiempos cortos de procesamiento, por
ejemplo el modelo desarrollado por [10], quienes desarrollaron un algoritmo llamado Max-Min, el
cualhace referencia a que puedan existir mejores soluciones pero que su solución se limita al tiempo y
máquina de procesamiento utilizada [11].
CLAIO-2016
907

Dadas las diferentes variantes que puede tener un modelo Timetabling, y más aún, la amplitud de formas
de solución, como diferentes meta-heurísticas, es necesario conocer los diferentes tipos de algoritmos que
han ido evolucionando a través del tiempo. Es así como, el análisis desarrollado por [3], aborda cuadros
comparativos entre diferentes heurísticas aplicadas a este tipo de problemas. Una vez contemplados
algunos problemas de asignación de horarios en universidades y los tipos de metodologías o heurísticas
existentes para resolverlos, las siguientes revisiones teóricas se centraran en el análisis de los problemas
multi-objetivo.
Un problema de optimización con una única función objetivo puede ser limitado, sobretodo en la
industria. [12], puesto que se están dejando de lado otros aspectos que resultan de interés en la solución al
problema. Es por ello, que al hablar de problemas multi-objetivo, se hace referencia a problemas en la
mayoría de las ocasiones con objetivos contradictorios [13]. Para Pinto existen diferentes tipos de “Mejor
Solución”, puede ser una “Solución óptima por Pareto”, una “solución eficiente o una “solución ideal”,
según sea el caso. Autores como [14], [15] y [16] proponen problemas con objetivos contradictorios; uno
con bienes y el otro desarrolla su modelo en los servicios, ambos terminan en soluciones por medio de
Meta-heurísticas. Como se dijo anteriormente el término de solución óptima en problemas multi-objetivo
es relativa, por eso autores como [17], prefieren catalogarlas como soluciones aproximadas, puesto que
según él “En todos los casos se estudia la calidad de los puntos obtenidos respecto al cubrimiento y
uniformidad. Posteriormente se estudia el comportamiento en problemas generales.” queriendo decir, que
cada caso es particular y depende del alcance y objetividad del problema estudiado.
Al igual que los modelos Timetabling, los problemas multi-objetivo tienden a ser NP [18], así él mismo
se hace un estudio algorítmico que permite agruparlos en función de ciertos niveles de conformidad. Por
lo anterior, el surgimiento de heurísticas que contemplen y resuelvan estos modelos son necesarias en el
campo de la investigación de operaciones, según [13], todos los métodos de solución tratan de
parametrizar las funciones objetivos tomadas en cuenta. Distintos métodos como la normalización lineal,
Maximización-Minimización, método Topsis, Normalización Vectorial, Método de calificación, entre
otros, ayudan a realizar dicha parametrización y delimitando la zona Pareto-Óptima del problema [17].
Estos algoritmos sumados a los desarrollados en los últimos años como la computación bio-inspirada
[19], logran recaer en que aunque no garantizan solución óptima, si se pueden llegar por medio de
algoritmos o heurísticas robustas a una solución eficiente en términos computacionales [20].La
combinación de los dos tipos de problemas aquí presentados y la variabilidad de ponderación estudiantil
hace que el camino escogido para solucionar la problemática presentada sea la unión de los dos modelos y
la simplificación de heurísticas por ponderaciones.
3 Descripción del problema
El problema se refiere a la decisión que enfrenta el estudiante de pregrado de ciertas instituciones
universitarias en Colombia para identificar los cursos a inscribir, lo cual se espera no sea una selección
aleatoria sino algo más estratégico, previniendo tener que prolongar el tiempo de terminación del plan de
estudios, debido a que alguno de los cursos restantes por matricular es prerrequisito de otros que aún no
ha cursado. Esto, se vería reflejado en tener que aplazar la inscripción de por lo menos un curso (para un
periodo académico posterior) y tener que inscribir una menor cantidad de cursos en el periodo actual pese
a contar con la disponibilidad presupuestal para inscribir más.
El problema se basa de dos decisiones: 1) el estudiante ve materias que están categorizadas de acuerdo a
una dificultad hallada históricamente en donde, si es difícil puede tardar más en aprobarla, y 2) en que la
materia sea prerrequisito de otras materias futuras. El problema radica en identificar para un estudiante
dado, una solución que le permita inscribir las materias más indicadas para él y determinar un horario que
tenga en cuenta sus preferencias y en donde la restricción demandante sea el cruce de horarios.
CLAIO-2016
908

4 Método de solución
4.1 Construcción Parámetros Iniciales
En primer lugar se hace necesario conocer la estructura del plan 4035 para el cual se operará el modelo,
en donde se identifica que el programa de ingeniería industrial está definido por créditos y no depende en
forma directa del semestre que se esté cursando, es decir, si se cumplen los prerrequisitos de una
determinada materia y se cuenta con el capital se podría matricular la materia. El plan está conformado
por 56 materias, en donde cada una de ellas cuenta con 4 grupos (horarios) distintos para cursarla. En la
parte izquierda del siguiente gráfico se representa el “morral” o conjunto de materias a seleccionar, de la
oferta de cursos que contempla el plan de estudios representada por la parte derecha de la figura.
Figura 1. Disponibilidad de materias al ingresar al siguiente periodo.
Luego, se procede a determinar cuáles son las condiciones o prerrequisitos necesarios para poder cursar
cada asignatura, ya que el modelo debe incorporar estas condiciones, sí como, el número de materias
anidadas por delante que tiene cada curso. Partiendo de esto, se define la expresión matemática que
expresala ponderación lineal:
Figura 2.Ecuación para el cálculo de la ponderación por materias anidadas.
Al aplicarla para cada uno de los cursos se obtiene lo siguiente; en el eje x la oferta de cursos y en eje y la
ponderación definida
Figura 3.Resultados ponderación de cada materia por ruta crítica.
Como se puede apreciar, la máxima ponderación es 1, lo cual significa que tiene un mayor número de
materias anidadas, mientras que 0 son las materias que tienen menos materias anidadas. A continuación se
contemplan datos históricos donde se recogieron estadísticas de aprobación, reprobación y repetición de
cada una de las materias del plan 4035; se realizó esta segunda ponderación con el fin de darle mayor
prevalencia a las materias que tienen un mayor grado de dificultad. Para esta ponderación, se parte del
supuesto de que un estudiante por mucho pierde la materia 2 veces, es decir, a la tercera vez de vista el
estudiante aprueba la materia.
CLAIO-2016
909

Cada una de estas gráficas, representa la probabilidad de ver la materia en uno, dos o tres semestres
respectivamente; las materias de alta probabilidad de matriculación por tercera vez responden a las más
complicadas dentro del plan históricamente. Contemplando la información anterior se procede a realizar
la ponderación de acuerdo a estos 3 datos de la siguiente manera:
𝑃𝑖 = 1 − (𝐸1𝑖 ∗ 0.00001 + 𝐸2𝑖 ∗ 0.001 + 𝐸3𝑖 ∗ 0.1) Siendo Pi: Ponderación de dificultad de aprobación de materia i; E1i: Probabilidad de ver la materia i la
primera vez, E2i: Probabilidad de ver la materia i la segunda vez, y E3i: Probabilidad de ver la materia i
la tercera vez
Como se puede apreciar la ponderación da una relevancia significativa a la probabilidad de ver la materia
por tercera vez, esto ya que si la probabilidad de ver la materia 3 veces antes de aprobarla es alta indique
que dicha materia es históricamente difícil, comportamiento contrario, cuando con solo ver la materia una
vez la probabilidad de aprobarla es mayor. Dada la complejidad de todos estos datos se procedió a realizar
la debida normalización, la cual correspondió a valores entre 0 y 1 de las dos variables incluidas (ruta
crítica e historia):
Figura 7. Ponderación de las variables por cada materia (Autores)
La figura (7), señala que las materias cuya variable ruta se acercan a uno, deben ser privilegiadas en la
selección, pues son prerrequisitos de más materias, mientras que con respecto a la variable dificultad entre
más cerca estén de 1 tienen una mayor probabilidad de aprobación.
4.2 Desarrollo Modelo
El diseño del modelo comprende dos etapas o dos modelos de solución, el primero determina las materias
a inscribir en el siguiente periodo, mientras que el segundo identifica el grupo o horario a matricular de
las materias seleccionadas por el primer modelo.
MODELO 1
Conjuntos
[i] Materias: Materias i del plan de estudios 4035 de Ingeniería Industrial de la Universidad Central.
[j] Alias de [i].
Figura 4.Probabilidad de ver la materia sólo una vez.
(Autores).
Figura 5. Probabilidad de ver la materia dos veces.
(Autores)
Figura 6.Probabilidad de ver la materia por tercera vez.
(Autores)
CLAIO-2016
910

Parámetros
Credi = Créditos de materia [i] PondDifi = ponderación dificultad materia [i] PondAbi = ponderación ruta crítica materia[i] Aj = Materia [j] ya vista por el estudiante
DispDin = Dinero disponible
CostCred = Costo de un crédito
Crit = Ponderación al objetivo de dificultad
𝑇𝑖,𝑗 = Matriz de prerrequisitos
Variable
Xi = Materia [i] a inscribir el siguiente semestre
Función objetivo
Z = max [∑(Crit ∗ PondDifi ∗ Xi + (1 − Crit) ∗ PondAbi ∗ Xi)
i
]
Restricciones
No seleccionar materias que ya ha cursado:
Xi ≤ 1 − Ai Restricción por prerrequisitos:
Xi ≤ ∑(𝐴𝑗 ∗ Ti,j) ∀ 𝑖
𝑗
Restricción de la disponibilidad de dinero:
∑(CostCred ∗ Credi ∗ Xi)
i
≤ DispDin
Restricción de mínimo 2 materias por semestre:
∑ Xi ≥
i
2
Restricción de máximo 6 materias por semestre:
∑ Xi ≤
i
6
Restricción de variable Xi tome valores binarios:
𝑋𝑖 = [0,1]
MODELO 2 Conjuntos
[i] Materias: Materias i escogidas por la solución
del primer modelo
[j] Grupos: grupos j pertenecientes a cada
materia
[k] Días de la semana
[l] Franja horaria del día, son tomadas por
intervalos de una hora
[m] Horario
Parámetros
M𝑖 = Materias [i] Hk,l,m = Horario [m] correspondiente
a la franja horaria [l]en el día [k] Pi,j,m = Horario [m] de grupo [j]de materia [i]
Poni,j = Ponderción de grupo [j] de
maetria [i] segun expectativas del estudiante
Variable
Xi,j = Grupo [j]de la Materia [i] a inscribir
Función objetivo
𝑍 = 𝑚𝑎𝑥 [∑(𝑃𝑜𝑛𝑖,𝑗 ∗ 𝑋𝑖,𝑗)
𝑖,𝑗
]
Restricciones
Sólo un grupo por materia:
∑ 𝑋𝑖,𝑗
𝑗
≤ 1 ∀ 𝑖
Restricción de cruces de horario
∑ (𝑋𝑖,𝑗 ∗ Pi,j,m ∗ Hk,l,m) ≤ 1 ∀ 𝑘, 𝑙
𝑖,𝑗,𝑚
Restricción de variable Xi,j es binaria:
𝑋𝑖,𝑗 = [01
]
4.3 Diseño de interface
Una vez desarrollada la formulación se diseñó y validó el siguiente aplicativo, el cual puede ser usado por
cada uno de los estudiantes del pregrado en cuestión para identificar los grupos a matricular. Primero, el
CLAIO-2016
911

estudiante deberá elegir entre todas las posibles opciones (parte izquierda de la siguiente gráfica) las
materias aprobadas hasta el momento, esto lo realizará dando clic sobre el nombre de la materia, también
el estudiante ingresará el dinero destinado para el semestre (presupuesto), y de acuerdo al parámetro de
ponderación Solver de Excel arrojará (en el recuadro de la derecha) la respuesta sugiriendo las materias a
matricular para el próximo periodo.
Figura 8.Diseño de la Interface en Excel (Autores)
La interface y el modelo respetan todas las restricciones de prerrequisitos, repetición, presupuesto y
además contempla el factor de ponderación para cada uno de los objetivos contemplados por el modelo.
Después el estudiante encontrará en la parte inferior un botón que dice “Asignación de Horario”, y al
pulsarlo aparecerá el recuadro de figura 9, en el cual deberá escribir un valor entre 1 y 10 según su grado
de preferencia frente a los grupos de cada una de las materias; donde 1 es poca preferencia y 10 alta
preferencia. Finalmente, dando clic en “Asignar horario” el estudiante conocerá los grupos a inscribir de
las materias recomendadas, obteniendo un resultado cono el mostrado en figura 10.
Figura 9.Preferecias del usuario (Autores)
Figura10.Respuesta de Interface en Excel (Autores)
5 Conclusiones
Se logró diseñar una interface que determina, para un periodo dado, las posibles materias que debe
ingresar el estudiante según la ponderación escogida. Hay materias que por su ponderación tienen una
prevalencia significativa ante las demás, haciendo parte de la ruta crítica. Además al maximizar la
ponderación realizada, se puede minimizar el tiempo de duración de pregrado planeando mejor los cursos
con prerrequisitos futuros. Al operar el modelo para estudiantes de primer semestre se obtiene que debe
matricular Matemáticas I, Química, Gestión de innovación, Inglés, Práctica de Ingeniería I y Economía.
Teniendo en cuenta que el estudiante tiene la disponibilidad de dinero para la carga completa.
Se espera que el modelo sirva como herramienta que oriente al estudiante la inscripción de cursos,
buscando hacer más eficiente su selección en cada periodo, minimizando el tiempo de terminación de sus
estudios de Ingeniería Industrial en la Universidad Central. Así mismo, se debe socializar el trabajo
desarrollado en otros programas de la universidad, con el fin de establecer la posibilidad de efectuarle
adaptaciones que permitan ser replicado a otros programas académicos. También, se espera que el modelo
sirva al programa y a la facultad para la planeación de espacios académicos, dado que si el modelo
sugiere los cursos a inscribir por estudiante, esto podría alimentar la planeación en la asignación de
recursos para el siguiente periodo académico.
Referencias
CLAIO-2016
912

[1] J. C. Cifuentes, «Programación de Estudiantes un Caso de Estudio (Universidad Central),» 24 9 2012. [En
línea]. Available: http://www.din.uem.br/sbpo/sbpo2012/pdf/arq0249.pdf. [Último acceso: 20 8 2015].
[2] R. M. J. &. R. P. A. Hernández, «Programación de Horarios de Clases y Asignación de Salas para la Facultad
de Ingenierıa de la Universidad Diego Portales Mediante un Enfoque de Programación Entera.,» Revista
Ingenierıa de Sistemas Volumen XXII., 2008.
[3] M. A. G. Q. E. H. P. &. R. R. E. S. Cubillos, «Problema del School Timetabling y algoritmos genéticos: una
revisión. Vínculos, 10(2), 259-276.,» 2014. [En línea]. Available:
http://revistas.udistrital.edu.co/ojs/index.php/vinculos/article/view/6478. [Último acceso: 25 Enero 2016].
[4] S. A.-Y. a. S. Sherali, «A mixed-integer programming approach to a class timetabling problem: A case study
with gender policies and traffic considerations.,» European Journal of Operational Research, 2007.
[5] O. P.-P. P. &. G.-R. J. L. Chávez-Bosquez, « Un algoritmo de Búsqueda Tabú con criterio de aspiración
probabilístico aplicado al problema de timetabling,» Revista de Matemática: Teoría y Aplicaciones, 22(1).,
2016.
[6] N. J. J. R. M. L. J. H. J. B. M. &. B. G. Rangel, «Análisis de la influencia de funciones de evaluación en el
desempeño de un enfoque de recocido simulado para la solución del problema de generación de horarios
universitarios.,» In Ciencias de la Ingeniería y Tecnología Handbook TI: Congreso Interdisciplinario de
Cuerpos Académicos (pp. 27-43), 2013.
[7] J. F. &. R. J. L. G. Solís, «Modelos de asignación de cargas académicas y organización de horarios para la
UJAT.,» Perspectivas docentes, , pp. 39-48, 2007.
[8] A. S. S. M. C. O. &. R. L. P. Crovo, «MODELOS DE PROGRAMACIÓN ENTERA PARA UN PROBLEMA
DE PROGRAMACIÓN DE HORARIOS PARA UNIVERSIDADES Ingeniare. Revista chilena de in,» Revista
Chilena de Ingenieria, vol. 15, nº 3, pp. 245-259, 2007.
[9] J. M. Mejía Caballero, «Asignación de horarios de clases universitarias mediante algoritmos evolutivos.,»
Universidad del Norte , 2008.
[10] J. K. w. Krzysztof Socha, «A MAX-MIN Ant System for the University Course Timetabling Problem,» pp. 1-
13, 2002.
[11] J. A. Mañas, «Análisis de algoritmos: Complejidad.,» 1997.
[12] C. A. P. &. E. M. G. Meneses, «Optimización multiobjetivo usando un algoritmo genético y un operador
elitista basado en un ordenamiento no-dominado (NSGA-II). Scientia Et Technica,» Scientia Et Technica, p.
Scientia Et Technica, 2007.
[13] R. Pinto, Operations research and management science handbook, edited by A. Ravi Ravindran., 2011.
[14] J. A. A. &. C. J. A. O. Pinilla, «Optimización multiobjetivo en la gestión de cadenas de suministro de
biocombustibles,» Ingeniería, pp. 7-19, 2015.
[15] M. Arsuaga Ríos, «Optimización multiobjetivo para la planificación de trabajos en entornos de computación
distribuida.,» Optimización multiobjetivo para la planificación de trabajos en entornos de computación
distribuida., pp. 8-12, 2015.
[16] J. C. &. T.-M. H. Gómez, «Construyendo híper-heurísticas generales para problemas de corte multi-objetivo.,»
Computación y Sistemas, 16(3), 321-334., 2012.
[17] M. H. G. R. O. L. A. R. &. M. A. B. Jiménez, «Soluciones aproximadas en problemas multiobjetivo,» In Actas
del XXX Congreso Nacional de Estadística e Investigación Operativa y de las IV Jornadas de Estadística
Pública (p. 29)., 2007.
[18] C. G. Martín, «Clasification en programacion multiobjetivo.,» Trabajos de investigación operativa, 1(1), 51-
59., 1986.
[19] S. Santander Jiménez, «Análisis e inferencia multiobjetivo de hipótesis filogenéticas mediante computación
paralela y bioinspirada.,» 2016.
[20] A. A. M. H. T. J. F. &. C. D. A. V. Mendoza, «Optimización multiobjetivo en una cadena de suministro,»
Revista Ciencias Estratégicas, pp. 295-308, 2015.
CLAIO-2016
913

Métodos de Preenchimento de Matrizes de Posto
Reduzido para o Tratamento de Dados Faltantes na
Análise Envoltória de Dados
Leonardo Tomazeli Duarte∗
Faculdade de Ciências Aplicadas (FCA)Universidade Estadual de Campinas (UNICAMP), Limeira, Brasil
Cristiano TorezzanFaculdade de Ciências Aplicadas (FCA)
Universidade Estadual de Campinas (UNICAMP), Limeira, [email protected]
Resumo
Na análise envoltória de dados (DEA) é necessário, via de regra, realizar algum tipo de pré-processamento dos dados considerados no processo de análise de eficiência. Por exemplo, emmuitas situações práticas, não se tem acesso à totalidade dos dados de entrada e sáıda referentesàs unidades tomadoras de decisão (DMUs), de modo que, em tais situações, torna-se necessáriodispor de alguma estratégia para lidar com esses dados faltantes. Neste contexto, o presentetrabalho propõe a aplicação de uma abordagem recente de preenchimento de matrizes, conhecidacomo aproximação de posto reduzido, para o pré-tratamento de dados faltantes em DEA. Pormeio de experimentos numéricos, a eficácia da abordagem proposta é avaliada, sobretudo noque diz respeito à proporção máxima de dados faltantes para a qual os resultados obtidos pelaDEA se mantem próximos aos obtidos na situação em que não há dados faltantes.
Palavras-chave: Análise envoltória de dados; Dados faltantes; Métodos de preenchimento dematrizes; Matrizes de posto reduzido.
1 Introdução
Desde seu surgimento, no final da década de 1970 [4], a análise envoltória de dados (DEA, do inglêsdata envelopment analysis) vem sendo intensamente utilizada para análise da eficiência relativaentre diferentes unidades tomadoras de decisão (DMUs, do inglês decision making units). TaisDMUs podem representar, por exemplo, filiais de uma empresa, hospitais de uma rede pública desaúde ou universidades de um determinado páıs ou região.
∗L. T. Duarte gostaria de agradecer à Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP)(Processo 2015/16325-1) e ao Conselho Nacional de Desenvolvimento Cient́ıfico e Tecnológico (CNPq) (Processo311786/2014-6) pelo financiamento de sua pesquisa.
CLAIO-2016
914

Em breves termos, a DEA pode ser classificada como uma ferramenta de apoio à decisão mul-ticriterial, que aborda o problema de análise de eficiência a partir da formulação de um modelo deprogramação matemática no qual há dois conjuntos fundamentais de dados. O primeiro deles, oconjunto de dados de entrada, compreende as quantidades de diferentes tipos de recursos utilizadospor cada uma das DMUs. Por exemplo, numa situação em que se deseja comparar universidades,os recursos poderiam representar informações como orçamento, número de professores no quadrodocente, área total da universidade, etc. O segundo conjunto de dados considerado na DEA contémos dados de sáıda, que, tipicamente, estão associados a diferentes tipos de resultados esperados paracada uma das DMUs. Logo, no problema de comparação de universidades, exemplos de dados desáıda incluem número de alunos graduados, número de publicações e número de patentes.
A definição das variáveis que constituirão os dados de entrada e de sáıda nem sempre é umatarefa trivial, de modo que existem diversos trabalhos que propõem diretrizes para tal escolha (ver,por exemplo, [6]). Após essa definição, ainda pode haver certas dificuldades que devem ser tratadasantes da aplicação da DEA. Um desses problemas, que é o foco do presente trabalho, diz respeitoàs situações em que há dados faltantes nas entradas e/ou sáıdas. De fato, nem sempre é posśıvelter acesso a todas as variáveis desejadas para todas as DMUs. Além disso, mesmo em situações nasquais é posśıvel levantar todos os dados de entrada e de sáıda, tal processo pode ser extremamentecustoso em diversos aspectos, o que desperta o interesse em métodos de pré-processamento capazesde lidar com dados faltantes de modo a não inviabilizar a aplicação da DEA.
Classicamente, o problema de dados faltantes vem sendo abordado a partir de ferramentasestat́ısticas, como a estimação de máxima verossimilhança ou a imputação a partir de estat́ısticasde dados vizinhos [12]. Alternativamente, é posśıvel lidar com esse problema por meio de modelosde incerteza baseados em conjuntos fuzzy [8]. Todavia, tanto a abordagem estat́ıstica quanto aquelabaseada em conjuntos fuzzy requerem, via de regra, informações espećıficas sobre o conjunto dedados original. De fato, na abordagem estat́ıstica, os métodos existentes operam — de modo diretoou indireto — com um modelo de distribuição de probabilidades. Já na abordagem via conjuntosfuzzy, modelos de funções de pertinência devem ser definidos previamente pelo usuário.
Uma abordagem mais recente para lidar com dados faltantes explora informações a priori maisgerais sobre os dados [2, 7]. Mais precisamente, a ideia por trás desses novos métodos se apoiana hipótese de que os conjuntos de dados a serem preenchidos podem ser representados por umamatriz cujo posto é significativamente inferior às suas dimensões; por este motivo, tal abordagemvem sendo denominada de métodos de preenchimento de matrizes de posto reduzido. Em termospráticos, a hipótese de posto reduzido, que é um dos pilares do processamento de dados em bigdata [13], pode ser entendida da seguinte maneira: mesmo que um conjunto de dados apresenteuma dimensão elevada, isto é, a matriz de dados tem várias colunas, as relações existentes entre asdiferentes variáveis do conjunto fazem com que a complexidade da matriz de dados — medida aquipelo seu posto — seja inferior ao número de colunas apresentado.
No contexto da DEA, tal hipótese surge naturalmente, pois, em muitas situações, há relaçõestanto entre as variáveis de entrada quanto entre as de sáıda. Por exemplo, no caso de comparaçãodas universidades, é natural haver correlação entre orçamento e o número de professores.
Diante do panorama apresentado, o presente trabalho tem como objetivo investigar a aplicaçãode métodos de preenchimento de matrizes de posto reduzido no contexto da DEA. Através deexperimentos numéricos, buscaremos analisar em quais situações é posśıvel lidar com dados faltantesde modo que a ordenação fornecida pela DEA para as diferentes DMUs seja próxima à ordenaçãoobtida no caso em que todos os dados são conhecidos. Com relação à organização do trabalho,
CLAIO-2016
915

a Seção 2 apresenta o modelo DEA considerado em nossa investigação. Na Seção 3, uma brevedescrição do abordagem de preenchimento de matrizes de posto reduzido é feita. Os experimentosnuméricos conduzidos são apresentados na Seção 4, e, na Seção 5, apresentamos as nossas conclusões.
2 Análise envoltória de dados
A DEA foi introduzida em 1978 por Charnes, Cooper Rhodes [4] e se consolidou como um paradigmametodológico no estudo da eficiência relativa entre unidades tomadoras de decisão. Desde então, atécnica vem sendo utilizada nas mais variadas áreas do conhecimento e tem se mantido como umtema de pesquisa bastante ativo [9].
A ampla aplicabilidade da DEA pode ser atribúıda a duas caracteŕısticas fundamentais: suaabordagem multicritério, que permite a inserção de diversas variáveis na análise de desempenhodas unidades e seu baixo custo computacional, visto que o modelo exige apenas a resolução de umproblema de programação linear para cada DMU envolvida.
A versatilidade da DEA permite também o desenvolvimento de diferentes interpretações e mo-delos, dentre os quais, pode-se destacar: o modelo radial CCR [4]; o modelo escalar BCC [11]; osmodelos multiplicativos [5]; os modelos atitivos estendidos [3]. Como o foco deste trabalho é ainvestigação de métodos para o preenchimento de entradas faltantes na matriz dos dados, o estudoserá baseado no modelo clássico CCR, entretanto os resultados obtidos aqui podem ser estendidosdiretamente para os demais modelos.
2.1 O modelo CCR-DEA
O modelo CCR, proposto originalmente em [4] e ainda amplamente utilizado, consiste em definira eficiência relativa entre diferentes DMUs como um problema de programação fracionária cujasvariáveis são os pesos que cada unidade deve adotar, para ponderar cada um dos critérios utilizadosna análise, de forma a maximizar sua eficiência em comparação com as demais unidades.
Considere n DMUs, cuja eficiência deve ser analisada com relação a m variáveis entradas,denotadas por xik e s variáveis de sáıda, denotadas por yrk. A medida de eficiência para a k-ésimaDMU é definida por
hk = maxvi,ur
s∑
r=1
uryrk
m∑
i=1
vixik
, (1)
onde os pesos vi ≥ 0 e ui ≥ 0 devem ser escolhidos para cada DMU respeitando a restrição
s∑
r=1
uryrj
m∑
i=1
vixij
≤ 1, for j = 1, · · · , n.
A taxa de eficiência hk varia entre 0 e 1, e a unidade k é considerada eficiente se for posśıvelencontrar um conjunto de pesos {v1, · · · , vm} e {u1, · · · , us} tal que hk = 1 e hj ≤ 1 para todo
CLAIO-2016
916

j 6= k. Assim, cada unidade pode formular um problema de otimização para encontrar os pesosque mais lhe favorecem na análise comparada. Esta liberdade na escolha de pesos é uma diferençaimportante da DEA em relação aos métodos gerais de agregação multicritério, que usualmenteutilizam o conjunto de pesos como parâmetros, não como variáveis.
A formulação fracionária (1) pode ser transformada no seguinte problema programação linear(PL):
Maximizar hk :=s∑
r=1
uryrk
Sujeito a
m∑
i=1
vixik= 1,
s∑
r=1
uryrj −m∑
i=1
vixij≤ 0, j = 1, ..., n
ur≥ 0, r = 1, ..., svi≥ 0, i = 1, ...,m.
(2)
O problema (2) deve ser resolvido para cada unidade e o resultado final é a determinação dehiperplanos que definem uma fronteira de eficiência. As DMUs que atingem hk = 1 estão sob afronteira e as demais, que ficam “envelopadas”, são declaradas relativamente ineficientes.
Embora não seja o interesse primordial da DEA, é posśıvel utilizar as eficiências hk para produziruma ordem parcial das unidades, definindo um ranking relativo entre as DMUs, ordenado do maiorpara o menor valor de hk. Essa abordagem baseada em ranking será considerada, no presentetrabalho, para investigar a eficiência dos métodos de preenchimento de dados faltantes no contextoda DEA.
3 Métodos de preenchimento de matrizes de posto reduzido
O problema de preenchimento de matrizes pode ser definido da seguinte maneira. Seja uma matrizA e suponha que se tenha acesso apenas a um subconjunto dos elementos de A, denotado por ΩA.O objetivo é determinar uma aproximação de A, representada por Â, cujos elementos nos ı́ndicesdeterminados por ΩA sejam os mais fiéis posśıveis aos valores de A em ΩA. Evidentemente, talproblema é mal-posto, pois há infinitas soluções para  tal que âij = aij , ∀ (i, j) ∈ ΩA. Logo, oproblema de preenchimento de matrizes requer alguma hipótese adicional sobre a matriz A.
Classicamente, o problema de preenchimento de matrizes é abordado considerando modelosprobabiĺısticos (ou fuzzy) que exigem um conhecimento detalhado sobre A. Mais recententemente,no entanto, uma nova abordagem baseada em uma propriedade mais geral de A foi proposta [2, 7].Tal propriedade é o posto, de modo que a hipótese considerada é que o posto de A é reduzido,ou seja, é consideravelmente inferior às dimensões de A. Em um contexto prático, tal hipótese sejustifica em situações nas quais há relações entre as linhas e/ou entre as colunas da matriz A.
Matematicamente, o problema de preenchimento de matrizes de posto reduzido pode ser for-mulado como o seguinte problema de otimização:
Minimizar posto(Â)Sujeito a âij = aij , ∀(i, j) ∈ ΩA
. (3)
CLAIO-2016
917

Há duas limitações inerentes a esse problema de otimização. A primeira delas é de ordem compu-tacional, pois se trata de um problema de otimização NP-hard [7]. A segunda limitação é de ordemprática, dado que, ao impor a restrição âij = aij , o modelo expresso em (3) não admite rúıdo.
Frente a tais limitações, é posśıvel considerar uma versão relaxada de (3), dada por:
Minimizar ||Â||∗Sujeito a
∑(i,j)∈ΩA
(âij − aij)2 ≤ δ, (4)
onde ||Â||∗ denota a norma nuclear de Â, isto é, a soma dos valores singulares de Â. Quanto àrestrição, há, agora, uma margem de rúıdo, ou seja, basta que a soma dos erros quadráticos entre e A nas posições (i, j) ∈ ΩA seja inferior a um valor pré-estabelecido δ. Há diversos algoritmospara a resolução do problema (4). No presente trabalho, consideraremos o método soft-impute,cujos os detalhes podem ser consultados em [10].
4 Experimentos numéricos
Com o intuito de verificar a eficiência de métodos de preenchimento de matrizes de posto reduzido noâmbito da DEA, a presente seção apresenta um conjunto de experimentos numéricos. Inicialmente,na Seção 4.1, discutimos o procedimento realizado para geração de dados, bem como o protocolodos experimentos. Em seguida, na Seção 4.2, os resultados obtidos são apresentados.
4.1 Geração de dados e protocolo dos experimentos
Os dados considerados na DEA podem ser representados pelas matrizes X ∈ Rm×n (dados deentrada) e Y ∈ Rs×n (dados de sáıda), respectivamente. Em nossas análises, consideraremos asituação onde há s = 1 sáıda, que é gerada a partir do seguinte modelo baseado na função deCobb-Douglas [1]:
y1k = exp(−τk)m∏
i=1
xαik, k = 1, . . . , n, (5)
onde α é uma constante que será fixada em α = 0.3 e τk modela a ineficiência da k-ésima DMU.Essas ineficiências serão obtidas a partir do valor absoluto de realizações de uma variável aleatórianormal de média zero e desvio padrão unitário. Com relação às entradas, a matriz X foi gerada deacordo com o seguinte modelo:
X = G1G2 + 30, (6)
onde G1 ∈ Rm×l e G2 ∈ Rl×n são matrizes cujos elementos são gerados a partir de realizações umavariável aleatória com distribuição normal de média zero e desvio padrão unitário. Note que talmodelo nos permite controlar o posto de X, que é dado por l. Além disso, no caso em que l forpequeno, quando comparado ao número de linhas de X, significa que as entradas consideradas naDEA apresentam fortes relações lineares entre śı. Por fim, assumiremos que todas as sáıdas sãoconhecidas, porém que há dados faltantes na matriz X. Tal estratégia nos permitirá investigar arelação entre a eficácia da etapa de preenchimento de X em função exclusivamente de l.
Os experimentos numéricos foram realizados de acordo com o protocolo ilustrado na Figura 1.Na primeira fase, aplica-se DEA sob a matrizes completas (sem dados faltantes) X e Y geradaspelos modelos expressos em (6) e (5), respectivamente. Com isto é posśıvel obter as eficiências
CLAIO-2016
918

“exatas” (isto é, considerando que não há dados faltantes) hk de cada DMU, bem como a posiçãozk obtida pela k-ésima DMU após ordenação do vetor h = {h1, h2, · · · , hn}. Em seguida, é realizadauma etapa de eliminação dos elementos de X — os ı́ndices dos elementos mantidos serão denotadospor ΩX — com uma taxa controlada de eliminação dada por p ∈ (0, 1). Tal processo resulta namatriz incompleta X̄, cujos elementos são idênticos aos elementos de X nos ı́ndices ΩX e vaziospara os ı́ndices que não se encontram em ΩX .
Num segundo momento, realiza-se uma etapa de preenchimento de X̄ a partir da resoluçãode (4), o que conduz à matriz estimada X̂ — note que tal processo não requer conhecimento damatriz original X. Finalmente, aplica-se DEA sobre X̂, obtendo as eficiências estimadas ĥk e asposições estimadas ẑk.
Matriz completa
X
DEA
Eficiências exatas
Ranking das DMUs
Apagamento
artificial
PreenchimentoMatriz incompleta
X̄
Matriz estimada
X̂
Ranking das DMUs
Eficiências estimadas
DEA
h ĥ
z ẑ
Comparação
Geração de
dados (4)
Figura 1: Esquema do protocolo utilizado nos experimentos numéricos.
Após a determinação dos vetores h = {h1, h2, · · · , hn}, ĥ = {ĥ1, ĥ2, · · · , ĥn}, z = {z1, z2, · · · , zn}e ẑ = {ẑ1, ẑ2, · · · , ẑn}, torna-se posśıvel comparar os resultados obtidos pela DEA nos seguintescasos: 1) se conhece exatamente a matriz de entrada X e 2) a matriz de entrada considerada, X̂,é uma aproximação de X obtida a partir de X̄. Para tanto, consideraremos as seguintes medidasde erro como métricas de desempenho:
• Eh =||h− ĥ||2||h||2
, onde ||h||2 =
√√√√n∑
i=1
h2i denota a norma euclidiana do vetor h.
Esta medida fornece o erro relativo em relação ao vetor de eficiências h, obtido com a matrizoriginal X e o vetor de eficiências ĥ, obtido com a matriz recuperada X̂.
• Ez = ||z− ẑ||K, onde ||z− ẑ||K denota a distância de Kendall tau normalizada entre as listasz e ẑ, definida da seguinte forma,
||τ1−τ2||K =2
n(n− 1)|{(i, j) : i < j, (τ1(i) < τ1(j)∧τ2(i) > τ2(j)∨(τ1(i) > τ1(j)∧τ2(i) < τ2(j)}|,
onde τ1(i) e τ2(i) representam, respectivamente, as posições do elemento i nas listas τ1 eτ2, e n denota o comprimento das listas. A métrica de Kendall tau normalizada é utilizadapara aferir distâncias entre rankings de forma que se verifiquem as seguintes propriedades: i)0 ≤ ||τ1 − τ2||K ≤ 1; ii) ||τ1 − τ2||K = 0 se, e somente se, i e j tem a mesma ordem nas listasτ1 e τ2; iii) ||τ1 − τ2||K = 1 se, e somente se, i e j tem ordens opostas nas listas τ1 e τ2.
CLAIO-2016
919
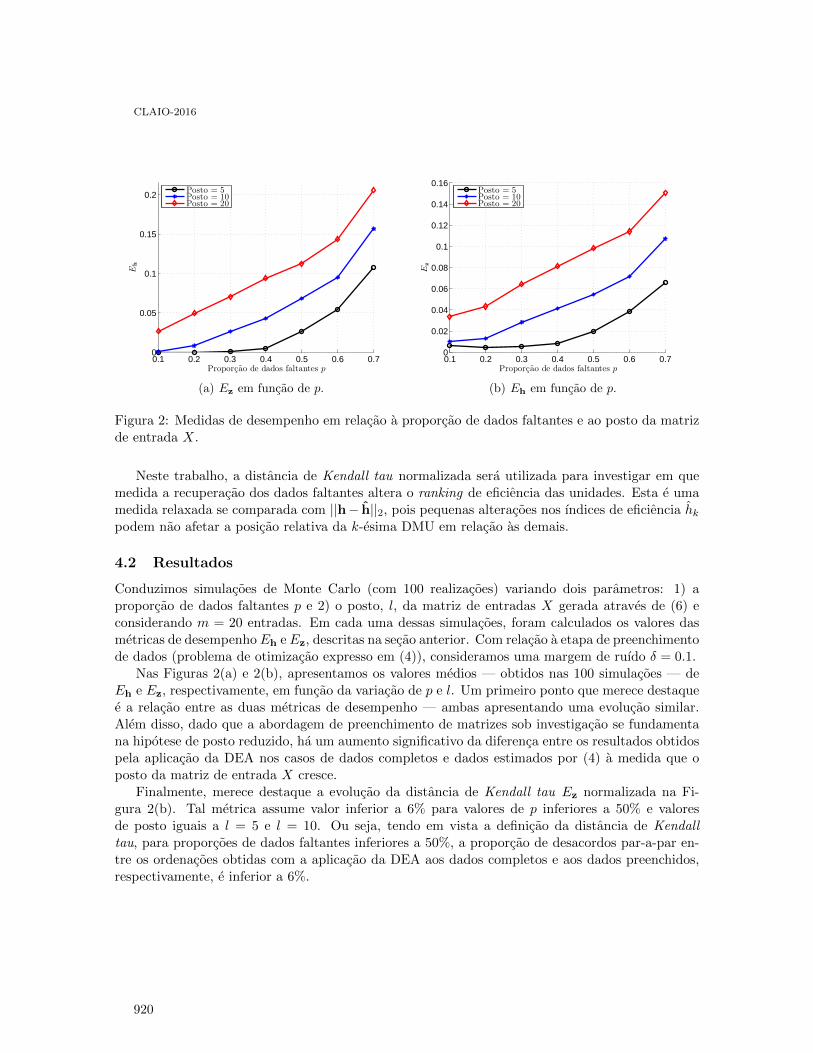
0.1 0.2 0.3 0.4 0.5 0.6 0.70
0.05
0.1
0.15
0.2
Proporção de dados faltantes p
Eh
Posto = 5Posto = 10Posto = 20
(a) Ez em função de p.
0.1 0.2 0.3 0.4 0.5 0.6 0.70
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
Proporção de dados faltantes p
Ez
Posto = 5Posto = 10Posto = 20
(b) Eh em função de p.
Figura 2: Medidas de desempenho em relação à proporção de dados faltantes e ao posto da matrizde entrada X.
Neste trabalho, a distância de Kendall tau normalizada será utilizada para investigar em quemedida a recuperação dos dados faltantes altera o ranking de eficiência das unidades. Esta é umamedida relaxada se comparada com ||h− ĥ||2, pois pequenas alterações nos ı́ndices de eficiência ĥkpodem não afetar a posição relativa da k-ésima DMU em relação às demais.
4.2 Resultados
Conduzimos simulações de Monte Carlo (com 100 realizações) variando dois parâmetros: 1) aproporção de dados faltantes p e 2) o posto, l, da matriz de entradas X gerada através de (6) econsiderando m = 20 entradas. Em cada uma dessas simulações, foram calculados os valores dasmétricas de desempenho Eh e Ez, descritas na seção anterior. Com relação à etapa de preenchimentode dados (problema de otimização expresso em (4)), consideramos uma margem de rúıdo δ = 0.1.
Nas Figuras 2(a) e 2(b), apresentamos os valores médios — obtidos nas 100 simulações — deEh e Ez, respectivamente, em função da variação de p e l. Um primeiro ponto que merece destaqueé a relação entre as duas métricas de desempenho — ambas apresentando uma evolução similar.Além disso, dado que a abordagem de preenchimento de matrizes sob investigação se fundamentana hipótese de posto reduzido, há um aumento significativo da diferença entre os resultados obtidospela aplicação da DEA nos casos de dados completos e dados estimados por (4) à medida que oposto da matriz de entrada X cresce.
Finalmente, merece destaque a evolução da distância de Kendall tau Ez normalizada na Fi-gura 2(b). Tal métrica assume valor inferior a 6% para valores de p inferiores a 50% e valoresde posto iguais a l = 5 e l = 10. Ou seja, tendo em vista a definição da distância de Kendalltau, para proporções de dados faltantes inferiores a 50%, a proporção de desacordos par-a-par en-tre os ordenações obtidas com a aplicação da DEA aos dados completos e aos dados preenchidos,respectivamente, é inferior a 6%.
CLAIO-2016
920

5 Conclusões
Propomos, no presente trabalho, a aplicação de métodos de preenchimento de matrizes de postoreduzido para o pré-tratamento de dados faltantes na matriz de entrada da análise envoltória dedados (DEA). Com o intuito de verificar o desempenho da abordagem proposta, conduzimos umconjunto de experimentos numéricos considerando diferentes valores de posto da matriz de entradae diferentes proporções de dados faltantes. Foi posśıvel observar, que mesmo no caso em que metadedos dados de entrada não estão dispońıveis, a aplicação do método de preenchimento investigadopermite que a DEA obtenha uma ordenação próximo àquela obtida na situação em que todos osdados de entrada são conhecidos.
Os próximos passos dessa pequisa incluem a aplicação da abordagem proposta em dados reais,bem como a busca por limitantes teóricos de desempenho da DEA em relação à proporção de dadosfaltantes.
Referências
[1] R. D. Banker, A. Charnes, and W. W. Cooper. Some models for estimating technical and scale ineffi-ciencies in data envelopment analysis. Management Science, 30(9):1078–1092, 1984.
[2] E. J. Candès and B. Recht. Exact matrix completion via convex optimization. Foundations of Compu-tational mathematics, 9(6):717–772, 2009.
[3] A. Charnes, W. W. Cooper, A. Y. Lewin, and L. Seiford. Data Envelopment Analysis: Theory, Metho-dology, and Application. Kluwer Academic Publishers, Norwell, MA, USA, 1st edition, 1995.
[4] A. Charnes, W. W. Cooper, and E. Rhodes. Measuring the efficiency of decision making units. EuropeanJournal of Operational Research, 2(6):429–444, 1978.
[5] A. Charnes, W.W. Cooper, L. Seiford, and J. Stutz. A multiplicative model for efficiency analysis.Socio-Economic Planning Sciences, 16(5):223 – 224, 1982.
[6] C. Cobb and P. H. Douglas. A theory of production. American Economic Review, 18, 1928.
[7] R.G. Dyson, R. Allen, A. S. Camanho, V. V. Podinovski, C. S. Sarrico, and E. A. Shale. Pitfalls andprotocols in DEA. European Journal of Operational Research, 132(2):245–259, 2001.
[8] T. Hastie, R. Tibshirani, and M. Wainwright. Statistical Learning with Sparsity: The Lasso and Gene-ralizations. CRC Press, 2015.
[9] C. Kao and S.-T. Liu. Data envelopment analysis with missing data: an application to universitylibraries in Taiwan. Journal of the Operational Research Society, pages 897–905, 2000.
[10] John S. Liu, Louis Y.Y. Lu, and Wen-Min Lu. Research fronts in data envelopment analysis. Omega,58:33 – 45, 2016.
[11] R. Mazumder, T. Hastie, and R. Tibshirani. Spectral regularization algorithms for learning largeincomplete matrices. The Journal of Machine Learning Research, 11:2287–2322, 2010.
[12] J. L. Schafer and J. W. Graham. Missing data: our view of the state of the art. Psychological methods,7(2):147, 2002.
[13] S. Theodoridis. Machine Learning: A Bayesian and Optimization Perspective. Academic Press, 2015.
CLAIO-2016
921

The multiperiod cutting stock problem with usable leftover
Gabriela Torres Agostinho
Departamento de Engenharia de Produção, FEB, UNESP, Bauru SP, Brasil.
Adriana Cristina Cherri
Departamento de Matemática, FC, UNESP, Bauru SP, Brasil.
Silvio Alexandre de Araujo
Departamento de Matemática Aplicada, IBILCE, UNESP, São José do Rio Preto, SP, Brasil.
Douglas Nogueira do Nascimento
Departamento de Computação, FC, UNESP, Bauru SP, Brasil.
Abstract
This paper aims to integrate two variations of the one-dimensional cutting stock problem: the cutting stock
problem with usable leftovers and the multiperiod cutting stock problem. Also, it tries to find a solution to
the problem resulting from this integration. The cutting stock problem with usable leftovers consists of
cutting large objects into smaller items in order to meet a known demand, minimizing the waste and
allowing generate retails that will be used to cut future items. In the multiperiod cutting stock problem
demands occur in a finite period of time, being possible to cut in advance a stored object to produce items
that have known demands in a future period of time. A mathematical model is proposed for the multiperiod
cutting stock problem with usable leftover and is being solved using simplex method with column
generation. Some preliminary computational results are presented with a simulation where each period is
considered individually.
Keywords: multiperiod cutting stock problem; usable leftovers; linear and integer optimization.
1 Introduction
The cutting stock problem (CSP) consists of cutting a set of objects available in stock in order to
produce a set of demanded items for clients or to add stock, seeking to optimize an objective function.
These problems appear in the production lines of several industries as paper, aluminum, steel, glass and
wood, among other. In the sixties several important works relating to CSP were published, highlighting the
papers Gilmore and Gomory (1961) and (1963).
A particularity of CSP consists in usable leftover of cutting patterns. This problem was cited by
Brown (1971) and is known in the literature as cutting stock problem with usable leftovers (CSPUL). In
this problem, a set of demanded items must be produced by cutting either standard objects or retails
available in stock. Similar to the CSP, the demands of items and the objects in stock are known. The
CLAIO-2016
922

demands must be met by cutting the available objects and retails, with the possibility to generate limited
quantities of predefined retails for stock.
Roodman (1986) considered the use of leftovers in the CSP to solve a one-dimensional problem
with several types of objects in stock. After the cutting process, the leftovers generated, since larger than a
certain length, were stored as retails to be used in the future. Scheithauer (1991) modified the problem
proposed by Gilmore and Gomory (1963) to consider the usable leftovers. The strategy used by this author
consists of including extra items (retails) in the problem without any demand to be met. Gradisar et al.
(1997) presented a mathematical model to solve the CSPUL, however, a heuristic procedure was used to
solve the problem. Gradisar et al (1999) developed a strategy to solve the CSPUL that combines linear
programming and heuristic procedure.
Abuabara and Morabito (2009) used the mathematical model proposed by Gradisar et al. (1997)
to solve the CSPUL in a Brazilian company that builds agricultural aircrafts. Cherri et al. (2009) proposed
modifications on constructive and residual heuristics of the literature for solving the CSPUL. Cui and Yang
(2010) proposed an extension for the model in Scheithauer (1991) that limits the objects in stock by
controlling the quantity of retails generated in the cutting patterns. Cherri et al. (2013) modified the
heuristics developed in Cherri et al. (2009). In addition to the waste minimization, the usage of stocked
retails was prioritized during the cutting process. Cherri et al. (2014) presented in a survey the existing
papers that investigate the one-dimensional CSPUL.
Arenales et al. (2015) proposed a mathematical model to solve the CSPUL with the objective of
minimizing the waste of material. By this model, retails have length and quantities previously defined and
can be generated for stock just to reduce the waste. This model was solved using the column generation
technique proposed in Gilmore and Gomory (1963) and optimal continuous solutions were obtained.
Poldi and Arenales (2010) studied another variation of CSP, that is the multiperiod cutting stock
problem (MCSP). In this problem, the demand of items is required in different periods of a finite planning
horizon, being possible to anticipate or not their production. The objects not used in a period are stored for
the next period together with the new acquired objects. Poldi and de Araujo (2016) extended the research
presented in Poldi and Arenales (2010) and generalized the mathematical model proposed by Gilmore and
Gomory (1963) and the arc flow model (Valério de Carvalho, 1999, 2002) to solve the MCSP. In these
models, the objects in stock were considered as both parameters and variables.
The integrations of the CSPUL and MCSP were not found in the literature and will be studied in
this paper. Thus, decisions about generating retails or anticipating the production of items must be taken.
A mathematical model to represent this problem was proposed. Implementations are being developed and
must provide good solutions for the problem. By convenience, we used CSPULM to refer to cutting stock
problem with usable leftovers multiperiod.
The remainder of the present paper is organized as follows: in Section 2 the CSPULM together
with the proposed mathematical model and the strategy solution are defined. As the proposed model is still
being implemented, in Section 3 a strategy to consider the CSPUL simulating periods is presented. In
Section 4 some computational tests using an approaching by period are presented. With these tests, we aim
to show that our approach using CSPULM is promising. Conclusions are presented in Section 5.
2 Problem definition and mathematical modeling
In a multiperiod problem a finite planning horizon is divided into T periods, t = 1, …, T. In each
period t of the planning horizon, objects are available in stock and the demand of items has to be met. The
multiperiod cutting stock problem with usable leftovers (MCSPUL) consists of cutting a set of standard
objects (objects bought on the market) or non-standard objects (retails generated in previous cuts) available
in stock in each period of the planning horizon, in order to produce a set of demanded items with the
objective of minimize the production costs. In this problem, in each period t, new retails can be generated
CLAIO-2016
923

in quantities and lengths previously defined. Furthermore, as the demand of items is known in the planning
horizon, it is possible to anticipate or not their production.
By the definition of the MCSPUL, there is a decision to be made: to generate retails or anticipate
the demand. The mathematical model proposed to solve this problem was based in Arenales et al. (2015).
The following data were used in the model:
S: number of types of standard objects. We denote object type s, s = 1, …, S;
R: number of types of retails in stock. We denote leftover type k, k =1, ..., R;
T: number of periods of time,
m: number of types of demanded items;
est: number of objects type s available in stock in period t, s = 1, …, S; t = 1, ..., T;
erkt: number of retails type k available in stock in period t, k = 1, ..., R; t = 1, ..., T;
dit: demand for item type i in period t, i = 1, …, m, t = 1, ..., T;
Jst: set of cutting patterns for object type s in period t, s = 1, ..., S; t = 1, ..., T;
Jst(k): set of cutting patterns for object type s generating a retail type k in period t, k = 1, …, R, s = 1,
…, S, t = 1, ..., T;
Jrkt: set of cutting patterns for retail type k in period t, k = 1, ..., R, t = 1, ..., T;
aijst: number of items type i in cutting pattern j for object type s in period t, i = 1, ..., m, j Jst, s = 1,
..., S, t = 1, ..., T;
aijskt: number of items type i in cutting pattern j for object type s generating a retail type k in period t,
i = 1, ..., m, j Jst(k), s = 1, ..., S, k = 1, ..., R, t = 1, ...,T;
arijkt: number of items type i in cutting pattern j for retail type k in period t, i = 1, ..., m, j Jrkt, s = 1,
..., S, t = 1, ..., T;
Ukt: maximum number allowed for retails type k in period t, k = 1, ..., R, t = 1, ...,T;
Parameters:
cjst: waste of cutting object type s according to pattern j in period t, j Jst, s = 1, ..., S, t = 1, ..., T;
cjskt: waste of cutting object type s according to pattern j when generating a retail type k in period t,
j Jst(k), s = 1, ..., S, k = 1, ..., R, t = 1, ...,T;
crjkt: waste of cutting retail type k according to pattern j in period t, j Jrkt, k = 1, ..., R; t = 1, ..., T;
pyit: cost to stock the item type i at the end of the period t, i = 1, ..., m, t = 1, ..., T;
pwst: cost to stock the object type s at the end of the period t, s = 1, ..., S; t = 1, ...,T;
pzkt: cost to stock the retail type k at the end of the period t, k = 1, ..., R, t = 1, ...,T;
Variables:
xjst: number of objects type s cut according to pattern j in period t, s = 1, ..., S, j Jst, t = 1, ..., T;
xjskt: number of objects type s cut according to pattern j and generating a retail type k in period t, s =
1, ..., S, j Jst(k), k = 1, ..., R, t = 1, ..., T;
xrjkt: number of retail type k cut according to pattern j in period t, s = 1, ..., S, j Jrkt, t = 1, ..., T;
yit: number of items type i anticipated for the period t, i = 1, ..., m, t = 1, ..., T;
wst: number of objects type s not used in period t, and available in period t + 1, s = 1, ..., S; t = 1, ...,
T; zkt: number of retails type k not used in period t, and available in period t + 1, k = 1, ..., R, t = 1, ...,
T;
CLAIO-2016
924

Mathematical Model:
Minimizing
1 1 1 1 ( ) 1 1 1 1st st kt
T S S R R m S R
jst jst jskt jskt jkt jkt it it st st kt kt
t s j J s k j J k k j Jr i s k
c x c x cr xr py y pw w pz z
(1)
Subject to
1
1 1 1 ( ) 1
,st st kt
S S R R
ijst jst ijskt jskt ijkt jkt t t it
s j J s k j J k k j Jr
a x a x ar xr y y d
i=1, ..., m ,t =1,...,T (2)
1
1 ( )
,st st
R
jst jskt t t st
j J k j J k
x x w w e
s = 1, ..., S, t = 1,...,T (3)
1 ,kt
jkt t t kt
j Jr
xr z z er
k= 1, ..., R , t = 1,...,T (4)
1 ( )
,st kt
S
jskt jkt kt kt
s j J k j Jr
x xr U er
k=1,..., R, t=1,…,T (5)
0,jstx s = 1, ..., S, t = 1, ..., T, stj J and integer; (6)
0,jsktx s = 1, ..., S, k = 1, ..., R, t = 1, ..., T, ( )stj J k and integer;
0jktxr , k = 1, ..., R, t = 1, ..., T, ktj Jr and integer;
0ity , i = 1, ..., m, t = 1, ..., T and integer;
0stw , s = 1, ..., S; t = 1, ...,T and integer;
0ktz , k = 1, ..., R; t = 1, ...,T and integer
In the model (1)-(6), the objective function (1) minimizes the waste and inventory costs. Constraint
(2) refers to demand of item in each period. Constraints (3) and (4) guarantee that the quantity of standard
objects or retails used during the cutting process is not higher than the available quantity in stock in each
period. Constraint (5) limits the quantity of retails that can be generated for each type during the cutting
process in each period. Constraint (6) refers to integrality and non-negativity of the variables used.
This model can be solved from modifications in the simplex method with column generation,
proposed by Gilmore and Gomory (1963) that is an efficient strategy to solve linear problems. As the
integrality conditions of the variables (constraint (6)) make the solution of the model (1)-(6) difficult to find
at the optimality, this conditions are relaxed and continuous solutions can be found to the problem.
Afterwards, rounding heuristic can be applied to find an integer solution.
We are currently implementing this solution method using language C with CPLEX software, that
is a mathematical optimization tool for solving mixed linear optimization problems, among others. The
current version of the program solves the model considering each period separately, according to what is
described in the next section. A heuristic procedure is also presented.
3 Simulation by periods and heuristic procedure
The simulation of time periods can be used to address the day by day production of a company. In
the simulation with the CSPUL, in each period (that can be measured in days, hours, etc) the demands are
met (lot for lot production) and information about the retails that were generated during the cutting process
CLAIO-2016
925

of the current period is transferred to the next period. Standard objects are always available and their
updating is not necessary. In each period, the retails generated in the previous period are included into the
stock. However, there is no inventory of items (Cherri et al., 2013). Using this simulation, it is possible
evaluate the advantages of the generation of retails during the planning horizon.
Although this situation considers periods of time, it cannot be classified as a multiperiod problem
since the item types and their demands are unknown for the future periods. Also, in a multiperiod problem
the inventory of the standard objects must be analyzed and replaced if necessary. For a multiperiod problem
see Poldi and Arenales (2010).
The simulation by periods was performed considering the model (1)-(6). As the integrality
constraints (6) were relaxed, a relax-and-fix heuristic was used to obtain integer solution for the problem.
According to Cherri (2013), the relax-and-fix heuristic solve the problem by stages and, in each stage, a
sub-problem of the original problem is solved exactly. Therefore, the integer variables of the problem are
divided in three groups: fixed variables, not fixed integer variables (free) and linearly relaxed integer
variables. In each step of the method, we have a sub-problem and each integer variable of the problem must
belong to one of these groups. After each step, a solution is obtained for the sub-problem. So, free integer
variables are fixed with the value of the found solution. From the relaxed set of integer variables, a new
subset of variables (a partition) is chosen to be composed of free integer variables. This procedure is realized
until all integer variables of the original problem have been fixed.
Basically, the developed procedure consists in:
Step 1: Generate a solution using the mathematical model (1)-(6), with the relaxed integrality constraints;
Step 2: Set as integer the variables related to the frequencies of the cutting patterns that provide waste
lower than or equal to 2% of the length of the cut object. If there are no cutting patterns that meet this
criteria, the frequency of the variable of the four cutting pattern with lower waste is set as integer.
Step 3: Solve the problem again, using the mathematical model (1)-(6);
Step 4: Set as integer the frequencies of the selected cutting patterns in step 2 using the integer value
obtained in the solution of step 3. The procedure does not require that all selected cutting patterns in
step 2 are in the solution of step 3, because in some iteration might not be possible to find a feasible
solution. The only requirement is that the solution of step 3 contains at least one of the cutting patterns
selected in step 2;
Step 5: Return to step 2 and repeat this procedure until all cutting pattern have integer values for the
frequencies.
In order to improve the performance of the heuristic procedure, as the leftover in the last cutting
pattern is generally very large, it is stored since it is as long as or longer than the smallest allowed retail.
When leftover like this is available in stock, the procedure ensures that it will be the first object to be cut.
With the integer solution, it is possible make the analysis of the solution using a simulation by periods.
4 Computational tests
Aiming to show that our approach using CSPULM is promising MCSPUL, we have conducted a
simulation with 5 periods of time (Cherri et al., 2013). With these tests, we have tried to simulate the daily
production of a company. Model (1)-(6) and the heuristic procedure were implemented using the OPL
interface of the software CPLEX 12.6. The experiments were executed on an Intel Core 2.20 GHz, 8 GB
RAM computer.
The generated problems consider one type of standard object with length 1200 and availability
enough to meet the items demand of all period. Three types of retails can be generated with lengths 400,
500 and 650. Fifteen types of items are generated in all periods. The lengths of the items were generated
CLAIO-2016
926

considering two size categories: medium (M) and large (L). For each category, the length was generated in
the following intervals: medium items (M): [140, 400] and large items (L): [300, 700].
The item demand was generated considering three categories: low (L), medium (M), and high (H).
For each category, the demand was generated in the following intervals: low demand (L): [1, 10]; medium
demand (M): [10, 50] and high demand (H): [50, 300]. The maximum number of generated retails of each
type was: Uk = 0, Uk = 2, Uk = 4, Uk = 8, k = 1, 2, 3. That is, when Uk = 8, at most 8 retails can be generated
to stock per period. In the tests, we also analyze the solution for the classical cutting stock problem (Uk =
0 erk = 0, k = 1, ..., 3);
Combining the length and demand categories, six instance classes were randomly generated. For
example, the class [L,H] represents a class with large items and high demand. These are the values that we
have established for the tests, but other values also could have been used.
Table 1 shows the average waste for the 5 periods using the relax-and-fix heuristic. In all classes,
in the first period the stock is composed only of standard objects, that is, erk = 0, k = 1, ..., 3. From the
second period, the retails generated in the first period will be in stock and must be cut.
Table 1: Average waste for 5 periods.
Class U = 0 U = 2 U = 4 U = 8
[M,L] 594.80 154.80 154.80 124.80
[M,M] 1328.00 638.00 542.00 558.00
[M,H] 2186.00 1674.40 1626.00 1606.00
[L,L] 1947.20 1447.20 1337.20 1247.20
[L,M] 15319.40 14020.80 13267.60 12267.60
[L,H] 122924.00 112584.00 111884.00 111484.00
Considering a simulation by periods with a lot for lot production, it is possible to observe by the
Table 1 that the waste decreases for larger values of U. This is an expected situation because the possibility
to generate retails increases the diversity of objects in stock for the next period. Thereby, there will be more
possibilities to generate the cutting patterns. Furthermore, the retails are generated during the cutting
processes just to reduce the waste. This justify the larger waste for U = 0.
Figure 1 depicts the percentage waste reduction for the integer solutions in terms of U related to
the classical CSP (U = 0).
Figure 1: Percentage of waste reduction for each instances classes.
By Figure 1, it is possible to observe that the percentage of waste reduction for each instances class
is very significant. For medium items there are more possibilities of combinations in a cutting pattern
compared to large items. Due this characteristic, for the classes [ML] and [MM] together with the possibility
of generate retail, that also increases the quality of the cutting process (Table 1), the percentage of waste
reduction was over 58%.
CLAIO-2016
927

5 Conclusions
In this paper, we present the multiperiod cutting stock problem with usable leftovers. In this
problem, in each period, new retails can be generated in quantities and length previously defined and, as
the demand of items is known in the planning horizon, it is possible to anticipate forward or not their
production. Thus, there is a decision that is to generate retails x anticipate the demand. A mathematical
model was proposed to represent this problem and the solution method is being developed.
To show that our approach is promising, we present solutions simulating periods of time, that is,
for each period we have a cutting stock problem to be solved whose stock depends on previous generated
retails together with the standard objects. Different from the multiperiod problem, for the simulation the
demand of items is not known previously and is not possible to anticipate it during the periods. The results
obtained for this problem showed clearly, in terms of wastes, that generate retails is better than consider
situations that do not allow the generation of retails.
As future reaserch, the implementations for the solution method to solve the multiperiod model
will be finished and computational tests will be performed to show the performance of the proposed model.
Compared to the results presented in Section 4, the expectative is to obtain better solutions. Since the whole
demand will be known in a period of time, it will be possible to anticipate de production of demanded items
or generate retails. This choice will be made during the cutting process according to the reduction on the
productions costs.
Acknowledgment
The authors would like to thank the Fundação de Amparo a Pesquisa do Estado de São Paulo
(FAPESP – Processes: 15/03066-8 and 14/01203-5) and Conselho Nacional de Desenvolvimento Científico
e Tecnológico (CNPq – Bolsista CNPq and Processes: 477481/2013-2 and 442034/2014-8) for the financial
support.
References
1. A. Abuabara and R. Morabito. Cutting optimization of structural tubes to build agricultural light aircrafts, Annals
of Operations Research, 149(1):149-165, 2009.
2. M. N. Arenales, A. C. Cherri, D. N. do Nascimento and A. C. G. Vianna. A new mathematical model for the
cutting stock/leftover problem, Pesquisa Operacional, 35(3):1-14, 2015.
3. A. R. Brown. Optimum packing and depletion: the computer in space and resource usage problem. Macdonald
– London and American Elsevier Inc, New York, 1971.
4. A. C. Cherri, M. N. Arenales and H. H. Yanasse. The one-dimensional cutting stock problem with usable leftover
– A heuristic approach. European Journal of Operational Research, 196(3):897-908, 2009.
5. A. C. Cherri, M. N. Arenales and H. H. Yanasse. The usable leftover one-dimensional cutting stock problem – a
priority-in-use heuristic. International Transactions in Operational Research, 20(2):189-199, 2013.
6. A. C. Cherri, M. N. Arenales and H. H. Yanasse. The one-dimensional cutting stock problem with usable leftovers
– A survey. European Journal of Operational Research, 236(2):395-402, 2014.
7. L. H. Cherri, Um método híbrido para o problema de dimensionamento de lotes. Dissertação de mestrado –
Instituto de Ciências Matemáticas e Computação, Universidade de São Paulo, 2013.
8. C. Chu and J. Antonio. Approximation algorithms to solvereal-life multicriteria cutting stock problems.
Operations Research, 47(4):495-508, 1999.
9. Y. Cui and Y. Yang. A heuristic for the one-dimensional cutting stock problem with usable leftover. European
Journal of Operational Research, 204(2):245-250, 2010.
CLAIO-2016
928

10. P. C. Gilmore and R. E. Gomory. A linear programming approach to the cutting stock problem. Operations
Research, 9(6):848-859, 1961.
11. P. C. Gilmore and R. E. Gomory. A linear programming approach to the cutting stock problem – Part II.
Operations Research, 11(6):863-888, 1963.
12. M. Gradisar, J. Jesenko, C. Resinovic. Optimization of roll cutting in clothing industry. Computers & Operational
Research, 24(10):945-953, 1997.
13. M. Gradisar, C. Resinovic and M. Kljajic. A hybrid approach for optimization of one-dimentional cutting.
European Journal of Operational Research, 119(3):719-728, 1999.
14. K. C. Poldi and M. N. Arenales. The problem of one-dimensional cutting stock multiperiod. Pesquisa
Operacional, 30(1):153-174, 2010.
15. K. C. Poldi and S. A. de Araujo. Mathematical models and a heuristic method for the multiperiod one-dimensional
cutting stock problem. Annals of Operations Research, 238(1):497-520, 2016.
16. G. M. Roodman. Near-optimal solutions to one-dimensional cutting stock problem. Computers and Operations
Research, 13(6):713-719, 1986.
17. G. Scheithauer. A note on handling residual length. Optimization, 22(3):461-466, 1991.
18. J. M. Valério de Carvalho. Exact solution of bin-packing problems using column generation and branch-and-
bound. Annals of Operations Research, 86:629-659, 1999.
19. J. M. Valério de Carvalho. LP models for bin packing and cutting stock problems. European Journal of
Operational Research, 144:253-273, 2002.
CLAIO-2016
929

Modelos matemáticos para o problema de
dimensionamento e sequenciamento de lotes em dois
estágios com limpezas periódicas
Alyne Toscano
Universidade Federal do Triângulo Mineiro
Deisemara Ferreira, Reinaldo Morabito
Universidade Federal de São Carlos
[email protected],[email protected]
Resumo
Neste trabalho é apresentado um estudo sobre o problema de planejamento e programaçãoda produção de bebidas à base de frutas. Trata-se de um problema de dimensionamento esequenciamento de lotes em dois estágios de produção com particularidades: presença de umestoque intermediário entre os estágios, limpezas periódicas no primeiro e segundo estágios e anecessidade de sincronia entre os estágios. Até onde se observou esse problema ainda não foiabordado na literatura. Como proposta de solução são apresentados dois modelos inteiro mistosque encontram uma solução aproximada para o problema. As soluções obtidas com os modelospassam por um pós-processamento em que é feito um ajuste da sincronia entre os dois estágios.Por serem modelos aproximados, em um a capacidade de produção é super estimada (Modelo1 - Otimista) e no outro sub estimada (Modelo 2 - Pessimista). Testes computacionais foramrealizados com instâncias baseadas em dados reais e mostram que o Modelo 1 encontra maissoluções factíveis e de melhor qualidade do que o Modelo 2.
Palavras-chave: Dimensionamento e Sequenciamento de Lotes; Bebidas à base de frutas; Lim-pezas Periódicas.
1 Introdução
Existe atualmente uma tendência mundial de consumo de alimentos funcionais (alimentos ou in-gredientes que possuem efeitos bené�cos à saúde). A Euromonitor Internacional [6] con�rma, porexemplo, o aumento do consumo e da produção mundial de bebidas não alcoólicas, tais como chás,sucos e bebidas à base de frutas. O crescimento desse nicho de mercado faz com que haja umamaior competitividade entre as indústrias de bebidas. Um dos diferenciais para obtenção do sucessoestá diretamente relacionado à redução de custos, inclusive custos de produção. Nesses custos estãoenvolvidos, por exemplo, os custos de parada de máquina e atraso. A redução destes custos dependede um planejamento e programação da produção otimizados à médio e curto prazos.
Jans e Degraeve [8] destacam que uma das áreas que apresenta maior crescimento, e é umadireção próspera para a pesquisa, é a resolução de problemas reais de dimensionamento de lotes,em que as características próprias de cada sistema de produção são os diferenciais dos modelos.
Existem na literatura alguns trabalhos que tratam o problema de planejamento da produção debebidas a longo prazo [7], [10]. Também existem trabalhos que tratam a programação da produção
CLAIO-2016
930

através de modelos de dimensionamento e sequenciamento de lotes e que levam em consideração asparticularidade especí�cas de cada tipo de produção, como em refrigerantes [4, 5] e cerveja [2]. Oprocesso de produção de bebidas à base de frutas possui características distintas dos outros processosde bebida: estoque intermediário entre os dois estágios de produção que garante um lote de folgapara o primeiro estágio; pasteurização e envase asséptico em embalagens cartonadas; controle dequalidade com limpezas periódicas; tempos e custos de limpezas periódicas �xos e tempos e custosde troca dependentes da sequência de produção. Até onde se pesquisou não existe nenhum trabalhona literatura que aborde todas essas características juntas nessa aplicação.
Neste trabalho estuda-se o planejamento e programação da produção de bebidas à base defrutas. Na Seção 2 é apresentada a descrição do problema. Dois modelos matemáticos para resolvero problema são apresentados na Seção 3. Testes computacionais foram realizados com instânciasbaseadas em dados reais e são apresentados na Seção 3. Na Seção são apresentadas as conclusões eas perspectivas para pesquisas futuros.
2 Descrição do Problema
As bebidas à base de frutas (sucos, néctares e refrescos), seguem basicamente o mesmo processode produção geral: preparo da bebida, pasteurização, envase e empacotamento. Essas etapas deprodução são divididas em dois estágios. O primeiro estágio, denominado Xaroparia, é compostopelo preparo da bebida. Os processos de pasteurização, envase e empacotamento compõem o segundoestágio, denominado Linha.
A produção se inicia em tanques preparatórios na xaroparia. Nesses tanques acontece a misturade água com os ingredientes que se transformam na bebida pronta para ser enviada à linha. Existeuma quantidade mínima de bebida que deve ser produzida devido ao uso de matéria-prima, e aquantidade máxima é de�nida pelo tamanho dos tanques preparatórios. Essas quantidades de�nemos lotes máximos e mínimos de produção. Depois de pronta a bebida é enviada através de tubulaçõespara tanques pulmões, que se encontram no segundo estágio (linha). Deles a bebida passa porpasteurizadores e segue para ser envasada em máquinas de envase. Ao receber o lote que estápronto na xaroparia, suponhamos um lote s, o tanque pulmão �ca abastecendo a linha com esselote s. Logo, a xaroparia é liberada para a produção do próximo lote (s + 1), enquanto a linhaestá envasando o lote s. Portanto, os tanques pulmões podem ser considerados como um estoqueintermediário de um lote entre o preparo e o envase da bebida nas máquinas de envase, pois possuema mesma capacidade dos tanques preparatórios.
As embalagens utilizadas no envase da bebida em cada linha de produção são embalagens car-tonadas e todas do mesmo tamanho, mudando apenas o rótulo. Logo, as paradas da linha ocorremapenas para a realização de limpezas, denominadas de CIP (Clear in Place). Os CIPs ocorrem emdois momentos: no início de cada período e a cada TLmax horas de produção contínua do mesmosabor. Na xaroparia também é necessária a realização de CIP no início do período e a cada TPmax
horas de preparo contínuo do mesmo sabor. Neste caso o tempo de produção contínua para exi-gência de um CIP, TPmax, é menor do que o da linha TLmax (Figura 1). Devido à relação com otempo, os CIPs realizados a cada determinado tempo de produção contínua do mesmo sabor sãodenominados limpezas periódicas. O tempo para a realização de uma limpezas periódica (CIP) é �xoe não dependem da sequência de produção. Para troca de sabor também são realizadas limpezas,porém, neste caso os tempos e os custos de troca são dependentes da sequência dos sabores.
Para que seja possível encontrar uma programação da produção factível para esse problema, épreciso considerar a sincronia entre os estágios. Os tempos em que o tanque preparatório (xaroparia
CLAIO-2016
931

- Estágio I) espera para enviar a bebida pronta para o tanque pulmão, e os tempos em que otanque pulmão (linha - Estágio II) �ca vazio (e a linha ociosa) esperando receber a bebida para serpasteurizada e envasada devem ser considerados para efeito de uso da capacidade. Na Figura 1 éapresentada uma programação da produção factível para um exemplar ilustrativo com um período.Estão representados dois itens �a� e �b�, um tanque preparatório e uma linha. As linhas pontilhadasna Figura 1 representam o instante em que o lote está sendo transferido do tanque preparatóriopara o tanque pulmão. Cinco situações de esperas são representadas nessa �gura (A, B, C, D, E).
Figura 1: Exemplar ilustrativo de uma programação da produção factível.
Dadas essas características, para realização do planejamento e programação da produção debebidas à base de frutas é preciso considerar: presença de estoque intermediário entre os estágios(tanque pulmão), que permite que um lote seja envasado na linha enquanto o próximo lote é prepa-rado na xaroparia; a necessidade de limpezas periódicas a cada TPmax horas de preparo contínuodo mesmo sabor na xaroparia e a cada TLmax horas de envase contínuo do mesmo sabor na linha;tempos e custos de troca de sabor dependentes da sequência de produção; e, a sincronia entre osestágios de produção, em que é preciso considerar as esperas que podem ocorrer tanto da xaropariapela linha quanto da linha pela xaroparia.
3 Modelos Matemáticos
Nesta seção são apresentados dois modelos inteiros mistos propostos para resolver o problema des-crito na Seção 2. Para controlar as limpezas periódicas e a sincronia entre os estágios, utiliza-sea estratégia de modelagem com subperíodos de tamanho variável e variáveis contínuas que contro-lam o tempo [1, 3]. O sequenciamento é realizado através de restrições de �uxo e de restrições doProblema do Caixeiro Viajante Assimétrico [9].
Esse modelos não calculam de maneira exata as esperas que acontecem entre os dois estágiosde produção. Essas esperas são apenas estimadas pelos modelos e descontadas da capacidade. Assoluções encontradas pelos modelos passam por um pós-processamento para ajuste da sincronia.No pós-processamento os tamanhos dos lotes e a sequência em que estes são produzidos não sãoalteradas. Um ajuste é realizado apenas nos tempos de início e �nal de cada lote para a inclusãodas esperas. Em alguns casos, após a realização desse pós-processamento não é possível encontrarsolução factível, pois a capacidade é ultrapassada.
A única diferença entre os modelos apresentados é a maneira de calcular o número de limpezasobrigatórias. Por serem modelos aproximados, em um a capacidade de produção é super estimada(Modelo 1 - Otimista) e no outro sub estimada (Modelo 2 - Pessimista). Os conjuntos, parâmetrose variáveis dos dois modelos são os mesmos e estão descritos a seguir.
Os conjuntos utilizados nos modelos são: J é conjunto de itens (sabores) (i e j ∈ J); M é o
CLAIO-2016
932

conjunto de tanques preparatórios/linha (m ∈ M) (considera-se que cada tanque preparatório estáligado diretamente a uma máquina); T é o conjunto de períodos (t ∈ T ); Omt é conjunto de lotesque podem ser produzidos pelo conjunto tanque preparatório/linha m no período t (o ∈ Omt).
Os parâmetros são: dIjt é a demanda em unidades do item j no período t; h+
j é o custo de estoque
de uma unidade do item j; h−j é o custo de atraso de uma unidade do item j; I+
j0 = 0 é o estoque em
unidades do item j no início do primeiro período do horizonte de planejamento; I−j0 = 0 é o atraso
em unidades do item j no início do primeiro período do horizonte de planejamento; i0 é o produtopara o qual o tanque é preparado no início de cada período (item fantasma); Bminj é a quantidademínima de produção, em litros, do item j em um tanque (lote mínimo de cada batelada); Bmaxj
é a quantidade máxima de produção, em litros, do item j em um tanque (lote máximo de cadabatelada) ρ é a quantidade de bebida em litros para produzir uma unidade de item; Tp é o tempo�xo de preparo de um lote, independente de sabor e quantidade; LP I é o tempo de uma limpezaperiódica na xaroparia; LP II é o tempo de uma limpeza periódica na linha; Clp é o custo de umalimpeza periódica na xaroparia e na linha; TCI
ij é o tempo de uma limpeza na xaroparia para troca
do item i para o item j; TCIIij é o tempo de uma limpeza na linha para troca do item i para o
item j; Cij é o custo de troca do item i para item j; Capmt é a capacidade total disponível emtempo, do conjunto xaroparia/linha m no período t; Sm é a velocidade de envase da máquina m dosegundo estágio em litros por hora; Mgde é estimativa do número máximo de tanques que podemser preparados em um período; TPmax é o tempo máximo de produção contínua do mesmo saborna xaroparia sem realização de limpeza; TLmax é o tempo máximo de produção contínua do mesmosabor na linha sem realização de limpeza.
As variáveis dos modelos são:
I+jt estoque em unidades do item j no �nal do período t
I−jt atraso em unidades do item j no �nal do período t
Xmjto quantidade produzida pelo conjunto xaroparia/linha m de itens do tipo jno período t no lote o
Ymjto = 1 se há produção pelo conjunto xaroparia/linha m do item j na batelada o no período tZmijt = 1 se existe uma troca do item i para o item j no período t; 0 caso contrárioZmjjt = 0 para todo item jVmjt variável auxiliar para eliminação de subrota envolvendo o item j no conjunto
xaroparia/linha m no período t
µI,smjto instante de início do preparo do lote o para o item j no tanque preparatório (xaroparia) m
no período t
µI,emjto instante de término do preparo do lote o para o item j no tanque preparatório (xaroparia) m
no período t
µII,smjto instante de início do envase do lote o para o item j na máquina (linha) m no período t
µII,emjto instante de término do envase do lote o para o item j na máquina (linha) m no período t
W Imjt número de limpeza periódicas realizadas na xaroparia m durante a produção do
sabor j no período tW II
mjt número de limpeza periódicas realizadas na linha m durante a produção dosabor j no período t
O Modelo 1 é dado pelas equações de (1) a (26).
Min ZI =∑
t∈T
∑
j∈J
(h+j I+
jt + h−j I−
jt) +∑
m∈M
∑
t∈T
∑
j∈J
∑
i∈Ji̸=j
Cij Zmijt +∑
m∈M
∑
j∈J
∑
t∈T
Clp(W Imjt + W II
mjt)
(1)
CLAIO-2016
933

s.a.:
I+j(t−1) + I−
jt +∑
m∈M
∑
o∈Omt
Xmjto = djt + I+jt + I−
j(t−1) ∀j ∈ J,∀t ∈ T (2)
ρXmjto ≥ Bminj Ymjto, ∀m ∈ M, ∀j ∈ J,∀t ∈ T, ∀o ∈ Omt (3)
ρXmjto ≤ min{Bmaxj , Sm TLmax} Ymjto, ∀m ∈ M, ∀j ∈ J,∀t ∈ T, ∀o ∈ Omt, (4)
Ymjt(o−1) ≥ Ymjto, ∀m ∈ M, ∀j ∈ J,∀t ∈ T, ∀o ∈ Omt, o > 1 (5)∑
o∈Omt
Ymi0to ≤ 1, ∀m ∈ M, ∀t ∈ T (6)
∑
j∈Jj ̸=i0
Zmi0jt ≥∑
i∈Ji̸=k
Zmikt, ∀m ∈ M, ∀k ∈ J,∀t ∈ T (7)
∑
i∈Ji̸=j
Zmijt =∑
i∈Ji̸=j
Zmjit, ∀m ∈ M, ∀j ∈ J,∀t ∈ T (8)
∑
j∈Jj ̸=i
Zmijt ≤ 1, ∀m ∈ M, ∀i ∈ J,∀t ∈ T (9)
Vmjt ≥ (Vmit + 1) − (|J | − 1)(1 − Zmijt), ∀t ∈ T, ∀m ∈ M, ∀i, j ∈ J \ i0, i ̸= j (10)∑
o∈Omt
Ymjto ≤ |O|∑
i∈Ji̸=j
Zmijt, ∀m ∈ M, ∀j ∈ J,∀t ∈ T, j ̸= i0 (11)
µI,smj1t ≥ LP I Zmi0jt, ∀m ∈ M, ∀j ∈ J,∀t ∈ T (12)
µI,emjto = µI,s
mjto + Tp Ymjto, ∀m ∈ M, ∀j ∈ J,∀t ∈ T, ∀o ∈ Omt (13)
µI,smj1t ≥ µI,e
miOt + TCIij − Mgde(1 − Zmijt), ∀m ∈ M, ∀i ∈ J,∀t ∈ T, i ̸= j, j ̸= i0 (14)
µI,smjto ≥ µI,e
mj(o−1)t, ∀m ∈ M, ∀j ∈ J,∀t ∈ T, ∀o ∈ Omt, o > 1 (15)
µII,smj1t ≥ max{LP II Zmi0jt, µI,e
mj1t} ∀m ∈ M, ∀j ∈ J,∀t ∈ T (16)
µII,emjto = µII,s
mjto + (Xmjto/Sm), ∀m ∈ M, ∀j ∈ J,∀t ∈ T, ∀o ∈ Omt (17)
µII,smj1t ≥ µII,e
miOt + TCIIij − Mgde(1 − Zmijt), ∀m ∈ M, ∀i ∈ J,∀t ∈ T, i ̸= j, j ̸= i0 (18)
µII,smjto ≥ µII,e
mj(o−1)t, ∀m ∈ M, ∀j ∈ J,∀t ∈ T, ∀o ∈ Omt, o > 1 (19)
µII,smjto ≥ µI,e
mjto, ∀m ∈ M, ∀j ∈ J,∀t ∈ T, ∀o ∈ Omt, o > 1 (20)
µI,smjto ≥ µII,s
mj(o−1)t + Mgde(1 − Ymjto), ∀m ∈ M, ∀j ∈ J,∀t ∈ T, ∀o ∈ Omt, o > 1 (21)
W Imjt ≥
(µII,smjto − µI,s
mjt1) − Mgde(1 − Ymjto)
TPmax− 1, ∀m ∈ M, ∀j ∈ J,∀o ∈ O, ∀t ∈ T (22)
W IImjt ≥
(µII,emjtO − µII,s
mjt1)
TLmax− 1, ∀m ∈ M, ∀j ∈ J,∀t ∈ T (23)
µI,emjtO ≤ Capmt − LP I
∑
i∈J
W Imit, ∀m ∈ M, ∀j ∈ J,∀t ∈ T (24)
CLAIO-2016
934

µII,emjtO ≤ Capmt − LP II
∑
i∈J
W IImit, ∀m ∈ M, ∀j ∈ J,∀t ∈ T (25)
Xmjto, I+jt , I
−jt , Vmjt, µ
I,smjto, µ
I,emjto, µ
II,smjto, µ
II,emjto ≥ 0; W I
mjt, WIImjt ∈ Z+;
Zmijt, Ymjto ∈ {0, 1} ∀m ∈ M, ∀i, j ∈ J, ∀t ∈ T, ∀o ∈ Omt. (26)
A função objetivo (1) minimiza os custos de estoque, atraso e troca, e penaliza o número delimpezas obrigatórias que são realizadas. O balanceamento de estoque e demanda é garantido pelasrestrições (2). As restrições (3) e (4) determinam os lotes mínimos e máximos de produção. As res-trições (5) eliminam simetrias fazendo com que os subperíodos ociosos �quem no �nal. As restrições(6) são utilizadas para garantir que o item fantasma seja produzido uma única vez e as restrições (7)para que ele seja o primeiro item do período. O item fantasma é utilizado para determinar o sabordo início do horizonte de planejamento, contabilizar a primeira limpeza obrigatória, e também ser oponto de início e chegada da sequência dos itens que serão produzidos. As restrições de conservaçãode �uxo são dadas em (8). As restrições (9) funcionam como corte para o problema, (10) eliminamsubrotas e (11) são restrições de setup. As restrições de (12) a (14) determinam o início e o �naldos lotes (tamanho dos subperíodos) na xaroparia incluindo para o primeiro lote do período (12)e quando há troca de sabor (14). Para não haver sobreposição entre os subperíodos são incluídasas restrições (15). De maneira análoga à xaroparia, os tempos contínuos dos lotes para a linha sãocontrolados pelas restrições de (16) a (19). A sincronia entre os dois estágios é dada pelas restrições(20) que garantem que o lote o do sabor j no conjunto tanque preparatório/linha m no período tserá iniciado no segundo estágio somente após o término do preparo desse lote no primeiro estágio;e pelas restrições (21) que asseguram que o lote o do sabor j no conjunto tanque preparatório/linham no período t só poderá começar a ser preparado depois que o lote o−1 estiver na linha, e portantoo tanque preparatório estiver liberado. No modelo otimista a contagem das limpezas periódicas nostanques preparatórios e nas linhas é realizada através das restrições (22) e (23) respectivamente.Essas restrições, juntamente com a minimização das variáveis W I
mjt e W IImjt na função objetivo cal-
culam o piso da divisão do tempo total em que �cou sendo preparada/envasada a bebida de sabor jpor TPmax e TLmax, respectivamente. O tempo utilizado com as limpezas periódicas é descontadodas restrições (24) e (25) que de�nem a capacidade. O domínio das variáveis é determinado por(26).
Note na Figura 1 que esperas podem acontecer no estágio I (C) enquanto está sendo realizadauma limpeza periódica no estágio II e vice-versa (D). Essas esperas podem in�uenciar no númerode limpezas periódicas e se não descontadas da capacidade podem in�uenciar na geração de planosde produção infactíveis. Na tentativa contabilizar essas esperas foi proposto o Modelo 2, chamadotambém modelo pessimista, pois nesse modelo pressupõe-se que essas esperas sempre vão acontecere portanto estas são incluídas na contagem das limpezas periódicas (27)-(28) e descontadas nasrestrições de capacidade (29)-(30). Portanto o Modelo 2 é dado pelas equações de (1) a (21), de(27) a (30), e com a restrição de domínio das variáveis (26).
W Imjt ≥
(µII,smjto − µI,s
mjt1) − Mgde(1 − Ymjto) + LP IIW IImjt
TPmax− 1, ∀m ∈ M, ∀j ∈ J,∀o ∈ O, ∀t ∈ T
(27)
W IImjt ≥
(µII,emjtO − µII,s
mjt1) + LP IW Imjt
TLmax− 1, ∀m ∈ M, ∀j ∈ J,∀t ∈ T (28)
µI,emjtO ≤ Capmt − LP I
∑
i∈J
W Imit − LP II
∑
i∈J
W IImit, ∀m ∈ M, ∀j ∈ J,∀t ∈ T (29)
CLAIO-2016
935
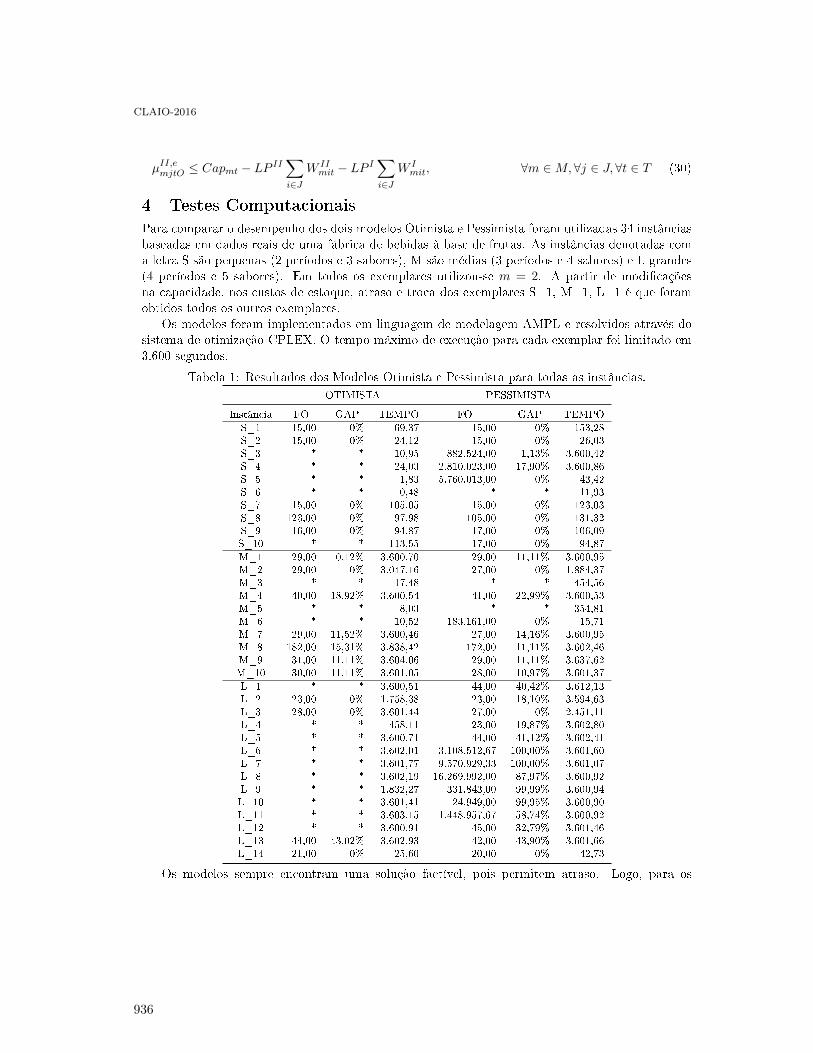
µII,emjtO ≤ Capmt − LP II
∑
i∈J
W IImit − LP I
∑
i∈J
W Imit, ∀m ∈ M, ∀j ∈ J,∀t ∈ T (30)
4 Testes Computacionais
Para comparar o desempenho dos dois modelos Otimista e Pessimista foram utilizadas 34 instânciasbaseadas em dados reais de uma fábrica de bebidas à base de frutas. As instâncias denotadas coma letra S são pequenas (2 períodos e 3 sabores), M são médias (3 períodos e 4 sabores) e L grandes(4 períodos e 5 sabores). Em todos os exemplares utilizou-se m = 2. A partir de modi�caçõesna capacidade, nos custos de estoque, atraso e troca dos exemplares S_1, M_1, L_1 é que foramobtidos todos os outros exemplares.
Os modelos foram implementados em linguagem de modelagem AMPL e resolvidos através dosistema de otimização CPLEX. O tempo máximo de execução para cada exemplar foi limitado em3.600 segundos.
Tabela 1: Resultados dos Modelos Otimista e Pessimista para todas as instâncias.
OTIMISTA PESSIMISTA
Instância FO GAP TEMPO FO GAP TEMPO
S_1 15,00 0% 69,37 15,00 0% 153,28S_2 15,00 0% 24,12 15,00 0% 26,03S_3 * * 10,95 882.524,00 1,13% 3.600,42S_4 * * 24,03 2.810.023,00 17,90% 3.600,86S_5 * * 1,83 5.760.013,00 0% 43,42S_6 * * 0,48 * * 11,93S_7 15,00 0% 105,05 15,00 0% 123,03S_8 123,00 0% 97,98 105,00 0% 131,32S_9 16,00 0% 94,87 17,00 0% 106,09S_10 * * 113,55 17,00 0% 94,87
M_1 29,00 0,12% 3.600,70 29,00 11,11% 3.600,95M_2 29,00 0% 3.047,16 27,00 0% 1.884,37M_3 * * 17,48 * * 454,56M_4 40,00 18,92% 3.600,54 41,00 22,99% 3.600,53M_5 * * 8,03 * * 354,81M_6 * * 10,52 183.161,00 0% 15,71M_7 29,00 11,52% 3.600,46 27,00 14,16% 3.600,95M_8 182,00 15,31% 3.838,42 172,00 11,11% 3.602,46M_9 31,00 11,11% 3.604,06 29,00 11,11% 3.637,62M_10 30,00 11,11% 3.601,05 28,00 10,97% 3.601,37
L_1 * * 3.600,51 44,00 40,42% 3.612,13L_2 23,00 0% 1.758,38 23,00 18,10% 3.594,63L_3 28,00 0% 3.601,44 27,00 0% 2.451,11L_4 * * 458,11 23,00 19,87% 3.602,80L_5 * * 3.600,71 44,00 41,12% 3.602,41L_6 * * 3.602,01 3.108.512,67 100,00% 3.601,60L_7 * * 3.601,77 9.570.929,33 100,00% 3.601,07L_8 * * 3.602,19 16.269.992,00 87,97% 3.600,92L_9 * * 1.832,27 331.843,00 99,99% 3.600,94L_10 * * 3.601,41 24.949,00 99,95% 3.600,90L_11 * * 3.603,15 1.448.957,67 58,74% 3.600,92L_12 * * 3.600,91 45,00 32,79% 3.601,46L_13 44,00 43,02% 3.602,93 42,00 43,90% 3.601,66L_14 21,00 0% 25,60 20,00 0% 42,73
Os modelos sempre encontram uma solução factível, pois permitem atraso. Logo, para os
CLAIO-2016
936

exemplares marcados com * na Tabela 1 não foi possível obter uma solução factível após o pós-processamento da solução obtida com o modelo. Os gaps apresentados na Tabela 1 também referem-se à solução do modelo e não à solução encontrada após o pós-processamento.
5 Conclusões e Perspectivas FuturasNeste trabalho foi apresentado um novo problema real de dimensionamento e sequenciamento delotes com particularidades que ainda não foram tratadas na literatura: dois estágios com presençade estoque intermediário e limpezas periódicas. Para resolver o problema foram propostos doismodelos inteiro misto que resolvem o problema de maneira aproximada, uma vez que as soluçõesobtidas com os modelos precisam passar por um pós-processamento e veri�cação de factibilidadecom relação à capacidade.
Os resultados mostraram que o modelo 2 encontra mais soluções factíveis e melhores resultadosdo que o modelo 1, como era esperado, pois o modelo pessimista estima de maneira mais realista asesperas que acontecem entre os estágios de produção. Porém, para algumas instâncias, esse modelotambém não consegue encontrar soluções factíveis. Mesmo sendo um modelo mais realista, algumasesperas podem deixar de ser contadas.
Como perspectivas futuras pretende-se fazer uma heurística de melhoria no �nal do pós-proces-samento das soluções, para que sempre seja possível encontrar uma solução factível. Além disso, estásendo desenvolvido um modelo integrado que represente o problema real de fato a �m de comparara qualidade das soluções encontradas pelos modelos apresentados.
AgradecimentosOs autores agradecem a FAPEMIG, ao CNPq processo n. 312569/2013-0 e a FAPESP processo n.2010/10133-0 pelo apoio �nanceiro dado para o desenvolvimento desse trabalho.
Referências[1] C. Almeder, D. Klabjan, R. Traxler and B. Almada-Lobo. Lead time considerations for the multi-level
capacitated lot-sizing problem. European Journal of Operational Research, 241, 727�738, 2015.[2] T. A. Baldo, M. O. Santos, B. Almada-Lobo and R. Morabito. An optimization approach for the lot
sizing and scheduling problem in the brewery industry. Computers & Industrial Engineering, 72, 58�71,2014.
[3] V. C. B. Camargo, F. M. B. Toledo and B. Almada-Lobo. Three time-based scale formulations for thetwo-stage lot sizing and scheduling in process industries. Journal of the Operational Research Society,
63, 1613�1630, 2012.[4] D. Ferreira, R. Morabito and S. Rangel. Solution approaches for the soft drink integrated production
lot sizing and scheduling problem. European Journal of Operational Research, 196, 697�706, 2009.[5] D. Ferreira, A. R. Clark, B. Almada-Lobo and R. Morabito. Single-stage formulations for synchroni-
sed two-stage lot sizing and scheduling in soft drink production. International Journal of Production
Economics, 136, 255�265, 2012.[6] Euromonitor Market Research on Fruit and Vegetable Juice. Euromonitor International, 2015.[7] L. Guimarães, D. Klabjan and B. Almada-Lobo. Annual production budget in the beverage industry.
Engineering Applications of Arti�cial Intelligence, 25, 229�241, 2012.[8] R. Jans and Z. Degraeve. Modeling industrial lot sizing problems: a review. International Journal of
Production Research, 46, 1619�1643, 2008.[9] T. Öncan, I. A. Kuban and G. Laporte. A comparative analysis of several asymmetric traveling salesman
problem formulations. Computers & Operations Research, 36, 637�654, 2009.[10] C. Sel and B. Bilgen. Hybrid simulation and MIP based heuristic algorithm for the production and
distribution planning in the soft drink industry. Journal of Manufacturing Systems, 33, 385�399, 2014.
CLAIO-2016
937

Modeling symmetry cuts for batch scheduling with
realease times and non-identical job sizes
Renan Spencer TrindadeUniversidade Federal do Rio de Janeiro
Olinto César Bassi de AraújoCTISM/Universidade Federal de Santa Maria
Marcia FampaUniversidade Federal do Rio de Janeiro
Felipe Martins MüllerUniversidade Federal de Santa Maria
Abstract
In this paper we propose a mixed integer linear programming (MILP) formulation for theproblem of minimizing the makespan on a single batch processing machine with release times andnon-identical job sizes. Due to important applications of this problem in industry, it has alreadybeen studied in the literature, but mostly addressed with heuristic procedures. Nevertheless, theexact solution for the problem has also been obtained in the literature by a branch-and-bound(B&B) algorithm applied to an MILP formulation. The number of symmetric solutions in thefeasible set of the problem makes the B&B algorithm very ine�cient. We, therefore, proposea new formulation for the problem with symmetry breaking cuts. Computational results showthat the new model clearly outperforms the classical model from the literature turning practicalthe optimality proof of solutions for instances of the problem with reasonable size.
Keywords: Mixed integer linear program; Batch scheduling on a single machine; Symmetry.
1 Introduction
Batch scheduling problems have several applications in industry as, for example, in shoe man-ufacturing [1], aircraft [2], metal [3, 4], and furniture manufacturing [5]. The particular batchscheduling problem considered in this paper, of minimizing the makespan on a single processingmachine, where jobs have di�erent release times and non-identical job sizes, models an importantproblem that appears in the reliability tests in the semiconductor industry, speci�cally in operations
CLAIO-2016
938

called burn-in (see [6]). This problem is categorized as 1|rj , sj , B|Cmax on the three-�eld systemproposed by [14].
Many heuristic methods have been applied to batch scheduling problems when release timesare not considered, as in [6] and [7]. A branch-and-bound method is proposed in [8]. A mixedinteger linear programming formulation is presented in [9]. The application of branch-and-pricemethod is proposed by [10]. Metaheuristics are also proposed, such as, simulated annealing in [9],a genetic algorithm in [11], Tabu Search in [12] and GRASP in [13]. Nevertheless, from our bestknowledge, there are only two papers in the literature that propose the application of metaheuristicsto the solution of 1|rj , sj , B|Cmax ([15, 16]). Also, a mathematical programming formulation forthe problem is presented in [16] and the problem is proven NP-hard, based on the fact that it isequivalent to problem 1|sj , B|Cmax in the particular case where all jobs have release time equal tozero rj = 0, ∀j ∈ J , and this last problem was proven NP-hard in [6].
In this paper, we propose a new mixed integer linear programming (MILP) formulation forthe 1|rj , sj , B|Cmax problem which includes symmetry breaking cuts. The model proposed is solvedby CPLEX and compared to the model presented in [16], showing through numerical results, thestrong impact of the symmetry cuts introduced. In Section 2, we present the MILP formulation forthe problem proposed in [16]. In Section 3, we propose our new MILP formulation for the problem,which includes symmetry breaking cuts. In Section 4, we present numerical results and some �nalremarks.
2 MILP formulation form the literature
The 1|rj , sj , B|Cmax problem can be formally de�ned as: given a set J of jobs, each elementj ∈ J has a release time rj , a processing time pj and a size sj . Each job j ∈ J must be assigned to abatch k ∈ K, not exceeding the capacity limit B of the machine. The batches must be scheduled onthe processing machine. The processing time of each batch k ∈ K is de�ned as Pk = max{pj , j ∈ k}.Each job j ∈ J becomes available at time rj , which means that jobs with di�erent release times areconsidered in this problem. The release time of batch k ∈ K is de�ned as Rk = max{rj , j ∈ k}.Jobs cannot be divided between batches. It's also not possible to add or remove jobs from themachine during the batch processing. The goal is to design and schedule the batches k ∈ K so thatthe processing time of the machine Cmax (makespan) is minimized. The number of batches useddepends on the number of jobs and the considered processing machine capacity. In the worst case,the number of batches is equal to the number of jobs, |K| = |J |.
The following MILP formulation for the problem is proposed in [16].Parameters
sj : size of job jpj : processing time of job jrj : release time of job jB : capacity of the machine
Decision variables
xi,j =
{1 if job j is assigned to batch k ;0 otherwise.
Pk : processing time of batch k
CLAIO-2016
939

Sk : starting time of batch k
min S|K| + P|K| (MILP1) (1)
s.t.∑
k∈Kxj,k = 1 ∀j ∈ J (2)
∑
j∈Jsjxj,k ≤ B ∀k ∈ K (3)
Pk ≥ pjxj,k ∀j ∈ J, ∀k ∈ K (4)
Sk ≥ rjxj,k ∀j ∈ J, ∀k ∈ K (5)
Sk ≥ Sk−1 + Pk−1 ∀k ∈ K : k > 1 (6)
Pk ≥ 0 ∀k ∈ K (7)
Sk ≥ 0 ∀k ∈ K (8)
xj,k ∈ {0, 1} ∀j ∈ J, ∀k ∈ K (9)
The objective function (1) minimizes the total processing time (makespan). In the model, themakespan is de�ned as the time required to complete the last batch. Constraint (2) states thateach job is assigned to only one batch. Constraint (3) states that each batch does not exceed themachine capacity. Constraint (4) determines the processing time of batch k. Constraints (5) and(6) determine the time when the batch k starts to be processed. Constraints (7), (8) and (9) de�nethe domains of the variables.
Problem MILP1 has a large number of symmetric solutions, which particularly occur in twosituations, presenting batches with identical con�gurations and same value for Cmax. The �rstsituation occurs when the number of batches used in a solution is less than |K|. In this case,clearly the model allows the same solution having its batches represented by di�erent indexes. Thesecond situation occurs when a modi�cation in the order in which the batches are processed doesnot change Cmax. This can happen, for example, when a group of adjacent batches are released atthe time when the machine starts to process, i.e., the machine is not idle when these batches startto be processed.
3 A new MILP formulation with symmetry cuts
The idea underlying the new mathematical formulation for 1|rj , sj , B|Cmax is to take the jobssorted by non-decreasing order of the release time, i.e., set r1 ≤ r2 ≤ . . . ≤ r|J |. The symmetriesexempli�ed in the previous section can be handled by de�ning the decision variables as
xi,j =
{1 if job j is assigned to batch k0 otherwise
, ∀k ∈ K,∀j ∈ J : j ≤ k. (10)
From this de�nition, it follows that a job can only be assigned to a batch if the index of the jobis less than or equal to the index of the batch. If in addition, it is enforced that batch k can only
CLAIO-2016
940

be used if job k is assigned to it, then any solution to problem 1|rj , sj , B|Cmax will be representedby sequential batches in the same order as the jobs.
Proposition 1 ensures that no optimal solution is cut o� when the problem is conceived in thisway.
Proposition 1. Any optimal solution for 1|rj , sj , B|Cmax can be represented considering batches
sequenced in non-decreasing order of the release time.
Proof. Let S represent an optimal schedule for 1|rj , sj , B|Cmax in which there are at least twobatches k and k′, such that the batch k is sequenced after the batch k′ and the respective releasetimes are such that Rk < Rk′ .
If all the batches in S are processed without inserted idle time, then it is possible to constructa new schedule S′ in which batch k precedes batch k′, with same makespan of S.
On the other hand, if the schedule S contains an inserted idle time immediately before batch k′,the exchange of the batches k and k′ will decrease the makespan value, and in this case the scheduleS is not optimal.
Considering the parameters and the variables Pk and Sk from model MILP1, together with thevariables x de�ned in (10), the proposed new mathematical model is given by:
min S|K| + P|K| (MILP2) (11)
s.t.∑
k∈K:j≤kxj,k = 1 ∀j ∈ J (12)
∑
j∈J :j≤ksjxj,k ≤ Bxk,k ∀k ∈ K (13)
xj,k ≤ xk,k ∀j ∈ J, ∀k ∈ K : j < k (14)
Pk ≥ pjxj,k ∀j ∈ J, ∀k ∈ K : j ≤ k (15)
Sk ≥ rkxk,k ∀k ∈ K (16)
Sk ≥ Sk−1 + Pk−1 ∀k ∈ K : k > 1 (17)
Pk ≥ 0 ∀k ∈ K (18)
Sk ≥ 0 ∀k ∈ K (19)
xj,k ∈ {0, 1} ∀j ∈ J, ∀k ∈ K : j ≤ k (20)
The objective function (11) minimizes the total processing time (makespan). As in modelMILP1, the makespan is de�ned as the time required to complete the last batch. Constraint (12) isa valid inequality which determines that each job is assigned to only one batch, with non smallerindex than the job index. Constraint (13) states that each batch does not exceed the machinecapacity. Disaggregated constraint (14) imposes that each job can only be assigned to an openbatch. Constraint (15) determines the processing time of batch k. Constraints (16) and (17)determine the time when the batch k starts to be processed. Constraint (16), in particular, is asymmetry cut that avoids the use of a batch that does not contain the job of the same index.Constraints (18), (19) and (20) de�ne the domains of the variables.
CLAIO-2016
941
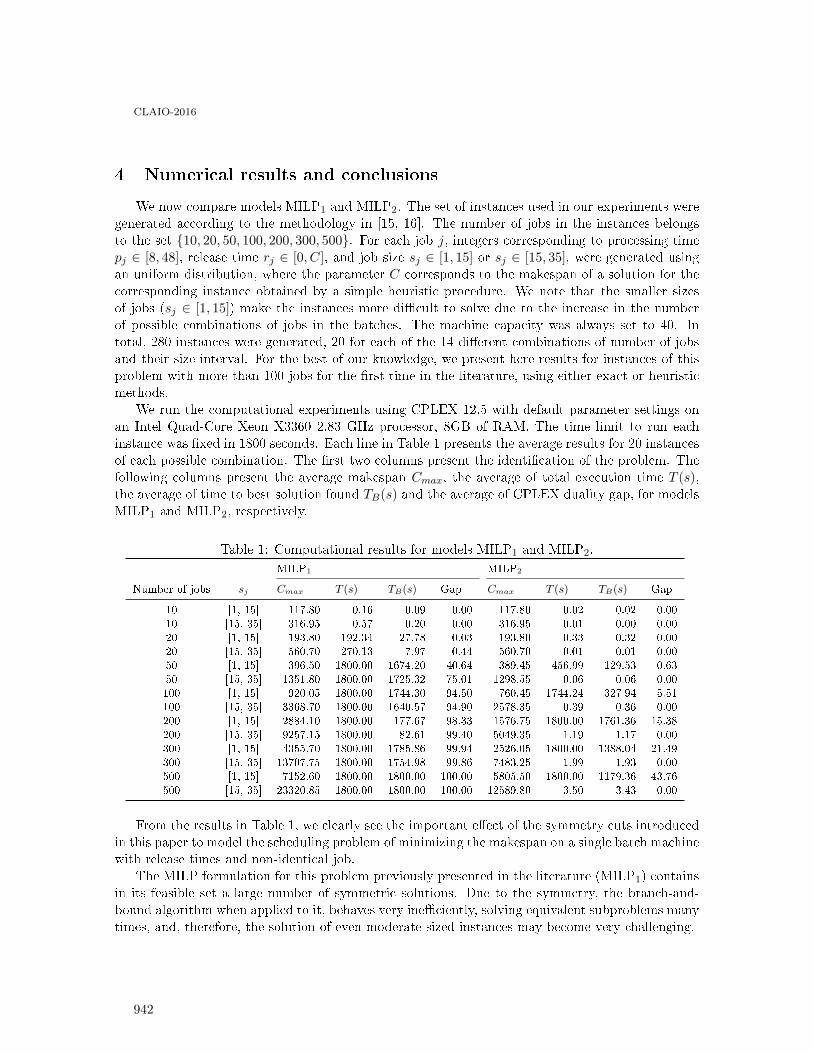
4 Numerical results and conclusions
We now compare models MILP1 and MILP2. The set of instances used in our experiments weregenerated according to the methodology in [15, 16]. The number of jobs in the instances belongsto the set {10, 20, 50, 100, 200, 300, 500}. For each job j, integers corresponding to processing timepj ∈ [8, 48], release time rj ∈ [0, C], and job size sj ∈ [1, 15] or sj ∈ [15, 35], were generated usingan uniform distribution, where the parameter C corresponds to the makespan of a solution for thecorresponding instance obtained by a simple heuristic procedure. We note that the smaller sizesof jobs (sj ∈ [1, 15]) make the instances more di�cult to solve due to the increase in the numberof possible combinations of jobs in the batches. The machine capacity was always set to 40. Intotal, 280 instances were generated, 20 for each of the 14 di�erent combinations of number of jobsand their size interval. For the best of our knowledge, we present here results for instances of thisproblem with more than 100 jobs for the �rst time in the literature, using either exact or heuristicmethods.
We run the computational experiments using CPLEX 12.5 with default parameter settings onan Intel Quad-Core Xeon X3360 2.83 GHz processor, 8GB of RAM. The time limit to run eachinstance was �xed in 1800 seconds. Each line in Table 1 presents the average results for 20 instancesof each possible combination. The �rst two columns present the identi�cation of the problem. Thefollowing columns present the average makespan Cmax, the average of total execution time T (s),the average of time to best solution found TB(s) and the average of CPLEX duality gap, for modelsMILP1 and MILP2, respectively.
Table 1: Computational results for models MILP1 and MILP2.
MILP1 MILP2
Number of jobs sj Cmax T (s) TB(s) Gap Cmax T (s) TB(s) Gap
10 [1, 15] 117.80 0.16 0.09 0.00 117.80 0.02 0.02 0.0010 [15, 35] 316.95 0.57 0.20 0.00 316.95 0.01 0.00 0.0020 [1, 15] 193.80 192.34 27.78 0.03 193.80 0.33 0.32 0.0020 [15, 35] 560.70 270.13 7.97 0.44 560.70 0.01 0.01 0.0050 [1, 15] 396.50 1800.00 1674.20 40.64 389.45 456.99 129.53 0.6350 [15, 35] 1351.80 1800.00 1725.32 75.01 1298.55 0.06 0.06 0.00100 [1, 15] 920.05 1800.00 1744.30 94.50 760.45 1744.24 327.94 5.51100 [15, 35] 3368.70 1800.00 1640.57 94.90 2578.35 0.39 0.36 0.00200 [1, 15] 2884.10 1800.00 177.67 98.33 1576.75 1800.00 1761.36 15.38200 [15, 35] 9257.15 1800.00 82.61 99.40 5049.35 1.19 1.17 0.00300 [1, 15] 4355.70 1800.00 1785.86 99.94 2526.05 1800.00 1388.04 21.49300 [15, 35] 13707.75 1800.00 1754.98 99.86 7483.25 1.99 1.93 0.00500 [1, 15] 7152.60 1800.00 1800.00 100.00 5805.50 1800.00 1179.36 43.76500 [15, 35] 23320.85 1800.00 1800.00 100.00 12589.80 3.50 3.43 0.00
From the results in Table 1, we clearly see the important e�ect of the symmetry cuts introducedin this paper to model the scheduling problem of minimizing the makespan on a single batch machinewith release times and non-identical job.
The MILP formulation for this problem previously presented in the literature (MILP1) containsin its feasible set a large number of symmetric solutions. Due to the symmetry, the branch-and-bound algorithm when applied to it, behaves very ine�ciently, solving equivalent subproblems manytimes, and, therefore, the solution of even moderate-sized instances may become very challenging.
CLAIO-2016
942

Motivated by this realization, the MILP2 formulation that we propose in this work incorporatessymmetry breaking cuts. The idea behind the symmetry cuts is based in rules that should be satis�edby the indexes assigned to di�erent batches, and considers the jobs sorted by non-decreasing orderof the release time. The formulation presented was proven to be correct, i.e., we proved that anyoptimal solution of the problem belongs to its feasible set.
We emphasize that for the �rst time in the literature, proven optimal solutions were presentedfor instances of the 1|rj , sj , B|Cmax problem with more than 100 jobs. In the time limit of 30minutes we could prove optimality for instances of up to 500 jobs, while only instances with up to20 jobs were solved to optimality by using formulation MILP1.
To our knowledge the results presented in this work constitute the state of the art for exactsolution algorithms for this NP-Hard problem, and as future work, we can mention the study ofpre-processing procedures, for example to reduce the possible number of batches in the solution.
References
[1] FANTI, M. P. and MAIONE, B. and PISCITELLI, G. and TURCHIANO, B. Heuristic schedulingof jobs on a multi-product batch processing machine International Journal of Production Research,34(8):2163�2186, 1996.
[2] Van De Rzee, D. J., Van Harten, A., and Schuur, P. C. Dynamic job assignment heuristics formulti-server batch operations- A cost based approach. International Journal of Production Research,35(11):3063�3094, 1997.
[3] Ram, B., and Patel, G. Modeling furnace operations using simulation and heuristics. Anals of the 30thConference on Winter Simulation, 957�963, 1998.
[4] Mathirajan, M., Sivakumar, A. I., and Chandru, V. Scheduling algorithms for heterogeneous batchprocessors with incompatible job-families. Journal of Intelligent Manufacturing, 15(6), 787�803, 2004.
[5] Yuan, J. J., Liu, Z. H., Ng, C. T., and Cheng, T. C. E. The unbounded single machine parallel batchscheduling problem with family jobs and release dates to minimize makespan. Theoretical ComputerScience, 320(2-3), 199�212, 2004.
[6] UZSOY, R. Scheduling a single batch processing machine with non-identical job sizes. InternationalJournal of Production Research, 32(7), 1615�1635, 1994.
[7] Ghazvini, F. J., and Dupont, L. Minimizing mean �ow times criteria on a single batch processingmachine with non-identical jobs sizes. International Journal of Production Economics, 55, 273�280,1998.
[8] Dupont, L., and Dhaenens-Flipo, C. Minimizing the makespan on a batch machine with non-identicaljob sizes: an exact procedure. Computers & Operations Research, 29(7), 807�819, 2002.
[9] Melouk, S., Damodaran, P., and Chang, P.-Y. Minimizing makespan for single machine batch processingwith non-identical job sizes using simulated annealing. International Journal of Production Economics,87(2), 141�147, 2004.
[10] Ra�ee Parsa, N., Karimi, B., and Husseinzadeh Kashan, A. A branch and price algorithm to minimizemakespan on a single batch processing machine with non-identical job sizes. Computers & OperationsResearch, 37(10), 1720�1730, 2010.
CLAIO-2016
943

[11] Kashan, a. H., Karimi, B., and Jolai, F. E�ective hybrid genetic algorithm for minimizing makespanon a single-batch-processing machine with non-identical job sizes. International Journal of ProductionResearch, 44(12), 2337�2360, 2006.
[12] Meng, Y., and Tang, L. A tabu search heuristic to solve the scheduling problem for a batch-processingmachine with non-identical job sizes. 2010 International Conference on Logistics Systems and IntelligentManagement (ICLSIM), Vol. 3, pp. 1703�1707, 2010.
[13] Damodaran, P., Ghrayeb, O., and Guttikonda, M. C. GRASP to minimize makespan for a capacitatedbatch-processing machine. The International Journal of Advanced Manufacturing Technology, 68(1-4),407�414, 2013.
[14] Graham, R. L., Lawler, E. L., Lenstra, J. K., and Rinnooy Kan, A. H. G. Optimization and approx-imation in deterministic sequencing and scheduling : a survey. Proceedings of the Advanced ResearchInstitute on Discrete Optimization and Systems Applications of the Systems Science Panel of NATOand of the Discrete Optimization Symposium Co-Sponsored by IBM Canada and SIAM Ban�, Aha. andVancouver, 5, 287�326, 1979.
[15] Chou, F.-D., Chang, P.-C., and Wang, H.-M. A hybrid genetic algorithm to minimize makespanfor the single batch machine dynamic scheduling problem. The International Journal of AdvancedManufacturing Technology, 31(3-4), 350�359, 2005.
[16] Xu, R., Chen, H., and Li, X. Makespan minimization on single batch-processing machine via ant colonyoptimization. Computers & Operations Research, 39(3), 582�593, 2012.
CLAIO-2016
944

Algoritmos exactos para subconjuntos de instancias
para el problema de programación de tareas flexibles
Daniel VegaDepartamento de Ingenieŕıa Informática, Universidad de Santiago de Chile
Victor ParadaDepartamento de Ingenieŕıa Informática, Universidad de Santiago de Chile
Resumen
La dificultad que se presenta en el problema de programación de tareas flexibles (FJSP), esampliamente conocida en el área de la optimización combinatoria y los problemas de scheduling.Diseñar un algoritmo, computacionalmente eficiente, que permita resolver de manera exacta di-versos conjuntos de instancias para el FJSP, continúa presentando un desaf́ıo. Diversas técnicashan sido empleadas para resolver el FJSP, sin embargo, generar algoritmos exactos sobre sub-conjuntos de instancias presenta un enfoque menos abordado. Mediante computación evolutivay programación genética (PG), se generan algoritmos exactos capaces de minimizar el tiempode procesamiento del conjunto de trabajos sobre máquinas factibles (makespan). Los resultadosmuestran que la generación automática de algoritmos (GAA) resulta una técnica exitosa al seraplicada sobre subconjuntos de instancias, encontrando una variedad de algoritmos exactos parael FJSP.Keywords: programación flexible; FJSP; programación genética.
1. Introducción
Para diversos problemas de optimización la calidad de un algoritmo heuŕıstico es dada por lacantidad de soluciones óptimas y el porcentaje de error que éste presenta al ser evaluado sobre undeterminado conjunto de instancias. Un gran número de soluciones óptimas y un bajo porcentajede error se traducen habitualmente en un algoritmo de gran calidad, mientras que, al disminuir lacantidad de valores óptimos encontrados y aumentar el porcentaje de error el algoritmo presenta unamenor calidad sobre un mismo problema. Es común observar que los resultados de una investigaciónse presenten a partir de la comparación de los resultados obtenidos por el algoritmo propuesto ylos existentes en la literatura, mediante el uso de benchmarks. Los teoremas no free lunch (NFL)establecen que no es posible que un único algoritmo sea capaz de superar al resto de algoritmosen todas las instancias de un problema [13], y en caso que se estuviese frente a tal algoritmo, sepodŕıa esperar que existiera un conjunto de instancias de prueba aún no probadas sobre el cualéste no presentaŕıa superioridad. Dado que no existe un ı́ndice que permita clasificar la dificultad
CLAIO-2016
945

de cada instancia, determinar sobre qué conjunto o subconjunto de instancias un algoritmo resultamás exitoso que otro es un tema poco abordado [11].
El problema de programación de tareas constituye un caso en el cual se debe determinar elerror más bajo para resolver un determinado conjunto de instancias y a los algoritmos heuŕısticosexistentes les es dif́ıcil resolver todas las instancias con eficiencia computacional. La combinatoriaque emana de la asignación del conjunto de tareas a las máquinas, que pueden tener opcionesparalelas, incrementa la dificultad computacional para navegar dentro del espacio de solucionescon el fin de encontrar la mejor solución posible, haciendo de este un problema perteneciente a laclase NP-Hard [14, 10]. Es posible encontrar una variedad de algoritmos que resuelven el FJSP demanera apróximada, existiendo un vaćıo al determinar la calidad de éstos sobre subconjuntos deinstancias de prueba.
Formalmente, el FJSP consta de un conjunto de m máquinas M = M1,M2, . . . ,Mm y unconjunto de n trabajos independientes J = J1, J2, . . . , Jn, tal que cada trabajo Jj está formado poruna secuencia de operaciones Oj1, Oj2, . . . , Ojnj , las que deben ser procesadas una después de otra,en base a una secuencia dada. Cada operación Ojh, debe ser procesada sobre una única máquinam elegida entre un subconjunto Mjh ⊆M de máquinas factibles, con un tiempo de procesamientofijo pkjh predefinido. Aśı, el problema consiste en asignar cada operación a una máquina factible,para luego secuenciar las operaciones sobre las máquinas a fin de minimizar el makespan (1).
makespan = maxj(Cj) (1)
donde Cj corresponde al tiempo de termino al completar el trabajo Jj . Aśı, la función objetivo delproblema queda determinada por (2).
minCmax = min{maxj(Cj)} (2)
Las instancias pueden ser categorizadas de acuerdo al tipo de operaciones que pueden realizarlas máquinas, determinando aśı su flexibilidad, pudiendo ser ésta total o parcial. Cuando todas lasoperaciones pueden ser procesadas por todas las máquinas Mjh = M , se dice que la flexibilidaddel sistema es total (T-FJSP). Por el contrario, cuando al menos una operación Ojh no puede serprocesada en todas las máquinas, la flexibilidad del problema es parcial (P-FJSP).
Existen ciertas restricciones que se deben considerar al buscar una solución para el FJSP, asaber:
- Todos los trabajos están disponibles para ser procesados inicialmente.
- Todos los tiempos de procesamiento de todos los trabajos son conocidos y constantes.
- La ausencia de máquinas no está permitida.
- El costo de transporte desde una máquina a otra es nulo.
- Cada máquina puede realizar solo una operación en un tiempo determinado de cualquiera delos trabajos disponibles.
- Las operaciones que están siendo procesadas no pueden ser interrumpidas.
- La operación de un trabajo no puede ser procesada hasta que sus antecesores lo hayan sido.
- Cada operación de un trabajo debe ser procesadas por al menos una máquina factible, pu-diendo existir operaciones que sean procesadas en más de una máquina factible.
CLAIO-2016
946

- Cada una de las máquinas está constantemente disponible para su uso.
- No hay restricciones de cola para las máquinas.
- No hay limitaciones de recursos a parte de la cantidad de máquinas.
- Todos los trabajos poseen la misma prioridad dentro del sistema.
El incremento de la capacidad computacional de las máquinas ha transformando en una prácticacada vez más común la generación automática de parámetros de algoritmos heuŕısticos, o bien denuevos algoritmos heuŕısticos. Este campo emergente dentro de la optimización combinatoria, hapermitido abordar diversos problemas de optimización, para los cuales, con bajo esfuerzo compu-tacional, se han podido combinar heuŕısticas existentes con el fin de configurar un nuevo algoritmo,o bien se han generado nuevos algoritmos a partir de la combinación de operaciones elementalesdando origen a la GAA. Esta nueva metodoloǵıa se encuadra dentro de la definición de las h́ıperheuŕısticas [1] y en el ámbito de los problemas de scheduling y problemas similares de optimizacióncombinatoria se ha mostrado promisoria para enfrentar problemas computacionalmente complejos,en los casos del problema de la mochila binaria [8], la coloración de vértices [4], el árbol de coberturageneralizado [5] con resultados numéricos interesantes. Sin embargo, en la literatura especializada,menos atención a recibido la generación automática de algoritmos para el FJSP.
En este trabajo se propone la combinación de diversas heuŕısticas existentes en la literatura [7]mediante el uso de programación genética (PG), con el fin de generar algoritmos que resuelvan demanera exacta diversos subconjuntos de instancias propuestas para el FJSP. En la segunda secciónse describen los materiales y métodos utilizados para la GAA, en la sección 2.1 se presenta ladefinición de PG, mientras que en la 2.2 la plataforma utilizada.
2. Diseño de los componentes básicos
2.1. Evolución de algoritmos
La técnica utilizada por los autores para la GAA ha sido la PG. En este tipo de técnica, las solu-ciones son estructuras que representan componentes elementales de programas, lo que permite quea partir de algunas especificaciones de alto nivel del problema en estudio, se produzca automáti-camente un programa que lo resuelva [6, 9]. Bajo este enfoque, también han sido evolucionadasestructuras capaces de resolver algunos problemas espećıficos de optimización de materia prima yde definición de horarios [2, 3]. Con esta misma mirada, es posible aprovechar heuŕısticas elemen-tales ya existentes o heuŕısticas espećıficamente diseñadas para el FJSP y combinarlas automáticay evolutivamente para dar origen a nuevos algoritmos que permitan encontrar soluciones de mejorcalidad.
Como toda técnica basada en computación evolutiva, la PG comienza con una población inicialde individuos, en este caso, programas computacionales generados aleatoriamente por computadormediante la combinación de elementos pertenecientes a un conjunto de funciones y terminales pre-viamente definidos. Generación tras generación, a través de operadores de selección, mutación ycruzamiento, los individuos de la población inicial dan paso a nuevas poblaciones evolucionadas.El conjunto de funciones puede ser definido en base a operadores aritméticos y lógicos, funcionesmatemáticas u otros elementos a considerar; en tanto que, el conjunto de terminales contempla en-tradas apropiadas al dominio del problema, las cuales se definen como valores constantes o funcionessin parámetros de entrada. Durante el proceso evolutivo, cada individuo es ejecutado y evaluado
CLAIO-2016
947

mediante una función de fitness, la cual evalúa la medida de adaptación de cada individuo frentea un subconjunto de casos de prueba. La PG emplea una estructura de datos de tipo árbol, dondelos nodos internos se componen de elementos provenientes desde el conjunto de funciones, mientrasque los nodos hojas, por elementos del conjunto de terminales (Tabla 1).
Tabla 1: Terminales empleados para el proceso evolutivo
Nombre Descripción
STP Inserta en la solución parcial la operación que tenga menor tiempo deprocesamiento dentro de las máquinas factibles disponibles.
SMPT Inserta en la solución parcial la operación que tiene menor tiempo deprocesamiento promedio, en la máquina con menor tiempo de procesa-miento disponible. Para esto, se evalúan todas las operaciones en todaslas máquinas factibles.
LMPT Inserta en la solución parcial la operación que tiene mayor tiempo deprocesamiento promedio, en la máquina con menor tiempo de procesa-miento disponible. Para esto, se evalúan todas las operaciones en todaslas máquinas factibles.
GOPNR Inserta en la solución parcial una operación perteneciente al trabajo quetenga más operaciones por realizar, en la máquina con menor tiempo deprocesamiento.
GOPNRWM Inserta en la solución parcial una operación perteneciente al trabajo quetenga más operaciones por realizar, en la máquina con mayor tiempo deprocesamiento y que presente además la menor cantidad de operacionesprocesadas.
GOPNRWMB Inserta en la solución parcial una operación perteneciente al trabajo quetenga más operaciones por realizar, en la máquina con mayor tiempo deprocesamiento y que presente además la mayor cantidad de operacionesprocesadas.
GOPNRTDES Inserta en la solución parcial una operación perteneciente al trabajoque tenga más operaciones por realizar, en la máquina cuyo tiempo deprocesamiento acumulado sea el menor.
2.2. Selección de casos de adaptación
Determinar un subconjunto adecuado de instancias de prueba para el proceso evolutivo consti-tuye una etapa clave en la GAA. Es sabido que si el conjunto de adaptación es reducido, existe unfenómeno de sobre aprendizaje en las instancias de prueba, lo que conduce a generar algoritmos quedegradan su desempeño frente a instancias desconocidas. Por otro lado, si el conjunto de prueba esdemasiado amplio se debe incurrir en un elevado tiempo computacional para determinar un algo-ritmo [12]. La determinación de los casos de adaptación fue realizada a partir de la comparación dela evaluación de los algoritmos exactos obtenidos durante el proceso evolutivo sobre cada una de las10 instancias del grupo SFJS, agrupadas de acuerdo al número de soluciones óptimas encontradas.Otro factor considerado para la selección de instancias fue su flexibilidad. La que permite generardos subconjuntos: SFJS 4, 5, 10 y SFJS 4, 7, 10 (Tabla 2).
CLAIO-2016
948

Tabla 2: Instancias con mayor número de soluciones óptimas
Instancia Flexibilidad Instancias que resuelve
SFJS4 parcial 2, 4, 7SFJS5 total 1, 5, 7SFJS7 total 2, 4, 7SFJS10 parcial 5, 7, 10
2.3. Plataforma utilizada
El entorno utilizado para llevar a cabo el proceso evolutivo de los algoritmos aśı como suevaluación, es ECJ 23, una libreŕıa diseñada para la investigación usando Computación Evolutivaprogramada en lenguaje de programación Java. La libreŕıa hace uso de la representación GP Tree.La plataforma es ejecutada sobre Windows 10, en un computador con procesador Intel Core i7-4790 de 3.6 GHz y 8 Gb de memoria RAM. Los parámetros empleados para el proceso evolutivo sedetallan en la Tabla 3.
Tabla 3: Resumen parámetros de evolución
Parámetro Valor
Tamaño de población 500Número de generaciones 50Probabilidad de cruzamiento 94 %Probabilidad de mutación 6 %Método de generación de población inicial Ramped Half and HalfMétodo de selección Torneo con tamaño 4Altura máxima de los individuos 15Altura máxima de la población inicial 6Método de reemplazo de población Remplazo completo en cada iteraciónNúmero de ejecuciones 30
3. Resultados
La selección de los casos de adaptación muestra que la generación de algoritmos exactos es-pecializados en una determinada instancia permite encontrar también soluciones óptimas al serevaluados sobre el resto de instancias pertenecientes al mismo grupo. La PG genera un total de 8algoritmos exactos para el subconjunto SFJS 4, 5, 10 y 3 algoritmos exactos para el subconjuntoSFJS 4, 7, 10. La evaluación de los 11 algoritmos óptimos muestra que es posible resolver de maneraexacta un conjunto mayor de instancias, a partir de la elección adecuada de un conjunto mı́nimo deéstas, mostrando con esto la relación que existe entre instancias de un mismo grupo. Este resultadosugiere que para el grupo SFJS los algoritmos heuŕısticos tienen distinto desempeño dependiendodel tipo de instancia que intentan resolver (Tabla 4).
CLAIO-2016
949

Tabla 4: Error relativo ( %) para los tres mejores algoritmos exactos de cada instancia
SFJS 4,5,10 SFJS 4,7,10A2E1 A7E1 A24E1 A8E2 A26E2 A29E2
SFJS1 0.0 0.0 0.0 0.0 0.0 0.0SFJS2 19.6 0.0 0.0 26.1 19.6 0.0SFJS3 34.8 34.8 34.8 52.0 15.3 34.8SFJS4 0.0 0.0 0.0 0.0 0.0 0.0SFJS5 0.0 0.0 0.0 21.0 0.0 0.0SFJS6 30.3 11.5 11.5 21.8 11.5 11.5SFJS7 0.0 0.0 0.0 0.0 0.0 0.0SFJS8 23.3 23.3 38.3 10.6 22.1 23.3SFJS9 2.3 2.3 2.3 2.3 14.29 2.38SFJS10 0.0 0.0 0.0 0.0 0.0 0.0
(a) Algoritmo A2E1 (b) Algoritmo A7E1 (c) Algoritmo A24E1
Figura 1: Mejores algoritmos obtenidos para el conjunto SFJS 4,5,10
El algoritmo exacto encontrado para cada una de las instancias no es el mismo. La evaluación delos subconjuntos del SFJS se realiza bajo dos experimentos: (a) experimento 1, correspondiente alsubconjunto SFJS 4,5,10 y (b) experimento 2, subconjunto de instancias SFJS 4,7,10. Los resultadosobtenidos, a partir de la comparación de los algoritmos que logran el total de soluciones óptimas altérmino de las 30 evoluciones realizadas en los experimentos 1 y 2, muestra que, pese a compartiruna gran cantidad de heuŕısticas comunes, los algoritmos generados son diferentes. La Figura 1presenta los tres mejores algoritmos obtenidos sobre el subconjunto SFJS 4, 5, 10. El algoritmoobtenido en la segunda generación para el experimento 1 (A2E1), Figura 1(a), obtiene el desempeñocomputacional más bajo, ponderando un 11.5 % de error relativo respecto al makespan sobre el totalde instancias del grupo, empleando la mayor cantidad de operaciones y heuŕısticas, generando unárbol de tamaño 15. Los algoritmos de la Figura 1(b) y Figura 1(c) presentan el mismo tamaño,śı como también una gran cantidad de terminales comunes. Por otro lado, el mejor algoritmo exactoobtenido durante el experimento 1 corresponde al algoritmo A7E1, Figura 1(b), el cual logra resolverde manera óptima 6 instancias de prueba, con un error relativo promedio de 7.21 %. El desempeñocomputacional obtenido por los algoritmos evaluados sobre el segundo grupo, correspondiente alas instancias SFJS 4, 7, 10, presenta resultados similares. El algoritmo exacto que presenta menorrendimiento sobre el total de instancias obtiene un 13.41 % de error relativo promedio, resolviendo4 instancias de manera exacta. A su vez, el mejor algoritmo del experimento2 (A29E2), Figura
CLAIO-2016
950

2(b), alcanza el mismo porcentaje de soluciones óptimas y error relativo que el algoritmo A7E1, sinembargo, el conjunto de heuŕısticas que lo compone es diferente, por lo que es posible afirmar que noexiste un único algoritmo capaz de resolver de manera exacta los 6 conjuntos de instancias comunesencontradas. La Figura 2 muestra los algoritmos exactos con mayor desempeño sobre el conjuntoSFJS encontrados mediante la PG para los experimentos 1 y 2. Tanto el algoritmo A7E1 como elalgoritmo A29E2, Figura 2(a) y Figura 2(b) respectivamente, presentan el mismo tamaño de árbol,al igual que la cantidad de operadores lógicos. El algoritmo A7E1 presenta un árbol equilibrado,mientras que el algoritmo A29E2 presenta una ramificación extra en la evaluación previa a laejecución del terminal STP inserto dentro del ciclo While. La presencia de una ramificación extra,junto a la variación en uno de los terminales, muestra que la similitud entre ambos algoritmos,sugiere que cada conjunto de instancias requiere su propio algoritmo óptimo.
(a) Álgoritmo A7E1 (b) Álgoritmo A29E2
Figura 2: Mejores algoritmos obtenidos para los conjuntos SFJS 4, 5, 10 y SFJS 4, 7, 10
4. Conclusiones
La búsqueda de un algoritmo eficiente capaz de encontrar el valor óptimo para cualquier con-junto de instancias sigue presentando un reto computacional. En la literatura es posible encontraralgoritmos altamente especializados para el FJSP, sin embargo, estos aún no permiten resolver ensu totalidad el pequeño grupo de instancias conocidas. Diseñar algoritmos competitivos resultaun proceso complejo y costoso, el cual emplea técnicas computacionalmente complejas. La PG,adoptando las bases de la computación evolutiva, permite generar cientos de algoritmos capaces deentregar una solución factible al problema de optimización. La capacidad de invención dada porlas combinaciones que puede realizar el computador mediante un árbol sintáctico, a partir de com-ponentes definidos como funciones y terminales, empleando PG, permite navegar sobre un amplioespacio de algoritmos factibles. La técnica explorada en este art́ıculo permite generar algoritmosexactos para subconjuntos de instancias del grupo SFJS. La GAA muestra ser una técnica efectivaen este campo de estudio, logrando generar diversos algoritmos exactos en tiempos computacio-nalmente bajos. El diseño que presentan los algoritmos exactos muestra además que éstos no sonúnicos, bajo el conjunto de funciones y terminales escogidos. Las caracteŕısticas y dureza en cadauna de las instancias, da cuenta que estás presentan ciertos elementos en común, los cuales permitenresolver, a partir de un conjunto reducido de éstas, un conjunto mayor. Generar algoritmos exactosa partir de subconjuntos de instancias puede mejorar la calidad de nuevos algoritmos diseñados
CLAIO-2016
951

para resolver el FJSP, a través del resultado del análisis de los algoritmos más exitosos sobre lasinstancias conocidas.
Referencias
[1] E. K. Burke, M. Gendreau, M. Hyde, G. Kendall, G. Ochoa, E. Özcan, and R. Qu. Hyper-heuristics: A survey of the state of the art. Journal of the Operational Research Society,64(12):1695–1724, 2013.
[2] E. K. Burke, M. Hyde, G. Kendall, and J. Woodward. A genetic programming hyper-heuristicapproach for evolving 2-d strip packing heuristics. Evolutionary Computation, IEEE Transac-tions on, 14(6):942–958, 2010.
[3] E. K. Burke, G. Kendall, and E. Soubeiga. A tabu-search hyperheuristic for timetabling androstering. Journal of Heuristics, 9(6):451–470, 2003.
[4] C. Contreras-Bolton, G. Gatica, and V. Parada. Automatically generated algorithms for thevertex coloring problem. PLoS ONE, 8(3), 3 2013.
[5] C. Contreras-Bolton, G. Gatica, C. Rey, and V. Parada. A multi-operator genetic algorithmfor the generalized minimum spanning tree problem. Expert Systems with Applications, 50:1–8,5 2016.
[6] J. R. Koza. Human-competitive results produced by genetic programming. Genetic Program-ming and Evolvable Machines, 11(3-4):251–284, 2010.
[7] S. S. Panwalkar and W. Iskander. A survey of scheduling rules. Operations research, 25(1):45–61, 1977.
[8] L. Parada, C. Herrera, M. Sepulveda, and V. Parada. Evolution of new algorithms for thebinary knapsack problem. Natural Computing, 15(1):181–193, 3 2016.
[9] R. Poli, W. B. Langdon, N. F. McPhee, and J. R. Koza. A field guide to genetic programming.Lulu. com, 2008.
[10] M. Saidi-Mehrabad and P. Fattahi. Flexible job shop scheduling with tabu search algorithms.The International Journal of Advanced Manufacturing Technology, 32(5-6):563–570, 2007.
[11] K. Smith-Miles and L. Lopes. Measuring instance difficulty for combinatorial optimizationproblems. Computers & Operations Research, 39(5):875–889, 2012.
[12] A. Teller and D. Andre. Automatically choosing the number of fitness cases: The rationalallocation of trials. Genetic Programming, 97:321–328, 1997.
[13] D. H. Wolpert and W. G. Macready. No free lunch theorems for optimization. EvolutionaryComputation, IEEE Transactions on, 1(1):67–82, 1997.
[14] W. Xia and Z. Wu. An effective hybrid optimization approach for multi-objective flexiblejob-shop scheduling problems. Computers & Industrial Engineering, 48(2):409–425, 2005.
CLAIO-2016
952

Decisión conjunta para la delineación de terreno y selección de
cultivos mediante el uso de modelos de optimización.
Marcelo Véliz Alcaíno Departamento de Industrias. Universidad Técnica Federico Santa María
Campus Santiago Vitacura. Av. Santa María 6400. Santiago. Chile [email protected]
Víctor M. Albornoz Departamento de Industrias. Universidad Técnica Federico Santa María
Campus Santiago Vitacura. Av. Santa María 6400. Santiago. Chile [email protected]
Resumen
Uno de los principales aspectos en apoyo a la toma de decisiones en agricultura es proveer métodos que permitan a los agricultores una adecuada gestión de esta actividad. Un primer problema en el manejo de cultivos que se debe enfrentar es cómo delinear zonas de manejo antes de plantar los cultivos, esto con el objetivo de mejorar su productividad y rendimiento. De este modo se busca que las zonas de manejo tengan propiedades relativamente homogéneas respecto a alguna propiedad. Un segundo problema que se debe resolver es la selección apropiada de cultivos que se van a plantar dentro de las zonas de manejo previamente delineadas. Se está en consecuencia ante un problema de naturaleza jerárquica que en el presente trabajo se propone abordar mediante un modelo de optimización que simultáneamente aborde ambas decisiones. Se muestra los resultados alcanzados en problemas preliminares y el trabajo de investigación futuro.
Palabras Clave: Investigación de Operaciones en Agricultura, planificación de cultivos,
programación entera.
1. Introducción
La investigación de operaciones es una disciplina que se ha llegado a aplicar a un amplio rango de problemas incluyendo operaciones relacionadas con agricultura. En este ámbito existen diversos modelos y estrategias para la gestión agrícola usando metodologías tales como modelos de optimización, simulación computacional, etc. Distintos trabajos han sido descritos en revisiones como [13], donde se presenta una recopilación de modelos de programación matemática orientados a decisiones de manejo en recursos naturales, entre ellos la agricultura.
En el caso particular del problema que permite determinar zonas de manejo agrícola, la mayoría de los enfoques están basados en algoritmos de agrupación justificados en la información obtenida de muestras de la tierra, ver por ejemplo [8] y [11], donde los autores usan información de
CLAIO-2016
953

relieves y de topografía de la tierra. Otros enfoques usan mapas de rendimiento, combinando información de muchas cosechas, como en [3]. También es posible encontrar trabajos donde se hace uso de métodos de agrupamiento, en los que a partir de datos del suelo se utilizan algoritmos de agrupación como el método fuzzy k-means para delinear las zonas, como en [12].
Por otra parte, en [4] se exploran métodos para delinear el terreno de cultivo mediante la consideración de un modelo de programación lineal entera (BILP) que minimiza la cantidad de zonas y toma en cuenta la homogeneidad respecto a alguna propiedad del suelo. En [1] se extiende el modelo anterior a uno bi-objetivo que junto con minimizar el número de zonas resultantes de la partición del terreno, maximiza el nivel de homogeneidad de las zonas propuestas, generando un set de soluciones óptimas formando una frontera eficiente. Con el set de zonas óptimo ya encontrado se procede a evaluar los cultivos apropiados para sembrar, mediante un modelo que maximiza el beneficio del agricultor de acuerdo a un conjunto dado de posibles cultivos. Se observa entonces una estructura jerárquica, pues se resuelven los problemas en etapas separadas y se agrega de hecho un nivel más relacionado con un problema operacional asociado al riego del terreno, basado a su vez en un modelo de optimización descrito en [5].
Adicionalmente, para mejorar el desempeño en la resolución de instancias de gran tamaño es que se han aplicado métodos de descomposición, como en el trabajo de [2] en el que se desarrolla una estrategia de generación de columnas para encontrar las zonas de manejo que formarán la partición del terreno.
En cuanto a la planificación de cultivos existe una abundante literatura donde a menudo se formulan problemas de programación lineal, algunos mono-objetivos, como en [5] donde se propone un modelo matemático que maximiza la utilidad tras vender los cultivos plantados en una parcela, esto tomando en consideración el rendimiento de ellos, y otros multi-objetivos, como el propuesto en [10] donde se desea maximizar el beneficio neto económico y el área irrigada con el propósito de encontrar un patrón de cultivo óptimo que asegure la utilización apropiada de la tierra disponible y los recursos hídricos, entre otros.
Dentro de este contexto, también se contemplan otros aspectos como la rotación de cultivos, donde se desea encontrar un set de cultivos óptimos dentro de un horizonte temporal más amplio y contemplar la necesidad de alternar cultivos a través de los períodos de producción. En [7], por ejemplo, se plantea un problema capaz de determinar el área cultivable asociada a una rotación de cultivos dentro de un horizonte establecido considerando una producción que respete ciertos restricciones ecológicas y además las cosechas pueden incluso ser inventariadas para cumplir la demanda en períodos posteriores.
En lo que sigue, este artículo se organiza en las siguientes secciones. La Sección 2 presenta distintos modelos matemáticos de optimización asociados a la planificación de cultivos, en la Sección 3 se presenta los resultados computacionales para instancias preliminares y, finalmente en la Sección 4 se enumeran conclusiones y posibles extensiones del trabajo descrito.
2. Metodología
En planificación agrícola los agricultores deben enfrentarse a numerosos problemas, dos muy importantes consisten en delinear correctamente el terreno, esto identificando las propiedades
CLAIO-2016
954

químicas, físicas y/o biológicas del suelo para reducir los costos de manejo asociados al tratamiento de la tierra, y posteriormente seleccionar los cultivos apropiados a cada zona previamente identificada, de manera que generen óptimos rendimientos económicos.
La delineación del terreno se puede enfrentar definiendo una partición mediante un conjunto de zonas rectangulares relativamente homogéneas respecto a alguna propiedad del suelo como el nitrógeno, fósforo, materia orgánica, etc. Estas agrupaciones reciben el nombre de cuarteles y tienen la particularidad de que no se sobreponen y son adyacentes entre sí. La formulación matemática de este problema en [4] se resume a continuación considerando la siguiente notación:
Conjuntos
�: ���������� ���
�: ��������� ����������
Parámetros
���: � �������1�������� �������������� ��������, 0��
�� : !����������������������������, ����������"úí�����������
�% : !�������������� ����, ����������"úí�����������
&: !�������������������������������������
(: )���������������� ������������������ �: )������������������� ������������������������� ����
*�: +����������������� á-� �������������� �������������ó
Y Variables de decisión
.�: 1������������������� ���������"��, 0��. &: !�������������������������������������
Modelo de Delineación del Terreno:
í0 .��∈% (1)
s.a.
0 ���.��∈%= 1,∀� ∈ � (2)
1 − ∑ 6� − 17�� ∑ -8�8∈9�∈%�� :( − ∑ ∑ -8�8∈9�∈% ; ≤ & (3)
.� ∈ =0,1>∀� ∈ ) (4)
El anterior es un problema cuya función objetivo en (1) se busca minimizar el número de cuarteles seleccionados y maximizar la homogeneidad de las zonas acuarteladas. La restricción (2) asegura que cada punto muestral s sea cubierto por sólo un cuartel. La restricción (3) corresponde a la obtención de un nivel de homogeneidad dado en términos del concepto de varianza relativa. Finalmente, en (4) se describe la naturaleza de las variables de decisión del modelo.
CLAIO-2016
955

Cabe destacar que la restricción (3) puede ser linealizada y reescrita de la siguiente manera.
0 :6� − 17�� ? 61 − &7�� ;.��∈%≤ 61 − &7�� (,∀@ ∈ A (5)
Resolviendo este problema se puede seleccionar zonas de manejo relativamente homogéneas, rectangulares y adyacentes entre sí, tal como muestra la siguiente figura para
diferentes valores de la constante α que mientras mayor define zonas o cuarteles con mayor nivel de homogeneidad respecto de la propiedad empleada:
Figura 1. Selección de zonas de manejo de acuerdo a un valor de varianza α
Una vez resuelto este problema se prosigue con la decisión de rotación de cultivos a ser plantados en estas zonas de manejo. Este es un problema de planificación que basado en [5] y [7] resumimos a continuación considerando la siguiente notación:
Conjuntos.
A: �����������������
�: ���������� ���
): ������������
�: ��������í����������� Parámetros:
B8�: B�����������������ó@������� ���@
CDE: C� �������������������� ���: )������������ �������������� ���������
FDE8 : +��� ��������������������������ó@������í�
Variable decisión:
-8�: � ���������1�����������������������@������� ����
CLAIO-2016
956

í0 0 B8�-8�8∈9�∈% (6)
s.a.
0 0 FDE8 -8�8∈9�∈%≥ CDE,∀� ∈ ), � ∈ � (7)
0 -8�8∈9≤ 1,∀� ∈ � (8)
-8� ∈ =0,1> (9)
La función objetivo (6) minimiza el costo asociado a plantar la rotación de cultivos en una determinada zona de manejo z. Las restricciones en (7) aseguran el cumplimiento de una demanda de cultivos en cada período de producción. La restricción (8) establece que sólo un plan de cultivos sea plantado en cada zona de manejo. Finalmente en (9) se describe la naturaleza de las variables de decisión del modelo.
Abordado el problema de asignación de cultivos a zonas de manejo en un esquema jerárquico puede conducir a soluciones sub-óptimas y por ello en el presente trabajo se propone un planteamiento simultáneo que permitiría tratar el problema de manera óptima mediante un único modelo de optimización bi-objetivo, que empleando la notación previamente introducida corresponde a la siguiente formulación:
í0 0 B8�-8�8∈9�∈%, í0 0 -8��∈%8∈9
(10)
s.a.
0 0 FDE8 -8�8∈9�∈%≥ CDE,∀� ∈ ), � ∈ � (11)
0 -8�8∈9≤ 1,∀� ∈ � (12)
0 0 ���-8�8∈9�∈%= 1,∀� ∈ � (13)
1 − ∑ 6� − 17�� ∑ -8�8∈9�∈%�� :( − ∑ ∑ -8�8∈9�∈% ; ≤ & (14)
& ∈ :0,1;, .� ∈ =0,1>∀� ∈ ), -8� ∈ =0,1>
La virtud de este planteamiento es que en un único modelo se es capaz de determinar cómo delinear el terreno y qué plantar en cada zona definida de acuerdo a propiedades del suelo que afectan directamente el rendimiento y por ende la productividad de los cultivos en cada período. Se está ante un problema bi-objetivo, el que puede ser resuelto con diversas estrategias descritas ampliamente por distintos autores, ver por ejemplo [6], resultando particularmente conveniente el
empleo del método H-constraint. Así entonces se puede abordar la resolución del mismo al
CLAIO-2016
957

minimizar el costo asociados al plan de cultivo propuesto para una cantidad dada de zonas de
manejo (*�7, considerando diferentes valores para este parámetro es posible conseguir la frontera
eficiente incorporando una restricción que asocie convenientemente las variables -8� con un límite superior de zonas de manejo, Problema que resulta ser el siguiente:
í0 0 B8�-8�8∈9�∈% (10)
s. a.
0 0 FDE8 -8�8∈9�∈%≥ CDE,∀� ∈ ), � ∈ � (11)
0 -8�8∈9≤ 1,∀� ∈ � (12)
0 0 ���-8�8∈9�∈%= 1,∀� ∈ � (13)
1 − ∑ 6� − 17�� ∑ -8�8∈9�∈%�� :( − ∑ ∑ -8�8∈9�∈% ; ≤ &
(14)
0 0 -8��∈%8∈9≤ *� (15)
& ∈ :0,1;, .� ∈ =0,1>∀� ∈ ), -8� ∈ =0,1>
3. Resultados
Para analizar las bondades del modelo propuesto se usaron 4 instancias, cada una de ellas con distinto número de puntos muestrales. En cada instancia hay 5 posibles rotaciones de cultivos y que deben satisfacer las necesidades de un horizonte de 4 períodos de tiempo. Se muestra los resultados
para un nivel de homogeneidad & = 0.5 y una cantidad máxima de *� = 4 zonas de manejo, parámetros que en la realidad están sujetos a la conveniencia y decisión del agricultor, quien debe considerar por ejemplo cuántas zonas son apropiadas, de acuerdo a su capacidad operacional instalada. Las instancias fueron resueltas usando CPLEX 12.4 como solver en un Samsun con Intel core i5-3317U, procesador 1.70GHz y 4Gb de memoria RAM. La siguiente tabla muestra los tamaños de las instancias consideradas:
Instancia
Puntos
muestrales Potenciales zonas de manejo
1 12 60
2 20 150
3 30 315
4 42 588
Tabla 1. Instancias y resultado de la función objetivo.
CLAIO-2016
958

En la Tabla 1 es posible apreciar que el número de las potenciales zonas de manejo aumentan considerablemente ante el aumento de puntos muestrales en el terreno, es esta característica del problema la que hace atractivo explorar un método de descomposición para instancias que consideren mayor cantidad de variables.
El detalle de la instancia 4 (con 42 puntos muestrales) se aprecia en la Figura 2, donde hay un total de 4 zonas de manejo, en cada una de las cuales el modelo opta por un determinado plan de cultivos asociados a una de las 5 rotaciones propuestas.
1 2 3 4 5 6 7
Rotación 1
8 9 10 11 12 13 14
Rotación 2
15 16 17 18 19 20 21
Rotación 3
22 23 24 25 26 27 28
Rotación 4
29 30 31 32 33 34 35
Rotación 5
36 37 38 39 40 41 42
Figura 2. Resultado de la optimización, cada color es una rotación de cultivos en el tiempo.
4. Conclusiones y Trabajo Futuro.
Como se presentó en este artículo, existen diversos modelos que resuelven importantes problemas en la agricultura, donde destacan un modelo que resuelve la delineación del terreno de acuerdo a propiedades inherentes del suelo en que se plantará y, por otra, uno que determina la mejor combinación de cultivos en los terrenos ya delimitados. Usualmente resueltos en un esquema jerárquico, en este artículo se formula de manera alternativa un modelo bi-objetivo que aborda de manera conjunta dicha problemática. El modelo propuesto ha sido resuelto de manera directa con un solver de programación entera para instancias preliminares. El trabajo que sigue da pie a un profundo análisis en su comparación con los resultados alcanzado en un esquema jerárquico ante instancias de mayor tamaño y complejidad, las cuales deberán ser resueltas a su vez mediante un método de descomposición como el de generación de columnas, ya empleado con éxito en trabajos preliminares de los autores.
Referencias.
1. V.M. Albornoz, N.M. Cid-García, R. Ortega and Y.A. Ríos-Solís,. A Hierarchical Planning Scheme Based on Precision Agriculture. In L.M. Pla-Aragones (ed.), Handbook of Operations Research in Agriculture and the Agri-Food Industry, Springer, 2015.
2. V.M. Albornoz and Ñanco, L.J. An empirical design of a column generation algorithm applied to a
management zone delineation problem. In Computational Management Science. State of the Art 2014. Fonseca, R.J., Weber, G.W. and Telhada,J. (Eds). Lecture Notes in Economics and Mathematical Systems 682: 201-208, Springer.
CLAIO-2016
959

3. S. Blackmore, R. Godwin and S. Fountas. The Analysis of Spatial and Temporal Trends in Yield Map Data
over Six Years. Biosystems Engineering 84 (4): 455–466, 2000.
4. N. Cid-Garcia, V. Albornoz, Y. Ríos-Solís and R. Ortega. Rectangular shape management zone delineation using integer linear programming. Computers and Electronics in Agriculture 93: 1–9, 2013.
5. N. Cid-Garcia, A. Bravo-Lozano and Y. Ríos-Solís. A crop planning and real-time irrigation method based on site-specific management zones and linear programming. Computers and Electronics in Agriculture 107:
20–28, 2014.
6. C. Coello. A comprehensive survey of evolutionary-based multiobjective optimization techniques. Knowledge and Information Systems 1(3): 269-308, 1999.
7. L.M.R.dos Santos, P. Michelon, M.N Arenales, and R.H. Silva Santos. Crop-rotation scheduling with adjacency constraints. Annals of Operations Research 190: 165-180, 2011.
8. C.W. Fraisse, K.A. Sudduth and N.R. Kitchen Delineation of site-specific management zones by unsupervised classification of topographic attributes and soil electrical conductivity. American Society of
Agricultural Engineers 44 (1):155-166, 2001.
9. E.O. Heady. Simplified presentation and logical aspects of linear programming technique. Journal of Farm
Economics 24(5): 1035–1048, 1954.
10. M. Mainuddin, A. Das Gupta and P.R. Onta. Optimal crop planning model for an existing groundwater irrigation Project in Thailand. Agricultural Water Management 33 (1): 43–62, 1996.
11. P. O’Neill, J. Shanahan and J. Schepers, Agronomic Responses of Corn Hybrids from Different Eras to Deficit and Adequate Levels of Water and Nitrogen. American Society of Agronomy 96 (6): 1660-1667, 2004.
12. J. Ortega, W. Foster and R. Ortega. Definición de sub-rodales para una silvicultura de precisión: una aplicación del método Fuzzy K-means. Ciencia e Investigación Agraria 29 (1), 35–44, 2002.
13. A. Weintraub A. and C. Romero. Operations Research Models and the Management of Agricultural and Forestry Resources: A Review and Comparison. Interfaces 36 (5) 446-457, 2006.
CLAIO-2016
960

EL PROBLEMA DE ASIGNACIÓN DE RECURSOS A UN SISTEMA DE
DISTRIBUCIÓN DE ENERGÍA ELÉCTRICA
Jairo Alberto Villegas Flórez
Universidad Tecnológica de Pereira
Carlos Julio Zapata Grisales
Universidad Tecnológica de Pereira
Gustavo Gatica
Universidad Andrés Bello
Universidad de Santiago de Chile
Resumen
La distribución de energía eléctrica es un sistema que requiere alta disponibilidad ya que el 90%de las
fallas afectan la continuidad del servicio. Todo sistema es susceptible de mejorar y dentro de las formas
que podrían aplicarse están: Protecciones especiales, automatización del sistema, respuesta más rápida de
las cuadrillas de mantenimiento, mantenimientos preventivos programados, etc. Actualmente, una falla es
reportada al centro de distribución donde se genera una orden de servicio, que es asignada a la cuadrilla
más cercana , sin embargo, la asignación no es eficiente ni uniforme, , lo cual es una debilidad porque no
se están optimizando los recursos, necesarios para mejorar la atención. En este artículo se propone,
mediante una técnica de ruteamiento de vehículos como el VRP1, la cual se solucionará usando una
heurística mediante un modelo MTZ para asignar a las cuadrillas las fallas que deben atender, de manera
que se optimicen el tiempo o la distancia a recorrer.
Palabras Claves: Continuidad; Cuadrilla ; MTZ; Ruteamiento; VRP
1 Vehicle Routing Problem
CLAIO-2016
961

1 Introducción
Un sistema de distribución de energía requiere de la continuidad de servicio, las fallas que allí se
presentan, pueden tener consecuencias tanto económicas como operativas significativas. Para las
actividades de mantenimiento y atención de fallas, todas las empresas necesitan al menos personal de
trabajo, camiones para movilizar a los operarios, herramientas especializadas y los insumos, los cuales
deben ser organizados para satisfacer la demanda y/o reparar las fallas. La forma como estos recursos son
organizados sirven para generar las órdenes de reparación del sistema.
La figura 1 muestra el esquema de cómo dividir un sistema de distribución de energía por zonas de
mantenimiento con sus respectivas cuadrillas de reparación [1].
FIGURA 1. SISTEMA DE DISTRIBUCIÓN DE ENERGÍA DIVIDIDO POR ZONAS Y CUADRILLAS
Un sistema eléctrico como el que se muestra en la figura 1[1] puede presentar fallas en cualquier instante
y no siempre es posible resolver cada una de ellas atendiéndolas inmediatamente por varias razones,
como por ejemplo, el departamento de mantenimiento no tenga la forma de planificar una cuadrilla2 de
reparación, o la cuadrilla de reparación no está disponible o cerca al momento de la ocurrencia, del
mismo o está en proceso de resolución de una falla, o en el merecido descanso. Luego, cómo contribuir en
una asignación eficiente de las cuadrillas de reparación, para minimizar los costos que implica la no
continuidad de servicio.
En un sistema eléctrico, se tienen identificadas los tipos de fallas[1],[2], por ello, cuando se presenta una
falla en el sistema los usuarios reportan al centro de distribución un problema de calidad en el servicio,
ejemplos de cómo generar una orden de servicio y asignar una cuadrilla, se pueden ver en [2] y [10]. Sin
embargo, la asignación no es transparente, uniforme, equitativa y generalmente, es según ubicación y
distancia de la cuadrilla a la falla, un ejemplo de VRP utilizado para aplicaciones con cuadrillas y
restauración de energía en un sistema de distribución de energía se puede ver en [3].
La forma que se plantea en este artículo para resolver la situación es usando un modelo de ruteamiento de
vehículos VRP y solucionarlo mediante una heurística, una aplicación de este modelo se puede ver en [9]
de forma tal que se atiendan todos los clientes, optimizando ya sea la distancia recorrida o minimizando el
tiempo de respuesta hasta el lugar de la falla.
2 Es el equipo de trabajo que es enviado a realizar las labores de mantenimiento
CLAIO-2016
962

Para la solución de este problema existen diferente formas de resolverlos, puede ser usando programación
lineal, técnicas exactas, heurísticas o técnicas que resuelven problemas combinatoriales como las
metaheurísticas [7].
En [4] y [8] desarrollan un estado del arte para el problema de ruteamiento de vehículos explicando todas
sus divisiones, además en [8] adicionan conceptos de localización de los depósitos, [9] soluciona un
problema de ruteamiento de vehículos con capacidad usando una heurística MTZ, [11] resuelve un
problema de ruteamientos de vehículos con ventanas de tiempo tipo hard y tiempos de servicio
estocásticos, como se puede ver existen diferentes variantes y enfoque para abordar la solución de este
tipo de problemas. Además muchos de estos enfoques se pueden abordar para la solución de nuestro
problema, ya que muchas de las restricciones que usan pueden aplicar, como por ejemplo el caso de [11]
donde existen ventanas de tiempo, estas se pueden aplicar al colocar como restricción una hora especifica
de atención de la falla o también si se quisiera aplicar tiempos de reparación de las fallas, que serían los
tiempos de servicio que se ve en [11]
2 Descripción del Problema
El problema del ruteamiento de vehículos se esquematiza de la siguiente forma: se tiene un grafo G(V,E)
que representa a los clientes V que son los nodos y unas distancias o arcos ij entre cada cliente que se
llaman arcos E [5], cabe aclarar la siguiente situación: si el vehículo tiene que ir de la ciudad 1 a la ciudad
2, esta distancia la llamaremos d12 y no tiene que ser necesariamente igual a d21, cada distancia dij 𝟄E
representa el camino de i a j y tiene asociado un costo Cij, también cabe aclarar que el VRP puede ser
tanto simétrico como asimétrico, para nuestro caso diremos que la distancia dij=dji, o sea que será
indiferente si la distancia es dij o dji, el objetivo principal es encontrar la ruta más corta posible que visite
exactamente una vez cada ciudad y luego retorne al lugar de origen, en[4] se puede ver una forma de dar
solución al TSP3 el cual sirve como punto de partida para resolver el VRP, si solo tuviéramos un vehículo.
El VRP se puede formular matemáticamente de una forma sencilla, su complejidad crece a medida que se
aumenta el número de clientes, para formular el VRP como un problema de PLE, haremos uso de una
variable Xij la cual tomará el valor de 1 si el arco de i a j es usado y 0 en caso contrario.
Para la formulación que nos interesa el problema queda de la siguiente manera:
{
}
∑∑
La ecuación (1) se refiere a la función objetivo, que busca minimizar la distancia recorrida por el
vehículo, adicional a esta función se deben plantear las restricciones de entrada y salida de cada cliente
[5].
3 Travel Salesman Problem
CLAIO-2016
963

∑
La ecuación (2) garantiza que se llega a un cliente cada vez.
∑
La ecuación (3) garantiza que se sale de un cliente cada vez.
∑
∑
Las ecuaciones 4 y 5 son para asegurar que todos los vehículos que salen del depósito ingresan
nuevamente a él.
La restricción (6) que satisface la conectividad de la solución y que no se viole la capacidad de cada
vehículo.
∑∑
̅
Dónde:
Es el conjunto de vértices que representan las fallas del sistema y v0 es el depósito
que en nuestro caso es el centro de mando.
C: es la matriz de distancias o de costos entre los vértices vi y vj
K: es el número de vehículos disponibles para atender la demanda,
r(s): es el número mínimo de vehículos para atender la demanda de los clientes,
Después de explicar el planteamiento básico del problema de ruteamiento de vehículos podemos hacer un
paralelo con el problema que nos atañe y es el ruteamiento de cuadrillas de reparación a las fallas
presentadas dentro de un sistema de distribución de energía eléctrica.
En primera instancia la demanda a atender seria binaria existe la falla o no existe, por lo tanto la función
objetivo antes que minimizar un costo de desplazamiento hasta el cliente, podría minimizar una distancia
hasta el lugar de la falla o un tiempo de desplazamiento hasta la misma, de la siguiente manera:
∑∑
CLAIO-2016
964

∑∑
La ecuación 7 minimizaría la distancia recorrida hasta la falla y la ecuación 8 minimizaría el tiempo de
recorrido hasta la falla, en ambos casos la variable activa el arco que visita la falla ubicada en la
posición ij.
Con el planteamiento de la función objetivo se procede a modelar las restricciones.
Para asegurar que el vehículo entre y salga una sola vez de cada falla visitada se hacen necesarias las
siguientes restricciones:
∑
∑
La ecuación 9 garantiza que entre al nodo o falla que va a reparar y la ecuación 10 garantiza que
abandona el nodo donde ya se reparó la falla.
Las ecuaciones 11 y 12 son las restricciones que nos garantizan que todos los vehículos en este caso las
cuadrillas de reparación que salen del centro de distribución, vuelven y retornan al mismo, en este caso
son las cuadrillas de reparación.
∑
∑
La restricción (13) que satisface la conectividad de la solución y que no se viole la capacidad de cada
vehículo, en nuestro caso consideraremos que los vehículos tienen capacidad infinita y que pueden
resolver todas las fallas asignadas en la ruta. En nuestro caso serían las cuadrillas que se tienen por cada
turno de ocho horas.
∑∑
̅
La Tabla 1 presenta un comparativo entre el modelo básico y los modelos propuestos para la solución del
problema.
TABLA 1: COMPARATIVO MODELO BÁSICO VS MODELOS PROPUESTOS. ELABORACIÓN FUENTE
PROPIA
Modelo Básico Modelo 1 (distancia) Modelo 2 (tiempo)
Función Objetivo ∑∑
∑∑
∑∑
CLAIO-2016
965

Restricciones de
entrada y salida ∑
∑
∑
∑
∑
∑
Restricciones de ida
y vuelta al depósito ∑
∑
∑
∑
∑
∑
Restricción de
conectividad ∑∑
∑∑
∑∑
CLAIO-2016
966

5 Conclusiones
La principal conclusión que podemos sacar de esta investigación, es que la aplicación de modelos
de programación lineal como son los de ruteamiento de vehículos sirven para mejorar la logística
de las empresas y optimizar los recursos que se tienen.
Aplicar modelos diferentes al modelo VRP puede ayudar a mejorar la logística en la asignación
de recursos, uno de ellos puede ser el modelo OVRP en el cual no se podría tener en cuenta el
tiempo desde la atención de la última falla hasta la llegada al centro de control de la empresa.
6 Recomendaciones y trabajos futuros
Además de emplear los modelos de ruteamiento de vehículo como el VRP o el OVRP, sería
interesante usar modelos que optimicen aspectos diferentes que puedan ayudar a la logística de la
empresa y tal caso podría ser la localización de un centro de distribución temporal o permanente
en la ciudad como se plantea en [8] donde haciendo una revisión de problemas combinados de
ruteo y localización
Otra consideración que se puede tener es adicionar al problema restricciones como ventanas de
tiempo TW4 y tiempos de reparación de la falla estocásticos SST
5, un ejemplo de ello se puede
ver en [11] donde resuelven un problema de ruteamiento con estas variables VRPHTWSST6 en
esta aplicación la ventana de tiempo es hard, pero no necesariamente tiene que ser así, ya que
también se puede trabajar ventanas de tiempo soft
4 Time Windows 5 Stochastic Services Times 6 Vehicle Routing Problem with Hard Time Windows and Sthochastic Services Times
CLAIO-2016
967

Referencias
[1] Burbano, O. L. Gonzalez, H, I y Hernandez, J.A. Silva, S. C. Zapata, C.J. Burbano, O. L. Gonzalez, H, I y Hernandez, J.A.
Modeling the Repair Process of a Power Distribution System. IEEE Transmission & Distribution Latin America
Conference, 2008
[2] Cardona, Anderson, Montealegre, Paola. Zapata, Carlos Julio. Problemas de Calidad del Servicio. Mundo Eléctrico No 58.
Pereira. Año 2004.
[3] Bhaba R, Sarker, Evangelos Triantaphyllou. Lawrence Mann Jr, Shaojun Wang. Departament of Industrial and
Engineering Technology. Resource Planning and a Depot Location Model for Electric Power Restoration. Lousiana
State University. European Journal of Operational Research. Octubre de 2002
[4] González, C. Orjuela, J y Rocha, L. (2011). Una revisión al estado del arte del problema de ruteo de vehículos:
Evolución histórica y métodos de solución. En: Ingeniería, Vol. 16, No. 2, pág. 35 – 55.
[5] Zabala, Paula. Tesis Doctoral Problemas de Ruteo de Vehículos, Departamento de Computación Facultad de
Ciencias Exactas y Naturales Universidad de Buenos Aires. Agosto de 2006.
[6] Gallego. R. Ramón, Hincapie. Isaza. Ricardo y Ríos. Porras. Carlos, y Técnicas Heurísticas Aplicadas al Cartero
Viajante (TSP), Revista Scientia Et Technica N° 24. Marzo de 2004
[7] Benavente. Magdalena, Bustos. Jaime Lüer. Armin y Venegas. Bárbara. El Problema de Rutas de Vehículos:
Extensiones y Métodos de Resolución, Estado del Arte. Universidad de la Frontera. Diciembre del 2009. Chile.
[8] Escobar, John. Linfati, Rodrigo y Adarme, Wilson. Problema de Localización y Ruteo con Restricciones de
Capacidad: Revisión de la Literatura. Fac. Ing., vol. 24 (39), pp. 85–98, Mayo-Ago. 2015
[9] Bektas, Tolga. Kara, Imdat y Laporte, Gilert. Departament of Industrial and Engineering. A note of the lifted
Miller-Tucker-Zemlin Subtour Eliminations Constraints for the Capacited Vehicle Routing Problem. Baskent
University. European Journal of Operational Research. Mayo de 2003.
[10] Díaz, J. Gallego, A. Marriaga, J. Ocampo, Patiño. J, and Zapata, C, J The Repair Process of Five Colombian
Power Distribution Systems. Transmission and Distribution Conference and Exposition IEEE: Latin America. 2010.
[11] Gendreau, M. Errico, F y Rousseau, L.M. Vehicle routing problem with hard time windows and stochastic
service time. Escuela Politécnica de Montreal. 2012
CLAIO-2016
968

Partição de conjuntos e metaheuŕısticas para o
problema de roteamento de véıculos com janelas de
tempo e múltiplos entregadores
Aldair Álvarez, Pedro MunariDepartamento de Engenharia de Produção, Universidade Federal de São Carlos, Brasil
[email protected], [email protected]
Resumo
Neste trabalho, estuda-se o problema de roteamento de véıculos com janelas de tempo emúltiplos entregadores, um problema de roteamento que integra as t́ıpicas decisões de pro-gramação e roteirização dos véıculos com a definição do tamanho da tripulação a ser designadaem cada rota. Este problema surge na distribuição de produtos em centros urbanos congestio-nados onde os clientes são atendidos de forma agrupada e, portanto, os tempos de serviço nosgrupos de clientes podem ser reduzidos ao incluir múltiplos entregadores nas rotas de entrega.O problema é abordado por meio de uma matheuŕıstica de duas fases que integra duas aborda-gens metaheuŕısticas e uma formulação por partição de conjuntos do problema. Experimentoscomputacionais mostram a eficiência da matheuŕıstica ao ser capaz de gerar soluções de boaqualidade de forma relativamente rápida quando comparada com métodos da literatura.
Keywords: Roteamento de véıculos; Múltiplos entregadores; Matheuŕıstica; Metaheuŕısticas.
1 Introdução
O problema de roteamento de véıculos e suas variantes têm sido grandemente estudadas dentroda literatura de Pesquisa Operacional, principalmente devido a sua dificuldade de resolução erelevância prática. Neste trabalho, estuda-se o Problema de Roteamento de Véıculos com Janelasde Tempo e Múltiplos Entregadores (VRPTWMD, do inglês Vehicle Routing Problem with TimeWindows and Multiple Deliverymen), uma extensão do Problema de Roteamento de Véıculos comJanelas de Tempo (VRPTW) em que os tempos de serviço dependem do número de entregadores darota de entrega. Portanto, no VRPTWMD, além das t́ıpicas decisões de programação e roteamentodos véıculos, deve se determinar o tamanho da tripulação de cada véıculo.
Este problema surge na distribuição de produtos em centros urbanos congestionados, onde ge-ralmente os véıculos não podem chegar até cada cliente para realizar o serviço requerido. Exemplost́ıpicos são fábricas de refrigerantes e cervejas que precisam reabastecer regularmente pequenosestabelecimentos comerciais como lojas de conveniência, restaurantes, entre outros. Estes estabele-cimentos se encontram tipicamente em regiões com alta concentração comercial, nas quais se tornadif́ıcil até mesmo estacionar os véıculos de entrega. Assim, clientes próximos entre si são agrupadosem torno de locais de estacionamento estratégicos e, a seguir, o véıculo estaciona no local e osentregadores seguem a pé até os clientes do grupo. Ao fazer as entregas dessa forma os tempos de
CLAIO-2016
969

serviço nos grupos podem ser relativamente longos, podendo inviabilizar o atendimento de outrosgrupos de clientes durante o horário de trabalho permitido. Nestes contextos, o uso de múltiplosentregadores se torna importante, pois pode reduzir o tempo de serviço em cada grupo de clientese, portanto, permite que todas as entregas possam ser feitas de forma viável.
Dado que o VRPTWMD foi recentemente proposto, há poucos trabalhos propondo métodos desolução para ele. Em [8], os autores modelam o VRPTWMD usando uma formulação com variáveisde fluxo e propõem duas abordagens metaheuŕısticas, a saber, Busca Tabu adaptativa e Otimizaçãopor Colônia de Formigas. Em [9], os autores propõem dois algoritmos metaheuŕısticos baseadosem Otimização por Colônia de Formigas e GRASP. Os algoritmos utilizaram o mesmo algoritmode construção e de busca local. Em [1], os autores desenvolvem duas abordagens metaheuŕısticasbaseadas em Busca Local Iterada (ILS, do inglês Iterated Local Search) e Busca em VizinhançaGrande (LNS, do inglês Large Neighborhood Search). Em [6], os autores propõem um algoritmobranch-price-and-cut para o problema. Este último é o único método exato proposto até o momentopara o problema.
Nos últimos anos, matheuŕısticas combinando heuŕısticas e metaheuŕısticas com formulações porpartição/cobertura de conjuntos têm sido utilizadas para resolver diferentes variantes do problemade roteamento de véıculos [3, 2, 13, 12]. Estes métodos compartilham prinćıpios semelhantes, emque uma metaheuŕıstica gera rotas de alta qualidade, as quais são mantidas em um conglomeradopara serem utilizadas por uma formulação de partição/cobertura de conjuntos do problema queentão é resolvida por um software de otimização. Seguindo essa linha, neste trabalho apresentamosuma matheuŕıstica utilizando esses mesmos prinćıpios para o VRPTWMD.
O restante deste trabalho está organizado como segue. Na Seção 2, descreve-se o problema eapresenta-se a formulação por partição de conjuntos para ele. A matheuŕıstica desenvolvida e seuscomponentes são descritos na Seção 3. Os resultados dos experimentos computacionais realizadossão descritos na Seção 4. Finalmente, na Seção 5, apresenta-se as conclusões deste trabalho.
2 Descrição do problema
Como foi mencionado anteriormente, o VRPTWMD é uma generalização do VRPTW que integraas decisões de programação e roteirização com a definição do tamanho da tripulação a ser designadaem cada rota. Portanto, o problema envolve a construção de um conjunto de rotas de entrega e aalocação de entregadores a elas. Deve-se considerar restrições de capacidade, de janelas de tempoe de entregadores dispońıveis enquanto se minimiza o custo total de operação, o qual é compostopelos custos de utilização de véıculos, de designação de entregadores e de distância percorrida.
Neste trabalho é assumido que os grupos de clientes são predefinidos. Portanto, as decisõesrelacionadas à seleção do local de estacionamento e os clientes que pertencem a cada grupo sãodados de entrada. Também assume-se que o tempo de serviço de cada grupo (dependente do númerode entregadores) é um dado de entrada.
No VRPTWMD, um conjunto de véıculos idênticos são inicialmente localizados em um depósito.Cada um deles pode realizar uma única rota de entrega. A demanda de cada grupo de clientes deveser atendida por exatamente um véıculo e dentro da janela de tempo do grupo. As rotas devemcomeçar e terminar no depósito. Além disso, dada uma solução S, seu custo é definido por:
c(S) = w1v + w2d+ w3t (1)
CLAIO-2016
970

onde v é o número de véıculos usados, d o número total de entregadores designados e t a distânciatotal percorrida em S. As constantes w1, w2 e w3 são os pesos de cada objetivo e definem aprioridade deles.
2.1 Formulação por partição de conjuntos para o VRPTWMD
O VRPTWMD pode ser modelado por meio de uma formulação por partição de conjuntos (SP,do inglês Set-Partitioning). Seja L o número máximo de entregadores permitidos a bordo em umúnico véıculo, D o número total de entregadores dispońıveis e n o número de grupos de clientes.Seja P l o conjunto de todas as rotas fact́ıveis usando l entregadores, l = 1, 2, . . . , L. Diz-se queo véıculo viaja em modo l quando o tamanho de sua tripulação é l. A cada rota p ∈ P l estãoassociados os seguintes parâmetros: clp representa seu custo e alpi, i = {1, . . . , n}, um coeficientebinário com valor 1 se e somente se o grupo i é atendido pela rota p em modo l. Além disso, sejaλlp uma variável binária igual a 1 se e somente se a rota p é selecionada. Usando esta notação, oVRPTWMD pode ser formulado como segue:
minL∑
l=1
∑
p∈P l
clpλlp (2a)
s.aL∑
l=1
∑
p∈P l
alpiλlp = 1, i = 1, . . . , n, (2b)
L∑
l=1
∑
p∈P l
lλlp ≤ D, (2c)
λlp ∈ {0, 1}, l = 1, . . . , L, p ∈ P l. (2d)
A função objetivo (2a) minimiza o custo total das rotas selecionadas. As restrições (2b) definemque cada grupo i deve ser atendido por uma única rota com um único número de entregadores l. Asrestrições (2c) impõem o limite no número total de entregadores que podem ser usados. Finalmente,o domı́nio da variável λlp é definido pelas restrições (2d).
Esta formulação foi proposta em [6] e pode ser obtida aplicando-se a decomposição de Dantzig-Wolfe na formulação por fluxo do VRPTWMD. Na prática, (2a)-(2d) pode conter um númeroenorme de variáveis dado que em geral o número de rotas nos conjuntos P l é exponencial emtermos do número de grupos de clientes.
3 Método de solução
Nesta seção apresentamos a matheuŕıstica proposta para o problema e cada um dos seus compo-nentes. O desenvolvimento deste método é motivado pelo fato de que existe a possibilidade de quesoluções fact́ıveis do problema possam conter rotas que também estejam na solução ótima.
3.1 Descrição da matheuŕıstica
O funcionamento e os componentes desta abordagem são esquematizados na Figura 1. Inicialmente,duas abordagens metaheuŕısticas são executadas de forma sequencial e todas as rotas das soluções
CLAIO-2016
971

intermediárias são armazenadas em um conglomerado até gerar o número predefinido de rotasiniciais. Ao finalizar a geração das rotas, um software de otimização é executado para resolvera formulação SP, para encontrar a melhor solução posśıvel dada pela combinação dessas rotasdentro do tempo limite. Adicionalmente, uma fase de pós-otimização é aplicada, na qual a soluçãoencontrada pelo modelo SP é repassada para as abordagens metaheuŕısticas, as quais são executadasem série para tentar melhorá-la. Uma única execução de cada metaheuŕıstica é aplicada e se umadelas consegue melhorar a solução, então uma nova execução das abordagens é realizada tentandomelhorar ainda mais a solução. Esse esquema adaptativo não é computacionalmente dispendioso epermite empregar as abordagens metaheuŕısticas mais frequentemente se elas forem bem-sucedidaspara melhorar a solução.
Formulação por partição de
conjuntos (SP)Solução
RotasAbordagens metaheurísticas
• Busca Local Iterada (ILS)
• Busca em Vizinhança Grande (LNS)
Figura 1: Estrutura da abordagem matheuŕıstica
3.2 Fase metaheuŕıstica
O objetivo desta fase é gerar rotas de alta qualidade, as quais serão usadas na segunda fase damatheuŕıstica. Essas rotas são geradas por meio da aplicação de duas abordagens metaheuŕısticaspara o VRPTWMD. A primeira abordagem utilizada é baseada na metaheuŕıstica Busca Local Ite-rada (ILS) enquanto a segunda é baseada na metaheuŕıstica Busca em Vizinhança Grande (LNS).Ambas as abordagens utilizam uma heuŕıstica construtiva baseada na heuŕıstica I1 [11], iniciali-zando as rotas com o grupo mais distante em relação ao depósito e definindo a tripulação do véıculocomo o número máximo de entregadores permitidos a bordo (3 entregadores). Estas abordagensmetaheuŕısticas foram propostas em [1].
3.2.1 Abordagem metaheuŕıstica baseada em ILS
A primeira abordagem utiliza em seu núcleo a metaheuŕıstica Busca Local Iterada [4], a qual aplicauma busca local repetidamente sobre um conjunto de soluções obtidas da perturbação dos ótimoslocais previamente visitados. Na abordagem utilizada, além das operações básicas de perturbação ebusca local, são utilizadas duas heuŕısticas adicionais espećıficas para o VRPTWMD (heuŕıstica deredução de rotas e heuŕıstica de redução de entregadores), com a intenção de melhorar o desempenhoda abordagem. Estas heuŕısticas exploram o tamanho da tripulação como variável de decisão pararefinar as soluções.
Nesta abordagem, a busca local é realizada com uma heuŕıstica de Busca de Vizinhança Variável[5] com Ordenação Aleatória. Esta heuŕıstica aplica repetidamente um conjunto de estruturasde vizinhança (operadores de busca local) para melhorar progressivamente a solução incumbente.São utilizados seis operadores inter-rotas, a saber: Shift(k,0), k={1,2,3}, Swap(1,1), Swap(2,1),Swap(2,2) e dois operadores intra-rotas, a saber: Or-opt-1 e 2-opt. Só movimentos fact́ıveis sãoadmitidos e a estratégia de primeira melhoria é utilizada nas estruturas de vizinhança. Além disso,sempre que uma estrutura de vizinhança consegue melhorar a solução, aplica-se a heuŕıstica deredução de rotas. Mais detalhes podem ser encontrados em [1].
CLAIO-2016
972

Para a fase de perturbação da abordagem, um dos dois procedimentos de perturbação consisteem uma heuŕıstica de remoção e inserção, a qual remove um número aleatório de grupos de clientesde uma rota dada e os insere nas rotas restantes. O segundo procedimento de perturbação é aheuŕıstica de redução de rotas proposta para o VRPTWMD em [1].
3.2.2 Abordagem metaheuŕıstica baseada em LNS
A segunda abordagem utilizada é baseada na metaheuŕıstica LNS [10], a qual tenta superar asdificuldades das buscas locais tradicionais, as quais só fazem pequenas modificações nas soluções econsequentemente podem não ser capazes de se deslocar eficientemente entre áreas promissoras doespaço de soluções. Na metaheuŕıstica LNS, a solução incumbente é iterativamente melhorada pormeio da aplicação alternada de operações de destruição e reparação. A abordagem aqui utilizadatambém aplica as heuŕısticas adicionais (redução de rotas e de entregadores) para melhorar seudesempenho. Ela foi proposta em [1] e utiliza quatro operadores de remoção diferentes. Cada umdeles toma como entrada uma solução fact́ıvel e retorna uma solução da qual foram extráıdos algunsgrupos de clientes. Os operadores utilizados foram: remoção aleatória, remoção da pior posição,remoção relacionada e remoção orientada pelo tempo. Operadores desse tipo foram propostos em[7] para um problema de coleta e entrega e foram adaptados para o VRPTWMD. Uma vez que asolução foi destrúıda pelo operador de remoção, a reparação dela é realizada utilizando um dos doisoperadores de inserção. Cada um deles toma como entrada uma solução incompleta e retorna umasolução completa, inserindo os grupos que foram extráıdos na fase de remoção. Os dois operadoresde inserção utilizados são: inserção gulosa e inserção tipo regret [1].
3.3 Fase de partição de conjuntos
Nesta fase da matheuŕıstica, a formulação por partição de conjuntos (SP) é resolvida considerandoum subconjunto de rotas da formulação (2a)-(2d). Esse subconjunto corresponde ao conglomeradode rotas que é gerado pelas abordagens metaheuŕısticas na primeira fase, utilizando as rotas de todasas soluções intermediárias dessa execução das metaheuŕıstica (não admitindo rotas repetidas). Aresolução da formulação é feita usando-se um software de otimização de propósito geral.
4 Experimentos computacionais
Todos os algoritmos foram implementados em linguagem C++, os experimentos foram executadosem um computador com processador Intel Core i7 3.40 GHz com 16 GB RAM e usando o CPLEX12.4 como software de otimização para resolver a formulação SP. Para evitar a lenta convergênciado software de otimização para fechar o gap de otimalidade em muitas instâncias, um tempo limitede 150 segundos foi imposto para resolver o modelo SP. A melhor solução inteira encontrada éreportada quando a formulação não é resolvida até a otimalidade. Experimentos computacionaispreliminares mostraram que este tempo fornece um bom balanço entre qualidade da solução encon-trada e o esforço computacional envolvido. Os parâmetros das metaheuŕısticas foram definidos comos mesmos valores usados em [1]. Na fase de pós-otimização do método, cada execução individualdas metaheuŕısticas é realizada durante 60 segundos. Além disso, duas variantes da matheuŕısticaforam testadas. Uma com um conglomerado de rotas grande (25.000 rotas) e uma versão com umconglomerado menor (10.000 rotas).
CLAIO-2016
973

Para avaliar o método foram utilizadas as instâncias de [11] para o VRPTW. No total são 56instâncias agrupadas em 6 conjuntos, a saber: R1, R2, C1, C2, RC1 e RC2, e cada uma possui 100nós (cada um deles assumido como um grupo de clientes)
Nessas instâncias, todos os dados originais são mantidos exceto os tempos de serviço, os quaisforam modificados de forma a representar o tempo de entrega da demanda acumulada dos clientesde cada grupo. A modificação nos tempos de serviço, conforme a proposta de [8], é dada por:
sil = min{rs ∗ di, T −max{wai , d0i} − di0}/l, i = 1, . . . , n, l = 1, 2, 3. (3)
onde di é a demanda do grupo i, rs é a taxa de serviço (nos experimentos adotou-se rs = 2), T é otempo máximo de retorno ao depósito e d0i = di0 é a distância entre o depósito e o grupo i. Alémdisso, os custos na função objetivo foram definidos com os mesmos valores usados por [8]: w1 = 1,0,w2 = 0,1 e w3 = 0,0001. Cada instância foi resolvida três vezes e os resultados são reportados eanalisados a seguir.
Inicialmente, comparamos os resultados obtidos pela matheuŕıstica com os das abordagens me-taheuŕısticas ILS e LNS como métodos de solução independentes, reportados em [1]. Vale destacarque a ILS e a LNS representam o estado da arte em relação a métodos metaheuŕısticos de soluçãopara o VRPTWMD. A Tabela 1 apresenta as médias dos melhores resultados (agrupados) geradospelos diferentes métodos para cada um dos conjuntos de instâncias. Os resultados mostram que, emtermos da qualidade das soluções obtidas, ambas as versões da matheuŕıstica são capazes de seremcompetitivas com as abordagens metaheuŕısticas na maioria dos conjuntos de instâncias (máximadiferença relativa de 2%). O maior ganho observado foi em termos do tempo computacional, já queo tempo médio utilizado pela matheuŕıstica para encontrar as soluções é sempre menor ao tempogasto pelas metaheuŕısticas.
Comparando só o desempenho das duas versões da matheuŕıstica, observa-se que a versão com omenor conglomerado requer menos tempo computacional para encontrar soluções com custo médiosimilar aos das soluções da versão com o conglomerado maior. Especificamente, a versão com omaior conglomerado encontrou a melhor solução em 6 das 12 instâncias do conjunto R1, em 6 das8 instâncias do conjunto RC1, em 6 das 11 instâncias do conjunto R2 e em 6 das 8 instâncias doconjunto RC2. Para os conjuntos C1 e C2 ambas a versões obtiveram as mesmas soluções paratodas as instâncias. No entanto, apesar do domı́nio em termos do número de melhores soluçõesencontradas, a versão com o maior conglomerado não supera amplamente a versão com o menorconglomerado em termos de resultados médios.
Posteriormente, foram comparados os resultados para cada instância do conjunto R1. Estasinstâncias foram detalhadamente abordadas em trabalhos prévios do VRPTWMD já que suascaracteŕısticas fazem com que elas representem mais acertadamente a importância dos tempos deserviço. A Tabela 2 apresenta as melhores soluções encontradas pela Otimização por Colônia deFormigas de [9], da ILS e LNS como métodos autônomos e da matheuŕıstica proposta usando oconglomerado grande. Os resultados mostram que a matheuŕıstica consegue encontrar a melhorsolução em 6 das 12 instâncias desse conjunto, sempre em tempos computacionais menores emrelação aos outros métodos comparados.
5 Conclusões
Neste trabalho, foi apresentada uma matheuŕıstica que integra duas abordagens metaheuŕısticascom uma formulação por partição de conjuntos para o VRPTWMD. Duas versões da matheuŕıstica
CLAIO-2016
974
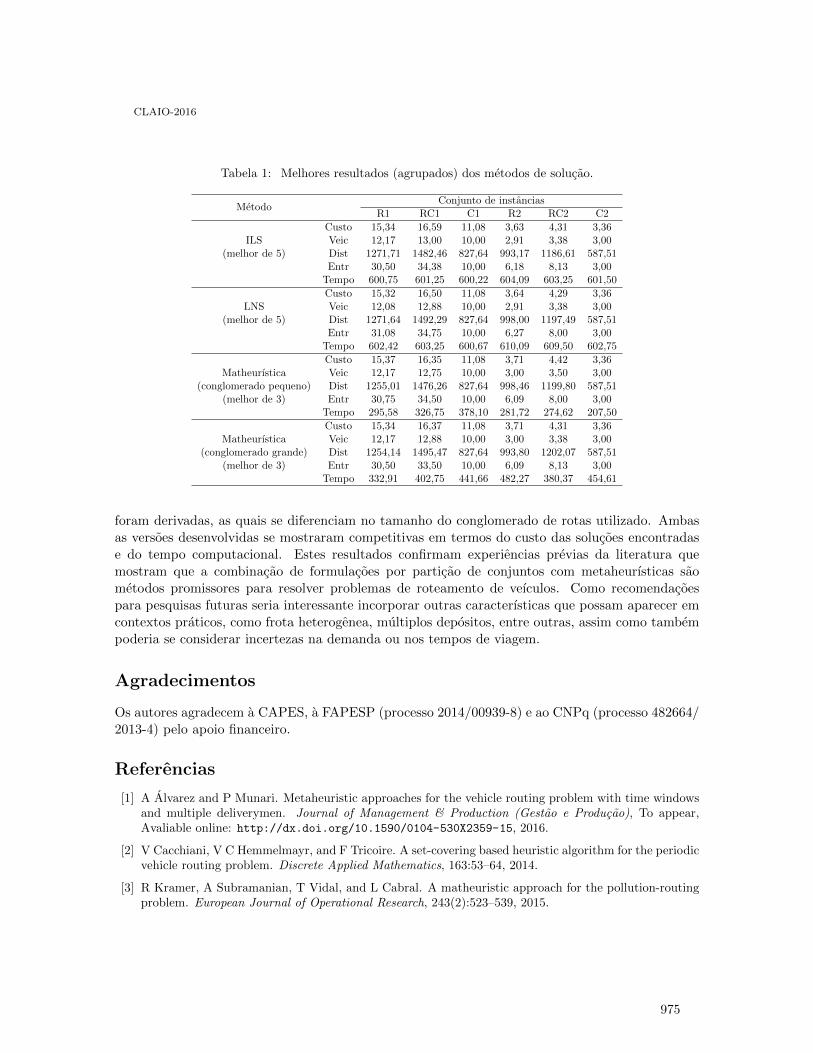
Tabela 1: Melhores resultados (agrupados) dos métodos de solução.
MétodoConjunto de instâncias
R1 RC1 C1 R2 RC2 C2
Custo 15,34 16,59 11,08 3,63 4,31 3,36ILS Veic 12,17 13,00 10,00 2,91 3,38 3,00
(melhor de 5) Dist 1271,71 1482,46 827,64 993,17 1186,61 587,51Entr 30,50 34,38 10,00 6,18 8,13 3,00
Tempo 600,75 601,25 600,22 604,09 603,25 601,50
Custo 15,32 16,50 11,08 3,64 4,29 3,36LNS Veic 12,08 12,88 10,00 2,91 3,38 3,00
(melhor de 5) Dist 1271,64 1492,29 827,64 998,00 1197,49 587,51Entr 31,08 34,75 10,00 6,27 8,00 3,00
Tempo 602,42 603,25 600,67 610,09 609,50 602,75
Custo 15,37 16,35 11,08 3,71 4,42 3,36Matheuŕıstica Veic 12,17 12,75 10,00 3,00 3,50 3,00
(conglomerado pequeno) Dist 1255,01 1476,26 827,64 998,46 1199,80 587,51(melhor de 3) Entr 30,75 34,50 10,00 6,09 8,00 3,00
Tempo 295,58 326,75 378,10 281,72 274,62 207,50
Custo 15,34 16,37 11,08 3,71 4,31 3,36Matheuŕıstica Veic 12,17 12,88 10,00 3,00 3,38 3,00
(conglomerado grande) Dist 1254,14 1495,47 827,64 993,80 1202,07 587,51(melhor de 3) Entr 30,50 33,50 10,00 6,09 8,13 3,00
Tempo 332,91 402,75 441,66 482,27 380,37 454,61
foram derivadas, as quais se diferenciam no tamanho do conglomerado de rotas utilizado. Ambasas versões desenvolvidas se mostraram competitivas em termos do custo das soluções encontradase do tempo computacional. Estes resultados confirmam experiências prévias da literatura quemostram que a combinação de formulações por partição de conjuntos com metaheuŕısticas sãométodos promissores para resolver problemas de roteamento de véıculos. Como recomendaçõespara pesquisas futuras seria interessante incorporar outras caracteŕısticas que possam aparecer emcontextos práticos, como frota heterogênea, múltiplos depósitos, entre outras, assim como tambémpoderia se considerar incertezas na demanda ou nos tempos de viagem.
Agradecimentos
Os autores agradecem à CAPES, à FAPESP (processo 2014/00939-8) e ao CNPq (processo 482664/2013-4) pelo apoio financeiro.
Referências
[1] A Álvarez and P Munari. Metaheuristic approaches for the vehicle routing problem with time windowsand multiple deliverymen. Journal of Management & Production (Gestão e Produção), To appear,Avaliable online: http://dx.doi.org/10.1590/0104-530X2359-15, 2016.
[2] V Cacchiani, V C Hemmelmayr, and F Tricoire. A set-covering based heuristic algorithm for the periodicvehicle routing problem. Discrete Applied Mathematics, 163:53–64, 2014.
[3] R Kramer, A Subramanian, T Vidal, and L Cabral. A matheuristic approach for the pollution-routingproblem. European Journal of Operational Research, 243(2):523–539, 2015.
CLAIO-2016
975

Tabela 2: Melhores resultados obtidos para o conjunto R1.
InstânciaMétodo R101 R102 R103 R104 R105 R106 R107 R108 R109 R110 R111 R112
Custo 23,67 20,95 15,94 12,70 17,64 15,13 12,81 11,70 15,12 13,92 13,01 11,80ACO-SR Veic 19 17 13 10 14 12 10 9 12 11 10 9(melhor Dist 1725,46 1533,40 1371,63 1045,68 1412,52 1301,34 1108,92 967,18 1229,72 1154,95 1134,16 996,32
de 5) Entr 45 38 28 26 35 30 27 26 30 28 29 27Temp 960 960 960 960 960 960 960 960 960 960 960 960
Custo 23,68 20,95 15,84 12,71 17,64 15,04 12,81 11,70 15,03 13,92 13,02 11,80ILS Veic 19 17 13 10 14 12 10 9 12 11 10 9
(melhor Dist 1757,40 1530,92 1410,73 1062,58 1412,52 1352,09 1140,79 965,31 1291,62 1187,49 1161,96 987,14de 5) Entr 45 38 27 26 35 29 27 26 29 28 29 27
Temp 600 601 601 601 600 600 603 601 600 600 602 600
Custo 23,68 20,95 15,94 12,71 17,64 15,03 12,91 11,70 14,43 13,92 13,11 11,80LNS Veic 19 17 13 10 14 12 10 9 11 11 10 9
(melhor Dist 1755,04 1531,36 1369,12 1072,41 1412,52 1328,21 1139,96 1011,37 1281,84 1219,12 1149,03 989,70de 5) Entr 45 38 28 26 35 29 28 26 33 28 30 27
Temp 600 603 603 603 600 601 600 601 605 603 607 603
Custo 23,67 20,95 15,84 12,70 17,64 15,13 12,81 11,70 15,03 13,92 12,91 11,80Matheuŕıstica Veic 19 17 13 10 14 12 10 9 12 11 10 9
conglomerado grande Dist 1720,11 1530,92 1381,35 1046,27 1412,52 1312,73 1121,06 964,44 1249,62 1169,86 1139,75 1001,09(melhor de 3) Entr 45 38 27 26 35 30 27 26 29 28 28 27
Temp 257 170 367 314 422 412 340 287 410 414 307 295
[4] HR Lourenço, OC Martin, and T Stützle. Iterated local search. In F Glover and G. A. Kochenberger,editors, Handbook of Metaheuristics, pages 321–353. Springer US, 2003.
[5] N Mladenovic and P Hansen. Variable neighborhood search. Computers & Operations Research,24:1097–1100, 1997.
[6] P Munari and R Morabito. A branch-price-and-cut for the vehicle routing problem with time windowsand multiple deliverymen. Technical report, Production Engineering Department, Federal University ofSão Carlos, 2016.
[7] D Pisinger and S Ropke. A general heuristic for vehicle routing problems. Computers & OperationsResearch, 34:2403–2435, 2007.
[8] V Pureza, R Morabito, and M Reimann. Vehicle routing with multiple deliverymen: Modeling andheuristic approaches for the vrptw. European Journal of Operational Research, 218(3):636–647, 2012.
[9] G Senarclens De Grancy and M Reimann. Vehicle routing problems with time windows and multipleservice workers: a systematic comparison between ACO and GRASP. Central European Journal ofOperations Research, 2014.
[10] P Shaw. Using constraint programming and local search methods to solve vehicle routing problems. InPrinciples and Practice of Constraint Programming - CP98, pages 417–431, 1998.
[11] M Solomon. Algorithms for the vehicle routing and scheduling problems with time window constraints.Operations Research, 35(2):254–265, 1987.
[12] A Subramanian, P Penna, E Uchoa, and L S Ochi. A hybrid algorithm for the heterogeneous fleetvehicle routing problem. European Journal of Operational Research, 221(2):285–295, 2012.
[13] J Villegas, C Prins, C Prodhon, A Medaglia, and N Velasco. A matheuristic for the truck and trailerrouting problem. European Journal of Operational Research, 230(2):231–244, 2013.
CLAIO-2016
976

















![[Acronym] Proceedings - UFG](https://static.fdokumen.com/doc/165x107/631430486ebca169bd0abf4b/acronym-proceedings-ufg.jpg)


