Pride and Penalty in Hawthorne's Tales - Digital Commons ...
Upload
independentCategory
view
0download
0
D878ndashD883 Nucleic Acids Research 2008 Vol 36 Database issue Published online 22 November 2007doi101093nargkm1021
PRIDE new developments and new datasetsPhilip Jones1 Richard G Cote1 Sang Yun Cho2 Sebastian Klie3
Lennart Martens1 Antony F Quinn1 David Thorneycroft1 and Henning Hermjakob1
1EMBL Outstation European Bioinformatics Institute (EBI) Wellcome Trust Genome Campus HinxtonCambridge CB10 1SD UK 2Department of Biochemistry Yonsei Proteome Research Center andBiomedical Proteome Research Center Yonsei University Seoul Korea and 3Martin Luther UniversityHalle-Wittenberg Halle-Saale Germany
Received September 19 2007 Revised October 24 2007 Accepted October 27 2007
ABSTRACT
The PRIDE (httpwwwebiacukpride) database ofprotein and peptide identifications was previouslydescribed in the NAR Database Special Edition in2006 Since this publication the volume of publicdata in the PRIDE relational database has increasedby more than an order of magnitude Severalsignificant public datasets have been added includ-ing identifications and processed mass spectragenerated by the HUPO Brain Proteome Projectand the HUPO Liver Proteome Project The PRIDEsoftware development team has made severalsignificant changes and additions to the userinterface and tool set associated with PRIDE Thefocus of these changes has been to facilitate thesubmission process and to improve the mecha-nisms by which PRIDE can be queried The PRIDEteam has developed a Microsoft Excel workbookthat allows the required data to be collated in aseries of relatively simple spreadsheets with auto-matic generation of PRIDE XML at the end of theprocess The ability to query PRIDE has beenaugmented by the addition of a BioMart interfaceallowing complex queries to be constructedCollaboration with groups outside the EBI hasbeen fruitful in extending PRIDE including anapproach to encode iTRAQ quantitative data inPRIDE XML
INTRODUCTION
The PRIDE database has been developed to provide astandards-compliant repository for mass-spectrometry-based proteomics data comprising identifications ofproteins peptides and post-translational modificationstogether with the mass spectra that provide evidencefor these identifications PRIDE has previously been
described in both Proteomics (1) and in the 2006 NARDatabase Special Edition (2) that should be referred to fora description of the PRIDE data structure PRIDE hasbeen reviewed by Mead and co-workers as one of the mostimportant proteomics data repositories in the field (3) andthe specific infrastructure in PRIDE to support dataprivacy and anonymous peer reviewing has been wellreceived by journals (4)
Several other databases exist for the purpose ofcapturing and disseminating proteomics data someof which provide their own data analysis pipelinesThe Global Proteome Machine Database (GPMDB)provides data from the GPM servers to support thevalidation of peptide MSMS spectra and protein cover-age patterns (5) PeptideAtlas provides a publicly acces-sible compendium of identifications from MSMS thathave been processed through PeptideProphet to providea uniform score (6) The Human Proteinpedia (httpwwwhumanproteinpediaorg) is a portal for communityannotation that is used as an addendum to the expertcurated Human Protein Reference Database (HPRD) (7)The Open Proteomics Database (OPD) is a publicdatabase of mass spectrometry-based proteomics data(8) Tranche provides a secure distributed file systemthat is designed to handle the sharing of massive datasets(httpwwwproteomecommonsorgdevdfs) PRIDEmakes use of Tranche to allow the sharing of massivedata files currently including search engine output filesand binary raw data from mass spectrometers that can beaccessed via a hyperlink from PRIDE The publicproteomics data repositories are now poised to focus oncollaboration and data sharing through membership ofthe ProteomExchange consortium (9) This will allow eachrepository to share their data in a collaborative fashionwhile remaining independent and able to focus theirefforts as they see fit
This article describes the new data available in PRIDEthe infrastructure being developed to support submissionto PRIDE and additions to the user interface that areintended to improve the utility of PRIDE as a query andanalysis tool
To whom correspondence should be addressed Tel +44 1223 492610 Fax +44 1223 494484 Email pjonesebiacuk
2007 The Author(s)
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (httpcreativecommonsorglicenses
by-nc20uk) which permits unrestricted non-commercial use distribution and reproduction in any medium provided the original work is properly cited
Some of the new developments in PRIDE addresslong-standing requirements that have been present sincethe inception of the PRIDE project such as the needfor more sophisticated and user-configurable query thatcan return results in multiple file formats Other develop-ments such as the PRIDE Wizard developed at theUniversity of Manchester address requirements that arebecoming increasingly important in proteomics such asthe use of quantitative labeling
At the same time proteomics journals are exertingincreasing pressure to submit data supporting proteomicsjournal submissions to public repositories in standardformats (10)
DATABASE DESCRIPTION
New data content
A significant number of new public datasets are availablein PRIDE The majority of recent PRIDE submissionshave accompanied corresponding journal submissionsindeed submission to PRIDE has regularly been usedto support manuscript submissions The accepted practiceis to maintain data privacy until publication of themanuscript PRIDE supports this by providing a mecha-nism for private data submission with the option ofgenerating a random username and password that willgrant access to the private dataset This anonymous logincan then be passed to peer reviewers allowing themconfidential access to the details of the proteomicsexperiment supporting the manuscript under review
At the time of writing PRIDE comprises 2703 publicexperiments out of a total of 3185 submitted experiments(85 of the total being public) All of the experiments inPRIDE are organized into projects to improve theaccessibility of the data via both the PRIDE browsepage and the PRIDE BioMart
The complete set of data in PRIDE covers 25 differentspecies including several model animal and plantspecies as well as fungi bacteria and viruses (Figure 1)Direct access to PRIDE data organized by species tissuesub-cellular location disease state and project name canbe obtained via the lsquoBrowse Experimentsrsquo menu itemPRIDE makes use of the NEWT taxonomy (11) toannotate species and selected ontologies from the OBOFoundry (httpobofoundryorg) that cover specificdomains to annotate other aspects of the sample typeThese include the BRENDA tissue ontology (12) theCell Type ontology (13) and the Gene Ontology (14) toannotate sub-cellular location Disease state is anno-tated using the Disease Ontology (httpdiseaseontologysourceforgenetoverview)
As may be expected the majority of identifications ofproteins and peptides come from human samplescomprising 81 of the peptide identifications inPRIDE (48 of unique peptide identifications inPRIDE) Apart from species-specific studies PRIDEalso contains an interesting dataset describing the proteincontent of an environmental community sample the acidmine drainage dataset described in Nature (15) in whicha community genomic dataset was searched to generate
strain-specific protein identifications for the residentacidophilic bacterial biofilmThe inception of the PRIDE project was in part
inspired and indeed funded by the HUPO PlasmaProteome Project (HPPP) Since the HPPP pilot phasehas been completed two other collaborative HUPOprojects have also contributed significant datasets toPRIDE including mass spectra The European HUPOBrain Proteome Project (HBPP) (16) has submitted 5555protein identifications to PRIDE based upon 154 132peptide identifications in both human and mouse braintissue The Beijing Proteome Research Center hassubmitted 32 421 separate protein identifications basedupon 299 869 peptide identifications in liver as part oftheir contribution to the international HUPO LiverProteome Project (HLPP) (1718)Part of the work of the PRIDE team has been to
contribute to the development of data conversions intoPRIDE XML format from commonly used proteomicanalysis pipelines A specific example of this is the largeset of data supporting an analysis of the proteome ofhuman cerebrospinal fluid (19) This dataset includes 890identified proteins based upon 49 185 peptide identifica-tions The analysis for this dataset was performed usingthe Trans-Proteomic Pipeline (TPP) (20) originally devel-oped by the Institute for Systems Biology The outputformats from the TPP (mzXML for mass spectrapepXML for peptide identifications and protXML forprotein identifications) were parsed and the publiclyavailable PRIDE core API was used to convert this datainto PRIDE XML format This work has since servedas the basis for importing other TPP-formatted data intoPRIDEThe large number and variety of bioinformatics data
resources available from the EBI can be dauntinghowever using and linking these resources can add valueto complex datasets This has been achieved with therecent submission from the Cellzome research teamreporting the interaction of protein kinases with smallinhibitory molecules (21) For this dataset bi-directionallinks to the IntAct database of molecular interactions
Figure 1 PRIDE includes data for 25 different species This pie chartillustrates the representation of each species in terms of the totalnumber of peptide identifications for each species
Nucleic Acids Research 2008 Vol 36 Database issue D879
(httpwwwebiacukintact) have been included fromPRIDE (22) PRIDE also links to ChEBI the EBIrsquosdatabase of chemical entities of biological interest (httpwwwebiacukchebi)It is of note that as the quantity of data submitted to
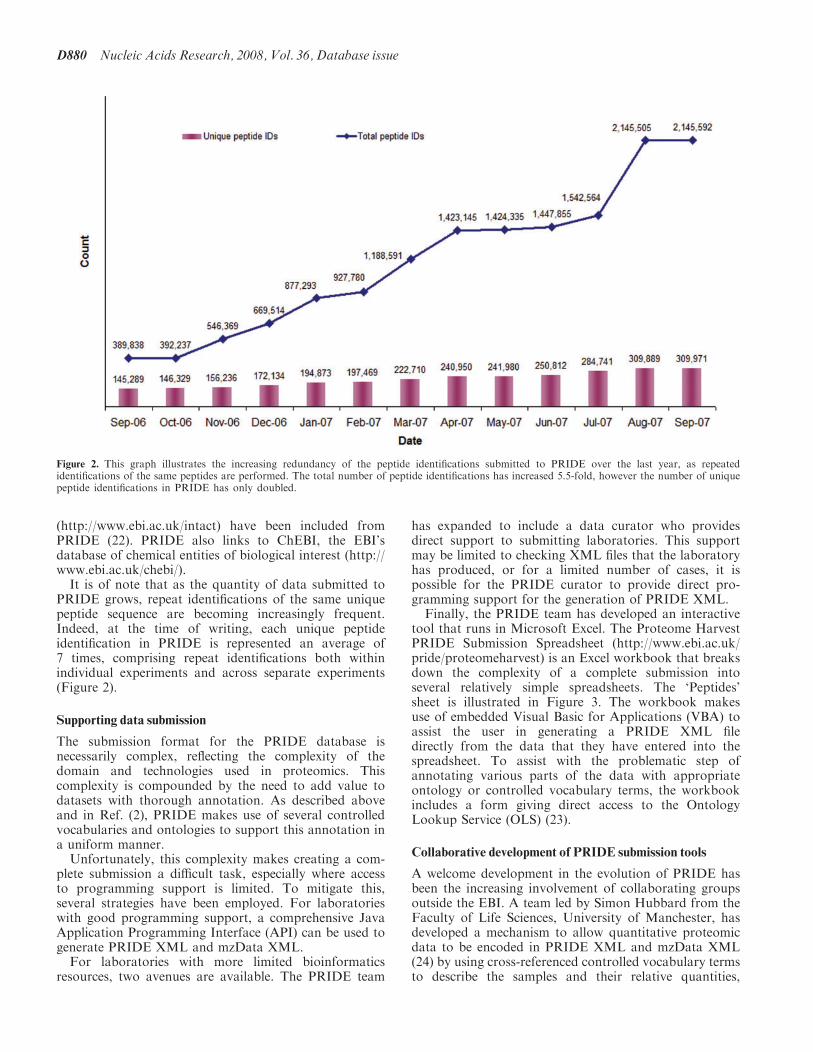
PRIDE grows repeat identifications of the same uniquepeptide sequence are becoming increasingly frequentIndeed at the time of writing each unique peptideidentification in PRIDE is represented an average of7 times comprising repeat identifications both withinindividual experiments and across separate experiments(Figure 2)
Supporting data submission
The submission format for the PRIDE database isnecessarily complex reflecting the complexity of thedomain and technologies used in proteomics Thiscomplexity is compounded by the need to add value todatasets with thorough annotation As described aboveand in Ref (2) PRIDE makes use of several controlledvocabularies and ontologies to support this annotation ina uniform mannerUnfortunately this complexity makes creating a com-
plete submission a difficult task especially where accessto programming support is limited To mitigate thisseveral strategies have been employed For laboratorieswith good programming support a comprehensive JavaApplication Programming Interface (API) can be used togenerate PRIDE XML and mzData XMLFor laboratories with more limited bioinformatics
resources two avenues are available The PRIDE team
has expanded to include a data curator who providesdirect support to submitting laboratories This supportmay be limited to checking XML files that the laboratoryhas produced or for a limited number of cases it ispossible for the PRIDE curator to provide direct pro-gramming support for the generation of PRIDE XML
Finally the PRIDE team has developed an interactivetool that runs in Microsoft Excel The Proteome HarvestPRIDE Submission Spreadsheet (httpwwwebiacukprideproteomeharvest) is an Excel workbook that breaksdown the complexity of a complete submission intoseveral relatively simple spreadsheets The lsquoPeptidesrsquosheet is illustrated in Figure 3 The workbook makesuse of embedded Visual Basic for Applications (VBA) toassist the user in generating a PRIDE XML filedirectly from the data that they have entered into thespreadsheet To assist with the problematic step ofannotating various parts of the data with appropriateontology or controlled vocabulary terms the workbookincludes a form giving direct access to the OntologyLookup Service (OLS) (23)
Collaborative development of PRIDE submission tools
A welcome development in the evolution of PRIDE hasbeen the increasing involvement of collaborating groupsoutside the EBI A team led by Simon Hubbard from theFaculty of Life Sciences University of Manchester hasdeveloped a mechanism to allow quantitative proteomicdata to be encoded in PRIDE XML and mzData XML(24) by using cross-referenced controlled vocabulary termsto describe the samples and their relative quantities
Figure 2 This graph illustrates the increasing redundancy of the peptide identifications submitted to PRIDE over the last year as repeatedidentifications of the same peptides are performed The total number of peptide identifications has increased 55-fold however the number of uniquepeptide identifications in PRIDE has only doubled
D880 Nucleic Acids Research 2008 Vol 36 Database issue
illustrating the extensibility of the PRIDE XML formatThis mechanism has been successfully demonstrated foriTRAQ labeling but has the scope to encompass otherquantitative techniques The same team has developedlsquoPrideWizard a tool that parses mass spectrometry dataand Mascot search engine output converting the collateddata to PRIDE XML This tool is available from httpwwwmcisborgsoftwarePrideWizard
IMPROVING QUERY ACCESS TO PRIDE
Providing query and visualization of the large andcomplex datasets describing complete proteomics experi-ments is challenging and problematic To attempt to meetthis challenge several new facilities have been added to thePRIDE user interface over the last two years and PRIDEhas also benefited from the re-engineering of the EBIwebsite including the new EB-eye search engine thatincorporates indexed data from almost every resource atthe EBI including PRIDE
Resolving the database accession problem
The PRIDE database is populated by submissions ofproteomic data from a wide variety of laboratories aroundthe world each of which selects a protein sequence orgenomic sequence database against which searches areperformed The criteria for selecting a database varies withthe species and the group concerned with the consequencethat the identifications in PRIDE do not fit under a singlesequence accession system This has proved problematic inthat searching PRIDE with an accession from onesequence database will not return results annotated witha different database even though they may identify thesame proteinThe PRIDE team has developed the Protein Identifier
Cross-Reference Service (PICR) (25) (httpwwwebiacukToolspicr) which is able to map protein sequenceidentifiers from over 60 different databases via UniParc(the UniProt Archive) (26) These cross-references are nowbeing included in the PRIDE database which will enable
Figure 3 A single sheet from the ProteomeHarvest PRIDE Submission SpreadsheetmdashPeptide Identification Data Entry
Nucleic Acids Research 2008 Vol 36 Database issue D881
users to successfully query PRIDE with their favoredaccession system The accession mapping task is per-formed for new data within 24 h and is refreshed for theentire PRIDE database every week A useful side-effect isthat the latest active accession is available for allsubmitted identifications irrespective of the time thathas passed since submission The submitted accession ismaintained in the PRIDE database The PRIDE team isnow working on including this mapping data in allPRIDE query and reporting mechanisms
The PRIDE BioMart query interface
The PRIDE database now includes a BioMart interface(27) that offers several advantages This query interfacecan be accessed from the menu item lsquoPRIDE BioMartrsquo onthe left of the PRIDE home page or directly at (httpwwwebiacukprideprideMartdo)The PRIDE BioMart provides access to public PRIDE
data from a query-optimized data warehouse that issynchronized with the main PRIDE database at regularintervals The BioMart interface allows simple or complexqueries to be built The user has control over how the datais filtered to restrict which records are included and isable to select the attributes equivalent to columns in aspreadsheet that are included in the results This avoidsthe need to search through a large table of results much ofwhich may be irrelevant allowing the user to focusspecifically on the information that is important to themThe user can specify how the results are formatted
choosing from an HTML table displayed in a browser acomma or tab-separated values file or a Microsoft Excelspreadsheet The results file can be compressed to speed updata retrieval The latest version of BioMart allowsasynchronous data access in which the user specifies an
email address to which a link to large result sets canbe sent
The PRIDE BioMart provides programmatic webservice access to public PRIDE data with the sameflexibility as the web form
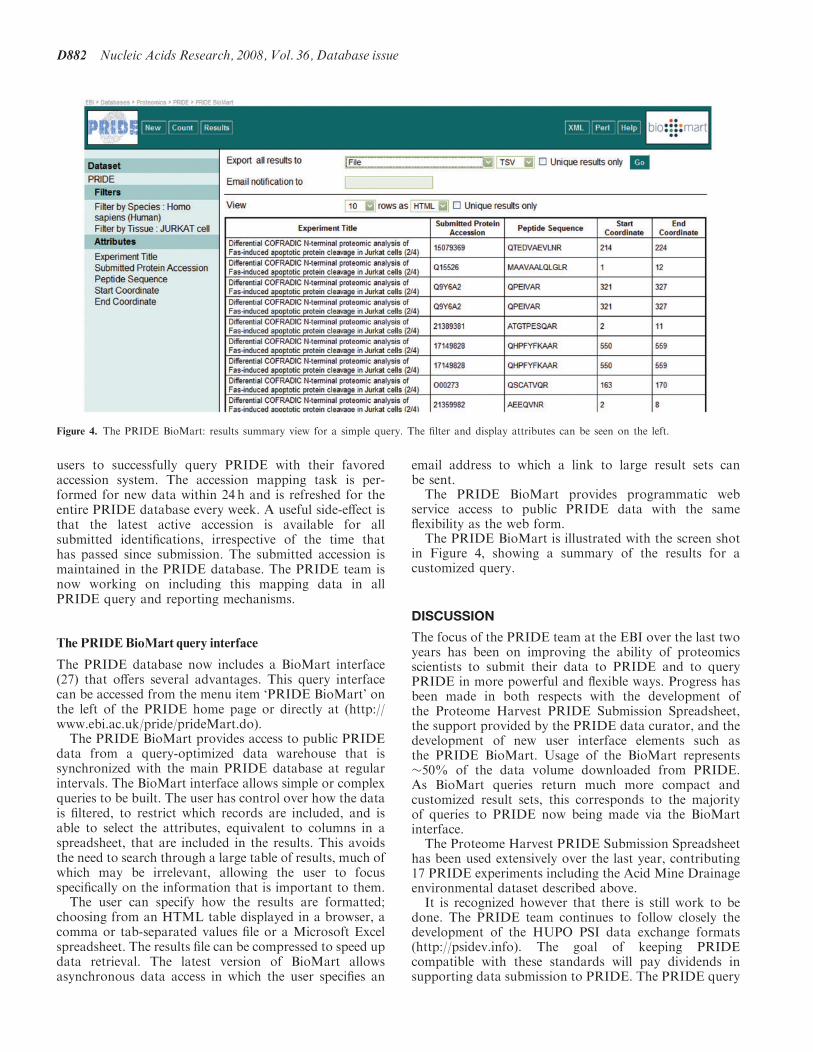
The PRIDE BioMart is illustrated with the screen shotin Figure 4 showing a summary of the results for acustomized query
DISCUSSION
The focus of the PRIDE team at the EBI over the last twoyears has been on improving the ability of proteomicsscientists to submit their data to PRIDE and to queryPRIDE in more powerful and flexible ways Progress hasbeen made in both respects with the development ofthe Proteome Harvest PRIDE Submission Spreadsheetthe support provided by the PRIDE data curator and thedevelopment of new user interface elements such asthe PRIDE BioMart Usage of the BioMart represents50 of the data volume downloaded from PRIDEAs BioMart queries return much more compact andcustomized result sets this corresponds to the majorityof queries to PRIDE now being made via the BioMartinterface
The Proteome Harvest PRIDE Submission Spreadsheethas been used extensively over the last year contributing17 PRIDE experiments including the Acid Mine Drainageenvironmental dataset described above
It is recognized however that there is still work to bedone The PRIDE team continues to follow closely thedevelopment of the HUPO PSI data exchange formats(httppsidevinfo) The goal of keeping PRIDEcompatible with these standards will pay dividends insupporting data submission to PRIDE The PRIDE query
Figure 4 The PRIDE BioMart results summary view for a simple query The filter and display attributes can be seen on the left
D882 Nucleic Acids Research 2008 Vol 36 Database issue
interface still requires further development including theincorporation of the Dasty2 DAS client (httpwwwebiacukdasty) to allow graphical visualization of peptideidentifications together with improvements to the mainPRIDE query interface and the PRIDE BioMart Aninteresting consequence of the incorporation of PICRprotein cross-references is that it will be possible to linkthe PRIDE BioMart directly to other BioMarts allowingfederated queries across these resources We intend to setup links to the BioMart services offered by Ensembl (28)and Reactome (29) over the next few months potentiallywith similar links in the reverse direction
ACKNOWLEDGEMENTS
The PRIDE team would like to thank all data submittersfor their contributions The authors would also like tothank Dr Rolf Apweiler for his support and Dr MatthieuVisser for his valuable suggestions SYC was sup-ported by a grant from the Korea Health 21RampDProject Ministry of Health amp Welfare Republic ofKorea (A030003 to Y-K Paik) Biotechnology andBiological Sciences Research Council (BBSB17239 BBE00573X1) Funding to pay the Open Access publicationcharges for the article was provided by the EuropeanUnion lsquolsquoProDaCrsquorsquo grant number LSHG-CT-2006-036814
Conflict of interest statement None declared
REFERENCES
1 MartensL HermjakobH JonesP AdamskiM TaylorCStatesD GevaertK VandekerckhoveJ and ApweilerR (2005)Pride the proteomics identifications database Proteomics 53537ndash3545
2 JonesP CoteRG MartensL QuinnAF TaylorCFDeracheW HermjakobH and ApweilerR (2006) Pride a publicrepository of protein and peptide identifications for the proteomicscommunity Nucleic Acids Res 34 D659ndashD663
3 MeadJA ShadforthIP and BessantC (2007) Public proteomicms repositories and pipelines available tools and biologicalapplications Proteomics 7 2769ndash2786
4 Editorial (2007) Democratizing proteomics data Nat Biotechnol25 262
5 CraigR CortensJC FenyoD and BeavisRC (2006) Usingannotated peptide mass spectrum libraries for protein identificationJ Proteome Res 5 1843ndash1849
6 DesiereF DeutschEW KingNL NesvizhskiiAI MallickPEngJ ChenS EddesJ LoevenichSN et al (2006)The peptideatlas project Nucleic Acids Res 34 D655ndashD658
7 PeriS NavarroJD AmanchyR KristiansenTZJonnalagaddaCK SurendranathV NiranjanV MuthusamyBGandhiTKB et al (2003) Development of human proteinreference database as an initial platform for approaching systemsbiology in humans Genome Res 13 2363ndash2371
8 PrinceJT CarlsonMW WangR LuP and MarcotteEM(2004) The need for a public proteomics repository NatBiotechnol 22 471ndash472
9 HermjakobH and ApweilerR (2006) The proteomicsidentifications database (pride) and the proteomexchangeconsortium making proteomics data accessible Expert RevProteomics 3 1ndash3
10 Editor (2007) Mind the technology gap Nat Methods 4 765ndash76511 PhanIQH PilboutSF FleischmannW and BairochA (2003)
Newt a new taxonomy portal Nucleic Acids Res 31 3822ndash382312 SchomburgI ChangA EbelingC GremseM HeldtC
HuhnG and SchomburgD (2004) Brenda the enzyme databaseupdates and major new developments Nucleic Acids Res 32D431ndashD433
13 BardJ RheeSY and AshburnerM (2005) An ontology for celltypes Genome Biol 6 R21
14 AshburnerM BallCA BlakeJA BotsteinD ButlerHCherryJM DavisAP DolinskiK DwightSS et al (2000)Gene ontology tool for the unification of biology the geneontology consortium Nat Genet 25 25ndash29
15 LoI DenefVJ VerberkmoesNC ShahMB GoltsmanDDiBartoloG TysonGW AllenEE RamRJ et al (2007)Strain-resolved community proteomics reveals recombining genomesof acidophilic bacteria Nature 446 537ndash541
16 HamacherM ApweilerR ArnoldG BeckerA BluggelMCarretteO ColvisC DunnMJ FrohlichT et al (2006) Hupobrain proteome project summary of the pilot phase andintroduction of a comprehensive data reprocessing strategyProteomics 6 4890ndash4898
17 HeF (2005) Human liver proteome project plan progress andperspectives Mol Cell Proteomics 4 1841ndash1848
18 ZhengJ GaoX BerettaL and HeF (2006) The human liverproteome project (hlpp) workshop during the 4th hupo worldcongress Proteomics 6 1716ndash1718
19 PanS ZhuD QuinnJF PeskindER MontineTJ LinBGoodlettDR TaylorG EngJ et al (2007) A combined datasetof human cerebrospinal fluid proteins identified bymulti-dimensional chromatography and tandem mass spectrometryProteomics 7 469ndash473
20 KellerA EngJ ZhangN LiX and AebersoldR (2005) Auniform proteomics msms analysis platform utilizing open xml fileformats Mol Syst Biol 1 20050017
21 BantscheffM EberhardD AbrahamY BastuckS BoescheMHobsonS MathiesonT PerrinJ RaidaM et al (2007)Quantitative chemical proteomics reveals mechanisms ofaction of clinical abl kinase inhibitors Nat Biotechnol 251035ndash1044
22 KerrienS Alam-FaruqueY ArandaB BancarzI BridgeADerowC DimmerE FeuermannM FriedrichsenA et al (2007)Intact ndash open source resource for molecular interaction dataNucleic Acids Res 35 D561ndashD565
23 CoteRG JonesP ApweilerR and HermjakobH (2006) Theontology lookup service a lightweight cross-platform tool forcontrolled vocabulary queries BMC Bioinformatics 7 97
24 SiepenJA SwainstonN JonesAR HartSR HermjakobHJonesP and HubbardSJ (2007) An informatic pipeline for thedata capture and submission of quantitative proteomic data usingitraq Proteome Sci 5 4
25 CoteRG JonesP MartensL KerrienS ReisingerF LinQLeinonenR ApweilerR and HermjakobH (2007) The proteinidentifier cross-reference (picr) service reconciling protein identifiersacross multiple source databases BMC Bioinformatics 8 401
26 LeinonenR DiezFG BinnsD FleischmannW LopezR andApweilerR (2004) Uniprot archive Bioinformatics 20 3236ndash3237
27 DurinckS MoreauY KasprzykA DavisS De MoorBBrazmaA and HuberW (2005) Biomart and bioconductor apowerful link between biological databases and microarray dataanalysis Bioinformatics 21 3439ndash3440
28 HubbardTJP AkenBL BealK BallesterB CaccamoMChenY ClarkeL CoatesG CunninghamF et al (2007)Ensembl 2007 Nucleic Acids Res 35 D610ndashD617
29 Joshi-TopeG GillespieM VastrikI DrsquoEustachioP SchmidtEde BonoB JassalB GopinathGR WuGR et al (2005)Reactome a knowledgebase of biological pathways Nucleic AcidsRes 33 D428ndashD432
Nucleic Acids Research 2008 Vol 36 Database issue D883

Some of the new developments in PRIDE addresslong-standing requirements that have been present sincethe inception of the PRIDE project such as the needfor more sophisticated and user-configurable query thatcan return results in multiple file formats Other develop-ments such as the PRIDE Wizard developed at theUniversity of Manchester address requirements that arebecoming increasingly important in proteomics such asthe use of quantitative labeling
At the same time proteomics journals are exertingincreasing pressure to submit data supporting proteomicsjournal submissions to public repositories in standardformats (10)
DATABASE DESCRIPTION
New data content
A significant number of new public datasets are availablein PRIDE The majority of recent PRIDE submissionshave accompanied corresponding journal submissionsindeed submission to PRIDE has regularly been usedto support manuscript submissions The accepted practiceis to maintain data privacy until publication of themanuscript PRIDE supports this by providing a mecha-nism for private data submission with the option ofgenerating a random username and password that willgrant access to the private dataset This anonymous logincan then be passed to peer reviewers allowing themconfidential access to the details of the proteomicsexperiment supporting the manuscript under review
At the time of writing PRIDE comprises 2703 publicexperiments out of a total of 3185 submitted experiments(85 of the total being public) All of the experiments inPRIDE are organized into projects to improve theaccessibility of the data via both the PRIDE browsepage and the PRIDE BioMart
The complete set of data in PRIDE covers 25 differentspecies including several model animal and plantspecies as well as fungi bacteria and viruses (Figure 1)Direct access to PRIDE data organized by species tissuesub-cellular location disease state and project name canbe obtained via the lsquoBrowse Experimentsrsquo menu itemPRIDE makes use of the NEWT taxonomy (11) toannotate species and selected ontologies from the OBOFoundry (httpobofoundryorg) that cover specificdomains to annotate other aspects of the sample typeThese include the BRENDA tissue ontology (12) theCell Type ontology (13) and the Gene Ontology (14) toannotate sub-cellular location Disease state is anno-tated using the Disease Ontology (httpdiseaseontologysourceforgenetoverview)
As may be expected the majority of identifications ofproteins and peptides come from human samplescomprising 81 of the peptide identifications inPRIDE (48 of unique peptide identifications inPRIDE) Apart from species-specific studies PRIDEalso contains an interesting dataset describing the proteincontent of an environmental community sample the acidmine drainage dataset described in Nature (15) in whicha community genomic dataset was searched to generate
strain-specific protein identifications for the residentacidophilic bacterial biofilmThe inception of the PRIDE project was in part
inspired and indeed funded by the HUPO PlasmaProteome Project (HPPP) Since the HPPP pilot phasehas been completed two other collaborative HUPOprojects have also contributed significant datasets toPRIDE including mass spectra The European HUPOBrain Proteome Project (HBPP) (16) has submitted 5555protein identifications to PRIDE based upon 154 132peptide identifications in both human and mouse braintissue The Beijing Proteome Research Center hassubmitted 32 421 separate protein identifications basedupon 299 869 peptide identifications in liver as part oftheir contribution to the international HUPO LiverProteome Project (HLPP) (1718)Part of the work of the PRIDE team has been to
contribute to the development of data conversions intoPRIDE XML format from commonly used proteomicanalysis pipelines A specific example of this is the largeset of data supporting an analysis of the proteome ofhuman cerebrospinal fluid (19) This dataset includes 890identified proteins based upon 49 185 peptide identifica-tions The analysis for this dataset was performed usingthe Trans-Proteomic Pipeline (TPP) (20) originally devel-oped by the Institute for Systems Biology The outputformats from the TPP (mzXML for mass spectrapepXML for peptide identifications and protXML forprotein identifications) were parsed and the publiclyavailable PRIDE core API was used to convert this datainto PRIDE XML format This work has since servedas the basis for importing other TPP-formatted data intoPRIDEThe large number and variety of bioinformatics data
resources available from the EBI can be dauntinghowever using and linking these resources can add valueto complex datasets This has been achieved with therecent submission from the Cellzome research teamreporting the interaction of protein kinases with smallinhibitory molecules (21) For this dataset bi-directionallinks to the IntAct database of molecular interactions
Figure 1 PRIDE includes data for 25 different species This pie chartillustrates the representation of each species in terms of the totalnumber of peptide identifications for each species
Nucleic Acids Research 2008 Vol 36 Database issue D879
(httpwwwebiacukintact) have been included fromPRIDE (22) PRIDE also links to ChEBI the EBIrsquosdatabase of chemical entities of biological interest (httpwwwebiacukchebi)It is of note that as the quantity of data submitted to
PRIDE grows repeat identifications of the same uniquepeptide sequence are becoming increasingly frequentIndeed at the time of writing each unique peptideidentification in PRIDE is represented an average of7 times comprising repeat identifications both withinindividual experiments and across separate experiments(Figure 2)
Supporting data submission
The submission format for the PRIDE database isnecessarily complex reflecting the complexity of thedomain and technologies used in proteomics Thiscomplexity is compounded by the need to add value todatasets with thorough annotation As described aboveand in Ref (2) PRIDE makes use of several controlledvocabularies and ontologies to support this annotation ina uniform mannerUnfortunately this complexity makes creating a com-
plete submission a difficult task especially where accessto programming support is limited To mitigate thisseveral strategies have been employed For laboratorieswith good programming support a comprehensive JavaApplication Programming Interface (API) can be used togenerate PRIDE XML and mzData XMLFor laboratories with more limited bioinformatics
resources two avenues are available The PRIDE team
has expanded to include a data curator who providesdirect support to submitting laboratories This supportmay be limited to checking XML files that the laboratoryhas produced or for a limited number of cases it ispossible for the PRIDE curator to provide direct pro-gramming support for the generation of PRIDE XML
Finally the PRIDE team has developed an interactivetool that runs in Microsoft Excel The Proteome HarvestPRIDE Submission Spreadsheet (httpwwwebiacukprideproteomeharvest) is an Excel workbook that breaksdown the complexity of a complete submission intoseveral relatively simple spreadsheets The lsquoPeptidesrsquosheet is illustrated in Figure 3 The workbook makesuse of embedded Visual Basic for Applications (VBA) toassist the user in generating a PRIDE XML filedirectly from the data that they have entered into thespreadsheet To assist with the problematic step ofannotating various parts of the data with appropriateontology or controlled vocabulary terms the workbookincludes a form giving direct access to the OntologyLookup Service (OLS) (23)
Collaborative development of PRIDE submission tools
A welcome development in the evolution of PRIDE hasbeen the increasing involvement of collaborating groupsoutside the EBI A team led by Simon Hubbard from theFaculty of Life Sciences University of Manchester hasdeveloped a mechanism to allow quantitative proteomicdata to be encoded in PRIDE XML and mzData XML(24) by using cross-referenced controlled vocabulary termsto describe the samples and their relative quantities
Figure 2 This graph illustrates the increasing redundancy of the peptide identifications submitted to PRIDE over the last year as repeatedidentifications of the same peptides are performed The total number of peptide identifications has increased 55-fold however the number of uniquepeptide identifications in PRIDE has only doubled
D880 Nucleic Acids Research 2008 Vol 36 Database issue
illustrating the extensibility of the PRIDE XML formatThis mechanism has been successfully demonstrated foriTRAQ labeling but has the scope to encompass otherquantitative techniques The same team has developedlsquoPrideWizard a tool that parses mass spectrometry dataand Mascot search engine output converting the collateddata to PRIDE XML This tool is available from httpwwwmcisborgsoftwarePrideWizard
IMPROVING QUERY ACCESS TO PRIDE
Providing query and visualization of the large andcomplex datasets describing complete proteomics experi-ments is challenging and problematic To attempt to meetthis challenge several new facilities have been added to thePRIDE user interface over the last two years and PRIDEhas also benefited from the re-engineering of the EBIwebsite including the new EB-eye search engine thatincorporates indexed data from almost every resource atthe EBI including PRIDE
Resolving the database accession problem
The PRIDE database is populated by submissions ofproteomic data from a wide variety of laboratories aroundthe world each of which selects a protein sequence orgenomic sequence database against which searches areperformed The criteria for selecting a database varies withthe species and the group concerned with the consequencethat the identifications in PRIDE do not fit under a singlesequence accession system This has proved problematic inthat searching PRIDE with an accession from onesequence database will not return results annotated witha different database even though they may identify thesame proteinThe PRIDE team has developed the Protein Identifier
Cross-Reference Service (PICR) (25) (httpwwwebiacukToolspicr) which is able to map protein sequenceidentifiers from over 60 different databases via UniParc(the UniProt Archive) (26) These cross-references are nowbeing included in the PRIDE database which will enable
Figure 3 A single sheet from the ProteomeHarvest PRIDE Submission SpreadsheetmdashPeptide Identification Data Entry
Nucleic Acids Research 2008 Vol 36 Database issue D881
users to successfully query PRIDE with their favoredaccession system The accession mapping task is per-formed for new data within 24 h and is refreshed for theentire PRIDE database every week A useful side-effect isthat the latest active accession is available for allsubmitted identifications irrespective of the time thathas passed since submission The submitted accession ismaintained in the PRIDE database The PRIDE team isnow working on including this mapping data in allPRIDE query and reporting mechanisms
The PRIDE BioMart query interface
The PRIDE database now includes a BioMart interface(27) that offers several advantages This query interfacecan be accessed from the menu item lsquoPRIDE BioMartrsquo onthe left of the PRIDE home page or directly at (httpwwwebiacukprideprideMartdo)The PRIDE BioMart provides access to public PRIDE
data from a query-optimized data warehouse that issynchronized with the main PRIDE database at regularintervals The BioMart interface allows simple or complexqueries to be built The user has control over how the datais filtered to restrict which records are included and isable to select the attributes equivalent to columns in aspreadsheet that are included in the results This avoidsthe need to search through a large table of results much ofwhich may be irrelevant allowing the user to focusspecifically on the information that is important to themThe user can specify how the results are formatted
choosing from an HTML table displayed in a browser acomma or tab-separated values file or a Microsoft Excelspreadsheet The results file can be compressed to speed updata retrieval The latest version of BioMart allowsasynchronous data access in which the user specifies an
email address to which a link to large result sets canbe sent
The PRIDE BioMart provides programmatic webservice access to public PRIDE data with the sameflexibility as the web form
The PRIDE BioMart is illustrated with the screen shotin Figure 4 showing a summary of the results for acustomized query
DISCUSSION
The focus of the PRIDE team at the EBI over the last twoyears has been on improving the ability of proteomicsscientists to submit their data to PRIDE and to queryPRIDE in more powerful and flexible ways Progress hasbeen made in both respects with the development ofthe Proteome Harvest PRIDE Submission Spreadsheetthe support provided by the PRIDE data curator and thedevelopment of new user interface elements such asthe PRIDE BioMart Usage of the BioMart represents50 of the data volume downloaded from PRIDEAs BioMart queries return much more compact andcustomized result sets this corresponds to the majorityof queries to PRIDE now being made via the BioMartinterface
The Proteome Harvest PRIDE Submission Spreadsheethas been used extensively over the last year contributing17 PRIDE experiments including the Acid Mine Drainageenvironmental dataset described above
It is recognized however that there is still work to bedone The PRIDE team continues to follow closely thedevelopment of the HUPO PSI data exchange formats(httppsidevinfo) The goal of keeping PRIDEcompatible with these standards will pay dividends insupporting data submission to PRIDE The PRIDE query
Figure 4 The PRIDE BioMart results summary view for a simple query The filter and display attributes can be seen on the left
D882 Nucleic Acids Research 2008 Vol 36 Database issue
interface still requires further development including theincorporation of the Dasty2 DAS client (httpwwwebiacukdasty) to allow graphical visualization of peptideidentifications together with improvements to the mainPRIDE query interface and the PRIDE BioMart Aninteresting consequence of the incorporation of PICRprotein cross-references is that it will be possible to linkthe PRIDE BioMart directly to other BioMarts allowingfederated queries across these resources We intend to setup links to the BioMart services offered by Ensembl (28)and Reactome (29) over the next few months potentiallywith similar links in the reverse direction
ACKNOWLEDGEMENTS
The PRIDE team would like to thank all data submittersfor their contributions The authors would also like tothank Dr Rolf Apweiler for his support and Dr MatthieuVisser for his valuable suggestions SYC was sup-ported by a grant from the Korea Health 21RampDProject Ministry of Health amp Welfare Republic ofKorea (A030003 to Y-K Paik) Biotechnology andBiological Sciences Research Council (BBSB17239 BBE00573X1) Funding to pay the Open Access publicationcharges for the article was provided by the EuropeanUnion lsquolsquoProDaCrsquorsquo grant number LSHG-CT-2006-036814
Conflict of interest statement None declared
REFERENCES
1 MartensL HermjakobH JonesP AdamskiM TaylorCStatesD GevaertK VandekerckhoveJ and ApweilerR (2005)Pride the proteomics identifications database Proteomics 53537ndash3545
2 JonesP CoteRG MartensL QuinnAF TaylorCFDeracheW HermjakobH and ApweilerR (2006) Pride a publicrepository of protein and peptide identifications for the proteomicscommunity Nucleic Acids Res 34 D659ndashD663
3 MeadJA ShadforthIP and BessantC (2007) Public proteomicms repositories and pipelines available tools and biologicalapplications Proteomics 7 2769ndash2786
4 Editorial (2007) Democratizing proteomics data Nat Biotechnol25 262
5 CraigR CortensJC FenyoD and BeavisRC (2006) Usingannotated peptide mass spectrum libraries for protein identificationJ Proteome Res 5 1843ndash1849
6 DesiereF DeutschEW KingNL NesvizhskiiAI MallickPEngJ ChenS EddesJ LoevenichSN et al (2006)The peptideatlas project Nucleic Acids Res 34 D655ndashD658
7 PeriS NavarroJD AmanchyR KristiansenTZJonnalagaddaCK SurendranathV NiranjanV MuthusamyBGandhiTKB et al (2003) Development of human proteinreference database as an initial platform for approaching systemsbiology in humans Genome Res 13 2363ndash2371
8 PrinceJT CarlsonMW WangR LuP and MarcotteEM(2004) The need for a public proteomics repository NatBiotechnol 22 471ndash472
9 HermjakobH and ApweilerR (2006) The proteomicsidentifications database (pride) and the proteomexchangeconsortium making proteomics data accessible Expert RevProteomics 3 1ndash3
10 Editor (2007) Mind the technology gap Nat Methods 4 765ndash76511 PhanIQH PilboutSF FleischmannW and BairochA (2003)
Newt a new taxonomy portal Nucleic Acids Res 31 3822ndash382312 SchomburgI ChangA EbelingC GremseM HeldtC
HuhnG and SchomburgD (2004) Brenda the enzyme databaseupdates and major new developments Nucleic Acids Res 32D431ndashD433
13 BardJ RheeSY and AshburnerM (2005) An ontology for celltypes Genome Biol 6 R21
14 AshburnerM BallCA BlakeJA BotsteinD ButlerHCherryJM DavisAP DolinskiK DwightSS et al (2000)Gene ontology tool for the unification of biology the geneontology consortium Nat Genet 25 25ndash29
15 LoI DenefVJ VerberkmoesNC ShahMB GoltsmanDDiBartoloG TysonGW AllenEE RamRJ et al (2007)Strain-resolved community proteomics reveals recombining genomesof acidophilic bacteria Nature 446 537ndash541
16 HamacherM ApweilerR ArnoldG BeckerA BluggelMCarretteO ColvisC DunnMJ FrohlichT et al (2006) Hupobrain proteome project summary of the pilot phase andintroduction of a comprehensive data reprocessing strategyProteomics 6 4890ndash4898
17 HeF (2005) Human liver proteome project plan progress andperspectives Mol Cell Proteomics 4 1841ndash1848
18 ZhengJ GaoX BerettaL and HeF (2006) The human liverproteome project (hlpp) workshop during the 4th hupo worldcongress Proteomics 6 1716ndash1718
19 PanS ZhuD QuinnJF PeskindER MontineTJ LinBGoodlettDR TaylorG EngJ et al (2007) A combined datasetof human cerebrospinal fluid proteins identified bymulti-dimensional chromatography and tandem mass spectrometryProteomics 7 469ndash473
20 KellerA EngJ ZhangN LiX and AebersoldR (2005) Auniform proteomics msms analysis platform utilizing open xml fileformats Mol Syst Biol 1 20050017
21 BantscheffM EberhardD AbrahamY BastuckS BoescheMHobsonS MathiesonT PerrinJ RaidaM et al (2007)Quantitative chemical proteomics reveals mechanisms ofaction of clinical abl kinase inhibitors Nat Biotechnol 251035ndash1044
22 KerrienS Alam-FaruqueY ArandaB BancarzI BridgeADerowC DimmerE FeuermannM FriedrichsenA et al (2007)Intact ndash open source resource for molecular interaction dataNucleic Acids Res 35 D561ndashD565
23 CoteRG JonesP ApweilerR and HermjakobH (2006) Theontology lookup service a lightweight cross-platform tool forcontrolled vocabulary queries BMC Bioinformatics 7 97
24 SiepenJA SwainstonN JonesAR HartSR HermjakobHJonesP and HubbardSJ (2007) An informatic pipeline for thedata capture and submission of quantitative proteomic data usingitraq Proteome Sci 5 4
25 CoteRG JonesP MartensL KerrienS ReisingerF LinQLeinonenR ApweilerR and HermjakobH (2007) The proteinidentifier cross-reference (picr) service reconciling protein identifiersacross multiple source databases BMC Bioinformatics 8 401
26 LeinonenR DiezFG BinnsD FleischmannW LopezR andApweilerR (2004) Uniprot archive Bioinformatics 20 3236ndash3237
27 DurinckS MoreauY KasprzykA DavisS De MoorBBrazmaA and HuberW (2005) Biomart and bioconductor apowerful link between biological databases and microarray dataanalysis Bioinformatics 21 3439ndash3440
28 HubbardTJP AkenBL BealK BallesterB CaccamoMChenY ClarkeL CoatesG CunninghamF et al (2007)Ensembl 2007 Nucleic Acids Res 35 D610ndashD617
29 Joshi-TopeG GillespieM VastrikI DrsquoEustachioP SchmidtEde BonoB JassalB GopinathGR WuGR et al (2005)Reactome a knowledgebase of biological pathways Nucleic AcidsRes 33 D428ndashD432
Nucleic Acids Research 2008 Vol 36 Database issue D883
(httpwwwebiacukintact) have been included fromPRIDE (22) PRIDE also links to ChEBI the EBIrsquosdatabase of chemical entities of biological interest (httpwwwebiacukchebi)It is of note that as the quantity of data submitted to
PRIDE grows repeat identifications of the same uniquepeptide sequence are becoming increasingly frequentIndeed at the time of writing each unique peptideidentification in PRIDE is represented an average of7 times comprising repeat identifications both withinindividual experiments and across separate experiments(Figure 2)
Supporting data submission
The submission format for the PRIDE database isnecessarily complex reflecting the complexity of thedomain and technologies used in proteomics Thiscomplexity is compounded by the need to add value todatasets with thorough annotation As described aboveand in Ref (2) PRIDE makes use of several controlledvocabularies and ontologies to support this annotation ina uniform mannerUnfortunately this complexity makes creating a com-
plete submission a difficult task especially where accessto programming support is limited To mitigate thisseveral strategies have been employed For laboratorieswith good programming support a comprehensive JavaApplication Programming Interface (API) can be used togenerate PRIDE XML and mzData XMLFor laboratories with more limited bioinformatics
resources two avenues are available The PRIDE team
has expanded to include a data curator who providesdirect support to submitting laboratories This supportmay be limited to checking XML files that the laboratoryhas produced or for a limited number of cases it ispossible for the PRIDE curator to provide direct pro-gramming support for the generation of PRIDE XML
Finally the PRIDE team has developed an interactivetool that runs in Microsoft Excel The Proteome HarvestPRIDE Submission Spreadsheet (httpwwwebiacukprideproteomeharvest) is an Excel workbook that breaksdown the complexity of a complete submission intoseveral relatively simple spreadsheets The lsquoPeptidesrsquosheet is illustrated in Figure 3 The workbook makesuse of embedded Visual Basic for Applications (VBA) toassist the user in generating a PRIDE XML filedirectly from the data that they have entered into thespreadsheet To assist with the problematic step ofannotating various parts of the data with appropriateontology or controlled vocabulary terms the workbookincludes a form giving direct access to the OntologyLookup Service (OLS) (23)
Collaborative development of PRIDE submission tools
A welcome development in the evolution of PRIDE hasbeen the increasing involvement of collaborating groupsoutside the EBI A team led by Simon Hubbard from theFaculty of Life Sciences University of Manchester hasdeveloped a mechanism to allow quantitative proteomicdata to be encoded in PRIDE XML and mzData XML(24) by using cross-referenced controlled vocabulary termsto describe the samples and their relative quantities
Figure 2 This graph illustrates the increasing redundancy of the peptide identifications submitted to PRIDE over the last year as repeatedidentifications of the same peptides are performed The total number of peptide identifications has increased 55-fold however the number of uniquepeptide identifications in PRIDE has only doubled
D880 Nucleic Acids Research 2008 Vol 36 Database issue
illustrating the extensibility of the PRIDE XML formatThis mechanism has been successfully demonstrated foriTRAQ labeling but has the scope to encompass otherquantitative techniques The same team has developedlsquoPrideWizard a tool that parses mass spectrometry dataand Mascot search engine output converting the collateddata to PRIDE XML This tool is available from httpwwwmcisborgsoftwarePrideWizard
IMPROVING QUERY ACCESS TO PRIDE
Providing query and visualization of the large andcomplex datasets describing complete proteomics experi-ments is challenging and problematic To attempt to meetthis challenge several new facilities have been added to thePRIDE user interface over the last two years and PRIDEhas also benefited from the re-engineering of the EBIwebsite including the new EB-eye search engine thatincorporates indexed data from almost every resource atthe EBI including PRIDE
Resolving the database accession problem
The PRIDE database is populated by submissions ofproteomic data from a wide variety of laboratories aroundthe world each of which selects a protein sequence orgenomic sequence database against which searches areperformed The criteria for selecting a database varies withthe species and the group concerned with the consequencethat the identifications in PRIDE do not fit under a singlesequence accession system This has proved problematic inthat searching PRIDE with an accession from onesequence database will not return results annotated witha different database even though they may identify thesame proteinThe PRIDE team has developed the Protein Identifier
Cross-Reference Service (PICR) (25) (httpwwwebiacukToolspicr) which is able to map protein sequenceidentifiers from over 60 different databases via UniParc(the UniProt Archive) (26) These cross-references are nowbeing included in the PRIDE database which will enable
Figure 3 A single sheet from the ProteomeHarvest PRIDE Submission SpreadsheetmdashPeptide Identification Data Entry
Nucleic Acids Research 2008 Vol 36 Database issue D881
users to successfully query PRIDE with their favoredaccession system The accession mapping task is per-formed for new data within 24 h and is refreshed for theentire PRIDE database every week A useful side-effect isthat the latest active accession is available for allsubmitted identifications irrespective of the time thathas passed since submission The submitted accession ismaintained in the PRIDE database The PRIDE team isnow working on including this mapping data in allPRIDE query and reporting mechanisms
The PRIDE BioMart query interface
The PRIDE database now includes a BioMart interface(27) that offers several advantages This query interfacecan be accessed from the menu item lsquoPRIDE BioMartrsquo onthe left of the PRIDE home page or directly at (httpwwwebiacukprideprideMartdo)The PRIDE BioMart provides access to public PRIDE
data from a query-optimized data warehouse that issynchronized with the main PRIDE database at regularintervals The BioMart interface allows simple or complexqueries to be built The user has control over how the datais filtered to restrict which records are included and isable to select the attributes equivalent to columns in aspreadsheet that are included in the results This avoidsthe need to search through a large table of results much ofwhich may be irrelevant allowing the user to focusspecifically on the information that is important to themThe user can specify how the results are formatted
choosing from an HTML table displayed in a browser acomma or tab-separated values file or a Microsoft Excelspreadsheet The results file can be compressed to speed updata retrieval The latest version of BioMart allowsasynchronous data access in which the user specifies an
email address to which a link to large result sets canbe sent
The PRIDE BioMart provides programmatic webservice access to public PRIDE data with the sameflexibility as the web form
The PRIDE BioMart is illustrated with the screen shotin Figure 4 showing a summary of the results for acustomized query
DISCUSSION
The focus of the PRIDE team at the EBI over the last twoyears has been on improving the ability of proteomicsscientists to submit their data to PRIDE and to queryPRIDE in more powerful and flexible ways Progress hasbeen made in both respects with the development ofthe Proteome Harvest PRIDE Submission Spreadsheetthe support provided by the PRIDE data curator and thedevelopment of new user interface elements such asthe PRIDE BioMart Usage of the BioMart represents50 of the data volume downloaded from PRIDEAs BioMart queries return much more compact andcustomized result sets this corresponds to the majorityof queries to PRIDE now being made via the BioMartinterface
The Proteome Harvest PRIDE Submission Spreadsheethas been used extensively over the last year contributing17 PRIDE experiments including the Acid Mine Drainageenvironmental dataset described above
It is recognized however that there is still work to bedone The PRIDE team continues to follow closely thedevelopment of the HUPO PSI data exchange formats(httppsidevinfo) The goal of keeping PRIDEcompatible with these standards will pay dividends insupporting data submission to PRIDE The PRIDE query
Figure 4 The PRIDE BioMart results summary view for a simple query The filter and display attributes can be seen on the left
D882 Nucleic Acids Research 2008 Vol 36 Database issue
interface still requires further development including theincorporation of the Dasty2 DAS client (httpwwwebiacukdasty) to allow graphical visualization of peptideidentifications together with improvements to the mainPRIDE query interface and the PRIDE BioMart Aninteresting consequence of the incorporation of PICRprotein cross-references is that it will be possible to linkthe PRIDE BioMart directly to other BioMarts allowingfederated queries across these resources We intend to setup links to the BioMart services offered by Ensembl (28)and Reactome (29) over the next few months potentiallywith similar links in the reverse direction
ACKNOWLEDGEMENTS
The PRIDE team would like to thank all data submittersfor their contributions The authors would also like tothank Dr Rolf Apweiler for his support and Dr MatthieuVisser for his valuable suggestions SYC was sup-ported by a grant from the Korea Health 21RampDProject Ministry of Health amp Welfare Republic ofKorea (A030003 to Y-K Paik) Biotechnology andBiological Sciences Research Council (BBSB17239 BBE00573X1) Funding to pay the Open Access publicationcharges for the article was provided by the EuropeanUnion lsquolsquoProDaCrsquorsquo grant number LSHG-CT-2006-036814
Conflict of interest statement None declared
REFERENCES
1 MartensL HermjakobH JonesP AdamskiM TaylorCStatesD GevaertK VandekerckhoveJ and ApweilerR (2005)Pride the proteomics identifications database Proteomics 53537ndash3545
2 JonesP CoteRG MartensL QuinnAF TaylorCFDeracheW HermjakobH and ApweilerR (2006) Pride a publicrepository of protein and peptide identifications for the proteomicscommunity Nucleic Acids Res 34 D659ndashD663
3 MeadJA ShadforthIP and BessantC (2007) Public proteomicms repositories and pipelines available tools and biologicalapplications Proteomics 7 2769ndash2786
4 Editorial (2007) Democratizing proteomics data Nat Biotechnol25 262
5 CraigR CortensJC FenyoD and BeavisRC (2006) Usingannotated peptide mass spectrum libraries for protein identificationJ Proteome Res 5 1843ndash1849
6 DesiereF DeutschEW KingNL NesvizhskiiAI MallickPEngJ ChenS EddesJ LoevenichSN et al (2006)The peptideatlas project Nucleic Acids Res 34 D655ndashD658
7 PeriS NavarroJD AmanchyR KristiansenTZJonnalagaddaCK SurendranathV NiranjanV MuthusamyBGandhiTKB et al (2003) Development of human proteinreference database as an initial platform for approaching systemsbiology in humans Genome Res 13 2363ndash2371
8 PrinceJT CarlsonMW WangR LuP and MarcotteEM(2004) The need for a public proteomics repository NatBiotechnol 22 471ndash472
9 HermjakobH and ApweilerR (2006) The proteomicsidentifications database (pride) and the proteomexchangeconsortium making proteomics data accessible Expert RevProteomics 3 1ndash3
10 Editor (2007) Mind the technology gap Nat Methods 4 765ndash76511 PhanIQH PilboutSF FleischmannW and BairochA (2003)
Newt a new taxonomy portal Nucleic Acids Res 31 3822ndash382312 SchomburgI ChangA EbelingC GremseM HeldtC
HuhnG and SchomburgD (2004) Brenda the enzyme databaseupdates and major new developments Nucleic Acids Res 32D431ndashD433
13 BardJ RheeSY and AshburnerM (2005) An ontology for celltypes Genome Biol 6 R21
14 AshburnerM BallCA BlakeJA BotsteinD ButlerHCherryJM DavisAP DolinskiK DwightSS et al (2000)Gene ontology tool for the unification of biology the geneontology consortium Nat Genet 25 25ndash29
15 LoI DenefVJ VerberkmoesNC ShahMB GoltsmanDDiBartoloG TysonGW AllenEE RamRJ et al (2007)Strain-resolved community proteomics reveals recombining genomesof acidophilic bacteria Nature 446 537ndash541
16 HamacherM ApweilerR ArnoldG BeckerA BluggelMCarretteO ColvisC DunnMJ FrohlichT et al (2006) Hupobrain proteome project summary of the pilot phase andintroduction of a comprehensive data reprocessing strategyProteomics 6 4890ndash4898
17 HeF (2005) Human liver proteome project plan progress andperspectives Mol Cell Proteomics 4 1841ndash1848
18 ZhengJ GaoX BerettaL and HeF (2006) The human liverproteome project (hlpp) workshop during the 4th hupo worldcongress Proteomics 6 1716ndash1718
19 PanS ZhuD QuinnJF PeskindER MontineTJ LinBGoodlettDR TaylorG EngJ et al (2007) A combined datasetof human cerebrospinal fluid proteins identified bymulti-dimensional chromatography and tandem mass spectrometryProteomics 7 469ndash473
20 KellerA EngJ ZhangN LiX and AebersoldR (2005) Auniform proteomics msms analysis platform utilizing open xml fileformats Mol Syst Biol 1 20050017
21 BantscheffM EberhardD AbrahamY BastuckS BoescheMHobsonS MathiesonT PerrinJ RaidaM et al (2007)Quantitative chemical proteomics reveals mechanisms ofaction of clinical abl kinase inhibitors Nat Biotechnol 251035ndash1044
22 KerrienS Alam-FaruqueY ArandaB BancarzI BridgeADerowC DimmerE FeuermannM FriedrichsenA et al (2007)Intact ndash open source resource for molecular interaction dataNucleic Acids Res 35 D561ndashD565
23 CoteRG JonesP ApweilerR and HermjakobH (2006) Theontology lookup service a lightweight cross-platform tool forcontrolled vocabulary queries BMC Bioinformatics 7 97
24 SiepenJA SwainstonN JonesAR HartSR HermjakobHJonesP and HubbardSJ (2007) An informatic pipeline for thedata capture and submission of quantitative proteomic data usingitraq Proteome Sci 5 4
25 CoteRG JonesP MartensL KerrienS ReisingerF LinQLeinonenR ApweilerR and HermjakobH (2007) The proteinidentifier cross-reference (picr) service reconciling protein identifiersacross multiple source databases BMC Bioinformatics 8 401
26 LeinonenR DiezFG BinnsD FleischmannW LopezR andApweilerR (2004) Uniprot archive Bioinformatics 20 3236ndash3237
27 DurinckS MoreauY KasprzykA DavisS De MoorBBrazmaA and HuberW (2005) Biomart and bioconductor apowerful link between biological databases and microarray dataanalysis Bioinformatics 21 3439ndash3440
28 HubbardTJP AkenBL BealK BallesterB CaccamoMChenY ClarkeL CoatesG CunninghamF et al (2007)Ensembl 2007 Nucleic Acids Res 35 D610ndashD617
29 Joshi-TopeG GillespieM VastrikI DrsquoEustachioP SchmidtEde BonoB JassalB GopinathGR WuGR et al (2005)Reactome a knowledgebase of biological pathways Nucleic AcidsRes 33 D428ndashD432
Nucleic Acids Research 2008 Vol 36 Database issue D883

illustrating the extensibility of the PRIDE XML formatThis mechanism has been successfully demonstrated foriTRAQ labeling but has the scope to encompass otherquantitative techniques The same team has developedlsquoPrideWizard a tool that parses mass spectrometry dataand Mascot search engine output converting the collateddata to PRIDE XML This tool is available from httpwwwmcisborgsoftwarePrideWizard
IMPROVING QUERY ACCESS TO PRIDE
Providing query and visualization of the large andcomplex datasets describing complete proteomics experi-ments is challenging and problematic To attempt to meetthis challenge several new facilities have been added to thePRIDE user interface over the last two years and PRIDEhas also benefited from the re-engineering of the EBIwebsite including the new EB-eye search engine thatincorporates indexed data from almost every resource atthe EBI including PRIDE
Resolving the database accession problem
The PRIDE database is populated by submissions ofproteomic data from a wide variety of laboratories aroundthe world each of which selects a protein sequence orgenomic sequence database against which searches areperformed The criteria for selecting a database varies withthe species and the group concerned with the consequencethat the identifications in PRIDE do not fit under a singlesequence accession system This has proved problematic inthat searching PRIDE with an accession from onesequence database will not return results annotated witha different database even though they may identify thesame proteinThe PRIDE team has developed the Protein Identifier
Cross-Reference Service (PICR) (25) (httpwwwebiacukToolspicr) which is able to map protein sequenceidentifiers from over 60 different databases via UniParc(the UniProt Archive) (26) These cross-references are nowbeing included in the PRIDE database which will enable
Figure 3 A single sheet from the ProteomeHarvest PRIDE Submission SpreadsheetmdashPeptide Identification Data Entry
Nucleic Acids Research 2008 Vol 36 Database issue D881
users to successfully query PRIDE with their favoredaccession system The accession mapping task is per-formed for new data within 24 h and is refreshed for theentire PRIDE database every week A useful side-effect isthat the latest active accession is available for allsubmitted identifications irrespective of the time thathas passed since submission The submitted accession ismaintained in the PRIDE database The PRIDE team isnow working on including this mapping data in allPRIDE query and reporting mechanisms
The PRIDE BioMart query interface
The PRIDE database now includes a BioMart interface(27) that offers several advantages This query interfacecan be accessed from the menu item lsquoPRIDE BioMartrsquo onthe left of the PRIDE home page or directly at (httpwwwebiacukprideprideMartdo)The PRIDE BioMart provides access to public PRIDE
data from a query-optimized data warehouse that issynchronized with the main PRIDE database at regularintervals The BioMart interface allows simple or complexqueries to be built The user has control over how the datais filtered to restrict which records are included and isable to select the attributes equivalent to columns in aspreadsheet that are included in the results This avoidsthe need to search through a large table of results much ofwhich may be irrelevant allowing the user to focusspecifically on the information that is important to themThe user can specify how the results are formatted
choosing from an HTML table displayed in a browser acomma or tab-separated values file or a Microsoft Excelspreadsheet The results file can be compressed to speed updata retrieval The latest version of BioMart allowsasynchronous data access in which the user specifies an
email address to which a link to large result sets canbe sent
The PRIDE BioMart provides programmatic webservice access to public PRIDE data with the sameflexibility as the web form
The PRIDE BioMart is illustrated with the screen shotin Figure 4 showing a summary of the results for acustomized query
DISCUSSION
The focus of the PRIDE team at the EBI over the last twoyears has been on improving the ability of proteomicsscientists to submit their data to PRIDE and to queryPRIDE in more powerful and flexible ways Progress hasbeen made in both respects with the development ofthe Proteome Harvest PRIDE Submission Spreadsheetthe support provided by the PRIDE data curator and thedevelopment of new user interface elements such asthe PRIDE BioMart Usage of the BioMart represents50 of the data volume downloaded from PRIDEAs BioMart queries return much more compact andcustomized result sets this corresponds to the majorityof queries to PRIDE now being made via the BioMartinterface
The Proteome Harvest PRIDE Submission Spreadsheethas been used extensively over the last year contributing17 PRIDE experiments including the Acid Mine Drainageenvironmental dataset described above
It is recognized however that there is still work to bedone The PRIDE team continues to follow closely thedevelopment of the HUPO PSI data exchange formats(httppsidevinfo) The goal of keeping PRIDEcompatible with these standards will pay dividends insupporting data submission to PRIDE The PRIDE query
Figure 4 The PRIDE BioMart results summary view for a simple query The filter and display attributes can be seen on the left
D882 Nucleic Acids Research 2008 Vol 36 Database issue
interface still requires further development including theincorporation of the Dasty2 DAS client (httpwwwebiacukdasty) to allow graphical visualization of peptideidentifications together with improvements to the mainPRIDE query interface and the PRIDE BioMart Aninteresting consequence of the incorporation of PICRprotein cross-references is that it will be possible to linkthe PRIDE BioMart directly to other BioMarts allowingfederated queries across these resources We intend to setup links to the BioMart services offered by Ensembl (28)and Reactome (29) over the next few months potentiallywith similar links in the reverse direction
ACKNOWLEDGEMENTS
The PRIDE team would like to thank all data submittersfor their contributions The authors would also like tothank Dr Rolf Apweiler for his support and Dr MatthieuVisser for his valuable suggestions SYC was sup-ported by a grant from the Korea Health 21RampDProject Ministry of Health amp Welfare Republic ofKorea (A030003 to Y-K Paik) Biotechnology andBiological Sciences Research Council (BBSB17239 BBE00573X1) Funding to pay the Open Access publicationcharges for the article was provided by the EuropeanUnion lsquolsquoProDaCrsquorsquo grant number LSHG-CT-2006-036814
Conflict of interest statement None declared
REFERENCES
1 MartensL HermjakobH JonesP AdamskiM TaylorCStatesD GevaertK VandekerckhoveJ and ApweilerR (2005)Pride the proteomics identifications database Proteomics 53537ndash3545
2 JonesP CoteRG MartensL QuinnAF TaylorCFDeracheW HermjakobH and ApweilerR (2006) Pride a publicrepository of protein and peptide identifications for the proteomicscommunity Nucleic Acids Res 34 D659ndashD663
3 MeadJA ShadforthIP and BessantC (2007) Public proteomicms repositories and pipelines available tools and biologicalapplications Proteomics 7 2769ndash2786
4 Editorial (2007) Democratizing proteomics data Nat Biotechnol25 262
5 CraigR CortensJC FenyoD and BeavisRC (2006) Usingannotated peptide mass spectrum libraries for protein identificationJ Proteome Res 5 1843ndash1849
6 DesiereF DeutschEW KingNL NesvizhskiiAI MallickPEngJ ChenS EddesJ LoevenichSN et al (2006)The peptideatlas project Nucleic Acids Res 34 D655ndashD658
7 PeriS NavarroJD AmanchyR KristiansenTZJonnalagaddaCK SurendranathV NiranjanV MuthusamyBGandhiTKB et al (2003) Development of human proteinreference database as an initial platform for approaching systemsbiology in humans Genome Res 13 2363ndash2371
8 PrinceJT CarlsonMW WangR LuP and MarcotteEM(2004) The need for a public proteomics repository NatBiotechnol 22 471ndash472
9 HermjakobH and ApweilerR (2006) The proteomicsidentifications database (pride) and the proteomexchangeconsortium making proteomics data accessible Expert RevProteomics 3 1ndash3
10 Editor (2007) Mind the technology gap Nat Methods 4 765ndash76511 PhanIQH PilboutSF FleischmannW and BairochA (2003)
Newt a new taxonomy portal Nucleic Acids Res 31 3822ndash382312 SchomburgI ChangA EbelingC GremseM HeldtC
HuhnG and SchomburgD (2004) Brenda the enzyme databaseupdates and major new developments Nucleic Acids Res 32D431ndashD433
13 BardJ RheeSY and AshburnerM (2005) An ontology for celltypes Genome Biol 6 R21
14 AshburnerM BallCA BlakeJA BotsteinD ButlerHCherryJM DavisAP DolinskiK DwightSS et al (2000)Gene ontology tool for the unification of biology the geneontology consortium Nat Genet 25 25ndash29
15 LoI DenefVJ VerberkmoesNC ShahMB GoltsmanDDiBartoloG TysonGW AllenEE RamRJ et al (2007)Strain-resolved community proteomics reveals recombining genomesof acidophilic bacteria Nature 446 537ndash541
16 HamacherM ApweilerR ArnoldG BeckerA BluggelMCarretteO ColvisC DunnMJ FrohlichT et al (2006) Hupobrain proteome project summary of the pilot phase andintroduction of a comprehensive data reprocessing strategyProteomics 6 4890ndash4898
17 HeF (2005) Human liver proteome project plan progress andperspectives Mol Cell Proteomics 4 1841ndash1848
18 ZhengJ GaoX BerettaL and HeF (2006) The human liverproteome project (hlpp) workshop during the 4th hupo worldcongress Proteomics 6 1716ndash1718
19 PanS ZhuD QuinnJF PeskindER MontineTJ LinBGoodlettDR TaylorG EngJ et al (2007) A combined datasetof human cerebrospinal fluid proteins identified bymulti-dimensional chromatography and tandem mass spectrometryProteomics 7 469ndash473
20 KellerA EngJ ZhangN LiX and AebersoldR (2005) Auniform proteomics msms analysis platform utilizing open xml fileformats Mol Syst Biol 1 20050017
21 BantscheffM EberhardD AbrahamY BastuckS BoescheMHobsonS MathiesonT PerrinJ RaidaM et al (2007)Quantitative chemical proteomics reveals mechanisms ofaction of clinical abl kinase inhibitors Nat Biotechnol 251035ndash1044
22 KerrienS Alam-FaruqueY ArandaB BancarzI BridgeADerowC DimmerE FeuermannM FriedrichsenA et al (2007)Intact ndash open source resource for molecular interaction dataNucleic Acids Res 35 D561ndashD565
23 CoteRG JonesP ApweilerR and HermjakobH (2006) Theontology lookup service a lightweight cross-platform tool forcontrolled vocabulary queries BMC Bioinformatics 7 97
24 SiepenJA SwainstonN JonesAR HartSR HermjakobHJonesP and HubbardSJ (2007) An informatic pipeline for thedata capture and submission of quantitative proteomic data usingitraq Proteome Sci 5 4
25 CoteRG JonesP MartensL KerrienS ReisingerF LinQLeinonenR ApweilerR and HermjakobH (2007) The proteinidentifier cross-reference (picr) service reconciling protein identifiersacross multiple source databases BMC Bioinformatics 8 401
26 LeinonenR DiezFG BinnsD FleischmannW LopezR andApweilerR (2004) Uniprot archive Bioinformatics 20 3236ndash3237
27 DurinckS MoreauY KasprzykA DavisS De MoorBBrazmaA and HuberW (2005) Biomart and bioconductor apowerful link between biological databases and microarray dataanalysis Bioinformatics 21 3439ndash3440
28 HubbardTJP AkenBL BealK BallesterB CaccamoMChenY ClarkeL CoatesG CunninghamF et al (2007)Ensembl 2007 Nucleic Acids Res 35 D610ndashD617
29 Joshi-TopeG GillespieM VastrikI DrsquoEustachioP SchmidtEde BonoB JassalB GopinathGR WuGR et al (2005)Reactome a knowledgebase of biological pathways Nucleic AcidsRes 33 D428ndashD432
Nucleic Acids Research 2008 Vol 36 Database issue D883
users to successfully query PRIDE with their favoredaccession system The accession mapping task is per-formed for new data within 24 h and is refreshed for theentire PRIDE database every week A useful side-effect isthat the latest active accession is available for allsubmitted identifications irrespective of the time thathas passed since submission The submitted accession ismaintained in the PRIDE database The PRIDE team isnow working on including this mapping data in allPRIDE query and reporting mechanisms
The PRIDE BioMart query interface
The PRIDE database now includes a BioMart interface(27) that offers several advantages This query interfacecan be accessed from the menu item lsquoPRIDE BioMartrsquo onthe left of the PRIDE home page or directly at (httpwwwebiacukprideprideMartdo)The PRIDE BioMart provides access to public PRIDE
data from a query-optimized data warehouse that issynchronized with the main PRIDE database at regularintervals The BioMart interface allows simple or complexqueries to be built The user has control over how the datais filtered to restrict which records are included and isable to select the attributes equivalent to columns in aspreadsheet that are included in the results This avoidsthe need to search through a large table of results much ofwhich may be irrelevant allowing the user to focusspecifically on the information that is important to themThe user can specify how the results are formatted
choosing from an HTML table displayed in a browser acomma or tab-separated values file or a Microsoft Excelspreadsheet The results file can be compressed to speed updata retrieval The latest version of BioMart allowsasynchronous data access in which the user specifies an
email address to which a link to large result sets canbe sent
The PRIDE BioMart provides programmatic webservice access to public PRIDE data with the sameflexibility as the web form
The PRIDE BioMart is illustrated with the screen shotin Figure 4 showing a summary of the results for acustomized query
DISCUSSION
The focus of the PRIDE team at the EBI over the last twoyears has been on improving the ability of proteomicsscientists to submit their data to PRIDE and to queryPRIDE in more powerful and flexible ways Progress hasbeen made in both respects with the development ofthe Proteome Harvest PRIDE Submission Spreadsheetthe support provided by the PRIDE data curator and thedevelopment of new user interface elements such asthe PRIDE BioMart Usage of the BioMart represents50 of the data volume downloaded from PRIDEAs BioMart queries return much more compact andcustomized result sets this corresponds to the majorityof queries to PRIDE now being made via the BioMartinterface
The Proteome Harvest PRIDE Submission Spreadsheethas been used extensively over the last year contributing17 PRIDE experiments including the Acid Mine Drainageenvironmental dataset described above
It is recognized however that there is still work to bedone The PRIDE team continues to follow closely thedevelopment of the HUPO PSI data exchange formats(httppsidevinfo) The goal of keeping PRIDEcompatible with these standards will pay dividends insupporting data submission to PRIDE The PRIDE query
Figure 4 The PRIDE BioMart results summary view for a simple query The filter and display attributes can be seen on the left
D882 Nucleic Acids Research 2008 Vol 36 Database issue
interface still requires further development including theincorporation of the Dasty2 DAS client (httpwwwebiacukdasty) to allow graphical visualization of peptideidentifications together with improvements to the mainPRIDE query interface and the PRIDE BioMart Aninteresting consequence of the incorporation of PICRprotein cross-references is that it will be possible to linkthe PRIDE BioMart directly to other BioMarts allowingfederated queries across these resources We intend to setup links to the BioMart services offered by Ensembl (28)and Reactome (29) over the next few months potentiallywith similar links in the reverse direction
ACKNOWLEDGEMENTS
The PRIDE team would like to thank all data submittersfor their contributions The authors would also like tothank Dr Rolf Apweiler for his support and Dr MatthieuVisser for his valuable suggestions SYC was sup-ported by a grant from the Korea Health 21RampDProject Ministry of Health amp Welfare Republic ofKorea (A030003 to Y-K Paik) Biotechnology andBiological Sciences Research Council (BBSB17239 BBE00573X1) Funding to pay the Open Access publicationcharges for the article was provided by the EuropeanUnion lsquolsquoProDaCrsquorsquo grant number LSHG-CT-2006-036814
Conflict of interest statement None declared
REFERENCES
1 MartensL HermjakobH JonesP AdamskiM TaylorCStatesD GevaertK VandekerckhoveJ and ApweilerR (2005)Pride the proteomics identifications database Proteomics 53537ndash3545
2 JonesP CoteRG MartensL QuinnAF TaylorCFDeracheW HermjakobH and ApweilerR (2006) Pride a publicrepository of protein and peptide identifications for the proteomicscommunity Nucleic Acids Res 34 D659ndashD663
3 MeadJA ShadforthIP and BessantC (2007) Public proteomicms repositories and pipelines available tools and biologicalapplications Proteomics 7 2769ndash2786
4 Editorial (2007) Democratizing proteomics data Nat Biotechnol25 262
5 CraigR CortensJC FenyoD and BeavisRC (2006) Usingannotated peptide mass spectrum libraries for protein identificationJ Proteome Res 5 1843ndash1849
6 DesiereF DeutschEW KingNL NesvizhskiiAI MallickPEngJ ChenS EddesJ LoevenichSN et al (2006)The peptideatlas project Nucleic Acids Res 34 D655ndashD658
7 PeriS NavarroJD AmanchyR KristiansenTZJonnalagaddaCK SurendranathV NiranjanV MuthusamyBGandhiTKB et al (2003) Development of human proteinreference database as an initial platform for approaching systemsbiology in humans Genome Res 13 2363ndash2371
8 PrinceJT CarlsonMW WangR LuP and MarcotteEM(2004) The need for a public proteomics repository NatBiotechnol 22 471ndash472
9 HermjakobH and ApweilerR (2006) The proteomicsidentifications database (pride) and the proteomexchangeconsortium making proteomics data accessible Expert RevProteomics 3 1ndash3
10 Editor (2007) Mind the technology gap Nat Methods 4 765ndash76511 PhanIQH PilboutSF FleischmannW and BairochA (2003)
Newt a new taxonomy portal Nucleic Acids Res 31 3822ndash382312 SchomburgI ChangA EbelingC GremseM HeldtC
HuhnG and SchomburgD (2004) Brenda the enzyme databaseupdates and major new developments Nucleic Acids Res 32D431ndashD433
13 BardJ RheeSY and AshburnerM (2005) An ontology for celltypes Genome Biol 6 R21
14 AshburnerM BallCA BlakeJA BotsteinD ButlerHCherryJM DavisAP DolinskiK DwightSS et al (2000)Gene ontology tool for the unification of biology the geneontology consortium Nat Genet 25 25ndash29
15 LoI DenefVJ VerberkmoesNC ShahMB GoltsmanDDiBartoloG TysonGW AllenEE RamRJ et al (2007)Strain-resolved community proteomics reveals recombining genomesof acidophilic bacteria Nature 446 537ndash541
16 HamacherM ApweilerR ArnoldG BeckerA BluggelMCarretteO ColvisC DunnMJ FrohlichT et al (2006) Hupobrain proteome project summary of the pilot phase andintroduction of a comprehensive data reprocessing strategyProteomics 6 4890ndash4898
17 HeF (2005) Human liver proteome project plan progress andperspectives Mol Cell Proteomics 4 1841ndash1848
18 ZhengJ GaoX BerettaL and HeF (2006) The human liverproteome project (hlpp) workshop during the 4th hupo worldcongress Proteomics 6 1716ndash1718
19 PanS ZhuD QuinnJF PeskindER MontineTJ LinBGoodlettDR TaylorG EngJ et al (2007) A combined datasetof human cerebrospinal fluid proteins identified bymulti-dimensional chromatography and tandem mass spectrometryProteomics 7 469ndash473
20 KellerA EngJ ZhangN LiX and AebersoldR (2005) Auniform proteomics msms analysis platform utilizing open xml fileformats Mol Syst Biol 1 20050017
21 BantscheffM EberhardD AbrahamY BastuckS BoescheMHobsonS MathiesonT PerrinJ RaidaM et al (2007)Quantitative chemical proteomics reveals mechanisms ofaction of clinical abl kinase inhibitors Nat Biotechnol 251035ndash1044
22 KerrienS Alam-FaruqueY ArandaB BancarzI BridgeADerowC DimmerE FeuermannM FriedrichsenA et al (2007)Intact ndash open source resource for molecular interaction dataNucleic Acids Res 35 D561ndashD565
23 CoteRG JonesP ApweilerR and HermjakobH (2006) Theontology lookup service a lightweight cross-platform tool forcontrolled vocabulary queries BMC Bioinformatics 7 97
24 SiepenJA SwainstonN JonesAR HartSR HermjakobHJonesP and HubbardSJ (2007) An informatic pipeline for thedata capture and submission of quantitative proteomic data usingitraq Proteome Sci 5 4
25 CoteRG JonesP MartensL KerrienS ReisingerF LinQLeinonenR ApweilerR and HermjakobH (2007) The proteinidentifier cross-reference (picr) service reconciling protein identifiersacross multiple source databases BMC Bioinformatics 8 401
26 LeinonenR DiezFG BinnsD FleischmannW LopezR andApweilerR (2004) Uniprot archive Bioinformatics 20 3236ndash3237
27 DurinckS MoreauY KasprzykA DavisS De MoorBBrazmaA and HuberW (2005) Biomart and bioconductor apowerful link between biological databases and microarray dataanalysis Bioinformatics 21 3439ndash3440
28 HubbardTJP AkenBL BealK BallesterB CaccamoMChenY ClarkeL CoatesG CunninghamF et al (2007)Ensembl 2007 Nucleic Acids Res 35 D610ndashD617
29 Joshi-TopeG GillespieM VastrikI DrsquoEustachioP SchmidtEde BonoB JassalB GopinathGR WuGR et al (2005)Reactome a knowledgebase of biological pathways Nucleic AcidsRes 33 D428ndashD432
Nucleic Acids Research 2008 Vol 36 Database issue D883

interface still requires further development including theincorporation of the Dasty2 DAS client (httpwwwebiacukdasty) to allow graphical visualization of peptideidentifications together with improvements to the mainPRIDE query interface and the PRIDE BioMart Aninteresting consequence of the incorporation of PICRprotein cross-references is that it will be possible to linkthe PRIDE BioMart directly to other BioMarts allowingfederated queries across these resources We intend to setup links to the BioMart services offered by Ensembl (28)and Reactome (29) over the next few months potentiallywith similar links in the reverse direction
ACKNOWLEDGEMENTS
The PRIDE team would like to thank all data submittersfor their contributions The authors would also like tothank Dr Rolf Apweiler for his support and Dr MatthieuVisser for his valuable suggestions SYC was sup-ported by a grant from the Korea Health 21RampDProject Ministry of Health amp Welfare Republic ofKorea (A030003 to Y-K Paik) Biotechnology andBiological Sciences Research Council (BBSB17239 BBE00573X1) Funding to pay the Open Access publicationcharges for the article was provided by the EuropeanUnion lsquolsquoProDaCrsquorsquo grant number LSHG-CT-2006-036814
Conflict of interest statement None declared
REFERENCES
1 MartensL HermjakobH JonesP AdamskiM TaylorCStatesD GevaertK VandekerckhoveJ and ApweilerR (2005)Pride the proteomics identifications database Proteomics 53537ndash3545
2 JonesP CoteRG MartensL QuinnAF TaylorCFDeracheW HermjakobH and ApweilerR (2006) Pride a publicrepository of protein and peptide identifications for the proteomicscommunity Nucleic Acids Res 34 D659ndashD663
3 MeadJA ShadforthIP and BessantC (2007) Public proteomicms repositories and pipelines available tools and biologicalapplications Proteomics 7 2769ndash2786
4 Editorial (2007) Democratizing proteomics data Nat Biotechnol25 262
5 CraigR CortensJC FenyoD and BeavisRC (2006) Usingannotated peptide mass spectrum libraries for protein identificationJ Proteome Res 5 1843ndash1849
6 DesiereF DeutschEW KingNL NesvizhskiiAI MallickPEngJ ChenS EddesJ LoevenichSN et al (2006)The peptideatlas project Nucleic Acids Res 34 D655ndashD658
7 PeriS NavarroJD AmanchyR KristiansenTZJonnalagaddaCK SurendranathV NiranjanV MuthusamyBGandhiTKB et al (2003) Development of human proteinreference database as an initial platform for approaching systemsbiology in humans Genome Res 13 2363ndash2371
8 PrinceJT CarlsonMW WangR LuP and MarcotteEM(2004) The need for a public proteomics repository NatBiotechnol 22 471ndash472
9 HermjakobH and ApweilerR (2006) The proteomicsidentifications database (pride) and the proteomexchangeconsortium making proteomics data accessible Expert RevProteomics 3 1ndash3
10 Editor (2007) Mind the technology gap Nat Methods 4 765ndash76511 PhanIQH PilboutSF FleischmannW and BairochA (2003)
Newt a new taxonomy portal Nucleic Acids Res 31 3822ndash382312 SchomburgI ChangA EbelingC GremseM HeldtC
HuhnG and SchomburgD (2004) Brenda the enzyme databaseupdates and major new developments Nucleic Acids Res 32D431ndashD433
13 BardJ RheeSY and AshburnerM (2005) An ontology for celltypes Genome Biol 6 R21
14 AshburnerM BallCA BlakeJA BotsteinD ButlerHCherryJM DavisAP DolinskiK DwightSS et al (2000)Gene ontology tool for the unification of biology the geneontology consortium Nat Genet 25 25ndash29
15 LoI DenefVJ VerberkmoesNC ShahMB GoltsmanDDiBartoloG TysonGW AllenEE RamRJ et al (2007)Strain-resolved community proteomics reveals recombining genomesof acidophilic bacteria Nature 446 537ndash541
16 HamacherM ApweilerR ArnoldG BeckerA BluggelMCarretteO ColvisC DunnMJ FrohlichT et al (2006) Hupobrain proteome project summary of the pilot phase andintroduction of a comprehensive data reprocessing strategyProteomics 6 4890ndash4898
17 HeF (2005) Human liver proteome project plan progress andperspectives Mol Cell Proteomics 4 1841ndash1848
18 ZhengJ GaoX BerettaL and HeF (2006) The human liverproteome project (hlpp) workshop during the 4th hupo worldcongress Proteomics 6 1716ndash1718
19 PanS ZhuD QuinnJF PeskindER MontineTJ LinBGoodlettDR TaylorG EngJ et al (2007) A combined datasetof human cerebrospinal fluid proteins identified bymulti-dimensional chromatography and tandem mass spectrometryProteomics 7 469ndash473
20 KellerA EngJ ZhangN LiX and AebersoldR (2005) Auniform proteomics msms analysis platform utilizing open xml fileformats Mol Syst Biol 1 20050017
21 BantscheffM EberhardD AbrahamY BastuckS BoescheMHobsonS MathiesonT PerrinJ RaidaM et al (2007)Quantitative chemical proteomics reveals mechanisms ofaction of clinical abl kinase inhibitors Nat Biotechnol 251035ndash1044
22 KerrienS Alam-FaruqueY ArandaB BancarzI BridgeADerowC DimmerE FeuermannM FriedrichsenA et al (2007)Intact ndash open source resource for molecular interaction dataNucleic Acids Res 35 D561ndashD565
23 CoteRG JonesP ApweilerR and HermjakobH (2006) Theontology lookup service a lightweight cross-platform tool forcontrolled vocabulary queries BMC Bioinformatics 7 97
24 SiepenJA SwainstonN JonesAR HartSR HermjakobHJonesP and HubbardSJ (2007) An informatic pipeline for thedata capture and submission of quantitative proteomic data usingitraq Proteome Sci 5 4
25 CoteRG JonesP MartensL KerrienS ReisingerF LinQLeinonenR ApweilerR and HermjakobH (2007) The proteinidentifier cross-reference (picr) service reconciling protein identifiersacross multiple source databases BMC Bioinformatics 8 401
26 LeinonenR DiezFG BinnsD FleischmannW LopezR andApweilerR (2004) Uniprot archive Bioinformatics 20 3236ndash3237
27 DurinckS MoreauY KasprzykA DavisS De MoorBBrazmaA and HuberW (2005) Biomart and bioconductor apowerful link between biological databases and microarray dataanalysis Bioinformatics 21 3439ndash3440
28 HubbardTJP AkenBL BealK BallesterB CaccamoMChenY ClarkeL CoatesG CunninghamF et al (2007)Ensembl 2007 Nucleic Acids Res 35 D610ndashD617
29 Joshi-TopeG GillespieM VastrikI DrsquoEustachioP SchmidtEde BonoB JassalB GopinathGR WuGR et al (2005)Reactome a knowledgebase of biological pathways Nucleic AcidsRes 33 D428ndashD432
Nucleic Acids Research 2008 Vol 36 Database issue D883
Copyright © 2022 FDOKUMEN